Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
6 - Randomness and Counting
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008, pp 184-240
-
- Chapter
- Export citation
Appendix C - On the Foundations of Modern Cryptography
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008, pp 482-522
-
- Chapter
- Export citation
3 - Variations on P and NP
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008, pp 108-126
-
- Chapter
- Export citation
9 - Probabilistic Proof Systems
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008, pp 349-415
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008, pp xxiii-xxiv
-
- Chapter
- Export citation
Preface
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008, pp xv-xvi
-
- Chapter
- Export citation
Appendix B - On the Quest for Lower Bounds
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008, pp 469-481
-
- Chapter
- Export citation
Contents
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008, pp vii-xii
-
- Chapter
- Export citation
2 - P, NP, and NP-Completeness
-
- Book:
- Computational Complexity
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008, pp 44-107
-
- Chapter
- Export citation
Least Periods of Factors of Infinite Words
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 43 / Issue 1 / January 2009
- Published online by Cambridge University Press:
- 12 March 2008, pp. 165-178
- Print publication:
- January 2009
-
- Article
- Export citation
Palindromic complexity of infinite words associatedwith non-simple Parry numbers
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 43 / Issue 1 / January 2009
- Published online by Cambridge University Press:
- 12 March 2008, pp. 145-163
- Print publication:
- January 2009
-
- Article
- Export citation
A Note on Freĭman's Theorem in Vector Spaces
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 297-305
-
- Article
- Export citation
-
A famous result of Freĭman describes the sets A, of integers, for which |A+A| ≤ K|A|. In this short note we address the analogous question for subsets of vector spaces over
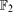 . Specifically we show that if A is a subset of a vector space over with |A+A| ≤ K|A| then A is contained in a coset of size at most 2O(K3/2 log K)|A|, which improves upon the previous best, due to Green and Ruzsa, of 2O(K2)|A|. A simple example shows that the size may need to be at least 2Ω(K)|A|.
. Specifically we show that if A is a subset of a vector space over with |A+A| ≤ K|A| then A is contained in a coset of size at most 2O(K3/2 log K)|A|, which improves upon the previous best, due to Green and Ruzsa, of 2O(K2)|A|. A simple example shows that the size may need to be at least 2Ω(K)|A|.
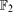 . Specifically we show that if
. Specifically we show that if An Analysis of the Height of Tries with Random Weights on the Edges
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 161-202
-
- Article
- Export citation
On the Number of Tetrahedra with Minimum, Unit, and Distinct Volumes in Three-Space
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 203-224
-
- Article
- Export citation
-
We formulate and give partial answers to several combinatorial problems on volumes of simplices determined by n points in 3-space, and in general in d dimensions.
(i) The number of tetrahedra of minimum (non-zero) volume spanned by n points in
 3 is at most
3 is at most 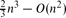 , and there are point sets for which this number is
, and there are point sets for which this number is 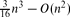 . We also present an O(n3) time algorithm for reporting all tetrahedra of minimum non-zero volume, and thereby extend an algorithm of Edelsbrunner, O'Rourke and Seidel. In general, for every
. We also present an O(n3) time algorithm for reporting all tetrahedra of minimum non-zero volume, and thereby extend an algorithm of Edelsbrunner, O'Rourke and Seidel. In general, for every 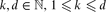 , the maximum number of k-dimensional simplices of minimum (non-zero) volume spanned by n points in d is Θ(nk).
, the maximum number of k-dimensional simplices of minimum (non-zero) volume spanned by n points in d is Θ(nk).(ii) The number of unit volume tetrahedra determined by n points in
3 is O(n7/2), and there are point sets for which this number is Ω(n3 log logn).(iii) For every
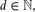 , the minimum number of distinct volumes of all full-dimensional simplices determined by n points in d, not all on a hyperplane, is Θ(n).
, the minimum number of distinct volumes of all full-dimensional simplices determined by n points in d, not all on a hyperplane, is Θ(n).

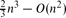 , and there are point sets for which this number is
, and there are point sets for which this number is 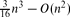 . We also present an
. We also present an 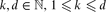 , the maximum number of
, the maximum number of 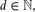 , the minimum number of distinct volumes of all full-dimensional simplices determined by
, the minimum number of distinct volumes of all full-dimensional simplices determined by The Random-Cluster Model, by Geoffrey Grimmett, Springer, 2006, 377pp., £69.00/$125.00/89.95 Euros.
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 317-318
-
- Article
- Export citation
Boundary Classes of Planar Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 287-295
-
- Article
- Export citation
On the Strong Chromatic Number of Random Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 271-286
-
- Article
- Export citation
-
Let G be a graph with n vertices, and let k be an integer dividing n. G is said to be strongly k-colourable if, for every partition of V(G) into disjoint sets V1 ∪ ··· ∪ Vr, all of size exactly k, there exists a proper vertex k-colouring of G with each colour appearing exactly once in each Vi. In the case when k does not divide n, G is defined to be strongly k-colourable if the graph obtained by adding
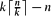 isolated vertices is strongly k-colourable. The strong chromatic number of G is the minimum k for which G is strongly k-colourable. In this paper, we study the behaviour of this parameter for the random graph Gn,p. In the dense case when p ≫ n−1/3, we prove that the strong chromatic number is a.s. concentrated on one value Δ + 1, where Δ is the maximum degree of the graph. We also obtain several weaker results for sparse random graphs.
isolated vertices is strongly k-colourable. The strong chromatic number of G is the minimum k for which G is strongly k-colourable. In this paper, we study the behaviour of this parameter for the random graph Gn,p. In the dense case when p ≫ n−1/3, we prove that the strong chromatic number is a.s. concentrated on one value Δ + 1, where Δ is the maximum degree of the graph. We also obtain several weaker results for sparse random graphs.
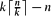 isolated vertices is strongly
isolated vertices is strongly Three Counter-Examples on Semi-Graphoids
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 239-257
-
- Article
- Export citation
A Short Proof of the Hajnal–Szemerédi Theorem on Equitable Colouring
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 265-270
-
- Article
- Export citation
Tail Estimates for Sums of Variables Sampled by a Random Walk
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 307-316
-
- Article
- Export citation
