Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
4 - Suffix arrays
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 146-176
-
- Chapter
- Export citation
1 - Tools
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 1-54
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 364-376
-
- Chapter
- Export citation
Index
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 377-383
-
- Chapter
- Export citation
6 - Indexes
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 219-242
-
- Chapter
- Export citation
8 - Approximate patterns
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 287-331
-
- Chapter
- Export citation
2 - Pattern matching automata
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 55-101
-
- Chapter
- Export citation
9 - Local periods
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 332-363
-
- Chapter
- Export citation
7 - Alignments
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 243-286
-
- Chapter
- Export citation
5 - Structures for indexes
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp 177-218
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Algorithms on Strings
- Published online:
- 03 October 2009
- Print publication:
- 09 April 2007, pp i-iv
-
- Chapter
- Export citation
A periodicity property of iterated morphisms
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 2 / April 2007
- Published online by Cambridge University Press:
- 18 July 2007, pp. 215-223
- Print publication:
- April 2007
-
- Article
- Export citation
Object oriented institutions to specify symbolic computationsystems
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 2 / April 2007
- Published online by Cambridge University Press:
- 18 July 2007, pp. 191-214
- Print publication:
- April 2007
-
- Article
- Export citation
Deciding inclusion of set constants over infinite non-strict data structures
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 2 / April 2007
- Published online by Cambridge University Press:
- 18 July 2007, pp. 225-241
- Print publication:
- April 2007
-
- Article
- Export citation
Sequential monotonicity for restarting automata
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 2 / April 2007
- Published online by Cambridge University Press:
- 18 July 2007, pp. 157-175
- Print publication:
- April 2007
-
- Article
- Export citation
Returning and non-returning parallel communicating finite automataare equivalent
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 2 / April 2007
- Published online by Cambridge University Press:
- 18 July 2007, pp. 137-145
- Print publication:
- April 2007
-
- Article
- Export citation
Three notes on the complexity of model checking fixpoint logic with chop
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 2 / April 2007
- Published online by Cambridge University Press:
- 18 July 2007, pp. 177-190
- Print publication:
- April 2007
-
- Article
- Export citation
An algorithm for deciding if a polyomino tiles the plane
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 2 / April 2007
- Published online by Cambridge University Press:
- 18 July 2007, pp. 147-155
- Print publication:
- April 2007
-
- Article
- Export citation
Balance properties of the fixed pointof the substitutionassociated to quadratic simple Pisot numbers
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 41 / Issue 2 / April 2007
- Published online by Cambridge University Press:
- 18 July 2007, pp. 123-135
- Print publication:
- April 2007
-
- Article
- Export citation
-
In this paper we will deal with the balance properties of the infinite binary words associated to β-integers when β is a quadratic simple Pisot number. Those words are the fixed points of the morphisms of the type $\varphi(A)=A^pB$
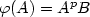 , $\varphi(B)=A^q$
, $\varphi(B)=A^q$ 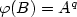 for $p\in\mathbb N$
for $p\in\mathbb N$ 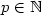 , $q\in\mathbb N$
, $q\in\mathbb N$ 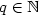 , $p\geq q$
, $p\geq q$ 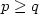 , where $\beta=\frac{p+\sqrt{p^2+4q}}{2}$
, where $\beta=\frac{p+\sqrt{p^2+4q}}{2}$ 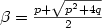 . We will prove that such word is t-balanced with $t=1+\left[(p-1)/(p+1-q)\right]$
. We will prove that such word is t-balanced with $t=1+\left[(p-1)/(p+1-q)\right]$ 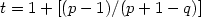 . Finally, in the case that p < q it is known [B. Adamczewski, Theoret. Comput. Sci.273 (2002) 197–224] that the fixed point of the substitution $\varphi(A)=A^pB$ , $\varphi(B)=A^q$ is not m-balanced for any m. We exhibit an infinite sequence of pairs of words with the unbalance property.
. Finally, in the case that p < q it is known [B. Adamczewski, Theoret. Comput. Sci.273 (2002) 197–224] that the fixed point of the substitution $\varphi(A)=A^pB$ , $\varphi(B)=A^q$ is not m-balanced for any m. We exhibit an infinite sequence of pairs of words with the unbalance property.
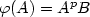
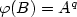
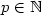
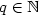
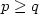
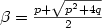
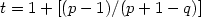
Preface
-
- Book:
- Visibility Algorithms in the Plane
- Published online:
- 14 August 2009
- Print publication:
- 29 March 2007, pp xi-xiv
-
- Chapter
- Export citation
