For model-based frequentist statistics, based on a parametric statistical model 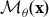 ${{\cal M}_\theta }({\bf{x}})$, the trustworthiness of the ensuing evidence depends crucially on (i) the validity of the probabilistic assumptions comprising
${{\cal M}_\theta }({\bf{x}})$, the trustworthiness of the ensuing evidence depends crucially on (i) the validity of the probabilistic assumptions comprising  ${{\cal M}_\theta }({\bf{x}})$, (ii) the optimality of the inference procedures employed, and (iii) the adequateness of the sample size (n) to learn from data by securing (i)–(ii). It is argued that the criticism of the postdata severity evaluation of testing results based on a small n by Rochefort-Maranda (2020) is meritless because it conflates [a] misuses of testing with [b] genuine foundational problems. Interrogating this criticism reveals several misconceptions about trustworthy evidence and estimation-based effect sizes, which are uncritically embraced by the replication crisis literature.
${{\cal M}_\theta }({\bf{x}})$, (ii) the optimality of the inference procedures employed, and (iii) the adequateness of the sample size (n) to learn from data by securing (i)–(ii). It is argued that the criticism of the postdata severity evaluation of testing results based on a small n by Rochefort-Maranda (2020) is meritless because it conflates [a] misuses of testing with [b] genuine foundational problems. Interrogating this criticism reveals several misconceptions about trustworthy evidence and estimation-based effect sizes, which are uncritically embraced by the replication crisis literature.


