


1. Eastern Andalusian Spanish laxing and harmony: Introduction and literature review
Eastern Andalusian Spanish (EAS) is a dialect spoken in the southeastern region of Spain. While its lexicon and morphology closely align with the peninsular standard, EAS exhibits some unique phonological features, including the (inter-related) processes of vowel laxing and harmony.
Whereas most varieties of Spanish have a five-vowel system (/a e i o u/), we may find (at least) three additional vowels in Eastern Andalusia: [ɛ a̞ ɔ]. The opening or laxing of /a/ appears to be less systematic compared to that of the mid vowels (Sanders Reference Sanders1994; Alonso, Canellada & Zamora Vicente Reference Alonso, Canellada and Zamora Vicente1950). Conversely, the laxing of high vowels /i/ and /u/ is debated. While Herrero de Haro (Reference Herrero de Haro2019), Zubizarreta (Reference Zubizarreta and Safir1979), and Alvar (Reference Alvar1955) argue that high vowels do undergo laxing, it is acknowledged that this process is less pronounced than in mid and low vowels. Furthermore, high vowels are notably absent from vowel harmony processes (Navarro Tomás Reference Navarro Tomás1939; Martínez Melgar Reference Martínez Melgar1994; Hualde & Sanders Reference Hualde and Sanders1995; Jiménez & Lloret Reference Jiménez and Lloret2009).
The appearance of lax vowels is phonetically conditioned and occurs when the word-final consonant is deleted. For instance, a word such as tres ‘three’ would be realized as [tɾɛ] (EAS) instead of [tɾes] (Standard Castilian), or [tɾeh] (varieties with aspiration). Given that word-final fricatives have long been aspirated in Andalusian (Zamora Vicente Reference Zamora-Vicente1989; Alonso Reference Alonso1969), one could reasonably speculate that [h] would have caused allophonic laxing of the preceding vowel. This, in turn, would allow for deletion of the aspiration. Following this counter-bleeding rule ordering, the diachrony of ves (‘see’, 2sg) would be the following:
Much of the literature on EAS vowels has concentrated on words historically ending in /s/. Nevertheless, allophonic laxing next to -r has been observed in many Spanish varieties (Perissinotto Reference Perissinotto1975; Matluck Reference Matluck1963; Navarro Tomás Reference Navarro Tomás1957; Lipski Reference Lipski1987; Morrison Reference Morrison2004; González de Anda Reference González de Anda2013). As EAS tends to delete most word-final consonants, it seems reasonable to assume that the deletion of -r would also result in lax vowels contrasting word-finally with their tense counterparts. Although several authors have claimed that the deletion of final liquids does not result in the same phenomena (Navarro Tomás Reference Navarro Tomás1939; Rodríguez Castellano & Palacio Reference Rodríguez-Castellano and Palacio1948; Jiménez & Lloret Reference Jiménez and Lloret2009, Reference Jiménez, Lloret, Colina and Martínez-Gil2019), Herrero de Haro (Reference Herrero de Haro2019) found that -r drives final vowel laxing. The following two representations might therefore be pictured:

The lax character of the final, unstressed vowel transmits its quality to the preceding stressed vowel and perhaps optionally to vowels in syllables before the stressed one as well by a process of vowel harmony (Navarro Tomás Reference Navarro Tomás1939; Palacio Reference Rodríguez-Castellano and Palacio1948; Salvador Reference Salvador1975; Mondéjar Cumpián, Reference Mondéjar Cumpián1979; Alarcos Llorach Reference Alarcos Llorach1983; Martínez Melgar Reference Martínez Melgar1994; Rodríguez Castellano & Palacio Reference Rodríguez-Castellano and Palacio1948; Sanders, 1998). The general distribution for EAS is exemplified with singular-plural pairs in Table 1.
To explain the acoustics behind the tense/lax vowel contrasts in Table 1, Jiménez & Lloret (Reference Jiménez and Lloret2009, Reference Jiménez and Lloret2018) and Kaplan (Reference Kaplan, Bennett, Bibbs, Brinkerhoff, Kaplan, Rich, Handel and Wax Cavallaro2020) have used the Advanced Tongue Root feature. ATR was first defined by Ladefoged (Reference Ladefoged1964) in a number of West African languages and is a binary feature that relates to a change in size of the pharyngeal cavity. This change is normally achieved by a tongue root advancement/retraction and larynx lowering (Lindau Reference Lindau1975, Reference Lindau1978). The acoustic consequence of vocal tract adjustment is primarily reflected in the first formant: −ATR vowels have a higher F1 (Halle & Stevens Reference Halle and Stevens1969); that is, −ATR vowels (lax) are lower than the corresponding +ATR (tense) pairs, as is the case in Eastern Andalusian Spanish (Soriano Reference Soriano, Astorkiza and Franco2012; Henriksen Reference Henriksen2017; Herrero de Haro Reference Herrero de Haro2017, Reference Herrero de Haro2019). Herrero de Haro (Reference Herrero de Haro2017, Reference Herrero de Haro2019) also notes that both shift in frontness and become more central. On the contrary, Henriksen (Reference Henriksen2017), who controlled for surrounding segments and word stress, found that only [e] and [ɛ] differ in frontness, while /o/ remained unchanged.
ATR harmony in EAS is believed to be a stress-dependent phenomenon. It is described as a process intended to increase perceptibility of a structurally weak (unstressed) vowel, by spreading its quality up to the stressed syllable. This harmonic pattern has been accounted for through Positional Licensing constraints in Optimality Theory (Jiménez & Lloret Reference Jiménez and Lloret2009, Reference Jiménez and Lloret2018; Kaplan Reference Kaplan, Bennett, Bibbs, Brinkerhoff, Kaplan, Rich, Handel and Wax Cavallaro2020; Davis & Pollock Reference Davis and Pollock2024). On the other hand, a coarticulatory motive is not contemplated as a possible origin of harmony. While stressed vowels tend to increase the effects of anticipatory coarticulation (Fowler Reference Fowler1981; Magen Reference Magen1997; Majors Reference Majors2006; Recasens Reference Recasens2016), the phenomenon at hand has been often described as spreading of features from unstressed (final) to stressed vowels. This stress-based distribution has parallels in Romance, such as in cases of metaphony (Maiden Reference Maiden1991, for Italo-Romance; Penny Reference Penny1969, Reference Penny1994; Hualde Reference Hualde1989 for Leonese Ibero-Romance dialects).
Mid vowel harmony in EAS

The fact is, however, that the potential presence of harmony in words with final stress has received very little attention. Many phonologists have limited their scope to harmony between word-final unstressed triggers, and stressed targets. This is no doubt due to the predominance of penultimate stress in Spanish (Quilis, Cantarero & Esgueva Reference Quilis, Cantarero and Esgueva1993; Alfano, Savy & Llisterri Reference Alfano, Savy and Llisterri2008).
In this study, I investigate the effects of word-final coda deletion (-r or -s) in words with final stress in Eastern Andalusian Spanish (EAS). Specifically, I compare the behavior of the two mid vowels in such contexts to that observed in words without a final coda, such as bebé ‘baby’.Footnote 1
This paper aims to address the following research questions:
-
1. Does deletion of -r and -s have the same effects on the adjacent mid vowel?
-
2. Do stressed mid vowels followed by a deleted -s or -r trigger leftward [−ATR] harmony, therefore targeting unstressed vowels?
-
3. Are native and non-native speakers of EAS able to identify the deleted consonant in perception?
The remainder of this paper is organized in the following manner. Section 2 is concerned with the production experiment (addressing Research Questions 1 and 2), which will consider both laxing and harmony. The perception experiment (Research Question 3) will be presented in Section 3 and only considers laxing. Lastly, Section 4 provides a discussion of the results, and poses some limitations of the study.
2. Production study
2.1. Research hypotheses
The research hypotheses concern both triggers and targets of laxing harmony:
-
1. Triggers: most previous work has concentrated on words underlyingly ending in -s, where this underlying or historical final consonant is left unpronounced. Herrero de Haro (Reference Herrero de Haro2019), however, has shown that other final consonants have similar opening effects. Although Herrero de Haro claims that the final vowels of words in -r and -s differ from each other, the difference appears to be minimal.
In this study, words ending in -s, -r, and those without an underlying final consonant will be compared. I therefore contrast two hypotheses:
-
H1: The final vowels of words underlyingly ending in -r or -s will be significantly different. Both will also be different from those underlyingly ending in a vowel in both F1 (height) and F2 (frontness) for /e/, and F1 (height) for /o/ (as found in Henriksen Reference Henriksen2017)
-
H2: There will be no significant difference in either F1 or F2 between vowels underlyingly followed by -r and -s. Both will be different from those underlyingly ending in a bare vowel in both F1 (height) and F2 (frontness) for /e/, and F1 (height) for /o/.
-
-
2. Targets: Most previous experimental work has focused on paroxytonic words and has examined the harmonization of a stressed V1 with a word-final unstressed V2, suggesting that harmony is a stress-dependent phenomenon. Here, contexts where the final vowel (V2) is stressed will be tested. I compare two hypotheses:
-
H3: There is propagation of laxing from a final lax, stressed vowel to a preceding vowel. V1 and V2 will have the same F1 and F2 values in words with a deleted consonant. They will also be different from formant values of vowels with no underlying final consonant.
-
H4: There is no propagation of laxing from a final, laxed stressed vowel to a preceding vowel; that is, V1 will remain tense, even when V2 is lax. This will lead to differences in F1 and F2 for /e/, and F1 for /o/, between both vowels within the word.
-
2.2. Methods
2.2.1. Participants
For this study, I recorded 19 speakers (10F, 9M) from Granada, a city in Eastern Andalusia. Recordings of one participant (F) were discarded due to background noise and recording quality concerns, leaving a total of 9F, 9M speakers. Participants ranged from 18 to 34 years (mean 24.27, SD 5.08). They all were residing in the capital city of Granad. Five participants had graduated from university, two held an associate degree, six were undertaking a bachelor’s degree, and five had achieved higher education (Master’s or Ph.D).
Participants were first asked to complete a language background questionnaire, where they were asked about their language use, parents’ dialect, place where they attended school, and other relevant sociolinguistic data. All EAS participants were born and raised in Granada, were currently residing in this city, and had parents from Andalusia. All participants had at least obtained their bachelor’s degree (if applicable) in Granada, and all reported to have at least 75% of daily interactions with other people from the region. The only exception was speaker 15, who also reported having few interactions with other people from Andalusia. This participant held a linguistics background (Ph.D.), although reported not being aware of the nature of the study. None had grown up speaking a different language at home.
2.2.2. Experimental task
As in other phonetics studies, a compromise had to be found between the competing goals of naturalness of the speech and control over the conditions. An oral alternative of a sentence completion task was designed to prompt a set of target words.
Stimuli used for the experiment consisted of recordings of an Eastern Andalusian Speaker from Almería, recorded in a phonetics lab. Participants used headphones to listen to the recording, which they would need to orally complete. The in-person experimental procedure was made up of three tasks, which consisted of the following:
-
1. Oral fill-in the gaps: Participants listened to the beginning of a sentence and completed it with the most fitting word. The expected answer is given in parentheses:
No me gusta el amarillo. Quiero un vestido de otro ____ (color).
‘I don’t like yellow. I want a dress of a different ____’ (color).
-
2. Conjugations: Participants heard a verb and were asked to conjugate it.
La forma de ‘yo’ para el pretérito del verbo “tomar”:_____ (tomé).
‘Say the ‘I’ form of the past tense of the verb “to take”:’ ____ (I took)
-
3. Antonyms: Participants listened to a word and were asked to say the opposite.
Mayor – ____ (menor)
‘Greater – ____ (smaller)’
The stimuli above prompted words with final stress, which were disyllabic or trisyllabic. These words ended in -or, -er, -es, -e, -o, balanced in number. It included both inflectional -r (comer ‘to eat’) and lexical -r (dolor ‘pain’). Ending -os could not be included, as it is infrequent word-finally in oxytones. The vowel in the pre-tonic syllable could be either /e/ or /o/, and distribution was also balanced. 30% of target distractors were included, eliciting paroxytonic (such as nunca) and pre-paroxytonic words (pájaro), Participants were recorded in a quiet room, using a ZoomH2N Handy recorder. By the end of the experiment, none of the participants were aware of the study’s purpose. In a debriefing questionnaire, many participants were under the impression that the experiment was a vocabulary test, where they had to guess the correct word. Pronunciation was not identified as the objective of the study.
2.2.3. Acoustic and statistical analysis
The recordings were manually segmented in Praat, focusing on stressed and pre-tonic vowels. Vowels were cropped to exclude formant transitions. Recordings with background noise, creakiness, devoicing, or vowels lasting shorter than 40 ms. were excluded from the analysis. Additionally, only words where -s or -r were not phonetically realized were included. This led to 89 vowel productions being discarded.
As also claimed by Herrero de Haro (Reference Herrero de Haro2017) for Almería, no aspiration in the recordings was observed or perceived. Similarly, Henriksen (Reference Henriksen2017) consistently uses the term deletion for his observations of Granada. However, the remanence of some potential aspiration cannot be entirely discarded, which could have been too subtle to be captured by the microphone.
A script was used to extract F1 and F2 mean values, as well as f0 and F3 (for normalization purposes), from the cropped vowels. Settings for formant extraction were set as a maximum number of formants of 5, maximum formant (Hz) as 5500 for female participants, and 5000 for male speakers. Formants were extracted at intervals of 25ms, and an average was calculated.
To validate the statistical significance of the variance in formant values, linear mixed-model regression analyses were conducted in R, using the lmer function in the lme4 package (Bates, Bolker, Mächler & Walker Reference Bates, Bolker, Mächler and Walker2015). Separate regressions were performed for the acoustic parameters F1 and F2. The effect of Position (V1, V2), Vowel (e, o) and Ending (-r, -s, V), as well as interactions, were included as fixed factors. Participant and Token were entered as random intercepts to account for individual variability and any potential differences by lexical word. For each regression analysis, the reference levels were set as follows: Ending = -r, Position = 2, and Vowel = /e/. Statistical significance was evaluated at an alpha level of α = .05; results with p
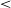 $\lt$
.05 were considered significant.
$\lt$
.05 were considered significant.
For F2, the effect of Vowel /o/ is expected to be significant, given that the intercept is a front vowel. In addition, laxing would be indicated through a centralization; a decrease in F2 for /e/, and an increase (Herrero de Haro Reference Herrero de Haro2017) or no change (Henriksen Reference Henriksen2017) in F2 for /o/, caused by Ending. Given that the lmer output will not directly address these research questions, Estimated Marginal Means (EMMs) pairwise comparisons were performed for the F2 analysis of /o/, using the emmeans package in R (Lenth Reference Lenth2024). These analyze the effect of Ending in V2 position, as well as differences between V1 and V2 within Ending.
The explained variance of the linear mixed-effects model was assessed using marginal and conditional R2. Selected random effects contribute additional explanatory power beyond the fixed effects, as evidenced by the increase from R2m to R2c. For F1, the marginal R² (R2m), representing the variance explained by the fixed effects, was 0.499. The conditional R² (R2c), representing the variance explained by both fixed and random effects, was 0.704. For F2, the marginal R² (R2m) was 0.733, and the conditional R² (R²c) was 0.86.
2.3. Results
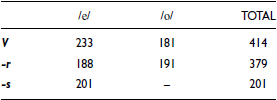
Instances in which final consonants were retained (N = 109) were excluded from the analysis. The final dataset comprised 994 words, including both words that underlyingly ended in a consonant (but where the consonant was deleted) and words that underlyingly ended in a bare vowel. The distribution of the target words is shown in Table 2.
Number of tokens by vowel and context

Before considering inferential statistics, a visualization of the result is offered. Participants’ average F1 and F2 values for the final, mid vowel are plotted in Figure 1, using the ggplot function in the ggplot2 library in R (Wickham Reference Wickham2016). Values were normalized using the Bark distance model normalization method (Syrdal & Gopal Reference Syrdal and Gopal1986), a vowel-intrinsic procedure that considers each individual token’s f0, F1, F2 and F3. Individual vowel spaces are included in Appendix A.
Final vowel (V2) by Condition (Bark normalized).

Final vowels (V2) were compared to the preceding (V1) in height and frontness. The results for F1 are presented in 2.3.1, and results for F2 are in 2.3.2.
2.3.1. F1
The intercept (/e/, V2, -r) had a significant estimate of 649.80 Hz. There was no difference between the final /e/ in words ending in -r and those ending in -s, as indicated by the non-significance of Ending (-s) (Est. 8.30, t = 0.46, p = .65). The effect of Ending (V) was significant (Est. −168.97, t = −10.20, p
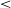 $\lt$
.001), indicating a higher final /e/ in words with no underlying final consonant. These effects held for both mid vowels: word-final /o/ before /r/ did not differ significantly from word-final /e/ before /r/, as shown by the non-significant effect of Vowel (/o/) (Est. = −24.43, t = −1.40, p = .17). Likewise, the effect of having no underlying consonant for word-final /e/ was similar to that for word-final /o/, as indicated by the non-significant interaction between Ending (V) and Vowel (/o/) (Est. = 23.84, t = 1.86, p = .07).
$\lt$
.001), indicating a higher final /e/ in words with no underlying final consonant. These effects held for both mid vowels: word-final /o/ before /r/ did not differ significantly from word-final /e/ before /r/, as shown by the non-significant effect of Vowel (/o/) (Est. = −24.43, t = −1.40, p = .17). Likewise, the effect of having no underlying consonant for word-final /e/ was similar to that for word-final /o/, as indicated by the non-significant interaction between Ending (V) and Vowel (/o/) (Est. = 23.84, t = 1.86, p = .07).
In terms of harmony, the penultimate /e/ was not significantly different from the final when the word ended in -r, as indicated by the non-significance of Position (V1) (Est. 1.29, t = 0.13, p = .90), suggesting harmonization. Similarly, the difference between the final and penultimate /e/ in words ending with -r was not significantly different from that in words with no underlying final consonant, as shown by the interaction between Ending (V) and Position (V1) (Est. = −13.91, t = −1.10, p = .27). These effects held for both mid vowels: word-final /o/ before /r/ did not differ significantly from word-final /e/ before /r/, as shown by the non-significant effect of Vowel (/o/) (Est. = −24.43, t = −1.40, p = .17). Likewise, word-final /o/ and /e/ with no underlying final consonant were not significantly different from each other, as indicated by the non-significant Ending (V) x Vowel (/o/) interaction (Est. = 23.84, t = 1.86, p = .07). In contrast, the penultimate /e/ was higher than the final in words ending in -s, compared to the corresponding difference in words ending in -r, as indicated by the Ending (-s) × Position (V1) interaction (Est. = −29.25, t = −2.79, p = .005). The output table for the F1 regression is presented in Appendix B1.
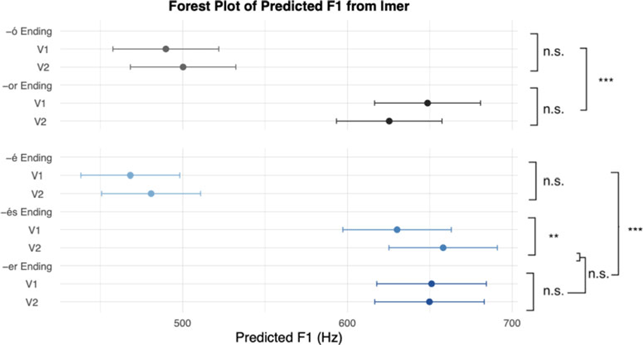
The following violin plots show F1 normalized values for /e/ (Figure 2a) and for /o/ (Figure 2b), by word-ending. Kernel density estimation was performed using the geom_violin() function from ggplot2 (Wickham Reference Wickham2016). Embedded boxplots show the median and interquartile ranges. Additional plots illustrating model results with non-normalized data are presented in Appendix B2
F1 (first formant) of the two vowels within the word: (a) mid, front vowel /e/; (b) mid, back vowel /o/.

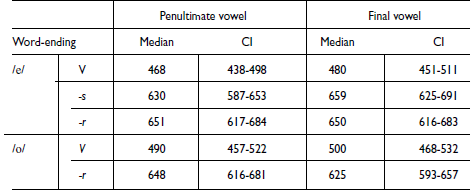
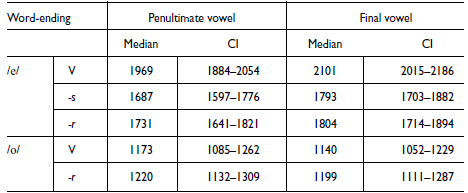
Median values of the F1 data by vowel, position and ending are presented in Table 3. In addition, 95% confidence intervals (CIs) were computed using estimated marginal means (EMMs) with the emmeans package (Lenth Reference Lenth2024).
Estimated medians and Confidence Intervals (CI), in Hz.

To summarize the results for F1, both word-final mid vowels have significantly more open realizations ( = higher F1) in words underlying ending in -r or -s than in words without an underlying final consonant. There is no difference in this respect between words ending in -r and words ending in -s. These findings offer support for H2 and against H1. There were also no significant differences in F1 between the final stressed vowel (V2) and the preceding unstressed vowel (V1) in words ending in -r, indicating harmonization. In words ending in -s, an estimated small difference of 29Hz was found. Given its limited size, this difference is attributed to phonetic environment, rather than any crucial difference between V1 and V2. These findings offer support for H3 and against H4.
2.3.2. F2
The intercept (reference levels /e/, V2, -r) returned a significant estimate of 1804.00 Hz (p
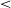 $\lt$
.001). The final /e/ did not differ between words ending in -s and -r, as indicated by the non-significant effect of Ending (-s) (Est. = −11.40, t = −0.31, p = .76). In contrast, when the word had no underlying final consonant, the final /e/ was significantly more fronted than in words ending in -r, as evidenced by the significant effect of Ending (V) (Est. = 296.52, t = 8.66, p
$\lt$
.001). The final /e/ did not differ between words ending in -s and -r, as indicated by the non-significant effect of Ending (-s) (Est. = −11.40, t = −0.31, p = .76). In contrast, when the word had no underlying final consonant, the final /e/ was significantly more fronted than in words ending in -r, as evidenced by the significant effect of Ending (V) (Est. = 296.52, t = 8.66, p
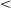 $\lt$
.001).
$\lt$
.001).
The penultimate /e/ in words ending in -r was more central than the final, as indicated by the significant effect of Position (1) (Est. −73.16, t = −3.14, p
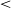 $\lt$
.01). The Ending (-s) x Position (1) interaction was not significant (Est. = −32.75, t = −0.99, p = .32), indicating that the V1 centralizing effect for /e/ found with -r ending was consistent in words ending in -s. The interaction between Ending (V) x Position (1) was significant (Est. −58.00, t = −1.94, p = .04), indicating greater differences between V1 and V2 /e/ in words without an underlying final consonant.
$\lt$
.01). The Ending (-s) x Position (1) interaction was not significant (Est. = −32.75, t = −0.99, p = .32), indicating that the V1 centralizing effect for /e/ found with -r ending was consistent in words ending in -s. The interaction between Ending (V) x Position (1) was significant (Est. −58.00, t = −1.94, p = .04), indicating greater differences between V1 and V2 /e/ in words without an underlying final consonant.
The two mid vowels /o/ and /e/ were different in frontness before -r, as reflected by the significance of Vowel (/o/) (Est. −605.22, t = −16.66, p
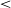 $\lt$
.001). This was expected, since /o/ is a back vowel. EMMs pairwise comparisons analyzing the effect of Ending (-r, V) in final (V2) position indicated that /o/ was more advanced (central) when the word ended in underlying -r than in a bare vowel (Est. 136.23, t = 5.74, p.
$\lt$
.001). This was expected, since /o/ is a back vowel. EMMs pairwise comparisons analyzing the effect of Ending (-r, V) in final (V2) position indicated that /o/ was more advanced (central) when the word ended in underlying -r than in a bare vowel (Est. 136.23, t = 5.74, p.
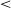 $\lt$
.001). Regarding harmony, comparisons analyzing the effect of Position (V1, V2) for /o/ by Ending indicate no significant difference between the two /o/ within the word when the word underlyingly ended in -r (Est. 15.0, t = .8, p. = .42), but a significantly more retracted /o/ in final position when the word ended in a bare vowel (Est. 61.9, t = 3.31, p. = .001). The output table for the F2 regression is presented in Appendix B3.
$\lt$
.001). Regarding harmony, comparisons analyzing the effect of Position (V1, V2) for /o/ by Ending indicate no significant difference between the two /o/ within the word when the word underlyingly ended in -r (Est. 15.0, t = .8, p. = .42), but a significantly more retracted /o/ in final position when the word ended in a bare vowel (Est. 61.9, t = 3.31, p. = .001). The output table for the F2 regression is presented in Appendix B3.
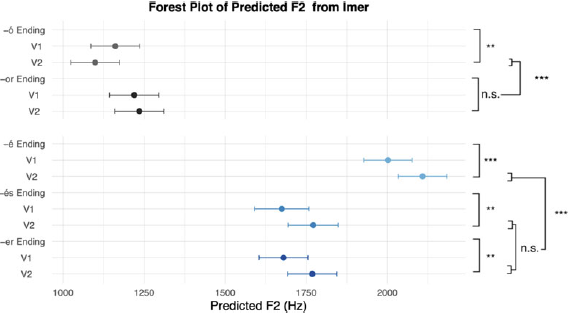
The violin plots in Figure 3 show the distribution of normalized F2 values for words containing two mid vowels in penultimate and final position. Additional plots illustrating model results with non-normalized data can be found in Appendix B4.
F2 (second formant) of the two vowels within the word: (a) mid, front vowel /e/; (b) mid, back vowel /o/.

Median values of F2 by Vowel, Position and Ending are presented in Table 4. Like for the F1 analysis, 95% confidence intervals (CIs) were computed using estimated marginal means (EMMs) with the emmeans package (Lenth Reference Lenth2024).
F2 median and Confidence Intervals (CI), in Hz.

2.4. Conclusion and discussion
These results provide evidence in favor of hypotheses H2 and H3. This constitutes evidence for laxing and harmony in words with final stress, as deletion of word-final -r and -s causes comparable changes in the formant structure of the two preceding mid vowels. In the V1 position, the vowel tends to be more centralized across word endings, likely due to the lack of stress on V1. Unstressed vowels have a shorter duration in Spanish (Enríquez, Casado & Santos Reference Enríquez, Casado and Santos1989; Llisterri, Machuca, de la Mota, Riera & Ríos 2003; Quilis, Cantarero & Esgueva Reference Quilis, Cantarero and Esgueva1993) which may have prevented the penultimate vowel from reaching its target F2 values.
Differences in formant values between tense and lax vowels are comparable to those found in words with penultimate stress. These fall within a range of 100–150 Hz for F1, while F2 differences for /e/ are reported to range from 150–300 Hz (Martínez Melgar Reference Martínez Melgar1994; Sanders Reference Sanders1994; Corbin Reference Corbin2006; Herrero de Haro Reference Herrero de Haro2019; Henriksen Reference Henriksen2017).
There was a finding not explained by H3: a shift in F2 for lax /o/. The back vowel was about 136Hz higher in words underlyingly ending in -r, as compared to those ending in a bare vowel. Rather than laxing after deletion of -r, it may potentially be the case of final vowel tensing with -ó. If we look at Figure 3, we may notice that V1 in coló appears to be as fronted as the two vowels in color. A somewhat more tense final vowel (in F2) is noted for both /e/ and /o/, which has frequently been pointed out in the Eastern Andalusian literature (Navarro Tomás Reference Navarro Tomás1939; Hualde & Sanders Reference Hualde and Sanders1995). Herrero de Haro (Reference Herrero de Haro2017), who observed changes in F2 between -or and -ó, attributed these changes to fronting after the deletion of -r. However, the opposite (namely, word-final vowel tensing) may well be the case.
In addition, an F1 decrease of 29Hz (estimate) in V1 position was found for words ending in -s (i.e., the penultimate vowel was slightly higher than the final in words such as bebés). I attribute this subtle difference in F1 between V1 and V2 in -es endings to phonetic environment. The penultimate vowel still remains completely distinct from those without an underlying consonant: the estimate F1 for V1 is 630Hz for words ending in -s, and 468Hz for words ending in a bare vowel.
In sum, this acoustic study revealed a significant difference in vowel quality between words underlyingly ending in stressed -e (e.g. bebé ‘baby’) and words underlyingly ending in either stressed -er or -es (e.g. beber ‘to drink’, bebés ‘babies’). No difference was found between the endings -er and -es. Similarly, underlying final stressed -o (coló ‘it sifted’) was different from the same vowel in -or (color ‘color’). The question that is addressed in the following section is whether these acoustic findings are mirrored in perception.
3. Study 2: Perception
3.1. Research hypothesis
Previous studies have found that native speakers are able to distinguish tense and lax vowels and successfully match a lax vowel with a deleted coda (Henriksen Reference Henriksen2017; Herrero de Haro Reference Herrero de Haro2019). Herrero de Haro (Reference Herrero de Haro2019) used stimuli with several different underlying but unpronounced final consonants. Participants in the study were not able to indicate which consonant had been deleted. Based on this previous research on the topic, I formulate the following hypothesis:
H5: Native EAS speakers will be able to discriminate between words underlyingly ending in a mid vowel, from words underlyingly ending in a mid-vowel followed by unpronounced -r or -s. However, they will not be able to distinguish between words ending in -r and in -s.
3.2. Methods
3.2.1. Participants
The same 19 speakers of Eastern Andalusian Spanish from Granada who participated in the production experiment were asked to participate in this perception experiment. In addition, 20 Northern Peninsular Spanish speakers from Bilbao were tested as a control group. These participants reported little contact with Eastern Andalusian. Most of them were also bilingual in Basque, which has the same vowel system as standard Spanish (no laxing).
3.2.2. Experimental task
The same speaker from Almería who produced the stimuli for the production experiment recorded the stimuli for the perception experiment, which was carried out in Qualtrics. Participants were presented with a written word, followed by two audios. They were instructed to select which one of the two audios was the representation of the written stimulus. The order of presentation of the two recordings was randomized, and participants only listened to each recording once.
The experiment started with three practice items. Then, a total of 43 trials (15 fillers, 28 experimental) were presented to participants. In the experimental trials, recordings contained contrasts between 1. [er] – [es], 2. [er] – [e], 3. [es] – [e], 4. [or] – [o], where the consonant was not pronounced, and the vowel was in those cases therefore lax. Regarding the written stimulus, it ended either in orthographic -r (-er, -or), -s (-és), -or a vowel (-é, -ó).Footnote 2 A sample stimulus is presented in Figure 4.
Sample stimulus presented to participants in Qualtrics.

There were two recordings and a single orthographical representation, rather than a single recording and two written words. If one recording had been matched with two written options, participants might have been biased toward choosing the spelling without a final consonant, regardless of vowel quality. It was a forced-choice task, and they could only listen to each recording once.
Most audios were original minimal pairs; for instance, in trials consisting of contrasts between labor ‘labor’ and lavó ‘washed, 3.sg’, beber ‘to drink’ and bebés ‘babies’, prever ‘to foresee’ and prevés ‘foresee, 2.sg’. However, the existence of minimal pairs in oxytonic words is limited. Some recordings were manipulated so that a tense ending was matched to a word that originally contained a lax vowel. For instance, as no contrast between hacer and hacé with a tense vowel exists in Castilian Spanish, the /e/ in café was cropped and placed after the end of aperiodic fricative noise in hacer. The naturalness of the result was tested with native speakers of Spanish, who could not perceive any anomaly. A variable named Manipulation (which accounted for manipulated vs. non-manipulated stimuli) was also added to the model, either as a fixed or a random factor. Likelihood ratio tests showed no significant improvement when ‘Manipulated’ was included (fixed: p = 0.2193; random: p = 0.9993). AIC and BIC values were also nearly identical. Therefore, the simpler baseline model without ‘Manipulated’ in the analysis was preferred. A full list of the contrasting recordings, as well as the target answer, are presented in Appendix C.
The recordings used as stimuli in the experiment exhibited particularly high F2 values for /e/ (a more fronted front vowel) and low F1 values for /o/ (a higher back vowel) compared to those of Granada participants.
3.2.3. Statistical analysis
Results were classified and quantified in two separate analyses:
-
1. Contrast accuracy: Trials were classified into four conditions, depending on the two audios present in each trial: 1. beber vs. bebés; 2. bebé vs. beber; 3. bebé vs. bebés; 4. coló vs. color. The dependent variable was the accuracy of the response, categorized either as correct (the selected recording and the written stimulus matched, with regards to the speaker’s intended production) or incorrect (there was a mismatch between the word and selected recording). Descriptive statistics were used to calculate the percentage of correct answers for each dialect (Native, Non-native). A generalized linear logistic mixed-effects model of the binomial family (glmer), using the lme4 package (Bates, Bolker, Mächler & Walker Reference Bates, Bolker, Mächler and Walker2015) was fitted to evaluate the effects of Condition and City on response accuracy. The model included fixed effects for Condition, City, and their interaction. Random intercepts for Participant and Token were included. Estimated marginal means (EMMs) were computed for each Condition-City combination and compared to a chance level of 0.5, using the emmeans package in R (Lenth Reference Lenth2024)
-
2. Selected recording (tense/lax). This helps reveal if participants tend to choose tense or lax recordings more often, regardless of the written form, simply because they are less familiar with one of the vowel qualities. As for the Type of contrast analysis, a logistic mixed-effects model was conducted. Fixed effects were Condition, City, and their interaction, with random intercepts for Participant and Token. EMMs were also calculated and compared to 0.5 chance.
3.3. Results
Results for the type of contrast analysis are presented in Figure 5. Below each bar, the corresponding p-values from the glmer outputs are included between brackets.
Perception, by condition: (a) native speakers; (b) non-native speakers.

Both groups selected the correct response above chance, except for non-native speakers in Condition 1 (-er, -es contrast) (p = .168). Native speakers particularly exceled when identifying tense-lax contrasts (p.
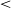 $\lt$
.001), and performed above chance in the -r, -s condition (p. = .01). As expected, Granada participants, native speakers of the variety, performed better than Bilbao participants. The output table for the regression is presented in Appendix B5.
$\lt$
.001), and performed above chance in the -r, -s condition (p. = .01). As expected, Granada participants, native speakers of the variety, performed better than Bilbao participants. The output table for the regression is presented in Appendix B5.
The analysis for the tense/lax recording analysis revealed significant differences between groups. Results are presented in Figure 6.
Perception, by vowel quality (accuracy: tense-vowel ending; lax-consonant ending): (a) native speakers; (b) non-native speakers.

Both groups associated a written consonant ending (e.g. bebés and color) with the recording containing the lax vowel, while native participants did so more consistently. However, non-native speakers often thought that the audios containing a lax vowel (for instance, a recording of beber/bebés and color) represented orthographical bebé and coló respectively. That is: control participants very frequently (44.3% of the trials) selected the lax recording when the written stimuli ended in a vowel without an underlying final consonant. In this case, Bilbao (control) speakers were not able to perform above chance (p = .26). The output table for the regression is presented in Appendix B6.
3.4. Conclusion
Results from perception partially contradict H5. EAS speakers can identify which consonant has been deleted above chance; however, their accuracy is very limited. This is not consistent with the results of production, where laxing after -r and -s deletion caused equivalent changes in the preceding vowel. In contrast, native speakers were highly accurate in identifying whether consonant deletion had occurred.
Native participants were also better at discriminating tense and lax word-final vowel contrasts than the control group of non-EAS speakers. In addition, non-native participants frequently selected the lax recording when the written stimulus ended in a vowel. This may be due to tense vowels in the stimuli being more peripheral than one would find in other varieties of Spanish (both within Granada speakers, and in other peninsular varieties). The existence of particularly tense vowels has been documented in Eastern Andalusian (Rodríguez Castellano & Palacio Reference Rodríguez-Castellano and Palacio1948; Alonso, Canellada & Zamora Vicente Reference Alonso, Canellada and Zamora Vicente1950; Hualde & Sanders Reference Hualde and Sanders1995).
In a debriefing questionnaire, participants were asked where the person in the stimuli was from. Many Granada speakers indicated that the speaker could be from Almería, Jaén or the outskirts of Granada, suggesting that the peripheral nature of the tense vowel is perhaps not native to the city center. The speaker who recorded the stimuli for the production experiment was, indeed, from a different town: Almería. This suggests that, within Eastern Andalusia, differences in vowel quality can be found. Still, EAS participants could successfully match vowel endings to tense recordings, and lax recordings to an underlying consonant.
4. Final conclusion and discussion
First, regarding the effects of lexical stress on the phenomenon, previous studies on EAS vowel harmony have focused on words with penultimate stress and have investigated the harmonization of a preceding unstressed vowel (Martínez Melgar Reference Martínez Melgar1994; Sanders 1998; Corbin Reference Corbin2006; Herrero de Haro Reference Herrero de Haro2019; Henriksen Reference Henriksen2017). Here, words with final stress have been analyzed, to find possible harmonization of the vowel in the preceding syllable. Results are very similar, which indicates that harmony in Eastern Andalusian Spanish appears to be stress independent. I would like to suggest that extension of −ATR may not be (at least uniquely) motivated by perceptual constraints, but rather by V-to-V coarticulation. Coarticulation is widely recognized as the primary source of phonologized harmony cross-linguistically (Boyce Reference Boyce1988; Ohala Reference Ohala1994; Kaun Reference Kaun, Hayes, Kirchner and Steriade2004, among others.).
A coarticulatory origin would also help to explain why high vowels are sometimes believed to lax, but not harmonize: Eastern Andalusian is reported to exhibit a weaker tense-lax contrast within high vowel pairs, where the distinction between / ʊ/ and /i u/ appears to be subtle (Herrero de Haro Reference Herrero de Haro2019; Henriksen Reference Henriksen2017), as does in many languages with ±ATR contrasts (Starwalt Reference Starwalt2008; Rose Reference Rose2017). The distance between lax and tense high vowels may not be large enough to cause assimilation of the preceding vowel.
Secondly, most previous work has compared words ending in underlying but deleted -s with words underlyingly ending in a vowel. Words ending in -r seem to show similar laxing and harmony effects as words ending in -s, so that words like, for instance, beber ‘to drink’ and bebés ‘babies’ are not significantly different from each other in formant structure, and both are different from bebé ‘baby’. The results of this acoustic study were partially contradicted by the perception experiment: despite not finding a difference in formant structure between word final -s and -r deletion, native EAS speakers were able to identify the deleted consonant above chance (albeit with limited accuracy). There may well be some perceptually subtle cues beyond F1 and F2 differences that could lead EAS speakers to distinguish them, such as some remaining aspiration, vowel length or F3, which were not considered in the analysis of production tokens.
I end with some remarks regarding possible morphological effects on EAS vowel harmony. Soriano (Reference Soriano, Astorkiza and Franco2012) was the first researcher to posit that only some inflectional suffixes other than -s could cause harmony based on research in Jaén, Eastern Andalusia. A morphemic /s/ (nenes ‘kids, pl’) has also been argued to make the vowel laxer in Andalusian, as compared to non-morphemic /s/ (jueves ‘Thursday’) (Rodríguez Castellano & Palacio Reference Rodríguez-Castellano and Palacio1948), although this was refuted by Henriksen (Reference Henriksen2017), indicating the opposite tendency. A similar claim was made for Venezuelan Spanish by Scrivner (Reference Scrivner and Orzco2014). Harmony with oxytones has also recently been argued to be different for morphological vs. non-morphological /s/ (Davis & Pollock Reference Davis and Pollock2024). Given the Spanish lexicon distributional patterns (very few words ending in -s with final stress, that also contain two mid vowels), it is difficult to consider the role of morphology in the harmonic process. Despite this naturalistic limitation, no difference between words such as revés ‘inside out’ (non-morphological) or bebés ‘babies’ (morphological) -s endings was observed; neither between the /o/ in color ‘color’ (non-morphological) and comer ‘to eat’ (morphological) -r.
Although no strong conclusions can be drawn based on morphological status of the underlying consonant, claiming that morphology does not play a role would not be new across laxing varieties of Spanish. Findings that EAS has stress-independent vowel harmony, also occurring with word-final -r, resemble the distribution described for a neighboring region: Murcia. In Murcian Spanish, the absence of any absolute-final coda consonant (except for nasals) will cause final vowel laxing, regardless of the morphological status of the deleted consonant. These now lax vowels trigger leftward vowel harmony, independent of stress patterns (Hernández-Campoy & Trudgill Reference Hernández-Campoy and Trudgill2002; Monroy & Hernández-Campoy Reference Monroy and Hernández-Campoy2015; Jiménez & Lloret, Reference Jiménez and Lloret2018). For instance, a word such as mejor ‘better’ would be realized as [mɛˈhɔ] in Murcian, and, according to traditional descriptions, [meˈhɔ] ̴ [meˈho] in Eastern Andalusian. In this data, Eastern Andalusian exhibits a similar pattern, with mejor being realized as [mɛˈhɔ].
Limitations of the study include the lack of consideration of vowel duration. Compensatory lengthening is a well-known cross-linguistic mechanism after loss of coda (De Chene & Anderson Reference De Chene and Anderson1979; Hayes Reference Hayes1989; Kavitskaya Reference Kavitskaya2002, among others). For Spanish, some studies found longer realizations for vowels preceding deleted -s (Hammond & Resnick Reference Hammond and Resnick1975; Carlson Reference Carlson2012). Vowel duration should therefore be considered in future research, in order to better understand the mechanisms behind the tense/lax contrast.
Acknowledgements
I would like to express my gratitude to the anonymous informants and community members who participated and helped share this study with others. I am grateful to my advisor, Dr. José Ignacio Hualde, for his help through the whole experiment planning and writing process. I also wish to thank Dr. Wenyue Ma for her help with the statistical analysis. Finally, I am thankful to the two anonymous reviewers for their thoughtful remarks and suggestions.
Appendices
Appendix A. Vowel spaces by speaker
A1. Individual speakers’ vowel spaces

Appendix B. Statistical model outputs and graphs
B1. Production: F1 linear mixed-effects model (LMM)
Model: F1 ∼ Ending * Vowel * Position + (1 | Speaker) + (1 | Token)
Estimation method: REML
REML criterion: 21722.5
Number of observations: 1915
Groups: Token = 65, Speaker = 18
Random Effects

Fixed Effects

B2. Production. Estimated F1 Values by Ending, Vowel, and Position (95% CIs, from Linear Mixed Model)
B3. Production: F2 linear mixed-effects model (LMM)
lmer function, lme4 package in R
Model: F2 ∼ Ending * Vowel * Position + (1 | Speaker) + (1 | Token)
Estimation method: REML
REML criterion: 24901.8
Number of observations: 1915
Groups: Token = 65, Speaker = 18
Random Effects

Fixed Effects

Estimated marginal means (EMMs) for F2
*Only relevant contrasts are included
By position:
pairwise ∼ Position | Vowel * Ending, adjust = “tukey”


By word-ending:
pairwise ∼ Ending | Vowel, at = list(Position = “2”), adjust = “tukey”
Vowel = o:

B4. Production. Estimated F2 Values by Ending, Vowel, and Position (95% CIs, from Linear Mixed Model and pairwise comparisons)
B5. Perception: Binomial generalized linear mixed-effects model (GLMM) by Condition. (glmer function, lme4 package in R)
Model: Accuracy ∼ Condition * City + (1 | Participant) + (1 | Frequency)
Family: Binomial (logit link)
Estimation method: Maximum likelihood (Laplace approximation)
Number of observations: 1102
Groups: Participant = 38, Frequency = 20
Random Effects

Fixed Effects

Estimated Marginal Means (Probability Scale)

B6. Perception: Binomial generalized linear mixed-effects model (GLMM) by recording (tense/lax)
(glmer function, lme4 package in R)
Accuracy ∼ City * TenseLax + (1 | Participant) + (1 | Frequency)
- Family: Binomial (logit link)
- Estimation method: Maximum likelihood (Laplace approximation)
- Number of observations: 1102
- Groups: Participant = 38, Frequency = 20
- AIC: 1092.8 | BIC: 1132.9 | logLik: −538.4
Random Effects

Fixed Effects

Estimated Marginal Means (Probability Scale)

Appendix C. Stimuli used for the perception experiment. Target answers are given in bold
Condition 1: -er vs. -és
-
1. Bebér – Bebés
-
2. Escocer – escocés
-
3. Remover - removés
-
4. Entrever – entrevés
-
5. Prever - Prevés
-
6. Hacer – francés (MANIPULATED)
-
7. Reponer – japonés (MANIPULATED)
Condition 2: -é vs. -er
-
8. Bebé-Beber
-
9. Prevé – Prever
-
10. Cavé – caber
-
11. Hallé- ayer
-
12. Alquilé – alquiler
-
13. Abracé – hacer
-
14. Recé – crecer (MANIPULATED)
Condition 3: -é vs. -és
-
15. Bebé – Bebés
-
16. Prevé – Prevés
-
17. Puré - purés
-
18. Café – cafés
-
19. Corsé-corsés
-
20. Esté - Estés
-
21. Abracé – francés (MANIPULATED)
Condition 4: -ó vs. -or
-
22. Labor – lavó
-
23. Amor – amó
-
24. Error – erró
-
25. Inventor - inventó
-
26. Cursor- cursó
-
27. Calor – caló
-
28. Color – coló
-
29. Humor – Fumó (MANIPULATED)
Distractors
-
40. Mesa - Misa
-
41. Harás - Darás
-
42. Peso – Pesó
-
43. Piso – pisó
-
44. Gira - Tira
-
45. Canto – Cantó
-
46. Allá - hallé
-
47. Interés – enteré
-
48. Piso - pisó
-
49. Café – hacer
-
50. Nace - Hace
-
51. Humo – fumo
-
52. Queso - Hueso
-
53. Pedir – medir
-
54. Recé - crecer








 Open access
Open access