Refine search
Actions for selected content:
48202 results in Computer Science
Aspects of Gert-Martin Greuel's Mathematical Work
-
-
- Book:
- Singularities and Computer Algebra
- Published online:
- 11 November 2009
- Print publication:
- 06 April 2006, pp xvii-xxxvi
-
- Chapter
- Export citation
Algorithmic Resolution of Singularities
-
-
- Book:
- Singularities and Computer Algebra
- Published online:
- 11 November 2009
- Print publication:
- 06 April 2006, pp 157-184
-
- Chapter
- Export citation
Superisolated Surface Singularities
-
-
- Book:
- Singularities and Computer Algebra
- Published online:
- 11 November 2009
- Print publication:
- 06 April 2006, pp 13-40
-
- Chapter
- Export citation
21 Years of SINGULAR Experiments in Mathematics
-
-
- Book:
- Singularities and Computer Algebra
- Published online:
- 11 November 2009
- Print publication:
- 06 April 2006, pp 247-272
-
- Chapter
- Export citation
Newton Polyhedra of Discriminants: A Computation
-
-
- Book:
- Singularities and Computer Algebra
- Published online:
- 11 November 2009
- Print publication:
- 06 April 2006, pp 185-210
-
- Chapter
- Export citation
Topology, Geometry, and Equations of Normal Surface Singularities
-
-
- Book:
- Singularities and Computer Algebra
- Published online:
- 11 November 2009
- Print publication:
- 06 April 2006, pp 351-372
-
- Chapter
- Export citation
Adjunction Conditions for One-Forms on Surfaces in Projective Three-Space
-
-
- Book:
- Singularities and Computer Algebra
- Published online:
- 11 November 2009
- Print publication:
- 06 April 2006, pp 301-314
-
- Chapter
- Export citation
Entropy generation in a model of reversible computation
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 93-105
- Print publication:
- April 2006
-
- Article
- Export citation
Increasing integer sequences andGoldbach's conjecture
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 107-121
- Print publication:
- April 2006
-
- Article
- Export citation
Different time solutions for the firing squad synchronizationproblem on basic grid networks
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 177-206
- Print publication:
- April 2006
-
- Article
- Export citation
-
We present several solutions tothe Firing Squad Synchronization Problem on grid networks ofdifferent shapes.The nodes are finite state processors thatwork in unison with other processors and in synchronized discrete steps. Thenetworks we deal with are: the line, the ring and the square.For all of these models we consider one- and two-waycommunication modes and we also constrain the quantity of informationthat adjacent processors can exchange at each step.We first present synchronization algorithms that work in time n 2, nlogn, $n\sqrt n$
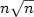 ,2n , where n is a total number of processors.Synchronization methods are described through so called signals that are then usedas building blocks to compose synchronization solutions for the cases that synchronization times are expressedby polynomials with nonnegative coefficients.
,2n , where n is a total number of processors.Synchronization methods are described through so called signals that are then usedas building blocks to compose synchronization solutions for the cases that synchronization times are expressedby polynomials with nonnegative coefficients.
A survey on transitivity in discrete time dynamical systems. application to symbolic systems and related languages
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 333-352
- Print publication:
- April 2006
-
- Article
- Export citation
Eye localization for face recognition
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 123-139
- Print publication:
- April 2006
-
- Article
- Export citation
Graph fibrations, graph isomorphism,and PageRank
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 227-253
- Print publication:
- April 2006
-
- Article
- Export citation
Unambiguous recognizable two-dimensional languages
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 277-293
- Print publication:
- April 2006
-
- Article
- Export citation
Quantum finite automata with control language
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 315-332
- Print publication:
- April 2006
-
- Article
- Export citation
Complexity classes for membrane systems
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 141-162
- Print publication:
- April 2006
-
- Article
- Export citation
String distances and intrusion detection:Bridging the gap between formal languages and computersecurity
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 303-313
- Print publication:
- April 2006
-
- Article
- Export citation
Towards a theory of practice in metaheuristics design: A machine learning perspective
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 353-369
- Print publication:
- April 2006
-
- Article
- Export citation
Probabilistic models for pattern statistics
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. 207-225
- Print publication:
- April 2006
-
- Article
- Export citation
Preface
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 2 / April 2006
- Published online by Cambridge University Press:
- 20 July 2006, pp. V-XIII
- Print publication:
- April 2006
-
- Article
- Export citation
