


1. Introduction
Lexical development during adolescence plays a crucial role in shaping not only language development but also in contributing to broader academic success (Nippold, Reference Nippold2002). Previous discussions and research on adolescents’ lexicon have focused on aspects of its quantity and quality (Berman, Reference Berman, Hoff and Shatz2007), or specific types of lexical knowledge (Shen & Crosson, Reference Shen and Crosson2023), demonstrating that lexical development is a continuous and dynamic process, and that the lexicon undergoes reorganization throughout the adolescent years. This period is characterized by the development of more sophisticated and nuanced vocabulary, laying a foundation for the complex academic demands encountered in later educational stages (Nagy et al., Reference Nagy, Townsend, Lesaux and Schmitt2012).
Lexical development during adolescence extends beyond simply acquiring a larger and more complex vocabulary; it also involves integrating these words into a highly interconnected lexical system. This developmental process can be effectively explored through a network perspective (Meara, Reference Meara2009). A well-developed lexical network is reflected by a larger network size and more connections between word nodes. These networks are dense, show stronger clustering of related items, and form distinct subgroups (Steyvers & Tenenbaum, Reference Steyvers and Tenenbaum2005). A commonly used method for constructing lexical networks is the word association task. By constructing associative networks and employing network analysis, researchers compute structural properties of networks that have practical implications on lexical access and language production. While distinct developmental patterns in word association networks have been identified in first-language populations and adult second language learners (Borodkin et al., Reference Borodkin, Kenett, Faust and Mashal2016; De Deyne et al., Reference De Deyne, Kenett, Anaki, Faust, Navarro and Jones2017), the potential of this approach to reveal the structural properties of adolescents’ mental lexical networks remains underexplored.
Previous research on lexical development in bilingual adolescent populations also remains limited, as studies during the school years have primarily focused on first-language speakers (Ricketts et al., Reference Ricketts, Lervåg, Dawson, Taylor and Hulme2020; Sun & Nippold, Reference Sun and Nippold2012). However, in today’s globalized world, bilingualism is increasingly prevalent in many countries. For example, in China, most students begin learning English during their primary school years, leading to the intertwined development of their Chinese and English lexicons. This raises important questions about potential similarities and differences in the mental lexicon network structures across their two languages. Building upon these gaps, the present study aims to employ word association tasks and network analysis to investigate the developmental trajectories and cross-language differences in the mental lexicon of Chinese–English bilingual adolescents.
1.1. Lexical development in bilingual adolescents
Lexical development during adolescence, especially in middle and high school, involves considerable growth and refinement that builds on the basic vocabulary established in early childhood. This period is characterized by expansion in vocabulary breadth, reflected in increases in the overall size of the lexicon, as well as development in vocabulary depth, reflected in richer and more elaborated knowledge of individual words. These changes are largely driven by increased exposure to academic language through education and reading activities (Nippold, Reference Nippold2018). Nonetheless, the paths of development for first language (L1) and second language (L2) lexicons tend to differ.
Word association research on L1 speakers has demonstrated different aspects of lexical development with increasing age in children and adolescents. For example, Shapiro (Reference Shapiro1964) found that school-aged children in Grades 4, 6, and 8 (approximately 9–14 years) produced more responses as they grew older. More recently, Henriksen (Reference Henriksen, Albrechtsen, Haastrup and Henriksen2008) reported a decline in invalid or unrelated responses among Danish adolescents from Grade 7 to Grade 13, suggesting larger vocabulary and greater lexical quality during this stage. Previous studies have also identified clear patterns in semantic organization. For example, Entwisle et al. (Reference Entwisle, Forsyth and Muuss1964) documented a syntactic-paradigmatic shift in English-speaking children aged 5 to 11 years, with younger participants giving more heterogeneous responses (often syntactic, based on sentence sequences) and older ones favouring homogeneous responses (paradigmatic, such as synonyms or category coordinates). This transition points to increasingly structured semantic networks. Comparable shifts have been observed in other groups, including children in Grades 1 through 4 (Palermo, Reference Palermo1971) and Persian-speaking children and adolescents from Grade 0 to Grade 12 (approximately 6–22 years; Namei, Reference Namei2004). Patterns of semantic convergence – measured as response commonality within groups or against adult norms – produced inconsistent findings. Zortea and De Salles (Reference Zortea and De Salles2012) compared Brazilian Portuguese-speaking children (aged 7–11 years) and adults, noting that children’s responses exhibited higher forward strength (stronger direct links) and lower diversity, implying reliance on a narrower set of associations compared to adults’ more varied lexicons. Henriksen (Reference Henriksen, Albrechtsen, Haastrup and Henriksen2008) observed increasing convergence toward adult norms from Grade 7 to Grade 10 among Danish adolescents, followed by a slight decrease by Grade 13, reflecting the complex development of commonality and individuality of the lexicon. In contrast, Cremer et al. (Reference Cremer, Dingshoff, de Beer and Schoonen2011) used Gini’s concentration index, a measure of the degree to which responses are concentrated in a limited number of categories, with higher values indicating greater concentration and lower dispersion (Wickens, Reference Wickens1989), to assess Dutch primary school children (aged 9–12 years) and adults, finding higher dispersion in children’s responses across categories while adults concentrated on meaning-related types, contrasting with Zortea and De Salles’s (Reference Zortea and De Salles2012) observations. Overall, the findings indicate consistent trends in L1 lexical development in aspects of vocabulary size and semantic organization, but results on convergence are mixed: some evidence points to more shared structures in older adolescents, while other studies highlight increased diversity. Moreover, most evidence comes from comparisons between children and adults, with limited focus on adolescents, leaving the development during this phase underexplored.
Research on L2 learners’ word associations has identified certain developmental patterns across grade levels and proficiency stages, though inconsistencies also exist. For example, contrary to the robust syntagmatic-paradigmatic shift observed in L1 acquisition, Orita (Reference Orita2002) found no evidence of such a shift among Japanese learners of English in middle and high school (approximately 13–17 years), although the overall number of responses increased, suggesting growth in L2 vocabulary size. Similarly, Namei (Reference Namei2004), in a study of Persian–Swedish bilingual children and adolescents, reported no clear developmental shift in L2 Swedish. Instead, with increasing age, phonological responses declined, while both syntagmatic and paradigmatic responses increased. Other studies have provided evidence of more systematic changes. Li et al. (Reference Li, Zhang and Zhou2022), examining Yi students learning Chinese as an L2 (Grade 4, Mean age = 10.45 years; Grade 10, Mean age = 17.18 years), found that associations were predominantly meaning-based, followed by form-based ones. Importantly, syntagmatic associations developed at a faster pace than paradigmatic or encyclopaedic associations from primary to high school, suggesting a progression in the organization of the L2 lexicon. Differences in associative convergence across age groups have also been documented. Cremer et al. (Reference Cremer, Dingshoff, de Beer and Schoonen2011) showed that L2 children in primary school (aged 9–12 years) generated more dispersed associative responses compared to L2 adults, a finding consistent with the observation by Zareva (Reference Zareva2007) that more proficient adult learners tend to produce convergent responses. Related insights have been provided by lexical availability tasks, which elicit words within specific semantic categories. Jiménez Catalán and Fitzpatrick (Reference Jiménez Catalán, Fitzpatrick and Catalán2014) reported that Grade 8 Spanish learners of English (aged 13–14 years) not only produced more words than Grade 6 (aged 11–12 years) students but also displayed greater lexical diversity, reflecting development in both vocabulary size and range. In a later study, Jiménez-Catalán (Reference Jiménez-Catalán2023) further showed that Grade 12 learners (Mean age = 17.6 years) with larger vocabularies also produced a higher type–token ratio than their peers with smaller lexicons. Taken together, research in L2 word association suggests two broad trends. First, while the syntagmatic-paradigmatic shift observed in L1 development is not consistently replicated in L2 contexts, learners nevertheless show a growing tendency towards meaning-based associations over time. Second, the L2 lexicon becomes progressively more convergent and structured as adolescents advance through grade levels, reflecting both growth in vocabulary size and refinement in semantic organization.
Research on bilingual lexical development has not only examined the trajectories of L1 and L2 separately but also highlighted cross-language differences in the development. Early evidence comes from Verhallen and Schoonen (Reference Verhallen and Schoonen1998), who used an extended word definition task with Grade 3 and Grade 5 Turkish–Dutch bilingual children (approximately 9–11 years). They found that children produced more meanings in L2 than in L1, and that Grade 5 pupils gave more meanings than Grade 3 pupils. Moreover, older children provided more taxonomical responses, suggesting a shift towards adult-like semantic organization. Namei (Reference Namei2004) offered further evidence from Persian–Swedish bilingual children and adolescents spanning Grade 0 to Grade 12 (aged 6–22 years). The study showed that from Grade 6 to Grade 12, cross-language differences in meaning-based associations (both paradigmatic and syntagmatic) increased. Importantly, this difference favoured the L2 rather than the L1, a pattern also observed by Sheng et al. (Reference Sheng, McGregor and Marian2006), who reported that Chinese–English bilingual children (aged 5–8 years) produced more paradigmatic associations in English than in Chinese. This contrasts with findings in bilingual adults: Fitzpatrick and Izura (Reference Fitzpatrick and Izura2011) demonstrated that Spanish–English bilingual adults produced more meaning- and collocation-based associations in their L1 than in their L2, suggesting an L1 advantage in adulthood. Beyond semantic organization, studies have also investigated the convergence of associations across languages. For example, Henriksen’s (Reference Henriksen, Albrechtsen, Haastrup and Henriksen2008) study revealed a decline in cross-language differences in the proportion of canonical associations across grades among Dutch–English bilingual adolescents, suggesting that L1 and L2 lexicon converge toward adult-like lexicon and gradually resemble each other. Nevertheless, the proportion of canonical associations remained higher in L1, indicating that L1 showed stronger convergence, whereas L2 responses remained more divergent. Thus, it appears that the L1 and L2 lexicons of bilingual adolescents develop to be better organized and convergent, but the relative advantage of L1 or L2 in these aspects is inconclusive.
1.2. Bilingual lexical development and word association networks
Much of the existing research on bilingual lexical development has examined the number, types, and convergence of word associations, as well as cross-language differences. However, fewer studies have approached the mental lexicons from a holistic perspective, treating them as integrated systems and investigating their overall structure (Meara & Wolter, Reference Meara and Wolter2004). The structural organization of the lexicon is of particular importance, as it influences lexical retrieval, semantic access, and language production. The network perspective, based on graph theory (Kiss, Reference Kiss1968), views words as nodes and associations as edges, and offers a means to capture these structural properties of the mental lexicon network. Such networks can be constructed using a variety of tasks, including semantic fluency, similarity judgments, and word association. From such networks, key structural measures can be derived (Steyvers & Tenenbaum, Reference Steyvers and Tenenbaum2005), which allow researchers to examine the structural organization of the mental lexicon and its functional consequences, as network configuration influences how lexical information is accessed, integrated, and produced, providing an important perspective for understanding developmental changes in L2 lexical systems.
The number of nodes (n) and edges (m) provides an estimate of network size, reflecting the diversity of lexical knowledge and the overall extent of associative links. Average degree (k) reflects how many direct connections each word has on average. In developmental terms, a higher k suggests that individual words are linked to a larger number of other words. This can indicate that vocabulary items are connected through multiple associations, which may support more flexible word use and easier retrieval (Wulff et al., Reference Wulff, Hills and Mata2022). Network density (D), in contrast, reflects how many of all possible connections in the network are actually present. It captures how tightly connected the vocabulary system is overall, rather than how well individual words are connected. Developmentally, changes in D may show whether vocabulary growth leads to a more tightly organized system or to greater differentiation as new words are added. Average shortest path length (ASPL) reflects the average number of steps required to move from one word to another in the network. When ASPL is shorter, words can be reached through fewer intermediary links, meaning that different parts of the vocabulary are more closely connected overall. This has been interpreted as reflecting more efficient global organization of the lexicon (Cosgrove et al., Reference Cosgrove, Beaty, Diaz and Kenett2023; Kenett et al., Reference Kenett, Anaki and Faust2014). Clustering coefficient (CC) reflects the extent to which words connected to a given word are also connected to each other. Higher CC values indicate that related words tend to form tightly connected groups. Such local clustering has been linked to the strengthening of structured semantic groupings within the lexicon (Siew, Reference Siew2019). Increases in CC may indicate that related words are increasingly organized into clearer thematic or categorical clusters, supporting more stable associations within specific areas of vocabulary. Modularity (Q) measures the extent to which the network can be partitioned into relatively distinct communities or subnetworks. Higher Q reflects a stronger division into specialized semantic domains, suggesting increasing differentiation and organization of lexical knowledge. Also, highly modular networks may reflect greater compartmentalization of knowledge and reduced flexibility in cross-domain activation, and these features have been linked to creative performance in language use (Campidelli et al., Reference Campidelli, Domanti, Fusi, Kenett and Agnoli2026). Finally, the small-world index (S) quantifies the balance between local clustering and global efficiency (Humphries & Gurney, Reference Humphries and Gurney2008). Small-world structures combine strong local interconnectedness with relatively short global path lengths and are generally considered to reflect efficient and flexible semantic systems (Steyvers & Tenenbaum, Reference Steyvers and Tenenbaum2005). Together, these measures allow for a systematic assessment of the overall structure and functional efficiency of the mental lexicon and provide insights into how lexical organization may develop during adolescence.
Large-scale lifespan studies of L1 associative networks provide important insights into adolescent development. Dubossarsky et al. (Reference Dubossarsky, De Deyne and Hills2017), analysing word association networks from more than 8,000 Dutch participants aged 10–84, reported that between ages 14 and 18, network entropy decreased while average degree increased, accompanied by decreases in ASPL and CC. Entropy here reflects the dispersion of responses across alternatives, with lower values indicating more convergent associations. These findings suggest that adolescence is not merely a transitional stage between childhood and adulthood but a distinct developmental phase characterized by unique structural changes in the lexicon. In contrast, L2 lexical network research has focused predominantly on adult learners (Borodkin et al., Reference Borodkin, Kenett, Faust and Mashal2016; Li et al., Reference Li, Jiang, Shang and Chen2021; Zhang & Ma, Reference Zhang and Ma2024). Li et al. (Reference Li, Jiang, Shang and Chen2021), for example, examined English word association networks of Chinese university students and found that as vocabulary size increased, CC decreased, average degree increased, and ASPL decreased, indicating that network expansion was accompanied by more efficient connectivity. Similarly, Feng and Liu (Reference Feng and Liu2023), using semantic fluency tasks with undergraduate and postgraduate learners of English, observed that more proficient learners’ networks had higher average degree and clustering, suggesting denser and better connected lexical structures. These findings underscore the influence of vocabulary size and proficiency on L2 network properties. However, no comparable studies have examined adolescent L2 learners, leaving unclear how network structures develop during this period. More recently, research has begun to investigate bilingual lexical networks, though with a primary focus on cross-language differences rather than developmental patterns. Borodkin et al. (Reference Borodkin, Kenett, Faust and Mashal2016) constructed group-based semantic networks from aggregated semantic fluency responses of English–Hebrew adult bilinguals and found that L1 networks exhibited longer average shortest paths and higher Q, whereas L2 networks were more locally clustered. Both networks, however, displayed small-world properties, reflecting structural efficiency. Similarly, Agustín-Llach and Palapanidi (Reference Agustín-Llach and Palapanidi2024) analysed group-level networks derived from aggregated responses of Greek–Spanish adult bilinguals and reported that L1 networks contained more nodes, edges, and higher average degree, while L2 networks showed longer average shortest paths and greater clustering. Although these findings confirm structural differences between L1 and L2 networks, they remain inconsistent regarding the direction and nature of these differences. Moreover, developmental evidence for adolescent bilinguals is lacking.
In summary, the network perspective has yielded valuable insights into understanding L1 and L2 lexicons among bilinguals as well as cross-language differences in lexical structure. Yet, the developmental trajectory of bilingual adolescents’ lexical networks remains unexplored. The present study addresses this gap by focusing on the following questions:
-
1. What developmental changes occur in the structural properties of L1 Chinese word association networks between Grade 8 students (aged 13–14 years) and Grade 11 students (aged 16–17 years)?
-
2. What developmental changes occur in the structural properties of L2 English word association networks between Grade 8 students (aged 13–14 years) and Grade 11 students (aged 16–17 years)?
-
3. What differences exist in the structural properties of word association networks between L1 Chinese and L2 English across Grade 8 students (aged 13–14 years) and Grade 11 students (aged 16–17 years)?
2. Method
2.1. Participants
Initially, 45 middle school students and 50 high school students were recruited from a public school in Wuxi, Jiangsu Province, eastern China. One middle school student was excluded due to repeated production of identical associative response words during testing, and one high school student was excluded for the same reason. Additionally, five high school students were excluded because more than half of their responses were blank. This resulted in a final sample of 88 participants.
The final sample consisted of two groups: 44 middle school students (Grade 8; aged 13–14 years, M = 13.21) and 44 high school students (Grade 11; aged 16–17 years, M = 16.18). Recruiting participants from the same school minimized potential confounds related to school-level differences. All participants were native speakers of Mandarin Chinese and had been learning English as L2 since Grade 3 of primary school.
To evaluate sample adequacy, a post hoc statistical power analysis was conducted based on a medium effect size (0.5), a significance level of .05, and a total sample size of 88 participants. The analysis yielded an achieved power of 0.913, indicating that the sample size was sufficient to detect effects of moderate magnitude in the present analyses.
2.2. Materials
The experimental materials consisted of 30 high-frequency English words selected from Nation’s (Reference Nation1990) first 1,000 and 2,000 word lists, along with their corresponding Chinese translation equivalents (see Appendix A). High-frequency words were chosen to ensure familiarity for both middle school and high school students, facilitating effective production of response words in the word association task. Prior research indicates that L2 learners exhibit lower completion rates for low-frequency words in such tasks (Higginbotham, Reference Higginbotham2010), and high-frequency stimuli are commonly used in bilingual word association studies with adolescents (Henriksen, Reference Henriksen, Albrechtsen, Haastrup and Henriksen2008).
The selected words were controlled for part of speech (nouns, verbs, adjectives), concreteness (concrete versus abstract), and word length to minimize confounding effects. A t-test confirmed a significant difference in concreteness between concrete and abstract words, t = 39.55, p < .001. However, an analysis of variance (ANOVA) revealed no significant differences in concreteness across parts of speech, F(2, 27) = 0.03, p = .971. Word length did not differ significantly between concrete and abstract words, U = 97.50, z = −0.63, p = .526, nor across parts of speech, H(2) = 1.06, p = .590, as verified by non-parametric tests.
2.3. Procedure
The study was conducted at the end of the spring semester in 2025, before the students’ summer holiday. The experimental tasks consisted of two word association tasks: one in Chinese and one in English. The tasks were administered in collaboration with the English teachers of the two classes to ensure smooth implementation. Participants completed the tasks using paper-based test booklets distributed in their regular classrooms. Instructions were provided by the teachers, who explained that for each cue word, participants should write down the first three words that came to mind immediately. They were explicitly instructed not to consult dictionaries or revise their responses to ensure spontaneous associations. To minimize the potential priming effect of L1 on L2, the English task was administered first, followed by the Chinese word association task two weeks later.
2.4. Analysis
A total of 88 participants produced 15,840 response words across the 30 cue words in both languages. After excluding blank responses, the valid response counts per grade and language were as follows: 3,954 Chinese responses and 3,925 English responses for the Grade 8 group; 3,948 Chinese responses and 3,957 English responses for the Grade 11 group. To further describe response completeness, the mean number of responses per participant was calculated for each group and language. Grade 8 participants produced an average of 89.86 responses in Chinese (SD = 0.51) and 89.21 responses in English (SD = 4.45). Grade 11 participants produced an average of 89.73 responses in Chinese (SD = 1.33) and 89.96 responses in English (SD = 0.21). These values indicate that participants generally completed nearly all response slots, with only limited variation across individuals.
Response words were then subjected to preliminary cleaning to ensure consistency and accuracy. For Chinese responses, processing involved correcting obvious typographical errors and standardizing adjectival forms. In Chinese, adjectives frequently include the particle de (的) at the end, but forms with and without de convey equivalent meanings and functions (e.g., yǒuyòng de [有用的, useful] and yǒuyòng [有用, useful] were standardized to yǒuyòng). For English responses, processing included: (a) correcting evident misspellings (e.g., sucess to success), (b) standardizing to American English spelling (e.g., recognise to recognize), and (c) converting plural nouns to their singular forms (e.g., cats to cat). A total of 654 Chinese responses (8.28% of the 7,902 valid Chinese responses) and 330 English responses (4.19% of the 7,882 valid English responses) underwent such treatment.
Following preprocessing, group-level networks were constructed separately for each grade (Grade 8 and Grade 10) and language (Chinese and English). Word association networks can be constructed in three ways: stimulus–response (S-R), stimulus–stimulus (S-S), and response–response (R-R). S-R networks require extensive stimulus and response word data, making them suitable for large-scale, snowball-style word association studies (Li et al., Reference Li, Jiang, Shang and Chen2021). S-S networks, which connect stimuli based on shared responses, face challenges in capturing the full complexity of semantic relationships due to the typically limited number of stimuli used. Studies employing this approach, such as De Deyne and Storms (Reference De Deyne and Storms2008), are relatively scarce, particularly in adolescent populations, making direct comparisons with our findings difficult. In this study, we adopted the R-R network approach, where response words are connected if they share a common stimulus. This method captures co-occurrence patterns in associations, highlighting shared semantic pathways. For example, when the stimulus river elicits responses water and fish, and drink elicits water and juice, then water serves as a mediator linking fish and juice, with drink acting as a hub in this graph. R-R networks thus reflect the co-occurrence features of associations, offering a robust framework for analysing semantic structures (see Appendix B for a worked example). The construction procedures follow established methodologies in semantic network research (Coronges et al., Reference Coronges, Stacy and Valente2007; Zortea et al., Reference Zortea, Menegola, Villavicencio and de Salles2014).
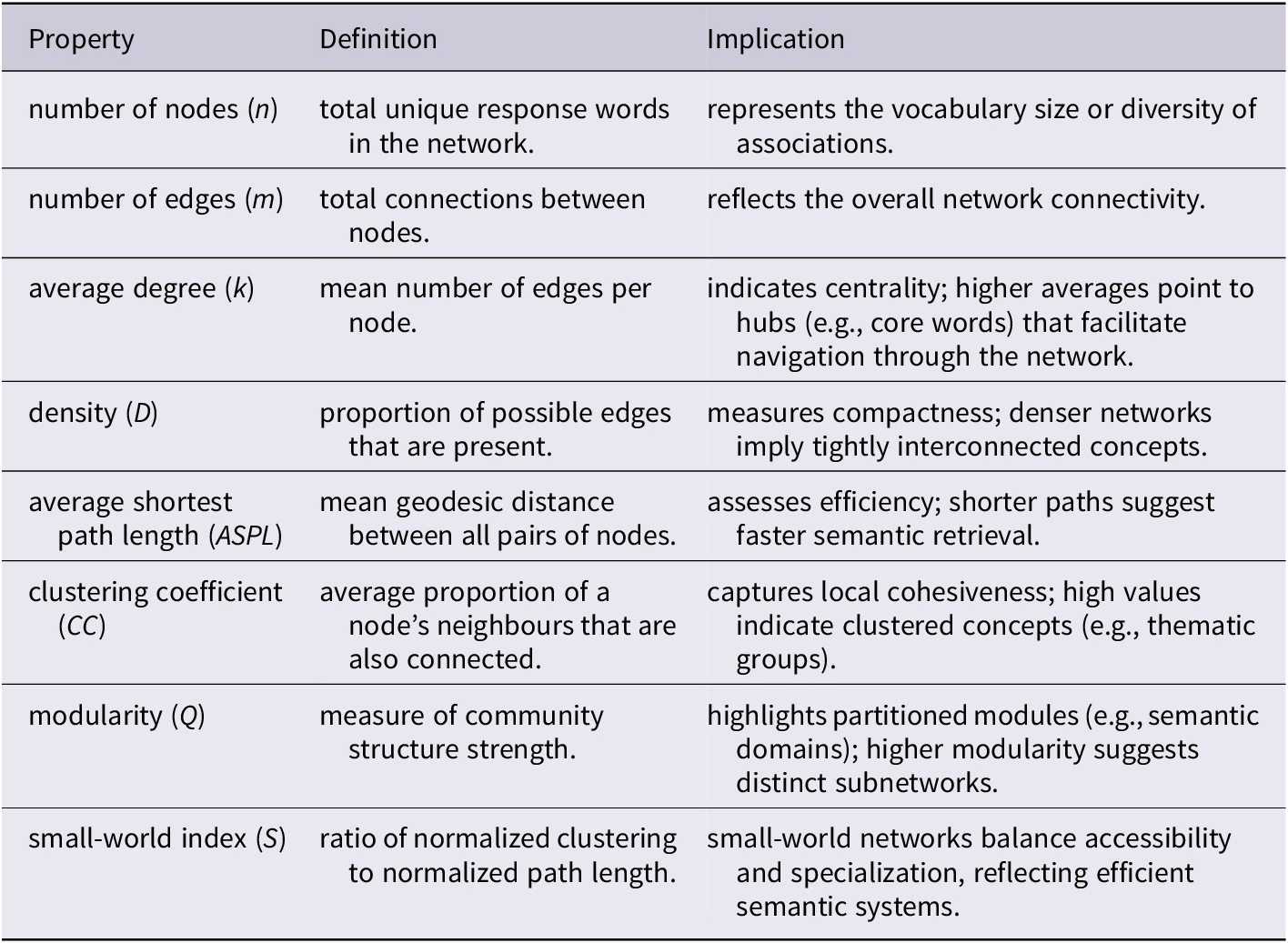
To construct R-R networks, duplicate response words under each stimulus were removed, retaining unique types and discarding redundant tokens. Responses produced by only one participant – typically considered idiosyncratic – were excluded, ensuring the networks reflect collective semantic patterns. The networks were built as undirected graphs, with response words as nodes and edges weighted by the frequency of co-occurrence across stimuli. Table 1 summarizes the definitions and practical interpretations of structural properties according to De Deyne and Storms (Reference De Deyne and Storms2008) and Newman (Reference Newman2006). These properties were computed using Python’s NetworkX library (Hagberg et al., Reference Hagberg, Schult and Swart2008).
Definitions and implication of word association network properties

To assess small-world characteristics, each original network was compared to 100 randomly generated graphs of equivalent size and density, constructed using an Erdős–Rényi model (Erdos & Rényi, Reference Erdos and Rényi1984), following the approach outlined by Borodkin et al. (Reference Borodkin, Kenett, Faust and Mashal2016) and Steyvers and Tenenbaum (Reference Steyvers and Tenenbaum2005). S was calculated using the method proposed by Humphries and Gurney (Reference Humphries and Gurney2008), which quantifies the balance between clustering and path length relative to random networks. Specifically, the CC, ASPL, and S of the original networks were compared to those of the random graphs using independent t-tests to determine significant differences, ensuring robust evaluation of small-world properties.
To enable statistical comparisons between networks across grades (Grade 8 versus Grade 11) and languages (Chinese versus English), we generated 100 connected subgraphs from each original network. Because each group-level lexical network represents a single large structure, direct inferential statistical comparisons across networks are not feasible. Subgraph sampling allows multiple comparable units to be derived from each network, enabling statistical testing while reducing biases associated with differences in overall network size. Each subgraph contained 200 nodes and was generated using a breadth-first search (BFS) procedure, following bootstrapping approaches used in previous lexical network studies (e.g., Borodkin et al., Reference Borodkin, Kenett, Faust and Mashal2016). Prior network sampling research has shown that BFS subgraphs containing approximately 10–30% of the original nodes preserve key topological properties (Leskovec & Faloutsos, Reference Leskovec and Faloutsos2006; Maiya & Berger-Wolf, Reference Maiya and Berger-Wolf2011), whereas sampling approximately 50% of nodes has been recommended to increase representativeness (Cosgrove et al., Reference Cosgrove, Kenett, Beaty and Diaz2021). Given that the networks in the present study contained approximately 350–500 nodes, a fixed subgraph size of 200 nodes was selected to fall within recommended sampling ranges and to ensure identical subgraph sizes across networks.
3. Results
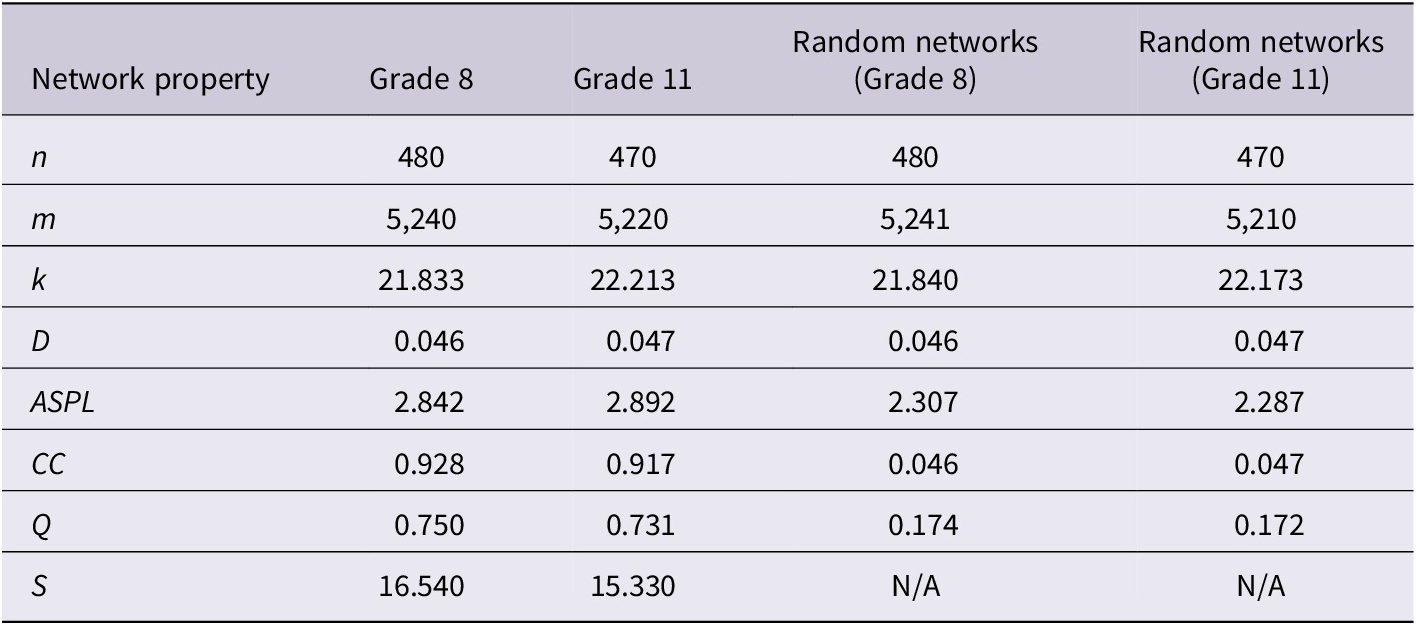
3.1. Research question 1: What developmental changes occur in the structural properties of L1 Chinese word association networks between Grade 8 and Grade 11 students?
Table 2 presents the structural properties of the Chinese word association networks together with the corresponding mean values of equivalent random networks. S is not reported for the random networks because it is defined as a ratio comparing the observed network to its random baseline and therefore is not applicable to the baseline networks themselves. Clearly, the Grade 11 network consisted of fewer nodes (n = 470) compared to the Grade 8 network (n = 480). This reduction in node count suggests that Grade 11 students produced a smaller variety of unique word types, indicating a higher degree of associative commonality. In contrast, Grade 8 students demonstrated more diverse associations, leading to a larger number of unique words in their network. Despite having fewer nodes, the Grade 11 network had a slightly higher average degree (k = 22.213) than the Grade 8 network (k = 21.833). This suggests that while Grade 11 students produced fewer unique associations overall, the associations they did make were more interconnected and central within their network.
Structural properties of Chinese word association networks and corresponding random networks

To evaluate small-world characteristics, the CC and ASPL of each original network were compared to those of 100 randomly generated Erdős–Rényi graphs of equivalent size and density. One-sample t-tests were conducted for these comparisons, followed by computation of the S as a confirmatory measure. For the Grade 8 network, the original ASPL (M = 2.842) was significantly longer than the mean ASPL of random networks (M = 2.307, SD = 0.01), t(99) = 548.05, p < .001. The original CC (M = 0.928) was also significantly higher than the mean CC of random networks (M = 0.046, SD = 0.001), t(99) = 7225.54, p < .001. These results, combined with an S value of 16.54, indicate small-world properties. Similarly, for the Grade 11 network, the original ASPL (M = 2.892) exceeded the mean ASPL of random networks (M = 2.287, SD = 0.01), t(99) = 603.37, p < .001. The original CC (M = 0.917) was greater than the mean CC of random networks (M = 0.047, SD = 0.001), t(99) = 8009.67, p < .001. With an S value of 15.33, the Grade 11 network also demonstrated small-world features, though the S value was lower than the Grade 8 network.
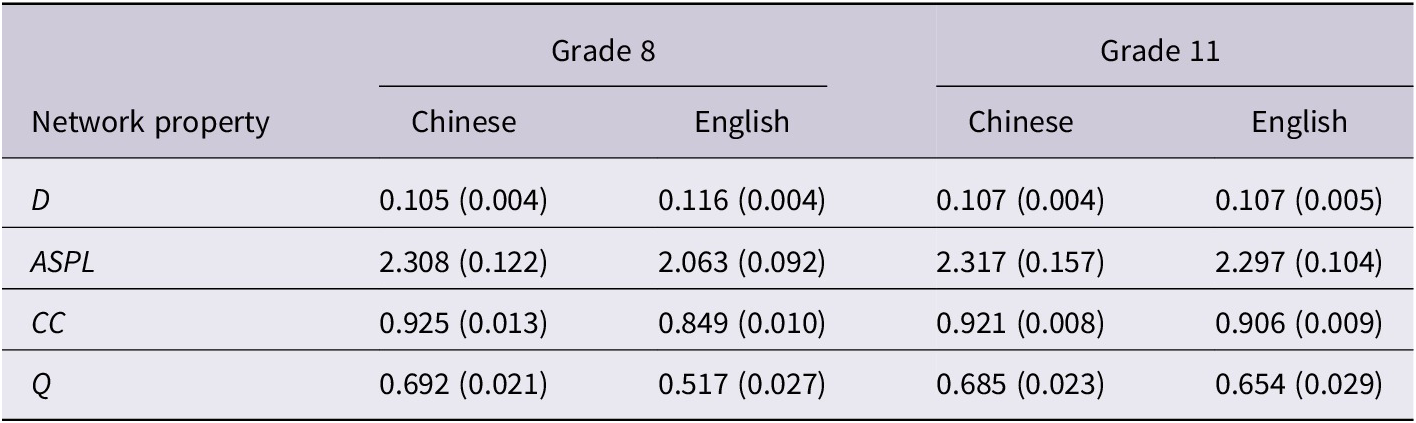
Independent samples t-tests were performed on 100 connected subgraphs (200 nodes each) extracted from each network to compare properties (D, ASPL, CC, Q) between grades. The t-test for D showed a significant difference, t(198) = −3.60, p < .001, with Grade 11 subgraphs exhibiting higher D than Grade 8. No significant difference was found for ASPL, t(198) = −0.47, p = .642, with similar means for Grade 8 and Grade 11. For CC, a significant difference emerged, t(198) = 2.40, p = .017, indicating higher CC in Grade 8 than Grade 11. Q also differed significantly, t(198) = 2.41, p = .017, with higher values in Grade 8 than Grade 11.
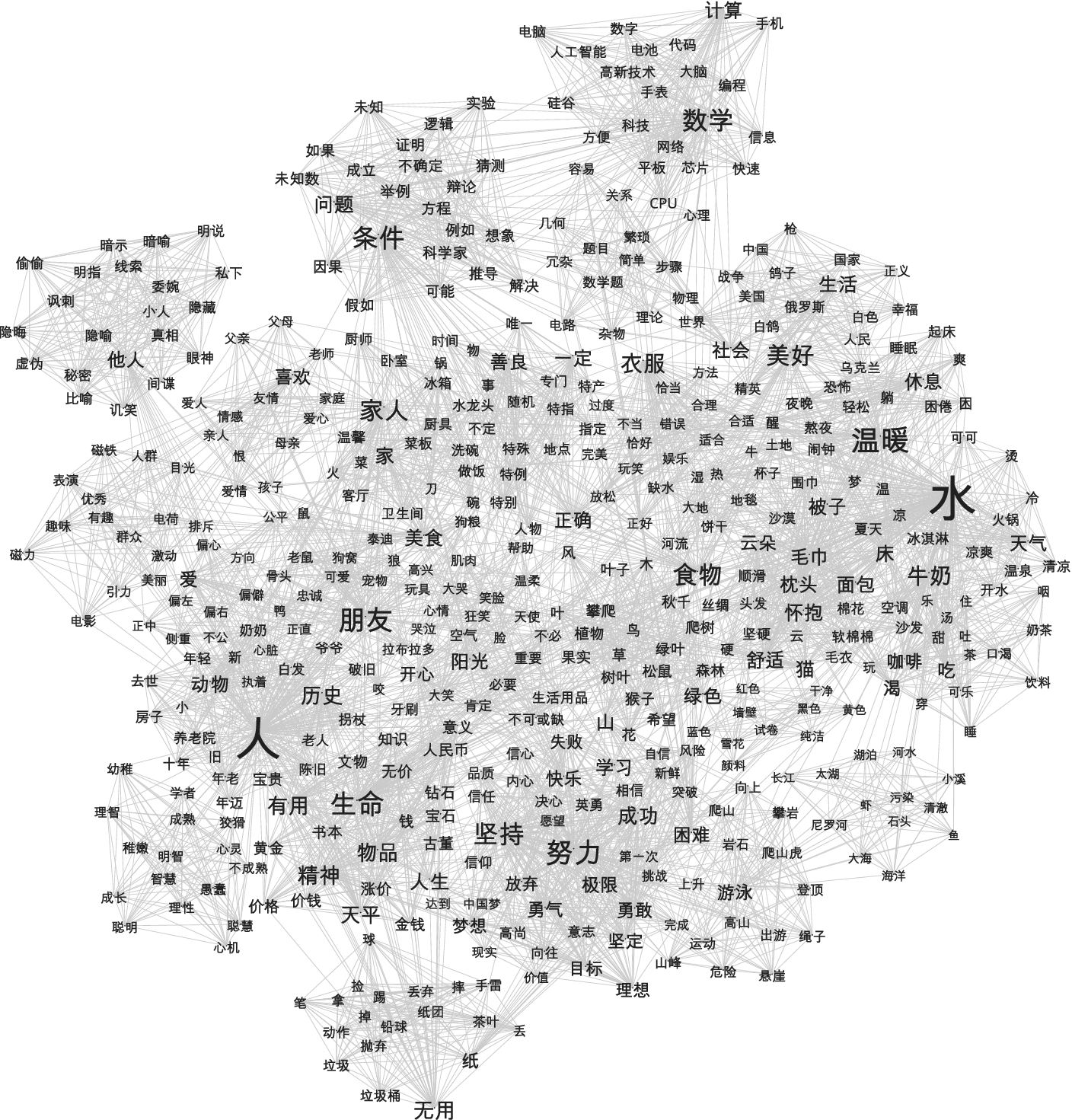
Figures 1 and 2 present the labelled visualizations of the Grade 8 and Grade 11 Chinese networks, respectively. In these figures, node size reflects degree, allowing identification of central lexical hubs. The Grade 8 network displays two prominent hubs, shuǐ (水, water) and rén (人, person), and contains a community that is connected to the main network via a single bridging node, indicating a relatively fragile connection between semantic domains. In contrast, the Grade 11 network shows rén (人, person) as the dominant central hub, with all communities connected through multiple bridging nodes, suggesting increased integration across semantic domains. Both networks contain secondary hubs consisting of frequently produced lexical items; however, these hubs differ qualitatively across developmental stages. The Grade 8 network includes words such as jiānchí (坚持, persistence), nǔlì (努力, effort), wēnnuǎn (温暖, warmth), péngyou (朋友, friend), and shēngmìng (生命, life), whereas the Grade 11 network includes shuǐ (水, water), chénggōng (成功, success), mùbiāo (目标, goal), wùpǐn (物品, item), and shíwù (食物, food). These patterns suggest developmental shifts in lexical organization and semantic mediation during adolescence.
Visualization of Grade 8 Chinese word association network, including node labels.

Visualization of Grade 11 Chinese word association network, including node labels.

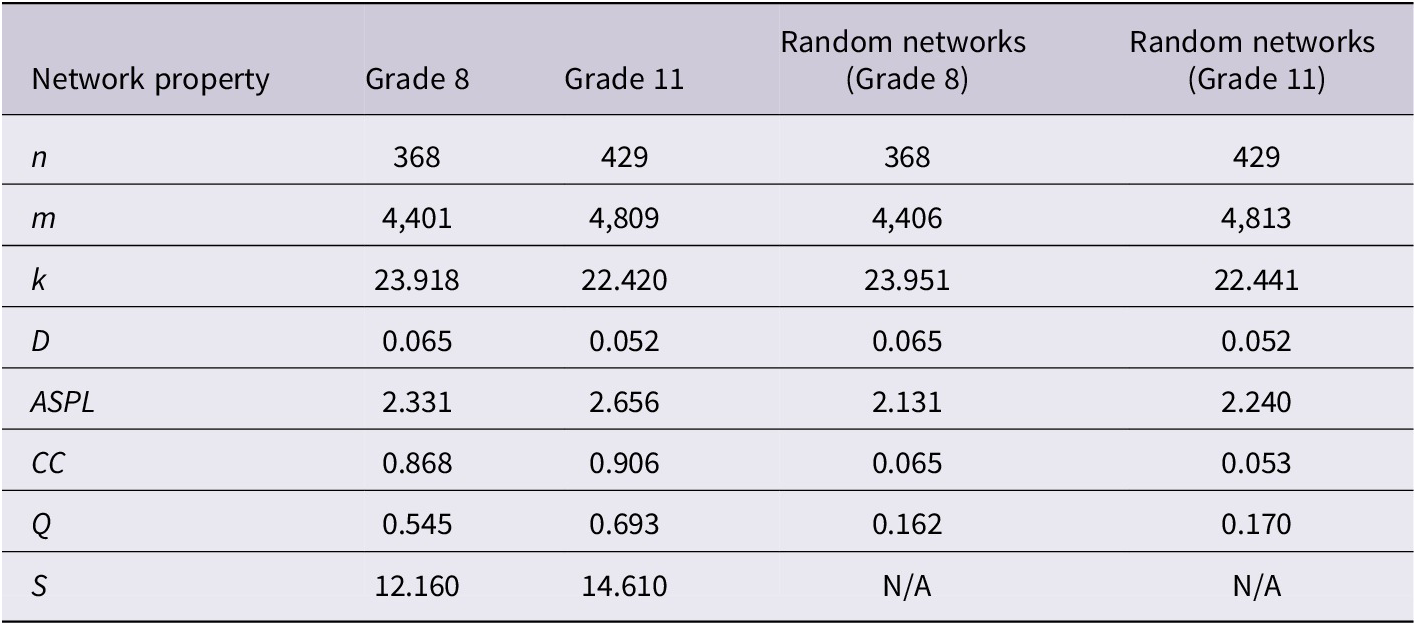
3.2. Research question 2: What developmental changes occur in the structural properties of L2 English word association networks between Grade 8 and Grade 11 students?
Table 3 presents the structural properties of the English networks together with the corresponding random network benchmarks. The Grade 11 network exhibited a larger number of nodes and edges compared to the Grade 8 network. However, k and D were lower in Grade 11, while ASPL, CC, and Q were higher, indicating differences in network structure between the two grade levels.
Structural properties of English word association networks and corresponding random networks

CC and ASPL of each English network were compared to those of 100 graphs to investigate small-world features. For the Grade 8 network, the original ASPL (M = 2.331) was significantly longer than the mean ASPL of random networks (M = 2.131, SD = 0.01), t(99) = 213.08, p < .001. The original CC (M = 0.868) was significantly higher than the mean CC of random networks (M = 0.065, SD = 0.002), t(99) = 4633.12, p < .001. These findings, along with an S value of 12.16, confirm small-world properties, marked by elevated local clustering and moderate global path lengths. Likewise, for the Grade 11 network, the original ASPL (M = 2.656) surpassed the mean ASPL of random networks (M = 2.240, SD = 0.01), t(99) = 371.35, p < .001. The original CC (M = 0.906) exceeded the mean CC of random networks (M = 0.053, SD = 0.001), t(99) = 5983.05. An S value of 14.61 further substantiates small-world features. Likewise, independent samples t-tests were conducted on 100 connected English subgraphs. A significant difference was observed for D, t(198) = 13.64, p < .001, with Grade 8 subgraphs showing higher D than Grade 11. For ASPL, a significant difference emerged, t(198) = −16.89, p < .001, indicating shorter paths in Grade 8 compared to Grade 11. The test for CC revealed a significant difference, t(198) = −43.06, p < .001, with lower CC in Grade 8 than Grade 11. Q also differed significantly, t(198) = −34.50, p < .001, showing lower values in Grade 8 than Grade 11.
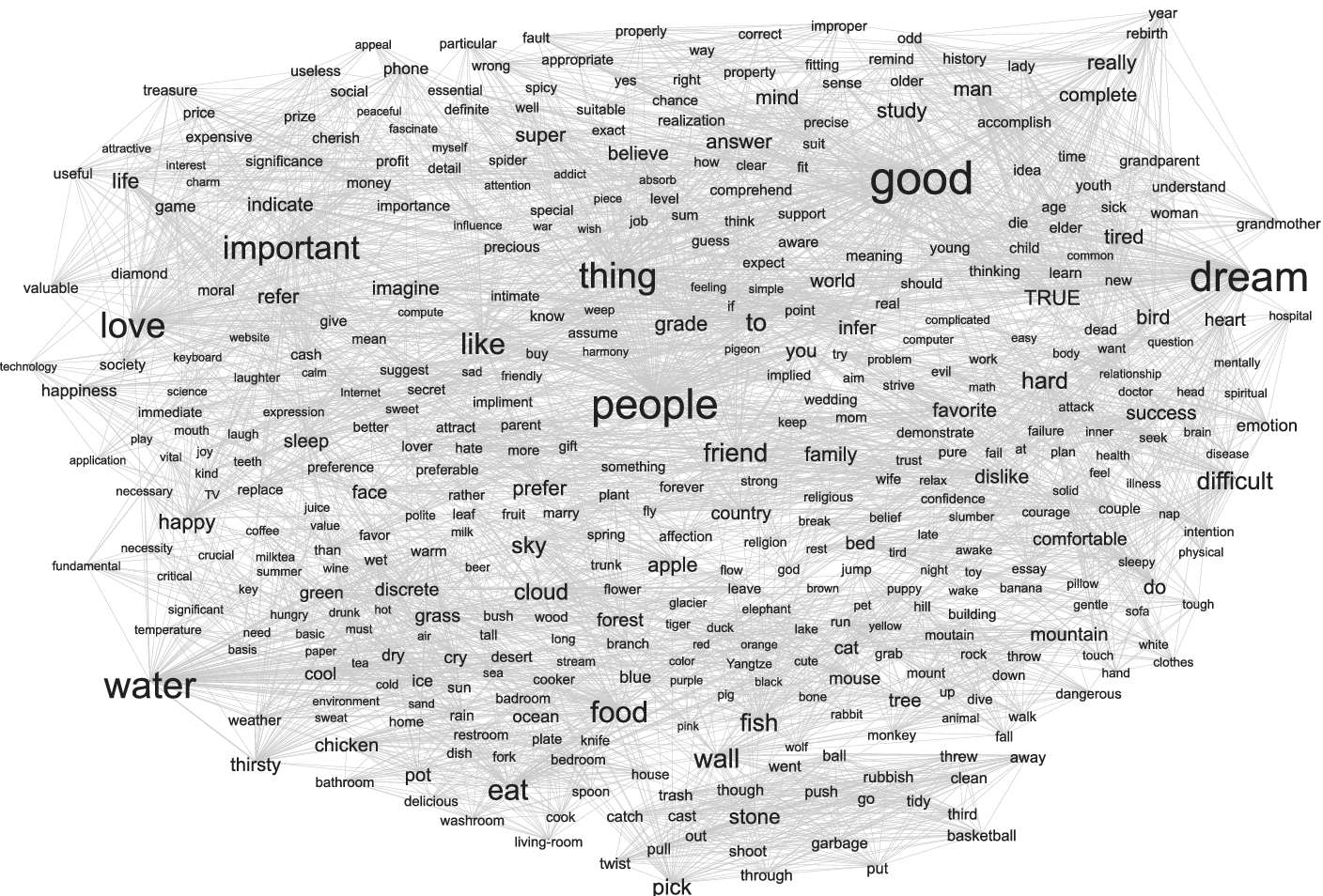
Again, network visualizations were generated using the same procedures and layout parameters described for the Chinese networks. Nodes represent words, edges represent associative links, and node size reflects degree. Figures 3 and 4 present the English word association networks for Grade 8 and Grade 11 students, respectively. The Grade 8 network demonstrates high connectivity with two primary hubs, identified as good and nice, alongside several secondary hubs forming localized clusters. The Grade 11 network also shows high connectivity but displays a more distributed hub structure, with good, dream, and people emerging as central nodes. The persistence of good as a central hub across grades suggests its stable mediating role in the developing L2 lexicon. Although both networks contain central and secondary hubs composed largely of high-frequency words, their lexical composition differs across grades. The Grade 8 network prominently features love, dream, people, water, and special, whereas the Grade 11 network includes thing, important, love, water, and food. These patterns indicate developmental shifts in associative organization within the L2 English lexicon.
Visualization of Grade 8 English word association network, including node labels.

Visualization of Grade 11 English word association network, including node labels.

3.3. Research question 3: What differences exist in the structural properties of word association networks between L1 Chinese and L2 English across Grade 8 and Grade 11 students?
To analyse the effects of grade and language on subgraph properties (D, ASPL, CC, Q), two-way nonparametric Scheirer–Ray–Hare tests were conducted in Python. These measures were selected as they represent key structural dimensions of lexical networks, including connectivity, global efficiency, local clustering, and community structure, and have been widely employed in previous lexical network studies (Agustín-Llach & Palapanidi, Reference Agustín-Llach and Palapanidi2024; Borodkin et al., Reference Borodkin, Kenett, Faust and Mashal2016; Cosgrove et al., Reference Cosgrove, Kenett, Beaty and Diaz2021; Fernández-Fontecha & Kenett, Reference Fernández-Fontecha and Kenett2022; Li et al., Reference Li, Jiang, Shang and Chen2021; Zortea et al., Reference Zortea, Menegola, Villavicencio and de Salles2014). Post hoc comparisons were conducted to investigate cross-language differences in each grade. Table 4 presents the descriptive statistics for each property by grade and language.
Descriptive statistics for subgraph properties by grade and language (M and SD)

Note: Due to the small values of the subgraph properties, values are reported to three decimal places.
For D, the Scheirer–Ray–Hare test revealed significant main effects of grade, H(1) = 1226.98, p < .001, η2 = 3.08, and language, H(1) = 1281.19, p < .001, η2 = 3.21, with no significant interaction, H(1) = −1120.40, p > .05. The post hoc comparisons showed a significant difference in Grade 8, with English higher than Chinese, U = 9705, p < .001, r = 0.81, but no significant difference in Grade 11, U = 5086, p = .835, r = 0.02. For ASPL, significant main effects were found for grade, H(1) = 1253.34, p < .001, η2 = 3.14, and language, H(1) = 1266.28, p < .001, η2 = 3.17, with no significant interaction, H(1) = −1141.54, p > .05. Within-grade comparisons showed a significant difference in Grade 8, with Chinese subgraph paths longer than English, U = 249, p < .001, r = 0.82, but no significant difference was shown in Grade 11, U = 4540, p = .262, r = 0.08. For CC, significant main effects emerged for grade, H(1) = 1220.04, p < .001, η2 = 3.06, and language, H(1) = 1444.57, p < .001, η2 = 3.62, with no significant interaction, H(1) = −1165.98, p > .05. Within-grade comparisons confirmed significant differences in both grades: in Grade 8, Chinese subgraphs exceeded English, U = 0, p < .001, r = 0.86; in Grade 11, Chinese subgraphs were also more clustered than English ones, U = 896, p < .001, r = 0.71. Finally, for Q, significant main effects were observed for grade, H(1) = 1223.66, p < .001, η2 = 3.07, and language, H(1) = 1398.62, p < .001, η2 = 3.51, with no significant interaction, H(1) = −1151.27, p > .05. Post hoc comparisons confirmed significant differences: in Grade 8, Chinese subgraphs were more modular than English subgraphs, U = 0, p < .001, r = 0.86; in Grade 11, Chinese subgraphs also showed higher Q than English ones, U = 2124, p < .001, r = 0.50.
4. Discussion
The present study examined developmental changes in the structural properties of word association networks in L1 Chinese and L2 English among Grade 8 and Grade 11 adolescents, as well as differences between the two languages across these grades. The findings revealed that in L1 Chinese, networks became less modular and less locally clustered from Grade 8 to Grade 11. In contrast, L2 English networks showed increased Q and clustering over the same period. Cross-language comparisons indicated more clustered, modular associative structures and longer paths in Chinese than in English, with such discrepancies more pronounced in Grade 8 than in Grade 11. These differences suggest that the L1 lexicon shows a more stabilized and differentiated associative structure, whereas the L2 lexicon reflects a system that is still developing and undergoing structural reorganization during adolescence.
Our results reveal distinct developmental patterns in the structure of L1 Chinese lexical networks from middle to high school, marked by increased degree and decreased Q and clustering from Grade 8 to Grade 11. These changes are consistent with prior network analyses of monolingual associative structures. For example, Dubossarsky et al. (Reference Dubossarsky, De Deyne and Hills2017) in their lifespan development study of L1 Dutch networks, found that in-degree and out-degree increased between ages 14 and 18, aligning with our observation of rising average degree in Grade 11. This suggests that during adolescence, not only are new words and concepts acquired, but existing ones also form additional connections (Uccelli & Rowe, Reference Uccelli, Rowe, Gleason and Ratner2022), reflecting parallel growth in vocabulary quantity and quality. Dubossarsky et al. (Reference Dubossarsky, De Deyne and Hills2017) also reported declining entropy during this developmental period, which they interpreted as reflecting increasing convergence in associative responses. Although entropy was not directly examined in the present study, a comparable pattern was observed in the distribution of response types. Grade 11 participants produced fewer unique response types (2,131 versus 2,254 in Grade 8) despite equivalent total numbers of responses. For example, to the cue word jiānchí (坚持, persistence), Grade 11 produced 15 instances of rúguǒ (如果, if) compared to 10 in Grade 8; for xìnyǎng (信仰, faith), 19 instances of jiāndìng (坚定, firm) versus 11; and for wēixiào (微笑, smile), 22 instances of kāixīn (开心, happy) versus 14. These examples suggest that associations produced by Grade 11 participants were more convergent than those produced by Grade 8 participants.
Similarly, Jeong and Hills (Reference Jeong and Hills2024), analysing English, Dutch, and Spanish associative networks, reported declining CC and rising ASPL between ages 16 and 20, with degree increasing in English and Spanish–patterns broadly consistent with our findings. Notably, while Dubossarsky et al. (Reference Dubossarsky, De Deyne and Hills2017) used S-S networks and Jeong and Hills (Reference Jeong and Hills2024) employed S-R networks, both yielded results similar to our R-R approach, suggesting universal regularities in adolescent L1 network development: rising average degree and falling CC. Our study extends this by documenting a decline in Q from Grade 8 to Grade 11, an indicator typically examined in ageing populations, where higher Q reflects diversified, individualized structures (Cosgrove et al., Reference Cosgrove, Beaty, Diaz and Kenett2023). The observed decrease suggests reduced semantic partitioning during adolescence, potentially stemming from schooling’s emphasis on shared conceptual frameworks. Literacy activities and classroom instruction often prioritize collective knowledge, such as standardized definitions and categorical hierarchies, which may consolidate associations around common themes while still allowing for individual variation in interpretation. This process fosters a balance: students acquire more communal understandings that enhance communicative efficiency, yet retain linguistic individualism (Nippold, Reference Nippold2007).
However, our findings diverge from some L1 associative network studies. For instance, Zortea et al. (Reference Zortea, Menegola, Villavicencio and de Salles2014) compared Portuguese networks in children (ages 8–12), adults (ages 17–45), and elders (ages 60–87), finding declining ASPL and rising degree and clustering from childhood to adulthood – opposite to our patterns. This discrepancy may arise from differing age groups; Zortea et al. (Reference Zortea, Menegola, Villavicencio and de Salles2014) skipped the 12–17 range we examined, and their adult network’s larger size (620 nodes, 19,306 edges) versus children’s (411 nodes, 7,738 edges) likely biased results toward greater connectivity. Nonetheless, our study revealed that both Grade 8 and Grade 11 networks exhibited small-world properties, consistent with Zortea et al.’s (Reference Zortea, Menegola, Villavicencio and de Salles2014) findings and other research (Morais et al., Reference Morais, Olsson and Schooler2013; Zhang & Ma, Reference Zhang and Ma2024), indicating that human mental lexicons maintain this efficient structure across lifespan stages. Our work supplements child-adult comparisons by focusing on adolescence, a period often overlooked in favour of child–adult–elder contrasts, yet critical for qualitative shifts beyond mere vocabulary growth (Berman, Reference Berman, Hoff and Shatz2007).
From a theoretical perspective, these patterns offer new insights into Tolchinsky and Berman’s (Reference Tolchinsky and Berman2023) developmental trajectories, which describe ages 13–19 as transitioning from nonconformist to autonomous and sometimes creative language use, characterized by divergence from norms and innovative associations. Contrary to expectations, our Grade 11 networks had fewer nodes and edges than Grade 8, with lower Q, suggesting more common responses and reduced semantic partitioning. This may indicate that Grade 11 adolescents remain in a “becoming conventional” stage, where associations stabilize around frequent, shared concepts rather than fully embracing autonomy. This evidence extends Tolchinsky and Berman’s (Reference Tolchinsky and Berman2023) developmental trajectories by highlighting blurred boundaries between phases. While they outline distinct shifts – from conventionality (ages 6–12) to autonomy (ages 13–19) – our data suggest overlap, with Grade 11 networks retaining conventional traits amid integration.
Broader adolescent L1 development research corroborates this convergence. Nippold (Reference Nippold1988) noted high school students increasingly define words via superordinate relations rather than functions, reflecting schooling’s role in conventionalizing semantics. Superordinates, learned through education, foster shared knowledge over individual experiences. Ricketts et al. (Reference Ricketts, Lervåg, Dawson, Taylor and Hulme2020) tracked British students’ oral vocabulary from Grades 6–7 to 8–9, finding reduced within-group variance during this period, indicating convergence. However, written and oral development diverge in adolescence, with writing showing stronger individualization via divergent thinking and perspective-taking (Berman, Reference Berman2017). Word association tasks, capturing rapid retrieval rather than reflection, may not fully reflect this; thus, our results complement rather than contradict, emphasizing the need for multifaceted approaches in future adolescent lexical development studies.
The findings for L2 English reveal an expansion in network size from Grade 8 to Grade 11, with increases in nodes and edges. This growth indicates that as language exposure accumulates, the L2 lexicon enlarges, incorporating more unique associations. Concurrently, the CC rose significantly (from 0.87 to 0.91), and the S increased (from 12.16 to 14.61), suggesting stronger local connectivity and enhanced overall network efficiency. Q also improved (from 0.54 to 0.69), implying greater differentiation into communities where intra-community links are denser than inter-community ones. Community detection analysis further showed that the Grade 8 network was partitioned into 12 clusters, whereas the Grade 11 network formed 11 clusters. Although the later network contains slightly fewer clusters, the higher Q suggests that words within each cluster are more closely connected and less randomly linked to words outside the cluster. In practical terms, this may mean that learners at the later stage tend to group related words together more consistently. This type of organization may help learners access related vocabulary more easily and use words more accurately when understanding or producing language. Stronger connections among related words may also help reduce confusion caused by loosely related associations and support smoother word access during communication. These developments align with Meara and Wolter’s (Reference Meara and Wolter2004) framework of vocabulary size and organization, which posits that L2 lexicon expansion and structural refinement occur synergistically: as vocabulary size grows, the network reorganizes to support more robust semantic relations, facilitating lexical processing and retrieval.
Although investigations of adolescent L2 semantic network development are scarce, comparisons with studies contrasting proficiency levels yield largely consistent patterns with our findings. For instance, Borodkin et al. (Reference Borodkin, Kenett, Faust and Mashal2016) used a semantic fluency task to construct networks for English–Hebrew bilinguals, distinguishing low- and high-proficiency Hebrew learners. They observed higher clustering and longer ASPL in advanced learners, mirroring our results where clustering and ASPL increased. The extended ASPL likely results from network expansion, as more nodes introduce additional pathways, potentially increasing retrieval complexity but also enabling richer conceptual integration (Steyvers & Tenenbaum, Reference Steyvers and Tenenbaum2005). However, Borodkin et al. (Reference Borodkin, Kenett, Faust and Mashal2016) did not conduct statistical tests between groups, leaving the significance of these differences unconfirmed. Similarly, Feng and Liu (Reference Feng and Liu2023) compared semantic networks from undergraduate and graduate Chinese–English learners via semantic fluency task, finding higher clustering in graduates, consistent with our Grade 11 increase. They also reported greater average degree in graduates, contrasting our decline (from 23.92 to 22.42). Average degree reflects the typical number of connections per node, signifying associative breadth; a decrease may indicate more focused, selective links rather than diffuse ones. This discrepancy may partly reflect differences in node numbers. In naturally occurring word association data, networks derived from different participant groups often vary in size, and such variation can influence structural metrics including average degree and density. Therefore, cross-study comparisons should be interpreted as descriptive and explanatory rather than inferential. In the present study, statistical inferences were based on size-controlled comparisons, and thus the cross-study observations reported here are intended only to provide possible contextual explanations rather than to substitute for the inferential results.
The substantial increase in Q from Grade 8 to Grade 11 highlights enhanced semantic compartmentalization, where words form tighter thematic groups. Higher Q supports lexical processing by allowing parallel activation within modules, aiding disambiguation and context-specific retrieval (Cosgrove et al., Reference Cosgrove, Beaty, Diaz and Kenett2023). In L2 usage, this may translate to improved fluency, as learners navigate specialized domains (e.g., academic versus everyday vocabulary) more adeptly. Overall, despite size growth, Grade 11 networks maintained elevated clustering and Q, substantiating the development and optimization of size and organization in L2 mental lexicon during adolescent years.
Comparisons with L1 Chinese networks reveal more pronounced changes in the L2 English networks. From Grade 8 to Grade 11, Chinese nodes decreased by 10 and edges by 20, with average degree rising 0.38, ASPL by 0.05, CC falling 0.01, and Q by 0.02. In English, nodes rose by 61 and edges by 408, with average degree dropping 1.5, ASPL rising 0.33, CC increasing 0.04, and Q by 0.15 – nearly every metric showed larger shifts in L2. This suggests that L1 networks approach maturity in middle school, entering a plateau where school-based learning yields incremental refinements rather than substantial growth, shifting focus to output proficiency and personalization. Conversely, L2 remains in a rapid expansion phase; high school adolescents encounter novel, complex English vocabulary through formal instruction and digital exposure to new language materials on a daily basis, fostering significant development and reorganization (Laufer & Vaisman, Reference Laufer and Vaisman2023). This asymmetry highlights the discrepancy in L1 and L2 lexical development among bilingual adolescents, especially when L2 input and usage are limited to the classroom environment.
Cross-language analyses revealed persistent yet diminishing differences between L1 Chinese and L2 English networks across Grade 8 and Grade 11, consistent with the patterns revealed in lexical development among younger Chinese–English children (Sheng et al., Reference Sheng, Lu and Kan2011). In both grades, Chinese networks were larger and more structured than English ones, though discrepancies were more evident in Grade 8. Specifically, in Grade 8, the Chinese network had 112 more nodes and 839 more edges than English, with significantly lower density but higher ASPL, CC, and Q. By Grade 11, differences narrowed: Chinese had 41 more nodes and 411 more edges, with higher CC and Q, but no significant differences in density or ASPL. These patterns suggest that while L1 networks maintain advantages in size and organization, L2 networks undergo accelerated maturation during adolescence, progressively aligning with L1 structures. This narrowing gap is also consistent with previous research which found that cross-language differences in the production of meaning-based associations as well as canonical associations dwindle as adolescents progress towards higher grade levels (Henriksen, Reference Henriksen, Albrechtsen, Haastrup and Henriksen2008; Namei, Reference Namei2004), which substantiate the generalizability of this development feature.
These findings offer two key insights. First, at each grade level, L1 networks outperform L2 in both size and structural properties, consistent with prior research on bilingual lexical networks. For example, Borodkin et al. (Reference Borodkin, Kenett, Faust and Mashal2016) found Hebrew L2 networks less clustered and more dispersed than English L1 networks. Similarly, Martinez and Vitevitch (Reference Martinez and Vitevitch2024) reported denser and more structurally diverse networks in monolingual English speakers than in Kaqchikel learners. In their interpretation, “creative” language use refers to the ability to produce a wider and less predictable range of associations, including responses that extend beyond direct or utilitarian relationships between words. For example, native speakers were more likely to generate compound expressions or connect concepts that were not obviously related, whereas learners tended to produce more straightforward and functionally direct associations. These differences suggest that richer lexical networks may support more flexible associative behaviour. Supporting this interpretation, Fernández-Fontecha and Kenett (Reference Fernández-Fontecha and Kenett2022) argue that semantic networks with stronger and more varied interconnections allow speakers to move more easily between concepts and increase the likelihood of producing diverse or less conventional associations. From this perspective, more structurally interconnected networks may enable speakers to access a broader range of lexical relationships during language use. Our results extend these by showing L1 superiority persists in adolescence, even as L2 advances. However, some studies report L2 surpassing L1 in certain properties, such as larger size or higher CC (Agustín-Llach & Palapanidi, Reference Agustín-Llach and Palapanidi2024). Such discrepancies may arise from adult samples with mature L2 proficiency or methodological variations, like smaller networks from fewer cue words in semantic fluency tasks (under 100 nodes) versus our larger word association networks (over 300 nodes) in the present study.
Second, L1–L2 differences decreased with grade level, evident in narrowing gaps: nodes from 112 to 41, edges from 839 to 411, ASPL from 0.51 to 0.23, CC from 0.06 to 0.01, and Q from 0.21 to 0.04. This convergence, achieved despite uniform preprocessing – where responses were pooled for cleaning then regrouped – indicates L1 development slows in middle to high school, entering a plateau of incremental refinement, while L2 enters a rapid growth phase fuelled by formal instruction. Adult bilingual studies often show enduring L1–L2 gaps, possibly because L2 input during school years is intensive in many developed regions of China, with English as a core subject. This differs from university-level L2 learners, whose L2 input and practice diminish in quantity. This disparity highlights how environmental factors modulate bilingual trajectories, with adolescent L2 benefiting from structured learning to bridge initial gaps.
5. Conclusion
Adopting word association network analysis, the present study revealed distinct developmental patterns in the structure of mental lexicon among Chinese–English bilingual adolescents. In L1 Chinese, networks showed reduced clustering and Q from middle to high school level, reflecting increased associative convergence. In L2 English, networks expanded in size, with higher clustering and Q, indicating structural maturation. Cross-language differences narrowed over grade levels, with L1 maintaining advantages in size and structure, though L2 showed accelerated growth during this period. Furthermore, in both L1 and L2 and in both grade levels, adolescents’ lexical networks all exhibited a clear small-world feature.
Despite these insights, limitations exist. The study did not analyse word association response types or convergence, and thus it remains open whether different aspects of word association develop simultaneously or not. Additionally, the present study adopted an R-R network construction approach, which captures associative patterns based on co-occurrence across cues. While this method provides valuable insights into the productive organization of the lexicon, future research may benefit from comparing R-R, S-S, and S-R approaches, as these methods highlight different aspects of lexical structure. Such comparisons would contribute to a more comprehensive understanding of bilingual lexical development. Finally, future research could move beyond single-round, group-level analyses by employing multiple rounds of word association or semantic fluency tasks to construct individual lexical networks. Such longitudinal designs would allow researchers to track how lexical networks change within individuals over time, providing insight into developmental trajectories that cannot be captured by cross-sectional comparisons alone. Individual networks would also make it possible to examine variability in rates and patterns of lexical reorganization, and to relate these changes to individual differences in language experience, proficiency, and other learner-related factors.
Acknowledgements
We would like to thank Mrs. Huang Xu for her valuable assistance during the initial data collection phase of this study.
Funding statement
This work was supported by National Social Science Fund of China under Grant [number 23BYY178].
Competing interests
The authors declare no competing interests.
Disclosure of use of AI tools
We declare that the AI tool, Grok3, was used solely for polishing text and correcting grammatical errors in the Introduction and Literature review sections of this manuscript. No AI tools were used for generating images, data, or original ideas within the manuscript. Grok3 was accessed via the platform (https://x.ai/grok) on August 10–18, 2025. We have no competing interests or potential biases arising from the use of Grok3 to declare.
Appendix A. Chinese and English cue words used in word association task

Appendix B. Worked example of R-R network construction
This appendix provides a simplified illustration of how R-R networks were constructed in the present study, following procedures described in Coronges et al. (Reference Coronges, Stacy and Valente2007) and Zortea et al. (Reference Zortea, Menegola, Villavicencio and de Salles2014).
Step 1: Tabulating word association responses
Assume that participants produce responses to three cue words as shown below:

Step 2: Removing duplicate tokens
Within each cue, repeated responses are collapsed into unique response types. For example, if multiple participants produce water in response to river, it is counted once for network construction but contributes to edge weighting across cues.
Step 3: Defining nodes
Each unique response word becomes a node in the network. In this example, these nodes include water, fish, boat, juice, cup, ice, and snow.
Step 4: Creating edges based on co-occurrence
Two response words are connected if they appear under the same cue. For instance:
-
• Under river, edges are created between water–fish, water–boat, and fish–boat.
-
• Under drink, edges are created between water–juice, water–cup, and juice–cup.
-
• Under cold, edges are created between water–ice, water–snow, and ice–snow.
Step 5: Assigning edge weights
Edge weight reflects the number of distinct cues under which two responses co-occur. If two responses appear together under multiple cues, their connection is strengthened accordingly. Edge weights therefore index contextual similarity across cues and indicate how consistently two concepts are co-activated.
Step 6: Network construction
The final network is represented as an undirected graph in which:
-
• Nodes represent response words
-
• Edges represent co-occurrence relationships
-
• Edge weights represent co-occurrence frequency across cues



 Open access
Open access