


1. Introduction
This study investigates the acquisition of English articles among native Dagbani (L1) speakers. English articles are claimed to be the most challenging functional elements in English in second language (L2) acquisition. Studies have shown that L2 learners both from article-having and article-less language backgrounds display variation in their acquisition patterns of the English article system (Ionin et al. Reference Ionin, Ko and Wexler2003, Reference Ionin, Ko and Wexler2004; Park Reference Park2005; Hawkins et al. Reference Hawkins, Al-Eid, Almahboob, Athanasopoulos, Chaengchenkit, Hu, Rezai, Jaensch, Jeon, Jiang, Leung, Matsunaga, Ortega, Sarko, Snape and Velasco-Zárate2006; Avery and Radišić Reference Avery and Radišić2007; Ionin et al. Reference Ionin, Zubizarreta and Maldonado2008; Park and Song Reference Park and Song2008; Trenkic Reference Trenkic, del Pilar Garcia Mayo and Hawkins2009; Chung Reference Chung2011, among others). Two patterns of non-target-consistent behavior have been identified among L2 learners: errors of omission and errors of substitution. Furthermore, it has been observed that L2 learners from languages that have articles transfer the article semantics of their L1 onto the L2 grammar, while learners from article-less languages supposedly fluctuate between using definiteness or specificity to regulate article use. This has been proposed to be due to an Article Choice Parameter (ACP) (Ionin Reference Ionin2003; Ionin et al. Reference Ionin, Ko and Wexler2003, Reference Ionin, Ko and Wexler2004; Ionin et al. Reference Ionin, Zubizarreta and Maldonado2008; Ionin et al. Reference Ionin, Zubizarreta and Philippov2009).
A number of studies with various L1–L2 English language pairs have investigated the ACPFootnote 1 and the Fluctuation Hypothesis (see section 2) and have made exciting findings both in support of and against these proposals.
Other scholars have reasoned that variability in English article acquisition patterns among L2 learners (L2 speakers) stems from mismatches in feature specifications on the lexical items between the learners’ L1 and the target L2, and thus requires feature reassembly for successful acquisition (Hawkins et al. Reference Hawkins, Al-Eid, Almahboob, Athanasopoulos, Chaengchenkit, Hu, Rezai, Jaensch, Jeon, Jiang, Leung, Matsunaga, Ortega, Sarko, Snape and Velasco-Zárate2006; Lardiere Reference Lardiere, Brugos, Micciulla and Smith2004, Reference Lardiere and Dekydspotter2005, Reference Lardiere, Liceras, Zobl and Goodluck2008; Shimanskaya Reference Shimanskaya2015; Shimanskaya and Slabakova Reference Shimanskaya and Slabakova2014). Other factors are whether the functional morphemes are overtly expressed in both the L1 and L2, whether they are overt in the L1 and covert in the L2, or whether they are overt in the L2 and covert in the L1 (Cho and Slabakova Reference Cho and Slabakova2014; Slabakova Reference Slabakova2009a, Reference Slabakova2009b, Reference Slabakova2016).
According to Cho and Slabakova (Reference Cho and Slabakova2014), a feature is directly expressed if its meaning is the primary function of the relevant morpheme and indirectly expressed if its meaning is not the primary function of the morpheme. For instance, definite and indefinite articles have the primary function of expressing the feature [definiteness] (hence, articles in English directly express definiteness); however, possessive and demonstrative pronouns can also express definiteness indirectly. Furthermore, a feature is overt if it has a surface morphological form, such as the for [definite] and -ed for [+past] in English, whereas covert features lack surface morphological markers or use other words; for example, adverbials in Mandarin Chinese to express [past] (Cho and Slabakova Reference Cho and Slabakova2014). Based on how morphological features are expressed in the L1 and L2, Cho and Slabakova (Reference Cho and Slabakova2014) argued that it is more challenging to acquire functional morphemes that are overt in one of the languages and covert in the other, than when the features have overt or direct functional morphology in both languages. This observation will be relevant to this study.
In L2 acquisition, the role of explicit learning has been argued to influence learning outcomes in different domains, including L2 article acquisition (Ionin and Montrul Reference Ionin and Montrul2010, Rebuschat and Williams Reference Rebuschat and Williams2012, Chrabaszcz and Jiang Reference Chrabaszcz and Jiang2014, Azaz Reference Azaz2016). For instance, Azaz (Reference Azaz2016) investigated crosslinguistic effects in the acquisition of determiner phrases (DPs) in Arabic by English speakers using a Grammaticality judgement task (GJT) and a Forced-choice task (FCT). The results showed L1 effects. The study also found that advanced Arabic learners made use of explicit knowledge of L1/L2 differences regarding definiteness, despite learners engaging in different task-handling procedures that varied in difficulty, with the GJT requiring more complicated skills. Further, some SLA scholars agree that conscious and explicit knowledge improves L2 performance in adult learning (Rebuschat and Williams Reference Rebuschat and Williams2012, Azaz Reference Azaz2016).
Our goal in this study is to investigate the Fluctuation Hypothesis (FH) and the role of L1 transfer in L2 English article acquisition among L1 Dagbani speakers. The Dagbani-English pair is interesting given the nature of the article system of Dagbani. Moreover, L1 Dagbani L2 English learners have not been studied in the L2 article acquisition literature. The only language whose article system is similar to Dagbani that has been studied in this way is Arabic, which has only one definite article and no indefinite article (Sarko Reference Sarko, del Pilar Garcia Mayo and Hawkins2009).
Although English and Dagbani are both article languages with article semantics based on definiteness, the articles in these languages are different with respect to how they express definiteness, specificity, and genericity. In brief, Dagbani has two morphological forms marking definiteness, while indefiniteness is unmarked (hence, the indefinite article is a zero morpheme). The two definite articles also encode definiteness in two different ways – via uniqueness or via previous mention (anaphoric reference). Certain bare nouns in Dagbani are unique and will have a definiteness interpretation; bare nouns have a generic reference; while specificity is encoded by indefinite quantifiers. Details of the Dagabni article system are provided in section 3.
In this article, we argue that the L1 plays a significant role in the patterns of article use among L1 Dagbani L2 English speakers and that this can be accounted for by Lardiere's (Reference Lardiere, Brugos, Micciulla and Smith2004, Reference Lardiere and Dekydspotter2005, Reference Lardiere, Liceras, Zobl and Goodluck2008) feature reassembly proposals. The article is structured as follows: We briefly review the literature on L2 acquisition of English articles in section 2 and the article systems of both Dagbani and English in section 3. In section 4, we provide an overview of data collection and methodology. The results are presented in section 5. We discuss the results and our predictions in section 6 and conclude the article in section 7.
2. Previous studies on English article acquisition
Several studies have investigated the acquisition of English articles among speakers with various L1s, mostly Russian, Korean, Japanese, and Spanish. Ionin (Reference Ionin2003) and Ionin et al. (Reference Ionin, Ko and Wexler2003, Reference Ionin, Ko and Wexler2004) argue that article semantics and interpretation may be influenced by definiteness (as in English) or specificity (as in Samoan). For instance, Ionin et al. (Reference Ionin, Ko and Wexler2004:12) observed that while article interpretation in English is based on definiteness with the used for definite and a/an used for indefinite reference, “Samoan is an example of a language that uses one article (le) in [+specific] environments and a different article (se) in [−specific] environments,” with definiteness being irrelevant in such contexts.
This observation led Ionin and colleagues to propose the Article Choice Parameter (ACP) and the Fluctuation Hypothesis (FH).
(1) The Article Choice Parameter (for two-article languages) (Ionin et al. Reference Ionin, Ko and Wexler2004:12)
A language that has two articles distinguishes them as follows:
• The Definiteness Setting: Articles are distinguished on the basis of definiteness.
• The Specificity Setting: Articles are distinguished on the basis of specificity.
(2) The Fluctuation Hypothesis (FH) (Ionin et al. Reference Ionin, Ko and Wexler2004:17)
a. L2 learners have full UG access to the two settings of the Article Choice Parameter.
b. L2 learners fluctuate between different parameter settings until the input leads them to set the parameter to the appropriate value.
The FH proposes that errors in L2 data stem from L2 learners fluctuating between the definiteness and specificity setting of the ACP. Since English articles are set to [±definite], with specificity signaled by the discourse context, L1 speakers from article-less languages fluctuate, in their use of the and a(n), between definiteness and specificity until the input guides them to the right setting. Ionin et al. (Reference Ionin, Ko and Wexler2004) thus argued that languages fall into two article grouping categories, as in (3), through which article use errors can be predicted.
(3) Article Grouping Cross-Linguistically: Two-Article Languages (Ionin et al., Reference Ionin, Ko and Wexler2004:13)

Typically, L2 English learners are predicted to overuse a in definite non-specific contexts and the in indefinite specific contexts, schematized in (4) with illustrative sentences in (5).
(4) Predictions of English article use patterns by speakers of article-less L1s (Ionin et al. Reference Ionin, Ko and Wexler2004)

(5) Article misuse contexts (Ionin et al. Reference Ionin, Zubizarreta and Philippov2009:338)
a. [+definite, −specific] context: target word is the.
I want to talk to the winner of this race – whoever that happens to be.
b. [−definite, +specific] context: target word is a
Professor Robertson is meeting with a student from her class – my best friend, Alice.
That is, many L2 speakers from article-less languages would incorrectly supply a in (5a) and the in (5b), resulting in article substitution errors. Ionin et al. (Reference Ionin, Ko and Wexler2004:17) further argued that “[i]n the absence of L1 transfer, L2 learners should have no initial preference for one parameter setting over another”. Thus if L2 learners have full UG access, it should be possible for them to access both parameter-settings until they have sufficient input to guide them to the right one appropriate for their L2.
Using a forced-choice elicitation task, Ionin et al. (Reference Ionin, Ko and Wexler2004) found support for the FH in their studies of Russian and Korean L1 speakers (both article-less languages). Examples (6)–(9) show sample dialogues for the context types in the elicitation task.
(6) [+definite, +specific] context (Ionin et al. Reference Ionin, Ko and Wexler2004:64)
Conversation between two police officers
Police Officer Clark: I haven't seen you in a long time. You must be very busy.
Police Officer Smith: Yes. Did you hear about Miss Sarah Andrews, a famous lawyer who was murdered several weeks ago? We are trying to find (a, the, ___) murderer of Miss Andrews – his name is Roger Williams, and he is a well-known criminal.
(7) [+definite, −specific] context (adopted from Ionin et al. Reference Ionin, Zubizarreta and Philippov2009:340)
A conversation between a mother and her son.
A: It's already 4 pm. Why isn't your sister home from school?
B: She just called and told me that she got into some trouble in school! She is talking to (a, the, ____) headteacher of her school! I don't know who that is. I hope she comes home soon.
(8) [−definite, +specific] context (Ionin et al. Reference Ionin, Ko and Wexler2004:66)
In an airport, in a crowd of people who are meeting arriving passengers
Man: Excuse me, do you work here?
Security guard: Yes.
Man: In that case, perhaps you could help me. I am trying to find (a, the, ___)
red-haired girl: I think that she flew in on Flight 2329.
(9) [−definite, −specific] context (Ionin et al. Reference Ionin, Ko and Wexler2004:66)
A conversation between a pupil and a librarian in a children's library.
A: I'd like to get something to read, but I don't know what myself.
B: Well, what are some of your interests? We have books on any subject.
A: Well, I like all sorts of things that move – cars, trains … I know! I would like to get (a, the, ___) book about airplanes! I like to read about flying!
The L1 Korean and L1 Russian L2 English learners fluctuated between the definiteness and specificity settings of the ACP, consistent with the FH predictions. Even though the L1 Koreans performed better in their article choice in all contexts than the L1 Russians, there was an overuse of the in [−definite, + specific] contexts and overuse of a in [+definite, −specific] contexts by both L1 groups.
Comparing L1 Russian patterns of article use with L1 Spanish (an article language), Ionin et al. (Reference Ionin, Zubizarreta and Maldonado2008:560) proposed the two possibilities in (10) to account for L1 transfer in relation to fluctuation.
(10) Two competing hypothesis (Ionin et al. Reference Ionin, Zubizarreta and Maldonado2008:560)
Possibility 1: Fluctuation overrides transfer
All L2 learners should fluctuate between definiteness and specificity in their L2-article choice. Thus, L2 learners from article (Spanish) and article-less (Russian) backgrounds will fluctuate in their article choice in English.
Possibility 2: Transfer overrides fluctuation
L2 learners whose L1 has articles transfer the article semantics from their L1 to their L2 while L2 learners whose L1 lacks articles will exhibit fluctuation.
Using the same forced-choice task as in Ionin et al. (Reference Ionin, Ko and Wexler2004), they found that the L1 Spanish speakers exhibited native-like article use, while the L1 Russians fluctuated. Results of their study led Ionin et al. (Reference Ionin, Zubizarreta and Maldonado2008) to conclude that the L1 Spanish group had transferred the article semantics of their L1 onto the L2 interlanguage grammar, while the lack of articles in Russian resulted in interchangeable use of articles as either definite or specific.
Other researchers have since investigated both the FH and L1 transfer effects, using a combination of different languages. For instance, Sarko (Reference Sarko, del Pilar Garcia Mayo and Hawkins2009) investigated L2 English article acquisition among L1 Syrian Arabic and L1 French speakers and found that neither L1 group fluctuated in their article choice. Since both French and Arabic are article languages, Sarko (Reference Sarko, del Pilar Garcia Mayo and Hawkins2009) concluded that these L2 learners had transferred the article semantics of their L1 onto the L2, which provided support for the Full Transfer/Full Access Hypothesis (FT/FA) (Schwartz and Sprouse Reference Schwartz and Sprouse1996, Reference Schwartz, Sprouse and Archibald2000; Schwartz Reference Schwartz, Flynn, Marthardjono and O'Neil1998). The FT/FA hypothesis proposes that the starting point of L2 learning is the L1 grammar, but L2 learners also have full access to UG in the acquisition process, and rely on it in cases where the L1 is insufficient for the learning task at hand (Gass Reference Gass2013).
Furthermore, Zdorenko and Paradis (Reference Zdorenko and Paradis2008) conducted a longitudinal corpus-based study of child L2 English learners whose L1s were either article languages (Spanish, Romanian and Arabic) or article-less languages (Chinese, Korean and Japanese). The study was conducted over a two-year period, where data were collected every six months. The results of the study revealed three patterns of article use: first, all children substituted the for a in indefinite specific contexts; second, all children used the in definite contexts more accurately than a in indefinite contexts regardless of their L1 background; and third, children from an articles-less L1 background omitted more articles than those from languages with articles at early stages of acquisition (p. 227). Thus, Zdorenko and Paradis found that L1 influence was limited, but that child L2 learners’ article use was target-like earlier than previously assumed. As a result, they concluded that fluctuation is a developmental process that overrides transfer in child L2 acquisition. Despite the remarkable findings made in that study, it remains unclear at what stage of a child's language development fluctuation ceases to operate.
Another important point in this discussion is that the specificity marking in Samoan on which Ionin et al. (Reference Ionin, Ko and Wexler2004) based the ACP and FH has been shown to be inaccurate. Based on new data from studies by Fuli (Reference Fuli2007) and Tryzna (Reference Tryzna, del Pilar Garcia Mayo and Hawkins2009), Ionin et al. (Reference Ionin, Zubizarreta and Philippov2009) observed that the article se is used only with non-specific indefinites, while definiteness is marked by the article le, whether in specific or nonspecific contexts. Thus, both definites and specific indefinites are marked by the same morpheme le. As a result, the proposed fluctuation context would seem to operate only in the [−definite, +specific] context. Hence, overuse of the with specific indefinites is consistent with natural language data in both child and adult acquisition studies, but overuse of a with non-specific definites [+definite, −specific] has no parallels in natural languages (Ionin et al. Reference Ionin, Zubizarreta and Philippov2009:342).
Given the new data on article semantics and specificity marking in Samoan, the fluctuation context of L2 English article acquisition seems to be limited to the [−definite, +specific] context.Footnote 2 However, it remains unknown whether fluctuation is still exhibited by L2 learners from article-less languages only, or whether L2 learners from article languages also exhibit fluctuation. More specifically, will L2 learners whose L1 lacks an overt indefinite article exhibit fluctuation in their article choice when learning English? The nature of the Dagbani article system is, therefore, particularly useful to explore this new question regarding the FH.
Finally, even though Ionin et al. (Reference Ionin, Ko and Wexler2004) ruled out the use of explicit learning strategies in their account of the L2 acquisition of English articles, some studies have shown that L2 learners use explicit learning strategies through classroom instruction (Butler Reference Butler2002, Hulstijn and Ellis Reference Jan H. and Ellis2005, Ionin et al. Reference Ionin, Zubizarreta and Philippov2009). Since L2 English acquisition in the Ghanaian context is largely classroom-based, with English language teaching taking a substantial amount of instructional time, learners might be likely to use some instructed knowledge in the L2 learning process.
3. Articles and definiteness in Dagbani and English
In this section, we outline the article system and the expression of definiteness and specificity in both Dagbani and English. We adopt Ionin et al.'s (Reference Ionin, Ko and Wexler2004:5) conception of definiteness and specificity as in (11).
(11) Definiteness and specificity defined informally (Ionin et al. Reference Ionin, Ko and Wexler2004:5)
a. If a Determiner Phrase (DP) of the form [D NP] is [+definite], then the speaker and the hearer presuppose the existence of a unique individual in the set denoted by the NP.
b. If a DP of the form [D NP] is … [+specific], then the speaker intends to refer to a unique individual in the set denoted by the NP and considers this individual to possess some noteworthy property.
We note for transparency's that Trenkic (Reference Trenkic2008) takes issue with the definition of specificity as presented in (11b), arguing that specificity is nothing more than “an intent to refer.” She maintains that the assertion of noteworthiness is problematic since the term is vague and may be difficult to argue for.Footnote 3
3.1 Articles and definiteness in Dagbani
Dagbani is a Gur language spoken in Northern Ghana by a little over two million speakers. The D-element of a Dagbani DP consists of articles, demonstratives, and quantifiers, which occur post-nominally (Olawsky Reference Olawsky1999, Reference Olawsky2004; Issah Reference Issah2013) (12a). Therefore, Dagbani is an article language that has a DP projection (Olawsky Reference Olawsky1999, Issah Reference Issah2013, Hiraiwa et al. Reference Hiraiwa, Akanlig-Pare, Atintono, Bodomo, Essizewa and Hudu2017, Inusah Reference Inusah2017). All the D-elements in the structure in (12b) post-modify the head noun, except for possessive pronouns that premodify the head noun.

Articles in Dagbani mark definiteness, and there are two grammatical morphemes for definite DPs and no grammatical marker for indefinite ones. Bare nouns mostly have indefinite interpretations, with some exceptions. The two definite articles in Dagbani are maa and la (Olawsky Reference Olawsky1999, Issah Reference Issah2013, Hiraiwa et al. Reference Hiraiwa, Akanlig-Pare, Atintono, Bodomo, Essizewa and Hudu2017, Inusah Reference Inusah2017).
The article maa marks a noun as definite if the noun was previously mentioned in the discourse or known to the hearer based on the discourse context (immediate situational knowledge or visible within the context). In contrast, la marks definiteness over what is generally known to both speaker and hearer (shared knowledge) (Olawsky Reference Olawsky1999, Issah Reference Issah2013), illustrated in (13).
(13) Using maa and la in discourse


In (13a), the noun bua ‘goat’ is indefinite the first time it is mentioned, but becomes definite when it is subsequently referred to, hence the presence of maa as a definite marker. In (13b), the noun yili ‘house’ gets a definite interpretation with la, which suggests that both speaker and hearer have common ground knowledge (discourse familiarity) about the particular house being referred to. Based on the functions of maa/la, Issah (Reference Issah2013) proposes that maa has anaphoric use, while la is not used anaphorically. Thus, the two are in complementary distribution since they cannot replace each other without changing the meaning of the sentence.
Also important is the fact that some nouns such as the sun, the moon, the sea, as well as some mountains and rivers are referred to without any definite markers, as in (14). These are unique entities, so using maa or la with them becomes redundant because they constitute common ground knowledge. Thus, with these nouns, definiteness is established based on uniqueness.

Furthermore, bare nouns (either singular or plural) in Dagbani can have a generic interpretation, as in (15a–b). Nouns that occur with maa or la cannot invoke a generic interpretation (i.e., refer to all individuals in the set denoted by the noun), as in (15c).

Therefore, articles in Dagbani mark only definiteness, while specificity is context-dependent. Olawsky (Reference Olawsky1999:40) suggests that specificity can be characterized in Dagbani by indefinite determiners/quantifiers such as so/shɛba ‘a certain/some’ (for animate nouns) and shɛli/shɛŋa (for inanimate nouns). He observed that when these indefinite determiners are combined with DPs, the indefinite determiners/quantifiers are translated as ‘a certain,’ ‘a,’ ‘some/any.’ Olawsky (Reference Olawsky1999) reasoned that the occurrence of these indefinite determiners might emphasize the indefiniteness of the noun, thus making it [+specific]. Both (16a–b) contain indefinite quantifiers that mark the DPs they occur with as specific but indefinite. The occurrence of the specificity marker so with the definite markers maa/la, leads to ungrammaticality, as in (16c).

To summarize, articles in Dagbani express definiteness, where maa and la mark DPs as definite, and most bare nouns are indefinite and/or generic. Specificity is expressed by using indefinite determiners and quantifiers in addition to discourse context.
3.2 Articles and definiteness in English
As mentioned above, article choice in English is based on definiteness, while specificity is determined by the discourse context. There are three articles: definite, indefinite, and zero. The zero/null article is usually used with plural count and uncountable nouns for generic purposes.
When the definite article is used, it is assumed that both the speaker and the hearer know the referent, which may either be based on shared knowledge of the world or the uniqueness of the referent (Swan Reference Swan2005), as in (17).
(17) Shared knowledge/Uniqueness
a. Pass me the salt, please.
b. The president of Ghana visits London tomorrow.
c. We haven't seen the sun for days now.
From (17a), the assumption is that the salt is in the immediate environment of both the speaker and the hearer. It is present and visible and can be uniquely identified by the interlocutors. In (17b), since there can only be one president of Ghana at a time, the referent is also uniquely identifiable. The sun and the moon are also unique entities based on our knowledge of the world. Furthermore, the definite article can be used to refer to previously mentioned nouns in the discourse, as in (18a–c) or when a noun is modified by, for example, next, same, only, best, as in (18d–f).
(18) The definite article in anaphoric reference. (Berry Reference Berry2012: 90)
a. I ate a cake and a roll; the roll made me sick. (direct anaphora)
b. The first time I rode my bike, the machine [bike] fell apart. (coreferential anaphora)
c. The first time I rode my bike, the bell fell off. (indirect anaphora)
d. The best person for the job is Emmanuel.
e. Daniel is the only person we can rely on for now.
The indefinite article is used, for instance, with singular count nouns (19a) to establish existential reference (19b) or for quantificational purposes (19c).
(19) The indefinite article
a. I bought a car.
b. There is a new student in class today.
c. Issa has a pen and three books.
All three articles – the, a(n), and the zero-article – can express generic reference, as illustrated in (20).
(20) Generic reference
a. The lion is a dangerous animal. (Berry Reference Berry2012:91)
b. A butterfly is an insect
c. Lions are dangerous animals.
Regarding specificity, both definite and indefinites can be specific or nonspecific, as in (21a–b) vs. (21c–d). This implies that specificity is context-governed in English. However, it has been observed that specificity can be marked by a referential this in colloquial English (Ionin, Reference Ionin2003, Ionin et al., Reference Ionin, Ko and Wexler2003), as in (21e). Examples (21a–b) are taken from Ionin et al. (Reference Ionin, Zubizarreta and Maldonado2008:558), while (21c–e) are taken from Ionin et al. (Reference Ionin, Ko and Wexler2003:246–247).
(21) Expressing specificity in English
a. I want to talk to the owner of this store – she is my neighbor, and I have an urgent message for her.
b. I want to talk to the owner of this store, whoever that is. I am going to complain about the quantity of the produce!
c. A man just proposed to me in the orangery (though I'm much too embarrassed to tell you who it was).
d. A man is in the women's bathroom (but I haven't dared to go in there to see who it is).
e. John has this weird purple telephone.
3.3 Cross-linguistic variation between Dagbani and English
The table in (22) illustrates how Dagbani and English are similar or different in the use of articles to encode definiteness as well as the featural variations that may exist between the two languages.
(22)
Table 1:Article use patterns for Dagbani and EnglishFootnote 4

The symbol [√] in (22) means that forms in the leftmost cell of the same row are used in the relevant context. The cells marked [x] and shaded in the chart are the problematic areas of article choice. For instance, the shaded cell for [+definite] context in English indicates that Dagbani speakers’ omission of the in their English L2 could mean that their L1 is impacting their choice, since bare unique nouns can be definite in Dagbani. Also, in all obligatory contexts for the indefinite article in English, if the Dagbani speakers fail to produce the article (article omission), this may suggest an L1 influence.
These differences will have some implications in the acquisition of L2 English articles among L1 Dagbani speakers in terms of feature reassembly and surface morphology.
The Feature Reassembly Hypothesis (FRH) (Lardiere Reference Lardiere, Brugos, Micciulla and Smith2004, Reference Lardiere, Liceras, Zobl and Goodluck2008, Reference Lardiere2009) argues that the variability in acquisition of functional morphology among L2 learners is based on the feature composition of these functional morphemes in the L1 and L2. That is, what constrains L2 acquisition is how grammatical features are morphosyntactically expressed across the two languages. For successful acquisition, L2 speakers need to figure out how the functional morphemes are expressed (direct vs. indirect or overt vs. covert), the transparency of the form-meaning mappings in both languages, the L1–L2 syntax-semantics mismatches, and whether or not reassembly of features between the two languages is required (Slabakova Reference Slabakova2009b, Reference Slabakova2009c, Reference Slabakova2016; Cho and Slabakova Reference Cho and Slabakova2014).
According to Hawkins et al. (Reference Hawkins, Al-Eid, Almahboob, Athanasopoulos, Chaengchenkit, Hu, Rezai, Jaensch, Jeon, Jiang, Leung, Matsunaga, Ortega, Sarko, Snape and Velasco-Zárate2006:20–23), articles in English are exponents of the category D in the DP, which have their terminal nodes encoded with the following feature bundles (23a) and the expression of these features by the lexical items in (23b).
(23)
a .The feature composition of articles
[D, +definite, ±singular] (= the)
[D, −definite, +singular] (= a)
[D, −definite, −singular] (= Ø)
b. The phonological exponents for feature insertion
a ↔ [D, −definite, +singular]
the ↔ [D, +definite]
Ø ↔ [D]
-
Hawkins et al. (Reference Hawkins, Al-Eid, Almahboob, Athanasopoulos, Chaengchenkit, Hu, Rezai, Jaensch, Jeon, Jiang, Leung, Matsunaga, Ortega, Sarko, Snape and Velasco-Zárate2006) also observed that these feature bundles and their phonological representations give the intuition that the indefinite article (a(n)) occurs only with singular count nouns, the definite article (the) occurs with definite nouns – either singular or plural – and the zero-article is the ‘elsewhere’ case in English. Thus, in using the, the uniqueness and/or familiarity of the referent must be accessible to both the speaker and hearer, either based on a prior mention or on shared world knowledge.
-
Furthermore, for the expression of generic reference, the feature bundles and their phonological expressions are set out in (24).
(24)
a. Feature bundles to express genericity
[D, +definite, +singular, +generic] (= the) for sentence and NP level genericity [D, −definite, +singular, +generic] (= a) at the sentence level
[D, −singular, +generic] (= Ø) for both sentence and NP level genericity
b. The phonological exponents for generic feature insertion
a ↔ [D, −definite, +singular, +generic]
the ↔ [D, +definite, +singular, +generic]
Ø ↔ [D, −singular, +generic]
Since Dagbani has two overt definite morphemes, maa and la, with different ways of expressing definiteness, the feature [definite] as encoded by the two articles will have their expression and phonological spell-out as in (25), following Hawkins et al.'s (Reference Hawkins, Al-Eid, Almahboob, Athanasopoulos, Chaengchenkit, Hu, Rezai, Jaensch, Jeon, Jiang, Leung, Matsunaga, Ortega, Sarko, Snape and Velasco-Zárate2006) approach to article feature specifications. Note that prior mention is crucial, which we have taken as establishing definiteness based on anaphoric reference, hence the feature [+anaphoric].
(25) Articles in Dagbani and their features
a. Feature bundles to express definiteness
[D, +definite, +anaphoric, ±singular] (= maa)
[D, +definite, −anaphoric, ±singular] (= la)
[D, ±definite, ±singular] (= Ø)
b. The phonological expression of the features
maa ↔ [D, +definite, +anaphoric, ±singular]
la ↔ [D, +definite, −anaphoric, ±singular]
Ø ↔ [D, ±definite, ±singular]
Since only bare nouns can express genericity in Dagbani (as discussed in section 3.1), (26) represents the feature bundles and their phonological expression for generic reference.
(26) Features for genericity in Dagbani
a. [D, ±singular, +generic] (= Ø)
b. Ø ↔ [D, ±singular, +generic]
The following are crucial differences between articles in Dagbani and English with regards to how L1 effects may influence L2 acquisition (of English).
➢ Full L1 transfer in the [definite] context should lead to accurate use of the in most obligatory contexts in the L2, since both languages have overt morphemes for marking definiteness. However, Dagbani has two surface morphological markers, while English has only one. In terms of morphological form-meaning pairing, this will be a two-to-one mapping of overt forms. Also, unique entities/referents in Dagbani may occur without a definite article and still have a definite interpretation whereas, in English, the will be obligatory in such contexts, except for most proper nouns (see Master Reference Master2003:4–5 for details). In terms of overtness of the functional morphology, this would represent a covert–overt mapping of functional morphological forms in the L1–L2 pair and could lead to omissions of the among the L2 speakers.
➢ In English, singular count nouns must occur with the indefinite article a(n), whereas these will occur in the bare form in Dagbani. This mismatch is another case of covert–overt expression of functional morphology in the L1–L2 pair. Assuming full L1 effects on the L2, especially when proficiency is low, L1 Dagbani speakers will omit a/an in most obligatory contexts in the L2. A new feature will need to be acquired for L2 indefiniteness, and surface morphology will have to be restructured (i.e., the L2 speakers will need to tease apart the feature bundles of the zero-article in Dagbani).
➢ In generic contexts, full L1 transfer will entail that the zero-article is used accurately. However, article omission may occur in generic contexts in English where the or a/an is obligatory. Also, in English, the generic feature has three surface morphological forms, whereas only the zero-article (either singular or plural bare nouns) can express generic reference in Dagbani. In terms of form-meaning mapping for the feature [generic], this will be a one-to-three mapping in the L1–L2, and in terms of the overtness of the functional morphology, will be a covert–overt mapping of forms.
4. The present study
The present study investigated the acquisition of L2 English articles among L1 Dagbani speakers. We were interested in examining both the FH and the role of the L1 in the acquisition process, given the nature of articles in these languages. Two experimental tasks were used:. first, we wanted to test the ACP and the FH using the forced-choice elicitation task (FCT); secondly, we also wanted to explore two crucial observations regarding L2 article acquisition in English. First, we examined the article acquisition difficulty hierarchy reported in studies such as Park (Reference Park2005), Avery and Radišić (Reference Avery and Radišić2007), Zdorenko and Paradis (Reference Zdorenko and Paradis2008), Mayo (Reference Mayo, del Pilar Garcia Mayo and Hawkins2009) to study which articles might be harder or easier to acquire among the Dagbani speakers. Second, we examined how a difference in task type might influence article use in L2 acquisition. Task effects have been reported in L2 acquisition of functional morphology (e.g., Butler Reference Butler2002, McDonald Reference McDonald2008, Chung Reference Chung2011). Hence, we employed the FCT and a comprehension task (an Acceptability judgement task – AJT) to explore whether or not a difference in task type can produce similar or different results. The following were our predictions:
Prediction I: L1 Dagbani L2 English learners will not fluctuate in the acquisition of English articles, since Dagbani and English are both article languages with the definiteness setting of the ACP Parameter. We expect L1 Dagbani speakers to transfer the article semantics of their L1 to the L2 interlanguage grammar, consistent with Ionin et al.'s (Reference Ionin, Zubizarreta and Maldonado2008:560) Possibility 2: Transfer overrides fluctuation (see (10)).
Prediction II: Given the form-meaning mapping variation between articles in Dagbani and English,Footnote 5
a. We predict that L1 transfer of the feature bundles of Dagbani articles onto the L2 grammar will lead to better performance in using the definite than the indefinite article, as there is overt–overt functional morphology for the definite article and covert–overt functional morphology for the indefinite article.
b. We expect the L2 speakers’ to score higher in the definite and indefinite article contexts than in the zero-article context, since the zero-article is complex in both languages, especially in L2 English (i.e., number, countability, definiteness, and genericity as features are associated with the use of the zero-article).
4.1 Participants
The participants for this study were 45 intermediate L1 Dagbani speakers and eight native English speakers. The L1 Dagbani speakers were high school students from Balogu junior high and Yendi senior high school. All the L1 Dagbani speakers had studied English as a second language for eight years or more since English is the official language of Ghana and the medium of instruction for all schools. Thus, the acquisition of English takes place in a classroom setting. The eight native English speakers were graduate students from different departments at UiT (The Arctic University of Norway) in Tromsø. The proficiency levels of all the participants were determined using the Oxford Quick Placement (Reference Park2001) test, which consisted of 40 multiple choice test items. Table 2 provides an overview of the participants.
Participants in the study
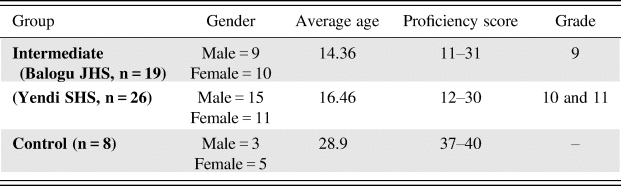
The L2 speakers had a proficiency range of 11–31 with an average score of 21. All L2 speakers whose scores were below the average (11–21) were grouped as low intermediate learners, and those who were above average (22–31) were categorized as the high intermediate group. Nonetheless, proficiency was treated as a continuous variable, since there was no significant difference between the two proficiency groups.
4.2 Experimental test
We used a Forced-choice test (FCT)Footnote 6 similar to the one used in Ionin et al. (Reference Ionin, Ko and Wexler2004), as well as an Acceptability judgement task (AJT)Footnote 7. The FCT had 24 dialogues classified into six context types. Sixteen of these were designed to test article use in four contexts: definite specific (+def, +spec), definite non-specific (+def, −spec), indefinite specific (−def, +spec) and indefinite non-specific (−def, −spec) contexts. In each dialogue, participants were asked to fill in a gap with the appropriate article (the, a(n), or Ø) based on the discourse in the dialogue (see section 2, examples (6)–(9) for sample dialogues).
We included eight additional dialogues to test zero-article use in English among Dagbani speakers, due to the nature of the Dagbani zero-article. More specifically, the eight dialogues in (27) were grouped into two contexts: generic singular and generic plural, where the zero-article was obligatory.
(27) Sample dialogues
a. Sample dialogue for [generic singular] contexts
-
A: I think physics can be interesting sometimes.
-
B: It's always interesting; just that you never had any interest in physics.
-
A: Well, it depends. But I just learned that nothing travels faster than _____ light.
-
b. Sample dialogue for [generic plural] contexts
-
A: I've learnt that one needs to include hobbies in your CV.
-
B: Yeah, I heard that too. So, what is your hobby?
-
A: I like to read ____ books on philosophy. I guess that is my hobby.
-
We expected that there would not be fluctuation in the FCT, since both Dagbani and English contain articles whose interpretation is influenced by definiteness. Also, based on L1 effects, the use of the should not be very problematic (due to the overt-overt nature of the surface morphology of the L1–L2 definite article), although, with unique nouns in the L2, L2 speakers could omit the definite article. However, the use of a/an will be challenging. Dagbani learners might omit the obligatory indefinite article, due to the difference in feature specification and surface morphology of indefiniteness in the L1–L2 pair. The choice of the zero-article, on the surface, should not be challenging in generic contexts under L1 effects, since all the dialogues required an obligatory zero-article. Nonetheless, due to L1–L2 feature specification and surface morphology for genericity and contexts where the and a/an are obligatory for generic reference, article use in L2 generic contexts might pose challenges to L1 Dagbani speakers.
The AJT had 50 sentences, 40 test sentences, and 10 fillers (all ungrammatical). The 40 sentences were grouped into 20 grammatical and 20 ungrammatical sentences. These grammatical and ungrammatical pairs were further categorized into four contexts, as in (28). The first item in the pair is grammatical and the second ungrammatical.
(28) Contexts in the AJT
a. definite vs. indefinite articles
b. definite vs. zero-articles
c. indefinite vs. definite articles
d. indefinite vs. zero-articles
Sample sentences for these contexts are found in (29)–(32). Participants were asked to rate each sentence on a Likert scale of 1–5 (where 1 = very bad, 2 = bad, 3 = good, 4 = very good, and 5 = I don't know).
(29) [definite vs. indefinite] context.
a. The moon is full and bright tonight.
b. A moon is full and bright tonight.
(30) [definite vs. zero] context
a. Please, pass me the bucket, I need it for something.
b. Please, pass me bucket, I need it for something.
(31) [indefinite vs. definite] context
a. My neighbor has a son and two beautiful daughters.
b. My neighbor has the son and two beautiful daughters.
(32) [indefinite vs. zero] context
a. We would like to buy a new car next year.
b. We would like to buy new car next year.
For the AJT, we predict different outcomes in different contexts. For example, in the contexts with [definite grammatical vs. indefinite ungrammatical] sentences, if more ungrammatical sentences with the indefinite article are accepted as grammatical by the L2 speakers, that would mean variable article use, or less mastery of L2 article semantics. On the other hand, in the [definite grammatical vs. zero-article ungrammatical] sentences, if the L2 speakers accept ungrammatical sentences with the zero-article as grammatical, especially for unique nouns, it would suggest L1 influence.
In the indefinite contexts, if more definite ungrammatical sentences in [indefinite grammatical vs. definite ungrammatical] article contexts are accepted as grammatical, it will suggest inconsistency, which can be accounted for through variation in surface morphology and features, especially if the ungrammatical sentences with the definite article contain nouns with unique reference. And in the [indefinite grammatical vs. zero-article ungrammatical] sentences, if more ungrammatical sentences with the zero-articles are accepted as grammatical, that will suggest L1 effects due to the L1 bare nouns having an indefinite interpretation.
Finally, in the ungrammatical zero-article sentences, if the L2 speakers accept more of these ungrammatical sentences as grammatical compared to definite ungrammatical or indefinite ungrammatical sentences, it will suggest L1 influence and imply that the L2 speakers are not able to tease apart the features of the zero-article in their L1–L2 mapping, or that they simply have not mastered the use of the zero-article in the L2, and require more input to guide them.
4.3 Procedure
The test was administered to the L2 learners in a classroom environment. Prior to the test, the participants received oral instructions, in English, on the experimental design in addition to written instructions, also in English, on the test, in order to ensure that they understood the procedure. The learners were then asked to respond to the test items as quickly as possible. They first completed the AJT, and then the participant background data questions, followed by the proficiency test, and finally the FCT. For both the AJT and the FCT, all test sentences and dialogues were pseudo-randomized to ensure that a sentence pair never appeared on the same page, a pair of grammatical/ungrammatical sentences never immediately followed each other, and that dialogues using the same contexts never followed each other. Thus, we ensured that sentences and dialogues with different constructions were evenly distributed throughout the tasks. Participants completed all the test items within 60 minutes and were given refreshments (biscuits and drinks) after the test for their time.
4.4 Statistical analysis
Various statistical computations were conducted at different levels of data analysis. We computed mean values for both the native and L2 learner groups to determine accuracy in the FCT across all conditions. We also calculated the correct responses for each context of article use in the FCT among the L2 speakers. Using mixed-effects logistic regression (implemented by Generalized Linear Mixed models - GLM), we modeled the data for condition and proficiency to determine both random and fixed effects and interaction between these variables. All conditions in the FCT were also compared in a pairwise manner. To assess the effect of definiteness and specificity for article choice, we also modeled definiteness and specificity on article choice to determine their effects and interaction.
In the AJT, we calculated mean scores for all grammatical and ungrammatical sentences across all conditions/contexts for the native control and L2 learner groups. We then modeled for condition and proficiency to determine their effects and interaction on the L2 speakers’ performance, and calculated the differences between grammatical and ungrammatical sentences for the definite and indefinite contexts.
Random effects were evaluated through likelihood ratio tests, and main effects through log-ratios. Data overfitting and variable collinearity were checked through bootstrapping. No post hoc tests were done because “one normally does not perform traditional post hoc tests when fitting a GLM” (Levshina Reference Levshina2015:196).
Finally, although proficiencyFootnote 8 was significant in both the FCT and the AJT, it was also related to participant data such as age, grade/level in school, and language use with friends (Dagbani or English), suggesting that these other variables might be confounded with proficiency. Tables of statistical results are provided throughout to support our analysis and discussion.
5. Results
The results of our study are presented in this section. We first present the results of the FCT, and then those of the AJT.
5.1 The Forced-choice task (FCT)
Figure 1 shows that the native controls performed as expected in all conditions. Mean scores ranged from 4–0, where 4 indicates that all participants correctly supplied the target article in all the relevant test sentences, and the reverse is true for the mean score of 0. The L2 learners, on the other hand, had variable performance across the six different conditions/contexts. Moreover, the L2 speakers’ performance in the generic contexts was very low compared to the other contexts, signaling that article use in these contexts was the most challenging.
Mean scores for all conditions for native controls and the L2 learner groups. Note: y-axis is the mean scores (0–4) for all six contexts. A mean score of 4 shows that all participants correctly supplied the target article for that context.

In what follows, we present the detailed article use patterns among the L2 learners and the native controls across the six conditions. To make things clearer, we have grouped all the context types into three: the definite context, the indefinite context, and the generic context. As indicated in Figure 1, the native controls scored 100% in almost all contexts. Their performance was target-like in both the definite/indefinite contexts (Table 3), and in the generic contexts, article choice was 100%. Detailed patterns are shown in Table 3.
Article use among the native controls in the definite and indefinite contexts

Table 4 shows the variable nature of article choice among the L2 learners. In all definite contexts, both a(n) and the zero-article (Ø) were used. In indefinite contexts, the definite article the and the zero-article (Ø) were also overused. Overuse of a(n) in the [+definite] context was high, especially in the [+definite, +specific] context (around 38%).
L2 learners’ article choice in definite and indefinite contexts

Our analysis revealed that there was a significant difference (p = 0.0518) between the L2 learners’ performance in the [+definite, +specific] and the [+definite, −specific] contexts.
In the indefinite contexts, the definite article was overused in both the [−definite, +specific] and in the [−definite, −specific] contexts, about 22% and 31%, respectively.
Despite the overuse of the in the [−definite, −specific] context, a pairwise comparison of all conditions showed that there was no statistically significant difference (p = 0.9401) in performance between the [−definite, +specific] and the [−definite, −specific] contexts. However, there was a main effect of condition (p<.05) in the [−definite, −specific] context, which indicated that the indefinite nonspecific context was a bit more challenging for the L2 speakers.
Overall, a generalized linear mixed model indicated that there was a main effect of proficiency (χ2 = 15.057, df = 1, p<.001) across the board. Also, there was a main effect of condition (χ2 = 24.318, df = 5, p<.001) in some contexts (see Table 5b), where the rate of supplying the correct article was better in the definite nonspecific contexts, compared with the definite specific contexts, and generally worse in both generic contexts. Nonetheless, there was no interaction between proficiency and condition type (χ2 = 1.8429, df = 5, p = 0.8704). The L2 speakers did not vary much among themselves, although performance across different sentences varied, as revealed by the random effects (see Table 5a).
Model for Condition and proficiency for L2 speakers. Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) [glmerMod]. The model statistics included AIC = 1263.4, BIC = 1332.9, logLik = −617.7, deviance = 1235.5, df.resid = 1047, a confidence level of 95%, and number of objects = 1061.

Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Given the general overuse of both the and a(n) across both definite and indefinite contexts, there was a need to determine whether article choice among the L2 speakers was influenced by definiteness or specificity. A generalized mixed-effect model revealed that there was a main effect of definiteness (χ2 = 12.11, df = 1, p<.001) on the L2 learners’ article use. There was no main effect for specificity (χ2 = 2.0472, df = 1, p = 0.1525), and no interaction between definiteness and specificity (χ2 = 2.5936, df = 1, p = 0.1073). Both random and main effects are shown in Table 6.
Models for definiteness and specificity, and L2 speakers’ choice of article. Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) [glmerMod]. Model stats: AIC = 676.3, BIC = 707.6, logLik = −331.2, deviance = 662.3, df.resid = 633, confidence level = 95%, and number of objects = 640.

Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Thus, holding specificity constant, the was generally used with definite DPs and a(n) with indefinite DPs in a target-consistent manner. On the other hand, holding definiteness constant, the was used more with nonspecific DPs and a(n) with specific DPs, a finding which contradicted observed patterns in the literature about article use based on specificity (see Ionin Reference Ionin2003; Ionin et al. Reference Ionin, Ko and Wexler2003, Reference Ionin, Ko and Wexler2004, among others for details). The indefinite article was used more in specific contexts than in nonspecific contexts.
Based on our results, we argue that there was no fluctuation in article choice among L2 learners. Article choice in the contexts assumed to be fluctuation contexts [+definite, −specific] and [−definite, +specific] was 81% and 71% respectively. Although a 71% accuracy in [−definite, +specific] context can be considered as fluctuation, the L2 speakers’ performance in the non-fluctuation contexts was even lower. Moreover, the L2 speakers’ article use was unaffected by specificity.
Accuracy in generic contexts was rather low among the L2 speakers, as shown in Table 7. In these contexts, the zero-article was obligatory.
Article use among the L2 learners in the generic contexts

The results revealed that both the and a(n) were overused in generic contexts. Overuse of a(n) (about 51%) in the generic plural context was a big surprise. A closer look at the data showed that errors of a(n) overuse in the generic plural context were mostly made in two dialogues: where the target DPs were elephants and earrings, respectively. In these dialogues, 31 learners (out of 45) chose an in (33) and 25 did so in (34).
(33) Dialogue 12
[generic plural] context
A: I watched this documentary on animals yesterday. It was nice but scary.
B: I've always loved animals. Do you know that some animals can be wonderful?
A: I heard that. People say ____ elephants can swim very well despite their size.
(34) Dialogue 24
[generic plural] context
A: I heard that George went to Italy last year. Do you know what he brought for his sister?
B: I know he would give her something valuable, but I can't guess.
A: Well, he brought his sister _____ earrings, which she loved so much.
Statistically, there was a main effect of condition (χ2 = 24.318, df = 5, p<.001) for both the generic singular and plural contexts, which suggests that both these contexts were difficult for the L2 speakers compared with other context types, as shown in Table 8. The p-values were adjusted using the Tukey method for comparing a family of six estimates. Also, tests were performed on the log odds ratio scale with a 95% confidence level.
A pairwise comparison of L2 speakers’ article use across all contexts and conditions

However, there was no significant difference (p = 0.9999) in article choice between the generic singular and plural contexts, which indicated that both contexts were equally challenging. Notice that accurate use of the zero-article was very low (see Table 4), suggesting that the L2 speakers have not mastered its usage in the L2.
5.2 Comparing use of the and a(n) across all the six contexts
Article overuse in all contexts of the FCT is presented in Table 9. Table 9 shows that in general, overuse of a/an was higher than overuse of the across all contexts. Overuse of the zero-article was very low across all contexts.
Article overuse in percentages among the L2 speakers in the FCT

The results suggest that using a/an was more difficult than using the since the indefinite article was overused more than the definite article. Both accuracy and overuse of the zero-article were generally poor among the L2 learners, implying that the L2 speakers had more problems with the use of the zero-article than both the definite and indefinite articles.
5.3 Overall results for the Acceptability judgement task (AJT)
We computed the results of the AJT as follows: For the grammatical sentences, a sentence was accepted as grammatical (correct judgement) if it was rated 3 or 4 on the Likert scale, and correctly judged as ungrammatical if it was rated 1 or 2. Based on this, mean scores were computed for both grammatical and ungrammatical categories.
The overall results for all conditions/contexts across speakers and categories are presented in Table 10. Also, in this task, there was a main effect of proficiency (χ2 = 4.0288, df = 1, p<.05). However, there was no effect of condition on grammaticality preference (χ2 = 1.1155, df = 1, p = 0.2909) and no interaction between proficiency and condition (χ2 = 0.3554, df = 1, p = 0.5511). Table 10 compares the performance of both the L2 group to the native control group in definite and indefinite contexts.
From both Table 10 and Figure 2, the results showed that the native controls performed as expected. They correctly accepted grammatical sentences (with a mean score of over 3.00) and rejected ungrammatical sentences (with a mean score of less than 2.00). The L2 speakers, on the other hand, showed variation in their judgements, both in the grammatical and ungrammatical sentences across different contexts.
Acceptability mean scores for definite and indefinite contexts for all participants. Note, the y-axis shows the mean scores (0–4) for grammatical and ungrammatical sentences
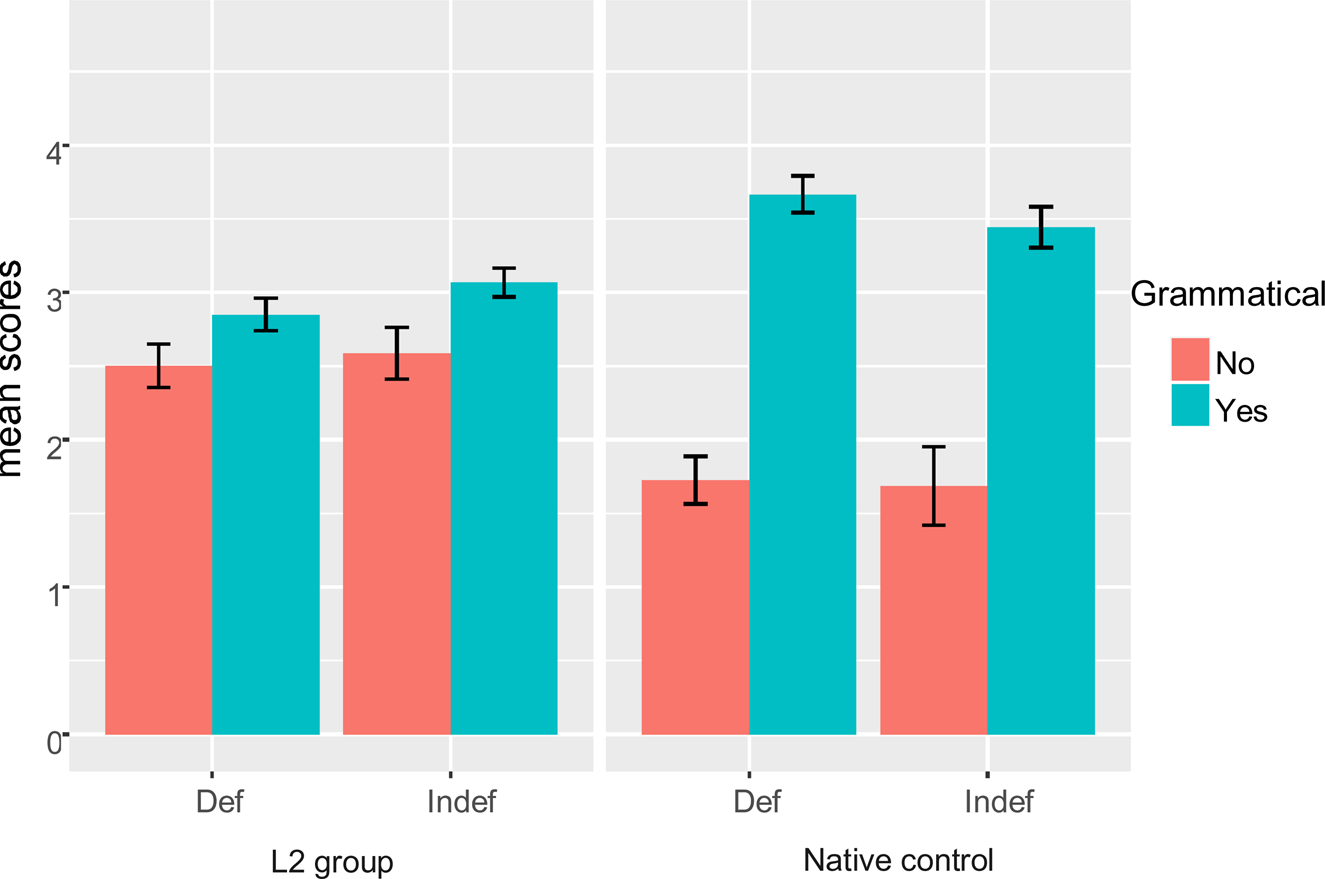
Mean scores in the acceptability judgement test for all participants

As noted earlier, the Dagbani L2 English learners had variable performance in the AJT. In the grammatical contexts, their performance in the indefinite article context (mean score of 3.1) was slightly better than in the definite article context (mean score of 2.9). This means that more grammatical sentences in the definite context were incorrectly judged as ungrammatical.
In the ungrammatical contexts, the L2 speakers performed a little better in the definite article context than in the indefinite article context, implying that more ungrammatical sentences with the indefinite article were incorrectly accepted as grammatical. However, these differences were not significant. The error rate between [grammatical as ungrammatical] vs. [ungrammatical as grammatical] for the definite contexts was lower than that of the indefinite contexts (4% vs. 7%; see Table 11 for details), even though, again, the difference was not significant.
Random and fixed-effects model of proficiency and condition on the L2 speakers’ performance in the AJT. Model stats: AIC = 2915.0, BIC = 2953.3, logLik = 1449.5, deviance = 2899.0, df. resid = 876, number of objects = 884, Confidence level 95%

Furthermore, the L2 speakers performed better in both the definite and indefinite ungrammatical contexts than in the zero-article context, since their mean scores were lower in both contexts (2.5 and 2.6 respectively) than in the ungrammatical sentences with the zero-article (mean score of 2.8). That is, they rejected more ungrammatical sentences with definite and indefinite articles than with zero-articles.
Finally, in the sentence pairs with the indefinite and the zero-article, all the sentence pairs were accepted as grammatical by no less than 27 participants, which indicates that the majority of the L2 speakers did not see any meaning difference between the grammatical sentences with the indefinite article and the ungrammatical sentences with the zero-article. On the other hand, in the sentence pairs with the definite article and the zero-article, only three pairs of grammatical and ungrammatical sentences were accepted.
A generalized linear mixed-model fit by maximum likelihood revealed that individual participants’ performance in the AJT did not vary much. However, there was a proficiency effect when considered alone but not when combined with condition type, as shown in Table 11b. Notice that in (11b), the fixed effects for all the variables centered around zero with very small t-values, suggesting that the differences are not statistically significant. The standard deviation for the residual in (11a) is also close to the other variables.
Table 12 shows a comparison of the L2 speakers’ mean performance for both grammatical and ungrammatical contexts to determine the difference in [grammatical as grammatical] vs. [grammatical as ungrammatical] sentences and vice versa across all contexts in the AJT.
Difference between grammatical and ungrammatical sentences and choice of article among the L2 speakers in the AJT. Note: Statistics relating toa are calculated over 4 and calculated over 2 forb, based on the upper values for grammatical and ungrammatical ratings on the Likert scale. Gram = grammatical, ungram = ungrammatical.

The differences between the grammatical and ungrammatical sentences for both the definite and indefinite contexts were almost the same (5.5% and 4.5%, respectively). In the zero-article context about 40% of the ungrammatical sentences with the zero-article were accepted as grammatical. The difference between [ungrammatical as ungrammatical] vs. [ungrammatical as grammatical] sentences in the zero-article context was about 20%, compared to 4.0% for the definite context and 7.0% for the indefinite context. Finally, on the ungrammatical side, the difference between the definite and zero-article contexts was about 15%, and between the indefinite and zero-article contexts about 10.5%.
These results suggest that overall, the L2 speakers performed better in ungrammatical definite context than in ungrammatical indefinite contexts (75% vs. 70.5%). In contrast, on the grammatical side, they performed better in the indefinite grammatical context than in the definite grammatical context (76.75% vs. 71.25%). Comparing the L2 speakers performance in the ungrammatical definite, indefinite, and zero-article contexts, we found that they performed poorly in the zero-article context. All the relevant statistics are bolded in Table 12.
5.4 Comparing the L2 learners’ performances in both tasks
Article use among the L2 learners in the FCT was variable across the different context types. In the definite contexts, article use accuracy was around 67.2% (53.3% for definite specific and 81.1% for definite non-specific contexts), while in the indefinite contexts, the accuracy was around 66.1% (71.1% for indefinite specific and 61.1% for indefinite non-specific contexts). Article overuse was widespread: Overuse of the across all contexts in the FCT averaged at 27.5%, whereas overuse of a(n) was about 34.2%. Both accurate use and overuse of the zero-article was deficient, as the zero-article was only accurately used about 29.5% and overused about 6.9%.
In the AJT, the L2 speakers' general performance in both the definite and indefinite contexts seem to be the same. They correctly accepted definite grammatical sentences about 71% of the time and incorrectly rejected definite grammatical sentences at a rate of about 29%. On the other hand, indefinite grammatical sentences were accepted 77% of the time and rejected 23% of the time. On the ungrammatical side, the L2 speakers correctly judged definite ungrammatical sentences as ungrammatical about 75% of the time, while accepting the definite ungrammatical sentences as grammatical about 25% of the time, compared to 70% and 30% respectively for indefinite ungrammatical sentences. Hence, their general performance in both the definite and indefinite contexts seem the same. Comparing both the definite and indefinite contexts to the zero-article context, the L2 speakers performed better in judging the definite and indefinite ungrammatical sentences than in judging the ungrammatical sentences with the zero-article.
6. Discussion
In this study, we predicted that L2 learners would not fluctuate in their article choice. We also predicted that their performance in definite contexts would be better than indefinite contexts, and finally, that their performance in both definite and indefinite contexts would also be better than in generic contexts. From the results, we found that article choice in the fluctuation contexts [+definite, −specific] and [−definite, +specific] among the Dagbani intermediate L2 English learners were highly accurate. This finding does not provide support for the Fluctuation Hypothesis, which is consistent with our first Prediction (I) (see Table 3).
Furthermore, if fluctuation is restricted to only the indefinite specific context, as proposed in Ionin et al. (Reference Ionin, Zubizarreta and Philippov2009), despite the fact that overuse of the exceeded 25% and could be interpreted as fluctuation, we believe that the accuracy rate of 71% article use in that context among these intermediate learners would not be taken as article use fluctuation. The L2 speakers produced a more non-target-consistent choice of articles where fluctuation would not be predicted, and overall, article choice was unaffected by specificity. When article use is based on specificity, the should be used more with specific contexts and a(n) with non-specific contexts, according to Ionin (Reference Ionin2003) and Ionin et al. (Reference Ionin, Ko and Wexler2003, Reference Ionin, Ko and Wexler2004). However, we found that when definiteness was held constant, the was used more with non-specific contexts and a(n) with specific contexts. This finding does not provide support for article use based on the Specificity setting of the ACP, and thus indirectly rules out the FH.
Our finding is consistent with what Schönenberger (Reference Schönenberger2014:103) found in her study of German and Russian L2 English learners, where one group of Russian learners produce non-consistent patterns of article misuse in contexts where accurate article use is predicted. Moreover, the general article use patterns in both definite and indefinite contexts were influenced by definiteness and not specificity, given that there was a main effect of definiteness, but not specificity in the L2 speakers’ article choice (see section 5.1), suggesting that article use was based on definiteness.
Despite the above, an interesting pattern was the non-target use of the in the [+def, +spec] context, which mostly occurred in two dialogues, illustrated in (35) and (36).
(35) Dialogue 14 in the FCT (Sarko Reference Sarko, del Pilar Garcia Mayo and Hawkins2009: 51)
A conversation between two friends at a store.
A: Come on! We have been in this shop for several hours now.
B: I can't make up my mind. Which shirt do you like best?
A: I prefer _____ shirt with stripes.
(36) Dialogue 20 in the FCT (from Ionin et al. Reference Ionin, Ko and Wexler2003:252)
A: I visited my friend Kelly yesterday. Kelly really likes animals – she has two cats and one dog. Kelly was busy preparing for an exam. So, I helped her out with her animals.
B: What did you do?
A: I took ___ dog for a walk. We really had so much fun.
The target noun in each dialogue involved a second-mentioned DP, thus unambiguously establishing definiteness. One possibility for using a could be that the L2 learners did not interpret these discourse contexts as definite. For example, in (35), the L2 speakers may have interpreted which to mean which shirt in the store as opposed to which particular shirt visible to the speaker and hearer within the discourse context. However, this explanation is not possible for (36). Also, for both dialogues, use of a could have been influenced by the application of some classroom grammar rules, as we discuss later.
Accurate article use in the definite and indefinite context was almost the same. However, when article overuse was considered across all six contexts of the FCT, overuse of a(n) was higher than the overuse of the (see Table 9). As a result, the (a) part of prediction in (II) is borne out in the FCT. Furthermore, a comparison of article use in the definite, indefinite, and zero-article contexts of the FCT shows that article use in both the definite and indefinite contexts was better than in the zero-article context. Even though the (b) part of prediction (II) seemed supported, that may not be fully accounted for by L1 influence, especially in the FCT. Both accurate use and overuse of the zero-article was very low in the generic contexts of the FCT, suggesting that the L2 speakers found it hard to use the zero-article. Our statistical analysis, as shown in Table 5b and Table 8, provides further support for this.
On the other hand, in the AJT, the first part of prediction (II) was weakly supported. Although the L2 speakers accepted more grammatical indefinite sentences compared to definite grammatical sentences, our analysis of their performance in [grammatical as grammatical] vs. [grammatical as ungrammatical] and [ungrammatical as ungrammatical] vs. [ungrammatical as grammatical] sentences revealed that the error differences in these contexts were in favor of the definite article context (see Table 12). Also, the (b) part of prediction (II) was again supported (see Tables 10 and 12). In the ungrammatical sentences, the L2 speakers performed better in definite and indefinite contexts than in the zero-article context.
Arguably, these patterns of article use reflect L1 transfer effects, given the mismatches in article systems and the features associated with them in the two languages. Further, the results also reflect the use of explicit learning strategies among L2 learners and a task effect due to time limitations.
The results may be accounted for by L1 transfer effects as well as a task effect and the use of explicit learning strategies. Using insights from Lardiere (Reference Lardiere, Brugos, Micciulla and Smith2004, Reference Lardiere, Liceras, Zobl and Goodluck2008, Reference Lardiere2009) and Hawkins et al.'s (Reference Hawkins, Al-Eid, Almahboob, Athanasopoulos, Chaengchenkit, Hu, Rezai, Jaensch, Jeon, Jiang, Leung, Matsunaga, Ortega, Sarko, Snape and Velasco-Zárate2006) concerning feature reassembly and feature expression on the English articles, as well as insights from Cho and Slabakova (Reference Cho and Slabakova2014), Shimanskaya and Slabakova (Reference Shimanskaya and Slabakova2014), and Slabakova's (Reference Slabakova2009b, Reference Slabakova2009c, Reference Slabakova2016) concerning notions of covert vs. overt and direct vs. indirect form-meaning expressions of functional morphemes, we argue that the article use patterns exhibited by the intermediate L2 English learners were due to L1 transfer and its interaction with the L2 input data.
First, regarding using of the, the L1–L2 functional morphology for definiteness is overt-to-overt, hence posing less of a challenge for the intermediate learners. However, the form-meaning of the features involved does not have a one-to-one mapping. In the L1, there are two overt forms (maa/la) for definiteness, hence, a two-to-one form-meaning mapping (and it could even be a three-to-one form-meaning mapping, since bare unique nouns can also be definite). On the other hand, in the L2, there is one overt form (the) for expressing definiteness (i.e., a one-to-one form-meaning mapping). For the L2 speakers to acquire the accurate use of the definite article in English, there should be a remapping of the two surface forms (maa/la) in the L1 to the single form (the) in the L2. Moreover, some bare nouns and nouns with the definite article can express definiteness in the L1, while in the L2, only nouns with the definite article can express definiteness. The difficult task, then, will be remapping the zero-article (bare nouns with definite interpretations) in the L1 into the overt form (the) in the L2.Footnote 9 The difference in surface morphology of the features associated with articles could be responsible for some of the challenges the L2 speakers had with the use of the in English, especially in accepting ungrammatical sentences in the AJT with the zero-article.
Furthermore, Dagbani has no overt form for indefiniteness. On the surface, this is a covert-to-overt expression of the functional morpheme in the L1–L2 language pair. In terms of feature expressions, the zero-article in Dagbani can have three meanings (definiteness, indefiniteness, and genericity; thus, a one-to-three form-meaning mapping), while in the L2, a(n) can express indefiniteness and genericity, thus a two-to-one form-meaning mapping. Based on these mismatches, L1 influence will sometimes lead the Dagbani L2 English learners to assume that indefiniteness can be marked with no article (bare nouns), while L2 input requires indefiniteness to be marked with a(n). Thus, the difference in feature specifications on the articles for indefiniteness and the L1–L2 variation in surface morphology could have influenced the interchangeable use of a(n) and the zero-article among the L2 speakers, especially in the generic context of the FCT. Also, notice that all ungrammatical sentences with the zero-article were accepted alongside the grammatical sentences with the indefinite article by over 27 participants in all sentence pairs. The close connection between the indefinite article and the zero-article in the L2 speakers’ article choice can be interpreted as the influence of the L1 zero-article features.
Finally, the zero form in Dagbani can indicate genericity as well as definiteness and indefiniteness. In the L2, the zero-article, the indefinite article, and the definite article can all express generic references. This mismatch between L2 input and L1 influence causes, as was clearly the case in the generic contexts (see Table 7), where the use of a(n) was rampant. We recognize that overuse of the in the generic context could not be due to L1 influence since, in Dagbani, no definite article is used with generic reference.
The remapping of these features and their surface morphology into the L2 forms will require more exposure to L2 input and a corresponding increase in proficiency. Our findings are thus consistent with other studies where L1 transfer effects have been reported (Hawkins et al. Reference Hawkins, Al-Eid, Almahboob, Athanasopoulos, Chaengchenkit, Hu, Rezai, Jaensch, Jeon, Jiang, Leung, Matsunaga, Ortega, Sarko, Snape and Velasco-Zárate2006; Snape et al. Reference Snape, Leung and Ting2006, among others). Furthermore, the issue is also complicated because there is limited input data since these are classroom-based learners with little or no exposure to native speaker input. With more input and increased proficiency, it is expected that the Dagbani L2 English learners will recover from L1 effects, and accuracy rates of article use will increase.
Apart from L1 effects, the results of our study also suggest that the L2 speakers relied on explicit learning strategies in their article choice, consistent with findings in other studies (Butler Reference Butler2002, Hulstijn and Ellis Reference Jan H. and Ellis2005, Ionin et al. Reference Ionin, Zubizarreta and Philippov2009). Evidence of this comes from the L2 speakers’ responses in the generic contexts, some of which are illustrated in (33) and (34). The learners’ choice of an in the contexts where the target DPs were elephants and earrings suggested that some of these learners were applying rules of English grammar (37), taught in class in relation to the use of English articles.
(37) Rules regarding the use of simple determiners/articles in English (Sam and Doe Reference Sam and Doe2012:42–43)
The articles (a/an, the, no article) are used before nouns to show whether the noun refers to particular or general examples.
Rule 1: a is used before a word beginning with a consonant sound (e.g., a banana, a child, a friend,
Rule 2: an is used before a word beginning with a vowel sound (a, e, i, o, u)
Examples: an apple, an eagle, an orange, and an uncle.
Rule 3: use a/an when you are not referring to anybody or anything in particular.
Examples: give me a chair (any chair). Give me an umbrella (any umbrella).
Rule 4: The is used before a word beginning with a consonant or a vowel sound. It is used when referring to a particular person or thing (e.g., My father bought me the book I asked for (a particular book). She ate the egg I had kept for her sister (a particular egg).
An anonymous reviewer argued that if the difference in overuse of the and a mostly occurred in the generic contexts, and we have explained that these errors mostly occurred in two dialogues where a grammar rule was supposedly misapplied, then that should not be taken as support for our prediction. However, we believe that this does not exclude an explanation related to the overt-covert nature of the surface morphology of the L1–L2. We agree that full L1 transfer will predict that the should not be used in generic contexts, but since the zero-article in Dagbani has complex features (combining indefiniteness and genericity) it is possible that L1 features of the zero-article could have influenced the use of the and a in those contexts. Thus, we found the misapplied grammar rule to be the most plausible account, given that L2 acquisition in this setting is classroom-based, which means that learners will explore several linguistic options (including UG access, L1 transfer, or explicit learning approaches) in the acquisition process.
From the rules in (37), we can see that using an among the L2 learners with elephants and earrings appeared to be influenced by the grammar Rules 1 and 2 concerning words beginning with a vowel in (37). The number feature on these DPs seems to have been overlooked by the learners who supplied an in such contexts.
The number feature (noun countability) is an issue identified as a major cause of article overuse and/or omission among some L2 English learners (Butler Reference Butler2002). However, we partially rule out this interpretation because there were other generic contexts where the target nouns did not start with a vowel, as in (38), where the L2 speakers did not use a(n), and only a few learners used a, implying that the problem was not with the number feature.
(38) Other plural generic contexts where an was not the choice
a. A: I learnt that one needs to include hobbies in your CV.
B: Yeah, I heard that too. So, what is your hobby?
A: I like to read ____ books on philosophy. I guess that is my hobby.
b. A: Something strange happened to me last night.
B: What was it? Were you scared?
A: When I went home after our party, there were ____ cats in my sitting room.
In dialogue (38a), the was chosen 21 times, the zero-article was chosen 14 times for, and a nine times. In (38b), 25 of the L2 speakers chose the zero-article, eight chose the, and 10 chose a. The overuse of both the and a in these dialogues can be explained by grammar Rules 1, 2 and 4 in (37). These data further provide support for the use of explicit knowledge in L2 acquisition, especially where learning is classroom-based. Similar results have been reported elsewhere (Ionin and Montrul Reference Ionin and Montrul2010, Chrabaszcz and Jiang, Reference Chrabaszcz and Jiang2014, Azaz Reference Azaz2016). Azaz (Reference Azaz2016) even recommended the integration of article semantics in structured input activities where explicit focus-on-form instruction must be expedited to create more reliable form-meaning connections in the acquisition of the target DPs in L2 article acquisition.
Overuse of the in the generic contexts was unexpected. For instance, in the sample dialogues where the was overused, full L1 transfer would predict that the L2 speakers would supply the zero-article (i.e., bare nouns as target-consistent forms). However, the article use of these intermediate learners seems to have been influenced by classroom instructions as well as limited input data. Given that the generic feature in English has three surface morphological forms, whereas, in the L1, it has a single zero form, the lack of in-depth exposure to L2 input could also have affected the use of the zero-article in English. Furthermore, as Ionin and Montrul (Reference Ionin and Montrul2010) have argued, L2 English learners must learn that generic interpretation in English is not available only for bare and definite nouns, but also for bare plural nouns and definite singular nouns, implying that the number feature is also crucial. This means that for learners to acquire the correct use of the zero-article, there should be enough positive evidence in the input and/or more negative evidence through in-depth instruction. Lastly, some of the L2 speakers could have erroneously interpreted some of the plural nouns, for instance, [… books on philosophy] and [… cats in my room] in (38) to be definite (and owned by the speaker), thus demanding the definite article. Therefore, we recommend further research on the acquisition of L2 English generic article use among Dagbani speakers to explore the impact of both L1 influence and instructed knowledge.
Finally, looking at the L2 speakers’ performance in both tasks, we argue that there was a task effect, possibly due to time limitations. The participants took the AJT first, followed by the proficiency test, a questionnaire on their background data, and finally the FCT. Separating the AJT and the FCT was meant to prevent task priming. Therefore, it is possible that in the FCT, participants rushed through the task by just inserting the, a(n), or zero in the dialogue contexts without paying much attention. This could account for the differences in their performances, especially in the definite and indefinite article contexts in the FCT and GJT (see section 5.4).
7. Conclusion
Our goal in this study was to investigate L2 English article acquisition among L1 Dagbani speakers to determine whether their acquisition patterns reflect L1 transfer effects or fluctuation, as argued in previous studies among different L1 speakers (Ionin et al. Reference Ionin, Ko and Wexler2003, Reference Ionin, Ko and Wexler2004; Ionin et al. Reference Ionin, Zubizarreta and Philippov2009; Mayo Reference Mayo, del Pilar Garcia Mayo and Hawkins2009; Sarko Reference Sarko, del Pilar Garcia Mayo and Hawkins2009, among others).
Our first hypothesis was that there would be no fluctuation in article choice among Dagbani L2 learners, since article interpretation in both languages is influenced by definiteness. The Dagbani intermediate L2 English learners had high accuracy scores in their article choice in English, based on definiteness. Their article use was unaffected by specificity in both definite and indefinite contexts, since there was no main effect of specificity. This finding provided support for L1 transfer (Schwartz and Sprouse Reference Schwartz and Sprouse1996, Reference Schwartz, Sprouse and Archibald2000; Schwartz Reference Schwartz, Flynn, Marthardjono and O'Neil1998) through the feature reassembly account (Lardiere Reference Lardiere, Brugos, Micciulla and Smith2004, Reference Lardiere and Dekydspotter2005, Reference Lardiere, Liceras, Zobl and Goodluck2008, Reference Lardiere2009). The Dagbani L2 English learners seemed to have transferred the article semantics of their L1 onto the L2 interlanguage grammar. These results are consistent with Ionin et al.'s (Reference Ionin, Zubizarreta and Maldonado2008:560) Proposal 2 (transfer overrides fluctuation) as well as findings in other previous studies (Hawkins et al. Reference Hawkins, Al-Eid, Almahboob, Athanasopoulos, Chaengchenkit, Hu, Rezai, Jaensch, Jeon, Jiang, Leung, Matsunaga, Ortega, Sarko, Snape and Velasco-Zárate2006; Mayo Reference Mayo2008, Reference Mayo, del Pilar Garcia Mayo and Hawkins2009; Sarko Reference Sarko, del Pilar Garcia Mayo and Hawkins2009; Ionin et al. Reference Ionin, Grolla, Montrul and Santos2014), which have reported L1 transfer effects.
We also predicted that accurate article use in the definite context would be better than article use in the indefinite context, which was borne out, although the difference was not significant. Finally, article use in both the definite and indefinite contexts was predicted to be better than article use in generic contexts, which prediction was borne out, consistent with previous studies (Park Reference Park2005, Park and Song Reference Park and Song2008). All these patterns of article choice among the L2 learners are accounted for under L1 transfer and the use of explicit learning strategies, as well as L2 input. We believe that with increased input and proficiency, the L1 Dagbani speakers should be able to recover from L1 effects and exhibit native-like accuracy in their production of English articles.















 Open access
Open access