

6.1 Introduction
This chapter discusses the role of frequency for Construction Grammar, especially concerning usage-based models of language (Bybee Reference Bybee2010). In doing so, the chapter addresses issues of language processing and production, but also concerns that are methodological, relating to the corpus-based study of constructions through various statistical techniques (Yoon & Gries Reference Yoon and Gries2016). The importance of frequency measurements in constructional research has grown over recent years, reflecting the continuing evolution of the field. This development can be illustrated by comparing three definitions of the term construction that have been proposed by Adele Goldberg (Reference Goldberg1995, Reference Goldberg2006, Reference Goldberg2019), and have had a considerable impact in the field:
(1) C is a CONSTRUCTION iffdef C is a form–meaning pair <Fi, Si> such that some aspect of Fi or some aspect of Si is not strictly predictable from C’s component parts or from other previously established constructions (Goldberg Reference Goldberg1995: 4).
(2) Any linguistic pattern is recognized as a construction as long as some aspect of its form or function is not strictly predictable from its component parts or from other constructions recognized to exist. In addition, patterns are stored as constructions even if they are fully predictable as long as they occur with sufficient frequency (Goldberg Reference Goldberg2006: 5).
(3) [C]onstructions are understood to be emergent clusters of lossy memory traces that are aligned within our high- (hyper!) dimensional conceptual space on the basis of shared form, function, and contextual dimensions (Goldberg Reference Goldberg2019: 7).
If the three definitions are compared side by side, several differences become apparent. The first definition places non-compositional meanings and idiosyncratic formal characteristics at its center. Constructions such as the Xer the Yer (Kay & Fillmore Reference Kay and Fillmore1999) or the way-construction (Goldberg Reference Goldberg1995) are well-known illustrations of these characteristics, which constitute a fundamental motivation for viewing constructions as conventionalized form–meaning pairings.
The second definition builds on the first one but explicitly includes frequency, which is understood in this context as token frequency, that is, the repeated occurrence of a linguistic pattern in language use. The definition claims that sufficient exposure to such a pattern will result in the mental representations of a construction, even if the pattern itself is transparent and rule-governed. To take an example, a string such as I don’t know conforms to the canonical syntax of English negated declarative sentences, and it conveys a meaning that is fully compositional. Still, given its high frequency of use, speakers of English are likely to store it redundantly in memory, as a construction. Besides semantic or formal idiosyncrasy, high frequency of use thus provides a second important criterion for constructionhood. The definition further suggests that there is a threshold that distinguishes entrenched constructions from patterns that occur more rarely and that are not mentally represented as such. Such a threshold presupposes a continuum of entrenchment between highly frequent, conventionalized constructions and rare patterns that represent chance co-occurrences of linguistic elements. Whereas I don’t know is highly entrenched, sentences such as I don’t row or I don’t sow are not. With its emphasis on frequency, Goldberg’s second definition reflects the increasingly close ties between Construction Grammar and both psycholinguistic work and corpus-based research.
The third definition further expands on frequency-related characteristics of constructions. Goldberg (Reference Goldberg2019: 7) states that this definition is more aligned with what is currently known about human memory, learning, and categorization. It is useful to unpack three aspects of the definition. First, constructions are viewed as clusters of memory traces, which means that repeated exposure to similar linguistic patterns eventually leads speakers to form generalizations. This can be illustrated with the ditransitive construction, which combines a subject, a verb, and two objects, as in Mary handed me an envelope or We sent them a message. These examples contain different words but instantiate the same structural pattern. The ensuing generalization is characterized as ‘lossy’, so that the mental representation of the construction is more abstract than the actual instances of language use that form its basis. At the same time, the generalization is anchored in usage, so that linguistic elements that appear especially frequently represent the prototype of the construction (Bybee Reference Bybee2010: 79). Second, Goldberg situates constructions in a high-dimensional conceptual space. Instances of constructions vary along several dimensions of form and meaning. A speaker who is exposed to such variation will form generalizations on the basis of that experience. For example, a speaker of English would register that in ordinary language use most instances of the ditransitive construction involve animate recipients, but that there are occasional exceptions, as in We gave the bathroom a makeover. Knowledge of constructions thus involves knowledge of variation, specifically including knowledge of the relative frequency of variants. A third aspect in which the definition breaks new ground concerns the role of context. Language use is sensitive to context, which means that frequency of use has to be understood relative to speech situations. The constructions that a speaker is likely to encounter in one context may be near-absent in another, depending for example on the formality of the situation or the social distance between the communicators. An example for this is offered by Hay and Foulkes (Reference Hay and Foulkes2016) in a study of pronunciation variation in New Zealand English. In words such as city, speakers may realize the intervocalic /t/ either as a voiceless alveolar stop [t] or as a voiced or flapped variant [d/ɾ]. The extralinguistic context influences speaker behavior, so that when speakers verbalize events that lie in the more distant past, they are relatively more likely to use the more traditional, voiceless variant (Hay & Foulkes Reference Hay and Foulkes2016: 322). The example shows that constructions are sensitive to subtle characteristics of the speech situation. In the light of this, what Goldberg’s third definition accomplishes is thus a more realistic, but ultimately also more complex, account of how frequencies of use shape speakers’ mental representations of constructions.
To summarize what has been said so far, frequency has become an increasingly important notion in constructional studies. Whereas initially the focus was centered on token frequency, current research takes into account a much broader range of frequency-related measures that often pertain to variation in language use. It is the purpose of this chapter to present an overview of the measures and techniques that have been used in constructional analyses, to outline what results can be obtained through their use, and to discuss how these results inform constructional theories of language.
The remainder of this chapter is structured as follows. Section 6.2 will offer definitions of frequency and will discuss the way frequency manifests itself in the use of constructions. The section will differentiate between token frequency, type frequency, relative frequency, frequency of co-occurrence, and dispersion. It will be explained how these aspects of frequency can be measured on the basis of corpus data, and how these measurements allow the observation of different frequency effects (Bybee Reference Bybee2010; Pfänder & Behrens Reference Pfänder, Behrens, Behrens and Pfänder2016) that relate to phenomena such as entrenchment, ease of processing, productivity, phonological reduction, and resistance to regularization, among others. These frequency effects will be illustrated on the basis of experimental and corpus-based analyses of lexical, morphological, and syntactic constructions. It will be discussed how the insights from these empirical studies feed back into the development of constructional theories. Throughout the section, the discussion will showcase corpus-based methods that draw on frequency as a means to analyze constructions. For each method that is featured it will be clarified what kind of frequency data enters the analysis, how that data is processed, and what can be learned from the results. Case studies from the corpus-based constructional literature will be used to illustrate relevant concepts.
Section 6.3 will turn to frontiers and open questions regarding the role of frequency in constructionist research. Not only is the relation between corpus frequencies and theoretical notions such as entrenchment far from trivial (Blumenthal-Dramé Reference Blumenthal-Dramé and Schmid2017), it is also important not to attribute effects to token frequency that can in fact be explained by other, correlating variables. Gries (Reference Gries2022a, Reference Gries and Boas2022b) suggests a number of avenues that should prompt constructional research to go beyond the use of frequency values, taking into account paradigmatic and syntagmatic variability as well as dispersion and contingency. These suggestions will be taken up in order to flesh out their implications for the future development of Construction Grammar.
6.2 Frequency Measures and Frequency Effects
This section discusses five different ways in which frequency manifests itself in language use and language processing. Token frequency, type frequency, relative frequency, frequency of co-occurrence, and dispersion will be presented individually, focusing on their respective effects and their relevance for constructional analyses. The discussion will also point towards interrelations between these aspects of frequency.
6.2.1 Token Frequency
Token frequency captures how often an element or structural pattern appears in language use. It is measured through counts of elements in linguistic corpora. For example, in the British National Corpus, the word time has a token frequency of more than 150,000, whereas the word chronology appears a mere 300 times. Token frequencies are commonly normalized, for example to instances per million words, in order to make them comparable across corpora. High token frequency is known to impact language processing in several ways (Ellis Reference Ellis2002). Five effects of high token frequency that have direct implications for constructionist theories of language are known as chunking, entrenchment, reduction, conservation, and conservatism.
The first of these, chunking, refers to the phenomenon that speakers cognitively process a string of linguistic elements as a holistic unit (Bybee & Scheibman Reference Bybee and Scheibman1999). This is the case for strings such as by the way or you know, which serve as discourse markers and thus convey meanings that go beyond the meaning of their component parts. By the way signals that the speaker temporarily deviates from the discourse topic (Fraser Reference Fraser2009). With you know the speaker can invite the hearer to draw an inference (Jucker & Smith Reference Jucker, Smith, Jucker and Ziv1998). Such non-compositional meanings, which constitute an important definitional criterion of constructionhood, are directly related to holistic processing, which in turn is driven by high token frequency. Chunking is further relevant for the processing of complex syntactic constructions. For example, speakers of English holistically represent constructions such as the Xer the Yer (Kay & Fillmore Reference Kay and Fillmore1999; Hoffmann Reference Hoffmann2019), so that when they hear an utterance that begins with The more I think about it, the first part of the construction will trigger expectations about how the utterance will be continued, thereby facilitating language processing. Another effect of chunking relates to syntactic constituency (Bybee Reference Bybee2010: 136). If a string of elements is frequently processed, speakers will treat it as a syntactic unit. Hilpert (Reference Hilpert, Dąbrowska and Divjak2015: 348) offers the example of the string sitting and waiting, arguing that its syntactic behavior in questions such as What are you sitting and waiting for? is that of a single verbal unit. Questioning the prepositional object of the verb waiting is only possible because sitting and waiting is processed as a chunk. By comparison, a question such as What are you walking and waiting for? sounds unidiomatic, since the string walking and waiting is not processed as a chunk and does not function as a single verbal constituent.
A second important effect of high token frequency is entrenchment. Repeated exposure to a linguistic unit increases the strength with which that unit is mentally represented. Elements and patterns that are highly entrenched can be retrieved from memory more quickly and more accurately (Ellis Reference Ellis2002: 152). A finding that is particularly relevant for Construction Grammar has been reported by Arnon and Snider (Reference Arnon and Snider2010), who conducted an experiment in which the participants had to indicate whether English n-grams like don’t have to worry and don’t have to wait are possible parts of grammatically formed sentences. Both fragments are indeed grammatically well-formed, but there is a difference in that the first one is more frequent than the other. The participants were quicker to confirm the grammaticality of the more frequent n-gram. Crucially, this is not due to the token frequency of the component words and word pairs, which were controlled for in such a way that they are actually identical in frequency. Entrenchment can thus be shown to facilitate language processing even at the level of multi-word units.
Another common effect of high token frequency concerns language production. Linguistic units that are used frequently tend to become phonologically reduced. Bybee and Thompson (Reference Bybee and Thompson1997: 576) give the example of BE supposed to, which can be reduced to [spostə] in utterances such as That’s not supposed to happen. Phonological reduction of this kind is common in cases of grammaticalization (Hopper & Traugott Reference Hopper and Traugott2003: 69), as for instance in the case of be going to and its reduction to gonna, or want to and wanna. The phonologically reduced forms can be shown to establish themselves as independent constructions that differ in terms of meaning and structure from their respective sources (Lorenz Reference Lorenz2013).
What the effects of chunking, entrenchment, and reduction show is that high token frequency is a powerful driver of language change. At the same time, high token frequency also has a conserving effect (Bybee & Thompson Reference Bybee and Thompson1997: 577). Linguistic elements that are frequently used are relatively more resistant to analogical change, which is apparent for example in irregular past tense formations such as keep – kept. Whereas keep has retained its irregular past by virtue of its high token frequency, less frequent verbs such as weep or leap have succumbed to analogical pressure and have adopted regularized past tense forms. The conserving effect of high token frequency is also evident in syntax, for example in English expressions that maintain older forms of sentential negation (Tottie Reference Tottie and Kastovsky1991; Bybee Reference Bybee2006). Whereas the canonical pattern for an English negated sentence involves do-support, as in I don’t believe that, post-verbal negation is preserved with modal auxiliaries (You should not believe that) and in fixed expressions that involve lexical verbs (make no mistake, it gives me no joy). In these cases, high frequency of use motivates the maintenance of the older syntactic patterns.
A speaker who experiences a linguistic unit with high token frequency forms increasingly clear expectations about its distributional behavior. This is even true for children who are still acquiring their first language. Children are known to produce overgeneralization errors such as *bringed for brought or *breaked for broke (Clark Reference Clark and MacWhinney1987: 19). Brooks et al. (Reference Brooks, Tomasello, Dodson and Lewis1999) showed that this phenomenon is sensitive to token frequency. Specifically, it was shown that children are less open towards new combinations of words and constructions if the words in question are highly frequent. In the study, children were encouraged to use intransitive verbs in a transitive way. Existing intransitive verbs were extended more readily if they were infrequent. That is, while children were reluctant to transitivize frequent verbs such as come (e.g., He came the car), they showed a greater tendency to transitivize infrequent intransitive verbs with the same meaning, as for example arrive (e.g., He arrived the car).
With regard to Goldberg’s (Reference Goldberg2006: 5) second definition of constructions, the effects discussed in this section motivate why token frequency is important to consider in constructional analyses. The effects also suggest that high token frequency tends to bring about non-predictable characteristics in constructions. An entrenched multi-word unit such as I don’t know is syntactically canonical and semantically transparent, but in actual usage that string will often be used in its phonologically reduced form dunno and with a non-compositional meaning. As a response to the question Would you like to watch Netflix?, the string I dunno would indicate that the speaker actually has a different preference. The inclusion of high token frequency as a definitional criterion of constructionhood is therefore fully compatible with a view of constructions as idiosyncratic linguistic units that need to be learned.
Token frequency is further relevant with regard to the influence of linguistic context on speakers’ choices between alternative options. Rivas and Brown (Reference Rivas and Brown2012) show this in a study of Spanish presentational constructions with haber ‘have’, as in Hubo problemas ‘There are problems’ (lit. haveSG problems). Prescriptively, the presentational construction calls for a singular form of the verb, regardless of whether the noun phrase that is presented is in the singular or the plural. That said, in many varieties of Spanish plural noun phrases may actually trigger plural agreement in the verb. Rivas and Brown (Reference Rivas and Brown2012) demonstrate that this phenomenon is sensitive to token frequency, more specifically the frequency with which a plural noun appears as a grammatical subject in other clause-level constructions. A plural noun such as estudiantes ‘students’, which frequently appears as a grammatical subject, exhibits a stronger tendency to trigger plural agreement than a plural noun such as fraternidades ‘fraternities’, which is used less often with the function of a grammatical subject.
6.2.2 Type Frequency
Type frequency represents the number of different variants of a construction in language use. More specifically, type frequency can be determined through the use of corpora by exhaustively extracting the instances of a given construction, so that the different elements that can fill a slot of that construction can be counted. The concept can be illustrated with the English regular past tense construction, which is a pattern with very high type frequency (Bybee Reference Bybee1995). The suffix -ed appears with a large number of verbs, yielding forms such as walked, painted, or opened. By comparison, the type frequency of forming the past tense through a vowel contrast, such as drink – drank, sing – sang, or swim – swam, is much lower. Type frequencies can not only be determined for morphological constructions but also for syntactic ones. For example, Israel (Reference Israel and Goldberg1996) investigated the diachronic growth in type frequency of the English way-construction by examining the main verbs that appeared in that construction during different historical periods.
Goldberg (Reference Goldberg2006: 99) points out that high type frequency is connected to productivity, that is, the ease with which speakers produce and process new instances of a construction. A construction that accommodates a broad range of elements as slot-fillers is more likely to be extended further to new elements, as opposed to a construction that occurs only with a select few. Corpus-based operationalizations of productivity often combine type counts with other measures, including token frequency and the relative prevalence of hapax legomena, that is, types that appear only once. For example, the measure of ‘potential productivity’ is calculated by taking the hapax legomena of a construction and dividing that number by the overall token frequency of the construction (Baayen Reference Baayen, Lüdeling and Kytö2009: 902). If a construction is used with high token frequency and a large ratio of its types occurs just once, this constitutes strong evidence that speakers regularly use that construction in creative ways.
Barðdal (Reference Barðdal2008: 34) argues that assessments of the productivity of a construction need to take into account the coherence between its types. Coherence can be defined both in terms of meaning and phonological similarity. Type frequency and coherence are seen as inversely correlated, so that if a construction occurs with many types, their coherence is likely to be low. Suttle and Goldberg (Reference Suttle and Goldberg2011: 1239) make a similar point when they relate the productivity of constructions to type frequency, variability, and similarity. If a speaker observes a pattern with a large number of types that are variable in terms of meaning, a new instance that is similar to any one of those types will have a good chance of being acceptable.
An effect of type frequency can be seen in a study by Brooks and Tomasello (Reference Brooks and Tomasello1999), who presented children between 2 and 4 years of age with nonce verbs such as meeking and tamming. The respective verbs were presented exclusively in either the active voice or the passive voice. After the training phase, the children were encouraged to use the verbs themselves, and they were provided with contexts that would favor either the use of the active or the passive. Brooks and Tomasello (Reference Brooks and Tomasello1999: 34) observe that the children are generally reluctant to generalize the verbs from one construction to the other, but they further note an asymmetry between the two constructions, namely that generalizations towards the passive, which is characterized by a relatively lower type frequency, are especially scarce.
Dąbrowska (Reference 168Dąbrowska2008) tests the respective effects of type frequency and phonological similarity in an experiment that prompts speakers of Polish to add dative endings to nonce nouns. In the Polish case system, the masculine dative ending -owi has a higher type frequency than the feminine dative endings -’e and -i, which in turn have higher type frequencies than the neuter dative ending -u. Dąbrowska (Reference 168Dąbrowska2008: 937) designed stimuli in such a way that the nonce words differed systematically in their phonological neighborhood density. Items with high neighborhood density were similar to a large number of existing words, whereas items with low neighborhood density were dissimilar to other elements in the Polish lexicon. The results indicate that performance is better if the type frequency of the case inflection is higher and if the phonological neighborhood is densely populated (Dąbrowska Reference 168Dąbrowska2008: 947).
Like high token frequency, high type frequency drives phonological reduction effects. Bybee (Reference Bybee2002) examined final t/d-deletion in a corpus of spoken English, comparing pre-vocalic deletion rates across auxiliaries with contracted negation (don’t), lexical items ending in an unstressed syllable with final nt (government, different), and regular past tense forms (kissed, burned). Bybee (Reference Bybee2002: 276) finds that the highest rates of pre-vocalic t/d-deletion are observed with regular past tenses, which can be motivated in terms of the high type frequency of that construction. This result is corroborated by Díaz-Campos and Gradoville (Reference Díaz-Campos, Gradoville and Ortiz-López2011), who study intervocalic d-deletion in Spanish participles with -ado and -ido. Deletion rates are higher with -ado, which is characterized by a relatively higher type frequency.
To summarize this section, type frequency is central for measures of constructional productivity, in which it interacts with both semantic coherence between types and phonological neighborhood density. High type frequency is furthermore correlated with rates of phonological reduction in forms that instantiate a pattern.
6.2.3 Relative Frequency
Relative frequency measurements compare the token frequency of one linguistic unit to that of one or several related linguistic units and express the result in terms of a ratio. This is often done with constructions that serve as alternative expressions of similar or near-identical concepts. For example, the English dative alternation comprises two constructions, the ditransitive construction (Mary gave John the book) and the prepositional dative construction (Mary gave the book to John), which both serve to express the transfer of an object between an agent and a recipient. The constructions differ in terms of the sequence with which the arguments of the verb are presented, which means that speakers’ choices between the two are commonly rooted in principles of information structure, such as the principle of end-focus (Hilpert Reference Hilpert, Aarts, MacMahon and Hinrichs2021). In naturally occurring language use, the ditransitive construction has higher token frequency than the prepositional dative construction (Bresnan et al. Reference Bresnan, Cueni, Nikitina, Baayen, Bouma, Krämer and Zwarts2007). Another pair of constructions with similar functions and a marked frequency asymmetry comprises the English active and passive. Sentences such as The dog bit the mailman or The mailman was bitten by the dog serve to express the same state of affairs with a difference in focus on either the agent or the patient. Passive sentences are much less frequent than active transitive sentences. As a third example, the English comparative can be formed morphologically and periphrastically, as in prouder or more proud (Hilpert Reference Hilpert2008). In general English usage, morphological comparatives vastly outnumber periphrastic comparatives.
Asymmetries in relative frequency influence language use and language processing in several ways. One such effect can be observed in structural priming (see also Chapters 8 and 23). When speakers process a syntactic construction, this increases the likelihood that they will produce that construction in subsequent language use (Bock Reference Bock1986). This tendency is frequency-sensitive. The so-called inverse-preference effect (Ferreira & Bock Reference Ferreira and Bock2006) is the phenomenon that in a pair of related constructions, structural priming is stronger for the construction with the lower relative frequency. Jaeger and Snider (Reference Jaeger and Snider2007) demonstrate this for the English dative alternation, in which prepositional datives yield a stronger priming effect, and for the English voice alternation, in which passives have a more pronounced impact. The inverse-preference effect has been widely replicated. For example, Rosemeyer and Schwenter (Reference Rosemeyer and Schwenter2019) document it for the Spanish past subjunctive forms -se vs. -ra in historical corpus data. Torres Cacoullos (Reference Torres Cacoullos, Adli, García García and Kaufmann2015) further documents a relation between priming and the analyzability of constructions. In a study that addresses the Spanish progressive with the copula estar ‘be’ and a gerund on the basis of historical corpus data, Torres Cacoullos tests whether speakers are more likely to use the progressive construction if they have been primed with other constructions that contain the verb estar, such as locative, resultative, and predicate adjective constructions. The data reveal that such priming effects exist and that they become increasingly weaker over time (Torres Cacoullos Reference Torres Cacoullos, Adli, García García and Kaufmann2015: 278). This suggests that the holistic unit status of the progressive construction has become strengthened over time.
Relative frequencies are also relevant for an effect that is known as statistical preemption (Goldberg Reference Goldberg2019). The basic premise of statistical preemption is that speakers form generalizations over pairs of constructions that serve comparable functions, such as the dative alternation or the morphological comparative and the periphrastic comparative. It is further assumed that speakers’ mental representations of these construction pairs comprise knowledge of the lexical items that they encounter in each construction. For example, speakers’ knowledge of the dative alternation would include the fact that verbs such as give, send, or promise occur both in the ditransitive construction and in the prepositional dative construction. Importantly, the relative frequency distribution of some verbs is highly asymmetric, so that for example the verb explain regularly occurs in the prepositional dative construction (She explained the problem to me), but not at all in the ditransitive construction (*She explained me the problem). Speakers subconsciously take note of such statistical asymmetries and interpret them as grammatical constraints. In more concrete terms, this reasoning process can be spelled out as follows. Speakers know that the ditransitive construction and the prepositional dative construction convey similar meanings and occur with similar sets of verbs. They register that the ditransitive construction is overall more frequent. Yet, they encounter the verb explain frequently in the prepositional dative construction, but not at all in the ditransitive construction. Since this imbalance could not be due to chance, it has to be the case that explain cannot be used in the ditransitive construction. In a study that approaches this issue experimentally, Boyd and Goldberg (Reference Boyd and Goldberg2011) expose participants to novel adjectives such as adax and ablim. Those forms phonologically resemble English adjectives such as awake or afraid, which can be used predicatively (The child is awake, The passenger is afraid) but not attributively (*the awake child, *the afraid passenger). In other words, their relative frequency distribution across predicative and attributive contexts is maximally asymmetrical. Boyd and Goldberg (Reference Boyd and Goldberg2011: 69) observe that the participants of their study avoided using forms like adax and ablim in attributive contexts. Statistical preemption can thus account for the fact that speakers do not produce certain expressions and find them ungrammatical, when they are asked about them. Entrenchment as such can only explain why certain expressions sound familiar to speakers, but it cannot explain the difference between previously unseen structures that are fully acceptable and unseen structures that are completely unacceptable.
Another effect of relative frequencies has been documented by Hilpert (Reference Hilpert2008) in a study of English comparative constructions. Adjectives such as proud or healthy can form the comparative either morphologically (prouder, happier) or periphrastically (more proud, more healthy). The variation between the two variants is influenced by a broad range of factors including the length of the adjective, its stress pattern, its final phonological segment, and its syntactic context (Hilpert Reference Hilpert2008: 407). Frequency of use impacts speakers’ choices in two ways. First, there is an effect of high token frequency. A highly frequent adjective such as easy has a stronger tendency to form the morphological comparative than a less frequent adjective with similar phonological characteristics, such as queasy. A second frequency effect concerns the relative frequency of adjectives in the positive form and its comparative formations. An adjective such as tall is frequently used comparatively, whereas this is not the case for adjectives such as red or square, which are less gradable. Highly gradable adjectives show a greater tendency to be used with the morphological comparative.
The main point to take away from this section is the following. Effects such as statistical preemption and the inverse-preference effect in structural priming reveal that speakers are sensitive to relative frequencies in language use, and that this sensitivity impacts their choices between constructions that function as mutual alternatives.
6.2.4 Frequency of Co-occurrence
Measuring frequencies of co-occurrence is one of the fundamental analytical techniques of corpus linguistics, which has a long tradition of studying collocations (Gries Reference Gries2013). Collocations can be broadly defined as multi-word units that exhibit varying degrees of fixedness. They are exemplified by word pairs with non-compositional, conventionalized meanings such as fast food, word combinations with elements that co-occur much more frequently than would be expected by chance, such as unmitigated disaster, and multi-word idiomatic expressions such as make hay while the sun shines. The term collocation has further been used to describe the regular co-occurrence of lexical items in close proximity, which is observed for example for the words refugee and crisis.
Whereas token frequency, type frequency, and relative frequency are measured through basic counts of instances in a corpus, frequencies of co-occurrence are studied in terms of various association measures, which include for example mutual information, log likelihood, or Delta P (Brezina Reference Brezina2018: 72). These measures take into account how often two linguistic elements appear together and how often the same elements appear on their own in other contexts. A comparison of the co-occurrence frequencies with the individual token frequencies shows how strongly the elements of a collocation are mutually associated. A collocation such as sustainable development can serve as an example. Table 6.1, which uses data from the British National Corpus, shows the token frequency of the collocation, the token frequencies of the individual elements that make up the collocation, and the total number of words in the corpus.
Table 6.1 A contingency table of sustainable development and its frequency in the BNC
| sustainable | NOT sustainable | Total | |
|---|---|---|---|
| development | 147 | 31,564 | 31,711 |
| NOT development | 518 | 96,954,478 | 96,954,996 |
| Total | 665 | 96,986,042 | 96,986,707 |
Table 6.1 shows that the collocation sustainable development appears 147 times in the corpus, which contains a total of almost 97 million words. Given the token frequencies of the individual words sustainable (665) and development (31,711), it can be computed how often the two words would be expected to appear together by pure chance. The expected frequency of the collocation is the product of the individual token frequencies divided by the total number of words in the corpus, which in this case yields a value of 0.22. So whereas less than one instance of sustainable development would be expected, almost 150 are observed, which indicates a high degree of mutual association between sustainable and development. Association measures express collocation strength through scores that allow comparisons between different word pairs, so that for example the mutual attraction of sustainable development can be compared to that of sustainable tourism or sustainable seafood.
Whereas the study of collocations has a long tradition that focuses on associations between specific words, the family of methods known as collostructional analysis (Stefanowitsch & Gries Reference Stefanowitsch and Gries2003; Gries & Stefanowitsch Reference Gries and Stefanowitsch2004a, Reference Gries, Stefanowitsch, Achard and Kemmer2004b) applies the concept of collocations to the analysis of mutual associations between a construction and the lexical items that appear within it. Collostructional analysis thus takes into account the grammatical context in which lexical words appear. Stefanowitsch and Gries (Reference Stefanowitsch and Gries2003: 219) illustrate this idea with the English [NOUN waiting to happen] construction. The construction has an initial slot for nouns that is typically filled by semantically negative words such as disaster or accident, as for example It’s a disaster waiting to happen or That was an accident waiting to happen. In order to analyze the mutual association between the construction and the nouns that occur in it, collostructional analysis determines the token frequency of the nouns in the construction, their overall token frequency in the corpus, and the overall token frequency of the construction as such. Table 6.2, taken from Stefanowitsch & Gries (Reference Stefanowitsch and Gries2003: 219), illustrates this for the noun accident. The lower right corner of the table represents the total of clause-level constructions in the British National Corpus. The co-occurrence frequency of accident and waiting to happen is much higher than would be expected.
Table 6.2 A contingency table of accident and the [N waiting to happen] construction
| accident | NOT accident | Total | |
|---|---|---|---|
| [N waiting to happen] | 14 | 21 | 35 |
| NOT [N waiting to happen] | 8,606 | 10,197,659 | 10,206,265 |
| Total | 8,620 | 10,197,680 | 10,206,300 |
The output of a collostructional analysis is a list of lexical elements that are ranked in terms of their strength of association with the construction that is being studied. Association measures that are used to obtain these rankings include the Fisher–Yates exact test and log likelihood (Flach Reference Flach2021). A collostructional analysis can not only determine the lexical elements that are most strongly associated with a construction, but it also serves to identify the elements that occur significantly less often than would be expected by chance. Inspecting the words that are repelled by a construction often yields useful insights into the semantic constraints that characterize its usage.
There is no single collocation measure that could be said to reflect mutual association in the best or most objective way. Rather, measures such as mutual information or log likelihood differ in the relative importance they assign to aspects such as the token frequency of a collocation or the mutual faithfulness of the component words. For example, the collocation unmitigated disaster is much less frequent than sustainable development, but when the adjective unmitigated is observed, it acts as a very strong cue for the upcoming noun disaster. Measures such as Delta P further allow researchers to take the directionality of association into account. For example, the word instead is a strong cue that the following word would be of. This association is not symmetric, since of is frequently preceded by other elements than instead. Conversely, the word vitro is typically preceded by in, but in is not a reliable indicator that the next word will be vitro.
Frequencies of co-occurrence lie at the heart of distributional semantic approaches (Turney & Pantel Reference Turney and Pantel2010), which model the meanings of linguistic units in terms of their collocational profiles. To give a simple example, the meaning of a word such as violin is reflected in its distributional behavior, which is to say that words such as piano, orchestra, play, or sonata are strongly represented in contexts in which the word violin appears. On the basis of a corpus, it is possible to generate a frequency list of all words that appear in the neighborhood of the word violin. With an association measure, that frequency list can be transformed into a vector of values that shows which words are overrepresented or underrepresented, so that a semantic profile of violin emerges. Distributional semantic techniques typically compare many such vectors to establish patterns of semantic similarity or dissimilarity in larger sets of linguistic units. Analyses of that kind are able to determine that, for example, words such as piano, flute, and cello have collocational profiles that are very similar to that of violin, whereas words such as rose, tulip, and daffodil conform to a profile that is altogether different. Perek (Reference Perek2018) uses a distributional semantic approach in a diachronic study of the English way-construction. He uses data from the Corpus of Historical American English (Davies Reference Davies2010) in order to compute semantic vectors for the lexical verbs that appear in the way-construction. By comparing the semantic vectors of verbs that enter the construction across historical periods of time, Perek finds that the verbs of the way-construction occupy an increasingly broader semantic range, specifically in the manner sense of the construction (e.g., John joked his way into the meeting). For the path-creation sense of the construction, there is a development towards increasingly more varied and also more abstract verbs, including groups such as verbs of ingestion (eat, drink, etc.), verbs of commercial transactions (buy, purchase, acquire, etc.), speech act verbs (mumble, whisper, etc.), and others (announce, explain, write, etc.). In general terms, Perek’s study illustrates how co-occurrence frequencies, put into the service of distributional semantic analyses, can reveal how constructions behave with regard to schematicity and abstractness. The elements that co-occur with a construction reflect its meaning, and historical shifts in the co-occurrence patterns between a construction and its lexical collocates can yield insights into the diachronic semantic trajectory of a construction.
Frequency of co-occurrence can be also shown to affect language processing and language use. Relevant evidence is presented by Gries et al. (Reference Gries, Hampe and Schönefeld2005), who devised a sentence completion task in which speakers had to find continuations for sentence fragments. Gries and colleagues used the English as-predicative construction (The idea was considered as a major innovation) as a case study. The participants were exposed to sentence fragments that contained a subject, a passive auxiliary, and a past participle, as in The idea was considered. Their task was to complete the fragment in any way they saw fit. Gries et al. measured how often the participants’ continuations resulted in a complete as-predicative construction. With regard to the verbs that appeared in the fragments, Gries et al. controlled for their token frequency as well as their frequency of co-occurrence with the as-predicative construction. For the latter, the Fisher–Yates exact test was used as an association measure (Gries et al. Reference Gries, Hampe and Schönefeld2005: 647). Verbs such as regard, describe, or see are strongly associated with the construction. The results of the experiment show that participants were more likely to complete a fragment with the as-predicative if the verb in the fragment was strongly attracted to the construction. By contrast, Gries et al. (Reference Gries, Hampe and Schönefeld2005: 659) did not observe an independent main effect of token frequency.
Another effect of co-occurrence frequency is observed by Hilpert and Flach (Reference Hilpert, Flach, Krawczak, Lewandowska-Tomaszczyk and Grygiel2022) in a study of a phenomenon that is called constructional contamination (Pijpops & Van de Velde Reference Pijpops and Van de Velde2016; Pijpops et al. Reference Pijpops, de Smet and Van de Velde2018). The term describes a relation between two constructions of a language, such that usage frequencies of one construction influence patterns of variation in another construction. Hilpert and Flach (Reference Hilpert, Flach, Krawczak, Lewandowska-Tomaszczyk and Grygiel2022) study constructional contamination in the English passive, which exhibits variation with regard to the adverbial modification of participles. In a passive sentence, the past participle can be either preceded by an adverb, as in The government was democratically elected, or it can be followed by an adverb, as in The government was elected democratically. Pijpops and Van de Velde (Reference Pijpops and Van de Velde2016) argue that variation of this kind can potentially be influenced by a construction that features word strings that can also appear in one of the variants. With regard to the English passive, sequences of an adverb and a participle occur in noun phrases such as a democratically elected government. If uses of this kind appear with high token frequency in language use, the prediction is that speakers will favor the adverb-initial variant of the passive. Hilpert and Flach (Reference Hilpert, Flach, Krawczak, Lewandowska-Tomaszczyk and Grygiel2022) test this prediction on the basis of data from the Corpus of Contemporary American English (Davies Reference Davies2008) and they find that the token frequency of adverb–participle combinations in English noun phrase constructions significantly biases speakers towards the use of adverb-initial passives. Beyond this effect of high token frequency, they further observe an effect of co-occurrence frequency. Combinations such as dimly lit or randomly selected are not highly frequent in English noun phrases. Yet, the fact that these collocations have a strong degree of mutual association may bias speakers towards adverb-initial order in the passive construction. Hilpert and Flach controlled for a possible effect of mutual association strength with covarying collexeme analysis (Gries & Stefanowitsch Reference Gries, Stefanowitsch, Achard and Kemmer2004b), which was used to determine degrees of mutual association between adverbs and participles in the English noun phrase construction. The results indicate that frequency of co-occurrence is a significant predictor of speakers’ bias towards adverb-initial order in the English passive construction.
The studies described in this section suggest that language processing and production are shaped by co-occurrence frequencies of linguistic units. The respective effects go beyond effects of high token frequency as such. Degrees of mutual association can impact language use even when the linguistic units in question are relatively low in token frequency.
6.2.5 Dispersion (Burstiness)
The dispersion, or burstiness, of a linguistic unit concerns the regularity with which it appears and reappears in language use. Two linguistic units with the same token frequency may behave very differently with regard to their dispersion, so that their respective tokens are either spaced out evenly and regularly or tightly clustered together. To take an example, consider the words without and system, which appear with roughly the same token frequency in the British National Corpus. Whereas without appears in just about every text that is featured in the corpus, this is not the case for system. Tokens of the word system have a greater chance of following each other in close proximity, but there are also longer stretches in the corpus that do not contain the word system at all. What this means is that without is more evenly dispersed than system.
Various techniques have been proposed to measure dispersion (Gries Reference Gries2008, Reference Gries, Gries, Wulff and Davies2010, Reference Gries2022a). The conceptual basis for most of these techniques is that a corpus is divided into parts. The corpus parts may be defined in terms of a fixed number of running words or by dividing the data into the different text documents that constitute the corpus. Based on such a division, it can be determined how frequently a given linguistic unit appears in each of the parts. The dispersion measure known as ‘range’ simply assesses the percentage of corpus parts in which a linguistic unit is represented (Gries Reference Gries2008: 407). The higher the range, the more even the dispersion. The dispersion measure deviation of proportions (Gries Reference Gries2008: 415) is based on more sophisticated calculations and is computed as follows. In a first step, a corpus is divided into parts and it is determined for each part how much of the corpus it represents. A text of 10,000 words would thus represent 1 percent of a corpus with one million words. To assess the dispersion of a linguistic unit in that corpus, its frequency in the entire corpus and in each corpus part is determined. For example, the word without might appear 400 times in the corpus as a whole, and six times in a first text of 10,000 words. This means that without is overrepresented in that corpus part. Whereas only 1 percent of tokens would be expected, the text in fact contains six tokens which add up to 1.5 percent. Deviation of proportions is calculated in such a way that for all corpus parts the differences between expected percentage and observed percentage are added up, and the sum of differences is divided by two. If the resulting value is close to 0, the analyzed word is very evenly distributed. Values close to 1 indicate a highly uneven dispersion.
An alternative to measuring dispersion on the basis of corpus parts is to observe distances between the tokens of a linguistic unit (Gries Reference Gries2008: 409). For the word without, the maximal distance will be lower than for the word London. If the distances are distributed in such a way that some of them are very large and most are very small, this indicates an uneven dispersion.
It has been argued that certain effects of token frequency are more adequately explained as effects of dispersion. For example, Adelman et al. (Reference Adelman, Brown and Quesada2006: 817) analyzed latencies in six separate data sets from experiments that included word-naming and lexical decision tasks, finding that dispersion (operationalized as range) is a better predictor of word-processing times than token frequency, and that token frequency has no measurable effect that would be independent of dispersion. Baayen (Reference Baayen, Jarema, Libben and Westbury2011: 454) draws a similar conclusion on the basis of data from lexical decision tasks, arguing that any effect of token frequency is minimal once variables such as dispersion, morphological family size, or syntactic entropy are controlled for. It is important to note in this context that most of the established measures of dispersion, including range, are known to correlate strongly with token frequency (Adelman et al. Reference Adelman, Brown and Quesada2006: 815; Baayen Reference Baayen, Jarema, Libben and Westbury2011: 445). Infrequent lexical items will necessarily appear in only a few corpus parts, whereas frequent items stand a better chance of being represented in a large percentage of the parts. In order to address this problem, Gries (Reference Gries2022a) has recently proposed a measure that avoids this correlation and thus allows for a more reliable assessment of the respective effects of token frequency and dispersion. Gries uses deviation of proportions as the basis for a new measure that is labeled DPnofreq. The measure calculates theoretical lower and upper bounds for the dispersion of a linguistic item, given its token frequency. In other words, the measure assesses whether a word could be potentially more even or more uneven in its dispersion. Unlike other dispersion measures, DPnofreq can yield high dispersion values for infrequent linguistic items. Gries (Reference Gries2022a: 29) uses data from lexical decision tasks to show that DPnofreq, in combination with the variables of token frequency and word length, outperforms other dispersion measures in predicting reaction times.
Besides facilitating greater ease of processing, evenness of dispersion also correlates with aspects of linguistic meaning. Using a distance-based measure of dispersion, Pierrehumbert (Reference Pierrehumbert, Santos, Linden and Ng’ang’a2012: 104) shows that linguistic units with more specialized meanings are dispersed less evenly. Specifically, in a comparison of deverbal nouns (evolution, failure, growth) and their verbal bases (evolve, fail, grow), the nouns show a stronger tendency to appear in bursts, whereas the verbs are dispersed more evenly. In a study with a similar outlook, Hilpert and Correia Saavedra (Reference Hilpert and Correia Saavedra2017) analyze a matched set of lexical words and grammatical items that are balanced in terms of their respective token frequencies. They use regression modeling to determine whether even dispersion, measured in terms of deviation of proportions (Gries Reference Gries2008), is predicted more accurately by high token frequency or by semantic generality. The results indicate that both token frequency and semantic generality have significant effects. The semantic effect is, however, considerably weaker than the frequency effect.
In comparison to other measures of frequency, dispersion has received relatively less attention in research that is concerned with constructions and Cognitive Linguistics more generally. The importance of considering dispersion and its effects has been argued forcefully by Gries in a series of papers (Reference Gries2008, Reference Gries, Gries, Wulff and Davies2010, Reference Gries2022a, Reference Gries and Boas2022b). Aside from the issues that have been presented in this section, Gries (Reference Gries and Boas2022b: 62) further suggests that the effects of dispersion on language learning merit further attention.
6.3 Conclusions and Outlook
The discussion in this chapter up to this point allows three broad conclusions. First, the notion of frequency has become increasingly central to research in usage-based Construction Grammar. This development is not only reflected in the definitions that Goldberg (Reference Goldberg1995, Reference Goldberg2006, Reference Goldberg2019) offers for the term construction, but also in a steadily growing number of studies that present their arguments on the basis of corpus-based frequency data. Second, frequency is considered in that work not just as token frequency, but as a range of several different measures. This chapter has reviewed studies drawing on token frequency, type frequency, relative frequency, co-occurrence frequency, and dispersion. Section 6.2 covered the ways in which these aspects of frequency are measured, and to what ends they are being analyzed. The third conclusion is that frequency is intimately related to issues of language processing and production. The discussion has touched on a wide variety of frequency effects, including the relation of high token frequency and entrenchment (Ellis Reference Ellis2002: 152), the inverse-preference effect that links relative frequency and structural priming (Ferreira & Bock Reference Ferreira and Bock2006), and the relation of uneven dispersion and specialized meaning (Pierrehumbert Reference Pierrehumbert, Santos, Linden and Ng’ang’a2012: 104). Understanding how these frequency effects work is important for theoretical work in Construction Grammar, notably with regard to the organization of constructions in a network (Diessel Reference Diessel2019; Schmid Reference Schmid2020) (see also Chapter 9).
It is without dispute that the increasingly thorough engagement with frequency-related issues has yielded useful insights and has thereby advanced Construction Grammar as a field. That said, there are also reasons to maintain a critical view of what has been accomplished and what still remains to be done. The remainder of this section will go over four points that merit attention. First, as Blumenthal-Dramé (Reference Blumenthal-Dramé and Schmid2017: 141) points out, “we are still a long way from fully understanding the intricate relationships among usage frequency, entrenchment, and other factors that might modulate the strength and autonomy of linguistic representations in our minds.” How exactly the experience of a string of words impacts the mental representation of a schematic construction that is instantiated by those words remains to be worked out, especially with regard to the interplay of token frequency, type frequency, and co-occurrence frequency. Second, it is crucial not to attribute effects to frequency without considering alternative explanations. Section 6.2.5 pointed to work that tested systematically whether the effects of token frequency persist if other frequency-related factors such as dispersion are included. Gries (Reference Gries and Boas2022b: 47) cautions against the reliance on token frequency measurements that do not take variability across corpora and corpus parts into account. Variability across and within corpora can be substantial but work that takes this variability into account remains the exception. Third, the aspects of frequency that were discussed in this chapter have not received the same kind of attention. Whereas measurements of token frequency and co-occurrence frequency are routinely applied in constructional analyses, measures of dispersion are rarely taken into account (Gries Reference Gries2008: 403), and in most studies that actually consider dispersion, the measures that are used are strongly confounded with token frequency (Gries Reference Gries2022a). What this means is that more work is necessary in order to realistically assess the effects of dispersion and the interplay between dispersion and other aspects of frequency. The fourth and final point is of a more general nature. Whereas this chapter has laid out (a) a range of different aspects of frequency, (b) measures that are intended to capture these aspects, and (c) effects on processing and production that stem from them, it is important to recognize that any linguistic phenomenon is likely to benefit from an analysis that takes these different aspects into account simultaneously in order to capture how different frequency effects interact. For example, in order to arrive at a comprehensive understanding of an argument structure construction such as the caused-motion construction (Goldberg Reference Goldberg1995), several different frequency measures would be useful. These include token frequencies of the construction as such, token and type frequencies of the elements that appear in its slots, co-occurrence frequencies of the construction and lexical elements, relative frequencies of constructions that are similar in form or function, and dispersion measures that assess the distribution of the construction across different parts of the used corpora. It is clear that while comprehensive analyses of this kind are laborious, they hold the promise of coming to terms with the multi-faceted role of frequency in language use, which is an important goal for the future development of Construction Grammar.
7.1 Data in Linguistics and Corpus Data in Construction Grammar
Data in linguistics can be classified along at least three different dimensions (based on Gries Reference Gries, Hoffmann and Trousdale2013a), each of which could, for simplicity’s sake, be heuristically divided into different points/ranges:
(1) How natural does the speaker perceive his (experimental) setting?
a. most natural, for example, speakers who know each other talk to each other in unprompted authentic dialog;
b. intermediately natural, for example, a speaker describes pictures handed to him by an experimenter;
c. least natural, for example, a speaker lies in an fMRI unit undergoing a brain activity scan while having to press one of three buttons in responses to digitally presented black-and-white pictorial stimuli.
(2) What (linguistic) stimulus does/did the speaker act on?
a. most natural, for example, speakers are presented with natural utterances and turns in authentic dialog;
b. intermediately natural, for example, speakers are presented isolated words by an experimenter in an association task;
c. least natural, for example, speakers are presented with isolated vowel phones.
(3) What (linguistic) units/responses does/did the subject produce?
a. most natural, for example, subjects produce natural and unconstrained responses to questions;
b. intermediately natural, for example, speakers respond with isolated words (e.g., to a definition);
c. least natural, for example, speakers respond with a phone out of context.
The present chapter is concerned with corpus-linguistic approaches in Construction Grammar (CxG), that is, with approaches that tend towards the more/most natural part of each of these dimensions. The notion of a corpus can be considered a prototype category with the prototype being a collection of machine-readable files that contain text and/or transcribed speech that are supposed to be representative of a certain language, dialect, variety, etc. and were produced in a communicative setting. That means that at least the prototypical corpus scores most natural on each of the above three dimensions. Often, corpus files are stored in Unicode encodings (so that all sorts of different orthographies can be appropriately represented) and come with some form of markup (e.g., information about the source of the text) as well as annotation (e.g., linguistic information such as part-of-speech tagging, lemmatization, etc. added to the text, often in the form of XML annotation). However, there are many corpora that differ from the above prototype along one or more of the above dimensions and of course corpora also vary wildly in terms of their size, annotation, ease of access, processability, etc. Accordingly, the prototypical corpus contains data that are a kind of good-news-bad-news situation. The good news is that corpus data often have a very high degree of ecological validity precisely because the production data they contain are not tainted by any artificiality. But that is also the bad news: Data that are not tainted by any artificiality is just another expression for ‘noisy and unbalanced’, which is one major reason why, as we will see below, the analysis of corpus data in CxG has become more and more heavily statistical – simply to deal with the multi-factorial, noisy, and redundant mess that corpus data often are.
Corpus data did not play a big role in CxG historically. It is probably fair to say that CxG is now a little more than thirty years old since the ‘founding’ publications are probably Lakoff (Reference Lakoff1987), Langacker (Reference Langacker1987), and Fillmore et al. (Reference Fillmore, Kay and O’Connor1988), to be followed by Goldberg (Reference Goldberg1991, Reference Goldberg1995) and Kay and Fillmore (Reference Kay and Fillmore1999). But while much of this earliest work was mostly theoretical in nature and did not rely much either on experimental or on observational corpus data, today that situation has drastically changed. To use language from usage-/exemplar-based linguistics: When I ‘grew up academically’ in the mid to late 1990s, learning about Cognitive Linguistics and CxG on the one hand and about corpus linguistics and Pattern Grammar (Hunston & Francis Reference Hunston and Francis2000) on the other, there were very few tokens of studies that, in some multi-dimensional exemplar space, would have scored highly both on the CxG and the corpus-linguistics dimensions; back in the 1990s I certainly did not form a productive category of ‘corpus-based CxG’. But then in the early aughts that all changed and CxG – in particular usage-based/cognitive CxG – has evolved at what seems like a breathtaking pace into a field of study in which we have moved
from works with virtually no corpus data (or that used corpora as a mere repository from which to pick fitting examples) to studies with systematic data retrieval and annotation processes often involving thousands of data points; and
from works that presented isolated examples as evidence for what is possible to studies with complex quantitative methods that show what is likely and that involve, for instance, multi-factorial or multivariate statistical analyses, ‘more traditional’ machine-learning or fancier deep-learning or construction-induction methods, or network analyses.
Μuch of that move really only happened within the last fifteen or so years. In 2013, I published an overview article “Data in Construction Grammar” (in Hoffmann & Trousdale’s Oxford Handbook of Construction Grammar), which had a mere five to six pages on corpus-based and/or computational (machine-learning) studies; this time around, even just sampling papers from leading journals publishing studies relevant to this overview (e.g., Cognitive Linguistics, Constructions and Frames, and Corpus Linguistics and Linguistic Theory) had to be restricted to a small number of recent years so as to avoid drowning in an unmanageable number of interesting and methodologically extremely diverse studies. The purpose of this chapter is to give an overview of the different applications of corpus-linguistic data and methods to linguistic phenomena from a CxG perspective. While the overview is unlikely to be truly representative of the field (along what dimensions anyway?), care was taken to represent studies that differ along a variety of essential parameters, including:
the language(s) studied;
the kind of language(s) studied: L1/native speaker data, L2/FL non-native speaker/learner data, indigenized-variety speaker data, …;
the resolution: individual speakers vs. variation between individuals vs. (dialectal) speech communities, …;
the temporal kind of study: synchronic vs. diachronic/longitudinal;
the (ranges and kinds of) corpora used;
the use to which corpora were put: a collection of examples vs. fine-grained (semi-manual) annotation vs. bottom-up/inductive processing vs. correlation with additional experimental results, …;
the question the study is trying to answer and, related to that, the ‘scientific goal’ of the study: description vs. hypothesis testing vs. exploration, …; and
the statistical methods used for the analysis of the corpus data: none/qualitative only vs. frequencies/probabilities vs. association measures vs. multi-factorial (predictive) modeling vs. exploratory and/or machine-/deep-learning kinds of methods, …
The overview will be structured according to the latter two criteria because (i) the two criteria are of course often very much related to each other and (ii) for many researchers it will be interesting to see which kinds of CxG questions corpus-linguistic data, their (typically) qualitative annotation, and their statistical analysis can help address. Also, it is particularly in the interplay of the last two criteria that corpus-based CxG has maybe most developed. Put differently, while the field is of course still concerned with definitional matters, questions of learnability, abstraction, and/or representation (both mental and formal), corpus-linguistic approaches have been and are now also targeting specific subsets of questions that in turn naturally come with specific degrees of quantitative methods. I will therefore proceed by discussing
raw/normalized frequency-based approaches;
studies involving associations and their strengths between different constructions and/or their parts; and
statistical modeling, machine-learning, and exploratory/inductive bottom-up approaches.
In each of these sections, I will try and highlight topical clusters, that is, areas/questions that appear to be targeted particularly frequently; Section 7.3 will conclude.
7.2 Corpus-Based Applications in CxG
7.2.1 Largely Qualitative Corpus Approaches
As mentioned above, the initial uses of corpus or corpus-like data in CxG papers were largely only presentative in nature and served to make some theoretical point(s) by means of authentic examples, but often without the kind of systematic feature annotation that is characteristic of much contemporary work. This pointing out a lack of multivariate annotation is not meant as a criticism, given the different goals of papers at the time, but what is perhaps a bit more critical is that some such literature often did not clarify whether examples provided were made up or attested (and, if they were attested, what the source was). For example, Fillmore et al. (Reference Fillmore, Kay and O’Connor1988: 519) discuss hundreds of example sentences but usually provide no information on them, let alone on their source. One time they state “we have come across incontrovertible cases of attested utterances of non-negative let alone sentences that seem perfectly natural and which there is no apparent justification to ignore as performance errors” and proceed to discuss their examples (71) and (72) by stipulating (admittedly likely) contexts in which they may have been uttered. Kay and Fillmore (Reference Kay and Fillmore1999) proceed in a similar way: We don’t learn much about where examples are from etc., and the same is true of many other studies such as Smith (Reference Smith1994), Kemmer and Verhagen (Reference Kemmer and Verhagen1994), Dancygier and Sweetser (Reference Dancygier and Sweetser1997), Morgan (Reference Morgan1997), Gutzmann and Henderson (Reference Gutzmann and Henderson2019), and many others, which were all introspection-based and, if they used the word data, typically used it to refer to introspective judgments and/or example sentences.
Crucially, this is not just some complaint from a quantitative corpus linguist who wants corpus examples for the sake of corpus examples; the point is that what seem like clear-cut judgments from native speakers on made-up or even attested examples can look very different once one looks at (larger) quantities of data – as Sinclair (Reference Sinclair1991: 100) said, “Language looks very different when you look at a lot of it at once.” For example, it is likely that traditional linguists would consider a sentence such as He [VP donated [REC her] [PAT transplant money]] ungrammatical, since it is widely held that the verb donate cannot be used ditransitively (even though its meaning is so similar to that of the prototypical ditransitive verb give). However, Stefanowitsch (Reference Stefanowitsch2006: 69) shows that even the British National Corpus – a great but by today’s standards not particularly large corpus – already contains at least one example exactly like this (in a maybe atypical newspaper headline, admittedly), and Stefanowitsch (Reference Stefanowitsch2007: 65) lists ten examples of donate used ditransitively from a variety of internet pages from .uk domains, all of which “do not conform to what we might think of as the default donate frame”; instead, they appear to instantiate a frame that Stefanowitsch describes as follows:
A donor transfers some of his/her money to a recipient. The recipient is an official organization who uses the money to advance some public or charitable cause or to pay for its own expenses in doing so. The donor is an individual who gives the money because s/he believes in the cause, and without expecting to profit personally. There is no personal relationship between the donor and the recipient.
Thus, while linguistics in general and CxG in particular have benefited a lot even from papers that did not feature corpus data or analyses, linguists clearly have no unbiased and axiomatically correct view of what is possible (i.e., what can or cannot be said; see Labov Reference Labov and Austerlitz1975), let alone what is likely. Even theoretical works without any kind of quantification might have turned out a bit different if corpora or corpus-like data had been consulted systematically, and I think it is fair to say that usage-based linguistics and CxG have evolved precisely in this direction. For instance, Hamunen (Reference Hamunen2017) is not the least bit quantitative but still not only bases its diachronic exploration of the Finnish Colorative Construction mostly on 1,741 examples from three different corpora/corpus-like databases (viz. the Finnish Syntax archive, the Digital Morphology Archive, and the Digital Dictionary of Finnish Dialects), but also highlights all made-up examples as such. Beliën (Reference Beliën, Yoon and Gries2016) explicitly points out this methodological turn –
the method is applied to corpus data, because they show what types of structures are actually produced by speakers, and in which contexts. Earlier studies, on the other hand, relied on isolated, constructed sentences, with diverging grammaticality (or acceptability) judgments as a result. The authentic data presented here were collected from the 38 million-word corpus of the Institute for Dutch Lexicology … and from the Internet.
– before discussing the failure of traditional syntactic constituency tests regarding the analysis of Dutch particle constructions. However, it seems to me that most more recent and contemporary studies based on corpus data do involve at least some kind of quantification and I think that there are very few questions, if any, that cannot or should not be studied quantitatively as a matter of principle (but of course, there may be situations where, for example, data sparsity may rule out the use of certain statistical methods); see Jenset and McGillivray (Reference Jenset and McGillivray2017: section 3.7); Gries (Reference Gries2019b: 25–29), or Gries (Reference Gries2021 [2009]: section 1.2) for more on this question. We now turn to the simplest kind of quantification: frequencies of (co-)occurrence and (conditional) probabilities.
7.2.2 Frequencies of (Co-)occurrence and Conditional Probabilities
In spite of the statistical simplicity of frequencies and probabilities, if they are applied in the right kind of research context, they can be instructive, as is evidenced by a variety of studies having to do with issues of frequency as a mechanism driving, affecting, or at least correlating with entrenchment, learning/acquisition, language change, and productivity. For instance, in the area of language acquisition/learning, by now classic studies such as Goldberg’s (Reference Goldberg and MacWhinney1999) analysis of L1 acquisition data from CHILDES (to determine how highly frequent semantically light verbs facilitate the acquisition of semantically similar argument structure constructions) or Ellis and Ferreira-Junior’s (Reference Ellis and Ferreira-Junior2009a, Reference Ellis and Ferreira-Junior2009b) longitudinal study of L2 acquisition of verb-argument constructions in the European Science Foundation corpus were among the first to empirically highlight the importance of frequency of occurrence (of constructions) and frequency of co-occurrence (words in constructional slots) for language acquisition/learning, or for the ubiquity of Zipfian distributions of constructions, or for material within slots of constructions. Another hugely influential application of conditional probabilities – as cue validity – is Goldberg et al. (Reference Goldberg, Casenhiser and Sethuraman2004), which shows that certain patterns (e.g., V-Obj-Loc) have very high cue validities for certain meanings (e.g., caused motion), which reinforces the notion of constructions as pairings of form and meaning reliable enough to facilitate acquisition based on recognizing association patterns and chunking.
Quantitatively similar applications can also be found in other areas. An example of how corpus frequencies can inform theoretical argumentation is Boas (Reference Boas, Achard and Kemmer2004), who challenges a Minimalist Program account of wanna contraction in English. He shows that less than 1 percent of the examples of wanna contraction in the Switchboard corpus are instances within WH-clauses, which is interesting because most analyses put a lot of emphasis on wanna contraction in WH-clauses even though wanna contraction is actually more frequent than want to in relative clauses. As Boas (Reference Boas, Achard and Kemmer2004: 482) argues, if a theory of language claims not only to be descriptively but also explanatorily adequate, the question for Ausín’s (Reference Ausín2001) minimalist program analysis is how it may account for these differences in distribution.
Another study that is based on statistically very down-to-earth percentage data but uses them to make valuable theoretical contributions is Gaeta and Zeldes (Reference Gaeta and Zeldes2017). They use DeWaC, a 1.6 billion-word corpus of web-based German to study -er compounds (with agent noun heads) from a Construction Morphology perspective. On the basis of type, token, and hapax counts, they explore with which frequencies different combinations and orders of compounds are attested and the direction in which prototypical instances are generalized, and argue that Construction Morphology’s flexibility (in terms of permitting different derivational pathways of compounds) makes it an approach that supersedes purely syntactic or purely morphological approaches.
Quantitatively similar work – using type and token frequencies – is also found in Quochi (Reference Quochi, Yoon and Gries2016), a paper on a radial-category family of Italian light-verb constructions and their acquisition in L1 data from the CHILDES database. Approximately 2,100 instances of fare (‘do’) + noun constructions from children and adults are investigated in terms of the nouns/noun categories they occur with and the type–token ratios of verb-related nouns. Tracking new types over time she finds, among other things, that fare + nouns derived from verbs by suffixation appear to be rote-learned rather than instances of creative production. The general time course of acquisition, Quochi observes, is one where children first pick up on the most frequent uses, then develop a more abstract schema, which becomes generalized to intransitive actions, a development that is compatible with usage-based approaches to language acquisition of the kind outlined by Tomasello (Reference Tomasello2003), among others.
Let us finally look at a couple of statistically simple yet interesting applications that also bridge the gap to studies that involve higher degrees of statistical complexity. One of these is Vázquez Rozas and Miglio’s (Reference Vázquez Rozas, Miglio, Yoon and Gries2016) study of which linguistic features are associated with Spanish and Italian speakers’ choices of experiencer-as-subject (ES) and experiencer-as-object (EO) constructions. They look at clauses with an experiencer and a stimulus, where some such clauses construe the experiencer as Subject and the stimulus as Object while others have experiencers coded as dative/accusative Objects and stimuli as Subjects. For Spanish, they rely on the ARTHUS corpus of American and Peninsular Spanish; for Italian, they combine several databases to approximate a similar (and similarly sized) corpus (La Repubblica, C-ORAL, and the BAdIP database). Both corpora were searched for two-argument clauses with active-voice feeling verbs (excluding volition verbs). The main body of their paper reports a variety of frequency/percentage results for many different features of the clauses, including experiencer animacy, person, number, syntactic category, as well as stimulus animacy and syntactic class, and register/genre. Specifically, they point out correlations between ES vs. EO choice and experiencer and stimulus characteristics. However, they go beyond these monofactorial explorations by also subjecting the data to a multi-factorial analysis using a conditional inference tree, which is much more able to identify complex relations and interactions in the data, in particular how discourse-related factors can interact with the syntactic form and semantic structure of the clause. Their paper therefore bridges the gap from frequency/percentages-only studies to the kind of multi-factorial work that seems to be the state of the art today and will be discussed more below.
Another interesting application is Chen (Reference Chen2017), a diachronic CxG study based on (i) contemporary Mandarin Chinese data from the Academia Sinica Balanced Corpus of Modern Chinese and (ii) diachronic data for Old Chinese, Middle Chinese, and Early Mandarin from the Academia Sinica Ancient Chinese Corpus. She tracks the frequency of senses and what they co-occur with to explore how diachronic realignment processes gave rise to a synchronic polysemy network of ‘one’-phrases in Mandarin involving counting/quantifying senses, but also meanings involving a negative-polarity sense and an attenuating positive polarity sense. As Chen concludes, “The associations [between ‘one’-phrases and already established constructions] have been shaped by the environments where the ‘one’-phrases frequently occur. The combination inherits syntactic, semantic, and pragmatic properties from the higher-level constructions, leading to new constructs” (Reference Chen2017: 97). This makes for a perfect transition to one of the, if not the, most widely used statistical methods in corpus-based CxG, the measurement of association strength and its implications for acquisition/learning, use, and change, which is the topic of the next section.
7.2.3 Association Strengths
Another frequent statistical method in corpus-based CxG involves a class of measures called association measures, that is, measures that are ultimately based on frequencies but then quantify the degree to which (typically two) elements from any level of the constructicon like or dislike to co-occur with each other; or, put differently, the degree to which the presence of one element makes the presence of another element more likely. This is a central issue for many questions, from as seemingly minute as the preference of words to occur with particular inflectional morphemes via the preference of words to occur in syntactic/argument structure constructions to, most fundamentally, actually any association of form and meaning (e.g., as when children determine from co-occurrence patterns that certain verbs have certain meaning and like to occur in certain constructions). The maybe most widely used statistical application in this context involves quantifying the degree of association between words and (slots of) constructions. The four papers by Stefanowitsch and Gries (Reference Gries2003, Reference Stefanowitsch and Gries2005) and Gries and Stefanowitsch (Reference Gries and Stefanowitsch2004a, Reference Gries, Stefanowitsch, Achard and Kemmer2004b) develop a family of methods referred to as ‘collostructional’ analysis (see also Chapter 6), a blend of collocation and construction:
collexeme analysis: the quantification of how much words are attracted to, or repelled by, a syntactically defined slot in a construction (e.g., the verb slot in the ditransitive construction or the noun slot in the N-waiting-to-happen construction);
(multiple) distinctive collexeme analysis: how much a word (dis)prefers to occur in a certain slot of two or more functionally similar constructions (e.g., the verb slot in the two constructions making up the dative alternation); and
two variants of covarying collexeme analysis: how much elements in two slots of one construction (dis)like to co-occur (e.g., the two verb slots in the into-causative, i.e., in V DONP into V-ing).
Most applications of either of these methods have been based on 2×2 co-occurrence tables such as Table 7.1, in which the elements’ and cell frequencies’ meanings depend on which analysis one conducts:
for a collexeme analysis of the ditransitive,
for a distinctive collexeme analysis of the dative alternation,
– element 1 might be one verb in the ditransitive or the prepositional dative (e.g., give), element 2 might be the ditransitive construction, and ‘not element 2’ would be the prepositional dative;
– a+b would be give’s frequency in the corpus, a+c would be the ditransitive’s frequency in the corpus, and b+d would be the frequency of the prepositional dative;
for a covarying collexeme analysis of the into-causative,
– element 1 might be one verb1 in the into-causative (e.g., trick) and element 2 would then be a verb2 in the into-causative (e.g., believe);
– a+b would be trick’s frequency in the verb1 slot of the into-causative, a+c would be believe’s frequency in the verb2 slot of the into-causative, and a would be the frequency of trick DONP into believing in the into-causative.
Table 7.1 A schematic co-occurrence table underlying nearly all association measures
| Element 2 | Not element 2 | Sum | |
|---|---|---|---|
| Element 1 | a | b | a+b |
| Not element 1 | c | d | c+d |
| Sum | a+c | b+d | N |
Each of these applications follows a very similar four-step template, which is identical to the same decades-old approach in collocation studies in non-CxG corpus linguistics:
(1) one retrieves (ideally) all instances of a construction of interest C;
(2) for the element(s) of interest (e.g., a verb in a slot of C) one computes (a) measure(s) of association that is/are (usually) based on the relevant 2×2 tables of the above kind;
(3) one sorts the elements of interest according to that association measure; and
(4) one analyzes the top x elements of interest (often called collexemes) in terms of their structural, semantic, or other functional characteristics.
This family of methods was already relatively widespread ten years ago, when it was already used in studies on near-synonymous constructions (alternations), where, for instance, the method was precise enough to discover the iconicity difference (Thompson & Koide Reference Thompson and Koide1987) between the ditransitive (small distances between recipient and patient) and the prepositional dative (larger distances between recipient and patient) and many other domains: for example, in the study of priming effects (Gries Reference Gries2005; Szmrecsanyi Reference Szmrecsanyi2006), L1/L2 acquisition and learning of constructions (Gries & Wulff Reference Gries and Wulff2005, Reference Gries and Wulff2009; Ellis & Ferreira-Junior Reference Ellis and Ferreira-Junior2009a, Reference Ellis and Ferreira-Junior2009b; Wulff & Gries Reference Wulff, Gries and Robinson2011, and especially the extremely comprehensive Ellis et al. Reference Ellis, Römer and O’Donnell2016), constructional change over time (Hilpert Reference Hilpert2006, Reference Hilpert2008), etc. In addition, the approach has received some experimental support (Gries et al. Reference Gries, Hampe and Schönefeld2005, Reference Gries, Hampe, Schönefeld, Rice and Newman2010) and has stimulated research that combined it with other methods. Backus and Mos (Reference Backus, Mos and Schönefeld2011), for instance, explore the productivity and similarity of two Dutch potentiality constructions – a derivational morpheme (-baar) and a copula construction (SUBJ COPfinite te INF) – and combine association measures with acceptability judgments. They report the results of a distinctive collexeme analysis to determine which verbs prefer which of the two constructions in the Corpus of Spoken Dutch, and follow this result up with a judgment experiment to probe more deeply into seemingly productive uses of the constructions. The authors find converging evidence such that acceptability is often correlated with corpus frequencies and lexical preferences (see also the chapters in Schönefeld Reference Schönefeld2011 for more examples of converging evidence and more on frequency vs. acceptability below).
More recent applications have broadened the scope even more, have used suggested improvements, and/or even extended the method and, thereby, have added to the theory of CxG. For example, Hoffmann et al. (Reference Hoffmann, Horsch and Brunner2019) extend collostructional analysis by exploring the elements in slots on a more schematic level and the correlations between what happens in a construction’s slots on that more abstract level. They study 1409 tokens of the comparative correlative constructions (e.g., the more, the merrier) from the 2015 part of the Corpus of Contemporary American English (COCA) in terms of several of the construction’s characteristics: the grammatical/phrasal filler type (of either comparative), the lexical filler, and the presence/absence of different kinds of deletion. They first apply a covarying collexeme analysis using the unidirectional association measure Delta P (Ellis & Ferreira-Junior Reference Ellis and Ferreira-Junior2009b; Gries Reference Gries2013b) rather than the usual bidirectional measures, and not only explore the words in the slots per se, but also in relation to the more schematic characteristics. Among other things, they find that the only filler types significantly attracted to each other are pairs of the same filler type, indicating that one’s account of the construction should not attempt to treat the construction’s slots as independent, an observation that can only be made when corpus data meet statistical methods in the analysis. Another example of the use of the unidirectional Delta P approach to collostructions is Rastelli’s (Reference Rastelli2020) analysis of lexical aspect in L2 Italian, which is not a study of argument structure (the ‘usual suspect’ in this type of analysis) but of lexeme–morpheme associations. A generally similar analytical approach, which also explores co-occurrences at multiple levels of generality, is pursued in Abdulrahim (Reference Abdulrahim2019), who studies ‘go’-constructions with three types of verbs in Modern Standard Arabic and their association to a variety of lexico-syntactic features. Abdulrahim uses a multi-dimensional extension of collostructions, so to speak, Hierarchical Configural Frequency Analysis (HCFA, Gries Reference Gries2021 [2009]; Stefanowitsch & Gries Reference Gries2005), a method that tries to identify over- and under-represented cells in multi-dimensional frequency tables.
None of the above should imply that collostructional analysis has not also been criticized, but much of the critique was based on a variety of misunderstandings with regard to both the method’s goals and their implementation. For instance, with regard to the former, Bybee (Reference Bybee2010: chapter 5) criticized collostructional analysis for its lack of considering semantics (especially on the input side of the analysis) when in fact the whole point of collostructional methods is to be able to infer semantic (or other functional patterns) from its output. Similarly, Bybee criticized the collostructional approach for a lack of discriminability in her results, but did not actually perform a full-fledged analysis herself: Rather than applying the method to all words in a certain construction and as described in the four steps above, she restricted her input to extremely low-frequency items that collostructional methods were not developed for and then performed only step 2 of the above four. Schmid and Küchenhoff (Reference Schmid and Küchenhoff2013) suffers from similar problems. For instance, they misunderstood how software handles extremely small values (e.g., <10–320) and falsely claim that one needs more powerful computers for collostructional computations (when all that is needed is a specific software package, which would allow any normal computer to handle such numbers); also, they object to how most collostructional applications compute association strength (using the p-value of a Fisher–Yates exact test), but at least some of their argumentation is self-contradictory: For instance, they criticize pFYE for, among other things, being bidirectional, but devote quite some space to discussing an alternative they prefer, the odds ratio, which is also bidirectional (for the specifics of this debate, see Bybee Reference Bybee2010: chapter 5 and Gries Reference Gries2012 for a rebuttal, as well as Schmid & Küchenhoff Reference Schmid and Küchenhoff2013 and Gries Reference Gries2015a for another rebuttal). Gries (Reference Gries2019a) is an attempt to place collostructional analysis on a new statistical foundation, by encouraging the use of many more and independent dimensions of information that an analyst should consider, namely frequency, association (independently of frequency and potentially bidirectionally), dispersion, entropy, and possibly others.
In some recent research, collostructional methods are now more often combined with other kinds of data and methods (see the discussion in Ellis et al. Reference Ellis, Römer and O’Donnell2016; Sommerer & Baumann Reference Sommerer and Baumann2021; Chen Reference Chen2022), and collostructional results are sometimes included as predictors or control variables, given how they can help bring item-specific (e.g., verb-specific) variability under statistical control. This may also help validate/critique the approach, but of course much remains to be done and by now many such attempts are underway. For example, Bernolet and Colleman (Reference Bernolet, Colleman, Yoon and Gries2016) raise the bar for just about all collostructional studies in that they take polysemy more seriously than nearly all others and incorporate sense information into the analysis. Gries (Reference Gries, Daems, Zenner, Heylen, Speelman and Cuyckens2015b) is a first step to try to disentangle the correlations between directions of attraction and experimental data in the as-predicative. Flach (Reference Flach, Sanchez-Stockhammer, Günther and Schmid2020b) revisits the frequency vs. association issue with data on gonna/wanna/gotta contraction and shows that contingency/association measures consistently outperform string frequency. Finally, Herbst (Reference Herbst2020) is an interesting new proposal to change one’s perspective on co-occurrence away from a view of items-attracted-to-constructions (as in all collostructional studies, e.g., verbs in the verb slot of an argument construction) to a view of items-in-constructions.
The above should not also imply that collostructional studies are the only examples of association measures in corpus-based CxG. As an example of a different kind of application, Cappelle et al. (Reference Cappelle, Depraetere and Lesuisse2019) retrieve n-grams involving necessity modal verb lemmas from the BNC that meet a frequency and an association strength threshold (50 and MI≥3 respectively). Adopting a perspective of “contexts as constructions,” they then cluster the modal verb lemmas on the basis of the contexts they share; they find a hierarchical cluster structure that can be represented as (([have to, need to], must), should) (with parentheses and square brackets indicating less and more robust clusters respectively). While not much is done with that specific quantitative result, Cappelle et al. proceed with some qualitative discussion of how the modals’ functions are reflected in terms of the preferred n-grams.
The second most widespread quantitative treatment of corpus data in CxG involves various kinds of modeling, to which we turn now.
7.2.4 Monofactorial, Multi-factorial, and Multivariate Approaches
Corpus-based CxG studies using both mono- and multi-factorial tests have increased substantially, especially over the last ten or so years. Petré and Anthonissen (Reference Petré and Anthonissen2020), for example, report results from monofactorial regressions on individual variation in diachronic data, finding, among other things, excellent fits of (i) first attestations of motionless be-going-to INF in the sixteenth to seventeenth centuries with time (the expected logistic s-curves) and (ii) within-individual uses of Nominativus-cum-Infinitivo and prepositional passive constructions. However, the ‘standard’ by now are multi-factorial/multivariate approaches. While I am splitting this section up into ‘inferential’ and ‘exploratory’ approaches, it needs to be pointed out that the dividing line is often more tenuous than one might think. Many studies use inferential tools, such as regression modeling, but incorporate a certain degree of exploration because their modeling involves model selection; similarly, a method like HCFA as in Abdulrahim (Reference Abdulrahim2019) also combines inferential and exploratory aspects. In addition, the notion of “exploratory” I am using is rather broad and intended to cover all methods covered in traditional statistics textbooks such as different kinds of cluster analyses, principal component/factor analysis, correspondence analysis, and multi-dimensional scaling, but also unsupervised machine-learning methods such as vector spaces and deep learning.
Inferential/Statistical Approaches
It seems as if the vast majority of multi-factorial corpus-based CxG studies uses some kind of regression modeling, that is, the application of statistical tools that are extensions of simple correlational statistics to situations where the behavior of one response variable (often the effect of a hypothesized cause–effect scenario) is explored with regard to how it varies as a function of multiple predictor variables (often the causes in that hypothesized cause–effect scenario). The range of applications of such methods is huge because they are useful for really any kind of correlational hypothesis and, at least as a proxy, for any kind of causal hypothesis that can be ‘translated’ into a correlational effect or pattern of effects.
As an example in the areas of individual variation and productivity, De Smet (Reference De Smet2020) studies constructional morphological productivity (-ly and -ness derivation) based on hapaxes across individuals in the NY Times and Hansard corpora in order to tease apart effects of token and type frequency (when controlling for several other factors in a series of linear models); interestingly, he finds an interaction effect between the frequency types that supports “a view of entrenchment as both a conservative and creative force in language” but also notes that “some variation remains irreducibly individual” (De Smet Reference De Smet2020: 251).
A big topic is alternation research on various phenomena and, by now, for various languages, and the field has come a long way since some of the earliest multi-factorial studies in Cognitive CxG (e.g., Gries Reference Gries2003), surpassing those in sample sizes and sophistication. De Vaere et al. (Reference De Vaere, De Cuypere and Willems2021) is a case in point. They study German geben ‘give’ in two alternating ditransitive constructions based on 1301 occurrences from the DeReKo corpus, which were annotated for twenty morphosyntactic, semantic, and pragmatic factors and submitted to a logistic regression model. Intriguingly, in some ways, they go much beyond the current standard:
Most existing studies assume (usually implicitly) that the effect of numeric predictors can be modeled with a straight line (i.e., a linear trend), which is surprising given that very many cognitive phenomena do not apply linearly: Learning, forgetting, priming, language change, etc. all involve curved trends. Laudably, De Vaere et al. accommodate this fact by allowing their numeric predictors to be curved.
Many existing studies run the risk of what is called overfitting, that is, the risk that a model that is fit on a certain data set fits that data set so well that it does not also generalize well to other data sets. De Vaere et al. use a statistical method called penalization, whose details are not relevant in the present context, to protect their analysis against that risk. In addition, they also use a technique called bootstrapping to make sure their model quality statistics do not exaggerate the model’s quality.
Many analyses of observational data suffer from the fact that linguistic predictors are often highly correlated with each other, a phenomenon called (multi-)collinearity. For example, NPs referring to discourse-given referents are often not just given but also short, definite, pronominal, etc. De Vaere et al. report collinearity diagnostics so that readers can contextualize their findings better.
They interpret their findings as providing evidence for the main meaning of geben being not so much literal transfer from one person to another (as in give or hand) but a more general transfer meaning, and highlight the fact that one of the constructions is often associated with the passive voice; this echoes Gries et al. (Reference Gries, Hampe and Schönefeld2005) and points to a more general need to include voice as a variable in collostructional and/or alternation studies (see also Pijpops et al. Reference Pijpops, De Smet and Van de Velde2018 for another application of logistic regression on constructional contamination).
Even more frequent than fixed-effects regressions are currently mixed-effects models, which in various ways take into consideration speaker-/file-specific effects (are there systematic individual differences between speakers or files?) as well as item-specific effects (are there systematic effects?). The following is just a small overview of the published work:
In non-native speaker/L2 research, Wulff and Gries (Reference Wulff and Gries2019, Reference Wulff, Gries, Le Bruyn and Paquot2021), Gries and Wulff (Reference Gries and Wulff2021), and Azazil (Reference Azazil2020). The study by Azazil is noteworthy for combining multiple predictive modeling methods (mixed-effects models and random forests) and for showing how such studies support the notion of frequency-based entrenchment of item-specific information.
In native speaker alternation research, Schäfer (Reference Schäfer2018) studies the measure NP alternation in the 21 billion-word German DECOW14A corpus and, on a theoretical level, concludes that speakers’ choices require mechanisms from both prototype and exemplar models, which makes an important contribution to corpus-based studies on (degrees of) mental representation and abstraction. Flach (Reference Flach, Sanchez-Stockhammer, Günther and Schmid2020b) is another relevant study mentioned in Section 7.2.3.
In work bringing together corpus and experimental data beyond that already mentioned above, Flach (Reference Flach2020a) explores the frequency–acceptability mismatch – the fact that corpus frequencies are often not a good predictor of acceptability ratings. She combines corpus data from COCA (collostructional results and the results of a correspondence analysis on go/come-V in nine different syntactic contexts) with the results of an acceptability-judgment experiment to explore, with mixed-effects modeling, what resolution of frequency is most related to the acceptability-judgment data. She concludes that “acceptability is a function of compatibility with a licensing schema, which accounts for the acceptability even of rare or corpus-absent patterns” (p. 636) and “acceptability patterns are better captured by complex than by simplistic measures” (p. 637); see also Gould & Michaelis (Reference Gould and Michaelis2018) or Busso et al. (Reference Busso, Perek and Lenci2021) for additional examples of studies coupling observational and experimental data.
In a diachronic (1300–2000) study of strong vs. weak past tense in several corpora of Old Dutch, De Smet and Van de Velde (Reference De Smet and Van de Velde2020) use mixed-effects modeling to show how the realization of past tense varies systematically with aspect (durative vs. punctual) and meaning (metaphorical vs. literal).
There is also a slowly growing set of studies that deal with ‘curvature’ in the structure between predictors and responses. For instance, apart from the above-mentioned De Vaere et al. (Reference De Vaere, De Cuypere and Willems2021), Wulff and Gries (Reference Wulff and Gries2019, Reference Wulff, Gries, Le Bruyn and Paquot2021) incorporate polynomial predictors in mixed-effects models for learner data, and Lorenz and Tizón-Couto (Reference Lorenz and Tizón-Couto2019) use generalized additive mixed models in their study on the role of corpus frequency on phonological reduction.
Another recent development in much of linguistics and also in corpus-based CxG is the use of ‘tree-based methods’ such as classification trees and random forests, that is, machine-learning methods that often appear to be an attractive plan B when the nature of the data seems to not license regression modeling. Tree-based methods try to identify structure in the relation(s) between a response and multiple predictors by determining how the data set can be split up repeatedly into successively smaller groups (based on the values of the predictors); to simplify a bit, each split increases the tree’s/forest’s ability to predict the response variable (which can be numeric, but is more often categorical, such as one of several constructional choices). For instance, Fonteyn and Nini (Reference Fonteyn and Nini2020) use both tree-based methods in a diachronic analysis of the gerund alternation (e.g., the eating of meat vs. eating meat) that included language-internal and -external factors and identify similarities and differences between different speakers in the 90 million-word EMMA corpus. Soares da Silva et al. (Reference Soares da Silva, Afonso, Palú and Franco2021) use a conditional inference tree to model, among other things, the alternation of overt and null se constructions in Brazilian and European Portuguese from two decades and find language-internal factors (the construal of the change of state or voice) as well as language-external factors (register) to be relevant. Finally, there is work that combines corpus and experimental data as well as mixed-effects modeling and tree-based statistics, for example, Azazil’s (Reference Azazil2020) study of frequency effects in the L2 acquisition of the catenative verb construction by German learners of English (following up on Gries & Wulff Reference Gries and Wulff2009 and Martinez-Garcia & Wulff Reference Martinez-Garcia and Wulff2012).
Finally, other kinds of computational modeling are also found: Liu and Ambridge (Reference Liu and Ambridge2021) is a study of four two-argument constructions involving actives and passives from the CCL corpus that uses Bayesian mixed-effects modeling but also naive discriminative learning (Baayen Reference Baayen2011), a computational learner without the hidden layers characteristic of many connectionist/neural network learners, that has been argued to “enjoy psychological plausibility” (Liu & Ambridge Reference Liu and Ambridge2021). Their results reflect how speakers balance information-structural and semantic constraints and suggest that competing constructions are retained because they offer speakers choices to express both topicalization and other implications. At the same time, their findings tell a cautionary tale as to the psychological reality of such learners because the computational learner improved when a cue that humans are sure to use – the specific lexical item – was removed from the learner. Nevertheless, such studies are interesting additions to the inventory of multi-factorial/multivariate methods that have taken corpus-based CxG by storm.
Exploratory/Computational Approaches
While there is of course the major body of work on Fluid Construction Grammar – see, for example, the special issue of Constructions and Frames (2017, Vol. 9, Issue 2), also Chapter 10 – there is now also much more computational-linguistic work in CxG than even eight to ten years ago. At the risk of some simplification, we can distinguish two main kinds of exploratory studies. First, there are those that are largely descriptive in nature; in such studies the starting point is one or more constructions and the goal is to see what we can learn about their function pole(s) from the results of exploratory tools applied to their distribution. Second, there are those exploratory studies whose focus is on identifying construction types and tokens in corpora in a bottom-up way; thus, in such studies, the starting point is not a construction whose distributional behavior is explored – instead, the starting point is a corpus and constructions extracted from it in an automated way are the endpoint/goal (see also Chapter 23). Over the last ten years or so, both kinds of studies have become noticeably more frequent.
As a first example of the former kind of exploratory studies, Flach (Reference Flach2021) uses a technique called variability-based neighbor clustering – a method to identify clusters in temporal data (e.g., acquisition or historical corpus data) that respects the temporal ordering of the data (Gries & Hilpert Reference Hilpert2008) – to identify temporal stages in the way the into-causative construction slots have become more lexically diverse over the last 200 years. She further shows how this change is accompanied by a subtle change in the construction’s semantics.
Next, consider the body of work by Hilpert and colleagues on modal constructions. For example, Hilpert (Reference Hilpert2016: 70) explicitly extends the theory by arguing that “knowledge of a construction includes probabilistic knowledge of how that construction is associated with lexical elements” and, accordingly, combines the logic underlying frequencies and association measures with the use of multivariate exploratory methods. Using data from COCA and COHA, he explores the similarities and diachronic development of the collocational profiles of a variety of English modal verbs. For instance, multi-dimensional scaling of modals based on collocate frequencies reveals, among other things, clines from informational to interpersonal uses and from deontic to epistemic modality. That kind of analysis is then extended to the diachronic data, reflecting how the location of may, for instance, in this ‘modal space’ changes over time. Then, Hilpert follows up on an earlier collostructional analysis with a diachronic semantic vector space analysis, whose results show in an unprecedented bird’s-eye view how the distribution of may’s collocates changes over time with regard to the dimensions of abstractness and volitionality/physicality. In a related paper, Hilpert and Flach (Reference Hilpert and Flach2020) contrast may and might by identifying and comparing their second-order collocates, using such a vector space method, and validate the accuracy of the collocational differences by (i) reducing the collocational space using multi-dimensional scaling and (ii) using a binary logistic regression to determine the classificatory power of the collocates for modal choice. While the obtained classification accuracies are only moderate, Hilpert and Flach (Reference Hilpert and Flach2020: 13) argue that second-order collocates “provide a statistical signal that facilitates the discrimination of deontic and epistemic modal meaning,” which in turn supports the notion of “linguistic knowledge as a network of symbolic units that are mutually interconnected at different levels of schematicity” (see also Hilpert & Saavedra Reference Hilpert and Saavedra2020 for a more general characterization of their methodology).
Apart from the increasing interest in vector space approaches, network-based approaches are also slowly garnering more attention. One particularly prominent example is maybe Ellis et al. (Reference Ellis, Römer and O’Donnell2016), who develop semantic networks for the verb-argument constructions they study (e.g., the V about N construction, the V across N construction, etc.), then derive a variety of statistics from those (e.g., betweenness and degree centrality, density, and others), and, most interestingly, apply a community-detection algorithm to them in order to identify a variety of semantically related coherent groups of verbs in these constructions; these in turn shed light on the polysemy of constructions and the prototypical members of semantic groups of constructions. Another example of a network study is Chen’s (Reference Chen2022) network of Mandarin Chinese space particles in the constructional schema zai + NP + space particle in the 10 million-word POS-tagged Sinica corpus. Approximately 26,000 pairs of nouns and particles from these constructions were analyzed with a network approach based on three inputs: (i) collostruction strengths between nouns and particles from a covarying collexeme analysis, (ii) similarities between the nouns from a word2vec model, and (iii) cosine similarities between the particles. Chen shows that the network exhibits a scale-free structure, meaning that only a few nodes are frequently connected to other units and that most other nodes are relatively unconnected – a striking emergence of the well-known Zipfian distribution of words in constructional slots at the level of a constructional network. Also, the network indicates that experientially and interactionally more prominent particles exhibit higher degrees of local clustering and, thus, more semantic homogeneity. These kinds of observations – and others, for example, about prototypicality within the network – would be extremely hard to make on the basis of just qualitative analysis and, therefore, testify to the power of these more advanced types of methods.
As for the kind of inductive construction-identification studies that constitute the second major area of exploratory/computational CxG work, one example is Martí et al. (Reference Martí, Taulé, Kovatchev and Salamó2019), whose DISCOver algorithm is “an unsupervised methodology for the automatic identification and extraction of lexico-syntactic patterns that are candidates for consideration as constructions.” This, too, is essentially a vector space method that involves identifying dimensions in co-occurrence data for lemmas and syntactic dependency relations in their contexts, specifically “tuples involving two lexical items (lemmas) related both by a dependency direction and a dependency label.” Their method, while tested on 15,000 lemmas from one specific corpus (the 94 million-word Diana-Araknion corpus of Spanish), is applicable to any corpus with POS and syntactic dependency annotation from which one can construct clusters of lemmas that are related by their preference for a set of lexico-syntactic contexts. Interestingly, the approach makes it possible to identify construction candidates that are actually attested in the data as well as unattested-but-likely construction candidates that merit scrutiny by the human analyst.
A somewhat similar approach is Dunn (Reference Dunn2018), who first runs a CxG induction approach (C2XG) on the ukWaC corpus and then uses the grammar learned from that to measure the similarity between inner- and outer-circle varieties of English (from the ICE project and the Leipzig corpora collection). The first part, the induction algorithm, requires as input three different levels of information for each ‘word’:
a lexical level consisting of whitespace-separated ‘words’;
a morphosyntactic level consisting of part-of-speech tags assigned to those words; and
a semantic level, which approximates the semantic/conceptual pole of a word with a distributional-semantics-based vector representation.
Thus, each word is represented as a combination of information of these levels in n-dimensional space, which can then be clustered (e.g., using k-means analysis, a kind of cluster analysis where data points are grouped into a user-defined number of clusters).
The second part of the analysis is a classification task that attempts to determine how well a machine-learning algorithm can predict English varieties from the (relative) frequencies of the construction candidates arrived at in the first step; in other words, the question is whether English varieties exhibit distinctive behavioral profile-like distributions of constructions. On a meta-theoretical level, this kind of work – cognitive sociolinguistic work that models many speakers of a variety as a whole – can provide the regionally-dialectally motivated counterpoint to studies of individual variation.
7.3 Concluding Remarks
Given all of the above, what is the state of the art in corpus-based CxG? I think it is fair to say that, after the field’s Big Bang in the late 1980s, the field is still exhibiting a rapid but healthy expansion. Compared to the relative (!) paucity of corpus studies discussed in Gries (Reference Gries, Hoffmann and Trousdale2013a), there is now a multitude of studies covering all the parameters mentioned at the beginning of this overview: (kinds of) languages studied; temporal orientation; range of corpora, registers, and genres; resolution (individual(s), speech communities); scientific goals (description, theoretical development, computational simulation); and statistical methods. Even from the highly selective review offered above, it seems as if nearly every combination of choices from these features is now a lively field of inquiry advanced by the continued development, application, and – by now often – combination of quantitative methods to constructional corpus data.
However, corpus-linguistic methods and analysis have not only simply become more frequent (to the point of being mainstream), they have also helped to advance the theory itself. From Goldberg’s revision of her definition of a construction from Goldberg (Reference Goldberg1995) to Goldberg (Reference Goldberg2006) (which did away with non-compositionality as a necessary condition but added sufficient frequency as a criterion) and Hilpert’s (Reference Hilpert2016) addition of probabilistic knowledge of how a construction is used to constructional knowledge, to Cappelle et al.’s (Reference Cappelle, Depraetere and Lesuisse2019) perspective of context-as-construction and Flach’s (Reference Flach2020a) determination of the level of granularity constructional co-occurrence matches best one of the oldest linguistic methods (acceptability judgments), there are many ways in which corpus-based CxG has made valuable contributions (even if many may need to be revised later). In addition, one cannot help but feel that the overall quality of the field has increased as well. I would like to think this is not only a subjective impression but an assessment that can also be supported by looking at a recent critical review of cognitive-linguistic work, of which much of CxG is probably a part, namely Dąbrowska (Reference Dąbrowska2016). She catalogued seven deadly sins of cognitive linguistics, which I would summarize as follows:
(1) excessive reliance on introspection;
(2) not treating the Cognitive Commitment seriously;
(3) not enough serious hypothesis testing;
(4) ignoring individual differences;
(5) neglecting the social aspect of language;
(6) assuming that we can deduce mental representations from patterns of use; and
While I ‘only’ agree with most of the points Dąbrowska is making, it does seem to me as if much of the CxG work summarized above addresses (mostly implicitly) many of these issues superbly. For instance:
regarding 1 and 2, we see much less reliance on introspection in general, but also the combination of corpus data with various kinds of experimental work, computational simulation, interrater reliability, etc.
regarding 3, we see a lot of hypothesis testing now, with a wide range of sophisticated statistical/machine-learning models and networks; and
regarding 4 and 5, we see more work on both these aspects.
And this does not even count the spread of CxG-inspired work into areas I have not discussed at all, for example, work on constructions and their preferences and alternations in indigenized varieties of World Englishes (as in Mukherjee & Gries Reference Mukherjee and Gries2009; Gries & Mukherjee Reference Gries and Mukherjee2010; Bernaisch et al. Reference Bernaisch, Gries and Mukherjee2014; Heller et al. Reference Heller, Bernaisch and Gries2017; Röthlisberger et al. Reference Röthlisberger, Grafmiller and Szmrecsanyi2017; Rautionaho & Deshors Reference Rautionaho and Deshors2018; Brunner & Hoffmann Reference Brunner and Hoffmann2020; Hoffmann Reference Hoffmann2020b, etc.). Thus, to my inevitably biased mind, the field can take a certain degree of pride in these developments which, in spite of the high degree of inertia of academia, have happened in a rather short period of time. That does not mean it is time to rest on our laurels (see Hoffmann Reference Hoffmann2020a for a recent call to include more psycholinguistic and neurolinguistic data to CxG’s arsenal), but it does inspire hope for high standards of, and interesting findings from, future research. It is a good time to be a corpus-based Construction Grammarian; here’s to the next ten to twenty years!
8.1 Introduction
Many of the various strands of Construction Grammar aim for some level of psychological validity, in that they make explicit claims about how grammar is stored in the minds of speakers. Some of them aim to capture grammar in a way that is at least compatible with what is known about human cognition, in line with Lakoff’s (Reference Lakoff1990) ‘cognitive commitment’. Others take this aim one step further and seek to describe the mental representation of grammatical phenomena as it is stored in the mind of speakers. Even for those scholars who do not seek to make any such cognitive claims and pursue a more descriptive orientation, the criterion of psychological adequacy is still a valid goal, as it should make grammatical descriptions more compatible with how ordinary speakers perceive the grammatical facts. Such research goals make it imperative for construction grammarians to rely on methods that directly tap into the knowledge of speakers at a cognitive level. One way to accomplish this is by investigating speakers’ behavior with language in controlled experimental conditions. Experimental methods are thus crucial to Construction Grammar research and theory-building.
Against this backdrop, this chapter discusses the use of experimental approaches in Construction Grammar. More specifically, it focuses on behavioral evidence for the constructional approach, that is, information derived from the behavior of language users on certain tasks. Largely pioneered and popularized by cognitive psychology, behavioral methods take the view that observations of external human behavior under various conditions can be interpreted as a reflection of internal cognition, and can thus be used to ground theories of cognitive representation and processing. In linguistics, such evidence is typically derived from psycholinguistic experiments that tap into the latent linguistic knowledge of speakers and/or their cognitive processing of language. By experiment we understand a type of data collection method that involves a procedure carefully designed to elicit a particular kind of behavior and applied consistently to a group of participants (the sample) in a controlled environment, with manipulations that create different conditions by varying certain aspects of the procedure, for instance properties of the stimuli presented to participants.
A distinction is sometimes drawn between online and offline evidence in behavioral methods. Offline evidence looks at the output of language processing in some form; examples include grammaticality judgments, answers to questions about the semantic interpretation of a sentence, or simply linguistic material (e.g., words, sentences) produced by participants in response to some instruction. Offline data are relatively easy to come by but, as they are typically the result of conscious reasoning, they can be subject to strategic responding and may not offer the most direct access to cognitive processes. Thus offline evidence should ideally be complemented with online evidence, which looks at the course of language processing itself. One of the most common types of online data in psycholinguistics is reaction times (RT), which measure the time it takes for participants to carry out a certain task, usually in the order of milliseconds. The assumption behind using reaction times as a source of behavioral data is that response latency is taken to be a reflection of the complexity of the mental process involved in completing the task, and thus differences in reaction time should reveal differences in cognitive processes and/or mental representations. Note that behavioral evidence is not the only source of data that can inform models of cognition; another is, for instance, neurological evidence, that is, data derived from the brain’s physiological response, such as measures of brain activity (e.g., ERPs), patterns of brain activation, and other forms of brain imaging (e.g., fMRI). This, however, is outside the scope of this chapter (but see Pülvermüller et al. Reference Pülvermüller, Cappelle, Shtyrov, Hoffmann and Trousdale2013).
This chapter will more specifically focus on behavioral evidence for three core ideas that characterize the constructional approach to grammar and set it apart from other approaches: (i) Phrasal constructions can convey meaning in and of their own; (ii) Constructions exist independently of particular lexical items; (iii) Grammar consists of a network of constructions related by various kinds of links. In doing so, typical types of procedures and manipulations are identified that are especially relevant to constructional research. Not all of the studies discussed in this chapter necessarily aim to show evidence for the constructional approach specifically, nor are they even necessarily framed in terms of constructions. However, as it will be argued when discussing their results, in all cases these findings are predicted by, or are compatible with, the theoretical principles of Construction Grammar, even if they sometimes predate Construction Grammar itself.
The chapter is structured as follows. Section 8.2 will discuss studies showing evidence for constructional meaning in language comprehension. Section 8.3 will focus on the phenomenon of structural priming and in particular the fact that it can involve the form and/or the meaning of sentences, indicating that both are part of the mental representation of grammar. Section 8.4 will look at evidence for the network approach of Construction Grammar. Finally, I conclude the chapter by commenting on some limitations of previous studies and offering prospects for future research.
8.2 Constructional Meaning in Language Comprehension
In this section, I discuss evidence that speakers rely on various aspects of meaning when processing sentences that do not always come from lexical items, but are best attributed to a syntactic construction. This includes event structure, that is, the general abstract meaning conveyed by an argument structure construction, as well as semantic entailments and presuppositions established in the course of interpretation. Evidence from language comprehension indicates that grammatical units, and not just words, convey meaning of their own, thus lending credence to the idea that the entirety of grammar consists of form–meaning pairs, including phrasal patterns of various kinds.
In a sorting task study, Bencini and Goldberg (Reference Bencini and Goldberg2000) adapted an earlier experiment by Healy and Miller (Reference Healy and Miller1970) that showed the importance of verbs in sentence interpretation. They asked participants to sort sixteen sentences into four groups according to their overall meaning, but where Healy and Miller pitted sentences with the same verbs against sentences with the same subject, Bencini and Goldberg crossed four verbs (throw, slide, get, and take) with four argument structure constructions: the Transitive construction, the Ditransitive construction, the Resultative construction, and the Caused-Motion construction. They found a stronger tendency for speakers to form groups of sentences with the same construction (e.g., Chris threw Linda the pencil with Beth got Liz an invitation) than with the same verb (e.g., Chris threw Linda the pencil with Pat threw the keys onto the roof). They conclude that general abstract meanings directly paired with overall sentence form independently of verbs are the main determinant of sentence meaning, rather than verbs themselves. This shows that constructional meaning is a salient dimension of similarity between sentences, and therefore a likely basis for establishing categories of sentences. Shin and Kim (Reference Shin and Kim2021) report similar findings from Korean, and several other studies also find the same effect with learners of English as a second language with various L1s, using the same or similar English sentences as Bencini and Goldberg (Reference Bencini and Goldberg2000); for instance, Gries and Wulff (Reference Gries and Wulff2005) for L1 German and Baicchi (Reference Baicchi2015) for L1 Italian, showing that second language learners too are sensitive to constructional levels of sentence meaning.
The results of sorting task experiments show that direct pairings of sentence forms with abstract meanings are at least possible, and the sheer preponderance of construction-based sorting makes it likely that such pairings are stored in the mental grammar and activated in language comprehension. However, it can be argued that they do not constitute the hardest kind of evidence for the psychological reality of constructions, as there still remains the possibility that lexical items themselves convey these aspects of meaning (as projectionist accounts of argument realization would argue, e.g., Pinker Reference Pinker1989). Hence, an even more compelling test for the cognitive reality of constructions may come from cases in which aspects of interpretation cannot plausibly come from words alone and therefore must come from syntactic constructions, since these words are novel and/or have no clear established meaning that could also include the meaning attributed to the construction. Three such studies are discussed below.
Kaschak and Glenberg (Reference Kaschak and Glenberg2000) used novel denominal verbs (e.g., to crutch) in two kinds of sentence contexts, the Ditransitive construction (e.g., Lyn crutched Tom the apple so he wouldn’t starve) vs. the simple Transitive construction (e.g., Lyn crutched the apple so Tom wouldn’t starve), to test how the construction influenced the interpretation of the sentence in the absence of any prior meaning or usage for the denominal verb. The sentences were embedded in short stories that invited a transfer interpretation, though only the ditransitive variant does actually convey transfer in and of itself. Accordingly, participants were more likely to match the ditransitive variant than the transitive one with an interpretation of transfer vs. an interpretation of ‘acting on something’ (and vice versa), both in a forced-choice comprehension test and in a paraphrase task. Likewise, they were also more likely to define the verb itself as expressing transfer after it was witnessed in the Ditransitive construction, even though all other aspects of the discourse context were kept identical.
Using a slightly different design, Kako (Reference Kako2006a) reports similar findings with ‘Jabberwocky’ sentences (Johnson & Goldberg Reference Johnson and Goldberg2013), that is, sentences consisting of nonce content words (e.g., The rom gorped the blick to the dax) in the manner of Lewis Carroll’s poem “Jabberwocky.” Participants were presented with Jabberwocky sentences using six different argument structure constructions, and were asked questions about the interpretation of each sentence relating to possible aspects of the constructional meaning, for example, “How likely is it that gorping involves someone or something exerting force on someone or something else?” Kako found that each of the six constructions triggered significantly different interpretations of Jabberwocky sentences that were in line with the constructional meaning (e.g., ‘exertion of force’ for the transitive construction), which could only originate from the syntax itself since the words were entirely nonsensical. In a related study, Kako (Reference Kako2006b) shows a similar pattern of findings for the typical properties of the agent and patient argument of transitive sentences, which participants had a significant tendency to match with definitions corresponding to Dowty’s (Reference Dowty1991) proto-roles, even when the verbs themselves were nonce words; this too can be interpreted as evidence that speakers store direct pairings of syntactic forms with abstract meanings.
Goldwater and Markman (Reference Goldwater and Markman2009) investigate the role of the semantics of two constructions in sentence comprehension: the Passive construction (e.g., These books were sold quickly) and the Middle construction (e.g., These books had sold quickly). The two constructions are quite similar both formally and semantically, but they crucially differ in terms of whether they construe the event as more or less agentive: Although neither of them needs to explicitly mention an agent, the Passive construction does presuppose the existence of an implicit agent causing a change-of-state, while the Middle construction construes the same change-of-state as self-initiated. Goldwater and Markman (Reference Goldwater and Markman2009) used stimuli sentences in which each of these constructions was followed by a to-infinitive purpose clause (e.g., These books were/had sold quickly to fund the trip), which also presupposes the existence of an agent and thus is presumably incompatible with the Middle construction. In a self-paced reading task where participants had to decide, at every word they read, whether the sentence still made sense, sentences with the Middle construction were more likely to be found nonsensical from the onset of the to-infinitive clause than those with the Passive construction. The same effect was found for both existing verbs and novel denominal verbs (e.g., to wine in the sense of ‘turn into wine’), showing that the role of the construction is in evidence even when no prior information about the verb is available; this in turn means that this semantic difference should be attributed to the construction alone.
Other comprehension studies report that formulating the same message using different syntactic constructions causes subtle yet robust and systematic differences in construal, in ways that are difficult (if possible at all) to attribute to lexical items alone. Such differences are compatible with a model of grammar in which phrasal patterns are directly paired with an abstract meaning or function independently of the lexical items they instantiate. For instance, Wittenberg and Snedeker (Reference Wittenberg and Snedeker2014) find that light-verb constructions with ditransitive syntax (e.g., Romeo is giving Juliet a kiss) are significantly more likely to be categorized as involving three participant roles (rather than just agent and patient) than semantically similar transitive sentences (e.g., Romeo is kissing Juliet). This suggests that the difference in syntax leads speakers to include an additional Theme role in their semantic representation of the sentence and to consider the event as one involving some form of transfer, in line with the semantics of the ditransitive construction (Goldberg Reference Goldberg1995). Wittenberg and Levy (Reference Wittenberg and Levy2017) report further differences in construal between light-verb constructions and their transitive verb counterparts, in terms of the estimated duration of the event and how many times it is understood to be repeated.
Using eye-tracking methods in a Visual World Paradigm, Divjak et al. (Reference Divjak, Milin and Medimorec2020) find different patterns of eye fixations on pictures presented to participants, depending on whether the picture was preceded by a sentence description of the scene or not (the latter being the ‘naturalistic viewing’), and also depending on the construction used in the description. Three pairs of constructions were contrasted: converse spatial prepositions (the poster is above the bed vs. the bed is below the poster), active vs. passive (the policeman arrested the thief vs. the thief was arrested by the policeman), and the variants of the dative alternation (the boy gave the girl a flower vs. the boy gave a flower to the girl). Differences were notably found in terms of which part of the picture mentioned in the sentence was looked at first and for how long, both between constructions in each pair and compared to naturalistic viewing. For instance, the Patient argument is more likely to be looked at first after a passive description (where it is realized as subject) than either after an active description or in the naturalistic viewing. This shows that language plays a role in guiding visual attention, in that different constructions bring focus to different parts of a scene. In a constructional approach, these effects are readily interpreted in terms of differences in construal originating in constructional meaning.
8.3 Constructions and Structural Priming
Priming is a psychological phenomenon whereby exposure to one type of stimulus (the prime) causes an effect on the subsequent processing of another type of stimulus (the target) (see also Chapters 6, 7, and 23). Priming is often interpreted as evidence for some sort of relationship between the mental representations of prime and target. A large body of evidence shows that sentences can also prime each other, a phenomenon typically known as structural priming (cf. Pickering & Branigan Reference Pickering and Branigan1999; Tooley & Traxler Reference Tooley and Traxler2010; Mahowald et al. Reference Mahowald, James, Futrell and Gibson2016; Branigan & Pickering Reference Branigan and Pickering2017). Such priming effects have been reported both in production and comprehension (e.g., Tooley & Traxler Reference Tooley and Traxler2010) and are widely documented in many languages besides English, including Dutch (Hartsuiker & Kolk Reference Hartsuiker and Kolk1998), German (Pappert & Pechmann Reference Pappert and Pechmann2013, Reference Pappert and Pechmann2014), Brazilian Portuguese (Ziegler, Morato, & Snedeker Reference Ziegler, Morato and Snedeker2019), Russian (Vasilyeva & Waterfall Reference Vasilyeva and Waterfall2011), and Mandarin Chinese (Cai et al. Reference Cai, Pickering and Branigan2012).
In the context of constructional research, priming effects between sentences sharing aspects of form and/or meaning have typically been used as evidence for the cognitive reality of constructions (cf. Goldberg & Bencini Reference Goldberg, Bencini, Tyler, Takada, Kim and Marinova2005; Bencini Reference Bencini, Hoffmann and Trousdale2013). For many scholars, priming provides a window into the cognitive representations underlying the production and comprehension of sentences (Branigan & Pickering Reference Branigan and Pickering2017). Priming effects suggest that there are aspects of sentence representation that are activated in language use and subsequently remain more readily available. Because structural priming effects occur independently of the specific lexical items used in sentences, they have been taken as evidence that at least some aspects of sentence representation are stored separately from lexical items, in line with the constructional approach (Konopka & Bock Reference 218Konopka and Bock2009; Bencini Reference Bencini, Hoffmann and Trousdale2013).
This section is structured as follows. In Section 8.3.1, I first introduce the notion of structural priming as it was initially identified in the first studies on this topic, that is, as the priming of syntactic structure across sentences. In Section 8.3.2, I discuss evidence that structural priming might not be entirely driven by syntax alone, in that overlap in thematic roles may also cause priming effects, independently of constituent structure. In Section 8.3.3, I report evidence that other aspects of sentence meaning may also cause priming, such as the abstract event structure conveyed by a construction. Overall, the priming literature suggests that various aspects of both the form and the meaning of sentences may be primed regardless of the lexical items involved, which is compatible with the Construction Grammar view that the mental representation of grammar consists of independent form–meaning pairs.
8.3.1 Priming of Syntax
Bock (Reference Bock1986) was the first study to report evidence for structural priming, that is, the fact that hearing a sentence with a certain syntactic structure makes it more likely for the same structure to be subsequently used. Participants were presented with prime sentences instantiating one of a pair of functionally similar syntactic structures: active vs. passive structure for transitive primes (e.g., One of the fans punched the referee vs. The referee was punched by one of the fans), and prepositional dative vs. double-object structure for ditransitive primes (e.g., The lifeguard tossed a rope to the struggling child vs. The lifeguard tossed the struggling child a rope). After each prime, a target picture was shown that could be described using either the structure exemplified by the prime sentence structure or the functionally similar structure (i.e., active vs. passive or double-object vs. prepositional dative). This design is diagrammed in Figure 8.1. Bock (Reference Bock1986) found that it was more likely for participants to describe each picture using the same structure as the one in the preceding prime sentence, even if the prime and target did not share the same verb.
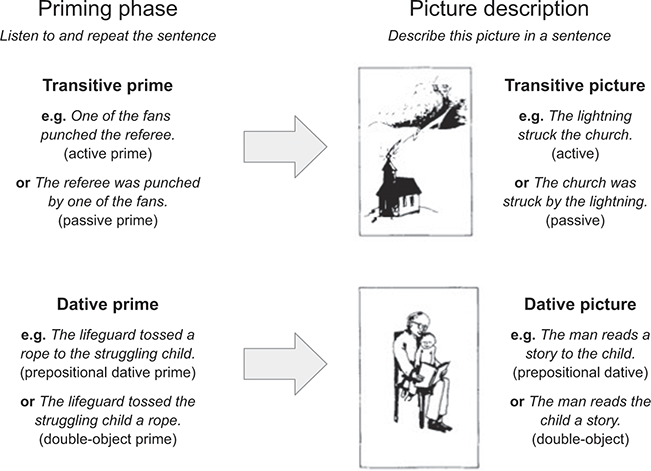
Figure 8.1 Experimental design of Bock’s study on structural priming
In subsequent studies, Bock (Reference Bock1989) and Bock and Loebell (Reference Bock and Loebell1990) argue for a purely syntactic account of structural priming, driven by the constituent structure of sentences alone, independently of the words occurring in it and the meaning that they convey. Bock (Reference Bock1989) finds that prepositional datives with to (e.g., A cheerleader offered a seat to her friend) and benefactives with for (e.g., A cheerleader saved a seat for her friend), which are matched in syntactic structure but differ in their preposition (to vs. for), equally prime to-datives (see also Pappert & Pechmann Reference Pappert and Pechmann2013 for a similar finding with the German equivalent of these alternations). Similarly, Bock and Loebell (Reference Bock and Loebell1990) find priming effects between pairs of sentences with the same structure but different meanings, notably in terms of event structure and thematic roles. They find that prepositional datives (e.g., The wealthy widow gave an old Mercedes to the church) and transitive locative sentences with to (e.g., The wealthy widow drove an old Mercedes to the church) equally prime prepositional datives, and that full passives (e.g., The construction worker was hit by the bulldozer) and intransitive locative sentences with by (e.g., The construction worker was digging by the bulldozer) equally prime full passive sentences. Because primes share the same structure as the target but not their meaning, Bock and Loebell (Reference Bock and Loebell1990) argue that syntactic structure alone causes priming, independently of semantics.
While Bock and Loebell’s (Reference Bock and Loebell1990) interpretation of these findings might seem at first blush to provide evidence for the autonomy of syntax, and thus indirectly against the constructional approach, a vast body of research since their seminal study has investigated the nature of structural priming more closely, and many scholars have argued against a purely syntax-driven account. While genuine cases of priming of syntactic structure alone have certainly been found, many studies report that various other aspects of the form and meaning of sentences can also drive priming. In fact, Bock’s (Reference Bock1989) and Bock and Loebell’s (Reference Bock and Loebell1990) original conclusions have since been criticized on the basis of possible confounds that may explain the priming effects for the pairs of constructions under study, and subsequent research suggests that these effects may be best attributed to semantic and lexical overlap. First, to-datives and for-benefactives on the one hand, and to-dative and to-locative sentences on the other hand, may not be as semantically distinct as assumed by Bock (Reference Bock1989) and Bock and Loebell (Reference Bock and Loebell1990) respectively. In many for-benefactives, the referent of the for-PP is the intended recipient of some item, similar to that of the to-PP in to-datives. As pointed out by Hare and Goldberg (Reference Hare, Goldberg, Hahn and Stoness1999), the use of to in to-datives can be seen as metaphorically related to the literal goal meaning of the preposition found in to-locatives, with transfer of possession construed as a metaphorical change of location (e.g., Jackendoff Reference Jackendoff1983). Moreover, some of the to-locative primes used in Bock and Loebell’s (Reference Bock and Loebell1990) experiment may not be purely locative and could actually be considered prepositional datives as well, for example, The hospital returned the bill to the patient by mistake (cf. Hare & Goldberg Reference Hare, Goldberg, Hahn and Stoness1999). To-datives and to-locatives also share one function word (the preposition to), and similarly, by-locative and passive sentences share even more of their lexical make-up, namely the auxiliary be and the preposition by. Hence, in addition to semantic similarity, lexical overlap may also explain these priming effects. These confounds suggest that structural priming might not be purely driven by shared syntactic structure, prompting Ziegler, Bencini, et al. (Reference Ziegler, Bencini, Goldberg and Snedeker2019) to conduct a follow-up study adding a condition to Bock and Loebell’s (Reference Bock and Loebell1990) original experiment. While Ziegler, Bencini, et al. (Reference Ziegler, Bencini, Goldberg and Snedeker2019) do replicate the critical by-locative to passive priming effect from Bock and Loebell (Reference Bock and Loebell1990), they also find that this effect disappears in the absence of lexical overlap: locative sentences with a different auxiliary from be and a different preposition from by (e.g., The 747 has landed near the airport control tower) do not prime passive sentences.
Importantly, the structural priming effects discussed above can occur independently of the lexical items involved. Ivanova et al. (Reference Ivanova, Pickering, Branigan, McLean and Costa2012) even report priming effects in the dative alternation when the prime sentence contains a nonce verb (e.g., The waitress brunks the book to the monk) or a verb that does not normally occur in these constructions (e.g., The waitress exists the ball to the monk), which confirms that structural priming does not rely on lexical information. Hence, it is hard to explain these priming effects without assuming at least some level of syntactic representation that is separate from lexis, which lines up with the constructional approach whereby aspects of sentence structure are stored and retrieved independently of particular lexical items (cf. Konopka & Bock Reference 218Konopka and Bock2009; Bencini Reference Bencini, Hoffmann and Trousdale2013). Moreover, since Construction Grammar posits that phrasal patterns are directly paired with meaning, it also predicts that constructions with similar forms as well as constructions with similar meanings should prime each other. Many priming studies do show that the semantic properties of constructions can also be a source of priming effects, in particular the abstract event structure conveyed by a construction and the thematic roles assigned to constructional slots.Footnote 1 These two kinds of priming effects are discussed in the next two sections.
8.3.2 Priming of Thematic Roles
Several studies show that overlap in thematic roles can create priming effects, either independently from syntactic structure or in addition to purely syntactic priming. In a picture-description task with transfer events similar to Bock’s (Reference Bock1986) experiment, Hare and Goldberg (Reference Hare, Goldberg, Hahn and Stoness1999) used three kinds of prime sentences: double-object (His editor offered Bob the hot story), to-dative (His editor promised the hot story to Bob), and ‘provide-with’ structures (His editor credited Bob with the hot story). The latter two have the same syntactic structure, but the provide-with sentences also have the same order of thematic roles as the double-object construction (Agent-Recipient-Theme), thus providing a semantic foil to syntactic priming. Hare and Goldberg (Reference Hare, Goldberg, Hahn and Stoness1999) find that provide-with sentences prime double-objects as much as double-objects themselves (as compared to a baseline with intransitive primes), thus providing evidence for priming of thematic roles independently of syntactic structure (see also Ziegler & Snedeker Reference Ziegler and Snedeker2018 for a replication of this finding).
Chang et al. (Reference Chang, Bock and Goldberg2003) report similar results using Rapid Serial Visual Presentation (RSVP, Potter & Lombardi Reference Potter and Lombardi1998), a protocol in which participants are asked to read a sentence word by word silently and then repeat the sentence out loud after a distractor task interfering with their memory. In such a design, priming effects are found when participants change the structure of the repeated sentence by using the structure of a prior prime sentence. Two related constructions involved in the so-called spray/load alternation were used to construct pairs of prime and target sentences: theme-location sentences (The chef sprayed oil onto the pan) and location-theme sentences (The chef sprayed the pan with oil). Chang et al. (Reference Chang, Bock and Goldberg2003) did find priming effects for both constructions, that is, location-theme sentences changed to theme-location after a theme-location prime, and vice versa. Because both constructions have the same syntactic structure, these effects can only be attributed to the repetition of thematic role assignment (see also Ziegler & Snedeker Reference Ziegler and Snedeker2018 for a replication using a similar picture-description design to Bock’s original studies). The same priming effect was also found between the variants of the corresponding spray/load alternation in Brazilian Portuguese (Ziegler, Morato, & Snedeker Reference Ziegler, Morato and Snedeker2019).
Pappert and Pechmann (Reference Pappert and Pechmann2014) report similar findings with the dative alternation in German, which has more flexible word order than English due to case marking. Specifically, the theme and recipient arguments in the double-object construction are marked, respectively, in the accusative and dative case, and while the Dative-Accusative order is more common (e.g., Der Händler verkauft [dem Bauern]DAT [einen Traktor]ACC ‘The merchant sells the farmer a tractor’), the opposite order is also possible (Der Händler verkauft [einen Traktor]ACC [dem Bauern]DAT). Pappert and Pechmann (Reference Pappert and Pechmann2014) find priming effects between the double-object and prepositional dative constructions in ways that are consistent with the order of thematic roles: NP-PP prepositional datives (e.g., Der Sohn schreibt einen Brief an die Mutter ‘The son writes a letter to his mother’) prime the Accusative-Dative double-object order, and shifted prepositional datives (PP-NP) prime the Dative-Accusative order, and vice versa. Finally, Cai et al. (Reference Cai, Pickering and Branigan2012) report similar effects in the dative alternation in Mandarin Chinese; they find that double-object primes with the ba-construction or the Topic construction, which both shift the order of the Theme argument before the Recipient, prime prepositional datives, which have the same order of thematic roles.
8.3.3 Priming of Semantics
The studies cited in the previous section show that a construction with a certain set of thematic roles may prime another construction with the same set of thematic roles presented in the same linear order, regardless of the formal realization of each role (cf. Ziegler & Snedeker Reference Ziegler and Snedeker2018). Other studies show priming effects to be sensitive to other aspects of constructional semantics besides thematic roles. Griffin and Weinstein-Tull (Reference Griffin and Weinstein-Tull2003) compare the effect of object-raising (e.g., A teaching assistant reported the exam to be too difficult) vs. object-control primes (e.g., Rover begged his owner to be more generous with food) on the production of object-raising targets in an RSVP task similar to Chang et al. (Reference Chang, Bock and Goldberg2003). Both object-raising and object-control sentences have the same constituent structure, that is, an NP followed by a to-infinitive VP. However, while the object-raising construction encodes a two-participant relation between the subject and a proposition (i.e., ‘The exam is difficult’ in the example above), similarly to a that-clause construction (e.g., A teaching assistant reported that the exam was too difficult), the object-control construction involves an additional participant of the verb realized as a direct object (his owner in the example above). In other words, the two constructions differ in event structure, that is, in constructional meaning, regardless of the verb instantiating them. Griffin and Weinstein-Tull (Reference Griffin and Weinstein-Tull2003) find more object-raising productions (as opposed to that-clause productions) after object-raising primes compared to a control condition, but this effect was weaker with object-control primes despite the same constituent structure. These results show that shared event structure meaning also causes priming, in addition to syntactic structure.
Similarly, Ziegler et al. (Reference Ziegler, Snedeker and Wittenberg2018) show that the priming of ditransitive sentences with give varies according to their event-structure properties, despite their shared syntax. Specifically, they compare so-called compositional ditransitives, that is, typical uses of the construction with a recipient and theme arguments (e.g., Big Bird gives Julia a feather), light-verb ditransitives (e.g., Bert gives Ernie a hug), and idiomatic ditransitives (e.g., Miss Piggy gives Kermit the cold shoulder) which are non-compositional. Importantly, both light-verb and idiomatic ditransitives are essentially two-place predicates with a patient realized as the first object, while compositional ditransitives are paired with a three-argument event structure. Ziegler, Bencini, et al. (Reference Ziegler, Bencini, Goldberg and Snedeker2019) find this difference in event structure to correspond to a difference in priming: While all three types of ditransitives prime compositional ditransitives, the priming effect is significantly stronger with other compositional ditransitive primes.
There is thus ample evidence that various aspects of the meaning conveyed by a construction are activated when instances of the construction are used, and such aspects make it more likely for constructions featuring the same aspects of meaning to be subsequently used. The same can also be seen in comprehension, in that items with a similar meaning to the meaning of a construction are processed faster following instances of that construction. In a reaction time study, Eddington and Ruiz de Mendoza Ibáñez (Reference Eddington, Ruiz de Mendoza Ibáñez, De Knop, Boers and De Rycker2010) presented participants with sentences, and they had to judge whether each sentence was grammatical as quickly as possible. In the list of sentences, targets for priming were constructed from six different argument structure constructions, such as the Resultative construction (e.g., Ron kicked the door open); prime sentences preceding each target were either instances of the same construction or sentences with the same formal pattern but without the same event-structure meaning (e.g., Josh thought the treatment unfair for the Resultative construction). They found that judgments were significantly faster following a prime that matched both the form and the meaning of the sentence than following one that matched only its form. This shows that witnessing an instance of a form–meaning pair speeds up subsequent processing of instances of the same form–meaning pair.
Johnson and Goldberg (Reference Johnson and Goldberg2013) similarly investigate the priming of constructional meaning using Jabberwocky sentences (see Section 8.2), for example, He daxed her the norp. Because none of these words convey meaning, the only source of semantic information associated with the sentence comes from the meaning of the construction, for example, the transfer meaning of the ditransitive construction in He daxed her the norp. They find that Jabberwocky sentences can prime a word matching the meaning of the construction (give for the ditransitive) or a word with a similar meaning (transfer), as measured by decreased reaction times in a lexical decision task. Busso et al. (Reference Busso, Perek and Lenci2021) use a similar methodology to study the processing of sentences with valency coercion in Italian, using prime sentences that combine an argument structure construction with an unusual yet compatible verb (e.g., La donna sbriciola pane agli uccelli ‘The woman crumbles bread for the birds’). Similarly to Johnson and Goldberg (Reference Johnson and Goldberg2013), they find that the four Italian argument structure constructions used in the experiment prime verbs that match the central meaning of the construction, for example, mettere ‘put’ for the Caused-Motion construction. In addition, this priming effect is found to vary according to the degree of compatibility between the verb and the construction, as measured by a grammaticality rating study (Busso et al. Reference Busso, Lenci and Perek2020); namely, the strength of priming increases with the acceptability of the prime sentence. This finding too can be explained through the notion of constructions as units of meaning: When a construction is successfully combined with a verb in a sentence involving valency coercion (high acceptability), the meaning of the construction is fully integrated with that of the verb and thus primes the related verb. However, if there are difficulties in combining the meaning of the verb with that of the construction (low acceptability), semantic integration of the constructional meaning may be unsuccessful or incomplete, which predicts that semantically related verbs are primed to a lesser degree.
In sum, there is evidence that constructions prime aspects of their form and/or meaning, in that not only can instances of the same construction prime each other, but they can also prime constructions with a similar form and/or meaning. While the exact mechanisms behind structural priming have been debated from the start (e.g., Chang et al. Reference Chang, Dell, Bock and Griffin2000; Ferreira & Bock Reference Ferreira and Bock2006), priming effects for both form and meaning suggest that form and meaning are stored in the cognitive representation of grammar, which gives further credence to the central constructional tenet that grammar consists of form–meaning pairs. Because these effects occur across different lexical items, they line up with the idea that abstract grammatical patterns are stored independently of lexical items.
8.4 Investigating the Constructional Network
Another central tenet of the constructional approach is the idea that constructions are related by various types of links and form a vast connected network (see also Chapter 9). This section examines behavioral evidence for this approach to the organization of grammar. I first discuss inheritance relations, that is, links between a construction and more specific instances of the construction, which may be stored along with the general construction. I then move on to other kinds of relations between constructions.
8.4.1 Inheritance Relations: Constructions and Their Instantiations
Inheritance is one of the most common and widely accepted relations between constructions across the many variants of Construction Grammar (see Pijpops et al. Reference Pijpops, Dirk Speelman, Van de Velde and Grondelaers2021 and Sommerer & Baumann Reference Sommerer and Baumann2021 for two recent studies on this topic). It essentially captures the commonalities in form and meaning between a range of ‘sister’ constructions into a more general ‘mother’ construction that they all inherit from. One of the most typical kinds of inheritance link is between an abstract construction and a lexically specific construction in which one of the slots of the abstract construction is filled by a specific lexical item, for instance between the ditransitive construction (NP V NP NP) and the ditransitive use of the verb bring (NP bring NP NP). This is illustrated in Figure 8.2. Inheritance relations are symbolized by arrows in Figure 8.2: They represent the fact that the form and meaning of the abstract ditransitive construction (top) is generalized from the double-object use of a range of verbs, including the four represented here (bottom); conversely, the form and meaning of the general construction is inherited by sub-constructions, including many more than these four, some of which may or may not be stored as verb-specific constructions.

Figure 8.2 Illustration of a constructional network with the ditransitive construction and four of its verb-specific constructions
Much of the evidence cited earlier in support of abstract constructional meaning is also, ipso facto, evidence for such inheritance links. For instance, Bencini and Goldberg’s (Reference Bencini and Goldberg2000) sorting task experiment illustrates speakers’ ability to extract the similarity in form and meaning between sentences with different verbs and consider them members of the same category. Many priming studies also provide evidence for abstract constructions and therefore for inheritance relations: The fact that instances of the same construction with different lexical items can prime each other precisely points to a higher, lexically independent level of representation linked to all of the lexically specific instantiations.
Importantly, just because a certain use of a lexical item is subsumed by a construction and can be arrived at by merging the item with this construction (cf. Goldberg Reference Goldberg1995) does not necessarily mean that this use is not stored as a construction itself, in line with Langacker’s (Reference Langacker1987) rejection of the ‘rule/list fallacy’. In other words, in a constructional approach, a construction and its lexically specific instantiations can coexist in the network of constructions with inheritance links between them, even if the latter exemplify fully predictable uses of the former. There is actually a large body of psycholinguistic research reporting differences in the processing of sentences with different verbs used in the same constructions in language comprehension, indicating differences in status in the mental grammar. In particular, many studies focus on temporarily ambiguous sentences like the ones below from Garnsey et al. (Reference Garnsey, Pearlmutter, Myers and Lotocky1997):
(1) The talented photographer accepted the money could not be spent yet.
(2) The novice plumber realized the mistake would cost someone some money.
Upon reading both sentences, the noun phrase following the first verb (accepted and realized) can be tentatively analyzed either as a direct object or as the subject of an embedded clause; only when the next word is read (i.e., an auxiliary verb, could or would) can it be decided that the latter analysis is correct. When such sentences are presented word by word or segment by segment in a self-paced reading task, which forces participants into an incremental way of reading, many studies find that participants will tend to make early assumptions about the syntactic frame the verb is used in, and thus predictions about the upcoming constituents, resulting in processing difficulties if these predictions are contradicted (Trueswell et al. Reference Trueswell, Tanenhaus and Kello1993; Garnsey et al. Reference Garnsey, Pearlmutter, Myers and Lotocky1997; Hare et al. Reference Hare, McRae and Elman2003; Traxler Reference Traxler2005; Wilson & Garnsey Reference Wilson and Garnsey2009). More precisely, such studies typically report so-called ‘garden-path effects’ at the disambiguating region, that is, a sharp increase in processing time that indicates reanalysis caused by the mismatch between the expected structure and the actual one.
Importantly for our present purposes, the presence of garden-path effects (and to some extent their strength, cf. Traxler Reference Traxler2005) is also found to depend on the specific verb used in the sentence. Verbs vary in their preference towards various syntactic frames, which can be measured by norming studies or corpus data (cf. Lapata et al. Reference Lapata, Keller and Schulte im Walde2001; Wiechmann Reference Wiechmann2008). Garden-path effects arise when a verb’s syntactic preference does not match the structure in temporarily ambiguous sentences. For example, while both accept and realize in (1) and (2) can be used either with a direct object NP or with a finite complement clause, accept is more commonly found with the former and realize with the latter, predicting processing difficulties at the disambiguating region for (1) but not (2) (and vice versa when a verb biased towards a complement clause is used with a direct object NP, cf. Wilson & Garnsey Reference Wilson and Garnsey2009). Note that while processing differences between verbs are most dramatic when measured by garden-path effects in temporarily ambiguous sentences, they can also be found with simpler and unambiguous structures. For example, Gries et al. (Reference Gries, Hampe and Schönefeld2005, Reference Gries, Hampe, Schönefeld, Rice and Newman2010) show that the most common verbs in the as-predicative construction (e.g., They regard this as a challenge), as measured by collostructional analysis (see also Chapters 6 and 7), are the most frequently chosen in a sentence completion task and are associated with shorter processing time of the construction in a self-paced reading experiment.
These processing effects which relate to the use of specific verbs in a given construction point to differences in storage of verb-construction combinations. Such differences are difficult to explain in a model which separates lexical and syntactic information, but they are readily compatible with the inheritance network approach of Construction Grammar, in which verb-specific sub-constructions can be posited along with the verb-general argument structure construction that they inherit from. Not all of the possible sub-constructions are necessarily stored, and those that are stored may have different levels of accessibility, explaining the reported differences in processing between different verbs.Footnote 2 Processing differences between uses of different verbs in the same structure are widely documented, but Perek (Reference Perek2015) also reports differences between uses of the same verb in different syntactic frames. In a variant of a self-paced reading task, participants were presented with sentences containing the commercial transaction verbs buy, pay, and sell, which can all be followed by a direct object and optionally by another prepositional phrase argument referring to another participant in the commercial transaction scene: the money (e.g., for €50), the buyer/recipient (e.g., to his cousin), the goods (e.g., for a bike), or the seller/source (e.g., from her neighbor). Perek (Reference Perek2015) finds differences in processing time between the two different types of argument available for each verb following the direct object (e.g., Sam sold his bike for £50 vs. Sam sold his bike to his cousin), which also correlate with differences in the frequency with which each verb occurs in these constructions in corpus data.
Finally, further evidence for differences in the cognitive status of different verb-construction combinations can also be found in the priming literature. First, there is a well-known ‘lexical boost’ in structural priming (Pickering & Branigan Reference Pickering and Branigan1998), whereby priming effects are stronger when prime and target share the same verb than when the verb changes. Such an effect is readily explained by the constructional approach: If a given verb-specific construction is stored in the network, it is activated by a prime sentence containing that verb and construction. The more general construction is also activated, but if the same sub-construction is used again in the target, it should be accessed with more ease than the combination of the general construction with a different verb (whether it is retrieved from another sub-construction or computed on the fly). Second, Bernolet and Hartsuiker (Reference Bernolet and Hartsuiker2010) find that the strength of priming effects in the Dutch dative alternation is inversely correlated with the syntactic preference of the verb used in the prime (see also Jaeger & Snider Reference Jaeger and Snider2007, Reference Jaeger and Snider2013). For instance, subjects were more likely to describe a picture using the prepositional dative construction following a prepositional dative prime, and this tendency was stronger if the prime sentence contained a verb that is more typically found in the double-object construction than the prepositional dative, such as aanbieden ‘offer’; hence the example De kok biedt een pistool aan aan de dokter ‘The cook offers a gun to the doctor’ was a stronger prime for prepositional datives than another prepositional dative sentence with a verb that does not show a preference for the double-object construction, such as verkopen ‘sell’. In other words, the stronger the preference of a verb for a particular construction, the less strongly this verb primes this construction, and vice versa. This finding too can be explained in the constructional network approach, if we consider that the syntactic preference of a verb for an argument structure construction correlates with the degree of entrenchment of the corresponding verb-specific construction. Entrenchment is usually taken to lead to a higher degree of autonomy (Bybee Reference Bybee2010); hence, if a prime sentence activates a more entrenched sub-construction, the more general construction should be less strongly activated than if the prime uses a less entrenched or even non-stored sub-construction, leading to a reduced priming effect.
8.4.2 Other Kinds of Links between Constructions
Besides inheritance, various other kinds of links between constructions have been proposed in the literature. These ‘horizontal’ relations, thus called in contrast to the ‘vertical’ relations of inheritance (Perek Reference Perek2012; Van de Velde Reference Van de Velde, Boogaart, Colleman and Rutten2014), have also started to gain attention in experimental studies.
Construction Grammar has characteristically emphasized ‘surface generalizations’ (Goldberg Reference Goldberg2002), capturing grammar in terms of generalizations of the same form and meaning across utterances, as opposed to deriving sentences from others when they are perceived to be semantically related (such as active/passive pairs and the variants of the dative alternation mentioned earlier). While this was a theoretically and empirically grounded move away from earlier generative and in particular derivational approaches, it has led constructional approaches to sideline relations of alternation between constructions with similar functions, for example, the ditransitive and to-dative constructions involved in the dative alternation (e.g., He threw Mary the ball vs. He threw the ball to Mary). More recently, some scholars have argued that such relations should also be part of the constructional network in some form, either as a special kind of link between constructions (Goldberg Reference Goldberg1995; Van de Velde Reference Van de Velde, Boogaart, Colleman and Rutten2014) or as ‘allostructions’ in the inheritance network, that is, sub-constructions of a more abstract ‘constructeme’, which captures their shared meaning paired with an underspecified form (Cappelle Reference Cappelle and Schönefeld2006; Perek Reference Perek2012, Reference Perek2015). While such highly abstract constructions might seem to clash with the constructional commitment to only describe constructions that are directly attested in language data (‘what you see is what you get’), constructemes and their allostructions arguably capture important aspects of language users’ knowledge and behavior, specifically the idea that more than one construction might be available to encode a certain type of message, and correspondingly that a given instance of a construction can be reformulated using another construction in the family, if the right conditions are met.Footnote 3
Several studies report evidence suggesting that such relations between constructions should be represented in the constructional network. Using a sorting task experiment design similar to Bencini and Goldberg’s (Reference Bencini and Goldberg2000) study, Perek (Reference Perek2012) finds that participants are more likely to group instances of the to-dative construction with the ditransitive construction than with instances of the Caused-Motion construction, although the latter are presumably members of the same constructional generalization of both form and meaning. This is interpreted as evidence that speakers notice the functional overlap between formally different constructions and may use this knowledge to establish relations between such constructions; they may then use those relations to infer that a word used in one construction can also be used in the other.
Support for alternations can also be found in priming studies. If the variants of an alternation are related in some way in the mental grammar, a prediction for the priming paradigm is that one variant of an alternation should prime the other variant at least to some extent (though of course not as strongly as itself). Classical priming studies (e.g., Bock Reference Bock1986, Reference Bock1989; Bock & Loebell Reference Bock and Loebell1990) have typically not tested this possibility, because they usually involve only two kinds of primes related by an alternation. Those studies measured priming effects by comparing productions after one kind of prime vs. the other kind, but they cannot measure whether production of one variant also increases production of the other variant, because they lack a baseline condition to compare this to; for instance, a prime sentence that is unrelated to either construction (e.g., an intransitive sentence) and should therefore not increase their production. More recent studies, however, do include such a baseline, and even though they do not address the question of alternations directly, they do report that variants of an alternation can prime each other. In a picture-description task with 4- to 5-year-old children, Goldwater et al. (Reference Goldwater, Tomlinson, Echols and Love2011) find that both variants of the dative alternation prime the other variant: Compared to a baseline condition in which participants were not exposed to any prime sentence, a to-dative prime increases the production of picture descriptions using the ditransitive construction, and vice versa. Similarly, in a priming study of active vs. passive constructions in Russian, Vasilyeva and Waterfall (Reference Vasilyeva and Waterfall2011) find that exposure to ‘canonical’ passives not only increases the production of the same construction both by children and adult speakers, but also the production of a number of other formally different constructions that fulfill the same discourse function (namely, emphasizing the patient argument), such as, for instance, the so-called Impersonal Active consisting of an active clause with a fronted accusative complement and no overt subject. These findings can be explained under the allostructions model: If one assumes that speakers generalize over these constructions on the basis of their shared function and distribution, activating one construction should activate their constructeme and contribute to activating the other constructions that inherit from it.
Perek (Reference Perek2015) further shows that alternation relations between constructions can be asymmetrical. In a sentence production task with novel verbs, speakers readily used a verb in the to-dative construction when they first witnessed that verb in the ditransitive construction, but not the other way around. Such an asymmetry is not found in the spray/load alternation, for example, He sprayed paint on the wall vs. He sprayed the wall with paint, in which verbs tend to be used in the same variant they were witnessed in. Perek finds that this pattern of results correlates with ratios of type frequencies between classes of verbs occurring in only one variant of the alternation (vs. both variants) in a corpus: There are many more verbs attested only in the to-dative construction than alternating verbs or ditransitive-only verbs, while in the locative alternation most verbs are restricted to one or the other variant and only a minority of verbs alternate. In a usage-based constructional approach, this correlation suggests that speakers internalize these statistical relations between constructions (see also Chapters 6 and 7).
Finally, there are other types of links recognized by various scholars. For example, Goldberg (Reference Goldberg1995) distinguishes between four types of inheritance: instance, subpart, polysemy, and metaphorical extension. These other links have typically received less attention in the literature and have not extensively been studied empirically (including experimentally). However, a notable exception to this is a recent study by Ungerer (Reference Ungerer2021) on metaphorical extension links. Specifically, Ungerer investigates the relation between the Caused-Motion construction (e.g., James rolled the ball down the hill) and the Resultative construction (e.g., Susan hammered the metal flat) by means of a priming experiment. Interestingly, he finds an effect of negative priming between the two constructions in a self-paced reading task: Sentences with the Caused-Motion construction are read more slowly after a Resultative construction prime, and vice versa. Even if it is not facilitatory, the very existence of the priming effect can be taken as evidence for some kind of relation between the two metaphorically related constructions.
8.5 Conclusion
As discussed throughout this chapter, there is a wealth of behavioral evidence from experimental studies that can be used to support the constructional approach to grammar, in particular three of its core tenets. First, the idea that phrasal constructions can convey meaning in and of their own is evidenced by the role of abstract constructional meaning in various language comprehension tasks, independently of particular lexical items, and also the finding that constructions can prime verbs with similar meanings. Because many of these comprehension experiments use nonce or novel verbs, they also show that constructions are stored independently of particular lexical items. This is further evidenced by structural priming studies, which consistently find that instances of a construction can prime each other, and that constructions can prime aspects of their form and/or meaning, even when the lexical items used in these constructions differ between prime and target. Finally, evidence for the organization of grammar into an inheritance network of constructions at various levels of specificity comes from studies showing processing differences between different verb-specific constructions. There is also experimental evidence for the existence of other types of links between constructions besides inheritance.
While the behavioral evidence reviewed above provides a robust empirical basis for Construction Grammar, I would like to conclude this chapter by highlighting some limitations of the current body of research and offer perspectives for future studies. First, the near totality of the existing evidence is centered on argument structure constructions, that is, constructions capturing how the arguments of verbs are realized (such as the ditransitive construction). The reason for this is largely historical: Argument structure has been a major focus of linguistic research for decades, including psycholinguistic research. These constructions are also prime examples of some of the main ideas that set Construction Grammar apart from other approaches (in particular lexicalist frameworks, e.g., Pinker Reference Pinker1989), and as such they have played a major role in the early years of Construction Grammar (Goldberg Reference Goldberg1995). However, this near-exclusive focus on one particular type of construction can be seen to be at odds with Construction Grammar’s commitment to account for the entirety of language: Any kind of linguistic pattern can be (and indeed should be) described as a form–meaning pair. Future research should address whether the psycholinguistic evidence found for argument structure constructions also extends to other types of constructions, and confirm that the same organizing principles apply to patterns of any kind. Second, while the studies cited here have been chosen so as to represent as wide a range of languages as possible, I have still found that the literature is largely dominated by studies on English. This area of research would benefit from similar studies on other languages in order to offer Construction Grammar more cross-linguistic empirical validation, in line with the growing recognition of language-specific factors in psycholinguistic studies. As argued by Perek and Hilpert (Reference Perek and Hilpert2014), English might indeed be a particularly ‘constructionally tolerant’ language, especially when compared to languages whose grammar appears to be more strongly driven by lexical items alone or by morphology. It remains to be seen to what extent cross-linguistic variation of this kind might translate into psycholinguistic differences. Finally, the relevant literature is rarely explicitly grounded in a constructional framework, which sometimes makes it difficult to appreciate the relevance of its findings for Construction Grammar theory. For instance, some psycholinguistic studies are still framed within the context of classical debates that are no longer relevant to Construction Grammar, such as whether the cognitive processing of some aspect of language is primarily driven by syntax or by the lexicon, which is a moot point in a framework that does not place a strict separation between the two. Both Construction Grammar and psycholinguistics would benefit from the wider adoption of at least some of the main tenets of Construction Grammar in psycholinguistic studies, and from the emergence of ‘constructionist psycholinguistics’ as a cognitive model of language processing with the concept of construction at its core. Construction grammarians and psycholinguists have much to learn from each other, but they do not always express their views in the most compatible way; hence more work needs to be done from both directions to build bridges between the two traditions.
9.1 Introduction
One of the most basic pillars of Construction Grammar is the idea that language is best conceptualized as a ‘network’ of constructions. Constructions are considered to be conventionalized form–meaning pairings or form–function units in the sense of de Saussure (Goldberg Reference Goldberg2006: 3; Diessel Reference Diessel2011: 830) and are understood to be cognitively stored (i.e., entrenched) in the minds of individual speakers. Importantly, constructions are not merely stored in an unrelated, list-like manner, but each construction constitutes a ‘node’ in a taxonomic network which has been termed the ‘constructicon’. The constructicon is seen as either the totality of a speaker’s stored constructions, or all the constructions of a particular language/linguistic variety. Functionally and/or formally related constructions form networks of ‘constructional families’ (e.g., Croft Reference Croft2001; Goldberg Reference Goldberg2003, Reference Goldberg2019; Croft & Cruse Reference Croft and Cruse2004; Barðdal & Gildea Reference Barðdal, Gildea, Barðdal, Smirnova, Sommerer and Gildea2015; Diessel Reference Diessel2019; Schmid Reference Schmid2020). Under such a view and in contrast to many generative models, grammatical (syntactic) knowledge is not understood as a set of rules operating mechanically on independent lexical items but, rather, an organized inventory of constructions at various levels of schematicity, complexity, and compositionality.Footnote 1 Crucially, grammatical networks/knowledge and lexical networks/knowledge are not kept apart in separate modules but interwoven in intricate parent and peer relations.
The general organization of the constructicon is a hotly debated issue (Diessel Reference Diessel2023; Ungerer & Hartmann Reference Ungerer and Hartmann2023). Scholars differ substantially when conceptualizing and sketching (changing) constructional networks. This chapter tries to discuss the current state of the art when modeling constructional networks. It will be structured as follows. First, we briefly position constructional network modeling within the broader field of domain-general network theory (Section 9.2.1). In Section 9.2.2, we show that networks can be and have been asserted at all linguistic levels (e.g., from phonology to morphosyntax to the lexicon). Afterwards, we proceed to the main sections (Section 9.3 and 9.4) in which we discuss the various types of links that have been postulated between constructions. First, we elaborate on vertical (taxonomic) relations with a focus on different types of inheritance (Section 9.3.1), the emergence of such vertical relations (Section 9.3.2), and the feature of ‘multiple inheritance’ (Section 9.3.3). This is followed by a discussion of horizontal links (Section 9.4.1) and the issue of many-to-many mappings (Section 9.4.2). Subsequently, we address diachronic change in the constructicon (Section 9.5) and end by discussing open questions related to the chosen network architecture (Section 9.6).
9.2 Networks in Science and Linguistics
9.2.1 Generalized (Domain-General) Network Theory
From a usage-based perspective, language is a Complex Adaptive System (CAS): Grammar is an emerging phenomenon, linguistic change happens through use, and the developing linguistic knowledge of a language learner lends itself well to being modeled as a network (Gell-Mann Reference Gell-Mann, Hawkins and Gell-Mann1992; Tomasello Reference Tomasello2003; Beckner et al. Reference Beckner, Blythe, Bybee, Christiansen, Croft, Ellis, Holland, Ke, Larsen-Freeman and Schoenemann2009; Bybee Reference Bybee2010; Steels Reference Steels2011; Diessel Reference Diessel2019, Reference Diessel2023). In general, the network view is motivated by two angles: On the one hand, empirical observations confirm that constructions influence each other in intricate ways which are best explained if one takes a network perspective of relations (Traugott & Trousdale Reference Trousdale2013; Schmid Reference Schmid2016; Hilpert & Diessel Reference Hilpert, Diessel and Schmid2017). On the other hand, an analogy is drawn to neural network structures in the brain. Construction Grammar is highly interested in general human cognition and adheres to the principle of cognitive plausibility (Boas Reference Boas, Hoffmann and Trousdale2013), as well as to the idea that language emerges from domain-general capacities (Hudson Reference Hudson2007: 5; Bybee Reference Bybee2010; Divjak Reference Divjak2019). If language is not unlike other mental capacities, it makes sense to assume that its organization is not sui generis.
Networks can be approached from a domain-general point of view. When doing so, one issue is of crucial importance, namely, that networks can take various shapes depending on how ‘dense’ they are, that is, how many and what kind of connections exist between the different components. Some networks are sparse, other networks consist of many interconnecting links. Components of networks are called ‘nodes’ (or ‘vertices’), connections between these nodes are called ‘links’ (or ‘edges’). These edges can be labeled or not, can be bidirectional, unidirectional, or non-directional, and can be weighted or unweighted (see Figure 9.1).

Figure 9.1 General network graph
Additional concepts from network analysis, a subdiscipline of mathematics known as ‘graph theory’, are walks, paths, (a)cyclicity, degrees, etc. This terminology is necessary to neatly approach a network’s mathematical characteristics (e.g., Ke et al. Reference Ke, Gong and Wang2008; Ogura & Wang Reference Ogura, Wang, Dossena, Dury and Gotti2008; Perc Reference Perc2014).Footnote 2
Remarkably, Construction Grammar has been slow in integrating the aforementioned concepts and the corresponding methodology. Getting a numerical grasp on the size and nature of a particular network can provide a quantitative operationalization on diachronic change (see Van de Velde & Fonteyn Reference Van de Velde and Fonteyn2017 for some pioneering work). For instance, comparing density changes over time can tell us something about the ‘entrenchment’ of a construction.
However, constructional networks may not readily compare to connectionist networks or neurological lattices. For example, in the vast majority of constructional network sketches, connections between nodes are not being ‘weighted’ (like in computational connectionist networks: Rumelhart & McClelland Reference Rumelhart and McClelland1986; Elman et al. Reference Elman, Bates, Johnson, Karmiloff-Smith, Parisi and Plunkett1996). The desire to work with an overarching network theory approach may ultimately be in conflict with doing justice to the linguistic facts. It remains to be seen how well language networks can be analyzed in a domain-general way.
The recent rapprochement between usage-based Construction Grammar and sociolinguistic approaches, and variationist perspectives in particular (see Colleman & Van de Velde Reference Colleman and Van de Velde2015 for references), adds to the network idea by highlighting the correspondence with social networks (Schmid Reference Schmid2016). In this chapter we will not discuss aspects of social diffusion (see Labov Reference Labov2007; Ke et al. Reference Ke, Gong and Wang2008), which is treated in detail in Chapter 19. But we feel the need to clarify the fact that linguists face two different types of networks. Language is both a symbolic network with interconnected signs, as well as a social tool, with speakers who form a network among themselves. Propagation of innovations thus plays out on two tiers: social diffusion (i.e., conventionalization) external to the linguistic system and system-internal diffusion within the lexicon or the grammar. Say, a new formal mutant of a given signifié arises, for example, analytic perfect replacing the old preterite (e.g., French je suis été vs. je fus ‘I was’). The new variant has to spread over the lexicon, encroaching on an ever-expanding range of verbs (see Coussé Reference Coussé2014 for a case study on Dutch) but it also has to propagate through the community, with new speakers adopting the variant (Petré & Van de Velde Reference Van de Velde and Booij2018). The two kinds of propagation are not always well separated in the literature, and studies that integrate both are relatively rare (Schmid Reference Schmid2020).
9.2.2 Assuming Networks at All Linguistic Levels
In Construction Grammar, the network view pervades the whole language: Networks can be found in phonology, syntax, morphology, the lexicon, and pragmatics.
In essence, Figure 9.2 brings out the very basic idea of ‘co-activation’, that is, the simultaneous activation of phonetically, morphologically, and semantically similar words when expressing a target word. When a speaker utters cat, phonetically similar words like rat, hat (but also: categorize, catharsis, etc.) resonate in the background and may surface in mispronunciation of contaminations. With regard to morphological families, language users may extend or generalize suffixes to new hosts, reorganizing the constructicon (Coussé Reference Coussé, Van Goethem, Norde, Coussé and Vanderbauwhede2018). The underlying mechanism behind these links is analogy (Fischer Reference Fischer, Hancil, Breban and Lozano2018) and in Construction Grammar, this analogical process is known as ‘activation spreading’ or ‘spreading activation’, where the use of a construction primes semantically and phonologically similar constructions (Traugott & Trousdale Reference Trousdale2013: 54–58; Diessel Reference Diessel2019: 201). The mechanism works at the lexical level as well as at the syntactic level, both syntagmatically (Szmrecsanyi Reference Szmrecsanyi2005) and paradigmatically (Pijpops & Van de Velde Reference Pijpops and Van de Velde2016).
9.2.3 Classification Schemes
Over time, several classification schemes for different types of links have been put forward. Early on, Goldberg (Reference Goldberg1995: 74–81) proposed the following four types of constructional links:
(1) instance links, existing between constructions of different degrees of specificity;
(2) polysemy links, which are posited between the prototypical sense of a construction and its extensions;
(3) metaphorical extension links, connecting a basic sense of a construction to a metaphorically extended sense; and
(4) subpart links, which hold between constructions of different degrees of complexity.
In recent years, other scholars have proposed more elaborate classification schemes to account for the different nature of connections between linguistic elements (e.g., Schmid Reference Schmid2020; Hilpert Reference Hilpert2021). For example, Diessel (Reference Diessel2019: 12f., 22) lists the following six relations:
(1) symbolic relations: associations between form and meaning;
(2) sequential relations: associations between linguistic elements in sequence;
(3) taxonomic relations: associations between representations at different levels of specificity;
(4) lexical relations: associations between lexemes;
(5) constructional relations: associations between constructions; and
(6) filler–slot relations: associations between particular items and slots of constructions.
A comparison between such classifications is outside the scope of this chapter. It is not always clear whether they aim at parsimony or exhaustiveness, and network classifications differ tremendously. Acknowledging this fact, we will present a two-dimensional network representation in which two main types of connections are being distinguished: vertical and horizontal – a basic distinction that can be found in most network sketches.
9.3 Vertical Links
Constructions are vertically related via so-called ‘inheritance’ links, which have also been termed ‘taxonomic’ links, ‘instance’ links, or ‘parent/mother–daughter relations’. Lower-level (more specific) constructions are said to inherit features from higher-level (more abstract) constructions through vertical links. Daughter constructions instantiate their higher-level mother constructions, and features of mother nodes percolate down to their daughters. The lower-level construction is thus a special, more specific instance of the higher-level construction (see above on instance links; cf. also Goldberg Reference Goldberg1995: 79f.; Hilpert Reference Hilpert2014: 59).
In Figure 9.3 we present a simplified network of a taxonomic hierarchy with vertical inheritance relations in NP constructions with possessive determiners.Footnote 3 On the highest level of the hierarchy, there is a fully schematic template (= ‘schema’), at mid-level in the hierarchy we find semi-specific constructions, and at the bottom there are fully specified constructions.

Figure 9.3 Vertical inheritance relations in NP constructions with possessive determiners
One main advantage of such a taxonomic network is that it allows general information from the higher levels to be passed onto all lower-level constructions. At the same time, more specific, non-shared information pertaining to (idiomatic) sub-regularities may be captured directly at the level of constructions positioned at various midpoints of the hierarchical network (Goldberg Reference Goldberg1995: 67; Boas Reference Boas, Hoffmann and Trousdale2013: 244). For example, the notion of {possessed entity}Footnote 4 is inherited from the mother node above, the notion that the entity is {possessed by speaker} is exclusively stored in the [my N]Cx node. The idiosyncratic meaning of {invitation to act} is specific to the [your turn]Cx construction. The constructions on the lowest level in Figure 9.3 deserve independent constructional status either due to their idiomatic nature or their high frequency. A search in the Corpus of Contemporary American English (COCA)Footnote 5 reveals that NPs like my life or our country are very frequent, at least in comparison to most other [POSS N]Cx combinations, a fact which – according to Goldberg’s (Reference Goldberg2006) definition of a construction – warrants their separate representation as constructional nodes.
9.3.1 Different Types of Inheritance (Default Inheritance vs. Total Entry)
In current modeling, three different interpretations of inheritance exist for capturing vertical relations: the complete inheritance model, the default (normal) inheritance model, and the full entry (redundant storage) model. The debate revolves around the question whether constructional information is stored only once or redundantly. The complete inheritance model postulates that any information is represented non-redundantly at the highest possible level and then inherited by all lower-level constructions. This way of modeling is economical in the sense that the cognitive load is reduced by not storing information more than once (Kay & Fillmore Reference Kay and Fillmore1999). It is particularly scholars who subscribe to this model who are also open to postulating abstract, purely syntactic nodes high up in the network without semantic specifications (see Section 9.3.2). At the same time, this model of inheritance frequently employs the notion of ‘multiple inheritance’ (Section 9.3.3).
In the default (normal) inheritance model (Lakoff Reference Lakoff1987; Goldberg Reference Goldberg1995), only information from above which does not conflict is inherited: Lower constructions may block inheritance from above and contain more specific information. In contrast, the full entry model redundantly specifies all information in every node in the network. Similar to the default inheritance model, a lower node does not necessarily change when the higher nodes change (Croft & Cruse Reference Croft and Cruse2004: 262–279; Boas Reference Boas, Hoffmann and Trousdale2013: 245; Hilpert Reference Hilpert2014: chapter 3, Reference Hilpert2021; Barðdal & Gildea Reference Barðdal, Gildea, Barðdal, Smirnova, Sommerer and Gildea2015: 4; Dąbrowska Reference Dąbrowska2017).
Some constructional approaches (e.g., Berkeley Construction Grammar and Sign-Based Construction Grammar) favor the complete inheritance model due to its elegance and for reasons of parsimony (e.g., Fillmore Reference Fillmore1988; Michaelis Reference Michaelis1994; Boas & Sag Reference Boas and Sag2012). However, most scholars in CxG adopt a default inheritance model or a full entry model (Ginzburg & Sag Reference Ginzburg and Sag2000: 5–8). Especially Cognitive Construction Grammar or Radical Construction Grammar allow for redundancy in mental storage (Croft Reference Croft2001; Goldberg Reference Goldberg2006; Bybee Reference Bybee2010). This means that the same semantic or formal information can be stored in more than one construction. Even if speakers form a linguistic generalization, it is possible that they still store the same information more than once. This is seen as unproblematic because “memory is cheap and computation is costly” (Diessel Reference Diessel2011: 834). Whereas a complete inheritance model maximizes storage parsimony, a full entry model maximizes computing parsimony. With complete inheritance, the redundant storage of information is minimized. In the full entry model, as much information as possible is stored in multiple places, so that online computation is minimized (Barsalou Reference Barsalou, Lehrer and Kittay1992). Inheritance is a crucial network feature; still, it has to be investigated in much more detail (especially multiple inheritance, see below).
9.3.2 Emergence of Vertical Relations
Constructional networks – from a usage-based, cognitive point of view – are ‘constructed’ in a bottom-up fashion during language acquisition. The repeated usage of a particular construct leads to its successful memorization and entrenchment. At the same time, the speaker’s ability to detect similarities between constructs (i.e., realizations of constructions in language production) and his/her ability to abstract and to analogize lead to the generalization of more schematic constructions (Tomasello Reference Tomasello2003; Rowland Reference Rowland2014; Diessel Reference Diessel2019: 30–32).
The repetition of varied items which share formal or functional similarities can lead to the formation of a variable schema. For example, structures with a high type frequency, that is, patterns which occur with many different lexicalizations (e.g., John kicks the ball, Peter kisses Mary), still share a common, albeit abstract meaning, namely, {A affects B}. The repeated exposure to such constructs can lead to the generalization of the abstract, transitive argument structure construction [Subj Vtr Obj] (Goldberg Reference Goldberg2006: 39, 98–101; Schmid Reference Schmid2016: 10–12).
To provide another example for vertical relations, Figure 9.4 shows a partial sketch of a taxonomic hierarchy of deictic NPs with a common noun head in English.

Figure 9.4 Partial network sketch of deictic NPs in Modern English
It is assumed that a child during his/her acquisition process, influenced by listening to many constructs including count nouns (CN) such as this doggie, this picture, this house, at one point recognizes and successfully stores the following semi-specific [[this]+[CNsg]]NPdef template, which corresponds to the meaning of {proximal singular entity}.Footnote 6 In a similar vein, the speaker will store the following form–meaning pairing: [[these]+[CNpl]]NPdef ↔ {proximal plural entity}.
The learner at one point will also conclude that this and these are both demonstrative markers of proximity, which presumably leads to the formation of an even more abstract schema [[DEMprox]+[CN]]NPdef. Once this node is in place and connected to the nodes below, information is inherited in a downwards manner. The learner establishes a similar relationship for distal demonstratives (that/those). This results in further abstractions/schematizations and linking and, ultimately, in the postulated network in Figure 9.4 (also see Hilpert’s Reference Hilpert2015 notion of ‘upward strengthening’).
9.3.3 Multiple Inheritance and Unification
Another design feature of the network is ‘multiple inheritance’ (henceforth also MI). This concept refers to constructions being instantiations of several higher constructions (Goldberg Reference Goldberg2003; Hudson Reference Hudson2007: 27–30; Van de Velde et al. Reference Van de Velde, De Smet and Ghesquière2013; Hilpert Reference Hilpert2014: 62–65). A particular construct (i.e., an actual expression) is usually the result of the parallel activation of several constructions. Note that this process has also been termed ‘fusion’, ‘unification’, or in some special cases ‘blending’ by other scholars (Herbst & Hoffmann Reference Herbst and Hoffmann2018; Hoffmann Reference Hoffmann2022). MI is a crucial feature for a slot-and-filler model of language which can ‘generate’ complex embedded linguistic structures. The term describes the fact that “any specific utterance’s structure is specified by a number of distinct schematic constructions” (Croft Reference Croft2001: 26). One construction can instantiate “several, successively more abstract constructions at the same time” (Hilpert Reference Hilpert2014: 63–65). Goldberg elaborated on MI already in 1995. Inheritance systems “may resemble tree diagrams if each child only has one parent, but in the general case they are ‘tangled’ and … this allows a given construction in the hierarchy to inherit from more than one dominant construction” (Goldberg Reference Goldberg1995: 73). On top of that, MI “allows us to capture the fact that instances of some construction type seem to resist being uniquely categorized in a natural way” (Reference Goldberg1995: 97).Footnote 7
For example, the sentence I didn’t sleep is an instantiation of both the ‘Intransitive Verb construction’ (a) [Sbj Vintranstive]Cx and the ‘Negative construction’ (b) [Sbj Aux-n’t V]Cx. As construction (a) does not provide any information about tense-aspect-mood or negation marking, this information is inherited from construction (b) and the sentence has multiple parents in the taxonomy of constructions which it belongs to (Croft Reference Croft2001: 26). Similarly, the ditransitive construction [Sbj Vditr Obj1 Obj2], as in He gave her a book, only specifies the predicate with its arguments. It does not specify the presence or position of other elements in the utterance, such as modal auxiliaries or negation as in an utterance like He won’t give her the book. For such an utterance, the ditransitive schematic template sketched above only provides a partial specification of the structure and the utterance will need to inherit information from other schemas as well (Croft Reference Croft2001: 26).Footnote 8
Multiple inheritance also plays a role in ‘syntactic amalgams’ (for a detailed presentation of this phenomenon, see Chapter 11). Lakoff’s (Reference Lakoff1974: 321) example John invited you’ll never guess how many people to his party is the unification of a ‘complement clause construction’ and a ‘transitive construction’. Also, the syntactic amalgam The Smiths felt it was an important enough song to put on their last single is another elucidating example of MI. The ‘attributive adjective’-construction which is instantiated by an important song and the ‘enough to-infinitive’-construction intertwine (Hilpert Reference Hilpert2014: 63). MI can also be observed in the semantic, lexical, and conceptual domain in the sense that, for example, the concept [cat] inherits properties from both [mammal] and [pet] (Hudson Reference Hudson2007, Reference Hudson2010; Trousdale Reference Trousdale2013). This makes MI an important cognitive, psychological concept as well.
MI features prominently in constructional textbooks and handbooks (Hoffmann & Trousdale Reference Trousdale2013; Hilpert Reference Hilpert2014; Hoffmann Reference Hoffmann2022: 272–275), as well as in some detailed case studies (Michaelis & Lambrecht Reference Michaelis and Lambrecht1996; Fried & Östman Reference Fried, Östman, Fried and Östman2004; De Smet & Van de Velde Reference De Smet and Van de Velde2013; Trousdale Reference Trousdale2013). In general, however, constructional accounts “often remain silent when it comes to detailing the specifics of how different constructions interact” (Boas Reference Boas, Hoffmann and Trousdale2013: 244) and the workings of unification are still a slightly underdeveloped concept in CxG.
9.4 Horizontal Links
While vertical links in the constructional network have received far more attention in the literature, constructions also entertain ‘lateral’, or ‘horizontal’ links (Norde & Morris Reference Norde, Morris, Van Goethem, Norde, Coussé and Vanderbauwhede2018; Diessel Reference Diessel2019: 199f.; Ungerer & Hartmann Reference Ungerer and Hartmann2023). This means that the ‘constructicon’ is not a top-down radiating diagram but, rather, a lattice, more fishnet than tree. When nodes are related by horizontal links, they have sometimes been called ‘sister nodes’ (Jackendoff & Audring Reference Jackendoff and Audring2016; Audring Reference Audring2019). Nodes are seen as sisters to each other if they are on the same level of complexity and are similar to each other in form and/or function. However, it is crucial to understand that lateral links come in different kinds and the feature of similarity cannot always be applied in a straightforward manner (see also Goldberg Reference Goldberg1995). In the following, we will discuss different kinds of horizontal links; for some additional layers of complexity, see also Chapter 13).
9.4.1 Types of Horizontal Links
The first kind of lateral links is drawn to establish the relations in a system of differential oppositions. This is an insight that goes back to structural linguistics: A constructional form–meaning pair can often be understood only by comparing it to formally related constructions that minimally differ. For example, the position of the main verb in continental Germanic languages like Dutch and German forms such a system. If the verb is placed in second position (V2), we have a declarative main clause. If the verb is placed at the end, we have a subordinate clause (V-late). If the verb is in first position (V1), we have a non-assertional context, like imperatives, questions, or an asyndetic conditional clause. This system is meaningful by its internal contrasts. This is visualized in Figure 9.5, where the various templates have been horizontally connected.

Figure 9.5 The position of the finite verb in Dutch clauses as a constructional network with horizontal relations
We can also apply the notion of horizontal connections to the network diagram presented in Figure 9.3. There, all the semi-specific templates with the different possessive pronouns (my, your, her, …) can be linked horizontally as well. They are considered sisters which are paradigmatically related.
A second kind of lateral link, reminiscent of the differential opposition relation, are links between alternating constructions, like the prepositional dative and the double-object dative (a.k.a. the dative alternation). These alternations typically express near-synonymous meanings and are felt as belonging to a set (mostly a pair) – see for example Szmrecsanyi et al. (Reference Szmrecsanyi, Grafmiller, Bresnan, Rosenbach, Tagliamonte and Todd2017) and Pijpops (Reference Pijpops2020) – and can be thought of as ‘allostructions’ (Cappelle Reference Cappelle and Schönefeld2006). Evidence for lateral links between allostructions and between their slot-fillers comes from lexical biases (Perek Reference Perek2015; Pijpops Reference Pijpops2019): For example, in the dative alternations some verbs associate more with the double-object construction and other verbs are more likely to occur in the prepositional dative. Typically, the verbal slot-fillers within one of the variants will semantically cluster.
Allostructions are linked through super-constructions or ‘constructemes’. The abstract constructeme on the top layer in Figure 9.6 only encodes those elements that are shared by both variants; the horizontally connected allostructions on the lower level specify those details which make the constructions differ from each other, in this case the different particle (‘Prt’) placement in the variants pick up the book vs. pick the book up.

Figure 9.6 Cappelle’s superconstruction/constructeme
The difference between these allostructions and the differential oppositions, then, is that allostructions are related primarily through their meaning and the differential relations through their form. The distinction is not always clear-cut, though. One could argue that active vs. passive verbs form a paradigm but it is equally possible to see the opposition in terms of an alternation, with a meaning difference.
A third kind of lateral link is used to express the fact that constructions that bear a formal similarity exert influence on one another, in processes like analogization or constructional contamination (Lorenz Reference Lorenz2013, Reference Lorenz, Sommerer and Smirnova2020; Pijpops & Van de Velde Reference Pijpops and Van de Velde2016; Pijpops et al. Reference Pijpops, De Smet and Van de Velde2018), that is, the process whereby etymologically related or unrelated constructions formally influence each other. Hilpert and Flach (Reference Hilpert, Flach, Krawczak, Lewandowska-Tomaszczyk and Grygiel2022) give an elucidating example of this process in English: Adverbial modification of be-passives displays word order variation, with the adverb either in front of the participle (the book was widely read) or after the participle (the book was read widely). Different adverb–participle combinations alternatively prefer one or the other order. The preference is laterally influenced by the frequency of occurrence in another construction, namely, adverbially modified attributive participles, which almost exclusively occur in the preposed variant (a widely read book). These loose connections that can even be etymologically unwarranted show that linguists’ analyses may diverge from the associations in actual usage, which easily violate constructional boundaries. In that sense, ordinary speech has multifarious lateral connections that surpass the parsimony-driven approach in many computational implementations of Construction Grammar.
A fourth kind of lateral link expresses polysemy and metonymical and metaphorical links between related constructions. This is, in fact, the semantic counterpart of the third kind of lateral link just mentioned. Polysemy does not occur only in the lexicon but also at the level of morphosyntax. For instance, the different s-genitives in English do not all express possession in its strict sense but form a set of polysemous meanings. Suzanne’s car, Suzanne’s father, Suzanne’s habits, Suzanne’s downfall, Suzanne’s support, Suzanne’s height have a common denominator of ‘association’ as metaphorical extensions of pure possession, and the extension is even more pronounced in cases like yesterday’s events (Taylor Reference Taylor1989). These polysemous instances are linked to one another on the basis of their semantic association. The reality of such lateral links is evidenced by the fact that the extension can proceed stepwise, in lateral directions, instead of shooting off separately from the mother node. That is, the various extensions are not individually sanctioned by one central meaning, but one extension can lead to the next, from sister to sister, so to speak.
A full-fledged analysis is provided by Geeraerts (Reference Geeraerts, Van Langendonck and Van Belle1998) on the Dutch Indirect Object, from which we reproduce Figure 9.7. Here we see that the Indirect Object in its core expresses a beneficial transfer of a concrete object to a recipient (the circle in the middle), from which various extensions radiate. The nodes in this network are connected by links, representing lateral relationships. A lateral relation can be posited between the nodes that are not directly connected to the core meaning (encircled in the diagram). So ‘stative relations instead of transfers’ are a form of generalization of ‘preconditions and resultant states instead of transfers’.

Figure 9.7 Radially expanding polysemy in the indirect object
A fifth kind of lateral link exists ‘in praesentia’, that is, syntagmatically. This is the situation in which a meaning is expressed by several forms, for example, 2sg meaning marked as an inflectional ending on the verb and as a pronoun, as in Gumawana Komu ku-mwela ‘you 2sg-climb’ (Siewierska Reference Siewierska2004: 120–127). Redundant expression can also occur within one single word, as in the expression of past time reference by a prefixed ‘augment’ e- and a suffixed sigmatic marker -s- in Ancient Greek and Old Indic aorists (Ancient Greek é-lu-s-a ‘I unbound’). Such multiple exponence (Harris Reference Harris2017) or multiple expression of a grammatical category often goes under the rubric of agreement. This kind of lateral link may seem to install redundancy and as such to amount to a violation of the one-form-one-meaning isomorphism. On the other hand, this kind of lateral redundancy offers evolutionary advantages, making a system robust against perturbations and allowing for evolvability (Whitacre & Bender Reference Whitacre and Bender2010; Van de Velde Reference Van de Velde, Boogaart, Colleman and Rutten2014; Winter Reference Winter2014). For an example of evolvability, see Van de Velde (Reference Van de Velde and Booij2018) on the fate of the Indo-European ŏ-grade in Germanic.
9.4.2 Many-to-Many Mappings
The previous section introduced a number of different kinds of horizontal relations. As mentioned, the first two types (i.e., differential oppositions and allostructions) are related. Both have to do with alternating ways of expressing related signifiés but the former type is form-based and the latter type is meaning-based. As constructions are pairings of form and meaning, the interaction between differential oppositions and allostructions will typically yield a constellation of many-to-many mappings, which, like multiple exponence (see above) makes language systems robust and evolvable. To elucidate what we mean, the visualization by Van de Velde et al. (Reference Van de Velde, Maekelberghe and Fonteyn2021), introduced here as Figures 9.8 and 9.9, may shed light on the matter.


Figure 9.9 Synonymy in symbolic-and-lateral relations
In the representation in Figure 9.8, lateral relations between both functions and forms are recognized. FunctionA could for instance be the expression of semantic roles (FunctionAi: agent; FunctionAii: patient; FunctionAiii: recipient; etc.). Form1 could be different cases (Form1i: nominative; Form1ii: accusative; Form1iii: dative; etc.). The lateral links between the constructions are the paradigmatic links. This is the situation in the case of differential oppositions.
For a full view of linguistic interaction, we need to acknowledge the second kind of lateral relationships introduced above, namely, those between the allostructions in a system of differential oppositions. In Figure 9.9, the diagram shown in Figure 9.8 is enriched by Form2, an alternate expression of FunctionA. Form2 could be expressed by, for example, prepositions or by word order. The lateral connections between Form1i and Form2i are allostruction links. In the dative alternation, for instance (Bresnan et al. Reference Bresnan, Cueni, Nikitina, Baayen, Bouma, Krämer and Zwarts2007; Röthlisberger et al. Reference Röthlisberger, Grafmiller and Szmrecsanyi2017; Zehentner Reference Zehentner2019; among many others), Form1i would be the alternant with the bare object and Form2i would be the prepositional dative.
This is the situation in the case of synonymy. The reverse situation applies in the case of homonymy (pleiotropy), where one form is used for the expression of multiple functions. Often, however, we have a network where there are many-to-many mappings between forms and functions (see Van de Velde Reference Van de Velde, Boogaart, Colleman and Rutten2014 on ‘degeneracy’): One function, say, argument realization, may be expressed by different forms, say, a case system, prepositions, or word order, whereas these forms may play a role in the expression of different functions; the case system and the prepositions do not express only argument realization but also locative relations, and word order may be linked to illocution or information structure.
Weakening or strengthening the vertical many-to-many links between Forms and Functions, while maintaining the lateral links, is a way to keep differential oppositions in position in terms of language change. As such, a network view is useful for coming to terms with the way languages gradually change, which brings us to diachronic Construction Grammar and how it models language change.
9.5 Changing Networks (Diachronic Construction Grammar)
Many historical linguists “see an excellent fit between the mechanisms of syntactic change and the basic principles of Construction Grammar” (Barðdal & Gildea Reference Barðdal, Gildea, Barðdal, Smirnova, Sommerer and Gildea2015: 9). A network architecture is a fitting tool for diachronic functional analyses because the model investigates change in form and function equally (Traugott & Trousdale Reference Trousdale2013: 231). Especially a cognitive constructionist approach lends itself very well to modeling morphological and syntactic change, as it understands change as a gradual, incremental, bottom-up process and stresses the importance of frequency, entrenchment, and general cognitive abilities like analogical reasoning, schematization, and categorization.
One challenge for constructional modeling is the simple fact that the constructicon constantly changes. Thus, it has to be discussed how the notion of change can be incorporated and how it can be visualized when sketching networks. Since Israel’s (Reference Israel and Goldberg1996) seminal diachronic paper of the way-construction, researchers have been developing a constructional model of linguistic change (Barðdal Reference Barðdal2008; Bergs & Diewald Reference Bergs and Diewald2009; Hilpert Reference Hilpert2013, Reference Hilpert2021; Traugott & Trousdale Reference Trousdale2013; Trousdale Reference Trousdale2014; Van de Velde Reference Van de Velde, Boogaart, Colleman and Rutten2014; Barðdal & Gildea Reference Barðdal, Gildea, Barðdal, Smirnova, Sommerer and Gildea2015; Torrent Reference Torrent, Barðdal, Smirnova, Gildea and Sommerer2015; Coussé et al. Reference Coussé, Andersson and Olofsson2018; Sommerer Reference Sommerer2018; Van Goethem et al. Reference Van Goethem, Norde, Coussé and Vanderbauwhede2018; Fonteyn Reference Fonteyn2019; Zehentner Reference Zehentner2019; Sommerer & Smirnova Reference Sommerer and Smirnova2020; Noël & Colleman Reference Noël, Colleman, Wen and Taylor2021).
In general, diachronic construction grammarians are interested in the following issues:
constructional change at all levels (phonological, morphological, semantic, syntactic changes);
competition between constructions;
changes in productivity;
changing frequency of constructions;
host-class expansion;
constructional conventionalization and spread in the community and the spread of constructions through different genres; and
changing slot and filler relations.
All these issues affect the assumed network structure. In diachronic Construction Grammar, linguistic change is reconceptualized as network change, that is, as change in the nodes and in the links. The network does not change only when new nodes are added, but primarily when node-external links between constructions are rearranged. Hilpert (Reference Hilpert, Coussé, Andersson and Olofsson2018) calls those ‘connectivity changes’, in which the network undergoes some rewiring. Links between existing constructions may fade and disappear or new links may emerge.
In general, the network can change in the following way (Smirnova & Sommerer Reference Smirnova, Sommerer, Sommerer and Smirnova2020: 3, adapted from Traugott & Trousdale Reference Trousdale2013 and Hilpert Reference Hilpert, Coussé, Andersson and Olofsson2018):
(1) via node creation and node loss (‘constructionalization’ and ‘constructional attrition’);
(2) via node-internal changes (‘constructional change’); and
(3) via node-external changes, that is, constructional network reconfiguration.
At the same time, it is well known that the frequency, productivity, or schematicity of a construction may increase or decrease over time and/or that a construction may experience host-class expansion (Himmelmann Reference Himmelmann, Bisang, Himmelmann and Wiemer2004; Hilpert Reference Hilpert2014; Perek Reference Perek2015; Van Goethem et al. Reference Van Goethem, Norde, Coussé and Vanderbauwhede2018).
Productivity and schematicity are characteristic features of one specific form–meaning pairing but, on the other hand, these developments might also correspond to a shift in the position of a specific node (e.g., a node moving up or down in the hierarchy) and/or to the establishment of a new node. Hilpert (Reference Hilpert2021: 55) thus argues that diachronic change “selectively seizes a conventionalized form–meaning pair of language, altering it in terms of its form, its function, any aspect of its frequency, its distribution in the linguistic community, or any combination of these.”
The process where a new construction develops diachronically has been termed ‘node emergence’ (Hilpert Reference Hilpert, Coussé, Andersson and Olofsson2018; Sommerer Reference Sommerer2018), ‘node creation’ (Torrent Reference Torrent, Barðdal, Smirnova, Gildea and Sommerer2015), and even ‘node genesis’ (Hieber Reference Hieber, Van Goethem, Norde, Coussé and Vanderbauwhede2018). However, the most frequently used term for the process is ‘constructionalization’, introduced initially in Noël (Reference Noël2007) and elaborated on in Traugott and Trousdale (Reference Trousdale2013). With regard to connectivity changes between constructions, Torrent (Reference Torrent, Barðdal, Smirnova, Gildea and Sommerer2015: 173) proposes two diachronic hypotheses: the Constructional Convergence Hypothesis and the Constructional Network Reconfiguration Hypothesis. The first claim is that “historically unrelated constructions are capable of participating in the same formally and functionally motivated network” (Torrent Reference Torrent, Barðdal, Smirnova, Gildea and Sommerer2015: 175). For example, adnumeral modification may derive from indefinite pronouns (some three hundred men), adverbials (approximately three hundred men), or (rebracketed) prepositions (around three hundred men) (Markey Reference Markey2022). The second hypothesis proposes that “inheritance relations in construction networks change over time as new constructions emerge” (Torrent Reference Torrent, Barðdal, Smirnova, Gildea and Sommerer2015: 175).
Emerging links and the addition of new nodes as well as the weakening of links is often visualized by dotted or broken lines, as can be seen by the network in Figure 9.10, which shows how in Late Middle English, the network of ditransitive constructions (including the dative alternation) changes.Footnote 9 Importantly, the figure also includes a fading constructional node: As indicated by the broken lines, the DOC sub-construction expressing {substitutive benefaction} as in Hold me the door, please, gradually disappeared over time, when the meaning of the DOC increasingly narrowed to a basic transfer-sense, possibly due to an increasingly strong association with the to_POC (Zehentner Reference Zehentner2019).

Figure 9.10 Network of benefactive transfer verbs (late Middle English/early ModE)
Many reasons exist why new node-external links are established. If a completely new construction emerges, it will be integrated into the network by linking it to other constructional nodes. Also, any type of semantic change can potentially lead to new links, for example, the developing metaphorical use of a construction might connect to nodes other than its literal use. Additionally, if a construction takes up a new discursive function, this may affect node-external linking. For example, when speakers use utterances like Hey dude!, Hey bro! as greeting devices, this will most likely lead also to new links to other more traditional greeting devices.
Another reason responsible for the rearrangement or disappearance of constructions is ‘divergence’. Constructions with high frequency in some contexts exhibit greater autonomy. This is known as ‘divergence’ (Hopper Reference Hopper, Traugott and Heine1991; Bybee Reference Bybee, Joseph and Janda2003) or ‘emancipation’ (Lorenz Reference Lorenz2013, Reference Lorenz, Sommerer and Smirnova2020). Certain subschemas that are used very often undergo semantic bleaching or phonological reduction and are often semantically opaque and independent from the meaning of their relatives because they have strong individual cognitive representations that do not need a direct comparison with other constructions (Bybee Reference Bybee, Joseph and Janda2003: 618).
9.6 How to Improve the Current Network Models: Open Questions
Several open questions remain about the nature of the postulated vertical and horizontal links. One open question related to vertical inheritance is how likely it is that speakers really abstract to higher schematic levels in their networks (Pijpops et al. Reference Pijpops, Speelman, Van de Velde and Grondelaers2021) and whether all speakers do this to the same extent (Dąbrowska Reference Dąbrowska2012). Lieven and Tomasello (Reference Lieven, Tomasello, Robinson and Ellis2008: 186) point out that “higher-level schemas may only be weakly represented and, indeed, they may sometimes only exist in the formalized grammars of linguists!” In a similar vein, Blumenthal-Dramé (Reference Blumenthal-Dramé2012: 29) states that “the most schematic constructions in the constructional hierarchy only represent potential (rather than actual) abstractions in the mental representation of speakers,” while Hilpert (Reference Hilpert2014: 57) maintains that “purely formal generalizations, that is constructions without meaning, have no natural place in the construct-i-con.” Several scholars argue that highly abstract mother nodes do not always need to be postulated. In some cases (in particular constructional families) it is likely that speakers stop to abstract at mid-level or only establish sister relations (Tabor et al. Reference Tabor, Galantucci and Richardson2004; Ferreira & Patson Reference Ferreira and Patson2007; Jackendoff & Audring Reference Jackendoff and Audring2016; Sommerer & Baumann Reference Sommerer and Baumann2021).
With respect to the basic definition of a construction, the problem is as follows. If constructions are form–meaning pairings that emerge over similar exemplars, which kind of meaning should we assume for such extremely abstract constructions and how similar do the sister nodes have to be in terms of form and function? In other words, is it always plausible and necessary to assume the existence of such high levels or can the linguistic knowledge of speakers be described equally well by staying on the lower levels, for example via horizontal links between sister nodes?
This question basically relates to two bigger issues, namely (i) whether the chosen constructional model allows abstract ‘formal’ templates which have no identifiable meaning (so-called ‘defective constructions’; Hoffmann Reference Hoffmann2022: chapter 7) and (ii) whether it strives for psychological plausibility. Whereas several scholars (e.g., Barðdal Reference Barðdal2008: 45) argue that schemas can and should be viewed from a primarily psycholinguistic perspective, for others schemas are descriptive devices created by the linguist and are not meant to correspond to mental representations. Whereas some scholars shy away from the possibility that information is stored redundantly, others see it as the psychologically more realistic approach. For example, usage-based analyses strive for cognitive plausibility and prioritize function over form. This means that they refrain from the postulation of highly abstract nodes if they are purely based on formal grounds and if it is unlikely that speakers abstract any functional or semantic similarities over the lower levels.
The next question pertains to the conceptual ground of the different sort of horizontal links. As mentioned above, the allostruction approach (Cappelle Reference Cappelle and Schönefeld2006; Perek Reference Perek2015) is based on shared semantics: Two formally divergent constructions are related horizontally, that is, they represent allostructions of one constructeme if they are synonymous. The paradigmatic approach, on the other hand, assumes that horizontal links are based on semantic distinction and opposition, not similarity. In both cases, the semantic dimension of constructions is given priority.
Another related question comes back to the psychological plausibility of the postulated links, similarly to the question raised above about vertical inheritance and the plausibility of the highest levels. If one looks at Figure 9.10, the constructions at the lowest level are related to each other in a double manner: Not only are they instantiated by a more schematic construction in the vertical dimension, they are also related by horizontal links at the same level of abstraction. The question is whether speakers really connect constructions in this way, or whether a more economical approach with only one (vertical? horizontal?) relation would suffice to capture the fact that these constructions are related to each other in a network. In other words, what is the division of labor between vertical and horizontal links?
A final desideratum is that Construction Grammar should incorporate quantitative measures to investigate networks and network changes. The overall emergent effects of different networks are qualitatively different. The speed at which innovations propagate or diffuse through a network is, naturally, heavily dependent on how the network is built: In a dense network with multiple links, innovations can spread more easily than in a sparse network. A first field to turn to for quantitative methods is the analysis of complex systems (Bar-Yam Reference Bar-Yam2002; Barabási Reference Barabási2016) but linguistic analyses of social networks (Ke et al. Reference Ke, Gong and Wang2008; Lev-Ari Reference Lev-Ari2018; Raviv et al. Reference Raviv, Meyer and Lev-Ari2019, Reference Raviv, Meyer and Lev-Ari2020) could also provide helpful tools to analyze the language-internal networks.
9.7 Summary
This chapter deals with a central tenet of Construction Grammar, namely, that the constructicon is organized as a network, where constructions are interrelated through different kinds of vertical and horizontal links. We have provided a typology of the various kinds of relations, pointing out that there is still confusion in the field as to what kinds of relations should be recognized and how they should be represented.
While there is a broad consensus concerning the fact that synchronic as well as diachronic analyses of the constructicon should be approached by taking this network-based nature into account, what largely remains to be integrated in Construction Grammar is the quantitative investigation of network properties, as found in studies in complex systems analysis and in social science.












