


1. Introduction
Children all over the world start learning English as a foreign language (EFL) at increasingly younger ages with attendance at afternoon schools outside their regular/mainstream day schools being common in many countries. There is limited research into classroom EFL learning in these younger ages, in particular outside Western Europe, and, specifically, on the impact of an earlier start on young L2 classroom learners. Our goal in this study is to investigate how the age at which children start their classroom EFL lessons impacts their acquisition of verbal morphology and what is the role of their L1. Specifically, we focus on 3SG-agreement and the past tense and present an empirical study of classroom learners in Moscow and Shanghai.
Unlike previous work, this field study is conducted in two countries outside Europe and North America, namely China and Russia, aiming to contribute to our understanding of young learners’ EFL learning in these contexts. Additionally, research on young EFL learners has primarily been conducted in mainstream day schools with designs focused on the national context of individual countries (e.g., García Mayo & Garcia Lecumberri, Reference García Mayo and Garcia Lecumberri2003; Muñoz, Reference Muñoz2006). In the current study, we present a cross-national design, exploiting the opportunities presented by international EFL schools, which run programs in various countries following a standardised curriculum and teaching approach. Such schools allow us to investigate young learners’ EFL development across countries and abstract from the specific educational context of individual countries. In this study, we examine the acquisition of verbal morphology by children attending after-school EFL classes at the same school, following the same curriculum and pedagogical approach. Our study, therefore, complements previous research investigating EFL acquisition in a single national context and within mainstream education.
Morphology is particularly challenging for both adult second language (aL2) and child second language learners (cL2) in naturalistic settings (e.g., DeKeyser, Reference DeKeyser2005; Hawkins & Chan, Reference Hawkins and Chan1997; Lardiere, Reference Lardiere2007; Paradis, Tulpar, & Arppe, Reference Paradis, Tulpar and Arppe2016) as well as instructed settings (e.g., Housen, Reference Housen, Granger, Hung and Petch-Tyson2002; Yang & Huang, Reference Yang and Huang2004). Verbal morphology is a well-researched topic; yet, investigating it in young learners through a cross-national design can provide new insights into how age and L1 might impact child L2 acquisition in an EFL-instructed setting. Our cross-national design involves two typologically distinct L1s: Russian, a language with a rich paradigm of verbal agreement and tense morphology, and Chinese, an isolating language with no agreement or tense morphology. Children may thus face a different learning challenge since Russian learners are already familiar with marking agreement and tense features morphologically on the verb, while Chinese learners are not.
In addition to L1, we investigate the effect of age (of onset) on the acquisition of verbal morphology by comparing children starting at different ages but with matched years of instruction.
1.1. The age factor in child second/foreign language acquisition
Research on the role of age in the acquisition of L2 grammar in naturalistic settings shows that children who start their L2 acquisition early have an advantage in ultimate attainment compared to those who start later in childhood or after it (e.g., Hyltenstam & Abrahamsson, Reference Hyltenstam, Abrahamsson, Doughty and Long2003; Johnson & Newport, Reference Johnson and Newport1989). For example, young children who immigrate to a new country and are immersed in the L2 at a very young age usually achieve native-like acquisition of the L2 grammar, whereas those who immigrate as adults often do not.
The advantage of an earlier start with L2 for ultimate attainment is well established for immersed learners who complete their primary and secondary education in their L2. However, the picture is more nuanced when we turn to classroom/FL learning studies, where learners are typically educated in their L1 and receive limited hours of FL learning classes as part of their mainstream curriculum or in FL schools. For instance, studies examining grammatical abilities in classroom settings and comparing earlier and later starters show that older starters are faster learners than younger ones (e.g., Cadierno et al., Reference Cadierno, Hansen, Lauridsen, Eskildsen, Fenyvesi, Hannibal Jensen and aus der Wieschen2020; Cadierno et al., Reference Cadierno, Hansen, Lauridsen, Eskildsen, Fenyvesi and Hannibal Jensen2022: comparing children starting EFL classes when they were 7–8 and 9–10, respectively, testing them over three consecutive years from onset; Cenoz, Reference Cenoz, García Mayo and García Lecumberri2003: testing children with different ages of onset at 4, 8, and 11 after 600 hours of instruction; Jaekel, Schurig, Florian, & Ritter, Reference Jaekel, Schurig, Florian and Ritter2017: testing children with ages of onset at 6–7 and 8–9 firstly in Year 5, that is, when children were 10–11, and subsequently in Year 7, when children were 12–13; Muñoz, Reference Muñoz2006: testing learners with different ages of onset at 8, 11, and 14, and in adulthood at different time points controlling for instruction time in English; Myles & Mitchell, Reference Myles and Mitchell2012: comparing children starting French at the ages of 5, 8, and 11, testing them three times: 9 weeks after they had been attending a course, 19 weeks, and two months later).
Older starters are thought to perform better due to cognitive maturity, the benefit of explicit instruction, and the ability to employ a wider range of learning strategies (e.g., Muñoz, Reference Muñoz2006). Not only do older learners learn faster, but they also do not seem to be disadvantaged for ultimate attainment since the majority of FL classroom studies have failed to establish an ultimate attainment advantage for younger starters (e.g., Muñoz, Reference Muñoz2006; Pfenninger & Singleton, Reference Pfenninger and Singleton2016: children tested at the beginning and end of secondary school, with early starters beginning English classes in Grade 3 of primary education and later starters upon entering secondary school).
Some studies, however, have indicated an advantage for younger starters in other language domains. Jaekel, Schurig, and Ritter (Reference Jaekel, Schurig and Ritter2022), assessing proficiency through reading and writing, found earlier learners who started at Grade 1 outperforming later learners starting at Grade 3 when tested in Grade 5. An early start advantage has also been found in phonemic discrimination for earlier starters (age of onset at 9 or later) compared to later starters (age of onset at 12–13) when all were tested as adults with an average age being 19.4 (Larson-Hall, Reference Larson-Hall2008). Finally, the same advantage has been shown for listening comprehension between early starters (who began English classes in elementary school) and late starters (who began English classes in secondary school) when tested as 18-year-olds (Pfenninger, Reference Pfenninger2014).
Most of the studies above have focused on children with an early age of onset, but typically after school entry age (6–7 years old). Few studies have considered children who start learning younger and before starting school. There are hypotheses suggesting that for morphosyntax, age effects begin at an even younger age (e.g., Meisel, Reference Meisel2009). Hence, more research is needed to determine whether an earlier age of onset in EFL learning provides any advantage for grammar acquisition.
1.2. The L1 factor in child second language acquisition
The age factor is intertwined with the L1; L2 children have already established their L1 when they start acquiring their L2, and hence the L1 may influence the acquisition of the L2. L1 effects are well-attested in various domains of child L2 (cL2). For example, Haznedar (Reference Haznedar, Hughes and Greenhill1997) as well as Mobaraki, Vainikka, and Young-Scholten (Reference Mobaraki, Vainikka, Young-Scholten, Haznedar and Gavruseva2008) found word order transfer from the children’s L1 to their L2 at the initial stages of acquisition. Paradis (Reference Paradis2011), testing children on the acquisition of verb morphology in English and with a mean exposure of 20 months, reports higher accuracy with past tense and agreement by children whose L1 marks tense morpho-phonologically compared to those whose L1 does not. In another study, Paradis et al. (Reference Paradis, Tulpar and Arppe2016) examining Chinese children’s accuracy in verb morphology after 6 years of immersion, found that not all children reached native-like levels of accuracy for one or more verb morphemes and pointed to the possibility of persistent L1 effects even for children with an early age of onset. Yang and Huang (Reference Yang and Huang2004), focusing on instructed learners of English with L1 Cantonese, attributed the learners’ rather low performance on verb morphology to L1 influence due to the absence of tense and agreement morphology in Cantonese. Finally, Rocca (Reference Rocca2007), testing Italian children learning English, found that they frequently used stative progressives that she interpreted as transfer of a prototypical feature of the Italian imperfective.
In sum, evidence for L1 effects on verb morphology, especially after the initial stages of learning (for a study on the initial stages of development, see Paradis, Rice, Crago, & Marquis, Reference Paradis, Rice, Crago and Marquis2008), is robust, as shown above. Still there is some unclarity on the effects of L1 in an EFL context of limited input.
1.3. Other factors that play a role in child L2 acquisition
Various other child-internal factors have been found to influence the L2 acquisition of grammar. Roehr-Brackin and Tellier (Reference Roehr-Brackin and Tellier2019) showed that analytic-language ability predicts achievement in L2 French grammar for English-speaking children learning French in classrooms. They further highlighted that analytic language ability and, more broadly, aptitude are dynamic in children under 12 years of age. Motivation (e.g., Djigunović & Nikolov, Reference Djigunović, Nikolov, Lamb, Csizér, Henry and Ryan2019; Skehan, Reference Skehan and Robinson2002), attitudes towards English L2 learning (Myles, Reference Myles2022), personality characteristics such as anxiety, extroversion/introversion, risk-taking, and self-esteem (e.g., Fenyvesi, Hansen, & Cadierno, Reference Fenyvesi, Hansen and Cadierno2020), as well as gender (e.g., Cadierno et al., Reference Cadierno, Hansen, Lauridsen, Eskildsen, Fenyvesi and Hannibal Jensen2022), have also been shown to impact L2 achievement.
Turning to contextual factors influencing L2 achievement in an FL setting, use of and exposure to English have been shown to be consistent predictors (Tragant & Muñoz, Reference Tragant and Muñoz2023). One of the strongest predictors of L2 achievement is the amount of out-of-school exposure to the language through media (e.g., Lindgren & Muñoz, Reference Lindgren and Muñoz2012). Other factors playing a role include the L1 literacy (e.g., Pfenninger & Singleton, Reference Pfenninger and Singleton2016), the educational background of learners’ parents (e.g., Butler & Le, Reference Butler and Le2018), the L2 proficiency of parents (Muñoz & Lindgren, Reference Muñoz, Lindgren and Enever2011), the cultural capital learners live in, and the status of the L2 language in society.
1.4. Verb morphology in English, Russian and Chinese and L2 learning
We chose Chinese and Russian as two languages that vary in different ways from English in relation to the features we are examining: Russian is broadly similar to English while Chinese is typologically quite distant from English. We capture cross-linguistic variation through generative parametric variation, meaning variation in the features associated with the functional category of Tense. Tense is a functional category encoding features of tense and agreement. Simplifying somewhat, tense features in English are realised through the auxiliaries be and have and bound morphology -ed in the past.Footnote 1 Agreement is morphologically expressed through the third person singular in the present through an affixed -s (and on the auxiliaries be (is/are/am) and have (have/has)).
Features may be interpretable or uninterpretable (Chomsky, Reference Chomsky and Webelhuth1995: 277). The interpretable features are associated with semantic features at the Logical Form (LF)Footnote 2 (e.g. past tense interpretation in “she studied”) while uninterpretable features are formal features void of semantic meaning (e.g., 3SG agreement in “she studies”). Thus, tense is an interpretable feature while agreement -s is an uninterpretable one. This distinction is central to the Interpretability Hypothesis (Tsimpli & Dimitrakopoulou, Reference Tsimpli and Dimitrakopoulou2007), which suggests that L2 learners find uninterpretable features more challenging than interpretable ones. According to this hypothesis, only semantic/LF-related features are accessible to L2 learners while formal/uninterpretable features not realised in the L1 are not available to L2 learners. The Interpretability Hypothesis predicts that, other things being equal, tense features will be more easily acquired than 3SG-agreement -s. Adding the effect of the L1–L2 typological similarity, we can predict that Russian learners will find tense and agreement morphology less challenging than Chinese learners, since the corresponding (abstract) tense and agreement features are part of the L1 Russian grammar, but not part of the L1 Chinese grammar.
Let us consider the respective phenomena under examination in the three languages in more detail. English marks person agreement only on third person singular in present (e.g., She play-s basketball.) and marks verbs for past tense (e.g., She climb-ed the ladder. /He made a house.).
We here consider Mandarin, Cantonese, and Shanghainese and refer to all three as Chinese, as they are all typologically similar with respect to the phenomena under focus; specifically, they are all isolating, they do not encode tense and agreement morphologically, and they may mark aspect through (mainly) unbound particles (Li & Thompson, Reference Li and Thompson1981).
Example in Chinese with generic/habitual interpretation:
1.
Laoshi jiao xuesheng.
Teacher teach student.
“A teacher teaches students.”
Example in Chinese with past interpretation:
2.
Ta shua le liba.
PR3SG. paint LE-PERF ASP fence.
“He painted the fence.”
Example (1) has a plain verb with no marking. Such examples usually have a habitual interpretation corresponding to the simple present.
Example (2) involves a personal pronoun and the aspectual marker le. “Ta” has a third-person interpretation, thus encoding interpretable person features, but crucially, there is no third-person agreement morphology on the verb.
“Le” is an unbound perfective marker usually found with past events but also used for future events. To indicate time reference, Chinese uses temporal adverbs, while discourse, context, and world knowledge can also situate an event in time. Thus, Chinese differs from English in that it lacks grammatical tense manifested in affixal morphology (or an unbound morpheme); further, as an isolating language, it lacks agreement.
Russian marks verbs with morphological affixes for both tense and agreement (Mezhevich, Reference Mezhevich2008); both are instantiated in the present and simple past as examples 3 and 4 show.
Example in Russian with generic interpretation:
3.
Stomatolog lech-it zuby.
Dentist cure-PRESENT.3SG teeth.
“A dentist cures teeth.”
Example in Russian with past and perfective interpretation:
4.
On po-krasi-l zabor.
He PERF-paint-PAST.MASC.SG fence.
“He painted the fence.”
In example (3), the present form of the verb is inflected for third person singular.
In Example (4), the prefix po- encodes perfective aspect while the affix -l conflates tense, gender, and number features. So, in the past (perfective), the verbal form agrees in gender and number with the subject.
To summarise, English and Russian realise both grammatical tense and agreement as morphological affixes on the verb while Chinese does not. Thus, Chinese learners need to acquire tense and agreement features which are absent from their L1; Russian learners can rely on the tense and agreement features in their L1 to acquire tense and agreement verbal morphology in English.
2. The present study
Our study investigates the role of age (of onset) and L1 on the acquisition of verbal morphology by L2 child classroom learners in an instructional FL classroom environment. Specifically, we consider the following research questions:
Research Question 1: Will the starting age of learning EFL play a role in the acquisition of verbal morphology? Will younger starters have an advantage in verbal morphology? Or will older learners outperform younger ones as much as previous research has shown, albeit in different contexts and with overall older child learners?
Research Question 2: Can we detect L1 influence? Will the presence of tense and agreement features in L1 Russian facilitate the acquisition of verbal morphology for Russian-speaking children in contrast to Chinese-speaking children who lack tense and agreement morphology in their L1? Will Russian learners achieve higher accuracy as a result of the L1 influence?
Research Question 3: Are uninterpretable features (i.e., 3SG-agreement) more challenging than interpretable (i.e., past tense) ones?
Previous studies suggest an advantage for older children regarding the first research question. Yet, no study has considered classroom learners in EFL schools complementing mainstream education. Further, unlike most of the previous studies, we consider learners with a very early age of onset (AoO: 4 and 7) to establish whether a potential advantage would manifest with an earlier AoO, at 4 in our study in comparison to learners with older ages of onset in previous studies. We further anticipate that Russian learners, whose language instantiates tense and agreement features, will outperform Chinese learners, whose language lacks these features. Finally, following the Interpretability Hypothesis, we expect that all learners will find past tense features easier to acquire than 3SG-agreement.
3. Method
3.1. Study design and rationale
To investigate the role of age, we tested 9- and 12-year-old children starting their EFL learning at 4 and 7, respectively, thus having had 5 years of instruction in the afternoon EFL schools we recruited them from. We compared Chinese and Russian learners and the acquisition of tense marking with 3SG-agreement. We present our method in detail in the following sections.
3.2. Instructional setting
The data collection was carried out in EF (Education First/English First) schools in Shanghai and Moscow which are private afternoon schools teaching EFL. These schools are complementary to mainstream day schools that children attended.
A standardised curriculum was followed in both countries, supported by books and online resources produced by EF. There was some variation in the number of teaching hours offered in each country. Thus, EF in Shanghai offered 2 academic hours (1 hour = 40′-45′) per week for all ages, while EF schools in Moscow gradually increased weekly teaching hours with age, offering 3 academic hours (1 hour = 40′-45′) to children 3–6, raising to 4 hours to children 7–9, and to 5 hours to children older than 9.
EF employed native speakers of English or qualified non-native speakers and provided in-house training. In Shanghai, EF teachers were (mostly) native speakers of English while in Russia, most teachers were Russian native speakers. All teachers followed the same EF internal curriculum and used the same materials (e.g., book series, online/interactive activities).
Teaching followed mostly a communicative approach blended with some behaviourist elements (e.g., drilling, rewards), especially for younger learners. There was more focus on form for older learners, although the approach remained communicative. At more advanced ages, drilling was abandoned. It is important to highlight that different book series were used for different ages so that children starting at 4 and children starting at 7 would not use the same books. The book series is different in content and teaching practice, as we will see below.
In our classroom observations, we saw that the lessons in both countries were highly interactive, and learners were engaged. The teachers would encourage participation, and learners generally seemed motivated (which was also confirmed through our parental questionnaires). The learning atmosphere was positive and relaxing, and students seemed comfortable.
Overall, the instructional settings in EF in the two countries were fairly similar, following a standardised curriculum, teaching resources, and similar approaches to teacher training and classroom pedagogy.
3.3. Teaching of the grammatical phenomena under focus in EF language schools
A child starting to learn English at EF at 3 or 4 would have a prolonged A0 CEFR level which lasted up to the age of 6. At this level only very basic structures were introduced. Simple present and present continuous were introduced with the former expected to be mastered at the ages of 7–8. The simple past was introduced later than the simple present at the ages of 7–8 to be mastered at the ages of 8–9. This means that children starting English at 4 would be exposed to the simple past at around the same age with children starting at 6. The key difference was that the younger groups would have earlier exposure to the language, including the present tense with the past tense introduced later.
3.4. Educational context in China and Russia
At the time of the data collection, in Shanghai, literacy in Mandarin officially started at age 6 (primary school one) in mainstream day schools. Preschool education started at age 3 up to 6 and was not obligatory, although the enrolment rate in urban areas was very high (98–99%) (Zhou, Reference Zhou2011). In preschool education, children were not explicitly taught academic skills; teachers followed informal literacy practices (China Preschool Education Research Society, 1999 as referenced in Li, Reference Li2013; Li, Corrie, & Wong, Reference Li, Corrie and Wong2008).
In Moscow, L1 literacy also started when children entered state day schools around the ages of 6.5–8 (Bodrova & Yudina, Reference Bodrova, Yudina, Roopnarine, Johnson, Quinn and Patte2018). Preschool education was not compulsory, but similarly to Shanghai, the vast majority of parents enrolled their children in preschool education which combined childcare and education (Bodrova & Yudina, Reference Bodrova, Yudina, Roopnarine, Johnson, Quinn and Patte2018). Thus, in Shanghai, children were introduced to literacy slightly earlier than in Moscow, something that was also confirmed through responses to our parental questionnaires. According to Chinese parents, on average, their child started to learn to read and write in Chinese at age 4, while according to Russian parents, the respective average age reported was 5.
Turning to cultural attitudes towards schooling, in Shanghai, there was a significant tendency towards early learning and achievement. As Sun, de Bot, and Steinkrauss (Reference Sun, de Bot and Steinkrauss2014) argue, “Chinese parents’ mindset is along the lines of the earlier, the better” and “we must not lose at the starting line” (p. 2). Education was of the outmost importance and a top priority for Chinese parents who had very high demands and expectations for their children (Hu & Szente, Reference Hu and Szente2009). The “one-child policy” held until recently in China had meant that parents paid even greater attention to their child’s academic achievements (Hu & Szente, Reference Hu and Szente2009) which were viewed as the determinant for their social upgrade in a very competitive market. It is not surprising then that in China, private English language schools, but also early learning centres aiming to boost children’s cognitive and general learning development, have been proliferating. By the time they reach 15 years of age, learners quit private language schools to focus on preparations for the “Gaokao” exam, the national exam determining their entrance to university.
In Moscow, children generally started English around one year later (not only privately but in day schools as well, as we shall see below) and continued attending classes at EF up to the age of 17 or so. Unfortunately, there is not much literature on parents’ attitudes towards education (at least in the English language). However, based on personal discussions with the EF teachers in Moscow and the children’s parents during the data collection, it seemed that Russian parents also value education and an early start.
3.5. Participants
L1-Chinese-speaking children
A total of 73 child participants were tested during the data collection in Shanghai. All children were native speakers of Chinese. They formed two groups: the first group involved 39 nine-year-olds (20 girls and 19 boys), and the second group involved 34 twelve-year-olds (16 girls and 18 boys). The younger group had a mean age of 9;7,Footnote 3 and the older group had a mean age of 12;6. Children were not exposed to English at home, as the home language as well as the parents’ L1 was mostly Chinese, including Mandarin and Cantonese; a few parents also reported Shanghainese as the home language which like Mandarin and Cantonese, does not instantiate tense and agreement. Children came from families of a high socioeconomic status and highly educated parents. The vast majority of the parents (124/144) had a university degree (>85%); the remaining few (20/144) had professional training or low/upper secondary education.
L1-Russian-speaking children
A total of 74 child learners were recruited at EF schools in Moscow. As with the Chinese children, two groups were formed, 32 nine-year-olds (14 girls and 18 boys) and 42 twelve-year-olds (19 girls and 23 boys). The younger group had an average age of 9;8 and the older ones 12;6. The children’s L1 and home language was always Russian. Russian was the mother tongue of all parents except for one father whose first language was Armenian. Children came from families of high socio-economic status. The vast majority of the parents (> 90%) had postgraduate education while only a few had professional training (7/147), and one reported elementary school while his/her partner had a postgraduate qualification.
Table 1 shows an overview of the groups of participants.
Overview of participants

Table 1. Long description
The table is organized into five columns. The first column contains the row labels. The remaining four columns are grouped under two main headers: Chinese and Russian.
* The Chinese group is divided into 9-year-olds and 12-year-olds.
* The Russian group is divided into 9-year-olds and 12-year-olds.
Data rows are as follows:
* N (Sample Size): For the Chinese group, there are 39 9-year-olds and 34 12-year-olds. For the Russian group, there are 32 9-year-olds and 42 12-year-olds.
* Mean age: For the Chinese group, the mean age is 9 years 7 months for the younger cohort and 12 years 6 months for the older cohort. For the Russian group, the mean age is 9 years 8 months for the younger cohort and 12 years 6 months for the older cohort.
3.6. Length of exposure and input
We operationalised length of exposure as the number of years of instruction at EF schools. In addition, we considered the academic hours of attendance for each child in EF since, as we saw earlier, for Russian children teaching hours increased with proficiency while in China the hours of classes remained constant for all levels. Further, Shanghai schools offered extra mini-intensive courses over holidays which were not available in Moscow. Table 2 summarises the mean academic hours for Russian and Chinese age groups. As can be seen, the younger group in Moscow had fewer hours of attendance than their counterparts in Shanghai. The gap closes for the older groups.
Mean academic hours and ranges of attendance in EF by both Chinese and Russian children

Table 2. Long description
The table consists of five columns and two rows.
Column headers from left to right are:
1. Academic hour equals 40 mins
2. C H underscore 9 y dot o dot
3. C H underscore 12 y dot o dot
4. R U underscore 9 y dot o dot
5. R U underscore 12 y dot o dot
The second row, titled Academic hours in E F, contains the following data points (mean followed by range in brackets):
- C H 9 year olds: 880 [384 to 1455.5]
- C H 12 year olds: 821 [546 to 1065]
- R U 9 year olds: 592 [242 to 697.5]
- R U 12 year olds: 804 [405 to 921.5]
We also need to consider English classes in day schools. In Shanghai, children started English at the age of 6 (primary 1) and received around 4 hours of instruction per week on average (Tan, Reference Tan2012). In Moscow, children started learning English at day schools at 8 years of age and received 3 academic hours per week. Hence, our Russian participants had received less overall teaching input in English than their Chinese counterparts at the time of data collection. The Russian nine-year-olds would have attended one year of English classes at their day school in comparison to 3 years attended by the Chinese nine-year-olds; in addition, Chinese nine-year-olds would have had more teaching hours per week overall in their day schools. These discrepancies are less pronounced for the twelve-year-olds; the Russian twelve-year-olds would have attended 4 years of English day school instruction in comparison to 6 years attended by the Chinese twelve-year-olds.
3.7. Proficiency
To assess the learners’ proficiency, we utilised the CEFR (Common European Framework for Reference for Languages, Council of Europe, 2001) levels of EF classes attended at the time of testing, based on teachers’ assessments. Additionally, we administered the Word Finding Vocabulary task (Renfrew, Reference Renfrew1995).
3.8. Class CEFR level
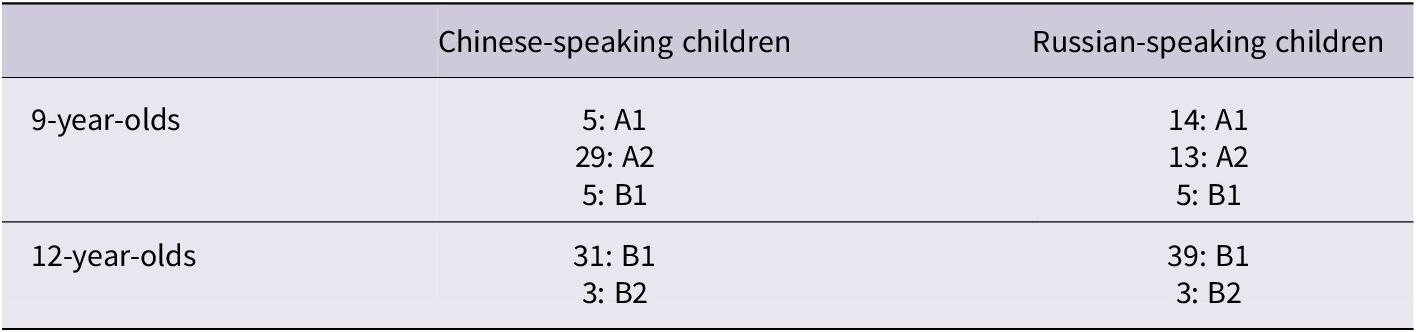
Table 3 shows the proficiency levels of the class children attended at the time of testing. The majority of the twelve-year-olds have reached B1 in both nationality groups which are comparable in proficiency. However, there is variation in the proficiency of the younger groups. In both nationality groups, a small number of nine-year-olds (5) have reached B1 with the rest in A. However, in the Russian group, the remaining children are split into A1 and A2 (14 and 13, respectively), while in the Chinese group, the vast majority (29) are A2; thus, more than twice Chinese year-olds are in A2 than Russian ones, which means that the Russian group is of lower overall proficiency.
Proficiency levels corresponding to the class children attended at time of testing

Table 3. Long description
The table consists of three columns and three rows.
Column headers from left to right are: Age group, Chinese-speaking children, and Russian-speaking children.
Row 1: 9-year-olds. For Chinese-speaking children, 5 are at level A 1, 29 are at level A 2, and 5 are at level B 1. For Russian-speaking children, 14 are at level A 1, 13 are at level A 2, and 5 are at level B 1.
Row 2: 12-year-olds. For Chinese-speaking children, 31 are at level B 1 and 3 are at level B 2. For Russian-speaking children, 39 are at level B 1 and 3 are at level B 2.
3.9. Word finding vocabulary task
The Word Finding Vocabulary Task (Renfrew, Reference Renfrew1995) captures children’s production of vocabulary. Children were asked to name the picture they saw on a computer screen (e.g., a cup). Each picture was presented individually on a PowerPoint presentation. There were in total 50 test items. Target words as specified in the task were scored with 1, and any other answer was scored with 0.
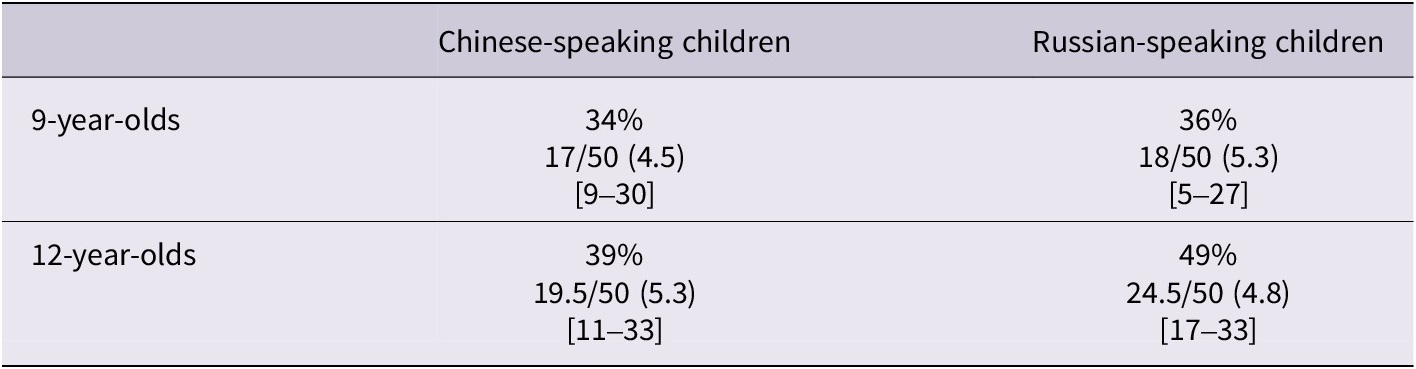
Table 4 summarises the mean vocabulary scores and ranges across groups. As can be seen, the group of Chinese nine-year-olds had a mean score of 17/50, while the group of Chinese twelve-year-olds had a 19.5/50 average score. As for the Russian children, the group of the nine-year-olds produced, on average, 18 correct words out of the 50, with the group of twelve-year-olds scoring 24.5/50.
Percentages of correct responses, average scores (standard deviations) and their ranges in brackets concerning children’s scores on the renfrew word finding vocabulary task

Table 4. Long description
The table consists of three columns and three rows. The first column lists the age groups, while the second and third columns provide data for Chinese-speaking children and Russian-speaking children, respectively. Each data cell contains the percentage of correct responses, the average score out of 50 with the standard deviation in open parenthesis close parenthesis, and the score range in brackets.
* Row 1, Header: The columns are Age Group, Chinese-speaking children, and Russian-speaking children.
* Row 2, 9-year-olds: Chinese-speaking children scored 34 percent, with an average of 17 all over 50 4.5 and a range of 9 to 30. Russian-speaking children scored 36 percent, with an average of 18 all over 50 5.3 and a range of 5 to 27.
* Row 3, 12-year-olds: Chinese-speaking children scored 39 percent, with an average of 19.5 all over 50 5.3 and a range of 11 to 33. Russian-speaking children scored 49 percent, with an average of 24.5 all over 50 4.8 and a range of 17 to 33.
Despite their lower proficiency, Russian nine-year-olds had vocabulary scores as high as the Chinese nine-year-olds. This discrepancy between CEFR level and vocabulary scores could be explained by the relatively high proportion of Russian-English cognates in the test. There were 14 cognate words out of a total sample of 50 (9 kloun/clown, 10 krokodil/crocodile, 12 kenguru/kangaroo, 19 gitara/guitaar, 25 drel/drill, 32 binokl/binoculars, 36 parashut/parachute, 37 magnit/magnet, 40 iglu/igloo, 42 mikrofon/microphone, 43 sedlo/saddle, 46 raketka/raquet, 48 kompas/compass, 49 termometr/thermometer). Note that microphone (mai ke feng) and guitar (ji ta) may also be considered cognates in the Chinese language.
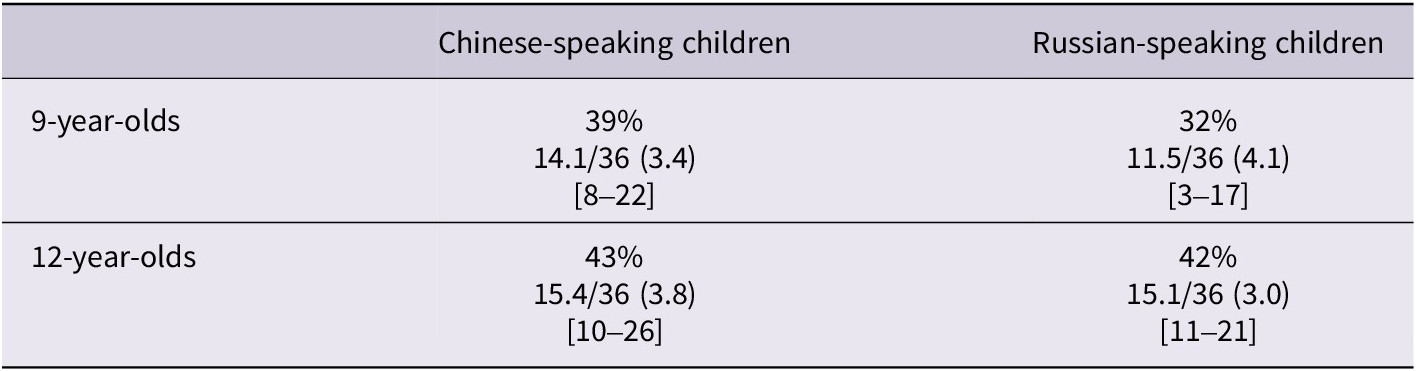
We removed the cognates from the word list and recalculated the vocabulary scores without them. Table 5 presents how the scores change. We can now see that the vocabulary scores correlate with the CEFR class levels. Younger Russians had lower vocabulary scores than their Chinese counterparts which corresponds to their lower CEFR proficiency. Older groups seem to have the same vocabulary size which corresponds to their comparable CEFR levels. It is noticeable, though, that there is only one point of difference in the average vocabulary score between Chinese nine-year-olds and twelve-year-olds, perhaps meaning that the task may not capture that well progression from A2 to B1.
Percentages of correct responses, average scores (standard deviations) and their ranges in brackets concerning children’s scores on the renfrew word finding vocabulary task

Table 5. Long description
The table consists of three columns and three rows.
Column headers from left to right are: Age group, Chinese-speaking children, and Russian-speaking children.
Row 1: 9-year-olds.
- Chinese-speaking children: 39 percent, average score 14.1 all over 36, standard deviation 3.4, range 8 to 22.
- Russian-speaking children: 32 percent, average score 11.5 all over 36, standard deviation 4.1, range 3 to 17.
Row 2: 12-year-olds.
- Chinese-speaking children: 43 percent, average score 15.4 all over 36, standard deviation 3.8, range 10 to 26.
- Russian-speaking children: 42 percent, average score 15.1 all over 36, standard deviation 3.0, range 11 to 21.
ANOVA analysis showed that there was a significant difference between the group means, F(3, 143) = 8.37, p < 0.001. Post-hoc tests using the Bonferroni method showed that only the Russian nine-year-olds had significantly lower scores on the Renfrew task than all the other groups (RU9 – CH9: p = 0.014, RU9 – CH12: p < 0.001, RU9-RU12: p < 0.001). There were no significant differences observed among the other groups (CH9, CH12, RU12) in their Renfrew task scores.
For statistical analyses in subsequent sections, we consider only the vocabulary scores without the cognates.
3.10. Experimental materials and questionnaires
Test of early grammatical impairment (TEGI)
To evaluate the influence of age and L1 on acquisition, we investigated the accuracy in the use of L2 English verbal morphology. Specifically, we used the TEGI (Rice & Wexler, Reference Rice and Wexler2001), a battery of elicited production tasks which includes production probes for third person singular (3SG) and past tense (regular and irregular). (See for TEGI studies in cL2: Chondrogianni & Marinis, Reference Chondrogianni and Marinis2011; Paradis et al., Reference Paradis, Tulpar and Arppe2016.)
The TEGI part capturing the 3SG-agreement consists of 10 test items following a practice item. The child would see a picture on a laptop screen depicting a person (e.g., a teacher, a dad), and the experimenter asked the child what each person does. For example, in the case of a picture depicting a teacher, the experimenter would say, “Here is a teacher. Tell me what a teacher does.” The use of the indefinite article seeks to elicit a generic description of what teachers do, with the target answer being “A teacher teaches.” Although the children were shown pictures, they were explicitly asked not to describe the people in the pictures.Footnote 4
We followed the TEGI guidelines with one exception: when the child gave a wrong answer, the experimenter did not provide the correct answer. This was to avoid the possibility of favouring older children who are better test-takers and may have had more practice than younger children with these types of tasks. However, the experimenter did correct if the child used the present continuous. For example, if the child said, “A teacher is teaching.” the experimenter would say, “Do not tell me what this teacher (pointing to the picture) is doing. Tell me what a teacher does. Any teacher.” or “Do not describe the picture. Tell me what any teacher does.”
The TEGI probe for past tense included 2 trial items and 18 test items: 10 targeting regular verbs and 8 targeting irregular verbs. Children were shown two pictures on a computer screen. The experimenter described the first picture and asked the child to describe the second one. For example, the experimenter said, “Here the boy is painting the fence (pointing at the first picture). Now he is done (pointing at the second picture). Tell me what he did. He …” Target answer: He painted (the fence).
As with the previous test, we followed the procedure indicated by the TEGI manual except for providing the correct answer in the example item when children did not provide the target.
3.11. Language background questionnaire
To collect information about children’s exposure to English and use outside their EF schools, we designed and administered a language background questionnaire. Questions concerned the AoO of learning English, for example at another school, parental L1, English language use at home, motivation, use of media in English, etc. (See Supplementary Material for details on the language background questionnaire).
3.12. Procedure
Our study was given approval from the Ethics Committee of our university’s School of the Humanities and Social Sciences. We administered parent information sheets through EF schools and obtained parental consent before testing the children. We tested children in a dedicated classroom in their EF schools. Each child had a one-to-one session with the experimenter, who always asked each child for oral consent before the testing. The whole process was recorded using a professional recording device. The testing session lasted on average 45 minutes with TEGI tasks lasting approximately 10′-15′ (we administered more tests not discussed in the present paper). Data were later transcribed orthographically by the experimenter.
3.13. Data coding and scoring of the probes
3.13.1. Coding and scoring of the TEGI 3SG
Correct answers were considered those which had a third-person singular subject and a verb marked with 3SG -s (e.g., “A father/He plays with his children.”) and were scored with 1. We scored with 0: i. the cases when the child used a third person singular subject and did not mark the verb with 3SG -s (e.g., *she play), ii. the instances of periphrastic marking (e.g., *He is play, she is playing, she can play; he does play), iii. Any other response using another tense form (e.g., simple past), plural subject, progressive participle -ing, does + verb-ing or noun, copula “be,” and iv. “No responses.”
3.14. Coding and scoring of the TEGI PAST
Correct answers were those inflected with –ed (e.g., She cleaned ) or the correct suppliance of the irregular form (e.g., He made ) and were scored with 1. We also scored with 1 answer using a lexical verb other than the targeted one but correctly inflected (e.g., tidied instead of target cleaned). Similarly, for irregular verbs (e.g., built instead of made). Instances of overregularization, e.g., *rided instead of rode, were coded separately and were scored with 1. All other answers were scored with 0: omission of inflection (e.g., She clean-∅ or He make), instances of periphrastic marking (e.g., “*The girl is/was clean her room. The boy is jumping,”), use of another tense, use of progressive participles as the main verb, instances of “did” + verb-ing or noun, “be” as a main verb, use of verbs such as hit, put, run for which we cannot be sure whether they were marked for past tense, use of another type of verb (e.g., regular instead of irregular), and “no responses.”
3.15. Statistical modelling
We conducted mixed-effects logistic regression (GMELR) analyses in R (R Core Team, 2014) to answer statistically our research questions repeated below:
-
a. whether there is an early age of onset advantage or an older age advantage as evidenced through accuracy in suppliance of agreement and past tense morphology,
-
b. whether Russians use 3SG-agreement and past tense markings more accurately than Chinese, and
-
c. whether 3SG-agreement is more challenging than past tense marking.
All categorical variables included as fixed effects were effect-coded (e.g., −0.5, 0.5) (Brehm & Alday, Reference Brehm and Alday2022). Continuous independent variables were z-score transformed. In all analyses, the level of significance was taken to be p < .05.
For the first two questions, we conducted three separate analyses, each considering accuracy in suppliance of 3SG-agreement, past regular tense or past irregular tense as the dependent variable in their respective models. The same procedure was followed for all three models. Each model would initially only include vocabulary scores and two variables serving as proxies for children’s input: hours of attendance at EF (formal instruction input) and use of media in English (out-of-school exposure). Subsequently, we introduced age (9: −.5, 12: .5) and first language (CH: −.5, RU: .5) variables into the model to assess their effects beyond differences in vocabulary and input. Finally, we included the interaction between age and first language. Model comparisons were performed using the anova function with criteria being the p-values and the model fit indices (e.g., AIC). Significant improvements in model fit due to the addition of fixed effects or interactions guided the retention of these variables in the final models.
To decide on the variables to include in our models, we considered the variation within them. Hence, we excluded SES measured through parental education as the vast majority of the children came from parents with high SES. Motivation and classroom enjoyment were also not controlled for because, again, parental questionnaires showed little variation. Further, a few children reported they started English outside EF at an earlier age than 4, but these were only 2 Chinese nine-year-olds and 9 Chinese twelve-year-olds. By contrast, no Russian nine-year-old had any previous exposure while there were 5 Russian twelve-year-olds reporting an earlier start outside EF. Due to the small variation and the fact that the number of children who had started learning English outside EF do not differ too much across populations, we did not include this aspect in our models.
To make sure there were no collinearity issues, we carried out a Variance Inflation Factor (VIF) analysis in R and found that there was no significant multicollinearity among all variables. Hence, including all variables described above in our models is justified.
Turning to the random structure, this included a random intercept for participants and a random intercept for items in all three models.
Finally, to examine statistically whether 3SG-agreement is more difficult than past tense, we again carried out a mixed effects logistic regression to compare children’s performance on 3SG-agreement and regular past tense. We excluded irregular past from this analysis since the irregular forms do not involve the application of a grammatical rule. Thus, the 3SG -s morpheme is compared with the -ed past morpheme. Considering again accuracy as the dependent variable, we included inflection (i.e., 3SG-agreement (coded as −.5) or past tense (coded as .5) as a fixed effect, and we specified a random intercept for participants and items, using (1|part) + (1|item) to define the random structure.
4. Results
4.1. Binomial logistic regression for TEGI 3SG-agreement
Figure 1 presents the means and standard deviations (SDs) of raw scores for 3SG agreement accuracy by group. Three children of the Chinese 9-year-olds and two of the Chinese 12-year-olds failed to do the task because of lack of time or lack of understanding of the instructions (likely a result of low proficiency). Similarly, one Russian 9-year-old was excluded due to unintelligible responses. All 42 Russian 12-year-old participants did the task.
Mean accuracy with 3SG-agreement and SDs per L1 and age group.

Results of the final model showed three significant main effects (cf. Table 6). The first significant main effect concerned age (β = 2.920 (SE = 0.571), z = 5.113, p < 0.001); older children were more accurate in their use of 3SG-agreement morphology than younger ones. The second significant main effect was the participants’ first language (β = −1.428 (SE = 0.557), z = −2.565, p = 0.010) with Chinese children outperforming the Russian children. Finally, there was a significant main effect of vocabulary (β = 0.997 (SE = 0.244), z = 4.095, p < 0.001) with higher scores related to higher 3SG-agreement accuracy. The interaction between age and first language did not improve the model fit. Figure 2 illustrates the predicted probabilities of accuracy in the production of the 3SG-agreement morpheme across different age groups and language groups.
The optimal model predicts accuracy based on the vocabulary score, the hours of instruction, the use of media in English per week, the age, and the L1. The model also includes a random intercept for participant and a random intercept for item. (Optimal Model: acc ~ zvoc + zhours + zmedia_use_min + age + first_lang + (1 | part) + (1 | item))

Table 6. Long description
The table is divided into two main sections: Fixed effects and Random effects.
Fixed effects section columns are Estimate, S E, z-value, and p.
- Intercept: Estimate -3.096, S E 0.344, z-value -9.008, p less than 0.001.
- Vocabulary: Estimate 0.997, S E 0.244, z-value 4.095, p less than 0.001.
- Hours of instruction in E F: Estimate -0.271, S E 0.255, z-value -1.066, p 0.286.
- Use of media in English per week: Estimate 0.133, S E 0.229, z-value 0.580, p 0.562.
- Age: Estimate 2.920, S E 0.571, z-value 5.113, p less than 0.001.
- L 1: Estimate -1.428, S E 0.557, z-value -2.565, p 0.010.
Random effects section columns are Groups, Name, Variance, and Std. Dev.
- Participant: Name Intercept, Variance 4.656, Std. Dev. 2.158.
- Item: Name Intercept, Variance 0.138, Std. Dev. 0.372.
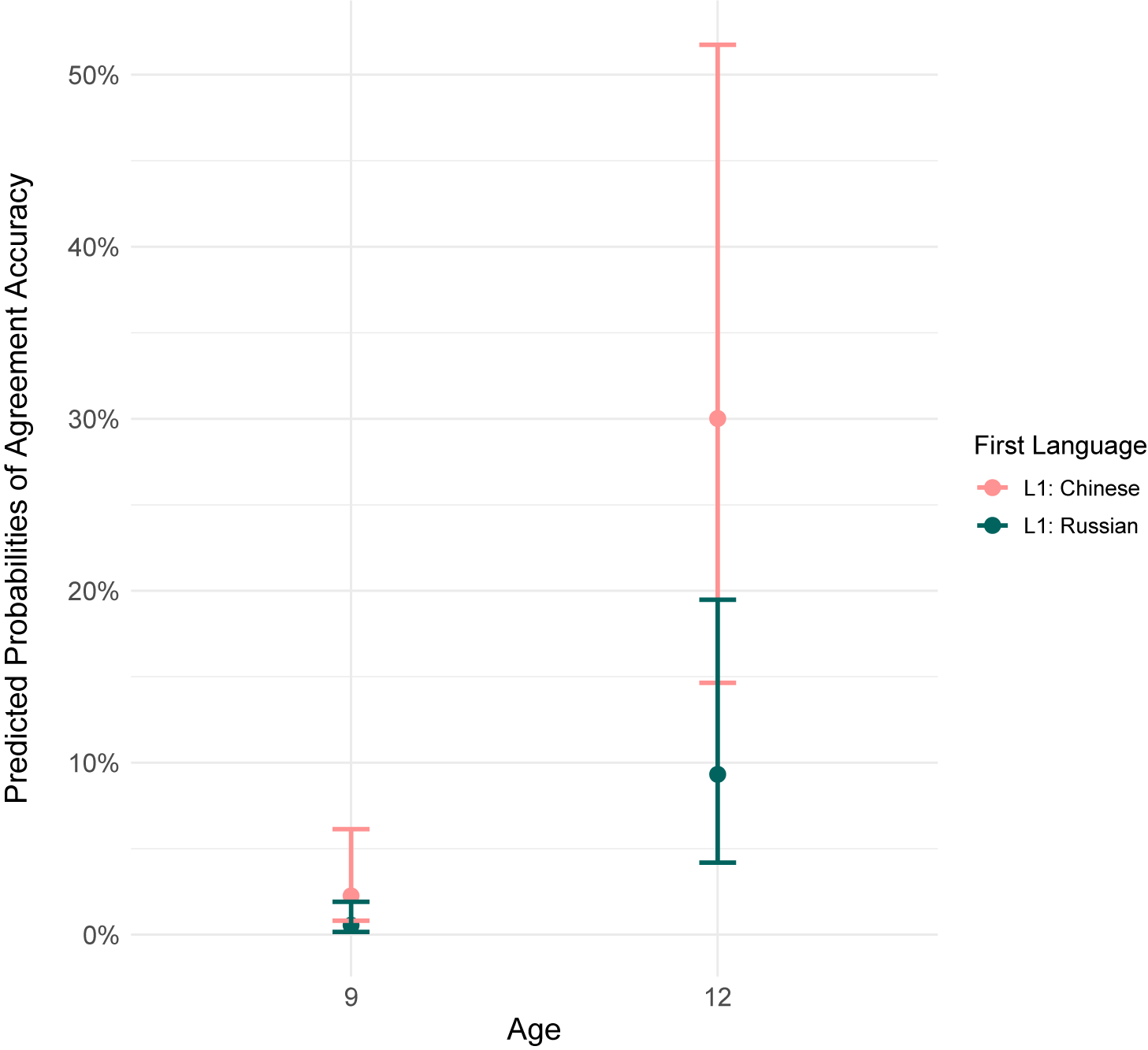
Predicted accuracy in 3SG-agreement after controlling for vocabulary, hours of instruction, and use of media. The point indicates the predicted average probability of a 3SG-agreement instance being produced accurately according to L1 and age. The whiskers indicate the 95% confidence interval.

Figure 2. Long description
The x-axis is labeled Age with two discrete points at 9 and 12. The y-axis is labeled Predicted Probabilities of Agreement Accuracy ranging from 0 percent to 50 percent in increments of 10 percent. A legend on the right identifies two groups. L 1 Chinese represented by light pink dots and L 1 Russian represented by dark teal dots.
At Age 9
* The L 1 Chinese group has a predicted probability near 2 percent with a 95 percent confidence interval whisker extending from approximately 1 percent to 6 percent.
* The L 1 Russian group has a predicted probability near 1 percent with a narrow whisker extending from 0 percent to 2 percent.
At Age 12
* The L 1 Chinese group shows a significant increase to a predicted probability of 30 percent. The 95 percent confidence interval is very wide, with whiskers extending from approximately 15 percent up to 52 percent.
* The L 1 Russian group shows a smaller increase to a predicted probability of approximately 9 percent. The whiskers extend from 4 percent to 20 percent.
4.2. Binomial logistic regression for TEGI past regular
Figure 3 presents means and SDs of raw scores for accuracy with regular past forms by group. Only 32 out of 39 Chinese 9-year-olds and 29 out of 32 Russian 9-year-olds completed the task. Additionally, two Chinese 12-year-olds did not complete the task, while all Russian 12-year-olds did. In cases where the task was not completed, this was due to time restrictions and/or difficulties with proficiency or comprehension of the instructions.
Mean accuracy with regular past and SDs per L1 and age group.

Results of the optimal model revealed two significant main effects (cf. Table 7). Specifically, there was a significant main effect of age (β = 3.607 (SE = 0.668), z = 5.402, p < 0.001), with older children being more accurate in their use of past tense morphology than younger ones, and a significant effect of vocabulary (β = 1.213 (SE = 0.277), z = 4.380, p < 0.001), with higher vocabulary scores related to higher accuracy with regular past tense. The interaction between age and first language did not improve the model fit. Figure 4 illustrates the predicted accuracy in the production of the regular past tense morpheme across different age groups and language groups.
The optimal model predicts accuracy based on the vocabulary score, the hours of instruction, the use of media in English per week, the age, and the L1. The model also includes a random intercept for participant and a random intercept for item. (Optimal Model: acc ~ zvoc + zhours + zmedia_use_min + age + first_lang + (1 | part) + (1 | item))

Table 7. Long description
The table is divided into two main sections.
Fixed effects section:
- Intercept: Estimate negative 0.559, S E 0.338, z-value negative 1.655, p 0.098.
- Vocabulary: Estimate 1.213, S E 0.277, z-value 4.380, p less than 0.001.
- Hours of instruction in E F: Estimate 0.003, S E 0.290, z-value 0.010, p 0.992.
- Use of media in English per week: Estimate 0.253, S E 0.291, z-value 0.870, p 0.384.
- Age: Estimate 3.607, S E 0.668, z-value 5.402, p less than 0.001.
- L 1: Estimate 0.003, S E 0.651, z-value 0.005, p 0.996.
Random effects section:
- Participant (Intercept): Variance 8.089, Standard Deviation 2.844.
- Item (Intercept): Variance 0.230, Standard Deviation 0.480.
Predicted accuracy in regular past tense after controlling for vocabulary, hours of instruction, and use of media. The point indicates the predicted average probability of a past tense -ed morpheme being produced accurately according to L1 and age. The whiskers indicate the 95% confidence interval.

4.3. Binomial logistic regression for TEGI irregular past
Figure 5 displays the means and SDs of raw scores for irregular past accuracy by group. The number of participants is the same as given for the regular past above.
Mean accuracy with irregular past and SDs per L1 and age group.

The final model demonstrated two significant main effects (cf. Table 8); a significant main effect of age (β = 3.420 (SE = 0.834), z = 4.102, p < 0.001) with older children outperforming younger ones, and a significant effect of vocabulary (β = 1.792 (SE = 0.447), z = 4.012, p < 0.001) with higher vocabulary scores related to higher accuracy with regular past tense. The interaction between age and first language did not improve the model fit. Figure 6 illustrates the predicted probabilities of accuracy of the production of the irregular past tense form across different age groups and first language groups.
The optimal model predicts accuracy based on the vocabulary score, the hours of instruction, the use of media in English per week, the age, and the L1. The model also includes a random intercept for participant and a random intercept for item. (Optimal Model: acc ~ zvoc + zhours + zmedia_use_min + age + first_lang + (1 | part) + (1 | item))

Table 8. Long description
The table is divided into two main sections.
Fixed effects section columns are Estimate, S E, z-value, and p.
- Intercept: Estimate -0.406, S E 0.380, z-value -1.070, p 0.284.
- Vocabulary: Estimate 1.792, S E 0.447, z-value 4.012, p less than 0.001.
- Hours of instruction in E F: Estimate 0.093, S E 0.387, z-value 0.240, p 0.810.
- Use of media in English per week: Estimate 0.311, S E 0.385, z-value 0.809, p 0.418.
- Age: Estimate 3.420, S E 0.834, z-value 4.102, p less than 0.001.
- L 1: Estimate 0.316, S E 0.831, z-value 0.381, p 0.703.
Random effects section columns are Groups, Name, Variance, and Std. Dev.
- Participant: Name Intercept, Variance 10.417, Std. Dev. 3.228.
- Item: Name Intercept, Variance 0.111, Std. Dev. 0.333.
Predicted accuracy in irregular past tense after controlling for vocabulary, hours of instruction, and use of media. The point indicates the predicted average probability of a past tense -ed morpheme being produced accurately according to L1 and age. The whiskers indicate the 95% confidence interval.

Figure 6. Long description
The y-axis is labeled Predicted Probabilities of Irregular Past Tense Accuracy, ranging from 0 percent to 75 percent. The x-axis is labeled Age, with two discrete points at 9 and 12. A legend on the right identifies two groups: L 1 Chinese represented by pink dots and L 1 Russian represented by dark teal dots.
At Age 9, both groups show low accuracy. The L 1 Chinese point is at approximately 10 percent with a confidence interval extending from near 5 percent to 33 percent. The L 1 Russian point is slightly higher at approximately 15 percent with a confidence interval from 5 percent to 43 percent.
At Age 12, both groups show a significant increase in accuracy. The L 1 Chinese point is at approximately 80 percent with a confidence interval from 47 percent to 95 percent. The L 1 Russian point is higher at approximately 85 percent with a confidence interval from 63 percent to 98 percent. The error bars for the L 1 Russian group are consistently taller than those for the L 1 Chinese group.
4.4. Binomial logistic regression for the asymmetry in the acquisition of features
Figure 7 shows the mean accuracy for agreement and past tense across each age and L1 group.
Mean accuracy for agreement vs. past tense for each age and L1 group.

Figure 7. Long description
The chart is organized into a two-by-two grid. The horizontal x-axis represents Inflection Type with categories agr and past. The vertical y-axis represents Mean Accuracy ranging from 0.0 to 0.6. Columns are divided by age groups 9 and 12. Rows are divided by first-language groups C H and R U. Each bar includes an error bar indicating variability.
* Top-Left Panel Age 9 C H. The agr bar is pink at approximately 0.1. The past bar is dark teal at approximately 0.3.
* Top-Right Panel Age 12 C H. The agr bar is pink at approximately 0.45. The past bar is dark teal at approximately 0.65.
* Bottom-Left Panel Age 9 R U. The agr bar is pink near 0.0. The past bar is dark teal at approximately 0.2.
* Bottom-Right Panel Age 12 R U. The agr bar is pink at approximately 0.25. The past bar is dark teal at approximately 0.7.
Across all groups, accuracy for past tense is higher than for agreement, and accuracy increases from age 9 to age 12.
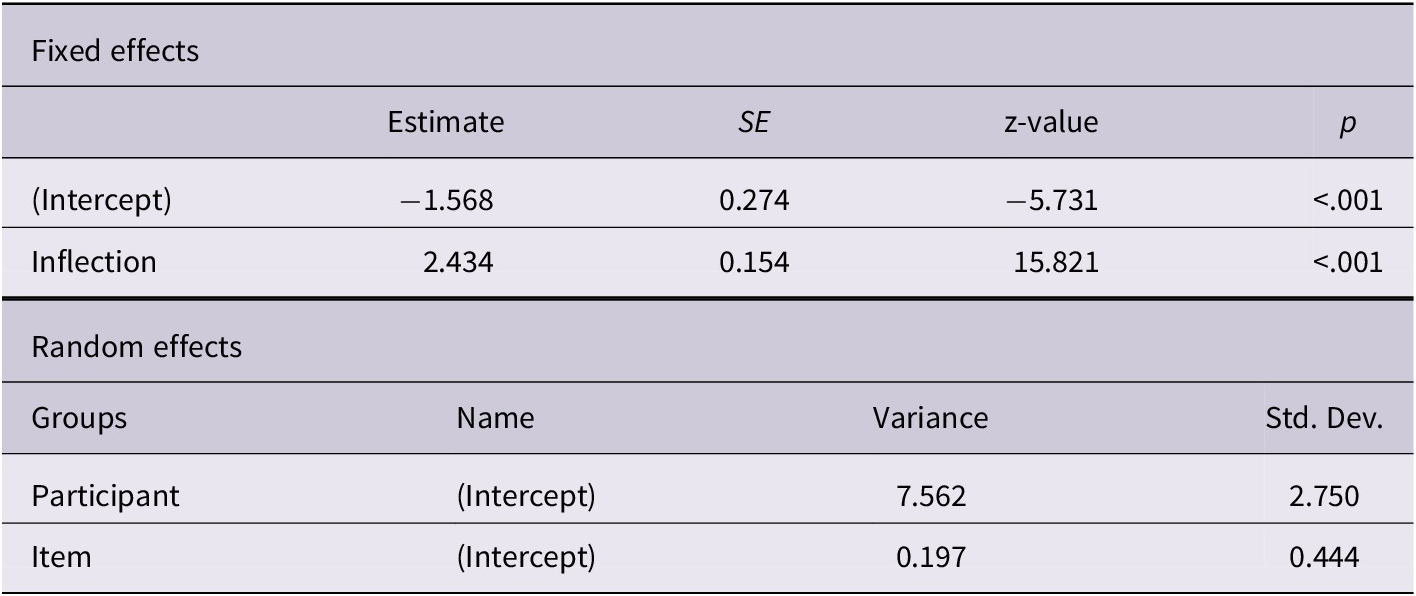
The model showed a significant main effect of inflection (β = 2.434 (SE = 0.154), z = 15.821, p < 0.001) with accuracy being higher on past tense compared to 3SG-agreement (cf. Table 9). This holds across ages and L1s.
The model predicts accuracy based on the type of inflection and includes a random intercept for the participant and a random intercept for the item. (Model: acc ~ inflection + (1 | part) + (1 | item))

Table 9. Long description
The table is divided into two main sections: Fixed effects and Random effects.
Fixed effects section:
* Intercept: Estimate of minus 1.568, S E of 0.274, z-value of minus 5.731, and p-value less than .001.
* Inflection: Estimate of 2.434, S E of 0.154, z-value of 15.821, and p-value less than .001.
Random effects section:
* Participant Groups: Name Intercept, Variance of 7.562, and Standard Deviation of 2.750.
* Item Groups: Name Intercept, Variance of 0.197, and Standard Deviation of 0.444.
5. Discussion
We begin our discussion considering the proficiency of learners before turning to our main questions.
5.1. Proficiency
Based on our research design, according to which all children would be 9 or 12 years old and would have had 5 years of instruction at EF, we expected that the two age groups across countries would be in the same proficiency levels. As we saw, Russian nine-year-olds were of lower proficiency than Chinese nine-year-olds, as almost half of the Russian nine-year-olds were in an A1 CEFR class level with only an eighth of the Chinese in that same level. Renfrew’s results excluding the cognate words, further confirmed the lower proficiency of Russian nine-year-olds. Older groups were of comparable proficiency with the vast majority in B1.
The question is why the younger groups differ in proficiency despite the fact that they have been attending the same language schools for the same number of years and how it is explained that older groups did not differ.
Despite the similar settings in EF schools in Shanghai and Russia, there are still some important differences in the English input children receive in each country which might help explain the differences in proficiency for the younger groups. In Shanghai, children start learning English in their day schools earlier (at 6 as opposed to 8) and for more hours (4 on average vs. 3) compared to Russians. Another reason may be the age literacy in L1 starts; parental questionnaires show that on average, Chinese children started literacy one year earlier than Russian children, at around 4 years of age. Taken together, these differences mean lower amounts of English instruction and later schooling for Russian children which may explain their lower proficiency. Additionally, parental attitudes and expectations may further compound these differences and indirectly lead to the observed proficiency difference between Russian and Chinese nine-year-olds.
It is unclear why these differences do not impact the older groups which show matching proficiency, as discussed below.
Older groups received comparable averages of EF academic hours (CH:821 vs. RU: 804) though with a higher average of hours in Chinese schools. Chinese children would also have had more input at their day school as they started English earlier and for more hours. We would expect that these differences in teaching input would perhaps lead to higher proficiency for the Chinese learners. It is striking that older groups are at the same EF CEFR class level, but Chinese seem to have reached that with many more hours of instruction coming from their day schools.
This cross-national study highlights the significance of wider educational factors in children’s learning and progress with the L2. Specifically, schooling is key as countries differ in their policies of when English is introduced, the intensity of schooling, and so forth. Other factors might play a role as well, such as parental attitudes to early years learning and potentially the similarity between L1 and L2 which we cannot explore further in the present study. However, it is clear that while the emphasis of the Chinese education system and parents on a strong and intense early start does seem to confer an advantage in L2 English proficiency to younger Chinese learners, this advantage does not seem to extend to later childhood, by which time Russian children seem to achieve similar proficiency with Chinese children.
5.2. The impact of age (of onset) on verbal morphology in EFL learning
Older children were consistently more accurate in their use of the target verbal morphology than younger children, in line with previous research. Through our statistical analyses, we controlled for input differences, adding such variables as covariates in our models (formal instruction hours at EF and informal learning through use of multimedia in English). After controlling for input, we found a significant effect of age.
We need to note that there were both quantitative and qualitative aspects of input we could not control for. Older starters receive more and richer input. Younger starters have fewer teaching hours than older ones because older children have consistently attended English in their day school for the whole 5-year period, while nine-year-olds will have had English at their day school for 1 or 3 years depending on the country. Further, there were qualitative differences in the EF curriculum across different ages related to the content covered, the timing in the introduction of the phenomena in question, and the teaching approach (see the section “Teaching of the grammatical phenomena under focus in EF language schools”). Yet, it is clear that in this real-life context and given the specific educational backgrounds, children attending afternoon EFL schools outside their regular/mainstream day schools show an older age advantage in grammar.
The higher accuracy of the older learners might be attributed to their overall higher proficiency which as discussed in the previous section, may be linked to a range of broader educational factors. For example, L1 literacy interacts with L2 proficiency (Cadierno et al., Reference Cadierno, Hansen, Lauridsen, Eskildsen, Fenyvesi and Hannibal Jensen2022). Younger children in both L1 cohorts would have less well-developed literacy skills than older ones. The more well-developed L1 skills can assist and accelerate L2 acquisition (Tribushinina, Dubinkina-Elgart, & Rabkina, Reference Tribushinina, Dubinkina-Elgart and Rabkina2020). Through schooling, older ones should have developed learning strategies that help their learning. They have more mature cognitive skills which are known to help general learning but also explicit language learning (Jaekel et al., Reference Jaekel, Schurig, Florian and Ritter2017; Muñoz, Reference Muñoz2006, Reference Muñoz2010; Pfenninger, Reference Pfenninger2014). Finally, older learners have more advanced language aptitude skills (e.g., language analytic ability); recent research has shown that language aptitude is dynamic in childhood, being developed up to the age of 12 (Roehr-Brackin & Tellier, Reference Roehr-Brackin and Tellier2019). We would thus expect older learners to have more developed language analytic ability compared to younger learners which would directly facilitate the acquisition of verbal morphology.
In sum, the age advantage in grammar observed in immersed or naturalistic contexts for younger children is not attested in instructed L2 learners with limited input even if children start their classes at a very young age. Older learners benefit from cognitive maturity, higher literacy skills, and more effective learning strategies, as previous research has consistently demonstrated, while they also had more input.
5.3. First language effects on verbal morphology in EFL learning
Turning to our question of L1 effects in the acquisition of 3SG-agreement and past tense comparing Russian and Chinese learners, we found that Chinese learners did significantly better in 3SG-agreement while the two L1 cohorts did not differ in past tense (regular and irregular). Further, there was no significant interaction between age and L1, suggesting that the effect of age does not vary depending on the learners’ first language. In other words, L1 effects are not influenced by age.
The fact that Chinese do better in 3SG-agreement is against our hypothesis. We argue that this is due to factors such as the quantity of input that we have already discussed, as well as the parental attitudes and the general cultural attitude towards schooling and English education (Bolton & Graddol, Reference Bolton and Graddol2012) which may influence Chinese children’s learning.
Another potential explanation for the observed “L1 effect” could be the higher number of native English teachers in Shanghai compared to non-native teachers in Moscow. This difference might influence the quality of language input, potentially explaining why Chinese learners demonstrate higher accuracy with 3SG-agreement. However, it is crucial to recognise that non-native teachers can possess near-native proficiency and employ highly effective pedagogical methods. On the other hand, not all native speakers may excel in teaching grammar. In any case, in contexts of limited input, where learning tends to rely more on explicit teaching methods, the influence of a teacher’s nativeness may be minimal compared to the broader impact of teaching effectiveness.
We also considered the possibility of whether the teaching method followed at their day mainstream schools may be important in interaction with the type of task we used to assess children’s production of morphemes. In a study in China on teachers’ and learners’ beliefs, questionnaire results revealed that the vast majority of the participants believed that the English examinations in schools and universities mostly assess a “command of English grammar” (Pan & Block, Reference Pan and Block2011). In classrooms in Shanghai mainstream schools, teachers follow a traditional approach to teaching grammar (e.g., Rao, Reference Rao2013) with a focus on form and exam oriented. Unfortunately, there is a dearth of research in EFL teaching in Russia. To the best of our knowledge, there is only one study (Tribushinina, et al., Reference Tribushinina, Dubinkina-Elgart and Rabkina2020) conducted in West Siberia, according to which EFL books are also form-focused and the teaching of grammar is explicit. Hence, it seems that the teaching methodology in interaction with the type of task we used may not explain these results.
This study appears to contradict findings from ESL studies in immersed contexts where children learn English naturalistically. In ESL contexts, Chinese learners have been found to be slower in acquiring verb morphology compared to learners with L1s with rich verbal morphology (e.g., Paradis, Reference Paradis2011; Paradis et al., Reference Paradis, Tulpar and Arppe2016). While this contrast deserves further empirical investigation, we may speculate that immersed learners might not have benefited from the form-focused instruction typical of EFL teaching which also appears to be a salient feature of English instruction in mainstream education in China.
5.4. Morpheme effects in EFL learning
The final question we aimed to address in this study was whether 3SG-agreement as a purely syntactic feature will be more challenging than the past tense which is interpretable.
Statistical analyses showed a significant effect of inflection with better performance on past tense than 3SG-agreement across age and L1 groups. This is in line with our hypothesis.
It is possible that the past tense is taught for a longer period of time because of the fact that regular and irregular verb forms exist, where the irregular ones may have to be rote-learned and thus may be more frequently presented in the input children receive. On the other hand, the past tense is introduced later than 3SG-agreement in the curriculum, and children get exposed to agreeing forms such as is/are or have/has as soon as they start English classes, and so exposure alone may not sufficiently explain this difference in accuracy across age and L1 groups.
We attribute this asymmetry in the acquisition of 3SG-agreement and past tense to the nature of the features involved, with interpretable past tense being earlier/more easily acquired. One might argue that agreement morphology is the exception in an unmarked paradigm and, thus, less salient for the learner and less noticeable. If that was the case, we would expect irregular past forms to be more accurate than regular past -ed forms, which was not attested. This would be expected because irregular forms do not depend on a morphological mapping in the same way as regular forms which we did not see. They could be considered salient as they are rote-learned as whole words.
6. Conclusion
The cross-national comparison adopted in this study brought up many aspects which are often overlooked when considering a single country’s context; from educational differences to parental attitudes and to even societal values, and emphasised that a range of factors may contribute to L2 learning. In this context, we found an older age advantage for grammar learning which was attributed to the higher cognitive maturity and analytic abilities of older children, while other underlying factors may include the higher quantity of input and the broader facilitative effects of schooling and literacy. We also found that at younger ages, Chinese children reach higher proficiency, again reflecting more input and potentially a stronger emphasis of parental and societal attitudes in China to early achievement. The same factors may also explain why Chinese learners outperform Russians in accuracy in agreement morphology. This study’s results reflect the reality for many learners around the world and how English is learned in afternoon EFL schools given the limited hours offered in such contexts. Vocabulary consistently predicted outcomes in all analyses, possibly reflecting the overall amount of input each child received. If vocabulary knowledge serves as an indirect measure or proxy for input, this suggests that the quantity of input is significant in these EFL contexts. Finally, learnability of the morphemes varied with past tense shown to be acquired more easily than 3SG-agreement. From a pedagogical perspective, it might be useful to consider the nature of the morphemes, as some may need more practice than others or different teaching strategies need to be employed.
We believe that cross-national comparisons can be very informative, and the current study is opening the ground for such research. Further research should examine the ultimate attainment of different starters in learning English, focusing on grammar achievement controlling for curriculum effects and controlling for the timing in the introduction of the phenomena. Administering detailed language background questionnaires to better control for exposure to English and perhaps match the groups in terms of hours, considering both school and out-of-school exposure, is essential.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S030500092500008X.
Acknowledgments
We thank the EF schools in Shanghai and Moscow and all the teaching staff who welcomed us at their premises. We are grateful to all the children who participated in this study and their parents. This research was conducted within the EF Education First Research Lab for Applied Language Learning at the Department of Theoretical and Applied Linguistics, University of Cambridge. The first author gratefully acknowledges a studentship from EF Education First.
Competing interest
The authors have no conflicts of interest to disclose.














 Open access
Open access