Refine search
Actions for selected content:
101421 results in Language and Linguistics
Grammaire du Vieux-Perse. Pp. xxiv + 266. By A. Meillet. Second edition, revised and enlarged by E. Benveniste. Paris: Ed. Champion, 1931.
-
- Journal:
- Language / Volume 9 / Issue 1-Part1 / March 1933
- Published online by Cambridge University Press:
- 22 April 2026, pp. 92-96
-
- Article
- Export citation
Publications Received
-
- Journal:
- Language / Volume 45 / Issue 2-Part1 / June 1969
- Published online by Cambridge University Press:
- 22 April 2026, pp. 478-482
-
- Article
- Export citation
The Three Greek Aorists in -κα
-
- Journal:
- Language / Volume 7 / Issue 2-Part1 / June 1931
- Published online by Cambridge University Press:
- 22 April 2026, pp. 125-130
-
- Article
- Export citation
Books Received
-
- Journal:
- Language / Volume 6 / Issue 3-Part1 / September 1930
- Published online by Cambridge University Press:
- 22 April 2026, pp. 273-277
-
- Article
- Export citation
The History of the Second Session
-
- Journal:
- Language / Volume 5 / Issue 3-Part3 / September 1929
- Published online by Cambridge University Press:
- 22 April 2026, pp. 5-10
-
- Article
- Export citation
High-Speed Computation of Lexicostatistical Indices
-
- Journal:
- Language / Volume 38 / Issue 3-Part1 / September 1962
- Published online by Cambridge University Press:
- 22 April 2026, pp. 274-278
-
- Article
- Export citation
Optional rules in the formation of the Old Church Slavonic aorist
-
- Article
- Export citation
-
Traditionally, the Old Church Slavonic verb is considered to be capable of forming three types of aorist. The so-called root aorist is presumably formed by adding personal endings directly to the stem (Diels §114.1), as in the forms of the verb ‘to fall with the basic stem in pad- : 1st sg.
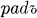 2d and 3d sg. pade, 1st du. padově, 2d du. padeta, 3d du. padete, 1st pl.
2d and 3d sg. pade, 1st du. padově, 2d du. padeta, 3d du. padete, 1st pl. 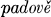 2d pl. padete, 3d pl.
2d pl. padete, 3d pl. 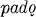 The so-called s-aorist (Diels §114.2) is presumably formed by adding the element s (which under certain conditions alternates with x) directly to the stem, as in the respective forms of ved- ‘lead’ and rek- ‘speak’:
The so-called s-aorist (Diels §114.2) is presumably formed by adding the element s (which under certain conditions alternates with x) directly to the stem, as in the respective forms of ved- ‘lead’ and rek- ‘speak’: 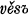 , vede, věsově, věsta, věste,
, vede, věsově, věsta, věste, 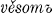 , věste,
, věste, 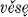 , and
, and 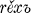 , reče, rěxově, rěsta, rěste,
, reče, rěxově, rěsta, rěste, 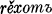 , rěste,
, rěste, 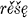 . The so-called x-aorist (Diels §114.3) is formed by adding the element ox, as in the x-aorist forms of ved- :
. The so-called x-aorist (Diels §114.3) is formed by adding the element ox, as in the x-aorist forms of ved- : 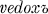 , vede, vedoxově, vedosta, vedoste,
, vede, vedoxově, vedosta, vedoste, 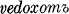 , vedoste, and
, vedoste, and 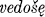 . In addition to automatic changes (such as x to š before a front vowel), it must be noted that the second and third persons singular are always formed on the root-aorist pattern; and that the third person plural ends in
. In addition to automatic changes (such as x to š before a front vowel), it must be noted that the second and third persons singular are always formed on the root-aorist pattern; and that the third person plural ends in 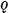 in the root aorist but in
in the root aorist but in 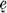 in the s- and x-aorists, as in the forms
in the s- and x-aorists, as in the forms 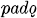 (root aor.),
(root aor.), 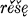 (s-aor.), and
(s-aor.), and 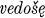 (x-aor.). The distribution of the various types of aorist among stem classes is the following: class 1.1 (cf. Diels §105–6) has all three types in stems that end in an obstruent, as in the forms
(x-aor.). The distribution of the various types of aorist among stem classes is the following: class 1.1 (cf. Diels §105–6) has all three types in stems that end in an obstruent, as in the forms 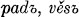 and
and 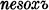 stems of class 1.1 that end in a sonorant take s-aorist only; stems of class 2.1 take either the root aorist or the s-aorist; stems of class 2.2 and 3–6 take the s-aorist; and stems of class 7 (irregular) require individual disposition.
stems of class 1.1 that end in a sonorant take s-aorist only; stems of class 2.1 take either the root aorist or the s-aorist; stems of class 2.2 and 3–6 take the s-aorist; and stems of class 7 (irregular) require individual disposition.
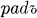 2d and 3d sg.
2d and 3d sg. 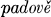 2d pl.
2d pl. 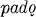 The so-called
The so-called 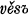 , vede, věsově, věsta, věste,
, vede, věsově, věsta, věste, 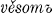 , věste,
, věste, 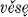 ,
,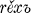 , reče, rěxově, rěsta, rěste,
, reče, rěxově, rěsta, rěste, 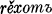 , rěste,
, rěste, 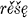 .
.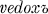 , vede, vedoxově, vedosta, vedoste,
, vede, vedoxově, vedosta, vedoste, 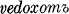 , vedoste,
, vedoste,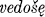 . In addition to automatic changes (such as
. In addition to automatic changes (such as 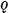 in the root aorist but in
in the root aorist but in 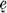 in the
in the 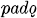 (root aor.),
(root aor.), 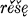 (
(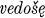 (
(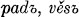 and
and 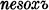 stems of class 1.1 that end in a sonorant take
stems of class 1.1 that end in a sonorant take Publications Received
-
- Journal:
- Language / Volume 27 / Issue 1-Part1 / March 1951
- Published online by Cambridge University Press:
- 22 April 2026, pp. 106-109
-
- Article
- Export citation
Introduzione alla storia delle lingue indeuropee. By Vladimir I. Georgiev. (Incunabula graeca, 9.) Pp. vi, 477. Rome: Edizioni dell' Ateneo, 1966.
-
- Journal:
- Language / Volume 44 / Issue 2-Part1 / June 1968
- Published online by Cambridge University Press:
- 22 April 2026, pp. 334-343
-
- Article
- Export citation
Dimensions of Grammatical Constructions
-
- Journal:
- Language / Volume 38 / Issue 3-Part1 / September 1962
- Published online by Cambridge University Press:
- 22 April 2026, pp. 221-244
-
- Article
- Export citation
Die nordamerikanischen Indianersprachen: ein Überblick über ihren Bau und ihre Besonderheiten. By Heinz-Jürgen Pinnow. Pp. xiv, 138, 2 maps. Wiesbaden: Verlag Otto Harrassowitz, 1964. DM 20.00.
-
- Journal:
- Language / Volume 43 / Issue 2-Part1 / June 1967
- Published online by Cambridge University Press:
- 22 April 2026, pp. 573-583
-
- Article
- Export citation
The Etymology of Dialectic Greek πoι and its Cognates
-
- Journal:
- Language / Volume 7 / Issue 3-Part1 / September 1931
- Published online by Cambridge University Press:
- 22 April 2026, pp. 173-178
-
- Article
- Export citation
-
[An argument to show that πoι is in ablaut relation to
 and its cognates.]
and its cognates.]
 and its cognates.]
and its cognates.]Notes and Personalia
-
- Journal:
- Language / Volume 14 / Issue 1-Part1 / March 1938
- Published online by Cambridge University Press:
- 22 April 2026, pp. 83-86
-
- Article
- Export citation
The Formation of the Tocharian Subjunctive
-
- Journal:
- Language / Volume 35 / Issue 2-Part1 / June 1959
- Published online by Cambridge University Press:
- 22 April 2026, pp. 157-179
-
- Article
- Export citation
Die illyrische Namengebung. By Hans Krahe. (Würzburger Jahrbücher für die Altertumswissenschaft I/2.167–225.) Pp. [59]. Würzburg: Verlag Ferdinand Schöningh, n.d.
-
- Journal:
- Language / Volume 24 / Issue 2-Part1 / June 1948
- Published online by Cambridge University Press:
- 22 April 2026, pp. 191-194
-
- Article
- Export citation
