


1. Introduction
The present study reports the results of a corpus-linguistic investigation of modal particles (MPs) in spoken German, with the aim of exploring new ways to systematize and model their combinatorial behavior using quantitative methods. While there is considerable research on the question of how modal particles combine from a wide variety of perspectives (e.g. Thurmair Reference Thurmair1989, Abraham Reference Abraham, Vogel and Comrie2000, Coniglio Reference Coniglio2011, Müller Reference Müller2018a), existing studies employ mostly qualitative, impressionistic methods, so that a rigorous, quantitative study is still missing.
Modal particles in German are uninflected, mostly unstressed function words that occur in the so-called mid-field. They are syntactically optional, yet often pragmatically required. Their function is seen in the pragmatic realm as many of them manage the discourse context and/or modify the illocution of the sentence (see Thurmair Reference Thurmair1989:37 for an overview of their characteristics). It is a longstanding observation that MPs exhibit a tendency to combine with one another to form two-part and sometimes longer sequences. Examples of such sequences are given in (1) and (2) (examples from Thurmair Reference Thurmair1989:213, 228; MP sequences are underlined):
-
(1) Ich wasch das Gemüse. Du kannst ja mal die Zwiebeln schneiden.
‘I am cleaning the vegetables. You may MP1 MP2 chop the onions’
-
(2) Max: Ich hab meinem Freund Geld geliehen für seine Firma und jetzt ist er
pleite. Das Geld seh ich sicher nie mehr wieder.
Ute: Du bist eben auch zu gutmütig.
‘Max: I lent my friend money for his company and now he is broke. I will probably never see the money again.
Ute: You are MP1 MP2 too good-natured.’
In (1), the particle mal acts as an illocution-mitigating device. The illocution “directive,” which is indirectly expressed here via a declarative sentence containing the modal verb können, is downtoned by the insertion of mal. In addition, the particle ja adds the assumption that it is known to the addressee that carrying out the action is possible (see explanation by Thurmair Reference Thurmair1989:213). In (2) the particle auch signals that the event expressed in the first sentence was expected by the second speaker, Ute, and eben signals that her explanation (that he is too gutmütig ∼ ‘good-natured/soft’) should be evident also to the interlocutor Max (see Thurmair Reference Thurmair1989:228).
Sequences like ja mal or eben auch in (1) and (2) raise two obvious questions, both of which have caught the attention of the research community. The first is whether there is a particular order in which these modal particles occur with one another and how this order can be modeled and explained. Ordering biases have been widely observed in the literature. For example, the particle ja (as in (1)) seems to prefer the first position when occurring in sequence with other MPs (Thurmair Reference Thurmair1989:286). These biases have given rise to a number of proposals with regard to how the ordering behavior is best modeled. The second question is which MPs co-occur with which other ones and how probable and/or frequent specific combinations are. This question of co-occurrence has also received attention in the literature, albeit to a lesser degree than the ordering aspect. We detail the answers that have been proposed to these questions further below (in section 2). What is striking about the literature investigating these aspects of MP combinations is that, even though these questions lend themselves well to quantitative analysis, almost all studies investigate them using introspection and/or qualitative methods.
Probably the most widely cited study on MP combinations is the monograph by Thurmair (Reference Thurmair1989). Thurmair describes the combinatorial behavior of nineteen modal particles and arrives at a number of generalizations about their combinability and ordering. Her study is based on authentic language data, more specifically a self-compiled corpus containing around 2,000 MP sequences (Thurmair Reference Thurmair1991:23). However, the nature of the methodological approach to analyzing this corpus is not made fully transparent. It seems to rely on qualitative and impressionistic judgments such that individual combinations are judged to be possible or impossible, with no quantitative analysis in terms of analyzing the frequencies of MP combinations being reported. Another monograph-length contribution is Müller (Reference Müller2018a). While Müller discusses general aspects of modal particle combinations, the empirical contribution focuses on a limited selection of MPs, namely the co-occurrences of ja/doch, halt/eben, and doch/auch. In discussing these sequences, Müller (Reference Müller2018a) focuses on the ordering aspect and discusses to what extent combinations of the MPs mentioned are reversible. Müller employs a combination of quantitative and qualitative approaches to working with corpus data, but only occasionally reports frequencies of the relevant MP sequences. Other contributions to modeling the combinatorial behavior of MPs, such as Abraham (Reference Abraham, Vogel and Comrie2000), Kwon (Reference Kwon2005), and Coniglio (Reference Coniglio2011), are similarly qualitative in their empirical approach and do not present a fully explicit analysis of the data. For example, Coniglio (Reference Coniglio2011:94) explains that his analyses are based on a mix of corpus data, grammaticality judgments, and prior research without clearly stating an empirical methodology.
Despite the strong bias toward qualitative analyses, there are some notable exceptions. One is Braber & McLelland (Reference Braber and McLelland2010), who report corpus results for combinations of modal particles in German and Dutch. Based on a self-compiled corpus of spontaneous conversations, they arrive at a sample containing about 300 tokens of MP combinations. In terms of quantitative analysis, they list the raw frequencies of the combinations (see Braber & McLelland Reference Braber and McLelland2010: table 1) and compare it to assumptions put forward in the literature. However, they do not attempt to further systematize the frequency data acquired. Another quantitative, corpus-linguistic study is Lemnitzer (Reference Lemnitzer, Lehr, Kammerer, Konerding, Storrer, Thimm and Wolski2001), which is based on a self-compiled corpus of newspaper articles. Lemnitzer focuses on the question which MPs frequently co-occur and reports having assessed quantitatively the strength of the link between two MPs (“die Stärke der Verbindung beider Elemente einer Kombination,” Lemnitzer Reference Lemnitzer, Lehr, Kammerer, Konerding, Storrer, Thimm and Wolski2001:352), but without providing the numerical results of this analysis.Footnote 1 Another corpus-linguistic study is Gutzmann & Turgay (Reference Gutzmann and Turgay2015), who study the syntactic behavior of MPs, including their combinatorial behavior, based on a self-compiled conversational corpus. However, their dataset consists of only sixty MP sequences, thus precluding firm conclusions. Despite the limitations mentioned above, these quantitative studies are able to show that some assumptions of Thurmair’s (Reference Thurmair1989) impressionistic analysis are borne out by their data while others are not. For example, Thurmair (Reference Thurmair1989:278–279) posits that the MP denn always occurs in first position when being combined with another MP (except for the combination with ja). In contrast, the quantitative analysis by Braber & McLelland (Reference Braber and McLelland2010:468) yields a number of hits of denn occurring in second position, specifically following halt and eben. A further example is that, based on quantitative analysis, Lemnitzer (Reference Lemnitzer, Lehr, Kammerer, Konerding, Storrer, Thimm and Wolski2001:364) reports that the sequence denn schon occurs frequently in declarative sentences, although in Thurmair’s (Reference Thurmair1989:235) account it is restricted to questions. While initial results such as these show the potential of a corpus-based, quantitative approach, previous corpus-linguistic studies did not explicitly address the question of modeling the combinatorial behavior of MPs based on quantitative analysis. It is this aim that we pursue in the present article. More specifically, we aim to investigate the questions of ordering and co-occurrence of modal particles based on a corpus-based, quantitative analysis of German modal particle sequences employing a representative sample from a speech corpus. In doing so we suggest new ways to systematize and model the combinatorial behavior of modal particles with regard to the aforementioned aspects. We do so by developing ordering models that are inductively developed from our data via statistical methods, before using quantitative methods to address the co-occurrence aspect. Finally, we suggest a way to integrate both aspects via the visualization method of a “directed graph.”
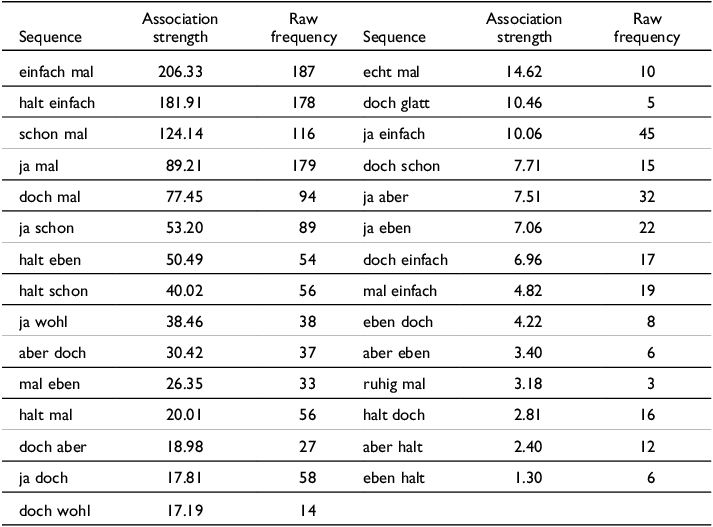
Attracted sequences in declarative sentences (statistically significant associations at p < 0.05 with a frequency of ≥ 3)

In the following, we first review prior attempts at modeling the combinatorial behavior of MPs in the literature and explain how we aim to contribute to these (section 2). We then explain which corpus we used and how data were extracted from it, as well as the methodological approaches employed (section 3). In section 4, we report the results of our analysis. We first report observed frequencies, before developing ordering models, and then addressing the question of co-occurrence, before finally moving on to a solution that integrates both aspects. In section 5 we discuss to what extent our findings tie in or contrast with prior research. Furthermore, we point out how the results may open up further perspectives on several longstanding questions regarding MP combinations, such as the question of reversibility and the question whether MP sequences can have a noncompositional function. Section 6 offers a conclusion and an outlook.
2. Attempts to systematize and model MP ordering and co-occurrence
In this section we provide an overview of suggestions made in the literature with regard to systematically analyzing the ordering and co-occurrence aspects of MP combinations. We start with the question of ordering, as this question has received more attention in prior research. Based on observations that the ordering of modal particles is not random, attempts to systematize ordering biases have been made. Most of these take the form of group or layering models, in which the modal particles are put into different groups that occur in a fixed order (see Müller Reference Müller2018a:11-20 for a good overview of the group models suggested). Interestingly, similar group/layering models have been suggested for extraclausal elements in other languages, for example, for the ordering of French turn-initial discourse particles (Vicher & Sankoff Reference Vicher and Sankoff1989), or the ordering of English sentence-initial discourse markers (Tagliamonte Reference Tagliamonte2016).
The first such model for MPs was suggested by Engel (Reference Engel and Moser1968). However, Engel did not clearly distinguish between adverbs and modal particles (see also Müller Reference Müller2018a:11). A widely cited model, explicitly geared toward the ordering of MPs, is the one by Helbig (Reference Helbig1994:75), which we illustrate here. The model by Helbig groups modal particles into six groups (a–f):
-
(a) denn, doch (unstressed), eigentlich, etwa, ja
-
(b) aber, eben, halt, vielleicht, wohl
-
(c) doch (stressed), schon
-
(d) auch, mal
-
(e) bloss, nur
-
(f) noch
The predictions of this model are that in combining MPs of different groups, their order will always adhere to the groups’ alphabetical ordering (a–f). It is not made clear how this grouping was developed, which suggests that it is based on native-speaker intuition. A second suggestion similarly involving groups of MPs and resting on the same ordering logic can be found in Thurmair (Reference Thurmair1991:33):

Thurmair’s (Reference Thurmair1991) grouping model is based on functional/syntactic motivations, such that each group contains particles that share a grammatical function with a different part of speech. According to Thurmair (Reference Thurmair1991), aber, denn, and doch are in one group, because these forms are also used as conjunctions, while einfach, schon, and mal, which function also as adverbs, are in a different group. A similar argument for the linear order of MPs can be found in Abraham (Reference Abraham, Vogel and Comrie2000), who applies the concept of grammaticalization to the historical emergence of MPs. He explains the order of MPs via their individual grammaticalization histories. We revisit this explanation in the discussion of our own results in section 5.2.
The structure of group models is appealing, as it suggests that the ordering behavior of individual MPs is characterized by systematic similarities that allow them to be assigned to groups. However, it is important to note that the models suggested are not based on transparent empirical analysis, nor have they been empirically validated. Furthermore, group models suffer from two architectural weaknesses: The first is that no clear predictions are made for MP combinations in which the two MPs belong to the same group. As stated by Thurmair (Reference Thurmair1991:31), “sequences of elements from one and the same group are not accounted for.” Müller (Reference Müller2018a:15) comments on this point and provides examples showing that the ordering of MPs within a group may also be restricted (Müller Reference Müller2018a:15–16). However, the scope or size of this issue still awaits empirical investigation. The second shortcoming of group models is that they automatically make wrong predictions when the order of two MPs belonging to different groups is reversible. An example is the arguably reversible combination of auch and mal, which are in two different groups in the model by Thurmair (Reference Thurmair1991) (example from Helbig & Kötz Reference Helbig and Kötz1981:42, as discussed in Müller Reference Müller2018a: 15). Apart from the statement by Müller (Reference Müller2018a:15) that these cases “seem rare,” this shortcoming of the models has not been empirically investigated or quantified. In sum, while the two mentioned aspects are obvious weaknesses of group models, it is so far unclear how serious these are in a quantitative sense. We aim to fill that gap by demonstrating how to develop a group model from corpus data via cluster analysis and assess its empirical accuracy in accounting for the ordering of MPs.
An alternative to the group-based modeling architecture discussed above can be found in Coniglio (Reference Coniglio2011), who presents an ordering hierarchy for individual modal particles. This hierarchy is simply a vector of all MPs, listed in a particular order from left to right, that is, MP1, MP2, MP3, … MPn. The prediction of this ordering hierarchy is that any MP should precede all MPs to the right and follow all MPs to the left in the hierarchy (see Koops & Lohmann Reference Koops and Lohmann2015, Lohmann & Koops Reference Lohmann, Koops, Kaltenböck, Keizer and Lohmann2016 for a similar suggestion on the phenomenon of English discourse markers). No grouping of MPs is assumed in this model.Footnote 2 We provide here the ordering hierarchy suggested by Coniglio (Reference Coniglio2011:94) for declarative sentences:Footnote 3
ja > denn > doch > halt/eben> wohl >…> DOCH > schon > mal
The advantage of this architecture is that it makes predictions for the ordering of all MPs that are part of the hierarchy, while group models do not make predictions for within-group sequences. The obvious disadvantage is that similarities in the ordering behavior of certain MPs that are captured by group models are disregarded by this simpler architecture. A further weakness is that hierarchies, just like group models, do not allow for reversals, that is, cases in which two particles occur in both possible orders.
We now move on to the question of co-occurrence, that is, the question of which MPs exhibit a tendency to combine with others. While the questions of ordering and co-occurrence are obviously related, given that MPs that co-occur do so in a particular order, it is important to note that the two can be investigated separately. This becomes clear when assessing the group models discussed above, as these focus on the order in which MPs occur relative to one another, but neglect the question which MPs are more or less likely to combine with one another. What we may deduce from the models suggested is that it is typically MPs from two different groups that are combined. However, interpreting the models in this way results in a massive overgeneralization of the co-occurrence behavior of MPs, as the models allow for all MPs to combine as long as the left-to-right order is adhered to. For example, while Thurmair’s (Reference Thurmair1991) group model allows for 114 different sequences, only a subset of these sequences seems to occur in her data, as she states in her previous publication that only fifty combinations are used (Thurmair Reference Thurmair1989:282). Hence, most sequences that are ‘possible’ do not actually occur. The upshot of these observations is that while overall there seems to be a tendency for MPs to combine, the mutual links between individual MPs may vary, resulting in possible and impossible, or likely and less likely sequences of modal particles.
The question of co-occurrence is explicitly addressed in some publications. Thurmair lists the possible MP combinations in different sentence types (Thurmair Reference Thurmair1989:282) and in a later publication (Thurmair Reference Thurmair1991:33) she provides a list of the “frequently occurring” combinations. For example, according to her analysis, 13 MP combinations are frequent in declarative sentences, which is a subset of the 24 “possible” sequences (see Thurmair Reference Thurmair1989:282). Similarly, Abraham (Reference Abraham, Vogel and Comrie2000:340) provides a table of acceptable, unacceptable, and dubious combinations in imperative sentences in the form of a table. Kwon (Reference Kwon2005:196) lists “possible” combinations for questions and declarative sentences. While the lists/tables by Thurmair (Reference Thurmair1989), Abraham (Reference Abraham, Vogel and Comrie2000), and Kwon (Reference Kwon2005) address the question of co-occurrence, it is not always clear how the results were arrived at. Kwon (Reference Kwon2005) mentions listing those sequences that are attested in his corpus, while Thurmair (Reference Thurmair1989, Reference Thurmair1991) and Abraham (Reference Abraham, Vogel and Comrie2000) do not report their methodological approach. None of these studies reports corpus frequencies. A further study investigating MP co-occurrence is Lemnitzer (Reference Lemnitzer, Lehr, Kammerer, Konerding, Storrer, Thimm and Wolski2001), who aims to identify MP “collocations” via corpus-linguistic analysis. He lists a number of combinations thus identified; yet, as mentioned above, it is not clear if and how the frequency or likelihood to co-occur was calculated as no quantitative information is given. To our knowledge, the only studies that provide frequency information on individual sequences, and in this sense address the question of co-occurrence in a quantitative fashion, are Braber & McLelland (Reference Braber and McLelland2010) and Gutzmann & Turgay (Reference Gutzmann and Turgay2015). The authors provide lists of raw frequencies, which thus indicate which MPs tend to form frequent sequences. However, these corpus studies also suffer from certain shortcomings: Gutzmann & Turgay (Reference Gutzmann and Turgay2015) detect only sixty MP sequences, their data sample is thus severely limited. Braber & McLelland (Reference Braber and McLelland2010) employ a larger corpus; however, by being restricted to interviews conducted in Berlin in the early 1990s on just one topic, this corpus is representative of only one variety and genre. Furthermore, neither of these two studies carries out analyses to quantify the strength of the link between co-occurring modal particles.
In summary, only small steps have been taken toward quantifying the co-occurrence tendencies in MP combinations, with most studies merely stating which combinations are possible or impossible. We aim to contribute to the investigation of the co-occurrence question by employing a test of statistical significance and an association score to identify probable and attracted sequences. Beyond addressing the question of how to investigate quantitatively the ordering as well as the co-occurrence question, we also propose an approach that integrates the two aspects. While it is possible to investigate ordering and co-occurrence separately, it is obvious that these two concepts are aspects of the same overall phenomenon of MP combinations, and it is usually the case that both are of interest to the researcher. It would therefore be desirable to develop a systematic form of presentation that captures both aspects at the same time. Such an integration is made possible via the method of a directed graph, which has been used in previous research on the combinatorial behavior of English discourse markers (Lohmann & Koops Reference Lohmann, Koops, Kaltenböck, Keizer and Lohmann2016), and which we apply to modal particles in this article.
3. Data and methodFootnote 4
3.1 Data extraction and filtering
In order to acquire a representative sample of modal particle use, we aimed for a large, balanced corpus of German speech. We decided to work with the FOLK corpus, a web-accessible corpus designed as a reference corpus for spoken German (Reineke Reference Reineke, Deppermann, Schmidt, Deppermann, Fandrych, Kupietz and Schmidt2023). The corpus is continuously updated and currently contains more than 400 conversations involving more than 1,300 speakers (see IDS 2024). Footnote 5 It is a stratified corpus that seeks to balance various demographic criteria of the speakers, that is, their age, educational background, variety spoken, as well as contextual variables such as the formality of the context (see Kaiser Reference Kaiser2018 for more information). The corpus is POS-annotated and contains a tag for modal particles that we used for data extraction. We retrieved the combinations of modal particles from the corpus in the time period August 16–23, 2023, by accessing the corpus interface of the Datenbank für gesprochenes Deutsch (IDS 2024). More specifically, we employed the CQP search interface ZuRecht, which allows POS-specific searches. Using the part-of-speech tag for modal particles (PTKMA), we performed a lemma search for all combinations occurring in the corpus in a two-step fashion: First we carried out a POS-search for two adjacent modal particles and created a lemma-specific overview of all combinations occurring in the corpus, that is, a type list of MP sequences. This step resulted in 116 combinations, featuring 20 individual MP types. These are:
einfach, mal, ja, schon, doch, halt, eben, wohl, aber, überhaupt, fei, nur, glatt, ruhig, denn, bloß, wirklich, echt, ausgerechnet, auch
From these 116 combinations we excluded repetitions of the same particle, for example, halt halt, as these may instantiate erroneously produced sequences. We then created concordances for the remaining 108 combinations and extracted them from the corpus, for example, separate concordances for ja mal as well as eben halt, etc. The 108 combinations instantiate 3,294 tokens that were further analyzed.
The POS-tagging in the FOLK corpus is based on an automatized tagging procedure, developed by Westpfahl et al. (Reference Westpfahl, Schmidt, Jonietz and Borlinghaus2017) and Westpfahl (Reference Westpfahl2020). The tag PTKMA captures so-called “Modal- und Abtönungspartikeln,” many of which contain homonymic counterparts in other word classes, mostly adverbs. The modal particles can be distinguished from these other word classes, as they occur in the mid-field and cannot be moved out of position (see tagging guidelines in Westpfahl et al. Reference Westpfahl, Schmidt, Jonietz and Borlinghaus2017). While this distinction is built into the tagging-procedure, it is not error-proof (see discussion in Westpfahl Reference Westpfahl2020), which is why we performed extensive manual filtering and coding of the data in order to exclude false hits. This filtering process involved the following steps: We excluded datapoints in cases where the MP sequence did not occur in the mid-field. Sequences occurring in incomplete utterances were excluded whenever it was not possible to determine the syntactic position of the sequence. Furthermore, we excluded occurrences of MP sequences in case one of the two particles clearly instantiated a different syntactic category. An example is the temporal adverbial use of eben, meaning ‘just now’. We furthermore coded the data with regard to a number of variables: We coded which sentence type the sequence occurs in and distinguish declarative sentences, polar questions, Wh-questions, imperatives, and exclamatives, as well as subordinate clauses, following the classification proposed in Thurmair (Reference Thurmair1989, Reference Thurmair1991).Footnote 6 We also coded whether additional MPs occurred adjacent to the two-part sequence. Of the 3,294 datapoints retrieved, 2,832 datapoints are sequences of two potential MPs, of which 2,115 datapoints were judged to instantiate proper MP combinations. While sequences longer than two MPs are interesting in their own right (255 tokens in our data), we focus solely on the two-part sequences, as longer sequences may exhibit distinct combinatorial behavior that cannot be reduced to the patterns found in two-part sequences and thereby pose complex empirical challenges. Of the 2,115 two-MP sequences, 1,567 tokens occurred in declarative sentences, 264 in imperatives, 254 in subordinate clauses, with 30 tokens distributed across the remaining sentence types. Given that the distribution and combinatorial behavior have been shown to be sensitive to sentence type (see e.g. Thurmair Reference Thurmair1989:48–49), lumping together different sentence types means glossing over potentially important patterns in the data. Therefore, most analyses reported in the following are based on the subsample of declarative sentences, as this is the sentence type containing the bulk of MP sequences in our data (see Kwon Reference Kwon2005:195 for a corresponding observation).
3.2 Methods employed
We carried out a number of quantitative analyses in order to address both the ordering and the co-occurrence question. In a first step, we simply counted the number of attested sequences and compared the result to the number of theoretically possible sequences. In addition, we checked how many sequences occur in both orders, so as to obtain a first idea of the aspect of reversibility.
In order to address the question of ordering, we pursued a multistep empirical approach to develop a group model that may capture the ordering tendencies in the data. In doing so, we focus on the subsample of declarative sentences. To that end, we calculated for every combination of particles a proportion that expresses that combination’s ordering preference, based on the frequencies of the two alternative orders. For example, in declarative sentences halt mal occurs 53 times in our sample, while the reverse ordering mal halt occurs only 3 times. Hence, halt mal is strongly preferred over mal halt. The proportions of the two sequences were calculated by dividing the frequency of each alternative order by the summed frequencies of both orders. Applied to the present example, this results in an ordering proportion of 53/56=0.946 for halt mal and 3/56=0.054 for mal halt, expressing the observation that in case of co-occurrence of these two particles, there is a strong tendency to place halt in first position. We calculated these proportions for all combinations of the sixteen modal particles attested in the subsample of declarative sentences (see section 4.1 for this subset of modal particles). In a second step, we created lists based on these ordering proportions for each individual MP. These lists contain all ordering proportions of an MP in all sequences featuring it in first position.Footnote 7 Thus, the lists express the overall ordering profile of a given MP. For instance, when a modal particle has a strong bias toward occurring in first position, the corresponding list consists of many proportions close to 1, while a bias toward second position should result in a list with many values close to 0. For unattested combinations we entered an ordering proportion of 0.5, which expresses an undecided positional bias.Footnote 8 These lists were then entered as vectors into R (R Core team 2024). We then combined these vectors to form a matrix of ordering proportions and calculated the Euclidean distance between all MPs in a pairwise fashion. This distance value expresses how similar or dissimilar a given pair of two MPs is with regard to the MPs’ positional biases when occurring in sequence with other MPs. In order to identify groups in the data that are similar with regard to their ordering behavior, we carried out a cluster analysis in R. To that end, we calculated a hierarchical cluster analysis based on the distance matrix by employing the hclust command of the stats package in R. In order to arrive at the most suitable clustering method we tested the options “complete,” “single,” “average,” “ward” (see Levshina Reference Levshina2015: ch. 15 for a discussion of these clustering options). To decide between the different methods, we calculated the agglomerative coefficient using the coef.hclust function of the cluster package in R, with higher values more accurately reflecting the structure in the data. We found that the ward method (as implemented in hclust via ward.D2) was characterized by the highest coefficient. In order to find a number of clusters that is well motivated by the data, we then calculated the average silhouette width for different numbers of clusters. The output of this calculation expresses how “well-formed” a given cluster solution is, in the sense of expressing the degree to which datapoints inside a cluster are similar to one another, while being dissimilar to datapoints in other clusters (see also Levshina Reference Levshina2015:311).
To put the groups into an ordered sequence, we combined the ordering vectors of all MPs contained in the individual clusters and calculated for each cluster its mean ordering proportion. We then ordered the groups by their mean ordering proportion in descending order and assessed the predictive accuracy of the cluster solution by testing which share of the data is correctly predicted by it. In a further step, we developed an ordering hierarchy based on the ordering proportions of the individual MPs, similar to the hierarchies suggested in the literature. This was achieved by simply ranking all sixteen MPs by their mean ordering proportions in descending order. This ordering hierarchy was also assessed with regard to its predictive accuracy.
In order to investigate the question of co-occurrence, we carried out a quantitative analysis that allows us to measure the strength of the link between any two MPs in our data. To do so, we first calculated a Fisher-exact test as described in Evert (Reference Evert2004) to test whether any combination of modal particles occurred statistically significantly (at p<0.05) more or less frequently than expected by chance. The test allows us to identify attracted sequences, which are those occurring more frequently than expected by chance, as well as repelled sequences, which are those occurring less frequently than expected by chance.Footnote 9 We then log-transformed the p-value of this calculation as a measure of association strength (using the equation -log10(p); see Evert Reference Evert2004:111, Baroni & Evert Reference Baroni and Evert2010). Beyond this being an established approach to investigate collocational strength, it fulfills two criteria we consider important in the present context. First, the association strength thus calculated is a symmetrical measure, that is, the association strength does not differ depending on whether we focus on the first or the second MP of a given combination. Second, the Fisher-exact test can deal with small frequencies (unlike, for example, chi-square).Footnote 10
As indicated above, in an additional analysis we aim to integrate the aspects of co-occurrence and ordering. To that end we used the methodological approach of directed graphs using the GraphViz resource (Gansner et al. Reference Gansner, North and Vo1993, Ellson et al. Reference Ellson, Gansner, Koutsofios, North, Woodhull and Jünger2004),Footnote 11 which we previously employed to illustrate the combinatorial relations of English utterance-initial discourse markers (Lohmann & Koops Reference Lohmann, Koops, Kaltenböck, Keizer and Lohmann2016). As input, we provided the statistically significantly attracted sequences which we identified in the previous step and treated them as directional connections between two MPs employing the graph-drawing algorithm dot of GraphViz (Gansner et al. Reference Gansner, North and Vo1993). Basing the graph on the output of our analysis of association strengths between MPs while adding the directionality of the connection allows us to integrate both the ordering and the co-occurrence aspect.
4. Results
In our data of 2,115 MP sequences we find 88 distinct combinations featuring 19 individual modal particles (the potential MP ausgerechnet was not found to instantiate a proper MP sequence in our data). When considering the two different orders in which any two elements may be combined, the number of possible combinations with 19 elements is 342. A first observation, therefore, is that only 25.7 percent of all possible combinations occur in the data. While any interpretation based on a limited sample needs to take into account that unattested sequences may be a result of working with sparse data, the finding nevertheless suggests that the co-occurrence of modal particles is not random and that there are strong combinatorial restrictions. Interestingly, this proportion closely corresponds to the one reported in Thurmair (Reference Thurmair1989:280), who states that only 50 out of 171 possible combinations (29.2 percent) occurred in her dataset.Footnote 12 Focusing on the subsample of declarative sentences shows that here it is 16 distinct modal particles featuring in 73 different combinations out of 240 possible ones (30.4 percent).Footnote 13 Of these, 31 are combinations for which only one order of elements is attested, while the remaining 42 are sequences whose reversal is attested at least once in our data. In further analyzing the combinatorial behavior within our sample, we focus on declarative sentences, which make up the bulk of data in our sample (1,567 of 2,115 tokens); see also section 3 above. For the sake of clarity, we repeat here the list of twenty modal particles that were used for the initial corpus searches with the sixteen MPs forming the set occurring in declarative sentences marked in boldface.
einfach, mal, ja, schon, doch, halt, eben, wohl, aber, überhaupt, fei, nur, glatt, ruhig, denn, bloß, wirklich, echt, ausgerechnet, auch
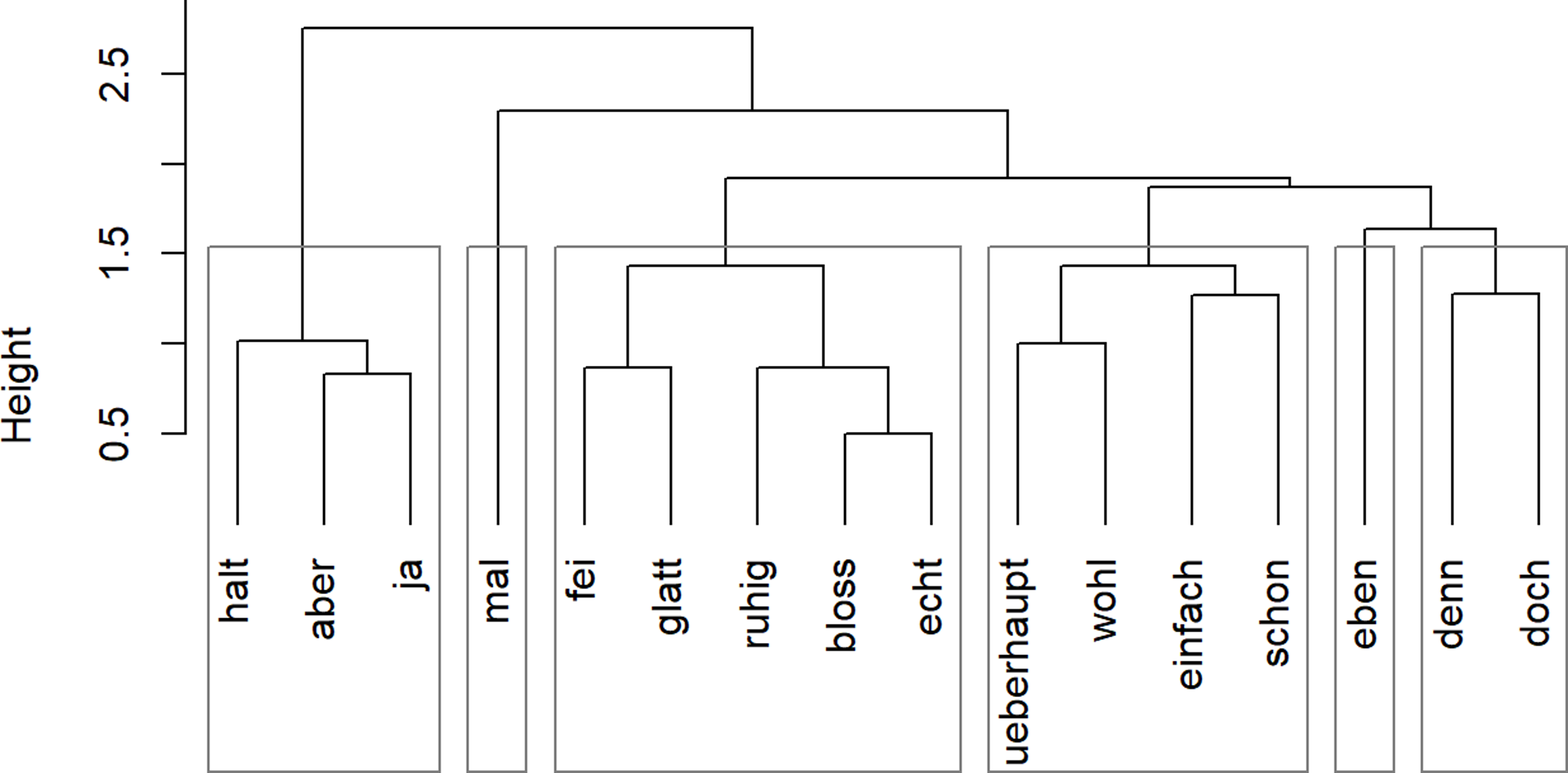
Based on these results, we address first the question of MP ordering. To that end we develop both a group model and an ordering hierarchy (see section 2) in a data-driven fashion. For the group model, we followed the methodological approach described in section 3.2.1, resulting in a clustering solution employing the “ward” agglomeration method. We inspected the silhouette width for different numbers of clusters. We found that the highest values are obtained for solutions with 2, 3, and 6 clusters. Since having only two or three groups introduces rather little structure to the data, and since having six groups corresponds fairly closely to group models put forward in the literature, we further pursue the analysis with this six-group solution. Figure 1 visualizes the cluster dendrogram highlighting the six clusters.
Dendrogram of cluster analysis based on ordering proportions (using the hclust function in R, method = ward.D2).

The dendrogram visualizing the different clusters indicates the grouping structure in the data. For example, we see that the cluster to the left contains the MPs ja, aber, and halt, while mal and eben feature in clusters of their own. We then ordered the clusters with regard to mean ordering proportion from highest (left) to lowest (right). The outcome of that ordering procedure is shown in the following (groups are separated by the > symbol):
ja, aber, halt > denn, doch > ruhig, bloss, echt, fei, glatt > eben > einfach, schon, überhaupt, wohl > mal
Inspecting the extreme ends of the scale, we see that ja, aber, and halt have a strong preference for occurring in first position, while mal has a strong bias to occur in second position. The other groups are positioned in between. We assessed the group model’s predictive accuracy by noting for each datapoint whether it was in accordance with the predictions of the model or violated it. MP sequences that involve two particles from the same group were coded as “not predicted/same group.” We find that of the 1,567 sequences in our data, 1,341 or 85.6 percent adhere to the ordering as gleaned from the group model, while 124 (7.9 percent) violate the predicted order. There are 102 (6.5 percent) same-group sequences for which the mode makes no predictions. A close inspection of the cases that violate the order shows that almost all of these sequences are ones that occur in both orders in our data (18 out of 22). The most frequent “violating” sequences are mal eben, doch aber, and mal einfach, all of which occur in both orders in our data. Thus, the model’s less-than-optimal performance is to a large extent due to its inability to capture the aspect of reversibility (see the discussion in section 2). The 102 tokens for which it does not make predictions are to a large extent due to same-group membership in the leftmost group, consisting of ja, aber, and halt, as these three MPs combine with one another fairly frequently, in particular in the sequences ja aber and ja halt. In summary, the group model that we arrived at in a bottom-up, data-driven fashion is able to predict MP ordering correctly for a fairly large share of the data. The less-than-optimal performance is due to it not being able to capture the aspect of reversibility in the data, as well as the combination of two MPs that are in the same group.
In addition to the group model, we also calculated a one-dimensional ordering hierarchy based on ordering proportions, which we provide here:
ja > halt > aber > echt > doch > denn > bloss, fei > überhaupt > ruhig > glatt,wohl > eben > einfach > schon > malFootnote 14
This ordering hierarchy accounts for 1,404/1,567 or 89.6 percent of the data, with 10.4 percent of the data violating the ordering hierarchy. Comparing the hierarchy with the group models, we are faced with a trade-off between the amount of violations and the amount of cases for which no prediction is made. While the hierarchy makes a prediction for every sequence in the data, a larger share of these predictions is wrong compared to the group model. Similar to the group model, the violations of the hierarchy are caused mostly by reversible sequences, as of the 25 sequences that occur in the data and constitute violations, 21 occur in both orders.
In order to address the question of co-occurrence, we carried out a quantitative analysis that identifies the statistically significantly attracted sequences along with their strength of association. This approach allows us to identify preferred combinations as well as to measure the linkage strength between any pair of MPs. The calculation of the Fisher-exact test reveals that of the 73 attested sequences in declarative sentences, 34 are statistically significantly attracted sequences, while 4 sequences were found to be statistically significantly repelled. In order to provide an overview, in table 1 we list the 29 attracted sequences that have a frequency in the data of at least three occurrences, so as to avoid putting too much emphasis on cases that are only rarely attested in the data. The table displays the raw observed frequency of the sequence and as a measure of association strength the log-transformed p-value of the Fisher-exact test.
Ordering the sequences by association strength shows that frequency and association strength are strongly correlated (Spearman’s rank correlation coefficient rho = 0.86, p<0.001). However, the two measures do not result in the exact same rank order. While at the top end of the table we find sequences with high association scores and high raw frequencies, when moving down the list differences can be observed, with sequences that are fairly frequent but only attracted to a moderate extent. Furthermore, there are sequences that occur in the data but are not associated with one another to a statistically significant degree (not displayed in the table). Among these are also sequences that are fairly frequent, namely ja halt and aber ja, which occur 19 and 13 times in the data, respectively. Since the individual frequencies of the particles occurring in these combinations are fairly high, these sequences’ frequencies are not sufficient to result in a statistically significant attraction. A further noteworthy result is that some reversals can be found in table 1, as with einfach and mal, halt and eben, and aber and doch both orders are significantly attracted sequences. In the following, we integrate the aspects of ordering and association by visualizing the network of combinatorial relationships between modal particles in the form of a directed graph. The graph-drawing algorithm dot (Gansner et al. Reference Gansner, North and Vo1993), which we employed, aims to draw a graph with short links between connected elements and with links pointing in the same overall direction. It may therefore visually reveal structure in the data that is not easily read off the purely numerically presented output.
In figure 2 we present a directed graph that is based on the significantly attracted sequences listed in table 1, thus taking into account the co-occurrence/association aspect. By visualizing the connections between MPs via directed arrows, the graph takes into account the ordering aspect. The MPs are visualized via nodes (ovals), with combinations of two MPs being visualized via arrows between them. Consequently, particles that occur in many attracted sequences have many arrows connecting them with other particles. We implemented bidirectional arrows to signal that both orders of the two MPs instantiate statistically significantly attracted sequences.
A directed graph of MP sequences (based on statistically significantly attracted sequences, gray arrows indicate unidirectional connections, black arrows indicate bidirectional connections).

5. Discussion
In the following we discuss the results and the theoretical implications of the empirical analysis. We do so by first comparing our results against findings and modeling solutions reported in prior research (in section 5.1) before moving on to a discussion of how the findings may contribute to a number of pertinent questions in research on modal particle combinations: First, we discuss MP ordering from a grammaticalization perspective and explore the account of MP ordering patterns possibly reflecting different grammaticalization histories (section 5.2). Then, we move on to the questions of reversibility (in section 5.3) and compositional meaning (in section 5.4).
5.1 Comparing the results to prior findings
We begin the discussion of the results by comparing the group model we developed via cluster analysis to similar models suggested in the literature. This brings out some similarities as well as differences. First of all, with six groups, the present group model contains a similar number of groups to the ones suggested in the literature, as Thurmair’s (Reference Thurmair1991) model features five groups, while Engel’s (Reference Engel and Moser1968) and Helbig’s (Reference Helbig1994) models each feature six groups. Comparing which MPs are grouped together across models is limited by the fact that the particles we analyzed do not correspond exactly to the sets in the literature. Still, some interesting commonalities can be detected. The modal particles ja, denn, and doch feature in the first, leftmost group in the models proposed by Engel (Reference Engel and Moser1968), Helbig (Reference Helbig1994), and Thurmair (Reference Thurmair1991) and can be found in the first two groups in our model. Aber is in the first group in the model by Thurmair (Reference Thurmair1991), likewise occurring in the first group in our model. Schon, einfach, and mal are grouped in the rightmost group in Thurmair (Reference Thurmair1991) and occur in the two rightmost groups in our solution. With mal in its own cluster following the one containing schon, our model corresponds more closely to Helbig’s (Reference Helbig1994) proposal, which also features the MP in a group (d) following the one containing schon (c). However, in Helbig (Reference Helbig1994) mal is followed by a group containing bloss, which in our model occupies a middle position. Quantifying the predictive accuracy of the model arrived at via cluster analysis shows that it is able to account for a large share of the data, which somewhat supports this model design. The two shortcomings of group models discussed above turn out to result in a relatively small share of datapoints that are not correctly predicted. The first shortcoming, namely, that the model makes no predictions for MPs in the same group, turns out to affect only a quantitatively modest share of 6.5 percent of the data. The share of datapoints clearly violating the model is 7.9 percent. This is mostly due to the inability of the model to capture reversible sequences. The alternative, modeling order via an ordering hierarchy, which is less popular in the literature, results in 10.4 percent violations, most of which are reversible sequences for which only one order is predicted by the hierarchy. We take up the aspect of reversibility again below (see section 5.4)
Our empirical analysis investigated the co-occurrence probability and association strength of MPs occurring in sequence. As mentioned above, in prior research the likelihood of certain sequences to be formed via the co-occurrence of individual particles had been judged mostly via intuition or impressionistic observation. One example of a study that mentions which combinations are frequent and that lists frequent sequences in declarative sentences is Thurmair (Reference Thurmair1991), which therefore lends itself to being compared to our results. Thurmair (Reference Thurmair1991) finds that the particle ja is particularly prone to featuring in MP combinations: Of the 13 frequently occurring sequences in Thurmair (Reference Thurmair1991:33), 5 feature ja. This observation corresponds to our findings in which seven sequences featuring ja are significantly attracted sequences (see table 1). A similar correspondence concerns the modal particle mal, as Thurmair (Reference Thurmair1991:33) lists three combinations with mal as frequently occurring, namely, ja mal, doch mal, and ruhig mal, all of which feature in table 1. Overall, Thurmair (Reference Thurmair1991:33) lists 13 combinations as frequently occurring in declarative sentences, of which 8 are significantly attracted in our dataset, these being ja mal, ja schon, ja wohl, halt eben, doch schon, doch mal, ruhig mal, doch wohl. In addition to Thurmair’s observations, we find a number of other attracted combinations, as the number of attracted sequences in our data is 34. In sum, we observe a sizable overlap between our quantitative findings and Thurmair’s (Reference Thurmair1989, Reference Thurmair1991) observations. At the same time, our quantitative approach is able to detect sequences overlooked via the more intuitive approach in her research. We may also compare our results to the frequencies of MP sequences observed in the two quantitative corpus studies that list occurrence frequencies, namely Braber & McLelland (Reference Braber and McLelland2010) and Gutzmann & Turgay (Reference Gutzmann and Turgay2015). Interestingly, the one MP sequence that occurs with a reasonably high frequency in Gutzmann & Turgay’s corpus (2015), einfach mal, is also the most frequent and the most strongly attracted one in our data. A comparison with the frequencies obtained by Braber & McLelland (Reference Braber and McLelland2010) reveals more differences than similarities: The top three sequences in terms of frequency in their data are eben auch, eben halt, and eben doch. Of these, eben doch and eben halt are statistically significantly attracted sequences. However, they are ranked only in 24th and 29th place, respectively. These differences may be explained by the fact that the analysis by Braber & McLelland is based on a highly specialized corpus in terms of region and genre. It is therefore not a big surprise that the present results contrast with their findings and correspond more closely to Thurmair’s findings, as both her study and ours are based on more balanced language samples.
We integrated the aspects of ordering and co-occurrence via a visualization in the form of a directed graph. This reveals some patterns that are not immediately obvious when simply going over the list of attracted sequences. First of all, it shows that some MPs are more well connected, thus more prone to occurring in sequences than others. This is shown via the number of incoming and outgoing arrows. For example, the MPs ja and mal are connected via many arrows, while glatt is found in only one attracted sequence. It is thus immediately obvious that the probability to occur in sequence is a particle-specific characteristic.Footnote 15 A further aspect that we may glean from the graph is that there is a strong bias toward unidirectional ordering. Simply counting the number of combinations occurring in both orders at least once revealed that a majority of 42 out of 73 sequences fulfill that criterion in our dataset of declarative sentences (see section 3.1). However, the operationalization via statistically significantly associated sequences offers a more nuanced approach that takes into account the probability of a sequence occurring by chance. Counting only those sequences that occur more frequently than expected by chance, as visualized via the graph, reveals a strong tendency toward unidirectionality that can be seen in the very low frequency of bidirectional arrows in the figure, with only three bidirectional arrows. The reversibly attracted sequences we find are aber<>doch, halt<>eben, and einfach<>mal. Interestingly, two of these have been reported in prior research. Thurmair (Reference Thurmair1989: 286–287) reports that the MPs aber and doch appear in both positions when occurring with one another, corresponding to our findings. Furthermore, we find that eben occurs in reversible order with halt, which corresponds to observations by Müller (Reference Müller and Assimakopoulos2017) and Abraham (Reference Abraham, Vogel and Comrie2000). Regarding the ordering aspect, the directed graph clearly shows positional differences between MPs. Some strongly prefer initial position as they are connected only via outgoing arrows, these being ja, ruhig, and echt, while others show a bias toward second position as they have only or mostly incoming arrows, in particular glatt and wohl but also einfach and mal, the latter two featuring only one or two outgoing arrows each, but a number of incoming arrows (four and seven respectively). The opposed ordering biases of ja and mal had been observed in Thurmair’s (Reference Thurmair1989) research, as these two particles uniformly prefer first and second position, respectively, according to her observations (Thurmair Reference Thurmair1989:282). Of course, the divergent tendencies of these two particles were already detected by the group model discussed above. However, the directed graph reveals the positional biases in a particle-specific fashion, which yields important additional insights: First, it illustrates links between MPs that are in the same group in the group-based model, such as aber combining with halt, as illustrated by the arrow from the former to the latter. Second, it shows that some MPs, in particular ruhig and echt, occur predominantly in first position, contrasting with their occupying positions in the middle of the ordering models. This discrepancy is due to the fact that the group models were based on ordering proportions that disregarded co-occurrence frequencies. Both ruhig and echt combine with only a few other MPs. Since in these cases both orders occurred with zero frequency, the corresponding ordering proportions were entered with a value of 0.5, which placed these MPs in the center of the ordering models or scales. In contrast, the directed graph, being based on attracted sequences with a greater-than-chance occurrence frequency, can be said to portray a more realistic picture of these two MPs’ combinatorial behavior, as it reveals their very selective combinatorial preferences. The example of ruhig and echt shows that, by integrating ordering and co-occurrence in one unified form of presentation, the combinatorial behavior of modal particles is illustrated in a fashion more representative of their actual usage. The directed graph reveals an intricate network of associations between modal particles that defies simple, one-dimensional grouping solutions. Instead, each MP is characterized by a fairly idiosyncratic combinatorial behavior in the sense that each particle differs with regard to which other particles it preferably co-occurs with, that is, is attracted to, as well as the positional bias in which this attraction is effective. By being able to integrate combinations that are frequently employed in both directions, it also implements the aspect of reversibility, in contrast to the ordering models discussed above.
5.2 Explaining ordering biases via the “grammaticalization legacy” of modal particles
We now move on to discussing three further theoretical perspectives that may be explored via our quantitative analyses and that relate to pertinent questions in research on MP combinations. We start with the question of how the ordering tendencies of modal particles may be accounted for. Two publications propose that MP ordering tendencies may be explained via the syntax of the grammatical classes that individual MPs originate from (Thurmair Reference Thurmair1991, Abraham Reference Abraham, Vogel and Comrie2000). Abraham (Reference Abraham, Vogel and Comrie2000) assumes that modal particles have come about via a process of grammaticalization and argues that MPs retain a certain “grammaticalization legacy” that continues to be reflected in their linear ordering preferences (Abraham Reference Abraham, Vogel and Comrie2000:343). Interestingly, we put forth the same argument about the persistence of source syntax for English utterance-initial discourse markers, based on the investigation of their combinatorial behavior (see Lohmann & Koops Reference Lohmann, Koops, Kaltenböck, Keizer and Lohmann2016). While Thurmair (Reference Thurmair1991) does not explicitly refer to grammaticalization, both Thurmair (Reference Thurmair1991) and Abraham (Reference Abraham, Vogel and Comrie2000) motivate their proposed ordering models via the grammatical class that the respective MPs are homophonous with. Thurmair (Reference Thurmair1991) suggests that MPs also occurring as conjunctions or discourse particles prefer first position, followed by MPs also occurring as sentence adverbs, followed by MPs with a focus particle homonym, followed by MPs with an adverbial homonym. This order is reflected in the group model she suggests (see section 2). Abraham’s (Reference Abraham, Vogel and Comrie2000:344) proposal is similar, yet simpler, in suggesting an order of coordinating conjunctions > adverbs > focus particles. It is important to note that Thurmair and Abraham based these suggestions on different sets of MPs compared to ours and that they did not focus on declarative sentences. Their accounts can thus not be applied directly to our results. Nevertheless, in order to test whether similar patterns can be found in our data we looked up our sixteen MPs in the Digitales Wörterbuch der Deutschen Sprache (DWDS) and noted the first word class(es) listed apart from “particle” in the order they appear to obtain an idea of possible ordering patterns with regard to original word classes. We list the sixteen MPs here as presented in the group model we developed (see section 4.1):
ja (answer particleFootnote 16 ), aber (conjunction), halt (interjection) > denn (conjunction), doch (conjunction) > ruhig (adjective), bloss (adjective), echt (adjective), fei (adjective), glatt (adjective) > eben (adverb) > einfach (adjective), schon (adverb), überhaupt (adverb), wohl (adjective) > mal (adverb)
The admittedly coarse classification brings out some interesting patterns. Three groups of MPs are identified: Those that originate from forms constituting independent, extrasyntactic units (ja, halt), those that originate from conjunctions (aber, denn, doch), and those having an adjectival or adverbial origin. It can be clearly seen in our data that those MPs that are also used as independent units (ja, halt) have a tendency toward first position, as these appear in the first group in our ordering model. This finding also corresponds to our analysis of English discourse marker combinations in utterance-initial position, as we observe that forms originating from independent discourse units precede those originating from intra-sentential elements (see the analysis in Koops & Lohmann Reference Koops and Lohmann2015 that we based on Auer’s Reference Auer1996 grammaticalization account). For the other MPs we observe that those with a conjunction origin precede those that originate from adjectives/adverbs. The ordering pattern observed may be explained by a persistence of sentence-syntactic word order, as conjunctions occur in initial position of the clause, while adjectives and adverbs occupy more central positions. This finding also corresponds to our results for English discourse markers. Overall, we observe that the left-to-right order corresponds to an order of outer toward inner sentence positions. Focusing on the statistically attracted sequences confirms this finding, as of the 29 combinations listed in table 1 and visualized in the directed graph, only three combinations disturb the mentioned ordering pattern (eben doch, aber halt, eben halt). Of the remaining combinations, a majority of 17 sequences combine MPs from different origins and adhere to the order described above. A case in point is the seven attracted sequences featuring ja, which originates from an answer particle and is found in first position in all of these combinations. In sum, our data seem to reflect a persistence of the original word classes of the MPs, similar to the observations by Thurmair (Reference Thurmair1991) and Abraham (Reference Abraham, Vogel and Comrie2000). And, interestingly, corresponding findings are observed for the ordering of discourse markers in utterance-initial position in English, indicating a possibly more general, cross-linguistically valid pattern. This demonstrates that the grammaticalization perspective certainly holds potential in explaining the ordering of MPs. More research pursuing this perspective, but employing a more detailed historical analysis of the individual MPs, would certainly be worthwhile.
5.3 Reversibility of MP combinations
We now turn to the question of the reversibility of MP combinations, specifically the prior observation that MP reversibility is rather limited. This observation has prompted the systematic investigation of the ordering question (see, e.g., Thurmair Reference Thurmair1989:288). Overall, our findings are consistent with this general observation. Specifically, our analysis of association strength (table 1) shows relatively few combinations that are statistically attracted in both directions. One of these is the case of einfach mal und mal einfach. Note that even though both sequences are significantly associated, einfach mal shows a much greater association strength (206.3) than the other (4.8). This again supports the general finding that MPs tend to prefer one order over the other. At the same time, we should not lose sight of the possibility that, when it does occur, reversibility can be systematic in the sense that two MPs may be regularly exploited in both orders. This possibility is discussed by Müller in a series of publications (Müller Reference Müller, Bayer and Struckmeier2016, Reference Müller and Assimakopoulos2017, Reference Müller2018a, Reference Müller2018b). Müller has argued that in cases where MP sequences are used in two opposite orders, both orders are functionally motivated. In the right discourse contexts, a particle that would otherwise be preferred in second position can be placed in initial position. Müller shows this specifically for the combinations of halt with eben, ja with doch, and doch with auch. Inspecting these combinations in our data shows that combinations of doch and auch do not occur in our data at all; with ja and doch we find a strong asymmetry, such that ja doch is among the strongly attracted sequences while the reversal does not occur at all. Asymmetries such as this one are noted by Müller, who views one of the two orders as “markiert” (Müller Reference Müller2018a). Of the sequences discussed by Müller, halt<>eben is the only one in our data in which reversibility is systematic in the sense that both orders are attracted sequences, which may be interpreted as an indication that both orders are conventionalized to a certain extent. It would be a worthwhile enterprise for future research to focus on these conventionalized reversals in particular. Those cases for which both orders are characterized by similar association strengths, and which are thus symmetrical attractions, may be particularly interesting. Based on our analysis, such a case is aber doch and doch aber, which are both statistically associated sequences, and which have relatively similar association strengths (30.42 and 18.98, respectively). Exploring the motivation for the relatively symmetrical attraction and thereby an assumed symmetrical conventionalization in cases such as this holds the potential to add a new aspect to Müller’s (Reference Müller2018a) observation of reversibility being a theoretically relevant phenomenon.
5.4 Compositionality of MP sequences
Another theoretical question that has been discussed in the literature on MPs is whether some MP combinations should be analyzed as single, lexicalized units. A key question here is whether in such cases the two MPs’ combined function can still be reduced to the sum of their individual functions or not. In other words, should the joint function of MPs in combination be generally viewed as additive, that is, as compositional? Or can it also be noncompositional? Our goal in reviewing this issue here is not to discuss or problematize the concept of compositionality per se, or to provide a new analysis of the degree of compositionality of specific MP combinations. Rather, we review how other authors have approached the compositionality question in order to pinpoint how quantitative criteria such as those developed in this article can inform and contribute to traditional analyses of the compositionality of MP combinations.
There seems to be general agreement that even when two MPs frequently co-occur, this does not necessarily indicate that their joint function is no longer derivable from the individual functions of the two elements (see Müller Reference Müller2018a:76). An example of a study pursuing the question of compositionality directly is Lemnitzer (Reference Lemnitzer, Lehr, Kammerer, Konerding, Storrer, Thimm and Wolski2001), who analyzes MP combinations found in a large German newspaper corpus, specifically those 43 combinations that display a significant degree of statistical association according to the maximum likelihood ratio measure.Footnote 17 Lemnitzer argues that 12 of the 43 combinations should be viewed as noncompositional, lexicalized units. His analysis employs syntactic and semantic/pragmatic criteria such as the omissibility of one of the two elements, the question whether the combined meaning can be readily analyzed as the combination of the two elements, and the question whether each individual MP is licensed to occur independently in a particular sentence type. Several of Lemnitzer’s MP combinations also occur in our list of attracted sequences (table 1), and some combinations that he analyzes as fully lexicalized also show a high association strength in our analysis (e.g. schon mal).Footnote 18 What we would like to add to his analysis and others like it is that it might be insightful to include the criterion of association strength in the analysis. Presumably, Lemnitzer’s set of statistically associated MP combinations also included some very strongly associated MP sequences and others that are not as strongly associated, even though all of them showed a significant effect of association. We suggest that the value of an MP combination’s association strength can be used as an additional criterion in assessing compositionality. Or, in another application of the same idea, association strength could be used as a discovery procedure for locating sequences that might show signs of noncompositionality. In fact, in a separate publication, Lemnitzer (Reference Lemnitzer1997) pursues just such an approach, though in a more limited analysis of only the MP denn, which occurs predominantly in questions. Here, Lemnitzer reports the results of the quantitative analysis in detail and identifies the sequence denn auch as one with very high association strength (Lemnitzer Reference Lemnitzer1997:181). Based on a qualitative analysis of occurrences of this sequence, he concludes that denn auch instantiates a complex item with a noncompositional function.Footnote 19 This analysis, which combines an explicitly named quantitative measure of association strength with traditional, qualitative criteria demonstrates the potential of such a dual methodological approach. It would be worthwhile to apply this approach on a larger scale, possibly using our list provided in table 1 as a starting point.
6. Conclusion and outlook
In the present article we have discussed the results of a quantitative analysis of combinations of modal particles extracted from a large corpus of German speech. We addressed the questions of MP ordering and co-occurrence of MPs, which had been investigated in prior research in a predominantly qualitative fashion. Our results show how the investigation of both aspects can profit from a transparent, rigorous quantitative approach. In addition, we also demonstrate how both aspects can be integrated with one another, using the visualization tool of a directed graph. Furthermore, we show how long-standing issues in the literature on MP combinations, in particular the motivation of ordering tendencies, the systematic occurrence of reversible sequences, and the possibility of noncompositional MP functions, can profit from these methods. All of these aspects await further investigation and we hope to have provided suitable starting points for more exhaustive analyses of these questions.
Having applied many of the quantitative methods discussed above to the combinatorial behavior of English utterance-initial discourse markers in previous publications (e.g. Koops & Lohmann Reference Koops and Lohmann2015, Lohmann & Koops Reference Lohmann, Koops, Kaltenböck, Keizer and Lohmann2016, Koops & Lohmann Reference Koops, Lohmann, Lohmann and Koops2022), we discovered interesting parallels between discourse markers in English and modal particles in German. Elements in both languages exhibit strong ordering tendencies that seem to be determined by their grammaticalization histories to a certain extent (see section 5.2 above). Even though modal particles and discourse markers differ with regard to their syntactic position, with discourse markers occurring in the sentence periphery in contrast to the central position that modal particles occupy, in both cases we observe that elements originating from independent left-peripheral units tend toward initial position in sequences. This interesting observation shows the potential for further exploring the commonalities between pragmatic units of different types with regard to their combinatorial behavior. In continuing this line of research, an aspect worth exploring would be to investigate to what extent both discourse markers and modal particles may be captured by similar functional explanations, beyond the explanation from the perspective of grammaticalization. In previous research it has been shown that the ordering of functions fulfilled by discourse markers in English differs between left-peripheral and right-peripheral sequences (e.g. Haselow Reference Haselow2019). It would be interesting to explore whether from a functional perspective sequences of modal particles align more closely with the left or the right periphery, given that they occupy a discourse/syntactic position that is central rather than peripheral. We hope that the present article may provide the research community with some useful methodological tools as well as theoretical starting points for the future investigation of this as well as further perspectives.


 Open access
Open access