

Introduction
Since the advent of brain imaging and its broad availability for research towards the beginning of the twenty-first century, researchers have extensively investigated typical and atypical language processing in the human brain (e.g., see reviews by Price, Reference Price2010, Reference Price2012). While processes and mechanisms underlying speech and language have gained particular momentum in the cognitive neurosciences, language aptitude has received comparatively little attention to date. Doubtless, a major strength of the neurosciences lies in the possibility of combining results of behavioural research with neuroimaging to gain a much more advanced understanding of the underlying properties of speech and language and what the linguistically gifted brain can look like. It is thus timely for language aptitude researchers to acknowledge the plethora of informative and ground-breaking findings and breakthroughs in neurolinguistics for foreign language learning (Biedroń, Reference Biedroń2015).
Bearing this in mind, the present chapter focuses on the neuroanatomical and neurofunctional correlates of language aptitude and aims to provide a solid basis for a future neurocognitive model of language aptitude that looks at aptitude from both a behavioural and neural perspective. In order to do so, several important cognitive variables, including musicality/music aptitude and working memory, will be discussed and set into context. Thereafter, we provide a comprehensive overview of our current knowledge on the neurobiological basis of language aptitude, both in terms of structural and functional correlates, with an emphasis on our own work dealing with structural variation in the auditory cortex and its relationship to higher language aptitude in children and adults. Following this in-depth introduction, we discuss developmental perspectives on the correlations between stable anatomical and other cognitive predictors for language and speech abilities, sharing recent findings from our own research.
Musical Ability and Language Aptitude
Finding a uniform definition for musicalityFootnote 1 is as challenging as arriving at one simple definition of language aptitude on which all (or at least most) researchers agree. While we certainly agree that musicality is “a natural, spontaneously developing trait based on and constrained by biology and cognition” (Honing et al., Reference Honing, ten Cate, Peretz and Trehub2015), this definition undoubtedly applies to a variety of skills and abilities, including language aptitude. In other words, the music-specific aspect is neglected. According to Gembris (Reference Gembris2013), musicality is a skill that enables us to experience music emotionally, understand it intellectually, and be able to create it by singing, playing an instrument, composing, or improvising. Putting together these two suggestions, we arrive at a more satisfactory definition of musicality that considers both a genetic predisposition and the many varieties in which it can express itself. Both of these qualities are partly included in Gordon’s (Reference Gordon2001) definition of musicality, according to which it is “a measure of a student’s potential to learn music [although] everyone has some level of music aptitude, is musical and can learn to listen and perform music with some degree of success” (p. 4). While finding the perfect definition for musicality goes far beyond the scope of this chapter, it is necessary to deal with the concepts we are trying to integrate in our neurocognitive basis of language aptitude. For the purpose of this chapter, it is sufficient to propose that musicality is a partly genetically predisposed trait that can be seen as an individual’s potential to experience music emotionally, understand it intellectually, and be able to create it in various forms (e.g., by singing, playing an instrument).
Let us now focus on the overlap between language aptitude and musicality or, starting from a broader perspective, the overlap between language and music. Language and music are two abilities that have been extensively researched, in particular with regard to their similarities and differences (see also recent summaries by Sammler, Reference Sammler2020 or Turker et al., Reference Turker, Sommer-Lolei and Christiner2018). On a very simple level, both can be described as auditory phenomena that are conveyed by sounds and are mostly specific to humans. When taking a closer look (please refer to Besson & Schön, Reference Besson and Schön2001 and Jackendoff, Reference Jackendoff2009, for details on the subsequently presented aspects), it is worth mentioning that they are not simply sounds but structural systems that consist of sequential events that unfold in time and follow some form of hierarchical organization. Both language and music are used for expressing emotions and thoughts, and for sharing knowledge and intentions. In the case of comparing singing and language production in speech, both systems even share the same anatomical production system, namely, the vocal tract apparatus plus the lungs and certain brain representations (the exact brain correlates for these two components still await future research). Given the numerous similarities, it is not surprising that the two often interact. For example, language is based on musical qualities (e.g., pitch, rhythm, timbre), and music is frequently accompanied by spoken language in the form of singing. A salient differentiation between the two domains concerns the use of pitch and melody only, because musical melodies exploit pitch ranges and variabilities significantly more than languages, where the range of pitch variability is rather limited (Chow & Brown, Reference Chow and Brown2018; Kogan & Reiterer, Reference Kogan and Reiterer2021).
Since language and music are so similar, many researchers have addressed the links between specific linguistic abilities, such as speech production, or comprehension, on the one hand, and musical abilities and/or training, on the other. If we take a closer look at the relationship between speech perception and musicality, we find that there is evidence for a relationship between pitch perception and speech perception, for instance. Professional musicians (whom one would assume to possess high musicality) are often reported to be more successful when detecting differences in pitch in both language and music (Besson et al., Reference Besson, Schön, Moreno, Santos and Magne2007; Burnham et al., Reference Burnham, Brooker and Reid2015; Marques et al., Reference Marques, Moreno, Castro and Besson2007; Schön et al., Reference Schön, Magne and Besson2004). Bowles et al. (Reference Bowles, Chang and Karuzis2016), for instance, found that pitch ability was a better predictor for second language aptitude in a tone language than general musicality and other cognitive abilities. Accordingly, they proposed that it might not be general musicality but rather specific musical traits that could predict advantages for second language learning. Their assertion goes hand in hand with findings by Delogu et al. (Reference Delogu, Lampis and Olivetti Belardinelli2006, Reference Delogu, Lampis and Olivetti Belardinelli2010), who reported that an enhanced discrimination of lexical tone was present in individuals with higher melodic abilities and more musical training. In a recent study from our own group, we found that overall musicality was driven mostly by melody discrimination ability (as measured by the Profile of Music Perception Skills musicality test battery, Fonseca-Mora et al., Reference Fonseca-Mora, Herrero Machancoses, Gryb and Reiterer2020) and could successfully predict reading fluency in learners of Spanish as a foreign language.
Apart from pitch processing, differences in rhythm perception have also been linked to speech comprehension. Nardo & Reiterer (Reference Nardo, Reiterer, Dogil and Reiterer2009) found that rhythm perception was linked to pronunciation talent in a second language (English in their study) and grammatical inferencing ability, as measured by the grammatical sensitivity test of the Modern Language Aptitude Test (MLAT; Carroll & Sapon, Reference Carroll and Sapon1959). On the other hand, a greater amount of musical training and more intensive foreign language learning experience has also been linked to enhanced rhythm perception (Bhatara et al., Reference Bhatara, Yeung and Nazzi2015). As a general conclusion from these findings, either more intensive experiences with music and language lead to better rhythm perception, or very good rhythm perception facilitated language learning processes and musical learning (e.g., by fostering interest in both due to ease of learning).
Less research has explicitly addressed the link between speech production skills and musical abilities. A Finnish research group (Milovanov et al., Reference Milovanov, Huotilainen, Välimäki, Esquef and Tervaniemi2008, Reference Milovanov, Pietilä, Tervaniemi and Esquef2010) explored the link between the two on the neural and behavioural levels and found that individuals with more musical training and higher musicality scored higher in second language pronunciation testing. Additionally, they found confirmation on the neural level, with the more gifted participants showing more prominent sound change–evoked brain activation to musical stimuli (Milovanov et al., Reference Milovanov, Huotilainen, Välimäki, Esquef and Tervaniemi2008, Reference Milovanov, Pietilä, Tervaniemi and Esquef2010). Other studies have found a correlation between specific musical abilities and second language pronunciation (Dolman & Spring, Reference Dolman and Spring2014; Slevc & Miyake, Reference Slevc and Miyake2006). Conversely, Vangehuchten et al. (Reference Vangehuchten, Verhoeven and Thys2015) found that good auditory capacity went hand in hand with phoneme and stress pattern reception in Spanish L2 learners, but pronunciation did not correlate with overall prosodic skills. It has also been shown that singing facilitates phrase learning in unfamiliar languages, meaning that vocabulary learning with a listen-and-sing strategy is more successful (Ludke et al., Reference Ludke, Ferreira and Overy2014).
Our own research provided evidence that speech imitation, accent faking in the native language, reading abilities, vocabulary learning, and grammatical sensitivity are linked to musical skills, even in Chinese native speakers (Reiterer, Reference Reiterer, Wen, Skehan, Biedroń, Li and Sparks2019; also summarized in chapters in Reiterer, Reference Reiterer2018). However, singers outperformed instrumentalists and non-instrumentalists/non-singers (i.e., non-musicians) on several productive language skills, suggesting that singing might improve articulation and motor skills related to language and music (Christiner & Reiterer, Reference Christiner and Reiterer2013, Reference Christiner and Reiterer2015). What is missing to date, but surely of considerable interest, would be to study longitudinally how musical training or high musicality, and also singing and general musical abilities at a young age, influence language learning in life at later stages.
On the neural level, it is clear that language and music both recruit a (partially overlapping) wide array of brain networks essential for processing visual, auditory, motor and memory-related information. Musical training leads to stronger brainstem responses to specific music- and language-relevant acoustic parameters like pitch (also discussed in Moreno & Bidelman, Reference Moreno and Bidelman2014; Wong et al., Reference Wong, Skoe, Russo, Dees and Kraus2007) and thus provides substantial benefits at the subcortical and cortical levels (Kraus & Chandrasekaran, Reference Kraus and Chandrasekaran2010). Studies with musicians have confirmed that musicianship leads to enhancements on various levels, including perceptual, language and high-level cognitive processes and mechanisms (Moreno et al., Reference Moreno, Bialystok and Barac2011; Roden et al., Reference Roden, Kreutz and Bongard2012; Schellenberg, Reference Schellenberg2011). Musical training is associated with positive, long-lasting benefits on auditory function and potentially motor processes, which is confirmed by studies showing how it leads to morphological changes in the precentral gyrus, motor areas and the auditory cortices (Kraus & Chandrasekaran, Reference Kraus and Chandrasekaran2010). An interesting, still ongoing longitudinal study (first findings presented in Seither-Preisler et al., Reference Seither-Preisler, Parncutt and Schneider2014) is currently exploring the role of the primary auditory cortex (the structure of Heschl’s gyrus [HG], to be specific) for musical and attentional skills, as well as literacy.
Findings from that study have so far shown that a large right HG (gross morphology and grey matter volume), which is involved in the processing of suprasegmental, slowly changing acoustic cues, signifies high musical potential.
Moreover, people who play musical instruments show faster and more intense processing of auditory input as well as better interhemispheric synchronization.
This study provides additional evidence that auditory cortex morphology is genetically predisposed, since musical training did not lead to any observable changes in terms of grey matter volumes or gyrification over a period of five years. The conclusion drawn from this study was that pre-existing anatomical factors, which in turn led to heightened efficiency, are the basis for an aptitude profile that develops into an outstanding competence profile over time and under the right circumstances (Seither-Preisler et al., Reference Seither-Preisler, Parncutt and Schneider2014; see also the discussion on their neurocognitive model of competence development).
Working Memory and Language Aptitude
In the past three decades, research on working memory and its significance for language learning has blossomed, and various language-based conditions (e.g., dyslexia, developmental language disorder) have been linked to deficits in working memory (for details, refer to Ullman et al., Reference Ullman, Almeida and Klingberg2014, Reference Ullman, Earle, Walenski and Janacsek2020), supporting the strong link between linguistic skills and working memory. Baddeley and colleagues (Baddeley et al., Reference Baddeley, Gathercole and Papagno1998; Baddeley & Hitch, Reference Baddeley and Hitch1974, Reference Baddeley and Hitch2000; Papagno et al., Reference Papagno, Valentine and Baddeley1991) were the first to suggest a robust link between the working memory system and novel word learning. They claimed that the phonological loop was critical for the learning of foreign languages given that vocabulary learning plays a very important role in language learning. This hypothetical association has been investigated by language aptitude researchers worldwide (Ellis, Reference Ellis1996; Kormos & Sáfár, Reference Kormos and Sáfár2008; Miyake & Friedman, Reference Miyake, Friedman, Healy and Bourne1998; Wen et al., Reference Wen, Biedroń and Skehan2017). Zhisheng Wen and Peter Skehan (e.g., Wen & Skehan, Reference Wen and Skehan2011, Reference Wen and Skehan2021) have focused on investigating the link between working memory and language aptitude in their past work. In their 2011 paper, they overtly argued for an incorporation of working memory in the construct of language aptitude, and this idea has received widespread support. Since the present chapter focuses more on the neurobiology of language aptitude and less on the link between working memory and language aptitude, we refrain from too much detail at this point. It is worth mentioning, though, that Linck et al. (Reference Linck, Osthus, Koeth and Bunting2014) performed a meta-analysis confirming the robust, positive relationship between working memory and second language comprehension and production. However, these authors concluded that more studies were needed to specifically advance theoretical models and fully understand the contributions of working memory to language learning outcomes. Wen’s (Reference Wen2016, Reference Wen, Wen, Skehan, Biedroń, Li and Sparks2019) phonological–executive working memory model, in which he combines language learning processes with working memory, sheds further light on the significance of this capacity for language aptitude.
Regarding the involvement of working memory in foreign language aptitude, some researchers have proposed that working memory exerts a central influence on language aptitude and is thus the strongest predictor thereof (Miyake & Friedman, Reference Miyake, Friedman, Healy and Bourne1998; Sawyer & Ranta, Reference Sawyer, Ranta and Robinson2001; Wen et al., Reference Wen, Biedroń and Skehan2017; Wen & Skehan, Reference Wen and Skehan2011, Reference Wen and Skehan2021). Their contention is supported by studies which reported that learners with higher working memory capacity significantly outperformed age-matched peers when learning a foreign language (Biedroń, Reference Biedroń2015; Van Den Noort et al., Reference Van Den Noort, Bosch and Hugdahl2006). Nonetheless, there is major disagreement on the specific components involved (e.g., the central executive or the phonological loop), how the components can be tested reliably, and whether they really relate to the known components of language aptitude (Jacquemot & Scott, Reference Jacquemot and Scott2006). Moreover, some researchers have questioned the impact working memory has been found to have on language aptitude, as they have not found a similar link in their own work (e.g., Winke, 2013). With regard to the theoretical concept of language aptitude, there has been an ongoing debate as to whether an incorporation of working memory would imply that language aptitude is alterable through training and experience. Although this idea has been frequently argued, a meta-analysis by Melby-Lervåg and Hulme (Reference Melby-Lervåg and Hulme2013) was inconclusive as to whether working memory can be significantly improved through training.
In two recent studies with adults (Turker et al., Reference Turker, Reiterer, Seither-Preisler and Schneider2017) and children (Turker et al., Reference Turker, Reiterer, Schneider and Seither-Preisler2019), we found some differences in the degree of association between working memory and language aptitude. In both studies we tested phonological working memory (digit span forward and backward, and non-word span), musicality (Advanced Measures of Music Audiation [AMMA]; Gordon, Reference Gordon1989) and language aptitude (MLAT; Carroll & Sapon, Reference Carroll and Sapon1959; or LLAMA, Meara, Reference Meara2005). The results of the first study with adults (Turker et al., Reference Turker, Reiterer, Seither-Preisler and Schneider2017) showed rather weak links between working memory and language aptitude scores as measured by the MLAT and the English pronunciation task. However, the Hindi direct speech imitation task – imitating an unknown language and thus also reflecting pronunciation aptitude – showed significant correlations with all three working memory tasks. The results of a further principal component analysis on the data of this first study showed that the tests assessed three similar, connected constructs, namely musical ability, language aptitude (the results of the MLAT and the Hindi score loaded moderately onto this component), and working memory capacity (all working memory tests and the Hindi score loaded onto this component). In the second study with children and teenagers (Turker et al., Reference Turker, Reiterer, Schneider and Seither-Preisler2019), and partially contrary to the findings of the earlier study, statistical analyses pointed towards a very strong link between language aptitude and working memory (e.g., consider the differences between high and low language aptitude learners on working memory tests and the Hindi score in Figure 10.1).

Figure 10.1 Differences in phonological working memory and speech imitation between high and low aptitude learners according to the overall results on the LLAMA language aptitude battery ( ,
, corrected for multiple comparisons): High aptitude learners significantly outperform low aptitude learners in digit span forward and backward and the Hindi speech imitation test
corrected for multiple comparisons): High aptitude learners significantly outperform low aptitude learners in digit span forward and backward and the Hindi speech imitation test
In the study with children and teenagers, all three working memory scales correlated with each other, and two correlated with language aptitude as measured by the LLAMA language aptitude battery. We also performed a principal component analysis using the same parameters as in the first study and included children’s mathematical abilities as well. The principal component analysis again extracted three major underlying components, namely mathematical abilities, language aptitude/working memory, and musical ability. Thus, the principal component analysis suggested that language aptitude and working memory were part of the same construct in the group of children and teenagers. All working memory and language aptitude tasks, including the Hindi score, loaded heavily onto this single component, clearly pointing towards a strong link between the measures. Thus, we concluded that working memory capacity could be more closely linked to language aptitude in the younger population than in the adult group (and note that similar results were reported by Hu et al., Reference Hu, Ackermann and Martin2013).
It is generally accepted that working memory develops and increases from child- to adulthood and peaks at around 30 years of age (Alloway & Alloway, Reference Alloway and Alloway2013). We tested this difference in performance with all the participants in the two studies mentioned above. Statistical analyses confirmed that all three working memory scales differed significantly according to age. This finding is consistent with suggestions from Wen (Reference Wen2016), who proposed that the effects of phonological working memory would be most prominent in the case of either very young subjects, less proficient learners, or adult learners in rather early stages of learning a foreign language (for further discussion, see Hu et al., Reference Hu, Ackermann and Martin2013; Hummel, Reference Hummel2009; O’Brien et al., Reference O’Brien, Segalowitz, Collentine and Freed2006). Consequently, the influence and importance of working memory might be dependent on learners’ age and proficiency. Possibly other abilities, such as metalinguistic awareness (e.g., Jessner, Reference Jessner1999), are also relevant during later stages and lead to a loss of significance of working memory for foreign language learning, or reduce the importance of low working memory to a certain extent. It has long been known in expertise and problem-solving research (Sternberg & Sternberg, Reference Sternberg and Sternberg2012) that working memory involvement decreases alongside, or as a function of, growing expertise in any domain (automatization, schematization, long-term memory shift). Highly proficient learners seem to become increasingly efficient and consequently “free up” working memory resources as they become more expert. In contrast, novices use their working memory to try to keep multiple features of a new learning process in mind. In the same way, children and teenagers or less proficient learners (novices) could rely much more on working memory as it fosters other abilities, like implicit learning or attention.
Researchers have argued that it is challenging to integrate a major component like working memory capacity into an overall concept of language aptitude while at the same time thinking that language aptitude is mostly innate and can therefore not easily be enhanced through training and/or language experience. Without doubt, there are numerous, still unanswered questions about the concept of language aptitude, and one of the major discussion points remains the involvement of working memory. However, a major concern is that high working memory capacity alone does not make a gifted language learner, and conversely, possessing a high language aptitude does not automatically require high working memory capacity. Furthermore, there is still no consensus on the specific subcomponents of working memory and how they are integrated in the second language learning process and at different stages of learning (as indicated in the last paragraph). In his parallel architecture account, for example, Jackendoff (Reference Jackendoff2007, Reference Jackendoff2010) proposed that linguistic working memory consists of three subparts, namely, phonological, syntactic, and semantic components. While this is certainly an attractive proposal, Jackendoff has not really clarified how to operationalize the different components in any overall framework of language learning. A major problem to date is that we cannot yet determine the exact amount of variation in individual learning behaviour that might be explained by working memory (Juffs & Harrington, Reference Juffs and Harrington2011), which makes it hard to integrate it into current models of language aptitude. Even so, we argue that working memory is one of the basic prerequisites for language learning and may be genetically determined, alongside other cognitive abilities like auditory processing, learning efficiency, comprehension knowledge and fluid reasoning (see the most recent update on the Cattell-Horn-Carroll model of intellectual abilities and general cognitive performance in Schneider & McGrew, Reference Schneider, McGrew, Flanagan and McDonough2018, and a suggestion of a neurocognitive model of language aptitude in Turker et al., Reference Turker2021).
On the neural level, the working memory network is very large, as is the case with language more generally, and there are numerous interconnected neurological areas that contribute to working memory functioning. The phonological loop, for instance, is thought to consist of a short-term storage in the inferior parietal lobe (IPL) and an articulatory subvocal rehearsal mechanism in the inferior frontal gyrus (IFG), the motor association area, and potentially the cerebellum (e.g., Müller & Knight, Reference Müller and Knight2006). An important source of evidence to clarify how areas are connected are lesion studies. The problem with such lesion studies, however (and the main basis for such claims), is that lesions are often extensive in nature, so that many skills can be impaired. A network may be compromised as connectivity is disrupted, even though a neurological region may not be implicated in a specific task at all (see discussion in Smith & Jonides, Reference Smith and Jonides1997). These findings are due to the large overlap with other skills and the difficulty of assessing only working memory. Apart from that, even if neuroimaging studies have shown several specific regions involved in the short-term storage of information, we know that the brain is far too complex to rely on such a modulatory basis (for an in-depth view, see Wager & Smith, Reference Wager and Smith2003). Therefore, it seems that the link between language aptitude and working memory is more extensively researched on the behavioural side, and it is hard to pinpoint overlapping mechanisms and processes in the brain.
To sum up, while it is tempting to add working memory into our current neurobiological model of language aptitude, we will treat it not as a core component of an initial language aptitude profile per se but rather as a developing, constantly interacting factor that might lead to high language aptitude and foster the development of talent at various stages without being fixed from the beginning.
The Neurobiology of Language Aptitude: Findings of Recent Research
It is not far-fetched to assume that the core brain areas related to language aptitude are probably those areas that contribute centrally to language, and that damage to these leads to significant impairments, hindering both speech production and comprehension (e.g., for the most important areas of language processing, see Hickok & Poeppel, Reference Hickok and Poeppel2004; Petrides, Reference Petrides2014; Price, Reference Price2010, Reference Price2012). What makes it hard to pinpoint specific areas is the large number of areas in the human brain that contribute to language processing. All core language regions are situated around the so-called Sylvian fissure and are therefore usually described as belonging to the peri-sylvian region (see Figure 10.2). Although the right hemisphere contributes to language processing as well, language is largely left-lateralized (Szaflarski et al., Reference Szaflarski, Holland, Schmithorst and Byars2006). In the frontal lobe, the major area of interest is the IFG (also still known as Broca’s area). Speech production and sensory processing requires the pre- and postcentral gyri (so-called motor areas responsible for physical aspects behind speech production), which are at in the posterior frontal and the anterior parietal lobe, respectively. The supramarginal and angular gyri (SMG/AG) in the IPL are involved in semantics and phonology, as well as speech comprehension. Last, auditory areas (underneath the Sylvian fissure) comprise the superior and middle temporal gyri (STG/MTG), vital regions for the processing of any kind of auditory input, such as music or speech (Petrides, Reference Petrides2014).

Figure 10.2 A visualization of areas typically activated during language processing including the left inferior frontal cortex, the motor areas, the auditory cortices bilaterally, and the left IPL
In recent years, the number of researchers exploring the neuroanatomical and neurofunctional bases of language aptitude has grown markedly. We have a much better understanding of what the neurobiological bases of language aptitude could look like compared to a decade ago (for an in-depth summary, see Turker et al., Reference Turker2021). For instance, Kepinska, Pereda et al. (Reference Kepinska, de Rover, Caspers and Schiller2017) investigated differences in novel grammar learning as measured by LLAMA F (Meara, Reference Meara2005) and differences in functional activation and structural connectivity between those with high and average language analytic abilities on the LLAMA F. Contrary to the neural efficiency hypothesis, which postulates that the better you are at doing something, the more efficiently your brain works and the fewer areas are activated (e.g., found in linguistically talented individuals in Reiterer et al., Reference Reiterer, Hu and Erb2011, and polyglots and hyper-polyglots in Jouravlev et al., Reference Jouravlev, Mineroff, Blank and Fedorenko2019), they reported that those with higher skills had significantly more activation in terms of magnitude and extent in mostly language-specific areas of the brain. Among them were the right and left IPL and very posterior portions of the STG and MTG.
Further exploring functional differences, Kepinska, de Rover, et al. (Reference Kepinska, de Rover, Caspers and Schiller2017) confirmed in an electroencephalography study that increasing proficiency in the language analytical task was supported by stronger local synchronization in right-hemispheric areas, combined with less mental effort in the highly skilled learners. These results are complemented by their findings related to structural connectivity. In that respect, Kepinska, de Rover, et al. (Reference Kepinska, de Rover, Caspers and Schiller2017) focused on the major fibre bundle connecting all language-relevant regions of the human brain along the Sylvian fissure, namely the arcuate fascicle. They could only find a very small difference within the anterior segment between those with high and average language analytic ability, and most surprisingly, this difference was only significant in the right hemisphere. The widespread but enhanced activation in the learners with high analytical abilities in Kepinska, Pereda, et al. (Reference Kepinska, de Rover, Caspers and Schiller2017) is to some degree similar to the study of Hu et al. (Reference Hu, Ackermann and Martin2013) who found enhanced left hemisphere peri-temporal and motor cortex activation in more talented speech imitators of English as a second language, but stands in contrast with the findings of Reiterer et al. (Reference Reiterer, Hu and Erb2011, Reference Reiterer, Hu, Sumathi and Singh2013). In their own work, these authors found that less widespread activation (i.e., more efficient processing) characterized the high ability group in speech imitation of an unknown language. The difference was particularly pronounced in the left hemisphere around the Sylvian fissure. To be more precise, the more gifted the learners, the more efficiently they engaged the core language/speech areas, and the less activation could be observed during the speech imitation task. Yet, at the same time, the higher ability groups’ lower activations were accompanied structurally by increased grey matter volumes in those main peri-sylvian areas – the inferior parietal plus inferior frontal/premotor compound (Reiterer et al., Reference Reiterer, Hu and Erb2011).
In a later study by Vaquero et al. (Reference Vaquero, Rodríguez-Fornells and Reiterer2017), the authors examined differences in the structural connectivity of neurological areas, similar to the analyses that had been performed by Kepinska, de Rover, et al. (Reference Kepinska, de Rover, Caspers and Schiller2017). The results showed that the good speech imitators had more fractional anisotropy (i.e., more directed white matter connections) in the left arcuate fasciculus, while bad Hindi speech imitators showed a higher volume of white matter connections in the right arcuate fascicle, specifically within the posterior segment. Their findings are in accordance with the left-hemispheric dominance for language, which suggests that differences in linguistic abilities should be most pronounced in the left and not the right hemisphere. Differences in structural connectivity were also reported by Xiang et al. (Reference Xiang, Dediu and Roberts2012), who used all four tests of the LLAMA language aptitude battery and found that each task was differentially related to specific pathways in the left hemisphere (e.g., connections in the temporal pathway predicted grammatical analytic abilities; connections in the parietal pathway predicted vocabulary learning and sound–symbol learning).
However, it should be noted that within these studies very different tasks, or rather linguistic phenomena, were used, so no general conclusions can be drawn. Kepinska and collaborators chose a grammatical learning task, whereas Reiterer focused on the learner’s ability to reproduce utterances in an unknown language. Xiang et al. included all the tasks of the LLAMA battery, not one specific subskill. Consequently, the difference in results could be either contrast- or task-specific, or even difficulty level–specific. An immediate and novel grammar learning task in the scanner might be more demanding for the brain than a mere phonetic “parroting” task of imitating just-heard sentences, for instance. To compare these tasks (language analysis/speech production) directly with regard to either locations or efficiency of processing might be problematic. Finally, Kepinska et al. compared high and average learners, a contrast that might not have been sufficient to show striking differences.
Very recently, Novén et al. (Reference Novén, Schremm, Nilsson, Horne and Roll2019) hypothesized that differences between very good and very bad foreign language learners could be the result of differences of cortical thickness (i.e., how thick the grey matter in specific brain regions is). They used LLAMA F to measure language analytical abilities and tested whether there was a significant link between cortical thickness within specific brain areas and scores on the test. They reported that high grammar aptitude, as measured by LLAMA F, was linked to higher cortical thickness in two brain regions, namely the left IFG and the left medial frontal gyrus (both regions in the inferior frontal cortex known to be implicated in a variety of linguistic tasks). To put it differently, the authors found that a thicker cortex in Broca’s area and a region in close proximity, are indicative of high grammar learning aptitude. They tested the same association for pitch discrimination, based on the assumption that pitch discrimination is related to phonetic learning and thus language aptitude. However, they only found a correlation with “cortical thickness in the right IFG” for the pitch discrimination task.
Inspired by the research of Seither-Preisler and Schneider (see Seither-Preisler et al., Reference Seither-Preisler, Parncutt and Schneider2014 or Serrallach et al., Reference Serrallach, Groß and Bernhofs2016) on the relationship between auditory cortex morphology, musicianship, and developmental disorders in childhood, the focus of our most recent research has been on the auditory cortex and its potential role for language aptitude. We thought it was particularly worthwhile to explore auditory cortex morphology for several reasons: (1) the auditory cortex’ importance as the starting location of speech processing in the brain, (2) the availability of already successfully applied manual segmentation methods (see, e.g., Schneider et al., Reference Schneider, Sluming, Roberts, Bleeck and Rupp2005), and (3) the aforementioned strong relationship between language and music, with musical abilities being linked to auditory cortex morphology in the right hemisphere (Benner et al., Reference Benner, Wengenroth and Reinhardt2017; Schneider et al., Reference Schneider, Sluming, Roberts, Bleeck and Rupp2005; Seither-Preisler et al., Reference Seither-Preisler, Parncutt and Schneider2014). Few previous studies had actually addressed the relevance of HG (the gyrus in which incoming auditory information is first processed) or the auditory cortex more generally for speech and language learning. Golestani et al. (Reference Golestani, Paus and Zatorre2002) first explored the anatomical correlates of learning novel speech sounds, finding that those individuals with higher white matter density in their left auditory cortex were significantly faster at learning novel speech sounds (a Hindi sound in their study). Several years later, Golestani & Pallier (Reference Golestani and Pallier2007) replicated these findings, reporting that greater white matter density was associated with faster speech perception learning. Interestingly, however, a later study by Golestani & Pallier (Reference Golestani and Pallier2007) found differences only in the left insula and the IPL between adept and less successful sound learners. Focusing on a very different group, Golestani et al. (Reference Golestani, Price and Scott2011) investigated structural plasticity in the expert phonetician brain and hypothesized that the auditory cortices of phoneticians would look differently than those of non-phoneticians. The results of their analyses showed that expert phoneticians had both significantly higher grey and white matter volumes in the left HG. They concluded that subjects either had been born with an ear for dialects (i.e., with higher grey and white matter volumes in that specific area) or the differences were a result of intense life-long training of phonology.
In our own studies (Turker et al., Reference Turker, Reiterer, Seither-Preisler and Schneider2017, Reference Turker, Reiterer, Schneider and Seither-Preisler2019, and summarized in Turker, Reference Turker, Reiterer, Schneider and Seither-Preisler2019) with adults and children, we found that right-hemispheric auditory cortex morphology was a potential neuroanatomical marker of foreign language aptitude. Whereas possessing more than one single gyrus in the right hemisphere was associated with high speech imitation ability (in adults) and high overall language aptitude (in children and adults), possessing a single gyrus was associated with low scores on the language aptitude test (see Figure 10.3 for the morphological types of HG distinguished in the analyses).

Figure 10.3 The four types of HG distinguished in the analyses of Turker et al. (Reference Turker, Reiterer, Schneider and Seither-Preisler2019): Single gyrus (single), common stem duplication (CSD; i.e., a common stem in the medial end of HG with two separate gyri on the lateral side), complete posterior duplication (CPD; two completely separate gyri), and multiple (i.e., more than two gyri) – in the previous study (Turker et al., Reference Turker, Reiterer, Seither-Preisler and Schneider2017), only the first three types (from left to right) were distinguished since multiple gyri (counted as CPDs then) were too rare to justify a separate category thereof
In the first study with adults, only gross structural variation (i.e., the major shapes and number of gyri in the auditory cortex) of the auditory cortex was analysed. In the second study with children and teenagers, an additional analysis examining differences in grey matter volumes in that specific region was applied to add a further dimension to the results. In the adult group, more complete gyri (i.e., fully developed, separate gyri) of HG in the right hemisphere correlated highly and significantly with higher speech imitation skills in the Hindi task and with higher overall language aptitude as measured by the MLAT (composite score of vocabulary learning, phonetic coding ability, and language analysis ability). Additionally, right auditory cortex morphology also correlated with higher musical ability as measured by the AMMA test, assessing rhythm and pitch discrimination ability. The findings of the second study (Turker et al., Reference Turker, Reiterer, Schneider and Seither-Preisler2019) showed that those children and teenagers with multiple gyri in their right auditory cortex were also more likely to be in the high language aptitude group as measured by the LLAMA language aptitude battery, assessing phonetic coding ability, vocabulary learning, sound–symbol association learning and language analysis ability (see Figure 10.4 for an exemplary visualization of the results). Additionally, the higher the grey matter volumes in subjects’ right auditory cortex, the higher they scored on the language aptitude test (see Figure 10.5). In this study, however, neither the Hindi score nor musicality could be linked to left- or right-hemispheric auditory cortex morphology.

Figure 10.4 Differences in HG, that is, auditory cortex anatomy, between high and low aptitude language learners (according to the LLAMA score), visualized in five examples from each category: Right-hemispheric auditory cortex morphology (darkest shading) in the form of multiple gyri and common stem duplications is significantly associated with high language aptitude in children and teenagers.

Figure 10.5 Linear regression analyses revealed that grey matter volume in right but not left auditory cortex predicted performance on the LLAMA language aptitude test in children and teenagers
According to Hickok & Poeppel’s (Reference Hickok and Poeppel2000, Reference Hickok and Poeppel2004) dual-stream model of language processing, acoustic speech signals, processed in the auditory cortex, are linked to conceptual–semantic representations and simultaneously passed on to motor speech regions for reproduction with the vocal tract. Logically, differences in auditory processing or in the structure of the auditory cortex could prove to be advantageous or disadvantageous for overall speech comprehension and processing. Moreover, recent research has suggested that there are very basic auditory processing differences in the general population, with about half of individuals aligning their own syllable production to a perceived rate, and the other half remaining impervious to the external rhythm (Assaneo et al., Reference Assaneo, Ripollés and Orpella2019; also explained in more depth in Assaneo & Poeppel, Reference Assaneo and Poeppel2018). These very general differences could potentially be associated with high or low phonological skills from very early in life. An interesting viewpoint comes from Brandt et al. (Reference Brandt, Gebrian and Slevc2012), who argued that without the ability to hear musically, it would be impossible to learn how to speak. They suggested that children acquired language as a sequence of syllables that are learnt in a specific rhythm; that is, language is learnt by each child as a sequence of rhythmic elements. However, their view could not explain why only the right auditory cortex should be involved in language aptitude. One explanation could be the relevance of the right auditory cortex for first language acquisition. Previous studies have found that speech input to infants is more dependent upon the right hemisphere, both in primary and secondary auditory areas (Perani et al., Reference Perani, Saccuman and Scifo2011). Similarly, numerous speech-related acoustic cues (e.g., prosody) are dominantly processed in the right hemisphere and are also a critical source of information for infants who acquire a native language (Homae et al., Reference Homae, Watanabe, Nakano, Asakawa and Taga2006). Homae et al. suggested that speech processing in the human infant brain develops gradually and starts with the analysis of pitch information. Additionally, they argued that even later stages of language learning depend highly on the recognition and memorization of prosodic contours of an unfamiliar language, features that are already right-lateralized in 10-month-old infants (Homae et al., Reference Homae, Watanabe, Nakano, Asakawa and Taga2006).
Conclusions and Avenues for Future Research
Any (neuro-)cognitive model of language aptitude (see our recent proposal in Turker et al., Reference Turker2021) will need to closely consider the relationship between language learning and working memory, as well as the interdependence between musical abilities, musical training, and (foreign) language learning. Regarding the role of music for language learning and consequently language aptitude, we propose that musicality or high musical abilities are likely to be part of the cognitive starter kit for auditory processing and thus intricately tied to an innate language aptitude profile. This would explain why we often observe a strong relationship between musical ability and language learning in the absence of musical training or musicianship. On the other hand, musical training has clearly been shown to enhance general auditory processing and positively influence language learning, suggesting that even at later stages and in the potential absence of excellent musicality or musical processing abilities, learning to play an instrument or to sing could benefit the foreign language learning process in a variety of ways, most obviously on the neural level.
With regard to working memory, we suggest that it is an essential prerequisite for language learning on a more general cognitive level and should thus already come into play at very early stages of learning (e.g., responses to deviations in auditory stimuli in a sequence, and thus a preliminary form of working memory, have already been confirmed in utero; Preissl et al., Reference Preissl, Lowery and Eswaran2005). In other words, working memory capacity is very likely to be genetically driven and part of the initial, genetic language aptitude profile, alongside other cognitive skills (e.g., fluid reasoning, learning efficiency). Our contention is supported by the mixed findings on working memory training, potentially providing evidence for the fact that a large portion of working memory is biologically determined, and only marginal differences can be achieved through training.
On the neural level, we argue that pre-existing anatomical markers for language aptitude lay the foundation for later differences associated with high language aptitude or highly successful language learning, such as better structural connections, higher functional efficiency, or better functional connectivity within language-specific regions. One of these regions could be the auditory cortex, given the predominance of this region for all early language learning stages (e.g., see the extensive summary of language learning stages in infancy and childhood in Skeide & Friederici, Reference Skeide and Friederici2016) and its importance for all language-related processes (i.e., aside from primary auditory and phonological analyses). At present, it seems impossible to clearly point to one specific property of the highly gifted linguistic brain, arguably because many ways lead to Rome and the brain has undergone such a variety of dynamic, plastic changes already in infancy and childhood. Most likely, anatomical variation in interaction with experience and the environment leads to higher efficiency, which in turn leads to differences in activation patterns and better structural connectivity between temporal areas and frontal areas.
To summarize, we suggest that the combination of inborn neuroanatomy and a cognitive starter kit for language learning form the basis of what develops into a linguistically talented person. Any future models of such talent will not only need to take into account the plethora of related cognitive and environmental variables that have been shown to impact all language learning processes but will also need to provide an in-depth view of the developmental, behavioural, and neural processes related to language learning at various stages. To further advance our understanding of language aptitude and its relationship to other related abilities, such as musicality or working memory capacity, longitudinal studies starting with children at very young ages are needed to elucidate the unfolding of language aptitude from behavioural and neural perspectives.
Introduction
The Linguistic Coding Differences Hypothesis (LCDH) developed by Sparks and Ganschow derives its name from native language (L1) research in reading. The major premises underlying the LCDH are that the primary factors for more and less successful second language (L2) learning are linguistic and that there are strong relationships between learners’ L1 achievement and their L2 achievement (Sparks & Ganschow, Reference Sparks and Ganschow1991, Reference Sparks and Ganschow1995; Sparks, Ganschow, & Pohlman, Reference Sparks, Ganschow and Pohlman1989). Sparks and Ganschow (Reference Sparks and Ganschow1993) posited the following: a) native language (L1) skills form a foundation for L2 learning; b) the primary causal factors in more and less successful L2 learning are linguistic; c) high-, average-, and low-achieving L2 learners will display individual differences (IDs) in their L1 skills; and d) IDs in L1 predict ultimate attainment in the L2 (see also Sparks, Reference Sparks1995). The LCDH also proposes that IDs in students’ L1 skills are related to and consistent with their aptitude for L2 learning and that L2 learning skill occurs along a continuum of very strong to very weak L2 learners. The claims of the LCDH are similar to Cummins’ (Reference Cummins1979) Linguistic Interdependence Hypothesis (L1 and L2 have a common underlying foundation) and Linguistic Threshold Hypothesis (L2 proficiency is moderated by one’s level of attainment in L1). From the outset, they speculated that the learning of an L2 is the learning of language and that the skills necessary for L2 learning will be language related. Like Skehan (Reference Skehan1998), they view language as special, that is, language is qualitatively different from other cognitive skills.
Initially, Sparks and Ganschow called their hypothesis the Linguistic Coding Deficit Hypothesis, developed primarily to explain the L2 learning problems of U.S. students who exhibited difficulties with L1 skills despite average or better intelligence. As they conducted research on the hypothesis, they changed the name from deficits to differences because their studies revealed that low-achieving and other at-risk L2 learners did not exhibit deficits (i.e., below average levels) in their L1 skills and L2 aptitude. Rather, low-achieving learners scored in the average to low average range on L1 measures (reading, spelling, writing, vocabulary) and the Modern Language Aptitude Test (MLAT) (Carroll & Sapon, 1959, Reference Carroll and Sapon2000). Starting in the 1990s, Sparks and Ganschow conducted numerous studies in L2 classes to determine the viability of the LCDH and published a summary of their findings with U.S. students (Ganschow & Sparks, Reference Ganschow and Sparks2001). In that paper, they reviewed their research and the work of other scholars on L2 learning from the 1960s through 2000. They proposed and answered several research questions:
Are there L1 skill and L2 aptitude differences between high- and low-achieving L2 learners?
Are there L2 achievement and proficiency differences among individuals who differ in L1 skills and L2 aptitude?
What are the best predictors of L2 proficiency and achievement?
Are there L1 skills and L2 aptitude differences in individuals who display differing levels of L2 anxiety?
Since that time, Sparks et al. have conducted additional studies, including longitudinal and retrospective investigations, on L1–L2 relationships. In this chapter, the answers to the aforementioned questions before 2001 are reviewed briefly. Then, their new studies conducted over the last 20 years are reviewed (see also Sparks, Reference Sparks2012, 2022a, b). Added to the list of questions reviewed in 2001 are two questions related to whether L2 learning is primarily a language-based activity:
Is there long-term, cross-linguistic transfer from L1 to L2 skills?
Are there relationships in the language skills for reading L1 and L2 alphabetic orthographies?
Are there L1 skill and L2 aptitude differences between high- and low-achieving L2 learners?
Are there L2 achievement and proficiency differences among individuals who differ in L1 skills and L2 aptitude?
Because research with U.S. L2 learners has found strong relationships among students’ L1 skills, L2 aptitude, and L2 proficiency and achievement, answers to the first two questions are reviewed in this section.
By 2001, L2 researchers had proposed a number of hypotheses to explain IDs in L2 learning and achievement. Some researchers maintained that variables such as attitude/motivation (Gardner, Reference Gardner1985), anxiety (Horwitz, Horwitz, & Cope, Reference Horwitz, Horwitz and Cope1986), and failure to use language learning strategies (Oxford, Reference Oxford, Parry and Stansfield1990) were causal factors in L2 learning differences. Other researchers focused on language-related variables and developed prognostic (aptitude) tests designed to predict one’s level of L1 achievement and proficiency. In particular, John Carroll paved the way for a major breakthrough in thinking about aptitude for L2 learning with the development of the MLAT (Carroll & Sapon, 1959, 2001), which identified four factors – phonetic coding, grammatical sensitivity, rote memorization ability, and inductive language learning ability – each of which measured distinct language skills. Carroll’s Model of School Learning (Carroll, Reference Carroll1963) recognized factors besides language aptitude thought to be necessary for successful L2 learning. Factors within the individual included aptitude (amount of time needed), ability to understand instruction, and perseverance, while factors in external conditions included opportunity (time allowed for learning, quality of instruction). Carroll’s model recognized that language aptitude (as measured by the MLAT) was necessary but not sufficient to attain L2 proficiency.
Starting in the 1990s, L1 educators Sparks and Ganschow, both of whom were learning disability (LD) and reading disability (dyslexia) specialists in the U.S.A., linked research on L1 learning and reading problems to research on L2 learning differences. Because of increased enrollments in U.S. secondary and postsecondary institutions starting in the 1960s, both L1 and L2 educators recognized that larger numbers of students were experiencing L2 learning problems. After introducing the LCDH in 1989, Sparks and Ganschow began a series of studies in the 1990s which found that high- and low-achieving L2 learners exhibited significant differences in L1 reading, spelling, and grammar skills and in L2 aptitude (MLAT) (Ganschow et al., Reference Ganschow, Sparks, Javorsky, Pohlman and Bishop-Marbury1991, Reference Sparks, Ganschow, Javorsky, Pohlman and Patton1992; Sparks et al., Reference Sparks, Ganschow, Fluharty and Little1996). Figure 11.1 depicts the scores of the high- and low-achieving groups on measures of L1 skills and L2 aptitude in studies conducted by Sparks, Ganschow, and colleagues. Other researchers had provided support for the finding of L1 differences between stronger and weaker L2 learners (e.g., see Dufva & Voeten, Reference Dufva and Voeten1999; Hulstijn & Bossers, Reference Hulstijn and Bossers1992; Humes-Bartlo, Reference Humes-Bartlo, Hyltenstam and Obler1989), particularly in L1 phonological (speech sounds) and phonological/orthographic (sound–symbol) skills (Kohonen, Reference Kohonen1995; Papagno, Valentine, & Baddeley, Reference Papagno, Valentine and Baddeley1991).

Figure 11.1 Continuum of scores on L1 skills and L2 aptitude measures for the high- and low-achieving L2 learners
Since 2001, Sparks and his colleagues have conducted a number of studies investigating the question of differences between high-achieving and low-achieving L2 learners, some of which are described in this section and subsequent sections. In a longitudinal study conducted over 10 years, they followed students from the beginning of 1st grade through the end of 10th grade, when two years of L2 study had been completed in 9th and 10th grades (Sparks, Patton, Ganschow, & Humbach, Reference Sparks, Patton, Ganschow and Humbach2009). The participants were administered several measures of L1 skills in elementary school, the MLAT in 9th grade, and, at the end of 10th grade, L2 proficiency tests that measured word decoding, reading comprehension, spelling, writing, oral language, and listening comprehension (Spanish, French, German). They were then divided into high, average, and low proficiency groups according to their scores on the L2 proficiency measure. Results revealed overall group differences on the L1 skill measures, the MLAT, and in L2 word decoding and spelling. Between-group comparisons showed that the high proficiency L2 learners exhibited stronger L1 skills than the average and low proficiency learners as early as 2nd grade. In another study with these participants, the authors administered L1 print exposure (reading volume) measures, divided the participants into high, average, and low print exposure groups, and compared them on the L1 skill, L2 aptitude, and L2 proficiency measures (Sparks et al., Reference Sparks, Patton and Ganschow2012). After controlling for IQ, findings showed that participants with a higher volume of L1 print exposure also displayed stronger L1 skills that emerged as early as 1st grade, higher L2 aptitude, and stronger oral and written L2 proficiency. The results of these studies, and others, confirmed that students with stronger L1 skills also exhibit higher L2 aptitude and achieve higher levels of L2 proficiency. Figure 11.2 depicts the scores of the high, average, and low proficiency groups on measures of L1 skills and L2 aptitude in studies conducted by Sparks, Ganschow, and colleagues.

Figure 11.2 Continuum of scores on L1 skills and L2 aptitude measures for the high, average, and low L2 proficiency groups
In a retrospective study, Sparks, Patton, and Ganschow (Reference Sparks, Patton and Ganschow2012) examined the L1 skills measured prior to enrolling in L2 courses, MLAT scores, and L2 proficiency profiles of 208 students who had completed two years of secondary-level L2 courses. A cluster analysis (k-means method) was performed to determine whether distinct cognitive and achievement profiles of more and less successful L2 learners would emerge. The results revealed three distinct profiles in which the high-achieving cluster scored in the above average range on most L1 and L2 measures; the average-achieving cluster scored in the average range; and the low-achieving cluster scored in the low average and below average range on most measures. Figure 11.3 depicts the scores of the three clusters on the L1 and L2 measures. The findings suggest that students’ levels of L1 skills developed prior to L2 exposure are strongly related to and consistent with their subsequent L2 aptitude and L2 proficiency, and that students’ L2 attainment is moderated by their level of L1 ability. In another longitudinal study over three years, high-, average-, and low-achieving U.S. L2 learners exhibited significant differences in L1 achievement skills, L1 cognitive processing skills (e.g., working memory), L1 print exposure, and L2 aptitude (MLAT) at the end of first-, second-, and third-year Spanish courses (Sparks, Patton, & Luebbers, Reference Sparks, Patton and Luebbers2019a). On all measures, the high-achieving group achieved significantly stronger scores than the average and low groups. The results suggested that IDs in L2 achievement reflect IDs in L1 skills; for example, students with higher achievement in L1 reading and spelling also attained higher achievement in L2 reading and spelling.

Figure 11.3 Scores  of the high (c1), average (c2), and low (c3) clusters on the MLAT, IQ, L1 skills, and L2 proficiency measures
of the high (c1), average (c2), and low (c3) clusters on the MLAT, IQ, L1 skills, and L2 proficiency measures
Sparks et al. have conducted a long line of research studies with U.S. learners classified as LD enrolled in L2 courses (e.g., see Ganschow & Sparks; Sparks, Reference Sparks2001, Reference Sparks2016). Given space constraints, that research is not reviewed here. However, this evidence has found that: a) there are no L1 skills, cognitive ability, and L2 aptitude differences between LD students and low-achieving (non-LD) students in L2 classes; and b) there is no evidence for an L2 “disability.” Instead, like L1 learning, L2 achievement runs along a continuum of very good to very poor L2 learners, with no evidence for a “cut point” below which an individual can be classified as “disabled” in L2.
What Are the Best Predictors of L2 Proficiency and Achievement?
In the 1960s and 1970s, studies revealed that language aptitude, as embodied in the MLAT, was a strong predictor of success in L2 learning. These findings had shown that: a) people vary in their language aptitude, b) variation in aptitude has considerable significance for language learning success, c) people with the same overall aptitude may exhibit differences in language component abilities (phonetic coding, grammar, memory), and d) IDs in L2 learning components have connections to L1 learning components (Skehan, Reference Skehan1989). However, Skehan (Reference Humes-Bartlo, Hyltenstam and Obler1989) reported that the language aptitude concept had fallen out of favor with L2 researchers. With the movement away from language aptitude testing, there was an increasing emphasis on variables such as motivation, language learning strategies, and other affective variables (e.g., language anxiety) thought to be important for L2 proficiency. Dörnyei and Skehan (Reference Dörnyei, Skehan, Doughty and Long2003) summarized research showing that IDs in learners’ language aptitude and motivation have been found to be consistently strong predictors of L2 achievement.
Prior to 2001, Sparks et al. conducted prediction studies with secondary-level U.S. L2 learners in which their L1 skill and L2 aptitude scores (on the MLAT) were used as predictor variables for L2 proficiency. In one study with 154 participants, they found that the best predictors of L2 course grades were students’ scores on the MLAT, their 8th grade English grade, and a measure of L1 spelling (Sparks, Ganschow, & Patton, Reference Sparks, Ganschow and Patton1995). In the second study, they followed the students through a second year of L2 courses and found that the best predictors of L2 proficiency were L1 vocabulary, L2 word decoding, and first-year L2 course grades (Sparks, Ganschow, Patton et al., Reference Sparks, Ganschow, Artzer, Siebenhar and Plageman1997). A factor analysis study with the test battery used in the two aforementioned studies yielded three factors: Verbal Memory (MLAT subtests I and V, L1 vocabulary), Phonological Coding/Recoding (L1 reading, L1 spelling, MLAT subtest II), and Cognitive Speed (timed measures of L1 skills and MLAT subtests III and IV) (Sparks et al., Reference Sparks, Javorsky, Patton and Ganschow1998). Multiple regression analyses using the three factors as predictor variables showed that all three factors were significant in predicting L2 proficiency.
Since 2001, Sparks and colleagues have conducted several investigations using L1 skill and L2 aptitude variables to predict L2 proficiency and achievement. In the 10-year longitudinal investigation cited earlier, L1 literacy skills in elementary school were strong predictors of L2 aptitude (MLAT) measured several years later, and L2 literacy (reading, spelling) skills in primary school were the best predictors of L2 proficiency in secondary school (Sparks et al., Reference Sparks, Patton, Ganschow, Humbach and Javorsky2006). In another study with these participants, L1 word decoding and spelling skills in elementary school were found to be the best predictor of L2 word decoding and spelling skills in high school (Sparks et al., Reference Sparks, Patton, Ganschow, Humbach and Javorsky2008). In yet another study with these participants, results revealed that L1 reading achievement in 10th grade made significant and unique contributions to L2 reading, L2 listening comprehension, and L2 oral proficiency after adjusting for the effects of early L1 literacy skills, cognitive ability, and L2 aptitude (Sparks, Patton, Ganschow, & Humbach, Reference Sparks, Patton, Ganschow and Humbach2009). Subsequent analyses showed that an environmental variable, L1 print exposure (reading volume), made unique contributions to L2 reading, L2 word decoding, L2 writing, L2 listening/speaking, and overall L2 proficiency even after controlling for the effects of L1 literacy in elementary school, cognitive ability, and L2 aptitude. In two similar studies with Hebrew-speaking elementary school students learning English, Kahn-Horwitz, Shimron, and Sparks (Reference Proctor, Carla, August and Snow2005, Reference Sparks2006) found that skills in L1 phonological awareness, L1 word decoding, and L1 vocabulary predicted L2 (English) reading skills and discriminated between strong and weak readers among learners of English as a foreign language.
Sparks et al. also conducted two prediction studies in which a factor analysis of a test battery that included L1 skills measured in primary school, cognitive ability, L2 aptitude (MLAT), and L2 affective measures (motivation, anxiety) was employed to predict oral and written L2 proficiency in secondary school (Sparks et al., Reference Sparks, Patton, Ganschow and Humbach2011). The analysis yielded four factors: Language Analysis (L1/L2 language comprehension, grammar, vocabulary), Phonology/Orthography (L1/L2 phonetic coding and phonological processing), IQ/Memory (L1 cognitive ability, L2 paired associate learning), and Self-Perception of Language Skills (L2 motivation, L2 anxiety). Multiple regression analyses showed that the four factors explained 76% of the variance in oral and written L2 proficiency. In a more recent study with a different set of participants, principal components analysis of a different test battery yielded three factors: Phonological and Orthographic Coding/Working Memory (L1 word decoding, L2 phoneme awareness, L1 working memory, L1 phonological memory), Language Analysis (L1 reading comprehension, L2 metacognitive knowledge, L1 writing, L2 vocabulary), and L2 Aptitude (all five MLAT subtests) (Sparks, Patton, & Luebbers, Reference Sparks, Patton, Luebbers, Wen, Skehan, Biedroń, Li and Sparks2019b). Multiple regression analyses with the three factors as predictor variables for L2 proficiency revealed that the Phonological and Orthographic Coding/Working Memory factor predicted the largest amount of variance in L2 word decoding and L2 spelling; the Language Analysis and L2 Aptitude factors predicted the largest amount of variance in L2 reading comprehension, L2 vocabulary, L2 writing, and L2 listening comprehension. These factor analysis studies suggested that L2 learning and L2 aptitude are componential, that is, efficient functioning of different L2 skills relies on different components of language. For example, L2 word decoding and L2 spelling rely primarily on the ability to learn and use letter–sound relationships, while L2 language comprehension, vocabulary, and writing rely primarily on the ability to analyze language and oral language comprehension.
In a recent longitudinal study, U.S. secondary students were administered measures of L1 written/oral achievement, L1 cognitive processing, and L2 aptitude. They were then followed over three years of learning Spanish and administered standardized measures of L2 literacy and oral proficiency at the end of each year (Sparks et al.,). Hierarchical regressions showed that IDs in L1 achievement in press alone (reading, writing, vocabulary, print exposure) accounted for substantial unique variance in L2 reading, writing, listening comprehension, and oral proficiency, while L2 aptitude accounted for additional unique variance at the end of each year. A new finding showed that variance explained by L1 skills for predicting L2 achievement increased from first to second to third year. The results lend additional support to the conclusion of strong L1–L2 connections and important relationships between IDs in L1 ability and L2 achievement.
The findings that L1 skills are important predictors of L2 proficiency provide support for the study of L1–L2 relationships, leading to the question of why the MLAT has been found to be an important predictor of L2 proficiency, even in the presence of L1 skills. In a previous paper, Sparks et al. speculated that L2 aptitude tests such as the MLAT preempt (cut out) the variance in L2 proficiency that might be explained by L1 skills (Sparks, Patton, Ganschow, & Humbach, Reference Sparks, Patton, Ganschow and Humbach2009). They cited Skehan and Ducroquet (Reference Skehan and Ducroquet1988), who followed children from age three years to 13–14 years and found that early L1 development prior to entering school was strongly correlated with L2 aptitude and L2 achievement many years later; even so, students’ performance on the L2 aptitude tests was a stronger predictor of L2 achievement than their early L1 skills. Likewise, in Sparks et al.’s studies, there have been strong relationships between L1 achievement skills in elementary school and L2 proficiency several years later, but L2 aptitude was a strong predictor of L2 proficiency even in the presence of L1 skills. A simple explanation for the superiority of the MLAT over L1 achievement for predicting L2 achievement is that L2 aptitude tests comprise basic language tasks that measure the skills necessary for language learning generally, whether in L1 or L2. For example, the MLAT Phonetic Coding subtest measures a student’s phonological/orthographic ability (sound–symbol learning), the same skill that is measured by L1 word decoding and spelling measures. In a new paper, Sparks and Dale (Reference Sparks and Dale2022) found that the prediction from MLAT to L2 achievement is significantly and substantially due to variance in the L1 abilities captured by the MLAT. A more complex explanation may be that the MLAT measures an “underlying language learning capacity which is similar in first and foreign language learning settings” and has “the capacity to function as a measure of the ability to learn from decontextualized material” (Skehan, Reference Skehan1989, p. 34). In effect, L2 aptitude tests may draw their predictive value from tapping into students’ metalinguistic skills (their ability to explicitly think about, reflect on, and manipulate language) and the view that language analytic ability and metalinguistic ability are “two sides of the same coin” (Ranta, Reference Ranta and Robinson2002, p. 163). Thus, L2 aptitude may be, at least in part, a proxy for students’ L1 language analytic abilities and their metalinguistic skills (Sparks, 2022a, b).
Are There L1 Achievement and L2 Aptitude Differences in Individuals with Differing Levels of Language Anxiety?
Affective explanations for more or less successful L2 learners have always held a special place among L2 educators. In particular, motivation for L2 learning is thought to play an important role in L2 proficiency (MacIntyre & Gardner, Reference MacIntyre and Gardner1991). L2 educators have also hypothesized that a special type of anxiety for language learning might be a causal factor in failure to master an L2. Horwitz, Horwitz, and Cope (Reference Horwitz, Horwitz and Cope1986) developed the Foreign Language Classroom Anxiety Scale (FLCAS) to survey the degree of anxiety for L2 learning. Research with the FLCAS found a negative relationship between anxiety and L2 course grades and L2 achievement (see reviews by Horwitz, Reference Horwitz2010; Trang, Reference Trang2012). Several years later, Horwitz and colleagues introduced the Foreign Language Classroom Reading Anxiety Scale (FLRAS) into the L2 literature (Saito, Garza, & Horwitz, Reference Saito, Garza and Horwitz1999). Like the FLCAS, they found negative correlations between L2 reading anxiety and L2 reading skills.
Early on, Sparks and Ganschow (Reference Sparks and Ganschow1991) investigated the L1 anxiety construct and raised the question of whether language anxiety is a cause or consequence of IDs in L2 aptitude and L2 achievement. They reported that the 33 items on the FLCAS were related to an individual’s speed of language processing, receptive and expressive language skills, and verbal memory (i.e., the items were language related) and proposed that L1 skills and L2 aptitude would be confounding variables when considering the role of anxiety for L2 learning. They also noted that students’ responses on the FLCAS may indirectly measure their language ability and/or reflect their self-perceptions of their language learning skills, not anxiety for language learning.
Prior to 2001, Sparks and Ganschow used Horwitz’s FLCAS to determine whether there would be language skill differences among university L2 learners classified as high, average, and low anxiety according to their responses on the FLCAS (Ganschow et al., Reference Ganschow, Sparks and Anderson1994). Their findings showed overall differences among the three groups in L1 skills and L2 aptitude (MLAT), and between-group differences in L1 skills and L2 aptitude favoring the low and average anxious groups. They replicated this study with high school L2 learners studying Spanish, French, and German and found similar results (Ganschow & Sparks, Reference Ganschow and Sparks1996). In a follow-up investigation with these high school L2 learners after two years of L2 courses, they found significant differences in the students’ oral and written L2 proficiency favoring the average and low anxious learners (Sparks, Ganschow, Artzer, et al., Reference Sparks, Ganschow, Artzer, Siebenhar and Plageman1997). These findings supported the hypothesis that language ability may be a confounding variable in affective explanations for L2 learning outcomes.
Since 2001, Sparks et al. have continued to study the L2 anxiety hypothesis. In one study, U.S. students were followed over 10 years (Sparks & Ganschow, Reference Sparks and Ganschow2007). Their L1 skills were measured in 1st–5th grades, the MLAT and the FLCAS were administered in 9th grade, and L2 oral and written proficiency measures were administered in 10th grade after two years of L2 courses. The students were divided into three groups – high, average, and low anxious – based on their FLCAS score and compared on the L1 and L2 measures. The findings showed that the low anxious group scored significantly higher than the high anxious group on the L1 skill measures as early as 2nd grade, the MLAT in 9th grade, and all L2 proficiency tests in 10th grade. Findings also revealed that the FLCAS administered in high school was negatively correlated with L1 measures of reading, spelling, and vocabulary as early as 1st grade. Sparks et al. noted that there was no a priori reason that students in 1st grade should be anxious about L2 learning several years before they encountered the L2 in 9th grade. The results suggested that the FLCAS is likely to be measuring students’ L1 ability, their (accurate) self-perceptions of their language learning skills, or both, and also that language ability and language (L2) aptitude are confounding variables in L2 anxiety research.
In another study, Sparks and Patton (Reference Sparks and Patton2013) conducted a path analysis and hierarchical regressions with the aforementioned dataset followed from 1st to 10th grades. The results of this investigation showed that the FLCAS accounted for significant unique variance in L1 skills in early elementary school several years before the students began L2 courses in 9th grade, and significant unique variance on the MLAT and L1 reading skills measured in 10th grade. Hierarchical regressions found that the FLCAS also predicted growth in L1 skills (reading, spelling, language) in elementary school from 1st to 5th grades and from elementary to high school (5th–10th grades). Here again, the authors suggested that there was no a priori reason that a survey purporting to tap language anxiety should predict unique variance and growth in L1 skills in elementary school and from middle school to high school many years before L2 courses, or that it should predict variance on an L2 aptitude test. The results suggested that the FLCAS is likely to be measuring IDs in students’ language skills and self-perceptions about their language learning ability, rather than a “special” anxiety unique to L2 learning.
Sparks et al. have also criticized the FLRAS (Saito, Garza, & Horwitz, Reference Saito, Garza and Horwitz1999) for the same reason as they criticized the FLCAS: The items are all related to an individual’s reading ability (Sparks, Ganschow, & Javorsky, Reference Sparks, Ganschow and Javorsky2000). In two recent studies with U.S. students followed over three years of L2 (Spanish) courses, the FLRAS (reading anxiety) and measures of L1 skills, L1 working and phonological memory, L1 print exposure and L1 reading attitudes, L1 metacognitive ability, MLAT, and L2 achievement (Spanish reading, spelling, vocabulary, writing, listening comprehension) were administered to the participants. In the first study (Sparks, Patton, & Luebbers, Reference Sparks, Patton and Luebbers2018a), the results showed that the FLRAS explained significant unique variance in most L1 skills and in L2 aptitude. Hierarchical regression analyses revealed that the FLRAS explained growth in L2 achievement from first- to second- to third-year Spanish courses. In the second study (Sparks et al., Reference Sparks, Luebbers, Castenada and Patton2018), the 266 participants were divided into three groups – low, average, and high anxious – and compared on the aforementioned L1 and L2 measures. Similar to studies with the FLCAS, the low anxiety group (on the FLRAS) scored significantly higher than the high anxiety group on all L1 measures, the MLAT, and the L2 achievement tests and scored significantly higher than the average anxiety group on most measures. The results also found negative correlations between the FLRAS and all L1 measures administered prior to the beginning of L2 courses. Like the FLCAS, Sparks et al. concluded that the FLRAS is also measuring IDs in students’ L1 skills, including cognitive processing (working memory), and L2 aptitude, not a special anxiety for language learning. Figure 11.4 depicts the scores of the high, average, and low anxiety groups on measures of L1 skills, L2 aptitude, and L2 proficiency in studies conducted by Sparks, Ganschow, and colleagues (see also Sparks & Alamer, 2022).
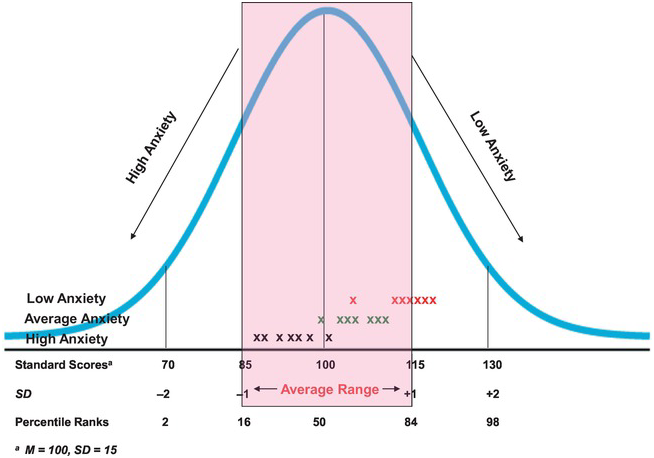
Figure 11.4 Continuum of scores on L1 skills, L2 aptitude, and L2 proficiency measures for the high, average, and low anxious groups
Sparks (Reference Sparks1995) outlined several ways in which L2 anxiety researchers could provide empirical support for their conjecture that anxiety is a causal factor in L2 learning, the most prominent of which was to measure and control for the obvious confounding variables – L1 skills and L2 aptitude. To the author’s knowledge of the studies, no researchers have followed this recommendation. L2 educators still contend that language anxiety “can impede the learning of the target language and hinder academic success; lead learners to abandon their studies; … sow the seeds of self-doubt … feelings of incompetence and degree of self-esteem” and create a host of other negative outcomes (Gkonou, Daubney, & Dawaele, Reference Gkonou, Daubney and Dawaele2017, p. 1). However, the results of investigations with L2 anxiety instruments and L1/L2 skills suggest that seeds of self-doubt, feelings of incompetence, low self-esteem, and anxiety itself are likely to come from a student’s lower levels of L1 ability and language aptitude, not anxiety.
Is There Long-Term, Cross-Linguistic Transfer from L1 to L2 Skills?
L2 researchers and educators have long suspected a relationship between L1 and L2 learning (Safa, Reference Safa2018), particularly for reading and spelling alphabetic languages (Geva & Verhoeven, Reference Geva and Verhoeven2000). Cross-linguistic transfer is the idea that language proficiency underlying cognitively demanding tasks, such as literacy and academic learning, is generally shared across languages. Once proficiency in one language is acquired, the cognitive components in L1 promote language and literacy development in L2. For reading, Seidenberg (Reference Seidenberg2013) and others have postulated that some aspects of reading are “universal (because people’s brain are essentially alike) and some are not (because of differences among writing systems and the languages they represent)” (p. 331) (see also Verhoeven & Perfetti, Reference Verhoeven and Perfetti2017, pp. 457–458). Numerous studies have found moderate to strong correlations between L1 and L2 word decoding and phonological awareness, and small to moderate correlations between L1 and L2 oral language skills (e.g., see Genesee et al., Reference Genesee, Geva, Dressler, Kamil, August and Shanahan2006; Melby-Lervåg & Lervåg, Reference Melby‐Lervåg and Lervåg2011).
In the U.S.A. and elsewhere, researchers have conducted studies with students learning to read English (ELLs) who have a wide variety of L1s with an eye toward cross-linguistic transfer (e.g., see Cárdenas-Hagan, Carlson, & Pollard-Durodola, Reference Cárdenas-Hagan, Carlson and Pollard-Durodola2007; Mancilla-Martinez & Lesaux, Reference Mancilla-Martinez and Lesaux2010; Shum et al., Reference Shum, Ho, Siegel and Au2016). However, to the author’s knowledge, no studies prior to 2001 had conducted systematic investigations that examined cross-linguistic transfer with U.S. students whose L1 is English and who were learning to read another language. As noted earlier, the great majority of U.S. students, all of whom are more or less proficient in English, begin L2 courses in secondary-level education. By 2001, Sparks et al. had established that there are strong relationships among U.S. students’ levels of L1 skills, L2 aptitude, and L2 achievement (course grades). However, with the time lag between learning to speak and read their L1 (1st grade) and starting L2 courses (9th grade), researchers had not examined the relationship between early L1 literacy skills and later L2 literacy and L2 oral language development.
Sparks et al. speculated that evidence for cross-linguistic transfer from L1 to L2 would provide support for the LCDH and claims that L1 skills serve as a foundation for L2 learning. To investigate the phenomenon of long-term, cross-linguistic transfer of L1–L2 skills in U.S. students, they conducted the longitudinal study over 10 years described earlier, in which they administered L1 literacy measures in 1st–5th grades, MLAT in 9th grade, and L2 proficiency and achievement tests at the end of 10th grade. In one study, Sparks, Patton, Ganschow, Humbach, & Javorsky (Reference Sparks, Patton, Ganschow, Humbach and Javorsky2009) divided the students who had completed two years of Spanish, French, or German into high, average, and low proficiency groups according to their L2 proficiency scores (combined reading, writing, oral production, listening comprehension) and compared the groups on the early L1 measures and MLAT. Results showed significant differences among the three groups on the L1 achievement measures from 2nd to 5th grades and the MLAT. On all L1 measures, the high-achieving group exhibited significantly stronger L1 skills (and L2 aptitude) than the average- and low-achieving L2 learners as early as 2nd grade. The findings showed that L1 skill differences among secondary L2 learners emerged early in elementary school and were related to L2 proficiency and achievement differences several years later in high school. In another study described earlier, they found that L1 word decoding and L1 spelling skills in elementary school explained over 50% of the variance in L2 word decoding and L2 spelling skills in high school.
In a recent study, 262 U.S. students were followed from 8th grade through two years of Spanish courses in 9th and 10th grades, and 51 of the students were followed through a third-year Spanish course (Sparks, Patton, & Luebbers, Reference Sparks, Patton and Luebbers2019a). For this study, the test battery included L1 skill measures and the MLAT administered in 8th grade as well as L1 cognitive processing skills (working memory, phonological short-term memory, metacognitive knowledge), L1 print exposure, L1 reading attitudes, L1 language analysis measures, and standardized measures of Spanish word decoding, reading comprehension, spelling, vocabulary, writing, and listening comprehension. The participants were divided into high-, average-, and low-achieving groups according to their scores on each of the six measures of Spanish achievement. At the end of the first- and second-year Spanish courses, findings showed significant overall group differences on most L1 achievement tests, all L1 cognitive processing measures, L1 print exposure, L1 language analysis, and L2 aptitude, in which the high-achieving group scored significantly higher than the other groups on all measures. There were significant between-group differences between the high vs. low-achieving groups on all L1 measures, and significant differences between the high vs. average and average vs. low groups on most L1 measures. Because the number of participants who enrolled in and completed third-year Spanish was small, the authors compared the 212 students who had completed the first- and second-year courses with the 51 students who had completed three years of Spanish on all measures. The results showed significant between-group differences on several of the L1 measures (word decoding, working memory, reading comprehension, writing, reading attitudes), the MLAT, and all six L2 achievement tests. A discriminant analysis procedure revealed that four measures best discriminated the two groups: L1 word decoding fluency, L1 reading comprehension, L1 working memory, and the MLAT. Other researchers have also reported findings supporting the claim of L1–L2 cross-linguistic transfer in French (Crombie, Reference Crombie1997), Chinese and English (Chung & Ho, Reference Chung and Ho2010), Finnish and English (Dufva & Voeten, Reference Dufva and Voeten1999), Hebrew and English (Kahn-Horwitz, Shimron, & Sparks, Reference Kahn-Horwitz, Shimron and Sparks2006), and Hungarian and Romanian (Gál & Orbán, Reference Gál and Orbán2013).
Several findings from the aforementioned investigations supported long-term, cross-linguistic transfer of L1–L2 skills. First, students’ early L1 skills played a role in IDs for L2 learning several years after they had mastered their L1. Second, the results showed that students’ L1 skills reflect their L2 achievement in the same skills, that is, students with lower L1 decoding, comprehension, vocabulary, and writing also achieved lower L2 word decoding, comprehension, vocabulary, and writing. Third, L1 and L2 learning may depend on basic language learning mechanics, especially the skills necessary for literacy. Fourth, there were strong correlations between L1 (English) and L2 (Spanish, French, German) literacy skills with more and less orthographic distance. Fourth, students with lower levels of L1 skills exhibited lower levels of L2 aptitude on the MLAT, which measures the language skills necessary to master L2s. Fifth, early L1 skills were strongly related to L2 proficiency and achievement several years after development and mastery of the L1. Sixth, findings that group differences existed in early L1 skills and L2 aptitude and that both early L1 skills and L2 aptitude discriminated between first-/second-year L2 learners vs. third-year L2 learners provided evidence that early L1 skills are strongly related to later L2 achievement.
Are There Relationships between Learning to Read L1 and L2 Alphabetic Orthographies?
The LCDH posits that the primary causal factors for L2 learning are linguistic and that there are strong relationships between students’ L1 ability and their L2 achievement. Sparks et al. have used this basic premise of their model to pursue a line of research related to the relationship between literacy in L1 and L2. Reading is a language-based skill that depends on the linguistic processes and knowledge initially developed for listening and speaking (Petscher et al., Reference Petscher, Cabell and Catts2020). The primary difference between spoken and written language is that for reading, children must extract meaning from print; for writing, they must write (spell) words to convey meaning. Although alphabetic writing systems vary in orthographic depth (i.e., shallow vs. deep orthographies), children must learn that spoken words are comprised of speech sounds (phonemes) and that letters correspond to these sounds. The idea that written symbols are associated with sounds, that is, the alphabetic principle, is the key lesson that children must learn to master word decoding. Once they learn to decode words, children can then make use of linguistic processes and knowledge to comprehend meaning. Skilled readers are generally those who have learned the alphabetic principle for reading (and spelling), while less skilled readers have difficulty with the skills necessary to read (and write) the language. In their volume that addresses reading development across languages and orthographies, Verhoeven and Perfetti (Reference Verhoeven and Perfetti2017) show that there are underlying universals of word reading, all of which require “sensitivity to the specific mapping of linguistic forms onto meaning. Awareness of both phonology and morphology is thus needed to learn how one’s writing system encodes one’s language” (p. 458). These authors note the assumption that reading is based on language appears to be universally shared.
In L1 reading research, the Simple View of Reading (SVR) model (Gough & Tunmer, Reference Gough and Tunmer1986; Hoover & Gough, Reference Hoover and Gough1990; Hoover & Tunmer, Reference Hoover and Tunmer2021) has widespread acceptance as both a theoretical and practical model for predicting students’ reading skills and teaching them to read. The SVR proposes that reading is the product of word decoding and oral language (listening) comprehension. Word decoding depends on efficient, accurate, and automatic retrieval of the phonological and orthographic codes for written words and is essential for reading comprehension. Language comprehension represents the linguistic processes used in the comprehension of oral language, for example, verbal ability, vocabulary, syntax, and inferences. The SVR posits that word decoding and language comprehension make independent contributions to reading skills. In L1 reading, there is voluminous evidence supporting the SVR model (Kilpatrick, Reference Kilpatrick2015, pp. 46–79, 118–119; Seidenberg, Reference Seidenberg2017, pp. 201–203), and findings have shown that decoding and listening comprehension explain most of the variance in reading comprehension skill (Hoover & Tunmer, Reference Hoover and Tunmer2020; Kim, Reference Kim2017). Researchers investigating the model have found that word decoding skill explains more variance in the early stages of learning to read, whereas the contribution of language comprehension increases in later grades (e.g., see Francis et al., Reference Francis, Fletcher, Catts, Tomblin, Paris and Stahl2005). Figure 11.5 depicts the SVR model.

Figure 11.5 Simple View of Reading (SVR) model
Koda (Reference Francis, Fletcher, Catts, Tomblin, Paris and Stahl2005) has suggested that the SVR can be a viable model to explain L2 reading, and recent research supports her view. Gottardo and Mueller (Reference Gottardo and Mueller2009) found that the model explains reading comprehension development in young ELL children, that is, both English oral language proficiency and word decoding are necessary for English reading comprehension. Proctor et al. (Reference Proctor, Carla, August and Snow2005) tested the SVR model with native Spanish speakers and found that English word-level reading skills were related to English reading comprehension, and also that English listening comprehension and English vocabulary were significantly and independently related to English reading comprehension. Droop and Verhoeven (Reference Droop and Verhoeven2003) found that both word decoding and oral language comprehension contributed to reading comprehension with Turkish students learning Dutch. Verhoeven and van Leeuwe (Reference Verhoeven and van Leeuwe2012) reported that the reading comprehension skills of both L1 and L2 learners can be predicted from their language (listening) comprehension and word decoding abilities. They also reported that the power of L2 word decoding to predict L2 reading comprehension diminishes over time, while the influence of L2 language comprehension increases.
Gough and Tunmer (Reference Gough and Tunmer1986) hypothesized that the SVR model has practical implications for the types of readers encountered by classroom teachers. The SVR posits that since reading skills can result only from the product of word decoding and language comprehension, there will be four types of readers. Good readers exhibit both good (average to above average) word decoding and good (average to above average) language comprehension. There will be three different types of poor readers: those with an inability to decode (dyslexia), inability to comprehend (hyperlexia), or inability to both decode and comprehend (mixed). Dyslexic readers have good (oral) language comprehension but exhibit a deficit in word decoding. Hyperlexic readers have strong word decoding accompanied by deficits in language comprehension. Mixed poor readers exhibit both poor word decoding and poor oral language comprehension skills. In L1 reading research, most good readers tend to be good comprehenders, and most poor decoders tend to be poor comprehenders, but the existence of hyperlexic readers shows that good decoding may not always be accompanied by good language comprehension. Likewise, the existence of dyslexic readers shows that good language comprehension may not always be accompanied by good word decoding. Studies over several years have validated the types of reader profiles proposed by the SVR model (e.g., see Catts, Reference Catts2018; Catts, Adolf, & Weismer, Reference Catts, Adlof and Weismer2006).
In contrast to many other countries, the U.S.A. is largely a monolingual society. Most students live in a home where the target L2 is not spoken, and they rarely encounter an L2 in social or academic contexts, except for the L2 classroom. L2 courses generally begin in 9th grade, and students are enrolled with the goal of meeting a graduation requirement, not to become fluent or literate in the language. The U.S. social context for L2 learning is problematic for several reasons, the most prominent being that U.S. students are learning to speak and comprehend the L2 at the same time as they are learning to read and write the L2, in 9th grade, in the absence of L2 vocabulary knowledge.
Given these contextual restraints, Sparks was interested in whether U.S. L2 learners would fit the types of readers proposed by the SVR model and whether language skills would explain the bulk of the variance in L2 reading comprehension. In his first study (Sparks, Reference Sparks2015), 165 high school students completing first- and second-year Spanish courses were administered tests of Spanish word decoding, vocabulary, and reading comprehension from the Batería-III Woodcock-Muñoz (Woodcock et al., 2004, Reference Woodcock, Muñoz-Sandoval, McGrew and Mather2007), a standardized achievement measure normed with native Spanish speakers. The findings showed that the majority (96%) of students fit the hyperlexic poor reader profile (good word decoding, poor reading comprehension) while 4% met the mixed poor reader profile (poor decoding, poor comprehension) when compared to same-age native Spanish speakers; however, no students fit the good or dyslexic reader profiles. All students displayed very low levels of Spanish vocabulary knowledge. In another study with this group, multiple regression analyses showed that Spanish word decoding and Spanish (oral) language comprehension explained 66% of the variance in Spanish reading comprehension, while Spanish vocabulary knowledge explained an additional 3% unique variance (Sparks & Patton, Reference Sparks and Patton2016). As predicted by the authors of the SVR, word decoding and oral language comprehension made separate, independent contributions to reading ability.
Sparks et al. conducted two additional studies with a random sample of U.S. L2 learners, whom they followed over three years of Spanish courses in high school. The students were administered measures from the Woodcock-Muñoz at the end of each year’s course that included Spanish word decoding, Spanish reading comprehension, and Spanish vocabulary. They were then classified into the reader types proposed by the SVR model. In the first study, results showed that 76%–98% of the students were classified as hyperlexic poor readers and that 4%–24% were classified as mixed poor readers at the end of first-, second-, and third-year Spanish courses (Sparks & Luebbers, Reference Sparks and Luebbers2018). No students fit the dyslexic profile (poor decoding, good comprehension), and only 14% fit the good reader profile but not until they were compared to much younger 2nd grade (7-year-old) native Spanish speakers. In a second study with these students, Sparks, Patton, and Luebbers (Reference Sparks, Patton and Luebbers2018b) performed a path analysis procedure and found that Spanish word decoding and oral language comprehension were the strongest predictors of Spanish reading comprehension, but Spanish vocabulary also contributed unique variance to Spanish reading ability. Spanish word decoding and Spanish reading comprehension made independent contributions to Spanish reading ability. U.S. students developed Spanish word decoding skills with relative ease in first-year Spanish but continued to exhibit severe difficulties in L2 reading comprehension and oral language (listening) comprehension, even by the end of third-year Spanish, because of their poor Spanish vocabulary and linguistic knowledge.
The aforementioned results were consistent with the premises of the SVR model and the LCDH. Regarding the SVR, the results supported the propositions that: a) U.S. readers studying Spanish would display variability in their reading profiles consistent with those proposed by the SVR model; b) Spanish word decoding and Spanish oral language comprehension would explain the bulk of variance in Spanish reading comprehension; and c) word decoding and language comprehension would make separate, independent contributions to reading comprehension once a certain level of word decoding in the L2 was attained. A new finding was that L2 oral language comprehension and L2 vocabulary were the limiting factors in proficient L2 reading comprehension. Regarding the LCDH, the results supported the premise that the primary causal factors for L2 reading are linguistic and that there are strong relationships between the skills necessary to read alphabetic orthographies in L1 (English) and L2 (Spanish). In a seminal publication, Sparks (Reference Sparks2021) described how the SVR model can be used to assess the language skills necessary for L2 reading, identify strong and weak L2 readers, and specify L2 readers’ strengths and weaknesses using readily available standardized cognitive and linguistic measures for English and Spanish.
Sparks’ findings have suggested that the question raised by Alderson (Reference Alderson, Alderson and Urquhart1984), Is L2 reading a reading problem or a language problem?, should be revised to ask the following: Is L2 reading a word decoding problem, a language comprehension problem, both a word decoding and language comprehension problem, or neither a decoding nor comprehension problem?
Conclusions
Sparks and Ganschow speculated that the learning of an L2 is the learning of language and that the skills necessary for L2 learning would be language related. Using their experiences as L1 reading and language specialists, they developed the LCDH to explain more and less successful L2 learning and tested their hypotheses concerning L1–L2 relationships. Prior to 2001, their findings with U.S. L2 learners provided empirical evidence for strong L1–L2 relationships and also supported John Carroll’s L2 aptitude model embodied in the MLAT, Peter Skehan’s seminal work on the L2 aptitude concept (and his claim that language is special when learning an L2), and Cummins’ Linguistic Interdependence Hypothesis (L1 and L2 have a common underlying proficiency) and Threshold Hypothesis (one’s level of L2 proficiency is moderated by one’s level of attainment in L1). Over the last 20 years, Sparks et al.’s empirical studies with different populations of L2 learners have generated additional evidence for important connections between L1 and L2 learning and for the phenomenon of long-term, cross-linguistic transfer of skills from L1 to L2. Likewise, their studies on L2 reading have shown that, like L1, learning to read an L2 is a language-based skill and that the most extensively researched and well-supported model for learning to read L1, the SVR, can be applied to learning to read an L2. The types of studies described in this chapter point the way for the L2 field to raise additional questions about the role of IDs in L1 for L2 learning, cross-linguistic transfer of L1 skills to L2, and long-term L1–L2 relationships.
Introduction
From a Complex Dynamic Systems Theory (CDST) perspective, second language development (SLD) studies place greater emphasis on the process by which variability emerges and not on the endpoint of acquisition (de Bot, Reference de Bot, Dörnyei, MacIntyre and Henry2015). Variability has been seen as an intrinsic property of the developmental process. Such variability is shown not only in the differences between and among language learners but also in their language performance, which may be very different from moment to moment (van Dijk, Verspoor, & Lowie, Reference van Dijk, Verspoor, Lowie, Verspoor, de Bot and Lowie2011). Traditionally, investigating causes of variability has been at the core of much SLD research that has examined the predictive ability of different learner individual differences (LIDs) variables. For example, researchers have acknowledged that language aptitude and working memory are important cognitive LIDs components that play a significant role in foreign language learning. Learners with stronger language aptitude would adapt to English as a foreign language (EFL) learning more successfully (Li, Reference Li2015; Wen & Skehan, Reference Wen and Skehan2021). However, the random “jumpstart” that learners demonstrate as underlying the learning process is usually averaged by groups and ignored because it might distort the “general or true” development (van Dijk, Verspoor, & Lowie, Reference van Dijk, Verspoor, Lowie, Verspoor, de Bot and Lowie2011).
Comparatively, language learning and development is a dynamic process from CDST’s processual approach, which offers a fresh perspective when construing the LIDs variables that are integrally associated with language learners (Zhang, Reference Zhang, Barnard and Li2016; Zhang & Zhang, Reference Zhang and Zhang2013). Moreover, thinking dynamically about relevant LIDs variables would enrich our understanding of L2 learning and its dynamic nature characterized by progression and regression (Larsen-Freeman, Reference Larsen-Freeman, van Pattern, Keating and Wulf2020). Motivation, for instance, has now been theorized as “directed motivational currents” and elevated with flowing motivational stages that are strongly associated with learners’ fluctuated learning processes (e.g., Chang & Zhang, Reference Chang and Zhang2020; Zheng, Lu, & Ren, Reference Zheng, Lu and Ren2020; Dörnyei, Ibrahim, & Muir, Reference Dörnyei, Ibrahim, Muir, Dörnyei, MacIntyre and Henry2015). Language aptitude and working memory have been consistently viewed as important cognitive LIDs components with a degree of stability in language learning. Moreover, language aptitude has been highlighted as a robust LIDs variable in that it is not a constant and innate intellectual capacity. Instead, language aptitude is seen as a conglomerate of individual characteristics that interact dynamically with other cognitive abilities, such as working memory and different learning conditions (Kormos, Reference Kormos, Granena and Long2013; Robinson, Reference Robinson2005). The question is whether there are any possibilities that language aptitude and working memory might fluctuate along with language learning. If they do, then what does the variability look like from a complex and dynamic perspective (Larsen-Freeman & Cameron, Reference Larsen-Freeman and Cameron2008)? Driven by such an interest, we designed this longitudinal study by following the CDST’s processual approach. We hypothesized that complex changes and variability patterns might lie beneath the intricate developmental process of L2 learners’ (in our case, EFL learners) language aptitude and working memory along with their listening development.
Literature Review
Language Aptitude
Language aptitude has been widely studied and found to be a significant LIDs factor influencing L2 learning and predicting language learning success (Skehan, Reference Skehan1989; Wen, Reference Wen, Wen, Skehan, Biedroń, Li and Sparks2019; Wen, Biedroń, & Skehan, Reference Wen, Biedroń and Skehan2017). There have been two different representative approaches to studying the predictive power of language aptitude. One approach is known as the product-oriented approach, which views language aptitude as a static LIDs variable that predicts L2 learning attainment irrespective of learning context and instruction type (e.g., Carroll, Reference Carroll1963; Carroll & Sapon, Reference Carroll and Sapon1959, 2002). However, Li’s (Reference Li2015) results of a meta-analysis have indicated that the importance of language aptitude has been exaggerated in studies conducted and reported in the last 50 years. The exaggeration arose from a lack of clarity about what the construct of aptitude exactly entails, the confusion resulting from the wide use of the Modern Language Aptitude Test (MLAT; Carroll & Sapon, Reference Carroll and Sapon1959, 2002) for measuring aptitude, and the fact that the MLAT has been widely adopted and validated in studies with large numbers of L2 learners. The other approach is the dynamic process-oriented approach held by Robinson (Reference Robinson2005), who emphasized the importance of various contextual factors, especially different learning stages, in understanding how aptitude mediates the L2 learning process and learner performance because aptitude may be sensitive to environmental factors and interacts with other LIDs factors, such as age or working memory, in explicit and implicit learning conditions (Li, Reference Li2015; Wen, Biedroń, & Skehan, Reference Wen, Biedroń and Skehan2017; Wen & Skehan, Reference Wen and Skehan2021).
Working Memory
Working memory (WM) is a multi-faceted memory system comprising the central executive (attentional control system), the phonological loop, the visuospatial sketchpad, and the episodic buffer (three subsidiary slave systems) (Baddeley, Reference Baddeley2000; Baddeley & Hitch, Reference Baddeley and Hitch1974). Similar to language aptitude, WM is also viewed as a prominent aspect in understanding the transient nature of L2 learning (Wen, Reference Wen2016; Wen & Juffs, Reference Wen, Juffs, Winke and Brunfaut2020; Wen & Li, Reference Wen, Li, Schwieter and Benati2019). For instance, a large effect size was reported in Zhao and Luo’s (Reference Zhao and Luo2020) meta-analysis for the relationship between WM and L2 learning. Learners with better WM capacity performed better in information storage and processing during L2 learning tasks. This might have occurred because WM could orchestrate the process of comprehension (e.g., L2 reading and listening) by keeping processed information active and updating learners’ understanding with new input (Brunfaut et al., Reference Brunfaut, Kormos, Michel and Ratajczak2021). With respect to L2 listening, different WM components were found to interact with learners’ L2 proficiency level; for example, phonological WM was found to be less influential among learners with higher L2 proficiency (Kormos & Sáfár, Reference Kormos and Sáfár2008). Most research in this area, however, has focused on either intensive or instructed foreign language learning, irrespective of the natural and dynamic features of learners’ language development from a longitudinal perspective.
The impact of WM on L2 learning has been mainly examined on the basis of viewing WM as a static construct. The intricate and dynamic changes that learners demonstrate on WM tests might be regarded as “noise” and neglected in researchers’ exploration into the generalisability of research findings in L2 development (Lowie & Verspoor, Reference Lowie and Verspoor2018). However, these changes and dynamics are viewed as the intrinsic property in CDST and its dynamic and process-oriented agendas. Learners’ actual performance, rather than competence, attracts CDST scholars’ attention.
Variability
Variability is a typical and inherent property of complex and dynamic systems, with its different degrees and patterns considered as central elements in the process of language development (Lowie & Verspoor, Reference Lowie and Verspoor2018; Verspoor et al., Reference Verspoor, Lowie, Chan and Vahtrick2017). The CDST perspective proposes that language learning is a developing system featured with a non-linear, dynamic, and emergent process, in which language learners would find their own optimal learning paths. A group of longitudinal studies has been conducted along this line within the CDST perspective. These studies demonstrated that students of similar backgrounds in similar circumstances showed variability in their development (e.g., Chan, Verspoor, & Vahtrick, Reference Chan, Verspoor and Vahtrick2015; Evans & Larsen-Freeman, Reference Evans and Larsen-Freeman2020; Larsen-Freeman, Reference Larsen-Freeman2006; Verspoor et al., Reference Verspoor, Lowie, Chan and Vahtrick2017). Despite being exposed to similar social contexts (e.g., educational systems), learners can demonstrate different developmental patterns, such as gradual or sudden increases or decreases in syntactic structures in L2 speaking and L2 writing productions, which are intrinsic properties of a self-organizing and developing system (de Bot, Lowie, & Verspoor, Reference de Bot, Lowie and Vespoor2005; Zheng, Reference Zheng2016).
Variability has been found to be an important component in predicting L1 Chinese adults’ English writing proficiency (Huang, Steinkrauss, & Verspoor, Reference Huang, Steinkrauss and Verspoor2021) and has also been found to be a prominent element in understanding the complexity of Chinese EFL learners’ listening development (Chang & Zhang, Reference Chang and Zhang2021). Learners’ engagement with learning tasks necessarily embraces the cognitive LIDs variables, such as language aptitude and WM. Different learners’ performance on these two variables has the characteristics of fluctuating or iterative processes, which show inter-individual variability (between individuals) or intra-individual variability (within individuals) at different levels (Verspoor, Lowie, & van Dijk, Reference Verspoor, Lowie and van Dijk2008; Zheng & Feng, Reference Zheng and Feng2017). Lee and Karmiloff-Smith (Reference Lee, Karmiloff-Smith, Granott and Parziale2002) proposed that high intra-individual variability indicates there might be developmental changes in learners’ language learning process since short-term variability is associated with long-term changes (e.g., the butterfly effect). Further, it is difficult to interpret the cause-and-effect relationship between variation in learners’ flexible and adaptive performance in L2 learning and changes in their language achievement because of the multilateral nature of variation and change. Thus, due to the interconnectedness and dynamic nature of EFL listening, development in learners’ cognitive variables may not be linear and could demonstrate dynamic aspects within the learning process. Accepting the position that variability is an important developmental phenomenon, the degree of variability could be seen as the intrinsic property of discovering when and how changes take place in a developmental process, and of understanding the different developmental patterns as well as interactions between different subsystems that different learners may orchestrate (van Dijk, Verspoor, & Lowie, Reference van Dijk, Verspoor, Lowie, Verspoor, de Bot and Lowie2011; Thelen & Smith, Reference Thelen and Smith1994). Some researchers used moving min–max graphs to visualize the different degrees of variability and different transition phases that learners have experienced in the dynamic development of L2 listening and writing in terms of accuracy, fluency, and complexity (Chang & Zhang, Reference Chang and Zhang2021; Spoelman & Verspoor, Reference Spoelman and Verspoor2010; Verspoor, Lowie, & van Dijk, Reference Verspoor, Lowie and van Dijk2008).
Variability, both inter-individually and intra-individually, might be identified from an individual’s scores on language aptitude and WM measures over time (Larsen-Freeman, Reference Larsen-Freeman, van Pattern, Keating and Wulf2020; Lowie & Verspoor, Reference Lowie and Verspoor2018). It might be a possible trait in language aptitude and WM; therefore, our assumption is that variability occurs during L2 learners’ development in language learning because language aptitude and WM play a significant role in L2 learners’ completion of different learning tasks (Li, Reference Li2015; Wen, Reference Wen, Wen, Skehan, Biedroń, Li and Sparks2019). In this respect, we hypothesized that the degree of variability provides opportunities for observing developmental changes in learners’ language aptitude and WM. To the best of our knowledge, no previous studies have examined the degree of variability (both inter-individually and intra-individually) in EFL listeners’ language aptitude and WM in natural language learning conditions with a longitudinal design, which is the setting in which this study took place. In this study, we investigated the following research questions:
1) Does variability exist in EFL learners’ language aptitude and working memory? If so, what are the variability patterns?
2) What is the nature of language aptitude and working memory variability?
Methods
Participants
The participants in the present study were three EFL learners (two females and one male) who attended a university in Northern China and were invited to participate in this longitudinal study on a voluntary basis. The participants were second-year students (19, 20, and 21 years old, respectively), all majoring in statistics. They attended English classes regularly throughout the academic year from 2016 to 2019, nearly six hours per week. The three learners were identified with similar English proficiency levels that were reported in our previous study (Chang & Zhang, Reference Chang and Zhang2021).
Instruments
Three instruments were used in this study. They were listening proficiency tests, the LLAMA language aptitude test, and WM measurements. These are described in detail in this section.
Listening Proficiency Tests
Learners’ listening performance was measured by the International English Language Testing System (IELTS) listening tests. Different versions of these tests were administered to the participants every six weeks, 30 times in total. The present study used IELTS listening tests for several reasons. First, the large numbers of IELTS tests that are available ensured no versions would be re-used during the 30 tests. Secondly, there are four independent sections for each listening test that focus on various topics, including social needs (e.g., hotel reservation) and academic discussions (e.g., botany classes), which avoided practice effects in this study. Thirdly, the materials were presented through dialogues or monologues with 10 follow-up questions provided in different formats (e.g., cloze test, table labeling and matching). All of these attributes contributed to the variety in presentation and difficulty of the IELTS listening tests, which are widely used and acknowledged for their reliability and validity. A participant receives one point for the correct answer to each question, and each section consists of 10 questions, with a maximum score of 40 points for each listening test.
LLAMA Language Aptitude Test
As a substitute for the MLAT (Carroll & Sapon, Reference Carroll and Sapon1959, 2002), the LLAMA battery (Meara, Reference Meara2005) was adopted to measure learners’ language aptitude (Granena, Reference Granena, Granena and Long2013). The LLAMA is loosely based on the MLAT, but it is language independent and has no restrictions on test-takers’ L1. Language independence is a highly desirable methodological feature for cognitive measures as it would avoid possible confounds that may arise in L1- or L2-based cognitive tests (Granena, Reference Granena, Granena and Long2013). The LLAMA test, moreover, is free to download online from the Lognostics website and easy to administer via computers. The LLAMA test contains four subtests measuring different aspects of language learning: LLAMA B is a test of vocabulary learning; LLAMA D is a test of sound recognition that requires previously heard sound sequences to be identified in new sequences; LLAMA E is a test of sound–symbol associations, and LLAMA F is a test of grammatical inferencing. With the exception of sound recognition (LLAMA D), the other three subtests include default study phases that last between two and five minutes. Questions were randomly selected and presented on the interface every time a subtest was used to avoid memorization of the question items. All testing phases were untimed. The scores for each of the LLAMA subtests ranged between 0 and 100 for LLAMA B, E, and F, and between 0 and 75 for LLAMA D (adjusted to 100 in data analysis to ensure consistency). Each subtest was individually and automatically scored. Thus, participants had four individual scores for each aspect of the aptitude measured by the LLAMA subtests, which were summed up as an overall score for data analysis in the current study.
Working Memory Measurements
Working memory was measured in our study using the Listening Span Test (LST). The LST is a revised and modified version based on the reading span test (RST) (Daneman & Carpenter, Reference Daneman and Carpenter1980). Similar to the RST, the LST is a complex WM task and a dual-task test that conforms to both the information processing and storage demand of WM (Kormos & Sáfár, Reference Kormos and Sáfár2008). It consists of 42 unrelated simple sentences that are affirmative and presented in the active voice. The sentences range from eight to 12 words in length, with every sentence ending with a different content word. The test involves four levels, starting at two sentences and extending up to five sentences, with each level containing three trials. Half of the 42 sentences are syntactically possible but semantically anomalous (e.g., It is true that all animals need a job). The remaining 21 sentences are grammatically and semantically normal sentences (e.g., The Eiffel Tower is a symbol of France).
Concerned about practice effects, we prepared three groups of 42 sentences with a random arrangement. During the implementation of the LST, participants listened to the 42 sentences only once, then judged whether the sentence was correct in meaning (True or False; measuring information processing) while retaining and writing down the last word of each sentence (measuring information storage), irrespective of the order of the sentences. The total numbers of correct meaning judgments (0–42 points) and dictating words (0–42 points) contributed to the absolute score of the LST, ranging from 0 to 84 points. The scores were then converted to z-scores for data processing.
Data Collection
Data collection started after the consent forms from all three participants were received. From 2016 to 2019, IELTS listening tests were distributed to three learners every six weeks, each test lasting for 40 minutes. Participants were administered the LLAMA language aptitude and WM tests of the LST every four months, 10 times altogether, which were followed by a stimulated recall in case of any confusion and questions. Stimulated recall is an introspective method used by researchers immediately after the participants complete the tasks. The procedure involves asking the participants to recall sequences of thoughts or mental processes they had while performing the tasks (Gass & Mackey, Reference Gass and Mackey2017). Data were collected on the main campus with the three participants from September 2016 to June 2018 before they graduated from the university. Later, data were mainly collected online through the video chat functions provided by the social media platforms used by Chinese students, such as QQ and WeChat, which enabled researchers to share computer screens with participants and monitor the data collection process.
Data Analysis
Data Preparation
The data used in the current study for analysis are as follows: a) three participants’ 10 scores of listening results, b) aptitude results (measured by the LLAMA aptitude test), and c) WM test results (measured by the LST). All raw scores were converted to z-scores for analysis and comparison.
Min–Max Graphs
Results of participants’ performance on language aptitude and WM were depicted by moving min–max graphs, which are commonly used to highlight the moving minima, maxima, and observed values while keeping the original raw data visible (Verspoor, de Bot, & Lowie, Reference Verspoor, de Bot and Lowie2011). Thus, variations that participants demonstrated on language aptitude and WM could be detected through the presentation of min–max graphs. Moreover, the moving maxima and minima values of learners’ performance could assist researchers in identifying learners’ variability changes as well as variability patterns in the developmental trajectory. On the basis of the 10 times measurement in the present study, the required minimum number of three consecutive measurement points was used as the predetermined moving window span for analysis (van Geert & van Dijk, Reference van Geert and van Dijk2002; Verspoor, de Bot, & Lowie, Reference Verspoor, de Bot and Lowie2011).
Monte Carlo Analysis
Monte Carlo analysis is one of the resampling (bootstrapping) methods and involves randomly drawing a large number of subsamples (e.g., 5,000) from the original sample. This resampling analysis is usually performed in Microsoft Excel through the statistical add-in Poptools (Hood, Reference Hood2009). We adopted Monte Carlo analysis in the present study to visualize the variability patterns of learners’ language aptitude and WM, particularly for exploring whether there would be unanticipated patterns in the collected data when focusing on intra-individual variability (van Geert, Steenbeek, & Kunnen, Reference van Geert, Steenbeek, Kunnen and Kunnen2012). It is important to look for unanticipated patterns because they may initiate a phase shift or result in a bifurcation in a learner’s language development (Larsen-Freeman, Reference Larsen-Freeman, van Pattern, Keating and Wulf2020). In the current study, learners’ original data were resampled and shuffled 5,000 times through Monte Carlo analysis with an exploration of statistical coincidence of each learner’s unexpected changes in the development of language aptitude and WM.
Results and Discussion
This section demonstrates our explorations into 1) EFL learners’ inter-individual variability in language aptitude and WM in terms of developmental trajectories by using the moving min–max graphs; 2) comparisons of EFL learners’ intra-individual variability in language aptitude and WM through Monte Carlo analysis; and 3) explanations of how to understand and interpret learners’ variability in language aptitude and WM in the process of EFL listening development.
Learners’ Inter-Individual Variability in Language Aptitude (LA) and WM
From a CDST perspective, a certain degree of variability exists in any multi-faceted complex system, such as LA and WM. Aiming to illustrate and visualize “developmental” variability, we adopted a simple and descriptive approach – the moving min–max graph – to analyze time serial data. We measured learners’ LA and WM 10 times, as shown in the horizontal axis represented (Figures 12.1 and 12.2). The moving min–max graph uses a moving window, a time frame that moves up one measurement occasion each time, which is easy to plot in Excel (van Geert & van Dijk, Reference van Geert and van Dijk2002; Verspoor, de Bot, & Lowie, Reference Verspoor, de Bot and Lowie2011). Three consecutive measuring occasions were the minimum predetermined moving window span, which was chosen for our study. Then, we calculated the maximum and minimum values of three consecutive measurements with the following series:
min(test1 … test3), min(test2 … test4), min(test3 … test5), etc.
max(test1 … test3), max(test2 … test4), max(test3 … test5), etc.
The results of the moving min–max graph depict the moving minima, maxima, and observed values of the variable, and highlight “the general pattern of variability while keeping the raw data visible” (Verspoor, de Bot, & Lowie, Reference Verspoor, de Bot and Lowie2011, p. 75). It can be seen from Figure 12.1 that participants’ scores on LA could range from 0 to 100 points (the vertical axis). Understanding the bandwidth of observed scores is essential to inspect the development of LA and WM in the moving min–max graphs, namely, the wider the bandwidth, the greater the amount of variation (van Dijk, Verspoor, & Lowie, Reference van Dijk, Verspoor, Lowie, Verspoor, de Bot and Lowie2011).


Figure 12.1 shows that maximal and minimal achievement is reached by three participants on different measurement occasions, resulting in a non-linear and fluctuating pattern, as the bandwidth of scores indicated. For instance, a rather smaller bandwidth was identified at data point 4 in P1’s case, while in P3’s case a much smaller bandwidth was reached at the last measurement occasion. We can also see some variability in P2’s case. The min–max graph depicts no strong difference in the bandwidth over time, but the band itself moves up between data points 4 and 5 and moves down from data points 7 and 8. These findings show that three participants’ output on LA is variable to some degree during our 10 observations over a span of 43 months.
Similarly, Figure 12.2 depicts the developmental traces of participants’ 10 times of performance (the horizontal axis) on the WM test. Participants’ WM scores ranged from 0 to 100 points as the vertical axis demonstrated in the diagram. In P1’s case, a much smaller bandwidth of variability reached data points 4 and 9 (from 70 points to 60 points), with a much wider bandwidth of variability between data points 5 and 8 (with a jump from 60 points to 80 points). Comparatively, a rather smaller bandwidth of variability was identified in P2’s performance on the fifth measurement occasion. We can also detect a smaller bandwidth of variability in P3’s performance at the first and last data points.
By looking at the different learning paths, we detected quite different types of learning processes in learners’ LA and WM. Similarly, within a homogeneous group in terms of motivation and language proficiency, three Dutch learners of English in Lowie and Verspoor’s (Reference Lowie and Verspoor2018) longitudinal study exhibited different developmental paths throughout the school year. In our current study, P1 and P2 seemed to be more variable in their development of LA and WM. Their developing patterns consist of clear stages or higher degrees of variability, which might indicate that they have obtained certain knowledge or rules in their language development and generalized instant acquisition (van Dijk, Verspoor, & Lowie, Reference van Dijk, Verspoor, Lowie, Verspoor, de Bot and Lowie2011). Comparatively, a slow and gradual learning trajectory with less variability in P3’s case might reflect that P3 experienced a “smooth” learning process in which this participant gradually accumulated knowledge and rules one by one. This finding has been supported by van Geert and van Dijk (Reference van Geert and van Dijk2002), who speculated that the bandwidth of scores of a competent individual should be considerably smaller than that of someone who is in the learning process. Our current findings are consistent with the CDST position that variability patterns demonstrated by participants in L2 writing are facilitative and should not be overlooked in understanding L2 development (Larsen-Freeman, Reference Larsen-Freeman, van Pattern, Keating and Wulf2020). Thus, we hypothesized that the variability in the three learners’ data would be meaningful in explaining the developmental process of LA and WM, which were tested through resampling the data, as explained in the next section.
Inter-Individual Variability Analysis
The results of the min–max graphs are exclusively descriptive in nature. The developmental processes in Figures 12.1 and 12.2 imply that there might be some forms of progression or regression of learners’ performance and use of LA and WM on the basis of our qualitative observation. We speculated that some learners’ developmental processes (e.g., P3’s) were more variable. Therefore, comparing the variability between participants became necessary, and this needed to be tested against chance. Aiming to test this hypothesis, we adopted the resampling methods of Monte Carlo comparative analysis. This method consists of randomly drawing a large number of subsamples (e.g., 5,000) from the original sample (van Dijk, Verspoor, & Lowie, Reference van Dijk, Verspoor, Lowie, Verspoor, de Bot and Lowie2011) as a remedy for the current small dataset. In our case, P1 achieved 52 points and 65 points at data points 1 and 2. We first calculated the distance between these two consecutive measurement scores of P1, receiving 13 points as P1’s first distance, then his second distance between data points 2 and 3, followed by his third distance between data points 3 and 4, etc. We did the same calculations for P2 and P3, receiving five groups of distance for each learner on the basis of our 10 observations. Then, all distances were averaged. We compared the difference between the average distance of P1 and the average distance of P2, the average distance of P1 and the average distance of P3, and finally the average distance of P2 and the average distance of P3. These differences were used as our original testing criterion.
Then, we set up a resampling model on the basis of the testing criterion. Specifically, the groups of the average distance of P1, P2, and P3 would be shuffled and reordered randomly through the Monte Carlo analysis in Poptools. Each time the data shuffled, the averages were reordered, then there would be new differences between these averages, forming a resampling model. The third step was to reshuffle the resampled model automatically 5,000 times (the minimum number according to the Monte Carlo analysis; van Geert & van Dijk, Reference van Geert and van Dijk2002). Finally, we compared the newly calculated difference with the original testing criterion to test our hypothesis. According to van Geert and van Dijk (Reference van Geert and van Dijk2002), only if the p-value is very low at a conventional significance level  would the difference between samples be considered as meaningful. In this case, the newly calculated difference between P1 and P2 was different from the original data, indicating P1 is more variable than P2 on average. We did this calculation on the three learners’ LA and WM, and the results of the statistical analyses are summarized in Table 12.1.
would the difference between samples be considered as meaningful. In this case, the newly calculated difference between P1 and P2 was different from the original data, indicating P1 is more variable than P2 on average. We did this calculation on the three learners’ LA and WM, and the results of the statistical analyses are summarized in Table 12.1.
Statistical results in Table 12.1 showed that P3’s performance on WM is significantly different from that of  and
and  , but no significant differences were found between P1’s and P2’s WM performance
, but no significant differences were found between P1’s and P2’s WM performance . Participants’ LA results were also analyzed and compared. As Table 12.1 shows, the results of P2’s performance on LA were significantly different from that of
. Participants’ LA results were also analyzed and compared. As Table 12.1 shows, the results of P2’s performance on LA were significantly different from that of  and
and  , while no significance was identified between P1 and
, while no significance was identified between P1 and  . Results of this might indicate that participants have different levels of LA and WM, as previous studies demonstrated (e.g., Wen & Juffs, Reference Wen, Juffs, Winke and Brunfaut2020; Wen & Li, Reference Wen, Li, Schwieter and Benati2019). Monte Carlo resampling techniques provided further evidence for the visual inspections of the moving min–max graphs, indicating that there might be more variability in the data of P3, which was partially confirmed by Monte Carlo analysis. In other words, learners might be different from their peers on some LIDs variables, such as LA or WM.
. Results of this might indicate that participants have different levels of LA and WM, as previous studies demonstrated (e.g., Wen & Juffs, Reference Wen, Juffs, Winke and Brunfaut2020; Wen & Li, Reference Wen, Li, Schwieter and Benati2019). Monte Carlo resampling techniques provided further evidence for the visual inspections of the moving min–max graphs, indicating that there might be more variability in the data of P3, which was partially confirmed by Monte Carlo analysis. In other words, learners might be different from their peers on some LIDs variables, such as LA or WM.
Learners’ Intra-Individual Variability in LA and WM
Verspoor et al. (Reference Verspoor, Lowie, Chan and Vahtrick2017) emphasized the importance of examining learners’ variability in understanding the learning process. Thus, we examined the time serial data in this section, focusing more on the “peaks” that each learner demonstrated during the observations. Our question is whether these peaks are coincidental “jumps” or significant “development.” In this case, we aimed at the intra-individual variability, also considered as the between-session variability, reflecting the significant level that learners experienced in language development. In consideration of the limited participants, the original dataset was shuffled through Monte Carlo analysis with three steps as follows.
We started by calculating each learner’s differences in LA and WM between two consecutive measurements; specifically, we calculated the difference between data points 1 and 2 through subtraction, then the difference between data points 1 and 3, followed by the difference between data points 1 and 4, etc. Then, we calculated the maximal positive and negative distance, forming the original dataset as the testing criterion.
In the second step, Monte Carlo analysis was arranged to shuffle each participant’s original data 5,000 times. Accordingly, 5,000 simulated models were resampled with identical maximum and minimum differences as the original data. These identical maximum and minimum differences were presented randomly. It is important to note that the first procedure of resampling only shuffled the original data rather than making any alterations, which ensured that each new model set was randomly drawn from the original pool (van Dijk, Verspoor, & Lowie, Reference van Dijk, Verspoor, Lowie, Verspoor, de Bot and Lowie2011; Verspoor et al., Reference Verspoor, Lowie, Chan and Vahtrick2017).
The third step of Monte Carlo analysis is to calculate the probability that the random simulated model was able to reproduce the maximum and minimum difference in the order of each learner demonstrated in the original dataset. Only if the probability was below 5% (similar to the significant p values) could we accept that these differences were not random or coincidental fluctuations (Verspoor, de Bot, & Lowie, Reference Verspoor, de Bot and Lowie2011). The results of our analyses are displayed in Table 12.2.
The results showed that the p-value of P2’s LA variability is  , indicating that the variations P2 demonstrated on LA are not coincidental but may reoccur along with the participant’s language development (Lowie & Verspoor, Reference Lowie and Verspoor2015; Verspoor, de Bot, & Lowie, Reference Verspoor, de Bot and Lowie2011). The fluctuations that P1 and P3 showed in their LA development are isolated jumps with insignificant p values (.264 and .057). This result suggests that P2 demonstrated the highest level of intra-individual variability in LA among the three learners. Comparatively, we inferred that all three EFL learners would demonstrate further variations on WM since the p values for their intra-individual variability are all significant, specifically, .007 for
, indicating that the variations P2 demonstrated on LA are not coincidental but may reoccur along with the participant’s language development (Lowie & Verspoor, Reference Lowie and Verspoor2015; Verspoor, de Bot, & Lowie, Reference Verspoor, de Bot and Lowie2011). The fluctuations that P1 and P3 showed in their LA development are isolated jumps with insignificant p values (.264 and .057). This result suggests that P2 demonstrated the highest level of intra-individual variability in LA among the three learners. Comparatively, we inferred that all three EFL learners would demonstrate further variations on WM since the p values for their intra-individual variability are all significant, specifically, .007 for  for
for  , and .032 for
, and .032 for  . This result suggests that these variations may not be coincidental “jumps” or significant “developments,” that is, participants may experience these peaks and valleys in their future performance on WM.
. This result suggests that these variations may not be coincidental “jumps” or significant “developments,” that is, participants may experience these peaks and valleys in their future performance on WM.
It is also known that individual learners may have their own distinctive learning trajectories. Learners would probably experience “jumps” again if they were experimental learners who would easily start with various attempts in their learning processes, especially in their development of WM. For example, with learners’ continuous and iterative exposure to English and their interaction with peers in English, their perception and memory about English vocabulary and pronunciation might be pruned and, as a result, their acquired forms might be divergent. Thus, learners are more likely to show irregular trajectories with a large proportion of errors and demonstrate more complicated or flexible learning curves in their future non-linear development with an increase in intra-individual variability, as scholars have pointed out (Evans & Larsen-Freeman, Reference Evans and Larsen-Freeman2020; van Dijk, Verspoor, & Lowie, Reference van Dijk, Verspoor, Lowie, Verspoor, de Bot and Lowie2011).
Figure 12.3 is provided for a better illustration of participants’ intra-individual variability. The maximum and minimum differences in the Monte Carlo analyses are marked as squares and circles in the diagram, representing learners’ fluctuating performance on LA and WM. The intra-individual variability patterns displayed in Figure 12.3 indicated that the three participants might have experienced very different learning processes. During the 10 times of measurement (represented by the horizontal axis), the intra-individual variability P1 demonstrated in LA was between +25 and −15 points, higher than the performance in WM (between +5 and −5). Similarly, P2 demonstrated a higher level of variability in LA (ranging between +15 and −20) than the performance in WM (ranging between +10 and −10). P3 also demonstrated variations in LA and WM at a similar range, between +15 and −20.

Figure 12.3 Learners’ intra-individual variability in language aptitude and working memory
Notes. WM = Working memory; LA = Language aptitude
Understanding LA and WM Variability in EFL Listening Development
First, inter-and intra-variability were identified from the three EFL learners’ performances on LA and WM measures from 2016 to 2019. Different from previous studies that have explored the aptitude construct and its effects on L2 learning, our study offered a dynamic perspective on the continuous variability in LA and WM, where the variability was regarded as a reflection, or trigger, of systematic changes and development that EFL learners may experience in their process of language learning (Verspoor et al., Reference Verspoor, Lowie, Chan and Vahtrick2017). For example, the min–max graphs visualized surface reflections of participants’ performance in LA and WM tests; further statistical results confirmed that P2 demonstrated higher variability in LA and that P3 was found to have higher variability in WM. Moreover, if we examine the longitudinal learning process, the three learners demonstrated different levels of intra-individual variability on LA and WM tests. For instance, P2 was found to exhibit higher variability in LA and WM and was also found to be the learner demonstrating the most variability in listening development, as was found in our previous study (Chang & Zhang, Reference Chang and Zhang2021).
Second, variability in our study is important and provides valuable information about the ongoing stages in the language developmental process. Different from SLA approaches that are mainly interested in exploring universal patterns or general trends of language development (Evans & Larsen-Freeman, Reference Evans and Larsen-Freeman2020; Lowie & Verspoor, Reference Lowie and Verspoor2018), we view variability as a typical characteristic of the dynamic nature of LA and WM. This is because LIDs variables are “not all stable but show salient temporal and situational variations” (Dörnyei, Reference Dörnyei and Macaro2010, p. 440). Thus, longitudinal observations on different measurement occasions provided us with an opportunity to understand the importance of LA and WM more broadly, as we understand that LA and WM as cognitive variables are multi-faceted and dynamic in nature. The main merit of this type of research lies in its potential benefit of examining variability (both inter-individually and intra-individually) of learners’ LA and WM from a CDST perspective. Within the complex dynamic system, actual data from the longitudinal observations of learners’ LA and WM should not be neglected. Instead, they should be studied closely to detect how learners’ LA and WM systems may change from one phase to the next, and to explore how learners behave when their LA and WM are in a stable state. According to Thelen and Smith (Reference Thelen and Smith1994), all the features that learners demonstrated on their inter-individual and intra-individual variability should also be treated as valuable and important data to be analyzed.
Finally, the effects of LA and WM may have been exaggerated or overlooked because learners’ LA and WM were measured only once in the majority of studies reported in the literature so far. However, language learning is a dynamically developing system affected by interconnected internal and external factors and often demonstrates unexpected changes (Chang & Zhang, Reference Chang and Zhang2020; Larsen-Freeman, Reference Larsen-Freeman, van Pattern, Keating and Wulf2020; Verspoor et al., Reference Verspoor, Lowie, Chan and Vahtrick2017) that would be associated with the variability that learners showed in LA and WM. Thus, consecutive measurements in longitudinal observation with time serial data should be used for presenting a complete picture of L2 development (Hiver & Al-Hoorie, Reference Hiver and Al-Hoorie2020). From a CDST orientation, more variability might be associated with more successful language learners. Each language learner would find his or her own learning path (Zheng & Feng, Reference Zheng and Feng2017). As shown in this study, learners were assumed to behave differently and showed different developmental patterns, evidenced in our longitudinal and microgenetic observations. Therefore, the relevance of instability and variability in LA and WM over time should be acknowledged in understanding their effects on L2 learning (Hiver & Al-Hoorie, Reference Hiver and Al-Hoorie2020; Verspoor, Lowie, & van Dijk, Reference Verspoor, Lowie and van Dijk2008). Human language and language learning are now widely accepted as complex, adaptive, and dynamic systems. With this proposal, spontaneous variations (e.g., inter- and intra-variability) would provide valuable insights into the fluctuating processes of language learning, and, thus, qualitative longitudinal and microgenetic observations would move beyond descriptions of the static phases with patterned language behaviors and focus on visualizing the dense recordings of actual developmental processes instead (Larsen-Freeman, Reference Larsen-Freeman, van Pattern, Keating and Wulf2020; van Geert & van Dijk, Reference van Geert and van Dijk2002; Zheng, Reference Zheng2016).
Conclusions
In the present study, we focused on two cognitive LIDs variables, LA and WM, and investigated their variability by tracking three EFL learners through LLAMA and the LST for 43 months from 2016 to 2019. Collected data were processed and analyzed through CDST techniques, such as the moving min–max graphs and the Monte Carlo method. Learners showed both inter- and intra-individual variations at different levels. Some learners demonstrated large differences within their own self-regulated learning system. The results of the current study provide a new CDST perspective in viewing LA and WM as dynamic in nature rather than being isolated or static personal traits (Niżegorodcew, Reference Niżegorodcew and Pawlak2012).
Implications
The adoption of the CDST framework with a longitudinal design in the current study allowed us to make unique observations on the non-linear development of LA and WM. Moreover, CDST methodological techniques such as min–max graphs and Monte Carlo analysis enabled us to investigate time series data, identify dynamic features, and examine variability patterns that contain meaningful information (Lowie, Reference Lowie, Ortega and Han2017).
There are three limitations in the current study. First, variability features were identified on a small sample size of three EFL listeners, which limits the generalization of the current findings. Thus, further explorations are necessarily needed with larger numbers of participants. Second, the study mainly explored LA and WM variability, which might overlook the contributions of other LIDs variables that future research might explore. Finally, with the major concern of the dynamic variability in LA and WM, quantitative methods were adopted for this study. Future studies may find it worthwhile to combine quantitative methods and qualitative analysis. For example, obtaining thorough qualitative data through think-aloud protocols or retrospective interviews might depict a more comprehensive understanding of learners’ developmental trajectories of LA, WM, and EFL listening.
Introduction
Many well-articulated objectives of foreign language education programs have included the mastery of five language skills, namely, listening, speaking, reading, writing, and translating/interpreting. Among these targets, the latter (i.e., translating/interpreting) is undeniably one of the most complex meaning-making activities, implicating a broad range of linguistic skills and social–cognitive processes (cf., Levý, Reference Levý1967/2018; Larson, Reference Larson1984). However, the composite nature and functioning of these sub-skills and processes that constitute translating and interpreting aptitude as well as their independent and interactional effects on the translating/interpreting process and real-time performance are still far from clear and definitive (cf. Liu, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019; Lin et al., Reference Alves and Jakobsen2021). In light of the burgeoning research enthusiasm for translating and interpreting studies in past decades, many theoretical discussions and empirical investigations have been conducted, offering clearer clues to the different facets of translating and interpreting aptitude. That notwithstanding, the field still needs a unified theory and is in dire need of an operational aptitude model to explain and predict translation products and interpreting processes and to encapsulate the broad range of complex interplaying factors that are at work during the different timescales (e.g., before, during, and after) implicated in the translating/interpreting activity.
After its development over several decades, the field of translating and interpreting has witnessed a growth of theoretical perspectives and models (Setton, Reference Setton and Chapelle2012). That said, most of the previous models of translating and interpreting are ad hoc manifestations of our constantly updating conceptualizations and interpretations of the multiple facets of the translating and interpreting process and products. They are theoretical artifacts reflecting our evolving perspectives and changing paradigms in translating/interpreting studies. For example, in line with the six developmental stages in cognitive translating and interpreting studies (CTIS; Xiao & Muñoz, Reference Xiao and Muñoz2020; Alves & Jakobsen, Reference Alves and Jakobsen2021), research paradigms have adjusted accordingly from the early product-oriented text-linguistic traditions focusing on the performance and products of translating and interpreting to the now more prevalent approaches tapping the cognitive processes of translating and interpreting (Alves, Reference Alves2003; Li, Lei, & He, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019). These paradigm shifts taking place in CTIS have given rise to the development of vibrant and successive “turns” of translating/interpreting studies (Pöchhacker, Reference Pöchhacker and Munday2009, Reference Pöchhacker2015).
These epistemic “turns” in translating and interpreting studies, such as the “sociological turn,” the “cognitive turn,” and the more recent “neural network turn,” all represent distinctive research focuses that have illuminated selective aspects of the translating/interpreting process, products, and training. Within each research paradigm, theoretical perspectives and models are formulated and take shape gradually, becoming the referential norm for some time until a newer “turn” develops. For example, theoretical models belonging to the “sociological turn” have highlighted the communicative interaction among translators/interpreters within the social–cultural environment. These include the Role Model by Alexieva (Reference Alexieva1997), which addresses the multi-parameter typology of interpreting constellations, and the Participation Model by Wadensjö (Reference Wadensjö1998/2014; derived from Goffman’s Reference Goffman1981 model), which conceptualizes interpreter agency from a sociological approach. Other cognitive-oriented models have taken a slightly different route by focusing on mental operations during the translating/interpreting process. These include the early cognitive short-term and working memory models from Gerver (Reference Gerver and Brislin1976), Moser (Reference Moser, Gerver and Wallace Sinaiko1978), and later, the Paris School (Seleskovitch & Lederer, Reference Seleskovitch and Lederer2002); the embodied, embedded, enacted, extended, affective (4EA) cognition approach (Muñoz Martín, Reference Muñoz Martín, Shreve and Angelone2010); Seeber’s (Reference Seeber2011) cognitive load model; and the noteworthy Effort Models of interpreting developed by Gile (Reference Gile1985, Reference Gile1995/2009). The latter is a series of refined models that focus on depicting the interpreter’s cognitive load and efforts implicated in receptive and productive stages and skills during interpreting. That said, these models were initially intended for simultaneous interpreting (SI) but were later expanded to explain sight interpreting and consecutive interpreting (CI) as well. Then, in the latest “neural network turn” that applies the most technology-savvy computational and big data knowledge to simulate human brain functions, models abound on the evolution and advancements of machine translation tools and applications. This technology-driven turn alone has spawned evolving theoretical models ranging from rule-based architectures in the early days to statistics-based models in the second generation, and now the generation of neural network models constitutes the mainstream.
All of the theoretical perspectives and models mentioned above are still highly relevant to some extent nowadays, though they are no longer as dominant. They continue to provide constant inspiration to researchers and practitioners who subscribe to these distinctively articulated research paradigms by applying research methods typical of each tradition. As a whole, these well-defined perspectives have made significant contributions to our current understanding of the translating and interpreting process. Notwithstanding this, these “turns”-driven perspectives, despite their unique contributions, still fall short of providing a unified theoretical framework within which translating and interpreting aptitude or competence can be explained adequately and predicted accurately as a highly complex social–cognitive activity that is situated and embodied within the external environment and the broader social–cultural context. Thus, we still need a unified theory that is comprehensive enough to succinctly encapsulate all the engaging agents/stakeholders and the interplaying factors and elements of the translating and interpreting activity in often superdiverse multilinguistic and multicultural environments. Furthermore, such a unified theory should be able to capture the fluid, dynamic interactions between the translator/interpreter and the other entire essential internal and external factors alongside the multiple timescales (before, during, and after) of the translating and interpreting process. In this sense, it is fair to say that current theoretical models of these turns-oriented perspectives have not moved very far from being sporadic, fragmented, or “solitude” pieces of the full picture of the translating and interpreting aptitude puzzle. That is to say, the translating and interpreting field still needs a grand theory that not only portrays the nature and the architecture of translating and interpreting aptitude but also explains and predicts its dynamic dimensions of emergence, development, and real-time performance.
To resolve most if not all of these issues, we believe that with the advent of the translanguaging concept some thirty years ago in Welsh revitalization education programs (Williams, Reference Williams1994, Reference Williams2002), translanguaging theory has gradually emerged and transformed into a practical and powerful theory explaining broad domains of human cognition and communication phenomena spanning the humanities and social sciences and beyond (Li, Reference Li2011a, Reference Li2011b, Reference Li2018, 2022; Li & Zhu, Reference Li and Zhu2013). Translating and interpreting, as multilingual-mediated communicative and social–cognitive activities, are constantly undergoing translanguaging between and beyond different linguistic structures and systems. By the same token, translating and interpreting as viewed from this translanguaging lens cover the full range of linguistic performance of multilingual language users, who are transcending the combination of structures, the alternation between systems, the transmission of information, as well as the representation of values, identities, and relationships. Given the intricate entanglements between translating/interpreting and translanguaging (Baynham & Lee, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019; Runcieman, Reference Alves and Jakobsen2021), we posit that it is now time for the field of translating and interpreting to construct a grand theory as a viable solution to a complete theoretical paradigm. Toward this end, we endeavor to incorporate and integrate emerging insights from key tenets of translanguaging theory (Li & Shen, Reference Alves and Jakobsen2021) into an aptitude model of translating and interpreting, with a view to explaining and predicting the emergence and development of the translating/interpreting process and to capturing the fluid and dynamic interactions between internal and external factors that are contributing to or exerting constraints on real-time performance and the final products of interpreting.
More specifically, in this chapter, we aim to answer four questions related to the definition, rationale, theory construction, and research methodology as well as practical applications of the translanguaging-informed aptitude model of translating and interpreting. These questions are:
1) What is translanguaging theory and why is it important for constructing a new translating and interpreting aptitude model?
2) What will a translanguaging-informed aptitude model of translating and interpreting look like?
3) How does the aptitude model work in socio-cognitively complex translating and interpreting practice?
4) What are the theoretical and methodological implications for future research and practice?
What Is Translanguaging Theory and Why Is It Important for Constructing an Aptitude Model of Translating and Interpreting?
In the recent monograph Translation and Translanguaging, written by Baynham and Lee (Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019), translanguaging is defined as “the creative selection and combination of communication modes (verbal, visual, gestural, and embodied) available in a speaker’s repertoire” (p. 24). Translanguaging as a theory of human cognition and communication has now gathered enormous momentum that permeates and transcends linguistic and disciplinary boundaries within a broad range of academic domains in humanities, social sciences, and beyond (Lee, Reference Alves and Jakobsen2021). In essence, translanguaging theory captures the complex, dynamic, situated/embodied, and adaptive interactions between human cognition and the superdiverse social–cultural milieu. Since its inception in the 1990s (Williams, Reference Williams1994), translanguaging theory has thrived, witnessing exponential growth in the publication of books and papers applying the model in these broad domains. These have included but are not limited to bilingual and multilingual education, pedagogical and classroom instruction, language policy and planning, arts and literature, business and legal genres, urban city spaces, and sports (Li & Shen, Reference Alves and Jakobsen2021).
Perceived this way, translanguaging practices are situated and locally occasioned, being influenced and shaped by not just the immediate linguistic contexts but also the external tools/aids and technological affordances via multiple communication modes and multimodal means (cf. Baynham & Lee, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019). Under this translanguaging lens, the implicated “languages” are no longer bounded entities but are typically conceived in the sense of “equitable multilingualism” (Ortega, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019), in which purist monolingual models and benchmarks are discarded while bilingual or multilingual language ideologies are favored and adopted.
On the other hand, the translating and interpreting process can be conceptualized as a social–cognitive activity that implicates a bi/multilingual individual translator/interpreter engaging in successive translanguaging “moments” of meaning-making. Such a translanguaging practice naturally implicates the translators/interpreters’ multilinguistic repertoires (L1, L2, and Lx proficiency) and cognitive capacities (e.g., working memory, attentional control) interacting with the external environment and social–cultural contexts in which their attitudes, beliefs, and ideologies also play a part in affecting their translating/interpreting behavior and performance. Such complex interactions among the interplaying elements give rise to “translanguaging moments,” spawning multilayered “translanguaging spaces” (Baynham & Lee, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019):
Translation can therefore be seen as embedded within a translanguaging space, at the same time as it is composed of successive translanguaging moments. This scalar view, best demonstrated in interpreting and think-aloud-protocols in translation, enables us to think of translation and translanguaging as being mutually embedded, such that we can speak of translation-in-translanguaging and translanguaging-in-translation.
By the same token, we can also argue that the two concepts of “translation-in-translanguaging” and “translanguaging-in-translation” proposed by Baynham and Lee (Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019) above can be further expanded and augmented by “translating/interpreting in translanguaging” and “translanguaging in translating/interpreting.” In essence, the practice of translating/interpreting can now be regarded as the “fluid, dynamic, and multiple interchanges of repertoires and resources” in that:
In superdiverse and translanguaging societies, source and target languages are no longer a one-to-one linguistic and cultural translation, but far more fluid, dynamic, and multiple interchanges of repertoires and resources that people access in multi-varied and multi-functional ways.
Runcieman further highlights the lens of translanguaging for pedagogy in interpreting:
How could we start designing task-based curricula in interpreting studies to mirror potentially complex translanguaging scenarios? An approach that draws on plurilingual task-based exercises [González-Davies Reference González-Davies2004; Cummins and Early Reference Cummins and Early2014; Carreres et al. Reference Carreres, Noriega-Sánchez and Calduch2018], may be adapted to interpreting activities in the classroom (p. 12) … There is undoubtedly much more research required into developing effective didactic models, but this might be a starting point.
In short, the situated and embodied contexts and environment surrounding the agent of the interpreter during the practice of translating and interpreting are congruent with the key tenets and principles of translanguaging theory. As such, we postulate that translanguaging theory represents an ideal theoretical framework to conceptualize the practice of translating and interpreting. By applying key tenets of the theory, we now turn to construct the aptitude model of translating and interpreting and specify its putative components or factors to capture the dynamic interactions of the interlocking elements that are at play while the translating and interpreting practice is occurring by the agent of translation and interpretation within the superdiverse social–cultural environment.
An Outline of the Translanguaging-Informed 3M Aptitude Model for Translating and Interpreting
To further delineate the key tenets of translanguaging theory and to evaluate its potential contributions to translating and interpreting practice, we are building a unified theory of translating and interpreting aptitude that portrays the nature and contexts of the translating and interpreting process and succinctly captures the dynamic interactions among the implicated agents and stakeholders within the superdiverse multilingual, multicultural, multisemiotic social and linguistic environment. Above all, we argue that multilayered “translanguaging spaces” (Li, Reference Li2011a) permeate the translating and interpreting process and products as a result of the successive moments of “translating and interpreting in translanguaging” and “translanguaging in translating and interpreting.”
The translanguaging-informed aptitude model of translating and interpreting consists of three broadly conceptualized levels, that of macro, meso, and micro (and referred to as the 3M aptitude model). As a “snapshot or crystallization of a theory” (Setton, Reference Pöchhacker2015, p. 263), the 3M aptitude model aims to simulate, predict, and explain the translating and interpreting process, products, and functions by gleaning insights from the key tenets of the translanguaging theory. As shown in Figure 13.1, the 3M model is schematically mapped to three levels (or domains), along with its social–cognitive and linguistic repertoires (stock of speech styles, registers, varieties, and languages) (cf. Coulmas, Reference Coulmas2005/2013; Spolsky, Reference Spolsky1998) of putative translanguaging spaces, namely, either “translating and interpreting in translanguaging” or “translanguaging in translating and interpreting.” We will next elaborate on putative factors and elements comprising each level to depict their key features and relational interactions.
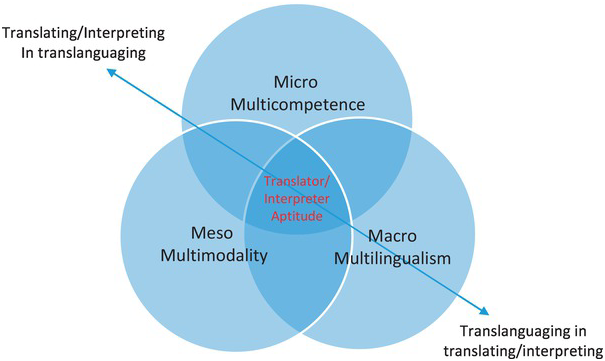
Figure 13.1 The schematic 3M aptitude model for translating and interpreting
The Micro Level: The Multicompetent Translator/Interpreter
The micro level of the translating and interpreting aptitude model represents the translator/interpreter’s innermost cognitive and mental activities or tasks as viewed under the microscopic lens of translanguaging. At this level, the key feature is the translator/interpreter’s “multicompetence” (Cook, Reference Cook, Cook and Li2016), namely all of the cognitive and mental capacities and processes the translator/interpreter brings to bear on his/her translating and interpreting behavior and performance. The translator/interpreter’s multicompetence at this level manifests itself during the essential skills and processes that are implicated in the translating/interpreting stages. For example, in the most complex activity of interpreting, to proceed and succeed in this task likely entails a heavy cognitive load or effort to be directed toward such stages and processes. These include listening and analysis (of the incoming input), memory storage of previous form or meaning, chunking of sound sequences or linguistic forms, meaning extractions and note-taking, speech planning, formulation, and production (cf. Gile, Reference Gile1995/2009). At this micro level of multicompetence, the interpreter’s disposable linguistic repertoires and resources (e.g., proficiency of L1, L2, and Lx) and their executive and attention control efficiency are fundamental and critical, while effects from the complexity or difficulty level of the interpreting task will weigh in as well (Setton, Reference Setton1999). Though the interpreting performance can be affected by the external environment or facilitated by technology on occasion (to be discussed further at the meso level) and by the broader social–cultural contexts (at the macro level), all of these specific interpreting stages and processes are mainly taking place at the micro level of “translanguaging moments,” either overtly (observed externally, such as note-taking) or covertly (only predicted or tapped and measured by psychometric and cognitive tests, such as working memory and attention control). It is these successive “translanguaging moments” that engender the fluid, instantaneous, dynamic, and creative moments that result in the products of interpreting.
Interpreted this way, Daniel Gile’s Effort Model (Reference Gile1995/2009) fits squarely into this micro level as it has also taken the cognitive load and efforts of the interpreting task as its very core. More importantly, Gile has helped to decompose and identify the behavioral stages of the interpreting process as consisting of listening (L), memory (M), oral production (P), and coordination (C) (summarized as the “L+M+P+C” model). Such a micro-level interpreting model has shed important light on interpreting pedagogy as it simulates the interpreting process and thus has provided inspiration for designing tailor-made instructions to help students and practitioners appreciate and understand the cognitive functions of the brain and also yield practical tools for interpreting training. As observed by Pöchhacker (Reference Pöchhacker2015), the original intention of this prevailing interpreting model “was not to describe the interpreting process but to highlight the theoretical and practical consequences of the limited availability of processing capacity (attentional resources) on the process” (p. 135). As such, these behavioral tasks (L, M, P, and C) constitute assessment criteria for gauging the interpreter’s micro-multicompetence.
Accumulating empirical support for possible factors influencing this level of multicompetence comes from studies probing into the mental cognitive processes underlying interpreting practice. These include such broad topics as problem-solving (e.g., Nitzke, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019), cognitive effort and load (e.g., Szarkowska et al., Reference Szarkowska, Krejtz, Dutka and Pilipczuk2016; Vieira, Reference Vieira2014), attention and cognitive control (e.g., Dong & Li, Reference Xiao and Muñoz2020), and skill acquisition and development (e.g., Massey, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019). Other studies have investigated cognitive individual differences such as working memory (e.g., Liu et al., Reference González-Davies2004; Yu & Dong, Reference Alves and Jakobsen2021) and the executive functions of updating, shifting, and inhibition (Nour et al., Reference Xiao and Muñoz2020; Timarová, Reference Pöchhacker2015) based on the framework by Miyake et al. (Reference Miyake, Friedman and Emerson2000) as well as other physiological and psychological factors (Rojo López & Korpal, Reference Xiao and Muñoz2020), such as anxiety (Chiang, Reference Chiang2010), stress (e.g., Korpal, Reference Korpal2016), emotions (e.g., Rojo López & Caro, Reference Rojo López, Caro and Muñoz Martín2016), and empathy (Korpal & Jasielska, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019).
It should also be noted from the translanguaging lens that during the interpreting practice, all of these cognitive efforts postulated at this micro-multicompetence level are mobilized in a coordinated manner and that there are occasionally some optimal “peak” (cf. Ericsson, Reference Ericsson, Baltes and Baltes1990) or “flow” moments (cf. Csikszentmihalyi, Reference Csikszentmihalyi1990) when the interpreter feels no cognitive load whatsoever but instead experiences some hard-earned blissful moments of creativity or criticality during the usually cognitively demanding meaning-making process of interpreting. Some highly professional interpreters have reported having their brains functioning automatically during interpreting even when they are knitting or playing sudoku games simultaneously. It will be illuminating to capture these “critical” translanguaging moments in future research. That is to say, at this multicompetence level of translanguaging in interpreting (the same can be said for translation), though the cognitive load as described by Daniel Gile is still mainstream and dominant, some occasional “liminal moments” (Li, Reference Li2011a) may likely occur at any of the different stages or tasks. These optimal moments can occur at any of the stages or tasks, such as the L, M, and NT (note-taking) stages during CI and the P and C tasks during SI. In addition, instead of treating these “liminal moments” as taking place in a linear manner, they are more likely to emerge as a result of “self-organization” as interpreted from the complex dynamic systems theory (CDST) approach (c.f. Van Geert, 2008; Van Geert & Verspoor, 2015; Yu & Dong, Reference Alves and Jakobsen2021). That is to say, when all of the relevant cognitive and linguistic abilities constituting the interpreter’s multicompetence are mobilized synergetically, the initially disorganized and chaotic mental system can sometimes be transformed into a patterned, ordered, and connected one, culminating in what Li (Reference Li2016) has called “translanguaging instinct.” The by-products of these transcending “liminal moments” are the creativity and criticality within the translanguaging spaces. Li (Reference Li2011a) defines both as follows:
[C]reativity can be defined as the ability to choose between following and flouting the rules and norms of behavior, including the use of language. It is about pushing and breaking the boundaries between the old and the new, the conventional and the original, and the acceptable and the challenging. Criticality refers to the ability to use available evidence appropriately, systematically, and insightfully to inform considered views of cultural, social, political, and linguistic phenomena, to question and problematize received wisdom, and to express views adequately through reasoned responses to situations”.
That is, during the interpreting practice, creative and critical moments can be expected to happen at the in-betweenness (i.e., “liminal moments”) of all the cognitive subtasks. These include, for example, the listening stage, when active and analytical listening is taking place by resorting to linguistic and extralinguistic knowledge for meaning-extraction; the memory and chunking stage, when the interpreter uses chunking and visualization to sort out the logic and explore the spatial and temporal dimensions; the note-taking stage (for CI mode only) stage, when the interpreter is scribbling symbols, numbers, and proper names and linking logic and other linguistic features to structure the speech output; the production stage, when the interpreter is expressing epistemological stance with proper pitch, volume, and attitude in line with the register; and finally, the coordination stage, when the interpreter is mobilizing all the efforts in a coordinated manner to orchestrate the desirable and optimal performance.
Meanwhile, we can also observe at this micro level how the interpreter’s multicompetence plays out in these successively dynamic and interactive movements of multisemiotic scenarios that implicate speech sounds, visual images and signals, written symbols, numbers or figures, etc. As already demonstrated by empirical studies, the interpreter’s multicompetence as a cognitive system consists of at least four attested components or processes (e.g., Dong, Reference Dong2018), which include multilingual proficiency, working and long-term memory capacity, executive and attention control, and other psychological factors, such as anxiety. Despite these emerging patterns related to multicompetence, no empirical research has been conducted to investigate the emergence and development of the translanguaging moments of creativity and criticality that occasionally arise from the “translanguaging spaces” during the interpreting process. Future research can aim to examine the origin and causes of these critical “liminal moments,” unveil their underlying mechanisms, and provide tailor-made guidelines for effective interpreter training to cultivate these hard-to-come-by peak performance moments during interpreting.
The Meso Level: Multimodal Affordances
The meso level of the aptitude model highlights the feature of multimodality that aims to capture the dynamic interactions taking place between the translator/interpreter’s inner multicompetence (as described at the micro level) and the externally available tools, aids, or technologies from the physical environment (e.g., terminology, glossary, dictionary, computer-aided tools, or machine translation software). From these relations between the key agent (i.e., the translator/interpreter) and the tools and other multimodal and multisemiotic resources (i.e., external objects), we envision successive and iterative translanguaging moments of translating/interpreting that are distinct from those at the micro level.
Related to multimodality featuring this meso level, the important concept of “affordances” should be also highlighted and explained. The term “affordances” was initially defined as the product of the animal-environment eco-system (Gibson, Reference Gibson1979/2014). Adopting the viewpoint of ecological psychology, Chemero (Reference Chemero2003) argues that affordances are the “relations between the abilities of organisms and features of the environment” (p. 189). Then, the term is used to refer to “a subject’s disposition to respond to environmental demands” (Dings, Reference Dings2018; cf. van Lier, Reference González-Davies2004). We are adopting Dings’ working definition in the 3M model. An increasing number of experiments using the psychological stimulus–response paradigm have suggested that affordances may indeed play “a substantial role in ambiguous contexts by reducing the uncertainty of such situations” (Silva et al., Reference Xiao and Muñoz2020, p. 1).
In the 3M aptitude model of translating and interpreting, we further expand the concept of “affordances” to refer to the multimodal and multisemiotic interactions between the translator/interpreter’s multicompetence (at the micro level) and the external tools, aids, and technologies available from the physical environment or workstation (e.g., the interpreting booth; Rojo López & Korpal, Reference Xiao and Muñoz2020). Affordances are manifested through various relational objects and actions. For example, they can be a demonstration of how the translator/interpreter acts and reacts to the available tools and resources. Alternatively, during interpreting, affordances refer to the equipment the interpreter brings for the job assignment (e.g., noise-reducing headsets, adapters, pencils, notebooks, microphones). Meanwhile, affordances can also refer to how the interpreter deals with the emergent environmental situations (e.g., by adjusting to the remote model of interpreting during the Covid pandemic era). Related to these affordances, other preparations the translator/interpreter makes for the assignment are also relevant. For an interpreter, these can include seemingly trivial matters, such as learning to arrive early at the interpreting site, adaptations that can be made to the interpreting cabinet, and the sorts of simulated practice that can be trialed.
Similarly, for a translator of written texts, s/he may have to determine which machine translation platforms to use to facilitate the translation task, how to segment the “source” language text and input it online, and which post-editing strategy should be adopted to guarantee the quality of the final version in the target language. S/he may also be interested in comparing the outcomes from human translation and machine translation to determine the reliability and usability of the latter and decide whether to draw on it as a reference to human translation. To do this, s/he may have to resort to some semantic measurement tools, such as the latent semantic analysis technique (Landauer et al., Reference Landauer, Foltz and Laham1998) to further his/her research.
All in all, the translator/interpreter’s disposition and reactions to these demands of the physical environment for the translating/interpreting activity constitute essential translanguaging spaces created at this meso level. The key feature of the affordances at this level is their multisemiotic nature and multimodality presented to the translator/interpreter, who will now leverage his/her “translanguaging instinct” (Li, Reference Li2016) to naturally draw upon these available linguistic, cognitive, and semiotic resources (Rajendram, Reference Alves and Jakobsen2021) within the translanguaging spaces created during the meaning-making process of translating/interpreting. It can also be predicted that with the translation quality and accuracy rate of some automatic machine translation platforms (e.g., Google Translate for written texts) and computer-aided interpreting tools (e.g., Interpretbank) continuously improving, the weightings of these elements at the meso level will play a much bigger role in influencing translating and interpreting practice in the future (Pöchhacker, 2022).
The Macro Level: Multilingual Society
The macro level of the translating and interpreting aptitude model features the boundary-crossing dimensions of translating/interpreting in translanguaging as embodied and situated within the superdiverse multilingual social–cultural milieu. Within this societal context, influence from the ideological and language policies, the political and power relations between the agents and the vested stakeholders, identity issues, and meaning negotiations are insidious and ubiquitous. In the interactions among the engaging agents and the vested stakeholders (e.g., the translator/interpreter, the employer, the client, the editor/publisher, the readers, the audience), the social constraints, cultural/historical norms (e.g., ideology, language policies), and national identity are key interplaying factors. Among these interactions taking place in the translanguaging spaces at this level, multilingual ideologies prevail over the purist monolingual or regulated bilingual language ideology (Baynham & Lee, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019; García & Li, 2014). That is why multilingualism is identified as the key feature highlighted at this level, as in Li’s (Reference Li2011a) own words, “Multilingualism by the very nature of the phenomenon is a rich source of creativity and criticality, as it entails tension, conflict, competition, difference, and change in several spheres, ranging from ideologies, policies, and practices to historical and current contexts” (p. 1223).
For example, language ideology issues penetrate and transcend multilingual society to influence the meaning-making decision process during translanguaging in translating/interpreting. Ideology, as defined by Meylaerts (Reference Meylaerts2007) refers to “the knowledge, beliefs, assumptions, expectations, and values held by groups of people about language use, language values, language users, language contact and, of course, translation in a particular geopolitical and institutional context” (p. 298). In addition, this macro level of language policy and ideology also represents the social–cultural consideration of translating/interpreting as reflected in the ethical codes of professional associations. As an individual player situated in this social–cultural–political milieu, the translator/interpreter is obliged to conform to the social–cultural norms and related ethical codes of the profession.
As can be expected, on some occasions, the translator/interpreter may feel threatened when his/her “neutrality” is challenged by the ideologies held by other groups of vested stakeholders. By power negotiation within the geopolitical and institutional contexts, as well as with the participants, the translator/interpreter puts him/herself in a translanguaging space by mobilizing all the communicative modes (verbal, visual, gestural, and embodied) available in his/her repertoire to fulfill the meaning-making action (of translating and interpreting). Interpreted in this way, we can depict the macro level of the translating/interpreting in translanguaging as taking place within the “translanguaging spaces” generated by interactions between the translator or interpreter that interplay with the social–cultural milieu in the spirit of “equitable multilingualism” (e.g., Ortega, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019).
A Fuller View of the 3M Aptitude Model of Translating and Interpreting
The 3M aptitude model of translating and interpreting depicted here lays out three levels of “translanguaging spaces” blending and overlapping during translating/interpreting practice as a meaning-making activity. As such, it encapsulates the dynamic interactions between a translator/interpreter’s individual-based multicompetence, which interplays with the multimodal and multisemiotic affordances in the external environment and the broader multilingual sociocultural context. The underlying assumption of the aptitude model is that translating/interpreting is by default a translanguaging practice that transcends these three separate but related levels of multicompetence, multimodal affordances, and multilingual societal context. In alignment with this overlapping area depicted in Figure 13.2, the “translanguaging spaces” created by successive “moments of meaning-making” can take the whole process as a unit of analysis or any specific task to highlight a certain level or timescale as the focus of inquiry. Regarding the boundaries of the translanguaging space, Li (2011) has emphasized that the interactions of multilingual individuals likely transcend and break down the artificial dichotomies between the individual and the psychological, the external, and the social in studies of bilingualism and multilingualism (p. 1234). That is to say, the overlapping area representing translator/interpreter aptitude in Figure 13.2 can be formed dynamically in real time or delayed with potential linguistic, cognitive, and semiotic repertoire utilized by a translator/interpreter consciously or subconsciously from each level to constitute the composite, blended translating and interpreting aptitude (as indicated in the overlapping core area).
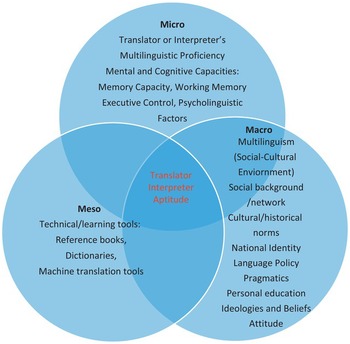
Figure 13.2 A fuller view of the aptitude model of translating and interpreting with indicative elements
To further illustrate these three levels (i.e., the macro, meso, and micro), we present a fuller view of the 3M model by mapping and aligning the essential elements into the multi-leveled translanguaging spaces created by the translating and interpreting process at each level. This is demonstrated in Figure 13.2, which was inspired by the ecological systems model proposed by Bronfenbrenner (Reference Bronfenbrenner1979, Reference Robinson2005) for human development in child psychology, revised and augmented by the latest developments in network approaches (Ettekal & Mahoney, 2017; Neal & Neal, Reference Neal and Neal2013). More specifically, we have identified the translator/interpreter’s individual-based multicompetence as the most fundamental and indicative element at the micro level. According to previous empirical investigations (e.g., Dong, Reference Dings2018; Yu & Dong, Reference Alves and Jakobsen2021), a translator/interpreter’s multicompetence at this micro level is likely to comprise his/her multilinguistic proficiencies and repertoires modulated by such mental and cognitive capacities as working memory and attention control (Liu et al., Reference Liu, Schallert and Carroll2004; Dong & Li, Reference Xiao and Muñoz2020). Then, the meso level depicts the interactions between the translator/interpreter’s agentive multicompetence interplaying with the external affordances via multimodal channels, including some learning tools and aids, such as dictionaries and reference books, or technological equipment including electronic devices, primary or secondary computer-aided translating and interpreting tools (e.g., Interpreterbank, Voyant tools; Will, Reference Xiao and Muñoz2020), currently available automatic translation programs such as Google Translate, DeepL, Youdao, Niutrans (Lin, Reference Xiao and Muñoz2020), or even the hardware and software at the language lab (Man et al., Reference Xiao and Muñoz2020). Finally, the macro level highlights the dynamic interactions between the translator/interpreter’s agentive multicompetence as constrained and shaped by the broader social–cultural norms and multilingual ideologies (Wang & Munday, Reference Xiao and Muñoz2020). Again, it should be noted that, though these indicative elements are identified at each level, they are by no means exhaustive and should not be regarded as bounded entities. Instead, the translanguaging spaces created at these putative levels are likely to be blended (as demonstrated in Figures 13.1 and 13.2). To quote from the Douglas Fir Group (Reference Rojo López, Caro and Muñoz Martín2016, p. 25) in advocating a unified theory of language development (also see Hult, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019), “no level exists on its own; each exists only through constant interaction with the others, such that each gives shape to and is shaped by the next, and all are considered essential” to understanding the translating and interpreting practice.
Putting the 3M Aptitude Model of Translating and Interpreting to the Test
Now that we have discussed the three conceptual levels of analysis postulated by the aptitude model of translating and interpreting, we turn to examine its application and utility by subjecting it to a situational analysis of translating/interpreting practice during the Covid pandemic in 2020. As the Covid pandemic has produced a great impact on the whole translating and interpreting ecology, it provides a representative and situated setting to put the 3M model to the test. At the very beginning of the outbreak in late 2019, the new coronavirus disease was called by its association with the name of the place it was first reported: Wuhan, China. As early as December 31, 2019, the translation of the virus name was based on the media statement issued by the Wuhan Municipal Health Commission from the country office of the World Health Organization (WHO) in China. Cognitively, this is a metonymic operation due to the geographic proximity: PLACE NAME FOR DISEASE NAME. Later, on January 5, 2020, the disease became known as the “pneumonia of unknown etiology (unknown cause) detected in Wuhan City.” Through its name association with the specific place, the disease name represents an alert and threat to public health similar to other earlier diseases, such as the Ebola virus in Africa, as indicated on the WHO website. In those early days, no ideological tension was reported surrounding the pandemic. However, with the reporting of increasing mortalities and of the exported infected cases to other countries, Wuhan, China has become a stigmatized name. In terms of metonymic studies, this stigmatization effect can be caused by the metonymic chain (Barcelona, Reference Barcelona, Ruiz de Mendoza Ibáñez and Peña Cervel2005), which refers to “direct or indirect series of conceptual metonymies guiding a series of pragmatic inferences” (pp. 328–331). In translation studies, this refers to a chain of such correlated semantic extensions or inferences found in multiple target language translations (Lin, Reference Alves and Jakobsen2021). Specifically, the derogative metonymic chain regarding the Covid pandemic and Wuhan, China starts from the concept of the disease itself, then to Wuhan where it was first reported, then to China of which Wuhan is a part, and eventually to the Chinese governmental system in dealing with the disease. Evans (Reference Pöchhacker2015) argues that this final step of metonymic reasoning belongs to “the secondary cognitive model.” As such, the metonymic chain is driven by ideologies that do not agree with the way in which China controlled and combated the disease. In our 3M model, this kind of metonymic chaining activity is empowered by elements at the macro level. What was more, visual maps were being drawn indicating the spread of the disease by connecting Wuhan, China with other places in the world as people were traveling and having contact with others, who spread the disease on a larger scale. In this virtual but empowered “translanguaging space,” the place-associated disease names (e.g., Wuhan Virus, China Virus), as designated by some media reports, revealed ideological intention and were manipulated by some groups of politicians to achieve certain political goals. Then, on February 11, 2020, the WHO finally announced that the pandemic outbreak caused by the novel coronavirus would be named COVID-19 to avoid unnecessary stigma. In this way, the disease name would not refer to any specific geographical locations, animals, individuals, or groups of people.
With regard to interpreting at the macro level, during the meaning negotiations, the “interpreter’s neutrality” (Pöchhacker, Reference Pöchhacker2015, p. 274) or “interaction power” (Mason & Ren, Reference Setton and Chapelle2012, p. 122) present a superdiverse and boundary-crossing multilingual characteristic, where the interpreting activity is no longer an issue of code-switching from the source language to the target language in the traditional dichotomies. Rather, it has become a translanguaging practice involving the interplay between all the agents, stakeholders, and embedded social–cultural norms, such as the attitudes and beliefs in which the interpreter is situated. Since the relationships among all the implicated participants are differentiated in various spatial and temporal circumstances, the three symbolic designations (COVID-19, Wuhan Virus, or China Virus) at the interpreter’s disposal are the different choices within the “translanguaging spaces” created by the momentary interactions between the interpreter’s multicompetence and the external environment nested within the broader social–cultural milieu. Accordingly, interpreters need to adjust the versions of the disease name by taking into account the ideological consequences during the meaning-making decision process, and such decisions are likely to transcend and collapse the linguistic boundaries between the “source text” and “target text” in the traditional dichotomy. In this sense, the final choice made by the interpreter is the artifact of his/her “translanguaging instinct” under ideological consideration.
Another consequence brought about by the COVID-19 pandemic to the interpreting service industry is the shift from on-site interpreting to remote interpreting via online platforms. This abrupt change in environment, conditions, and equipment requirements challenges the interpreter’s previous perceptions of interpreting and highlights the newly emergent dynamic interplays between the interpreter and the available tools, aids, or technology affordances. The interpreter needs to mobilize all of his/her linguistic repertoire and online platforms and equipment to adapt to the virtual interaction with other participants. They may need to learn how to use new functions and skills of online interpreting platforms and techniques, such as screen sharing, document uploading, messaging in the chatroom for event participants, and even polling. Under the translanguaging lens, the interpreter resorts to more multisemiotic, multimodal, and multifaceted interactive ways to commit to the meaning-making process of interpreting. In these meso-level translanguaging spaces, interpreting utterances mingle with multisemiotic and multimodal operations of the online interpreting platforms, where the situational uncertainties and potential threats are substantially reduced by these available tools or technological resources. Notwithstanding, similar to the instability of the Internet and the delayed transmission of sounds and images, the communicative interactions among the participants can sometimes be jeopardized and compromised. These newly emerging meso-level issues will likely force the prevailing professional norms of interpreter training to transform to meet these new demands.
As for the micro level, the example of remote interpreting and the focus on the cognitive process of interpreting is most relevant. During on-site interpreting, which was common before the Covid pandemic, a spacious booth with an excellent view provided the interpreter with an interactive visual space from which the interpreter could detect the facial expressions and gestures of the speaker and the audience, thus facilitating and enhancing his/her interpreting performance. The ongoing multisemiotic translanguaging space was characterized by successive liminal moments embedded in the listening, analyzing, producing, and coordinating tasks in the non-linear cognitive process of sense-making. Nowadays, however, in this Covid pandemic era, remote interpreting has become the norm, during which the interpreter has to interpret based on the video streams coming via online platforms employing screen sharing. In these circumstances, the interpreter has very limited opportunities in the virtual environment to observe and detect the speaker’s facial expressions or gestures and the audience’s responses. In these limited multisemiotic and interactive translanguaging spaces, all the interpreting tasks still need to proceed (against all the odds) without the interpreter being able to have any clues from the speakers and the audience. These more adverse conditions from the Covid pandemic are likely to increase the cognitive load of the interpreting task and place a more demanding burden on the interpreter at the micro level, where the mental and cognitive capacities of the interpreter are more taxed. Both conditions will have detrimental consequences for the interpreting process and performance.
By the same token, interpreter training during this Covid pandemic will need to take these additional conditions into account. At the micro level, the interpreter has to adapt to the paucity of face-to-face, information-rich responses that an on-site audience would generously offer. At the meso level, s/he must be skillful and speedy in using extra online tools to convey the message, which reduces the valuable time of the interpreting process. At the macro level, it will be more challenging for an interpreter to select the right diction with the correct nuance for a particular audience due to the lack of in-person interaction. When all these factors overlap and blend, the increased degree of difficulty will call for a greater aptitude for the interpreter.
From the above analysis, we can summarize that the aptitude model of translating and interpreting categorized into three levels provides a panoramic view of the interplaying factors that influence these activities. Seen through the translanguaging lens, translating and interpreting are meaning-making activities in which the translator/interpreter’s multicompetence interplays with the external environment of linguistic and technological affordances within the superdiverse, multilingual social–cultural milieu. Then, in terms of hierarchy, the translating and interpreting process can be viewed at three levels – the macro, meso, and micro layers – and each layer has key specific components that should happen either independently or interactionally during the translating and interpreting process. It is thus hoped that the translanguaging lens has enabled us to construct this aptitude model of translating/interpreting to emulate, predict, and explain the translating/interpreting process and products.
Conclusion: A Translanguaging Research Agenda for Interpreting Studies
To conclude, the translanguaging-informed 3M model of translating and interpreting constructed here allows us to reconceptualize translating and interpreting aptitude more comprehensively and thoroughly. From this translanguaging viewpoint, aptitude for translating and interpreting should be conceived as the blended or overlapping process of three defining properties nested within networks of indicative elements: (1) at the micro level, the person- or individual-based agency of multicompetence; (2) at the meso level, the tool-based or technology-driven affordances of the external environment; and (3) at the macro level, the socially–politically normed multilingual ideologies. Theoretically, given its comprehensiveness, the 3M aptitude model of translating and interpreting has perceivable advantages over previous level-specific or element-specific models to simulate or analyze certain aspects of the translating and interpreting process. More importantly, given its blending and overlapping portrayal, such a translanguaging-informed aptitude model allows us to adequately capture the complex, dynamic, and fluid interactions of the situated embodied processes that figure prominently in the successive translanguaging moments of meaning-making during translating/interpreting. Such a portrayal resonates well with the foundational theory of lexical concepts and cognitive models of Evans (Reference Evans2010) and the embodied simulation theory of Bergen (Reference Setton and Chapelle2012) in conceptualizing mechanisms of meaning-making that also underpin and transcend the translating and interpreting process and products.
Furthermore, the 3M aptitude model will entail concerted efforts from multiple disciplines and integrated research methods spanning linguistics, sociology, ethnography, psychology, and other humanities and social sciences domains in future endeavors. To facilitate this, we highlight and recommend some potential research methods from the well-established approach of the CDST (Hiver & Al-Hoorie, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019; Larsen-Freeman & Cameron, Reference Larsen-Freeman and Cameron2008; Verspoor et al., Reference Verspoor, De Bot and Lowie2011) as both approaches have much in common in “transcending disciplines” when probing the indicative elements influencing second language acquisition and development (Hiver et al., Reference Alves and Jakobsen2021; Larsen-Freeman, Reference Larsen-Freeman, Ortega and Han2017) in which translating/interpreting skill is an integral part (Wen, Reference Wen2016, Reference Alves and Jakobsen2021). Table 13.1 summarizes the three levels of the translating and interpreting aptitude model alongside their embedded components and features, augmented by recommended research methods that can be adopted in future research. In this sense, we hope that the aptitude model of translating and interpreting will not just transcend and break down cognitive, social, and linguistic boundaries within the individual, but also transcend disciplinary boundaries, achieving what Holmes has called “disciplinary utopia” (as cited in Xiao & Muñoz, Reference Xiao and Muñoz2020).
Table 13.1 The 3M aptitude model of translating and interpreting
| Levels | Micro Level (Multicompetence) (CDST-Driven) | Meso Level (Multimodality) | Macro Level (Multilingualism) |
|---|---|---|---|
| The focus of interactions with the translator/ interpreter | Linguistic competence; Cognitive processes; | External contexts; Technological affordances | Superdiverse environment; Social–cultural norms; Identity |
| Examples | Basic linguistic knowledge and skills; Basic cognitive abilities: Memory capacities, Attentional control; Coordination | Tools and aids (e.g., dictionaries); Equipment and technologies (lab facilities, machine translation) | Cultural norms; Social networks; Group dynamics; National identity Language policies; Ideologies; Attitudes; Beliefs; Pragmatics |
| Research methods recommended | Think-aloud protocols; Psychometric and cognitive testing; Neurocognitive techniques (EEG, fMRI, etc.) | Classroom observation; Audio–video recording; Questionnaires; Surveys; Interviews Human vs. machine translation comparison | Questionnaires; Surveys; Ethnographies; Narrative analysis; Social network analysis; Corpus-based studies; Computer modeling |
Looking to the future, then, a translanguaging research agenda for translating and interpreting studies can expect to help frame and guide future research toward more specific directions, couched within the “translanguaging turn” in translating/interpreting theory, research, and practice (Han, Wen & Runcieman, forthcoming). Future studies can be designed to investigate these interplaying indicative elements at each or all of the three depicted levels here, namely, the macro, the meso, and the micro. Also, given the interdisciplinary perspective adopted by the aptitude model, we call for synergetic cooperation and collaborations (even when it means “adversarial collaborations”; Wen & Schwieter, Reference Wen, Schwieter, Schwieter and Wen2022) among scholars to make concerted efforts from different “turns” of translating/interpreting studies and from neighboring disciplines, such as sociology and cultural studies, linguistics, applied linguistics, education, psychology, cognitive science, computer science, and neuroscience as well as from experts in more specialized research domains and diverse genres in arts, literature, law, and business, and even in sports and other more distal domains beyond humanities and social sciences. No doubt, the essence of the translanguaging theory lies in its flexibility, dynamics, adaptiveness, inclusiveness, and openness in breaking down cognitive, societal, linguistic, semiotic, and technological boundaries and artificial divisions and dichotomies (such as the social–cognitive divide: Atkinson, Reference Atkinson and Atkinson2011; Douglas Fir Group, 2016; Hult, 2019; and the quantitative–qualitative divide: Hiver et al., Reference Alves and Jakobsen2021). Such a translanguaging view and method is congruent with the current mainstream trends of multilingual societies of superdiversity, multiculturality, and multisemiotics (Ortega, Reference Liu, Wen, Skehan, Biedroń, Li and Sparks2019; Li, 2022). We cannot wait to embrace this new and exciting translanguaging era in translating and interpreting studies (Runcieman, Reference Alves and Jakobsen2021; Han, Wen & Runcieman, forthcoming).















