


 . Besides Element Theory and strict CV, we argue that this analysis provides further support to a substance-free view of phonology, in which phonological representations do not necessarily have a universal, fixed phonetic implementation.
. Besides Element Theory and strict CV, we argue that this analysis provides further support to a substance-free view of phonology, in which phonological representations do not necessarily have a universal, fixed phonetic implementation.1. Introduction
Many Czech suffixes trigger palatalisation of elements to their left. Some minimal pairs of suffixes involve the same vowel, but differ in that one member of the pair does not, while the other does, trigger palatalisation. A case in point are the so-called ‘hard’ and ‘soft’ agreement markers, orthographically -ý and -í, respectively, but both corresponding to the same sound /i:/. While -ý does not trigger palatalisation of the consonant to its left, -í does, as the following pair of adjective forms shows:

The contrast is systematic: -ý is never preceded by [ɟ], and -í is never preceded by [d], and this complementary distribution extends to the other sounds that can precede these inflection markers (see §4 for more discussion of this point). The existence of such contrasts shows that what triggers palatalisation is a property of the suffix, and that two suffixes that sound alike can have different palatalisation-triggering properties. At the same time, it is the element to the left of the suffix that shows the visible effect of palatalisation. This type of pattern is not restricted to Czech, but is characteristic of the Slavic family as a whole.
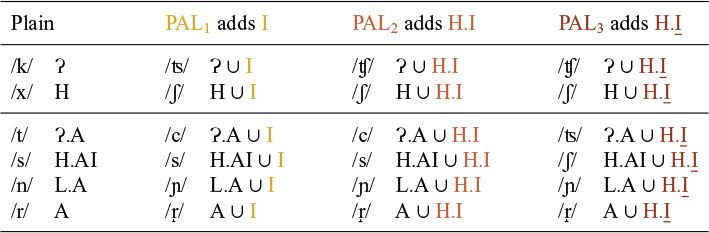
A further noteworthy fact is that palatalisation is not a uniform process. Different palatalising suffixes trigger different types of palatalisation, even though they may begin with the same vowel. The palatalising suffix -ě /ɛ/, for example, which marks the dative singular of feminine nouns, changes /k/ into /ʦ/, while the suffix -ěn /ɛn/ of the passive past participle changes /k/ into /ʧ/ (examples provided in Table 1). This state of affairs represents another instance of what we claimed in the previous paragraph, namely that two similar-sounding objects – such as the /ɛ/ of the f.dat marker and that of the pass.ptcp – can display different phonological behaviours, as they trigger different types of palatalisation.
Small and big palatalisation in Czech (Scheer Reference Scheer2001).

Our objectives in this article are twofold. The first is an empirical one. We start off by discussing the two different types of palatalisation distinguished in Scheer (Reference Scheer2001). We then proceed to show that there are additional patterns on top of the ones discussed by Scheer, such as the ones triggered by the comparative suffix -ěj and the causative suffix -i. Our second aim is theoretical. There has been quite a bit of discussion in the literature on the topic of palatalisation in Slavic (see Halle Reference Halle2005; Rubach Reference Rubach, van Oostendorp, Ewen, Hume and Rice2011; Krämer & Urek Reference Krämer and Urek2016 and references cited therein), which has shaped the debate over phonology and its representations. We will develop an analysis which adopts two main ingredients. The first concerns the particular decomposition of sounds into their component parts, such as has been proposed in the framework of Element Theory (Backley Reference Backley2011). The second ingredient we shall need is the strict CV framework familiar from the work of Lowenstamm (Reference Lowenstamm, Durand and Laks1996) and Scheer (Reference Scheer2004).
2. The data
2.1. Small and big palatalisation
As a starting point of our discussion of palatalisation in Czech, we describe the data reviewed in Scheer (Reference Scheer2001). Scheer distinguishes two types of palatalisation, which he labels, following traditional descriptions, ‘small’ palatalisation (also called second palatalisation) and ‘big’ palatalisation (or first palatalisation). Table 1 lists the two types of palatalisation for all the consonants that are liable to being affected by it. In the orthography, the diacritic on the ě (widely known under its Czech name háček ‘little hook’) marks the fact that it is a palataliser.Footnote 1 When ě is attached to the base, the háček sometimes appears on the preceding consonant (as in že, če, ře), sometimes on the vowel (in tě, ně, pě, bě) and sometimes not at all, as with the labials and /l/, to mark the absence of palatalisation.
The first column of Table 1 lists the base sound. These are ordered from top to bottom according to their place of articulation (velar, coronal and labial). To the right of the first column, we find the sounds that result from small palatalisation, followed by an example. Small palatalisation is indicated by light shading. The rightmost columns show the effect of big palatalisation (darker shading). In some cases, there is no difference between small and big palatalisation (e.g., ![]() ,
, ![]() and
and ![]() become
become ![]() ,
, ![]() and
and ![]() , respectively, in both palatalisation patterns). With
, respectively, in both palatalisation patterns). With ![]() and
and ![]() (and possibly also with
(and possibly also with ![]() ), small palatalisation has no visible effect, which is indicated by the absence of any shading. An even more extreme scenario is represented by
), small palatalisation has no visible effect, which is indicated by the absence of any shading. An even more extreme scenario is represented by ![]() , which never palatalises.
, which never palatalises.
The labials present an interesting pattern in a number of respects. Small palatalisation does not result in a change in the articulation of the base sound, but rather in the insertion of a front vocoid between the labial and the suffix. In the case of ![]() , this extra segment takes the form of
, this extra segment takes the form of ![]() (Short Reference Short, Comrie and Corbett1993: 459). Rather counterintuitively, the big palatalisation has no effect in the labials, as indicated by the absence of shading. We come to the peculiar behaviour of the labials at the end of this section.
(Short Reference Short, Comrie and Corbett1993: 459). Rather counterintuitively, the big palatalisation has no effect in the labials, as indicated by the absence of shading. We come to the peculiar behaviour of the labials at the end of this section.
A brief comment is in order on the the underlying representation of the sound affected by palatalisation. In the case of small palatalisation, the examples in Table 1 show both the nominative and the dative singular forms. The idea that the nominative represents the base sound of the final consonant of the base is well-supported, in that it appears when the base is followed by the non-palatalising suffix -a. In the case of big palatalisation, however, the nature of the base sound is not always so obvious, because the bases are mostly followed by the theme vowel -i, which is itself a (small) palataliser. For example, in the case of the participle nuc-en ![]() ‘forced’, the base is represented by the infinitive nut-it
‘forced’, the base is represented by the infinitive nut-it ![]() ‘to force’, where the final segment of the base is a palatal
‘to force’, where the final segment of the base is a palatal ![]() . The assumption that the base has an underlying
. The assumption that the base has an underlying ![]() is supported by the fact that no i-verb has a root ending in
is supported by the fact that no i-verb has a root ending in ![]() . This means that, in the case of the suffix -ěn, the base sound is often not directly observable.
. This means that, in the case of the suffix -ěn, the base sound is often not directly observable.
A further relevant data point concerning the suffix -ěn is that its palatalisation pattern is not always consistently the same. In Table 1, it is listed as a big palataliser, but it is possible to identify verbs where -ěn shows the pattern of small palatalisation. Combined with what we said at the end of the previous paragraph about the infinitive, this leads to a situation where the infinitive and the participle are indistinguishable, both displaying the pattern of small palatalisation, as in poctít ![]() ‘to favour’
‘to favour’
 $\sim $
poctěn
$\sim $
poctěn ![]() ‘favoured’ and radit
‘favoured’ and radit ![]() ‘to advise’
‘to advise’
 $\sim $
raděn
$\sim $
raděn ![]() ‘advised’. Furthermore, verbs with theme vowel e and a root ending in
‘advised’. Furthermore, verbs with theme vowel e and a root ending in ![]() have a passive participle with
have a passive participle with ![]() (e.g., kácet ‘to cut down’
(e.g., kácet ‘to cut down’
 $\sim $
kácen ‘cut down’), which would also be consistent with small palatalisation of underlying
$\sim $
kácen ‘cut down’), which would also be consistent with small palatalisation of underlying ![]() . Finally, some (athematic) verbs do not even palatalise at all when followed by the passive participle suffix, like mést ‘to sweep’
. Finally, some (athematic) verbs do not even palatalise at all when followed by the passive participle suffix, like mést ‘to sweep’
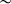 $\sim $
meten ‘swept’ and krást ‘to steal’
$\sim $
meten ‘swept’ and krást ‘to steal’
 $\sim $
kraden ‘stolen’. The latter class in particular suggests that, in the case of the suffix -en, the vowel and the palataliser may lead independent lives, as the vowel occurs without the palataliser. While these facts complicate the empirical picture, we feel that it is safe to set them aside for now, since they do not call into question the existence of the two different types of palatalisation that we discuss here. We hope to come back to the more complex patterns discussed in this paragraph in future work.
$\sim $
kraden ‘stolen’. The latter class in particular suggests that, in the case of the suffix -en, the vowel and the palataliser may lead independent lives, as the vowel occurs without the palataliser. While these facts complicate the empirical picture, we feel that it is safe to set them aside for now, since they do not call into question the existence of the two different types of palatalisation that we discuss here. We hope to come back to the more complex patterns discussed in this paragraph in future work.
A final noteworthy fact is the scarcity of data for two sounds, ![]() and
and ![]() . The first of these appears to be a phoneme that is restricted to loan words (e.g.,
. The first of these appears to be a phoneme that is restricted to loan words (e.g., ![]() ‘league’) and proper names (e.g.,
‘league’) and proper names (e.g., ![]() ‘Olga’), and is otherwise so infrequent in Czech that it cannot be reliably attributed to any of the patterns we discuss. A similar data scarcity problem exists for
‘Olga’), and is otherwise so infrequent in Czech that it cannot be reliably attributed to any of the patterns we discuss. A similar data scarcity problem exists for ![]() . For small palatalisation, Scheer lists the Slovak place name Bystrica, but otherwise nouns with roots ending in
. For small palatalisation, Scheer lists the Slovak place name Bystrica, but otherwise nouns with roots ending in ![]() appear to be absent from Czech in this particular declension (although a reviewer points out that there are such nouns in other declensions, like noc ‘night’ and tác ‘plate’). The verbal pair péci
appear to be absent from Czech in this particular declension (although a reviewer points out that there are such nouns in other declensions, like noc ‘night’ and tác ‘plate’). The verbal pair péci ![]()
 $\sim $
pečen
$\sim $
pečen ![]() ‘to bake’ may well involve a palatalised /k/, as this sound appears in the past participle pekl ‘baked’ and the noun pekárna ‘bakery’. This would in effect mean that the apparent
‘to bake’ may well involve a palatalised /k/, as this sound appears in the past participle pekl ‘baked’ and the noun pekárna ‘bakery’. This would in effect mean that the apparent ![]() pattern is in effect a
pattern is in effect a ![]() pattern. This latter possibility is in fact entirely consistent with the analysis we shall develop. Since data that show the patterns of palatalisation for both
pattern. This latter possibility is in fact entirely consistent with the analysis we shall develop. Since data that show the patterns of palatalisation for both ![]() and /ʦ/ are too scarce to base any reliable conclusions on, we shall henceforth ignore both these sounds (although [ʦ] will make an appearance in the analysis as the result of big palatalisation applied to /t/).
and /ʦ/ are too scarce to base any reliable conclusions on, we shall henceforth ignore both these sounds (although [ʦ] will make an appearance in the analysis as the result of big palatalisation applied to /t/).
2.2. Additional patterns
We now turn to two additional patterns, one involving the comparative suffix -ějš and the other shown by the causative suffix -i. Following Caha et al. (Reference Caha, De Clercq and Vanden Wyngaerd2019), we take the comparative suffix to consist of two morphemes -ěj and -š. We henceforth refer to the suffix as -ěj, since this is all we shall need to study the additional palatalisation patterns. Table 2 lists the relevant patterns. The shading in this table (and the ones to follow) is the same as in Table 1.Footnote 2 We notice that, in terms of the distinction between small and big palatalisation that we discussed earlier, comparative -ěj shows a mixed pattern: in the velars, it triggers big palatalisation, but in the coronals and the labials, we see the pattern typical of small palatalisation.
Comparative -ěj.
A similar pattern, but with a twist, is found with the causative suffix -i. This is shown in Table 3. Since we know that the hard adjectival agreement marker -ý does not trigger palatalisation, we use adjectives to represent the base, and restrict ourselves to causative verbs derived from adjectives. Where this is not possible (as with s and z), we take recourse to nouns. The verbs are frequently accompanied by a prefix, like z- or o-, and the causative -i is followed by the past participle marker -l. Again, we see mixed pattern: big palatalisation with the velars, and small palatalisation with the coronals. The labials now fail to palatalise, which is typical of the pattern of big palatalisation.
Causative -i.
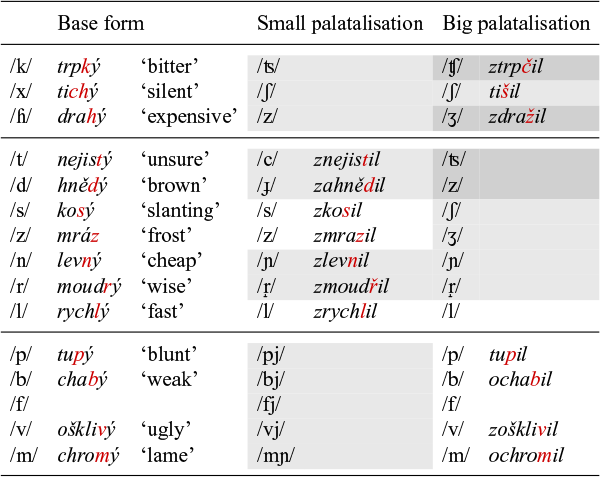
Putting these facts together, it would appear that we end up with four different patterns. These are schematised in Table 4a. However, we will argue that the state of affairs depicted in Table 4a. results from the interplay of two different factors. The first is the nature of the palataliser, and the second is whether a palataliser that is underlyingly present surfaces in the output, or remains unassociated. The failure of palatalisers to surface can be observed systematically in labials, in particular with the passive participle suffix -ěn and the causative -i, where big palatalisation has no visible effect. The velars and the coronals clearly show that a suffix-associated palataliser must be present in the big palatalisation pattern, and so the absence of palatalisation with the labials has to be due to the fact that something in the UR does not show in the output. We shall call this property output invisibility. In §4.3.3, we shall develop an analysis for output invisibility with the labials that relies on the association (or rather, the lack thereof) of elements on the melodic tier (like palatalisers) with CV slots. This allows us to remove the labials from Table 4a., and identify the three different palatalisation patterns shown in Table 4b.
Summary of palatalisation patterns.
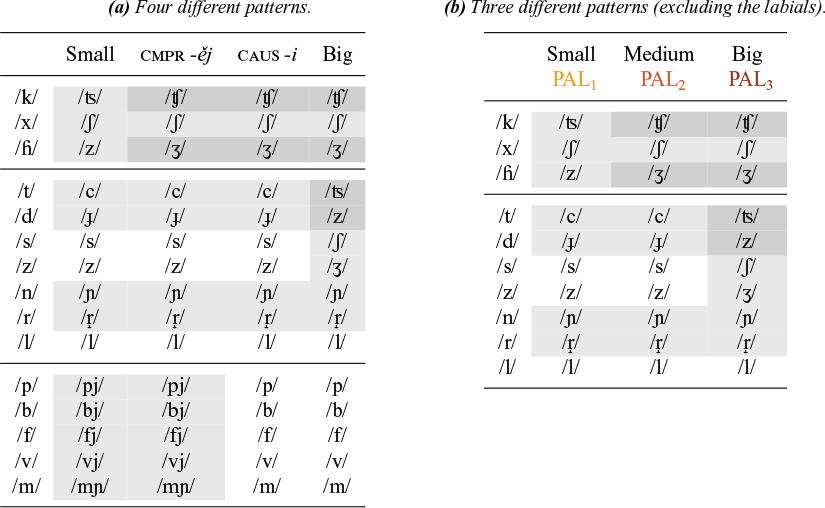
The three remaining patterns now show the unadulterated effect of the first factor involved, which is the nature of the palataliser. We accordingly call them small, medium and big palatalisation, and we take them to be triggered by three different types of palatalisers. For now, we simply refer to these palatalisers as PAL1, PAL2 and PAL3. §4 will be devoted to developing an analysis of their internal structure. It is these palatalisers that are associated with certain suffixes, and which trigger the effects on elements to their left.
In the remainder of the article, we shall make one further simplification of the data, which involves pairs of phonemes that differ with respect to voice, like ![]() ,
, ![]() ,
, ![]() ,
, ![]() and
and ![]() . This is because, once we have the analysis of the voiceless members of these oppositions in place, extending it to the voiced members is trivial. That removes the voiced sounds
. This is because, once we have the analysis of the voiceless members of these oppositions in place, extending it to the voiced members is trivial. That removes the voiced sounds ![]() from the table. This will be our starting point for the analysis in the following section.
from the table. This will be our starting point for the analysis in the following section.
3. Theoretical prerequisites
In this section, we sketch the theoretical background that we shall be assuming in our analysis, to be developed in the next section. This background involves Element Theory and strict CV. Before presenting some of the basics of these theories, we devote some general remarks to palatalisation, and its previous treatment in the literature.
3.1. Previous approaches to palatalisation
As Krämer & Urek (Reference Krämer and Urek2016: 1) write, palatalisation is
probably the most common phonological assimilatory process, maybe only second to nasal place assimilation, varying immensely in its phonological and morphological conditions cross-linguistically. Phonetically this phenomenon also shows a wide range of variation and it is not quite clear which patterns and processes should be subsumed under palatalization.
Because of this, the formalisation of palatalisation has triggered a lively theoretical debate, which centres mostly on the properties of the representational component of phonology. Indeed, whereas most researchers agree in analysing palatalisation as feature spreading/sharing, different proposals have been put forward concerning the set of rules and/or constraints involved in the palatalisation operation, and the typology of phonological features and their geometric organisation (Chomsky & Halle Reference Chomsky and Halle1968; Clements Reference Clements1985; Hume Reference Hume1992; Clements & Hume Reference Clements, Hume and Goldsmith1995; Halle et al. Reference Halle, Vaux and Wolfe2000; Calabrese Reference Calabrese2005; Halle Reference Halle2005; Morén Reference Morén2006; Bateman Reference Bateman2007; Kochetov Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011; Krämer & Urek Reference Krämer and Urek2016). This disagreement has some relatively far-reaching consequences, as despite the amount of work targeting palatalisation
some of the problems with the formal modeling of palatalization have not been resolved. In part, these difficulties appeared to stem from a more fundamental problem – the persistent use of traditional featural representations (with some modifications), which were assumed to be inviolable, universal and innate (Kochetov Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011: 1686).
Another representational assumption shared by traditional models is the idea that features are phonetically grounded. Thus, the objects involved in palatalisation (i.e., the trigger and the target) are represented in an extremely phonetically faithful way, there being no slack between the set of phonological features they consist of and their phonetic implementation. As noted by Kochetov (Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011: 1684), although this has
contributed to a more empirically adequate account of cross-linguistic patterns of palatalization, it became clear that the same representations have often stood in the way of further empirical coverage of the phenomenon […]. This particularly applies to cases of palatalization that can be considered less phonetically natural, such as place-changing processes resulting in anterior coronals or involving labial consonants.
These processes are understood as the spreading of some phonological features from the trigger that add a secondary palatal articulation to the target, followed by a process that changes the place (and manner) of articulation of the target (and, in approaches based on Chomsky & Halle Reference Chomsky and Halle1968, by the application of a set of marking conventions). For instance, Chomsky & Halle (Reference Chomsky and Halle1968: 422) formalise the so-called First Velar Palatalisation in Slavic (/k g x/ → [ʧ ʤ ʃ]) as in (2), treating it as a clear case of assimilation in which the [−back] feature of the front vowels triggering the palatalisation affects preceding velar ([−anterior]) targets:

However, the change from stops to coronal affricates and fricatives can be hardly understood as a case of assimilation alone, for front vowels lack the features acquired by the target, namely [+coronal, +delayed release, +strident]. To reach the desired result, the assimilation rule needs to be supplemented with the set of marking conventions in (3), which fills in the unmarked values of underspecified (u) features (Kochetov Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011: 1678).

These conventions imply that the postalveolar affricates and fricatives ![]() are less marked than the palatal or palato-alveolar stops
are less marked than the palatal or palato-alveolar stops ![]() , since the latter lack stridency and delayed release. These marking conventions formally encode the typological observation that ‘when velar obstruents are fronted, it is simpler for them also to become strident palato-alveolars with delayed release’ (Chomsky & Halle Reference Chomsky and Halle1968: 423). Despite the fact that combining rules with marking conventions allowed a satisfactory level of descriptive adequacy, nothing determined when such marking convention should be applied, nor whether these conventions are appropriate for specific cases of palatalisation. For instance, whereas postalveolar affricates are less marked than palatal or postalveolar stops, even less marked are alveolar or labial stops, which are never produced by palatalisation. Furthermore, as already mentioned, place-changing palatalisation processes would consist of two different processes, namely fronting/secondary palatalisation (e.g.,
, since the latter lack stridency and delayed release. These marking conventions formally encode the typological observation that ‘when velar obstruents are fronted, it is simpler for them also to become strident palato-alveolars with delayed release’ (Chomsky & Halle Reference Chomsky and Halle1968: 423). Despite the fact that combining rules with marking conventions allowed a satisfactory level of descriptive adequacy, nothing determined when such marking convention should be applied, nor whether these conventions are appropriate for specific cases of palatalisation. For instance, whereas postalveolar affricates are less marked than palatal or postalveolar stops, even less marked are alveolar or labial stops, which are never produced by palatalisation. Furthermore, as already mentioned, place-changing palatalisation processes would consist of two different processes, namely fronting/secondary palatalisation (e.g., ![]() →
→ ![]() ) plus simplification (e.g.,
) plus simplification (e.g., ![]() →
→ ![]() ; see Kochetov Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011: 1677 for further details). The fact that what intuitively looks like a unitary process (‘an obvious case of regressive assimilation’, per Chomsky & Halle Reference Chomsky and Halle1968: 308) is formalised in terms of two unrelated processes blurs the naturalness the proponents of approaches adopting traditional, phonetically-grounded features were after, and adds to the complexity and the abstractness of the proposed analyses.
; see Kochetov Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011: 1677 for further details). The fact that what intuitively looks like a unitary process (‘an obvious case of regressive assimilation’, per Chomsky & Halle Reference Chomsky and Halle1968: 308) is formalised in terms of two unrelated processes blurs the naturalness the proponents of approaches adopting traditional, phonetically-grounded features were after, and adds to the complexity and the abstractness of the proposed analyses.
Even in approaches that dispense with marking conventions and try to derive the naturalness and (im)possibility of specific process from the geometric properties of featural representations (Clements Reference Clements1985; Sagey Reference Sagey1988; Hume Reference Hume1992; Clements & Hume Reference Clements, Hume and Goldsmith1995; Halle Reference Halle1995, Reference Halle2005; Halle et al. Reference Halle, Vaux and Wolfe2000; Calabrese Reference Calabrese2005; Morén Reference Morén2006; among others), similar problems remain. As argued by Kochetov (Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011: 1684), even if such approaches further improved on descriptive adequacy of cross-linguistic patterns of palatalisation, ‘some of the processes that could be easily stated in the SPE-style approach […] could no longer be stated in the feature geometry approach without making some ad hoc stipulations’ [emphasis added].
Similar problems are inherited by OT-based accounts that more or less explicitly adopt feature geometric representations, the main difference being that in OT systems the observed variation is explained in terms of constraint ranking. For instance, as Kochetov (Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011: 1684) notes, the relative resistance to palatalisation of labials can be formalised as a universally fixed hierarchy of constraints penalising palatalised labials, dorsals and coronals as in (4a) (Chen Reference Chen1996), and the height asymmetry of triggers as a fixed hierarchy of Palatalise constraints indexed for vowel height as in (4b) (Rubach Reference Rubach2003).

A possible solution to the problems inherited from feature-geometric approaches is the use of more detailed, phonetically realistic representations. For instance, Chen (Reference Chen1996) combines feature-geometric representations with articulatory gestures, and analyses Japanese, Polish and Swati palatalisation patterns as all involving the spreading of V-Place[coronal] from front vocoids, which produces abstract complex segments featuring both a secondary place and the original primary place (e.g., [Dorsal]/V-Place[Coronal]). In such a system, the observed cross-linguistic variation would derive from differences in how these abstract complex segments are phonetically implemented in articulatory gestures. For instance, depending on the language, [Dorsal]/V-Place[Coronal] can be phonetically interpreted as ![]() ,
, ![]() ,
, ![]() or
or ![]() . This approach, though, is insufficient in accounting for cases where, as in several Slavic languages, one and the same segment (e.g.,
. This approach, though, is insufficient in accounting for cases where, as in several Slavic languages, one and the same segment (e.g., ![]() ) undergoes different types of palatalisation.
) undergoes different types of palatalisation.
As we show below, our proposal provides a different solution to the aforementioned problems of feature-geometric approaches, namely those related to the need to postulate more than one (assimilatory) process, and to cross- and intra-linguistic variation. A crucial component of our solution involves desisting from the attempt of defining a universal featural characterisation of segments, which has been proved unsuccessful by a couple of decades of feature-geometric research (Uffmann Reference Uffmann, van Oostendorp, Ewen, Hume and Rice2011). We instead adopt an approach where the internal representation of segments emerges as a function of the segments’ phonological behaviour, rather than of their phonetic correlates (Mielke Reference Mielke2008; Dresher Reference Dresher2009). We thus abandon phonetically grounded features and resort instead to a substance-free version of Element Theory (Kaye et al. Reference Kaye, Lowenstamm and Vergnaud1985; Harris Reference Harris1994; Harris & Lindsey Reference Harris, Lindsey, Durand and Katamba1995; Backley Reference Backley2011; Scheer & Kula Reference Scheer and Kula2018), which is grounded in a strict approach to modularity (Fodor Reference Fodor1983; Scheer Reference Scheer2012).
In such an approach, where phonology and phonetics resort to different lexica, that is to different representational primitives, the observed variation can be built into the phonology–phonetics interface: different languages will phonetically interpret the same set of elements differently because their phonology–phonetics interfaces map the shared abstract phonological representation onto the corresponding acoustic form in an arbitrary way (Scheer Reference Scheer2012). Hence, substance-freeness and strict modularity give us a way out of postulating more than one process, as they do not require us to distinguish between a process that spreads a palatalising feature/element and one that changes the manner specification of the palatalised segment. For instance, this system allows us to model the palatalisation of ![]() to
to ![]() as being due to the spreading of a single feature/element I (see (20)), followed by a lexical-insertion type of phonology–phonetics mapping that arbitrary assigns the abstract
as being due to the spreading of a single feature/element I (see (20)), followed by a lexical-insertion type of phonology–phonetics mapping that arbitrary assigns the abstract ![]() representation the acoustic properties of
representation the acoustic properties of ![]() . Our system thus makes use of Chen’s (Reference Chen1996) hypothesis that the same phonological representation can be phonetically interpreted differently on a language-specific basis, but it makes it possible to formally model the fact that one and the same segment can display different types of palatalisation within a single language. As we show below, this follows from the hypothesis that the factor responsible for palatalisation is not to be found in the featural makeup of the vowel that follows the palatalised consonant on the surface, but on the presence of different sets of floating elements that associate to the palatalised consonant. By teasing apart audible front vowels and palatalisers, we can also provide an account for why one and the same segment undergoes different kinds of palatalisation even if, on the surface, it is followed by the same vowel (see, e.g., §4.1). In what follows, we introduce and describe in detail the theoretical toolkit we need to develop such system.
. Our system thus makes use of Chen’s (Reference Chen1996) hypothesis that the same phonological representation can be phonetically interpreted differently on a language-specific basis, but it makes it possible to formally model the fact that one and the same segment can display different types of palatalisation within a single language. As we show below, this follows from the hypothesis that the factor responsible for palatalisation is not to be found in the featural makeup of the vowel that follows the palatalised consonant on the surface, but on the presence of different sets of floating elements that associate to the palatalised consonant. By teasing apart audible front vowels and palatalisers, we can also provide an account for why one and the same segment undergoes different kinds of palatalisation even if, on the surface, it is followed by the same vowel (see, e.g., §4.1). In what follows, we introduce and describe in detail the theoretical toolkit we need to develop such system.
3.2. Element Theory
Unlike previous approaches, we dispense with traditional, articulatorily-based featural representations and instead adopt a substance-free take on phonology (Reiss Reference Reiss2018; Scheer Reference Scheer2019; Reiss & Volenec Reference Reiss and Volenec2022; Chabot Reference Chabot2022, Reference Chabot2023), where the internal structure of segments is determined by a segment’s language-specific phonological behaviour, rather than by its phonetic properties (despite a tendency for the two to correlate; see, e.g., Scheer Reference Scheer, Honeybone and Salmons2015). As we will show below, this allows us to avoid having to decompose place-changing palatalisation processes into two formally unrelated processes.
A model that incorporates these properties is Element Theory (Kaye et al. Reference Kaye, Lowenstamm and Vergnaud1985; Harris Reference Harris1994; Harris & Lindsey Reference Harris, Lindsey, Durand and Katamba1995; Backley Reference Backley2011; Scheer & Kula Reference Scheer and Kula2018). In its standard version (Backley Reference Backley2011), this model assumes the six unary representational primitives in Table 5, where the elements are presented with their acoustic correlates and the phonological categories they instantiate. Note that the ‘Acoustic correlate’ and ‘Phonological categories’ columns of Table 5 list the phonetic and phonological properties that commonly correlate with the relevant elements. This does not mean that these correlations hold universally: given the assumption that the elemental makeup of segments primarily derives from their phonological behaviour, and that the phonological behaviour of segments is language-specific, there is no reason to expect that segments that belong to a category in the rightmost column of Table 5 will necessarily feature the corresponding element. For instance, as we shall see in §4.1, we do not assume that all voiceless obstruents contain H, that all nasals contain Ɂ, or that all velar consonants contain U.
The elements (Backley Reference Backley2017).

Elements are unary primes that can be used for the representation of both vowels and consonants, and can be either a head or a non-head, where headedness correlates with greater acoustic and phonological prominence (Backley Reference Backley2017). Crucially, despite having an acoustic signature, elements are mainly interpreted as cognitive primes reflecting the phonological knowledge of a language user. This means that, during acquisition, the language learner infers the underlying representation of segments from the way they behave phonologically, rather than how they sound. If two segments sound the same, but behave differently, then at a deeper level these two segments are different; that is, they have two different underlying representations. Thus, we expect cases of similar sounding segments with different underlying representations, and this is exactly what we find in Czech (see below; see also Compton & Dresher Reference Compton and Dresher2011 for an example from Inuit).
Following Harris (Reference Harris1994) and Botma (Reference Botma2004), we assume that within a segment, elements are geometrically arranged in a structure featuring a root node (●), which dominates a manner, a place and a laryngeal node, as depicted in (5). Furthermore, following Kaye et al. (Reference Kaye, Lowenstamm and Vergnaud1985) and subsequent work, we assume that each element – for example, A, I and U in the place node – sits on its own tier, which, in an approach that further assumes a geometrical arrangement of elements, means that elements are arranged on different tiers in each node too.

In assuming the presence of this root note as a constituent that contains all the features of a segment (Clements Reference Clements1985), we deviate somewhat from mainstream strict CV. There are several reasons for doing this. One is that we need to be able to refer to sets of elements as units targeted by the phonological computation and by the phonetic interpretation. For instance, the very concept of floating segment, that is, of a set of elements that is not associated with any C or V slot, would be meaningless if there were no node collecting all the elements it consists of prior to its association with a C/V slot. The need for root nodes in strict CV has recently also been argued for by Ziková (Reference Ziková2018), Faust (Reference Faust2025) and Scheer (Reference Scheer2022: 480, fn. 44), who explicitly points out that ‘timing units (x-slots, Cs and Vs […], moras etc.) are not the same thing as root nodes. The latter have no timing properties but rather define segments.’
The full set of nodes can be found in consonants, with the manner node hosting Ɂ, H, L or A (or a combination thereof); the place node hosting A, I or U (or a combination thereof) and the laryngeal node hosting L or H. This is shown in (6), where consonanthood is represented by the root node associating to a C slot. Some elements can be in more than one node. L is used to represent nasals (manner node), as well as voicing and low tones (laryngeal node). Similarly, A is standardly used to represent coronals (place node), as well as laterals (manner node). Given that laterals can have different places of articulation, we believe that they must have both a [manner] and a [place]. Thus, we conclude that A can sit in the manner node. This is in accordance with Backley’s proposal in Table 5 (see Kula Reference Kula2002 for a proposal featuring the same elements occurring in several nodes).

Vowels, on the other hand, are traditionally represented with just the place node and the root node, the latter associated with a V slot, as in (7). This does not mean that vowels necessarily lack the manner and laryngeal nodes, and we can indeed find languages that allow for vowels containing the element Ɂ (representing laryngealised or creaky quality), or the element L (in nasalised vowels), or, possibly, the element H (representing spread glottis) for devoiced or breathy-voiced vowels. As Czech vowels do not show contrasts suggesting the activity of such nodes, we abstain from representing them (unless there is an independent reason for doing so, as in (31) in §4.3.3).

For ease of exposition in the representations that follow, we shall verticalise the subsegmental geometry in (5), putting the manner node above the place node as in (8). Distinguishing manner and place will become important later, when we distinguish phonemes that both have the element A, but one (/s/) has A as a place element, and the other (/r/) has it as a manner element (see §4.3.2 for discussion).

3.3. Strict CV
The use of C and V to encode the consonanthood or the vowelhood of a set of elements is grounded in strict CV (Lowenstamm Reference Lowenstamm, Durand and Laks1996; Scheer Reference Scheer2004; Passino Reference Passino2013; Polgárdi Reference Polgárdi2014; Faust Reference Faust2014, Reference Faust2015, Reference Faust2017; Enguehard Reference Enguehard2017; Fathi Reference Fathi2017; Lampitelli Reference Lampitelli2017; Lahrouchi Reference Lahrouchi2018; Scheer Reference Scheer2019; Newell Reference Newell2021). Strict CV is a theory of phonological representations that maintains that all phonological strings are sequences of CV skeletal units. More precisely, the x-slots encoding time units in standard autosegmental approaches (Goldsmith Reference Goldsmith1976) are replaced by skeletal slots encoding both time units and their ‘syllabic’ status, which can be either consonantal (C) or vocalic (V). These slots strictly alternate: each C slot is followed by a V slot, and each V slot is followed by a C slot or by nothing. No other syllabic constituent is given primitive status.
Thus, what superficially looks like a geminate (as in (9a)) or a consonant cluster (as in (9b)), will phonologically consist of a CVCV sequence whose left-hand V has no melodic content. The same goes for long vowels (as in (9c)) and hiatuses (as in (9d)), which are composed of a CVCV sequence with an internal empty C.

As strict CV does not accord any autonomous/formal status to the syllable (nor to the rhyme), patterns that can be explained with reference to syllabic structure (e.g., open syllable lengthening, closed syllable shortness, extrasyllabicity, coda effects, positional strength and vowel–zero alternations) must be given an alternative explanation. Given the flat structure of strict CV representations, this explanation must be found in the lateral relations established between CV slots. These relations are assumed to be a function of the forces discharged by full or parametrically licensed (see below) V slots, which always apply leftward and come in two flavours: government and licensing. The former is conceived of as a force that aims at silencing its target. If the target of government is empty, it can stay silent (e.g., no epenthesis), whereas if it contains some melodic structure, such structure is reduced (e.g., lenition). The final V is special in a number of respects. Two separate parameters determine (i) whether it can be empty or not and (ii) if empty, whether it can show lateral action, that is, whether it can govern and license or not. If the first parameter is switched off, the relevant language fills in the final empty V slot via epenthesis, and by virtue of being full, this V slot can govern a preceding empty V slot. If the first parameter is switched on, final empty V is allowed (and words may phonetically end in a consonant). In this case, the second parameter determines whether the final empty V slot is a proper governor or not. If it is not a proper governor, we may see vowel–zero alternations at the right edge of the word, as in Czech loket_ ‘elbow.nom.sg’, where the final V slot is empty (indicated by the underscore) but not a proper governor, so that the prefinal V slot cannot be silent, hence the epenthesis of e. In contrast, the genitive adds a final vowel e, which governs the prefinal V slot, allowing it to be silent: lok_te ‘elbow.gen.sg’.
Licensing works the other way around, as it supports the pronunciation of the melodic content of its target.Footnote 3 These relations are represented in (10), where the leftward arrows on top of the CV tier stand for government, and the ones at the bottom stand for licensing. (Despite the fact that the bottom arrows link elements on the melody tier, licensing is in fact discharged by V slots on the CV tier.)

In a fairly standard version of strict CV (Scheer Reference Scheer2004), the distribution of the two lateral forces depends on three principles: (i) a position cannot at the same time be governed and licensed; (ii) government takes precedence over licensing; and (iii) a full V has to discharge both forces. Government ‘goes to the preceding empty nucleus […], or to the preceding Onset if the preceding nucleus is not empty […]. Licensing, in turn, affects the position that escaped government’ (Scheer & Cyran Reference Scheer and Cyran2018: 274). Let us see how the system works in (10).
In (10a), the full V3 scans the string leftward, finds the empty V2 and discharges its government force on it, while it discharges its licensing force on C3. Since V2 is governed by V3, it can stay silent. By virtue of being governed, it cannot itself discharge any force. Because of this, it cannot govern the empty V1, which is thus filled in by epenthesis (indicated by the arrow linking the root node of A to V1). For the same reason, V2 cannot license C2, hence the weak status of a position corresponding to traditional codas. In (10b), V3 is empty. In a language like Czech, where a final empty V cannot govern, empty V2 is ungoverned, and therefore gets filled in by epenthesis (this is the case with the Czech form loket ‘elbow’ mentioned earlier). Once V2 has been filled in by epenthesis, it becomes a licit lateral actor, and it can govern V1, which can remain unpronounced, as well as license C2. If instead we are dealing with a language where final empty V can be a licit lateral actor, as in (10c), final V2 can govern the empty V1 and license C2.
The fact that we assume the presence of a root node to which elements of melody are linked implies that we introduce an additional vertical dimension, which generates additional analytical options, which we shall make use of in the analysis we develop below. In the standard case, a C or V slot is associated with a set of melodic elements. This association is mediated by the root node, as shown in (11a): the melodic elements (Ɂ or A) are associated with a root node, and the root node is associated with the C or V slot. However, C and V slots can also host no melody in two different ways, as shown in (11b) and (11c); in (11b), the C or V is associated with a root node but no melody, while in (11c), it is associated with nothing at all. Conversely, (sets of) melodic elements can also lack a C/V host, again in two different ways, as shown in (11d) and (11e). In (11d), the melodic elements are associated with a root node, which itself is floating, that is, it is not associated with a C or V slot. (11e) represents floating melodic elements, which are associated neither to a root node nor to a C/V slot.Footnote 4

We analyse palatalisers as floating elements, that is, as cases of (11e). These floating elements are not a primitive of the morphological composition, nor are they part of the base that shows the effects of palatalisation. Rather, these floating elements are associated, in the lexical representation, with the suffix triggering the palatalisation. Thus, Czech palatalisation is a case of featural affixation (Akinlabi Reference Akinlabi1996; Wolf Reference Wolf2007; Trommer Reference Trommer2012; McPherson Reference McPherson2017). The floating palatalising elements show visible effects on the final consonant of the base, because, following basic autosegmental assumptions, they strive to associate to the leftmost available slot. The specific details of the mechanism responsible for the association of floating material are rarely spelled out in the literature, an exception being McCarthy (Reference McCarthy1981: 382), who maintains that the association of the (floating) elements sitting on the melodic tiers with the skeletal nodes abides by the following conventions:

As we shall see in §4.3, these definitions do not exactly cover our case, since the unassociated melodic elements (our floating palatalisers) will need to associate with melody-bearing elements (i.e., the root node of of the base-final C slot) that already contain some element. We believe a minimal reformulation of (12a) will allow this:
This formulation will allow association of floating elements to start at the root node of the base-final C slot, even if that is already filled with melodic material. Association will not be able to reach further leftward into the root because of the ban on crossing association lines. If for some reason association with the final C of the base is impossible (e.g., if it is a labial; see §4.3.3 for discussion), association will target the root node of the V that follows the base-final C and so on. If no proper association can be established, elements may remain floating, in which case they are not phonetically realised.
Following John (Reference John2014) and Ziková (Reference Ziková2018), we further assume that the association of floating melodic elements with C/V slots must always be mediated by a root node. Concretely, a floating element like the one in (11e), with no root node, cannot attach to a C/V slot without a root node as in (11c), as there would be no root node to mediate the association. In order to be able to associate at all, a floating element as in (11e) needs something to its left like (11a) or (11b).
3.4. An alternative scenario
Before proceeding to the actual analysis, there is an alternative scenario that we need to consider (and, as it shall turn out, dismiss). The lateral activity of the palataliser could also be taken to follow from the fact that all the palatalising suffixes discussed so far involve the front vowels e or i, both of which contain the element I. This I could be argued to be the factor responsible for palatalisation. Under such a scenario, we would be dealing with a case of (11a) rather than (11d) or (11e), with I spreading leftward. There are three arguments suggesting that this alternative scenario is incorrect, and that the palataliser is indeed an additional floating element (or set of elements), as in (11d) or (11e).
The first argument is that palatalisation is not only triggered by morphemes that begin with a front vowel (thus a vowel containing I), but also by morphemes starting with back vowels. Table 6 lists a number of these suffixes, like the suffix -an, which derives demonyms from place names; -atý, which derives adjectives and -ova, which is a verbal thematic suffix. A detailed study of suffixes starting with back vowels can be found in Beranová (Reference Beranová2009).Footnote 5
Palatalisation triggered by suffixes with back vowels (Beranová Reference Beranová2009).
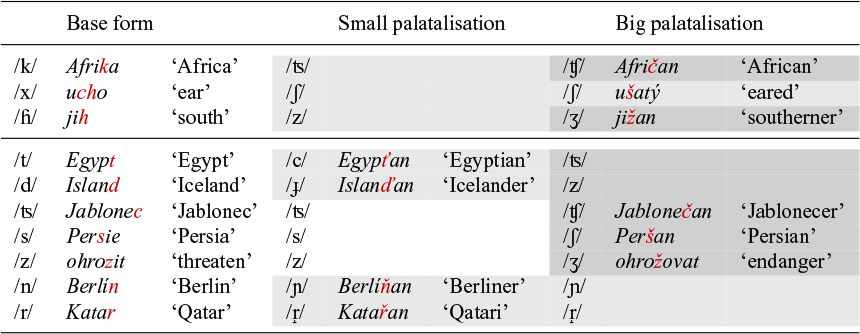
A second, more compelling, argument supporting the claim that the palataliser is independent of the vowel of the suffix is that not all morphemes starting with a front vowel trigger palatalisation. For example, in verbs of the a-class (which have a theme vowel -a preceding the infinitival suffix -t), the imperative is formed by adding the suffix -ej to the base. This suffix is minimally different from the comparative -ěj in that it does not trigger palatalisation, as shown in Table 7.
Imperative -ej with a-class verbs.

Finally, there is the fact that different morphemes starting with the same front vowel trigger different palatalisation patterns, as we saw above for the -ě suffix of the loc/dat.f.sg, the comparative morpheme -ěj and the passive participle suffix -ěn. In each of these three cases, the initial segment ě is identical, yet they trigger different palatalisation patterns. This fact would seem hard to account for under the simple assumption that the I element of front vowels spreads leftward, triggering palatalisation.
The hypothesis that the factor responsible for palatalisation is a floating set of elements or features that gets associated with the base-final consonantal segment, rather than the vowel one sees on the surface, is in line with previous accounts of palatalisation in Slavic, such as Ketner (Reference Ketner2005), who proposes an OT account of Czech; Gussmann (Reference Gussmann, Fisiak and Puppel1992) and Zdziebko (Reference Zdziebko2015) for Polish and Bidwell (Reference Bidwell1962), Iosad & Morén-Duolljá (Reference Iosad and Morén-Duolljá2010) and Padgett (Reference Padgett, Brown, Cooper, Fisher, Kesici, Predolac and Zec2010) for Russian.
In the next section, we show how the formal tools provided by Element Theory and strict CV allow us to neatly model the Czech palatalisation patterns.
4. Analysis
4.1. Overview
As we mentioned in the previous section, Czech displays cases of similar-sounding segments that have different underlying representations, thereby providing support to a substance-free take on phonology. Czech thus also provides support for the hypothesis that ‘featural representations […] possibly reflect local generalizations, specific to certain morphological domains or lexical strata (as, for example, in cases of multiple palatalization processes targeting the same consonants). However, these and many other implications for analyses of palatalization have not yet been explored’ (Kochetov Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011: 1686 emphasis added). In this article, we do explore these implications and provide a formal modelling of the different palatalisation processes targeting Czech consonants, showing that the differences in the degree to which a consonant is palatalised are a function of its underlying representation interacting with that of the exponents of different morphosyntactic objects.
Our proposal for the elemental composition of the three palatalisers is summarised in Table 8, where X is a variable standing for whatever the element composition is of the plain – that is, unpalatalised – consonant. PAL1 adds the element I to the plain sound; PAL2 adds H.I and PAL3 adds H.I. We use the symbol
 $\cup $
to indicate a property of the phonetic interpretation of the combination of the elements of the palatalisers with those of the preceding segments, which is that they compose in the manner of members of a set, which can only contain a single occurrence of the same member; that is,
$\cup $
to indicate a property of the phonetic interpretation of the combination of the elements of the palatalisers with those of the preceding segments, which is that they compose in the manner of members of a set, which can only contain a single occurrence of the same member; that is, ![]() (Postma Reference Postma2019: 11). In the same manner, adding H or I to a node that already contains it does not add anything. We use the
(Postma Reference Postma2019: 11). In the same manner, adding H or I to a node that already contains it does not add anything. We use the
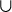 $\cup $
notation in a purely descriptive manner, without wanting to imply that there is a formal operation of set union involved. For our purposes, it suffices to assume that for the process of phonetic interpretation, multiple occurrences in the same C or V slot of the same element below the place, manner or laryngeal node count as one. The reason for this is that adding a specific element to a node of a segment that already contains that element has no phonological nor phonetic consequence.Footnote
6
$\cup $
notation in a purely descriptive manner, without wanting to imply that there is a formal operation of set union involved. For our purposes, it suffices to assume that for the process of phonetic interpretation, multiple occurrences in the same C or V slot of the same element below the place, manner or laryngeal node count as one. The reason for this is that adding a specific element to a node of a segment that already contains that element has no phonological nor phonetic consequence.Footnote
6
The elemental composition of the three palatalisers.

The consonants featuring in the small, medium and big palatalisation patterns (see Table 4b) have the elements of their plain alternant (represented as X in Table 8), plus those of the relevant palataliser: I for PAL1, ![]() for PAL2 and
for PAL2 and ![]() for PAL3. The Element-Theoretic representations we shall provide will allow us to develop an analysis where the apparently irregular picture that appears from the phonetics of the palatalised consonants (summarised in Table 4b) is fully regular.
for PAL3. The Element-Theoretic representations we shall provide will allow us to develop an analysis where the apparently irregular picture that appears from the phonetics of the palatalised consonants (summarised in Table 4b) is fully regular.
As can be seen, the palatalisers are in a containment relation. PAL1 contains only I, which represents frontness; PAL2 contains I plus H, the element that represents frication (in the case of fricatives) or audible release (in the case of stops) and PAL3 contains H plus the headed version of I, which stands for palatality (Backley Reference Backley2011).Footnote 7 This relation, coupled with the resulting incremental representational complexity, formally translates the degrees or strengths of palatalisation we discussed above. As we shall see below, the decomposition of the palatalisers into two distinct atoms H and I also explains the fact that palatalisation triggers a change in both the place and the manner of articulation of the targeted consonant (see Ketner Reference Ketner2005 for an account of Czech palatalisation in terms of assibilation).
We now proceed to overviews of the elemental makeup of individual sets of sounds, starting with the velars and coronals, shown in Table 9. In our tables, we adopt the convention that the elements relating to manner are separated by a dot from the elements relating to place.
Plain and palatalised velar and coronal consonants.
The two leftmost columns show the IPA symbol and the elemental composition of the plain alternants, while the other columns show, from left to right, the IPA symbol and elemental composition of the small, medium and big palatalised alternants. The palatalised alternants consistently feature the elements of the corresponding plain alternant plus those of the relevant palataliser.
Detailed representations of the Czech morphemes containing the palatalisers will be given in §4.2. As for the representation of the plain alternants of the base-final consonants (in the second column of Table 9), we adopt a relatively conservative approach (see, e.g., Gussmann Reference Gussmann2007, Cyran Reference Cyran2010 and Zdziebko Reference Zdziebko2015, Reference Zdziebko2022 for comparable element-theory-based representation of other Slavic languages). We take the velar consonants to be underspecified for place of articulation, that is, to have no place element. This is in line with most previous work on Slavic (Harris & Lindsey Reference Harris, Lindsey, Durand and Katamba1995; Rice Reference Rice1996; Gussmann Reference Gussmann2007; Cyran Reference Cyran2010; Zdziebko Reference Zdziebko2015, Reference Zdziebko2022), and possibly explains why, upon palatalisation, velars shift their place of articulation so easily.Footnote
8
Coronal consonants contain the place elements A and/or I, which are both traditionally used for coronality (Backley Reference Backley2011). Coronal stops contain the manner element Ɂ, and fricatives H. Nasal and rhotic coronal consonants are represented as ![]() and A, respectively.
and A, respectively.
Voiced obstruents are not shown in Table 9 and subsequent tables. This is because their representation is entirely predictable on the basis of their voiceless counterparts, to which they are identical except that they add the element L, representing voicing, in the laryngeal node. For example, /d/ would be represented as ![]() , and its palatalised alternants would be
, and its palatalised alternants would be ![]() ,
, ![]() and Ɂ
and Ɂ ![]() , respectively; the other voiced obstruents have similar representations (see Backley Reference Backley2017 for arguments supporting the need for expressions containing multiple heads). Another sound absent from Table 9 is the lateral approximant /l/. It is subject to the exceptionless generalisation that it never undergoes palatalisation in Czech. We return to this sound in §4.3.4 below.
, respectively; the other voiced obstruents have similar representations (see Backley Reference Backley2017 for arguments supporting the need for expressions containing multiple heads). Another sound absent from Table 9 is the lateral approximant /l/. It is subject to the exceptionless generalisation that it never undergoes palatalisation in Czech. We return to this sound in §4.3.4 below.
We next present an overview of the labials in Table 10. As discussed above, labial consonants behave differently from other consonants with respect to palatalisation. First, the palatalisers never manage to fully palatalise them; that is, labials never change their place of articulation, nor their manner of articulation. Second, the palatalisers can surface autonomously. As Table 10 shows, PAL1 and the PAL2 of the comparative surface after the labial consonant as ‘a fully developed palatal element’ (Short Reference Short, Comrie and Corbett1993: 459) – that is, as a front vocoid, which we shall argue in §4.3.3 is actually a vowel.
Plain and palatalised labial consonants.

Another peculiarity (which seems to be specific to Czech) is that ‘after bilabial /m/ nasal resonance extends over both segments’, resulting in [mɲ] (Short Reference Short, Comrie and Corbett1993: 459).Footnote 9 This is shown in the PAL1 and comparative -ěj columns of Table 10.
The bisegmental nature of the palatalisation is indicated by the en dash in the representations (e.g., ![]() ). The output invisibility of PAL2 of the causative and PAL3 is indicated by putting the palataliser in brackets (e.g.,
). The output invisibility of PAL2 of the causative and PAL3 is indicated by putting the palataliser in brackets (e.g., ![]() ) in the first row under the causative -i heading). As we argue below, the output invisibility of the palataliser with labials is not related to the strength of the palataliser, but to the skeletal profile of the suffix, more specifically whether the initial vowel of the suffix is itself associated with a V slot. The table thus brings out the fact that, although there are four columns or patterns of palatalisation, there are only three different palatalisers.
) in the first row under the causative -i heading). As we argue below, the output invisibility of the palataliser with labials is not related to the strength of the palataliser, but to the skeletal profile of the suffix, more specifically whether the initial vowel of the suffix is itself associated with a V slot. The table thus brings out the fact that, although there are four columns or patterns of palatalisation, there are only three different palatalisers.
The behaviour of Czech labial consonants fits with the palatalisation typology described by, among others, Bateman (Reference Bateman2007), who shows that labials are the consonants least affected by palatalisation, and that when they do palatalise, they tend to acquire a secondary place of articulation rather than changing their manner of articulation (Bateman Reference Bateman2007: 47). As a matter of fact, she observes that labial consonants ‘never show full palatalization in purely phonological contexts’, and that ‘even when labials do appear to show full palatalization, this is the result of historical changes’ (Bateman Reference Bateman2007: 85). Bateman (Reference Bateman2007: 47) explains these facts in terms of articulationFootnote 10 :
[P]honological full palatalization of labials is not expected to occur because of the articulators involved in producing labial consonants on the one hand and the palatalization triggers on the other: the lips and the tongue, respectively. These articulators can move independently of one another, therefore there is no pressure for full palatalization to occur.
As we will discuss later in §4.3.3, an autosegmental phonology-based account of the failure of labial consonants to palatalise can be developed that derives this failure from the assumption that, in some languages (e.g., those that do not have front rounded vowels), the elements I and U are unable to merge to create a complex place IU, an impossibility standardly attributed to the hypothesis that, in those languages, I and U sit on the same tier (Kaye et al. Reference Kaye, Lowenstamm and Vergnaud1985; Postma Reference Postma2019). In Czech, the ill-formedness of IU is shown by the fact that Czech does not have front rounded vowels (such as ![]() ; Janků Reference Janků2022), and does not allow for palatalisation of labials, suggesting that I and U cannot be combined, which in turn suggests that, in the place node, the tiers of U and I are conflated into one. Because of this, they are in competition, and a well-formed Czech representation can feature at most one of them.
; Janků Reference Janků2022), and does not allow for palatalisation of labials, suggesting that I and U cannot be combined, which in turn suggests that, in the place node, the tiers of U and I are conflated into one. Because of this, they are in competition, and a well-formed Czech representation can feature at most one of them.
In sum, we maintain that an approach that exploits the representational technology of Element Theory and strict CV also allows us to provide a neat account of the palatalisation patterns of labial consonants: to derive (i) why labials cannot be fully palatalised; (ii) why the palatalisers themselves can fail to surface; and (iii) when they do surface, how they do so – as a vowel or as a palatalised nasal.
Before showing the specifics of the analysis of the different palatalisation patterns of Czech, and introducing the relevant morphemes and their representation, we expound the logic we adopted for establishing the elemental structure of Czech segments, palatalisers included. As we mentioned above, we assume standard Element Theory, which gives us a set of six elements, augmented by the distinction between heads and non-heads. Assuming that this (plus the C/V given by strict CV and the subsegmental geometrical structure) is all language learners have at their disposal, we maintain that language learners start building their phonological representations by mapping the elements onto the acoustic signatures the elements encode by default. Crucially, if the phonological behaviour gives the learners reasons for doing that, they modify the previously established mappings, and update their phonological representations (Hamann Reference Hamann2009, Reference Hamann, Botma, Kula and Nasukawa2010; Cyran Reference Cyran, Cyran, Kardela and Szymanek2012; Scheer Reference Scheer, Cyran and Szpyra-Kozlowska2014; Cavirani Reference Cavirani2015).Footnote
11
In reconstructing the phonological representations of Czech consonants and of the palatalisers, we followed the same procedure: we started from commonly assumed element–acoustic signature mappings (see Backley Reference Backley2011 and Table 5 for standard mappings, and Zdziebko Reference Zdziebko2015, Reference Zdziebko2022 for mappings previously proposed for Slavic languages), and we updated the resulting representations when required by the phonology – in our case, by palatalisation patterns. An important guiding principle we adopted was building the system (i.e., the union of Tables 9 and 10) in such a way that there is no underlying representation that corresponds to several phonetic interpretations. We maintain that this follows if we assume that, at the phonology–phonetics interface, a given phonological object is mapped onto the corresponding abstract acoustic object (akin to the ‘sound image’ of Paul Reference Paul1880), in the same way, a concept is mapped onto the corresponding phonological form (Boersma Reference Boersma2009, Reference Boersma, Benz and Matthausch2011; Hamann Reference Hamann, Botma, Kula and Nasukawa2010; Cavirani Reference Cavirani2015; Scheer Reference Scheer2022).Footnote
12
For instance, we expect a single grammar to map the element A associated with a V node to a single consistent sound image, such as [a]. In the same way, in English, the concept cat is mapped onto ![]() . What we do not expect, is for a single grammar to map the element A associated with a V node to both [a] and [u], in the same way, as we do not expect it to map cat onto both
. What we do not expect, is for a single grammar to map the element A associated with a V node to both [a] and [u], in the same way, as we do not expect it to map cat onto both ![]() and
and ![]() . The opposite scenario, though, namely one where a single acoustic object corresponds to different underlying representations, is not problematic. For instance, in English, the string [kæt] can realise both a noun and a verb (as in to cat around); that is, it can have different morphosyntactic representations. In the same way, [ə] can be the realisation of the element A associated with a V node, as well as the realisation of the enhanced release of a plosive (Hall Reference Hall2006; Cavirani Reference Cavirani2015; Ridouane & Cooper-Leavitt Reference Ridouane and Cooper-Leavitt2019; Hamann & Miatto Reference Hamann, Miatto, Kim, Miatto, Petrović and Repetti2024), which, in some Element-Theoretic analyses, is represented by the element H (Backley Reference Backley2011). In such cases, the difference between the two similar-sounding objects would be signalled by a difference in phonological behaviour (Compton & Dresher Reference Compton and Dresher2011; Hamann Reference Hamann, Bowern and Evans2015), just as the difference between the noun and the verb cat is signalled by a difference in morphosyntactic distribution.
. The opposite scenario, though, namely one where a single acoustic object corresponds to different underlying representations, is not problematic. For instance, in English, the string [kæt] can realise both a noun and a verb (as in to cat around); that is, it can have different morphosyntactic representations. In the same way, [ə] can be the realisation of the element A associated with a V node, as well as the realisation of the enhanced release of a plosive (Hall Reference Hall2006; Cavirani Reference Cavirani2015; Ridouane & Cooper-Leavitt Reference Ridouane and Cooper-Leavitt2019; Hamann & Miatto Reference Hamann, Miatto, Kim, Miatto, Petrović and Repetti2024), which, in some Element-Theoretic analyses, is represented by the element H (Backley Reference Backley2011). In such cases, the difference between the two similar-sounding objects would be signalled by a difference in phonological behaviour (Compton & Dresher Reference Compton and Dresher2011; Hamann Reference Hamann, Bowern and Evans2015), just as the difference between the noun and the verb cat is signalled by a difference in morphosyntactic distribution.
4.2. The palatalisers
Among the morphemes triggering small palatalisation (PAL1) we have the suffix expressing the locative and dative of feminine nouns in the singular: -ě. Its representation is given in (14). (For ease of exposition, we do not show the elemental composition of ![]() in this and subsequent representations, except where necessary.) As discussed above, we argue that the factor responsible for palatalisation is not the audible vowel
in this and subsequent representations, except where necessary.) As discussed above, we argue that the factor responsible for palatalisation is not the audible vowel ![]() , but a floating place element I that belongs to the same morpheme. We also maintain that the initial C slot of loc/dat.f.sg -ě, as well as of other suffixes, is associated with an empty root node, which will serve as the host for the spreading of the L element of the base-final
, but a floating place element I that belongs to the same morpheme. We also maintain that the initial C slot of loc/dat.f.sg -ě, as well as of other suffixes, is associated with an empty root node, which will serve as the host for the spreading of the L element of the base-final ![]() in (29) and the A element of the base-final /l/ in (34).Footnote
13
in (29) and the A element of the base-final /l/ in (34).Footnote
13

As an example of PAL2, in (15), we give the representation of the comparative suffix -ěj. In this case, too, the factor responsible for palatalisation is not the audible ![]() , but some floating element. We argue that PAL2, unlike PAL1, contains two such floating elements: the manner element H and the place element I. Given that we assume strict CV, this morpheme ends with an empty V slot, as does -ěn in (17). (We remain agnostic on whether this final V slot contains a root node.)
, but some floating element. We argue that PAL2, unlike PAL1, contains two such floating elements: the manner element H and the place element I. Given that we assume strict CV, this morpheme ends with an empty V slot, as does -ěn in (17). (We remain agnostic on whether this final V slot contains a root node.)

Another PAL2 morpheme we will make use of in the derivations below is the causative suffix -i. Like comparative -ěj,, it contains the two floating elements H and I. However, unlike in the case of -ěj, these are followed by a floating segment. This floating segment consists of a root node associated with I, and surfaces as ![]() when associated with a V slot. Its representation is shown in (16). As we shall show in §4.3.3, this representation allows us to derive output invisibility, the failure of the palataliser to surface independently when following a labial consonant.
when associated with a V slot. Its representation is shown in (16). As we shall show in §4.3.3, this representation allows us to derive output invisibility, the failure of the palataliser to surface independently when following a labial consonant.

PAL3 is exemplified by the morpheme -ěn lexicalising pass.ptcp, whose representation is shown in (17). PAL3 is a stronger version of PAL2, as its I element is headed, while that of PAL2 is unheaded. As in the previous morphemes, the palatalisers are floating elements. Like causative -i, the palataliser of the pass.ptcp -ěn morpheme shows output invisibility following labials. We take this to mean that the elements of the audible vowel ![]() , namely AI, are associated with a floating root node, as was the case with causative -i in (16). Details of how this works will be provided in §4.3.3.
, namely AI, are associated with a floating root node, as was the case with causative -i in (16). Details of how this works will be provided in §4.3.3.

Note that this morpheme is potentially decomposable into two morphemes, namely H.I plus ![]() on the one hand, and
on the one hand, and ![]() on the other. An argument supporting this decomposition can be found in the fact that in verbs of the a-class, the pass.ptcp morpheme surfaces as -an, whereas in other verb classes, n is always preceded by e, as in čekat–čekán ‘to wait’ vs. sušit–sušen ‘to dry’, sedět–seděn ‘to sit’.Footnote
14
We take this to suggest that the a theme vowel occupies the same position as ě, and that the e and i theme vowels are outcompeted by ě. As this has no effect on the palatalisation patterns this article focuses on, we do not explore this issue further.
on the other. An argument supporting this decomposition can be found in the fact that in verbs of the a-class, the pass.ptcp morpheme surfaces as -an, whereas in other verb classes, n is always preceded by e, as in čekat–čekán ‘to wait’ vs. sušit–sušen ‘to dry’, sedět–seděn ‘to sit’.Footnote
14
We take this to suggest that the a theme vowel occupies the same position as ě, and that the e and i theme vowels are outcompeted by ě. As this has no effect on the palatalisation patterns this article focuses on, we do not explore this issue further.
4.3. Derivations
In this section, we describe in detail the derivation of the palatalisation patterns discussed in §2. We start from the derivation of palatalised velars (§4.3.1), which is followed by the derivation of palatalised coronals (§4.3.2) and labials (§4.3.3). The derivation of the failed palatalisation of ![]() is described in a dedicated section at the end (§4.3.4).
is described in a dedicated section at the end (§4.3.4).
As already anticipated, three crucial components of our analysis are the hypotheses that (i) the palatalisers are floating elements that look for an available host; (ii) the appropriate hosts for floating elements are root nodes (more precisely, the manner and place nodes they contain); and (iii) floating elements look for an available root node from left to right (see (13)). In what follows, we show how such hypotheses allows us to model the whole set of palatalisation patterns discussed in §2.
4.3.1. Velar consonants
We begin our detailed discussion of the derivation by looking at how velar consonants are modified by the three kinds of palatalisers we discussed in the previous section, namely loc/dat.f.sg -ě (PAL1), comparative -ěj (PAL2) and pass.ptcp -ěn. Since causative -i (PAL3) will become relevant only with labial consonants, we will ignore it in this section.
What we need to derive are the palatalised alternants of ![]() , whose representations and IPA transcriptions are given in Table 11 (which in part repeats Table 9). For reason of space, we only give the full derivation of the palatalised alternants of the velar stop
, whose representations and IPA transcriptions are given in Table 11 (which in part repeats Table 9). For reason of space, we only give the full derivation of the palatalised alternants of the velar stop ![]() . The derivation of the velar fricative would be identical to that of
. The derivation of the velar fricative would be identical to that of ![]() , provided that one replaces Ɂ with H. Similarly, the derivation of the voiced velar consonants would be identical to that of their voiceless counterparts, provided that one adds the L element representing voicing in the laryngeal node.
, provided that one replaces Ɂ with H. Similarly, the derivation of the voiced velar consonants would be identical to that of their voiceless counterparts, provided that one adds the L element representing voicing in the laryngeal node.
Plain and palatalised velar consonants.

In (18), we give the representation of a base ending with a velar stop. What precedes ![]() is irrelevant, and we represent it with an ellipsis.Footnote
15
We assume that silent V slots at the end of a base have a root node with no element attached. In certain cases (to be discussed later on), the floating palataliser will associate with this V and surface as the vocalic segment
is irrelevant, and we represent it with an ellipsis.Footnote
15
We assume that silent V slots at the end of a base have a root node with no element attached. In certain cases (to be discussed later on), the floating palataliser will associate with this V and surface as the vocalic segment ![]() . In other cases, it will serve as the host for the floating IA and I that we have postulated in the suffixes -ěn and -i, respectively.
. In other cases, it will serve as the host for the floating IA and I that we have postulated in the suffixes -ěn and -i, respectively.

As an example of PAL1, in (19), we show the morpheme expressing locative and dative case in feminine singular nouns, repeated from (14).

When a base ending in ![]() is concatenated with a PAL1 morpheme, the floating palataliser tries to associate to the leftmost object it can without crossing association lines. As can be seen in (20), the leftmost available object is the root node containing
is concatenated with a PAL1 morpheme, the floating palataliser tries to associate to the leftmost object it can without crossing association lines. As can be seen in (20), the leftmost available object is the root node containing ![]() , which has Ɂ in the manner node and nothing in the place node. Root nodes farther to the left are inaccessible because of the association line connecting Ɂ to its root node. Thus, the palataliser associates to this root node, as in (20a). This results in a consonantal segment containing Ɂ in the manner node and I in the place node, as in (20b), which is interpreted by the phonetic module as [ʦ]. We assume that a reduction operation deletes a sequence of empty VC slots (shown in light grey) (Gussmann & Kaye Reference Gussmann and Kaye1993). This results in the surface representation in (20c).
, which has Ɂ in the manner node and nothing in the place node. Root nodes farther to the left are inaccessible because of the association line connecting Ɂ to its root node. Thus, the palataliser associates to this root node, as in (20a). This results in a consonantal segment containing Ɂ in the manner node and I in the place node, as in (20b), which is interpreted by the phonetic module as [ʦ]. We assume that a reduction operation deletes a sequence of empty VC slots (shown in light grey) (Gussmann & Kaye Reference Gussmann and Kaye1993). This results in the surface representation in (20c).

Let us now see how to derive the second palatalised alternant of ![]() , which is [ʧ]. As discussed above, a morpheme containing PAL2 is comparative -ěj, shown in (21) (repeated from (15)).
, which is [ʧ]. As discussed above, a morpheme containing PAL2 is comparative -ěj, shown in (21) (repeated from (15)).

As in the previous case, when concatenated with a base, the floating palataliser elements in -ěj scan the phonological string from left to right looking for an available root node. In this case as well, the leftmost available root node is the one containing Ɂ. The palatalisers H and I associate to it as shown in (22a), and VC reduction applies, yielding a root node containing the segment ɁH.I as in (22b), which is interpreted by the phonetic module as [ʧ].

Finally, we look at what happens when a base ending in /k/ concatenates with a morpheme bearing PAL3, like pass.ptcp -ěn in (23), repeated from (17).

In this case, we need to accommodate the two floating palataliser elements – palataliser H and I – and the floating segment ![]() . As in the preceding examples, upon concatenation, floating elements look for an available root node by scanning the phonological string from left to right. The floating H and I find the root node containing Ɂ and associate to it. The next floating object, the segment
. As in the preceding examples, upon concatenation, floating elements look for an available root node by scanning the phonological string from left to right. The floating H and I find the root node containing Ɂ and associate to it. The next floating object, the segment ![]() , follows the same procedure: it scans the phonological string from left to right looking for an available host to associate to. Unlike floating elements without a root node, floating root nodes look for an available C/V slot. Associating with the C slot containing Ɂ would imply crossing the association line linking the base-final V node to its root node. Hence, the floating root node containing
, follows the same procedure: it scans the phonological string from left to right looking for an available host to associate to. Unlike floating elements without a root node, floating root nodes look for an available C/V slot. Associating with the C slot containing Ɂ would imply crossing the association line linking the base-final V node to its root node. Hence, the floating root node containing ![]() associates to the base-final V slot as in (24a). This yields (24b), which features Ɂ H.I in the base-final C slot and
associates to the base-final V slot as in (24a). This yields (24b), which features Ɂ H.I in the base-final C slot and ![]() in the base-final V. The phonetic module interprets this as [ʧɛn].
in the base-final V. The phonetic module interprets this as [ʧɛn].

The reader may note that ɁH.I and ɁH.I are interpreted identically – that is, as [ʧ] – by the phonetic module. A similar situation is found with the fricative /ʃ/, which corresponds to four different underlying representations. First, it is the outcome of small, medium and big palatalisation of velar /x/. /x/ is represented by the sole element H, which turns into [ʃ] when merged with any of PAL1 (I), PAL2 (![]() ) or PAL3 (
) or PAL3 (![]() ). Furthermore, [ʃ] is also the outcome of big palatalisation applied to /s/, in which capacity it corresponds to
). Furthermore, [ʃ] is also the outcome of big palatalisation applied to /s/, in which capacity it corresponds to ![]() . Thus, four different underlying representations have the same phonetic interpretation. We show these for convenience in Table 12. The union operation on the relevant elements (applied at the level of phonetic interpretation) will in fact obscure the difference between small and medium palatalisation for /x/ and /s/.Footnote
16
. Thus, four different underlying representations have the same phonetic interpretation. We show these for convenience in Table 12. The union operation on the relevant elements (applied at the level of phonetic interpretation) will in fact obscure the difference between small and medium palatalisation for /x/ and /s/.Footnote
16
Representations for plain and palatalised /x/ and /s/, four of which yield /ʃ/.

As discussed in §4.1, we maintain that this is not a problem if the phonology–phonetics interface works by lexical access (Hamann Reference Hamann, Botma, Kula and Nasukawa2010; Boersma Reference Boersma, Benz and Matthausch2011; Scheer Reference Scheer, Cyran and Szpyra-Kozlowska2014, Reference Scheer2022): Czech has one palatalised alternant of /x/, namely [ʃ], which is generated when merging the ‘weakest’ palataliser, PAL1. Given that there is no other palatalised alternant of /x/ available in the Czech phonetic lexicon, the phonetic module will always map the resulting structure onto [ʃ], even if we merge stronger palatalisers. Returning to the velars, something similar holds for /k/. In this case, however, the Czech phonetic lexicon has two palatalised alternants: [ʦ] (PAL1) and [ʧ] (PAL2 and PAL3).
4.3.2. Coronal consonants
The set of plain and palatalised coronal consonants is given in Table 13 (which partly repeats Table 9). As in the case of velar consonants, the three degrees of palatalisation consistently show I, ![]() and
and ![]() , respectively.Footnote
17
, respectively.Footnote
17
Plain and palatalised coronal consonants.

The derivation of coronal consonants is identical to that of the velar consonants: upon concatenation, the floating palatalisers contained in the suffix scan the phonological string from left to right, and associate to the leftmost available root node – that is, the one associated with the base-final C slot – thereby generating the palatalised alternants given in the PAL1, PAL2 and PAL3 columns of Table 13. The resulting representations are then interpreted by the phonetic module in the same fashion we saw above, namely through lexical access. As discussed above, this allows for the presence of similar-sounding phones corresponding to different underlying representations.
Although the derivation of the palatalised alternants of the coronal consonants adds nothing to the mechanics that we saw earlier with the velars, we want to show the derivation of the palatalised alternants of ![]() and
and ![]() , as this gives us a chance to show the role played by the subsegmental geometry in (8), repeated here as (25):
, as this gives us a chance to show the role played by the subsegmental geometry in (8), repeated here as (25):

As shown in Table 13, the PAL1 and PAL2 alternants of ![]() and the PAL2 alternant of
and the PAL2 alternant of ![]() display the same set of elements: H, A and I. The same holds for the PAL3 alternants of
display the same set of elements: H, A and I. The same holds for the PAL3 alternants of ![]() and
and ![]() , which both display H, A and I. Although sets contain the same elements, they differ in their internal structure. In their plain alternant,
, which both display H, A and I. Although sets contain the same elements, they differ in their internal structure. In their plain alternant, ![]() has the element H in the manner node and the elements AI in the place node (represented as
has the element H in the manner node and the elements AI in the place node (represented as ![]() ), while
), while ![]() has the A element only, which we assume is in the manner node (in
has the A element only, which we assume is in the manner node (in ![]() as well as in
as well as in ![]() ; see §4.3.4). When merged with the palatalisers, the difference between these two structures is maintained. This is shown in the compact notation by the position of the dot: palatalised
; see §4.3.4). When merged with the palatalisers, the difference between these two structures is maintained. This is shown in the compact notation by the position of the dot: palatalised ![]() has
has ![]() (or
(or ![]() ), whereas platalised
), whereas platalised ![]() has
has ![]() (or
(or ![]() ).
).
The representations in (26) and (27) depict this graphically. In (26a), we have a base ending in ![]() that concatenates with comparative -ěj. As shown in (26b), the root node of the base-final C slot of the output form contains the element H in the manner node and the elements AI in the place node. (In (26b), and in subsequent representations, we do not repeat an element when it occurs more then once in the same node of a single segment, as we assume that adding a specific element to a node that already contains that element has no phonological or phonetic consequences.)
that concatenates with comparative -ěj. As shown in (26b), the root node of the base-final C slot of the output form contains the element H in the manner node and the elements AI in the place node. (In (26b), and in subsequent representations, we do not repeat an element when it occurs more then once in the same node of a single segment, as we assume that adding a specific element to a node that already contains that element has no phonological or phonetic consequences.)

In contrast, ![]() has the element A in the manner node, and nothing else; this is shown in (27a).Footnote
18
When it is concatenated with comparative -ěj, the palatalisers associate to the root node containing
has the element A in the manner node, and nothing else; this is shown in (27a).Footnote
18
When it is concatenated with comparative -ěj, the palatalisers associate to the root node containing ![]() , resulting in a structure that features the elements H and A in the manner node and the element I in the place node, as in (27b).
, resulting in a structure that features the elements H and A in the manner node and the element I in the place node, as in (27b).

Thus, the geometrical difference between the palatalised alternants of ![]() and
and ![]() accounts for the different phonetic interpretations of two apparently similar sets of elements, which surface as [s] and [r̝], respectively.Footnote
19
accounts for the different phonetic interpretations of two apparently similar sets of elements, which surface as [s] and [r̝], respectively.Footnote
19
4.3.3. Labial consonants
As we observed above, the Czech labials seem to be unable to palatalise: either the palatal element is pronounced as a separate glide, or it remains unpronounced. In addition, the labials seemed to necessitate that we distinguish not three but four patterns of palatalisation. Yet we have claimed that there are only three different palatalisers, as shown in Table 14 (repeated from §4.1).
Plain and palatalised labial consonants (input).

In this section, we shall explain how the underlying representations in Table 14 lead to the observed output. What we need to derive is (i) the failure of the palatalisers to modify a base-final labial consonant; (ii) their realisation as a ‘fully developed palatal element’ (Short Reference Short, Comrie and Corbett1993: 459) instead; (iii) the (apparent) failure of the palatalisers to surface at all with certain suffixes; and (iv) the appearance of ![]() following
following ![]() .
.
Let us start from the derivation of forms in which the palataliser surfaces as a separate palatal vocoid following an obstruent (represented by ![]() and
and ![]() in Table 14). The derivation is shown in (28), with a form ending in
in Table 14). The derivation is shown in (28), with a form ending in ![]() that concatenates with comparative -ěj.
Footnote
20
The crucial difference between velar and coronal consonants on the one hand, and labial consonants on the other is that the latter contain the element U, which in Czech cannot merge or coalesce with I to create a complex place element IU (Janků Reference Janků2022).
that concatenates with comparative -ěj.
Footnote
20
The crucial difference between velar and coronal consonants on the one hand, and labial consonants on the other is that the latter contain the element U, which in Czech cannot merge or coalesce with I to create a complex place element IU (Janků Reference Janků2022).
Thus, when PAL2 concatenates with a base ending in ![]() and its floating elements look for the leftmost available root node, H associates to the root node hosting
and its floating elements look for the leftmost available root node, H associates to the root node hosting ![]() , namely
, namely ![]() , but I does not, because it is repelled by the U element of
, but I does not, because it is repelled by the U element of ![]() , as shown in (28a). As a consequence, I tries to associate to the second-leftmost slot, which is the base-final V. As nothing prevents this, the palataliser associates with that slot, as shown in (28b), surfacing as
, as shown in (28a). As a consequence, I tries to associate to the second-leftmost slot, which is the base-final V. As nothing prevents this, the palataliser associates with that slot, as shown in (28b), surfacing as ![]() in (28c).Footnote
21
in (28c).Footnote
21

This analysis implies that the separate palatal segment that follows labials is a vowel rather than a consonant (whence our notation p-ěj → [piɛj] in (28)). We therefore expect it to sound and behave like a vowel, and there is indeed some empirical evidence that this is correct. In Czech, vowels in infinitives undergo templatic lengthening (Caha & Scheer Reference Caha, Scheer, Antonenko, Bailyn and Bethin2008). Examples of this are given in part (a) of Table 15. However, the vowel ě never lengthens, as shown in part (b) of Table 15. M. Ziková and A. Poĺomská (p.c.) suggest that this is because ě is already long. This would be precisely what is implied by our analysis in (28), where the melodic content of the grapheme -ě is associated with two V-slots. In contrast, if I were associated with the C slot, generating a complex segment ![]() , the length property of -ě would be quite unexpected. The phenomenon of output invisibility following labials (see Table 14) would also be hard to explain.
, the length property of -ě would be quite unexpected. The phenomenon of output invisibility following labials (see Table 14) would also be hard to explain.
Vowel length alternations in Czech verbs.

A further piece of evidence that ě does not lengthen comes from Czech dialect data discussed in Caha et al. (Reference Caha, De Clercq and Vanden Wyngaerd2024). In the dialects of Central Moravia, four patterns of comparative adverb formation are attested, as shown in Table 16. Classes I and II are characterised by the apparent absence of any overt adverbial ending, the morphemes -ěj and -š in the rightmost (adverbial) column being also found in the adjectival comparative (middle column). However, Caha et al. (Reference Caha, De Clercq and Vanden Wyngaerd2024) argue that there is nevertheless an underlying adverbial morpheme, which can be seen at work in classes III and IV, where in the adverbs, the final vowel of the root is lengthened. Moreover, if they end in a non-labial consonant, this consonant is palatalised (drah-ý ‘expensive’ → dráž ). This same palatalising and lengthening morpheme is present in classes I and II, but its effects are invisible, since the preceding consonant (-š) is already palatal, and the preceding vowel (in this case -ě) fails to lengthen. This is, then, another case where -ě does not lengthen in a context where other vowels do. From the present perspective, the reason for this is that -ě is already long.
Central Moravian comparative adjectives and adverbs (Caha et al. Reference Caha, De Clercq and Vanden Wyngaerd2024: 15).

Let us now show the derivation of the forms where the palataliser surfaces as a palatal nasal consonant. As observed by Short (Reference Short, Comrie and Corbett1993: 459), ‘after bilabial /m/ nasal resonance extends over both segments’. In strict CV terms, this means that the L element encoding nasality spreads to the following C slot. The fact that the nasal consonant following ![]() is
is ![]() suggests that what spreads is the L element only, rather than the root node hosting it.Footnote
22
suggests that what spreads is the L element only, rather than the root node hosting it.Footnote
22
(29) shows the consecutive steps in the derivation. The floating I of the palataliser cannot associate to the root node containing L and U because it is repelled by U; at the same time, the floating H of the palataliser can associate leftward, as shown in (29a). L and H join in the manner node, and this manner spreads over two consecutive C nodes as in (29b). As the representation shows, this spreading prevents I from associating to the root node of the final V slot of the base. The floating element I therefore associates to the next leftmost available root node, which is the one of the initial C of -ěj, which already hosts LH. As a consequence, the palataliser affects the nasal in the suffix-initial C slot, which surfaces as [ɲ] in (29c).

We now need to show why, in some cases, the palataliser fails to surface. As we discussed above, this happens with the morpheme expressing causativity, whose representation is shown in (30), repeated from (16).

As shown, this morpheme comprises two floating elements: the palataliser PAL2, which consists of H and I, and the floating vowel ![]() , which consists of a root node linked to the element I. As in the examples discussed above, when concatenated with a base, the floating elements scan the resulting phonological string from left to right looking for an available root node. If the leftmost available root node contains a labial, its U element blocks the association of I, while no issue arises with H, which associates to the root node and joins Ɂ, as in (31a). The palataliser then turns to the next available slot, which is the root node of the base-final V, and since there is nothing to prevent its association, it links to that. The same holds for the floating segment
, which consists of a root node linked to the element I. As in the examples discussed above, when concatenated with a base, the floating elements scan the resulting phonological string from left to right looking for an available root node. If the leftmost available root node contains a labial, its U element blocks the association of I, while no issue arises with H, which associates to the root node and joins Ɂ, as in (31a). The palataliser then turns to the next available slot, which is the root node of the base-final V, and since there is nothing to prevent its association, it links to that. The same holds for the floating segment ![]() , which joins the palataliser in the base-final V, as shown in (31b). As the floating
, which joins the palataliser in the base-final V, as shown in (31b). As the floating ![]() and the palataliser I are identical, their merger generates an identical segment, which surfaces as
and the palataliser I are identical, their merger generates an identical segment, which surfaces as ![]() in (31c).
in (31c).

The same effect can be observed when a base ending in a labial is concatenated with a PAL3 such as passive participial -ěn, repeated again in (32).

In this case as well, the H of PAL3 associates with the root node containing ![]() , while I cannot do so because of the presence of U, as shown in (33a). I therefore associates to the root node of the base-final V slot, where it is joined by the floating root node of the
, while I cannot do so because of the presence of U, as shown in (33a). I therefore associates to the root node of the base-final V slot, where it is joined by the floating root node of the ![]() vowel of the suffix, shown as IA in (33b). This results in the set of elements I, I and A, which surfaces as [ɛ] in (33c); as in (31c), we collapse the two instances of I.Footnote
23
vowel of the suffix, shown as IA in (33b). This results in the set of elements I, I and A, which surfaces as [ɛ] in (33c); as in (31c), we collapse the two instances of I.Footnote
23

In Table 17, we present an overview of the labials that shows the output counterparts to the inputs given in Table 14.
Plain and palatalised labial consonants (output).

4.3.4. The lateral consonant
In this section, we discuss the consonant that, despite being commonly characterised as coronal, behaves like a labial: ![]() . As a coronal, it could be expected to have the element A and/or I. Diachrony in many cases supports such a representation, as in cases of Latin
. As a coronal, it could be expected to have the element A and/or I. Diachrony in many cases supports such a representation, as in cases of Latin ![]() becoming
becoming ![]() in Italian (e.g., Latin plenum ‘full’, flora ‘flower’, oculus ‘eye’ → Italian pieno, fiore and occhio). However, there is also evidence that
in Italian (e.g., Latin plenum ‘full’, flora ‘flower’, oculus ‘eye’ → Italian pieno, fiore and occhio). However, there is also evidence that ![]() (like labials) contains U. For example, in the Italian dialect of Pontremolese, Latin
(like labials) contains U. For example, in the Italian dialect of Pontremolese, Latin ![]() in codas developed into either
in codas developed into either ![]() (i.e., A or I) or
(i.e., A or I) or ![]() (i.e., U) depending on the context. Between segments containing A,
(i.e., U) depending on the context. Between segments containing A, ![]() developed into [w] (e.g., Latin cal(i)du(m) ‘warm.m.sg’ → Pontremolese [kawd]), whereas when the surrounding segments contain U,
developed into [w] (e.g., Latin cal(i)du(m) ‘warm.m.sg’ → Pontremolese [kawd]), whereas when the surrounding segments contain U, ![]() developed into [r] (e.g., Latin col(a)phu(m) ‘strike’ → Pontremolese [kurp]; Cavirani Reference Cavirani2015). This development of
developed into [r] (e.g., Latin col(a)phu(m) ‘strike’ → Pontremolese [kurp]; Cavirani Reference Cavirani2015). This development of ![]() into a [u]-like sound is widely documented cross-linguistically, and suggests that laterals contain U. This is confirmed by some diachronic evidence from within Slavic, where
into a [u]-like sound is widely documented cross-linguistically, and suggests that laterals contain U. This is confirmed by some diachronic evidence from within Slavic, where ![]() developed into a [u]-like sound in Polish, as in
developed into a [u]-like sound in Polish, as in ![]() ‘head’, from Proto-Slavic *glava. The difference between ‘clear’ ([i]-like) and ‘dark’ ([u]-like)
‘head’, from Proto-Slavic *glava. The difference between ‘clear’ ([i]-like) and ‘dark’ ([u]-like) ![]() may also be thought of in terms of the presence of U in dark /l/. More precisely, in languages that display such dark variants, they are represented as containing A and U (Backley Reference Backley2011).
may also be thought of in terms of the presence of U in dark /l/. More precisely, in languages that display such dark variants, they are represented as containing A and U (Backley Reference Backley2011).
The Czech lateral ![]() is described in traditional grammars as a coronal, more specifically an apico-alveolar lateral approximant of light or neutral quality (Hála Reference Hála1962; Dankovičová Reference Dankovičová1999). However, as claimed by Šimáčková (Reference Šimáčková, Kügler, Féry and van de Vijver2009: 125), this pronunciation of
is described in traditional grammars as a coronal, more specifically an apico-alveolar lateral approximant of light or neutral quality (Hála Reference Hála1962; Dankovičová Reference Dankovičová1999). However, as claimed by Šimáčková (Reference Šimáčková, Kügler, Féry and van de Vijver2009: 125), this pronunciation of ![]() is the one assumed by ‘language professionals who work with orthoepic rules’ (emphasis in the original). This pronunciation is frequently replaced by a darker pronunciation, especially in weak contexts, such as coda position, and by speakers of younger generations, which are apparently more liberal with respect to prescriptive rules.
is the one assumed by ‘language professionals who work with orthoepic rules’ (emphasis in the original). This pronunciation is frequently replaced by a darker pronunciation, especially in weak contexts, such as coda position, and by speakers of younger generations, which are apparently more liberal with respect to prescriptive rules.
This description suggests two possibilities for the analysis of Czech ![]() : one where
: one where ![]() does not have U, and one where it does. If we take
does not have U, and one where it does. If we take ![]() to contain I and no U (as suggested by a reviewer), then the analysis of the absence of palatalisation with
to contain I and no U (as suggested by a reviewer), then the analysis of the absence of palatalisation with ![]() can be kept relatively simple, as shown in row (a) of Table 18. The small palatalisation will have no effect, since it does not change the underlying representation. That leaves us with three different underlying representations. This analysis requires us to assume that these all map onto the same phonetic interpretation. Under this approach, there is no principled connection between the behaviour of lateral
can be kept relatively simple, as shown in row (a) of Table 18. The small palatalisation will have no effect, since it does not change the underlying representation. That leaves us with three different underlying representations. This analysis requires us to assume that these all map onto the same phonetic interpretation. Under this approach, there is no principled connection between the behaviour of lateral ![]() and the labials.
and the labials.
Plain and palatalised lateral /l/: two possible representations.

What this analysis does not explain, however, is why we get the dark, [w]-like pronunciation of ![]() in weak contexts reported by Šimáčková (Reference Šimáčková, Kügler, Féry and van de Vijver2009). We therefore adopt the alternative analysis where Czech lateral /l/ does contain U, and where there is consequently a representational commonality with the labials. For concreteness, we shall assume that it is represented as A.U, where A represents the liquid class, and U the place. This analysis is represented in row (b) of Table 18. Under this approach, we expect
in weak contexts reported by Šimáčková (Reference Šimáčková, Kügler, Féry and van de Vijver2009). We therefore adopt the alternative analysis where Czech lateral /l/ does contain U, and where there is consequently a representational commonality with the labials. For concreteness, we shall assume that it is represented as A.U, where A represents the liquid class, and U the place. This analysis is represented in row (b) of Table 18. Under this approach, we expect ![]() to behave like other segments containing U, and thus not to change its place and manner of articulation when combined with a palataliser. This is indeed what we observe, for
to behave like other segments containing U, and thus not to change its place and manner of articulation when combined with a palataliser. This is indeed what we observe, for ![]() never turns into [ʎ] or [lj]. Formally, as we saw for the labial consonants in the previous section, the surfacing of a final
never turns into [ʎ] or [lj]. Formally, as we saw for the labial consonants in the previous section, the surfacing of a final ![]() followed by a palataliser as [ʎ] is prevented by the impossibility of combining two segments containing U and I. This is shown in (34), where a stem ending in -l is followed by loc/dat.f.sg -ě. Once I has tried and failed to associate to the root node containing U, the I might in principle still associate to the base-final V slot, generating [lj] rather than the attested [l]. As shown in (34a), we hypothesise that laterals behave like labial nasals, which spread to the following C slot (see fn. 21). Because of this association, the palataliser cannot associate to the root node of the base-final V slot, as that would require crossing an already established association line. The other way the palataliser might surface is by associating to the root node of the suffix-initial C slot. However, if this root node is associated with the lateral, the palataliser cannot associate there either, as the lateral contains U, which repels the palataliser’s I as in (34b). As a consequence, the palataliser stays afloat (or perhaps merges with the root node containing
followed by a palataliser as [ʎ] is prevented by the impossibility of combining two segments containing U and I. This is shown in (34), where a stem ending in -l is followed by loc/dat.f.sg -ě. Once I has tried and failed to associate to the root node containing U, the I might in principle still associate to the base-final V slot, generating [lj] rather than the attested [l]. As shown in (34a), we hypothesise that laterals behave like labial nasals, which spread to the following C slot (see fn. 21). Because of this association, the palataliser cannot associate to the root node of the base-final V slot, as that would require crossing an already established association line. The other way the palataliser might surface is by associating to the root node of the suffix-initial C slot. However, if this root node is associated with the lateral, the palataliser cannot associate there either, as the lateral contains U, which repels the palataliser’s I as in (34b). As a consequence, the palataliser stays afloat (or perhaps merges with the root node containing ![]() , that is, IA, yielding IA, as shown in (34c); compare (33c)).Footnote
24
, that is, IA, yielding IA, as shown in (34c); compare (33c)).Footnote
24

Note that the representation in (34) would normally predict that the lateral should surface as long, for it is associated with two C slots. We argue that the pronunciation of this structure as phonetically long is prevented by a general ban on geminates in Czech (Bičan Reference Bičan2011), which forces ![]() to surface as [l]. (This can be understood as a case of virtual geminate, on which see Ségèral & Scheer Reference Ségèral, Scheer and Dziubalska-Kołaczyk2001.)
to surface as [l]. (This can be understood as a case of virtual geminate, on which see Ségèral & Scheer Reference Ségèral, Scheer and Dziubalska-Kołaczyk2001.)
5. Conclusion
In this article, we examined different palatalisation patterns in Czech. Following Scheer (Reference Scheer2001), we identified two patterns: ‘small’ palatalisation (e.g., /k/ → [ʦ]; /t/ → [c]) and ‘big’ palatalisation (e.g., /k/ → [ʧ], /t/ → [ʦ]). In line with what has been observed in the typological literature (Bateman Reference Bateman2007; Kochetov Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011), Czech labials are not modified. Instead, palatalisation may manifest itself as the surfacing of a front vocoid after the labial; if the labial is nasal /m/, the vocoid nasalises to [ɲ]. Alternatively, palatalisers following labials may show output invisibility – the absence of any visible sign of palatalisation.
We extended Scheer’s (Reference Scheer2001) typology and identified a third pattern, which we dubbed ‘medium’ palatalisation. The difference between medium palatalisation and the other two patterns is not so much in how much the base segment is modified, but rather in the classes of base segment affected by palatalisation: whereas velar bases surface as if they were affected by big palatalisation, coronals show the effect of small palatalisation. Furthermore, the medium palatalisation can be further split into two patterns, depending on whether labials pattern with small palatalisation (resulting in [i] or [ɲ]) or big palatalisation (no [i] or [ɲ]) (see Tables 2 and 3).
Besides this empirical contribution, we have provided a formal modelling of the patterns that exploits the representational technology of strict CV (Lowenstamm Reference Lowenstamm, Durand and Laks1996; Scheer Reference Scheer2004) and Element Theory (Kaye et al. Reference Kaye, Lowenstamm and Vergnaud1985; Harris Reference Harris1994; Harris & Lindsey Reference Harris, Lindsey, Durand and Katamba1995; Backley Reference Backley2011; Scheer & Kula Reference Scheer and Kula2018), arguing that the three degrees of palatalisation are triggered by three different palatalisers. We represent those as floating elements contained in the suffixes that concatenate with the base. These three sets of floating elements stand in an inclusion relation, from small (I) through medium (![]() ) to big (
) to big (![]() ). The hypothesis that these palatalisers are floating elements, and that suffixes containing them might also contain floating segments (represented as sets of elements that behave like units), required us to find a representational way to distinguish between floating elements and floating segments. We departed from standard strict CV and resorted to the root node, which mediates between the element level of representation and the skeletal level where C- and V-slots reside (for similar proposals, see John Reference John2014; Ziková Reference Ziková2018; Scheer Reference Scheer2022; Cavirani Reference Cavirani2022b; Faust Reference Faust2025).
). The hypothesis that these palatalisers are floating elements, and that suffixes containing them might also contain floating segments (represented as sets of elements that behave like units), required us to find a representational way to distinguish between floating elements and floating segments. We departed from standard strict CV and resorted to the root node, which mediates between the element level of representation and the skeletal level where C- and V-slots reside (for similar proposals, see John Reference John2014; Ziková Reference Ziková2018; Scheer Reference Scheer2022; Cavirani Reference Cavirani2022b; Faust Reference Faust2025).
The hypothesis that the palatalisation patterns are triggered by floating palatalisers, rather than by the vowel of the suffix, allowed us to account for the facts that (i) palatalisation can also be triggered by suffixes with back vowels (Table 6); (ii) palatalisation is not triggered by all front vowels (Table 7); and (iii) similar-sounding vowels trigger different palatalisation patterns. This is in line with other accounts of palatalisation in Slavic (see, e.g., Ketner Reference Ketner2005 for Czech; Gussmann Reference Gussmann, Fisiak and Puppel1992 and Zdziebko Reference Zdziebko2015 for Polish and Bidwell Reference Bidwell1962, Iosad & Morén-Duolljá Reference Iosad and Morén-Duolljá2010 and Padgett Reference Padgett, Brown, Cooper, Fisher, Kesici, Predolac and Zec2010 for Russian), and provides support for the hypothesis that ‘featural representations […] possibly reflect local generalizations, specific to certain morphological domains or lexical strata (as, for example, in cases of multiple palatalization processes targeting the same consonants)’ (Kochetov Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011: 1686).
As noted by Kochetov (Reference Kochetov, van Oostendorp, Ewen, Hume and Rice2011), throughout its long history, the formal modelling of palatalisation has been affected by ‘difficulties [which] appeared to stem from a […] fundamental problem – the persistent use of traditional featural representations (with some modifications), which were assumed to be inviolable, universal, and innate’. We maintain that our Element-Theoretic analysis improves on previous accounts, and provides a neat formal modelling of the palatalisation patterns observed. This is obtained by exploiting the substance-free take on phonology (Reiss Reference Reiss2018; Scheer Reference Scheer2019; Reiss & Volenec Reference Reiss and Volenec2022; Chabot Reference Chabot2022, Reference Chabot2023) and, to a lesser extent, on Element Theory. This allows us to devise a representational account of the three palatalisation patterns of Czech, and of the Czech consonant inventory, where, despite phonetic appearances (Table 19a), the palatalised consonants that pattern together all contain the same palatalisers (Table 19b).
The patterns of small, medium and big palatalisation.

We also showed that Element Theory and strict CV allow for a neat modelling of (i) the unexpected behaviour of labials (Table 10), which cannot merge with palatalising I because it is incompatible with their U element; (ii) the surfacing of the palatalisers as self-standing segments, or their complete absence, which is related to the CV profile of the suffix; and (iii) the fact that, when the palataliser does surface, it can do so either as a vowel [i] or as a palatalised nasal. The appearance of the nasal is due to the spreading of the nasal element L from the root node of the base-final C slot to the root node of the suffix-initial C slot, where it joins the palataliser (§4.3.3).
Finally, the hypothesis that the Czech lateral ![]() contains the U element allowed us to account for the fact that it behaves like a labial consonant, in that it resists palatalisation (§4.3.4).
contains the U element allowed us to account for the fact that it behaves like a labial consonant, in that it resists palatalisation (§4.3.4).
Acknowledgements
We would like to express our sincere gratitude to the audiences at De Grote Taaldag (Utrecht), the Slavic Linguistics Colloquium (Humboldt Uuniversität, Berlin), the LingLunch (Université Paris Cité), the Rencontres du Réseau français de Phonologie (Amiens), the NanoDays (Masaryk Univerzita, Brno) and the CRISSP Research Discussion, for whom this material was presented. We are also indebted to Markéta Ziková, Anna Poĺomská and Gabriela Složilová for discussion of and help with the Czech data. We also owe a debt of gratitude to Tobias Scheer and four anonymous reviewers for Phonology, whose comments have led to substantive improvements in the article.
Funding statement
This research was supported by a grant from the KU Leuven research fund to the project Comparatives under the Microscope (COMIC; Grant No. C14/20/041).
Competing interests
The authors declare that there are no competing interests regarding the publication of this article.
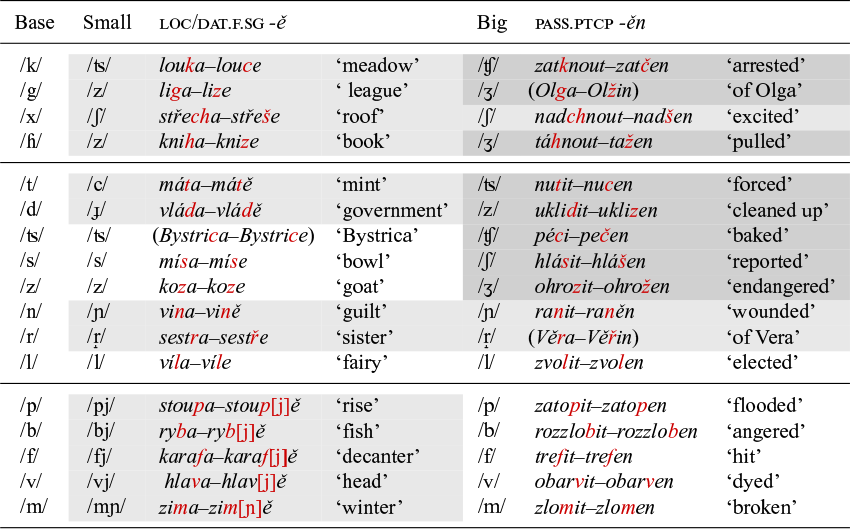
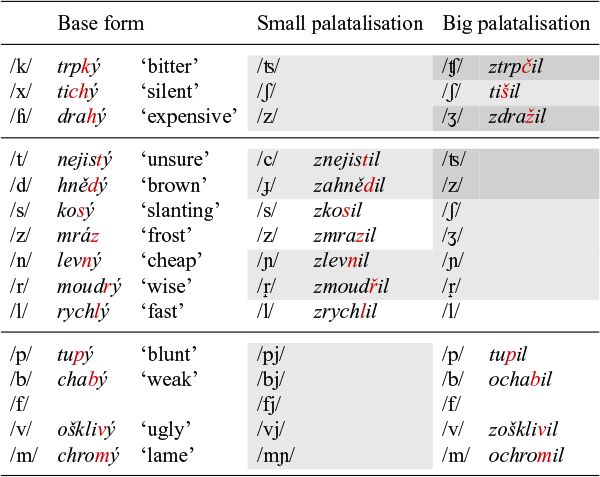
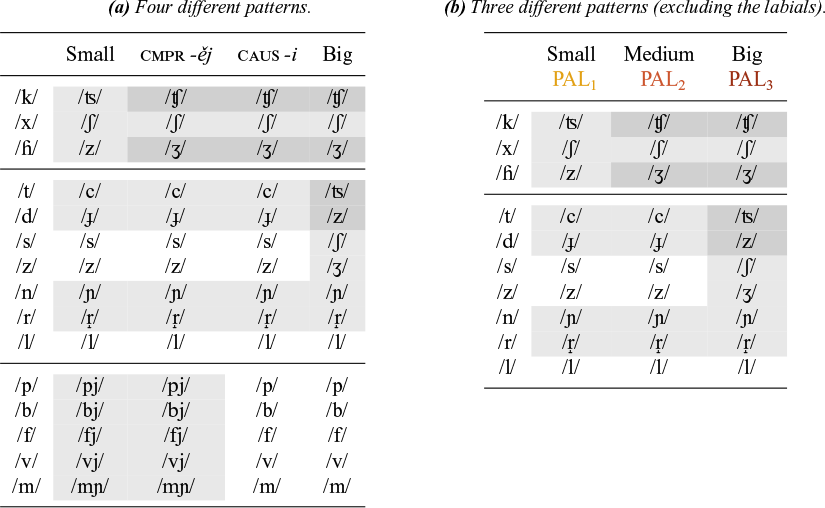
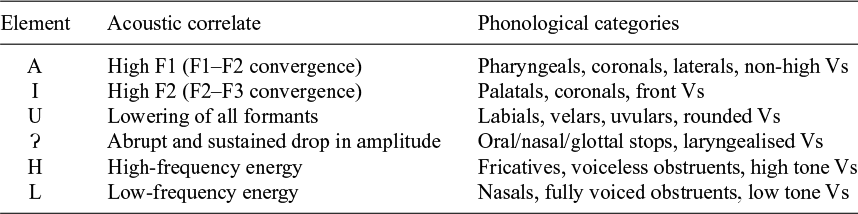
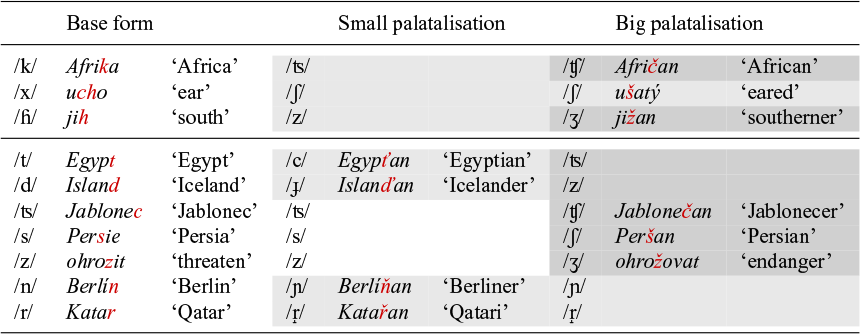
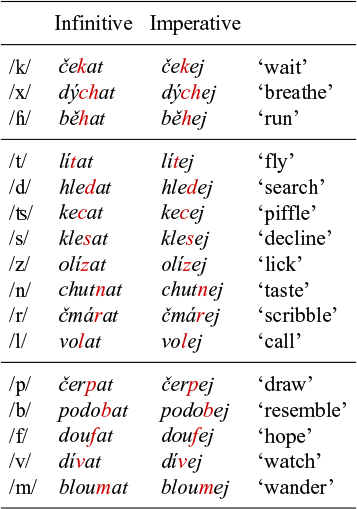

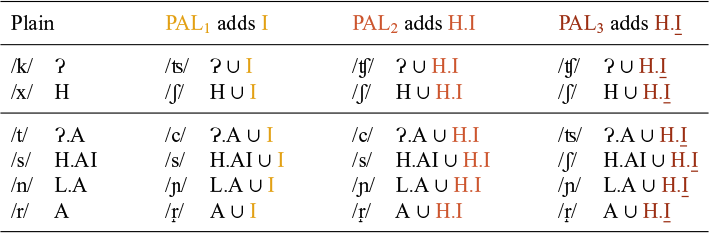
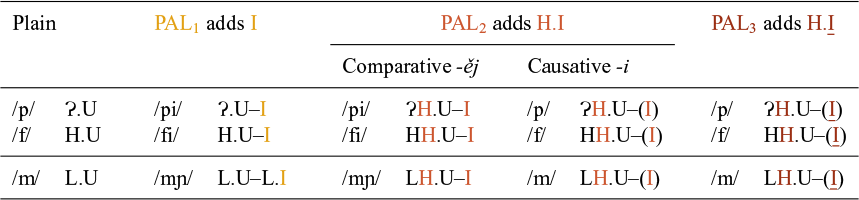



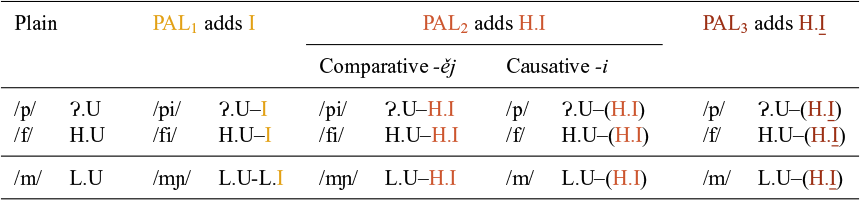
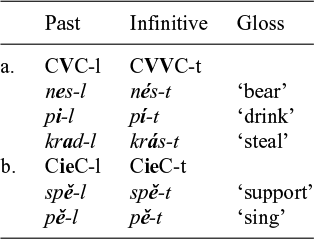



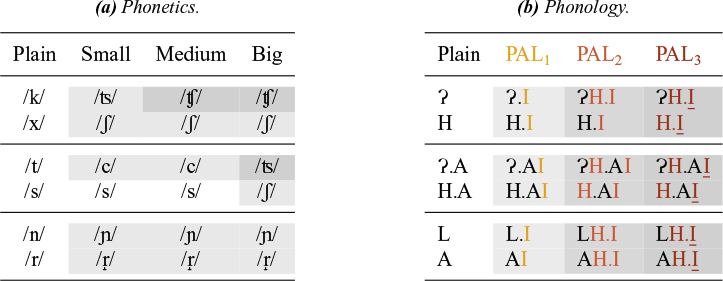

 Open access
Open access