

6.1 Introduction
With this chapter, we will turn to the grammar of discourse. We will start with the most direct interface of the sentence and the discourse, which is the expression of connections between sentences. This means that grammatical aspects of the discourse itself will now become part of our discussion. Although we are still dealing with elements of grammar, we will explore how they connect to form units beyond the level of the sentence. The discussion will therefore center no longer just on sentence analysis, but will turn to concepts and ideas closer to the field of discourse analysis (see our note on this subfield of linguistics in Chapter 2).
While there are two ways of expanding a sentence, subordination and coordination, discourse proceeds through the sequence, that is, the coordination, of sentences (or non-clausal units). Within the sentence, the elements that can be coordinated are phrases or clauses: Example (1) illustrates the coordination of two noun phrases and (2) the coordination of two clauses. Coordinating conjunctions, such as and, but, and or, also commonly referred to as “coordinators,” are the lexical category for elements that signal phrasal or clausal coordination.
(1) Jimmy likes apples and pears.
(2) Jimmy likes apples and Jimmy likes pears.
Coordinators connect elements of equal syntactic status. None of the constituents in (1) or (2) is a dependent element, which is why coordinate structures within the sentence are also described as “non-headed” constructions (Reference Huddleston and PullumHuddleston & Pullum 2002: 1275).
It is only a small step from a non-headed structure, that is, from coordination within the sentence, to the coordination of utterances in discourse. Coordinators also connect units of discourse, although, in writing, we often feel a little uncomfortable about using an item like and or but at the beginning of a new sentence. However, in speech, initiating a new turn using one of these coordinators is common, even when the next turn is uttered by a different speaker. This is shown in Example (3), where speaker b adds an utterance (And Jimmy likes pears) to the one made by speaker a (Jimmy likes apples).
(3)
a: Jimmy likes apples. b: And Jimmy likes pears.
The overt expression of the coordination of utterances is something very common in natural discourse, starting already in early childhood speech. In Example (4), which is from the CHILDES corpus, a large database of child interaction with their caretakers, the clause beginning with and easily connects two utterances across the turns of two different speakers (there will be more on connectives in language acquisition in Section 6.2).
(4)
child: Nina has dolly sleeping. adult: The doll is sleeping too? child: And the man’s sleeping on the big bed. [Nina; 2 years, 2 months] (example from Reference DiesselDiessel 2004: 159)
The early and natural use of a coordinator for expressing connections in discourse, that is, without constructing a proper coordinate sentence, shows that the discourse-related function of coordinators, that is, their use as connectives, is part of their grammatical function.
Leaving the domain of grammar in discourse and turning to the grammar of discourse also means that the elements we will be looking at are more loosely connected to the core clause. For example, one could argue that, in a sequence like (3) or (4), and does not establish a syntactic connection at all, but works as a discourse marker (a category to be discussed in more detail in Chapter 8). Think of sentence connectives not so much as a way of expanding the core clause, but of adding a new one. This means you are adopting a discourse-oriented view: The function of a coordinator as a discourse connective is more to initiate than to truly connect (Biber et al. 2021: 87). Still, and, for example, does not carry all properties of a real extra-clausal element (these properties will be discussed in detail in Chapter 8). For instance, sentence-initial and, as in (3) and (4), is not mobile in position, unlike a connective adverb like however, and is not usually set off by intonation or punctuation from the rest of the clause (Jimmy, *and/however, likes pears).
Using a term from discourse analysis here, the relationship between sentences as units of discourse is called conjunction. Note that this term has no plural here because it refers to an area of the grammar of discourse and not to the part-of-speech class of conjunctions. Conjunction in this new sense covers all words and expressions that connect sentences or sections in a text. In discourse analysis, conjunction constitutes one crucial area of discourse cohesion, which is the cover term for all sorts of linguistic ties in a text, including lexical ties, substituting expressions, or the phenomenon of ellipsis. Conjunction is a grammatical type of cohesion, referring to the grammatical ties that express the semantic and pragmatic relationships in a text. To put it most simply, conjunction expresses how what is to follow in a text is connected to what has come before.
We will start this chapter with a discussion of what is at first sight the most basic semantic type of conjunction: additive conjunction. This choice might surprise you, since the idea of “addition” seems to mean rarely more than just continuity in a text or discourse. Which raises the question: Why express addition in discourse at all? There is no obvious answer to this question, which is exactly why we want to ask why, in the case of a simple additive relation, the next sentence in a discourse does not always open without a connective. This option is what we call a “zero” coordination. The contrast to the coordination with and is illustrated in Examples (5) and (6).
(5) Jimmy likes apples. And Jimmy likes pears. (sentence coordination with and)
(6) Jimmy likes apples. Jimmy likes pears. (“zero” coordination)
In this chapter, we will explore this opposition of sentence coordination by and or zero more closely, using both the variationist and the text-linguistic approach. We will then proceed by discussing other semantic types of conjunction and see how their usage varies within and across texts.
 Go to Exercise 1 to apply the distinction between the coordination of clauses and of sentences.
Go to Exercise 1 to apply the distinction between the coordination of clauses and of sentences.
After reading this chapter, you will be able to:
distinguish coordination within the sentence from the use of grammatical elements as discourse connectives;
recognize and classify different elements that function as connectives;
identify the four semantic types of conjunction and their different forms of expression;
investigate characteristic patterns of the expression of conjunction in different types of discourse.
Concepts, Constructions, and Keywords
additive relation, adversative connectives, causative connectives, clausal coordination vs. sentence coordination, conjunction, connective adjuncts, coordinators, narrative mode, temporal connectives, “zero” expression of sentence coordination
6.2 Additive Conjunction from a Variationist Perspective: Overt Marking vs. “Zero”
Additive conjunction expresses a relation of “addition” in the discourse. The connective element can be one of the additive coordinators, that is, and or or, or it can be an adjunct with additive meaning. Additive adjuncts include the adverbs moreover or furthermore, and prepositional phrases such as in addition or in the same way. Using a syntactic coordinator, most notably using sentence-initial and, is therefore only one out of several syntactic options to initiate a new sentence and to connect it to the preceding discourse.
An additive relation can also apply if there is no overt discourse connective (as in (6) above: Jimmy likes apples. Jimmy likes pears.). There is no real semantic difference between (5) and (6): Additive conjunction constitutes a proper case of variation in the area of discourse syntax. The choice of marking or zero must therefore be one governed by the discourse. Which contribution to the discourse does and as a connective make at all, in the light of this semantic equivalence? Does it make a difference whether a speaker or writer uses initial and or not? Discourse analysts have shown that, within a sequence of utterances, a change from zero connections to sentence- or turn-initial and signals some kind of “turn” within the discourse (Reference SchiffrinSchiffrin 1987). By analogy, a change from and to zero can have a similar effect. This means, if there is a preference in a given context to use and, or no and, this is exactly what leaves the speaker with the possibility for a switch in order to express some kind of contrast.
Let us turn to an example. You are probably aware that many style manuals do not consider and at the beginning of a sentence in written text to be a good choice. In contrast to speech, where we often continue by using and, a written text, like a novel, will mostly contain zero connections between sentences. Still, we sometimes find individual occurrences of sentence-initial and in such texts, for example, when and signals the end of an episode, which is what you see in Example (7).
(7) Deep down here by the dark water lived old Gollum, a small slimy creature. I don’t know where he came from, nor who or what he was. He was a Gollum – as dark as darkness, except for two big round pale eyes in his thin face. He had a little boat, and he rowed about quite quietly on the lake.
Gollum got into his boat and shot off from the island, while Bilbo was sitting on the brink altogether flummoxed and at the end of his way and wits. Suddenly up came Gollum and whispered and hissed:
“Bless us and splash us, my precioussss! It guess it’s a choice feast; at least a tasty morsel it’d make us, Gollum!”
And when he said Gollum he made a horrible swallowing noise in his throat. That is how he got his name, though he always called himself “my precious.”

In Example (7), the function of the connective and in the penultimate sentence of the passage results from the contrast to the regularity of zero connections, as explained above. With the use of and at the beginning of the last paragraph in (7), the episode ends and Gollum is now readily introduced into the discourse. This function is similar to the one of the formula And they lived happily ever after, which we know from many fairy tale endings.
In contrast to written texts, in which sentence-initial and is used scarcely overall, the overt expression of additive conjunction is common in spoken discourse. The reason is that, in natural speech, and easily supports the mere continuity of the discourse, for example, as a filler item or a marker of progression. We all know oral storytelling that proceeds by the typical and then-connections, associated, in particular, with early childhood speech (see Figure 6.1).

Figure 6.1 And then-connections in early childhood storytelling
In early childhood speech, children do not yet connect their utterances by way of a coordinator. Conjunction comes to be expressed approximately around their second birthday (Reference Bloom, Hafitz and LifterBloom et al. 1980), the first coordinator, in fact, being and. Based on data from the CHILDES corpus, we know that and is used as a discourse connective before it is used as a syntactic coordinator, that is, it connects turns or discourse units before connecting clauses within the sentence (Reference DiesselDiessel 2004). The evidence for this finding is intonation, in that the uses of and connecting sentences in discourse, and not constituent clauses, are preceded by an intonation pattern and/or a pause indicating the end of that utterance. Children tend to use independent utterances beginning with and especially after a speaker change (Reference DiesselDiessel 2004: 159), like in (8):
(8)
child: Piggy went to market. adult: Yes. child: And piggy had none. [Naomi; 2 years, 7 months] (example from Reference DiesselDiessel 2004)
In (8), which was produced by a child aged two years and seven months, and occurs as a marker of speech continuity. This function of and is similar to a pattern we also see in adult speech, from which the children obviously learn this.
Another reason why and is common in speech is that it can connect elements on all levels of discourse organization. These elements can be units of content or information, as in Example (8), or different verbal acts. This means that sentence-initial coordinators have a semantic or a pragmatic function. In that respect, they differ from many other discourse connectives. Take, for example, the dialog in (9), where a nutritionist is discussing Halloween snacks. Some of the uses of and relate to the content of the talk, for instance, the different Halloween giveaways (gum, pretzels, tattoos). Other links in the text connect different verbal acts, such as explaining (And kids like gum) and, later, recommending (and actually, the kids will have these a lot longer).
(9)
It is a characteristic of and as a discourse connective that it can establish both semantic and pragmatic links among the units of a discourse. By contrast, some connective adverbs and phrases, like in addition, provide semantic links only, that is, they connect ideas (as in Sugarless gum. […] In addition, there are pretzels), but less easily different verbal acts (?In addition, the kids will have these a lot longer.)
To summarize, we have seen that the basic function of an additive connective in discourse is to signal continuation and that this is ultimately the most basic way of turning utterances into discourse. If and is used, the additive link can support a semantic and/or a pragmatic relation between utterances. In spoken discourse we find the expression of additive meaning to be much more common than in written discourse, where it is subject to a prescriptive attitude (see our Good to Know box on prescriptive grammar below). Another reason is that a written text, like an essay or a blog entry, already possesses a material continuity through the medium or genre, making the support of mere continuation less obvious.
We have also seen how the discourse function of and as a connective arises from the contrast to zero, that is, we have so far looked at the connective using the variationist approach (as introduced in Chapter 2). Turning to the text-linguistic approach in Section 6.3, we will explore how the use of sentence- and turn-initial and varies across different types of discourse.
 Good to Know: Prescriptive Grammar and Sentence-Initial Coordinators
Good to Know: Prescriptive Grammar and Sentence-Initial CoordinatorsThe interest in grammar in discourse is something that linguists share with language instructors. Perhaps you have experienced yourself a rather negative attitude against the use of coordinators at sentence beginnings. School teachers often express a critical attitude toward sentence-initial and when they supervise and grade young children’s writing (Reference CrystalCrystal 1995). Nowadays, grammar checkers also play a role: By putting a wavy line under any sentence-initial coordinator, they also impose a rule against them. Other sources adopt a more descriptive attitude. The American Heritage Dictionary notes the existence of a prescriptive grammar rule that judges sentence-initial and as “incorrect,” but goes on to state that “this stricture has been ignored by writers from Shakespeare to Joyce Carol Oates” (www.ahdictionary.com). A usage-based reference grammar, such as the GSWE (Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021), comments on the existence of the proscription, but takes an interest in it only as far as the attitude helps to explain register variation. For example, the proscription of sentence-initial and is influential for the expression of conjunction in academic prose, but much less so in informal texts. Overall, while prescriptive sources have an impact on patterns of language use, they do not necessarily have an impact on grammar development. We return to this distinction in the account of textual variation that follows in Section 6.3.
6.3 Text-Linguistic Variation: Additive Conjunction in Different Types of Discourse
So far, we have seen that additive conjunction is the most obvious relation of continuity in discourse and, in that, competes with the zero expression of sentence coordination. Following this discussion based on the variationist approach, we now turn to the text-linguistic perspective. Note that this perspective means that we will look just at the occurrence of and at the beginning of sentences and no longer compare zero beginnings and uses of and. Following our explanation given in Chapter 2, a text-linguistic approach here means that the object of investigation is the pattern of occurrence of additive conjunction in different types of texts.
Let us first turn to written discourse, where we can expect a strong influence of the prescriptive attitude against sentence-initial and. For example, the GSWE describes the prescription as being “most influential in academic prose,” whereas the use of and as a connective is higher in fiction and news texts, mostly because these also contain embedded dialog (Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021: 87). Interestingly, there is also corpus data from academic discourse in which the connective and does not turn out to be all that infrequent. One study found that sentence-initial and, compared to other additive connectives (e.g., moreover, furthermore, or in addition), was “the most frequently occurring additive marker in academic writing” (Reference BellBell 2007: 184). Figure 6.2 illustrates the occurrence of sentence-initial and in the corpus of that study (average rates per 100,000 words as the dependent variable on the y-axis), showing the results here for five different academic journals (the predictor variable on the x-axis).

Figure 6.2 Initial and in five academic journals Per ~100,000 words.
As we can see in Figure 6.2, sentence-initial and is used in academic texts, but particularly in journals from disciplines in the humanities (history, philosophy, anthropology). By contrast, the use of initial and seems to be much lower within disciplines from the natural sciences (psycholinguistics, chemistry). We can explain this finding if we come back to one aspect of the use of and that we discussed in Section 6.2. We saw there that it can help structuring the discourse by switching from zero to the use of and in order to signal a certain turn in the discourse. Similar to the shift from zero to and in Example (7), where the sentence with and concluded a chain of actions, and in humanities discourse was also found to conclude “argument chaining” (Reference BellBell 2007: 194). As an illustration, check out Example (10):
(10) Gilligan’s reporting also relied solely on a single Downing Street source, Minister of Defense employee and former UN weapons inspector David Kelly. Kelly claimed that […]. In the end, this series of events, one of many narratives surrounding the Iraq war and the intelligence that enabled the war, would lead to the August 2003 Hutton Inquiry in Britain, an attempt to explore Kelly’s death that also engaged prewar intelligence and the reporting of the BBC. And it is with the Hutton inquiry that dramatic historiographies of the nascent Iraq War began to make their way to the British stage, […]. (COCA, Academic, 2007)
The text excerpt in (10) contains and at the beginning of the last sentence, which is also the end of the author’s chain of argument. By using and, the writer is able to mark a contrast: Since one form of connection, namely zero, has been the norm so far, deviating from that norm of connection is apt to signal that something different is coming. In (10), for example, when using and, the author turns from the listing of facts to a generalization and thereby concludes the line of argument.
Turning to spoken discourse, for the reasons we discussed in Section 6.2, we can expect that sentence- or turn-initial and is considerably more frequent. In contrast to the results for written discourse shown by Figure 6.2, in which all rates per 100,000 words are below 50, a simple search for initial and in different sections of COCA (described in the toolbox of this chapter) enables us to confirm this assumption. For example, when we did this search, there was a rate of occurrence of almost 1,000 per 100,000 words in spoken news (9,629 per 1 million words in Fox, details in the toolbox). The toolbox also demonstrates again (see also Chapter 2) how to calculate the rates of occurrence for different sections, and Exercise 5 (Level 2) asks you to discuss more data on the use of and in some written sections of COCA.
 Studying Rates of Occurrence of Connectives in a Corpus
Studying Rates of Occurrence of Connectives in a CorpusWhen we want to retrieve sentence-initial and in an electronic corpus, we can use the corresponding part-of-speech (POS) tag for the word class of conjunctions and add a full stop plus capitalize and. For example, having applied this search to four sections in the COCA corpus, we received the following number of hits (note that, if you are using a corpus such as COCA, to which text samples are constantly being added, the exact frequencies increase from year to year): 1,719 tokens in academic writing (field of education), 4,375 in academic writing (humanities), 60,662 in spoken news (Fox) and 131,478 in spoken news (NPR). These numbers confirm our understanding that sentence-initial and is much more typical of spoken discourse, but they also seem to offer a challenge in that the number in one type of speech is twice as large as in the other.
We therefore need to take into account that the four sub-corpora in COCA are different in size. When we did the search in 2019, the Fox news section had 6.3 million words, while the National Public Radio (NPR) corpus had 17.4 million words. In the academic sub-corpus, the sub-corpus for education had 9.4 million words and the humanities one had 11.9 million words. As a next step, we therefore need to calculate normalized rates of occurrence, as described in Chapter 2, which will provide us with averaged values for the occurrence of sentence-initial and for each corpus section.
Using the formula given in Chapter 2 (which is: (raw count ÷ total word count) × reference size in number of words), the rates of occurrence per million words look like this:
These numbers clearly confirm that written and spoken discourse differ considerably in the use of and at sentence beginnings. Both academic disciplines have much lower rates than the spoken news. By contrast, the difference within the discourse type of spoken news now appears to be less distinct. What looked like a noticeable difference when dealing with absolute frequencies (131,478 on NPR being more than twice of the 60,662 occurrences in Fox) has turned out to be one due mainly to corpus size. However, the finding that some academic texts contain considerably more occurrences of and at sentence beginnings than others has remained robust.
A final aspect of our discussion of the use of connective and in different types of discourse will concern the mode of discourse (see Figure 2.2 in Chapter 2). Next to the opposition of speech and writing, which we have dealt with so far, we want to show that it is the presence of the rhetorical mode of narration that is also more closely associated with the expression of additive conjunction than other modes of discourse. To understand why the discourse we refer to here is more about mode, rather than genre, note that narration not only means telling personal stories and anecdotes, or writing fiction, but is a term that also captures the way information is presented in the discourse of news, politics, or science. Narration is described as a “basic” mode of structuring a text, one that applies to many genres (Reference VirtanenVirtanen 1992). Note that speakers also narrate extensively in conversations, which is why the analysis of oral storytelling is an important issue in conversation analysis.
Why is a narrative mode relevant to the phenomenon of additive conjunction? The defining property of narration is that the discourse verbalizes experience, which is why narrative discourse typically deals with past events that happened in a sequence. Discourse in which the sequence of two, or more, sentences corresponds to the sequence of events has been described as possessing a “narrative syntax” (Reference LabovLabov 2013). To cite a famous example by E. M. Reference ForsterForster (1927), the sequence The king died. And then the queen died. has narrative syntax, even though it does not necessarily have a plot, which would suggest some kind of causal relationship (as in The king died. And then the queen died of grief.) A narrative mode of discourse therefore means that the text has a structure that is based on experience and chronology.
The connective and, the basic form of expression for continuity, is highly suitable for this mode of discourse and for the narrative syntax (also compare Figure 6.1), which is supported by observations based on spoken discourse. For example, in a study based on the Fisher corpus, a corpus of American telephone conversations, by far the most typical pairwise combination of connective elements in sentence-initial position was and in combination with then (Reference Lohmann, Koops, Kaltenböck, Keizer and LohmannLohmann & Koops 2016). The score for and then was about three times as high as the next combination with and in the hierarchy (which was and so). Without going into the exact measure of how the difference was calculated (if you are interested, you could consult the reference), this finding reflects a close association of the occurrence of connective and with narrative syntax and temporal continuity in a text. Interestingly, the reversed sequences also occurred at distinctly different frequencies: so and, but not then and, was also observed (see Reference Lohmann, Koops, Kaltenböck, Keizer and LohmannLohmann & Koops 2016: 442 and Section 8.4 on discourse marker sequences).
Let us also turn to written discourse, which will highlight that, despite the close association with oral storytelling, the use of sentence-initial and in narration is not necessarily a matter of an oral or colloquial style. The excerpt in (11) is from a historical academic text, taken from Robert Hooke’s Micrographia, which is a famous scientific text of the seventeenth century. We know that, in those early days of science, scientists often reported, that is, narrated, their scientific activities, rather than presenting a proper argument (Reference OhDorgeloh 2005).
(11) About eight years since, upon casually reading the Explication of this odd Phænomenon, by the most Ingenious Des Cartes, I had a great desire to be satisfied, what that Substance was that gave such a shining and bright Light: And to that end I spread a sheet of white Paper, and on it, observing the place where several of these Sparks seemed to vanish, I found certain very small, black, but glittering Spots of a movable Substance. […]
The passage illustrates what we have just described as a “narrative” syntax: The sequence of the clauses and sentences corresponds to the sequence of the steps in the experiment. Using and to initiate a new sentence (And to that end I spread …) or clause (and on it … I found) reflects the narrative mode of this discourse, which was common in those early scientific texts.
In sum, we have seen that, from the text-linguistic perspective, and is a discourse connective that turns out to be associated with spoken and with narrative discourse. In addition to this text-linguistic pattern, we have seen that and in written discourse is not altogether uncommon and enables the writer to mark an argumentative shift.
Go to Exercise 2, which is about the association of the connective and with the narrative mode of discourse, and to Exercises 6 and 7 (Level 2) for interpreting data on sentence-initial and in written discourse. Find out more about the use of and in spoken discourse in Exercise 3.
6.4 Connective Adjuncts
So far, we have dealt with one semantic type of conjunction, the expression of additive conjunction. We concentrated our discussion on the discourse connective and, which belongs to the lexical class of coordinators but also functions as a discourse connective. We now turn to other connective elements, which differ from and syntactically (they are adjuncts rather than syntactic coordinators) as well as semantically (by expressing a relation beyond mere addition).
As we discussed in Section 6.2, a connective adjunct can be an adverb or a phrase. There are simple adverbs, such as so or then, which just express the relation in discourse, while more complex adverbs and connective phrases combine the meaning of a discourse relation with an element referring back to something in the previous discourse. These different items could be ordered in a cline of increasing complexity, in which the meaning of the discourse connection, expressed either by the adverb or by the preposition, is enriched by more and more material. An example of such a cline (for temporal connectives) is shown in Figure 6.3.
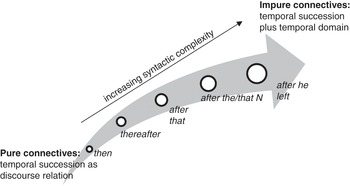
Figure 6.3 Cline of temporal connectives
The categorical distinction corresponding to the beginning and end of the cline in Figure 6.3 is the one between “pure” and “impure” connective adjuncts (Reference Huddleston and PullumHuddleston & Pullum 2002: 777). For example, then is a pure connective, as it just expresses a temporal succession in discourse. By contrast, phrases with a temporal preposition (after that/the N) do not just connect, but also specify the temporal domain within which the clause applies, which is why they are impure connectives. Whereas impure connectives also add content, pure connective adjuncts are just functional elements within the grammar of discourse.
We can equally apply this distinction to the other types of conjunction: For example, a connective adjunct for expressing a result or reason can come from the lexical class of adverbs, like so or consequently, but it can also be a phrase, such as as a result or for this reason. These phrases do not just connect, but combine the connective element with a way of pointing backward: As a result (of this) or for this reason, for example, establish a causal relation and refer backward to this or this reason. Similarly, under these circumstances is an additive connective, but at the same time functions as a clausal modifier, carrying abstract locative meaning.
Impure connective adjuncts belong more closely to the core clause and are not only a phenomenon of the grammar of discourse. The borderline status between sentence adjunct and discourse connective can be made obvious by checking whether the adjunct can be the focused element in an it-cleft construction (see Chapter 5 for more on cleft constructions). See, for example, the contrast between (12a) and (13a), where only the impure connective adjunct in (13a) can be foregrounded by a cleft construction, as in (13b):
a. Jimmy likes fruit. Consequently, he likes apples.
b. Jimmy likes fruit. *It is consequently that he likes apples.
a. Jimmy likes fruit. For this reason, he likes apples.
b. Jimmy likes fruit. It is for this reason that he likes apples.
Still, the distinction between pure connective elements and clausal modifiers as impure connectives remains a little fuzzy. For this reason, when turning to the semantic types of connective adjuncts in Section 6.5, we use pure connectives as examples wherever possible. Just bear in mind that there are many more items that can be used within each category.
Consult Exercise 3 for an opportunity to retrieve the different syntactic categories that function as connectives in a text.
Turning now to the semantic types of links that different connectives provide within discourse, we use an established semantic classification. According to this classification, there are four main types of discourse relations, which are listed in Table 6.1.
Table 6.1 Semantic types of conjunction and their syntactic realizations
| Examples of … | … additive adverbs | … additive prepositional phrases |
|---|---|---|
| Additive | also, alternatively, besides, moreover, similarly | in addition, for instance |
| Adversative | however, yet, conversely, instead | despite this, by contrast |
| Causative | so, hence, consequently | as a result, for this reason, because of this |
| Temporal | first(ly), then, finally, previously | after that, at the same time, in the end, next time |
Next to additive conjunction, discussed at length in Section 6.3, you see in Table 6.1 that there are three other core semantic types. Let us look at each of these below by variation on a single example. You will see two instances for each semantic type, because we also want to distinguish between semantic and pragmatic uses of these relations in discourse. As discussed above when looking at the discourse function of and, this distinction relates to the question of whether the link is one based on the content of the discourse or on what the speaker/writer is doing (the verbal act).
Adversative: The adversative relation is similar to the additive relation but adds something to the discourse in a contrastive sense.
(14) In this class, you do not have to submit a paper. Instead, you are required to write at least a paragraph for every session. (adversative, semantic)
(15) In this class, you do not have to submit a paper. Instead, let me tell you how I would like you to work here. (adversative, pragmatic)
Causative: The semantic type of causative (also sometimes referred to as “causal”) connectives expresses relations such as result, purpose, and reason.
(16) In this class, you do not have to submit a paper. Consequently, there will be more time for reading. (causative, semantic)
(17) In this class, you do not have to submit a paper. So what do you have to do instead? (causative, pragmatic)
Temporal/sequential: Temporal relations express a proper temporal progression, or they relate to the internal relations of ordering or structuring the discourse.
(18) In this class, you do not have to submit a paper. Next time, this will be different. (temporal, semantic)
(19) In this class, you do not have to submit a paper. Now, what are the reading assignments? (temporal, pragmatic)
When looking at examples (14) through (19), you may have noticed that some connective adjuncts, like instead, express a semantic or a pragmatic connection in discourse. Others, notably so, now and then, characteristically express a pragmatic relation. As you will learn in Chapter 8, this latter type of adverbs is likely to become a real extra-clausal element, that is, a discourse marker. Classifying them as discourse markers means that one emphasizes their function as a bracketing device within the discourse, while dealing with them as connectives here means we focus on the connections that they express.
Turning to the role of discourse in the use of connectives, we will take a closer look at academic texts in Section 6.5. Choosing these texts is not random, since connectives are often used to support scientific argumentation. Before turning to this discourse type, you should go to Exercise 4 to identify the four semantic types that we have discussed in this section.
6.5 Connectives in Academic Discourse
To conclude our discussion of connectives, we will look at the usage of connectives in academic English. The findings that we discuss here are mainly about research articles and textbooks, but we will also turn to some differences between professional academic and student writing.
For a first look at some findings, the obvious question to ask is whether all semantic types discussed in Section 6.4 are used in academic writing to roughly the same extent. For example, since doing science usually means presenting evidence in order to develop or contradict a position, it is plausible to assume that expressions of causative and adversative relations are more likely in academic texts than temporal or additive connectives. This means that we expect causative and adversative connectives to be more pervasive in academic texts than expressions of the other two relations.
Table 6.2 gives us a first idea whether this assumption is borne out by corpus-based results. The data was collected for a study of connective adjuncts in English (and Chinese) academic writing (Reference GaoGao 2016). The table shows the results for English academic articles, based on a corpus of research articles from four different disciplines.
Table 6.2 Normalized frequency of connective adjuncts in academic articles
| Semantic type of connective adjunct | Rate of occurrence (per 10,000 words) |
|---|---|
| Additive | 1.14 |
| Adversative | 0.73 |
| Causative | 0.58 |
| Temporal/sequential | 0.43 |
| Total | 2.88 |
The results in Table 6.2 are normalized rates of occurrence, which show that, counter to our initial expectation, additive conjunction is the most pervasive semantic type expressed by connectives in academic texts: Its frequency is about twice as high as the frequency of causative or temporal connectives. More in line with what we predicted, the adversative type is also quite common in academic texts. With regard to our initial assumption, causative conjunction occurs to a lower extent than expected.
Remember that, since we are using the text-linguistic approach here, this data documents a pattern as characteristic of a discourse type. Academic discourse is dense in both information and argumentation, which is what the presence of additive and adversative connectives plausibly reflects. Other work dealing with academic registers has found similar proportions in related discourse types. For instance, in academic textbooks the most frequent connective adjuncts are however, thus, for example, and therefore (Reference BiberBiber 2006).
It is interesting to compare this pattern of professional academic discourse to the academic texts produced by students. A data set that allows for this comparison is shown in Table 6.3, based on writings from the field of literary studies (Reference Shaw, Charles, Pecorari and HunstonShaw 2009). The table gives the results (rates of occurrence) for five connective adjuncts, and not for all adjuncts used in the text, which is why the numbers do not reflect the overall use of connective items. However, the total of connectives is given in the final row.
Table 6.3 Frequency of five connective adjuncts in academic writing
| student corpus literary writing | professional corpus literary writing | professional corpus adjusted for density | |
|---|---|---|---|
| however | 122.6 | 61.9 | 93.3 |
| yet | 104.0 | 57.5 | 86.7 |
| thus | 80.5 | 55.2 | 83.2 |
| therefore | 86.7 | 16.7 | 25.2 |
| for example | 50.8 | 22.0 | 33.2 |
| all connectives | 844 | 560 | – |
The table shows the frequency per 100,000 words of five specific connectives and the overall number of connectives in different types of academic writing.
By looking at the first three columns of Table 6.3, we may be surprised to see that the frequency of the five connectives is higher in the texts written by students than in professional academic writing. We could speculate on whether or not this difference is due to a lack of experience, resulting in an overuse, but one could also argue that it can be due to a difference in genre. After all, student essays are not (yet) exactly the same type of writing as published research articles.
Apart from this difficulty of comparison, the results in Table 6.3 pose another challenge, which is dealt with by the numbers in the fourth column. Since it turned out in the data that there is an overall higher frequency of connectives in the student corpus, the results for the professional corpus had to be adjusted for their density. This adjustment was necessary because, ultimately, the author of that study wanted to know how frequent each of the five connective elements was in comparison. For example, how frequent would however have been if both groups of writers had used connectives to the same extent? To this end, the frequency of each adjunct had to be adjusted for density. An adjusted frequency results from multiplying each individual rate of occurrence by the ratio of the total frequencies, that is, here by 844/560. For example, however has an adjusted frequency of 93.3 (844 ÷ 560 × 61.9). This value would be its rate of occurrence in professional literary writing if this discourse had overall the same rate of occurrence for connectives. In this way, the adjusted numbers in the fourth column of Table 6.3 inform us about the frequency that each item would have if the overall density of connectives were the same in both corpora.
Resulting from this adjustment, Figure 6.4, based on Table 6.3 (columns two and four), with normalized rates of occurrence as the dependent variable on the y-axis, enables us to compare the two types of discourse for their pattern of use of the five connective elements.

Figure 6.4 Five adjuncts in student and professional literary criticism
Figure 6.4 highlights two outcomes. On the one hand, it shows that the texts produced by students by and large have a similar pattern of occurrence for these five connectives as the professional discourse. For example, both groups of writers use however and yet most frequently. On the other hand, there are also differences, for example, in that four out of the five connectives show higher rates of occurrence in the writing by students. One might conclude that students overuse these connective expressions, but we also have to bear in mind the limitations of the data set (with just five lexical items). It would equally make sense to assume that the professional writers used a wider range of connectives, including and or but. Exercise 8 (Level 2) will return to this question.
In sum, the occurrence of connectives in academic texts has indicated that the different semantic types and expressions of conjunction do not vary randomly, but with the discourse type. It has also become obvious that the overt expression of conjunction is to some extent dependent on the experience of the writers and on the genre. In the literature, many other patterns of genre variation are discussed (for some, see our notes for Further Reading at the end of this chapter). For example, there is a well-known preference for temporal connectives in narrative and instructive texts and for the expression of additive conjunction in descriptive and informative texts. It can also be quite interesting to look at your own academic writing, which is what we suggest in Exercise 9.
6.6 Summary
In this chapter, we have introduced you to one area of the grammar of discourse, looking at the various syntactic elements that function as discourse connectives. We started with one semantic type of conjunction, the additive relation, and explored the use of and as one possible connective for expressing this relation. We discussed the close association of the use of sentence- or turn-initial and with spoken and narrative discourse, as reflected in corpora by higher rates of occurrence in the corresponding discourse types. We also saw that, in discourse where additive relations are less commonly expressed, switching to and at the beginning of a sentence enables the writer to signal the end of a chain or some kind of turn.
We then turned to the different semantic classes of conjunction and looked at their syntactic realizations as well as at their occurrence in academic texts. We learned that there is a characteristic usage of the four types of conjunction within the academic register, but that their use also depends on the writer. For example, we saw that students tend to use more connectives, but show less variation, compared to the texts written by more experienced academics.
We also touched on the procedures for dealing with the frequencies of connectives as gathered from large-size corpora. For corpus sections of a different size, we saw how to deal with normalized rates rather than absolute frequencies. For interpreting rates of occurrence against the background of a different density of the overall category, you learned how to adjust frequencies of individual items for their density.
6.7 Exercises
Level 1: Classification and Application
1. Identify all cases of clausal coordination within the sentence and of the use of a coordinator as sentence connective in excerpt A. What are the criteria that you go by? Looking at the occurrences that you find, and considering that this is a children’s book, is there a pattern you expected to see?
A. Once upon a time there was a deep and wide river, and in this river lived a crocodile. I do not know whether you have ever seen a crocodile; but if you did see one, I am sure you would be frightened. They are very long, twice as long as your bed; and they are covered with hard green or yellow scales; and they have a wide flat snout, and a huge jaw with hundreds of sharp teeth, so big that it could hold you all at once inside it. This crocodile used to lie all day in the mud, half under water, basking in the sun, and never moving; but if any little animal came near, he would jump up, and open his big jaws, and snap it up as a dog snaps up a fly. And if you had gone near him, he would have snapped you up too, just as easily. (Reference RouseRouse, The Crocodile and the Monkey, 2019)
2. Discuss whether the occurrence of and as a discourse connective in excerpt B is from the context of a narrative or a non-narrative mode in the discourse. What are the linguistic signals that indicate the presence of narration? Why do you think and is used, in contrast to the sentences beginning with zero-connections?
B. Wim Wenders’ “Alice in the Cities” is about a disinterested togetherness between a German journalist (with a heart of a poet) in the middle of a creative block and a pre-adolescent girl who unexpectedly found herself in his care. It is also about a unique psychological atmosphere which is created by these two protagonists and which becomes the very style of the film – relaxed, tender, warm, more than just life. Thirdly, the film is about creative process when the object of creative effort is life itself. And, finally, it is about the geography of two cultures, American pre-globalist (and impulsively entrepreneurial) and European post-fascist (knowingly existential). (CORE, mixed register, 2009)
3. Underline all connective adjuncts in passages C and D. Indicate whether they are formally adverbs or prepositional phrases. Which ones are pure connectives (in that they do not add content, but only structure the discourse, as explained in Section 6.4)?
C. In a nutshell, can you explain the process? First we break down the shot to determine the number of layers that will be needed based on the subject matter, shot length and camera movement. Then the individual elements are rotoscoped out so that they can be manipulated independently. Next we apply depth and roundness to the individual elements using proprietary software and then we need to paint in the occlusions that were created by offsetting those objects as part of the depth process. Basically we round the objects and then shift them left and right to create the offset that would appear if you were in the position of the camera. Then we clean it up so that the viewer doesn’t know it’s been manipulated. (CORE, Interview, undated)
D. Incredibly, you can design three identical websites using exactly the same design and wording but with only the colours changed between them and elicit entirely different responses from visitors to each of the sites. For this reason alone, colour should be your main consideration when looking at the design of your website or even your company’s corporate colours. (CORE, Advice, 2012)
4. Classify all sentence connectives (in italics) in the following examples by the four semantic types of conjunction (additive, temporal, adversative, causative).
(20) […] when I returned from the bedroom, Thomas Jefferson and his toolbox were gone. I went outside to look for him and saw that his bright yellow van was still parked out front. I waited a few moments, not knowing what to do. Finally I approached the van and saw that Thomas Jefferson was sitting inside, holding his face in his hands. (COCA, Fiction, 2012)
(21) The volume highlights three particular assumptions that are inherent to and embedded within current trauma discourse. First, this discourse operates on the basis of a strongly individualist approach to human life, with a marked emphasis on the disengaged self and on intrapsychic conflicts. However, this notion of the self may not be valid in many non-western cultures, which are predicated on alternative notions of the self and its relationship to others. Secondly, it is assumed that the forms of mental disorder that are described by western psychiatry map unproblematically onto those found elsewhere. However, in non-western contexts, it is likely that the idioms of distress vary considerably; the emergence of a particular symptom does not necessarily mean that it has the same meaning or significance across different cultures. Finally, the emergence of a professionalized trauma discourse has tended towards the handing over of memory to experts to pronounce on its meaning and significance. (COCA, Academic, 2008)
(22) Adolescent relationships often take unexpected twists and turns. Therefore, it is important to regularly reflect on the process and outcomes associated with peer network interventions. (COCA, Academic, 2013)
(23) An experimental randomized design would allow for an evaluation of whether implementation of the SCS model itself, rather than other potential variables (e.g., school policies, other programs), cause observed outcomes. Therefore, the current study was implemented to utilize a randomized design within a large urban school district with more than 80,000 students. (COCA, Academic, 2013)
Level 2: Interpretation and Research Design
5. Table 6.4 contains the results from a search in COCA for occurrences of and at sentence beginnings. Why are the results difficult to compare, and what could you do about this? Which news sections are similar in their use of and, and can you try to explain why?
6. Collect your own set of data about the usage of sentence-initial and in two different genres from a corpus (use, for instance, sub-sections of magazine and newspaper texts in COCA). Set up a table with absolute as well as normalized rates of occurrence. Choose a diagram that is suitable to illustrate your results.
7. In Section 6.2. we argued that and at the beginning of a sentence is much more likely to occur in speech than in writing. In a study of differences across types of professional spoken discourse, Reference Iyeiri, Yaguchi, Baba, Askedal, Roberts and MatsushitaIyeiri et al. (2010) found the following rates of occurrence for the use of turn-initial and:
Range of rates of occurrence in three speech files (per 10,000 words) Speech at press conferences 0.6 – 1.3 Speech at meetings on reading tests 11.9 – 23.2
In the light of what you have learned in this chapter about the discourse functions of initial and, discuss possible reasons for the difference.
8. It has been suggested that a possible reason for the higher frequency of connective adjuncts in student writing is that professional writers hesitate less to use and and but, instead of connective adjuncts like furthermore or however. Look at the frequencies (taken from Reference Shaw, Charles, Pecorari and HunstonShaw 2009) as given in Table 6.5. Do they confirm this assumption? Write a short text to discuss your observations. As background of your discussion, take into account what we noted in Section 6.2 about the negative attitude that many adult speakers have toward the use of sentence-initial coordinators in written discourse.
9. Analyze a sample of your own academic writing for the expression of conjunction. Which connectives do you commonly use? Imagine an editor criticizing your language use for containing sentence-initial coordinators (and or but) or connective adverbs (like so, now, and then). If you had a conversation with this editor, what would you say from a linguistic perspective?
Table 6.4 Frequency of connective and for three written sections of COCA
| NEWS (Local) | NEWS (National) | NEWS (Sports) | |
|---|---|---|---|
| sentence-initial and | 3,013 | 4,709 | 9,523 |
| size of section (words in million) | 6.0 | 6.6 | 14.0 |
The table shows the absolute frequency of connective and and the corpus size for three written sections of COCA.
Table 6.5 Occurrence per 100,000 words of four types of connectives
| student corpus literary writing | professional corpus adjusted for density | |
|---|---|---|
| however | 122.6 | 98.3 |
| furthermore | 6.2 | 13.8 |
| and | 6.2 | 48.0 |
| but | 27.2 | 57.0 |
Further Reading
One classic reference work for the grammar of discourse, or cohesion, in English, on which this chapter also builds, is Reference Halliday and HasanHalliday & Hasan (1976). Its basic classification scheme for cohesion, as also used in this chapter, is covered by most textbooks on discourse analysis or discourse studies; see, for example, Reference Renkema and SchubertRenkema & Schubert (2018: ch. 6).
Reference SandersSanders (1997) introduces the distinction of semantic and pragmatic relations in discourse. See Reference Spooren and SandersSpooren & Sanders (2008) on the acquisition of discourse relations and Reference van Silfhout, Evers-Vermeul and Sandersvan Silfhout et al. (2015) on experimental work that documents how readers benefit from connectives as processing signals in texts.
For connectives in academic writing, see, for example, Reference BellBell (2007) and Reference GaoGao (2016). The acquisition of sentence coordination in early childhood is described in Reference DiesselDiessel (2004: ch. 7). Reference Kalajahi, Seyed, Neufeld and AbdullahRezvani et al. (2017) document the frequency of connectives in different sections of the BNC and COCA. Reference DupontDupont (2021) describes the occurrence of adversative connectives (contrasted with French) based on large corpora of editorials and research writing.
7.1 Introduction
In Chapter 6, we started dealing with the grammar of discourse, that is, with elements of grammar that have a function across the boundary of the single sentence. We saw that each sentence, as an upcoming unit of discourse, is related to the previous discourse by different types of relations and that these relations can be expressed by different connectives. In this chapter, we turn to another type of sentence connections: those created by pronouns and ellipsis. For example, when talking about a friend, perhaps in one sentence you call this friend by name and, in the next, using a pronoun (he, she, they). Given that you and your interlocutor already know what or who you are talking about, you could also omit the reference to that person altogether (Sue? Is not here.). In this way, pronouns and ellipsis also establish ties across sentence boundaries, which originate in so-called “chains of reference.”
Reference is the technical term for the relation between a linguistic expression and its referent. The relation is illustrated in a famous model, the semiotic triangle, which you see in Figure 7.1. The model highlights that the meaning of a linguistic expression cannot be said to be directly the object (or any other aspect of the world) that the speaker is dealing with. Instead, any real-life entity that language can be about has an indirect relation to its linguistic expression, the two being linked via a learned mental representation (called the concept) in the speakers’ minds. For example, when talking about your friend as my neighbor or the guy next door, you refer to that person by uttering these noun phrases since you have learned that the lexemes neighbor and guy can both express the concept of a male adult person.

It is very common that speakers and writers refer to the objects, persons, or ideas they talk about more than once. The relation between several linguistic expressions which have the same referent is called co-reference. It results in a sequence, or “chain,” of co-referential elements, which point backward or, more rarely so, forward in the text. Co-referential elements in discourse can be lexical expressions, that is, when the same lexeme is used more than once, or pronouns, the category of grammar for expressing co-reference.
As an example, take a look at the excerpt in (1), which is a text about two professional basketball players. In the magazine article, one player, Nurkic, is quoted talking about a colleague, Lillard. In the beginning, Lillard is referred to by his name and as the guy, that is, by two noun phrases with a lexical head, which set up Nurkic’s use of pronouns for referring to his colleague. In the last sentence of (1), reference to that player is omitted altogether (Ain’t no fake).
(1) I talked to Nurkic earlier this season, before his injury, and in the middle of a career year, he credited Lillard, the guy who’s never going to let his big man walk away to the end of the bench. “It’s hard to explain day-by-day what he means to us,” Nurkic said. “But I think the most important thing for me, and for anybody on the team. He never changes. No matter what happens to the team or to us as individuals, he’s the same person. Ain’t no fake.” (COCA, Magazine, 2019)
So, the entire chain of co-reference in (1) looks like the one in Figure 7.2.
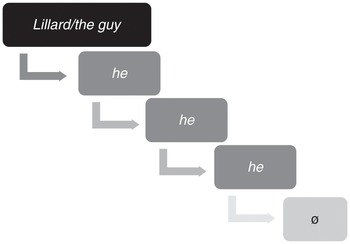
Figure 7.2 Chain of reference based on Example (1)
While the last sentence in (1) contains an elliptical reference (henceforth ellipsis), in the three previous clauses Nurkic refers to Lillard using a pronoun. A pronoun is thus the grammatical expression of a co-referential noun phrase. Note that, at the discourse level, the grammar of pronouns works somewhat differently from the grammar inside the clause. In formal linguistics, inside the clause, co-reference is shown by what is called coindexing, which means two elements within a structural unit refer to the same referent. For example, the sentence John said he would be late can be interpreted with coindexing (Johni said hei would be late), shown by adding the same index i twice, but would also be grammatically correct with no coindexing, that is, with John and he being different persons (Johni said hej would be late). By contrast, co-reference in discourse never relies on coindexing, but is always established pragmatically. Co-reference in discourse relies on retrieving the most likely referent for a pronoun from the previous discourse.
Like connectives, which we discussed in Chapter 6, pronouns and ellipsis contribute to the grammatical cohesion within discourse. By contrast, using different words for the same referent establishes lexical cohesion. For example, if Nurkic in (1) had wanted to use lexical instead of grammatical cohesion, he could have referred to Lillard by his name or as my colleague, somebody’s brother or friend, or the like. In this chapter we will only deal with co-reference in as far as it is expressed by grammatical cohesion.
In the following, we will first look at the different types of pronouns and ellipsis. We will then explore some characteristic patterns of occurrence of pronouns and ellipsis as observed in different kinds of discourse. We will see that these patterns are closely related to the thematic structure of a text. Stories, for instance, deal with a limited number of characters and therefore often possess more referential continuity than, say, non-fictional texts, such as dictionary entries. But there are also systematic differences among different kinds of stories. For example, research on reading comprehension found that stories for children tend to contain more continuous chains of reference, since this is less demanding for the working memory (Reference Oakhill and GarnhamOakhill & Garnham 1988). Researchers have also observed that, for persons with reading difficulties, a text with fewer pronouns and more lexical repetition is easier to process (Reference Yuill and OakhillYuill & Oakhill 2010). We will return to some psycholinguistic aspects of pronouns and their interpretation in sections 7.2 and 7.3. We will also discuss that some types of discourse contain fewer pronouns than others because they require a high degree of precision, for instance, professional texts in science or law. We will touch upon such differences when turning to the text-linguistic approach in Section 7.4.
After reading the chapter, you will be able to:
detect the different forms of pronominal reference and types of ellipsis in texts;
describe and explain the patterns of the occurrence of pronouns and ellipsis in different types of discourse;
interpret and develop a research design for studies of referential expression in discourse.
Concepts, Constructions, and Keywords
accessibility, anaphoric/cataphoric reference, demonstrative pronouns, ellipsis, endophoric/exophoric reference, extended reference, givenness, personal pronouns, reference, semantic/pragmatic principles (of pronoun interpretation), subject ellipsis, textual/situational recoverability, world knowledge
7.2 Types of Pronominal Reference
Pronominal reference is one of the cohesive ties within the system of cohesion as proposed by the classic text-linguistic work of Reference Halliday and HasanHalliday & Hasan (1976). Within that system, reference is described as the semantic relation between two elements in discourse that refer to the same entity, as illustrated by Example (2):
(2) Sue left. Maybe she’s sick.
Sue and she in (2) are co-referential. Pronouns express co-reference by virtue of being grammatical pro-forms, that is, they instruct the reader to search in the surrounding discourse for an interpretation. In (2), the pronoun is pointing backward, which is called anaphoric reference. When a pronoun is pointing forward, this is called cataphoric reference. In contrast to anaphoric reference, which easily connects noun phrases across sentence boundaries, cataphoric pronouns are more challenging to interpret and are therefore more likely to be used within the sentence. For example, in (3), she is likely to refer to Sue while, in (4), it could also be the case that somebody else left for the reason of Sue being sick.
(3) Since she left, I suppose that Sue is sick.
(4) She left. I suppose that Sue is sick.
More complexity is added by the fact that the pronoun they can be used as a singular or plural pronoun. So, in a sentence like Since they left, I suppose that Sue is sick, they could or could not be used cataphorically. If you’re interested in pronouns and language change, read our Good to Know box on singular they.
Good to KnowWord of the Decade: Singular they
The American Dialect Society voted they as “Word of the Decade” in 2020, recognizing the growing use of the pronoun to refer to an individual person without making any assumption about their gender identity (American Dialect Society, 2020). (Note what we just did? We used their to refer back to the singular noun person, which is exactly what this usage note is about.) The use of they to refer to an individual person is also known as “singular they.” Singular they/them/theirs is not exactly new. It dates back to the fourteenth century and can be found frequently in the works of much-admired writers, like Jane Austen (“they say every body is in love once in their lives”) and William Shakespeare (“There’s not a man I meet but doth salute me, as if I were their well-acquainted friend” Reference ShakespeareShakespeare, The Comedy of Errors, 1981 [1623]: IV.iii). They is also not the only pronoun that can be used to refer back to singular and plural antecedents. Most people who think that singular they creates unhelpful ambiguity don’t seem to be too bothered by the fact that the pronoun you can also refer to singular or plural antecedents and that sentences like You are right are, if seen in isolation, just as ambiguous as sentences with they. It should be noted that in many of the

examples of singular they, they refers back to an antecedent that is notionally plural. The pronoun everybody, to go back to the example from Jane Austen, for example, is grammatically singular (we would say Everybody is happy, not Everybody are happy), but notionally everybody refers to more than just one person. This is not really what the rise of “singular they” is all about. No, singular they
was crowned Word of the Decade because it is increasingly used as a pronoun referring to an individual, in response to the need of a pronoun that doesn’t classify individuals as either male or female. People may prefer to be addressed as they because they think of gender as a non-binary category, in which case neither he nor she nor a more complex expression like he or she would be appropriate to refer to them. Therefore, we should really be talking about the rise of they as a non-binary pronoun instead of just “singular they.” At American universities and schools, for example, it is now quite common for students and instructors to state their pronouns when they introduce themselves, with they being a common choice, and everyone is expected to respectfully use the pronouns a person selects for themselves.
In 2017, the Associated Press Stylebook, the most influential style guide for journalists in the US, updated its section on gender to reflect that “[n]ot all people fall under one of two categories for sex or gender, according to leading medical organizations, so avoid references to both, either or opposite sexes or genders as a way to encompass all people” (Reference EastonEaston 2017). Specifically, in stories “about people who identify as neither male nor female or ask not to be referred to as he/she/him/her: Use the person’s name in place of a pronoun or otherwise reword the sentence, whenever possible. If they/them/theirs use is essential, explain in the text that the person prefers a gender-neutral pronoun.” For example, in a picture essay about people who returned to New York City beaches as soon as they re-opened in summer 2020 after the first wave of the COVID-19 epidemic, The New York Times wrote about a person called Kelsey Rondeau, “who uses they/them pronouns,” that “Rondeau was laid off from their work as a live entertainment performer when the pandemic began” (Reference RosaRosa 2020). Note that in this example the use of singular they is established as a personal choice before the pronoun is actually used, so that readers will not be startled. They likely would not be. In 2019 the non-partisan Pew Research Center found that 42 percent of adult Americans say that forms should list a gender option other than “man” or “woman” for people who don’t identify as either (Reference Geiger and GrafGeiger & Graf 2019). In the same year, Merriam-Webster announced that its dictionary would now include the non-binary use of they (“used to refer to a single person whose gender identity is nonbinary”) as one of the four standard meanings of anaphoric they. That same year several states in the US started offering “non-binary” as a third gender option on driver’s licenses. Social media platforms like Twitter, Instagram, or LinkedIn now allow users to include their pronoun choice in their profiles. Non-binary they has spread so quickly because it fills a need (better than newly created pronouns like zir or zem). It clearly deserves the Word of the Decade crown.
The process of pronoun interpretation, or, more technically speaking, anaphora resolution, is a fascinating topic. In principle, the meaning of a pronoun is very vague, as illustrated by the following Haiku, written by the American poet Clement Hoyt (Reference van den Heuvelvan den Heuvel 2000):

In real life, however, interpreting pronouns works pretty smoothly. Many discourse linguists have claimed that there is a principle of “natural sequential aboutness,” which means that we tend to interpret pronouns as referring to something or somebody that has just been mentioned (Reference BoschBosch 1983). This principle holds as long as our semantic and pragmatic expectations do not tell us otherwise. For example, following this principle, in (5), She and Sue are likely to be interpreted as co-referential while, in (6), they are not.
(5) She was sick. That’s why Sue took the day off.
(6) She screamed. That’s why Sue ran away.
In (5), both the discourse expectations triggered by the connective expression that’s why and our general knowledge conform to an interpretation whereby Sue left because she was sick. In (6), however, this natural interpretation of the second sentence being about the same referent as the first is blocked by our world knowledge, which suggests that screaming is probably not a reason why a person is leaving. We can therefore generalize that pronoun interpretation follows syntactic principles, as in (3), and an expected continuity of aboutness in discourse, as in (5), but that beyond the sentence there must also be a semantic and pragmatic plausibility.
The role of general, pragmatic knowledge in pronoun interpretation is an issue that has interested, in particular, psycholinguists. Reference EhrlichEhrlich (1980) carried out several famous experiments in which the interpretation of pronouns required either just grammatical knowledge or also a check for pragmatic plausibility. For example, in the sentence Jane blamed Bill because he spilled the coffee, the difference in gender determines that there is only one person that can be co-referential with the pronoun (assuming that both Jane and Bill choose traditional binary pronouns). By contrast, in Steve blamed Frank because he spilled the coffee the pronoun can refer to either of the two males. The interpretation that it was Frank, the one being blamed, who spilled the coffee thus requires a pragmatic inference, and not just grammatical knowledge. In Ehrlich’s experiments, it turned out that the subjects who were shown sentences of that type and then had to pick a referent for the pronoun, completed this task faster with those sentences that required just grammatical knowledge. It took them longer to interpret the pronoun if the two noun phrases were of the same gender and the subjects also needed to apply their world knowledge for pronoun interpretation. The insights gained from these experiments established a position most linguists nowadays agree with: Readers first apply grammatical knowledge when interpreting a pronoun and only turn to their wider, general knowledge when they need to.
Since the 1980s, more psycholinguists have sought to understand the details of the process of pronoun understanding. Two classic approaches stand out, which were originally in conflict with one another (for references, see the Further Reading section). According to one approach, speakers are found to apply grammar-based strategies when interpreting pronouns, such as a “subject assignment” or “grammatical role parallelism” strategy. For example, in an experiment subjects interpreted the referent of her in sentences like (7) and (8) differently, preferring the subject as the pronoun’s antecedent. By contrast, in a sentence like (9), listeners or readers are likely to interpret her as referring to Sally, presumably because they watch out for a “structural parallelism,” that is, for the same syntactic role of both the pronoun and its referent (Reference Chambers and SmythChambers & Smyth 1998).
(7) Sue defeated Sally, and all their friends criticized her. [her = Sue]
(8) Sally was defeated by Sue, and all their friends criticized her. [her = Sally]
(9) Sue defeated Sally, and the trainer insulted her. [her = Sally]
(10) Sue defeated Sally, and their trainer congratulated her. [her = Sue]
In contrast to such grammar-based strategies, in a sentence like (10), her is again more likely to refer to Sue, but this time due to the semantics of the verb congratulate. This interpretation relates to the world knowledge that readers and listeners have about the act of congratulating. Similarly, when subjects in an experiment were asked to complete a sequence like in (11) or (12), the difference in the last word of the first sentence caused different interpretations of the pronoun they. Here, it is again world knowledge about what kind of entities can be delighted and what kind of entities can be delicious which contributes to picking the right referent (Reference MitkovMitkov 2014).
(11) The children had sweets. They were delighted.
(12) The children had sweets. They were delicious.
The findings about sentences like examples (10)–(12) support what is called in the literature a “coherence-based” approach to pronoun interpretation, in contrast to the grammar-based strategies we illustrated above. Many linguists nowadays agree that there is truth in both theories and that neither a coherence-based approach nor grammar-based principles “can do it alone” (Reference ArielAriel 2013: 39; Reference Kehler and RohdeKehler & Rohde 2013). This position is in line with the treatment of pronouns as an area of discourse syntax, that is, with the view that pronouns are subject both to grammatical rules and usage-based principles.
Another property of pronouns is that they support the thematic continuity of a text. This function in discourse is not limited to third-person pronouns, which are most of the time interpreted as expressing an endophoric kind of reference. Endophoric reference means that the referential relation is located within the discourse (like the relation between the guy and he in Ex. (1)). By contrast, first- and second-person pronouns express a situational (technically termed exophoric) kind of reference, which means that the listener or reader is instructed to retrieve the referent within the discourse situation (for instance, the speaker being the referent of the pronoun I in the sentence I talked to Nurkic in (1)). Exophoric pronouns do not establish ties among themselves, but they can also be co-referential and contribute to the thematic continuity within a text. For example, in a textbook like this one, we sometimes address you, our readers, by the second-person pronoun you and thereby also create a continuity of reference. Note, however, that the distinction between first- and second-person pronouns as exophoric and third-person pronouns as endophoric pronouns is not absolute: Like it in the Haiku shown above, a third-person pronoun can also refer to an object or person outside the discourse, which means it can also be used exophorically.
To complete the set of pronouns within the system of grammatical reference, the last group to consider are demonstrative pronouns. Demonstrative pronouns are the elements this, that, these, and those, which in principle can be pronouns or demonstrative determiners (like in this book or those problems). Demonstrative pronouns contribute to grammatical cohesion since they are used, not only exophorically, referring to the local or temporal discourse situation, but also endophorically, referring back (or forward) in the text. When referring within the discourse, demonstrative pronouns often have what is known as a “propositional referent,” which means they refer to an entire proposition (Reference WebberWebber 1991). A case of propositional reference is illustrated in (14), contrasting with (13), where it co-refers only with the NP (a book).
(13) Charlotte wrote a book. It was a difficult read but the sales were spectacular.
(14) Charlotte wrote a book. This was a difficult job but the sales were spectacular. (Reference Çokal, Sturt and FerreiraÇokal et al. 2018: 276)
Psycholinguists have observed that readers have a clear preference for interpreting the pronoun it as referring to entities in discourse, and for this as referring to a proposition, like in the second sentence in (14). Measuring the reading times of subjects under different conditions in an experiment (it/this referring to either a proposition or an NP), researchers observed that it takes a subject longer to read sentence pairs different from the ones in (13) and (14), that is, sentences in which either a proposition is referred to by it or an NP referent is referred to by this (Reference Çokal, Sturt and FerreiraÇokal et al. 2018). Similar outcomes were achieved with children for whom it had turned out to be more difficult to process the pronoun it when its antecedent was a proposition rather than a noun phrase (Reference Megherbi, Seigneuric, Oakhill and BuenoMegherbi et al. 2019). These insights from psycholinguistics and language acquisition show that the processing of demonstrative pronouns in discourse is different, to some extent, from the one of personal pronouns: Demonstratives tend to instruct the reader to combine the subject and the predicate when resolving the pronoun’s reference. For this reason, demonstrative pronouns often have the function of expressing extended reference in discourse.
To sum up the types of pronominal reference we have discussed so far, take a look at Figure 7.3, which contains the different types of pronouns within the overall system of grammatical cohesion.

Figure 7.3 Pronouns within the system of grammatical cohesion
Using the typology in Figure 7.3 to detect and classify pronouns in discourse, you should now be able to take on Exercises 1 and 2.
7.3 Pronouns within Discourse
We now turn to the question of how pronouns are used in discourse, starting with a well-known pattern that most of you will know from reading or analyzing literature. Fictional narration makes frequent use of pronouns since, as noted in the introduction, telling a story typically entails some continuity of the characters. As examples, let’s have a look at the excerpts in (15) and (16), the initial paragraphs of two famous nineteenth-century English novels:
(15) There was no possibility of taking a walk that day. We had been wandering, indeed, in the leafless shrubbery an hour in the morning; but since dinner (Mrs. Reed, when there was no company, dined early) the cold winter wind had brought with it clouds so sombre, and a rain so penetrating, that further out-door exercise was now out of the question.
I was glad of it: I never liked long walks, especially on chilly afternoons: dreadful to me was the coming home in the raw twilight, with nipped fingers and toes, and a heart saddened by the chidings of Bessie, the nurse, and humbled by the consciousness of my physical inferiority to Eliza, John, and Georgiana Reed. (Reference BrontëBrontë, Jane Eyre, 1981 [1847]: 1)
(16) Emma Woodhouse, handsome, clever, and rich, with a comfortable home and happy disposition, seemed to unite some of the best blessings of existence; and had lived nearly twenty-one years in the world with very little to distress or vex her.
She was the youngest of the two daughters of a most affectionate, indulgent father; and had, in consequence of her sister’s marriage, been mistress of his house from a very early period. Her mother had died too long ago for her to have more than an indistinct remembrance of her caresses […]. (Reference AustenAusten, Emma, 1985 [1815]: 37)
In a literary studies class, you may have learned that it is the perspective of narration that determines most the choice of pronouns in a novel. If the story is told by a first-person narrator, first-person, exophoric pronouns are typically used (as in (15)). By contrast, as in (16), if the story is told by a narrator who is not a character, a novel is likely to contain more third-person pronouns. More specific aspects of pronoun use in literary discourse are discussed at length within stylistics. For example, in so-called “unreliable” narration, the referents of pronouns are often left opaque. A well-known example is the first sentence of the novel One Flew over the Cuckoo’s Nest, “They’re out there,” in which the anaphoric pronoun they cannot be familiar to the reader and is therefore used to signal the presence of an unreliable narrator (Reference ShortShort 1996: 268).
It is a general requirement, and one not limited to fictional narration, that interpreting a pronoun requires an NP that is retrievable. From the discourse perspective, this means that the referent of a pronoun must be given information, a status whose relevance we already pointed out in Chapters 3 to 5. We discussed there that the givenness of information is not always determined just by the discourse, but that givenness ultimately refers to a state of knowledge on the part of the addressee. Applied to pronouns, this means that whether or not a pronoun is felicitous ultimately depends on the status of the referent in the reader’s or listener’s mind, resulting from conditions of both memory and attention. We know that speakers also use and comprehend so-called “unheralded” pronouns, which have no explicit co-referring noun phrase, but make reference to knowledge and beliefs shared by the interlocutors (known as the “common ground”). For example, in a corpus study dealing with telephone speech, it was found that such unheralded, long-distance pronouns made up to between 5 percent (for he and she) and 13.9 percent (for they) of third-person pronouns, that is, in these cases a pronoun was used although another referent, to which the pronoun might also have referred, had intervened (Reference Gerrig, Horton and StentGerrig et al. 2011). For example, speakers on the phone variably referred both to their friends and parents as they and just assumed that their conversation partner would be able to interpret the pronoun from the context (e.g., They’re coming back tomorrow night).
From a psycholinguistic viewpoint, the givenness expressed by a pronoun reflects the mental accessibility of an element in discourse (Reference ArielAriel 1988). For example, referring to somebody by name usually marks a lower degree of accessibility than referring to that person by using a pronoun. Similarly, a definite noun phrase (the guy) marks a referent as being more accessible than an indefinite one (a guy). However, researchers have noted that what precisely determines different degrees of mental accessibility is a complex matter, influenced by many conditions in the discourse. Factors discussed in the pertinent literature range from the inherent prominence of referents in some situations (such as babies being almost always prominent in their parents’ mind) to being the topic of the discourse, to having been more or less recently cued or mentioned (for a summary, see Reference Ariel, Schilperoord, Sanders and SpoorenAriel 2001). In addition, the discourse itself creates expectations about the continuity of reference. For example, eye-tracking experiments have shown that subjects expect referential information to be less accessible if the discourse they listen to contains markers of disfluency (e.g., hesitation markers of fillers like uh or um). By contrast, fluency of the discourse and, in particular, deaccented noun phrases created an expectation of givenness, which led the subjects to choose the most directly accessible entity as the most likely referent (Reference Arnold, Tanenhaus, Gibson and PearlmutterArnold & Tanenhaus 2011).
In view of these many factors that influence what is more and less accessible to the reader or listener, it is helpful to look at pronouns in relation to other forms of reference. In a classic model, the different syntactic realizations of a referring expression are ranked in a so-called “givenness hierarchy” (Reference Gundel, Hedberg and ZacharskiGundel et al. 1993), in which the respective degree of givenness reflects a state within the addressee’s mind. As you see in Figure 7.4, pronouns rank high in these conditions: (stressed) third-person pronouns have the attribute “activated.” The ranking further highlights the unidirectional entailment of all options, showing that pronouns (he, she, it, they, this, and that) represent a kind of givenness that includes a familiar, identifiable, and referential status.

The position of pronouns within the hierarchy in Figure 7.4 shows that they are close to the “in focus” end of the scale. This means that the referent of a pronoun must be in the short-term memory, either due to the immediate co-text or to the context of the discourse (Reference Gundel, Hedberg and ZacharskiGundel et al. 1993: 278). However, how an entity enters the short-term memory, and how long it stays there, is again a complex question, to which psycholinguists have also dedicated a lot of research. For example, there are experiments designed to find out if reference is retrieved faster if the co-referential expression in the preceding sentence is focused. This would mean that a constituent highlighted within a cleft construction would be retrieved faster than a constituent that is not focused (e.g., it is easier to retrieve a giraffe as a target referent with a preceding sentence like What the kids like best about the zoo is the giraffes rather than It is only the kids that like the giraffes best about the zoo) (Reference Cowles, Garnham, Gibson and PearlmutterCowles & Garnham 2011). The results confirm the role of the previous discourse, even if they are not always conclusive because there are many other effects, for instance, grammatical subjects being always “preferred antecedents” (Reference KaiserKaiser 2011: 1659). Other experiments found effects of the structure of the discourse: In a text completion task, where students were shown text fragments with a protagonist that was either expressed by a noun phrase or proper name or by a pronoun and were then asked to continue the story, pronouns in the fragments caused participants to continue the same episode, whereas full noun phrases or proper names often prompted them to carry out a more substantial topic shift, for instance, they introduced a new character (Reference Vonk, Hustinx and SimonsVonk et al. 1992).
Good to KnowThe Secret Life of Pronouns – What Using Pronouns Can Tell about Speakers
James W. Pennebaker, the author of a famous book titled The Secret Life of Pronouns, is a psychologist who has done numerous studies based on automated word counts from large and diverse corpora. Much of his work has dealt with the question of the extent to which the frequency of certain word classes, especially pronouns, allows us to make predictions about the speaker. In Pennebaker’s work we find an in-depth look at some gender stereotypes, such as the one that women talk more emotionally and therefore use more personal pronouns (with less specific information) than men. Other findings from his work correlate a low use of pronouns, notably first-person singular I, with lying and self-deception. For example, in dating ads, the use of first-person pronouns was found to be the “best general predictor of honesty” (Reference PennebakerPennebaker 2011: 156). In other work, Pennebaker and various co-workers have been able to show that higher frequencies of pronouns in discourse go together with a lower social status and fewer chances of power, leadership, and academic success.
Such research outcomes are fascinating but, at the same time, they point to the limits of the area of discourse syntax as we have defined it. Yes, we are interested here in how grammar works in language use, that is, in discourse, but discourse syntax does not cover the question of how speakers of different character and background deal with different topics at different occasions. As we pointed out in Chapter 2, variation based on the background of the speaker is a core area of sociolinguistics. Out of the many aspects that define a discourse situation, aspects of social role and personality of speakers are highly complex variables for the study of language variation and fall outside the scope of this book.
Overall, both the position of pronouns within the givenness hierarchy and the insights from psycholinguistic work we discussed lend support to the position that pronouns are used “to maintain reference” (Reference Cowles, Garnham, Gibson and PearlmutterCowles & Garnham 2011: 317). This means they are generally associated with a high degree of continuity in discourse. We will now explore how this generalization accounts for different referential strategies within different types of discourse.
7.4 Pronouns across Types of Discourse
Before turning to pronouns, let us briefly consider the question of how spoken and written texts are likely to differ with regard to their patterns of reference in general. These patterns concern both the number of referents and the form of referring expressions preferred in a discourse. It is helpful to recall the semiotic triangle (Figure 7.1) here, because it highlights that referents are the different persons or objects dealt with in a text, while referring expressions are the linguistic forms chosen to write or talk about them. As we could see in the givenness hierarchy in Section 7.3, pronouns are only one linguistic option for expressing reference and thus only one aspect of the pattern of reference in a text.
Recall our initial example. When discussing the text excerpt on NBA basketball players in (1), we saw that different expressions (the guy and he) are used for dealing with the same referent. Similarly, the text excerpt in (17), which is about dog training, contains several references to dog owners: The writer uses the expressions dog owners, owners, puppy owners, and them. The text therefore has a similar referential continuity as Example (1), discussed at the beginning of this chapter, but, in comparison, we see it has fewer pronouns.
(17) Dog training can be a pretty overwhelming task, but proper training and socialization are very important for every dog. So many dog owners choose not to skip this step. Armed with snacks and patience owners usually get pretty good results at getting their puppies to listen to them. Although some puppy owners are not afraid to take this task to a whole new level. Take for instance Anna Brisbin, a voice actress, and a YouTuber from Los Angeles, who decided to train her dog, not in English but in Harry Potter spells. (Reference AndželikaAndželika 2019)

It requires an automated text analysis to investigate different types of discourse with respect to both the number of referents and of referring expressions, which is why we only report some general tendencies here. Overall, research comparing spoken and written discourse has found that conversation has the highest density of referring expressions, including many pronouns, and at the same time the lowest frequency of different referents. By contrast, academic and technical discourses possess a high frequency of different referents, but a lower total of referring expressions. News texts are characteristically high both in the total number of referring expressions and in the number of different referents. Fiction is found to possess the lowest total number of referring forms and a comparatively low number of different referents (all findings from Reference Biber and SvartvikBiber 1992). Note that these findings are about the overall number of referring expressions in the discourses investigated, not just about pronouns.
While determining the extent of all references requires a complex procedure of text analysis, varieties of discourse are more easily compared just for the occurrence of pronouns. Any corpus tagged for word classes enables you to do so, that is, retrieve and compare the frequency of pronouns across different discourse types in a corpus. For example, in COCA (where the part-of-speech tag for personal pronouns is _pp*), our search across different corpus sections at the time of writing this book yielded the frequencies shown in Table 7.1 (for dealing with individual frequencies per section, see the toolbox in Chapter 6). Bear in mind that the exact numbers will have changed by the time of your reading this chapter, since COCA, like many other corpora, is constantly being modified and enlarged. Note that, as explained in Chapters 2 and 6, the numbers from COCA that we use here are normalized frequencies, not the absolute frequencies of occurrence.
Table 7.1 Rates of occurrence of personal pronouns* in five sections of COCA
| Spoken | Fiction | Magazine | News | Academic |
|---|---|---|---|---|
| 87,508 | 91,321 | 42,026 | 38,693 | 19,009 |
* Per million words.
The bar chart in Figure 7.5 shows the frequency of pronouns in the five registers from Table 7.1 (the rate of occurrence per one million words is now the dependent variable on the y-axis). Figure 7.5 conforms to what we have already noted about the general pattern of reference in spoken as opposed to written discourse: Spoken discourse is distinctly higher in the frequency of pronouns than most written discourse. However, what we also detect is that the frequency of pronouns in fiction is even higher than in speech, reflecting that most fiction is narration, which usually has a high continuity in reference (the story characters). Another reason why spoken discourse has comparatively fewer pronouns than fiction may be the occurrence of non-clausal units in spoken language: Many utterances in spoken discourse are not complete sentences and contain few or no noun phrases at all (e.g., utterances like Fine or Great). As for written non-fiction, Figure 7.5 shows that magazine and news writing are considerably lower in pronoun use than speech, with academic texts being very low.

Figure 7.5 Distribution of personal pronouns in five registers
The rate of occurrence is per 1 million words.
The results in Figure 7.5 can also be understood in the light of the distinction of endophoric and exophoric reference we introduced above. Returning to the psychological conditions of pronoun interpretation (illustrated in Figure 7.4), an activated information status, the prerequisite for pronoun use, requires a shared discourse situation. In written discourse, this referential activation can rely on the physical continuity of the text, which ensures the interpretation of both endophoric and exophoric pronouns (like in examples (15) and (16)). By contrast, spoken discourse relies mostly on shared situational knowledge and is therefore typically higher in exophoric than in endophoric reference. Dissolving this distinction of speech versus writing a bit, we touch upon pronouns in electronic discourse in our next Good to Know box.
For practicing the retrieval and analysis of pronouns in discourse, turn to Exercises 3 and 4. We suggest in both exercises, not only to identify the number of pronouns, but to contrast these findings with the overall number of noun phrases. If applied to a single text or a small corpus, this analysis can easily be done manually, enabling you also to look at the proportion of grammatical, as opposed to lexical, forms of reference. Exercises 7 and 8 (Level 2) deal with the interpretation of data on pronoun use in other types of discourse.
Good to KnowPronouns in Digital Discourse – Written Speech or Spoken Writing?Over the last twenty years, web-based language use, such as the discourse of emails, text messages, postings or blog entries, has received a considerable amount of attention in discourse-related work (e.g., Reference SquiresSquires 2016). A core point of interest in this research is the question of whether electronic discourse is more like spoken or written discourse (e.g., Reference Renkema and SchubertRenkema & Schubert 2018, see also Chapter 9 for a more in-depth discussion). Since we saw in this section that spoken and written language differ distinctly with regard to the expression of reference, pronouns as a core area of grammatical cohesion are a good candidate for dealing with this issue.
Early work on electronic discourse emphasized that its use of pronouns is similar to speech. One study, for example, found a proportion of about 64 percent of all pronouns were first-person in computer conferencing (a genre comparable to forum postings; Reference Yates and HerringYates 1996). Other studies have found the language of weblogs to be more diverse. For example, early corporate blogging turns out to contain a considerable amount of exophoric, first- and second-person pronouns (Reference PuschmannPuschmann 2010), while other blog texts appear to be more exclusively based on endophoric reference (Reference HoffmannHoffmann 2012). In addition, blogs usually show a characteristic use of exophoric, demonstrative pronouns, with which their writers refer to other web-based material, such as pictures or videos. Web-based discourse is therefore not only constituted by grammatical cohesion within the text itself, but also relies on references to the many other components presented throughout the web. In addition to reflecting connections within the text or to a shared context, digital discourse thus certainly inheres a specific kind of givenness, which is due to its web-based environment.
7.5 Types of Ellipsis
Ellipsis is another type of grammatical cohesion in discourse. It results from the omission of an element that the listener or reader is able to recover, either from the previous discourse or from the discourse situation. Before we consider the discourse conditions of ellipsis, let’s explore which syntactic elements can be affected.
In the most common cases of ellipsis, the omitted element is a word, typically a noun, as in (18), but other types of lexical material are also possible, as illustrated in (19)–(21):
(18) These dogs are trained in English, those (dogs) in Harry Potter spells.
(19) I don’t train my dogs in English. Do you (train your dog in English)?
(20) That’s how you keep your dog from running away. (Do you have) Any questions?
(21) (I) Didn’t manage to keep the dog from running away today. (I) Had a horrible time.
Apart from these cases of ellipsis, there are also so-called “compressed” clauses (if necessary, when in trouble) (Reference Wiechmann and KerzWiechmann & Kerz 2013), which often have a formulaic character. These formulaic clauses are less directly triggered by the discourse context, which is why they will not be included in our discussion.
When ellipsis occurs, the reader or listener must recover the missing information from the discourse or the discourse situation. For this reason, discourse in which ellipsis occurs is usually highly interactive, such as conversation or texting. In conversation, the resulting utterances are often only clause fragments. For example, in its chapter dedicated to the grammar of conversation, the GSWE shows a proportion of 38.6 percent of the units of conversation in the corpus to be non-clausal (Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021: 1065). A dialog with non-clausal utterances is shown below in (22a): a sequence in which only three out of seven utterances are full clauses. The remaining four utterances are non-clausal (really, training dogs, yes, do you?), as illustrated by (22b) and (22c).
(22a)
a: So, you train your dog in Harry Potter spells? b: Really? c: What are you talking about? a: Training dogs. d: Yes. I don’t train my dogs in English. Do you?
(22b) (We are talking about) training dogs.
(22c) Do you (train your dogs in English)?
Ellipsis is common in spoken discourse for a variety of reasons, including speed and economy. The instances in (22a) are all follow-up questions or remarks within an ongoing dialog, in which knowledge of the previous utterance is easily presupposed. Verb phrase, or verb plus noun phrase ellipsis, is therefore a particularly common feature of highly interactive discourse.
Subject ellipsis, as in (21), is the most common subtype of noun phrase ellipsis, since, as also discussed in Chapter 4, the subject role is normally associated with givenness and being the topic. The phenomenon of subject ellipsis is also known as “zero anaphora” for languages other than English in which the subject position can be left empty (like Chinese or Japanese). However, sentences with no overt subject are not uncommon in informal spoken English (e.g., Reference OhOh 2005, Reference Oh2006). For example, subject ellipsis is again found to occur in utterances that are close follow-ups of a preceding utterance (a sequence like You know what I did last night? Ø Did a terrible thing … ; Reference OhOh 2005: 278).
We will focus on subject ellipsis in the remainder of this chapter, because it is an interesting characteristic of some informal types of written discourse, such as casual notes or informal letters, diary entries (Reference Haegeman and IhsaneHaegeman & Ihsane 1999; Reference NariyamaNariyama 2004; Reference WeirWeir 2012), or texts and emails. See examples (23) and (24) from online blogs of the CORE corpus:
(23) Yesterday had a fairly slow day. Went for a walk up Mt Rogers. Then had Nat and Andrew over to play […] (CORE, Personal Blog, 2009)
(24) Can’t eat, can’t rest. Went to see my doctor today who wrote me a letter to show them. (CORE, Personal Blog, 2007)
Focusing on subject ellipsis, we now turn to some patterns of its use in both spoken and written discourse.
Turn to Exercise 5 for identifying cases of subject ellipsis in a text.
7.6 Subject Ellipsis: The Discourse Perspective
In this section, we will directly combine the variationist and the text-linguistic perspective, exploring both the most common syntactic variants of subject ellipsis and the discourse types in which it occurs. Let’s start with the question of which syntactic types of subjects are preferred. One highly common type is ellipsis with the first-person singular (I) as subject NP, as in Example (25).
(25) When we moved into this house, inherited a then-5 yr old Thermador glass cooktop. We’ve now been here 10 years, so it’s celebrating its’ 15th year. We remodeled the kitchen 3 years ago, with new appliances, but I chose to keep the Thermador. Took awhile to learn how to regulate the heat properly, […] (COCA, Web, 2012)
In a study of informal discourse (covering natural conversation, TV dialogs, and letters), the proportion of first-person subject ellipsis, like in (25), ranged from 20.4 percent (conversation) to 47.2 percent (TV dialog) to 82.4 percent (letters) of all omitted subjects (Reference NariyamaNariyama 2004). This shows that first-person subjects are truly common, but not necessarily the most common type of subject ellipsis in all registers. For example, the same study found that ellipsis with the impersonal pronoun it made up 61.2 percent in conversation. It could be a matter of discussion whether conventionalized formulas such as doesn’t matter or sounds good, which also fell into this category, should be seen as proper, that is, syntactically productive, instances of subject ellipsis. However, it was rightly observed that many of these formulas also reflected a view of the speaker (doesn’t matter [to me], sounds good [to me]). For this reason, one could conclude that most subjects in subject ellipsis are “centred on the first person” (Reference NariyamaNariyama 2004: 258).
These outcomes show subject ellipsis as being closely associated with interactive, speaker-centered discourse, but the subjectless clauses found in letters also indicate that the personal, informal character is easily transferred to other registers. Especially in written discourse, where we expect sentences to be complete and explicit, violating this expectation can cause an inference of “casualness both in register and content” (Reference NariyamaNariyama 2004: 248). So, (I’ve) gotta go sounds more evasive and less binding than the complete sentence I’ve got to go, which implies a more concrete commitment on the part of the speaker. This effect of subject ellipsis is typically achieved in those kinds of written discourse that are meant to be informal or occur under limitations of space. An interesting register to look at in this regard is blog writing, the discourse we also used for illustration in (23) through (25). In a corpus of 204,997 words taken from blogs, there were 235 occurrences of subject ellipsis (Reference Teddiman and NewmanTeddiman & Newman 2007). Note that it would be even better to be able to relate the occurrence of subject ellipsis to the number of sentences in the corpus; however, as for this study, no syntactic parsing was carried out so that no number of clauses is indicated. Figure 7.6 gives the results for this data set, illustrating the proportions of the different types of subjects that were omitted. (This time we are presenting proportions as a pie chart; see our discussion of proportional frequency charts and Figure 2.6 in Chapter 2.)

Figure 7.6 Proportions of omitted subjects in online blogs
Figure 7.6 illustrates that, again, by far the majority (69 percent) of all cases of ellipsis in the corpus result from the omission of the pronoun I (sentences like hope this is alright, decided yesterday to do the trip). The study thus confirms that the main syntactic pattern of ellipsis, reflecting the speaker’s prominence, is not only a characteristic of informal speech, but also applies to informal writing.
Let us conclude our discussion of ellipsis in discourse by pointing out some parallels with the use of pronouns. When exactly do speakers make use of subject ellipsis within a given text or discourse? The core condition is similar to pronouns, namely that the referent needs to be accessible; for subject ellipsis, this means that it must be fully recoverable. In an elliptical reference, the referent is either anaphorically recoverable from the preceding text, or situationally recoverable, if the referent is retrievable within the surrounding situation.
Textual recoverability is illustrated by the contrast between (26) and (27). While the sequence of sentences in (26) is fine, in (27) subject ellipsis sounds odd and is unlikely to occur.
(26) Sue is very tired today. She came home late last night. (She) missed the bus.
(27) Sue is very tired today. She came home late last night. Bill couldn’t drive her. ?(She) missed the bus.
The reason for the difference between (26) and (27) is that, in (27), it is almost impossible to interpret Sue as the referent of the missing subject. To achieve this interpretation, the speaker would at least have to use a right-dislocation (Missed the bus, Sue).
The referent of a third-person pronoun (like he, she, or they), if omitted, can normally be retrieved from the preceding sentence. By contrast, it can also be a pronoun with an extended reference. As noted in Section 7.2, both it and this potentially signal reference to a proposition or a longer stretch of discourse as a whole. In (28), for example, it in the third sentence subsumes the entire previous sentence, that is, it refers to both events expressed by the constituent verb phrases.
(28) My mom is sick. I visited her yesterday and brought her a cake and flowers. (It) seems to have done her a lot of good.
Situational recoverability applies to the omission of subjects whose referent is identifiable, not within the text itself, but within the discourse situation. These subjects are most often first-person pronouns, like in the examples (23) and (24) already discussed above. However, other pronouns, such as you, he or she, and they, are sometimes also recovered situationally. In these cases, the situation clarifies the reference, which is what you see in Example (29):
(29) (I/you/we/he/she/they) should’ve known better.
Many conventionalized expressions rely on situational recoverability, such as wouldn’t mind/mind (a drink, coffee, …), will do, or see you later. These sentences are hardly perceived as cases of subject ellipsis, but they nonetheless require discourse conditions where the subject must be recoverable.
Turn to Exercise 6 for analyzing utterances taken from dialogs, applying the distinction between the textual and situational recoverability of subjects in ellipsis.
When doing Exercise 6, you will notice that the examples you are asked to analyze are from dialogs of TV series. The nature of this task highlights that the construction is often used in scripted dialog to indicate casual talk.
7.7 Summary
In this chapter, we have dealt with the grammatical ties in discourse that result from pronouns and ellipsis. We introduced the concept of co-reference and looked at different types of pronouns. We saw that, when expressing endophoric reference, pronouns establish co-referential ties, and, with that, chains of reference within discourse. By contrast, when used for exophoric reference, pronouns in the first place point to a shared situation. We also discussed principles of pronoun interpretation and the concept of givenness in discourse from a psycholinguistic viewpoint. We explored givenness in discourse in the sense of an entity being recoverable for the interlocutor, which means that the referent is mentally accessible. We then saw that this status of a referent is equally a condition of elliptical references and, more specifically, of subject ellipsis in discourse.
We discussed data concerning the use of both pronouns and ellipsis in discourse and saw that there are some characteristic patterns of text-linguistic variation. While exophoric pronouns and ellipsis are primarily indicators of an interactive and oral language use, we also looked at patterns of variation within the written medium, for example, pronouns in literary or electronic discourse and subject ellipsis in informal types of writing.
7.8 Exercises
Level 1: Classification and Application
1. Highlight all pronouns in the passage below, which is the beginning of the prologue of the story The Moon Maid by Edgar Rice Burroughs (2002). Classify each pronoun according to the boxes in Figure 7.3 (double-dipping is possible). Considering what you have learned about anaphoric and cataphoric reference and that this is the beginning of the book, would you expect the discourse to begin like this?
A. I met him in the Blue Room of the Transoceanic Liner Harding the night of Mars Day – June 10, 1967. I had been wandering about the city for several hours prior to the sailing of the flier watching the celebration, dropping in at various places that I might see as much as possible of scenes that doubtless will never again be paralleled – a world gone mad with joy. There was only one vacant chair in the Blue Room and that at a small table at which he was already seated alone. I asked his permission and he graciously invited me to join him, rising as he did so, his face lighting with a smile that compelled my liking from the first.
2. The referent of he, a boy named Julian, in the passage above is introduced in more detail a bit later in the novel. An excerpt of this section is given below. Identify all pronouns and classify them according to the classification scheme presented in Section 7.2. Are there cases of extended reference?
B. My name is Julian. I am called Julian 5th. I come of an illustrious family – my great-great-grandfather, Julian 1st, a major at twenty-two, was killed in France early in The Great War. My great-grandfather, Julian 2nd, was killed in battle in Turkey in 1938. My grandfather, Julian 3rd, fought continuously from his sixteenth year until peace was declared in his thirtieth year. He died in 1992 and during the last twenty-five years of his life was an Admiral of the Air, being transferred at the close of the war to command of the International Peace Fleet, which patrolled and policed the world. He also was killed in line of duty, as was my father who succeeded him in the service.
At sixteen I graduated from the Air School and was detailed to the International Peace Fleet, being the fifth generation of my line to wear the uniform of my country. That was in 2016, and I recall that it was a matter of pride to me that it rounded out the full century since Julian 1st graduated from West Point, and that during that one hundred years no adult male of my line had ever owned or worn civilian clothes. (200 words)
3. Analyze the text given in Exercise 2 for its rates of occurrence (per 100 words) of both nouns and pronouns (count strings of two nouns, like in Peace Fleet, even if not hyphenated, as one noun). How many different referents does the proper name Julian refer to in the text? How many referring expressions in the passage refer to the narrator’s grandfather, Julian 3rd?
4. The passage below is a history text about the peace treaty ending World War I. Look at the pattern of reference that the text shows and compare your observation to the results of your analysis from Exercises 1–3 above. Using the givenness hierarchy of Figure 7.4, find out which noun phrases in the text refer to a referent that is fully activated. Which ones have a referent that is only familiar or uniquely identifiable?
C. On 11 November 1918, an armistice came into effect ending the war in Western Europe – but this did not mean the return of peace. The armistice was effectively a German surrender, as its conditions ended any possibility of Germany continuing the war. Similar agreements had already been signed by Bulgaria, Turkey and Austria. However, the peace treaties which officially ended the First World War were not signed until 1919. In the interim, fighting continued in many regions, as armed groups pursued nationalist, revolutionary or counter-revolutionary aims. Russia was torn apart by a civil war, which claimed more Russian lives than had the world war. The peace settlements were imposed by the victors, rather than negotiated, and have since been criticised as laying the foundations of future conflicts. In fact, the conditions imposed upon the defeated powers were not unduly harsh, but the treaties contained many compromise solutions to difficult issues. As a consequence, their long-term success was limited, but they did not in themselves make the Second World War inevitable. (Imperial War Museum, 2021)
5. Identify the cases of subject ellipsis in the following discourse. Which ones rely on anaphoric recoverability, and which ones on situational recoverability? Is there a case of an extended reference for the omitted pronoun it? Which kind of discourse do you think this is from?
D. If the conservatory connection can be isolated from main house, it’s allowed (or was when I installed a rad in mine). Who’s going to know anyway!! Quite. Ours already had two radiators connected to the main supply, and also a building regs certificate. I’m guessing they fitted the radiators after the certificate was issued? Anyway, keeps the room usable all year round. We’ve got an air conditioning unit in ours, was fitted by the previous owners. Seems to work really well on the few occassions we’ve used it to warm it up. They’re supposed to be pretty efficient too, no idea on how much they cost to buy/install though. I’ve just gone through the rubbish job of lifting the old conservatory floor tiles and the screed to instal Heatmat on Thermal Insulation Boards … messy job, but oh my the difference is incredible, now have a room that can be used all year round. Got electric u/f heating in ours and it’s OK but uses a LOT of watts so given up with it for the winter. For the odd weekend that we do want to use the conservatory, esp over Xmas, I fire up a gas space heater, ten mins and it’s too hot. (CORE, Interactive Discussion, 2012)
6. How is the referent of each of the grammatical subjects omitted in the following utterances (taken from dialogs from the Corpus of American Soap Operas) recoverable in the discourse? Distinguish between anaphoric and situational elliptical reference (disregarding distance as a factor of recoverability). Discuss how your findings can be seen as being typical of scripted dialog.
| Angelo: | Oh, the hotshot lawyer. Yeah, I thought you looked familiar. Can’t believe your brother turned out to be a baby-napper. Seemed like such a stand-up kid. (SOAP, Young and Restless, 2011) |
| Clayton: | I found a relatively new investment group. Seemed like a good opportunity, but the past day or so I haven’t been able to access my account. (SOAP, Guiding Light, 2009) |
| Kendall: | It’s your journal. I carry it with me everywhere I go. I read it all the time. Makes me feel closer to you, like you’re still with me. (SOAP, All my children, 2011) |
| Carly: | The Galaxy Club. South of Market. I was very good at my job. Made great tips. (SOAP, As the World Turns, 2010) |
| Brooke: | And that’s something that Ridge could never get past. Took me a long time to realize that. (SOAP, Bold and Beautiful, 2009) |
Level 2: Interpretation and Research Design
7. In Section 7.4, we discussed the differences between spoken and written discourse and the properties of electronic discourse regarding pronoun use. Table 7.2 gives you the average rates of occurrence for the pronoun you across different types of blogs from the CORE corpus (CORE being an acronym for the Corpus of Online Registers of English). Discuss these findings in the light of the psycholinguistic background on pronoun interpretation, as discussed in Section 7.3. What kind of results would you predict for the occurrence of third-person, i.e., endophoric, pronouns against the general assumption which we discussed that pronouns are used to maintain reference?
8. Choose samples of two text varieties (approximately 500 words each) about the same topic and from the same medium (for example, a short news report and a commentary on the same topic). How do they differ either in their proportion of endophoric and exophoric pronouns or in the occurrence of personal and demonstrative pronouns? Formulate your research question (paying special attention to being specific about the object of investigation, which is in this case the textual varieties) as well as a hypothesis and a prediction about the difference that you expect to find. Present your findings both in the form of a table and as a suitable graph.
9. In Section 7.6, we discussed certain formulas containing subject ellipsis, such as doesn’t matter, sounds good, or would be nice. Can you think of other conventionalized expressions containing subject ellipsis? You may use your own speech, or look at some dialogs in series, films, or fiction.
10. Both newspaper headlines and advertising are well known for the frequent use of ellipsis. Collect five instances of elliptical sentences from each kind of discourse and compare them. How are they different in the form and function of ellipsis?
Table 7.2 Frequency* of you in five sections of the CORE corpus
| Opinion blog | Religion blog/sermon | Personal blog | Travel blog | News report/blog | Informational blog |
|---|---|---|---|---|---|
| 9,312.26 | 7,964.45 | 11,677.85 | 9,216.78 | 6,069.48 | 11,999.82 |
* Per million words.
Further Reading
There is a lot of interesting evidence on the interpretation of pronouns in the psycholinguistic literature. Classic references on grammar-based factors and the so-called centering theory are Reference Grosz, Joshi and WeinsteinGrosz et al. (1995) or Reference Chambers and SmythChambers & Smyth (1998). For the pragmatic, coherence-based approaches, see Reference ArielAriel (2013) and Reference Gardelle and SorlinGardelle & Sorlin (2015). For more recent, empirical studies on pronoun resolution, see, for example, Reference Holler and SuckowHoller & Suckow (2016).
The notion of accessibility is also discussed in the literature as “salience.” For psycholinguistic studies and the expression of accessibility/salience in discourse, including zero anaphora, see a special issue of Discourse Processes (Reference Sanders and GernsbacherSanders & Gernsbacher 2004) or Reference Branco, McEnery and MitkovBranco et al. (2005). Classic work on anaphora in English discourse is Reference FoxFox (1986, Reference Fox and Tomlin1987), on English in comparison to other languages, see Reference FoxFox (ed., 1996). Most work in stylistics also touches on pronouns in literary discourse, for instance, Reference ToolanToolan (2013) or Reference Gibbons and MacraeGibbons & Macrae (2018).
On features of grammatical cohesion in web-based discourse, see Reference Biber and ConradBiber & Conrad (2019: ch. 7) and Reference SquiresSquires (2016). Reference HoffmannHoffmann (2012) discusses grammatical cohesion, including the expression of reference, in personal weblogs. On ellipsis in different registers (for instance, conversation as opposed to storytelling), see Reference Travis and LindstromTravis & Lindstrom (2016).
8.1 Introduction
We now turn to some elements of discourse syntax which do not belong to the core clause but are placed outside, or inserted within, it. To start with an example, take a look at the sequence in Example (1) and its illustration in Figure 8.1, which is a sequence of utterances made by a literary critic on NBC.

Figure 8.1 Discourse markers as separate from the clause
|
You will notice that the elements marked in italics in (1) come from different syntactic categories: well is just a word, an adverb, whereas you know is, from a syntactic viewpoint, a minimal, somewhat incomplete, clause. However, we feel that these elements occur as rather separate from the rest of the construction, both in terms of their position and their function. For example, no content modification is added to the proposition of the sentence I think fans of Stephen King will see a lot in it by adding well and you know. The separation from the clause is also shown by the punctuation, which indicates that, in the original spoken discourse, the elements were set off by intonation.
The terminology used in the linguistic literature to refer to these elements is varied. Discourse markers, the term we are using here, is the most common term. Elsewhere, such elements outside or inserted within the clause are also referred to in the literature as discourse or pragmatic particles, parentheticals, or extra-clausal constituents.
This variety in terminology is symptomatic, in that it is a bit of a challenge to define both precisely and consistently what a discourse marker is. Syntactically, discourse markers are not only adverbs and considered “small” clauses, like the elements highlighted in (1), but also coordinating or subordinating conjunctions, such as and, but or because (or ’cause/coz, since we are dealing with speech here). From the point of view of their function, many discourse markers in fact express a connection, while others mark a boundary and thereby help organize speech. The borderline between connectives, as discussed in Chapter 6, and discourse markers is therefore a bit fluid. For example, the adverbs now and then can be temporal adjuncts, and also, when placed sentence-initially, temporal connectives, which is why we have already come across them both in Chapters 3 and 6. Now we will see that these adverbs also occur in discourse when no temporal connection is at play. While in the example in (2), now expresses a temporal connection, in (3), it does not provide a temporal frame for the clause that follows. In (3), the presence of another temporal adjunct (on Tuesday) further indicates that now is no longer part of the proposition, but that it only marks a boundary between two utterances.
(2) […] when I met my husband I was this strong, independent woman. Now, with three kids, I want to be taken care of. (COCA, Magazine, 2011)
(3) Thanks for helping to elevate and maintain the standards in our society. Now, folks, on Tuesday, I told you about […]. (COCA, Spoken, 1996)
When exploring additive connectives in Chapter 6, we noted a similar pattern for the varying uses of and. We saw that the conjunction variably expresses a semantic, additive relation between two propositions or a pragmatic turn, marking a boundary between utterances. As evidence for this distinction, we checked whether and can be replaced by in addition: if this is not possible, the relation is not semantic, but pragmatic, and and resembles more of a discourse marker than a connective (see Section 6.2).
Despite some overlap, discourse markers are therefore an area of discourse grammar that we will look at separately. In contrast to connective elements, one primary function of a discourse marker is to bracket speech or talk (Reference SchiffrinSchiffrin 1987), in the sense of marking a link or signaling a boundary between discourse units, like in Example (3).
The other function of discourse markers is that they typically provide some clue about the speaker’s or the listener’s role in the discourse (their attitude, current action, or the like). If you look again at the discourse markers in (1), you will notice that, in the given context, well marks the beginning of the utterance as a response and you know, in addition to bracketing the sequence, invites the listener’s participation or consent. Most discourse markers also have such an interactive function – they support the ongoing interaction.
In the following, we explore the role of several discourse markers and will take a closer look at these two functions. The discussion will focus on a selection of items, since the category of discourse marker comprises a large group of lexemes and lexicalized phrases, rather than a closed set of grammatical elements. We will start with a discussion of the category as a whole, focusing on its formal and functional characteristics in Section 8.2. We then turn to the functions of then as a discourse marker in Section 8.3 and to the question of discourse marker sequencing in Section 8.4. Section 8.5 deals with the discourse marker you know as used in different types of discourse and Section 8.6 with the question of how discourse markers emerge and develop. We are aware that a lot of interesting work in this area is about speaker-based variation, going beyond the role of discourse. See the boxes on like as a discourse marker as well as on discourse marker use and language proficiency later in this chapter and our recommendations for further reading at the end of this chapter.
After reading this chapter you will be able to:
recognize and describe the two primary functions that define a discourse marker;
find out where words like and, because, but, now, or, so, then, and well, or sequences like you know and I mean, are used as discourse markers, i.e., as units outside the clause, and where they are elements inside the clause;
retrieve discourse markers from a corpus and analyze their function using information from the surrounding discourse;
investigate patterns of variation concerning the position and sequencing of discourse markers.
Concepts, Constructions, and Keywords
discourse markers vs. freestanding markers (e.g., yes, ok), interjections (oh, ah), bracketing (speech or talk), inference, discourse marker sequence, comment/parenthetical clause, matrix clause hypothesis, grammaticalization
8.2 Discourse Marker: A Category of Grammar?
Let’s start by defining the category of discourse markers by those attributes that are most widely agreed upon in the literature (for example, Reference DikDik 1997; Reference SchourupSchourup 1999; Reference Kaltenböck, Keizer and LohmannKaltenböck et al. 2016). One attribute, which we have already discussed, is syntactic: an element is a discourse marker if it occurs outside or in addition to the core clause, that is, if it is optional. We saw in the examples in the introduction that this property often means that the discourse marker is set off from the clause by intonation. In scripted speech or online writing, punctuation has a corresponding function, although we must be aware that, especially in online writing, punctuation is often used quite creatively. Overall, a first characteristic of a discourse marker is that it tends to occur at syntactic boundaries, very commonly at sentence beginnings, but also parenthetically within the clause or in the right clause periphery, that is, at the end of the clause (for more on this, see Section 8.3 below). In (1), for example, we have seen the use of you know in all three positions: in the beginning, in the middle, and at the end of the clause (you know, I think fans of Stephen King will see, you know, a lot in it, you know).
This more peripheral syntactic status of the category of discourse markers has a semantic counterpart in that the presence of a discourse marker does not affect the propositional meaning of the sentence. For example, if we delete now from the sentence in (3), as in (4), the sentence does not gain a different interpretation in the sense of its proposition. Remember that, as outlined in Chapter 1, the proposition is the truth-conditional meaning of a sentence, which, in (4), remains unaffected.
(4) Thanks for helping to elevate and maintain the standards in our society. Ø, folks, on Tuesday, I told you about […].
The third defining feature of the category of discourse markers is their function in discourse. As we have already seen in the introduction, there are two main functions of a discourse marker: they are used to connect or mark a boundary within speech (bracketing function), and they provide cues for the understanding between speaker and listener (interactive function). Behind these tasks, there is perhaps a more general, superordinate function, relating to the discourse as a whole. Discourse markers contribute to the fact that a discourse, our talk, needs to make sense as a whole, that is, they support its coherence. Since discourse develops linearly (in contrast to sentence grammar, which largely builds upon hierarchical relations; as explained in Chapter 2), marking connections and boundaries simplifies the process of understanding for the hearer and thereby helps to “negotiate” what should be a meaningful whole (Reference Jucker and ZivJucker & Ziv 1998). For example, in (3) above, repeated here as (5), the occurrence of now enables the listener to recognize a turn in the discourse, which is the beginning of a new section of the talk.
(5) Thanks for helping to elevate and maintain the standards in our society. Now, folks, on Tuesday, I told you about […]. (COCA, Spoken, 1996)
Having discussed the core properties of discourse markers, let us turn to their syntactic realization. Since our focus is on grammar here, we will mainly deal with those items that could in principle also be used syntactically, that is, as elements inside the sentence. For a start, we will take a look at a set of discourse markers that is widely discussed in the literature. This set is based on Reference SchiffrinSchiffrin (1987) and comprises the discourse markers and, because, but, I mean, now, or, so, then, well, and you know. Comparing this list to other possible elements that are also often seen as discourse markers (e.g., Reference BrintonBrinton 1996), we can recognize which types of items could in principle be added. The difference is illustrated by Figure 8.2:

Figure 8.2 Two inventories of discourse markers
The discourse markers in the largest font size in Figure 8.2 are the ones we are going to focus on in the following. There are two reasons for this choice. First, several of the elements that are not highlighted do not necessarily precede, follow, or interrupt a clause. The items oh, ok, (all) right, and yes/no commonly occur just on their own, which means they are often freestanding markers. The other group of discourse markers we will largely neglect are those that occur almost anywhere in the clause and not necessarily at syntactic boundaries. Based just on the set of items contained in Figure 8.2, this property applies to almost, basically, and like, which are all commonly used as phrasal modifiers. Although they can also be filler items, in which case they meet the criterion of marking a boundary, these words do not share all properties of a discourse marker as described above, that is, they are not typically used for bracketing the discourse. While discourse markers characteristically mark the boundary of a clause or a sentence, phrasal modifiers commonly occur inside a clause. Look at the example in (6) for illustration:
(6) And, I mean, amazingly, you know, this like chance meeting on a bench in Regent’s Park resulted in this incredible company. (COCA, Spoken, 2017)
In (6), and, I mean and you know occur turn-initially and thus at the beginning of the clause. By contrast, like has a function that relates closely to the level of the phrase: It seems to have enabled the speaker to search for, or possibly emphasize, the word chance meeting. And although like can mark just a pause and is also found clause-initially (Like, that’s not happening), leading some of the literature to distinguish like as a discourse marker from like within the clause being a mere particle (Reference D’ArcyD’Arcy 2007), from our point of view like is a less typical instance, which is why we do not include it in our discussion (but see our box on like as a marker of the speech of an entire generation).
In contrast to modifiers within the phrase and to freestanding discourse markers, the elements highlighted in Figure 8.2 constitute very typical instances of the category of discourse markers. In addition, they all share the property that they can initiate a new grammatical unit: a new clause, sentence, or turn. Clause- or turn-initial occurrence could therefore be a fourth defining attribute for the category of discourse markers (Reference SchourupSchourup 1999).
In addition to the challenge of delimiting discourse markers as a category, another issue one needs to decide is when exactly an item is used as a discourse marker and when it is still an element within the core clause. For example, the sequence you know also occurs within sentences when it is a true matrix clause. Often, like in Example (7), when you know is a main clause, the construction will keep the complementizer that but, as you see in Example (8), this is not necessarily the case. In (8), you know is still likely to be the main clause, since an alternative for the tag right? would be the tag question don’t you?, rather than isn’t it?.
(7) You’re just angry because you know that this is the right thing to do. (COCA, TV, 2017)
(8) You know this isn’t a competition, right? (COCA, TV, 2019)
In contrast to (7) and (8), where you know is not used as a discourse marker, in (1) and (6) above, the sequence you know was syntactically more “marginal” (Reference BrintonBrinton 1996: 34). However, the boundary between uses as a main clause as opposed to a more marginal, parenthetical one is not always easy to draw, even if intonation, notably the presence of a pause, often indicates use as a discourse marker. We will come back to this distinction in our discussion of the development of discourse markers and their grammaticalization in the history of English in Section 8.6.
Exercises 1 and 2 provide an opportunity to identify elements as discourse markers and to distinguish syntactic from discourse marker uses.
Good to Know Like – One of the Most Hated Words in EnglishIn its usage note on like, dictionary publisher Merriam-Webster points out that the various uses of like are “a particularly bountiful source of irritation for people who get annoyed by the language habits of other people.” Which uses are we talking about? The word like has many meanings and many different syntactic uses in English. It can be a verb (Do you like broccoli?), a noun (We talked about our likes and dislikes), an adjective (The portrait is very like), a preposition (This cake tastes like a slice of heaven), and a conjunction (Looks like you don’t remember his name). There’s also quotative (be) like, as in (9), whose function is to recreate speech or inner monolog in the narration of stories, as in (10). Quotative (be) like is often associated with the speech of young middle-class females from the San Fernando Valley in California, immortalized in the song “Valley Girl” by American songwriter Frank Zappa in the early 1980s.
(9) [H]e asked me, “Can we switch seats?” And I was like, “Oh, yeah, sure. Okay.” (GloWbE-US, 2011)
Quotative (be) like was first documented in the speech of speakers born in the 1960s and it was accelerated by speakers born ten years later. Those speakers are middle-aged today and still use quotative like, as do many others. We can’t really say anymore that quotative like is a marker of the speech of adolescents.
Additionally, there is the use of like as a discourse marker, typically as an introductory element, as in (10), which is receiving just as much negative attention as quotative like by language prescriptivists.
(10) They never went out in a small canoe. Like, we went from here to Cape Beale. They had great large war canoes. (Reference D’ArcyD’Arcy 2017: 14)
In this context, like signals “exemplification, illustration, elaboration, or qualification” (Reference D’ArcyD’Arcy 2017: 14) of a previous utterance. In (10), the first sentence makes a general claim about the use (or non-use) of small canoes. The second sentence, introduced by like, provides an illustration of that claim, which continues in the third sentence. Unlike quotative like, like as a discourse marker does not co-occur with be and is not grammatically required. Some people therefore think that it is just a filler word, a step up from um or er, but like clearly adds to the meaning of the sentence (if not in a propositional way). For a full account of like and its history see Reference D’ArcyD’Arcy (2017).
Let’s return to the functional properties of the category of discourse markers. We discussed above that discourse markers have two main functions: a bracketing function, which means to establish a connection and/or mark a boundary between units of talk, and an interactive function, providing an orientation for the listener. In this context, it is necessary to point out that the function of most discourse markers is variable since it depends on and is influenced by the context. Putting this more systematically, any function identified for a given marker is potentially multi-fold in two senses (Reference Kaltenböck, Keizer and LohmannKaltenböck et al. 2016: 10). On the one hand, the function of a discourse marker can vary from discourse to discourse. A case that we already discussed in Chapter 6 is the use of and as a connective, which listeners or readers interpret, in accordance with the context, as additive, temporal, or causal. In (11), for example, and is additive, whereas in (12) it expresses a temporal succession.
(11) Horses forever changed life on the Great Plains. They allowed tribes to hunt more buffalo than ever before. They tipped the balance of power in favor of mounted warriors. And they became prized as wealth. For Native Americans today, horses endure as an emblem of tradition and a source of pride, pageantry, and healing. (COCA, Magazine, 2014)
(12) But go back to the example of the Bush tax cuts, which were supposedly temporary when they got passed. They worked. People liked them. And they became permanent law, which is where […] we are today. (COCA, Spoken, 2017)
Similarly to these examples from written discourse, and in spoken language also either connects discourse segments or expresses a succession. In many contexts a given discourse marker will have more than one function, which is something we also see in (12). And not only expresses a sequence of facts here and is bracketing the sequence of information, it can also be said to introduce the speaker’s next argument, that is, to have an interactive function.
With this co-presence of the functions of discourse markers in mind, let us now turn to more specific, individual functions within the set of items we want to look at here. The typical functions of these discourse markers are shown in Table 8.1, each now paired with an example for illustration. Examples (13) through (20) were retrieved from COCA, using the surface form of each discourse marker. As you see, we extracted the attestation plus more of the preceding discourse, which we did using the context + function (see our toolbox below on the need for contextual information and how to retrieve such information from a corpus such as COCA).
Table 8.1 Typical functions of discourse markers*
| Element and its Discourse Function | Discourse Function in Context |
|---|---|
|
|
| (14) Granted, $150 a year is a low recurring cost for a platform with such promising health benefits. Because have you seen a vet bill lately? (COCA, Magazine, 2015) |
| (15) Google doesn’t have an iPhone app. So it’s limited to being used like other social media. (COCA, Spoken, 2011) | |
| (16) Thanks for helping to elevate and maintain the standards in our society. Now, folks, on Tuesday, I told you about […]. (COCA, Spoken, 1996) |
| (17) Who else drives you to one-up them the way that I do? Bane. No, he doesn’t. Superman. Superman’s not a bad guy. Then I’d say that I don’t currently have a bad guy. (COCA, Spoken, 2017) | |
| (18) […] it’s clear that this company could not have become what it became without without the both of you. I mean, you both brought different skill sets to this. And, I mean, amazingly, you know, this like chance meeting on a bench in Regent’s Park resulted in this incredible company. (COCA, Spoken, 2017) | |
| (19) How insane not to have taken something more substantive than a thin silk wrap, as he’d suggested before they’d left. But despite the forecast, Vicki’d refused to believe the temperature would really drop so fast. (COCA, Fiction, 2012) |
| (20) My aunt and cousin Vivian used to shop there the day after Thanksgiving. Or was it the day after Christmas? (COCA, Fiction, 2010) |
* Terminology is based on Reference SchiffrinSchiffrin 1987.
The reason why, with Table 8.1, we present illustrative examples rather than quantitative data on the occurrence in discourse, is that a category that is described by its function in discourse, like the one of discourse markers, can only be retrieved in a corpus that is parsed for syntactic structure (such as the International Corpus of English, which some of the studies we report from below have used). In an unparsed corpus, like COCA, the discourse markers are formally identical to their occurrence as elements within the sentence, which is why, with this area of discourse syntax, we reach the limits of basic corpus-linguistic, quantitative methodology. Instead, what we can do is to look at the concrete functions in actual discourse, taking into account that these functions are variable and influenced by the surrounding text, as discussed above. In order to do so, we need to be able to extract discourse markers from a corpus together with their surrounding text, which is described in the toolbox below.
Based on the functions illustrated in Table 8.1, we turn to work on discourse markers in Section 8.3. We will first discuss some properties of discourse markers using the variationist approach, namely their position in the clause and their sequences. From the text-linguistic perspective, we will then look at findings on the use of discourse markers in actual spoken discourse as well as in represented speech.
Go to Exercise 3 for investigating the functions of discourse markers as attested in language usage.
The function of an element of discourse grammar, and of a discourse marker, in particular, does not depend just on the overall type of discourse in which it occurs. Corpus sections (like spoken, academic, news, and the like), which classify the source of an attestation according to its external situation, provide only insufficient contextual information. Rather than this source information, which comes automatically with the attestation, we need more information about the surrounding discourse, that is, about the co-text of an attestation (on the distinction of context and co-text, see the discussion in Section 2.2).
In COCA and the other corpora at the English Corpora interface, one gets access to a so-called “Expanded Context” after clicking on any of the fields with source information (corpus section, year of publication, or publication title). When the Context+ screen opens, you will be shown both more detailed source information and a longer stretch of the text the search item is from. Such an expanded co-text is useful particularly when you want to look closely at what was going on in the interaction before a marker occurs. Are different speakers taking regular turns here? What is the communicative function of previous utterances? Information like this enables you to identify functions such as presented in Table 8.1, that is, they help to determine whether an utterance is a response, serves the structuring or connection of arguments and information, and/or addresses specific roles of the discourse participants.
8.3 Variation in Position: Bracketing vs. Interactive Function of then
We have already pointed out that discourse markers have a strong tendency to occur sentence- or turn-initially. As discussed in Chapter 3, the relevance of the initial position is often explained by cognitive factors: we discussed them as signposts that guide the reader or listener through the discourse. We noted that this function applies to the sentence-initial placement of adjuncts and also saw in Chapter 6 that something similar is true for connectives.
Against this importance of sentence beginnings, the existence of “final connectors” may surprise us, although this is how adverbs like then, though or anyway in sentence-final position are sometimes referred to in the literature (e.g., Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021: 879; Reference LenkerLenker 2010). The late occurrence of a connective marker seems to be counter-intuitive, since expressing the type of connection for the sentence after its proposition might require that the sentence needs to be re-processed. Therefore, we need to ask why one might want to place a succession marker like then, not initially, as in example (17) in Table 8.1 above, but turn-finally, like in (21).
(21) Superman’s not a bad guy. I’d say that I don’t currently have a bad guy, then.
Then in (21), used at the end of the second sentence, does not just mark a relation of sequence between the two utterances but seems to signal something else. What could this be? We have a true case of syntactic variation here, which means we should look at the placement of then using the variationist approach. Let’s explore this case of variation in more detail.
As illustrated by Example (17) in Table 8.1, then typically marks a temporal succession within discourse. However, when used utterance-finally, we find that the meaning of then is no longer just temporal. In contrast to (17) and Example (22) below, where then does mark a progression; in Examples (21) and (23), then expresses a causal relation, that is, it signals more of a conclusion.
(22) Then, where did you go?
(23) Where did you go, then?
This causal meaning of utterance-final then can be explained by an inference: Since the marking of succession occurs only in retrospect, the utterance is interpreted “as the inferred result” of a preceding utterance or discourse segment (e.g., Reference HaselowHaselow 2011: 3606; Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021: 870). The difference in function is also signaled phonologically: then in (23) would be uttered with rising intonation and preceded by a pause (Where did you go, thén?), in contrast to a temporal adjunct in sentence-final position (Where did you go thèn?; Reference Quirk, Greenbaum, Leech and SvartvikQuirk et al. 1985: 643). By placing then utterance-finally, the speaker signals that they are drawing a conclusion from, and not just continuing, the previous discourse. This means that sentence-final then is not so much a device of bracketing the talk by linking neighboring utterances, but that it situates the entire utterance into a wider context of assumptions and is therefore more interactive.
If the meaning of then is in fact different in these two positions, an interesting empirical question is which of these two meanings the main function for the discourse marker then is. Let us take a look at corpus-based data. According to one study (Haselow 2011), from a set of 1,000 attestations containing then (taken from the British component of the International Corpus of English), only 118 (12 percent) were in fact truly clause- or turn-initial. As illustrated by Figure 8.3, 24 percent of the instances of then occurred in final position, while the largest proportion of the occurrences of then (48 percent) were in fact those following a conjunction (and or but). However, in these combinations (and then, but then), then is no longer really autonomous, initiating the next utterance, but is linked more closely to the connective element and expresses a temporal relation between the preceding and the next utterance. In the presence of a coordinator, then functions more like a temporal adjunct again, no longer as a proper discourse marker. According to Figure 8.3, the discourse marker then is thus more common as an inferential marker than as a discourse marker of succession. We therefore have to conclude that the bracketing function of then is less frequent than the interactive one, that is, then as a discourse marker primarily signals something like a conclusion.
Figure 8.3 Positions of adverb then in 1,000 attestations from the ICE_GB corpus/spoken component
| attestations with then | |
| Initial | 118 |
| Initial after and or but | 480 |
| Medial | 62 |
| Final | 240 |
| if/when … then | 100 |
| Total | 1,000 |
There are some other interesting properties going together with the utterance-final function of then. These aspects are exemplified in (24), which is an attestation of the sentence in (23) taken from the COCA corpus. In (24), speaker a reacts to speaker b’s turn (I didn’t go home), asking b for further information.
(24)
a: Did something happen at home? b: I didn’t go home. a: So, where did you go, then? (COCA, Movie, 1994)
In example (24), the speaker wants to get some information, and the inference expressed by then is that the previous discourse has made them wonder. Like in this example, it has been found that then is typically used for performing such so-called “directive” speech acts. As you may know, with a directive, the speaker is seeking to get the listener to carry out a certain action (such as providing information, like in (24)). For example, out of about 200 utterances containing utterance-final then from two spoken language corpora, by far the majority (147 out of 181, or 81 percent) were utterances in which the speaker was seeking information (Reference HaselowHaselow 2012). By contrast, according to the same study, and as shown in Figure 8.4, other utterance-final adverbs, like though, actually or anyway, occurred predominantly in so-called “assertives” or “other” speech acts, that is, in non-directive speech acts.
Figure 8.4 Final adverbs as discourse markers with different speech acts
| then | though | anyway | actually | |
|---|---|---|---|---|
| Directives | 147 | 16 | 8 | 8 |
| Assertives | 5 | 156 | 10 | 26 |
| Other | 29 | 13 | 133 | 136 |
The fact that utterance-final then is associated with the presence of a directive speech act strengthens the analysis that its function is primarily interactive. This view is also supported by the data in Figure 8.5, which shows that by far the majority (94 percent) of all cases of final then occur in a contribution to the discourse that is made by a new interlocutor, and only rarely to one uttered by the same speaker.

Figure 8.5 Final adverbs in dialogic vs. monologic sequences
| then | though | anyway | actually | |
|---|---|---|---|---|
| both utterances by different speakers | 170 | 111 | 66 | 90 |
| both utterances by the same speaker | 11 | 74 | 85 | 80 |
In sum, findings on the positions of then, based on the variationist approach, have revealed interesting functional differences. Using final then, speakers do not just signal their progression to the next turn, but they typically express a request for information and ask their interlocutors to react. When in final position, then is more clearly interactive and dialogic than when placed utterance-initially. We can therefore generalize that different positions for a discourse marker are associated with different functions within discourse.
8.4 More Syntactic Variation: Discourse Marker Sequences
Another interesting aspect of discourse markers that we can explore using the variationist approach is their sequencing. As we have seen in several examples above, discourse markers typically occur in clusters, which raises two questions: which discourse markers are likely to co-occur? And how are they characteristically ordered? While these questions are mainly empirical, with many combinations being possible, they also lend support to the more theoretical position that discourse markers are a category of their own. The fact that sequences such as you know and or and but occur at all indicates that the elements involved are discourse markers, which obviously means being rather unrestricted by the syntax of the underlying grammatical category (Reference SchiffrinSchiffrin 1987: 32).
As we saw when looking at the function of and then in narrative discourse in Chapter 6, initial connectives followed by a discourse marker are very common. The sequence and then appears to be the most frequent combination of two discourse markers, but the sequences but then and and so are also quite prevalent. According to one study, all three were among the ten most frequent sequences of two discourse markers, based on a statistical value that used both individual frequencies and the frequencies of the combinations and, on that basis, measured the so-called “association strength” (Reference Lohmann, Koops, Kaltenböck, Keizer and LohmannLohmann & Koops 2016; the method is described in detail on p. 428). According to this measure, the ranking of the ten most frequently occurring combinations was as given in Figure 8.6.

Figure 8.6 Ranking of ten strongly associated combinations of discourse markers
For retrieving data on discourse marker sequences, one again faces the problem that a corpus does not distinguish discourse marker uses from other occurrences of the lexemes involved. For instance, for the sequence and so, we easily get more than 40,000 hits in COCA, but not all of these hits contain so as a discourse marker. Apart from the proper uses of so as a discourse marker, like the one shown in (25), there will also be many false positives (like in and so it is, or and so on), which one will first have to discard.
(25)
Interviewer: Really? So you were recruited by – what was it? – Boeing right out of school, right? You worked for them before you even graduated? Interviewee: Correct, yes. Interviewer: And so tell us what your job is. Interviewee: So I’m a rocket structural engineer. (COCA, Spoken, 2019)
The excerpt in (25) is from a job interview and illustrates the sequence and so, but also contains two single uses of the discourse marker so. These uses of so are clearly interactive: so introduces both a question (So you were recruited … ?) and an answer to a question (So I’m a rocket structural engineer), which corresponds to the function of so as marking a result (see Table 8.1) at the level of the exchange. For example, it is not the fact that the applicant is a rocket structural engineer that results from the previous question, but the answer by itself. In combination with and, this interactive function is augmented by a connective: and so now marks a new turn and establishes a connection, combining a bracketing function and an interactive function of this discourse marker sequence (see Section 8.2).
Let us also look at the reversed sequence so and, which is equally documented by corpus data. For example, in COCA, for so and preceded by a comma (which limits the search to the beginning of a syntactic unit or turn), we received a set of 76 occurrences, one of these being the utterance in (26). Studies in the area of discourse marker sequencing equally report a more than marginal number for this sequence (206, for example, according to Reference Koops and LohmannKoops & Lohmann 2015), which indicates that, even if less common, the combination so and is attested and constitutes a true case of sequential variation.
(26) The question is whether it’s different if – if you’re getting a normal night of sleep and then potentially trying to nap or not getting much sleep at all and then trying to nap, and by the way, so and then there’s talk about potentially introducing this in some high schools? (COCA, Spoken, 2015)
In (26), which is about taking naps during school lessons, so does not mark just a new turn in the discourse but occurs with a certain discontinuity. Since talking about napping in general does not necessarily result in talking about napping in some schools, the two topics are connected at a more general level of thematic continuity. This function of so in (26), resulting from a more abstract relation, is described in the literature as so being a “main idea marker” (Reference MüllerMüller 2005: 68). Interestingly, this function almost never applies when so occurs in second position (Reference Koops and LohmannKoops & Lohmann 2015: 255), that is, following a connective, like in (25). By contrast, in (26), the more abstract function of so is further reflected by the insertion of and, strengthening the connection.
Figure 8.6 also allows for some interesting observations concerning the discourse marker you know, which, as we can see, is involved in five out of the ten most common combinations. This finding is not a surprise in the light of what we pointed out to be its typical function (Table 8.1). Like in Examples (1) and (18), you know signals or invites participation, which is a basic interactive function. A closer look at the most common sequences containing you know reveals some more unexpected patterns of use. In you know because and you know I mean, based on clausal syntax, we would expect the reversed sequence. Interestingly, based on a larger set of data, it turns out that sequences with initial you know “constitute the bulk of the unpredicted cases” (Reference Koops and LohmannKoops & Lohmann 2015: 253). This observation is partly due to the overall high frequency of you know in the data, which suggests that another factor in discourse marker sequencing is the mere frequency of the elements involved. However, this aspect does not seem to apply to all elements to the same extent: I mean, for example, although generally rather frequent in speech, only occurs once in the sequences given in Figure 8.6.
There are two general insights about discourse markers that we gain from this closer look at the issue of sequential variation. On the one hand, discourse markers continue to have certain syntactic preferences, and with that, to a certain extent, they remain related to their syntactic counterparts. On the other hand, the lexemes and clauses involved, when being discourse markers, possess more flexibility, a property which opens the possibility for a functional differentiation. Different sequences of discourse markers thus perform different functions in discourse, they have different “functional correlates” (Reference Koops and LohmannKoops & Lohmann 2015: 256). This insight also highlights the nature of discourse syntax in general, being less driven by the syntactic principles of clause grammar, but rather by the surrounding discourse.
8.5 The Role of Discourse Type: Functions of You Know in Speech and Writing
Having dealt with the variationist perspective on discourse markers, let’s now turn to their use in different types of discourse. From the discussion so far, we know that we should start with spoken discourse, since, as described above, discourse markers are elements with a primary bracketing or interactive function relating to speech or talk (e.g., Reference DikDik 1997: 381; Reference Kaltenböck, Keizer and LohmannKaltenböck et al. 2016: 2). Of course, discourse markers equally occur in scripted speech or dialogs in fiction, such as in novels or films. For example, in the excerpt in (27) from Alice in Wonderland, Alice, talking to a mouse, uses you know like in natural spoken discourse. She uses it twice, and she certainly doesn’t mean that the mouse is supposed to know what she is talking about.
(27) “Are you – are you fond – of – of dogs?” The Mouse did not answer, so Alice went on eagerly: “There is such a nice little dog near our house I should like to show you! A little bright-eyed terrier, you know, with oh, such long curly brown hair! And it’ll fetch things when you throw them, and it’ll sit up and beg for its dinner, and all sorts of things – I can’t remember half of them – and it belongs to a farmer, you know, and he says it’s so useful, it’s worth a hundred pounds! He says it kills all the rats and – oh dear!” cried Alice in a sorrowful tone, “I’m afraid I’ve offended it again!” For the Mouse was swimming away from her as hard as it could go, and making quite a commotion in the pool as it went.
(Reference CarrollCarroll, Alice’s Adventures in Wonderland, 1991 [1865]: ch. II)
Contrary to the meaning of you know as a matrix clause, what Alice expresses by you know in (27) is that the information she is giving is new and newsworthy, probably even quite shocking, to her interlocutor, the Mouse. You know in this sense supports her presentation of content, which corresponds to the function of you know marking information and inviting participation (Table 8.1). Using you know as a discourse marker reflects a rather precise idea that Alice has about the Mouse as an interlocutor, particularly about its attitude regarding dogs (Figure 8.7). Research using the text-linguistic approach has highlighted this function of you know as marking shared information. For example, research on different registers found that there are higher rates of usage in conversations among friends than among strangers, and lower ones in the speech of high-status speakers or in discourse addressed to a larger audience (Reference Jucker and ZivJucker & Ziv 1998; Reference Fox Tree and SchrockFox Tree & Schrock 2002).

Figure 8.7 You know in fictional dialog
For working with frequencies of you know based on a corpus, one faces the problem again that it needs to be retrieved with some reliability as a discourse marker, as separate from a syntactic matrix clause. One way out is to make use of punctuation here, that is, add a comma after you know, which works reasonably well (note that, in COCA, you have to separate the comma by a blank space). Based on this search strategy, Figure 8.8 shows the rates of occurrence of you know (normalized to one million words, as described in Section 2.4) in seven sections of COCA. It is not surprising that it is mainly spoken discourse and, to some extent, TV and movie scripts that show a high frequency of you know: this outcome is clearly in line with the general function of bracketing talk and/or serving interaction. By contrast, in written discourse, the rates of occurrence are extremely low and most likely result mainly from speech or dialog embedded within written text (like in example (27)).

Figure 8.8 You know as a discourse marker in seven sections of COCA
The graph shows occurrences per 1 million words.
In online discourse, which in Figure 8.8 is represented by blog and other web-based discourse, the occurrence of discourse markers also results from a more interactive nature of these discourse types. For example, in (28), taken from a blog titled “100 Reasons NOT to Go to Graduate School,” you know is not used in the context of direct speech, but can certainly be said to have an interactive function.
(28) Personally, I feel having a comfortable salary is better than doing something you love. So a high paid job you hate/are numb to is worth it? You know, that is an argument they make for law school, and I don’t think it really holds water […]. (COCA, Blog, 2012)
In (28), you know introduces information that provides background information to the main line of thought. Presenting “off-record” information is one of the interactive functions of you know (Reference Fox Tree and SchrockFox Tree & Schrock 2002; Reference Jucker and ZivJucker & Ziv 1998), which has been found to apply in online writing similarly to speech (Reference Fox TreeFox Tree 2015: 68).
Overall, using the text-linguistic approach has shown that the function of you know as a discourse marker applies to interactive discourse, rather than being limited to the written medium. As we will see in the final section, on the history of discourse markers, they often originate in functions that were just as common in writing as in speech.
You should now be able to take on Exercise 4, which asks you to interpret frequency data on the positioning and the distribution of two other discourse markers.
8.6 Variation in Discourse over Time: The Development of Discourse Markers
As almost all grammatical elements, discourse markers are and have been subject to change. Several elements we dealt with in this chapter have been in use since Old English, but their function shifted with the documents in which they typically occurred. For example, the function of then (Þa) in Old English narratives was one of “peak-marking,” signaling that the maximum point of tension in the story was reached, but became one of a mere “sequencer” in Middle English (Reference Wårvik and JuckerWårvik 1995). Some discourse markers became obsolete in the history of English, such as methinks, whereas several clausal discourse markers, like I mean and you know, emerged during the Middle English period (Reference Brinton, Jucker and TaavitsainenBrinton 2010).
There is an ongoing debate about the origin and development of these clausal discourse markers, which include a few other clauses (such as I think, I guess, or you see) and are also called “comment clauses” (Reference BrintonBrinton 2011). There is historical evidence that, for example, the development of you see (or see) as a discourse marker has gone along with a rise of you see in matrix clauses with the complementizer that omitted. This observation has led to the assumption that the omission of that caused a syntactic reanalysis of you see, which thereby developed from a main clause to a parenthetical comment clause. This assumption is called the “matrix clause hypothesis” (e.g., Reference Kaltenböck, Heine and KutevaKaltenböck et al. 2011). Other historical linguists have argued that comment clauses must have evolved out of a broader variety of constructions. For example, you know and I see could easily have developed, not only from first-person matrix clauses, but also from other clauses, for instance, as you know and as you see (Reference BrintonBrinton 2017). According to this view, it is not possible to say with certainty that the development of a discourse marker has been caused by a single pattern of syntactic variation.
There is more consensus in the literature that the most common process through which discourse markers come about is one of grammaticalization (some authors call it “pragmaticalization,” since what changes is the expression of pragmatic functions). Grammaticalization typically begins with the loss of specific semantics, known as “bleaching,” and with a loss of the categorial restrictions that applied to the original category. For example, as we discussed in Section 8.5, you know as a discourse marker has lost its original meaning as well as the syntactic properties of a matrix clause, in that it is no longer limited to occur in a fixed position (see Ex. (27)).
Grammaticalization is also the origin of discourse markers that have, syntactically, been adverbs. A well-known and more recent case is the use of actually as a discourse marker (Reference OhOh 2000; Reference CliftClift 2001; Reference AijmerAijmer 2013), which is very common, especially in the speech of the younger generation (Reference WatersWaters 2009). Originally, actually was a VP adjunct, meaning “in fact” or “in reality,” but the adverb has undergone a semantic change and turned into a discourse marker (e.g., Reference Traugott and DasherTraugott & Dasher 2009). In contemporary discourse, actually is found not only within the VP, but in all sentence positions, that is, clause-initially as well as clause-finally. As examples, look at (29) and (30):
(29)
a: You say in your piece that the wall was certified in 1995 by Jamie Gorelick. It actually started with Bush 41 and with Reagan. And all she did was recertify it. Not only that, but John Ashcroft recertified the very same things Jamie Gorelick did. b: No. a: And the 9/11 Commission was very specific about this, and they actually mentioned that in their report. b: Actually, the law you’re talking about, FISA, was enacted in 1978. (COCA, Spoken, 2006)
(30)
a: Because President Trump promised to drain the swamp and he flooded his national security team with that exact swamp. b: Well, I agree with that, actually. (COCA, Spoken, 2019)
Examples (29) and (30) illustrate that actually can be used as a VP adjunct (actually started, actually mentioned), but also occurs at the beginning or at the end of an utterance. Nowadays, in all three positions actually expresses an attitude of the speaker, indicating some kind of opposition or discrepancy between the interlocutors (Reference Smith, Jucker, Hedberg and ZacharskiSmith & Jucker 2000). For example, in (29), actually emphasizes that the clausal proposition is counter to expectation (It actually started … , they actually mentioned that …). At the beginning of a new turn, like at the end of (29), actually marks this turn as being a correction (Actually, the law you are talking about was enacted in 1978). In (30), in utterance-final position, actually softens the speaker’s opposing view (I agree with that, actually).
These interactive functions, together with the variable position in the clause, justifies considering actually as a discourse marker rather than as a clausal adjunct. In addition, there is evidence from corpora that actually is today much more frequent in speech than in writing (e.g., Reference OhOh 2000; Reference AijmerAijmer 2013). Based on one corpus study that looked at a variety of registers (Reference AijmerAijmer 2013), Figure 8.9 shows the pattern of occurrence of actually in spoken and written discourse in comparison to its semantic correlate in fact.
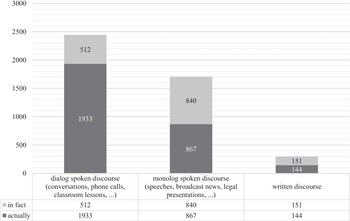
As we can see in Figure 8.9, actually and in fact are both clearly more common in speech than in writing. However, we also see that, in dialog, actually is considerably more frequent than in fact. This finding suggests that actually is now commonly used as a discourse marker. By contrast, as you may know, its use in writing is often heavily criticized, for example, as being “the most futile, overused word on the Internet” (Reference CarusilloCarusillo 2014). The description as “futile” results from its semantic bleaching, which shows that actually has grammaticalized and is perceived now primarily as a discourse marker.
This is now a good time to check out Exercise 5, which looks at different positions of actually, contrasting spoken and written discourse.
Good to Know: Language Proficiency and Discourse Marker UseAs we have seen throughout this chapter, discourse markers are common in speech and important for an efficient communication. Competence in using them is therefore also of importance for second-language learners. Research in this area indicates that discourse markers often fall short of a native-like usage. Learners rarely acquire this competence in the classroom, which is why characteristic differences often remain for a long time (Reference Hellermann and VergunHellermann & Vergun 2007; Reference PolatPolat 2011).
For example, in a study of spoken discourse by American and German advanced speakers of English (elicited through the mutual retelling and discussion of a movie), many systematic differences were in fact observed (Reference MüllerMüller 2005). While only so was most commonly used in the speech of both groups, the preferences for the other discourse markers differed quite substantially. The native group used like and you know more often, whereas the German speakers used well much more than those two. Overall, with the exception of well, all other discourse markers were used far more by the native speakers: so was twice as frequent, and you know and like even five times as frequent. And although well is particularly common in learner speech, it also became obvious that the functions of well are quite different. While, in the speech of non-natives, it is used mostly for managing the flow of the talk, most notably, as a marker of hesitation and pausing, well has more specific functions as a marker of response in native usage, for example, the expression of disagreement (Reference AijmerAijmer 2011; Reference BuysseBuysse 2015).
8.7 Summary
In this chapter we have explored elements which are rather loosely connected to the grammar of the clause and primarily serve the needs of spoken, interactive discourse. We looked at several typical discourse markers, pointing out their defining properties and characteristic functions in discourse. We saw that discourse markers are placed in variable positions within the sentence, that these are associated with different functions in the discourse, and that discourse markers also occur in characteristic sequences.
We then turned to the use of discourse markers in different text types, showing that they are closely associated with the online production of spoken discourse. We also saw that they occur in embedded or scripted speech and online writing and that, ultimately, the function of a discourse marker is variable and has to be analyzed based on the surrounding text. Finally, we touched on the development of discourse markers and what to learn from their grammaticalization.
8.8 Exercises
Level 1: Classification and Application
1. The discourse below is from a news interview, in which a film director (Kevin MacDonald = speaker a) tells a CBS moderator (Chris Wragge = speaker b) about the making of the YouTube documentary “Life in a Day.” Circle all elements in this discourse that you consider to be discourse markers and describe the bracketing and/or interactive function they perform. Are your findings in line with the properties of a discourse marker described in Section 8.2?
b: It was July 24, 20 – 2010, and I am sure a lot of thought must had gone into why you chose this day, right?
a: No. No. There was – there was very little thought. Well, the thought was it’s after the World Football Cup, Soccer Cup –
b: Okay. All right.
a: – as you call it here. And I thought, well, during that nobody, except in America is going to take part because nobody in America is interested in soccer.
b: Yeah.
a: So we laughed all round in here.
b: That was like soccer what?
a: So – so and then we – we wanted to do it before the big – the big holidays in August.
b: Sure.
a: But the big thing was, you know, should we do it on a – should we do on a weekday or on a – on a weekend.
b: Weekend.
a: We went for a weekend because we thought more people would take part, and we were – we were right.
b: And finally where can people see this?
a: They can see it in theaters.
b: Yeah.
a: – starting this Friday. It’s a limited release to begin with and then expanding out. So go and see it.
b: Life in a Day, folks. Really good stuff. Kevin, great – great to see you this morning. Thanks so much. We appreciate it.
a: Thank you, Chris. Thanks for having me on.
b: And just as another reminder for you Life in a Day opens in theaters this Friday, so go out there […].
2. In sentences a. to e., you will find uses of some of the elements discussed in Section 8.2. Decide if the element is used as a discourse marker or whether it has a grammatical function inside the clause. Are there borderline cases?
a. When designing flying vehicles, there are many aspects of which we can be certain but there are also many uncertainties. Most are random, and others are just not well understood. (COCA, Magazine, 2018) b. […] he has a radical plan to win community support: he wants to open up the long-isolated island to guided tours. The proposal has met with, well, mixed reactions. (COCA, News, 2000) c. You traditionally have started with the “10 blue links” result, which has taken you to a place where you could often refine your search in a context specific fashion. What do I mean by context specific? I mean that this specific search allows you to specify attributes unique to the type of thing you are searching for. (COCA, Web, 2012) d. a: So, do you think it’s the right picture or not? b: I think you’ve got it down cold. So, I have a question for you, then. (COCA, Blog, 2012) e. He didn’t think she’d remember; he’d mentioned his birthday last week, but she hadn’t taken it up then. (COCA, Web, 2012)
3. Apply the more specific functions of individual discourse markers, which are listed in Table 8.1, to the elements you found in Exercises 1 and 2. Are there uses where the element functioning as a discourse marker could be said to have more than one function?
4. In Section 8.3, we looked at the position of then as a discourse marker and saw by looking at the data in Figure 8.3 that, for then by itself, the initial position is less common than the final one. In Figure 8.10 on the next page, there is a similar set of results for the two other discourse markers we discuss in more detail in this chapter, you know and actually. Do these elements behave similarly to then, or is there a difference in the corresponding pattern of syntactic variation? In the light of what is said in Section 8.5 about the text-linguistic pattern of variation of you know as a discourse marker, would you expect to see differences in its positioning of these two in spoken vs. written text varieties?

5. Section 8.6 dealt with the process that led to the use of actually as a discourse marker rather than a VP-adjunct. Figure 8.11 shows the distribution of actually across different positions within the sentence, contrasting the pattern of occurrence in spoken and written discourse. How does the use in these two text varieties differ? Why do you think the chart presents the data as proportional frequencies (in percentages), rather than as rates of occurrence?
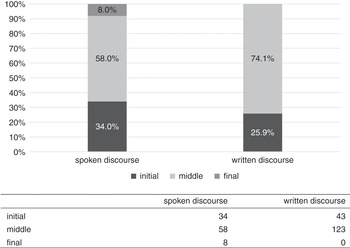
Figure 8.11 Positioning of actually in spoken and written discourse
Level 2: Interpretation and Research Design
6. In Section 8.4, we pointed out that sequences of discourse markers going against the grammar of the underlying elements (such as and but or so and) are nonetheless possible. Which other sequences of the discourse markers dealt with in Section 8.2 do you consider unexpected from a grammatical point of view? Which ones do you nonetheless find attested in a corpus?
7. We saw in Section 8.5 that the main pattern of text-linguistic variation in the use of discourse markers reflects the opposition of spoken and written, as well as of more and less interactive, discourse. Below you see data on the occurrence of the discourse marker well in different types of spoken discourse. How do you account for the differences? What kind of chart would you choose as an illustration?
Table 8.2 Occurrences* of the discourse marker well in five types of spoken discourse
| Private conversations | Telephone calls | Business transactions | Unscripted speeches | Broadcast talks | |
|---|---|---|---|---|---|
| well | 6,965 | 9,943 | 5,646 | 4,843 | 735 |
* Per 1 million words.
8. Think about a project in which you could look at the occurrence of discourse markers in scripted dialogs (such as from novels or film scripts). Which discourse markers would you choose to investigate? How would you go about retrieving these in a text corpus? Think about discussing your outcomes in relation to the question of how authentic (i.e., close to natural speech) scripted dialog is.
9. Do you observe any emergence of new discourse markers in online writing? How would you go about studying these when using a text-linguistic approach? Which aspect of the use of discourse markers in online discourse could one look at using a variationist research design?
Further Reading
An overview of the research concerning the history of discourse markers is provided in Reference Brinton, Jucker and TaavitsainenBrinton (2010). Individual work on discourse markers has been published in countless journal articles over the last thirty years (only some of which are included in our reference list) as well as in many edited volumes, for example, Reference FischerFischer (2006) or Reference Kaltenböck, Keizer and LohmannKaltenböck et al. (2016). Sequences of discourse markers are dealt with in Reference Cuenca and CribleCuenca & Crible (2019) and Reference HaselowHaselow (2019).
On discourse markers in teenage speech, see, for example, Reference AndersenAndersen (2001) and Reference TagliamonteTagliamonte (2005). On the use of markers as varying by age and gender, see Reference BeechingBeeching (2016); for variation across varieties of English, see Reference AijmerAijmer (2013) as well, for example, as Reference BurridgeBurridge (2014) on ’cos and because in Australian English. A considerable amount of work on discourse markers is also dedicated to their use by non-native speakers; see, for instance, Reference AijmerAijmer (2011) on well, or Reference BuysseBuysse (2012, Reference Buysse2020) on so and actually.
For a more theoretical discussion of discourse markers and attempts for a coherent definition, see Reference SchourupSchourup (1999), Reference Fraser and FischerFraser (2006, Reference Fraser2009) or the introduction to Reference Kaltenböck, Keizer and LohmannKaltenböck et al. (2016). On the topic of grammaticalization and the rise of discourse markers, you could consult The Oxford Handbook of Grammaticalization (Reference Heine and NarrogHeine & Narrog, 2011), especially the entry on the relationship between grammaticalization and pragmaticalization (Reference Diewald, Heine and NarrogDiewald 2011), or Reference Heine, Kaltenböck, Kuteva and LongHeine et al. (2021).
9.1 Introduction: The Role of Register and Genre
We have explored throughout this book how syntax is influenced by the surrounding discourse, and we have noted that many types of discourse have characteristic features at various levels of sentence structure. For example, we discussed how syntactic variation happening at the beginning, in the middle, or at the end of a sentence can be triggered by the surrounding text (Chapters 3 to 5), but at the same time we saw that the use of these variants is also influenced by the discourse situation, by external, non-linguistic factors such as the medium, topic, and the purpose of a text. In Chapters 6 and 7, we turned to the expression of discourse cohesion and looked at connectives, pronouns, and ellipsis and their occurrence in different types of text, for instance, the use of connectives in the academic register, of pronouns in fiction, or of ellipsis in informal speech or writing. Finally, in Chapter 8, we explored elements used as discourse markers, which is a characteristic of spoken discourse.
In this final chapter, we now turn to a discussion of discourse varieties as such, which means we will look at some of their features in the area of grammar. We will explore a few selected registers and genres more closely. Before we start you should note that, as discussed in Chapter 2, we are using the terms register and genre here in accordance with the approach of Reference Biber and ConradBiber & Conrad (2019), where both concepts are described as referring to situational varieties of language use. This means we follow their approach of considering register and genre as being different perspectives for analyzing discourse, and “not as different kinds of texts or varieties” (Reference Biber and ConradBiber & Conrad 2019: 2). This approach entails that one can in principle look at every kind of discourse both from a register and from a genre perspective. While, with the register perspective, the analysis focuses on what is common and frequent in a discourse, the genre perspective is concerned with what is typical and conventional. For example, a genre, like a prayer, a sonnet, or a solicitation for a donation, often has a specific rhetorical organization. These genres also have linguistic characteristics that are not necessarily overall pervasive, like the opening in a solicitation letter, the couplet in a Shakespearean sonnet, or the boundary marker “Amen” in a prayer. Both the rhetorical structure and such single features belonging to a genre are its typical characteristics. At the same time, texts of these genres can be equally studied from the register perspective, focusing on the linguistic features that are more frequent or pervasive in this type of text when compared to other registers: For example, most letters and prayers also contain many first- or second-person pronouns. Since registers differ by the extent to which grammatical features are used in them, and not in the single occurrence of a given feature, they have to be studied on the basis of a sufficient sample of discourse. Since the focus is on features that are pervasive, this analysis can also be based just on text excerpts, as from an electronic corpus, and not necessarily on complete texts. By contrast, genres need to be studied on the basis of complete texts. In reverse, this means that any genre, but not any register, can be looked at both from the register and from the genre perspective.
Genre being the term used for this chapter highlights that, in the following, we will explore types of texts in terms of characteristics that are either common (in the sense of frequent) or typical. We will start with a discussion of the principled distinction between spoken and written genres (Section 9.2) and then explore one genre and one register more thoroughly. In Section 9.3, we take a close look at a highly conventionalized genre that is well known by academics, which is scientific abstracts, and, in Section 9.4, we explore some characteristic features of digital discourse.
Having studied this chapter, you will be able to:
identify key grammatical features of the registers of spoken and written genres and understand limitations that exist for applying that distinction;
detect both genre and register features in a scientific abstract and discuss their discourse motivations;
develop a research design for studying the nominal character of the register that is commonly used in abstracts and other types of academic writing;
recognize and discuss features of online writing as linguistic innovation taking place in digital discourse.
Concepts, Constructions, and Keywords
agentivity, because X, CARS model, (phrasal/clausal) complexity, conceptually spoken vs. written language, digital discourse, hashtag, inanimate subject, linguistic innovation, mediality, netspeak, noun phrase, scientific abstract, textisms, Twitter
9.2 Grammar and Medium: Written vs. Spoken Genres
The medium, or channel, is one of the most important parameters that motivates register and genre variation. When speaking, we have less time for planning what we are going to say, we cannot erase what we have said, and we are usually in more direct, often more personal, contact with our audience. Participants in spoken discourse are typically in face-to-face contact and therefore also rely on non-linguistic cues, such as gestures, facial expression, or intonation. By contrast, the written register typically has quite a delay between production and reception, which is why it is often more carefully planned or edited. In addition, the written register can make use of visual cues, such as spelling, punctuation, and layout.
This description of the spoken as opposed to the written register is a highly stereotypical one. It might mislead us to think that written discourse necessarily has linguistic characteristics opposite to speech. However, this view focuses not just on the channel of communication, but ultimately on a whole group of situational characteristics. For example, in most situations where we speak, we are less interested in communicating just information, but are also concerned with establishing and living our relations, expressing our attitudes and feelings. This is a distinction, not only of the medium, but one of the purpose, of the so-called “interpersonal” function of speech (Reference Biber and ConradBiber & Conrad 2019: 88). And it is true that, in most spoken registers, the social and emotional functions of language are more important than just informational ones. On the other hand, there are also texts that contain a lot of information and are therefore carefully planned, but will ultimately be spoken (sermons, or speeches in politics, for instance), or those that are written quite spontaneously and not addressed to a wider audience (text messages, for example).
A useful approach for disentangling these various aspects of speech as opposed to writing is to distinguish between medially and conceptually oral or written registers (Reference Koch and OesterreicherKoch & Oesterreicher 1985). Following this approach, the spoken/written distinction is a true dichotomy only from the point of view of the medium. The spoken language uses the phonic code, while the written language is conveyed through the graphic code. Texts can easily change from one code into another: For example, important speeches usually start out in written form, to be read aloud, then they are delivered orally, and later they may be archived or shared in printed form. By contrast, the conceptual distinction between spoken and written discourse is not a simple dichotomy, but rather a continuum between idealized poles of typically written texts (texts that are not only written in a medial sense, but also carefully planned and highly edited) and typically oral texts (texts that are not only oral in the medial sense, but also produced spontaneously in a space shared by speaker and addressee). It refers to the communicative strategies that are employed, which involves planning, editing, and having a certain purpose in mind. Conversation, on the one hand, and written, published texts, on the other, are something like the idealized poles of this continuum of conceptually oral and written language, with many degrees being possible in between. For example, an oral presentation in a university classroom is conceptually less oral than a private conversation among students; and an academic lecture, which has been prepared by way of detailed lecture notes, is still conceptually less written than a printed, published text, since the communicative strategies during a lecture in most cases involve some interaction. Or think of an oral exam, which is probably situated somewhere in the middle of this continuum: It is carefully planned and highly informational, but the discourse situation nonetheless means that there is a lot of interaction. Summarizing these examples, take a look at Figure 9.1, which illustrates this continuum of conceptually oral and written language.

Figure 9.1 University genres as conceptually spoken and written language
The idea of conceptually spoken vs. written language still does not capture all the situational characteristics of a genre with an effect on grammar. For example, as we discussed in Chapter 7, it is not easy to tell where to put digital registers on the oral–written continuum. As we discussed there, apart from the medium, the purpose of a discourse and the expected audience also play a crucial role. Distinctions such as the one between informational and non-informational registers, or the one between discourse for a specialist as opposed to a non-specialist audience, can be as powerful as the spoken–written distinction in triggering linguistic variation (Reference Biber and GrayBiber & Gray 2016).
From the point of view of concrete linguistic features, the spoken–written distinction is also not a very clear one. The research in this area justifies the overall position that the differences within speech or writing can generally be as great as the differences across the two modes. In fact, we cannot expect to find true linguistic markers of the phonic or graphic medium, since most elements of grammar can, in principle, occur in all media. Still, due to the circumstances under which we produce most oral speech (face-to-face contact, no time for planning), spoken discourse has overall less variation than written registers. As Reference Biber and ConradBiber & Conrad (2019: 261) note in their discussion of registers: “[A]n author can create almost any kind of text in writing, and so written texts can be highly similar to spoken texts, or they can be dramatically different. In contrast, all spoken texts are surprisingly similar linguistically, regardless of communicative purpose.” This is why we want to take a brief look at some features of this one (idealized) pole of the spoken–written continuum before turning to written genres later in the chapter.
Before continuing your reading, turn to Exercise 1 in order to apply the distinction between medially and conceptually oral and written language.
Among the most typical grammatical features of the spoken mode described in reference grammars are incomplete clauses and overall shorter clauses, a higher density of verbs, a higher use of interrogative and imperative sentences and of coordination rather than subordination, more active verb forms, and the regular use of contractions and ellipsis. In addition to these features of grammar, there are also phenomena that directly result from the production of spoken language: in particular, its relative disfluency, which usually causes pausing, repetition, re-starts and re-formulations, as well as the insertion of discourse markers or parenthetical clauses. For example, in Chapter 7, we discussed the occurrence of elliptical clauses as a feature of spoken discourse, and in Chapter 8 we looked at discourse markers as different kinds of elements that are typically inserted within the clause in spoken discourse. For example, in the utterance in (1), which is taken from the GSWE, the clause contains a parenthetical clause (I think) as well as a re-start and re-formulation (I don’t think you sh-).
(1) Dad, I don’t think you sh-, I think you should leave Chris home. (Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021: 1056)
In the corpus of conversations used for the GSWE, non-clausal units account for more than one-third (38.6 percent) of all units of conversations (Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021: 1065). The average length of these units in the corpus is only two words, which is all the more surprising since the units that were counted also include, for example, interjections (oh, ah), response forms (mhm, okay), or signals of hesitation (uh, er). Interjections, by their very nature, do not interact with other elements in the utterance, which is why we didn’t deal with them as discourse markers in Chapter 8. You could find out more about them by studying the linguistic sub-discipline of Conversation Analysis, or by consulting the GSWE, which contains an entire chapter dedicated to the “grammar of conversation” (Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021: ch. 14; also see Further Reading at the end of this chapter).
For a corresponding view of the written mode, let us just note here that some typical features seem to be the opposite of the spoken mode features. For example, most written discourse contains twice as many nouns than verbs with considerably more embedding, both within the sentence as well as within the noun phrase itself (Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021; Reference Biber and GrayBiber & Gray 2010, Reference Biber and Gray2016). In addition, we can expect most written discourse, if it is written to be printed and published, to contain complete rather than incomplete sentences and more varied syntactic structures. A higher complexity of sentences as well as a higher occurrence use of the passive voice are therefore among the classic grammatical characteristics that are usually referred to when describing the syntax of the written mode. However, when we think of writing that takes place online, it is obvious that these texts probably turn out to be more varied, or hybrid, in their use of such grammatical characteristics. In view of the overall larger variety of the written media and their genres, we’ll take a closer look at a few selected genres in the remainder of the chapter.
Turn to Exercise 2 for identifying features of grammar that have been described in this section as being typical of the spoken and the written medium.
9.3 A Genre and Its Grammar: Research Article Abstracts
9.3.1 Typical of the Genre: The Handling of Agentivity
Academic writing is an important part of every scholar’s career and, as you perhaps know from Academic Writing courses, involves quite a few regularities and conventions. Among these, one that is often discussed concerns the role of the scientist being the agent both in the research process and in the written documentation when publishing the outcomes. As discussed in Chapter 4, the linguistic category of agent denotes an argument of the verb, referring to the willful and sentient initiator of an action. Since most scientific activity rests upon the observation and analysis of empirical evidence, clauses like the ones in (2) are statements of the kind most scientists make, in one way or another, in their writing: In both clauses, the scientist is the initiator of the activities that are expressed (observe and argue). However, you will find that clauses like the ones in (3) and (4) are usually more likely to occur in written discourse, since these are utterances that leave the scientist as the initiator of what is being reported implicit.

(2) I observed that … (Therefore) I argue that …
(3) Based on the comprehensive literature survey, it is observed that most of the research done so far is either sector-specific or consolidated by taking a sample of few companies irrespective of their sectorial belonging. (COCA, Academic, 2018)
(4) It is argued that mentoring is a teaching-learning process to which participants bring specific responsibilities. (COCA, Academic, 2013)
One core question about grammar as it is used in scientific texts thus has to do with the scientist being almost always the agent, and it is quite interesting to see how this role is expressed. As we discussed in Chapter 4, the agent role tends to be mapped to the grammatical subject, like in (2), but the passive voice as in (3) and (4) does not conform to that tendency. The expression of agentivity is a crucial area of genre-based syntactic variation, guided by the question of whether a scientific text will be more “author-centred” or more “object-centred” (Reference AtkinsonAtkinson 1992).
One genre that is highly symptomatic of how these options are handled is the scientific abstract. An abstract accompanies many scientific publications, for example, book announcements, conference presentations, research reports, and, what we will look at here, articles from scientific journals. Abstracts can be described as a genre of “distillation” (Reference SwalesSwales 2004), a property that highlights that abstracts contain a high condensation of information and are meant to be skimmed rather than read linearly (Reference GledhillGledhill 1995). As a result, the abstract is a genre that is highly likely to possess typical, that is, stand-alone, conventionalized features and, in addition, enables us to look at grammar in academic discourse based on complete texts, rather than text excerpts (compare Section 9.1).
As described above, a genre is often defined by its rhetorical organization, and one feature of the abstract is that its structure typically mirrors the conventionalized “packaging” of the research process that we also observe in many research article introductions (Reference AtkinsonAtkinson 1992). One well-known model for describing an introduction is the CARS model (Reference SwalesSwales 1990, Reference Swales2004), named after the acronym for ‘Creating A Research Space’ and consisting of three so-called rhetorical “moves:” (1) establishing a research territory, where a scientist sets the context for the research, (2) establishing a niche, which is the space of knowledge to be filled through the new research, and (3) occupying this niche by announcing a research space that the publication is going to fill (Reference SwalesSwales 1990: 141). Many abstracts have a similar organization and a corresponding typical pattern of syntactic variation.
Let us turn to an example and look at the abstract in (5) (a text you may be familiar with because it was shown in Exercise 6 of Chapter 2):
(5) In this paper we analyse variable presence of the complementizer that, i.e. I think that/Ø this is interesting, in a large archive of British dialects. Situating this feature within its historical development and synchronic patterning, we seek to understand the mechanism underlying the choice between that and zero. Our findings reveal that, in contrast to the diachronic record, the zero option is predominant – 91 percent overall. Statistical analyses of competing factors operating on this feature confirm that grammaticalization processes and grammatical complexity play a role. (Tagliamonte & Smith, 2005)
As you can see, the abstract in (5) is structured closely in accordance with the CARS model. The text starts out by presenting the research topic (variable presence of the complementizer that), then turns to its research question (the mechanism underlying the choice between that and zero) and moves on to saying how this will be done, announcing findings and analyses. With that structure, (5) has what is currently the typical, conventional structure for the genre of abstracts.
What is also typical of the genre is the combination of presenting these moves with corresponding verbs of argumentation (analyze, understand, confirm). These verbs reflect an important property of modern science writing that can be described as “shaping” scientific knowledge, rather than just noting a discovery of findings (Reference BazermanBazerman 1988). What scientists nowadays do with their texts is both present their observations and provide an argument. While early science still had a focus on “facts over arguments” (Reference Gross, Harmon and ReidyGross et al. 2002: 19), modern scientific texts are part of an ongoing scientific debate, which has a social component as well. The publication process and the genre are significant both for the scientist and for the discipline, a property that brought forth and certainly strengthened the role of the abstract as a genre.
You will have noted, though, that none of the three argumentative moves in (5) makes use of the passive voice. Considering the attention that the passive often gets both in style manuals and academic writing classes, this outcome may result from the fact that academics are typically criticized there for overusing the passive. But what are the alternatives? What we find in the abstract in (5) is the pattern that you saw in (1), the agented active (I found, we see, I think, we argue): It is used twice in the text (we analyze, we seek to understand). The abstract also contains a sentence in which an inanimate noun phrase is the grammatical subject of an active, agentive verb (our findings reveal, our analyses confirm). This sentence pattern makes the facts speak for themselves and moves the researcher more into the background. By contrast, the passive, as illustrated by (3) and (4), is not attested here. As discussed in Chapter 4, the passive would move the former object into the topic position (the presence of … is analyzed) or, alternatively, it could take it as a non-referential, “dummy” subject (it is analyzed that …). Both passive constructions would minimize the visibility of the researcher, turning them into an implicit agent (as explained in Section 4.3.1).
Table 9.1 provides a summary of the two active voice and the passive voice patterns available for dealing with the agent role of the scientist in a science text.
Turning to abstracts with regard to this aspect of grammar, one finds that writers in science tend to use the strategy shown in the third column of Table 9.1, that is, they make use of the active voice, but often avoid direct reference to themselves as an explicit agent. For example, in a study that we carried out ourselves, we analyzed 160 abstracts from eight different disciplines (twenty abstracts per discipline) and looked at all clauses containing an argumentative verb (like suggest, conclude, propose, argue, …). The most important finding was that, with a few rare exceptions, these verbs occurred in all of the abstracts. The other outcome was that the verbs were often used without a first-person subject (Reference Dorgeloh, Wanner, Corrigan, Moravcsik, Ouli and WheatleyDorgeloh & Wanner 2009). Figure 9.2 gives you the results in detail for four different academic disciplines. What is shown on the y-axis is the absolute number of argumentative events in the corpus with their different realizations (note that passives include both short and by-passives).

Figure 9.2 Scientific argumentation in abstracts from different disciplines
Figure 9.2 illustrates that, within that corpus of abstracts, an active voice clause with an inanimate subject was more common than either an agented active clause or the passive voice. The data also shows that the use of these strategies varies to a certain extent across academic disciplines. Clauses for explicit argumentation are overall more common in the humanities and the social sciences (this is also in part due to the fact that the abstracts here are often longer), but they also have a stronger preference for an inanimate subject (the agented active accounts for 35.5 percent of all clauses in biology, but only for 10.9 percent in economics and 23.7 percent in linguistics). Another interesting finding from that study was that, in the humanities and the social sciences (such as linguistics, education, or economics), the inanimate subject was often a metatextual entity, something like paper or article (like in this paper argues, this article analyzes). By contrast, in an experiment-based science like biology, other types of inanimate subjects (these/this data, these results) prevailed.
Based on such findings, we learn that, for the expression of agentivity, the abstract as a genre allows for a considerable amount of syntactic variation within a text and, as we have seen, across disciplines. There are also sometimes preferences of individual authors or journals. Both the range of variation and the preference of a single author is what we find in the text in (6), which is from the same journal as (5), but in which the writer consistently uses the passive voice.
(6) In this article various constructions of English with the form A + N are considered, with particular reference to stress patterns. It is shown that there are several such patterns, and that stress patterns do not correlate with fixed effects. It is also argued that a simple division between compound and phrase does not seem to provide a motivation for the patterns found. The patterns seem to be determined partly by factors which are known to influence stress patterns in N + N constructions, and partly by lexical class, though variability in which expression belongs to which class is acknowledged. It is concluded that this is an area of English grammar that needs further research. (Reference BauerBauer 2020)
Despite this outcome on the range of variation, it can still be generalized that abstracts without any overt kind of argumentative statement are rare (Reference Dorgeloh, Wanner, Härtl and TappeDorgeloh & Wanner 2003). Imagine the abstract above without reporting verbs; it could just as well be a Wikipedia entry. If the explicit argumentative moves are not present, the purpose and typical organization of the abstract are not established, that is, what is typical of the genre would be missing.
Exercise 3 provides an opportunity to identify the different strategies for dealing with agentivity in abstracts from different academic disciplines that we have just discussed.
9.3.2 Noun Phrase and Phrasal Complexity
Let us now turn to another widely discussed grammatical property of the register we have to expect in an abstract. As discussed in Section 9.2, sentence complexity is a property which most people believe to distinguish speech from writing and, in particular, expect to encounter in academic texts. And while it is certainly true that we find many written texts that contain long and complex sentences, at a closer look, dependent clauses as such often turn out to be more common in speech than in writing (Reference Biber and GrayBiber & Gray 2010). For example, we can note that the first sentence of the abstract in (5), repeated below as (7), contains no dependent clause at all, which could be reformulated as in (8):
(7) In this paper we analyze variable presence of the complementizer that, i.e. I think that/Ø this is interesting, in a large archive of British dialects.
(8) We will analyze under which circumstances the complementizer that is present and will discuss to what extent its presence is variable, and we will look at data that comes from a large archive of British dialects.
Example (8) is a sentence with three embedded clauses whereas the clause in (7) is, technically speaking, just a simple main clause. By contrast, in (7) it is the noun phrase introducing the research topic that is more complex: variable presence of the complementizer that is both premodified (variable) and postmodified (of the complementizer that), that is, it exemplifies complexity both within the noun phrase and of a phrasal kind. By contrast, in (8), the noun phrases referring to the topic (the complementizer that, its presence) are simple, that is, with no embedded, modifying phrases. When exploring grammatical complexity as a feature of scientific texts, we therefore focus on complexity within the noun phrase rather than within the clause.
Embedding within the noun phrase is generally a characteristic of highly informational and, in particular, scientific genres and registers. Abstracts with their need for the distillation and condensation of information (Section 9.2 above) are prone to making use of such structures, resulting from syntactic compression rather than elaboration (Reference Biber and GrayBiber & Gray 2010, Reference Biber and Gray2011; see also Reference Biber and ConradBiber & Conrad 2019: ch. 6). For example, (8) is more elaborate with finite, tensed verbs and explicit clausal relations (under which circumstances, to what extent) while, in (7), the information in the form of noun phrases is more compressed. It is packaged into phrases rather than clauses, with phrasal (rather than clausal) structures also within the phrase (e.g., variable presence of the complementizer being a phrase and one with a prepositional phrase as modifier). Complex noun phrases of that type can be expected to be common in abstracts since they are part of the register in which those are written.
What would be the research design for exploring that assumption more closely? Since there is no simple syntactic or lexical marker corresponding to complexity, we will have to look at different patterns that make a noun phrase more complex. We therefore first need to refer to the overall structure of the noun phrase. A noun phrase is defined by its nominal head and, in case this head is a lexical noun, not a pronoun, has four major components. Two of these components are optional, functioning as modifier or complement to the head noun. The examples in Table 9.2 illustrate these four components.
Table 9.2 Components of noun phrase structure
| Class | Determiner | Premodifier | Head | Postmodifier | Example |
|---|---|---|---|---|---|
| 1 | + | + | these implications | ||
| 2 | + | + | + | these important physical implications | |
| 3 | + | + | + | the implications of Miller’s famous formula | |
| 4 | + | + | + | + | the full implications of Darwin’s revolution |
Table 9.2 gives us a system for analyzing and classifying noun phrase complexity, which is also applied in other studies (Reference Schaub, Schubert and Sanchez-StockhammerSchaub 2016; Reference Schaub, Schubert and Sanchez-StockhammerSchilk & Schaub 2016). According to this system, Class 1 noun phrases are NPs with no modification, including pronouns and proper nouns, Class 2 are premodified NPs, Class 3 are postmodified NPs, and, finally, class 4 includes all NPs that are both pre- and postmodified. Before returning to the genre of abstracts, let us take a short look at the occurrence of these noun phrase types in the academic register in general.
Figure 9.3 is based on a study by Reference Schaub, Schubert and Sanchez-StockhammerSchaub (2016), who sampled 8,000 noun phrases from academic texts in the humanities and three other registers. Note that the data is not based on US American or British English, but that the texts came from different regional varieties of English (Canadian, Indian, Jamaican, Hong Kong, and Singapore English). The chart shows the complexity of noun phrases in the proportions of the four classes that we derived from Table 9.2. For a more precise description of the method of collecting noun phrases for such an analysis, see the toolbox below.

Figure 9.3 Complexity in noun phrases of academic writing and three other registers
Figure 9.3 shows that only around 40 percent of the noun phrases in academic writing are simple noun phrases and that around 60 percent contain at least one modifier. It also shows that, in the academic register, about 20 percent of all the noun phrases belong to Class 4, that is, are both premodified and postmodified. This outcome is in clear contrast to all the other registers, which all have more than 50 percent simple, that is, unmodified, noun phrases. We can conclude that complex, in the sense of more modified, noun phrases are clearly more common in the academic register (in the varieties that were examined).
It is usually not possible to extract all noun phrases from an (unparsed) corpus, which is why the data we discuss in this box result from a different procedure (Reference Schaub, Schubert and Sanchez-StockhammerSchilk & Schaub 2016). The data shown in Figure 9.3 is based on a given sample of noun phrases as it was found in a corpus of texts, and not on the occurrence of different noun phrase types per register (which would be their text-linguistic variation). Here, with the same amount of noun phrases from each register, the researcher is able to determine the different proportions of the types of noun phrases as presented in Table 9.2.
When producing the database for such an analysis, there are a few important steps to be followed. First, you need to compile a corpus with a given number of (randomly chosen) texts of one or several genres (several texts are needed because it is necessary to represent a genre as fully as possible). Next, in each text you now search manually for a given number of the first (for example, 400) NPs, a procedure leading you to your preliminary database. Since you should also minimize the possible effect of different text sections, in which noun phrase complexity may not be distributed evenly, you then produce a random sample of x (for example, 150) NPs out of that initial collection, giving you your final database. These NPs then have to be categorized according to the four classes provided by Table 9.2. You will have the opportunity to practice this method in Exercise 9 (Level 2).
With Figure 9.3, we have looked at the pattern of syntactic variation within the noun phrase as depending on the register. The pattern we have discerned is that noun phrases are clearly more complex in academic writing (and, with that, in all likelihood also in abstracts) when compared to other registers.
Since, with the procedure we have described, we look at percentages based on a given set of noun phrases, let us emphasize again that the resulting observations are not directly about a case of text-linguistic variation. As explained in Section 2.5 and at several points throughout this book, a proper look at register variation would have to be based on the actual frequencies of different noun phrase types in a corpus, for example, the frequency of simple versus modified noun phrases, or of phrasal compared to clausal modifiers. For example, in that text-linguistic tradition, it has been found that the average (i.e., normalized) frequency of premodifying nouns and adjectives and of postmodifying prepositional phrases is considerably higher than the one of clausal modifiers, that is, relative clauses (Reference Biber and GrayBiber & Gray 2010: 8). Also, it has been observed that especially the relative density of NN-strings, that is, the use of nouns as modifiers (e.g., in (6) stress patterns, rather than patterns of stress), has steadily increased in the development of academic genres (Reference Biber and GrayBiber & Gray 2011, Reference Biber and Gray2016). While this section has introduced you to the method of studying noun phrase complexity based on sampled noun phrases, there is also a wealth of data available on the text-linguistic variation in this area. This data could provide you with the different rates of usage of the different aspects of noun phrase structure and would enable you to look at their frequency relative to the length of the text or corpus. For publications in this area, see Further Reading at the end of this chapter.
Turn to Exercises 4 and 5 for classifying noun phrases and observing the different types of noun phrase complexity in texts. Exercise 9 (Level 2) asks you to produce your own sample of noun phrases for a comparison of noun phrase complexity across genres.
9.4 Register Features of Digital Discourse
9.4.1 Digital Discourse as an Environment for Linguistic Innovation
In Section 9.2 we discussed the distinction between spoken and written language from a medial as well as a conceptual perspective, building on a distinction by Reference Koch and OesterreicherKoch & Oesterreicher (1985). Little could Koch and Oesterreicher have known at the time how much the boundaries between spoken and written language would be blurred by the rapid success of what was called “the new media.” It may be hard to imagine now, but in 1985, business communication did not happen through e-mail or Slack channels. Nobody carried a cell phone or began their day by checking their social media accounts, and the word text was mostly used as a noun. People who wanted to buy a toaster or book a hotel could not easily read reviews written by other customers. Families did not communicate in WhatsApp groups, customer service representatives did not communicate via online chats, and politicians did not announce campaign events on Twitter. What all these forms of communication have in common is that they use medially written language in a way that often reminds us more of spoken discourse (in a 2013 TED talk, linguist John McWhorter memorably referred to texting as “fingered speech;” Reference McWhorterMcWhorter 2013). Text messages, tweets, and chat messages are often produced without much planning or editing; online discourse is transient, has interpersonal functions, and shows grammatical characteristics of spoken language, such as the use of sentence fragments, first- and second-person pronouns, and frequent turn-taking. Medially, however, the language used in digital discourses, also known as “computer-mediated communication,” is written, which is a setting normally associated with more formal language. From the get-go, linguists who studied the language of digital registers discussed if computer-mediated communication has brought about linguistic formats that are truly new and could only exist in the digital environment, and how these formats use existing mechanisms in new patterns. Linguists have also addressed the perception that the spread of digital writing leads to a loss of grammatical abilities, especially in young people (for details, see our Good to Know box at the end of Section 9.4.3).
In his book Language and the Internet, first published in 2007 (the year the first iPhone was released and one year after Twitter was founded), David Crystal coined the term “netspeak” for the kind of language used in digital discourse. The term suggests that digital discourse is truly of its own kind – not spoken, not written, but merging characteristics of both spoken and written language, “a genuine third medium” (Reference CrystalCrystal 2007: 52). This line of thinking has shifted toward a consensus that the language used in digital discourse is as heterogeneous as the language of conventionally spoken or written discourse, and research questions around digital discourse have moved from cataloguing digital genres and their linguistic characteristics to questions about the impact of digital communication on language development (Reference SquiresSquires 2016) and the nature of human interaction (Reference TurkleTurkle 2015).
In this section, we want to focus on two innovations brought about or sped up by digital registers: hashtags as an innovation resulting from the technological affordances of the digital medium and the because X construction as an innovation based on an existing grammatical element (because as a syntactic subordinator and preposition with limited complementation). Hashtags can be seen in the tradition of digital registers to use spelling and punctuation creatively to set a “typographical tone of voice” (Reference McCullochMcCulloch 2019: 109). These typographical choices include the omission of letters (tmrw, “tomorrow”) simply to shorten words, the lengthening of words (yesssssss) to add emphasis, as well as the creative use of punctuation marks. Sometimes the extra message lies in the absence of a feature rather than in its presence. In short text messages, it is common not to put a period at the end of the utterance. Ending a sentence with a period in this type of discourse sends a message beyond just signaling the end of a syntactic unit. Often, the use of a period at the end of a text is interpreted as a somewhat aggressive declaration that the speaker is done with engaging. To check if this interpretation holds across registers or is tied specifically to digital discourse, Reference Gunraj, Drumm-Hewitt, Dashow, Upadhyay and KlinGunraj et al. (2016) compared the use of periods at the end of utterances in texts and handwritten notes. They presented participants with one-line text messages and handwritten notes (Wanna come?) and answers that either included or didn’t include a period (Sure./Sure). They found that the presence of a period led to the perception of the message as less sincere in texts (but not in handwritten notes) and concluded that in digital discourse standard punctuation marks are indeed used in innovative, pragmatically meaningful ways.
9.4.2 Hashtags: #informationpackaging #coolstuff
Unlike the period or exclamation mark, hashtags have their origin in digital discourse. They were originally developed to tag the general topic of a message on microblogging platforms and to facilitate the organizing of groups on Twitter (former Google employee Chris Messina is usually credited as the person who introduced the hashtag to Twitter in 2007). The hashtag consists of the pound sign (#) – also known as the number sign outside the US – followed by linguistic material. Hashtags can be individual words, acronyms, phrases, or full sentences. They may or may not be integrated into the syntax of the message. Depending on the platform, the number of hashtags per message can be limited. This sounds as if there is not a lot of order around hashtags, but linguists have identified several distinct functions performed by hashtags. Based on a study of a 100-million-word Twitter corpus, Reference ZappavignaZappavigna (2015) recognizes three main functions of hashtags: textual, experiential, and interpersonal. The textual function is to organize a post and to convey metadata status to a word or phrase, that is, to make the word or phrase searchable. At the typographical level, this happens through using the # symbol, which Zappavigna considers a form of punctuation. The hashtag may be integrated into the syntax of the post, as in (9), or it may be added at the beginning or end, as in (10). Using textual hashtags is built on the assumption that other people might search for posts on a specific topic and might use the same hashtags.
(9) Myself and #GeorgeClooney on set @Nespresso commercial!!!
(Twitter, @NickyWhelan, 2015)
(10) #sandiegofire 300,000 people evacuated in San Diego County now
(Twitter, @nateritter, 2007)
The experiential function of a hashtag is to say what the post is about, which is another way of saying that hashtags can serve the same function as verbal topic markers and topic-marking constructions, such as topicalization and left-dislocation (as discussed in Chapter 3). What we see here, then, is that a tool afforded by the digital environment provides an innovative way to package the information in a text. Crucially, the hashtag does not only serve the function to establish the topic of the discourse, it also helps create “searchable talk” as a way to enact “ambient community” (Reference ZappavignaZappavigna 2015: 280) – it enables individuals to affiliate with other people on Twitter who are interested in the same things they are. This function of hashtags also plays an important role in marketing campaigns, like #ShareACoke by Coca Cola. Finally, the interpersonal function of hashtags is to add stance to a post and thus enact a relationship with the ambient audience, as in (11).
(11) @easyJet so I gather my flight tomorrow is cancelled for tomorrow to Sharm. No email yet or message sent #madashell (Twitter, @NickyUser, 2015)
Here, the hashtag #madashell does not have the function to identify the post as one about the topic “mad as hell,” rather, it is a concise way (only ten characters) to add a level of commentary (namely that the writer is “mad as hell”) to the post about a delayed flight. Zappavigna notes that interpersonal hashtags often are very long and specific (#SocialMediaIsNotAsImportantAsYouThinkItIsKyle) and can thus counteract the original aggregating function of hashtags.
The popularity of hashtags is reflected in the election of the word hashtag as Word of the Year 2014 by the American Dialect Society and in the election of the hashtag #blacklivesmatter as Word of the Year two years later. Ben Zimmer, chair of the ADS New Words Committee, conceded at the time that “#blacklivesmatter may not fit the traditional definition of a word,” but he argued that the hashtag deserved to be considered because it was a forceful example of linguistic innovation (American Dialect Society 2015).

And forceful hashtags certainly are: They have spread not only beyond the borders of Twitter, but also beyond the context of digital media and even medially written registers. As stated above, they are used in marketing campaigns, not only on social media, but also in print, as well as in spoken discourse, where they cannot have the same range of functions as in digital formats.
Using the word hashtag in spoken discourse to perform the textual function of actual hashtags can easily come across as comical, as in the following excerpt in (12), taken from the award-winning Canadian comedy show Schitt’s Creek (Season 6, Episode 2, first aired in 2020). Moira Rose, a soap opera actress trying to revive her career via connecting with fans on social media, is entering a store that is co-owned by her son David Rose and his fiancé, Patrick, who gently points out to her that she is not using the word hashtag correctly.
(12)
Moira (holding up her cell phone, recording): Bongiorno, boys! David: Oh no! Moira: Say hello to all my hashtag “frands!” It’s a little word I assembled to consecrate my fans, who are also my friends. David: Okay, “frands” doesn’t sound nice. Moira: To all of you asking “What is this little mercantile establishment with the almost gallery-like austerity?” Well, it so happens it’s also owned by my son, David Rose. Say hi, David … David: Okay, I would rather not, thanks. Moira: … and his hashtag fiancé, Patrick. Patrick: I don’t think you have to say “hashtag” when you’re just talking, Mrs. Rose.
Overall, we see that hashtags are a linguistic innovation that has been brought about by the digital medium. They serve a range of functions, some of them inherent to the medium, others of a more general kind, like packaging information.
You should now be able to address Exercise 6, which asks you to consider different types of hashtags.
9.4.3 Because X: A New Chapter in a Preposition’s Life
While hashtags are a linguistic innovation that could only have started in digital discourse, due to the embedded technology, digital registers also contribute to the spread of constructions that align with patterns of language change which are not contingent on a particular register, but which may be favored by the situational settings of digital discourse. One such construction is the spread of a new(-ish) complementation pattern after because. The “old” because falls into one of the following two classes: Either it is a conjunction that introduces a finite clause, as in (13) and (14), or it behaves as a preposition that must be followed by another PP, introduced by of, as in (15). (Alternatively, one might analyze the sequence because of as a complex preposition. For our discussion here it does not really matter which analysis is applied.)
(13) Neal, are you here tomorrow? Because we’re making a Costco run. (COCA, TV, 2014)
(14) We picked this postcard out for you because you look like Pluto. (COCA, Spoken, 1992)
(15) Austen’s Mrs. Bennet can be seen as a woman given over to frivolity partly because of her husband’s lack of interest in her character. (COCA, Academic, 1993)
The “new” because, or, more precisely, the new use of because, differs from these uses in that it can be followed by a noun phrase (or even a bare noun), as in (16a)–(16c), an adjective or adjective phrase, as in (17), or an interjection, as in (18). The following examples are all from Twitter:
a. I had my FB disabled because reasons (@AmbuloKing, 2021)
b. I just ordered lots of Chinese dumplings, because NYC!! (@AnitaTimeOut, 2021)
c. Ok minirant. Been travelling since the last 2 days. First of all, I cant stop to eat because covid (@honey_crypt, 2021)
(17) Then I make plans and cancel … . because tired (@CupidsAaro, 2021)
(18) Wow. The arrogance. The selfishness. The greed. The sheer audacity. Millions of people either haven’t gotten vaccinated yet or don’t plan to at all but yes let’s rush back to normal because yay! (@FierceAssSistah, 2021)
Because of the syntactic variability of the linguistic material after because, Reference Bohmann and SquiresBohmann (2016), whose corpus-based study we explain in more detail below, refers to examples like (16)–(18) as the because X complementation. What all because X instances have in common is that they are shorter than the more traditional uses of because. In many cases, as in the examples above, X in because X consists of only one word (because reasons, because tired, because yay). In this way, because X is a form of complementation that aligns with several language change trends that have been identified for the development of Modern English well before the arrival of Twitter (Reference Leech, Hundt, Mair and SmithLeech et al. 2009): (a) densification (using fewer words or fewer characters to express the same thing – think delish and natch instead of delicious and naturally); (b) a shift of written language to incorporating constructions more characteristic of spoken language (shorter constructions, for example, fewer modifiers, fewer passive constructions, and more ellipsis); and (c) a spread of constructions identified as Americanisms, such as the spread of the mandative subjunctive (They demanded that he leave). With these trends in mind, it makes sense to expect that posts on Twitter, with its limitations on number of characters, its high frequency of non-standard spellings and punctuation that is so characteristic of digital discourse, and its high number of users from the United States are a fertile ground for the spread of because X. In a variationist study based on about 12,000 tweets containing the word because, Reference Bohmann and SquiresBohmann (2016) found that because X occurred almost as often as because of (6.3 percent vs. 7.7 percent of all tokens), but both occurred much more rarely than because as a conjunction, see Figure 9.4.

In 38.8 percent of because X cases (because reasons), X was a noun (because reasons), in 9.8 percent an adjective (because tired). The remainder was made up of interjections, clause fragments, hashtags, hyperlinks, adverbs, and emoji. For a second step in his analysis, however, Bohmann decided to conceptualize the use of because X as a binary choice between the traditional use of because (because + clause, because + of) and the new use of because.
In this second step Bohmann examined if there was any correlation between the choice of because X (over one of the traditional uses of because) and high scores in terms of linguistic density, colloquialness, proficiency as Twitter user (based on metrics such as use of hashtags, @-mentions, number of followers, frequency of postings), and geographical origin of tweets. In order to do this, he had to operationalize linguistic density and colloquialness, which is tricky because some of the relevant linguistic markers cannot easily be parsed automatically. For density, he relied on factors like the shortening of the word because, length of the tweet, mean word length, and noun-verb ratio (a higher noun-verb ratio contributes to a denser text); for colloquialness, he used an established formula for measuring how context-dependent a text is, as measured through part-of-speech frequencies as well as the non-standard spelling of because (coz, cos, bc), which mimics the low degree of formality characteristic of spoken language. The home country of the user was established by checking the user’s Twitter profile. The expectation was that one would see the central position American English holds in the development of written English would be reflected in higher numbers of because X used by speakers from the US.
What Bohmann found was that the three most significant predictors for because X all related to density: length of tweet, mean word length, choice of coz/cos/bc over the longer form because (obviously, all shortened forms of because are also non-standard forms of because). A discourse that favors short, compact utterances is an environment that favors the choice of because X, although not to the extent that because X becomes the dominant form. Bohmann did not find a clear correlation between a low formality score and a preference for because X (less formal tweets actually showed a preference for a clausal complementation pattern). With regard to digital discourse proficiency, he found that the metrics he included to determine a proficiency score did not uniformly behave as predictors for the use of because X. Lastly, he did not find confirmation for the hypothesis that because X is most popular in the US. He concluded that Twitter as an “inherently dense format” is “an ideal environment for a newly emerging, metalinguistically salient, and economical construction like because X” (Reference Bohmann and SquiresBohmann 2016: 170 f.). Unlike the hashtag, because X is not contingent on the digital medium, but the settings of the digital discourse favor its use.
There is a lot, of course, that this study did not address. For example, Bohmann only looked at the shortening of because, since this was a word that occurred in all tweets under examination. He did not look at other shortened words, mainly because this would require extensive manual coding (for example, someone might spell tomorrow as tmrw or tw, but how would the software know that, considering that shortened forms could be idiosyncratic). There is also no consideration of linguistic markers beyond parts of speech that are characteristic of informal language. For example, it might be interesting to look at whether or not tweets that use because X contain fewer passives and fewer modifiers than tweets that use because of. Referring back to the distinction we have used throughout this book, Bohmann’s study took a variationist perspective, that is, he looked at the impact of the discourse medium on the choice of because variant. We should note that this does not necessarily mean that because X is more pervasive in the register he studied than in others, that is, his results do not reflect a text-linguistic perspective.
As with any empirical study, one always has to balance out the desire for a broad data basis with the feasibility of the analysis. This is something that by now you will have seen in your own empirical projects. Still, what we can observe is how digital registers, especially those that put limits on the length of texts, can amplify existing trends toward compact expressions, even at the level of complementation after a functional category such as a preposition – not normally the most fertile ground for linguistic innovation. In January 2014 the American Dialect Society crowned the new because Word of the Year 2013 – because useful!
You should now be able to handle Exercise 7, which asks you to retrieve because X constructions from a corpus (which is harder than it sounds).
Good to Know: Texting Doesn’t Ruin Your Grammar!Many people are concerned that extensive texting – with its characteristic truncated syntax, acronyms, and alternative spellings, also known as “textisms” – has a negative impact on children’s ability to use standard syntax and spelling and to express complex ideas. In 2006, many politicians and pundits ridiculed a decision by the Scottish Qualifications Authority not to penalize students for using elements of texting language in their English high school exams, which had made waves internationally. Others, including the British national newspaper The Guardian, praised the SQA as “champions of reason.”
Is there any way to determine who is right? In 2016, a team of Dutch linguists and child development specialists (Reference van Dijk, Merel, Vasić, Avrutin and Blomvan Dijk et al. 2016) attempted just that. They set out to test empirically if heavy use of texting influenced children’s grammar performance as well as their executive functions in general (for example, the ability to disregard irrelevant or distracting information). In their experimental study, they elicited text messages from fifty-five Dutch 5th and 6th graders and also collected text messages produced by the students in a natural setting. They then looked at the number of “textisms”
used (including unconventional spelling and words borrowed from English) as well as the number of omitted words. In order to determine children’s grammar abilities, participants underwent a standardized vocabulary test (they had to point to a picture that corresponded to the word said by the experimenter) as well as a sentence repetition task. You may think that just repeating a sentence tells you more about someone’s memory than their grammar abilities, but psycholinguistic research has established that in order to repeat utterances longer than one or two words, speakers must use their syntactic knowledge to parse the sentence before they repeat it. The Dutch team found that there was a clear relationship between the frequency of using word omission and participants’ grammar abilities – in a positive way. The more the students utilized word omission in their texts, the better they performed in the repetition task. The researchers interpreted this result as a sign that omitting the right kind of word in a text requires syntactic knowledge and that heavy users of texting constantly train their grammar system in ways that other people don’t. (The relationship between use of other linguistic features related to texting language – alternative spelling etc. – and grammar abilities was less clear.)

The study was carried out based on data from Dutch, but there is no reason to believe that the results are language specific. We can think of textese as a genre-based language variety – and the more often speakers have to switch from one variety to another, the more they train their grammar awareness. In other words, texting does not ruin your grammar, it sharpens your sense of it.
9.5 Summary
In this chapter, we have introduced you to grammatical patterns in discourse that are tied to the situational settings as well as the conventions of a particular genre. Such patterns may be either pervasive (such as the use of passive voice in scientific abstracts) or typical (such as the use of hashtags in tweets). We saw that some of these patterns can be explained by considering the modality of the discourse situation. Writing often, but not exclusively, happens in situations that allow for planning and editing, speaking is often, but not exclusively, linked to situations in which utterances are produced spontaneously, in turns, and without much planning. As a prototypical written genre, we discussed the scientific abstract and specifically looked at the linguistic representation of agentivity. We saw that the needs of a discipline to background the involvement of human agents in experiments can lead to innovative constructions, such as the active voice with impersonal, metatextual subjects (this paper argues …). We also examined the way in which scientific genres handle the need to condense information without losing precision, namely through syntactic compression in noun phrases rather than through elaboration in subordinate clauses. We then turned to a discussion of where digital genres fit on the continuum of conceptually spoken vs. written language and which linguistic features may be brought about or favored by the register of digital discourses. Specifically, we discussed how hashtags combine both innovative and traditional functions of structuring the discourse and that social media platforms with character limits are a particularly fertile ground for densifications like the because X construction. In this way, we showed that digital genres, while opening new avenues for the features of a register, are not of a completely different kind and fit the overall pattern of language variation to serve the needs of the discourse.
9.6 Exercises
Level 1: Classification and Application
1. Classify the following situations in which discourse is produced making use of the distinction between medially and conceptually oral or written language.

a. a discussion at a restaurant table

b. a person writing a text message

c. somebody in an interview

d. a person delivering a speech

e. somebody writing and carefully editing a text
2. Classify the two text excerpts below, both taken from discourse that was published online (the excerpts are from the CORE corpus). Identify grammatical features that we discussed in Section 9.2 as typically occurring in speech or in writing. Discuss your findings in the light of the role of the medium as determining a register. Which features have more to do with other aspects of the discourse situation, such as the purpose of the text, or the expected audience?
A. Hello all, I hope some can offer me some advice? Sorry if this is a long post but really don’t know where to turn. I have a dog called Frankie, who is 5.5 years old. He came to live with me when he was 1, after his original owners (who I knew through work) had twins and said they couldn’t give him the attention he needed. It now turns out they lied and he didn’t like the babies, strangers or other dogs but chose not to tell me. He is a Jack Russell cross with some other small dog, not sure what! Frankie has always had anxiety/ aggression issues …. (CORE, Interactive Discussion, 2012)
B. Frank claims he has a nice apartment. Was brought up to believe the two most important things in life are family and friends. He goes to the track 3–4 times a year. He has never seen a shrink, does not have a drinking problem nor has he taken any drugs. Likes milk and sugar in his coffee. Was 25 years old at the time of the first season. Can breakdance. Has a grandmother. Hangs out a Panama Joes alot – to see twins. He once got bitten by a dog. He gets sick by meat factories. If he ever has a kid, he will name it Eddie. Disgusted by the sport of boxing. Uses Sprat deodorant. He has not given any thought about his own funeral arrangements. His stomach has coreners. Is crazy about Lana Turner. Was a good student, always did his homework. He likes dogs. Played High School hockey. Alleges his sisters name is Jenny (but in another episode he claims he has no sister). (CORE, Description of a person, undated)
3. In Section 9.3, we discuss three different strategies for dealing with the expression of agentivity in scientific abstracts. Analyze the three abstracts below for the occurrence of these strategies. Which ones do you find, and how much variation is there within each text? Do you find a difference that may be related to the last abstract coming from a different discipline?
C. This article introduces a quantitative method for identifying newly emerging word forms in large time-stamped corpora of natural language and then describes an analysis of lexical emergence in American social media using this method, based on a multi-billion-word corpus of Tweets collected between October 2013 and November 2014. In total 29 emerging word forms, which represent various semantic classes, grammatical parts-of-speech and word formation processes, were identified through this analysis. These 29 forms are then examined from various perspectives in order to begin to better understand the process of lexical emergence. (Reference Grieve, Nini and GuoGrieve et al. 2017)
D. In this paper we analyse variable presence of the complementizer that, i.e. I think that/Øthis is interesting, in a large archive of British dialects. Situating this feature within its historical development and synchronic patterning, we seek to understand the mechanism underlying the choice between that and zero. Our findings reveal that, in contrast to the diachronic record, the zero option is predominant – 91 percent overall. Statistical analyses of competing factors operating on this feature confirm that grammaticalization processes and grammatical complexity play a role. However, the linguistic characteristics of a previously grammaticalized collocation, I think, exerts a greater effect. Its imprint is visible in multiple internal factors which constrain the zero option in the other contexts. We argue that this recurrent pattern in discourse propels the zero option through the grammar. These findings contribute to research arguing for a strong relationship between frequency and reanalysis in linguistic change. (Tagliamonte & Smith 2005)
E. From 1932 to 1973, Chicago women who wanted to avoid the high costs and impersonal treatment of the city’s maternity wards had another option: they could choose to give birth at home, attended by obstetricians and nurses of the Chicago Maternity Center (CMC). As the rest of the nation moved toward the hospital as the normalized place of delivery, low-income white women and women of color in Chicago continued to assert not only their preference for home birth but also their demand for affordable, dignified, and family-centered care. When the CMC was threatened with closure, women from diverse backgrounds joined together to save this alternative maternity option. This article explores how these Chicago mothers resisted hospitalization and asserted their right to choose home birth years before the women’s health movement offered a similar critique. (Reference LewisLewis 2018)
4. The noun phrases below were retrieved from texts written by academic authors in the natural sciences. Classify the noun phrases using the classification scheme we introduced in Section 9.3.2 for the different degrees of noun phrase complexity (simple, premodified, postmodified, pre- and postmodified). Which noun phrases have other noun phrases embedded within them and could therefore be analyzed further for noun phrase complexity?
Attested noun phrase Type of NP a large number of experimental and theoretical studies actual experimental applications the general theory of magnetic resonance line shape the theory the density matrix for the system at a temperature T the efficiency of energy transfer the expansion the strong interaction the extra energy in its electric field strong interaction effects in our experiments the magnetic field dependence of the rate at which energy is absorbed from the electromagnetic field by a spin system a manner that efficiently meshes with our F-flatness constraints
5. Using the same classification scheme for noun phrase complexity as in Exercise 4, analyze the abstracts from Exercise 3 as a text corpus. Collect a sample of thirty noun phrases and determine the proportions of the four different classes. Note: You should only analyze first-level noun phrases, i.e., no noun phrases that are embedded in another noun phrase (for instance, if a quantitative method for identifying newly emerging word forms is the second NP in text C., newly emerging word forms should not be taken as a separate NP).
6. In Section 9.4.2 we discussed different functions that hashtags can take. Apply the three functions that were introduced to the tweets below while also paying attention to the position of the hashtag in the tweet. Is there any relationship between the two?
Tweet 1: On this World Health Day, let’s pledge that we’ll prioritize our health above all – be it Mental or Physical Health. And we’ll make this world a healthier and happier place. #WorldHealthDay #HealthForAll #MentalHealthMatters
Tweet 2: I know it’s a #FirstWorldProblem but I’m angry that my 2021 #Toyota Camry is spending the weekend in the shop because of a bad O2 sensor. I bought a new car because I don’t have time for car problems. #disappointed
Tweet 3: Can’t flip over a vault and stick a perfect landing but hey, still proud to show off my #vaccine card. #FullyVaccinated
Tweet 4: #BREAKING: The #CDS on Thursday will ease indoor #mask guidance for fully vaccinated people, allowing them to safely stop wearing masks inside in most places, a government source told the AP. #pandemic #covid19 #safety
7. Applying the lexical shortcut route we introduced in Chapter 3, let’s study the use of because X based on specific lexical items. Two nouns that occur with some frequency in the because X construction are reasons (because reasons) and science (because science). Do a search for these in the Corpus of Global Web-Based English (GloWbE). What do you find? Is there any indication that the construction is more popular in American English than elsewhere? Are there any false positives you have to rule out?
Level 2: Interpretation and Research Design
8. Scientific podcasts are a well-established genre, but there is not a lot of research on them. Pick a scientific podcast that makes transcripts available (such as the podcast published by the journal Science), download four or five transcripts, and assess, based on the grammatical features we discussed in Section 9.2, if their linguistic profile is closer to prototypically written or prototypically spoken language. (Obviously, your analysis will be based on a very small sample.) Explain your choice of linguistic variable(s).
9. Using the sampling method described in the toolbox of Section 9.3.2, analyze two written genres for their preferred type of noun phrase. You should come up with a sample of fifty noun phrases from each text type. How many noun phrases will you first have to collect (approximately)?
10. Bohmann’s study of because X was published in 2016 and the data comes from Twitter. How would one go about it if one wanted to know if because X has spread since then? Which genre(s) might be good candidates to look at? What might be challenges for a corpus linguistic approach? Might there be different ways to assess if because X has spread? Develop a research design, starting with a testable hypothesis.
Further Reading
A comprehensive overview of the grammatical features of spoken English can be found in chapter 14 of the Grammar of Spoken and Written English (Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021). A detailed analysis of the bundles of linguistic features in which speech and writing differ is the study of Reference BiberBiber (1988). For an introduction to Conversation Analysis, see, for example, Reference CliftClift (2016). On the hybrid nature of online registers with regard to features of the spoken and written mode, see Reference Biber and EgbertBiber & Egbert (2018).
A detailed description of the noun phrase in English is given in Reference BerlageBerlage (2014). The development of written English toward more compressed sentence structures is described, for example, in Reference MairMair (2006), Reference Leech, Hundt, Mair and SmithLeech et al. (2009), and Reference Biber and GrayBiber & Gray (2011). A wealth of data on the frequency and types of pre- and postmodifiers within the complex noun phrase is also provided by the GSWE (Reference Biber, Johansson, Leech, Conrad and FineganBiber et al. 2021: ch. 8). Data on the occurrence of categories reflecting a phrasal or clausal discourse style in the academic as opposed to other registers is contained, for example, in Reference Biber and GrayBiber & Gray (2016: ch. 3).
For an overview of trends and topics in the analysis of computer-mediated communication since its beginnings, see Reference Herring, Bou-Franch and Garcés-Conejos BlitvichHerring (2019). Herring describes how earlier scholarship focused on textual features of digital genres, but now includes the analysis of multimodal discourses. If you are mostly interested in how language development on the Internet fits with language change in general, check out Reference McCullochMcCulloch (2019), written for a non-academic audience, and the articles in Reference SquiresSquires (2016). If you would like to learn more about different strands of research on hashtags, see Reference Heyd and PuschmannHeyd & Puschmann (2017), who compare hashtags in social media to hashtag graffiti in public spaces. If you want to learn more about ongoing trends in the syntactic development of English, especially with regard to colloquialization and density, the overview chapter by Reference Mair, Leech, Aarts, McMahon and HinrichsMair & Leech (2020) is a good start. For an overview of trends in the analysis of syntax and genre in the digital domain, see Reference Dorgeloh, Wanner, Aarts, Bowie and PopovaDorgeloh & Wanner (2020).































