


1. Introduction
The Psycholinguistic Grain Size Theory (PGST) (Ziegler & Goswami, Reference Ziegler and Goswami2005) posits that reading abilities develop in tune with language-specific orthographic properties. Word recognition and decoding are shaped by orthographic depth, i.e., the consistency and predictability of grapheme-phoneme correspondences (GPCs) (Katz & Frost, Reference Katz, Frost, Frost and Katz1992), and this modulates the speed at which children learn to read (Seymour et al., Reference Seymour, Aro and Erskine2003). Cognitive abilities related to reading (e.g., phonological processing skills or visual processing skills) also develop differently in each language, depending on orthographic depth (Lallier & Carreiras, Reference Lallier and Carreiras2018; Ziegler & Goswami, Reference Ziegler and Goswami2005).
In the last few decades, there has been a surge of interest in the effects of biliteracy on reading development: if reading is modulated by language-specific orthographic properties, it follows that learning to read two different orthographies may shape the cognitive and neural underpinnings of reading in unique ways. Lallier & Carreiras (Reference Lallier and Carreiras2018) proposed that learning to read two orthographies with different degrees of orthographic depth may lead to cognitive changes that accommodate the demands of the orthographic systems being learned. However, most of the evidence in support of this hypothesis is currently limited to early (biliterate) bilinguals, while less is known about the effects of biliteracy in late biliterates, i.e., individuals who acquire another language sequentially, after having learned to read in their first language (L1). Beyond differences in the onset of reading, late biliterates have less exposure to their second language(s) (L2), and likely lower reading proficiency levels in their L2(s) than in their L1. This is important because both exposure and proficiency in the L1 and L2 are factors that modulate the extent to which orthographic depth affects reading strategies (de León Rodríguez et al., Reference de León Rodríguez, Buetler, Eggenberger, Laganaro, Nyffeler, Annoni and Müri2016, Reference de León Rodríguez, Mouthon, Annoni and Khateb2022). Finally, typological differences between the L1 and L2 (Botezatu, Reference Botezatu2023) and whether a transparent orthography (e.g., Italian) is learned before an opaque orthography (e.g., English) or vice versa (Paulesu et al., Reference Paulesu, Bonandrini, Zapparoli, Rupani, Mapelli, Tassini, Schenone, Bottini, Perry and Zorzi2021) play a role in bilingual reading, as discussed below.
Within the literature on late biliterates, individuals with reading disorders, such as those with developmental dyslexia (DD) (henceforth: dyslexia), remain comparatively understudied. Individuals with dyslexia find it difficult to automatize word recognition and decoding, often manifesting as slow and/or inaccurate reading (again, depending on the orthographic depth of their native languages, Ziegler & Goswami, Reference Ziegler and Goswami2005). Although the locus of the dyslexia deficit is still being debated, recent research pointing towards multi-factorial models of dyslexia suggests that different processing levels involved in reading may be affected (Lallier et al., Reference Lallier, Molinaro, Lizarazu, Bourguignon and Carreiras2017; Lorusso & Toraldo, Reference Lorusso and Toraldo2023; Perry et al., Reference Perry, Zorzi and Ziegler2019; Ziegler et al., Reference Ziegler, Perry and Zorzi2020). The most investigated ones are the phonological processing level and the visual processing level (e.g., Bosse et al., Reference Bosse, Tainturier and Valdois2007; Landerl et al., Reference Landerl, Ramus, Moll, Lyytinen, Leppänen, Lohvansuu, O’Donovan, Williams, Bartling, Bruder, Kunze, Neuhoff, Tóth, Honbolygó, Csépe, Bogliotti, Iannuzzi, Chaix, Démonet and Schulte-Körne2013; Lobier et al., Reference Lobier, Zoubrinetzky and Valdois2012; Vellutino et al., Reference Vellutino, Fletcher, Snowling and Scanlon2004). If the phonological and/or visual cognitive processes involved in reading are impaired, then cross-linguistic modulations of reading skills and subskills may be less likely to surface in late biliterates with dyslexia (Venagli et al., Reference Venagli, Kupisch and Lallier2025).
Understanding how exposure to and the acquisition of an orthographically opaque language (L2 English) affect decoding strategies in L2 learners with and without dyslexia is important, particularly because L2 learners acquire their L2 in formal settings, and their reading and writing abilities may develop better and faster than their oral language abilities (e.g., Vender & Nardon, Reference Vender and Nardon2023). Moreover, understanding the interaction between dyslexia and L2 reading, and whether reading strategies are affected (and potentially boosted) by cross-linguistic modulations can inform practitioners and policymakers on the needs of dyslexic individuals in foreign language learning.
For these reasons, this study sets out to investigate the effects of L2 proficiency on L1 and L2 reading strategies in late biliterates with and without dyslexia. In doing so, we will test two contrasting accounts of reading in biliterate bilinguals: the hypothesis that reading strategies undergo accommodation (Lallier & Carreiras, Reference Lallier and Carreiras2018), or adaptation (Casaponsa et al., Reference Casaponsa, Carreiras and Duñabeitia2015; de León Rodríguez et al., Reference de León Rodríguez, Buetler, Eggenberger, Laganaro, Nyffeler, Annoni and Müri2016, Reference de León Rodríguez, Mouthon, Annoni and Khateb2022; Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019; Hoversten et al., Reference Hoversten, Brothers, Swaab and Traxler2017; Hoversten & Traxler, Reference Hoversten and Traxler2020; Paulesu et al., Reference Paulesu, Bonandrini, Zapparoli, Rupani, Mapelli, Tassini, Schenone, Bottini, Perry and Zorzi2021). Accommodation means that biliterates develop hybrid reading strategies based on the different demands of the two orthographic systems they are acquiring, while adaptation means that biliterates develop language-specific reading strategies that are selectively deployed when decoding each orthographic system. We present data from Italian high school students with a wide spectrum of English (L2) reading proficiency levels, thus allowing us to assess whether, and to what extent, reading proficiency in a non-native orthographically opaque L2 plays a role in determining cross-linguistic modulations of L1 and L2 word recognition and decoding strategies in learners whose native language has a transparent orthographic system. The combination of a transparent L1 and an opaque L2 allows us to specifically focus on whether adolescent English as a foreign language (EFL) learners with and without dyslexia are able to develop large-grain decoding strategies (better suited for an opaque orthography like English) and in which context they deploy such strategies, while also accounting for the role of dyslexia-specific deficits such as a limited ability to process multiple visual elements simultaneously (Valdois, Reference Valdois2022).
2. Background
2.1. Reading development and reading strategies in monolinguals
The Dual Route Cascaded (e.g., Coltheart et al., Reference Coltheart, Rastle, Perry, Langdon and Ziegler2001) and the Connectionist Dual Process (e.g., Perry et al., Reference Perry, Ziegler and Zorzi2010) are amongst the most influential models of visual word recognition and reading (aloud). According to these models, reading (aloud) involves two distinct procedures: a lexical procedure and a sublexical procedure. Within both models, lexical reading is achieved through the interactive activation of orthographic and phonological entries in the mental lexicon, while sublexical reading relies on a more costly computational process whereby each grapheme in a word is systematically converted into the corresponding phoneme.
Lexical and sublexical reading abilities are underpinned by phonological and visuo-attentional processes. Accordingly, phonological and/or visuo-attentional cognitive deficits, which might originate from atypical neural oscillations in the visual and/or auditory modality (Lallier et al., Reference Lallier, Molinaro, Lizarazu, Bourguignon and Carreiras2017), may cause dyslexia and explain the variety of reading profiles typically observed in this population (e.g., phonological, surface, or mixed profiles, see Zoubrinetzky et al., Reference Zoubrinetzky, Bielle and Valdois2014). In line with this, individuals with dyslexia are consistently found to have poorer phonological awareness (e.g., Landerl et al., Reference Landerl, Ramus, Moll, Lyytinen, Leppänen, Lohvansuu, O’Donovan, Williams, Bartling, Bruder, Kunze, Neuhoff, Tóth, Honbolygó, Csépe, Bogliotti, Iannuzzi, Chaix, Démonet and Schulte-Körne2013; Vellutino et al., Reference Vellutino, Fletcher, Snowling and Scanlon2004). Visual processing deficits that are independent of phonological deficits have also been observed in dyslexia (e.g., Facoetti et al., Reference Facoetti, Trussardi, Ruffino, Lorusso, Cattaneo, Galli, Molteni and Zorzi2010; Valdois, Reference Valdois2022), such as a poorer or narrower visual attention span (VAS), which may hinder the ability to build up an orthographic lexicon (Bosse et al., Reference Bosse, Tainturier and Valdois2007; Lobier et al., Reference Lobier, Zoubrinetzky and Valdois2012; Valdois et al., Reference Valdois, Bosse and Tainturier2004) and consequently, to efficiently operate on lexical reading strategies.
Finally, lexical and sublexical reading difficulties have also been linked to specific fixation patterns during reading: Individuals with dyslexia tend to fixate words more often and for a longer time compared to typical readers (e.g., Hutzler & Wimmer, Reference Hutzler and Wimmer2004), which, in the case of lexical reading, might be an index of slower lexical access possibly linked to limited VAS abilities. In the case of sublexical reading, instead, more and longer fixations might be indicative of decoding difficulties linked to phonological deficits, or to visuo-spatial attention orienting abilities (see Lallier et al., Reference Lallier, Molinaro, Lizarazu, Bourguignon and Carreiras2017).
How fast reading skills and related cognitive subskills are developed as well as the way dyslexia manifests (as a deficit in word reading, pseudoword reading, or both) may further depend on the orthographic depth of a language (Ziegler & Goswami, Reference Ziegler and Goswami2005). According to the PGST, transparent orthographies, like Italian, facilitate phonological decoding, i.e., the process of learning and automatizing the alphabetic principle and grapheme-phoneme conversions. Indeed, children learn to read accurately earlier in orthographically transparent languages than in opaque ones (Seymour et al., Reference Seymour, Aro and Erskine2003). Children learning to read opaque orthographies, instead, face more challenges due to inconsistencies and irregularities at the phoneme and grapheme (small-grain size) level, which implies that a larger number of GPCs must be learnt. To overcome these challenges, readers of opaque orthographies rely more on the processing of larger phonological grain size units (e.g., bigrams, and trigrams). These differences in “default” grain size processing strategies may then lead to developmental differences in the preferred reading pathway (lexical versus sublexical) across individuals of different orthographies, which may persist into adulthood (Ziegler & Goswami, Reference Ziegler and Goswami2005).
Evidence in support of the PGST is extensive (see Borleffs et al., Reference Borleffs, Maassen, Lyytinen and Zwarts2019 for an overview). In addition to the varying speeds at which children become fluent readers, children learning to read transparent versus opaque orthographies show differences in their preferred reading strategies. For instance, Ziegler et al. (Reference Ziegler, Perry, Jacobs and Braun2001) compared L1 English and L1 German readers’ latencies when presented with words and pseudowords in their native languages, thus contrasting an opaque orthography (English) and a more transparent orthography (German). The German readers were more affected by length effects, which were interpreted as a stronger reliance on “smaller grains”. In contrast, the English participants showed a larger Body Neighbourhood (Body-N) effect, which refers to reading latencies being higher when words share an orthographic rhyme (e.g., “late, date, fate are Body-Ns of “hate”, Ziegler et al., Reference Ziegler, Perry, Jacobs and Braun2001, p. 380). This effect has been interpreted as evidence of a greater reliance on larger grain sizes, as sensitivity to orthographic rhymes requires the processing of larger visual units during reading. Taken together, their results suggest that when presented with identical (pseudo)words, readers of different orthographies engage in different decoding strategies (see also Rau et al., Reference Rau, Moll, Snowling and Landerl2015). Finally, cross-linguistic research has demonstrated that the predictive power of reading-related cognitive abilities changes depending on orthographic depth in both typical and dyslexic readers (Landerl et al., Reference Landerl, Ramus, Moll, Lyytinen, Leppänen, Lohvansuu, O’Donovan, Williams, Bartling, Bruder, Kunze, Neuhoff, Tóth, Honbolygó, Csépe, Bogliotti, Iannuzzi, Chaix, Démonet and Schulte-Körne2013; Ziegler et al., Reference Ziegler, Bertrand, Tóth, Csépe, Reis, Faísca, Saine, Lyytinen, Vaessen and Blomert2010). Notably, reading strategies are flexible (Buetler et al., Reference Buetler, de León Rodríguez, Laganaro, Müri, Spierer and Annoni2014, p. 2): while one reading pathway may be predominantly used as a “default” strategy, experienced readers can alternate between reading pathways and modulate the phonological and visual grain sizes on which they rely.
In summary, reading procedures depend on the lexicality (i.e., real words versus pseudowords) and frequency of the word (Coltheart et al., Reference Coltheart, Rastle, Perry, Langdon and Ziegler2001; Perry et al., Reference Perry, Ziegler and Zorzi2010) as well as on the orthographic depth of one’s native language, and both can modulate the preferred grain size units for decoding (Ziegler & Goswami, Reference Ziegler and Goswami2005). Readers of transparent orthographies tend to rely more on smaller (phonological and visual) grains and sublexical procedures, whilst readers of opaque orthographies rely more on larger grains and lexical procedures (Lallier & Carreiras, Reference Lallier and Carreiras2018), although both can flexibly alternate between them (Buetler et al., Reference Buetler, de León Rodríguez, Laganaro, Müri, Spierer and Annoni2014; Lallier et al., Reference Lallier, Martin, Acha and Carreiras2021).
2.2. Reading development and reading strategies in early and late biliterate bilinguals
It is unclear whether bilinguals access their lexicon in a fully selective or a non-selective manner (Hoversten & Traxler, Reference Hoversten and Traxler2020). A fully selective account predicts that bilinguals directly access lexical representations in the target language, thus inhibiting non-target representations. Non-selective accounts, by contrast, assume parallel activation of all language nodes, as also implemented in the Bilingual Interactive Activation model (BIA+, Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002), which assumes that items of different languages are fully integrated within the bilingual mental lexicon. Studies investigating these hypotheses have led to mixed results, also because factors such as the degree of activation of lexical entries over time, as well as the influence of the language mode (language context), have not been directly investigated (Hoversten & Traxler, Reference Hoversten and Traxler2020, pp. 2–3). Hoversten and Traxler (Reference Hoversten and Traxler2020) found that the language context or the presence of non-target-language words in a sentence can affect the degree of activation of each language, providing evidence for a partially selective account of lexical access. Using the authors’ words, bilinguals can “zoom in” and “zoom out” of each language flexibly depending on fine-grained and coarse linguistic cues. However, whether these factors can also determine the size of phonological and visual grains that are processed while reading (i.e., decoding strategies) remains unclear (Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019).
As to the visual and phonological grains processed while reading, the Grain Size Accommodation Hypothesis (GSAH, Lallier & Carreiras, Reference Lallier and Carreiras2018) predicts that early, balanced biliterates develop reading strategies that accommodate the orthographic demands of all their languages, thus resulting in hybrid strategies that differ from those of monolinguals. For instance, an Italian–English balanced biliterate would be expected to operate on larger grains than a monolingual reader of Italian (transparent orthography) when decoding an unfamiliar (pseudo)word, due to experience with an opaque orthographic system (English) that triggers the processing of large grain size units. The predictions of the GSAH are based on non-selective models of word recognition in bilinguals such as the BIA+ (Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002, p. 182), which, in the context of written word recognition, predicts that factors such as language proficiency, item frequency, and the recency of language use modulate the speed at which lexical representations are activated. Notably, within the BIA+, language nodes are not expected to modulate lexical activation and, therefore, cannot trigger language-specific reading strategies. Following this assumption, the reading strategies in biliterate readers would be hybrid (Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019, p. 6). However, language-specific orthographic markers have been shown to trigger the activation of language-specific representations and modulate reading strategies in early biliterates (Casaponsa et al., Reference Casaponsa, Carreiras and Duñabeitia2015; Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019; Lallier et al., Reference Lallier, Martin, Acha and Carreiras2021). For instance, Lallier et al. (Reference Lallier, Martin, Acha and Carreiras2021) have shown that embedding complex French graphemes (grapheme clusters that map into one phoneme) in real Basque words boosts the processing of larger grain size units and, in turn, Basque lexical reading in French–Basque biliterate bilinguals, as indexed by faster real word reading time (WRT). This was not observed for Basque real words embedding simple graphemes (1:1 grapheme-phoneme correspondence) nor in Spanish–Basque biliterate bilinguals, indicating that the size of orthographic representations processed while reading depends on whether the native languages are transparent (Basque/Spanish) or opaque (French), and on item-specific features.
While most of the evidence in support of the GSAH comes from studies with early biliterates reading isolated (pseudo)words in their two languages (Lallier & Carreiras, Reference Lallier and Carreiras2018), studies taking language context into account have shown that language-selective lexical access is more likely to emerge when (pseudo)words are embedded in language-specific sentences. For instance, Egan et al. (Reference Egan, Oppenheim, Saville, Moll and Jones2019) investigated written word recognition in English–Welsh early biliterate adults using cognates embedded in English and Welsh sentences. They found that participants relied on smaller grains when reading cognates embedded in Welsh sentences as compared to those embedded in English sentences, as indicated by a higher number of first-pass fixations on target words in the former context. Based on these findings, Egan et al. (Reference Egan, Oppenheim, Saville, Moll and Jones2019) concluded that the language context is likely to activate language nodes which, in turn, trigger language-specific reading strategies. These findings challenge the prediction of the GSAH (Lallier & Carreiras, Reference Lallier and Carreiras2018) that early biliterates develop hybrid reading strategies different from those of monolinguals. Indeed, when comparing English–Welsh bilinguals to English monolinguals, Egan et al. (Reference Egan, Oppenheim, Saville, Moll and Jones2019) found no difference between the two groups in English word reading, possibly indicating that reading strategies for early bilinguals are language-specific and adapted to the target language, rather than becoming hybrid. However, the use of a sentence-reading task might also explain why Egan et al. (Reference Egan, Oppenheim, Saville, Moll and Jones2019) found no difference in real-word reading: indeed, the presence of a semantic and a syntactic context might conceal the more basic perceptual-attentional “mechanistic” strategies of reading considered in the GSAH.
In short, from this growing body of literature on early biliterates, two hypotheses can be contrasted: The first hypothesis is that the reading system develops to accommodate the demands of all the orthographic systems acquired by an individual (Accommodation Hypothesis, Lallier & Carreiras, Reference Lallier and Carreiras2018), thus deviating from those of monolinguals. The second hypothesis is that balanced bilinguals’ reading strategies are adapted to the target language, depending on the language context (Adaptation Hypothesis, e.g., Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019).
2.3. Late biliteracy and the role of proficiency
It is well known that proficiency and exposure play a crucial role in language development, and reading development is no exception. Nevertheless, most reading studies with early biliterates have not addressed the role of reading proficiency, often because participants in these studies were simultaneous biliterates with relatively balanced proficiency levels in the two languages (Lallier & Carreiras, Reference Lallier and Carreiras2018). However, balanced reading proficiency in the two languages is rare in late biliterates because reading skills depend on general L2 proficiency, language/reading exposure, the visual–spatial properties of the L1 and L2 scripts, their orthographic consistency, as well as the nature of the linguistic information encoded in a writing system (e.g., phonemes, morphemes) (see Perfetti et al., Reference Perfetti, Liu, Fiez, Nelson, Bolger and Tan2007).
As in early biliterates, reading strategies can also be transferred across languages in late biliterates (Sun-Alperin & Wang, Reference Sun-Alperin and Wang2011). In the latter case, given sequential acquisition, L2 proficiency appears to play a more substantial role. de León Rodríguez et al. (Reference de León Rodríguez, Buetler, Eggenberger, Laganaro, Nyffeler, Annoni and Müri2016) compared French–German and German–French late biliterates at low proficiency levels when reading aloud isolated words and pseudowords in their two languages. L1 German readers were found to rely on small-grain size strategies when decoding (pseudo)words in both languages, while L1 French readers processed larger visual grains, thus resulting in a lower number of fixations when reading words in L1 French (opaque), but not in L2 German (transparent). By contrast, Treutlein et al. (Reference Treutlein, Schöler and Landerl2017) showed that highly proficient L1 German–L2 English late biliterates could flexibly switch between small and large-grain strategies, suggesting that they acquired decoding strategies that accommodate the demands of both their orthographies. Their participants read pseudowords derived from either their L1 or L2. In order to assess the role of L2 proficiency and reading exposure, they compared children and university students. While inexperienced readers (children) were more likely to rely on smaller grains, regardless of the target language, experienced readers (university students) were able to switch between small and large-grain size strategies to decode pseudowords. Taken together, these results suggest that inexperienced L2 learners tend to focus on small visual grains when reading in their L2, while experienced L2 readers tend to accommodate the properties of their new (L2) orthography, as predicted by the GSAH (Lallier & Carreiras, Reference Lallier and Carreiras2018). However, more research on the role of proficiency in potential accommodation/adaptation processes in late biliterates is needed, ideally considering proficiency on a continuum.
In addition to L2 proficiency, L1 orthographic properties play a central role for cross-linguistic modulations in late biliterates. For instance, Botezatu (Reference Botezatu2023) compared L1 English monolinguals with L2 English late biliterates whose L1s differed in terms of orthographic depth (Spanish: transparent, Chinese: opaque) performing a (visual) lexical decision task in English. Using event-related potential (ERP) measures, the authors found larger P200 responses to irregular stimuli in L1 Chinese–L2 English late biliterates with low English proficiency, indicating sensitivity to orthographic depth and poor decoding skills in the L2. Note that larger P200 responses have typically been associated to “higher competition among phonological forms” (Botezatu, Reference Botezatu2023, p. 240). Such an effect was not observed in L1 Chinese–L2 English biliterates with high proficiency in English, whose P200 response to irregular English words was absent and did not differ from those of English monolinguals, arguably because of their opaque L1 (Chinese; Botezatu, Reference Botezatu2023). Notably, L1 Spanish–L2 English late biliterates showed the opposite pattern, which the author attributed to the orthographic consistency of their native language (Spanish). Previous studies had indeed shown that the acquisition of a transparent orthography prior to an opaque orthography or vice versa can affect L2 reading development and the extent to which orthographic processing strategies and representations are separated in the two languages (Paulesu et al., Reference Paulesu, Bonandrini, Zapparoli, Rupani, Mapelli, Tassini, Schenone, Bottini, Perry and Zorzi2021). Paulesu et al. (Reference Paulesu, Bonandrini, Zapparoli, Rupani, Mapelli, Tassini, Schenone, Bottini, Perry and Zorzi2021) measured the reading times for Italian and English words presented in blocked (same language) versus mixed (L1 and L2) lists in highly proficient L1 Italian–L2 English and L1 English–L2 Italian late biliterates (translators). When comparing L1 and L2 reading latencies in mixed versus blocked lists, the authors found stronger switching costs in the Italian–English group than in the English–Italian group (i.e., a greater L1 advantage in blocked lists). This result indicates an effect of acquisition order, so that learning a transparent orthography before an opaque one may boost one’s ability to keep their decoding systems separated. Alternatively, learning to read in a transparent orthography might not promote the switch from sublexical to lexical reading strategies as much as learning to read opaque orthographies does. This is because relying on sublexical reading procedures in a transparent system is always efficient, whilst readers of opaque orthographies need to switch more between lexical strategies (large grains) and sublexical strategies (small grains), which might explain the reduced switching cost for the English–Italian bilingual group. Paulesu et al. (Reference Paulesu, Bonandrini, Zapparoli, Rupani, Mapelli, Tassini, Schenone, Bottini, Perry and Zorzi2021, p. 15) proposed that orthographic accommodation effects, such as those proposed by the GSAH, and “order effects” could be two extremes of a spectrum, with accommodation effects being more likely when two orthographic systems are acquired early and simultaneously. However, how L1 and L2 reading proficiency determine late biliterates’ position along this spectrum remains unclear. Notably, existing research on this population has yet to directly examine whether reading strategies undergo an accommodation process (Accommodation Hypothesis, Lallier & Carreiras, Reference Lallier and Carreiras2018) or are selectively accessed (Adaptation Hypothesis, Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019) depending on the language context in which (pseudo)words are embedded.
3. The present study
As previously noted, only a few studies have explored the effects of L2 reading proficiency and dyslexia on L1 and L2 word recognition and decoding in late biliterates, especially studies that also take into account the language context in which words appear. In a previous study on the sample of participants studied herein (Italian high school students with and without dyslexia), we showed that higher L2 reading proficiency boosts the processing of larger visual grains in typically developing L2 learners, but to a lesser extent in learners with dyslexia. This result has been interpreted as evidence that cross-linguistic modulation of reading-related cognitive abilities is less likely to occur in the presence of a reading impairment (Venagli et al., Reference Venagli, Kupisch and Lallier2025). However, the task used in this study was not language-dependent. Hence, it remained unclear whether these cognitive changes are also reflected in reading behaviour and, more specifically, in the way pseudowords are decoded when embedded in L1 versus L2 sentences. For this reason, we implemented an eye-tracking sentence-reading task following Egan et al. (Reference Egan, Oppenheim, Saville, Moll and Jones2019) to test the predictions of the Accommodation and Adaptation hypotheses in late biliterates. We focused on the number and duration of first-pass fixations made on (pseudo)words embedded in (L1) Italian vs. (L2) English sentences. These measures were taken as an index of the visual grain sizes that are processed during decoding, with fewer and faster first-pass fixations indicating the processing of larger grain size units. The study addresses the following research questions (RQs):
RQ1: Is there an effect of L2 reading proficiency on L1 (Italian) and L2 (English) reading strategies in late biliterates during sentence reading?
RQ2: Is there a difference between typical readers and individuals with dyslexia?
Predictions under the Accommodation (Lallier & Carreiras, Reference Lallier and Carreiras2018) and Adaptation (Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019) hypotheses are as follows. The Accommodation Hypothesis predicts that at higher levels of L2 reading proficiency, late biliterates use hybrid grain strategies in their two languages. Hence, there should be no difference in terms of first-pass fixation number and duration when decoding orthographically identical (pseudo)words in their L1 and L2. By contrast, under the Adaptation Hypothesis, we expect highly proficient biliterates to adapt their reading strategies to the target language, thus relying on smaller grains in Italian than in English (in line with Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019). Moreover, we examine the effect of L2 reading proficiency on a continuum, predicting a significant effect on both languages under the Accommodation Hypothesis. By contrast, the Adaptation Hypothesis predicts that L2 reading proficiency only modulates L2 decoding strategies. As for group differences, dyslexic readers are expected to make more and longer first-pass fixations compared to typical readers (Hutzler & Wimmer, Reference Hutzler and Wimmer2004), regardless of the language. Finally, based on previous findings (Venagli et al., Reference Venagli, Kupisch and Lallier2025), we expect that the reading strategies of learners with dyslexia are less affected by cross-linguistic accommodation processes, hence, by L2 reading proficiency.
Limitations in testing these hypotheses in the context of late biliteracy should, however, be noted: First, in testing the Adaptation Hypothesis, a language-specific context needs to be provided along with target (pseudo)words that are identical in the two languages. This compromises comparability between this study and those directly testing the Accommodation Hypothesis (Lallier & Carreiras, Reference Lallier and Carreiras2018), which mostly rely on single-word reading paradigms. Second, the comparison between reading strategies in the two languages should be carefully interpreted since one is a native language, and the other is an L2 (we refer to this as “language-status effect”). This may prevent us from observing the effects predicted by the Adaptation Hypothesis (Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019), especially when frequent and familiar words are accounted for. To avoid such language-status effects, this paper mostly focuses on pseudowords, because these allow us to investigate the decoding of unknown and orthographically (almost) identical strings in both languages. Finally, because the target pseudowords needed to remain nearly identical across the two languages (following Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019), they could all be decoded using single-letter GPCs (see Section 4). However, preceding words should trigger a reliance on small versus large-grain processing that would presumably carry over to the decoding of the target (pseudo)word. Thus, even when stimuli are fully decodable at the single-letter level, readers may differ in the extent to which they rely on small versus larger grain size processing strategies.
4. Method
4.1. Participants
Ninety high school students participated in the study (Age: M = 17.03 years; SD = 1.41, Range = 14.11–20.50). Twenty-nine participants had a formal diagnosis of dyslexia (henceforth: DYS group), which was assessed by authorized Italian clinical institutes according to national regulations. One participant was excluded because of stuttering. The remaining sixty-one participants had no diagnosis of dyslexia (henceforth: TD group), but four had other specific learning disorders (e.g., dyscalculia and dysgraphia) and were thus excluded from the control sample, along with participants whose performance in two or more standardized reading measures was 2SD below the average of their age (N = 6). There was no age difference between the two groups (p = .321). All participants were native speakers of Italian and were first exposed to L2 English either in the first grade of primary school or in kindergarten (Age of onset: M = 5.66; SD = 0.86). Note that in the Italian school context, reading is first acquired in Italian and L1 literacy instruction officially starts in first grade. For a more detailed description of the sample, see Venagli et al. (Reference Venagli, Kupisch and Lallier2025). The final sample included fifty-one TD and twenty-eight DYS participants.
4.2. Materials and procedure
Participants were tested individually in a quiet room at their school. The experimental procedure was split into two sessions: one focusing on Italian and the other on English. Task instructions were provided in Italian and English, respectively. The language of interaction between the participant and the researcher was always Italian. The order of the sessions was counterbalanced across participants. Each session lasted 40–60 minutes, with a gap of 4 to 7 days. Both sessions started with an eye-tracking sentence-reading task. Because this study was part of a larger project, participants were administered a series of additional tests tapping into reading-related cognitive abilities. The Italian session included (i) standardized tests to assess L1 lexical and sublexical reading abilities according to national parameters (Cornoldi et al., Reference Cornoldi, Baldi and Giofrè2017; Cornoldi & Candela, Reference Cornoldi and Candela2015; Montesano et al., Reference Montesano, Valenti and Cornoldi2020), (ii) a spoonerism task to assess phonological awareness skills, (iii) the forward and backward digit span tasks to assess phonological short-term and working memory skills (Monaco et al., Reference Monaco, Costa, Caltagirone and Carlesimo2013), (iv) a lexical decision task under articulatory suppression to measure orthographic knowledge (Montesano et al., Reference Montesano, Valenti and Cornoldi2020), and (v) the LexITA to assess vocabulary size (Amenta et al., Reference Amenta, Badan and Brysbaert2020). The English session included (i) a questionnaire to gather socio-linguistic information (Supplementary Appendix A), (ii) the LexTALE to measure vocabulary size (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012), (iii) the visual-1-back task to assess VAS (Lallier et al., Reference Lallier, Acha and Carreiras2016), and (iv) Olson et al.’s (Reference Olson, Forsberg, Wise, Rack and Lyon1994) Orthographic Coding task to assess English orthographic knowledge (EOK hereafter). Participants’ performance in the English Orthographic Coding task is central to this study. This task requires participants to discriminate between a real English word and a pseudo-homophone as quickly and accurately as possible. Crucially, using pseudo-homophones implies that participants cannot rely on phonological decoding to perform the lexical decision task. This measure was taken as a proxy for English reading exposure and proficiency, with the reasoning that faster responses indicate faster activation of orthographic representations in English. A detailed description of the tests used for the neuropsychological assessment is provided in Venagli et al. (Reference Venagli, Kupisch and Lallier2025) and Venagli (Reference Venagli2025).
Eye-tracking reading task. The eye-tracking sentence-reading task, which directly addresses the RQs, was implemented following Egan et al. (Reference Egan, Oppenheim, Saville, Moll and Jones2019). The manipulated independent variables were Language (L1: Italian versus L2: English) and Lexicality (Words versus Pseudowords), as reported in Table 1. In total, participants read 32 sentences in each language: 24 experimental sentences, and 8 filler sentences. All target words were embedded in the middle of the sentence. The experimental sentences were divided into two lists, counterbalanced across participants. All sentences were presented in a randomized order. Participants were asked to read the sentences aloud and to press the space bar to continue.
Experimental sentence example. Sentences in the two languages are equivalent translations

The cognates between Italian and English were all real words, whereas pseudowords were designed to ensure their phonotactic and graphotactic plausibility in both languages. Orthographic Levenshtein distance (LD) was controlled for all (pseudo)words, ensuring that target (pseudo)words had a maximum of two-grapheme differences between the two languages (e.g., Italian: semplicità, English: simplicity). Morphological properties were also controlled by maintaining all Italian (pseudo)words with the final suffix -(i)tà and all English (pseudo)words with the final suffix -(i)ty. All target (pseudo)words were equally long (on the basis of graphemes) in the two languages.
All experimental sentences and target (pseudo)words were piloted prior to data collection. A norming experiment was administered to 19 participants, including 13 L1 Italian speakers (L2 English), 3 native English speakers, and 3 individuals proficient in both Italian and English as an L2 (L1 German). In this norming experiment, participants were asked to rate the familiarity of the target words and the naturalness of the experimental sentences on a scale of 1 to 5, with 1 indicating high unfamiliarity/unnaturalness, and 5 indicating high familiarity/naturalness. Additionally, the predictability of the target word within the sentence was evaluated using a sentence completion task. To prevent reading errors resulting from predictive strategies, the similarity of the pseudowords to real words was also tested, ensuring that none of the pseudowords resembled existing words in either Italian or English. All experimental items were re-adapted according to the norming test results prior to data collection. Experimental sentences and norming results are reported in Supplementary Appendix B.
Word frequency and bigram frequency (i.e., the frequency of two graphemes occurring together in a language) were also measured. Word frequency was measured using the Python package wordfreq.3 (Speer, Reference Speer2022). To measure the bigram frequency of the target (pseudo)words, the SUBTLEX-IT (Crepaldi et al., Reference Crepaldi, Keuleers, Mandera and Brysbaert2013) and the SUBTLEX-US (Brysbaert & New, Reference Brysbaert and New2009) were used for Italian and English, respectively. In terms of word frequency, there was no significant difference between Italian and English words (Table 2). However, similarly to Paulesu et al. (Reference Paulesu, Bonandrini, Zapparoli, Rupani, Mapelli, Tassini, Schenone, Bottini, Perry and Zorzi2021), bigram frequency for cognates and pseudowords was higher in Italian compared to English; it is possible that these differences result from linguistic structural properties and the use of different corpora.
Word and bigram frequency by language and lexicality. Model formula: lm(formula = dependent variable ~ language)

Apparatus. The task was implemented using Experiment Builder (SR Research Experiment Builder 2.3.1, 2020). We used the EyeLink Portable Duo and recorded eye movements monocularly at 1000 Hz (lens: 25 mm). The experiment started with a 9-point calibration. The experimental sentences were always presented on a single line (black, Arial, 17 pt, white background) at the centre of a 1024 x 768-pixel screen, keeping an eye-to-screen distance of 520 mm. Given that Arial is not a monospaced font, we controlled for (pseudo)word length effects by calculating the length of the interest area (IA) in pixels and used this measure as a covariate in subsequent analyses.
5. Results
5.1. Preliminary tests
The results of the preliminary tests are reported in Table 3. Group differences and age effects were investigated with (g)lm models in R (formula = Response ~ Age * Group). Although different cognitive profiles are often described within dyslexia, our sample was not divided into specific subtypes. Instead, we characterized participants based on their observed reading and cognitive profiles. Compared with their TD peers, DYS participants showed significantly lower scores across all background measures (except for the forward digit span), with difficulties emerging especially in the test tapping into phonological awareness (Figure 1).
Descriptive results and group differences in preliminary tests

Participants’ performance in WRT, word reading errors (WRE), pseudoword reading time (PWRT), pseudoword reading errors (PWRE), spoonerism task (PA), forward digit span (pSTM), backward digit span (pWM), and visual-1-back task (VAS).

5.2. Eye-tracking data
Data analysis of eye movements was conducted using (generalized) linear mixed effect models with the (g)lmer functions from the lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) in R (R Core Team, 2023, version 4.2.1). The emmeans and emtrends functions (emmeans package, Lenth, Reference Lenth2024) were used for the post-hoc analyses of the interaction terms. The model selection was performed with the functions anova and drop1 from the stats package (R Core Team, 2023). In what follows, we report the results of two key dependent variables: (i) first-pass fixation count on the target (pseudo)words, which was analysed with glmer models assuming a Poisson distribution. First-pass fixation count is defined as the total number of fixations on the target (pseudo)word during its first encounter, thus before any forward or backward regression outside the IA was made. The other dependent variable was (ii) the gaze duration (i.e., duration of first-pass fixations), which was modelled with the lmer function. Duration measures were log-transformed prior to the analysis and continuous variables were scaled. These measures reflect early processing in word decoding and recognition and allow us to determine the grain-size strategy used during decoding, with fewer and shorter first-pass fixations reflecting a large-grain decoding strategy; by contrast, a higher number, and thus longer, first-pass fixations reflect the processing of smaller visual grains (see Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019). Analyses of other eye-tracking measures for both cognates and pseudowords (i.e., first fixation duration, total fixation count, and total dwell time) are reported in Supplementary Table C1 (cognates) and Supplementary Table C2 (pseudowords) in Supplementary Appendix C. All models tested the three-way interaction between EOK, Language (Italian versus English sentences), and Group (DYS versus TD). Further, all models controlled for the length of the IA in pixels (henceforth: IA Length) and included random intercepts for participants and items.
Word recognition strategies. The analysis of first-pass fixation count on cognates yielded a non-significant three-way interaction between Language, Group, and EOK (χ2 = 0.15, p = .696), but significant main effects of Language (χ2 = 15.38, p < .001), EOK (χ2 = 14.80, p < .001), and Group (χ2 = 9.37, p = .002) emerged, indicating that (i) participants make overall more fixations to read words in their L2 (English) as compared to the L1 (Italian), that (ii) EOK reduces the number of fixations in both languages, and that (iii) participants with dyslexia make overall more fixations than their typically developing peers. The effect of IA Length was also significant (χ2 = 70.13, p < .001).
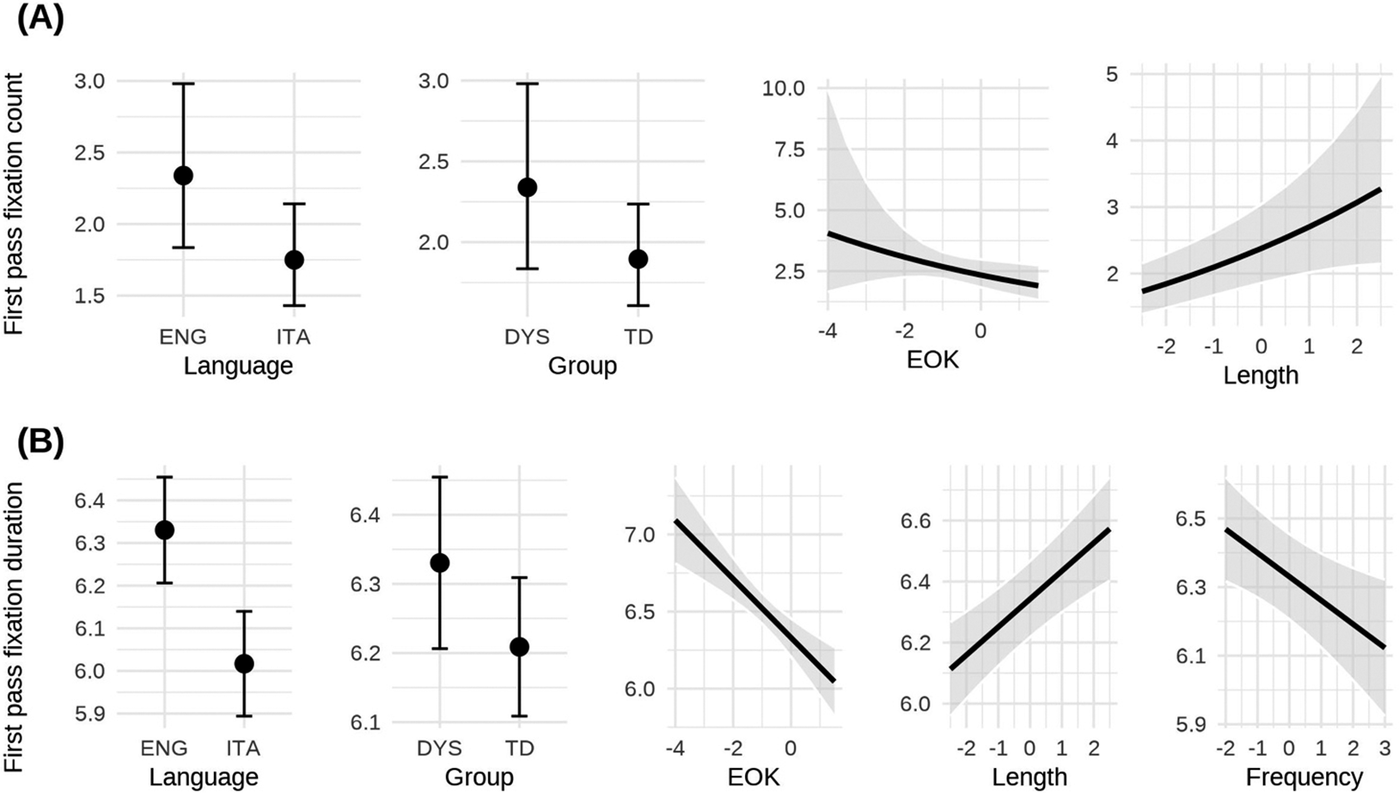
Similarly, the analysis of participants’ gaze duration on Italian versus English (cognate) words yielded a non-significant three-way interaction between EOK, Group, and Language (χ2 = 0.09, p = .764), but significant main effects of Language (χ2 = 18.77, p < .001), EOK (χ2 = 19.78, p < .001), and IA Length (χ2 = 19.78, p < .001) emerged. Group was not significant (χ2 = 2.77, p = .096). Notably, there was a significant interaction between Language and EOK (χ2 = 5.32, p = .021), indicating that gaze duration decreased with higher EOK, with the effect being more pronounced for English compared to Italian. Results for real words are summarized in Supplementary Table C1 (Supplementary Appendix C). Main effects for both models are illustrated in Figure 2.
Main effects for the models assessing first-pass fixation count (a) and duration (b): Cognates.

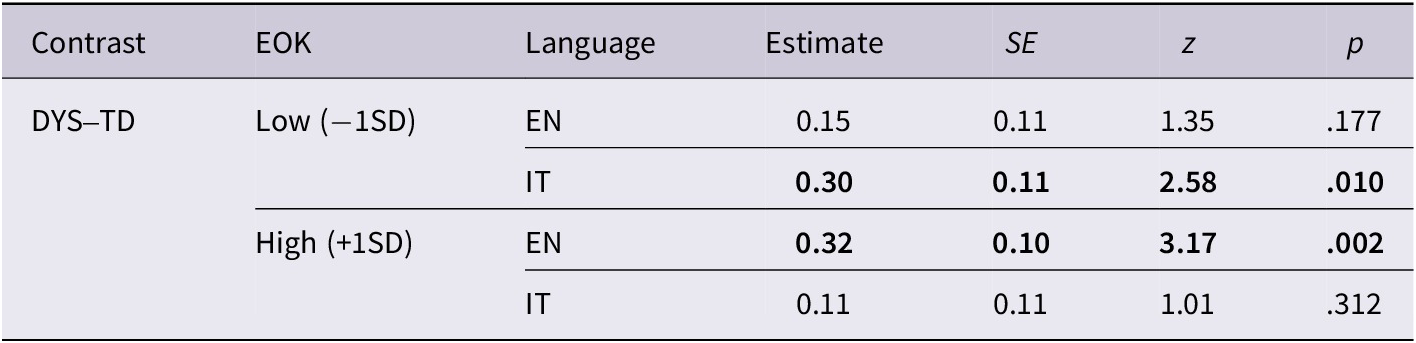
Decoding strategies. The best-fit model analysing the first-pass fixation count on pseudowords yielded a significant main effect of Group (χ2 = 10.40, p = .001), Language (χ2 = 12.85, p < .001), and IA Length (χ2 = 32.94, p < .001). The three-way interaction between Group, Language, and EOK was also significant (χ2 = 5.04, p = .025). The interaction term was further analysed to assess (i) differences between the two languages at high (+1SD) and low (-1SD) levels of EOK, (ii) differences between Groups in Italian and English at high and low levels of EOK, and (iii) to assess the effect of EOK on the two languages and groups.
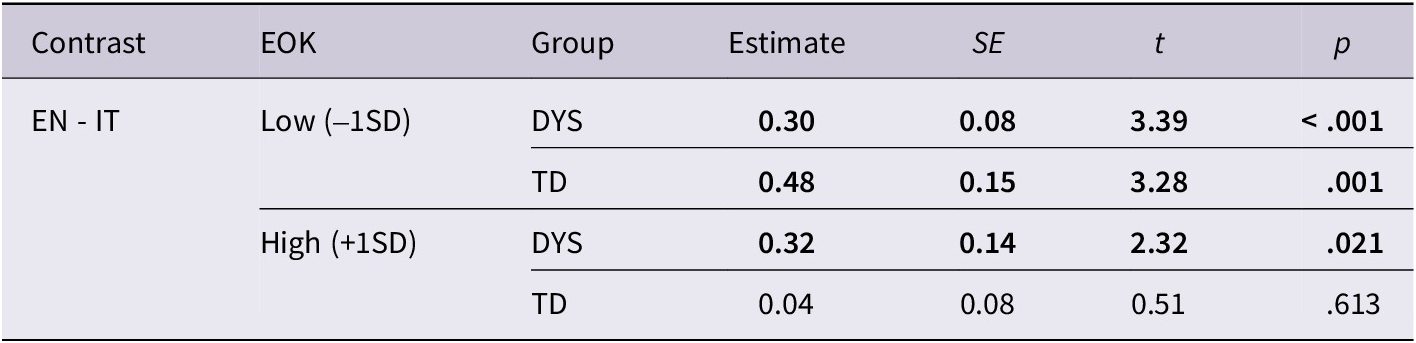
The post-hoc analysis showed that DYS participants made a significantly higher number of first-pass fixations on English pseudowords as compared to Italian pseudowords, both at low (β = 0.21, SE = 0.05, z = 4.34, p < .001) and high (β = 0.24, SE = 0.10, z = 2.50, p = .012) levels of EOK. TD participants, instead, fixated English pseudowords more often than Italian pseudowords at low levels of EOK (β = 0.35, SE = 0.11, z = 3.23, p = .001), but not at high levels of EOK (β = 0.02, SE = 0.05, z = 0.46, p = .644), as illustrated in Figure 3. The emmeans analysis assessing Group differences is reported in Table 4.
Differences in terms of first-pass fixation between Italian and English (x axis) at low (left panel) and high EOK levels (right panel) in typically developing learners (blue) and those with dyslexia (red). *p < .05, **p < .01, ***p < .001.

Post-hoc analysis assessing Group differences in each language (Italian versus English) at low and high EOK levels. Formula: emmeans (model, pairwise ~ Group | Language | EOK, at = list (EOK = c(−1,1)), adjust = “bonferroni”). Significant contrasts are highlighted in bold

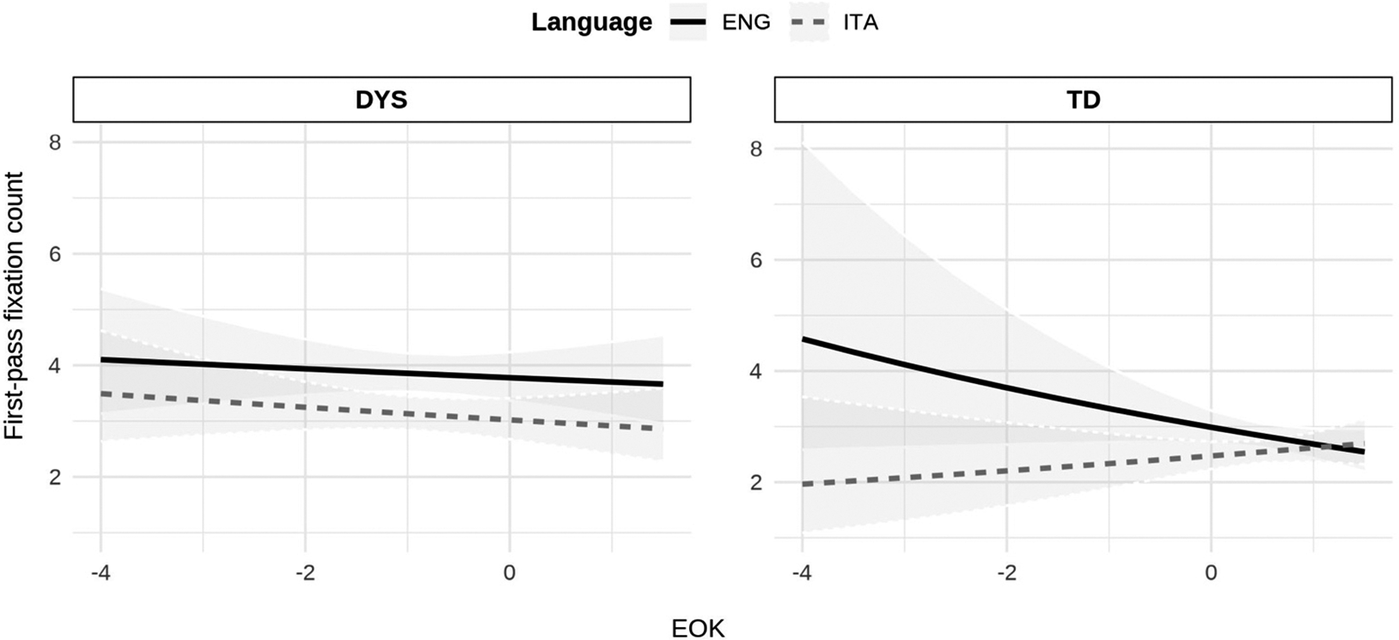
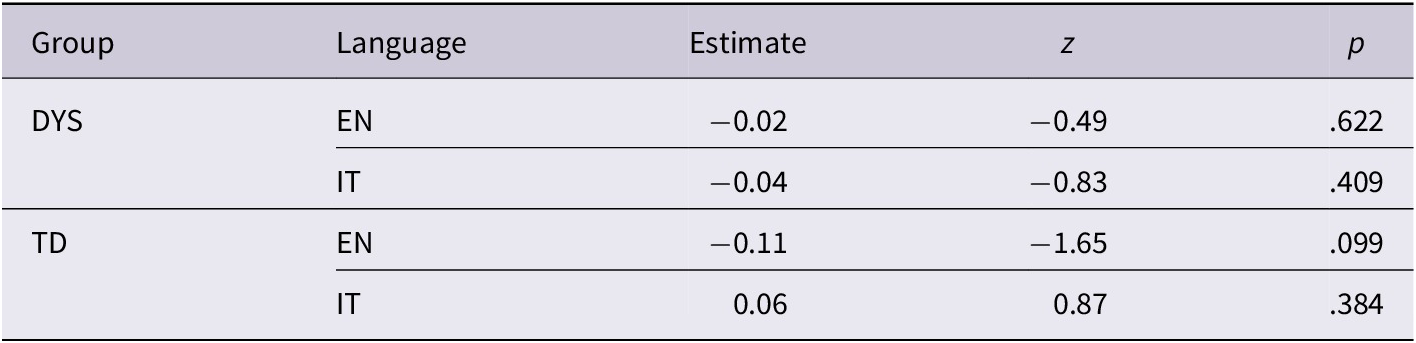
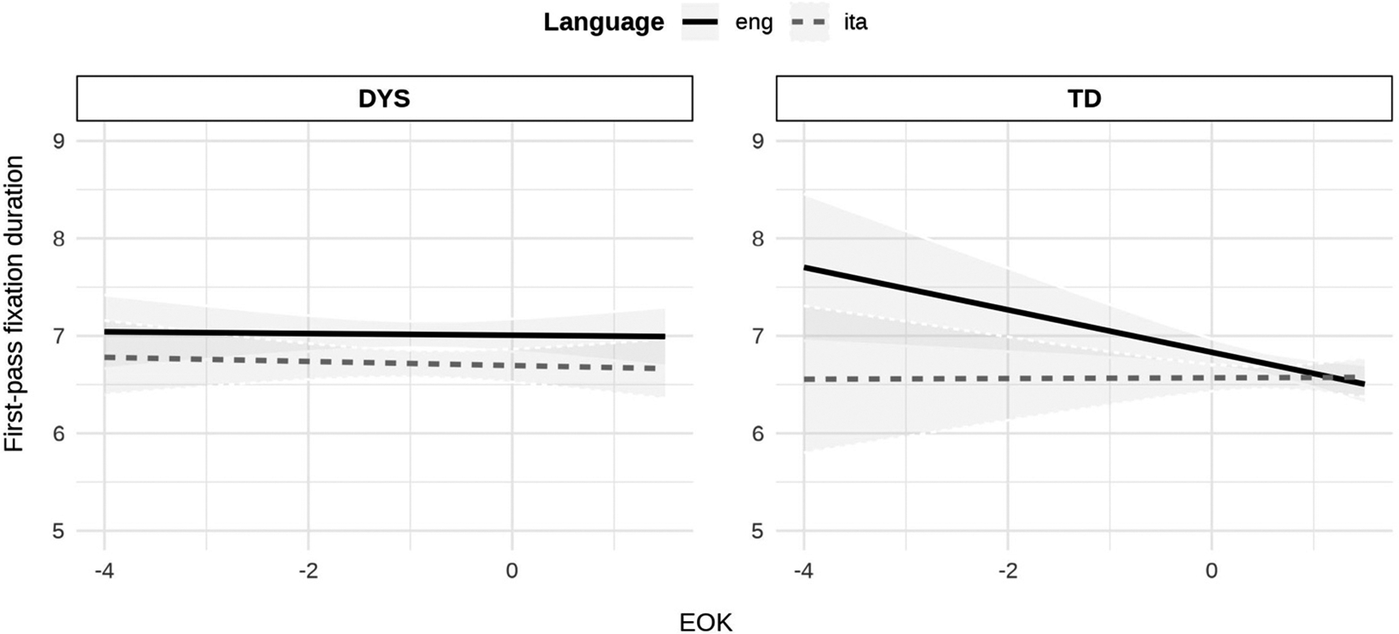
Finally, the function emtrends was used to compare the direction and strength of the English reading proficiency effect on Italian and English pseudowords in DYS and TD. The analysis showed that whilst the effect of EOK did not reach the significance threshold in the post-hoc analysis (Table 5), its effect played out significantly differently on Italian and English in TD participants (β = −0.16, SE = 0.07, z = −2.43, p = .015) but not in DYS (β = 0.02, SE = 0.04, z = 0.36, p = .716), as illustrated in Figure 4.
Effect of EOK on L1 (orange, dotted) and L2 (blue, continuous) decoding strategies (as indexed by first-pass fixation count) of learners with (left panel, DYS) and without dyslexia (right panel, TD).

Post-hoc analysis assessing the effect of English reading proficiency on each Language and Group. Formula: emtrends(model, pairwise ~ Language | Group, var = “EOK,” infer = T, adjust = “bonferroni”)

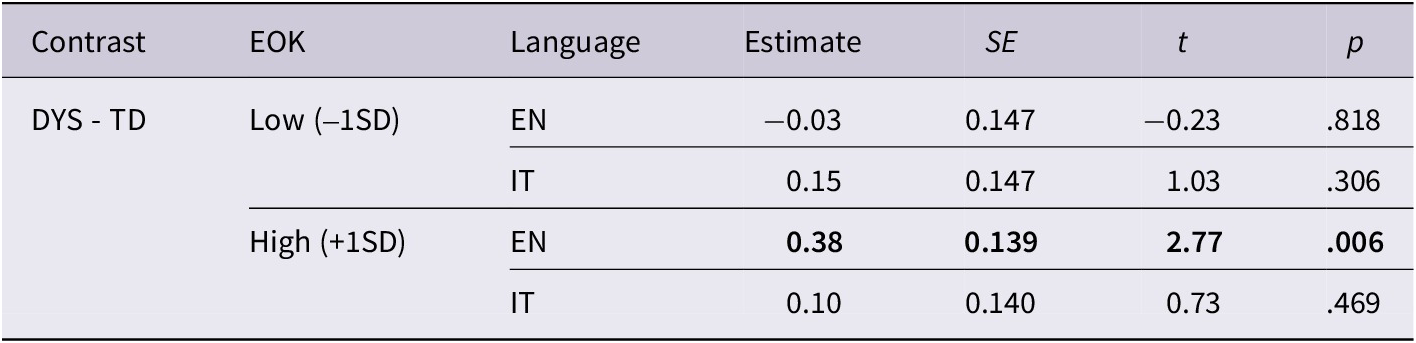
As for gaze duration, the best-fit model yielded a significant effect of Language (χ2 = 10.55, p = .001), IA Length (χ2 = 7.85, p = .005), and a significant three-way interaction between Language, Group, and EOK (χ2 = 4.79, p = .029). The post-hoc analysis assessed differences between Italian and English at low (−1SD) and high (+1SD) levels of EOK. The results showed, once again, that differences between Italian and English were always significant, except for TD participants with high EOK (Table 6). Group differences, instead, only emerged in English pseudoword reading at high levels of EOK (+1SD), with DYS participants making significantly longer first-pass fixations than TD participants (Table 7). Finally, the emtrends output showed that the effect of EOK on the duration of the first-pass fixations was only significant for TD participants with high EOK (+1SD), with higher proficiency corresponding to faster fixations (β = −0.22, SE = 0.09, t = −2.58, p = .011), and confirming the previous analysis on the first-pass fixation count showing that the effect of EOK played out significantly differently on the two languages in this group (β = −0.22, SE = 0.09, t = −2.52, p = .012), but not on DYS, as illustrated in Figure 5.
Post-hoc analysis assessing Language differences for each Group at low and high English reading proficiency (EOK) levels. Formula: emmeans(model, pairwise ~ Language | Group | EOK, at = list(EOK = c(−1,1)), adjust = “bonferroni”). Significant contrasts are highlighted in bold

Post-hoc analysis assessing Group differences for each Language at low and high English reading proficiency (EOK) levels. Formula: emmeans(model, pairwise ~ Group | Language | EOK, at = list(EOK = c(−1,1)), adjust = “bonferroni”). Significant contrasts are highlighted in bold

Effect of English reading proficiency on L1 (grey, dotted) and L2 (black, continuous) decoding strategies (as indexed by gaze/first-pass fixation duration) of learners with dyslexia (left panel, DYS) and without dyslexia (right panel, TD).

6. Discussion
We investigated the effect of L1 and L2 (reading) proficiency on the L1 (here: Italian) and L2 (here: English) decoding strategies of L2 learners with and without dyslexia. Specifically, we tested the hypotheses that (i) decoding strategies develop to accommodate the demands of both languages (one being highly transparent and the other extremely opaque), or that (ii) decoding strategies are adapted to the target language. Venagli et al. (Reference Venagli, Kupisch and Lallier2025) have shown that L2 reading proficiency can boost reading-related cognitive abilities, such as VAS, also in late biliterates, providing first evidence in favour of the GSAH (Lallier & Carreiras, Reference Lallier and Carreiras2018) for this learner type. However, whether such orthography-specific cross-linguistic modulations of reading-related cognitive abilities also extend to reading behaviour remains unclear. Previous evidence suggests that the presence of fine- and coarse-grained linguistic cues prompts partially selective lexical access in unbalanced bilinguals (Hoversten & Traxler, Reference Hoversten and Traxler2020) and in balanced bilinguals, who were shown to adapt their reading strategies to the target language (Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019). We recorded the number and duration of first-pass fixations made on Italian and English (pseudo)words that were almost identical between the two languages, but embedded in Italian or English sentences to provide a monolingual reading mode along with strong linguistic cues. Although the task embedded both real (cognate) and pseudowords, the latter were particularly relevant to test our hypotheses because they help assess whether late biliterates employ different grain-size strategies to decode nearly identical, unknown orthographic strings or whether they rely on hybrid strategies depending on the language of the sentence, as well as on their L2 reading proficiency level, or on the presence of a reading impairment such as dyslexia. Further, by focusing on pseudowords, we avoided a language-status effect that could have resulted from comparing a native and a non-native language. In what follows, we discuss our results in terms of word recognition (cognate word reading) and decoding (pseudoword reading) strategies.
6.1. L2 proficiency effects on word recognition
The analyses of real (cognate) words suggest that Italian words were recognized faster (i.e., fewer and shorter first-pass fixations) than English words by all participants. This was expected because lexical access is likely to be faster in a native language as compared to a non-native language due to higher proficiency in the former, regardless of dyslexia. This result aligns with Paulesu et al.’s (Reference Paulesu, Bonandrini, Zapparoli, Rupani, Mapelli, Tassini, Schenone, Bottini, Perry and Zorzi2021) finding of an L1 advantage in reading latencies in proficient Italian–English late biliterates. Crucially, we expected that differences between the two languages in terms of first-pass fixation count and gaze duration would be attenuated at higher L2 proficiency, reflecting faster lexical access. Our analysis confirmed this prediction, as we found a two-way interaction between Language and English proficiency in the analysis of gaze duration (though not in the analysis of the first-pass fixation count), showing that higher English proficiency reduced the duration of the first-pass fixations on English words, but not on Italian words, where no differences between the two languages at higher L2 proficiency levels were found. This was the case for both typical and dyslexic readers, and it might indicate that at higher proficiency levels, participants process L2 words through the lexical route rather than relying on sublexical decoding strategies. Lexical processing may be further enhanced by the presence of cognates, since they activate L1 lexical representations alongside L2 representations.
As for group differences, we anticipated that dyslexic participants would differ from typically developing participants in making more and longer fixations (Hutzler & Wimmer, Reference Hutzler and Wimmer2004). However, these differences were expected to be more pronounced in the L2 than in the L1 because previous studies had indicated that in their native language, dyslexic readers can efficiently operate on the lexical route (see Barca et al., Reference Barca, Burani, Di Filippo and Zoccolotti2006, for Italian). Group differences emerged in all measures, which means that learners with dyslexia made more and longer fixations than their typically developing peers. The lack of significant two- and three-way interactions between group, language, and English proficiency indicates that these differences are neither attenuated at higher levels of L2 proficiency, nor in the L1 compared to the L2. One possibility is that this reflects a stronger reliance on sublexical reading strategies in dyslexic readers compared to typical readers (e.g., Hawelka et al., Reference Hawelka, Gagl and Wimmer2010).
6.2. L2 proficiency effects on (pseudoword) decoding
For pseudoword decoding, we expected differences between Italian and English to be significant at low levels of English reading proficiency, regardless of dyslexia. English reading proficiency was measured by means of a lexical decision task using real words and pseudo-homophones (Olson et al., Reference Olson, Forsberg, Wise, Rack and Lyon1994), and accounting for speed–accuracy trade-off scores. More specifically, we expected more and longer first-pass fixations on pseudowords in English sentences compared to Italian sentences. Previous studies had shown that low-proficiency late biliterates rely on smaller visual units (e.g., decoding of single graphemes) when reading in their L2 (de León Rodríguez et al., Reference de León Rodríguez, Buetler, Eggenberger, Laganaro, Nyffeler, Annoni and Müri2016; Treutlein et al., Reference Treutlein, Schöler and Landerl2017). Our analysis confirmed this for typically developing and dyslexic readers, as both fixated pseudowords significantly more often and for longer when these appeared in English sentences than when they appeared in Italian sentences.
Does L2 reading proficiency attenuate these differences and lead to the processing of larger visual grains? The Accommodation Hypothesis predicts no language difference in first-pass fixations at higher levels of L2 reading proficiency because it assumes similar (hybrid) strategies for the decoding of (identical) pseudowords regardless of the language context. Under the Adaptation Hypothesis, instead, we expected participants to rely on different decoding strategies depending on the target language (Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019), hence showing a stronger reliance on smaller grain size strategies in their transparent L1 compared to their opaque L2. Our analysis showed that for typically developing participants, differences between Italian and English ceased to be significant at high L2 reading proficiency levels, in line with the predictions of the Accommodation Hypothesis. For learners with dyslexia, instead, differences between the two languages remained significant (though to a lesser degree) even at high levels of English reading proficiency. This trend, however, was not in the direction predicted under the Adaptation Hypothesis (i.e., more fixations in the transparent language compared to the opaque language, indexing a small-grain strategy). Rather, learners with dyslexia fixated pseudowords more often and for longer in English sentences than in Italian sentences. In other words, while typically developing late biliterates seem to gradually operate on larger visual grains as L2 (reading) proficiency increases – arguably because of a more “trained” L2 decoding system – learners with dyslexia constantly show an L1 advantage, over-relying on smaller grain size units when reading in a non-native orthography. These results align with Treutlein et al. (Reference Treutlein, Schöler and Landerl2017), who found that proficient German–English late biliterates could flexibly switch between small- and large-grain strategies when reading in a non-native opaque orthography. Crucially, however, our results on participants with dyslexia do not align with this. Instead, the presence of a reading impairment appears to prevent the development of large-grain reading strategies, as also observed in Venagli et al. (Reference Venagli, Kupisch and Lallier2025) for the same set of participants.
To further explore the role of L2 proficiency on decoding strategies, we examined the effect of English reading proficiency on a continuum. Under the Accommodation Hypothesis, L2 reading proficiency should reduce the number of fixations on both Italian and English pseudowords, thus reflecting the processing of larger (hybrid) visual grains as proficiency in the non-native language with opaque orthography increases. Under the Adaptation Hypothesis, instead, L2 proficiency should affect decoding only in the L2. The analysis of both first-pass fixation count and gaze duration in dyslexic participants revealed that L2 reading proficiency did not modulate decoding strategies, neither in Italian nor in English (Figure 4 and Figure 5, left panels). By contrast, in typical readers, L2 reading proficiency affected reading differently in the two languages: as participants’ reading proficiency in the L2 increased, the number and duration of first-pass fixations on pseudowords in English sentences decreased, suggesting that they increasingly process larger visual grains. No such effect was observed for pseudowords in Italian sentences (Figures 4 and 5, right panels). Once again, these results suggest that less sensitivity to the L2 orthographic system makes dyslexic individuals rely more on smaller visual grains when reading in English, regardless of their L2 reading proficiency. By contrast, typical readers seem to start processing larger visual grains as proficiency in the L2 increases, although this effect only emerged in their L2 and not in their L1 (Italian), possibly because their L1 system is already well trained to observe such cross-linguistic modulations, as predicted under the Accommodation Hypothesis.
In terms of group differences, we expected learners with dyslexia to make more and longer fixations than typical readers (Hutzler & Wimmer, Reference Hutzler and Wimmer2004), regardless of the language (L1 Italian versus L2 English). Notably, our analysis showed that differences between participants with and without dyslexia in terms of first-pass fixation count (but not duration) in Italian only emerged at lower levels of English proficiency, thus showing that both typical and dyslexic readers operate on similar visual grains to decode pseudowords in Italian. Moreover, while the two groups used similar strategies to decode pseudowords in English at low L2 reading proficiency levels, differences emerged at high proficiency levels, with dyslexic participants consistently making more and longer first-pass fixations. This may suggest that individuals with dyslexia are able to compensate for their decoding difficulties in a transparent orthography, whereas these difficulties remain apparent in a more phonologically demanding, opaque orthography, regardless of their L2 proficiency. Alternatively, the presence of dyslexia may prevent these learners from becoming sensitive to the statistical regularities of the English orthography (given its opacity), thus triggering the processing of smaller visual grains even at higher proficiency levels.
To summarize, our results show an L1 advantage in pseudoword decoding – as evidenced by fewer and faster first-pass fixations in Italian than in English – in both typical and dyslexic readers with low L2 reading proficiency. This pattern of results aligns with previous studies on low-proficiency late biliterates (Botezatu, Reference Botezatu2023; de León Rodríguez et al., Reference de León Rodríguez, Buetler, Eggenberger, Laganaro, Nyffeler, Annoni and Müri2016). However, among typically developing participants with high L2 reading proficiency, differences in the number and duration of first-pass fixations in Italian and English ceased to be significant. This suggests that these readers rely on similar visual grains when decoding pseudowords, independently of language context. Such a pattern is consistent with Lallier and Carreiras’ (Reference Lallier and Carreiras2018) GSAH, since experience with a non-native orthographic system is supposed to foster cognitive changes that lead to the development of hybrid decoding strategies, reflecting the “non-selective” nature of the reading system (Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002). However, caution is needed when interpreting our findings, as we compared a native (L1) and a non-native (L2) decoding system. One could argue that the effects predicted by the Adaptation Hypothesis, specifically the reliance on smaller visual grains in the more orthographically transparent language (L1 Italian), might not be easily detectable in late biliterates due to their highly trained L1 reading system. It is important to recognize that, in Italian, the “visual window” for the efficient decoding of (pseudo)words spans up to three graphemes (Perry & Long, Reference Perry and Long2022, p. 6). Thus, even though Italian is transparent, decoding does not necessarily proceed systematically grapheme-by-grapheme; young adults may have already developed a more advanced, large-grain decoding strategy, which prevents us from observing a proper adaptation, as found by Egan et al. (Reference Egan, Oppenheim, Saville, Moll and Jones2019), whose participants were early, balanced bilinguals. Finally, our results suggest that the ability of late biliterates to transfer reading skills and subskills across languages may be influenced by the presence of a reading impairment, in addition to L2 reading proficiency. In other words, a well-trained L1 reading system might be a prerequisite to observing cross-linguistic modulations in L1 and L2 reading. Indeed, no effect of L2 proficiency was observed on the decoding skills of dyslexic participants, aligning with previous findings (Venagli et al., Reference Venagli, Kupisch and Lallier2025).
6.3. Limitations and future directions
Does a higher level of L2 (reading) proficiency need to be reached to observe cross-linguistic modulations in dyslexia? What is the effect of learning more than one L2, as is the case for some participants in our sample? These questions remain unanswered and point to two methodological limitations of the present study. First, most participants with dyslexia had lower English reading proficiency scores, making it difficult to tease apart dyslexia-related effects from those of L2 proficiency in our analysis. Second, some participants reported knowing more than one L2 (mostly German, French, and/or Spanish). Although we believe that additional languages might play a role, potentially boosting cross-linguistic modulations, practical limitations limit our ability to further analyse this effect (e.g., lack of proficiency data and higher variability in terms of age of onset for languages that are not English). However, the languages our participants mentioned have more consistent orthographic systems than English, and they are typically acquired later in the Italian school system (i.e., beginning of sixth grade or high school). Thus, we believe that our participants’ experience with other foreign-language orthographies will not overpower their experience with English. Another limitation stems from the design of the experimental materials. Comparing reading between a highly transparent and a highly opaque orthographic system inherently involves comparing two languages that differ substantially in their phoneme-grapheme correspondences. As a result, the materials were somewhat biased towards Italian, in that they mostly involved simple graphemes, which could be a confounding factor and could potentially limit the reliance on larger visual grains during decoding (Lallier et al., Reference Lallier, Martin, Acha and Carreiras2021). To address these limitations, and to test the causality of the relationship between L2 proficiency and cross-linguistic modulations of reading strategies, future studies should consider longitudinal approaches to examine the effects of learning an opaque L2 from an early age, ideally testing late L2 learners at various stages of L2 acquisition and levels of L2 proficiency.
Moreover, future studies should take into account all the languages known by a participant and delve deeper into how different reading practices can affect the reading network in these learners. Finally, studies testing other language combinations would be necessary to advance our understanding of how late biliteracy affects reading, both at the behavioural and cognitive level, as well as to enhance our knowledge of how late biliteracy interacts with DD.
7. Conclusions
We examined the effects of L2 reading proficiency on L1 and L2 word recognition and decoding in late biliterates with and without dyslexia. Building on previous findings on early biliterates, we contrasted two hypotheses: the Accommodation Hypothesis (Lallier & Carreiras, Reference Lallier and Carreiras2018), which posits that late biliterates develop hybrid reading strategies that accommodate the demands of all their languages, and the Adaptation Hypothesis (e.g., Egan et al., Reference Egan, Oppenheim, Saville, Moll and Jones2019), which postulates that reading strategies are accessed (partially) selectively depending on the linguistic context. Our findings suggest that developing reading proficiency in a non-native opaque orthography can promote the processing of larger visual grains during L2 pseudoword decoding. However, this was only observed in typically developing participants and not in those with dyslexia, suggesting that a well-trained L1 system may be a prerequisite for cross-linguistic modulation of reading strategies. The results in typical readers provide partial support for the GSAH (Lallier & Carreiras, Reference Lallier and Carreiras2018) and align with our previous study, which has shown VAS bootstrapping effects driven by English reading proficiency in typical readers (Venagli et al., Reference Venagli, Kupisch and Lallier2025). Notably, L2 proficiency effects were also observed in word recognition, regardless of dyslexia. Despite some limitations, our study showed that cross-linguistic influences of the reading system may also emerge in late biliterates.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0305000926100701.
Data availability statement
Anonymized data and analysis scripts can be accessed via OSF: https://osf.io/qnr73/overview?view_only=0cc37fa364a54ee49cbddd49197b2ff3.
Acknowledgments
We would like to thank Maria Luisa Lorusso and Maria Teresa Guasti for their valuable feedback on the ideas presented here, as well as the teachers and students of the Liceo Europeo di Arconate, Liceo Claudio Cavalleri, and Istituto Gregorio Mendel, Milan, Italy, for their support and for granting permission to collect the data.
Author contribution
Conceptualization: I.V., T.M., C.M., M.L., T.K.; Data Curation: I.V., Formal Analysis: I.V., Investigation: I.V., Methodology: I.V., T.M., C.M., M.L., T.K.; Resources: I.V., T.M., C.M., T.K.; Software: I.V., Supervision: T.M., C.M., M.L., T.K.; Visualization: I.V., Writing (Original Draft): I.V.; Writing (Review & Editing): I.V., T.M., C.M., M.L., T.K.
Funding statement
This project was conducted as part of the first author’s doctoral studies, which were funded by an LGFG scholarship awarded to the first author by the state of Baden-Württemberg at the University of Konstanz, Germany.
Competing interests
The authors declare none.
Ethics statement
All protocols in this study were approved by the Ethics Committee of the University of Konstanz in compliance with the specific regulations of the University for ethical experimentation and data storage, with the Declaration of Helsinki in its current version as developed by the World Medical Association, and with relevant national and international law and regulations.








 Open access
Open access