Refine search
Actions for selected content:
49525 results in Computer Science
Appendix - The Teyjus System
-
- Book:
- Programming with Higher-Order Logic
- Published online:
- 05 August 2012
- Print publication:
- 11 June 2012, pp 277-288
-
- Chapter
- Export citation
2 - First-Order Horn Clauses
-
- Book:
- Programming with Higher-Order Logic
- Published online:
- 05 August 2012
- Print publication:
- 11 June 2012, pp 34-74
-
- Chapter
- Export citation
Preface
-
- Book:
- Programming with Higher-Order Logic
- Published online:
- 05 August 2012
- Print publication:
- 11 June 2012, pp xi-xiv
-
- Chapter
- Export citation
11 - Encoding a Process Calculus Language
-
- Book:
- Programming with Higher-Order Logic
- Published online:
- 05 August 2012
- Print publication:
- 11 June 2012, pp 261-276
-
- Chapter
- Export citation
4 - Typed λ-Terms and Formulas
-
- Book:
- Programming with Higher-Order Logic
- Published online:
- 05 August 2012
- Print publication:
- 11 June 2012, pp 96-117
-
- Chapter
- Export citation
7 - Computations over λ-Terms
-
- Book:
- Programming with Higher-Order Logic
- Published online:
- 05 August 2012
- Print publication:
- 11 June 2012, pp 175-210
-
- Chapter
- Export citation
10 - Computations over Functional Programs
-
- Book:
- Programming with Higher-Order Logic
- Published online:
- 05 August 2012
- Print publication:
- 11 June 2012, pp 247-260
-
- Chapter
- Export citation
5 - Using Quantification at Higher-Order Types
-
- Book:
- Programming with Higher-Order Logic
- Published online:
- 05 August 2012
- Print publication:
- 11 June 2012, pp 118-149
-
- Chapter
- Export citation
NASH EQUILIBRIUMS IN TWO-PERSON RED-AND-BLACK GAMES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. 323-336
-
- Article
- Export citation
DELAYS AT SIGNALIZED INTERSECTIONS WITH EXHAUSTIVE TRAFFIC CONTROL*
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. 337-373
-
- Article
- Export citation
LIKELIHOOD RATIO AND HAZARD RATE ORDERINGS OF THE MAXIMA IN TWO MULTIPLE-OUTLIER GEOMETRIC SAMPLES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. 375-391
-
- Article
- Export citation
OPTIMAL REPLACEMENT POLICIES UNDER ENVIRONMENT-DRIVEN DEGRADATION
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. 405-424
-
- Article
- Export citation
UNIFORM CONVERGENCE TO A LAW CONTAINING GAUSSIAN AND CAUCHY DISTRIBUTIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. 437-448
-
- Article
- Export citation
SOME UNIFIED RESULTS ON COMPARING LINEAR COMBINATIONS OF INDEPENDENT GAMMA RANDOM VARIABLES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. 393-404
-
- Article
- Export citation
A LOSS SYSTEM WITH SKILL-BASED SERVERS UNDER ASSIGN TO LONGEST IDLE SERVER POLICY
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. 307-321
-
- Article
- Export citation
-
We consider a memoryless loss system with servers
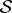 = {1, …, J}, and with customer types
= {1, …, J}, and with customer types 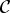 = {1, …, I}. Servers are multi-type: server j works at rate μj, and can serve a subset of customer types C(j). An arriving customer will go to the longest idling server which can serve him, or be lost. We obtain a simple explicit steady-state distribution for this system, and calculate various performance measures of this system in steady state. We provide some illustrative examples. We compare this system with a similar system discussed recently by Adan, Hurkens, and Weiss [1]. We also show that this system is insensitive, the results hold also for general service time distributions.
= {1, …, I}. Servers are multi-type: server j works at rate μj, and can serve a subset of customer types C(j). An arriving customer will go to the longest idling server which can serve him, or be lost. We obtain a simple explicit steady-state distribution for this system, and calculate various performance measures of this system in steady state. We provide some illustrative examples. We compare this system with a similar system discussed recently by Adan, Hurkens, and Weiss [1]. We also show that this system is insensitive, the results hold also for general service time distributions.
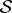 = {1, …,
= {1, …, 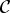 = {1, …,
= {1, …, PES volume 26 issue 3 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
INFINITE-SERVER QUEUES WITH BATCH ARRIVALS AND DEPENDENT SERVICE TIMES—CORRIGENDUM
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, p. 455
-
- Article
-
- You have access
- Export citation
PES volume 26 issue 3 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. b1-b3
-
- Article
-
- You have access
- Export citation
A GENERALIZED MEMORYLESS PROPERTY
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. 425-436
-
- Article
- Export citation
Inequalities: Theory of Majorization and Its Applications, 2nd edition by A. W. Marshall, I. Olkin and B. C. Arnold, Springer.
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 26 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 08 June 2012, pp. 449-453
-
- Article
- Export citation
