


1. Introduction
English is a language characterised by great flexibility with respect to word class boundaries. Nouns easily take on the function of verbs and vice versa, as ad hoc formations like to winter the cattle or the more lexicalised to pay a call illustrate. Words like open, close or calm can be used as Adjective (A), Verb (V) and Noun (N). Category membership is gradient and individual members of A, V and N can undergo functional shift (see e.g. Aarts Reference Aarts2007; Keizer Reference Keizer and van Lier2023; Shao, Zheng & De Smet Reference Shao, Zheng and De Smet2024). With respect to the category boundary between N and A, Denison (Reference Denison, Hundt, Mollin and Pfenninger2017: 303) provides a list of nouns that have recently shifted to A. This can be taken as preliminary evidence that the use of N as A is on the increase. More recent instances are illustrated in the following examples in (1).

Nouns can modify other nouns. What appears, superficially, as a NN sequence (or starts out as a NN sequence) may be reinterpreted as an AN sequence over time. In other words, the modifying N can be argued to have constructionalised into an A.
Previous research started out from serendipitous finds of N>A changes. De Smet (Reference De Smet2012: 621–8) and Denison (Reference Denison2013: 160–4) study individual items that have undergone category change from N to A. They argue that count noun key and noncount fun take different paths in the N>A shift, arising in the attributive modifier and predicative complement function, respectively. However, diachronic evidence in De Smet (Reference De Smet2012) is limited to only two words and the approach is top-down (from the pre-selected nouns to the corpus data). In this article, we take a more bottom-up approach, using the Oxford English Dictionary (OED) as a data source (see also Rohdenburg Reference Rohdenburg, Krug and Schlüter2013) to compile a set of N>A shifts, extracting adjectives with prior attested use as N from 1700 onward with the aim of providing a bird’s eye view of the spread of the N>A shift as a pattern. In addition, we present a corpus-based case study on genius, which is of particular interest because the noun genius can be both count (when referring to a person) and noncount (when referring to a person’s intellect). The variable feature ‘countability’ gives rise to an increased potential for underspecification of the word. When used predicatively, the interpretation of genius is underspecified: This is genius, can mean ‘This is intelligence’ or ‘This is intelligent’.
In the following, we provide some theoretical background, review previous research on the N>A shift and introduce our research questions (section 2). In section 3, we describe our approach to data extraction from the OED, and the collection of supplementary evidence from available corpora as well as the subsequent annotation process. Section 4 presents the case study on the N>A shift of the word genius, including background on data retrieval, definition of the variable context, annotation for predictor variables and the statistical modelling we applied to our dataset. The case study provides important additional quantitative and qualitative data on the question of whether countability of the nouns in question is an important factor for category shift to A. Section 5 concludes the article with a discussion of the advantages and limitations of the approach we take on the shift of the N>A in Late Modern English (LModE) and an outlook on future studies.
2. Background and previous research on the N>A shift
We consider parts of speech (PoS) to be prototypically structured categories. Our analysis of lexical categorisation is based on Croft’s (Reference Croft2001, Reference Croft2022) model in which PoS are conceived of as being made up of two dimensions – discourse function/propositional act (reference, modification, predication) and semantic class (object, property, action). Category shift in this model emerges from atypical use of lexical roots, for instance when a lexical root that typically refers (to entities or concepts) takes on the role of a modifier, as in examples (1a–d). In a predication construction, lexical roots that express a property may serve the modifying function, especially if they are premodified, as in This is very important. Thus, the object-denoting lexical roots in examples (1a–d) take on modifying function in a predicating construction, what is referred to as the predicative use of an adjective in traditional grammar.
De Smet (Reference De Smet2012) and Denison (Reference Denison2013, Reference Denison, Hundt, Mollin and Pfenninger2017) discuss the N>A shift of key and fun. The studies reveal important properties that facilitate the transition. Since both object and property lexical roots can modify N, key is underspecified with respect to its word class, as in (2a). When key is used predicatively as in (2b), it is clearly adjectival because count noun key would require a determiner in this environment. Noncount noun fun by contrast occurs freely without a determiner. Consequently, predicatively used fun is underspecified with respect to its word class, and its use in predicative position allows N>A shift, as illustrated in (2c). Fun can also function as attributive adjective as in (2d).

De Smet (Reference De Smet2012: 625) comments that the A status of fun is unambiguous when used attributively with or without an additional intensifier, a point we return to in more detail in section 3.2. Denison (Reference Denison2013: 162), on the other hand, considers the prenominal modifier position as permissible for fun as both N and A, as in fun-room, fun jotting and fun fair. De Smet (Reference De Smet2012: 622–4) and Denison (Reference Denison2013: 161–4, Reference Denison, Hundt, Mollin and Pfenninger2017: 306–7) list the following strong indicators of the A status of N>A words:
-
(i) combination with intensifiers such as very, so, too, as, rather;
-
(ii) comparative/superlative forms (synthetic or analytic);
-
(iii) postmodifier use;
-
(iv) coordination with adjectives;
-
(v) preceding a clear adjective.
Both De Smet (Reference De Smet2012: 622) and Denison (Reference Denison2013: 166) consider coordination with adjectives as indicator of fun/key being A. Although coordination of adjectives and nouns is not strictly impossible, coordination between items of the same word class is far more common (De Smet: 622, fn. 17). Feist (Reference Feist2009, Reference Feist2012) discusses premodifier order in some detail. Premodifiers are subject to constraints on their relative order: certain types of adjectives typically precede others, and modifying adjectives typically precede modifying nouns, illustrated in an expensive visitor experience vs *a visitor expensive experience (see also De Smet Reference De Smet2012: 624; Denison Reference Denison2013: 166–7, Reference Denison, Hundt, Mollin and Pfenninger2017: 305). Although there are exceptions suggesting that this ordering ‘rule’ is merely a strong tendency (see Huddleston & Pullum et al.’s notion of ‘labile ordering’, 2002: 452–4), N-A orderings for premodifiers are much less common than A-N (Denison Reference Denison2013: 166, fn. 13). Indicators (i)–(v) serve as the basis for our analysis of the N>A shifts in the OED.
While key and fun share important indicators of the N>A shift, the two nouns take different paths on their way to adjectivehood according to De Smet (Reference De Smet2012) and Denison (Reference Denison2013). De Smet (Reference De Smet2012: 621–30) presents corpus evidence showing that the adjectival use of key starts off from attributive position, whereas the new adjective fun was initially restricted to predicative position. The study suggests that differences in paths to adjectivehood are due to the fact that key is a count noun whereas fun is noncount (De Smet Reference De Smet2012: 622–5). Denison (Reference Denison2013: 160–7) discusses how the two words transit from N to A and the uses which are more suggestive of A status. While Denison (Reference Denison2013: 161, 164, 165) implies a similar trajectory for count and noncount nouns, individual examples that he lists, specifically dinosaur and killer in predicative context (Denison Reference Denison2013: 162, 166), open up the possibility of alternative paths for the N>A shift, even though in the absence of diachronic data this alternative lacks empirical support.
While De Smet’s (Reference De Smet2012) analysis of the different trajectories that key and fun take on their path from N to A is convincing at first sight, a question that needs to be asked is whether countability as a key factor also emerges from a broader set of nouns. We use the OED as our data source and take a more systematic type-based approach to the N>A shift to investigate the role that countability plays. In addition, we carry out a case study on genius, which provides an interesting test bed for his hypothesis as genius can be both count and noncount. In this article we aim to answer the following research questions:
RQ 1: Are there any subtypes of N>A words that emerge as particularly interesting from a systematic study of the OED data?
RQ 2: Do shifted adjectives predominantly occur in attributive position first before they are attested in predicative position and is there a connection with the property of countability?
3. A type-based approach to N>A category shifts
3.1. Data retrieval and annotation
We are interested in the development of the N>A shift in LModE. In order to obtain a sizeable dataset of lexemes attested first as N and then as A, we used the OED as our starting point. Due to the gradient nature of category membership, it comes as no surprise that PoS assignment in the OED may give rise to debate. The first word in combinations like family farm, desktop computers and name producers are listed as both N and A in the OED because they premodify a noun. We therefore did not take the OED’s PoS assignment as given but manually filtered the items returned by our OED search for clear instances of N>A shift using the criteria from De Smet (Reference De Smet2012) and Denison (Reference Denison2013). Furthermore, we supplemented the OED evidence with corpus data, searching for instances of attributive or predicative use whenever only one use was attested in the OED. Additional data come from the Merriam-Webster Dictionary, the Corpus of Historical American English (Reference DaviesCOHA, Davies Reference Davies2008) and/or the Corpus of Contemporary American English (Reference DaviesCOCA, Davies Reference Davies2008–).
The aim of our article is not to provide a study that traces the quantitative development of the N>A shift as such. Instead, our focus is on retrieving a dataset that allows us to (i) move beyond the previously attested instances of simplex nouns shifting to A and towards a broader set of different types of N shifting to A, and (ii) test the hypothesis that count nouns first shift to A in attributive function whereas noncount nouns shift to A in predicative function. Neither research question (RQ1 and RQ2) requires a dataset that is exhaustive or definitive.
Instances of the category shift were retrieved from the online version of the dictionary before the update to the new website.Footnote 2 Using the advanced search function, we targeted ‘n. and adj.’ and ‘n1. and adj.’, yielding 900 and 300 instances, respectively. For the first search, we applied the OED’s sorting function by frequency, subsequently analysing the first 800 instances. For both searches, all instances were manually filtered. Manual post-editing was done on the basis of the following criteria:
-
• first attested A use after 1700;
-
• A develops both attributive and predicative functions (with additional corpus evidence taken into consideration).
The first criterion filters out those instances where the shift occurred before 1700. This drastically reduced the number of types initially retrieved. The second criterion is relevant to our research question with respect to different trajectories for the function of A. We documented examples of both attributive and predicative use of the shifted adjectives, as shown in (3). Predicative use of the shifted adjectives includes those following copular be as well as verbs like seem, look, sound, as in (4).

While we focus primarily on N>A shift cases that are attested in both attributive and predicative function, we also briefly comment on N>A words that are limited to either of the two functions below. For the analysis of the data – the features of words that have undergone N>A shift – we annotate the data in the following way.
-
• Use: attributive or predicative
-
• Countability of the noun: count, noncount, both
One complication for the data collection turned out to be polysemy. Some shifted adjectives are recorded with several senses in the OED. The difficulty is to discern whether these are the result of polysemy in the source noun or developments from the first A sense. We decided to not treat later A senses as separate types in our analysis. For instance, the shifted adjective peak has three senses in the OED, but they are all related. We only documented the earliest sense (‘of a varying quantity, etc.: that has reached a peak; maximum, greatest; optimal, first-rate’, OED, s.v. peak, n. & adj.). There are exceptions, however. If the A senses are not closely related to each other and are derived from different N senses, we included them as separate instances of the category shift. For instance, our data include two entries for gas. The first adjectival gas means ‘powered by gas as a fuel, operating by means of gas’. The second adjectival gas means ‘very amusing, funny; great’ and is derived from a separate nominal sense (OED, s.v. gas, n. & adj.). The first two senses of adjectival plastic (‘that moulds’ and ‘able to be moulded’) appeared earlier than 1700 and thus are not listed in our data. We include the third sense (‘of or relating to plastic as a material’) because it is derived from a separate N sense and appeared after 1700 (OED, s.v. plastic, n. & adj.).
Apart from nouns that shifted to A before 1700, we excluded nouns that can also be used as colour terms (e.g. ginger, chocolate, salmon, almond, lavender, mahogany) on the grounds that the N>A shift can occur ad hoc for this subcategory. Common nouns like ginger and gold are examples of the cross-linguistically well-attested metonymic shift that allows for the instantaneous uses of these nouns as adjectives, as searches in List et al.’s (Reference List, Tjuka, Blum, Kučerová, Ugarte, Rzymski, Greenhill and Forkel2025) concepticon amply illustrate. Moreover, we excluded instances with an obvious source in a variety of English as a second language, as for instance high blood, which emerges in Philippine English (OED, s.v. high blood, n. & adj.), as these merit investigation in their own right. Instances where A was derived from a different base, as in the case of ham (‘incompetent’), which derives from hamfatter, hamfat, a term used in US slang to refer to an incompetent actor (OED, s.v. hamfatter, n.), were also excluded. One of the reasons for doing so is that the coding for countability for such instances is not straightforward.
Premodification by an intensifier, including more and most for comparative and superlative form, is a strong indicator of A status of the word, as can be seen from the examples in (5). Inflection for comparison is also a strong indicator of the shift to A, as shown in (6). Coordination with a prototypical adjective marks the shift less clearly but in most contexts can be considered to provide supporting evidence of shift to adjectivehood, as illustrated in (7).



We do not include the N>A shifts in our analysis if the adjectival use occurs only in one function. For instance, even though the highlighted words in (8) appear in typical A positions, we do not include those words in our analysis because they only occur in attributive function. This also applies to the shifted adjectives that only occur in predicative position, such as street, cockeye, country and endgame in (9).


Nouns that are shifted to A can be count or noncount. Examples of adjectives shifted from count nouns are key, epic, nut; examples of adjectives from noncount nouns are fun, crap, plastic. Some are shifted from nouns that are both count and noncount like genius, punk, anathema. One aim of this article is to explore the relation between the countability of the nouns and the path of the category shift, i.e. whether the N>A shift occurs first in attributive or in predicative position.
Our search in the OED yielded a total of 357 N>A shifts (types) in the period 1700–2010 (including those that occur in only one function).Footnote 6 Once we further thinned the dataset to those occurring both attributively and predicatively, 207 of the nouns that shifted to A remain. The dataset can be found at https://osf.io/frez3
3.2. Results
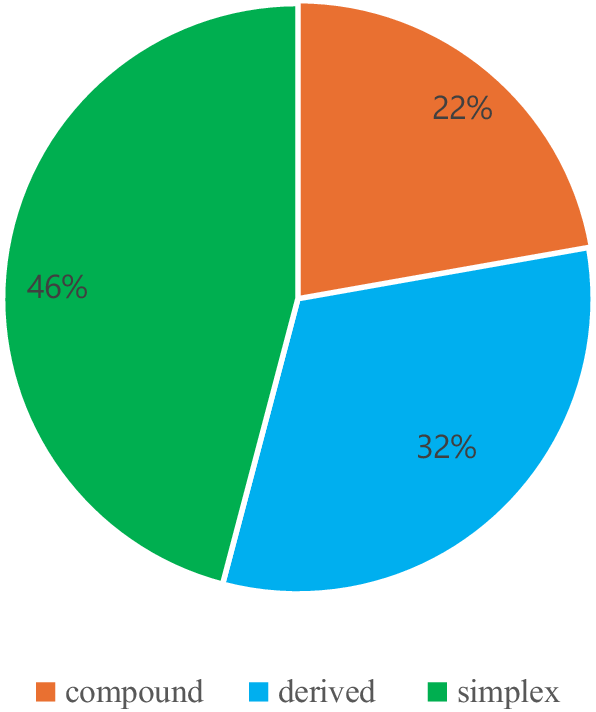
Unlike previous work (De Smet Reference De Smet2012; Denison Reference Denison2013) on the N>A shift, which largely focused on simplex nouns undergoing shift to A,Footnote 7 our OED-derived dataset provides a somewhat broader view of the different types undergoing category shift. Alongside simplex forms, such as key, epic, ace, fake, niche, baby, beast, our dataset includes derived nouns, some of which have a clear nominal suffix, such as regulation, specialist, immigrant, novelty, minority, vegetarian, and compound or noun phrase forms, such as fairy tale, real time, major league, mirror image, science fiction, special needs, high pressure.
Figure 1 shows the distribution of the different types of nouns in the set of shifted adjectives that are attested in attributive and predicative use. The shifted adjectives are more often simplex words at 46 per cent, followed by derived nouns (32 per cent) and compound nouns (22 per cent).
Morphology of shifted A attested in attributive and predicative function

Three subtypes of N>A draw our attention because of their systematic use as A. Firstly, our dataset contains a noticeable number of N>A shifts from nouns with the suffix -ist, which denotes a person. The examples in (10) show -ist appearing in contexts where prototypical adjectives occur, i.e. they are ‐ist adjectives.

The second subtype is material N>A shift such as brick wall, metal bridge, gold ring, a well-recognised pattern (see e.g. Marchand Reference Marchand1969: 361; Huddleston Reference Huddleston1984: 328; Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985: 1562; Huddleston & Pullum et al. Reference Huddleston and Pullum2002: 536–7, 1643; Giegerich Reference Giegerich, Lieber and Štekauer2009: 184). Thus, it comes as no surprise that many material nouns are attested as A in the OED, e.g. platinum, plastic, nickel, cardboard, polyester, etc. The question is whether they are really A when used attributively and the modified nouns are related by the implicit grammatical meaning ‘made of’. In cardboard box, plastic pipes, nickel coin, the attribute can also be interpreted as N. However, the adjectival status of such material words is clear in contexts where only prototypical adjectives appear, as in (11a, b) where cardboard and plastic are modified by an adverb. We included only those material nouns in our dataset where such clear A uses are attested.

Some material nouns also developed metaphorical meanings. In (12a), plastic does not mean ‘made of plastic’, instead, it is used figuratively, meaning ‘artificial, unnatural; superficial, insincere’. In (12b), cardboard means ‘flimsy, insubstantial; unreal, stereotyped, one-dimensional’. As mentioned in section 3.1 about annotation, we do not count the extended metaphorical sense of cardboard and plastic as a separate instance of N>A.

The third prominent subtype of N>A shift concerns adjectives shifted from compounds in the form of high-N and low-N (usually written hyphenated when used as A), as shown in (13).

Interestingly, low-key, high-key, low-pressure, high-pressure, high-voltage, top-flight, top-notch are listed in the OED as N and A, but only as A in dictionaries like the Cambridge Dictionary (online) or the Merriam-Webster Dictionary (online). This suggests that they are no longer analysed as noun phrases. Like the lexical constructionalisation of Nsman (e.g. swordsman) that Trousdale (Reference Trousdale, Davidse, Breban, Brems and Mortelmans2012: 190–2) discusses, high-N and low-N shifted adjectives (plus other adjectives that are in the form of a noun phrase) result from the lexicalisation of noun phrases, and the meaning of the univerbated form is non-compositional.
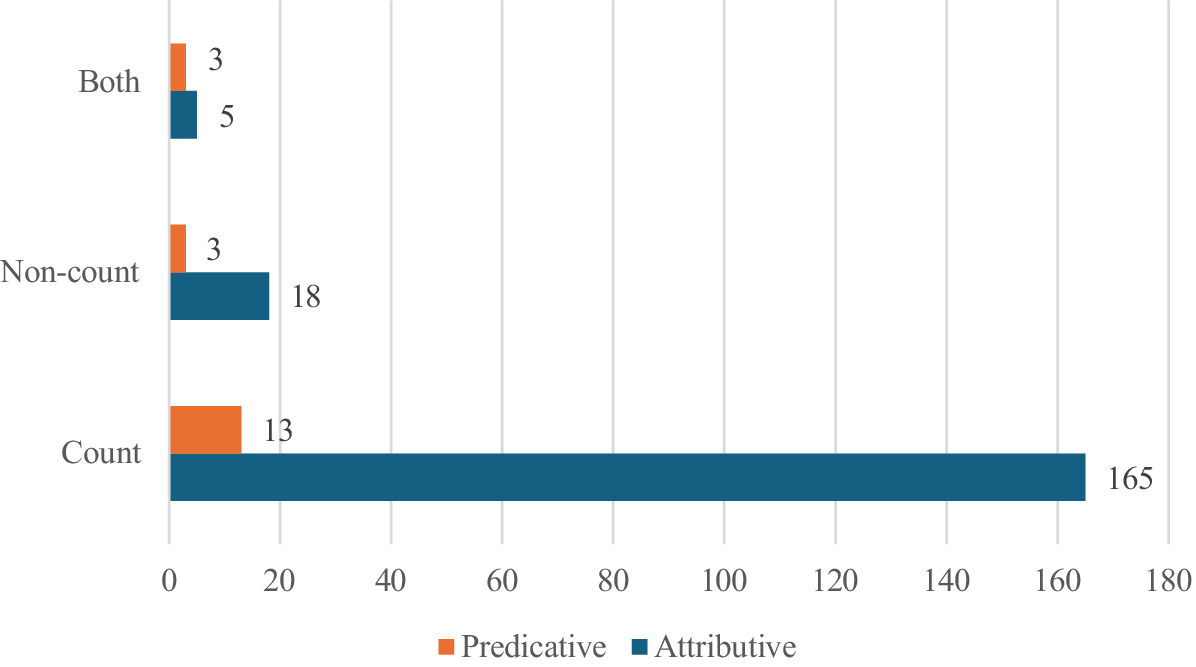
Figure 2 shows the attested N>A shifts from the OED which have both functions. Of the 207 shifted adjectives, 187 appeared first in attributive function and 20 are first attested in predicative function. Based on these numbers, the N>A shift predominantly occurs in attributive function before being attested in predicative function. This is expected because N can also modify N, and because attribution is the prototypical function of A (see Croft Reference Croft2001, Reference Croft2022).
Attributive and predicative adjectival uses of N>A types in the OED and supplementary data by first function and countability

Figure 2 also includes the countability information of the nouns undergoing shift. Among the 178 count nouns, 165 first appear as A in attributive function and only 13 first appear as A in predicative function. Among the 21 noncount nouns, 18 first appear as A in attributive function and three first in predicative function. There are 8 shifted adjectives from nouns that can be both count and noncount; 5 are first used attributively and 3 are first used predicatively. De Smet’s (Reference De Smet2012: 621–30) and Denison’s (Reference Denison2013: 160–7) studies on key and fun indicates that count and noncount nouns take different paths in the N>A shift with the noncount noun fun starting off in predicative function and the count noun key first appearing in attributive function before being used predicatively. However, our findings provide a different view.
Firstly, not every noncount noun is like fun, whose N>A shift starts off in predicative use. The N>A shifts in (14) are from noncount nouns and they appeared in attributive function before being used predicatively.

De Smet (Reference De Smet2012: 625) states that the A status of attributively used fun is unambiguous with or without an additional intensifier. However, in fun time (‘time characterized by recreation, entertainment, or amusement’) (OED, s.v. fun time), fun room (‘a room used for amusement’) (OED, s.v. fun room), fun is a noun. Fun is underspecified in fun runner. Fun runner is derived from fun run and means ‘a person who runs for fun, rather than competitively’ (OED, s.v. fun runner), and therefore fun is a noun. However, it could in principle also refer to ‘a runner who is fun’ in which case fun would be an adjective. Without context, we cannot decide the word class of fun in this collocation.
Material nouns like nickel, plastic, platinum, polyester, cardboard are noncount and are attested as A in the OED. Those shifted adjectives first appeared in attributive use. Though it is disputable whether the first appearance of the attributively used material words is really A or still N, our data provide evidence that the unambiguous attributive use after a degree adverb appeared before the predicative use:

Furthermore, adjectives that appeared in predicative use first are not exclusively shifted from noncount nouns. County is a count noun. As shown in (16a, b), the earliest examples of its adjectival use in the OED are predicative, with the attributive use attested a few decades later (16c, d). The adjective county means ‘That has the social status or characteristics of a county family’ (OED, s.v. county, n. & adj.).

Similarly, count nouns such as ghetto, nut, plateau appear as A in predicative position before being used attributively, as the examples in (17) show, thus providing further evidence that the diachronic case study on key and fun does not support a generalisation of different trajectories for adjectives shifted from count and noncount nouns.

Figure 2 also shows the situation with nouns that are both count and noncount. From those nouns, some shifted adjectives appear in attributive use first, such as novelty, whereas others are first used predicatively, such as antiseptic. Section 4 provides a detailed discussion on genius.
What we thus learn from the OED data is that not all adjectives shifted from count nouns start off in attributive position, and that not all adjectives shifted from noncount nouns were at first restricted to predicative position and became available for attributive use later. Instead, our data show a more general trend for both count and noncount nouns to first shift to A in attributive function.
4. Token-based developments: a case study on genius
English borrowed genius from Latin; its earliest attestation as N in the OED dates from 1328. Genius can be a count noun, meaning ‘an exceptionally intelligent or talented person, or one with exceptional skill in a particular area of art, science, etc.’ (OED, s.v. genius, n. & adj. II.8b.). It can also be noncount and means ‘innate intellectual or creative power of an exceptional or exalted type; instinctive and extraordinary capacity for imaginative creation, original thought, invention, or discovery’ (OED, s.v. genius, n. & adj. II.9.). From 1924, genius is attested as an A meaning ‘very clever or ingenious; (more generally) extremely good’ (OED, s.v. genius n. & adj.). In section 3.2, we already saw from the OED evidence that some nouns which are both count and noncount can first appear in attributive function and some in predicative function. In this section, we use corpus data from American English for a close-up on the category shift of genius to A and what role its Janus-headed countability might have played.
4.1. Methodology
4.1.1. Data extraction and manual post-editing
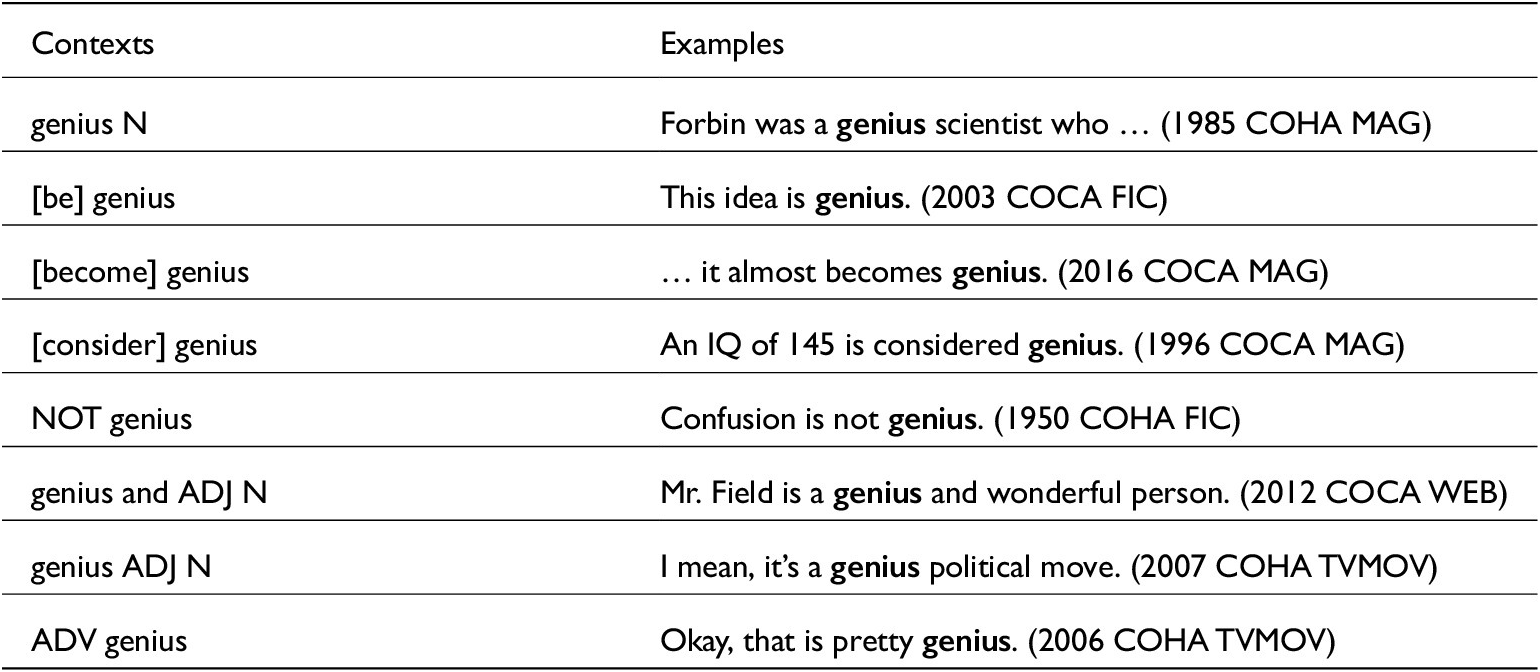
From COHA and COCA, we extracted all instances of genius in a set of contexts where it had the potential of having shifted from N>A in attributive or predicative function, as shown in table 1.Footnote 9
Genius search in COHA and COCA

These searches also yielded a number of false positives which we removed from the dataset for analysis. We did not include instances of genius as a pseudo-title, i.e. where it was directly followed by a proper name, as in (18).
We also excluded attestations in titles of journals, poems, books, TV shows as in (19a), brand or trade names as in (19b). Likewise excluded from our dataset were instances from clear non-native speaker and non-standard contexts as in (19c). Finally, we removed set phrases like genius loci, genius manqué from the initial dataset.

The search for ‘genius N’ retrieved false positives such as (20), where genius and N do not constitute a single phrase.
What is also excluded is the adverbial use of genius, as in (21). Here genius is used as a premodifier for an adjective. Similar constructions are be street smart and be rock funny.

4.1.2. Analysing variable functions of genius
When genius appears in a slot where typically A but not N occur, as in (22), its adjective status is clear. However, not all instances are straightforward with respect to their status as N or A. In this section, we give examples of clearcut instances and provide discussion of those disambiguated in context.
Remaining unclear instances were marked ‘u’ in our data.

4.1.2.1. Attributive uses
When genius modifies a noun without adverbial modification, the interpretation hinges on the relationship between genius and the head noun. The combi-nation genius N can either mean ‘N for/of geniuses’, where genius is a count noun, or it can mean ‘intelligent N’, where genius is an adjective. If genius N means ‘intelligent N’, genius should be an adjective rather than a noncount noun meaning ‘intelligence or intellect’, because modification is the prototypical function of A (Croft Reference Croft2001, Reference Croft2022).
Genius school, genius grant are NN compounds that are listed in the OED with the interpretation ‘school for geniuses’, ‘grant for geniuses’. More examples where genius is a noun are shown in (23), and the interpretation is ‘the N for/of geniuses’.

Some genius N combinations are AN, where genius means ‘intelligent, brilliant, extremely good’, as in (24).

Some genius N combinations are vague and allow both interpretations. Among our genius dataset, genius preceding a noun with reference to a person is a case in point. As shown in (25), the combinations can either mean ‘an intelligent scientist’, ‘an intelligent criminal’ or ‘a scientist who is a genius’, ‘a criminal who is a genius’. We thus annotate instances of genius that modify a person as unclear.

4.1.2.2. Predicative uses
When genius is used predicatively, BE genius can either be interpreted as ‘be intelligent’ as in (26a) or ‘be intelligence’ as in (26b). Genius cannot be a noun in (26a) because genius does not equal the way. Genius in (26b) cannot be an adjective because we cannot say ‘all he had was intelligent’. Genius in (26c) is underspecified, because both interpretations ‘what is intelligent’ and ‘what is intelligence’ are possible.

4.1.2.3. Disambiguation – structure and context
As mentioned before, when genius premodifies a noun with reference to a person, its category status is underspecified. However, parallelism can play a role in interpretation. Parallelism with nouns in construction pushes the interpretation towards N as in (27), where the genius kids is parallel to the cement-head football kids, and genius is more likely to be a noun.
Structure and context also disambiguate predicatively used genius. In (28a) ‘BE A (for sb) to’ infinitive construction disambiguates the category status, and genius is an adjective rather than a noun. Parallelism with a prototypical adjective in construction pushes the interpretation of genius towards A, as in (28b). Similarly, when genius occurs in parallel with a noun, as in (28c), this supports the analysis of genius as a noun.

The sequence genius and ADJ N is ambiguous. Genius can be a noun and coordinate with another noun that is modified by an adjective, or genius can be an adjective and coordinate with another adjective. For instance, (29a) can be interpreted either as ‘Mr. Field is a prodigy and wonderful person’ or ‘Mr. Field is an intelligent and wonderful person’. However, genius in (29b) can only be a noun.Footnote 10

Ambiguity also manifests in the sequence ADJ genius N. For instance, in (30a) he can be either one of the ‘strange intelligent types’ or ‘types of strange genius’. However, genius in (30b) must be a noun because of the order of the premodifiers (*my strong, mathematical intelligent son is ungrammatical). The interpretation is ‘my son who is strong and a mathematical genius’. In (30c), the nominal reading of genius is decided by the context (‘the myth of the eccentric genius’).

Examples from bridging contexts (Evans & Wilkins Reference Evans and Wilkins2000; Heine Reference Heine, Wischer and Diewald2002: 84) are also attested in our data. In (31), the syntactic parallelism works in both directions: genius is in the middle, towards the left are structures supporting interpretation as N, while towards the right we find structures supporting interpretation as A. Genius is underspecified – it can either be N (‘system that develops geniuses’) or A (‘intelligent development system’).

BE genius enough is also unclear and creates a bridging context, shown in (32). The construction can be interpreted as ‘be intelligent enough’ and genius is an adjective. Alternatively, the construction is analogous to ‘be man/woman enough’Footnote 11, and thus genius is a noun. We annotated genius in such a construction as unclear in our data.
4.1.3. Annotation
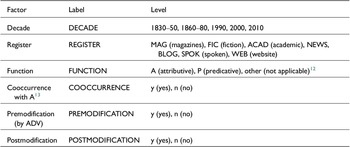
After postediting, our dataset of N>A genius consists of 2,174 examples where genius is potentially A. We annotated the data for a set of external and internal predictor variables (see table 2).
Overview of annotation categories
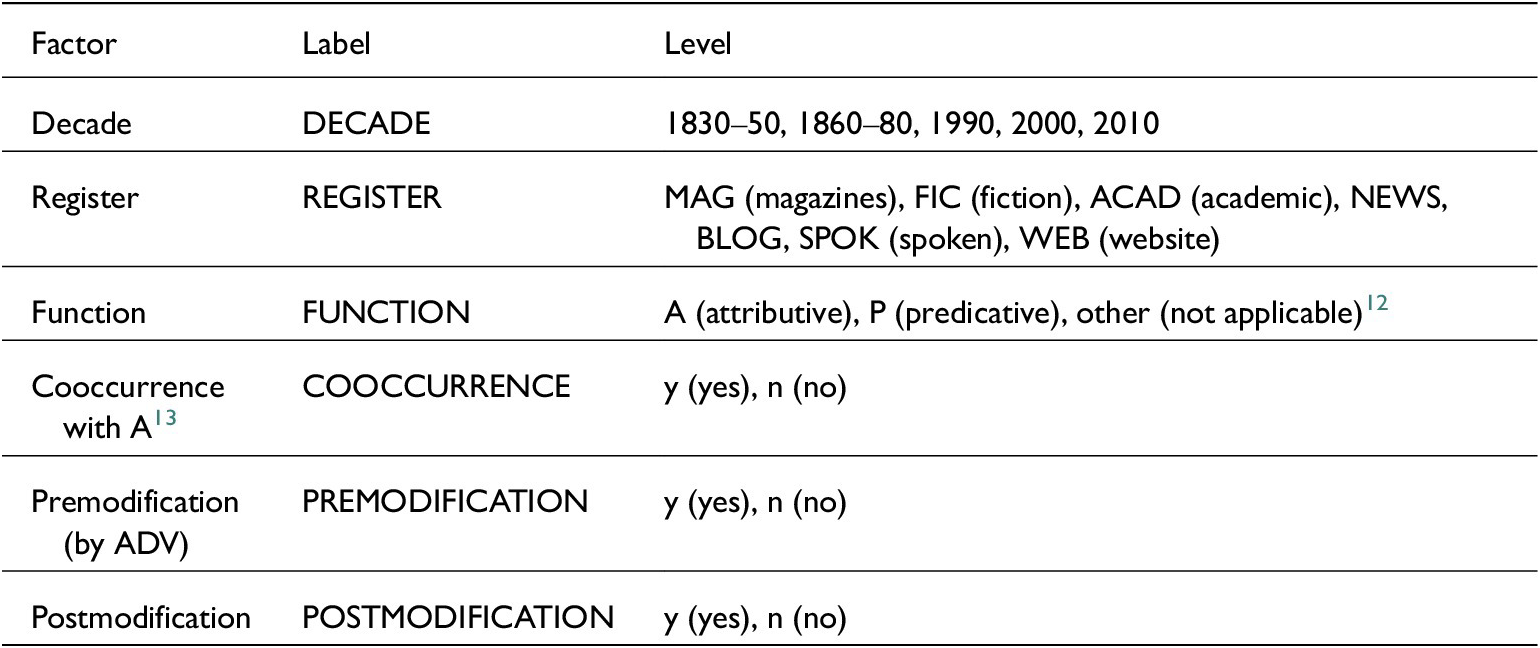
For the first decades, we collated the hits into thirty-year subperiods (1830–50, 1860–80, 1890–1910, etc.) on account of their overall low frequency (see section 4.2). As register is not strictly comparable across COHA and COCA, we decided to recode all instances from TV and MOVIE as SPOK (spoken) and subsumed instances of NF/ACAD under academic (ACAD) texts.
4.1.4. Statistical modelling
In order to gauge the importance that the predictor variables that we coded for are likely to have had in N>A shift of genius, we fitted a random forest (RF) and conditional inference trees (ctree) to our data using the partykit in R (Strobl, Hothorn & Zeileis Reference Strobl, Hothorn and Zeileis2009; Strobl, Malley & Tutz Reference Strobl, Malley and Tutz2009). The RF employs permutation testing, which, unlike traditional regression analysis, does not rely on the assumption of normally distributed data. Instead, it generates a distribution through repeated resampling of the observed dataset. The algorithm builds many individual regression trees from random subsets of the data and aggregates their results to form the random forest. The RF approach estimates the relative importance of predictor variables but does not provide information about the direction of their effects or possible interactions between them. In contrast, a single ctree, while less robust than an RF, offers a more transparent way to explore and visualise potential interactions among predictor variables. The ctree algorithm uses recursive partitioning to make predictions, splitting the data into binary branches that maximise homogeneity within resulting groups. The terminal nodes, or ‘leaves’, of the ctree reveal how combinations of predictors influence the selection of a specific outcome or variant. An additional advantage of the RF and ctree approach is that, unlike other types of multifactorial modelling, they allow for the modelling of dependent variables with three outcomes.Footnote Footnote Footnote 14
4.2. Results
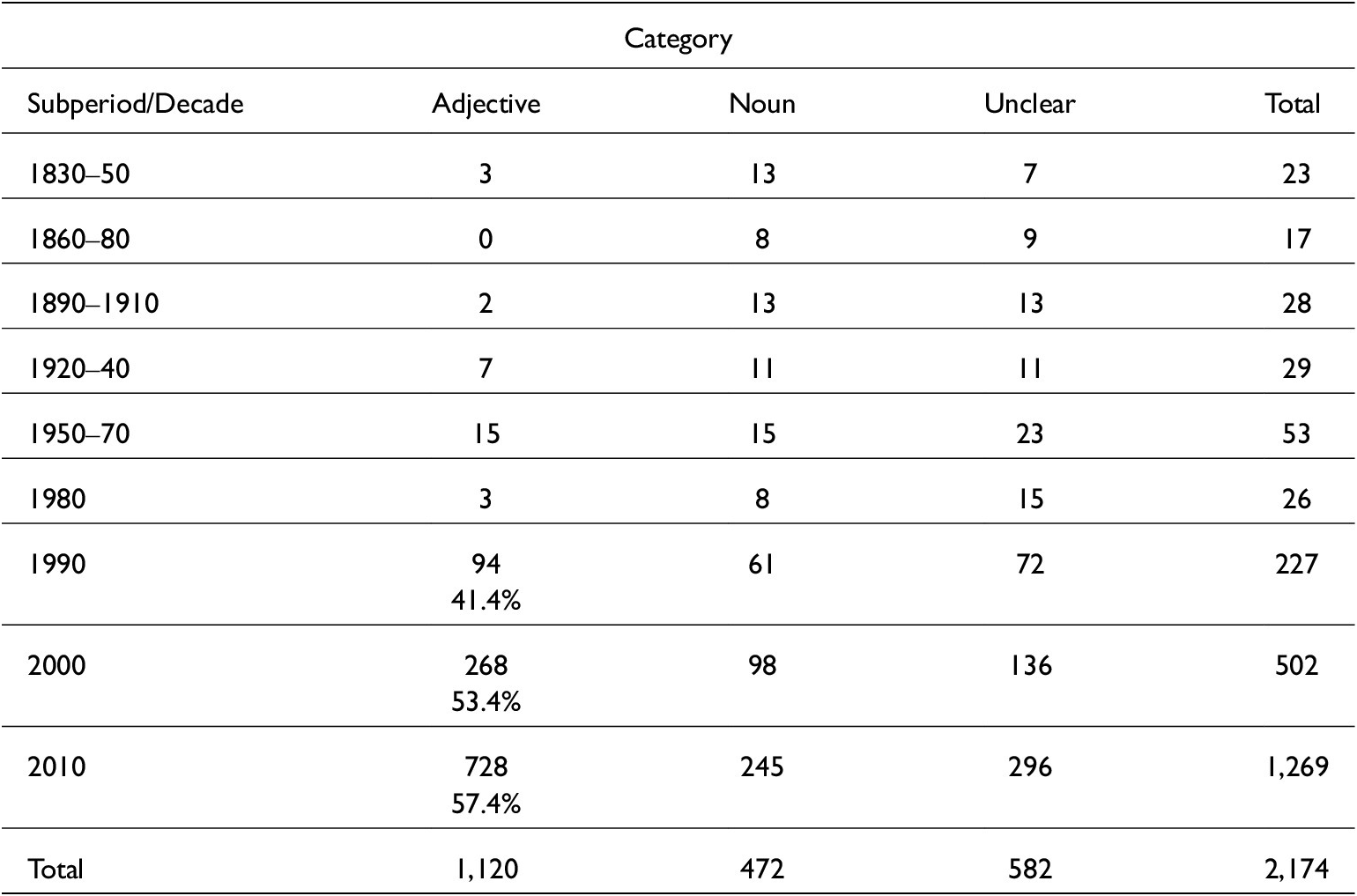
With respect to the distribution across time, the data are very unevenly split. While the first unambiguous instances of genius as A date from the 1840s, datasets of >50 instances per decade are only found from the 1990s onwards (see table A1 in the Appendix). Of the 2,174 potentially adjectival uses of genius, 582 are underspecified, 472 are N and 1,120 are A.
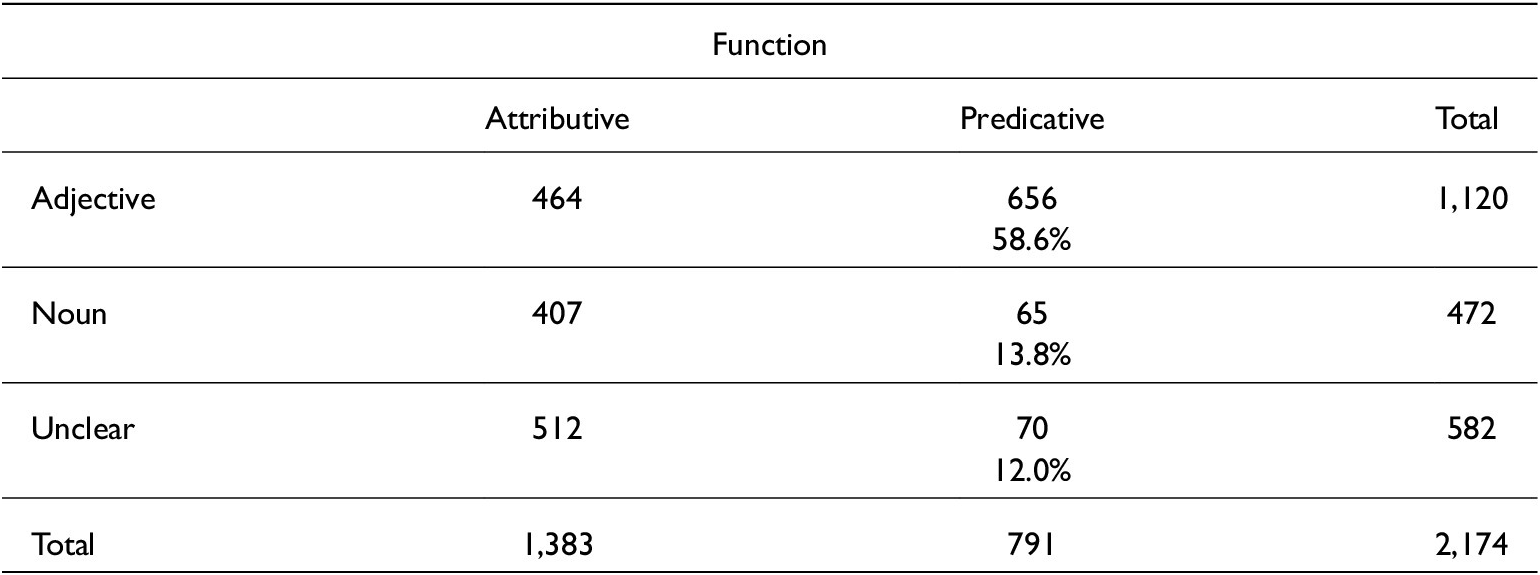
For the years 1950–80, the proportion of unambiguous adjectival uses amounts to only 22.8 per cent. This proportion increases to 41.4 per cent in 1990, and to 43.4 per cent and 47.4 per cent in 2000 and 2010, respectively. There is thus a substantial increase in adjectival use of genius at the end of the twentieth century. Moreover, unambiguous A are not distributed evenly across the two functions in our dataset, with the majority (656 of 1,121 or 58.5 per cent) occurring in predicative function (see table A2 in the Appendix).
Figure 3 shows the results of the RF analysis (based on a total of 500 trees).
The RF returns the FUNCTION (attributive vs predicative) as the most important variable, followed by REGISTER and DECADE, with COOCCURRENCE as the least important variable and the two types of modification as insignificant predictors for categorisation. The single conditional inference tree also returned FUNCTION as the first split in the tree, as seen in figure 4.
Variable importance ranking for genius as adjective (vs noun or unclear) in COHA and COCA

Conditional inference tree for genius

Interestingly, COOCCURRENCE with an adjective shows interaction with genius in attributive function relatively early in the tree (node 2), with co-occurring adjectives patterning frequently with unclear instances or adjectives (node 12). For attributively used genius without a co-occurring adjective, register is an important predictor variable: the split at node 3 reveals a tendency for academic writing, news and magazines (node10), as well as fiction (node 11) to have fewer adjectival uses of genius than the more informal text categories (BLOG, SPOK, WEB). For these three registers, we see that premodification has an impact (node 4) in that instances without a premodifying adverb are less likely to be adjectival uses of genius than those with premodification (compare nodes 5 with 7 and 8).
Let us now move to the interplay of factors in predicative function on the right-hand side of the tree. This is where the diachronic dimension has a clear impact, with decades prior to 1990 having fewer adjectival uses than those including and following 1990 (node 13). For the most recent data, we see an additional interaction effect with REGISTER (node 15), where academic writing and magazines have overall fewer adjectival uses of genius than the other registers, but with an increase in genius as A in the 2000s and 2010s (compare nodes 17 and 18). In predicative function, genius is particularly likely to be used as A in BLOG, FIC, NEWS, SPOK and WEB registers (node 19).
Importantly for our study, both the RF and the ctree return the functional slot (attribution vs predication) as the most important factor in the categorisation of genius as adjective (vs noun or unclear).
4.3. Qualitative analysis: data that antedate the OED
The earliest OED attestation of adjective genius is from 1924, as shown in (33).Footnote 15 We found examples in COHA that antedate the OED’s first attestation, listing a few in (34). In (35) genius seems to be an adjective at first sight because of the exclamation mark. However, it turns out to be a metaphorical use of genius as divine inspiration and thus genius is a noun. Example (36) is also worth mentioning. Genius is vague, and both A and N interpretations work for the structure and the context. The interpretation can be either ‘which he considered intelligence’ or ‘which he considered intelligent’.

5. Conclusion and outlook
Inspired by previous research on category shift from N to A (De Smet Reference De Smet2012; Denison Reference Denison2013, Reference Denison, Hundt, Mollin and Pfenninger2017) we carried out a bottom-up type-based study of the phenomenon. Our dataset includes different types of N>A shift in terms of the word formation of the shifted nouns. Adjectives shifted from simplex nouns are the most frequent type, followed by those shifted from derived nouns. Adjectives shifted from compound nouns are the least frequent type. Interesting subtypes are adjectives shifted from nouns with the suffix -ist, from material nouns, and from compounds or noun phrases of the type high-N, low-N. The category shift predominantly occurs in attributive function first and later in predicative function regardless of the countability of the nouns undergoing shift to A. Thus, our results provide a new perspective on previous findings of key and fun with respect to the (non)generalisability of the two different paths of the N>A shift (De Smet Reference De Smet2012).
The token-based study on genius provides further insights into the relationship between countability of the noun and the path to adjectivehood. The prediction based on findings of key and fun is that for a noun that can be both count and noncount, attributive and predicative function would be equally likely as functional slots for the shifted adjective. However, the result of the statistical modelling on our dataset where genius is potentially A goes against this prediction. Both the RF and the ctree return the functional slot (attributive vs predicative) as the most important factor in the lexical categorisation of genius. In addition, the ctree shows the more detailed interplay of factors in both functions, where we see how co-occurrence with an adjective, register, premodification and decade play their roles in categorising genius as A, N or unclear.
The limitations of our approach on the N>A shift in LModE is that the data analysis of the N>A shift types is based primarily on the OED. Comparison with Denison’s (Reference Denison2013: 165, 2017: 303) list of serendipitous finds of recent shift to A reveals that our data do not include those, because their category shift is not recorded in the OED yet. As the N>A shift typically occurs first in attributive position, a corpus-based approach that starts from constructions which foster neoanalysis as A might prove fruitful in future studies.
It seems that nouns with -ist ending have systematically undergone N>A shift. This subtype deserves further investigation, and it would be interesting to see whether there is constructional context that provides evidence of neoanalysis of -ist nouns as A having taken place. Since nouns with -ist suffix are count nouns, BE + -ist is likely to be a context where -ist nouns would be unambiguously A. The search of ‘BE realist’ in COHA and COCA generates ample evidence of realist as A, as the examples in (37) illustrate:

What is also intriguing about the N>A shift of -ist nouns is that almost all of them have a corresponding adjective ending in -istic, which expresses a similar meaning or even the same meaning as the adjective that is isomorphic with the noun (e.g. capitalist – capitalistic, specialist – specialistic, terrorist – terroristic, modernist – modernistic, minimalist – minimalistic). Questions to be answered in future research with respect to this N>A template are: which form of derived adjectives appeared first, N>A shifted adjectives or -istic adjectives? And how do the two forms compete against each other?
Furthermore, language models can be applied for further investigation. Work is under way to see whether a word embedding modelFootnote 16 provides evidence for potential N>A shifts.
Acknowledgements
The research was supported by the Swiss National Science Foundation (209413). The authors are grateful to the editor Laurel Brinton and the anonymous reviewers for their constructive comments and suggestions on previous versions of this article.
Appendix
Overall development of genius (potential A contexts) in COHA and COCA

Distribution of genius by functional slot in COHA and COCA




 Open access
Open access