Refine search
Actions for selected content:
48495 results in Computer Science
Acknowledgements
-
- Book:
- Principles of Constraint Programming
- Published online:
- 15 December 2009
- Print publication:
- 28 August 2003, pp xi-xii
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Principles of Constraint Programming
- Published online:
- 15 December 2009
- Print publication:
- 28 August 2003, pp 387-400
-
- Chapter
- Export citation
Welcome to the Educational Pearls Column
-
- Journal:
- Journal of Functional Programming / Volume 13 / Issue 5 / September 2003
- Published online by Cambridge University Press:
- 27 August 2003, pp. 835-838
-
- Article
-
- You have access
- Export citation
Stack-based typed assembly language
-
- Journal:
- Journal of Functional Programming / Volume 13 / Issue 5 / September 2003
- Published online by Cambridge University Press:
- 27 August 2003, pp. 957-959
-
- Article
-
- You have access
- Export citation
Syntactic accidents in program analysis: on the impact of the CPS transformation
-
- Journal:
- Journal of Functional Programming / Volume 13 / Issue 5 / September 2003
- Published online by Cambridge University Press:
- 27 August 2003, pp. 867-904
-
- Article
-
- You have access
- Export citation
Formatting: a class act
-
- Journal:
- Journal of Functional Programming / Volume 13 / Issue 5 / September 2003
- Published online by Cambridge University Press:
- 27 August 2003, pp. 935-944
-
- Article
-
- You have access
- Export citation
Programming graphical user interfaces with Scheme
-
- Journal:
- Journal of Functional Programming / Volume 13 / Issue 5 / September 2003
- Published online by Cambridge University Press:
- 27 August 2003, pp. 839-866
-
- Article
-
- You have access
- Export citation
The Educational Pearls column
-
- Journal:
- Journal of Functional Programming / Volume 13 / Issue 5 / September 2003
- Published online by Cambridge University Press:
- 27 August 2003, pp. 833-834
-
- Article
-
- You have access
- Export citation
CPS transformation of flow information, Part II: administrative reductions
-
- Journal:
- Journal of Functional Programming / Volume 13 / Issue 5 / September 2003
- Published online by Cambridge University Press:
- 27 August 2003, pp. 925-933
-
- Article
-
- You have access
- Export citation
CPS transformation of flow information
-
- Journal:
- Journal of Functional Programming / Volume 13 / Issue 5 / September 2003
- Published online by Cambridge University Press:
- 27 August 2003, pp. 905-923
-
- Article
-
- You have access
- Export citation
Producing all ideals of a forest, functionally
-
- Journal:
- Journal of Functional Programming / Volume 13 / Issue 5 / September 2003
- Published online by Cambridge University Press:
- 27 August 2003, pp. 945-956
-
- Article
-
- You have access
- Export citation
Open-domain textual question answering techniques
-
- Journal:
- Natural Language Engineering / Volume 9 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 14 August 2003, pp. 231-267
-
- Article
- Export citation
Analysis of the grammatical functions between adnoun and noun phrases in Korean using Support Vector Machines
-
- Journal:
- Natural Language Engineering / Volume 9 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 12 August 2003, pp. 269-280
-
- Article
- Export citation
An approach to the formal specification of lingware
-
- Journal:
- Natural Language Engineering / Volume 9 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 12 August 2003, pp. 211-230
-
- Article
- Export citation
Evaluation-driven design of a robust coreference resolution system
-
- Journal:
- Natural Language Engineering / Volume 9 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 12 August 2003, pp. 281-306
-
- Article
- Export citation
Decomposition strategies for configuration problems
-
- Article
- Export citation
-
The paper introduces and discusses the notion of decomposition of a configuration problem within the framework of a structured logical approach. The paper describes under which conditions a given configuration problem can be decomposed into a set of noninteracting subproblems and how to exploit such a decomposition, both for improving the performance of the configurator and for supporting interactive configuration. Different kinds of decomposition are considered, but all of them exploit, as much as possible, the explicit representation of the partonomic relations in the
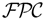 language, a KL-One like representation formalism augmented with constraints for expressing complex interrole relations. The paper introduces a notion of boundness among constraints, which is used for formally specifying different types of decomposition. One decomposition strategy aims at singling out the components and subcomponents that are directly related to the constraints put by the user's requirements; the configurator exploits such decomposition by first configuring that portion of the product and then configuring the parts that are not related to the user's requirements. Another decomposition strategy verifies whether the set of constraints for the product to be configured can be split into a set of noninteracting problems. In such a case the configurator solves the configuration problem by splitting the whole search space into a set of smaller search spaces. Different combinations of these two decomposition techniques are considered, and the impact of the decomposition strategies on the performance of the configurator is evaluated via a set of experiments using the configuration of computer systems as a test bed. The results of the experiments show a significant reduction of the computational effort (both in terms of number of backtrackings and in CPU time) when decomposition strategies are used.
language, a KL-One like representation formalism augmented with constraints for expressing complex interrole relations. The paper introduces a notion of boundness among constraints, which is used for formally specifying different types of decomposition. One decomposition strategy aims at singling out the components and subcomponents that are directly related to the constraints put by the user's requirements; the configurator exploits such decomposition by first configuring that portion of the product and then configuring the parts that are not related to the user's requirements. Another decomposition strategy verifies whether the set of constraints for the product to be configured can be split into a set of noninteracting problems. In such a case the configurator solves the configuration problem by splitting the whole search space into a set of smaller search spaces. Different combinations of these two decomposition techniques are considered, and the impact of the decomposition strategies on the performance of the configurator is evaluated via a set of experiments using the configuration of computer systems as a test bed. The results of the experiments show a significant reduction of the computational effort (both in terms of number of backtrackings and in CPU time) when decomposition strategies are used.