Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
State complexity of cyclic shift
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 42 / Issue 2 / April 2008
- Published online by Cambridge University Press:
- 13 December 2007, pp. 335-360
- Print publication:
- April 2008
-
- Article
- Export citation
-
The cyclic shift of a language L, defined as SHIFT(L) = {vu | uv ∈ L},is an operation known to preserve both regularity and context-freeness.Its descriptional complexity has been addressed in Maslov'spioneering paper on the state complexity of regular language operations[Soviet Math. Dokl.11 (1970) 1373–1375],where a high lower bound for partial DFAs using a growing alphabet was given.We improve this result by using a fixed 4-letter alphabet, obtaining a lower bound (n-1)! . 2(n-1)(n-2),which shows that the state complexity of cyclic shift is2n2+ nlogn - O(n) for alphabets with at least 4 letters.For 2- and 3-letter alphabets, we prove $2^{\Theta(n^2)}$
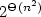 state complexity.We also establish a tight 2n2+1 lower bound forthe nondeterministic state complexity of this operation using a binary alphabet.
state complexity.We also establish a tight 2n2+1 lower bound forthe nondeterministic state complexity of this operation using a binary alphabet.
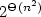
A morphic approach to combinatorial games: the Tribonacci case
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 42 / Issue 2 / April 2008
- Published online by Cambridge University Press:
- 13 December 2007, pp. 375-393
- Print publication:
- April 2008
-
- Article
- Export citation
On the Laplacian Eigenvalues of Gn,p
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 6 / November 2007
- Published online by Cambridge University Press:
- 01 November 2007, pp. 923-946
-
- Article
- Export citation
-
We investigate the Laplacian eigenvalues of sparse random graphs Gnp. We show that in the case that the expected degree d = (n-1)p is bounded, the spectral gap of the normalized Laplacian
is o(1). Nonetheless, w.h.p. G = Gnp has a large subgraph core(G) such that the spectral gap of
Poisson Representation of a Ewens Fragmentation Process
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 6 / November 2007
- Published online by Cambridge University Press:
- 01 November 2007, pp. 819-827
-
- Article
- Export citation
Regular Partitions of Hypergraphs: Regularity Lemmas
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 6 / November 2007
- Published online by Cambridge University Press:
- 01 November 2007, pp. 833-885
-
- Article
- Export citation
Regular Partitions of Hypergraphs: Counting Lemmas
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 6 / November 2007
- Published online by Cambridge University Press:
- 01 November 2007, pp. 887-901
-
- Article
- Export citation
Teasing Apart Two Trees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 6 / November 2007
- Published online by Cambridge University Press:
- 01 November 2007, pp. 903-922
-
- Article
- Export citation
Graphs with Large Girth Not Embeddable in the Sphere
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 6 / November 2007
- Published online by Cambridge University Press:
- 01 November 2007, pp. 829-832
-
- Article
- Export citation
-
In 1972, Rosenfeld asked if every triangle-free graph could be embedded in the unit sphere Sd in such a way that two vertices joined by an edge have distance more than
Distance Hereditary Graphs and the Interlace Polynomial
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 6 / November 2007
- Published online by Cambridge University Press:
- 01 November 2007, pp. 947-973
-
- Article
- Export citation
Parallel approximation to high multiplicity scheduling problems VIA smooth multi-valued quadratic programming
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 42 / Issue 2 / April 2008
- Published online by Cambridge University Press:
- 25 September 2007, pp. 237-252
- Print publication:
- April 2008
-
- Article
- Export citation
Learning tree languages from text
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 4 / October 2007
- Published online by Cambridge University Press:
- 25 September 2007, pp. 351-374
- Print publication:
- October 2007
-
- Article
- Export citation
Efficiency of automata in semi-commutation verification techniques
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 42 / Issue 2 / April 2008
- Published online by Cambridge University Press:
- 25 September 2007, pp. 197-215
- Print publication:
- April 2008
-
- Article
- Export citation
Combinatoire de mots récurrentsde complexité n+2
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 4 / October 2007
- Published online by Cambridge University Press:
- 25 September 2007, pp. 425-446
- Print publication:
- October 2007
-
- Article
- Export citation
7 - Graphical Games
- from I - Computing in Games
-
-
- Book:
- Algorithmic Game Theory
- Published online:
- 31 January 2011
- Print publication:
- 24 September 2007, pp 159-180
-
- Chapter
- Export citation
I - Computing in Games
-
- Book:
- Algorithmic Game Theory
- Published online:
- 31 January 2011
- Print publication:
- 24 September 2007, pp 1-2
-
- Chapter
- Export citation
Index
-
- Book:
- Algorithmic Game Theory
- Published online:
- 31 January 2011
- Print publication:
- 24 September 2007, pp 737-754
-
- Chapter
- Export citation
18 - Routing Games
- from III - Quantifying the Inefficiency of Equilibria
-
-
- Book:
- Algorithmic Game Theory
- Published online:
- 31 January 2011
- Print publication:
- 24 September 2007, pp 461-486
-
- Chapter
- Export citation
Foreword
-
-
- Book:
- Algorithmic Game Theory
- Published online:
- 31 January 2011
- Print publication:
- 24 September 2007, pp xiii-xvi
-
- Chapter
- Export citation
5 - Combinatorial Algorithms for Market Equilibria
- from I - Computing in Games
-
-
- Book:
- Algorithmic Game Theory
- Published online:
- 31 January 2011
- Print publication:
- 24 September 2007, pp 103-134
-
- Chapter
- Export citation
11 - Combinatorial Auctions
- from II - Algorithmic Mechanism Design
-
-
- Book:
- Algorithmic Game Theory
- Published online:
- 31 January 2011
- Print publication:
- 24 September 2007, pp 267-300
-
- Chapter
- Export citation
