


1. Introduction
Research on the distribution of referring expressions has argued that the choice of referring expressions is not random (Ariel Reference Ariel1988, Reference Ariel1990, Reference Ariel1991, Reference Ariel, Sanders, Schilperoord and Spooren2001; see also Chafe Reference Chafe and Li1976, Sanford & Garrod Reference Sanford and Garrod1981, Givón Reference Givón and Givon1983, Gundel et al. Reference Gundel, Hedberg and Zacharski1993). Taking (1) as an example, the addressee needs to identify who she refers to in a given discourse context to successfully understand the sentence. This task would be simple if there is only one antecedent available. However, if there are multiple potential antecedents, as would be the case when (1) is preceded by (2), sentence (1) becomes ambiguous, as she could refer to either Jane or Mary. Consequently, the addressee’s interpretation of the sentence could even differ from what the speaker intended.
Given this, the question is: considering the rampant use of pronouns with multiple potential antecedents in daily language use, how can language users efficiently communicate without misleading or misunderstanding each other in most cases?
There have been various approaches to this question, among which is Accessibility Theory (Ariel Reference Ariel1990). According to this theory, language use is guided by cognitively motivated principles, such as saliency or mental accessibility, resulting in a direct correlation between the cognitive status of an antecedent and the expression referring to it (Ariel Reference Ariel1988, Reference Ariel1991, Reference Ariel, Sanders, Schilperoord and Spooren2001; for related proposals and discussion, see also Chafe Reference Chafe and Li1976, Sanford & Garrod Reference Sanford and Garrod1981, Givón Reference Givón and Givon1983, Grosz et al. Reference Grosz, Joshi and Weinstein1983, Reference Grosz, Weinstein and Joshi1995, Gernsbacher Reference Gernsbacher1990, Arnold Reference Arnold1998, Walker et al. Reference Walker, Joshi, Prince, Walker, Joshi and Prince1997, Carminati Reference Carminati2002, Kehler Reference Kehler2002, Kaiser Reference Kaiser2006, Kehler & Rohde Reference Kehler and Rohde2013). The idea is based on the observation that, at any given moment, linguistic information is not equally activated but rather accessible to varying degrees depending on various factors, such as topicality (i.e. global discourse topic vs. local discourse topic vs. non-topic), recency (e.g. antecedent mentioned within the same sentence vs. 2 to 3 sentences away), grammatical role (i.e. subject vs. non-subject), competition (i.e. number of matching discourse referents between the last mention of the antecedent and the anaphor), and linear position within a sentence (i.e. sentence-initial vs. non-initial position). For example, the two potential antecedents in (2), Jane and Mary, are interpreted to have different degrees of mental accessibility, with Jane having a higher degree of accessibility than Mary, as Jane is the topic, subject, and the first-mentioned NP of the sentence.
In addition, Accessibility Theory argues that the relative degrees of accessibility of an antecedent are encoded for the forms of its referring expressions. These expressions serve as markers of mental accessibility that speakers rely on, guiding the addressee’s interpretation so that sentences would be interpreted as the speaker intended (Gordon et al. Reference Gordon, Grosz and Gilliom1993, Arnold Reference Arnold2010; cf. Fukumura & van Gompel Reference Fukumura and van Gompel2012, Nappa & Arnold, Reference Nappa and Arnold2014 for a further discussion of encoding and interpretational use of referring expressions). Within this framework, the form–function correlation among accessibility markers is not random but follows three criteria that signal the degree of accessibility of a referring expression: informativity, rigidity, and attenuation. Specifically, the more lexical information a form encodes (informativity; e.g. the Israeli linguist vs. the linguist; Ariel Reference Ariel1991: 450), the more uniquely it identifies a referent (rigidity; e.g. Ellen Prince vs. the linguist; Ariel Reference Ariel1991: 450), and the less phonologically reduced it is (attenuation; e.g. United States of America vs. U.S.; Ariel Reference Ariel1991: 451; cf.; see also Givón, Reference Givón and Givon1983), the lower its associated degree of accessibility. Conversely, forms that are less informative, less rigid, and more phonologically attenuated are interpreted as referring to highly accessible antecedents. Along these lines, full names are typically more lexically informative, more rigid (and thus more uniquely referring), and less phonologically attenuated than pronouns (e.g. she). Accordingly, full names are predicted to mark lower accessibility than pronouns. By contrast, null pronouns (pro) represent the highest level of accessibility, as they are the least lexically informative, the least rigid, and the most phonologically attenuated—having no phonological realization at all. The idea was formalized as the Accessibility Marking Scale hierarchy, covering a wide range of referring expressions in Ariel (Reference Ariel1990, Reference Ariel1991).
The predictions about the different accessibility markers have been supported by cross-linguistic studies of production data. For example, in the examination of written text in Hebrew, Ariel (Reference Ariel1991) found that linguistic information tends to be first introduced with full names (63.8%), while re-evoking the information tends to be achieved by a higher accessibility marker (66.2%) (Ariel Reference Ariel1991). The explanation is that when first mentioned, linguistic information has a low degree of mental accessibility, as its mental representation must be retrieved from long-term memory. Thus, this retrieval is done using a full name, a lower accessibility marker (see also Ariel Reference Ariel1988, Reference Ariel, Sanders, Schilperoord and Spooren2001). In contrast, when re-mentioned, the notion is already more accessible and thus requires less information to be re-evoked. This can be done using a higher accessibility marker such as a definite NP or pronoun. Accessibility Theory receives further support from Arnold’s (Reference Arnold1998) studies of written texts in English, Spanish, and Mapudungun. She found that the more recently a reference was mentioned (e.g. the previous clause vs. 2–5 clauses back) and the more syntactically prominent the referent is (e.g. subject vs. object referent), the more likely it is to be referred to using a high accessibility marker, such as pronouns or zero.
The predictions about different accessibility markers have also been supported by cross-linguistic studies on the comprehension of referring expressions. For example, in English, Gordon et al. (Reference Gordon, Grosz and Gilliom1993) found increased processing difficulty when names were repeatedly used (e.g. “Bruno was the bully of the neighborhood. Bruno chased Tommy all the way home from school one day…”) compared to when a pronoun was used to refer to the previously mentioned subject (e.g. “Bruno was the bully of the neighborhood. He chased Tommy all the way home from school one day…”). This effect, known as the repeated-name penalty, was particularly pronounced when the antecedent was in a structurally prominent position. This finding is consistent with Accessibility Theory, which posits that a low accessibility marker, such as a name, is harder to process if it is used to refer to a highly accessible antecedent.
On the other hand, Carminati (Reference Carminati2002) examined the interpretational biases of null and overt pronouns in Italian using various structures, including globally ambiguous sentences, as shown in (3).

The results demonstrated a clear division of labor between null and overt pronouns in Italian. For the null pronoun condition, the subject referent (e.g. Mario in (3)) was chosen as the antecedent 80.72% of the time, while the object referent (e.g. Giovanni) was chosen 83.33% of the time for the overt pronoun condition. Based on these results, Carminati (Reference Carminati2002) proposed the Position of Antecedent Hypothesis, which argues that null pronouns prefer antecedents occurring in syntactically more prominent positions—such as Spec-IP, the preverbal subject position—than overt pronouns. Under this proposal, prominence is determined by syntactic position, with Spec-IP being more prominent than positions lower in the syntactic tree. However, the results discussed above are also consistent with Accessibility Theory, as Carminati noted in her work (see also Gelormini-Lezama & Almor Reference Gelormini-Lezama and Almor2011).Footnote 1
Similar results were obtained by Contemori and Di Dominico (Reference Contemori and Di Domenico2021). Using globally ambiguous sentences, similar to (3), Contemori and Di Dominico examined pronoun resolution in both Italian and Spanish. They replicated Carminati’s results in Italian, finding that 75% of null pronouns were interpreted as referring to the subject referent, while 78% of overt pronouns were interpreted as referring to the object referent. In Spanish, although their interpretational biases were weaker than in Italian, null and overt pronouns still exhibited interpretational patterns distinct from one another: the subject referent was chosen as the antecedent 62% of the time for null pronouns, while the object referent was chosen 58% of the time for overt pronouns (see also Bel & García-Alcaraz Reference Bel, García-Alcaraz, Judy and Perpiñán2015; for similar results in Catalan and Greek, see Mayol & Clark Reference Mayol and Clark2010 and Papadopoulou et al. Reference Papadopoulou, Peristeri, Plemenou, Marinis and Tsimpli2015, respectively).
On the other hand, Filiaci et al. (Reference Filiaci, Sorace and Carreiras2014) reported mixed results for the overt pronoun condition in Spanish. They employed a self-paced reading time method to examine the processing of sentences with null and overt pronouns in both Spanish and Italian. In these sentences, the referent of the pronouns was disambiguated based on contextual information, biasing either the subject referent interpretation (e.g. “When Carlo i asked Diego j for help to prepare for the exam, he i/proi passed it with excellent marks”) or the object referent interpretation (e.g. “When Carlo i helped Diego j to prepare for the exam, he j/proj passed it with excellent marks”). They found that the processing of the null pronoun condition was facilitated when the antecedent occurred in the subject position rather than the object position in both Spanish and Italian. However, for the overt pronoun, the results were mixed in Spanish, while the object referent preference was clearly confirmed in Italian (see Keating et al. Reference Keating, VanPatten and Jegerski2011 for similar results in Spanish). That is, in their Experiment 2, reading time measures of spill-over regions in Spanish were consistent with those in Italian, showing faster reading times when the antecedent for overt pronouns occurred in the object position. However, reading times of target regions in Experiment 1, as well as reaction times to comprehension questions in both Experiment 1 and Experiment 2, did not reveal any effect of the antecedent type for the overt pronoun in Spanish. Additionally, analyses of correct answer rates showed that the overt pronoun condition was even significantly more accurately answered with the subject antecedent than with the object antecedent. The results of Contemori and Di Dominico (2021), Filiaci et al. (Reference Filiaci, Sorace and Carreiras2014), and Keating et al. (Reference Keating, VanPatten and Jegerski2011) suggest that, compared to Italian, pronouns in Spanish display greater flexibility. These findings also highlight the importance of considering different linguistic features, even when comparing superficially equivalent linguistic expressions in two typologically related languages (Sorace & Filiaci Reference Sorace and Filiaci2006). For example, differences in pronominal inventory could lead to variation in how referential distinctions are encoded and interpreted across languages, even when the surface forms appear comparable. These results can also be interpreted to suggest that languages may vary in their mental accessibility distinctions (Ariel Reference Ariel1990, Reference Ariel, Sanders, Schilperoord and Spooren2001). Specifically, in Italian, the accessibility distinctions between null and overt pronouns seem to be stronger than in Spanish. Consequently, overt pronouns might exhibit greater flexibility in their use in Spanish than in Italian.
On the other hand, studies on discourse-oriented languages – where referential resolution relies more critically on discourse context than on verb morphology – have not revealed a clear division of labor between null and overt pronouns. This highlights the need for further cross-linguistic research using typologically diverse languages to better understand how referential expressions are processed across different grammatical systems. For example, Zhang and Kwon (Reference Zhang and Kwon2022) examined interpretational biases for null and overt pronouns in Chinese using globally ambiguous sentences, as illustrated in (4). Their findings revealed that Chinese speakers exhibited a subject antecedent preference for both null and overt pronouns, suggesting that the presence or absence of phonological material does not straightforwardly distinguish between different types of referential dependencies in Chinese.
In their Experiment 1, null pronouns were interpreted as referring to the subject antecedent (e.g. Li Gang) in 84% of the cases, while only 16% were assigned to the object antecedent (e.g. Wang Qiang). For overt pronouns, the subject was chosen 65.3% of the time, and the object 34.7% (see also Yang et al. Reference Yang, Gordon, Hendrick and Wu1999, Reference Yang, Gordon, Hendrick and Hue2003; For comparable results in Japanese, see Ueno & Kehler Reference Ueno and Kehler2016). Although both pronoun types exhibited a subject bias, Zhang and Kwon interpreted these results as compatible with Accessibility Theory, based on the relative preference: null pronouns more strongly favored subject antecedents, while overt pronouns showed a comparatively weaker subject bias and were relatively more likely to refer to object antecedents.
In Korean, findings have been mixed. For example, using globally ambiguous sentences as in (5), Kweon (Reference Kweon2011) reported results aligning with those of Carminati (Reference Carminati2002).

In her study, 81.1% of null pronouns were interpreted as referring to the subject antecedent (e.g. Inho in (5)), whereas only 31.4% of overt pronouns were. Conversely, 68.6% of overt pronouns were interpreted as referring to the object antecedent (e.g. Sungki), compared to just 18.9% of null pronouns. Based on these findings, Kweon argued for a clear division of labor between null and overt pronouns in Korean, with syntactic position playing a key role in antecedent selection. Kweon took the results to support Carminati’s (Reference Carminati2002) Position of Antecedent Hypothesis.
In contrast, Choe (Reference Choe2021) reported findings that differed from those of Kweon (Reference Kweon2011). She found that both null and overt pronouns were more likely to refer to the subject antecedent than the object antecedent, although the subject antecedent bias was stronger for null pronouns (91%) than for overt pronouns (73%). These results align with Zhang and Kwon’s findings in Chinese but differ from Kweon (Reference Kweon2011)’s findings in Korean. Although Choe found that part of her data involving a particular type of connective aligned with Kweon (Reference Kweon2011), it remains unclear which specific properties of those connectives contributed to the differing results.
1.1. The present study
Previous studies have presented mixed results across languages. While research on Italian consistently demonstrates a clear division of labor between null and overt pronouns, findings in Spanish, Chinese, and Korean have been more variable, often revealing weaker distinctions between the two forms. However, despite this variability, prior work has rarely examined how interpretive biases of referring expressions vary across discourse contexts – the very question we aim to address in this study. In doing so, we follow Ariel (Reference Ariel1990: Section 4.2) in assuming that accessibility markers do not have language-independent, absolute accessibility thresholds. Rather, only the relative ordering of accessibility markers is universal, while the accessibility values associated with each marker are language- and context-sensitive. Accordingly, we systematically manipulate discourse contexts across three experiments to examine how contextual differences influence the interpretation of referential forms.
Korean provides an ideal testing ground for this investigation. As a discourse-oriented language, referential resolution in Korean relies more heavily on discourse context than on morphosyntactic cues such as gender or verbal agreement (Kwon & Sturt Reference Kwon and Sturt2013). This contrasts with many Indo-European languages, where verbal agreement and grammatical gender can provide additional structural cues for referential interpretation. Examining Korean therefore allows us to evaluate the cross-linguistic generalizability of Accessibility Theory across distinct grammatical systems. Thus, across the three experiments, we progressively increase contextual complexity: Experiment 1 examines sentences with a single antecedent; Experiment 2 introduces two potential antecedents with disambiguating cues; and Experiment 3 presents globally ambiguous contexts in which referential form plays a central role in interpretation.
At the same time, prior Korean studies present limitations that cloud interpretation. None assessed the naturalness of the intended readings, raising concerns that some materials may not have reflected everyday usage or intuitive interpretations (Ariel Reference Ariel2013). Because Accessibility Theory predicts a correlation between the felicity of a referring expression and the match between its form and the accessibility of its antecedent, naturalness ratings provide an important behavioral measure for evaluating this alignment. By incorporating naturalness judgments, the present study offers a more realistic assessment of how referential form and discourse accessibility interact in Korean.
Moreover, unlike Kweon (Reference Kweon2011) and Choe (Reference Choe2021), who examined ku ‘he’ and kunye ‘she’ as overt pronouns, we employ kyay, a gender-neutral third-person pronoun commonly used in spoken Korean. While ku/kunye occur primarily in literary registers, kyay is widely used in everyday discourse and is therefore better suited for investigating natural referential resolution. In addition, kyay is phonologically more explicit than a null pronoun but less informative than a full NP, allowing us to sample distinct points along the accessibility scale. For these reasons, we focus on kyay as the overt pronoun.Footnote 2 Previous Korean studies also face methodological constraints. For example, Kweon (Reference Kweon2011) used a small item set (n = 12), limiting statistical power, whereas Choe (Reference Choe2021) adopted an unusually high target-to-filler ratio (40 targets to 24 fillers), potentially increasing the salience of the manipulation.
The present study aims to address these gaps and advance our understanding of the cognitive mechanisms underlying referring expressions through three experiments in Korean that vary discourse context, use a more rigorous design, and incorporate both naturalness-rating and antecedent-choice tasks. In doing so, we include full NPs alongside null and overt pronouns, enabling a broader test of Accessibility Theory. Although the theory covers a range of referring expressions, most experimental work has focused on pronouns. Thus, adding full NPs allows a fuller evaluation of the mechanisms underlying referential choice and resolution.
2. Experiment 1
Experiment 1 presents a questionnaire rating study evaluating the predictions of Accessibility Theory. In particular, in Experiment 1, we focus on a discourse context with only one potential antecedent (Senhuy), as exemplified in (6).

Most previous comprehension studies on referential expressions have involved two discourse referents, as discussed in the Introduction. However, Accessibility Theory (Ariel Reference Ariel1988, Reference Ariel1991, Reference Ariel, Sanders, Schilperoord and Spooren2001) makes similar predictions even in contexts containing only a single antecedent. In this study, we take advantage of this novel environment to test the theory’s predictions more directly. Specifically, when a referent is the only available antecedent in the discourse context, its saliency is predicted to be high (Ariel Reference Ariel, Sanders, Schilperoord and Spooren2001: 31). Consequently, the antecedent should be referred to with a high-accessibility marker. If this prediction holds, target sentences should receive higher naturalness ratings with null pronouns than with overt pronouns, and higher ratings with overt pronouns than with full NPs. Alternatively, adjacent accessibility markers may not differ substantially in accessibility, leading to no clear contrast in their use. Experiment 1 examines these possibilities.
2.1. Methods
2.1.1. Participants
Thirty-nine native speakers of Korean (mean age = 25; 27 females) participated in the study. At the time of testing, they were all enrolled in either an undergraduate or a graduate program in Seoul, Korea. All participants received English education growing up, as English is part of the standard school curriculum in Korea. However, no participant reported being a fluent bilingual or having spent more than two years abroad.Footnote 3 They received KRW 4000 for their participation.
2.1.2. Materials
Each experimental item was preceded by a context sentence introducing one discourse referent (e.g. Seunghuy in (6a)), which served as the topic and subject of that sentence. This referent was then referred to in the target sentence using one of the three referring expressions shown in (6b): a null pronoun, an overt pronoun, or a full NP. For overt pronouns, we used the gender-neutral demonstrative pronoun kyay (Sohn Reference Sohn1999). This pronoun is commonly used for younger individuals or in situations where discourse participants are of equal status and are on terms where personal names are used, as in the target sentences in the experiment. For full NPs, we employed noun phrases consisting of a demonstrative followed by a noun (e.g. that friend, that girl, etc.).
There were 39 sets of stimuli, and three lists were created using a Latin square design, ensuring each set was evenly distributed across the lists. Additional 108 filler sentences of similar structural complexity were added to each list, and the lists were pseudo-randomized to prevent sentences from the same condition from being presented consecutively to participants. For each item, a naturalness rating question was presented using a Likert scale (1: very unnatural to 7: very natural).
2.1.3. Procedures
An advertisement for the experiment was posted on a social network popular among college students in Korea. Participants were selected based on a language background survey. The experiment was conducted on the PCIbex platform, and participants received a link to access it. They were instructed to complete the study in a quiet environment where they could devote at least 20 minutes to the task. Upon completing the task, participants were required to send an email to one of the authors, who verified their completion of the task.
2.1.4. Data analysisFootnote 4
Data from three items were excluded due to presentational errors. The remaining naturalness ratings were analyzed using ordinal regression models with the cumulative link mixed model (CLMM) function from the ordinal package (Christensen Reference Christensen2023) in R (R Core Team 2024), as the data were collected on a Likert scale and treated as ordinal. The pronoun type was included as a fixed-effect factor (null pronoun vs. overt pronoun vs. full NP), and the factor was numerically coded using treatment coding, with the null pronoun condition serving as the reference level. The regression also included participants and items as random factors. We constructed models with the maximal random effects structure permitted by the design and convergence, with the goal of incrementally simplifying the structure until convergence was achieved (Barr et al. Reference Barr, Levy, Scheepers and Tily2013). In Table 2, the ‘Slope’ column specifies whether the final model includes the random slope parameter corresponding to each fixed-effect predictor. In addition, to examine differences between the overt pronoun and full NP conditions, Holm-adjusted pairwise post hoc analyses were conducted.
2.2. Results and discussion
The results of Experiment 1 are presented in Table 1, with the corresponding statistical analyses reported in Table 2. Overall, the sentence ratings were high, suggesting that the experimental sentences were well accepted by native speakers of Korean. Based on the Accessibility Marking Scale, we predicted that referents with high mental salience – such as a sole discourse referent in the subject position – would be most effectively referred to using null pronouns. This prediction was confirmed: statistical analysis revealed significant simple effects of referring expression type, with null pronouns receiving significantly higher ratings than both full NPs and overt pronouns. However, no significant difference was found between the overt pronoun and full NP conditions (β = 0.19, SE = 0.19, z = 1.01, n.s.), contrary to our prediction (under a strict interpretation of the accessibility scale) that overt pronouns should refer more effectively to highly accessible antecedents than full NPs.
Naturalness rating results (1–7 scale) of Experiment 1

Cumulative link mixed-model results for naturalness ratings in Experiment 1 (threshold estimates ‘3|4’, ‘4|5’, etc. indicate transition points between adjacent categories on the 7-point Likert scale). Coefficients, standard errors, z-values, and p-values are reported for referring expression type (simple contrasts, treatment-coded). The ‘Slope’ column indicates whether the random slope parameter corresponding to the effect was included in the model for participants (p) or items (i)

In summary, the results of Experiment 1 appear partially consistent with the predictions of Accessibility Theory based on the accessibility scale. First, sentences containing null pronouns received the highest naturalness ratings, supporting the claim that null pronouns function as the highest-accessibility markers. Second, although sentences with overt pronouns and full NPs also received relatively high ratings, the results did not reveal a reliable distinction between these two forms in terms of their associated accessibility. While the lack of a clear distinction between overt pronouns and full NPs might appear to challenge Accessibility Theory, this outcome also accords with the view that adjacent markers on the accessibility scale need not always exhibit distinct patterning across all contexts. We return to this issue in the General Discussion.
In Experiment 2, we further test the predictions of Accessibility Theory in a discourse context featuring two potential antecedents and an interpretational bias to guide referential resolution.
3. Experiment 2
In Experiment 2, we introduced a sentential context containing two potential antecedents, following a design similar to those used in previous studies. As in Experiment 1, we employed kyay, a commonly used gender-neutral pronoun in Korean, along with full NPs to allow for a more comprehensive test of the predictions made by Accessibility Theory. Each target sentence was preceded by a context sentence, as illustrated in (7).

Unlike in Experiment 1, however, the context sentences in Experiment 2 introduced two potential referents – one in the subject position and one in the object position. The target sentences then featured a referring expression – either a null pronoun, an overt pronoun (kyay), or a full NP – in the subject position; all referring expressions were gender-neutral. The discourse contexts were carefully constructed so that the referring expression in each target sentence could be interpreted as referring to either the subject or the object of the preceding sentence. To this end, the target sentences consistently contained gender-definite or gender-biased nouns (e.g. prince, fisherman, female executive, sea navigator), while the preceding context sentences introduced a potential antecedent with either matching or mismatching gender (e.g. Mary or Tom) in the subject or object position. We used both gender-definite (32 items) and gender-biased (four items) nouns due to the limited availability of gender-definite nouns in Korean that naturally fit the experimental contexts. Nevertheless, previous research has shown that language comprehenders actively rely on gender cues during sentence processing to resolve pronouns, regardless of whether the critical noun is gender-definite or gender-biased (Sturt Reference Sturt2003) – particularly in anaphoric dependencies where the potential antecedent precedes the gendered noun (Kreiner et al. Reference Kreiner, Sturt and Garrod2008), as is the case in our target sentences. Accordingly, we predict that the interpretation of the referring expressions will be guided by the gender information provided in the discourse context.
According to the Accessibility Marking Scale, in subject-biased contexts (e.g. ‘Tom often took Mary to the sea’ in 7a), the target sentences’ naturalness ratings are expected to be highest for null pronouns, as they represent the highest accessibility markers. Conversely, the naturalness ratings are expected to be lowest for full NPs, due to the use of a low accessibility marker to refer to a highly accessible antecedent. The ratings for the overt pronoun condition are predicted to be lower than those for null pronouns but higher than those for full NPs. In object-biased contexts (e.g. ‘Mary often took Tom to the sea’ in 7a), the naturalness ratings for the Full NP condition are predicted to be highest, whereas the ratings for the Null pronoun condition are predicted to be lowest. The ratings for the overt pronoun condition are predicted to be intermediate.
3.1. Methods
3.1.1. Participants
Fifty-two native speakers of Korean (mean age = 26.9 years; 46 female) participated in Experiment 2 and received 5,000 KRW for their participation. At the time of testing, they were all enrolled in either an undergraduate or a graduate program in Seoul, Korea. All participants received English education as part of the standard school curriculum in Korea. However, none reported being fluent bilinguals or having spent more than two years abroad.
3.1.2. Materials
Thirty-six sets of experimental stimuli, similar to (7), were created. For ease of presentation, we used English names in (7), but in the experiment, Korean female or male names were used. In Korean, both topic and nominative case markers can be used for sentential subjects. Accordingly, among the 36 sentence sets, 16 used the nominative case marker, while the remaining 20 used the topic marker for overt pronouns and full NPs. In these sentences, the subject consistently served as the agent. Among the objects, 24 out of 36 had the recipient role, and the remaining 12 functioned as the theme. Among the 36 items, 32 employed gender-definite nouns (e.g. female doctor), while the remaining four employed gender-biased nouns (soccer player, fisherman, welder, and sea navigator).Footnote 5 These experimental sentences were distributed into six lists according to a Latin square design, with each list including an additional 84 filler sentences of similar length and complexity.
3.1.3. Procedure
The experiment was conducted individually in a quiet lab. Participants were asked to first evaluate the naturalness of the second sentence (i.e. the target sentence) using a Likert scale (1: very unnatural to 7: very natural), based on the provided context, as illustrated in (8).

Additionally, to ensure the sentences were interpreted as intended, participants were required to answer a comprehension question, as shown in (9). The choices provided for this question were a female and a male name, appropriate to the context. The entire experiment took between 10 and 20 minutes to complete.

3.1.4. Data analysis
The naturalness ratings in Experiment 2 were analyzed using the same cumulative link mixed-effects modeling approach as in Experiment 1, with the addition of Context Bias as an extra fixed-effect factor. The comprehension question accuracy data were analyzed using a generalized linear mixed-effects model (Baayen Reference Baayen2008, Baayen et al. Reference Baayen, Davidson and Bates2008, Jaeger Reference Jaeger2008) with a binary distribution. In both analyses, the fixed-effect factors were referring expression type (null pronoun, overt pronoun, full NP) and context bias (subject-biased vs. object-biased). Referring expression type was treatment-coded, with the null pronoun serving as the reference level, and context bias was sum-coded. Random intercepts for participants and items were included. When examining how naturalness ratings differed between correctly and incorrectly answered trials, we restricted the analysis to the factor Correctness, excluding other experimental factors. This decision was made because the number of incorrect responses was small and highly uneven across certain subconditions, making it difficult to draw statistically robust conclusions. We therefore fitted a cumulative link mixed model with Correctness as a fixed effect, and by-subject and by-item random slopes for this predictor. In all the analyses, we started with the maximal random effect structure when constructing models (Barr et al. Reference Barr, Levy, Scheepers and Tily2013). When the models with maximal random effect often did not converge, we progressively simplified the random effect structure until the model converged. In Table 3, we indicate in the ‘slope’ column whether the random slope parameter corresponding to a fixed-effect predictor was included in the final model that we report. P-values were obtained using lmerTest (Kuznetsova et al. Reference Kuznetsova, Brockhoff and Rune2017; version 3.1-3) in R (R Core Team 2024). Finally, to examine differences between the overt pronoun and full NP conditions, Holm-adjusted pairwise post hoc analyses were conducted for both comprehension question accuracy and naturalness ratings.
Generalized linear mixed-effects model results for comprehension question accuracy in Experiment 2. Coefficients, standard errors, z-values, and p-values are reported for referring expression type (simple contrasts, treatment-coded) and contextual bias (main effect, sum-coded). The ‘Slope’ column indicates whether the random slope parameter corresponding to each effect was included in the model for participants (p) or items (i)

3.2. Results and discussion
3.2.1. Comprehension question accuracy
The comprehension question accuracy results are presented in Figure 1, with the corresponding statistical analysis detailed in Table 3. Error rates varied significantly across conditions, with the lowest error rate observed for the Null pronoun condition in the subject-biased context (22 incorrect responses; 7.1% error rate). In contrast, the highest error rate was also found for the Null pronoun condition, but in the object-biased context (124 incorrect responses; 39.7% error rate). The other referential forms showed less pronounced differences between the subject- and object-biased contexts. The Full NP condition yielded 65 (20.6% error rate) and 63 (20.5% error rate) incorrect responses in the subject- and object-biased contexts, respectively. Similarly, the Overt pronoun condition incurred 57 (18.6% error rate) and 69 (21.8% error rate) incorrect responses in the subject- and object-biased contexts, respectively.
Correct comprehension answer rates of Experiment 2.

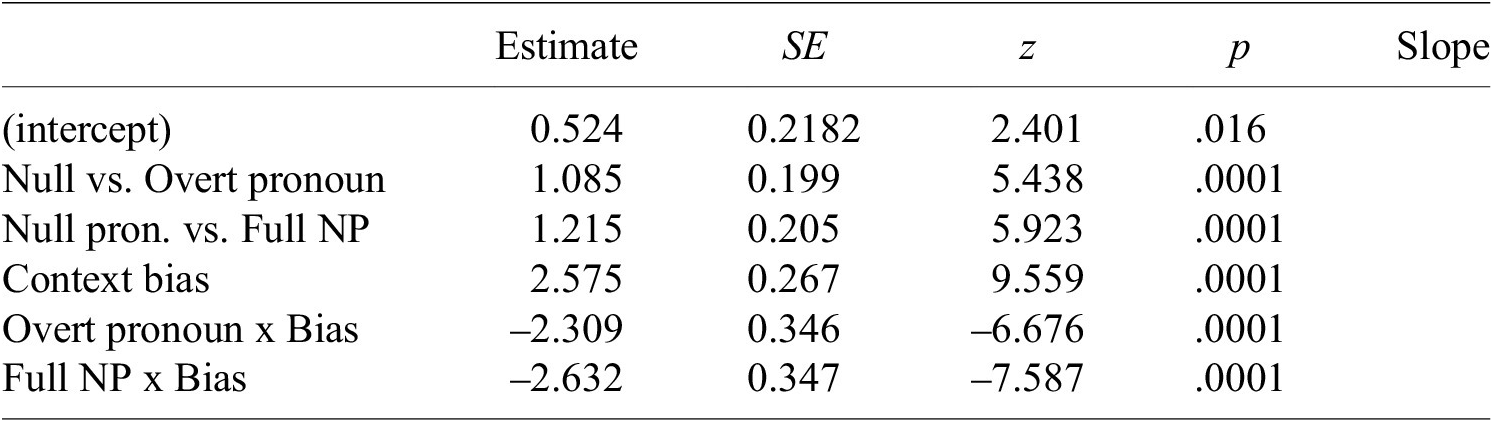
The statistical analyses revealed a significant main effect of contextual bias (sum-coded), significant simple contrasts for referring expression type (treatment-coded with the null pronoun as the reference level), and a significant interaction between the two factors. The significant interaction between referring expression type and contextual bias suggests that the context bias effect is modulated by the referring expression type. Holm-corrected post hoc pairwise comparisons revealed that the error rate for the Null pronoun condition was significantly higher in the Object-biased condition than in the Subject-biased condition (β = –2.575, SE = 0.269, z = –9.559, p <.0001). In contrast, the Overt pronoun and Full NP conditions did not exhibit such asymmetry between the subject- and object-biased contexts (Overt pronoun: β = –0.265, SE = 0.217, z = –1.22, n.s.; Full NP: β = 0.057, SE = 0.216, z = 0.265, n.s.).
Additionally, the Null pronoun condition elicited significantly lower error rates than the other two conditions in the Subject-biased context (Null vs. Overt pronouns: β = 1.224, SE = 0.280, z = 4.376, p = .0001; Null pronouns vs. Full NPs: β = 1.417, SE = 0.276, z = 5.137, p <.0001). In contrast, in the Object-biased context, the error rate for the Null pronoun condition was significantly higher compared to the other two conditions (Null vs. Overt pronouns: β = –1.085, SE = 0.200, z = –5.438, p <.0001; Null pronouns vs. Full NPs: β = –1.216, SE = 0.205, z = –5.923, p <.0001). No significant differences were found between the Full NP and Overt pronoun conditions across all contextual conditions (n.s.).
These findings suggest that the intended disambiguation was largely successful, although the object-biased null pronoun condition introduced greater interpretive difficulty. This pattern is consistent with Accessibility Theory: the low accuracy rate for this condition indicates that two cues – the interpretational bias of null pronouns favoring the subject referent and the gender bias associated with the noun – jointly influenced sentence interpretation. When these cues point in opposite directions and conflict with one another, as in the object-biased context with pro, referential resolution becomes more difficult, leading to reduced accuracy. In contrast, when referring expressions exhibit weaker interpretive biases, as is the case with overt pronouns and full NPs, competing cues may not cause comparable difficulty in referential resolution.
3.2.2. Naturalness ratings
The naturalness results for correctly answered trials are presented in Figure 2, and the corresponding statistical analysis results are provided in Table 4. As in the comprehension accuracy results, the statistical analyses revealed a significant main effect of contextual bias (sum-coded), significant simple contrasts for referring expression type (treatment-coded with the null pronoun as the reference level), and a significant interaction between the two factors. Holm-adjusted post-hoc pairwise comparisons revealed that this interaction was primarily driven by the Null pronoun condition. Specifically, the effect of context manipulation was significant only for the Null pronoun condition, but not for the Overt pronoun or Full NP conditions. In the Null pronoun condition, naturalness ratings were significantly higher when the null pronoun referred to the subject antecedent than when it referred to the object antecedent (β = –1.06, SE = 0.35, z = –3.04, p = .028.). In contrast, neither the Overt pronoun condition (β = –0.08, SE = 0.21, z = –0.37, p = 1.00.) nor the Full NP condition (β = 0.48, SE = 0.24, z = 2.04, p = .381) showed a significant difference between subject-biased and object-biased contexts. Moreover, in the object-biased context, the Null pronoun condition was rated as significantly less natural than both the Full NP (β = –1.04, SE = 0.25, z = –4.24, p <.001) and Overt pronoun conditions (β = –0.96, SE = 0.25, z = –3.77, p = .002). In contrast, in the subject-biased context, the Null pronoun condition did not differ significantly from either the Overt pronoun (β = 0.02, SE = 0.26, z = 0.09, p = 1.00) or the Full NP condition (β = 0.50, SE = 0.24, z = 2.07, p = .381). Across all context conditions, there was no significant difference between the Full NP and Overt pronoun conditions.
Mean naturalness ratings of Experiment 2 (1–7 scale). Error bars indicate standard errors.

Cumulative link mixed-model results for naturalness ratings in Experiment 2. Coefficients, standard errors, z-values, and p-values are reported for referring expression type (simple contrasts, treatment-coded) and contextual bias (main effect, sum-coded). The ‘Slope’ column indicates whether a random slope for each effect was included in the model for participants (p) or items (i)

We also compared the naturalness ratings of incorrectly answered trials with those of correctly answered trials. The analysis revealed a significant main effect of accuracy (β = 0.38, SE = 0.13, z = 3.05, p = .002), driven by significantly lower naturalness ratings for incorrectly answered trials (M = 4.05, SE = 0.09) than for correctly answered trials (M = 4.40, SE = 0.04). These results suggest that although participants selected interpretations of the referring expressions that differed from our intended ones, their social knowledge of typical gender biases still influenced their perceived naturalness of the sentences.
Importantly, the systematic relationship between comprehension accuracy and naturalness ratings indicates that participants’ evaluations were not random but reflected sensitivity to the intended manipulation. When contextual and gender cues were consistent, form–function correlations (e.g. null pronouns referring to highly accessible, subject antecedents) were clearly observed, resulting in higher accuracy and higher naturalness ratings. In contrast, when contextual or gender cues conflicted, some participants followed the interpretation guided by the form–function correlation, while others relied on gender information, leading to reduced accuracy and lower perceived naturalness.
In summary, as in Experiment 1, the results of Experiment 2 appear to be only partially consistent with the predictions of Accessibility Theory based on the accessibility scale. In line with the theory, sentences containing null pronouns were most accurately interpreted in subject-biased contexts, but least accurately interpreted in object-biased contexts, relative to those containing overt pronouns or full NPs. These findings from Experiment 2 confirm the results of Experiment 1 that null pronouns in Korean are particularly specialized for retrieving antecedents with very high degree of mental accessibility. However, the Overt Pronoun and Full NP conditions did not differ from each other in any condition, nor did they show asymmetries between subject- and object-biased contexts. We return to this issue in the General Discussion.
In Experiment 3, we further evaluate the predictions of Accessibility Theory in a globally ambiguous discourse context in Korean, again using a commonly used gender-neutral pronoun (kyay) and including full NPs to provide a more comprehensive test of the theory.
4. Experiment 3
Experiment 3 was designed to evaluate the predictions of Accessibility Theory in globally ambiguous contexts in Korean. As in Experiments 1 and 2, we employed null pronouns, overt pronouns (kyay), and full NPs. To facilitate comparison across experiments, the experimental items in Experiment 3 were adapted directly from those in Experiment 2. Specifically, the sentences in Experiment 3 were identical to those in Experiment 2, except that the context sentences in Experiment 3 featured two personal names of the same gender, as illustrated in (10).

This modification introduced ambiguity regarding the antecedent of the referring expressions in (10b), which was the only difference from the design of Experiment 2, where the referents were unambiguously identifiable based on gender information provided in the discourse context.
Experiments 1 and 2 revealed no significant difference between overt pronouns and full NPs. Furthermore, all types of referring expressions received high naturalness ratings when referring to the subject antecedent, although the subject bias was strongest for null pronouns. Based on these findings, we predict that in Experiment 3, null pronouns will elicit more subject referent interpretations than either overt pronouns or full NPs, which are expected to pattern similarly. In contrast, Accessibility Theory predicts a graded pattern: null pronouns, as the highest accessibility markers, should elicit the strongest subject preference, followed by overt pronouns, and then full NPs, which are predicted to be associated with the least subject-biased interpretations.
4.1. Methods
4.1.1. Participants
Thirty-eight college students residing in Korea participated in the study and received KRW 5,000 for their participation (female = 27; mean age = 24 years). All participants, born and raised in Korea, were native Korean speakers. No participant reported being a fluent bilingual, having received bilingual exposure apart from English education in school, or having spent more than two years abroad.
4.1.2. Materials
Thirty-six sets of sentences with three conditions similar to (10) were constructed. Three lists were created according to a Latin Square design and additional 109 filler sentences with similar complexity and length were added to each list. Stimuli were pseudo-randomized such that no sentences from the same condition would appear in a row.
4.1.3. Procedures
Participants were recruited online by posting an advertisement on a social network popular among college students in Korea. They underwent screening for their language background before being invited to participate in the experiment on PCIbex online. Sentences were presented one at a time, each followed by two questions. As in Experiment 2, participants first evaluated the naturalness of the second sentence (i.e. the target sentence) using a Likert scale ranging from 1 (very unnatural) to 7 (very natural). They were also required to identify to whom the referring expression in the target sentence referred. The choices for this question were the personal names used in the context sentence. The entire experiment took approximately 20 minutes to complete.
4.1.4. Data analysis
The data were analyzed separately for the naturalness ratings and antecedent-choice responses. The naturalness ratings were analyzed using ordinal regression models implemented with the cumulative link mixed model (CLMM) function from the ordinal package (Christensen Reference Christensen2023) in R (R Core Team 2024), as the data were collected on a Likert scale and treated as ordinal. The antecedent-choice data were analyzed using generalized linear mixed-effects models (GLMMs) with a binary logistic link function, as the dependent variable was categorical (subject vs. object choice). In both analyses, Referring Expression Type (null pronoun, overt pronoun, full NP) was included as a fixed-effect factor and was numerically coded using treatment coding, with the null pronoun condition serving as the reference level. Participants and items were included as random factors. Models were constructed with the maximal random-effects structure justified by the design and model convergence, and were incrementally simplified until convergence was achieved (Barr et al. Reference Barr, Levy, Scheepers and Tily2013). In Table 6, the ‘Slope’ column indicates whether the final model includes a random slope parameter corresponding to each fixed-effect predictor. We also conducted Holm-adjusted pairwise post hoc analyses to examine differences between the overt pronoun and full NP conditions for both antecedent choice and naturalness ratings.
4.2. Results and discussion
The raw antecedent choice results are presented in Figure 3, the mean naturalness ratings in Table 5, and the statistical analysis results in Table 6.
Subject vs. Object antecedent choice by referring expression type in Experiment 3.

Mean naturalness ratings (SE) of Experiment 3 (1–7 scale)

Cumulative link mixed-model results for naturalness ratings (using clmm) and generalized linear mixed-effects model results for antecedent choice (using glmer) in Experiment 3. Coefficients, standard errors, z-values, and p-values are reported for referring expression type (simple contrasts, treatment-coded). The ‘Slope’ column indicates whether a random slope for this effect was included in the model for participants (p) or items (i)

4.2.1. Antecedent choice
The antecedent choice results were overall consistent with the predictions of Accessibility Theory, unlike in Experiments 1 and 2. The regression analysis showed that antecedent interpretation varied significantly across referring expression types (Table 6). This was because the null pronoun condition significantly elicited more subject antecedent interpretations than the overt pronoun condition, which in turn elicited more subject referent interpretations than the full NP conditions (β = 0.416, SE = 0.166, z = 2.507, p <.015). The pattern was reversed for the object referent interpretations, with the Full NP conditions eliciting more object antecedent interpretations than the Overt pronoun condition (β = −0.42, SE = 0.17, z = −2.51, p = .012), and the Null pronoun condition eliciting the fewest object referent interpretations. These results suggest that, as predicted by Accessibility Theory, null and overt pronouns and full NPs are markers of different levels of accessibility in Korean.
4.2.2. Naturalness ratings
Naturalness ratings did not differ across the three types of referring expressions (Null pronouns: M = 5.3, SE = 0.075; Overt pronouns: M = 5.3, SE = 0.069; Full NPs: M = 5.4, SE = 0.071). This suggests that sentences were well received by native Korean speakers for their interpreted reading, regardless of the experimental condition. Given that these sentences were designed to be ambiguous, these results also indicate that the sentences with different referring expressions do not differ in their naturalness when their interpretational biases are met (see Antecedent choice results above).
In summary, the findings from Experiment 3 align with Accessibility Theory, showing that different referring expressions in Korean correspond to varying levels of mental accessibility. Null pronouns were most likely to refer to subject antecedents, while full NPs were most likely to refer to object antecedents. Overt pronouns exhibited an object interpretation bias but to a lesser extent than full NPs. In addition, the high naturalness rating results suggest that these patterns reflect natural language use in Korean. We address these findings further in the General Discussion.
5. General Discussion and Conclusion
The present study set out to examine how interpretive biases of referring expressions are shaped by discourse context, motivated by mixed findings across languages and theoretical assumptions about context-sensitivity in referential resolution. While research on Italian has revealed a robust division of labor between null and overt pronouns, studies in Spanish, Chinese, and Korean have yielded more variable results, often showing weaker distinctions. Crucially, prior work has rarely investigated how such interpretive patterns vary across discourse contexts. This is despite Accessibility Theory (Ariel Reference Ariel1990) proposing that only the relative ordering of accessibility markers is universal, while the strength of each marker is language- and context-sensitive. To address this gap, the present study systematically manipulated discourse contexts in Korean – a discourse-oriented language lacking robust morphosyntactic cues such as gender and number agreement and thus providing an ideal test case for evaluating the cross-linguistic applicability of Accessibility Theory and context-sensitivity in referential resolution. Our experiments also addressed several methodological limitations in earlier Korean studies by including more naturalistic materials, using a broader range of referential forms (including full NPs), and employing kyay, a gender-neutral overt pronoun commonly used in colloquial speech. Through three experiments involving naturalness ratings and antecedent-choice tasks, we evaluated how contextual differences influence the interpretation of null pronouns, overt pronouns, and full NPs within the accessibility framework. This approach allowed for a more comprehensive evaluation of the predictions made by Accessibility Theory across a wider range of referential forms.
Across three experiments, we observed robust evidence that Korean null pronouns serve as the highest accessibility markers. They were rated as most natural when coreferential with subject antecedents (Experiment 1: M = 6.41 out of 7), least natural with object antecedents (Experiment 2: M = 3.94), and most strongly associated with subject interpretation in an ambiguous context (Experiment 3: 70.6% subject choice). These findings are fully consistent with the predictions of Accessibility Theory, reinforcing the view that null pronouns in Korean signal high antecedent accessibility. In contrast, overt pronouns (kyay) and full NPs showed context-sensitive variation in their interpretive patterns. In Experiments 1 and 2, both forms were rated as natural for subject antecedent interpretations but did not show a clear preference in object antecedent contexts. In Experiment 3, however, both forms showed an object antecedent bias, with a stronger effect for full NPs (64.7%) than for overt pronouns (57.2%). This pattern suggests that while null pronouns consistently function as high-accessibility markers, the interpretive status of overt pronouns and full NPs is more sensitive to discourse context.
These results also shed light on the status of kyay within the Korean referential system. Although kyay historically derives from a demonstrative plus noun compound (‘that child’), it is now a commonly used gender-neutral pronoun in spoken Korean. Our results suggest that kyay occupies a middle position on the accessibility scale. It is semantically more informative than a null pronoun and exhibits greater referential rigidity, as it specifies that the antecedent is likely to be a human referent with whom the speaker feels familiar. Even when it refers to an inanimate object, the use of kyay implies that the referent is something the speaker feels a sense of familiarity with (see Section 1). This contrasts with a null pronoun, which carries no such restriction. At the same time, kyay is more phonologically attenuated than a full NP. This pattern reinforces the form–function correlation central to Accessibility Theory, which posits that languages calibrate referential expressions to balance communicative efficiency with cognitive economy, thereby reflecting systematic relationships between form and function. In this sense, kyay, as an accessibility marker, achieves an efficient balance between explicitness and effort, providing sufficient information for the addressee’s interpretation while minimizing redundant linguistic material, thereby promoting efficient communication among language users.
Importantly, our findings refine existing predictions of Accessibility Theory. While the theory posits a universal ordering of referring expressions along an accessibility scale, it also claims mental accessibility associated with each referring expression can vary across languages (for a related discussion, see Ariel Reference Ariel1990: 69–93). Our results support this more nuanced view: adjacent forms on the scale – such as overt pronouns and full NPs in Korean – may not exhibit categorical interpretive differences across all contexts, but they do reveal systematic, context-dependent patterns. This is consistent with Ariel’s (Reference Ariel1990) proposal that accessibility values are not absolute but context- and language-specific. In our study, the three-way distinction between referential forms became most apparent in Experiment 3, which involved globally ambiguous discourse contexts where no semantic or structural constraints resolved the reference. Under such conditions, the interpretation of the referring expression may be more sensitive to the form–function correlations predicted by Accessibility Theory. In contrast, in Experiments 1 and 2, which involved contexts where only one antecedent was plausible – either because only one discourse entity was mentioned (Experiment 1) or because gender information served to disambiguate the referent (Experiment 2) – distinctions arose only between null and non-null forms. These results suggest that i) the primary accessibility contrast in Korean lies between null and non-null forms, and ii) that the contrast between the two may consistently affect referential resolution under various contexts. In contrast, accessibility contrast between overt pronouns and full NPs would be too small to be detected under certain contexts where the impact of accessibility-driven form selection is minimized due to lack of referential ambiguity. Instead, in such contexts, the referring expression may be coindexed with the sole antecedent available, even if the form does not optimally match the referent’s accessibility status. That is, while language users may be sensitive to accessibility distinctions, the lack of true ambiguity might diminish the observable effect of form–function correlations associated with accessibility markers especially when a non-null form is used.
Taken together, these findings contribute to a broader cross-linguistic picture, suggesting that languages differ in the granularity with which they encode accessibility distinctions across referential forms (Ariel Reference Ariel1990). Cross-linguistic variation between Italian, Spanish, and Korean, for example, appears to stem from how individual systems calibrate the universal accessibility hierarchy. Italian, with its two distinct series of third-person subject pronouns (lui/lei vs. egli/ella; Cardinaletti & Starke Reference Cardinaletti, Starke and Van Riemsdijk1999), exhibits a robust division of labor between null and overt pronouns. By contrast, Spanish, which lacks this morphological contrast, shows more flexible use of overt pronouns and weaker accessibility-based asymmetries (Filiaci et al. Reference Filiaci, Sorace and Carreiras2014). Korean presents yet another configuration: although it possesses multiple overt pronouns (e.g. kyay, ku/kunye), our results suggest a more flexible use of overt pronouns in Korean than in Italian. This may be because these forms differ primarily in register, rather than in morphosyntactic properties, as the strong and weak pronouns do in Italian. Alternatively, this flexibility may stem from the fact that ku/kunye, and kyay all developed relatively recently from demonstratives combined with nouns, for example, kunye from ku + nye (‘that’ + ‘female’) and kyay from ku + ay (‘that’ + a contracted form of the noun meaning ‘child’). Such cross-linguistic diversity supports the view that, while the ordering of accessibility markers may be universal, the relative distance between them – and the degree to which form–function correlations surface in interpretation – are language-specific. These findings underscore the importance of testing accessibility-based predictions across typologically diverse languages using carefully controlled discourse contexts.
Now, turning to the discussion of previous studies of Korean against ours, we compare our results with those reported in previous studies of Korean. Our findings from Experiment 3 align with Kweon (Reference Kweon2011) but diverge from those reported by Choe (Reference Choe2021). Note that both studies employed a different type of overt pronoun (ku/kunye ‘he/she’) from the one used in the present study (kyay), and that neither included full NPs as referential expressions. Notably, neither Kweon nor Choe interpreted their findings within the framework of Accessibility Theory. Nevertheless, the similarity in results between our study and Kweon (Reference Kweon2011) suggests that, despite differences in historical development (ku/kunye reflecting Western influence vs. kyay without such influence) and usage patterns (ku/kunye being largely restricted to literary contexts, whereas kyay is commonly used in everyday speech), overt pronouns appear to serve a similar referential function. This raises the possibility that the interpretation of overt pronouns is governed by shared cognitive mechanisms underlying referential resolution, such as mental accessibility. However, to confirm this possibility, it will be important to replicate her findings with greater statistical reliability, given that Kweon’s results were based on a relatively small set of experimental items (n = 12).
On the other hand, the results reported in Choe (Reference Choe2021) appear more compatible with our findings from Experiments 1 and 2, in which both overt pronouns and full NPs showed a subject bias – albeit weaker than that observed for null pronouns. One possible explanation for the absence of a clear distinction between null and overt pronouns in Choe’s study – as opposed to the findings of Kweon (Reference Kweon2011) and our Experiment 3 – may lie in methodological limitations. As discussed in the Introduction, Choe employed an unusually low number of filler items (n = 24) relative to the number of target items (n = 40), which may have increased participants’ awareness of the experimental manipulation and biased their responses. Another possibility is that Choe’s target items may not have been fully referentially ambiguous, contrary to the intended design. This may have led to patterns similar to those observed in Experiments 1 and 2 of our study, in which the referential expression had only one plausible antecedent.
A final caveat concerns the use of the plain declarative form (-ta) in our stimuli. While this form is less colloquial than other sentence enders (e.g. -eyo/-e) with which kyay would typically be used, it was chosen to minimize morphological variation across stimuli. Although the plain declarative form (-ta) occasionally appears in spoken Korean – particularly with rising intonation when speakers convey excitement – it is possible that its relative formality influenced participants’ interpretations. Future research should further examine how verbal morphology and speech style interact with discourse context in shaping pronominal interpretation in Korean.
In summary, the current study provides novel empirical evidence that the interpretation of referring expressions in Korean aligns with the predictions of Accessibility Theory. In contexts of global ambiguity – where interpretive preferences are most revealing – we observed a clear division of labor among null pronouns, overt pronouns, and full NPs. Null pronouns consistently functioned as the highest accessibility markers, strongly favoring subject antecedents and yielding the highest naturalness ratings and subject-antecedent choices. Full NPs, by contrast, exhibited the strongest object antecedent bias, while overt pronouns showed an intermediate pattern, consistent with their relative position on the accessibility scale. Crucially, however, the accessibility distinction between overt pronouns and full NPs was not always robust, suggesting that this boundary may be more gradient or context-sensitive in Korean. These findings highlight that form-function correlations may manifest with differing granularity across languages and contexts. Finally, by incorporating naturalness ratings and including full NPs alongside more commonly used pronominal forms, this study offers a more comprehensive test of Accessibility Theory than previous works.
Acknowledgments
We are grateful to the editor and the reviewers for their thoughtful and constructive feedback. Their careful evaluation and suggestions greatly strengthened this manuscript. Any remaining errors are our own.
Funding Note
This research was supported by the Academy of Korean Studies Fellowship Program, awarded to the first author.
AI Use Statement
The author(s) used ChatGPT solely for grammatical and spelling checks. The content, analysis, and interpretation presented in the manuscript are entirely the authors’ own.









 Open access
Open access