Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
28 - A Formal Proof of Correctness
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 408-410
-
- Chapter
- Export citation
7 - The Loop Invariant for Lower Bounds
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 85-94
-
- Chapter
- Export citation
12 - Parsing with Context-Free Grammars
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 159-168
-
- Chapter
- Export citation
13 - Definition of Optimization Problems
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 171-172
-
- Chapter
- Export citation
19 - Examples of Dynamic Programs
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 295-323
-
- Chapter
- Export citation
11 - Recursive Images.
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 153-158
-
- Chapter
- Export citation
14 - Graph Search Algorithms
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 173-197
-
- Chapter
- Export citation
25 - Asymptotic Growth
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 377-387
-
- Chapter
- Export citation
27 - Recurrence Relations
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 398-407
-
- Chapter
- Export citation
21 - Randomized Algorithms
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 346-354
-
- Chapter
- Export citation
16 - Greedy Algorithms
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 225-250
-
- Chapter
- Export citation
Part One - Iterative Algorithms and Loop Invariants
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 3-4
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp i-vi
-
- Chapter
- Export citation
Part five - Exercise Solutions
-
- Book:
- How to Think About Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 19 May 2008, pp 411-436
-
- Chapter
- Export citation
Quasirandom Groups
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 3 / May 2008
- Published online by Cambridge University Press:
- 01 May 2008, pp. 363-387
-
- Article
- Export citation
Negative Correlation in Graphs and Matroids
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 3 / May 2008
- Published online by Cambridge University Press:
- 01 May 2008, pp. 423-435
-
- Article
- Export citation
Large-Deviation Approximations for General Occupancy Models
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 3 / May 2008
- Published online by Cambridge University Press:
- 01 May 2008, pp. 437-470
-
- Article
- Export citation
Linkedness and Ordered Cycles in Digraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 3 / May 2008
- Published online by Cambridge University Press:
- 01 May 2008, pp. 411-422
-
- Article
- Export citation
An Approximation by Lacunary Sequence of Vectors
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 3 / May 2008
- Published online by Cambridge University Press:
- 01 May 2008, pp. 339-345
-
- Article
- Export citation
-
Let
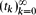 be a sequence of real numbers satisfying
be a sequence of real numbers satisfying 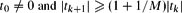 for each k ≥ 0, where M ≥ 1 is a fixed number. We prove that, for any sequence of real numbers
for each k ≥ 0, where M ≥ 1 is a fixed number. We prove that, for any sequence of real numbers 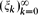 , there is a real number ξ such that
, there is a real number ξ such that 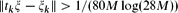 for each k ≥ 0. Here,
for each k ≥ 0. Here, 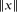 denotes the distance from
denotes the distance from 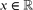 to the nearest integer. This is a corollary derived from our main theorem, which is a more general matrix version of this statement with explicit constants.
to the nearest integer. This is a corollary derived from our main theorem, which is a more general matrix version of this statement with explicit constants.
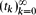 be a sequence of real numbers satisfying
be a sequence of real numbers satisfying 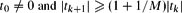 for each
for each 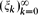 , there is a real number ξ such that
, there is a real number ξ such that 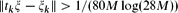 for each
for each 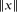 denotes the distance from
denotes the distance from 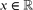 to the nearest integer. This is a corollary derived from our main theorem, which is a more general matrix version of this statement with explicit constants.
to the nearest integer. This is a corollary derived from our main theorem, which is a more general matrix version of this statement with explicit constants.An Elementary Construction of Constant-Degree Expanders
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 3 / May 2008
- Published online by Cambridge University Press:
- 01 May 2008, pp. 319-327
-
- Article
- Export citation
