Refine search
Actions for selected content:
48282 results in Computer Science
Argumentation-based negotiation
-
- Journal:
- The Knowledge Engineering Review / Volume 18 / Issue 4 / December 2003
- Published online by Cambridge University Press:
- 06 October 2004, pp. 343-375
-
- Article
- Export citation
Context matching for electronic marketplaces: a case study
-
- Journal:
- The Knowledge Engineering Review / Volume 18 / Issue 4 / December 2003
- Published online by Cambridge University Press:
- 06 October 2004, pp. 317-328
-
- Article
- Export citation
A NOTE ON BOUNDS AND MONOTONICITY OF SPATIAL STATIONARY COX SHOT NOISES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 18 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 01 October 2004, pp. 561-571
-
- Article
- Export citation
ROUTING OF AIRPLANES TO TWO RUNWAYS: MONOTONICITY OF OPTIMAL CONTROLS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 18 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 01 October 2004, pp. 533-560
-
- Article
- Export citation
LIKELIHOOD RATIO ORDERING OF THE INSPECTION PARADOX
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 18 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 01 October 2004, pp. 503-510
-
- Article
- Export citation
HOW TO OBTAIN BATHTUB-SHAPED FAILURE RATE MODELS FROM NORMAL MIXTURES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 18 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 01 October 2004, pp. 511-531
-
- Article
- Export citation
An abstract monadic semantics for value recursion
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 38 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 15 October 2004, pp. 375-400
- Print publication:
- October 2004
-
- Article
- Export citation
MONOTONICITY IN LAG FOR NONMONOTONE MARKOV CHAINS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 18 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 01 October 2004, pp. 485-492
-
- Article
- Export citation
Foreword
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 38 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 15 October 2004, pp. 275-276
- Print publication:
- October 2004
-
- Article
- Export citation
WHEN ARE ON–OFF SOURCES SIS?: CONDITIONS AND APPLICATIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 18 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 01 October 2004, pp. 423-443
-
- Article
- Export citation
Termination checking with types
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 38 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 15 October 2004, pp. 277-319
- Print publication:
- October 2004
-
- Article
- Export citation
-
The paradigm of type-based termination is explored for functional programming with recursive data types. The article introduces $\boldsymbol{\Lambda_\mu^+}$
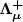 , a lambda-calculus with recursion, inductive types, subtyping and bounded quantification. Decorated type variables representing approximations of inductive types are used to track the size of function arguments and return values.The system is shown to be type safe and strongly normalizing.The main novelty is a bidirectional type checking algorithm whose soundness is established formally.
, a lambda-calculus with recursion, inductive types, subtyping and bounded quantification. Decorated type variables representing approximations of inductive types are used to track the size of function arguments and return values.The system is shown to be type safe and strongly normalizing.The main novelty is a bidirectional type checking algorithm whose soundness is established formally.
Coproducts of Ideal Monads
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 38 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 15 October 2004, pp. 321-342
- Print publication:
- October 2004
-
- Article
- Export citation
THE TIME-TO-EMPTY FOR TANDEM JACKSON NETWORKS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 18 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 01 October 2004, pp. 493-502
-
- Article
- Export citation
JOIN MINIMUM COST QUEUE FOR MULTICLASS CUSTOMERS: STABILITY AND PERFORMANCE BOUNDS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 18 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 01 October 2004, pp. 445-472
-
- Article
- Export citation
COMPOUND RANDOM VARIABLES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 18 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 01 October 2004, pp. 473-484
-
- Article
- Export citation
Comparing the succinctness of monadic query languages over finite trees
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 38 / Issue 4 / October 2004
- Published online by Cambridge University Press:
- 15 October 2004, pp. 343-373
- Print publication:
- October 2004
-
- Article
- Export citation
Optimizing LRU Caching for Variable Document Sizes
-
- Journal:
- Combinatorics, Probability and Computing / Volume 13 / Issue 4-5 / July 2004
- Published online by Cambridge University Press:
- 24 September 2004, pp. 627-643
-
- Article
- Export citation
Asymptotics of Multivariate Sequences II: Multiple Points of the Singular Variety
-
- Journal:
- Combinatorics, Probability and Computing / Volume 13 / Issue 4-5 / July 2004
- Published online by Cambridge University Press:
- 24 September 2004, pp. 735-761
-
- Article
- Export citation
Special Issue on Analysis of Algorithms
-
- Journal:
- Combinatorics, Probability and Computing / Volume 13 / Issue 4-5 / July 2004
- Published online by Cambridge University Press:
- 24 September 2004, pp. 415-417
-
- Article
- Export citation
On Some Parameters in Heap Ordered Trees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 13 / Issue 4-5 / July 2004
- Published online by Cambridge University Press:
- 24 September 2004, pp. 677-696
-
- Article
- Export citation
