


1. Introduction
Around 20 years ago, Stephen Anco and George Bluman [Reference Anco and Bluman2, Reference Anco and Bluman3] introduced a comprehensive practical method for determining conservation laws of partial differential equations (PDEs) in Kovalevskaya form. The method is based on finding adjoint symmetries and applying Helmholtz conditions.Footnote
1
A key part of the calculation is the inversion of the total divergence operator
 $\mathrm{Div}$
to obtain the components of the conservation law. Usually, this can be done by using a homotopy operator, but the following three problems may occur with the standard homotopy formula (which is given by Olver in [Reference Olver8]).
$\mathrm{Div}$
to obtain the components of the conservation law. Usually, this can be done by using a homotopy operator, but the following three problems may occur with the standard homotopy formula (which is given by Olver in [Reference Olver8]).
-
1. The homotopy formula uses definite integrals. This works well if the divergence is a differential polynomial; by contrast, rational polynomials commonly have a singularity at one limit. Hickman [Reference Hickman7] and Poole & Hereman [Reference Poole and Hereman9] suggest avoiding these by working in terms of indefinite integrals, an approach that we use throughout this paper. Alternatively, one can move the singularity by modifying the dependent variable (see Anco & Bluman [Reference Anco and Bluman3] and Poole & Hereman [Reference Poole and Hereman9]).
-
2. Scaling is fundamental to the homotopy approach to inversion. For instance, varying the scaling parameter in the standard homotopy formula moves contributions from variables along a ray to the origin. However, scaling does not change rational polynomials that are homogeneous of degree zero, so the standard inversion process does not work for such terms. Deconinck & Nivala [Reference Deconinck and Nivala5] discussed this problem in some detail (for one independent variable only) and suggested possible workarounds, but commented, ‘We are unaware of a homotopy method that algorithmically avoids all problems like the ones demonstrated
 $\ldots$
’. Poole & Hereman [Reference Poole and Hereman9] proposed an approach that works well for problems with one independent variable, but noted the difficulties of extending this to multiple independent variables (in a way that can be programmed).
$\ldots$
’. Poole & Hereman [Reference Poole and Hereman9] proposed an approach that works well for problems with one independent variable, but noted the difficulties of extending this to multiple independent variables (in a way that can be programmed). -
3. The standard homotopy operator applies to a star-shaped domain and integrates along rays to the origin, changing all Cartesian coordinates at once. This gives an inefficient inversion, in the sense that the number of terms is generally very much greater than necessary; the homotopy formula creates superfluous elements of
$\mathrm{ker}(\mathrm{Div})$
. For polynomial divergences, Poole & Hereman [Reference Poole and Hereman9] removed curls by parametrizing all terms given by the homotopy formula and optimizing the resulting linear system. This approach is very effective, because (except where there are cancellations) the homotopy formula tends to include every possible term that can appear in an inversion. However, it is unclear whether this approach can be generalized to non-polynomial divergences. Moreover, the removal of curl terms takes extra processing time and does not allow for the possibility that new terms might appear in the most concise inversion of the divergence. If inversion could be done with respect to one independent variable at a time, this might prevent the occurrence of superfluous curls from the outset.


Example 1.1. To illustrate the inefficiency of homotopy operators on star-shaped domains, consider the following divergence in
 $\mathbb{R}^3$
:
$\mathbb{R}^3$
:
 \begin{equation*} {\mathcal {C}}(x,y,z)=2xy\cos z. \end{equation*}
\begin{equation*} {\mathcal {C}}(x,y,z)=2xy\cos z. \end{equation*}
The homotopy operator based on a star-shaped domain gives
 ${\mathcal{C}}=\mathrm{div}(x\phi,y\phi,z\phi )$
, where
${\mathcal{C}}=\mathrm{div}(x\phi,y\phi,z\phi )$
, where
 \begin{align*} \phi &=\int _{0}^1\lambda ^2{\mathcal{C}}(\lambda x,\lambda y,\lambda z)\,\,\mathrm{d}\lambda \\[5pt] &=2xy\left \{\left (z^{-1}-12z^{-3}+24z^{-5}\right )\sin z +\left (4z^{-2}-24z^{-4}\right )\cos z\right \}. \end{align*}
\begin{align*} \phi &=\int _{0}^1\lambda ^2{\mathcal{C}}(\lambda x,\lambda y,\lambda z)\,\,\mathrm{d}\lambda \\[5pt] &=2xy\left \{\left (z^{-1}-12z^{-3}+24z^{-5}\right )\sin z +\left (4z^{-2}-24z^{-4}\right )\cos z\right \}. \end{align*}
By comparison, for a given divergence
 ${\mathcal{C}}(x,y,z)$
that has no singularities on the coordinate axes, using a homotopy formula that integrates one variable at a time gives
${\mathcal{C}}(x,y,z)$
that has no singularities on the coordinate axes, using a homotopy formula that integrates one variable at a time gives
 ${\mathcal{C}}=\mathrm{div}(F,G,H)$
, where
${\mathcal{C}}=\mathrm{div}(F,G,H)$
, where
 \begin{equation*} F=\int _0^x{\mathcal {C}}(\lambda,y,z)\,\mathrm {d}\lambda,\qquad G=\int _0^y{\mathcal {C}}(0,\lambda,z)\,\mathrm {d}\lambda,\qquad H=\int _0^z{\mathcal {C}}(0,0,\lambda )\,\mathrm {d}\lambda. \end{equation*}
\begin{equation*} F=\int _0^x{\mathcal {C}}(\lambda,y,z)\,\mathrm {d}\lambda,\qquad G=\int _0^y{\mathcal {C}}(0,\lambda,z)\,\mathrm {d}\lambda,\qquad H=\int _0^z{\mathcal {C}}(0,0,\lambda )\,\mathrm {d}\lambda. \end{equation*}
This recovers the concise form
 $(F,G,H)=(x^2y\cos z,0,0)$
. However, the use of the lower limit makes the formula over-elaborate (and unsuitable for treating singularities). Indefinite integration is far more straightforward:
$(F,G,H)=(x^2y\cos z,0,0)$
. However, the use of the lower limit makes the formula over-elaborate (and unsuitable for treating singularities). Indefinite integration is far more straightforward:
So the homotopy formula for star-shaped domains gives
 $14$
more terms than the simple form above; the superfluous terms amount to
$14$
more terms than the simple form above; the superfluous terms amount to
 \begin{equation*} \mathrm {curl}\left (4xy^2\left \{\left (3z^{-2}-6z^{-4}\right )\sin z -\left (z^{-1}-6z^{-3}\right )\cos z\right \},\,\,x^2y\sin z,\,\, xy\phi/2\right ). \end{equation*}
\begin{equation*} \mathrm {curl}\left (4xy^2\left \{\left (3z^{-2}-6z^{-4}\right )\sin z -\left (z^{-1}-6z^{-3}\right )\cos z\right \},\,\,x^2y\sin z,\,\, xy\phi/2\right ). \end{equation*}
The current paper extends the efficient one-variable-at-a-time approach to total derivatives. Indefinite integration is used, as advocated by Hickman [Reference Hickman7] for standard homotopy operators; it avoids the complications resulting from singularities. From the computational viewpoint, the biggest advantage of integration with respect to just one independent variable is that the major computer algebra systems have efficient procedures for computing antiderivatives.
The keys to inverting a total divergence one variable at a time are ‘partial Euler operators’ (see Section 3). These enable the inversion of a total derivative
 $D_x$
to be written as an indefinite line integral. Section 4 introduces a new iterative method for inverting a given total divergence; typically, this does not produce superfluous terms and very few iterations are needed. Furthermore, it can cope with components that are unchanged by the relevant scaling operator.
$D_x$
to be written as an indefinite line integral. Section 4 introduces a new iterative method for inverting a given total divergence; typically, this does not produce superfluous terms and very few iterations are needed. Furthermore, it can cope with components that are unchanged by the relevant scaling operator.
The methods in this paper are systematic, leading to procedures that are intended to be suitable for implementation in computer algebra systems.
2. Standard differential and homotopy operators
Here is a brief summary of the standard operators that are relevant to total divergences; for further details, see Olver [Reference Olver8]. The independent variables
 $\textbf{x} = (x^1,\ldots, x^p)$
are local Cartesian coordinates, and the dependent variables
$\textbf{x} = (x^1,\ldots, x^p)$
are local Cartesian coordinates, and the dependent variables
 $\textbf{u}=(u^1,\ldots,u^q)$
may be real- or complex-valued. The Einstein summation convention is used to explain the main ideas and state general results. In examples, commonly used notation is used where this aids clarity. All functions are assumed to be locally smooth, to allow the key ideas to be presented simply.
$\textbf{u}=(u^1,\ldots,u^q)$
may be real- or complex-valued. The Einstein summation convention is used to explain the main ideas and state general results. In examples, commonly used notation is used where this aids clarity. All functions are assumed to be locally smooth, to allow the key ideas to be presented simply.
Derivatives of each
 $u^\alpha$
are written as
$u^\alpha$
are written as
 $u^\alpha _{\textbf{J}}$
, where
$u^\alpha _{\textbf{J}}$
, where
 ${\textbf{J}}=(j^1,\ldots,j^p)$
is a multi-index; each
${\textbf{J}}=(j^1,\ldots,j^p)$
is a multi-index; each
 $j^i$
denotes the number of derivatives with respect to
$j^i$
denotes the number of derivatives with respect to
 $x^i$
, so
$x^i$
, so
 $u^\alpha _{\textbf{0}}= u^\alpha$
. The variables
$u^\alpha _{\textbf{0}}= u^\alpha$
. The variables
 $x^i$
and
$x^i$
and
 $u^\alpha _{\textbf{J}}$
can be regarded as jet space coordinates. The total derivative with respect to
$u^\alpha _{\textbf{J}}$
can be regarded as jet space coordinates. The total derivative with respect to
 $x^i$
,
$x^i$
,
 \begin{equation*} D_i=\frac {\partial }{\partial x^i}+u^\alpha _{{\textbf{J}} +{\boldsymbol {1}}_i}\,\frac {\partial }{\partial u^\alpha _{\textbf{J}}}\,,\quad \text {where}\quad {\textbf{J}} +{\boldsymbol {1}}_i=(j^1,\ldots,j^{i-1},j^i+1,j^{i+1},\ldots, j^p), \end{equation*}
\begin{equation*} D_i=\frac {\partial }{\partial x^i}+u^\alpha _{{\textbf{J}} +{\boldsymbol {1}}_i}\,\frac {\partial }{\partial u^\alpha _{\textbf{J}}}\,,\quad \text {where}\quad {\textbf{J}} +{\boldsymbol {1}}_i=(j^1,\ldots,j^{i-1},j^i+1,j^{i+1},\ldots, j^p), \end{equation*}
treats each
 $u^\alpha _{\textbf{J}}$
as a function of
$u^\alpha _{\textbf{J}}$
as a function of
 $\textbf{x}$
. To keep the notation concise, write
$\textbf{x}$
. To keep the notation concise, write
 \begin{equation*} D_{\textbf{J}}=D_1^{j^1}D_2^{j^2}\cdots D_p^{j^p}; \end{equation*}
\begin{equation*} D_{\textbf{J}}=D_1^{j^1}D_2^{j^2}\cdots D_p^{j^p}; \end{equation*}
note that
 $u^\alpha _{\textbf{J}}=D_{\textbf{J}}(u^\alpha )$
. Let
$u^\alpha _{\textbf{J}}=D_{\textbf{J}}(u^\alpha )$
. Let
 $[{\textbf{u}}]$
represent
$[{\textbf{u}}]$
represent
 $\textbf{u}$
and finitely many of its derivatives; more generally, square brackets around an expression denote the expression and as many of its total derivatives as are needed.
$\textbf{u}$
and finitely many of its derivatives; more generally, square brackets around an expression denote the expression and as many of its total derivatives as are needed.
A total divergence is an expression of the form
 \begin{equation*} {\mathcal {C}}=\mathrm {Div}({\textbf{F}})\;:\!=\; D_iF^i({\textbf{x}},[{\textbf{u}}]). \end{equation*}
\begin{equation*} {\mathcal {C}}=\mathrm {Div}({\textbf{F}})\;:\!=\; D_iF^i({\textbf{x}},[{\textbf{u}}]). \end{equation*}
(If all
 $F^i$
depend on
$F^i$
depend on
 $\textbf{x}$
only,
$\textbf{x}$
only,
 $\mathcal{C}$
is an ordinary divergence.) A conservation law of a given system of partial differential equations (PDEs),
$\mathcal{C}$
is an ordinary divergence.) A conservation law of a given system of partial differential equations (PDEs),
 ${\mathcal{A}}_\ell ({\textbf{x}},[{\textbf{u}}])=0,\ \ell =1,\ldots,L$
, is a total divergence that is zero on all solutions of the system; each
${\mathcal{A}}_\ell ({\textbf{x}},[{\textbf{u}}])=0,\ \ell =1,\ldots,L$
, is a total divergence that is zero on all solutions of the system; each
 $F^i$
is a finite sum of terms. By using elementary algebraic operations (in particular, expanding logarithms of products and products of sums), the number of linearly independent terms may be maximized. When the number of linearly independent terms is maximal for each
$F^i$
is a finite sum of terms. By using elementary algebraic operations (in particular, expanding logarithms of products and products of sums), the number of linearly independent terms may be maximized. When the number of linearly independent terms is maximal for each
 $i$
, we call the result the fully expanded form of
$i$
, we call the result the fully expanded form of
 $\textbf{F}$
.
$\textbf{F}$
.
When
 $p\gt 1$
, the
$p\gt 1$
, the
 $p$
-tuple of components,
$p$
-tuple of components,
 $\textbf{F}$
, is determined by
$\textbf{F}$
, is determined by
 $\mathcal{C}$
up to a transformation of the form
$\mathcal{C}$
up to a transformation of the form
 \begin{equation} F^i\longmapsto F^i+D_j\left \{f^{ij}({\textbf{x}},[{\textbf{u}}])\right \},\qquad \text{where}\ f^{ji}=-f^{ij}. \end{equation}
\begin{equation} F^i\longmapsto F^i+D_j\left \{f^{ij}({\textbf{x}},[{\textbf{u}}])\right \},\qquad \text{where}\ f^{ji}=-f^{ij}. \end{equation}
(If
 $p=3$
, such a transformation adds a total curl to
$p=3$
, such a transformation adds a total curl to
 $\textbf{F}$
.) The total number of terms in
$\textbf{F}$
.) The total number of terms in
 $\textbf{F}$
is the sum of the number of terms in all of the fully expanded components
$\textbf{F}$
is the sum of the number of terms in all of the fully expanded components
 $F^i$
. If this cannot be lowered by any transformation (2.1), we call
$F^i$
. If this cannot be lowered by any transformation (2.1), we call
 $\textbf{F}$
minimal. Commonly, there is more than one minimal
$\textbf{F}$
minimal. Commonly, there is more than one minimal
 $\textbf{F}$
, any of which puts the inversion of
$\textbf{F}$
, any of which puts the inversion of
 $\mathrm{Div}$
in as concise a form as possible. If
$\mathrm{Div}$
in as concise a form as possible. If
 $p=1$
, the sole component
$p=1$
, the sole component
 $F^1$
(also denoted
$F^1$
(also denoted
 $F$
) is determined up to an arbitrary constant, so the number of non-constant terms is fixed.
$F$
) is determined up to an arbitrary constant, so the number of non-constant terms is fixed.
The formal adjoint of a differential operator (with total derivatives),
 $\mathcal{D}$
, is the unique differential operator
$\mathcal{D}$
, is the unique differential operator
 ${\mathcal{D}}^{\dagger}$
such that
${\mathcal{D}}^{\dagger}$
such that
 \begin{equation*}f\hspace{0.167em}\mathcal Dg-{(\mathcal D^{\dagger}f)}g\end{equation*}
\begin{equation*}f\hspace{0.167em}\mathcal Dg-{(\mathcal D^{\dagger}f)}g\end{equation*}
is a total divergence for all functions
 $f({\textbf{x}},[{\textbf{u}}])$
and
$f({\textbf{x}},[{\textbf{u}}])$
and
 $g({\textbf{x}},[{\textbf{u}}])$
. In particular,
$g({\textbf{x}},[{\textbf{u}}])$
. In particular,
 \begin{equation} (D_{\textbf{J}})^{\boldsymbol{\dagger}}=(\!-\!D)_{\textbf{J}}\;:\!=\;(\!-\!1)^{|{\textbf{J}}|}D_{\textbf{J}},\quad \text{where}\quad |{\textbf{J}}|=j^1+\cdots +j^p. \end{equation}
\begin{equation} (D_{\textbf{J}})^{\boldsymbol{\dagger}}=(\!-\!D)_{\textbf{J}}\;:\!=\;(\!-\!1)^{|{\textbf{J}}|}D_{\textbf{J}},\quad \text{where}\quad |{\textbf{J}}|=j^1+\cdots +j^p. \end{equation}
Thus, the (standard) Euler–Lagrange operator corresponding to variations in
 $u^\alpha$
is
$u^\alpha$
is
 \begin{equation*} {\textbf{E}}_{u^\alpha }=(\!-\!D)_{\textbf{J}}\frac {\partial }{\partial u^\alpha _{\textbf{J}}}\,. \end{equation*}
\begin{equation*} {\textbf{E}}_{u^\alpha }=(\!-\!D)_{\textbf{J}}\frac {\partial }{\partial u^\alpha _{\textbf{J}}}\,. \end{equation*}
Total divergences satisfy a useful identity: a function
 ${\mathcal{C}}({\textbf{x}},[{\textbf{u}}])$
is a total divergence if and only if
${\mathcal{C}}({\textbf{x}},[{\textbf{u}}])$
is a total divergence if and only if
 \begin{equation} {\textbf{E}}_{u^\alpha }({\mathcal{C}})=0,\qquad \alpha =1,\ldots,q. \end{equation}
\begin{equation} {\textbf{E}}_{u^\alpha }({\mathcal{C}})=0,\qquad \alpha =1,\ldots,q. \end{equation}
Given a Lagrangian function
 $L({\textbf{x}},[{\textbf{u}}])$
, the Euler–Lagrange equations are
$L({\textbf{x}},[{\textbf{u}}])$
, the Euler–Lagrange equations are
 ${\textbf{E}}_{u^\alpha }(L)=0$
. Given a set of Euler–Lagrange equations that are polynomial in the variables
${\textbf{E}}_{u^\alpha }(L)=0$
. Given a set of Euler–Lagrange equations that are polynomial in the variables
 $({\textbf{x}},[{\textbf{u}}])$
, the function
$({\textbf{x}},[{\textbf{u}}])$
, the function
 $\overline{L}$
given by the homotopy formula
$\overline{L}$
given by the homotopy formula
 \begin{equation} \overline{L}({\textbf{x}},[{\textbf{u}}])=\int _{0}^1u^\alpha \left \{{\textbf{E}}_{u^\alpha }(L)\right \}\!\big |_{[{\textbf{u}}\mapsto \lambda{\textbf{u}}]}\,\mathrm{d}\lambda \end{equation}
\begin{equation} \overline{L}({\textbf{x}},[{\textbf{u}}])=\int _{0}^1u^\alpha \left \{{\textbf{E}}_{u^\alpha }(L)\right \}\!\big |_{[{\textbf{u}}\mapsto \lambda{\textbf{u}}]}\,\mathrm{d}\lambda \end{equation}
differs from
 $L$
by a total divergence. (The same applies to many, but not all, non-polynomial Euler–Lagrange equations.)
$L$
by a total divergence. (The same applies to many, but not all, non-polynomial Euler–Lagrange equations.)
When
 $p=1$
, the equation
$p=1$
, the equation
 $P(x,[{\textbf{u}}])=D_xF$
is invertible (at least, for polynomial
$P(x,[{\textbf{u}}])=D_xF$
is invertible (at least, for polynomial
 $P$
) by the following standard homotopy formula:
$P$
) by the following standard homotopy formula:
 \begin{equation} F(x,[{\textbf{u}}])=\!\int _{0}^1\sum _{i=1}^\infty D_x^{i-1}\!\left (u^\alpha \!\left \{\sum _{k\geq i}\binom{k}{i}(\!-\!D_x)^{k-i}\frac{\partial P(x,[{\textbf{u}}])}{\partial (D_x^ku^\alpha )}\right \}\Bigg |_{[{\textbf{u}}\mapsto \lambda{\textbf{u}}]}\right )\!\,\mathrm{d}\lambda +\int _{0}^1\!xP(\lambda x,[0])\,\mathrm{d}\lambda. \end{equation}
\begin{equation} F(x,[{\textbf{u}}])=\!\int _{0}^1\sum _{i=1}^\infty D_x^{i-1}\!\left (u^\alpha \!\left \{\sum _{k\geq i}\binom{k}{i}(\!-\!D_x)^{k-i}\frac{\partial P(x,[{\textbf{u}}])}{\partial (D_x^ku^\alpha )}\right \}\Bigg |_{[{\textbf{u}}\mapsto \lambda{\textbf{u}}]}\right )\!\,\mathrm{d}\lambda +\int _{0}^1\!xP(\lambda x,[0])\,\mathrm{d}\lambda. \end{equation}
The operator acting on
 $P$
in the braces above is the higher Euler operator of order
$P$
in the braces above is the higher Euler operator of order
 $i$
for
$i$
for
 $p=1$
. When
$p=1$
. When
 $p\geq 2$
, the standard homotopy formula is similar, but somewhat more complex (see Olver [Reference Olver8] for details); it is based on higher Euler operators and integration along rays in a totally star-shaped domain. The following example illustrates that even for quite simple divergences, this formula commonly yields inversions with many superfluous terms.
$p\geq 2$
, the standard homotopy formula is similar, but somewhat more complex (see Olver [Reference Olver8] for details); it is based on higher Euler operators and integration along rays in a totally star-shaped domain. The following example illustrates that even for quite simple divergences, this formula commonly yields inversions with many superfluous terms.
Example 2.1. The Benjamin–Bona–Mahony (BBM) equation,
 $u_{t}-uu_x-u_{xxt}=0$
, has a conservation law
$u_{t}-uu_x-u_{xxt}=0$
, has a conservation law
 \begin{equation} {\mathcal{C}}=D_xF+D_tG=(u^2+2u_{xt})(u_{t}-uu_x-u_{xxt}). \end{equation}
\begin{equation} {\mathcal{C}}=D_xF+D_tG=(u^2+2u_{xt})(u_{t}-uu_x-u_{xxt}). \end{equation}
The standard homotopy formula gives
 \begin{align*} F&=-\frac{1}{3}uu_{xxtt}+\frac{2}{3}u_{x}u_{xtt}-\frac{1}{3}u_{t}u_{xxt}-\frac{1}{3}u_{xt}^2-\frac{1}{2}uu_{tt}+\frac{1}{2}u_{t}^2-\frac{2}{3}u^2u_{xt}+\frac{2}{3}uu_xu_{t}-\frac{1}{4}u^4,\\[5pt] G&=\frac{1}{3}uu_{xxxt}-\frac{1}{3}u_{x}u_{xxt}-\frac{2}{3}u_{xx}u_{xt}+\frac{1}{2}uu_{xt}+\frac{1}{2}u_xu_{t}-\frac{1}{3}u^2u_{xx}-\frac{2}{3}uu_{x}^2+\frac{1}{3}u^3, \end{align*}
\begin{align*} F&=-\frac{1}{3}uu_{xxtt}+\frac{2}{3}u_{x}u_{xtt}-\frac{1}{3}u_{t}u_{xxt}-\frac{1}{3}u_{xt}^2-\frac{1}{2}uu_{tt}+\frac{1}{2}u_{t}^2-\frac{2}{3}u^2u_{xt}+\frac{2}{3}uu_xu_{t}-\frac{1}{4}u^4,\\[5pt] G&=\frac{1}{3}uu_{xxxt}-\frac{1}{3}u_{x}u_{xxt}-\frac{2}{3}u_{xx}u_{xt}+\frac{1}{2}uu_{xt}+\frac{1}{2}u_xu_{t}-\frac{1}{3}u^2u_{xx}-\frac{2}{3}uu_{x}^2+\frac{1}{3}u^3, \end{align*}
a total of 17 terms. By contrast, careful integration by inspection yields
 \begin{equation} {\mathcal{C}}=D_x\left (u_t^2-u_{xt}^2-u^2u_{xt}-\frac{1}{4}u^4\right )+D_t\left (\frac{1}{3}u^3\right ), \end{equation}
\begin{equation} {\mathcal{C}}=D_x\left (u_t^2-u_{xt}^2-u^2u_{xt}-\frac{1}{4}u^4\right )+D_t\left (\frac{1}{3}u^3\right ), \end{equation}
which is minimal, having only five terms in the components.
The homotopy formulae above can be applied or adapted to some, but not all, classes of non-polynomial Lagrangians and divergences.
3. Partial Euler operators and partial scalings
This section introduces some ideas and results that underpin integration with respect to one independent variable at a time. The independent variable over which one integrates is distinguished; this is denoted by
 $x$
. For instance, if
$x$
. For instance, if
 $x=x^1$
, replace the derivative index
$x=x^1$
, replace the derivative index
 $\textbf{J}$
by
$\textbf{J}$
by
 $({\textbf{I}},j)$
, where
$({\textbf{I}},j)$
, where
 $j=j^1$
and
$j=j^1$
and
 ${\textbf{I}}=(j^2,\ldots,j^{p})$
. So the dependent variables and their derivatives are denoted
${\textbf{I}}=(j^2,\ldots,j^{p})$
. So the dependent variables and their derivatives are denoted
 \begin{equation*} u^\alpha _{{\textbf{I}},\,j}=D_x^{\,j}u^\alpha _{\textbf{I}},\qquad \text {where}\ u^\alpha _{\textbf{I}}=u^\alpha _{{\textbf{I}},0}. \end{equation*}
\begin{equation*} u^\alpha _{{\textbf{I}},\,j}=D_x^{\,j}u^\alpha _{\textbf{I}},\qquad \text {where}\ u^\alpha _{\textbf{I}}=u^\alpha _{{\textbf{I}},0}. \end{equation*}
In examples, however, we write each
 $u^\alpha _{\textbf{I}}$
more simply (as
$u^\alpha _{\textbf{I}}$
more simply (as
 $u$
,
$u$
,
 $v_y$
,
$v_y$
,
 $u_{yt}$
, and so on), using, j for
$u_{yt}$
, and so on), using, j for
 $D_x^{\,j}$
.
$D_x^{\,j}$
.
3.1 Partial Euler operators
The partial Euler operator with respect to
 $x$
and
$x$
and
 $u^\alpha _{\textbf{I}}$
is obtained by varying each
$u^\alpha _{\textbf{I}}$
is obtained by varying each
 $u^\alpha _{\textbf{I}}$
independently, treating
$u^\alpha _{\textbf{I}}$
independently, treating
 $x$
as the sole independent variable:
$x$
as the sole independent variable:
 \begin{equation}{\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x}=(\!-\!D_x)^j\frac{\partial }{\partial u^\alpha _{\textbf{I},j}}\,. \end{equation}
\begin{equation}{\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x}=(\!-\!D_x)^j\frac{\partial }{\partial u^\alpha _{\textbf{I},j}}\,. \end{equation}
Consequently, the standard Euler operator with respect to
 $u^\alpha$
amounts to
$u^\alpha$
amounts to
 \begin{equation} {\textbf{E}}_{u^\alpha }=(\!-\!D)_{\textbf{I}}{\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x}\,. \end{equation}
\begin{equation} {\textbf{E}}_{u^\alpha }=(\!-\!D)_{\textbf{I}}{\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x}\,. \end{equation}
Similarly, the partial Euler operator with respect to
 $x$
and
$x$
and
 $u^\alpha _{\textbf{I},k}$
is
$u^\alpha _{\textbf{I},k}$
is
 \begin{equation}{\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}=(\!-\!D_x)^j\frac{\partial }{\partial u^\alpha _{\textbf{I},j+k}}\,. \end{equation}
\begin{equation}{\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}=(\!-\!D_x)^j\frac{\partial }{\partial u^\alpha _{\textbf{I},j+k}}\,. \end{equation}
Note that
 \begin{equation} {\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}=\frac{\partial }{\partial u^\alpha _{\textbf{I},k}}\!-\!D_x{\textbf{E}}^x_{u^\alpha _{{\textbf{I}},k+1}}. \end{equation}
\begin{equation} {\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}=\frac{\partial }{\partial u^\alpha _{\textbf{I},k}}\!-\!D_x{\textbf{E}}^x_{u^\alpha _{{\textbf{I}},k+1}}. \end{equation}
The following identities are easily verified; here,
 $f({\textbf{x}},[{\textbf{u}}])$
is an arbitrary function.
$f({\textbf{x}},[{\textbf{u}}])$
is an arbitrary function.
 \begin{align} {\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x}(D_x f)=0, \end{align}
\begin{align} {\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x}(D_x f)=0, \end{align}
 \begin{align} {\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}(D_x f)=\frac{\partial f}{\partial u^\alpha _{{\textbf{I}},k-1}}\,,\qquad k\geq 1, \end{align}
\begin{align} {\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}(D_x f)=\frac{\partial f}{\partial u^\alpha _{{\textbf{I}},k-1}}\,,\qquad k\geq 1, \end{align}
 \begin{align} {\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}(D_i f)=D_i\left ({\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}(f)\right )+{\textbf{E}}^x_{u^\alpha _{{\textbf{I}}-{\boldsymbol{1}}_i,k}}(f),\qquad x^i\neq x, \end{align}
\begin{align} {\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}(D_i f)=D_i\left ({\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}(f)\right )+{\textbf{E}}^x_{u^\alpha _{{\textbf{I}}-{\boldsymbol{1}}_i,k}}(f),\qquad x^i\neq x, \end{align}
where the last term in (3.7) is zero if
 $j^i=0$
.
$j^i=0$
.
3.2 Inversion of
$\boldsymbol{D}_\boldsymbol{x}$

The identities (3.5), (3.6) and (3.7) are central to the inversion of total divergences, including the following inversion of
 $P=D_xF$
as an indefinite line integral.
$P=D_xF$
as an indefinite line integral.
Lemma 3.1. If
 $P(\boldsymbol{x},[\boldsymbol{u}])=D_xF$
, then, up to an (irrelevant) arbitrary function of all independent variables other than
$P(\boldsymbol{x},[\boldsymbol{u}])=D_xF$
, then, up to an (irrelevant) arbitrary function of all independent variables other than
 $x$
,
$x$
,
 \begin{equation} F(\boldsymbol{x},[\boldsymbol{u}])=\int \left (P-\sum _{k\geq 1}u^\alpha _{\boldsymbol{I},k}\,\boldsymbol{E}_{u^\alpha _{\boldsymbol{I},k}}^{x}(P)\right )\!\,\mathrm{d} x+\sum _{k\geq 0}\boldsymbol{E}^x_{u^\alpha _{\boldsymbol{I},k+1}}(P)\,\mathrm{d}u^\alpha _{\boldsymbol{I},k}\,. \end{equation}
\begin{equation} F(\boldsymbol{x},[\boldsymbol{u}])=\int \left (P-\sum _{k\geq 1}u^\alpha _{\boldsymbol{I},k}\,\boldsymbol{E}_{u^\alpha _{\boldsymbol{I},k}}^{x}(P)\right )\!\,\mathrm{d} x+\sum _{k\geq 0}\boldsymbol{E}^x_{u^\alpha _{\boldsymbol{I},k+1}}(P)\,\mathrm{d}u^\alpha _{\boldsymbol{I},k}\,. \end{equation}
Proof. By the identity (3.6),
 \begin{equation*} F({\textbf{x}},[{\textbf{u}}])=\int \frac {\partial F}{\partial x}\,\,\mathrm {d} x+\sum _{k\geq 0}{\textbf{E}}^x_{u^\alpha _{{\textbf{I}},k+1}}(D_xF)\,\mathrm {d}u^\alpha _{\textbf{I},k}\,. \end{equation*}
\begin{equation*} F({\textbf{x}},[{\textbf{u}}])=\int \frac {\partial F}{\partial x}\,\,\mathrm {d} x+\sum _{k\geq 0}{\textbf{E}}^x_{u^\alpha _{{\textbf{I}},k+1}}(D_xF)\,\mathrm {d}u^\alpha _{\textbf{I},k}\,. \end{equation*}
Moreover,
 \begin{equation*} P=\frac {\partial F}{\partial x}+\sum _{k\geq 1}u^\alpha _{\textbf{I},k}\,\frac {\partial F}{\partial u^\alpha _{{\textbf{I}},k-1}}=\frac {\partial F}{\partial x}+\sum _{k\geq 1}u^\alpha _{\textbf{I},k}\,{\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}(D_x F)\,. \end{equation*}
\begin{equation*} P=\frac {\partial F}{\partial x}+\sum _{k\geq 1}u^\alpha _{\textbf{I},k}\,\frac {\partial F}{\partial u^\alpha _{{\textbf{I}},k-1}}=\frac {\partial F}{\partial x}+\sum _{k\geq 1}u^\alpha _{\textbf{I},k}\,{\textbf{E}}_{u^\alpha _{\textbf{I},k}}^{x}(D_x F)\,. \end{equation*}
Substituting
 $P$
for
$P$
for
 $D_xF$
completes the proof.
$D_xF$
completes the proof.
Example 3.1. Locally, away from its singularities, the function
 \begin{equation} P=\frac{u_{xx}v_y-u_xv_{xy}}{v_y^2}+\frac{uv_x-u_xv}{v(u+v)}+\frac{1}{x} \end{equation}
\begin{equation} P=\frac{u_{xx}v_y-u_xv_{xy}}{v_y^2}+\frac{uv_x-u_xv}{v(u+v)}+\frac{1}{x} \end{equation}
belongs to
 $\mathrm{im}(D_x)$
, but cannot be inverted using the standard homotopy formula. Substituting
$\mathrm{im}(D_x)$
, but cannot be inverted using the standard homotopy formula. Substituting
 \begin{align*} &\boldsymbol{E}^x_{u_{,1}}(P)=\frac{\partial P}{\partial u_x}-D_x\frac{\partial P}{\partial u_{xx}}=-\frac{1}{u+v}\,, &&\boldsymbol{E}^x_{u_{,2}}(P)=\frac{\partial P}{\partial u_{xx}}=\frac{1}{v_y}\,,\\[5pt] &\boldsymbol{E}^x_{v_{,1}}(P)=\frac{\partial P}{\partial v_{x}}=\frac{u}{v(u+v)}\,, &&\boldsymbol{E}^x_{v_{y,1}}(P)=\frac{\partial P}{\partial v_{xy}}=-\frac{u_x}{v_y^2}\,, \end{align*}
\begin{align*} &\boldsymbol{E}^x_{u_{,1}}(P)=\frac{\partial P}{\partial u_x}-D_x\frac{\partial P}{\partial u_{xx}}=-\frac{1}{u+v}\,, &&\boldsymbol{E}^x_{u_{,2}}(P)=\frac{\partial P}{\partial u_{xx}}=\frac{1}{v_y}\,,\\[5pt] &\boldsymbol{E}^x_{v_{,1}}(P)=\frac{\partial P}{\partial v_{x}}=\frac{u}{v(u+v)}\,, &&\boldsymbol{E}^x_{v_{y,1}}(P)=\frac{\partial P}{\partial v_{xy}}=-\frac{u_x}{v_y^2}\,, \end{align*}
into (3.8) yields the inversion:
 \begin{equation} F=\int \frac{\,\mathrm{d} x}{x} -\frac{\,\mathrm{d} u}{u+v}\,+\frac{\,\mathrm{d} u_x}{v_y} +\frac{u\,\mathrm{d} v}{v(u+v)}-\frac{u_x\,\mathrm{d} v_y}{v_y^2}\, =\, \ln \left |\frac{xv}{u+v}\right |+\frac{u_x}{v_y}\,. \end{equation}
\begin{equation} F=\int \frac{\,\mathrm{d} x}{x} -\frac{\,\mathrm{d} u}{u+v}\,+\frac{\,\mathrm{d} u_x}{v_y} +\frac{u\,\mathrm{d} v}{v(u+v)}-\frac{u_x\,\mathrm{d} v_y}{v_y^2}\, =\, \ln \left |\frac{xv}{u+v}\right |+\frac{u_x}{v_y}\,. \end{equation}
3.3 Integration by parts
From here on, we will restrict attention to total divergences
 $\mathcal{C}$
whose fully expanded form has no terms that depend on
$\mathcal{C}$
whose fully expanded form has no terms that depend on
 $\textbf{x}$
only. Such terms can be inverted easily by evaluating an indefinite integral, as explained in the Introduction. Henceforth, all indefinite integrals denote antiderivatives with the minimal number of terms in their fully expanded form. Any arbitrary constants and functions that would increase the number of terms are set to zero. This restriction facilitates the search for minimal inversions.
$\textbf{x}$
only. Such terms can be inverted easily by evaluating an indefinite integral, as explained in the Introduction. Henceforth, all indefinite integrals denote antiderivatives with the minimal number of terms in their fully expanded form. Any arbitrary constants and functions that would increase the number of terms are set to zero. This restriction facilitates the search for minimal inversions.
The indefinite line integral formula (3.8) is closely related to integration by parts. To see this, we introduce a positive ranking on the variables
 $u^\alpha _{{\textbf{J}}}\,$
; this is a total order
$u^\alpha _{{\textbf{J}}}\,$
; this is a total order
 $\preceq$
that is subject to two conditions:
$\preceq$
that is subject to two conditions:
 \begin{equation*} (i)\,\ u^\alpha \prec u^\alpha _{{\textbf{J}}}\,,\quad {\textbf{J}}\neq \textbf{0},\qquad (ii)\,\ u^\beta _{{\textbf{I}}}\prec u^\alpha _{{\textbf{J}}}\Longrightarrow D_{{\textbf{K}} }u^\beta _{{\textbf{I}}}\prec D_{{\textbf{K}} }u^\alpha _{{\textbf{J}}}\,. \end{equation*}
\begin{equation*} (i)\,\ u^\alpha \prec u^\alpha _{{\textbf{J}}}\,,\quad {\textbf{J}}\neq \textbf{0},\qquad (ii)\,\ u^\beta _{{\textbf{I}}}\prec u^\alpha _{{\textbf{J}}}\Longrightarrow D_{{\textbf{K}} }u^\beta _{{\textbf{I}}}\prec D_{{\textbf{K}} }u^\alpha _{{\textbf{J}}}\,. \end{equation*}
The leading part of a differential function is the sum of terms in the function that depend on the highest-ranked
 $u^\alpha _{\textbf{J}}$
, and the rank of the function is the rank of its leading part (see Rust et al. [Reference Rust, Reid and Wittkopf12] for details and references). Let
$u^\alpha _{\textbf{J}}$
, and the rank of the function is the rank of its leading part (see Rust et al. [Reference Rust, Reid and Wittkopf12] for details and references). Let
 $f({\textbf{x}},[{\textbf{u}}])$
denote the leading part of the fully expanded form of
$f({\textbf{x}},[{\textbf{u}}])$
denote the leading part of the fully expanded form of
 $F$
and let
$F$
and let
 $\mathrm{U}_{,k}$
denote the highest-ranked
$\mathrm{U}_{,k}$
denote the highest-ranked
 $u^\alpha _{\textbf{I},k}$
; then the highest-ranked part of
$u^\alpha _{\textbf{I},k}$
; then the highest-ranked part of
 $P=D_xF$
is
$P=D_xF$
is
 $\mathrm{U}_{,k+1}\partial f/\partial \mathrm{U}_{,k}$
. Then (3.8) includes the contribution
$\mathrm{U}_{,k+1}\partial f/\partial \mathrm{U}_{,k}$
. Then (3.8) includes the contribution
 \begin{equation*} \int {\textbf{E}}^x_{\mathrm {U}_{,k+1}}(P)\,\mathrm {d} \mathrm {U}_{,k}=\int \frac {\partial f}{\partial \mathrm {U}_{,k}}\,\,\mathrm {d} \mathrm {U}_{,k}= f + \text{lower-ranked terms}. \end{equation*}
\begin{equation*} \int {\textbf{E}}^x_{\mathrm {U}_{,k+1}}(P)\,\mathrm {d} \mathrm {U}_{,k}=\int \frac {\partial f}{\partial \mathrm {U}_{,k}}\,\,\mathrm {d} \mathrm {U}_{,k}= f + \text{lower-ranked terms}. \end{equation*}
Integration by parts gives the same result. Subtracting
 $f$
from
$f$
from
 $F$
and iterating shows that evaluating the line integral (3.8) is equivalent to integrating by parts from the highest-ranked terms downwards.
$F$
and iterating shows that evaluating the line integral (3.8) is equivalent to integrating by parts from the highest-ranked terms downwards.
Integration by parts is useful for splitting a differential expression
 $P({\textbf{x}},[{\textbf{u}}])$
, with
$P({\textbf{x}},[{\textbf{u}}])$
, with
 $P({\textbf{x}},[0])=0$
, into
$P({\textbf{x}},[0])=0$
, into
 $D_xF$
and a remainder,
$D_xF$
and a remainder,
 $R$
, whose
$R$
, whose
 $x$
-derivatives are of the lowest-possible order. The splitting is achieved by the following procedure.
$x$
-derivatives are of the lowest-possible order. The splitting is achieved by the following procedure.
Procedure A. Integration by parts
-
Step 0. Choose a positive ranking in which
$u^\alpha _{{\textbf{I}},0}\prec D_xu^\beta$
for all
$\alpha,{\textbf{I}}$
and
$\beta$
. (We call such rankings
$x$
-dominant.) Initialize by setting
$F\;:\!=\;0$
and
$R\;:\!=\;0$
. -
Step 1. Identify the highest-ranked
$u^\alpha _{\textbf{I},k}$
in
$P$
; denote this by
$\mathrm{U}_{,k}$
. If
$k=0$
, add
$P$
to
$R$
and stop. Otherwise, determine the leading part,
$g$
, of
$P$
. -
Step 2. Determine the sum
$h\mathrm{U}_{,k}$
of all terms in the fully expanded form of
$g$
that are of the form
$\gamma \mathrm{U}_{,k}$
, where
$\gamma$
is ranked no higher than
$\mathrm{U}_{,k-1}$
, and let
\begin{equation*} H=\int h\,\mathrm {d}\mathrm {U}_{,k-1}\,. \end{equation*}
-
Step 3. Update
$F, R$
and
$P$
, as follows:If
\begin{equation*} F\;:\!=\;F+H,\qquad R\;:\!=\;R+g-h\mathrm {U}_{,k},\qquad P\;:\!=\;P-g+h\mathrm {U}_{,k}\!-\!D_xH. \end{equation*}
$P\neq 0$
, return to Step 1. Otherwise output
$F$
and
$R$
, then stop.


























The reason for choosing an
 $x$
-dominant ranking is to ensure that the derivative order with respect to
$x$
-dominant ranking is to ensure that the derivative order with respect to
 $x$
outweighs all other ranking criteria. Consequently, the minimally ranked remainder cannot contain
$x$
outweighs all other ranking criteria. Consequently, the minimally ranked remainder cannot contain
 $x$
-derivatives of unnecessarily high order.
$x$
-derivatives of unnecessarily high order.
Example 3.2. To produce a concise inversion of a conservation law of the Harry Dym equation (see Example 4.1 below), it is necessary to split
 \begin{equation*} P=-\frac {8}{3}u^2u_{,4}-\frac {16}{3}uu_{,1}u_{,3}-4uu_{,2}^2+4u_{,1}^2u_{,2}-u^{-1}u_{,1}^4\,. \end{equation*}
\begin{equation*} P=-\frac {8}{3}u^2u_{,4}-\frac {16}{3}uu_{,1}u_{,3}-4uu_{,2}^2+4u_{,1}^2u_{,2}-u^{-1}u_{,1}^4\,. \end{equation*}
Procedure A gives the splitting
 \begin{equation*} P=D_x\!\left \{-\frac {8}{3}u^2u_{,3}+\frac {4}{3}u_{,1}^3\right \}-4uu_{,2}^2-u^{-1}u_{,1}^4\,. \end{equation*}
\begin{equation*} P=D_x\!\left \{-\frac {8}{3}u^2u_{,3}+\frac {4}{3}u_{,1}^3\right \}-4uu_{,2}^2-u^{-1}u_{,1}^4\,. \end{equation*}
Example 3.3. The ranking criterion in Step 2 of Procedure A ensures that there are no infinite loops. It is not enough that terms are linear in the highest-ranked
 $x$
-derivative, as shown by the following splitting of
$x$
-derivative, as shown by the following splitting of
 \begin{equation*} P=\frac {v_{,3}}{u_{y}}+\frac {u_{,2}}{v_{y}} \end{equation*}
\begin{equation*} P=\frac {v_{,3}}{u_{y}}+\frac {u_{,2}}{v_{y}} \end{equation*}
For the positive
 $x$
-dominant ranking defined by
$x$
-dominant ranking defined by
 $v\prec u\prec v_y$
, Procedure A yields
$v\prec u\prec v_y$
, Procedure A yields
 \begin{equation*} P=D_x\!\left \{\frac {v_{,2}}{u_{y}}+\frac {u_{,1}}{v_{y}}\right \}+\frac {v_{,2}u_{y,1}}{u_{y}^2}+\frac {u_{,1}v_{y,1}}{v_{y}^2}\,. \end{equation*}
\begin{equation*} P=D_x\!\left \{\frac {v_{,2}}{u_{y}}+\frac {u_{,1}}{v_{y}}\right \}+\frac {v_{,2}u_{y,1}}{u_{y}^2}+\frac {u_{,1}v_{y,1}}{v_{y}^2}\,. \end{equation*}
Both terms in the remainder are linear in their highest-ranked
 $x$
-derivatives, which are
$x$
-derivatives, which are
 $v_{,2}$
and
$v_{,2}$
and
 $v_{y,1}$
, respectively. However, further integration by parts would return
$v_{y,1}$
, respectively. However, further integration by parts would return
 $P$
to a form with a higher-ranked remainder.
$P$
to a form with a higher-ranked remainder.
3.4 Partial scalings
To investigate partial Euler operators further, it is helpful to use a variant of the homotopy approach. The partial scaling (by a positive real parameter,
 $\lambda$
) of a function
$\lambda$
) of a function
 $f({\textbf{x}},[{\textbf{u}}])$
with respect to
$f({\textbf{x}},[{\textbf{u}}])$
with respect to
 $x$
and
$x$
and
 $u^\alpha _{\textbf{I}}$
is the mapping
$u^\alpha _{\textbf{I}}$
is the mapping
 \begin{equation*} \sigma _{u^\alpha _{\textbf{I}}}^{x}\;:\;(f;\;\lambda )\mapsto f\big |_{\{u^\alpha _{\textbf{I},j}\mapsto \lambda u^\alpha _{\textbf{I},j},\ j\geq 0\}}. \end{equation*}
\begin{equation*} \sigma _{u^\alpha _{\textbf{I}}}^{x}\;:\;(f;\;\lambda )\mapsto f\big |_{\{u^\alpha _{\textbf{I},j}\mapsto \lambda u^\alpha _{\textbf{I},j},\ j\geq 0\}}. \end{equation*}
Again, each
 $u^\alpha _{\textbf{I}}$
is treated as a distinct dependent variable. Note the identity
$u^\alpha _{\textbf{I}}$
is treated as a distinct dependent variable. Note the identity
 \begin{equation} \sigma _{u^\alpha _{\textbf{I}}}^{x} D_x= D_x \sigma _{u^\alpha _{\textbf{I}}}^{x}\,. \end{equation}
\begin{equation} \sigma _{u^\alpha _{\textbf{I}}}^{x} D_x= D_x \sigma _{u^\alpha _{\textbf{I}}}^{x}\,. \end{equation}
Definition 3.1. The partial scaling
 $\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a good scaling for a given differential function
$\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a good scaling for a given differential function
 $f(\boldsymbol{x},[\boldsymbol{u}])$
if
$f(\boldsymbol{x},[\boldsymbol{u}])$
if
 \begin{equation} \sigma _{u^\alpha _\boldsymbol{I}}^{x}(f;\;\lambda )=\int \frac{\,\mathrm{d}}{\,\mathrm{d} \lambda }\!\left (\sigma _{u^\alpha _\boldsymbol{I}}^{x}(f;\;\lambda )\right )\,\mathrm{d} \lambda, \end{equation}
\begin{equation} \sigma _{u^\alpha _\boldsymbol{I}}^{x}(f;\;\lambda )=\int \frac{\,\mathrm{d}}{\,\mathrm{d} \lambda }\!\left (\sigma _{u^\alpha _\boldsymbol{I}}^{x}(f;\;\lambda )\right )\,\mathrm{d} \lambda, \end{equation}
for all
 $\lambda$
in some neighborhood of
$\lambda$
in some neighborhood of
 $1$
.
$1$
.
By definition, the partial scaling
 $\sigma _{u^\alpha _{\textbf{I}}}^{x}$
fails to be a good scaling for
$\sigma _{u^\alpha _{\textbf{I}}}^{x}$
fails to be a good scaling for
 $f$
if and only if there are terms that are independent of
$f$
if and only if there are terms that are independent of
 $\lambda$
in the fully expanded form of
$\lambda$
in the fully expanded form of
 $\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\lambda )$
. The simplest cause of this is that the fully expanded form of
$\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\lambda )$
. The simplest cause of this is that the fully expanded form of
 $f$
has terms that are independent of
$f$
has terms that are independent of
 $u^\alpha _{\textbf{I}}$
and its
$u^\alpha _{\textbf{I}}$
and its
 $x$
-derivatives. However, this is not the only cause, as the following example illustrates.
$x$
-derivatives. However, this is not the only cause, as the following example illustrates.
Example 3.4. The scalings
 $\sigma ^y_{u}$
and
$\sigma ^y_{u}$
and
 $\sigma ^y_v$
are not good scalings for
$\sigma ^y_v$
are not good scalings for
 \begin{equation} {\mathcal{C}}=u_{x}(2u+v_{y})-v_{x}(u_y+2v_{yy})+\frac{u_{x}}{u^2}+\frac{v_{yy}}{v_{y}}+\frac{2u_{y}}{u}\ln |u|, \end{equation}
\begin{equation} {\mathcal{C}}=u_{x}(2u+v_{y})-v_{x}(u_y+2v_{yy})+\frac{u_{x}}{u^2}+\frac{v_{yy}}{v_{y}}+\frac{2u_{y}}{u}\ln |u|, \end{equation}
because (in fully expanded form),
 \begin{align} \sigma ^y_{u}({\mathcal{C}};\;\lambda )=\lambda (2uu_{x}-v_{x}u_y)+\frac{u_{x}}{\lambda ^2 u^2}+\frac{2u_{y}}{u}\ln (\lambda )+\left \{u_{x}v_{y}-2v_{x}v_{yy}+\frac{v_{yy}}{v_{y}}+\frac{2u_{y}}{u}\ln |u|\right \}, \end{align}
\begin{align} \sigma ^y_{u}({\mathcal{C}};\;\lambda )=\lambda (2uu_{x}-v_{x}u_y)+\frac{u_{x}}{\lambda ^2 u^2}+\frac{2u_{y}}{u}\ln (\lambda )+\left \{u_{x}v_{y}-2v_{x}v_{yy}+\frac{v_{yy}}{v_{y}}+\frac{2u_{y}}{u}\ln |u|\right \}, \end{align}
 \begin{align} \sigma ^y_{v}({\mathcal{C}};\;\lambda )&=\lambda (u_{x}v_{y}-2v_{x}v_{yy}) +\left \{2uu_{x}-v_{x}u_y+\frac{u_{x}}{u^2}+\frac{v_{yy}}{v_{y}}+\frac{2u_{y}}{u}\ln |u|\right \}. \end{align}
\begin{align} \sigma ^y_{v}({\mathcal{C}};\;\lambda )&=\lambda (u_{x}v_{y}-2v_{x}v_{yy}) +\left \{2uu_{x}-v_{x}u_y+\frac{u_{x}}{u^2}+\frac{v_{yy}}{v_{y}}+\frac{2u_{y}}{u}\ln |u|\right \}. \end{align}
The terms in braces are independent of
 $\lambda$
; in (3.14) (resp. (3.15)), some of these depend on
$\lambda$
; in (3.14) (resp. (3.15)), some of these depend on
 $u$
(resp.
$u$
(resp.
 $v$
) and/or its
$v$
) and/or its
 $y$
-derivatives. Part of the scaled logarithmic term is independent of
$y$
-derivatives. Part of the scaled logarithmic term is independent of
 $\lambda$
, though part survives differentiation. Note that
$\lambda$
, though part survives differentiation. Note that
 $\sigma ^y_{u}$
is a good scaling for the term
$\sigma ^y_{u}$
is a good scaling for the term
 $u_{x}/u^2$
; the singularity at
$u_{x}/u^2$
; the singularity at
 $u=0$
is not an obstacle.
$u=0$
is not an obstacle.
Lemma 3.2. The partial scaling
 $\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a good scaling for
$\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a good scaling for
 $f(\boldsymbol{x},[\boldsymbol{u}])$
if and only if
$f(\boldsymbol{x},[\boldsymbol{u}])$
if and only if
 \begin{equation} f=\lim _{\lambda \rightarrow 1}\int \frac{\,\mathrm{d}}{\,\mathrm{d} \lambda }\!\left (\sigma _{u^\alpha _\boldsymbol{I}}^{x}(f;\;\lambda )\right )\,\mathrm{d} \lambda. \end{equation}
\begin{equation} f=\lim _{\lambda \rightarrow 1}\int \frac{\,\mathrm{d}}{\,\mathrm{d} \lambda }\!\left (\sigma _{u^\alpha _\boldsymbol{I}}^{x}(f;\;\lambda )\right )\,\mathrm{d} \lambda. \end{equation}
Proof. If
 $\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a good scaling, (3.16) is a consequence of
$\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a good scaling, (3.16) is a consequence of
 $f=\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;1)$
and local smoothness. Conversely, suppose that (3.16) holds and let
$f=\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;1)$
and local smoothness. Conversely, suppose that (3.16) holds and let
 $\mu$
be a positive real parameter that is independent of
$\mu$
be a positive real parameter that is independent of
 $\lambda$
. Then for
$\lambda$
. Then for
 $\mu$
sufficiently close to
$\mu$
sufficiently close to
 $1$
,
$1$
,
 \begin{equation*} \sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )=\lim _{\lambda \rightarrow 1}\int \frac {\,\mathrm {d}}{\,\mathrm {d} \lambda }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\lambda \mu )\right )\,\mathrm {d} \lambda =\lim _{\lambda \rightarrow \mu }\int \frac {\,\mathrm {d}}{\,\mathrm {d} \lambda }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\lambda )\right )\,\mathrm {d} \lambda =\int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )\right )\,\mathrm {d} \mu. \end{equation*}
\begin{equation*} \sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )=\lim _{\lambda \rightarrow 1}\int \frac {\,\mathrm {d}}{\,\mathrm {d} \lambda }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\lambda \mu )\right )\,\mathrm {d} \lambda =\lim _{\lambda \rightarrow \mu }\int \frac {\,\mathrm {d}}{\,\mathrm {d} \lambda }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\lambda )\right )\,\mathrm {d} \lambda =\int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )\right )\,\mathrm {d} \mu. \end{equation*}
Therefore,
 $\sigma _{u^\alpha _{\textbf{I}}}^{x}$
is a good scaling.
$\sigma _{u^\alpha _{\textbf{I}}}^{x}$
is a good scaling.
The use of the limit in (3.16) is needed to deal with any values of
 $u^\alpha _{\textbf{I},k}$
for which the integral is an indeterminate form. For other values, simple substitution of
$u^\alpha _{\textbf{I},k}$
for which the integral is an indeterminate form. For other values, simple substitution of
 $\lambda =1$
gives the limit.
$\lambda =1$
gives the limit.
Given a partial scaling
 $\sigma _{u^\alpha _{\textbf{I}}}^{x}$
and a differential function
$\sigma _{u^\alpha _{\textbf{I}}}^{x}$
and a differential function
 $f({\textbf{x}},[{\textbf{u}}])$
, let
$f({\textbf{x}},[{\textbf{u}}])$
, let
 \begin{equation} \pi _{u^\alpha _{\textbf{I}}}^{x}(f)=\lim _{\lambda \rightarrow 1}\int \frac{\,\mathrm{d}}{\,\mathrm{d} \lambda }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\lambda )\right )\,\mathrm{d} \lambda. \end{equation}
\begin{equation} \pi _{u^\alpha _{\textbf{I}}}^{x}(f)=\lim _{\lambda \rightarrow 1}\int \frac{\,\mathrm{d}}{\,\mathrm{d} \lambda }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\lambda )\right )\,\mathrm{d} \lambda. \end{equation}
For
 $\mu$
sufficiently close to
$\mu$
sufficiently close to
 $1$
(using
$1$
(using
 $\widehat{f}$
as shorthand for
$\widehat{f}$
as shorthand for
 $\pi _{u^\alpha _{\textbf{I}}}^{x}(f)$
),
$\pi _{u^\alpha _{\textbf{I}}}^{x}(f)$
),
 \begin{equation*} \sigma _{u^\alpha _{\textbf{I}}}^{x}(\widehat {f};\;\mu )=\!\int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )\right )\!\,\mathrm {d} \mu =\!\int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left \{ \int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )\right )\,\mathrm {d} \mu \right \}\!\,\mathrm {d} \mu =\!\int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(\widehat {f};\;\mu )\right )\!\,\mathrm {d} \mu ; \end{equation*}
\begin{equation*} \sigma _{u^\alpha _{\textbf{I}}}^{x}(\widehat {f};\;\mu )=\!\int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )\right )\!\,\mathrm {d} \mu =\!\int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left \{ \int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )\right )\,\mathrm {d} \mu \right \}\!\,\mathrm {d} \mu =\!\int \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(\widehat {f};\;\mu )\right )\!\,\mathrm {d} \mu ; \end{equation*}
the first equality comes from the proof of Lemma 3.2. Therefore,
 $\sigma _{u^\alpha _{\textbf{I}}}^{x}$
is a good scaling for
$\sigma _{u^\alpha _{\textbf{I}}}^{x}$
is a good scaling for
 $\pi _{u^\alpha _{\textbf{I}}}^{x}(f)$
. Moreover, there are no terms in the fully expanded form of the remainder,
$\pi _{u^\alpha _{\textbf{I}}}^{x}(f)$
. Moreover, there are no terms in the fully expanded form of the remainder,
 $f-\pi _{u^\alpha _{\textbf{I}}}^{x}(f)$
, for which
$f-\pi _{u^\alpha _{\textbf{I}}}^{x}(f)$
, for which
 $\sigma _{u^\alpha _{\textbf{I}}}^{x}$
is a good scaling, because
$\sigma _{u^\alpha _{\textbf{I}}}^{x}$
is a good scaling, because
 \begin{equation*} \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )\right )-\frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(\widehat {f};\;\mu )\right )=0. \end{equation*}
\begin{equation*} \frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(f;\;\mu )\right )-\frac {\,\mathrm {d}}{\,\mathrm {d} \mu }\!\left (\sigma _{u^\alpha _{\textbf{I}}}^{x}(\widehat {f};\;\mu )\right )=0. \end{equation*}
So
 $\pi _{u^\alpha _{\textbf{I}}}^{x}$
is the projection that maps a given function onto the component which has
$\pi _{u^\alpha _{\textbf{I}}}^{x}$
is the projection that maps a given function onto the component which has
 $\sigma _{u^\alpha _{\textbf{I}}}^{x}$
as a good scaling.
$\sigma _{u^\alpha _{\textbf{I}}}^{x}$
as a good scaling.
Definition 3.2. The partial scaling
 $\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a poor scaling for a given differential function
$\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a poor scaling for a given differential function
 $f(\boldsymbol{x},[\boldsymbol{u}])$
if
$f(\boldsymbol{x},[\boldsymbol{u}])$
if
 $f-\pi _{u^\alpha _\boldsymbol{I}}^{x}(f)$
depends on any
$f-\pi _{u^\alpha _\boldsymbol{I}}^{x}(f)$
depends on any
 $u^\alpha _{\boldsymbol{I},k}\,$
.
$u^\alpha _{\boldsymbol{I},k}\,$
.
For instance, both
 $\sigma ^y_{u}$
and
$\sigma ^y_{u}$
and
 $\sigma ^y_v$
are poor scalings for (3.13), as explained in Example 3.4. Section 4.3 addresses the problem of inverting divergences such as (3.13) that have poor scalings. First, we develop the inversion process for general divergences. The following results are fundamental.
$\sigma ^y_v$
are poor scalings for (3.13), as explained in Example 3.4. Section 4.3 addresses the problem of inverting divergences such as (3.13) that have poor scalings. First, we develop the inversion process for general divergences. The following results are fundamental.
Theorem 3.1.
Let
 $f(\boldsymbol{x},[\boldsymbol{u}])$
be a differential function.
$f(\boldsymbol{x},[\boldsymbol{u}])$
be a differential function.
-
1. If
$f=D_x F$
, then
$f\in \mathrm{ker}(\boldsymbol{E}_{u^\alpha _\boldsymbol{I}}^{x})$
for all
$\alpha$
and
$\boldsymbol{I}$
; moreover,
(3.18)
\begin{equation} \pi _{u^\alpha _\boldsymbol{I}}^{x}(F)=\lim _{\lambda \rightarrow 1}\int \sum _{j\geq 0} u^\alpha _{\boldsymbol{I},j}\,\sigma _{u^\alpha _\boldsymbol{I}}^{x}\!\left (\boldsymbol{E}^x_{u^\alpha _{\boldsymbol{I},j+1}}(f);\;\lambda \right )\,\mathrm{d} \lambda. \end{equation}
-
2. If
$f\in \mathrm{ker}(\boldsymbol{E}_{u^\alpha _\boldsymbol{I}}^{x})$
, then
$\pi _{u^\alpha _\boldsymbol{I}}^{x}(f)\in \mathrm{im}(D_x)$
. -
3. If
$g=\boldsymbol{E}_{u^\alpha _\boldsymbol{I}}^{x}(f)$
, then, up to terms in
$\mathrm{im}(D_x)$
,(3.19)
\begin{equation} \pi _{u^\alpha _\boldsymbol{I}}^{x}(f)=\lim _{\lambda \rightarrow 1}\int u^\alpha _\boldsymbol{I}\,\sigma _{u^\alpha _\boldsymbol{I}}^{x}\!\left (g;\;\lambda \right )\,\mathrm{d} \lambda. \end{equation}










Proof. All three statements are proved by expanding
 $\pi _{u^\alpha _{\textbf{I}}}^{x}(f)$
:
$\pi _{u^\alpha _{\textbf{I}}}^{x}(f)$
:
 \begin{align} \pi _{u^\alpha _{\textbf{I}}}^{x}(f) =\lim _{\lambda \rightarrow 1}\int \sum _{j\geq 0}u^\alpha _{\textbf{I},j}\,\sigma _{u^\alpha _{\textbf{I}}}^{x}\!\left (\frac{\partial f}{\partial u^\alpha _{\textbf{I},j}};\;\lambda \right )\,\mathrm{d} \lambda \end{align}
\begin{align} \pi _{u^\alpha _{\textbf{I}}}^{x}(f) =\lim _{\lambda \rightarrow 1}\int \sum _{j\geq 0}u^\alpha _{\textbf{I},j}\,\sigma _{u^\alpha _{\textbf{I}}}^{x}\!\left (\frac{\partial f}{\partial u^\alpha _{\textbf{I},j}};\;\lambda \right )\,\mathrm{d} \lambda \end{align}
 \begin{align} =\lim _{\lambda \rightarrow 1}\int u^\alpha _{\textbf{I}}\,\sigma _{u^\alpha _{\textbf{I}}}^{x}\!\left ({\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x}(f);\;\lambda \right )\,\mathrm{d} \lambda +D_xh. \end{align}
\begin{align} =\lim _{\lambda \rightarrow 1}\int u^\alpha _{\textbf{I}}\,\sigma _{u^\alpha _{\textbf{I}}}^{x}\!\left ({\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x}(f);\;\lambda \right )\,\mathrm{d} \lambda +D_xh. \end{align}
Here,
 $h({\textbf{x}},[{\textbf{u}}])$
is obtained by integrating by parts, using the identity (3.11).
$h({\textbf{x}},[{\textbf{u}}])$
is obtained by integrating by parts, using the identity (3.11).
If
 $f=D_x F$
, the identity (3.5) amounts to
$f=D_x F$
, the identity (3.5) amounts to
 $f\in \mathrm{ker}({\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x})$
. Replace
$f\in \mathrm{ker}({\textbf{E}}_{u^\alpha _{\textbf{I}}}^{x})$
. Replace
 $f$
by
$f$
by
 $F$
in (3.20) and use the identity (3.6) to obtain (3.18). Statements
$F$
in (3.20) and use the identity (3.6) to obtain (3.18). Statements
 $2$
and
$2$
and
 $3$
come directly from (3.21).
$3$
come directly from (3.21).
Note that (3.18) is a homotopy formula for (at least partially) inverting
 $D_xF$
, giving a third way to do this. The line integral formula (3.8) carries out the full inversion in one step, but may take longer to compute.
$D_xF$
, giving a third way to do this. The line integral formula (3.8) carries out the full inversion in one step, but may take longer to compute.
4. The inversion method for Div
This section introduces a procedure to invert
 $\mathrm{Div}$
, with a ranking heuristic (informed by experience) that is intended to keep the calculation short and efficient. To motivate the procedure, it is helpful to examine a simple example.
$\mathrm{Div}$
, with a ranking heuristic (informed by experience) that is intended to keep the calculation short and efficient. To motivate the procedure, it is helpful to examine a simple example.
Example 4.1. Wolf et al. [Reference Wolf, Brand and Mohammadzadeh14] introduced computer algebra algorithms that can handle general (non-polynomial) conservation laws and used these to derive various rational conservation laws of the Harry Dym equation. In the (unique)
 $x$
-dominant positive ranking, the equation is
$x$
-dominant positive ranking, the equation is
 ${\mathcal{A}}=0$
, with
${\mathcal{A}}=0$
, with
 \begin{equation*} {\mathcal {A}}=u_t-u^3u_{,3}. \end{equation*}
\begin{equation*} {\mathcal {A}}=u_t-u^3u_{,3}. \end{equation*}
The highest-order conservation law derived in Wolf et al. [Reference Wolf, Brand and Mohammadzadeh14] is
 ${\mathcal{C}}={\mathcal{Q}}{\mathcal{A}}$
, where
${\mathcal{C}}={\mathcal{Q}}{\mathcal{A}}$
, where
 \begin{equation*} {\mathcal {Q}}=-8uu_{,4}-16u_{,1}u_{,3}-12u_{,2}^2+12u^{-1}u_{,1}^2u_{,2}-3u^{-2}u_{,1}^4\,. \end{equation*}
\begin{equation*} {\mathcal {Q}}=-8uu_{,4}-16u_{,1}u_{,3}-12u_{,2}^2+12u^{-1}u_{,1}^2u_{,2}-3u^{-2}u_{,1}^4\,. \end{equation*}
Note that
 $\sigma ^x_{u}$
is a good scaling for
$\sigma ^x_{u}$
is a good scaling for
 $\mathcal{C}$
. The first step in inverting
$\mathcal{C}$
. The first step in inverting
 ${\mathcal{C}}=D_xF+D_tG$
is to apply the partial Euler operator
${\mathcal{C}}=D_xF+D_tG$
is to apply the partial Euler operator
 $\boldsymbol{E}_{u}^{x}$
, to annihilate the term
$\boldsymbol{E}_{u}^{x}$
, to annihilate the term
 $D_xF$
. There are only two independent variables, so the identity (3.2) shortens the calculation to
$D_xF$
. There are only two independent variables, so the identity (3.2) shortens the calculation to
 \begin{equation*} \boldsymbol{E}_{u}^{x}({\mathcal {C}})=D_t(\boldsymbol{E}^x_{u_t}({\mathcal {C}}))=D_t({\mathcal {Q}}). \end{equation*}
\begin{equation*} \boldsymbol{E}_{u}^{x}({\mathcal {C}})=D_t(\boldsymbol{E}^x_{u_t}({\mathcal {C}}))=D_t({\mathcal {Q}}). \end{equation*}
Applying (3.19), then using Procedure A to integrate by parts (see Example 3.2) gives
 \begin{align*}{\mathcal{Q}}&=\boldsymbol{E}_{u}^{x}\!\left \{-\frac{8}{3}u^2u_{,4}-\frac{16}{3}uu_{,1}u_{,3}-4uu_{,2}^2+4u_{,1}^2u_{,2}-u^{-1}u_{,1}^4\right \}\\[5pt] &=\boldsymbol{E}_{u}^{x}\!\left \{-4uu_{,2}^2-u^{-1}u_{,1}^4\right \}. \end{align*}
\begin{align*}{\mathcal{Q}}&=\boldsymbol{E}_{u}^{x}\!\left \{-\frac{8}{3}u^2u_{,4}-\frac{16}{3}uu_{,1}u_{,3}-4uu_{,2}^2+4u_{,1}^2u_{,2}-u^{-1}u_{,1}^4\right \}\\[5pt] &=\boldsymbol{E}_{u}^{x}\!\left \{-4uu_{,2}^2-u^{-1}u_{,1}^4\right \}. \end{align*}
Therefore,
 \begin{equation*} {\mathcal {C}}=D_t\left (-4uu_{,2}^2-u^{-1}u_{,1}^4\right )+\widetilde {{\mathcal {C}}}, \end{equation*}
\begin{equation*} {\mathcal {C}}=D_t\left (-4uu_{,2}^2-u^{-1}u_{,1}^4\right )+\widetilde {{\mathcal {C}}}, \end{equation*}
where
 $\boldsymbol{E}_{u}^{x}(\widetilde{{\mathcal{C}}})=0$
. As
$\boldsymbol{E}_{u}^{x}(\widetilde{{\mathcal{C}}})=0$
. As
 $\sigma ^x_{u}$
is a good scaling for
$\sigma ^x_{u}$
is a good scaling for
 \begin{equation*} \widetilde {{\mathcal {C}}}={\mathcal {Q}}{\mathcal {A}}+8uu_{,2}u_{t,2}+4u^{-1}u_{,1}^3u_{t,1}+\{4u_{,2}^2-u^{-2}u_{,1}^4\}u_t\,, \end{equation*}
\begin{equation*} \widetilde {{\mathcal {C}}}={\mathcal {Q}}{\mathcal {A}}+8uu_{,2}u_{t,2}+4u^{-1}u_{,1}^3u_{t,1}+\{4u_{,2}^2-u^{-2}u_{,1}^4\}u_t\,, \end{equation*}
the second part of Theorem 3.1 states that
 $\widetilde{{\mathcal{C}}}\in \mathrm{im}(D_x)$
; consequently,
$\widetilde{{\mathcal{C}}}\in \mathrm{im}(D_x)$
; consequently,
 \begin{equation*} G=-4uu_{,2}^2-u^{-1}u_{,1}^4\,. \end{equation*}
\begin{equation*} G=-4uu_{,2}^2-u^{-1}u_{,1}^4\,. \end{equation*}
Either the line integral (3.8) or Procedure A completes the inversion, giving
 $\widetilde{{\mathcal{C}}}=D_xF$
, where
$\widetilde{{\mathcal{C}}}=D_xF$
, where
 \begin{equation*} F=8uu_{,2}u_{t,1}-\{8uu_{,3}+8u_{,1}u_{,2}-4u^{-1}u_{,1}^3\}u_t+4u^4u_{,3}^2+4u^3u_{,2}^3-6u^2u_{,1}^2u_{,2}^2+3uu_{,1}^4u_{,2}-\frac {1}{2}u_{,1}^6. \end{equation*}
\begin{equation*} F=8uu_{,2}u_{t,1}-\{8uu_{,3}+8u_{,1}u_{,2}-4u^{-1}u_{,1}^3\}u_t+4u^4u_{,3}^2+4u^3u_{,2}^3-6u^2u_{,1}^2u_{,2}^2+3uu_{,1}^4u_{,2}-\frac {1}{2}u_{,1}^6. \end{equation*}
The fully expanded form of
 $(F,G)$
is minimal, having
$(F,G)$
is minimal, having
 $11$
terms rather than the
$11$
terms rather than the
 $12$
terms in Wolf et al. [Reference Wolf, Brand and Mohammadzadeh14]. (Note: there is an equivalent conservation law, not in the form
$12$
terms in Wolf et al. [Reference Wolf, Brand and Mohammadzadeh14]. (Note: there is an equivalent conservation law, not in the form
 ${\mathcal{Q}}{\mathcal{A}}$
, that has only
${\mathcal{Q}}{\mathcal{A}}$
, that has only
 $10$
terms.)
$10$
terms.)
4.1 A single iteration
The basic method for inverting a given total divergence one independent variable at a time works similarly to the example above. Suppose that after
 $n$
iterations the inversion process has yielded components
$n$
iterations the inversion process has yielded components
 $F^i_n$
and that an expression of the form
$F^i_n$
and that an expression of the form
 ${\mathcal{C}}=D_if_n^i$
remains to be inverted. For the next iteration, let
${\mathcal{C}}=D_if_n^i$
remains to be inverted. For the next iteration, let
 ${\textbf{E}}_{u}^{x}$
be the partial Euler operator that is applied to
${\textbf{E}}_{u}^{x}$
be the partial Euler operator that is applied to
 $\mathcal{C}$
. Here,
$\mathcal{C}$
. Here,
 $u$
is one of the variables
$u$
is one of the variables
 $u^\alpha _{\textbf{I}}$
, which is chosen to ensure that for each
$u^\alpha _{\textbf{I}}$
, which is chosen to ensure that for each
 $i$
such that
$i$
such that
 $x^i\neq x$
,
$x^i\neq x$
,
 \begin{equation} {\textbf{E}}_{u}^{x} D_if_n^i =D_i{\textbf{E}}_{u}^{x} f_n^i. \end{equation}
\begin{equation} {\textbf{E}}_{u}^{x} D_if_n^i =D_i{\textbf{E}}_{u}^{x} f_n^i. \end{equation}
This requires care, in view of the identity (3.7). However, it is achievable by using the variables
 $u^\alpha _{\textbf{I}}$
in the order given by a ranking that is discussed in Section 4.2. This ranking is entirely determined by user-defined rankings of the variables
$u^\alpha _{\textbf{I}}$
in the order given by a ranking that is discussed in Section 4.2. This ranking is entirely determined by user-defined rankings of the variables
 $x^j$
and
$x^j$
and
 $u^\alpha$
.
$u^\alpha$
.
Taking (3.5) into account leads to the identity
 \begin{equation} {\textbf{E}}_{u}^{x}({\mathcal{C}})=\sum _{x^i\neq x}D_i({\textbf{E}}_{u}^{x}(f_n^i)), \end{equation}
\begin{equation} {\textbf{E}}_{u}^{x}({\mathcal{C}})=\sum _{x^i\neq x}D_i({\textbf{E}}_{u}^{x}(f_n^i)), \end{equation}
which, with together with Theorem 3.1, is the basis of the inversion method. The method works without modification provided that:
-
• there are no poor scalings for any terms in
$\mathcal{C}$
; -
• the fully expanded form of
$\mathcal{C}$
has no terms that are linear in
$[{\textbf{u}}]$
.



We begin by restricting attention to divergences for which these conditions hold, so that
 \begin{equation} {\textbf{E}}_{u}^{x}({\mathcal{C}})=\sum _{x^i\neq x}D_i({\textbf{E}}_{u}^{x}(\pi _u^x f_n^i)), \end{equation}
\begin{equation} {\textbf{E}}_{u}^{x}({\mathcal{C}})=\sum _{x^i\neq x}D_i({\textbf{E}}_{u}^{x}(\pi _u^x f_n^i)), \end{equation}
where every term in
 ${\textbf{E}}_{u}^{x}(\pi _u^x f_n^i)$
depends on
${\textbf{E}}_{u}^{x}(\pi _u^x f_n^i)$
depends on
 $[{\textbf{u}}]$
. The modifications needed if either condition does not hold are given in Sections 4.3 and 4.4.
$[{\textbf{u}}]$
. The modifications needed if either condition does not hold are given in Sections 4.3 and 4.4.
The iteration of the inversion process runs as follows. Calculate
 ${\textbf{E}}_{u}^{x}({\mathcal{C}})$
, which is a divergence
${\textbf{E}}_{u}^{x}({\mathcal{C}})$
, which is a divergence
 $D_iP^i$
with no
$D_iP^i$
with no
 $D_x$
term, by (4.3); it involves at most
$D_x$
term, by (4.3); it involves at most
 $p-1$
(but commonly, very few) nonzero functions
$p-1$
(but commonly, very few) nonzero functions
 $P^i$
. Invert this divergence, treating
$P^i$
. Invert this divergence, treating
 $x$
as a parameter. If it is possible to invert in more than one way, always invert into the
$x$
as a parameter. If it is possible to invert in more than one way, always invert into the
 $P^i$
for which
$P^i$
for which
 $x^i$
is ranked as low as possible; the reason for this is given in the next paragraph. If
$x^i$
is ranked as low as possible; the reason for this is given in the next paragraph. If
 ${\textbf{E}}_{u}^{x}({\mathcal{C}})$
has nonlinear terms that involve derivatives with respect to more than one
${\textbf{E}}_{u}^{x}({\mathcal{C}})$
has nonlinear terms that involve derivatives with respect to more than one
 $D_i$
(excluding
$D_i$
(excluding
 $D_x$
), this is accomplished by iterating the inversion process with as few independent variables as are needed. Otherwise,
$D_x$
), this is accomplished by iterating the inversion process with as few independent variables as are needed. Otherwise,
 $P^i$
can be determined more quickly by using integration by parts (Procedure A, with
$P^i$
can be determined more quickly by using integration by parts (Procedure A, with
 $x$
replaced by the appropriate
$x$
replaced by the appropriate
 $x^i$
), and/or the method for linear terms (see Procedure B in Section 4.4). Note that this shortcut can be used whenever there are only two independent variables.
$x^i$
), and/or the method for linear terms (see Procedure B in Section 4.4). Note that this shortcut can be used whenever there are only two independent variables.
At this stage, check that the fully expanded form of each
 $P^i$
has no terms that are ranked lower than
$P^i$
has no terms that are ranked lower than
 $u$
. If any term is ranked lower than
$u$
. If any term is ranked lower than
 $u$
, stop the calculation and try a different ranking of the variables
$u$
, stop the calculation and try a different ranking of the variables
 $x^j$
and/or
$x^j$
and/or
 $u^\alpha$
. This is essential because, to satisfy (4.1) and avoid infinite loops, the variables
$u^\alpha$
. This is essential because, to satisfy (4.1) and avoid infinite loops, the variables
 $u^\alpha _{\textbf{I}}$
that are chosen to be
$u^\alpha _{\textbf{I}}$
that are chosen to be
 $u$
in successive iterations must progress upwards through the ranking. Where there is a choice of inversion, the rank of each term in
$u$
in successive iterations must progress upwards through the ranking. Where there is a choice of inversion, the rank of each term in
 $P^i$
is maximized by using the
$P^i$
is maximized by using the
 $x^i$
of minimum order; this avoids unnecessary re-ranking.
$x^i$
of minimum order; this avoids unnecessary re-ranking.
Having found and checked
 $P^i$
, use (3.21) to obtain
$P^i$
, use (3.21) to obtain
 \begin{equation} \pi _u^x(f_n^i)=\left \{\lim _{\lambda \rightarrow 1}\int u\,\sigma _u^x\!\left (P^i;\;\lambda \right )\,\mathrm{d} \lambda \right \} +D_xh^i, \end{equation}
\begin{equation} \pi _u^x(f_n^i)=\left \{\lim _{\lambda \rightarrow 1}\int u\,\sigma _u^x\!\left (P^i;\;\lambda \right )\,\mathrm{d} \lambda \right \} +D_xh^i, \end{equation}
for arbitrary functions
 $h^i({\textbf{x}},[{\textbf{u}}])$
. Apply Procedure A to the function in braces and choose
$h^i({\textbf{x}},[{\textbf{u}}])$
. Apply Procedure A to the function in braces and choose
 $h^i$
to make the right-hand side of (4.4) equal the remainder from this procedure. This yields the representation of
$h^i$
to make the right-hand side of (4.4) equal the remainder from this procedure. This yields the representation of
 $\pi _u^x(f_n^i)$
that has the lowest-order derivatives (with respect to
$\pi _u^x(f_n^i)$
that has the lowest-order derivatives (with respect to
 $x$
) consistent with the inversion of
$x$
) consistent with the inversion of
 $D_iP^i$
; call this representation
$D_iP^i$
; call this representation
 $f^i$
. Commonly, such a lowest-order representation is needed to obtain a minimal inversion.
$f^i$
. Commonly, such a lowest-order representation is needed to obtain a minimal inversion.
By Theorem 3.1, there exists
 $\phi$
such that
$\phi$
such that
 \begin{equation} \pi _u^x\left ({\mathcal{C}}-\sum _{x^i\neq x}D_if^i\right )=D_x\phi, \end{equation}
\begin{equation} \pi _u^x\left ({\mathcal{C}}-\sum _{x^i\neq x}D_if^i\right )=D_x\phi, \end{equation}
because (by construction) the expression in parentheses belongs to
 $\mathrm{ker}({\textbf{E}}_{u}^{x})$
. Use the line integral formula (3.8) or Procedure A to obtain
$\mathrm{ker}({\textbf{E}}_{u}^{x})$
. Use the line integral formula (3.8) or Procedure A to obtain
 $\phi$
, then set
$\phi$
, then set
 $f^i\;:\!=\;\phi$
for
$f^i\;:\!=\;\phi$
for
 $x^i=x$
. Now update: set
$x^i=x$
. Now update: set
 \begin{equation*} {\mathcal {C}}\;:\!=\;{\mathcal {C}}\!-\!D_if^i,\qquad F^i_{n+1}\;:\!=\;F^i_n+f^i. \end{equation*}
\begin{equation*} {\mathcal {C}}\;:\!=\;{\mathcal {C}}\!-\!D_if^i,\qquad F^i_{n+1}\;:\!=\;F^i_n+f^i. \end{equation*}
4.2 Ranking and using the variables
Having described a single iteration, we now turn to the question of how to choose
 $x$
and
$x$
and
 $u$
effectively. The starting point is to construct a derivative-dominant ranking of the variables
$u$
effectively. The starting point is to construct a derivative-dominant ranking of the variables
 $u^\alpha _{\textbf{J}}$
. This is a positive ranking that is determined by:
$u^\alpha _{\textbf{J}}$
. This is a positive ranking that is determined by:
-
• a ranking of the independent variables,
$x^1\prec x^2\prec \cdots \prec x^p$
; -
• a ranking of the dependent variables,
$u^1\prec u^2\prec \cdots \prec u^q$
.


(Later in this section, we give a heuristic for ranking the dependent and independent variables effectively.) The derivative-dominant ranking (denoted
 ${\textbf{u}}_p$
) is constructed iteratively, as follows.
${\textbf{u}}_p$
) is constructed iteratively, as follows.
 \begin{align*}{\textbf{u}}_0&=u^1\prec \cdots \prec u^q,\\[5pt] {\textbf{u}}_1&={\textbf{u}}_0\prec D_1{\textbf{u}}_0 \prec D_1^2{\textbf{u}}_0 \prec \cdots,\\[5pt] {\textbf{u}}_2&={\textbf{u}}_1\prec D_2{\textbf{u}}_1 \prec D_2^2{\textbf{u}}_1 \prec \cdots,\\[5pt] \vdots &\qquad \vdots \\[5pt] {\textbf{u}}_p&={\textbf{u}}_{p-1}\prec D_p{\textbf{u}}_{p-1} \prec D_p^2{\textbf{u}}_{p-1} \prec \cdots. \end{align*}
\begin{align*}{\textbf{u}}_0&=u^1\prec \cdots \prec u^q,\\[5pt] {\textbf{u}}_1&={\textbf{u}}_0\prec D_1{\textbf{u}}_0 \prec D_1^2{\textbf{u}}_0 \prec \cdots,\\[5pt] {\textbf{u}}_2&={\textbf{u}}_1\prec D_2{\textbf{u}}_1 \prec D_2^2{\textbf{u}}_1 \prec \cdots,\\[5pt] \vdots &\qquad \vdots \\[5pt] {\textbf{u}}_p&={\textbf{u}}_{p-1}\prec D_p{\textbf{u}}_{p-1} \prec D_p^2{\textbf{u}}_{p-1} \prec \cdots. \end{align*}
In practice, very few
 $u^\alpha _{\textbf{J}}$
are needed to carry out many inversions of interest, but it is essential that these are used in the order given by their ranking, subject to a constraint on
$u^\alpha _{\textbf{J}}$
are needed to carry out many inversions of interest, but it is essential that these are used in the order given by their ranking, subject to a constraint on
 $|{\textbf{I}}|$
that is explained below.
$|{\textbf{I}}|$
that is explained below.
Given an independent variable,
 $x$
, we call
$x$
, we call
 $u^\alpha _{\textbf{I}}$
relevant if the updated
$u^\alpha _{\textbf{I}}$
relevant if the updated
 $\mathcal{C}$
depends on
$\mathcal{C}$
depends on
 $u^\alpha _{\textbf{I},k}$
for some
$u^\alpha _{\textbf{I},k}$
for some
 $k\geq 0$
. The first set of iterations uses
$k\geq 0$
. The first set of iterations uses
 $x=x^1$
. For the initial iteration,
$x=x^1$
. For the initial iteration,
 $u$
is the lowest-ranked relevant
$u$
is the lowest-ranked relevant
 $u^\alpha$
. In the following iteration,
$u^\alpha$
. In the following iteration,
 $u$
is the next-lowest-ranked relevant
$u$
is the next-lowest-ranked relevant
 $u^\alpha$
and so on, up to and including
$u^\alpha$
and so on, up to and including
 $u^q$
. (From (3.7), the condition (4.1) holds whenever
$u^q$
. (From (3.7), the condition (4.1) holds whenever
 $u=u^\alpha,\ \alpha = 1,\ldots, q$
.) After these iterations, the updated
$u=u^\alpha,\ \alpha = 1,\ldots, q$
.) After these iterations, the updated
 $\mathcal{C}$
is independent of
$\mathcal{C}$
is independent of
 $\textbf{u}$
and its unmixed
$\textbf{u}$
and its unmixed
 $x$
-derivatives.
$x$
-derivatives.
If the updated
 $\mathcal{C}$
has any remaining
$\mathcal{C}$
has any remaining
 $x$
-derivatives, these are mixed. Thus, as
$x$
-derivatives, these are mixed. Thus, as
 $\mathcal{C}$
has no linear terms, a necessary condition for the inversion to be minimal is that every
$\mathcal{C}$
has no linear terms, a necessary condition for the inversion to be minimal is that every
 $f_n^i$
is independent of
$f_n^i$
is independent of
 $\textbf{u}$
and its unmixed
$\textbf{u}$
and its unmixed
 $x$
-derivatives. Consequently, (4.1) holds for
$x$
-derivatives. Consequently, (4.1) holds for
 $u=u^\alpha _{\textbf{I}}$
whenever
$u=u^\alpha _{\textbf{I}}$
whenever
 $|{\textbf{I}}|=1$
, because
$|{\textbf{I}}|=1$
, because
 \begin{equation*} {\textbf{E}}^x_{u^\alpha _{{\textbf{I}}-{\boldsymbol {1}}_i}}(f_n^i)=0,\qquad x^i\neq x. \end{equation*}
\begin{equation*} {\textbf{E}}^x_{u^\alpha _{{\textbf{I}}-{\boldsymbol {1}}_i}}(f_n^i)=0,\qquad x^i\neq x. \end{equation*}
Therefore, the process can be continued using each relevant
 $u=u^\alpha _{\textbf{I}}$
with
$u=u^\alpha _{\textbf{I}}$
with
 $|{\textbf{I}}|=1$
in the ranked order. Iterating, the same argument is used with
$|{\textbf{I}}|=1$
in the ranked order. Iterating, the same argument is used with
 $|{\textbf{I}}|=2,3,\ldots$
, until
$|{\textbf{I}}|=2,3,\ldots$
, until
 $\mathcal{C}$
is independent of
$\mathcal{C}$
is independent of
 $x$
-derivatives. Now set
$x$
-derivatives. Now set
 $x=x^2$
and iterate, treating
$x=x^2$
and iterate, treating
 $x^1$
as a parameter. In principle, this can be continued up to
$x^1$
as a parameter. In principle, this can be continued up to
 $x=x^p$
; in practice, only a very few iterations are usually needed to complete the inversion. The best rankings invert many terms at each iteration. On the basis of some experience with conservation laws, the following heuristic for ranking the variables
$x=x^p$
; in practice, only a very few iterations are usually needed to complete the inversion. The best rankings invert many terms at each iteration. On the basis of some experience with conservation laws, the following heuristic for ranking the variables
 $x^j$
and
$x^j$
and
 $u^\alpha$
is recommended.
$u^\alpha$
is recommended.
Ranking heuristic. Apply criteria for ranking independent variables, using the following order of precedence.
-
1. Any independent variables that occur in the arguments of arbitrary functions of
$\textbf{x}$
should be ranked as high as possible, if they multiply terms that are nonlinear in
$[{\textbf{u}}]$
. For instance, if nonlinear terms in a divergence depend on an arbitrary function,
$f(t)$
, set
$x^p=t$
. -
2. If independent variables occur explicitly in non-arbitrary functions, they should be ranked as high as possible (subject to 1 above), with priority going to variables with the most complicated functional dependence. For instance, if
$\mathcal{C}$
is linear in
$x^i$
and quadratic in
$x^j$
, then
$x^i\prec x^j$
(so
$i\lt j$
in our ordering). -
3. If an unmixed derivative of any
$u^\alpha$
with respect to
$x^i$
is the argument of a function other than a rational polynomial, rank
$x^i$
as low as possible. -
4. Set
$x^i\prec x^j$
if the highest-order unmixed derivative (of any
$u^\alpha$
) with respect to
$x^i$
is of higher order than the highest-order unmixed derivative with respect to
$x^j$
. -
5. Set
$x^i\prec x^j$
if there are more occurrences of unmixed
$x^i$
-derivatives (in the fully expanded divergence) than there are of unmixed
$x^j$
-derivatives. -
6. Apply criteria
$3$
,
$4$
, and
$5$
in order of precedence, replacing unmixed by ‘minimally mixed’ derivatives. Minimally mixed means that there are as few derivatives as possible with respect to any other variable(s).






















The derivative indices
 $\textbf{J}$
in a derivative-dominant ranking are ordered according to the ranking of the independent variables. This can be used to rank the dependent variables; if there is more than one dependent variable in
$\textbf{J}$
in a derivative-dominant ranking are ordered according to the ranking of the independent variables. This can be used to rank the dependent variables; if there is more than one dependent variable in
 $\mathcal{C}$
, use the following criteria in order.
$\mathcal{C}$
, use the following criteria in order.
-
1. Let
$u^\alpha \prec u^\beta$
if
$\mathcal{C}$
is linear in
$[u^\alpha ]$
and nonlinear in
$[u^\beta ]$
. -
2. Let
$u^\alpha \prec u^\beta$
if the lowest-ranked derivative of
$u^\alpha$
that occurs in
$\mathcal{C}$
is ranked lower than the lowest-ranked derivative of
$u^\beta$
in
$\mathcal{C}$
. (In conservation laws, the lowest-ranked derivative of
$u^\alpha$
is commonly the undifferentiated
$u^\alpha$
, which corresponds to
${\textbf{J}}=0$
.) -
3. Let
$u^\alpha \prec u^\beta$
if the lowest-ranked derivative of
$u^\alpha$
in the fully expanded form of
$\mathcal{C}$
occurs in more terms than the corresponding derivative of
$u^\beta$
does.
















These two sets of criteria are not exhaustive (allowing ties, which must be broken), but the aim that underlies them is to carry as few terms as possible into successive iterations of the procedure. Partial Euler operators with respect to unmixed derivatives are used in the earliest iterations; commonly, these are sufficient to complete the inversion.
4.3 How to deal with poor scalings
To remove an earlier restriction on the inversion process, we now address the problem of poor scalings, namely, that
 $u^\alpha _{\textbf{I}}$
and its
$u^\alpha _{\textbf{I}}$
and its
 $x$
-derivatives (denoted
$x$
-derivatives (denoted
 $[u^\alpha _{\textbf{I}}]_x$
) may occur in terms that belong to
$[u^\alpha _{\textbf{I}}]_x$
) may occur in terms that belong to
 ${\mathcal{C}}-\pi _{u^\alpha _{\textbf{I}}}^{x}({\mathcal{C}})$
. Such terms (when fully expanded) are products of homogeneous rational polynomials in
${\mathcal{C}}-\pi _{u^\alpha _{\textbf{I}}}^{x}({\mathcal{C}})$
. Such terms (when fully expanded) are products of homogeneous rational polynomials in
 $[u^\alpha _{\textbf{I}}]_x$
of degree zero and logarithms of a single element of
$[u^\alpha _{\textbf{I}}]_x$
of degree zero and logarithms of a single element of
 $[u^\alpha _{\textbf{I}}]_x$
. We refer to these collectively as zero-degree terms.
$[u^\alpha _{\textbf{I}}]_x$
. We refer to these collectively as zero-degree terms.
To overcome this difficulty, we modify the approach used by Anco & Bluman [Reference Anco and Bluman3] to treat singularities. In our context,
 $[u^\alpha _{\textbf{I}}]_x$
is replaced by
$[u^\alpha _{\textbf{I}}]_x$
is replaced by
 $[u^\alpha _{\textbf{I}}+U^\alpha _{\textbf{I}}]_x$
, where
$[u^\alpha _{\textbf{I}}+U^\alpha _{\textbf{I}}]_x$
, where
 $U^\alpha _{\textbf{I}}$
is regarded as a new dependent variable that is ranked higher than
$U^\alpha _{\textbf{I}}$
is regarded as a new dependent variable that is ranked higher than
 $u^\alpha _{\textbf{I}}$
. This approach works equally well for logarithms, ensuring that
$u^\alpha _{\textbf{I}}$
. This approach works equally well for logarithms, ensuring that
 $\pi _{u^\alpha _{\textbf{I}}}^{x}$
is a good scaling for all terms that depend on
$\pi _{u^\alpha _{\textbf{I}}}^{x}$
is a good scaling for all terms that depend on
 $[u^\alpha _{\textbf{I}}]_x$
, so that its kernel consists only of terms that are independent of these variables. At the end of the calculation, all members of
$[u^\alpha _{\textbf{I}}]_x$
, so that its kernel consists only of terms that are independent of these variables. At the end of the calculation, all members of
 $[U^\alpha _{\textbf{I}}]_x$
are set to zero. Note that there is no need to replace
$[U^\alpha _{\textbf{I}}]_x$
are set to zero. Note that there is no need to replace
 $u^\alpha _{\textbf{I}}$
in terms that are not zero-degree in
$u^\alpha _{\textbf{I}}$
in terms that are not zero-degree in
 $[u^\alpha _{\textbf{I}}]_x$
, as total differentiation preserves the degree of homogeneity.Footnote
2
$[u^\alpha _{\textbf{I}}]_x$
, as total differentiation preserves the degree of homogeneity.Footnote
2
Example 4.2. To illustrate the inversion process for divergences that have zero-degree terms, we complete Example 3.4 by inverting
 \begin{equation*} {\mathcal {C}}=D_xF+D_yG=u_{x}(2u+v_{y})-v_{x}(u_y+2v_{yy})+\frac {u_{x}}{u^2}+\frac {v_{yy}}{v_{y}}+\frac {2u_{y}}{u}\ln |u|; \end{equation*}
\begin{equation*} {\mathcal {C}}=D_xF+D_yG=u_{x}(2u+v_{y})-v_{x}(u_y+2v_{yy})+\frac {u_{x}}{u^2}+\frac {v_{yy}}{v_{y}}+\frac {2u_{y}}{u}\ln |u|; \end{equation*}
this has no linear terms. The ranking heuristic gives
 $y\prec x$
and
$y\prec x$
and
 $u\prec v$
. The rest of the calculation goes as follows.
$u\prec v$
. The rest of the calculation goes as follows.
-
1.
${\mathcal{C}}-\pi _u^y({\mathcal{C}})$
has just one zero-degree term (in
$[u]_y$
), namely
$(2u_y/u)\ln |u|$
. Replace this term by
$(2(u_y+U_y)/(u+U))\ln |u+U|$
. -
2. Calculate
$\boldsymbol{E}_u^y({\mathcal{C}})=2u_x+v_{xy}-2u_xu^{-3}=D_x\{2u+v_y+u^{-2}\}=D_x\{\boldsymbol{E}_u^y(u^2+uv_y-u^{-1})\}$
. No term in
$2u+v_y+u^{-2}$
is ranked lower than
$u$
, as
$u$
is the lowest-ranked variable. -
3. Then
$\pi _u^y({\mathcal{C}}\!-\!D_x\{u^2+uv_y-u^{-1}\})=D_y\{-uv_x+(\ln |u+U|)^2\}$
. -
4. Now set
$U=0$
to yield the remainder
${\mathcal{C}}_1={\mathcal{C}}\!-\!D_x\{u^2+uv_y-u^{-1}\}\!-\!D_y\{-uv_x+(\ln |u|)^2\}$
at the close of the first iteration. This amounts to
${\mathcal{C}}_1=-2v_xv_{yy}+v_{yy}/v_y$
. -
5. The second iteration starts with
${\mathcal{C}}_1-\pi _v^y({\mathcal{C}}_1)=v_{yy}/v_y$
; as this term is zero-degree in
$[v]_y$
, replace it by
$(v_{yy}+V_{yy})/(v_y+V_y)$
. -
6. Calculate
$\boldsymbol{E}_v^y({\mathcal{C}}_1)=-2v_{xyy}=D_x\{-2v_{yy}\}=D_x\{E_v^y(-vv_{yy})\}=D_x\{E_v^y(v_y^2)\}$
. Note that
$-2v_{yy}$
is not ranked lower than
$v$
. -
7. Then
$\pi _v^y({\mathcal{C}}_1\!-\!D_x\{v_y^2\})=D_y\{-2v_xv_y+\ln |v_y+V_y|\}$
. -
8. Now set
$V=0$
to yield the remainder
${\mathcal{C}}_2={\mathcal{C}}_1\!-\!D_x\{v_y^2\}\!-\!D_y\{-2v_xv_y+\ln |v_y|\}=0$
at the close of the second iteration. The inversion process stops, having yielded the output
\begin{equation*} F=u^2+uv_y-u^{-1}+v_y^2,\qquad G=-uv_x+(\ln |u|)^2-2v_xv_y+\ln |v_y|. \end{equation*}






















Note that the homotopy formula (3.18) for inverting
 $D_xF$
can be adjusted in the same way, whenever
$D_xF$
can be adjusted in the same way, whenever
 $\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a poor scaling for
$\sigma _{u^\alpha _\boldsymbol{I}}^{x}$
is a poor scaling for
 $\boldsymbol{E}^x_{u^\alpha _{\boldsymbol{I},j+1}}(D_xF)$
.
$\boldsymbol{E}^x_{u^\alpha _{\boldsymbol{I},j+1}}(D_xF)$
.
4.4 Linear divergences
The inversion process runs into a difficulty when a given divergence has terms that are linear in
 $[{\textbf{u}}]$
, with mixed derivatives. Then it is possible to invert in more than one way, some of which may not produce a minimal result. To address this, it is helpful to invert using a different process. Suppose that
$[{\textbf{u}}]$
, with mixed derivatives. Then it is possible to invert in more than one way, some of which may not produce a minimal result. To address this, it is helpful to invert using a different process. Suppose that
 $\mathcal{C}$
is a linear divergence (in fully expanded form). Instead of using the derivative-dominant ranking, integrate by parts, working down the total order
$\mathcal{C}$
is a linear divergence (in fully expanded form). Instead of using the derivative-dominant ranking, integrate by parts, working down the total order
 $|{\textbf{J}}|$
of the derivatives
$|{\textbf{J}}|$
of the derivatives
 $u^\alpha _{\textbf{J}}$
. For a given total order, we will invert the mixed derivatives first, though this is not essential.
$u^\alpha _{\textbf{J}}$
. For a given total order, we will invert the mixed derivatives first, though this is not essential.
Starting with the highest-order derivatives, one could integrate each term
 $f({\textbf{x}})u^\alpha _{\textbf{J}}$
in
$f({\textbf{x}})u^\alpha _{\textbf{J}}$
in
 $\mathcal{C}$
by parts with respect to any
$\mathcal{C}$
by parts with respect to any
 $x^i$
such that
$x^i$
such that
 $j^i\geq 1$
, yielding the remainder
$j^i\geq 1$
, yielding the remainder
 $\!-\!D_i(f)u^\alpha _{{\textbf{J}}-{\boldsymbol{1}}_i}$
. If
$\!-\!D_i(f)u^\alpha _{{\textbf{J}}-{\boldsymbol{1}}_i}$
. If
 $D_{\textbf{J}}$
is a mixed derivative, we seek to choose
$D_{\textbf{J}}$
is a mixed derivative, we seek to choose
 $D_i$
in a way that keeps the result concise. Here are some simple criteria that are commonly effective, listed in order of precedence.
$D_i$
in a way that keeps the result concise. Here are some simple criteria that are commonly effective, listed in order of precedence.
-
1.
$f$
is independent of
$x^i$
. -
2.
$\mathcal{C}$
includes the term
$D_i(f)u^\alpha _{{\textbf{J}}-{\boldsymbol{1}}_i}$
. -
3.
$f$
is linear in
$x^i$
.






These criteria can be used as an initial pass to invert
 $\mathcal{C}$
at least partially, leaving a remainder to be inverted that may have far fewer terms than
$\mathcal{C}$
at least partially, leaving a remainder to be inverted that may have far fewer terms than
 $\mathcal{C}$
does.
$\mathcal{C}$
does.
Integrating the remainder by parts is straightforward if each
 $u^\alpha _{\textbf{J}}$
is an unmixed derivative. If
$u^\alpha _{\textbf{J}}$
is an unmixed derivative. If
 $\textbf{J}$
denotes a mixed derivative, integrate with respect to each
$\textbf{J}$
denotes a mixed derivative, integrate with respect to each
 $x^i$
such that
$x^i$
such that
 $j^i\geq 1$
in turn, multiplying each result by a parameter (with the parameters summing to
$j^i\geq 1$
in turn, multiplying each result by a parameter (with the parameters summing to
 $1$
). Iterate until either the remainder has a factor that is zero for some choice of parameters or there is no remainder. The final stage is to choose the parameters so as to minimize the number of terms in the final expression. Although this produces a minimal inversion, it comes at the cost of extra computational time spent doing all possible inversions followed by the parameter optimization.
$1$
). Iterate until either the remainder has a factor that is zero for some choice of parameters or there is no remainder. The final stage is to choose the parameters so as to minimize the number of terms in the final expression. Although this produces a minimal inversion, it comes at the cost of extra computational time spent doing all possible inversions followed by the parameter optimization.
Example 4.3. Consider the linear divergence
 \begin{equation*} {\mathcal {C}}=\left (\frac {1}{6}f'(t)y^3+f(t)xy\right )\!(u_{xt}-u_{yy}), \end{equation*}
\begin{equation*} {\mathcal {C}}=\left (\frac {1}{6}f'(t)y^3+f(t)xy\right )\!(u_{xt}-u_{yy}), \end{equation*}
where
 $f$
is an arbitrary function. The first of the simple criteria above yields
$f$
is an arbitrary function. The first of the simple criteria above yields
 \begin{equation*} {\mathcal {C}}=D_x\!\left \{\frac {1}{6}f'y^3u_t\right \}+fxyu_{xt}-\left (\frac {1}{6}f'y^3+fxy\right )\!u_{yy}; \end{equation*}
\begin{equation*} {\mathcal {C}}=D_x\!\left \{\frac {1}{6}f'y^3u_t\right \}+fxyu_{xt}-\left (\frac {1}{6}f'y^3+fxy\right )\!u_{yy}; \end{equation*}
The second criterion is not helpful at this stage, but the third criterion gives
 \begin{equation*} {\mathcal {C}}=D_x\!\left \{\left (\frac {1}{6}f'y^3+fxy\right )\!u_t\right \}-fyu_{t}-\left (\frac {1}{6}f'y^3+fxy\right )\!u_{yy}. \end{equation*}
\begin{equation*} {\mathcal {C}}=D_x\!\left \{\left (\frac {1}{6}f'y^3+fxy\right )\!u_t\right \}-fyu_{t}-\left (\frac {1}{6}f'y^3+fxy\right )\!u_{yy}. \end{equation*}
The remainder has no mixed derivatives; integrating it by parts produces the minimal inversion
 \begin{equation} {\mathcal{C}}=D_x\!\left \{\left (\frac{1}{6}f'y^3+fxy\right )\!u_t\right \}+D_y\!\left \{\left (\frac{1}{2}f'y^2+fx\right )\!u-\left (\frac{1}{6}f'y^3+fxy\right )\!u_y\right \}+D_t\!\left \{-fyu\right \}\!. \end{equation}
\begin{equation} {\mathcal{C}}=D_x\!\left \{\left (\frac{1}{6}f'y^3+fxy\right )\!u_t\right \}+D_y\!\left \{\left (\frac{1}{2}f'y^2+fx\right )\!u-\left (\frac{1}{6}f'y^3+fxy\right )\!u_y\right \}+D_t\!\left \{-fyu\right \}\!. \end{equation}
Example 4.4. To illustrate the parametric approach, consider
 \begin{equation*} {\mathcal {C}}=\exp (t-x^2)(tu_{xtt}+2x(t+1)u_t). \end{equation*}
\begin{equation*} {\mathcal {C}}=\exp (t-x^2)(tu_{xtt}+2x(t+1)u_t). \end{equation*}
The simple criteria are irrelevant at present, so instead introduce parameters
 $\lambda _l$
and consider all possible inversions of the mixed derivative terms. Step-by-step, one obtains the following.
$\lambda _l$
and consider all possible inversions of the mixed derivative terms. Step-by-step, one obtains the following.
 \begin{align*}{\mathcal{C}}&=D_x\!\left \{\lambda _1\exp (t-x^2)tu_{tt}\right \}+D_t\!\left \{(1-\lambda _1)\exp (t-x^2)tu_{xt}\right \}\\[5pt] &\quad +\exp (t-x^2)\{2\lambda _1xtu_{tt}-(1-\lambda _1)(t+1)u_{xt}+2x(t+1)u_t\}\\[5pt] &=D_x\!\left \{\exp (t-x^2)\{\lambda _1tu_{tt}-\lambda _2(1-\lambda _1)(t+1)u_{t}\}\right \}\\[5pt] &\quad +D_t\!\left \{\exp (t-x^2)\{(1-\lambda _1)tu_{xt}+2\lambda _1xtu_{t}-(1-\lambda _2)(1-\lambda _1)(t+1)u_{x}\}\right \}\\[5pt] &\quad +(1-\lambda _2)(1-\lambda _1)\exp (t-x^2)\{2x(t+1)u_{t}+(t+2)u_{x}\}. \end{align*}
\begin{align*}{\mathcal{C}}&=D_x\!\left \{\lambda _1\exp (t-x^2)tu_{tt}\right \}+D_t\!\left \{(1-\lambda _1)\exp (t-x^2)tu_{xt}\right \}\\[5pt] &\quad +\exp (t-x^2)\{2\lambda _1xtu_{tt}-(1-\lambda _1)(t+1)u_{xt}+2x(t+1)u_t\}\\[5pt] &=D_x\!\left \{\exp (t-x^2)\{\lambda _1tu_{tt}-\lambda _2(1-\lambda _1)(t+1)u_{t}\}\right \}\\[5pt] &\quad +D_t\!\left \{\exp (t-x^2)\{(1-\lambda _1)tu_{xt}+2\lambda _1xtu_{t}-(1-\lambda _2)(1-\lambda _1)(t+1)u_{x}\}\right \}\\[5pt] &\quad +(1-\lambda _2)(1-\lambda _1)\exp (t-x^2)\{2x(t+1)u_{t}+(t+2)u_{x}\}. \end{align*}
As the remainder has a factor
 $(1-\lambda _2)(1-\lambda _1)$
, the inversion is complete if either parameter is set to
$(1-\lambda _2)(1-\lambda _1)$
, the inversion is complete if either parameter is set to
 $1$
. The minimal (two-term) inversion has
$1$
. The minimal (two-term) inversion has
 $\lambda _1=1$
, which gives
$\lambda _1=1$
, which gives
 ${\mathcal{C}}=D_xF+D_tG$
, where
${\mathcal{C}}=D_xF+D_tG$
, where
 \begin{equation*} F=t\exp (t-x^2)u_{tt}\,,\qquad G=2xt\exp (t-x^2)u_{t}\,. \end{equation*}
\begin{equation*} F=t\exp (t-x^2)u_{tt}\,,\qquad G=2xt\exp (t-x^2)u_{t}\,. \end{equation*}
For
 $\lambda _1\neq 1, \lambda _2=1$
, the inversion has three terms if
$\lambda _1\neq 1, \lambda _2=1$
, the inversion has three terms if
 $\lambda _1=0$
, or five terms otherwise.
$\lambda _1=0$
, or five terms otherwise.
Note the importance of factorizing the remainder to stop the calculation once a possible parameter choice occurs. If we had continued the calculation without setting either
 $\lambda _i$
to
$\lambda _i$
to
 $1$
, it would have stopped at order zero, not one, giving an eleven-term inversion for general
$1$
, it would have stopped at order zero, not one, giving an eleven-term inversion for general
 $\lambda _i$
.
$\lambda _i$
.
To summarize, one can invert a divergence that is linear in
 $[{\textbf{u}}]$
by applying the following procedure.
$[{\textbf{u}}]$
by applying the following procedure.
Procedure B. Iinversion of a linear total divergence
-
Step 0. Identify the maximum derivative order,
$N=|{\textbf{J}}|$
, of the variables
$u^\alpha _{\textbf{J}}$
that occur in
$\mathcal{C}$
. Set
$F^i\;:\!=\;0,\ i=1\ldots,p$
. -
Step 1. While
$\mathcal{C}$
has at least one term of order
$N$
, do the following. Select any such term,
$f({\textbf{x}})u^\alpha _{\textbf{J}}$
, and determine a variable
$x^i$
over which to integrate. If desired, parametrize for mixed derivatives, as described above. Set
$F^i\;:\!=\;F^i+fu^\alpha _{{\textbf{J}}-{\boldsymbol{1}}_i}$
for the chosen
$i$
(with the appropriate modification if parameters are used), and update the remainder by setting
${\mathcal{C}}\;:\!=\;{\mathcal{C}}-f({\textbf{x}})u^\alpha _{\textbf{J}}\!-\!D_i(f)u^\alpha _{{\textbf{J}}-{\boldsymbol{1}}_i}$
. Once
$\mathcal{C}$
has no terms of order
$N$
, continue to Step 2. -
Step 2. If
$\mathcal{C}$
is nonzero and cannot be set to zero by any choice of parameters, set
$N\;:\!=\;N-1$
and return to Step 1; otherwise, set
$\mathcal{C}$
to zero and carry out parameter optimization (if needed), give the output
$F^i,\ i=1,\ldots,p$
, then stop.

















4.5 Summary: a procedure for inverting Div
Having addressed potential modifications, we are now in a position to summarize the inversion process for any total divergence
 $\mathcal{C}$
whose fully expanded form has no terms depending on
$\mathcal{C}$
whose fully expanded form has no terms depending on
 $\textbf{x}$
only.
$\textbf{x}$
only.
Procedure C.
Inversion of
 ${\mathcal{C}}=D_iF^i$
${\mathcal{C}}=D_iF^i$
-
Step 0. Let
${\mathcal{C}}_\ell$
be the linear part of
$\mathcal{C}$
. If
${\mathcal{C}}_\ell =0$
, set
${\mathcal{C}}_0\;:\!=\;{\mathcal{C}}$
and
$F_0^i\;:\!=\;0,\ i=1,\ldots,p$
. Otherwise, invert
${\mathcal{C}}_\ell$
using the technique described in Procedure B above, to obtain functions
$F_0^i$
that satisfy
${\mathcal{C}}_\ell =D_iF_0^i$
. Set
${\mathcal{C}}_0\;:\!=\;{\mathcal{C}}-{\mathcal{C}}_\ell$
. Choose a derivative-dominant ranking for
${\mathcal{C}}_0$
(either using the ranking heuristic or otherwise). In the notation used earlier, set
$x\;:\!=\;x^1$
and
$u$
to be the lowest-ranked relevant
$u^\alpha$
; typically,
$u\;:\!=\;u^1$
. Set
$n\;:\!=\;0$
; here
$n+1$
is the iteration number. -
Step 1. Calculate
${\mathcal{C}}_n-\pi _u^x({\mathcal{C}}_n)$
; if this includes terms depending on
$[u]_x$
, replace
$[u]_x$
in these terms only by
$[u+U]_x$
. -
Step 2. Apply the process detailed in Section 4.1 (with
${\mathcal{C}}_n$
replacing
$\mathcal{C}$
). Provided that the ranking check is passed, this yields components
$f^i$
, which may depend on
$[U]_x$
. If the ranking check is failed, choose a different ranking of
$x^j$
and
$u^\alpha$
for the remainder of the inversion process and return to Step 1, starting with the lowest-ranked
$x$
and (relevant)
$u$
and working upwards at each iteration. -
Step 3. Replace all elements of
$[U]_x$
in
$f^i$
by zero. -
Step 4. Update: set
$F^i_{n+1}\;:\!=\;F^i_n+f^i,\ {\mathcal{C}}_{n+1}\;:\!=\;{\mathcal{C}}_n\!-\!D_if^i$
and
$n\;:\!=\;n+1$
. If
${\mathcal{C}}_{n+1}= 0$
, output
$F^i=F^i_{n+1}$
and stop. Otherwise, update
$u$
and
$x$
as detailed in Section 4.2 and return to Step 1.




































Example 4.5. As an example with linear terms, the Khokhlov–Zabolotskaya equation,
 \begin{equation*} u_{xt}-uu_{xx}-u_x^2-u_{yy}=0, \end{equation*}
\begin{equation*} u_{xt}-uu_{xx}-u_x^2-u_{yy}=0, \end{equation*}
has a conservation law (see Poole & Hereman [11]) that involves an arbitrary function,
 $f(t)$
:
$f(t)$
:
 \begin{equation*} {\mathcal {C}}=D_xF+D_yG+D_tH=\left (\frac {1}{6}f'y^3+fxy\right )\!\left (u_{xt}-uu_{xx}-u_x^2-u_{yy}\right ). \end{equation*}
\begin{equation*} {\mathcal {C}}=D_xF+D_yG+D_tH=\left (\frac {1}{6}f'y^3+fxy\right )\!\left (u_{xt}-uu_{xx}-u_x^2-u_{yy}\right ). \end{equation*}
The linear part
 ${\mathcal{C}}_\ell$
of
${\mathcal{C}}_\ell$
of
 $\mathcal{C}$
is inverted by Procedure B, as shown in Example 4.3. From (4.6), Step 0 in Procedure C gives
$\mathcal{C}$
is inverted by Procedure B, as shown in Example 4.3. From (4.6), Step 0 in Procedure C gives
 \begin{equation*} F_0=\left (\frac {1}{6}f'y^3+fxy\right )\!u_t\,,\qquad G_0=\left (\frac {1}{2}f'y^2+fx\right )\!u-\left (\frac {1}{6}f'y^3+fxy\right )\!u_y\,, \qquad H_0=-fyu. \end{equation*}
\begin{equation*} F_0=\left (\frac {1}{6}f'y^3+fxy\right )\!u_t\,,\qquad G_0=\left (\frac {1}{2}f'y^2+fx\right )\!u-\left (\frac {1}{6}f'y^3+fxy\right )\!u_y\,, \qquad H_0=-fyu. \end{equation*}
The remainder
 ${\mathcal{C}}-{\mathcal{C}}_\ell$
is
${\mathcal{C}}-{\mathcal{C}}_\ell$
is
 \begin{equation*} {\mathcal {C}}_0=-\left (\frac {1}{6}f'y^3+fxy\right )\!\left (uu_{xx}+u_x^2\right ). \end{equation*}
\begin{equation*} {\mathcal {C}}_0=-\left (\frac {1}{6}f'y^3+fxy\right )\!\left (uu_{xx}+u_x^2\right ). \end{equation*}
With the derivative-dominant ranking
 $x\prec y\prec t$
, only one iteration is needed to complete the inversion, because
$x\prec y\prec t$
, only one iteration is needed to complete the inversion, because
 $\boldsymbol{E}_{u}^{x}({\mathcal{C}}_0)=0$
. Then
$\boldsymbol{E}_{u}^{x}({\mathcal{C}}_0)=0$
. Then
 \begin{equation*} \pi _u^x({\mathcal {C}}_0)=D_x\!\left \{\frac {1}{2}fyu^2-\left (\frac {1}{6}f'y^3+fxy\right )\!uu_x\right \}, \end{equation*}
\begin{equation*} \pi _u^x({\mathcal {C}}_0)=D_x\!\left \{\frac {1}{2}fyu^2-\left (\frac {1}{6}f'y^3+fxy\right )\!uu_x\right \}, \end{equation*}
and as
 ${\mathcal{C}}_0=\pi _u^x({\mathcal{C}}_0)$
, the calculation stops after updating, giving the output
${\mathcal{C}}_0=\pi _u^x({\mathcal{C}}_0)$
, the calculation stops after updating, giving the output
 \begin{equation*} F=\left (\frac {1}{6}f'y^3+fxy\right )\!\left (u_t-uu_x\right )+\frac {1}{2}fyu^2,\qquad G=\left (\frac {1}{2}f'y^2+fx\right )\!u-\left (\frac {1}{6}f'y^3+fxy\right )\!u_y,\qquad H=-fyu. \end{equation*}
\begin{equation*} F=\left (\frac {1}{6}f'y^3+fxy\right )\!\left (u_t-uu_x\right )+\frac {1}{2}fyu^2,\qquad G=\left (\frac {1}{2}f'y^2+fx\right )\!u-\left (\frac {1}{6}f'y^3+fxy\right )\!u_y,\qquad H=-fyu. \end{equation*}
This corresponds to the minimal result in Poole & Hereman [11].
Example 4.6. In every example so far, all iterations have used
 $u=u^\alpha$
, but not
$u=u^\alpha$
, but not
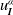 $u^\alpha _\boldsymbol{I}$
for
$u^\alpha _\boldsymbol{I}$
for
 $|I|\neq 0$
. The BBM equation from Example 2.1 illustrates the way that the process continues unhindered once the current
$|I|\neq 0$
. The BBM equation from Example 2.1 illustrates the way that the process continues unhindered once the current
 $\mathcal{C}$
is independent of all elements of
$\mathcal{C}$
is independent of all elements of
 $[u^\alpha ]_x$
. The conservation law (2.6) is
$[u^\alpha ]_x$
. The conservation law (2.6) is
 \begin{equation*} {\mathcal {C}}=D_xF+D_tG=(u^2+2u_{xt})(u_{t}-uu_x-u_{xxt}); \end{equation*}
\begin{equation*} {\mathcal {C}}=D_xF+D_tG=(u^2+2u_{xt})(u_{t}-uu_x-u_{xxt}); \end{equation*}
it has no linear part or zero-degree terms. The ranking heuristic gives
 $x\prec t$
. The first iteration using
$x\prec t$
. The first iteration using
 $\boldsymbol{E}_{u}^{x}$
is similar to what we have seen so far, giving the following updates:
$\boldsymbol{E}_{u}^{x}$
is similar to what we have seen so far, giving the following updates:
 \begin{equation*} {\mathcal {C}}_1=2u_{xt}(u_t-u_{xxt}),\qquad F_1=-\frac {1}{4}u^4-u^2u_{xt},\qquad G_1=\frac {1}{3}u^3. \end{equation*}
\begin{equation*} {\mathcal {C}}_1=2u_{xt}(u_t-u_{xxt}),\qquad F_1=-\frac {1}{4}u^4-u^2u_{xt},\qquad G_1=\frac {1}{3}u^3. \end{equation*}
At this stage,
 ${\mathcal{C}}_1$
is independent of
${\mathcal{C}}_1$
is independent of
 $[u]_x$
and equals
$[u]_x$
and equals
 $\pi ^x_{u_t}({\mathcal{C}}_1)$
. In the second iteration, the ranking requires us to apply
$\pi ^x_{u_t}({\mathcal{C}}_1)$
. In the second iteration, the ranking requires us to apply
 $\boldsymbol{E}^x_{u_t}$
. This annihilates
$\boldsymbol{E}^x_{u_t}$
. This annihilates
 ${\mathcal{C}}_1$
; consequently,
${\mathcal{C}}_1$
; consequently,
 ${\mathcal{C}}_1$
is a total derivative with respect to
${\mathcal{C}}_1$
is a total derivative with respect to
 $x$
. Inverting this gives the final (minimal) result,
$x$
. Inverting this gives the final (minimal) result,
 \begin{equation*} F=-\frac {1}{4}u^4-u^2u_{xt}-u_{xt}^2+u_t^2,\qquad G=\frac {1}{3}u^3, \end{equation*}
\begin{equation*} F=-\frac {1}{4}u^4-u^2u_{xt}-u_{xt}^2+u_t^2,\qquad G=\frac {1}{3}u^3, \end{equation*}
which was obtained by inspection in Example 2.1.
The Appendix lists inversions of various other divergences; in each case, the inversion produced by Procedure C and the ranking heuristic is minimal and takes very few iterations to complete.
4.6 Splitting a divergence using discrete symmetries
A given divergence may have discrete symmetries between various terms in its fully expanded form. If the divergence has very many terms that are connected by a particular discrete symmetry group, it can be worth splitting these into disjoint divergences that are mapped to one another by the group elements. Then it is only necessary to invert one of these divergences, using the symmetries to create inversions of the others without the need for much extra computation. However, to use Procedure C, it is necessary to check that all split terms are grouped into divergences; this check is done by using the criterion (2.3).
Polynomial divergences can first be split by degree, yielding divergences that are homogeneous in
 $[{\textbf{u}}]$
. Such splitting does not add significantly to the computation time, nor does it need to be checked using (2.3), which holds automatically. Splitting by degree can make it easy to identify terms that are linked by discrete symmetries, as illustrated by the following example.
$[{\textbf{u}}]$
. Such splitting does not add significantly to the computation time, nor does it need to be checked using (2.3), which holds automatically. Splitting by degree can make it easy to identify terms that are linked by discrete symmetries, as illustrated by the following example.
Example 4.7. In Cartesian coordinates
 $(x,y)$
, the steady non-dimensionalized von Kármán equations for a plate subject to a prescribed axisymmetric load function,
$(x,y)$
, the steady non-dimensionalized von Kármán equations for a plate subject to a prescribed axisymmetric load function,
 $p(x^2+y^2)$
, are
$p(x^2+y^2)$
, are
 ${\mathcal{A}}_\ell =0$
,
${\mathcal{A}}_\ell =0$
,
 $\ell =1,2$
, where
$\ell =1,2$
, where
 \begin{align*}{\mathcal{A}}_1&=u_{xxxx}+2u_{xxyy}+u_{yyyy}-u_{xx}v_{yy}+2u_{xy}v_{xy}-u_{yy}v_{xx}-p,\\[5pt] {\mathcal{A}}_2&=v_{xxxx}+2v_{xxyy}+v_{yyyy}+u_{xx}u_{yy}-u_{xy}^2\,. \end{align*}
\begin{align*}{\mathcal{A}}_1&=u_{xxxx}+2u_{xxyy}+u_{yyyy}-u_{xx}v_{yy}+2u_{xy}v_{xy}-u_{yy}v_{xx}-p,\\[5pt] {\mathcal{A}}_2&=v_{xxxx}+2v_{xxyy}+v_{yyyy}+u_{xx}u_{yy}-u_{xy}^2\,. \end{align*}
Here
 $u$
is the displacement and
$u$
is the displacement and
 $v$
is the Airy stress. This is a system of Euler–Lagrange equations. By Noether’s Theorem, the one-parameter Lie group of rotational symmetries yields the following conservation law (see Djondjorov and Vassilev [Reference Djondjorov, Vassilev, Bertram, Constanda and Struthers6]):
$v$
is the Airy stress. This is a system of Euler–Lagrange equations. By Noether’s Theorem, the one-parameter Lie group of rotational symmetries yields the following conservation law (see Djondjorov and Vassilev [Reference Djondjorov, Vassilev, Bertram, Constanda and Struthers6]):
 \begin{equation*} {\mathcal {C}}=(yv_x-xv_y){\mathcal {A}}_2-(yu_x-xu_y){\mathcal {A}}_1\,. \end{equation*}
\begin{equation*} {\mathcal {C}}=(yv_x-xv_y){\mathcal {A}}_2-(yu_x-xu_y){\mathcal {A}}_1\,. \end{equation*}
This conservation law has linear, quadratic and cubic terms, so
 $\mathcal{C}$
can be inverted by summing the inversions of each of the following divergences:
$\mathcal{C}$
can be inverted by summing the inversions of each of the following divergences:
 \begin{align*}{\mathcal{C}}_\ell &=(yu_x-xu_y)p,\\[5pt] {\mathcal{C}}_q&=(yv_x-xv_y)( v_{xxxx}+2v_{xxyy}+v_{yyyy})-(yu_x-xu_y)(u_{xxxx}+2u_{xxyy}+u_{yyyy}),\\[5pt] {\mathcal{C}}_c&=(yv_x-xv_y)(u_{xx}u_{yy}-u_{xy}^2)+(yu_x-xu_y)(u_{xx}v_{yy}-2u_{xy}v_{xy}+u_{yy}v_{xx}). \end{align*}
\begin{align*}{\mathcal{C}}_\ell &=(yu_x-xu_y)p,\\[5pt] {\mathcal{C}}_q&=(yv_x-xv_y)( v_{xxxx}+2v_{xxyy}+v_{yyyy})-(yu_x-xu_y)(u_{xxxx}+2u_{xxyy}+u_{yyyy}),\\[5pt] {\mathcal{C}}_c&=(yv_x-xv_y)(u_{xx}u_{yy}-u_{xy}^2)+(yu_x-xu_y)(u_{xx}v_{yy}-2u_{xy}v_{xy}+u_{yy}v_{xx}). \end{align*}
The quadratic terms have an obvious discrete symmetry,
 $\Gamma _1\;:\;(x,y,u,v)\mapsto (\!-\!x,y,v,u)$
, which gives a splitting into two parts, each of which is a divergence:
$\Gamma _1\;:\;(x,y,u,v)\mapsto (\!-\!x,y,v,u)$
, which gives a splitting into two parts, each of which is a divergence:
 \begin{equation*} {\mathcal {C}}_q=\overline {{\mathcal {C}}}_q+\Gamma _1(\overline {{\mathcal {C}}}_q), \end{equation*}
\begin{equation*} {\mathcal {C}}_q=\overline {{\mathcal {C}}}_q+\Gamma _1(\overline {{\mathcal {C}}}_q), \end{equation*}
where
 \begin{equation*} \overline {{\mathcal {C}}}_q=(yv_x-xv_y)(v_{xxxx}+2v_{xxyy}+v_{yyyy}). \end{equation*}
\begin{equation*} \overline {{\mathcal {C}}}_q=(yv_x-xv_y)(v_{xxxx}+2v_{xxyy}+v_{yyyy}). \end{equation*}
Consequently, we can invert
 ${\mathcal{C}}_q$
by inverting
${\mathcal{C}}_q$
by inverting
 $\overline{{\mathcal{C}}}_q$
and applying the symmetry
$\overline{{\mathcal{C}}}_q$
and applying the symmetry
 $\Gamma _1$
.
$\Gamma _1$
.
Note that
 $\overline{{\mathcal{C}}}_q$
has a discrete symmetry,
$\overline{{\mathcal{C}}}_q$
has a discrete symmetry,
 $\Gamma _2\;:\;(x,y,v)\mapsto (y,-x,v)$
, which gives
$\Gamma _2\;:\;(x,y,v)\mapsto (y,-x,v)$
, which gives
 \begin{equation*} \overline {{\mathcal {C}}}_q=g+\Gamma _2(g),\quad \text {where}\quad g=(yv_x-xv_y)(v_{xxxx}+v_{xxyy}). \end{equation*}
\begin{equation*} \overline {{\mathcal {C}}}_q=g+\Gamma _2(g),\quad \text {where}\quad g=(yv_x-xv_y)(v_{xxxx}+v_{xxyy}). \end{equation*}
Checking (2.3) shows that this is not a valid splitting into divergences, because
 \begin{equation*} \boldsymbol{E}_v(g)=-2v_{xxxy}-2v_{xyyy}\neq 0. \end{equation*}
\begin{equation*} \boldsymbol{E}_v(g)=-2v_{xxxy}-2v_{xyyy}\neq 0. \end{equation*}
If necessary, split divergences can be inverted using different rankings. However, in this simple example, a single ranking works for all (nonlinear) parts. One tie-break is needed: let
 $x\prec y$
. The ranking heuristic gives
$x\prec y$
. The ranking heuristic gives
 $v\prec u$
for the cubic terms; the variables
$v\prec u$
for the cubic terms; the variables
 $[u]$
are not relevant in the inversion of
$[u]$
are not relevant in the inversion of
 $\overline{{\mathcal{C}}}_q$
. Procedure C gives the following minimal inversions,
$\overline{{\mathcal{C}}}_q$
. Procedure C gives the following minimal inversions,
 \begin{align*}{\mathcal{C}}_\ell &=D_x(yup)+D_y(\!-\!xup),\\[5pt] \overline{{\mathcal{C}}}_q&=D_x\{F_q(x,y,[v])\}+D_y\{G_q(x,y,[v])\},\\[5pt] {\mathcal{C}}_c&=D_xF_c+D_yG_c\,, \end{align*}
\begin{align*}{\mathcal{C}}_\ell &=D_x(yup)+D_y(\!-\!xup),\\[5pt] \overline{{\mathcal{C}}}_q&=D_x\{F_q(x,y,[v])\}+D_y\{G_q(x,y,[v])\},\\[5pt] {\mathcal{C}}_c&=D_xF_c+D_yG_c\,, \end{align*}
where
 \begin{align*} F_q(x,y,[v])=&\ y\left \{v_xv_{xxx}-\frac{1}{2}v_{xx}^2+2v_xv_{xyy}+v_{xy}^2+vv_{yyyy}-\frac{1}{2}v_{yy}^2\right \}\\[5pt] &+x\left \{-v_yv_{xxx}+v_{xx}v_{xy}-2v_yv_{xyy}\right \}+v_yv_{xx}\,,\\[5pt] G_q(x,y,[v])=&\ y\left \{-2v_{xx}v_{xy}-vv_{xyyy}+v_yv_{xyy}\right \}+x\left \{-\frac{1}{2}v_{xx}^2+v_{xy}^2-v_yv_{yyy}+\frac{1}{2}v_{yy}^2\right \}+vv_{xyy}\,,\\[5pt] F_c=&\ y\left (u_xu_{yy}v_x+\frac{1}{2}u_x^2v_{yy}\right )+x\left (u_yu_{xy}v_y+\frac{1}{2}u_y^2v_{xy}\right )-\frac{1}{2}u_y^2v_y\,,\\[5pt] G_c=&\ -y\left (u_xu_{xy}v_x+\frac{1}{2}u_x^2v_{xy}\right )-x\left (u_yu_{xx}v_y+\frac{1}{2}u_y^2v_{xx}\right )+\frac{1}{2}u_x^2v_x\,. \end{align*}
\begin{align*} F_q(x,y,[v])=&\ y\left \{v_xv_{xxx}-\frac{1}{2}v_{xx}^2+2v_xv_{xyy}+v_{xy}^2+vv_{yyyy}-\frac{1}{2}v_{yy}^2\right \}\\[5pt] &+x\left \{-v_yv_{xxx}+v_{xx}v_{xy}-2v_yv_{xyy}\right \}+v_yv_{xx}\,,\\[5pt] G_q(x,y,[v])=&\ y\left \{-2v_{xx}v_{xy}-vv_{xyyy}+v_yv_{xyy}\right \}+x\left \{-\frac{1}{2}v_{xx}^2+v_{xy}^2-v_yv_{yyy}+\frac{1}{2}v_{yy}^2\right \}+vv_{xyy}\,,\\[5pt] F_c=&\ y\left (u_xu_{yy}v_x+\frac{1}{2}u_x^2v_{yy}\right )+x\left (u_yu_{xy}v_y+\frac{1}{2}u_y^2v_{xy}\right )-\frac{1}{2}u_y^2v_y\,,\\[5pt] G_c=&\ -y\left (u_xu_{xy}v_x+\frac{1}{2}u_x^2v_{xy}\right )-x\left (u_yu_{xx}v_y+\frac{1}{2}u_y^2v_{xx}\right )+\frac{1}{2}u_x^2v_x\,. \end{align*}
Applying
 $\Gamma _1$
to
$\Gamma _1$
to
 $\overline{{\mathcal{C}}}_q$
gives the following minimal inversion for
$\overline{{\mathcal{C}}}_q$
gives the following minimal inversion for
 $\mathcal{C}$
:
$\mathcal{C}$
:
 \begin{equation*} {\mathcal {C}}=D_x\!\left \{yup +F_q(x,y,[v])-F_q(x,y,[u]) +F_c\right \}+D_y\!\left \{-xup +G_q(x,y,[v])-G_q(x,y,[u]) +G_c\right \}. \end{equation*}
\begin{equation*} {\mathcal {C}}=D_x\!\left \{yup +F_q(x,y,[v])-F_q(x,y,[u]) +F_c\right \}+D_y\!\left \{-xup +G_q(x,y,[v])-G_q(x,y,[u]) +G_c\right \}. \end{equation*}
Note that the tie-break
 $x\prec y$
causes the inversion to break the symmetry
$x\prec y$
causes the inversion to break the symmetry
 $\Gamma _2$
that is apparent in
$\Gamma _2$
that is apparent in
 $\overline{{\mathcal{C}}}_q$
. As it turns out, this symmetry can be restored without increasing the overall number of terms, by adding components of a trivial conservation law (which are of the form (2.1)). It is an open question whether such preservation of symmetry and minimality is achievable in general.
$\overline{{\mathcal{C}}}_q$
. As it turns out, this symmetry can be restored without increasing the overall number of terms, by adding components of a trivial conservation law (which are of the form (2.1)). It is an open question whether such preservation of symmetry and minimality is achievable in general.
In Djondjorov & Vassilev [Reference Djondjorov, Vassilev, Bertram, Constanda and Struthers6], the inversion of
 $\mathcal{C}$
for the special case
$\mathcal{C}$
for the special case
 $p=0$
has 62 terms, which are grouped according to their physical meaning. By contrast, the minimal inversion above has just 46 (resp. 48) terms when
$p=0$
has 62 terms, which are grouped according to their physical meaning. By contrast, the minimal inversion above has just 46 (resp. 48) terms when
 $p$
is zero (resp. nonzero), a considerable saving. Moreover, by exploiting the symmetry
$p$
is zero (resp. nonzero), a considerable saving. Moreover, by exploiting the symmetry
 $\Gamma _1$
, only 28 (resp. 30) of these terms are determined using Procedure C. However, in seeking an efficient inversion, we have ignored the physics. It would be interesting to understand the extent to which the use of a minimal inversion obscures the underlying physics.
$\Gamma _1$
, only 28 (resp. 30) of these terms are determined using Procedure C. However, in seeking an efficient inversion, we have ignored the physics. It would be interesting to understand the extent to which the use of a minimal inversion obscures the underlying physics.
5. Concluding remarks
Partial Euler operators and partial scalings make it possible to invert divergences with respect to one independent variable at a time, a byproduct being that some contributions to other components are determined at each iteration step. Although each iteration involves a fair amount of computation, very few iterations are needed for many systems of interest.
Given the potential complexity of functions, it is unlikely that every divergence can be inverted, even in principle, by Procedure C. The question of how to prove or disprove this is open. In practice, products of mixed derivatives present the greatest challenge to concise inversion, although the option of re-ranking part-way through the procedure enables a divide-and-conquer approach to be taken.
The focus of this work has been on inverting the total divergence operator Div. However, this immediately applies to expressions that can be recast as total divergences. For instance, for
 $p=3$
, the total curl
$p=3$
, the total curl
 ${\textbf{F}}=\mathrm{Curl}(\textbf{G})$
can be inverted by writing
${\textbf{F}}=\mathrm{Curl}(\textbf{G})$
can be inverted by writing
 \begin{equation} F^i=\mathrm{Div}(H^{ij}\textbf{e}_j)=D_jH^{ij},\qquad H^{ij}\;:\!=\;\epsilon ^{ijk}G_k=-H^{ji}, \end{equation}
\begin{equation} F^i=\mathrm{Div}(H^{ij}\textbf{e}_j)=D_jH^{ij},\qquad H^{ij}\;:\!=\;\epsilon ^{ijk}G_k=-H^{ji}, \end{equation}
where
 $\epsilon ^{ijk}$
is the Levi–Civita symbol, then inverting one component at a time and using the results at each stage to simplify the remainder of the calculation. Once
$\epsilon ^{ijk}$
is the Levi–Civita symbol, then inverting one component at a time and using the results at each stage to simplify the remainder of the calculation. Once
 $H^{ij}$
is known, the identity
$H^{ij}$
is known, the identity
 $G_l=\frac{1}{2}\epsilon _{ijl}H^{ij}$
recovers
$G_l=\frac{1}{2}\epsilon _{ijl}H^{ij}$
recovers
 $\textbf{G}$
. Typically, a minimal inversion is achieved by using a different ranking for each
$\textbf{G}$
. Typically, a minimal inversion is achieved by using a different ranking for each
 $F^i$
, in accordance with the ranking heuristic. Here is a simple illustration of the general approach.
$F^i$
, in accordance with the ranking heuristic. Here is a simple illustration of the general approach.
Example 5.1. In Cartesian coordinates, invert
 $(F^x,F^y,F^z)=\mathrm{Curl}(G_x,G_y,G_z)$
, where
$(F^x,F^y,F^z)=\mathrm{Curl}(G_x,G_y,G_z)$
, where
 \begin{align*} F^x&=u_x(u_{yy}-u_{zz})+u_yu_{xy}-u_zu_{xz}\,,\\[5pt] F^y&=u_y(u_{zz}-u_{xx})+u_zu_{yz}-u_xu_{xy}\,,\\[5pt] F^z&=u_z(u_{xx}-u_{yy})+u_xu_{xz}-u_yu_{yz}\,. \end{align*}
\begin{align*} F^x&=u_x(u_{yy}-u_{zz})+u_yu_{xy}-u_zu_{xz}\,,\\[5pt] F^y&=u_y(u_{zz}-u_{xx})+u_zu_{yz}-u_xu_{xy}\,,\\[5pt] F^z&=u_z(u_{xx}-u_{yy})+u_xu_{xz}-u_yu_{yz}\,. \end{align*}
Begin by using Procedure C with
 $y\prec z\prec x$
. In two iterations, this gives
$y\prec z\prec x$
. In two iterations, this gives
 \begin{equation*} F^x=D_y(u_xu_y)+D_z(\!-\!u_xu_z). \end{equation*}
\begin{equation*} F^x=D_y(u_xu_y)+D_z(\!-\!u_xu_z). \end{equation*}
With
 $(x,y,z)$
replacing the indices
$(x,y,z)$
replacing the indices
 $(1,2,3)$
in (5.1), let
$(1,2,3)$
in (5.1), let
 \begin{equation*} H^{xy}=u_xu_y=-H^{yx},\qquad H^{xz}=u_xu_z=-H^{zx}. \end{equation*}
\begin{equation*} H^{xy}=u_xu_y=-H^{yx},\qquad H^{xz}=u_xu_z=-H^{zx}. \end{equation*}
Therefore
 \begin{equation*} D_zH^{yz}=F^{y}\!-\!D_xH^{yx}=u_yu_{zz}+u_zu_{yz}\,. \end{equation*}
\begin{equation*} D_zH^{yz}=F^{y}\!-\!D_xH^{yx}=u_yu_{zz}+u_zu_{yz}\,. \end{equation*}
One could invert this by a further iteration with the ranking
 $z\prec y$
, though it is inverted more quickly by the line integral formula, which gives
$z\prec y$
, though it is inverted more quickly by the line integral formula, which gives
 $H^{yz}=u_yu_z$
. Finally,
$H^{yz}=u_yu_z$
. Finally,
 \begin{equation*} G_x=u_yu_z,\qquad G_y=u_xu_z,\qquad G_z=u_xu_y. \end{equation*}
\begin{equation*} G_x=u_yu_z,\qquad G_y=u_xu_z,\qquad G_z=u_xu_y. \end{equation*}
Acknowledgments
I am grateful to Willy Hereman for discussions on homotopy operators and many helpful comments on a draft of this paper, and to the Centre International de Rencontres Mathématiques in Luminy for support and hospitality during the conference Symmetry and Computation. I would like to thank the Isaac Newton Institute for Mathematical Sciences for support and hospitality during the program Geometry, Compatibility and Structure Preservation in Computational Differential Equations; this provided the opportunity to develop much of the theory described above. I also thank the referees for their constructive comments.
Conflicts of interest
None.
A Appendix
Procedure C has been tested on the following conservation laws. In every case, the procedure coupled with the ranking heuristic yields a minimal inversion.
Kadomtsev–Petviashvili (KP) equation
There are two forms of the KP equation, depending on which of
 $\epsilon =\pm 1$
is chosen. In either case, it has a conservation law,
$\epsilon =\pm 1$
is chosen. In either case, it has a conservation law,
 \begin{align*}{\mathcal{C}}&=f(t)y\left (u_{xt}+uu_{xx}+u_x^2+u_{4x}+\epsilon u_{yy}\right )\\[5pt] &=D_x\!\left \{fy\left (u_t+uu_x+u_{xxx}\right )\right \}+D_t\!\left \{\epsilon f(yu_u-u)\right \}. \end{align*}
\begin{align*}{\mathcal{C}}&=f(t)y\left (u_{xt}+uu_{xx}+u_x^2+u_{4x}+\epsilon u_{yy}\right )\\[5pt] &=D_x\!\left \{fy\left (u_t+uu_x+u_{xxx}\right )\right \}+D_t\!\left \{\epsilon f(yu_u-u)\right \}. \end{align*}
With the ranking
 $x\prec y\prec t$
, the procedure requires three iterations to obtain this inversion.
$x\prec y\prec t$
, the procedure requires three iterations to obtain this inversion.
Potential Burgers equation (see Wolf et al. [Reference Wolf, Brand and Mohammadzadeh14])
The potential Burgers equation has a conservation law for each
 $f(x,t)$
such that
$f(x,t)$
such that
 $f_t+f_{xx}=0$
:
$f_t+f_{xx}=0$
:
 \begin{equation*} {\mathcal {C}}=f\exp (u/2)(u_t-u_{xx}-\frac {1}{2}u^2)=D_x\{\exp (u/2)(2f_x-fu_x)\}+D_t\{2\exp (u/2)f\}. \end{equation*}
\begin{equation*} {\mathcal {C}}=f\exp (u/2)(u_t-u_{xx}-\frac {1}{2}u^2)=D_x\{\exp (u/2)(2f_x-fu_x)\}+D_t\{2\exp (u/2)f\}. \end{equation*}
The inversion requires one iteration with
 $x\prec t$
, exchanging
$x\prec t$
, exchanging
 $f_t$
and
$f_t$
and
 $-f_{xx}$
twice.
$-f_{xx}$
twice.
Zakharov–Kuznetzov equation (see Poole & Hereman [11])
The Zakharov–Kuznetzov equation is
 ${\mathcal{A}}=0$
, where
${\mathcal{A}}=0$
, where
 \begin{equation*} {\mathcal {A}}=u_t+uu_x+u_{xxx}+u_{xyy}\,. \end{equation*}
\begin{equation*} {\mathcal {A}}=u_t+uu_x+u_{xxx}+u_{xyy}\,. \end{equation*}
It has a conservation law
 \begin{align*}{\mathcal{C}}&=(u^2+2(u_{xx}+u_{yy})){\mathcal{A}}\\[5pt] &=D_x\{(\frac{1}{2}u^2+u_{xx}+u_{yy})^2+2u_xu_t\}+D_y\{2u_yu_t\}+D_t\{\frac{1}{3}u^3-u_x^2-u_y^2\}. \end{align*}
\begin{align*}{\mathcal{C}}&=(u^2+2(u_{xx}+u_{yy})){\mathcal{A}}\\[5pt] &=D_x\{(\frac{1}{2}u^2+u_{xx}+u_{yy})^2+2u_xu_t\}+D_y\{2u_yu_t\}+D_t\{\frac{1}{3}u^3-u_x^2-u_y^2\}. \end{align*}
The fully expanded form has just eleven terms, and the inversion requires two iterations.
Short-pulse equation (see Brunelli [Reference Brunelli4])
The short-pulse equation,
 ${\mathcal{A}}=0$
, with
${\mathcal{A}}=0$
, with
 \begin{equation*} {\mathcal {A}}=u_{xt}-u-uu_x^2-\frac {1}{2}u^2u_{xx}\,, \end{equation*}
\begin{equation*} {\mathcal {A}}=u_{xt}-u-uu_x^2-\frac {1}{2}u^2u_{xx}\,, \end{equation*}
has the following conservation law involving a square root:
 \begin{align*}{\mathcal{C}}&=u_x(1+u_x^2)^{-1/2}{\mathcal{A}}\\[5pt] &=D_x\{-\frac{1}{2}u^2(1+u_x^2)^{1/2}\}+D_t\{(1+u_x^2)^{1/2}\}. \end{align*}
\begin{align*}{\mathcal{C}}&=u_x(1+u_x^2)^{-1/2}{\mathcal{A}}\\[5pt] &=D_x\{-\frac{1}{2}u^2(1+u_x^2)^{1/2}\}+D_t\{(1+u_x^2)^{1/2}\}. \end{align*}
With
 $x\prec t$
, this can be inverted in one iteration.
$x\prec t$
, this can be inverted in one iteration.
Nonlinear Schrödinger equation
Splitting the field into its real and imaginary parts gives the system
 ${\mathcal{A}}_1=0,\ {\mathcal{A}}_2=0$
, with
${\mathcal{A}}_1=0,\ {\mathcal{A}}_2=0$
, with
 \begin{equation*} {\mathcal {A}}_1=-v_t+u_{xx}+(u^2+v^2)u,\qquad {\mathcal {A}}_2=u_t+v_{xx}+(u^2+v^2)v. \end{equation*}
\begin{equation*} {\mathcal {A}}_1=-v_t+u_{xx}+(u^2+v^2)u,\qquad {\mathcal {A}}_2=u_t+v_{xx}+(u^2+v^2)v. \end{equation*}
One of the conservation laws is
 \begin{align*}{\mathcal{C}}&=u_t{\mathcal{A}}_1+v_t{\mathcal{A}}_2\\[5pt] &=D_x\!\left \{2u_xu_t+2v_xv_t\right \}+D_t\!\left \{\frac{1}{2}\left (u^2+v^2\right )-u_x^2-v_x^2\right \}. \end{align*}
\begin{align*}{\mathcal{C}}&=u_t{\mathcal{A}}_1+v_t{\mathcal{A}}_2\\[5pt] &=D_x\!\left \{2u_xu_t+2v_xv_t\right \}+D_t\!\left \{\frac{1}{2}\left (u^2+v^2\right )-u_x^2-v_x^2\right \}. \end{align*}
With the ranking
 $u\prec v$
and
$u\prec v$
and
 $x\prec t$
, the procedure requires two iterations.
$x\prec t$
, the procedure requires two iterations.
Itô equations (see Wolf [Reference Wolf13])
The equations are
 ${\mathcal{A}}_1=0,\ {\mathcal{A}}_2=0$
, with
${\mathcal{A}}_1=0,\ {\mathcal{A}}_2=0$
, with
 \begin{equation*} {\mathcal {A}}_1=u_t-u_{xxx}-6uu_x-2vv_x\,,\qquad {\mathcal {A}}_2=v_t-2u_xv-2uv_x\,. \end{equation*}
\begin{equation*} {\mathcal {A}}_1=u_t-u_{xxx}-6uu_x-2vv_x\,,\qquad {\mathcal {A}}_2=v_t-2u_xv-2uv_x\,. \end{equation*}
This system has a rational conservation law,
 \begin{align*}{\mathcal{C}}&=2v^{-1}{\mathcal{A}}_1+v^{-4}\left (vv_{xx}-\frac{3}{2}v_x^2-2uv^2\right ){\mathcal{A}}_2\\[5pt] &=D_x\!\left \{v^{-3}\left (v_xv_t-2u_{xx}v^2-2u_xvv_x-uv_x^2-4u^2v^2-4v^4\right )\right \}+D_t\!\left \{v^{-3}\left (2uv^2-\frac{1}{2}v_x^2\right )\right \}. \end{align*}
\begin{align*}{\mathcal{C}}&=2v^{-1}{\mathcal{A}}_1+v^{-4}\left (vv_{xx}-\frac{3}{2}v_x^2-2uv^2\right ){\mathcal{A}}_2\\[5pt] &=D_x\!\left \{v^{-3}\left (v_xv_t-2u_{xx}v^2-2u_xvv_x-uv_x^2-4u^2v^2-4v^4\right )\right \}+D_t\!\left \{v^{-3}\left (2uv^2-\frac{1}{2}v_x^2\right )\right \}. \end{align*}
With the ranking
 $u\prec v$
and
$u\prec v$
and
 $x\prec t$
, the procedure requires two iterations.
$x\prec t$
, the procedure requires two iterations.
Navier–Stokes equations
The (constant-density) two-dimensional Navier–Stokes equations are
 ${\mathcal{A}}_\ell =0,\ \ell =1,2,3$
, where
${\mathcal{A}}_\ell =0,\ \ell =1,2,3$
, where
 \begin{equation*} {\mathcal {A}}_1=u_t+uu_x+vu_y+p_x-\nu (u_{xx}+u_{yy}),\quad {\mathcal {A}}_2=v_t+uv_x+vv_y+p_y-\nu (v_{xx}+v_{yy}),\quad {\mathcal {A}}_3=u_x+v_y\,. \end{equation*}
\begin{equation*} {\mathcal {A}}_1=u_t+uu_x+vu_y+p_x-\nu (u_{xx}+u_{yy}),\quad {\mathcal {A}}_2=v_t+uv_x+vv_y+p_y-\nu (v_{xx}+v_{yy}),\quad {\mathcal {A}}_3=u_x+v_y\,. \end{equation*}
This system has a family of conservation laws involving two arbitrary functions,
 $f(t)$
and
$f(t)$
and
 $g(t)$
, namely
$g(t)$
, namely
 \begin{align*}{\mathcal{C}}&=f{\mathcal{A}}_1+g{\mathcal{A}}_2+(fu+gv-f'x-g'y){\mathcal{A}}_3\\[5pt] &=D_x\{fu^2+guv+fp-\nu (fu_x+gv_x)-(f'x+g'y)u\}\\[5pt] &\quad +D_y\{fuv+gv^2+gp-\nu (fu_y+gv_y)-(f'x+g'y)v\}+D_t\{fu+gv\}. \end{align*}
\begin{align*}{\mathcal{C}}&=f{\mathcal{A}}_1+g{\mathcal{A}}_2+(fu+gv-f'x-g'y){\mathcal{A}}_3\\[5pt] &=D_x\{fu^2+guv+fp-\nu (fu_x+gv_x)-(f'x+g'y)u\}\\[5pt] &\quad +D_y\{fuv+gv^2+gp-\nu (fu_y+gv_y)-(f'x+g'y)v\}+D_t\{fu+gv\}. \end{align*}
Procedure C consists of a linear inversion and two further iterations, using the ranking
 $x\prec y\prec t$
. The three-dimensional Navier–Stokes equations have a similar conservation law, which requires a linear inversion and three further iterations.
$x\prec y\prec t$
. The three-dimensional Navier–Stokes equations have a similar conservation law, which requires a linear inversion and three further iterations.
Procedure C and the ranking heuristic have also been tested on some divergences not arising from conservation laws, with high order or complexity. Again, the output in each case is a minimal inversion.
High-order derivatives
The divergence is
 \begin{align*}{\mathcal{C}}&=u_{5x}u_{4y}+u_{2x,2y}u_{2x,3y}\\[5pt] &=D_x\!\left \{u_{4x}u_{4y}-u_{3x}u_{x,4y}+(u_{2x,2y})^2 \right \}+D_t\!\left \{u_{3x}u_{2x,3y}-u_{3x,y}u_{2x,2y} \right \}. \end{align*}
\begin{align*}{\mathcal{C}}&=u_{5x}u_{4y}+u_{2x,2y}u_{2x,3y}\\[5pt] &=D_x\!\left \{u_{4x}u_{4y}-u_{3x}u_{x,4y}+(u_{2x,2y})^2 \right \}+D_t\!\left \{u_{3x}u_{2x,3y}-u_{3x,y}u_{2x,2y} \right \}. \end{align*}
With the ranking
 $x\prec y$
, the procedure requires three iterations. The other ranking,
$x\prec y$
, the procedure requires three iterations. The other ranking,
 $y\prec x$
, also produces a minimal inversion after three iterations; it is higher order in
$y\prec x$
, also produces a minimal inversion after three iterations; it is higher order in
 $x$
but lower order in
$x$
but lower order in
 $y$
:
$y$
:
 \begin{equation*} {\mathcal {C}}=D_x\!\left \{u_{4x,2y}u_{2y}-u_{3x,2y}u_{x,2y}+(u_{2x,2y})^2 \right \}+D_t\!\left \{u_{5x}u_{3y}-u_{5x,y}u_{2y} \right \}. \end{equation*}
\begin{equation*} {\mathcal {C}}=D_x\!\left \{u_{4x,2y}u_{2y}-u_{3x,2y}u_{x,2y}+(u_{2x,2y})^2 \right \}+D_t\!\left \{u_{5x}u_{3y}-u_{5x,y}u_{2y} \right \}. \end{equation*}
High-order derivatives and explicit dependence
The divergence is
 \begin{align*}{\mathcal{C}}&=t(u_yu_{xttt}-u_xu_{yttt})\\[5pt] &=D_x\!\left \{-tuu_{yttt} \right \}+D_y\!\left \{tuu_{xttt}) \right \}. \end{align*}
\begin{align*}{\mathcal{C}}&=t(u_yu_{xttt}-u_xu_{yttt})\\[5pt] &=D_x\!\left \{-tuu_{yttt} \right \}+D_y\!\left \{tuu_{xttt}) \right \}. \end{align*}
With the ranking
 $x\prec y\prec t$
, the procedure requires one iteration. This illustrates the value of the second criterion for ranking independent variables; if
$x\prec y\prec t$
, the procedure requires one iteration. This illustrates the value of the second criterion for ranking independent variables; if
 $t$
is ranked lower than
$t$
is ranked lower than
 $x$
and
$x$
and
 $y$
, the procedure fails at the first check.
$y$
, the procedure fails at the first check.
Exponential dependence
The divergence is
 \begin{align*}{\mathcal{C}}&=\left (u_{xx}u_y^2-2u_{yy}\right )\exp (u_x)\\[5pt] &=D_x\!\left \{u_y^2 \exp (u_x)\right \}+D_t\!\left \{-2u_y \exp (u_x)\right \}. \end{align*}
\begin{align*}{\mathcal{C}}&=\left (u_{xx}u_y^2-2u_{yy}\right )\exp (u_x)\\[5pt] &=D_x\!\left \{u_y^2 \exp (u_x)\right \}+D_t\!\left \{-2u_y \exp (u_x)\right \}. \end{align*}
With the ranking
 $x\prec y$
, the procedure requires one iteration.
$x\prec y$
, the procedure requires one iteration.
Trigonometric dependence
The divergence is
 \begin{align*}{\mathcal{C}}&=\left (u_{xx}u_{yyy}-u_{xxy}u_{xyy}\right )\cos (u_x)\\[5pt] &=D_x\!\left \{u_{yyy} \sin (u_x)\right \}+D_t\!\left \{-u_{xyy} \sin (u_x)\right \}. \end{align*}
\begin{align*}{\mathcal{C}}&=\left (u_{xx}u_{yyy}-u_{xxy}u_{xyy}\right )\cos (u_x)\\[5pt] &=D_x\!\left \{u_{yyy} \sin (u_x)\right \}+D_t\!\left \{-u_{xyy} \sin (u_x)\right \}. \end{align*}
With the ranking
 $x\prec y$
, the procedure requires one iteration.
$x\prec y$
, the procedure requires one iteration.


 Open access
Open access