1 Introduction
1.1 Stress at the Word Level
The languages in the world can be divided roughly into two types of word-prosodic systems. One type, probably a minority, has tone.Footnote 1 A tone language uses different pitches or melodies to differentiate between words in the lexicon, just as the vowels and the consonants do. The second type, which is the type that we address in the present chapter, has stress. When a language has stress, every word has one syllable which in some sense is more important, or more prominent, than any other syllable in the same word. This is also the crucial difference between tone and stress. In a tone language there is no difference in prominence attached to the syllables that make up the word, whereas stress is a culminative property: only one syllable can be the strongest (the prosodic head) within a constituent – such as a word.Footnote 2
Which syllable is the prosodic head of the word is often predictable. For languages with fixed stress there is just one single rule that determines the position of the word stress for the entire lexicon. Hungarian words, for instance, always have stress on the initial syllable; in Weri (a Papuan language; Boxwell and Boxwell Reference Boxwell, Boxwell and Wurm1966) the stress is always on the last syllable of the word. Other languages may have more complex rule systems for assigning stress to words. In weight-sensitive languages such as English, German and Dutch, the complexity of (the rhyme portion of) the syllables determines where the stress goes, at least in monomorphemic words. For instance, stress in Dutch simplex words goes to the final syllable if it is superheavy (i.e. contains more than two morae in its rhyme); if not, stress goes to the pre-final syllable if this syllable is at least heavy (has two morae in the rhyme portion). It has been estimated that a relatively small portion of the monomorphemic lexicon is stressed by exception, that is, deviates from the weight-sensitive stress assignment (e.g. 15 per cent exceptions in Dutch; Langeweg Reference Langeweg1988). The exceptions would be cases of unpredictable (or ‘lexical’) stress. In some languages, there are so many exceptions to any regularity one might want to formulate that stress rules do not make sense. Russian and Greek are often cited as examples of such lexical-stress languages.
Linguistically speaking, the inventory of stressed syllables in a language is richer (i.e. with a greater diversity of segmental structures) than that of unstressed syllables (see, for instance, the counts for Swedish (and four other languages) by Carlson et al. Reference Carlson, Elenius, Granstrom and Hunnicutt1985 and for Dutch by van Heuven and Hagman Reference Heuven, Hagman, Coopmans and Hulk1988). Moreover, stressed syllables typically resist deleting or assimilating segments to neighbouring unstressed syllables, and whereas unstressed syllables tend to assimilate to adjacent stressed syllables, are susceptible to weakening processes and deletions. In this chapter we will not, however, be concerned with the linguistic properties of stressed syllables. The focus of interest will be on the phonetic realization of stress at the word and sentence level.
1.2 Stress at the Sentence Level
Prosody is hierarchically structured. Where one syllable is the prosodic head of the word domain, one word will be the prosodic head of the phrase or utterance it occurs in. Typically, when a word receives sentence stress, the marking of this stress will fall on the syllable within the word that carries the word stress. A syllable in a word with sentence stress has all the phonetic markers of a word stress plus some characteristics that mark it as a sentence stress. Which words in an utterance receive sentence stress and which ones do not depends on the syntax-prosody interface of the language. In Romance languages, for instance, the location of the sentence stresses is largely, if not fully, determined by the syntactic structure of the utterance. In Spanish, the sentence stress (indicated by capitals) will invariably be on the nouns in (1) even though the pragmatic contrast (indicated by square brackets) is in the prepositions (Ladd Reference Ladd1996):
(1)
¿Quiere café [con] LEche o café [sin] LEche? ‘Require-you coffee [with] MILK or coffee [without] MILK?’
In other languages, such as those in the Germanic family, sentence stresses are assigned by default to specific words on the basis of the syntactic/prosodic structure of the utterance, but the default rules may be overridden by pragmatic considerations that delete or move sentence stresses so as to express the focus structure of the utterance. Typically only the prosodic head of a prosodic constituent that is in focus, that is, contributes new and contextually unpredictable information to the discourse, receives sentence stress, whereas sentence stresses are deleted (or moved away) from words and phrases that are out of focus, that is, contain relatively unimportant and contextually given information. Thus, in (2a) there is a contrast between two phrases: the girl and the old man. By default, sentence stress in the latter phrase goes to the noun, which is the prosodic head of the NP. In (2b), however, the pragmatic contrast is between the adjectives young and old. In this situation pragmatic rules delete the default sentence stress from the noun and reassign it to the adjective.
(2a) Is Lesley [the GIRL] or [the old MAN]?
(2b) Is Lesley the [YOUNG] man or the [OLD] man?
1.3 Acoustic Correlates and Perceptual Cues
The purpose of the present chapter is to present and discuss the way word and sentence stress are phonetically marked. It has been known since the 1950s that stress (whether at the word or sentence level) is never marked by a single acoustical property (for a survey see Lehiste Reference Lehiste1970). To make the stressed syllable stand out from its neighbours, it is produced with greater physiological effort on the part of the speaker than its unstressed counterpart (e.g. Ladefoged Reference Ladefoged and Ladefoged1967). The greater effort will be exerted at any stage in the speech production process, that is, by the subglottal mechanism (more air is pushed out of the lungs), by the glottal (laryngeal) system (contraction of laryngeal muscles, generating a change in pitch) and by the supraglottal organs (e.g. larger and faster displacement of lips, tongue and jaw, yielding more clearly articulated vowels and consonants). The greater effort is seen, first of all, in closer approximation of articulatory target configurations for segments in stressed syllables. More extreme articulatory movements require more time than small displacements of the vocal organs. The result of this is that segments in stressed syllables have longer durations – all else being equal – than unstressed segments.Footnote 3 Moreover, in terms of the theory of articulatory phonology (e.g. Browman and Goldstein Reference Browman and Goldstein1992), there is relatively little overlap between adjacent segments in a stressed syllable. In contradistinction to this, unstressed segments greatly overlap, which leads to considerable reduction of segmental contrast. This also accounts elegantly for the observation that segments at the edges of stressed syllables tend to maintain their identity (resist coarticulation with an adjacent segment in an unstressed syllable) whilst unstressed segments across the syllable boundary are disproportionally affected by coarticulation (e.g. Dogil and Williams Reference Dogil, Williams and van der Hulst1999).Footnote 4
Effort expended at the laryngeal level of speech production takes the form of contracting selected muscles that influence the speed with which the vocal folds vibrate during phonation. The result may be a rapid increase (through activation of cricothyroid and vocalis muscles) or decrease (through activation of the sternohyoid muscle) of the repetition rate of the glottal cycle, causing, respectively, a rise and fall of vocal pitch. A secondary effect of laryngeal effort may be a tightening of the vocal folds (musculi vocales), which will then snap together more forcefully than when in a less tightened state. Finally, increased effort at the subglottal level will push more air per unit of time through the glottis, causing, first of all, an increase in intensity of the sound produced by the glottal siren. Secondarily, the greater volume-velocity of the airstream through the glottis boosts the Bernoulli suction effect. The increased suction and the tightening of the vocalis muscles conspire to shorten the closing phase of the glottal cycle, which causes the spectrum to become flatter (boosting the intensity of higher harmonics, thereby generating a louder sound – I will come back to this later).
In this chapter we will not deal any further with the physiological basis of stress (but see Erickson and Kawahara Reference Erickson and Kawahara2016 for a well-documented survey of current issues). We will concentrate on the acoustic consequences of increased versus decreased effort (as foreshadowed in the above) and ask (i) what acoustic correlates can be found for the difference between a stressed syllable and its unstressed counterpart, and (ii) what the relative importance is of each acoustic correlate in the marking of stress. At the same time we will consider the question of what acoustic properties are used by human listeners and to what extent these are used to decide whether or not a syllable is stressed. We will make a strict terminological distinction here between acoustic correlates of stress (which can be used, for instance, to identify a stressed syllable by some computer algorithm) and the perceptual cues used by the human listener. We will see that some acoustic correlates, notably the (peak) intensity of a syllable, allow excellent separation of stressed from unstressed tokens but are hardly used by the human listener.
There is no need, a priori, for the three subsystems of speech production to expend extra effort on the production of a stressed syllable in equal proportion. We may speculate, in fact, that languages differ in the way they exploit effort in each subsystem. For instance, Germanic languages seem to exploit the gradation of supralaryngeal effort more than Romance languages do. More generally, we will ask to what extent the acoustic correlates and perceptual cues of stress have the same ranking order across languages or are differently ordered from one language to the next. If the latter should be the case, then we may ask the supplementary question if the order of importance of correlates and cues can be predicted from the phonological structure of the language at issue.
2 Acoustic Correlates
2.1 Some Methodological Considerations
When trying to find acoustic correlates of stress, it is generally not a good idea to just compare acoustic properties of successive syllables in a word. If the segmental make-up of the syllables is different, the correlates of stress are obscured by the intrinsic and co-intrinsic properties of the segments. For instance, open vowels have inherently greater intensity (Lehiste and Peterson Reference Lehiste and Peterson1959) and longer duration than close vowels (Peterson and Lehiste Reference Peterson and Lehiste1960), so that an unstressed open vowel may, in fact, seem more stressed than a closed stressed vowel, as may happen in the English noun impact. Several tricks have been suggested to eliminate, or correct for, such inherent segmental properties. One is to run some extrinsic normalization procedure by which the intensity or duration of a segment is expressed in standard deviations away from the mean value of that segment (i.e. z-normalization) as produced by the individual speaker in a larger corpus of materials (e.g. Potisuk, Gandour and Harper Reference Potisuk, Gandour and Harper1996).Footnote 5 Another way out would be to use so-called reiterant speech (Larkey Reference Larkey1982, Liberman and Streeter Reference Liberman and Streeter1978, Nakatani and Shaffer Reference Nakatani and Shaffer1978). In this speech mode the speaker replaces the syllables in a target word by repetitions of the same segmental structure; for example, repetitions of /ma/ or /lɪs/. For instance, the target utterance please say import again would be produced as please say mama again, or please say lislis again. The claim is that the speaker dubs all (and only) the prosodically relevant variations onto the reiterant version of the original utterance so that no normalization for intrinsic segmental differences is needed. A potential problem with these techniques is that stressed and unstressed syllables are compared syntagmatically, that is, in different linear positions in a larger structure, such as an initial stressed and a final unstressed syllable – so that, strictly speaking, the researcher does not know whether he measures correlates of stress or of sequential position. The safest precaution, therefore, would be to compare stressed and unstressed versions of the same syllables in a paradigmatic way; for instance, by comparing the stressed and unstressed realizations of the first and second syllables in a minimal stress pair such as the IMport versus to imPORT. This solution, of course, can only be used if the language has at least one minimal stress pair – which means that it cannot be used in languages with fixed stress.Footnote 6
It has also been found expedient to measure the correlates of stress separately for stress at the word level and at the sentence level. This is generally achieved by (paradigmatically) comparing tokens of stressed and unstressed syllables in a minimal stress pair which was produced in the same position in a surface-syntactically identical sentence with and without focus on the target. Focus on the target word, indicated in (3a–c) in square brackets, is often manipulated by having the speaker answer different questions that highlight one constituent or the other as in (3a–c):
(3a)
Q: who borrowed a chainsaw? A: [OScar] borrowed a chainsaw
(3b)
Q: what did oscar borrow? A: oscar borrowed [a CHAINsaw]
(3c)
Q: did oscar buy a chainsaw? A: (no,) oscar [BORrowed] a chainsaw
The recordings now contain tokens of the words Oscar, borrow and chainsaw produced with and without sentence stress, which can be directly compared: any difference between the readings must be the consequence of presence versus absence of sentence stress. The difference between stressed and unstressed syllables in the tokens that are produced without sentence stress (out of focus) will then be a matter of word stress only (indicated by bolded small capitals). Examining the effects of word and sentence stress in a single experimental setup using minimal stress pairs can only be achieved by using highly contrived contexts, for instance, with target words used metalinguistically (as citation forms), as in (4a–d):Footnote 7
(4a)
Q: did you read ‘the import’ or ‘the sale’ again? A: i read [‘the IMport’] again
(4b)
Q: did you read ‘to import’ or ‘to sell’ again? A: i read [‘to imPORT’] again
(4c)
Q: did you read ‘the import’ again or write it down? A: i [READ] ‘the import’ again
(4d)
Q: did you read ‘to import’ again or write it down? A: i [READ] ‘to import’ again
We will now briefly review what has been reported in the literature on the acoustical marking of word and sentence stress. I will draw on publications on Dutch and English but occasionally digress to other languages. We will begin by discussing properties that are found equally in word and sentence stress and finish by zooming in on those properties that differentiate word from sentence stress (and are found, therefore, only when a syllable occurs in a word with sentence stress).
2.2 Acoustic Properties of Word Stress
2.2.1 Temporal Organization
Since the work by Fry (Reference Fry1955) it has been clear that stressed syllables – all else being equal – are longer than their unstressed counterparts. Fry measured the duration of the first and second vowels (V1 and V2) in five English minimal stress pairs (noun-verb pairs contract, digest, object, permit and subject) spoken once by 12 American speakers in sentence-final position in a fixed carrier Where is the accent in …, which elicits sentence stress on the target words.Footnote 8 With the duration of V1 and V2 as predictors, a Linear Discriminant Analysis (Klecka Reference Klecka1980), a classification algorithm often used for this purpose, yields correct classification of stress pattern in 83 per cent of the cases.Footnote 9, Footnote 10 After z-normalizing V1 and V2 duration within minimal stress pairs, the percentage of correct classification of stress pattern increases to 93. Using Fry’s data, we may apply intrinsic normalization by computing the relative duration of the first vowel (V1%) as a percentage of the summed durations of V1 and V2. Comparing the V1 percent values for each of Fry’s 60 minimal stress pairs, we find just one single case in which V1% was the same for the noun and the verb reading of the pair; in all other 59 cases V1% was larger for the noun (initial stress) than for the verb (final stress) reading (98% correct classification). The conclusion was that vowel duration (especially when expressed relatively within a token) is a very good correlate of stress. Fry (Reference Fry1955: 765), however, remarks that consonant duration ratios were ‘not materially affected by the shift of stress’. Since word stress is generally believed to be a property of a syllable, this conclusion deserves further scrutiny. I turn to data on Dutch to examine effects of stress on subsyllabic units, that is, vowels, onset and coda consonants, separately.
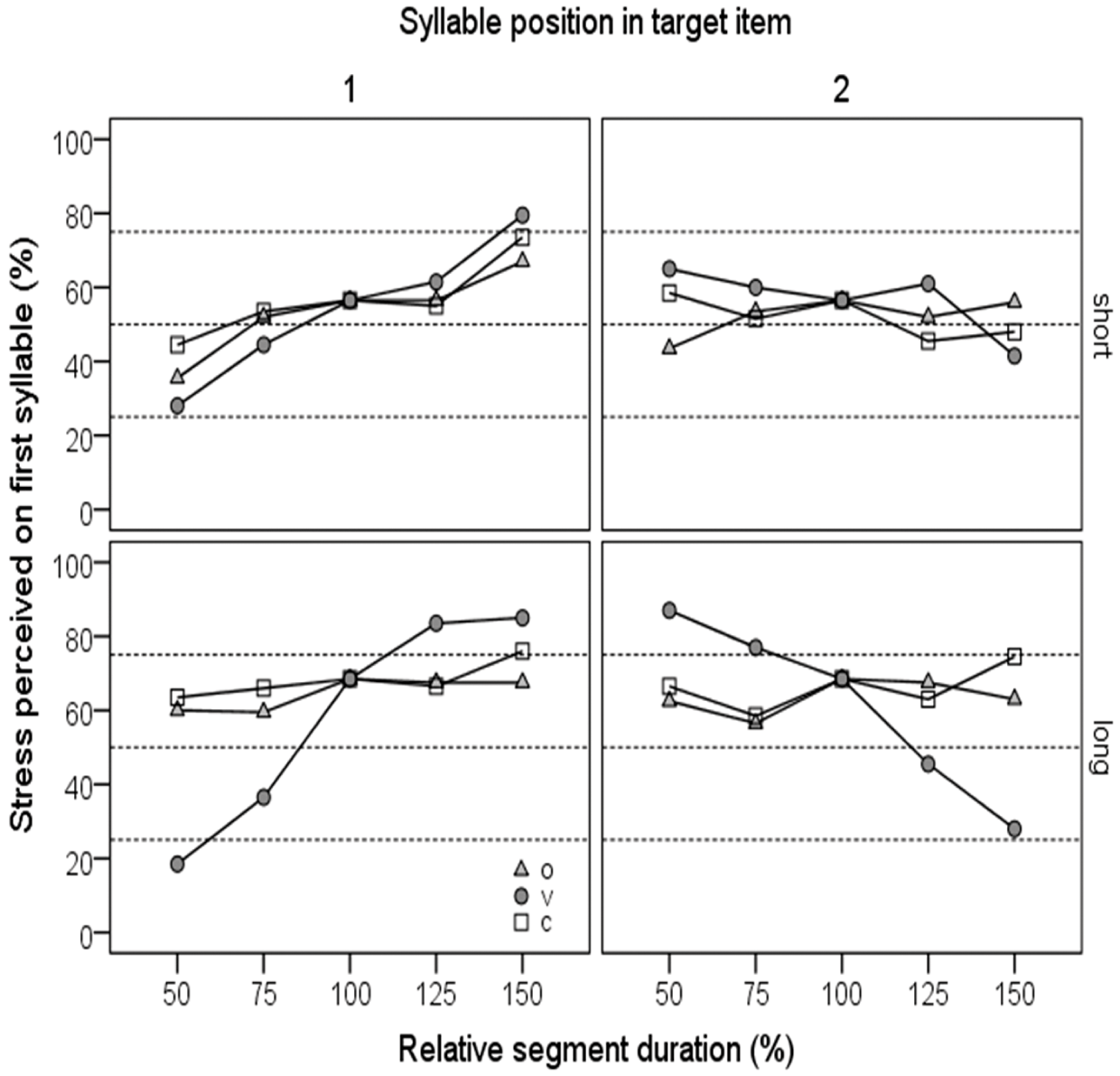
An early study that examined the effect of stress on the durations of subsyllabic units in Dutch can be found in Nooteboom (Reference Nooteboom1972: appendices 11–12). Target items were non-words /pɑpɑpɑp/ and /papapap/, with short/lax /ɑ/ and long/tense /a/, respectively. These items were spoken with stress on the first, second and third syllable in turn in carrier sentences such that they were either ‘accented’ (with sentence stress) or ‘unaccented’ (word stress only). A large number of tokens were produced by each of two male Dutch speakers for each of the 3 (stress position) × 2 (accentuation) × 2 (vowel length) = 12 non-word types (between 17 and 26 tokens per type by speaker SG; between 12 and 24 by speaker IS). Duration of all plosives /p/ in positions C1 to C4 were measured physiologically (rather than acoustically) using electronic switches that were activated by lip contacts, as were the durations of the vowels in V1, V2 and V3. A summary of the results is seen in Figure 1.1. This figure plots the segment durations, in milliseconds (ms), of C1, V1, C2, V2, C3, V3 and C4, in this order, along the X-axis, with separate lines for items with initial, medial and final stress. The four panels are arranged by vowel length (rows) and by accentuation (columns).
Figure 1.1 Duration (ms) of seven segments in the sequence /pVpVpVp/ as a function of stress position (initial, medial, final) in accented versus unaccented non-words with short (lax) and long (tense) vowels.
The relative effects of stress on the temporal make-up of the non-words are very similar for accented and unaccented items – although durations are consistently longer overall under sentence stress. Hardly any effects of stress can be seen in the final syllable.Footnote 11 There are very large differences in the durations of V1 and V2 depending on the stress position. When the item is spoken with initial stress, V1 is very long and V2 short (ratio V1/V2 > 1). With medial stress, this pattern reverses completely, with a very short V1 and a very long V2 (ratio < 1), while items with final stress have intermediate vowel durations for V1 and V2 (ratio ≈ 1).Footnote 12 The crucial observation, however, is that the effect of stress position on the duration of the consonant segments, though small in absolute terms, appears to be quite consistent as well: it is nearly always the case that a C, whether onset or coda, is somewhat longer on average in the stressed version of the syllable than in the unstressed version (i.e. in a paradigmatic comparison).Footnote 13
An experiment on a smaller scale involving both words and reiterant non-words in Dutch shows that the lengthening effect of stress is most clearly and consistently seen in the rhyme portions of the syllables (Sluijter and van Heuven Reference Sluijter and Heuven1995). The effect of stress on onset consonants is less systematic or absent.
2.2.2 Intensity
The intensity of the sound pressure wave has long been considered as an acoustical correlate of stress. Intensity (or sound pressure) is proportional to the square of the amplitude of the speech waveform averaged over a moving time-window that is long enough to include two glottal pulses (typically with an integration time of 20 ms for the male voice range and 10 ms for a female voice). Absolute intensity is expressed in Watts per square inch (or dynes per cm2). However, since in speech we are not so much interested in absolute sound pressures as in relative differences between sound pressures, intensities are usually expressed in decibels (dB). When two intensities differ in terms of Watts by a 1:10 ratio, the stronger of the two has a 20 dB greater relative intensity; when the power ratio is 1:100, the relative intensity difference is 40 dB; and when the ratio is 1:1000, the difference is 60 dB. So each time the absolute intensity difference is multiplied by 10, there is a 20 dB increase in intensity. The perceptual span between the weakest sound pressure that can be detected in silence (the threshold of hearing, axiomatically set at 0 dB) and the strongest sound pressure that can be tolerated without crossing the pain threshold is 120 dB. Generally, the dynamic range of a spoken utterance is rather restricted, somewhere in between 55 and 75 dB above the threshold of hearing. When screaming, intensity levels rise to some 85 dB, and by whispering low intensities in the 40 to 55 dB range are afforded.
Intensities of speech sounds are unstable as they vary considerably (intensity drops in the order of 5 dB) when the speaker inadvertently turns his head or when some object momentarily intervenes between the speaker’s mouth and the listener’s ears. Intensity differences of similar magnitude have commonly been reported as correlates of stress. These differences are small but prove reliable correlates (i.e. with little variability) of sentence stress but are even smaller and less reliable when word stress is signalled (cf. Lea Reference Lea and Hyman1977, Beckman Reference Beckman1986 for English; van Katwijk Reference Katwijk1974, Rietveld Reference Rietveld1984, Sluijter Reference Sluijter1995, Sluijter and van Heuven Reference Sluijter and Heuven1996a for Dutch). In all these (and other) studies, peak intensity was measured, which is usually reached shortly after the vowel onset. Lea (Reference Lea and Hyman1977) and Beckman (Reference Beckman1986) suggested alternative correlates of accent, viz. the intensity integral (the summation of intensities throughout the stressed vowel) or average intensity (as the preceding but normalized for vowel duration). The intensity integral proved a very stable correlate of stress, but it should be pointed out that the intensity and duration correlates are conflated here into one complex cue. Obviously, the combined correlate will be more successful than either of its components. As a general rule, we advocate the use of multiple simplex correlates rather than singular complex indexes as the latter obscure whatever systematic interactions exist among the component correlates.
Since open vowels have more intrinsic intensity than close vowels (see Section 2.1), using raw peak intensity as a direct correlate of stress is rather pointless. In a paradigmatic comparison, that is, comparing the stressed and unstressed reading of the same vowel in the same position in minimal stress pairs (as in Fry Reference Fry1955), the stressed version had more decibels than the unstressed counterpart in 52 out of 60 V1 pairs and in 55 V2 pairs. Note that the decibel is a logarithmic measure, so that the difference (obtained by subtraction) rather than a ratio (obtained by division) between the (peak) intensities of two vowels (e.g. in a stressed syllable and in an unstressed counterpart) is used here as the correlate of stress. Moreover, it is nearly always the case that the intensity difference between V1 and V2 was more positive in the noun reading (with stress on V1) than in the corresponding verb reading (with stress on V2). Out of 60 comparisons, 58 behaved as predicted, in one case the relationship was reversed and in one more the noun and the verb reading had the same intensity difference between V1 and V2. This makes (peak) intensity, and especially the intensity difference between stressed and unstressed syllables, a very reliable acoustic correlate of stress in English. It should be pointed out in this context that Fry (Reference Fry1955) is often misquoted. It is not the case that his data show that intensity is a poor acoustic correlate of stress or that it is a poorer correlate than duration.
2.2.3 Spectral Balance
Accent in Western Germanic languages has often been equated with the expenditure of vocal effort, which is correlated with perceived loudness. The most obvious acoustic correlate of physiological effort and perceived loudness, it was held, is vocal intensity. As was explained in Section 1.3, increased pulmonary effort causes a larger volume-velocity of airflow through the glottis. The result is not just the generation of larger glottal pulses but also, and more importantly, of a more strongly asymmetrical glottal pulse (Figure 1.2). Typically, the closing phase of the glottal period is shortened, yielding a smaller opening quotient (the duty cycle of the glottal pulse, that is, the proportion of the time the glottis is open relative to the period duration), and the trailing edge of the glottal period is steeper. The greater steepness of the glottal closure, as well as its more abrupt ending, cause the generation of relatively strong higher harmonics in the glottal pulse. As a result, the spectral tilt of vocalic sounds produced with greater vocal effort emphasizes the higher frequencies. The spectral tilt of the glottal period produced with average effort has a –12 dB/octave roll-off.Footnote 14 When speakers (or rather, singers) were asked to produce sustained vowel sounds with great vocal effort, the spectral tilt proved less steep, due to the fact that there was a relative boost of frequencies between 500 and 2000 Hz (Gauffin and Sundberg Reference Gauffin and Sundberg1989). It has been shown that a similar phenomenon can be observed during the production of local vocal effort, that is, during the production of a stressed syllable (Sluijter and van Heuven Reference Sluijter and Heuven1996a for Dutch; Sluijter et al. Reference Sluijter, Shattuck-Hufnagel, Stevens and Heuven1995 for American English; Fant and Kruckenberg Reference Fant and Kruckenberg1995, Heldner Reference Heldner2003 for Swedish; Campbell Reference Campbell1995 for Japanese; see also Campbell and Beckman Reference Campbell and Beckman1995, Sluijter Reference Sluijter1995).

Figure 1.2 Effect of normal versus raised voice on volume-velocity of airflow through glottis (top left) and its first derivative (bottom left). The right-hand panel shows the effect of decreased Open Quotient (OQ) and Closure Quotient (CQ) due to raised voice on the spectral envelop (difference is exaggerated). t1: maximum flow during glottal cycle, t2 fastest decrease of glottal flow, t3 complete glottal closure (no flow).
Measuring the spectral balance (or ‘tilt’) is not without problems. Ideally, one needs to strip away the influence of resonances brought about by cavities in the supraglottal tract from the vocal output radiated from the mouth, so that the spectrum of the unfiltered glottal waveform is recovered. Once a clean glottal spectrum is available, the spectral tilt is a matter of fitting a simple linear regression function through the harmonics (plotted along a logarithmic frequency axis), and measuring its slope coefficient in dB/octave. Undoing the resonance effects of the vocal tract is done by inverse filtering. Inverse filtering software is now readily available (e.g. Airas et al. Reference Airas, Pulakka, Bäckström and Alku2005) but the routines are not included in more comprehensive speech-processing packages. In lieu of full-fledged inverse filtering, some fast-and-dirty approximations have been suggested by Stevens (Reference Stevens1998) and were applied in earlier research (Sluijter Reference Sluijter1995, Sluijter et al. Reference Sluijter, Shattuck-Hufnagel, Stevens and Heuven1995, Sluijter and van Heuven Reference Sluijter and Heuven1996b). When it is not necessary to know the absolute values of spectral tilt (e.g. when no comparison across different vowels is being made), a simpler approximation of spectral tilt is afforded by measuring intensity in four contiguous filter bands (one base filter 0–0.5 KHz, and three contiguous octave filters: 0.5–1 KHz, 1–2 KHz, 2–4 KHz, cf. Gauffin and Sundberg Reference Gauffin and Sundberg1989, Sluijter Reference Sluijter1995). A linear regression line fitted through the four intensity levels at the filter bands’ centre frequencies (plotted along a log frequency axis) yields the spectral tilt measure. In fact, we found that the intensity levels in the base and highest octave filter did not vary much as a function of accent level, so that a good substitute of spectral balance was obtained by just measuring mean vowel intensity (at the overall intensity peak) in the 0.5–2 KHz band (Sluijter Reference Sluijter1995, Sluijter and van Heuven Reference Sluijter and Heuven1996a).
The effects of stress on spectral tilt at the sentence (left-hand column) and word level (right-hand column) can be seen in Figure 1.3 for a paradigmatic comparison of selected syllables in the Dutch minimal stress pair canon ~ kanon /ˈkanɔn ~ kaˈnɔn/ ‘round song ~ cannon’ and reiterant mimicry by five male and five female speakers.

Figure 1.3 Effects of sentence (left-hand column) and word (right-hand column) stress on spectral tilt. Intensity (in dB) is plotted for four frequency bands (B1: <.5 KHz, B2: .5–1 KHz, B3: 1–2 KHz, B4: 2–4 KHz).
Figure 1.3 shows that generally no effects of stress can be observed in the base band (< .5 KHz). Effects are strong in the higher frequency bands, causing flatter spectral tilt, especially under sentence stress, and more clearly so in the initial syllable than in the final syllable.
2.2.4 Spectral Expansion
Stressed vowels have often been described as ‘clear’ (or, spectrally expanded), reflecting greater articulatory effort and precision. These vowels lack the spectral reduction that is characteristic of unstressed vowels. The acoustic consequences of vowel expansion and reduction can be examined by measuring the centre frequencies of the lowest two resonances of the vocal tract, the first and second formants, where F1 (the lowest resonance) reflects degree of openness of the vowel and F2 (the second-lowest resonance) reflects vowel backness and lip protrusion (i.e. the length of the oral cavity). Degree of vowel expansion is best expressed in terms of the Euclidean distance of a vowel away from the centre of the (acoustical) vowel space, which is defined by the mean value of F1 and F2 found for the individual speaker, when the speaker has produced an equal number of all the vowels in his language (under identical circumstances). For an average male speaker this will be an F1 at 500 Hz and an F2 at 1500 Hz.Footnote 15 Spectrally reduced vowel tokens will then be closer to the centre of the vowel space than their full or expanded counterparts.
An exemplary study of the effects of stress on vowel quality in Dutch was done by van Bergem (Reference Bergem1993). In Dutch the acoustical effects of stress on vowel quality are particularly noticeable − maybe more so than in any other language. Figure 1.4 illustrates the effects of word and sentence stress on the expansion/reduction of the long (tense) Dutch vowels /e:, o:, a:/ read by 15 male speakers. The position of the schwa (averaged over 300 tokens across consonant environments and speakers) may serve as the centre of gravity of the vowel space. Spectral expansion is largest for vowels pronounced in isolation (‘isol’). Some reduction is visible when these vowels occur in the stressed syllable of focally accented words (‘+S+A’). Considerable reduction is observed for stressed vowels in unaccented words (‘+S−A’) or for unstressed vowels in accented words (‘−S+A’). Severe spectral reduction is applied to the unstressed vowels of unaccented words (‘−S−A’): here the spectral distance to the centre of gravity /ə/ is minimal. Similar results were obtained for reiterant American-English non-words by Sluijter et al. Reference Sluijter, Shattuck-Hufnagel, Stevens and Heuven1995 (for details, see Sluijter Reference Sluijter1995: 116–17, see also Section 2.3).

Figure 1.4 F1 and F2 (Bark) of three Dutch tense peripheral vowels produced by 15 male speakers in five stress conditions
Automatic classification of stress by spectral expansion of Dutch vowels was done by Sluijter and van Heuven (Reference Sluijter and Heuven1996a) in the minimal stress pair /ˈkanɔn ~ kaˈnɔn/ (see Section 2.2.3) and their reiterant versions (/nana/) produced in a short carrier with and without word and sentence stress (four combinations). Predictors in the LDA were the F1 and F2 of V1 and V2. Percentages of correct stress identification were 84 and 77 for words with and without sentence stress, respectively, and 68 and 71 for the reiterant non-words. These identification scores are better than chance (= 50%) but are poorer than what was observed for most other stress correlates (see following section).
2.2.5 Resistance to Coarticulation
One characteristic of a spectrally expanded stressed syllable is that it shows minimal influence of coarticulation with abutting syllables, which in turn are strongly influenced by the adjacent stressed syllable. So properties of the stressed syllable are anticipated in the preceding syllable, and perseverate into the following syllable, but the stressed syllable itself is hardly influenced by the abutting unstressed syllables. Resistance to coarticulation was claimed to be the most important correlate of stress in Lithuanian by Dogil and Williams (Reference Dogil, Williams and van der Hulst1999; see also Pakerys Reference Pakerys1982, Reference Pakerys1987).
One way in which the mutual coarticulatory influence of abutting syllables can be quantified would be to locate the beginning and end of vowel-onto-vowel formant transitions (if the formants do not move in synchrony, study the behaviour of F2 only) from the preceding syllable into the stressed syllable, and from the stressed into the following syllable (cf. Öhman Reference Öhman1967). Then determine the point along the time axis where half of the formant trajectory (i.e. half of the F2 frequency difference between the consecutive vowels) from the stressed to the unstressed vowel (and vice versa) has been covered. The coarticulatory window of the stressed syllable is then expressed as the time interval between the preceding and following 50 per cent points divided by the duration of the stressed syllable. The larger the relative window size, the more resistant the syllable is to coarticulation. I am not familiar with published data on measurements of resistance to coarticulation.
2.3 Acoustic Correlates of Sentence StressFootnote 16
Theories have been proposed in which there is no principled difference between word and sentence stress. In such views, for example, in American structuralism (Bloch and Trager Reference Bloch and Trager1942) and early Generative Phonology (Chomsky and Halle Reference Chomsky and Halle1968, Halle and Keyser Reference Halle and Keyser1971), sentence stresses were seen as merely stronger degrees of stress along a continuum, where degrees of stress differ along all stress-related acoustic parameters in proportion. More recently, phonetic research has brought to light, however, that sentence stresses – used to place constituents in focus – are marked in a principally differently way from mere word stresses. Typically, as long as there is no sentence stress on a word, the speaker makes no effort to change the vocal pitch. To be true, there may well be a small rise–fall contour on any vowel (with or without word stress) but this is due to an involuntary response of the glottal mechanism to the greater transglottal pressure that comes about when the oral tract opens during the articulation of the vowel sound; during the articulation of consonants the oral tract is fully or partially closed so that intraoral impedance yields a transglottal pressure drop causing the vocal folds to vibrate more slowly. It has been estimated that the involuntary effect of mouth opening on the rate of vocal fold vibration does not normally exceed a threshold of four semitones (a frequency rise and subsequent fall of less than 25%). Only when a word is produced with sentence stress does the speaker issue a voluntary command to the glottal muscles that brings about a change in vocal pitch that (greatly) exceeds the four-semitone threshold.Footnote 17 Listeners intuitively know that small changes in vocal pitch require no planned action on the part of the speaker and therefore ignore these as a stress cue.
For a pitch change to impart sentence stress on a syllable, the change has to be strictly local, that is, has to take place within a time window that does not exceed the duration of a syllable. Gradual pitch movements (rises or falls that span a longer sequence of syllables) can never be prominence lending (’t Hart, Collier and Cohen Reference Hart, Collier and Cohen1990). Yet, not every large and fast change in vocal pitch is associated with sentence stress. Fast pitch changes may also be used to mark prosodic boundaries. The difference between prominence-lending and boundary-marking pitch changes is in their timing relative to the segmental structure of the syllable. In Dutch, for instance, an equally large and fast pitch rise located in the first half of a syllable imparts prominence (sentence stress) but it marks the syllable as domain-final (intonation domain boundary or question marker) rather than stressed when executed in the final portion of the syllable (end of rise aligned to end of voicing). The phonetic details of the segmental alignments are quite subtle. Pitch movements (or the component L and H targets) may be synchronized (‘anchored’) to segmental landmarks or with respect to each other (Caspers and van Heuven Reference Heuven, House and Touati1993, Ladd et al. Reference Ladd, Faulkner, Faulkner and Schepman1999, Ladd, Mennen and Schepman Reference Ladd, Mennen and Schepman2000), the synchronization may be affected by phonological properties of the (stressed) syllable (Dilley, Ladd and Schepman Reference Dilley, Ladd and Schepman2005) and differ across languages (e.g. Arvaniti, Ladd and Mennen Reference Arvaniti, Ladd and Mennen1998 for Greek versus Ladd, Mennen and Schepman Reference Ladd, Mennen and Schepman2000 for Dutch) and even across dialects within a single language (e.g. van Leyden and van Heuven Reference Leyden and Heuven2006).
Data collected by Sluijter et al. Reference Sluijter, Shattuck-Hufnagel, Stevens and Heuven1995 (see Sluijter Reference Sluijter1995: 106–16 for a more extended report) illustrate the point. Three male and three female speakers of American English each recorded two tokens of four minimal stress pairs (the noun–verb pairs export, uplift, digest and compact) as well as their reiterant versions with syllables /bi/, /bɛ/ and /bɑ/ medially in fixed carrier sentences such that targets received either sentence stress or not. The f0 peak location was determined in each token as well as the excursion size of the f0 movement (in semitones). The size of the f0 change under sentence stress was two to three times larger (in semitones) than in items with word stress only. Most of the f0 movements associated with word stress only were below four semitones. When the token was produced with sentence stress it was nearly always the case that the f0 peak fell within the confines of the stressed syllable (in fact, without a single exception for the words) affording perfect identification of stress pattern in the four lexical pairs and near perfect stress identification in the reiterant versions (98% correct). However, when the tokens were produced with word stress only (and with a sentence stress on the phrase-final word), the location of the f0 peak was distributed more evenly over the two syllables and was aligned with the stress in only 65 per cent of the cases (chance = 50%).
Secondary correlates of Dutch sentence stress can be found in temporal organization. It has been shown for Dutch that words with sentence stress are lengthened by some 10 to 15 per cent. Interestingly, all segments – whether stressed or not – in the word are lengthened to the same extent. The lengthening is restricted to only the word that carries the sentence stress; no lengthening spills over to adjacent words even if these are within the focus domain headed by the target – indicating that the lengthening is a correlate of sentence stress rather than of focus (Eefting Reference Eefting1991, van Heuven Reference Heuven, Barbiers, Rooryck and van de Weijer1998).Footnote 18 Languages appear to differ in the domain they use for lengthening under sentence stress. It has been found for English that this domain is the within-word foot (excluding pre-stress syllables from the lengthening domain) rather than the (morpho-syntactic) word (Turk and Sawush Reference Turk and Sawush1997). I am not familiar with attempts to evaluate the effectiveness of lengthening effects in automatic identification of sentence stress. My expectation would be that the contribution of accentual lengthening will be minor.
2.4 Relative Strength of Stress Correlates
The relative strength of acoustic correlates of stress (or of any other linguistic distinction) can be estimated by applying some technique to compute effect size (see Section 2.2.1). However, when the statistical distributions of acoustic correlates differ between samples, as they do in our case when correlates are measured for a sample of words with initial stress and a second sample of the stress partners with final stress (i.e. members of minimal stress pairs), more complex techniques are called for. I find it expedient to use the LDA automatic classification algorithm as an estimator of effect size. The number of (above chance) classification errors would then serve as a good approximation of the relative strength of an acoustic correlate of stress. Normally, LDA uses multiple predictors to classify objects into categories. So, it seems tempting at first sight to have the algorithm make its classification with all measured acoustic correlates of stress in one run. This, however, defeats the purpose of the exercise. The acoustic properties of stress are generally correlated, some moderately, others more strongly. The LDA removes the shared variance from all but the most successful predictor, so that we will not get a true view of the effect sizes of the less successful predictors. Therefore, we routinely run the LDA with single predictors, repeating the procedure as many times as there are predictors. Only in this way can the percentages of successful classification be meaningfully compared. It is also necessary to instruct the LDA to assume equal probabilities for the two categories it has to predict (stressed, unstressed) rather than to compute a priori probabilities from the actual frequencies in the input data.
Sluijter and van Heuven (Reference Sluijter and Heuven1996a) applied the LDA to the classification of initial and final stressed members of reiterant minimal stress pairs produced with and without sentence stress by six native speakers of American English.Footnote 19 Analyses were run separately for word stress (targets outside focus) and sentence stress (targets in focus). Predictors were in both conditions: (i) the location of the f0 peak (in first or second syllable), (ii) relative duration of the first syllable, (iii) difference in peak intensity between the syllables, (iv) the difference in Euclidean distance of the vowel from the centre of the formant space and (v) the difference between the two syllables in five glottal parameters (a) B1 (an estimate of completeness of glottal closure), (b) estimated tilt of source spectrum based on fundamental and amplitude of F2, (c) tilt based on difference between fundamental and amplitude of F3, (d) difference in Open Quotient (OQ estimated by the difference in amplitude between fundamental and second harmonic) and (e) difference in amplitude of voicing (= amplitude of fundamental). The results are presented in Figure 1.5.
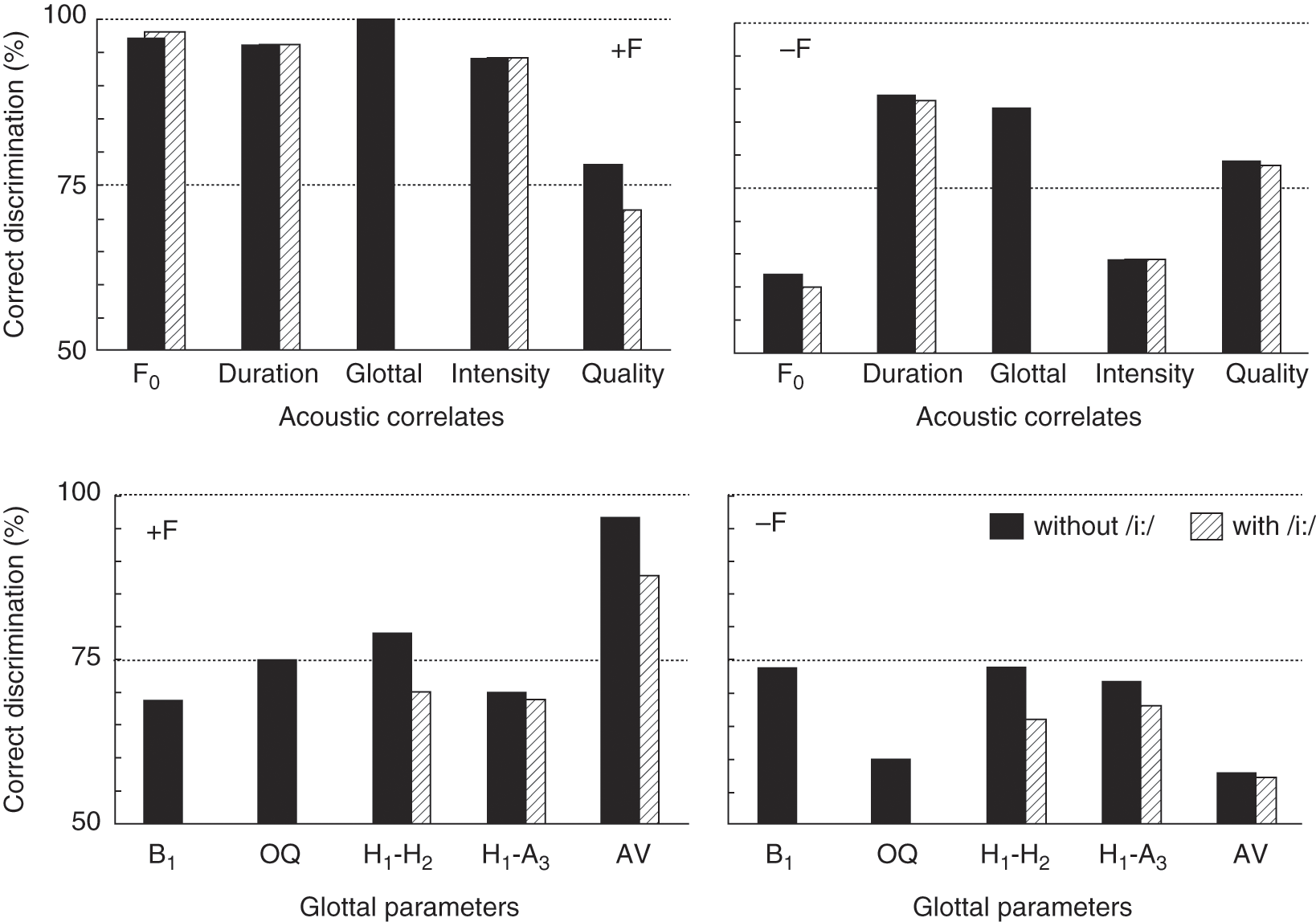
Figure 1.5 Correct classification (%) by Linear Discriminant Analysis of sentence stress (+F, left-hand panels) and word stress (−F, right-hand panels) in American-English reiterant disyllables /bibi/, /bɛbɛ/ and /bɑbɑ/. Predictors are the traditional acoustic correlates of stress (top panels) or estimates of glottal parameters (bottom panels).
F0, duration and intensity afforded very good classification of stress pattern for sentence stress (above 95% correct), vowel quality yielded only 80% correct classification. The estimated glottal source parameters afforded between 69 and 79% correct classification (the latter for spectral tilt between fundamental and F2), with an exception of amplitude of the fundamental, which yielded 97% correct and was in fact slightly better as a predictor than just overall peak intensity). Much poorer classification was obtained for word stress (in words out of focus). Location of the f0 peak, intensity, OQ and amplitude of fundamental were all between 60 and 65 per cent correct (chance = 50%). B1 and the two tilt measures were at 75 per cent correct. The best classification was given by duration and vowel quality (both at 80%).
A provisional conclusion from this comparison of parameter strengths would be that the difference between initial and final stress is more clearly marked in English when it is a matter of sentence stress than when we are dealing with just word stress. The effect sizes of the parameters differ substantially between sentence stress and word stress. The location of the f0 peak, peak intensity and amplitude of the fundamental are strong correlates in the sentence stress condition but not for word stress. Duration is a reliable correlate in both conditions, and so is spectral quality – be it less reliable than duration. The spectral tilt measures are only moderately successful correlates.
3 Perceptual Cues of Word and Sentence Stress
In the preceding sections we have seen that both word and sentence stress are acoustically marked by at least five different correlates. In an acoustic study it is quite possible to determine the relative strength of each variable as a successful correlate of stress, simply because the categorization of utterances is done by a computer algorithm and does not require the services of human listeners. When we want to establish the perceptual relevance simultaneously of all the acoustic correlates for a human listener, the problem arises that the experiments become unmanageably large and time consuming – a burden especially on the part of the human subjects. The practical solution is that the experiments are simplified in either of two ways (but hybrids between these two types also occur): (i) only two or three parameters at the most are included in the stimulus materials with maximally seven steps (values) along each parameter (7 × 7 × 7 = 343 stimulus types can be presented once in about half an hour) or (ii) more parameters are systematically varied but the number of steps for each parameter is severely limited, typically to two values – one realistic for stress and the other for no stress, often implemented as a straightforward exchange of values between the two extremes as found in natural tokens. Classical examples of type (i) studies are Fry (Reference Fry1955, Reference Fry1958), Morton and Jassem (Reference Morton and Jassem1965), and Mol and Uhlenbeck (Reference Mol and Uhlenbeck1956). Type (ii) studies were done more recently by, for example, Beckman (Reference Beckman1986) for English and Japanese, Ortega-Llebaria, Vanrell and Prieto (Reference Ortega-Llebaria, Vanrell and Prieto2010) and Ortega-Llebaria and Prieto (Reference Ortega-Llebaria and Prieto2011) for Spanish and Catalan.
Limiting the presentation, again, to just Dutch and English, we will now review the perceptual cue value for human listeners of the stress correlates discussed in Section 2. These studies typically compare the cue value of pairs of acoustic correlates in relatively small sets of stimuli. For instance, Fry published a series of three experiments comparing the perceptual strength of vowel duration (as a baseline condition) with that of three other parameters, viz. peak intensity (1955), fundamental frequency (1958) and vowel quality (1965).Footnote 20 If done properly, the three experiments should yield a rank order of perceptual importance for the four correlates.
3.1 Duration versus Intensity
Figure 1.6a (left-hand panel) shows the main results of the perception study by Fry (Reference Fry1955). In the experiments, the durations of V1 and V2 in each of five minimal stress pairs (object, subject, digest, compact, import, see Section 2.2.1) were varied in five steps between (and including) values found (averaged over ten speakers) in natural tokens with initial and with final stress. These five duration steps were systematically combined with five intensity differences (by amplifying V1 and at the same time attenuating V2) such that the V1–V2 difference varied between +10 and –10 dB. Listeners had to indicate for each of the 5 (word types) × 5 (vowel duration ratios) × 5 (intensity differences) = 125 stimulus types whether they perceived it as a noun (initial stress) or as a verb (final stress). Unfortunately, Fry did not present the results for the individual stimulus types. Instead, Figure 1.6 (after Fry’s Figure 3) presents percent perceived initial stress for the five duration steps (averaged over words and intensity steps) and for the five intensity steps (averaged over words and duration ratios).

Figure 1.6a Initial stress perceived (%) as a function of intensity difference between V1 and V2 (in dB) and of duration ratio between V1 and V2 in minimal stress pairs in English (after Fry Reference Fry1955).
Figure 1.6b As Figure 6a but for Dutch.
The results show a cross-over from stress perceived on the first syllable to the second syllable. The cross-over takes place between duration steps two and three and is both steep (within one stimulus step) and convincing (75% agreement on either side of the boundary). In contrast to this, the intensity difference is inconsequential: although there is a gentle trend for more initial stress to be perceived as V1 has more decibels than V2, the difference is limited to some 20 percentage points; the boundary width, which can only be estimated by extrapolation, would be some 15 times wider than for duration. This shows that duration outweighs intensity in Fry’s experiment roughly by a factor of 15.
Figure 1.6b (right-hand panel) shows the results of a similar experiment run by Sluijter, van Heuven and Pacilly (Reference Sluijter, Heuven and Pacilly1997) for a single Dutch minimal stress pair: the reiterant non-word nana. The results are the same as in English: a complete cross-over is obtained by varying the vowel durations, while the intensity difference does influence stress by a small amount only, certainly not enough to bring about a cross-over. There are more and smaller stimulus steps, which makes the cross-over appear somewhat more gradual. Also, the targets were presented medially in a sentence frame wil je [target] ZEGgen ‘will you [target] SAY’ with the sentence stress on the final verb; the stimulus variations were suggestive of word stress only – the range of intensity differences in the Dutch stimuli was much smaller (but reflected actual speech production) than that in Fry’s English materials with sentence stress on the targets.
Figure 1.7a is a quasi three-dimensional plot of per cent initial stress (numbers in the circles at the X–Y coordinates) perceived as a joint function of the difference in vowel duration (seven steps along the X-axis) and of the difference in intensity (seven steps along the Y-axis). The boundary in the figure separates the white area with a majority of initial-stress decisions from the dark area with a majority of final stress responses. The boundary is defined as a straight line; it is the discriminant function that is computed by an LDA that optimally predicts stress responses from the X and Y predictors. The discriminant function defines all combinations of X and Y values for which the stress response would be undecided (50–50%) – it is a two-parameter category boundary.
If the boundary runs at a 45° angle, the X and Y parameters would be of equal strength. In the figure the boundary runs at an angle that is much steeper than 45°, though not completely vertical. The steep angle indicates that the duration parameter outweighs the intensity parameter as a stress cue. The figure also shows that intensity variations are largely inconsequential: they cannot swing the majority decision from initial to final stress for six out of seven duration steps; only when V1 = 170 ms and V2 = 245 ms does intensity yield a (shallow) cross-over from 43 to 60 per cent initial-stress responses.

Figure 1.7a–b Percentage of initial stress perceived as a function of temporal structure (duration of V1 and V2, horizontal) and of intensity difference (vertical). In panel A the intensity in V1 and V2 was varied uniformly (amplification/attenuation of gain factor); in panel B intensity variations were made selectively at frequencies above 500 Hz only (yielding differences in spectral tilt).
3.2 Duration versus Selective Intensity (Affecting Spectral Slope)
Sluijter et al. (Reference Sluijter, Heuven and Pacilly1997) also included a set of stimuli in which the same intensity differences were generated on V1 and V2 but in such a way that no differences were made at frequencies below 500 Hz and all the changes were concentrated at frequencies above 500 Hz, thereby creating a change in spectral slope. This selective manipulation of intensity is a more realistic model of what a human speaker does when producing differences in loudness between vowels (see Sections 2.2.2–2.2.3). The results now show that (selective) intensity differences (affecting spectral tilt) are as strong a stress cue as are the duration differences: the boundary now runs at a 45° angle. In this experiment, the stimuli had been presented over headphones with artificial reverberation added. The reverb (which was realistic of room acoustics) obscures the temporal details in the stimulus. When the same materials were presented over headphones without reverb, the effects of selective intensity (affecting spectral tilt) were smaller than those of duration but still larger than those of uniform intensity differences (not affecting spectral tilt).
3.3 Contribution of Consonant versus Vowel Duration
Now that we have seen that duration generally outweighs other cues for word stress, let us examine the effects of the duration of subsyllabic units such as the onset consonant, the vocalic nucleus and the coda consonant. An experiment that addresses this issue was reported by van Heuven (Reference Heuven, Kager, Grijzenhout and Sebregts2014). In reiterant stimuli, with short/lax vowels (/pɑfpɑf, tɑstɑs/), and with long/tense vowels (/pɑfpɑf, tɑstɑs/) the durations of onset, nucleus and coda were varied separately in steps of 50, 75, 100, 125 and 150 per cent of the original duration. The stimuli were synthesized from diphones which had been excerpted from stressed syllables produced in nonsense words with sentence stress, so that all original segments were equally suggestive of (strong) stress.
Figure 1.8 plots the percentage of perceived initial stresses as a function of the duration manipulation (shortening or lengthening by 0, 25 or 50% of the original segment duration) of the onset, nucleus or coda segment in first or second syllable with tense (long) versus lax (short) vowels.

Figure 1.8 Per cent stress perceived on first syllable as a function of relative duration of manipulated segment (onset, vocalic nucleus, coda) in either first (left panels) or second (right panels) syllables with short/lax (upper panels) or long/tense (lower panels) vowel. Target segments are embedded in reiterant CVC.CVC non-words.
Figure 1.8 shows that, overall, effects of changing the duration of the vocalic nucleus are large but changes in consonant durations, whether in the onset or in the coda, have little or no effect on stress perception. A complete cross-over from stress perceived on the first syllable to stress perceived on the second syllable is found for vowel duration change, except when the vowel is phonologically short (lax) and in the final syllable of the target non-word (top-right panel). Moreover, the effect of changing the (vowel) duration is weaker overall when the changes are implemented in the second (final) syllable than in the initial syllable.Footnote 21 Changing the duration of a consonant only affects stress perception if the change takes place in a word-initial syllable with a short (lax) vowel (top-left panel) but even then the effect is still somewhat smaller for consonants than for the vowel. In this condition, it does not matter whether the consonant is in the onset or in the coda. So, it seems safe to conclude that the older literature was right in assuming that vowel duration by itself, rather than syllable duration or rhyme duration, is the relevant duration cue for stress perception.
3.4 Duration versus Vowel Quality
The only study on the effect of vowel quality on stress perception in English was done by Fry (Reference Fry1965). Fry manipulated the formants of vowels in four minimal stress pairs (contrast, digest, object, subject). While keeping pitch and intensity differences constant, the duration ratio and formant structure of V1 and V2 were varied in three steps for each parameter, creating a 3 × 3 = 9 item stimulus space for each noun–verb pair, that is, 45 stimuli in all. Formants F1 and F2 in V1 were manipulated for three words pairs (contrast, digest, object) while keeping V2 constant; formants in V2 were varied in object and subject while keeping V1 constant. The formant manipulations were such that either F1 or F2 or both moved just one step closer towards the centre of the vowel space (suggesting vowel reduction). No attempt was made to systematically create multiple steps of equal magnitude along a spectral reduction/expansion continuum. Figure 1.9a shows Fry’s results. In the figure, the duration and formant changes have been plotted such that stimulus steps cue initial stress more strongly going from left to right. The results indicate that changing the vowel quality has a systematic but small effect such that stress is less likely to be perceived on the syllable with reduced vowel quality; the tendency is somewhat stronger when the vowel quality is reduced in the F2 dimension (backness and rounding) than in the F1 dimension (height) and is strongest when both quality dimensions are affected simultaneously. The effect of vowel quality is small, and does not yield a convincing cross-over: initial stress percentage changes from 45 to 60. The effect of vowel duration is clearly much stronger. Even with the smaller range of duration variation adopted in this experiment, there is a convincing cross-over spanning more than 50 percentage points.
Figure 1.9a Percentage initial stress perceived in English as a function of V1/V2 duration ratio and of vowel reduction in F1 (left), F2 (middle) or both (right) in either V1 (steps f1–f3) or V2 (steps f4–f6) (after Fry Reference Fry1965).

Figure 1.9b Percentage of initial stress perceived in Dutch as a function of V1/V2 duration ratio and spectral reduction in V1.
Fry (Reference Fry1965) did not vary vowel quality in terms of an acoustic continuum. A more direct comparison of vowel duration (temporal expansion/reduction) and vowel quality (spectral expansion/reduction) was made for Dutch by van Heuven and de Jonge (Reference Heuven and Jonge2011), who varied the V1/V2 ratio and the vowel quality of V1 in the Dutch minimal stress pair canon ~ kanon (see Section 2.2.3 ) in seven steps along each continuum. Targets were presented in post-focal position (no f0 movement on the target) in a carrier ik heb GISteren een canon (kanon) gehoord /ɪk hɛp [ˈɣɪstərən]+F ən ˈkanɔn (kaˈnɔn) ɣəhort/ ‘I have yesterday a canon (cannon) heard’, that is, ‘I heard a canon (cannon) yesterday.’
The results are shown in Figure 1.9b, in quasi-3D format. Obviously, convincing cross-overs are obtained for the duration steps. Just one, very incomplete, change from perceived initial stress to final stress is obtained by changing vowel quality from clear to fully reduced to schwa; this change is obtained only when the duration cue is ambiguous, that is, at duration step four. Fry’s conclusion is confirmed here: vowel reduction is clearly a much weaker stress cue than vowel duration.
3.5 Duration versus Fundamental Frequency
Let us, finally, examine the perceptual effects of varying the size and segmental alignment of f0 changes as a cue for stress. As I pointed out earlier, in natural human speech the f0 change has to exceed a certain threshold (say ≥ 4 semitones) in order to function as a stress cue, and if it does it typically imparts sentence stress on the word that carries the f0 change. Since sentence stress outranks word stress, this makes the f0 change the strongest stress cue of all. Fry (Reference Fry1958) was among the first to examine the effect of f0 change on stress perception, comparing its strength with that of varying the duration ratio of V1 and V2 in the English noun–verb pair subject. The duration ratio was varied as in Fry (Reference Fry1955) in five steps covering the natural range of duration variation found for this word pair. In one experiment, Fry synthesized the syllable sub- on a flat 97 Hz followed by stepwise f0 rise to -ject of 5, 10, 15, 20, 30, 40, 60 and 90 Hz. This set of eight rises was supplemented with a similar set of eight falls, with the level higher f0 on sub- and the low 97 Hz pitch on -ject.Footnote 22 The total set of 5 (V1/V2 ratios) × 8 (step sizes) × 2 (directions) = 80 stimuli was judged for stress position (noun or verb) by a mixed group of 41 American and English native listeners. The results bear out that the frequency step-up generated stress on the second syllable (between 61 and 75% for the various f0 changes but averaged over duration ratios) whilst a step down yields stress on the first syllable (between 48 and 80%), that is, the higher-pitch syllable is heard as stressed. The absolute size of the step, however, was inconsequential: a 5 Hz increment was as influential as a 90 Hz change. On average, however, the effect of changing f0 turned out to be smaller than that of varying the duration ratio. Unfortunately, Fry does not give the full breakdown of results for each combination of duration ratio and f0 change so that we cannot check to what extent the f0 change can be counteracted by the vowel duration ratio.
In a second experiment, Fry (Reference Fry1958) combined the five vowel duration ratios with 16 different f0 contours. The contours were more realistic approximations of English intonation patterns. The f0 change was not an instantaneous step up or down on the syllable boundary but a rise or fall that extended over a certain time span. Rises and falls were executed either over the entire vowel duration or started at the temporal midpoint of the vowel. F0 movements were linear changes as a function of time, between 97 and 130 Hz. The choice of contours was rather arbitrary and has no systematic structure. Nevertheless, some regularities can be observed in the results. Two f0 contours always yield initial stress, even if the duration ratio strongly suggests final stress. Three contours always yield a majority of final-stress judgements. In the remaining 11 contours there was always at least one duration ratio that could swing the stress from initial to final, thereby counteracting the effect of f0. In retrospect it seems reasonable to exclude a number of the f0 contours on the grounds that they do not constitute legal intonation patterns on a single word in English. For instance, it seems impossible to have a fall on the first syllable followed by a rise on the second (or a rise followed by a fall). Other patterns have late rises in the final syllable, which suggest question intonation rather than sentence stress. Be this as it may, some patterns, however, seem perfectly plausible. Contour A is basically an H*L on the first syllable while contour B is the same H*L but synchronized with the second syllable. Pattern E is an H* followed by a level boundary. Patterns M and N have an H*L on the second syllable with a short plateau between the H* and the L. A and E always generate a majority of initial stress responses while B, M and N always have a majority of final stress judgements. So, our conclusion should probably be that an f0 chance involving a properly aligned H* target attracts a majority of stress responses that cannot be counteracted by any duration ratio. Even for the most extreme duration ratios, however, there is always an f0 pattern that can swing the judgements from initial to final stress.
Bolinger (Reference Bolinger1958) reports four experiments in which f0 and intensity were varied as cues for sentence stress in short English sentences made up of (mainly) monosyllabic words. The overall result is that f0 changes attract stress judgements much more than intensity differences do. In the crucial experiment Bolinger systematically combined five temporal organizations of the minimal stress pair undertaking (initial stress: ‘what a mortician does’; penultimate stress: ‘enterprise’) with 16 different f0 patterns.Footnote 23
Bolinger does not present the results in full but summarizes as follows (Reference Bolinger1958: 125): ‘In all but 3 patterns the majority of the listeners reacted as the experimenter had predicted on the basis of pitch, and in only one of the 3 could the discrepancy be correlated with duration.’ The three pitch patterns that did not conform to the hypothesis (probably, the higher f0 will attract stress, and later highs will be more prominent ceteris paribus) are the only results specified in full. Table 1.1, curiously enough, shows two pitch patterns for which duration yields a full cross-over (from 13 to 88% initial stress in the level f0 pattern, and from 13 to 75% in the 100–80–90–80 pattern). The 90–80–90–80 pattern yields a preponderance of penultimate stress judgements, which is what we would predict from the hypothesis.
Table 1.1 Initial stress perceived (%) on undertaking for five temporal organizations (onset and rhyme durations in ms) systematically combined with three f0 patterns (level f0 on successive syllables, in Hz) (after Bolinger Reference Bolinger1958: 126)
| Onset and rhyme durations (ms) | F0 on successive syllables (Hz) | Mean | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| un | d | er | t | a | k | ing | 80–80–80–80 | 90–80–90–80 | 100–80–90–80 | |
| 170 | 65 | 170 | 65 | 155 | 70 | 320 | 88 | 29 | 38 | 52 |
| 210 | 40 | 95 | 60 | 180 | 30 | 310 | 50 | 29 | 25 | 35 |
| 230 | 30 | 80 | 55 | 200 | 50 | 260 | 50 | 00 | 13 | 22 |
| 145 | 15 | 80 | 85 | 215 | 50 | 250 | 13 | 14 | 50 | 26 |
| 180 | 30 | 70 | 45 | 170 | 25 | 250 | 75 | 14 | 75 | 57 |
| Mean | 55 | 17 | 40 | 38 | ||||||
Van Katwijk (Reference Katwijk1974: 76–88) varied f0 movements in a Dutch reiterant nonsense item /sœsœsœs/ in a rather realistic fashion. F0 changes were implemented relative to a fixed declination of 5 st/s. Keeping intensity, quality and duration constant, f0 rises and falls of 3 st during 100 ms were generated at 11 different time points in the stimulus, as indicated in Table 1.2. In this table the alignment is specified for the onset of the f0 movement with respect to the duration of a segment. For instance, ‘V1 00’ means that the f0 movement begins at 0% of the duration of the first vowel, that is, at the vowel onset. Van Katwijk also generated three stimuli with rise–fall contours, and two stimuli (one rise, one fall) with 6-st excursion sizes (during 200 ms). Another 15 stimuli, with multiple f0 movements, will not be discussed here.
Table 1.2 Number of (sentence) stresses perceived on first, second and third syllable in the Dutch nonsense word /sœsœsœs/ by 45 Dutch listeners (free choice) for 27 f0 configurations (rise, fall, rise–fall) with 3-st and 6-st excursion sizes (after van Katwijk Reference Katwijk1974: 81–3)
| Rise 3 st | Fall 3 st | Rise–fall 3 st | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| align | S1 | S2 | S3 | align | S1 | S2 | S3 | align | S1 | S2 | S3 |
| V100 | 31 | 6 | 9 | C150 | 22 | 5 | 6 | V100 | 41 | 2 | 6 |
| V125 | 33 | 10 | 4 | V100 | 36 | 4 | 1 | C275 | 9 | 42 | 3 |
| V150 | 13 | 35 | 6 | V150 | 36 | 4 | 8 | C350 | 5 | 4 | 38 |
| C200 | 8 | 39 | 10 | C225 | 37 | 8 | 6 | Rise 6st | |||
| C250 | 6 | 44 | 6 | C275 | 35 | 6 | 7 | C100 | 7 | 44 | 21 |
| V200 | 4 | 37 | 6 | V200 | 22 | 18 | 4 | Fall 6st | |||
| V250 | 11 | 18 | 32 | V250 | 19 | 17 | 18 | C250 | 35 | 20 | 24 |
| C300 | 16 | 4 | 43 | C325 | 20 | 9 | 19 | ||||
| C350 | 14 | 2 | 45 | C375 | 17 | 4 | 32 | ||||
| V300 | 16 | 3 | 39 | V300 | 12 | 3 | 28 | ||||
| V350 | 22 | 4 | 6 | V350 | 17 | 2 | 4 | ||||
The results show that the location of the f0 movement greatly influences the perception of stress. A simple pitch rise or a rise+fall combination located at the beginning of a syllable (preferably beginning before the vowel onset) suffices to attract a clear majority of stress responses to that syllable (indicated by shading in Table 1.2). Simple falls tend to attract fewer stress judgements than rises do, especially when they are associated with the medial or final syllable.Footnote 24 For a simple f0 fall to impart stress on a syllable it has to be aligned rather late in the syllable or even in the beginning of the next syllable. The complex rise–fall movement does not attract more stress judgements than a simple rise; long 6-st rises and falls do not attract more stress judgements than 3-st exemplars. Van Katwijk also generated stimuli with differences in vowel duration (lengthening either V1, V2 or V3 by 30%) and in intensity (adding 5 dB to each vowel in turn), but never in combination with f0 or with each other so that there are no stimuli in which stress parameters contradict one another.
3.6 Perceptual Cues: Conclusion
The above pairwise comparisons of stress cues in English and Dutch lead to the overall conclusion that the most important perceptual cue for stress is a change in fundamental frequency (if properly aligned with the segmental structure). The second-most influential cue is temporal organization, specifically the duration ratio between the stressed and the unstressed version of the vowels (rather than of the consonants). Intensity would seem to rank third, but only if it is implemented such that the gain or loss of intensity is concentrated in frequency bands above 500 Hz, thereby affecting the slope of the spectrum (the flatter the spectrum, the greater the perceived loudness). Overall intensity and vowel quality are found to be the weakest stress cues. It is not clear from the experiments reviewed which would be the weaker of the two.
I should point out, however, that the older literature on perceptual cues of stress does not really substantiate the claims it makes. Both Fry and Bolinger (for English) as well as van Katwijk (for Dutch) insist that f0 change is a stronger stress cue than duration but the claim seems tenuous, either because the experiment does not allow the conclusion to be drawn, or because the crucial data were not presented. Although Fry’s (Reference Fry1958) results provide at least circumstantial evidence, it is not the case that an f0 change can never be overridden by temporal cues in his materials.
The most important conclusion is that the strength of acoustic correlates of stress and the perceptual cue value of these correlates are not rank ordered in a one-to-one fashion. This has two reasons. First, the location of an f0 change is a strong correlate of stress in speech production but only if the f0 change exceeds a threshold of three to four semitones and if it is appropriately aligned with the segmental structure. When words do not receive sentence stress, the f0 change is no longer a reliable correlate. For f0 change to be a perceptual cue, no such threshold seems to be required. A change from 97 to 104 Hz is enough to evoke final-stress perception, while a fall of the same magnitude yields initial stress. Therefore, f0 change may be perceptually the strongest cue but it is acoustically unreliable. Second, the human listener does not rely on uniform intensity differences between stressed and unstressed syllables. This probably makes intensity the weakest perceptual cue of all, even though it is acoustically quite reliable.Footnote 25 Differences in vowel duration are both perceptually strong and acoustically highly reliable, for both word stress and sentence stress.
4 Cross-linguistic Differences in Phonetic Marking of Stress
There has been some speculation on the question whether or not any language that uses the linguistic parameter of stress also uses the same correlates, with the same order of relative importance of these acoustic correlates and as cues to stress perception. The general feeling is that different correlates (and different perceptual cues) are employed depending on the structure of the language under analysis. We will discuss two sets of differences between languages, and their consequences for stress marking. The first set of differences concerns the type of stress system a language employs, whereas the second source of difference is located in the relative exploitation within a language of stress parameters for other linguistic contrasts.
4.1 Contrastive versus Demarcative Stress
It seems reasonable to assume that languages with fixed stress have a smaller need for strongly marked stress positions than languages in which the position of the stressed syllable varies from word to word. In the latter type of language the position of the stress within the word is a potentially contrastive property, whereas in the former type words are never distinguished from each other by the position of the stress because stress is invariably in the same position for all the words in the language.Footnote 26
We would predict, therefore, that the size of the pitch movements does not vary as a function of the type of stress system of the language, but that the difference between stressed and unstressed syllables in non-focused words is less clearly marked along all the non-pitch parameters correlating with accent.Footnote 27 Although hardly any research has been done to check these predictions, there is some evidence that the basic prediction is correct. Dogil and Williams (Reference Dogil, Williams and van der Hulst1999) present a comparative study of Polish (fixed penultimate stress) and German (quantity-sensitive plus lexical stress) stress marking, and conclude that stress position is less clearly marked in Polish. Similar results were found more recently in a strictly controlled cross-linguistic study of Spanish and Greek (with contrastive stress) versus Hungarian (fixed initial stress) and Turkish (fixed final stress) by Vogel, Athanasopoulou and Pincus (Reference Vogel, Athanasopoulou, Pincus, Goedemans, Heinz and van der Hulst2016). Their results (Figure 1.10) show that the same set of acoustic stress parameters (applied in the same manner across the four languages) affords good to excellent automatic classification of stressed and unstressed syllables at the word level for the two contrastive-stress languages but not for the fixed-stress languages. Classification is much better for sentence stress – with the notable exception of Turkish (65% correct).
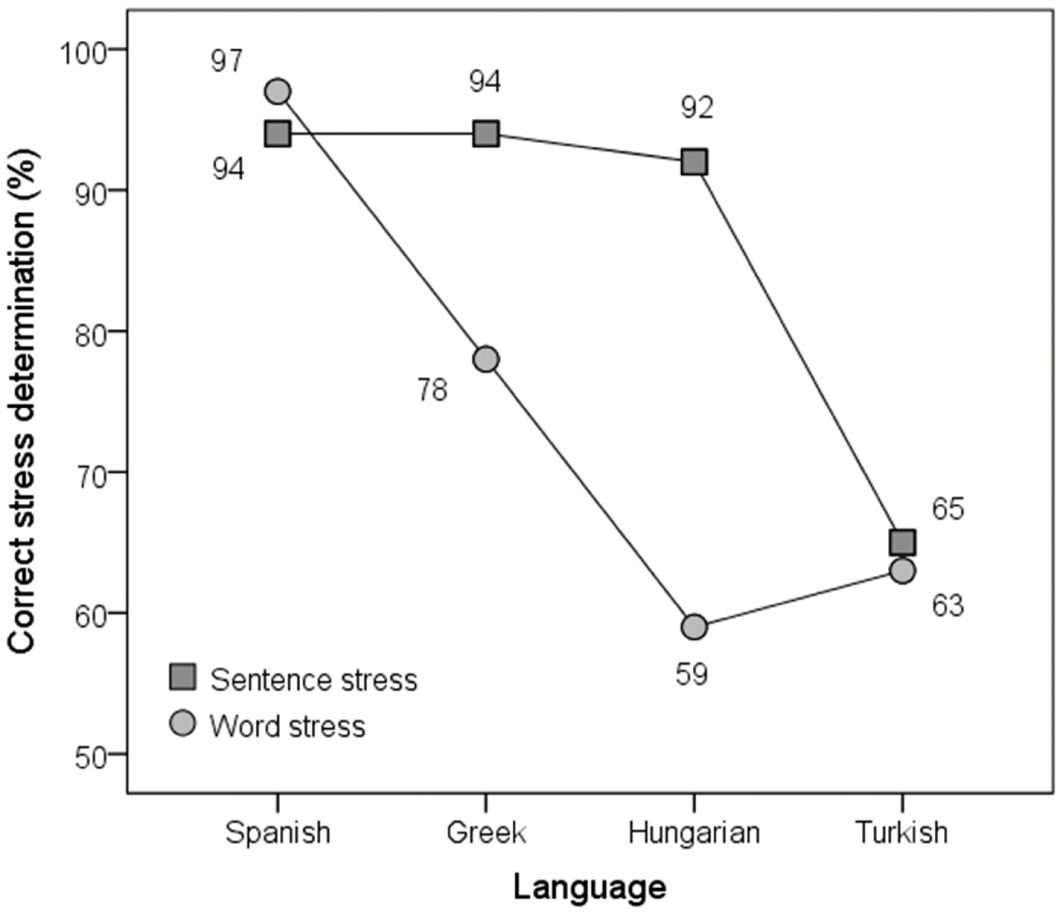
Figure 1.10 Automatic classification of syllables as stressed or unstressed (per cent correct) for two variable-stress languages (Spanish, Greek) and two fixed-stress languages (Hungarian, Turkish). Target words were either in focus (sentence stress) or out of focus (word stress).
4.2 Functional Load Hypothesis
Berinstein (Reference Berinstein1979) was the first to formulate what would later come to be called the functional load hypothesis (FLH) of stress marking. The FLH predicts that stress parameters will drop to a lower rank in the hierarchy of stress cues when they are also employed in the segmental phonology of the language. For instance, if a language has a length contrast in the vowel system, vowel duration – which is normally a strong cue for stress – can no longer function effectively in the signalling of stress. Berinstein (Reference Berinstein1979) is often quoted in support of the FLH; for example, by Cutler (Reference Cutler, Pisoni and Remez2005). It is not difficult to see, however, that Berinstein’s claim is contradicted by her own results.
Berinstein presented sequences of four synthesized syllables /bɪ/ to native listeners of four different languages: English (36 listeners), Spanish (22), K’ekchi (31) and Caqchiquel (46). The latter two are closely related Mayan Indian languages spoken in Guatemala.Footnote 28 English and Spanish have variable stress while K’ekchi and Cachiquel have fixed stress on the final syllable. Orthogonally to this, English and K’ekchi, unlike Spanish and Caqchiquel, have a length contrast in their vowel system. In the /bɪbɪbɪbɪ/ sequences the standard vowel duration was 100 ms. The vowel duration in one syllable deviated from the standard and was adjusted to 70, 120, 140, 160 or 200 ms. This yielded a stimulus set of 1 (standard) + 4 (positions) × 5 (durations) = 21 types. Figure 1.11 shows the percentage of stresses perceived by the four groups of listeners on the deviant syllable as a function of the size of the duration increment.Footnote 29 The results show that English listeners are much more sensitive to the duration increment than the other three groups. Spanish listeners are rather insensitive, while the Guatemalan listeners were virtually insensitive: their responses are (marginally) above chance only for the largest duration increment.

Figure 1.11 Stress perceived (%) by native listeners of four different languages on deviant syllable as a function of duration increment of deviant vowel in sequences /bɪbɪbɪbɪ/ synthesized on a 100-Hz monotone.
These results clearly run counter to the prediction of the FLH. The duration parameter is compromised in the vowel length contrast in English but not in Spanish and yet duration is a much more powerful stress cue in English. Similarly, given that K’ekchi has a vowel length contrast and Caqchiquel has none, the FLH predicts that duration should be a better stress cue in Caqchiquel, but there is no difference between these languages in the way they (fail to) use duration as a stress cue.
Native listeners are perfectly able to decompose segment duration into multiple sources of variation (e.g. Klatt Reference Klatt1976 for English, Nooteboom Reference Nooteboom, Myers, Anderson and Laver1981 for Dutch). Nooteboom and Doodeman (Reference Nooteboom and Doodeman1980), for instance, elegantly show that Dutch listeners adjust the category boundary between long and short vowels in the minimal pair /tɑk ~ tɑ:k/ ‘branch’ ~ ‘task’ with great precision depending on the depth of the prosodic break following the target word. By the same token, listeners appear to be able to decompose vowel duration into one part that is caused by a phonemic length opposition and another that is governed by stress. For this decomposition to work, the stress pattern on the target word should not be ambiguous, that is, the same segment string should not exist as a minimal stress pair in the language. So in a language with fixed stress, such as K’ekchi or Caqchiquel, there would be no problem. In English or Dutch minimal stress pairs, effortless decomposition of duration might be compromised.
Vogel, Athanasopoulou and Pincus (Reference Vogel, Athanasopoulou, Pincus, Goedemans, Heinz and van der Hulst2016) compared the strength of correlates of word and sentence stress in Hungarian, Spanish, Greek and Turkish (see previous section). Of these languages only Hungarian has a phonemic length contrast in the vowel system. All four languages (Figure 1.12) show a slight elongation of vowels (whether stressed or unstressed) when the target word was in focus (i.e. produced with sentence stress). Duration did not vary as a function of word stress in Hungarian (as predicted by the FLH). However, duration did not vary as correlate of word stress in Spanish and Turkish either, which would run counter to the FLH.Footnote 30 Vowel duration turned out to be a strong correlate of word stress in Greek but even more so under sentence stress. If we add to this the knowledge that vowel duration is a highly reliable correlate of stress, both at the word and at the sentence level in English and Dutch (see Section 3.1), two languages that exploit vowel duration in a segmental contrast (tense versus lax vowels), we are left with little evidence supporting the feasibility of the Functional Load Hypothesis. Note, finally, that Vogel et al. measured acoustical correlates; the issue of the perceptual strength of the various stress cues is not addressed directly in their chapter.
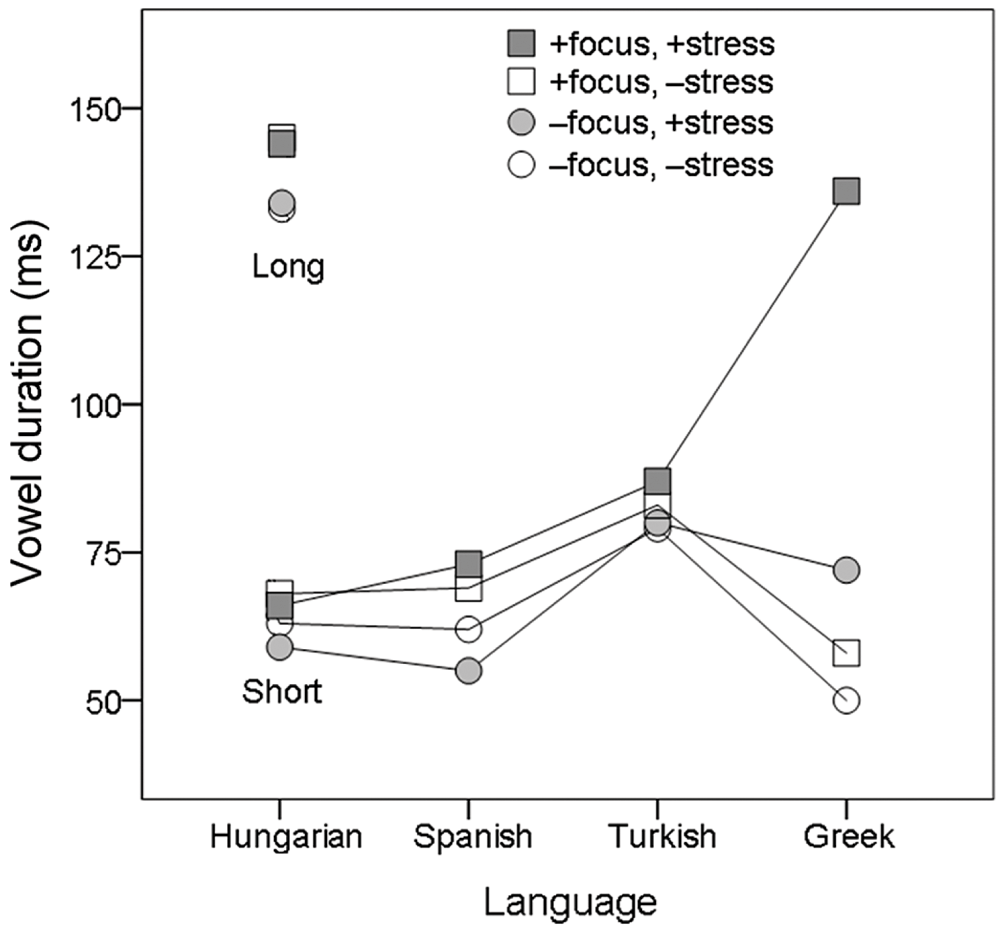
Figure 1.12 Vowel duration (ms) in four languages broken down by syllables with and without word stress and words with and without sentence stress (+focus and −focus, respectively). Of these only Hungarian has a short–long opposition in the vowel system.
Differences in intensity and/or spectral tilt have never been advanced as primary cues of segmental contrasts. The only stress parameter that might also be exploited in segmental contrasts, other than duration, would be vowel quality, especially vowel bleaching, also known as spectral vowel reduction, that is, the tendency for unstressed vowels to assume a schwa-like quality. This parameter, however, has always been claimed to be the least effective stress parameter (see Section 3.4), so that it makes little sense to examine the position of this parameter in the rank order of stress cues: it will be the least important one, no matter if the language has spectral vowel reduction or not.
Although there seems little support for the FLH in the segmental domain, the situation may well be different when stress-related parameters are in competition with other prosodic contrasts. What, for instance, if a language has both stress and lexical tone? In such cases it might be more difficult for the listener to disentangle the various cues for the competing contrasts.
Potisuk, Gandour and Harper (Reference Potisuk, Gandour and Harper1996) investigated the acoustical correlates of stress in Thai, a language with five different lexical tones (high, mid, low, falling, rising) and with a length contrast in the vowels. The authors assumed that pitch would not be a high-ranking correlate of stress given that pitch is known to be the primary correlate of lexical tone. They also assumed that duration could not be an important stress cue since it was already implicated in the vowel length contrast. The results showed that the distinctive pitch pattern of the five tones remained basically the same between stressed and unstressed syllables, so that the lexical tone contrast would not be compromised much in unstressed syllables. However, in unstressed syllables, the pitch range was substantially reduced so that the tone distance between high, mid and low was smaller and the contour tones (rising, falling) would be flatter. This is very much the same mechanism that Mandarin Chinese relies on when signalling the difference between words in and out of focus (e.g. Shih Reference Shih1988, Chen and Gussenhoven Reference Chen and Gussenhoven2008). Automatic classification of syllables as stressed versus unstressed was largely unsuccessful when based on mean pitch and/or the standard deviation of the pitch contour on the syllable. Intensity was not significantly affected by stress for any of the five tones. Duration (of the rhyme portion of the syllable) proved the strongest stress correlate. An LDA with rhyme duration as the only predictor yielded 99 per cent correct stress decisions. These results, then, are in line with the idea that stress parameters can be used simultaneously in segmental and prosodic contrasts but not in simultaneous prosodic contrasts. It should be noted that stress in the study by Potisuk et al. (Reference Potisuk, Gandour and Harper1996) is sentence stress only. The 25 target word pairs appeared in sentence-initial position and were contrasting strong–strong versus weak–strong syllable sequences in adjective-plus-noun phrases. Comparisons were made only of the strong versus weak initial syllables (paradigmatic comparison).
Remijsen (Reference Remijsen, Gussenhoven and Warner2002) investigated Samate Ma’ya, a language spoken in the Raja Ampat archipelago off the coast of Papua (Indonesia). The language has both lexical tone and stress but does not have a vowel length contrast. Acoustic correlates of stress were the pitch contour, intensity, loudness (i.e. intensity in selected frequency bands), vowel quality (expansion/reduction) and duration. Figure 1.13 presents the success of each of the four parameters in signalling the difference between a stressed versus an unstressed version of a syllable (left-hand panel) or between the high, rising and falling tone on the syllable. The results show a perfect inverse relationship between the parameters’ positions in the rank order of word-prosodic cues.
Figure 1.13 Per cent correct automatic classification of stress (left-hand panel) and lexical tone (right-hand panel) in Samate Ma’ya on the basis of the same four acoustic parameters.
So, the conclusion seems warranted that the Functional Load Hypothesis makes sense as long as parameters are in competition within the domain of prosody. There is no obvious competition when the same parameter is used separately in the segmental and prosodic domain. The original idea, as formulated by, for example, Berinstein (Reference Berinstein1979), Hayes (Reference Hayes1995) and Posituk et al. (Reference Potisuk, Gandour and Harper1996) was that the Functional Load Hypothesis should work when stress-related parameters were also involved in lexical contrasts. This, on second thoughts, seems to be too strong a generalization. What matters is that the FLH is valid only within the domain of prosody. Lexical distinctions that are non-prosodic in nature, such as segmental length contrasts, do not noticeably take part in the competition for resources. This provisional conclusion is based mainly on the results of acoustic studies, where the degree of success with which an automatic decision whether a syllable is stressed or unstressed is used to rank order the strength of the stress parameters. Only Berinstein tested the effects of duration directly in a perception experiment. In Section 3.6 we saw that the order of importance may deviate between acoustic correlates and perceptual cues. Before we take a definitive stance on the feasibility of the Functional Load Hypothesis, we need to compare cross-linguistic results in both the acoustic and the perceptual domain.
[N]ot all feet are rhythmic in nature.
1 Introduction
One of the major unresolved issues in the study of word-accentual systems is determining what exactly counts as “stress-accent,” “pitch-accent or”, simply “accent” in a more neutral and inclusive sense. In languages such as English, where certain more “prominent” syllables can be uncontroversially identified by a combination of phonological properties and phonetic effect concerning both the suprasegmental features of pitch, duration, and intensity as well as segmental realizations, there is no hesitation in attributing these effects to stress and metrical structure. Controversy arises in languages where the effects are less pronounced, have little or no effect on segments, or mark phrasal domains rather than words. The purpose of this chapter is twofold. First, I describe the positional prominence effects that are found in several African tone languages claimed not to have stress-accent. Second, I suggest that these effects can be identified with a more general notion of “word accent” only if we allow for more than one position of “accent” per word. In what follows I show that while stem-initial and word-penultimate prominence can be identified as word accent in the sense to be defined in Section 2, the foot structures involved in prosodic morphology should instead be identified as templates that may be quite independent and distinct from word accent. I begin in Section 2 with a brief introduction to the problems involved in identifying and characterizing word accent. I then present three African case studies of apparent metrical phenomena in Ibibio (Section 3), Punu (Section 4), and Lulamogi (Section 5), each followed by a discussion of whether the phenomena in question should be identified with the more familiar effects of stress-accent. In Section 6 I conclude that rather than viewing evidence of positional prominence as a kind of “accent,” “accent” should be subsumed under the more general notion of positional prominence. By making this move we minimize the terminological problems and focus on the typology of how languages privilege phonological properties and their realization by position.
2 The Problem
Despite the extraordinary amount of research on the subject, a number of issues continue to plague the study of stress and accent. On the conceptual side there is the question of what counts as “stress” or “accent.” In earlier work I attempted to clarify what should be identified as “stress-accent” by imposing the following requirements (Hyman Reference Hyman2006: 231):
(1) A language with stress-accent is one in which there is an indication of word-level metrical structure meeting the following two central criteria:
a. obligatoriness (OblHead): every lexical word has at least one syllable marked for the highest degree of metrical prominence (primary stress)
b. culminativity (CulmHead): every lexical word has at most one syllable marked for the highest degree of metrical prominence
Besides limiting these properties to the word domain, explicit in both of these criteria is that the stress-bearing unit is the syllable (cf. Hayes Reference Hayes1995: 49, Hyman Reference Hyman2009: 217). Thus, I cited the culminative H(igh) tone of Somali as violating the criteria in (1) in two senses: first, the H is not assigned by syllable, but rather restrictively appears on either the penultimate or the final mora of the word, sometimes assigned as an exponent of the morphology:Footnote 1
(2)
a. masculine feminine ínan ‘boy’ inán ‘girl’ qaálin ‘young m. camel’ qaalín ‘young f. camel’ daméer ‘he-donkey’ dameér ‘she-donkey’ b. singular plural túug ‘thief’ tuúg ‘thieves’ kálax ‘ladle’ kaláx ‘ladles’ doofáar ‘pig’ doofaár ‘pigs’
While the above moraic distribution also results in the H never appearing on a prepenultimate syllable, the syllable is quite beside the point – also prohibited would be words such as *qáalin and *doófaar, where the H appears on the antepenultimate mora. That H tone placement can be contrastive on a long vowel; for example, túug ‘thief’ versus tuúg ‘thieves’ shows, at the very least, that more than stress-accent has to be involved. In fact, stress is quite beside the point. This is because of the second violation of (1): although culminative (“at most one H tone per word”), H tone is not obligatory. Subject nouns and main clause verbs often lack H tone and their syllables and moras prosodically undifferentiated, as seen in (3).Footnote 2
(3)
a. inan wáa dhaʕay ‘a boy fell’ (ínan ‘boy’) b. inan-i wáa dhaʕday ‘a girl fell’ (inán ‘girl’)
Still, I am sure that there will be some who insist that the Somali H tone is a “pitch-accent,” notion which I have long considered to be problematic, at best (Hyman Reference Hyman2006, Reference Hyman2009). Definitions of a broader concept of “word accent” that would include both stress-accent and pitch-accent are often vague or subjective. Thus compare the following definitions of “accent” and “pitch-accent”:
We will use the term “accent” for a lexical mark (predictable or unpredictable) of syllables that are somehow “special” and “stress” for a metrical structure and its associated phonetic cues.
For the purpose of this survey, we defined pitch-accent systems as systems in which one syllable is more prominent than the other syllables in the same word, a prominence that is achieved by means of pitch.
To avoid misunderstandings, then, when languages are characterized as having pitch-accent systems in the sections that follow, this means that their tone systems clearly have one or more of the processes described above: culminativity, obligatoriness, positional restrictions and/or tone-stress interactions.
[In Zulu] the contrast is between privative /H/ versus Ø, hence pitch-accent.
This assumes that we know what is meant by “prominence” and implies that we can tell which metrical structures necessarily indicate accent: in many Bantu languages, reduplicants are restricted to two syllables in what might reasonably be viewed as a strong–weak foot. Should such “metrical structure” be considered a manifestation of “accent”? Similarly, the two OT constraints OblHead and CulmHead suggest that we have a clear idea of what counts as a “head.” Presumably, in languages with fixed stress, an initial or final syllable would be the prosodic head of the word, while the greater bulk and licensing of phonological contrasts might suggest that root is the prominent head of the word, as opposed to its affixes.
While the above indicates conceptual issues yet to be resolved, there are corresponding methodological issues concerning the interpretation of the available database. Descriptions are often incomplete, thereby creating “the difficulty of inferring a pattern from limited data” (de Lacy Reference de Lacy and van der Hulst2014: 156). In some cases the descriptions are unreliable. There has been growing recent recognition of the methodological problems involved in the identification and interpretation of the facts on which stress and accent analyses (and ultimately theories) have been based:Footnote 4
A weakness of the various foot typologies … is that they have relied for evidence on non-native impressions of stress, often in underdocumented languages for which no corroborating reports may be available.
Yidiny has a central place in stress typologies • unique or almost unique • but the analytical facts are based on the impressionistic descriptions of a single fieldworker.
Currently, there is no way to detect phonological inputs or outputs directly, and at least in some cases the procedures that are used have not been proven to be valid. It is to be expected, then, that if any description is presented as evidence for a Generative theory, it should be accompanied by an extensive justification for its use.
Perhaps StressTyp (Goedemans and van der Hulst Reference Goedemans, van der Hulst, Everaert, Musgrave and Dimitriadis2009) should give a score from 1 to 5, indicating the reliability of a stress or accent analysis, giving a point for such criteria as (i) two or more independent, converging studies, (ii) multiple arguments for the analysis, and (iii) instrumental validation. Of course, English stress would get a top score by any measure. However, this would not settle the issue of whether certain metrical constituents should be identified as accentual domains. My strategy has been to avoid the practice of placing the label “accent” on things, focusing instead on the properties that define the typological differences between word-prosodic systems. In this context, this means mapping out the prosodic and other phonological skewings that we find at the (prosodic) word level. In the current context this includes (i) cases where there are greater contrasts in one versus another position, and (ii) cases where there are different realizations of contrasts in one versus another position.
In Hyman (Reference Hyman and van der Hulst2014) I proposed that differential treatments of syllable positions in a word should be scrutinized as accent, whether or not there is clear evidence of foot structure. This could involve either suprasegmentals (e.g. tone, vowel length) and/or segmental properties which may exhibit more contrasts, different realizations, or different faithfulness relations between input versus output (a contrast may neutralize in one versus another position). However, I do not think this solves the question in my title. Instead, what I propose here is that the “accent” question is merely a terminological one, and that what we should be focusing on is the various ways in which different positions are singled out for special treatment – whether linguist A or B wants to call this “accent” or not.
In this study, two such positions will be scrutinized: stem-initial and word-penultimate. These are of course widespread positions for the placement of stress-accent cross-linguistically, as seen in the table in (4), based on my notes for Hyman (Reference Hyman and Hyman1977):
(4)
initial peninitial penultimate final totals Stem 15 0 1 4 20 Word 27 9 37 21 94 Phrase 5 0 2 2 9 totals 47 9 40 27 123
Case studies concerning three African tone languages will be presented in the following subsections: Ibibio (Section 3), Punu (Section 4), Lulamogi (Section 5).
3 Ibibio
The prosodic structure of Ibibio, a Cross-River language spoken in Nigeria, has been the subject of several insightful studies (Urua Reference Urua2000, Akinlabi and Urua Reference Akinlabi and Urua2002, Harris and Urua Reference Harris and Urua2001, Harris Reference Harris, Local, Ogden and Temple2004) to which we can add corresponding discussions of mutually intelligible Efik (Welmers Reference Welmers1966, Reference Welmers1973, Cook Reference Cook1969, Reference Cook1985, Hyman Reference Hyman1990). The following summarizes the properties of the prosodic stem in Ibibio, which consists of a root and possible suffix, but excludes prefixes:Footnote 5
(5)
a. prosodic stem structures: CV, CVC, CVVC, CVCV, CVVCV, CVCCV b. stem-initial consonants: b f m t d s n y ɲ k ŋ kp w c. coda consonants: p m t n y k ŋ d. intervocalic VCV: β m ɾ n ɣ ŋ e. intervocalic VCCV: pp mm tt nn yy kk ŋŋ
As seen, the prosodic stem can have one, two, or three moras and, except for CV, will have two consonants, the second of which can be geminate when intervocalic. Two things are particularly striking about the distribution of consonants. First, there is a larger inventory of contrasting consonants in stem-initial position: /f/, /d/, /s/, /ɲ/, /kp/, and /w/ do not occur as second consonant within the prosodic stem. Second, the second consonant obstruent system contrasts only three consonants, realized as voiceless stops [p, t, k] as coda and [pp, tt, kk] when geminated, and as the weakened continuants [β, ɾ, ɣ] intervocalically. (Urua Reference Urua2000: 25 describes the weakened velar as uvular [ʁ].) Crucially, [β, ɾ, ɣ] occur only stem-internally, as stem-initial [b, t, k] occur even when preceded by a vowel prefix: è-bé ‘husband,’ é-tôp ‘message,’ è-kà ‘mother’ (Urua Reference Urua2000: 24).
Evidence that metrical structure is involved in the above consonant distributions comes from the prosodic morphology. As the derivations in (6a–c) show, the negative suffix /-ke/ undergoes significant modifications when affixed to a CV, CVC, or CVVC root (Akinlabi and Urua Reference Akinlabi and Urua2002):
(6)
a. CV dí → dííɣé ‘not come’ /díV-ké/ dó → dóóɣó ‘not be’ /dóV-ké/ b. CVC dép → déppé ‘not buy’ /dép-ké/ dát → dáttá ‘not take’ /dát-ké/ kɔ̀k → kɔ̀kkɔ́ ‘not vomit’ /kɔ̀k-ké/ dóm → dómmó ‘not bite’ /dóm-ké/ bén → bénné ‘not carry [with hand]’ /bén-ké/ kɔ̀ŋ → kɔ̀ŋŋɔ́ ‘not knock’ /kɔ̀ŋ-ké/ dáy → dáyyá ‘not lick’ /dáy-ké/ c. CVVC déép → dééβé ‘not scratch’ /déép-ké/ síít → sííɾé ‘not seal an opening’ /síít-ké/ wúúk → wúúɣó ‘not drive something in’ /wúúk-ké/ wèèm → wèemé ‘not flow’ /wèèm-ké/ ɲɔ̀ɔ̀n → ɲɔ̀ɔ̀nɔ́ ‘not crawl’ /ɲɔ̀ɔ̀n -ké/ kɔ́ɔ́ŋ → kɔ́ɔ́ŋɔ́ ‘not hang on hook’ /kɔ́ɔ́ŋ-ké/ d. CVCV tòβó → tòβóké ‘not make an order’ /tòpó-ké/ sàŋá → sàŋáké ‘not walk’ /sàŋá-ké/ e. CVCCV dáppá → dáppáké ‘not dream’ /dáppá-ké/ sɨ́tté → sɨ́ttéké ‘not remove stopper’ /sítté-ké/ wɔ́ŋŋɔ́ → wɔ́ŋŋɔ́ké ‘not turn’ /wɔ́ŋŋɔ́-ké/ f. CVVCV dààɾá → dààɾáké ‘not rinse’ /dààtá-ké/ yɔ́ɔ́ŋɔ́ → yɔ́ɔ́ŋɔ́ké ‘not plaster [a wall]’ /yɔ́ɔ́ŋɔ́-ké/ tòòɾó → tòòɾóké ‘not praise’ /tòòtó-ké/
In (6a–c) the vowel of the negative suffix /-ke/ assimilates to the root vowel in backness and roundness. In addition, in (6a) the CV root lengthens, and the /k/ of the negative suffix /-ke/ spirantizes to [ɣ]. In (6b) the /k/ drops out with compensatory lengthening (gemination) of the preceding root-final consonant. (Efik differs here in allowing the Ck sequence.) In (6c) the /k/ drops out without effect, presumably because a CVVC.CV with an initial superheavy syllable is not allowed. Akinlabi and Urua propose that the negative forms in (6a–c) impose a heavy–light trochaic foot structure into which the negative suffix can be incorporated. In (6d–f), where the base form is already bisyllabic, /-ke/ cannot join and therefore is realized without change on the surface.Footnote 6 Akinlabi and Urua are very clear that there is otherwise no stress in Ibibio:
One important fact is that Ibibio does not have stress prominence, so evidence for the prosodic foot can only be sought from other parts of the phonology and morphology.
The heavy–light trochee seen in (6) is, however, not a requirement across the board. Urua (Reference Urua2000: 157) makes clear that there are several different foot structures. Thus, the passive/reflexive assigns a CVCV structure (cf. Urua Reference Urua1999: 253, Akinlabi and Urua Reference Akinlabi and Urua2002: 139), while the frequentative often assigns CVVC (Urua Reference Urua1999: 247).
(7)
root passive/reflexive dɨ́p ‘hide’ dɨ́βé ‘hide oneself’ yàt ‘wear (on head)’ yàɾá ‘wear on one’s head’ màn ‘give birth’ màná ‘be born’ kɔ́ɔ́k ‘stack’ kɔ́ɣɔ́ ‘be stacked’ kɔ́ɔ́ŋ ‘hang’ kɔ́ŋɔ́ ‘be hung, hang on oneself’
(8)
root frequentative wèt ‘write’ wèèt ɲám ‘sell’ ɲáám wòt ‘kill’ wòòt
These different shapes, CVVCV, CVCV, CVVC, are all recognizable as alternative foot structures. As such they are reminiscent of the “binyanim” of Arabic (McCarthy Reference McCarthy1981), more than stress feet. The one thing that might suggest “accent” is that the first syllable always has more contrasts in its onset and vowel positions than the second syllable. As I put it in Hyman (Reference Hyman1990):
[in] several languages of the Nigeria-Cameroon area … there is a single domain which I have referred to variously as the stem or the foot which determines the distribution and realization of consonants, vowels and tones. Particularly interesting is the special treatment given to exactly one syllable per such domain.
As such, one could identify the initial foot syllable as positionally prominent, even though its CV, CVV, or CVVC shape varies.
When we look out a bit beyond into Northwest Bantu, we see a continuation of the same idea, but with the possibility of longer domains. In Koyo [Bantu; Congo] the prosodic stem contains from one to four CV syllables, the fourth limited to the durative verb suffix -gV.Footnote 7 As seen in (9), there are fewer consonant contrasts as one progresses from first (C1V1) to fourth (C4V4) syllable:
(9)
C1: p b w m mb t l s n nd ts dz y ɲ ndz k h ŋg C2: b m mb r l s n nd y ɲ ndz g C3: m r l s n g C4: g
The consonants /p/, /w/, /ts/, /dz/, /h/, and /ŋg/ are in fact limited to stem-initial position, while /mb/, /nd/, /y/, /ɲ/, and /ndz/ are limited to the first two syllables. In addition, /t/ and /k/ are realized [t] and [k] as C1, but as [r] and [g] in later positions in the prosodic stem:
(10)
a. /i-tɔtɔ/ → i-tɔrɔ ‘banana’ b. /o-kokó/ → o-kogó ‘sugarcane’ c. /o-tokiti/ → o-togiri ‘sweat’
As seen in the above examples, this is not intervocalic lenition, or at least if it is, it must take place at the stem level, since vowel prefixes do not affect stem-initial consonants. In other Bantu languages prosodic stems have a four-syllable maximum, and the bracketed internal syllables of CV[CV]CV and CV[CVCV]CV domains function as an internal “prosodic trough.” This occurs in Yaka (Hyman Reference Hyman1998, Reference Hyman2008) and in Punu (next section).
4 Punu
In this and the next section I will present two other Bantu languages which also do not have stress-accent, but in which stem-initial and word-penultimate positions are prominent. In Bantu, verbs have the following (common) word structure:

In Punu [Bantu; Gabon], the underlying vowel contrasts establish that the stem-initial CV(:)C root is a position of prominence (Kwenzi Mikala Reference Kwenzi Mikala and Nsuka-Nkutsi1980, Fontaney Reference Fontaney and Nsuka-Nkutsi1980). First, the five vowels /i, ɛ, u, ɔ, a/ contrast only in CVC roots. In the following examples, u- is the infinitive prefix, while -a is the default final vowel on verbs:
(12)
u-bíl-a ‘to call’ u-búl-a ‘to hit, break’ u-bɛ́l-a ‘to be wrong’ u-bɔ̌l-a ‘to rot, be rotten’ u-bál-a ‘to shine’
In other positions, only the three vowels /i, u, a/ contrast:
(13)
a. prefixes: mu-βé:ɣu ‘raphia palm,’ pl. mi-βé:ɣu dí-bi ‘bad thing or action,’ pl. má-bi b. suffixes: (both productive and frozen – see (16)) c. monosyllabic stems: ú-βi ‘to be cooked,’ ú-βu ‘to cease,’ ú-ba ‘to be’ (historically *Ci-a, *Cu-a, *Ca-a)
Second, with very few exceptions, vowel length contrasts only on the stem initial CVC root (Kwenzi Mikala Reference Kwenzi Mikala and Nsuka-Nkutsi1980: 8):
(14)
/i/ – /i:/ : u-sǐng-a ‘to rub’ u-sǐ:ng-a ‘to accept’ /ɛ/ – /ɛ:/ : u-wɛ́l-a ‘to be ready’ u-wɛ́:l-a ‘to marry’ /u/ – /u:/ : u-bǔng-a ‘to waste’ u-bǔ:ng-a ‘to move’ /ɔ/ – /ɔ:/ : mutú mɔ́si ‘another man’ mutú mɔ̂:si ‘one man’ /a/ – /a:/ : di-bǎla ‘tree (sp.)’ dibǎ:la ‘male’
In addition to the above underlying constraints, phonological rules affecting post-root vowels suggest that these latter are in positions of non-prominence. First, short /a/ is realized [ə] in post-root position (but [a] in prefixes and roots):
(15)
a. /ma-bâg-a/ → [ma-bâɣə] ‘knives’ b. /u-bɔ́k-asán-a/ → [u-bɔ́k-əsə́n-ə] ‘to kill each other’
Kwenzi Mikala does, however, add:
Toutefois, on rencontre [a] en finale lorsqu’une phrase est inachevée ou interrompue. Ce phénomène est toujours marqué par une intonation suspensive.
It is likely that such cases of phrase-final [a] undergo pre-boundary lengthening and are exempt from reduction for this reason.
In addition, post-root /a/ and /i/ are subject to anticipatory front- and round harmony before final /-i/ and /-u/:
(16)
a. -bíng-as-an-a → -bíng-əsən-ə ‘roll (sth.)’ (general, “default” final /-a/) -bund-ig-il-a → -bund-iɣil-ə ‘slander’ b. -bíng-as-an-i → -bíng-isin-i ‘roll (sth.)’ (present, subjunctive /-i/) -bund-ig-il-i → -bund-iɣil-i ‘slander’ c. -bíng-as-an-u → -bíng-usun-u ‘be rolled’ (passive /-u/) -bund-ig-il-u → -bund-uɣul-u ‘be slandered’
As seen, the root vowel is neither affected, nor does it trigger harmony on pre- or post-root vowels. Thus, /-bund-ig-il-a/ does not trigger progressive rounding harmony in (16a), nor does the root /-bíng-/ undergo rounding harmony in /-bíng-as-an-u/ in (16c). It is therefore clear that the stem-initial syllable is singled out for prominence as it is in Ibibio and Koyo.
This is, however, not all: the penult is also important. With few exceptions, HL, SL, and LH tonal contours are restricted to the root syllable only when occurring in penultimate position, (H = high tone, L = low, S = superhigh):Footnote 8
(17)
a. /u-gab-á/ → u-ɣǎb-ə ‘to divide, share in several pieces, distribute’ b. /u-gab-an-á/ → u-ɣab-ə́n-ə ‘to share sth. between several people’ c. /u-gab-as-an-á/ → u-ɣab-əs-ə́n-ə ‘to share things habitually with each other’
Again, prefixes are different from suffixes, supporting a LH rising tone when a noun stem is monosyllabic:
(18)
a. ǐ-du ‘mortar’ b. ǐ-tu ‘confidence’ c. dǐ-tu ‘leech’
To account for these facts I propose the initial prominence occurs at the stem level and this latter penultimate prominence at the word-level. In (18), there is only penultimate prominence when the stem is monosyllabic. This I assume is due to avoidance of final prominence, a common property of stress-accent systems. Initial prominence both licenses the prefixal rising tone in (18) and accounts for the fact that (non-prominent) /Ca/ stems are realized [Cə]:
(19)
a. /ú-ba/ → ú-bə ‘to be’ b. /bú-ta/ → bú-tə ‘gun’
A final effect of the word-penultimate prominence is that, with very few exceptions, long vowels are shortened in pre-penultimate position:
(20)
a. u-wɛ́:l-a ‘to marry’ vs. u-wɛ́l-↓án-a ‘to marry each other’ b. mi:la ‘rivers’ vs. milá mya:mi ‘my rivers’ c. á-tsí-wɛ:la nkwɛ́:la běji ‘he got married twice’
In (20a) there is pre-penultimate shortening of the root vowel of -wɛ́:l- ‘marry’ occurs when a derivational suffix, here reciprocal -an-, is added. In (20b) that the same pre-penultimate shortening takes place in a noun + possessive pronoun sequence, which constitutes a tight bond, as in many other Bantu languages. Finally, (20c) shows that there is no shortening between major constituents.
To summarize, stem-initial and word-penultimate positions are prosodically privileged in Punu.
5 Lulamogi
A rather interesting, but slightly different parallel to Punu is found in Lulamogi, a small understudied Bantu language closely related to Luganda, often grouped with Lusoga, but dialectal with Lugwere (Nabirye Reference Nabirye2013, Hyman and Merrill Reference Hyman, Merrill, Léonard and Petit2016).Footnote 9 Although not quite as dramatic as in Punu, stem-initial and penultimate syllables are positions of prominence: (i) all five vowels /i, e, u, o, a/ contrast in CV stem-initial syllables – prefixes and stem-internal syllables contrast the three vowels /i, u, a/; (ii) a HL falling tone can only occur on penultimate (and, marginally, final) bimoraic syllables – á-ká-sáàle ‘arrow,’ ii-nâ /i-náa/ ‘four.’ The interesting difference between Punu and Lulamogi concerns vowel length.
First, Lulamogi has an underlying vowel length contrast. In the following examples, ó-ku- marks the infinitive consisting of the ‘augment’ morpheme /ó-/ and the noun class 15 prefix /-ku-/:
(21)
/i/ – /i:/ : ó-ku-siβ-á ‘to tie’ ó-ku-siiβ-á ‘to fast’ /e/ – /e:/ : ó-ku-sen-á ‘to draw (water)’ ó-ku-seen-á ‘to become thin’ /u/ – /u:/ : ó-ku-tum-á ‘to send’ ó-ku-tuum-á ‘to jump’ /o/ – /u:/ : ó-ku-hol-á ‘to lend (money)’ ó-ku-hool-á ‘to show favoritism’ /a/ – /a:/ : ó-ku-many-á ‘to know’ ó-ku-maany-á ‘to pluck’
Differing from Punu, underlying length occurs most often on the penult in underlying representations, but is not restricted to the initial stem syllable: ó-ku-tegéér-á ‘to know,’ ó-ku-holóót-á ‘to snore.’ In addition, length on stem vowels does not shorten pre-penultimately: ó-ku-hool-ágán-á ‘to favor each other,’ ó-ku-tegéér-ágán-á ‘to know/agree with each other,’ ó-ku-siiβ-íl-ágán-a ‘to fast for each other.’
Besides lexical long vowels, derived vowel length may arise from heteromorphemic V+V sequences, but with complications. Except for a later process of final vowel shortening (FVS), whenever V+V coalescence involves two stem (e.g. root + suffix) vowels, a long vowel results:
(22)
a. /ó-ku-ti-a/ → ó-ku-ty-á ‘to fear’ /ó-ku-ti-a =kú/ → ó-ku-ty-áá =ku ‘to fear a little’ b. /ó-ku-ti-is-i-a/ → ó-ku-ti-is-y-á ‘to frighten’ /ó-ku-ti-is-i-a =kú/ → ó-ku-ti-is-y-áá =ku ‘to frighten a little’
In (22a) the intermediate form is ó-ku-ty-áá, whose length undergoes FVS but is preserved when an enclitic follows such as =ku ‘a little.’ The same FVS process is observed in the first example of (22b), where /-is-i-/ consists of two causative suffixes. The examples in (23) now show that coalescence of a sequence of prefixal vowel + stem-initial vowel also results in a long vowel:
(23)
subject prefix /tu-/ /tu + et-a/ → tw-eet-â ‘we call’ /tu + agal-a/ → tw-aagál-a ‘we search’ object prefix /-mu-/ /tu + mu + et-a/ → tú-mw-eet-â ‘we call him’ /tu + mu + agal-a/ → tú-mw-aagál-à ‘we search for him’ infinitive prefix /ku-/ /ó-ku + et-a / → ó-kw-eet-á ‘to call’ /ó-ku + agal-a/ → ó-kw-aagál-á ‘to search’
Taken together, the generalization is that V+V coalescence will result in a long vowel if either or both of the vowels belong to the stem.
In contrast, a sequence of two prefixal vowels results in a short vowel, unless the stem is monosyllabic:
(24)
a. /tu + a + βal-a/ → tw-á-βal-á ‘we will count’ (future -a-) /tu + a + gu-a/ → tw-áá-gw-a ‘we will fall’ b. /tu + e + βal-a/ → tw-e-βál-a ‘we count ourselves’ (reflexive -e-) /tu + e + ti-a/ → tw-ee-ty-â ‘we fear ourselves’ c. /tu + a + e + βal-a/ → tw-éβal-á ‘we will count ourselves’ /tu + a + e + ti-a/ → tw-éé-ty-a ‘we will fear ourselves’ (future + reflexive -a-e-)
In order to account for the length variation in (24), the analysis has to refer to both stem versus prefix and penultimate position: a prefixal V + stem always results in a long vowel (VV), but a prefixal V + another prefixal V results in a short vowel (V) unless in penultimate position, that is, before [σ]stem. As in Punu, the Lulamogi facts suggest both stem-initial and word-penultimate prominence. Interestingly, the two can never coincide, since (unlike other Bantu languages), the verb stem is never initial in Lulamogi – the imperative requires a second person prefix:
(25)
2sg. subject 2pl. subject 2sg. reflexive 2pl. reflexive óó-ty-e mú-ty-e ‘fear!’ w-éé-ty-é mw-éé-ty-é ‘fear yourself/ves’ ó-βal-é mú-βal -é ‘count!’ w-é-βál-é mw-é-βál-é ‘count yourself/ves’ /o-e-/ /mu-e-/
There are two problems with an accentual analysis. The first is that all stem vowels act the same with respect to vowel length, not just the first stem syllable. This would then seem to be a case of where preserving stem moras is “ranked higher” than preserving prefix moras. If we assume that the shortening rule targets the second of the two Vs in sequence, there will be no loss of mora if the second V is a stem mora, that is, independent of whether the first V is prefixal or belongs to the stem.Footnote 10
While some might identify the stem-initial and penultimate positions with left- and right-trochaic structures, we need to be careful not to automatically interpret foot structure evidence from prosodic morphology as “accent.” Like Luganda, Lulamogi seems to like its reduplicant to consist of a single iamb if it can be, a foot that is not accentual. In the following examples, the reduplicated form has the meaning “to do something a little here and there, typically badly”:
(26)
a. CV-V stem: ó-ku-li-á ‘to eat’ → ó-ku- [ly-aa] -ly-á b. CVC-V stem: ó-ku-sek-á ‘to laugh’ → ó-ku- [sek-áá] -sék-á c. CVVC-V stem: ó-ku-leet-á ‘to bring’ → ó-ku-leet-á-léét-á CVCVC-V stem: ó-ku-tolók-á ‘to escape’ → ó-ku-tolók-á-tólók-á
In this particular corner of the morphology, Lulamogi appears to favor an iamb, much as Ibibio favors “feet” of different shapes in negative, passive/reflexive and frequentative forms of the verb.
6 Conclusion
To summarize, Ibibio and Koyo show clear privileging of stem-initial position, while Punu and Lulamogi exploit two different positions: stem-initial and word-penultimate. In Lulamogi the five vowels /i, e, u, o, a/ contrast in stem-initial position only, while a HL falling tone is not permitted in prepenultimate position. The Punu examples show that there can be different prominences (accents) at different levels, stem versus word. Lulamogi also crucially refers to the stem versus word. Finally, prosodic morphology in Ibibio and (marginally) Lulamogi shows that different constructions may impose different prosodic shapes. Overall, the cited examples suggest that positional prominence effects might be taken as evidence for foot structure. However, what’s missing are several of the properties of stress-accent systems. For example, none of the examples (or other Bantu cases I am familiar with) provide evidence of iterating feet. Instead, there seem to be one or more specific positions whose “prominence” is indicated by their special licensing properties or which lack such prominence by virtue of restricted contrasts and/or undergoing reduction or assimilation. The latter was shown to be the case in Punu. In most Bantu languages vowel harmony is root-controlled (Clements Reference Clements1981), with post-root vowels assimilating to the root vowel. In (16), however, it was seen that final -i and -u trigger harmony in Punu, while the root vowel does not. Does this mean that the final syllable is also a position of prominence? Such a case can even be made for Lulamogi, which contrasts only the three vowels /i, u, a/ stem-internally, but all five vowels /i, e, u, o, a/ in both stem-initial and stem-final positions:
- (27)
a. é-kí-sígì ‘eyebrow’
b. ó-n-zígè ‘locust’
c. é-n-zígù ‘misunderstanding’
d. ó-mu-zigó ‘butter’
e. ó-ku-sig-á ‘to plant’
At some point positions of prominence become too numerous, and thereby cease to be good candidates for an “accentual” interpretation. Specifically, once one loosens the criteria for stress-accent in (1), the case for accent becomes muddled, elusive, and unhelpful. For this reason we should focus on the properties and care less about what we call them.
1 Introduction
This chapter examines a link between the asymmetric tolerance of word-edge lapse among binary-stress languages and the phonetic realization of stress. Phonological stress typologies are classically agnostic as to how stress is realized (e.g. Kager Reference Kager2001, Gordon Reference Gordon2002, Alber Reference Alber2005, Kager Reference Kager2005). This chapter, however, proposes that there are differences in the typology depending on the phonetic manifestation of stress. The connection explored here is that the word-edge specific phonetics of final syllables can relate to the rhythmic stress pattern in some languages. Specifically, whether or not a language tolerates a final stress lapse is shown to be correlated with whether the language uses duration in its realization of stress. For those languages that do use duration and tolerate a final stress lapse, the hypothesis is put forward that the final lengthening inherent in the final syllable continues the rhythmic pattern of the word, without the final syllable needing to bear stress.
Binary-stress languages are those languages with some level of stress occurring (generally speaking) on every other syllable. Typically, such systems are thought of as assigning stresses in words in either a strong–weak (trochaic) pattern, or a weak–strong (iambic) pattern starting from either the left edge (“left-aligned”) or the right edge (“right-aligned”) of a word. While a distinction can almost always be made between the single primary stress (generally the first or last stress in the word) and the other, secondary, stresses, the discussion here is concerned with the overall alternating patterns and so will conflate degrees of stress under the term “rhythmic stress.” Rhythmic stress can be interrupted by languages allowing adjacent unstressed syllables (stress lapse) or adjacent stressed syllables (stress clash). A typical reason for stress clash occurs in weight-sensitive languages where heavy syllables often draw a stress, which may then occur adjacent to either a rhythmic stress or another stress-drawing heavy syllable. Typological work on rhythmic stresses is often confined to quantity-insensitive languages (where even if heavy syllables exist, they do not affect the stress pattern) and the stress patterns that quantity-sensitive languages employ in words with all light syllables. Clash is fairly rare in these systems (Gordon Reference Gordon2002) but lapse is not uncommon.
The binary stress pattern may be interrupted by lapse either adjacent to the primary stress (what Gordon Reference Gordon2002 called “internal lapse”) or at a word edge (“external lapse”). Cases of internal lapse classically arise when the primary stress is affiliated with a different word edge from the secondary stress alternations. For example, verbs in the Austronesian language Lenakel bear primary stress (σ́) on the penult and have secondary stress (σ̀) on the initial syllable and every other syllable thereafter, which can lead to word-internal lapses, as in tɨ̀.na.gà.ma.ɾɔl.gέy.gεy ‘you (pl.) will be liking it’ (Lynch Reference Lynch1978: 19). Such cases are not relevant to the discussion here, as we will be looking at stress patterns that occur when the primary stress is part of the same rhythmic pattern as the secondary stresses. In such languages we could theoretically get an external lapse on either side; however, in practice, initial stress lapses are extremely rare.Footnote 1 By contrast, cases of final lapse in binary stress languages are notably common. Some examples are given in (1). (Note that here and elsewhere feet are not marked, as the focus is on the rhythmic pattern, although trochaic and iambic foot types will sometimes be referred to in order to concisely describe stress patterns.)
(1) Examples of binary-stress languages that allow final lapse
| English | jù.nɪ.vɹ̩́.sɪ.ɾi | ‘university’ | |
| Pintupi | pú.liŋ.kà.la.tju | ‘we (sat) on the hill’ | Hansen and Hansen (Reference Hansen and Hansen1969) |
| Hixkaryana | tóh.ku.rjéː.ho.na | ‘to Tohkurye’ | Derbyshire (Reference Derbyshire1985) |
| Finnish | ó.pet.tè.le.mà.na.ni | ‘as something I have | van der Hulst (Reference Hulst, Goedemans, van der Hulst and van Zanten2010) |
| been learning’ |
The opportunity does not even arise, of course, in languages with regular penultimate stress, like Tuvaluan, which places primary stress on the penult (and secondary stresses on every other syllable preceding it; Besnier Reference Besnier2000). But others, like Maranungku, which has the pattern of syllabic trochees from the left (like Pintupi and Finnish, shown above), will carry the alternating rhythm through to the end (unlike Pintupi and Finnish) and so prevent a final lapse; for example, láŋ.ka.rà.te.tì ‘prawn’ (Tryon Reference Tryon1970).
The commonness of final stress lapse in rhythmic stress languages seems surprising, given that internal lapse is relatively rare and initial lapse is exceedingly rare. The following sections explore the prevalence of word-final stress lapse and offer an explanation for why it is so widely tolerated.
2 Approaches
Final stress lapse can be seen as a consequence of forces known to influence stress patterns. Related to the lapse-asymmetry is the fact that many languages never allow stress on the word-final syllable, which is captured by excluding the final syllable from stress-related rules or requirements. This tendency is generally referred to either as extrametricality (Liberman and Prince Reference Liberman and Prince1977, Hayes Reference Hayes1982) or as non-finality, after the Optimality Theory (henceforth, OT) constraint, which either forbids the final syllable from being included in a foot (the more direct instantiation of extrametricality; Prince and Smolensky Reference Prince and Smolensky1993) or forbids a stress from occurring on the syllable at the right edge of the word (Walker Reference Walker1996). Rhythmic stress systems with extrametricality/non-finality will naturally lead to instances of final stress lapse. Further, in accounts of the stress typology that use feet, final lapse naturally falls out as the effect of footing binary trochees from the left, since a final syllable will be left over in words with an odd number of syllables: (σ́σ)(σ̀σ)σ. There are reasons to think that the tolerance for final stress lapse goes beyond these factors, however.
If the final syllable tendency to be excluded from any stress-related rules or structure accounts for the prevalence of final stress lapse, then we should expect to see the final syllable avoided in right-aligned stress systems as well as left-aligned ones. That is, we expect to see many languages that are like Latin, where a trochee is placed one syllable in from the right edge: σ(σ́σ)σ. The StressTyp database (Goedemans and van der Hulst Reference Goedemans and van der Hulst.2014),Footnote 2 however, yields just seven such cases out of the 35 languages that foot trochees from the right, with a rightmost headfoot. This contrasts sharply with the 22 trochee-from-the-left, headfoot left, languages that are listed as tolerating final stress lapse out of the 37 total of the type.Footnote 3 In Gordon’s (Reference Gordon2002) typology of quality-insensitive stress patterns, rhythmic stress languages in which stress falls on the initial syllable and every other syllable following excluded the final syllable in 14/29 cases.Footnote 4 The comparison of extrametricality/non-finality affecting 20 percent of right-aligned trochees, compared to 48~62 percent of left-aligned trochees, indicates that final syllable exclusion may not be the only force at work.
Nor can the prevalence of final stress lapse be put down to the natural consequence of footing an odd-syllabled string. A language like Pintupi could continue the alternating rhythm if it allowed degenerate feet, as in: (σ́σ)(σ̀σ)(σ̀). Viewing the difference as a choice of whether to allow a single syllable to form a degenerate foot when doing so would continue the rhythmic pattern, we would expect to find languages behaving similarly at both the left and right edges. There are only eight languages (identified looking at both StressTyp and Gordon Reference Gordon2002) which assign stress on the final and every other syllable preceding and all eight stress the initial syllable when a stress lapse would otherwise result: (σ̀)(σσ̀)(σσ́). So while half or fewer of trochee-from-the-left systems require a degenerate foot, all iamb-from-the-right systems require one. (This latter observation is well known from Kager Reference Kager2001.) This indicates that there is a pressure for alternating stress word-initially that is not there to the same extent word-finally. Thus we see that while both extrametricality/non-finality and the tension between alternating stress and ideal feet can lead to final stress lapse, the typological distributions indicate that neither is sufficient to explain the prevalence of final stress lapse.
Theoretical accounts of the stress typology couched in OT include asymmetric constraints in order to allow word-final, but not word-initial lapses. The basic tension in OT approaches is between *Lapse and Non-Finality, which (for cases where a stress falls on the antepenult in a binary-stress system) gives the choice of continuing the rhythm through the final syllable, despite the pressure of Non-Finality, or tolerating a stress lapse in order to keep stress off the final syllable. In Gordon’s (Reference Gordon2002) grid-based account of the stress typology, his constraint Align Edges requires that both the initial and the final syllable bear stress, but a higher ranking of the asymmetric constraint Non-Finality will force the word-final syllable to not satisfy Align Edges. Since there is no constraint to force stress off a word-initial syllable, the system cannot generate a word-initial lapse. In his foot-based typology, Kager (Reference Kager2001, Reference Kager2005) uses an OT constraint that directly licenses word-final lapses: Lapse-at-End, defined as “[any] lapse must be adjacent to the right edge.” (The constraint set of Kager Reference Kager2001, Reference Kager2005 also includes Lapse-at-Peak to allow word-internal lapses adjacent to the primary stress.) The account of Alber (Reference Alber2005) has a more indirect asymmetric constraint to allow word-final stress lapse. Her typology includes only leftward alignment of feet, excluding rightward alignment entirely. Thus, leftward alignment can generate leftmost trochees with a final lapse, (σ́σ)(σ̀σ)σ, and leftmost iambs without an initial lapse, (σ́)(σσ́)(σσ̀),Footnote 5 but since there is no rightmost alignment there is no way to generate an initial lapse, σ(σσ̀)(σσ́). In van der Hulst’s (Reference Hulst and van der Hulst2014) account of the stress typology encoded as rhythm parameters, final lapse results from systems where secondary stresses (“rhythm” in van der Hulst’s system) “echo” a left-aligned primary stress (“accent”) but stop short due to Non-Finality. The mirror image, with an initial lapse, cannot occur however, because there is no parameter to exclude the initial syllable from the word rhythm, and so the alternating rhythm will always pervade the left edge of the word.
Clearly, the final syllable tends to be behave differently, in a way that is not mirrored by the initial syllable. The theoretical accounts summarized model this behavior, but they do not explain why the asymmetry exists. As noted, non-finality is not sufficient motivation for the difference in word edges, as we see it occurring more frequently in systems that can be described as assigning stress from left to right.
This chapter takes a different kind of approach by looking at evidence that languages’ tolerance of final stress lapse is linked to their phonetic properties. Languages that allow a final stress lapse are predicted to have a durational increase in their stressed syllables and also have word-level final lengthening. In such cases, the phonetic increase in duration due to final lengthening may allow the rhythmic pattern that has been realized with duration-cued stress to be perceived as continuing through the final syllable, without the final syllable actually bearing a stress. While this approach is not incompatible with the OT accounts discussed, it could be more directly modeled, which will be addressed in the conclusion.
Stressed syllables commonly stand out perceptually because of their longer duration, higher intensity (loudness),Footnote 6 and/or higher pitch.Footnote 7 (See van Heuven, Chapter 1 this volume, for details of potential stress correlates in general and their relative realization in English and Dutch specifically.) Different languages use different combinations of these phonetic cues. For example, the Trans-New Guinea language Awara uses intensity and pitch (Quigley Reference Quigley2003), as does the Amazonian language Ese’eja (Rolle and Vuillermet, Chapter 12, this volume). The Australian language Gayo uses duration and pitch (Eades Reference Eades2005), and the Panoan language Matsés uses duration and intensity (Fleck Reference Fleck2003). Languages may have only one suprasegmental correlate, as in the Australian language Nhanda, which uses only duration (Blevins Reference Blevins2001), or use all three, as in the Austronesian language Tuvaluan (Besnier Reference Besnier2000). Languages can also differ within themselves as to the phonetic realization of different levels of stress, as described for Gilbertese (Kager and Martinez-Paricio, Chapter 5 this volume).
Independent of stress, both the left and the right edges of a word are subject to phonetic augmentation. The initial syllable exhibits initial strengthening, a cross-linguistic phenomenon in which the onset of the initial syllable shows increased duration (e.g. Oller Reference Oller1973) and a stronger articulation (e.g. Keating et al. Reference Keating, Cho, Fourgerson and Hus2003). A syllable at the right edge of the word is subjected to final lengthening, a cross-linguistic phenomenon (although its degree varies by language, and it can be suppressed in a language [e.g. Gordon et al. Reference Gordon, Jany, Nash and Takara2010]) that occurs at the right edge of prosodic boundaries: at the word, phrase, and utterance levels. Word-level final lengthening was found by Lindblom (Reference Lindblom1968) for Swedish and by Oller (Reference Oller1973) for English. It has been demonstrated that final lengthening affects the rime of the syllable preceding the prosodic boundary (Crystal and House Reference Crystal and House.1990, Wightman et al. Reference Wightman, Shattuck-Hufnagel, Ostendorf and Price1992). This difference in phonetic augmentation at the left versus right edge of the word provides a potential explanation for the tolerance of stress lapse word-finally, if the phonetic lengthening inherent in the position can be perceived as part of the rhythm of the word.
Unstressed syllables exhibiting final lengthening have a phonetic similarity to stressed syllables in languages which use duration to realize stress. The idea explored here is that the word-edge phonetics of the right edge can contribute to the rhythm of the word in rhythmic stress languages under certain circumstances. The remainder of this chapter looks at two sources of evidence for a connection between a language’s phonetic realization of stress and tolerance of a final stress lapse and then sketches out a theoretical implementation. The following section looks at typological evidence for this connection and then the section following turns to evidence from perception experiments.
3 Database
If the possibility of final lengthening being perceived as a word-level prominence explains the relative acceptability of word-final stress lapse, we would expect to find a correlation between whether a language allows a final lapse and whether it has duration as a stress correlate. We can look for such a correlation using Lunden and Kalivoda’s (Reference Lunden and Kalivoda2016) online, ongoing compilation of languages’ reported stress correlates.
The database currently contains information for 53 languages with binary stress, from 26 different families, for which information on both the stress pattern and the acoustic correlate(s) of stress is available. The database includes languages with acoustically measured correlates whenever the information is available, but relies mainly on the information in published grammars and theses and occasionally information solicited directly from linguists familiar with the language. Languages are categorized as tolerating a final lapse as long as they allow a final lapse to occur in some forms. For example, English is listed as tolerating final lapse because of words like A.mé.ri.ca even though many words without a final stress lapse also exist (e.g. Mà.ssa.chú.setts). Although the hypothesis that final lengthening contributes to the rhythmic pattern also depends on the presence of word-final lengthening in a language, this information is almost never mentioned in grammars. It therefore is not possible to consider as a factor statistically.Footnote 8 Further, the phonetic cues to primary and secondary stress can be different, but it is rare that they are discussed separately, and therefore the database does not distinguish between them. (The question of which stress-level cues are most relevant for the proposed theory will be discussed in Section 5.) For each language description with stated stress cues, the question is asked, for each of the possible correlates, whether it is claimed to play a role in the realization of stress in the language, and coded accordingly.
The database encodes only suprasegmental cues, and so does not include whether vowel quality is a factor in stress, mainly because vowel reduction is not usually included in descriptions of the realization of stress. As we will see in Section 4, however, the vowel quality difference between stressed and unstressed syllables can be very important. Flemming (Reference Flemming2005) proposes that vowel quality and duration are inherently linked, where vowels will only have time to be fully realized when there is sufficient duration. If the duration and vowel quality are consistently interconnected in this way, then we potentially do not need to encode them as separate stress correlates, although systematic phonetic evidence is needed to show their interdependence across languages.
We find a striking imbalance when we examine the correlation between tolerance of a final stress lapse and the use of duration in the stress correlate database. Twenty-one out of 23 of the languages that can tolerate a final stress lapse use duration as a cue to stress. On the other hand, languages that do not tolerate a final stress lapse are no more or less likely to cue stress with duration. This distribution is shown in the graph in (2).
(2) Correlation between final lapse tolerance and duration as a stress correlate


This is what would be expected if the use of duration in stress were, in essence, licensing final stress lapse. On the other hand, if the use of duration as a stress cue were in no way linked to the tolerance of final stress lapse, then we would expect duration to be equally likely to be used as a stress correlate whether a language tolerates a final stress lapse or does not. This is exactly the type of correlation-less distribution we see if we look at pitch or intensity and the tolerance of final stress lapse.
(3)
a. Final lapse tolerance and use of pitch b. Final lapse tolerance and use of intensity

In both the cases of intensity and pitch, languages are no more or less likely to use these stress correlates based on whether or not they permit a final stress lapse, and thus the properties seem to be independent of each other. A binomial logistic regression shows a significant correlation between whether a language allows a final lapse and whether it uses duration as a cue to stress (Wald 𝜒2=6.616, 𝑃=0.010, ).Footnote 9 There is no such correlation for pitch (Wald 𝜒2=0.111, 𝑃=0.739) or intensity (Wald 𝜒2=0.002, 𝑃=0.968).Footnote 10
Looking at the distribution of duration in (2), we notice that only two languages that tolerate a final lapse fail to have duration as a stress correlate.Footnote 11 However, in seven cases, the final lapses were extremely restricted, occurring only with suffixes, or, in some cases, only with a particular suffix. For example, the Arawakan language Ashéninka Perené has primary stress on the penultimate syllable with secondary stress on alternating preceding syllables, but no affixes bear secondary stress (Mihas Reference Mihas2010). If we recategorize these seven cases as not tolerating a final lapse (since the cases where they do so are morpheme-dependent), then we find that 15 out of the 16 languages that tolerate final stress lapse use duration as a correlate of stress (as do 22 out of the 37 that do not tolerate a stress lapse). Running the same full model, the results are unchanged: the use of duration significantly correlates with final lapse tolerance (Wald 𝜒2=4.076, 𝑃=0.044), whereas neither the use of pitch nor intensity does (Wald 𝜒2=2.598, 𝑃=0.107; Wald 𝜒2=0.514, 𝑃=0.474). The robust correlation found between final lapse tolerance and a language’s use of duration as a stress correlate supports the proposal that rhythmic stress languages do avoid a lapse in rhythm at either word edge, given that final lengthening serves to continue the rhythm through the end of the word in languages that realize stress through duration (and assuming the presence of final lengthening). The fact that there are very few rhythmic-stress languages which both tolerate final stress lapse and fail to use duration means we are no longer faced with the huge imbalance between initial lapse and final lapse typologically: they are both attested but quite rare.
We also see that languages without final lapse are as likely as not to have duration as a stress correlate. This is not unreasonable, because many of the no-lapse-allowing languages with duration have either penultimate stress (e.g. Lenakel; Lynch Reference Lynch1978) or stress that varies between the penult and the final (e.g. Pashto; Tegey and Robson Reference Tegey and Robson1996) and so there is no opportunity for a final lapse to occur. Therefore we do not want to say that a language will tolerate final stress lapse if it uses duration as a stress correlate; rather, we can conclude that those languages that allow a final stress lapse are highly likely to use duration as a stress correlate. This supports the hypothesis that a final stress lapse is tolerated by many languages because the duration inherent in the final syllable is reminiscent of (one of) the stress correlate(s) in the language, giving the perception of rhythmic alternation even in the absence of phonological stress.
4 Perceptional Rhythm
If rhythmic-based stress that is cued by duration can be perceptually continued through an unstressed syllable with final lengthening, then we should be able to see experimental evidence of this. The results of three new perception experiments (and reference to one presented previously) which address this prediction are shown. The general setup of the experiments is consistent: subjects were played auditory stimuli consisting of five-syllable strings that varied in strength – for example, BAbaBAbaBA (where capitals indicate stressed syllables) – and were asked, for each string, whether it was “alternating” or “not alternating.” While BAbaBAbaBA is clearly alternating and BAbaBAbaba is clearly not alternating, the question of interest is how subjects would categorize strings in which the final syllable in a BAbaBAbaba string reflected word-final phonetics.
4.1 Methods
The stimuli and procedure that are common to all three perception experiments are given below. The participant information and experiment-specific stimuli are given in the subsequent experiment-specific subsections.
4.1.1 Stimuli
The experiments used five types of syllable strings, the syllables for which were made with the speech synthesizer MBROLA (Dutoit et al. Reference Dutoit, Pagel, Pierret, Bataille and van der Vreken1996), using American male voice us3. The syllables [bɑ], [bi], and [bu] were created for stressed syllables, with corresponding [bə], [bɪ], and [bʊ] in non-final unstressed syllables. Pitch was made to peak at 140 Hz in stressed vowels (20% of the way through) and at 120 Hz in basic unstressed vowels. Intensity was manipulated in Praat (Boersma and Weenink Reference Boersma and Weenink.2014), where unstressed syllables were multiplied down (0.5 of original) and then the syllables were concatenated into strings. Beyond the basic unstressed syllable described, two additional unstressed syllables with word-edge phonetic characteristics were also created. In order to simulate initial strengthening, syllables were given a pitch that peaked at 130 Hz (20% of the way through the vowel) and an intensity higher than that of other unstressed syllables (multiplied down 0.75, rather than 0.5). To simulate word-final phonetics, the full vowel quality was used and vowels were 120 ms.Footnote 12
Five different types of syllable strings were constructed: fully alternating strings, strings with initial lapse, strings with initial lapse but with an initial syllable with initial-strengthening, strings with final lapse, and strings with final lapse but with a final syllable with final-lengthening. Each of these string types were constructed with the three different vowels and replicated four times in the experiment, with the exception of the fully alternating strings, which were replicated eight times, for a total of 72 strings all together.
4.1.2 Procedure
Experiments were run through Amazon’s Mechanical Turk, via ibex (Drummond Reference Drummond2014). Turkers were required to pass an audio qualification test before they were allowed to do an experiment. The qualification gave them alternating and not alternating syllable strings (based on the syllable ‘da’). They were told the answers to the first two and then asked to categorize eight further strings, none of which included any syllables with word-edge characteristics. Subjects who qualified (by getting at least nine out of ten correct) and completed an experiment received $1. Each subject’s responses to the 24 fully alternating test strings were checked and the data from subjects who failed to identify over two-thirds of these strings correctly was discarded, since being able to correctly identify truly fully alternating strings is a prerequisite to deciding whether strings with final lengthening should be categorized the same way.
4.2 When Duration is a Cue to Stress
4.2.1 Experiment 1a
The first version of the experiment was set up to test whether syllables with final lengthening are perceived as alternating when stressed syllables are longer than unstressed syllables. The phonetics of the syllables were as described in Section 4.1.1, with stressed syllable vowels being 120 ms and non-final-lengthened unstressed vowels 60 ms. Thus, unstressed lengthened final syllables had the vowel quality and duration
of stressed syllables but the pitch (which fell to 110 Hz) and intensity of unstressed syllables. The waveforms of the stimuli are shown in (4) along with the terms that will be used to refer to each of them. Note that while there are two forms with initial lapse and two forms with final lapse, in each case the term is used to refer to the form without phonetic edge augmentation. The augmented form is referred to as the “ … test” form as these are the strings that are of interest; specifically, whether responses to them differ from those to the plain lapse strings.
(4) Experiment 1a stimuli

We can judge whether or not final lengthening does in fact continue the rhythmic pattern based on a three-part criteria. First, we should see a notable increase in “alternating” responses in strings with stress lapse but final lengthening (final test strings) over strings with final lapse and no final lengthening (final lapse). Second, “alternating” responses for final test strings should be around or above 50 percent, indicating that it is at least confusable with truly alternating strings. (This is separate from the first requirement because it might be the case that final lapse strings were heard as alternating 50 percent or more of the time.) Third, the increase between final test strings over final lapse strings should be notably greater than any increase between strings with initial lapse but initial-strengthening (initial test) and strings with initial lapse and no strengthening (initial lapse).
Sixty-one monolingual native English speakers took the experiment (male=28; mean age=33). The percent of “alternating” responses for each string type is shown in the graph in (5).
(5) Percentage of strings identified as alternating: duration as a stress correlate
It is evident that no lapse strings were overwhelmingly correctly identified as alternating, and that the mistaken categorization of strings with a stress lapse as being alternating is fairly low and consistent across string types, with the exception of those with final lengthening.
The results of the final test strings satisfy all three criteria laid out above. They are indeed significantly more likely to be perceived as alternating than final lapse strings (𝑃<0.001, pairwise comparison as part of a binomial logistic regression with string type as the fixed factor). They are identified as alternating 60.7 percent of the time, well over the 50 percent confusability threshold. And the increase in “alternating” responses due to the final edge syllable is clearly much greater than the increase due to the initial edge syllable. Therefore we conclude that we are seeing results consistent with the unstressed-but-lengthened final syllable continuing the alternating rhythm.
It is worth examining the data further to see whether the mixed responses to final test strings is due to varying answers across subjects or whether it is in fact due to a binomial distribution within subjects.Footnote 13 While 49.2 percent of the subjects usually classified the final test strings as alternating (three-fourths of the time or more), only 26.2 percent rarely did (one-fourth of the time or less). The remaining 24.6 percent varied their responses, indicating that 73.8 percent of subjects found final test strings either confusable with no lapse strings or in fact generally heard them as alternating. The fact that close to three-fourths of the subjects found them at least confusable with no lapse strings indicates that the high number of final test strings identified as alternating is not due to a few of the subjects always labeling them as such, but rather was a more general perceptual categorization.
There were some differences in responses by vowel type but all vowel types showed essentially the same distribution of responses. One difference is that initial lapse, with and without initial strengthening, was more likely to be identified as alternating if the stressed vowel was [ɑ]. The increase in “alternating” responses in (5) for initial test strings is in fact due to the [ɑ] strings: there is no significant increase in [i] or [u] strings (𝑃=0.584, 𝑃=0.258). All final lapse strings were equally likely to be identified as alternating, regardless of the vowel. While the increase in “alternating” responses for final test strings varied by vowel (all are significantly different from each other; 𝑃<0.001), for all three vowels there is a significant increase in final test strings identified as alternating over the final lapse strings (𝑃<0.001 within each vowel). Therefore, although we see some magnitude differences, the crucial finding (final syllables with edge phonetics can have a rhythmic effect) holds for all three vowels.
4.2.2 Experiment 1b: Deschenes, Kalivoda, and Lunden Reference Deschenes, Kalivoda and Lunden2012
The final vowels in final test strings were like the stressed vowels in both duration and vowel quality, but unlike stressed vowels in pitch or intensity. The phonetics of the syllables, including the unstressed syllables with final lengthening, were based on a production experiment with native English speakers. Because the final vowel quality of the final unstressed syllable in this production experiment was generally in between that of stressed and unstressed pronunciations of the same vowel, we might be concerned that using the full vowel quality of stressed syllables in word-final, unstressed syllables (as a “slightly reduced” vowel could not be produced in the synthesized stimuli) was in fact what caused the high percentage of “alternating” responses to the final test strings. However, Deschenes, Kalivoda, and Lunden (Reference Deschenes, Kalivoda and Lunden2012) found the same pattern of responses to the same types of stimuli constructed using syllables of the relevant types extracted from the English production experiment.
The 44 subjects (male=15, mean age=20) in the Deschenes, Kalivoda, and Lunden study were students at the University of Georgia who received $5 for their participation. They heard the same types of stimuli (strings of repeated syllables), where the stressed syllables were originally produced with stress, the plain unstressed syllables were word-internal syllables that were unstressed, and the edge syllables were the actually produced unstressed word-initial or word-final syllables in the production experiment.
(6) Percentage of strings identified as alternating: stimuli constructed from real speech (Deschenes, Kalivoda, and Lunden Reference Deschenes, Kalivoda and Lunden2012)

As can be seen, we see essentially the same distribution of responses as was found with the synthesized stimuli, and the final test strings were identified as alternating 65.4 percent of the time, similar to the 60.7 percent of “alternating” responses with the synthesized final test strings. Thus, we can conclude that the use of the full vowel quality used in stressed syllables in the unstressed word-final syllables is not what caused the notable number of “alternating” responses in the experiment with synthesized stimuli.
4.2.3 Experiment 2
Having established that the unreduced vowel quality is not inappropriate for the final vowels in final test strings, we want to investigate what the individual effects of final lengthening and vowel quality are on final unstressed syllables.Footnote 14 In the two experiments discussed, final test strings differ from final lapse strings in two ways and we would like to be able to disentangle the effect of duration and vowel quality. The working hypothesis is that the duration due to final lengthening is the cause of the perception of final test strings as being alternating. We will see, however, that when final lengthening is present without the quality of a full vowel, such strings do not typically get identified as alternating.
For this experiment, again run with synthesized stimuli on Mechanical Turk, only no lapse, final lapse, and final test strings were used, with three different kinds of phonetic cues in final test strings. One set had lengthened vowels but the vowel quality of unstressed syllables (duration only), a second had the duration of unstressed vowels but the vowel quality of stressed syllables (vowel only), and a third was like the final test strings in the first experiment, with the duration and vowel quality of the stressed syllables (duration and vowel). The subjects were 48 monolingual native English speakers (males=20; mean age=35).
(7) Percentage of strings identified as alternating: different word-final phonetics

Surprisingly, we see that lengthening alone does not show a significant increase in “alternating” responses over final lapse strings (𝑃=0.065). While we see a significant jump in the percentage of strings identified as alternating between final lapse and vowel only strings (𝑃<0.001), the percentage of alternating responses to vowel only strings is 44.8 percent, below the 50 percent threshold of confusability. It is only when final syllables have both the duration and the vowel quality of stressed syllables that we see the percentage of alternating responses being both significantly greater than those for the final lapse strings (𝑃<0.001) and reaching the threshold of confusability, with 54.0 percent “alternating” responses.
We have seen support for the idea that word-final phonetics can contribute to the perception of rhythm when stress is cued through duration. However, at least for English speakers, it seems that there are two crucial phonetic aspects to a word-final syllable: duration and vowel quality. The prediction is that a language without stress-based vowel reduction could get the rhythmic effect from final lengthening alone. But if vowel quality in fact piggybacks, so to speak, on duration, we might expect any language with duration-cued stress to show some degree of reduction in unstressed syllables and less or no reduction in unstressed word-final syllables.
4.3 Experiment 3: When Duration is Not a Cue to Stress
We have seen that the phonetic characteristics of final vowels in English can give the impression that the stress-based rhythm of the word is continued through the end of a word that ends in two unstressed syllables. The preceding discussion has focused on the phonetic characteristics of the final syllable that make this possible. Now we want to turn to look at the rhythmic properties of the word that are at issue. In Section 3 we saw that very few languages that did not use duration as a cue to stress tolerated a final stress lapse. This is consistent with the hypothesis at hand: even though final lengthening is presumably present in non-duration-cued stress languages, it does not continue the rhythm of the stress system.
In order to test this perceptually, new syllables were created in MBROLA that had the pitch, intensity, and vowel quality of the previously created stressed syllables, but were not longer than unstressed syllables. The vowel quality difference between stressed and non-final unstressed syllables was maintained. The waveforms for experiment stimuli are shown in (8).
(8) Experiment 3 stimuli

These stimuli therefore had non-duration-based rhythm. The only longer vowels came from the final syllables in the final test strings. The question was whether the final-lengthened syllables would be heard as contributing to the rhythm of word when the stress-based rhythm was not duration-based. Fifty-five monolingual native English speakers took the experiment through Mechanical Turk (male=35; mean age=31). The results are shown in (9).
(9) Percentage of strings identified as alternating: Duration not a stress correlate

The subjects were again able to correctly categorize the no lapse strings. However, we see a very different effect of strings having either type of edge syllable from what was previously found. This shows that although the stress cues in the strings were not what the subjects were used to from their native language, they were able to perceive them, and further, perceived the phonetic characteristics of the edge syllables differently in light of them.
Looking at the final test strings, we see that although there is a significant increase in “alternating” responses over final lapse strings (𝑃<0.001), the amount (17.6%) does not reach the confusability threshold, and, of course, is not a greater increase than is seen for initial lapse strings. Remember that the final test strings in fact alternate in vowel quality, since the phonetic characteristics of final syllables include full(er) vowels. So while we saw in (7) that vowel quality was needed to elicit the perception of rhythm, we see here that it is not sufficient to do so. If it is only the vowel quality that is important, then we would expect the alternating vowel quality in the final test strings to have produced a higher number of “alternating” responses than we see in (9). The low number of “alternating” responses for the final test strings is in line with the database finding that very few languages that did not use duration in their realization of stress in fact tolerate final lapse, and is also consistent with the hypothesis that this is because of a true lapse in rhythm in those cases.
There is a strikingly high percentage of “alternating” responses to initial lapse and initial test strings. Initial lapses seem to be more difficult to perceive in non-duration-cued stress for English speakers. Further, and perhaps more interestingly, initial test strings have the kind of effect that we saw before with final test strings: they are identified as alternating significantly more often than initial lapse strings (𝑃<0.001), they are identified as being alternating at least 50 percent of the time (in fact, 64.9%), and the increase is greater than we find between the strings with final stress lapse. The fact that initial lapse strings now seem to be behaving the way we previously saw final test strings behave makes sense, since the phonetic characteristics of initial strengthening now align with the cues to stress (higher pitch and intensity), which could then reasonably lead to the perception of a rhythmically alternating string. And in fact, stress in the language known to tolerate initial lapse, Winnebago, is realized through pitch and intensity (Miner Reference Miner1979). It is worth noting, however, that this study placed all edge cues on the vowels and used identical consonants in each syllable, while initial-strengthening actually affects the initial consonant more than the following vowel. It is therefore unclear whether initial-strengthening should be generally expected to be able to contribute to the rhythm in languages that cue stress with pitch and intensity.
4.4 Summary of Experiment Findings
Despite the entangled effects of duration and vowel quality for English speakers, we have seen that the phonetics of word-final unstressed syllables can contribute to the perception of a rhythmic alternation throughout the word, provided that stress is cued with duration. If stress is not cued with duration, the phonetic characteristics of a final syllable do not cause the perception of the rhythmic pattern being continued. The results from the perception experiments fall in line with the correlations found in the database between a language’s use of duration in the realization of stress and its tolerance of final stress lapse.
5 Theoretical Implications
We have seen evidence that the phonetic characteristics of word-final syllables can contribute to the perceptual rhythm of a word. Given this connection, we might wonder whether final lengthening has sometimes been perceived as stress by linguists in the field. In fact, the suggestion that this might be the case has been made by Hayes (Reference Crowhurst and Hewitt.1995: 100). Among languages that stress the initial syllable and every other thereafter, he found seven languages that do not exclude the final syllable compared with 12 that do exclude it. Those that do not would require, in his foot-based pre-OT account, a degenerate foot in odd-syllabled words, which his theory avoids. Hayes specifically proposes the possibility that phrase-final lengthening could be responsible for linguists mishearing final stress in the seven relevant languages that are documented as having final stress in odd-syllabled words. This suggestion is not consistent with the results found here, however. One of the languages in Hayes (1995) described as having the (σ́σ)(σ̀σ)(σ̀) pattern is Czech. Dubĕda and Votrubec Reference Dubĕda and Votrubec(2005) found that stress is cued with pitch in Czech, and specifically not with duration. As the final experiment in the previous section demonstrated, final lengthening is unlikely to be heard as continuing the rhythmic pattern in non-duration-based-stress languages. Given the evidence explored here, we might instead ask if final lengthening contributes to the rhythm of a word, why languages that do use duration to cue stress have been heard and documented as having a final stress lapse. The assumption is that a stress lapse is distinguishable from what we might call a rhythmic lapse. The fact that syllable strings with unstressed final syllables with final lengthening were identified as alternating significantly less than strings where every other syllable was stressed suggests that there is a distinction. As final lengthening will be present when the penult bears a stress as well as when it does not, linguists presumably factor out the final lengthening inherent in the final position when determining stress. While we clearly need more acoustic comparisons of phonetic final lengthening in stressed and unstressed syllables across languages, it seems reasonable to assume that the word-final-edge phonetics are never going to exactly match those of phonological stress. Presumably the two remain distinct, even in languages like English where we have seen confusability. There has been a call for more careful investigation of stress systems (e.g. de Lacy Reference Lacy and van der Hulst2014, Gordon Reference Gordon and van den Hulst2014) and certainly clarifying the status of final syllables should be among those points given attention.
A language’s phonetic realization of primary and secondary stress can differ, and so a relevant question is whether duration must crucially be a cue to stress for both stress levels, or whether it must only be a cue to either primary or secondary stress. This question cannot be answered at the present time, as the perception studies only used one level of stress, and reported cues to primary and secondary stress levels are combined in the database (as not enough studies report them separately to allow for further subdivision). While we might expect that it is secondary stress which is crucial for setting up the rhythm of the word, other possibilities exist. Since words tend to be short, we might expect the majority of words to have only a single stressed syllable, and in those cases the cues to primary stress would be the only relevant ones. Further, it is unknown whether final lengthening would have the effect it did in Experiment 1a if the initial syllable were stressed with a phonetic realization that included duration but the subsequent stresses were not cued with duration. Since duration would be a cue to prominence in such languages, it is possible that final lengthening could still have a perceptual effect of prominence, even when the closest stress does not use duration. Thus, whether it is the phonetic cues to primary, secondary, or both stress levels that are relevant here is an open question.
Returning to the typology as it is currently understood, we now have a rationale for the relatively large number of languages that tolerate final stress lapse. We have seen that such languages are likely to use duration in their realization of stress, and that the phonetic characteristics of final lengthening in English can lead to the perception of continued rhythm. We would like to see the results of perception studies on speakers of other languages, including those, like English, which tolerate a final stress lapse, have a stress-based duration difference, and have word-edge phonetic characteristics which create the perception of a continued rhythmic pattern. We would expect to find the same perceptual effect with the final test strings as was found for English speakers.
If final stress lapse is tolerated in many languages because it does not interrupt the rhythm of the word, this allows us to reframe the typology. One option to implement the theory that two adjacent unstressed syllables can still be perceived as continuing the rhythm of the word in language in which duration is cued by stress (and which has final lengthening) would be to redefine the requirement against stress lapse (instantiated in OT through the constraint *Lapse) as a phonetic-based *Prominence-Lapse that would not penalize two adjacent unstressed syllables as long as they exhibited a rhythmic alternation (either through stress or through phonetic prominence). Such a constraint would be violated by two adjacent unstressed syllables at the end of the word in some languages and not in others, depending on whether final syllables under a stress lapse were perceived as alternating in prominence. In a language like English, we have reason to think that a final stress lapse does not interrupt the rhythm of the word, and, therefore, that a word like a.spá.ra.gus would not run afoul of a phonetic-based no-lapse requirement. On the other hand, a word-final stress lapse in a language like Czech would violate such a requirement, since stress is realized through pitch, and not duration.
The current proposal changes the approach from the viewpoint of extrametricality/non-finality, which sets aside the final syllable, to one where, in many cases, the final syllable does not need to be stressed to maintain the rhythm and therefore there is no reason to do so. This is compatible with the OT approach to stress systems which treats stressed syllables or feet as marked, meaning that having more of them is penalized (through Alignment constraints that pull all stresses/feet as close to a word edge as is tolerated given higher-ranked constraints). Under the typical OT approach to stress, a stress (or foot with a head) exists in order to satisfy a higher-ranked markedness constraint like *Lapse. But given the constraint *Prominence-Lapse, there would be no motivation to stress the final syllable in a language with duration-cued stress and final lengthening. Given that the stress correlates database includes languages like the Uralic language Enets (Künnap Reference Künnap1999), which do stress the final syllable in odd-syllabled words, despite using duration as a cue to stress, it seems we need both the traditional *Lapse constraint and the proposed *Prominence-Lapse in the constraint set. (Another possibility is that such languages do not tolerate a final stress lapse because final lengthening is suppressed.) Examples of how *Prominence-Lapse can work is shown in the tables in (10) and (11), assuming systems of primary stress on the initial syllable and secondary stress every other syllable thereafter, excluding the final syllable (in (10)) or including the final syllable (in (11)). (The stress alignment constraints are shown evaluated gradiently, but result is the same if they are evaluated categorically.)
(10) Language with duration-cued stress

In a language with duration-cued stress, if *Prominence-Lapse is ranked higher than *Lapse, then a final stress lapse will be tolerated in an odd-syllabled string like (10b). Either a third stress (candidate (10a)) or non-edge stresses (candidate (10c)) will incur an unnecessary number of alignment violations (here, of stresses, but could of course be of feet). In a language without duration-cued stress, however, *Prominence-Lapse will work exactly like *Lapse, as shown in (11).
(11) Language without duration-cued stress

In (11), we see that candidate (b) incurs a fatal violation of *Prominence-Lapse, since of course any final lengthening in the final syllable will not contribute to continuing the rhythm of the word as stress is not cued through duration. Speakers presumably learn through experience whether there is an alternation in prominence over two unstressed syllables in their language or not, which is reflected in the differing evaluation of *Prominence-Lapse.
Notice, however, that non-finality cannot be removed from the constraint set. We still find it active in a language like Hixkaryana which is analyzed as footing iambs from the left with non-finality (Kager Reference Kager1999), for example a.ʧó.wo.wo ‘wind’. Such systems are difficult to analyze in foot-less systems, and in fact “every even syllable from the left excepting the final syllable” is a pattern predicted not to exist in the system of Gordon (Reference Gordon2002).Footnote 15 But if we assume that the final stress lapse nevertheless carries an alternation in rhythm (and that stress is realized through duration) then a foot-less OT analysis is possible.Footnote 16
6 Conclusion
This chapter has explored the relationship between the word-edge phonetic effects on final syllables and languages’ stress patterns, uncovering a relationship between the tolerance of word-final stress lapse and the use of duration as a stress correlate. Evidence that there is a connection has come from demonstrating that a correlation exists between languages that tolerate a final stress lapse and those that use duration as a cue to stress. A one-way implication was found to hold: while languages that use duration as a cue to stress are no more or less likely to tolerate final stress lapse, almost all languages that tolerate a final stress use duration as a cue to stress. Assuming the presence of word-level final lengthening, it is the case that two unstressed syllables at the right edge of the word will still alternate in duration, and, when duration is a cue to stress, it is consistent to think that this non-stressed-based prominence contributes to the rhythm of the word. Support for this perceptual argument comes from the experiments discussed in Section 4, where strings of syllables that set up a stress-based rhythmic alternation but end in word-final lapse, with the final syllable bearing the characteristics of a word-final syllable (longer, and having a fuller vowel quality than non-final unstressed syllables), were found to be confusable with syllable strings that had a stress-based rhythmic alternation throughout.
If the proposed connection between final lapse and the use of duration is correct, this is a case where a phonetic presence (of duration) from completely different sources (phonological stress, word-edge phonetics) can play a role in the perception of a phonological phenomenon (rhythm). It also raises the possibility that more such connections could be found, especially as our knowledge (and certainty level) of languages’ stress correlates improves.
1 Introduction
The typology of word prosody still remains a subject of debate, though it has been widely discussed since Trubetzkoy (Reference Trubetzkoy1939). Tone and stress remain the central units of classification (see Gordon Reference Gordon2016 for a recent example), which is justified at least by their frequent occurrence in some best-studied world languages. However, there is not an established consensus about the content (and, therefore, definitions) of these two terms. It is also not yet clear if a classification which includes only stress and tone is exhaustive in a sense that it covers all the main types of word prosody.
Such a binary typology is promoted, for example, in the influential works by Hyman (Reference Hyman2006, Reference Hyman2009). Hyman postulates a lexical tone when “an indication of pitch enters into the lexical realisation of at least some morphemes” (2006: 229). A lexical stress, in turn, is suggested if “there is an indication of word-level metrical structure meeting the following two central criteria”: obligatoriness and culminativity, that is, when every lexical word has at least and at most one syllable marked for the highest degree of metrical prominence (a primary stress; ibid.: 231). Hyman is clear enough about the object of this typology: it includes only the prosodic units which enter the lexical phonology and can be represented as autonomous suprasegmental entities, relatively independent from particular vowels and consonants and the syntagmatic distributions of their features (such as harmonies, distributional constraints, see ibid.: 228–229). In this chapter, I will adhere to this understanding of word prosody.
Van der Hulst (Reference Hulst, van Oostendorp, Even, Hume and Rice2011, Reference Hulst and van der Hulst2014a) points out that Hyman’s definition of tone is very liberal, as it no longer entails “tonal contrast” (i.e. distinctivity). Taking a stance against the maximization of tone at the cost of giving up pitch distinctivity, he promotes a broad notion of accent, which would include stress-accent as one of the types of accent and permits the lack of both culminativity and obligatoriness. Van der Hulst maximizes “the use of accents to the expense of not just non-contrastive ‘tones’, but even to the expense of (allegedly) contrastive tones” (2011: 1017). In his view, “only languages that have a more than binary pitch contrast are necessarily tonal” (ibid.), however, the reasons for why exactly the binary pitch contrast is decisive are not immediately obvious.
In Hyman’s typology, the definitions of tone and stress are based on different criteria. Tone is defined through its phonetic cue, with a reference to morphemes (following Welmers Reference Welmers1959: 2), while stress through its functional properties (namely, placement rules) within a word. Therefore, if a prosodic unit is realized phonetically through pitch, is linked to morphemes, but also abides by the placement rules of word stress, it becomes logically indeterminable within this classification (e.g. in Nubi, as described in Gussenhoven Reference Gussenhoven2006). Such units are often called “pitch accents,” and the notion itself produces a lot of controversy. For example, Hyman is likely to include the Nubi case under the lexical tone based on its phonetic realization, while van der Hulst prefers an accentual interpretation based on its functional properties (see Hyman Reference Hyman2006, Reference Hyman2009, van der Hulst Reference Hulst, van Oostendorp, Even, Hume and Rice2011).
Another case which is not properly tackled by such a binary distinction includes units which are clearly word-prosodic in the narrow sense of word prosody stated above, but are realized through non-pitch cues and do not necessarily comply with the stress rules. Both Hyman (Reference Hyman2006: 238–240) and van der Hulst (Reference Hulst and Hulst1999: 92–93, Reference Hulst and van der Hulst2014a: 9) mention word-prosodic units with phonetic exponents other than pitch (e.g. duration, laryngealization, pharyngealization, nasalization), but do not analyze them in depth. The main debate is unfolding around the pitch versus metrical structure issue. However, such uncanonic units have been accounted for in earlier works; for example, in Lehiste (Reference Lehiste1970), Greenberg and Kashube (Reference Greenberg and Kashube1976), and Lockwood (Reference Lockwood1983). Ivanov (Reference Ivanov and Elizarenkova1975) aims at the systematic synchronic and diachronic typology of prosodic systems with “laryngealised and pharyngealised tonemes.” His overview, in fact, also includes some classical tones which have laryngealization and pharyngealization as a secondary phonetic cue reinforcing the pitch exponent. In this chapter, I focus only on the cases which have a non-pitch cue as a primary phonetic exponent. While the “pitch-accent” is both stress and tone in Hyman’s typology, these types of prosodic units are neither classical word stress, nor classical tone.
Hyman (Chapter 2 this volume) addresses some cases of an emerging prominence in tonal languages which cannot yet be called stress as it is lacking some of its essential properties (see similar cases also in Vydrin Reference Vydrine2017). Such phenomena are neither stress nor tone, but they do not quite (yet) belong to the word prosody in the aforementioned sense. Some of these cases are still more naturally analysed as positional constraints on occurrence of certain types/features of phonemes (like harmonies etc.). Other cases represent incomplete phonologization, being at the border between lexical and sublexical prosody (phonology and phonetics).
Prosody of compounds represents another cluster of interesting cases, this time between lexical and post-lexical prosody. Hyman formulates his definitions of stress and tone as applied to the “lexical words.” He does not specifically discuss compounds, but usually refers to them as a post-lexical phenomenon equal to phrase-making and typically exhibiting stress subordination: “lexical stresses interact at the post-lexical level, for example compounding/phrasal stress” (2009: 217), “another metrical property is one whereby the prominent features are ‘subordinated’ (e.g. reduced or deleted) in phrasal contexts, typically on the head word of a compound or head-complement construction” (2009: 228; see also 2006: 234).
However, traditional lexical phonology includes compounds, where phonology interacts with morphology unlike in phrases, in the lexicon (Mohanan Reference Mohanan1986, Giegerich Reference Giegerich2015: 1–4). Compounds, especially those with idiomatized semantics and phonological and morphological signs of lexicalization, are also lexical words (at least according to certain criteria). Therefore, Hyman’s definitions of word-prosodic units should be ideally applicable to them. No comprehensive typology of the prosody of compounds has been done yet, and this field constitutes an area for future research. As it is shown below for Danish and Estonian, compounds are often claimed to have more than one primary stress. If some of these compounds could be also proven to comply with most criteria for lexical words, such cases could possibly violate stress culminativity.
Even if compounds are mentioned in this chapter as a potentially challenging case for the existing word-prosodic typology, I actually focus on another type of case. Word-prosodic phonological units of Estonian and Danish, which are the main object of analysis, belong to the same group of cases as stress(-accent) and tone in a sense that they are neither phonemic features, nor sub- or post-lexical phenomena. They are full-fledged autosegmental word-prosodic units in their own right, entering “into the lexical realisation of at least some morphemes.” The word-prosodic phonological status of these units is borne out by a number of phonetic, phonological, and morphonological features which are discussed below. However, they fit neither the definition of stress nor the one of tone, due to their non-pitch-based primary phonetic exponents and the lack of culminativity and (for Danish stød) obligatoriness on the word level.
Considering such relatively unusual phenomena enables us to look at the debate on the distinction between the notions of stress, accent, and tone from a slightly different angle. I propose to include these units under the phonological notion of “accent” which is understood in a broad way as a “locational aspect of prominence” (van der Hulst Reference Hulst, van Oostendorp, Even, Hume and Rice2011: 1004, cf. also Fox Reference Fox2000 and Section 6) and has stress-, pitch-, quantity-, laryngealization-, pharyngealization-accents and may be some other types of accents as its subcategories.
2 Danish and Estonian Prosody as Case Studies
In this chapter, I will describe the lexical phonology of Standard Estonian and Standard (Copenhagen) Danish with a focus on two examples of word-prosodic units with a non-pitch-based primary phonetic exponent. The prosody of these languages is relatively well studied from both phonetic and phonological points of view. Estonian, as many other Finnic and Saami languages, exhibits word prosody based on durational patterns. Danish, in turn, is famous for its “stød” (prosodic glottalization), an idiosyncratic feature against the background of other Scandinavian languages.
I will discuss the phonetic aspects (in both production and perception) and the phonological functioning of the two phenomena, paying special attention to their relation to pitch and stress in the respective languages. The aim is to bring together the facts that will demonstrate that Estonian quantity patterns and Danish stød are (i) prosodic, (ii) lexicalized, (iii) do not use pitch as a primary phonetic cue, and (iv) are intrinsically linked to stress in both languages. In the end, I will compare these prosodic units with functionally similar cases of pitch-based word prosody in other languages and will try to put them in the framework of the mainstream word-prosodic typology, as well as discuss ways to make the typology more coherent.
3 Danish Stød
The Danish term “stød” refers to the lexicalized syllabic glottal prosody found in the majority of Danish dialects (apart for the southernmost area, see map 1 in Ejskjær Reference Ejskjær1990: 71). I will consider the best investigated system of Copenhagen Danish, with some references to dialects and other Scandinavian languages.
3.1 Production and Perception of Stød
Experimental investigations show an extreme variability in the acoustic properties, timing, and the exact domain of realization of stød, yet the accuracy of its perception by speakers is consistent (Riber Petersen Reference Riber Petersen1973, Bundgaard Reference Bundgaard1980, Fischer-Jørgensen Reference Fischer-Jørgensen1989, Grønnum and Basbøll Reference Grønnum, Basbøll, Bel and Martin2002, 2007, 2012, Hansen Reference Hansen2015). This acoustic variability is one of the indications of the prosodic rather than segmental nature of stød. Prototypically it is a so-called creaky voice, that is, non-modal aperiodic vocal-fold vibrations with a perturbation in amplitude and an abrupt F0 dip. However, Grønnum and Basbøll (2007) corroborated earlier findings of Fischer-Jørgensen (Reference Fischer-Jørgensen1989) that stød can lack both creaking and F0 perturbation. They described the articulatory mechanism behind it as a “ballistic” gesture of constricted glottis (stiffening of vocal folds, cf. Grønnum and Basbøll 2007: 199–200), which happens as a low-pass filtered muscular response to a transient neural command at the sonorant onset of the syllable rhyme. Once the command is executed, a reaction of the vocal folds is no longer controlled, hence the wide variation in the acoustic realization attested, as well as the gradual rise and fall in muscular activity observed with EMG by Fischer-Jørgensen (Reference Fischer-Jørgensen1989). Accuracy of stød perception by the speakers shows that they are perfectly able to grasp the underlying articulatory cue of constricted glottis despite the surface acoustic variation. The faithfulness of manifestation (in whatever form) and perception at certain positions in certain morphemes reveal the lexicalized nature of stød.
Stød has been represented as a tonal feature, where an “L tone [is] squeezed back into a H stressed syllable to form the second part of a bitonal HL pitch accent” (Grønnum 2015) in a number of works, also in order to get rid of a separate prosodic category “stød” (Riad Reference Riad and Lahiri2000: 265). However, as experimental research shows, the pitch movement is not a primary “programmed” cue for stød, but a random surface outcome, which can also be absent. The momentary gesture of stød stays far from the realization of the tone, where both the timing and the mode of vibration of the vocal folds are controlled resulting in a particular melody within a domain of a certain length. Even if stød has historically evolved out of a melodic pattern, as Riad (e.g. Reference Riad and Lahiri2000) suggests, it cannot be considered a pitch-based feature from the synchronic phonetic point of view (notably, Ito and Mester (Reference Ito and Mester2015: 11) suspended their earlier HL analysis of stød in the light of this evidence).
3.2 Functioning of Stød in Simplex Words
In Copenhagen Danish, a stød can occur only in stressed heavy syllables, which contain either a long vowel or a vowel followed by a sonorant. It distinguishes numerous minimal pairs (examples from Grønnum et al. Reference Grønnum, Vazquez-Larruscaín and Basbøll2013: 70):
(1)
a. vend! [vɛnˀ] ‘turn!’ – ven [vɛn] ‘friend’ b. læser [ˈlɛːˀsɐ] ‘reads’ – læser [ˈlɛːsɐ] ‘reader’ c. hvalen [ˈvæːˀln̩] ‘the whale’ – valen [ˈvæːln̩] ‘numb’ d. huset [ˈhuːˀsð̩] ‘the house’ – huset [ˈhuːsð̩] ‘housed’ e. gælder [ˈg̊ɛlˀɐ] ‘is valid’ – gæller [ˈg̊ɛlɐ] ‘gills’
The rules of stød distribution in heavy syllables are intricate: “It is almost invariably true that heavy syllables in native-like monomorphemic words have stød in monosyllables and oxytones and non-stød in disyllables and paroxytones … This neat pattern evaporates, however, in inflection and derivation” (Grønnum, Vazquez-Larruscaín, and Basbøll Reference Grønnum, Vazquez-Larruscaín and Basbøll2013: 72). For example, one observes all four combinations of stød presence and absence in the plural formation:
(2)
a. bil [b̥iːˀl] ‘car’ – biler [ˈb̥iːˀlɐ] ‘cars’ b. han [han] ‘male’ – hanner [ˈhanʔɐ] ‘males’ c. ven [vɛn] ‘friend’ – venner [ˈvɛnɐ] ‘friends’ d. sum [sɔmʔ] ‘sum’ – summer [ˈsɔmɐ] ‘sums’
While some authors have tried to formulate the rules of a stød appearance (Hansen Reference Hansen1943), Basbøll (Reference Basbøll2005, Reference Basbøll, Barnes, Bremmer Jr, Lerchner and Nielsen2008) came up with a “non-stød” model which presents stød as an unmarked prosody for heavy syllables and accounts for the cases of its absence. The proposed set of “non-stød” rules includes lexical specification of individual words, the properties of suffixes in derivation or inflection, and structural conditioning in compounding. The first two plural models with stød (2a–b), for example, are productive, while the last two (2c–d) are not. Stød is also absent from the phonotactically non-native-like vocabulary (e.g. many English and French loans). Some such stødless stems nevertheless exhibit productive stød addition, or a latent stød (Basbøll Reference Basbøll2005, Grønnum, Vazquez-Larruscaín, and Basbøll Reference Grønnum, Vazquez-Larruscaín and Basbøll2013), in declension, which resembles the behavior of floating tones:
(3)
paté [pʰaˈtse] ‘pâté’ > patéen [pʰaˈtseːˀn̩] ‘the pâté’
In total, stød is a default prosody in heavy syllables, linked to the native-like phonotactic structures and productive derivative models. At the same time, phonologically and even morphologically it is not completely predictable, cf. ven in (1a, 2c), where a stød is allowed by both phonology and morphology yet is absent. Synchronically this is a lexical specification of this particular stem. Such cases are the most clear evidence for the lexicalized nature of the stød. I agree with a view taken by Gress-Wright that stød is lexically specified for certain stems and not for others, can be added or taken away by morphonological processes, and phonology predicts only the cases where it “cannot occur, not where it can occur” (2008: 191). The stød versus non-stød contrast carries the highest functional load in paroxytonic disyllables.
The functioning of stød in compounds is largely governed by the stress rules; therefore, the relevant facts of the Danish stress system should be discussed first.
3.3 Danish Stress
Danish stress is lexicalized. Stressed syllables differ from unstressed in that they can have stød, long vowels, and cannot have reduced vowels. One can distinguish some default stress placement principles, but they are violated by numerous lexically specified exceptions (Basbøll Reference Basbøll2005: 395ff.). Typically two degrees of stress prominence are distinguished: primary and secondary. The hierarchy of stress prominence in compounds indicates the existence of sublexical stress groups and by itself is a sign of a lexical rather than a post-lexical prosody. Primary stress placement in compounds by default is governed by the syntactic relations between the members; however, there also exist cases of irregular lexicalized stress placement (Basbøll Reference Basbøll2005: 494; p.c.):
(4)
a. landbo + højskolen > Landbohøjskolen [lanb̥oˈhʌi̯ˌsg̊oːl̩n] [ˈlanb̥oːˀ] [ˈhʌi̯ˌsg̊oːl̩n] ‘College of Agriculture and Veterinary ‘farmer’ ‘high school’ Medicine’ instead of regular *[ˈlanb̥oˌhʌi̯ˌsg̊oːl̩n] b. station + forstander > stationsforstander [sd̥aˈʃoːˀnsfʌˌsd̥anˀɐ] [sd̥aˈʃoːˀn] [ˈfɒːˌsd̥anˀɐ] ‘station head,’ instead of *[sd̥aˈʃoːˀnsˌfɒːˌsd̥anˀɐ] ‘station’ ‘head’
The position of the primary stress is therefore overall unpredictable, with a tendency to place it as close to the left word edge as possible (with an exception of a productive final stress rule in “French-like” words). Primary stress is phonetically well detectable as it has a clear pitch correlate (a L*H melody in Standard Danish with a variability across dialects, see Fischer-Jørgensen Reference Fischer-Jørgensen1984: 73, Rischel Reference Rischel, Jacobsen, Bleses, Madsen and Thomsen2003, Grønnum, Vazquez-Larruscaín, and Basbøll Reference Grønnum, Vazquez-Larruscaín and Basbøll2013: 86).
Primary stress is usually one per lexical word, either a simplex or a complex, or it covers a fully stressed word with its en- and proclitics (auxiliary words, cf. Andersen Reference Andersen, Hjelmslev and Andersen1954), which complies with the Hyman’s stress definition. On the post-lexical level, however, Danish manifests various kinds of prosodic incorporations (see overview in Basbøll Reference Basbøll2005: 517–530) with a stress loss or downgrading in the normally primarily stressed words. This is typical for verbs (5a) or words in the vocative function (5b):
(5)
a. spille bolden [ˈsb̥elə ˈb̥ʌlˀd̥n̩] – spille bold [sb̥elə ˈb̥ʌlˀd̥] ‘to play the ball’ ‘to play ball, to ball-play’ b. solskin [ˈsoːlˌsg̊enʔ] – Du er sød, Solskin! [ˌsoːlˌsg̊enʔ] ‘You are sweet, Sunshine!’ (a nickname for a girl)
At the post-lexical level, stress culminativity could therefore be thought to be violated, if we presume that there is no phonetic distinction between the “tertiary stress” and the “absence of stress” (Basbøll (Reference Basbøll2005: 340) sees it as a merely terminological question). However, the typology of the lexical stress behavior at the post-lexical level is not yet developed to make any strong claims. Let us still note a possible challenging case even for the lexical stress culminativity. These are morphological compounds which contain two primary stresses (Andersen Reference Andersen, Hjelmslev and Andersen1954, Hansen and Lund Reference Hansen and Lund.1983, Grønnum 2001, Basbøll Reference Basbøll2005). They form two subclasses: a closed list of certain lexicalized indications of time, place, or quantity (6a–b) and an open productive model called “conventionalised emphasis” by Basbøll (Reference Basbøll2005: 511–513). In the second class, the first member with an emphatic, often vulgar, meaning is used as a point of a metaphoric comparison with the second member (6c–d):
(6)
a. juleaften [ˈjuːləˈɑfd̥n̩] ‘Christmas Eve’ b. femogtyve [ˈfɛmʔʌˈtsyːʊ] ‘twenty five’ c. brandfarlig [ˈb̥ʁɑnˈfɑːli] ‘bloody dangerous’ (lit. ‘dangerous as fire,’ cf. with a neutral [ˈb̥ʁɑnˌfɑːli] ‘inflammable’) d. skidejordbrun (kjole) [ˈsg̊iːð̩ˈjoɐ̯ˌb̥ʁuːˀn] ‘earthbrown-as-shit (dress)’
The second subclass of cases could be said to involve pragmatics, which overrules the default stress placement rule. However, this cannot be applied to the first subclass. Only some of these words have a morphological model of copulative compounds with two semantic heads (6a). Also, not all of them are productively created at the post-lexical level. For example, jule- in juleaften (6a) cannot be used as a separate word, which indicates that the whole compound is a lexicon entry. These words do not behave like free noun phrases prosodically either. The functioning of stød in such words (see also Section 3.4) follows the compound model rather than the model for free noun phrases. For example, stød is lost from stang [ˈsd̥ɑŋʔ] ‘rod’ in (7a) in the same way as from [ˈlɑŋʔ] ‘long’ in a pragmatically neutral compound (7b), and unlike in a free noun phrase (7c) (Andersen Reference Andersen, Hjelmslev and Andersen1954; Basbøll Reference Basbøll2005: 511–512):
(7)
a. en stangdrukken fyr [ˈsd̥ɑŋˈd̥ʁɔg̊ŋ̩] ‘a dead drunk fellow’ b. en langtrukken forestilling [ˈlɑŋˌtsʁɔg̊ŋ̩] ‘a long-drawn performance’ c. en lang drukken fyr [ˈlɑŋʔ ˈd̥ʁɔg̊ŋ̩] ‘a long drunk fellow’
Compounds with more than one primary stress (expressed with F0 pitch rise in Danish) cannot be therefore prosodically equaled to free phrases and completely excluded from the lexical phonology (see also Basbøll Reference Basbøll2005: 467). Hyman’s term “lexical word” needs at least a clarification in order to outline the scope of applicability for his definition of lexical stress more clearly.
The placement and the phonetic properties of Danish secondary stress arouse controversy. It does not have a clear pitch correlate, so unstressed and secondarily stressed syllables cannot be distinguished on the basis of the pitch movement. The most obvious cue is the presence of the vowel length and stød (and the absence of reduced vowels):
There seems to be widespread agreement among Danish phoneticians and phonologists that the retainment of stød – and many would add “and of phonological vowel length” – is crucial in the characterization of secondary stress.
This gives a somewhat circular definition. The prosodic conditions for stød and long vowels are defined on the basis of stress placement, while the presence of a secondary stress is often detected by the very fact of the occurrence of stød and long vowels (cf. a similar problem for Estonian in Section 4.3). However, there are minimal pairs where a secondarily stressed component (8a) can be opposed to an unstressed one (8b) even without the means of stød and vowel length (Heger Reference Heger1981: 118, Basbøll Reference Basbøll2005: 327–330):
(8)
a. efter-middagen [ˈɛfd̥ɐˌmeˌd̥æːʔn̩] after||mid|day ‘the dinner you get after’ (a productively constructed compound) b. eftermiddagen [ˈɛfd̥ɐmeˌd̥æːʔn̩] after|mid||day ‘afternoon’ (a lexicalized compound)
Length has been supposed to be a secondary stress correlate in such cases. Phonetic experiments in Fischer-Jørgensen (Reference Fischer-Jørgensen1984: 109) suggested a longer duration of segments in secondarily stressed than in unstressed syllables, however, the results were not unambiguous.
The difficulty in distinguishing between secondary stress and stresslessness brings with it the problem of defining the domain of the secondary stress. The domain is clearly a sublexical prosodic unit, as there can be numerous secondarily stressed groups in one prosodic word under a primary stress. Scholars taking an OT approach (Ito and Mester Reference Ito and Mester2015, Iosad Reference Iosad2016a) suggest the existence of the foot (mono- or disyllabic) in Danish; however, they do not give their explicit definition of the foot. The implied foot seems a complicated formal construction allowing the authors to formulate the stød occurrence rules as always productive. Iosad’s analysis suggests a recursive foot, that is, the possibility of including one type of foot (a minimal foot) into another (a non-minimal one). Ito and Mester’s approach allows a lot of irregular extrametricality, including extrametrical single syllables between two monosyllabic feet as in (9b), or a sequence of two extrametrical syllables, as in (9c), as well as, apparently, even stressless feet (9a). The correlation of the stød with the primary versus secondary stress in compounds is not specifically discussed.
The author of the present chapter views the foot in a language with a metrical stress, such as Danish, as a phonetically detectable and strictly stress-based phenomenon, rather than a formal analytical tool or a simple explication of the phonotactic principles of the word structure.Footnote 1 From this point of view, it is unclear why, for example, su in (9b) should be extrametrical, while in (9a) it is not (the phonetic transcription of the Danish school pronunciation of the Latin word “island” is given after Basbøll Reference Basbøll2005: 266 and a suggested foot structure after Ito and Mester Reference Ito and Mester2015: 18).
(9)
a. insula [ˈenʔsula] [(ˈenʔ)(su.la)] nom.sg b. insulae [ˈenʔsuˌlɛːʔ] [(ˈenʔ)su(ˌlɛ:ʔ)] dat/gen.sg or nom.pl c. insularum [ensuˈlɑː(ʁ)ɔm] [en.su(ˈlɑ:.rɔm)] gen.pl
Poor phonetic detectability of a secondary stress in the absence of stød and vowel length does not allow a unique indentification of the stress-based foot in Danish. For example, it is unclear why the supposedly unstressed disyllabic sequences in (4a, 5a, 9c) cannot be analysed as secondarily stressed. An optional presence of stød and/or vowel length in an incorporated word (10a) or a compound member (10b) can indicate that these units should be considered secondarily stressed (as for example in 5b) rather than unstressed. Whether any such unit carries a secondary stress, or there exist whole unstressed words and compound members of various length, is still an open question.
A coherent foot structure would also imply a possibility of dividing any word into foot constituents without lapses of more than two syllables (viz. van der Hulst Reference Hulst and Hulst1999: 46–49) and irregular extrametricality. However, for long compounds this seems sometimes controversial. For example, the transcription given in Basbøll (Reference Basbøll2005: 522) gives only one stress for the incorporated constructed long compound in (10b). Even if the vowel length and quality of the first syllable could indicate a secondary stress, a lapse between the initial and the final syllable is still too long for a foot rhythm language.
(10)
a. afhente penge [ɑʊ̯(ˌ)hɛn(ʔ)d̥ə ˈphɛŋŋ̩] ‘collect money’ b. quasioperationalisere væk [khvæ(ˑ)siob̥əʁɑɕonaliˌseːʔɐ ˈvɛg̊] ‘quasi-operationalize away’
The relevance of the foot as a coherent sublexical rhythmic unit is therefore questionable for Danish. If the foot is not relevant, one can ask if the domain of the secondary stress should be defined on morphological grounds only; for example, as a sequence of a secondarily stressed morpheme/word plus clitics, without any reference to a morphology-independent rhythmic module (unlike in Estonian, see Section 4.3).
At the same time, productive rules of stød insertion in long loanwords give some support for the foot approach. There is a tendency for such words with a final primary stress to have a stød and with a penultimate stress not to have it. Ito and Mester (Reference Ito and Mester2015: 13–14) explain this with a different foot structure: a monosyllabic final foot gets a stød (11a), while a disyllabic one (11b) does not (cf. also 9b versus 9a, c). The tendency is, however, violated in the native-like vocabulary and not so straightforward even in the loanwords. For example, the default pronunciation of (11b) is without a final schwa, so the synchronic disyllabicity of the final foot could be put under question. Derivatives from loanwords can also violate the pattern, cf. the possible pronunciations of (11c) given in Basbøll (Reference Basbøll2005: 74–75):
(11)
a. papir [phaˈpiɐ̯ˀ] ‘paper’ b. metode [meˈtsoːð̩ ~ meˈtsoːðə] ‘method’ c. metodisk [meˈtsoːʔðisg̊ ~ meˈtsoːðisg̊] ‘methodical’
If the foot approach is applied to Danish, one should also be able to formulate the rules of assigning rhythmic secondary stresses in the cases like (10), and such stresses should be phonetically detectable. Additional phonetic and perceptual experiments are apparently needed to clarify these questions.
3.4 Stød and Stress
As the stød occurs under both primary and secondary stress, a lexical compound (12) or a simplex word following a prosodic model of compounds (9b) can contain more than one stød:
(12)
a. landsmand [ˈlanˀsˌmanˀ] ‘fellow countryman’ b. glanspapirtræ [ˈg̊lanˀsphaˌpiɐ̯ˀˌtsʁ̥ɛːˀ] ‘tree made of glittering Christmas paper’
Productive tendencies revealing active prosodic regularities between stød and stress can be best observed in loanwords and compounds. The dynamics of these processes leads toward the “simplification and generality” in stød distribution rules (Grønnum and Basbøll 2007: 203). It has already been mentioned that loanwords reveal a closer association of stød with the final rather than the penultimate stress (9, 11), and now other processes will be reviewed.
Stød (and the vowel length, cf. 4b) can be lost with a loss of stress; for example, from the middle parts of three-member compounds (Martinet Reference Martinet1937, Brink and Lund Reference Brink and Lund1975, Basbøll Reference Basbøll2005: 496–497). This is happening in the speech of younger Copenhagen Danish speakers and is also solicited by a fast speech rate and a high frequency of compounds (13a). Stød is lost only when a stress degree on the middle part is reduced from secondary to zero, cf. salg [salˀ] ‘sales’ in a X | Y || Z compound structure in (13b). However, a stress downgrade from primary to secondary, as in a X || Y | Z structure, does not result in stød loss (13c).
(13)
a. undervandsbåd ‘submarine’ under|water||boat [ˈɔnɐˌvanˀsˌb̥ɔːˀð] > [ˈɔnɐvansˌb̥ɔðˀ] b. udsalgschef ‘sales manager’ out|sales||boss [ˈuð̩ˌsalsˌʃɛːˀf] c. undersalgschef ‘vice sales manager’ under||sales|boss [ˈɔnɐˌsalˀsˌʃɛːˀf]
Another process shows a close prosodic association of stød with the right boundary of the word (noticed since Hansen Reference Hansen1943 and formulated as the RightmostAccent constraint in Ito and Mester Reference Ito and Mester2015: 15–16). The word-end signaling function of stød is increasing: not only it is never lost from a final member of compounds, but it can also be productively added (14a–b). This phenomenon was called the “new stød” (nystød) in Hansen (Reference Hansen1943), and in modern speech it penetrates even simplex words with a prosodic structure of compounds (14c–d; Grønnum and Basbøll 2007, 2012). The dialect of Zealand Danish, where stød can occur also in light syllables (open with a short vowel), shows the same tendencies for the spread of the “short-vowel stød” in the last members of compounds (Ejskjær Reference Ejskjær1990, Iosad Reference Iosad2016a).
At the same time, stød (together with the vowel length) is often lost from initial members of compounds, especially the monosyllabic ones (14e–g; Basbøll Reference Basbøll2005: 334–336, 497–499; Grønnum, Vazquez-Larruscaín and Basbøll Reference Grønnum, Vazquez-Larruscaín and Basbøll2013: 76). Initial members typically carry primary stress, which is, as said, rather associated with the left word boundary.
(14)
a. vælde [ˈvɛlə] ‘to rush’ > overvælde [ˈɒwʌˌvɛlˀə] ‘to overwhelm’ b. tælle [ˈtʰɛlə] ‘to count’ > fortælle [fʌˈtʰɛlˀə] ‘to recount, tell’ c. embede [ˈɛmˌb̥eːˀðə] ‘office (a post)’ d. uhyre [ˈuˌhyːˀɐ] ‘monster’ e. træ [ˈtsʁɛːˀ] ‘wood’ > trækasse [ˈtsʁaˌkhasə] ‘wooden box’ f. vin [ˈviːˀn] ‘wine’ > vinglas [ˈviːnˌg̊las] ‘wine-glass’ g. under [ˈɔnˀɐ] ‘under’ > undergå [ˈɔnɐˌg̊ɔːˀ] ‘undergo’
Native-like compounds therefore manifest an ongoing prosodic dissociation of stød (a word-end signal) from the primary stress (a word-beginning signal). Stød in compounds gets more closely associated with the secondary stress.
3.5 Stød and Pitch
The pitch movement in Danish has two main functions: marking the primary stress at the lexical level and the intonation at the post-lexical level (see Grønnum Reference Grønnum, Hirst and Cristo1998: 134 for a two-level intonation model of Danish). In Copenhagen Danish, the melodic pattern for primarily stressed prosodic groups is L*H, though in dialects it can also be H*L (Grønnum, Vazquez-Larruscaín and Basbøll Reference Grønnum, Vazquez-Larruscaín and Basbøll2013: 86). Stød, even when realized through pitch (see Section 3.1), is in any case a local, syllable-level melodic event, “a brief and more or less explicit lowering of F0, … independent of its location on the F0 pattern” of a primarily stressed group (ibid.: 81).
Stød distribution across Danish dialects does not correlate with that of the L*H and H*L primary stress patterns: both patterns include those with and without stød. Synchronically stød is therefore not linked to any specific melodic pattern of primary stress.
In the Zealand Danish dialect, stød obviously coexists with a paradigm of two lexical pitch-accents. Two different primary stress melodic patterns were lexicalized after the apocope of the final vowel. One pitch contour corresponds to the contour of original monosyllables, the other, with a late peak, to that of original disyllables. This dialect, independently of these newly acquired pitch-accents, also has the Standard Danish stød, as well as the “short-vowel stød.” Both types of stød combine with both melodic contours (Ejskjær Reference Ejskjær1990, Larsen Reference Larsen, Hald, Lisse and Sørensen1976, Iosad Reference Iosad2016a).
These facts reveal a synchronic phonetic and functional independence of stød from pitch phenomena in Danish.Footnote 2 At the same time, there are obvious diachronic connections. For example, stød corresponds to the pitch-accent in southern Danish dialects. Ejskjær (Reference Ejskjær1990) supposes that the former had disappeared and left behind a rising melody, which came into contrast with a default falling contour. A diachronic connection of the Danish stød to Swedish and Norwegian word pitch-accents (namely, to Accent 1) is also widely discussed (see, for example, Riad Reference Riad2014, Lahiri and Wetterlin Reference Lahiri, Wetterlin and Haug2015, Iosad Reference ChapIosad, Giles, Chapot, Cooimans, Foster and Tesio2016b). However, such diachronic links do not necessarily imply a synchronic connection. In synchrony, there is a number of important functional differences between stød and the Scandinavian accents (summed up in Grønnum, Vazquez-Larruscaín and Basbøll Reference Grønnum, Vazquez-Larruscaín and Basbøll2013: 70). For example, stød occurs only in heavy syllables, while no such restrictions apply to accents. At the same time, accents need at least two syllables as a domain of phonetic realization and become neutralized in the monosyllabic foot, while stød does not. Additionally, there can be several støds, but only one accent per a compound. In general, stød is associated with a syllable, while these accents are associated with a word. These phonetic and functional facts indicate that the prosodic laryngealization in Danish is a phonological category in itself, which cannot be completely equaled to the Scandinavian pitch-accents.
3.6 Summary of the Properties of Danish Word Prosody
The comparison of the Danish stød with “canonical” instances of tone and stress (Hyman Reference Hyman and Zendejas2014a, Reference Hyman and van der Hulst2014b) reveals that it combines the typological properties of both. Stød as a very local acoustic event stays close to the prototypical tone, which is a syllable-level phenomenon. Stød is also neither culminative nor obligatory at the word level, and it carries a distinctive function, typical for tone. Furthermore, there are diachronic connections between stød and pitch-based accents. Stød is also highly lexicalized, with a lot of irregularities violating any neat constraints that could be imposed on its phonological and morphological distribution. This general unpredictability of stød placement is not common for a prototypical stress.
Many properties of stød are stress-like though: the acoustic variability, the sensitivity to the syllable weight, some degree of culminativity and the boundary signal function. The dynamic prosodic processes in compounds and loanwords increase the demarcative and culminative functions of stød and decrease the distinctive function: there is a general tendency to have only one stød at the right boundary of a word. The “new stød” phenomenon also decreases the distinctive function of stød: “the net result is that more and more heavy syllables will have stød, and the need to formulate the principles for its absence will diminish accordingly” (Grønnum and Basbøll 2007: 205).
Given that stød is a clearly prosodic feature in Danish (unlike, for example, long vowels) and shows an increasing amount of stress-like properties, there is a question of whether it should be treated as a feature of the stress system or as an independent word-prosodic unit. The static distribution of stød indicates its hierarchic subordination to stress. Stød location always coincides with that of stress, while the reverse does not hold. The dependency on stress is observed also in the dynamic prosodic processes: “loss of stress invariably results in loss of stød, but gaining stress does not automatically result in gaining stød” (Gress-Wright Reference Gress-Wright2008: 197).
Some facts point in the opposite direction though. Ito and Mester have proposed the RightmostAccent constraint governing stød location as independent from stress constraints, because “the locus of primary accent and that of the glottal accent … need not coincide” (2015: 16). As said, in long words the primary stress tends to stay at the left word edge, while stød stays at the right one. The location of secondary stress in long words is often detected only through the presence of stød and long vowels, which raises a question of the phonetic reality of secondary stress independently of these two features. If phonetic experiments of the future reveal no robustness in the acoustics and perception of secondary stress, one could doubt its relevance for the description of Danish phonology, especially outside of the cases of a downgraded primary stress in compounds. In such a system, stress and stød will be clearly independent word-prosodic units, as there are no morphological reasons to postulate a secondary stress on the syllables with stød in the words like (9b, 14c–d).
If, in turn, the results on the durational correlates of stress obtained by Fischer-Jørgensen (Reference Fischer-Jørgensen1984) are corroborated and especially if the relevance of the foot for Danish is confirmed with more evidence, the Danish stød can be described within the stress system. In this case Danish will have an uncommon type of distinctive stress which would include “a set of ‘stress phonemes’” (Fox Reference Fox2000: 134), in the same way as one speaks about the paradigmaticity of tonal values. The prototypical stress does not have a paradigm of several types of stress values, while the prototypical tone does (e.g. H, L, M, HL, or LH value could be chosen from a paradigm as a prosodic mark for each syllable in Guro, cf. Kuznetsova Reference Kuznetsova2007). The pitch-accent can be understood as a distinctive stress (with a pitch-based paradigm of values) in cases where the pitch-based feature is entirely dependent on the stress feature, or at least co-dependent with it (cf. types (c) and (d) in Hyman Reference Hyman2006: 238). In the case of Danish, the paradigm of stress values would be based on the laryngealization feature, that is, one could speak of the stress distinguishing between the “stød-accent” and the “non-stød accent.” For heavy stressed syllables, the stød-accent is an unmarked prosody. However, in the word-prosodic system of Danish as a whole, the stød-accent is a marked feature, as it occurs only in some stressed heavy syllables and does not occur in stressed light syllables at all. In longer words with more than one stress group, the stød-accent is rather associated with the secondary stress degree than with the primary one. Estonian word prosody discussed further makes an even stronger case for a non-pitch-based paradigmatic stress system.
4 Estonian Quantities
Estonian typically serves as an example of a three-way quantity contrast. A prosodic component inside this contrast had been recognized already since Wiedemann (Reference Wiedemann1875). The Standard Estonian system will be discussed with some references to dialects.
4.1 Phonetics and Perception of Quantities
Vast phonetic and phonological research has shown that Estonian quantity patterns are realized within the foot (prototypically disyllabic, also mono- and trisyllabic, see Lippus et al. Reference Lippus, Asu, Teras and Tuisk2013, Pajusalu Reference Pajusalu2015 for the latest overviews). Proportional quantitative correlations between key segments in the foot nucleus (a sequence from the first syllable vowel throughout the second syllable vowel) are a cornerstone in the production and perception of quantities. These three key segments are the first syllable vowel or diphthong, the second syllable vowel, and the coda of the first syllable (if present). Proportional relationships between them are irrelevant to the particular segmental structure of the foot and can be formulated for each foot quantity (Q1–Q3) as follows (Eek and Meister Reference Eek and Meister2004: 271):
(15)
a. Q1: σ1 nucleus < σ2 nucleus b. Q2: σ1 nucleus ≥ σ1 coda ≤ σ2 nucleus c. Q3: σ1 nucleus < σ1 coda > σ2 nucleus
This scheme is very abstract and it allows the theoretical division of long vowels and consonants into two parts (which is not substantiated in phonetics). However, it is a useful tool to grasp the essential principle of distinction between prosodic templates under variable instantiations in concrete segmental structures (see some examples in 16). Following the (uncanonical) abbreviations of the authors, “σ1 nucleus” can be a short vowel, the first part of a long vowel or a diphthong, “σ1 coda” stands for the last element of the first syllable (i.e. the second part of a long vowel or a diphthong, the first consonant in a cluster, or the first part of a geminate), while “σ2 nucleus” equals the second syllable vowel.
Perceptual experiments confirm these findings: speakers tend to perceive a different degree of quantity when the proportions within the foot change (Liiv Reference Liiv1961, Lehiste 1997, Eek Reference Eek1986, Krull Reference Krull1998, Lippus Reference Lippus2011). The quantity degree is indeterminable for speakers on the basis of the first syllable only, with the minimal stimulus sufficient for recognition being the coda of the first syllable plus the vowel of the second syllable. This is one of the reasons to disagree with a view expressed in Prince (Reference 143Prince1980) and Prillop (Reference Prillop2013) that a syllable in Q3 always makes an independent monosyllabic foot. The only case where the absolute segmental duration played a clearly distinctive role was the recognition of the first phonemically short vowel in Q1 (Lehiste and Danforth Reference Lehiste and Danforth1977, Eek and Meister Reference Eek and Meister1997).
A prosodic nature of quantities and their link to stress was also shown by Lehiste (Reference Lehiste1985) in the study on a secret “pi-language,” where words are distorted by inserting a pi-syllable after the first vowel of each word. The pi acquires the primary stress and the quantity of the original foot: `saag [ˈz̥aːˑg̊] ‘saw’ (Q3) > [z̥aˈb̥iːˑg̊], ´seadus [ˈz̥ead̥uz̥] ‘law’ (Q2) > [z̥eˈb̥iad̥uz̥] (Q2). The study also revealed that long vowels are categorized as monophonemic, while diphthongs are biphonemic.
4.2 Functioning of Quantity in Single-Foot Words
Examples showing segmental and suprasegmental quantitative contrasts in a disyllabic foot are given in (16) (Viitso Reference Viitso and Erelt2003: 13–16; the phonetic transcription of quantity is given according to the measurements in the respective structures in Eek and Meister (Reference Eek and Meister2003, Reference Eek and Meister2004)).
(16)
Q1: a. ´lagi [ˈlag̊iː] ‘ceiling’ h. ´vina [ˈvinaː] ‘streak of smoke’ b. ´saki [ˈz̥akˑiˑ] ‘jag:gen’ i. ´linna [ˈlinˑaˑ] ‘city:gen’ Q2: c. ´saagi [ˈz̥aːg̊iˑ] ‘yield/saw:gen’ j. ´viina [ˈviːnaˑ] ‘vodka:gen’ m. ´laugu [ˈlaug̊uˑ] ‘leek:gen’ d. ´saate [ˈz̥aːtˑeˑ] ‘can:2pl’ n. ´Pauka [ˈb̥aukˑaˑ] ‘a dog’s name’ Q3: e. `sakki [ˈz̥akːˑi] ‘jag:prt’ k. `linna [ˈlinːˑa] ‘city:prt’ f. `saagi [ˈz̥aːˑg̊i] ‘saw:prt’ l. `viina [ˈviːˑna] ‘vodka:prt’ o. `laugu [ˈlauˑg̊u] ‘eyelid:prt’ g. `saaki [ˈz̥aːkːi] ‘yield:prt’ p. `lauku [ˈlaukːuˑ] ‘leek:prt’
The system of the three quantities is not structurally homogeneous. The phonological partition into two binary contrasts, a segmental and a suprasegmental one, has been suggested in numerous works, starting from Trubetzkoy (Reference Trubetzkoy1939). The version explicated below follows the most elaborated functional conceptions by Viitso (esp. Reference Viitso1978, Reference Viitso1981, Reference Viitso2008) and Eek (e.g. Reference Eek1986, Reference Eek1990), with an exception in that I consider Estonian word-prosodic units as foot accents rather than syllabic accents. First, there are segmental contrasts of long versus short vowels (only in stressed syllables) and fortis versus lenis consonants. Second, there is a suprasegmental contrast of two foot accents: light /´/ and heavy /`/. The phonological interpretation of the words from (16) is given in (17).
(17)
light accent a. /´laki/ h. /´vina/ b. /´sakːi/ i. /´linːa/ c. /´saːki/ j. /´viːna/ m. /´lauku/ d. /´saːtːe/ n. /´paukːa/ heavy accent e. /`sakːi/ k. /`linːa/ f. /`saːki/ l. /`viːna/ o. /`lauku/ g. /`saːkːi/ p. /`laukːu/
The phonological distinction between Q1 and Q2 feet manifests only at the segmental level. Q1 feet have a short first syllable (open with a short vowel), and Q2 feet a long first syllable (closed and/or containing a long vowel or a diphthong). From the phonemic point of view, these feet are therefore in a complementary distribution (cf. 17a–b, c; h–i, j). Prosodically, they manifest as a default light accent. The feet in Q3, in turn, can have an identical phonemic structure with those in Q2 and contrast with the latter only in accent (cf. 17b–e; c–f; j–l; i–k; m–o).Footnote 3 Contrasts in trisyllabic feet are the same as in the disyllabic. All monosyllabic feet carry heavy accent (18a–c). There are monosyllabic clitics which do not carry any accent. However, if they acquire a pragmatically motivated phrasal stress, they get also the Q3 (18d).
(18)
a. `saag [ˈz̥aːˑg̊] ‘saw’ c. `maa [ˈmaːˑ] ‘land, ground’ b. `saak [ˈz̥aːkː] ‘yield, harvest’ d. ma [ma ~ ˈmaːˑ] ‘I’
The foot-level contrast of accents, based on quantitative proportions, and the segmental durational contrast of vowels and consonants are at the phonological core of the Estonian quantity system. Absolute durations of Estonian segments result from a phonetic tendency toward foot isochrony, when “the duration of the sound/syllable is inversely proportional to the word length” (Eek Reference Eek1990: 259), superimposed on these phonological contrasts. An isochronic property is, for example, the absolute duration of the phonologically short second syllable vowel. It is in an inverse relationship with the duration of the first syllable, and is affected by the structure of the second syllable, the whole foot, and the whole word. In the Q1 foot, the second vowel undergoes automatic lengthening (16a, h),Footnote 4 which is a cross-linguistically rare feature for unstressed vowels (see, for example, Lehiste Reference Lehiste and Sebeok1960, Reference Lehiste1965, Eek Reference Eek1990, Pajusalu et al. Reference Pajusalu, Help, Lippus, Niit, Teras and Viitso2005).
In inflection and derivation, the light accent often alternates with heavy (19; viz. Viitso Reference Viitso and Erelt2003: 27). There are numerous minimal pairs of grammatical forms, as well as some lexical pairs, which contrast only in accent, so the functional load of accents is extremely high. Accents are productive: loanwords or abbreviations acquire inflectional accentual paradigms according to their structure; some are prosodically treated as compounds, cf. selected forms of ´ame`tüst in (19d). A non-initial heavy accent can be assigned in loanwords to the original position of stress: ke`fiir ‘kefir’ (cf. Russian кефи́р).
(19)
light accent heavy accent a. Q1 ´lagi nom – Q3 `lakki prt ‘ceiling’ b. Q2 ´sauna gen – Q3 `sauna prt ‘sauna’ c. Q2 ´saada imp – Q3 `saatta inf ‘send’ d. Q2 ´ame´tüsti gen – Q3 ´ame`tüsti prt ‘amethyst’
4.3 Estonian Stress
Estonian quantities, like stød, are directly linked to stress. Moreover, while stød can be absent from stressed syllables, the quantity manifestation in the nucleus of any foot in Estonian is obligatory. The phonology and phonetics of Estonian stress and its relation to quantities are discussed in numerous works (e.g. Hint Reference Hint1973, Viitso Reference Viitso1979, Eek Reference Eek1986, Lehiste Reference Lehiste, Fikkert and Jacobs2003, Pajusalu et al. Reference Pajusalu, Help, Lippus, Niit, Teras and Viitso2005, Lippus, Asu and Kalvik Reference Lippus, Asu, Kalvik, Campbell, Gibbon and Hirst2014).
The Estonian stress system has two important distinctions. First, stress can be primary and secondary. Second, there is a clear distinction between the default, morphologically unbound foot-rhythmic stress and the morphologically bound lexicalized stress (cf. van der Hulst Reference Hulst2010, Reference Hulst and van der Hulst2014b), first made for Estonian by Hint (Reference Hint1973). Examples are given in (20); all possible stress pattern distributions in simplex words up to five syllables can be found in Viitso (Reference Viitso and Erelt2003: 17).
Estonian prosody, unlike Danish, contains a robust rhythmic stress module. By default, any piece of Estonian speech is rhythmically divided into feet. Rhythmic stress is always foot-initial and it combines trochaic and dactylic patterns: a trochee for di- and tetrasyllables, a dactyl for trisyllables, and alternating patterns for longer words, cf. a regular variation in hexasyllables like (20a). Such rhythmic stress placement alternations indicate the morphological unboundedness of the former. Rhythmic stress placement variability is manifest also when words are combined into phrases and sentences.
Lexicalized stresses interrupt the default stress cycle and restart it. They are strictly fixed at a certain place in certain morphemes: roots, inflectional (20b, d) and derivational (20e) affixes. Lexicalized stress is therefore morphologically bound and cannot shift to another syllable, cf. a variable rhythmic (20a) versus a fixed lexicalized (20b) secondary stress placement. It is placed on the bounding affix itself (20e), or, more rarely, on the previous affix (20f, where it is bounded to the -nna suffix).
Lexicalized stress does not necessarily follow default stress placement rules, cf. (20c) with a default rhythmic stress in (20d), as well as a non-initial stress in (20f, g, i). There even exist minimal pairs which are contrasted in the position of lexicalized stress (20h–i; Viitso Reference Viitso1979: 144). In addition to its fixed nature, lexicalized stress differs from rhythmic stress by a number of important properties. First, the former can be either primary or secondary (as in 20e), while the latter is only secondary. Second, rhythmically stressed feet exhibit only the durational patterns Q1 and Q2, while lexicalized stress can have all the three quantities. Lexicalized stress, both primary (19) and secondary (20b, d, e), therefore distinguishes between the light and the heavy accents, while rhythmic stress does not. Third, monosyllabic feet can carry only a lexicalized stress (with a heavy accent), but not rhythmic. The opinions on the latter fact, though, are not unanimous (see discussion in Eek Reference Eek1975, Hint Reference Hint1978, Viitso Reference Viitso1979, Reference Viitso1982, Pajusalu et al. Reference Pajusalu, Help, Lippus, Niit, Teras and Viitso2005, Pajusalu Reference Pajusalu2009), but up to now there have not been any phonetic experiments to corroborate rhythmically stressed monosyllabic feet. Monosyllabic words and affixes are lexically marked as either carrying the lexicalized stress, which is primary for words (18c) and secondary for affixes (20e), or stressless (18d, 20a, c, h).
(20)
a. ´kavala-ma-le-gi [ˈg̊avaˑˌlamaˑˌleg̊iˑ ~ ˈg̊avaˑlaˌmaleˑg̊i] cunning=cmp-all-emph ‘even without more cunning’ b. ´rabele-´mine [ˈrab̥eˑleˌmine(ˑ)] flounder-nmlz ‘floundering’ c. ´kõhetu-ma-ta [ˈg̊ɘheˑˌtˑumatˑa] slim=cmp-abess ‘without more slim’ d. ´kõhetu-´mata ~ ´kõhetu-`mata [ˈg̊ɘheˑtˑuˌmatː(ˑ)a] get_slim-sup:abess ‘without getting slim’ e. ´ela-ja-`lik [ˈelaˑjaˌlikːˑ] live=ag=adj ‘beastly’ f. laul-´ja-nna [lau̯lˈjanˑa] sing=ag=fem ‘female singer’ g. ai`täh [ai̯ˈtˑæhː] thanks ‘thanks!’ h. ´lomb-ardi [ˈlomb̥ard̥i] limp=nmlz.gen ‘of lame’ i. lom´bardi [lomˈb̥ard̥i] pawn_shop.gen ‘of pawn shop’ (cf. Russian ломбáрд)
This contrast between primary and secondary stress has a lot in common with Danish. The main differences are that in Estonian stress the pitch cue is subordinated to the durational cue and that word stress is superimposed on foot stress.
The primary cue for foot stress is quantity, namely the presence of one of the three quantity patterns. Pitch seems to be the secondary cue for foot stress, though there are not many studies on pitch in secondarily stressed feet, that is, in the prosodic context where no word-level stress interferes. Perceptual experiments (Eek Reference Eek, Shannon and Shockey1987) suggested that listeners compare the height of F0 on adjacent vowels and estimate the syllable with a higher F0 as stressed, as well as in the case of secondary stress. Eek (Reference Eek1986: 51) supposed that in secondary stress “the stressedness is probably determined by an interruption of the general fall of the F0 of the word,” that is, F0 “commences its fall from a frequency higher than that of the end of the last, unstressed syllable” (see also F0 curves given in Figures 3–6 in Asu and Nolan Reference Asu and Nolan2007). To generalize, a break in the pitch fall generally signalizes a new foot stress. Yet, Lippus, Asu, and Kalvik(Reference Lippus, Asu, Kalvik, Campbell, Gibbon and Hirst2014) found no significant pitch differences between secondarily stressed and unstressed vowels, however, on the basis of somewhat heterogeneous data.
The pitch, in turn, is the primary cue for word-level stress, as it helps to distinguish between primary and secondary stress. Stress has a default H*L pitch cue, with primary stress having the highest H* peak in the word: not just a break in the pitch fall, but a significant jump in pitch (Eek Reference Eek1990: 258, Asu Reference Asu2004). The simulated shift of this highest peak from the first vowel to the second changes the primary stress pattern: ´kanata [ˈg̊ana(ˑ)tˑa] ‘without a hen’ was perceived as ka `natta [g̊a ˈnatːˑa] ‘also fishpot(prt)’ or, if also the third vowel was made longer, ka ´nata [g̊a ˈnatˑaˑ] ‘also fishpot(gen)’ (Eek and Meister Reference Eek and Meister2003: 910). In a phrase, the primary stress pitch peaks manifest gradual lowering toward the end of the phrase, that is, a downstepping pattern is observed as in Danish (cf. Figure 3 in Asu and Nolan Reference Asu and Nolan2007: 572 and Figure 7 in Grønnum Reference Grønnum, Hirst and Cristo1998: 145). The duration is, in turn, a secondary cue for word-level stress, as the durations of segments in primarily stressed feet were found to be longer than in secondarily stressed feet (Lehiste Reference Lehiste1965, Sepp Reference Sepp1980, Eek Reference Eek1990, Pajusalu et al. Reference Pajusalu, Help, Lippus, Niit, Teras and Viitso2005, Lippus, Asu, and Kalvik Reference Lippus, Asu, Kalvik, Campbell, Gibbon and Hirst2014).
The existence of the strong durational cue for stress weakens the functional load of the pitch cue and the robustness of its manifestation at the lexical level. Word-stress related pitch cues are often completely absent from utterances, which are not only the cases of clitics (21a) and prosodic incorporation of verbs (21b versus 21c) as in Danish (Viitso Reference Viitso1979: 136–137, Hallap Reference Hallap and Ikola1980).Footnote 5 The cases of such “low accentuation” account for 60% of all the statement utterances in Asu (Reference Asu2004). “Low accentuation can be chosen at any point in the utterance, but once it has been chosen, the intonation contour cannot revert to high accentuation” (Asu and Nolan Reference Asu and Nolan2007: 576). Even in these cases, stress-related temporary structures are typically present. For example, a monosyllabic clitical pronoun sa (21a) is unstressed at both the word level and the foot level. However, a disyllabic form of a pronoun (21d; Viitso Reference Viitso1983: 59) or a combination of two monosyllabic clitics (21f; Eek Reference Eek1990: 258) will exhibit a Q1 and Q2 foot pattern respectively and can be said to be stressed at least at the foot level.
(21)
Sa ´tuled. a. [z̥a Hˈd̥uleˑd̥] sa you ‘You will come’ Ta `ütles, et `too ´tuli `tagasi. b. [Hˈtoːˑ ˌd̥uliː Hˈd̥ag̊aˑz̥i] too tul=i that come=pst ‘He said that that one came back’ c. [Hˈtoːˑ Hˈd̥uːliː Hˈd̥ag̊aˑz̥i] too tuli bring:imp fire ‘He said that bring the fire back!’ ´Ega ´isa ´taga ei `räägi. d. [Hˈiz̥aˑ ˌd̥ag̊aˑ] ta=ga he=com ‘And father does not speak to him’ e. [Hˈiz̥aˑ Hˈd̥ag̊aˑ] taga behind ‘And father does not gossip’ Kas sa ´tuled? f. [ˌkasːa Hˈd̥uleˑd̥] kas sa q you ‘Will you come?’
As pitch is primarily associated with word stress and quantity patterns with foot stress, phonetically and functionally the latter is a more robust category and takes over the biggest part of the demarcative function. Word-level stress, in turn, is a weak category and can be more easily overridden in speech by post-lexical processes (such as the pragmatic-driven intonational mechanisms) than in Danish.
Accents, which are lexicalized foot stresses, define the overall prosodic pattern of a word (Eek Reference Eek1986: 48). The only thing which is clearly word-level and cannot be completely predicted by accents is a distribution of primary and secondary stresses in multifoot words (cf. 22a–b with the same accentual pattern). However, the existing studies on stress in compounds and even on simplex multifoot words show a lack of clarity about this distribution.
The default rule is, presumably, that there is one primary stress per morphological word and it coincides with the leftmost accent, which is typically on the first syllable of the word (though not always, cf. 20f, g). However, phonological studies on compound stress (Hint Reference Hint1973, Eek Reference Eek1975, Reference Eek1986, Viitso Reference Viitso1979: 142, Reference Viitso and Erelt2003: 19, Reference Viitso2008: 183) suggest a much higher violability scale for primary stress culminativity than in Danish, as well as abundant variation in stress degree patterns. These studies typically distinguish between regressive and progressive stress models in two-member compounds, with the latter model having two primary stresses (cf. 22a versus b; Viitso Reference Viitso1979: 142). Two-member compounds, as in Danish, are often lexicalized (e.g. ´sini- in (22c) cannot be used as a separate word), so their prosody, as argued before, cannot be considered as a completely post-lexical phenomenon. Longer complex words often combine lexicalized (lexical) and productive (post-lexical) compounding, which is not always easy to distinguish between. In any case, for all but one member (22d, e), long Estonian compounds generally do not exhibit primary stress downgrading, as in Danish, and therefore contain more than one primary stress.
The obligatoriness of the second stress downgrading in the unmarked regressive model also actually raises questions. Viitso (Reference Viitso1979: 144, Reference Viitso2008: 182) calls secondary stress in such compounds (22f, h) “somewhat stronger” than in simplex words of the same segmental structure (22g, i). It could mean that in compounds like (22f, h), where secondary stress is a downgraded primary stress, the former can be optionally pronounced as primary (with a H*L pitch), while in simplex words this is not possible. The optional lack of stress downgrading in the regressive compounding model is suggested also by a stress degree variability in simplex loanwords treated as prosodic compounds (22j; Viitso Reference Viitso and Erelt2003: 19).
There have not yet been any phonetic research on stress in Estonian compounds; therefore, all these issues are yet to be settled. Observed disagreement between phonologists in their intuitive judgements about stress placement can arise from differences in their theoretical frameworks, conceptions about observable stress cues, and even dialectal background (Viitso Reference Viitso1979: 148). Phonetic experiments on multifoot simplex words produce contradictory results; for example, on the length of the consonantal onset of presumably unstressed versus secondarily stressed syllables (Gordon Reference Gordon1997), or on duration being the strongest correlate of secondary stress (Lippus, Pajusalu, and Teras Reference Lippus, Pajusalu, Teras, Hoffmann and Mixdorff2006, Lippus, Asu, and Kalvik Reference Lippus, Asu, Kalvik, Campbell, Gibbon and Hirst2014; cf. with the previous claims on the lack of such correlation in Pajusalu et al. Reference Pajusalu, Help, Lippus, Niit, Teras and Viitso2005). Such disagreements signal the lack of robustness in word stress manifestation.
Interesting facts were revealed in experimental studies on simplex words consisting of several Q1 feet (Sepp Reference Sepp1980, Pajusalu et al. Reference Pajusalu, Help, Lippus, Niit, Teras and Viitso2005), where automatic lengthening of V2 helps to better see the foot structure of a long word. First, impressionistic secondary stress perception by the phoneticians who carried out the experiments sometimes differed from the real temporary patterns observed in such words. The durational patterns of tetra-, penta-, and hexasyllabic words were clustered in one–two main types, which roughly corresponded to the foot structures suggested for such words by phonologists. The foot-level stress rhythm (which, as said, has duration as its main cue) is therefore present without any significant lapses. Unfortunately, pitch was not studied in these experiments. However, for example, in hexasyllabic words the absolute duration of the stressed vowel was longest in the third foot, and V2 automatic lengthening, typical for Q1, was most pronounced in the second foot (which made authors suggest a compound prosodic model). The point is that the durational structure of long words shows the foot division (i.e. the foot stresses), but does not univocally point out the most prominent position in a word (i.e. the primary stress). Given that the pitch cues for primary stresses are often absent from speech under “low accentuation” and that compounds in general tend not to single out only one stress in a word, one could even doubt the need of the word stress in the phonological description of Estonian. The lexicalized foot stress (i.e. the accent) could be a sufficient category in and of itself.
There is still a question about the possibility of foot stress lapses inside a morphological word.Footnote 6 Such a lapse would mean the violability of the obligatoriness of the foot-level stress. It is discussed, for example, whether words like (22k) have a four-syllable stress group (Hint Reference Hint1973: 135). To establish this, the temporal structure of such words should be phonetically studied. These studies can also corroborate an alternative view that such words should rather to be treated as prosodic compounds with either a secondarily stressed monosyllabic foot (cf. Eek Reference Eek1975: 12), or an extrametrical unstressed syllable which belongs to the second foot (cf. Viitso Reference Viitso1979: 143, Reference Viitso2008: 183). In the lack of clear counter-evidence, the foot stress in Estonian should be for now considered strictly culminative and obligatory. For a much weaker category of the word stress, at least culminativity seems violable and, at the post-lexical level, also obligatoriness.
(22)
a. ´õhu`auk [ˈɘhuˑˌau̯kː] air.gen|hole ‘airvent’ b. ´õhu`auk [ˈɘhuˑˈau̯kː] air.gen|hole ‘airpocket’ c. ´sini`valge [ˈz̥iniˑˈvalːˑg̊e] blue|white ‘blue and white’ d. `all`maa`raud`tee [ˈalːˑˌmaːˑˈrau̯ˑd̥ˌd̥eːˑ] under|ground:gen||iron|road ‘underground’ e. `all`vee´laeva`baas [ˈalːˑˌveːˑˈlaevaˈb̥aːˑz̥j] under|water:gen||ship|||base ‘submarine base’ f. ´tule`tikk [ˈd̥uleˑˌd̥ikː ~ ?ˈd̥uleˑˈd̥ikːˑ] fire|stick ‘match’ g. ´pime=`dik [ˈb̥imeˑˌd̥ikː] dark=nmlz ‘twilight’ h. ´häda´vale [ˈhäd̥aˑˌvaleˑ ~ ?ˈhäd̥aˑˈvaleˑ] trouble|lie ‘forced lie’ i. ´sada-va-le [ˈz̥ad̥aˑˌvaleˑ] pour-ptc.act.prs-all ‘to a pouring one’ j. ´imperia`lism [ˈimpˑerjaˌliz̥jˑm ~ ˌimpːerjaˈliz̥jˑm ~ ˈimpˑerjaˈliz̥jˑm] ‘imperialism’ k. ´eksperimen`taalne ?[ˈekz̥periˌmenˈtˑaːˑlne ~ ˈekz̥peri+menˈtˑa ːˑlne] ‘experimental’
4.4 Quantities and Stress
As said, a quantity pattern is an obligatory manifestation of foot stress. Dynamic processes in the acquisition and loss of lexicalized foot stresses (i.e. accents) also highlight this close link between the two (Hint Reference Hint1973, 1980, Viitso Reference Viitso1979, Reference Viitso1982, Reference Viitso and Erelt2003, Reference Viitso2008; Lehiste Reference Lehiste, Rauch and Carr1983, Eek Reference Eek1986, Pajusalu Reference Pajusalu2009). Especially revealing are the processes with marked heavy accent (Q3).
For example, in loanwords with a long first syllable and non-initial stress with heavy accent, the latter tends to shift to the initial syllable to comply with a default accentual pattern. This brings along heavy accent loss or shift to the initial position (23a, b). The shift of accent, in turn, causes a change in the inflectional type (23c, d).
(23)
a. ke`fiir [g̊eˈfˑiːˑr] > k`eefir [ˈg̊eː(ˑ)fˑir] kefir b. termi`naal [ˌd̥ermiˈnaːˑl] > ´terminal [ˈd̥erminal] (a) terminal c. ke´fiiri – ke`fiiri > k`eefiri – k`eefirit kefir:gen – prt d. termi´naali – termi`naali > ´terminali – ´terminali terminal:gen – prt
The inflectional type also gradually changes with a loss of final secondary stress with a heavy accent in di- or trisyllabic words. They acquire a default trochaic or dactyl pattern correspondingly, cf. a fragment of a changing declination for the word “forester” in (24).
(24)
`mets`nik [ˈmetˑz̥ˌnikː] `metsnik [ˈmetˑz̥nikˑ] ´metsnik [ˈmetz̥nikˑ] nom `mets´niku [ˈmetˑz̥ˌnikˑu] `metsniku [ˈmetˑz̥nikˑu] ´metsniku [ˈmetz̥nikˑu] gen `mets`nikku [ˈmetˑz̥ˌnikːu] > `mets`nikku [ˈmetˑz̥ˌnikːu] > ´metsnikut [ˈmetz̥ni(ˌ)kˑutˑ] prt `mets`nikkude [ˈmetˑz̥ˌnikːud̥e] `mets`nikkude [ˈmetˑz̥ˌnikːud̥e] ´metsnikute [ˈmetz̥niˌkˑutˑe] gen:pl
The heavy accent can also disappear with a loss of stress from the middle members of three-part compounds: m`õis + n`ik + l`ik > m`õisnikl`ik > m`õisniklik ‘landlord:gen’ (Hint Reference Hint1973, Viitso Reference Viitso1979: 147; cf. a similar process in Danish).
4.5 Quantity, Pitch, and Other Cues
In this section, I will briefly examine the role of additional phonetic cues which support the quantity contrasts. The segmental opposition of short and long vowels is reinforced by vowel quality, which is more centralized in short vowels and more peripheral in long vowels (Eek and Meister Reference Eek and Meister1998, Eek Reference Eek2008, Lippus Reference Lippus2011, Lippus et al. Reference Lippus, Asu, Teras and Tuisk2013). The contrast of lenis and fortis consonants in stops and s is accompanied by the voicedness versus voicelessness of respective sounds. Additional cues for the distinction between the two accents include the pitch contour (noticed as early as Polivanov 1928), the tenseness of articulation (Eek Reference Eek1973, Reference Eek1986), and the intensity (Liiv Reference Liiv1985, Eek Reference Eek1986, Eek and Meister Reference Eek and Meister1997).
The relevancy of the pitch cue in production and perception of accents is discussed in a number of works. In heavily accented feet with a long first vowel or a diphthong, the pitch fall happens early, within the first syllable vowel. This is opposed to the default pattern, where the pitch fall begins at the second syllable vowel. The latter is observed either in other types of heavily accented structures, or under the light accent (Põldre Reference Põldre1937, Lehiste Reference Lehiste and Sebeok1960, Liiv Reference Liiv1961, Eek Reference Eek1986, Lippus et al. Reference Lippus, Asu, Teras and Tuisk2013). Perceptual studies showed that pitch cue is the second most important in the perception of accents after the temporal structure, with a modified pitch contour being able to influence this perception (Liiv Reference Liiv1961, Lehiste Reference Lehiste and Hallap1975, Lehiste and Danforth Reference Lehiste and Danforth1977, Niit Reference Niit1977, Reference Niit1978, Eek Reference Eek1986, Reference Eek, Shannon and Shockey1987, Eek and Meister Reference Eek and Meister1997, Lippus, Pajusalu, and Allik Reference Lippus, Pajusalu and Allik2009).
Some authors have even claimed that Estonian is phonetically developing toward a tonal accent language (Lippus and Remmel Reference Lippus and Remmel1976, Lehiste Reference Lehiste, Gårding, Bruce and Bannert1978). The comparison of pitch in the archive recordings of 1920s and contemporary Estonian speech (Lippus Reference 142Lippus and Ross2012) also seems to support this hypothesis. In the archive data, the pitch pattern was similar for all the quantities while the temporal differences were very pronounced. In the contemporary data, “the differences between the temporal structure of Q2 and Q3 are smaller, and different pitch patterns are often used to emphasise the opposition” (ibid.: 98). Such a development could also be corroborated by the typological studies on the evolution of rare phonological contrasts, such as the ternary quantitative contrast. Ternary contrast is unstable and tends either to disappear or to develop additional reinforcing phonetic cues (McRobbie-Utasi Reference McRobbie-Utasi, Toivonen and Nelson2007, Kuznetsova Reference Kuznetsova, Hilpert, Duke, Mertzlufft, Östman and Rießler2015).
However, synchronically the pitch cue can still be considered only secondary for Estonian accents (the same way as for the Danish stød). As said, it exists in only a part of the foot structures, those with a long vowel or a diphthong (e.g. 16c–f, d–g, m–o, n–p). Moreover, it can also be absent even in structurally valid conditions, such as in cases when feet get the above-mentioned “low accentuation” or their pitch is otherwise significantly modified for intonational purposes (Eek Reference Eek1986: 39). Temporary cue is, in turn, universal in both cases and therefore primary. This phonetically differs Estonian quantity-based accents from, for example, functionally similar Franconian pitch-based foot accents, where the pitch cue, though variable, has been shown as the most stable phonetic correlate of accents (Gussenhoven and Peters Reference Gussenhoven and Peters2004, Köhnlein Reference Köhnlein2016).
Like Danish, Estonian also reveals dialectal variability in the pitch contour related to stress (viz. Asu Reference Asu2005, Asu and Salveste Reference Asu and Salveste2012). This is attributed to the influence of pitch patterns from neighboring languages (Swedish and Latvian, see Niit Reference Niit1980Footnote 7.) There also exists dialectal variability in the degrees of prominence of durational patterns (Sepp Reference Sepp1980, Pajusalu et al. Reference Pajusalu, Help, Lippus, Niit, Teras and Viitso2005, Lippus, Pajusalu, and Teras Reference Lippus, Pajusalu, Teras, Hoffmann and Mixdorff2006). It includes a complete absence of the heavy accent from the Coastal dialect of Estonia (Kalvik Reference Kalvik2004) and is attributed to Finnish influence. As in Danish, the dialectal variability in durational and pitch patterns shows no correlation, which confirms a lack of co-independence between these two features.
Intensity as a cue for foot and word stresses has not yet been thoroughly studied in Estonian. It seems to be at least an additional cue for the distinction of accents. “The curve of the overall intensity of a stressed syllable with long vowel matter follows on the whole the F0 contour” (Eek Reference Eek1986: 42). This means that in the first syllable intensity is more evenly distributed through a long vowel or a diphthong of a lightly accented foot. In a heavily accented foot, intensity distribution is more unbalanced, with the first half of a long vowel or a diphthong carrying the intensity maximum. There was also a bigger difference in the intensity of stressed and unstressed syllables under the heavy accent than under the light accent. Perceptual experiments (Eek and Meister Reference Eek and Meister1997: 90) showed that amplitude manipulation played a significant role also in recognition between light and heavy accents in feet with a short first vowel (e.g. 16b–e, i–k), where the pitch cue cannot be used. The short V2 in the heavily accented foot also undergoes a qualitative reduction (Liiv Reference Liiv1985, Eek Reference Eek1986, Eek and Meister Reference Eek and Meister1997). In general, though, “in the perception of prominence Estonian listeners are more responsive to duration than amplitude cues” (Eek and Meister Reference Eek and Meister1997: 90, see also Lehiste and Fox Reference Lehiste and Fox1992).
In total, “a greater and namely localized effort should be taken into account” in the pronunciation of the heavy accent, which means “not only the subglottal pressure, but also the tenseness of the articulators” (Eek Reference Eek1986: 43). A higher tenseness of articulation under the heavy accent, as compared to the light, was shown in the example of palatalized consonants (Eek Reference Eek1973). The two accents “are differentiated by the even versus localized distribution of pronunciation energy” (Eek Reference Eek1986: 47), which is manifest through the collaborative work of several phonetic cues: duration, pitch, amplitude, and tenseness of articulation.
4.6 Summary on the Properties of Estonian Word Prosody
The typological prosodic properties of the three Estonian quantities are different at the word and foot levels. At the word level, their profile is close to that of stød, though with more stress-like features. On one hand, as with tone, they are neither obligatory nor culminative, have some link to the pitch and, most importantly, create a phonological paradigm of two accents with a distinctive function. At the same time, unlike stød, they are realized in a domain larger than the syllable (the foot) and are not always lexicalized. In long words, they can also be purely rhythmic and form different (though always predictable) types of feet within the same word. However, at the foot level almost all the properties become stress-like, including the definitional obligatoriness and culminativity. The main uncanonical feature remains the paradigm of accents.
In Section 3.6, the pros and cons of seeing the Danish stød and stress as one system have been discussed. In Estonian we see a much more complete isotopy of stress and quantities. The latter are the main manifestation of the former, and the two features cannot be really drawn apart on either phonetic or functional grounds. Given the paradigm of the two quantitative accents, it is justified to claim that Estonian has a distinctive (“paradigmatic”) stress, which is not pitch-based, but functionally similar to Lithuanian, Latvian, Swedish, Norwegian pitch-accents: “It is the ‘isotopy’ of accents and the stress that serves as a basis for the assumption that the Baltic and Scandinavian accents are qualitatively different stresses” (Eek Reference Eek1986: 48; see also Viitso Reference Viitso1979: 144, Reference Viitso2008: 180–182).
Given also the “conspiracy” of phonetic features in the distinction between the two accents, the contrast could be described in a more general way through the balanced/controlled versus unbalanced/ballistic articulatory energy distribution between the components of foot:
The articulation energy of A2 [=Q2] is balanced between two syllables. In an A3 [=Q3] foot the energy is unbalanced. It is centered at the end of stressed syllable rhyme … This treatment is similar to the contrast controlled versus ballistic presented by Harms (Reference Harms1978).
The ballistic shot of articulatory energy in the heavy accent happens in the end of the stressed syllable, and is a local phenomenon much like the Danish stød. The light accent (especially Q2), on the contrary, requires articulatory control throughout the foot of all the features: quantity, pitch contour, a segmental contact at the syllable boundary (Harms Reference Harms1978: 31).
This kind of phonetic “feature conspiracy” as in the foot-level distinction of accents, though, is not observed for word-level stress functions. As discussed in Section 4.3, duration and pitch do not consistently work together to create a robust phonetic category of a single culminative and obligatory primary stress and a coherent distinction between different levels of stress degrees within a morphological word. Secondary stress, especially a non-lexicalized one, is a particularly elusive category which still produces contradictions amongst Estonian phonologists and in the results of phonetic experiments. All phonetic cues here are especially weak, variable, and mistimed. As said, Estonian phonetics gives a much higher preference to foot stress over word stress and even indicates the lack of a need for the latter as a separate phonological category (more experiments and theoretical work on compounds are needed though).
5 Parallels in Danish and Estonian Word Prosody
The word prosody of Estonian and Danish, though atypical cross-linguistically, reveals a lot of structural and even phonetic similarities. This is, apparently, in part a result of contact influence inside the Circum-Baltic contact area (viz. Dahl and Koptjevskaja-Tamm Reference Dahl and Koptjevskaja-Tamm2001). The phonological profile of both Danish and Estonian is very innovative in comparison to their respective cognate languages, and the prosodic development of Finnic and Scandinavian (north Germanic) languages has a lot in common. The major driving force in both groups has been the prosodic reinforcement of the initial stressed syllables along with the apocope of the non-initial ones. Estonian (together with Livonian) and Danish have developed initial syllable prominence and non-initial syllable apocope up to the highest point in their respective groups.
One of the remarkable outcomes of this development is the high level of isotopy between a non-tonic prosodic feature and stress: laryngealization in Danish and quantity in Estonian. For Danish, one could still find arguments against seeing stød as a part of the stress system (cf. Section 3.6), while in Estonian this isotopy is complete. If also considering stød as a stress feature, one could speak in both cases about lexicalized distinctive stress where paradigmaticity is based on a non-pitch feature. Already Jakobson (Reference Jakobson1962a: 156–158, Reference Jakobson1962c: 243–244) included both Danish and Estonian in a large Circum-Baltic Sprachbund of languages with two distinctive varieties of word stress, “des langues à deux variétés distinctes de l’accent de mot” (Jakobson Reference Jakobson1962c: 244). A functional perspective allowed him to neglect surface phonetic differences between the “polytonal” and the “glottal” manifestations of this contrast in various languages of the Baltic area and reveal their underlying structural similarity (ibid.; on Estonian inside the “polytonic” Baltic area see also Eek Reference Eek1986: 47, Wiik Reference Wiik1997, Sutrop Reference Sutrop1999).
It is noteworthy that in both Danish and Estonian research traditions the term “ballistic” was independently used to refer to the marked member inside the stress paradigm (if we also see the Danish stress as distinctive), stød and Q3 respectively. At a deeper level, one could speak of the contrast between even versus uneven energy distribution, as Eek has proposed for Estonian. Controlled phonetic features (e.g. vocal-fold vibration, timing, F0 curve, subglottal pressure, tenseness of articulation) are opposed to the ballistic articulatory gesture (momentary vocal-fold stiffening, local peak in lengthening, intensity, or F0 curve). The “controlled” pattern results in both languages in an unmarked (non-stød or light) accent, and the “ballistic” pattern in a marked (stød or heavy) accent. The latter is linked only to heavy syllables, which have enough segmental space to allow the ballistic gesture to be realized.
There are other functional similarities in the lexicalized stress of the two languages: the general unpredictability of its placement (with a tendency toward initial stress), the high functional load of accentual contrasts in inflection and derivation, as well as the prosodic rules of stress degree reduction and loss in compounding.
The most important difference between Danish and Estonian word prosody is the existence of a rhythmic stress module and therefore an indisputable relevance of foot in the latter. While metrical foot relevance is under question and the main metrical unit is the word in Danish, foot stress is phonetically and functionally stronger than word stress in Estonian.
Estonian foot accents are functionally similar to Latvian, Lithuanian, Swedish, Norwegian, Franconian, and Serbo-Croatian pitch-accents. Functionally speaking, in languages like Swedish and Norwegian there is a foot-based stress-accent, and “overlaid on this essentially syntagmatic phenomenon is a paradigmatic pitch contrast of a rather limited sort. … A (culminative, syntagmatic) accent … is itself subject to further (distinctive, paradigmatic) differentiation through tone” (Fox Reference Fox2000: 250). However, under Hyman’s typology, all these languages would be treated as a combination of stress and tone (Reference Hyman2006: 237, Table I), while Estonian would not be. On potential cases of prosodic laryngealization or quantity Hyman (Reference Hyman2006: 240) concludes the following:
The features of glottality, length and tone can have very stress-like qualities, but crucially not obligatoriness – unless they are in fact implicated in the realisation of SA [=stress-accent].
The latter is exactly the case in Estonian, where quantity is directly involved in the manifestation of stress and is therefore obligatory and culminative. Hyman would presumably put such a language in the [+stress-accent, tone] box of his Table I, together with English, Russian, Turkish, Finnish, and apart from the Swedish-Norwegian type. Such a configuration would not grasp the crucial functional feature which unites Estonian stress with Swedish-Norwegian stress: the existence of the set of distinctive accents linked to stress. Fox (Reference Fox2000: 265), who presents the same classification as Hyman, notes that “although this scheme adequately reflects the use of tone and accent in different languages, it produces rather meaningless groupings, treating Mandarin and Cantonese as different types, but Zulu and Swedish as the same.” He also provides a more detailed variant of this scheme, but acknowledges a limited heuristic value of both. Possibilities of giving a different typological account for the cases like Danish and Estonian will be discussed in Section 6.
One could trace parallels also in the dynamic processes of Estonian and Danish word prosody. Both cases are uncanonical, so we observe developments toward more prototypical word-prosodic units. To start developing toward prototypical stress, Estonian and Danish should first of all get rid of stress distinctivity. To evolve in the direction of the canonical tone, they should begin by making the pitch a primary cue in the distinction of accents. Both trends can be observed in Estonian and Danish, especially in their dialects.
In Copenhagen Danish, stød is further spreading throughout the heavy syllables. If this trend continues to its extreme and all heavy syllables acquire stød, stød-stress will be in complementary distribution with non-stød stress. That will mean the loss of stress distinctivity: stød will become just an automatic phonetic feature of stressed heavy syllables. In dialects with short-vowel stød we see the spread of stød also into the domain of light syllables. Such a tendency, if developed, could make stød an automatic feature of any stressed syllable. Both possibilities, though, remain completely hypothetical for now.
As said, there is also a tendency to make stød a demarcative word-end feature, which also means a decrease in the distinctive function. On the other hand, in the southernmost Danish dialects, where stød has presumably turned into the pitch-accent (see Section 3.5), we also observe the development in the direction of tone.
In Standard Estonian, we observe the tendency toward a rise in prominence of the pitch cue, which is especially clear in comparison with the audio data from 1920s. On the other hand, the development toward prototypical stress is found in the Coastal dialect, where Q2 and Q3 merge and stress distinctivity is therefore lost (see Section 4.5).
6 Function-based Word-Prosodic Typology to Account Best for Danish and Estonian?
Phonological units, being a product of human brainwork, are symbolic entities like any other language items (cf. Kuznetsova Reference Kuznetsova, Vydrin and Kuznetsova2014 on the phoneme). Word-prosodic units are born at the conventional intersection between phonetic cues and prosodic functions. Realizational and functional parameters are two mutually independent sets of variables which could be kept apart to achieve clearer classifications. Corbett (Reference Corbett2010: 4) has proposed three components for synchronic morphological typology: forms, functions, and the mapping between the two. In the same way, three separate typologies could be considered for word prosody. The deductive (cf. Dressler Reference Dressler1979) typology of phonetic cues should identify all those phonetic cues which are producible, perceivable, and can be used prosodically (and all sets of their possible combinations used in a single prosodic unit as a separate module). The typology of prosodic functions should list all the possible variables within every functional dimension of prosodic units (and, separately, their combinations in a single unit).Footnote 8 The typology of word-prosodic units should then describe all the possible relations between the (sets of) phonetic cues and prosodic functions. All these are still unfulfilled tasks.
As for the existing classifications of word-prosodic units, three main directions taken in studies since 1930s can be identified. They present different types of configurations of realizational and functional parameters in the definitions of the main units: stress-accent and tone.
The first one bases both definitions upon the phonetic realization only. For example, Gordon (Reference Gordon2016: 219) proposes “to fall back on the assumption that the phonetic realization of prominence in the two types of languages differ” (tone relies on fundamental frequency and stress on other features). The drawbacks of this view have been long discussed; for example, in some languages stress can also rely on pitch as the main perceptual cue (Lehiste Reference Lehiste1970, Hyman Reference Hyman and Napoli1978: 2).
The second, mainstream, direction can be called mixed as it bases tone on realizational (pitch) and (stress-)accent on functional (placement) parameters. It is represented in Hyman’s typology, as well as, for example, in Gussenhoven (Reference Gussenhoven2004: 42), where tone is claimed to be a measurable phenomenon, and accent an analytical notion. These views reflect the origins of modern tone and stress conceptions. The pitch-based definition of phonological tone was first given in the landmark work by Pike (Reference Pike1948), while the basis for function-based stress conceptions was laid by the Prague School phonologists (Jakobson Reference Jakobson1962b, Trubetzkoy Reference Trubetzkoy1939 and their followers). To be more precise, Hyman accepted the tone definition by Welmers (Reference Welmers1959: 2), who had added the morphonological aspect to Pike’s notion of tone. Crucially, however, this notion is still based on pitch, and consequently the definitions of stress and tone are not mutually exclusive from a logical point of view. As discussed in Section 1, they create a heterogeneous classification and fuel discussions on pitch-accent, which stays at their logical intersection.
The third direction gives purely function-based definitions to both tone and stress, being in this sense more consistent than the second one. It allows complete abstraction from a variability of phonetic cues linked to similar prosodic functions (Fox Reference Fox2000: 134). On the one hand, it distinguishes between the functionally different pitch-based phenomena (Voorhoeve Reference Voorhoeve1973, McCawley Reference McCawley and Fromkin1978), and on the other hand, recognizes that tonal function can be realized though phonetic cues other than pitch (Lockwood Reference Lockwood1983: 131, Fox Reference Fox2000: 264). The latter case includes tonal systems which are mostly based on pitch contrasts, but use laryngealization and/or pharyngealization as primary or secondary exponents for certain tones within the paradigm (e.g. in Vietnamese, Burmese, Chinese, Siamese, Bamileke varieties, as listed in Ivanov Reference Ivanov and Elizarenkova1975). Such an approach still remains relatively unexplored. Van der Hulst presents a fairly robust functional theory of phonological accent separated from phonetic rhythm (Reference Hulst2010, Reference Hulst2012, Reference Hulst and van der Hulst2014b) and notes that tone is just as an analytical notion, as is accent (Reference Hulst2012: 1519). However, as said in Section 1, he does not give a strict definition of accent which would clearly divide the instances of accent and tone, nor does he further explore a functional notion of tone.
A typical functionally based distinction between accent and tone highlights the culminative/syntagmatic function of accent versus the distinctive/paradigmatic function of tone (Hyman Reference Hyman and Napoli1978: 2, Fox Reference Fox2000: 244). The cases of the distinctive (“paradigmatic”) stress, such as in Estonian, Swedish-Norwegian, or even Safwa, as described in Voorhoeve (Reference Voorhoeve1973, cf. also van Zanten and Dol Reference Zanten, Dol, van der Hulst, Goedemans and van Zanten2011: 121), though, cannot be well accounted for by this distinction. A better way to define tone and accent might be through the values of the location (or density) variable. As Voorhoeve (Reference Voorhoeve1973: 4) put it, instead of box-model typologies, we might “move in the direction of a scalar model with defined extremes: all vowels specified for prosodic distinctions, on the one hand, and no vowels specified for prosodic distinctions on the other hand” (cf. also Voorhoeve Reference Voorhoeve1968). Phonological tone would then include only the cases at the left extreme, where every vowel is underlyingly specified for a prosodic marking, regardless of which phonetic cues are used in its realization. The right extreme, in turn, would correspond to an absence of any lexical word prosody (as in French). All various instances of accent will occupy an intermediate zone where only some syllables receive a prosodic marking while others are left prosodically unspecified. Lockwood (Reference Lockwood1983), for example, treats Estonian prosody as tonal, but this does not comply with the definitional requirement for tone to specify each syllable for a prosodic marking. Therefore, as van der Hulst (Reference Hulst2012: 1519) also notes, Lockwood’s Estonian “tones” should rather be considered accents. In addition to stress, accent will also include all other kinds of not necessarily culminative or obligatory prosodic units, such as the Danish stød. Hyman (Chapter 2 this volume) also applies the term “accent” to such features, but the scope of his notion is broader than what is proposed here, as it also includes the cases of an emerging word prosody. I would rather restrict the term “accent” to full-fledged phonological word-prosodic units, applying a more general notion of “prominence” to such borderline cases of incomplete phonologization.
Of course, even with this restriction, there always exist pivotal cases. Do we have to consider word prosody in Nubi or Japanese as H marks on some syllables versus zeros on other syllables (and speak about accent reduction rules), or do we have to specify each syllable for H and L values (and claim tone assimilation rules)? To decide this, due consideration of all functional and phonetic properties of a particular prosodic unit is needed. The location variable proposed as the definitional one for accent and tone is only the best representation of the main types of convergence of various functional and phonetic criteria, but it is not sufficient by itself to distinguish between tone and accent.
After having considered all the formal and functional properties of any given prosodic unit in a language, one can use one of the three location variable values to define and name this unit: (i) if it marks every syllable in a word it is “tone,” (ii) if it does not mark every syllable it is “accent,” and (iii) if it does not phonologically mark any syllable then it does not belong to the lexical phonology at all (is a post-lexical or a phonetic phenomenon). Symbolization, achieved also by labeling, is at the core of the human cognition process. By labeling prosodic units according to the unified principles, we can create a basis for accurate cross-linguistic comparisons.
To consider these formal and functional typological parameters before (or even instead of) typologizing the word-prosodic units or language types is what Fox (Reference Fox2000: 265–266) and Hyman (Reference Hyman2009) actually propose. Hyman (Reference Hyman and Zendejas2014a, Reference Hyman and van der Hulst2014b) calls for applying the canonical method, when the “definitions are taken to their logical end point, enabling [the researcher] to build theoretical spaces of possibilities” (Corbett Reference Corbett2007: 9), to the word-prosodic typology (cf. a similar approach through the Roschian prototypes in Lockwood Reference Lockwood1983: 131). For example, we can define canonical tone through a set of prototypical values for a number of criteria (features). The most canonical value of each feature can be opposed to the least canonical value, with the prototype [+tone] in total being opposed to the least canonical extreme possible [-tone]. All possible combinations of the values between these extremes can be arranged within a kind of a Boolean lattice, or a “periodic table” (viz. Corbett Reference Corbett2015: 173), giving all possible intermediate cases. The most appropriate set of criteria for such an enterprise is yet to be determined.
According to the scalar model described above, it actually turns out that [-tone] corresponds not to the prototypical stress-accent, but rather to an absence of any word prosody. Stress comes out as just one of the intermediate cases between the two logical extremes. In fact, it does not seem easy to build a robust prototype for stress. For example, Hyman has vacillated between the demarcative (Reference Hyman and Hyman1977, Reference Hyman and van der Hulst2014b) and the distinctive (Reference Hyman2009) function which should be typical of prototypical stress. The definition for stress given in Hyman (Reference Hyman2006) was called “often too inclusive” in Hyman (Chapter 2 this volume). Later versions of the definition (Reference Hyman2006, passim) excluded the cases of non-culminative or non-obligatory units that had been considered under the notion of stress in Hyman (Reference Hyman and Hyman1977). The definition and prototype for tone have stayed far more coherent.
It should also be noted that a functional conception with mutually exclusive notions for tone and accent allows coexistence of several word-prosodic units within a particular language system, only they should be manifested through different phonetic cues to be distinguishable from each other. The word-prosodic typology of languages (i.e. possible variants of combinations of word-prosodic units in one system) is a task in itself, not feasible before the three aforementioned and much more compact typologies are completed.
7 Conclusion
Prosodic studies are progressively developing all over the world. Most attention is, however, dedicated to the research on intonation (post-lexical prosody), while the typology of lexical prosody still remains the subject of interest of a relatively narrow scholastic circle. Even within this circle there is not a consensus on what the central units of classification are, how they should be defined, or what exactly is the lexical word, which is the main domain of these units. One of the roots of the latter problem can be seen, for example, in the cases of Danish and Estonian: even if the primary stress is described relatively well both phonetically and phonologically, the secondary stress remains dramatically understudied. At the same time, for basic field descriptions of languages, which still remain one of the major tasks of modern linguistics, a clear word-prosodic classification might be of much help.
Looking into uncanonical cases of word prosody helps to see the traditional theoretical notions of tone and stress, which have more than a half-century of history, from a different angle and reassess them. The cases of Danish and Estonian are examples of well-described major European languages; however, they are not single exceptions. Prosodic quantity, laryngealization, and pharyngealization in different configurations are attested, among others, in Livonian, Soikkola Ingrian, some Saami languages, Udihe, Tuvan (viz. Kuznetsova Reference Kuznetsova2009: 21–22). Also, a growing number of languages without any lexicalized prosody (as French) are being revealed, especially in Asia, Indonesia, and Africa (viz. Himmelmann Reference Himmelmann, Ewing and Klamer2010: 48, 66–67, Goedemans and van Zanten Reference Goedemans, van Zanten, Caspers, Chen, Heeren, Pacilly, Schiller and van Zanten2014.)Footnote 9 The theory of word prosody should attune itself to this evidence rather than ignore or misinterpret it. Using function-based rather than exponent-based terminology for the main units and applying the canonical typology method seem to be perspective directions in this enterprise.
Abbreviations
- 2
2 person
- ABESS
abessive
- ACT
active
- ADJ
adjective
- AG
agentive
- ALL
allative
- CMP
comparative
- COM
comitative
- DAT
dative
- EMPH
emphatic
- FEM
feminine
- GEN
genitive
- IMP
imperative
- INF
infinitive
- NMLZ
nominalization
- NOM
nominative
- PL
plural
- PRS
present
- PRT
partitive
- PST
past
- PTC
participle
- Q
question
- SG
singular
- SUP
supine