Refine search
Actions for selected content:
48243 results in Computer Science
4 - Systems integration and competitive advantage
-
- Book:
- The Business of Projects
- Published online:
- 22 September 2009
- Print publication:
- 27 October 2005, pp 88-116
-
- Chapter
- Export citation
Index
-
- Book:
- The Business of Projects
- Published online:
- 22 September 2009
- Print publication:
- 27 October 2005, pp 301-312
-
- Chapter
- Export citation
Recognizing when heuristics can approximate minimum vertex covers is complete for parallel access to NP
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 1 / January 2006
- Published online by Cambridge University Press:
- 15 October 2005, pp. 75-91
- Print publication:
- January 2006
-
- Article
- Export citation
Series which are both max-plus and min-plus rational are unambiguous
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 1 / January 2006
- Published online by Cambridge University Press:
- 15 October 2005, pp. 1-14
- Print publication:
- January 2006
-
- Article
- Export citation
-
Consider partial maps ∑* → $\mathbb R$
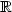 with a rationaldomain. We show that two families of such series are actually thesame: the unambiguous rational series on the one hand, and the max-plus and min-plus rational series on the other hand.The decidability of equality was known to hold in both families withdifferent proofs, so the above unifies the picture. We give an effective procedure to build an unambiguous automaton froma max-plus automaton and a min-plus one that recognize the same series.
with a rationaldomain. We show that two families of such series are actually thesame: the unambiguous rational series on the one hand, and the max-plus and min-plus rational series on the other hand.The decidability of equality was known to hold in both families withdifferent proofs, so the above unifies the picture. We give an effective procedure to build an unambiguous automaton froma max-plus automaton and a min-plus one that recognize the same series.
On a complete set of operationsfor factorizing codes
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 1 / January 2006
- Published online by Cambridge University Press:
- 15 October 2005, pp. 29-52
- Print publication:
- January 2006
-
- Article
- Export citation
On Christoffel classes
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 1 / January 2006
- Published online by Cambridge University Press:
- 15 October 2005, pp. 15-27
- Print publication:
- January 2006
-
- Article
- Export citation
Theories of orders on the set of words
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 40 / Issue 1 / January 2006
- Published online by Cambridge University Press:
- 15 October 2005, pp. 53-74
- Print publication:
- January 2006
-
- Article
- Export citation
-
It is shown that small fragments of the first-order theory of the subword order, the (partial) lexicographic path ordering on words, the homomorphism preorder, and the infix order are undecidable. This is in contrast to the decidability of the monadic second-order theory of the prefix order [M.O. Rabin, Trans. Amer. Math. Soc., 1969] and of the theory of the total lexicographic path ordering [P. Narendran and M. Rusinowitch, Lect. Notes Artificial Intelligence, 2000] and, in case of the subword and the lexicographic path order, improves upon a result by Comon & Treinen [H. Comon and R. Treinen, Lect. Notes Comp. Sci., 1994]. Our proofs rely on the undecidability of the positive ∑1-theory of $(\mathbb N,+,\cdot)$
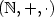 [Y. Matiyasevich, Hilbert's Tenth Problem, 1993] and on Treinen's technique [R. Treinen, J. Symbolic Comput., 1992] that allows to reduce Post's correspondence problem to logical theories.
[Y. Matiyasevich, Hilbert's Tenth Problem, 1993] and on Treinen's technique [R. Treinen, J. Symbolic Comput., 1992] that allows to reduce Post's correspondence problem to logical theories.
Part III - Out of the sandbox
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 583-584
-
- Chapter
- Export citation
24 - Embedded Java
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 651-682
-
- Chapter
- Export citation
11 - Image handling and processing
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 365-389
-
- Chapter
- Export citation
12 - More techniques and tips
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 390-410
-
- Chapter
- Export citation
Contents
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp v-xii
-
- Chapter
- Export citation
4 - More about objects in Java
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 91-131
-
- Chapter
- Export citation
20 - Distributed computing – putting it all together
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 549-572
-
- Chapter
- Export citation
22 - The Java Native Interface (JNI)
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 585-624
-
- Chapter
- Export citation
9 - Java input/output
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 287-326
-
- Chapter
- Export citation
15 - Client/server with sockets
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 448-470
-
- Chapter
- Export citation
21 - Introduction to web services and XML
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 573-582
-
- Chapter
- Export citation
Index
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 697-708
-
- Chapter
- Export citation
Appendix 3 - Java floating-point
-
- Book:
- JavaTech, an Introduction to Scientific and Technical Computing with Java
- Published online:
- 08 January 2010
- Print publication:
- 13 October 2005, pp 693-696
-
- Chapter
- Export citation
