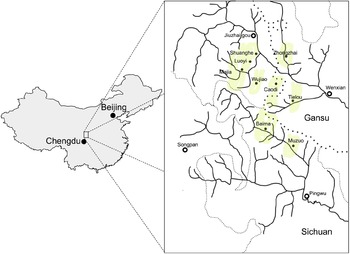
The Baima language (/pêkê/, Chinese 白马语 báimăyŭ, ISO-639 code bqh) is a little-studied Tibeto-Burman (Bodic or Himalayish) language spoken in the southwestern part of the People’s Republic of China. Approximately 10,000 people, who traditionally reside in three counties in Sichuan Province (Pingwu 平武, Songpan 松潘 (in Written Tibetan, hereafter WT, zung chu), and Jiuzhaigou 九寨沟 (WT gzi rtsa sde dgu), and in one county in Gansu Province (Wenxian 文县), speak the Baima language (see Sichuan Sheng Minzu Yanjiusuo 1980, Zeng & Xiao Reference Zeng and Youyuan1987), see Figure 1.Footnote 1 The largest concentrations of Baima speakers are in Baima Township (白马乡, Baima /tôpû/) of Pingwu County, and in Tielou Township (铁楼乡) of Wenxian County.
Distribution of the Baima language (adapted from Sichuan Sheng Minzu Yanjiusuo 1980). Black dots with white centers indicate county seats, black dots indicate townships, shaded areas indicate Baima villages.
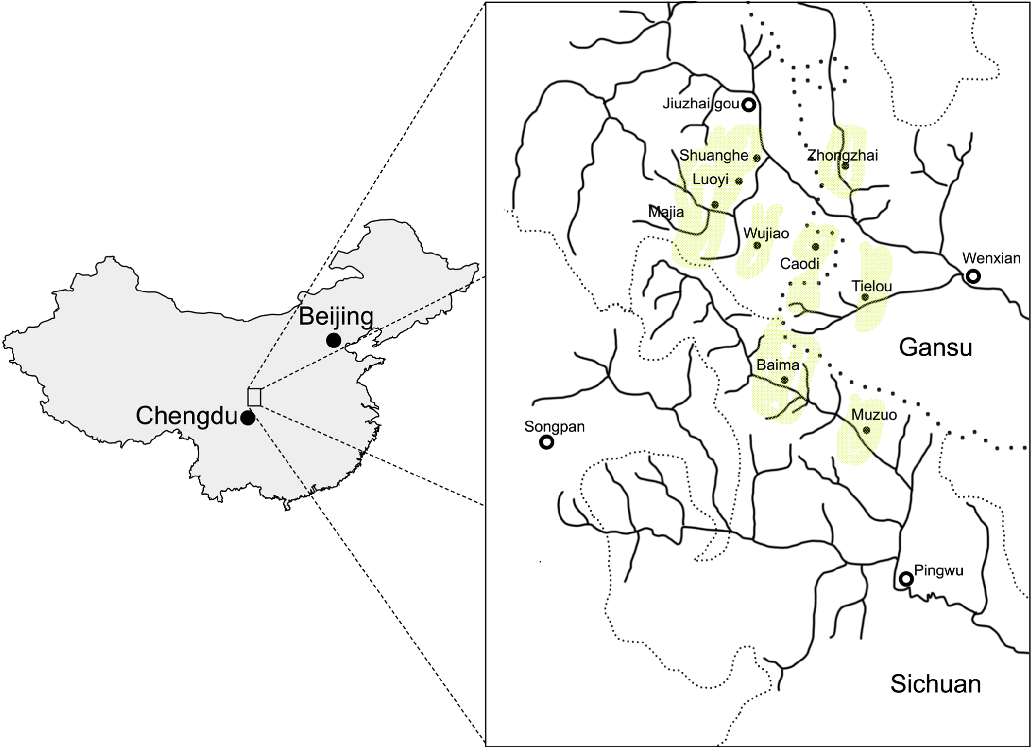
The area of distribution of the Baima language lies at the historical Sino-Tibetan border, in a multi-ethnic and multi-lingual region. In all counties of its present distribution, immediate linguistic neighbors of Baima include varieties of Mandarin (mostly Southwestern Mandarin), and varieties of Tibetan (or Tibetic) languages.Footnote 2 In Songpan County, Baima is additionally neighbored by the local variety of the Rma (or Qiang) language (see Evans & Sun Reference Evans and Sun2015).
The basic vocabulary of Baima is mostly of Tibetan origin (Zhang Reference Zhang1994a, b; Huang & Zhang Reference Huang and Minghui1995), and Baima also exhibits characteristic phonological features of Tibetic languages (see Tournadre Reference Tournadre2005, Reference Tournadre, Thomas and Hill2014).Footnote 3 At the same time, Baima is not mutually intelligible with other Tibetic varieties in its neighborhood, and it is considered a distinct language by its speakers. The linguistic affiliation of Baima – as a Tibetic language (Zhang Reference Zhang1994a, b; Huang & Zhang Reference Huang and Minghui1995) or a Bodic language distinct from Tibetic languages (H. Sun Reference Sun1980, Reference Sun2003; Nishida & Sun Reference Nishida and Hongkai1990 ; H. Sun et al. Reference Sun, Chirkova and Guangkun2007) – has long been disputed, mainly due to the controversy surrounding the ethnic classification of the Baima group (see Chirkova Reference Chirkova2007 for an overview).
Previous work on Baima has mostly concentrated on the variety spoken in Baima Township of Pingwu County. In Baima, this variety is called /tôpû kʰâ̠kê/. It has been described in Nishida & Sun (Reference Nishida and Hongkai1990), Huang & Zhang (Reference Huang and Minghui1995), H. Sun, Chirkova & Liu (Reference Sun, Chirkova and Guangkun2007), and Feng (Reference Feng2017) (all in Chinese), and it is also the focus of the present Illustration. In Pingwu County, Baima speakers are a minority, Chinese speakers making up the majority. Pingwu Baima is in contact with the local variety of Mandarin Chinese (which belongs to the Chengyu cluster 成渝小片 of the Chuanqin group 川黔片 of Southwestern Mandarin dialects, Li Reference Li2012: 85). To our knowledge, there are no longer any monolingual speakers of Pingwu Baima, as all age groups are bilingual in the local variety of Mandarin. Mandarin (both the local variety and the closely related Standard Mandarin, the official language of the People’s Republic of China) also dominates the education system and work in public domains. As a result, Baima is mostly restricted to family and community events, and is therefore endangered.
Baima is remarkable for its phonological complexity, and for a number of features that are typologically uncommon. These include non-modal phonation type contrasts in both consonants and vowels, four series of affricates contrasting in place of articulation, a three-way manner contrast in fricatives, a large vowel inventory with eleven monophthongs and four diphthongs, and a tonal system characterized by syllable-level contrasts, involving the redundant use of pitch, voice quality, and vowel length. This Illustration aims to (i) present the exceptionally rich phonetic and phonological system of Baima in a language that makes it accessible also to a non-Chinese speaking audience, and (ii) provide an updated phonological analysis of Baima. The main points of difference from previous analyses include (i) epiglottalization as secondary articulation in Baima consonants, and (ii) voice quality of the vowel as one of the phonetic correlates of tone.Footnote 4 Of these, epiglottalization as secondary articulation in consonants has not been previously reported for Tibetic languages. Its development in Baima may possibly be attributable to language contact. Notably, distinctive secondary articulations (such as velarization or uvularization) are being progressively discovered and explored in northern Rma varieties (e.g. Evans Reference Evans2006, Evans & J. Sun Reference Evans and Sun2015, Evans et al. Reference Evans, Sun, Chiu and Liou2016), which are immediate linguistic neighbors of Baima.
The sample words in this Illustration come from two sets of field recordings in Pingwu made in 2015 and 2019. Both sets contain words spoken in isolation (a basic vocabulary list of 2,000 words, with an average of three repetitions per word) and a few short texts by one male speaker, Mr. Li Degui 李德贵. Born in 1939 in Luotongba 洛通坝 village (Baima /jɑ̀ruʦkʰuɛ̂/), Mr. Li has been bilingual in Baima and Mandarin since childhood. Prior to retirement, Mr. Li worked as an elementary school teacher. He continues to speak Baima in his everyday life with family and friends.
Phonation types and the voice quality of the syllable
The three contrastive tones in Baima – high falling, mid, low – are related to different phonation types in vowels, respectively, tense, modal, and lax. In addition, in the high falling tone, there is a binary phonation contrast in consonants: epiglottalized and non-epiglottalized. Epiglottalized consonants have a harsh voice quality. Epiglottalized consonants include (i) non-nasalized voiced stops, affricates, and fricatives; (ii) prenasalized stops and affricates; and (iii) nasals, and lateral and palatal approximants. Non-epiglottalized consonants include (i) non-nasalized voiceless stops, affricates and fricatives; (ii) prenasalized (voiced) stops and affricates; and (iii) nasals, and lateral and palatal approximants.
Non-modal vowels and vowels adjacent to epiglottalized consonants share some acoustic features (such as a lower harmonics-to-noise ratio, a higher spectral slope, a lower f0 relative to modal vowels). In addition, vowels adjacent to epiglottalized consonants are characterized by higher F1, which indexes laryngeal raising, and lower strength of excitation (SoE), which indexes a greater constriction in the larynx or vocal tract and weaker voicing (see Garellek Reference Garellek2020 and references therein). Non-modal vowels and vowels adjacent to epiglottalized consonants also display differences in timing. Non-modal vowel phonation (tense, lax) persists throughout the entire vowel, whereas non-modal phonation due to consonantal epiglottalization typically lasts for less than half of the vowel duration.
The voice quality of syllables beginning with non-epiglottalized consonants depends on the default voice quality of the tone. The voice quality of syllables beginning with epiglottalized consonants, on the other hand, results from the interaction of the default voice quality of the tone and the harsh voice quality due to consonantal epiglottalization. The consonant-derived harshness typically does, but need not, replace the tone’s default voice quality. Table 1 provides an overview of phonation types associated with different syllable onsets and tones in our data. Quantitative descriptions of various phonation types are provided in sections on consonants and tones.
Phonation types associated with different syllable onsets and tones. T = voiceless unaspirated obstruent, Tʰ = voiceless aspirated obstruent, D = (non-nasalized) voiced obstruent, ND = prenasalized stop or affricate, S = sonorant, V = vowel. Shaded cells show non-occurring combinations.

A combination of a binary phonation contrast on consonants and a three-way phonation contrast on vowels, as described in this Illustration, is unusual for Tibetic languages and, more broadly, for other Tibeto-Burman languages of Southwestern and Southern China, many of which, similar to Baima, contrast tone and phonation (such as Yi or Bai languages). Given the complex interactions between syllable onsets and tones (as in Table 1) and variability of in the realization of consonant-derived harshness, the Baima data at our disposal do not lend themselves straightforwardly to a reanalysis in terms of syllable-level contrasts in register that is separate from tone. For that reason, this Illustration focuses more on the phonetic details of phonation contrasts in this language. The unusualness of the Baima system naturally warrants further investigation, based on larger data sets and more speakers (a follow-up study is in preparation). The historical development of the Baima tonal system from Old Tibetan is discussed in Chirkova (Reference Chirkova2021).
Consonants
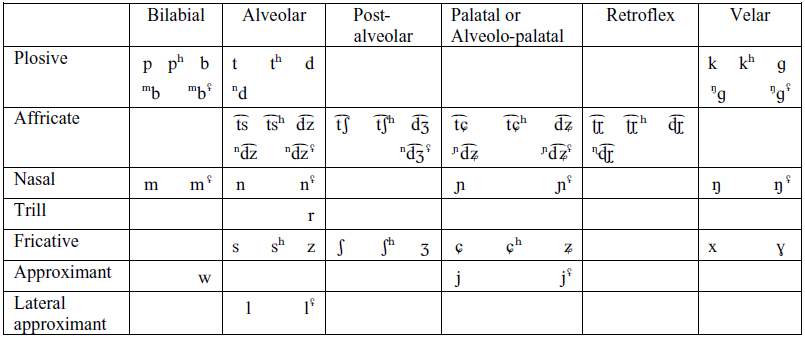
The Baima consonant inventory consists of 57 phonemes, presented in the consonant table below. Sequences of a nasal and a voiced stop or a voiced affricate (e.g. mb, nd, nd͡ʒ), which are treated as nasal–stop and nasal–affricate clusters in previous descriptions of Baima, are here analyzed as unitary segments (prenasalized stops and prenasalized affricates). Arguments for our analysis include: (i) in such sequences, the place of articulation of the nasal is always homorganic with that of the stop or the affricate, (ii) such sequences only occur in syllable-initial position, (iii) such sequences have a duration comparable to that of other consonants in syllable-initial position. Conversely, phonological evidence that would argue for a cluster analysis (such as compensatory lengthening, resyllabification, or independent tone specification) is unavailable in Baima.
Contrastive epiglottalized prenasalized stops and affricates, nasals, and lateral and palatal approximants are notated with the IPA superscript voiced epiglottal fricative (or trill) (e.g. mbʢ). In our corpus, contrastive epiglottalized vs. non-epiglottalized pairs with prenasalized stops and affricates are only attested at the bilabial and velar places of articulation for prenasalized stops, and at the alveolar and alveolo-palatal places of articulation for prenasalized affricates. All words with prenasalized postalveolar affricates in the high falling tone are epiglottalized and marked for epiglottalization in transcriptions. All words with prenasalized alveolar stops and prenasalized retroflex affricates in the high falling tone, on the other hand, are non-epiglottalized. Examples include [nd͡ʒʢâ̠] ‘to eat (ipfv)’, [nd͡ʒʢû̠] ‘snout’, [ⁿdə̂] ‘this’, [ⁿdâ̠] ‘to tremble’; [ɳɖ͡ɽɛ̂] ‘ghost’, [ɳɖ͡ɽə̂] ‘female yak’.
/ʈ͡ɽ ʈ͡ɽʰ ɖ͡ɽ/, which are treated as retroflex affricates in previous descriptions of Baima (/ʈ͡ʂ ʈ͡ʂʰ ɖ͡ʐ/), are in our data, rather sequences of a stop and a trill, which is raised and fricated. We analyze /ʈ͡ɽ ʈ͡ɽʰ ɖ͡ɽ/ as unitary segments, for there are no phonological arguments to treat them as clusters. Note that in our notation, /ɽ/ represents not a voiced retroflex flap (its IPA official meaning), but a fricated postalveolar trill, for which there is currently no IPA symbol. In our choice of the symbol /ɽ/, we follow conventions in Spajić et al. (Reference Spajić, Ladefoged and Bhaskararao1996). In their work on trills in Toda, they use /ɽ/ for the retroflex trill in that language.
In our corpus, all consonant phonemes in the consonant table can occur at the onset position of monosyllabic roots in the language. The following minimal and near-minimal sets illustrate consonant phonemes in Baima.

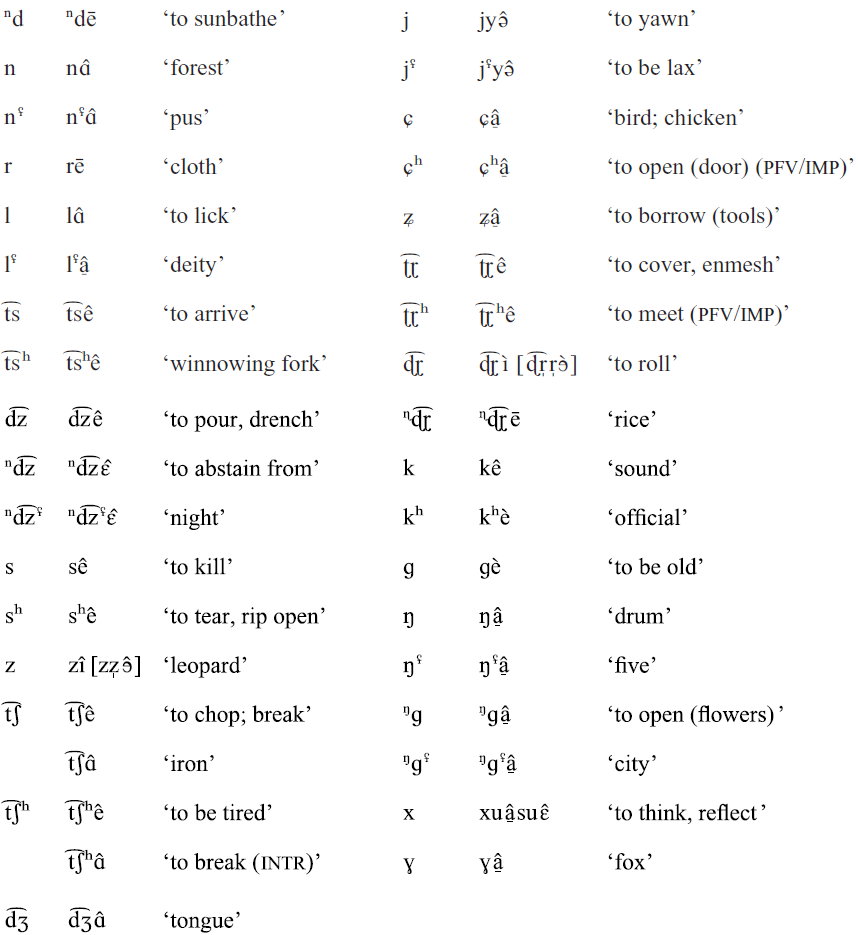
Voicing and epiglottalization in non-nasalized obstruents
Baima non-nasalized stops, affricates, and fricatives contrast in voicing; voiceless stops, affricates, and fricatives are further differentiated in terms of aspiration. Voiced obstruents are epiglottalized. Degrees of both voicing and epiglottalization in voiced obstruents may vary.
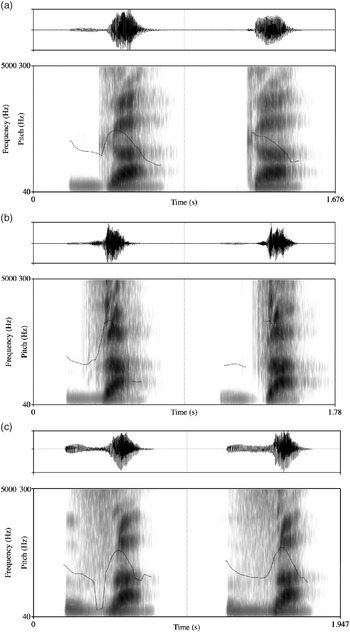
In word-initial position, Baima (non-nasalized) voiced stops, affricates, and fricatives may be realized (i) as voiced (that is, showing voicing lead through much or all of the closure and through release), (ii) as prevoiced (with voicing diminishing throughout the closure and/or non-existent during release), and also as (iii) devoiced. In addition, voiced stops, affricates, and fricatives may be realized as prenasalized. This is illustrated in Figure 2, which shows waveforms, spectrograms, and pitch tracks for two repetitions of the words /ɡâ̠/ ‘horn’ (Figure 2a), /d͡zâ̠/ ‘mountain peak’ (Figure 2b), and /zâ̠/ ‘to filter’ (Figure 2c).
Waveforms, spectrograms, and pitch tracks for the two repetitions of the words ![]() ‘horn’ (2a);
‘horn’ (2a); ![]() ‘mountain peak’ (2b), and
‘mountain peak’ (2b), and ![]() ‘to filter’ (2c).
‘to filter’ (2c).
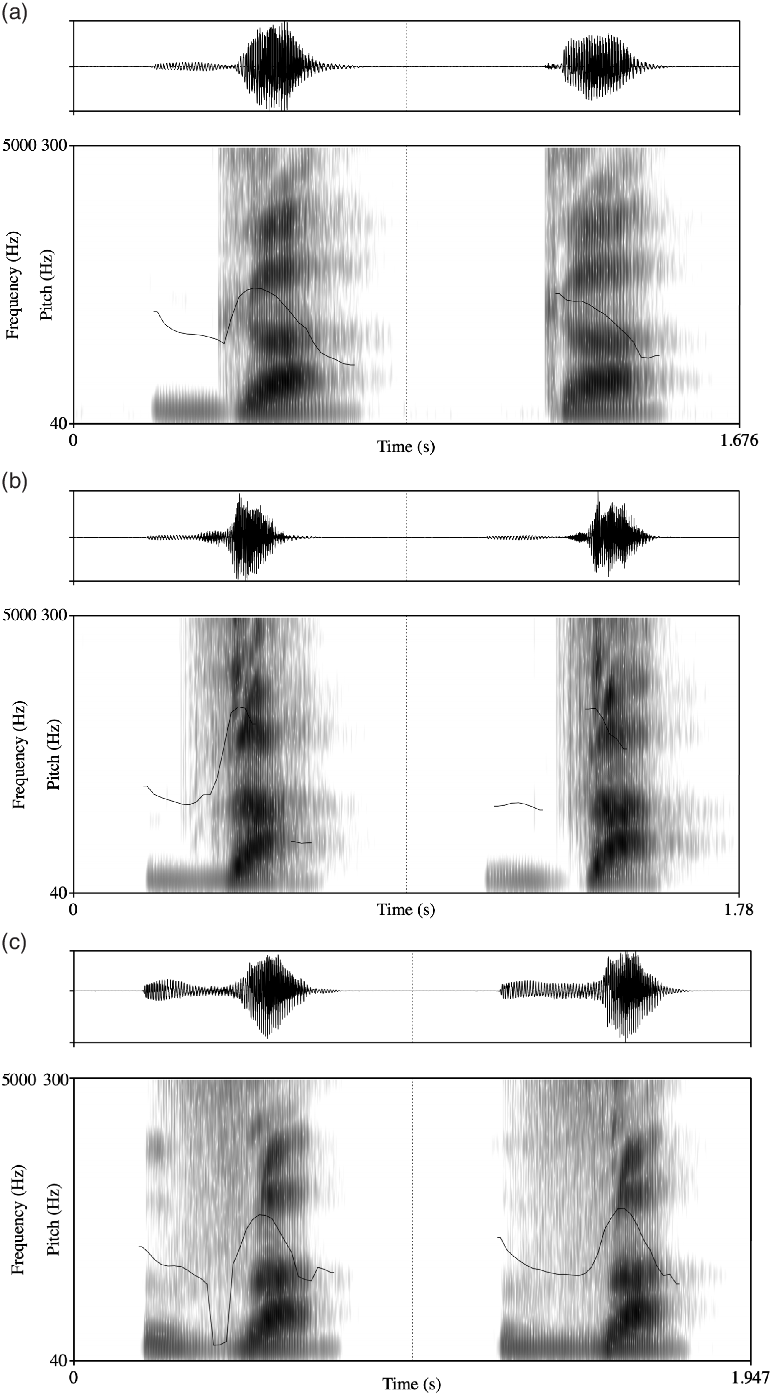
As shown in Figure 2a, the first of the two repetitions of the word /ɡâ̠/ is voiced, [ɡa̠]; whereas the second repetition is devoiced ([ɡ˚a̠]). Of the two repetitions of the word /d͡zâ̠/ ‘mountain peak’ in Figure 2b, the first is again voiced, whereas the second is prevoiced. Finally, the first repetition of the word /zâ̠/ ‘to filter’ in Figure 2c is prenasalized at the beginning and then shows diminishing voicing halfway through the frication period. The second repetition is fully voiced. Voiced obstruents are likely undergoing devoicing in Baima (see below), and prenasalization may be used as a strategy to facilitate voicing (due to the phonetic affinity between prenasalization and voiced consonants, see Ohala Reference Ohala and MacNeilage1983: 194–201). In those words in our corpus, where voiced obstruents occur intervocalically, voiced obstruents are more consistently voiced (as in /noʦɡâ̠/ ‘cow horn’).
Voiced stops, affricates, and fricatives are characterized by a distinctive harsh voice quality, which is clearly observable over approximately half of the vowel duration, but may also persist throughout the entire vowel. Relative to vowels adjacent to non-epiglottalized (voiceless) stops, affricates, and fricatives, vowels following epiglottalized stops, affricates, and fricatives are characterized by (i) a lower harmonics-to-noise ratio (measured here using harmonics-to-noise ratio below 500 Hz [HNR05]), (ii) a higher harmonic ratio (difference between the amplitude of the first and second harmonics, corrected for the effects of formants and bandwidths [H1*–H2*]), and (iii) high to low SoE, (iv) higher F1, and (v) lower f0 values.
The acoustic characteristics of vowels adjacent to voiced stops, affricates, and fricatives are illustrated in Figure 3 on the basis of three minimal pairs at the alveolar and velar places of articulation: /dâ̠/ ‘to grind (pfv/imp)’ vs. /tâ̠/ ‘to look (ipfv)’; /ɡâ̠/ ‘horn’ vs. /kâ̠/ ‘to be bright’; /ɡɑ̂/ ‘to bind’ vs. /kɑ̂/ ‘hoe’ (three repetitions per word, a total of 18 tokens). We segmented the vowel and further divided it into five regions: 0–20
 $\%$
, 20–40
$\%$
, 20–40
 $\%$
, 40–60
$\%$
, 40–60
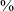 $\%$
, 60–80
$\%$
, 60–80
 $\%$
and 80–100
$\%$
and 80–100
 $\%$
of the vowel duration. We then used VoiceSauce (Shue et al. Reference Shue, Keating, Vicenik and Yu2011) to measure (i) HNR05, (ii) H1*–H2*, (iii) SoE, (iv) F1, and (v) f0 at these regions over the segmented intervals. Figure 3 shows the time courses of these measures over the vowel.
$\%$
of the vowel duration. We then used VoiceSauce (Shue et al. Reference Shue, Keating, Vicenik and Yu2011) to measure (i) HNR05, (ii) H1*–H2*, (iii) SoE, (iv) F1, and (v) f0 at these regions over the segmented intervals. Figure 3 shows the time courses of these measures over the vowel.
Time courses of HNR05 (dB) (3a), H1*–H2* (dB) (3b), SoE (3c), F1(Hz) (3d), and f0 (Hz) (3e) for vowels in the three minimal pairs with voiced stop onsets (in black) and voiceless unaspirated stop onsets (in gray) at the alveolar and velar places of articulation before the vowels ![]() and /ɑ/, uttered in isolation. The x-axis represents vowel duration divided into five regions: 0–20
and /ɑ/, uttered in isolation. The x-axis represents vowel duration divided into five regions: 0–20
 $\%$
, 20–40
$\%$
, 20–40
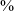 $\%$
, 40–60
$\%$
, 40–60
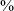 $\%$
, 60–80
$\%$
, 60–80
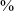 $\%$
, 80–100
$\%$
, 80–100
 $\%$
. The number of analyzed tokens is 18.
$\%$
. The number of analyzed tokens is 18.

As shown in Figure 3, vowels following voiced stops are characterized by (i) higher H1*–H2* values throughout approximately half of the vowel duration, and (ii) lower HNR05, (iii) high-to-low SoE, (iv) higher F1, (v) lower f0 throughout the entire vowel duration, as relative to vowels following voiceless stops. Hence, vowels adjacent to voiced stops generally conform to the characteristics of harsh vowels, as defined in Garellek (Reference Garellek2020) (low HNR05, high-to-low H1*–H2*, low SoE, high F1, low f0).Footnote 7 We note that f0 differences on vowels adjacent to voiced and voiceless obstruents is one major phonetic correlate to the voicing and phonation contrast in obstruents in Baima. The magnitude of f0 perturbations (which in Figure 3, ranges from over 40 Hz to almost 70 Hz) is considerably greater than what is common for languages with voicing contrasts (ranging from 8 to 16 Hz, as reported for English, Swedish, German, Dutch, Italian, and French in Coetzee et al. Reference Coetzee, Beddor, Shedden, Styler and Wissing2018: 187), and similar to f0 differences found in languages analyzed as undergoing incipient tonogenesis (such as Seoul Korean or Afrikaans). Large f0 differences between Baima voiced and voiceless obstruents may be suggestive of a change in progress, whereby f0 is overtaking other multiple covarying cues as the primary cue for the voicing contrast in obstruents. (F0 differences of similar magnitude are also observed in contrastive pairs with epiglottalized and non-epiglottalized prenasalized obstruent and sonorant onsets, see below.Footnote 8)
While vowels adjacent to the sample words with voiced stops in Figure 3 are markedly harsh, the degree of harshness in vowels following voiced obstruents may vary. This can be illustrated with the two repetitions of the words /dÌ̂/ ‘ogress, a man-eating female demon’ and /dɞ̂/ ‘stone’. For each word, the first repetition is characterized by higher levels of noise and weaker voicing, as compared to the second repetition.
Contrastive epiglottalization in prenasalized obstruents and sonorants
In the high falling tone, we observe a contrast between epiglottalized and non-epiglottalized prenasalized stops and affricates (/mbʢ ᵑɡʢ nd͡zʢ ɲd͡ʑʢ/ – /mb ᵑɡ ⁿd͡z ɲd͡ʑ/) and epiglottalized and non-epiglottalized nasals (/mʢ nʢ ɲʢ Ŋʢ/ – /m n ɲ Ŋ/). (Near) minimal pairs include: /mbʢû/ ‘to fly’ vs. /mbû/ ‘insect’; /ᵑɡʢâ̠/ ‘city’ vs. /ᵑɡâ̠/ ‘to open (flowers)’; /nd͡zʢô/ ‘lake’ vs. /ⁿd͡zô/ ‘dzo (a hybrid of yak and domestic cattle)’; /ɲd͡ʑʢɑ̂/ ‘to be cold’ vs. /ɲd͡ʑɛ̂/ ‘to win’; /mʢɑ̂/ ‘army’ vs. /mâ̠/ ‘wound’; /nʢɑ̂/ ‘pus’ vs. /nɑ̂/ ‘forest’; /ɲʢô/ ‘to be mad’ vs. /ɲô/ ‘to buy’ (ipfv); /Ŋʢâ̠/ ‘five’ vs. /Ŋâ̠/ ‘drum’. This contrast is also exceptionally observed in one near-minimal pair with lateral approximant initial consonants (/lʢâ̠/ ‘deity’ vs. /lɑ̂/ ‘to lick’) and two (near) minimal pairs with palatal approximant initial consonants (/jʢyə̂/ ‘to be lax’ vs. /jyə̂/ ‘to yawn’; /jʢyɛ̂/ ‘to collapse, fall down’ vs. /jyɛʦ/ ‘lung’).
Epiglottalized prenasalized obstruents and sonorants are characterized by a harsh quality observed both on the initial consonant and at the onset of the following vowel. This is illustrated in Figure 4 on the basis of three (near) minimal pairs with epiglottalized and non-epiglottalized nasals (/mʢɑ̂/ ‘army’ vs. /mâ̠/ ‘wound’, /nʢɑ̂/ ‘pus’ vs. /nɑ̂/ ‘forest’, /Ŋʢâ̠/ ‘five’ vs. /Ŋâ̠/ ‘drum’), measured over the entire syllable (onset and vowel). The difference in amplitude between the first and second harmonics is corrected for the effects of formants and bandwidths for vowels and palatal approximants (H1*–H2*) and uncorrected for consonants (H1–H2) (because the correction is only tested for vowels, see discussion in Garellek Reference Garellek, Katz and Assmann2019: 91).
Time courses of HNR05 (dB) (4a), H1–H2 (dB) (4b left), H1*–H2* (dB) (4b right), SoE (4c), F1 (Hz) (d), and f0 (Hz) (4e) in three (near) minimal pairs with epiglottalized nasals (in black) and non-epiglottalized nasals (in gray). The x-axis represents onset and vowel duration divided, respectively, into five regions: 0–20
 $\%$
, 20–40
$\%$
, 20–40
 $\%$
, 40–60
$\%$
, 40–60
 $\%$
, 60–80
$\%$
, 60–80
 $\%$
, 80–100
$\%$
, 80–100
 $\%$
. Results for HNR05 (dB), SoE, and f0 (Hz) are presented in the same plot. Results for the difference in amplitude between the first and second harmonics are presented separately for the onset (uncorrected measures, H1–H2) and for the vowel (corrected measures, H1*–H2*). F1 (Hz) measures are only taken over the vowel. Based on three (near) minimal pairs at the bilabial, alveolar, and velar places of articulation before the vowels
$\%$
. Results for HNR05 (dB), SoE, and f0 (Hz) are presented in the same plot. Results for the difference in amplitude between the first and second harmonics are presented separately for the onset (uncorrected measures, H1–H2) and for the vowel (corrected measures, H1*–H2*). F1 (Hz) measures are only taken over the vowel. Based on three (near) minimal pairs at the bilabial, alveolar, and velar places of articulation before the vowels ![]() and /ɑ/, uttered in isolation. The total number of tokens is 18.
and /ɑ/, uttered in isolation. The total number of tokens is 18.

As can be seen in Figure 4, epiglottalized nasals are characterized by (i) low HNR05, (ii) high H1–H2, (iii) low SoE, and (iv) low f0. Vowels adjacent to epiglottalized prenasalized stops and affricates, on the other hand, are characterized by (i) low HNR05, (ii) high H1*–H2*, (iii) high to low SoE, (iv) high F1, and (v) low f0 values throughout approximately half of the vowel duration.Footnote 9 Hence, compared to voiced stops, the non-modal quality in epiglottalized nasals is phased earlier in the voiced portion of the syllable.
Affricates
In previous analyses, Baima has been described as having four series of affricates, contrasting in place of articulation: alveolar (/t͡s t͡sʰ d͡z/), postalveolar (/t͡ʃ t͡ʃʰ d͡ʒ/), alveolo-palatal (/t͡ɕ t͡ɕʰ d͡ʑ/), and retroflex (/ʈ͡ʂ ʈ͡ʂʰ ɖ͡ʐ/). We note that in our data, the latter series are rather sequences of a stop and a trill, which is raised and fricated (/ʈ͡ɽ ʈ͡ɽʰ ɖ͡ɽ/), than those of a stop and a fricative. Examples include:
/t͡sâ̠/ ‘grass’ – /t͡ʃâ̠/ ‘tea’ – /t͡ɕâ̠/ ‘hair’ – /ʈ͡ɽâ̠/ ‘to sever, cut’
/t͡sʰâ̠/ ‘salt’; ‘to ache’ – /t͡ʃʰâ̠/ ‘pair’ – /t͡ɕʰɑ̂/ ‘blood’ – /ʈ͡ɽʰâ̠/ ‘to be fine’
/d͡zɑ̀/ ‘moon; month’ – /d͡ʒɑ̂/ ‘tongue’ – /d͡ʑɑ̂/ ‘to mend (ipfv)’ – /ɳɖ͡ɽɑ̄/ ‘to be good’
/ⁿd͡zɛ̂/ ‘to abstain from’ – /ⁿd͡ʒɛ̀/ ‘fang, sharp protruding teeth’ – /ɲd͡ʑɛ̂/ ‘to win’ – /ɳɖ͡ɽɛ̂/ ‘ghost’
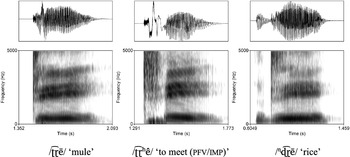
The stop release and the voicing of the trill with a periodical waveform in /ʈ͡ɽ/ and /ɖ͡ɽ/ are clearly visible in waveforms and spectrograms. The trill part in /ʈ͡ɽʰ/ is more fricated and devoiced. Furthermore, /ʈ͡ɽʰ/ has a clear period of aspiration between the frication portion and the vowel. This is illustrated in Figure 5, which provides waveforms and spectrograms of the near-minimal set /ʈ͡ɽeʦ/ ‘mule’, /ʈ͡ɽʰê/ ‘to meet (pfv/imp)’, and /ɳɖ͡ɽeʦ/ ‘rice’.
The stop–trill segments may have a trill release, involving one to three contacts. Figure 6 illustrates a production of /ɖ͡ɽÌ̀/ ‘to roll’, which has two full contacts (about 17 ms apart), marked by two arrows.
After the two full contacts in /ɖ͡ɽÌ̀/ ‘to roll’, we observe several more periods, visible as alternating presence and absence of energy on the spectrogram. These alternations suggest aerodynamically induced movements of the tongue tip, with the tongue tip vibrating and approaching a closure. Note also that the trill part of the segment in Figure 6 is accompanied by fricative noise: the high frequency energy noise in the 3000–5000 Hz region. In voiceless aspirated fricatives, the number of contacts is more difficult to see (as in the word /ʈ͡ɽʰê/ ‘to meet (pfv/imp)’ in Figure 5).
Waveforms and spectrograms for the words //ʈ͡ɽē/ ‘mule’, /ʈ͡ɽʰê/ ‘to meet (PFV/IMP)’, and /ɳɖ͡ɽē/ ‘rice’.

Waveform and spectrogram for the word /ɖ͡ɽì/ ‘to roll’. Arrows indicate contacts between the tip of the tongue and the roof of the mouth.

In line with previous analyses we treat /ʈ͡ɽ ʈ͡ɽʰ ɖ͡ɽ/ as retroflexes. This preliminary conclusion is based on kinesthetic sensations during the imitation of these sounds.Footnote 10 For this study, we were not able to collect palatographic and linguagraphic data that would provide reliable information on the contact areas on both the tongue and the palate, and ascertain the place and manner of articulation for the four contrastive affricate series in Baima. For the present analysis, we examined center of gravity (COG) values, which in studies on perceptual cues for differentiating place of articulation for fricatives and affricates (e.g. Jongman, Wayland & Wong Reference Jongman, Wayland and Wong2000, Gordon, Barthmaier & Sands Reference Gordon, Barthmaier and Sands2002, Lee, Zhang & Li Reference Lee, Zhang and Li2014), have been suggested as providing salient acoustic cues for the place of articulation. COG and its standard deviation (SD) were measured in Praat (Boersma & Weenink Reference Boersma and Weenink2020) over a 25.6 ms window centered at the middle of the frication part of the affricate. All recordings were first filtered under 500 Hz and above 10,000 Hz in order to remove ambient noise and the effect of voicing. The number of analyzed tokens ranged between three (for /ɖ͡ɽ/)Footnote 11 and twelve per affricate (89 tokens in total), see Table 2.
COG values (Hz) for the spectral slices taken from the middle of the frication portion of [t͡s], [t͡ʃ], [t͡ɕ], [ʈ͡ɽ]. Based on 89 tokens.
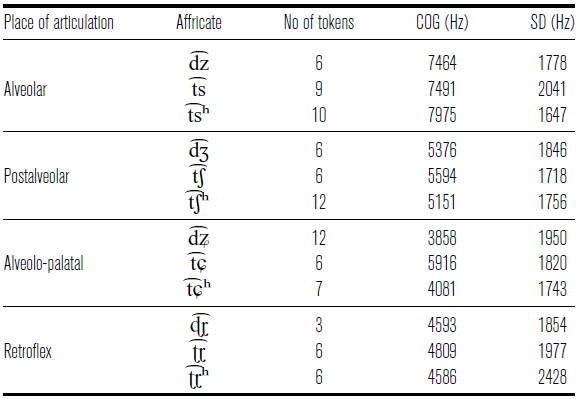
Our results show the highest COG values for alveolar affricates, followed by postalveolar affricates. Alveolo–palatals and retroflex affricates appear to be articulated further back in the mouth than the former two series. Similar values in alveolo-palatals and retroflexes potentially suggest a similar place of articulation. (We note that the observed COG pattern for the alveolo-palatal voiceless unaspirated affricate /t͡ɕ/ has higher COG than the postalveolar counterpart /t͡ʃ/. The unexpectedly high values may be due to palatalization, which in /t͡ɕ/ raises formants and the COG in the frication part. We suggest that the exact degree of palatalization varies for alveolo-palatals, /t͡ɕ/ being produced with a higher degree of palatalization than its voiced and voiceless unaspirated counterparts.)
An important characteristic of retroflex consonants, distinguishing them from other non-anterior coronals (i.e. postalveolars and alveolo-palatals) is a lowered third formant (see Hamann (Reference Hamann2003: 27, 53–64) for detailed discussion, and references therein). Language-specific investigations of retroflexes furthermore suggest that the transitions from a vowel into a consonant (or VC transitions) show a more distinct lowering of the third formant for retroflexes than the transitions from a consonant into a vowel (or the CV transitions). The CV transitions from retroflexes are further closer to those from other coronals, especially apicals (ibid.). In our corpus consisting of words with the CV structure spoken in isolation, we could only investigate the CV transitions from retroflexes. We used two near-minimal sets involving the four affricate series in two vowel environments: (1) followed by /a̠/ (that is, /t͡sâ̠/ ‘grass’ – /t͡ʃâ̠/ ‘tea’ – /t͡ɕâ̠/ ‘hair’ – /ʈ͡ɽâ̠/ ‘to sever, cut’) and (2) followed by /e/ (that is, /t͡sʰê/ ‘winnowing fork’ – /t͡ʃʰê/ ‘to be tired’ – /ʈ͡ɽʰê/ ‘to meet (pfv/imp)’). We segmented the vowel, divided it into five regions (as above), and extracted F3 values for the vowels in the analyzed words. Figure 7 shows the mean F3 values for the two vowels in the data set.
Mean F3 values of the vowel /a̠/, following voiceless unaspirated alveolar, postalveolar, alveolo-palatal, and retroflex affricates (left), and mean F3 values of the vowel /e/, following voiceless aspirated alveolar, postalveolar, alveolo-palatal, and retroflex affricates (right). Based on two near-minimal sets: (1) /t͡sâ̠/ ‘grass’ – /t͡ʃâ̠/ ‘tea’ – /t͡ɕâ̠/ ‘hair’ – /ʈ͡ɽâ̠/ ‘to sever, cut’ (three repetitions per word, a total of 12 tokens), and (2) /t͡sʰê/ ‘winnowing fork’ – /t͡ʃʰê/ ‘to be tired’ – /ʈ͡ɽʰê/ ‘to meet (PFV/IMP)’ (three repetitions per word, a total of 9 tokens). The x-axis represents vowel duration divided into five regions: 0–20
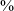 $\%$
, 20–40
$\%$
, 20–40
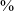 $\%$
, 40–60
$\%$
, 40–60
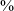 $\%$
, 60–80
$\%$
, 60–80
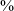 $\%$
, 80–100
$\%$
, 80–100
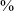 $\%$
. /t͡s/ in black dotted line, /t͡ʃ/ in gray solid line, /t͡ɕ/ in gray dashed line, /ʈ͡ɽ/ in black solid line.
$\%$
. /t͡s/ in black dotted line, /t͡ʃ/ in gray solid line, /t͡ɕ/ in gray dashed line, /ʈ͡ɽ/ in black solid line.

Figure 7 shows that the retroflex affricates /ʈ͡ɽ/ and /ʈ͡ɽʰ/ affect the following vowels, lowering F3 in the first half of the vowel’s duration. In the second half of the vowel, F3 raises to its average values for /a̠/ and /e/.
Results in this section provisionally support the previous analysis of /ʈ͡ɽ ʈ͡ɽʰ ɖ͡ɽ/ as retroflexes. However, this preliminary conclusion needs to be confirmed in a larger and more diverse corpus, and it also remains to be substantiated by instrumental investigation. In particular, palatographic and linguagraphic data would be essential to further explore this interesting type of sound.
Aspiration contrast in voiceless fricatives
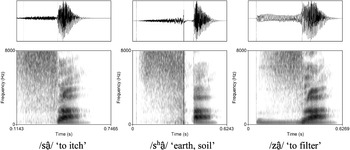
Similar to stops and affricates, Baima fricatives distinguish between voiceless unaspirated, voiceless aspirated, and voiced counterparts. Cross-linguistically, such a distinction is more common in stops and affricates, and rarer in fricatives. Despite its rarity cross-linguistically, the three-way manner contrast in fricatives is commonly attested in Tibetic languages of the Amdo and Kham groups, at the border of which Baima is spoken (see X. Wang Reference Wang1988, Sh. Wang & Chen Reference Wang and Chen2010 for instrumental studies). In Baima, the three-way contrast between voiceless unaspirated, voiceless aspirated, and voiced fricatives is observed at the alveolar, postalveolar, and alveolo-palatal places of articulation. Figure 8 illustrates the contrast with a minimal set at the alveolar place of articulation: /sâ̠/ ‘to itch’, /sʰâ̠/ ‘earth, soil’, /zâ̠/ ‘to filter’.
Waveforms and spectrograms for the minimal set /sâ̠/ ‘to itch’, /sʰâ̠/ ‘earth, soil’, /zâ̠/ ‘to filter’. The dashed lines mark the onset of frication noise and the onset of voicing, the solid line marks the beginning of the aspiration period in the voiceless aspirated fricative /sʰ/.
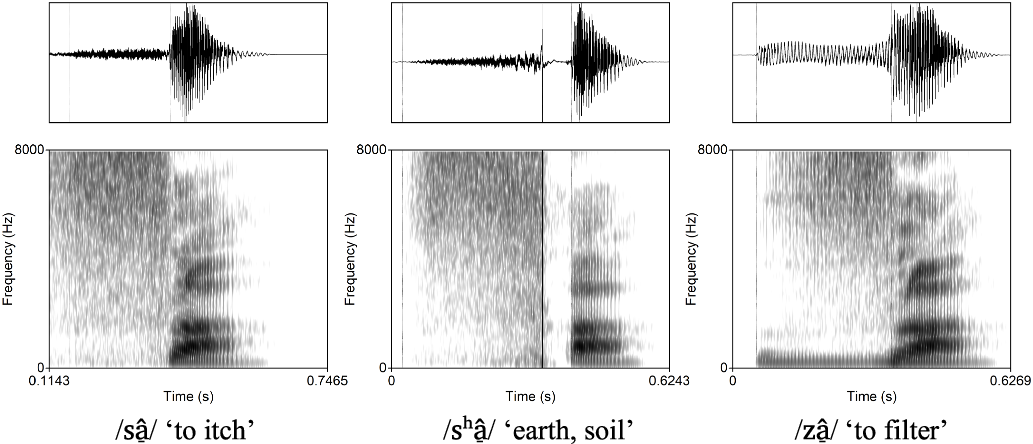
Number of tokens analyzed, mean duration and mean standard deviation (in ms) of voiceless unaspirated, voiceless aspirated, and voiced fricatives at the alveolar, postalveolar, and alveolo-palatal places of articulation.
In our corpus, voiceless aspirated fricatives have longer duration than their unaspirated and voiced counterparts. This is shown in Table 3, which compares the mean duration of voiceless unaspirated, voiceless aspirated, and voiced fricatives, as measured in 12 (near) minimal sets of fricatives at the alveolar, postalveolar, and alveolo-palatal places of articulation, together with all remaining examples of words with voiceless aspirated fricatives in our corpus. Duration measures for each fricative were made from the waveform and spectrogram. The onset of noise in the waveform and the presence of high resonant frequencies in the spectrogram were taken as benchmarks for determining the beginning of the fricative. The offset of noise in the waveform and the appearance of vowel formants in the spectrogram were taken to indicate the end of the fricative and the beginning of the vowel, see Figure 8.
The mean duration of the aspiration period in aspirated fricatives (across all possible vowel contexts) is just 7 ms (SD 9 ms). (In measuring the aspiration duration in aspirated fricatives, the visible decrease in amplitude of the aperiodic waveform, along with the appearance of vowel formants in the spectrogram was taken as benchmark for determining the beginning of the aspiration period, whereas the onset of vowel periodicity was taken to indicate the end of the aspiration period, see Figure 8.) That is considerably shorter than the duration of the aspiration period in aspirated stops and affricates (respectively, 102 ms, SD 17 ms; and 46 ms, SD 12 ms, as based on a small sample of 20 aspirated stops and 20 aspirated affricates).
In our corpus, voiceless aspirated fricatives do not occur before the close vowels /i ʉ ʊ/ (and there is only one example before the close back vowel /u/, /ʃʰù/ ‘mushroom’), whereas voiceless unaspirated and voiced fricatives all occur in this environment (e.g. /ʑÌ̂/ ‘writing, letter, character’, /sʉʦ/ ‘who’, /zʊ̀/ ‘to close (door) (pfv/imp)’). This is noteworthy because the same co-occurrence patterns have been reported for some other Tibetic and non-Tibetic Tibeto-Burman languages that have a similar three-way manner contrast in fricatives (e.g. Sgaw Karen, Salgado, Slavic & Ye Reference Salgado, Slavic and Ye2013; Kami Tibetan, Chirkova Reference Chirkova and Jackson2014).
Compared to fricatives at other places of articulation, Baima velar fricatives /x/ and /ɣ/ have a more restricted distribution. Furthermore, word-initially, /x/ is only found in loanwords from Mandarin. Examples include: /xuâ̠suɛ̂/ ‘to think, reflect’ (Standard Mandarin, hereafter Mandarin, huásuàn 划算 ‘consider, deliberate’), /xua̠ʦᵑɡua̠ʦ/ ‘minority official (in imperial China)’ (Mandarin fānguān 番官). /x/ also occurs word-medially between two vowels in a few native Baima words. In such cases, it likely represents a historical lenition of /p/, as in /ʃòxù/ [ʃofv̩̀] ‘wealthy, rich’ (the Written Tibetan etymology for this word is phyug po). Realization of /x/ as [f] before the rhyme /u/ is a characteristic feature of the Mandarin dialect of Pingwu (Pingwuxian Xianzhi Bianzuan Weiyuanhui 1997: 900), as well as of Southwestern Mandarin dialects in general (e.g. Yuan Reference Yuan2001: 29). The voiced velar fricative /ɣ/ only occurs before /a̠/, /ɣâ̠/ ‘fox’.
Trill
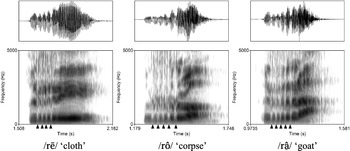
Baima trill /r/ is produced with a series of rapid aerodynamically induced movements of the tongue tip that involve contact of the tip of the tongue against the alveolar ridge. In our data there is a general tendency for the alveolar trill to involve four to five contacts, as shown in Figure 9. A contact, that is, a moment of closure of the oral cavity, is reflected on the spectrograms by reduction of energy.
Waveforms and spectrograms for the words /rē/ ‘cloth’, /rô/ ‘corpse’, and /râ̠/ ‘goat’ with arrows indicating contacts between the tip of the tongue and the roof of the mouth.

Syllabic consonants
Some syllables in the corpus have a nucleus that is a voiced prolongation of the initial consonant. These include syllables that begin with the alveolar trill, alveolar, postalveolar, retroflex affricates, and alveolar and postalveolar fricatives. The latter portion of such syllabic consonants tends to be realized as a vowel with a formant structure that is similar to that of the preceding consonant. This generally represents a centralized close-mid vowel. Examples include: [rr̩ɘ̂] ‘snake’, [t͡sʰz̩ɘ̂] ‘joint’, [ɖ͡rr̩ɘ̀] ‘to roll’, [zz̩ɘ̂] ‘leopard’, [ʃʒ̩ɘ̂] ‘louse’. Figure 10 provides waveforms and spectrograms of the words [rr̩ɘ̂] ‘snake’ and [zz̩ɘ̂] ‘leopard’ (see also the word /ɖ͡ɽÌ̀/ [ɖ͡rr̩ɘ̀] ‘to roll’ in Figure 6).
Waveforms, spectrograms, and formant tracks for the words [rr̩ɘ̂] ‘snake’ and [zz̩ɘ̂] ‘leopard’.
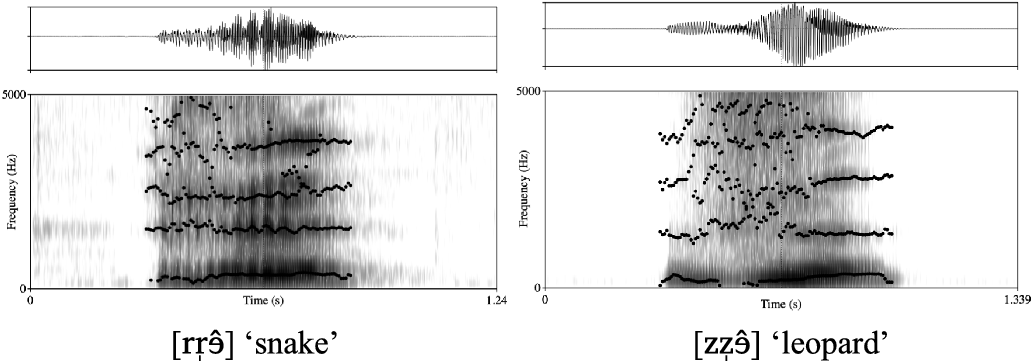
Syllabic consonants in Baima are contrastive with syllables with alveolar trill, alveolar, postalveolar, retroflex affricates, and alveolar and postalveolar fricatives onsets followed by schwa. Examples include: [rr̩ɘ̂] ‘snake’ vs. [rə̂] ‘mountain range’, [ʃʒ̩ɘ̂] ‘louse’ vs. [ʃə̂] ‘to die (pfv)’, compare also [t͡ʃʒ̩ɘ̂] ‘one’ vs. [t͡ʃʰə̂] ‘what’.
The exact nature of the nucleus – a genuine vowel, a syllabic approximant (after alveolar trill and retroflex affricate onsets), a syllabic fricative (after alveolar, postalveolar, and alveolo-palatal affricates and fricatives onsets) – is open to varied interpretation. In our analysis, we follow the tradition in Sinitic languages (e.g. Chao 1972 [Reference Chao1948]) to analyze such consonant-like syllabic segments as conditioned variants of high vowels, in the case of Baima, the vowel /i/.
Vowels
Baima has a large vowel inventory consisting of 11 monophthongs, three native diphthongs, and one diphthong that only occurs in loanwords from Mandarin (/ua̠/).
Monophthongs
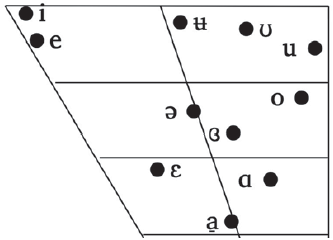
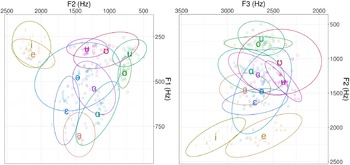
Figure 11 shows the mean F1 and F2 (11a), and F2 and F3 (11b) values for Baima monophthongs, as produced by our speaker. F1 values demonstrate the closed–open domain (from /i/ to /a̠/), F2 the front–back domain (from /i/ to /u/), and F3 the presence of lip rounding (highest degree of lip rounding for /ʉ/ and /ʊ/).
Acoustic vowel plots showing vowel phonemes with ellipses fit to the data and average F1–F2 values (left). Acoustic vowel plots showing vowel phonemes with ellipses fit to the data and average F2–F3 values (right). Formants were sampled at the token midpoint using the website Visible Vowels (https://www.visiblevowels.org). Based on 245 tokens across different initial consonants and tones from the Baima recordings of one male speaker in this Illustration.

/ʊ/ has two allophones in complementary distribution: [y] and [ʊ]. [y] occurs after alveolar onsets. Examples include: [tỳ] ‘poison’, [dỳ] ‘bracelet’, [tʰỳ] ‘rice gruel; to be watery’, [lỳ] ‘to leak, overflow’. [ʊ] occurs after bilabial stops and nasals, and after postalveolar, and retroflex onsets. Examples include [mbʊ̂] ‘awl’, [ʈɽʰʊ̀] ‘woolen cloth’, [ɡʊ̀] ‘to wait’, [tɕêʃʊ̂] ‘knife sheath’.
The open-mid central rounded vowel /ɞ/ mostly appears in the words with the high falling tone (the default voice quality of which is tense), and /o/ mostly appears in the words with the mid and low tones (the default voice quality of which is respectively, modal and lax). However, in our data we have minimal pairs, in which the two vowels are contrasted in words with the high falling tone. Examples include: /kɞ̂/ ‘to dig’ – /kô/ ‘to be full’; /jɞ̂/ ‘year’ – /jô/ ‘road’. For that reason, /ɞ/ and /o/ are analyzed as separate phonemes.
The difference between the open vowels /a̠/ and /ɑ/ is, for many non-native ears, rather subtle. Minimal pairs include /t͡ʃâ̠/ ‘tea’ vs. /t͡ʃɑ̂/ ‘iron’, /t͡ʃʰâ̠/ ‘pair’ vs. /t͡ʃʰɑ̂/ ‘to break (intr)’, /t͡ɕâ̠/ ‘hair’ vs. /t͡ɕɑ̂/ ‘to weigh (pfv/imp)’, /d͡ʑâ̠/ ‘hundred’ vs. /d͡ʑɑ̂/ ‘to mend (ipfv)’, /kâ̠/ ‘to be bright’ vs. /kɑ̂/ ‘hoe’, /ʑâ̠/ ‘to borrow (tools)’ vs. /ʑɑ̂/ ‘male yak’.
Table 4 illustrates Baima vowels phonemes by minimal sets of contrasts in the three contrastive tones after alveolar stop initial consonants.
Examples of Baima monophthongs in words with alveolar stop initial consonants in the three tones.

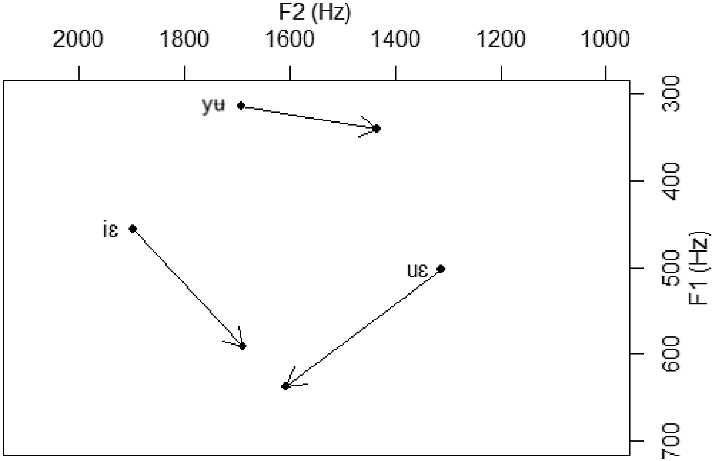
Average F1–F2 values for native Baima diphthongs. Based on 24 tokens.
Examples of diphthongs in words with alveolar onsets in the three tones.

Diphthongs
The three native Baima diphthongs (/iɛ yʉ uɛ/) are plotted in Figure 12 in an F1–F2 space.
Of the three diphthongs that occur in Baima native vocabulary, /uɛ/ and /yʉ/ have broad distribution; they may occur after alveolar stops, affricates, fricatives; postalveolar affricates and fricatives; alveolo-palatal affricates, fricatives, nasal, palatal approximant; and velar stops. In addition, /uɛ/ also occurs as an onsetless syllable, /uɛ̀/ ‘can’ (which word we did not record in isolation, see the appended text). /iɛ/ only occurs after bilabial, alveolar, and velar stops, and only in the mid and low tones.
The diphthong /uɛ/ is realized as [yɛ] after alveolopalatal onsets, as in [ɕyɛʦ] ‘mouse’, [ʑyɛ̀] ‘knife handle’; and as [uɛ] before other onsets, as in [suɛʦ] ‘hemp’, [ʒuɛ̀] ‘flea’.
Examples of diphthongs in words with alveolar onsets are presented in Table 5. Examples of the diphthong /ua̠/ include: /xuâ̠suɛ̂/ ‘to think, reflect’ (Mandarin huásuàn 划算 ‘consider, deliberate’), /ʃuâ̠tsÌ̂/ ‘brush’ (Mandarin shuāzi 刷子).
Syllable structure
Baima has a simple syllable structure of the (C)V type, where C (which is optional) can be any consonant in the consonant table, and V stands for vowel. Examples include:
In onsetless syllables with open and open-mid vowels in the low tone, which is correlated with lax (or harsh) phonation (see below), we observe weak voiced frication (variously heard as the phonetic segment [ɦ], [ʕ], or [⨂]). Examples include: /ɑ̀ò/ [ɦɑ̀ò] ‘temple’, /ɑ̀pâ̠/ [ʕɑ̀pâ̠] ‘wind’, /ɛ̀ndʊ̂/ [⨂ɛ̀ndŷ] ‘to gather, assemble’. Onsetless syllables with the vowels /ə/ and /a̠/ in the high falling tone, which is correlated with tense (or harsh) phonation, may be preceded by a glottal (or pharyngeal, or epiglottal) stop (in some words we also observe creaky phonation on the vowel). Examples include: /â̠pâ̠/ [ʔâ̠pâ̠] ‘father’, /â̠î/ [ʡâ̰î] ‘old women’, /ə̂ə̂/ [ʡə̂ʡə̂] ‘expression of agreement’. The occurrence of weak voiced frication, on the one hand, and the glottal (pharyngeal or epiglottal) stop, on the other hand, is therefore predictable, and the two are not analyzed as phonemes.Footnote 12
The two Baima approximants, /j/ and /w/, are clearly phonemic before non-close vowels. Examples include: /ɛ̀ndʊ̂/ ‘to gather, assemble’ – /jɛ̀/ ‘to weave’; /ɑ̀ò/ ‘temple’ – /tʃʰûjô/ ‘buffalo, water ox’; /â̠pâ̠/ ‘father’ – /jâ̠mbâ̠/ [ja̠˜̂mpâ̠] ‘fool’; /jɑʦ/ ‘hand’, /wɑʦ/ ‘goiter’, /ɑ̀ɑ̀/ ‘expression of disagreement’.
The distribution of the two approximants in relation to onsetless syllables with close vowels is more difficult to analyze, given the limited number of relevant examples in our corpus. We have a few clear examples of onsetless syllables with close front vowels in monosyllabic and disyllabic words, as in /â̠̂Ì̂/ ‘old woman’. We also have examples, where close front vowels are preceded by the approximant /j/, with a clear segment boundary (similar to its realization before close-mid, open-mid, and open vowels). Examples include /jyə̂/ ‘to yawn’, /jyɛʦ/ ‘lung’. In such words, /j/ is characterized by lesser energy than that of the following vowel, and it is marked by frication in addition to voicing. Overall, words with the onset /j/ tend to have a greater degree of frication in the high falling tone than in the mid and low tones (compare the words /jyə̂/ ‘to yawn’; /jê/, /â̠jê/ ‘to be bad’; /jyɛʦ/ ‘lung’; /jɛ̀/ ‘to weave’).
In the case of monosyllabic morphemes with close back vowels, in the vast majority of cases, /ʊ/ and /u/ in monosyllabic and disyllabic words are preceded by an approximant-like element. (One exception is the word /uɛ̀/ [uɛ̀] ‘can’ in the appended text.) Here again, in words in the high falling tone, the approximant-like element tends to have a greater degree of frication than in words with the mid and low tones. Examples include /wû/ [vû] ‘rice polishings’, /wʊʦpâ̠/ [ʋʊʦpâ̠] ‘bellows’. In our corpus, we also have examples of onsetless [u], as in /moʦû/ [mʌʦv̩̂] ‘much, many’.
In sum, the data that we have at our disposal are inconclusive as to the distribution of glides in relation to onsetless syllables with close vowels. It is possible that some glides are phonetically-conditioned variants, preceding close vowels in vowel-initial syllables, but more data are necessary to support this conclusion.
Prosodic organization
Monosyllabic words
Baima is a tone language with a complex interrelation between (a) pitch height, (b) voice quality of the vowel, and (c) vowel length.
Baima has three contrastive tones, which in a prepausal position all end in a falling pitch contour. The high falling tone has a falling contour throughout the vowel duration. The mid tone is level throughout most of its duration, with a small fall at the end. The low tone is low rising. This is illustrated in Figure 13 with the minimal triplet /ɲɛ̂/ ‘fire’, /ɲɛʦ/ ‘to sleep’, and /ɲɛ̀/ ‘mountain god’, uttered in isolation by our male speaker (three repetitions per word). The figure presents mean f0 and duration across three repetitions. The f0 values were extracted at every ten percent of the duration, from 10
 $\%$
to 90
$\%$
to 90
 $\%$
, and at 2
$\%$
, and at 2
 $\%$
and 98
$\%$
and 98
 $\%$
. The latter was selected in order to exclude the extremes time points of 0
$\%$
. The latter was selected in order to exclude the extremes time points of 0
 $\%$
and 100
$\%$
and 100
 $\%$
, which were preceded or followed by silence.
$\%$
, which were preceded or followed by silence.
Pitch contours and vowel duration in the three tones. Based on the minimal triplet /ɲɛ̂/ ‘fire’, /ɲɛ̄/ ‘to sleep’, and /ɲɛ̀/ ‘mountain god’ (mean of three repetitions per word, a total of 9 tokens), uttered in isolation by our male speaker. High falling tone (HF) in solid line, mid tone (M) in dotted line, low tone (L) in dashed line.

When followed by another syllable, the mid and low tones are realized as mid and low level, respectively. Examples include: /tʉʦtʉʦ/ ‘orphan’, /xua̠ʦᵑɡua̠ʦ/ ‘minority official (in imperial China)’; /ʃòxù/ ‘wealthy, rich’, /pʰɛ̀ nô/ ‘in the belly’ (from /pʰɛ̀/ ‘belly; stomach’, /nô/ ‘inside’). The high falling tone consistently has a falling pitch contour, both in a prepausal position and when followed by another syllable. Examples include: /tôpû/ ‘Baima township’; /jâ̠mbâ̠/ ‘fool’. When followed by another syllable, the high falling tone is frequently realized as mid falling. Examples include:

As can be seen in the minimal set in Figure 13, words in the high falling tone are shorter, whereas words in the mid and low tones are longer. Consecutive temporal analysis revealed that the mean vowel duration (mean of three repetitions) is 225 ms in the high falling tone, 503 ms in the mid tone, and 511 ms in the low tone. Relative vowel duration hence cross-cuts the three contrastive pitch categories. Differences in vowel duration are further illustrated in Figure 14, which shows mean duration of Baima monophthongs in the same sample of 245 tokens, as used in the plots in Figure 11 above.
Mean duration and mean standard deviation (in s) of Baima monophthongs, based on 245 tokens across different initial consonants and tones from the Baima recordings of one male speaker in this Illustration.

The three shortest vowels in Figure 14 (/ə ɞ a̠/) only occur in the high falling tone.Footnote 13 The longest vowel in Figure 14 (/o/) mainly occurs in the mid and low tones, but it is also contrastive with the short vowel /ɞ/ in the high falling tone (see examples in the section on vowels). Overall, the eight vowels that occur in all three tones (that is, /i e ɛ ʉ ʊ u o ɑ/) are shorter in the high falling tone, and longer in the mid and low tones.Footnote 14 The eight vowels that occur in all three tones do not differ in vowel quality.
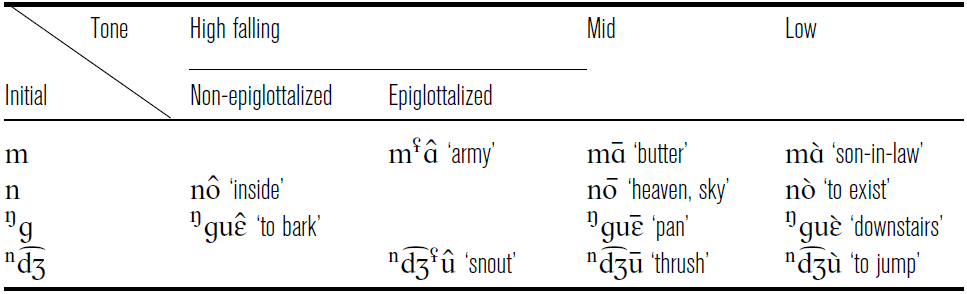
Syllables with sonorant and prenasalized stops and affricate onsets allow the full set of tonal contrasts. Table 6 provides additional examples of minimal triplets for tone in our corpus.
Phonation differences in the three tones are illustrated in Figure 15 on the basis of two minimal triplets for tone: (i) /ɲɛ̂/ ‘fire’, /ɲɛʦ/ ‘to sleep’, /ɲɛ̀/ ‘mountain god’, and (ii) /nô/ ‘inside’, /noʦ/ ‘heaven, sky’, /nò/ ‘to exist’ (with three repetitions per word, a total of 18 tokens).
Examples of tone contrasts on words with sonorant and prenasalized stop and affricate onsets.
Time courses of HNR05 (dB) (left) and H1*–H2* (dB) (right) in two minimal triplets for tone: (i) /ɲɛ̂/ ‘fire’, /ɲɛ̄/ ‘to sleep’, /ɲɛ̀/ ‘mountain god’, and (ii) /nô/ ‘inside’, /nō/ ‘heaven, sky’, /nò/ ‘to exist’ (with three repetitions per word, a total of 18 tokens). The x-axis represents vowel duration divided into five regions: 0–20
 $\%$
, 20–40
$\%$
, 20–40
 $\%$
, 40–60
$\%$
, 40–60
 $\%$
, 60–80
$\%$
, 60–80
 $\%$
, 80–100
$\%$
, 80–100
 $\%$
. High falling tone in black solid line, mid tone in light gray dotted line, low tone in gray dashed line.
$\%$
. High falling tone in black solid line, mid tone in light gray dotted line, low tone in gray dashed line.

Figure 15 shows that the mid tone is characterized by the highest HNR05 and the lowest H1*–H2* values in the set, suggesting periodic voicing, low level of noise, and therefore, modal voice quality. Vowels in the low tone are characterized by the highest H1*–H2* values in the set, and HNR05 values that are lower than in the vowels in the mid tone, but higher than in the vowels in the high falling tone (suggesting some noise and somewhat irregular voicing). Given these characteristics, vowels in the low tone can be defined as having breathy-like, lax voice quality. Finally, vowels in the high falling tone are characterized by the lowest HNR05 values in the set, suggesting weak voicing and high levels of noise. H1*–H2* values in vowels in the high falling tone are higher than in modal vowels in the mid tone, but lower than in lax vowels in the low tone. They are most tense-like in the set.
The non-modal phonation type that co-occurs with the low tone can vary from lax (as in /lʊ̀/ ‘to leak, overflow’, /ɡʊ̀/ ‘to wait’) to harsh (as in /jɛ̀/ ‘to weave’ or /dɛ̀/ ‘bottom part’). Alternation between lax and harsh phonation is likely a by-product of lax (breathy) phonation with a low tone, in which a speaker tends to lower his larynx (see Liu et al. Reference Liu, Lin, Yang and Kong2020: 13 for detailed explanation and references therein). Overall, the association of low tone with breathy phonation is commonly observed in Tibetic languages of China (e.g. J. Sun Reference Sun1997, Reference Sun, Bradley, LaPolla, Michailovsky and Thurgood2001; Huber Reference Huber2005), Bodic languages outside China (e.g. Mazaudon & Michaud Reference Mazaudon and Michaud2008) as well as, more broadly, in languages of other subgroups of the Tibeto-Burman language family (e.g. Jianchuan Bai, Edmondson et al., published online 27 April 2020) and in languages of other language families of Southeast Asia (e.g. Hmu, Hmong-Mien, Liu et al. Reference Liu, Lin, Yang and Kong2020).
Polysyllabic words and compounds
Baima morphemes (lexical and grammatical) are generally monosyllabic, but words are generally disyllabic. Polysyllabic words are mostly composite, formed through compounding. Content morphemes in Baima are specified for lexical tone (e.g. /reʦ/ ‘cloth’; /mbû/ ‘insect’; /kʰâ̠/ ‘mouth’; /kʰɑ̀/ ‘snow’). Grammatical morphemes (such as the indefinite marker /ʃi/ or the conjunctions /rɛ/ and /ɲi/ in the appended text) do not occur in isolation, and their lexical tone cannot be determined. In connected speech, grammatical morphemes are prosodically weak, they usually have shorter duration than content morphemes and no fixed tone value (tone on grammatical morphemes is not marked in the appended text).
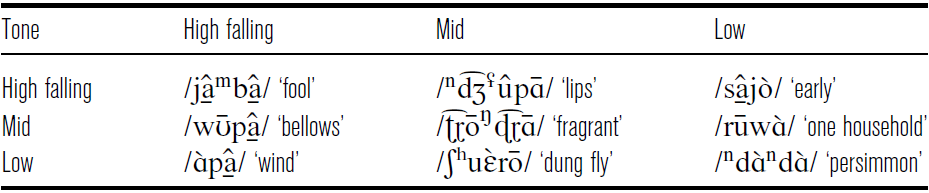
In polysyllabic words, each syllable bears its own (etymological) tone (correlated with a specific phonation type). Table 7 provides examples of all nine possible combinations of the three contrastive tones in disyllabic words.
Examples of disyllabic words with nine possible combinations of tones.
When words combine into compounds, no tonal change occurs, each word preserves its etymological tone. Consider the following examples: /t͡ɕʰÌ̂Ŋuɛʦ tsâ̠/ ‘foxtail grass’, from /t͡ɕʰÌ̂/ ‘dog’, /Ŋuɛʦ/ ‘tail’, /tsâ̠/ ‘grass’; /â̠Ì̂ nɑʦ/ ‘agaric, wood ear mushroom’, from /â̠Ì̂/ ‘old woman’, /nɑʦ/ ‘ear’; /ɕâ̠ rɛ ʃʰɑ̀/ ‘game and wild animals’, from /ɕâ̠/ ‘bird; chicken’, /ʃʰɑ̀/ ‘wild animals’ (/rɛ/ conjunction, does not occur in isolation).
The appended text in this Illustration provides several examples of words ‘in focus’ position (sentence-level stress). The phonetic correlates of phrasal prominence in Baima are: (i) a distinctive rising pitch contour (pitch accent), overlaid over the etymological tone of the word in focus, and (ii) longer duration of the vowel. Take as an example the sentence [ʑè sʉ̌ː ɲd͡ʑɛ̂ ʃi tɛ̂ tâ̠ ʃâ̠ ʈ͡ɽû dzɛ̀ ɲi] ‘let’s see which one of the two of us will win’, where the word is focus is /sʉʦ/. This word is lengthened and carries a rising pitch contour, which is distinct from its mid-level pitch contour in isolation (/sʉʦ/ ‘who’). In the appended text, the intonational pitch accent is marked by a rising tone and the length diacritic on the vowel (‘ǎː’).
Transcription of the recorded text ‘The North Wind and the Sun’
The original audio and video recordings (made with a Zoom H6 Handy Recorder, an AKG C520L headset microphone) have been made available to the JIPA along with this analysis.
Transcription of recorded passage with interlinear morphemic glossing
This passage is transcribed phonemically, using the symbols presented in the consonant and vowel charts. Abbreviations used in interlinear glossing follow the Leipzig Glossing Rules (LGR, http://www.eva.mpg.de/lingua/resources/glossing-rules.php). Non-standard abbreviations (those not included in the LGR) are: conj = conjunction, ego = egophoric, hor = hortative, itrj = interjection, itsf = intensifying verbal marker.Footnote 15


Acknowledgments
We would like to thank our Baima language consultant, Mr. Li Degui for his patience, assistance, and continuous support of our work. We are indebted to the journal’s editors Marc Garellek and Marija Tabain and the three anonymous reviewers for their detailed reviews and insightful suggestions, which helped to improve both the analysis and the presentation of the Illustration. Thanks are also due to Radek Skarnitzl for his helpful suggestions and to Paul van Els for creating Figure 1 in this paper. We gratefully acknowledge the financial support of the OP VVV project no. CZ.02.2.69/0.0/0.0/17_050/0008466 for Tanja Kocjančič Antolík. This work is also partially supported by a public grant overseen by the French National Research Agency (ANR) as part of the program ‘Investissements d’Avenir’ (reference: ANR-10-LABX-0083). It contributes to the IdEx Université de Paris - ANR-18-IDEX-0001.
Supplementary material
To view supplementary material for this article (including audio files to accompany the 752 language examples), please visit https://doi.org/10.1017/S0025100321000219.