




Introduction
Exposure to input through reading is a key source of second language (L2) vocabulary learning. Learners gradually acquire different aspects of word knowledge through repeated encounters with L2 words in context. However, vocabulary acquisition is not solely determined by the quantity of input; input quality also plays an equally critical role (Webb & Nation, Reference Webb and Nation2017). In particular, repeated exposure to and use of words across varied contexts enhances input quality and promotes the enrichment and consolidation of lexical knowledge (Chandy et al., Reference Chandy, Serrano and Pellicer-Sánchez2025; Joe, Reference Joe1998; Webb & Nation, Reference Webb and Nation2017).
Although input variability can take various forms, such as phonetic variation (e.g., talker variability; Uchihara et al., Reference Uchihara, Webb, Saito and Trofimovich2022) and morphological variation (e.g., derivations and inflections; Reynolds, Reference Reynolds2015), this study focuses on contextual diversity (CD), defined as the number of distinct contexts represented by different genres and topics in which a word appears (Adelman et al., Reference Adelman, Brown and Quesada2006; Hulme et al., Reference Hulme, Begum, Nation and Rodd2023; Rosa et al., Reference Rosa, Salom and Perea2022). The CD is considered an important source of variability as it is reported to facilitate the formation of form-meaning mappings in both first language (L1) (Johns et al., Reference Johns, Dye and Jones2016; Mak et al., Reference Mak, Hsiao and Nation2021; Rosa et al., Reference Rosa, Tapia and Perea2017, Reference Rosa, Salom and Perea2022) and L2 contexts (Frances et al., Reference Frances, Martin and Duñabeitia2020; Nguyen, Reference Nguyen2023). Contextual variability is thought to enhance learners’ inferencing and memory by activating broader background knowledge and promoting deeper semantic processing (Pagán & Nation, Reference Pagán and Nation2019; Pulido, Reference Pulido2007; Yamashita, Reference Yamashita, Jeon and In’nami2022).
Despite the potential benefits of CD, much of the supporting evidence comes from studies on L1 children learning novel words. In L2 contexts, empirical research is still limited. Despite a few studies examining the CD effects on L2 vocabulary learning (e.g., Chandy et al., Reference Chandy, Serrano and Pellicer-Sánchez2025), their operationalization of the contextual variability (i.e., a direct comparison between repeated exposures to the same sentence and different sentences) did not necessarily mirror authentic reading experiences learners have with texts from diverse genres and topics. Thus, it remains unclear whether, and to what extent, contextually varied input supports incidental vocabulary learning in more ecologically valid reading conditions.
To address this gap, the present study investigates the CD effects on incidental vocabulary learning among Japanese learners of English as a foreign language (EFL). Specifically, it examines whether reading multiple texts of varied genres and topics facilitates the incidental learning of L2 words. This research sheds light on how encountering new words in varied contextual discourses shapes L2 incidental vocabulary learning and offers pedagogical implications for optimizing vocabulary instruction through reading.
Literature review
Incidental vocabulary learning from reading
Given the conceptual ambiguity of incidental vocabulary learning from a psychological perspective (Webb, Reference Webb, Teng and Reynolds2024), this study adopts a methodological definition: Vocabulary learning that occurs when learners are not explicitly aware of upcoming vocabulary tests and engage in meaning-focused reading tasks (Durrant et al., Reference Durrant, Siyanova-Chanturia, Kremmel and Sonbol2022; Hulstijn, Reference Hulstijn, Doughty and Long2003; Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019). Numerous studies have demonstrated the occurrence of incidental vocabulary learning in both L1 (Jenkins et al., Reference Jenkins, Stein and Wysocki1984) and L2 (Horst et al., Reference Horst, Cobb and Meara1998; Pellicer-Sánchez et al., Reference Pellicer-Sánchez, Webb and Wang2024; Teng, Reference Teng2024a). A meta-analysis by Webb et al. (Reference Webb, Uchihara and Yanagisawa2023) reports that L2 learners acquire approximately 17% of the target words immediately after reading and retain 15% of the learned words. Although the number of encounters is positively correlated with vocabulary learning (r = .41; Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019), repetition alone accounts for only a modest portion of the variance (17%). Moreover, studies have reported inconsistent findings on the optimal number of repetitions, ranging from 6 (Rott, Reference Rott1999) to 20 (Waring & Takaki, Reference Waring and Takaki2001). These findings suggest that incidental learning gains likely vary as a function of multiple variables beyond repetition alone. For example, Webb et al. (Reference Webb, Uchihara and Yanagisawa2023) indicated that moderating variables include a range of learner profiles (e.g., L2 proficiency and institutional level), material and activity features (e.g., text type, text audience, spacing, and mode of input), and methodological features (e.g., prior knowledge of target words and test format).
Incidental vocabulary learning from reading entails a dynamic interplay between bottom-up and top-down cognitive processes involved in text comprehension (Koda, Reference Koda, Koda and Yamashita2018; Smith et al., Reference Smith, Snow, Serry and Hammond2021; Yamashita, Reference Yamashita, Jeon and In’nami2022). Through bottom-up processing, L2 readers construct a textbase by analyzing explicitly stated linguistic information. Top-down processing, in turn, enables them to integrate background knowledge into the product of bottom-up processing (i.e., textbase) to understand the content. During such complicated processing executed for reading comprehension, word learning can occur only on the condition that readers encountering unfamiliar words (a) recognize a gap in their lexical knowledge, (b) infer meaning from context, and (c) associate the L2 form with the inferred meaning and relevant contextual cues (de Bot et al., Reference de Bot, Paribakht and Wesche1997). When any of the steps fail, incidental vocabulary learning is less likely to occur.
Contextual diversity and vocabulary learning
Defining CD remains an open question. One simple way of its operationalization is to manipulate the repetition of text input by comparing verbatim input (e.g., reading the same texts multiple times) with varied input (e.g., reading different texts in which the same target words appear multiple times) (Chandy et al., Reference Chandy, Serrano and Pellicer-Sánchez2025; Durrant & Schmitt, Reference Durrant and Schmitt2010; Li et al., Reference Li, Wu and Liu2023; Liu & Todd, Reference Liu and Todd2016). Liu and Todd (Reference Liu and Todd2016) found that the varied-input group reading seven different texts achieved significantly higher scores on the meaning recognition test than the verbatim group reading the same text seven times (but for mixed findings, for example, see Durrant & Schmitt, Reference Durrant and Schmitt2010). Using the eye-tracking technology, Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2025) demonstrated that contextually diverse contexts elicited more attention, indexed by slower total fixation duration and longer initial fixations, to unknown words while reading. Participants who read different sentences showed significantly longer processing time than those who read the same sentence repeatedly, indicating that reading contextually diverse texts may lead to deeper processing and stronger memory (for similar results with L1 learners, see Pagán & Nation, Reference Pagán and Nation2019). Although this line of research sheds light on the role of CD in vocabulary learning, it is important to note that the definition of CD adopted by earlier studies does not accurately reflect the degree of actual variability that learners encounter in real-life L2 input (e.g., extensive reading, Webb & Chang, Reference Webb and Chang2015b).
The traditional approach (i.e., contrasting verbatim with varied conditions, as reviewed above) can be interpreted as the operationalization of CD at the linguistic or local level (e.g., target words are embedded in various contexts surrounded by different words). However, in the real-life reading environment, learners could repeatedly encounter words in multiple passages that are contextually diverse at the discursive, or global level. This global account of CD concerns variability at the discourse level, such as genres and topics. The two perspectives of CD align with the concepts of verbal and nonverbal contexts proposed by Engelbart and Theuerkauf (Reference Engelbart and Theuerkauf1999). Verbal context refers to grammar and semantics, whereas nonverbal contexts refer to situations, descriptions, subjects, and global clues such as general knowledge that are relevant to learning topics. The framework highlights the importance of considering not only linguistic variability occurring from lexico-grammatical features of a text but also non-linguistic variability at the global level (i.e., genres and topics).
Genre and topic are similar but refer to different concepts (Biber & Conrad, Reference Biber and Conrad2009; Lee, Reference Lee2001). Genre, typically conceptualized as the purpose of texts with different structural styles of texts, has been operationalized in L2 reading studies as a binary distinction between narrative and expository texts, while topic refers to the thematic content of a text (e.g., sports, health, or technology), rather than its structural style. In other words, genres define how information is presented, whereas topics denote what the text is about. Although the definition of genre remains debated, there are two major approaches to determining genre differences. One is a linguistic approach, which relies on the quantitative analysis of linguistic features such as co-occurrences of words (Biber, Reference Biber1992; Biber & Conrad, Reference Biber and Conrad2009); the other is a rhetoric approach, which emphasizes readers’ perceptual interpretation and the communicative purpose achieved by the text (Hyland, Reference Hyland2002, Reference Hyland2021; Lee, Reference Lee2001; Suchomel, Reference Suchomel2021). The former allows us to determine text genre more objectively, whereas the latter approach may better reflect the psychological reality underlying the perception of genre differences.
Regarding the topic, we based our classification on general topical domains rather than specific topics (Biber & Conrad, Reference Biber and Conrad2009). General topical domains refer to broader categories of topics such as science, society, religion, and sports, whereas specific topics are indicative of individual, more narrowly defined subjects or storylines within those domains. Since Graesser et al. (Reference Graesser, McNamara and Kulikowich2011) demonstrated that indices of Coh-Metrix, which can help automatically analyze text characteristics, differed significantly between science and society topics, even within the same expository genre, we chose these two topical domains.
Previous research showed that genres and topics yield differences in text characteristics and affect vocabulary learning. Narrative texts, characterized by temporally sequenced events and human agents, tend to facilitate comprehension due to their familiar discourse structure and cohesive elements (Mar et al., Reference Mar, Li, Nguyen and Ta2021). Supporting this view, Webb et al.’s (Reference Webb, Uchihara and Yanagisawa2023) meta-analysis suggests that narrative texts yield greater vocabulary gains (g = 1.43) than expository texts (g = 0.61). However, most studies in this domain have predominantly employed narrative texts, and few have directly compared different genres, limiting our understanding of how genre-specific features affect incidental vocabulary learning (Arai & Takizawa, Reference Arai and Takizawa2024). Moreover, previous comparisons have tended to dichotomize genres (narrative vs. expository) and inevitably overlooked variation within each genre that differs in thematic content and communicative style (e.g., topic differences). The influence of topic variations also needs to be considered as a potential variable contributing to L2 vocabulary learning (Cancino, Reference Cancino2023; Pulido, Reference Pulido2003, Reference Pulido2007). When topic familiarity is higher, learners can leverage background knowledge to compensate for their lack of understanding, improve their overall comprehension of the text, direct greater attentional resources for encoding, and eventually learn unknown words efficiently while reading.
In the literature of incidental vocabulary learning (Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019; Webb et al., Reference Webb, Uchihara and Yanagisawa2023), linguistic features (e.g., vocabulary) are often controlled, for example, by ensuring that lexical coverage is appropriate for the target population. However, comparable attention has not been paid to non-linguistic variables (e.g., background knowledge), and it remains underexplored whether and how variability at the non-linguistic level enhances (or hinders) incidental vocabulary learning from reading. The present study operationalizes CD at a global level with variations in both genre and topic across different texts. Unlike previous studies that manipulated CD by varying linguistic (or local) contexts within a single topic (e.g., Durrant & Schmitt, Reference Durrant and Schmitt2010; Liu & Todd, Reference Liu and Todd2016), we adopt a discourse-level approach (i.e., global CD), wherein target words appear in texts with different genres and topics. This allows us to examine the influence of CD while accounting for potential effects of non-linguistic contextual variability on L2 vocabulary learning.
Theoretical basis and empirical support for contextual diversity
Theoretical basis. Reading contextually diverse texts is theorized to facilitate the encoding of both linguistic and non-linguistic cues associated with newly encountered words. When reading, learners must retrieve lexical meanings while simultaneously activating relevant background knowledge (Yamashita, Reference Yamashita, Jeon and In’nami2022). This dual activation of linguistic and non-linguistic memory engages deeper processing, integrating personal experience and world knowledge, which in turn strengthens memory consolidation for L2 vocabulary (Craik & Lockhart, Reference Craik and Lockhart1972). Eye-tracking studies have shown that CD induced greater attention to unknown items (i.e., deeper processing). Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2025) demonstrated that contextually diverse texts induced slower total fixation durations and longer initial fixations compared to non-diverse texts, indicating that reading contextually diverse texts involves deeper cognitive engagement. Similarly, in L1 reading research, Pagán and Nation (Reference Pagán and Nation2019) reported longer reading times and fixations during exposure to novel words in varied contexts, along with faster processing during subsequent reading. These findings suggest that contextually diverse input may increase attentional engagement, thereby promoting stronger memory formation.
Furthermore, Bolger et al.’s instance-based memory model of word learning (Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008) accounts for the benefit of CD for word learning while considering the activation of wider background knowledge. This model suggests that when we learn words from reading, contextualized episodic memory of encounters with words incrementally accumulates, and the summation of memories shapes word meaning. In addition, higher CD (i.e., exposure to a wider range of different contexts) is expected to create richer memory traces that can resonate during subsequent encounters, thereby facilitating the learning of word meanings.
Empirical support. The theoretical benefits of CD have received partial support from existing studies, predominantly in L1 settings (Hulme et al., Reference Hulme, Begum, Nation and Rodd2023; Johns et al., Reference Johns, Dye and Jones2016; Joseph & Nation, Reference Joseph and Nation2018; Mak et al., Reference Mak, Hsiao and Nation2021; Norman et al., Reference Norman, Hulme, Sarantopoulos, Chandran, Shen, Rodd, Joseph and Taylor2023; Rosa et al., Reference Rosa, Tapia and Perea2017, Reference Rosa, Salom and Perea2022). For instance, Rosa et al. (Reference Rosa, Tapia and Perea2017) found that Spanish-speaking children who read texts from three distinct genres (fables, science, and math) demonstrated significantly higher gains across four vocabulary measures compared to those who read the same genre. This pattern was replicated in a follow-up study with adolescents (Rosa et al., Reference Rosa, Salom and Perea2022). Similarly, Johns et al. (Reference Johns, Dye and Jones2016) found that L1 English university students recognized target words more quickly and accurately after reading passages drawn from varied topics (high contextual diversity [HCD]) versus a single topic (low contextual diversity [LCD]), as shown by lexical decision and semantic similarity tasks.
Conversely, some studies reported the opposite trend. Hulme et al. (Reference Hulme, Begum, Nation and Rodd2023) and Norman et al. (Reference Norman, Hulme, Sarantopoulos, Chandran, Shen, Rodd, Joseph and Taylor2023) found that learners in LCD conditions outperformed those in HCD conditions. One explanation is that narrower contexts, by maintaining consistent topics and vocabulary, may enhance familiarity and support inferencing, essentially simulating the conditions of narrow reading (Schmitt & Carter, Reference Schmitt and Carter2000). In narrow reading, repeated exposure to similar content reduces lexical burden and facilitates a meaning-inference process through accumulated discourse knowledge. In contrast, HCD conditions may increase cognitive demand without the benefits of increasing content familiarity, especially for less proficient learners.
In the L2 domain, evidence for global CD effects remains limited. Frances et al. (Reference Frances, Martin and Duñabeitia2020) examined Spanish learners of English who encountered pseudowords across four levels of contextual variability. Vocabulary gains were significantly greater in the higher variability conditions across multiple outcome measures (form recall, recognition, picture matching). Nguyen (Reference Nguyen2023) similarly found that reading paired narrative and expository texts led to greater vocabulary gains than narrative-only input among Thai university students. These studies suggest that global CD, particularly across genres, can enhance L2 incidental vocabulary acquisition.
However, methodological limitations in these studies should merit further exploration. First, in Frances et al. (Reference Frances, Martin and Duñabeitia2020), the amount of textual information available for each target word varied considerably because participants read different amounts of text for each target word. The authors manipulated CD by altering the number of texts in which each word appeared. Specifically, there were four conditions as a within-subject design: (a) 2 of the 8 target words occurred eight times within a single 100-word story (the lowest CD condition), (b) two words appeared four times in two texts, (c) two words appeared twice in two texts, and (d) two words appeared once in each of the eight different stories (the highest CD condition). Consequently, learners were exposed to only one text for two target words, but to eight different texts for the other two. Second, in Nguyen’s (Reference Nguyen2023) study, while the length and number of texts were controlled, participants encountered each target item only once, where vocabulary learning might be severely underestimated. Also, the treatment involved text enhancement and output tasks to prompt text comprehension, in which learners’ attention was likely directed to target words. These methodological variations, consequently, provide limited insights into how CD affects incidental vocabulary learning. The current study was designed to address these methodological limitations (i.e., issues with frequency of occurrence, lexical coverage, and text length) to determine the impact of CD on incidental vocabulary learning from reading.
Prior vocabulary knowledge and text comprehension
Among reader-related factors, prior vocabulary knowledge (vocabulary size) has received the most extensive attention in research on incidental vocabulary learning (see Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019, for a review). Learners with a larger vocabulary are better equipped to process textual information fluently and allocate cognitive resources to infer meanings and activate background knowledge, enabling them to build coherent text representations and learn new words more efficiently (Kintsch & Welsch, Reference Kintsch, Welsch, Hockley and Lewandowsky1991; Pulido, Reference Pulido2007; Yamashita, Reference Yamashita, Jeon and In’nami2022). In contrast, learners with limited vocabulary may struggle with surface-level processing (i.e., retrieving word meanings) (Webb & Chang, Reference Webb and Chang2015a), leaving little attentional capacity for higher-level processing such as inference-making and vocabulary learning (Robinson, Reference Robinson, Doughty and Long2003). Consistent with this view, empirical studies have shown that learners with larger vocabulary knowledge, as measured by instruments like the Vocabulary Levels Test, tend to acquire more L2 single words (Teng, Reference Teng2024b; Webb & Chang, Reference Webb and Chang2015a) as well as multiword sequences (Vilkaitė, Reference Vilkaitė2017; Vu & Peters, Reference Vu and Peters2022, Reference Vu and Peters2023) from reading than those with limited vocabulary knowledge. Scholars conducting corpus-based studies have attempted to establish the threshold of lexical coverage necessary for effective reading comprehension, with estimates ranging from 95% (Laufer, Reference Laufer, Lauren and Nordman1989) to 98% or higher (Nation, Reference Nation2006; Pellicer-Sánchez et al., Reference Pellicer-Sánchez, Webb and Wang2024). Zhang and Zhang (Reference Zhang and Zhang2022) conducted a meta-analysis and demonstrated that vocabulary knowledge significantly impacted L2 reading comprehension (r = .57, p < .01). Recent research suggests that the relationship between lexical coverage and reading comprehension tends to be linear and that there may not be a single threshold for adequate reading comprehension (Webb, Reference Webb2021; Webb et al., Reference Webb, Pellicer-Sánchez and Wang2025). The relationship may also vary depending on relevant factors such as topic familiarity (Schmitt et al., Reference Schmitt, Jiang and Grabe2011) and genre (Kremmel et al., Reference Kremmel, Indrarathne, Kormos and Suzuki2023). Although mixed on the cut-off points guaranteeing optimal comprehension, these findings indicate that higher lexical coverage is associated with greater comprehension and increased opportunities for word learning.
The importance of prior vocabulary knowledge may be even more critical when learners are exposed to contextually diverse input. According to the Cognitive Load Theory (Sweller, Reference Sweller1988; Sweller et al., Reference Sweller, van Merriënboer and Paas2019), learners with limited vocabulary knowledge are hypothesized to face increased extraneous cognitive load when reading contextually diverse texts. With insufficient lexical support, these learners may struggle to process surface-level linguistic information and, as a result, have limited capacity to activate or apply background knowledge. In contrast, learners with larger vocabulary sizes can process texts more easily and direct more attention to unfamiliar items, making contextual inferencing more feasible. Also, in the HCD condition in particular, where readers were exposed to texts from different genres and topics, the required cognitive load can be expected to be higher. This reasoning suggests that CD benefits L2 vocabulary learning if learners possess adequate prior vocabulary knowledge (i.e., a desirable level, Bjork & Kroll, Reference Bjork and Kroll2015; Suzuki et al., Reference Suzuki, Nakata and Dekeyser2019). Accordingly, this study aims to reveal, if any, the moderating role of prior vocabulary knowledge (or vocabulary size) in incidental word learning under varying levels of CD.
The current study
As reviewed above, prior research has suggested that CD facilitates vocabulary learning. However, existing studies have focused predominantly on L1 learners with limited evidence available for L2 populations. Furthermore, several methodological limitations regarding the control of frequency of exposure to target items, lexical coverage, and use of output tasks in earlier L2 studies made it difficult to draw firm conclusions about the effects of CD on L2 incidental vocabulary acquisition. Addressing these gaps is essential for understanding how contextual variability, as a key dimension of input quality (Webb & Nation, Reference Webb and Nation2017), influences word learning in L2 contexts.
To this end, the present study adopted a pretest–posttest–delayed posttest design to investigate the effects of CD on L2 incidental vocabulary learning with Japanese EFL learners. Participants in the two experimental groups—HCD and LCD—encountered 10 target words 6 times while reading 3 different texts in English. Following the global perspective of CD (Engelbart & Theuerkauf, Reference Engelbart and Theuerkauf1999), we manipulated CD as a function of varying genres (narrative vs. expository) and topics (science vs. society). Specifically, the HCD group read three texts differing in both genre and topic (i.e., narrative, science-themed expository, and society-themed expository), while the LCD group read three texts representing a single genre and topic (e.g., three narratives, three science texts, or three society texts). Vocabulary learning was assessed using meaning recall and meaning recognition tests. To examine how prior vocabulary knowledge modulates the CD effects on vocabulary learning, we measured participants’ vocabulary breadth using the updated Vocabulary Levels Test (uVLT; Webb et al., Reference Webb, Sasao and Ballance2017). Accordingly, this study was guided by the following research questions:
-
1. To what extent does exposure to L2 words in texts with higher CD lead to greater lexical gains compared to in texts with lower CD?
-
2. To what extent does prior vocabulary knowledge modulate the effects of CD on vocabulary learning from reading?
Method
Reading materials, dataset, and analysis code are accessible through OSF (https://osf.io/5xzj6/overview).
Participants
A total of 164 Japanese undergraduate students (aged 18–21) enrolled in 4 English classes participated in this study. Because participants were assigned to classes based on TOEFL scores obtained upon university entry, they were considered to be at pre-intermediate to intermediate levels. Forty participants were excluded from the final analysis due to one or more of the following reasons: (a) absence from treatment sessions, (b) substantial prior knowledge of the target words as indicated by pretest scores (i.e., exceeding 50% accuracy on either the meaning recall or recognition tests), or (c) self-reported engagement in the external learning of the target words outside the treatment sessions. Consequently, the data from 124 participants were retained for statistical analysis. Participants attended a 90-minute English class once a week, taught by the same instructor across all groups. One class was assigned to a test-only control group, while the remaining three classes formed experimental groups (see Procedure and Table 4).
Vocabulary tests
We administered meaning recall and meaning recognition tests before the treatment (pretest), immediately after the treatment (immediate posttest), and one week after the treatment (delayed posttest) to measure vocabulary gain and retention. The meaning recall test preceded the meaning recognition test to prevent learners from seeing the meanings of the target items (Nation & Webb, Reference Nation and Webb2011). Since the learning activity in the present study primarily focused on meaning (i.e., learners attended to the semantic content of the reading materials), we concentrated on the retrieval of the word meaning cued by the L2 written form. These tests help capture the learning of form-meaning mapping with varying degrees of precision from partial to fuller knowledge (Durrant et al., Reference Durrant, Siyanova-Chanturia, Kremmel and Sonbol2022; Kremmel & Schmitt, Reference Kremmel and Schmitt2016). In the meaning recall test, participants translated L2 target words into L1 equivalents as accurately as possible while encouraged to provide the word meanings represented in the reading materials (e.g., baboon: “animals living in forests and sometimes come down to cities”). In the meaning recognition test, participants selected the correct meaning of a target word from four options. Each question included one correct answer and three distractors with the same part of speech as the correct answer, and their meanings were not too far from the correct meaning. For example, for encumber, the three distractors were threaten, remove, and observe. Two intermediate- to advanced-level Japanese EFL learners who did not participate in this experiment reviewed the distractors to confirm that the distractors could not easily be eliminated based on mere differences in semantics and orthography from the correct answers. Other issues pointed out through the review process were rectified (e.g., two choices semantically indistinct were removed).
In addition, we employed the updated Vocabulary Levels Test (uVLT; Webb et al., Reference Webb, Sasao and Ballance2017) in the first week of the procedure to measure prior vocabulary knowledge (see Table 1). According to the suggested threshold of mastery of each frequency level (i.e., 29/30 for 1K to 3K levels, 24/30 for 4K and 5K levels, Webb et al., Reference Webb, Sasao and Ballance2017), 59.7% of the participants were considered to master the most frequent 1,000 word families, 26.6% of the participants mastered the most frequent 2,000 words or more, and 4.03% mastered the most frequent 3,000 words or more. Preliminary analysis confirmed no significant difference between the HCD and LCD (see Online Appendix S1).
Mean and standard deviation (in parentheses) of uVLT for five frequency levels

Table 1. Long description
Content flagged by safety filters.
Note. The theoretical maximum score per frequency level = 30.
Reading materials
We developed nine written texts representing two genres (Narrative and Expository) and two topics within expository texts (Science and Society), producing three discourse units of reading texts: (a) Narrative, (b) Expository (Science), and (c) Expository (Society). Participants in the HCD condition read one text each from (a), (b), and (c), whereas those in the LCD condition read three texts from one discourse unit (see Table 4). We selected nine texts from the British Council and EPFL news (https://news.epfl.ch/), with three for each discourse unit (see Table 2).
Information on nine texts.

Table 2. Long description
From the top row, the table lists nine texts: A walk in the forest, Bad habits, Mystery train, Animals in the city, Street art, Youtuber, Dogs and avocados, Dreams, and Hand sensor. For each, columns provide: Genre and topic (Narrative or Expository with subtopics Society or Science); Length in words (ranging from 950 to 1035); Lexical coverage with the most frequent 2,000 words (from 922 to 995 words, percentages from 95.0 to 97.8); Type/token ratio (from 0.32 to 0.39); Comprehension test scores with standard deviation (highest 5.55 for A walk in the forest, lowest 3.73 for Hand sensor); Familiarity ratings with standard deviation (highest 3.9 for Hand sensor, lowest 2.03 for Mystery train). The note below clarifies that comprehension scores are means out of 6 and familiarity is rated on a five-point Likert scale.
Note. The comprehension score was the mean of the comprehension test scores per text (max = 6) across all participants. Topic familiarity was rated by the participants with a five-point Likert scale.
To determine the differences at the discourse levels (i.e., genre and topic variations), we first followed the New Rhetoric Approach to account for the readers’ perceptual interpretation and the text’s communicative purpose (Hyland, Reference Hyland2002, Reference Hyland2021; Lee, Reference Lee2001; Suchomel, Reference Suchomel2021). This emphasis was critical for confirming that readers could perceive genre distinctions, ensuring these perceptions were accurately reflected in the experimental materials. As for the topic, we based our classification on general topical domains (Biber & Conrad, Reference Biber and Conrad2009) with a particular focus on science and society topics (for the evidence showing linguistic differences, see Graesser et al., Reference Graesser, McNamara and Kulikowich2011). We subdivided expository texts into two topical categories: Science, which included texts describing natural phenomena and technology (e.g., biology, medicine, engineering), and Society, which included texts addressing social and cultural issues (e.g., lifestyle, art, media).
Accordingly, the selection and categorization of texts were initially based on the evaluation by relevant stakeholders specific to our target context (i.e., EFL contexts in Japan). The first author, a Japanese EFL teacher, searched for candidate texts by checking titles and reading the full passages. When the content was not overly specific and could be classified into one of the three text categories (narrative, science-themed expository, or society-themed expository), the text was retained. Another experienced EFL instructor verified the classification and the appropriateness of the content for their undergraduate students. Two Japanese EFL learners (one advanced and one intermediate), who did not participate in the experiment, also confirmed that the classification was legitimate, denoting perceptually distinctive features across three different types of texts. To confirm whether the selected materials represent distinctive linguistic properties across different genres and topics (i.e., for the linguistic features approach, see Biber & Conrad, Reference Biber and Conrad2009), we conducted corpus-based analyses of the target texts using Coh-Metrix indices (Graesser et al., Reference Graesser, McNamara, Louwerse and Cai2004, Reference Graesser, McNamara and Kulikowich2011). The results showed that narrative texts exhibited higher Narrativity (i.e., M = 1.58 for narrative texts, whereas M = 0.12 for both topics of expository texts), confirming that our perceptual classification was supported by quantitative analysis of the linguistic characteristics (for the full results, see Online Appendix S2).
After the text selection, we seeded 10 target words so that each word appeared twice per text. Because participants in the experimental groups read three texts, they encountered each target word six times in total. The six encounters are regarded as a minimal threshold of repetition leading to substantial vocabulary learning (e.g., Rott, Reference Rott1999; Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019). To minimize the primacy and recency effects on learning, target words were not placed at the beginning or end of sentences. The results of a pilot study with different participants of similar proficiency levels indicated that most of our participants mastered the most frequent 2,000 words. Thus, to ensure that over 95% of the words in each text were within the most frequent 2,000 words (Laufer, Reference Laufer, Lauren and Nordman1989), we paraphrased or replaced low-frequency words with high-frequency synonyms. The 95% threshold was determined based on both methodological and empirical considerations. Methodologically, seeding 20 occurrences of the target words in a 1,000-word text resulted in a maximum achievable coverage of approximately 98%, even before other necessary contextual modifications were made. Empirically, previous studies on lexical coverage have suggested that repeated encounters with unknown words, together with opportunities to infer their meanings from context, can potentially increase lexical coverage as learners read a text, thereby facilitating text comprehension (Laufer, Reference Laufer2020; for reviews, see Webb, Reference Webb2021). The frequency profile analysis using the Compleat Lexical Tutor (Cobb, Reference Cobbn.d., ver. 8.5, accessed on 1 January 2024) indicated that all adapted texts contained 95% of words within the most frequent 2,000 words level, plus other words considered familiar to our participants (proper nouns and loanwords). After the text modification, two native English speakers reviewed all texts to ensure grammatical accuracy and naturalness. Based on their feedback, additional adjustments were made to rectify any unnatural phrasing. The classroom instructor reviewed all texts and confirmed that the level of the texts was appropriate for the students. Table 2 shows that the proportion of low-frequency words, type-token ratios, and word counts are comparable across all texts.
Target words
We selected 10 target words comprising 6 nouns and 4 verbs (see Table 3). The ratio of nouns to verbs (6:4) reflected the distribution in natural language use (Webb, Reference Webb2007). Given that some target words carried multiple meanings, we ensured that only one meaning was used consistently across all texts to avoid semantic ambiguity. Using Nation’s (Reference Nation2012, Reference Nation2016) BNC/COCA 25,000-word lists, we sampled target words from the most frequent 5,000 (5K) to 11,000 (11K) words. We determined this range by referring to the results of the uVLT administered to learners of comparable proficiency in the previous semester and through consultation with the instructor of the target class (i.e., higher than 5K level).Footnote 1 The results of uVLT confirmed the frequency range falling outside our participants’ lexical knowledge (see Table 1). One instructor of academic English courses and two Japanese graduate students, advanced users of L2 English, reviewed the selected words and confirmed that the words were unlikely to be familiar to the participants.
Target words, Japanese translations, and frequency level

Table 3. Long description
The table has three columns: Target words, Japanese translations, and Frequency level. The first row lists [N] baboon, ヒヒ, 10K. The second row lists [N] lore, 知識, 9K. The third row lists [N] luster, つや, 8K. The fourth row lists [N] paucity, 不足, 10K. The fifth row lists [N] plateau, 高原, 6K. The sixth row lists [N] surveillance, 見張り, 5K. The seventh row lists [V] encumber, 妨げる, 10K. The eighth row lists [V] insinuate, ほのめかす, 9K. The ninth row lists [V] relish, 楽しむ, 5K. The tenth row lists [V] soothe, やわらげる, 5K. The table footnote states that [N] indicates nouns and [V] refers to verbs.
Note. [N] indicates nouns, and [V] refers to verbs.
Text comprehension and topic familiarity
To ensure that learners stay focused on the meaning of the texts while engaging in the reading activity, we set six True or False questions for each text. We developed the questions from the parts that did not involve understanding of the target items to avoid practice effects resulting from engagement with the words. After the creation of the questions, we piloted the difficulty with two Japanese EFL learners who did not participate in this study. We confirmed no significant difference in comprehension scores between the HCD (M = 4.76, SD = 1.16) and LCD (M = 4.61, SD = 1.03) with a Welch’s t-test, t(88.48) = 0.805, p = .423.Footnote 2 Since the questions were included for the purpose of drawing learners’ attention to the content as part of the methodological operationalization of incidental vocabulary learning (Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019), we did not use the comprehension scores for further statistical analysis. Topic familiarity was measured via a five-point Likert scale. The participants were required to rate their familiarity with the topics after reading each text. There was no significant difference between the HCD (M = 2.74, SD = 1.09) and LCD (M = 2.79, SD = 1.05) groups in topic familiarity, t(85.93) = −0.27, p = .787.
Procedure
Data collection lasted for three weeks (for the schedule, see Figure 1). In Week 1, participants consented to participate and then completed two pretests (i.e., meaning recall and recognition, in this order) followed by the updated VLT. This test order is recommended by Nation and Webb (Reference Nation and Webb2011), as it prevents test takers from figuring out the answers from the options provided in the recognition test, which in turn may risk inflating the scores of the recall test administered subsequently. Note that presentation of target items was randomized across participants as well as across three test timings to prevent potential learning by taking the same tests multiple times.
The procedure for the experimental groups over three weeks.

Figure 1. Long description
At the far left, a yellow box labeled u V L T, Pretests is anchored above Day 1. A red arrow below points right and reads 1 week later. Three blue boxes follow in sequence: Text 1, Comprehension test, Familiarity rating; Text 2, Comprehension test, Familiarity rating; Text 3, Comprehension test, Familiarity rating. These are grouped under Day 2. Next is a green box labeled Immediate posttests. At the far right, an orange box labeled Delayed posttests, Background questionnaire is above Day 3. Another red arrow below points right and reads 1 week later. The entire sequence is overlaid by a large blue rightward arrow, indicating the procedural flow from Day 1 through Day 3.
One week later (Week 2), we conducted cluster random sampling with convenience sampling (Mackey & Gass, Reference Mackey and Gass2022). First, one class was allocated to a test-only control group, and three classes were assigned to experimental groups. Next, to further control the effects of text presentation order and other potential variables pertaining to text-related features (e.g., topic familiarity and text difficulty), three subgroups were created within each experimental condition and counterbalanced (see Table 4). Within each of the three experimental classes, participants were individually and randomly assigned to one of the subsets in either the HCD or LCD condition. These subgroups read different texts in varying orders. During the learning session, participants read three texts in their assigned condition and answered six true/false binary comprehension questions and completed ratings of topic familiarity after reading each text. After completing the treatment, participants took unannounced immediate posttests.
The subgroups in the experimental groups

Table 4. Long description
From left to right, the columns are labeled Set-H1, Set-H2, Set-H3, Set-L1, Set-L2, and Set-L3. In the first row, Set-H1 contains Narrative 1, Set-H2 contains Society 2, Set-H3 contains Science 3, Set-L1 contains Narrative 1, Set-L2 contains Science 1, and Set-L3 contains Society 1. In the second row, Set-H1 contains Science 1, Set-H2 contains Narrative 2, Set-H3 contains Society 3, Set-L1 contains Narrative 2, Set-L2 contains Science 2, and Set-L3 contains Society 2. In the third row, Set-H1 contains Society 1, Set-H2 contains Science 2, Set-H3 contains Narrative 3, Set-L1 contains Narrative 3, Set-L2 contains Science 3, and Set-L3 contains Society 3. Sets H1, H2, and H3 correspond to the high contextual diversity condition, while Sets L1, L2, and L3 correspond to the low contextual diversity condition.
Note. Sets H1–3 were used for the high contextual diversity (HCD) condition; Sets L1–3 were used for the low contextual diversity (LCD) condition.
In Week 3, participants took unannounced delayed posttests and completed a questionnaire. The questionnaire asked about their demographic information, English learning experience, daily use of English, and whether they had looked up the meanings of target words at any stage.
Because this study focused on incidental vocabulary learning, participants were not informed about the true purpose of the study until the experiment was completed. After the questionnaire was completed, we debriefed about the study’s purpose and procedures in detail, and participants were given opportunities to ask questions. They were also assured that their decision to participate in this research would not affect their course grades. Moreover, participants were informed that they could withdraw their consent to provide data at any time.
Scoring and analysis
For the meaning recall test, we first adopted both strict and lenient scoring methods. In the strict scoring, only responses that matched the exact meanings of the target words (e.g., L1 translations) or described the word meanings represented in the reading materials were marked as correct (e.g., for the word baboon: “animals living in forests and sometimes come down to cities”). In the lenient scoring, we additionally gave credit for responses denoting partial information about the target words (e.g., baboon: “animal”). The lenient scoring resulted in nearly all answers being marked as correct; therefore, we used the scores based on the strict scoring for statistical analyses. The first author marked all answers, and a Japanese English teacher scored 10 % of the entire responses independently (Mackey & Gass, Reference Mackey and Gass2022). Cohen’s kappa coefficient was 0.83, indicating sufficient inter-rater consistency (Landis & Koch, Reference Landis and Koch1977). For the meaning recognition test, one point was assigned for each correct answer.
Cronbach’s alpha was calculated to check reliability for the meaning recall and meaning recognition tests at immediate and delayed posttests: meaning recall (immediate posttest: α = .80; delayed posttest: α = .69), meaning recognition (immediate posttest: α = .49; delayed posttest: α = .56). Although alphas for meaning recall test scores can be considered within the acceptable range (i.e., closer to or higher than α = .70), those for meaning recognition tests appeared relatively low. To further evaluate the reliability of the meaning recognition test and to estimate the number of additional items required to attain acceptable reliability, we conducted two supplemental analyses. First, we examined a test-retest consistency based on the test scores from the test-only control group (see Schmitt et al., Reference Schmitt, Nation and Kremmel2020, for the suggestion). This analysis confirmed that there were (a) moderate to strong correlations between test scores (r = .54 to .78, ps < .001), (b) no significant differences in the mean test scores (ps > .05), and homogeneity of variance (Levene’s test, p > .05) across three test timings (see Online Appendix S5 for the results in greater detail). These results suggested the sufficient internal consistency of the meaning recognition test, at least for the research purpose (i.e., an experimental study with not a high-stakes purpose). We interpreted the relatively small alpha mainly because of the relatively small number of target items (k = 10). See Online Appendix S5 for the full results of follow-up analysis to verify that the reduced alpha was mainly attributed to the limited number of items rather than the issue with the reliability of the test.
Data analysis
Prior to the main inferential analyses, we conducted outlier inspection (defined as data points exceeding ± 2.5 SDs). Missing data and responses from participants who reported looking up target word meanings outside of the classroom were also excluded from the analysis (n = 40). Therefore, data from the remaining 124 participants were analyzed.
To answer two research questions, we used R (version 4.5.2) to conduct inferential statistical analyses. To confirm the extent to which vocabulary gain is attributable to treatment rather than test effects, and more importantly, to examine whether CD leads to vocabulary learning (RQ1), we conducted generalized linear mixed effects modeling (GLMM) to compare the difference in vocabulary learning among three groups (two experimental and one control). Since the dependent variables (meaning recall and meaning recognition scores) were coded as binary outcomes (0 = incorrect, 1 = correct), we utilized a logistic regression model. Predictors included Group (0 = Control vs. 1 = HCD vs. 2 = LCD), uVLT (z-score), and Time (0 = Pretest, 1 = Immediate posttest, 2 = Delayed posttest). The uVLT scores were included as a covariate to control for the initial difference in baseline vocabulary knowledge (see Supporting Appendix S1). Topic familiarity was not included as the data were not available for the control group. We included a two-way interaction between the Group and Time because previous studies showed the influence of CD may vary depending on time (Chandy et al., Reference Chandy, Serrano and Pellicer-Sánchez2025). Random intercepts for participants and items were included to account for individual and item variability. This analysis allowed us to assess the learning through the treatment session (HCD vs. LCD vs. Control) as well as differences among the groups (for additional analysis with a three-way interaction among Group, Time, and uVLT, see Supplemental Material S9).
Second, to further scrutinize the influence of CD (i.e., HCD-LCD contrast specifically) while controlling for potential variables such as topic familiarity and prior knowledge of target items, and the interaction between CD and prior vocabulary knowledge (RQ2), we constructed separate GLMM models for each immediate and delayed posttest. Predictors included CD (0 = LCD vs. 1 = HCD), uVLT (z-score), Pretest score (0 = incorrect, 1 = correct), and topic familiarity (z-score) with an interaction term between CD and uVLT. Including pretest scores (as recommended by Maie et al., Reference Maie, Eguchi and Uchihara2024) and topic familiarity as covariates enabled us to investigate the effects of CD while accounting for prior vocabulary knowledge and familiarity with the reading topics. To avoid building unduly complicated models and to reveal when the CD effects emerged, we built separate models for each time point and the meaning recall and recognition test. Cohen’s d was calculated from the odds ratio using the formula below (Chinn, Reference Chinn2000):

We evaluated models by checking the variance inflation factor (VIF), overdispersion, and residual Q-Q plots with the DHARMa package (see Session Information through OSF). All adjusted VIF values were below 9 (see Online Supporting Appendix S6), suggesting an acceptable range of multicollinearity (Hair et al., Reference Hair, Babin, Anderson and Black2019), and the dispersion parameters were well below 1, indicating no overdispersion (Bolker et al., Reference Bolker, Brooks, Clark, Geange, Poulsen, Stevens and White2009). Q–Q plots showed acceptable distributional patterns of residuals, and scatterplot matrices of continuous predictors indicated approximately linear relationships among variables, no extreme outliers, and no strong pairwise correlations (r > .70; see Online Appendix S8).
Results
RQ1: Group comparisons (HCD vs. LCD vs. control)
For the meaning recall test, LCD yielded slightly larger relative gains than HCD at the immediate posttest (15.5% for LCD vs. 14.4% for HCD). In contrast, at the delayed posttest, HCD showed greater relative gains than LCD (26.0% for HCD vs. 21.0% for LCD) (see Table 5). These results suggest that while LCD may facilitate initial encoding, HCD may be more beneficial for longer-term retention. The control group showed little learning at the immediate posttest (relative gain with the pretest score as the baseline = 1.9%), yet it demonstrated a relatively larger gain at the delayed posttest (9.5%), suggesting potential test effects. Given the potential test effect and the limited number of target words, we also compared absolute (raw) gain scores (posttest minus pretest) between each experimental group and the control group. Participants in the HCD condition gained 1.13 words and 1.65 words at the delayed posttest, whereas those in the LCD condition learned 1.24 and 1.07 words for the immediate and delayed posttest, respectively.
Means, standard deviations (in brackets), and 95% confidence intervals for meaning recall

Table 5. Long description
From left to right, the first column lists groups: H C D (n equals 50), L C D (n equals 42), and Control (n equals 32). The next columns show pretest, immediate posttest, delayed posttest, relative gain percent pre-immediate, and relative gain percent pre-delayed. For H C D, pretest mean is 0.84, standard deviation 0.87, confidence interval 0.59 to 1.09; immediate posttest mean is 2.16, standard deviation 1.62, confidence interval 1.70 to 2.62; delayed posttest mean is 3.24, standard deviation 2.10, confidence interval 2.64 to 3.84; relative gain percent pre-immediate is 14.4, standard deviation 16.2, confidence interval 9.84 to 19.0; relative gain percent pre-delayed is 26.0, standard deviation 32.4, confidence interval 19.7 to 32.4. For L C D, pretest mean is 0.69, standard deviation 0.75, confidence interval 0.46 to 0.92; immediate posttest mean is 2.12, standard deviation 1.77, confidence interval 1.57 to 2.67; delayed posttest mean is 2.64, standard deviation 1.79, confidence interval 2.08 to 3.20; relative gain percent pre-immediate is 15.5, standard deviation 17.7, confidence interval 9.95 to 21.0; relative gain percent pre-delayed is 21.0, standard deviation 26.5, confidence interval 15.4 to 26.5. For Control, pretest mean is 0.53, standard deviation 0.95, confidence interval 0.19 to 0.87; immediate posttest mean is 0.72, standard deviation 1.08, confidence interval 0.33 to 1.11; delayed posttest mean is 1.41, standard deviation 1.52, confidence interval 0.86 to 1.95; relative gain percent pre-immediate is 1.91, standard deviation 7.64, confidence interval minus 0.85 to 4.66; relative gain percent pre-delayed is 9.5, standard deviation 12.1, confidence interval 5.13 to 13.9. Maximum possible score is 10.
Note. Max = 10.
The GLMM results revealed no significant main effect of Group, indicating that overall meaning recall accuracy of each HCD and LCD was not significantly different from that of the control group (see Table 6 and Figure 2). The main effect of Time was significant for the delayed posttest, indicating higher odds of a correct response at the delayed posttest than at the pretest across the three groups. Interaction between Group and Time was also significant for each combination except LCD × Delayed posttest. The post hoc test (for the full results, see Online Supporting Appendix S7) showed that at the immediate posttest, both experimental groups achieved significantly higher odds of a correct response than the control group (ps = .001; d = 0.82 for HCD, d = 0.80 for LCD). At the delayed posttest, both the HCD and LCD groups showed significantly higher odds of correct response than the control group (p < .001, d = 0.70 for HCD; p = .046, d = 0.46 for LCD). As for the comparison between HCD and LCD, no significant differences were observed across any testing time (ps > .05).
GLMM for the meaning recall test (Control vs. HCD vs. LCD)

Table 6. Long description
Beginning at the top, the intercept row shows beta minus 3.93, odds ratio 0.02 with 95 percent confidence interval 0.01 to 0.06, z minus 7.27, p less than .001, and Cohen’s d minus 2.17 with confidence interval minus 2.75 to minus 1.58. The next row, Group H C D, has beta 0.39, odds ratio 1.47 with confidence interval 0.64 to 3.37, z 0.91, p .364, and Cohen’s d 0.21 with confidence interval minus 0.25 to 0.67. Group L C D shows beta 0.11, odds ratio 1.11 with confidence interval 0.47 to 2.65, z 0.24, p .809, and Cohen’s d 0.06 with confidence interval minus 0.42 to 0.54. Time Immediate has beta 0.42, odds ratio 1.53 with confidence interval 0.74 to 3.14, z 1.15, p .249, and Cohen’s d 0.23 with confidence interval minus 0.16 to 0.63. Time Delayed presents beta 1.47, odds ratio 4.37 with confidence interval 2.26 to 8.45, z 4.38, p less than .001, and Cohen’s d 0.81 with confidence interval 0.45 to 1.18. u V L T shows beta 0.56, odds ratio 1.75 with confidence interval 1.39 to 2.22, z 4.68, p less than .001, and Cohen’s d 0.31 with confidence interval 0.18 to 0.44. The H C D times immediate interaction has beta 1.10, odds ratio 3.01 with confidence interval 1.30 to 7.00, z 2.56, p .010, and Cohen’s d 0.61 with confidence interval 0.14 to 1.07. L C D times immediate interaction shows beta 1.35, odds ratio 3.85 with confidence interval 1.59 to 9.28, z 3.00, p .003, and Cohen’s d 0.74 with confidence interval 0.26 to 1.23. H C D times delayed interaction has beta 0.88, odds ratio 2.41 with confidence interval 1.10 to 5.28, z 2.21, p .027, and Cohen’s d 0.49 with confidence interval 0.05 to 0.92. L C D times delayed interaction presents beta 0.73, odds ratio 2.07 with confidence interval 0.91 to 4.73, z 1.74, p .082, and Cohen’s d 0.40 with confidence interval minus 0.05 to 0.86.
Regression lines and 95% confidence intervals by group and time for the meaning recall test.

Figure 2. Long description
From left to right, the panels are Pre, Immediate, and Delayed. Each panel plots V L T z-score on the x axis from minus 1 to 1 and Predicted probability on the y axis from 0 percent to 50 percent. Three regression lines per panel represent Control in green, H C D in red, and L C D in blue, each with a shaded 95 percent confidence interval. In all panels, predicted probability increases with higher V L T z-score. H C D and L C D groups show higher recall probabilities than Control at all time points, with H C D slightly above L C D. The gap between groups is largest in the Delayed panel. Confidence intervals are widest at higher probabilities. The legend at right identifies group colors.
For the meaning recognition test, LCD yielded larger relative gains than HCD at the immediate posttest (27.7% for LCD vs. 23.7% for HCD). In contrast, at the delayed posttest, HCD demonstrated greater relative gains than LCD (26.0% for HCD vs. 18.0% for LCD) (see Table 7). Absolute gains showed that participants in the HCD group learned 1.46 words at the immediate posttest and 1.52 words at the delayed posttest. Participants in the LCD condition attained 1.89 words at the immediate posttest and 1.28 words at the delayed posttest. These results suggest a similar trend that while LCD may be beneficial for initial encoding immediately after reading, HCD may facilitate longer-term retention.
Means, standard deviations (in brackets), and 95% confidence intervals for meaning recognition

Table 7. Long description
From left to right, the first column lists groups: H C D (n equals 50), L C D (n equals 42), and control (n equals 32). The next columns show pretest, immediate posttest, delayed posttest, relative gain percent (pre-immediate), and relative gain percent (pre-delayed). For H C D, pretest mean is 3.80, standard deviation 1.64, confidence interval [3.39, 4.21]; immediate posttest mean is 5.32, standard deviation 2.14, confidence interval [4.71, 5.93]; delayed posttest mean is 5.48, standard deviation 2.16, confidence interval [4.87, 6.09]; relative gain percent (pre-immediate) is 23.7, standard deviation 34.0, confidence interval [14.0, 33.3]; relative gain percent (pre-delayed) is 26.0, standard deviation 33.2, confidence interval [16.5, 35.4]. For L C D, pretest mean is 3.24, standard deviation 1.16, confidence interval [2.88, 3.60]; immediate posttest mean is 5.19, standard deviation 1.71, confidence interval [4.66, 5.72]; delayed posttest mean is 4.55, standard deviation 1.67, confidence interval [4.03, 5.07]; relative gain percent (pre-immediate) is 27.7, standard deviation 27.8, confidence interval [19.1, 36.4]; relative gain percent (pre-delayed) is 18.0, standard deviation 25.6, confidence interval [10.0, 26.0]. For control, pretest mean is 3.72, standard deviation 1.71, confidence interval [3.10, 4.33]; immediate posttest mean is 3.78, standard deviation 1.84, confidence interval [3.12, 4.45]; delayed posttest mean is 3.69, standard deviation 1.65, confidence interval [3.09, 4.28]; relative gain percent (pre-immediate) is minus 3.62, standard deviation 38.2, confidence interval [minus 17.4, 10.1]; relative gain percent (pre-delayed) is minus 7.19, standard deviation 40.2, confidence interval [minus 21.7, 7.30]. Maximum score is 10.
Note. Max = 10.
The results of GLMM showed the main effect of Group was significant for LCD, suggesting the LCD condition tended to achieve higher accuracy than the control group. The main effect of Time was not significant. Interaction between Group × Time was significant for all combinations, indicating both HCD and LCD achieved significantly higher recognition accuracy in the immediate posttest and the delayed posttest (see Table 8 and Figure 3). Post-hoc pairwise comparisons (see Online Supporting Appendix S7) showed HCD showed significantly higher odds of a correct response, suggesting better recognition accuracy than the control group at the immediate posttest (p = .04, d = 0.28), whereas no significant difference was observed between LCD and the control group (p = .091). At the delayed posttest, HCD outperformed the control group with higher odds of a correct response (p = .006, d = 0.35), while LCD did not, indicating that only HCD led to significantly higher recognition accuracy than the control group (see Online Appendix S7). Between HCD and LCD, the former group outperformed the latter at the delayed posttest (p = .033, d = 0.26), suggesting that higher CD resulted in greater retention of target items at the recognition level.
GLMM for the meaning recognition test (Control vs. HCD vs. LCD)

Table 8. Long description
The table has six columns: Predictor, beta, odds ratio with 95 percent confidence interval, z, p, and Cohen’s d with 95 percent confidence interval. From top to bottom, the predictors and their values are: Intercept, beta negative 0.45, odds ratio 0.64 [0.32, 1.26], z negative 1.30, p 0.194, Cohen’s d negative 0.25 [negative 0.62, 0.13]; Group H C D, beta negative 0.25, odds ratio 0.78 [0.52, 1.18], z negative 1.18, p 0.240, Cohen’s d negative 0.14 [negative 0.36, 0.09]; Group L C D, beta negative 0.53, odds ratio 0.59 [0.38, 0.90], z negative 2.43, p 0.015, Cohen’s d negative 0.29 [negative 0.53, negative 0.06]; Time Immediate, beta 0.03, odds ratio 1.03 [0.72, 1.48], z 0.19, p 0.853, Cohen’s d 0.02 [negative 0.18, 0.22]; Time Delayed, beta negative 0.02, odds ratio 0.98 [0.69, 1.41], z negative 0.09, p 0.926, Cohen’s d negative 0.01 [negative 0.21, 0.19]; u V L T, beta 0.36, odds ratio 1.44 [1.27, 1.63], z 5.63, p less than 0.001, Cohen’s d 0.20 [0.13, 0.27]; H C D times immediate, beta 0.75, odds ratio 2.12 [1.34, 3.36], z 3.22, p 0.001, Cohen’s d 0.42 [0.16, 0.67]; L C D times immediate, beta 0.98, odds ratio 2.67 [1.66, 4.29], z 4.04, p less than 0.001, Cohen’s d 0.54 [0.28, 0.80]; H C D times delayed, beta 0.89, odds ratio 2.43 [1.53, 3.84], z 3.78, p less than 0.001, Cohen’s d 0.49 [0.24, 0.74]; L C D times delayed, beta 0.71, odds ratio 2.03 [1.26, 3.27], z 2.91, p 0.004, Cohen’s d 0.39 [0.13, 0.65]. Significant effects are observed for Group L C D, u V L T, and all interaction terms, with p values less than 0.05.
Regression lines and 95% confidence intervals by group and time for the meaning recognition test.

Figure 3. Long description
From left to right, the panels are labeled Pre, Immediate, and Delayed. Each panel plots V L T z-score on the x axis from minus 1.0 to 1.0 and predicted probability on the y axis from 40 percent to 55 percent. Three colored lines represent groups: green for Control, red for H C D, and blue for L C D. All lines show a positive trend, with probability increasing as V L T z-score increases. In the Pre panel, Control starts near 46 percent, H C D near 44 percent, and L C D near 40 percent. In the Immediate panel, all groups increase, with Control and H C D converging near 50 percent, L C D slightly lower. In the Delayed panel, H C D is highest, followed by Control, then L C D. Shaded regions around each line indicate 95 percent confidence intervals, with overlap between groups. The legend at right identifies group colors.
RQ2: Prior vocabulary knowledge as a moderator of CD effects
For the meaning recall test, no significant effect of CD emerged at either the immediate or delayed posttest, indicating CD did not affect meaning recall accuracy significantly (see Tables 9 and 10). Vocabulary knowledge (uVLT) was a significant predictor in the immediate posttest (Immediate: β = 0.53, p = .026, d = 0.29), suggesting that learners with larger vocabulary knowledge achieved higher odds of correctly recognizing the target meaning. None of the CD × uVLT interactions reached significance, suggesting that the influence of CD did not differ depending on learners’ vocabulary knowledge across each test timing at the recall level.
GLMM for the meaning recall test (immediate posttest)

Table 9. Long description
The table has six columns labeled Predictor, beta, O R with 95 percent confidence interval, Cohen’s d with 95 percent confidence interval, z, and p. The first row lists Intercept with beta negative 2.12, O R 0.12 [0.06, 0.25], Cohen’s d negative 1.17 [negative 1.56, negative 0.77], z negative 5.80, p less than .001. The second row is C D colon H C D with beta 0.01, O R 1.01 [0.57, 1.80], Cohen’s d 0.01 [negative 0.31, 0.32], z 0.03, p .975. The third row is u V L T with beta 0.53, O R 1.69 [1.06, 2.68], Cohen’s d 0.29 [0.03, 0.54], z 2.22, p .026. The fourth row is Familiarity with beta 0.08, O R 1.09 [0.83, 1.43], Cohen’s d 0.05 [negative 0.10, 0.20], z 0.60, p .549. The fifth row is Pretest with beta 2.86, O R 17.46 [7.11, 43.01], Cohen’s d 1.58 [1.08, 2.07], z 6.23, p less than .001. The sixth row is H C D times u V L T with beta negative 0.01, O R 0.99 [0.52, 1.87], Cohen’s d negative 0.01 [negative 0.36, 0.35], z negative 0.04, p .967.
GLMM for the meaning recall test (delayed posttest)

Table 10. Long description
Beginning at the top row, the Intercept has a beta of minus 1.65, odds ratio 0.19 with 95 percent confidence interval 0.09 to 0.40, Cohen’s d minus 0.91 with interval minus 1.32 to minus 0.51, z value minus 4.40, and p less than .001. The next row, C D colon H C D, shows beta 0.38, odds ratio 1.46 with interval 0.86 to 2.49, Cohen’s d 0.21 with interval minus 0.08 to 0.50, z value 1.41, p .159. The third row, u V L T, has beta 0.24, odds ratio 1.27 with interval 0.83 to 1.95, Cohen’s d 0.13 with interval minus 0.10 to 0.37, z value 1.09, p .274. The fourth row, Familiarity, beta minus 0.13, odds ratio 0.88 with interval 0.68 to 1.13, Cohen’s d minus 0.07 with interval minus 0.21 to 0.07, z value minus 1.03, p .305. The fifth row, Pretest, beta 2.45, odds ratio 11.60 with interval 4.86 to 27.60, Cohen’s d 1.35 with interval 0.87 to 1.83, z value 5.52, p less than .001. The final row, H C D times u V L T, beta 0.17, odds ratio 1.18 with interval 0.66 to 2.14, Cohen’s d 0.09 with interval minus 0.23 to 0.42, z value 0.56, p .575. Each column is labeled as Predictor, beta, odds ratio with 95 percent confidence interval, Cohen’s d with 95 percent confidence interval, z, and p.
For the meaning recognition test, no CD effect was found at the immediate posttest, and at the delayed posttest, suggesting CD did not result in significantly different accuracy in the meaning recognition test (see Tables 11 and 12). Vocabulary knowledge (uVLT) also showed significant main effects at the delayed posttest (β = 0.41, p = .027, d = 1.51), indicating the importance of prior vocabulary knowledge for the retention of target items at the recognition level.
GLMM for the meaning recognition test (immediate posttest)

Table 11. Long description
From the top row downward, the predictors listed are Intercept, C D colon H C D, u V L T, Familiarity, Pretest, and H C D times u V L T. For each, columns display beta, odds ratio with ninety-five percent confidence interval, Cohen’s d with confidence interval, z value, and p value. The Intercept has beta minus zero point three five, odds ratio zero point seven one [zero point four two, one point one nine], Cohen’s d minus zero point one nine [minus zero point four eight, zero point zero nine], z minus one point three one, p point one nine zero. C D colon H C D has beta minus zero point one six, odds ratio zero point eight five [zero point five eight, one point two five], Cohen’s d minus zero point zero nine [minus zero point three one, zero point one three], z minus zero point eight two, p point four one one. u V L T has beta zero point zero three, odds ratio one point zero three [zero point seven six, one point four one], Cohen’s d zero point zero two [minus zero point one five, zero point one nine], z zero point two zero, p point eight four four. Familiarity has beta minus zero point zero eight, odds ratio zero point nine two [zero point seven six, one point one two], Cohen’s d minus zero point zero four [minus zero point one five, zero point zero six], z minus zero point eight two, p point four one five. Pretest has beta one point five eight, odds ratio four point eight four [three point three four, seven point zero three], Cohen’s d zero point eight seven [zero point six seven, one point zero eight], z eight point three one, p less than point zero zero one. H C D times u V L T has beta zero point six two, odds ratio one point eight five [one point one nine, two point eight nine], Cohen’s d zero point three four [zero point zero nine, zero point five nine], z two point seven one, p point zero zero seven. Pretest and H C D times u V L T are statistically significant, as indicated by their p values.
GLMM for the meaning recognition test (delayed posttest)

Table 12. Long description
Starting from the top row, the intercept has a beta of minus 0.91, odds ratio 0.40 with 95 percent confidence interval 0.22 to 0.75, Cohen’s d minus 0.50 with interval minus 0.84 to minus 0.16, z minus 2.87, p point zero zero four. The next row, C D colon H C D, beta 0.42, odds ratio 1.51 with interval 0.97 to 2.37, Cohen’s d 0.23 with interval minus 0.02 to 0.48, z 1.82, p point zero six nine. The third row, u V L T, beta 0.41, odds ratio 1.51 with interval 1.05 to 2.16, Cohen’s d 0.23 with interval 0.03 to 0.43, z 2.21, p point zero two seven. The fourth row, Familiarity, beta minus 0.05, odds ratio 0.95 with interval 0.76 to 1.19, Cohen’s d minus 0.03 with interval minus 0.15 to 0.09, z minus 0.44, p point six five nine. The fifth row, Pretest, beta 2.04, odds ratio 7.65 with interval 5.09 to 11.50, Cohen’s d 1.12 with interval 0.90 to 1.35, z 9.79, p less than point zero zero one. The final row, H C D times u V L T, beta 0.09, odds ratio 1.09 with interval 0.66 to 1.81, Cohen’s d 0.05 with interval minus 0.23 to 0.33, z 0.34, p point seven three six.
As for the interaction between CD × uVLT, it is notable that the interaction was significant at the immediate posttest (β = 0.62, p = .007, d = 0.34; see Figure 4). This interaction indicates that the effect of CD varied according to learners’ vocabulary size: learners with larger vocabulary knowledge were more likely to achieve higher recognition accuracy under the HCD condition, whereas those with smaller vocabulary knowledge tended to benefit more from the LCD condition, especially in the immediate posttest. At the delayed posttest, this interaction was no longer significant (β = 0.09, p = .736), suggesting that the moderating influence of vocabulary knowledge on CD effects was prominent in the early stages of learning.
Interaction between CD and uVLT for the meaning recognition at the immediate posttest.

Figure 4. Long description
The x-axis is labeled V L T z-score, ranging from approximately minus 1.5 to 2.5. The y-axis is labeled Probability of Accurate Recognition, ranging from 20 percent to 70 percent. Two lines are plotted: the H C D group is shown in red and increases linearly from about 20 percent at the lowest z-score to over 60 percent at the highest, with a shaded confidence band. The L C D group is shown in blue and remains nearly flat at around 40 percent across all z-scores, also with a shaded confidence band. The legend at the right identifies H C D in red and L C D in blue. The graph title is Predicted probabilities of Recognition.
Discussion
This study investigated how CD affects incidental vocabulary learning from reading while considering the moderating influence of prior vocabulary knowledge. In terms of relative gains, experimental groups achieved more than 10% higher in meaning recall and more than 20% higher in meaning recognition than those in the test-only control group, suggesting that reading texts with carefully controlled lexical coverage (i.e., six encounters with target items in three texts with higher than 95% lexical coverage in this study) may facilitate incidental vocabulary learning to some extent. The results with absolute gains also indicated that although both experimental groups showed learning, the amount is not so large (approximately 1 to 2 words out of the 10 target words), which is aligned with previous meta-analysis (17% for immediate posttest and 15% for the delayed posttest, Webb et al., Reference Webb, Sasao and Ballance2017). In addition, although the GLMM results suggested the possible superiority of HCD over LCD, especially in the delayed meaning recognition test, the absolute difference was only 0.24 (1.52 in HCD vs. 1.28 in LCD).
Regarding RQ1 on the effects of CD, although HCD and LCD led to similar learning gains, results suggested the potential advantage of HCD, especially in the meaning recognition test. In the first model, which included the test-only control group as a reference group, HCD achieved significantly higher accuracy than the control group on the meaning recognition test at both the immediate (p = .040, d = 0.28) and delayed posttests (p = .006, d = 0.35), whereas LCD did not (p = .091 for the immediate posttest and p = .688 for the delayed posttest). Although the effect size was small, these findings provide indirect evidence supporting the benefit of higher contextual variability for incidental vocabulary learning. Furthermore, post hoc analysis for the meaning recognition test in the first model revealed a significantly higher score at the delayed posttest for HCD compared to LCD (p = .033, d = 0.26, 95% CI [0.06, 0.45]). However, the results of the second model also showed a tendency that HCD outperformed LCD on the delayed meaning recognition test, again with a small effect (p = .069, d = 0.23). Taken together, although the effect sizes were small, the results suggest that increased contextual variability may facilitate meaning recognition, particularly if such effects accumulate over the course of a long-term, extensive reading program. At the same time, this interpretation should be treated cautiously because the effect sizes were modest and the second model suggested that the effect of CD varied depending on learners’ baseline vocabulary knowledge. Below, we discuss cognitive mechanisms underlying the potential advantage of contextually varied input for L2 vocabulary learning.
First, greater CD may be more likely to result in deeper cognitive processing (Craik & Lockhart, Reference Craik and Lockhart1972; Craik & Tulving, Reference Craik and Tulving1975). Exposure to contextually diverse texts likely promoted greater noticing of and attention to unfamiliar words during reading (Chandy et al., Reference Chandy, Serrano and Pellicer-Sánchez2025; Pagán & Nation, Reference Pagán and Nation2019), engaging deeper lexical processing. Compared to the LCD group, the HCD group may have paid more attention to unknown words with deeper processing induced by exposure to greater contextual variability at the discourse level. The level-of-processing account was also drawn to explain the benefit of varied input over verbatim repetition, as argued by Liu and Todd (Reference Liu and Todd2016), that learners’ reading different texts helps maintain a higher level of attentional engagement, whereas repeated reading lowers the perceived need to understand unknown words for achieving overall comprehension.
Although different in focus (i.e., global vs. local CD), the present results align with the argument by Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2025) that, despite small immediate learning, greater CD appeared to foster more stable long-term retention with a sustained greater attention to target items. In their study, although reading a single text repeatedly (lower CD) led to greater learning gains in the immediate meaning recognition test compared to reading three different texts (higher CD), it also led to greater loss of the learning. This suggests that lower CD may be more conducive to initial word encoding due to the availability of coherent contextual clues; however, the resulting processing may be shallower than that of higher CD. Greater contextual variability requires learners to engage more deeply with unknown words because broader contextual clues are introduced and encoded at each encounter with the same L2 word. The deeper processing induced by higher CD may account for the potential advantage of HCD for retention observed in this study.
Furthermore, the present results support the instance-based memory model of word learning (Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008), which suggests that CD fosters more consolidated word memories with incremental resonant memory of different contexts. Although participants read different texts in both experimental conditions, greater variability of genres and topics in which a target word appeared for the HCD condition may provide more memory traces for the resonance process, which might have strengthened word memory. Taken together, these findings indicate that although reading thematically and discursively related texts (i.e., lower CD) may support text comprehension, greater CD fosters deeper, more elaborative processing with richer episodic memory, which in turn supports durable lexical retention.
As for RQ2, the moderating effect of prior vocabulary knowledge on CD effects was observed in meaning recognition at the immediate posttest. The significant CD × uVLT interaction indicated that learners with larger vocabulary knowledge benefited more in the HCD condition (i.e., above a score of approximately 125 on the uVLT in this study), whereas those with smaller vocabulary knowledge benefited less. In other words, especially for the encoding of the target words, sufficient prior vocabulary knowledge is a prerequisite for benefiting from higher CD, and lower CD may favor lexically less proficient learners. Due to the limited cognitive resources (Sweller, Reference Sweller1988; Sweller et al., Reference Sweller, van Merriënboer and Paas2019), the processing demands of HCD input may exceed the cognitive capacity for learners with lower lexical proficiency and therefore constrain learning. Because learners in the HCD condition read three different texts that differed in genres and topics, those with limited vocabulary knowledge may have struggled to integrate diverse linguistic and discourse-level information efficiently. The lack of vocabulary knowledge may have reduced the efficiency of bottom-up processing, depleted attentional resources for inefficient lexical retrieval, and left little cognitive resource necessary for making successful inferences about the meaning of unknown words (Kintsch & Welsch, Reference Kintsch, Welsch, Hockley and Lewandowsky1991; Sweller et al., Reference Sweller, van Merriënboer and Paas2019). In contrast, for lexically proficient learners, reading contextually diverse texts may provide richer semantic and discourse-level cues, which can activate broader background knowledge and facilitate deeper semantic elaboration and memory encoding (Craik & Lockhart, Reference Craik and Lockhart1972; Yamashita, Reference Yamashita, Jeon and In’nami2022).
From a different theoretical viewpoint, the benefit of CD can also be explained by the framework of desirable difficulty (Bjork & Kroll, Reference Bjork and Kroll2015; Suzuki et al., Reference Suzuki, Nakata and Dekeyser2019). Specifically, a greater extent of prior vocabulary knowledge may mitigate the perceived difficulty of the task (i.e., reading for comprehension); consequently, the level of challenge presented in the HCD condition may be more beneficial for learners with high lexical proficiency. Notably, unlike previous studies manipulating CD through lexical or sentence-level variation (e.g., Liu & Todd, Reference Liu and Todd2016), we adopted the global approach to operationalizing the CD condition (i.e., genre and topic levels); therefore, our manipulation of CD likely introduced an additional layer of cognitive demands at the discourse level, beyond lexico-grammatical processing. Especially for the HCD condition, both genre and topic varied across texts, which may have induced a greater cognitive demand. Learners with a larger vocabulary knowledge may have perceived this condition to be challenging yet cognitively stimulating, thus rendering the task difficulty desirable, with the support of vocabulary knowledge. Conversely, for learners with limited vocabulary knowledge, the difficulty could exceed the threshold of a “desirable” level of cognitive difficulty, and it was likely perceived as overwhelmingly demanding. In contrast, the LCD condition may have been relatively undemanding for most learners, since genre and topic were coherent across the three texts. This consistency likely allowed readers to reuse similar background knowledge and discourse schemas, reducing cognitive effort. In this sense, LCD may have been neither too difficult for lower-proficiency learners nor sufficiently challenging for higher-proficiency learners, which could explain the weaker moderating role of vocabulary knowledge in this condition.
Conclusion
This study examined the effects of CD on L2 incidental vocabulary learning, and the findings suggested that CD potentially affects L2 vocabulary learning from reading, with the effect varying depending on learners’ prior vocabulary knowledge. Although HCD and LCD produced comparable gains overall, the benefits of HCD were limited to learners with larger vocabulary knowledge. In contrast, learners in the LCD condition showed robust learning gains regardless of vocabulary size, highlighting LCD input as a broadly facilitative and pedagogically valuable context for learners across proficiency levels.
These findings offer useful insights into how to optimize reading-based vocabulary instruction. First, regarding the influence of variability of reading materials, given that LCD led to learning gains comparable to HCD and that CD showed a significant interaction with uVLT scores, repeated exposure to thematically related content may be particularly beneficial for lower-proficiency learners. Reading texts with coherent genres and topics can activate consistent background knowledge, thereby supporting comprehension and retention (Chang, Reference Chang2019). Once learners have built a sufficient lexical foundation and discourse familiarity through narrow reading, they may be better prepared to benefit from contextually diverse texts involving varied genres and topics. Second, another promising approach is to scaffold reading input by sequencing activities from narrow reading to more diverse reading contexts. Narrow reading, where learners repeatedly encounter shared vocabulary across texts, can reduce lexical load and facilitate word recognition (Schmitt & Carter, Reference Schmitt and Carter2000). Therefore, for maximizing incidental vocabulary gains, particularly among lower-proficiency learners, it may be pedagogically beneficial to initiate reading programs with low CD materials first and gradually transition to high CD input as learners’ vocabulary knowledge and comprehension skills develop. Teachers also need to take students’ background knowledge and lexical proficiency into consideration for designing instruction.
Despite its methodological strengths, the present study has several limitations. First, the findings are based on a small number of target words (k = 10), which may limit the generalizability of the results and should be further tested in future research. This number was a result of our effort to ensure precise control over lexical coverage while maintaining enough repetitions of each target word (i.e., six times). These are the methodological issues identified in a review of previous studies (e.g., Frances et al., Reference Frances, Martin and Duñabeitia2020) that we tried to address in the current study. To address this issue, future studies should adopt a longitudinal design using longer texts while maintaining sufficient repetition for each target item (e.g., Webb & Chang, Reference Webb and Chang2015a, Reference Webb and Chang2015b). In addition, future research needs to investigate the CD effects longitudinally to clarify how extended exposure to different text types influences vocabulary acquisition over time. Learners may become familiar with a particular discourse type through repeated exposure (Chang, Reference Chang2019), which could affect the effectiveness of contextually diverse input. Indeed, Mak et al. (Reference Mak, Hsiao and Nation2021) found that LCD was more effective for initial word learning, whereas HCD yielded greater benefits once learners had first encountered new words in coherent and familiar contexts. This suggests that the effects of CD may vary depending on the timing and sequencing of exposure, highlighting the need for future research to examine such time-dependent influences of CD.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0272263126101818.
Data availability statement
Data and R code are available in OSF: https://osf.io/5xzj6/overview
Acknowledgments
We would like to express our sincere gratitude to the audience at AAAL in Denver for their helpful feedback. We are also deeply grateful to Dr. Ryuya Komuro and Dr. Ryo Maie for their continued support with data analysis and encouraging feedback. We also thank Dr. Eva Puimège for her valuable comments on refining the research design and Dr. Aline Godfroid for her helpful feedback on interpreting the results. We are grateful to Victoria-Anne Flood and Jessica Laine Rose for their contributions to material development. Finally, we thank the students who participated in this study.
Funding statement
This project was supported by the JSPS KAKENHI Grant Number 24K00080.
Competing interests
The author declares none.









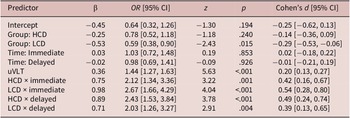









 Open access
Open access