


“This is play.”
(Bateson, Reference Bateson1955)
1. Introduction
Iconic words are widespread in natural languages (Nuckolls, Reference Nuckolls1999; Perniss, Thompson, & Vigliocco, Reference Perniss, Thompson and Vigliocco2010), and scholars working on them have long drawn attention to their expressive and playful nature (Samarin, Reference Samarin1970; Jakobson & Waugh, Reference Jakobson and Waugh1979; Klamer, Reference Klamer2002). However, empirical studies of when and why some words appear more playful and performative than others are rare. Here we study the intersection of iconicity and playfulness using new data on funniness and iconicity for thousands of English words. We propose that structural markedness underlies both funniness and iconicity, and test this theory by combining linguistic analysis with quantitative evidence from human lexical ratings. We also introduce and benchmark a method for estimating lexical ratings on the basis of distributional semantics, allowing us to test the generalizability of our proposals. The method is applicable more generally to the task of substantially increasing the intersection between sets of lexical ratings.
Substantial numbers of iconic words are found in many of the world’s languages, often in the form of an open lexical class of ideophones, but also scattered across the lexicon as sensory words that show phonaesthetic form–meaning associations (Nuckolls, Reference Nuckolls1999; Dingemanse, Reference Dingemanse, Akita and Pardeshi2019). The marked phonology of iconic words has been connected to playful and expressive functions of language (Samarin, Reference Samarin1970; Zwicky & Pullum, Reference Zwicky, Pullum, Aske, Beery, Michaelis and Filip1987; Kunene, Reference Kunene, Voeltz and Kilian-Hatz2001; Haiman, Reference Haiman, MacWhinney, Malchukov and Moravcsik2014), and ideophones have been defined – only partly tongue-in-cheek – as “those words which are such fun to use” (Welmers, Reference Welmers1973). In an independent strand of research, people have recently started to investigate the perceived funniness of word forms (Westbury, Shaoul, Moroschan, & Ramscar, Reference Westbury, Shaoul, Moroschan and Ramscar2016; Engelthaler & Hills, Reference Engelthaler and Hills2018). One aim of this paper is to make these worlds meet. Playfulness and iconicity are pervasive features of language. In investigating them together, this paper seeks to contribute to a recentering of linguistics, which has focused mostly on the referential function of language to the neglect of its poetic, expressive, and other functions (Jakobson, Reference Jakobson and Sebeok1960).
1.1. research questions and theoretical background
What makes people think of words as iconic? What makes people think of words as funny? And is there a relation between the two? These questions are motivated by prior work on the link between playfulness and performativity in language and communication (Fortune, Reference Fortune1962; Samarin, Reference Samarin1970; Dingemanse, Reference Dingemanse2011). For instance, ideophones and other forms of expressive language often show elements of phonetic and linguistic play, drawing attention to themselves for purposes of dramatisation and entertainment (Samarin Reference Samarin1970). Likewise, puns and word plays are characterised by the use of linguistic material for aesthetic purposes (Jakobson & Waugh, Reference Jakobson and Waugh1979). Recent work suggests that words are rated as funnier when they have improbable orthographic or phonological structure (Westbury & Hollis, Reference Westbury and Hollis2019). We propose that perceptions of words as iconic and/or funny may be underpinned by a shared semiotic mechanism: foregrounding by means of structural markedness.
In linguistics, foregrounding has been defined as the use of linguistic signs “in such a way that this use itself attracts attention” (Havránek, Reference Havránek and Garvin1964, p. 10). Foregrounding in this sense can be achieved in several ways, including lexical choice, prosody, and most importantly for present purposes, by structural markedness: formal properties of lexical roots that make them stand out from other words. Work on iconicity has shown that iconic words often show such structural markedness in the form of phonotactic patterns and structures that deviate from other segments of vocabulary (Samarin, Reference Samarin1970; Klamer, Reference Klamer2002; Nuckolls, Nielsen, Stanley, & Hopper, Reference Nuckolls, Nielsen, Stanley and Hopper2016). These special formal characteristics help signal their special status as depictions (Nuckolls, Reference Nuckolls1999; Dingemanse, Reference Dingemanse, Akita and Pardeshi2019). In semiotic terms, structural markedness can serve as a meta-communicative signal that draws attention to the word qua word and thereby invites language users to treat it as playful, poetic, and performative.
Behind the linguistic sense of foregrounding lies theoretical work in human ethology and sociology, according to which metacommunicative signals can frame strips of behaviour as “play” versus “not play” (Bateson, Reference Bateson1955) or as “nonserious” versus “serious” (Goffman, Reference Goffman1974). Bateson suggested that this metacommunicative distinction marks a major transition in the evolution of communication. Goffman showed its relevance in everyday social interaction, where we regularly combine serious actions with acting, playing, and pretending. This brings into view a deeper conceptual connection between playfulness and iconicity: both belong to a world of make-believe where words are valued for their performative character as much as their informative content.
While funniness and iconicity have been connected conceptually, their relation has not been studied empirically in a large dataset. This is what we do here using lexical ratings for thousands of words. Databases of lexical norms have long been used to achieve experimental control and model psycholinguistic processes. The growing number of properties and dimensions for which norms are available makes such resources increasingly important in quantitative studies of many fundamental questions in the language sciences (Winter, Reference Winter2019). For instance, cross-linguistic collections of iconicity ratings can be used to better understand modality-specific affordances for iconicity (Perlman, Little, Thompson, & Thompson, Reference Perlman, Little, Thompson and Thompson2018); and ratings of affective meaning can be investigated for their relation to phonetic and sublexical measures of affect (Aryani, Conrad, Schmidtke, & Jacobs, Reference Aryani, Conrad, Schmidtke and Jacobs2018).
With many sets of lexical ratings within easy reach, it is important to understand their affordances and limitations (Motamedi, Little, Nielsen, & Sulik, Reference Motamedi, Little, Nielsen and Sulik2019). In sufficiently large datasets, almost any combination of lexical ratings will show some correlation. This makes it important to constrain analytical degrees of freedom by means of theory. The theory-driven proposal of this paper is that foregrounding, achieved through structural markedness, unites playfulness and iconicity. This implies two predictions for the kind of lexical data we study: (i) high iconicity ratings and high funniness ratings should go hand in hand; and (ii) words rated high in funniness and iconicity should show relatively larger degrees of structural markedness. Although we test these predictions using lexical data from English, given the generality of the account, we expect the findings to hold across a wide range of languages. We see this study therefore as improving our theoretical and empirical grasp of the relation between playfulness and iconicity.
2. Methods and materials
Our starting point is the intersection of recently published funniness ratings (Engelthaler & Hills, Reference Engelthaler and Hills2018) and iconicity ratings (Perry, Perlman, Winter, Massaro, & Lupyan, Reference Perry, Perlman, Winter, Massaro and Lupyan2017), illustrated in Figure 1. Both sets of human ratings have been collected by asking people to rate words on continuous scales, with every word rated by at least 10 people. For the iconicity ratings, people were asked to rate words on a scale that runs from –5 (anti-iconic or “words that sound like the opposite of what they mean”) via 0 (arbitrary or “words that do not sound like what they mean or the opposite”) to 5 (iconic or “words that sound like what they mean”). As Figure 1, panel B shows, the negative end of the scale was underused; subsequent analysis suggests that it was also used less consistently (Motamedi et al., Reference Motamedi, Little, Nielsen and Sulik2019). The positive end of the scale successfully picked out words that show iconicity, defined (for spoken languages) as perceptual resemblances between aspects of word sound and meaning (Svantesson, Reference Svantesson2017).
The intersection of iconicity and funniness ratings for 1419 words. A: Scatterplot of iconicity and funniness ratings in which each dot corresponds to a word. A loess function generates the smoothed conditional mean with 0.95 confidence interval. Panels B and C show the distribution of iconicity and funniness ratings in this dataset.

Among the items rated high in iconicity in this study are also quite a few morphologically complex words with analysable compositional structure, like ‘dishwasher’, ‘skateboard’, ‘downpour’, ‘seaweed’, ‘corkscrew’, ‘airplane’, and ‘bedroom’. Morphological analysability is quite distinct from perceptual resemblances between sound and meaning (for instance, it is only accessible to those who already know the meaning of the compound elements), so such words are not actually iconic in the sense used in the rating study (Perry, Perlman, & Lupyan, Reference Perry, Perlman and Lupyan2015). However, it is easy to see why naive participants would treat them as words that “sound like what they mean”. We will later see that these analysable compounds may introduce a bias that is amplified in imputed ratings.
For the funniness ratings, people were asked to rate words on a scale from 1 to 5 in terms of funniness (Figure 1, panel C). As the instructions mentioned, “The rating scale ranges from 1 (humourless = not funny at all) to 5 (humorous = most funny)”. Because participants were instructed to interpret the scale in terms of funniness, we think the ratings are best described as “funniness ratings” rather than “humour norms” (which is what Engelthaler and Hills call them). Humour is a broad field of study: the perceived funniness of words is only one aspect of a phenomenon that ranges from the fine details of prosody and phonology (Menninghaus, Bohrn, Altmann, Lubrich, & Jacobs, Reference Menninghaus, Bohrn, Altmann, Lubrich and Jacobs2014; Westbury & Hollis, Reference Westbury and Hollis2019) to discourse and ethnopragmatics (Glenn, Reference Glenn2003; Levisen, Reference Levisen2018), and whose stylistic realisations include puns, allusions, jokes, and anecdotes (Dynel, Reference Dynel2009; Attardo, Reference Attardo, Winter-Froemel and Thaler2018).
To test the generalisability of our findings, we developed a meaning-based algorithm to estimate funniness and iconicity for any English word. The algorithm works in two steps. First, it is trained on a large corpus of natural language text. Using the lexical co-occurence statistics in this corpus, it learns semantic relationships between millions of English words (words that appear in similar contexts are treated as similar in meaning). Second, it is trained to predict the iconicity (or funniness) of words that have already been rated by experimental participants. Once it can accurately predict known ratings, it is asked to predict iconicity (or funniness) for new words. It is able to do this for virtually any new word by using the semantic relationships it learned in step one.
For example, say the new word is ‘waggle’. In step one, the algorithm learned that ‘waggle’ occurs in similar contexts to ‘wiggle’ and ‘wobble’. In step two, it learned that ‘wiggle’ and ‘wobble’ were rated as highly iconic by participants. As a result, it predicts that ‘waggle’ will be highly iconic too. Technically, our algorithm is based on a linear regression model that predicts experimental ratings from word vectors trained on Wikipedia (Bojanowski, Grave, Joulin, & Mikolov, Reference Bojanowski, Grave, Joulin and Mikolov2017). Similar methods have been studied elsewhere (see, e.g., Mandera, Keuleers, & Brysbaert, Reference Mandera, Keuleers and Brysbaert2015; Hollis, Westbury, & Lefsrud, Reference Hollis, Westbury and Lefsrud2017; Thompson & Lupyan, Reference Thompson, Lupyan, Kalish, Rau, Zhu and Rogers2018). By combining lexical co-occurrence statistics with funniness ratings for 4996 English words and with iconicity ratings for 2945 English words, we estimated funniness and iconicity ratings for a total of 70202 words. We call these the imputed ratings to distinguish them from the human ratings.
The following subsets of the data will feature most prominently in the analyses below (Figure 2): set A, 1419 words that people have rated for both funniness and iconicity; set B, 3577 words for which we compare human funniness ratings with imputed iconicity ratings; and set C, 63680 words for which only imputed ratings are available. Set A allows us to establish the ground truth about the relation between iconicity and funniness ratings and about the occurrence of cues of structural markedness. Set B allows us to test whether our imputation method makes sense. Set C allows us see whether the iconicity–funniness relation holds even in words for which we have only imputed ratings, and whether the formal cues of structural markedness also show up in these words.
Venn diagram of lexical data used in the study. Sets 1 and 2 represent human word-level ratings for iconicity (n = 2945) and funniness (n = 4996). These are also the training data for the imputed ratings in set 3, the full set of 70202 words for which we imputed values for funniness and iconicity. The main datasets used in the analyses are set A, the 1419 words for which both human iconicity and human funniness ratings are available; set B, the 3577 words for which we have human funniness ratings but only imputed iconicity ratings; and set C, the 63680 words for which only imputed ratings are available.

We supplement the data with SUBTLEX-US frequency norms (Van Heuven, Mandera, Keuleers, & Brysbaert, Reference Van Heuven, Mandera, Keuleers and Brysbaert2014), removing 62 words for which no frequency data is available (1 from the funniness ratings and 61 from the iconicity ratings). We further add lexical decision times (Keuleers, Lacey, Rastle, & Brysbaert, Reference Keuleers, Lacey, Rastle and Brysbaert2012), phonotactic data from the Irvine Phonotactic Online Dictionary (Vaden, Halpin, & Hickok, Reference Vaden, Halpin and Hickok2009), and data on number of morphemes from the British Lexicon Project (Balota et al., Reference Balota, Yap, Hutchison, Cortese, Kessler, Loftis and Treiman2007).
2.1. analysis
We conduct all analyses using R version 3.6.1 (R Core Team, 2019). The most important packages in our analysis pipeline are tidyverse (Wickham, Reference Wickham2017), ggplot2 (Wickham, Reference Wickham2016), car (Fox & Weisberg, Reference Fox and Weisberg2019) and ppcor (Kim, Reference Kim2015). For all linear models reported below, variance inflation factors are below 2, indicating no problems with (multi)collinearity, and visual inspection of Q-Q plots and residuals plotted against fitted values revealed no deviations from normality or homoscedasticity. All data and analyses are available through the online materials at <https://osf.io/7s6xc/>.
The analysis comes in four parts. First, using human ratings, we examine the relation between funniness ratings and three other variables: iconicity ratings (our main focus), word frequency (a known covariate of both funniness and iconicity), and lexical decision time (reported by Engelthaler & Hills (Reference Engelthaler and Hills2018) as the most important correlate of funniness ratings after frequency). Second, we go beyond known iconicity ratings to test the relation between funniness ratings and imputed iconicity. This is a first benchmark of the imputation method and serves to test whether the relation identified for human ratings also holds for imputed iconicity ratings. Third, we investigate the relation between imputed funniness and imputed iconicity ratings as a further test of the generalisability of the imputation method. In all these analyses, we control for frequency and lexical decision time. Finally, we investigate the structural properties of the highest rated words and inductively identify cues of structural markedness to explain the relation between funniness ratings and iconicity ratings.
3. Results
3.1. funniness and iconicity
We first consider the relation of funniness ratings to frequency and lexical decision time, the two measures identified by Engelthaler and Hills (Reference Engelthaler and Hills2018) as the strongest correlates for perceived funniness. Like them, we find that uncorrected correlations in the full dataset hover around 28%, with log frequency negatively correlating with funniness (less frequent words are rated as more funny) and lexical decision time positively (words with longer reaction times are rated as more funny). A linear model with funniness as dependent variable and frequency and lexical decision time as predictors shows a role for both, though a larger portion of the variance is accounted for by frequency (F = 454.1, p < .0001, partial η2 = 8.3%) than by lexical decision time (F = 100.4, p < .0001, partial η2 = 2%).
To assess the role of iconicity we carry out this analysis for the subset of 1419 words for which we have both iconicity and funniness ratings, and compare linear models with and without iconicity as an additional predictor. We find that, in this subset, as expected, funniness ratings are partially predicted by frequency and lexical decision time. Model comparison shows that a model including iconicity as a predictor provides a significantly better fit (F = 63.7, p < .0001) and explains a larger portion of the variance (adjusted R2 = 0.188 versus 0.152). In this fuller model, while frequency remains the strongest (negative) correlate of funniness ratings (F = 258.8, p < .0001, partial η2 = 15.5%), iconicity is the second strongest predictor (F = 63.7, p < .0001, partial η2 = 4.3%), followed at some distance by lexical decision time (F = 8.9, p = .003, partial η2 = 0.6%).
Since iconicity is also known to bear a weak relation to word frequency (Winter, Perlman, Perry, & Lupyan, Reference Winter, Perlman, Perry and Lupyan2017), we test whether the relation between iconicity and funniness ratings is reducible to the effect of frequency using partial correlations (Kim, Reference Kim2015). In set A, we find that there is 20.6% of covariance between iconicity and funniness that is not explained by word frequency: words rated higher in iconicity are still rated higher in funniness, controlling for frequency (r = 0.206, p < .0001). The relation between iconicity and funniness ratings, controlling for frequency, is depicted in Figure 3, panel A.
Relations between funniness and iconicity after controlling for word frequency, in: A words with human ratings; B words with human funniness ratings and imputed iconicity ratings; C words for which we only have imputed ratings. Funniness is residualised to control for frequency, so scales on the y-axis are not directly relatable to the original 1–5 rating scale.

Table 1 shows example words from the four quadrants of the funniness and iconicity ratings space. Many highly iconic words are rated as highly funny, and many words rated as not iconic are rated as not funny. Areas where the ratings deviate bring to light other mediating factors. For instance, ‘buttocks’, ‘chimp’, and ‘blonde’ are rated as highly funny but not iconic; their funniness rating is likely derived from co-occurrence relations (e.g., appearance in joke genres) rather than from any phonological characteristics. On the other hand, highly iconic words like ‘roar, ‘crash’, and ‘scratch’ are low in funniness ratings, likely because they are associated with negative events. The word ‘sunshine’ is an example of a non-iconic word that is likely rated as highly iconic because of its transparent compositional structure; about 10% of the top 150 nouns with high iconicity ratings are of this type.
Sample words from the extremes of each quadrant of funniness and iconicity ratings (total n = 1419)

3.2. funniness and imputed iconicity (known unknowns)
As a first test of the imputation method we look at the intersection of funniness ratings and imputed iconicity ratings for the 3577 words that have been human-rated for funniness but not iconicity (Figure 3, panel B). We formulate a linear model with funniness rating as the dependent variable. Model comparison shows that a model including imputed iconicity as predictor provides a significantly better fit (F = 451.8, p < .0001) and explains more than double the amount of variance (adjusted R2 = 0.187 versus 0.084) than a model with just log frequency and lexical decision time. In the fuller model, imputed iconicity rises to be the strongest predictor (F = 451.8, p < .0001, partial η2 = 11.2%), followed by frequency (F = 245.7, p < .0001, partial η2 = 6.4%) and lexical decision time (F = 127.4, p < .0001, partial η2 = 3.4%). A partial correlations analysis shows that imputed iconicity values correlate with funniness ratings at at least the same level as actual iconicity ratings, controlling for frequency (r = 0.32, p < .0001).
Many of the words identified as high in iconicity by our imputation method (Table 2) are clearly imitative in origin, as seen for example in OED definitions like ‘swish’ “to make the sound expressed by ‘swish’”, ‘chug’ “a plunging, muffled, or explosive sound”, ‘oomph’ “the quality of being exciting, energetic, or sexually attractive (imitative in origin)”. Words high in funniness and low in imputed iconicity include animals (‘heifer’, ‘sheepdog’) and taboo words (‘nudist’, ‘harlot’), replicating the patterns seen above and confirming the generalizability of our imputation method. However, as above, about 10% of the top 200 nouns with high imputed iconicity are compound nouns with transparent but non-iconic structure (e.g., ‘heartbeat’, ‘mouthful’, ‘handshake’, ‘bellboy’, ‘comeback’, ‘catchphrase’), suggesting the imputation method is sensitive to the presence of such words in the training set.
Sample words from the extremes of each quadrant of funniness and imputed iconicity ratings (total n = 3577)

Although not our focus here, in the online materials we report a further quality check of the imputation method on the inverse set of data (testing how human iconicity ratings covary with imputed funniness for 1526 words), which is consistent with our results.
3.3. imputed iconicity and imputed funniness (unknown unknowns)
With the imputation technique validated against human funniness ratings, we can move on to the next step: the relation between imputed funniness and imputed iconicity in the set of 63680 words for which we have no human ratings (Figure 3, panel C). We formulate a linear model with imputed funniness as the dependent variable. Model comparison shows that a model including imputed iconicity as a predictor provides a significantly better fit (F = 4536.3, p < .0001) and explains a much larger portion of the variance (adjusted R2 = 0.237 versus 0.057) than a model with just log frequency and lexical decision time. In the fuller model, imputed iconicity rises to be the strongest predictor (F = 4552.9, p < .0001, partial η2 = 19.1%), followed by frequency (F = 1241.8, p < .0001, partial η2 = 6.1%) and lexical decision time (F = 182.4, p < .0001, partial η2 = 0.9%). A partial correlations analysis shows that imputed iconicity values show 43% covariance with imputed funniness ratings, controlling for word frequency (r = 0.43, p < .0001).
As above, many of the words identified as high in iconicity by our imputation method are clearly imitative in origin: ‘whoosh’, ‘whirr’, ‘chomp’, etc. (Table 3). Words low in imputed iconicity and high in funniness include animals (‘pigs’, ‘monkeys’, ‘penguins’) but also words from other languages (‘herr’, ‘beau’, ‘raja’), consistent with co-occurrence relations in the discursive context of jokes. For high imputed iconicity and low imputed funniness we find negatively valenced words like ‘slashes’, ‘gunshots’, ‘swelter’, and ‘cries’, though the iconic quality of some of these words is less clear, a sign of limitations of the semantically based imputation method. About 15% of a random sample of 200 out of the top 3560 nouns with high imputed iconicity (a sample size chosen to be proportionate to the other datasets) are analysable compounds like ‘fireworm’, ‘uppercut’, ‘woodwork’, ‘biotech’, suggesting that the imputation method may be amplifying the bias toward non-iconic analysable compounds introduced in the training set. The extreme of the opposite quadrant of low imputed iconicity and low imputed funniness seems to pick up mostly rare words.
Sample words from the extremes of each quadrant of imputed funniness and imputed iconicity ratings (n = 63680)

3.4. structural properties
With the relation between funniness and iconicity established in human as well as imputed ratings, we turn to the structural properties of words rated high in funniness and iconicity. The prediction is that they should show signs of structural markedness. Our analyses in this section are part confirmatory, part exploratory. The confirmatory part investigates the role of phonological improbability as a proxy for structural markedness, in line with our hypothesis that markedness, as a form of foregrounding, makes it more likely for words to be seen as playful and iconic. The exploratory part examines the set of words rated highest for iconicity and funniness to inductively characterize cues of structural markedness in these words, and then traces these cues across other segments of the dataset to examine the generalisability of the findings.
3.4.1. Log letter frequency
Prior work has shown that phonemic and orthographic improbability may help to explain funniness ratings; in particular, log letter frequency (a measure of orthographic unexpectedness) emerges as a strong correlate of perceived word funniness (Westbury & Hollis, Reference Westbury and Hollis2019). We reproduce this result in the human-rated subset of words, finding that a model including log letter frequency provides a significantly better fit (F = 93.899, p < .0001) and explains a larger portion of the variance (adjusted R2 = 0.208 vs. 0.188) than the second model in §3.1 above with just word frequency, iconicity, and lexical decision time as predictors.
Our theory of structural foregrounding predicts that log letter frequency (insofar as it is a proxy of markedness) will show a relation to both funniness and iconicity ratings. Partial correlations indeed show that funniness rating and log letter frequency have a covariance of –15.7% controlling for iconicity, and that iconicity and log letter frequency have a covariance of –16.3% controlling for funniness ratings (all p < .0001 correcting for multiple comparisons). In other words, log letter frequency relates as strongly to iconicity as to funniness.
We construct a linear model predicting the combined funniness and iconicity ranking of words (standardized to z-scores and summed). Model comparison shows that a model including log letter frequency provides a significantly better fit (F = 96.41, p < .0001) and explains a larger portion of the variance (adjusted R2 = 0.18 vs. 0.13) than a model with just word frequency and lexical decision time as predictors. In this model, word frequency is the most important predictor (F = 219.96, p < .0001, partial η2 = 13.5%), followed by log letter frequency (F = 96.41, p < .0001, partial η2 = 6.4%), while the influence of lexical decision time is dwarfed (F = 2.89, p = .09, partial η2 = 0.2%), perhaps because words with lower log letter frequency have higher lexical decision times in general.
Somewhat to our surprise, the relatively coarse measure of log letter frequency is more informative than more subtle phonological and phonotactic measures from the Irvine Phonotactic Online Dictionary (Vaden et al., Reference Vaden, Halpin and Hickok2009). For the current dataset, the measures of phonological density, biphone probability, and triphone probability do not seem to offer additional explanatory power beyond log letter frequency, as reported in the online materials. Perhaps this reflects the written origin of the iconicity and funniness ratings.
3.4.2. Structural analysis
To better understand the structural properties of words rated high in iconicity and funniness, we carried out a linguistic analysis of the combined upper ten percentiles of iconicity and funniness ratings, representing 80 words. We catalogued the phonotactic complexity of these words and found three recurring cues of structural markedness. Of these words, 38% had complex onsets, as in ‘flap’, ‘sniff’, ‘drizzle’; 20% had complex codas, as in ‘oink’, ‘whirl’, ‘clunk’; and 11% had the expressive verbal diminutive suffix ‘-le’ as in ‘tingle’, ‘wobble’, ‘wiggle’ (Table 4). These cues do not exhaust the structurally marked properties of the individual words, but they are the most readily recognisable.
Cues of structural markedness identified in the highest-rated words; their relative prevalence in the top 80 versus the remaining 1339 words of set A

Each of these inductively identified cues turns out to be connected to playfulness and sound symbolism. The complex onsets and codas are examples of phonaesthemes: submorphemic elements often showing non-arbitrary form–meaning associations (Kwon & Round, Reference Kwon and Round2014). The verbal suffix ‘-le’ is connected to iterative and diminutive meanings that often have a ludic or non-serious character (Dressler & Merlini Barbaresi, Reference Dressler and Merlini Barbaresi1994; Audring, Booij, & Jackendoff, Reference Audring, Booij and Jackendoff2017); in many of the higher-rated words it is connected to a sense of movement and plurality. These same cues of structural markedness are much rarer in the remaining 1339 words in set A: complex onsets occur in 15%, complex codas in only 5%, and the verbal suffix ‘-le’ in only 0.6% of words (Figure 4, panels A–C).
The relation between structural markedness and A funniness ratings, B iconicity ratings, and C funniness and iconicity together, all in set A (1419 human-rated words). Ratings are rescaled to 0–100 percentiles for comparability. Each dot represents 14 or 15 words. Solid lines and shading represent a loess function of cumulative markedness with 95% confidence intervals. Other lines show relative prevalence of complex onsets, codas, and verbal diminutives.
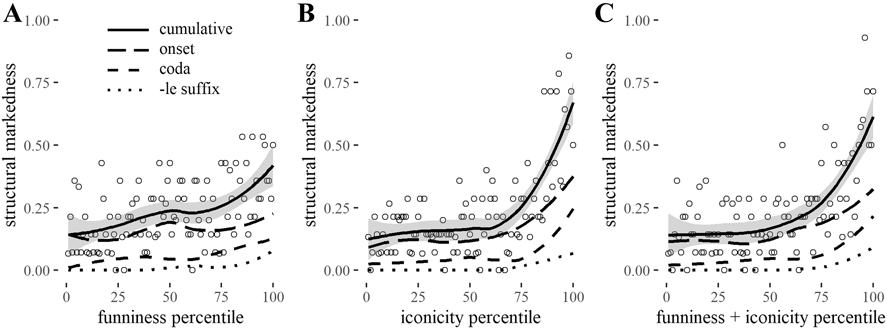
As the cues can co-occur in words, we sum them to form a cumulative measure of structural markedness (so ‘cat’ and ‘ape’ score 0, ‘flap’ and ‘dump’ score 1 for their complex onset or coda, and ‘clunk’ and ‘drizzle’ both score 2 for their combinations of onset, coda, and/or verbal diminutive suffix). Operationalised in this way, the average cumulative structural markedness of the set of 80 high-iconicity high-funniness words is much higher than expected if they resembled a randomly drawn sample from the larger dataset (0.69 versus 0.20, t(82.7) = 6.23, p < .0001, Cohen’s d = 0.9). Revisiting the linear model predicting the combined funniness and iconicity ranking of words, model comparison shows that a model including this new measure of cumulative markedness as predictor provides a significantly better fit (F = 52.78, p < .0001) and explains a larger portion of the variance (adjusted R2 = 0.21 vs. 0.18) than a model with word frequency, lexical decision time, and log letter frequency. Figure 4 shows the patterning of cumulative structural markedness along with the individual cues for funniness rating percentiles, iconicity rating percentiles, and combined percentiles.
As a final test of the utility of our imputation method we trace the inductively identified structural properties of high-iconicity high-funniness words in the subset of data for which we have only imputed ratings. We find a similarly skewed distribution of structural markedness: in the upper ten percent of imputed iconicity ratings, 23% of 6368 words contain one or more cues of structural markedness (examples are ‘swoosh’, ‘squish’, ‘crush’, ‘dribble’, ‘crackles’, ‘flickered’), whereas this level is only 9% in the remaining 57312 words (examples are ‘snowman’, ‘drank’, ‘spaceport’, ‘trench’, ‘swedish’, ‘schubert’). Comparison of models with combined imputed funniness and iconicity as a dependent variable shows that a linear model including cumulative markedness as predictor provides a significantly better fit (F = 337.3, p < .0001) and explains a little bit more of the variance (adjusted R2 = 0.124 vs. 0.109) than a model with just word frequency, lexical decision time, and log letter frequency (see figures in the online materials). In other words, the inductively identified structural correlates of human iconicity and funniness ratings also show up in words for which we have only imputed ratings.
4. Discussion
We have found that human ratings for funniness and iconicity show a tendency to converge, especially at the higher end: words like ‘zigzag’, ‘squeak’, and ‘waddle’ are rated as highly iconic and highly funny. This underlines the special relation between playfulness and performativity and makes it relevant to examine underlying factors. We found that a measure of phonological unexpectedness, previously shown to correlate with funniness ratings (Westbury & Hollis, Reference Westbury and Hollis2019), correlates at least as strongly with iconicity ratings. While prior work has ascribed the phonological unexpectedness of funny words to a theory of humour based on incongruity (Westbury et al., Reference Westbury, Shaoul, Moroschan and Ramscar2016), the finding that it applies just as strongly to iconic words strengthens the case for the more general theoretical account we propose here, according to which structural markedness unites playful and iconic words. A linguistic analysis of high-iconicity high-funniness words helped identify three reliable cues of structural markedness in English: complex onsets, complex codas, and the verbal suffix ‘-le’. These structural properties, we propose, exemplify the metacommunicative cues that help foreground words and invite us to experience them as playful, poetic, and performative. The strongly skewed distribution of these cues across the vocabulary provides further supporting evidence for this role.
Our theoretical account does not lead us to expect that iconicity and funniness ratings are uniformly consonant across the board, and indeed discrepancies bring to light other contributing factors. Words rated high in iconicity but low in funniness tend to present vivid depictions of negatively valenced events like ‘crash’ or ‘roar’, reproducing a familiar relation between word funniness and valence that is independent of iconicity (Westbury & Hollis, Reference Westbury and Hollis2019). Words rated high in funniness but low in iconicity like ‘buttocks’ or ‘blonde’ tend to be associated with taboos and socio-semantic categories that figure in some genres of Anglo jokes. This is a contributor to ratings that is more likely to be culturally variable than structural markedness cues (Low, Reference Low2011), which has implications for the cross-linguistic generalisability of funniness ratings.
Imputed iconicity ratings correlate well with human funniness ratings and show the same general patterns we find in the training datasets. Remarkably, the correlation is amplified in successively larger datasets: it is 20.6% in the core set of human ratings, goes up to 32.3% when comparing imputed iconicity ratings to human funniness ratings (n = 3577), and up again to 42.8% in the two sets of imputed ratings (n = 63680). That at least some of the same broad patterns show up in a dataset at least twenty times as large as the training set suggests that imputation can be a useful pursuit.
The structural markedness cues inductively discovered in the training set –complex onsets, codas, and evaluative morphology – also show up in words for which no human ratings are available. This is notable because the vector-based imputation method is primarily based on distributional semantics and not on explicit word-level form–meaning associations. It means that the imputation method is relatively reliable and can be used to increase the coverage of lexical ratings beyond small sets of seed words, generating new data for follow-up research. For instance, high imputed iconicity words can be put to the test in experimental or corpus-based investigations of iconicity, and words with high imputed funniness can be used in research on verbal humour, substantially extending the existing funniness ratings.
4.1. generalisations and predictions
We have found that words perceived as highly funny and highly iconic are united in showing signs of structural markedness, consistent with the theory that structural markedness can function as a metacommunicative cue inviting playful and performative interpretations (Bateson, Reference Bateson1955). Our account generates predictions in the areas of comparative linguistics, cultural evolutionary modelling, and corpus studies of multimodal language use.
In the domain of comparative linguistics, our account provides an explanatory framework for qualitative observations reported for languages around the world, from the playful connotations of ts-initial words in Greek (Joseph, Reference Joseph, Hinton, Nichols and Ohala1994) and the “attitude of playfulness” detected in imitative words in Spanish and Basque (Pharies, Reference Pharies1990, p. 107) to the mirth associated with ideophones in Alto-Perene (Arawak, Peru; Mihas, Reference Mihas2012), Hamar (Omotic, Ethiopia; Lydall, Reference Lydall, Yimam, Pankhurst, Chapple, Admassu, Pankhurst and Teferra2000), Kalam (Trans New Guinea, Papua New Guinea; Pawley, Reference Pawley, McElhanon and Reesink2010), and Shona (Bantu, Zimbabwe; Fortune, Reference Fortune1962). Such observations, along with the quantitative evidence from English presented here, make us confident that the predictions of our account – that high iconicity and high funniness go together, and that they are underpinned by signs of structural markedness – should hold across a wide variety of languages.
To the extent that structural markedness serves as a metacommunicative signal of playfulness and performativity, it also has consequences for the cultural evolution of lexical structure. Our prediction is that structural markedness confers a selective advantage on words intended to be iconic and/or funny, as their recognisability would make them more fit to survive processes of cultural transmission in which the recognition of such intentions is functionally important. This prediction is ripe for testing in laboratory experiments or computational models of cultural evolution.
Metacommunicative cues that say “this is play” are of course also found beyond the phonotactic structures studied here in written words. As the Prague school linguist Havránek wrote, “conventional conversational devices are automatized, but to liven up the conversation and to achieve surprise (wonderment) foregrounded units are used” (Havránek, Reference Havránek and Garvin1964, p. 10). Our account predicts that, in everyday language use, words framed as special by means of performative foregrounding – from expressive prosody to playful morphology – are more likely to be perceived as both playful and iconic. Again, qualitative observations from across languages support this view, for instance in the form of work on ideophones as playful multimodal depictions (Dingemanse, Reference Dingemanse2011; Ibarretxe-Antuñano, Reference Ibarretxe-Antuñano2017) and on reduplication as a sign of playfulness (Rastall, Reference Rastall2004; Haiman, Reference Haiman, MacWhinney, Malchukov and Moravcsik2014). Here as elsewhere our predictions are not deterministic but probabilistic: not all reduplicated words are funny or iconic, but given the possible role of reduplication as a metacommunicative sign of play, it is more likely for such words to be used and perceived that way.
Most generally, the kind of metacommunicative framing studied here in lexical items is associated with depiction as a mode of communication (Clark, Reference Clark2016). Depiction often lends itself to playful connotations, for at least two reasons: (i) the sensory imagery offered by depictions give us a palpable sense of presence by enabling us to experience what it is like to perceive the scene depicted (Lydall, Reference Lydall, Yimam, Pankhurst, Chapple, Admassu, Pankhurst and Teferra2000); and (ii) the selectivity of depictions foregrounds salient sensory features and backgrounds others much like cartoons or caricatures can do, and to similar playful effect (Samarin, Reference Samarin1969). Indeed, both vivid sensory imagery (Graesser, Long, & Mio, Reference Graesser, Long and Mio1989) and selectivity and exaggeration (Kris & Gombrich, Reference Kris and Gombrich1938) are connected to humour and playfulness. So ‘whiff’, ‘waddle’, and ‘zigzag’ may be perceived as funny not just because of their marked phonology, but also because of their depictive semiotics. To the extent that words prone to be used depictively occur in similar distributional contexts (from vivid stories to entertaining dialogues), this may also help to explain the performance of our imputation method, which relies primarily on distributional semantics.
We arrive, therefore, at a more precise characterisation of the link between playfulness and iconicity. Summing up the lessons learned:
I. While not all funny words are iconic, and not all iconic words are funny, many highly iconic words are perceived as funny.
II. Words perceived as iconic and funny feature cues of structural markedness that serve to foreground them and invite perceptions of playfulness and performativity.
III. The link between playfulness and iconicity is further reinforced by the depictive semiotics of iconic words, in particular their vivid sensory imagery and selective depictive properties.
To the best of our knowledge, our study is the first large-scale investigation of English vocabulary (and perhaps of vocabulary in any language) to firmly establish points I–II both in human-rated words and in a much larger set of words with imputed ratings. Point III has not been the main target of this study and represents an important area for future research.
4.2. limitations and recommendations
Norm imputation can distort rating scales and can amplify rating artefacts (Mandera et al., Reference Mandera, Keuleers and Brysbaert2015), as we saw for analysable compound nouns like ‘footstep’, ‘catchphrase’, and ‘biotech’, which received high imputed iconicity ratings probably because of artefacts introduced in the original ratings data. The relative proportion of such words went up from 10% in the training set to an estimated 15% in the larger set of imputed ratings. So, while a large majority of words in the higher end of the combined imputed ratings are clear and uncontroversial examples of funny and iconic words, there is some reason to be cautious. One way to mitigate the consequences of the bias introduced by analysable compounds is to focus on monomorphemic words, which do not allow the conflation of iconicity with analysability. The online materials show that the patterns reported above emerge even more clearly in monomorphemic words, and all quantitative findings are at least as strong in the 8642 monomorphemic words for which we have human and imputed ratings.
We inductively identified three simple structural cues of markedness that occurred in up to 38% of the highest-rated words and that helped explain the relation between iconicity and funniness over and above other known factors. No doubt there are many more contributors to perceived funniness and iconicity, ranging from phonetic features to distributional and semantic properties (Westbury, Hollis, Sidhu, & Pexman, Reference Westbury, Hollis, Sidhu and Pexman2017). For instance, German words with voiceless consonants tend to be perceived as more arousing and negative (Aryani et al., Reference Aryani, Conrad, Schmidtke and Jacobs2018), and English auditory and tactile words tend to be more iconic (Winter et al., Reference Winter, Perlman, Perry and Lupyan2017). It is also likely that bottom-up data-driven approaches could identify more cues correlated with non-arbitrary structure in the lexicon (Nuckolls et al., Reference Nuckolls, Nielsen, Stanley and Hopper2016; Pimentel, McCarthy, Blasi, Roark, & Cotterell, Reference Pimentel, McCarthy, Blasi, Roark and Cotterell2019), and could be used to further boost the performance of methods for imputing lexical ratings.
The combination of quantitative and qualitative analysis employed here brings out some of the strengths and weaknesses of lexical ratings, both collected and imputed. Ratings can reveal robust correlations which can be made sense of using linguistic analysis. However, potential ambiguities in instructions can introduce artefacts and imputation methods can amplify them. Our recommendation is to never take ratings at face value and to always triangulate robustness and validity using other methods or data. With that caveat in mind, however, imputed ratings can serve to increase data coverage and allow confirmatory and exploratory analyses in large-scale datasets that will remain, for some time at least, out of reach of human-collected ratings.
5. Conclusions
The use of structurally marked words to evoke the playful and poetic is probably as old as the use of language itself. Here we have examined the theory that the structural markedness of words can serve as a metacommunicative signal (Bateson, Reference Bateson1955), allowing words to break frame and attract attention to themselves as playful and performative. Our investigation has put the playfulness of iconic words on a firm empirical footing. We have found formal cues of structural markedness whose distribution strongly correlates with people’s perceptions of words as funny and iconic. We have introduced and benchmarked a method for imputing lexical ratings of funniness and iconicity, with reason for cautious optimism about the generalisability of the results. And we examined some of the strengths and limitations of lexical ratings by combining qualitative and quantitative analysis.
Approaching iconicity using quantitative methods may seem to take away the magic of make-believe these words thrive on (Dingemanse, Reference Dingemanse2014). Likewise, explaining humour has been compared to dissecting an animal: you understand it better, but it dies in the process (White, Reference White, White and White1941). If, as our study suggests, structural markedness helps to explain the relation between funniness and iconicity, at least we have killed two birds with one stone ¯\_(ツ)_/¯.
Linguistics has long focused on the referential function of language to the exclusion of its expressive and poetic potential (Crystal, Reference Crystal1996; Jakobson, Reference Jakobson and Sebeok1960). Studying ludic aspects of the lexicon is valuable if linguistics is to be a truly comprehensive science of language. But there is more to it than that. As Bateson (Reference Bateson1955) noted, the metacommunicative abstraction involved in the ability to distinguish “play” from “not play” may well hold one of the keys to the origins of communication and therefore the evolution of language. Here we have seen that some of the metacommunicative signals to tell the playful from the prosaic may well be built into the very texture of the lexicon.
Online materials
An Rmarkdown code notebook of all analyses in this paper, along with Python code for the rating imputation method, all data files, and a set of supplementary analyses can be found in the OSF repository at <https://osf.io/7s6xc/>.
Acknowledgements
This work has benefited from audience feedback at the 12th Iconicity in Language & Literature Symposium in Lund, May 2019. For helpful and incisive comments, we are grateful to Marieke Woensdregt (to whom we owe the point about the cultural evolutionary import of structural markedness) and to two anonymous reviewers. Thanks also to Luca Bischetti for feedback on the preprint and to Bodo Winter for once tweeting that “iconicity is just plain fun”. MD is funded by the Dutch Research Council (grant 016.vidi.185.205). BT acknowledges generous support from a Levinson scholarship through the Language and Cognition Department at the MPI for Psycholinguistics.
Contributions: MD designed the research, conducted the quantitative and linguistic analyses, and wrote the first draft. BT designed and described the imputation method and contributed imputed ratings and letter frequency measures. Both authors contributed to revisions of the paper and approve of the final version.









 Open access
Open access