


1. Introduction
Happiness is a complex concept that has been intensively researched from many perspectives (Stavrova, Reference Stavrova2019), but the linguistic aspects of this phenomenon and of the related positive emotions such as joy are still under-researched (e.g. Pflug, Reference Pflug2009). What can we learn about these concepts from language? Can a linguistically oriented piece of research help us to uncover how people understand happiness and joy, and can it reveal cross-cultural differences? What methods could be used to find answers to such questions?
This article focuses on two closely connected concepts – happiness and joy – in three West Slavic languages – Polish (PL), Czech (CZ) and Slovak (SK). These highly inflected and etymologically related languages represent three communities that share significant historical experience, including life under the Eastern European communist regime in the 20th century and the subsequent transition into democracy. Such experience has been identified as a factor that influences happiness (Djankov et al., Reference Djankov, Nikolova and Zilinsky2016; see Section 2). At the same time, happiness and positive emotions are under-analysed in West Slavic cultures. This all makes Polish, Czech and Slovak particularly interesting subjects for research.
The presented research is based on data retrieved from large multilingual comparable corpora and uses specialised corpus tools for the analysis of semantically similar words (word embedding; see Section 3). Basic expressions for the concepts of happiness (szczęście PL, štěstí CZ, šťastie SK) and joy (radość PL, radost CZ, radosť SK) in Polish, Czech and Slovak are analysed and compared with corresponding results for the words happiness, luck and joy in English (EN) (see Section 4). I could not include other (so-called non-dominant or minority) West Slavic languages, such as Kashubian, Lower Sorbian, Upper Sorbian or Pannonian Rusyn (Brankačkec et al., Reference Brankačkec, Kocková, Knoll and Greenberg2024), in the analysis as no suitable data are available for the type of analysis I present in this study.
The main research questions are as follows:
-
(1) What information about similarities and differences between the concepts of happiness and joy in Polish, Czech, Slovak and English can be reconstructed from the automated measurement of the semantic similarity of lexical units (word embedding) in large language corpora?
-
(2) What are the advantages and limitations of the data obtained through the word-embedding analysis for the reconstruction of speakers’ understanding of the concepts of happiness and joy?
Based on the previous research on happiness and joy (summarised in Section 2), I have several expectations (hypotheses) concerning the concepts of happiness and joy in the analysed languages (specification of research question (1)):
-
(1a) There is a difference in the conceptualisation of happiness between English and the three West Slavic languages (e.g. Djankov et al., Reference Djankov, Nikolova and Zilinsky2016; cf. Section 2). I expect that the component of luck (chance) will play a role in the difference (e.g. Oishi et al., Reference Oishi, Graham, Kesebir and Galinha2013; cf. Section 2.1).
-
(1b) The conceptualisation of happiness is similar in Polish, Czech and Slovak, but it is not identical; I expect that differences in the conceptualisation are related to religion (cf. Section 2.2).
-
(1c) The conceptualisation of joy is similar in English, Polish, Czech and Slovak.
-
(1d) The concepts of happiness and joy are related in all four analysed languages.
Expectations (1c) and (1d) were chosen as the starting points because there has not been enough research on the concept of joy in the West Slavic languages to date (see Section 2.2).
-
(1e) Because the research is mostly inductive (see Section 3), other features of happiness and/or joy, not mentioned above, may be revealed by the analysis.
In the case of the second research question, I have the following expectations (hypotheses):
-
(2a) The word-embedding analysis can be used for the reconstruction of speakers’ understanding of concepts and of the cross-cultural concept differences. This expectation is based on the theoretical assumptions that lexical units are related to the concepts as their lexical exponents and that speakers’ understanding of the world can, to a certain degree, be reconstructed from language (e.g. Bartmiński, Reference Bartmiński2010; Wierzbicka, Reference Wierzbicka1997, Reference Wierzbicka2004; Scheer, Reference Scheer2012; cf. Section 2.1).
-
(2b) The main limitation of the word-embedding analysis is its automatic character. I expect that human oversight and human interpretation of the results are necessary (cf. Section 3.2).
In the following sections, I summarise relevant research to date (Section 2), with a special focus on language and linguistics (Section 2.1) and on Polish, Czech and Slovak (Section 2.2). I then go on to set out the nature of the data and the research methods (Section 3). Section 4 presents an analysis of words semantically similar to the above-listed basic expressions for happiness and joy in English and the three West Slavic languages. The article ends with a general discussion and a conclusion (Section 5).
Throughout the article, I use italics for lexical units and other linguistic examples and standard type for concepts. I use the following abbreviations for the analysed languages: EN (English), PL (Polish), CZ (Czech) and SL (Slovak). In order to avoid repeated and lengthy web links to results of the word-embedding analysis by SEMÄ (Section 3.2) in the body of the article, I have listed all such web links in the section ʻWeb links to SEMÄ resultsʼ at the end of the article (before ʻDataʼ and ʻReferencesʼ) and refer to them by numbered abbreviations (e.g. SEMÄ result 1).
2. Happiness and joy: research to date
Happiness is a concept that is highly valued in many cultures and that has been studied for centuries (Stavrova, Reference Stavrova2019). Joy has not attracted so much attention in academia, but it is usually included in various studies of emotions (e.g. Ekman, Reference Ekman2015; Gruber, Reference Gruber2019). A large body of research on happiness and related phenomena such as well-being and life satisfaction (e.g. Humpert, Reference Humpert2010; Stavrova, Reference Stavrova2019) has already been accumulated in psychology, sociology and the economic sciences. In contrast to this, linguistic analyses are far less frequent, especially in Slavic languages.
Happiness is a very complex phenomenon with multiple facets (cognitive, affective, hedonic, eudaimonic) (cf. Stavrova, Reference Stavrova2019). The affective aspect of happiness represented by the emotions is important for this analysis because it can explain the relationship between happiness and joy as reflected in the linguistic data (see Section 4). Happiness is related to and influenced by multiple individual and societal phenomena (e.g. Olivos, Reference Olivos2020; Stavrova, Reference Stavrova2019). Societal factors are also relevant for the analysed West Slavic cultures (see below).
The accumulated research confirms that the concept of happiness varies from culture to culture (e.g. Olivos, Reference Olivos2020) and can change over time (Inglehart et al., Reference Inglehart, Foa, Peterson and Welzel2008). The research by Inglehart et al. (Reference Inglehart, Foa, Peterson and Welzel2008) is important for this study because it describes changes in the level of happiness in countries that experienced the fall of the communist regime and whose inhabitants have increasing ‘free choice in how to live their lives’ (Inglehart et al., Reference Inglehart, Foa, Peterson and Welzel2008, 279). Inglehart et al. (Reference Inglehart, Foa, Peterson and Welzel2008) also note that the collapse of the communist regime was preceded by falling levels of subjective well-being. In addition, Djankov et al. (Reference Djankov, Nikolova and Zilinsky2016) describe a lower overall level of happiness in Eastern European countries and call it ʻthe happiness gapʼ in Eastern Europe. Although the general expectation is that this ʻhappiness gapʼ would gradually close (cf. Humpert, Reference Humpert2010), Djankov et al. (Reference Djankov, Nikolova and Zilinsky2016) observe that it still exists and is not indeed closing.
A range of research methods have been used to study happiness; a large body of research is comparative (e.g. World Happiness Report, n.d. https://worldhappiness.report/about/; retrieved April 16, 2025). In cross-cultural comparative research, methods such as questionnaire surveys are common (e.g. Oxford Happiness Questionnaire, cf. Hills & Argyle, Reference Hills and Argyle2002; Bucher, Reference Bucher2021). Cross-cultural comparisons of happiness are complicated by the fact that achieving cross-cultural comparability is problematic (Cieciuch et al., Reference Cieciuch, Davidov, Schmidt and Algesheimer2019). It might also be difficult to interpret what the differences in the level of happiness mean for the research participants (e.g. Shiraev & Levy, Reference Shiraev and Levy2020). Cross-cultural comparative research must, therefore, tackle the key problem of reconstructing people’s understanding of happiness. I believe that language can be a fruitful source of such information.
2.1. Happiness, joy, language and linguistics
As noted, the relationship between happiness and language is under-studied (e.g. Pflug, Reference Pflug2009), even though the study of language can enrich our understanding of various complex concepts, including happiness (Oishi et al., Reference Oishi, Graham, Kesebir and Galinha2013). Scheer (Reference Scheer2012) also suggests that language is important for communicating and understanding emotions: language helps us ‘name’ the individually unique experience, categorise it and communicate it. A focus on language also makes us aware that seemingly equivalent linguistic units may have different ‘meanings’ in various languages and cultures (cf. Mikołajczuk, Reference Mikołajczuk2013; Wierzbicka, Reference Wierzbicka2004, see below).
Language has been used in several ways in research on happiness. Some researchers study how people talk about happiness, using either spontaneous or induced verbal production. For example, Moreno-Ortiz et al. (Reference Moreno-Ortiz, Pérez-Hernández and García-Gámez2022) have used such data to identify ‘food’ and ‘newness’ as signals of happiness in speakers of English. Linguistic production can also be analysed for typical structures used by speakers who are or are not happy (e.g. Vine et al., Reference Vine, Boyd and Pennebaker2020). What is important is the finding that not only overtly positive expressions are important; negative or neutral expressions are equally so (e.g. Moreno-Ortiz et al., Reference Moreno-Ortiz, Pérez-Hernández and García-Gámez2022; Vine et al., Reference Vine, Boyd and Pennebaker2020).
Verbal associations of happiness are another possible source of data. It has been proven that they are culture-specific and therefore relevant for cross-cultural research. For example, Shin et al. (Reference Shin, Suh, Eom and Kim2018) have found that the most frequent lexical association of happiness for speakers of Korean was ‘family’, and for speakers of American English, it was ‘smile’.
The research by Oishi et al. (Reference Oishi, Graham, Kesebir and Galinha2013) is particularly relevant for my analysis, although no West Slavic language has been included in the study. Oishi et al. (Reference Oishi, Graham, Kesebir and Galinha2013) analysed dictionary definitions of happiness in 30 languages, and they showed that 24 out of the 30 languages see luck or fortune as a component of happiness. This component was not present in translation dictionaries in the United States, Argentina, Ecuador, India, or Kenya. The analysis of changes in the definition of happiness in American English since the 18th century has shown that the presence of the component of luck or fortune has been decreasing, both in Webster’s dictionary and in the speeches of American presidents, with a salient drop around the year 1920, that is, soon after the end of the First World War (Oishi et al., Reference Oishi, Graham, Kesebir and Galinha2013).
Within linguistics, cognitive and cultural linguistics are highly relevant for my study (e.g. Lakoff, Reference Lakoff2016). These approaches pay close attention to detailed analyses of various complex concepts, including emotions and happiness. Conceptual metaphors (e.g. Lakoff & Johnson, Reference Lakoff and Johnson1987) as a specific mechanism of human thinking about emotions have been studied by Kövecses (Reference Kövecses2017, Reference Kövecses2000). Kövecses lists numerous metaphors of emotion (mostly in English), including metaphors of happiness (e.g. happiness is a fluid in a container, happiness is insanity; Kövecses, Reference Kövecses2017, 160 and 164), and shows cross-cultural differences and changes over time (Kövecses, Reference Kövecses2017). Emotions and happiness are also conceptualised through metonymies that are related to various aspects of human experience, for example, the behavioural, physiological and expressive reactions to the given psychological state (cf. metonymies such as bright eyes for happiness, smiling for happiness; Kövecses, Reference Kövecses2017, 161). Although the topic of metaphors and metonymies is important for cognitive linguistics, the corpus methods applied in this study are not designed for metaphor and metonymy analysis.
Cognitive linguistics also attempts to explain emotions on the more general level of cognitive models (e.g. Kövecses, Reference Kövecses2000), cultural scripts or scenarios (e.g. Goddard & Wierzbicka, Reference Goddard and Wierzbicka2014; Wierzbicka, Reference Wierzbicka and Trosborg2010), or the linguistic image of the world (e.g. Bartmiński, Reference Bartmiński2010). This field overlaps with the more general topic of lay theories (e.g. Sedláková, Reference Sedláková2004, see below). All these theoretical approaches see language as a major ‘vehicle’ of these culturally shared models, scenarios or images and can profit from linguistic analyses of corpus data.
Kövecses’s theory of cognitive models proposes general models of emotions that include components such as the cause of the emotion, the existence of the emotion, attempt at control, loss of control and action (e.g. Kövecses, Reference Kövecses2017). Kövecses combines the concepts of happiness and joy into a single cognitive model (Kövecses, Reference Kövecses2017).
Wierzbicka (Reference Wierzbicka1997; Reference Wierzbicka2004) and Goddard and Wierzbicka (Reference Goddard and Wierzbicka2014) study the values hidden ‘behind’ the lexicon of a given language. Wierzbicka (Reference Wierzbicka1997; Reference Wierzbicka and Trosborg2010) develops the theory of cultural key words as those words that denote values that are important in the given culture. Wierzbicka believes that by analysing these words, we can reveal the system of values of the given community. Cultural scripts are then ‘tacit norms, values and practices widely shared, and widely known (on an intuitive level) in a given society’ (Wierzbicka, Reference Wierzbicka and Trosborg2010, 43). We could ask whether ‘happiness’ is a cultural key word in any of the languages analysed in this study, but again we would need different research methods to demonstrate it.
Goddard and Wierzbicka (Reference Goddard and Wierzbicka2014) also describe mental scenarios for happiness and show that there are significant cross-cultural differences. For example, the English word happiness has developed from describing a rare and very good feeling to (just) a good feeling that should ideally last a lifetime, but in German, Glück ʻhappiness, luckʼ has preserved the original meaning of an exceptionally good and rare feeling. The findings concerning the German Glück ʻhappiness, luckʼ are relevant for West Slavic languages because of the longitudinal influence of German in the region. Wierzbicka (Reference Wierzbicka2004) and Goddard and Wierzbicka (Reference Goddard and Wierzbicka2014) have also demonstrated that there are differences in the concept of happiness between British and American English and that the component of fortune or luck is important. This demonstration of differences between British and American English is important because it shows that it would be beneficial to use specific sources of data (i.e. corpora) not only for individual languages but also for different varieties of the same language.
Bartmiński’s theory of the linguistic image of the world (linguistic worldview; Bartmiński, Reference Bartmiński2010) states that each language represents a certain interpretation of the world and that we can reconstruct this interpretation from language. The theory also believes that a culture-specific understanding, categorisation and evaluation of the world is transferred between generations through language. The analysis of language can thus show us the everyday (naïve, lay) understanding of happiness and joy which is specific to the given linguistic community.
Bartmiński’s theory is close to so-called lay theories. I define a lay theory as a non-specialist understanding of phenomena (e.g. happiness). Lay theories of emotions and happiness are related to lay (folk) psychology (e.g. Sedláková, Reference Sedláková2004) and are incorporated into a whole system of lay theories of other aspects of human experience. Lay theories are usually structured, based on models and practically oriented towards lay people’s experience and everyday needs (Sedláková, Reference Sedláková2004).
The research to date has studied lay theories of happiness with respect to people’s beliefs about factors that influence happiness (e.g. Furnham et al., Reference Furnham, Cheng and Shirasu2001) and has revealed that the lay understanding rarely corresponds to findings by academics (e.g. Furnham et al., Reference Furnham, Cheng and Shirasu2001; Pflug, Reference Pflug2009). Cross-cultural differences in lay theories have also been observed, for example, between the United States of America and Japan (Uchida & Kityama, Reference Uchida and Kityama2009), between the United Kingdom of Great Britain and Northern Ireland, China and Japan (Furnham et al., Reference Furnham, Cheng and Shirasu2001), or between Germany and South Africa (Pflug, Reference Pflug2009). Language is recognised as an important medium that spreads lay theories in the community (e.g. Visakko & Voutilainen, Reference Visakko and Voutilainen2020) and that can be used for their reconstruction (e.g. Scheer, Reference Scheer2012). Lay theories in children have also been examined. For example, Pivarč shows that Czech primary school children associate happiness with ‘interpersonal aspects of life and with the need for personal growth’ (Pivarč, Reference Pivarč2023, 138).
Joy has attracted much less attention than happiness, but Mikołajczuk (e.g. Reference Mikołajczuk2007; Reference Mikołajczuk2009; Reference Mikołajczuk2013) has analysed the concept of radość ʻjoyʼ in Polish from the perspective of cognitive linguistics, which is highly relevant for this study (see Section 2.2).
2.2. Polish, Czech and Slovak
Polish, Czech and Slovak represent national languages of three countries – Poland, the Czech Republic and Slovakia – which have interwoven cultural and historical experience. According to the World Atlas of Languages (n.d.) (https://en.wal.unesco.org/; retrieved April 16, 2025), there are approximately 37.8 million speakers of Polish in Poland, 9.2 million speakers of Czech in the Czech Republic and 4.2 million speakers of Slovak in Slovakia (additional speakers of each language live outside these states and speakers of other languages live in these countries). Slavic linguistics and historical linguistics see the three languages as genetically closely related and as culturally and sociolinguistically close (e.g. Brankačkec et al., Reference Brankačkec, Kocková, Knoll and Greenberg2024; Rejzek, Reference Rejzek2021).
In addition to their close geographical position in Europe, Polish-, Czech- and Slovak-speaking communities share much historical experience. For example, Czechs and Slovaks lived in a common state for most of the 20th century, and all three communities experienced life under the communist regime in the second half of the 20th century. These geographical and political factors have both been identified as important for the experience of happiness (see Section 2). However, it is important to keep in mind that each of these communities also has its own unique experiences that may influence happiness. There is also a difference in the role religion plays in the three countries: while religion is alive in Polish and Slovak society, Czech society has experienced a longitudinal decrease in interest in institutionalised religion (e.g. Havlíček et al., Reference Havlíček, Klingorová and Lysák2017).
The World Happiness Report for 2024 (https://data.worldhappiness.report/table) states that the 3-year average value of ʻhappinessʼ (or ʻlife evaluationʼ) scores between 6 and 7 points (out of the maximum of 10) for all three countries (Poland 6.673; Czech Republic 6.775; Slovakia 6.221). It also reports that the average value of ʻhappinessʼ has grown during the last 12 years (since 2012) in all three countries, but this growth corresponds to less than one point on the scale (Poland 0.851; Czech Republic 0.485; Slovakia 0.252).
There has been relatively little linguistically oriented research on happiness and joy in these languages. As mentioned above, Mikołajczuk (Reference Mikołajczuk2007, Reference Mikołajczuk2009, Reference Mikołajczuk2013) has analysed the Polish radość ʻjoyʼ in detail. She states that there are several different ʻmodelsʼ of radość ʻjoyʼ in Polish (Mikołajczuk, Reference Mikołajczuk2009): joy as a reaction to an event; joy related to activity; joy associated with sensory perception; joy associated with entertaining oneself; joy as being merry; joy without a cause; and joy in the form of a permanent, deep, and highly valued state of ʻpermanent happinessʼ. In a later study, Mikołajczuk (Reference Mikołajczuk2013) offers a suggestion to classify radość ʻjoyʼ as superordinate to szczęście ʻhappinessʼ. In my analysis of corpus data, the subordinate–superordinate relationship has not been confirmed (see Section 4). There is no in-depth linguistic analysis of happiness and joy in Czech and Slovak, but selected lexical units denoting happiness and/or joy are mentioned in several analyses based on various theoretical backgrounds (e.g. Bergerová et al., Reference Bergerová, Vaňková, Mostýn, Cieślarová and Malá2015; Kyseľová & Ivanová, Reference Kyseľová and Ivanová2013; Pala & Šáchová, Reference Pala and Šáchová1986; Saicová Římalová, Reference Saicová Římalová, Sytar, Schillová, Skwarska and Veselý2025).
Wilson et al. (Reference Wilson, Lewandowska-Tomaszczyk, Niiya, Fontaine, Scherer and Soriano2013) focus on happiness and contentment in English and szczęście ʻhappinessʼ and zadowolenie ʻsatisfaction, contentmentʼ in Polish from the point of view of components of the emotion meanings (e.g. valence, power, arousal, novelty). They conclude that the Polish szczęście ʻhappinessʼ is associated with higher arousal, energy and activation than the English happiness, probably because of the component of luck connected to the polysemic Polish szczęście ʻhappinessʼ (Wilson et al., Reference Wilson, Lewandowska-Tomaszczyk, Niiya, Fontaine, Scherer and Soriano2013, 481). They also state that the Polish szczęście ʻhappinessʼ is a more intense emotion than the English happiness (Wilson et al., Reference Wilson, Lewandowska-Tomaszczyk, Niiya, Fontaine, Scherer and Soriano2013, 481). Rodziewicz (Reference Rodziewicz2010) points towards a possible shared basic understanding of happiness in Slavic languages that contains components such as success, wealth, generosity in interpersonal relations, short duration and unattainability.
3. Data and methods
The research is based on an analysis of the semantic similarity between words (word embedding, see Section 3.2) which uses data retrieved from the Aranea corpora (Section 3.1).
3.1. Data
The Aranea corpora (Benko, Reference Benko, Sojka, Horák, Kopeček and Pala2014) used in my research are comparable corpora in 27 different languages (Garabík, Reference Garabík2024), with a focus on languages spoken or taught in Slovakia and in its neighbouring countries (http://aranea.juls.savba.sk/aranea_about/index.html, retrieved February 4, 2026). They are available through the Slovak National Corpus portal (https://korpus.sk/ and http://aranea.juls.savba.sk/) and hosted, among others, by the Czech National Corpus (https://korpus.cz/). There are other corpora suitable for comparative research (e.g. the InterCorp corpora of the Czech National Corpus, https://intercorp.korpus.cz/; the parallel corpora par of the Slovak National Corpus, https://korpus.sk/en/corpora-and-databases/snc-corpora/parallel-corpora/), but I have chosen the Aranea corpora because the SEMÄ tool (Section 3.2) was trained on them, is bound to them and cannot be transferred elsewhere.
The Aranea corpora contain texts retrieved from the Internet and offer collections of similar size. The Aranea corpora used in the research are listed in Table 1. It was not possible to choose a specific variety of English (which would be more appropriate for a cross-cultural comparison) because the SEMÄ tool does not distinguish between different varieties of English.
The Aranea corpora used in the research, their size and web links to further information (all information retrieved April 23, 2025)

3.2. Methods: word embedding and the SEMÄ tool
My research is based on the analysis of semantic similarity (word embedding). The data for the analysis were obtained through the SEMÄ tool of the Slovak National Corpus (Garabík, Reference Garabík2020; https://www.juls.savba.sk/sem%C3%A4.html). This tool uses an incorporated neural network to analyse the semantic similarity between lexical units according to their distribution. It is also able to visualise and measure ʻthe degreeʼ of semantic similarity between lexical units (see below).
The general mechanism of the analysis by SEMÄ builds upon the traditional structuralist and distributionalist (e.g. Matthews, Reference Matthews2005) ideas which suggest that: (a) ‘language is not merely a bag of words but a tool with particular properties which have been fashioned in the course of its use’ (Harris, Reference Harris1954, 156); (b) the meaning of a unit can be defined by the relationships between the given unit and other units; and (c) ‘difference in meaning correlates with difference of distribution’ (Harris, Reference Harris1954, 156).
Using today’s computational and corpus methods, the linguistic units and the relationships between them can be represented as vectors in vector space. SEMÄ represents each lexeme as a unique vector (Garabík, Reference Garabík2024, 34). Such methods are usually called ‘word embedding’ (Garabík, Reference Garabík2020, 604). Garabík (Reference Garabík2024, 34) believes that this type of vector representation is useful, for example, in lexicography. I test the suitability of this approach for cross-cultural comparison of concepts.
Technically, the SEMÄ tool is powered by Gensim (ʻGenerate similarityʼ, https://radimrehurek.com/gensim/index.html, retrieved February 4, 2026). Gensim is an open-source Python library of algorithms that can be used to represent plain digital texts as vectors in a multidimensional space (cf. Řehůřek & Sojka, Reference Řehůřek and Sojka2010, 46–47) and to automatically discover semantic structures of texts. The algorithms are based on the analysis of statistical co-occurrence patterns within the given corpus, and they can be trained without human supervision (cf. https://radimrehurek.com/gensim/intro.html#design-principles, retrieved February 4, 2026). The SEMÄ visualisation of data uses the Gnuplot software (Garabík, Reference Garabík2020), a programme that produces graphs from data or functions and enables users to present and explore data in a graphical mode (http://gnuplot.info/, retrieved February 4, 2026; cf. Janert, Reference Janert2016). The SEMÄ tool also offers a link to the raw dimensionality coordinates in a Gnuplot format. SEMÄ has a user-friendly web interface with query fields; no specific query language is required to formulate the queries. The basic results of the analysis by SEMÄ are available freely to all users; access to occurrences and other data in the Aranea corpora requires registration.
The SEMÄ tool offers three basic models of analysis: a) the model trained on lemmas and parts of speech, b) the model trained on word forms and c) the model trained on character n-grams on the sub-word level (Garabík, Reference Garabík2020, 606–607). I have used the model based on lemmas and parts of speech because the semantic information crucial for my analysis is carried by lemmas. This model is also recommended as the most suitable model for linguistic analysis by the authors of SEMÄ (https://www.juls.savba.sk/sem(c3a4).html, retrieved February 7, 2026). The model based on word forms would be more suitable for the analysis of inflectional forms and syntactic features and the model based on character n-grams for the analysis of compound words (cf. Garabík, Reference Garabík2020, 606–607).
The SEMÄ tool is able to visualise the similarities and differences between vectors that represent the semantics of each lexical unit in several formats (cf. Garabík, Reference Garabík2020; https://www.juls.savba.sk/sem(c3a4).html, retrieved February 7, 2026). The visualisations place the analysed lexical unit into the centre of an abstract space and show its relationships to words that appear to be semantically similar to the given unit in the given corpus. They also organise the semantically similar words into clusters, adding extra information about the relationships within the group of semantically similar units. Each lexical unit is represented by a circle whose size reflects the unit’s frequency in the corpus. The Gnuplots for the lexical units analysed in my research can be viewed in SEMÄ results 1–9 (section ʻWeb links to SEMÄ resultsʼ).
The SEMÄ tool is also able to measure the degree of semantic similarity between two words (see Tables 2–5 in Section 4). Because the meanings of the words are represented as vectors (see above), basic vector arithmetic can be performed on them, that is, the addition and subtraction of vectors that corresponds to the addition and subtraction of meanings (Garabík, Reference Garabík2020). The degree of semantic similarity of various units can also be quantified as the difference between the respective vectors. SEMÄ measures semantic similarity between two units using the angle θ between the corresponding vectors: vectors representing semantically highly similar words are close to being parallel; vectors representing semantically unrelated words are close to forming a right angle (Garabík, Reference Garabík2020). SEMÄ then presents the degree of semantic similarity in numerical form as sin θ: this number is close to zero for semantically similar words (the closer to zero the number is, the smaller the semantic difference between the units) and close to one for semantically unrelated words (Garabík, Reference Garabík2020).
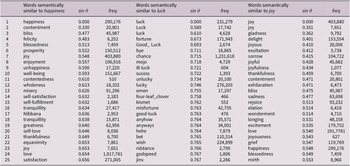
The first 25 semantically most similar words to the English words happiness, luck and joy according to SEMÄ, their sin θ and absolute frequency (ordered according to sin θ)

Sources: SEMÄ results 1, 2, 3.
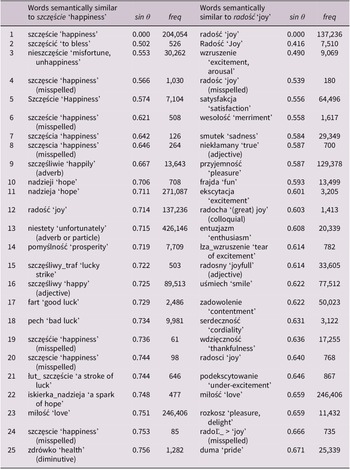
The first 25 semantically most similar words to the Polish words szczęście ʻhappinessʼ, radość ʻjoyʼ according to SEMÄ, their basic translation into English, their sin θ and absolute frequency (ordered according to sin θ)

Sources: SEMÄ results 4, 5.
The first 25 semantically most similar words to the Czech words štěstí ʻhappinessʼ, radost ʻjoyʼ according to SEMÄ, their basic translation into English, their sin θ and absolute frequency (ordered according to sin θ)

Sources: SEMÄ results 6, 7.
The first 25 semantically most similar words to the Slovak words šťastie ʻhappinessʼ, radosť ʻjoyʼ according to SEMÄ, their basic translation into English, their sin θ and absolute frequency (ordered according to sin θ)

Sources: SEMÄ results 8, 9.
The main advantage of the SEMÄ tool is its ability to offer new insights into word meanings and semantic relationships in the lexicon. The relationships are reconstructed automatically from large bodies of texts, and the tool uses a relatively low threshold for frequency (10 occurrences in the given corpus; Garabík, Reference Garabík2020). The tool is, therefore, efficient, sensitive and able to discover relationships that a human researcher might not look for. For example, the results of the analysis typically contain synonyms of the analysed lexical units, which is an intuitively expected outcome. However, the automatic analysis based on distribution and co-occurrence can also reveal other types of relationships, such as: a) relationships between lexical units that are semantically similar but belong to different parts of speech; b) relationships between the analysed unit and its antonyms, which can be reconstructed, for example, from contexts where the analysed lexical unit combines with negation; c) relationships between the analysed lexical unit and other parts of speech that often co-occur in syntactic constructions (cf. Section 4). Some of these relationships may be ‘rare, but relevant’ (Garabík, Reference Garabík2020, 605).
The low threshold for frequency and the automatic character of the analysis are also the main disadvantages of the SEMÄ tool. The low threshold for frequency makes the tool sensitive to typing errors, mis-lemmatisation, or mis-tokenisation (Garabík, Reference Garabík2020). It can also fail to connect units that belong together (e.g. various spelling variants of the same unit) or can propose connections that are in fact only coincidental (see Section 4). The incorporated neural network and the fact that the system is trained without human supervision (see above) also make the exact inner mechanisms of the analysis opaque for human users. This is a drawback of all similar automatic tools of computerised natural language processing (e.g. Lane & Dyshel, Reference Lane and Dyshel2025). In the case of SEMÄ, the results of the similarity measurements, the frequency data, the visualisations and lists of all concordances from the Aranea corpora are available for further linguistic research, but the description of the calculation procedure is not available.
Linguistic research that uses the SEMÄ tool thus starts at a more abstract level than it usually does: not with sets of occurrences of given linguistic items that the linguists would analyse, but with the more abstract measurements of semantic similarity produced by the SEMÄ tool. This is also the reason I do not present and discuss examples of contextualised corpus attestations of the analysed lexical units in my study. Such examples would illustrate the usage of the words in the given language, but they would bring little information about the complex measurement procedure. In contrast to this, I have used the corpus attestations to reveal obvious mistakes in the results, such as mis-lemmatisations (see below).
I have compensated for the above-mentioned limitations of the SEMÄ tool by manually checking the data (e.g. for typing errors or mis-lemmatisation) and by applying my own (human) interpretation of the results (see Section 4). During the manual check of the data, I used the linked concordances in the Aranea corpora (see above) in the SEMÄ results to check whether the lexical unit listed in the results corresponds to the data (e.g. whether there are any mis-lemmatisations or whether the relevant meaning of a potentially polysemous lexical unit is taken into account). I comment on the typing errors, mis-lemmatisation and other similar phenomena in passim in Section 4.
4. Results: happiness and joy – an analysis of semantically similar words
The following West Slavic lexical units were analysed in this study: szczęście PL, štěstí CZ, šťastie SK, as basic lexical units denoting happiness; and radość PL, radost CZ, radosť SK as basic lexical units denoting joy. The expressions happiness and joy were used as the basic lexical units denoting the two analysed concepts in English. The lexical unit luck was added as the English lexical expression for the component of luck because I expect that this component will be important in the West Slavic concept of happiness (cf. expectation (1a) in Section 1).
The basic (ʻdictionaryʼ) definitions of the West Slavic lexical units denoting happiness are very similar; the same is true of the three lexical units for joy. Lexical units denoting happiness (szczęście PL, štěstí CZ, šťastie SK) are all polysemous, with two basic meanings: (a) ʻthe feeling or state of full satisfaction, blissʼ, and (b) ʻfavourable circumstancesʼ (Filipec et al., Reference Filipec and Daneš2012; Kačala et al., Reference Kačala, Pisarcikova and Považaj2003; Żmigrodzki et al., Reference Żmigrodzki, Bańko, Batko-Tokarz, Bobrowski, Czelakowska, Grochowski, Przybylska, Waniakowa and Węgrzynek2004–2024). In addition to this, the Czech noun is assigned the meaning ʻsuccessʼ by Filipec et al. (Reference Filipec and Daneš2012). Dictionary definitions thus place Polish, Czech and Slovak among those languages that associate happiness with luck (see Section 2.1). According to ʻdictionaryʼ definitions, the West Slavic lexical units denoting joy (radość PL, radost CZ, radosť SK) primarily denote emotional states of joy and psychological satisfaction (Filipec et al., Reference Filipec and Daneš2012; Kačala et al., Reference Kačala, Pisarcikova and Považaj2003; Żmigrodzki et al., Reference Żmigrodzki, Bańko, Batko-Tokarz, Bobrowski, Czelakowska, Grochowski, Przybylska, Waniakowa and Węgrzynek2004–2024). The Slovak and Polish dictionaries (Kačala et al., Reference Kačala, Pisarcikova and Považaj2003; Żmigrodzki et al., Reference Żmigrodzki, Bańko, Batko-Tokarz, Bobrowski, Czelakowska, Grochowski, Przybylska, Waniakowa and Węgrzynek2004–2024) add the metonymical meaning ʻsomething or someone who is causing joyʼ.
The three West Slavic lexical units for happiness are etymologically related and so are the three lexical units for joy. Etymological dictionaries state that the West Slavic lexical units denoting happiness (szczęście PL, štěstí CZ, šťastie SK) are related to a compound lexical unit where the initial sъ meant ʻgoodʼ and the remaining part (čęść PL, čęstъ CZ, čęst SK) meant ʻpartʼ; the reconstructed meaning is thus ʻgood partʼ (Boryś, Reference Boryś2008; Králik, Reference Králik2015; Machek, Reference Machek1957; Rejzek, Reference Rejzek2015). The West Slavic lexical units denoting joy (radość PL, radost CZ, radosť SK) are related to older adjectives rad PL, rád CZ and rád SK, all meaning ʻgladʼ (Boryś, Reference Boryś2008; Králik, Reference Králik2015; Machek, Reference Machek1957; Rejzek, Reference Rejzek2015). These adjectives are present in all Slavic languages, but they do not have many etymological relatives (e.g. rather in English; Machek, Reference Machek1957, 412). The etymology of these adjectives is not clear. According to Rejzek (Reference Rejzek2015, 576–577), the original meaning might have been ʻto successfully carry outʼ or ʻto cheer upʼ. Mikołajczuk (Reference Mikołajczuk2007, 58) links the Polish noun radość ʻjoyʼ to the reconstructed adjective *radъ ʻcontent, merryʼ.
The data for the analysis were retrieved from the Aranea corpora using the SEMÄ tool (see Section 3.2). I used the visualisation in two-dimensional graphs (Gnuplots) produced by SEMÄ as the basis for a verbal description of relationships between semantically similar words (cf. SEMÄ results 1–9). I also used the sin θ measure (see Section 3) of the first 25 words that were identified as the most semantically similar to the analysed lexical units (see Tables 2–5). SEMÄ’s query interface was used to formulate the queries; queries for lemmas were used to retrieve the data (see Section 3.2). The results are valid as of March 2025. The results are presented as follows: happiness, luck and joy in English (Section 4.1); happiness and joy in the three West Slavic languages (Section 4.2); and a comparison of happiness and joy in the three West Slavic languages and in English (Section 4.3).
4.1. English happiness, luck and joy
Table 2 summarises the results of the sin θ measurement of semantic similarity for words indicated by SEMÄ as the first 25 semantically closest words to the words happiness, luck and joy (cf. SEMÄ results 1, 2, 3). Absolute frequencies (freq) for each item are also included.
In the table, the analysed noun is always the first item in the list because any word is understandably most similar to itself. There are also some items that seem unrelated or only loosely related to the concepts of happiness, luck and joy (e.g. hehe as a result for luck), and some units are listed repeatedly, which might reflect a detected different behaviour of some sub-meanings of the polysemous units or it might be a mistake of the automated analysis that uses a low threshold (see Section 3.2). The results for happiness and joy are also more ʻcompactʼ than the results for luck. For example, the sin θ between the given word and the last item in the list is 0.553 for joy, 0.656 for happiness and 0.767 for luck, even though there are several repeated items in the results for luck. This might signal that there are more semantically closer synonyms to happiness and joy than to luck in English, but the result may again be influenced by the automated nature of the analysis.
In the following sections, I summarise the results for the lexical units happiness (Section 4.1.1), luck (Section 4.1.2) and joy (Section 4.1.3) and discuss the relationship between the three related concepts of happiness, luck and joy in English (Section 4.1.4).
4.1.1. Happiness
The SEMÄ results for the word happiness (cf. SEMÄ result 1 and Table 2) contain a relatively large set of abstract nouns that denote various psychological-emotional states that are close to happiness or that can be seen as related to it (e.g. satisfaction, well-being, thankfulness, tranquillity, self-love, self-fulfilment, self-satisfaction, contentment, contentedness, Nibbana, bliss, prosperity, enjoyment). Some antonyms of happiness understood as the psychological-emotional state are present (unhappiness, misery). The network contains a relatively high number of elements, but only a few of them are visualised as bigger circles that reflect the high frequency of the lexical items in the corpus (see Section 3.2). Among the visualised elements, love and joy appear to be the most important.
4.1.2. Luck
The results for the word luck (cf. SEMÄ result 2 and Table 2) reveal synonyms of luck (e.g. chance, good luck, fortune), words related to fate (e.g. kismet, omen) and words for items that can secure good luck (four-leaf clover). Antonyms denoting ʻbad luckʼ or concepts related to it (e.g. misfortune, ill-luck, unlucky, jinx) and the words wish and bet, which can function as both a noun and a verb, are also present.
4.1.3. Joy
The results for the word joy (cf. SEMÄ result 3 and Table 2) contain synonyms or near synonyms of joy as a positive emotion (delight, elation, joyfulness, excitement, rejoice, etc.), synonyms or near synonyms for sadness, representing the emotion opposite to joy (e.g. sadness, grief, sorrow, longing) and a cluster of expressions related to happiness (happiness, bliss, blessedness, contentment). Love, thankfulness and (to a lower degree) happiness are marked as frequent among the semantically similar words.
4.1.4. Relationships between happiness, luck and joy in English
The SEMÄ results (see Table 2) show that the concepts of happiness and luck denoted by the lexemes happiness and luck are distinct in English. This distinction is signalled by the fact that the lists of semantically similar words for the lexemes happiness and luck lack shared semantically similar words (the lists for happiness and luck are different). In addition to this, the opposites listed among the results for happiness and luck profile different meanings: the opposite misery, listed among the words semantically most similar to happiness, corresponds to happiness conceptualised as an emotion or a psychological state; the opposites ill-luck, unlucky and misfortune, listed among the words semantically most similar to luck, correspond to luck understood as chance, (good) fortune or (good) luck.
The results also signal that the concepts of happiness and joy are close, but the concepts of luck and joy are distant in English. This is indicated, for example, by the following signs of semantic closeness between the lexemes happiness and joy and semantic distance between the lexemes luck and joy: Happiness is listed among the words most semantically similar (sin θ 0.548) to joy, and (vice versa) joy is listed among the words most semantically similar to happiness (sin θ 0.548). Both words also share some semantically close words (e.g. contentment, love, thankfulness). Contrary to this, there is no similar overlap in the results for joy and luck.
4.2. West Slavic concepts of happiness and joy
Table 3 (Polish), Table 4 (Czech) and Table 5 (Slovak) summarise sin θ measurements and absolute frequencies (freq) for 25 words that have been identified as semantically most similar to the analysed nouns for happiness and joy in each of the three West Slavic languages. The tables present the results as they were produced by the SEMÄ tool. That is why they contain multiple spelling varieties and typing mistakes (e.g. szczęscie, szczęśćie in Polish; štestí, stěstí, uspěch, ůspěch in Czech) presented as separate items as well as multiple occurrences of the same item (e.g., in other than the representative form, szczęścia ʻhappinessʼ PL corresponds to G.sg, N.pl., A.pl or V.pl). Some units with an initial capital letter may represent proper nouns. This all is a result of the above-mentioned limitations of the method (see Section 3.2). At this stage, human oversight is important – for example, multiple occurrences of the same item might reflect different contexts (e.g. different syntactic constructions) that the given word is used in, or it may be a side-effect of the automated analysis. It would be useful if the researcher could ask SEMÄ to unite selected items and re-calculate the measurements, but such a function of SEMÄ is not currently available. At the same time, the low-frequency threshold (see Section 3.2) highlights spelling varieties that might signal various developmental tendencies in the given language (e.g. the simplification of orthography).
In the following sections, I discuss the results for the West Slavic lexical units denoting happiness (Section 4.2.1) and joy (Section 4.2.2). I then compare the concepts of happiness, luck and joy in Polish, Czech and Slovak (Section 4.2.3).
4.2.1. Happiness
The results for happiness in the three West Slavic languages (cf. SEMÄ results 4, 6, 8 and the similarity measurements in Tables 3–5) point towards the rich derivative morphology of Polish, Czech and Slovak. The results for the Polish noun szczęście ʻhappinessʼ (cf. SEMÄ result 4), Czech štěstí ʻhappinessʼ (cf. SEMÄ result 6) and Slovak šťastie ʻhappinessʼ (cf. SEMÄ result 8) reveal multiple words derivationally related to the basic nouns, for example, the adjective szczęśliwy ʻhappyʼ in Polish, the adjective šťastný ʻhappyʼ, the diminutive štěstíčko ʻhappiness, little good luckʼ, the noun štěstěna ʻFortunaʼ in Czech, and the adjective šťastný ʻhappyʼ and the noun šťastena ʻFortunaʼ in Slovak. Some positive qualities such as joy, love and hope are also present in all three West Slavic languages (radość ʻjoyʼ PL, miłość ʻloveʼ PL, nadzieja ʻhopeʼ PL; radost ʻjoyʼ CZ, láska ʻloveʼ CZ, naděje ʻhopeʼ CZ; radosť ʻjoyʼ SK, láska ʻloveʼ SK, nádej ʻhopeʼ SK). The Czech and Slovak results include success (úspěch ʻsuccessʼ CZ, úspech ʻsuccessʼ SK); the Polish results do not. Antonyms are present in all three languages (nieszczęście ʻunhappiness, misfortuneʼ PL, pech ʻbad luckʼ PL; neštěstí ʻunhappiness, misfortuneʼ CZ, smůla ʻbad luckʼ CZ; nešťastie ʻunhappiness, misfortuneʼ SK, smola ʻbad luckʼ SK).
4.2.2. Joy
The results (cf. SEMÄ results 5, 7, 9 and the similarity measurements in Tables 3–5) for West Slavic nouns denoting joy – radość PL (cf. SEMÄ result 5), radost CZ (cf. SEMÄ result 7), radosť SK (cf. SEMÄ result 9) – confirm the relationship between joy and feeling joyful, being merry (represented by, e.g., wesolość ʻmerrimentʼ PL, veselost ʻmerrimentʼ CZ, veselosť ʻmerrimentʼ SK) as well as love (e.g. miłość ʻloveʼ PL, láska ʻloveʼ CZ, láska ʻloveʼ SK). The results for all three languages also include various positive emotions that can be interpreted as related to joy, but having a different intensity – either higher (e.g. excitement – wzruszenie ʻexcitement, arousalʼ, ekscytacja ʻexcitementʼ, entuzjazm ʻenthusiasmʼ, and colloquial radocha ʻgreat joyʼ in Polish; nadšení ʻexcitementʼ, euforie ʻeuphoriaʼ in Czech; nadšenie ʻexcitementʼ, eufória ʻeuphoriaʼ in Slovak) or lower (e.g. satisfaction, contentment – zadowolenie ʻsatisfactionʼ PL, satysfakcja ʻsatisfactionʼ PL; potěšení ʻpleasureʼ CZ; potešenie ʻpleasureʼ SK). Nouns denoting sadness are present in Polish and Czech (smutek ʻsadnessʼ PL; smutek ʻsadnessʼ, ʻa state of mourningʼ CZ) but not in Slovak. The Czech results include nouns denoting fear (strach ʻfearʼ CZ) and fun (e.g. legrace ʻfunʼ CZ), but the Polish and Slovak results do not.
4.2.3. Similarities and differences between happiness, luck and joy in Polish, Czech and Slovak
The results based on corpus data (cf. Tables 3–5 and SEMÄ results 4–9) show that despite the etymological relatedness and the general semantic similarity of the analysed lexical units (see above), there are not only similarities but also cross-cultural differences between the three West Slavic languages.
The results confirm that in all three languages happiness is associated with both the psychological-emotional state of happiness and the component of fortune or (good) luck. This is indicated by the fact that antonyms to both these meanings are present among the semantically close words, that is, nieszczęście PL, neštěstí CZ, nešťastie SK denoting ʻunhappinessʼ or ʻmisfortuneʼ, and pech PL, smůla CZ, smola SK denoting ʻbad luckʼ. The emotion-luck duality is also signalled by other semantically close words: lexical units such as łut_szczęście (i.e. łut szczęścia) ʻstroke of luck’ PL, fart ʻgood luckʼ PL, vrtkavé ‘unstable’ SK, šťastěna ʻFortunaʼ SK, or štěstíčko ʻhappiness, little good luckʼ CZ are all typically associated with fortune and good luck. Words related to concepts such as love (miłość ʻloveʼ PL; láska ʻloveʼ CZ; láska ʻloveʼ SK) are typically associated with happiness as the psychological-emotional state. It is interesting that no synonyms for chance (e.g. náhoda ʻchanceʼ CZ) are present in the results.
According to the sin θ measurement (Tables 3–5), the tightness of the association between happiness and luck differs between the given languages. The Czech štěstí ʻhappinessʼ is more tightly associated with ʻfortune, (good) luckʼ than šťastie ʻhappinessʼ in Slovak and szczęście ʻhappinessʼ in Polish, which is a finding that was not expected beforehand (see Section 1). The difference is indicated by the fact that the opposites of happiness as a psychological-emotional state in Polish and Slovak (e.g. nieszczęście ʻunahppiness, misfortuneʼ PL, sin θ 0.553; nešťastie ʻunhappiness, misfortuneʼ SK, sin θ 0.697) are measured as semantically closer to the respective basic nouns szczęście ʻhappinessʼ PL and šťastie ʻhappinessʼ SK than the opposites for fortune and good luck (pech ʻbad luckʼ PL, sin θ 0.734; smola ʻbad luckʼ SK, sin θ 0.725). In Czech, the situation is reversed: smůla ʻbad luckʼ (i.e. the opposite of ʻfortune, good luckʼ) is semantically closer to štěstí ʻhappinessʼ than is neštěstí ʻunhappiness, misfortuneʼ (i.e. the opposite for happiness as the psychological-emotional state) to štěstí ʻhappinessʼ (cf. smůla ʻbad luckʼ CZ, sin θ 0.558; neštěstí ʻunhappiness, misfortuneʼ CZ, sin θ 0.708). The importance of ʻfortune, (good) luckʼ in the Czech štěstí ʻhappinessʼ is also supported by the high similarity between štěstí ʻhappinessʼ and the diminutive štěstíčko (ʻhappiness, little good luckʼ, sin θ 0.484), because this diminutive is frequently (but not exclusively) used in contexts where good luck or good fortune are relevant. In addition to this, the Czech noun neštěstí ʻunhappiness, misfortuneʼ can refer not only to unhappiness but also to bad luck. It is also used for various types of serious accidents, especially when people are injured or killed (e.g. vlakové neštěstí ʻtrain accidentʼ).
The results confirm the relationship between happiness and joy in all three languages but also reveal some differences in the nature of this relationship. The similarity between the basic nouns for happiness and joy is closest in Czech (sin θ between štěstí ʻhappinessʼ CZ and radost ʻjoyʼ CZ is 0.565). It is less close in Slovak (sin θ between šťastie ʻhappinessʼ SK and radosť ʻjoyʼ SK is 0.625) and least close in Polish (the list of the 25 words most similar to Polish szczęście ʻhappinessʼ includes radość ʻjoyʼ with sin θ 0.714, but the list of the 25 words most similar to Polish radość ʻjoyʼ does not include the word szczęście ʻhappinessʼ).
There are also some differences between the three languages concerning the opposites of joy. Results for Czech show sadness as the antonym of radost ʻjoyʼ (smutek ʻsadnessʼ, ʻa state of mourningʼ CZ, sin θ 0.679), but also fear (strach ʻfearʼ CZ, sin θ 0.678). There is only one antonym of radość ʻjoyʼ in the Polish results, and it refers to sadness (smutek ʻsadnessʼ PL, sin θ 0.584). No antonym of radosť ʻjoyʼ appears among the 25 words semantically most similar to radosť ʻjoyʼ in Slovak. The results thus signal that Czech joy might be more complex than joy in Slovak and Polish because it is connected to both sadness and fear.
The analysis also revealed some aspects specific to each of the three languages and cultures. For example, the results for the noun denoting happiness in Slovak contain lexical units typical of religious contexts (e.g. božie_požehnanie ʻgod’s blessingʼ SK, sin θ 0.687), but there are no lexemes specific to religious contexts in the Czech results. This difference corresponds to the different role religion plays in the two societies (see Section 2.2). Contrary to expectations (cf. Section 1), there are no overtly religious lexical units among the Polish results, although nadzieja ʻhopeʼ PL (nadzieji, sin θ 0.706; nadzieja, sin θ 0.711) and miłość ʻloveʼ PL (sin θ 0.751) can also function in this context. The inconsistencies in the results are not surprising, as the relationship between religion and happiness is complex and not yet fully understood (cf. Lewis et al., Reference Lewis, Adamová, Cruise, Mäkinen and Hájek2010).
Another difference between the three languages concerns the concept of joy. The results for the Czech noun radost ʻjoyʼ show a connection between joy and fun (e.g. legrace ʻfunʼ CZ, sin θ 0.598; the expressive nouns sranda ʻfunʼ CZ sin θ 0.690, bžunda ʻfunʼ CZ sin θ 0.693, psina ʻfunʼ CZ sin θ 0.701), which is not apparent in Slovak or Polish. One might ask whether this finding is related to the (auto)stereotype of Czech people as having a highly specific type of humour (e.g. Labischová, Reference Labischová2013).
Finally, the Slovak results for the noun radosť ʻjoyʼ contain the word škodoradosť (a compound noun with the meaning ʻmalevolent joy, gloatʼ, sin θ 0.681), but Czech and Polish do not. Škodoradosť ʻmalevolent joyʼ SK is an interesting example of a specific emotion sometimes known by the German term Schadenfreude ʻmalevolent joyʼ (Ekman & Cordaro, Reference Ekman and Cordaro2011; Ekman, Reference Ekman2015). It denotes a positive emotion that one feels when something bad happens to an enemy (the emotion is often evaluated as morally doubtful). The corpus data concerning škodoradosť ʻmalevolent joyʼ in Slovak (cf. SEMÄ result 10) show that it is semantically close to zlomyseľnosť ʻmaliceʼ SK (sin θ 0.314) and závisť ʻenvyʼ SK (sin θ 0.402). Equivalents of Schadenfreude ʻmalevolent joyʼ also exist in Czech and Polish (škodolibá radost ʻmalevolent joyʼ CZ; złośliwa radość ʻmalevolent joyʼ PL, cf. Mikołajczuk, Reference Mikołajczuk2007), but they did not appear among the results for Czech and Polish joy, probably because of their multi-word form. This highlights one of the limitations of the SEMÄ tool that focuses on lexemes; a tool that would be able to work with larger multi-word units would be beneficial for cross-cultural comparisons.
4.3. Comparison of the three West Slavic languages and English
Nouns denoting happiness in the three West Slavic languages (szczęście PL ʻhappinessʼ; štěstí CZ ʻhappinessʼ; šťastie SK ʻhappinessʼ; Section 4.2) show similarity to both of the English words happiness and luck (Section 4.1), but this similarity is not symmetric and the asymmetry is different for each of the three West Slavic languages.
The results for Polish place szczęście ʻhappinessʼ close to the English word happiness, with shared similarity to the words nieszczęście ʻunhappiness, misfortuneʼ PL and unhappiness EN, radość ʻjoyʼ PL and joy EN, miłość ʻloveʼ PL and love EN. Only one item in the results for szczęście ʻhappinessʼ PL is shared with the English word luck (i.e. pech ʻbad luckʼ PL, sin θ 0.734, and misfortune EN, sin θ 0.763). The results are skewed by a high number of repeated items in the Polish results, but further investigation of the following approx. 30 items in the list (not included in Table 3 in Section 4.2) revealed only one additional item shared with the English luck: sukces ʻsuccessʼ PL (50th item in the list, sin θ 0.786) and success EN (sin θ 0.722).
The results for Slovak place the Slovak noun šťastie ʻhappinessʼ between the English words happiness and luck. Šťastie ʻhappinessʼ SK and happiness EN share similarity to the words radosť ʻjoyʼ SK and joy EN, láska ʻloveʼ SK and love EN, nešťastie ʻunhappiness, misfortuneʼ SK and misery EN, and partly to sebavedomie ʻself-confidenceʼ SK and self-satisfaction EN, self-fulfilment EN, self-love EN. Šťastie ʻhappinessʼ SK and luck EN then share similarity to the words úspech ʻsuccessʼ SK and success EN, smola ʻbad luckʼ SK and bad-luck EN, žičit ʻto wishʼ SK (and partly splnené prianie ʻfulfilled wishʼ SK) and wish EN.
Czech shows the highest asymmetry among the three West Slavic languages. The Czech noun štěstí ʻhappinessʼ appears to be more similar to the English luck than to the English happiness. For example, the list of words semantically similar to the Czech štěstí ʻhappinessʼ is more similar to the list of words semantically similar to luck EN than to the list of words semantically similar to happiness EN. There are more items shared by štěstí ʻhappinessʼ CZ and luck EN (e.g. úspěch ʻsuccessʼ CZ and success EN, přát ʻto wishʼ CZ and wish EN, smůla ʻbad luckʼ CZ and bad luck EN, štěstěna ʻFortunaʼ CZ and fortune EN) than between štěstí ʻhappinessʼ CZ and happiness EN (radost ʻjoyʼ CZ and joy EN, láska ʻloveʼ CZ and love EN, neštěstí ʻunhappiness, misfortuneʼ CZ and misery EN). However, we can also observe that the similarity measurement between štěstí ʻhappinessʼ CZ and láska ʻloveʼ CZ (sin θ 0.683) is very similar to that between happiness EN and love EN (sin θ 0.654), as is the similarity between štěstí ʻhappinessʼ CZ and radost ʻjoyʼ CZ (sin θ 0.565) and joy EN and happiness EN (sin θ 0.548). Czech and English nouns denoting happiness are thus similarly semantically close to the nouns denoting love and joy.
The results for nouns denoting happiness in all four languages share the presence of words denoting such positive qualities as love (e.g. love EN, miłość ʻloveʼ PL, láska ʻloveʼ CZ, láska ʻloveʼ SK). This result might be influenced by the custom (shared by all the analysed cultures) to wish others happiness together with other positive phenomena such as love or success. The importance of the context of wishes in Czech and Slovak culture is supported by the presence of the verbs přát ʻto wishʼ CZ (sin θ 0.650) and žičiť ʻto wishʼ SK (sin θ 0.734) among the words semantically similar to nouns denoting happiness. There is no lexical unit denoting a wish among the English results for the noun happiness. The ambiguity of the words denoting happiness in West Slavic wishes is also noteworthy. It is not always clear whether the wish concerns the psychological-emotional state or good luck (e.g. hodně štěstí a zdraví ʻa lot of happiness/luck and healthʼ CZ as a birthday wish).
Interestingly, words denoting health (zdravíčko CZ, sin θ 0.675; zdravíčko SK, sin θ 0.745; zdrówko PL, sin θ 0.756; all three expressions are diminutive) are present only in the results for the West Slavic nouns denoting happiness. There is no lexical unit for health in the results for the English noun happiness, and no lexical unit denoting health was found by an additional search among the first 50 words indicated by SEMÄ (cf. SEMÄ result 1) as semantically similar to happiness.
The similarity measurements for nouns denoting joy (joy EN, radost ʻjoyʼ CZ, radosť ʻjoyʼ SK, radość ʻjoyʼ PL; Sections 4.1, 4.2) show that there are several synonyms for sadness as opposites to the English joy, all indicated as semantically close to the English word joy (sorrow EN, sin θ 0.415; sadness EN, sin θ 0.477; grief EN, sin θ 0.547). The results for the three West Slavic languages also detect sadness as an opposite, but only in Czech (smutek ʻsadnessʼ, ʻa state of mourningʼ) and Polish (smutek ʻsadnessʼ). The semantic difference is also measured as higher than in English, especially in Czech (sin θ 0.679 for Czech, sin θ 0.584 for Polish).
All three West Slavic languages differ from English in the semantic closeness between nouns denoting joy and words denoting open signs of joy, such as the Polish wesołość ʻcheerfulnessʼ PL (sin θ 0.558), uśmiech ʻsmileʼ PL (sin θ 0.622) and Slovak veselosť ʻcheerfulnessʼ SK (sin θ 0.609). In Czech, this cluster covers not only veselost ʻcheerfulnessʼ CZ (sin θ 0.673) but also various synonyms for fun, even expressive ones (legrace ʻfunʼ CZ, sin θ 0.598; sranda ʻfunʼ CZ, sin θ 0.690; bžunda ʻfunʼ CZ, sin θ 0.693; psina ʻfunʼ CZ, sin θ 0.701; see also Section 4.2). According to these results, West Slavic (and especially Czech) joy is of a more extravert character than English joy.
5. General discussion and conclusion
I will conclude by discussing answers to the two research questions and their specifications formulated in Section 1:
-
(a) Using data from large multilingual corpora and the word-embedding analysis of words semantically similar to the basic nouns denoting happiness and joy in Polish, Czech, Slovak and English, I was able to reconstruct the following similarities and differences between the corresponding concepts of happiness and joy (research question (1)):
The linguistic data reveal that happiness and luck are largely distinct in English, but happiness in West Slavic languages is strongly associated with fortune and (good) luck, which confirms the expectation (hypothesis) (1a). The relationship between happiness and luck in West Slavic languages is indicated especially by the fact that antonyms denoting bad luck (e.g. pech ʻbad luckʼ PL, smůla ʻbad luckʼ CZ, smola ʻbad luckʼ SK) or names for Fortuna (e.g. štěstěna ʻFortunaʼ CZ, šťastena ʻFortunaʼ SK) are revealed as semantically close to the West Slavic nouns denoting happiness. The corpus results thus confirm that Polish, Czech and Slovak belong to the large group of languages/cultures that associate happiness with a strong component of fortune or chance (Oishi et al., Reference Oishi, Graham, Kesebir and Galinha2013, see Section 2.1). Depending on context, the West Slavic lexical unit denoting happiness corresponds to the English lexical unit happiness, or luck, which should be taken into account in cross-linguistic comparisons.
As predicted in the expectation (hypothesis) (1b), the analysis also shows differences between the concepts of happiness in Polish, Czech and Slovak. Based on the analysis of the words most semantically close to the nouns denoting happiness, happiness in Polish is close to happiness in English, happiness in Slovak lies between English happiness and luck and happiness in Czech is closer to English luck than to English happiness. However, the role of religion as a distinguishing factor was confirmed only partly. The results for Slovak signal the relevance of the religious context, but no such associations are indicated by the Czech results, and the results for Polish are inconclusive. The expectation that religion will not be important in Czech happiness is in accordance with the diminished role of institutionalised religion in Czech society (e.g. Havlíček et al., Reference Havlíček, Klingorová and Lysák2017), but the inconclusive results for Polish happiness were not expected.
The corpus-based results also reveal that the concepts of happiness and joy are interconnected both in the three West Slavic languages and in English and thus confirm the expectation (hypothesis) (1d). However, the expectation (hypothesis) (1c) that the concept will be the same in all four languages was not confirmed because the results reveal several differences in the conceptualisation of joy between all four languages. The analysis of the words most semantically close to the nouns denoting joy shows that the West Slavic joy is associated with external manifestations of this emotion and with cheerfulness, which is not a central feature of the concept of joy in English. The opposite of joy is typically sadness in both English and the West Slavic languages, except for Czech, which sees both sadness and fear as the opposites of this positive emotion. The results for the English noun joy also contain a larger number of synonyms for sadness than do the results for nouns denoting joy in Polish, Czech and Slovak, which could indicate a stronger association between the concepts of joy and sadness in English than in the West Slavic languages.
The analysis also highlighted other cross-cultural differences (expectation (1e)). The results for West Slavic languages revealed an association between the concepts of happiness, health and wishes, which is not manifested in the results for English. The concept of ʻmalevolent joyʼ resurfaced among the West Slavic languages in Slovak.
Finally, the results for the three West Slavic languages show that the similarities and differences between genetically and culturally connected languages are far from being straightforward. Various combinations of cross-linguistic (and cross-cultural) relations may appear. For example, two languages can be closer to each other than to the third language (e.g. Polish and Slovak are closer to each other than to Czech in the conceptualisation of joy, cf. different relations between joy, sadness, fear and fun), or the three languages may represent a spectrum (e.g. different level of semantic closeness between happiness as the psychological-emotional state and luck).
-
(b) Regarding the advantages and limitations of the word-embedding analysis of corpus data (research question (2)), I believe that the method has proven fruitful for the analysis of the concepts and their cross-cultural differences. We need, however, to take into account the limitations of the method and interpret the results with caution. This corresponds to expectations (hypotheses) (2a) and (2b), which is an expected outcome.
One of the main advantages of the method is its ability to analyse much larger quantities of data than human researchers would be able to. The automatic mechanisms can also point towards connections that a human researcher would not probably discover. The disadvantages relate to various mistakes of the automated analysis that require manual checking of the data; many of these mistakes are the price paid for the sensitivity of the given tool.
Any corpus-based research also depends on the size, composition and quality of the corpora being used. The Aranea corpora used in this study are sufficiently large, diverse and comparable, which improves the validity of the results. The fact that the data were retrieved from texts produced by human beings, not by the automated procedures of large linguistic models, is an important advantage for any analysis of culture-specific concepts.
The written character of the corpora used in the study is another limitation of the research. It would also be useful to have corpora of specific varieties of the analysed languages. This is especially true for English because we already know that there are differences between happiness in British English and happiness in American English (see Section 2.1). The results for English in this study are thus generalised from different varieties of English and are less specific to a certain culture than would be desirable. I believe this drawback is acceptable because my analysis focuses on the three West Slavic languages.
The word-embedding analysis is useful for cross-cultural research on concepts, but it could also be used for partial reconstruction of various lay theories (see Section 2). However, it is important to bear in mind that the method operates at the level of lexical units. Other methods suitable for more complex phenomena spanning over larger linguistic units would have to be added to the methodological design of such research (cf. Bartmiński, Reference Bartmiński2010).
Considering the overall advantages and disadvantages, I believe that the research presented in this study offers new insights into the concepts of happiness and joy in English and the three chosen West Slavic languages. I also believe that the corpus-based analysis of the semantically similar words is able to highlight interesting similarities and differences between the analysed languages and that it can be a fruitful complement to the existing methods of research not only on happiness and joy but also on other complex concepts. It could enrich the repertoire of quantitative methods in cognitive approaches to language (e.g. Janda, Reference Janda2013), the research methods in cross-cultural comparative studies (see Section 2), and methods of investigation of concept construal in different cultures.
Data availability statement
All data are available in the corpora listed in the Data section; queries used in the research are listed in the text of the article and in the section Web links to SEMÄ results.
Competing interests
The author declares none.
Use of artificial intelligence (AI) tools
The word-embedding tool SEMÄ of the Slovak National Corpus (https://www.juls.savba.sk/sem(c3a4)_en.html) used in the research includes artificial neural network; the tool and its usage are described in Section 3.2 of the article.
Web links to SEMÄ results
(1) https://www.juls.savba.sk/sem%C3%A4/?lang=en&kio=lemma&visualsel=gnuplot&topn=24&wpos=happiness&wneg=# (retrieved March 17, 2025)
(2) https://www.juls.savba.sk/sem%C3%A4/?lang=en&kio=lemma&visualsel=gnuplot&topn=24&wpos=luck&wneg=# (retrieved March 17, 2025)
(3) https://www.juls.savba.sk/sem%C3%A4/?lang=en&kio=lemma&visualsel=gnuplot&topn=24&wpos=joy&wneg=# (retrieved March 17, 2025)
(4) https://www.juls.savba.sk/sem%C3%A4/?lang=pl&kio=lemma&visualsel=gnuplot&topn=24&wpos=szcz%C4%99%C5%9Bcie&wneg= (retrieved March 17, 2025)
(5) https://www.juls.savba.sk/sem%C3%A4/?lang=pl&kio=lemma&visualsel=gnuplot&topn=24&wpos=rado%C5%9B%C4%87&wneg=# (retrieved March 17, 2025)
(6) https://www.juls.savba.sk/sem%C3%A4/?lang=cs&kio=lemma&visualsel=gnuplot&topn=24&wpos=%C5%A1t%C4%9Bst%C3%AD&wneg=# (retrieved March 17, 2025)
(7) https://www.juls.savba.sk/sem%C3%A4/?lang=cs&kio=lemma&visualsel=gnuplot&topn=24&wpos=radost&wneg=# (retrieved March 17, 2025)
(8) https://www.juls.savba.sk/sem%C3%A4/?lang=sk&kio=lemma&visualsel=gnuplot&topn=24&wpos=%C5%A1%C5%A5astie&wneg=# (retrieved March 17, 2025)
(9) https://www.juls.savba.sk/sem%C3%A4/?lang=sk&kio=lemma&visualsel=gnuplot&topn=24&wpos=rados%C5%A5&wneg=# (retrieved March 17, 2025)
(10) https://www.juls.savba.sk/sem%C3%A4/?lang=sk&kio=lemma&visualsel=gnuplot&topn=24&wpos=%C5%A1kodorados%C5%A5&wneg=# (retrieved April, 29, 2025)
Data
Araneum Bohemicum Maius. http://ucts.uniba.sk/aranea_about/_bohemicum.html & http://aranea.juls.savba.sk/
Araneum Polonicum Maius. http://ucts.uniba.sk/aranea_about/_polonicum.html & http://aranea.juls.savba.sk/
Araneum Slovacum Maius. http://ucts.uniba.sk/aranea_about/_slovacum.html & http://aranea.juls.savba.sk/
Czech National Corpus – Český národní korpus. https://www.korpus.cz/
Filipec et al. (Reference Filipec and Daneš2012)
GENSIM: Topic modelling for humans. https://radimrehurek.com/gensim/index.html
Gnuplot. http://gnuplot.info/
InterCorp. https://intercorp.korpus.cz/
Kačala et al. (Reference Kačala, Pisarcikova and Považaj2003)
SEMÄ. https://www.juls.savba.sk/sem(c3a4)_en.html
Slovak National Corpus – Slovenský národný korpus. https://korpus.sk/ & http://aranea.juls.savba.sk/
Żmigrodzki et al. (Reference Żmigrodzki, Bańko, Batko-Tokarz, Bobrowski, Czelakowska, Grochowski, Przybylska, Waniakowa and Węgrzynek2004–2024)




 Open access
Open access