Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Reconstructing Odd Necklaces
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 4 / July 2007
- Published online by Cambridge University Press:
- 01 July 2007, pp. 503-514
-
- Article
- Export citation
The Generic Chaining: Upperand Lower Bounds of Stochastic Processes, by Michel Talagrand, Springer-Verlag,2005, 222 pp., £61.50/$99.00/79.95 Euros.
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 4 / July 2007
- Published online by Cambridge University Press:
- 01 July 2007, pp. 659-660
-
- Article
- Export citation
Substitutions par des motifs en dimension 1
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 3 / July 2007
- Published online by Cambridge University Press:
- 25 September 2007, pp. 267-284
- Print publication:
- July 2007
-
- Article
- Export citation
Combinatorial and arithmetical properties of infinite words associated with non-simple quadratic Parry numbers
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 3 / July 2007
- Published online by Cambridge University Press:
- 25 September 2007, pp. 307-328
- Print publication:
- July 2007
-
- Article
- Export citation
Decidability of code properties
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 3 / July 2007
- Published online by Cambridge University Press:
- 25 September 2007, pp. 243-259
- Print publication:
- July 2007
-
- Article
- Export citation
-
We explore the borderline between decidability and undecidability of the following question: “Let C be a class of codes. Given a machine ${\mathfrak{M}}$
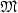 of type X, is it decidable whether the language $L({{\mathfrak{M}}})$
of type X, is it decidable whether the language $L({{\mathfrak{M}}})$ 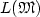 lies in C or not?” for codes in general, ω-codes, codes of finite and bounded deciphering delay, prefix, suffix and bi(pre)fix codes, and for finite automata equipped with different versions of push-down stores and counters.
lies in C or not?” for codes in general, ω-codes, codes of finite and bounded deciphering delay, prefix, suffix and bi(pre)fix codes, and for finite automata equipped with different versions of push-down stores and counters.
Sampling Regular Graphs and a Peer-to-Peer Network
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 4 / July 2007
- Published online by Cambridge University Press:
- 01 July 2007, pp. 557-593
-
- Article
- Export citation
Searching for a Black Hole in Synchronous Tree Networks¶
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 4 / July 2007
- Published online by Cambridge University Press:
- 01 July 2007, pp. 595-619
-
- Article
- Export citation
Thresholds and Expectation Thresholds
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 495-502
-
- Article
- Export citation
Orbital Chromatic and Flow Roots
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 401-407
-
- Article
- Export citation
-
The chromatic polynomial PΓ(x) of a graph Γ is a polynomial whose value at the positive integer k is the number of proper k-colourings of Γ. If G is a group of automorphisms of Γ, then there is a polynomial OPΓ,G(x), whose value at the positive integer k is the number of orbits of G on proper k-colourings of Γ.
It is known that real chromatic roots cannot be negative, but they are dense in
∞). Here we discuss the location of real orbital chromatic roots. We show, for example, that they are dense in
We also look at orbital flow roots. Here things are more complicated because the orbit count is given by a multivariate polynomial; but it has a natural univariate specialization, and we show that the roots of these polynomials are dense in the negative real axis.
First-Order Definability of Trees and Sparse Random Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 375-400
-
- Article
- Export citation
-
Let D(G) be the smallest quantifier depth of a first-order formula which is true for a graph G but false for any other non-isomorphic graph. This can be viewed as a measure for the descriptive complexity of G in first-order logic.
We show that almost surely
Colouring Random Regular Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 459-494
-
- Article
- Export citation
Limit Law of the Length of the Standard Right Factor of a Lyndon Word
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 417-434
-
- Article
- Export citation
-
Consider the set of finite words on a totally ordered alphabet with two letters. We prove that the distribution of the length of the standard right factor of a random Lyndon word with length n, divided by n, converges to
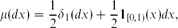 when n goes to infinity. The convergence of all moments follows. This paper thus completes the results of [2], in which the limit of the first moment is given.
when n goes to infinity. The convergence of all moments follows. This paper thus completes the results of [2], in which the limit of the first moment is given.
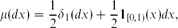
The Angel Game in the Plane
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 345-362
-
- Article
- Export citation
The Angel of Power 2 Wins
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 363-374
-
- Article
- Export citation
Extremal Graphs for a Graph Packing Theorem of Sauer and Spencer
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 409-416
-
- Article
- Export citation
-
Let G1 and G2 be graphs of order n with maximum degree Δ1 and Δ2, respectively. G1 and G2 are said to pack if there exist injective mappings of the vertex sets into [n], such that the images of the edge sets do not intersect. Sauer and Spencer showed that if
On the Expansion of the Giant Component in Percolated (n, d,λ) Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 445-457
-
- Article
- Export citation
-
Let d ≥ d0 be a sufficiently large constant. An
On a Class of Non-Regenerative Sampling Distributions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 3 / May 2007
- Published online by Cambridge University Press:
- 01 May 2007, pp. 435-444
-
- Article
- Export citation
Contents
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp v-vi
-
- Chapter
- Export citation
3 - String searching with a sliding window
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 102-145
-
- Chapter
- Export citation
Preface
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp vii-viii
-
- Chapter
- Export citation
