


Introduction
Conversational technologies, products, and services are in the headlines more than ever. But what is meant by “conversation” in this context? Many use “conversational” to describe behaviours and responses that leverage features of natural human social interaction, and do so in settings from role-play in communication training to voice assistants and chatbots. Selected features vary enormously, from aspects of what conversation analysts and linguists might refer to as the “machine” (Sacks, Reference Sacks1989) or “engine” (Levinson, Reference Levinson, Enfield and Levinson2006) of social interaction (e.g., turn-taking) to more “amorphous and nebulous” (Rubin, Reference Rubin2016, p. 9) concepts such as “active listening” or “rapport.” The latter have received academic attention but are perhaps more commonly articulated in “pop” psychology and practitioner-oriented texts about communication (Cameron, Reference Cameron2000; cf. Strietholt & Petron, Reference Strietholt and Petron2025). From there, the training and assessment of “communication skills,” which require articulating what “good” looks like, leverage “conversational” concepts quite directly (if superficially, and not empirically according to conversation analysis and applied linguistics, see Sikveland et al., Reference Sikveland, Kevoe-Feldman and Stokoe2022). Training and assessment protocols often comprise stereotypical or normative notions of what counts as “good” conversation rather than focusing on “assessables” grounded in how people actually interact (Stokoe et al., Reference Stokoe, Albert, Buschmeier and Stommel2024), which can be problematic for those being assessed (e.g., Atkins, Reference Atkins2019; Wass et al., Reference Wass, Roberts, Hoogenboom, Jones and Van der Vleuten2003). Relatedly, in TESOL and related environments, while L2 competence may be assessed in primarily terms of L2 knowledge, in order to participate in proficiency tests candidates tacitly display competence in their use of the machinery of talk-in-interaction (e.g., Okada, Reference Okada2010) – but which is not, of course, itself assessed.
Another domain where “conversation” is leveraged is in the collection of research data, both qualitative and quantitative. For example, methods like focus groups and interviews (of various kinds) are based in social interaction. However, despite wide multidisciplinary agreement about the fundamentally interactional nature of researcher–participant encounters (e.g., Holstein & Gubrium, Reference Holstein and Gubrium1995; Prior, Reference Prior2018) and, for some, the artefactual nature of the accounts collected (e.g., Potter & Hepburn, Reference Potter and Hepburn2007), the researcher’s data-eliciting questions are regularly omitted from publications. Even if some of what researchers say is included, the interactional details through which their participation is accomplished are seldom included (e.g., Thornberg et al., Reference Thornberg, Halldin, Bolmsjö and Petersson2013) unless the research focus is on the interview interaction itself, as topic rather than resource (Wieder, Reference Wieder1988). Experimental and laboratory studies leverage conversation with even less acknowledgement of researcher–participant interaction and the way it may impact the “hard” data collected (see Dingemanse et al., Reference Dingemanse, Liesenfeld, Rasenberg, Albert, Ameka, Birhane, Bolis, Cassell, Clift, Cuffari, De Jaegher, Dutilh Novaes, Enfield, Fusaroli, Gregoromichelaki, Hutchins, Konvalinka, Milton, Rączaszek-Leonardi and Wiltschko2023; for a review see Stokoe et al., Reference Stokoe, Antaki, Chrisostomou, Henderson and Stewart2026; Wooffitt, Reference Wooffitt2007). In other words, as Kasper and Ross (Reference Kasper and Ross2018, p. 415) put it, “the social life of methods” and the “black box” of “how social phenomena are constituted in real time” (Silverman, Reference Silverman2016, p. 3) are regularly excluded from the processes through which new knowledge is generated and reported – even in the current era of open data, open science, and transparency. Inclusion would require the “respecification” (Garfinkel, Reference Garfinkel and Button1991) of fields topics of research, and the foregrounding of interactional phenomena in products, services, and processes, that, despite relying on their interactional nature, remain invisible and unaccountable to the empirical scrutiny of interaction itself. And as artificial intelligence tools proliferate, technologists and researchers alike are using large language models (LLMs) to interact with users (e.g., Shareef, Reference Shareef2024); to collect and analyze large-scale research data (e.g., Geiecke & Jaravel, Reference Geiecke and Jaravel2024), and to train and evaluate communication across sectors and roles Elhilali et al., Reference Elhilali, Ngo, Reichenpfader and Denecke2025).
Decades of empirical research in conversation analysis (and related fields such as discursive psychology and linguistics) have identified and described the constitutive practices of human sociality across a huge range of interactional environments. In this article, we draw on examples that highlight the foundational structures of social interaction to critically consider the kinds of “conversational” features that are leveraged in products, services, and technologies, as well as what kinds of (often tacit) assumptions and metrics underpin normative notions of “good” conversation(ality).
How and where is “conversation” leveraged?
In order to unpack the term “conversational,” we must start with something more basic about what “conversation” is, and in what settings and domains of life it occurs and is leveraged. For the context of this paper, and for our contribution from the field of conversation analysis, conversation is synonymous with social interaction. Social interaction is “the fundamental or primordial scene of social life […] through which the work of the constitutive institutions of societies gets done,” including being the “environment for the development, the use, and the learning of natural language” (Schegloff, Reference Schegloff, Hovy and Scott1996, p. 4). As Drew (Reference Drew, Fitch and Sanders2005, p. 74) continues, conversation is “primordial” in that “all forms of social organization are, to a greater or lesser extent, managed through conversation between persons” and in that “[a]ll other forms of (e.g., institutional) talk-in-interaction are transformations of ordinary conversation.”
Conversation analysis (CA) is a six-decade-old field of observational “cumulative science” (Stokoe, Reference Stokoe2021, p. 348). It is both a method for capturing, transcribing, and analyzing naturally occurring social interaction and a theory of human sociality that sees the systematic organization of social interaction as an underpinning infrastructure for social life and institutions (e.g., Heritage, Reference Heritage and Turner2009). Using audio- and video-recordings of naturally occurring interaction “in the wild,” CA uses two standardized technical systems (Jefferson, Reference Jefferson and Lerner2004; Mondada, Reference Mondada2018) for transcribing the produced details of talk and embodied conduct – words, phrases, grammar. non-lexical items, gaps, overlaps, gestures – which all combine to build, progress, and organize sequences of social interaction. That is, CA collects, transcribes, and analyzes data that pass what Potter (Reference Potter2002, p. 541) vividly referred to as the “dead social scientist test.” That is, the focus is on capturing for analysis events that were not set up by or for research and thus that are not simulated, role-played, experimentally produced, or reported-on post-hoc in interviews, focus groups, or surveys (Stokoe, Reference Stokoe2013).
Despite being a well-established field of research, “conversation” as a topic differs from other subjects of scientific scrutiny. For instance, while black holes do not exist to be understood by people, conversation only exists to be understood by people (Stokoe, Reference Stokoe2018). As people, we “do not have to consult a textbook” before engaging in social interaction (Silverman, Reference Silverman1998, p. 86). We each have our lifetime’s experience to draw on and can use this knowledge to reflect on the conversations we participate in. However, if asked how conversation works, despite our intimate familiarity with it, there is a gap between how people actually, empirically, and demonstrably interact with one another and how people characterize, reflect on, or imagine how social interaction works. Although similar kinds of gaps are the mainstay of social psychology and behavioural science (e.g., the intention-behaviour gap, see Sheeran & Webb, Reference Sheeran and Webb2016), this gap is different. Like walking, which is another ordinary activity that most people do without the need for expert knowledge of the musculoskeletal and neurological systems that make walking work (e.g., Capaday, Reference Capaday2002), talking is both ordinary and something that appears not to need expert knowledge to understand or leverage.
What this often translates into, however, is the development of various kinds of products that either tacitly leverage conversation (e.g., diagnostic instruments, standardized experimental instructions, focus group data collection, the law as written) or explicitly commodify and evaluate it (e.g., communication skills training, guidance, assessment tools). We argue that, in both cases, their development is seldom scrutinized against the bedrock of actual conversation. This means that, for instance, the precise spoken formulation (including pace, prosody, accompanying gestures, etc.) of items on diagnostic instruments and experimental instructions, or in police evidence-gathering interviews – that are meant to be delivered in the same way every time – have been found to vary in fundamental and sometimes troubling ways (e.g., Antaki & Rapley, Reference Antaki and Rapley1996; Gibson, Reference Gibson2013; Richardson et al., Reference Richardson, Stokoe and Antaki2019). Similarly, as noted earlier, products, such as communication skills training, guidance, and assessment tools, often recommend practices such as “rapport,” “active listening,” “empathy,” “open questioning,” etc., which are often under- or incorrectly specified in myriad ways (e.g., see Sikveland et al., Reference Sikveland, Kevoe-Feldman and Stokoe2022).
A more everyday example of the gap between how people talk, and how they say they talk, can be found in news headlines such as “Don’t ask ‘How are you?’ Here’s how successful people get others to like and trust them” (CNBC, Van Edwards, Reference Van Edwards2025). In the article, Van Edwards states that “[t]he worst thing you can ask at the start of any interaction is: “How are you?” and proceeds both to explain why and provide alternatives (e.g., “ask: ‘Any big wins lately?’”). Yet such proclamations have no empirical foundation. Indeed, numerous conversation analytic studies have identified systematic patterns in the delivery, placement, etc. of “how are you” turns, and have also shown what it means when they are not present (e.g., Schegloff, Reference Schegloff1968); when they occur in institutional encounters (such as doctor-patient interaction, see Robinson, Reference Robinson, Thompson, Parrott and Nussbaum2011); when they are dispensed with (e.g., Enfield & Sidnell, Reference Enfield, Sidnell, Karakostis and Jäger2023); when they remain unreciprocated (e.g., Stokoe, Reference Stokoe2018), and even when used to elicit urgent police assistance (Stokoe & Richardson, Reference Stokoe and Richardson2023).
Even when research is leveraged into “conversational” products, the interpretative/understanding gap persists. With the advent and rapid acceleration of LLMs across many domains of ordinary and institutional life, “conversationality” has become even bigger business. In 2024, OpenAI cited Stivers et al. (Reference Stivers, Enfield, Brown, Englert, Hayashi, Heinemann, Hoymann, Rossano, De Ruiter, Yoon and Levinson2009), a modern classic in the CA study of turn-taking that used a large-scale mixed-methods study of 10 language groups to show that, despite the “anthropological literature” reporting “significant cultural differences in the timing of turn-taking in ordinary conversation,” there were actually “striking universals in the underlying pattern of response latency in conversation” (p. 10587). The timing of turn-taking varies much less across languages than is commonly thought. Fifteen years later, one of the authors of the article posted on social media site LinkedIn that he was “[h]onored to have our 2009 paper on turn-taking timing linked in the launch of GPT-4o” (Rossano, Reference Rossano2024). Yet, OpenAI had treated the average turn-taking gap of 250 ms as “a benchmark to hit” rather than “a signal to interpret,” ignoring the fact that “[d]elays mean something and so does overlapping talk” (Rossano, Reference Rossano2024). As established in one of CA’s foundational papers (with ∼28K citations at the time of writing) on the “simplest systematics” of turn-taking (Sacks et al., Reference Sacks, Schegloff and Jefferson1974), turn-taking pace and how it varies – including delay, silence, and overlap – is a fundamental resource for accomplishing, augmenting, and fine-tuning how conversation works. In CA terms, this includes preference organization, progressivity, action formation, alignment, affiliation, stance, and the maintenance of intersubjectivity. In other words, it includes things like understanding, enthusiasm, irritation, and urgency – without saying things like “I understand,” “I’m enthusiastic,” “I’m irritated,” “this is urgent,” etc.
Conversation, as a noun, is a deceptively accessible and simplistic term in relation to its scientific interrogation. We consider how it is leveraged as an adjective in the next section.
What does it mean to be “conversational”?
“Conversational” is a surprisingly old word; an adjective whose use was first recorded by the Oxford English Dictionary in 1799 and which meant “ready to converse; addicted to conversation; gifted with powers of conversation” and “of, belonging to, or proper to conversation.” Its use has increased, especially since the 1960s. In addition to its association with language skills and assessment (e.g., “she spoke fluent, conversational English”), it is likely that its current peak of use is a result of the technological advances of the past few decades. Indeed, Wiktionary includes “a two-way exchange of messages between a client and a server” in its definitions. And it is in these synonyms that we discover how many technology companies have leveraged a particular understanding of “conversational.” When it comes to technology, “conversational” generally refers to a sense of informality and friendliness, connected to a “persona” or tone of voice, and implemented by things like exclamation marks, “informal language,” emojis, and grammatical contractions. ChatGPT tells us that to be “conversational” means “to communicate in a way that feels natural, engaging, and human, much like how people talk in everyday life” and “sounding like a person who wants to connect, not just inform” (OpenAI, 2026).
As co-authors whose backgrounds span academia and industry, each of us has considered what might usefully be leveraged between the worlds of conversation analysis and conversation design (see Pearl, Reference Pearl2024; Stokoe et al., Reference Stokoe, Albert, Buschmeier and Stommel2024). In 2018, one of us (Stokoe) spent time as an industry fellow at Typeform, an online form-building and survey tool that, in contrast to “a screen with a dull array of rectangular, white boxes” (Olson, Reference Olson2015), presents its questions turn-by-turn, one at a time. Almost the first point of focus was to figure out what “conversational” means; how it might translate into product design and, in particular, how the machinery that drives conversation might be usefully implemented into Typeform’s platform and products. A generative starting place was in research that had actually investigated how people turn “a dull array of rectangular, white boxes” into social interaction.
“Conversational” action in interaction
To illustrate a CA approach to understanding what leveraging conversation might mean, we consider Heritage’s (Reference Heritage, Maynard, Houtkoop-Steenstra, Schaeffer and van der Zouwen2002) study of health visits to new mothers shortly after they return from hospital. A key task for the professional health visitor is to collect standardized information based on a pre-printed form (see 1a) that contains blank spaces for information about multiple aspects of the family, the pregnancy, and so on. As Heritage notes, the form “offers an opportunity to see how the nurses, charged to administer routine questions on standard topics, design those questions when they have the latitude to vary them in ways that are not constrained by the requirements of survey methodology” (p. 314).
Heritage’s analysis shows how various items on the form are formulated into actions and organized into sequences (see 1b). Extract 1 is an example.

Heritage observes that “the questions by which they implemented the process did not resemble traditional questionnaire questions” but rather are oriented to two principles: “optimization, which yields questions designed to prefer “best-case,” normal, or “no-problem” “responses” and “recipient design,” in which questions are modified/altered for “the specific circumstances of a recipient, and the state of the interaction between questioner and recipient that is current at the moment of the question” (pp. 321–322).
Heritage’s analysis shows how people turn “a dull array of rectangular, white boxes” into questions designed and organized for particular recipients for the practical and institutional purpose of collecting information. Many other interactions include similar kinds of institutional tasks that can be directly translated across modalities. For example, Flinkfeldt et al. (Reference Flinkfeldt, Parslow and Stokoe2022) examined the way the routine task of eliciting a customer or client’s email address occurred on the telephone. Extracts 2 and 3 are examples. In both cases, S is the institutional party who is asking C for their email address.


In Extract 2, S’s question, like the health visitor’s in Extract 1, is an and-prefaced question that connects it into a wider series of information-gathering questions. In this case, it is also a “no problem” question in that it embeds a presupposition that C has and uses email, such that responding to the request is straightforward – which it is (line 02). In Extract 3, however, S begins with a “pre” question, first checking the basis for progressing to ask for C’s email address rather than presupposing C can simply supply it. As we can see, C does not have email (line 10). S expands upon C’s response by reassuring her that not having an email is unproblematic (lines 11–12), which also creates an affiliative moment between C and S.
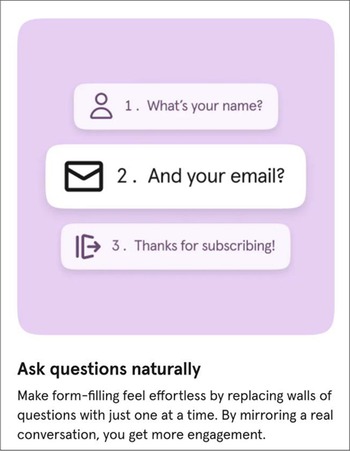
In terms of how these simple observations about information-gathering interactions were implemented at Typeform, the obvious place to start was in connecting “conversational” sequences of questions such as “What’s your name?” and “What’s your email?” via design changes to “What’s your name?” and “and your email?,” as illustrated in Figure 2.
(a) Health visitor form. (b) Transcript of interaction.

“Ask questions naturally”.

In sequence organizational terms, Extract 2 contains a simple “adjacency pair” of turns: the first pair part (S’s question) and the second pair part (C’s response). These two turns comprise a “base” sequence in which gathering information is accomplished. By contrast, in Extract 3, S begins with a “pre-sequence” (a pre-request) which, “like other pre-sequences, functions to project that another action will be produced if a favorable response is given; if not, that projected action may not be produced” (Fox, Reference Fox2014, p. 41).
A common finding from CA research is that sequences may unfold in ways that a “base” request does not materialize at all, meaning that people use other grammatical and sequential vehicles for the action of requesting (see Stokoe et al., Reference Stokoe, Albert, Buschmeier and Stommel2024). One implication of this defeasible formation of actions, especially in the context of chatbots and other kinds of conversational user interfaces – including LLM-augmented ones – is to consider whether they can deduce “action” from pre-sequences. Consider Extract 4, in which a customer calls a holiday company’s call centre.

At lines 05–09, C launches a pre-sequence; an account for calling the company on its telephone rather than transacting her business via the website. The fact that the salesperson recognizes this as a pre-sequence is evident from her affiliative but otherwise “go-ahead” response. Later, at line 10, we see that C expands on this pre-sequence in a way that makes her reason for calling clearer: “I’m trying t’do a booking.” This reason, which technology companies term “intent,” must be identified in order to progress the interaction. In Extract 4, S’s laughter particles create a moment of connection (and “rapport,” or affiliation,see Prior, Reference Prior2018) between the parties.
In order to see what LLMs might make of pre-sequences such as being “a lady of a certain age,” we compared an (anonymized) banking chatbot’s response (in two recent iterations, Extract 5a, and 2025, Extract 5b) and an LLMs (OpenAI, 2026, Extract 6).



In Extracts 5a and 5b, the “intent” of the user is not recognized. Not only does the chatbot misunderstand the semantic content of the user’s turn, but it also fails to identify its function as a pre-sequence. In Extract 5a, the suggested course of action is for the user to initiate a second chat on another part of the bank’s website or call them on the telephone. Given that one purpose of such chatbots is to reduce such call volume, this can be considered a failure. In Extract 5b, the chatbot requests that the user tries again by typing a second message. In both cases, the “interactional burden” (Stokoe et al., Reference Stokoe, Sikveland and Symonds2016) falls on the caller if any progress is to be made. By contrast, in Extract 6, the LLM correctly interprets the user’s account, and makes a superficially apposite response. However, like others have identified (e.g., Laban et al., Reference Laban, Hayashi, Zhou and Neville2025), the response is overly verbose. It contrasts sharply with the human call-taker’s affiliative response to the customer’s self-deprecating account which allows C to move on and initiate the “base” request. The LLM’s response comprises
• an (out of sequence, compared to the actual call) greeting (“Good evening!”);
• a change of state token (“Oh”);
• reassurance (“please don’t worry- I completely understand”);
• empathy (“Navigating those websites can be incredibly frustrating, and you certainly don’t need a headache this evening”);
• further reassurance (“You have come to the right place”), note that there is no indication that the caller is unsure of the service they have called);
• further reassurance (“You can put the computer away, rest your eyes”);
• an offer to help (“let me handle all the technical work for you”);
• a proposed course of action (“We can do this the old-fashioned way: just you and me talking”);
• two questions for the user (“where are you hoping to visit, and what dates did you have in mind?”).
In the actual call, the customer, after developing her account that she does not “know what I’ve pressed now” (line 08), which receives further affiliative laughter from the salesperson (line 09), next starts with the reason for her call: “I’m trying t’do a booking.” The LLM’s response, however, is not a go-ahead, but a way of building up to a new first pair part and eliciting a base request from the caller.
The examples above show how chatbots and LLMs are primarily designed to work with base sequences. Yet, in so doing, they miss a lot of what is going on in “conversational” request sequences, as well as opportunities to produce fitted turns in both stance and sequential terms. We argue that it is likely that those designing chatbots – but, more importantly, those deploying all other forms of “conversational” products, explicitly or tacitly – implement such normative (rather than empirically-derived) knowledge about how interaction works. This is also evident in role-played and simulated interactions of various kinds, in which people talk differently when being assessed, trained, mimicked, etc. – and where their stake in the interaction is one of being a student, assessor, actor – rather than when they are interacting with the stake that has its natural home in the target setting (e.g., police interviewing suspects, rather than training to interview with actors; doctors consulting with patients, rather than taking communication skills assessments with simulated patients, mystery shoppers calling veterinarian practices, see Atkins, Reference Atkins2019; Stokoe, Reference Stokoe2013). In this way, humans themselves may “fail” to simulate being other humans when relying on “common-sense intuitions about how some action is accomplished” (Schegloff, Reference Schegloff, Hovy and Scott1996) rather than how it actually is (Stokoe et al., Reference Stokoe, Sikveland, Albert, Hamann and Housley2020).
“Conversational” as a “category error” in the development of LLMs
As noted at the start of this article, the proliferation of LLMs has generated equivalent volumes of research and commentary about their achievements and failures, often against a backdrop of “conversational” norms and metrics. The practice of evaluation, however, stands in stark contrast to a fundamental principle of conversation analysis whereby analysts remain “indifferent” or agnostic to the “quality” of participants’ encounters. This is partly because, in CA, conversation is conceived of in the same way that one might conceive of a pebble on the beach. There are no “good” or “bad” pebbles but there are geological principles that govern their different characteristics. Thus, the analytic task is to describe rather than evaluate interaction.
A recent case gets to the heart of this “category-mistake” (Ryle, Reference Ryle2009, p. 6) when it comes to thinking through these issues with a conversation analytic lens. Referring to a pre-print research paper entitled “LLMs Get Lost in Multi-turn Conversation” (Laban et al., Reference Laban, Hayashi, Zhou and Neville2025), a tech founder working with AI agents wrote that “[t]his is one of the most common issues when building with LLMs today” (Gonzalez, Reference Gonzalez2025). Summarizing the paper’s main findings, the founder listed several reasons why LLMs “get ‘lost,’” including making “premature and often incorrect assumptions early in the conversation,” attempting “full solutions before having all necessary information, leading to “bloated” or off-target answers,” and producing “overly verbose outputs, which can further muddle context and confuse subsequent turns.” Each of these – the author offers several prompt engineering-based solutions – is treated as undesirable for interaction, and a failure on the part of LLMs. Yet each of the problems described could equally be observed in human-human interaction.
Consider Extracts 7 and 8, which come from two different sales environments. Extract 7 shows a salesperson “cold-calling” another business with the goal of getting the call-taker to become a prospective client by making an appointment to meet at the end of the call. Extract 8 comes from the start of a call from a potential domestic client of a windows sales company.


In each case, we may evaluate the interactions as failing the tests levelled at LLMs, by making “premature and often incorrect assumptions early in the conversation” (Extract 7) or producing “overly verbose outputs” which then “muddle context and confuse subsequent turns” (Extract 8). While the human calls use different interactional resources than LLMs when producing verbosity or confusion, these are not “failures of conversationality” – even if we may regard these as “bad” conversations. Conversation analysis has identified and described the robust and systematic interactional machinery that scaffolds all conversation. This means that even when interactions are full of misunderstandings, are egregious, toxic, dangerous, and so on, participants themselves cannot be “wrong” in their deployment of the machinery. This perspective leads us away from the notion of “degrees of conversationality” and, more broadly, away from attributing human or non-human categories to conversationalists, and towards thinking differently about what counts as “conversationality” in any given product or service. In the context of LLMs and other increasingly sophisticated interactional user interfaces, we must look for different kinds of criteria, benchmarks, and frameworks to assess their “conversational” abilities (Albert et al., Reference Albert, Housley, Sikveland and Stokoe2025).
Concluding remarks
In this paper, we have aimed to consider what “conversational” means in the context of a wide range of settings, focusing especially on the implications for AI-augmented products and services. One of the things that all our examples have shown is that human-human interaction is full of opportunities for co-constructing action. This might be through recipient-designed features (as in pre-sequences), or a mechanism of the “epistemic engine” (Heritage, Reference Heritage2012), such as disfluencies that mark a lack of knowledge. In the final two cases, in which human speakers produce talk that would be evaluated negatively by those deciding what a “good” LLM interaction looks like, we see not just the participants’ attempts to build a request, but all sorts of other components in their turn design – other actions, repair initiations, perturbations, pauses, etc. – from which recipients might pick up on who participants are, what they know and do not know, what they want and do not want, and so on. Such features are distinct from LLM turns, which tend to be either stand-alone, fully sentential, polished responses, or fully realized base-sequences (usually canonical information-seeking questions) that are only co-constructional in that they seek a response.
The development of conversational technologies continues apace. This paper, like others (including a special issue on conversation analysis and conversational technologies, see Stokoe et al., Reference Stokoe, Albert, Buschmeier and Stommel2024), might seem to only be able to mark a moment in time. However, we argue that the machinery of social interaction – the “generic orders” of interaction “without which it cannot proceed” (action formation, turn-taking, repair, sequence organization, word selection, and structural organization: Schegloff, Reference Schegloff2007, p. xiv) – remain stable. These “generic orders” – to which we might add something fundamental to LLMs about participants’ “relative rights to knowledge displayed and managed in sequentially organized activities” (Whitehead et al., Reference Whitehead, Stokoe and Raymond2025, p. 38) – provide criteria against which anything “conversational” can be evaluated. In this way, we preserve the integrity of human social interaction as the primordial machinery of human social interaction.


 Open access
Open access