


1. Introduction
When talking to infants, adults adjust to the situation and modify numerous properties of their speech, including its syntactic, semantic and acoustic characteristics. This special register is referred to as infant-directed speech (IDS) and is typically different from the way adults talk to each other (adult-directed speech, ADS). Higher fundamental frequency, lower speech and articulation rate, simplified grammar, and more frequent repetitions compared to ADS are all considered to be common features of IDS (Genovese et al., Reference Genovese, Spinelli, Lauro, Aureli, Castelletti and Fasolo2020; Harmati-Pap et al., Reference Harmati-Pap, Vadász, Tóth and Kas2024; Kuhl et al., Reference Kuhl, Andruski, Chistovich, Chistovich, Kozhevnikova, Ryskina and Lacerda1997; Saint-Georges et al., Reference Saint-Georges, Chetouani, Cassel, Apicella, Mahdhaoui, Muratori and Cohen2013).
Although voice quality is not widely regarded as a typical characteristic of IDS, several recent studies have indicated that speakers modify this feature as well when switching from ADS to IDS (Cheng et al., Reference Cheng, McClay and Yeung2024; McClay et al., Reference McClay, Cebioglu, Broesch and Yeung2022; Miyazawa et al., Reference Miyazawa, Shinya, Martin, Kikuchi and Mazuka2017). The vibration of the vocal folds can lead to multiple phonation types, depending on the size of the glottal opening (Garellek, Reference Garellek2019; Ladefoged, Reference Ladefoged1973). The different phonation types form a continuum. A typical breathy voice is produced when voicing occurs with less vocal fold approximation. In the prototypical creaky voice, phonation happens with more approximation. The model voice is somewhere between these two extremes. Vocal fold vibration yields a periodic waveform in modal voice, whereas in breathy and creaky voices, aperiodic noise also emerges (Garellek, Reference Garellek2019). Three recent studies have found that Canadian English, Czech, and Japanese native-speaker mothers produce a breathier voice in IDS than in ADS (Cheng et al., Reference Cheng, McClay and Yeung2024; Chládková et al., Reference Chládková, Černá, Paillereau, Skarnitzl and Oceláková2019; Miyazawa et al., Reference Miyazawa, Shinya, Martin, Kikuchi and Mazuka2017). These works applied widely used acoustic measures of vocal fold approximation or the periodicity in the acoustic signal relative to its noisiness for the analysis of voice quality. Cheng et al. (Reference Cheng, McClay and Yeung2024) have found that Canadian English-speaking mothers use a breathier voice in IDS than in ADS. Their results were based on a re-analysis of material from an earlier study that had reported entirely different conclusions (McClay et al., Reference McClay, Cebioglu, Broesch and Yeung2022). McClay et al. (Reference McClay, Cebioglu, Broesch and Yeung2022) did not report any difference between the two registers, but Cheng et al. (Reference Cheng, McClay and Yeung2024) found such differences in their later, more detailed analysis. In McClay et al. (Reference McClay, Cebioglu, Broesch and Yeung2022), the authors also reported on the speech characteristics of mothers from Vanuatu, whose IDS was found to be less breathy than their ADS, implying an opposite trend than in other investigated languages. However, the Vanuatu results were not re-analysed in their later work that included more detailed investigations.
The question arises of what purpose a breathy voice may serve in IDS. It has been suggested that speakers use certain acoustic features of IDS (e.g., increased fundamental and formant frequencies) to appear less aggressive or threatening to infants since these characteristics generally coincide with smaller body sizes (Kalashnikova et al., Reference Kalashnikova, Carignan and Burnham2017). Moreover, it has also been proposed that the properties of IDS may serve the purpose of signalling positive emotions and approachability (Benders, Reference Benders2013; Hilton et al., Reference Hilton, Moser, Bertolo, Lee-Rubin, Amir, Bainbridge and Mehr2022; Mády et al., Reference Mády, Gyuris, Gärtner, Kohári, Szalontai, Reichel, Frota, Cruz and Vigário2022). Generally, children tend to show a preference for IDS over ADS, and their attention is also increased when they listen to IDS (Háden et al., Reference Háden, Mády, Török and Winkler2020; ManyBabies Consortium, 2020; Spinelli et al., Reference Spinelli, Fasolo and Mesman2017). The acoustic properties of this register may help children recognize that they are the addressees of the speech, which may contribute to the language learning process (Senju & Csibra, Reference Senju and Csibra2008). These features may also support the child’s speech perception, yielding faster and more effective language development (Rosslund et al., Reference Rosslund, Mayor, Óturai and Kartushina2022; Spinelli et al., Reference Spinelli, Fasolo and Mesman2017). As for voice quality, it is known that small children tend to produce breathier voices than older ones and adults (Kent et al., Reference Kent, Eichhorn and Vorperian2021; Zhang, Reference Zhang2021). Therefore, using a breathier voice in IDS may be motivated by trying to adapt to the child’s assumed or actual speech production. It has also been shown that happy speech involving a breathy voice attracts children’s attention even more than emotional speech with a modal voice (Kao et al., Reference Kao, Sera and Zhang2022). This may be related to the fact that positive emotions tend to be associated with a breathy voice, as reported by studies investigating English and Hungarian speech (Anikin, Reference Anikin2020; Bartók, Reference Bartók2018).
The acoustic properties of IDS may change with the age of the child. Certain features of this register, such as the lower articulation rate or the higher fundamental frequency, approach the values of ADS as the child ages (Kalashnikova & Burnham, Reference Kalashnikova and Burnham2018; Narayan & McDermott, Reference Narayan and McDermott2016). Meanwhile, some other IDS features remain largely unchanged throughout the child’s first 2 years, for example, the larger vowel space (Cox et al., Reference Cox, Dideriksen, Keren-Portnoy, Roepstorff, Christiansen and Fusaroli2023). To the best of our knowledge, no studies have yet investigated the development of the longitudinal changes of voice quality in IDS across different ages of the same children. In the existing literature, the ages of the children vary widely. Japanese native speaker mothers were studied while interacting with their infants aged 18 to 24 months (Miyazawa et al., Reference Miyazawa, Shinya, Martin, Kikuchi and Mazuka2017), and Czech native speaker mothers were analysed in the prenatal stage, that is, during pregnancy (Chládková et al., Reference Chládková, Černá, Paillereau, Skarnitzl and Oceláková2019). In a study investigating Canadian English, the children’s ages ranged from 6 to 22 months, and the authors found no relationship between age and voice quality (Cheng et al., Reference Cheng, McClay and Yeung2024).
In the present study, we investigate whether and how speakers modify their voice quality in IDS compared to ADS in an understudied language, Hungarian. As in other languages, different voice quality types in Hungarian may also have special functions in prosodic phrasing. For example, the phrase-final boundaries are typically marked with a creaky voice in several languages (e.g., English, Japanese), including Hungarian (Garellek, Reference Garellek2022; Kawahara & Shinya, Reference Kawahara and Shinya2008; Markó, Reference Markó2013). In a more recent pilot study, Kohári et al. (Reference Kohári, Reichel, Szalontai and Mády2024) investigated voice quality at the phrase boundaries in Hungarian IDS. The results showed that the vowels at phrase-final boundaries in IDS shifted from a creaky voice to a more modal voice. In the present study, we aimed to exclude such known systematic occurrences of creaky voice since we focused on the general characteristics of IDS. In Hungarian, it was also shown that vowels in hiatus positions and the initial positions of intonational phrases are often realized with creaky voice qualities, similarly to observations in English and other languages (Garellek, Reference Garellek2022; Markó, Reference Markó2013). Yet, even in the absence of such prosodic or phonological conditions, creaky voice is still a frequent phenomenon in Hungarian, found in approximately 20% of the produced vowels (Gráczi et al., Reference Gráczi, Markó and Takács2017). Besides a creaky voice, a breathy voice also appears in Hungarian speech, typically when expressing positive emotions (Bartók, Reference Bartók2018). Although a creaky voice in Hungarian speech is relatively frequent even within phrases, mothers may use a breathier voice when talking to their infants, similarly to Canadian English, Czech, and Japanese speakers. In our analysis, we apply widely used and thoroughly validated voice quality indices: spectral tilt and periodicity measures for the sake of reliability (Cheng et al., Reference Cheng, McClay and Yeung2024; Garellek, Reference Garellek2019). Furthermore, we employ a longitudinal design, studying the same speaker repeatedly at key stages of the infant’s language development (Bergelson & Swingley, Reference Bergelson and Swingley2012, Reference Bergelson and Swingley2015; Tincoff & Jusczyk, Reference Tincoff and Jusczyk2012). We assumed that a breathy voice is stably present in IDS until the child starts to actively produce words. This assumption is supported by previous results, which indicated a clear difference between the two registers in this respect, even for mothers of older children (Miyazawa et al., Reference Miyazawa, Shinya, Martin, Kikuchi and Mazuka2017).
2. Methods
2.1. Participants
We analysed data from 20 first-time mothers who were native Hungarian speakers. The participants, aged 26–38 years (
 $ M=30.4 $
years,
$ M=30.4 $
years,
 $ SD=4.0 $
), reported no hearing or speech difficulties. All mothers lived in Budapest or nearby towns and had completed high school or higher education. Recruitment took place at the Birth Centre of the Military Hospital (Budapest, Hungary) during the birth of their first child. The participating children (14 boys, 6 girls) were all typically developing.
$ SD=4.0 $
), reported no hearing or speech difficulties. All mothers lived in Budapest or nearby towns and had completed high school or higher education. Recruitment took place at the Birth Centre of the Military Hospital (Budapest, Hungary) during the birth of their first child. The participating children (14 boys, 6 girls) were all typically developing.
2.2. Materials and recording procedure
The participants were instructed to use an illustrated storybook to narrate a story. The book contained sentences to be read aloud, as well as images without text, about which the participants were asked to tell a story. The purpose of the spontaneous speech part was to help the mothers produce the read sentences more naturally. The read sentences were included to ensure that the phonetic aspects of the measurements could be properly controlled. After familiarizing themselves with the storybook, participants first narrated the story to the experimenter (ADS) and then to their child (IDS). The experiments were repeated when the children were approximately 4, 8, and 18 months old (first session:
 $ M= $
4 months and 8.3 days,
$ M= $
4 months and 8.3 days,
 $ SD=6.9 $
; second session:
$ SD=6.9 $
; second session:
 $ M= $
8 months and 7.0 days,
$ M= $
8 months and 7.0 days,
 $ SD=9.7 $
; third session:
$ SD=9.7 $
; third session:
 $ M= $
18 months and 7.9 days,
$ M= $
18 months and 7.9 days,
 $ SD=6.6 $
). The same storybook was used at all three age points. The timing was chosen to follow the basic stages of language development, as described in the literature (Bergelson & Swingley, Reference Bergelson and Swingley2012, Reference Bergelson and Swingley2015; Tincoff & Jusczyk, Reference Tincoff and Jusczyk2012). On the one hand, we intended to contrast the preverbal stage (4- and 8-month old) with a later one in which the children communicate actively and produce words (18 months). On the other hand, the intermediate 8-month age was selected to allow a comparison between this age, when infants have already begun to understand words, and their respective 4-month-old phase. In the latter, such comprehension is not assumed, yet infants in this stage already possess the ability to discover certain features of the speech signal. The recordings were made in the laboratory of the Institute of Cognitive Neuroscience and Psychology, Research Centre for Natural Sciences, Hungarian Academy of Sciences, with a head-mounted hypercardioid microphone (Beyerdynamic TG H74c) at a 44.1 kHz sampling rate and digitized at 16 bits using an M-Audio two-channel USB external sound card.
$ SD=6.6 $
). The same storybook was used at all three age points. The timing was chosen to follow the basic stages of language development, as described in the literature (Bergelson & Swingley, Reference Bergelson and Swingley2012, Reference Bergelson and Swingley2015; Tincoff & Jusczyk, Reference Tincoff and Jusczyk2012). On the one hand, we intended to contrast the preverbal stage (4- and 8-month old) with a later one in which the children communicate actively and produce words (18 months). On the other hand, the intermediate 8-month age was selected to allow a comparison between this age, when infants have already begun to understand words, and their respective 4-month-old phase. In the latter, such comprehension is not assumed, yet infants in this stage already possess the ability to discover certain features of the speech signal. The recordings were made in the laboratory of the Institute of Cognitive Neuroscience and Psychology, Research Centre for Natural Sciences, Hungarian Academy of Sciences, with a head-mounted hypercardioid microphone (Beyerdynamic TG H74c) at a 44.1 kHz sampling rate and digitized at 16 bits using an M-Audio two-channel USB external sound card.
2.3. Data analysis
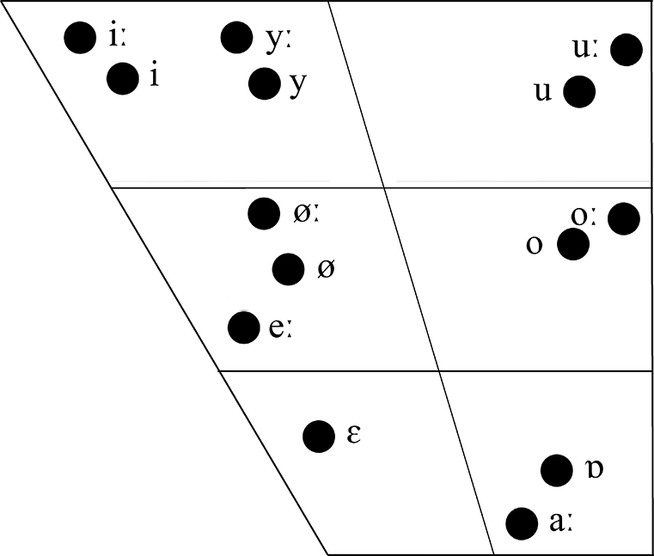
Ten read sentences were utilized for acoustic analysis, ensuring that the same vowels were examined in identical phonetic contexts (consonant environment and prosodic position) for both registers. The samples were first segmented automatically with MAUS (Kisler et al., Reference Kisler, Reichel and Schiel2017) and then manually corrected using Praat 6.1.08 (Boersma & Weenink, Reference Boersma and Weenink2019). Vowel sounds that appeared at least four times in the read IDS and ADS of each speaker were selected for evaluation to enable statistical analyses. The following five Hungarian vowels were analysed in the present study: /ɒ/, /aː/, /ɛ/, /i/, and /o/ (Figure 1). As the voice quality of phrase-final syllables and the vowels in phrase-initial positions tends to differ from the modal voice in Hungarian speech (Markó, Reference Markó2013), those vowels and syllables were excluded from the analysis. There were no occurrences of vowels in hiatus positions in the material. We examined 6,775 vowels in total. Acoustic parameters associated with voice quality were estimated using VoiceSauce (Shue et al., Reference Shue, Keating, Vicenik and Yu2011). We utilized the STRAIGHT algorithm of VoiceSauce to measure F0 (Kawahara et al., Reference Kawahara, De Cheveigne, Banno, Takahashi and Irino2005) with default settings. The frequencies of the vowel formants (F1, F2) were calculated using the Praat software.
Schematic representation of the Hungarian vowel inventory reproduced from Markó et al. (Reference Markó, Deme, Bartók, Gráczi and Csapó2018).

For voice quality analysis, we selected three measures (H1*–H2*, H1*–A1*, and CPP) that are associated with the perception of voice quality (Garellek, Reference Garellek2019) and have shown differences between IDS and ADS in previous studies (Cheng et al., Reference Cheng, McClay and Yeung2024; Miyazawa et al., Reference Miyazawa, Shinya, Martin, Kikuchi and Mazuka2017). F0, F1, and F2 outliers were excluded from the voice quality analysis when their values were outside the 2.5 standard deviation interval around the mean for the given speaker (cf. Garellek & Esposito, Reference Garellek and Esposito2023). The first quantity to be determined was a measure of spectral tilt, calculated as the difference between the amplitudes corresponding to the first and second harmonics of the fundamental frequency (H1*–H2*) corrected for the effects of the vowel’s formants (Iseli et al., Reference Iseli, Shue and Alwan2007). The H1*–H2* measure is related to the openness of the vocal folds. The more open the vocal folds are during phonation, the higher the value of this measure. In the case of a breathy voice, the vocal folds are more open, yielding higher H1*–H2*, while glottalization is characterized by low and modal voice by intermediate values (Garellek, Reference Garellek2019). H1*–A1* is similar to H1*–H2* and was earlier also considered to be a relevant measure for IDS-related phenomena (Cheng et al., Reference Cheng, McClay and Yeung2024). Here, instead of H2* (the second harmonic of F0), the subtracted amplitude is that of the harmonic that is the closest to F1. Similarly to the previous measure, higher values of H1*–A1* are typical for breathy voice, and lower values for creaky voice, with the modal voice in between. The Cepstral Peak Prominence (CPP) is the difference, in dB, between the dominant cepstral peak at the quefrency q0 = 1/F0 and the value of a linear regression cepstral baseline evaluated at q0 (Hillenbrand et al., Reference Hillenbrand, Cleveland and Erickson1994). When the vibration of the vocal folds is strongly periodic and the phonation is not noisy, the CPP is high. This is typically observed in the modal voice. When the vocal folds exhibit aperiodic vibrations with lower energy, the noise (inharmonic) components are stronger in the signal. This situation commonly occurs during the production of breathy voice and creaky voice, both of which yield lower CPP. Values of CPP have been found to show clear differences between IDS and ADS (Cheng et al., Reference Cheng, McClay and Yeung2024).
We conducted the statistical analyses in R 4.4.0 (R Core Team, 2021). We fitted separate linear mixed-effects models for the voice quality measures (H1*–H2*, H1*–A1*, CPP), utilizing the lmerTest package (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017). We followed the basic rules of model selection (Winter, Reference Winter2019). The initial model was built with the fixed factors including register (IDS/ADS), infant age (4, 8, and 18 months), vowel (/ɒ/, /aː/, /ɛ/, /i/, and /o/), and with all possible interactions among all these fixed factors. The maximal model included by-speaker random intercepts and slopes for all fixed effects. We simplified the random effect structure based on variance values until the model convergence was achieved. Backward stepwise model selection was performed via likelihood ratio tests using the “anova” function. The best minimal model was selected by excluding the interactions and fixed factors that did not contribute to the model. The lmerTest package (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017) was applied to estimate
 $ p $
-values based on Satterthwaite approximations. Tukey’s post hoc tests were carried out to account for multiple comparisons utilizing the emmeans package (Lenth et al., Reference Lenth, Singmann, Love, Buerkner and Herve2019) when needed. We estimated conditional
$ p $
-values based on Satterthwaite approximations. Tukey’s post hoc tests were carried out to account for multiple comparisons utilizing the emmeans package (Lenth et al., Reference Lenth, Singmann, Love, Buerkner and Herve2019) when needed. We estimated conditional
 $ {R}^2 $
and marginal
$ {R}^2 $
and marginal
 $ {R}^2 $
values using the MuMIn package (Bartoń, Reference Bartoń2024).
$ {R}^2 $
values using the MuMIn package (Bartoń, Reference Bartoń2024).
3. Results
Descriptive statistics for all voice quality measures are reported in Table 1, separately for the registers (IDS and ADS). On average, the spectral tilt measures (H1*–H2*, H1*–A1*) seemed to be higher in IDS than in ADS, indicating the presence of the breathier voice in the former register. The CPP measure – quantifying the periodicity – showed a slight difference between the two registers, with somewhat lower values for IDS, implying that the phonation is less periodic than in ADS. This difference is also a specific characteristic of breathy voice compared to modal voice.
Mean and standard deviation (in brackets) of three voice quality measures and fundamental frequency in IDS (
 $ n=3125 $
) and ADS (
$ n=3125 $
) and ADS (
 $ n=3232 $
)
$ n=3232 $
)

Based on the detailed statistical results, it can be stated with confidence that the register clearly affected the H1*–H2* measure (Table 2). IDS typically exhibited higher values than ADS in this respect, indicating breathier phonation in IDS. However, this effect varied depending on the baby’s age and the investigated vowel; therefore, we performed a post hoc test. For 4 and 18 months of the infants’ age, the IDS register had higher H1*–H2* than ADS (4 months:
 $ b=-1.16 $
,
$ b=-1.16 $
,
 $ SE=0.29 $
,
$ SE=0.29 $
,
 $ df=72.50 $
,
$ df=72.50 $
,
 $ t=-4.06 $
,
$ t=-4.06 $
,
 $ p<0.001 $
; 18 months:
$ p<0.001 $
; 18 months:
 $ b=-0.71 $
,
$ b=-0.71 $
,
 $ SE=0.29 $
,
$ SE=0.29 $
,
 $ df=73.30 $
,
$ df=73.30 $
,
 $ t=-2.50 $
,
$ t=-2.50 $
,
 $ p=0.015 $
). When the infants were 8 months old, the same trend still appeared, but the register had only a marginal effect on this voice quality measure (
$ p=0.015 $
). When the infants were 8 months old, the same trend still appeared, but the register had only a marginal effect on this voice quality measure (
 $ b=-0.45 $
,
$ b=-0.45 $
,
 $ SE=0.29 $
,
$ SE=0.29 $
,
 $ df=71.20 $
,
$ df=71.20 $
,
 $ t=-1.58 $
,
$ t=-1.58 $
,
 $ p=0.120 $
). The detailed post hoc test results related to H1*–H2* values are available in Supplemental Materials. Based on the post hoc tests, all vowels except for /i/ showed higher H1*–H2* in IDS than in ADS, implying that most vowels were typically breathier in IDS. The infant’s age did not influence the values of the H1*–H2* measure, and the post hoc test revealed that neither within IDS nor ADS did the age (4, 8, and 18 months) affect voice quality. Furthermore, age had no notable impact on the voice quality of any specific vowel.
$ p=0.120 $
). The detailed post hoc test results related to H1*–H2* values are available in Supplemental Materials. Based on the post hoc tests, all vowels except for /i/ showed higher H1*–H2* in IDS than in ADS, implying that most vowels were typically breathier in IDS. The infant’s age did not influence the values of the H1*–H2* measure, and the post hoc test revealed that neither within IDS nor ADS did the age (4, 8, and 18 months) affect voice quality. Furthermore, age had no notable impact on the voice quality of any specific vowel.
The final linear mixed-effects regression model predicting H1*–H2* Regression model: H1*–H2*
 $ \sim $
Register + Age + Vowel + Register:Age Register:Vowel + Age:Vowel + (1 + Register+Age|Speaker), marginal
$ \sim $
Register + Age + Vowel + Register:Age Register:Vowel + Age:Vowel + (1 + Register+Age|Speaker), marginal
 $ {R}^2=0.09 $
, conditional
$ {R}^2=0.09 $
, conditional
 $ {R}^2=0.18 $
$ {R}^2=0.18 $

Note: ***: p < .001, **: p < .01, *: p < .05.
The analysis of the other spectral tilt measure, H1*–A1*, revealed a similar relationship between voice quality and register as the H1*–H2* measure (Table 3). The higher values of H1*–A1* in IDS (compared to ADS) indicate a breathier voice. The detailed results of the post hoc tests related to the H1*–A1* measure are reported in the Supplemental Materials. The test confirmed that this voice quality measure was systematically higher for most vowels in IDS than ADS, implying breathier voice production. Just as for H1*–H2*, the H1*–A1* values for the vowel /i/ were an exception and showed an opposite trend. The infant’s age did not affect either voice quality in general or the difference between the two registers. Moreover, the pairwise comparison within the realizations of each vowel also showed that age did not influence any of the vowels in this respect. To sum up, IDS was characterized by a breathier voice than ADS regardless of the infant’s age.
The final linear mixed-effects regression model predicting H1*–A1* Regression model: H1*–A1*
 $ \sim $
Register + Age + Vowel + Register:Vowel + Age:Vowel + (1 + Vowel+Age|Speaker), marginal
$ \sim $
Register + Age + Vowel + Register:Vowel + Age:Vowel + (1 + Vowel+Age|Speaker), marginal
 $ {R}^2=0.02 $
, conditional
$ {R}^2=0.02 $
, conditional
 $ {R}^2=0.17 $
$ {R}^2=0.17 $

Note: ***: p < .001, **: p < .01, *: p < .05.
We investigated the voice quality features of IDS not only with the spectral tilt measures (H1*–H2*, H1*–A1*) but also using CPP, which was introduced to quantify the periodicity of the signal. As expected, this measure also showed a difference between the two registers. The CPP values in IDS were generally lower than in ADS (Table 4), indicating that a less periodic voice was typical in this register, which is also a characteristic feature of breathy voice. The register, however, was found to interact with the vowel quality, but – as the pairwise tests revealed – this effect was clearly detectable only for the vowels /aː/ and /ɛ/. There, the CPP values were significantly lower in IDS than in ADS. The CPP values for the other vowels did not exhibit any significant register-specific differences (see the post hoc test results in the Supplementary Material). The infant’s age did not affect voice quality either in itself or in interaction with other factors; its inclusion as a parameter did not increase the model’s explanatory power, therefore, it was not incorporated into our final model. Generally, it can be concluded that, in terms of CPP, too, IDS showed the characteristics of a breathy voice, although this was not detectable in all vowels.
The final linear mixed-effects regression model predicting CPP Regression model: CPP
 $ \sim $
Register + Vowel + Vowel:Register + (1 + Age|Speaker), marginal
$ \sim $
Register + Vowel + Vowel:Register + (1 + Age|Speaker), marginal
 $ {R}^2=0.03 $
conditional
$ {R}^2=0.03 $
conditional
 $ {R}^2=0.22 $
$ {R}^2=0.22 $

Note: ***: p < .001, **: p < .01, *: p < .05.
We also addressed the question of whether the fundamental frequency of speech differs in the two registers, similarly to studies investigating other languages (Benders, Reference Benders2013; Narayan & McDermott, Reference Narayan and McDermott2016). The results showed that the fundamental frequency of the vowels was higher in IDS than in ADS (Table 5). However, the children’s age did not affect the fundamental frequency of vowels.
The final linear mixed-effects regression model predicting F0 Regression model: F0
 $ \sim $
Register + Age + Vowel + (1 + Age|Speaker), marginal
$ \sim $
Register + Age + Vowel + (1 + Age|Speaker), marginal
 $ {R}^2=0.04 $
, conditional
$ {R}^2=0.04 $
, conditional
 $ {R}^2=0.13 $
$ {R}^2=0.13 $

Note: ***: p < .001, **: p < .01, *: p < .05.
4. Discussion
IDS can be distinguished from ADS by its numerous known semantic and acoustic features (Genovese et al., Reference Genovese, Spinelli, Lauro, Aureli, Castelletti and Fasolo2020; Wang et al., Reference Wang, Houston and Seidl2018). In agreement with the literature (Hilton et al., Reference Hilton, Moser, Bertolo, Lee-Rubin, Amir, Bainbridge and Mehr2022; Kuhl et al., Reference Kuhl, Andruski, Chistovich, Chistovich, Kozhevnikova, Ryskina and Lacerda1997), our analysis has also confirmed that the fundamental frequencies in IDS tend to be higher than those in ADS. Recent studies have drawn attention to another defining and potentially ubiquitous feature of IDS, breathy voice quality (Cheng et al., Reference Cheng, McClay and Yeung2024; Chládková et al., Reference Chládková, Černá, Paillereau, Skarnitzl and Oceláková2019; Miyazawa et al., Reference Miyazawa, Shinya, Martin, Kikuchi and Mazuka2017). In our analyses, we investigated this relatively understudied property of IDS in Hungarian and evaluated whether and to what extent this feature changes as the infant ages.
Our results demonstrated that IDS typically exhibits a breathier voice than ADS, aligning with previous results on Canadian English-, Czech-, and Japanese-speaking mothers (Cheng et al., Reference Cheng, McClay and Yeung2024; Chládková et al., Reference Chládková, Černá, Paillereau, Skarnitzl and Oceláková2019; Miyazawa et al., Reference Miyazawa, Shinya, Martin, Kikuchi and Mazuka2017). To summarize, both spectral voice quality measures and those quantifying the periodicity of the phonation imply that Hungarian-speaking mothers also differentiate generally between the two registers in their voice quality. The cross-linguistic emergence of breathy voice in IDS may be motivated by several factors. First, when communicating with each other, people tend to adapt the characteristics of their speech to the other person (Bernhold & Giles, Reference Bernhold and Giles2020). Such speech and phonetic adaptation may be driven not only by the perceived acoustic cues in the situation but also by previous experiences or stereotypes. Indeed, some of the features of IDS (e.g., higher fundamental frequency, lower speech rate) are also typical traits of children’s speech (Payne et al., Reference Payne, Post, Astruc, Prieto and Vanrell2012; Zhang, Reference Zhang2021). Clearly, the presence of these features of IDS is motivated by numerous other factors as well, yet, in the case of voice quality, it is important to note that the children’s phonation is typically breathier than that of adults (Kent et al., Reference Kent, Eichhorn and Vorperian2021; Zhang, Reference Zhang2021). The acoustic differences in the fundamental frequency and voice quality can be derived from anatomical differences between adults and children, namely in vocal fold length and thickness (Zhang, Reference Zhang2021). These body size-dependent characteristics may also carry additional culture-specific meaning. In British English, women with breathier voices were perceived as happier and more attractive, and men with breathier voices were rated as friendlier and happier. (Noble & Xu, Reference Noble and Xu2011; Xu et al., Reference Xu, Lee, Wu, Liu and Birkholz2013). Certainly, the expression of emotions and the representation of personality traits through voice quality can be largely culture-dependent. In interpreting the present results, it is important to emphasize that Hungarian native speakers also tend to associate breathy voice with positive emotions (Bartók, Reference Bartók2018). While the use of breathy voice in IDS may serve to express positive emotions or reflect phonetic adaptation, it seems less likely that speakers would use breathy voice for a direct pedagogical purpose. However, the speaker’s change of register from ADS to IDS may also serve as a signal to children, indicating that relevant information will follow and is worthy of their attention. Thus, it cannot be ruled out that this attention-raising aspect of IDS may facilitate language acquisition (Senju & Csibra, Reference Senju and Csibra2008). Studies have shown that a happy sound produced with a breathy voice maintained an infant’s attention more than a happy sound with a modal voice or a neutral sound with any voice quality (Kao et al., Reference Kao, Sera and Zhang2022). This attention-maintaining function of breathy voice may, therefore, indirectly contribute to language development.
The acoustic features of IDS may be modified as the child ages; thus, we also investigated whether the breathiness of the voice changes with the infant’s age. Generally, our results indicated that child’s age – up to 18 months – had no effect on the mother’s voice quality. This is in agreement with the earlier results that even at 2 years, the voice quality difference between the two registers was clearly detectable (Miyazawa et al., Reference Miyazawa, Shinya, Martin, Kikuchi and Mazuka2017). Some acoustic features of IDS, such as speech rate and fundamental frequency, change in the first few years of a child’s life, while others, like vowel space area and
 $ {F}_0 $
variability, remain relatively stable (Cox et al., Reference Cox, Dideriksen, Keren-Portnoy, Roepstorff, Christiansen and Fusaroli2023). It appears that the breathy voice quality of Hungarian IDS belongs to the latter category, showing no detectable changes over the first 18 months. This implies that parents are, in a certain sense, motivated to maintain this feature of IDS. The need for continuous positive emotion expression or the constant phonetic adaptation can be the reason why the breathy voice remains a stable, permanent element of the IDS repertoire, regardless of the child’s age.
$ {F}_0 $
variability, remain relatively stable (Cox et al., Reference Cox, Dideriksen, Keren-Portnoy, Roepstorff, Christiansen and Fusaroli2023). It appears that the breathy voice quality of Hungarian IDS belongs to the latter category, showing no detectable changes over the first 18 months. This implies that parents are, in a certain sense, motivated to maintain this feature of IDS. The need for continuous positive emotion expression or the constant phonetic adaptation can be the reason why the breathy voice remains a stable, permanent element of the IDS repertoire, regardless of the child’s age.
5. Limitations and future directions
The research reported in the present study had several limitations, which may be worth extending and further investigating in the future. First, the results of our measurements indicated that the phonation of IDS is indeed characterized by a breathier voice, while the analyses also revealed differences between the various vowels. This is not surprising, given the fact that vowel quality largely influences the values of the studied voice quality measures, even though the spectral tilt measures are corrected for vowel formants (Garellek & Esposito, Reference Garellek and Esposito2023). In our material, the vowel /i/ was the one that occurred in the smallest number of phonetic contexts, so the investigation of further factors would not be feasible in more complex linear mixed models than those applied here. Previous literature on IDS has reported voice quality differences between vowels (Cheng et al., Reference Cheng, McClay and Yeung2024), but a detailed analysis of which vowels differ, in what contexts, and to what extent in the two registers is left for future targeted research. It should be noted that not all syllables in speech need to be breathy to create a certain general perception in the listener. Secondly, the voice quality measure related to the periodicity also did not exhibit a difference for all vowels between the two registers. Note that based on this particular measure (CPP) alone, creaky and breathy voices cannot be distinguished, as both of these voice quality types yield lower CPP values than modal voice. In Hungarian, it is known that certain prosodic and phonetic positions may trigger the emergence of creaky voice (Markó, Reference Markó2013; thus, these situations were excluded from our analyses. However, Hungarian has a rather large ratio of syllables pronounced with creaky voices for which we currently do not have an explanation (Gráczi et al., Reference Gráczi, Markó and Takács2017). This peculiarity of Hungarian may affect the interpretation of CPP-related results. Further research is needed to clarify how the rarely observed creaky voice in ADS is realized in IDS. Finally, this study investigated read sentences integrated into spontaneous storytelling. Future research should examine the voice quality of spontaneous IDS and compare the acoustic characteristics across different speech styles.
6. Conclusion
To conclude, this study revealed that Hungarian mothers’ speech addressed to their infants exhibits a breathier voice. These findings are in line with previous studies of Japanese, Canadian English, and Czech IDS (Cheng et al., Reference Cheng, McClay and Yeung2024; Chládková et al., Reference Chládková, Černá, Paillereau, Skarnitzl and Oceláková2019; Miyazawa et al., Reference Miyazawa, Shinya, Martin, Kikuchi and Mazuka2017). The breathy voice was found to be continuously present in the mothers’ IDS throughout the first 18 months of the infants’ age. The appearance of a breathy voice may be motivated by the mother’s phonetic adaptation to the child’s speech characteristics or by expressing positive emotions towards the child. Among the acoustic characteristics of IDS, voice quality is a relatively underexplored feature that can help increase and maintain the child’s attention. Whether and to what extent this function can also contribute to the child’s language development remains an open question for future research.
Abbreviations
- ADS
-
adult-directed speech
- IDS
-
infant-directed speech
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0305000926100506.
Acknowledgements
We would like to thank all the families who have contributed to this study. We gratefully acknowledge the work of Katalin Pirsel and Luca Garai, who contributed to the annotation of the sentences.
Funding statement
This study was supported by the Hungarian National Research, Development and Innovation Office (grants PD134775 and K115385), and by the János Bolyai Research Scholarship of the Hungarian Academy of Sciences (BO/160/25).
Competing interests
The authors declare no competing interests.






















 Open access
Open access