Refine listing
Actions for selected content:
Natural Language Engineering, Volume 27 - November 2021
- This volume was published under a former title. See this journal's title history.
Contents
Article
Neural machine translation of low-resource languages using SMT phrase pair injection
-
- Published online by Cambridge University Press:
- 17 June 2020, pp. 271-292
-
- Article
- Export citation
Text classification with semantically enriched word embeddings
-
- Published online by Cambridge University Press:
- 06 April 2020, pp. 391-425
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Survey Paper
A systematic review of unsupervised approaches to grammar induction
-
- Published online by Cambridge University Press:
- 27 October 2020, pp. 647-689
-
- Article
- Export citation
Article
Mining, analyzing, and modeling text written on mobile devices
-
- Published online by Cambridge University Press:
- 10 October 2019, pp. 1-33
-
- Article
- Export citation
Introduction
Processing negation: An introduction to the special issue
-
- Published online by Cambridge University Press:
- 14 December 2020, pp. 119-120
-
- Article
- Export citation
Article
Temporally anchored spatial knowledge: Corpora and experiments
-
- Published online by Cambridge University Press:
- 20 May 2020, pp. 519-543
-
- Article
- Export citation
Nonuniform language in technical writing: Detection and correction
-
- Published online by Cambridge University Press:
- 06 March 2020, pp. 293-314
-
- Article
- Export citation
Survey Paper
Recent advances in processing negation
-
- Published online by Cambridge University Press:
- 17 December 2020, pp. 121-130
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Article
Towards syntax-aware token embeddings
-
- Published online by Cambridge University Press:
- 08 July 2020, pp. 691-720
-
- Article
- Export citation
Transfer learning for Turkish named entity recognition on noisy text
-
- Published online by Cambridge University Press:
- 28 January 2020, pp. 35-64
-
- Article
- Export citation
Universal Lemmatizer: A sequence-to-sequence model for lemmatizing Universal Dependencies treebanks
-
- Published online by Cambridge University Press:
- 27 May 2020, pp. 545-574
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Is your document novel? Let attention guide you. An attention-based model for document-level novelty detection
-
- Published online by Cambridge University Press:
- 24 April 2020, pp. 427-454
-
- Article
- Export citation
-
Detecting, whether a document contains sufficient new information to be deemed as novel, is of immense significance in this age of data duplication. Existing techniques for document-level novelty detection mostly perform at the lexical level and are unable to address the semantic-level redundancy. These techniques usually rely on handcrafted features extracted from the documents in a rule-based or traditional feature-based machine learning setup. Here, we present an effective approach based on neural attention mechanism to detect document-level novelty without any manual feature engineering. We contend that the simple alignment of texts between the source and target document(s) could identify the state of novelty of a target document. Our deep neural architecture elicits inference knowledge from a large-scale natural language inference dataset, which proves crucial to the novelty detection task. Our approach is effective and outperforms the standard baselines and recent work on document-level novelty detection by a margin of
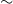 $\sim$3% in terms of accuracy.
$\sim$3% in terms of accuracy.
Constrained BERT BiLSTM CRF for understanding multi-sentence entity-seeking questions
-
- Published online by Cambridge University Press:
- 13 February 2020, pp. 65-87
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Computational generation of slogans
-
- Published online by Cambridge University Press:
- 03 June 2020, pp. 575-607
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Focus of negation: Its identification in Spanish
-
- Published online by Cambridge University Press:
- 08 July 2020, pp. 131-152
-
- Article
- Export citation
Syntax-ignorant N-gram embeddings for dialectal Arabic sentiment analysis
-
- Published online by Cambridge University Press:
- 16 March 2020, pp. 315-338
-
- Article
- Export citation
Imparting interpretability to word embeddings while preserving semantic structure
-
- Published online by Cambridge University Press:
- 09 June 2020, pp. 721-746
-
- Article
- Export citation
Sentiment analysis in Turkish: Supervised, semi-supervised, and unsupervised techniques
-
- Published online by Cambridge University Press:
- 17 April 2020, pp. 455-483
-
- Article
- Export citation
Linguistic knowledge-based vocabularies for Neural Machine Translation
-
- Published online by Cambridge University Press:
- 02 July 2020, pp. 485-506
-
- Article
- Export citation
Investigating translated Chinese and its variants using machine learning
-
- Published online by Cambridge University Press:
- 03 April 2020, pp. 339-372
-
- Article
- Export citation