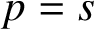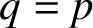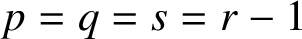Refine search
Actions for selected content:
3876 results in Optimization
13 - Linear Complementarity Problems and Quitting Games
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 236-254
-
- Chapter
- Export citation
10 - The Vanishing Discount Factor Approach and Uniform Equilibrium in Absorbing Games
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 173-194
-
- Chapter
- Export citation
3 - Strategic-Form Games: A Review
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 49-54
-
- Chapter
- Export citation
7 - B-Graphs and the Continuity of the Limit limλ→0 ʋλ(s;q,r)
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 94-110
-
- Chapter
- Export citation
2 - A Tauberian Theorem and Uniform ∈-Optimality in Hidden Markov Decision Problems
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 35-48
-
- Chapter
- Export citation
11 - Ramsey’s Theorem and Two-Player Deterministic Stopping Games
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 195-210
-
- Chapter
- Export citation
6 - Semi-Algebraic Sets and the Limit of the Discounted Value
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 82-93
-
- Chapter
- Export citation
1 - Markov Decision Problems
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 5-34
-
- Chapter
- Export citation
Dedication
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp v-vi
-
- Chapter
- Export citation
References
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 255-264
-
- Chapter
- Export citation
9 - Uniform Equilibrium
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 128-172
-
- Chapter
- Export citation
Contents
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp vii-x
-
- Chapter
- Export citation
12 - Infinite Orbits and Quitting Games
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 211-235
-
- Chapter
- Export citation
4 - Stochastic Games: The Model
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 55-61
-
- Chapter
- Export citation
5 - Two-Player Zero-Sum Discounted Games
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 62-81
-
- Chapter
- Export citation
8 - Kakutani’s Fixed-Point Theorem and Multiplayer Discounted Stochastic Games
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 111-127
-
- Chapter
- Export citation
DISPERSAL OF HYDROGEN IN THE RETINA—A THREE-LAYER MODEL
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 64 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 10 May 2022, pp. 1-22
-
- Article
- Export citation

A Course in Stochastic Game Theory
-
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022
THREE-DIMENSIONAL ANALYTICAL SOLUTION OF THE ADVECTION-DIFFUSION EQUATION FOR AIR POLLUTION DISPERSION
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 64 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 26 April 2022, pp. 40-53
-
- Article
- Export citation
EXPLICIT NORDSIECK SECOND DERIVATIVE GENERAL LINEAR METHODS FOR ODES
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 64 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 25 April 2022, pp. 69-88
-
- Article
- Export citation
-
The paper deals with the construction of explicit Nordsieck second derivative general linear methods with s stages of order p with
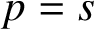 $p=s$ and high stage order
$p=s$ and high stage order 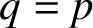 $q=p$ with inherent Runge–Kutta or quadratic stability properties. Satisfying the order and stage order conditions together with inherent stability conditions leads to methods with some free parameters, which will be used to obtain methods with a large region of absolute stability. Examples of methods with r external stages and
$q=p$ with inherent Runge–Kutta or quadratic stability properties. Satisfying the order and stage order conditions together with inherent stability conditions leads to methods with some free parameters, which will be used to obtain methods with a large region of absolute stability. Examples of methods with r external stages and 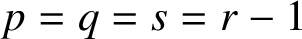 $p=q=s=r-1$ up to order five are given, and numerical experiments in a fixed stepsize environment are presented.
$p=q=s=r-1$ up to order five are given, and numerical experiments in a fixed stepsize environment are presented.