



Impact Statement
This work underscores the potential of domain-augmented large language models to reshape literature synthesis in flood modeling, enabling faster and more informed decision-making in risk assessment.
1. Introduction
Floods affect around 200 million people annually and cause over half of all disaster-related damages globally (Ritchie and Rosado, Reference Ritchie and Rosado2024). Flood susceptibility mapping (FSM) plays a vital role in identifying at-risk areas to support planning and emergency response. While traditional FSM methods, such as physical and numerical models, are often costly and complex, machine learning (ML) models offer accurate and efficient alternatives. Despite their growing use, inconsistencies in data preprocessing, feature selection, model setup, and validation hinder the reproducibility and generalization of ML-based FSM approaches (Pourzangbar et al., Reference Pourzangbar, Oberle, Kron, Franca, Gourbesville and Caignaert2024).
Emerging large language models (LLMs), including ChatGPT, have attracted significant attention across scientific disciplines. ChatGPT, developed by OpenAI (2023), is a generative matural language processing (NLP) model capable of producing context-aware text responses and assisting with tasks such as programming support, content drafting, and literature exploration (Ray, Reference Ray2023; Surameery and Shakor, Reference Surameery and Shakor2023). Prior studies have highlighted its usefulness in summarization and interactive refinement when guided by structured prompts (Halloran et al., Reference Halloran, Mhanna and Brunner2023), although questions remain regarding the consistency and domain-specific reliability of its outputs in specialized scientific contexts. Rapid academic adoption, reflected in thousands of publications since 2023, underscores both its potential and the need for systematic evaluation in domain-specific applications.
Integrating ChatGPT into water science and disaster management has opened new research opportunities, though challenges persist (Hosseini and Pourzangbar, Reference Hosseini and Pourzangbar2026). In disaster management, it supports knowledge dissemination and data analysis but faces limitations in real-time responsiveness, data quality, and interpretability, requiring rigorous validation (Xue et al., Reference Xue, Xu and Xu2023; Haider et al., Reference Haider, Rashid, Tariq and Nadeem2024). In water science, ChatGPT is useful for qualitative tasks and has shown value in hydrology and Earth sciences, although it may occasionally produce errors in quantitative analyses (Foroumandi et al., Reference Foroumandi, Moradkhani, Sanchez-Vila, Singha, Castelletti and Destouni2023). In specialized fields like water treatment and desalination, it simplifies technical tasks but often needs human oversight (Ray et al., Reference Ray, Peddinti, Verma, Puppala, Kim, Singh and Kwon2024). The environmental footprint, particularly high freshwater consumption during model training, raises sustainability concerns (Egbemhenghe et al., Reference Egbemhenghe, Ojeyemi, Iwuozor, Emenike, Ogunsanya, Anidiobi and Adeniyi2023). While ChatGPT shows potential for supporting scientific workflows, to the best of the authors’ knowledge, its consistency and domain-specific performance in FSM—particularly in literature synthesis and technical ranking tasks—remain insufficiently evaluated. We believe that sooner rather than later, LLMs will become increasingly integrated into scientific workflows, and thus understanding their strengths and limitations in domain-specific applications becomes essential. This study evaluates and compares the performance of different ChatGPT configurations in responding to literature-informed questions related to ML-based FSM. ChatGPT was selected due to its accessibility, configurable knowledge integration features, and widespread use in academic environments. Rather than positioning ChatGPT as a replacement for modeling tools, we examine its role as a literature-support system within FSM research workflows. This design enables explicit examination of how domain-specific retrieval augmentation influences literature-consistency in structured FSM queries, while not constituting validation of performance in novel or out-of-corpus applications. Our focus is on assessing response agreement, ranking consistency, and computational efficiency within a controlled benchmarking framework. The novelty of this work lies in systematically benchmarking AI-generated outputs against a curated review dataset, providing empirical insight into the behavior of general-purpose and domain-augmented GPT systems in FSM-related knowledge tasks. Furthermore, this study contributes to ongoing discussions on how LLM-based systems may be systematically evaluated for use in hydrological research contexts.
2. Material and methods
2.1. Benchmark data
Pourzangbar et al. (Reference Pourzangbar, Oberle, Kron and Franca2025) reviewed over 100 studies on ML-based FSM from 2013 to 2023. This review forms the basis for the benchmark dataset used in this study, serving as a structured reference for evaluating model-generated responses. The review proposed a comprehensive framework covering data preprocessing, model development, validation, and post-processing. The study identified key aspects such as data considerations, algorithm selection, and modeling procedures. Through comparative analysis, the review synthesized common modeling practices and performance trends in ML-based FSM studies. Emphasizing data preprocessing, feature engineering, and model configuration, the study also proposed innovations to enhance modeling quality. The structured findings of this review were mapped onto the five key evaluation questions and used as the benchmark dataset. Notably, the same corpus of reviewed articles was later provided as reference material to the domain-augmented GPT configuration (hereafter referred to as “Chat-FSM”), enabling controlled assessment of retrieval consistency against the synthesized literature outcomes.
2.2. ChatGPT models
Three ChatGPT-based configurations were employed in this study: ChatGPT-4o, ChatGPT-4, and a domain-augmented GPT-4 configuration incorporating selected literature (Chat-FSM). ChatGPT-4 and ChatGPT-4o are advanced OpenAI models that outperform GPT-3 in contextual understanding, coherence, and response generation (OpenAI, 2023). Both are trained using text prediction and reinforcement learning from human feedback (RLHF) and can process text, images, and third-party data (Abdullah et al., Reference Abdullah, Madain and Jararweh2022). GPT-4 is a large multimodal model reported to perform strongly across a range of academic and professional benchmark tasks (Oxford Analytica, 2023). ChatGPT-4o extends GPT-4 by adding audio input, faster responses, support for over 50 languages, and improved literary analysis, while being more cost-effective. Both models feature a 128,000-token context window, with knowledge cutoffs in December 2023 (GPT-4) and October 2023 (ChatGPT-4o) (Montañés, Reference Montañés2024).
Chat-FSM was developed using OpenAI’s Custom GPT environment with integrated document upload capabilities, allowing retrieval-augmented generation over a curated document collection. The system does not involve model fine-tuning or custom API-level pipeline modifications. Instead, it operates by combining document retrieval from the uploaded corpus with the pretrained capabilities of the base GPT-4 model. For this setup, Chat-FSM was granted retrieval access to a collection of 100 scientific publications—the same set of articles used to construct the benchmark dataset (Section 2.1)—focused on ML-based FSM. Using this identical corpus as the retrieval source enables a controlled evaluation of how effectively the model reproduces the synthesized findings from the literature. Chat-FSM lacks web browsing and external data analysis capabilities, relying solely on uploaded PDFs for knowledge. Its scope is limited to ML applications in FSM, with predefined conversation starters to guide exploration.
While the primary evaluation focuses on literature-consistency benchmarking, an additional out-of-corpus test was conducted to address concerns regarding potential circular validation and to provide a preliminary assessment of generalizability beyond the configured knowledge base. Specifically, Chat-FSM was evaluated against an independent benchmark FSM study (Zhuang et al., Reference Zhuang, Gong, Fang, Shen, Tang, Lin, Chen and Zhang2026) that was not included among the 100 articles used for knowledge augmentation. This external reference enabled examination of whether the model could synthesize relevant concepts without direct retrieval access to the source material, thereby offering an initial indication of its behavior in out-of-corpus scenarios.
2.3. Methodology
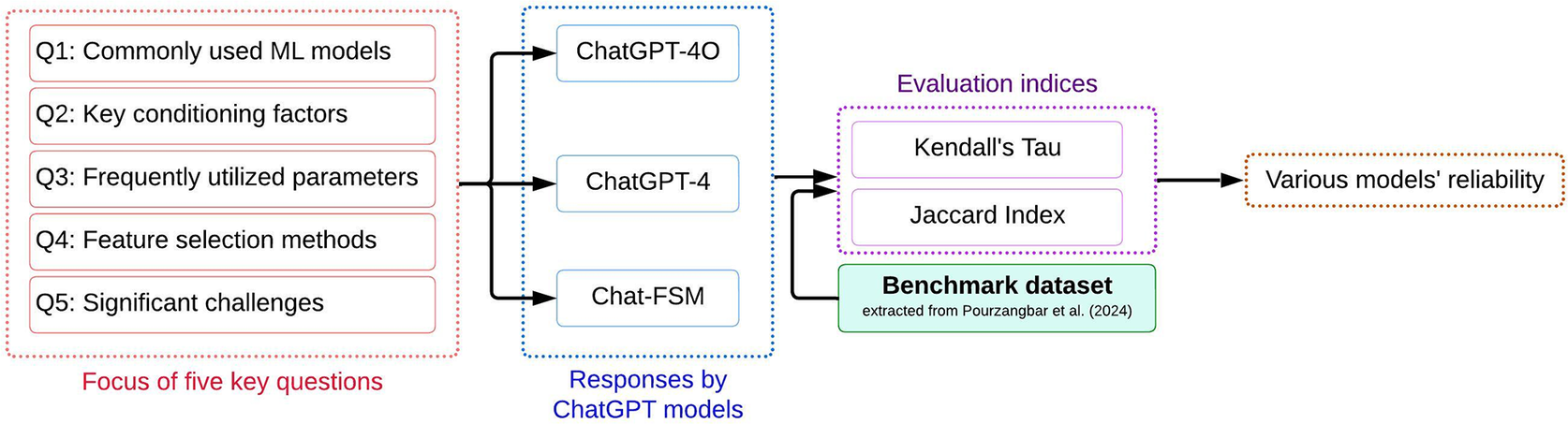
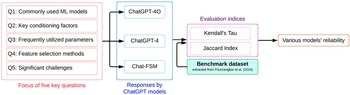
To systematically evaluate the performance of the selected ChatGPT configurations, five key literature-informed questions were designed, focusing on ML models, conditioning factors, feature selection methods, and major challenges in FSM (Table 1). These questions target frequently reported themes in ML-based FSM literature to enable structured benchmarking of model-generated responses. The fixed question set ensures comparability across models and facilitates quantitative assessment of content overlap and ranking consistency. Model responses were compared against the benchmark dataset (Section 2.1) using content-overlap and rank-correlation metrics to quantify agreement in both item presence and ordering. The evaluated questions primarily assess literature retrieval and structured ranking consistency rather than context-dependent analytical reasoning. Queries such as identifying commonly used models or frequently reported conditioning factors examine alignment with published trends. In contrast, tasks requiring model selection for specific geographic, hydrological, or data-scarce contexts involve synthesis and expert judgment that extend beyond the scope of the present benchmarking framework. Accordingly, the findings should be interpreted as assessing literature-consistency rather than full analytical reasoning capability. Figure 1 summarizes the comparative evaluation framework implemented in this study.
Five key questions designed in this study to assess the agreement of different ChatGPT configurations with the benchmark dataset

The procedure used in this study to evaluate the agreement of different ChatGPT configurations with the FSM benchmark dataset.
2.3.1. Out-of-corpus generalization
In addition to the primary literature-consistency evaluation, an out-of-corpus assessment was conducted using an independent FSM benchmark study not included in the retrieval corpus, allowing preliminary examination of generalization behavior beyond the configured knowledge base. For the out-of-corpus evaluation, we selected the study by Zhuang et al. (Reference Zhuang, Gong, Fang, Shen, Tang, Lin, Chen and Zhang2026), which combines social media-derived flash flood inventories with machine learning-based modeling in a typhoon-affected coastal environment. As this study was not included in the 100-article corpus used to configure Chat-FSM, it was employed as an independent external benchmark to assess the model’s generalizability and robustness beyond the training domain. Three questions were designed to evaluate conceptual transfer across three dimensions (Table 2). First, the selected study employs social media–derived flash flood inventories, representing an emerging data source in susceptibility modeling and providing a suitable test of whether the model can generalize to new forms of observational input. Second, the study explicitly addresses methodological limitations and reporting biases associated with social media data, enabling assessment of whether Chat-FSM can recognize uncertainties and data-quality constraints rather than merely describing advantages. Third, the study incorporates typhoon frequency as a region-specific hydro-meteorological driver, requiring compound hazard reasoning and evaluation of its expected influence on model performance. Together, these dimensions allow a structured examination of generalization beyond the configured literature corpus.
Three out-of-corpus questions designed to evaluate the generalization behavior of Chat-FSM through comparison with an independent benchmark study (Zhuang et al., Reference Zhuang, Gong, Fang, Shen, Tang, Lin, Chen and Zhang2026)
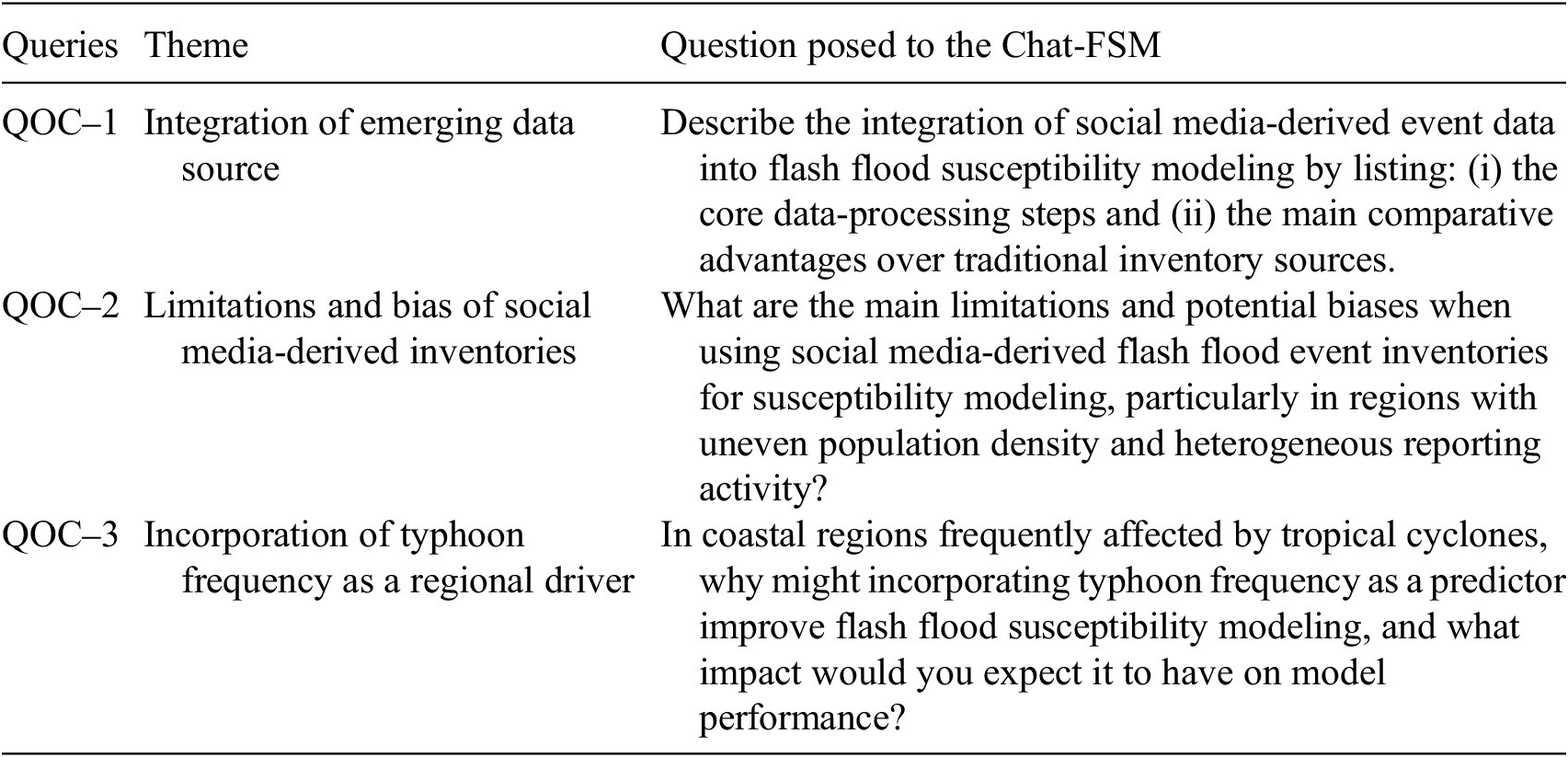
Abbreviation: QOC = Question-Out-of-Corpus.
2.4. Inference statistics
The evaluation followed a structured approach. First, the ChatGPT models were prompted to generate ranked lists of machine learning models and parameters relevant to flood susceptibility mapping. Next, responses were reviewed by the authors to ensure semantic alignment between model outputs and benchmark components prior to quantitative comparison. Finally, the degree of agreement in content and ranking was quantified using two statistical measures: the Jaccard Index for content match and Kendall Tau for rank correlation (Mulekar and Brown, Reference Mulekar, Brown, Alhajj and Rokne2017).
Each of the five key questions was posed to the three configurations, and their responses were analyzed to quantify agreement with the benchmark dataset. For each question (except Q5), the output was a list of 10 components. Responses were compared to the Benchmark data using two criteria: Match and Ranking. Match refers to the presence of a component in both the model’s response and the Benchmark list, regardless of order, indicating content overlap. Ranking assesses the degree of ordinal alignment between the model’s ordering and the benchmark ordering, reflecting consistency in relative prioritization. For instance, if a model ranks “RF” first while the Benchmark ranks it fourth, the component matches, but the ranking differs. This dual-criteria approach enables a comprehensive assessment of both content and structure.
To quantitatively compare model agreement in terms of Match and Ranking, Kendall’s Tau (τ), and the Jaccard Index (
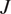 $ J $
) were calculated (Eqs. 1–2). Kendall’s Tau measures ordinal correlation between the model-generated ranking and the benchmark ranking, ranging from 1 (complete discordance) to 1 (perfect concordance), and was computed on overlapping components (Kendall, Reference Kendall1938). The Jaccard Index quantifies set similarity as the ratio of the intersection to the union of elements in the two lists, ranging from 0 (no overlap) to 1 (perfect overlap) (Jaccard, Reference Jaccard1901).
$ J $
) were calculated (Eqs. 1–2). Kendall’s Tau measures ordinal correlation between the model-generated ranking and the benchmark ranking, ranging from 1 (complete discordance) to 1 (perfect concordance), and was computed on overlapping components (Kendall, Reference Kendall1938). The Jaccard Index quantifies set similarity as the ratio of the intersection to the union of elements in the two lists, ranging from 0 (no overlap) to 1 (perfect overlap) (Jaccard, Reference Jaccard1901).
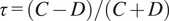 $$ \tau =\left(C-D\right)/\left(C+D\right) $$
$$ \tau =\left(C-D\right)/\left(C+D\right) $$
 $$ J\left(A,B\right)=\left|A\cap B\right|/\left|A\cup B\right| $$
$$ J\left(A,B\right)=\left|A\cap B\right|/\left|A\cup B\right| $$
where C and D denote the number of concordant and discordant pairs, respectively. A pair is concordant if the relative order of two elements is consistent across both lists, and discordant otherwise.
3. Results
3.1. Literature-consistency benchmark results
The comparative agreement between the ChatGPT configurations and the benchmark dataset is summarized in Supplementary Appendix B (Tables B1–B5 and Figures B1–B4). The following sections analyze the degree of content overlap and ranking consistency across the five evaluation questions. These questions address commonly reported ML models for FSM, key conditioning factors, frequently utilized input parameters, feature selection methods, and documented gaps and challenges identified in the reviewed literature.
Question 1: “Rank the top 10 machine learning models from most to least frequently used and best-performing in flood susceptibility modeling. Provide the list in descending order of their combined frequency and performance.”
The benchmark dataset and corresponding model responses for this question are presented in Supplementary Appendix B (Table B1 and Figure B1). Based on the data in Table B1, the Jaccard Index and Kendall’s Tau were calculated for each configuration, as summarized in Table 3. Although its ranking correlation (Kendall’s Tau = 0.205) is lower, Chat-FSM shows the highest level of content overlap with the benchmark (Jaccard Index = 0.636) among the evaluated configurations. ChatGPT-4o exhibits moderate content overlap (Jaccard Index = 0.428) but achieves the highest rank correlation (Kendall’s Tau = 0.244), indicating stronger ordinal alignment with the benchmark ordering among overlapping components. In contrast, ChatGPT-4 exhibits lower agreement levels under both metrics (Jaccard Index = 0.385; Kendall’s Tau = 0.022). Notably, none of the evaluated configurations included several models highlighted in the benchmark dataset, such as Bagging ensembles, long short-term memory (LSTM), and deep belief networks. Additionally, some configurations proposed models such as logistic regression, K-nearest neighbors, and Naïve Bayes, which were not ranked among the top 10 most frequently reported models in the benchmark dataset. The benchmark dataset indicates an increasing emphasis in recent literature on ensemble and hybrid modeling strategies, such as random forest combined with optimization algorithms. This trend was not prominently reflected in the responses generated by the evaluated configurations.
Question 2: “Identify and rank the top 10 most important input parameters for flood susceptibility mapping based on their reported impact on model performance. List them from most to least important.”
Inference statistics of different ChatGPT models considering Q1

The benchmark data and corresponding model responses shown in Supplementary Table B2 and Figure B2 were used to compute the Jaccard Index and Kendall Tau, as summarized in Table 4. For consistency in the comparison, “geology” was treated as a composite category encompassing rocks (lithology), soils, minerals, tectonic features, and geological history. As such, both “soil type” and “lithology” are considered subcategories of “geology” and were included under this classification when calculating the match and ranking indices. Inspection of Table 3 indicates limited ordinal agreement between model-generated rankings and the benchmark ordering of input parameters, as reflected by negative Kendall’s Tau coefficients across all configurations; however, Chat-FSM exhibited comparatively higher agreement levels in both content overlap and rank correlation relative to ChatGPT-4o and ChatGPT-4.
Question 3: “Rank the top 10 most frequently used input parameters in machine learning models for flood susceptibility mapping, based solely on how often they appear across various studies. Provide a numbered list in descending order of frequency.”
Inference statistics of different ChatGPT models considering Q2

The benchmark dataset and corresponding model responses—shown in Supplementary Table B3 and Figure B3—were used to compute the Jaccard Index and Kendall’s Tau, with results summarized in Table 5. In terms of content overlap (Jaccard Index), ChatGPT-4 achieved complete set agreement with the benchmark list, whereas ChatGPT-4o and Chat-FSM exhibited moderate levels of overlap. However, in terms of ordinal alignment, ChatGPT-4 exhibits the lowest Kendall’s Tau coefficient (−0.822), followed by ChatGPT-4o (−0.244), indicating inverse correlation with the benchmark ordering. Chat-FSM, although exhibiting a comparatively higher Tau value, still demonstrates limited rank correlation with the benchmark ordering.
Question 4: “Identify and rank the top 10 most frequently utilized feature selection methods for determining the importance of conditioning factors in flood susceptibility modeling. List them in descending order of frequency.”
Inference statistics of different ChatGPT models considering Q3

The benchmark dataset and corresponding model responses shown in Supplementary Table B4 and Figure B4 were used to compute the Jaccard Index and Kendall’s Tau, as summarized in Table 6. Inspection of Table 6 indicates limited agreement between the model-generated lists and the benchmark, reflected in low content overlap and modest or negative rank correlation values. Based on these agreement metrics, the generated responses show limited consistency with the benchmark ordering for feature selection methods under the defined evaluation framework.
Question 5: “What are the top five most significant gaps and challenges in developing machine learning models for flood susceptibility mapping, considering aspects like data availability, model generalizability, interpretability, and integration with hydrological knowledge? Rank them from most to least critical based on their impact on model performance and applicability.”
Inference statistics of different ChatGPT models considering Q4

Both the benchmark dataset and the evaluated ChatGPT configurations identify data availability and quality as central challenges in ML-based FSM (Table B5). The benchmark dataset emphasizes strategies reported in the reviewed literature, such as expanding data inputs through augmentation and fusion, integrating climate change indicators, and incorporating social media data in data-scarce regions. It also highlights the importance of physical interpretation and trade-off analysis in flood risk assessment. In contrast, the ChatGPT-generated responses tend to emphasize technical aspects related to model robustness and adaptability. ChatGPT-4o and ChatGPT-4 frequently highlight model generalizability across regions, interpretability, and integration with physical or hydrological knowledge as important considerations in FSM applications. Chat-FSM places comparatively greater emphasis on mitigating overfitting, improving feature selection, and enhancing interpretability.
The distinction lies in emphasis: the benchmark dataset reflects literature trends that prioritize expansion of data inputs and practical data-gap mitigation, whereas the ChatGPT-generated responses place greater weight on methodological aspects such as generalization, explainability, and multi-scale integration. These differences illustrate variation in thematic prioritization rather than categorical correctness.
3.2. Out-of-corpus generalization results
The out-of-corpus generalization assessment was conducted using the Chat-FSM configuration. As the primary objective of this experiment was to examine whether domain-configured retrieval augmentation enables conceptual transfer beyond the configured literature corpus, the evaluation focused on the custom retrieval-augmented system. The previously tested standard ChatGPT configurations were not included in this additional experiment. Accordingly, this assessment isolates the behavior of the retrieval-augmented system when exposed to an independent benchmark study not represented in its knowledge base. Three evaluation questions (QOC-1 to QOC-3; c.f. Table 2) were formulated based on the content of this external study. For each question, the benchmark answer was derived directly from the selected paper and compared with the response generated by Chat-FSM (Supplementary Appendix A contains the Chat-FSM responses to these questions, and Supplementary Appendix B includes a comparison between the benchmark and Chat-FSM responses).
For QOC-1 and QOC-2, which focus on the integration of social media–derived flash-flood inventories, the model responded that the information was not available in the provided documents. This behavior indicates that the system correctly recognized the absence of relevant knowledge within its retrieval corpus rather than generating unsupported or hallucinated explanations. While this conservative response avoids misinformation, it also highlights a limitation: when the uploaded literature does not cover the queried topic, the model cannot generalize beyond the knowledge contained in its indexed documents. In contrast, for QOC-3, which examines the role of typhoon frequency as a predictor in flash-flood susceptibility modeling, the model produced a detailed explanation that largely aligned with the benchmark response extracted from the selected paper. The generated answer correctly identified key mechanisms discussed in the literature, including the relationship between tropical cyclones and intense short-duration rainfall, the representation of regional hazard exposure in cyclone-prone coastal areas, and the expected improvement in predictive performance metrics such as model accuracy. Additionally, the model introduced further explanatory elements such as cyclone pathways and spatial differentiation of flood susceptibility which, although not explicitly discussed in the benchmark paper, remain conceptually consistent with established hydrometeorological reasoning.
4. Discussion
4.1. Variability across ChatGPT versions
Each ChatGPT configuration was included for a specific reason: ChatGPT-4o represents a more recent publicly accessible model (in comparison to others); ChatGPT-4 is widely used in academic workflows; and Chat-FSM, configured with retrieval access to FSM literature, represents a domain-augmented configuration. Their inclusion enables comparative analysis across general-purpose and literature-augmented systems.
The results reveal measurable differences in content overlap and rank correlation across configurations. For ML model rankings (Q1), Chat-FSM exhibited the highest content overlap with the benchmark dataset, whereas ChatGPT-4o and ChatGPT-4 showed lower levels of agreement, including omission of several models highlighted in the benchmark synthesis. For conditioning factors (Q2), all configurations demonstrated limited ordinal agreement with the benchmark ordering, although Chat-FSM showed comparatively higher content overlap. For feature selection methods (Q4), agreement levels were low across all configurations, indicating substantial divergence from the benchmark list under both metrics. The out-of-corpus generalization results suggest that Chat-FSM demonstrates strong reasoning and explanatory capability when the queried concepts are represented within its retrieval knowledge base. However, its performance remains dependent on the coverage of the provided literature, and it is unable to supply substantive answers when relevant information is absent from the indexed documents. This behavior reflects the inherent characteristics of retrieval-augmented systems, where generalization is constrained by the scope of the underlying document corpus. Observed differences likely stem from variations in training data exposure, knowledge cut-off dates, and architectural configurations. ChatGPT-4o and ChatGPT-4 rely on general pretraining and reinforcement learning from human feedback, whereas Chat-FSM operates under a retrieval-augmented setup constrained to a defined corpus of FSM literature. These configuration differences influence response patterns and levels of agreement under the defined benchmarking framework. Notably, higher content overlap in the domain-augmented configuration reflects improved literature-consistency rather than validated superiority in broader analytical reasoning.
Large language models are continuously updated, which may lead to variability in generated outputs over time. The findings indicate that while LLM-based systems can efficiently generate literature-aligned summaries, their outputs should be interpreted within the context of benchmark-based agreement rather than assumed domain reliability, particularly in high-stakes applications such as flood risk management.
4.2. Implications of model variability for literature-based FSM support
Variability across ChatGPT configurations in literature-informed FSM responses may affect confidence in their consistency, particularly if such outputs are interpreted without awareness of their benchmark-based limitations. While ChatGPT-generated outputs may assist with exploratory literature review and conceptual comparison, their use in formal decision-making should be approached cautiously, given the observed variability in agreement with literature-derived benchmarks.
Over-reliance on GPT-generated summaries without independent verification may lead to incomplete representation of literature trends or methodological considerations identified in structured reviews. For example, omission of models emphasized in the benchmark synthesis may influence how methodological options are perceived within exploratory analyses. Additionally, generalized responses may not fully capture location-specific hydrological or socio-environmental nuances that are typically addressed through domain expertise. Accordingly, ChatGPT-based tools are best positioned as supplementary literature-support systems rather than substitutes for domain expertise. Cross-verification with structured reviews and collaboration with domain experts can help contextualize AI-generated outputs, particularly in complex applications such as flood susceptibility assessment.
4.3. Energy efficiency of the process
The energy implications of ChatGPT systems can be considered from two perspectives: (1) model training and development, which are resource-intensive processes external to this study, and (2) application-level use during deployment, which is the focus of the present comparison. Training large language models such as GPT-3 requires substantial computational resources, which have been associated with significant energy and water consumption (George et al., Reference George, George and Martin2023), with reported freshwater usage reaching up to 700,000 liters in certain data centers and potentially higher in other regions (Egbemhenghe et al., Reference Egbemhenghe, Ojeyemi, Iwuozor, Emenike, Ogunsanya, Anidiobi and Adeniyi2023). These considerations highlight the broader sustainability challenges associated with large-scale AI development.
Within the defined experimental setup, this study compares the time required for manual literature synthesis with that required for AI-assisted response generation. Reviewing 100 articles to construct the benchmark dataset required approximately 400 hours, whereas ChatGPT-4o generated responses to the five predefined questions in approximately 75 seconds. Under this specific comparison, manual synthesis required approximately 19,200 times more time than response generation using ChatGPT-4o. While this ratio reflects differences in task structure and evaluation scope, it illustrates the potential efficiency gains of AI-assisted literature summarization under controlled benchmarking conditions.
5. Limitations and future research directions
ChatGPT’s training and data access are continuously evolving, meaning its responses may vary over time. First, this study does not aim to present definitive answers for FSM modeling but rather evaluates the consistency of ChatGPT-generated outputs through comparison with a literature-derived benchmark dataset. Therefore, the responses should not be interpreted as authoritative references for model development. Second, the five selected questions were designed to represent core themes in ML-based FSM; however, they restrict the scope of evaluation to structured literature-based queries rather than broader real-world modeling applications. In particular, the evaluated questions primarily examine literature retrieval and ranking consistency, whereas context-dependent analytical reasoning—such as recommending models for specific hydrological or data-scarce scenarios—was beyond the scope of the present study. In addition, the out-of-corpus experiment showed that although Chat-FSM demonstrates reliable reasoning when relevant concepts exist within its retrieval corpus, its performance is inherently constrained by the coverage of the indexed literature, and it cannot provide substantive answers for topics that are not represented in the available documents. Future research should expand the range of evaluation scenarios, including additional out-of-corpus benchmarks and context-specific problem settings, to further examine generalization behavior. Finally, prompt engineering plays a significant role, as variations in prompt structure can influence generated outputs. Future studies should systematically investigate how prompt formulation affects content overlap and ranking alignment, thereby clarifying the sensitivity of benchmarking outcomes to prompt design.
6. Conclusions
This study evaluated the agreement of baseline and domain-augmented ChatGPT configurations with a literature-derived benchmark in the context of ML-based Flood Susceptibility Mapping (FSM). By comparing responses from ChatGPT-4o, ChatGPT-4, and a retrieval-augmented GPT-4 configuration (Chat-FSM) against a structured synthesis of 100 reviewed articles, measurable differences in content overlap and ranking correlation were identified. Overall, the domain-augmented Chat-FSM configuration exhibited the highest level of content overlap with the benchmark dataset, reflecting improved literature-consistency under the defined evaluation framework. ChatGPT-4 demonstrated comparatively stronger rank correlation in selected cases, whereas ChatGPT-4o generally showed lower agreement levels under the evaluated metrics. Across configurations, feature selection methods displayed limited agreement with benchmark rankings, highlighting variability in how models prioritize methodological components. In addition to agreement analysis, application-level efficiency comparisons indicated substantial time differences between manual literature synthesis and AI-assisted response generation under controlled conditions. However, these efficiency gains should be interpreted within the scope of structured benchmarking rather than as validation of broader analytical reliability.
In conclusion, ChatGPT-based systems demonstrate measurable variation in literature-consistency across configurations, with retrieval-augmented setups yielding higher agreement under controlled benchmarking conditions. However, their performance remains constrained by the coverage of the indexed literature, limiting their ability to address topics absent from the provided documents. Therefore, human expertise remains essential for critical reasoning, methodological design, and context-specific flood susceptibility assessment.
Open peer review
To view the open peer review materials for this article, please visit http://doi.org/10.1017/eds.2026.10037.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/eds.2026.10037.
Author contribution
Conceptualization: M.J.F., A.P.; Data curation: M.J.F., A.P.; Formal analysis: M.J.F., A.P.; Investigation: M.J.F., A.P.; Methodology: M.J.F., A.P.; Validation: M.J.F., A.P.; Visualization: M.J.F., A.P.; Writing - original draft: M.J.F., A.P.; Writing - review & editing: M.J.F., A.P.; Funding acquisition: M.J.F.; Project administration: M.J.F.; Resources: M.J.F.; Supervision: M.J.F.
Data availability statement
The Chat-FSM GPT, configured with retrieval access to 100 reviewed articles, is available for free access via the following GitHub link: https://chatgpt.com/g/g-j9VsJLbne-chatfsm-1. The details of the benchmark data can be found in Pourzangbar et al. (Reference Pourzangbar, Oberle, Kron and Franca2025). The responses of ChatGPT models are available in Supplementary Appendix A.









 Open access
Open access
Comments
Dear Professor Monteleoni,
We would like to submit a paper for possible publication in the Environmental Data Science. The manuscript entitled:
“How reliable is ChatGPT as virtual assistant in Flood Susceptibility Mapping?”
By Dr. Ali Pourzangbar & Prof. Mário J. Franca
Institute for Water and Environment (IWU), Karlsruhe Institute of Technology (KIT), Karlsruhe, Germany
ali.pourzangbar@kit.edu; mario.franca@kit.edu
In the current contribution (with two appendices), we explored the growing role and reliability of Large Language Models, i.e., ChatGPT, in answering key questions given the use of Machine Learn-ing models in Flood Susceptibility Mapping (FSM). We designed five key questions related to FSM, and the responses are extracted from our review article (published in the Journal of Flood Risk Man-agement) titled “Analysis of the Utilization of Machine Learning to Map Flood Susceptibility” (https://doi.org/10.1111/jfr3.70042), which analyzed 100 articles on the application of Machine Learning in FSM. These responses serve as benchmark data. Then, the same questions are made (i) directly to ChatGPT-4 and ChatGPT-4o with no further information, and (ii) to ChatGPT-4, as a basis for analysis, using the articles from the review as reference material (named Chat-FSM).
Our intention with this manuscript is to contribute to the discussion on how scientists and engineers can working in hydrological sciences make professional use of such AI tools as ChatGPT. We have significantly expanded our discussion on how much ChatGPT’s responses are reliable and how they can benefit flood managers and practitioners. Additionally, we analyzed the reasons behind the dis-crepancies between different ChatGPT models and their implications on the reliability of Flood Sus-ceptibility Mapping (FSM).
We believe this paper will provide valuable insights into the journal’s readership, especially given the increasing interest in applying AI to flood management. Thank you for considering our revised manu-script for publication.
Sincerely yours,
Ali Pourzangbar
Karlsruhe Institute of Technology (KIT)