






1. Introduction
One of the main reasons for modelling epidemics is to understand the effects of different preventive measures, such as vaccination and non-pharmaceutical interventions. During the recent Covid-19 pandemic, research on the effects of various non-pharmaceutical interventions, including social distancing, case isolation, contact tracing and lockdown, has received much attention. Some related papers (e.g. [Reference Ferguson, Laydon, Nedjati Gilani, Imai, Ainslie, Baguelin, Bhatia, Boonyasiri and Cucunuba Perez10, Reference Flaxman, Mishra, Gandy, Unwin, Mellan, Coupland, Whittaker, Zhu and Berah12, Reference Longini, Nizam, Xu, Ungchusak, Hanshaoworakul, Cummings and Halloran19]) have been highly influential on public health policies.
This paper focuses on the preventive measure known as contact tracing. Contact tracing is traditionally performed by public health agency officers who interview diagnosed individuals and then call the named contacts to advise them to self-quarantine and test, which is often referred to as manual contact tracing. This type of contact tracing has been successful in reducing transmission of many epidemics, such as Ebola [Reference Swanson, Altare, Wesseh, Nyenswah, Ahmed, Eyal, Hamblion, Lessler, Peters and Altmann24], SARS [Reference Lloyd-Smith, Galvani and Getz18], influenza [Reference Agarwal and Bhadauria1], and measles [Reference Liu, Enanoria, Zipprich, Blumberg, Harriman, Ackley, Wheaton, Allpress and Porco17]. In the present paper, we investigate a different type of contact tracing: digital contact tracing. In the case of Covid-19, [Reference Ferretti, Wymant, Kendall, Zhao, Nurtay, Abeler-Dörner, Parker, Bonsall and Fraser11] suggested that manual contact tracing is not rapid enough to control the epidemic, and the idea arose of developing a contact tracing app: once an app-user is diagnosed, a warning message will be instantaneously sent out to all the app-users who have recently been near the confirmed case for a sufficient duration. Such notified contacts are then advised to test and quarantine themselves. Several contact tracing apps have been developed and released (e.g. [Reference Ferretti, Wymant, Kendall, Zhao, Nurtay, Abeler-Dörner, Parker, Bonsall and Fraser11, Reference Wymant, Ferretti, Tsallis, Charalambides, Abeler-Dörner, Bonsall, Hinch, Kendall and Milsom25] in the UK and [Reference Klinkenberg, Leung and Wallinga14] in the Netherlands).
Various papers exist that analyse digital contact tracing (e.g. [Reference Barrat, Cattuto, Kivelä, Lehmann and Saramäki7, Reference Kretzschmar, Rozhnova and Van Boven15, Reference Kucharski, Klepac, Conlan, Kissler, Tang, Fry, Gog, Edmunds and Emery16, Reference Pollmann, Schönert, Müller, Pollmann, Resconi, Wiesinger, Haack, Shtembari and Turcati21]), focusing on simulation-based epidemic models, and the results of [Reference Rizi, Faqeeh, Badie-Modiri and Kivelä22] are based on a combination of simulations and mean-field analysis of the related percolation problem. Several papers on digital contact tracing for Covid-19 (e.g. [Reference Cencetti, Santin, Longa, Pigani, Barrat, Cattuto, Lehmann, Salathe and Lepri9, Reference Ferretti, Wymant, Kendall, Zhao, Nurtay, Abeler-Dörner, Parker, Bonsall and Fraser11]) are based on the mathematical model first introduced in [Reference Fraser, Riley, Anderson and Ferguson13] in terms of recursive equations for analysing the timing of infectiousness and the appearance of symptoms. In particular, the results of [Reference Ferretti, Wymant, Kendall, Zhao, Nurtay, Abeler-Dörner, Parker, Bonsall and Fraser11] showed that the Covid-19 epidemic was unlikely to be contained only by manual tracing.
Modelling contact tracing is mathematically challenging and does not easily lend itself to analysis using differential equations. This paper focuses on the beginning of an outbreak before a massive fraction of the population has been infected. For this reason, we use stochastic models, which are also suitable because the outcome of contact tracing itself is random rather than deterministic. The early phase of an epidemic without preventive measures can often be approximated by a suitable branching process (e.g. [Reference Ball and Donnelly3]) using the underlying model assumption that once an individual has been infected, they behave (transmit) independently of their infector. When contact tracing is introduced, this independence breaks down and other methods need to be developed. In the past few decades there has been some progress in more rigorous analyses of epidemic models with manual contact tracing (e.g. [Reference Ball, Knock and O’Neill5, Reference Barlow6, Reference Müller, Kretzschmar and Dietz20]).
In [Reference Zhang and Britton27], we considered a Markovian SIR epidemic model with manual contact tracing which assumes that once individuals are diagnosed, manual tracing is performed without delay, thus reaching each contact with probability p. In the present paper, we analyse a model with digital contact tracing by assuming that a fraction
 $\pi$
of individuals install a contact tracing app (and follow the advice if notified). Once an app-user is diagnosed, all their app-using contacts are notified, with the result that these contacts isolate and test themselves without delay. For those who test positive, their app-using contacts are also notified, and so on. Furthermore, for both manual and digital contact tracing, we assume that traced individuals who have recovered naturally are also identified and are subject to contact tracing. Note the conceptual difference between digital and manual contact tracing: manual contact tracing may happen if a contacted individual is traced (which happens with probability p), whereas digital contact tracing happens if both the individuals are app-users, thus creating an app-using connection (or edge).
$\pi$
of individuals install a contact tracing app (and follow the advice if notified). Once an app-user is diagnosed, all their app-using contacts are notified, with the result that these contacts isolate and test themselves without delay. For those who test positive, their app-using contacts are also notified, and so on. Furthermore, for both manual and digital contact tracing, we assume that traced individuals who have recovered naturally are also identified and are subject to contact tracing. Note the conceptual difference between digital and manual contact tracing: manual contact tracing may happen if a contacted individual is traced (which happens with probability p), whereas digital contact tracing happens if both the individuals are app-users, thus creating an app-using connection (or edge).
Using large-population asymptotics, we prove that the early epidemic process with digital tracing may be approximated by a two-type branching process where type-1 ‘individuals’ are app-using components (in terms of app-users) and type-2 individuals are non-app-users. We then analyse the model with both types of contact tracing in place, i.e. reaching a fraction p of all contacts using manual contact tracing and additionally all app-using contacts if the tested individual is an app-user (making up a fraction
 $\pi$
of the community). The limiting process in this case is shown to be a two-type branching process, where both type 1 and type 2 represent the to-be-traced components, referred to as ‘macro-individuals’, but type 1 starts with an app-user and type 2 with a non-app-user.
$\pi$
of the community). The limiting process in this case is shown to be a two-type branching process, where both type 1 and type 2 represent the to-be-traced components, referred to as ‘macro-individuals’, but type 1 starts with an app-user and type 2 with a non-app-user.
We derive reproduction numbers for the two limiting processes. These reproduction numbers are hard to interpret, however, being reproduction numbers of multi-type branching processes where some of the types are not actual individuals but rather groups of individuals. The reproduction numbers therefore reflect the average number of new clumps infected by such clumps during the early phase of the epidemic. These average numbers need not be the same as the average number of individuals that one typical infected individual infects during the beginning of the outbreak, which would define the individual basic reproduction number. The important connection between such complicated reproduction numbers and individual reproduction numbers is that they are either both above 1 (the super-critical case), both below 1 (the sub-critical case), or both exactly 1. Because the multi-type reproduction numbers are hard to interpret, we also derive corresponding individual reproduction numbers.
However, individual reproduction numbers may also be defined differently depending on whom specific infections are attributed to. For example, in a household epidemic model, if all infections in a household are attributed to the person infecting the household index case, then this will give rise to one individual reproduction number. In contrast, attributing infections to the person who actually infected the individual (a more natural but also less mathematically tractable definition) gives rise to the individual basic reproduction number. As a consequence, there may also be different individual reproduction numbers for a given model (relating to the time ordering of when infections occur). Fortunately, they also share the property of all being larger than 1, smaller than 1, or equal to 1. For a further treatment of various reproduction numbers and their interpretation, we refer to [Reference Ball, Pellis and Trapman4]. An interesting observation is that the component reproduction number for the digital-only model may in fact increase with
 $\pi$
, the fraction of app-users. Still, it is proven that the corresponding individual reproduction number is monotonically decreasing with
$\pi$
, the fraction of app-users. Still, it is proven that the corresponding individual reproduction number is monotonically decreasing with
 $\pi$
, as expected.
$\pi$
, as expected.
We also compare the digital (only) contact tracing model with the manual (only) contact tracing model of [Reference Zhang and Britton27] to see how the critical app-using fraction
 $\pi_{\mathrm{c}}$
relates to the critical fraction
$\pi_{\mathrm{c}}$
relates to the critical fraction
 $p_{\mathrm{c}}$
of contacts that are manually contact-traced, with all other model parameters being equal. We prove that
$p_{\mathrm{c}}$
of contacts that are manually contact-traced, with all other model parameters being equal. We prove that
 $\pi_{\mathrm{c}}>p_{\mathrm{c}}$
and, as a by-product, obtain a new explicit expression for
$\pi_{\mathrm{c}}>p_{\mathrm{c}}$
and, as a by-product, obtain a new explicit expression for
 $p_{\mathrm{c}}$
that was given only implicitly in [Reference Zhang and Britton27].
$p_{\mathrm{c}}$
that was given only implicitly in [Reference Zhang and Britton27].
In Section 2, we define the digital contact tracing model as well as the model having both manual and digital contact tracing. In Section 3, we present the main results and provide some intuition. Next, we give the proofs and explain more about approximating the initial phase of the epidemic in a large population (Section 4 for digital tracing only and Section 5 for both types of tracing). Then, in Section 6, we illustrate our results numerically, compare the effects of manual and digital contact tracing, and investigate their combined effect. Finally, in Section 7 we summarize our conclusions and discuss potential improvements of the present models.
2. Model description
2.1. The epidemic model
First, we consider a continuous-time Markovian SIR (Susceptible
 $\rightarrow$
Infectious
$\rightarrow$
Infectious
 $\rightarrow$
Recovered) epidemic spreading in a closed, homogeneously mixing population of fixed size n. Initially there is one infectious individual, and the rest are susceptible. An infectious individual makes contact at rate
$\rightarrow$
Recovered) epidemic spreading in a closed, homogeneously mixing population of fixed size n. Initially there is one infectious individual, and the rest are susceptible. An infectious individual makes contact at rate
 $\beta$
, each time with an individual chosen uniformly at random from the population. The individual-to-individual contact rate is thus
$\beta$
, each time with an individual chosen uniformly at random from the population. The individual-to-individual contact rate is thus
 ${\beta}/{n}$
. If the contacted individual is susceptible, they become infected immediately; otherwise, nothing happens. Each infectious individual recovers naturally at rate
${\beta}/{n}$
. If the contacted individual is susceptible, they become infected immediately; otherwise, nothing happens. Each infectious individual recovers naturally at rate
 $\gamma$
and plays no further part in the disease spreading (thus having an infectious period, denoted by
$\gamma$
and plays no further part in the disease spreading (thus having an infectious period, denoted by
 $T_{I}$
, exponentially distributed with mean
$T_{I}$
, exponentially distributed with mean
 ${1}/{\gamma}$
).
${1}/{\gamma}$
).
To incorporate contact tracing, we add a testing strategy to this SIR model. We assume that once infected, infectious individuals test positive and are immediately isolated (referred to as ‘diagnosed’) after random periods, which are independent and identically distributed according to a random variable
 $T_{\mathrm{D}} \sim \mathrm{Exp}(\delta)$
. Therefore, infectious individuals can stop spreading the disease after a random time
$T_{\mathrm{D}} \sim \mathrm{Exp}(\delta)$
. Therefore, infectious individuals can stop spreading the disease after a random time
 $\min\{T_{I}, T_{\mathrm{D}}\} \sim \mathrm{Exp}(\gamma+\delta)$
, either through natural recovery (at rate
$\min\{T_{I}, T_{\mathrm{D}}\} \sim \mathrm{Exp}(\gamma+\delta)$
, either through natural recovery (at rate
 $\gamma$
) or diagnosis (at rate
$\gamma$
) or diagnosis (at rate
 $\delta$
). All the random quantities described are assumed to be mutually independent. The epidemic stops when no infectious individuals remain in the population.
$\delta$
). All the random quantities described are assumed to be mutually independent. The epidemic stops when no infectious individuals remain in the population.
In this epidemic model (with testing but without contact tracing), each infectious period follows an exponential distribution with intensity
 $\gamma+\delta.$
Consequently, it is straightforward to compute the mean number of secondary infections produced by a single infective before recovery or diagnosis:
$\gamma+\delta.$
Consequently, it is straightforward to compute the mean number of secondary infections produced by a single infective before recovery or diagnosis:
 \begin{equation} R_0 = \frac{\beta}{\gamma + \delta}.\end{equation}
\begin{equation} R_0 = \frac{\beta}{\gamma + \delta}.\end{equation}
To emphasize the effect of contact tracing, we refer to this as the basic reproduction number
 $R_0$
, though more correctly
$R_0$
, though more correctly
 $R_0$
should represent the situation without testing (so
$R_0$
should represent the situation without testing (so
 $\delta\to 0$
and
$\delta\to 0$
and
 $R_0$
will be equal to
$R_0$
will be equal to
 ${\beta}/{\gamma}$
). However, we use expression (1) to study the impact of contact tracing versus no contact tracing, assuming the testing rate remains unchanged.
${\beta}/{\gamma}$
). However, we use expression (1) to study the impact of contact tracing versus no contact tracing, assuming the testing rate remains unchanged.
2.2. The epidemic model with digital contact tracing
We add digital contact tracing to the epidemic model in Subsection 2.1 by assuming that a fraction
 $\pi$
of individuals use the tracing app (and follow the recommendations) and that individuals mix uniformly irrespective of whether they use the app, i.e. each individual is an app-user with probability
$\pi$
of individuals use the tracing app (and follow the recommendations) and that individuals mix uniformly irrespective of whether they use the app, i.e. each individual is an app-user with probability
 $\pi$
independently. In the following, we assume that
$\pi$
independently. In the following, we assume that
 $0<\pi \le 1$
unless otherwise specified. Clearly, when
$0<\pi \le 1$
unless otherwise specified. Clearly, when
 $\pi=0$
there is no digital tracing, so we would have the same epidemic model as in Subsection 2.1.
$\pi=0$
there is no digital tracing, so we would have the same epidemic model as in Subsection 2.1.
The infectious individuals (either app-users or non-app-users) recover naturally at rate
 $\gamma$
and are diagnosed at rate
$\gamma$
and are diagnosed at rate
 $\delta$
. The digital contact tracing procedure is defined as follows. If and when an infectious app-user is diagnosed, all app-using contacts of the infective will be notified, with the result that they test and isolate themselves without delay, and so stop spreading the disease if infectious. The app-using contacts who have been infected, including those who have recovered, are then also assumed to trigger digital tracing among their app-using contacts without delay according to the same procedure, and so on.
$\delta$
. The digital contact tracing procedure is defined as follows. If and when an infectious app-user is diagnosed, all app-using contacts of the infective will be notified, with the result that they test and isolate themselves without delay, and so stop spreading the disease if infectious. The app-using contacts who have been infected, including those who have recovered, are then also assumed to trigger digital tracing among their app-using contacts without delay according to the same procedure, and so on.
2.3. The epidemic model with digital and manual contact tracing
Finally, we describe the epidemic model with digital contact tracing when there is also manual contact tracing in place and call this the combined model. First, following the assumption in Subsection 2.2, a fraction
 $\pi$
of the community are app-users and follow the instructions. If such an app-user is diagnosed, all of their app-using contacts (on average being a fraction
$\pi$
of the community are app-users and follow the instructions. If such an app-user is diagnosed, all of their app-using contacts (on average being a fraction
 $\pi$
of all contacts) will be traced. To this, we now add manual contact tracing by assuming that once an infectious individual is diagnosed, app-user or not, each of their contacts will be reached independently by manual tracing with probability p. This means that for diagnosed app-users, all app-using contacts will be traced, and each non-app-using contact will be traced manually with probability p. For diagnosed non-app-users, each contact, app-user or not, will be traced manually with probability p. As before, all traced individuals are tested and isolated without delay if testing positive. Traced individuals who test positive, including those who have recovered, are then contact-traced in the same manner without delay, and so on. The model parameters are summarized in Table 1.
$\pi$
of all contacts) will be traced. To this, we now add manual contact tracing by assuming that once an infectious individual is diagnosed, app-user or not, each of their contacts will be reached independently by manual tracing with probability p. This means that for diagnosed app-users, all app-using contacts will be traced, and each non-app-using contact will be traced manually with probability p. For diagnosed non-app-users, each contact, app-user or not, will be traced manually with probability p. As before, all traced individuals are tested and isolated without delay if testing positive. Traced individuals who test positive, including those who have recovered, are then contact-traced in the same manner without delay, and so on. The model parameters are summarized in Table 1.
Table 1. Model parameters

3. Main results
The main goal of this paper is to analyse the initial phase of the epidemic with digital contact tracing in place. We start by showing that the epidemic converges to a limiting process, asymptotically as the population size n grows to infinity.
3.1. Digital contact tracing only
Let
 $E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
denote the epidemic model with digital contact tracing only in a population of size n (defined in Subsection 2.2). It is convenient to consider the epidemic as a two-type process where the type of infective corresponds to whether they are app-users or not. The limiting process, denoted by
$E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
denote the epidemic model with digital contact tracing only in a population of size n (defined in Subsection 2.2). It is convenient to consider the epidemic as a two-type process where the type of infective corresponds to whether they are app-users or not. The limiting process, denoted by
 $E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
, is described as follows. Each alive (i.e. infectious) individual gives birth to (i.e. infects) app-users at rate
$E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
, is described as follows. Each alive (i.e. infectious) individual gives birth to (i.e. infects) app-users at rate
 $\beta\pi$
and non-app-users at rate
$\beta\pi$
and non-app-users at rate
 $\beta(1-\pi)$
, recovers naturally at rate
$\beta(1-\pi)$
, recovers naturally at rate
 $\gamma$
, and is diagnosed at rate
$\gamma$
, and is diagnosed at rate
 $\delta$
(the individual is considered dead, not giving rise to any more births, in both cases). Moreover, if a diagnosed individual is an app-user, all of their app-using offspring as well as their parent (if an app-user) are diagnosed at the same time. Such diagnosed individuals will, in turn, lead to all app-users among their offspring and parent being diagnosed without delay, and so on.
$\delta$
(the individual is considered dead, not giving rise to any more births, in both cases). Moreover, if a diagnosed individual is an app-user, all of their app-using offspring as well as their parent (if an app-user) are diagnosed at the same time. Such diagnosed individuals will, in turn, lead to all app-users among their offspring and parent being diagnosed without delay, and so on.
The limit process in terms of app-users and non-app-users will not be a branching process when contact tracing is in place, since an infectious app-user may be contact-traced by its app-using infector or one of its app-using infectees, thus giving rise to dependence between individuals, which violates the basic assumption of independence in branching processes. But if we instead treat non-app-users as one type of individual and ‘app-using components’ (consisting of a whole transmission chain of app-users) as a second type of ‘macro-individual’, this process will evolve according to a two-type branching process (see Figure 1 in the next section for an illustration). This holds because there will never be contact tracing between any combination of such individuals, thus making individuals behave independently.
Next, we study the birth and death of app-using components. Such a component starts with one infectious app-user infected by a non-app-user (we call this the root of the component). The component can then grow as the root infects other app-users, who in turn infect more app-users, and so on. Eventually, the whole app-using component will die out (i.e. stop spreading the infection) either when someone within the component is diagnosed (leading to immediate tracing and diagnosis of the whole component) or when all individuals in the component recover naturally. While the component has infectious individuals, it can also infect non-app-users. These infected non-app-users can subsequently infect other non-app-users and app-users; in the latter case, new app-using components are created.
Following multi-type branching process theory [Reference Athreya and Ney2, Reference Becker and Marschner8], we define
 \begin{equation} M=\left(\begin{array}{c@{\quad}c}m_{11} & m_{12}\\m_{21} & m_{22}\end{array}\right)\end{equation}
\begin{equation} M=\left(\begin{array}{c@{\quad}c}m_{11} & m_{12}\\m_{21} & m_{22}\end{array}\right)\end{equation}
as the next-generation matrix of the limiting two-type branching process, where
 $m_{ij}$
is the expected number of secondary infections of type j produced by a single infected individual of type i, for
$m_{ij}$
is the expected number of secondary infections of type j produced by a single infected individual of type i, for
 $i,j=1,2$
(type 1 refers to app-using components and type 2 to non-app-users). Then, a major outbreak occurs with positive probability if and only if the largest eigenvalue of M, denoted by
$i,j=1,2$
(type 1 refers to app-using components and type 2 to non-app-users). Then, a major outbreak occurs with positive probability if and only if the largest eigenvalue of M, denoted by
 $R_{\mathrm{D}}$
, is above 1 (the elements of M are derived in Subsection 4.2). We call
$R_{\mathrm{D}}$
, is above 1 (the elements of M are derived in Subsection 4.2). We call
 $R_{\mathrm{D}}$
the effective reproduction number for the epidemic with digital tracing.
$R_{\mathrm{D}}$
the effective reproduction number for the epidemic with digital tracing.
We summarize our findings in the following proposition and corollary.
Proposition 1. Consider the sequence of epidemic processes with digital tracing,
 $E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
for each population size n, starting with one random initial infective and the rest susceptible. Then on any finite time interval,
$E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
for each population size n, starting with one random initial infective and the rest susceptible. Then on any finite time interval,
 $E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
converges in distribution to the limit process
$E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
converges in distribution to the limit process
 $E^{}_{\mathrm{ D}}(\beta,\gamma,\delta,\pi)$
as
$E^{}_{\mathrm{ D}}(\beta,\gamma,\delta,\pi)$
as
 $n\to\infty.$
$n\to\infty.$
Corollary 1. The limit process
 $E^{}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
is super-critical, meaning that it will grow beyond all limits with positive probability if and only if
$E^{}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
is super-critical, meaning that it will grow beyond all limits with positive probability if and only if
 $R_{\mathrm{ D}}>1$
, where
$R_{\mathrm{ D}}>1$
, where
 \begin{equation} R_{\mathrm{D}} = \frac{R_{0}(1-\pi)}{2}+\sqrt{\frac{( R_{0}(1-\pi))^2}{4}+f(\pi)R_{0}\pi}\end{equation}
\begin{equation} R_{\mathrm{D}} = \frac{R_{0}(1-\pi)}{2}+\sqrt{\frac{( R_{0}(1-\pi))^2}{4}+f(\pi)R_{0}\pi}\end{equation}
with
 \begin{equation} f(\pi)= \frac{(1-\pi)}{2 \pi \delta}\left(\beta \pi-\gamma-\delta+\sqrt{(\beta \pi+\gamma+\delta)^2-4\beta \pi \gamma}\right).\end{equation}
\begin{equation} f(\pi)= \frac{(1-\pi)}{2 \pi \delta}\left(\beta \pi-\gamma-\delta+\sqrt{(\beta \pi+\gamma+\delta)^2-4\beta \pi \gamma}\right).\end{equation}
Let
 $Z^{(n)}_{\mathrm{D}}$
be the final number of infected in the whole epidemic
$Z^{(n)}_{\mathrm{D}}$
be the final number of infected in the whole epidemic
 $E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
. Then if
$E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
. Then if
 $R_{\mathrm{D}} > 1$
,
$R_{\mathrm{D}} > 1$
,
 $Z^{(n)}_{\mathrm{D}} {\to} \infty$
with positive probability, whereas if
$Z^{(n)}_{\mathrm{D}} {\to} \infty$
with positive probability, whereas if
 $R_{\mathrm{D}} \leq 1$
then the final fraction getting infected,
$R_{\mathrm{D}} \leq 1$
then the final fraction getting infected,
 $\bar Z^{(n)}_{\mathrm{D}}$
, satisfies
$\bar Z^{(n)}_{\mathrm{D}}$
, satisfies
 $\bar Z^{(n)}_{\mathrm{D}} = Z^{(n)}_{\mathrm{D}}/n \overset{\mathrm{p}}{\to} 0$
(a minor outbreak for sure).
$\bar Z^{(n)}_{\mathrm{D}} = Z^{(n)}_{\mathrm{D}}/n \overset{\mathrm{p}}{\to} 0$
(a minor outbreak for sure).
Our next result compares the effect of digital contact tracing with the effect of manual contact tracing. More precisely, we compare the current model with the manual contact tracing model of [Reference Zhang and Britton27], which has the same transmission model, no digital contact tracing, but instead a kind of manual contact tracing where each contact is traced upon diagnosis, independently, with probability p. Keeping all epidemic parameters fixed and equal in the two models, we compare
 $\pi_{\mathrm{c}}$
, the app-using fraction for which
$\pi_{\mathrm{c}}$
, the app-using fraction for which
 $R_{\mathrm{D}}=1$
, with
$R_{\mathrm{D}}=1$
, with
 $p_{\mathrm{c}}$
, the critical fraction manually contact-traced such that the corresponding manual reproduction number satisfies
$p_{\mathrm{c}}$
, the critical fraction manually contact-traced such that the corresponding manual reproduction number satisfies
 $R_{\mathrm{M}}=1$
. The following theorem shows that a larger app-using fraction is needed than the manual tracing probability so as to reduce the reproduction number to 1.
$R_{\mathrm{M}}=1$
. The following theorem shows that a larger app-using fraction is needed than the manual tracing probability so as to reduce the reproduction number to 1.
Theorem 1. Let
 $\beta,\delta,\gamma >0$
be fixed parameters and assume
$\beta,\delta,\gamma >0$
be fixed parameters and assume
 $R_{0}=\beta/(\delta+\gamma)>1$
(otherwise contact tracing is unnecessary). Then
$R_{0}=\beta/(\delta+\gamma)>1$
(otherwise contact tracing is unnecessary). Then
 \begin{align*}\pi_{\mathrm{c}} > p_{\mathrm{c}} = \frac{\beta-(\gamma+\delta)}{\beta-\gamma}.\end{align*}
\begin{align*}\pi_{\mathrm{c}} > p_{\mathrm{c}} = \frac{\beta-(\gamma+\delta)}{\beta-\gamma}.\end{align*}
The reproduction number
 $R_{\mathrm{D}}$
cannot be interpreted as some mean number of infections caused by one individual, since it is based on a two-type branching process in which one of the types is a to-be-traced component. A notable consequence of this is seen in Figure 5a, where it can be observed that
$R_{\mathrm{D}}$
cannot be interpreted as some mean number of infections caused by one individual, since it is based on a two-type branching process in which one of the types is a to-be-traced component. A notable consequence of this is seen in Figure 5a, where it can be observed that
 $R_{\mathrm{D}}$
is not monotonically decreasing in
$R_{\mathrm{D}}$
is not monotonically decreasing in
 $\pi$
; in some situations, increasing the fraction of app-users can lead to a larger reproduction number!
$\pi$
; in some situations, increasing the fraction of app-users can lead to a larger reproduction number!
In Subsection 4.4 we therefore derive an individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
for the epidemic with digital tracing,
$R^\mathrm{(ind)}_{\mathrm{D}}$
for the epidemic with digital tracing,
 \begin{equation*} R^\mathrm{(ind)}_{\mathrm{D}}= \frac{\pi f(\pi)}{1-\pi +\pi f(\pi)} + (1-\pi) \frac{\beta}{\delta+\gamma},\end{equation*}
\begin{equation*} R^\mathrm{(ind)}_{\mathrm{D}}= \frac{\pi f(\pi)}{1-\pi +\pi f(\pi)} + (1-\pi) \frac{\beta}{\delta+\gamma},\end{equation*}
with
 $f(\pi)$
given by (4). For this individual reproduction number
$f(\pi)$
given by (4). For this individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
, we have the following theorem showing that it is monotonically decreasing in
$R^\mathrm{(ind)}_{\mathrm{D}}$
, we have the following theorem showing that it is monotonically decreasing in
 $\pi$
. The subsequent theorem shows that
$\pi$
. The subsequent theorem shows that
 $R^\mathrm{(ind)}_{\mathrm{D}}$
is indeed an epidemic threshold.
$R^\mathrm{(ind)}_{\mathrm{D}}$
is indeed an epidemic threshold.
Theorem 2. Let
 $\beta$
,
$\beta$
,
 $\gamma$
and
$\gamma$
and
 $\delta$
be fixed. Then
$\delta$
be fixed. Then
 $R^\mathrm{(ind)}_{\mathrm{D}}$
is monotonically decreasing in
$R^\mathrm{(ind)}_{\mathrm{D}}$
is monotonically decreasing in
 $\pi.$
That is, for any
$\pi.$
That is, for any
 $0\leq \pi_{1}<\pi_{2}\leq 1$
, we have
$0\leq \pi_{1}<\pi_{2}\leq 1$
, we have
 $R^\mathrm{(ind)}_{\mathrm{D}}(\pi_{1}) > R^\mathrm{(ind)}_{\mathrm{D}}(\pi_{2})$
.
$R^\mathrm{(ind)}_{\mathrm{D}}(\pi_{1}) > R^\mathrm{(ind)}_{\mathrm{D}}(\pi_{2})$
.
Theorem 3. Let
 $\beta$
,
$\beta$
,
 $\gamma$
and
$\gamma$
and
 $\delta$
be fixed. Then
$\delta$
be fixed. Then
 $R_{\mathrm{D}}=R^\mathrm{(ind)}_{\mathrm{D}}=1$
at
$R_{\mathrm{D}}=R^\mathrm{(ind)}_{\mathrm{D}}=1$
at
 $\pi = \pi_{\mathrm{c}}$
, and
$\pi = \pi_{\mathrm{c}}$
, and
 $R_{\mathrm{D}}>1$
as well as
$R_{\mathrm{D}}>1$
as well as
 $R^\mathrm{(ind)}_{\mathrm{D}}>1$
if
$R^\mathrm{(ind)}_{\mathrm{D}}>1$
if
 $\pi<\pi_{\mathrm{c}}$
, with the opposite being true if
$\pi<\pi_{\mathrm{c}}$
, with the opposite being true if
 $\pi>\pi_{\mathrm{c}}$
.
$\pi>\pi_{\mathrm{c}}$
.
3.2. Combined model with manual and digital contact tracing
Finally, we state related results as above, but now for the beginning of the epidemic in the combined model of Subsection 2.3, including digital as well as manual contact tracing, which we denote by
 $E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
. More specifically, the result shows that the combined tracing model is well approximated by the multi-type process defined in the text, and that this process when characterized by its to-be-traced components allows for a branching process description.
$E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
. More specifically, the result shows that the combined tracing model is well approximated by the multi-type process defined in the text, and that this process when characterized by its to-be-traced components allows for a branching process description.
Proposition 2. Consider a sequence of epidemic processes with both manual and digital tracing,
 $E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
for population size n, starting with one initial infective. Then on any finite time interval,
$E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
for population size n, starting with one initial infective. Then on any finite time interval,
 $E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
converges in distribution to the limit process
$E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
converges in distribution to the limit process
 $E^{}_{\mathrm{ DM}}(\beta,\gamma,\delta,p,\pi)$
as
$E^{}_{\mathrm{ DM}}(\beta,\gamma,\delta,p,\pi)$
as
 $n\to\infty.$
$n\to\infty.$
Corollary 2. Let
 $Z^{(n)}_{\mathrm{DM}}$
be the final number infected in the whole epidemic
$Z^{(n)}_{\mathrm{DM}}$
be the final number infected in the whole epidemic
 $E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
. If the reproduction number
$E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
. If the reproduction number
 $R_{\mathrm{DM}} > 1,$
then
$R_{\mathrm{DM}} > 1,$
then
 $Z^{(n)}_{\mathrm{DM}} {\to} \infty$
with non-zero probability; and if
$Z^{(n)}_{\mathrm{DM}} {\to} \infty$
with non-zero probability; and if
 $R_{\mathrm{DM}} \leq 1,$
then the final fraction
$R_{\mathrm{DM}} \leq 1,$
then the final fraction
 $\bar Z^{(n)}_{\mathrm{DM}} = Z^{(n)}_{\mathrm{DM}}/n \overset{\mathrm{p}}{\to} 0$
, i.e. there will be a minor outbreak for sure.
$\bar Z^{(n)}_{\mathrm{DM}} = Z^{(n)}_{\mathrm{DM}}/n \overset{\mathrm{p}}{\to} 0$
, i.e. there will be a minor outbreak for sure.
Table 2. Key quantities related to the epidemic processes and their corresponding limit branching processes

Table 2 lists the important quantities.
4. Approximation of the initial phase in a large community with digital tracing only
In this section, we first prove Proposition 1 in Subsection 4.1 and then, in Subsection 4.2, derive the effective reproduction number for digital tracing and prove Corollary 1. In Subsection 4.3, the proof of Theorem 1 is presented, where we compare the effectiveness of manual and digital tracing analytically. Finally, in Subsection 4.4, we derive an individual reproduction number for digital tracing and prove Theorems 2 and 3.
4.1. Proof of Proposition 1
We recall that for a population of size n, the epidemic process with digital contact tracing is denoted by
 $E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
, where there is one initial infective. The limit process
$E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
, where there is one initial infective. The limit process
 $E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
is defined as follows. There are two types of individuals: non-app-users and app-users. At time
$E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
is defined as follows. There are two types of individuals: non-app-users and app-users. At time
 $t=0$
, there is one initial ancestor (who has the same type as the initial case in
$t=0$
, there is one initial ancestor (who has the same type as the initial case in
 $E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
). During the lifetime, each individual gives birth to app-users at rate
$E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
). During the lifetime, each individual gives birth to app-users at rate
 $\beta\pi$
and non-app-users at rate
$\beta\pi$
and non-app-users at rate
 $\beta(1-\pi)$
. Individuals recover naturally at rate
$\beta(1-\pi)$
. Individuals recover naturally at rate
 $\gamma$
and are diagnosed at rate
$\gamma$
and are diagnosed at rate
 $\delta.$
Once an app-user is diagnosed, all of their app-using descendants and their parent (if an app-user) are diagnosed at the same time, and so on. In particular, if traced individuals have recovered, they will still be diagnosed, implying that their app-using contacts will also be traced, and so on.
$\delta.$
Once an app-user is diagnosed, all of their app-using descendants and their parent (if an app-user) are diagnosed at the same time, and so on. In particular, if traced individuals have recovered, they will still be diagnosed, implying that their app-using contacts will also be traced, and so on.
First, we note that there is a new infection, recovery, or diagnosis in the epidemic whenever a new birth, death, or removal occurs in
 $E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
, respectively. The rates of recovery (
$E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
, respectively. The rates of recovery (
 $\gamma$
) and diagnosis (
$\gamma$
) and diagnosis (
 $\delta$
) are the same as those of death and removal. An infection is ‘successful’ only when the contacted person is susceptible. Let
$\delta$
) are the same as those of death and removal. An infection is ‘successful’ only when the contacted person is susceptible. Let
 $S_{n}(t)$
be the number of susceptibles in the nth epidemic
$S_{n}(t)$
be the number of susceptibles in the nth epidemic
 $E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
at time t; then the probability that a given infective infects a new app-user is
$E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
at time t; then the probability that a given infective infects a new app-user is
 $\pi S_{n}(t)/n$
. This implies that the rate of new infection of app-users is
$\pi S_{n}(t)/n$
. This implies that the rate of new infection of app-users is
 $\beta\pi S_{n}(t)/n$
. On the other hand, the rate of birth to app-users is
$\beta\pi S_{n}(t)/n$
. On the other hand, the rate of birth to app-users is
 $\beta\pi.$
When n is large and at the beginning of the epidemic, we have
$\beta\pi.$
When n is large and at the beginning of the epidemic, we have
 $S_{n}(t)\approx n,$
so the rate of infection of app-users is close to the app-using birth rate in the limit process
$S_{n}(t)\approx n,$
so the rate of infection of app-users is close to the app-using birth rate in the limit process
 $E_{\mathrm{D}}(\beta,\gamma,\delta,\pi).$
Similarly, the rate of infection of non-app-users,
$E_{\mathrm{D}}(\beta,\gamma,\delta,\pi).$
Similarly, the rate of infection of non-app-users,
 $\beta(1-\pi) S_{n}(t)/n$
, is close to the rate of birth to non-app-users,
$\beta(1-\pi) S_{n}(t)/n$
, is close to the rate of birth to non-app-users,
 $\beta(1-\pi).$
Using the standard coupling arguments for epidemic models (see [Reference Ball and Donnelly3]), it can be shown that on any fixed time horizon the epidemic
$\beta(1-\pi).$
Using the standard coupling arguments for epidemic models (see [Reference Ball and Donnelly3]), it can be shown that on any fixed time horizon the epidemic
 $E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
converges in distribution to the limit process
$E^{(n)}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
converges in distribution to the limit process
 $E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
as
$E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
as
 $n \to \infty.$
$n \to \infty.$
As discussed in Section 3, instead of describing
 $E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
in terms of the actual individuals, we treat it as a process of app-using components and non-app-users, which is a two-type branching process. If there are currently k alive (i.e. infectious) app-users in an app-using component, and each such individual gives birth to (infects) new app-users at rate
$E_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
in terms of the actual individuals, we treat it as a process of app-using components and non-app-users, which is a two-type branching process. If there are currently k alive (i.e. infectious) app-users in an app-using component, and each such individual gives birth to (infects) new app-users at rate
 $\beta \pi$
, the total birth rate is
$\beta \pi$
, the total birth rate is
 $k\beta \pi$
. Each individual recovers naturally at rate
$k\beta \pi$
. Each individual recovers naturally at rate
 $\gamma$
, so the overall recovery rate equals
$\gamma$
, so the overall recovery rate equals
 $k\gamma$
. Finally, the whole component is diagnosed once one of the k infectious individuals is diagnosed, so the total rate of diagnosis is
$k\gamma$
. Finally, the whole component is diagnosed once one of the k infectious individuals is diagnosed, so the total rate of diagnosis is
 $k \delta$
. While having k infectious app-users, the component generates new (i.e. infects) non-app-users at rate
$k \delta$
. While having k infectious app-users, the component generates new (i.e. infects) non-app-users at rate
 $k\beta(1- \pi)$
, whereas the component cannot give birth to new app-using components because any infected app-user will belong to the same component. On the other hand, the non-app-users give birth to new app-using components at rate
$k\beta(1- \pi)$
, whereas the component cannot give birth to new app-using components because any infected app-user will belong to the same component. On the other hand, the non-app-users give birth to new app-using components at rate
 $\beta \pi$
and non-app-users at rate
$\beta \pi$
and non-app-users at rate
 $\beta(1- \pi)$
.
$\beta(1- \pi)$
.
In Figure 1, we illustrate how the two types of ‘individuals’, app-using components (surrounded by dashed lines) and non-app-users (square-shaped nodes), grow and eventually die out. We set the app-user A1 to be the initial case. While the app-using component
 $C^\mathrm{(app)}_{1}$
evolves (as new app-users get infected or existing ones recover), it infects two non-app-users N1 and N2. The non-app-user N1 infects one non-app-user and one new app-using component
$C^\mathrm{(app)}_{1}$
evolves (as new app-users get infected or existing ones recover), it infects two non-app-users N1 and N2. The non-app-user N1 infects one non-app-user and one new app-using component
 $C^\mathrm{(app)}_{2}$
with root A2, whereas N2 infects two other non-app-users. Once the app-user A2 is diagnosed, the whole app-using component
$C^\mathrm{(app)}_{2}$
with root A2, whereas N2 infects two other non-app-users. Once the app-user A2 is diagnosed, the whole app-using component
 $C^\mathrm{(app)}_{2}$
will die out.
$C^\mathrm{(app)}_{2}$
will die out.

Figure 1. Example of the dynamics of app-using components and non-app-users for the model with digital contact tracing: the circular nodes represent app-users and the squares non-app-users. The white, black, and grey shadings correspond to infectious, diagnosed, and naturally recovered, respectively. A rectangular region surrounded by dashed lines represents an app-using component, and the area is hatched with diagonal lines when the whole component is diagnosed and removed.
The advantage of the approximation outlined above is that multi-type branching processes are well studied (see e.g. [Reference Athreya and Ney2, Reference Becker and Marschner8]). As a consequence, in the next subsection, we derive an effective reproduction number which has a threshold value of 1, determining whether a major outbreak is possible or not.
4.2. Proof of Corollary 1
From standard multi-type branching process theory [Reference Athreya and Ney2, Reference Becker and Marschner8], the limit process
 $E^{}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
is known to be sub-critical if
$E^{}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
is known to be sub-critical if
 $R_{\mathrm{D}}<1$
, critical if
$R_{\mathrm{D}}<1$
, critical if
 $R_{\mathrm{D}}=1$
, and super-critical if
$R_{\mathrm{D}}=1$
, and super-critical if
 $R_{\mathrm{D}} > 1$
, where
$R_{\mathrm{D}} > 1$
, where
 $R_{\mathrm{D}}$
is the largest eigenvalue of the mean-offspring matrix M defined by (2), which is given by
$R_{\mathrm{D}}$
is the largest eigenvalue of the mean-offspring matrix M defined by (2), which is given by
 \begin{equation} R_{\mathrm{D}} = \frac{m_{11}+m_{22}}{2}+\sqrt{\frac{(m_{11}+m_{22})^2}{4}-m_{11}m_{22}+m_{12}m_{21}}.\end{equation}
\begin{equation} R_{\mathrm{D}} = \frac{m_{11}+m_{22}}{2}+\sqrt{\frac{(m_{11}+m_{22})^2}{4}-m_{11}m_{22}+m_{12}m_{21}}.\end{equation}
Let
 $Z_{\mathrm{D}}$
be the total progeny of
$Z_{\mathrm{D}}$
be the total progeny of
 $E^{}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
. Then
$E^{}_{\mathrm{D}}(\beta,\gamma,\delta,\pi)$
. Then
 $Z_{\mathrm{D}} < \infty$
(the process goes extinct) with probability 1 if
$Z_{\mathrm{D}} < \infty$
(the process goes extinct) with probability 1 if
 $R_{\mathrm{ D}}<1$
; and if
$R_{\mathrm{ D}}<1$
; and if
 $R_{\mathrm{D}}>1$
,
$R_{\mathrm{D}}>1$
,
 $Z_{\mathrm{D}} = \infty$
(the process grows beyond all limits) with a strictly positive probability. Then it follows from Proposition 1 that if
$Z_{\mathrm{D}} = \infty$
(the process grows beyond all limits) with a strictly positive probability. Then it follows from Proposition 1 that if
 $R_{\mathrm{D}} > 1$
,
$R_{\mathrm{D}} > 1$
,
 $\:Z^{(n)}_{\mathrm{D}} \to \infty$
with non-zero probability (there may be a large outbreak of the epidemic), and if
$\:Z^{(n)}_{\mathrm{D}} \to \infty$
with non-zero probability (there may be a large outbreak of the epidemic), and if
 $R_{\mathrm{D}} \leq 1,$
$R_{\mathrm{D}} \leq 1,$
 $\:Z^{(n)}_{\mathrm{D}} \to Z_{\mathrm{D}}$
, implying that the final fraction getting infected,
$\:Z^{(n)}_{\mathrm{D}} \to Z_{\mathrm{D}}$
, implying that the final fraction getting infected,
 $Z^{(n)}_{\mathrm{D}}/n$
, tends to 0. Hence, we have proved that
$Z^{(n)}_{\mathrm{D}}/n$
, tends to 0. Hence, we have proved that
 $R_{\mathrm{D}}$
is an epidemic threshold. We denote the effective reproduction number for the epidemic model with digital tracing by
$R_{\mathrm{D}}$
is an epidemic threshold. We denote the effective reproduction number for the epidemic model with digital tracing by
 $R_{\mathrm{D}}$
.
$R_{\mathrm{D}}$
.
To get an explicit expression for
 $R_{\mathrm{D}}$
, we derive the elements
$R_{\mathrm{D}}$
, we derive the elements
 $m_{ij}$
as follows. First, we note that the app-using components (type 1) cannot give birth to new app-using components, since app-users infected by an app-using component will belong to the same component. Consequently, we have that
$m_{ij}$
as follows. First, we note that the app-using components (type 1) cannot give birth to new app-using components, since app-users infected by an app-using component will belong to the same component. Consequently, we have that
 \begin{equation} m_{11}= 0.\end{equation}
\begin{equation} m_{11}= 0.\end{equation}
As for non-app users, they will never be reached by digital tracing and thus spread the infection like in the epidemic without any contact tracing. That is, each infectious non-app-user infects non-app-users at rate
 $\beta(1-\pi)$
and app-users at rate
$\beta(1-\pi)$
and app-users at rate
 $\beta\pi$
, where the infectious periods of non-app-users are independent and identically exponentially distributed with intensity
$\beta\pi$
, where the infectious periods of non-app-users are independent and identically exponentially distributed with intensity
 $\delta+\gamma$
. Hence, the numbers of app-using components (type 1) and non-app-users (type 2) infected by one typical non-app-user are geometrically distributed with support
$\delta+\gamma$
. Hence, the numbers of app-using components (type 1) and non-app-users (type 2) infected by one typical non-app-user are geometrically distributed with support
 $\{0,1,2,\ldots\}$
and, respectively, mean
$\{0,1,2,\ldots\}$
and, respectively, mean
 \begin{equation} m_{21}=\frac{\beta\pi}{\delta+\gamma}=R_{0}\pi\end{equation}
\begin{equation} m_{21}=\frac{\beta\pi}{\delta+\gamma}=R_{0}\pi\end{equation}
and mean
 \begin{equation} m_{22}=\frac{\beta(1-\pi)}{\delta+\gamma}=R_{0}(1-\pi),\end{equation}
\begin{equation} m_{22}=\frac{\beta(1-\pi)}{\delta+\gamma}=R_{0}(1-\pi),\end{equation}
where
 $R_{0}$
is given by (1).
$R_{0}$
is given by (1).
Finally, it remains to compute
 $m_{12}.$
Let X(t) be the number of infectious app-users in an app-using component at time t, with
$m_{12}.$
Let X(t) be the number of infectious app-users in an app-using component at time t, with
 $X(0)=1.$
We know that
$X(0)=1.$
We know that
 $\{X(t), t\geq 0\}$
behaves as a linear birth–death process with birth rate
$\{X(t), t\geq 0\}$
behaves as a linear birth–death process with birth rate
 $\beta \pi$
(new app-users infected) and death rate
$\beta \pi$
(new app-users infected) and death rate
 $\gamma$
(natural recovery), and this process stops when a diagnosis event happens at rate
$\gamma$
(natural recovery), and this process stops when a diagnosis event happens at rate
 $\delta$
(the whole component is then diagnosed). Further, at time s, the component gives birth to new components at rate
$\delta$
(the whole component is then diagnosed). Further, at time s, the component gives birth to new components at rate
 $X(s)\beta(1-\pi).$
Let T be the random variable representing the time of first diagnosis. Then
$X(s)\beta(1-\pi).$
Let T be the random variable representing the time of first diagnosis. Then
 \begin{equation*} \begin{split} m_{12} & = \mathbb{E}\left[\int_{0}^{T} \beta(1-\pi) X(t) \,{\mathrm{d}} t\right]\\ & = \beta(1-\pi) \mathbb{E}[A], \end{split}\end{equation*}
\begin{equation*} \begin{split} m_{12} & = \mathbb{E}\left[\int_{0}^{T} \beta(1-\pi) X(t) \,{\mathrm{d}} t\right]\\ & = \beta(1-\pi) \mathbb{E}[A], \end{split}\end{equation*}
where we set
 \begin{align*}A \,:\!= \int_{0}^{T} X(t) \,{\mathrm{d}} t.\end{align*}
\begin{align*}A \,:\!= \int_{0}^{T} X(t) \,{\mathrm{d}} t.\end{align*}
The process
 $\{X(t)\}$
is piecewise constant, and the jump rate of X(t) is proportional to X(t). More precisely, the contribution to the integral between two jumps
$\{X(t)\}$
is piecewise constant, and the jump rate of X(t) is proportional to X(t). More precisely, the contribution to the integral between two jumps
 $T_i$
and
$T_i$
and
 $T_{i+1}$
(prior to T) is
$T_{i+1}$
(prior to T) is
 $X(T_i )Y$
, where
$X(T_i )Y$
, where
 $Y\sim \mathrm{Exp}((\beta \pi + \gamma + \delta)X(T_i))$
. But this contribution is simply
$Y\sim \mathrm{Exp}((\beta \pi + \gamma + \delta)X(T_i))$
. But this contribution is simply
 $1\cdot \tilde Y$
where
$1\cdot \tilde Y$
where
 $\tilde Y\sim \mathrm{Exp}(\beta \pi + \gamma + \delta)$
. For this reason, A equals the integral of 1 integrated up until the first time a new process
$\tilde Y\sim \mathrm{Exp}(\beta \pi + \gamma + \delta)$
. For this reason, A equals the integral of 1 integrated up until the first time a new process
 $\{\tilde{X}(t), t\geq 0\}$
, which is a random time-change version of the process
$\{\tilde{X}(t), t\geq 0\}$
, which is a random time-change version of the process
 $\{X(t),t\geq 0\}$
, reaches the value 0. More precisely, the time span of
$\{X(t),t\geq 0\}$
, reaches the value 0. More precisely, the time span of
 $\{\tilde{X}(t)\}$
is slowed down by
$\{\tilde{X}(t)\}$
is slowed down by
 $\{X(t)^{-1}\}$
at time t. This new process
$\{X(t)^{-1}\}$
at time t. This new process
 $\{\tilde{X}(t), t\geq 0\}$
is therefore a continuous-time random walk going up at
$\{\tilde{X}(t), t\geq 0\}$
is therefore a continuous-time random walk going up at
 $\beta \pi$
, going down at
$\beta \pi$
, going down at
 $\gamma$
, and absorbing at zero. Let
$\gamma$
, and absorbing at zero. Let
 $\tilde{T}_{\mathrm{ rw}}=\inf\{t > 0\,:\, \tilde{X}(t)=0\}$
and
$\tilde{T}_{\mathrm{ rw}}=\inf\{t > 0\,:\, \tilde{X}(t)=0\}$
and
 $\tilde{T}=\tilde{T}_{\mathrm{rw}} \land \tilde{T}_{\mathrm{D}},$
where
$\tilde{T}=\tilde{T}_{\mathrm{rw}} \land \tilde{T}_{\mathrm{D}},$
where
 $\tilde{T}_{\mathrm{D}} \sim \mathrm{Exp}(\delta)$
, which is independent of
$\tilde{T}_{\mathrm{D}} \sim \mathrm{Exp}(\delta)$
, which is independent of
 $\{\tilde{X}(t), t\geq 0\}$
and hence independent of
$\{\tilde{X}(t), t\geq 0\}$
and hence independent of
 $\tilde{T}_{\mathrm{rw}}$
. Then it follows that
$\tilde{T}_{\mathrm{rw}}$
. Then it follows that
 $A=\int_0^T X(t)\,{\mathrm{d}} t$
and
$A=\int_0^T X(t)\,{\mathrm{d}} t$
and
 $\tilde T=\int_0^{\tilde T} 1\,{\mathrm{d}} t$
have the same distribution. As a consequence,
$\tilde T=\int_0^{\tilde T} 1\,{\mathrm{d}} t$
have the same distribution. As a consequence,
 \begin{equation*}\begin{split} \mathbb{E}[A] &= \mathbb{E}[\tilde{T}] \\ &= \int_{0}^{\infty} \mathbb{P}(\tilde{T}_{\mathrm{rw}} >t) \mathbb{P}(\tilde{T}_{\mathrm{D}} >t)\,{\mathrm{d}} t \\ &= \int_{0}^{\infty} \mathbb{P}(\tilde{T}_{\mathrm{rw}} >t) {\mathrm{e}}^{-\delta t}\,{\mathrm{d}} t \\ &= \frac{1-\phi(\delta)}{\delta},\end{split}\end{equation*}
\begin{equation*}\begin{split} \mathbb{E}[A] &= \mathbb{E}[\tilde{T}] \\ &= \int_{0}^{\infty} \mathbb{P}(\tilde{T}_{\mathrm{rw}} >t) \mathbb{P}(\tilde{T}_{\mathrm{D}} >t)\,{\mathrm{d}} t \\ &= \int_{0}^{\infty} \mathbb{P}(\tilde{T}_{\mathrm{rw}} >t) {\mathrm{e}}^{-\delta t}\,{\mathrm{d}} t \\ &= \frac{1-\phi(\delta)}{\delta},\end{split}\end{equation*}
where
 $\phi(\delta) \,:\!= \mathbb{E}[{\mathrm{e}}^{-\delta \tilde{T}_{\mathrm{rw}}}]$
.
$\phi(\delta) \,:\!= \mathbb{E}[{\mathrm{e}}^{-\delta \tilde{T}_{\mathrm{rw}}}]$
.
Further, if we condition on the first jump of
 $\{\tilde{X}(t), t\geq 0\}$
, we get the following equation for
$\{\tilde{X}(t), t\geq 0\}$
, we get the following equation for
 $\phi(\delta)$
:
$\phi(\delta)$
:
 \begin{equation*} \phi(\delta) = \frac{\beta \pi+\gamma}{\beta \pi+\gamma+\delta} \left(\frac{\beta \pi}{\beta \pi+\gamma}\phi(\delta)^2+\frac{\gamma}{\beta \pi+\gamma}\right),\end{equation*}
\begin{equation*} \phi(\delta) = \frac{\beta \pi+\gamma}{\beta \pi+\gamma+\delta} \left(\frac{\beta \pi}{\beta \pi+\gamma}\phi(\delta)^2+\frac{\gamma}{\beta \pi+\gamma}\right),\end{equation*}
which has two roots,
 $\phi(\delta)=\big(\beta \pi+\gamma+\delta\pm\sqrt{(\beta \pi+\gamma+\delta)^2-4\beta \pi \gamma}\big)/({2\beta \pi})$
. Since
$\phi(\delta)=\big(\beta \pi+\gamma+\delta\pm\sqrt{(\beta \pi+\gamma+\delta)^2-4\beta \pi \gamma}\big)/({2\beta \pi})$
. Since
 $\phi(0)=1$
, we get
$\phi(0)=1$
, we get
 \begin{equation*} \phi(\delta) = \frac{\beta \pi+\gamma+\delta-\sqrt{(\beta \pi+\gamma+\delta)^2-4\beta \pi \gamma}}{2\beta \pi},\end{equation*}
\begin{equation*} \phi(\delta) = \frac{\beta \pi+\gamma+\delta-\sqrt{(\beta \pi+\gamma+\delta)^2-4\beta \pi \gamma}}{2\beta \pi},\end{equation*}
implying that
 \begin{equation*} \mathbb{E}[A] = \frac{\beta \pi-\gamma-\delta+\sqrt{(\beta \pi+\gamma+\delta)^2-4\beta \pi \gamma}}{2\beta \pi \delta}.\end{equation*}
\begin{equation*} \mathbb{E}[A] = \frac{\beta \pi-\gamma-\delta+\sqrt{(\beta \pi+\gamma+\delta)^2-4\beta \pi \gamma}}{2\beta \pi \delta}.\end{equation*}
Hence we obtain
 \begin{equation*} m_{12} = f(\pi)\,:\!= \beta(1-\pi) \mathbb{E}[A] \end{equation*}
\begin{equation*} m_{12} = f(\pi)\,:\!= \beta(1-\pi) \mathbb{E}[A] \end{equation*}
for
 $0 < \pi \leq 1$
.
$0 < \pi \leq 1$
.
In conclusion, the effective component reproduction number
 $R_{\mathrm{D}}$
for the model with digital tracing only is the largest eigenvalue of the matrix
$R_{\mathrm{D}}$
for the model with digital tracing only is the largest eigenvalue of the matrix
 $M=(m_{ij})$
, which is given by (3).
$M=(m_{ij})$
, which is given by (3).
Remark 1. It can be easily checked that
 \begin{align*} \lim_{\pi \to 0} f(\pi) = \frac{\beta(\gamma+\delta)+\beta\delta-\beta\gamma}{2\delta (\gamma+\delta)}=\frac{\beta}{\gamma+\delta} = R_{0}.\end{align*}
\begin{align*} \lim_{\pi \to 0} f(\pi) = \frac{\beta(\gamma+\delta)+\beta\delta-\beta\gamma}{2\delta (\gamma+\delta)}=\frac{\beta}{\gamma+\delta} = R_{0}.\end{align*}
This implies that the reproduction number
 $R_{\mathrm{D}}$
converges to the basic reproduction number
$R_{\mathrm{D}}$
converges to the basic reproduction number
 $R_{0}$
when
$R_{0}$
when
 $\pi\to 0$
, as expected:
$\pi\to 0$
, as expected:
 \begin{align*}\lim_{\pi \to 0} R_{\mathrm{ D}}(\pi)=R_{0}=\frac{\beta}{\gamma+\delta}.\end{align*}
\begin{align*}\lim_{\pi \to 0} R_{\mathrm{ D}}(\pi)=R_{0}=\frac{\beta}{\gamma+\delta}.\end{align*}
Remark 2. The analytical expression for
 $f(\pi)$
can be used to obtain an analytical expression also for the manual tracing model considered in [Reference Zhang and Britton27]. A related birth and death process was studied there. Considering such a to-be-traced component with size k, the component would increase by 1 at rate
$f(\pi)$
can be used to obtain an analytical expression also for the manual tracing model considered in [Reference Zhang and Britton27]. A related birth and death process was studied there. Considering such a to-be-traced component with size k, the component would increase by 1 at rate
 $k\beta p$
, decrease by 1 at rate
$k\beta p$
, decrease by 1 at rate
 $k\gamma$
, and jump to 0 at rate
$k\gamma$
, and jump to 0 at rate
 $k\delta.$
And before jumping, the component gave birth to new components at rate
$k\delta.$
And before jumping, the component gave birth to new components at rate
 $k\beta (1-p).$
Using similar arguments to the above, we get the following explicit expression for the reproduction number (which in [Reference Zhang and Britton27] was expressed using an infinite sum):
$k\beta (1-p).$
Using similar arguments to the above, we get the following explicit expression for the reproduction number (which in [Reference Zhang and Britton27] was expressed using an infinite sum):
 \begin{equation}R^\mathrm{(c)}_{\mathrm{M}}(p) = f(\pi=p)= \frac{1-p}{2 p \delta} \Big(\beta p-\gamma-\delta+\sqrt{(\beta p+\gamma+\delta)^2-4\beta p \gamma}\Big).\end{equation}
\begin{equation}R^\mathrm{(c)}_{\mathrm{M}}(p) = f(\pi=p)= \frac{1-p}{2 p \delta} \Big(\beta p-\gamma-\delta+\sqrt{(\beta p+\gamma+\delta)^2-4\beta p \gamma}\Big).\end{equation}
4.3. Proof of Theorem 1
In this section, we compare the separate effects of manual and digital contact tracing by proving Theorem 1. We fix the epidemic parameters
 $\beta,\delta$
, and
$\beta,\delta$
, and
 $\gamma$
such that
$\gamma$
such that
 $\beta/(\delta+\gamma)>1$
, and consider the reproduction number for manual tracing,
$\beta/(\delta+\gamma)>1$
, and consider the reproduction number for manual tracing,
 $R^\mathrm{(c)}_{\mathrm{M}}(p)$
, and the one for digital tracing,
$R^\mathrm{(c)}_{\mathrm{M}}(p)$
, and the one for digital tracing,
 $R^{}_{\mathrm{D}}(\pi)$
, as functions of p and
$R^{}_{\mathrm{D}}(\pi)$
, as functions of p and
 $\pi$
, respectively. We first state and prove two lemmas.
$\pi$
, respectively. We first state and prove two lemmas.
Lemma 1. Suppose that
 $R_0=\beta/(\delta+\gamma)>1$
. Then the critical manual reporting probability
$R_0=\beta/(\delta+\gamma)>1$
. Then the critical manual reporting probability
 $p_{\mathrm{c}}$
(satisfying
$p_{\mathrm{c}}$
(satisfying
 $R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}})=1$
) is given by
$R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}})=1$
) is given by
 \begin{equation} p_{\mathrm{c}} = \frac{\beta-(\gamma+\delta)}{\beta-\gamma}.\end{equation}
\begin{equation} p_{\mathrm{c}} = \frac{\beta-(\gamma+\delta)}{\beta-\gamma}.\end{equation}
Proof. First, we show the existence of the critical probability
 $p_{\mathrm{c}}$
. Based on Remarks 1 and 2,
$p_{\mathrm{c}}$
. Based on Remarks 1 and 2,
 $R^\mathrm{(c)}_{\mathrm{M}}(p)$
is continuous in p with
$R^\mathrm{(c)}_{\mathrm{M}}(p)$
is continuous in p with
 $R^\mathrm{(c)}_{\mathrm{M}}(0)=R_{0}>1$
and
$R^\mathrm{(c)}_{\mathrm{M}}(0)=R_{0}>1$
and
 $R^\mathrm{(c)}_{\mathrm{M}}(1)=0<1$
. By the intermediate value theorem, there exists at least one
$R^\mathrm{(c)}_{\mathrm{M}}(1)=0<1$
. By the intermediate value theorem, there exists at least one
 $p_{\mathrm{c}}$
in (0,1) such that
$p_{\mathrm{c}}$
in (0,1) such that
 $R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}})=1.$
$R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}})=1.$
Next, we compute
 $p_{\mathrm{c}}$
and show that there is only one
$p_{\mathrm{c}}$
and show that there is only one
 $p_{\mathrm{c}}$
. Without loss of generality, we can assume that
$p_{\mathrm{c}}$
. Without loss of generality, we can assume that
 $\gamma+\delta=1$
; then the formula for
$\gamma+\delta=1$
; then the formula for
 $R^\mathrm{(c)}_{\mathrm{M}} $
in (9) becomes
$R^\mathrm{(c)}_{\mathrm{M}} $
in (9) becomes
 \begin{align*} R^\mathrm{(c)}_{\mathrm{M}}(p) &= \frac{(1-p)}{2 p (1-\gamma)} \Big(\beta p-1+\sqrt{(\beta p+1)^2-4\beta p \gamma}\Big)\\&= \frac{1}{2(1-\gamma)} \frac{(1-p)}{p } \Big(\beta p-1+\sqrt{(\beta p-1)^2+4\beta p (1-\gamma)}\Big)\\&= \frac{(1-p)}{2(1-\gamma)}\left(\beta-\frac{1}{p}+\sqrt{\left(\beta-\frac{1}{p}\right)^2+4\beta (1-\gamma)\frac{1}{p}}\right).\end{align*}
\begin{align*} R^\mathrm{(c)}_{\mathrm{M}}(p) &= \frac{(1-p)}{2 p (1-\gamma)} \Big(\beta p-1+\sqrt{(\beta p+1)^2-4\beta p \gamma}\Big)\\&= \frac{1}{2(1-\gamma)} \frac{(1-p)}{p } \Big(\beta p-1+\sqrt{(\beta p-1)^2+4\beta p (1-\gamma)}\Big)\\&= \frac{(1-p)}{2(1-\gamma)}\left(\beta-\frac{1}{p}+\sqrt{\left(\beta-\frac{1}{p}\right)^2+4\beta (1-\gamma)\frac{1}{p}}\right).\end{align*}
It follows by standard calculations that
 $R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}}) = 1$
is equivalent to
$R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}}) = 1$
is equivalent to
 \begin{equation*} p_{\mathrm{c}} = \frac{\beta -1}{\beta-\gamma}.\end{equation*}
\begin{equation*} p_{\mathrm{c}} = \frac{\beta -1}{\beta-\gamma}.\end{equation*}
We recall that the parameters have been scaled so far. Returning to the original scale, we have
 \begin{equation*} p_{\mathrm{c}} = \frac{\beta -(\gamma+\delta)}{\beta-\gamma}.\end{equation*}
\begin{equation*} p_{\mathrm{c}} = \frac{\beta -(\gamma+\delta)}{\beta-\gamma}.\end{equation*}
Lemma 2. Let
 $p_{\mathrm{c}}$
be the critical manual reporting probability such that
$p_{\mathrm{c}}$
be the critical manual reporting probability such that
 $R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}})=1.$
Then there exists at least one
$R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}})=1.$
Then there exists at least one
 $\pi_{\mathrm{c}}$
lying in
$\pi_{\mathrm{c}}$
lying in
 $(p_{\mathrm{c}}, 1)$
that satisfies
$(p_{\mathrm{c}}, 1)$
that satisfies
 $R^{}_{\mathrm{D}}(\pi_{\mathrm{c}})=1.$
$R^{}_{\mathrm{D}}(\pi_{\mathrm{c}})=1.$
Proof. First, we know that
 $R^{}_{\mathrm{D}}(\pi)$
is continuous in
$R^{}_{\mathrm{D}}(\pi)$
is continuous in
 $\pi$
and that when
$\pi$
and that when
 $\pi=1$
,
$\pi=1$
,
 $R^{}_{\mathrm{D}}=0.$
Letting
$R^{}_{\mathrm{D}}=0.$
Letting
 $\pi = p_{\mathrm{c}}$
in (3) gives
$\pi = p_{\mathrm{c}}$
in (3) gives
 \begin{equation} R_{\mathrm{D}}(p_{\mathrm{c}}) = \frac{R_{0}(1-p_{\mathrm{c}})}{2}+\sqrt{\frac{( R_{0}(1-p_{\mathrm{c}}))^2}{4}+R_{0}p_{\mathrm{c}}} > 1\end{equation}
\begin{equation} R_{\mathrm{D}}(p_{\mathrm{c}}) = \frac{R_{0}(1-p_{\mathrm{c}})}{2}+\sqrt{\frac{( R_{0}(1-p_{\mathrm{c}}))^2}{4}+R_{0}p_{\mathrm{c}}} > 1\end{equation}
(the first equality follows from
 $f(p_{\mathrm{c}})= R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}})=1$
). Then it follows by the intermediate value theorem that there exists at least one
$f(p_{\mathrm{c}})= R^\mathrm{(c)}_{\mathrm{M}}(p_{\mathrm{c}})=1$
). Then it follows by the intermediate value theorem that there exists at least one
 $\pi_{\mathrm{c}}$
lying in
$\pi_{\mathrm{c}}$
lying in
 $(p_{\mathrm{c}}, 1)$
that satisfies
$(p_{\mathrm{c}}, 1)$
that satisfies
 $R^{}_{\mathrm{D}}(\pi_{\mathrm{c}})=1.$
$R^{}_{\mathrm{D}}(\pi_{\mathrm{c}})=1.$
Lemma 3. For any critical app-using fraction
 $\pi_{\mathrm{c}}$
such that
$\pi_{\mathrm{c}}$
such that
 $R^{}_{\mathrm{D}}(\pi_{\mathrm{c}})=1,$
the reproduction number with manual tracing at
$R^{}_{\mathrm{D}}(\pi_{\mathrm{c}})=1,$
the reproduction number with manual tracing at
 $p=\pi_{\mathrm{c}}$
is below 1, i.e.
$p=\pi_{\mathrm{c}}$
is below 1, i.e.
 \begin{equation*} R^\mathrm{(c)}_{\mathrm{M}}(\pi_{\mathrm{c}}) < 1.\end{equation*}
\begin{equation*} R^\mathrm{(c)}_{\mathrm{M}}(\pi_{\mathrm{c}}) < 1.\end{equation*}
Proof. The equality
 $R_{\mathrm{D}}(\pi_{\mathrm{c}})=1$
is equivalent to
$R_{\mathrm{D}}(\pi_{\mathrm{c}})=1$
is equivalent to
 \begin{equation*} R^\mathrm{(c)}_{\mathrm{M}}(\pi_{\mathrm{c}})= \frac{1-R_{0}(1-\pi_{\mathrm{c}})}{R_{0}\pi_{\mathrm{c}}}=1-\frac{R_{0}-1}{R_{0}\pi_{\mathrm{c}}}. \end{equation*}
\begin{equation*} R^\mathrm{(c)}_{\mathrm{M}}(\pi_{\mathrm{c}})= \frac{1-R_{0}(1-\pi_{\mathrm{c}})}{R_{0}\pi_{\mathrm{c}}}=1-\frac{R_{0}-1}{R_{0}\pi_{\mathrm{c}}}. \end{equation*}
On the other hand, we get
 $({R_{0}-1})/({R_{0}\pi_{\mathrm{c}}}) >0$
, since
$({R_{0}-1})/({R_{0}\pi_{\mathrm{c}}}) >0$
, since
 $R_{0}>1$
by assumption. This implies that
$R_{0}>1$
by assumption. This implies that
 $R^\mathrm{(c)}_{\mathrm{M}}(\pi_{\mathrm{c}})$
is smaller than 1.
$R^\mathrm{(c)}_{\mathrm{M}}(\pi_{\mathrm{c}})$
is smaller than 1.
We are now ready to prove Theorem 1.
Proof of Theorem 1. By Lemma 2, we know that there exists at least one
 $\pi_{\mathrm{c}}$
lying between
$\pi_{\mathrm{c}}$
lying between
 $p_{\mathrm{c}}$
and 1. Suppose that there exists a
$p_{\mathrm{c}}$
and 1. Suppose that there exists a
 $\pi'$
which is smaller than
$\pi'$
which is smaller than
 $p_{\mathrm{c}}$
(
$p_{\mathrm{c}}$
(
 $\pi' < p_{\mathrm{c}}$
) and such that
$\pi' < p_{\mathrm{c}}$
) and such that
 $R_{\mathrm{D}}(\pi =\pi') =1. $
Then, by Lemma 3, the reproduction number with manual tracing at point
$R_{\mathrm{D}}(\pi =\pi') =1. $
Then, by Lemma 3, the reproduction number with manual tracing at point
 $p=\pi'$
satisfies
$p=\pi'$
satisfies
 \begin{align*}R^\mathrm{(c)}_{\mathrm{M}}(\pi') < 1.\end{align*}
\begin{align*}R^\mathrm{(c)}_{\mathrm{M}}(\pi') < 1.\end{align*}
Again using the facts that
 $R^\mathrm{(c)}_{\mathrm{M}}(p=0)=R_{0}>1$
and that
$R^\mathrm{(c)}_{\mathrm{M}}(p=0)=R_{0}>1$
and that
 $R^\mathrm{(c)}_{\mathrm{M}}(p)$
is continuous in p, by the intermediate value theorem there must exist one p
′ lying in
$R^\mathrm{(c)}_{\mathrm{M}}(p)$
is continuous in p, by the intermediate value theorem there must exist one p
′ lying in
 $(0,\pi')$
such that
$(0,\pi')$
such that
 \begin{align*}R^\mathrm{(c)}_{\mathrm{M}}(p') = 1.\end{align*}
\begin{align*}R^\mathrm{(c)}_{\mathrm{M}}(p') = 1.\end{align*}
On the other hand, with Lemma 1 we have shown that
 $p'=p_{\mathrm{c}},$
implying that
$p'=p_{\mathrm{c}},$
implying that
 $\pi' > p_{\mathrm{c}}$
, which leads to a contradiction. Hence, there does not exist a
$\pi' > p_{\mathrm{c}}$
, which leads to a contradiction. Hence, there does not exist a
 $\pi'$
which is smaller than
$\pi'$
which is smaller than
 $p_{\mathrm{c}}$
and such that
$p_{\mathrm{c}}$
and such that
 $R_{\mathrm{D}}(\pi') = 1.$
$R_{\mathrm{D}}(\pi') = 1.$
4.4. The effective individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
$R^\mathrm{(ind)}_{\mathrm{D}}$

The interpretation of
 $R_{\mathrm{D}}$
is complicated in that the two types in the limiting branching process are different kinds of objects: type-2 individuals are actual individuals (non-app-users), but type 1 consists of ‘macro-individuals’, the to-be-traced app-using components. In this section, our aim is therefore to convert
$R_{\mathrm{D}}$
is complicated in that the two types in the limiting branching process are different kinds of objects: type-2 individuals are actual individuals (non-app-users), but type 1 consists of ‘macro-individuals’, the to-be-traced app-using components. In this section, our aim is therefore to convert
 $R_{\mathrm{D}}$
to an individual reproduction number
$R_{\mathrm{D}}$
to an individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
.
$R^\mathrm{(ind)}_{\mathrm{D}}$
.
We first derive
 $R^\mathrm{(ind)}_{\text{D-A}}$
, the average number of individuals (of any type) infected by a newly infected app-user, and
$R^\mathrm{(ind)}_{\text{D-A}}$
, the average number of individuals (of any type) infected by a newly infected app-user, and
 $R^\mathrm{(ind)}_{\text{D-N}}$
, the average number of individuals (of any type) infected by a newly infected non-app-user. We note that each infection, irrespective of the type of infector, is of an app-user with probability
$R^\mathrm{(ind)}_{\text{D-N}}$
, the average number of individuals (of any type) infected by a newly infected non-app-user. We note that each infection, irrespective of the type of infector, is of an app-user with probability
 $\pi$
and a non-app-user with probability
$\pi$
and a non-app-user with probability
 $1-\pi$
. This implies that
$1-\pi$
. This implies that
 $R^\mathrm{(ind)}_{\mathrm{D}}$
can be expressed as the sum
$R^\mathrm{(ind)}_{\mathrm{D}}$
can be expressed as the sum
 \begin{equation} R^\mathrm{(ind)}_{\mathrm{D}} = \pi R^\mathrm{(ind)}_{\text{D-A}} + (1-\pi) R^\mathrm{(ind)}_{\text{D-N}} .\end{equation}
\begin{equation} R^\mathrm{(ind)}_{\mathrm{D}} = \pi R^\mathrm{(ind)}_{\text{D-A}} + (1-\pi) R^\mathrm{(ind)}_{\text{D-N}} .\end{equation}
It remains to compute
 $R^\mathrm{(ind)}_{\text{D-A}}$
and
$R^\mathrm{(ind)}_{\text{D-A}}$
and
 $R^\mathrm{(ind)}_{\text{D-N}}$
. From the previous results in Subsection 4.2, we see that a given app-using component infects, on average,
$R^\mathrm{(ind)}_{\text{D-N}}$
. From the previous results in Subsection 4.2, we see that a given app-using component infects, on average,
 $m_{12}$
non-app-users. Let
$m_{12}$
non-app-users. Let
 $\mu^\mathrm{(A)}_{\mathrm{c}}$
be the mean number of app-users that ever get infected in an app-using component. All but one of these
$\mu^\mathrm{(A)}_{\mathrm{c}}$
be the mean number of app-users that ever get infected in an app-using component. All but one of these
 $\mu^\mathrm{(A)}_{\mathrm{c}}$
are infected within the component, and there are, on average,
$\mu^\mathrm{(A)}_{\mathrm{c}}$
are infected within the component, and there are, on average,
 $m_{12}$
‘external’ infections. So in total, there are on average
$m_{12}$
‘external’ infections. So in total, there are on average
 $(\mu^\mathrm{(A)}_{\mathrm{c}} -1)+m_{12}$
infections by an app-using component. As a consequence, the average number of infections per app-user,
$(\mu^\mathrm{(A)}_{\mathrm{c}} -1)+m_{12}$
infections by an app-using component. As a consequence, the average number of infections per app-user,
 $R^\mathrm{(ind)}_{\text{D-A}}$
, is given by
$R^\mathrm{(ind)}_{\text{D-A}}$
, is given by
 \begin{equation} R^\mathrm{(ind)}_{\text{D-A}} = \frac{(\mu^\mathrm{(A)}_{\mathrm{c}} -1)+m_{12}}{\mu^\mathrm{(A)}_{\mathrm{c}}},\end{equation}
\begin{equation} R^\mathrm{(ind)}_{\text{D-A}} = \frac{(\mu^\mathrm{(A)}_{\mathrm{c}} -1)+m_{12}}{\mu^\mathrm{(A)}_{\mathrm{c}}},\end{equation}
where we recall from (4) that
 $m_{12} = f(\pi).$
$m_{12} = f(\pi).$
Next, we compute
 $\mu^\mathrm{(A)}_{\mathrm{c}}$
. We recall that the size of an app-using component jumps up by 1 if there is a new app-user infection, down by 1 if an app-user recovers naturally, and goes to 0 if an app-user is diagnosed. When considering only the number of jumps the process makes, we can forget the jump rates and simply let each time step correspond to a jump. The true process starts at
$\mu^\mathrm{(A)}_{\mathrm{c}}$
. We recall that the size of an app-using component jumps up by 1 if there is a new app-user infection, down by 1 if an app-user recovers naturally, and goes to 0 if an app-user is diagnosed. When considering only the number of jumps the process makes, we can forget the jump rates and simply let each time step correspond to a jump. The true process starts at
 $X_0=1$
and jumps up, down, or to 0 with probabilities
$X_0=1$
and jumps up, down, or to 0 with probabilities
 $\beta\pi/(\beta\pi+\gamma+\delta)$
,
$\beta\pi/(\beta\pi+\gamma+\delta)$
,
 $\gamma/(\beta\pi+\gamma+\delta)$
, or
$\gamma/(\beta\pi+\gamma+\delta)$
, or
 $\delta/(\beta\pi+\gamma+\delta)$
, respectively, and the process is absorbed when it hits 0 for the first time, K. Let
$\delta/(\beta\pi+\gamma+\delta)$
, respectively, and the process is absorbed when it hits 0 for the first time, K. Let
 $X^{+}$
be the number of up-jumps before the process is absorbed to 0; then we have
$X^{+}$
be the number of up-jumps before the process is absorbed to 0; then we have
 \begin{equation} \mu^\mathrm{(A)}_{\mathrm{c}} = 1+\mathbb{E}[{X}^{+}].\end{equation}
\begin{equation} \mu^\mathrm{(A)}_{\mathrm{c}} = 1+\mathbb{E}[{X}^{+}].\end{equation}
In order to get an expression for
 $\mathbb{E}[{X}^{+}]$
, we extend the process
$\mathbb{E}[{X}^{+}]$
, we extend the process
 $X=\{X_k\}$
to
$X=\{X_k\}$
to
 $\tilde{X}=\{\tilde{X}_k\}$
, which is a renewal process (see Figure 2 for an illustration). More precisely,
$\tilde{X}=\{\tilde{X}_k\}$
, which is a renewal process (see Figure 2 for an illustration). More precisely,
 $ \tilde{X}_k = X_k$
for
$ \tilde{X}_k = X_k$
for
 $k \leq K$
; once absorbed, we continue the
$k \leq K$
; once absorbed, we continue the
 $\tilde{X}$
process by making it jump up to 1 with probability
$\tilde{X}$
process by making it jump up to 1 with probability
 $\beta\pi/(\beta\pi+\gamma+\delta)$
and stay at 0 with the remaining probability. As a consequence,
$\beta\pi/(\beta\pi+\gamma+\delta)$
and stay at 0 with the remaining probability. As a consequence,
 $\tilde{X}$
will jump up to 1 after a number of time steps
$\tilde{X}$
will jump up to 1 after a number of time steps
 $N\sim \mathrm{Geo}(\beta\pi/(\beta\pi+\gamma+\delta))$
(
$N\sim \mathrm{Geo}(\beta\pi/(\beta\pi+\gamma+\delta))$
(
 $N\ge 1$
), and then the process restarts: a renewal has occurred. We also note that the process
$N\ge 1$
), and then the process restarts: a renewal has occurred. We also note that the process
 $\tilde{X}$
makes an up-jump with probability
$\tilde{X}$
makes an up-jump with probability
 $\beta\pi/(\beta\pi+\gamma+\delta)$
each time, whether it is currently at 0 or not.
$\beta\pi/(\beta\pi+\gamma+\delta)$
each time, whether it is currently at 0 or not.

Figure 2. Illustration of the extended process
 $\{\tilde{X}_k\}$
. At first, the original process X hits 0 at the
$\{\tilde{X}_k\}$
. At first, the original process X hits 0 at the
 $K_1$
th jump (after a total of
$K_1$
th jump (after a total of
 $X^{+}=4$
up-jumps); then it stays at zero for
$X^{+}=4$
up-jumps); then it stays at zero for
 $N_1$
time steps before jumping up to 1, so a renewal occurs. Next, the process restarts and makes a number
$N_1$
time steps before jumping up to 1, so a renewal occurs. Next, the process restarts and makes a number
 $K_2$
of jumps until it is absorbed to 0; then, after
$K_2$
of jumps until it is absorbed to 0; then, after
 $N_2$
time steps, a second renewal happens. The numbers
$N_2$
time steps, a second renewal happens. The numbers
 $K_{1}$
and
$K_{1}$
and
 $K_{2}$
are independent and identically distributed copies of K, and
$K_{2}$
are independent and identically distributed copies of K, and
 $N_{1}$
and
$N_{1}$
and
 $N_{2}$
are independent and identically distributed copies of N.
$N_{2}$
are independent and identically distributed copies of N.
Let
 $\tilde{X}^{+}_k$
denote the total number of up-jumps the extended process
$\tilde{X}^{+}_k$
denote the total number of up-jumps the extended process
 $\tilde{X}$
has made up to the k’th jump. Using the renewal reward theorem (see e.g. [Reference Ross23, Chapter 7.4]), we have
$\tilde{X}$
has made up to the k’th jump. Using the renewal reward theorem (see e.g. [Reference Ross23, Chapter 7.4]), we have
 \begin{equation} \lim_{k \to \infty}\frac{\mathbb{E}[\tilde{X}^{+}_k]}{k} = \frac{\mathbb{E}[{X}^{+}]+1}{\mathbb{E}[K]+\mathbb{E}[N]}.\end{equation}
\begin{equation} \lim_{k \to \infty}\frac{\mathbb{E}[\tilde{X}^{+}_k]}{k} = \frac{\mathbb{E}[{X}^{+}]+1}{\mathbb{E}[K]+\mathbb{E}[N]}.\end{equation}
Clearly
 $\tilde{X}^{+}_k\sim \mathrm{Bin}(k,\, \beta\pi/(\beta\pi+\gamma+\delta))$
with expectation
$\tilde{X}^{+}_k\sim \mathrm{Bin}(k,\, \beta\pi/(\beta\pi+\gamma+\delta))$
with expectation
 $k\beta\pi/(\beta\pi+\gamma+\delta).$
The left-hand side of (15) therefore equals
$k\beta\pi/(\beta\pi+\gamma+\delta).$
The left-hand side of (15) therefore equals
 $\beta\pi/(\beta\pi+\gamma+\delta)$
. And, as stated above, N is geometrically distributed with success probability
$\beta\pi/(\beta\pi+\gamma+\delta)$
. And, as stated above, N is geometrically distributed with success probability
 ${\beta\pi}/({\beta\pi+\gamma+\delta})$
on the support
${\beta\pi}/({\beta\pi+\gamma+\delta})$
on the support
 $\{1,2,3,\ldots\}$
, so
$\{1,2,3,\ldots\}$
, so
 \begin{equation*} \mathbb{E}[N] = \frac{\beta\pi+ \gamma+\delta}{\beta\pi}.\end{equation*}
\begin{equation*} \mathbb{E}[N] = \frac{\beta\pi+ \gamma+\delta}{\beta\pi}.\end{equation*}
It follows from (15) that
 \begin{equation} \mathbb{E}[{X}^{+}]+1 =1+\frac{\beta \pi}{\beta \pi+ \gamma+\delta}\, \mathbb{E}[K].\end{equation}
\begin{equation} \mathbb{E}[{X}^{+}]+1 =1+\frac{\beta \pi}{\beta \pi+ \gamma+\delta}\, \mathbb{E}[K].\end{equation}
To derive
 $\mathbb{E}[K]$
, we first recall that
$\mathbb{E}[K]$
, we first recall that
 $f(\pi)$
is the total number of non-app-users infected by an app-using component, so we can write
$f(\pi)$
is the total number of non-app-users infected by an app-using component, so we can write
 $f(\pi)$
as
$f(\pi)$
as
 \begin{equation*} f(\pi) = \mathbb{E}\left[\sum_{i=1}^{K} X^\mathrm{(na)}_{i}\right],\end{equation*}
\begin{equation*} f(\pi) = \mathbb{E}\left[\sum_{i=1}^{K} X^\mathrm{(na)}_{i}\right],\end{equation*}
where
 $X^\mathrm{(na)}_{i}$
denotes the number of non-app-users infected between the
$X^\mathrm{(na)}_{i}$
denotes the number of non-app-users infected between the
 $(i-1)$
th and ith jump. For the distribution of
$(i-1)$
th and ith jump. For the distribution of
 $X^\mathrm{(na)}_{i}$
, we briefly outline the idea as follows. At the
$X^\mathrm{(na)}_{i}$
, we briefly outline the idea as follows. At the
 $(i-1)$
th jump, suppose that there are l infectives in the component; then the time until the next, i.e. ith, jump is exponentially distributed with intensity
$(i-1)$
th jump, suppose that there are l infectives in the component; then the time until the next, i.e. ith, jump is exponentially distributed with intensity
 $l(\beta\pi+\gamma+\delta).$
During this time, such a component infects non-app-users at rate
$l(\beta\pi+\gamma+\delta).$
During this time, such a component infects non-app-users at rate
 $l\beta(1-\pi)$
. It follows that the distribution of
$l\beta(1-\pi)$
. It follows that the distribution of
 $X^\mathrm{(na)}_{i}$
is geometrically distributed with success probability
$X^\mathrm{(na)}_{i}$
is geometrically distributed with success probability
 \begin{align*}\frac{l({\beta\pi+\gamma+\delta})}{l({\beta\pi+\gamma+\delta}+\beta(1-\pi))}=\frac{{\beta\pi+\gamma+\delta}}{{\beta+\gamma+\delta}}\end{align*}
\begin{align*}\frac{l({\beta\pi+\gamma+\delta})}{l({\beta\pi+\gamma+\delta}+\beta(1-\pi))}=\frac{{\beta\pi+\gamma+\delta}}{{\beta+\gamma+\delta}}\end{align*}
on the support
 $\{0,1,2,\ldots\}.$
Because the success probability is independent of the current state l, this implies that the
$\{0,1,2,\ldots\}.$
Because the success probability is independent of the current state l, this implies that the
 $X^\mathrm{(na)}_{i}$
are not only independent but also identically distributed. Consequently, we obtain
$X^\mathrm{(na)}_{i}$
are not only independent but also identically distributed. Consequently, we obtain
 \begin{equation} f(\pi) =\mathbb{E}[K]\frac{\beta(1-\pi)}{\beta\pi+\gamma+\delta}.\end{equation}
\begin{equation} f(\pi) =\mathbb{E}[K]\frac{\beta(1-\pi)}{\beta\pi+\gamma+\delta}.\end{equation}
Together with (14) and (16), this gives
 \begin{equation} \mu^\mathrm{(A)}_{\mathrm{c}} =1+\frac{\pi}{1-\pi}f(\pi).\end{equation}
\begin{equation} \mu^\mathrm{(A)}_{\mathrm{c}} =1+\frac{\pi}{1-\pi}f(\pi).\end{equation}
Finally, it follows from (13) that
 \begin{equation} R^\mathrm{(ind)}_{\text{D-A}} = \frac{f(\pi)}{1-\pi +\pi f(\pi)}.\end{equation}
\begin{equation} R^\mathrm{(ind)}_{\text{D-A}} = \frac{f(\pi)}{1-\pi +\pi f(\pi)}.\end{equation}
For non-app-users the analysis is easier, since a given infectious non-app-user infects on average
 $m_{21}+m_{22}$
individuals (app-users and non-app-users). Using (7) and (8), it follows that
$m_{21}+m_{22}$
individuals (app-users and non-app-users). Using (7) and (8), it follows that
 \begin{equation} R^\mathrm{(ind)}_{\text{D-N}} = m_{21} + m_{22}=\frac{\beta}{\delta+\gamma},\end{equation}
\begin{equation} R^\mathrm{(ind)}_{\text{D-N}} = m_{21} + m_{22}=\frac{\beta}{\delta+\gamma},\end{equation}
which is identical to
 $R_{0}$
in (1). This is not surprising as non-app-users will never be contact-traced. Substituting (19) and (20) into (12) gives
$R_{0}$
in (1). This is not surprising as non-app-users will never be contact-traced. Substituting (19) and (20) into (12) gives
 \begin{equation} R^\mathrm{(ind)}_{\mathrm{D}}= \frac{\pi f(\pi)}{1-\pi +\pi f(\pi)} + (1-\pi) R_{0},\end{equation}
\begin{equation} R^\mathrm{(ind)}_{\mathrm{D}}= \frac{\pi f(\pi)}{1-\pi +\pi f(\pi)} + (1-\pi) R_{0},\end{equation}
with
 $f(\pi)$
defined in (4) and
$f(\pi)$
defined in (4) and
 $R_{0}={\beta}/({\delta+\gamma})$
.
$R_{0}={\beta}/({\delta+\gamma})$
.
4.4.1. Proof of Theorem 2
Our aim is to prove that the derivative
 $R^\mathrm{(ind)}_{\mathrm{D}}{'}(\pi)$
is negative. Without loss of generality, we assume that
$R^\mathrm{(ind)}_{\mathrm{D}}{'}(\pi)$
is negative. Without loss of generality, we assume that
 $\delta+\gamma=1$
; then we have
$\delta+\gamma=1$
; then we have
 $R_0 = \beta$
and
$R_0 = \beta$
and
 $f(\pi)=(1-\pi)g(\pi)/({2 \pi \delta})$
with
$f(\pi)=(1-\pi)g(\pi)/({2 \pi \delta})$
with
 $g(\pi)\,:\!=\beta \pi-1+\sqrt{(\beta \pi-1)^2+4\beta \pi \delta} \geq 0.$
Together with (21), this implies that
$g(\pi)\,:\!=\beta \pi-1+\sqrt{(\beta \pi-1)^2+4\beta \pi \delta} \geq 0.$
Together with (21), this implies that
 \begin{align*} R^\mathrm{(ind)}_{\mathrm{D}}(\pi)&= \frac{(1-\pi)g(\pi)/(2 \delta)}{(1-\pi) + (1-\pi)g(\pi)/(2 \delta)} + (1-\pi) \beta = \frac{g(\pi)}{2\delta+g(\pi)}+ (1-\pi) \beta. \end{align*}
\begin{align*} R^\mathrm{(ind)}_{\mathrm{D}}(\pi)&= \frac{(1-\pi)g(\pi)/(2 \delta)}{(1-\pi) + (1-\pi)g(\pi)/(2 \delta)} + (1-\pi) \beta = \frac{g(\pi)}{2\delta+g(\pi)}+ (1-\pi) \beta. \end{align*}
By differentiating the equation above with respect to
 $\pi$
, we get
$\pi$
, we get
 \begin{align*} R^\mathrm{(ind)}_{\mathrm{D}}{'}(\pi) &= \frac{g{'}(\pi)(2\delta+g(\pi))-g(\pi)g{'}(\pi)}{(2\delta+g(\pi))^2}-\beta = \frac{2\delta g{'}(\pi)}{(2\delta+g(\pi))^2}-\beta. \end{align*}
\begin{align*} R^\mathrm{(ind)}_{\mathrm{D}}{'}(\pi) &= \frac{g{'}(\pi)(2\delta+g(\pi))-g(\pi)g{'}(\pi)}{(2\delta+g(\pi))^2}-\beta = \frac{2\delta g{'}(\pi)}{(2\delta+g(\pi))^2}-\beta. \end{align*}
Further, the derivative of g is given by
 \begin{align*} g{'}(\pi)&=\beta + \frac{(\beta \pi -1)\beta+2\beta\delta}{\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}}\\ & = \beta \left(1+\frac{\beta \pi-1+2\delta}{\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}}\right)\\ & = \frac{\beta (2\delta+g(\pi))}{\sqrt{(\beta \pi+1)^2-4\beta \pi \gamma}}.\end{align*}
\begin{align*} g{'}(\pi)&=\beta + \frac{(\beta \pi -1)\beta+2\beta\delta}{\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}}\\ & = \beta \left(1+\frac{\beta \pi-1+2\delta}{\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}}\right)\\ & = \frac{\beta (2\delta+g(\pi))}{\sqrt{(\beta \pi+1)^2-4\beta \pi \gamma}}.\end{align*}
Then
 $R^\mathrm{(ind)}_{\mathrm{D}}{'}(\pi)$
satisfies
$R^\mathrm{(ind)}_{\mathrm{D}}{'}(\pi)$
satisfies
 \begin{align*} R^\mathrm{(ind)}_{\mathrm{D}}{'}(\pi) &= \frac{2\delta \beta (2\delta+g(\pi))}{(2\delta+g(\pi))^2\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}} - \beta\\ &= \frac{2\delta \beta}{(2\delta+g(\pi))\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}}-\beta\\ & = \frac{\beta h(\pi)}{(2\delta+g(\pi))\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}}, \end{align*}
\begin{align*} R^\mathrm{(ind)}_{\mathrm{D}}{'}(\pi) &= \frac{2\delta \beta (2\delta+g(\pi))}{(2\delta+g(\pi))^2\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}} - \beta\\ &= \frac{2\delta \beta}{(2\delta+g(\pi))\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}}-\beta\\ & = \frac{\beta h(\pi)}{(2\delta+g(\pi))\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}}, \end{align*}
with
 \begin{align*} h(\pi)&\,:\!=2\delta-2\delta\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}-g(\pi)\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}\\ &= 2\delta-2\delta\sqrt{(\beta \pi-1)^2+4\beta \pi \delta} - (\beta\pi -1)\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}-(\beta \pi-1)^2-4\beta \pi \delta.\end{align*}
\begin{align*} h(\pi)&\,:\!=2\delta-2\delta\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}-g(\pi)\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}\\ &= 2\delta-2\delta\sqrt{(\beta \pi-1)^2+4\beta \pi \delta} - (\beta\pi -1)\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}-(\beta \pi-1)^2-4\beta \pi \delta.\end{align*}
Since
 $\beta, \delta >0$
and
$\beta, \delta >0$
and
 $g(\pi) \geq 0,$
we complete the proof by showing that
$g(\pi) \geq 0,$
we complete the proof by showing that
 \begin{align*} h(\pi) &\leq 2\delta-2\delta(1-\beta\pi)-(\beta \pi-1)^2-(\beta \pi-1)^2-4\beta \pi \delta \\ &= -2(\beta \pi-1)^2-2\beta\pi\delta <0,\end{align*}
\begin{align*} h(\pi) &\leq 2\delta-2\delta(1-\beta\pi)-(\beta \pi-1)^2-(\beta \pi-1)^2-4\beta \pi \delta \\ &= -2(\beta \pi-1)^2-2\beta\pi\delta <0,\end{align*}
where the first inequality follows from
 $\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}\geq 1-\beta\pi.$
$\sqrt{(\beta \pi-1)^2+4\beta \pi \delta}\geq 1-\beta\pi.$
4.4.2. Proof of Theorem 3
First, we assume
 $0<\pi<1.$
Upon multiplying both sides of (21) by
$0<\pi<1.$
Upon multiplying both sides of (21) by
 $1-\pi +\pi f(\pi)$
,
$1-\pi +\pi f(\pi)$
,
 $R^\mathrm{(ind)}_{\mathrm{D}} = 1$
is equivalent to
$R^\mathrm{(ind)}_{\mathrm{D}} = 1$
is equivalent to
 \begin{equation*} \pi f(\pi)R_{0}(1-\pi)= (1-\pi)-(1-\pi)^2 R_{0}.\end{equation*}
\begin{equation*} \pi f(\pi)R_{0}(1-\pi)= (1-\pi)-(1-\pi)^2 R_{0}.\end{equation*}
As a consequence,
 \begin{equation} f(\pi)= \frac{1-R_{0}(1-\pi)}{\pi R_{0}}.\end{equation}
\begin{equation} f(\pi)= \frac{1-R_{0}(1-\pi)}{\pi R_{0}}.\end{equation}
On the other hand, it follows from (3) that
 $R_{\mathrm{D}} = 1$
is equivalent to
$R_{\mathrm{D}} = 1$
is equivalent to
 \begin{equation*} \frac{( R_{0}(1-\pi))^2}{4}-R_{0}(1-\pi)+1 =\frac{( R_{0}(1-\pi))^2}{4}+f(\pi)R_{0}\pi,\end{equation*}
\begin{equation*} \frac{( R_{0}(1-\pi))^2}{4}-R_{0}(1-\pi)+1 =\frac{( R_{0}(1-\pi))^2}{4}+f(\pi)R_{0}\pi,\end{equation*}
which gives the same result as in (22). Thus, we have shown that
 $R^\mathrm{(ind)}_{\mathrm{D}} =1$
is equivalent to
$R^\mathrm{(ind)}_{\mathrm{D}} =1$
is equivalent to
 $R_{\mathrm{D}}=1$
. Identical arguments can be used to show that
$R_{\mathrm{D}}=1$
. Identical arguments can be used to show that
 $R^\mathrm{(ind)}_{\mathrm{D}} <1$
is equivalent to
$R^\mathrm{(ind)}_{\mathrm{D}} <1$
is equivalent to
 $R_{\mathrm{D}} < 1$
, as well as the opposite inequality.
$R_{\mathrm{D}} < 1$
, as well as the opposite inequality.
In addition, when
 $\pi=0,$
it can be easily shown that
$\pi=0,$
it can be easily shown that
 $R^\mathrm{(ind)}_{\mathrm{D}}=R_{\mathrm{D}}=R_{0}.$
If
$R^\mathrm{(ind)}_{\mathrm{D}}=R_{\mathrm{D}}=R_{0}.$
If
 $\pi=1,$
i.e. everyone is an app-user, there is one app-using component that will eventually die out, implying that
$\pi=1,$
i.e. everyone is an app-user, there is one app-using component that will eventually die out, implying that
 $R^\mathrm{(ind)}_{\mathrm{D}}$
will be below 1 (sub-critical). Then using (3) gives
$R^\mathrm{(ind)}_{\mathrm{D}}$
will be below 1 (sub-critical). Then using (3) gives
 $R_{\mathrm{D}}=0.$
So both
$R_{\mathrm{D}}=0.$
So both
 $R_{\mathrm{D}}$
and
$R_{\mathrm{D}}$
and
 $R^\mathrm{(ind)}_{\mathrm{D}}$
are below 1 when
$R^\mathrm{(ind)}_{\mathrm{D}}$
are below 1 when
 $\pi=1.$
$\pi=1.$
Remark 3. Similar to the situation for the individual component reproduction for manual contact tracing (see [Reference Zhang and Britton27]), this individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
does not possess the traditional interpretation of the basic reproduction number, namely the average number of infections caused by infected people at the beginning of the outbreak. This is due to the delicate timing of event issues in an exponentially growing situation, closely related to the settings explained in [Reference Ball, Pellis and Trapman4]. More specifically, when we derive the component reproduction number (upon which the individual reproduction number is based), we consider how many new components a component infects, but we do not keep track of when in time individuals of components get infected. For instance, root individuals of components might on average infect more new individuals than other individuals in the component, since they are not traced by their infector, and root individuals are infected earlier than other individuals in the component. So, at the beginning of an epidemic that grows exponentially, these root individuals are over-represented when computing the mean number of infections among those infected early in the epidemic. However, our individual reproduction number
$R^\mathrm{(ind)}_{\mathrm{D}}$
does not possess the traditional interpretation of the basic reproduction number, namely the average number of infections caused by infected people at the beginning of the outbreak. This is due to the delicate timing of event issues in an exponentially growing situation, closely related to the settings explained in [Reference Ball, Pellis and Trapman4]. More specifically, when we derive the component reproduction number (upon which the individual reproduction number is based), we consider how many new components a component infects, but we do not keep track of when in time individuals of components get infected. For instance, root individuals of components might on average infect more new individuals than other individuals in the component, since they are not traced by their infector, and root individuals are infected earlier than other individuals in the component. So, at the beginning of an epidemic that grows exponentially, these root individuals are over-represented when computing the mean number of infections among those infected early in the epidemic. However, our individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
still possesses the important threshold property as shown in Theorem 3.
$R^\mathrm{(ind)}_{\mathrm{D}}$
still possesses the important threshold property as shown in Theorem 3.
5. Approximation of the initial phase in a large community for the combined model
We now analyse the early stage of the epidemic with both manual and digital contact tracing. First, we define the limit process
 $E_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
as follows. In the process, individuals are either app-users or non-app-users. There is one initial ancestor who has the same type as the initial case in
$E_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
as follows. In the process, individuals are either app-users or non-app-users. There is one initial ancestor who has the same type as the initial case in
 $E^{(n)}_{\mathrm{ DM}}(\beta,\gamma,\delta,p,\pi)$
. During the lifetime, each individual gives birth to app-users with manual tracing link at rate
$E^{(n)}_{\mathrm{ DM}}(\beta,\gamma,\delta,p,\pi)$
. During the lifetime, each individual gives birth to app-users with manual tracing link at rate
 $\beta\pi p$
and without link at rate
$\beta\pi p$
and without link at rate
 $\beta\pi (1-p)$
, and gives birth to non-app-users with manual tracing link at rate
$\beta\pi (1-p)$
, and gives birth to non-app-users with manual tracing link at rate
 $\beta(1-\pi)p$
and without link at rate
$\beta(1-\pi)p$
and without link at rate
 $\beta(1-\pi)(1-p).$
Individuals recover naturally at rate
$\beta(1-\pi)(1-p).$
Individuals recover naturally at rate
 $\gamma$
and are diagnosed at rate
$\gamma$
and are diagnosed at rate
 $\delta.$
Once diagnosed, each of the individual’s descendants and parent with manual tracing link are diagnosed immediately, and so on. If such a diagnosed individual is an app-user, all of their app-using descendants, as well as their parent (if an app-user), will also be diagnosed at the same time, and so on. Note that tracing is also iterated for traced individuals who have recovered naturally upon diagnosis, so their parents and descendants are diagnosed according to the same rule. We first prove Proposition 2, which is proved similarly to Proposition 1.
$\delta.$
Once diagnosed, each of the individual’s descendants and parent with manual tracing link are diagnosed immediately, and so on. If such a diagnosed individual is an app-user, all of their app-using descendants, as well as their parent (if an app-user), will also be diagnosed at the same time, and so on. Note that tracing is also iterated for traced individuals who have recovered naturally upon diagnosis, so their parents and descendants are diagnosed according to the same rule. We first prove Proposition 2, which is proved similarly to Proposition 1.
5.1. Proof of Proposition 2
First, we note that the only difference between the n-epidemic
 $E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
and the limit process
$E^{(n)}_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
and the limit process
 $E_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
is that the rate of new infections in the epidemic is deflated by the factor
$E_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
is that the rate of new infections in the epidemic is deflated by the factor
 $S(t)/n$
, since infectious contacts result in infection only if the contacted person is still susceptible. Using standard coupling arguments as described in the proof of Proposition 1, it can be shown that the time
$S(t)/n$
, since infectious contacts result in infection only if the contacted person is still susceptible. Using standard coupling arguments as described in the proof of Proposition 1, it can be shown that the time
 $T_n$
of first contact with an already infected person tends to infinity in probability as
$T_n$
of first contact with an already infected person tends to infinity in probability as
 $n\to\infty$
, and prior to this the epidemic and the limiting process agree completely. Consequently, the n-epidemic converges in distribution to
$n\to\infty$
, and prior to this the epidemic and the limiting process agree completely. Consequently, the n-epidemic converges in distribution to
 $E_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
on any finite time interval.
$E_{\mathrm{DM}}(\beta,\gamma,\delta,p,\pi)$
on any finite time interval.
Following a similar idea to the proof of Theorem 4.1 in Subsection 4.1, we describe this limit process
 $E_{\mathrm{ DM}}(\beta,\gamma,\delta,p,\pi)$
in terms of to-be-traced components. For the combined model, the app-users could be traced not only by app-users but also by non-app-users with probability p. Further, non-app-users could be traced by individuals (either app-users or non-app-users) with probability p. Accordingly, to-be-traced components also contain infections between app-users and non-app-users and between pairs of app-users, who will be traced manually. Moreover, new components are created if an app-user infects a non-app-user without manual contact tracing taking place or if a non-app-user infects either type and there is no manual contact tracing. The new components thus differ only in how they are created, i.e. with an app-user (infected by a non-app-user without manual contact tracing) or a non-app-user (without manual contact tracing), and given the current state, the evolution of such components does not depend on how they were initiated and is therefore the same for both types of components. There will be no contact tracing between any of these components, which thus makes them evolve independently, as stipulated for branching processes. We give an example in Figure 3 to illustrate how the two types of components (starting with an app-user or a non-app-user) grow and reproduce. We start with case 1, which is the root of the component
$E_{\mathrm{ DM}}(\beta,\gamma,\delta,p,\pi)$
in terms of to-be-traced components. For the combined model, the app-users could be traced not only by app-users but also by non-app-users with probability p. Further, non-app-users could be traced by individuals (either app-users or non-app-users) with probability p. Accordingly, to-be-traced components also contain infections between app-users and non-app-users and between pairs of app-users, who will be traced manually. Moreover, new components are created if an app-user infects a non-app-user without manual contact tracing taking place or if a non-app-user infects either type and there is no manual contact tracing. The new components thus differ only in how they are created, i.e. with an app-user (infected by a non-app-user without manual contact tracing) or a non-app-user (without manual contact tracing), and given the current state, the evolution of such components does not depend on how they were initiated and is therefore the same for both types of components. There will be no contact tracing between any of these components, which thus makes them evolve independently, as stipulated for branching processes. We give an example in Figure 3 to illustrate how the two types of components (starting with an app-user or a non-app-user) grow and reproduce. We start with case 1, which is the root of the component
 $C^\mathrm{(NA)}_{1}$
, which generates two new components
$C^\mathrm{(NA)}_{1}$
, which generates two new components
 $C^\mathrm{(NA)}_{2}$
and
$C^\mathrm{(NA)}_{2}$
and
 $C^\mathrm{(A)}_{3}$
. The component
$C^\mathrm{(A)}_{3}$
. The component
 $C^\mathrm{(NA)}_{2}$
has as its root non-app-user 2, and
$C^\mathrm{(NA)}_{2}$
has as its root non-app-user 2, and
 $C^\mathrm{(A)}_{3}$
starts with app-user 3. Once individual 1 is diagnosed, the whole component
$C^\mathrm{(A)}_{3}$
starts with app-user 3. Once individual 1 is diagnosed, the whole component
 $C^\mathrm{(NA)}_{1}$
is diagnosed.
$C^\mathrm{(NA)}_{1}$
is diagnosed.

Figure 3. Example of the process of to-be-traced components started by app-users and non-app-users for the combined model; the circles represent app-users and the squares non-app-users. The nodes in white, black, and grey correspond to infectious, diagnosed, and naturally recovered individuals, respectively. A rectangular region surrounded by dashed lines represents a component, and the rectangle is hatched with diagonal lines when the component is diagnosed. Solid edges stand for contacts that could be traced by either manual or digital contact tracing (so there are always solid edges between pairs of app-users), whereas dashed edges represent infectious contacts that will not be traced.
5.2. Proof of Corollary 2
We see that the combined model can be approximated by a suitable two-type branching process during the early stage of the epidemic, where type-1 ‘individuals’ are to-be-traced components starting with an app-user and type-2 ‘individuals’ are components with a non-app-user as root. Let
 $M^\mathrm{(c)}$
be the corresponding mean-offspring matrix,
$M^\mathrm{(c)}$
be the corresponding mean-offspring matrix,
 \begin{equation} M^\mathrm{(c)}=\left(\begin{array}{c@{\quad}c}m^\mathrm{(c)}_{11} & m^\mathrm{(c)}_{12}\\[5pt]m^\mathrm{(c)}_{21} & m^\mathrm{(c)}_{22}\end{array}\right),\end{equation}
\begin{equation} M^\mathrm{(c)}=\left(\begin{array}{c@{\quad}c}m^\mathrm{(c)}_{11} & m^\mathrm{(c)}_{12}\\[5pt]m^\mathrm{(c)}_{21} & m^\mathrm{(c)}_{22}\end{array}\right),\end{equation}
where element
 $m^\mathrm{(c)}_{ij}$
is the mean number of new components of type j produced by a single component of type i, for
$m^\mathrm{(c)}_{ij}$
is the mean number of new components of type j produced by a single component of type i, for
 $i,j =1,2.$
Let
$i,j =1,2.$
Let
 $R_{\mathrm{DM}}$
be the largest eigenvalue of
$R_{\mathrm{DM}}$
be the largest eigenvalue of
 $M^\mathrm{(c)}$
; then
$M^\mathrm{(c)}$
; then
 $R_{\mathrm{DM}}$
can be expressed similarly to the digital reproduction number
$R_{\mathrm{DM}}$
can be expressed similarly to the digital reproduction number
 $R_{\mathrm{D}}$
as shown in (5), but with
$R_{\mathrm{D}}$
as shown in (5), but with
 $m^\mathrm{(c)}_{ij}$
replacing
$m^\mathrm{(c)}_{ij}$
replacing
 $m_{ij}$
. Similar to
$m_{ij}$
. Similar to
 $R_{\mathrm{D}}$
,
$R_{\mathrm{D}}$
,
 $R_{\mathrm{DM}}$
determines whether a major outbreak is possible or not. We call
$R_{\mathrm{DM}}$
determines whether a major outbreak is possible or not. We call
 $R_{\mathrm{DM}}$
the effective component reproduction number for the combined model. As shown in the proof of Corollary 1, it follows from standard multi-type branching process theory [Reference Athreya and Ney2, Reference Becker and Marschner8] that the limit process
$R_{\mathrm{DM}}$
the effective component reproduction number for the combined model. As shown in the proof of Corollary 1, it follows from standard multi-type branching process theory [Reference Athreya and Ney2, Reference Becker and Marschner8] that the limit process
 $E_{\mathrm{DM}}$
will surely go extinct if
$E_{\mathrm{DM}}$
will surely go extinct if
 $R_{\mathrm{DM}} \leq 1$
. If
$R_{\mathrm{DM}} \leq 1$
. If
 $R_{\mathrm{DM}}>1$
, the process will grow beyond all limits with non-zero probability. Then, by Proposition 2, it can be shown that if
$R_{\mathrm{DM}}>1$
, the process will grow beyond all limits with non-zero probability. Then, by Proposition 2, it can be shown that if
 $R_{\mathrm{DM}} > 1$
there will be a large outbreak of the epidemic with non-zero probability, whereas if
$R_{\mathrm{DM}} > 1$
there will be a large outbreak of the epidemic with non-zero probability, whereas if
 $R_{\mathrm{DM}} \leq 1$
there will be a minor outbreak for sure.
$R_{\mathrm{DM}} \leq 1$
there will be a minor outbreak for sure.
In the following, we derive the elements
 $m^\mathrm{(c)}_{ij}$
. We first note that the to-be-traced components may also contain non-app-users that are manually traced, so it is necessary to track both the number of infectious app-users and the number of infectious non-app-users in the component. Let
$m^\mathrm{(c)}_{ij}$
. We first note that the to-be-traced components may also contain non-app-users that are manually traced, so it is necessary to track both the number of infectious app-users and the number of infectious non-app-users in the component. Let
 $N^{(i)}_{j}(t)$
be the number of infectious type-j individuals in the component, starting with one type-i individual at time t
$N^{(i)}_{j}(t)$
be the number of infectious type-j individuals in the component, starting with one type-i individual at time t
 $(i,j=1,2),$
where we take type 1 to be app-users and type 2 to be non-app-users. When the components are born (
$(i,j=1,2),$
where we take type 1 to be app-users and type 2 to be non-app-users. When the components are born (
 $t=0$
), we have
$t=0$
), we have
 $N^\mathrm{(1)}(0)=(1,0)$
, whereas
$N^\mathrm{(1)}(0)=(1,0)$
, whereas
 $N^\mathrm{(2)}(0)=(0,1)$
. Suppose that at time t there are k infectious app-users and l infectious non-app-users in a component starting with a type-i individual, denoted by
$N^\mathrm{(2)}(0)=(0,1)$
. Suppose that at time t there are k infectious app-users and l infectious non-app-users in a component starting with a type-i individual, denoted by
 \begin{equation*} N^{(i)}(t)\,:\!= (N^{(i)}_{1}(t), N^{(i)}_{2}(t))=(k,l).\end{equation*}
\begin{equation*} N^{(i)}(t)\,:\!= (N^{(i)}_{1}(t), N^{(i)}_{2}(t))=(k,l).\end{equation*}
There are five different competing events that can occur: an app-user is newly infected by an app-user or with a manual tracing link by a non-app-user (
 $N^{(i)}(t)+(1,0)$
); one of the k app-users recovers naturally (
$N^{(i)}(t)+(1,0)$
); one of the k app-users recovers naturally (
 $N^{(i)}(t)-(1,0)$
); a non-app-user is newly infected with a manual tracing link irrespective of the type of the infector (
$N^{(i)}(t)-(1,0)$
); a non-app-user is newly infected with a manual tracing link irrespective of the type of the infector (
 $N^{(i)}(t)+(0,1)$
); one of the l non-app-users recovers naturally (
$N^{(i)}(t)+(0,1)$
); one of the l non-app-users recovers naturally (
 $N^{(i)}(t)-(0,1)$
); or one of the
$N^{(i)}(t)-(0,1)$
); or one of the
 $k+l$
infectious individuals (of either type) is diagnosed, so the whole component is diagnosed (drops to (0,0)). The corresponding transition rates are given by
$k+l$
infectious individuals (of either type) is diagnosed, so the whole component is diagnosed (drops to (0,0)). The corresponding transition rates are given by
 \begin{align*}N^{(i)}(t^{-}) \to \left\{\begin{array}{l@{\quad}l} N^{(i)}(t)+(1,0) & \text{at rate } k\beta\pi+l\beta\pi p, \\ N^{(i)}(t)+(\!-1,0) & \text{at rate } k\gamma,\\ N^{(i)}(t)+(0,1) & \text{at rate } (k+l)\beta(1-\pi)p,\\ N^{(i)}(t)+(0,-1) & \text{at rate } l\gamma,\\ (0,0) & \text{at rate } (k+l)\delta .\end{array}\right.\end{align*}
\begin{align*}N^{(i)}(t^{-}) \to \left\{\begin{array}{l@{\quad}l} N^{(i)}(t)+(1,0) & \text{at rate } k\beta\pi+l\beta\pi p, \\ N^{(i)}(t)+(\!-1,0) & \text{at rate } k\gamma,\\ N^{(i)}(t)+(0,1) & \text{at rate } (k+l)\beta(1-\pi)p,\\ N^{(i)}(t)+(0,-1) & \text{at rate } l\gamma,\\ (0,0) & \text{at rate } (k+l)\delta .\end{array}\right.\end{align*}
Next, we describe the birth of new components. We note that only infections with no digital or manual contact tracing links create a new component. This can only occur to pairs of non-app-users or pairs of app-users and non-app-users, but it never happens between two app-users. As a consequence, given that
 $N^{(i)}(t)=(k,l)$
(k infectious app-users and l infectious non-app-users), the component gives birth to new components with an app-user as root at rate
$N^{(i)}(t)=(k,l)$
(k infectious app-users and l infectious non-app-users), the component gives birth to new components with an app-user as root at rate
 $l\beta\pi(1-p)$
and gives birth to new components with a non-app-user as root at rate
$l\beta\pi(1-p)$
and gives birth to new components with a non-app-user as root at rate
 $(k+l)\beta(1-\pi)(1-p).$
Based on the previous discussion, we have derived the birth rates of new components of type i conditional on
$(k+l)\beta(1-\pi)(1-p).$
Based on the previous discussion, we have derived the birth rates of new components of type i conditional on
 $N^{(i)}(t)$
. The expected total numbers
$N^{(i)}(t)$
. The expected total numbers
 $m^\mathrm{(c)}_{ij}$
of new type-j components produced by a type-i component are therefore the expected values of these expressions integrated over time:
$m^\mathrm{(c)}_{ij}$
of new type-j components produced by a type-i component are therefore the expected values of these expressions integrated over time:
 \begin{align} m^\mathrm{(c)}_{11} &= \int_{0}^{\infty}\mathbb{E}[N^\mathrm{(1)}_{2}(t)]\beta\pi(1-p) \,{\mathrm{d}} t, \end{align}
\begin{align} m^\mathrm{(c)}_{11} &= \int_{0}^{\infty}\mathbb{E}[N^\mathrm{(1)}_{2}(t)]\beta\pi(1-p) \,{\mathrm{d}} t, \end{align}
 \begin{align} m^\mathrm{(c)}_{12} &= \int_{0}^{\infty}(\mathbb{E}[N^\mathrm{(1)}_{1}(t)]+\mathbb{E}[N^\mathrm{(1)}_{2}(t)])\beta(1-\pi)(1-p) \,{\mathrm{d}} t, \end{align}
\begin{align} m^\mathrm{(c)}_{12} &= \int_{0}^{\infty}(\mathbb{E}[N^\mathrm{(1)}_{1}(t)]+\mathbb{E}[N^\mathrm{(1)}_{2}(t)])\beta(1-\pi)(1-p) \,{\mathrm{d}} t, \end{align}
 \begin{align} m^\mathrm{(c)}_{21} &= \int_{0}^{\infty}\mathbb{E}[N^\mathrm{(2)}_{2}(t)]\beta\pi(1-p) \,{\mathrm{d}} t, \end{align}
\begin{align} m^\mathrm{(c)}_{21} &= \int_{0}^{\infty}\mathbb{E}[N^\mathrm{(2)}_{2}(t)]\beta\pi(1-p) \,{\mathrm{d}} t, \end{align}
 \begin{align} m^\mathrm{(c)}_{22} &= \int_{0}^{\infty}(\mathbb{E}[N^\mathrm{(2)}_{1}(t)]+\mathbb{E}[N^\mathrm{(2)}_{2}(t)])\beta(1-\pi)(1-p) \,{\mathrm{d}} t. \\[8pt]\nonumber\end{align}
\begin{align} m^\mathrm{(c)}_{22} &= \int_{0}^{\infty}(\mathbb{E}[N^\mathrm{(2)}_{1}(t)]+\mathbb{E}[N^\mathrm{(2)}_{2}(t)])\beta(1-\pi)(1-p) \,{\mathrm{d}} t. \\[8pt]\nonumber\end{align}
We have not been able to derive
 $\mathbb{E}[N^{(i)}_{j}(t)]$
analytically. The main reason is that not all of the four jump rates are linear in the number of infectious individuals. In particular, the rate at which
$\mathbb{E}[N^{(i)}_{j}(t)]$
analytically. The main reason is that not all of the four jump rates are linear in the number of infectious individuals. In particular, the rate at which
 $N^{(i)}=(k,l)$
increases in the first component equals
$N^{(i)}=(k,l)$
increases in the first component equals
 $k\beta\pi+l\beta\pi p$
(nonlinear in
$k\beta\pi+l\beta\pi p$
(nonlinear in
 $k+l$
).
$k+l$
).
In Section 6, we perform simulations to derive the
 $m^\mathrm{(c)}_{ij}$
and numerically compute the component reproduction number
$m^\mathrm{(c)}_{ij}$
and numerically compute the component reproduction number
 $R_{\mathrm{DM}}$
for given parameters. Based on the numerical results, we examine how
$R_{\mathrm{DM}}$
for given parameters. Based on the numerical results, we examine how
 $R_{\mathrm{DM}}$
depends on the manual tracing probability p and the app-using fraction
$R_{\mathrm{DM}}$
depends on the manual tracing probability p and the app-using fraction
 $\pi$
.
$\pi$
.
6. Numerical investigation
In this section, we numerically study the effects of digital contact tracing, as well as the combined effect of both types of contact tracing. For all the numerical results (except Table 3), we take the epidemic parameters to be fixed:
 $\beta = \frac{6}{7}$
and
$\beta = \frac{6}{7}$
and
 $\gamma =\frac{1}{7}$
so that the reproduction number without any testing or contact tracing is
$\gamma =\frac{1}{7}$
so that the reproduction number without any testing or contact tracing is
 ${\beta}/{\gamma}=6$
. When also considering diagnosis (
${\beta}/{\gamma}=6$
. When also considering diagnosis (
 $\delta >0$
), we would have the basic reproduction number
$\delta >0$
), we would have the basic reproduction number
 $R_0 = {\beta}/({\gamma+\delta})$
smaller than 6. The code used for this section is available on GitHub at [Reference Zhang26].
$R_0 = {\beta}/({\gamma+\delta})$
smaller than 6. The code used for this section is available on GitHub at [Reference Zhang26].
Table 3. Results from 10 000 simulated epidemics and the corresponding limiting branching processes

6.1. Comparison of digital and manual tracing only
In Figure 4a we plot the necessary testing rate measured by the testing level
 ${\delta}/({\delta + \gamma})$
, for which the manual
${\delta}/({\delta + \gamma})$
, for which the manual
 $R^\mathrm{(c)}_{\mathrm{M}}$
given by (9) equals 1 and the digital component reproduction number
$R^\mathrm{(c)}_{\mathrm{M}}$
given by (9) equals 1 and the digital component reproduction number
 $R^{}_{\mathrm{D}}$
given by (3) equals 1, for given values of p and
$R^{}_{\mathrm{D}}$
given by (3) equals 1, for given values of p and
 $\pi$
, respectively. The figure confirms Theorem 1 in showing that for a given testing level
$\pi$
, respectively. The figure confirms Theorem 1 in showing that for a given testing level
 ${\delta}/({\delta + \gamma})$
, a larger app-using fraction
${\delta}/({\delta + \gamma})$
, a larger app-using fraction
 $\pi$
is required than the tracing probability p for the model with manual contact tracing.
$\pi$
is required than the tracing probability p for the model with manual contact tracing.
One potential explanation for this could be that the effectiveness of digital contact tracing is more related to the square of the fraction of app-users (
 $\pi^2$
): the digital tracing is carried out only if both the confirmed case and the contact are app-users. In Figure 4b we therefore plot the critical combination of
$\pi^2$
): the digital tracing is carried out only if both the confirmed case and the contact are app-users. In Figure 4b we therefore plot the critical combination of
 ${\delta}/({\delta + \gamma})$
against
${\delta}/({\delta + \gamma})$
against
 $\pi^2$
instead. It can be seen that the curve for
$\pi^2$
instead. It can be seen that the curve for
 $\pi^2$
is closer to that for p but still different; we still need a larger value of
$\pi^2$
is closer to that for p but still different; we still need a larger value of
 $\pi^2$
for the reproduction number to equal unity. An alternative explanation is that there is a fraction
$\pi^2$
for the reproduction number to equal unity. An alternative explanation is that there is a fraction
 $1-\pi$
of individuals who will never be digitally contact-traced, whereas manual tracing can reach all individuals. This suggests that digital tracing requires a higher effectiveness among app-users to compensate for the absence of contact tracing among non-app-users.
$1-\pi$
of individuals who will never be digitally contact-traced, whereas manual tracing can reach all individuals. This suggests that digital tracing requires a higher effectiveness among app-users to compensate for the absence of contact tracing among non-app-users.

Figure 4. (a) The red curve shows the combinations of the testing fraction
 ${\delta}/({\delta + \gamma})$
and the fraction
${\delta}/({\delta + \gamma})$
and the fraction
 $\pi$
of app-users for which
$\pi$
of app-users for which
 $R_{\mathrm{D}}=1$
for digital contact tracing, and the blue curve shows the combinations of the testing fraction
$R_{\mathrm{D}}=1$
for digital contact tracing, and the blue curve shows the combinations of the testing fraction
 ${\delta}/({\delta + \gamma})$
and the tracing probability p for which
${\delta}/({\delta + \gamma})$
and the tracing probability p for which
 $R_{\mathrm{ M}}=1$
in manual contact tracing. (b) The same curves are plotted as in (a), but now with
$R_{\mathrm{ M}}=1$
in manual contact tracing. (b) The same curves are plotted as in (a), but now with
 $\pi^2$
instead of
$\pi^2$
instead of
 $\pi$
on the horizontal axis (motivated by the fact that both individuals have to be app-users for digital tracing to take place).
$\pi$
on the horizontal axis (motivated by the fact that both individuals have to be app-users for digital tracing to take place).
6.2. The individual and component reproduction numbers for digital tracing only
In Figure 5 we plot the variation of the digital reproduction number
 $R_{\mathrm{D}}$
and individual reproduction number
$R_{\mathrm{D}}$
and individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
with the testing fraction
$R^\mathrm{(ind)}_{\mathrm{D}}$
with the testing fraction
 ${\delta}/({\delta + \gamma})$
and the fraction of app-users
${\delta}/({\delta + \gamma})$
and the fraction of app-users
 $\pi$
. By looking at the colours at the bottom or the dashed curves at
$\pi$
. By looking at the colours at the bottom or the dashed curves at
 $R_{\mathrm{D}}=6, 8,$
and 10 in Figure 5a, we observe that the component reproduction number
$R_{\mathrm{D}}=6, 8,$
and 10 in Figure 5a, we observe that the component reproduction number
 $R_{\mathrm{D}}$
is not monotonically decreasing in
$R_{\mathrm{D}}$
is not monotonically decreasing in
 $\pi$
. This is at first surprising, since we expect a smaller reproduction number with more app-users.
$\pi$
. This is at first surprising, since we expect a smaller reproduction number with more app-users.
This non-monotonicity of
 $R_{\mathrm{D}}$
can be explained as follows. First of all, it can be easily seen from (7) and (8) that the element
$R_{\mathrm{D}}$
can be explained as follows. First of all, it can be easily seen from (7) and (8) that the element
 $m_{21}$
is increasing while
$m_{21}$
is increasing while
 $m_{22}$
is decreasing with
$m_{22}$
is decreasing with
 $\pi.$
Then, at a very low level of the testing fraction, increasing
$\pi.$
Then, at a very low level of the testing fraction, increasing
 $\pi$
leads to more app-users, and hence the size of the app-using component will grow even if fewer non-app-users will be infected per app-user. The average number of non-app-users infected by one app-using component
$\pi$
leads to more app-users, and hence the size of the app-using component will grow even if fewer non-app-users will be infected per app-user. The average number of non-app-users infected by one app-using component
 $m_{12}$
may thus increase with
$m_{12}$
may thus increase with
 $\pi$
. Then, according to the expression for
$\pi$
. Then, according to the expression for
 $R_{\mathrm{D}}$
in (3),
$R_{\mathrm{D}}$
in (3),
 $R_{\mathrm{D}}$
could increase with
$R_{\mathrm{D}}$
could increase with
 $\pi$
when the testing fraction
$\pi$
when the testing fraction
 ${\delta}/({\delta + \gamma})$
is low. On the other hand, we see from Figure 5b that the individual reproduction number
${\delta}/({\delta + \gamma})$
is low. On the other hand, we see from Figure 5b that the individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
is monotonically decreasing in
$R^\mathrm{(ind)}_{\mathrm{D}}$
is monotonically decreasing in
 $\pi$
, as was proven in Theorem 2.
$\pi$
, as was proven in Theorem 2.

Figure 5. Heatmaps of the effective reproduction numbers for digital tracing: (a)
 $R_{\mathrm{D}}$
and (b)
$R_{\mathrm{D}}$
and (b)
 $R^\mathrm{(ind)}_{\mathrm{D}}$
vary with the testing fraction
$R^\mathrm{(ind)}_{\mathrm{D}}$
vary with the testing fraction
 ${\delta}/({\delta + \gamma})$
in
${\delta}/({\delta + \gamma})$
in
 $[0.01,0.83]$
and the fraction of app-users
$[0.01,0.83]$
and the fraction of app-users
 $\pi$
in
$\pi$
in
 $[0.01,0.99]$
, with
$[0.01,0.99]$
, with
 $\beta=\frac{6}{7}$
and
$\beta=\frac{6}{7}$
and
 $\gamma=\frac{1}{7}$
fixed. The white solid lines indicate where the corresponding reproduction number equals 1; the black dashed lines in (a) are for
$\gamma=\frac{1}{7}$
fixed. The white solid lines indicate where the corresponding reproduction number equals 1; the black dashed lines in (a) are for
 $R_{\mathrm{D}}=2,4,6,8,10$
from top to bottom, and the black dashed lines in (b) are for
$R_{\mathrm{D}}=2,4,6,8,10$
from top to bottom, and the black dashed lines in (b) are for
 $R^\mathrm{(ind)}_{\mathrm{D}}=3, 2.5,2,1.5$
from left to right.
$R^\mathrm{(ind)}_{\mathrm{D}}=3, 2.5,2,1.5$
from left to right.
In Figure 6 we illustrate Theorem 3, which states that the two reproduction numbers
 $R^{}_{\mathrm{D}}$
and
$R^{}_{\mathrm{D}}$
and
 $R^\mathrm{(ind)}_{\mathrm{D}}$
have the same threshold at 1. As before, we fix
$R^\mathrm{(ind)}_{\mathrm{D}}$
have the same threshold at 1. As before, we fix
 $\beta=\frac{6}{7}$
and
$\beta=\frac{6}{7}$
and
 $\gamma = \delta = \frac{1}{7}$
such that
$\gamma = \delta = \frac{1}{7}$
such that
 $R_0=3$
and half of the infected are diagnosed (and subject to being contact-traced). The two reproduction numbers are plotted as functions of
$R_0=3$
and half of the infected are diagnosed (and subject to being contact-traced). The two reproduction numbers are plotted as functions of
 $\pi$
, the fraction of app-users. The figure shows that the reproduction numbers are different but that they both attain the value 1 for the same critical fraction of app-users,
$\pi$
, the fraction of app-users. The figure shows that the reproduction numbers are different but that they both attain the value 1 for the same critical fraction of app-users,
 $\pi_{\mathrm{c}} \approx 94\%$
.
$\pi_{\mathrm{c}} \approx 94\%$
.

Figure 6. Plot of curves of
 $R^\mathrm{(ind)}_{\mathrm{D}}$
(in red) and
$R^\mathrm{(ind)}_{\mathrm{D}}$
(in red) and
 $R^{}_{\mathrm{D}}$
(in blue) against
$R^{}_{\mathrm{D}}$
(in blue) against
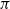 $\pi$
with
$\pi$
with
 $\beta=\frac{6}{7}, \gamma=\frac{1}{7}$
, and
$\beta=\frac{6}{7}, \gamma=\frac{1}{7}$
, and
 $\delta=\frac{1}{7}$
fixed. The horizontal dashed line indicates where the reproduction number equals 1, and the vertical dashed line stands for the critical
$\delta=\frac{1}{7}$
fixed. The horizontal dashed line indicates where the reproduction number equals 1, and the vertical dashed line stands for the critical
 $\pi_{\mathrm{c}} \approx 0.94$
.
$\pi_{\mathrm{c}} \approx 0.94$
.
6.3. Effect of combining digital and manual tracing
We now illustrate the effect of the combined model by computing
 $R_{\mathrm{DM}}$
numerically as follows. For
$R_{\mathrm{DM}}$
numerically as follows. For
 $\beta=\frac{6}{7}$
,
$\beta=\frac{6}{7}$
,
 $\gamma=\frac{1}{7}$
, two distinct values
$\gamma=\frac{1}{7}$
, two distinct values
 $\frac{1}{7}$
and
$\frac{1}{7}$
and
 $\frac{1}{28}$
for
$\frac{1}{28}$
for
 $\delta$
, and a grid of values for
$\delta$
, and a grid of values for
 $\pi$
(the fraction of app-users) and p (the fraction of contacts that are traced manually), we perform 10 000 simulations to compute the integrals in (24)–(27) for each simulation (without expectation). We then take averages over the simulations to obtain estimates of the four elements
$\pi$
(the fraction of app-users) and p (the fraction of contacts that are traced manually), we perform 10 000 simulations to compute the integrals in (24)–(27) for each simulation (without expectation). We then take averages over the simulations to obtain estimates of the four elements
 $m^\mathrm{(c)}_{ij}$
, and compute the largest eigenvalue to obtain estimates of
$m^\mathrm{(c)}_{ij}$
, and compute the largest eigenvalue to obtain estimates of
 $R^{}_{\mathrm{DM}}$
. In Figure 7 we plot the heatmaps of
$R^{}_{\mathrm{DM}}$
. In Figure 7 we plot the heatmaps of
 $R^{}_{\mathrm{DM}}$
as functions of p and
$R^{}_{\mathrm{DM}}$
as functions of p and
 $\pi$
for the two choices of
$\pi$
for the two choices of
 $\delta$
. We see from Figure 7a that
$\delta$
. We see from Figure 7a that
 $R^{}_{\mathrm{DM}}$
seems monotonically decreasing in both
$R^{}_{\mathrm{DM}}$
seems monotonically decreasing in both
 $\pi$
and p, as expected when
$\pi$
and p, as expected when
 $\delta=\frac{1}{7}$
, but the monotonicity fails when
$\delta=\frac{1}{7}$
, but the monotonicity fails when
 $\delta$
is smaller, as seen in Figure 7b. This can be explained in a similar way to the phenomenon for
$\delta$
is smaller, as seen in Figure 7b. This can be explained in a similar way to the phenomenon for
 $R_{\mathrm{D}}$
. For example, suppose that
$R_{\mathrm{D}}$
. For example, suppose that
 $\pi$
and
$\pi$
and
 $\delta$
are both small; then the size of a component (starting with either an app-user or a non-app-user) may increase with p since more infections happen within a component. As a consequence, such a component may, in fact, infect slightly more new components, thus resulting in a larger reproduction number. However, on the individual scale, a much larger component infecting slightly more new components would still imply that each individual will infect fewer new individuals. Here, it might be possible to derive an individual reproduction number,
$\delta$
are both small; then the size of a component (starting with either an app-user or a non-app-user) may increase with p since more infections happen within a component. As a consequence, such a component may, in fact, infect slightly more new components, thus resulting in a larger reproduction number. However, on the individual scale, a much larger component infecting slightly more new components would still imply that each individual will infect fewer new individuals. Here, it might be possible to derive an individual reproduction number,
 $R^\mathrm{(ind)}_{\mathrm{DM}}$
, which one would expect decreases monotonically in both
$R^\mathrm{(ind)}_{\mathrm{DM}}$
, which one would expect decreases monotonically in both
 $\pi$
and p, but we have not pursued this route, partly because the expression for the component reproduction number
$\pi$
and p, but we have not pursued this route, partly because the expression for the component reproduction number
 $R^{}_{\mathrm{DM}}$
is complicated in itself. But if we focus on the curve
$R^{}_{\mathrm{DM}}$
is complicated in itself. But if we focus on the curve
 $R_{\mathrm{DM}}=1$
in Figure 7b, it seems to be monotone, suggesting that decreasing one of the contact tracing procedures requires the other to be increased in order to maintain herd immunity. A proof of this is missing.
$R_{\mathrm{DM}}=1$
in Figure 7b, it seems to be monotone, suggesting that decreasing one of the contact tracing procedures requires the other to be increased in order to maintain herd immunity. A proof of this is missing.

Figure 7. Heatmaps of the effective reproduction number
 $R_{\mathrm{DM}}$
varying with the manual tracing probability p in
$R_{\mathrm{DM}}$
varying with the manual tracing probability p in
 $[0,0.99)$
and the fraction of app-users
$[0,0.99)$
and the fraction of app-users
 $\pi$
in
$\pi$
in
 $[0,0.99)$
, with
$[0,0.99)$
, with
 $\beta=\frac{6}{7}$
and
$\beta=\frac{6}{7}$
and
 $ \gamma=\frac{1}{7}$
fixed, and for (a)
$ \gamma=\frac{1}{7}$
fixed, and for (a)
 $\delta=\frac{1}{7}$
and (b) the smaller
$\delta=\frac{1}{7}$
and (b) the smaller
 $\delta=\frac{1}{28}$
. The white solid lines indicate where
$\delta=\frac{1}{28}$
. The white solid lines indicate where
 $R_{\mathrm{DM}}=1$
; the black dashed lines in (a) are for
$R_{\mathrm{DM}}=1$
; the black dashed lines in (a) are for
 $R_{\mathrm{DM}}=2.5,2,1.5$
from left to right, and those in (b) are for
$R_{\mathrm{DM}}=2.5,2,1.5$
from left to right, and those in (b) are for
 $R_{\mathrm{DM}}=8,6,4,2$
.
$R_{\mathrm{DM}}=8,6,4,2$
.
All of the above results are for the limiting processes
 $E_{\mathrm{D}}$
and
$E_{\mathrm{D}}$
and
 $E_{\mathrm{DM}}$
. To see how the results fit the finite-n case, we perform
$E_{\mathrm{DM}}$
. To see how the results fit the finite-n case, we perform
 $10\,000$
simulations of the epidemic for
$10\,000$
simulations of the epidemic for
 $n = 1000$
and 5000, starting with one initial infective. We choose the parameters in four different cases: without any contact tracing (
$n = 1000$
and 5000, starting with one initial infective. We choose the parameters in four different cases: without any contact tracing (
 $p=\pi=0$
), with digital tracing only (
$p=\pi=0$
), with digital tracing only (
 $p=0,\pi=\frac{2}{3}$
), with manual tracing only (
$p=0,\pi=\frac{2}{3}$
), with manual tracing only (
 $p=\frac{2}{3},\pi=0$
), and with both manual and digital tracing (
$p=\frac{2}{3},\pi=0$
), and with both manual and digital tracing (
 $p=\pi=\frac{2}{3}$
), while keeping
$p=\pi=\frac{2}{3}$
), while keeping
 $\beta=0.8, \gamma=\frac{1}{7}$
, and
$\beta=0.8, \gamma=\frac{1}{7}$
, and
 $\delta=\frac{1}{7}$
fixed. It can be seen from Table 3 that the fraction of major outbreaks (defined by having more than 10% infected) is distinctly away from 0 when the reproduction number exceeds 1 and is very close to 0 when the reproduction number is smaller than 1 (thus supporting Corollaries 1 and 2). In addition to our epidemic simulations, we have included a column for the limiting results (denoted by
$\delta=\frac{1}{7}$
fixed. It can be seen from Table 3 that the fraction of major outbreaks (defined by having more than 10% infected) is distinctly away from 0 when the reproduction number exceeds 1 and is very close to 0 when the reproduction number is smaller than 1 (thus supporting Corollaries 1 and 2). In addition to our epidemic simulations, we have included a column for the limiting results (denoted by
 $n=\infty$
), for which we simulate the corresponding limiting branching process with a single ancestor 10 000 times. We then determine the limit fraction of major outbreaks, defined as scenarios with more than 1000 individuals born. The results indicate that our limiting approximations are effective.
$n=\infty$
), for which we simulate the corresponding limiting branching process with a single ancestor 10 000 times. We then determine the limit fraction of major outbreaks, defined as scenarios with more than 1000 individuals born. The results indicate that our limiting approximations are effective.
7. Discussion
In this paper, we have analysed a Markovian epidemic model with digital contact tracing, without or with manual contact tracing. For the epidemic model with digital tracing only, the early stage of the epidemic was proven to converge to a two-type branching process (as the population size
 $n\to\infty$
), with one type being to-be-traced app-using components and the other being non-app-users, and with
$n\to\infty$
), with one type being to-be-traced app-using components and the other being non-app-users, and with
 $R_{\mathrm{D}}$
being the largest eigenvalue of the of mean-offspring matrix of the two-type branching process. An individual reproduction number
$R_{\mathrm{D}}$
being the largest eigenvalue of the of mean-offspring matrix of the two-type branching process. An individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
was also derived. We investigated both analytically and numerically how
$R^\mathrm{(ind)}_{\mathrm{D}}$
was also derived. We investigated both analytically and numerically how
 $R_{\mathrm{D}}$
and
$R_{\mathrm{D}}$
and
 $R^\mathrm{(ind)}_{\mathrm{D}}$
depended on model parameters as well as on each other. The reproduction number
$R^\mathrm{(ind)}_{\mathrm{D}}$
depended on model parameters as well as on each other. The reproduction number
 $R_{\mathrm{D}}$
was shown to be non-monotone in
$R_{\mathrm{D}}$
was shown to be non-monotone in
 $\pi$
(the fraction of app-users) in general, whereas the individual reproduction number
$\pi$
(the fraction of app-users) in general, whereas the individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{D}}$
was proven to be monotonically decreasing in
$R^\mathrm{(ind)}_{\mathrm{D}}$
was proven to be monotonically decreasing in
 $\pi$
. When comparing digital tracing with manual tracing, it was proven that a smaller tracing probability p is needed than the corresponding app-using fraction
$\pi$
. When comparing digital tracing with manual tracing, it was proven that a smaller tracing probability p is needed than the corresponding app-using fraction
 $\pi$
in order to lower the reproduction number down to 1.
$\pi$
in order to lower the reproduction number down to 1.
We then analysed the combined model and proved that the beginning of the epidemic converges to a different two-type branching process, with both types being to-be-traced components, differing only in the type of root (app-user or non-app-user). The corresponding reproduction number had a rather complicated expression, which currently can only be evaluated numerically, and it was shown numerically not to be monotonically decreasing in
 $\pi$
and p in general.
$\pi$
and p in general.
There are several extensions of the present model that would make it more realistic. On the one hand, we have assumed that there is no delay in both manual and digital contact tracing, i.e. any traced contact (by either manual or digital tracing) is assumed to be immediately diagnosed. This neglects a crucial difference between manual and digital tracing: manual tracing is time- and labour-intensive, so there is often a delay between the case confirmation and notification of contacts, whereas digital tracing is designed to avoid (or shorten) this delay. Additionally, a limitation of a contact tracing app is that there could be close contacts that can lead to transmission but are too short to be registered by the app. For this reason, it would be of interest to extend our model to allow for infectious contacts between app-users that are not registered with a certain (small) probability and thus do not lead to tracing. It is, however, not straightforward to analyse such an extended model, since it mixes aspects of both digital (requiring both to be app-users) and manual (the possibility that such an app contact is not recorded) contact tracing. Further, we make the simplifying assumption that traced individuals who have by then recovered are also identified and contact-traced (see [Reference Müller, Kretzschmar and Dietz20], which does not make this assumption). In reality, this may happen for individuals who have recently recovered, but perhaps not for those who have recovered several weeks earlier. Therefore, the results in this paper give an upper bound on how effective the real contact tracing would be.
A different extension would be to consider a structured community (e.g. a social network) combined with homogeneous random contacts. Then, digital contact tracing would work in the same way for random contacts and contacts in the social network (as long as both are app-users), whereas manual contact tracing would most likely only happen on the social network (for example, very rarely would one be able to name the person one sat next to in the bus).
On the mathematical side, we have focused only on the early stage of the epidemic. Analysing later parts of the epidemic remains an open problem. Moreover, obtaining a more explicit expression for
 $ R_{\mathrm{DM}}$
in the combined model could shed more light on the effect of combining digital and manual contact tracing. For instance,
$ R_{\mathrm{DM}}$
in the combined model could shed more light on the effect of combining digital and manual contact tracing. For instance,
 $ R_{\mathrm{DM}}$
was shown numerically not to be monotone in
$ R_{\mathrm{DM}}$
was shown numerically not to be monotone in
 $\pi$
and p, but one would expect the critical curve
$\pi$
and p, but one would expect the critical curve
 $R_{\mathrm{DM}}=1$
to be monotone in the
$R_{\mathrm{DM}}=1$
to be monotone in the
 $(\pi ,p)$
plane (cf. Figure 7a and 7b), but a proof of this is missing. Further, it would be of interest to derive an individual reproduction number
$(\pi ,p)$
plane (cf. Figure 7a and 7b), but a proof of this is missing. Further, it would be of interest to derive an individual reproduction number
 $R^\mathrm{(ind)}_{\mathrm{ DM}}$
and prove properties for it, e.g. that it has the same threshold as
$R^\mathrm{(ind)}_{\mathrm{ DM}}$
and prove properties for it, e.g. that it has the same threshold as
 $R_{\mathrm{DM}}$
and that it decreases monotonically in both
$R_{\mathrm{DM}}$
and that it decreases monotonically in both
 $\pi$
and p.
$\pi$
and p.
Despite these model limitations, we consider this work an important step in increasing our understanding of the effects of different forms of contact tracing on spreading disease.
Acknowledgements
We thank Frank Ball for his idea of deriving a simplified expression for the component reproduction number
 $R^\mathrm{(c)}_{\mathrm{M}}$
for manual tracing in [Reference Zhang and Britton27], which also made it possible to simplify the reproduction number
$R^\mathrm{(c)}_{\mathrm{M}}$
for manual tracing in [Reference Zhang and Britton27], which also made it possible to simplify the reproduction number
 $R_{\mathrm{D}}$
in the current paper.
$R_{\mathrm{D}}$
in the current paper.
Funding information
T.B. is grateful to the Swedish Research Council (grant 2020-04744) for financial support.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.























































 Open access
Open access