



Aujourd’hui, les spécialistes qui ont recours aux sondages sont confrontés à de nombreux obstacles : certaines personnes sont difficiles à joindre, les taux de réponse sont très faibles, et la qualité des réponses diminue. Ces problèmes, bien connus des spécialistes depuis un certain temps (Agans et al., Reference Agans, Zeng, Shook-Sa, Boynton, Brewer, Sutfin and Goldstein2021; Berinsky, Reference Berinsky2017; de Heer et de Leeuw, Reference De Heer, de Leeuw, Groves, Dillman, Eltinge and Little2002; Yeager et al., Reference Yeager, Krosnick, Chang, Javitz, Levendusky, Simpser and Wang2011), rendent la réalisation de sondages véritablement représentatifs extrêmement coûteuse (Hillygus, Reference Hillygus and Berinski2015). Dans ce contexte, de plus en plus d’entreprises et de chercheur·e·s se tournent vers des formes de sondages plus accessibles, comme les enquêtes en ligne, dont les participants ne sont pas sélectionnés selon un processus aléatoire (Couper, Reference Couper2017; Olson et al., Reference Olson, Wagner and Anderson2021; Kennedy et al., Reference Kennedy, Popky and Keeter2023). Ce changement dans la manière de constituer les échantillons soulève une question importante : Comment s’assurer que le phénomène observé ne soit pas dû à la sélection de nos cas, mais bien qu’il reflète une tendance se retrouvant dans la population étudiée?
Cette note de recherche propose un aperçu accessible, en français, d’une littérature majoritairement anglophone et très technique, qui s’est penchée sur cette question. Nous présenterons d’abord le principe d’ignorabilité, qui permet de mieux comprendre ce qu’est un biais de sélection. Nous explorerons ensuite comment certaines techniques de pondération peuvent corriger ce biais. Enfin, nous proposerons quelques pistes pour mieux utiliser des données qui sont parfois impossibles à corriger complètement. Pour illustrer ces enjeux, commençons par un exemple.
L’intuition de la prise d’échantillons
Disons que nous désirons estimer le taux de participation des prochaines élections fédérales. Demander à chaque électeur inscrit s’il compte aller voter, c’est-à-dire faire un recensementFootnote 1 , est évidemment hors de portée. Cela est simplement trop coûteux et inutile. En effet, nous savons intuitivement qu’en sélectionnant soigneusement un certain nombre de répondants, nous serons en mesure d’estimer le taux de participation.Footnote 2 Or, la qualité de l’estimation à laquelle nous parviendrons découlera directement de la stratégie de sélection retenue, c’est-à-dire de notre échantillonnage.
Considérons un instant un échantillon de 1000 étudiant.e.s sur le campus d’une université.Footnote 3 Immédiatement, nous pouvons émettre des doutes sur la représentativité de cet échantillon. Les étudiant.e.s universitaires ne représentent qu’un segment bien particulier des électeurs. Ils sont jeunes, éduqués et bien souvent plus engagés que le reste de la population. On peut donc s’attendre à ce que cet échantillon conduise à une surévaluation du taux de participation et qu’il y ait un biais dans l’estimation en raison de la sélection des cas, ce qu’on appelle un biais de sélection. Ce biais est dû à une erreur de couverture, soit le produit d’une liste de contacts ne comprenant pas tous les individus d’une population ou des individus en trop – nous avons trop de jeunes universitaires et il nous était impossible d’obtenir d’autres types d’électeurs (Weisberg, Reference Weisberg2005).Footnote 4
Plus formellement, on peut définir le biais de sélection ainsi : il s’agit de la différence entre la valeur réelle et la valeur estimée due à la sélection des cas. Si nous sélectionnons uniquement des individus ayant voté lors du précédent scrutin – ce qui est connu comme une sélection reposant sur la variable dépendante (Brady et Collier, Reference Brady and Collier2010 : 349; Geddes, Reference Geddes1990) – nous ne serons pas surpris d’estimer des taux de participation très élevés. Formulé autrement, lorsque la règle d’échantillonnage n’assure pas la représentativité des cas, il est impossible pour les chercheur.e.s d’exclure la possibilité que la quantité mesurée (moyenne, écart-type, corrélation, etc.) soit due au processus de sélection.
La seule règle d’échantillonnage qui assure l’absence de biais de sélection est la sélection aléatoire des cas; on parle alors de sondage probabiliste,Footnote 5 pourvu que la couverture soit appropriée et que le taux de non-réponse ne soit pas corrélé à la variable d’intérêt. Or, il est difficile d’obtenir une liste exhaustive d’individus de laquelle tirer aléatoirement des répondants sans être confronté à des problèmes de couverture. Même une liste de courriels exhaustive omettrait tout individu n’en ayant pas, ouvrant ainsi la possibilité à un biais de sélection. De plus, il y a toujours le problème de la non-réponse : les individus qui acceptent de répondre aux sondages diffèrent de ceux qui refusent de le faire, ce qui a une incidence sur l’inférence.Footnote 6 La prochaine section porte sur les conditions à satisfaire pour obtenir un échantillon représentatif, ce qui nous amènera à réfléchir aux modalités à suivre afin d’identifier comment un sondage non probabiliste peut se montrer représentatif d’une population.
S’assurer de la représentativité des sondages
Quelles sont les conditions qui, une fois remplies, permettent aux chercheur.e.s d’ignorer le processus de sélection des cas comme source de biais potentiel? Le principe d’ignorabilité suggère deux conditions : (1) l’échangeabilité (exchangeability) et (2) la positivité (positivity).Footnote
7
Reprenons notre estimation du taux de participation aux prochaines élections. Notre variable d’intérêt (ou variable dépendante) est la réponse à une question du type « Avez-vous l’intention de voter aux prochaines élections? » et peut être identifiée par la variable
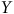 $Y$
. Nous pouvons également dénoter l’âge des répondants avec la variable
$Y$
. Nous pouvons également dénoter l’âge des répondants avec la variable
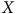 $X$
, notre variable explicative (ou variable indépendante). Afin de caractériser la prise d’échantillon, imaginons une variable
$X$
, notre variable explicative (ou variable indépendante). Afin de caractériser la prise d’échantillon, imaginons une variable
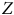 $Z$
prenant la valeur de 1 pour les individus ayant été sélectionnés et 0 dans le cas contraire.
$Z$
prenant la valeur de 1 pour les individus ayant été sélectionnés et 0 dans le cas contraire.
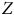 $Z$
possède ainsi une valeur pour chaque membre de la population.
$Z$
possède ainsi une valeur pour chaque membre de la population.
La Figure 1 présente différents processus générateurs de données (la sélection des cas et la mesure de nos variables) pouvant intervenir lors de notre étude sur la participation électorale.Footnote
8
Le panneau (a) de la Figure 1 représente une situation où les valeurs de
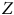 $Z$
ne sont pas influencées par une autre variable ayant une relation avec
$Z$
ne sont pas influencées par une autre variable ayant une relation avec
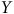 $Y$
. C’est le résultat escompté lorsque nous utilisons un sondage probabiliste. Comme aucune autre influence n’a déterminé l’appartenance à l’échantillon, on pourrait théoriquement échanger des individus sélectionnés avec ceux exclus sans affecter significativement l’estimation du taux de participation. Ce scénario respecte alors la première condition, l’échangeabilité, soit la capacité d’échanger les unités échantillonnées avec celles ayant été exclues sans modifier de manière significative la quantité d’intérêt.
$Y$
. C’est le résultat escompté lorsque nous utilisons un sondage probabiliste. Comme aucune autre influence n’a déterminé l’appartenance à l’échantillon, on pourrait théoriquement échanger des individus sélectionnés avec ceux exclus sans affecter significativement l’estimation du taux de participation. Ce scénario respecte alors la première condition, l’échangeabilité, soit la capacité d’échanger les unités échantillonnées avec celles ayant été exclues sans modifier de manière significative la quantité d’intérêt.
Représentation du mécanisme des biais de sélection.
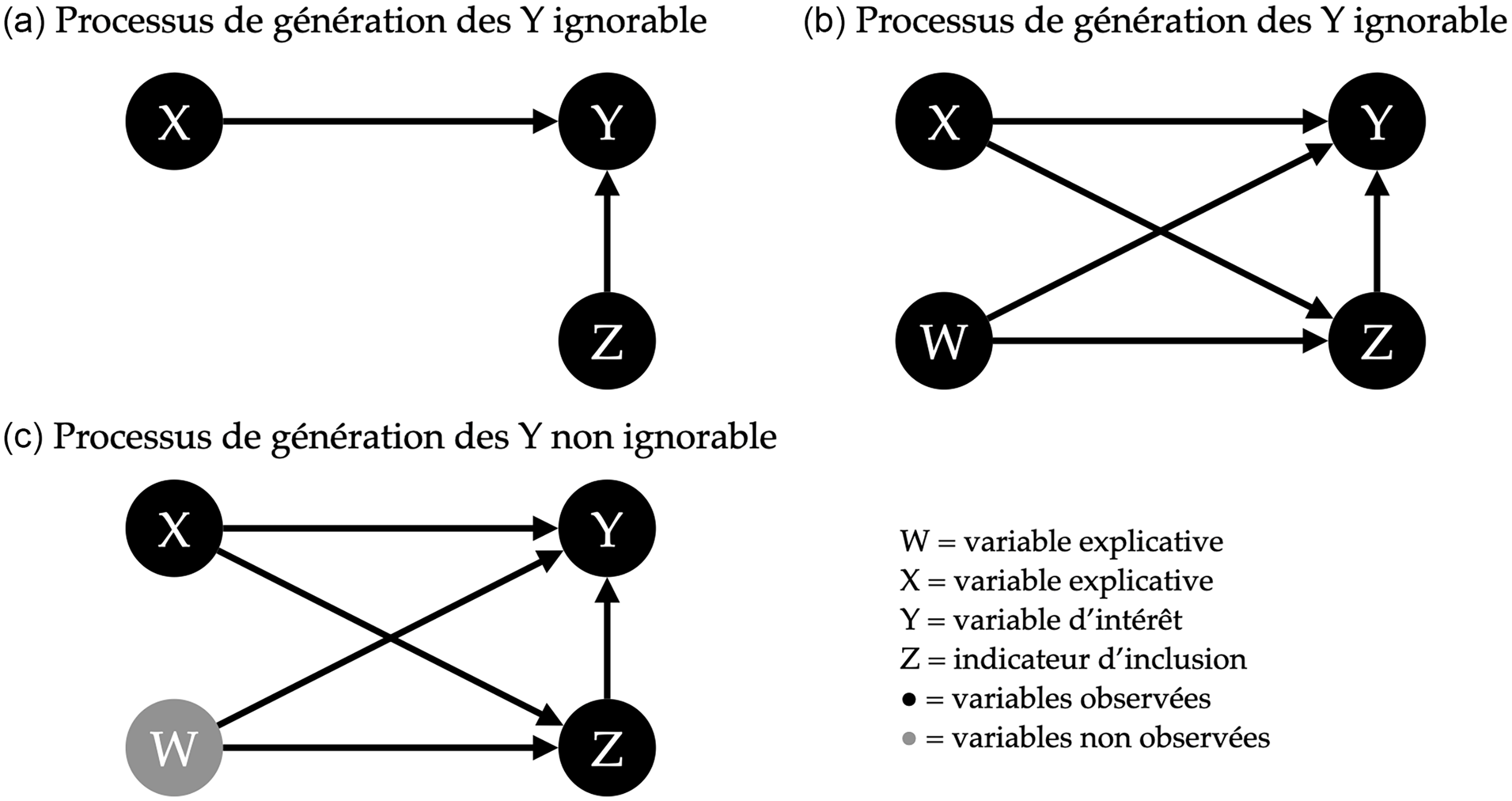
Si nous utilisons une règle non probabiliste pour la sélection des répondants, comme sélectionner aléatoirementFootnote
9
des personnes se promenant sur le campus d’une université, nous pourrions nous retrouver dans une situation où l’échantillon surreprésente les 18 à 30 ans. Le panneau (b) illustre cette situation. Si nous tentions ici d’estimer le taux de participation, nous observerions un taux de participation plus élevé que dans la population générale. On pourrait alors parler d’un biais positif dans l’estimation. Toutefois, puisque
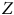 $Z$
est uniquement déterminé par l’âge (
$Z$
est uniquement déterminé par l’âge (
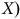 $X)$
et que celui-ci est mesuré dans ce scénario, il serait possible d’estimer l’intention de vote sans biais pour chaque catégorie d’âge de
$X)$
et que celui-ci est mesuré dans ce scénario, il serait possible d’estimer l’intention de vote sans biais pour chaque catégorie d’âge de
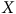 $X$
. On peut alors considérer que les individus inclus dans le sondage sont interchangeables avec les individus exclus à l’intérieur de chaque sous-groupe, ou qu’ils sont conditionnellement échangeables. Si, en plus, chaque sous-groupe de
$X$
. On peut alors considérer que les individus inclus dans le sondage sont interchangeables avec les individus exclus à l’intérieur de chaque sous-groupe, ou qu’ils sont conditionnellement échangeables. Si, en plus, chaque sous-groupe de
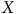 $X$
est représenté dans l’échantillon – suivant notre exemple, des répondants de 18 à 30 ans, de 31 à 50 et de 51 ans et plus – nous allons satisfaire la condition de positivité. Celle-ci demande que toutes les valeurs possibles des variables exerçant une influence sur le processus de sélection (
$X$
est représenté dans l’échantillon – suivant notre exemple, des répondants de 18 à 30 ans, de 31 à 50 et de 51 ans et plus – nous allons satisfaire la condition de positivité. Celle-ci demande que toutes les valeurs possibles des variables exerçant une influence sur le processus de sélection (
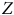 $Z$
) ainsi que sur la variable dépendante (
$Z$
) ainsi que sur la variable dépendante (
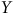 $Y$
) soient présentes dans l’échantillon. Autrement dit, si nous respectons l’échangeabilité, mais que l’échantillon ne contient pas de personnes de plus de 30 ans, il devient impossible d’ajuster l’échantillon à l’aide de poids de pondération ou toute autre technique que ce soit. On ne peut pas inventer des individus qui sont absents du sondage. Ainsi, au panneau (b), puisque nous observons toutes les valeurs possibles de
$Y$
) soient présentes dans l’échantillon. Autrement dit, si nous respectons l’échangeabilité, mais que l’échantillon ne contient pas de personnes de plus de 30 ans, il devient impossible d’ajuster l’échantillon à l’aide de poids de pondération ou toute autre technique que ce soit. On ne peut pas inventer des individus qui sont absents du sondage. Ainsi, au panneau (b), puisque nous observons toutes les valeurs possibles de
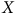 $X$
et qu’il s’agit de la seule variable influençant
$X$
et qu’il s’agit de la seule variable influençant
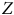 $Z$
et
$Z$
et
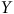 $Y$
, le processus générateur des données (PGD) est ignorable.
$Y$
, le processus générateur des données (PGD) est ignorable.
Reprenons le même sondage, mais imaginons cette fois que nous ignorons que l’échantillon a été collecté sur un campus. Nous constatons une surreprésentation de jeunes répondants puisque nous mesurons l’âge, mais nous ignorons d’où provient cette surreprésentation. Cette situation est présentée au panneau (c) de la Figure 1. Dans le cas présent, en gris,
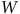 $W$
représente la variable non mesurée « aller à l’université » qui biaise à la hausse notre mesure du taux de participation. L’échangeabilité n’est donc plus uniquement conditionnelle à
$W$
représente la variable non mesurée « aller à l’université » qui biaise à la hausse notre mesure du taux de participation. L’échangeabilité n’est donc plus uniquement conditionnelle à
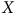 $X$
comme au panneau (b), mais également conditionnelle à
$X$
comme au panneau (b), mais également conditionnelle à
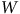 $W$
. Puisque nous n’avons pas mesuré
$W$
. Puisque nous n’avons pas mesuré
 $W$
, le processus générateur des données n’est plus ignorable et il nous est impossible de le corriger. Rappelons que même si nous avions mesuré
$W$
, le processus générateur des données n’est plus ignorable et il nous est impossible de le corriger. Rappelons que même si nous avions mesuré
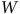 $W$
, il faudrait tenir compte de la condition additionnelle de positivité pour être en mesure de corriger notre estimation, c’est-à-dire avoir des non-universitaires dans l’échantillon. La prochaine section s’attarde à ce que l’on entend par « correction ».
$W$
, il faudrait tenir compte de la condition additionnelle de positivité pour être en mesure de corriger notre estimation, c’est-à-dire avoir des non-universitaires dans l’échantillon. La prochaine section s’attarde à ce que l’on entend par « correction ».
Post-stratification et « raking »
Lorsque nous « corrigeons » un sondage, nous voulons nous assurer que les proportions de certaines variables correspondent à celles retrouvées dans la population afin d’éviter de donner trop de poids (ou trop peu) à certaines catégories de la population et ainsi améliorer notre estimation. Les variables brisant la condition d’échangeabilité, mais pour lesquelles la positivité est respectée,Footnote 10 revêtent ainsi un intérêt particulier. Différentes techniques permettent d’arriver à ce résultat. Nous nous concentrerons sur les deux techniques phares des méthodes de calibrationFootnote 11 : la post-stratification et le « raking ».
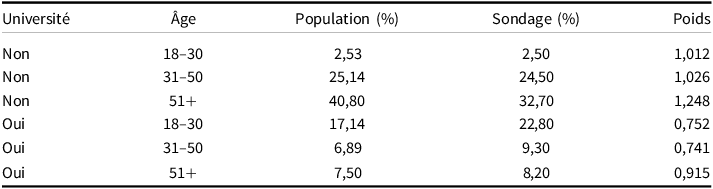
La post-stratificationFootnote 12 s’effectue en trois étapes : 1) la sélection des variables, 2) la création d’une table de stratification et 3) le calcul des poids de pondération. Comme nous l’avons vu, la sélection des variables est importante puisqu’il faut sélectionner les variables pour lesquelles la condition d’échangeabilité n’est pas respectée, sans quoi la pondération ne permettra pas de corriger le biais de sélection. Une condition pratique s’ajoute ici : il faut connaître la distribution de cette variable dans la population à l’étude. Ceci est nécessaire pour la deuxième étape, la création d’une table de stratification dont un exemple est présenté dans le Tableau 1.
Exemple de tableau de stratification
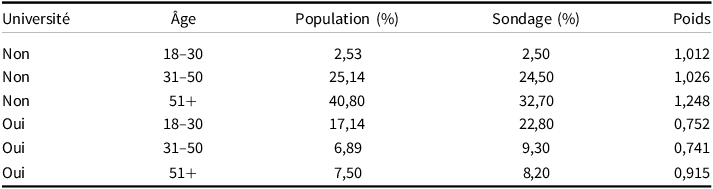
Ce dernier présente les proportions croisées de l’âge et d’une scolarité universitaire dans la population et le sondage. Clairement, la règle d’échantillonnage n’a pas reproduit les mêmes ratios populationnels. Pour les corriger, il faut créer des poids de pondération qui, une fois multipliés aux unités du sondage, permettront de corriger l’estimation du taux de participation. Par exemple, le poids pour la catégorie diplôme universitaire de plus de 51 ans est calculé selon la formule suivante :
 $${w_i} = {{Population{{\left( \% \right)}_{ij}}} \over {Sondage{{\left( \% \right)}_{ij}}}} = {{\hbox {7,50}} \over {\hbox {8,20}}} = {\hbox{0,915}}$$
$${w_i} = {{Population{{\left( \% \right)}_{ij}}} \over {Sondage{{\left( \% \right)}_{ij}}}} = {{\hbox {7,50}} \over {\hbox {8,20}}} = {\hbox{0,915}}$$
où
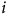 $i$
représente un répondant et
$i$
représente un répondant et
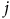 $j$
la rangée du tableau de stratification correspondante. Remarquons que, si nous multiplions la proportion du sondage avec le poids de pondération correspondant, nous obtenons la proportion populationnelle (
$j$
la rangée du tableau de stratification correspondante. Remarquons que, si nous multiplions la proportion du sondage avec le poids de pondération correspondant, nous obtenons la proportion populationnelle (
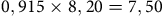 ${\hbox0,915 \times 8,20 = 7,50}$
). Une moyenne concernant une variable d’intérêt (
${\hbox0,915 \times 8,20 = 7,50}$
). Une moyenne concernant une variable d’intérêt (
 $\overline y$
) pourra alors être corrigée en multipliant les valeurs de
$\overline y$
) pourra alors être corrigée en multipliant les valeurs de
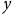 $y$
par les poids de pondération :
$y$
par les poids de pondération :
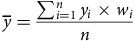 $$\overline y = {{\sum\nolimits_{i = 1}^n {{y_i}} \times {w_i}} \over n}$$
$$\overline y = {{\sum\nolimits_{i = 1}^n {{y_i}} \times {w_i}} \over n}$$
Malgré sa simplicité d’application, la post-stratification est rarement utilisée en pratique puisqu’elle exige que chaque catégorie croisée du tableau soit connue dans la population. Ces données croisées pouvant potentiellement être utilisées pour identifier les individus, elles sont rarement rendues accessibles par les entités gouvernementales les recueillant. Par exemple, Statistique Canada rend seulement disponibles les données agrégées, c’est-à-dire la proportion d’individus d’un certain âge, la proportion d’individus avec un diplôme universitaire, etc.
Le raking offre une solution alternative à la post-stratification, qui se distingue par l’utilisation de ces données agrégées. Cette technique emploie une méthode itérative; son algorithme est donc intégré à des progiciels (packages) comme anesrake (Pasek, Reference Pasek2018)Footnote 13 développés en langage R. Si nous reprenons notre exemple, le Tableau 2 contient les proportions croisées des deux variables telles que recueillies dans le sondage. Nous savons à l’aide des données agrégées du recensement que la population contient 19,67 pour cent d’individus de 18 à 30 ans, 32,03 pour cent entre 31 et 50 ans, et 48,3 pour cent de 51 ans et plus, ainsi que 31,53 pour cent d’universitaires et 68,47 pour cent de non-universitaires. Pour retrouver ces quantités par raking, il faut d’abord multiplier les cellules de chaque rangée par leur ratio respectif du total à atteindre et du total actuel. Pour passer du Tableau 2 au Tableau 3, il faut multiplier chaque cellule de la rangée « Université Non » par 68,47 ÷ 59,70 = 1,146901 et chaque cellule de la rangée « Université Oui » par 31,53 ÷ 40,30 = 0,782382. De cette façon, on obtient le bon total pour ce qui est des proportions du statut d’universitaire. Or, les proportions pour l’âge sont toujours incorrectes.
Exemple de raking – Proportions du sondage

Exemple de raking – Étape 1

Pour les corriger, il faut ensuite faire la multiplication des cellules par colonnes, et ce, à partir du Tableau 3. Le Tableau 4 présente les résultats de l’exercice qui a pour conséquence de déséquilibrer les ratios du statut d’universitaire. Il faudra donc répéter l’étape 1 puis l’étape 2, toujours à partir du dernier tableau produit, jusqu’à la convergence des deux types de ratios. Dans le cadre de cet exemple, il faudra répéter les deux étapes quatorze fois avant d’arriver à la convergence présentée au Tableau 5. Après avoir atteint la convergence, les poids de pondération seront calculés pour chaque cellule en divisant la quantité de convergence et la quantité originale. Ainsi, pour les universitaires de 18 à 30 ans, le poids de pondération sera 17,10 ÷ 22,80 = 0,750090 afin de pallier leur surreprésentation dans l’échantillon.
Exemple de raking – Étape 2

Exemple de raking – Convergence

Note: Quantités en pourcentage. Exemple inspiré de Lohr (Reference Lohr2021 : 750–752).
Soulignons que le raking ne produit pas nécessairement les mêmes proportions croisées que l’on retrouverait dans une table de stratification. Cette approximation peut rendre le raking moins efficace que la post-stratification lorsque les croisements entre groupes ne sont pas répartis aléatoirement (Caughey et al., Reference Caughey, Berinsky, Sara Chatfield, Schickler and Sekhon2020). La section qui suit présente divers cas où la pondération se montre plus ou moins en mesure de corriger le biais induit.
Corriger le biais de sélection en pratique
Dans des conditions idéales, la pondération corrige parfaitement le biais de sélection. Une démonstration de ce point est réalisée dans l’Annexe A.1.1 à l’aide de simulations. Néanmoins, en pratique, notre capacité de correction est limitée par : (1) l’impossibilité de connaître le PGD; et (2) la disponibilité limitée des variables dont nous connaissons les valeurs dans la population. Typiquement, ces variables se limitent au profil sociodémographique des répondants – des variables à la racine de la plupart des phénomènes étudiés en sciences sociales. Or, celles-ci sont suffisantes si et seulement si elles sont fortement corrélées à la variable dépendante (
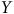 $Y$
) et à la ou aux variables à la source du biais de sélection (Mercer et al., Reference Mercer, Kreuter, Keeter and Stuart2017). Pour illustrer ce point, nous avons besoin de données répliquant plus fidèlement la réalité des interactions entre les variables présentes dans un sondage typique, variables pour lesquelles les valeurs populationnelles sont connues. Nous proposons l’utilisation des données d’un sondage à grand
$Y$
) et à la ou aux variables à la source du biais de sélection (Mercer et al., Reference Mercer, Kreuter, Keeter and Stuart2017). Pour illustrer ce point, nous avons besoin de données répliquant plus fidèlement la réalité des interactions entre les variables présentes dans un sondage typique, variables pour lesquelles les valeurs populationnelles sont connues. Nous proposons l’utilisation des données d’un sondage à grand
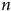 $n$
qui nous servira de population d’étude et duquel nous pourrons prendre plusieurs échantillons. Les données de Projet Quorum
Footnote
14
comprennent les réponses complètes de 12 494 répondants collectées du 26 janvier 2021 au 7 mars 2022 sur certains enjeux phares du contexte de la pandémie de COVID-19 – les applications de traçage, les restrictions sanitaires et les valeurs démocratiques. Considérons donc ce sondage comme la population à l’étude et imaginons vouloir estimer le niveau de pessimisme (
$n$
qui nous servira de population d’étude et duquel nous pourrons prendre plusieurs échantillons. Les données de Projet Quorum
Footnote
14
comprennent les réponses complètes de 12 494 répondants collectées du 26 janvier 2021 au 7 mars 2022 sur certains enjeux phares du contexte de la pandémie de COVID-19 – les applications de traçage, les restrictions sanitaires et les valeurs démocratiques. Considérons donc ce sondage comme la population à l’étude et imaginons vouloir estimer le niveau de pessimisme (
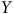 $Y$
) dans cette même population (une échelle de 0 à 1).
$Y$
) dans cette même population (une échelle de 0 à 1).
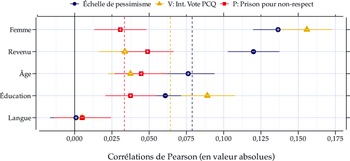
Imaginons également que nous avons accès à 3 sondages non probabilistes de 1000 individus et à la distribution dans la population (1) du genre, (2) du revenu, (3) de l’âge, (4) de l’éducation et (5) de la langue. Le premier sondage, nous le voyons dans les données, surreprésente les femmes. Nous devrions ainsi être en mesure de corriger ce biais si nous respectons la positivité – plus précisément si nous avons des hommes dans l’échantillon. Or, les deux autres surreprésentent respectivement les individus ayant l’intention de voter pour le Parti conservateur du Québec (PCQ) et les individus appuyant l’idée que l’État devrait emprisonner les individus ne respectant pas les mesures sanitaires. La Figure 2 présente les relations entre nos variables de pondération, l’échelle de pessimisme et les variables causant le biais de sélection dans la population.
Force de la relation avec les variables d’intérêts.
Notes: Données issues de Projet Quorum et collectées du 26 janvier 2021 au 7 mars 2022;
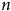 $n$
=12 494. Les signes à l’intérieur des points représentent la direction de la relation. Les lignes pointillées correspondent à la corrélation moyenne entre les variables de pondération et les variables d’intérêts. Intervalles de confiance (95 %) générées par bootstrap à l’aide du progiciel confintr (Mayer, Reference Mayer2023). Libellé des questions au Tableau A.2 dans l’Annexe A.
$n$
=12 494. Les signes à l’intérieur des points représentent la direction de la relation. Les lignes pointillées correspondent à la corrélation moyenne entre les variables de pondération et les variables d’intérêts. Intervalles de confiance (95 %) générées par bootstrap à l’aide du progiciel confintr (Mayer, Reference Mayer2023). Libellé des questions au Tableau A.2 dans l’Annexe A.
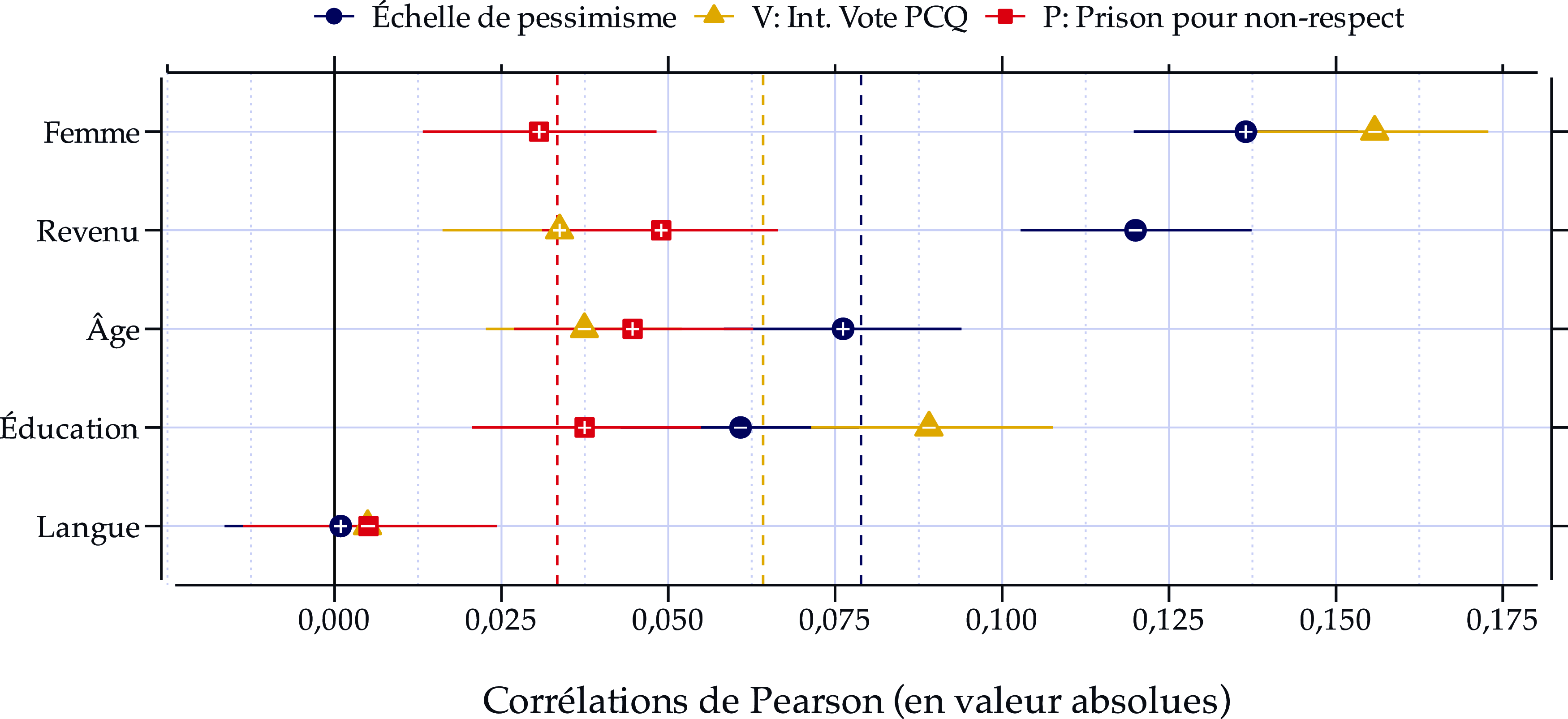
Notons d’abord que parmi les variables sociodémographiques, seuls le genre (
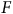 $F$
) et le revenu possèdent une corrélation importante avec l’échelle de pessimisme. Ceci indique qu’il nous sera impossible de corriger significativement un biais sur l’échelle de pessimisme si nous nous restreignons à l’éducation et à la langue, par exemple. Le premier sondage surreprésente les femmes. Puisque le genre est la variable sociodémographique la plus corrélée avec le pessimisme dans ce contexte, nous pouvons nous attendre à ce que l’estimation soit biaisée à la hausse. Or, puisqu’il est inclus dans les variables de pondération, nous devrions être en mesure de corriger ce biais.
$F$
) et le revenu possèdent une corrélation importante avec l’échelle de pessimisme. Ceci indique qu’il nous sera impossible de corriger significativement un biais sur l’échelle de pessimisme si nous nous restreignons à l’éducation et à la langue, par exemple. Le premier sondage surreprésente les femmes. Puisque le genre est la variable sociodémographique la plus corrélée avec le pessimisme dans ce contexte, nous pouvons nous attendre à ce que l’estimation soit biaisée à la hausse. Or, puisqu’il est inclus dans les variables de pondération, nous devrions être en mesure de corriger ce biais.
Notons ensuite que ces mêmes variables sont moins corrélées en moyenne avec l’intention de vote pour le PCQ (
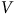 $V$
) et encore moins corrélées en moyenne avec l’emprisonnement lié au non-respect des mesures sanitaires (
$V$
) et encore moins corrélées en moyenne avec l’emprisonnement lié au non-respect des mesures sanitaires (
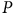 $P$
). Ceci implique que si ces variables (
$P$
). Ceci implique que si ces variables (
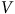 $V$
et
$V$
et
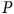 $P$
) sont fortement corrélées avec le pessimisme – et elles le sont (
$P$
) sont fortement corrélées avec le pessimisme – et elles le sont (
 $Corr\left( {V,Y} \right) = - 0,17$
;
$Corr\left( {V,Y} \right) = - 0,17$
;
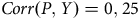 $Corr\left( {P,Y} \right) = 0,25$
) – nous ne pourrons que partiellement réduire le biais à l’aide des variables sociodémographiques. Afin d’estimer le pouvoir de correction de ces variables sociodémographiques dans le contexte des trois sondages, simulons la prise de 100 échantillons de 1000 personnes pour chaque contexte (biais causé par
$Corr\left( {P,Y} \right) = 0,25$
) – nous ne pourrons que partiellement réduire le biais à l’aide des variables sociodémographiques. Afin d’estimer le pouvoir de correction de ces variables sociodémographiques dans le contexte des trois sondages, simulons la prise de 100 échantillons de 1000 personnes pour chaque contexte (biais causé par
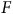 $F$
,
$F$
,
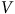 $V$
et
$V$
et
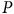 $P$
).Footnote
15
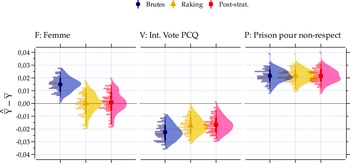
La Figure 3 présente la distribution des biais induits, leur moyenne, ainsi que ce qu’il en advient lorsqu’il est corrigé par raking et post-stratification.
$P$
).Footnote
15
La Figure 3 présente la distribution des biais induits, leur moyenne, ainsi que ce qu’il en advient lorsqu’il est corrigé par raking et post-stratification.
Effet des techniques de correction sur l’estimation du niveau de pessimisme.
Note: Données simulées à partir de Projet Quorum. 100 échantillons de 1000 unités par cas.
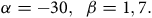 ${\rm{\alpha }} = - 30,\;\;\beta = 1,7.\;$
Variables :
${\rm{\alpha }} = - 30,\;\;\beta = 1,7.\;$
Variables :
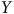 $Y$
l’échelle de pessimisme,
$Y$
l’échelle de pessimisme,
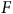 $F$
s’identifier comme femme,
$F$
s’identifier comme femme,
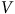 $V$
intention de voter pour le PCQ,
$V$
intention de voter pour le PCQ,
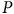 $P$
opinion sur l’emprisonnement des individus ne respectant pas les mesures sanitaires. Corrélations :
$P$
opinion sur l’emprisonnement des individus ne respectant pas les mesures sanitaires. Corrélations :
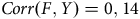 $Corr\left( {F,Y} \right) = 0,14$
;
$Corr\left( {F,Y} \right) = 0,14$
;
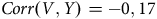 $Corr\left( {V,Y} \right) = - 0,17$
;
$Corr\left( {V,Y} \right) = - 0,17$
;
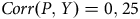 $Corr\left( {P,Y} \right) = 0,25$
.
$Corr\left( {P,Y} \right) = 0,25$
.
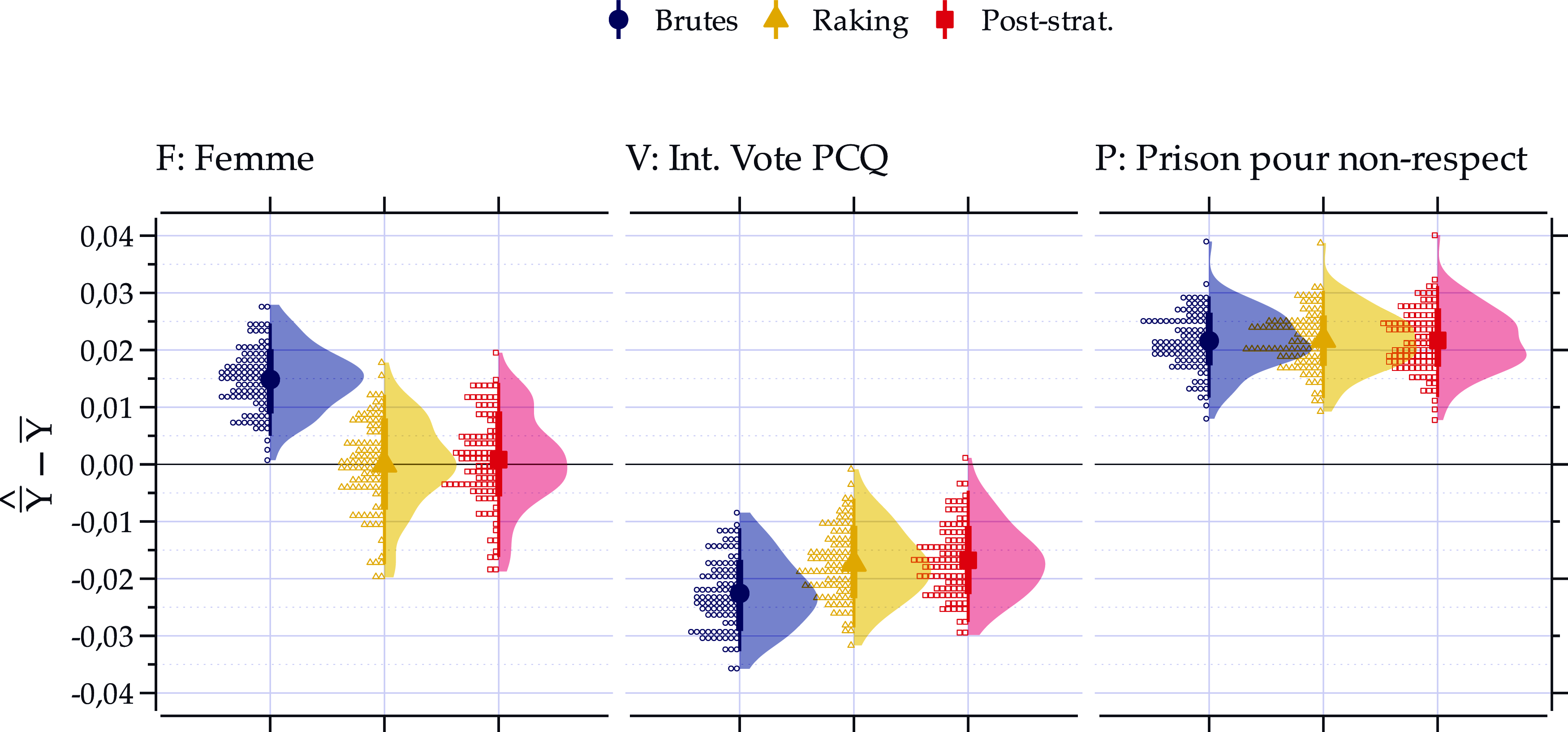
Comme prévu, il est possible de constater un biais dans l’estimation du pessimisme dans chacun des cas, positif lorsque la corrélation avec
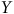 $Y$
est positive et négatif dans le cas contraire. Pour le premier sondage, la pondération basée sur les variables sociodémographiques suffit à corriger le biais en moyenne.Footnote
16
Ce n’est pas surprenant, puisque le biais vient du genre et que nous corrigeons pour cette variable. Lorsque la variable causant le biais ne se retrouve pas dans les variables de correction, comme dans les deux autres cas, le pouvoir de correction de la pondération devient une fonction de la relation entre les variables de correction et la variable causant le biais. On constate que nous arrivons à corriger l’estimation partiellement dans le deuxième sondage et pas du tout dans le troisième.
$Y$
est positive et négatif dans le cas contraire. Pour le premier sondage, la pondération basée sur les variables sociodémographiques suffit à corriger le biais en moyenne.Footnote
16
Ce n’est pas surprenant, puisque le biais vient du genre et que nous corrigeons pour cette variable. Lorsque la variable causant le biais ne se retrouve pas dans les variables de correction, comme dans les deux autres cas, le pouvoir de correction de la pondération devient une fonction de la relation entre les variables de correction et la variable causant le biais. On constate que nous arrivons à corriger l’estimation partiellement dans le deuxième sondage et pas du tout dans le troisième.
La pondération a donc la capacité de corriger parfaitement les biais de sélection, même lorsque le processus d’échantillonnage n’est pas aléatoire. Or, il faut connaître le PGD afin d’être en mesure d’identifier les variables qui empêchent de respecter la condition d’échangeabilité. Ceci est une quasi-impossibilité pour les sondages non probabilistes. En effet, sans contrôle du PGD et avec des théories limitées sur ce à quoi il peut ressembler, les chercheur.e.s ne peuvent présenter qu’une présomption théorique limitée par les variables disponibles dans les données du recensement. Même lorsque le PGD hypothétique est proche de la réalité, les chercheur.e.s sont limité.e.s par les données du recensement. Les modèles de prédiction des attitudes allaient au-delà des variables sociodémographiques dès 1960 (Campbell et al., Reference Campbell, Converse, Miller and Stokes1960), alors l’idée qu’un seul vecteur de pondération basé sur des variables sociodémographiques suffise à corriger même une seule estimation apparaît absurde.
Cet état de fait est reflété par des études appliquées s’étant penchées sur la qualité des données non probabilistes comme celles de Dutwin et Buskirk (Reference Dutwin and Buskirk2017), Felderer et al. (Reference Felderer, Kirchner and Kreuter2019), MacInnis et al. (Reference MacInnis, Krosnick, Ho and Cho2018), Pasek et Krosnick (Reference Pasek and Krosnick2010), Stern et al. (Reference Stern, Bilgen, McClain and Hunscher2017), et Yeager et al. (Reference Yeager, Krosnick, Chang, Javitz, Levendusky, Simpser and Wang2011). Toutes ces études comparent des sondages probabilistes à des sondages non probabilistes et toutes concluent que la pondération n’arrive pas à effacer les biais induits. Seuls quelques cas rapportent un tel succès : Ansolabehere et Schaffner (Reference Ansolabehere and Schaffner2014), Gelman et al. (Reference Gelman, Goel, Rivers and Rothschild2016), et Wang et al. (Reference Wang, Rothschild, Goel and Gelman2015).Footnote 17 Ces études témoignent bien plus de la difficulté de la tâche que d’une solution miracle. Encore une fois, l’incapacité à effacer le biais de sélection n’est pas due à une limite technique ou statistique de la correction, mais bien à un échec de la sélection des variables de pondération.
Un plus grand
 $n$
, ça vaut la peine?
$n$
, ça vaut la peine?
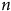
Pour un échantillon probabiliste, augmenter la taille (
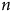 $n$
) permet de réduire l’erreur d’échantillonnage pour la moyenne d’une variable
$n$
) permet de réduire l’erreur d’échantillonnage pour la moyenne d’une variable
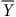 $\overline Y$
selon
$\overline Y$
selon
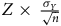 $Z \times {{{\sigma _Y}} \over {\sqrt n }}$
(Lohr, Reference Lohr2021). Cette même intuition ne doit toutefois pas être transférée au contexte non probabiliste. À la lumière du principe d’ignorabilité, il est effectivement possible de définir le biais de sélection comme la différence entre la moyenne estimée (
$Z \times {{{\sigma _Y}} \over {\sqrt n }}$
(Lohr, Reference Lohr2021). Cette même intuition ne doit toutefois pas être transférée au contexte non probabiliste. À la lumière du principe d’ignorabilité, il est effectivement possible de définir le biais de sélection comme la différence entre la moyenne estimée (
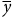 $\overline y$
) et la moyenne de la population (
$\overline y$
) et la moyenne de la population (
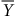 $\overline Y$
) en fonction de la taille de l’échantillon (
$\overline Y$
) en fonction de la taille de l’échantillon (
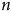 $n$
), la taille de la population (
$n$
), la taille de la population (
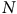 $N$
), l’écart-type de
$N$
), l’écart-type de
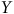 $Y$
dans la population (
$Y$
dans la population (
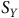 ${S_Y}$
), ainsi que la corrélation entre
${S_Y}$
), ainsi que la corrélation entre
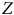 $Z$
et
$Z$
et
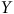 $Y$
(Lohr, Reference Lohr2021).Footnote
18
Formellement, l’équation se comprend comme suit :
$Y$
(Lohr, Reference Lohr2021).Footnote
18
Formellement, l’équation se comprend comme suit :
Si l’équation peut paraître intimidante, il s’agit en fait de la multiplication de trois termes : 1)
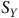 ${S_Y}$
est l’écart-type de la variable d’intérêt dans la population; 2) le terme sous la racine carrée est essentiellement un ratio entre la taille de la population et la taille de l’échantillon; et 3)
${S_Y}$
est l’écart-type de la variable d’intérêt dans la population; 2) le terme sous la racine carrée est essentiellement un ratio entre la taille de la population et la taille de l’échantillon; et 3)
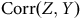 ${\rm{Corr}}\left( {Z,Y} \right)$
correspond à la corrélation entre la variable d’intérêt et le processus de sélection. Le pouvoir de l’aléatoire est alors évident : si
${\rm{Corr}}\left( {Z,Y} \right)$
correspond à la corrélation entre la variable d’intérêt et le processus de sélection. Le pouvoir de l’aléatoire est alors évident : si
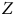 $Z$
est déterminée aléatoirement, alors sa corrélation avec
$Z$
est déterminée aléatoirement, alors sa corrélation avec
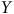 $Y$
sera 0 et le biais disparaîtra.
$Y$
sera 0 et le biais disparaîtra.
Bien que les simulations présentées plus haut le permettent, il est rare d’avoir le contrôle sur l’écart-type de
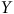 $Y$
ou sur sa corrélation avec
$Y$
ou sur sa corrélation avec
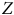 $Z$
(dans le contexte d’un échantillon non probabiliste). Ces éléments sont plutôt fixés par la nature lors de la prise de l’échantillon. Dans ce contexte, l’unique valeur exerçant une influence sur le biais de
$Z$
(dans le contexte d’un échantillon non probabiliste). Ces éléments sont plutôt fixés par la nature lors de la prise de l’échantillon. Dans ce contexte, l’unique valeur exerçant une influence sur le biais de
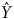 $\hat Y$
et qui peut être contrôlée est
$\hat Y$
et qui peut être contrôlée est
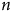 $n$
. À première vue, le terme central
$n$
. À première vue, le terme central
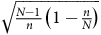 $\sqrt {{{N - 1} \over n}\left( {1 - {n \over N}} \right)} $
diminue lorsque
$\sqrt {{{N - 1} \over n}\left( {1 - {n \over N}} \right)} $
diminue lorsque
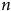 $n$
augmente, ce qui justifierait l’intuition selon laquelle augmenter
$n$
augmente, ce qui justifierait l’intuition selon laquelle augmenter
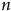 $n$
réduit
$n$
réduit
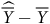 $\widehat {\overline Y} - \overline Y$
. Simulons une prise d’échantillon auprès de 31 000 000 d’unités dont le PGD correspond à celui du panneau (b) de la Figure 1 (
$\widehat {\overline Y} - \overline Y$
. Simulons une prise d’échantillon auprès de 31 000 000 d’unités dont le PGD correspond à celui du panneau (b) de la Figure 1 (
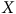 $X$
influence
$X$
influence
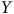 $Y$
et
$Y$
et
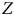 $Z$
, et
$Z$
, et
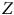 $Z$
influence
$Z$
influence
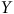 $Y$
) en variant le
$Y$
) en variant le
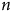 $n$
(de 1 000 à 20 000 000) pour tester cette intuition.
$n$
(de 1 000 à 20 000 000) pour tester cette intuition.
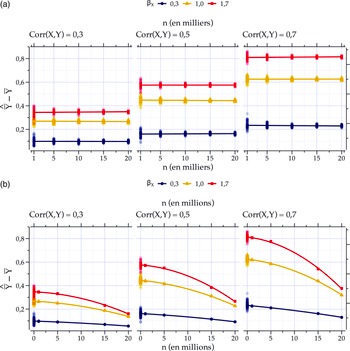
Le panneau (a) de la Figure 4 est catégorique : le seul effet positif d’une augmentation du
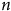 $n$
d’un échantillon non probabiliste est une diminution de la variance du biais et non pas une diminution du biais lui-même. En effet, indépendamment de la
$n$
d’un échantillon non probabiliste est une diminution de la variance du biais et non pas une diminution du biais lui-même. En effet, indépendamment de la
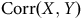 ${\rm{Corr}}\left( {X,Y} \right)$
ou de la force de la relation entre
${\rm{Corr}}\left( {X,Y} \right)$
ou de la force de la relation entre
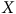 $X$
et
$X$
et
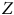 $Z$
(
$Z$
(
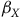 ${\beta _X}$
), le biais moyen en espérance demeure le même alors que
${\beta _X}$
), le biais moyen en espérance demeure le même alors que
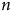 $n$
augmente. Il ne s’agit d’ailleurs pas de petites augmentations de
$n$
augmente. Il ne s’agit d’ailleurs pas de petites augmentations de
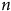 $n$
; même à 20 000 unités, le biais ne bouge pas. Pour percevoir une diminution du biais, il faut un échantillon contenant 5 000 000 d’unités, comme le montre le panneau (b). Or, un
$n$
; même à 20 000 unités, le biais ne bouge pas. Pour percevoir une diminution du biais, il faut un échantillon contenant 5 000 000 d’unités, comme le montre le panneau (b). Or, un
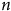 $n$
de cette magnitude n’est pas suffisant pour corriger complètement le biais. En fait, la différence est négligeable dans les cas où le biais d’origine est élevé. Pire encore, à
$n$
de cette magnitude n’est pas suffisant pour corriger complètement le biais. En fait, la différence est négligeable dans les cas où le biais d’origine est élevé. Pire encore, à
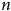 $n$
= 15 000 000, soit approximativement la moitié de la population simulée, le biais n’est toujours pas corrigé. Augmenter le
$n$
= 15 000 000, soit approximativement la moitié de la population simulée, le biais n’est toujours pas corrigé. Augmenter le
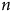 $n$
n’est donc pas une stratégie viable à la correction des sondages non probabilistes. Ceci est dû au fait que
$n$
n’est donc pas une stratégie viable à la correction des sondages non probabilistes. Ceci est dû au fait que
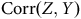 ${\rm{Corr}}\left( {Z,Y} \right)$
est partiellement dépendante de
${\rm{Corr}}\left( {Z,Y} \right)$
est partiellement dépendante de
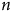 $n$
, de sorte que la corrélation augmente alors que
$n$
, de sorte que la corrélation augmente alors que
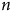 $n$
augmente.Footnote
19
Augmenter
$n$
augmente.Footnote
19
Augmenter
 $n$
n’a donc de mérite que lorsque l’objectif est de respecter la condition de positivité, dans le but, par exemple, de s’assurer d’avoir suffisamment de francophones dans un échantillon canadien.
$n$
n’a donc de mérite que lorsque l’objectif est de respecter la condition de positivité, dans le but, par exemple, de s’assurer d’avoir suffisamment de francophones dans un échantillon canadien.
Effet de la taille d’échantillon sur la magnitude de
 $\widehat {\overline Y} - \;\overline Y$
.
$\widehat {\overline Y} - \;\overline Y$
.
Note: Données issues d’une simulation. Tendances générées par régression linéaire (OLS). Points correspondant à la moyenne du biais brut des itérations. Dans tous les cas, N = 31 000 000, Y est continu et distribué normalement (
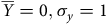 $\overline Y = 0,{\sigma _y} = 1$
),X est une échelle de Likert à 4 niveaux (0, 1, 2, 3), et Z est binaire (0, 1), indiquant l’inclusion dans l’échantillon.
$\overline Y = 0,{\sigma _y} = 1$
),X est une échelle de Likert à 4 niveaux (0, 1, 2, 3), et Z est binaire (0, 1), indiquant l’inclusion dans l’échantillon.
Que doit-on faire alors?
En l’absence de connaissance du PGD, la sélection aléatoire constitue la meilleure solution pour éviter le biais de sélection. Il faut toutefois s’assurer d’avoir une couverture appropriée et que la non-réponse ne soit pas corrélée à la variable d’intérêt. Or, l’accès à des échantillons probabilistes est souvent impossible. Il existe néanmoins une avenue permettant de mobiliser les données issues d’échantillons non probabilistes : les analyses de sensibilité.Footnote 20
Développées par Rosenbaum (Reference Rosenbaum2005), celles-ci ont pour objectif de donner une idée de la vulnérabilité face à un éventuel biais de variable omise des résultats d’une analyse causale basée sur des données observationnelles. En évaluant la force qu’une variable non mesurée devrait avoir pour nullifier l’effet mesuré, voire l’inverser, et en la comparant avec la corrélation d’une des variables mesurées avec la variable d’intérêt, les analyses de sensibilité permettent de relativiser l’influence d’un potentiel biais de variable omise (Cinelli et Hazlett, Reference Cinelli and Hazlett2020). Ce faisant, il est possible de défendre les résultats d’une analyse causale réalisée à partir de données observationnelles devant la critique du biais de variable omise. Certes, la relation n’est pas identifiée, mais l’analyse peut permettre de découvrir qu’une variable omise devrait avoir une relation beaucoup trop grande avec
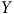 $Y$
pour significativement influencer la mesure de l’effet.
$Y$
pour significativement influencer la mesure de l’effet.
Hartman et Huang (Reference Hartman and Huang2024) adaptent l’analyse de sensibilité au contexte descriptif en se concentrant sur la différence entre les poids de pondération estimés et les poids de pondération idéaux (
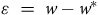 ${\rm{\varepsilon \;}} = \;w - {w^*}$
). L’équation 1 est alors reformulée ainsi :
${\rm{\varepsilon \;}} = \;w - {w^*}$
). L’équation 1 est alors reformulée ainsi :
 $${\rm{Biais}}\left( {\overline y} \right) = E\left[ {\overline y - \overline Y} \right] = E\left[ {{\rm{Corr}}\left( {\varepsilon, Y} \right)} \right] \times \sqrt {{S_Y} \times {S_w} \times \;{{R_\varepsilon ^2} \over {1 - R_\varepsilon ^2}}\;} \;\forall \;R_\varepsilon ^2 \lt 1$$
$${\rm{Biais}}\left( {\overline y} \right) = E\left[ {\overline y - \overline Y} \right] = E\left[ {{\rm{Corr}}\left( {\varepsilon, Y} \right)} \right] \times \sqrt {{S_Y} \times {S_w} \times \;{{R_\varepsilon ^2} \over {1 - R_\varepsilon ^2}}\;} \;\forall \;R_\varepsilon ^2 \lt 1$$
où
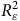 $R_{\rm{\varepsilon }}^2$
est le ratio de variation en
$R_{\rm{\varepsilon }}^2$
est le ratio de variation en
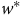 ${w^*}$
expliqué par
${w^*}$
expliqué par
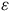 ${\rm{\varepsilon }}$
et est
${\rm{\varepsilon }}$
et est
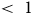 $ \lt \;1$
. L’idée est de faire varier
$ \lt \;1$
. L’idée est de faire varier
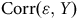 ${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
afin d’identifier les conditions sous lesquelles l’ajustement des poids de pondération est insuffisant. Ceci permet alors d’identifier les situations où pondérer en utilisant les variables disponibles du recensement suffit à corriger le biais et les situations où des analyses descriptives sont à éviter. Or, cette approche repose sur les chercheur.e.s pour poser les valeurs de
${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
afin d’identifier les conditions sous lesquelles l’ajustement des poids de pondération est insuffisant. Ceci permet alors d’identifier les situations où pondérer en utilisant les variables disponibles du recensement suffit à corriger le biais et les situations où des analyses descriptives sont à éviter. Or, cette approche repose sur les chercheur.e.s pour poser les valeurs de
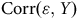 ${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
et de
${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
et de
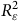 $R_{\rm{\varepsilon }}^2$
, ce qui ne règle pas totalement le problème, car ces décisions reposent toujours sur le contexte théorique et sur l’idée que les chercheur.e.s se font du PGD.
$R_{\rm{\varepsilon }}^2$
, ce qui ne règle pas totalement le problème, car ces décisions reposent toujours sur le contexte théorique et sur l’idée que les chercheur.e.s se font du PGD.
Pour diminuer les effets découlant de ce problème, Hartman et Huang (Reference Hartman and Huang2024) produisent des graphes de contours (contour plots). Ceux-ci permettent de visualiser plusieurs combinaisons de
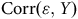 ${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
et de
${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
et de
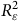 $R_{\rm{\varepsilon }}^2$
ainsi que leur impact sur le biais théorique
$R_{\rm{\varepsilon }}^2$
ainsi que leur impact sur le biais théorique
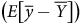 $\left(E\left[ {\overline y - \overline Y} \right]\right)$
. Prenons comme exemple l’un des échantillons biaisés sur le genre ayant été produit à la Figure 3. Suivant la procédure de Hartman et Huang (Reference Hartman and Huang2024), nous produisons des poids de pondération à l’aide de raking. Rappelons que, dans ce scénario, nous avons uniquement accès aux variables sociodémographiques pour produire nos poids de pondération. Nous obtenons alors un échantillon produisant une moyenne de pessimisme (
$\left(E\left[ {\overline y - \overline Y} \right]\right)$
. Prenons comme exemple l’un des échantillons biaisés sur le genre ayant été produit à la Figure 3. Suivant la procédure de Hartman et Huang (Reference Hartman and Huang2024), nous produisons des poids de pondération à l’aide de raking. Rappelons que, dans ce scénario, nous avons uniquement accès aux variables sociodémographiques pour produire nos poids de pondération. Nous obtenons alors un échantillon produisant une moyenne de pessimisme (
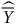 $\widehat {\overline Y}$
) est à 0,39 et la moyenne pondérée (
$\widehat {\overline Y}$
) est à 0,39 et la moyenne pondérée (
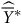 ${\widehat {\overline Y}^*}$
) est à 0,42 là où nous savons que la valeur populationnelle est à 0,415. Nous pouvons également calculer la variance de notre estimation (
${\widehat {\overline Y}^*}$
) est à 0,42 là où nous savons que la valeur populationnelle est à 0,415. Nous pouvons également calculer la variance de notre estimation (
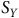 ${S_Y}$
) ainsi que la variance des poids de pondérations (
${S_Y}$
) ainsi que la variance des poids de pondérations (
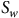 ${S_w}$
).
${S_w}$
).
Puisque
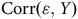 ${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
et de
${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
et de
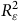 $R_{\rm{\varepsilon }}^2$
varient respectivement entre −1 et 1 et 0 et 1, nous sommes en mesure de produire un biais théorique pour chaque combinaison possible. Ceux-ci sont présentés à la Figure 5 panneau (a) et correspondent aux lignes noires à l’intérieure du graphique. Ainsi, un biais de +0,2 peut être produit par toutes les combinaisons de valeurs de
$R_{\rm{\varepsilon }}^2$
varient respectivement entre −1 et 1 et 0 et 1, nous sommes en mesure de produire un biais théorique pour chaque combinaison possible. Ceux-ci sont présentés à la Figure 5 panneau (a) et correspondent aux lignes noires à l’intérieure du graphique. Ainsi, un biais de +0,2 peut être produit par toutes les combinaisons de valeurs de
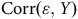 ${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
et de
${\rm{Corr}}\left( {{\rm{\varepsilon }},Y} \right)$
et de
 $R_{\rm{\varepsilon }}^2$
se trouvant sur la ligne. Seul, ce graphique n’est pas très informatif. Le véritable tour de force de Hartman et Huang (Reference Hartman and Huang2024) est d’y superposer deux informations additionnelles.
$R_{\rm{\varepsilon }}^2$
se trouvant sur la ligne. Seul, ce graphique n’est pas très informatif. Le véritable tour de force de Hartman et Huang (Reference Hartman and Huang2024) est d’y superposer deux informations additionnelles.
Sensibilité de l’estimation à un biais de variable omise.
Note: Données simulées à partir de Projet Quorum. Analyse réalisée sur l’un des échantillons de la Figure 3 pour chaque variable utilisée pour biaiser l’échantillon. Poids de pondérations produit à partir de raking sur les variables socio-démographiques utilisées plus haut.
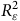 $R_{\rm{\varepsilon }}^2$
est le ratio de variation en
$R_{\rm{\varepsilon }}^2$
est le ratio de variation en
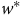 ${w^*}$
expliqué par
${w^*}$
expliqué par
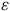 ${\rm{\varepsilon }}$
.
${\rm{\varepsilon }}$
.
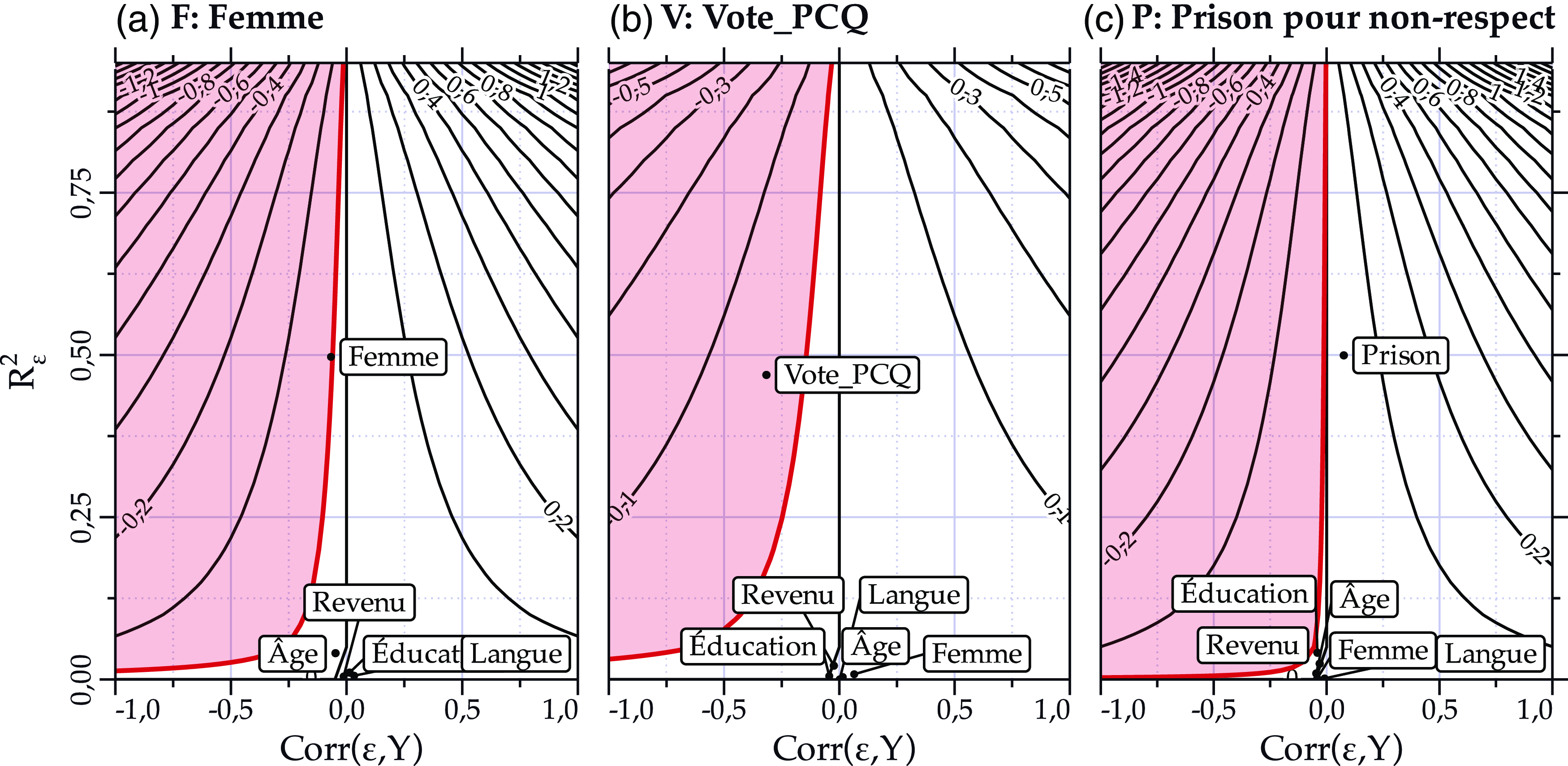
D’abord, une zone critique établie par le chercheur en fonction du contexte spécifique au sondage. Imaginons que notre sondage est commandé par le gouvernement afin d’évaluer s’il est nécessaire de réaliser une intervention auprès de la population et que cette intervention sera faite si le niveau de pessimisme atteint 0,4 en moyenne. Un biais de 0,39-0,4=-0,01 et plus viendrait alors changer la prise de décision; il s’agit de la zone représentée en rouge sur la figure.
Ensuite, il est possible de calculer la variance expliquée des poids de pondération (
 $R_{\rm{\varepsilon }}^2$
) par le retrait successif de chaque variable de pondération. Ainsi, à tour de rôle, les poids de pondération sont recalculés sans utiliser la variable Femme, puis Éducation, puis Revenu, etc. De cette façon, il est possible d’évaluer la sensibilité de l’estimation à l’inclusion de différentes variables dans le calcul des poids de pondération. Au panneau (a) de la Figure 5, il est clair que l’estimation est beaucoup plus sensible à l’inclusion de la variable Femme. En ce sens, la variance expliquée (
$R_{\rm{\varepsilon }}^2$
) par le retrait successif de chaque variable de pondération. Ainsi, à tour de rôle, les poids de pondération sont recalculés sans utiliser la variable Femme, puis Éducation, puis Revenu, etc. De cette façon, il est possible d’évaluer la sensibilité de l’estimation à l’inclusion de différentes variables dans le calcul des poids de pondération. Au panneau (a) de la Figure 5, il est clair que l’estimation est beaucoup plus sensible à l’inclusion de la variable Femme. En ce sens, la variance expliquée (
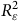 $R_{\rm{\varepsilon }}^2$
) par cette variable est beaucoup plus élevée que celle expliquée par les autres, ce qui fait en sorte que, lorsque Femme est exclue des variables de pondération, l’estimation se retrouve à l’intérieure de la zone critique. Cela est évident dans le cas présent, puisque l’échantillon surreprésente les femmes. Or, pour un véritable sondage, cette technique permet d’identifier le niveau de sensibilité de nos estimations aux choix de variables de pondération.
$R_{\rm{\varepsilon }}^2$
) par cette variable est beaucoup plus élevée que celle expliquée par les autres, ce qui fait en sorte que, lorsque Femme est exclue des variables de pondération, l’estimation se retrouve à l’intérieure de la zone critique. Cela est évident dans le cas présent, puisque l’échantillon surreprésente les femmes. Or, pour un véritable sondage, cette technique permet d’identifier le niveau de sensibilité de nos estimations aux choix de variables de pondération.
Si des estimations populationnelles de sondage de qualité (comme ceux de l’Étude électorale canadienne) sont disponibles, il est également possible de réaliser cet exercice pour des variables ne se retrouvant pas dans les données du recensement. C’est ce que nous faisons aux panneaux (b) et (c) de la Figure 5. Nous simulons d’abord un sondage de qualité en prenant un échantillon aléatoire des données de Projet Quorum. Ceci nous permet d’estimer les proportions populationnelles de Vote_PCQ et Prison, respectivement. Puis nous répétons l’exercice réalisé plus haut pour Femme.
Au terme de l’exercice, nous concluons que l’estimation sous un biais provenant de Vote_PCQ est très sensible à son exclusion alors que le biais provenant de Prison est dans la « bonne » direction, c’est-à-dire que le biais causé augmente le niveau de pessimisme, éloignant l’estimation de la zone critique.
Conclusion
Nous nous sommes intéressés à la question de la correction des sondages non probabilistes à l’aide de la post-stratification et du raking. En raison du biais de sélection, leur utilisation est problématique lorsqu’il est question de quantités descriptives. Nous avons établi le principe d’ignorabilité comme l’appareillage théorique devant guider l’échantillonnage. Ce dernier précise que, pour être ignorable, un PGD doit respecter deux conditions : l’échangeabilité et la positivité. La condition d’échangeabilité est satisfaite lorsqu’il est possible d’échanger n’importe quelles valeurs de
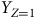 ${Y_{Z = 1}}$
pour n’importe quelles valeurs de
${Y_{Z = 1}}$
pour n’importe quelles valeurs de
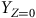 ${Y_{Z = 0}}$
sans substantiellement influencer la moyenne estimée
${Y_{Z = 0}}$
sans substantiellement influencer la moyenne estimée
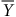 $\overline Y$
en espérance. La positivité est quant à elle respectée lorsque l’entièreté des valeurs possibles des variables et combinaisons de variables entrant dans le PGD est mesurée.
$\overline Y$
en espérance. La positivité est quant à elle respectée lorsque l’entièreté des valeurs possibles des variables et combinaisons de variables entrant dans le PGD est mesurée.
Ces conditions à la correction ont été testées empiriquement. Lorsqu’elles sont observées, les techniques de correction nullifient l’effet du biais de sélection. Ceci pointe vers les limites pratiques et non techniques de la pondération. En effet, être en mesure de définir parfaitement le PGD est, par définition, impossible. À cela s’ajoute le fait que certaines variables ne sont tout simplement pas accessibles en raison d’un manque de ressources ou d’enjeux éthiques; de plus, au-delà des variables sociodémographiques contenues dans le recensement, les quantités populationnelles sont le plus souvent inconnues.
Que donc faut-il retenir au terme de cet exercice? D’abord, la réalité de la recherche effectuée en sciences sociales empêchera la correction de la plupart des inférences descriptives issues d’échantillons non probabilistes. Ceci demeurera le cas aussi longtemps que les variables pour lesquelles les valeurs populationnelles sont connues ne seront pas étendues au-delà des variables sociodémographiques. Néanmoins, et il s’agit du deuxième point clé, cela n’implique pas le rejet dogmatique de l’utilisation des données non probabilistes. Celles-ci peuvent se montrer fort utiles lorsque l’on désire tester le libellé de certaines questions avant leur utilisation, réaliser une expérience de sondage ou lorsque l’ignorabilité est respectée. Cela n’est pas sans rappeler les sages paroles de King et al. (Reference King, Keohane and Verba1994: 27) : « Social scientists often find themselves with problematic data and little chance to acquire anything better; thus, they have to make the best of what they have ». En ce sens, relativiser le biais attendu à l’aide d’analyses de sensibilité est peut-être la meilleure façon de valoriser ce type de données.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0008423925100528
Conflit d’intérêt
Les auteurs n’ont aucun conflit d’intérêt à déclarer.
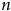
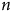






















 Open access
Open access