
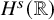


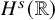
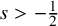
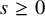
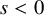
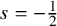
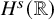
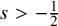
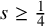
1. Introduction
We consider solutions
 $q\colon {{\mathbb {R}}}\times {{\mathbb {R}}}\rightarrow \mathbb {C}$
of the nonlinear Schrödinger equation
$q\colon {{\mathbb {R}}}\times {{\mathbb {R}}}\rightarrow \mathbb {C}$
of the nonlinear Schrödinger equation
 $$ \begin{align} i\frac d{dt}q = - q" \pm 2|q|^2q, \end{align} $$
$$ \begin{align} i\frac d{dt}q = - q" \pm 2|q|^2q, \end{align} $$
and the (complex Hirota) modified Korteweg–de Vries equation
 $$ \begin{align} \frac d{dt}q = - q"' \pm 6|q|^2q', \end{align} $$
$$ \begin{align} \frac d{dt}q = - q"' \pm 6|q|^2q', \end{align} $$
with initial data
 $q(0)\in H^s({{\mathbb {R}}})$
. The upper choice of signs yields the defocusing cases of these equations, while the lower signs correspond to the focusing cases. In this paper, the symbols
$q(0)\in H^s({{\mathbb {R}}})$
. The upper choice of signs yields the defocusing cases of these equations, while the lower signs correspond to the focusing cases. In this paper, the symbols
 $\pm $
and
$\pm $
and
 $\mp $
will only be used in the context of this dichotomy. By restricting (mKdV) to the case of real initial data, we recover the classical mKdV equation of Miura [Reference Miura46]:
$\mp $
will only be used in the context of this dichotomy. By restricting (mKdV) to the case of real initial data, we recover the classical mKdV equation of Miura [Reference Miura46]:
 $$\begin{align} \frac d{dt}q = - q"' \pm 2 (q^3)'. \end{align} $$
$$\begin{align} \frac d{dt}q = - q"' \pm 2 (q^3)'. \end{align} $$
To treat both the defocusing and focusing versions of (NLS) and (mKdV) within the same framework, throughout this paper, we adopt the notation
 $$ \begin{align*}r:=\pm \bar q. \end{align*} $$
$$ \begin{align*}r:=\pm \bar q. \end{align*} $$
With this convention, both (NLS) and (mKdV) are Hamiltonian equations with respect to the following Poisson structure on Schwartz space: Given
 $F,G\colon \mathcal {S}\rightarrow \mathbb {C}$
,
$F,G\colon \mathcal {S}\rightarrow \mathbb {C}$
,
 $$ \begin{align} \{F,G\} := \tfrac1i \int \tfrac{\delta F}{\delta q}\tfrac{\delta G}{\delta r} - \tfrac{\delta F}{\delta r}\tfrac{\delta G}{\delta q} \,dx, \end{align} $$
$$ \begin{align} \{F,G\} := \tfrac1i \int \tfrac{\delta F}{\delta q}\tfrac{\delta G}{\delta r} - \tfrac{\delta F}{\delta r}\tfrac{\delta G}{\delta q} \,dx, \end{align} $$
where our notation for functional derivatives is the classical one (see (2.2)). Correspondingly, any Hamiltonian
 $H\colon \mathcal {S}\rightarrow {{\mathbb {R}}}$
generates a flow, which we denote by
$H\colon \mathcal {S}\rightarrow {{\mathbb {R}}}$
generates a flow, which we denote by
 $e^{tJ\nabla H}$
, via the equation
$e^{tJ\nabla H}$
, via the equation
 $$ \begin{align} i\dfrac d{dt} q = \frac{\delta H}{\delta r}, \quad\text{or equivalently,}\quad i\dfrac d{dt} r = - \frac{\delta H}{\delta q}. \end{align} $$
$$ \begin{align} i\dfrac d{dt} q = \frac{\delta H}{\delta r}, \quad\text{or equivalently,}\quad i\dfrac d{dt} r = - \frac{\delta H}{\delta q}. \end{align} $$
In particular, since Hamiltonians are real-valued, the relations
 $q=\pm \bar r$
are preserved by any such flow.
$q=\pm \bar r$
are preserved by any such flow.
With these conventions, the equations (NLS) and (mKdV) are the Hamiltonian flows associated to
 $$\begin{align*}H_{\mathrm{NLS}} := \int q' r' + q^2r^2\,dx \quad\text{and}\quad H_{\mathrm{mKdV}} := \tfrac1i \int q' r" + 3q^2rr'\,dx, \end{align*}$$
$$\begin{align*}H_{\mathrm{NLS}} := \int q' r' + q^2r^2\,dx \quad\text{and}\quad H_{\mathrm{mKdV}} := \tfrac1i \int q' r" + 3q^2rr'\,dx, \end{align*}$$
respectively. Two other important Hamiltonians are the mass and momentum,
 $$\begin{align*}M:=\int qr\,dx \quad\text{and}\quad P=\tfrac1{i}\int qr'\,dx , \end{align*}$$
$$\begin{align*}M:=\int qr\,dx \quad\text{and}\quad P=\tfrac1{i}\int qr'\,dx , \end{align*}$$
which generate phase rotations and spatial translations, respectively. While our names for the basic conserved quantities agree with the usual parlance in the defocusing case, their signs are reversed in the focusing case; in particular, the mass becomes negative definite. However, this sign change is offset by a corresponding sign change in the Poisson structure, so the dynamics remains those given in (NLS) and (mKdV).
All four functions M, P,
 $H_{\mathrm {NLS}}$
, and
$H_{\mathrm {NLS}}$
, and
 $H_{\mathrm {mKdV}}$
Poisson commute. While commutation with M and P merely represent gauge and translation invariance, the commutativity of
$H_{\mathrm {mKdV}}$
Poisson commute. While commutation with M and P merely represent gauge and translation invariance, the commutativity of
 $H_{\mathrm {NLS}}$
and
$H_{\mathrm {NLS}}$
and
 $H_{\mathrm {mKdV}}$
is surprising and a first sign of a very profound property of these equations: they are completely integrable.
$H_{\mathrm {mKdV}}$
is surprising and a first sign of a very profound property of these equations: they are completely integrable.
One expression of this complete integrability is the existence of an infinite family of commuting flows. Taken together, these form the AKNS–ZS hierarchy. This name honors the authors of the seminal papers [Reference Ablowitz, Kaup, Newell and Segur1, Reference Zakharov and Shabat56]. For an authoritative introduction to this hierarchy, with particular attention to the Hamiltonian structure, we recommend [Reference Faddeev and Takhtajan16].
The odd and even numbered Hamiltonian flows in the AKNS–ZS hierarchy behave differently under
 $(q,r)\mapsto (\bar q,\bar r)$
. In particular, conjugation acts as a time-reversal operator for M and
$(q,r)\mapsto (\bar q,\bar r)$
. In particular, conjugation acts as a time-reversal operator for M and
 $H_{\mathrm {NLS}}$
but leaves the P and
$H_{\mathrm {NLS}}$
but leaves the P and
 $H_{\mathrm {mKdV}}$
flows unchanged. This leads to a number of significant differences in our treatment of (NLS) and (mKdV).
$H_{\mathrm {mKdV}}$
flows unchanged. This leads to a number of significant differences in our treatment of (NLS) and (mKdV).
As we will discuss more fully below, it has been known for a long time that both (NLS) and (mKdV) are globally well-posed for sufficiently regular initial data. In fact, the question of what constitutes sufficiently regular initial data has occupied several generations of researchers. We are now able to give a definitive answer:
Theorem 1.1 (Global well-posedness of the NLS and mKdV).
Let
 $s>-\frac 12$
. Then the equations (NLS) and (mKdV) are globally well-posed for all initial data in
$s>-\frac 12$
. Then the equations (NLS) and (mKdV) are globally well-posed for all initial data in
 $H^s({{\mathbb {R}}})$
in the sense that the solution map
$H^s({{\mathbb {R}}})$
in the sense that the solution map
 $\Phi $
extends uniquely from Schwartz space to a jointly continuous map
$\Phi $
extends uniquely from Schwartz space to a jointly continuous map
 $\Phi \colon {{\mathbb {R}}}\times H^s({{\mathbb {R}}})\rightarrow H^s({{\mathbb {R}}})$
.
$\Phi \colon {{\mathbb {R}}}\times H^s({{\mathbb {R}}})\rightarrow H^s({{\mathbb {R}}})$
.
Here, we are evidently taking the well-posedness of (NLS) and (mKdV) on Schwartz space for granted. This has been known for a long time [Reference Kato30, Reference Tsutsumi54].
The threshold
 $s=-\tfrac 12$
appearing in Theorem 1.1 is both sharp and necessarily excluded. It is also the scaling-critical regularity. Indeed, each evolution in the AKNS-ZS hierarchy admits a scaling symmetry of the form
$s=-\tfrac 12$
appearing in Theorem 1.1 is both sharp and necessarily excluded. It is also the scaling-critical regularity. Indeed, each evolution in the AKNS-ZS hierarchy admits a scaling symmetry of the form
 $$ \begin{align} q_\lambda(t,x) = \lambda q(\lambda^m t, \lambda x), \quad\text{or, equivalently,}\quad \widehat{q_\lambda}(t,\xi) = \hat q(\lambda^m t, \xi/\lambda), \end{align} $$
$$ \begin{align} q_\lambda(t,x) = \lambda q(\lambda^m t, \lambda x), \quad\text{or, equivalently,}\quad \widehat{q_\lambda}(t,\xi) = \hat q(\lambda^m t, \xi/\lambda), \end{align} $$
where m denotes the ordinal position of the Hamiltonian. For example,
 $m=0$
for M, while (NLS) corresponds to
$m=0$
for M, while (NLS) corresponds to
 $m=2$
and (mKdV) to
$m=2$
and (mKdV) to
 $m=3$
.
$m=3$
.
While a great many dispersive equations have recently been shown to be well-posed at the scaling-critical regularity, this fails for (NLS) and (mKdV). In fact, one has instantaneous norm inflation: For every
 $s\leq -\frac 12$
and
$s\leq -\frac 12$
and
 $\varepsilon>0$
, there is a Schwartz solution
$\varepsilon>0$
, there is a Schwartz solution
 $q(t)$
to (NLS) satisfying
$q(t)$
to (NLS) satisfying
 $$ \begin{align} \| q(0) \|_{H^s} < \varepsilon \quad\text{and}\quad \sup_{|t|<\varepsilon} \| q(t) \|_{H^s}> \varepsilon^{-1}. \end{align} $$
$$ \begin{align} \| q(0) \|_{H^s} < \varepsilon \quad\text{and}\quad \sup_{|t|<\varepsilon} \| q(t) \|_{H^s}> \varepsilon^{-1}. \end{align} $$
This was shown for (NLS) in [Reference Christ, Colliander and Tao11, Reference Kishimoto40, Reference Oh48]. In Appendix A, we revisit this work, giving a simplified presentation and showing that the same norm inflation holds also for (mKdV), as well as other members of the hierarchy. This ill-posedness effect does not seem to have been noticed before.
This norm inflation argument does not extend to (mKdVℝ ). Nevertheless, in the appendix, we show (seemingly for the first time) that a slightly weaker form of ill-posedness holds in the focusing case (see Proposition A.3). Previously, [Reference Birnir, Ponce and Svanstedt2] showed that the data-to-solution map cannot be extended continuously to the delta-function initial data in the focusing case. The analogous assertion for NLS (both focusing and defocusing) was proved in [Reference Kenig, Ponce and Vega35].
Let us turn our attention to the existing well-posedness theory. The advent of Strichartz estimates [Reference Strichartz53] had a transformative effect on the study of nonlinear dispersive equations. These estimates provide an elegant and efficient expression of the dispersive effect and allowed researchers to pass beyond the regularity required to make sense of the nonlinearity pointwise in time. In [Reference Tsutsumi55], Tsutsumi used this new tool to prove global well-posedness of (NLS) in
 $L^2({{\mathbb {R}}})$
.
$L^2({{\mathbb {R}}})$
.
We know of no further progress in the scale of
 $H^s$
spaces since that time. Here is one reason: No ingenious harmonic analysis estimate, nor clever choice of metric, can reduce matters to a contraction mapping argument. Such constructions lead to solutions that depend analytically on the initial data; however, in [Reference Christ, Colliander and Tao10, Reference Christ, Colliander and Tao11, Reference Kenig, Ponce and Vega35], it is shown that the data-to-solution map cannot even be uniformly continuous on bounded subsets of
$H^s$
spaces since that time. Here is one reason: No ingenious harmonic analysis estimate, nor clever choice of metric, can reduce matters to a contraction mapping argument. Such constructions lead to solutions that depend analytically on the initial data; however, in [Reference Christ, Colliander and Tao10, Reference Christ, Colliander and Tao11, Reference Kenig, Ponce and Vega35], it is shown that the data-to-solution map cannot even be uniformly continuous on bounded subsets of
 $H^{s}({{\mathbb {R}}})$
when
$H^{s}({{\mathbb {R}}})$
when
 $s<0$
.
$s<0$
.
Due to the derivative in the nonlinearity, Strichartz estimates alone do not suffice to understand the behavior of (mKdV). By bringing in local-smoothing and maximal-function estimates, Kenig–Ponce–Vega [Reference Kenig, Ponce and Vega33], were able to prove that (mKdV) is locally well-posed in
 $H^s({{\mathbb {R}}})$
for all
$H^s({{\mathbb {R}}})$
for all
 $s\geq \frac 14$
. The solution they construct depends analytically on the initial data. Moreover, the threshold
$s\geq \frac 14$
. The solution they construct depends analytically on the initial data. Moreover, the threshold
 $s=\tfrac 14$
is sharp if one seeks solutions that depend uniformly continuously on the initial data. This was shown in [Reference Christ, Colliander and Tao10, Reference Kenig, Ponce and Vega35]. In the case of (NLS), the critical threshold for analytic well-posedness coincides with an exact conservation law, namely, that of
$s=\tfrac 14$
is sharp if one seeks solutions that depend uniformly continuously on the initial data. This was shown in [Reference Christ, Colliander and Tao10, Reference Kenig, Ponce and Vega35]. In the case of (NLS), the critical threshold for analytic well-posedness coincides with an exact conservation law, namely, that of
 $M(q)$
. Thus, Tsutsumi’s result is automatically global in time [Reference Tsutsumi55]. Due to the absence of any obvious conservation law at regularity
$M(q)$
. Thus, Tsutsumi’s result is automatically global in time [Reference Tsutsumi55]. Due to the absence of any obvious conservation law at regularity
 $s=\frac 14$
, it was unclear at that time whether the Kenig–Ponce–Vega solutions to (mKdV) are, in fact, global in time. This was subsequently shown for (mKdVℝ
) through the construction of suitable almost conserved quantities. For
$s=\frac 14$
, it was unclear at that time whether the Kenig–Ponce–Vega solutions to (mKdV) are, in fact, global in time. This was subsequently shown for (mKdVℝ
) through the construction of suitable almost conserved quantities. For
 $s>\frac 14$
, this was proved by Colliander–Keel–Staffilani–Takaoka–Tao [Reference Colliander, Keel, Staffilani, Takaoka and Tao15] with the endpoint added later by Guo and Kishimoto [Reference Guo24, Reference Kishimoto39].
$s>\frac 14$
, this was proved by Colliander–Keel–Staffilani–Takaoka–Tao [Reference Colliander, Keel, Staffilani, Takaoka and Tao15] with the endpoint added later by Guo and Kishimoto [Reference Guo24, Reference Kishimoto39].
With the exact threshold for analytic (or even uniformly continuous) dependence settled, the question immediately arises as to what happens at lower regularity: What lies in the sizable gap remaining between these well-posedness results and the known breakdown of continuity at
 $s=-\frac 12$
? This gap corresponds to regularities
$s=-\frac 12$
? This gap corresponds to regularities
 $-\frac 12<s<0$
for (NLS) and
$-\frac 12<s<0$
for (NLS) and
 $-\frac 12<s<\frac 14$
for (mKdV).
$-\frac 12<s<\frac 14$
for (mKdV).
For typical Schrödinger equations in
 ${{\mathbb {R}}}^d$
with polynomial nonlinearities, there is no gap between analytic local well-posedness and the onset of ill-posedness [Reference Christ, Colliander and Tao11]. Thus, it is all the more remarkable to discover a region of nonperturbative well-posedness in this setting. This phenomenon appears to be a remarkable feature of completely integrable systems, and investigating it necessitates methods that take advantage of this integrability.
${{\mathbb {R}}}^d$
with polynomial nonlinearities, there is no gap between analytic local well-posedness and the onset of ill-posedness [Reference Christ, Colliander and Tao11]. Thus, it is all the more remarkable to discover a region of nonperturbative well-posedness in this setting. This phenomenon appears to be a remarkable feature of completely integrable systems, and investigating it necessitates methods that take advantage of this integrability.
A natural first step toward understanding solutions in this delicate region is to seek a priori
 $H^s$
bounds. While boundedness of solutions would obviously follow from well-posedness, proving boundedness is typically a first step. It is also the principal challenge in the construction of weak solutions. On the other hand, showing impossibility of such bounds would give ill-posedness.
$H^s$
bounds. While boundedness of solutions would obviously follow from well-posedness, proving boundedness is typically a first step. It is also the principal challenge in the construction of weak solutions. On the other hand, showing impossibility of such bounds would give ill-posedness.
Early successes in this direction include [Reference Christ, Colliander and Tao13, Reference Koch and Tataru41, Reference Koch and Tataru42] for (NLS) and [Reference Christ, Holmer and Tataru14] for (mKdV). Recently, the definitive result in this direction was obtained in [Reference Killip, Vişan and Zhang38, Reference Koch and Tataru43], where exact conservation laws were constructed that control the
 $H^s$
norm of solutions all the way down to
$H^s$
norm of solutions all the way down to
 $s>-\tfrac 12$
. Given the norm inflation discussed earlier, one cannot go any lower. The macroscopic conservation laws constructed in [Reference Killip, Vişan and Zhang38, Reference Koch and Tataru43] interact with the scaling symmetry in a useful way; indeed, this was already employed in [Reference Killip, Vişan and Zhang38] to connect differing regularities and to obtain bounds in Besov spaces. Another important consequence of this interaction is that when
$s>-\tfrac 12$
. Given the norm inflation discussed earlier, one cannot go any lower. The macroscopic conservation laws constructed in [Reference Killip, Vişan and Zhang38, Reference Koch and Tataru43] interact with the scaling symmetry in a useful way; indeed, this was already employed in [Reference Killip, Vişan and Zhang38] to connect differing regularities and to obtain bounds in Besov spaces. Another important consequence of this interaction is that when
 $s<0$
, it guarantees equicontinuity of orbits (cf. Definition 4.5 and Proposition 4.6 below). This seems to have been first noted explicitly in [Reference Killip and Vişan37] and will play several important roles in what follows.
$s<0$
, it guarantees equicontinuity of orbits (cf. Definition 4.5 and Proposition 4.6 below). This seems to have been first noted explicitly in [Reference Killip and Vişan37] and will play several important roles in what follows.
One example of the significance of equicontinuity is that it connects well-posedness at different regularities: If
 $\sigma>s$
, then existence and uniqueness of solutions with initial data in
$\sigma>s$
, then existence and uniqueness of solutions with initial data in
 $H^s$
automatically guarantees the same for initial data in
$H^s$
automatically guarantees the same for initial data in
 $H^\sigma $
. That the
$H^\sigma $
. That the
 $H^s$
-solution remains in
$H^s$
-solution remains in
 $H^\sigma $
at later times follows from the existence of a priori bounds. However, continuity of the data-to-solution map in
$H^\sigma $
at later times follows from the existence of a priori bounds. However, continuity of the data-to-solution map in
 $H^\sigma $
requires more; convergence at low regularity together with boundedness at higher regularity does not guarantee convergence at the higher regularity. Equicontinuity in
$H^\sigma $
requires more; convergence at low regularity together with boundedness at higher regularity does not guarantee convergence at the higher regularity. Equicontinuity in
 $H^\sigma $
is the simple necessary and sufficient condition for convergence in
$H^\sigma $
is the simple necessary and sufficient condition for convergence in
 $H^\sigma $
under these circumstances. There are two further aspects of the history we wish to discuss before describing the methods we employ: well-posedness results outside the scale of
$H^\sigma $
under these circumstances. There are two further aspects of the history we wish to discuss before describing the methods we employ: well-posedness results outside the scale of
 $H^s$
spaces and for these partial differential equations (PDEs) posed on the torus.
$H^s$
spaces and for these partial differential equations (PDEs) posed on the torus.
By working in Fourier–Lebesgue and modulation spaces, several researchers succeeded in studying well-posedness questions outside the scale of
 $H^s$
spaces. For (NLS), for example, analytic local well-posedness was shown in almost-critical spaces by Grünrock [Reference Grünrock19] and Guo [Reference Guo23]. For (mKdV), analogous almost-critical results in Fourier–Lebesgue spaces were obtained in [Reference Grünrock18, Reference Grünrock and Vega22]. The threshold for analytic well-posedness of (mKdV) in modulation spaces was determined in [Reference Chen and Guo8, Reference Oh and Wang50]; however, this still does not coincide with scaling criticality.
$H^s$
spaces. For (NLS), for example, analytic local well-posedness was shown in almost-critical spaces by Grünrock [Reference Grünrock19] and Guo [Reference Guo23]. For (mKdV), analogous almost-critical results in Fourier–Lebesgue spaces were obtained in [Reference Grünrock18, Reference Grünrock and Vega22]. The threshold for analytic well-posedness of (mKdV) in modulation spaces was determined in [Reference Chen and Guo8, Reference Oh and Wang50]; however, this still does not coincide with scaling criticality.
Each of the three types of spaces (Fourier–Lebesgue, modulation, and Sobolev) has a very different character; nevertheless, each of the spaces just described can be enveloped by
 $H^s$
provided one takes
$H^s$
provided one takes
 $s>-\frac 12$
sufficiently close to
$s>-\frac 12$
sufficiently close to
 $-\frac 12$
. Conversely, both Fourier–Lebesgue and modulation spaces suppress high frequencies more strongly than negative regularity
$-\frac 12$
. Conversely, both Fourier–Lebesgue and modulation spaces suppress high frequencies more strongly than negative regularity
 $H^s$
spaces; this substantially reduces the dangers of high-high-low interactions, which are the dominant source of instability in these models.
$H^s$
spaces; this substantially reduces the dangers of high-high-low interactions, which are the dominant source of instability in these models.
We are not aware of any global well-posedness results in Fourier–Lebesgue spaces close to criticality. However, by ingeniously exploiting the way Galilei boosts interact with the conservation laws constructed in [Reference Killip, Vişan and Zhang38], Oh and Wang [Reference Oh and Wang49] obtained global bounds in modulation spaces, which then yield global well-posedness in these spaces.
In order to construct solutions via a contraction mapping argument, one must employ an array of subtle norms expressing the dispersive effect. The question arises whether there might be other solutions that are continuous in
 $H^s$
but lie outside the auxiliary space. This is the question of unconditional uniqueness, pioneered by Kato [Reference Kato31, Reference Kato32]. For the latest advances in this direction, see [Reference Guo, Kwon and Oh25, Reference Kwon, Oh and Yoon44]. We now give a quick review of what is known for (NLS) and (mKdV) posed on the circle (i.e., for periodic initial data). In the Euclidean setting, dispersion causes solutions to spread out. This is impossible on the circle, there is nowhere to spread to. Nevertheless, Bourgain [Reference Bourgain3, Reference Bourgain4] proved that select Strichartz estimates do hold (expressing a form of decoherence). As an application, these new estimates were used to prove global well-posedness of (NLS) in
$H^s$
but lie outside the auxiliary space. This is the question of unconditional uniqueness, pioneered by Kato [Reference Kato31, Reference Kato32]. For the latest advances in this direction, see [Reference Guo, Kwon and Oh25, Reference Kwon, Oh and Yoon44]. We now give a quick review of what is known for (NLS) and (mKdV) posed on the circle (i.e., for periodic initial data). In the Euclidean setting, dispersion causes solutions to spread out. This is impossible on the circle, there is nowhere to spread to. Nevertheless, Bourgain [Reference Bourgain3, Reference Bourgain4] proved that select Strichartz estimates do hold (expressing a form of decoherence). As an application, these new estimates were used to prove global well-posedness of (NLS) in
 $L^2(\mathbb {T})$
and local well-posedness of (mKdV) in
$L^2(\mathbb {T})$
and local well-posedness of (mKdV) in
 $H^{1/2}(\mathbb {T})$
. Global well-posedness of (mKdVℝ
) in
$H^{1/2}(\mathbb {T})$
. Global well-posedness of (mKdVℝ
) in
 $H^{1/2}(\mathbb {T})$
was subsequently proved in [Reference Colliander, Keel, Staffilani, Takaoka and Tao15]. Moreover, [Reference Christ, Colliander and Tao10] showed that these results match the threshold for analytic (or uniformly continuous) dependence on the initial data.
$H^{1/2}(\mathbb {T})$
was subsequently proved in [Reference Colliander, Keel, Staffilani, Takaoka and Tao15]. Moreover, [Reference Christ, Colliander and Tao10] showed that these results match the threshold for analytic (or uniformly continuous) dependence on the initial data.
For (NLS) on the circle, this
 $L^2$
threshold also marks the boundary for even continuous dependence on the initial data. This was shown in [Reference Burq, Gérard and Tzvetkov6, Reference Christ, Colliander and Tao12, Reference Guo and Oh26] and represents a sharp distinction from the line case. This “premature” breakdown of well-posedness is now understood as arising from an infinite phase rotation, which, in turn, suggests a suitable renormalization, namely, Wick ordering the nonlinearity. This point of view has been confirmed in [Reference Christ9, Reference Grünrock and Herr21, Reference Oh and Wang49], where Wick-ordered NLS is shown to be globally well-posed in (almost-critical) Fourier–Lebesgue spaces where the traditional (NLS) is ill-posed.
$L^2$
threshold also marks the boundary for even continuous dependence on the initial data. This was shown in [Reference Burq, Gérard and Tzvetkov6, Reference Christ, Colliander and Tao12, Reference Guo and Oh26] and represents a sharp distinction from the line case. This “premature” breakdown of well-posedness is now understood as arising from an infinite phase rotation, which, in turn, suggests a suitable renormalization, namely, Wick ordering the nonlinearity. This point of view has been confirmed in [Reference Christ9, Reference Grünrock and Herr21, Reference Oh and Wang49], where Wick-ordered NLS is shown to be globally well-posed in (almost-critical) Fourier–Lebesgue spaces where the traditional (NLS) is ill-posed.
For (mKdVℝ
) on the circle,
 $H^{1/2}$
is not the threshold for continuous dependence. In [Reference Kappeler and Topalov29], Kappeler and Topalov proved well-posedness in
$H^{1/2}$
is not the threshold for continuous dependence. In [Reference Kappeler and Topalov29], Kappeler and Topalov proved well-posedness in
 $L^2(\mathbb {T})$
; this was shown to be sharp by Molinet [Reference Molinet47]. By renormalizing the nonlinearity (to remove an infinite transport term), well-posedness was then shown in [Reference Kappeler and Molnar28] for a larger Fourier–Lebesgue class of initial data (see also [Reference Schippa52]). The recent work [Reference Chapouto7] dramatically clarifies the situation regarding the full complex equation (mKdV): It is shown that
$L^2(\mathbb {T})$
; this was shown to be sharp by Molinet [Reference Molinet47]. By renormalizing the nonlinearity (to remove an infinite transport term), well-posedness was then shown in [Reference Kappeler and Molnar28] for a larger Fourier–Lebesgue class of initial data (see also [Reference Schippa52]). The recent work [Reference Chapouto7] dramatically clarifies the situation regarding the full complex equation (mKdV): It is shown that
 $H^{1/2}$
is the threshold for continuous dependence in this setting; moreover, it is shown that to go below this threshold (even in Fourier–Lebesgue spaces), a second renormalization is required.
$H^{1/2}$
is the threshold for continuous dependence in this setting; moreover, it is shown that to go below this threshold (even in Fourier–Lebesgue spaces), a second renormalization is required.
Given the known thresholds for continuous dependence on the circle, the proof of Theorem 1.1 must employ some property of our equations that distinguishes the line and the circle cases! This will be the local smoothing effect, that is, a gain of regularity locally in space on average in time. This constitutes a significant point of departure from [Reference Killip and Vişan37], where the arguments developed do not distinguish between the two geometries.
The local smoothing estimates that are relevant to us involve fractional numbers of derivatives. Correspondingly, some prudence is required in selecting the proper way to localize in space. We do so by choosing a fixed family of Schwartz cutoff functions
 $$ \begin{align} \psi(x) := \operatorname{\mathrm{sech}}(\tfrac x{99}) \quad\text{and}\quad \psi_h(x) := \psi(x - h), \end{align} $$
$$ \begin{align} \psi(x) := \operatorname{\mathrm{sech}}(\tfrac x{99}) \quad\text{and}\quad \psi_h(x) := \psi(x - h), \end{align} $$
whose particular properties will allow it to be used throughout the analysis. Corresponding to this cut-off, we define local smoothing norms by
 $$ \begin{align} \|q\|_{X^\sigma}^2 := \sup\limits_{h\in {{\mathbb{R}}}}\int_{-1}^1\|\psi_h^6 q\|_{H^\sigma}^2\,dt. \end{align} $$
$$ \begin{align} \|q\|_{X^\sigma}^2 := \sup\limits_{h\in {{\mathbb{R}}}}\int_{-1}^1\|\psi_h^6 q\|_{H^\sigma}^2\,dt. \end{align} $$
In Lemma 2.2, we will see that this norm is strong enough to control any other choice of Schwartz-class cut-off function.
The restriction of time to the interval
 $[-1,1]$
in (1.6) was a rather arbitrary choice; however, we see little advantage to introducing additional time parameters. Results for alternate time intervals (or indeed other spatial intervals) can be achieved by a simple covering argument, using time- and space-translation invariance.
$[-1,1]$
in (1.6) was a rather arbitrary choice; however, we see little advantage to introducing additional time parameters. Results for alternate time intervals (or indeed other spatial intervals) can be achieved by a simple covering argument, using time- and space-translation invariance.
We are now ready to state the local smoothing estimates we prove for the solutions constructed in Theorem 1.1. As the gain in regularity differs between the two evolutions, it is easier to state our results separately:
Theorem 1.2 (Local smoothing: NLS).
Fix
 $-\frac 12<s<0$
. Given initial data
$-\frac 12<s<0$
. Given initial data
 $q_0\in H^s({{\mathbb {R}}})$
, the corresponding solution
$q_0\in H^s({{\mathbb {R}}})$
, the corresponding solution
 $q(t)$
to NLS constructed in Theorem 1.1 satisfies
$q(t)$
to NLS constructed in Theorem 1.1 satisfies
 $$ \begin{align} \| q \|_{X^{s+\frac12}} \lesssim \Big( 1 + \| q_0 \|_{H^s}\Big)^{\frac8{1+2s}} \| q_0 \|_{H^s}; \end{align} $$
$$ \begin{align} \| q \|_{X^{s+\frac12}} \lesssim \Big( 1 + \| q_0 \|_{H^s}\Big)^{\frac8{1+2s}} \| q_0 \|_{H^s}; \end{align} $$
moreover,
 $q_0\mapsto q(t)$
is a continuous mapping from
$q_0\mapsto q(t)$
is a continuous mapping from
 $H^s$
to
$H^s$
to
 $X^{s+\frac 12}$
.
$X^{s+\frac 12}$
.
Theorem 1.3 (Local smoothing: mKdV).
Fix
 $-\frac 12<s<\frac 12$
. The solution
$-\frac 12<s<\frac 12$
. The solution
 $q(t)$
to mKdV with initial data
$q(t)$
to mKdV with initial data
 $q_0\in H^s({{\mathbb {R}}})$
constructed in Theorem 1.1 satisfies
$q_0\in H^s({{\mathbb {R}}})$
constructed in Theorem 1.1 satisfies
 $$ \begin{align} \| q \|_{X^{s+1}} \lesssim \Big( 1 + \| q_0 \|_{H^s}\Big)^{\frac{11}{1+2s}} \| q_0 \|_{H^s}; \end{align} $$
$$ \begin{align} \| q \|_{X^{s+1}} \lesssim \Big( 1 + \| q_0 \|_{H^s}\Big)^{\frac{11}{1+2s}} \| q_0 \|_{H^s}; \end{align} $$
moreover,
 $q_0\mapsto q(t)$
is a continuous mapping from
$q_0\mapsto q(t)$
is a continuous mapping from
 $H^s$
to
$H^s$
to
 $X^{s+1}$
.
$X^{s+1}$
.
Estimates of this type are well-known for the underlying linear equations and readily proven either by Fourier-analytic techniques, or by explicit monotonicity identities. In the special cases where one has a suitable microscopic conservation law, the latter technique can be adapted to nonlinear problems. Indeed, the original local smoothing effect was the case
 $s=0$
of (1.8), which was proven in [Reference Kato30] by employing the microscopic conservation law
$s=0$
of (1.8), which was proven in [Reference Kato30] by employing the microscopic conservation law
 $$ \begin{align*}\partial_t\big( |q|^2\big) + \partial_x^3 \big( |q|^2 \big) - 3 \partial_x \big( |q'|^2 \pm |q|^4 \big) =0 \end{align*} $$
$$ \begin{align*}\partial_t\big( |q|^2\big) + \partial_x^3 \big( |q|^2 \big) - 3 \partial_x \big( |q'|^2 \pm |q|^4 \big) =0 \end{align*} $$
satisfied by solutions of (mKdV). The analogous microscopic conservation law for (NLS) is
 $$ \begin{align*}\partial_t 2\operatorname{Im} (\bar q q' ) - \partial_x^3 \big( |q|^2 \big) + \partial_x \big( 4|q'|^2 \pm 2 |q|^4 \big) =0, \end{align*} $$
$$ \begin{align*}\partial_t 2\operatorname{Im} (\bar q q' ) - \partial_x^3 \big( |q|^2 \big) + \partial_x \big( 4|q'|^2 \pm 2 |q|^4 \big) =0, \end{align*} $$
which yields (1.7) with
 $s=\frac 12$
.
$s=\frac 12$
.
When the sought-after regularity does not match a known conservation law, local smoothing results for nonlinear PDE have traditionally been proven perturbatively, building on the corresponding estimates for the underlying linear equation. In particular, the arguments of [Reference Tsutsumi55] can be used to show that (1.7) continues to hold for
 $s\geq 0$
. That (1.8) continues to hold for
$s\geq 0$
. That (1.8) continues to hold for
 $s\geq \frac 14$
was proved in [Reference Kenig, Ponce and Vega33]; indeed, there the local smoothing effect was crucial to even constructing solutions.
$s\geq \frac 14$
was proved in [Reference Kenig, Ponce and Vega33]; indeed, there the local smoothing effect was crucial to even constructing solutions.
Due to the breakdown in uniform continuity of the data-to-solution map at low regularity, we cannot expect the nonlinear flow to be well modeled by a linear flow, and so some truly nonlinear technique is needed to prove Theorems 1.2 and 1.3. It is the discovery of a new one-parameter family of microscopic conservation laws for these equations that will allow us to achieve such low regularity. As local smoothing is a linear effect, it is surprising that the loss of uniform continuity is not accompanied by any lessening of this effect — the estimates we obtain exhibit the same derivative gain as seen for the linear equation.
As we shall see, the proof of Theorem 1.1 relies crucially on the local smoothing effect (though in a rather stronger form than presented in Theorems 1.2 and 1.3). With this in mind, it is natural to begin our discussion of the methods employed in this paper by describing how local smoothing is to be proved.
Local smoothing estimates also allow us to make better sense of the nonlinearity. Note that Theorem 1.1 already allows us to make sense of the nonlinearity taken holistically: If
 $q_n$
are Schwartz solutions converging to q in
$q_n$
are Schwartz solutions converging to q in
 $L^\infty _t H^s$
, then directly from the equation, we see that the corresponding sequence of nonlinearities converge, for example, as spacetime distributions. By contrast, one may seek to make sense of the individual factors in the nonlinearity in a way that allows them to be multiplied; this is where local smoothing helps.
$L^\infty _t H^s$
, then directly from the equation, we see that the corresponding sequence of nonlinearities converge, for example, as spacetime distributions. By contrast, one may seek to make sense of the individual factors in the nonlinearity in a way that allows them to be multiplied; this is where local smoothing helps.
For example, our results show that for any
 $s>-1/2$
, solutions of (mKdVℝ
) with initial data in
$s>-1/2$
, solutions of (mKdVℝ
) with initial data in
 $H^s({{\mathbb {R}}})$
belong to
$H^s({{\mathbb {R}}})$
belong to
 $L^3_{t,x}$
on all compact regions of spacetime. Analogously, we see that solutions to (NLS) are locally
$L^3_{t,x}$
on all compact regions of spacetime. Analogously, we see that solutions to (NLS) are locally
 $L^3_{t,x}$
whenever
$L^3_{t,x}$
whenever
 $s\geq -1/6$
.
$s\geq -1/6$
.
1.1. Outline of the proof
As we have mentioned earlier, (NLS) and (mKdV) belong to an infinite hierarchy of evolution equations whose Hamiltonians Poisson commute. Among PDEs, this phenomenology was first discovered in the case of the Korteweg–de Vries equation [Reference Gardner, Greene, Kruskal and Miura17]. And it was these discoveries that Lax [Reference Lax45] elegantly codified by introducing the Lax pair formalism (the monograph [Reference Faddeev and Takhtajan16] employs a parallel approach based around the zero-curvature condition).
As noted above, Lax pairs for (NLS) and (mKdV) were introduced in [Reference Ablowitz, Kaup, Newell and Segur1, Reference Zakharov and Shabat56]. Several different (but equivalent) choices of these operators exist in the literature. Our convention will be to use Lax operators
 $$ \begin{align} L(\varkappa) := \begin{bmatrix}\varkappa - \partial & q\\-r&\varkappa + \partial\end{bmatrix} \quad\text{as well as}\quad L_0(\varkappa) := \begin{bmatrix}\varkappa - \partial & 0\\0&\varkappa + \partial\end{bmatrix}. \end{align} $$
$$ \begin{align} L(\varkappa) := \begin{bmatrix}\varkappa - \partial & q\\-r&\varkappa + \partial\end{bmatrix} \quad\text{as well as}\quad L_0(\varkappa) := \begin{bmatrix}\varkappa - \partial & 0\\0&\varkappa + \partial\end{bmatrix}. \end{align} $$
Here,
 $\varkappa $
denotes the spectral parameter (which will always be real in this paper). The second member of the Lax pair (traditionally denoted P) can be taken to be
$\varkappa $
denotes the spectral parameter (which will always be real in this paper). The second member of the Lax pair (traditionally denoted P) can be taken to be
 $$ \begin{align*} i \begin{bmatrix}2\partial^2-qr & -q\partial-\partial q\\ r\partial+\partial r & -2\partial^2+qr\end{bmatrix} \quad\text{and}\quad \begin{bmatrix} - 4\partial^3 + 3 qr\partial + 3 \partial qr & 3q'\partial +3\partial q' \\ 3r'\partial+3\partial r' & -4\partial^3 + 3 qr\partial + 3 \partial qr \end{bmatrix}, \end{align*} $$
$$ \begin{align*} i \begin{bmatrix}2\partial^2-qr & -q\partial-\partial q\\ r\partial+\partial r & -2\partial^2+qr\end{bmatrix} \quad\text{and}\quad \begin{bmatrix} - 4\partial^3 + 3 qr\partial + 3 \partial qr & 3q'\partial +3\partial q' \\ 3r'\partial+3\partial r' & -4\partial^3 + 3 qr\partial + 3 \partial qr \end{bmatrix}, \end{align*} $$
for (NLS) and (mKdV), respectively.
The Lax equation
 $\partial _t L = [P,L]$
guarantees that the Lax operators at different times are conjugate. In the setting of finite matrices, this would guarantee that the characteristic polynomial of L is independent of time. In the case of (1.9), renormalization is required — indeed, L is not even bounded, let alone trace-class. Such a renormalization was presented in [Reference Killip, Vişan and Zhang38] based on the renormalized Fredholm determinant
$\partial _t L = [P,L]$
guarantees that the Lax operators at different times are conjugate. In the setting of finite matrices, this would guarantee that the characteristic polynomial of L is independent of time. In the case of (1.9), renormalization is required — indeed, L is not even bounded, let alone trace-class. Such a renormalization was presented in [Reference Killip, Vişan and Zhang38] based on the renormalized Fredholm determinant
 $\operatorname{\mathrm{det}}_2(1+A) = \operatorname{\mathrm{det}} (1+A) e^{-\operatorname {\mathrm {tr}}(A)}$
. Concretely, it was shown in [Reference Killip, Vişan and Zhang38] that
$\operatorname{\mathrm{det}}_2(1+A) = \operatorname{\mathrm{det}} (1+A) e^{-\operatorname {\mathrm {tr}}(A)}$
. Concretely, it was shown in [Reference Killip, Vişan and Zhang38] that
 $$ \begin{align*}\pm \log \operatorname{\mathrm{det}}_2 [ L_0(\varkappa)^{-1} L(\varkappa;q)] \end{align*} $$
$$ \begin{align*}\pm \log \operatorname{\mathrm{det}}_2 [ L_0(\varkappa)^{-1} L(\varkappa;q)] \end{align*} $$
is well-defined, conserved for Schwartz solutions, and coercive. This was the origin of the coercive macroscopic conservation laws constructed in that paper. The regularities of these laws were adjusted by integrating against a suitable measure in
 $\varkappa $
.
$\varkappa $
.
Unfortunately, such macroscopic conservation laws are of no use in proving local smoothing. We need not only microscopic conservation laws but coercive microscopic conservation laws. In Section 4, we present our discovery of just such a density
 $\rho $
and its attendant currents j. We feel that this is an important contribution to the much-studied algebraic theory of these hierarchies. Moreover, it is the driver of all that follows.
$\rho $
and its attendant currents j. We feel that this is an important contribution to the much-studied algebraic theory of these hierarchies. Moreover, it is the driver of all that follows.
We do not have a systematic way of finding microscopic conservation laws attendant to the conservation of the perturbation determinant. If we compare the answer for KdV from [Reference Killip and Vişan37] with that developed in this paper, it is tempting to predict that it should always be a rational function of components of the diagonal Green’s function. However, we have also found the corresponding quantity for the Toda lattice [Reference Harrop-Griffiths, Killip and Vişan27], and, in that case, it is a transcendental function of entries in the Green’s matrix. On the other hand, the closely related one-parameter family of macroscopic conservation laws
 $$ \begin{align} \frac{\partial\ }{\partial \varkappa} \log\operatorname{\mathrm{det}}_2 [ L_0(\varkappa)^{-1} L(\varkappa;q)] = \operatorname{\mathrm{tr}}\big\{ L(\varkappa;q)^{-1} - L_0(\varkappa)^{-1} \big\} \end{align} $$
$$ \begin{align} \frac{\partial\ }{\partial \varkappa} \log\operatorname{\mathrm{det}}_2 [ L_0(\varkappa)^{-1} L(\varkappa;q)] = \operatorname{\mathrm{tr}}\big\{ L(\varkappa;q)^{-1} - L_0(\varkappa)^{-1} \big\} \end{align} $$
are easily seen to admit a microscopic representation based on the diagonal of the Green’s function. The associated density
 $\gamma $
turns out to be far inferior for what we need to do here. Indeed, in Lemma 4.9, we will show that, unfortunately, the current corresponding to
$\gamma $
turns out to be far inferior for what we need to do here. Indeed, in Lemma 4.9, we will show that, unfortunately, the current corresponding to
 $\gamma $
is not adequately coercive. This undermines its utility for proving local smoothing. In principle, one could recover a
$\gamma $
is not adequately coercive. This undermines its utility for proving local smoothing. In principle, one could recover a
 $\rho $
-like object by integrating
$\rho $
-like object by integrating
 $\gamma $
in energy. (Of course, this need only agree with
$\gamma $
in energy. (Of course, this need only agree with
 $\rho $
up to a mean-zero function.) In fact, we pursued this approach for a long time while still seeking the true form of
$\rho $
up to a mean-zero function.) In fact, we pursued this approach for a long time while still seeking the true form of
 $\rho $
. We can attest that this approach is extremely painful and dramatically increases the number of subtle cancellations that need to be exhibited later in the argument.
$\rho $
. We can attest that this approach is extremely painful and dramatically increases the number of subtle cancellations that need to be exhibited later in the argument.
The proof of local smoothing is far and away the most lengthy and complicated part of the paper, comprising the entirety of Section 5 and employing crucially all of the preceding analysis. One reason is that we actually need a two-parameter family of estimates that go far beyond the simple a priori bounds (1.7) and (1.8). The role of the first of these two parameters is easy to explain at this time: it acts as a frequency threshold in the local smoothing norm. This refinement will allow us to prove that the high-frequency contribution to the local-smoothing norm is controlled (in a very quantitative way) by the high-frequency portion of the initial data. This is the essential ingredient in the continuity claims made in Theorems 1.2 and 1.3. (The basic question of whether such continuity holds for Kato’s original estimate [Reference Kato30] seems to have been open up until now.)
This extra frequency parameter also plays a major role in Section 6, where it is used to show that an
 $H^s$
-precompact set of Schwartz-class initial data leads to a collection of solutions that is
$H^s$
-precompact set of Schwartz-class initial data leads to a collection of solutions that is
 $H^s$
-precompact at later times. In view of the equicontinuity of orbits mentioned earlier, this is a question of tightness.
$H^s$
-precompact at later times. In view of the equicontinuity of orbits mentioned earlier, this is a question of tightness.
As local smoothing estimates control the flow of the
 $H^s$
norm through compact regions of spacetime, it is natural to attempt to employ them to prove tightness in
$H^s$
norm through compact regions of spacetime, it is natural to attempt to employ them to prove tightness in
 $H^s$
. However, it is precisely the fact that the transport of
$H^s$
. However, it is precisely the fact that the transport of
 $H^s$
norm cannot exceed the total
$H^s$
norm cannot exceed the total
 $H^s$
norm available that is used to prove Theorems 1.2 and 1.3; thus, these results do not provide sufficient control to yield tightness! Our tightness result relies crucially on the extra frequency parameter to demonstrate that there is little local smoothing norm residing at high frequencies and, consequently, little high-speed transport of
$H^s$
norm available that is used to prove Theorems 1.2 and 1.3; thus, these results do not provide sufficient control to yield tightness! Our tightness result relies crucially on the extra frequency parameter to demonstrate that there is little local smoothing norm residing at high frequencies and, consequently, little high-speed transport of
 $H^s$
-norm.
$H^s$
-norm.
The compactness result just enunciated guarantees the existence of weak solutions. To obtain well-posedness, we must verify uniqueness (i.e., that different subsequences do not lead to different solutions), as well as continuous dependence on the initial data. To achieve that, we will rely crucially on ideas introduced in [Reference Killip and Vişan37] and further developed in [Reference Bringmann, Killip and Visan5, Reference Killip, Murphy and Visan36].
While these papers provide a useful precedent on overall strategy, they provide no guidance on how to implement it. The first triumph of this paper is to construct the algebraic and analytic framework needed for this type of analysis in the AKNS-ZS hierarchy. We will see that even though the two equations belong to the same hierarchy, the fundamental monotonicity laws for (NLS) and (mKdV) are different; moreover, neither equation provides significant guidance in finding the numerous cancellations necessary to treat the other.
The first step in this strategy is the introduction of regularized Hamiltonians indexed by a scalar parameter
 $\kappa $
. The flows induced by these Hamiltonians should (a) be readily seen to be well-posed, (b) commute with the full flows, and (c) converge to the full flows as
$\kappa $
. The flows induced by these Hamiltonians should (a) be readily seen to be well-posed, (b) commute with the full flows, and (c) converge to the full flows as
 $\kappa \to \infty $
. Such flows are introduced in Section 4 where they are easily proven to have properties (a) and (b). That they enjoy property (c) in the desired topology, however, is highly nontrivial. This is the subject of Section 7, which is the climax of this paper.
$\kappa \to \infty $
. Such flows are introduced in Section 4 where they are easily proven to have properties (a) and (b). That they enjoy property (c) in the desired topology, however, is highly nontrivial. This is the subject of Section 7, which is the climax of this paper.
Due to their commutativity, the problem of controlling the difference between the full and regularized flows can be reduced to controlling the evolution under the difference Hamiltonian (that is, the difference of the full and regularized Hamiltonians). In fact, this is the key insight of the commuting flow paradigm introduced in [Reference Killip and Vişan37]: instead of needing to estimate the distance between two solutions (which is rendered intractable by the breakdown of uniformly continuous dependence), one need only study a single evolution, albeit under a much more complicated flow.
The difference flow retains all the bad behavior of the original PDE; indeed, the regularized flows are (by construction) relatively harmless. All obstacles that prevented previous researchers from successfully analyzing solutions in this nonperturbative regime are retained. To succeed, we will need to rely on a number of new insights; these include the new two-parameter local smoothing estimates, a novel change of unknown, and the demonstration of myriad cancellations between the full flow and its regularized counterpart.
The necessity of employing a (diffeomorphic) change of variables is common also to [Reference Bringmann, Killip and Visan5, Reference Killip and Vişan37]. In those works, the new variable is the diagonal Green’s function. The fact that this originates from a microscopic conservation law places one derivative in a favorable position. Alas, all conservation laws for the NLS/mKdV hierarchy are quadratic in q, and so none can offer a diffeomorphic change of variables.
In place of the diagonal Green’s function that proved so successful in the treatment of the KdV hierarchy, we adopt an off-diagonal entry
 $g_{12}(x)$
of the Green’s function as our new variable. Among its merits are the following: it has a relatively accessible time evolution; as an integral part of the definition of
$g_{12}(x)$
of the Green’s function as our new variable. Among its merits are the following: it has a relatively accessible time evolution; as an integral part of the definition of
 $\rho $
, it is something for which we need to develop extensive estimates anyway; the mapping
$\rho $
, it is something for which we need to develop extensive estimates anyway; the mapping
 $q\mapsto g_{12}$
is a diffeomorphism; and, lastly, it gains one degree of regularity, which aids in estimating nonlinear terms.
$q\mapsto g_{12}$
is a diffeomorphism; and, lastly, it gains one degree of regularity, which aids in estimating nonlinear terms.
Nevertheless, this change of variables comes with significant shortcomings. Foremost, it is not possible to control the evolution of
 $g_{12}$
without employing local smoothing (or some other manifestation of the underlying geometry). For, otherwise, one would obtain results for the circle that are known to be false!
$g_{12}$
without employing local smoothing (or some other manifestation of the underlying geometry). For, otherwise, one would obtain results for the circle that are known to be false!
At this moment, it is important to remember that we are discussing the difference flow and that our ambition is to prove that it converges to the identity as
 $\kappa \to \infty $
. Concomitant with this, the local smoothing effect deteriorates rapidly as
$\kappa \to \infty $
. Concomitant with this, the local smoothing effect deteriorates rapidly as
 $\kappa \to \infty $
. This inherent deterioration in the local smoothing estimates means that in order to treat all regularities
$\kappa \to \infty $
. This inherent deterioration in the local smoothing estimates means that in order to treat all regularities
 $s>-\frac 12$
, we must discover every cancellation available between the full and regularized flows. This, in turn, necessitates the carefully premeditated decomposition of error terms in Section 7 and the stringent estimation of paraproducts in Section 5.
$s>-\frac 12$
, we must discover every cancellation available between the full and regularized flows. This, in turn, necessitates the carefully premeditated decomposition of error terms in Section 7 and the stringent estimation of paraproducts in Section 5.
Due to the need for local smoothing estimates, we will only be able to verify convergence locally in space. The tightness results of Section 6 are therefore essential for overcoming this deficiency.
In Section 8, we prove Theorem 1.1. The tools we develop in the first seven sections allow us to prove Theorem 1.1 in the range
 $-\frac 12<s<0$
. This suffices for (NLS) but leaves the gap
$-\frac 12<s<0$
. This suffices for (NLS) but leaves the gap
 $[0,\frac 14)$
for (mKdV). To close this gap, we construct suitable macroscopic conservation laws for both equations that allow us to prove the equicontinuity of orbits in
$[0,\frac 14)$
for (mKdV). To close this gap, we construct suitable macroscopic conservation laws for both equations that allow us to prove the equicontinuity of orbits in
 $H^s$
for
$H^s$
for
 $0\leq s<\frac 12$
and so deduce well-posedness from that at lower regularity. This is interesting even for (NLS), where, for example, global in time equicontinuity of orbits in
$0\leq s<\frac 12$
and so deduce well-posedness from that at lower regularity. This is interesting even for (NLS), where, for example, global in time equicontinuity of orbits in
 $L^2$
does not seem to have been shown previously (nor is it trivially derivable from the standard techniques).
$L^2$
does not seem to have been shown previously (nor is it trivially derivable from the standard techniques).
Section 9 is devoted to proving Theorems 1.2 and 1.3. All the ingredients we need for the range
 $-\frac 12<s<0$
are presented already in Section 5. Thus, the majority of Section 9 is devoted to proving local smoothing for (mKdV) over the range
$-\frac 12<s<0$
are presented already in Section 5. Thus, the majority of Section 9 is devoted to proving local smoothing for (mKdV) over the range
 $0\leq s<\frac 12$
by using a new underlying microscopic conservation law.
$0\leq s<\frac 12$
by using a new underlying microscopic conservation law.
In closing, let us quickly recapitulate the structure of the paper that follows. Section 2 discusses myriad preliminaries: settling notation, verifying basic properties of the local smoothing spaces, and proving a variety of commutator estimates. In Section 3, we discuss the (matrix-valued) Green’s function of the Lax operator, with particular emphasis at the confluence of the two spatial coordinates. Section 4 introduces the conserved density
 $\rho $
and derives equations for the time evolution of this and other important quantities. Section 5 proves local smoothing estimates, not only for (NLS) and (mKdV), but also for the associated difference flows. It is essential for what follows that these local smoothing estimates contain an additional frequency cut-off parameter. The freedom to vary this parameter plays a crucial role, for example, in Section 6, where these local smoothing estimates are used to control the transport of
$\rho $
and derives equations for the time evolution of this and other important quantities. Section 5 proves local smoothing estimates, not only for (NLS) and (mKdV), but also for the associated difference flows. It is essential for what follows that these local smoothing estimates contain an additional frequency cut-off parameter. The freedom to vary this parameter plays a crucial role, for example, in Section 6, where these local smoothing estimates are used to control the transport of
 $H^s$
-norm. Section 7 uses local smoothing to demonstrate the convergence of the regularized flows to the full PDEs by proving that the difference flow approximates the identity. In Section 8, we prove Theorem 1.1. Section 9 addresses Theorems 1.2 and 1.3. Appendix A gives a new presentation of existing ill-posedness results for (NLS), extending them to other members of the hierarchy, including (mKdV).
$H^s$
-norm. Section 7 uses local smoothing to demonstrate the convergence of the regularized flows to the full PDEs by proving that the difference flow approximates the identity. In Section 8, we prove Theorem 1.1. Section 9 addresses Theorems 1.2 and 1.3. Appendix A gives a new presentation of existing ill-posedness results for (NLS), extending them to other members of the hierarchy, including (mKdV).
2. Some notation and preliminary estimates
For the remainder of the paper, we constrain
 $$ \begin{align*}s\in (-\tfrac12,0) \end{align*} $$
$$ \begin{align*}s\in (-\tfrac12,0) \end{align*} $$
and all implicit constants are permitted to depend on s. In view of the scaling (1.3), it will suffice to prove all our theorems under a small-data hypothesis. For this purpose, we introduce the notation
 $$ \begin{align} B_\delta := \left\{q\in H^s:\|q\|_{H^s}\leq \delta\right\}. \end{align} $$
$$ \begin{align} B_\delta := \left\{q\in H^s:\|q\|_{H^s}\leq \delta\right\}. \end{align} $$
We use angle brackets to represent the pairing:
 $$ \begin{align*}\langle f, g\rangle = \int \overline{f(x)} g(x)\,dx. \end{align*} $$
$$ \begin{align*}\langle f, g\rangle = \int \overline{f(x)} g(x)\,dx. \end{align*} $$
In addition to being the natural inner product on (complex)
 $L^2({{\mathbb {R}}})$
, this also informs our notions of dual space (the dual of
$L^2({{\mathbb {R}}})$
, this also informs our notions of dual space (the dual of
 $H^s({{\mathbb {R}}})$
is
$H^s({{\mathbb {R}}})$
is
 $H^{-s}({{\mathbb {R}}})$
) and of functional derivatives: If
$H^{-s}({{\mathbb {R}}})$
) and of functional derivatives: If
 $F:\mathcal {S}\to \mathbb {C}$
is
$F:\mathcal {S}\to \mathbb {C}$
is
 $C^1$
, then
$C^1$
, then
 $$ \begin{align} \tfrac{d\ }{d\theta}\Big|_{\theta=0} F(q+\theta f) = \big\langle \bar f, \tfrac{\delta F}{\delta q}\big\rangle \pm \big\langle f, \tfrac{\delta F}{\delta r}\big\rangle. \end{align} $$
$$ \begin{align} \tfrac{d\ }{d\theta}\Big|_{\theta=0} F(q+\theta f) = \big\langle \bar f, \tfrac{\delta F}{\delta q}\big\rangle \pm \big\langle f, \tfrac{\delta F}{\delta r}\big\rangle. \end{align} $$
For real-valued F, the functions
 $\tfrac {\delta F}{\delta q}$
and
$\tfrac {\delta F}{\delta q}$
and
 $\tfrac {\delta F}{\delta \bar q}=\pm \tfrac {\delta F}{\delta r}$
are complex conjugates. These are functional analogues of the (Wirtinger) directional derivatives of complex analysis — q and
$\tfrac {\delta F}{\delta \bar q}=\pm \tfrac {\delta F}{\delta r}$
are complex conjugates. These are functional analogues of the (Wirtinger) directional derivatives of complex analysis — q and
 $\bar q$
are not independent variables!
$\bar q$
are not independent variables!
We write
 $\mathfrak I_p$
for the
$\mathfrak I_p$
for the
 $\ell ^p$
Schatten class over the Hilbert space
$\ell ^p$
Schatten class over the Hilbert space
 $L^2({{\mathbb {R}}})$
. For most of our analysis, the Hilbert–Schmidt class
$L^2({{\mathbb {R}}})$
. For most of our analysis, the Hilbert–Schmidt class
 $\mathfrak I_2$
will suffice.
$\mathfrak I_2$
will suffice.
Commensurate with our choice of time interval in (1.6), all spacetime norms will also be taken over this time interval (unless the contrary is indicated explicitly). Thus, for any Banach space Z and
 $1\leq p\leq \infty $
, we define
$1\leq p\leq \infty $
, we define
 $$\begin{align*}\|q\|_{L^p_t Z} := \big\| \|q(t) \|_Z \big\|_{L^p(dt;[-1,1])}. \end{align*}$$
$$\begin{align*}\|q\|_{L^p_t Z} := \big\| \|q(t) \|_Z \big\|_{L^p(dt;[-1,1])}. \end{align*}$$
Our convention for the Fourier transform is
 $$ \begin{align*} \hat f(\xi) = \tfrac{1}{\sqrt{2\pi}} \int_{{\mathbb{R}}} e^{-i\xi x} f(x)\,dx, \quad\text{whence}\quad \widehat{fg}(\xi) = \tfrac{1}{\sqrt{2\pi}} [\hat f * \hat g] (\xi). \end{align*} $$
$$ \begin{align*} \hat f(\xi) = \tfrac{1}{\sqrt{2\pi}} \int_{{\mathbb{R}}} e^{-i\xi x} f(x)\,dx, \quad\text{whence}\quad \widehat{fg}(\xi) = \tfrac{1}{\sqrt{2\pi}} [\hat f * \hat g] (\xi). \end{align*} $$
We shall repeatedly employ a “continuum partition of unity” device based on the cut-off
 $\psi _h^{12}$
. Specifically, as
$\psi _h^{12}$
. Specifically, as
 $$ \begin{align} \int_{{\mathbb{R}}} \psi(x-h)^{12} \,dh \equiv \tfrac{512}{7}, \quad\text{so}\quad f(x) = \tfrac{7}{512} \int_{{\mathbb{R}}} f(x) \psi_h^{12}(x)\,dh \end{align} $$
$$ \begin{align} \int_{{\mathbb{R}}} \psi(x-h)^{12} \,dh \equiv \tfrac{512}{7}, \quad\text{so}\quad f(x) = \tfrac{7}{512} \int_{{\mathbb{R}}} f(x) \psi_h^{12}(x)\,dh \end{align} $$
in
 $H^\sigma ({{\mathbb {R}}})$
sense, for any
$H^\sigma ({{\mathbb {R}}})$
sense, for any
 $f\in H^\sigma ({{\mathbb {R}}})$
and any
$f\in H^\sigma ({{\mathbb {R}}})$
and any
 $\sigma \in {{\mathbb {R}}}$
.
$\sigma \in {{\mathbb {R}}}$
.
2.1. Sobolev spaces
For real
 $|\kappa |\geq 1$
and
$|\kappa |\geq 1$
and
 $\sigma \in {{\mathbb {R}}}$
, we define the norm
$\sigma \in {{\mathbb {R}}}$
, we define the norm
 $$\begin{align*}\|q\|_{H^\sigma_\kappa}^2 := \int \left(4\kappa^2 + \xi^2\right)^\sigma|\hat q(\xi)|^2\,d\xi \end{align*}$$
$$\begin{align*}\|q\|_{H^\sigma_\kappa}^2 := \int \left(4\kappa^2 + \xi^2\right)^\sigma|\hat q(\xi)|^2\,d\xi \end{align*}$$
and write
 $H^\sigma := H^\sigma _1$
.
$H^\sigma := H^\sigma _1$
.
For
 $-\frac 12<s<0$
, elementary considerations yield
$-\frac 12<s<0$
, elementary considerations yield
 $$ \begin{align} \|f\|_{L^\infty}\leq \|\hat{f}\|_{L^1}\leq \|f\|_{H^{s+1}_\kappa} \big\|(|\xi|^2+4\kappa^2)^{-\frac{s+1}2}\big\|_{L^2}\lesssim |\kappa|^{-(s +\frac12)}\|f\|_{H^{s+1} _\kappa}. \end{align} $$
$$ \begin{align} \|f\|_{L^\infty}\leq \|\hat{f}\|_{L^1}\leq \|f\|_{H^{s+1}_\kappa} \big\|(|\xi|^2+4\kappa^2)^{-\frac{s+1}2}\big\|_{L^2}\lesssim |\kappa|^{-(s +\frac12)}\|f\|_{H^{s+1} _\kappa}. \end{align} $$
Consequently, we have the following algebra property:
 $$ \begin{align} \| f g \|_{H^{s+1}_\kappa} \lesssim |\kappa|^{-(\frac12+s)} \| f \|_{H^{s+1}_\kappa} \| g \|_{H^{s+1}_\kappa}. \end{align} $$
$$ \begin{align} \| f g \|_{H^{s+1}_\kappa} \lesssim |\kappa|^{-(\frac12+s)} \| f \|_{H^{s+1}_\kappa} \| g \|_{H^{s+1}_\kappa}. \end{align} $$
Arguing by duality and using the fractional product rule, Sobolev embedding, and (2.4), we may bound
 $$ \begin{align} \|qf\|_{H^s}&\lesssim \|q\|_{H^s} \|f\|_{L^\infty} + \|q\|_{L^{\frac2{1-2|s|}}} \||\nabla|^{|s|}f\|_{L^{\frac1{|s|}}}\notag\\ &\lesssim \|q\|_{H^s} \big[ |\kappa|^{-(s+\frac12)}\|f\|_{H^{s+1}_\kappa} + \||\nabla|^{\frac12}f\|_{ L^2}\big]\\ &\lesssim |\kappa|^{-(s+\frac12)} \|q\|_{H^s}\|f\|_{H^{s+1}_\kappa}.\notag \end{align} $$
$$ \begin{align} \|qf\|_{H^s}&\lesssim \|q\|_{H^s} \|f\|_{L^\infty} + \|q\|_{L^{\frac2{1-2|s|}}} \||\nabla|^{|s|}f\|_{L^{\frac1{|s|}}}\notag\\ &\lesssim \|q\|_{H^s} \big[ |\kappa|^{-(s+\frac12)}\|f\|_{H^{s+1}_\kappa} + \||\nabla|^{\frac12}f\|_{ L^2}\big]\\ &\lesssim |\kappa|^{-(s+\frac12)} \|q\|_{H^s}\|f\|_{H^{s+1}_\kappa}.\notag \end{align} $$
Lemma 2.1. If
 $s'<s$
,
$s'<s$
,
 $|\kappa |\geq 1$
, and
$|\kappa |\geq 1$
, and
 $q\in H^s$
, then
$q\in H^s$
, then
 $$ \begin{align} \|q\|_{H^s_\kappa}^2\approx_{s,s'} \int_{|\kappa|}^\infty \varkappa^{2(s - s')}\|q\|_{H^{s'}_\varkappa}^2\,\tfrac{d\varkappa}\varkappa. \end{align} $$
$$ \begin{align} \|q\|_{H^s_\kappa}^2\approx_{s,s'} \int_{|\kappa|}^\infty \varkappa^{2(s - s')}\|q\|_{H^{s'}_\varkappa}^2\,\tfrac{d\varkappa}\varkappa. \end{align} $$
Proof. By scaling, it suffices to consider the case
 $\kappa = 1$
. We may then write
$\kappa = 1$
. We may then write
 $$\begin{align*}\int_1^\infty \varkappa^{2(s - s')}(4\varkappa^2 + \xi^2)^{s'}\,\tfrac{d\varkappa}\varkappa = |\xi|^{2s} \int_{\frac1{|\xi|}}^\infty \varkappa^{2(s - s')}(4\varkappa^2 + 1)^{s'}\,\tfrac{d\varkappa}\varkappa. \end{align*}$$
$$\begin{align*}\int_1^\infty \varkappa^{2(s - s')}(4\varkappa^2 + \xi^2)^{s'}\,\tfrac{d\varkappa}\varkappa = |\xi|^{2s} \int_{\frac1{|\xi|}}^\infty \varkappa^{2(s - s')}(4\varkappa^2 + 1)^{s'}\,\tfrac{d\varkappa}\varkappa. \end{align*}$$
By considering the cases
 $|\xi |\leq 2$
and
$|\xi |\leq 2$
and
 $|\xi |>2$
separately, we may bound
$|\xi |>2$
separately, we may bound
 $$\begin{align*}|\xi|^{2s} \int_{\frac1{|\xi|}}^\infty \varkappa^{2(s - s')}(4\varkappa^2 + 1)^{s'}\,\tfrac{d\varkappa}\varkappa\approx_{s,s'}(4 + \xi^2)^s, \end{align*}$$
$$\begin{align*}|\xi|^{2s} \int_{\frac1{|\xi|}}^\infty \varkappa^{2(s - s')}(4\varkappa^2 + 1)^{s'}\,\tfrac{d\varkappa}\varkappa\approx_{s,s'}(4 + \xi^2)^s, \end{align*}$$
and the estimate (2.7) then follows from the Fubini-Tonelli theorem.
2.2. Local smoothing spaces
It will be important to consider a one-parameter family of local smoothing norms, generalizing that presented in the Introduction. To this end, given
 $\kappa \geq 1$
and
$\kappa \geq 1$
and
 $\sigma \in {{\mathbb {R}}}$
, we define the local smoothing space
$\sigma \in {{\mathbb {R}}}$
, we define the local smoothing space
 $$\begin{align*}\|q\|_{X^\sigma_\kappa}^2 := \sup_{h\in {{\mathbb{R}}}} \big\|\tfrac{\psi_h^6q}{\sqrt{4\kappa^2 - \partial^2}} \big\|_{L^2_t H^{\sigma+1}}^2, \end{align*}$$
$$\begin{align*}\|q\|_{X^\sigma_\kappa}^2 := \sup_{h\in {{\mathbb{R}}}} \big\|\tfrac{\psi_h^6q}{\sqrt{4\kappa^2 - \partial^2}} \big\|_{L^2_t H^{\sigma+1}}^2, \end{align*}$$
so that
 $X^\sigma _1 = X^\sigma $
, where we write
$X^\sigma _1 = X^\sigma $
, where we write
 $\tfrac {\psi _h^6q}{\sqrt {4\kappa ^2 - \partial ^2}} = (4\kappa ^2 - \partial ^2)^{-\frac 12}(\psi _h^6q)$
. At this moment, placing the inverse differential operators under their arguments (rather than in front of them) may seem clumsy; however, the mere act of writing out (3.23) in traditional form will quickly convince the reader of the virtue of this approach.
$\tfrac {\psi _h^6q}{\sqrt {4\kappa ^2 - \partial ^2}} = (4\kappa ^2 - \partial ^2)^{-\frac 12}(\psi _h^6q)$
. At this moment, placing the inverse differential operators under their arguments (rather than in front of them) may seem clumsy; however, the mere act of writing out (3.23) in traditional form will quickly convince the reader of the virtue of this approach.
To ease dimensional analysis, the
 $X^\sigma _\kappa $
spaces have been defined to scale the same as
$X^\sigma _\kappa $
spaces have been defined to scale the same as
 $H^\sigma $
spaces.
$H^\sigma $
spaces.
Our next lemma allows us to understand the effect of changing the localizing function
 $\psi ^6$
or the regularity
$\psi ^6$
or the regularity
 $\sigma $
in the definition of the local smoothing norm:
$\sigma $
in the definition of the local smoothing norm:
Lemma 2.2. Given
 $\kappa \geq 1$
,
$\kappa \geq 1$
,
 $\sigma \in {{\mathbb {R}}}$
, and
$\sigma \in {{\mathbb {R}}}$
, and
 $\phi \in \mathcal {S}$
,
$\phi \in \mathcal {S}$
,
 $$ \begin{align} \big\|\tfrac{\phi q}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}\lesssim_{\phi,\sigma} \|q\|_{X^{\sigma}_\kappa}. \end{align} $$
$$ \begin{align} \big\|\tfrac{\phi q}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}\lesssim_{\phi,\sigma} \|q\|_{X^{\sigma}_\kappa}. \end{align} $$
Moreover, if
 $s-1\leq \sigma '\leq \sigma $
, then
$s-1\leq \sigma '\leq \sigma $
, then
 $$ \begin{align} \|q\|_{X^{\sigma'}_\kappa}\lesssim \kappa^{\frac{\sigma'-\sigma}{1 + \sigma-s}}\left(\|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}\right). \end{align} $$
$$ \begin{align} \|q\|_{X^{\sigma'}_\kappa}\lesssim \kappa^{\frac{\sigma'-\sigma}{1 + \sigma-s}}\left(\|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}\right). \end{align} $$
Proof. We begin by discussing (2.8). Let
 $T_h:L^2\to L^2$
denote the operator with integral kernel
$T_h:L^2\to L^2$
denote the operator with integral kernel
 $$ \begin{align*}\frac{(4+\xi^2)^{\frac{\sigma+1}2}}{(4\kappa^2 +\xi^2)^{\frac{1}2}} \widehat{\phi \psi_h^6}(\xi-\eta) \frac{(4\kappa^2+\eta^2)^{\frac{1}2}}{(4+\eta^2)^{\frac{\sigma+1}2}}. \end{align*} $$
$$ \begin{align*}\frac{(4+\xi^2)^{\frac{\sigma+1}2}}{(4\kappa^2 +\xi^2)^{\frac{1}2}} \widehat{\phi \psi_h^6}(\xi-\eta) \frac{(4\kappa^2+\eta^2)^{\frac{1}2}}{(4+\eta^2)^{\frac{\sigma+1}2}}. \end{align*} $$
By applying Schur’s test, we find that
 $$ \begin{align*}\| T_h \|_{\mathrm{op}} \lesssim \| \phi \psi_h^6\|_{H^{|\sigma|+2}} \quad\text{and so}\quad \int_{{\mathbb{R}}} \| T_h \|_{\mathrm{op}} \,dh \lesssim_\phi 1. \end{align*} $$
$$ \begin{align*}\| T_h \|_{\mathrm{op}} \lesssim \| \phi \psi_h^6\|_{H^{|\sigma|+2}} \quad\text{and so}\quad \int_{{\mathbb{R}}} \| T_h \|_{\mathrm{op}} \,dh \lesssim_\phi 1. \end{align*} $$
Moreover, this bound holds uniformly in
 $\kappa $
. Thus, by employing (2.3), we find
$\kappa $
. Thus, by employing (2.3), we find
 $$ \begin{align*}\big\|\tfrac{\phi q}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}} \lesssim \int \big\|\tfrac{\phi\psi_h^{12} q}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}\,dh \lesssim \int_{{\mathbb{R}}} \| T_h \|_{\mathrm{op}} \| q \|_{X^\sigma_\kappa} \,dh \lesssim_\phi \| q \|_{X^\sigma_\kappa}, \end{align*} $$
$$ \begin{align*}\big\|\tfrac{\phi q}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}} \lesssim \int \big\|\tfrac{\phi\psi_h^{12} q}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}\,dh \lesssim \int_{{\mathbb{R}}} \| T_h \|_{\mathrm{op}} \| q \|_{X^\sigma_\kappa} \,dh \lesssim_\phi \| q \|_{X^\sigma_\kappa}, \end{align*} $$
which settles (2.8).
Turning to (2.9), and setting
 $N=\kappa ^{\frac 1{1 + \sigma - s}}$
, we have
$N=\kappa ^{\frac 1{1 + \sigma - s}}$
, we have
 $$ \begin{align*} \|\tfrac{\psi_h^6 q}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{\sigma'+1}}&\lesssim \kappa^{-1 + \frac{\sigma' + 1 -s}{1 + \sigma-s}} \|(\psi_h^6q)_{\leq N}\|_{L^\infty_t H^s} + \kappa^{\frac{\sigma'-\sigma}{1 + \sigma-s}}\big\|P_{>N}\tfrac{\psi_h^6q}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}. \end{align*} $$
$$ \begin{align*} \|\tfrac{\psi_h^6 q}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{\sigma'+1}}&\lesssim \kappa^{-1 + \frac{\sigma' + 1 -s}{1 + \sigma-s}} \|(\psi_h^6q)_{\leq N}\|_{L^\infty_t H^s} + \kappa^{\frac{\sigma'-\sigma}{1 + \sigma-s}}\big\|P_{>N}\tfrac{\psi_h^6q}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}. \end{align*} $$
Taking the supremum over h, we obtain the estimate (2.9).
Next, we record several commutator-type estimates that we will use in the later sections.
Lemma 2.3. Fix
 $\kappa \geq 1$
. Then
$\kappa \geq 1$
. Then
 $$ \begin{align} \big\|\big[\psi_h, \tfrac{1}{4\kappa^2-\partial^2}\big]q\big\|_{H^\sigma}&\lesssim \kappa^{-3+\sigma-s} \|q\|_{H^s_\kappa} \!\quad\text{for}\quad\!\! -1\leq \sigma\leq 3+s, \end{align} $$
$$ \begin{align} \big\|\big[\psi_h, \tfrac{1}{4\kappa^2-\partial^2}\big]q\big\|_{H^\sigma}&\lesssim \kappa^{-3+\sigma-s} \|q\|_{H^s_\kappa} \!\quad\text{for}\quad\!\! -1\leq \sigma\leq 3+s, \end{align} $$
 $$ \begin{align} \big\|\big[\psi_h, \tfrac{\partial^\ell}{4\kappa^2-\partial^2}\big]q\big\|_{H^\sigma}&\lesssim \kappa^{-3+\ell +\sigma-s} \|q\|_{H^s_\kappa} \!\quad\text{for}\quad\!\! 1\leq \sigma+\ell\leq 3+s,\, \ell=1,2, 3, \end{align} $$
$$ \begin{align} \big\|\big[\psi_h, \tfrac{\partial^\ell}{4\kappa^2-\partial^2}\big]q\big\|_{H^\sigma}&\lesssim \kappa^{-3+\ell +\sigma-s} \|q\|_{H^s_\kappa} \!\quad\text{for}\quad\!\! 1\leq \sigma+\ell\leq 3+s,\, \ell=1,2, 3, \end{align} $$
uniformly for
 $h\in {{\mathbb {R}}}$
. Moreover, for
$h\in {{\mathbb {R}}}$
. Moreover, for
 $\ell =2,3,4$
and
$\ell =2,3,4$
and
 $2+s\leq \sigma +\ell \leq 4+s$
,
$2+s\leq \sigma +\ell \leq 4+s$
,
 $$ \begin{align} \big\|\big[\psi_h,\tfrac{\partial^\ell}{4\kappa^2 - \partial^2}\big]q\big\|_{L_t^2H^\sigma}&\lesssim \kappa^{-2+\frac12(\ell + \sigma-s)}\big[\|q\|_{X_\kappa^{s+1}} + \|q\|_{L_t^\infty H^s}\big], \end{align} $$
$$ \begin{align} \big\|\big[\psi_h,\tfrac{\partial^\ell}{4\kappa^2 - \partial^2}\big]q\big\|_{L_t^2H^\sigma}&\lesssim \kappa^{-2+\frac12(\ell + \sigma-s)}\big[\|q\|_{X_\kappa^{s+1}} + \|q\|_{L_t^\infty H^s}\big], \end{align} $$
uniformly for
 $h\in {{\mathbb {R}}}$
.
$h\in {{\mathbb {R}}}$
.
Proof. The estimate (2.10) follows from the observation that
 $$ \begin{align} \big[\psi_h, \tfrac1{4\kappa^2-\partial^2}\big]&= \tfrac1{4\kappa^2-\partial^2}\big(\psi_h"-2\partial \psi_h'\big)\tfrac1{4\kappa^2-\partial^2}. \end{align} $$
$$ \begin{align} \big[\psi_h, \tfrac1{4\kappa^2-\partial^2}\big]&= \tfrac1{4\kappa^2-\partial^2}\big(\psi_h"-2\partial \psi_h'\big)\tfrac1{4\kappa^2-\partial^2}. \end{align} $$
The lower bound on
 $\sigma $
expresses that the maximum possible decay in
$\sigma $
expresses that the maximum possible decay in
 $\kappa $
is
$\kappa $
is
 $\kappa ^{-4-s}$
.
$\kappa ^{-4-s}$
.
To handle
 $\ell =1,2,3$
, we also use the fact that
$\ell =1,2,3$
, we also use the fact that
 $$ \begin{align*}\big[\psi_h, \tfrac{\partial^\ell}{4\kappa^2-\partial^2}\big] = \big[\psi_h, \tfrac1{4\kappa^2-\partial^2}\big]\partial^\ell+ \tfrac1{4\kappa^2-\partial^2}[\psi_h, \partial^\ell], \end{align*} $$
$$ \begin{align*}\big[\psi_h, \tfrac{\partial^\ell}{4\kappa^2-\partial^2}\big] = \big[\psi_h, \tfrac1{4\kappa^2-\partial^2}\big]\partial^\ell+ \tfrac1{4\kappa^2-\partial^2}[\psi_h, \partial^\ell], \end{align*} $$
from which we see that the maximum possible decay in
 $\kappa $
is
$\kappa $
is
 $\kappa ^{-2-s}$
.
$\kappa ^{-2-s}$
.
We now turn to (2.12) and write
 $$ \begin{align*} \big[\psi_h, \tfrac{\partial^\ell }{4\kappa^2-\partial^2}\big] &=\tfrac{\partial^\ell}{(4\kappa^2-\partial^2)^2}\big(\psi_h"-2\partial \psi_h'\big) + \tfrac1{4\kappa^2-\partial^2} \big[\psi_h"-2\partial \psi_h', \tfrac{\partial^\ell }{4\kappa^2-\partial^2}\big]\\ &\quad + \tfrac1{4\kappa^2-\partial^2}\sum_{m=0}^{\ell-1} c_m \partial^{m} \psi_h^{(\ell-m)}q. \end{align*} $$
$$ \begin{align*} \big[\psi_h, \tfrac{\partial^\ell }{4\kappa^2-\partial^2}\big] &=\tfrac{\partial^\ell}{(4\kappa^2-\partial^2)^2}\big(\psi_h"-2\partial \psi_h'\big) + \tfrac1{4\kappa^2-\partial^2} \big[\psi_h"-2\partial \psi_h', \tfrac{\partial^\ell }{4\kappa^2-\partial^2}\big]\\ &\quad + \tfrac1{4\kappa^2-\partial^2}\sum_{m=0}^{\ell-1} c_m \partial^{m} \psi_h^{(\ell-m)}q. \end{align*} $$
Using (2.8), this readily yields
 $$ \begin{align*} \big\|\big[\psi_h,\tfrac{\partial^\ell}{4\kappa^2 - \partial^2}\big]q\big\|_{L_t^2H^\sigma}&\lesssim \|q\|_{X_\kappa^{\sigma + \ell-3}}\end{align*} $$
$$ \begin{align*} \big\|\big[\psi_h,\tfrac{\partial^\ell}{4\kappa^2 - \partial^2}\big]q\big\|_{L_t^2H^\sigma}&\lesssim \|q\|_{X_\kappa^{\sigma + \ell-3}}\end{align*} $$
We also have the following estimates:
Lemma 2.4. Let
 $\sigma>0$
,
$\sigma>0$
,
 $\kappa \geq 1$
, and
$\kappa \geq 1$
, and
 $f,g\in \mathcal C([-1,1];\mathcal {S})$
. If
$f,g\in \mathcal C([-1,1];\mathcal {S})$
. If
 $|\varkappa |\geq 1$
, then
$|\varkappa |\geq 1$
, then
 $$ \begin{align} \|(2\varkappa - \partial)f\|_{X^\sigma_\kappa} \lesssim |\varkappa|\|f\|_{X^\sigma_\kappa} + \|f\|_{X^{\sigma+1}_\kappa} \lesssim \|(2\varkappa - \partial)f\|_{X^\sigma_\kappa} + \|f\|_{L^\infty_t H^\sigma}. \end{align} $$
$$ \begin{align} \|(2\varkappa - \partial)f\|_{X^\sigma_\kappa} \lesssim |\varkappa|\|f\|_{X^\sigma_\kappa} + \|f\|_{X^{\sigma+1}_\kappa} \lesssim \|(2\varkappa - \partial)f\|_{X^\sigma_\kappa} + \|f\|_{L^\infty_t H^\sigma}. \end{align} $$
Further, we have the product estimates
 $$ \begin{align} \|fg\|_{X^\sigma_\kappa} \lesssim |\varkappa|^{-(s+\frac12)}\left(\|f\|_{X^\sigma_\kappa}\|g\|_{L^\infty_t H^{s+1}_\varkappa} + \|f\|_{L^\infty_t H^{s+1}_\varkappa}\|g\|_{X^{\sigma}_\kappa} \right), \end{align} $$
$$ \begin{align} \|fg\|_{X^\sigma_\kappa} \lesssim |\varkappa|^{-(s+\frac12)}\left(\|f\|_{X^\sigma_\kappa}\|g\|_{L^\infty_t H^{s+1}_\varkappa} + \|f\|_{L^\infty_t H^{s+1}_\varkappa}\|g\|_{X^{\sigma}_\kappa} \right), \end{align} $$
 $$ \begin{align} \|fg\|_{X^\sigma_\kappa} \lesssim |\varkappa|^{-(s+\frac12)}\Big[\|f\|_{X^\sigma_\kappa}\|g\|_{L^\infty_t H^{s+1}_\varkappa}+\|f\|_{L^\infty_t H^s_\varkappa}\big(|\varkappa|\|g\|_{X^\sigma_\kappa} + \|g\|_{X^{\sigma+1}_\kappa}\big)\Big],\!\! \end{align} $$
$$ \begin{align} \|fg\|_{X^\sigma_\kappa} \lesssim |\varkappa|^{-(s+\frac12)}\Big[\|f\|_{X^\sigma_\kappa}\|g\|_{L^\infty_t H^{s+1}_\varkappa}+\|f\|_{L^\infty_t H^s_\varkappa}\big(|\varkappa|\|g\|_{X^\sigma_\kappa} + \|g\|_{X^{\sigma+1}_\kappa}\big)\Big],\!\! \end{align} $$
 $$ \begin{align} \| f g \|_{X^\sigma_\kappa \cap L^\infty_t H^{s+1}_\varkappa} \lesssim |\varkappa|^{-(\frac12+s)} \| f \|_{X^\sigma_\kappa \cap L^\infty_t H^{s+1}_\varkappa} \| g \|_{X^\sigma_\kappa \cap L^\infty_t H^{s+1}_\varkappa}. \end{align} $$
$$ \begin{align} \| f g \|_{X^\sigma_\kappa \cap L^\infty_t H^{s+1}_\varkappa} \lesssim |\varkappa|^{-(\frac12+s)} \| f \|_{X^\sigma_\kappa \cap L^\infty_t H^{s+1}_\varkappa} \| g \|_{X^\sigma_\kappa \cap L^\infty_t H^{s+1}_\varkappa}. \end{align} $$
All estimates are uniform in
 $\kappa $
and
$\kappa $
and
 $\varkappa $
.
$\varkappa $
.
Proof. By translation invariance, it suffices to prove the estimates for a fixed choice of
 $\psi _h$
on the left-hand side. For simplicity, we take
$\psi _h$
on the left-hand side. For simplicity, we take
 $h=0$
.
$h=0$
.
We start with (2.14). By Plancherel, we have
 $$ \begin{align*} &4\varkappa^2\big\|\tfrac{\psi^6f}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}^2 + \big\|\tfrac{\psi^6f}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+2}}^2 \approx \big\|\tfrac{(2\varkappa - \partial)(\psi^6f)}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}^2. \end{align*} $$
$$ \begin{align*} &4\varkappa^2\big\|\tfrac{\psi^6f}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}^2 + \big\|\tfrac{\psi^6f}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+2}}^2 \approx \big\|\tfrac{(2\varkappa - \partial)(\psi^6f)}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^{\sigma+1}}^2. \end{align*} $$
On the other hand,
 $(2\varkappa - \partial )(\psi ^6f) = \psi ^6 (2\varkappa - \partial )f - (\psi ^6)' f$
. Thus, the first inequality in (2.14) follows from (2.8); the second is elementary.
$(2\varkappa - \partial )(\psi ^6f) = \psi ^6 (2\varkappa - \partial )f - (\psi ^6)' f$
. Thus, the first inequality in (2.14) follows from (2.8); the second is elementary.
For the product estimates (2.16) and (2.15), we first decompose dyadically to obtain
 $$ \begin{align} \|\tfrac{\psi^6fg}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{\sigma+1}}^2\approx \sum_{N} \tfrac{N^{2\sigma+2}}{\kappa^2 + N^2} \Big| \sum_{N_1,N_2} \big\|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\big\|_{L^2_{t,x}} \Big|^2. \end{align} $$
$$ \begin{align} \|\tfrac{\psi^6fg}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{\sigma+1}}^2\approx \sum_{N} \tfrac{N^{2\sigma+2}}{\kappa^2 + N^2} \Big| \sum_{N_1,N_2} \big\|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\big\|_{L^2_{t,x}} \Big|^2. \end{align} $$
For the high-low interactions, where
 $N_2\ll N_1\approx N$
, we use Bernstein’s inequality at low frequency to bound
$N_2\ll N_1\approx N$
, we use Bernstein’s inequality at low frequency to bound
 $$ \begin{align*} \|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\|_{L^2_{t,x}} &\lesssim \|(\psi^3 f)_{N_1}\|_{L^2_{t,x}}\|(\psi^3g)_{N_2}\|_{L^\infty_{t,x}}\\ &\lesssim N_2^{\frac12}(|\varkappa| + N_2)^{-(s+1)}\|(\psi^3 f)_{N_1}\|_{L^2_{t,x}}\|g\|_{L^\infty_t H^{s+1}_\varkappa}. \end{align*} $$
$$ \begin{align*} \|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\|_{L^2_{t,x}} &\lesssim \|(\psi^3 f)_{N_1}\|_{L^2_{t,x}}\|(\psi^3g)_{N_2}\|_{L^\infty_{t,x}}\\ &\lesssim N_2^{\frac12}(|\varkappa| + N_2)^{-(s+1)}\|(\psi^3 f)_{N_1}\|_{L^2_{t,x}}\|g\|_{L^\infty_t H^{s+1}_\varkappa}. \end{align*} $$
After summing in
 $N,N_1,N_2$
, we obtain a contribution to
$N,N_1,N_2$
, we obtain a contribution to
 $\mathrm {RHS}$
(2.18) that is
$\mathrm {RHS}$
(2.18) that is
 $$\begin{align*}\lesssim |\varkappa|^{-2(s+\frac12)}\|f\|_{X^\sigma_\kappa}^2\|g\|_{L^\infty_t H^{s+1}_\varkappa}^2. \end{align*}$$
$$\begin{align*}\lesssim |\varkappa|^{-2(s+\frac12)}\|f\|_{X^\sigma_\kappa}^2\|g\|_{L^\infty_t H^{s+1}_\varkappa}^2. \end{align*}$$
For the high-high interactions where
 $N\lesssim N_1\approx N_2$
, we use Bernstein’s inequality at the output frequency to bound
$N\lesssim N_1\approx N_2$
, we use Bernstein’s inequality at the output frequency to bound
 $$ \begin{align*} \|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\|_{L^2_{t,x}} &\lesssim N^{\frac12}\|(\psi^3f)_{N_1}(\psi^3g)_{N_2}\|_{L^2_tL^1} \\ &\lesssim N^{\frac12}(|\varkappa| + N_1)^{-(s+1)}\|(\psi^3 f)_{N_1}\|_{L^2_{t,x}}\|g\|_{L^\infty_t H^{s+1}_\varkappa}. \end{align*} $$
$$ \begin{align*} \|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\|_{L^2_{t,x}} &\lesssim N^{\frac12}\|(\psi^3f)_{N_1}(\psi^3g)_{N_2}\|_{L^2_tL^1} \\ &\lesssim N^{\frac12}(|\varkappa| + N_1)^{-(s+1)}\|(\psi^3 f)_{N_1}\|_{L^2_{t,x}}\|g\|_{L^\infty_t H^{s+1}_\varkappa}. \end{align*} $$
After summation, we again obtain a contribution to
 $\mathrm {RHS}$
(2.18) that is
$\mathrm {RHS}$
(2.18) that is
 $$\begin{align*}\lesssim |\varkappa|^{-2(s+\frac12)}\|f\|_{X^\sigma_\kappa}^2\|g\|_{L^\infty_t H^{s+1}_\varkappa}^2. \end{align*}$$
$$\begin{align*}\lesssim |\varkappa|^{-2(s+\frac12)}\|f\|_{X^\sigma_\kappa}^2\|g\|_{L^\infty_t H^{s+1}_\varkappa}^2. \end{align*}$$
For the low-high interactions, where
 $N_1\ll N_2\approx N$
, we proceed similarly to the case of the high-low interactions, using Bernstein’s inequality at low frequency to bound
$N_1\ll N_2\approx N$
, we proceed similarly to the case of the high-low interactions, using Bernstein’s inequality at low frequency to bound
 $$ \begin{align*} \|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\|_{L^2_{t,x}} &\lesssim \|(\psi^3f)_{N_1}\|_{L^\infty_{t,x}}\|(\psi^3g)_{N_2}\|_{L^2_{t,x}}\\ &\lesssim N_1^{\frac12}(|\varkappa| + N_1)^{-(s+1)}\|f\|_{L^\infty_t H^{s+1}_\varkappa}\|(\psi^3g)_{N_2}\|_{L^2_{t,x}}. \end{align*} $$
$$ \begin{align*} \|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\|_{L^2_{t,x}} &\lesssim \|(\psi^3f)_{N_1}\|_{L^\infty_{t,x}}\|(\psi^3g)_{N_2}\|_{L^2_{t,x}}\\ &\lesssim N_1^{\frac12}(|\varkappa| + N_1)^{-(s+1)}\|f\|_{L^\infty_t H^{s+1}_\varkappa}\|(\psi^3g)_{N_2}\|_{L^2_{t,x}}. \end{align*} $$
In this case, we obtain a contribution to
 $\mathrm {RHS}$
(2.18) that is
$\mathrm {RHS}$
(2.18) that is
 $$\begin{align*}\lesssim |\varkappa|^{-2(s+\frac12)}\|f\|_{L^\infty_t H^{s+1}_\varkappa}^2\|g\|_{X^\sigma_\kappa}^2. \end{align*}$$
$$\begin{align*}\lesssim |\varkappa|^{-2(s+\frac12)}\|f\|_{L^\infty_t H^{s+1}_\varkappa}^2\|g\|_{X^\sigma_\kappa}^2. \end{align*}$$
This completes the proof of (2.15). Alternatively, we may bound
 $$ \begin{align*} \|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\|_{L^2_{t,x}}\lesssim N_1^{\frac12}(|\varkappa| + N_1)^{-s}\|f\|_{L^\infty_t H^s_\varkappa}\|(\psi^3g)_{N_2}\|_{L^2_{t,x}}, \end{align*} $$
$$ \begin{align*} \|P_N\big[(\psi^3f)_{N_1}(\psi^3g)_{N_2}\big]\|_{L^2_{t,x}}\lesssim N_1^{\frac12}(|\varkappa| + N_1)^{-s}\|f\|_{L^\infty_t H^s_\varkappa}\|(\psi^3g)_{N_2}\|_{L^2_{t,x}}, \end{align*} $$
to obtain a contribution to
 $\mathrm {RHS}$
(2.18) of
$\mathrm {RHS}$
(2.18) of
 $$\begin{align*}\lesssim |\varkappa|^{-2(s+\frac12)}\|f\|_{L^\infty_t H^s_\varkappa}^2\Big(|\varkappa|\|g\|_{X^\sigma_\kappa} + \|g\|_{X^{\sigma+1}_\kappa}\Big)^2, \end{align*}$$
$$\begin{align*}\lesssim |\varkappa|^{-2(s+\frac12)}\|f\|_{L^\infty_t H^s_\varkappa}^2\Big(|\varkappa|\|g\|_{X^\sigma_\kappa} + \|g\|_{X^{\sigma+1}_\kappa}\Big)^2, \end{align*}$$
which completes the proof of (2.16).
2.3. Operator estimates
For
 $0<\sigma <1$
and
$0<\sigma <1$
and
 $|\kappa |\geq 1$
, we define the operator
$|\kappa |\geq 1$
, we define the operator
 $(\kappa \mp \partial )^{-\sigma }$
using the Fourier multiplier
$(\kappa \mp \partial )^{-\sigma }$
using the Fourier multiplier
 $(\kappa \mp i\xi )^{-\sigma }$
, where, for
$(\kappa \mp i\xi )^{-\sigma }$
, where, for
 $\arg z\in (-\pi ,\pi ]$
, we define
$\arg z\in (-\pi ,\pi ]$
, we define
 $$ \begin{align} z^{-\sigma} = |z|^{-\sigma}e^{-i\sigma \arg z}. \end{align} $$
$$ \begin{align} z^{-\sigma} = |z|^{-\sigma}e^{-i\sigma \arg z}. \end{align} $$
We observe that with this convention, for all
 $|\kappa |\geq 1$
, we have
$|\kappa |\geq 1$
, we have
 $$\begin{align*}\left((\kappa \mp \partial)^{-\sigma}\right)^* = (\kappa \pm \partial)^{-\sigma}, \end{align*}$$
$$\begin{align*}\left((\kappa \mp \partial)^{-\sigma}\right)^* = (\kappa \pm \partial)^{-\sigma}, \end{align*}$$
and readily obtain the estimate
 $$\begin{align*}\left\|(\kappa \mp \partial)^{-\sigma}\right\|_{\mathrm{op}}\leq |\kappa|^{-\sigma}. \end{align*}$$
$$\begin{align*}\left\|(\kappa \mp \partial)^{-\sigma}\right\|_{\mathrm{op}}\leq |\kappa|^{-\sigma}. \end{align*}$$
We will make frequent use of the following Hilbert–Schmidt estimates:
Lemma 2.5. For all
 $q\in H^s_\kappa ({{\mathbb {R}}})$
,
$q\in H^s_\kappa ({{\mathbb {R}}})$
,
 $$ \begin{align} \|(\kappa - \partial)^{\frac s2-\frac14}q(\kappa + \partial)^{\frac s2 - \frac14}\|_{\mathfrak I_2}^2 &\lesssim \|q\|_{H^s_\kappa}^2, \end{align} $$
$$ \begin{align} \|(\kappa - \partial)^{\frac s2-\frac14}q(\kappa + \partial)^{\frac s2 - \frac14}\|_{\mathfrak I_2}^2 &\lesssim \|q\|_{H^s_\kappa}^2, \end{align} $$
 $$ \begin{align} \|(\kappa - \partial)^s q(\kappa + \partial)^{- \frac34 -\frac s2}\|_{\mathfrak I_2}^2 &\lesssim \kappa^{-\frac12(1+2s)}\|q\|_{H^s_\kappa}^2, \end{align} $$
$$ \begin{align} \|(\kappa - \partial)^s q(\kappa + \partial)^{- \frac34 -\frac s2}\|_{\mathfrak I_2}^2 &\lesssim \kappa^{-\frac12(1+2s)}\|q\|_{H^s_\kappa}^2, \end{align} $$
 $$ \begin{align} \|(\kappa - \partial)^{-\frac12}q(\kappa + \partial)^{-\frac12}\|_{\mathfrak I_2}^2 &\approx \int \log\big(4 + \tfrac{\xi^2}{\kappa^2}\big)\frac{|\hat q(\xi)|^2}{\sqrt{4\kappa^2 + \xi^2}}\,d\xi. \end{align} $$
$$ \begin{align} \|(\kappa - \partial)^{-\frac12}q(\kappa + \partial)^{-\frac12}\|_{\mathfrak I_2}^2 &\approx \int \log\big(4 + \tfrac{\xi^2}{\kappa^2}\big)\frac{|\hat q(\xi)|^2}{\sqrt{4\kappa^2 + \xi^2}}\,d\xi. \end{align} $$
Moreover, for any real
 $|\kappa |\geq 1$
,
$|\kappa |\geq 1$
,
 $$ \begin{align} \|(\kappa - \partial)^{-(1+s)} f (\kappa + \partial)^{-(1+s)}\|_{\mathrm{op}} &\lesssim \kappa^{-\frac12(1+2s)} \|f\|_{H^{-(1+s)}_\kappa}. \end{align} $$
$$ \begin{align} \|(\kappa - \partial)^{-(1+s)} f (\kappa + \partial)^{-(1+s)}\|_{\mathrm{op}} &\lesssim \kappa^{-\frac12(1+2s)} \|f\|_{H^{-(1+s)}_\kappa}. \end{align} $$
Proof. By scaling, it suffices to consider
 $\kappa = 1$
. By Plancherel’s theorem, we have
$\kappa = 1$
. By Plancherel’s theorem, we have
 $$ \begin{align*} \|(1 - \partial)^{-\alpha}q(1 + \partial)^{-\beta}\|_{\mathfrak I_2}^2 &= \operatorname{\mathrm{tr}}\left\{(1 - \partial^2)^{-\alpha}q(1 - \partial^2)^{-\beta}\bar q\right\}\\ &= \tfrac1{2\pi}\iint \frac{|\hat q(\xi-\eta)|^2\,d\eta\, d\xi}{\left(1 + \xi ^2\right)^{\alpha}\left(1 + \eta^2\right)^{\beta}}. \end{align*} $$
$$ \begin{align*} \|(1 - \partial)^{-\alpha}q(1 + \partial)^{-\beta}\|_{\mathfrak I_2}^2 &= \operatorname{\mathrm{tr}}\left\{(1 - \partial^2)^{-\alpha}q(1 - \partial^2)^{-\beta}\bar q\right\}\\ &= \tfrac1{2\pi}\iint \frac{|\hat q(\xi-\eta)|^2\,d\eta\, d\xi}{\left(1 + \xi ^2\right)^{\alpha}\left(1 + \eta^2\right)^{\beta}}. \end{align*} $$
For the particular choices of
 $\alpha $
and
$\alpha $
and
 $\beta $
relevant to (2.20) and (2.21), we have
$\beta $
relevant to (2.20) and (2.21), we have
 $$\begin{align*}\int \frac1{\left(1 + (\xi + \eta)^2\right)^{\alpha}\left(1 + \eta^2\right)^{\beta}}\,d\eta \lesssim (4 + \xi^2)^s, \end{align*}$$
$$\begin{align*}\int \frac1{\left(1 + (\xi + \eta)^2\right)^{\alpha}\left(1 + \eta^2\right)^{\beta}}\,d\eta \lesssim (4 + \xi^2)^s, \end{align*}$$
from which we obtain (2.20). The estimate (2.22) can be proved in a parallel manner (see [Reference Killip, Vişan and Zhang38, Lemma 4.1]).
Arguing by duality, the key observation to prove (2.23) is that
 $$ \begin{align*}\bigg| \int f g h \,dx \bigg| \lesssim |\kappa|^{-\frac12(1+2s)}\| f \|_{H^{-(1+s)}_\kappa} \| g \|_{H^{1+s}_\kappa} \| h \|_{H^{1+s}_\kappa}, \end{align*} $$
$$ \begin{align*}\bigg| \int f g h \,dx \bigg| \lesssim |\kappa|^{-\frac12(1+2s)}\| f \|_{H^{-(1+s)}_\kappa} \| g \|_{H^{1+s}_\kappa} \| h \|_{H^{1+s}_\kappa}, \end{align*} $$
which combines the duality of
 $H^\sigma _\kappa $
and
$H^\sigma _\kappa $
and
 $H^{-\sigma }_\kappa $
with the algebra property (2.5).
$H^{-\sigma }_\kappa $
with the algebra property (2.5).
Our next two lemmas are devoted to similar bounds, but employing the local smoothing norm on the right-hand side. The former employs the local smoothing norm pertinent to (NLS), while the latter is relevant to (mKdV).
By introducing spatial localization, we obtain the following improvements:
Lemma 2.6. We have the estimates
 $$ \begin{align} &\|(\varkappa - \partial)^{-\frac12}(\psi_h q)(\varkappa + \partial)^{-\frac12}\|_{L^2_t\mathfrak I_2}^2\lesssim |\varkappa|^{-1}\kappa^{- \frac{4s}3}\Big(\|q\|_{X^{s+\frac12}_\kappa}^2 + \|q\|_{L^\infty_t H^s}^2\Big), \end{align} $$
$$ \begin{align} &\|(\varkappa - \partial)^{-\frac12}(\psi_h q)(\varkappa + \partial)^{-\frac12}\|_{L^2_t\mathfrak I_2}^2\lesssim |\varkappa|^{-1}\kappa^{- \frac{4s}3}\Big(\|q\|_{X^{s+\frac12}_\kappa}^2 + \|q\|_{L^\infty_t H^s}^2\Big), \end{align} $$
 $$ \begin{align} \|(\varkappa - \partial)^{-\frac12}(\psi_hq)(\varkappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^4 \lesssim |\varkappa|^{-3} \big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\|q\|_{L^\infty_tH^s}^2\Big(\|q\|_{X^{s+\frac12}_\kappa}^2 + \|q\|_{L^\infty_t H^s}^2\Big), \end{align} $$
$$ \begin{align} \|(\varkappa - \partial)^{-\frac12}(\psi_hq)(\varkappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^4 \lesssim |\varkappa|^{-3} \big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\|q\|_{L^\infty_tH^s}^2\Big(\|q\|_{X^{s+\frac12}_\kappa}^2 + \|q\|_{L^\infty_t H^s}^2\Big), \end{align} $$
uniformly for
 $|\varkappa |\geq \kappa ^{\frac 23}\geq 1$
,
$|\varkappa |\geq \kappa ^{\frac 23}\geq 1$
,
 $q\in \mathcal C([-1,1];H^s)\cap X^{s+\frac 12}_\kappa $
, and
$q\in \mathcal C([-1,1];H^s)\cap X^{s+\frac 12}_\kappa $
, and
 $h\in {{\mathbb {R}}}$
.
$h\in {{\mathbb {R}}}$
.
Proof. By translation invariance, it suffices to consider the case
 $h=0$
. Given a dyadic number
$h=0$
. Given a dyadic number
 $N\geq 1$
, we define
$N\geq 1$
, we define
 $$\begin{align*}\Lambda_N = (\varkappa - \partial)^{-\frac12}(\psi q)_N(\varkappa + \partial)^{-\frac12}, \end{align*}$$
$$\begin{align*}\Lambda_N = (\varkappa - \partial)^{-\frac12}(\psi q)_N(\varkappa + \partial)^{-\frac12}, \end{align*}$$
presaging the notation (3.5). Employing (2.22), we may bound
 $$ \begin{align} \|\Lambda_N\|_{L^2_t\mathfrak I_2}^2 \lesssim \frac{ \log(4 + \tfrac{N^2}{\varkappa^2})}{N^{2s} (|\varkappa|+N)}\min\Big\{\|q\|_{L^\infty_t H^s}^2, \ \frac{(\kappa + N)^2}{N^{3}}\|q\|_{X^{s+\frac12}_\kappa}^2\Big\}. \end{align} $$
$$ \begin{align} \|\Lambda_N\|_{L^2_t\mathfrak I_2}^2 \lesssim \frac{ \log(4 + \tfrac{N^2}{\varkappa^2})}{N^{2s} (|\varkappa|+N)}\min\Big\{\|q\|_{L^\infty_t H^s}^2, \ \frac{(\kappa + N)^2}{N^{3}}\|q\|_{X^{s+\frac12}_\kappa}^2\Big\}. \end{align} $$
The estimate (2.24) now follows by taking a square root and summing over
 $N\in 2^{\mathbb {N}}$
.
$N\in 2^{\mathbb {N}}$
.
From Bernstein’s inequality, we have
 $$\begin{align*}\|\Lambda_N\|_{L^\infty_t \mathrm{op}} \lesssim |\varkappa|^{-1} \|(\psi q)_N\|_{L^\infty_{t,x}}\lesssim |\varkappa|^{-1}N^{\frac12 -s}\|q\|_{L^\infty_tH^s}, \end{align*}$$
$$\begin{align*}\|\Lambda_N\|_{L^\infty_t \mathrm{op}} \lesssim |\varkappa|^{-1} \|(\psi q)_N\|_{L^\infty_{t,x}}\lesssim |\varkappa|^{-1}N^{\frac12 -s}\|q\|_{L^\infty_tH^s}, \end{align*}$$
which combined with the first part of (2.26) yields
 $$ \begin{align} \|\Lambda_N\|_{L^\infty_t \mathrm{op}} \lesssim N^{-s}\min \Big\{ |\varkappa|^{-1}N^{\frac12},(|\varkappa| + N)^{-\frac12}\big[\log(4 + \tfrac{N^2}{\varkappa^2})\big]^{\frac12}\Big\}\|q\|_{L^\infty_tH^s}. \end{align} $$
$$ \begin{align} \|\Lambda_N\|_{L^\infty_t \mathrm{op}} \lesssim N^{-s}\min \Big\{ |\varkappa|^{-1}N^{\frac12},(|\varkappa| + N)^{-\frac12}\big[\log(4 + \tfrac{N^2}{\varkappa^2})\big]^{\frac12}\Big\}\|q\|_{L^\infty_tH^s}. \end{align} $$
Thus, we may prove (2.25) via first interpolating between (2.26) and (2.27), and then summing over
 $N\in 2^{\mathbb {N}}$
. This is most easily accomplished by breaking the sum at
$N\in 2^{\mathbb {N}}$
. This is most easily accomplished by breaking the sum at
 $\kappa ^{\frac 23}$
and
$\kappa ^{\frac 23}$
and
 $|\varkappa |$
.
$|\varkappa |$
.
Lemma 2.7. Fix
 $2\leq p <\infty $
. Then
$2\leq p <\infty $
. Then
 $$ \begin{align*} & \|(\varkappa - \partial)^{-\frac12}(\psi_h q)(\varkappa + \partial)^{-\frac12}\|_{L^p_t\mathfrak I_p}^p \\ &\quad \lesssim |\varkappa|^{1-p} \Big[ \kappa^{\frac p2(\frac12-s)-\frac12} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{p(\frac12-s)-3} \log^p\big|\tfrac{4\varkappa^2}{\kappa}\big| \Big] \Big[\|q\|_{X^{s+1}_\kappa}^2 + \|q\|_{L^\infty_t H^s}^2\Big], \notag \end{align*} $$
$$ \begin{align*} & \|(\varkappa - \partial)^{-\frac12}(\psi_h q)(\varkappa + \partial)^{-\frac12}\|_{L^p_t\mathfrak I_p}^p \\ &\quad \lesssim |\varkappa|^{1-p} \Big[ \kappa^{\frac p2(\frac12-s)-\frac12} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{p(\frac12-s)-3} \log^p\big|\tfrac{4\varkappa^2}{\kappa}\big| \Big] \Big[\|q\|_{X^{s+1}_\kappa}^2 + \|q\|_{L^\infty_t H^s}^2\Big], \notag \end{align*} $$
uniformly for
 $|\varkappa |\geq \kappa ^{\frac 12}\geq 1$
,
$|\varkappa |\geq \kappa ^{\frac 12}\geq 1$
,
 $q\in \mathcal C([-1,1];B_\delta )\cap X^{s+1}_\kappa $
, and
$q\in \mathcal C([-1,1];B_\delta )\cap X^{s+1}_\kappa $
, and
 $h\in {{\mathbb {R}}}$
. Moreover, the factor
$h\in {{\mathbb {R}}}$
. Moreover, the factor
 $(1+\tfrac {\kappa ^2}{\varkappa ^2})$
may be deleted if
$(1+\tfrac {\kappa ^2}{\varkappa ^2})$
may be deleted if
 $p\leq 5$
.
$p\leq 5$
.
Proof. We mimic the proof of Lemma 2.6, replacing (2.26) with
 $$ \begin{align} \|\Lambda_N\|_{L^2_t\mathfrak I_2}^2 &\lesssim \frac{\log(4 + \tfrac{N^2}{\varkappa^2})}{N^{2s}(|\varkappa|+N)} \min\Big\{\|q\|_{L^\infty_t H^s}^2,\ \frac{(\kappa + N)^2}{N^{4}}\|q\|_{X^{s+1}_\kappa}^2\Big\} \end{align} $$
$$ \begin{align} \|\Lambda_N\|_{L^2_t\mathfrak I_2}^2 &\lesssim \frac{\log(4 + \tfrac{N^2}{\varkappa^2})}{N^{2s}(|\varkappa|+N)} \min\Big\{\|q\|_{L^\infty_t H^s}^2,\ \frac{(\kappa + N)^2}{N^{4}}\|q\|_{X^{s+1}_\kappa}^2\Big\} \end{align} $$
and reusing (2.27). We simply interpolate and then sum. Note that the logarithmic factor is only necessary when
 $p(\frac 12-s)\in \{3,5\}$
. When
$p(\frac 12-s)\in \{3,5\}$
. When
 $p\leq 5$
, the extra factor can be neglected due to the other summand and the constraint
$p\leq 5$
, the extra factor can be neglected due to the other summand and the constraint
 $\smash {|\varkappa |\geq \kappa ^{\frac 12}}$
.
$\smash {|\varkappa |\geq \kappa ^{\frac 12}}$
.
In order to apply Lemmas 2.6 and 2.7, we will need to bring some power of the localizing function
 $\psi $
adjacent to copies of q and r. This is the role of the following:
$\psi $
adjacent to copies of q and r. This is the role of the following:
Lemma 2.8 (Multiplicative commutators).
For
 $|\varkappa |,|\kappa |\geq 1$
,
$|\varkappa |,|\kappa |\geq 1$
,
 $\sigma \in {{\mathbb {R}}}$
, and any integer
$\sigma \in {{\mathbb {R}}}$
, and any integer
 $|\ell |\leq 12$
, we have the following estimate uniformly for
$|\ell |\leq 12$
, we have the following estimate uniformly for
 $h\in {{\mathbb {R}}}$
and
$h\in {{\mathbb {R}}}$
and
 $u\in \mathcal {S}$
,
$u\in \mathcal {S}$
,
 $$ \begin{align} \|\psi_h^\ell(\varkappa - \partial)^{-1}\psi_h^{-\ell} u \|_{H^{\sigma}_\kappa} \lesssim_{\sigma} \| (\varkappa - \partial)^{-1} u \|_{H^{\sigma}_\kappa}. \end{align} $$
$$ \begin{align} \|\psi_h^\ell(\varkappa - \partial)^{-1}\psi_h^{-\ell} u \|_{H^{\sigma}_\kappa} \lesssim_{\sigma} \| (\varkappa - \partial)^{-1} u \|_{H^{\sigma}_\kappa}. \end{align} $$
Further, if
 $N\geq 1$
is a dyadic integer,
$N\geq 1$
is a dyadic integer,
 $1\leq p\leq \infty $
, and
$1\leq p\leq \infty $
, and
 $n\geq 0$
, we have
$n\geq 0$
, we have
 $$ \begin{align} \|\psi_h^{\ell}\tfrac{\partial^n}{4\kappa^2 - \partial^2}\psi_h^{-\ell}P_N\|_{L^p\rightarrow L^p}\lesssim_{n} \tfrac{N^n}{(\kappa + N)^2}. \end{align} $$
$$ \begin{align} \|\psi_h^{\ell}\tfrac{\partial^n}{4\kappa^2 - \partial^2}\psi_h^{-\ell}P_N\|_{L^p\rightarrow L^p}\lesssim_{n} \tfrac{N^n}{(\kappa + N)^2}. \end{align} $$
Proof. By translation invariance, it suffices to consider the case
 $h=0$
.
$h=0$
.
Using Schur’s test and the explicit kernel (3.3), we find
 $$ \begin{align} \|\psi^{-\ell} (\varkappa - \partial)^{-1}\psi^\ell\|_{L^p\to L^p}\lesssim \varkappa^{-1}. \end{align} $$
$$ \begin{align} \|\psi^{-\ell} (\varkappa - \partial)^{-1}\psi^\ell\|_{L^p\to L^p}\lesssim \varkappa^{-1}. \end{align} $$
We will need this shortly. It is important, here, that the exponential decay of the convolution kernel is faster than that of the function
 $\psi ^\ell $
. This is a reason both for the large constant
$\psi ^\ell $
. This is a reason both for the large constant
 $99$
appearing in (1.5) and for requiring a bound on the size of
$99$
appearing in (1.5) and for requiring a bound on the size of
 $\ell $
.
$\ell $
.
We first consider the estimate (2.29). By duality, it suffices to consider the case
 $\sigma \geq 0$
. For
$\sigma \geq 0$
. For
 $z\in \mathbb {C}$
, we write
$z\in \mathbb {C}$
, we write
 $$\begin{align*}B_\ell(z) := (4\kappa^2 - \partial^2)^{\frac{z}2}\psi^\ell (\varkappa - \partial)^{-1}\psi^{-\ell}(\varkappa - \partial) (4\kappa^2 - \partial^2)^{-\frac{z}2}, \end{align*}$$
$$\begin{align*}B_\ell(z) := (4\kappa^2 - \partial^2)^{\frac{z}2}\psi^\ell (\varkappa - \partial)^{-1}\psi^{-\ell}(\varkappa - \partial) (4\kappa^2 - \partial^2)^{-\frac{z}2}, \end{align*}$$
with the intention of using complex interpolation to prove
 $\|B_\ell (\sigma )\|\lesssim _{\sigma ,\ell } 1$
, which implies (2.29). As imaginary powers of
$\|B_\ell (\sigma )\|\lesssim _{\sigma ,\ell } 1$
, which implies (2.29). As imaginary powers of
 $\kappa ^2 - \partial ^2$
are unitary, we find
$\kappa ^2 - \partial ^2$
are unitary, we find
 $$\begin{align*}\|B_\ell(\sigma)\|_{\mathrm{op}} \leq \|B_\ell(0)\|_{\mathrm{op}}^{(m-\sigma)/m} \|B_\ell(m)\|_{\mathrm{op}}^{\sigma/m} \end{align*}$$
$$\begin{align*}\|B_\ell(\sigma)\|_{\mathrm{op}} \leq \|B_\ell(0)\|_{\mathrm{op}}^{(m-\sigma)/m} \|B_\ell(m)\|_{\mathrm{op}}^{\sigma/m} \end{align*}$$
for any integer
 $m\geq \sigma $
. For concreteness, we choose the least such integer.
$m\geq \sigma $
. For concreteness, we choose the least such integer.
Combining
 $|\psi '|\lesssim \psi $
and (2.31) with the rewriting
$|\psi '|\lesssim \psi $
and (2.31) with the rewriting
 $$ \begin{align*} B_\ell(0)= 1 + \psi^\ell (\varkappa - \partial)^{-1} \psi^{-\ell} \big[\psi^\ell \big(\partial \psi^{-\ell}\big)\big], \quad\text{yields}\quad \|B_\ell(0)\|_{\mathrm{op}} \lesssim 1. \end{align*} $$
$$ \begin{align*} B_\ell(0)= 1 + \psi^\ell (\varkappa - \partial)^{-1} \psi^{-\ell} \big[\psi^\ell \big(\partial \psi^{-\ell}\big)\big], \quad\text{yields}\quad \|B_\ell(0)\|_{\mathrm{op}} \lesssim 1. \end{align*} $$
Turning our attention now to
 $B_\ell (m)$
, we notice that
$B_\ell (m)$
, we notice that
 $$ \begin{align*}\tilde B_\ell(m) = (2\kappa+\partial)^m B_\ell(0) (2\kappa+\partial)^{-m} \quad\text{satisfies}\quad \|\tilde B_\ell(m)\|_{\mathrm{op}} =\|B_\ell(m)\|_{\mathrm{op}}; \end{align*} $$
$$ \begin{align*}\tilde B_\ell(m) = (2\kappa+\partial)^m B_\ell(0) (2\kappa+\partial)^{-m} \quad\text{satisfies}\quad \|\tilde B_\ell(m)\|_{\mathrm{op}} =\|B_\ell(m)\|_{\mathrm{op}}; \end{align*} $$
moreover, we may expand
 $\tilde B_\ell (m)$
as
$\tilde B_\ell (m)$
as
 $$ \begin{align*}1 + \sum \tbinom{m}{m_1,m_2,m_3,m_4} \big[ \psi^{-\ell} \big(\partial^{m_2} \psi^\ell\big)\big] \big[ \psi^{\ell} (\varkappa - \partial)^{-1} \psi^{-\ell} \big]\big[\psi^{\ell} \big( \partial^{1+m_3}\psi^{-\ell} \big)\big] \Big[\tfrac{(2\kappa)^{m_1} \partial^{m_4}}{(2\kappa+\partial)^{m}}\Big], \end{align*} $$
$$ \begin{align*}1 + \sum \tbinom{m}{m_1,m_2,m_3,m_4} \big[ \psi^{-\ell} \big(\partial^{m_2} \psi^\ell\big)\big] \big[ \psi^{\ell} (\varkappa - \partial)^{-1} \psi^{-\ell} \big]\big[\psi^{\ell} \big( \partial^{1+m_3}\psi^{-\ell} \big)\big] \Big[\tfrac{(2\kappa)^{m_1} \partial^{m_4}}{(2\kappa+\partial)^{m}}\Big], \end{align*} $$
where the sum is over all decompositions
 $m=m_1+m_2+m_3+m_4$
using nonnegative integers. The key observation that finishes the proof is that each operator in square brackets is bounded; indeed, for every
$m=m_1+m_2+m_3+m_4$
using nonnegative integers. The key observation that finishes the proof is that each operator in square brackets is bounded; indeed, for every
 $n\geq 0$
, we have
$n\geq 0$
, we have
 $$ \begin{align} | \partial^n \psi(x) | \lesssim_n \psi(x), \quad\text{whence}\quad \| \psi^{-\ell}(\partial^{n} \psi^\ell) \|_{L^\infty} \lesssim_{n} 1 \end{align} $$
$$ \begin{align} | \partial^n \psi(x) | \lesssim_n \psi(x), \quad\text{whence}\quad \| \psi^{-\ell}(\partial^{n} \psi^\ell) \|_{L^\infty} \lesssim_{n} 1 \end{align} $$
for any integers
 $\ell $
and
$\ell $
and
 $n\geq 0$
.
$n\geq 0$
.
The proof of (2.30) employs similar ideas: We first write
 $$\begin{align*}\psi^{\ell}\tfrac{\partial^n}{4\kappa^2 - \partial^2}\psi^{-\ell}P_N = \sum_{m=0}^n\tbinom nm \psi^\ell \tfrac1{4\kappa^2 - \partial^2} (\partial^m \psi^{-\ell}) (4\kappa^2 - \partial^2)\tfrac{\partial^{n-m}}{4\kappa^2 - \partial^2}P_N, \end{align*}$$
$$\begin{align*}\psi^{\ell}\tfrac{\partial^n}{4\kappa^2 - \partial^2}\psi^{-\ell}P_N = \sum_{m=0}^n\tbinom nm \psi^\ell \tfrac1{4\kappa^2 - \partial^2} (\partial^m \psi^{-\ell}) (4\kappa^2 - \partial^2)\tfrac{\partial^{n-m}}{4\kappa^2 - \partial^2}P_N, \end{align*}$$
which shows that we need only prove
 $$ \begin{align} \|(4\kappa^2 - \partial^2) (\partial^m \psi^{-\ell}) \tfrac1{2\kappa - \partial}\psi^{\ell} \psi^{-\ell}\tfrac1{2\kappa + \partial}\psi^{\ell}\|_{L^{p'}\rightarrow L^{p'}}\lesssim_{m}1. \end{align} $$
$$ \begin{align} \|(4\kappa^2 - \partial^2) (\partial^m \psi^{-\ell}) \tfrac1{2\kappa - \partial}\psi^{\ell} \psi^{-\ell}\tfrac1{2\kappa + \partial}\psi^{\ell}\|_{L^{p'}\rightarrow L^{p'}}\lesssim_{m}1. \end{align} $$
This is easily verified, by commuting the derivatives and employing (2.31) and (2.32).
3. The diagonal Green’s functions
The role of this section is to introduce three central characters in the analysis, namely,
 $g_{12}$
,
$g_{12}$
,
 $g_{21}$
, and
$g_{21}$
, and
 $\gamma $
, and to develop some basic estimates for them. What unifies these objects is that they all arise from the Green’s function associated to the Lax operator
$\gamma $
, and to develop some basic estimates for them. What unifies these objects is that they all arise from the Green’s function associated to the Lax operator
 $L(\kappa )$
introduced in (1.9). Recall
$L(\kappa )$
introduced in (1.9). Recall
 $$ \begin{align} L(\kappa) = L_0(\kappa) + \begin{bmatrix}0 & q\\-r&0 \end{bmatrix},\quad\text{where}\quad L_0(\kappa) := \begin{bmatrix}\kappa - \partial & 0\\0&\kappa + \partial\end{bmatrix}. \end{align} $$
$$ \begin{align} L(\kappa) = L_0(\kappa) + \begin{bmatrix}0 & q\\-r&0 \end{bmatrix},\quad\text{where}\quad L_0(\kappa) := \begin{bmatrix}\kappa - \partial & 0\\0&\kappa + \partial\end{bmatrix}. \end{align} $$
We shall only consider
 $\kappa \in {{\mathbb {R}}}$
with
$\kappa \in {{\mathbb {R}}}$
with
 $|\kappa |\geq 1$
. Note that
$|\kappa |\geq 1$
. Note that
 $$ \begin{align} L(\kappa)^* = \begin{cases} -L(-\kappa) \quad & \text{in the defocusing case} r=\bar q,\\ -[\begin{smallmatrix} 1&\ 0\\0&-1\end{smallmatrix}]L(-\kappa) [\begin{smallmatrix} 1& 0\\0&-1\end{smallmatrix}] & \text{in the focusing case} r=-\bar q. \end{cases} \end{align} $$
$$ \begin{align} L(\kappa)^* = \begin{cases} -L(-\kappa) \quad & \text{in the defocusing case} r=\bar q,\\ -[\begin{smallmatrix} 1&\ 0\\0&-1\end{smallmatrix}]L(-\kappa) [\begin{smallmatrix} 1& 0\\0&-1\end{smallmatrix}] & \text{in the focusing case} r=-\bar q. \end{cases} \end{align} $$
Evidently, both identities hold for
 $L_0$
, since then
$L_0$
, since then
 $q=r=0$
.
$q=r=0$
.
We will be constructing the Green’s function, which is matrix valued, perturbatively from the case
 $q=r=0$
. By direct computation, one finds that
$q=r=0$
. By direct computation, one finds that
 $$\begin{align*}R_0(\kappa) := L_0(\kappa)^{-1} = \begin{bmatrix}(\kappa - \partial)^{-1} & 0\\0&(\kappa + \partial)^{-1}\end{bmatrix} \end{align*}$$
$$\begin{align*}R_0(\kappa) := L_0(\kappa)^{-1} = \begin{bmatrix}(\kappa - \partial)^{-1} & 0\\0&(\kappa + \partial)^{-1}\end{bmatrix} \end{align*}$$
admits the integral kernel

For
 $\kappa <0$
, we may use
$\kappa <0$
, we may use
 $G_0(x,y;-\kappa ) =-G_0(y,x;\kappa )$
, which follows from (3.2).
$G_0(x,y;-\kappa ) =-G_0(y,x;\kappa )$
, which follows from (3.2).
Formally, at least, the resolvent identity indicates that
 $R(\kappa ):=L(\kappa )^{-1}$
can be expressed as
$R(\kappa ):=L(\kappa )^{-1}$
can be expressed as
 $$ \begin{align} R = R_0 + \sum_{\ell = 1}^\infty (-1)^{\ell}\sqrt{R_0}\left(\sqrt{R_0}(L - L_0)\sqrt{R_0}\right)^\ell\sqrt{R_0}. \end{align} $$
$$ \begin{align} R = R_0 + \sum_{\ell = 1}^\infty (-1)^{\ell}\sqrt{R_0}\left(\sqrt{R_0}(L - L_0)\sqrt{R_0}\right)^\ell\sqrt{R_0}. \end{align} $$
Here, and below, fractional powers of
 $R_0$
are defined via (2.19). This series forms the foundation of everything in this section; its convergence will be verified shortly as part of proving Proposition 3.1. With a view to this, we adopt the following notations:
$R_0$
are defined via (2.19). This series forms the foundation of everything in this section; its convergence will be verified shortly as part of proving Proposition 3.1. With a view to this, we adopt the following notations:
 $$ \begin{align} \Lambda := (\kappa - \partial)^{-\frac12}q(\kappa + \partial)^{-\frac12} \quad\text{and}\quad \Gamma := (\kappa + \partial)^{-\frac12}r(\kappa - \partial)^{-\frac12}, \end{align} $$
$$ \begin{align} \Lambda := (\kappa - \partial)^{-\frac12}q(\kappa + \partial)^{-\frac12} \quad\text{and}\quad \Gamma := (\kappa + \partial)^{-\frac12}r(\kappa - \partial)^{-\frac12}, \end{align} $$
whose significance is that
 $$ \begin{align} \sqrt{R_0}(L - L_0)\sqrt{R_0} = \begin{bmatrix} 0 &\Lambda \\ -\Gamma & 0\end{bmatrix}. \end{align} $$
$$ \begin{align} \sqrt{R_0}(L - L_0)\sqrt{R_0} = \begin{bmatrix} 0 &\Lambda \\ -\Gamma & 0\end{bmatrix}. \end{align} $$
These operators also satisfy
 $$ \begin{align} \|\Lambda\|_{\mathfrak I_2} = \|\Gamma\|_{\mathfrak I_2} \lesssim |\kappa|^{-(s+\frac12)}\|q\|_{H^s_\kappa}, \end{align} $$
$$ \begin{align} \|\Lambda\|_{\mathfrak I_2} = \|\Gamma\|_{\mathfrak I_2} \lesssim |\kappa|^{-(s+\frac12)}\|q\|_{H^s_\kappa}, \end{align} $$
as is easily deduced from either (2.20) or (2.22).
Proposition 3.1 (Existence of the Green’s function).
There exists
 $\delta>0$
so that
$\delta>0$
so that
 $L(\kappa )$
is invertible, as an operator on
$L(\kappa )$
is invertible, as an operator on
 $L^2({{\mathbb {R}}})$
, for all
$L^2({{\mathbb {R}}})$
, for all
 $q\in B_\delta $
and all real
$q\in B_\delta $
and all real
 $|\kappa |\geq 1$
. The inverse
$|\kappa |\geq 1$
. The inverse
 $R(\kappa ):=L(\kappa )^{-1}$
admits an integral kernel
$R(\kappa ):=L(\kappa )^{-1}$
admits an integral kernel
 $G(x,y;\kappa )$
so that
$G(x,y;\kappa )$
so that
 $$ \begin{align} q \mapsto G - G_0 \end{align} $$
$$ \begin{align} q \mapsto G - G_0 \end{align} $$
is a continuous mapping from
 $H^s_\kappa ({{\mathbb {R}}})$
to the space of Hilbert–Schmidt operators from
$H^s_\kappa ({{\mathbb {R}}})$
to the space of Hilbert–Schmidt operators from
 $H^{-\frac 34 - \frac s2}_\kappa $
to
$H^{-\frac 34 - \frac s2}_\kappa $
to
 $H^{\frac 34 + \frac s2}_\kappa $
. Moreover,
$H^{\frac 34 + \frac s2}_\kappa $
. Moreover,
 $G-G_0$
is continuous as a function of
$G-G_0$
is continuous as a function of
 $(x,y)\in {{\mathbb {R}}}^2$
. Lastly,
$(x,y)\in {{\mathbb {R}}}^2$
. Lastly,
 $$ \begin{align} \partial_xG(x,y;\kappa) &= \begin{bmatrix}\kappa&q(x)\\r(x)&-\kappa\end{bmatrix}G(x,y;\kappa) + \begin{bmatrix}-\delta(x-y)&0\\0&\delta(x-y)\end{bmatrix}, \end{align} $$
$$ \begin{align} \partial_xG(x,y;\kappa) &= \begin{bmatrix}\kappa&q(x)\\r(x)&-\kappa\end{bmatrix}G(x,y;\kappa) + \begin{bmatrix}-\delta(x-y)&0\\0&\delta(x-y)\end{bmatrix}, \end{align} $$
 $$ \begin{align} \partial_yG(x,y;\kappa) &= G(x,y;\kappa)\begin{bmatrix}-\kappa&q(y)\\r(y)&\kappa\end{bmatrix} + \begin{bmatrix}\delta(x-y)&0\\0&-\delta(x-y)\end{bmatrix}, \end{align} $$
$$ \begin{align} \partial_yG(x,y;\kappa) &= G(x,y;\kappa)\begin{bmatrix}-\kappa&q(y)\\r(y)&\kappa\end{bmatrix} + \begin{bmatrix}\delta(x-y)&0\\0&-\delta(x-y)\end{bmatrix}, \end{align} $$
in the sense of distributions.
Proof. From (3.7), we have
 $$ \begin{align*}\big\| \sqrt{R_0}(L - L_0)\sqrt{R_0} \,\big\|_{\mathfrak I_2}\leq \sqrt2 \|\Lambda\|_{\mathfrak I_2} \lesssim \|q\|_{H^s_\kappa} \lesssim \delta \end{align*} $$
$$ \begin{align*}\big\| \sqrt{R_0}(L - L_0)\sqrt{R_0} \,\big\|_{\mathfrak I_2}\leq \sqrt2 \|\Lambda\|_{\mathfrak I_2} \lesssim \|q\|_{H^s_\kappa} \lesssim \delta \end{align*} $$
uniformly for
 $|\kappa |\geq 1$
. Thus, for
$|\kappa |\geq 1$
. Thus, for
 $\delta>0$
sufficiently small, the series (3.4) converges in operator norm uniformly for
$\delta>0$
sufficiently small, the series (3.4) converges in operator norm uniformly for
 $|\kappa |\geq 1$
. It is elementary to then verify that the sum acts as a (two-sided) inverse to
$|\kappa |\geq 1$
. It is elementary to then verify that the sum acts as a (two-sided) inverse to
 $L(\kappa )$
.
$L(\kappa )$
.
This argument also yields that
 $R-R_0 \in \mathfrak I_2$
. In particular, it admits an integral kernel in
$R-R_0 \in \mathfrak I_2$
. In particular, it admits an integral kernel in
 $L^2({{\mathbb {R}}}^2)$
. To prove (3.8) is continuous, we only need to verify that the series defining
$L^2({{\mathbb {R}}}^2)$
. To prove (3.8) is continuous, we only need to verify that the series defining
 $R-R_0$
converges in the sense of Hilbert–Schmidt operators from
$R-R_0$
converges in the sense of Hilbert–Schmidt operators from
 $H^{-\frac 34 - \frac s2}_\kappa $
to
$H^{-\frac 34 - \frac s2}_\kappa $
to
 $H^{\frac 34 + \frac s2}_\kappa $
. This follows readily from (2.20).
$H^{\frac 34 + \frac s2}_\kappa $
. This follows readily from (2.20).
The continuity of
 $G-G_0$
as a function of
$G-G_0$
as a function of
 $(x,y)$
follows from the Hilbert–Schmidt bound on (3.8) because
$(x,y)$
follows from the Hilbert–Schmidt bound on (3.8) because
 $\frac 34 + \frac s2>\frac 12$
.
$\frac 34 + \frac s2>\frac 12$
.
For regular q, the identities (3.9) and (3.10) precisely express the fact that G is an integral kernel for
 $R(\kappa )$
. The issue of how to make sense of them for irregular q is settled by (3.8).
$R(\kappa )$
. The issue of how to make sense of them for irregular q is settled by (3.8).
From the jump discontinuities evident in (3.3), we see that one cannot expect to restrict
 $G(x,y;\kappa )$
to the
$G(x,y;\kappa )$
to the
 $x=y$
diagonal in a meaningful way. However, as we have just shown,
$x=y$
diagonal in a meaningful way. However, as we have just shown,
 $G-G_0$
is continuous. This allows us to unambiguously define the continuous functions
$G-G_0$
is continuous. This allows us to unambiguously define the continuous functions
 $$ \begin{align*} \gamma(x;\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa)\big[ G_{11}(x,x;\kappa) + G_{22}(x,x;\kappa) \big] - 1,\\ g_{12}(x;\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa) G_{12}(x,x;\kappa),\\ g_{21}(x;\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa) G_{21}(x,x;\kappa). \end{align*} $$
$$ \begin{align*} \gamma(x;\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa)\big[ G_{11}(x,x;\kappa) + G_{22}(x,x;\kappa) \big] - 1,\\ g_{12}(x;\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa) G_{12}(x,x;\kappa),\\ g_{21}(x;\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa) G_{21}(x,x;\kappa). \end{align*} $$
Here, subscripts indicate matrix entries. While the inclusion of the factor
 $\operatorname {\mathrm {sgn}}(\kappa )$
may seem unnecessary, it has the esthetical virtue of eliminating corresponding factors in many subsequent formulas, such as (3.12)–(3.14) below.
$\operatorname {\mathrm {sgn}}(\kappa )$
may seem unnecessary, it has the esthetical virtue of eliminating corresponding factors in many subsequent formulas, such as (3.12)–(3.14) below.
If
 $q\in B_\delta \cap \mathcal {S}$
, we may use the identities (3.9) and (3.10) for G to obtain
$q\in B_\delta \cap \mathcal {S}$
, we may use the identities (3.9) and (3.10) for G to obtain
 $$ \begin{align} \gamma' &= 2\left(qg_{21} + rg_{12}\right), \end{align} $$
$$ \begin{align} \gamma' &= 2\left(qg_{21} + rg_{12}\right), \end{align} $$
 $$ \begin{align} g_{12}' &= 2\kappa g_{12} + q[\gamma + 1], \end{align} $$
$$ \begin{align} g_{12}' &= 2\kappa g_{12} + q[\gamma + 1], \end{align} $$
 $$ \begin{align} g_{21}' &= - 2\kappa g_{21} + r[\gamma + 1], \end{align} $$
$$ \begin{align} g_{21}' &= - 2\kappa g_{21} + r[\gamma + 1], \end{align} $$
in the sense of distributions. Combining (3.11), (3.12), and (3.13) yields the further identity
 $$ \begin{align} \nonumber 2(\kappa-\varkappa)&\big[ g_{12}(\kappa)g_{21}(\varkappa) - g_{21}(\kappa)g_{12}(\varkappa) \big]\\ &= \partial_x \big\{ g_{12}(\kappa)g_{21}(\varkappa) + g_{21}(\kappa)g_{12}(\varkappa) - \tfrac{[\gamma(\kappa)+1][\gamma(\varkappa)+1]}{2}\big\}, \end{align} $$
$$ \begin{align} \nonumber 2(\kappa-\varkappa)&\big[ g_{12}(\kappa)g_{21}(\varkappa) - g_{21}(\kappa)g_{12}(\varkappa) \big]\\ &= \partial_x \big\{ g_{12}(\kappa)g_{21}(\varkappa) + g_{21}(\kappa)g_{12}(\varkappa) - \tfrac{[\gamma(\kappa)+1][\gamma(\varkappa)+1]}{2}\big\}, \end{align} $$
which recurs several times in our analysis. From (3.2), we also have
 $$ \begin{align} \gamma(\kappa) &= \bar \gamma(-\kappa) \quad\text{and}\quad g_{12}(\kappa) = \pm \bar g_{21}(-\kappa). \end{align} $$
$$ \begin{align} \gamma(\kappa) &= \bar \gamma(-\kappa) \quad\text{and}\quad g_{12}(\kappa) = \pm \bar g_{21}(-\kappa). \end{align} $$
From the series representation (3.4) of the resolvent, we naturally can deduce corresponding series representations of
 $g_{12}$
,
$g_{12}$
,
 $g_{21}$
, and
$g_{21}$
, and
 $\gamma $
. These are effectively power-series in terms of q and r, albeit with each term being a paraproduct, rather than a monomial. In what follows, we shall often need to discuss individual terms in these series so, being sensitive to the order of such terms in q and r, we adopt the following notations:
$\gamma $
. These are effectively power-series in terms of q and r, albeit with each term being a paraproduct, rather than a monomial. In what follows, we shall often need to discuss individual terms in these series so, being sensitive to the order of such terms in q and r, we adopt the following notations:
 $$ \begin{align} g_{12}^{[2m+1]}(\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa) (-1)^{m-1}\Big\langle \delta_x,\ (\kappa - \partial)^{-\frac12}\Lambda \left(\Gamma\Lambda\right)^m(\kappa + \partial)^{-\frac12}\delta_x\Big\rangle, \end{align} $$
$$ \begin{align} g_{12}^{[2m+1]}(\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa) (-1)^{m-1}\Big\langle \delta_x,\ (\kappa - \partial)^{-\frac12}\Lambda \left(\Gamma\Lambda\right)^m(\kappa + \partial)^{-\frac12}\delta_x\Big\rangle, \end{align} $$
 $$ \begin{align} g_{21}^{[2m+1]}(\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa) (-1)^{m}\Big\langle \delta_x,\ (\kappa + \partial)^{-\frac12}\Gamma \left(\Lambda\Gamma\right)^m(\kappa - \partial)^{-\frac12}\delta_x\Big\rangle,\quad \end{align} $$
$$ \begin{align} g_{21}^{[2m+1]}(\kappa) &:= \operatorname{\mathrm{sgn}}(\kappa) (-1)^{m}\Big\langle \delta_x,\ (\kappa + \partial)^{-\frac12}\Gamma \left(\Lambda\Gamma\right)^m(\kappa - \partial)^{-\frac12}\delta_x\Big\rangle,\quad \end{align} $$
with
 $g_{12}^{[2m]}(\kappa )=g_{21}^{[2m]}(\kappa ):= 0$
, and similarly,
$g_{12}^{[2m]}(\kappa )=g_{21}^{[2m]}(\kappa ):= 0$
, and similarly,
 $\gamma ^{[2m+1]}(\kappa ):=0$
and
$\gamma ^{[2m+1]}(\kappa ):=0$
and
 $$ \begin{align} \nonumber \gamma^{[2m]}(\kappa) &:= (-1)^m \operatorname{\mathrm{sgn}}(\kappa)\Big\langle \delta_x,\ (\kappa - \partial)^{-\frac12}(\Lambda\Gamma)^m(\kappa - \partial)^{-\frac12}\delta_x\Big\rangle \\ &\quad + (-1)^m\operatorname{\mathrm{sgn}}(\kappa)\Big\langle \delta_x,\ (\kappa + \partial)^{-\frac12}(\Gamma\Lambda)^m (\kappa + \partial)^{-\frac12}\delta_x\Big\rangle. \end{align} $$
$$ \begin{align} \nonumber \gamma^{[2m]}(\kappa) &:= (-1)^m \operatorname{\mathrm{sgn}}(\kappa)\Big\langle \delta_x,\ (\kappa - \partial)^{-\frac12}(\Lambda\Gamma)^m(\kappa - \partial)^{-\frac12}\delta_x\Big\rangle \\ &\quad + (-1)^m\operatorname{\mathrm{sgn}}(\kappa)\Big\langle \delta_x,\ (\kappa + \partial)^{-\frac12}(\Gamma\Lambda)^m (\kappa + \partial)^{-\frac12}\delta_x\Big\rangle. \end{align} $$
In this way, we see that
 $$ \begin{align} g_{12}(\kappa) = \sum_{\ell=1}^\infty g_{12}^{[\ell]}(\kappa),\quad g_{21}(\kappa) = \sum_{\ell=1}^\infty g_{21}^{[\ell]}(\kappa), \quad\text{and}\quad \gamma(\kappa) = \sum_{\ell=2}^\infty \gamma^{[\ell]}(\kappa). \end{align} $$
$$ \begin{align} g_{12}(\kappa) = \sum_{\ell=1}^\infty g_{12}^{[\ell]}(\kappa),\quad g_{21}(\kappa) = \sum_{\ell=1}^\infty g_{21}^{[\ell]}(\kappa), \quad\text{and}\quad \gamma(\kappa) = \sum_{\ell=2}^\infty \gamma^{[\ell]}(\kappa). \end{align} $$
In particular, we note that the expansion of
 $g_{12}$
contains only terms with q appearing once more than r, while the expansion of
$g_{12}$
contains only terms with q appearing once more than r, while the expansion of
 $\gamma $
contains only terms of even order, with q and r appearing equally. Analogous to our notation for individual terms, we write tails of these series as
$\gamma $
contains only terms of even order, with q and r appearing equally. Analogous to our notation for individual terms, we write tails of these series as
 $$ \begin{align*}g_{12}^{[\geq m]}(\kappa) := \sum_{\ell=m}^\infty g_{12}^{[\ell]}(\kappa). \end{align*} $$
$$ \begin{align*}g_{12}^{[\geq m]}(\kappa) := \sum_{\ell=m}^\infty g_{12}^{[\ell]}(\kappa). \end{align*} $$
We also extend these “square bracket” notations to algebraic combinations of these series (see, for example, (3.38)).
For small indices, it is possible to find explicit representations of the individual paraproducts via the explicit form of
 $G_0$
; however, this quickly becomes overwhelming. A more systematic approach can be based on iteration of the identities
$G_0$
; however, this quickly becomes overwhelming. A more systematic approach can be based on iteration of the identities
 $$ \begin{align*}g_{12} = - (2\kappa-\partial)^{-1} [q+\gamma q],\quad g_{21} = (2\kappa+\partial)^{-1} [r+\gamma r], \quad\text{and}\quad \gamma = 2g_{12} g_{21} -\tfrac12 \gamma^2, \end{align*} $$
$$ \begin{align*}g_{12} = - (2\kappa-\partial)^{-1} [q+\gamma q],\quad g_{21} = (2\kappa+\partial)^{-1} [r+\gamma r], \quad\text{and}\quad \gamma = 2g_{12} g_{21} -\tfrac12 \gamma^2, \end{align*} $$
which follow from (3.12), (3.13), and (3.31), respectively. Pursuing either method, one is led to
 $$ \begin{align} g_{12}^{[1]}(\kappa) = - \tfrac q{2\kappa - \partial},\qquad g_{12}^{[3]} (\kappa)= \tfrac2{2\kappa - \partial}\big(q\cdot\tfrac r{2\kappa + \partial}\cdot \tfrac q{2\kappa - \partial}\big), \end{align} $$
$$ \begin{align} g_{12}^{[1]}(\kappa) = - \tfrac q{2\kappa - \partial},\qquad g_{12}^{[3]} (\kappa)= \tfrac2{2\kappa - \partial}\big(q\cdot\tfrac r{2\kappa + \partial}\cdot \tfrac q{2\kappa - \partial}\big), \end{align} $$
 $$ \begin{align} g_{21}^{[1]}(\kappa) = \tfrac r{2\kappa + \partial},\qquad\hphantom{-} g_{21}^{[3]} (\kappa)= \tfrac{-2}{2\kappa + \partial}\big(r\cdot \tfrac q{2\kappa - \partial}\cdot\tfrac r{2\kappa + \partial}\big), \end{align} $$
$$ \begin{align} g_{21}^{[1]}(\kappa) = \tfrac r{2\kappa + \partial},\qquad\hphantom{-} g_{21}^{[3]} (\kappa)= \tfrac{-2}{2\kappa + \partial}\big(r\cdot \tfrac q{2\kappa - \partial}\cdot\tfrac r{2\kappa + \partial}\big), \end{align} $$
as well as
 $$ \begin{align} \gamma^{[2]}(\kappa) &= - 2\,\tfrac q{2\kappa - \partial}\cdot\tfrac r{2\kappa + \partial},\quad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad \end{align} $$
$$ \begin{align} \gamma^{[2]}(\kappa) &= - 2\,\tfrac q{2\kappa - \partial}\cdot\tfrac r{2\kappa + \partial},\quad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad \end{align} $$
 $$ \begin{align} \gamma^{[4]}(\kappa) &= \tfrac q{2\kappa - \partial}\cdot \tfrac 4{2\kappa + \partial}\big(r\cdot\tfrac q{2\kappa - \partial}\cdot \tfrac r{2\kappa + \partial}\big) + \tfrac4{2\kappa - \partial}\big(q\cdot\tfrac r{2\kappa + \partial}\cdot \tfrac q{2\kappa - \partial}\big)\cdot \tfrac r{2\kappa + \partial} \\ &\quad - 2\,\tfrac q{2\kappa - \partial}\cdot\tfrac r{2\kappa + \partial}\cdot \tfrac q{2\kappa - \partial}\cdot\tfrac r{2\kappa + \partial}. \notag \end{align} $$
$$ \begin{align} \gamma^{[4]}(\kappa) &= \tfrac q{2\kappa - \partial}\cdot \tfrac 4{2\kappa + \partial}\big(r\cdot\tfrac q{2\kappa - \partial}\cdot \tfrac r{2\kappa + \partial}\big) + \tfrac4{2\kappa - \partial}\big(q\cdot\tfrac r{2\kappa + \partial}\cdot \tfrac q{2\kappa - \partial}\big)\cdot \tfrac r{2\kappa + \partial} \\ &\quad - 2\,\tfrac q{2\kappa - \partial}\cdot\tfrac r{2\kappa + \partial}\cdot \tfrac q{2\kappa - \partial}\cdot\tfrac r{2\kappa + \partial}. \notag \end{align} $$
Here, dots emphasize occurrences of pointwise multiplication.
With these preliminaries out of the way, we are now ready to present some basic estimates on
 $g_{12}$
,
$g_{12}$
,
 $g_{21}$
, and
$g_{21}$
, and
 $\gamma $
. Propositions 3.2 and 3.3 focus on properties that hold pointwise in time; later in Lemma 3.4 and Corollary 3.5, we employ local smoothing spaces.
$\gamma $
. Propositions 3.2 and 3.3 focus on properties that hold pointwise in time; later in Lemma 3.4 and Corollary 3.5, we employ local smoothing spaces.
Proposition 3.2 (Properties of
 $g_{12}$
and
$g_{21}$
).
$g_{12}$
and
$g_{21}$
).


There exists
 $\delta>0$
so that for all real
$\delta>0$
so that for all real
 $|\kappa |\geq 1$
, the maps
$|\kappa |\geq 1$
, the maps
 $q\mapsto g_{12}(\kappa )$
and
$q\mapsto g_{12}(\kappa )$
and
 $q\mapsto g_{21}(\kappa )$
are (real analytic) diffeomorphisms of
$q\mapsto g_{21}(\kappa )$
are (real analytic) diffeomorphisms of
 $B_\delta $
into
$B_\delta $
into
 $H^{s+1}$
satisfying the estimates
$H^{s+1}$
satisfying the estimates
 $$ \begin{align} \|g_{12}(\kappa)\|_{H^{s+1}_\kappa} + \|g_{21}(\kappa)\|_{H^{s+1}_\kappa} \lesssim \|q\|_{H^s_\kappa}. \end{align} $$
$$ \begin{align} \|g_{12}(\kappa)\|_{H^{s+1}_\kappa} + \|g_{21}(\kappa)\|_{H^{s+1}_\kappa} \lesssim \|q\|_{H^s_\kappa}. \end{align} $$
Further, the remainders satisfy the estimate
 $$ \begin{align} \|g_{12}^{[\geq 3]}(\kappa)\|_{H^{s+1}_\kappa} + \|g_{21}^{[\geq 3]}(\kappa)\|_{H^{s+1}_\kappa} \lesssim |\kappa|^{-(2s+1)}\|q\|_{H^s_\kappa}^3, \end{align} $$
$$ \begin{align} \|g_{12}^{[\geq 3]}(\kappa)\|_{H^{s+1}_\kappa} + \|g_{21}^{[\geq 3]}(\kappa)\|_{H^{s+1}_\kappa} \lesssim |\kappa|^{-(2s+1)}\|q\|_{H^s_\kappa}^3, \end{align} $$
uniformly in
 $\kappa $
. Finally, if q is Schwartz, then so are
$\kappa $
. Finally, if q is Schwartz, then so are
 $g_{12}(\kappa )$
and
$g_{12}(\kappa )$
and
 $g_{21}(\kappa )$
.
$g_{21}(\kappa )$
.
Proof. It suffices to consider the case
 $\kappa \geq 1$
, as the case
$\kappa \geq 1$
, as the case
 $\kappa \leq -1$
is similar; moreover, by (3.15), it suffices to consider
$\kappa \leq -1$
is similar; moreover, by (3.15), it suffices to consider
 $g_{12}(\kappa )$
. Recalling (3.20), we obtain
$g_{12}(\kappa )$
. Recalling (3.20), we obtain
 $$ \begin{align} \|g_{12}^{[1]}(\kappa)\|_{H^{s+1}_\kappa} = \|q\|_{H^s_\kappa}. \end{align} $$
$$ \begin{align} \|g_{12}^{[1]}(\kappa)\|_{H^{s+1}_\kappa} = \|q\|_{H^s_\kappa}. \end{align} $$
To bound the remaining terms in the series, we employ duality and Lemma 2.5:
 $$ \begin{align*} \big|\langle f, g_{12}^{[\geq 3]}(\kappa)\rangle\big|&\leq \|(\kappa + \partial)^{-(1+s)}\bar f(\kappa - \partial)^{-(1+s)}\|_{\mathrm{op}}\|(\kappa - \partial)^s q (\kappa+\partial)^{-(\frac34+\frac s2)}\|_{\mathfrak I_2}^2\\ &\qquad\qquad \times\sum_{\ell=1}^\infty\|(\kappa - \partial)^{-\frac14+\frac{s}2}q(\kappa + \partial)^{-\frac14+\frac{s}2}\|_{\mathfrak I_2}^{2\ell-1}\kappa^{-(\ell-1)(1+2s)}\\ &\lesssim |\kappa|^{-(2s+1)} \|f\|_{H^{-(1+s)}_\kappa} \|q\|_{H_\kappa^s}^3, \end{align*} $$
$$ \begin{align*} \big|\langle f, g_{12}^{[\geq 3]}(\kappa)\rangle\big|&\leq \|(\kappa + \partial)^{-(1+s)}\bar f(\kappa - \partial)^{-(1+s)}\|_{\mathrm{op}}\|(\kappa - \partial)^s q (\kappa+\partial)^{-(\frac34+\frac s2)}\|_{\mathfrak I_2}^2\\ &\qquad\qquad \times\sum_{\ell=1}^\infty\|(\kappa - \partial)^{-\frac14+\frac{s}2}q(\kappa + \partial)^{-\frac14+\frac{s}2}\|_{\mathfrak I_2}^{2\ell-1}\kappa^{-(\ell-1)(1+2s)}\\ &\lesssim |\kappa|^{-(2s+1)} \|f\|_{H^{-(1+s)}_\kappa} \|q\|_{H_\kappa^s}^3, \end{align*} $$
provided
 $\delta>0$
is sufficiently small. This proves (3.25) and completes the proof of (3.24).
$\delta>0$
is sufficiently small. This proves (3.25) and completes the proof of (3.24).
We wish to apply the inverse function theorem to obtain the diffeomorphism property. At the linearized level, we already have
 $$\begin{align*}\tfrac{\delta g_{12}}{\delta q}(\kappa)\big|_{q=0} = - (2\kappa - \partial)^{-1} \quad\text{and}\quad \tfrac{\delta g_{12}}{\delta r}(\kappa)\big|_{q=0} = 0 \end{align*}$$
$$\begin{align*}\tfrac{\delta g_{12}}{\delta q}(\kappa)\big|_{q=0} = - (2\kappa - \partial)^{-1} \quad\text{and}\quad \tfrac{\delta g_{12}}{\delta r}(\kappa)\big|_{q=0} = 0 \end{align*}$$
which is an isomorphism, as noted already in (3.26). At the nonlinear level, we apply the resolvent identity, which shows that for any test function
 $f\in \mathcal {S}$
, we have
$f\in \mathcal {S}$
, we have
 $$ \begin{align*} {\left.\frac d{d\varepsilon}\right|}_{\varepsilon = 0} G(x,z;q + \varepsilon f) &= -\int G(x,y;q)\begin{bmatrix}0&f(y)\\\mp\bar f(y)&0\end{bmatrix}G(y,z;q)\,dy. \end{align*} $$
$$ \begin{align*} {\left.\frac d{d\varepsilon}\right|}_{\varepsilon = 0} G(x,z;q + \varepsilon f) &= -\int G(x,y;q)\begin{bmatrix}0&f(y)\\\mp\bar f(y)&0\end{bmatrix}G(y,z;q)\,dy. \end{align*} $$
Repeating the analysis used to prove (3.25), we find
 $$ \begin{align*} \big\| \tfrac{\delta g_{12}}{\delta r}(\kappa) \big\|_{H^s_\kappa\rightarrow H^{s+1}_\kappa} + \big\| \tfrac{\delta g_{12}}{\delta q}(\kappa)+ (2\kappa - \partial)^{-1} \big\|_{H^s_\kappa\rightarrow H^{s+1}_\kappa} \lesssim \delta^2|\kappa|^{-(2s+1)} \lesssim \delta^2 \end{align*} $$
$$ \begin{align*} \big\| \tfrac{\delta g_{12}}{\delta r}(\kappa) \big\|_{H^s_\kappa\rightarrow H^{s+1}_\kappa} + \big\| \tfrac{\delta g_{12}}{\delta q}(\kappa)+ (2\kappa - \partial)^{-1} \big\|_{H^s_\kappa\rightarrow H^{s+1}_\kappa} \lesssim \delta^2|\kappa|^{-(2s+1)} \lesssim \delta^2 \end{align*} $$
and so deduce that the diffeomorphism property holds for
 $\delta>0$
sufficiently small, which can be chosen independent of
$\delta>0$
sufficiently small, which can be chosen independent of
 $|\kappa |\geq 1$
.
$|\kappa |\geq 1$
.
Next, we seek to show
 $g_{12} \in \mathcal {S}$
whenever
$g_{12} \in \mathcal {S}$
whenever
 $q\in B_\delta \cap \mathcal {S}$
, beginning with a consideration of derivatives. For any
$q\in B_\delta \cap \mathcal {S}$
, beginning with a consideration of derivatives. For any
 $h\in {{\mathbb {R}}}$
, we have
$h\in {{\mathbb {R}}}$
, we have
 $$\begin{align*}g_{12}(x+h;q) = g_{12}(x;q(\cdot + h)). \end{align*}$$
$$\begin{align*}g_{12}(x+h;q) = g_{12}(x;q(\cdot + h)). \end{align*}$$
In particular, differentiating n times with respect to h and evaluating at
 $h=0$
, we may use duality to bound
$h=0$
, we may use duality to bound
 $$ \begin{align*} \|\partial_x^n g_{12}(\kappa)\|_{H^{s+1}} &\leq \sum\limits_{\ell=0}^\infty\sum\limits_{\substack{\sigma\in \mathbb{N}^{2\ell+1}\\|\sigma| = n}}\binom n\sigma |\kappa|^{-(2s+1)\ell}\prod\limits_{m=1}^{2\ell+1} \|\partial_x^{\sigma_m}q\|_{H^s}\\ &\leq \sum\limits_{\ell=0}^\infty C^{2\ell+1}(2\ell+1)^n|\kappa|^{-(2s+1)\ell} \|q\|_{H^s}^{2\ell}\|\partial_x^nq\|_{H^s}\lesssim_{n}\|\partial_x^nq\|_{H^s}, \end{align*} $$
$$ \begin{align*} \|\partial_x^n g_{12}(\kappa)\|_{H^{s+1}} &\leq \sum\limits_{\ell=0}^\infty\sum\limits_{\substack{\sigma\in \mathbb{N}^{2\ell+1}\\|\sigma| = n}}\binom n\sigma |\kappa|^{-(2s+1)\ell}\prod\limits_{m=1}^{2\ell+1} \|\partial_x^{\sigma_m}q\|_{H^s}\\ &\leq \sum\limits_{\ell=0}^\infty C^{2\ell+1}(2\ell+1)^n|\kappa|^{-(2s+1)\ell} \|q\|_{H^s}^{2\ell}\|\partial_x^nq\|_{H^s}\lesssim_{n}\|\partial_x^nq\|_{H^s}, \end{align*} $$
where the constant
 $C = C(s)> 0$
may be chosen independent of
$C = C(s)> 0$
may be chosen independent of
 $\kappa $
. To handle spatial weights, we observe that
$\kappa $
. To handle spatial weights, we observe that
 $$\begin{align*}x^n(\kappa - \partial)^{-1} = \sum\limits_{m=0}^n(-1)^m \frac{n!}{(n-m)!} (\kappa - \partial)^{-m-1}x^{n-m}. \end{align*}$$
$$\begin{align*}x^n(\kappa - \partial)^{-1} = \sum\limits_{m=0}^n(-1)^m \frac{n!}{(n-m)!} (\kappa - \partial)^{-m-1}x^{n-m}. \end{align*}$$
In particular, by duality, we may bound
 $$ \begin{align*} \|x^ng_{12}(\kappa)\|_{H^{s+1}} &\leq \sum\limits_{\ell=0}^\infty \sum\limits_{m=0}^nC^{2\ell+1}\frac{n!}{(n-m)!} |\kappa|^{-m-(2s+1)\ell}\|x^{n-m}q\|_{H^s}\|q\|_{H^s}^{2\ell}\\ &\lesssim_{n} \|\langle x\rangle^n q\|_{H^s}. \end{align*} $$
$$ \begin{align*} \|x^ng_{12}(\kappa)\|_{H^{s+1}} &\leq \sum\limits_{\ell=0}^\infty \sum\limits_{m=0}^nC^{2\ell+1}\frac{n!}{(n-m)!} |\kappa|^{-m-(2s+1)\ell}\|x^{n-m}q\|_{H^s}\|q\|_{H^s}^{2\ell}\\ &\lesssim_{n} \|\langle x\rangle^n q\|_{H^s}. \end{align*} $$
Combining these, we see that if
 $q\in B_\delta \cap \mathcal {S}$
, then
$q\in B_\delta \cap \mathcal {S}$
, then
 $g_{12}(\kappa )\in \mathcal {S}$
.
$g_{12}(\kappa )\in \mathcal {S}$
.
Proposition 3.3 (Properties of
$\gamma $
).

There exists
 $\delta>0$
so that for all real
$\delta>0$
so that for all real
 $|\kappa |\geq 1$
, the map
$|\kappa |\geq 1$
, the map
 $q\mapsto \gamma (\kappa )$
is bounded from
$q\mapsto \gamma (\kappa )$
is bounded from
 $B_\delta $
to
$B_\delta $
to
 $L^1\cap H^{s+1}$
, and we have the estimates
$L^1\cap H^{s+1}$
, and we have the estimates
 $$ \begin{align} \|\gamma(\kappa)\|_{H^{s+1}_\kappa} &\lesssim |\kappa|^{-(s + \frac12)}\|q\|_{H^s_\kappa}^2, \end{align} $$
$$ \begin{align} \|\gamma(\kappa)\|_{H^{s+1}_\kappa} &\lesssim |\kappa|^{-(s + \frac12)}\|q\|_{H^s_\kappa}^2, \end{align} $$
 $$ \begin{align} \|\gamma(\kappa)\|_{L^\infty} &\lesssim |\kappa|^{-(2s +1)}\|q\|_{H^s_\kappa}^2, \end{align} $$
$$ \begin{align} \|\gamma(\kappa)\|_{L^\infty} &\lesssim |\kappa|^{-(2s +1)}\|q\|_{H^s_\kappa}^2, \end{align} $$
 $$ \begin{align} \|\gamma(\kappa)\|_{L^1} &\lesssim \|q\|_{H^{-1}_\kappa}^2 + |\kappa|^{-2(2s+1)-1}\|q\|_{H^s_\kappa}^4, \end{align} $$
$$ \begin{align} \|\gamma(\kappa)\|_{L^1} &\lesssim \|q\|_{H^{-1}_\kappa}^2 + |\kappa|^{-2(2s+1)-1}\|q\|_{H^s_\kappa}^4, \end{align} $$
 $$ \begin{align} \|\gamma^{[\geq 4]}(\kappa)\|_{L^1}&\lesssim |\kappa|^{-2(2s+1) - 1}\|q\|_{H^s_\kappa}^4, \end{align} $$
$$ \begin{align} \|\gamma^{[\geq 4]}(\kappa)\|_{L^1}&\lesssim |\kappa|^{-2(2s+1) - 1}\|q\|_{H^s_\kappa}^4, \end{align} $$
uniformly in
 $\kappa $
. Further, we have the quadratic identity
$\kappa $
. Further, we have the quadratic identity
 $$ \begin{align} \gamma + \tfrac12\gamma^2 = 2g_{12}g_{21}, \end{align} $$
$$ \begin{align} \gamma + \tfrac12\gamma^2 = 2g_{12}g_{21}, \end{align} $$
and if q is Schwartz, then so is
 $\gamma (\kappa )$
.
$\gamma (\kappa )$
.
Proof. Once again, it suffices to consider the case
 $\kappa \geq 1$
. Using (2.5) and (3.22), we obtain
$\kappa \geq 1$
. Using (2.5) and (3.22), we obtain
 $$ \begin{align*} \|\gamma^{[2]}\|_{H_\kappa^{s+1}}\lesssim \kappa^{-(s+\frac12)}\| q\|_{H^s_\kappa}^2. \end{align*} $$
$$ \begin{align*} \|\gamma^{[2]}\|_{H_\kappa^{s+1}}\lesssim \kappa^{-(s+\frac12)}\| q\|_{H^s_\kappa}^2. \end{align*} $$
To handle
 $\gamma ^{[\geq 4]}$
, we use the series representation (3.19) and the same duality argument used to prove (3.25). The estimate (3.28) then follows from (3.27) via (2.4).
$\gamma ^{[\geq 4]}$
, we use the series representation (3.19) and the same duality argument used to prove (3.25). The estimate (3.28) then follows from (3.27) via (2.4).
Setting
 $\varkappa =\kappa $
in (3.14), we find that
$\varkappa =\kappa $
in (3.14), we find that
 $$ \begin{align*}\partial_x \big\{ 2 g_{12}(x;\kappa)g_{21}(x;\kappa) - \tfrac12\gamma(x;\kappa)^2 - \gamma(x;\kappa) \big\} = 0. \end{align*} $$
$$ \begin{align*}\partial_x \big\{ 2 g_{12}(x;\kappa)g_{21}(x;\kappa) - \tfrac12\gamma(x;\kappa)^2 - \gamma(x;\kappa) \big\} = 0. \end{align*} $$
From (3.24) and (3.27), we see that the term in braces vanishes as
 $|x|\to \infty $
. Thus, the quadratic identity (3.31) follows by integration.
$|x|\to \infty $
. Thus, the quadratic identity (3.31) follows by integration.
By using this quadratic identity, we may write
 $$ \begin{align} \gamma^{[\geq 4]} = - \tfrac12 \gamma^2 + 2g_{12}^{[\geq 3]}\cdot g_{21} + 2g_{12}^{[1]}\cdot g_{21}^{[\geq 3]}. \end{align} $$
$$ \begin{align} \gamma^{[\geq 4]} = - \tfrac12 \gamma^2 + 2g_{12}^{[\geq 3]}\cdot g_{21} + 2g_{12}^{[1]}\cdot g_{21}^{[\geq 3]}. \end{align} $$
By Proposition 3.2 and (3.27), we have
 $$ \begin{align*} \|g_{12}^{[\geq 3]}\|_{L^2}+\|g_{21}^{[\geq 3]}\|_{L^2}&\lesssim |\kappa|^{-(1+s)}\big[\|g_{12}^{[\geq 3]}\|_{H^{s+1}_\kappa}+ \|g_{21}^{[\geq 3]}\|_{H^{s+1}_\kappa}\big] \lesssim |\kappa|^{-(2+3s)}\|q\|_{H^s_\kappa}^3\\ \|g_{12}\|_{L^2}+\|g_{21}\|_{L^2}&\lesssim |\kappa|^{-(1+s)} \big( \|g_{12}\|_{H_\kappa^{s+1}}+\|g_{21}\|_{H_\kappa^{s+1}}\big)\lesssim |\kappa|^{-(1+s)}\|q\|_{H^s_\kappa} \\ \|\gamma\|_{L^2}&\lesssim |\kappa|^{-(1+s)}\|\gamma\|_{H^{s+1}_\kappa}\lesssim|\kappa|^{-(\frac 32 +2s)}\|q\|_{H^s_\kappa}^2. \end{align*} $$
$$ \begin{align*} \|g_{12}^{[\geq 3]}\|_{L^2}+\|g_{21}^{[\geq 3]}\|_{L^2}&\lesssim |\kappa|^{-(1+s)}\big[\|g_{12}^{[\geq 3]}\|_{H^{s+1}_\kappa}+ \|g_{21}^{[\geq 3]}\|_{H^{s+1}_\kappa}\big] \lesssim |\kappa|^{-(2+3s)}\|q\|_{H^s_\kappa}^3\\ \|g_{12}\|_{L^2}+\|g_{21}\|_{L^2}&\lesssim |\kappa|^{-(1+s)} \big( \|g_{12}\|_{H_\kappa^{s+1}}+\|g_{21}\|_{H_\kappa^{s+1}}\big)\lesssim |\kappa|^{-(1+s)}\|q\|_{H^s_\kappa} \\ \|\gamma\|_{L^2}&\lesssim |\kappa|^{-(1+s)}\|\gamma\|_{H^{s+1}_\kappa}\lesssim|\kappa|^{-(\frac 32 +2s)}\|q\|_{H^s_\kappa}^2. \end{align*} $$
Thus
 $$ \begin{align*} \|\gamma^{[\geq 4]}\|_{L^1} &\lesssim \|\gamma\|_{L^2}^2 + \|g_{12}^{[\geq 3]}\|_{L^2}\|g_{21}\|_{L^2} + \|g_{12}^{[1]}\|_{L^2}\|g_{21}^{[\geq 3]}\|_{L^2}\lesssim |\kappa|^{-(3+4s)}\|q\|_{H^s_\kappa}^4, \end{align*} $$
$$ \begin{align*} \|\gamma^{[\geq 4]}\|_{L^1} &\lesssim \|\gamma\|_{L^2}^2 + \|g_{12}^{[\geq 3]}\|_{L^2}\|g_{21}\|_{L^2} + \|g_{12}^{[1]}\|_{L^2}\|g_{21}^{[\geq 3]}\|_{L^2}\lesssim |\kappa|^{-(3+4s)}\|q\|_{H^s_\kappa}^4, \end{align*} $$
which yields the estimate (3.30). The estimate (3.29) then follows from applying the Cauchy-Schwarz inequality to (3.22).
If
 $q\in B_\delta \cap \mathcal {S}$
, then from Proposition 3.2 and the quadratic identity (3.31), we see that
$q\in B_\delta \cap \mathcal {S}$
, then from Proposition 3.2 and the quadratic identity (3.31), we see that
 $\gamma + \frac 12\gamma ^2\in \mathcal {S}$
. As
$\gamma + \frac 12\gamma ^2\in \mathcal {S}$
. As
 $H^{s+1}$
is an algebra, we may then bound
$H^{s+1}$
is an algebra, we may then bound
 $$ \begin{align*} \|\partial_x^n \gamma\|_{H^{s+1}}\left(1 - \|\gamma\|_{H^{s+1}}\right) &\leq \left\|\partial_x^n\left(\gamma + \tfrac12\gamma^2\right)\right\|_{H^{s+1}} + \left(2^{n-1} - 1\right)\|\gamma\|_{H^{n+s}}^2,\\ \|x^n \gamma\|_{H^{s+1}}\left(1 - \|\gamma\|_{H^{s+1}}\right) &\leq \left\|x^n\left(\gamma + \tfrac12\gamma^2\right)\right\|_{H^{s+1}}, \end{align*} $$
$$ \begin{align*} \|\partial_x^n \gamma\|_{H^{s+1}}\left(1 - \|\gamma\|_{H^{s+1}}\right) &\leq \left\|\partial_x^n\left(\gamma + \tfrac12\gamma^2\right)\right\|_{H^{s+1}} + \left(2^{n-1} - 1\right)\|\gamma\|_{H^{n+s}}^2,\\ \|x^n \gamma\|_{H^{s+1}}\left(1 - \|\gamma\|_{H^{s+1}}\right) &\leq \left\|x^n\left(\gamma + \tfrac12\gamma^2\right)\right\|_{H^{s+1}}, \end{align*} $$
so using the estimate (3.27), we see that
 $\gamma (\kappa )\in \mathcal {S}$
, provided
$\gamma (\kappa )\in \mathcal {S}$
, provided
 $0<\delta \ll 1$
is sufficiently small.
$0<\delta \ll 1$
is sufficiently small.
Next, we consider local smoothing estimates for
 $g_{12} = g_{12}(\varkappa )$
and
$g_{12} = g_{12}(\varkappa )$
and
 $\gamma = \gamma (\varkappa )$
. We consider both (NLS) and (mKdV) here, and so must allow two values for
$\gamma = \gamma (\varkappa )$
. We consider both (NLS) and (mKdV) here, and so must allow two values for
 $\sigma $
, namely,
$\sigma $
, namely,
 $s+\frac 12$
and
$s+\frac 12$
and
 $s+1$
. In fact, the proof below works uniformly on the interval
$s+1$
. In fact, the proof below works uniformly on the interval
 $[s+\frac 12,s+1]$
.
$[s+\frac 12,s+1]$
.
Lemma 3.4 (Local smoothing estimates for
$g_{12}$
,
$\gamma $
).


Let
 $\sigma \in \{ s+\frac 12,s+1\}$
. Then there exists
$\sigma \in \{ s+\frac 12,s+1\}$
. Then there exists
 $\delta>0$
, so that for all real
$\delta>0$
, so that for all real
 $|\kappa |\geq 1$
,
$|\kappa |\geq 1$
,
 $|\varkappa |\geq 1$
, and
$|\varkappa |\geq 1$
, and
 $q\in \mathcal C([-1,1];B_\delta )\cap X^\sigma _\kappa $
, the functions
$q\in \mathcal C([-1,1];B_\delta )\cap X^\sigma _\kappa $
, the functions
 $g_{12} = g_{12}(\varkappa )$
and
$g_{12} = g_{12}(\varkappa )$
and
 $\gamma = \gamma (\varkappa )$
satisfy the estimates
$\gamma = \gamma (\varkappa )$
satisfy the estimates
 $$ \begin{align} |\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa} &\lesssim \|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}, \end{align} $$
$$ \begin{align} |\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa} &\lesssim \|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}, \end{align} $$
 $$ \begin{align} |\varkappa|\|g_{12}^{[\geq 3]}\|_{X^\sigma_\kappa} + \|g_{12}^{[\geq 3]}\|_{X^{\sigma+1}_\kappa} &\lesssim |\varkappa|^{-(2s+1)}\|q\|_{L^\infty_t H^s_\varkappa}^2\left(\|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}\right), \end{align} $$
$$ \begin{align} |\varkappa|\|g_{12}^{[\geq 3]}\|_{X^\sigma_\kappa} + \|g_{12}^{[\geq 3]}\|_{X^{\sigma+1}_\kappa} &\lesssim |\varkappa|^{-(2s+1)}\|q\|_{L^\infty_t H^s_\varkappa}^2\left(\|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}\right), \end{align} $$
 $$ \begin{align} |\varkappa|\|\gamma\|_{X^\sigma_\kappa} + \|\gamma\|_{X^{\sigma+1}_\kappa} &\lesssim |\varkappa|^{-(s+\frac12)}\|q\|_{L^\infty_t H^s_\varkappa}\left(\|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}\right), \end{align} $$
$$ \begin{align} |\varkappa|\|\gamma\|_{X^\sigma_\kappa} + \|\gamma\|_{X^{\sigma+1}_\kappa} &\lesssim |\varkappa|^{-(s+\frac12)}\|q\|_{L^\infty_t H^s_\varkappa}\left(\|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}\right), \end{align} $$
where the implicit constants are independent of
 $\kappa ,\varkappa $
.
$\kappa ,\varkappa $
.
Proof. Applying the product estimate (2.15) with the quadratic identity (3.31) and the symmetry relation (3.15), we may bound
 $$ \begin{align*} |\varkappa|\|\gamma\|_{X^\sigma_\kappa} + \|\gamma\|_{X^{\sigma+1}_\kappa}&\lesssim |\varkappa|^{-(s+\frac12)}\|\gamma\|_{L^\infty_t H^{s+1}_\varkappa}\left(|\varkappa|\|\gamma\|_{X^\sigma_\kappa} + \|\gamma\|_{X^{\sigma+1}_\kappa}\right)\\ &\quad +|\varkappa|^{-(s+\frac12)} \max_{\pm\varkappa}\|g_{12}\|_{L^\infty_t H^{s+1}_\varkappa}\max_{\pm\varkappa}\left(|\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa}\right). \end{align*} $$
$$ \begin{align*} |\varkappa|\|\gamma\|_{X^\sigma_\kappa} + \|\gamma\|_{X^{\sigma+1}_\kappa}&\lesssim |\varkappa|^{-(s+\frac12)}\|\gamma\|_{L^\infty_t H^{s+1}_\varkappa}\left(|\varkappa|\|\gamma\|_{X^\sigma_\kappa} + \|\gamma\|_{X^{\sigma+1}_\kappa}\right)\\ &\quad +|\varkappa|^{-(s+\frac12)} \max_{\pm\varkappa}\|g_{12}\|_{L^\infty_t H^{s+1}_\varkappa}\max_{\pm\varkappa}\left(|\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa}\right). \end{align*} $$
In view of (3.27), taking
 $0<\delta \ll 1$
sufficiently small (independently of
$0<\delta \ll 1$
sufficiently small (independently of
 $\varkappa $
) and using (3.24), we get
$\varkappa $
) and using (3.24), we get
 $$ \begin{align} |\varkappa|\|\gamma\|_{X^\sigma_\kappa} + \|\gamma\|_{X^{\sigma+1}_\kappa}\lesssim |\varkappa|^{-(s+\frac12)}\|q\|_{L^\infty_t H^s_\varkappa} \max_{\pm\varkappa}\left(|\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa}\right). \end{align} $$
$$ \begin{align} |\varkappa|\|\gamma\|_{X^\sigma_\kappa} + \|\gamma\|_{X^{\sigma+1}_\kappa}\lesssim |\varkappa|^{-(s+\frac12)}\|q\|_{L^\infty_t H^s_\varkappa} \max_{\pm\varkappa}\left(|\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa}\right). \end{align} $$
As a consequence, the estimate (3.35) follows from the estimate (3.33).
To prove the estimate (3.33), we first apply the estimate (2.14) to obtain
 $$ \begin{align} |\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa} \lesssim \|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s} + |\varkappa|\|g_{12}^{[\geq 3]}\|_{X^\sigma_\kappa} + \|g_{12}^{[\geq 3]}\|_{X^{\sigma+1}_\kappa}. \end{align} $$
$$ \begin{align} |\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa} \lesssim \|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s} + |\varkappa|\|g_{12}^{[\geq 3]}\|_{X^\sigma_\kappa} + \|g_{12}^{[\geq 3]}\|_{X^{\sigma+1}_\kappa}. \end{align} $$
From the identity (3.12) for
 $g_{12}$
, we see that
$g_{12}$
, we see that
 $g_{12}^{[\geq 3]} = -(2\varkappa - \partial )^{-1} (q\gamma )$
. Thus, employing (2.14), we find
$g_{12}^{[\geq 3]} = -(2\varkappa - \partial )^{-1} (q\gamma )$
. Thus, employing (2.14), we find
 $$\begin{align*}|\varkappa|\|g_{12}^{[\geq 3]}\|_{X^\sigma_\kappa} + \|g_{12}^{[\geq 3]}\|_{X^{\sigma+1}_\kappa} \lesssim \|q\gamma\|_{X^\sigma_\kappa} + \|q\gamma\|_{L^\infty_t H^s}. \end{align*}$$
$$\begin{align*}|\varkappa|\|g_{12}^{[\geq 3]}\|_{X^\sigma_\kappa} + \|g_{12}^{[\geq 3]}\|_{X^{\sigma+1}_\kappa} \lesssim \|q\gamma\|_{X^\sigma_\kappa} + \|q\gamma\|_{L^\infty_t H^s}. \end{align*}$$
To continue, we use (2.16) together with (3.27) and (3.36) for
 $\gamma $
to obtain
$\gamma $
to obtain
 $$\begin{align*}\|q\gamma\|_{X^\sigma_\kappa}\lesssim |\varkappa|^{-(2s+1)}\|q\|_{L^\infty_t H^s_\varkappa}^2 \Big[\|q\|_{X^\sigma_\kappa} +\max_{\pm \varkappa}\big(|\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa}\big)\Big]. \end{align*}$$
$$\begin{align*}\|q\gamma\|_{X^\sigma_\kappa}\lesssim |\varkappa|^{-(2s+1)}\|q\|_{L^\infty_t H^s_\varkappa}^2 \Big[\|q\|_{X^\sigma_\kappa} +\max_{\pm \varkappa}\big(|\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa}\big)\Big]. \end{align*}$$
Using (2.6) and (3.27), we may bound
 $$ \begin{align*} \|q\gamma\|_{L^\infty_t H^s}&\lesssim |\varkappa|^{-(2s+1)} \|q\|_{L^\infty_t H^s}\|q\|_{L^\infty_t H^s_\varkappa}^2. \end{align*} $$
$$ \begin{align*} \|q\gamma\|_{L^\infty_t H^s}&\lesssim |\varkappa|^{-(2s+1)} \|q\|_{L^\infty_t H^s}\|q\|_{L^\infty_t H^s_\varkappa}^2. \end{align*} $$
As a consequence,
 $$ \begin{align*} &\max_{\pm \varkappa}\big(|\varkappa|\|g_{12}^{[\geq 3]}\|_{X^\sigma_\kappa} + \|g_{12}^{[\geq 3]}\|_{X^{\sigma+1}_\kappa}\big) \\ &\quad\lesssim |\varkappa|^{-(2s+1)} \|q\|_{L^\infty_t H^s_\varkappa}^2\Big[\|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}+\max_{\pm \varkappa}\big(|\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa}\big)\Big]. \end{align*} $$
$$ \begin{align*} &\max_{\pm \varkappa}\big(|\varkappa|\|g_{12}^{[\geq 3]}\|_{X^\sigma_\kappa} + \|g_{12}^{[\geq 3]}\|_{X^{\sigma+1}_\kappa}\big) \\ &\quad\lesssim |\varkappa|^{-(2s+1)} \|q\|_{L^\infty_t H^s_\varkappa}^2\Big[\|q\|_{X^\sigma_\kappa} + \|q\|_{L^\infty_t H^s}+\max_{\pm \varkappa}\big(|\varkappa|\|g_{12}\|_{X^\sigma_\kappa} + \|g_{12}\|_{X^{\sigma+1}_\kappa}\big)\Big]. \end{align*} $$
Combining this with (3.37) and choosing
 $0<\delta \ll 1$
sufficiently small (independently of
$0<\delta \ll 1$
sufficiently small (independently of
 $\kappa ,\varkappa $
), we obtain (3.33) and so also (3.34).
$\kappa ,\varkappa $
), we obtain (3.33) and so also (3.34).
Due to the structure of our microscopic conservation law, the functions
 $g_{12}$
and
$g_{12}$
and
 $\gamma $
will frequently occur in the combination
$\gamma $
will frequently occur in the combination
 $\frac {g_{12}(\varkappa )}{2 + \gamma (\varkappa )}$
. Naturally, this may also be written as a power series in q and r, and we adapt our square brackets notation accordingly:
$\frac {g_{12}(\varkappa )}{2 + \gamma (\varkappa )}$
. Naturally, this may also be written as a power series in q and r, and we adapt our square brackets notation accordingly:
 $$\begin{align*}\tfrac{g_{12}}{2 + \gamma} = \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]} + \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]} = \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]} + \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[3]} + \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}, \end{align*}$$
$$\begin{align*}\tfrac{g_{12}}{2 + \gamma} = \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]} + \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]} = \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]} + \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[3]} + \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}, \end{align*}$$
where the leading order terms are given by
 $$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]} = \tfrac12 g_{12}^{[1]} \quad\text{and}\quad \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[3]} = \tfrac12 g_{12}^{[3]} - \tfrac14g_{12}^{[1]}\gamma^{[2]}, \end{align} $$
$$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]} = \tfrac12 g_{12}^{[1]} \quad\text{and}\quad \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[3]} = \tfrac12 g_{12}^{[3]} - \tfrac14g_{12}^{[1]}\gamma^{[2]}, \end{align} $$
and the remainders by
 $$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]} &= \tfrac12 g_{12}^{[\geq 3]} - \tfrac{g_{12}\gamma}{2(2 + \gamma)}, \end{align} $$
$$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]} &= \tfrac12 g_{12}^{[\geq 3]} - \tfrac{g_{12}\gamma}{2(2 + \gamma)}, \end{align} $$
 $$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]} &= \tfrac12 g_{12}^{[\geq 5]} - \tfrac14g_{12}^{[1]}\gamma^{[\geq 4]} - \tfrac14g_{12}^{[\geq 3]}\gamma + \tfrac{g_{12}\gamma^2}{4(2 + \gamma)}. \end{align} $$
$$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]} &= \tfrac12 g_{12}^{[\geq 5]} - \tfrac14g_{12}^{[1]}\gamma^{[\geq 4]} - \tfrac14g_{12}^{[\geq 3]}\gamma + \tfrac{g_{12}\gamma^2}{4(2 + \gamma)}. \end{align} $$
Our earlier results yield the following information about these quantities:
Corollary 3.5. Let
 $\sigma \in \{ s+\frac 12,s+1\}$
. Then there exists
$\sigma \in \{ s+\frac 12,s+1\}$
. Then there exists
 $\delta>0$
so that for all real
$\delta>0$
so that for all real
 $|\kappa |\geq 1$
and
$|\kappa |\geq 1$
and
 $|\varkappa |\geq 1$
, we have the estimates
$|\varkappa |\geq 1$
, we have the estimates
 $$ \begin{align} |\varkappa|\big\|\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big\|_{H^s} + \big\| \tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big\|_{H^{s+1}} &\lesssim \|q\|_{H^s}, \end{align} $$
$$ \begin{align} |\varkappa|\big\|\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big\|_{H^s} + \big\| \tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big\|_{H^{s+1}} &\lesssim \|q\|_{H^s}, \end{align} $$
 $$ \begin{align} |\varkappa|\big\|\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{H^s} + \big\| \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{ H^{s+1}} &\lesssim |\varkappa|^{-(2s+1)}\|q\|_{ H^s_\varkappa}^2\|q\|_{H^s}, \end{align} $$
$$ \begin{align} |\varkappa|\big\|\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{H^s} + \big\| \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{ H^{s+1}} &\lesssim |\varkappa|^{-(2s+1)}\|q\|_{ H^s_\varkappa}^2\|q\|_{H^s}, \end{align} $$
for any
 $q\in B_\delta $
. Moreover, for
$q\in B_\delta $
. Moreover, for
 $q\in \mathcal C([-1,1];B_\delta )\cap X^\sigma _\kappa $
,
$q\in \mathcal C([-1,1];B_\delta )\cap X^\sigma _\kappa $
,
 $$ \begin{align} |\varkappa|\big\|\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big\|_{X^\sigma_\kappa} + \big\|\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big\|_{X^{\sigma+1}_\kappa} \lesssim \|q\|_{X^{\sigma}_\kappa} + \|q\|_{L^\infty_t H^s}, \end{align} $$
$$ \begin{align} |\varkappa|\big\|\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big\|_{X^\sigma_\kappa} + \big\|\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big\|_{X^{\sigma+1}_\kappa} \lesssim \|q\|_{X^{\sigma}_\kappa} + \|q\|_{L^\infty_t H^s}, \end{align} $$
 $$ \begin{align} |\varkappa|\big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\big\|_{X^\sigma_\kappa} + \big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\big\|_{X^{\sigma+1}_\kappa} \lesssim |\varkappa|^{-(2s+1)} \|q\|_{L^\infty_t H^s_\varkappa}^2\Big(\|q\|_{X^{\sigma}_\kappa} + \|q\|_{L^\infty_t H^s}\Big), \end{align} $$
$$ \begin{align} |\varkappa|\big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\big\|_{X^\sigma_\kappa} + \big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\big\|_{X^{\sigma+1}_\kappa} \lesssim |\varkappa|^{-(2s+1)} \|q\|_{L^\infty_t H^s_\varkappa}^2\Big(\|q\|_{X^{\sigma}_\kappa} + \|q\|_{L^\infty_t H^s}\Big), \end{align} $$
 $$ \begin{align} |\varkappa|\big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}\big\|_{X^\sigma_\kappa} + \big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}\big\|_{X^{\sigma+1}_\kappa} \lesssim |\varkappa|^{-2(2s+1)} \|q\|_{L^\infty_t H^s_\varkappa}^4\Big(\|q\|_{X^{\sigma}_\kappa} + \|q\|_{L^\infty_t H^s}\Big), \end{align} $$
$$ \begin{align} |\varkappa|\big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}\big\|_{X^\sigma_\kappa} + \big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}\big\|_{X^{\sigma+1}_\kappa} \lesssim |\varkappa|^{-2(2s+1)} \|q\|_{L^\infty_t H^s_\varkappa}^4\Big(\|q\|_{X^{\sigma}_\kappa} + \|q\|_{L^\infty_t H^s}\Big), \end{align} $$
where
 $g_{12}=g_{12}(\varkappa )$
and
$g_{12}=g_{12}(\varkappa )$
and
 $\gamma =\gamma (\varkappa )$
.
$\gamma =\gamma (\varkappa )$
.
Proof. From (3.20) and (3.38), we see that
 $$ \begin{align*}|\varkappa|\big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]}\big\|_{H^s} + \big\| \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]}\big\|_{ H^{s+1}} \approx \big\| (2\varkappa-\partial) \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[1]}\big\|_{ H^s} \approx \|q\|_{H^s}. \end{align*} $$
$$ \begin{align*}|\varkappa|\big\|\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]}\big\|_{H^s} + \big\| \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]}\big\|_{ H^{s+1}} \approx \big\| (2\varkappa-\partial) \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[1]}\big\|_{ H^s} \approx \|q\|_{H^s}. \end{align*} $$
Thus, (3.41) will follow once we prove (3.42). Moreover, using also (3.12), we find
 $$ \begin{align*}(2\varkappa-\partial) \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]} = - \tfrac{\gamma}{2(2+\gamma)} q + \tfrac{g_{12}}{(2 + \gamma)^2} \gamma' \end{align*} $$
$$ \begin{align*}(2\varkappa-\partial) \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]} = - \tfrac{\gamma}{2(2+\gamma)} q + \tfrac{g_{12}}{(2 + \gamma)^2} \gamma' \end{align*} $$
and thence
 $$ \begin{align*} \text{LHS}(3.42) &\lesssim \big\| \tfrac{\gamma}{2+\gamma} q \big\|_{H^s} + \big\| \tfrac{g_{12}}{(2 + \gamma)^2} \gamma' \big\|_{H^{s}} \\ &\lesssim |\varkappa|^{-(s+\frac12)} \|q\|_{H^s} \big\| \tfrac{\gamma}{2+\gamma} \big\|_{ H^{s+1}_\varkappa} + |\varkappa|^{-(2s+1)} \|q\|_{H^s}\|q\|_{H^s_\varkappa} \big\| \tfrac{g_{12}}{(2 + \gamma)^2} \big\|_{ H^{s+1}_\varkappa}, \end{align*} $$
$$ \begin{align*} \text{LHS}(3.42) &\lesssim \big\| \tfrac{\gamma}{2+\gamma} q \big\|_{H^s} + \big\| \tfrac{g_{12}}{(2 + \gamma)^2} \gamma' \big\|_{H^{s}} \\ &\lesssim |\varkappa|^{-(s+\frac12)} \|q\|_{H^s} \big\| \tfrac{\gamma}{2+\gamma} \big\|_{ H^{s+1}_\varkappa} + |\varkappa|^{-(2s+1)} \|q\|_{H^s}\|q\|_{H^s_\varkappa} \big\| \tfrac{g_{12}}{(2 + \gamma)^2} \big\|_{ H^{s+1}_\varkappa}, \end{align*} $$
where the second step was an application of (2.6) and (3.27). To handle the remaining rational functions, we expand as series and employ the algebra property (2.5), together with (3.24) and (3.27). This yields (3.41) for
 $\delta>0$
sufficiently small.
$\delta>0$
sufficiently small.
Next, we prove (3.44), since (3.43) follows from this, (3.38), and (2.14).
In order to prove (3.44), we first employ (3.39). The requisite estimate for the first term was given already in Lemma 3.4. The second summand can be treated by combining that lemma with the algebra property (2.17).
It remains to prove (3.45). Recalling the expansion (3.40), the last two terms are easily controlled using (3.34), (3.35), (3.43), and Lemma 2.4. To control the first two terms, we use (3.12) and (3.32).
4. Conservation laws and dynamics
At a formal level, the logarithmic perturbation determinant
 $\log \operatorname{\mathrm{det}} (L_0^{-1}L)$
(multiplied by
$\log \operatorname{\mathrm{det}} (L_0^{-1}L)$
(multiplied by
 $\operatorname {\mathrm {sgn}}(\kappa )$
) is given by
$\operatorname {\mathrm {sgn}}(\kappa )$
) is given by
 $$ \begin{align*} \operatorname{\mathrm{sgn}}(\kappa)\sum_{\ell=1}^\infty\frac{(-1)^{\ell-1}}\ell \operatorname{\mathrm{tr}}\left\{\left(\sqrt{R_0}\left(L - L_0\right)\sqrt{R_0}\right)^\ell\right\}. \end{align*} $$
$$ \begin{align*} \operatorname{\mathrm{sgn}}(\kappa)\sum_{\ell=1}^\infty\frac{(-1)^{\ell-1}}\ell \operatorname{\mathrm{tr}}\left\{\left(\sqrt{R_0}\left(L - L_0\right)\sqrt{R_0}\right)^\ell\right\}. \end{align*} $$
For
 $\ell>1$
, the trace is well-defined because the operator is trace class. For
$\ell>1$
, the trace is well-defined because the operator is trace class. For
 $\ell =1$
, this fails; however, in view of (3.6), it is natural to regard the trace as being zero in this case. In fact, (3.6) implies that only the even
$\ell =1$
, this fails; however, in view of (3.6), it is natural to regard the trace as being zero in this case. In fact, (3.6) implies that only the even
 $\ell $
contribute to this sum.
$\ell $
contribute to this sum.
With this in mind, we adopt the following as our rigorous definition of A:
 $$ \begin{align} A(\kappa; q) := \operatorname{\mathrm{sgn}}(\kappa) \sum_{m=1}^\infty \tfrac{(-1)^{m-1}}{m} \operatorname{\mathrm{tr}}\left\{(\Lambda\Gamma)^m \right\}. \end{align} $$
$$ \begin{align} A(\kappa; q) := \operatorname{\mathrm{sgn}}(\kappa) \sum_{m=1}^\infty \tfrac{(-1)^{m-1}}{m} \operatorname{\mathrm{tr}}\left\{(\Lambda\Gamma)^m \right\}. \end{align} $$
We will prove the convergence of this series in Lemma 4.1 below, as well as deriving several other basic properties.
The quantity A is readily seen to be closely related to the quantity
 $\alpha (\kappa ;q)$
that formed the center point of the analysis in [Reference Killip, Vişan and Zhang38]. Concretely, for
$\alpha (\kappa ;q)$
that formed the center point of the analysis in [Reference Killip, Vişan and Zhang38]. Concretely, for
 $\kappa \geq 1$
,
$\kappa \geq 1$
,
 $$ \begin{align} \alpha(\kappa;q) = \pm \operatorname{Re} A(\kappa;q) = \pm \tfrac 12\big[A(\kappa;q) - A(-\kappa;q)\big] \end{align} $$
$$ \begin{align} \alpha(\kappa;q) = \pm \operatorname{Re} A(\kappa;q) = \pm \tfrac 12\big[A(\kappa;q) - A(-\kappa;q)\big] \end{align} $$
(see (4.3) below). In that paper, it was shown that
 $\alpha (q)$
is preserved under the NLS and mKdV flows. In fact, the argument given there even shows that
$\alpha (q)$
is preserved under the NLS and mKdV flows. In fact, the argument given there even shows that
 $A(\kappa ;q)$
is conserved. However, for our purposes here, we need several stronger assertions of a similar flavor.
$A(\kappa ;q)$
is conserved. However, for our purposes here, we need several stronger assertions of a similar flavor.
First, we need that
 $A(\kappa ;q)$
is conserved under all flows generated by the real and imaginary parts of
$A(\kappa ;q)$
is conserved under all flows generated by the real and imaginary parts of
 $A(\varkappa ;q)$
for general
$A(\varkappa ;q)$
for general
 $\varkappa $
. This is proved in Lemma 4.3 below, and will yield the conservation of
$\varkappa $
. This is proved in Lemma 4.3 below, and will yield the conservation of
 $\alpha $
under our regularized Hamiltonians. This allows us to obtain a priori bounds for these regularized flows.
$\alpha $
under our regularized Hamiltonians. This allows us to obtain a priori bounds for these regularized flows.
Second, we rely on our discovery of a microscopic expression of the conservation of A; this will be essential in our development of local smoothing estimates. The relevant density
 $\rho $
is introduced in Lemma 4.1 (see (4.6)). The corresponding currents (for various flows) are collected in Corollary 4.14, building on a number of intermediate results.
$\rho $
is introduced in Lemma 4.1 (see (4.6)). The corresponding currents (for various flows) are collected in Corollary 4.14, building on a number of intermediate results.
Lemma 4.1 (Properties of A).
There exists
 $\delta>0$
so that for all
$\delta>0$
so that for all
 $q\in B_\delta $
and real
$q\in B_\delta $
and real
 $|\kappa |\geq 1$
, the series (4.1) defining A converges absolutely. Moreover,
$|\kappa |\geq 1$
, the series (4.1) defining A converges absolutely. Moreover,
 $$ \begin{align} A(\kappa) = - \bar A(-\kappa), \end{align} $$
$$ \begin{align} A(\kappa) = - \bar A(-\kappa), \end{align} $$
 $$ \begin{align} \tfrac{\delta A}{\delta q} = g_{21},\qquad \tfrac{\delta A}{\delta r} = - g_{12}, \qquad \gamma' = 2\left(q\tfrac{\delta A}{\delta q} - r\tfrac{\delta A}{\delta r} \right), \end{align} $$
$$ \begin{align} \tfrac{\delta A}{\delta q} = g_{21},\qquad \tfrac{\delta A}{\delta r} = - g_{12}, \qquad \gamma' = 2\left(q\tfrac{\delta A}{\delta q} - r\tfrac{\delta A}{\delta r} \right), \end{align} $$
 $$ \begin{align} \tfrac{\partial A}{\partial \kappa} = \int \gamma(x;\kappa)\,dx \quad\text{and}\quad A(\kappa) = - \int_\kappa^{\operatorname{\mathrm{sgn}}(\kappa)\infty} \int\gamma(x;\varkappa)\,dx\,d\varkappa, \end{align} $$
$$ \begin{align} \tfrac{\partial A}{\partial \kappa} = \int \gamma(x;\kappa)\,dx \quad\text{and}\quad A(\kappa) = - \int_\kappa^{\operatorname{\mathrm{sgn}}(\kappa)\infty} \int\gamma(x;\varkappa)\,dx\,d\varkappa, \end{align} $$
 $$ \begin{align} A = \int \rho(x;\kappa)\, dx ,\quad\text{where}\quad \rho(\kappa)=\frac{qg_{21}(\kappa)-rg_{12}(\kappa)}{2+\gamma(\kappa)}. \end{align} $$
$$ \begin{align} A = \int \rho(x;\kappa)\, dx ,\quad\text{where}\quad \rho(\kappa)=\frac{qg_{21}(\kappa)-rg_{12}(\kappa)}{2+\gamma(\kappa)}. \end{align} $$
Proof. First, we observe that the series (4.1) converges absolutely and uniformly for
 $|\kappa |\geq 1$
and
$|\kappa |\geq 1$
and
 $q\in B_\delta $
, provided
$q\in B_\delta $
, provided
 $0<\delta \ll 1$
. This follows from the estimate (3.7). In the same way, convergence holds for the term-wise derivative of the series (4.1) with respect to
$0<\delta \ll 1$
. This follows from the estimate (3.7). In the same way, convergence holds for the term-wise derivative of the series (4.1) with respect to
 $\kappa $
. The terms appearing are exactly those from (3.18) and (3.19), and so we may deduce that
$\kappa $
. The terms appearing are exactly those from (3.18) and (3.19), and so we may deduce that
 $$ \begin{align*}\frac{\partial A}{\partial \kappa} = \int \gamma(x;\kappa)\,dx. \end{align*} $$
$$ \begin{align*}\frac{\partial A}{\partial \kappa} = \int \gamma(x;\kappa)\,dx. \end{align*} $$
This proves the first assertion in (4.5) as well as justifying 1.10. The second assertion of (4.5) then follows, since (3.7) guarantees that
 $A(\kappa )\to 0$
uniformly on
$A(\kappa )\to 0$
uniformly on
 $B_\delta $
as
$B_\delta $
as
 $|\kappa |\to \infty $
.
$|\kappa |\to \infty $
.
The conjugation symmetry (4.3) follows immediately from (3.15) and (4.5).
Differentiating the series (4.1) with respect to r yields the series (3.19) for
 $g_{12}$
with an additional minus sign, thus giving the second assertion in (4.4). The first assertion follows in a parallel manner, or by invoking conjugation symmetry. The third part of (4.4) follows from the first two parts via (3.11).
$g_{12}$
with an additional minus sign, thus giving the second assertion in (4.4). The first assertion follows in a parallel manner, or by invoking conjugation symmetry. The third part of (4.4) follows from the first two parts via (3.11).
We now turn our attention to (4.6). First, we must clarify what we mean by
 $\int \rho $
. When
$\int \rho $
. When
 $q\in \mathcal {S}$
, then
$q\in \mathcal {S}$
, then
 $\rho $
also belongs to Schwartz class (for
$\rho $
also belongs to Schwartz class (for
 $\delta $
small enough), and so the integral can be taken in the classical sense. For
$\delta $
small enough), and so the integral can be taken in the classical sense. For
 $q\in H^s$
, however, we interpret this integral via the duality between
$q\in H^s$
, however, we interpret this integral via the duality between
 $H^s$
and
$H^s$
and
 $H^{-s}$
, noting that
$H^{-s}$
, noting that
 $$ \begin{align*}q,r \in H^{s}({{\mathbb{R}}}) \quad\text{and}\quad \tfrac{g_{21}(\kappa)}{2+\gamma(\kappa)} , \tfrac{g_{12}(\kappa)}{2+\gamma(\kappa)} \in H^{1+s}({{\mathbb{R}}}) \hookrightarrow H^{-s}({{\mathbb{R}}}) \end{align*} $$
$$ \begin{align*}q,r \in H^{s}({{\mathbb{R}}}) \quad\text{and}\quad \tfrac{g_{21}(\kappa)}{2+\gamma(\kappa)} , \tfrac{g_{12}(\kappa)}{2+\gamma(\kappa)} \in H^{1+s}({{\mathbb{R}}}) \hookrightarrow H^{-s}({{\mathbb{R}}}) \end{align*} $$
(see Corollary 3.5). By density and continuity, it suffices to verify (4.6) for
 $q\in \mathcal {S}$
.
$q\in \mathcal {S}$
.
Differentiating (3.12), (3.13), and (3.31) with respect to
 $\kappa $
and then combining these with the original versions shows
$\kappa $
and then combining these with the original versions shows
 $$ \begin{align*} \partial_x\Big(g_{12}\tfrac{\partial g_{21}}{\partial\kappa} - \tfrac{\partial g_{12}}{\partial\kappa} g_{21}\Big) & =-\gamma(2+\gamma) + (1+\gamma)\tfrac{\partial\ }{\partial\kappa}\big(qg_{21}-rg_{12}\big) - \big(qg_{21}-rg_{12}\big) \tfrac{\partial\gamma}{\partial\kappa}. \end{align*} $$
$$ \begin{align*} \partial_x\Big(g_{12}\tfrac{\partial g_{21}}{\partial\kappa} - \tfrac{\partial g_{12}}{\partial\kappa} g_{21}\Big) & =-\gamma(2+\gamma) + (1+\gamma)\tfrac{\partial\ }{\partial\kappa}\big(qg_{21}-rg_{12}\big) - \big(qg_{21}-rg_{12}\big) \tfrac{\partial\gamma}{\partial\kappa}. \end{align*} $$
Using also (3.11), we obtain
 $$ \begin{align*} - \big( g_{12}\tfrac{\partial g_{21}}{\partial\kappa} - \tfrac{\partial g_{12}}{\partial\kappa} g_{21}\big) \gamma' = -\gamma(2+\gamma)\tfrac{\partial\ }{\partial\kappa}\big(qg_{21}-rg_{12}\big)+ \big(qg_{21}-rg_{12}\big)(1+\gamma)\tfrac{\partial\gamma}{\partial\kappa}. \end{align*} $$
$$ \begin{align*} - \big( g_{12}\tfrac{\partial g_{21}}{\partial\kappa} - \tfrac{\partial g_{12}}{\partial\kappa} g_{21}\big) \gamma' = -\gamma(2+\gamma)\tfrac{\partial\ }{\partial\kappa}\big(qg_{21}-rg_{12}\big)+ \big(qg_{21}-rg_{12}\big)(1+\gamma)\tfrac{\partial\gamma}{\partial\kappa}. \end{align*} $$
These identities then combine to show
 $$ \begin{align*} \partial_x\frac{g_{12}\tfrac{\partial g_{21}}{\partial\kappa} - \tfrac{\partial g_{12}}{\partial\kappa} g_{21}}{2+\gamma} &= - \gamma + \frac{\partial\ }{\partial\kappa}\frac{qg_{21}-rg_{12}}{2+\gamma} , \end{align*} $$
$$ \begin{align*} \partial_x\frac{g_{12}\tfrac{\partial g_{21}}{\partial\kappa} - \tfrac{\partial g_{12}}{\partial\kappa} g_{21}}{2+\gamma} &= - \gamma + \frac{\partial\ }{\partial\kappa}\frac{qg_{21}-rg_{12}}{2+\gamma} , \end{align*} $$
which can then be integrated in x to yield
 $$ \begin{align*} \frac{\partial\ }{\partial\kappa} \int \frac{qg_{21}-rg_{12}}{2+\gamma}\,dx = \int \gamma\,dx = \frac{\partial A}{\partial\kappa}. \end{align*} $$
$$ \begin{align*} \frac{\partial\ }{\partial\kappa} \int \frac{qg_{21}-rg_{12}}{2+\gamma}\,dx = \int \gamma\,dx = \frac{\partial A}{\partial\kappa}. \end{align*} $$
The veracity of (4.6) then follows by observing that both sides of (4.6) vanish in the limit
 $|\kappa |\to \infty $
.
$|\kappa |\to \infty $
.
Next, we show that our basic Hamiltonians arise as coefficients in the asymptotic expansion of
 $A(\kappa )$
as
$A(\kappa )$
as
 $\kappa \to \infty $
. This will also be important for introducing our renormalized flows later on.
$\kappa \to \infty $
. This will also be important for introducing our renormalized flows later on.
Lemma 4.2. For
 $q\in B_\delta \cap \mathcal {S}$
,
$q\in B_\delta \cap \mathcal {S}$
,
 $$ \begin{align} A(\kappa)=\tfrac1{2\kappa} M + \tfrac{-i}{(2\kappa)^2} P + \tfrac{(-i)^2}{(2\kappa)^3} H_{\mathrm{NLS}} + \tfrac{(-i)^3}{(2\kappa)^4} H_{\mathrm{mKdV}} + O(\kappa^{-5}) \end{align} $$
$$ \begin{align} A(\kappa)=\tfrac1{2\kappa} M + \tfrac{-i}{(2\kappa)^2} P + \tfrac{(-i)^2}{(2\kappa)^3} H_{\mathrm{NLS}} + \tfrac{(-i)^3}{(2\kappa)^4} H_{\mathrm{mKdV}} + O(\kappa^{-5}) \end{align} $$
as an asymptotic series on Schwartz class.
Proof. While the first few terms can readily be discovered by brute force, we follow a systematic method based on the biHamiltonian relations
 $$ \begin{align} \nonumber -2\kappa \tfrac{\delta A}{\delta q} &= \partial\tfrac{\delta A}{\delta q} - r\big[\gamma+1\big] = \partial\tfrac{\delta A}{\delta q} + 2r\partial^{-1}\big(r\tfrac{\delta A}{\delta r} - q\tfrac{\delta A}{\delta q}\big) - r,\\ 2\kappa \tfrac{\delta A}{\delta r} &= \partial\tfrac{\delta A}{\delta r} + q\big[\gamma+1\big] = \partial\tfrac{\delta A}{\delta r} - 2q\partial^{-1}\big(r\tfrac{\delta A}{\delta r} - q\tfrac{\delta A}{\delta q}\big) + q, \end{align} $$
$$ \begin{align} \nonumber -2\kappa \tfrac{\delta A}{\delta q} &= \partial\tfrac{\delta A}{\delta q} - r\big[\gamma+1\big] = \partial\tfrac{\delta A}{\delta q} + 2r\partial^{-1}\big(r\tfrac{\delta A}{\delta r} - q\tfrac{\delta A}{\delta q}\big) - r,\\ 2\kappa \tfrac{\delta A}{\delta r} &= \partial\tfrac{\delta A}{\delta r} + q\big[\gamma+1\big] = \partial\tfrac{\delta A}{\delta r} - 2q\partial^{-1}\big(r\tfrac{\delta A}{\delta r} - q\tfrac{\delta A}{\delta q}\big) + q, \end{align} $$
which, in view of (4.4), are merely a recapitulation of (3.12) and (3.13).
By iterating (4.8), we find
 $$ \begin{align} \nonumber \tfrac{\delta A}{\delta r} &= - g_{12} = \tfrac{q}{2\kappa} + \tfrac{q'}{(2\kappa)^2} + \tfrac{q"-2q^2r}{(2\kappa)^3} + \tfrac{q"'-6qq'r}{(2\kappa)^4} + O(\kappa^{-5}), \\ \tfrac{\delta A}{\delta q} &= g_{21} = \tfrac{r}{2\kappa} - \tfrac{r'}{(2\kappa)^2} + \tfrac{r"-2qr^2}{(2\kappa)^3} - \tfrac{r"'-6qrr'}{(2\kappa)^4} + O(\kappa^{-5}), \end{align} $$
$$ \begin{align} \nonumber \tfrac{\delta A}{\delta r} &= - g_{12} = \tfrac{q}{2\kappa} + \tfrac{q'}{(2\kappa)^2} + \tfrac{q"-2q^2r}{(2\kappa)^3} + \tfrac{q"'-6qq'r}{(2\kappa)^4} + O(\kappa^{-5}), \\ \tfrac{\delta A}{\delta q} &= g_{21} = \tfrac{r}{2\kappa} - \tfrac{r'}{(2\kappa)^2} + \tfrac{r"-2qr^2}{(2\kappa)^3} - \tfrac{r"'-6qrr'}{(2\kappa)^4} + O(\kappa^{-5}), \end{align} $$
which can then be integrated to recover the series for A; indeed,
 $$ \begin{align*}A(q) = \int_0^1 \partial_\theta A(\theta q)\,d\theta = \int_0^1 \langle \bar q, \tfrac{\delta A}{\delta q}(\theta q)\rangle + \langle \bar r, \tfrac{\delta A}{\delta r}(\theta q)\rangle \,d\theta. \end{align*} $$
$$ \begin{align*}A(q) = \int_0^1 \partial_\theta A(\theta q)\,d\theta = \int_0^1 \langle \bar q, \tfrac{\delta A}{\delta q}(\theta q)\rangle + \langle \bar r, \tfrac{\delta A}{\delta r}(\theta q)\rangle \,d\theta. \end{align*} $$
In following this algorithm, we have found it convenient to successively update the asymptotic expansion of
 $\gamma $
using (3.31), rather than compute
$\gamma $
using (3.31), rather than compute
 $\partial ^{-1}(r\tfrac {\delta A}{\delta r} - q\tfrac {\delta A}{\delta q})$
by laboriously finding complete derivatives. We record here the key result:
$\partial ^{-1}(r\tfrac {\delta A}{\delta r} - q\tfrac {\delta A}{\delta q})$
by laboriously finding complete derivatives. We record here the key result:
 $$ \begin{align*} \tfrac12\gamma = -\tfrac{qr}{(2\kappa)^2} - \tfrac{q'r-qr'}{(2\kappa)^3} & - \tfrac{q"r - q'r' + qr"-3q^2r^2}{(2\kappa)^4} \\ &-\tfrac{q"'r - q"r' + q'r" - qr"' - 6qq'r^2 + 6q^2rr'}{(2\kappa)^5} + O(\kappa^{-6}). \end{align*} $$
$$ \begin{align*} \tfrac12\gamma = -\tfrac{qr}{(2\kappa)^2} - \tfrac{q'r-qr'}{(2\kappa)^3} & - \tfrac{q"r - q'r' + qr"-3q^2r^2}{(2\kappa)^4} \\ &-\tfrac{q"'r - q"r' + q'r" - qr"' - 6qq'r^2 + 6q^2rr'}{(2\kappa)^5} + O(\kappa^{-6}). \end{align*} $$
This technique is easily automated on a computer algebra system, which we have done as a check on our hand computations.
Although the mechanical interpretation of the Poisson bracket (1.1) originates in real-valued observables F and G, the definition makes sense for complex-valued functions as well. In view of the conjugation symmetry (4.3), the following guarantees the commutation of both the real and imaginary parts of A:
Lemma 4.3 (Poisson brackets).
There exists
 $\delta>0$
so that for all real
$\delta>0$
so that for all real
 $|\kappa |,|\varkappa |\geq 1$
and
$|\kappa |,|\varkappa |\geq 1$
and
 $q\in B_\delta \cap \mathcal {S}$
, we have
$q\in B_\delta \cap \mathcal {S}$
, we have
 $$ \begin{align} \{A(\kappa),A(\varkappa)\} = 0. \end{align} $$
$$ \begin{align} \{A(\kappa),A(\varkappa)\} = 0. \end{align} $$
Proof. If
 $\kappa = \varkappa $
, there is nothing to prove. Suppose now that
$\kappa = \varkappa $
, there is nothing to prove. Suppose now that
 $\kappa \neq \varkappa $
. From (4.4) and then (3.14), we deduce that
$\kappa \neq \varkappa $
. From (4.4) and then (3.14), we deduce that
 $$ \begin{align*} \{A(\kappa),A(\varkappa)\} &= \tfrac1{i} \int g_{12}(\kappa)g_{21}(\varkappa) - g_{21}(\kappa)g_{12}(\varkappa) =0.\\[-46pt] \end{align*} $$
$$ \begin{align*} \{A(\kappa),A(\varkappa)\} &= \tfrac1{i} \int g_{12}(\kappa)g_{21}(\varkappa) - g_{21}(\kappa)g_{12}(\varkappa) =0.\\[-46pt] \end{align*} $$
As shown already in [Reference Killip, Vişan and Zhang38], the conservation of
 $A(\kappa )$
leads to global in time control on the
$A(\kappa )$
leads to global in time control on the
 $H^s$
norm. Rather than simply recapitulate that argument, which was based on the series (4.1), we will present a proof that brings the density
$H^s$
norm. Rather than simply recapitulate that argument, which was based on the series (4.1), we will present a proof that brings the density
 $\rho $
to center stage. This approach will be essential later, when we introduce localizations (see Lemmas 5.2 and 6.3).
$\rho $
to center stage. This approach will be essential later, when we introduce localizations (see Lemmas 5.2 and 6.3).
Proposition 4.4 (A priori bound).
There exists
 $\delta>0$
so that for all
$\delta>0$
so that for all
 $q\in B_\delta $
and
$q\in B_\delta $
and
 $\kappa \geq 1$
, we have
$\kappa \geq 1$
, we have
 $$ \begin{align} \int_\kappa^\infty \varkappa^{2s+1}\alpha(\varkappa)\,\frac{d\varkappa}\varkappa \approx_s \|q\|_{H^s_\kappa}^2. \end{align} $$
$$ \begin{align} \int_\kappa^\infty \varkappa^{2s+1}\alpha(\varkappa)\,\frac{d\varkappa}\varkappa \approx_s \|q\|_{H^s_\kappa}^2. \end{align} $$
Choosing
 $\delta>0$
even smaller if necessary, we deduce the a priori estimate
$\delta>0$
even smaller if necessary, we deduce the a priori estimate
 $$ \begin{align} \|q(t)\|_{H^s_\kappa}\lesssim \|q(0)\|_{H^s_\kappa} \quad\text{uniformly for}\quad q(0)\in B_\delta\cap \mathcal{S} \end{align} $$
$$ \begin{align} \|q(t)\|_{H^s_\kappa}\lesssim \|q(0)\|_{H^s_\kappa} \quad\text{uniformly for}\quad q(0)\in B_\delta\cap \mathcal{S} \end{align} $$
for any Hamiltonian flow that is continuous on Schwartz class and preserves
 $A(\varkappa )$
for all
$A(\varkappa )$
for all
 $|\varkappa |\geq 1$
.
$|\varkappa |\geq 1$
.
Proof. We first decompose
 $\rho (\varkappa )= \rho ^{[2]} (\varkappa )+ \rho ^{[\geq 4]}(\varkappa )$
with
$\rho (\varkappa )= \rho ^{[2]} (\varkappa )+ \rho ^{[\geq 4]}(\varkappa )$
with
 $$ \begin{align} \rho^{[2]} (\varkappa)&= \tfrac12\big(q\cdot\tfrac r{2\varkappa + \partial} + \tfrac q{2\varkappa - \partial}\cdot r\big), \end{align} $$
$$ \begin{align} \rho^{[2]} (\varkappa)&= \tfrac12\big(q\cdot\tfrac r{2\varkappa + \partial} + \tfrac q{2\varkappa - \partial}\cdot r\big), \end{align} $$
 $$ \begin{align} \rho^{[\geq 4]} (\varkappa) &= q\cdot \big(\tfrac{g_{21}(\varkappa)}{2+\gamma(\varkappa)}\big)^{[\geq 3]} - r\cdot (\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}. \end{align} $$
$$ \begin{align} \rho^{[\geq 4]} (\varkappa) &= q\cdot \big(\tfrac{g_{21}(\varkappa)}{2+\gamma(\varkappa)}\big)^{[\geq 3]} - r\cdot (\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}. \end{align} $$
Inspired by (4.2), we compute
 $$ \begin{align} \pm \int \tfrac12\big[\rho^{[2]}(x;\varkappa)-\rho^{[2]}(x;-\varkappa)\big]\,dx = 2\varkappa \int\frac{|\hat q(\xi)|^2\,d\xi}{4\varkappa^2+\xi^2} \end{align} $$
$$ \begin{align} \pm \int \tfrac12\big[\rho^{[2]}(x;\varkappa)-\rho^{[2]}(x;-\varkappa)\big]\,dx = 2\varkappa \int\frac{|\hat q(\xi)|^2\,d\xi}{4\varkappa^2+\xi^2} \end{align} $$
and so, invoking (2.7), deduce that
 $$ \begin{align} \pm \int_\kappa^\infty \! \int \tfrac12\big[\rho^{[2]}(x;\varkappa)-\rho^{[2]}(x;-\varkappa)\big] \varkappa^{2s}\,dx\,d\varkappa \approx \|q\|_{H^s_\kappa}^2. \end{align} $$
$$ \begin{align} \pm \int_\kappa^\infty \! \int \tfrac12\big[\rho^{[2]}(x;\varkappa)-\rho^{[2]}(x;-\varkappa)\big] \varkappa^{2s}\,dx\,d\varkappa \approx \|q\|_{H^s_\kappa}^2. \end{align} $$
On the other hand, interpolating the bounds in (3.42), we find
 $$ \begin{align} \big\| \big(\tfrac{g_{21}(\varkappa)}{2+\gamma(\varkappa)}\big)^{[\geq 3]} \big\|_{H^{-s}} \lesssim |\varkappa|^{-2(1+2s)} \delta \|q\|_{H^s_\varkappa}^2 \end{align} $$
$$ \begin{align} \big\| \big(\tfrac{g_{21}(\varkappa)}{2+\gamma(\varkappa)}\big)^{[\geq 3]} \big\|_{H^{-s}} \lesssim |\varkappa|^{-2(1+2s)} \delta \|q\|_{H^s_\varkappa}^2 \end{align} $$
and consequently,
 $$ \begin{align} \int_\kappa^\infty \bigg| \int \tfrac12\big[\rho^{[\geq 4]}(x;\varkappa)-\rho^{[\geq 4]}(x;-\varkappa)\big]\varkappa^{2s}\,dx \bigg| d\varkappa \lesssim \kappa^{-(1+2s)} \delta^2 \|q\|_{H^s_\kappa}^2. \end{align} $$
$$ \begin{align} \int_\kappa^\infty \bigg| \int \tfrac12\big[\rho^{[\geq 4]}(x;\varkappa)-\rho^{[\geq 4]}(x;-\varkappa)\big]\varkappa^{2s}\,dx \bigg| d\varkappa \lesssim \kappa^{-(1+2s)} \delta^2 \|q\|_{H^s_\kappa}^2. \end{align} $$
Thus, (4.11) follows by choosing
 $\delta>0$
sufficiently small.
$\delta>0$
sufficiently small.
To deduce (4.12), we exploit continuity in time.
Proposition 4.4 is the key to proving equicontinuity of orbits. The proper extension of the notion of equicontinuity from the setting of the Arzelà–Ascoli theorem to Sobolev spaces was discussed already by M. Riesz [Reference Riesz51].
Definition 4.5 (Equicontinuity).
A set
 $Q\subset H^s$
is said to be equicontinuous if
$Q\subset H^s$
is said to be equicontinuous if
 $$\begin{align*}\limsup_{\delta\to0}\sup_{q\in Q}\sup_{|y|<\delta}\|q(\cdot +y) - q(\cdot)\|_{H^s} = 0. \end{align*}$$
$$\begin{align*}\limsup_{\delta\to0}\sup_{q\in Q}\sup_{|y|<\delta}\|q(\cdot +y) - q(\cdot)\|_{H^s} = 0. \end{align*}$$
Beyond boundedness and equicontinuity, the other key ingredient needed for compactness is tightness (see Definition 6.1).
Proposition 4.6 (Equicontinuity of orbits).
Suppose that
 $Q\subset B_\delta \cap \mathcal {S}$
is equicontinuous in
$Q\subset B_\delta \cap \mathcal {S}$
is equicontinuous in
 $H^s$
. Let
$H^s$
. Let
 $H_1,H_2$
be Hamiltonians with flows that are continuous on Schwartz class and preserve
$H_1,H_2$
be Hamiltonians with flows that are continuous on Schwartz class and preserve
 $A(\varkappa )$
for all
$A(\varkappa )$
for all
 $|\varkappa |\geq 1$
. Then the set
$|\varkappa |\geq 1$
. Then the set
 $$\begin{align*}Q^* = \left\{e^{J\nabla\left(tH_1 + \tau H_2\right)}q:q\in Q,\,t,\tau\in {{\mathbb{R}}},\,\kappa\geq 1\right\} \end{align*}$$
$$\begin{align*}Q^* = \left\{e^{J\nabla\left(tH_1 + \tau H_2\right)}q:q\in Q,\,t,\tau\in {{\mathbb{R}}},\,\kappa\geq 1\right\} \end{align*}$$
is equicontinuous in
 $H^s$
.
$H^s$
.
Proof. By Plancherel (cf. [Reference Killip and Vişan37, Section 4]), it is easy to show that a bounded set
 $Q\subset H^s$
is equicontinuous if and only if
$Q\subset H^s$
is equicontinuous if and only if
 $$\begin{align*}\lim\limits_{\kappa\rightarrow+\infty}\sup\limits_{q\in Q}\|q\|_{H^s_\kappa} = 0. \end{align*}$$
$$\begin{align*}\lim\limits_{\kappa\rightarrow+\infty}\sup\limits_{q\in Q}\|q\|_{H^s_\kappa} = 0. \end{align*}$$
The result then follows directly from the estimate (4.12).
Next, we address the question of how
 $\gamma $
,
$\gamma $
,
 $g_{12}$
, and
$g_{12}$
, and
 $g_{21}$
evolve when taking
$g_{21}$
evolve when taking
 $A(\kappa )$
as the Hamiltonian. As a complex-valued function,
$A(\kappa )$
as the Hamiltonian. As a complex-valued function,
 $A(\kappa )$
cannot be a true Hamiltonian. Nevertheless, there is a natural vector field associated to it by Hamilton’s equations. We caution the reader that this vector field does not respect the relation
$A(\kappa )$
cannot be a true Hamiltonian. Nevertheless, there is a natural vector field associated to it by Hamilton’s equations. We caution the reader that this vector field does not respect the relation
 $r = \pm \bar q$
. Ultimately, we would like to restrict to the real and imaginary parts of
$r = \pm \bar q$
. Ultimately, we would like to restrict to the real and imaginary parts of
 $A(\kappa )$
; however, it is convenient to temporarily retain this illusory complex Hamiltonian and recover the real and imaginary parts later using (4.3). This context is important for our next two results: the evolution equations we derive for the
$A(\kappa )$
; however, it is convenient to temporarily retain this illusory complex Hamiltonian and recover the real and imaginary parts later using (4.3). This context is important for our next two results: the evolution equations we derive for the
 $A(\kappa )$
vector field really represent a complex linear combination of the vector fields associated to the real and imaginary parts (taken separately).
$A(\kappa )$
vector field really represent a complex linear combination of the vector fields associated to the real and imaginary parts (taken separately).
Proposition 4.7 (Lax representation).
For distinct
 $\kappa ,\varkappa \in {{\mathbb {R}}}\setminus (-1,1)$
,
$\kappa ,\varkappa \in {{\mathbb {R}}}\setminus (-1,1)$
,
 $$ \begin{align*} - 2(\kappa-\varkappa)\begin{bmatrix}0 & \tfrac{\delta A(\kappa)}{\delta r} \\ \tfrac{\delta A(\kappa)}{\delta q} & 0 \end{bmatrix} &= L(\varkappa) \begin{bmatrix}0 & \tfrac{\delta A(\kappa)}{\delta r} \\ \tfrac{\delta A(\kappa)}{\delta q} & 0 \end{bmatrix} + \begin{bmatrix}0 & \tfrac{\delta A(\kappa)}{\delta r} \\ \tfrac{\delta A(\kappa)}{\delta q} & 0 \end{bmatrix} L(\varkappa) \\ &\quad + \tfrac12 \left[ L(\varkappa),\ \begin{bmatrix}\gamma(\kappa)+1 & 0 \\ 0 & -\gamma(\kappa)-1 \end{bmatrix} \right]. \end{align*} $$
$$ \begin{align*} - 2(\kappa-\varkappa)\begin{bmatrix}0 & \tfrac{\delta A(\kappa)}{\delta r} \\ \tfrac{\delta A(\kappa)}{\delta q} & 0 \end{bmatrix} &= L(\varkappa) \begin{bmatrix}0 & \tfrac{\delta A(\kappa)}{\delta r} \\ \tfrac{\delta A(\kappa)}{\delta q} & 0 \end{bmatrix} + \begin{bmatrix}0 & \tfrac{\delta A(\kappa)}{\delta r} \\ \tfrac{\delta A(\kappa)}{\delta q} & 0 \end{bmatrix} L(\varkappa) \\ &\quad + \tfrac12 \left[ L(\varkappa),\ \begin{bmatrix}\gamma(\kappa)+1 & 0 \\ 0 & -\gamma(\kappa)-1 \end{bmatrix} \right]. \end{align*} $$
Equivalently, under the
 $A(\kappa )$
vector field,
$A(\kappa )$
vector field,
 $U :=[\begin {smallmatrix} 1&0\\0&-1 \end {smallmatrix}] L(\varkappa )$
obeys
$U :=[\begin {smallmatrix} 1&0\\0&-1 \end {smallmatrix}] L(\varkappa )$
obeys
 $$ \begin{align} \frac{d\ }{dt} U = [ P, U] \quad\text{with}\quad P = \tfrac{1}{2i(\kappa-\varkappa)}\begin{bmatrix}\frac12(\gamma(\kappa) + 1) & - g_{12}(\kappa)\\g_{21}(\kappa)&-\frac12(\gamma(\kappa) + 1)\end{bmatrix}. \end{align} $$
$$ \begin{align} \frac{d\ }{dt} U = [ P, U] \quad\text{with}\quad P = \tfrac{1}{2i(\kappa-\varkappa)}\begin{bmatrix}\frac12(\gamma(\kappa) + 1) & - g_{12}(\kappa)\\g_{21}(\kappa)&-\frac12(\gamma(\kappa) + 1)\end{bmatrix}. \end{align} $$
Corollary 4.8. Fix distinct
 $\kappa ,\varkappa \in {{\mathbb {R}}}\setminus (-1,1)$
. Then under the
$\kappa ,\varkappa \in {{\mathbb {R}}}\setminus (-1,1)$
. Then under the
 $A(\kappa )$
vector field,
$A(\kappa )$
vector field,
 $$ \begin{align} i\frac d{dt}q = - g_{12}(\kappa) \quad\text{and}\quad i\frac d{dt}r = - g_{21}(\kappa). \end{align} $$
$$ \begin{align} i\frac d{dt}q = - g_{12}(\kappa) \quad\text{and}\quad i\frac d{dt}r = - g_{21}(\kappa). \end{align} $$
Moreover,
 $$ \begin{align} \nonumber i \frac{d\ }{dt} g_{12}(\varkappa) &= \tfrac{ 1}{2(\kappa - \varkappa)} \big\{ [\gamma(\kappa)+1] g_{12}(\varkappa) - g_{12}(\kappa)[\gamma(\varkappa)+1] \big\}, \\ i \frac{d\ }{dt} g_{21}(\varkappa) &= \tfrac{-1}{2(\kappa - \varkappa)} \big\{ [\gamma(\kappa)+1] g_{21}(\varkappa) - g_{21}(\kappa)[\gamma(\varkappa)+1] \big\}, \end{align} $$
$$ \begin{align} \nonumber i \frac{d\ }{dt} g_{12}(\varkappa) &= \tfrac{ 1}{2(\kappa - \varkappa)} \big\{ [\gamma(\kappa)+1] g_{12}(\varkappa) - g_{12}(\kappa)[\gamma(\varkappa)+1] \big\}, \\ i \frac{d\ }{dt} g_{21}(\varkappa) &= \tfrac{-1}{2(\kappa - \varkappa)} \big\{ [\gamma(\kappa)+1] g_{21}(\varkappa) - g_{21}(\kappa)[\gamma(\varkappa)+1] \big\}, \end{align} $$
and
 $\partial _t \gamma (\varkappa ) + \partial _x j_\gamma (\varkappa ,\kappa ) =0$
, where
$\partial _t \gamma (\varkappa ) + \partial _x j_\gamma (\varkappa ,\kappa ) =0$
, where
 $$ \begin{align} j_\gamma(\varkappa,\kappa) := \tfrac{-i}{2(\kappa - \varkappa)^2} \Big[g_{12}(\kappa)g_{21}(\varkappa)+g_{12}(\varkappa)g_{21}(\kappa) - \tfrac{\gamma(\kappa)\gamma(\varkappa) + \gamma(\varkappa) + \gamma(\kappa)}2 \Big]. \end{align} $$
$$ \begin{align} j_\gamma(\varkappa,\kappa) := \tfrac{-i}{2(\kappa - \varkappa)^2} \Big[g_{12}(\kappa)g_{21}(\varkappa)+g_{12}(\varkappa)g_{21}(\kappa) - \tfrac{\gamma(\kappa)\gamma(\varkappa) + \gamma(\varkappa) + \gamma(\kappa)}2 \Big]. \end{align} $$
Lastly,
 $\partial _t \rho (\varkappa ) + \partial _x j(\varkappa ,\kappa ) = 0$
with
$\partial _t \rho (\varkappa ) + \partial _x j(\varkappa ,\kappa ) = 0$
with
 $$ \begin{align} j(\varkappa,\kappa):= -i \frac{g_{12}(\kappa)g_{21}(\varkappa)+g_{21}(\kappa)g_{12}(\varkappa)}{2(\kappa-\varkappa)(2+\gamma(\varkappa))} + i \frac{\gamma(\kappa)}{4(\kappa-\varkappa)}. \end{align} $$
$$ \begin{align} j(\varkappa,\kappa):= -i \frac{g_{12}(\kappa)g_{21}(\varkappa)+g_{21}(\kappa)g_{12}(\varkappa)}{2(\kappa-\varkappa)(2+\gamma(\varkappa))} + i \frac{\gamma(\kappa)}{4(\kappa-\varkappa)}. \end{align} $$
Proof. The identities (4.20) simply recapitulate (1.2) and (4.4).
Combining (1.2), the resolvent identity, and Proposition 4.7, we have
 $$ \begin{align*} i \frac{d\ }{dt} G(x,z;\varkappa) &= - \int G(x,y;\varkappa)\begin{bmatrix}0&\tfrac{\delta A}{\delta r}(y)\\\tfrac{\delta A}{\delta q}(y)&0\end{bmatrix}G(y,z;\varkappa)\,dy\\ &= \tfrac1{2(\kappa - \varkappa)}\left(\begin{bmatrix}0&\tfrac{\delta A}{\delta r}(x)\\\tfrac{\delta A}{\delta q}(x)&0\end{bmatrix}G(x,z;\varkappa) + G(x,z;\varkappa)\begin{bmatrix}0&\tfrac{\delta A}{\delta r}(z)\\\tfrac{\delta A}{\delta q}(z)&0\end{bmatrix}\right)\\ &\qquad + \tfrac1{4(\kappa - \varkappa)}[\gamma(x;\kappa)+1] \begin{bmatrix}1&0\\0&-1\end{bmatrix}G(x,z;\varkappa) \\ &\qquad - \tfrac1{4(\kappa - \varkappa)}G(x,z;\varkappa)[\gamma(z;\kappa)+1]\begin{bmatrix}1&0\\0&-1\end{bmatrix}. \end{align*} $$
$$ \begin{align*} i \frac{d\ }{dt} G(x,z;\varkappa) &= - \int G(x,y;\varkappa)\begin{bmatrix}0&\tfrac{\delta A}{\delta r}(y)\\\tfrac{\delta A}{\delta q}(y)&0\end{bmatrix}G(y,z;\varkappa)\,dy\\ &= \tfrac1{2(\kappa - \varkappa)}\left(\begin{bmatrix}0&\tfrac{\delta A}{\delta r}(x)\\\tfrac{\delta A}{\delta q}(x)&0\end{bmatrix}G(x,z;\varkappa) + G(x,z;\varkappa)\begin{bmatrix}0&\tfrac{\delta A}{\delta r}(z)\\\tfrac{\delta A}{\delta q}(z)&0\end{bmatrix}\right)\\ &\qquad + \tfrac1{4(\kappa - \varkappa)}[\gamma(x;\kappa)+1] \begin{bmatrix}1&0\\0&-1\end{bmatrix}G(x,z;\varkappa) \\ &\qquad - \tfrac1{4(\kappa - \varkappa)}G(x,z;\varkappa)[\gamma(z;\kappa)+1]\begin{bmatrix}1&0\\0&-1\end{bmatrix}. \end{align*} $$
This quantity is actually a continuous function of x and z (as can be seen from the middle expression), and so we may restrict to
 $z=x$
. Thus, by (4.4),
$z=x$
. Thus, by (4.4),
 $$ \begin{align*} i \tfrac{d\ }{dt} G(x,x;\varkappa) &= \tfrac{-1}{2(\kappa - \varkappa)}\begin{bmatrix}g_{12}(\kappa)g_{21}(\varkappa)-g_{12}(\varkappa)g_{21}(\kappa)\!\! & g_{12}(\kappa)[\gamma(\varkappa)+1] \\ -g_{21}(\kappa)[\gamma(\varkappa)+1] & \!\!g_{12}(\kappa)g_{21}(\varkappa)-g_{12}(\varkappa)g_{21}(\kappa) \end{bmatrix} \\ &\quad {} + \tfrac{\gamma(\kappa)+1}{2(\kappa - \varkappa)} \begin{bmatrix}0&g_{12}(\varkappa)\\-g_{21}(\varkappa)&0\end{bmatrix}. \end{align*} $$
$$ \begin{align*} i \tfrac{d\ }{dt} G(x,x;\varkappa) &= \tfrac{-1}{2(\kappa - \varkappa)}\begin{bmatrix}g_{12}(\kappa)g_{21}(\varkappa)-g_{12}(\varkappa)g_{21}(\kappa)\!\! & g_{12}(\kappa)[\gamma(\varkappa)+1] \\ -g_{21}(\kappa)[\gamma(\varkappa)+1] & \!\!g_{12}(\kappa)g_{21}(\varkappa)-g_{12}(\varkappa)g_{21}(\kappa) \end{bmatrix} \\ &\quad {} + \tfrac{\gamma(\kappa)+1}{2(\kappa - \varkappa)} \begin{bmatrix}0&g_{12}(\varkappa)\\-g_{21}(\varkappa)&0\end{bmatrix}. \end{align*} $$
This then yields (4.21) directly and (4.22) by invoking (3.14).
The claim (4.23) follows from a lengthy computation using (4.21), (4.22), (3.14), and (3.31).
Corollary 4.8 shows that both
 $\rho (\varkappa )$
and
$\rho (\varkappa )$
and
 $\gamma (\varkappa )$
obey microscopic conservation laws. From Lemma 4.1, we see that the corresponding macroscopic conservation laws are
$\gamma (\varkappa )$
obey microscopic conservation laws. From Lemma 4.1, we see that the corresponding macroscopic conservation laws are
 $A(\varkappa )$
and
$A(\varkappa )$
and
 $\partial _\varkappa A(\varkappa )$
, respectively; thus, these two microscopic conservation laws are closely related. In the analysis that follows, we shall rely exclusively on the conservation law associated to
$\partial _\varkappa A(\varkappa )$
, respectively; thus, these two microscopic conservation laws are closely related. In the analysis that follows, we shall rely exclusively on the conservation law associated to
 $\rho $
, rather than
$\rho $
, rather than
 $\gamma $
. Let us explain why.
$\gamma $
. Let us explain why.
As we saw already in (1.10), the quantity
 $\gamma $
arises very naturally in the theory, and indeed, it was the basis of our initial investigations of the problem. While it may be possible to build the entire theory around
$\gamma $
arises very naturally in the theory, and indeed, it was the basis of our initial investigations of the problem. While it may be possible to build the entire theory around
 $\gamma $
, we can attest that this approach rapidly becomes extremely tiresome. It took us a very long time to discover the density
$\gamma $
, we can attest that this approach rapidly becomes extremely tiresome. It took us a very long time to discover the density
 $\rho $
that expresses the conservation of
$\rho $
that expresses the conservation of
 $A(\varkappa )$
, and this innovation has immensely simplified all that follows. A major virtue of
$A(\varkappa )$
, and this innovation has immensely simplified all that follows. A major virtue of
 $\rho $
compared to
$\rho $
compared to
 $\gamma $
is coercivity.
$\gamma $
is coercivity.
The goal of our next lemma is to give a simple expression of this distinction, by looking only at the quadratic terms in the currents associated to the basic Hamiltonians appearing as coefficients in the expansion (4.7). In particular, Lemma 4.9 shows that the current
 $j_\gamma $
associated with
$j_\gamma $
associated with
 $\gamma $
is not coercive under the (mKdV) flow.
$\gamma $
is not coercive under the (mKdV) flow.
Note that the terms in the series (4.7) are alternately real and imaginary. Correspondingly, to exploit the coercivity of
 $\operatorname {Im} j$
exhibited below, we shall need to use
$\operatorname {Im} j$
exhibited below, we shall need to use
 $\operatorname {Im} \rho $
when studying (NLS) and
$\operatorname {Im} \rho $
when studying (NLS) and
 $\operatorname {Re} \rho $
when studying (mKdV). It is also instructive to remember that monotone observables must be odd (not even) under time reversal.
$\operatorname {Re} \rho $
when studying (mKdV). It is also instructive to remember that monotone observables must be odd (not even) under time reversal.
The identities (4.24) and (4.25) appearing in the proof below also show us that neither
 $\operatorname {Re} j$
nor
$\operatorname {Re} j$
nor
 $\operatorname {Re} j_\gamma $
possess any coercivity.
$\operatorname {Re} j_\gamma $
possess any coercivity.
Lemma 4.9 (Coercivity of the current).
The coefficients in the asymptotic series
 $$ \begin{align*} \int \operatorname{Im} j^{[2]}(\varkappa,\kappa)\,dx = \pm \sum_{\ell=0}^\infty \bigg\{ \frac{(-1)^\ell (2\ell+1)}{(2\kappa)^{2\ell+2}} \varkappa{\mkern 2mu} C_{\ell}(\varkappa) + \frac{(-1)^{\ell+1}(\ell+1)}{(2\kappa)^{2\ell+3}} C_{\ell+1}(\varkappa) \bigg\} \end{align*} $$
$$ \begin{align*} \int \operatorname{Im} j^{[2]}(\varkappa,\kappa)\,dx = \pm \sum_{\ell=0}^\infty \bigg\{ \frac{(-1)^\ell (2\ell+1)}{(2\kappa)^{2\ell+2}} \varkappa{\mkern 2mu} C_{\ell}(\varkappa) + \frac{(-1)^{\ell+1}(\ell+1)}{(2\kappa)^{2\ell+3}} C_{\ell+1}(\varkappa) \bigg\} \end{align*} $$
are coercive; indeed,
 $$ \begin{align*} C_\ell = \int \frac{2{\mkern 1mu}\xi^{2\ell} |\hat q(\xi)|^2}{4\varkappa^2+\xi^2} \,d\xi. \end{align*} $$
$$ \begin{align*} C_\ell = \int \frac{2{\mkern 1mu}\xi^{2\ell} |\hat q(\xi)|^2}{4\varkappa^2+\xi^2} \,d\xi. \end{align*} $$
The corresponding asymptotic series for
 $j_\gamma $
is
$j_\gamma $
is
 $$ \begin{align*} \int \operatorname{Im} j_\gamma^{[2]}(\varkappa,\kappa)\,dx = \pm \sum_{\ell=0}^\infty \bigg\{ \frac{(-1)^\ell (2\ell+1)}{(2\kappa)^{2\ell+2}} \frac{\partial [\varkappa{\mkern 2mu} C_{\ell}(\varkappa)]}{\partial\varkappa} + \frac{(-1)^{\ell+1}(\ell+1)}{(2\kappa)^{2\ell+3}} \frac{\partial C_{\ell+1}(\varkappa)}{\partial\varkappa} \bigg\}. \end{align*} $$
$$ \begin{align*} \int \operatorname{Im} j_\gamma^{[2]}(\varkappa,\kappa)\,dx = \pm \sum_{\ell=0}^\infty \bigg\{ \frac{(-1)^\ell (2\ell+1)}{(2\kappa)^{2\ell+2}} \frac{\partial [\varkappa{\mkern 2mu} C_{\ell}(\varkappa)]}{\partial\varkappa} + \frac{(-1)^{\ell+1}(\ell+1)}{(2\kappa)^{2\ell+3}} \frac{\partial C_{\ell+1}(\varkappa)}{\partial\varkappa} \bigg\}. \end{align*} $$
The coefficients appearing for even powers of
 $\kappa $
are never sign definite; this undermines the utility of
$\kappa $
are never sign definite; this undermines the utility of
 $\gamma $
.
$\gamma $
.
Proof. From (4.23), we readily find
 $$ \begin{align} \int j^{[2]}(\varkappa,\kappa)\,dx = \int \frac{2i\varkappa-\xi}{(2\kappa-i\xi)^2} \frac{\hat q(\xi) \hat r(-\xi) }{4\varkappa^2+\xi^2} \,d\xi, \end{align} $$
$$ \begin{align} \int j^{[2]}(\varkappa,\kappa)\,dx = \int \frac{2i\varkappa-\xi}{(2\kappa-i\xi)^2} \frac{\hat q(\xi) \hat r(-\xi) }{4\varkappa^2+\xi^2} \,d\xi, \end{align} $$
from which the expansion is readily verified. The analogous formula for
 $j_\gamma $
is
$j_\gamma $
is
 $$ \begin{align} \int j_\gamma^{[2]}(\varkappa,\kappa)\,dx = 2 \int \frac{4\varkappa\xi+i(\xi^2 -4 \varkappa^2)}{(2\kappa-i\xi)^2} \frac{\hat q(\xi) \hat r(-\xi) }{(4\varkappa^2+\xi^2)^2} \,d\xi. \end{align} $$
$$ \begin{align} \int j_\gamma^{[2]}(\varkappa,\kappa)\,dx = 2 \int \frac{4\varkappa\xi+i(\xi^2 -4 \varkappa^2)}{(2\kappa-i\xi)^2} \frac{\hat q(\xi) \hat r(-\xi) }{(4\varkappa^2+\xi^2)^2} \,d\xi. \end{align} $$
The fact that this coincides with the
 $\varkappa $
-derivative of (4.24) is not a coincidence; it reflects the first identity in (4.5).
$\varkappa $
-derivative of (4.24) is not a coincidence; it reflects the first identity in (4.5).
It is easy to verify that
 $\partial _\varkappa [\varkappa {\mkern 2mu} C_{\ell }(\varkappa )]$
is never sign definite because it contains the factor
$\partial _\varkappa [\varkappa {\mkern 2mu} C_{\ell }(\varkappa )]$
is never sign definite because it contains the factor
 $\xi ^2 - 4\varkappa ^2$
.
$\xi ^2 - 4\varkappa ^2$
.
In view of the asymptotic expansion (4.7), Corollary 4.8 provides an efficient method for deriving the evolutions of
 $g_{12}$
and
$g_{12}$
and
 $\gamma $
under (NLS) and (mKdV), although they are also readily computable directly from the definitions.
$\gamma $
under (NLS) and (mKdV), although they are also readily computable directly from the definitions.
Corollary 4.10 (Induced flows).
Fix
 $\varkappa \in {{\mathbb {R}}}\setminus (-1,1)$
. Under the M flow (i.e., phase rotation),
$\varkappa \in {{\mathbb {R}}}\setminus (-1,1)$
. Under the M flow (i.e., phase rotation),
 $$ \begin{align}i\frac d{dt} g_{12} &= g_{12} \quad\text{and}\quad i\frac d{dt}\gamma = 0. \end{align} $$
$$ \begin{align}i\frac d{dt} g_{12} &= g_{12} \quad\text{and}\quad i\frac d{dt}\gamma = 0. \end{align} $$
Under the P flow (i.e., spatial translation),
 $$ \begin{align} \frac d{dt}g_{12} &= g_{12}' \quad\text{and}\quad \frac d{dt}\gamma = \gamma'. \end{align} $$
$$ \begin{align} \frac d{dt}g_{12} &= g_{12}' \quad\text{and}\quad \frac d{dt}\gamma = \gamma'. \end{align} $$
Under the
 $H_{\mathrm {NLS}}$
flow (NLS),
$H_{\mathrm {NLS}}$
flow (NLS),
 $$ \begin{align} i\frac d{dt}g_{12} &= - g_{12}" + 4qrg_{12} + 2q^2g_{21}, \end{align} $$
$$ \begin{align} i\frac d{dt}g_{12} &= - g_{12}" + 4qrg_{12} + 2q^2g_{21}, \end{align} $$
 $$ \begin{align} i\frac d{dt}\gamma &= \big\{ 2rg_{12} - 2qg_{21} - 4\varkappa\gamma \big\}'. \end{align} $$
$$ \begin{align} i\frac d{dt}\gamma &= \big\{ 2rg_{12} - 2qg_{21} - 4\varkappa\gamma \big\}'. \end{align} $$
Under the
 $H_{\mathrm {mKdV}}$
flow (mKdV),
$H_{\mathrm {mKdV}}$
flow (mKdV),
 $$ \begin{align} \frac d{dt}g_{12} &= - g_{12}"' + 6qrg_{12}' + 6qg_{21}q' + 6g_{12}rq', \end{align} $$
$$ \begin{align} \frac d{dt}g_{12} &= - g_{12}"' + 6qrg_{12}' + 6qg_{21}q' + 6g_{12}rq', \end{align} $$
 $$ \begin{align} \frac d{dt}\gamma &= - \gamma"' + \big\{ 12\varkappa(rg_{12} - qg_{21}) - 12\varkappa^2\gamma + 6qr(1 + \gamma)\big\}'. \end{align} $$
$$ \begin{align} \frac d{dt}\gamma &= - \gamma"' + \big\{ 12\varkappa(rg_{12} - qg_{21}) - 12\varkappa^2\gamma + 6qr(1 + \gamma)\big\}'. \end{align} $$
These expressions highlight two phenomena that are worthy of note. The first is that the evolution of
 $\gamma $
has the structure of a microscopic conservation law. This has been discussed already, in the context of (4.22).
$\gamma $
has the structure of a microscopic conservation law. This has been discussed already, in the context of (4.22).
Although rather less obvious, these formulas also show that
 $g_{12}$
obeys the linearized equation around the trajectory q. To explain why, let us first consider a generic one-parameter family of solutions
$g_{12}$
obeys the linearized equation around the trajectory q. To explain why, let us first consider a generic one-parameter family of solutions
 $q(t;\tau )$
to a given PDE, say (NLS). Here,
$q(t;\tau )$
to a given PDE, say (NLS). Here,
 $\tau $
is the parameter, while t is time. Evidently, the parametric derivative of q obeys the linearized equation:
$\tau $
is the parameter, while t is time. Evidently, the parametric derivative of q obeys the linearized equation:
 $$ \begin{align*}i\partial_t \tfrac{\partial q}{\partial \tau} = -\partial^2_x \tfrac{\partial q}{\partial \tau} \pm 4 |q|^2 \tfrac{\partial q}{\partial \tau} \pm 2q^2 \tfrac{\partial \bar q}{\partial \tau}. \end{align*} $$
$$ \begin{align*}i\partial_t \tfrac{\partial q}{\partial \tau} = -\partial^2_x \tfrac{\partial q}{\partial \tau} \pm 4 |q|^2 \tfrac{\partial q}{\partial \tau} \pm 2q^2 \tfrac{\partial \bar q}{\partial \tau}. \end{align*} $$
This should be compared to (4.28), noting the conjugation symmetry (3.15).
Finally, to apply this general reasoning to the case at hand, we define our parametric family of solutions to the H-flow with initial data
 $q_0$
via
$q_0$
via
 $$ \begin{align*}q(t;\tau) = \exp\big\{tJ\nabla H + \tau J\nabla A(\varkappa)\big\}q_0 \end{align*} $$
$$ \begin{align*}q(t;\tau) = \exp\big\{tJ\nabla H + \tau J\nabla A(\varkappa)\big\}q_0 \end{align*} $$
and then apply (4.4).
4.1. Regularized and difference flows
As discussed in the Introduction, a key ingredient in our arguments is the decomposition of the full evolution into two commuting parts. The first is a regularized part, that captures the dominant portion of the dynamics, while being very tame at high frequencies. The second part, which we call the difference flow, restores the proper evolution to the high frequencies, but otherwise is very close to the identity.
The starting point for the corresponding decomposition of the Hamiltonian is (4.7), which we essentially rearrange to isolate an approximation to the true Hamiltonian. While we wish to consider only real-valued Hamiltonians and taking real and imaginary parts of (4.7) is a transparent way to do this, we should also acknowledge a more subtle point: in order to obtain local smoothing for the difference flow, it is essential that the regularized Hamiltonian retains the same conjugation/time-reversal symmetry as the full Hamiltonian.
Definition 4.11. Associated to each
 $\kappa \geq 1$
, we define regularized Hamiltonians
$\kappa \geq 1$
, we define regularized Hamiltonians
 $$ \begin{align} H_{\mathrm{NLS}}^{\kappa} &= - 8\kappa^3\operatorname{Re} A(\kappa) + 4\kappa^2 M = - 4\kappa^3 \big[ A(\kappa) - A(-\kappa)\big] + 4\kappa^2 M , \end{align} $$
$$ \begin{align} H_{\mathrm{NLS}}^{\kappa} &= - 8\kappa^3\operatorname{Re} A(\kappa) + 4\kappa^2 M = - 4\kappa^3 \big[ A(\kappa) - A(-\kappa)\big] + 4\kappa^2 M , \end{align} $$
 $$ \begin{align} H_{\mathrm{mKdV}}^{\kappa} &= 16\kappa^4\operatorname{Im} A(\kappa) + 4\kappa^2 P = -8i\kappa^4 \big[ A(\kappa) + A(-\kappa)\big] + 4\kappa^2 P , \end{align} $$
$$ \begin{align} H_{\mathrm{mKdV}}^{\kappa} &= 16\kappa^4\operatorname{Im} A(\kappa) + 4\kappa^2 P = -8i\kappa^4 \big[ A(\kappa) + A(-\kappa)\big] + 4\kappa^2 P , \end{align} $$
as functions on
 $B_\delta \cap \mathcal {S}$
, as well as difference Hamiltonians,
$B_\delta \cap \mathcal {S}$
, as well as difference Hamiltonians,
 $$ \begin{align} H_{\mathrm{NLS}}^{\mathrm{diff}} = H_{\mathrm{NLS}}-H_{\mathrm{NLS}}^{\kappa} \quad\text{and}\quad H_{\mathrm{mKdV}}^{\mathrm{diff}} = H_{\mathrm{mKdV}} - H_{\mathrm{mKdV}}^\kappa. \end{align} $$
$$ \begin{align} H_{\mathrm{NLS}}^{\mathrm{diff}} = H_{\mathrm{NLS}}-H_{\mathrm{NLS}}^{\kappa} \quad\text{and}\quad H_{\mathrm{mKdV}}^{\mathrm{diff}} = H_{\mathrm{mKdV}} - H_{\mathrm{mKdV}}^\kappa. \end{align} $$
One of the key features of the regularized flows is that they are readily seen to be well-posed:
Proposition 4.12 (Global well-posedness of the regularized flows).
There exists
 $\delta>0$
so that for all
$\delta>0$
so that for all
 $\kappa \geq 1$
, the
$\kappa \geq 1$
, the
 $H_{\mathrm {NLS}}^{\kappa }$
and
$H_{\mathrm {NLS}}^{\kappa }$
and
 $H_{\mathrm {mKdV}}^{\kappa }$
flows
$H_{\mathrm {mKdV}}^{\kappa }$
flows
 $$\begin{align}i\frac d{dt}q &= 4\kappa^3\left(g_{12}(\kappa) - g_{12}(-\kappa)\right) + 4\kappa^2q, \end{align}$$
$$\begin{align}i\frac d{dt}q &= 4\kappa^3\left(g_{12}(\kappa) - g_{12}(-\kappa)\right) + 4\kappa^2q, \end{align}$$
 $$\begin{align}\ \frac d{dt}q &= 8\kappa^4\left(g_{12}(\kappa) + g_{12}(-\kappa)\right) + 4\kappa^2q' \end{align}$$
$$\begin{align}\ \frac d{dt}q &= 8\kappa^4\left(g_{12}(\kappa) + g_{12}(-\kappa)\right) + 4\kappa^2q' \end{align}$$
are globally well-posed for initial data in
 $B_\delta $
. These solutions conserve
$B_\delta $
. These solutions conserve
 $\alpha (\varkappa )$
for every
$\alpha (\varkappa )$
for every
 $\varkappa \geq 1$
. Moreover, if the initial data are Schwartz, then so are the corresponding solutions.
$\varkappa \geq 1$
. Moreover, if the initial data are Schwartz, then so are the corresponding solutions.
Proof. The evolution equations follow directly from (4.32) and (4.33) by applying (4.3) and (4.4). Using the diffeomorphism property of the map
 $q\mapsto g_{12}(\kappa )$
proved in Proposition 3.2, we may view the equations (NLSκ
) and (mKdVκ
) as ordinary differential equations in
$q\mapsto g_{12}(\kappa )$
proved in Proposition 3.2, we may view the equations (NLSκ
) and (mKdVκ
) as ordinary differential equations in
 $H^s$
, the latter after making the change of variables
$H^s$
, the latter after making the change of variables
 $$\begin{align*}(t,x) \mapsto (t,x - 4\kappa^2 t). \end{align*}$$
$$\begin{align*}(t,x) \mapsto (t,x - 4\kappa^2 t). \end{align*}$$
Local well-posedness then follows from the Picard-Lindelöf theorem. Further, as the map
 $q\mapsto g_{12}(\kappa )$
preserves the Schwartz class, it is clear that if
$q\mapsto g_{12}(\kappa )$
preserves the Schwartz class, it is clear that if
 $q(0)\in B_\delta \cap \mathcal {S}$
, then the corresponding solution remains Schwartz. Finally, to extend the solution globally in time, we first observe that for
$q(0)\in B_\delta \cap \mathcal {S}$
, then the corresponding solution remains Schwartz. Finally, to extend the solution globally in time, we first observe that for
 $q(0)\in B_\delta \cap \mathcal {S}$
, we may apply Lemma 4.3 to deduce the conservation of
$q(0)\in B_\delta \cap \mathcal {S}$
, we may apply Lemma 4.3 to deduce the conservation of
 $\alpha (\varkappa )$
for all
$\alpha (\varkappa )$
for all
 $\varkappa \geq 1$
. Applying Proposition 4.4, we may then extend the solution globally in time for
$\varkappa \geq 1$
. Applying Proposition 4.4, we may then extend the solution globally in time for
 $q(0)\in B_\delta \cap \mathcal {S}$
and then for all
$q(0)\in B_\delta \cap \mathcal {S}$
and then for all
 $q(0)\in B_\delta $
by approximation.
$q(0)\in B_\delta $
by approximation.
From Lemma 4.3, we see that the full and regularized Hamiltonian evolutions commute (at least on Schwartz space). This allows us to obtain evolution equations for the difference Hamiltonians by simply combining the corresponding vector fields. In this way, Proposition 4.12 together with Corollaries 4.8 and 4.10 yields the following:
Corollary 4.13 (Difference flows).
Consider any
 $\kappa ,\varkappa \geq 1$
and any initial data in
$\kappa ,\varkappa \geq 1$
and any initial data in
 $B_\delta \cap \mathcal {S}$
. Under the NLS difference flow,
$B_\delta \cap \mathcal {S}$
. Under the NLS difference flow,
 $$ \begin{align} i\frac d{dt}q = - q" + 2q^2r - 4\kappa^3\left(g_{12}(\kappa)- g_{12}(-\kappa)\right) - 4\kappa^2q, \end{align} $$
$$ \begin{align} i\frac d{dt}q = - q" + 2q^2r - 4\kappa^3\left(g_{12}(\kappa)- g_{12}(-\kappa)\right) - 4\kappa^2q, \end{align} $$
 $$ \begin{align} \begin{cases} i\frac d{dt}g_{12}(\varkappa) &= - g_{12}(\varkappa)" + 4qrg_{12}(\varkappa) + 2q^2g_{21}(\varkappa)\\ &\quad + \frac{2\kappa^3}{\kappa - \varkappa} \big\{ [\gamma(\kappa)+1] g_{12}(\varkappa) - g_{12}(\kappa)[\gamma(\varkappa)+1] \big\}\\ &\quad + \frac{2\kappa^3}{\kappa + \varkappa} \big\{ [\gamma(-\kappa)+1] g_{12}(\varkappa) - g_{12}(-\kappa)[\gamma(\varkappa)+1] \big\}\\ &\quad - 4\kappa^2g_{12}(\varkappa), \end{cases} \end{align} $$
$$ \begin{align} \begin{cases} i\frac d{dt}g_{12}(\varkappa) &= - g_{12}(\varkappa)" + 4qrg_{12}(\varkappa) + 2q^2g_{21}(\varkappa)\\ &\quad + \frac{2\kappa^3}{\kappa - \varkappa} \big\{ [\gamma(\kappa)+1] g_{12}(\varkappa) - g_{12}(\kappa)[\gamma(\varkappa)+1] \big\}\\ &\quad + \frac{2\kappa^3}{\kappa + \varkappa} \big\{ [\gamma(-\kappa)+1] g_{12}(\varkappa) - g_{12}(-\kappa)[\gamma(\varkappa)+1] \big\}\\ &\quad - 4\kappa^2g_{12}(\varkappa), \end{cases} \end{align} $$
and under the mKdV difference flow
 $$ \begin{align} \frac d{dt}q = - q"' + 6qrq' - 8\kappa^4\left(g_{12}(\kappa) + g_{12}(-\kappa)\right) - 4\kappa^2q', \end{align} $$
$$ \begin{align} \frac d{dt}q = - q"' + 6qrq' - 8\kappa^4\left(g_{12}(\kappa) + g_{12}(-\kappa)\right) - 4\kappa^2q', \end{align} $$
 $$ \begin{align} \begin{cases} \frac d{dt}g_{12}(\varkappa) &=- g_{12}(\varkappa)"' + 6qrg_{12}(\varkappa)' + 6qq'g_{21}(\varkappa) + 6rq'g_{12}(\varkappa)\\ &\quad + \frac{4\kappa^4}{\kappa - \varkappa} \big\{ [\gamma(\kappa)+1] g_{12}(\varkappa) - g_{12}(\kappa)[\gamma(\varkappa)+1] \big\}\\ &\quad - \frac{4\kappa^4}{\kappa + \varkappa} \big\{ [\gamma(-\kappa)+1] g_{12}(\varkappa) - g_{12}(-\kappa)[\gamma(\varkappa)+1] \big\}\\ &\quad - 4\kappa^2g_{12}(\varkappa)'. \end{cases} \end{align} $$
$$ \begin{align} \begin{cases} \frac d{dt}g_{12}(\varkappa) &=- g_{12}(\varkappa)"' + 6qrg_{12}(\varkappa)' + 6qq'g_{21}(\varkappa) + 6rq'g_{12}(\varkappa)\\ &\quad + \frac{4\kappa^4}{\kappa - \varkappa} \big\{ [\gamma(\kappa)+1] g_{12}(\varkappa) - g_{12}(\kappa)[\gamma(\varkappa)+1] \big\}\\ &\quad - \frac{4\kappa^4}{\kappa + \varkappa} \big\{ [\gamma(-\kappa)+1] g_{12}(\varkappa) - g_{12}(-\kappa)[\gamma(\varkappa)+1] \big\}\\ &\quad - 4\kappa^2g_{12}(\varkappa)'. \end{cases} \end{align} $$
We end this section with the following result, which encapsulates the microscopic conservation law attendant to
 $A(\varkappa )$
under the various flows considered in this paper.
$A(\varkappa )$
under the various flows considered in this paper.
Corollary 4.14. For
 $\kappa ,\varkappa \geq 1$
and initial data in
$\kappa ,\varkappa \geq 1$
and initial data in
 $B_\delta \cap \mathcal {S}$
, we have
$B_\delta \cap \mathcal {S}$
, we have
 $$ \begin{align} \partial_t\rho(\varkappa) + \partial_x j_\star = 0, \end{align} $$
$$ \begin{align} \partial_t\rho(\varkappa) + \partial_x j_\star = 0, \end{align} $$
for each of the NLS, mKdV, and difference flows, the currents are given by
 $$ \begin{align*} &j_{\mathrm{NLS}}(\varkappa) = - i\left(\tfrac{ q'\cdot g_{21}(\varkappa) + r'\cdot g_{12}(\varkappa)}{2 + \gamma(\varkappa)} - qr + 2\varkappa \rho(\varkappa)\right),\\ &j_{\mathrm{mKdV}}(\varkappa) = \tfrac{ (q" - 2q^2r)\cdot g_{21}(\varkappa) - (r" - 2r^2q)\cdot g_{12}(\varkappa)}{2 + \gamma(\varkappa)} - q'r + qr' + 2i\varkappa j_{\mathrm{NLS}}(\varkappa),\\ &j_{\mathrm{NLS}}^{\mathrm{diff}}(\varkappa,\kappa) = j_{\mathrm{NLS}}(\varkappa) + 4\kappa^3\left(j(\varkappa,\kappa) - j(\varkappa,-\kappa)\right),\\ &j_{\mathrm{mKdV}}^{\mathrm{diff}}(\varkappa,\kappa) = j_{\mathrm{mKdV}}(\varkappa) + 8i\kappa^4\left(j(\varkappa,\kappa) + j(\varkappa,-\kappa)\right) + 4\kappa^2\rho(\varkappa). \end{align*} $$
$$ \begin{align*} &j_{\mathrm{NLS}}(\varkappa) = - i\left(\tfrac{ q'\cdot g_{21}(\varkappa) + r'\cdot g_{12}(\varkappa)}{2 + \gamma(\varkappa)} - qr + 2\varkappa \rho(\varkappa)\right),\\ &j_{\mathrm{mKdV}}(\varkappa) = \tfrac{ (q" - 2q^2r)\cdot g_{21}(\varkappa) - (r" - 2r^2q)\cdot g_{12}(\varkappa)}{2 + \gamma(\varkappa)} - q'r + qr' + 2i\varkappa j_{\mathrm{NLS}}(\varkappa),\\ &j_{\mathrm{NLS}}^{\mathrm{diff}}(\varkappa,\kappa) = j_{\mathrm{NLS}}(\varkappa) + 4\kappa^3\left(j(\varkappa,\kappa) - j(\varkappa,-\kappa)\right),\\ &j_{\mathrm{mKdV}}^{\mathrm{diff}}(\varkappa,\kappa) = j_{\mathrm{mKdV}}(\varkappa) + 8i\kappa^4\left(j(\varkappa,\kappa) + j(\varkappa,-\kappa)\right) + 4\kappa^2\rho(\varkappa). \end{align*} $$
5. Local smoothing
The goal of this section is to prove local smoothing estimates, not only for the NLS and mKdV flows, but also for the difference flows. To do this, we will be using an integrated form of the microscopic conservation law (4.37) for
 $A(\varkappa )$
:
$A(\varkappa )$
:
 $$ \begin{align} \int_{-1}^1\int_{{\mathbb{R}}} j_\star(t,x;\varkappa)\,\psi_h^{12}(x)\,dx\,dt = \int \big[\rho(1,x;\varkappa) - \rho(-1,x;\varkappa)\big]\,\Psi_h(x)\,dx, \end{align} $$
$$ \begin{align} \int_{-1}^1\int_{{\mathbb{R}}} j_\star(t,x;\varkappa)\,\psi_h^{12}(x)\,dx\,dt = \int \big[\rho(1,x;\varkappa) - \rho(-1,x;\varkappa)\big]\,\Psi_h(x)\,dx, \end{align} $$
where
 $h\in {{\mathbb {R}}}$
is a translation parameter,
$h\in {{\mathbb {R}}}$
is a translation parameter,
 $\psi _h$
is as in (1.5),
$\psi _h$
is as in (1.5),
 $$ \begin{align} \Psi_h(x) := \int_{-\infty}^x\psi_h^{12}(y)\,dy, \end{align} $$
$$ \begin{align} \Psi_h(x) := \int_{-\infty}^x\psi_h^{12}(y)\,dy, \end{align} $$
and the currents are as recorded in Corollary 4.14.
Eventually, we will take a supremum over
 $h\in {{\mathbb {R}}}$
as in (1.6). With this in mind, implicit constants in this section are always to be interpreted as independent of h.
$h\in {{\mathbb {R}}}$
as in (1.6). With this in mind, implicit constants in this section are always to be interpreted as independent of h.
Control of the local smoothing norm will originate in the coercivity of the LHS(5.1) that we have already hinted at in Lemma 4.9. The first result in this section, Lemma 5.1, shows that this coercivity of the quadratic currents survives in the presence of localization. As noted already in Section 4, we will need to take the real or imaginary part of (5.1), depending on the flow in question.
To continue, we will show how to control the RHS(5.1) in Lemma 5.2. This leaves us to control the higher order terms in the currents; this is the topic of Lemma 5.3. In estimating such terms, it is convenient to combine the key norms:
 $$ \begin{align*} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2 := \|q\|_{X_\kappa^{s+\frac12}}^2 + \|q\|_{L^\infty_t H^s}^2 \quad\text{and}\quad {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 := \|q\|_{X_\kappa^{s+1}}^2 + \|q\|_{L^\infty_t H^s}^2, \end{align*} $$
$$ \begin{align*} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2 := \|q\|_{X_\kappa^{s+\frac12}}^2 + \|q\|_{L^\infty_t H^s}^2 \quad\text{and}\quad {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 := \|q\|_{X_\kappa^{s+1}}^2 + \|q\|_{L^\infty_t H^s}^2, \end{align*} $$
with the convention that a missing subscript means
 $\kappa =1$
.
$\kappa =1$
.
The proofs of Lemmas 5.1 and 5.3 are both quite substantial. With this in mind, we delay presenting these proofs until after giving the main results of this section, namely, Propositions 5.4, 5.5, 5.6, and 5.8.
Lemma 5.1 (Estimates for
$j_\star ^{[2]}$
).

Fix
 $\delta>0$
sufficiently small. Then
$\delta>0$
sufficiently small. Then
 $$ \begin{align} \operatorname{Im} \int j_{\mathrm{NLS}}^{[2]}(\varkappa)\,\psi_h^{12}\,dx &= \pm 2\|(\psi_h^{6}q)'\|_{H^{-1}_\varkappa}^2 + \mathcal O\Big(\|q\|_{H^{-\frac12}_\varkappa}^2\Big), \end{align} $$
$$ \begin{align} \operatorname{Im} \int j_{\mathrm{NLS}}^{[2]}(\varkappa)\,\psi_h^{12}\,dx &= \pm 2\|(\psi_h^{6}q)'\|_{H^{-1}_\varkappa}^2 + \mathcal O\Big(\|q\|_{H^{-\frac12}_\varkappa}^2\Big), \end{align} $$
 $$ \begin{align} \operatorname{Re}\int j_{\mathrm{mKdV}}^{[2]}(\varkappa)\,\psi_h^{12}\,dx &= \mp 6\varkappa\|(\psi_h^{6} q)'\|_{H^{-1}_\varkappa}^2 + \mathcal O\Big(\|(\psi_h^{6} q)'\|_{H^{-\frac12}_\varkappa}\|q\|_{H^{-\frac12}_\varkappa} + \|q\|_{H^{-\frac12}_\varkappa}^2\Big), \end{align} $$
$$ \begin{align} \operatorname{Re}\int j_{\mathrm{mKdV}}^{[2]}(\varkappa)\,\psi_h^{12}\,dx &= \mp 6\varkappa\|(\psi_h^{6} q)'\|_{H^{-1}_\varkappa}^2 + \mathcal O\Big(\|(\psi_h^{6} q)'\|_{H^{-\frac12}_\varkappa}\|q\|_{H^{-\frac12}_\varkappa} + \|q\|_{H^{-\frac12}_\varkappa}^2\Big), \end{align} $$
uniformly for
 $q\in B_\delta \cap \mathcal {S}$
,
$q\in B_\delta \cap \mathcal {S}$
,
 $\varkappa \geq 1$
, and
$\varkappa \geq 1$
, and
 $h\in {{\mathbb {R}}}$
. Analogously,
$h\in {{\mathbb {R}}}$
. Analogously,
 $$ \begin{align} \operatorname{Im} \int j_{\mathrm{NLS}}^{\mathrm{diff}}{}^{[2]}(\varkappa,\kappa)\,\psi_h^{12}\,dx &= \pm 2\int \frac{\xi^4(8\kappa^2 + \xi^2)|\widehat{\psi_h^6 q}(\xi)|^2\,d\xi}{(4\varkappa^2 + \xi^2)(4\kappa^2 + \xi^2)^2} + \mathcal O\Big(\|q\|_{H^{-\frac12}_\varkappa}^2\Big),\!\!\! \end{align} $$
$$ \begin{align} \operatorname{Im} \int j_{\mathrm{NLS}}^{\mathrm{diff}}{}^{[2]}(\varkappa,\kappa)\,\psi_h^{12}\,dx &= \pm 2\int \frac{\xi^4(8\kappa^2 + \xi^2)|\widehat{\psi_h^6 q}(\xi)|^2\,d\xi}{(4\varkappa^2 + \xi^2)(4\kappa^2 + \xi^2)^2} + \mathcal O\Big(\|q\|_{H^{-\frac12}_\varkappa}^2\Big),\!\!\! \end{align} $$
 $$ \begin{align} \operatorname{Re}\int j_{\mathrm{mKdV}}^{\mathrm{diff}\;[2]}(\varkappa,\kappa)\,\psi_h^{12}\,dx &= \mp 2\varkappa\int \frac{(20\kappa^2 + 3\xi^2)\xi^4|\widehat{\psi_h^{6}q}(\xi)|^2\,d\xi}{(4\varkappa^2 + \xi^2)(4\kappa^2 + \xi^2)^2} \\ &\quad + \mathcal O\Big(\|\tfrac{(\psi_h^{6}q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{H^{-\frac12}_\varkappa}\|q\|_{H^{-\frac12}_\varkappa} + \|q\|_{H^{-\frac12}_\varkappa}^2\Big),\notag \end{align} $$
$$ \begin{align} \operatorname{Re}\int j_{\mathrm{mKdV}}^{\mathrm{diff}\;[2]}(\varkappa,\kappa)\,\psi_h^{12}\,dx &= \mp 2\varkappa\int \frac{(20\kappa^2 + 3\xi^2)\xi^4|\widehat{\psi_h^{6}q}(\xi)|^2\,d\xi}{(4\varkappa^2 + \xi^2)(4\kappa^2 + \xi^2)^2} \\ &\quad + \mathcal O\Big(\|\tfrac{(\psi_h^{6}q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{H^{-\frac12}_\varkappa}\|q\|_{H^{-\frac12}_\varkappa} + \|q\|_{H^{-\frac12}_\varkappa}^2\Big),\notag \end{align} $$
uniformly for
 $q\in B_\delta \cap \mathcal {S}$
,
$q\in B_\delta \cap \mathcal {S}$
,
 $\kappa ,\varkappa \geq 1$
, and
$\kappa ,\varkappa \geq 1$
, and
 $h\in {{\mathbb {R}}}$
.
$h\in {{\mathbb {R}}}$
.
Lemma 5.2 (Estimate for
$\rho $
).

Let
 $q\in B_\delta \cap \mathcal {S}$
and
$q\in B_\delta \cap \mathcal {S}$
and
 $\Psi _h$
be defined as in (5.2). Then for
$\Psi _h$
be defined as in (5.2). Then for
 $\varkappa \geq 1$
, we have the estimate
$\varkappa \geq 1$
, we have the estimate
 $$ \begin{align} \left|\int \rho(\varkappa)\,\Psi_h\,dx\right| \lesssim \|q\|_{H^{-\frac12}_\varkappa}^2 + \varkappa^{-2(2s+1)}\delta^2\|q\|_{H^s}^2, \end{align} $$
$$ \begin{align} \left|\int \rho(\varkappa)\,\Psi_h\,dx\right| \lesssim \|q\|_{H^{-\frac12}_\varkappa}^2 + \varkappa^{-2(2s+1)}\delta^2\|q\|_{H^s}^2, \end{align} $$
where the implicit constant is independent of
 $h,\varkappa $
.
$h,\varkappa $
.
Proof. As in the proof of Proposition 4.4, we write
 $\rho (\varkappa ) = \rho ^{[2]} (\varkappa )+ \rho ^{[\geq 4]}(\varkappa )$
. From (4.13), we bound
$\rho (\varkappa ) = \rho ^{[2]} (\varkappa )+ \rho ^{[\geq 4]}(\varkappa )$
. From (4.13), we bound
 $$\begin{align*}\left|\int \rho^{[2]}(\varkappa)\,\Psi_h\,dx\right| \lesssim \|\Psi_h q\|_{H^{-\frac12}_\varkappa}\|q\|_{H^{-\frac12}_\varkappa}\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*}$$
$$\begin{align*}\left|\int \rho^{[2]}(\varkappa)\,\Psi_h\,dx\right| \lesssim \|\Psi_h q\|_{H^{-\frac12}_\varkappa}\|q\|_{H^{-\frac12}_\varkappa}\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*}$$
Using (4.14) and (4.17), we may bound
 $$\begin{align*}\left|\int \rho^{[\geq 4]}(\varkappa)\,\Psi_h\,dx\right| \lesssim \varkappa^{-2(2s+1)}\delta^2\|q\|_{H^s}^2. \end{align*}$$
$$\begin{align*}\left|\int \rho^{[\geq 4]}(\varkappa)\,\Psi_h\,dx\right| \lesssim \varkappa^{-2(2s+1)}\delta^2\|q\|_{H^s}^2. \end{align*}$$
This completes the proof of the lemma.
To control the contribution of the remaining part
 $j_\star ^{[\geq 4]}$
of the current, we use the following lemma. The proof of this result will take up the majority of this section.
$j_\star ^{[\geq 4]}$
of the current, we use the following lemma. The proof of this result will take up the majority of this section.
Lemma 5.3 (Estimates for
$j_\star ^{[\geq 4]}$
).

Let
 $q\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
with
$q\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
with
 $\delta>0$
sufficiently small. For any
$\delta>0$
sufficiently small. For any
 $\varkappa \geq 1$
, we have
$\varkappa \geq 1$
, we have
 $$ \begin{align} \left\|\int j_{\mathrm{NLS}}^{[\geq 4]}(\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} &\lesssim \varkappa^{-2(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}}^2, \end{align} $$
$$ \begin{align} \left\|\int j_{\mathrm{NLS}}^{[\geq 4]}(\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} &\lesssim \varkappa^{-2(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}}^2, \end{align} $$
 $$ \begin{align} \left\|\int j_{\mathrm{mKdV}}^{[\geq 4]}(\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t}& \lesssim \big[\varkappa^{-1}+\varkappa^{-2(2s+1)}\log^4|2\varkappa|\big]\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align} $$
$$ \begin{align} \left\|\int j_{\mathrm{mKdV}}^{[\geq 4]}(\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t}& \lesssim \big[\varkappa^{-1}+\varkappa^{-2(2s+1)}\log^4|2\varkappa|\big]\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align} $$
Moreover, if
 $\kappa \geq 8$
and
$\kappa \geq 8$
and
 $\varkappa \in [\kappa ^{\frac 23},\frac 12\kappa ]\cup [2\kappa ,\infty )$
, then
$\varkappa \in [\kappa ^{\frac 23},\frac 12\kappa ]\cup [2\kappa ,\infty )$
, then
 $$ \begin{align} \left\|\int \! j_{\mathrm{NLS}}^{\mathrm{diff}}{}^{[\geq 4]}(\varkappa,\kappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} &\lesssim \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)} + \varkappa^{-2(2s+1)}\big]\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
$$ \begin{align} \left\|\int \! j_{\mathrm{NLS}}^{\mathrm{diff}}{}^{[\geq 4]}(\varkappa,\kappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} &\lesssim \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)} + \varkappa^{-2(2s+1)}\big]\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
whereas for
 $\varkappa \in [\kappa ^{\frac 12},\frac 12 \kappa ]\cup [2\kappa ,\infty )$
, we have
$\varkappa \in [\kappa ^{\frac 12},\frac 12 \kappa ]\cup [2\kappa ,\infty )$
, we have
 $$ \begin{align} \left\|\int \! j_{\mathrm{mKdV}}^{\mathrm{diff}\;[\geq 4]}(\varkappa,\kappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} &\lesssim \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)} + \varkappa^{-2(2s+1)}\log|2\varkappa|\big] \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align} $$
$$ \begin{align} \left\|\int \! j_{\mathrm{mKdV}}^{\mathrm{diff}\;[\geq 4]}(\varkappa,\kappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} &\lesssim \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)} + \varkappa^{-2(2s+1)}\log|2\varkappa|\big] \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align} $$
In all cases, the implicit constant is independent of h,
 $\varkappa $
, and
$\varkappa $
, and
 $\kappa $
.
$\kappa $
.
The restriction
 $\kappa \geq 8$
(rather than
$\kappa \geq 8$
(rather than
 $\kappa \geq 1$
) appearing in this proposition is imposed to avoid confusion in the meaning of the constraints on
$\kappa \geq 1$
) appearing in this proposition is imposed to avoid confusion in the meaning of the constraints on
 $\varkappa $
. It guarantees that in both cases, the first interval is nonempty.
$\varkappa $
. It guarantees that in both cases, the first interval is nonempty.
The fact that the
 $\kappa =1$
case of (5.11) yields a better bound than (5.9) warrants explanation. Ultimately, this is because LHS(5.11) requires a much more detailed analysis in order to achieve a satisfactory bound. The bound (5.9) could be improved by a parallel analysis; however, this is not needed for what follows.
$\kappa =1$
case of (5.11) yields a better bound than (5.9) warrants explanation. Ultimately, this is because LHS(5.11) requires a much more detailed analysis in order to achieve a satisfactory bound. The bound (5.9) could be improved by a parallel analysis; however, this is not needed for what follows.
With these estimates in hand, we are now able to prove our local smoothing estimates:
Proposition 5.4 (Local smoothing for the NLS).
There exists
 $\delta>0$
so that for any
$\delta>0$
so that for any
 $q(0)\in B_\delta \cap \mathcal {S}$
, the solution
$q(0)\in B_\delta \cap \mathcal {S}$
, the solution
 $q(t)$
of (NLS) satisfies the estimate
$q(t)$
of (NLS) satisfies the estimate
 $$ \begin{align} \|q\|_{X^{s+\frac12}}^2 \lesssim \|q(0)\|_{H^s}^2. \end{align} $$
$$ \begin{align} \|q\|_{X^{s+\frac12}}^2 \lesssim \|q(0)\|_{H^s}^2. \end{align} $$
Further, we have the high-frequency estimate
 $$ \begin{align} \big\|(\psi_h^6q)^{\prime}\|_{L_t^2 H_\kappa^{s-\frac{1}{2}}}^2\lesssim \|q(0)\|_{H^s_\kappa}^2 + \kappa^{-(2s+1)}\delta^2 \|q(0)\|_{H^s}^2, \end{align} $$
$$ \begin{align} \big\|(\psi_h^6q)^{\prime}\|_{L_t^2 H_\kappa^{s-\frac{1}{2}}}^2\lesssim \|q(0)\|_{H^s_\kappa}^2 + \kappa^{-(2s+1)}\delta^2 \|q(0)\|_{H^s}^2, \end{align} $$
uniformly for
 $\kappa \geq 1$
.
$\kappa \geq 1$
.
Proof. Consider the imaginary part of (5.1). Applying the estimates (5.3) and (5.8) to the LHS and the estimate (5.7) to the RHS, we obtain
 $$ \begin{align*} \|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \|q\|_{L^\infty_t H^{-\frac12}_\varkappa}^2 +\varkappa^{-2(2s+1)}\delta^2\left(\|q\|_{X^{s+\frac12}}^2 + \|q\|_{L^\infty_t H^s}^2\right), \end{align*} $$
$$ \begin{align*} \|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \|q\|_{L^\infty_t H^{-\frac12}_\varkappa}^2 +\varkappa^{-2(2s+1)}\delta^2\left(\|q\|_{X^{s+\frac12}}^2 + \|q\|_{L^\infty_t H^s}^2\right), \end{align*} $$
where the implicit constant is independent of
 $h,\varkappa $
. We then choose
$h,\varkappa $
. We then choose
 $-\frac 12<s'<s$
and apply the a priori estimate (4.12) to obtain
$-\frac 12<s'<s$
and apply the a priori estimate (4.12) to obtain
 $$ \begin{align*} \|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varkappa^{-(2s'+1)} \|q(0)\|_{H^{s'}_\varkappa}^2+ \varkappa^{-2(2s+1)}\delta^2\left(\|q\|_{X^{s+\frac12}}^2 + \|q(0)\|_{H^s}^2\right). \end{align*} $$
$$ \begin{align*} \|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varkappa^{-(2s'+1)} \|q(0)\|_{H^{s'}_\varkappa}^2+ \varkappa^{-2(2s+1)}\delta^2\left(\|q\|_{X^{s+\frac12}}^2 + \|q(0)\|_{H^s}^2\right). \end{align*} $$
Taking
 $\kappa \geq 1$
and using (2.7), we obtain
$\kappa \geq 1$
and using (2.7), we obtain
 $$ \begin{align} \nonumber\|(\psi_h^6 q)'\|_{L^2_t H^{s-\frac12}_\kappa}^2 &\approx\int_\kappa^\infty \varkappa^{2s+1}\|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2\,\tfrac{d\varkappa}\varkappa\\ &\lesssim \|q(0)\|_{H^s_\kappa}^2 + \kappa^{-(2s+1)}\delta^2\left(\|q\|_{X^{s+\frac12}}^2 + \|q(0)\|_{H^s}^2\right). \end{align} $$
$$ \begin{align} \nonumber\|(\psi_h^6 q)'\|_{L^2_t H^{s-\frac12}_\kappa}^2 &\approx\int_\kappa^\infty \varkappa^{2s+1}\|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2\,\tfrac{d\varkappa}\varkappa\\ &\lesssim \|q(0)\|_{H^s_\kappa}^2 + \kappa^{-(2s+1)}\delta^2\left(\|q\|_{X^{s+\frac12}}^2 + \|q(0)\|_{H^s}^2\right). \end{align} $$
To complete the proof, we take
 $\kappa = 1$
to deduce
$\kappa = 1$
to deduce
 $$ \begin{align*} \|\psi_h^6q\|_{L^2_t H^{s+\frac12}}^2 &\lesssim \|P_{>1}(\psi_h^6 q)'\|_{L^2_t H^{s-\frac12}}^2 + \|P_{\leq 1}(\psi_h^6 q)\|_{L^\infty_t H^s}^2 \\ &\lesssim \delta^2\|q\|_{X^{s+\frac12}}^2 + \|q(0)\|_{H^s}^2. \end{align*} $$
$$ \begin{align*} \|\psi_h^6q\|_{L^2_t H^{s+\frac12}}^2 &\lesssim \|P_{>1}(\psi_h^6 q)'\|_{L^2_t H^{s-\frac12}}^2 + \|P_{\leq 1}(\psi_h^6 q)\|_{L^\infty_t H^s}^2 \\ &\lesssim \delta^2\|q\|_{X^{s+\frac12}}^2 + \|q(0)\|_{H^s}^2. \end{align*} $$
Taking the supremum over
 $h\in {{\mathbb {R}}}$
and choosing
$h\in {{\mathbb {R}}}$
and choosing
 $0<\delta \ll 1$
sufficiently small, we obtain the estimate (5.12). The claim (5.13) then follows from (5.12) and (5.14).
$0<\delta \ll 1$
sufficiently small, we obtain the estimate (5.12). The claim (5.13) then follows from (5.12) and (5.14).
An essentially identical argument yields the corresponding result for the mKdV:
Proposition 5.5 (Local smoothing for the mKdV).
There exists
 $\delta>0$
so that for any
$\delta>0$
so that for any
 $q(0)\in B_\delta \cap \mathcal {S}$
, the solution
$q(0)\in B_\delta \cap \mathcal {S}$
, the solution
 $q(t)$
of (mKdV) satisfies the estimate
$q(t)$
of (mKdV) satisfies the estimate
 $$ \begin{align} \|q\|_{X^{s+1}}^2\lesssim \|q(0)\|_{H^s}^2. \end{align} $$
$$ \begin{align} \|q\|_{X^{s+1}}^2\lesssim \|q(0)\|_{H^s}^2. \end{align} $$
Further, we have the high-frequency estimate
 $$ \begin{align} \big\|(\psi_h^6q)'\|_{L^2_t H_\kappa^{s}}^2\lesssim \|q(0)\|_{H^s_\kappa}^2 + \kappa^{-(2s+1)}\log^4\!|2\kappa| \, \delta^2 \|q(0)\|_{H^s}^2, \end{align} $$
$$ \begin{align} \big\|(\psi_h^6q)'\|_{L^2_t H_\kappa^{s}}^2\lesssim \|q(0)\|_{H^s_\kappa}^2 + \kappa^{-(2s+1)}\log^4\!|2\kappa| \, \delta^2 \|q(0)\|_{H^s}^2, \end{align} $$
uniformly for
 $\kappa \geq 1$
.
$\kappa \geq 1$
.
Proof. Consider the real part of (5.1). Applying (5.4) and (5.9) to the LHS and applying (5.7) to the RHS, we deduce that
 $$ \begin{align*} \varkappa\|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varepsilon\|(\psi_h^6 q)'\|^2_{L^2_t H^{-\frac12}_\varkappa} + (1 + \tfrac1\varepsilon)\|q\|_{L^\infty_t H^{-\frac12}_\varkappa}^2\\ & \quad + \big[\varkappa^{-1}+\varkappa^{-2(2s+1)}\log^4\!|2\varkappa|\big]\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2 \end{align*} $$
$$ \begin{align*} \varkappa\|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varepsilon\|(\psi_h^6 q)'\|^2_{L^2_t H^{-\frac12}_\varkappa} + (1 + \tfrac1\varepsilon)\|q\|_{L^\infty_t H^{-\frac12}_\varkappa}^2\\ & \quad + \big[\varkappa^{-1}+\varkappa^{-2(2s+1)}\log^4\!|2\varkappa|\big]\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2 \end{align*} $$
for any
 $0<\varepsilon <1$
. Here, the implicit constant is independent of
$0<\varepsilon <1$
. Here, the implicit constant is independent of
 $h,\varkappa , \varepsilon $
. Applying the a priori estimate (4.12), for any
$h,\varkappa , \varepsilon $
. Applying the a priori estimate (4.12), for any
 $-\frac 12<s'<s$
, we obtain
$-\frac 12<s'<s$
, we obtain
 $$ \begin{align*} \varkappa\|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varepsilon\|(\psi_h^6 q)'\|_{L^2_t H^{-\frac12}_\varkappa}^2+ (1 + \tfrac1\varepsilon)\varkappa^{-(2s'+1)}\|q(0)\|_{H^{s'}_\varkappa}^2\\ & \quad + \big[\varkappa^{-1}+\varkappa^{-2(2s+1)}\log^4\!|2\varkappa|\big]\delta^2\Big(\|q\|_{X^{s+1}}^2 + \|q(0)\|_{H^s}^2\Big). \end{align*} $$
$$ \begin{align*} \varkappa\|(\psi_h^6 q)'\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varepsilon\|(\psi_h^6 q)'\|_{L^2_t H^{-\frac12}_\varkappa}^2+ (1 + \tfrac1\varepsilon)\varkappa^{-(2s'+1)}\|q(0)\|_{H^{s'}_\varkappa}^2\\ & \quad + \big[\varkappa^{-1}+\varkappa^{-2(2s+1)}\log^4\!|2\varkappa|\big]\delta^2\Big(\|q\|_{X^{s+1}}^2 + \|q(0)\|_{H^s}^2\Big). \end{align*} $$
Using the estimate (2.7), we obtain
 $$ \begin{align*} \|(\psi_h^6 q)'\|_{L^2_t H^s_\kappa}^2&\approx \int_{\kappa}^\infty\varkappa^{2s+2}\|(\psi_h^6 q)'\|_{H^{-1}_\varkappa}^2\,\tfrac{d\varkappa} \varkappa \\ &\lesssim \varepsilon \|(\psi_h q)'\|_{L^2_t H^s_\kappa}^2 + (1 + \tfrac1\varepsilon)\|q(0)\|_{H^s_\kappa}^2\\ & \quad + \big[\kappa^{2s}+\kappa^{-(2s+1)}\log^4\!|2\kappa|\big]\delta^2\Big(\|q\|_{X^{s+1}}^2 + \|q(0)\|_{H^s}^2\Big). \end{align*} $$
$$ \begin{align*} \|(\psi_h^6 q)'\|_{L^2_t H^s_\kappa}^2&\approx \int_{\kappa}^\infty\varkappa^{2s+2}\|(\psi_h^6 q)'\|_{H^{-1}_\varkappa}^2\,\tfrac{d\varkappa} \varkappa \\ &\lesssim \varepsilon \|(\psi_h q)'\|_{L^2_t H^s_\kappa}^2 + (1 + \tfrac1\varepsilon)\|q(0)\|_{H^s_\kappa}^2\\ & \quad + \big[\kappa^{2s}+\kappa^{-(2s+1)}\log^4\!|2\kappa|\big]\delta^2\Big(\|q\|_{X^{s+1}}^2 + \|q(0)\|_{H^s}^2\Big). \end{align*} $$
Choosing
 $0<\varepsilon <1$
sufficiently small to defeat the implicit constant, we get
$0<\varepsilon <1$
sufficiently small to defeat the implicit constant, we get
 $$ \begin{align} \|(\psi_h^6 q)'\|_{L^2_t H^s_\kappa}^2 &\lesssim \|q(0)\|_{H^s_\kappa}^2+ \big[\kappa^{2s}+\kappa^{-(2s+1)}\log^4\!|2\kappa|\big]\delta^2\Big(\|q\|_{X^{s+1}}^2 + \|q(0)\|_{H^s}^2\Big). \end{align} $$
$$ \begin{align} \|(\psi_h^6 q)'\|_{L^2_t H^s_\kappa}^2 &\lesssim \|q(0)\|_{H^s_\kappa}^2+ \big[\kappa^{2s}+\kappa^{-(2s+1)}\log^4\!|2\kappa|\big]\delta^2\Big(\|q\|_{X^{s+1}}^2 + \|q(0)\|_{H^s}^2\Big). \end{align} $$
To complete the proof, we apply the estimate (5.17) with
 $\kappa = 1$
to bound
$\kappa = 1$
to bound
 $$ \begin{align*} \|\psi_h^6 q\|_{L^2_t H^{s+1}}^2 &\lesssim \|P_{>1}(\psi_h^6 q)'\|_{L^2_t H^s}^2 + \|P_{\leq 1}(\psi_h^6 q)\|_{L^\infty_t H^s}^2 \\ &\lesssim \delta^2\|q\|_{X^{s+1}}^2 + \|q(0)\|_{H^s}^2. \end{align*} $$
$$ \begin{align*} \|\psi_h^6 q\|_{L^2_t H^{s+1}}^2 &\lesssim \|P_{>1}(\psi_h^6 q)'\|_{L^2_t H^s}^2 + \|P_{\leq 1}(\psi_h^6 q)\|_{L^\infty_t H^s}^2 \\ &\lesssim \delta^2\|q\|_{X^{s+1}}^2 + \|q(0)\|_{H^s}^2. \end{align*} $$
Taking the supremum over
 $h\in {{\mathbb {R}}}$
and choosing
$h\in {{\mathbb {R}}}$
and choosing
 $0<\delta \ll 1$
sufficiently small, we obtain (5.15). The estimate (5.16) then follows from (5.15), (5.17), and the observation that
$0<\delta \ll 1$
sufficiently small, we obtain (5.15). The estimate (5.16) then follows from (5.15), (5.17), and the observation that
 $\kappa ^{2s}\|q(0)\|_{H^s}^2\lesssim \|q(0)\|_{H^s_\kappa }^2$
.
$\kappa ^{2s}\|q(0)\|_{H^s}^2\lesssim \|q(0)\|_{H^s_\kappa }^2$
.
In Propositions 5.4 and 5.5, the parameter
 $\kappa $
plays the role of a frequency threshold. The fact that we obtain decay as
$\kappa $
plays the role of a frequency threshold. The fact that we obtain decay as
 $\kappa \to \infty $
will be essential both for proving tightness and for proving that the data-to-solution map is continuous in the local smoothing norm.
$\kappa \to \infty $
will be essential both for proving tightness and for proving that the data-to-solution map is continuous in the local smoothing norm.
We now turn to proving local smoothing for the difference flows. In this context,
 $\kappa $
takes on a new meaning as the parameter appearing in the regularized Hamiltonians (see (4.34)). In this role,
$\kappa $
takes on a new meaning as the parameter appearing in the regularized Hamiltonians (see (4.34)). In this role,
 $\kappa $
marks a border (in frequency space): it is only for frequencies below
$\kappa $
marks a border (in frequency space): it is only for frequencies below
 $\kappa $
that the regularized and full Hamiltonian flows well-approximate one another. Correspondingly, it is only for frequencies above
$\kappa $
that the regularized and full Hamiltonian flows well-approximate one another. Correspondingly, it is only for frequencies above
 $\kappa $
that we can expect to recover the full local smoothing effects documented above for (NLS) and (mKdV).
$\kappa $
that we can expect to recover the full local smoothing effects documented above for (NLS) and (mKdV).
Proposition 5.6 (Local smoothing for the NLS difference flow).
There exists
 $\delta>0$
so that for any
$\delta>0$
so that for any
 $q(0)\in B_\delta \cap \mathcal {S}$
and
$q(0)\in B_\delta \cap \mathcal {S}$
and
 $\kappa \geq 8$
, the solution
$\kappa \geq 8$
, the solution
 $q(t)$
of the NLS difference flow (NLS-diff) with parameter
$q(t)$
of the NLS difference flow (NLS-diff) with parameter
 $\kappa $
satisfies the estimate
$\kappa $
satisfies the estimate
 $$ \begin{align} \|q\|_{X^{s+\frac12}_\kappa}^2\lesssim \|q(0)\|_{H^s}^2, \end{align} $$
$$ \begin{align} \|q\|_{X^{s+\frac12}_\kappa}^2\lesssim \|q(0)\|_{H^s}^2, \end{align} $$
where the implicit constant is independent of
 $\kappa $
.
$\kappa $
.
Proof. Let us write
 $I=[\kappa ^{\frac 23},\frac 12\kappa ]\cup [2\kappa ,\infty )$
, which is the region of
$I=[\kappa ^{\frac 23},\frac 12\kappa ]\cup [2\kappa ,\infty )$
, which is the region of
 $\varkappa $
over which the estimate (5.10) will be proved.
$\varkappa $
over which the estimate (5.10) will be proved.
Taking the imaginary part of (5.1) and applying (5.5), (5.10), and (5.7), we find
 $$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \|q\|_{L^\infty_t H^{-\frac12}_\varkappa}^2 + \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)} + \varkappa^{-2(2s+1)}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*} $$
$$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \|q\|_{L^\infty_t H^{-\frac12}_\varkappa}^2 + \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)} + \varkappa^{-2(2s+1)}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*} $$
uniformly for
 $\varkappa \in I$
. Choosing
$\varkappa \in I$
. Choosing
 $-\frac 12<s'<s$
and employing the a priori estimate (4.12), we deduce that
$-\frac 12<s'<s$
and employing the a priori estimate (4.12), we deduce that
 $$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varkappa^{-(2s'+ 1)}\|q(0)\|_{H^{s'}_\varkappa}^2 + \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)} + \varkappa^{-2(2s+1)}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*} $$
$$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varkappa^{-(2s'+ 1)}\|q(0)\|_{H^{s'}_\varkappa}^2 + \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)} + \varkappa^{-2(2s+1)}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*} $$
uniformly for
 $\varkappa \in I$
. Next, we wish to integrate out
$\varkappa \in I$
. Next, we wish to integrate out
 $\varkappa $
.
$\varkappa $
.
By Lemma 2.1, we have
 $$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s-\frac12}_{\kappa^{2/3}}}^2 \approx\int_{\kappa^{\frac23}}^\infty \varkappa^{2s+1}\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2\tfrac{d\varkappa}\varkappa, \end{align*} $$
$$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s-\frac12}_{\kappa^{2/3}}}^2 \approx\int_{\kappa^{\frac23}}^\infty \varkappa^{2s+1}\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2\tfrac{d\varkappa}\varkappa, \end{align*} $$
from which it follows that
 $$ \begin{align} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s-\frac12}_{\kappa^{2/3}}}^2 &\approx\int_I \varkappa^{2s+1}\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2\tfrac{d\varkappa}\varkappa , \end{align} $$
$$ \begin{align} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s-\frac12}_{\kappa^{2/3}}}^2 &\approx\int_I \varkappa^{2s+1}\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2\tfrac{d\varkappa}\varkappa , \end{align} $$
because the integrand on the interval
 $[\kappa /2,2\kappa ]$
is comparable to that on
$[\kappa /2,2\kappa ]$
is comparable to that on
 $[2\kappa ,4\kappa ]$
.
$[2\kappa ,4\kappa ]$
.
Proceeding in this way, we find that
 $$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s-\frac12}_{\kappa^{2/3}}}^2 \lesssim \|q(0)\|_{H^s}^2 + \kappa^{-\frac13(1+2s)}\delta^2\Big(\|q\|_{X^{s+\frac12}_\kappa}^2 + \|q(0)\|_{H^s}^2\Big). \end{align*} $$
$$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s-\frac12}_{\kappa^{2/3}}}^2 \lesssim \|q(0)\|_{H^s}^2 + \kappa^{-\frac13(1+2s)}\delta^2\Big(\|q\|_{X^{s+\frac12}_\kappa}^2 + \|q(0)\|_{H^s}^2\Big). \end{align*} $$
To complete the proof, we decompose
 $$ \begin{align*} \|\tfrac{\psi_h^6 q}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s+\frac32}}^2 &\lesssim \|\tfrac1{\sqrt{4\kappa^2 - \partial^2}}P_{\leq\kappa^{\frac23}}(\psi_h^6 q)\|_{L^2_t H^{s+\frac32}}^2 + \|\tfrac1{\sqrt{4\kappa^2 - \partial^2}}P_{>\kappa^{\frac23}}(\psi_h^6 q)\|_{L^2_t H^{s+\frac32}}^2\\ &\lesssim \|q(0)\|_{H^s}^2 + \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s-\frac12}_{\kappa^{2/3}}}^2\\ &\lesssim \|q(0)\|_{H^s}^2 + \delta^2\|q\|_{X^{s+\frac12}_\kappa}^2. \end{align*} $$
$$ \begin{align*} \|\tfrac{\psi_h^6 q}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s+\frac32}}^2 &\lesssim \|\tfrac1{\sqrt{4\kappa^2 - \partial^2}}P_{\leq\kappa^{\frac23}}(\psi_h^6 q)\|_{L^2_t H^{s+\frac32}}^2 + \|\tfrac1{\sqrt{4\kappa^2 - \partial^2}}P_{>\kappa^{\frac23}}(\psi_h^6 q)\|_{L^2_t H^{s+\frac32}}^2\\ &\lesssim \|q(0)\|_{H^s}^2 + \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s-\frac12}_{\kappa^{2/3}}}^2\\ &\lesssim \|q(0)\|_{H^s}^2 + \delta^2\|q\|_{X^{s+\frac12}_\kappa}^2. \end{align*} $$
Taking the supremum over
 $h\in {{\mathbb {R}}}$
, we obtain the estimate (5.18) whenever
$h\in {{\mathbb {R}}}$
, we obtain the estimate (5.18) whenever
 $0<\delta \ll 1$
is sufficiently small, depending only on s.
$0<\delta \ll 1$
is sufficiently small, depending only on s.
Next, we record a corollary of Proposition 5.6, which will be used in Section 7.
Corollary 5.7. There exists
 $\delta>0$
so that for any
$\delta>0$
so that for any
 $q(0)\in B_\delta \cap \mathcal {S}$
and
$q(0)\in B_\delta \cap \mathcal {S}$
and
 $\kappa \geq 8$
, the solution
$\kappa \geq 8$
, the solution
 $q(t)$
of the NLS difference flow (NLS-diff) with parameter
$q(t)$
of the NLS difference flow (NLS-diff) with parameter
 $\kappa $
satisfies
$\kappa $
satisfies
 $$ \begin{align} \sup_{h\in {{\mathbb{R}}}} \|P_{N} (\psi_h^6 q)\|_{L_{t,x}^2} \lesssim \|q(0)\|_{H^s} \begin{cases} N^{-s} \quad &\text{if} \ \,N\leq \kappa^{\frac23},\\ \kappa N^{-(\frac32+s)} \quad &\text{if} \ \,\kappa^{\frac23}\leq N\leq \kappa,\\ N^{-(\frac12+s)} \quad &\text{if} \ \,N\geq \kappa,\\ \end{cases} \end{align} $$
$$ \begin{align} \sup_{h\in {{\mathbb{R}}}} \|P_{N} (\psi_h^6 q)\|_{L_{t,x}^2} \lesssim \|q(0)\|_{H^s} \begin{cases} N^{-s} \quad &\text{if} \ \,N\leq \kappa^{\frac23},\\ \kappa N^{-(\frac32+s)} \quad &\text{if} \ \,\kappa^{\frac23}\leq N\leq \kappa,\\ N^{-(\frac12+s)} \quad &\text{if} \ \,N\geq \kappa,\\ \end{cases} \end{align} $$
uniformly for
 $N\geq 1$
and
$N\geq 1$
and
 $\kappa \geq 1$
. Consequently,
$\kappa \geq 1$
. Consequently,
 $$ \begin{align} \sup_{h\in {{\mathbb{R}}}} \big\| \psi_h^6\tfrac{\partial^\ell q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2} +\sup_{h\in {{\mathbb{R}}}} \big\| \tfrac{\partial^\ell (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}\lesssim \|q(0)\|_{H^s} \begin{cases} \kappa^{-2+ \frac23(l-s)} \quad &\text{if} \ \,\ell=0,1,\\ \kappa^{-(\frac12+s)} \quad &\text{if} \ \,\ell=2, \end{cases} \end{align} $$
$$ \begin{align} \sup_{h\in {{\mathbb{R}}}} \big\| \psi_h^6\tfrac{\partial^\ell q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2} +\sup_{h\in {{\mathbb{R}}}} \big\| \tfrac{\partial^\ell (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}\lesssim \|q(0)\|_{H^s} \begin{cases} \kappa^{-2+ \frac23(l-s)} \quad &\text{if} \ \,\ell=0,1,\\ \kappa^{-(\frac12+s)} \quad &\text{if} \ \,\ell=2, \end{cases} \end{align} $$
uniformly for
 $\kappa \geq 1$
.
$\kappa \geq 1$
.
Proof. The claim (5.20) follows immediately from (5.18) and Bernstein inequalities. To obtain (5.21), we decompose into Littlewood–Paley pieces, use (5.20) and Lemma 2.8, and then sum.
Proposition 5.8 (Local smoothing for the mKdV difference flow).
There exists
 $\delta>0$
so that for any
$\delta>0$
so that for any
 $q(0)\in B_\delta \cap \mathcal {S}$
and
$q(0)\in B_\delta \cap \mathcal {S}$
and
 $\kappa \geq 8$
, the solution
$\kappa \geq 8$
, the solution
 $q(t)$
of the mKdV difference flow (mKdV-diff) with parameter
$q(t)$
of the mKdV difference flow (mKdV-diff) with parameter
 $\kappa $
satisfies
$\kappa $
satisfies
 $$ \begin{align} \|q\|_{X^{s+1}_\kappa}^2\lesssim \|q(0)\|_{H^s}^2, \end{align} $$
$$ \begin{align} \|q\|_{X^{s+1}_\kappa}^2\lesssim \|q(0)\|_{H^s}^2, \end{align} $$
where the implicit constant is independent of
 $\kappa $
.
$\kappa $
.
Proof. Consider the real part of (5.1). Applying the estimates (5.6), (5.11), and (5.7), we deduce that
 $$ \begin{align*} \varkappa\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varepsilon\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|^2_{L^2_t H^{-\frac12}_\varkappa} + (1 + \tfrac1\varepsilon)\|q\|_{L^\infty_t H^{-\frac12}_\varkappa}^2\\ &\quad\ + \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)} + \varkappa^{-2(2s+1)}\log|2\varkappa|\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
$$ \begin{align*} \varkappa\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varepsilon\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|^2_{L^2_t H^{-\frac12}_\varkappa} + (1 + \tfrac1\varepsilon)\|q\|_{L^\infty_t H^{-\frac12}_\varkappa}^2\\ &\quad\ + \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)} + \varkappa^{-2(2s+1)}\log|2\varkappa|\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
uniformly for
 $0<\varepsilon <1$
and
$0<\varepsilon <1$
and
 $\varkappa \in I:= [\kappa ^{\frac 12},\frac 12\kappa ]\cup [2\kappa ,\infty )$
.
$\varkappa \in I:= [\kappa ^{\frac 12},\frac 12\kappa ]\cup [2\kappa ,\infty )$
.
Choosing
 $-\frac 12<s'<s$
and applying the a priori estimate (4.12), this becomes
$-\frac 12<s'<s$
and applying the a priori estimate (4.12), this becomes
 $$ \begin{align*} \varkappa\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varepsilon\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-\frac12}_\varkappa}^2+ \varkappa^{-(2s'+1)}(1 + \tfrac1\varepsilon)\|q(0)\|_{H^{s'}_\varkappa}^2\\ &\quad\ + \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)} + \varkappa^{-2(2s+1)}\log|2\varkappa|\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
$$ \begin{align*} \varkappa\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2 &\lesssim \varepsilon\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-\frac12}_\varkappa}^2+ \varkappa^{-(2s'+1)}(1 + \tfrac1\varepsilon)\|q(0)\|_{H^{s'}_\varkappa}^2\\ &\quad\ + \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)} + \varkappa^{-2(2s+1)}\log|2\varkappa|\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
Next, we wish to integrate over
 $\varkappa \in I$
. Using Lemma 2.1 as in the proof of Proposition 5.6, we obtain the following analogues of (5.19):
$\varkappa \in I$
. Using Lemma 2.1 as in the proof of Proposition 5.6, we obtain the following analogues of (5.19):
 $$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^s_{\kappa^{1/2}}}^2 &\approx\int_I \varkappa^{2s+2}\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2\tfrac{d\varkappa}\varkappa \approx\int_I \varkappa^{2s+1}\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-\frac12}_\varkappa}^2\tfrac{d\varkappa}\varkappa. \end{align*} $$
$$ \begin{align*} \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^s_{\kappa^{1/2}}}^2 &\approx\int_I \varkappa^{2s+2}\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-1}_\varkappa}^2\tfrac{d\varkappa}\varkappa \approx\int_I \varkappa^{2s+1}\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{-\frac12}_\varkappa}^2\tfrac{d\varkappa}\varkappa. \end{align*} $$
Proceeding in this way, and choosing
 $0<\varepsilon <1$
sufficiently small, we obtain
$0<\varepsilon <1$
sufficiently small, we obtain
 $$\begin{align*}\big\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^s_{\kappa^{1/2}}}^2\lesssim \|q(0)\|_{H^s}^2 + \delta^2\|q\|_{X^{s+1}_\kappa}^2. \end{align*}$$
$$\begin{align*}\big\|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\big\|_{L^2_t H^s_{\kappa^{1/2}}}^2\lesssim \|q(0)\|_{H^s}^2 + \delta^2\|q\|_{X^{s+1}_\kappa}^2. \end{align*}$$
To complete the proof, we decompose
 $$ \begin{align*} \|\tfrac{\psi_h^6 q}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s+2}}^2 &\lesssim \|\tfrac1{\sqrt{4\kappa^2 - \partial^2}}P_{\leq\kappa^{\frac12}}(\psi_h^6 q)\|_{L^2_t H^{s+2}}^2 + \|\tfrac1{\sqrt{4\kappa^2 - \partial^2}}P_{>\kappa^{\frac12}}(\psi_h^6 q)\|_{L^2_t H^{s+2}}^2\\ &\lesssim \|q(0)\|_{H^s}^2 + \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s}_{\kappa^{1/2}}}^2\\ &\lesssim \|q(0)\|_{H^s}^2 + \delta^2\|q\|_{X^{s+1}_\kappa}^2. \end{align*} $$
$$ \begin{align*} \|\tfrac{\psi_h^6 q}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s+2}}^2 &\lesssim \|\tfrac1{\sqrt{4\kappa^2 - \partial^2}}P_{\leq\kappa^{\frac12}}(\psi_h^6 q)\|_{L^2_t H^{s+2}}^2 + \|\tfrac1{\sqrt{4\kappa^2 - \partial^2}}P_{>\kappa^{\frac12}}(\psi_h^6 q)\|_{L^2_t H^{s+2}}^2\\ &\lesssim \|q(0)\|_{H^s}^2 + \|\tfrac{(\psi_h^6 q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{L^2_t H^{s}_{\kappa^{1/2}}}^2\\ &\lesssim \|q(0)\|_{H^s}^2 + \delta^2\|q\|_{X^{s+1}_\kappa}^2. \end{align*} $$
Taking the supremum over
 $h\in {{\mathbb {R}}}$
, we obtain the estimate (5.18) whenever
$h\in {{\mathbb {R}}}$
, we obtain the estimate (5.18) whenever
 $0<\delta \ll 1$
is sufficiently small, depending only on s.
$0<\delta \ll 1$
is sufficiently small, depending only on s.
Proposition 5.8 directly yields the following analogue of Corollary 5.7:
Corollary 5.9. There exists
 $\delta>0$
so that for any
$\delta>0$
so that for any
 $q(0)\in B_\delta \cap \mathcal {S}$
and
$q(0)\in B_\delta \cap \mathcal {S}$
and
 $\kappa \geq 8$
, the solution
$\kappa \geq 8$
, the solution
 $q(t)$
of the mKdV difference flow (mKdV-diff) with parameter
$q(t)$
of the mKdV difference flow (mKdV-diff) with parameter
 $\kappa $
satisfies
$\kappa $
satisfies
 $$ \begin{align*} \sup_{h\in {{\mathbb{R}}}} \|P_{N} (\psi_h^6 q)\|_{L_{t,x}^2} \lesssim \|q(0)\|_{H^s} \begin{cases} N^{-s} \quad &\text{if} \ \,N\leq \kappa^{\frac12},\\ \kappa N^{-(2+s)} \quad &\text{if} \ \,\kappa^{\frac12}\leq N\leq \kappa,\\ N^{-(1+s)} \quad &\text{if} \ \,N\geq \kappa,\\ \end{cases} \end{align*} $$
$$ \begin{align*} \sup_{h\in {{\mathbb{R}}}} \|P_{N} (\psi_h^6 q)\|_{L_{t,x}^2} \lesssim \|q(0)\|_{H^s} \begin{cases} N^{-s} \quad &\text{if} \ \,N\leq \kappa^{\frac12},\\ \kappa N^{-(2+s)} \quad &\text{if} \ \,\kappa^{\frac12}\leq N\leq \kappa,\\ N^{-(1+s)} \quad &\text{if} \ \,N\geq \kappa,\\ \end{cases} \end{align*} $$
uniformly for
 $N\geq 1$
and
$N\geq 1$
and
 $\kappa \geq 8$
. Consequently,
$\kappa \geq 8$
. Consequently,
 $$ \begin{align*} \sup_{h\in {{\mathbb{R}}}} \big\| \psi_h^6\tfrac{\partial^\ell q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2} +\sup_{h\in {{\mathbb{R}}}} \big\| \tfrac{\partial^\ell (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}\lesssim \|q(0)\|_{H^s} \begin{cases} \kappa^{-2+ \frac12(l-s)} \quad &\text{if} \ \,\ell=0,1,\\ \kappa^{-(1+s)} \quad &\text{if} \ \,\ell=2, \end{cases} \end{align*} $$
$$ \begin{align*} \sup_{h\in {{\mathbb{R}}}} \big\| \psi_h^6\tfrac{\partial^\ell q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2} +\sup_{h\in {{\mathbb{R}}}} \big\| \tfrac{\partial^\ell (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}\lesssim \|q(0)\|_{H^s} \begin{cases} \kappa^{-2+ \frac12(l-s)} \quad &\text{if} \ \,\ell=0,1,\\ \kappa^{-(1+s)} \quad &\text{if} \ \,\ell=2, \end{cases} \end{align*} $$
uniformly for
 $\kappa \geq 2$
.
$\kappa \geq 2$
.
We now turn to the proof of Lemma 5.1:
Proof of Lemma 5.1.
We introduce the paraproduct
 $\mathbf R[q,r]$
with symbol
$\mathbf R[q,r]$
with symbol
 $$\begin{align*}R(\xi,\eta) = \tfrac1{2(2\varkappa - i\xi)} + \tfrac1{2(2\varkappa + i\eta)} \end{align*}$$
$$\begin{align*}R(\xi,\eta) = \tfrac1{2(2\varkappa - i\xi)} + \tfrac1{2(2\varkappa + i\eta)} \end{align*}$$
so that by (4.13), we may write
 $$\begin{align*}\rho^{[2]}(x;\varkappa)=\mathbf R[q,r](x) = \frac1{2\pi}\int R(\xi,\eta)\hat q(\xi)\hat r(\eta) e^{ix(\xi+\eta)}\,d\xi\,d\eta. \end{align*}$$
$$\begin{align*}\rho^{[2]}(x;\varkappa)=\mathbf R[q,r](x) = \frac1{2\pi}\int R(\xi,\eta)\hat q(\xi)\hat r(\eta) e^{ix(\xi+\eta)}\,d\xi\,d\eta. \end{align*}$$
We then observe that the quadratic part of the current
 $j(\varkappa ,\kappa )$
defined in (4.23) may be written as
$j(\varkappa ,\kappa )$
defined in (4.23) may be written as
 $$\begin{align*}j^{[2]}(\varkappa,\kappa) = i\mathbf R[\tfrac q{2\kappa - \partial},\tfrac r{2\kappa + \partial}]. \end{align*}$$
$$\begin{align*}j^{[2]}(\varkappa,\kappa) = i\mathbf R[\tfrac q{2\kappa - \partial},\tfrac r{2\kappa + \partial}]. \end{align*}$$
Expanding in powers of
 $\kappa $
, we readily obtain the expressions
$\kappa $
, we readily obtain the expressions
 $$ \begin{align*} j_{\mathrm{NLS}}^{[2]}(\varkappa) &= i\Big(\mathbf R[q,r'] - \mathbf R[q',r]\Big),\\ j_{\mathrm{mKdV}}^{[2]} (\varkappa) &= \big(\mathbf R[q,r]\big)" - 3 \mathbf R[q',r'], \end{align*} $$
$$ \begin{align*} j_{\mathrm{NLS}}^{[2]}(\varkappa) &= i\Big(\mathbf R[q,r'] - \mathbf R[q',r]\Big),\\ j_{\mathrm{mKdV}}^{[2]} (\varkappa) &= \big(\mathbf R[q,r]\big)" - 3 \mathbf R[q',r'], \end{align*} $$
for the NLS and mKdV flows, as well as the expressions
 $$ \begin{align*} j_{\mathrm{NLS}}^{\mathrm{diff}}{}^{[2]}(\varkappa,\kappa) &= i\Big(\mathbf R[q,r'] - \mathbf R[q',r]\Big) - 16\kappa^4i\Big(\mathbf R[\tfrac q{4\kappa^2 - \partial^2},\tfrac {r'}{4\kappa^2 - \partial^2}] - \mathbf R[\tfrac{q'}{4\kappa^2 - \partial^2},\tfrac r{4\kappa^2 - \partial^2}]\Big),\\ j_{\mathrm{mKdV}}^{\mathrm{diff}}{}^{[2]} (\varkappa,\kappa)&= \big(\mathbf R[q,r]\big)" - 3 \mathbf R[q',r'] - 16\kappa^4\big(\mathbf R[\tfrac{q}{4\kappa^2 - \partial^2},\tfrac{r}{4\kappa^2 - \partial^2}]\big)" + 48\kappa^4 \mathbf R[\tfrac{q'}{4\kappa^2 - \partial^2},\tfrac{r'}{4\kappa^2 - \partial^2}]\\ &\quad + 4\kappa^2 \mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}] \end{align*} $$
$$ \begin{align*} j_{\mathrm{NLS}}^{\mathrm{diff}}{}^{[2]}(\varkappa,\kappa) &= i\Big(\mathbf R[q,r'] - \mathbf R[q',r]\Big) - 16\kappa^4i\Big(\mathbf R[\tfrac q{4\kappa^2 - \partial^2},\tfrac {r'}{4\kappa^2 - \partial^2}] - \mathbf R[\tfrac{q'}{4\kappa^2 - \partial^2},\tfrac r{4\kappa^2 - \partial^2}]\Big),\\ j_{\mathrm{mKdV}}^{\mathrm{diff}}{}^{[2]} (\varkappa,\kappa)&= \big(\mathbf R[q,r]\big)" - 3 \mathbf R[q',r'] - 16\kappa^4\big(\mathbf R[\tfrac{q}{4\kappa^2 - \partial^2},\tfrac{r}{4\kappa^2 - \partial^2}]\big)" + 48\kappa^4 \mathbf R[\tfrac{q'}{4\kappa^2 - \partial^2},\tfrac{r'}{4\kappa^2 - \partial^2}]\\ &\quad + 4\kappa^2 \mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}] \end{align*} $$
for the corresponding difference flows. (Alternatively, we may use the definition of the currents from Corollary 4.14 to compute the quadratic components directly.)
If we could simply replace
 $q,r$
by
$q,r$
by
 $\psi _h^6q,\psi _h^6r$
in these expressions, rather than integrating them against
$\psi _h^6q,\psi _h^6r$
in these expressions, rather than integrating them against
 $\psi _h^{12}$
, then we would obtain the leading order terms in (5.3)–(5.6). Thus, the focal point of our analysis will be bounding the various commutator terms that arise.
$\psi _h^{12}$
, then we would obtain the leading order terms in (5.3)–(5.6). Thus, the focal point of our analysis will be bounding the various commutator terms that arise.
Proof of (5.3). Using the above expression, we may write
 $$ \begin{align*} \mathrm{LHS}(5.3) &= \pm 2\|(\psi_h^{6}q)'\|_{H^{-1}_\varkappa}^2 + \operatorname{Re}\int \Big(\mathbf R[q,r']\,\psi_h^{12} - \mathbf R[\psi_h^{6}q,(\psi_h^{6} r)']\Big)\,dx\\ &\quad - \operatorname{Re}\int\Big(\mathbf R[q',r]\,\psi_h^{12} - \mathbf R[(\psi_h^{6} q)',\psi_h^{6}r]\Big)\,dx. \end{align*} $$
$$ \begin{align*} \mathrm{LHS}(5.3) &= \pm 2\|(\psi_h^{6}q)'\|_{H^{-1}_\varkappa}^2 + \operatorname{Re}\int \Big(\mathbf R[q,r']\,\psi_h^{12} - \mathbf R[\psi_h^{6}q,(\psi_h^{6} r)']\Big)\,dx\\ &\quad - \operatorname{Re}\int\Big(\mathbf R[q',r]\,\psi_h^{12} - \mathbf R[(\psi_h^{6} q)',\psi_h^{6}r]\Big)\,dx. \end{align*} $$
By symmetry, it suffices to bound
 $$ \begin{align*} &\int \Big(\mathbf R[q,r']\,\psi_h^{12} - \mathbf R[\psi_h^{6}q,(\psi_h^{6}r)']\Big)\,dx\\ &\qquad = \int [\psi_h^{6},\tfrac1{2(2\varkappa - \partial)}] q\cdot \psi_h^{6} r'\,dx - \int \tfrac1{2(2\varkappa - \partial)}(\psi_h^{6}q)\cdot (\psi_h^{6})'r\,dx\\ &\qquad\quad + \int \psi_h^{6} q\cdot [\psi_h^{6},\tfrac\partial{2(2\varkappa + \partial)}]r\,dx, \end{align*} $$
$$ \begin{align*} &\int \Big(\mathbf R[q,r']\,\psi_h^{12} - \mathbf R[\psi_h^{6}q,(\psi_h^{6}r)']\Big)\,dx\\ &\qquad = \int [\psi_h^{6},\tfrac1{2(2\varkappa - \partial)}] q\cdot \psi_h^{6} r'\,dx - \int \tfrac1{2(2\varkappa - \partial)}(\psi_h^{6}q)\cdot (\psi_h^{6})'r\,dx\\ &\qquad\quad + \int \psi_h^{6} q\cdot [\psi_h^{6},\tfrac\partial{2(2\varkappa + \partial)}]r\,dx, \end{align*} $$
which may be bounded by
 $$ \begin{align*} &\left|\int \Big(\mathbf R[q,r']\,\psi_h^{12} - \mathbf R[\psi_h^{6}q,(\psi_h^{6}r)']\Big)\,dx\right|\\ &\qquad \leq \|[\psi_h^{6},\tfrac1{2(2\varkappa - \partial)}] q\|_{H^{\frac32}_\varkappa}\|\psi_h^{6} r'\|_{H^{-\frac32}_\varkappa} + \|\tfrac1{2(2\varkappa - \partial)}(\psi_h^{6} q)\|_{H^{\frac12}_\varkappa}\|(\psi_h^{6})'r\|_{H^{-\frac12}_\varkappa}\\ &\qquad\quad + \|\psi_h^{6} q\|_{H^{-\frac12}_\varkappa}\|[\psi_h^{6},\tfrac\partial{2(2\varkappa + \partial)}]r\|_{H^{\frac12}_\varkappa}\\ &\qquad\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2, \end{align*} $$
$$ \begin{align*} &\left|\int \Big(\mathbf R[q,r']\,\psi_h^{12} - \mathbf R[\psi_h^{6}q,(\psi_h^{6}r)']\Big)\,dx\right|\\ &\qquad \leq \|[\psi_h^{6},\tfrac1{2(2\varkappa - \partial)}] q\|_{H^{\frac32}_\varkappa}\|\psi_h^{6} r'\|_{H^{-\frac32}_\varkappa} + \|\tfrac1{2(2\varkappa - \partial)}(\psi_h^{6} q)\|_{H^{\frac12}_\varkappa}\|(\psi_h^{6})'r\|_{H^{-\frac12}_\varkappa}\\ &\qquad\quad + \|\psi_h^{6} q\|_{H^{-\frac12}_\varkappa}\|[\psi_h^{6},\tfrac\partial{2(2\varkappa + \partial)}]r\|_{H^{\frac12}_\varkappa}\\ &\qquad\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2, \end{align*} $$
as required.
Proof of (5.5). We observe that the difference
 $ j_{\mathrm {NLS}}^{[2]} - j_{\mathrm {NLS}}^{\mathrm {diff}}{}^{[2]} $
has an identical expression to
$ j_{\mathrm {NLS}}^{[2]} - j_{\mathrm {NLS}}^{\mathrm {diff}}{}^{[2]} $
has an identical expression to
 $j_{\mathrm {NLS}}^{[2]}$
with q replaced by
$j_{\mathrm {NLS}}^{[2]}$
with q replaced by
 $\tfrac {4\kappa ^2 q}{4\kappa ^2 - \partial ^2}$
. The estimate (5.5) then follows from the estimate (5.3) and the estimates
$\tfrac {4\kappa ^2 q}{4\kappa ^2 - \partial ^2}$
. The estimate (5.5) then follows from the estimate (5.3) and the estimates
 $$\begin{align*}\|\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}q\|_{H^{-\frac12}_\varkappa}\lesssim \|q\|_{H^{-\frac12}_\varkappa} \quad\text{and}\quad \|\partial[\psi_h^{6},\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}]q\|_{H^{-\frac12}_\varkappa}\lesssim \|q\|_{H^{-\frac12}_\varkappa}. \end{align*}$$
$$\begin{align*}\|\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}q\|_{H^{-\frac12}_\varkappa}\lesssim \|q\|_{H^{-\frac12}_\varkappa} \quad\text{and}\quad \|\partial[\psi_h^{6},\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}]q\|_{H^{-\frac12}_\varkappa}\lesssim \|q\|_{H^{-\frac12}_\varkappa}. \end{align*}$$
Proof of (5.4). Integrating by parts, we find
 $$ \begin{align*} \mathrm{LHS}(5.4) &= \mp 6\varkappa\|(\psi_h^{6} q)'\|_{H^{-1}_\varkappa}^2 + \operatorname{Re}\int \mathbf R[q,r]\,(\psi_h^{12})"\,dx\\ &\quad - 3\operatorname{Re}\int \Big(\mathbf R[q',r']\,\psi_h^{12}- \mathbf R[(\psi_h^{6}q)',(\psi_h^{6}r)']\Big)\,dx. \end{align*} $$
$$ \begin{align*} \mathrm{LHS}(5.4) &= \mp 6\varkappa\|(\psi_h^{6} q)'\|_{H^{-1}_\varkappa}^2 + \operatorname{Re}\int \mathbf R[q,r]\,(\psi_h^{12})"\,dx\\ &\quad - 3\operatorname{Re}\int \Big(\mathbf R[q',r']\,\psi_h^{12}- \mathbf R[(\psi_h^{6}q)',(\psi_h^{6}r)']\Big)\,dx. \end{align*} $$
As in the proof of Lemma 5.2, the second term may be readily bounded by
 $$\begin{align*}\left|\int \mathbf R[q,r]\,(\psi_h^{12})"\,dx\right|\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*}$$
$$\begin{align*}\left|\int \mathbf R[q,r]\,(\psi_h^{12})"\,dx\right|\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*}$$
For the remaining term, we write
 $$ \begin{align*} &\int \Big(\mathbf R[q',r']\,\psi_h^{12} - \mathbf R[(\psi_h^{6}q)',(\psi_h^{6}r)']\Big)\,dx\\ &\qquad = \int [\psi_h^{6},\tfrac\partial{2(2\varkappa - \partial)}]q\cdot (\psi_h^{6} r)'\,dx - \int \tfrac\partial{2(2\varkappa - \partial)}(\psi_h^{6}q)\cdot (\psi_h^{6})' r\,dx \\ &\qquad \quad - \int [\psi_h^{6},\tfrac\partial{2(2\varkappa - \partial)}]q\cdot (\psi_h^{6})' r\,dx + \int (\psi_h^{6} q)'\cdot [\psi_h^{6},\tfrac\partial{2(2\varkappa + \partial)}]r\,dx\\ &\qquad \quad - \int (\psi_h^{6})' q\cdot \tfrac\partial{2(2\varkappa + \partial)}(\psi_h^{6} r)\,dx - \int (\psi_h^{6})' q\cdot[\psi_h^{6},\tfrac\partial{2(2\varkappa + \partial)}] r\,dx. \end{align*} $$
$$ \begin{align*} &\int \Big(\mathbf R[q',r']\,\psi_h^{12} - \mathbf R[(\psi_h^{6}q)',(\psi_h^{6}r)']\Big)\,dx\\ &\qquad = \int [\psi_h^{6},\tfrac\partial{2(2\varkappa - \partial)}]q\cdot (\psi_h^{6} r)'\,dx - \int \tfrac\partial{2(2\varkappa - \partial)}(\psi_h^{6}q)\cdot (\psi_h^{6})' r\,dx \\ &\qquad \quad - \int [\psi_h^{6},\tfrac\partial{2(2\varkappa - \partial)}]q\cdot (\psi_h^{6})' r\,dx + \int (\psi_h^{6} q)'\cdot [\psi_h^{6},\tfrac\partial{2(2\varkappa + \partial)}]r\,dx\\ &\qquad \quad - \int (\psi_h^{6})' q\cdot \tfrac\partial{2(2\varkappa + \partial)}(\psi_h^{6} r)\,dx - \int (\psi_h^{6})' q\cdot[\psi_h^{6},\tfrac\partial{2(2\varkappa + \partial)}] r\,dx. \end{align*} $$
The first three summands, here, may be bounded in magnitude via
 $$ \begin{align*} \|[\psi_h^{6},\tfrac\partial{2(2\varkappa - \partial)}]q\|_{H^{\frac12}_\varkappa}\|(\psi_h^{6} r)'\|_{H^{-\frac12}_\varkappa} + \|\tfrac\partial{2(2\varkappa - \partial)}&(\psi_h^{6} q)\|_{H^{\frac12}_\varkappa}\|(\psi_h^{6})' r\|_{H^{-\frac12}_\varkappa} \lesssim \|(\psi_h^{6} q)'\|_{H^{-\frac12}_\varkappa} \|q\|_{H^{-\frac12}_\varkappa} \end{align*} $$
$$ \begin{align*} \|[\psi_h^{6},\tfrac\partial{2(2\varkappa - \partial)}]q\|_{H^{\frac12}_\varkappa}\|(\psi_h^{6} r)'\|_{H^{-\frac12}_\varkappa} + \|\tfrac\partial{2(2\varkappa - \partial)}&(\psi_h^{6} q)\|_{H^{\frac12}_\varkappa}\|(\psi_h^{6})' r\|_{H^{-\frac12}_\varkappa} \lesssim \|(\psi_h^{6} q)'\|_{H^{-\frac12}_\varkappa} \|q\|_{H^{-\frac12}_\varkappa} \end{align*} $$
and
 $$ \begin{align*} \|[\psi_h^{6},\tfrac\partial{2(2\varkappa - \partial)}]q\|_{H^{\frac12}_\varkappa}\|(\psi_h^{6})' r\|_{H^{-\frac12}_\varkappa} &\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2, \end{align*} $$
$$ \begin{align*} \|[\psi_h^{6},\tfrac\partial{2(2\varkappa - \partial)}]q\|_{H^{\frac12}_\varkappa}\|(\psi_h^{6})' r\|_{H^{-\frac12}_\varkappa} &\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2, \end{align*} $$
both of which are acceptable. The remaining three summands can then be estimated in a parallel fashion; indeed, this is tantamount to replacing
 $\varkappa $
by
$\varkappa $
by
 $-\varkappa $
.
$-\varkappa $
.
Proof of (5.6). Integrating by parts several times, we obtain the identity
 $$ \begin{align*} \mathrm{LHS}(5.6) &= \mp 2\varkappa\int \tfrac{(20\kappa^2 + 3\xi^2)\xi^4}{(4\varkappa^2 + \xi^2)(4\kappa^2 + \xi^2)^2}|\widehat{\psi_h^{6}q}|^2\,d\xi\\ &\quad - 3\operatorname{Re}\int \Big(\mathbf R[\tfrac{q"'}{4\kappa^2 - \partial^2},\tfrac{r"'}{4\kappa^2 - \partial^2}]\,\psi_h^{12} - \mathbf R[\tfrac{(\psi_h^{6} q)"'}{4\kappa^2 - \partial^2},\tfrac{(\psi_h^{6}r)"'}{4\kappa^2 - \partial^2}]\Big)\,dx\\ &\quad - 20\kappa^2\operatorname{Re}\int \Big(\mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}]\,\psi_h^{12} - \mathbf R[\tfrac{(\psi_h^{6}q)"}{4\kappa^2 - \partial^2},\tfrac{(\psi_h^{6}r)"}{4\kappa^2 - \partial^2}]\Big)\,dx\\ &\quad + \operatorname{Re}\int \mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})"\,dx\\ &\quad + 20\kappa^2\operatorname{Re}\int \mathbf R[\tfrac{q'}{4\kappa^2 - \partial^2},\tfrac{r'}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})"\,dx\\ &\quad - 4\kappa^2\operatorname{Re}\int \mathbf R[\tfrac{q}{4\kappa^2 - \partial^2},\tfrac{r}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})""\,dx. \end{align*} $$
$$ \begin{align*} \mathrm{LHS}(5.6) &= \mp 2\varkappa\int \tfrac{(20\kappa^2 + 3\xi^2)\xi^4}{(4\varkappa^2 + \xi^2)(4\kappa^2 + \xi^2)^2}|\widehat{\psi_h^{6}q}|^2\,d\xi\\ &\quad - 3\operatorname{Re}\int \Big(\mathbf R[\tfrac{q"'}{4\kappa^2 - \partial^2},\tfrac{r"'}{4\kappa^2 - \partial^2}]\,\psi_h^{12} - \mathbf R[\tfrac{(\psi_h^{6} q)"'}{4\kappa^2 - \partial^2},\tfrac{(\psi_h^{6}r)"'}{4\kappa^2 - \partial^2}]\Big)\,dx\\ &\quad - 20\kappa^2\operatorname{Re}\int \Big(\mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}]\,\psi_h^{12} - \mathbf R[\tfrac{(\psi_h^{6}q)"}{4\kappa^2 - \partial^2},\tfrac{(\psi_h^{6}r)"}{4\kappa^2 - \partial^2}]\Big)\,dx\\ &\quad + \operatorname{Re}\int \mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})"\,dx\\ &\quad + 20\kappa^2\operatorname{Re}\int \mathbf R[\tfrac{q'}{4\kappa^2 - \partial^2},\tfrac{r'}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})"\,dx\\ &\quad - 4\kappa^2\operatorname{Re}\int \mathbf R[\tfrac{q}{4\kappa^2 - \partial^2},\tfrac{r}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})""\,dx. \end{align*} $$
The final three terms are lower order errors that may be bounded by
 $$ \begin{align*} &\left|\int \mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})"\,dx\right| \lesssim \|\tfrac{q"}{4\kappa^2 - \partial^2}\|_{H^{-\frac12}_\varkappa}^2\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2\\ &\left|\kappa^2\int \mathbf R[\tfrac{q'}{4\kappa^2 - \partial^2},\tfrac{r'}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})"\,dx\right|\lesssim \kappa^2\|\tfrac{q'}{4\kappa^2 - \partial^2}\|_{H^{-\frac12}_\varkappa}^2 \lesssim \|q\|_{H^{-\frac12}_\varkappa}^2,\\ &\left|\kappa^2\int \mathbf R[\tfrac{q}{4\kappa^2 - \partial^2},\tfrac{r}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})""\,dx\right|\lesssim \kappa^2\|\tfrac q{4\kappa^2 - \partial^2}\|_{H^{-\frac12}_\varkappa}^2\lesssim \kappa^{-2}\|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*} $$
$$ \begin{align*} &\left|\int \mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})"\,dx\right| \lesssim \|\tfrac{q"}{4\kappa^2 - \partial^2}\|_{H^{-\frac12}_\varkappa}^2\lesssim \|q\|_{H^{-\frac12}_\varkappa}^2\\ &\left|\kappa^2\int \mathbf R[\tfrac{q'}{4\kappa^2 - \partial^2},\tfrac{r'}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})"\,dx\right|\lesssim \kappa^2\|\tfrac{q'}{4\kappa^2 - \partial^2}\|_{H^{-\frac12}_\varkappa}^2 \lesssim \|q\|_{H^{-\frac12}_\varkappa}^2,\\ &\left|\kappa^2\int \mathbf R[\tfrac{q}{4\kappa^2 - \partial^2},\tfrac{r}{4\kappa^2 - \partial^2}]\,(\psi_h^{12})""\,dx\right|\lesssim \kappa^2\|\tfrac q{4\kappa^2 - \partial^2}\|_{H^{-\frac12}_\varkappa}^2\lesssim \kappa^{-2}\|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*} $$
For the first commutator term, we estimate
 $$ \begin{align*} &\left|\int \Big(\mathbf R[\tfrac{q"'}{4\kappa^2 - \partial^2},\tfrac{r"'}{4\kappa^2 - \partial^2}]\,\psi_h^{12} - \mathbf R[\tfrac{(\psi_h^{6} q)"'}{4\kappa^2 - \partial^2},\tfrac{(\psi_h^{6}r)"'}{4\kappa^2 - \partial^2}]\Big)\,dx\right|\\ &\qquad\lesssim \|[\psi_h^{6},\tfrac{\partial^3}{(2\varkappa - \partial)(4\kappa^2 - \partial^2)}]q\|_{H^{\frac12}_\varkappa}\|\tfrac{\partial^3}{4\kappa^2 - \partial^2}(\psi_h^{6} q)\|_{H^{-\frac12}_\varkappa}\\ &\qquad \quad + \Big\{\|[\psi_h^{6},\tfrac{\partial^3}{(2\varkappa - \partial)(4\kappa^2 - \partial^2)}]q\|_{H^{\frac12}_\varkappa}+ \|\tfrac{\partial^3}{4\kappa^2 - \partial^2}(\psi_h^{6} q)\|_{H^{-\frac12}_\varkappa}\Big\}\|[\psi_h^{6},\tfrac{\partial^3}{4\kappa^2 - \partial^2}]q\|_{H^{-\frac12}_\varkappa}\\ &\qquad\lesssim \|q\|_{H^{-\frac12}_\varkappa}\|\tfrac{(\psi_h^{6}q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{H^{-\frac12}_\varkappa} + \|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*} $$
$$ \begin{align*} &\left|\int \Big(\mathbf R[\tfrac{q"'}{4\kappa^2 - \partial^2},\tfrac{r"'}{4\kappa^2 - \partial^2}]\,\psi_h^{12} - \mathbf R[\tfrac{(\psi_h^{6} q)"'}{4\kappa^2 - \partial^2},\tfrac{(\psi_h^{6}r)"'}{4\kappa^2 - \partial^2}]\Big)\,dx\right|\\ &\qquad\lesssim \|[\psi_h^{6},\tfrac{\partial^3}{(2\varkappa - \partial)(4\kappa^2 - \partial^2)}]q\|_{H^{\frac12}_\varkappa}\|\tfrac{\partial^3}{4\kappa^2 - \partial^2}(\psi_h^{6} q)\|_{H^{-\frac12}_\varkappa}\\ &\qquad \quad + \Big\{\|[\psi_h^{6},\tfrac{\partial^3}{(2\varkappa - \partial)(4\kappa^2 - \partial^2)}]q\|_{H^{\frac12}_\varkappa}+ \|\tfrac{\partial^3}{4\kappa^2 - \partial^2}(\psi_h^{6} q)\|_{H^{-\frac12}_\varkappa}\Big\}\|[\psi_h^{6},\tfrac{\partial^3}{4\kappa^2 - \partial^2}]q\|_{H^{-\frac12}_\varkappa}\\ &\qquad\lesssim \|q\|_{H^{-\frac12}_\varkappa}\|\tfrac{(\psi_h^{6}q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{H^{-\frac12}_\varkappa} + \|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*} $$
The second commutator term is bounded similarly:
 $$ \begin{align*} &\left|\kappa^2\int \Big(\mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}]\,\psi_h^{12} - \mathbf R[\tfrac{(\psi_h^{6}q)"}{4\kappa^2 - \partial^2},\tfrac{(\psi_h^{6}r)"}{4\kappa^2 - \partial^2}]\Big)\,dx\right|\lesssim \|q\|_{H^{-\frac12}_\varkappa}\|\tfrac{(\psi_h^{6}q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{H^{-\frac12}_\varkappa} + \|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*} $$
$$ \begin{align*} &\left|\kappa^2\int \Big(\mathbf R[\tfrac{q"}{4\kappa^2 - \partial^2},\tfrac{r"}{4\kappa^2 - \partial^2}]\,\psi_h^{12} - \mathbf R[\tfrac{(\psi_h^{6}q)"}{4\kappa^2 - \partial^2},\tfrac{(\psi_h^{6}r)"}{4\kappa^2 - \partial^2}]\Big)\,dx\right|\lesssim \|q\|_{H^{-\frac12}_\varkappa}\|\tfrac{(\psi_h^{6}q)"}{\sqrt{4\kappa^2 - \partial^2}}\|_{H^{-\frac12}_\varkappa} + \|q\|_{H^{-\frac12}_\varkappa}^2. \end{align*} $$
This completes the proof of the lemma.
We now turn to the proof of Lemma 5.3. Here, we will use the estimates of Lemmas 2.6 and 2.7 to obtain bounds for the tails of the series defining
 $g_{12},g_{21},\gamma $
. However, these estimates are not sufficient to capture cancellations that occur for several quartic terms in the currents
$g_{12},g_{21},\gamma $
. However, these estimates are not sufficient to capture cancellations that occur for several quartic terms in the currents
 $j_{\mathrm {NLS}}^{\mathrm {diff}}$
and
$j_{\mathrm {NLS}}^{\mathrm {diff}}$
and
 $j_{\mathrm {mKdV}}^{\mathrm {diff}}$
. For this reason, we start by proving several quadrilinear estimates that are designed to capture the additional smallness that arises from these cancellations.
$j_{\mathrm {mKdV}}^{\mathrm {diff}}$
. For this reason, we start by proving several quadrilinear estimates that are designed to capture the additional smallness that arises from these cancellations.
For any
 $\kappa \geq 1$
and multiindex
$\kappa \geq 1$
and multiindex
 $\beta \in \{0,1,2\}^4$
, we introduce the class
$\beta \in \{0,1,2\}^4$
, we introduce the class
 $S(\beta ;\kappa )$
of smooth symbols
$S(\beta ;\kappa )$
of smooth symbols
 $m\colon {{\mathbb {R}}}^4\rightarrow \mathbb {C}$
that may be written as
$m\colon {{\mathbb {R}}}^4\rightarrow \mathbb {C}$
that may be written as
 $$ \begin{align} m(\xi;\kappa) = C\tfrac{\xi_1^{\beta_1}\xi_2^{\beta_2}\xi_3^{\beta_3}\xi_4^{\beta_4}}{(\kappa^2 + \xi_1^2)(\kappa^2 + \xi_2^2)(\kappa^2 + \xi_3^2)(\kappa^2 + \xi_4^2)}, \end{align} $$
$$ \begin{align} m(\xi;\kappa) = C\tfrac{\xi_1^{\beta_1}\xi_2^{\beta_2}\xi_3^{\beta_3}\xi_4^{\beta_4}}{(\kappa^2 + \xi_1^2)(\kappa^2 + \xi_2^2)(\kappa^2 + \xi_3^2)(\kappa^2 + \xi_4^2)}, \end{align} $$
for a constant
 $C\in \mathbb {C}$
. We write
$C\in \mathbb {C}$
. We write
 $m[f_1,\ldots ,f_4]$
for the paraproduct with this symbol.
$m[f_1,\ldots ,f_4]$
for the paraproduct with this symbol.
While it is often natural to consider paraproducts as multilinear operators, we shall only be applying them to q and to objects subordinate to q, in the sense of (5.24). Thus, it is more natural to view these paraproducts as polynomial-like functions of q. When it comes to estimating these nonlinear expressions, the first step will always be to isolate the two highest frequency terms and use local smoothing to control them (integrability in time forbids using local smoothing for more than two factors). Correspondingly, a multilinear point of view would lead to right-hand sides containing a sum over all permutations of the arguments. Here, we see the virtue of phrasing them as nonlinear estimates and of subordinating their arguments to q.
For the NLS, we have the following lemma:
Lemma 5.10 (Quartic estimate for the NLS).
Let
 $|\varkappa |\geq \kappa ^{\frac 23}\geq 1$
and the Schwartz functions
$|\varkappa |\geq \kappa ^{\frac 23}\geq 1$
and the Schwartz functions
 $q,f\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfy
$q,f\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfy
 $$ \begin{align} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align} $$
$$ \begin{align} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align} $$
Let
 $m\in S(\beta ;\kappa )$
, where
$m\in S(\beta ;\kappa )$
, where
 $1\leq |\beta |\leq 5$
and at most one
$1\leq |\beta |\leq 5$
and at most one
 $\beta _j = 2$
. Then we have the paraproduct estimate
$\beta _j = 2$
. Then we have the paraproduct estimate
 $$ \begin{align} \big\| m[q,r,q,\psi_h^{12}\tfrac f{2\varkappa + \partial}] \big\|_{L^1_{t,x}} \lesssim \kappa^{|\beta| - 7 -\frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
$$ \begin{align} \big\| m[q,r,q,\psi_h^{12}\tfrac f{2\varkappa + \partial}] \big\|_{L^1_{t,x}} \lesssim \kappa^{|\beta| - 7 -\frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
where the implicit constant is independent of
 $\kappa $
,
$\kappa $
,
 $\varkappa $
, and
$\varkappa $
, and
 $h\in {{\mathbb {R}}}$
, and
$h\in {{\mathbb {R}}}$
, and
 $\psi $
is as in (1.5).
$\psi $
is as in (1.5).
Proof. By space-translation invariance, we may assume
 $h=0$
.
$h=0$
.
By Bernstein’s inequality, for
 $0\leq j\leq 2$
, we may bound
$0\leq j\leq 2$
, we may bound
 $$ \begin{align*} \tfrac{N^j}{(\kappa + N)^2}\|(\psi^3q)_N\|_{L^2_{t,x}}& \lesssim \kappa^{-2} N^{j-s-\frac52} \min\{N^{\frac52},\kappa N,\kappa^2 \} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\\ \tfrac{N^j}{(\kappa + N)^2}\|\big(\psi^3\tfrac f{2\varkappa + \partial}\big)_N\|_{L^2_{t,x}}& \lesssim |\varkappa|^{-(s+\frac12)}(|\varkappa| + N)^{s-\frac12} \kappa^{-2} N^{j-s-\frac52} \min\{N^{\frac52},\kappa N,\kappa^2 \} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}, \end{align*} $$
$$ \begin{align*} \tfrac{N^j}{(\kappa + N)^2}\|(\psi^3q)_N\|_{L^2_{t,x}}& \lesssim \kappa^{-2} N^{j-s-\frac52} \min\{N^{\frac52},\kappa N,\kappa^2 \} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\\ \tfrac{N^j}{(\kappa + N)^2}\|\big(\psi^3\tfrac f{2\varkappa + \partial}\big)_N\|_{L^2_{t,x}}& \lesssim |\varkappa|^{-(s+\frac12)}(|\varkappa| + N)^{s-\frac12} \kappa^{-2} N^{j-s-\frac52} \min\{N^{\frac52},\kappa N,\kappa^2 \} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}, \end{align*} $$
which we will use to estimate high-frequency terms. Using Bernstein’s inequality again, we also find that for
 $0\leq j\leq 2$
,
$0\leq j\leq 2$
,
 $$ \begin{align*} &\sum\limits_{M\leq N}\tfrac{M^j}{(\kappa + M)^2}\|(\psi^3q)_M\|_{L^\infty_{t,x}}\lesssim \kappa^{-2}N^{\frac12-s} \min\{ N^j,\kappa^j\}\delta,\\ &\sum\limits_{M\leq N}\tfrac{M^j}{(\kappa + M)^2}\|\big(\psi^3\tfrac f{2\varkappa + \partial}\big)_M\|_{L^\infty_{t,x}}\!\lesssim |\varkappa|^{-(s+\frac12)}(|\varkappa| + N)^{s-\frac12}\kappa^{-2}N^{\frac12-s} \min\{ N^j,\kappa^j\}\delta, \end{align*} $$
$$ \begin{align*} &\sum\limits_{M\leq N}\tfrac{M^j}{(\kappa + M)^2}\|(\psi^3q)_M\|_{L^\infty_{t,x}}\lesssim \kappa^{-2}N^{\frac12-s} \min\{ N^j,\kappa^j\}\delta,\\ &\sum\limits_{M\leq N}\tfrac{M^j}{(\kappa + M)^2}\|\big(\psi^3\tfrac f{2\varkappa + \partial}\big)_M\|_{L^\infty_{t,x}}\!\lesssim |\varkappa|^{-(s+\frac12)}(|\varkappa| + N)^{s-\frac12}\kappa^{-2}N^{\frac12-s} \min\{ N^j,\kappa^j\}\delta, \end{align*} $$
which we will use to estimate low frequency terms.
For dyadic
 $N_j\geq 1$
, we write
$N_j\geq 1$
, we write
 $$ \begin{align*} m_{N_1,N_2,N_3,N_4} := m\big[\psi^{-3}(\psi^3q)_{N_1},\psi^{-3}(\psi^3r)_{N_2},\psi^{-3}(\psi^3q)_{N_3},\psi^9(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\big], \end{align*} $$
$$ \begin{align*} m_{N_1,N_2,N_3,N_4} := m\big[\psi^{-3}(\psi^3q)_{N_1},\psi^{-3}(\psi^3r)_{N_2},\psi^{-3}(\psi^3q)_{N_3},\psi^9(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\big], \end{align*} $$
so that
 $$\begin{align*}\big\| m[q,r,q,\psi^{12}\tfrac f{2\varkappa + \partial}] \big\|_{L^1_{t,x}} \leq \sum\limits_{N_j\geq 1} \big\| m_{N_1,N_2,N_3,N_4} \big\|_{L^1_{t,x}}. \end{align*}$$
$$\begin{align*}\big\| m[q,r,q,\psi^{12}\tfrac f{2\varkappa + \partial}] \big\|_{L^1_{t,x}} \leq \sum\limits_{N_j\geq 1} \big\| m_{N_1,N_2,N_3,N_4} \big\|_{L^1_{t,x}}. \end{align*}$$
As the estimates will be symmetric in the first three terms, we may assume that
 $N_1\geq N_2\geq N_3$
. Our strategy will be to bound the two highest frequency terms in
$N_1\geq N_2\geq N_3$
. Our strategy will be to bound the two highest frequency terms in
 $L^2_{t,x}$
to take advantage of the local smoothing norms, and the two lowest frequencies in
$L^2_{t,x}$
to take advantage of the local smoothing norms, and the two lowest frequencies in
 $L^\infty _{t,x}$
. Concretely, when
$L^\infty _{t,x}$
. Concretely, when
 $N_4\leq N_2$
, we apply Lemma 2.8, to obtain
$N_4\leq N_2$
, we apply Lemma 2.8, to obtain
 $$ \begin{align*} \big\| m_{N_1,N_2,N_3,N_4} \big\|_{L^1_{t,x}}&\lesssim\|\psi^3\tfrac{\partial^{\beta_1}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|\psi^3\tfrac{\partial^{\beta_2}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_2}\|_{L^2_{t,x}}\\ &\quad\times \|\psi^3\tfrac{\partial^{\beta_3}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|\psi^{-9}\tfrac{\partial^{\beta_4}}{4\kappa^2 - \partial^2}\psi^9(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\|_{L^\infty_{t,x}}\\ &\lesssim \tfrac{N_1^{\beta_1}N_2^{\beta_2}N_3^{\beta_3}N_4^{\beta_4}}{(\kappa + N_1)^2(\kappa + N_2)^2(\kappa + N_3)^2(\kappa + N_4)^2}\|(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|(\psi^3q)_{N_2}\|_{L^2_{t,x}}\\ &\quad\times\|(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\|_{L^\infty_{t,x}}, \end{align*} $$
$$ \begin{align*} \big\| m_{N_1,N_2,N_3,N_4} \big\|_{L^1_{t,x}}&\lesssim\|\psi^3\tfrac{\partial^{\beta_1}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|\psi^3\tfrac{\partial^{\beta_2}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_2}\|_{L^2_{t,x}}\\ &\quad\times \|\psi^3\tfrac{\partial^{\beta_3}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|\psi^{-9}\tfrac{\partial^{\beta_4}}{4\kappa^2 - \partial^2}\psi^9(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\|_{L^\infty_{t,x}}\\ &\lesssim \tfrac{N_1^{\beta_1}N_2^{\beta_2}N_3^{\beta_3}N_4^{\beta_4}}{(\kappa + N_1)^2(\kappa + N_2)^2(\kappa + N_3)^2(\kappa + N_4)^2}\|(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|(\psi^3q)_{N_2}\|_{L^2_{t,x}}\\ &\quad\times\|(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\|_{L^\infty_{t,x}}, \end{align*} $$
whereas, when
 $N_4>N_2$
, we obtain instead
$N_4>N_2$
, we obtain instead
 $$ \begin{align*} \big\| m_{N_1,N_2,N_3,N_4} \big\|_{L^1_{t,x}}&\lesssim\tfrac{N_1^{\beta_1}N_2^{\beta_2}N_3^{\beta_3}N_4^{\beta_4}}{(\kappa + N_1)^2(\kappa + N_2)^2(\kappa + N_3)^2(\kappa + N_4)^2}\|(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|(\psi^3q)_{N_2}\|_{L^\infty_{t,x}}\\ &\qquad\qquad\times\|(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|\big(\psi^3 \tfrac f{2\varkappa + \partial}\big)_{N_4}\|_{L^2_{t,x}}. \end{align*} $$
$$ \begin{align*} \big\| m_{N_1,N_2,N_3,N_4} \big\|_{L^1_{t,x}}&\lesssim\tfrac{N_1^{\beta_1}N_2^{\beta_2}N_3^{\beta_3}N_4^{\beta_4}}{(\kappa + N_1)^2(\kappa + N_2)^2(\kappa + N_3)^2(\kappa + N_4)^2}\|(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|(\psi^3q)_{N_2}\|_{L^\infty_{t,x}}\\ &\qquad\qquad\times\|(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|\big(\psi^3 \tfrac f{2\varkappa + \partial}\big)_{N_4}\|_{L^2_{t,x}}. \end{align*} $$
We then sum over the lowest two frequencies and invoke the estimates laid out above. When
 $N_4\leq N_2$
, this leads to a bound of the form
$N_4\leq N_2$
, this leads to a bound of the form
 $$ \begin{align*}\sum_{N_1\geq N_2} \Gamma_{N_1,N_2} \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*} $$
$$ \begin{align*}\sum_{N_1\geq N_2} \Gamma_{N_1,N_2} \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*} $$
where
 $\Gamma $
is the matrix
$\Gamma $
is the matrix
 $$ \begin{align*} \Gamma_{N_1,N_2} := |\varkappa|^{-(s+\frac12)}&(|\varkappa| + N_2)^{s-\frac12}\kappa^{-8}N_1^{\beta_1 - \frac52 - s}N_2^{\beta_2 - \frac32 - 3s}\\ &\times \min\{N_1^{\frac52},\kappa N_1,\kappa^2\}\min\{N_2^{\beta_3 + \beta_4 + \frac52},\kappa N_2^{\beta_3 + \beta_4 + 1},\kappa^{\beta_3 + \beta_4 + 2}\}. \end{align*} $$
$$ \begin{align*} \Gamma_{N_1,N_2} := |\varkappa|^{-(s+\frac12)}&(|\varkappa| + N_2)^{s-\frac12}\kappa^{-8}N_1^{\beta_1 - \frac52 - s}N_2^{\beta_2 - \frac32 - 3s}\\ &\times \min\{N_1^{\frac52},\kappa N_1,\kappa^2\}\min\{N_2^{\beta_3 + \beta_4 + \frac52},\kappa N_2^{\beta_3 + \beta_4 + 1},\kappa^{\beta_3 + \beta_4 + 2}\}. \end{align*} $$
When on the other hand
 $N_4> N_2$
, we are led to a bound of the form
$N_4> N_2$
, we are led to a bound of the form
 $$ \begin{align*}\sum_{N_1\geq N_4} \Gamma_{N_1,N_4} \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2 + \sum_{N_4\geq N_1} \Big[\tfrac{|\varkappa| + N_4}{|\varkappa| + N_1}\Big]^{s-\frac12}\Gamma_{N_4,N_1} \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2 , \end{align*} $$
$$ \begin{align*}\sum_{N_1\geq N_4} \Gamma_{N_1,N_4} \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2 + \sum_{N_4\geq N_1} \Big[\tfrac{|\varkappa| + N_4}{|\varkappa| + N_1}\Big]^{s-\frac12}\Gamma_{N_4,N_1} \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2 , \end{align*} $$
with corresponding permutations of the indices
 $\beta $
.
$\beta $
.
In this way, we see that the proof can be completed by proving
 $$ \begin{align*} \sum_{N \geq M } \Gamma_{N,M} \lesssim \kappa^{|\beta| - 7 -\frac83(s+\frac12)}. \end{align*} $$
$$ \begin{align*} \sum_{N \geq M } \Gamma_{N,M} \lesssim \kappa^{|\beta| - 7 -\frac83(s+\frac12)}. \end{align*} $$
As the matrix entries are monotone in
 $|\varkappa |$
, it suffices to prove the bound when
$|\varkappa |$
, it suffices to prove the bound when
 $|\varkappa |=\kappa ^{2/3}$
. Summing first in N, we are left to estimate
$|\varkappa |=\kappa ^{2/3}$
. Summing first in N, we are left to estimate
 $$ \begin{align} \sum_{M\geq 1} \kappa^{-8-\frac13(2s+1)} (\kappa^{\frac23} + M&)^{s-\frac12} M^{\beta_2-\frac32(2s+1)}\min\Big\{M^{\beta_3+\beta_4+\frac52}[\kappa^{\beta_1-\frac12-s}+ \kappa^{\frac23(\beta_1-s)}], \notag\\ &\kappa^2 M^{\beta_3+\beta_4+1} [\kappa^{\beta_1-\frac32-s}+ M^{\beta_1-\frac32-s}], \ \kappa^{\beta_3+\beta_4 +4} M^{\beta_1-\frac52-s}\Big\}. \end{align} $$
$$ \begin{align} \sum_{M\geq 1} \kappa^{-8-\frac13(2s+1)} (\kappa^{\frac23} + M&)^{s-\frac12} M^{\beta_2-\frac32(2s+1)}\min\Big\{M^{\beta_3+\beta_4+\frac52}[\kappa^{\beta_1-\frac12-s}+ \kappa^{\frac23(\beta_1-s)}], \notag\\ &\kappa^2 M^{\beta_3+\beta_4+1} [\kappa^{\beta_1-\frac32-s}+ M^{\beta_1-\frac32-s}], \ \kappa^{\beta_3+\beta_4 +4} M^{\beta_1-\frac52-s}\Big\}. \end{align} $$
From here, one need only consider the cases
 $M\leq \kappa ^{\frac 23}$
,
$M\leq \kappa ^{\frac 23}$
,
 $\kappa ^{\frac 23}\leq M\leq \kappa $
, and
$\kappa ^{\frac 23}\leq M\leq \kappa $
, and
 $M\geq \kappa $
.
$M\geq \kappa $
.
For the mKdV, we have the following variation:
Lemma 5.11 (Quartic estimates for the mKdV).
Let
 $m\in S(\beta ;\kappa )$
with
$m\in S(\beta ;\kappa )$
with
 $1\leq |\beta |\leq 8$
. For any
$1\leq |\beta |\leq 8$
. For any
 $|\varkappa |\geq \sqrt \kappa \geq 1$
and any Schwartz functions
$|\varkappa |\geq \sqrt \kappa \geq 1$
and any Schwartz functions
 $q,f\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfying
$q,f\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfying
 $$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}, \end{align*}$$
$$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}, \end{align*}$$
we have the paraproduct estimate
 $$ \begin{align} \nonumber \big\| m[q,r,q,\psi_h^{12} &\tfrac f{2\varkappa + \partial}] \big\|_{L^1_{t,x}} + \big\| m[q,r,q,\tfrac f{2\varkappa + \partial}]\,\psi_h^{12} \big\|_{L^1_{t,x}}\\ &\lesssim \Big[\tfrac{\kappa^{-2s}}{|\varkappa|}+|\varkappa|^{-2(2s+1)}\log\big|\tfrac{4\varkappa^2}{\kappa}\big|\Big]\kappa^{|\beta|-8}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} \nonumber \big\| m[q,r,q,\psi_h^{12} &\tfrac f{2\varkappa + \partial}] \big\|_{L^1_{t,x}} + \big\| m[q,r,q,\tfrac f{2\varkappa + \partial}]\,\psi_h^{12} \big\|_{L^1_{t,x}}\\ &\lesssim \Big[\tfrac{\kappa^{-2s}}{|\varkappa|}+|\varkappa|^{-2(2s+1)}\log\big|\tfrac{4\varkappa^2}{\kappa}\big|\Big]\kappa^{|\beta|-8}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
where the implicit constant is independent of
 $\kappa , \varkappa ,$
and
$\kappa , \varkappa ,$
and
 $h\in {{\mathbb {R}}}$
. Moreover, if
$h\in {{\mathbb {R}}}$
. Moreover, if
 $|\beta |\geq 2$
,
$|\beta |\geq 2$
,
 $$ \begin{align} \bigg|\iint m\big[q,r,q,\psi_h^{12} &\tfrac f{2\varkappa + \partial}\big]\,dx\,dt\bigg| \lesssim \kappa^{|\beta|-9-2s}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align} $$
$$ \begin{align} \bigg|\iint m\big[q,r,q,\psi_h^{12} &\tfrac f{2\varkappa + \partial}\big]\,dx\,dt\bigg| \lesssim \kappa^{|\beta|-9-2s}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align} $$
Remark 5.12. As we will see in the proof, it is not essential that the first three entries in the paraproduct are exactly q, r, and q. Rather, we only require that they obey the same estimates as q, in the manner that f does. As we shall seldom need this extra generality, we have chosen to present the lemma in this more representative form.
Proof. The proof is essentially identical to that of Lemma 5.10. By space-translation symmetry, we may assume
 $h=0$
.
$h=0$
.
We will reuse the
 $L^\infty _{t,x}$
bounds appearing in the proof of Lemma 5.10; however, the
$L^\infty _{t,x}$
bounds appearing in the proof of Lemma 5.10; however, the
 $L^2_{t,x}$
local smoothing bounds used to treat the high-frequency terms must be adapted to the mKdV setting. Specifically, we will use
$L^2_{t,x}$
local smoothing bounds used to treat the high-frequency terms must be adapted to the mKdV setting. Specifically, we will use
 $$ \begin{align*} \tfrac{N^j}{(\kappa + N)^2}\|(\psi^3q)_N\|_{L^2_{t,x}} &\lesssim \kappa^{-2} N^{j-3-s} \min\{N^3,\kappa N, \kappa^2 \} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa},\\ \tfrac{N^j}{(\kappa + N)^2}\|\big(\psi^3\tfrac f{2\varkappa + \partial}\big)_N\|_{L^2_{t,x}} &\lesssim |\varkappa|^{-(s+\frac12)}(|\varkappa| + N)^{s - \frac12} \kappa^{-2} N^{j-3-s} \min\{N^3,\kappa N, \kappa^2 \} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*} $$
$$ \begin{align*} \tfrac{N^j}{(\kappa + N)^2}\|(\psi^3q)_N\|_{L^2_{t,x}} &\lesssim \kappa^{-2} N^{j-3-s} \min\{N^3,\kappa N, \kappa^2 \} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa},\\ \tfrac{N^j}{(\kappa + N)^2}\|\big(\psi^3\tfrac f{2\varkappa + \partial}\big)_N\|_{L^2_{t,x}} &\lesssim |\varkappa|^{-(s+\frac12)}(|\varkappa| + N)^{s - \frac12} \kappa^{-2} N^{j-3-s} \min\{N^3,\kappa N, \kappa^2 \} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*} $$
Proceeding as in the proof of (5.25), we take
 $$ \begin{align*} m_{N_1,N_2,N_3,N_4} := m\big[\psi^{-3}(\psi^3q)_{N_1},\psi^{-3}(\psi^3r)_{N_2},\psi^{-3}(\psi^3q)_{N_3},\psi^{9}(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\big], \end{align*} $$
$$ \begin{align*} m_{N_1,N_2,N_3,N_4} := m\big[\psi^{-3}(\psi^3q)_{N_1},\psi^{-3}(\psi^3r)_{N_2},\psi^{-3}(\psi^3q)_{N_3},\psi^{9}(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\big], \end{align*} $$
so that
 $$\begin{align*}\|m[q,r,q,\psi^{12}\tfrac f{2\varkappa + \partial}]\|_{L^1_{t,x}} \leq \sum\limits_{N_j\geq 1}\|m_{N_1,N_2,N_3,N_4}\|_{L^1_{t,x}}, \end{align*}$$
$$\begin{align*}\|m[q,r,q,\psi^{12}\tfrac f{2\varkappa + \partial}]\|_{L^1_{t,x}} \leq \sum\limits_{N_j\geq 1}\|m_{N_1,N_2,N_3,N_4}\|_{L^1_{t,x}}, \end{align*}$$
or
 $$ \begin{align*} \tilde m_{N_1,N_2,N_3,N_4} := m\big[\psi^{-3}(\psi^3q)_{N_1},\psi^{-3}(\psi^3r)_{N_2},\psi^{-3}(\psi^3q)_{N_3},\psi^{-3}(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\big], \end{align*} $$
$$ \begin{align*} \tilde m_{N_1,N_2,N_3,N_4} := m\big[\psi^{-3}(\psi^3q)_{N_1},\psi^{-3}(\psi^3r)_{N_2},\psi^{-3}(\psi^3q)_{N_3},\psi^{-3}(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\big], \end{align*} $$
 $$\begin{align*}\|m[q,r,q,\tfrac f{2\varkappa + \partial}]\,\psi^{12}\|_{L^1_{t,x}} \leq \sum\limits_{N_j\geq 1}\|\tilde m_{N_1,N_2,N_3,N_4}\,\psi^{12}\|_{L^1_{t,x}}. \end{align*}$$
$$\begin{align*}\|m[q,r,q,\tfrac f{2\varkappa + \partial}]\,\psi^{12}\|_{L^1_{t,x}} \leq \sum\limits_{N_j\geq 1}\|\tilde m_{N_1,N_2,N_3,N_4}\,\psi^{12}\|_{L^1_{t,x}}. \end{align*}$$
As in the proof of (5.25), it suffices to restrict our attention to the case
 $N_1\geq N_2\geq N_3\geq N_4$
. With
$N_1\geq N_2\geq N_3\geq N_4$
. With
 $\ell =3,9$
, we may bound
$\ell =3,9$
, we may bound
 $$ \begin{align*} \text{LHS}(5.27)&\lesssim \!\!\sum\limits_{N_1\geq N_2\geq N_3\geq N_4}\!\!\|\psi^3\tfrac{\partial^{\beta_1}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|\psi^3\tfrac{\partial^{\beta_2}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_2}\|_{L^2_{t,x}}\\ &\qquad\quad\times \|\psi^3\tfrac{\partial^{\beta_3}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|\psi^{-\ell}\tfrac{\partial^{\beta_4}}{4\kappa^2 - \partial^2}\psi^\ell(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\|_{L^\infty_{t,x}}\\ &\lesssim \!\!\!\sum\limits_{N_1\geq N_2\geq N_3\geq N_4}\!\!\!\!\tfrac{N_1^{\beta_1}N_2^{\beta_2}N_3^{\beta_3}N_4^{\beta_4}}{(\kappa + N_1)^2(\kappa + N_2)^2(\kappa + N_3)^2(\kappa + N_4)^2}\|(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|(\psi^3q)_{N_2}\|_{L^2_{t,x}}\\ &\qquad\quad\times\|(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\|_{L^\infty_{t,x}}. \end{align*} $$
$$ \begin{align*} \text{LHS}(5.27)&\lesssim \!\!\sum\limits_{N_1\geq N_2\geq N_3\geq N_4}\!\!\|\psi^3\tfrac{\partial^{\beta_1}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|\psi^3\tfrac{\partial^{\beta_2}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_2}\|_{L^2_{t,x}}\\ &\qquad\quad\times \|\psi^3\tfrac{\partial^{\beta_3}}{4\kappa^2 - \partial^2}\psi^{-3}(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|\psi^{-\ell}\tfrac{\partial^{\beta_4}}{4\kappa^2 - \partial^2}\psi^\ell(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\|_{L^\infty_{t,x}}\\ &\lesssim \!\!\!\sum\limits_{N_1\geq N_2\geq N_3\geq N_4}\!\!\!\!\tfrac{N_1^{\beta_1}N_2^{\beta_2}N_3^{\beta_3}N_4^{\beta_4}}{(\kappa + N_1)^2(\kappa + N_2)^2(\kappa + N_3)^2(\kappa + N_4)^2}\|(\psi^3q)_{N_1}\|_{L^2_{t,x}}\|(\psi^3q)_{N_2}\|_{L^2_{t,x}}\\ &\qquad\quad\times\|(\psi^3q)_{N_3}\|_{L^\infty_{t,x}}\|(\psi^3\tfrac f{2\varkappa + \partial})_{N_4}\|_{L^\infty_{t,x}}. \end{align*} $$
Summing in
 $N_3\geq N_4\geq 1$
we obtain a bound of a constant multiple of
$N_3\geq N_4\geq 1$
we obtain a bound of a constant multiple of
 $$ \begin{align*} &\sum\limits_{N_1\geq N_2}|\varkappa|^{-(s+\frac12)}(|\varkappa| + N_2)^{s-\frac12}\kappa^{-8}N_1^{\beta_1-3-s}N_2^{\beta_2 - 2 - 3s}\min\{N_1^3,\kappa N_1,\kappa^2\}\\ &\qquad \qquad\qquad\qquad\times\min\{N_2^{\beta_3 + \beta_4 + 3},\kappa N_2^{\beta_3 + \beta_4 + 1}, \kappa^{\beta_3 + \beta_4 + 2}\}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
$$ \begin{align*} &\sum\limits_{N_1\geq N_2}|\varkappa|^{-(s+\frac12)}(|\varkappa| + N_2)^{s-\frac12}\kappa^{-8}N_1^{\beta_1-3-s}N_2^{\beta_2 - 2 - 3s}\min\{N_1^3,\kappa N_1,\kappa^2\}\\ &\qquad \qquad\qquad\qquad\times\min\{N_2^{\beta_3 + \beta_4 + 3},\kappa N_2^{\beta_3 + \beta_4 + 1}, \kappa^{\beta_3 + \beta_4 + 2}\}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
Proceeding as in Lemma 5.10 and summing in
 $N_1$
, we are led to control the following analogue of (5.26):
$N_1$
, we are led to control the following analogue of (5.26):
 $$ \begin{align*} \sum_{M\geq 1} \kappa^{-8} |\varkappa|^{-(s+\frac12)} (|\varkappa|& + M)^{s-\frac12} M^{\beta_2-2-3s}\min\Big\{M^{\beta_3+\beta_4+3}[\kappa^{\beta_1-1-s}+ \kappa^{\frac12(\beta_1-s)}], \notag\\ &\kappa^2 M^{\beta_3+\beta_4+1} [\kappa^{\beta_1-2-s}+ M^{\beta_1-2-s}], \ \kappa^{\beta_3+\beta_4 +4} M^{\beta_1-3-s}\Big\}. \end{align*} $$
$$ \begin{align*} \sum_{M\geq 1} \kappa^{-8} |\varkappa|^{-(s+\frac12)} (|\varkappa|& + M)^{s-\frac12} M^{\beta_2-2-3s}\min\Big\{M^{\beta_3+\beta_4+3}[\kappa^{\beta_1-1-s}+ \kappa^{\frac12(\beta_1-s)}], \notag\\ &\kappa^2 M^{\beta_3+\beta_4+1} [\kappa^{\beta_1-2-s}+ M^{\beta_1-2-s}], \ \kappa^{\beta_3+\beta_4 +4} M^{\beta_1-3-s}\Big\}. \end{align*} $$
Once again, this requires consideration of individual cases. Unlike in Lemma 5.10, the final bound depends upon
 $|\varkappa |$
and so we cannot exploit monotonicity; thus, we need to treat separately
$|\varkappa |$
and so we cannot exploit monotonicity; thus, we need to treat separately
 $\kappa ^{\frac 12}\leq |\varkappa |\leq \kappa $
and
$\kappa ^{\frac 12}\leq |\varkappa |\leq \kappa $
and
 $|\varkappa |\geq \kappa $
. Evaluating these sums carefully reveals that (5.27) can be improved to
$|\varkappa |\geq \kappa $
. Evaluating these sums carefully reveals that (5.27) can be improved to
 $$ \begin{align} \text{LHS(5.27)} \lesssim \Big[\tfrac{\kappa^{-2s}}{\kappa+|\varkappa|}+|\varkappa|^{-2(2s+1)}\log\big|\tfrac{4\varkappa^2}{\kappa}\big|\Big]\kappa^{|\beta|-8}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 \end{align} $$
$$ \begin{align} \text{LHS(5.27)} \lesssim \Big[\tfrac{\kappa^{-2s}}{\kappa+|\varkappa|}+|\varkappa|^{-2(2s+1)}\log\big|\tfrac{4\varkappa^2}{\kappa}\big|\Big]\kappa^{|\beta|-8}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 \end{align} $$
in two cases: (i) if
 $|\beta |\geq 3$
or (ii) if
$|\beta |\geq 3$
or (ii) if
 $|\beta |=2$
and no individual
$|\beta |=2$
and no individual
 $\beta _j=2$
. These bounds suffice to prove (5.28) because if
$\beta _j=2$
. These bounds suffice to prove (5.28) because if
 $|\beta |=2$
and some factor has two derivatives (i.e., some
$|\beta |=2$
and some factor has two derivatives (i.e., some
 $\beta _j=2$
), then we may integrate by parts to redistribute one of the derivatives and recover case (ii).
$\beta _j=2$
), then we may integrate by parts to redistribute one of the derivatives and recover case (ii).
Next, we prove another pair of lemmas that will act as replacements for Lemmas 2.6, 2.7 in certain situations:
Lemma 5.13. Let
 $|\varkappa |\geq \kappa ^{\frac 23}\geq 1$
and
$|\varkappa |\geq \kappa ^{\frac 23}\geq 1$
and
 $f_1,f_2\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfy
$f_1,f_2\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfy
 $$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f_j \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*}$$
$$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f_j \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*}$$
Then we have the estimate
 $$ \begin{align} \|(\varkappa - \partial)^{-\frac12}(\psi_h f_1\cdot\psi_h\tfrac{f_2}{2\varkappa - \partial})(\varkappa + \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2}^2\lesssim |\varkappa|^{-3}\big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align} $$
$$ \begin{align} \|(\varkappa - \partial)^{-\frac12}(\psi_h f_1\cdot\psi_h\tfrac{f_2}{2\varkappa - \partial})(\varkappa + \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2}^2\lesssim |\varkappa|^{-3}\big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align} $$
Proof. By translation invariance, we may take
 $h=0$
. Decomposing dyadically and using (2.22) yields
$h=0$
. Decomposing dyadically and using (2.22) yields
 $$\begin{align*}\mathrm{LHS}(5.30) \lesssim \sum_{N\geq 1} (|\varkappa| + N)^{-1}\log\big(4 + \tfrac{N^2}{|\varkappa|^2}\big) \big\|P_N( \psi f_1\cdot \psi\tfrac {f_2}{2\varkappa - \partial}\big)\big\|_{L^2_{t,x}}^2, \end{align*}$$
$$\begin{align*}\mathrm{LHS}(5.30) \lesssim \sum_{N\geq 1} (|\varkappa| + N)^{-1}\log\big(4 + \tfrac{N^2}{|\varkappa|^2}\big) \big\|P_N( \psi f_1\cdot \psi\tfrac {f_2}{2\varkappa - \partial}\big)\big\|_{L^2_{t,x}}^2, \end{align*}$$
in which we then substitute the bound
 $$\begin{align*}\big\|P_N( \psi f_1\cdot \psi\tfrac {f_2}{2\varkappa - \partial}\big)\big\|_{L^2_{t,x}}\leq \bigg\| \sum_{N_1,N_2\geq 1}\big\|P_N\big( (\psi f_1)_{N_1}\cdot \big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big)\big\|_{L^2}\bigg\|_{L^2_t}. \end{align*}$$
$$\begin{align*}\big\|P_N( \psi f_1\cdot \psi\tfrac {f_2}{2\varkappa - \partial}\big)\big\|_{L^2_{t,x}}\leq \bigg\| \sum_{N_1,N_2\geq 1}\big\|P_N\big( (\psi f_1)_{N_1}\cdot \big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big)\big\|_{L^2}\bigg\|_{L^2_t}. \end{align*}$$
We then proceed using the Littlewood–Paley trichotomy:
 $\underline{\mathrm{Case\ 1{:}}\ N_2 \ll N_1 \approx N}$
. Applying Bernstein’s inequality, we bound
$\underline{\mathrm{Case\ 1{:}}\ N_2 \ll N_1 \approx N}$
. Applying Bernstein’s inequality, we bound
 $$ \begin{align*} \big\|P_N\big( (\psi f_1)_{N_1}\cdot \big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big)\big\|_{L^2_{t,x}} &\lesssim \|(\psi f_1)_{N_1}\|_{L^2_{t,x}}\|\big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\|_{L^\infty_{t,x}}\\ &\lesssim N_1^{-s-\frac32}\min\{N_1^{\frac32},\kappa + N_1\} N_2^{\frac12-s}(|\varkappa| + N_2)^{-1}\delta {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*} $$
$$ \begin{align*} \big\|P_N\big( (\psi f_1)_{N_1}\cdot \big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big)\big\|_{L^2_{t,x}} &\lesssim \|(\psi f_1)_{N_1}\|_{L^2_{t,x}}\|\big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\|_{L^\infty_{t,x}}\\ &\lesssim N_1^{-s-\frac32}\min\{N_1^{\frac32},\kappa + N_1\} N_2^{\frac12-s}(|\varkappa| + N_2)^{-1}\delta {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*} $$
Observing that for fixed
 $N\geq 1$
, we have
$N\geq 1$
, we have
 $$\begin{align*}\sum_{1\leq N_2\lesssim N}N_2^{\frac12-s}(|\varkappa| + N_2)^{-1}\lesssim |\varkappa|^{-1}(N\wedge |\varkappa|)^{\frac12-s}, \end{align*}$$
$$\begin{align*}\sum_{1\leq N_2\lesssim N}N_2^{\frac12-s}(|\varkappa| + N_2)^{-1}\lesssim |\varkappa|^{-1}(N\wedge |\varkappa|)^{\frac12-s}, \end{align*}$$
we are led to estimate
 $$ \begin{align*} &\quad \sum_{N\geq 1}|\varkappa|^{-2}(N\wedge |\varkappa|)^{1-2s}(|\varkappa| + N)^{-1}\log(4 + \tfrac{N^2}{|\varkappa|^2}) N^{-2s-3}\min\{N^3,(\kappa + N)^2\} \\ &\qquad\qquad\lesssim |\varkappa|^{-3} \big[ \kappa^{\frac23 - \frac{8s}3}+|\varkappa|^{-4s} \big]. \end{align*} $$
$$ \begin{align*} &\quad \sum_{N\geq 1}|\varkappa|^{-2}(N\wedge |\varkappa|)^{1-2s}(|\varkappa| + N)^{-1}\log(4 + \tfrac{N^2}{|\varkappa|^2}) N^{-2s-3}\min\{N^3,(\kappa + N)^2\} \\ &\qquad\qquad\lesssim |\varkappa|^{-3} \big[ \kappa^{\frac23 - \frac{8s}3}+|\varkappa|^{-4s} \big]. \end{align*} $$
 $\underline{\mathrm{Case\ 2{:}}\ N_1 \ll N_2\approx N}$
. A similar argument yields the estimate
$\underline{\mathrm{Case\ 2{:}}\ N_1 \ll N_2\approx N}$
. A similar argument yields the estimate
 $$ \begin{align*} &\big\|P_N\big( (\psi f_1)_{N_1}\cdot \big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big)\big\|_{L^2_{t,x}}\lesssim N_1^{\frac12-s}(|\varkappa| + N_2)^{-1}N_2^{-s-\frac32}\min\{N_2^{\frac32},\kappa + N_2\} \delta {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*} $$
$$ \begin{align*} &\big\|P_N\big( (\psi f_1)_{N_1}\cdot \big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big)\big\|_{L^2_{t,x}}\lesssim N_1^{\frac12-s}(|\varkappa| + N_2)^{-1}N_2^{-s-\frac32}\min\{N_2^{\frac32},\kappa + N_2\} \delta {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*} $$
This then leads us to evaluate
 $$\begin{align*}\sum_{N\geq 1}(|\varkappa| + N)^{-3}\log(4 + \tfrac{N^2}{\varkappa^2})N^{-2(1+2s)}\min\{N^3,(\kappa + N)^2\}, \end{align*}$$
$$\begin{align*}\sum_{N\geq 1}(|\varkappa| + N)^{-3}\log(4 + \tfrac{N^2}{\varkappa^2})N^{-2(1+2s)}\min\{N^3,(\kappa + N)^2\}, \end{align*}$$
which yields the same bound as in Case 1.
 $\underline{\mathrm{Case\ 3{:}}\ N_1\approx N_2 \gtrsim N}$
. Bernstein’s inequality implies
$\underline{\mathrm{Case\ 3{:}}\ N_1\approx N_2 \gtrsim N}$
. Bernstein’s inequality implies
 $$ \begin{align*} \big\|P_N\big( (\psi f_1)_{N_1}\cdot &\big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big\|_{L^2} \\ &\lesssim N^{\frac12} \big\|(\psi f_1)_{N_1} \big\|_{L^2} \cdot N_1^{-s} (|\varkappa|+N_1)^{-1} \big\|(2\varkappa-\partial)\big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big\|_{H^{s}}. \end{align*} $$
$$ \begin{align*} \big\|P_N\big( (\psi f_1)_{N_1}\cdot &\big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big\|_{L^2} \\ &\lesssim N^{\frac12} \big\|(\psi f_1)_{N_1} \big\|_{L^2} \cdot N_1^{-s} (|\varkappa|+N_1)^{-1} \big\|(2\varkappa-\partial)\big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big\|_{H^{s}}. \end{align*} $$
Thus, applying Cauchy–Schwarz to the sum, we obtain
 $$ \begin{align*} \bigg\| \sum_{N_1\approx N_2\gtrsim N}\big\|P_N\big( (\psi & f_1)_{N_1}\cdot \big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big)\big\|_{L^2}\bigg\|_{L^2_t}^2\\ &\lesssim N \sum\limits_{N_1\gtrsim N} N_1^{-4s-3}(|\varkappa| + N_1)^{-2}\min\{N_1^3,(\kappa + N_1)^2\} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*} $$
$$ \begin{align*} \bigg\| \sum_{N_1\approx N_2\gtrsim N}\big\|P_N\big( (\psi & f_1)_{N_1}\cdot \big(\psi\tfrac {f_2}{2\varkappa - \partial}\big)_{N_2}\big)\big\|_{L^2}\bigg\|_{L^2_t}^2\\ &\lesssim N \sum\limits_{N_1\gtrsim N} N_1^{-4s-3}(|\varkappa| + N_1)^{-2}\min\{N_1^3,(\kappa + N_1)^2\} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*} $$
We are then left to evaluate the sum
 $$ \begin{align*} &\quad \sum_{N\geq 1} \sum_{N_1\gtrsim N} \tfrac N{|\varkappa| + N}\log\big(4 + \tfrac{N^2}{|\varkappa|^2}\big) N_1^{-4s-3}(|\varkappa| + N_1)^{-2}\min\{N_1^3,(\kappa + N_1)^2\} \\ &\lesssim \sum\limits_{N_1\geq 1}|\varkappa|^{-1}(|\varkappa| + N_1)^{-2} N_1^{-4s-2}\min\{N_1^3,(\kappa + N_1)^2\}, \end{align*} $$
$$ \begin{align*} &\quad \sum_{N\geq 1} \sum_{N_1\gtrsim N} \tfrac N{|\varkappa| + N}\log\big(4 + \tfrac{N^2}{|\varkappa|^2}\big) N_1^{-4s-3}(|\varkappa| + N_1)^{-2}\min\{N_1^3,(\kappa + N_1)^2\} \\ &\lesssim \sum\limits_{N_1\geq 1}|\varkappa|^{-1}(|\varkappa| + N_1)^{-2} N_1^{-4s-2}\min\{N_1^3,(\kappa + N_1)^2\}, \end{align*} $$
which ultimately yields a contribution identical to that of Cases 1 and 2.
In the case of the mKdV, we have the following analogue:
Lemma 5.14. Let
 $|\varkappa |\geq \kappa ^{\frac 12}\geq 1$
and
$|\varkappa |\geq \kappa ^{\frac 12}\geq 1$
and
 $f_1,f_2,f_3\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfy
$f_1,f_2,f_3\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfy
 $$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f_j \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*}$$
$$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f_j \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*}$$
Then we have the estimates
 $$ \begin{align} &\|(\varkappa - \partial)^{-\frac12}(\psi_h f_1\cdot\psi_h\tfrac{f_2}{2\varkappa - \partial})(\varkappa + \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2}^2 \end{align} $$
$$ \begin{align} &\|(\varkappa - \partial)^{-\frac12}(\psi_h f_1\cdot\psi_h\tfrac{f_2}{2\varkappa - \partial})(\varkappa + \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2}^2 \end{align} $$
 $$ \begin{align} &\qquad\qquad \lesssim |\varkappa|^{-3}\big[\kappa^{\frac12-2s} + |\varkappa|^{-1 - 4s}\log|2\varkappa|\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2,\notag\\ &\|(\varkappa - \partial)^{-\frac12}(\psi_h f_1\cdot\psi_h\tfrac{f_2}{2\varkappa - \partial}\cdot\psi_h\tfrac{f_3}{2\varkappa + \partial})(\varkappa + \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2}^2\\ &\qquad\qquad \lesssim |\varkappa|^{-5}\big[ \kappa^{1-3s} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{-6s} \log |2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2.\notag \end{align} $$
$$ \begin{align} &\qquad\qquad \lesssim |\varkappa|^{-3}\big[\kappa^{\frac12-2s} + |\varkappa|^{-1 - 4s}\log|2\varkappa|\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2,\notag\\ &\|(\varkappa - \partial)^{-\frac12}(\psi_h f_1\cdot\psi_h\tfrac{f_2}{2\varkappa - \partial}\cdot\psi_h\tfrac{f_3}{2\varkappa + \partial})(\varkappa + \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2}^2\\ &\qquad\qquad \lesssim |\varkappa|^{-5}\big[ \kappa^{1-3s} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{-6s} \log |2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2.\notag \end{align} $$
Proof. The estimate (5.31) follows from the same argument used to prove (5.30); all that changes are the specific powers inside the sums.
Thus, it remains to consider the estimate (5.32). Proceeding as in the proof of (5.30), we may assume that
 $h=0$
and bound
$h=0$
and bound
 $$\begin{align*}\mathrm{LHS}(5.32) \lesssim \sum\limits_{N\geq 1}(|\varkappa| + N)^{-1}\log\big(4 + \tfrac{N^2}{\varkappa^2}\big)\big\|P_N\big(\psi f_1\cdot \psi\tfrac{f_2}{2\varkappa - \partial}\cdot\psi\tfrac{f_3}{2\varkappa + \partial}\big)\big\|_{L^2_{t,x}}^2. \end{align*}$$
$$\begin{align*}\mathrm{LHS}(5.32) \lesssim \sum\limits_{N\geq 1}(|\varkappa| + N)^{-1}\log\big(4 + \tfrac{N^2}{\varkappa^2}\big)\big\|P_N\big(\psi f_1\cdot \psi\tfrac{f_2}{2\varkappa - \partial}\cdot\psi\tfrac{f_3}{2\varkappa + \partial}\big)\big\|_{L^2_{t,x}}^2. \end{align*}$$
We then decompose further by frequency, using
 $$ \begin{align*} &\big\|P_N\big(\psi f_1\cdot \psi\tfrac{f_2}{2\varkappa - \partial}\cdot\psi\tfrac{f_3}{2\varkappa + p}\big)\big\|_{L^2_{t,x}}\\ &\qquad \leq \bigg\| \sum\limits_{N_1,N_2,N_3\geq 1} \big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2} \bigg\|_{L^2_t}. \end{align*} $$
$$ \begin{align*} &\big\|P_N\big(\psi f_1\cdot \psi\tfrac{f_2}{2\varkappa - \partial}\cdot\psi\tfrac{f_3}{2\varkappa + p}\big)\big\|_{L^2_{t,x}}\\ &\qquad \leq \bigg\| \sum\limits_{N_1,N_2,N_3\geq 1} \big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2} \bigg\|_{L^2_t}. \end{align*} $$
As everything is symmetric under the
 $N_2\leftrightarrow N_3$
interchange, we may reduce matters to four possible cases:
$N_2\leftrightarrow N_3$
interchange, we may reduce matters to four possible cases:
 $\underline{\mathrm{Case\ 1{:}}\ \min \{N_1,N\}\geq \max \{N_2,N_3\}}$
. Here, we apply Bernstein’s inequality to bound
$\underline{\mathrm{Case\ 1{:}}\ \min \{N_1,N\}\geq \max \{N_2,N_3\}}$
. Here, we apply Bernstein’s inequality to bound
 $$ \begin{align*} &\big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2_{t,x}}\\ &\qquad \leq \|(\psi f_1)_{N_1}\|_{L^2_{t,x}}\|\big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\|_{L^\infty_{t,x}}\|\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\|_{L^\infty_{t,x}}\\ &\qquad \lesssim N_1^{-s-2}\min\{N_1^2,\kappa + N_1\}N_2^{\frac12-s}(|\varkappa| + N_2)^{-1}N_3^{\frac12-s}(|\varkappa| + N_3)^{-1}\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*} $$
$$ \begin{align*} &\big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2_{t,x}}\\ &\qquad \leq \|(\psi f_1)_{N_1}\|_{L^2_{t,x}}\|\big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\|_{L^\infty_{t,x}}\|\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\|_{L^\infty_{t,x}}\\ &\qquad \lesssim N_1^{-s-2}\min\{N_1^2,\kappa + N_1\}N_2^{\frac12-s}(|\varkappa| + N_2)^{-1}N_3^{\frac12-s}(|\varkappa| + N_3)^{-1}\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*} $$
Summing in
 $N_2,N_3$
and then in
$N_2,N_3$
and then in
 $N_1\approx N$
using the Cauchy-Schwarz inequality, we obtain a contribution to
$N_1\approx N$
using the Cauchy-Schwarz inequality, we obtain a contribution to
 $\mathrm {RHS}$
(5.32) that is
$\mathrm {RHS}$
(5.32) that is
 $$ \begin{align*} &\lesssim \sum\limits_{N\geq 1}|\varkappa|^{-4}(N\wedge |\varkappa|)^{2-4s}(|\varkappa| + N)^{-1}\log\big(4 + \tfrac{N^2}{\varkappa^2}\big)N^{-2s-4}\min\{N^4,(\kappa + N)^2\} \delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 \\ &\lesssim |\varkappa|^{-5} \big[\kappa^{1-3s}+ \big(1+\tfrac{\kappa^2}{\varkappa^2}\big)|\varkappa|^{-6s} \log|2\varkappa| \big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
$$ \begin{align*} &\lesssim \sum\limits_{N\geq 1}|\varkappa|^{-4}(N\wedge |\varkappa|)^{2-4s}(|\varkappa| + N)^{-1}\log\big(4 + \tfrac{N^2}{\varkappa^2}\big)N^{-2s-4}\min\{N^4,(\kappa + N)^2\} \delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 \\ &\lesssim |\varkappa|^{-5} \big[\kappa^{1-3s}+ \big(1+\tfrac{\kappa^2}{\varkappa^2}\big)|\varkappa|^{-6s} \log|2\varkappa| \big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
 $\underline{\mathrm{Case\ 1{:}}\ \min \{N_2,N\}\geq \max \{N_1,N_3\}}$
. A similar argument, this time placing
$\underline{\mathrm{Case\ 1{:}}\ \min \{N_2,N\}\geq \max \{N_1,N_3\}}$
. A similar argument, this time placing
 $\psi \frac {f_2}{2\varkappa - \partial }$
in
$\psi \frac {f_2}{2\varkappa - \partial }$
in
 $L^2_{t,x}$
yields the estimate
$L^2_{t,x}$
yields the estimate
 $$ \begin{align*} &\big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2_{t,x}}\\ &\qquad \lesssim N_1^{\frac12-s}(|\varkappa| + N_2)^{-1}N_2^{-s-2}\min\{N_2^2,\kappa + N_2\}N_3^{\frac12-s}(|\varkappa| + N_3)^{-1}\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}, \end{align*} $$
$$ \begin{align*} &\big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2_{t,x}}\\ &\qquad \lesssim N_1^{\frac12-s}(|\varkappa| + N_2)^{-1}N_2^{-s-2}\min\{N_2^2,\kappa + N_2\}N_3^{\frac12-s}(|\varkappa| + N_3)^{-1}\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}, \end{align*} $$
which yields a contribution to
 $\mathrm {RHS}$
(5.32) of
$\mathrm {RHS}$
(5.32) of
 $$\begin{align*}\lesssim \sum\limits_{N\geq 1}|\varkappa|^{-2}(N\wedge |\varkappa|)^{1-2s}(|\varkappa| + N)^{-3}\log\big(4 + \tfrac{N^2}{\varkappa^2}\big)N^{-4s-3}\min\{N^4,(\kappa + N)^2\} \delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*}$$
$$\begin{align*}\lesssim \sum\limits_{N\geq 1}|\varkappa|^{-2}(N\wedge |\varkappa|)^{1-2s}(|\varkappa| + N)^{-3}\log\big(4 + \tfrac{N^2}{\varkappa^2}\big)N^{-4s-3}\min\{N^4,(\kappa + N)^2\} \delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*}$$
which yields an identical contribution to Case 1.
 $\underline{\mathrm{Case\ 3{:}}\ \min \{N_1,N_2\}\geq \max \{N_3,N\}}$
. Here, we apply Bernstein’s inequality at the output frequency and sum using the Cauchy-Schwarz inequality in
$\underline{\mathrm{Case\ 3{:}}\ \min \{N_1,N_2\}\geq \max \{N_3,N\}}$
. Here, we apply Bernstein’s inequality at the output frequency and sum using the Cauchy-Schwarz inequality in
 $N_1\approx N_2$
so that for fixed
$N_1\approx N_2$
so that for fixed
 $N\geq 1$
, we obtain
$N\geq 1$
, we obtain
 $$ \begin{align*} &\left\|\sum\limits_{N_1\approx N_2\gtrsim N_3,N}\big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2}\right\|_{L^2_t}^2\\ &\qquad\lesssim N \left\| \sum\limits_{N_1\approx N_2\gtrsim N_3,N} \|(\psi f_1)_{N_1}\|_{L^2}\|\big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\|_{L^2}\|\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\|_{L^\infty}\right\|_{L^2_t}^2\\ &\qquad \lesssim N \sum\limits_{N_1\gtrsim N}N_1^{-4s-4}\min\{N_1^4,(\kappa + N_1)^2\}(|\varkappa| + N_1)^{-2}|\varkappa|^{-2}(N_1\wedge |\varkappa|)^{1-2s}\delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
$$ \begin{align*} &\left\|\sum\limits_{N_1\approx N_2\gtrsim N_3,N}\big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2}\right\|_{L^2_t}^2\\ &\qquad\lesssim N \left\| \sum\limits_{N_1\approx N_2\gtrsim N_3,N} \|(\psi f_1)_{N_1}\|_{L^2}\|\big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\|_{L^2}\|\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\|_{L^\infty}\right\|_{L^2_t}^2\\ &\qquad \lesssim N \sum\limits_{N_1\gtrsim N}N_1^{-4s-4}\min\{N_1^4,(\kappa + N_1)^2\}(|\varkappa| + N_1)^{-2}|\varkappa|^{-2}(N_1\wedge |\varkappa|)^{1-2s}\delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
We then obtain a contribution to
 $\mathrm {RHS}$
(5.32) of
$\mathrm {RHS}$
(5.32) of
 $$ \begin{align*} &\lesssim \sum\limits_{N\geq 1} \tfrac N{|\varkappa| + N}\log\big(4 + \tfrac{N^2}{\varkappa^2}\big) \sum\limits_{N_1\gtrsim N}N_1^{-4s-4}\min\{N_1^4,(\kappa + N_1)^2\}\\ &\qquad\qquad\qquad\times(|\varkappa| + N_1)^{-2}|\varkappa|^{-2}(N_1\wedge |\varkappa|)^{1-2s}\delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2\\ &\lesssim \sum\limits_{N_1\geq 1} |\varkappa|^{-3}N_1^{-4s-3}\min\{N_1^4,(\kappa + N_1)^2\}(|\varkappa| + N_1)^{-2}(N_1\wedge |\varkappa|)^{1-2s}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
$$ \begin{align*} &\lesssim \sum\limits_{N\geq 1} \tfrac N{|\varkappa| + N}\log\big(4 + \tfrac{N^2}{\varkappa^2}\big) \sum\limits_{N_1\gtrsim N}N_1^{-4s-4}\min\{N_1^4,(\kappa + N_1)^2\}\\ &\qquad\qquad\qquad\times(|\varkappa| + N_1)^{-2}|\varkappa|^{-2}(N_1\wedge |\varkappa|)^{1-2s}\delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2\\ &\lesssim \sum\limits_{N_1\geq 1} |\varkappa|^{-3}N_1^{-4s-3}\min\{N_1^4,(\kappa + N_1)^2\}(|\varkappa| + N_1)^{-2}(N_1\wedge |\varkappa|)^{1-2s}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
which gives an identical contribution to Cases 1 and 2.
 $\underline{\mathrm{Case\ 4{:}}\ \min \{N_2,N_3\}\geq \max \{N_1,N\}}$
. Arguing as in Case 3, for fixed
$\underline{\mathrm{Case\ 4{:}}\ \min \{N_2,N_3\}\geq \max \{N_1,N\}}$
. Arguing as in Case 3, for fixed
 $N\geq 1$
, we may bound
$N\geq 1$
, we may bound
 $$ \begin{align*} &\left\|\sum\limits_{N_2\approx N_3\gtrsim N_1,N}\big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2}\right\|_{L^2_t}^2\\ &\qquad \lesssim N \sum\limits_{N_2\gtrsim N}N_2^{-6s-3}\min\{N_2^4,(\kappa + N_2)^2\}(|\varkappa| + N_2)^{-4}\delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
$$ \begin{align*} &\left\|\sum\limits_{N_2\approx N_3\gtrsim N_1,N}\big\|P_N\big((\psi f_1)_{N_1}\cdot \big(\psi\tfrac{f_2}{2\varkappa - \partial}\big)_{N_2}\cdot\big(\psi\tfrac{f_3}{2\varkappa + \partial}\big)_{N_3}\big)\big\|_{L^2}\right\|_{L^2_t}^2\\ &\qquad \lesssim N \sum\limits_{N_2\gtrsim N}N_2^{-6s-3}\min\{N_2^4,(\kappa + N_2)^2\}(|\varkappa| + N_2)^{-4}\delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
which yields a contribution to
 $\mathrm {RHS}$
(5.32) of
$\mathrm {RHS}$
(5.32) of
 $$\begin{align*}\sum\limits_{N_2\geq 1} |\varkappa|^{-1}N_2^{-6s-2}\min\{N_2^4,(\kappa + N_2)^2\}(|\varkappa| + N_2)^{-4}\delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*}$$
$$\begin{align*}\sum\limits_{N_2\geq 1} |\varkappa|^{-1}N_2^{-6s-2}\min\{N_2^4,(\kappa + N_2)^2\}(|\varkappa| + N_2)^{-4}\delta^4 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*}$$
This gives an identical contribution to the previous cases.
We are now in a position to prove our main error estimates for the NLS:
Lemma 5.15 (Error estimates for the NLS).
There exists
 $\delta>0$
so that for all real
$\delta>0$
so that for all real
 $|\varkappa |\geq \kappa ^{\frac 23}\geq 1$
, Schwartz functions
$|\varkappa |\geq \kappa ^{\frac 23}\geq 1$
, Schwartz functions
 $q,f\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfying
$q,f\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfying
 $$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}, \end{align*}$$
$$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}, \end{align*}$$
and
 $\chi \in \{(\psi ^\ell )^{(j)}: 6\leq \ell \leq 12, \, j=0,1 \}$
, we have the estimates
$\chi \in \{(\psi ^\ell )^{(j)}: 6\leq \ell \leq 12, \, j=0,1 \}$
, we have the estimates
 $$ \begin{align} &\left\|\int \tfrac f{2\varkappa + \partial}\, g_{12}^{[\geq 3]}(\pm\kappa)\,\chi_h\,dx\right\|_{L^1_t} \lesssim |\varkappa|^{-1}\kappa^{- 1 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
$$ \begin{align} &\left\|\int \tfrac f{2\varkappa + \partial}\, g_{12}^{[\geq 3]}(\pm\kappa)\,\chi_h\,dx\right\|_{L^1_t} \lesssim |\varkappa|^{-1}\kappa^{- 1 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
 $$ \begin{align} &\left\|\int f\,\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\chi_h\,dx\right\|_{L^1_t}\lesssim |\varkappa|^{-3} \big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
$$ \begin{align} &\left\|\int f\,\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\chi_h\,dx\right\|_{L^1_t}\lesssim |\varkappa|^{-3} \big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
 $$ \begin{align} &\left\|\gamma(\pm\kappa)^{[\geq 4]}\,\chi_h\right\|_{L^1_{t,x}} \lesssim \kappa^{-2 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
$$ \begin{align} &\left\|\gamma(\pm\kappa)^{[\geq 4]}\,\chi_h\right\|_{L^1_{t,x}} \lesssim \kappa^{-2 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
 $$ \begin{align} &\left\|\int \tfrac f{2\varkappa + \partial}\,\big(g_{12}^{[\geq 3]}(\kappa) + g_{12}^{[\geq 3]}(-\kappa)\big) \psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \kappa^{- 2 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
$$ \begin{align} &\left\|\int \tfrac f{2\varkappa + \partial}\,\big(g_{12}^{[\geq 3]}(\kappa) + g_{12}^{[\geq 3]}(-\kappa)\big) \psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \kappa^{- 2 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align} $$
which are uniform in
 $\kappa $
,
$\kappa $
,
 $\varkappa $
, and
$\varkappa $
, and
 $h\in {{\mathbb {R}}}$
. As ever,
$h\in {{\mathbb {R}}}$
. As ever,
 $\chi _h(x):= \chi (x-h)$
.
$\chi _h(x):= \chi (x-h)$
.
Proof. By translation invariance, it suffices to consider the case
 $h=0$
. Our basic technique, here, is to expand using the series (3.19), commute copies of
$h=0$
. Our basic technique, here, is to expand using the series (3.19), commute copies of
 $\psi $
, and then use Hölder’s inequality in trace ideals. We first exhibit this technique to prove the auxiliary result (5.37) before turning our attention to the principal claims.
$\psi $
, and then use Hölder’s inequality in trace ideals. We first exhibit this technique to prove the auxiliary result (5.37) before turning our attention to the principal claims.
Given a test function
 $F\in \mathcal C([-1,1];\mathcal {S})$
, using (3.19), we may write
$F\in \mathcal C([-1,1];\mathcal {S})$
, using (3.19), we may write
 $$\begin{align*}\operatorname{\mathrm{sgn}}(\varkappa) \int F\,g_{12}(\varkappa)^{[\geq 3]} \psi^4 \,dx = \sum_{\ell=1}^\infty (-1)^{\ell-1} \operatorname{\mathrm{tr}}\left\{\Lambda(\Gamma\Lambda)^{\ell}(\varkappa + \partial)^{-\frac12}\psi^4 F(\varkappa - \partial)^{-\frac12}\right\}. \end{align*}$$
$$\begin{align*}\operatorname{\mathrm{sgn}}(\varkappa) \int F\,g_{12}(\varkappa)^{[\geq 3]} \psi^4 \,dx = \sum_{\ell=1}^\infty (-1)^{\ell-1} \operatorname{\mathrm{tr}}\left\{\Lambda(\Gamma\Lambda)^{\ell}(\varkappa + \partial)^{-\frac12}\psi^4 F(\varkappa - \partial)^{-\frac12}\right\}. \end{align*}$$
Applying Lemma 2.8 followed by the operator estimates (3.7) and (2.25), we obtain
 $$ \begin{align*} &\left\|\operatorname{\mathrm{tr}}\left\{\Lambda(\Gamma\Lambda)^{\ell}(\varkappa + \partial)^{-\frac12}\psi^4 F(\varkappa - \partial)^{-\frac12}\right\}\right\|_{L^1_t}\\ &\qquad\lesssim \|\Lambda\|_{L^\infty_t\mathfrak I_2}^{2\ell-2}\|(\varkappa - \partial)^{-\frac12}(\psi q)(\varkappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^3\|(\varkappa + \partial)^{-\frac12}(\psi F)(\varkappa - \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}\\ &\qquad\lesssim C^\ell |\varkappa|^{-(2s+1)(\ell-1)-3}\big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\delta^{2(\ell-1)}\\ &\qquad\qquad\qquad\qquad\times\|q\|_{L^\infty_tH^s}^{\frac32}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^{\frac32}\|F\|_{L^\infty_t H^s}^{\frac12}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert F \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^{\frac12}, \end{align*} $$
$$ \begin{align*} &\left\|\operatorname{\mathrm{tr}}\left\{\Lambda(\Gamma\Lambda)^{\ell}(\varkappa + \partial)^{-\frac12}\psi^4 F(\varkappa - \partial)^{-\frac12}\right\}\right\|_{L^1_t}\\ &\qquad\lesssim \|\Lambda\|_{L^\infty_t\mathfrak I_2}^{2\ell-2}\|(\varkappa - \partial)^{-\frac12}(\psi q)(\varkappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^3\|(\varkappa + \partial)^{-\frac12}(\psi F)(\varkappa - \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}\\ &\qquad\lesssim C^\ell |\varkappa|^{-(2s+1)(\ell-1)-3}\big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\delta^{2(\ell-1)}\\ &\qquad\qquad\qquad\qquad\times\|q\|_{L^\infty_tH^s}^{\frac32}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^{\frac32}\|F\|_{L^\infty_t H^s}^{\frac12}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert F \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^{\frac12}, \end{align*} $$
where the implicit constant is independent of
 $\ell $
. Summing in
$\ell $
. Summing in
 $\ell $
and applying Young’s inequality, we obtain
$\ell $
and applying Young’s inequality, we obtain
 $$ \begin{align} \Big\|\int F\,& g_{12}^{[\geq 3]}(\varkappa)\,\psi^4 \,dx\Big\|_{L^1_t}\lesssim |\varkappa|^{-3}\big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\delta{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\Big(\|F\|_{L^\infty_t H^s}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} + \delta{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert F \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\Big). \end{align} $$
$$ \begin{align} \Big\|\int F\,& g_{12}^{[\geq 3]}(\varkappa)\,\psi^4 \,dx\Big\|_{L^1_t}\lesssim |\varkappa|^{-3}\big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\delta{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\Big(\|F\|_{L^\infty_t H^s}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} + \delta{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert F \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\Big). \end{align} $$
The estimate (5.33) follows immediately from (5.37) by setting
 $\varkappa =\pm \kappa $
,
$\varkappa =\pm \kappa $
,
 $F=\frac {\chi }{\psi ^4}\frac f{2\varkappa + \partial }$
and using (2.8) and (2.14) to bound
$F=\frac {\chi }{\psi ^4}\frac f{2\varkappa + \partial }$
and using (2.8) and (2.14) to bound
 ${\left \vert \kern -0.25ex\left \vert \kern -0.25ex\left \vert F \right \vert \kern -0.25ex\right \vert \kern -0.25ex\right \vert }_{\mathrm {NLS}_\kappa }\lesssim |\varkappa |^{-1} {\left \vert \kern -0.25ex\left \vert \kern -0.25ex\left \vert q \right \vert \kern -0.25ex\right \vert \kern -0.25ex\right \vert }_{\mathrm {NLS}_\kappa }$
.
${\left \vert \kern -0.25ex\left \vert \kern -0.25ex\left \vert F \right \vert \kern -0.25ex\right \vert \kern -0.25ex\right \vert }_{\mathrm {NLS}_\kappa }\lesssim |\varkappa |^{-1} {\left \vert \kern -0.25ex\left \vert \kern -0.25ex\left \vert q \right \vert \kern -0.25ex\right \vert \kern -0.25ex\right \vert }_{\mathrm {NLS}_\kappa }$
.
We turn now to (5.34) and recall that
 $$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}= \tfrac12 g_{12}^{[\geq 3]} -\tfrac{g_{12}\gamma}{2(2 + \gamma)}. \end{align} $$
$$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}= \tfrac12 g_{12}^{[\geq 3]} -\tfrac{g_{12}\gamma}{2(2 + \gamma)}. \end{align} $$
By (5.37), the contribution of the first term to the left-hand side of (5.34) is easily seen to be acceptable. To estimate the contribution of the second term on the right-hand side of (5.38), we take
 $f_1 = \chi f/\psi ^4$
and
$f_1 = \chi f/\psi ^4$
and
 $f_2 = (2\varkappa - \partial ) \tfrac {g_{12}(\varkappa )}{2 + \gamma (\varkappa )}$
and apply the estimate (5.30) to bound
$f_2 = (2\varkappa - \partial ) \tfrac {g_{12}(\varkappa )}{2 + \gamma (\varkappa )}$
and apply the estimate (5.30) to bound
 $$\begin{align*}\|(\varkappa \pm \partial)^{-\frac12}(\psi^2 f_1\tfrac{f_2}{2\varkappa-\partial})(\varkappa \pm \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2} \lesssim |\varkappa|^{-\frac32}\big[\kappa^{\frac13 - \frac{4s}3} + |\varkappa|^{-2s}\big]\delta{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}, \end{align*}$$
$$\begin{align*}\|(\varkappa \pm \partial)^{-\frac12}(\psi^2 f_1\tfrac{f_2}{2\varkappa-\partial})(\varkappa \pm \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2} \lesssim |\varkappa|^{-\frac32}\big[\kappa^{\frac13 - \frac{4s}3} + |\varkappa|^{-2s}\big]\delta{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}, \end{align*}$$
where we have used (2.14) with the estimates (3.41), (3.43) to bound
 $$ \begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f_2 \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} = {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert (2\varkappa - \partial) \tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)} \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*} $$
$$ \begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f_2 \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} = {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert (2\varkappa - \partial) \tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)} \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*} $$
We then use (3.19) to write
 $$ \begin{align*} \int \!\tfrac{\chi f g_{12}(\varkappa)}{2(2 + \gamma(\varkappa))}\, \gamma\,dx = \operatorname{\mathrm{sgn}}(\varkappa)\sum\limits_{\ell=1}^\infty(-1)^{\ell}\Big[&\operatorname{\mathrm{tr}}\left\{(\Lambda\Gamma)^\ell(\varkappa -\partial)^{-\frac12}(\psi^4 f_1\,\tfrac{f_2}{2\varkappa-\partial})(\varkappa - \partial)^{-\frac12}\right\}\\ +{}& \operatorname{\mathrm{tr}}\left\{(\Gamma\Lambda)^\ell(\varkappa +\partial)^{-\frac12}(\psi^4 f_1\,\tfrac{f_2}{2\varkappa-\partial})(\varkappa + \partial)^{-\frac12}\right\}\Big]. \end{align*} $$
$$ \begin{align*} \int \!\tfrac{\chi f g_{12}(\varkappa)}{2(2 + \gamma(\varkappa))}\, \gamma\,dx = \operatorname{\mathrm{sgn}}(\varkappa)\sum\limits_{\ell=1}^\infty(-1)^{\ell}\Big[&\operatorname{\mathrm{tr}}\left\{(\Lambda\Gamma)^\ell(\varkappa -\partial)^{-\frac12}(\psi^4 f_1\,\tfrac{f_2}{2\varkappa-\partial})(\varkappa - \partial)^{-\frac12}\right\}\\ +{}& \operatorname{\mathrm{tr}}\left\{(\Gamma\Lambda)^\ell(\varkappa +\partial)^{-\frac12}(\psi^4 f_1\,\tfrac{f_2}{2\varkappa-\partial})(\varkappa + \partial)^{-\frac12}\right\}\Big]. \end{align*} $$
Repeating our basic technique using (2.25), we obtain
 $$ \begin{align} \left\|\int f_1\,\tfrac{f_2}{2\varkappa-\partial}\, \gamma(\varkappa)\,\psi^{4 }\,dx\right\|_{L^1_t}&\lesssim \|(\varkappa - \partial)^{-\frac12}(\psi q)(\varkappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^2\|(\varkappa - \partial)^{-\frac12}(\psi^2 f_1\,\tfrac{f_2}{2\varkappa-\partial}) (\varkappa - \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2}\notag\\ &\lesssim |\varkappa|^{-3}\big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2,\end{align} $$
$$ \begin{align} \left\|\int f_1\,\tfrac{f_2}{2\varkappa-\partial}\, \gamma(\varkappa)\,\psi^{4 }\,dx\right\|_{L^1_t}&\lesssim \|(\varkappa - \partial)^{-\frac12}(\psi q)(\varkappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^2\|(\varkappa - \partial)^{-\frac12}(\psi^2 f_1\,\tfrac{f_2}{2\varkappa-\partial}) (\varkappa - \partial)^{-\frac12}\|_{L^2_t \mathfrak I_2}\notag\\ &\lesssim |\varkappa|^{-3}\big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2,\end{align} $$
which completes the proof of (5.34). The estimate (5.35) follows analogously using (2.25) with
 $\varkappa = \kappa $
:
$\varkappa = \kappa $
:
 $$ \begin{align} \bigg\|\int F\, \gamma^{[\geq 4]}(\kappa)\,\chi\,dx\bigg\|_{L^1_t}&\lesssim \|(\kappa - \partial)^{-\frac12}(\psi q)(\kappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^4 \|(\kappa \pm \partial)^{-\frac12}\|_{\mathrm{op}}^2 \|\chi F \psi^{-4}\|_{L^\infty_{t,x}} \notag\\ &\lesssim \kappa^{- 2 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2\|F\|_{L^\infty_{t,x}}. \end{align} $$
$$ \begin{align} \bigg\|\int F\, \gamma^{[\geq 4]}(\kappa)\,\chi\,dx\bigg\|_{L^1_t}&\lesssim \|(\kappa - \partial)^{-\frac12}(\psi q)(\kappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^4 \|(\kappa \pm \partial)^{-\frac12}\|_{\mathrm{op}}^2 \|\chi F \psi^{-4}\|_{L^\infty_{t,x}} \notag\\ &\lesssim \kappa^{- 2 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2\|F\|_{L^\infty_{t,x}}. \end{align} $$
Finally, we consider (5.36). Arguing in the same style, we bound
 $$ \begin{align*} & \left\|\int g_{12}^{[\geq 5]}(\kappa)\, \tfrac f{2\varkappa + \partial}\psi^{12}\,dx\right\|_{L^1_t} \\ &\quad \lesssim \|\Lambda\|_{L^\infty_t\mathfrak I_2} \|(\kappa - \partial)^{-\frac12}(\psi q)(\kappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^4 \|(\kappa - \partial)^{-\frac12}( \psi^8 \tfrac f{2\varkappa + \partial})(\kappa + \partial)^{-\frac12}\|_{L^\infty_t\mathrm{op}}\\ &\quad \lesssim \kappa^{- 2 - \frac{11}6(2s+1)}\delta^3{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2\|\tfrac f{2\varkappa + \partial}\|_{L^\infty_{t,x}}\\ &\quad \lesssim \kappa^{- 2 - \frac{13}6(2s+1)}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*} $$
$$ \begin{align*} & \left\|\int g_{12}^{[\geq 5]}(\kappa)\, \tfrac f{2\varkappa + \partial}\psi^{12}\,dx\right\|_{L^1_t} \\ &\quad \lesssim \|\Lambda\|_{L^\infty_t\mathfrak I_2} \|(\kappa - \partial)^{-\frac12}(\psi q)(\kappa + \partial)^{-\frac12}\|_{L^4_t\mathfrak I_4}^4 \|(\kappa - \partial)^{-\frac12}( \psi^8 \tfrac f{2\varkappa + \partial})(\kappa + \partial)^{-\frac12}\|_{L^\infty_t\mathrm{op}}\\ &\quad \lesssim \kappa^{- 2 - \frac{11}6(2s+1)}\delta^3{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2\|\tfrac f{2\varkappa + \partial}\|_{L^\infty_{t,x}}\\ &\quad \lesssim \kappa^{- 2 - \frac{13}6(2s+1)}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*} $$
where we have used that
 $|\varkappa |\geq \kappa ^{\frac 23}$
to estimate
$|\varkappa |\geq \kappa ^{\frac 23}$
to estimate
 $ \|\tfrac f{2\varkappa + \partial }\|_{L^\infty _{t,x}}\lesssim \kappa ^{-\frac 13(2s+1)}\delta $
. For the remaining term, we observe that integrating by parts we may write
$ \|\tfrac f{2\varkappa + \partial }\|_{L^\infty _{t,x}}\lesssim \kappa ^{-\frac 13(2s+1)}\delta $
. For the remaining term, we observe that integrating by parts we may write
 $$\begin{align*}\int g_{12}^{[3]}(\kappa)\,\tfrac f{2\varkappa + \partial}\,\psi^{12}\,dx = \int m[q,r,q,\psi^{12} \tfrac f{2\varkappa + \partial}]\,dx, \end{align*}$$
$$\begin{align*}\int g_{12}^{[3]}(\kappa)\,\tfrac f{2\varkappa + \partial}\,\psi^{12}\,dx = \int m[q,r,q,\psi^{12} \tfrac f{2\varkappa + \partial}]\,dx, \end{align*}$$
where the symbol
 $$\begin{align*}m(\xi_1,\xi_2,\xi_3,\xi_4) = \tfrac2{(2\kappa + i\xi_2) (2\kappa - i\xi_3)(2\kappa + i\xi_4)} \end{align*}$$
$$\begin{align*}m(\xi_1,\xi_2,\xi_3,\xi_4) = \tfrac2{(2\kappa + i\xi_2) (2\kappa - i\xi_3)(2\kappa + i\xi_4)} \end{align*}$$
is a sum of terms in
 $\kappa ^{5 - |\beta |}S(\beta ;2\kappa )$
for
$\kappa ^{5 - |\beta |}S(\beta ;2\kappa )$
for
 $0\leq |\beta |\leq 5$
, where at most one
$0\leq |\beta |\leq 5$
, where at most one
 $\beta _j = 2$
. In particular, when considering the sum
$\beta _j = 2$
. In particular, when considering the sum
 $g_{12}^{[3]}(\kappa ) + g_{12}^{[3]}(-\kappa )$
, we see that the terms with even
$g_{12}^{[3]}(\kappa ) + g_{12}^{[3]}(-\kappa )$
, we see that the terms with even
 $|\beta |$
cancel, and hence
$|\beta |$
cancel, and hence
 $$\begin{align*}\int \Big(g_{12}^{[3]}(\kappa) + g_{12}^{[3]}(-\kappa)\Big)\,\tfrac f{2\varkappa + \partial}\,\psi^{12}\,dx = \int \widetilde m[q,r,q,\psi^{12} \tfrac f{2\varkappa + \partial}]\,dx, \end{align*}$$
$$\begin{align*}\int \Big(g_{12}^{[3]}(\kappa) + g_{12}^{[3]}(-\kappa)\Big)\,\tfrac f{2\varkappa + \partial}\,\psi^{12}\,dx = \int \widetilde m[q,r,q,\psi^{12} \tfrac f{2\varkappa + \partial}]\,dx, \end{align*}$$
where the symbol of
 $\widetilde m$
is given by a sum of terms in
$\widetilde m$
is given by a sum of terms in
 $\kappa ^{5 - |\beta |}S(\beta ;2\kappa )$
for
$\kappa ^{5 - |\beta |}S(\beta ;2\kappa )$
for
 $|\beta | = 1,3,5$
and at most one
$|\beta | = 1,3,5$
and at most one
 $\beta _j = 2$
. Applying the estimate (5.25), we then obtain
$\beta _j = 2$
. Applying the estimate (5.25), we then obtain
 $$\begin{align*}\left\|\int \Big(g_{12}^{[3]}(\kappa) + g_{12}^{[3]}(-\kappa)\Big)\,\tfrac f{2\varkappa + \partial}\,\psi^{12}\,dx\right\|_{L^1_t}\lesssim \kappa^{-2 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*}$$
$$\begin{align*}\left\|\int \Big(g_{12}^{[3]}(\kappa) + g_{12}^{[3]}(-\kappa)\Big)\,\tfrac f{2\varkappa + \partial}\,\psi^{12}\,dx\right\|_{L^1_t}\lesssim \kappa^{-2 - \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*}$$
which completes the proof of (5.36).
Similar arguments yield the following error estimates for the mKdV:
Lemma 5.16 (Error estimates for the mKdV).
There exists
 $\delta>0$
so that for all real
$\delta>0$
so that for all real
 $|\varkappa |\geq \kappa ^{\frac 12}\geq 1$
,
$|\varkappa |\geq \kappa ^{\frac 12}\geq 1$
,
 $q,f\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfying
$q,f\in \mathcal C([-1,1];B_\delta \cap \mathcal {S})$
satisfying
 $$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}, \end{align*}$$
$$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}, \end{align*}$$
and
 $\chi \in \{(\psi ^\ell )^{(j)}: 6\leq \ell \leq 12, \, j=0,1,2 \}$
, we have the estimates
$\chi \in \{(\psi ^\ell )^{(j)}: 6\leq \ell \leq 12, \, j=0,1,2 \}$
, we have the estimates
 $$ \begin{align} \nonumber & \bigg\|\int f\, g_{12}^{[3]}(\varkappa)\,\chi_h\,dx\bigg\|_{L^1_t} + \bigg\|\int f\, \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\chi_h\,dx\bigg\|_{L^1_t} \\ &\quad \lesssim |\varkappa|^{-3}\big[\kappa^{\frac12 - 2s}+ |\varkappa|^{-1-4s}\log^4\!|2\varkappa|\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} \nonumber & \bigg\|\int f\, g_{12}^{[3]}(\varkappa)\,\chi_h\,dx\bigg\|_{L^1_t} + \bigg\|\int f\, \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\chi_h\,dx\bigg\|_{L^1_t} \\ &\quad \lesssim |\varkappa|^{-3}\big[\kappa^{\frac12 - 2s}+ |\varkappa|^{-1-4s}\log^4\!|2\varkappa|\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
 $$ \begin{align} &\left\|\int f\, \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\,\chi_h\,dx\right\|_{L^1_t} \lesssim |\varkappa|^{-4-(s+\frac12)}\big[\kappa^{\frac34 - \frac{5s}2} + |\varkappa|^{-\frac12-5s}\log^6\!|2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} &\left\|\int f\, \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\,\chi_h\,dx\right\|_{L^1_t} \lesssim |\varkappa|^{-4-(s+\frac12)}\big[\kappa^{\frac34 - \frac{5s}2} + |\varkappa|^{-\frac12-5s}\log^6\!|2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
 $$ \begin{align} &\bigg\|\int g_{21}^{[3]}(\pm\varkappa)\, \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\chi_h\,dx\bigg\|_{L^1_t} \lesssim |\varkappa|^{-5} \big[\kappa^{1-2s}+ |\varkappa|^{-4s}\big] \delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} &\bigg\|\int g_{21}^{[3]}(\pm\varkappa)\, \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\chi_h\,dx\bigg\|_{L^1_t} \lesssim |\varkappa|^{-5} \big[\kappa^{1-2s}+ |\varkappa|^{-4s}\big] \delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
 $$ \begin{align} &\left\|\int \tfrac f{2\varkappa + \partial}\, \big(g_{12}^{[\geq 3]}(\kappa) + g_{12}^{[\geq 3]}(-\kappa)\big)\,\chi_h\,dx\right\|_{L^1_t}\lesssim \big[ \kappa^{-1} + |\varkappa|^{-1} \big]\kappa^{-2-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} &\left\|\int \tfrac f{2\varkappa + \partial}\, \big(g_{12}^{[\geq 3]}(\kappa) + g_{12}^{[\geq 3]}(-\kappa)\big)\,\chi_h\,dx\right\|_{L^1_t}\lesssim \big[ \kappa^{-1} + |\varkappa|^{-1} \big]\kappa^{-2-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
 $$ \begin{align} &\left\|\int \tfrac f{2\varkappa + \partial}\,\big(g_{12}^{[\geq 3]}(\kappa) - g_{12}^{[\geq 3]}(-\kappa) - \tfrac1{2\kappa^3}q^2r\big)\,\chi_h\,dx\right\|_{L^1_t} \lesssim \kappa^{-3-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} &\left\|\int \tfrac f{2\varkappa + \partial}\,\big(g_{12}^{[\geq 3]}(\kappa) - g_{12}^{[\geq 3]}(-\kappa) - \tfrac1{2\kappa^3}q^2r\big)\,\chi_h\,dx\right\|_{L^1_t} \lesssim \kappa^{-3-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
 $$ \begin{align} \left\|\gamma(\pm\kappa)^{[\geq 4]}\,\chi_h\right\|_{L^1_{t,x}} \lesssim \kappa^{-\frac52-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} \left\|\gamma(\pm\kappa)^{[\geq 4]}\,\chi_h\right\|_{L^1_{t,x}} \lesssim \kappa^{-\frac52-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
 $$ \begin{align} \left\|\int \Big(\gamma(\kappa)^{[\geq 4]} - \gamma(-\kappa)^{[\geq 4]}\Big)\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \kappa^{-3-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} \left\|\int \Big(\gamma(\kappa)^{[\geq 4]} - \gamma(-\kappa)^{[\geq 4]}\Big)\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \kappa^{-3-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
 $$ \begin{align} &\left\|\int \Big(\gamma(\kappa)^{[\geq 4]} + \gamma(-\kappa)^{[\geq 4]} - \tfrac3{2\kappa^2}qr\big(q\cdot \tfrac r{4\kappa^2 - \partial^2} + \tfrac q{4\kappa^2 - \partial^2}\cdot r\big)\Big)\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \kappa^{-3-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} &\left\|\int \Big(\gamma(\kappa)^{[\geq 4]} + \gamma(-\kappa)^{[\geq 4]} - \tfrac3{2\kappa^2}qr\big(q\cdot \tfrac r{4\kappa^2 - \partial^2} + \tfrac q{4\kappa^2 - \partial^2}\cdot r\big)\Big)\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \kappa^{-3-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
where the implicit constants are independent of
 $\kappa $
,
$\kappa $
,
 $\varkappa $
, and
$\varkappa $
, and
 $h\in {{\mathbb {R}}}$
.
$h\in {{\mathbb {R}}}$
.
Proof. The basic technique is that used to prove Lemma 5.15; however, new cancellations need to be exhibited. We begin with the estimates on
 $\gamma $
.
$\gamma $
.
Mimicking (5.40) but using Lemma 2.7 with
 $p=4$
yields (5.46). When taking
$p=4$
yields (5.46). When taking
 $p=6$
, we obtain instead
$p=6$
, we obtain instead
 $$ \begin{align} \big\| \gamma(\pm\kappa)^{[\geq 6]}\chi \big\|_{L^1_{t,x}}&\lesssim [\kappa^{-5-3s}+\kappa^{-6-6s}\log(2\kappa)]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 \\ &\lesssim \kappa^{-4-2s}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2.\notag \end{align} $$
$$ \begin{align} \big\| \gamma(\pm\kappa)^{[\geq 6]}\chi \big\|_{L^1_{t,x}}&\lesssim [\kappa^{-5-3s}+\kappa^{-6-6s}\log(2\kappa)]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 \\ &\lesssim \kappa^{-4-2s}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2.\notag \end{align} $$
This estimate reduces (5.47) and (5.48) to consideration of the quartic terms, for which we turn to (3.23). Evidently, every term in (5.47) and (5.48) can be written as a sum of paraproducts with symbols conforming to (5.23); however, by forming these particular linear combinations, we eliminate all terms with
 $|\beta |=0$
. Thus, we may apply Lemma 5.11 (with
$|\beta |=0$
. Thus, we may apply Lemma 5.11 (with
 $\varkappa =\kappa $
) and so deduce (5.47) and (5.48).
$\varkappa =\kappa $
) and so deduce (5.47) and (5.48).
Applying our basic technique to
 $g_{12}$
using Lemma 2.7 with
$g_{12}$
using Lemma 2.7 with
 $p=4$
yields
$p=4$
yields
 $$ \begin{align*} \bigg\|\int f\, g_{12}^{[3]}(\varkappa)\,\chi_h\,dx\bigg\|_{L^1_t} + \bigg\|\int f g_{12}^{[\geq 3]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t} \lesssim \text{RHS(5.41)}. \end{align*} $$
$$ \begin{align*} \bigg\|\int f\, g_{12}^{[3]}(\varkappa)\,\chi_h\,dx\bigg\|_{L^1_t} + \bigg\|\int f g_{12}^{[\geq 3]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t} \lesssim \text{RHS(5.41)}. \end{align*} $$
Taking
 $p=5$
and using also (3.7) yields
$p=5$
and using also (3.7) yields
 $$ \begin{align*} \bigg\|\int f g_{12}^{[\geq 5]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t} \lesssim \text{RHS(5.42)} , \end{align*} $$
$$ \begin{align*} \bigg\|\int f g_{12}^{[\geq 5]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t} \lesssim \text{RHS(5.42)} , \end{align*} $$
These constitute a significant step toward proving (5.41) and (5.42). In view of (5.38), the proof of (5.41) is completed by the following:
 $$ \begin{align} \bigg\|\int f \tfrac{g_{12}}{2+\gamma} \gamma \,\chi\,dx\bigg\|_{L^1_t} &\lesssim |\varkappa|^{-3} \big[\kappa^{\frac12 - 2s} + |\varkappa|^{-1-4s}\log^4|2\varkappa|\big] \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
$$ \begin{align} \bigg\|\int f \tfrac{g_{12}}{2+\gamma} \gamma \,\chi\,dx\bigg\|_{L^1_t} &\lesssim |\varkappa|^{-3} \big[\kappa^{\frac12 - 2s} + |\varkappa|^{-1-4s}\log^4|2\varkappa|\big] \delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align} $$
which is a consequence of the argument used in (5.39) but using Lemma 2.7 and (5.31) in place of their NLS analogues.
To prove (5.42), we use (3.32) and
 $\gamma ^{[2]} = 2g_{12}^{[1]}g_{21}^{[1]}$
to rewrite (3.40) as
$\gamma ^{[2]} = 2g_{12}^{[1]}g_{21}^{[1]}$
to rewrite (3.40) as
 $$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]} = \tfrac12g_{12}^{[\geq 5]} - \tfrac{g_{12}(4 + \gamma)}{4(2+\gamma)}\gamma^{[\geq 4]} + \tfrac{g_{12}g_{21}}{2 + \gamma}g_{12}^{[\geq 3]} - \tfrac12g_{12}^{[1]}g_{21}^{[1]} g_{12}^{[\geq 3]} + \tfrac{g_{12}}{2 + \gamma}g_{12}^{[1]}g_{21}^{[\geq 3]}. \end{align} $$
$$ \begin{align} \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]} = \tfrac12g_{12}^{[\geq 5]} - \tfrac{g_{12}(4 + \gamma)}{4(2+\gamma)}\gamma^{[\geq 4]} + \tfrac{g_{12}g_{21}}{2 + \gamma}g_{12}^{[\geq 3]} - \tfrac12g_{12}^{[1]}g_{21}^{[1]} g_{12}^{[\geq 3]} + \tfrac{g_{12}}{2 + \gamma}g_{12}^{[1]}g_{21}^{[\geq 3]}. \end{align} $$
The contribution of the first term was handled already.
Consider, now, the second term in (5.51). Applying Lemma 2.4 together with the estimates (3.27), (3.35), (3.41), and (3.43), we find that
 $$\begin{align*}F=\chi f\tfrac{g_{12}(4 + \gamma)}{2(2+\gamma)\psi^5} \quad\text{satisfies}\quad {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert F \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim |\varkappa|^{-(s+\frac12)}\delta{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*}$$
$$\begin{align*}F=\chi f\tfrac{g_{12}(4 + \gamma)}{2(2+\gamma)\psi^5} \quad\text{satisfies}\quad {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert F \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim |\varkappa|^{-(s+\frac12)}\delta{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*}$$
Thus, applying the basic technique and using Lemma 2.7 with
 $p=5$
shows
$p=5$
shows
 $$ \begin{align*} \left\|\int \tfrac{g_{12}(4 + \gamma)}{2(2+\gamma)}\gamma^{[\geq 4]} \,\chi\,dx\right\|_{L^1_t} &\lesssim \text{RHS(5.42)}. \end{align*} $$
$$ \begin{align*} \left\|\int \tfrac{g_{12}(4 + \gamma)}{2(2+\gamma)}\gamma^{[\geq 4]} \,\chi\,dx\right\|_{L^1_t} &\lesssim \text{RHS(5.42)}. \end{align*} $$
The remaining three terms in (5.51) are handled in a parallel fashion, which we demonstrate using the first term. Set
 $F= f_1\,\frac {f_2}{2\varkappa -\partial } \, \frac {f_3}{2\varkappa +\partial }$
with
$F= f_1\,\frac {f_2}{2\varkappa -\partial } \, \frac {f_3}{2\varkappa +\partial }$
with
 $f_1 = \chi f/\psi ^6$
,
$f_1 = \chi f/\psi ^6$
,
 $f_2 = (2\varkappa - \partial )\frac {g_{12}}{2 + \gamma }$
, and
$f_2 = (2\varkappa - \partial )\frac {g_{12}}{2 + \gamma }$
, and
 $f_3 = (2\varkappa + \partial )g_{21}$
. Then (5.32) implies
$f_3 = (2\varkappa + \partial )g_{21}$
. Then (5.32) implies
 $$ \begin{align*} \|(\varkappa - \partial)^{-\frac12}\psi^3 & F(\varkappa + \partial)^{-\frac12}\|_{L^2_t\mathfrak I_2}^2 \\ &\lesssim |\varkappa|^{-5}\big[ \kappa^{1-3s} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{-6s} \log |2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
$$ \begin{align*} \|(\varkappa - \partial)^{-\frac12}\psi^3 & F(\varkappa + \partial)^{-\frac12}\|_{L^2_t\mathfrak I_2}^2 \\ &\lesssim |\varkappa|^{-5}\big[ \kappa^{1-3s} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{-6s} \log |2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
Thus, applying Lemma 2.7 with
 $p=6$
, we find
$p=6$
, we find
 $$ \begin{align*} \left\|\int F\,g_{12}^{[\geq 3]}(\varkappa)\,\psi^6\,dx\right\|_{L^1_t} &\lesssim |\varkappa|^{-5}\big[ \kappa^{1-3s} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{-6s} \log^6\! |2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
$$ \begin{align*} \left\|\int F\,g_{12}^{[\geq 3]}(\varkappa)\,\psi^6\,dx\right\|_{L^1_t} &\lesssim |\varkappa|^{-5}\big[ \kappa^{1-3s} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{-6s} \log^6\! |2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
which is no larger than RHS(5.42). This completes the proof of (5.42).
We turn now to (5.43). Combining (5.42) with (3.21) and Lemma 2.4 yields
 $$ \begin{align*} \bigg\|\int g_{21}^{[3]}(\pm\varkappa)\, \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t} &\lesssim |\varkappa|^{-1-(1+2s)} \cdot\text{RHS(5.42)} \lesssim \text{RHS(5.43)}. \end{align*} $$
$$ \begin{align*} \bigg\|\int g_{21}^{[3]}(\pm\varkappa)\, \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t} &\lesssim |\varkappa|^{-1-(1+2s)} \cdot\text{RHS(5.42)} \lesssim \text{RHS(5.43)}. \end{align*} $$
To continue, we employ (3.38). From Lemma 2.7 and (2.20), we find that
 $$ \begin{align*} \bigg|\iint g_{21}^{[3]}\,F\psi^3\,dx\,dt\bigg| &\lesssim\|(\varkappa-\partial)^{-\frac12}\psi q(\varkappa + \partial)^{-\frac12}\|_{L^6_t\mathfrak I_6}^3\|(\varkappa - \partial)^{-\frac12}F(\varkappa + \partial)^{-\frac12}\|_{L^2_t\mathfrak I_2}\\ &\lesssim |\varkappa|^{-3}\big[\kappa^{\frac12 - \frac{3s}2}+ (1+\tfrac{\kappa}{|\varkappa|}\big)|\varkappa|^{-3s}\log^3\!|2\varkappa| \big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\|F\|_{L^2_{t,x}} \end{align*} $$
$$ \begin{align*} \bigg|\iint g_{21}^{[3]}\,F\psi^3\,dx\,dt\bigg| &\lesssim\|(\varkappa-\partial)^{-\frac12}\psi q(\varkappa + \partial)^{-\frac12}\|_{L^6_t\mathfrak I_6}^3\|(\varkappa - \partial)^{-\frac12}F(\varkappa + \partial)^{-\frac12}\|_{L^2_t\mathfrak I_2}\\ &\lesssim |\varkappa|^{-3}\big[\kappa^{\frac12 - \frac{3s}2}+ (1+\tfrac{\kappa}{|\varkappa|}\big)|\varkappa|^{-3s}\log^3\!|2\varkappa| \big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\|F\|_{L^2_{t,x}} \end{align*} $$
and consequently, that
 $$ \begin{align*} \bigg\|\int g_{21}^{[3]}(\pm\varkappa)\, g_{12}^{[3]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t} &\lesssim\big\|g_{21}^{[3]}(\pm\varkappa)\psi^3\big\|_{L^2_{t,x}}^2 \lesssim \text{RHS(5.43)}. \end{align*} $$
$$ \begin{align*} \bigg\|\int g_{21}^{[3]}(\pm\varkappa)\, g_{12}^{[3]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t} &\lesssim\big\|g_{21}^{[3]}(\pm\varkappa)\psi^3\big\|_{L^2_{t,x}}^2 \lesssim \text{RHS(5.43)}. \end{align*} $$
On the other hand, using Lemma 2.7, (3.22), and (5.32), we get
 $$ \begin{align*} &\bigg\|\int g_{21}^{[3]}(\pm\varkappa)\, g_{12}^{[1]}(\varkappa) \gamma^{[2]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t}\\ &\lesssim\|(\varkappa-\partial)^{-\frac12}(\psi q)(\varkappa + \partial)^{-\frac12}\|_{L^6_t\mathfrak I_6}^3\|(\varkappa - \partial)^{-\frac12}\psi^3 g_{12}^{[1]}(\varkappa) \gamma^{[2]}(\varkappa)(\varkappa + \partial)^{-\frac12}\|_{L^2_t\mathfrak I_2}\\ &\lesssim |\varkappa|^{-6}\big[ \kappa^{1-3s} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{-6s} \log^6\! |2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 \lesssim \text{RHS(5.43)}. \end{align*} $$
$$ \begin{align*} &\bigg\|\int g_{21}^{[3]}(\pm\varkappa)\, g_{12}^{[1]}(\varkappa) \gamma^{[2]}(\varkappa)\,\chi\,dx\bigg\|_{L^1_t}\\ &\lesssim\|(\varkappa-\partial)^{-\frac12}(\psi q)(\varkappa + \partial)^{-\frac12}\|_{L^6_t\mathfrak I_6}^3\|(\varkappa - \partial)^{-\frac12}\psi^3 g_{12}^{[1]}(\varkappa) \gamma^{[2]}(\varkappa)(\varkappa + \partial)^{-\frac12}\|_{L^2_t\mathfrak I_2}\\ &\lesssim |\varkappa|^{-6}\big[ \kappa^{1-3s} + \big(1+\tfrac{\kappa^2}{\varkappa^2}\big) |\varkappa|^{-6s} \log^6\! |2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2 \lesssim \text{RHS(5.43)}. \end{align*} $$
This completes the proof of (5.43).
It remains to prove (5.44) and (5.45). We begin by reducing matters to the quartic terms. As
 $|\varkappa |\geq \sqrt \kappa $
, so
$|\varkappa |\geq \sqrt \kappa $
, so
 $\|\tfrac f{2\varkappa + \partial }\|_{L^\infty _{t,x}}\lesssim \kappa ^{-\frac 12(s+\frac 12)}\delta $
. Thus, we find
$\|\tfrac f{2\varkappa + \partial }\|_{L^\infty _{t,x}}\lesssim \kappa ^{-\frac 12(s+\frac 12)}\delta $
. Thus, we find
 $$\begin{align*}\left\|\int \tfrac f{2\varkappa + \partial}\cdot g_{12}^{[\geq 5]}(\pm\kappa)\,\chi\,dx\right\|_{L^1_t}\lesssim \kappa^{-\frac92-3s}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*}$$
$$\begin{align*}\left\|\int \tfrac f{2\varkappa + \partial}\cdot g_{12}^{[\geq 5]}(\pm\kappa)\,\chi\,dx\right\|_{L^1_t}\lesssim \kappa^{-\frac92-3s}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*}$$
by applying Lemma 2.7 with
 $p=5$
.
$p=5$
.
Regarding the quartic terms, we observe that
 $$\begin{align*}\int \tfrac f{2\varkappa + \partial}\cdot \Big(g_{12}^{[3]}(\kappa) - \tfrac1{4\kappa^3}q^2r\Big)\,\chi\,dx = \int m[q,r,q,\chi \tfrac f{2\varkappa + \partial}]\,dx, \end{align*}$$
$$\begin{align*}\int \tfrac f{2\varkappa + \partial}\cdot \Big(g_{12}^{[3]}(\kappa) - \tfrac1{4\kappa^3}q^2r\Big)\,\chi\,dx = \int m[q,r,q,\chi \tfrac f{2\varkappa + \partial}]\,dx, \end{align*}$$
where the lowest order terms cancel to give a symbol m that is a sum of terms in
 $\kappa ^{5 - |\beta |}S(\beta ;2\kappa )$
for
$\kappa ^{5 - |\beta |}S(\beta ;2\kappa )$
for
 $1\leq |\beta |\leq 8$
. Thus, (5.27) may be applied, which then yields (5.44). To obtain (5.45), we use (5.28) instead. This is possible due to the absence of any
$1\leq |\beta |\leq 8$
. Thus, (5.27) may be applied, which then yields (5.44). To obtain (5.45), we use (5.28) instead. This is possible due to the absence of any
 $|\beta |=1$
terms in the multiplier.
$|\beta |=1$
terms in the multiplier.
We are finally in a position to undertake the proof of Lemma 5.3:
Proof of Lemma 5.3.
We consider each of the currents in turn.
Proof of (5.8). From Corollary 4.14 and (4.14),
 $$\begin{align*}j_{\mathrm{NLS}}^{[\geq 4]} = - i (2\varkappa + \partial)q\cdot \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} + i (2\varkappa - \partial) r\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}. \end{align*}$$
$$\begin{align*}j_{\mathrm{NLS}}^{[\geq 4]} = - i (2\varkappa + \partial)q\cdot \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} + i (2\varkappa - \partial) r\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}. \end{align*}$$
Writing
 $$ \begin{align*}\psi_h^6 (2\varkappa + \partial)q= 2\varkappa (\psi_h^6 q) - (\psi_h^6)' q + (\psi_h^6 q)^{\prime}_{\leq \varkappa} +(\psi_h^6 q)^{\prime}_{>\varkappa} \end{align*} $$
$$ \begin{align*}\psi_h^6 (2\varkappa + \partial)q= 2\varkappa (\psi_h^6 q) - (\psi_h^6)' q + (\psi_h^6 q)^{\prime}_{\leq \varkappa} +(\psi_h^6 q)^{\prime}_{>\varkappa} \end{align*} $$
and invoking (5.34) and (3.44), we estimate
 $$ \begin{align*} \left\|\int j_{\mathrm{NLS}}^{[\geq 4]}(\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} &\lesssim \varkappa^{-2(2s+1)} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}}^2 + \|(\psi_h^6 q)^{\prime}_{>\varkappa}\|_{L_t^2 H^{-(s+\frac32)}} \big\| \psi_h^6 \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\big\|_{L_t^2 H^{s+\frac32}}\\ &\lesssim \varkappa^{-2(2s+1)} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}}^2, \end{align*} $$
$$ \begin{align*} \left\|\int j_{\mathrm{NLS}}^{[\geq 4]}(\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} &\lesssim \varkappa^{-2(2s+1)} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}}^2 + \|(\psi_h^6 q)^{\prime}_{>\varkappa}\|_{L_t^2 H^{-(s+\frac32)}} \big\| \psi_h^6 \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\big\|_{L_t^2 H^{s+\frac32}}\\ &\lesssim \varkappa^{-2(2s+1)} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}}^2, \end{align*} $$
which completes the proof of (5.8).
Proof of (5.9). From Corollary 4.14, we compute
 $$ \begin{align*} j_{\mathrm{mKdV}}^{[\geq 4]} &= (4\varkappa^2 + 2\varkappa \partial + \partial^2)q\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} - (4\varkappa^2 - 2\varkappa\partial + \partial^2)r\cdot\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\\ &\quad - 2q^2 r\tfrac{g_{21}}{2+\gamma} + 2r^2q\tfrac{g_{12}}{2 + \gamma}. \end{align*} $$
$$ \begin{align*} j_{\mathrm{mKdV}}^{[\geq 4]} &= (4\varkappa^2 + 2\varkappa \partial + \partial^2)q\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} - (4\varkappa^2 - 2\varkappa\partial + \partial^2)r\cdot\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\\ &\quad - 2q^2 r\tfrac{g_{21}}{2+\gamma} + 2r^2q\tfrac{g_{12}}{2 + \gamma}. \end{align*} $$
Focusing on the first line in our expression for
 $j_{\mathrm {mKdV}}^{[\geq 4]}$
, we write
$j_{\mathrm {mKdV}}^{[\geq 4]}$
, we write
 $$ \begin{align} \psi_h^3 &(4\varkappa^2 + 2\varkappa \partial + \partial^2)q = 4\varkappa^2(\psi_h^3 q) + 2\varkappa(\psi_h^3 q)'+(\psi_h^3 q)"- 2\varkappa (\psi_h^3)' q + (\psi_h^3)" q - 2 [(\psi_h^3)' q]' . \end{align} $$
$$ \begin{align} \psi_h^3 &(4\varkappa^2 + 2\varkappa \partial + \partial^2)q = 4\varkappa^2(\psi_h^3 q) + 2\varkappa(\psi_h^3 q)'+(\psi_h^3 q)"- 2\varkappa (\psi_h^3)' q + (\psi_h^3)" q - 2 [(\psi_h^3)' q]' . \end{align} $$
Thus, using Bernstein’s inequality and (3.44), we estimate
 $$ \begin{align*} &\left\|\int P_{>\varkappa} \big[\psi_h^3 (4\varkappa^2 + 2\varkappa \partial + \partial^2)q\big] \cdot \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\quad\lesssim \varkappa^{-(1+2s)} \|\psi_h q\|_{L_t^2 H^{s+1}} \big\|\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{X^{s+2}}\lesssim \varkappa^{-2(2s+1)} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
$$ \begin{align*} &\left\|\int P_{>\varkappa} \big[\psi_h^3 (4\varkappa^2 + 2\varkappa \partial + \partial^2)q\big] \cdot \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\quad\lesssim \varkappa^{-(1+2s)} \|\psi_h q\|_{L_t^2 H^{s+1}} \big\|\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{X^{s+2}}\lesssim \varkappa^{-2(2s+1)} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
On the other hand, an application of (5.41) yields
 $$ \begin{align*} &\left\| \int P_{\leq \varkappa} \big[\psi_h^3 (4\varkappa^2 + 2\varkappa \partial + \partial^2)q\big] \cdot \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]} \,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad\qquad\lesssim \big[\varkappa^{-1}+ \varkappa^{-2(2s+1)}\log^4\!|2\varkappa|\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
$$ \begin{align*} &\left\| \int P_{\leq \varkappa} \big[\psi_h^3 (4\varkappa^2 + 2\varkappa \partial + \partial^2)q\big] \cdot \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]} \,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad\qquad\lesssim \big[\varkappa^{-1}+ \varkappa^{-2(2s+1)}\log^4\!|2\varkappa|\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
We now demonstrate how to estimate the contribution of the final two terms in our expression for
 $j_{\mathrm {mKdV}}^{[\geq 4]}$
, using the former as our example. We first decompose into frequencies, as follows:
$j_{\mathrm {mKdV}}^{[\geq 4]}$
, using the former as our example. We first decompose into frequencies, as follows:
 $$\begin{align*}\left\|\int q^2r\,\tfrac{g_{21}(\varkappa)}{2+\gamma(\varkappa)}\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim\sum\limits_{N_j\geq 1}\left\|\int (\psi_h^{3}q)_{N_1}(\psi_h^{3}r)_{N_2}(\psi_h^{3}q)_{N_3}\big(\psi_h^{3}\tfrac{g_{21}}{2+\gamma}\big)_{N_4}\,dx\right\|_{L^1_t}, \end{align*}$$
$$\begin{align*}\left\|\int q^2r\,\tfrac{g_{21}(\varkappa)}{2+\gamma(\varkappa)}\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim\sum\limits_{N_j\geq 1}\left\|\int (\psi_h^{3}q)_{N_1}(\psi_h^{3}r)_{N_2}(\psi_h^{3}q)_{N_3}\big(\psi_h^{3}\tfrac{g_{21}}{2+\gamma}\big)_{N_4}\,dx\right\|_{L^1_t}, \end{align*}$$
where the two highest frequencies must be comparable. By exploiting symmetries, we may reduce consideration to two cases, namely,
 $N_1\sim N_2\geq N_3\vee N_4$
and
$N_1\sim N_2\geq N_3\vee N_4$
and
 $N_1\sim N_4 \gtrsim N_2\geq N_3$
.
$N_1\sim N_4 \gtrsim N_2\geq N_3$
.
To estimate the low frequencies, we use
 $$ \begin{align} \|(\psi_h^{3}q)_{N}\big\|_{L^\infty_{t,x}}&\lesssim N^{\frac12-s}\delta, \end{align} $$
$$ \begin{align} \|(\psi_h^{3}q)_{N}\big\|_{L^\infty_{t,x}}&\lesssim N^{\frac12-s}\delta, \end{align} $$
 $$ \begin{align} \big\|\big(\psi_h^{3}\tfrac{g_{21}}{2+\gamma}\big)_{N}\big\|_{L^\infty_{t,x}}&\lesssim (\varkappa+N)^{-1}N^{\frac12-s}\delta, \end{align} $$
$$ \begin{align} \big\|\big(\psi_h^{3}\tfrac{g_{21}}{2+\gamma}\big)_{N}\big\|_{L^\infty_{t,x}}&\lesssim (\varkappa+N)^{-1}N^{\frac12-s}\delta, \end{align} $$
which follow from Bernstein’s inequality and (3.41). To estimate the high frequencies, we use
 $$ \begin{align*} \|(\psi_h^{3}q)_{N}\|_{L^2_{t,x}}&\lesssim N^{-1-s}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}},\\ \big\|\big(\psi_h^{3}\tfrac{g_{21}}{2+\gamma}\big)_{N}\big\|_{L^2_{t,x}}&\lesssim (\varkappa+N)^{-1}N^{-1-s}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}, \end{align*} $$
$$ \begin{align*} \|(\psi_h^{3}q)_{N}\|_{L^2_{t,x}}&\lesssim N^{-1-s}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}},\\ \big\|\big(\psi_h^{3}\tfrac{g_{21}}{2+\gamma}\big)_{N}\big\|_{L^2_{t,x}}&\lesssim (\varkappa+N)^{-1}N^{-1-s}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}, \end{align*} $$
which follow from Bernstein’s inequality and (3.43). Estimating the two lowest frequency terms in
 $L^\infty _{t,x}$
and the two highest frequency terms in
$L^\infty _{t,x}$
and the two highest frequency terms in
 $L^2_{t,x}$
, we obtain
$L^2_{t,x}$
, we obtain
 $$ \begin{align*} \left\|\int q^2r\tfrac{g_{21}(\varkappa)}{2+\gamma(\varkappa)}\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \big[\varkappa^{-1} +\varkappa^{-2(2s+1)}\log|2\varkappa|\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
$$ \begin{align*} \left\|\int q^2r\tfrac{g_{21}(\varkappa)}{2+\gamma(\varkappa)}\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \big[\varkappa^{-1} +\varkappa^{-2(2s+1)}\log|2\varkappa|\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
This completes the proof of (5.9).
Proof of (5.10). Recall that
 $\varkappa \in [\kappa ^{\frac 23},\frac 12\kappa ]\cup [2\kappa ,\infty )$
. We decompose
$\varkappa \in [\kappa ^{\frac 23},\frac 12\kappa ]\cup [2\kappa ,\infty )$
. We decompose
 $$ \begin{align*} j_{\mathrm{NLS}}^{\mathrm{diff}}{}^{[\geq 4]} &= \underbrace{-i\big(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}\big)(2\varkappa + \partial)q\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_1}\\ &\quad \underbrace{+ i\big(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}\big)(2\varkappa - \partial)r\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_2}\\ &\quad \underbrace{- \Big(\tfrac{2i\kappa^3}{\kappa - \varkappa}g_{12}(\kappa)^{[\geq 3]} + \tfrac{2i\kappa^3}{\kappa + \varkappa}g_{12}(-\kappa)^{[\geq 3]}\Big)\cdot\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}}_{\mathbf{err}_3}\\ &\quad \underbrace{- \Big(\tfrac{2i\kappa^3}{\kappa - \varkappa}g_{21}(\kappa)^{[\geq 3]} + \tfrac{2i\kappa^3}{\kappa + \varkappa}g_{21}(-\kappa)^{[\geq 3]}\Big)\cdot\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}}_{\mathbf{err}_4} \underbrace{+ \tfrac{i\kappa^3}{\kappa - \varkappa}\gamma(\kappa)^{[\geq 4]} + \tfrac{i\kappa^3}{\kappa + \varkappa}\gamma(-\kappa)^{[\geq 4]}}_{\mathbf{err}_5} \end{align*} $$
$$ \begin{align*} j_{\mathrm{NLS}}^{\mathrm{diff}}{}^{[\geq 4]} &= \underbrace{-i\big(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}\big)(2\varkappa + \partial)q\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_1}\\ &\quad \underbrace{+ i\big(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}\big)(2\varkappa - \partial)r\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_2}\\ &\quad \underbrace{- \Big(\tfrac{2i\kappa^3}{\kappa - \varkappa}g_{12}(\kappa)^{[\geq 3]} + \tfrac{2i\kappa^3}{\kappa + \varkappa}g_{12}(-\kappa)^{[\geq 3]}\Big)\cdot\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}}_{\mathbf{err}_3}\\ &\quad \underbrace{- \Big(\tfrac{2i\kappa^3}{\kappa - \varkappa}g_{21}(\kappa)^{[\geq 3]} + \tfrac{2i\kappa^3}{\kappa + \varkappa}g_{21}(-\kappa)^{[\geq 3]}\Big)\cdot\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}}_{\mathbf{err}_4} \underbrace{+ \tfrac{i\kappa^3}{\kappa - \varkappa}\gamma(\kappa)^{[\geq 4]} + \tfrac{i\kappa^3}{\kappa + \varkappa}\gamma(-\kappa)^{[\geq 4]}}_{\mathbf{err}_5} \end{align*} $$
and note that by symmetry, it suffices to consider the contributions of the terms
 $\mathbf {err}_j$
with
$\mathbf {err}_j$
with
 $j=1,3,5$
.
$j=1,3,5$
.
For
 $\mathbf {err}_1$
, we first write
$\mathbf {err}_1$
, we first write
 $$\begin{align*}\big(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}\big)(2\varkappa + \partial)q = -\tfrac{4\kappa^2\varkappa^2}{\kappa^2- \varkappa^2}\tfrac{2\varkappa + \partial}{4\kappa^2 - \partial^2}q - \tfrac{(2\varkappa + \partial)\partial^2}{4\kappa^2 - \partial^2}q. \end{align*}$$
$$\begin{align*}\big(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2}\big)(2\varkappa + \partial)q = -\tfrac{4\kappa^2\varkappa^2}{\kappa^2- \varkappa^2}\tfrac{2\varkappa + \partial}{4\kappa^2 - \partial^2}q - \tfrac{(2\varkappa + \partial)\partial^2}{4\kappa^2 - \partial^2}q. \end{align*}$$
Using Lemma 2.8 together with (3.44), we estimate the contribution of the high frequencies as follows:
 $$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \psi^3_h\tfrac1{2\kappa + \partial}\psi_h^{-3}\big(\psi_h^3\tfrac{2\varkappa + \partial}{2\kappa - \partial}q\big)_{>\varkappa}\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^9\,dx\right\|_{L^1_t}\\ &\quad\lesssim \tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2} \big\| \big(\psi_h^3\tfrac{2\varkappa + \partial}{2\kappa - \partial}q\big)_{>\varkappa}\big\|_{L^2_t H^{-\frac52-s}} \varkappa^{-(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} \lesssim\varkappa^{-2(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2,\\ &\left\|\int \psi_h^3\tfrac1{2\kappa + \partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^2}{2\kappa - \partial}q\big)_{>\varkappa}\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^9\,dx\right\|_{L^1_t}\\ &\quad\lesssim \big\| \big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^2}{2\kappa - \partial}q\big)_{>\varkappa}\big\|_{L^2_t H^{-\frac52-s}} \varkappa^{-(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} \lesssim\varkappa^{-2(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*} $$
$$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \psi^3_h\tfrac1{2\kappa + \partial}\psi_h^{-3}\big(\psi_h^3\tfrac{2\varkappa + \partial}{2\kappa - \partial}q\big)_{>\varkappa}\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^9\,dx\right\|_{L^1_t}\\ &\quad\lesssim \tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2} \big\| \big(\psi_h^3\tfrac{2\varkappa + \partial}{2\kappa - \partial}q\big)_{>\varkappa}\big\|_{L^2_t H^{-\frac52-s}} \varkappa^{-(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} \lesssim\varkappa^{-2(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2,\\ &\left\|\int \psi_h^3\tfrac1{2\kappa + \partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^2}{2\kappa - \partial}q\big)_{>\varkappa}\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^9\,dx\right\|_{L^1_t}\\ &\quad\lesssim \big\| \big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^2}{2\kappa - \partial}q\big)_{>\varkappa}\big\|_{L^2_t H^{-\frac52-s}} \varkappa^{-(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} \lesssim\varkappa^{-2(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*} $$
The two low-frequency terms are estimated using Lemma 2.8 and (5.34):
 $$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \psi_h^3\tfrac1{2\kappa + \partial}\psi_h^{-3}\big(\psi_h^3\tfrac{2\varkappa + \partial}{2\kappa - \partial}q\big)_{\leq \varkappa}\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^9\,dx\right\|_{L^1_t} \\ &\qquad\qquad\qquad\qquad\lesssim \tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2} \cdot \tfrac{\varkappa}{\kappa^2} \cdot |\varkappa|^{-3} \big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2 \end{align*} $$
$$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \psi_h^3\tfrac1{2\kappa + \partial}\psi_h^{-3}\big(\psi_h^3\tfrac{2\varkappa + \partial}{2\kappa - \partial}q\big)_{\leq \varkappa}\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^9\,dx\right\|_{L^1_t} \\ &\qquad\qquad\qquad\qquad\lesssim \tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2} \cdot \tfrac{\varkappa}{\kappa^2} \cdot |\varkappa|^{-3} \big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2 \end{align*} $$
and similarly,
 $$ \begin{align*} &\left\|\int \psi_h^3\tfrac1{2\kappa + \partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^2}{2\kappa - \partial}q\big)_{\leq \varkappa}\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^9\,dx\right\|_{L^1_t} \\ &\qquad\qquad\qquad\qquad\lesssim \min\big\{\tfrac{\varkappa^3}{\kappa^2},\varkappa\big\} \cdot |\varkappa|^{-3} \big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*} $$
$$ \begin{align*} &\left\|\int \psi_h^3\tfrac1{2\kappa + \partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^2}{2\kappa - \partial}q\big)_{\leq \varkappa}\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^9\,dx\right\|_{L^1_t} \\ &\qquad\qquad\qquad\qquad\lesssim \min\big\{\tfrac{\varkappa^3}{\kappa^2},\varkappa\big\} \cdot |\varkappa|^{-3} \big[\kappa^{\frac23 - \frac{8s}3} + |\varkappa|^{-4s}\big] \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*} $$
Collecting these estimates, we deduce that
 $$\begin{align*}\left\|\int \mathbf{err}_1\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)} + \varkappa^{-2(2s+1)}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*}$$
$$\begin{align*}\left\|\int \mathbf{err}_1\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \big[\tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)} + \varkappa^{-2(2s+1)}\big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*}$$
To estimate the contribution of
 $\mathbf {err}_3$
, we define
$\mathbf {err}_3$
, we define
 $ f = (2\varkappa + \partial )\big (\tfrac {g_{21}(\varkappa )}{2 + \gamma (\varkappa )}\big ), $
and apply the estimates (3.41) and (3.43) to see that
$ f = (2\varkappa + \partial )\big (\tfrac {g_{21}(\varkappa )}{2 + \gamma (\varkappa )}\big ), $
and apply the estimates (3.41) and (3.43) to see that
 $$\begin{align*}\|f\|_{L^\infty_t H^s}\lesssim \delta \quad\text{and}\quad {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*}$$
$$\begin{align*}\|f\|_{L^\infty_t H^s}\lesssim \delta \quad\text{and}\quad {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}\lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}. \end{align*}$$
We then write
 $$ \begin{align*} \mathbf{err}_3 &= -\tfrac{2i\kappa^3\varkappa}{\kappa^2 - \varkappa^2}\Big(g_{12}(\kappa)^{[\geq 3]} - g_{12}(-\kappa)^{[\geq 3]}\Big)\cdot \tfrac f{2\varkappa + \partial}\\ &\quad -\tfrac{2i\kappa^4}{\kappa^2 - \varkappa^2}\Big(g_{12}(\kappa)^{{[\geq 3]}} + g_{12}(-\kappa)^{{[\geq 3]}}\Big)\cdot \tfrac f{2\varkappa + \partial}. \end{align*} $$
$$ \begin{align*} \mathbf{err}_3 &= -\tfrac{2i\kappa^3\varkappa}{\kappa^2 - \varkappa^2}\Big(g_{12}(\kappa)^{[\geq 3]} - g_{12}(-\kappa)^{[\geq 3]}\Big)\cdot \tfrac f{2\varkappa + \partial}\\ &\quad -\tfrac{2i\kappa^4}{\kappa^2 - \varkappa^2}\Big(g_{12}(\kappa)^{{[\geq 3]}} + g_{12}(-\kappa)^{{[\geq 3]}}\Big)\cdot \tfrac f{2\varkappa + \partial}. \end{align*} $$
Applying the estimate (5.33) to the first term and the estimate (5.36) to the second, we obtain
 $$\begin{align*}\left\|\int \mathbf{err}_3\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*}$$
$$\begin{align*}\left\|\int \mathbf{err}_3\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \tfrac\kappa{\kappa + \varkappa}\kappa^{-\frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2. \end{align*}$$
Finally, using (5.35), we estimate the contribution of
 $\mathbf {err}_5$
by
$\mathbf {err}_5$
by
 $$\begin{align*}\left\|\int \mathbf{err}_5\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \tfrac{\kappa}{\kappa + \varkappa} \kappa^{- \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*}$$
$$\begin{align*}\left\|\int \mathbf{err}_5\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \tfrac{\kappa}{\kappa + \varkappa} \kappa^{- \frac43(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa}^2, \end{align*}$$
which completes the proof of (5.10).
Proof of (5.11). Recall that
 $\varkappa \in [\kappa ^{\frac 12},\frac 12\kappa ]\cup [2\kappa ,\infty )$
. We decompose
$\varkappa \in [\kappa ^{\frac 12},\frac 12\kappa ]\cup [2\kappa ,\infty )$
. We decompose
 $$ \begin{align*} &j_{\mathrm{mKdV}}^{\mathrm{diff}\;[\geq 4]} = \underbrace{(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2})(2\varkappa + \partial)q'\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_1}\\ &\quad \underbrace{+ (1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2})(2\varkappa - \partial)r'\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_2}\\ &\quad \underbrace{+ \big(\tfrac{4\kappa^4}{\kappa - \varkappa}g_{12}^{[\geq 3]}(\kappa) - \tfrac{4\kappa^4}{\kappa + \varkappa}g_{12}^{[\geq 3]}(-\kappa) - \tfrac{2\kappa^2}{\kappa^2 - \varkappa^2}q^2r\big)\cdot\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}}_{\mathbf{err}_3}\\&\quad \underbrace{+\big(\tfrac{4\kappa^4}{\kappa - \varkappa}g_{21}^{[\geq 3]}(\kappa) - \tfrac{4\kappa^4}{\kappa + \varkappa}g_{21}^{[\geq 3]}(-\kappa) + \tfrac{2\kappa^2}{\kappa^2 - \varkappa^2} r^2q\big)\cdot\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}}_{\mathbf{err}_4}\\ &\quad \underbrace{-\Big[\tfrac{2\kappa^4}{\kappa - \varkappa}\gamma^{[\geq 4]}(\kappa) - \tfrac{2\kappa^4}{\kappa + \varkappa}\gamma^{[\geq 4]}(-\kappa) - \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}qr\big(q\tfrac r{4\kappa^2 - \partial^2} + r\tfrac q{4\kappa^2 - \partial^2}\big)\Big]}_{\mathbf{err}_5}\\ &\quad \underbrace{+ \tfrac{4\varkappa^4}{\kappa^2 - \varkappa^2}r\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}+ \tfrac{2\varkappa^2}{\kappa^2 - \varkappa^2}q^2r\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_6}\\ &\quad \underbrace{- \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}q^2r\tfrac r{4\kappa^2 - \partial^2} - \tfrac{\varkappa^4}{\kappa^2 - \varkappa^2}rg_{12}^{[1]}(\varkappa)\gamma^{[2]}(\varkappa) - \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2}qg_{21}^{[3]}(\varkappa)+ \tfrac{\varkappa^2}{\kappa^2 - \varkappa^2}q^2rg_{21}^{[1]}(\varkappa)}_{\mathbf{err}_7}\\ &\quad\underbrace{ - \tfrac{4\varkappa^4}{\kappa^2 - \varkappa^2}q\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}- \tfrac{2\varkappa^2}{\kappa^2 - \varkappa^2}r^2q\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_8}\\ &\quad\underbrace{- \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}r^2q\tfrac q{4\kappa^2 - \partial^2} + \tfrac{\varkappa^4}{\kappa^2 - \varkappa^2}qg_{21}^{[1]}(\varkappa)\gamma^{[2]}(\varkappa) + \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2}r\cdot g_{12}^{[3]}(\varkappa)- \tfrac{\varkappa^2}{\kappa^2 - \varkappa^2}r^2qg_{12}^{[1]}(\varkappa)}_{\mathbf{err}_9}. \end{align*} $$
$$ \begin{align*} &j_{\mathrm{mKdV}}^{\mathrm{diff}\;[\geq 4]} = \underbrace{(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2})(2\varkappa + \partial)q'\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_1}\\ &\quad \underbrace{+ (1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2})(2\varkappa - \partial)r'\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_2}\\ &\quad \underbrace{+ \big(\tfrac{4\kappa^4}{\kappa - \varkappa}g_{12}^{[\geq 3]}(\kappa) - \tfrac{4\kappa^4}{\kappa + \varkappa}g_{12}^{[\geq 3]}(-\kappa) - \tfrac{2\kappa^2}{\kappa^2 - \varkappa^2}q^2r\big)\cdot\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}}_{\mathbf{err}_3}\\&\quad \underbrace{+\big(\tfrac{4\kappa^4}{\kappa - \varkappa}g_{21}^{[\geq 3]}(\kappa) - \tfrac{4\kappa^4}{\kappa + \varkappa}g_{21}^{[\geq 3]}(-\kappa) + \tfrac{2\kappa^2}{\kappa^2 - \varkappa^2} r^2q\big)\cdot\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}}_{\mathbf{err}_4}\\ &\quad \underbrace{-\Big[\tfrac{2\kappa^4}{\kappa - \varkappa}\gamma^{[\geq 4]}(\kappa) - \tfrac{2\kappa^4}{\kappa + \varkappa}\gamma^{[\geq 4]}(-\kappa) - \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}qr\big(q\tfrac r{4\kappa^2 - \partial^2} + r\tfrac q{4\kappa^2 - \partial^2}\big)\Big]}_{\mathbf{err}_5}\\ &\quad \underbrace{+ \tfrac{4\varkappa^4}{\kappa^2 - \varkappa^2}r\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}+ \tfrac{2\varkappa^2}{\kappa^2 - \varkappa^2}q^2r\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_6}\\ &\quad \underbrace{- \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}q^2r\tfrac r{4\kappa^2 - \partial^2} - \tfrac{\varkappa^4}{\kappa^2 - \varkappa^2}rg_{12}^{[1]}(\varkappa)\gamma^{[2]}(\varkappa) - \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2}qg_{21}^{[3]}(\varkappa)+ \tfrac{\varkappa^2}{\kappa^2 - \varkappa^2}q^2rg_{21}^{[1]}(\varkappa)}_{\mathbf{err}_7}\\ &\quad\underbrace{ - \tfrac{4\varkappa^4}{\kappa^2 - \varkappa^2}q\cdot\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}- \tfrac{2\varkappa^2}{\kappa^2 - \varkappa^2}r^2q\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}}_{\mathbf{err}_8}\\ &\quad\underbrace{- \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}r^2q\tfrac q{4\kappa^2 - \partial^2} + \tfrac{\varkappa^4}{\kappa^2 - \varkappa^2}qg_{21}^{[1]}(\varkappa)\gamma^{[2]}(\varkappa) + \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2}r\cdot g_{12}^{[3]}(\varkappa)- \tfrac{\varkappa^2}{\kappa^2 - \varkappa^2}r^2qg_{12}^{[1]}(\varkappa)}_{\mathbf{err}_9}. \end{align*} $$
While the validity of this equality is, of course, elementary, the particular grouping of terms (and the addition of an extra term in
 $\mathbf {err}_5$
that is then subtracted in
$\mathbf {err}_5$
that is then subtracted in
 $\mathbf {err}_7$
and
$\mathbf {err}_7$
and
 $\mathbf {err}_9$
) represents a very delicate accounting for numerous cancellations.
$\mathbf {err}_9$
) represents a very delicate accounting for numerous cancellations.
As we will see, each term in this expansion individually yields an acceptable contribution to (5.11). We will treat
 $\mathbf {err}_1, \mathbf {err}_3, \mathbf {err}_5, \mathbf {err}_6$
, and
$\mathbf {err}_1, \mathbf {err}_3, \mathbf {err}_5, \mathbf {err}_6$
, and
 $\mathbf {err}_7$
in turn. The remaining terms are covered by this analysis and conjugation symmetry.
$\mathbf {err}_7$
in turn. The remaining terms are covered by this analysis and conjugation symmetry.
For
 $\mathbf {err}_1$
, we first write
$\mathbf {err}_1$
, we first write
 $$\begin{align*}(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2})(2\varkappa + \partial)q' = -\tfrac{4\kappa^2\varkappa^2}{\kappa^2- \varkappa^2}\tfrac{(2\varkappa + \partial)\partial}{4\kappa^2 - \partial^2}q - \tfrac{(2\varkappa + \partial)\partial^3}{4\kappa^2 - \partial^2}q. \end{align*}$$
$$\begin{align*}(1 - \tfrac{\kappa^2}{\kappa^2 - \varkappa^2}\tfrac{4\kappa^2}{4\kappa^2 - \partial^2})(2\varkappa + \partial)q' = -\tfrac{4\kappa^2\varkappa^2}{\kappa^2- \varkappa^2}\tfrac{(2\varkappa + \partial)\partial}{4\kappa^2 - \partial^2}q - \tfrac{(2\varkappa + \partial)\partial^3}{4\kappa^2 - \partial^2}q. \end{align*}$$
Proceeding as in the proof of (5.10) and using (3.44), we estimate the contribution of the second term as follows:
 $$ \begin{align*} &\left\|\int \psi_h^3\tfrac1{2\kappa+\partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^3}{2\kappa - \partial}q\big)_{>\varkappa}\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \big\| \big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^3}{2\kappa - \partial}q\big)_{>\varkappa}\big\|_{L^2_t H^{-(3+s)}}\big\| \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{X_\kappa^{2+s}}\lesssim \varkappa^{-2(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2,\\ &\left\|\int \psi_h^3\tfrac1{2\kappa+\partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^3}{2\kappa - \partial}q\big)_{\leq\varkappa}\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \big\| \big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^3}{2\kappa - \partial}q\big)_{\leq\varkappa}\big\|_{L^2_t H^{-(2+s)}} \big\| \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{X_\kappa^{1+s}}\lesssim\varkappa^{-2(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
$$ \begin{align*} &\left\|\int \psi_h^3\tfrac1{2\kappa+\partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^3}{2\kappa - \partial}q\big)_{>\varkappa}\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \big\| \big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^3}{2\kappa - \partial}q\big)_{>\varkappa}\big\|_{L^2_t H^{-(3+s)}}\big\| \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{X_\kappa^{2+s}}\lesssim \varkappa^{-2(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2,\\ &\left\|\int \psi_h^3\tfrac1{2\kappa+\partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^3}{2\kappa - \partial}q\big)_{\leq\varkappa}\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \big\| \big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial^3}{2\kappa - \partial}q\big)_{\leq\varkappa}\big\|_{L^2_t H^{-(2+s)}} \big\| \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\big\|_{X_\kappa^{1+s}}\lesssim\varkappa^{-2(1+2s)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
To estimate the term with fewer derivatives, we write
 $\big (\tfrac {g_{21}}{2 + \gamma }\big )^{[\geq 3]} =\big (\tfrac {g_{21}}{2 + \gamma }\big )^{[\geq 5]}+ \big (\tfrac {g_{21}}{2 + \gamma }\big )^{[3]}$
. Arguing as above and using (3.45) in place of (3.44), we get
$\big (\tfrac {g_{21}}{2 + \gamma }\big )^{[\geq 3]} =\big (\tfrac {g_{21}}{2 + \gamma }\big )^{[\geq 5]}+ \big (\tfrac {g_{21}}{2 + \gamma }\big )^{[3]}$
. Arguing as above and using (3.45) in place of (3.44), we get
 $$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \psi_h^3\tfrac1{2\kappa+\partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial}{2\kappa - \partial}q\big)_{>\varkappa}\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\big\| \big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial}{2\kappa - \partial}q\big)_{>\varkappa}\big\|_{L^2_t H^{-(3+s)}}\big\| \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\big\|_{X_\kappa^{2+s}}\\ &\qquad \lesssim \varkappa^{-3(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
$$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \psi_h^3\tfrac1{2\kappa+\partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial}{2\kappa - \partial}q\big)_{>\varkappa}\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\big\| \big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial}{2\kappa - \partial}q\big)_{>\varkappa}\big\|_{L^2_t H^{-(3+s)}}\big\| \big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\big\|_{X_\kappa^{2+s}}\\ &\qquad \lesssim \varkappa^{-3(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2, \end{align*} $$
while using (5.42), we estimate
 $$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \psi_h^3\tfrac1{2\kappa+\partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial}{2\kappa - \partial}q\big)_{\leq\varkappa}\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad \lesssim \tfrac{|\varkappa|^{-(s+\frac12)}}{\kappa^2+\varkappa^2} \big[\kappa^{\frac34 - \frac{5s}2} +|\varkappa|^{-(\frac12+5s)}\log^6\!|2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2\lesssim \mathrm{RHS}({5.11}). \end{align*} $$
$$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \psi_h^3\tfrac1{2\kappa+\partial}\psi_h^{-3}\big(\psi_h^3\tfrac{(2\varkappa + \partial)\partial}{2\kappa - \partial}q\big)_{\leq\varkappa}\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\,\psi_h^{9}\,dx\right\|_{L^1_t}\\ &\qquad \lesssim \tfrac{|\varkappa|^{-(s+\frac12)}}{\kappa^2+\varkappa^2} \big[\kappa^{\frac34 - \frac{5s}2} +|\varkappa|^{-(\frac12+5s)}\log^6\!|2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2\lesssim \mathrm{RHS}({5.11}). \end{align*} $$
It remains to estimate the contribution of the quartic terms, which we expand using (3.38) and treat the two parts separately.
Setting
 $m_1=\frac {i\xi _1}{4\kappa ^2+\xi _1^2}$
and
$m_1=\frac {i\xi _1}{4\kappa ^2+\xi _1^2}$
and
 $m_2=\frac {-\xi _1^2}{4\kappa ^2+\xi _1^2}$
and using (3.21) and (3.22), we have
$m_2=\frac {-\xi _1^2}{4\kappa ^2+\xi _1^2}$
and using (3.21) and (3.22), we have
 $$ \begin{align*}\tfrac{(2\varkappa + \partial)\partial q}{4\kappa^2 - \partial^2} \, g_{21}^{[1]}(\varkappa) \gamma^{[2]}(\varkappa) = -\tfrac{4}{\varkappa}m_1\big[ q, \tfrac{\varkappa\, r}{2\varkappa + \partial}, \tfrac{\varkappa\, q}{2\varkappa - \partial}, \tfrac{r}{2\varkappa + \partial}\big] - \tfrac{2}{\varkappa^2}m_2\big[ q, \tfrac{\varkappa\, r}{2\varkappa + \partial}, \tfrac{\varkappa\, q}{2\varkappa - \partial}, \tfrac{r}{2\varkappa + \partial}\big]. \end{align*} $$
$$ \begin{align*}\tfrac{(2\varkappa + \partial)\partial q}{4\kappa^2 - \partial^2} \, g_{21}^{[1]}(\varkappa) \gamma^{[2]}(\varkappa) = -\tfrac{4}{\varkappa}m_1\big[ q, \tfrac{\varkappa\, r}{2\varkappa + \partial}, \tfrac{\varkappa\, q}{2\varkappa - \partial}, \tfrac{r}{2\varkappa + \partial}\big] - \tfrac{2}{\varkappa^2}m_2\big[ q, \tfrac{\varkappa\, r}{2\varkappa + \partial}, \tfrac{\varkappa\, q}{2\varkappa - \partial}, \tfrac{r}{2\varkappa + \partial}\big]. \end{align*} $$
Applying both (5.27) and (5.28) from Lemma 5.11, we deduce that
 $$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \tfrac{(2\varkappa + \partial)\partial}{4\kappa^2 - \partial^2}q\,\big[g_{21}^{[1]}\gamma^{[2]}\big](\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \mathrm{RHS}({5.11}). \end{align*} $$
$$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \tfrac{(2\varkappa + \partial)\partial}{4\kappa^2 - \partial^2}q\,\big[g_{21}^{[1]}\gamma^{[2]}\big](\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \mathrm{RHS}({5.11}). \end{align*} $$
For the remaining quartic term, we first use (3.13) to write
 $$ \begin{align*} \psi_h^{12}g_{21}^{[3]}(\varkappa) &= \tfrac{1}{2\varkappa+\partial}\big[ r\gamma^{[2]}(\varkappa) \psi_h^{12}\big] + \tfrac{1}{2\varkappa+\partial} \big[(\psi_h^{12})' g_{21}^{[3]}(\varkappa)\big]\\ &= \tfrac{1}{2\varkappa+\partial}\big[ r\gamma^{[2]}(\varkappa) \psi_h^{12}\big] + \tfrac{1}{(2\varkappa+\partial)^2}\big[ r\gamma^{[2]}(\varkappa) (\psi_h^{12})'\big]+ \tfrac{1}{(2\varkappa+\partial)^2} \big[(\psi_h^{12})" g_{21}^{[3]}(\varkappa)\big] \end{align*} $$
$$ \begin{align*} \psi_h^{12}g_{21}^{[3]}(\varkappa) &= \tfrac{1}{2\varkappa+\partial}\big[ r\gamma^{[2]}(\varkappa) \psi_h^{12}\big] + \tfrac{1}{2\varkappa+\partial} \big[(\psi_h^{12})' g_{21}^{[3]}(\varkappa)\big]\\ &= \tfrac{1}{2\varkappa+\partial}\big[ r\gamma^{[2]}(\varkappa) \psi_h^{12}\big] + \tfrac{1}{(2\varkappa+\partial)^2}\big[ r\gamma^{[2]}(\varkappa) (\psi_h^{12})'\big]+ \tfrac{1}{(2\varkappa+\partial)^2} \big[(\psi_h^{12})" g_{21}^{[3]}(\varkappa)\big] \end{align*} $$
and so
 $$ \begin{align*} &\left\|\int \tfrac{(2\varkappa + \partial)\partial q}{4\kappa^2 - \partial^2}\, g_{21}^{[3]}(\varkappa)\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\leq\left\|\int \tfrac{(2\varkappa + \partial)\partial q}{(2\varkappa-\partial)(4\kappa^2 - \partial^2)} r\gamma^{[2]}(\varkappa) \psi_h^{12}\,dx\right\|_{L^1_t}+ \left\|\int \tfrac{(2\varkappa + \partial)\partial q}{(2\varkappa-\partial)^2(4\kappa^2 - \partial^2)}\, r\gamma^{[2]}(\varkappa) (\psi_h^{12})'\,dx\right\|_{L^1_t} \\ &\quad+ \left\|\int \tfrac{(2\varkappa + \partial)\partial q}{(2\varkappa-\partial)^2(4\kappa^2 - \partial^2)}\, g_{21}^{[3]}(\varkappa) (\psi_h^{12})" \,dx\right\|_{L^1_t}. \end{align*} $$
$$ \begin{align*} &\left\|\int \tfrac{(2\varkappa + \partial)\partial q}{4\kappa^2 - \partial^2}\, g_{21}^{[3]}(\varkappa)\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\leq\left\|\int \tfrac{(2\varkappa + \partial)\partial q}{(2\varkappa-\partial)(4\kappa^2 - \partial^2)} r\gamma^{[2]}(\varkappa) \psi_h^{12}\,dx\right\|_{L^1_t}+ \left\|\int \tfrac{(2\varkappa + \partial)\partial q}{(2\varkappa-\partial)^2(4\kappa^2 - \partial^2)}\, r\gamma^{[2]}(\varkappa) (\psi_h^{12})'\,dx\right\|_{L^1_t} \\ &\quad+ \left\|\int \tfrac{(2\varkappa + \partial)\partial q}{(2\varkappa-\partial)^2(4\kappa^2 - \partial^2)}\, g_{21}^{[3]}(\varkappa) (\psi_h^{12})" \,dx\right\|_{L^1_t}. \end{align*} $$
Using (5.27) again, we see that the contribution arising from the first two terms above is acceptable. For the last term, we estimate
 $$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \tfrac{(2\varkappa + \partial)\partial q}{(2\varkappa-\partial)^2(4\kappa^2 - \partial^2)}\, g_{21}^{[3]}(\varkappa) (\psi_h^{12})" \,dx\right\|_{L^1_t}\\ &\, \lesssim \tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2} \big\| \tfrac{(2\varkappa + \partial)\partial}{(2\varkappa-\partial)^2(4\kappa^2 - \partial^2)}q\big\|_{L^\infty_t H^{-(1+s)}} \big\|g_{21}^{[3]}(\varkappa)\big\|_{L^\infty_t H^{1+s}}\lesssim |\varkappa|^{-2(2s+1)} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
$$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2}\left\|\int \tfrac{(2\varkappa + \partial)\partial q}{(2\varkappa-\partial)^2(4\kappa^2 - \partial^2)}\, g_{21}^{[3]}(\varkappa) (\psi_h^{12})" \,dx\right\|_{L^1_t}\\ &\, \lesssim \tfrac{\kappa^2\varkappa^2}{\kappa^2+ \varkappa^2} \big\| \tfrac{(2\varkappa + \partial)\partial}{(2\varkappa-\partial)^2(4\kappa^2 - \partial^2)}q\big\|_{L^\infty_t H^{-(1+s)}} \big\|g_{21}^{[3]}(\varkappa)\big\|_{L^\infty_t H^{1+s}}\lesssim |\varkappa|^{-2(2s+1)} \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*} $$
Collecting the estimates above, we obtain
 $$\begin{align*}\left\|\int \mathbf{err}_1\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \mathrm{RHS}({5.11}). \end{align*}$$
$$\begin{align*}\left\|\int \mathbf{err}_1\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \mathrm{RHS}({5.11}). \end{align*}$$
For
 $\mathbf {err}_3$
, we start by writing
$\mathbf {err}_3$
, we start by writing
 $$ \begin{align*} \mathbf{err}_3 &= \tfrac{4\kappa^5}{\kappa^2 - \varkappa^2}\big(g_{12}(\kappa)^{[\geq 3]} - g_{12}(-\kappa)^{[\geq 3]} - \tfrac1{2\kappa^3}q^2r\big)\,\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\\ &\quad + \tfrac{4\kappa^4\varkappa}{\kappa^2 - \varkappa^2}\big(g_{12}(\kappa)^{[\geq 3]} + g_{12}(-\kappa)^{[\geq 3]}\big)\,\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}. \end{align*} $$
$$ \begin{align*} \mathbf{err}_3 &= \tfrac{4\kappa^5}{\kappa^2 - \varkappa^2}\big(g_{12}(\kappa)^{[\geq 3]} - g_{12}(-\kappa)^{[\geq 3]} - \tfrac1{2\kappa^3}q^2r\big)\,\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\\ &\quad + \tfrac{4\kappa^4\varkappa}{\kappa^2 - \varkappa^2}\big(g_{12}(\kappa)^{[\geq 3]} + g_{12}(-\kappa)^{[\geq 3]}\big)\,\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}. \end{align*} $$
We then apply the estimates (5.44) and (5.45) with
 $f=(2\varkappa +\partial )\frac {g_{21}(\varkappa )}{2 + \gamma (\varkappa )}$
together with (3.41) and (3.43) to bound
$f=(2\varkappa +\partial )\frac {g_{21}(\varkappa )}{2 + \gamma (\varkappa )}$
together with (3.41) and (3.43) to bound
 $$\begin{align*}\left\|\int \mathbf{err}_3\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*}$$
$$\begin{align*}\left\|\int \mathbf{err}_3\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*}$$
For
 $\mathbf {err}_5$
, we may write
$\mathbf {err}_5$
, we may write
 $$ \begin{align*} \mathbf{err}_5 &= - \tfrac{2\kappa^5}{\kappa^2 - \varkappa^2}\Big(\gamma(\kappa)^{[\geq 4]} - \gamma(-\kappa)^{[\geq 4]}\Big) \\ &\quad - \tfrac{2\kappa^4\varkappa}{\kappa^2 - \varkappa^2}\Big(\gamma(\kappa)^{[\geq 4]} + \gamma(-\kappa)^{[\geq 4]} - \tfrac3{2\kappa^2}qr\big(q\cdot\tfrac r{4\kappa^2 - \partial^2} + r\cdot\tfrac q{4\kappa^2 - \partial^2}\big)\Big) \end{align*} $$
$$ \begin{align*} \mathbf{err}_5 &= - \tfrac{2\kappa^5}{\kappa^2 - \varkappa^2}\Big(\gamma(\kappa)^{[\geq 4]} - \gamma(-\kappa)^{[\geq 4]}\Big) \\ &\quad - \tfrac{2\kappa^4\varkappa}{\kappa^2 - \varkappa^2}\Big(\gamma(\kappa)^{[\geq 4]} + \gamma(-\kappa)^{[\geq 4]} - \tfrac3{2\kappa^2}qr\big(q\cdot\tfrac r{4\kappa^2 - \partial^2} + r\cdot\tfrac q{4\kappa^2 - \partial^2}\big)\Big) \end{align*} $$
and then use (5.47) and (5.48) to bound
 $$\begin{align*}\left\|\int \mathbf{err}_5\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*}$$
$$\begin{align*}\left\|\int \mathbf{err}_5\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \tfrac\kappa{\kappa + \varkappa}\kappa^{-(2s+1)}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2. \end{align*}$$
For
 $\mathbf {err}_6$
, we first apply the estimate (5.42) to bound
$\mathbf {err}_6$
, we first apply the estimate (5.42) to bound
 $$ \begin{align*} &\left\|\int \tfrac{4\varkappa^4}{\kappa^2 - \varkappa^2}r\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\,\psi_h^{12}\,dx\right\|_{L^1_t} \\ &\qquad\lesssim \tfrac{\varkappa^{-(s+\frac12)}}{\kappa^2 + \varkappa^2}\big[\kappa^{\frac34-\frac{5s}2}+ \varkappa^{-(\frac12+5s)}\log^6|2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2\lesssim \mathrm{RHS}({5.11}). \end{align*} $$
$$ \begin{align*} &\left\|\int \tfrac{4\varkappa^4}{\kappa^2 - \varkappa^2}r\cdot\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\,\psi_h^{12}\,dx\right\|_{L^1_t} \\ &\qquad\lesssim \tfrac{\varkappa^{-(s+\frac12)}}{\kappa^2 + \varkappa^2}\big[\kappa^{\frac34-\frac{5s}2}+ \varkappa^{-(\frac12+5s)}\log^6|2\varkappa|\big]\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2\lesssim \mathrm{RHS}({5.11}). \end{align*} $$
Next, we use (3.20) and
 $[\psi _h^{12},\tfrac {\partial }{2\varkappa - \partial }] = -\frac {2\varkappa }{2\varkappa - \partial }(\psi _h^{12})'\frac 1{2\varkappa - \partial }$
to write
$[\psi _h^{12},\tfrac {\partial }{2\varkappa - \partial }] = -\frac {2\varkappa }{2\varkappa - \partial }(\psi _h^{12})'\frac 1{2\varkappa - \partial }$
to write
 $$ \begin{align*} \psi_h^{12}\,q^2r &= \psi_h^{12}\,4\varkappa^3g_{12}^{[3]}(\varkappa) + \tfrac{4\varkappa^3}{2\varkappa - \partial}\big[(\psi_h^{12})'g_{12}^{[3]}(\varkappa)\big]\\ &\quad - \tfrac{\partial}{2\varkappa - \partial}\big[\psi_h^{12}q\tfrac{2\varkappa r}{2\varkappa + \partial}\tfrac{2\varkappa q}{2\varkappa - \partial}\big] + \psi_h^{12}\,q\tfrac{r'}{2\varkappa + \partial}\tfrac{2\varkappa q}{2\varkappa - \partial} - \psi_h^{12}\,qr\tfrac{q'}{2\varkappa - \partial}. \end{align*} $$
$$ \begin{align*} \psi_h^{12}\,q^2r &= \psi_h^{12}\,4\varkappa^3g_{12}^{[3]}(\varkappa) + \tfrac{4\varkappa^3}{2\varkappa - \partial}\big[(\psi_h^{12})'g_{12}^{[3]}(\varkappa)\big]\\ &\quad - \tfrac{\partial}{2\varkappa - \partial}\big[\psi_h^{12}q\tfrac{2\varkappa r}{2\varkappa + \partial}\tfrac{2\varkappa q}{2\varkappa - \partial}\big] + \psi_h^{12}\,q\tfrac{r'}{2\varkappa + \partial}\tfrac{2\varkappa q}{2\varkappa - \partial} - \psi_h^{12}\,qr\tfrac{q'}{2\varkappa - \partial}. \end{align*} $$
From Corollary 3.5 and elementary manipulations, we have
 $$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert \tfrac1{2\varkappa + \partial} \big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]} \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim \varkappa^{-3-2s}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*}$$
$$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert \tfrac1{2\varkappa + \partial} \big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]} \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}\lesssim \varkappa^{-3-2s}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}. \end{align*}$$
Thus, by taking
 $m_1(\xi ) = \frac {i\xi _2}{2\kappa + i\xi _2}$
,
$m_1(\xi ) = \frac {i\xi _2}{2\kappa + i\xi _2}$
,
 $m_2(\xi ) = \frac {i\xi _3}{2\kappa - i\xi _3}$
, and applying (5.43) to the first term, (5.41) to the second, and (5.27), (3.42), and (3.44) to the remaining terms, we have
$m_2(\xi ) = \frac {i\xi _3}{2\kappa - i\xi _3}$
, and applying (5.43) to the first term, (5.41) to the second, and (5.27), (3.42), and (3.44) to the remaining terms, we have
 $$ \begin{align*} &\left\|\int \tfrac{2\varkappa^2}{\kappa^2 - \varkappa^2}q^2r\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim\tfrac{\varkappa^5}{\kappa^2 + \varkappa^2}\left\|\int g_{12}^{[3]}(\varkappa)\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\quad + \tfrac{\varkappa^5}{\kappa^2 + \varkappa^2}\left\|\int (\psi_h^{12})'g_{12}^{[3]}(\varkappa) \cdot \tfrac 1{2\varkappa + \partial} \big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,dx\right\|_{L^1_t}\\ &\qquad\quad + \tfrac{\varkappa^3}{\kappa^2 + \varkappa^2}\left\|\int m_1\Big[q,\tfrac{2\kappa + \partial}{2\varkappa + \partial}\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]},\tfrac{2\varkappa q}{2\varkappa - \partial},\tfrac{r}{2\varkappa + \partial}\Big]\,\psi^{12}_h\,dx\right\|_{L^1_t}\\ &\qquad\quad + \tfrac{\varkappa^2}{\kappa^2 + \varkappa^2}\left\|\int m_1\Big[q,\tfrac{2\kappa + \partial}{2\varkappa + \partial}r,\tfrac{2\varkappa q}{2\varkappa - \partial},\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\Big]\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\quad + \tfrac{\varkappa^2}{\kappa^2 + \varkappa^2}\left\|\int m_2\Big[q,r,\tfrac{2\kappa - \partial}{2\varkappa - \partial}q,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\Big]\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim\mathrm{RHS}({5.11}). \end{align*} $$
$$ \begin{align*} &\left\|\int \tfrac{2\varkappa^2}{\kappa^2 - \varkappa^2}q^2r\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim\tfrac{\varkappa^5}{\kappa^2 + \varkappa^2}\left\|\int g_{12}^{[3]}(\varkappa)\,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\quad + \tfrac{\varkappa^5}{\kappa^2 + \varkappa^2}\left\|\int (\psi_h^{12})'g_{12}^{[3]}(\varkappa) \cdot \tfrac 1{2\varkappa + \partial} \big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\,dx\right\|_{L^1_t}\\ &\qquad\quad + \tfrac{\varkappa^3}{\kappa^2 + \varkappa^2}\left\|\int m_1\Big[q,\tfrac{2\kappa + \partial}{2\varkappa + \partial}\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]},\tfrac{2\varkappa q}{2\varkappa - \partial},\tfrac{r}{2\varkappa + \partial}\Big]\,\psi^{12}_h\,dx\right\|_{L^1_t}\\ &\qquad\quad + \tfrac{\varkappa^2}{\kappa^2 + \varkappa^2}\left\|\int m_1\Big[q,\tfrac{2\kappa + \partial}{2\varkappa + \partial}r,\tfrac{2\varkappa q}{2\varkappa - \partial},\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\Big]\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\quad + \tfrac{\varkappa^2}{\kappa^2 + \varkappa^2}\left\|\int m_2\Big[q,r,\tfrac{2\kappa - \partial}{2\varkappa - \partial}q,\big(\tfrac{g_{21}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\Big]\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim\mathrm{RHS}({5.11}). \end{align*} $$
For
 $\mathbf {err}_7$
, we first observe that
$\mathbf {err}_7$
, we first observe that
 $$ \begin{align*} &-\tfrac{2\varkappa^4}{\kappa^2-\varkappa^2}\int qg_{21}^{[3]}(\varkappa)\,\psi_h^{12}\, dx\\ &\qquad= \tfrac{4\varkappa^4}{\kappa^2-\varkappa^2}\int \tfrac{q}{2\varkappa-\partial}\tfrac{r}{2\varkappa+\partial}\tfrac{q}{2\varkappa-\partial}\, r\,\psi_h^{12}\,dx - \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2}\int \tfrac{q}{2\varkappa-\partial}g_{21}^{[3]}(\varkappa)\,(\psi_h^{12})'\, dx. \end{align*} $$
$$ \begin{align*} &-\tfrac{2\varkappa^4}{\kappa^2-\varkappa^2}\int qg_{21}^{[3]}(\varkappa)\,\psi_h^{12}\, dx\\ &\qquad= \tfrac{4\varkappa^4}{\kappa^2-\varkappa^2}\int \tfrac{q}{2\varkappa-\partial}\tfrac{r}{2\varkappa+\partial}\tfrac{q}{2\varkappa-\partial}\, r\,\psi_h^{12}\,dx - \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2}\int \tfrac{q}{2\varkappa-\partial}g_{21}^{[3]}(\varkappa)\,(\psi_h^{12})'\, dx. \end{align*} $$
Applying (5.41), the second integral contributes a constant multiple of
 $$ \begin{align*}\tfrac{1}{\kappa^2+\varkappa^2}\big[ \kappa^{\frac12-2s} +\varkappa^{-(1+4s)}\log^4|2\varkappa| \big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2\lesssim\mathrm{RHS}({5.11}). \end{align*} $$
$$ \begin{align*}\tfrac{1}{\kappa^2+\varkappa^2}\big[ \kappa^{\frac12-2s} +\varkappa^{-(1+4s)}\log^4|2\varkappa| \big]\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa}^2\lesssim\mathrm{RHS}({5.11}). \end{align*} $$
Thus, the remaining quartic terms are
 $$ \begin{align*} - \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}q^2r\tfrac r{4\kappa^2 - \partial^2} + \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2} \tfrac{q}{2\varkappa-\partial}\tfrac{r}{2\varkappa+\partial}\tfrac{q}{2\varkappa-\partial}\, r +\tfrac{\varkappa^2}{\kappa^2-\varkappa^2}q^2r\tfrac{r}{2\varkappa+\partial}. \end{align*} $$
$$ \begin{align*} - \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}q^2r\tfrac r{4\kappa^2 - \partial^2} + \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2} \tfrac{q}{2\varkappa-\partial}\tfrac{r}{2\varkappa+\partial}\tfrac{q}{2\varkappa-\partial}\, r +\tfrac{\varkappa^2}{\kappa^2-\varkappa^2}q^2r\tfrac{r}{2\varkappa+\partial}. \end{align*} $$
A quick computation shows that
 $$ \begin{align*} &- \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}q^2r\tfrac r{4\kappa^2 - \partial^2}+\tfrac{\varkappa^2}{\kappa^2-\varkappa^2}q^2r\tfrac{r}{2\varkappa+\partial}\\ &\qquad =-\tfrac{2\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} q^2\tfrac{r}{4\kappa^2 - \partial^2}\tfrac r{2\varkappa + \partial} -\tfrac{6\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} m_1\big[q,\tfrac{2\kappa+\partial}{2\varkappa+\partial}r,q,\tfrac r{2\varkappa+\partial}\big]\\ &\qquad\quad - \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}m_2\big[q,\tfrac{r'}{2\varkappa+\partial},q,\tfrac r{2\varkappa+\partial}\big]-\tfrac{\varkappa^2}{\kappa^2-\varkappa^2}m_3\big[q,r,q,\tfrac{r}{2\varkappa+\partial}\big], \end{align*} $$
$$ \begin{align*} &- \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}q^2r\tfrac r{4\kappa^2 - \partial^2}+\tfrac{\varkappa^2}{\kappa^2-\varkappa^2}q^2r\tfrac{r}{2\varkappa+\partial}\\ &\qquad =-\tfrac{2\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} q^2\tfrac{r}{4\kappa^2 - \partial^2}\tfrac r{2\varkappa + \partial} -\tfrac{6\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} m_1\big[q,\tfrac{2\kappa+\partial}{2\varkappa+\partial}r,q,\tfrac r{2\varkappa+\partial}\big]\\ &\qquad\quad - \tfrac{3\kappa^2\varkappa}{\kappa^2 - \varkappa^2}m_2\big[q,\tfrac{r'}{2\varkappa+\partial},q,\tfrac r{2\varkappa+\partial}\big]-\tfrac{\varkappa^2}{\kappa^2-\varkappa^2}m_3\big[q,r,q,\tfrac{r}{2\varkappa+\partial}\big], \end{align*} $$
where
 $m_1(\xi )= \frac {i\xi _2}{2\kappa +i\xi _2} \frac {1}{4\kappa ^2 + \xi _4^2}$
,
$m_1(\xi )= \frac {i\xi _2}{2\kappa +i\xi _2} \frac {1}{4\kappa ^2 + \xi _4^2}$
,
 $m_2(\xi ) = \frac {i\xi _4}{4\kappa ^2 + \xi _4^2}$
and
$m_2(\xi ) = \frac {i\xi _4}{4\kappa ^2 + \xi _4^2}$
and
 $m_3(\xi )= \frac {(i\xi _2)^2}{4\kappa ^2+\xi _2^2}$
. To continue, we observe that
$m_3(\xi )= \frac {(i\xi _2)^2}{4\kappa ^2+\xi _2^2}$
. To continue, we observe that
 $$ \begin{align*} &-\tfrac{2\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} q^2\tfrac{r}{4\kappa^2 - \partial^2}\tfrac r{2\varkappa + \partial} + \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2} \tfrac{q}{2\varkappa-\partial}\tfrac{r}{2\varkappa+\partial}\tfrac{q}{2\varkappa-\partial}\,r\\ &\qquad=\tfrac{4\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} m_4\big[\tfrac{2\kappa-\partial}{2\varkappa-\partial}q,r,\tfrac{2\varkappa q}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big] -\tfrac{2\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} m_4\big[\tfrac{2\kappa-\partial}{2\varkappa-\partial}q,r,\tfrac{q'}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big]\\ &\qquad \quad -\tfrac{\varkappa^2}{2(\kappa^2-\varkappa^2)}m_3\big[\tfrac{2\varkappa q}{2\varkappa-\partial},r,\tfrac{2\varkappa q}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big], \end{align*} $$
$$ \begin{align*} &-\tfrac{2\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} q^2\tfrac{r}{4\kappa^2 - \partial^2}\tfrac r{2\varkappa + \partial} + \tfrac{2\varkappa^4}{\kappa^2-\varkappa^2} \tfrac{q}{2\varkappa-\partial}\tfrac{r}{2\varkappa+\partial}\tfrac{q}{2\varkappa-\partial}\,r\\ &\qquad=\tfrac{4\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} m_4\big[\tfrac{2\kappa-\partial}{2\varkappa-\partial}q,r,\tfrac{2\varkappa q}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big] -\tfrac{2\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2} m_4\big[\tfrac{2\kappa-\partial}{2\varkappa-\partial}q,r,\tfrac{q'}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big]\\ &\qquad \quad -\tfrac{\varkappa^2}{2(\kappa^2-\varkappa^2)}m_3\big[\tfrac{2\varkappa q}{2\varkappa-\partial},r,\tfrac{2\varkappa q}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big], \end{align*} $$
where
 $m_4(\xi ) = \frac {i\xi _1}{2\kappa -i\xi _1} \frac {1}{4\kappa ^2+\xi _2^2}$
. Applying the estimate (5.27), we obtain
$m_4(\xi ) = \frac {i\xi _1}{2\kappa -i\xi _1} \frac {1}{4\kappa ^2+\xi _2^2}$
. Applying the estimate (5.27), we obtain
 $$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_1\big[q,\tfrac{2\kappa+\partial}{2\varkappa+\partial}r,q,\tfrac r{2\varkappa + \partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\qquad + \tfrac{\kappa^2\varkappa}{\kappa^2 +\varkappa^2}\left\|\int m_2\big[q,\tfrac{r'}{2\varkappa+\partial},q,\tfrac r{2\varkappa + \partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\qquad+\tfrac{\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_3\big[q,r,q,\tfrac{r}{2\varkappa+\partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\qquad + \tfrac{\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_3\big[\tfrac{\varkappa q}{2\varkappa-\partial},r,\tfrac{\varkappa q}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t} \\ &\qquad\qquad+ \tfrac{\kappa^2\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_4\big[\tfrac{2\kappa-\partial}{2\varkappa-\partial}q,r,\tfrac{\varkappa q}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t} \\ &\qquad\qquad+ \tfrac{\kappa^2\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_4\big[\tfrac{2\kappa-\partial}{2\varkappa-\partial}q,r,\tfrac{q'}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \mathrm{RHS}({5.11}). \end{align*} $$
$$ \begin{align*} &\tfrac{\kappa^2\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_1\big[q,\tfrac{2\kappa+\partial}{2\varkappa+\partial}r,q,\tfrac r{2\varkappa + \partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\qquad + \tfrac{\kappa^2\varkappa}{\kappa^2 +\varkappa^2}\left\|\int m_2\big[q,\tfrac{r'}{2\varkappa+\partial},q,\tfrac r{2\varkappa + \partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\qquad+\tfrac{\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_3\big[q,r,q,\tfrac{r}{2\varkappa+\partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\qquad + \tfrac{\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_3\big[\tfrac{\varkappa q}{2\varkappa-\partial},r,\tfrac{\varkappa q}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t} \\ &\qquad\qquad+ \tfrac{\kappa^2\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_4\big[\tfrac{2\kappa-\partial}{2\varkappa-\partial}q,r,\tfrac{\varkappa q}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t} \\ &\qquad\qquad+ \tfrac{\kappa^2\varkappa^2}{\kappa^2 +\varkappa^2}\left\|\int m_4\big[\tfrac{2\kappa-\partial}{2\varkappa-\partial}q,r,\tfrac{q'}{2\varkappa-\partial},\tfrac{r}{2\varkappa+\partial}\big]\,\psi_h^{12}\,dx\right\|_{L^1_t} \lesssim \mathrm{RHS}({5.11}). \end{align*} $$
Collecting all our bounds, we obtain the estimate (5.11).
6. Tightness
Let
 $\chi \in \mathcal C^\infty _c$
be an even nonnegative function supported in
$\chi \in \mathcal C^\infty _c$
be an even nonnegative function supported in
 $\{|x|\leq 1\}$
with
$\{|x|\leq 1\}$
with
 $\|\chi \|_{L^1} = 1$
, and define
$\|\chi \|_{L^1} = 1$
, and define
 $$\begin{align*}\phi(x) = \int_0^{|x|} \chi(y-2)\,dy. \end{align*}$$
$$\begin{align*}\phi(x) = \int_0^{|x|} \chi(y-2)\,dy. \end{align*}$$
For
 $R\geq 1$
, we define the rescaled function
$R\geq 1$
, we define the rescaled function
 $\phi _R(x) = \phi (\frac xR)$
. Notice that
$\phi _R(x) = \phi (\frac xR)$
. Notice that
 $\phi _R$
plays the role of a smooth cut-off to large
$\phi _R$
plays the role of a smooth cut-off to large
 $|x|$
and so leads naturally to the following formulation of tightness:
$|x|$
and so leads naturally to the following formulation of tightness:
Definition 6.1. A bounded subset
 $Q\subset H^s$
is tight in
$Q\subset H^s$
is tight in
 $H^s$
if
$H^s$
if
 $$\begin{align*}\phi_Rq\rightarrow 0\text{ in }H^s\text{ as }R\rightarrow \infty, \text{ uniformly for }q\in Q. \end{align*}$$
$$\begin{align*}\phi_Rq\rightarrow 0\text{ in }H^s\text{ as }R\rightarrow \infty, \text{ uniformly for }q\in Q. \end{align*}$$
We first prove that tightness of q implies tightness of
 $g_{12}$
:
$g_{12}$
:
Lemma 6.2. For
 $\delta>0$
sufficiently small,
$\delta>0$
sufficiently small,
 $$ \begin{align} \|\phi_Rg_{12}\|_{H^{s+1}_\varkappa} &\lesssim \|\phi_Rq\|_{H^s_\varkappa} + (|\varkappa| R)^{-1}\|q\|_{H^s_\varkappa}, \end{align} $$
$$ \begin{align} \|\phi_Rg_{12}\|_{H^{s+1}_\varkappa} &\lesssim \|\phi_Rq\|_{H^s_\varkappa} + (|\varkappa| R)^{-1}\|q\|_{H^s_\varkappa}, \end{align} $$
 $$ \begin{align} \|\phi_Rg_{12}^{[\geq 3]}\|_{H^{s+1}_\varkappa} &\lesssim |\varkappa|^{-(2s+1)}\delta^2\Big(\|\phi_Rq\|_{H^s_\varkappa} + (|\varkappa| R)^{-1}\|q\|_{H^s_\varkappa}\Big), \end{align} $$
$$ \begin{align} \|\phi_Rg_{12}^{[\geq 3]}\|_{H^{s+1}_\varkappa} &\lesssim |\varkappa|^{-(2s+1)}\delta^2\Big(\|\phi_Rq\|_{H^s_\varkappa} + (|\varkappa| R)^{-1}\|q\|_{H^s_\varkappa}\Big), \end{align} $$
 $$ \begin{align} \|\phi_R\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\|_{H^{s+1}_\varkappa} &\lesssim |\varkappa|^{-(2s+1)}\delta^2\Big(\|\phi_Rq\|_{H^s_\varkappa} + (|\varkappa| R)^{-1}\|q\|_{H^s_\varkappa}\Big), \end{align} $$
$$ \begin{align} \|\phi_R\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\|_{H^{s+1}_\varkappa} &\lesssim |\varkappa|^{-(2s+1)}\delta^2\Big(\|\phi_Rq\|_{H^s_\varkappa} + (|\varkappa| R)^{-1}\|q\|_{H^s_\varkappa}\Big), \end{align} $$
uniformly for
 $|\varkappa |\geq 1$
,
$|\varkappa |\geq 1$
,
 $R\geq 1$
, and
$R\geq 1$
, and
 $q\in B_\delta $
. Here,
$q\in B_\delta $
. Here,
 $g_{12} = g_{12}(\varkappa )$
and
$g_{12} = g_{12}(\varkappa )$
and
 $\gamma = \gamma (\varkappa )$
.
$\gamma = \gamma (\varkappa )$
.
Proof. Using the identity (3.12), we write
 $$\begin{align*}\phi_Rg_{12} = - \tfrac1{2\varkappa - \partial}\big(\phi_Rq(1 + \gamma)\big) - \tfrac1{2\varkappa - \partial}\big(\phi_R'g_{12}\big), \end{align*}$$
$$\begin{align*}\phi_Rg_{12} = - \tfrac1{2\varkappa - \partial}\big(\phi_Rq(1 + \gamma)\big) - \tfrac1{2\varkappa - \partial}\big(\phi_R'g_{12}\big), \end{align*}$$
so the estimate (6.1) follows from the estimates (3.24) and (3.27).
Similarly, the estimate (6.2) follows from the identity
 $$\begin{align*}\phi_Rg_{12}^{[\geq 3]} = - \tfrac1{2\varkappa - \partial}\big(\phi_Rq\gamma\big) - \tfrac1{2\varkappa - \partial}\big(\phi_R'g_{12}^{[\geq 3]}\big) \end{align*}$$
$$\begin{align*}\phi_Rg_{12}^{[\geq 3]} = - \tfrac1{2\varkappa - \partial}\big(\phi_Rq\gamma\big) - \tfrac1{2\varkappa - \partial}\big(\phi_R'g_{12}^{[\geq 3]}\big) \end{align*}$$
and the estimates (3.25) and (3.27). The estimate (6.3) is then a corollary of the estimates (6.1), (6.2), (2.5), and (3.39).
We will prove tightness for solutions of (NLS) and (mKdV) by considering the equation satisfied by
 $\operatorname {Re}\rho (\varkappa )$
. Our next lemma shows that this is a suitable quantity to consider. The utility of this density should not be conflated with that of the currents used to prove the local smoothing effect. In particular, in the (NLS) setting, it is the imaginary part of
$\operatorname {Re}\rho (\varkappa )$
. Our next lemma shows that this is a suitable quantity to consider. The utility of this density should not be conflated with that of the currents used to prove the local smoothing effect. In particular, in the (NLS) setting, it is the imaginary part of
 $\rho $
that is used to prove local smoothing.
$\rho $
that is used to prove local smoothing.
Lemma 6.3. For
 $\delta $
sufficiently small, we have
$\delta $
sufficiently small, we have
 $$ \begin{align} \|\phi_Rq\|_{H^s}^2\approx \int_1^\kappa \varkappa^{2s+1}\Big(\pm \operatorname{Re}\int \rho\,\phi_R^2\,dx\Big)\,\tfrac{d\varkappa}{\varkappa} + \mathcal O\Big(R^{-2}\|q\|_{H^s}^2 + \|q\|_{H^s_\kappa}^2\Big), \end{align} $$
$$ \begin{align} \|\phi_Rq\|_{H^s}^2\approx \int_1^\kappa \varkappa^{2s+1}\Big(\pm \operatorname{Re}\int \rho\,\phi_R^2\,dx\Big)\,\tfrac{d\varkappa}{\varkappa} + \mathcal O\Big(R^{-2}\|q\|_{H^s}^2 + \|q\|_{H^s_\kappa}^2\Big), \end{align} $$
uniformly for
 $q\in B_\delta \cap \mathcal {S}$
,
$q\in B_\delta \cap \mathcal {S}$
,
 $R\geq 1$
, and
$R\geq 1$
, and
 $\kappa \geq 1$
.
$\kappa \geq 1$
.
Proof. As in the proof of Lemma 5.1, we write
 $$\begin{align*}\rho^{[2]} = \mathbf R[q,r] = \tfrac12\big(q\cdot\tfrac r{2\varkappa + \partial} + \tfrac q{2\varkappa - \partial}\cdot r\big) \end{align*}$$
$$\begin{align*}\rho^{[2]} = \mathbf R[q,r] = \tfrac12\big(q\cdot\tfrac r{2\varkappa + \partial} + \tfrac q{2\varkappa - \partial}\cdot r\big) \end{align*}$$
and compute that
 $$\begin{align*}\operatorname{Re} \int \mathbf R[\phi_R q,\phi_R r]\,dx = \pm 2\varkappa\|\phi_Rq\|_{H^{-1}_\varkappa}^2. \end{align*}$$
$$\begin{align*}\operatorname{Re} \int \mathbf R[\phi_R q,\phi_R r]\,dx = \pm 2\varkappa\|\phi_Rq\|_{H^{-1}_\varkappa}^2. \end{align*}$$
Applying Lemma 2.1, we then obtain
 $$\begin{align*}\|\phi_Rq\|_{H^s}^2\approx \int_1^\kappa \varkappa^{2s+1}\Big(\pm \operatorname{Re} \int \mathbf R[\phi_R q,\phi_R r]\,dx\Big)\,\tfrac{d\varkappa}{\varkappa} + \mathcal O\Big(\|q\|_{H^s_\kappa}^2\Big). \end{align*}$$
$$\begin{align*}\|\phi_Rq\|_{H^s}^2\approx \int_1^\kappa \varkappa^{2s+1}\Big(\pm \operatorname{Re} \int \mathbf R[\phi_R q,\phi_R r]\,dx\Big)\,\tfrac{d\varkappa}{\varkappa} + \mathcal O\Big(\|q\|_{H^s_\kappa}^2\Big). \end{align*}$$
It remains to bound the contribution of the difference
 $$ \begin{align*} \int \rho\,\phi_R^2\,dx - \int \mathbf R[\phi_R q,\phi_R r]\,dx &= \int \Big(\mathbf R[q,r]\,\phi_R^2 - \mathbf R[\phi_R q,\phi_R r]\Big)\,dx\\ &\quad + \int \Big(q\cdot \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} - r\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\Big)\,\phi_R^2\,dx. \end{align*} $$
$$ \begin{align*} \int \rho\,\phi_R^2\,dx - \int \mathbf R[\phi_R q,\phi_R r]\,dx &= \int \Big(\mathbf R[q,r]\,\phi_R^2 - \mathbf R[\phi_R q,\phi_R r]\Big)\,dx\\ &\quad + \int \Big(q\cdot \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} - r\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\Big)\,\phi_R^2\,dx. \end{align*} $$
For the first term, we bound
 $$ \begin{align*} \left|\int \Big(\mathbf R[q,r]\,\phi_R^2 - \mathbf R[\phi_R q,\phi_R r]\Big)\,dx\right| &\lesssim \|\phi_R q\|_{H_\varkappa^s} \big\| \big[ \phi_R, \tfrac1{2\varkappa-\partial}\big]q\big\|_{H_\varkappa^{-s}}\\ &\lesssim \varkappa^{-(1+2s)} (\varkappa R)^{-1}\|\phi_R q\|_{H^s_\varkappa}\|q\|_{H^s_\varkappa}. \end{align*} $$
$$ \begin{align*} \left|\int \Big(\mathbf R[q,r]\,\phi_R^2 - \mathbf R[\phi_R q,\phi_R r]\Big)\,dx\right| &\lesssim \|\phi_R q\|_{H_\varkappa^s} \big\| \big[ \phi_R, \tfrac1{2\varkappa-\partial}\big]q\big\|_{H_\varkappa^{-s}}\\ &\lesssim \varkappa^{-(1+2s)} (\varkappa R)^{-1}\|\phi_R q\|_{H^s_\varkappa}\|q\|_{H^s_\varkappa}. \end{align*} $$
For the second term, we apply the estimate (6.3) and Young’s inequality to bound
 $$ \begin{align*} \left|\int q\, \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\,\phi_R^2\,dx\right| &\lesssim \varkappa^{-(2s+1)}\|\phi_R q\|_{H^s_\varkappa}\|\phi_R\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\|_{H^{s+1}_\varkappa}\\ &\lesssim \varkappa^{-2(2s+1)}\delta^2\|\phi_Rq\|_{H^s_\varkappa}^2 + \varkappa^{-2(2s+1)}(\varkappa R)^{-2}\delta^2\|q\|_{H^s_\varkappa}^2. \end{align*} $$
$$ \begin{align*} \left|\int q\, \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\,\phi_R^2\,dx\right| &\lesssim \varkappa^{-(2s+1)}\|\phi_R q\|_{H^s_\varkappa}\|\phi_R\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\|_{H^{s+1}_\varkappa}\\ &\lesssim \varkappa^{-2(2s+1)}\delta^2\|\phi_Rq\|_{H^s_\varkappa}^2 + \varkappa^{-2(2s+1)}(\varkappa R)^{-2}\delta^2\|q\|_{H^s_\varkappa}^2. \end{align*} $$
As a consequence, we may integrate to obtain
 $$ \begin{align*} &\int_1^\kappa\varkappa^{2s+1}\left|\int \rho\,\phi_R^2\,dx - \operatorname{Re} \int \mathbf R[\phi_R q,\phi_R r]\,dx\right|\,\tfrac{d\varkappa}\varkappa\\ &\qquad\qquad\qquad\lesssim R^{-1}\|\phi_Rq\|_{H^s}\|q\|_{H^s} + \delta^2\|\phi_Rq\|_{H^s}^2 + \delta^2R^{-2}\|q\|^2_{H^s}, \end{align*} $$
$$ \begin{align*} &\int_1^\kappa\varkappa^{2s+1}\left|\int \rho\,\phi_R^2\,dx - \operatorname{Re} \int \mathbf R[\phi_R q,\phi_R r]\,dx\right|\,\tfrac{d\varkappa}\varkappa\\ &\qquad\qquad\qquad\lesssim R^{-1}\|\phi_Rq\|_{H^s}\|q\|_{H^s} + \delta^2\|\phi_Rq\|_{H^s}^2 + \delta^2R^{-2}\|q\|^2_{H^s}, \end{align*} $$
from which we derive the estimate (6.4) by taking
 $\delta $
sufficiently small.
$\delta $
sufficiently small.
We now arrive at the center piece of this section:
Proposition 6.4 (Tightness of the flows).
For
 $\delta>0$
sufficiently small, the following holds: If
$\delta>0$
sufficiently small, the following holds: If
 $Q\subset B_\delta \cap \mathcal {S}$
is tight and equicontinuous in
$Q\subset B_\delta \cap \mathcal {S}$
is tight and equicontinuous in
 $H^s$
, then
$H^s$
, then
 $$\begin{align*}\Big\{q(t) = e^{tJ\nabla H_\star}q:q\in Q,\;t\in [-1,1]\Big\}\quad\text{is tight in} H^s. \end{align*}$$
$$\begin{align*}\Big\{q(t) = e^{tJ\nabla H_\star}q:q\in Q,\;t\in [-1,1]\Big\}\quad\text{is tight in} H^s. \end{align*}$$
Here,
 $\star =\mathrm {NLS},\mathrm {mKdV}$
.
$\star =\mathrm {NLS},\mathrm {mKdV}$
.
We will prove this result for each of the two flows separately. One element common to both is the following: For
 $\sigma = s+\frac 12$
or
$\sigma = s+\frac 12$
or
 $\sigma = s+1$
, we have
$\sigma = s+1$
, we have
 $$ \begin{align} \|\psi_h^6(\phi_R^2)' F\|_{L_h^1L_t^2H^\sigma}&\lesssim \|\psi_h^3(\phi_R^2)'\|_{L^1_hH^1}\|\psi_h^3F\|_{L^\infty_hL^2_tH^\sigma} \lesssim \|F\|_{X^\sigma}. \end{align} $$
$$ \begin{align} \|\psi_h^6(\phi_R^2)' F\|_{L_h^1L_t^2H^\sigma}&\lesssim \|\psi_h^3(\phi_R^2)'\|_{L^1_hH^1}\|\psi_h^3F\|_{L^\infty_hL^2_tH^\sigma} \lesssim \|F\|_{X^\sigma}. \end{align} $$
Proof of Proposition 6.4 for (NLS).
Taking
 $t\in [-1,1]$
and
$t\in [-1,1]$
and
 $R\geq 1$
, we multiply the equation (4.37) by
$R\geq 1$
, we multiply the equation (4.37) by
 $\phi _R^2$
, take the real part, and integrate by parts to obtain
$\phi _R^2$
, take the real part, and integrate by parts to obtain
 $$ \begin{align} \operatorname{Re}\int \big[\rho(t) - \rho(0)\big]\, \phi_R^2\,dx = \operatorname{Re}\int_0^t \int j_{\mathrm{NLS}}\,(\phi_R^2)' \,dx\,d\tau. \end{align} $$
$$ \begin{align} \operatorname{Re}\int \big[\rho(t) - \rho(0)\big]\, \phi_R^2\,dx = \operatorname{Re}\int_0^t \int j_{\mathrm{NLS}}\,(\phi_R^2)' \,dx\,d\tau. \end{align} $$
Choosing
 $\kappa \geq 1$
and applying the estimate (6.4) and the a priori estimate (4.12), we obtain
$\kappa \geq 1$
and applying the estimate (6.4) and the a priori estimate (4.12), we obtain
 $$ \begin{align*} \|\phi_R q\|_{L^\infty_tH^s}^2 &\lesssim \|\phi_R q(0)\|_{H^s}^2 + R^{-2}\|q(0)\|_{H^s}^2 + \|q(0)\|_{H^s_\kappa}^2\\ &\quad + \int_1^\kappa \varkappa^{2s+1} \bigg\| \int j_{\mathrm{NLS}}\,(\phi_R^2)' \,dx \bigg\|_{L^1_t}\,\tfrac{d\varkappa}\varkappa. \end{align*} $$
$$ \begin{align*} \|\phi_R q\|_{L^\infty_tH^s}^2 &\lesssim \|\phi_R q(0)\|_{H^s}^2 + R^{-2}\|q(0)\|_{H^s}^2 + \|q(0)\|_{H^s_\kappa}^2\\ &\quad + \int_1^\kappa \varkappa^{2s+1} \bigg\| \int j_{\mathrm{NLS}}\,(\phi_R^2)' \,dx \bigg\|_{L^1_t}\,\tfrac{d\varkappa}\varkappa. \end{align*} $$
Integrating by parts and using (3.11), we may write
 $$ \begin{align*} \int j_{\mathrm{NLS}}\,(\phi_R^2)'\,dx &= -i \int q \,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - \tfrac12r\Big)\,(\phi_R^2)'\,dx \\ &\quad + i \int r \,\Big( (2\varkappa + \partial)\tfrac{g_{12}}{2 + \gamma} + \tfrac12q\Big)\,(\phi_R^2)'\,dx\\ &\quad - \tfrac{i}{2} \int \log[2 + \gamma] \,(\phi_R^2)"'\,dx. \end{align*} $$
$$ \begin{align*} \int j_{\mathrm{NLS}}\,(\phi_R^2)'\,dx &= -i \int q \,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - \tfrac12r\Big)\,(\phi_R^2)'\,dx \\ &\quad + i \int r \,\Big( (2\varkappa + \partial)\tfrac{g_{12}}{2 + \gamma} + \tfrac12q\Big)\,(\phi_R^2)'\,dx\\ &\quad - \tfrac{i}{2} \int \log[2 + \gamma] \,(\phi_R^2)"'\,dx. \end{align*} $$
For the final term, we may apply (3.28) and (4.12) to obtain
 $$ \begin{align*} \bigg\| \int \log[2 + \gamma] \,(\phi_R^2)"'\,dx\bigg\|_{L^1_t} \lesssim R^{-2}. \end{align*} $$
$$ \begin{align*} \bigg\| \int \log[2 + \gamma] \,(\phi_R^2)"'\,dx\bigg\|_{L^1_t} \lesssim R^{-2}. \end{align*} $$
The remaining two terms are treated identically, so it suffices to consider the first. We decompose
 $$ \begin{align} q=\tfrac{4\kappa^2q}{4\kappa^2-\partial^2} - \tfrac{\partial^2q}{4\kappa^2-\partial^2} \end{align} $$
$$ \begin{align} q=\tfrac{4\kappa^2q}{4\kappa^2-\partial^2} - \tfrac{\partial^2q}{4\kappa^2-\partial^2} \end{align} $$
and estimate the contribution of the low frequency term via
 $$ \begin{align*} &\bigg\| \int\tfrac{4\kappa^2q}{4\kappa^2-\partial^2} \,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_t}\\ &\qquad\qquad\lesssim \big\|\tfrac{\kappa^2q}{4\kappa^2-\partial^2}\big\|_{L_t^\infty H^{-s}} \big\|(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\big)\big\|_{L_t^\infty H^{s}}\\ &\qquad\qquad\lesssim \kappa^{-2s}\|q\|_{L_t^\infty H^{s}} \big\|(\phi_R^2)'\big \|_{H^1} \Big(\|(2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma}\|_{L_t^\infty H^s} + \|q\|_{L_t^\infty H^s}\Big)\\ &\qquad\qquad\lesssim R^{-\frac12}\kappa^{-2s}\|q(0)\|_{H^s}^2. \end{align*} $$
$$ \begin{align*} &\bigg\| \int\tfrac{4\kappa^2q}{4\kappa^2-\partial^2} \,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_t}\\ &\qquad\qquad\lesssim \big\|\tfrac{\kappa^2q}{4\kappa^2-\partial^2}\big\|_{L_t^\infty H^{-s}} \big\|(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\big)\big\|_{L_t^\infty H^{s}}\\ &\qquad\qquad\lesssim \kappa^{-2s}\|q\|_{L_t^\infty H^{s}} \big\|(\phi_R^2)'\big \|_{H^1} \Big(\|(2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma}\|_{L_t^\infty H^s} + \|q\|_{L_t^\infty H^s}\Big)\\ &\qquad\qquad\lesssim R^{-\frac12}\kappa^{-2s}\|q(0)\|_{H^s}^2. \end{align*} $$
To continue, we use (2.3) to express the high-frequency term via
 $$ \begin{align*} &\int\tfrac{\partial^2q}{4\kappa^2-\partial^2} \,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - \tfrac 12r\Big)\,(\phi_R^2)'\,dx \\ &\qquad = \tfrac{7}{512} \iint \Big(\big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q + \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\Big) \,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx\,dh. \end{align*} $$
$$ \begin{align*} &\int\tfrac{\partial^2q}{4\kappa^2-\partial^2} \,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - \tfrac 12r\Big)\,(\phi_R^2)'\,dx \\ &\qquad = \tfrac{7}{512} \iint \Big(\big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q + \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\Big) \,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx\,dh. \end{align*} $$
For the commutator term, we apply the local smoothing estimates (3.43) and (5.12), together with (2.11) and (6.5) to bound
 $$ \begin{align*} &\bigg\| \int \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q \,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}}\\ &\qquad \lesssim \big\|\big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q\big\|_{L^\infty_{t,h} H^{-(s+\frac12)}}\big\|\psi_h^6(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\big)\big\|_{L^1_hL_t^2H^{s+\frac12}}\\ &\qquad \lesssim \kappa^{-(2s+\frac32)} \|q(0)\|_{H^s}\Big(\big\|(2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} \big\|_{X^{s+\frac12}} + \|q\|_{X^{s+\frac12}}\Big)\\ &\qquad \lesssim \kappa^{-(2s+\frac32)}\|q(0)\|_{H^s}^2. \end{align*} $$
$$ \begin{align*} &\bigg\| \int \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q \,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}}\\ &\qquad \lesssim \big\|\big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q\big\|_{L^\infty_{t,h} H^{-(s+\frac12)}}\big\|\psi_h^6(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\big)\big\|_{L^1_hL_t^2H^{s+\frac12}}\\ &\qquad \lesssim \kappa^{-(2s+\frac32)} \|q(0)\|_{H^s}\Big(\big\|(2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} \big\|_{X^{s+\frac12}} + \|q\|_{X^{s+\frac12}}\Big)\\ &\qquad \lesssim \kappa^{-(2s+\frac32)}\|q(0)\|_{H^s}^2. \end{align*} $$
For the remaining term, we use (3.43), (5.12), (5.13), and (6.5), as follows:
 $$ \begin{align*} &\bigg\| \int \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2} \,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx \bigg\|_{L^1_{t,h}}\\ &\qquad \lesssim \big\|\tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_h^\infty L^2_t H^{-(s+\frac12)}}\big\|\psi_h^6(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\big)\big\|_{L^1_hL_t^2H^{s+\frac12}}\\ &\qquad \lesssim \kappa^{-(2s+1)} \|(\psi_h^6q)'\|_{L_h^\infty L^2_t H_\kappa^{s-\frac12}}\Big(\big\|(2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} \big\|_{X^{s+\frac12}} + \|q\|_{X^{s+\frac12}}\Big)\\ &\qquad \lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s} +\kappa^{-\frac32(2s+1)} \delta\|q(0)\|_{H^s}^2. \end{align*} $$
$$ \begin{align*} &\bigg\| \int \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2} \,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx \bigg\|_{L^1_{t,h}}\\ &\qquad \lesssim \big\|\tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_h^\infty L^2_t H^{-(s+\frac12)}}\big\|\psi_h^6(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\big)\big\|_{L^1_hL_t^2H^{s+\frac12}}\\ &\qquad \lesssim \kappa^{-(2s+1)} \|(\psi_h^6q)'\|_{L_h^\infty L^2_t H_\kappa^{s-\frac12}}\Big(\big\|(2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} \big\|_{X^{s+\frac12}} + \|q\|_{X^{s+\frac12}}\Big)\\ &\qquad \lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s} +\kappa^{-\frac32(2s+1)} \delta\|q(0)\|_{H^s}^2. \end{align*} $$
Combining these bounds, we see that for any
 $\kappa \geq 1$
we have the estimate
$\kappa \geq 1$
we have the estimate
 $$ \begin{align*} \|\phi_R q\|_{L^\infty_t H^s}^2 &\lesssim \|\phi_R q(0)\|_{H^s}^2 +\|q(0)\|_{H^s_\kappa}^2 + \delta \|q(0)\|_{H^s_\kappa} \\ &\quad + \kappa^{2s+1} R^{-2} + \big( \kappa R^{-\frac12} + \kappa^{-(s+\frac12)}\big)\delta^2. \end{align*} $$
$$ \begin{align*} \|\phi_R q\|_{L^\infty_t H^s}^2 &\lesssim \|\phi_R q(0)\|_{H^s}^2 +\|q(0)\|_{H^s_\kappa}^2 + \delta \|q(0)\|_{H^s_\kappa} \\ &\quad + \kappa^{2s+1} R^{-2} + \big( \kappa R^{-\frac12} + \kappa^{-(s+\frac12)}\big)\delta^2. \end{align*} $$
Taking the supremum over
 $q(0)\in Q$
and using that Q is tight, we obtain
$q(0)\in Q$
and using that Q is tight, we obtain
 $$ \begin{align*} \limsup_{R\rightarrow\infty}\sup_{q(0)\in Q}\|\phi_Rq\|_{L^\infty_t H^s}^2 &\lesssim \sup\limits_{q(0)\in Q} \delta \|q(0)\|_{H^s_\kappa}+ \kappa^{-(s+\frac12)} \delta^2. \end{align*} $$
$$ \begin{align*} \limsup_{R\rightarrow\infty}\sup_{q(0)\in Q}\|\phi_Rq\|_{L^\infty_t H^s}^2 &\lesssim \sup\limits_{q(0)\in Q} \delta \|q(0)\|_{H^s_\kappa}+ \kappa^{-(s+\frac12)} \delta^2. \end{align*} $$
Using that Q is equicontinuous, the result follows by sending
 $\kappa \rightarrow \infty $
.
$\kappa \rightarrow \infty $
.
Proof of Proposition 6.4 for (mKdV).
Mimicking the argument given in the (NLS) case reduces matters to proving a suitable
 $L^1_t$
estimate for
$L^1_t$
estimate for
 $$ \begin{align} \int & j_{\mathrm{mKdV}}\,(\phi_R^2)'\,dx \\ &= \int q'\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\Big)\,(\phi_R^2)'\,dx + \int r' \,\Big( (2\varkappa + \partial)\tfrac{g_{12}}{2 + \gamma} + q\Big)\,(\phi_R^2)'\,dx \notag\\ &\quad + \int q\,\big(\tfrac{g_{21}}{2 + \gamma}\big)' (\phi_R^2)"\,dx - \int r \,\big(\tfrac{g_{12}}{2 + \gamma}\big)' (\phi_R^2)"\,dx - 2\varkappa \int qr \,(\phi_R^2)'\,dx \notag\\ &\quad -2 \int \rho \,qr \,(\phi_R^2)'\,dx + \int \rho \,(4\varkappa^2 + \partial^2)(\phi_R^2)'\,dx .\notag \end{align} $$
$$ \begin{align} \int & j_{\mathrm{mKdV}}\,(\phi_R^2)'\,dx \\ &= \int q'\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\Big)\,(\phi_R^2)'\,dx + \int r' \,\Big( (2\varkappa + \partial)\tfrac{g_{12}}{2 + \gamma} + q\Big)\,(\phi_R^2)'\,dx \notag\\ &\quad + \int q\,\big(\tfrac{g_{21}}{2 + \gamma}\big)' (\phi_R^2)"\,dx - \int r \,\big(\tfrac{g_{12}}{2 + \gamma}\big)' (\phi_R^2)"\,dx - 2\varkappa \int qr \,(\phi_R^2)'\,dx \notag\\ &\quad -2 \int \rho \,qr \,(\phi_R^2)'\,dx + \int \rho \,(4\varkappa^2 + \partial^2)(\phi_R^2)'\,dx .\notag \end{align} $$
From Corollary 3.5, (2.16), (4.12), and (5.15), we have
 $$ \begin{align} \| \rho \|_{L^\infty_t H^s} + \| \rho \|_{X^{s+1}} \lesssim \|q(0)\|_{H^s}^2. \end{align} $$
$$ \begin{align} \| \rho \|_{L^\infty_t H^s} + \| \rho \|_{X^{s+1}} \lesssim \|q(0)\|_{H^s}^2. \end{align} $$
Thus, we may estimate the final term in (6.8) as follows:
 $$ \begin{align*} \bigg\| \int \rho \,(4\varkappa^2 + \partial^2)(\phi_R^2)'\,dx\bigg\|_{L^1_t} \lesssim\big(\varkappa^2 R^{-\frac12} + R^{-\frac52}\big)\|q(0)\|_{H^s}^2. \end{align*} $$
$$ \begin{align*} \bigg\| \int \rho \,(4\varkappa^2 + \partial^2)(\phi_R^2)'\,dx\bigg\|_{L^1_t} \lesssim\big(\varkappa^2 R^{-\frac12} + R^{-\frac52}\big)\|q(0)\|_{H^s}^2. \end{align*} $$
To estimate the contribution of the remaining terms, we rely on the decomposition (6.7). We first bound the low-frequency contribution to each of the terms in (6.8), before treating the high-frequency terms. From (3.41) and (4.12), we have
 $$ \begin{align*} &\bigg\|\int \tfrac{4\kappa^2q'}{4\kappa^2-\partial^2}\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma}- r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_t}\\ &\qquad\lesssim \big\|\tfrac{\kappa^2q'}{4\kappa^2-\partial^2}\big\|_{L_t^\infty H^{-s}}\big\|(\phi_R^2)'\big\|_{H^1} \big\| (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\big\|_{L_t^\infty H^{s}} \lesssim \kappa^{1-2s} R^{-\frac12}\|q(0)\|_{H^s}^2. \end{align*} $$
$$ \begin{align*} &\bigg\|\int \tfrac{4\kappa^2q'}{4\kappa^2-\partial^2}\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma}- r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_t}\\ &\qquad\lesssim \big\|\tfrac{\kappa^2q'}{4\kappa^2-\partial^2}\big\|_{L_t^\infty H^{-s}}\big\|(\phi_R^2)'\big\|_{H^1} \big\| (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\big\|_{L_t^\infty H^{s}} \lesssim \kappa^{1-2s} R^{-\frac12}\|q(0)\|_{H^s}^2. \end{align*} $$
Arguing similarly, we also obtain
 $$ \begin{align*} \bigg\| \int \tfrac{4\kappa^2q}{4\kappa^2-\partial^2}\,\big(\tfrac{g_{21}}{2 + \gamma}\big)' \,(\phi_R^2)"\,dx\bigg\|_{L^1_t}&\lesssim \kappa^{-2s} R^{-\frac32}\|q(0)\|_{H^s}^2,\\ \varkappa\bigg\| \int \tfrac{4\kappa^2q}{4\kappa^2-\partial^2}\,r \,(\phi_R^2)'\,dx\bigg\|_{L^1_t}&\lesssim \varkappa\kappa^{-2s} R^{-\frac12}\|q(0)\|_{H^s}^2. \end{align*} $$
$$ \begin{align*} \bigg\| \int \tfrac{4\kappa^2q}{4\kappa^2-\partial^2}\,\big(\tfrac{g_{21}}{2 + \gamma}\big)' \,(\phi_R^2)"\,dx\bigg\|_{L^1_t}&\lesssim \kappa^{-2s} R^{-\frac32}\|q(0)\|_{H^s}^2,\\ \varkappa\bigg\| \int \tfrac{4\kappa^2q}{4\kappa^2-\partial^2}\,r \,(\phi_R^2)'\,dx\bigg\|_{L^1_t}&\lesssim \varkappa\kappa^{-2s} R^{-\frac12}\|q(0)\|_{H^s}^2. \end{align*} $$
For the penultimate term in (6.8), we decompose both q and r according to (6.7):
 $$ \begin{align*} \bigg\| \int \tfrac{4\kappa^2q}{4\kappa^2-\partial^2}\, \tfrac{4\kappa^2 r}{4\kappa^2-\partial^2}\, \rho (\phi_R^2)'\,dx\bigg\|_{L^1_t} &\lesssim \big\|\tfrac{\kappa^2 q}{4\kappa^2-\partial^2}\big\|_{L^\infty_t H^{s+1}}^2 \big\|\rho \big\|_{L^\infty_t H^s} \big\|(\phi_R^2)' \big\|_{H^1} \\ &\lesssim \kappa^2 R^{-\frac12} \|q(0)\|_{H^s}^4. \end{align*} $$
$$ \begin{align*} \bigg\| \int \tfrac{4\kappa^2q}{4\kappa^2-\partial^2}\, \tfrac{4\kappa^2 r}{4\kappa^2-\partial^2}\, \rho (\phi_R^2)'\,dx\bigg\|_{L^1_t} &\lesssim \big\|\tfrac{\kappa^2 q}{4\kappa^2-\partial^2}\big\|_{L^\infty_t H^{s+1}}^2 \big\|\rho \big\|_{L^\infty_t H^s} \big\|(\phi_R^2)' \big\|_{H^1} \\ &\lesssim \kappa^2 R^{-\frac12} \|q(0)\|_{H^s}^4. \end{align*} $$
To estimate the contribution of the high-frequency term in the decomposition (6.7), we use (2.3). For example, we write
 $$ \begin{align*} & \bigg\| \int\tfrac{\partial^3q}{4\kappa^2-\partial^2} \,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - \tfrac 12r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_t} \\ &\qquad \lesssim \bigg\| \int \Big(\big[\psi_h^6, \tfrac{\partial^3}{4\kappa^2-\partial^2}\big]q + \tfrac{\partial^3(\psi_h^6q)}{4\kappa^2-\partial^2}\Big) \,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}}. \end{align*} $$
$$ \begin{align*} & \bigg\| \int\tfrac{\partial^3q}{4\kappa^2-\partial^2} \,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - \tfrac 12r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_t} \\ &\qquad \lesssim \bigg\| \int \Big(\big[\psi_h^6, \tfrac{\partial^3}{4\kappa^2-\partial^2}\big]q + \tfrac{\partial^3(\psi_h^6q)}{4\kappa^2-\partial^2}\Big) \,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}}. \end{align*} $$
Using (3.43), (5.15), (6.5), and (2.11), we get
 $$ \begin{align*} &\bigg\| \int \big[\psi_h^6, \tfrac{\partial^3}{4\kappa^2-\partial^2}\big]q\,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}} \\ &\qquad\lesssim \big\|\big[\psi_h^6, \tfrac{\partial^3}{4\kappa^2-\partial^2}\big]q\big\|_{L_h^\infty L_t^\infty H^{-(s+1)}}\big\|\psi_h^6(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\big)\big\|_{L_h^1 L_t^2 H^{s+1}}\\ & \qquad\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}\|q(0)\|_{H^s_\kappa}. \end{align*} $$
$$ \begin{align*} &\bigg\| \int \big[\psi_h^6, \tfrac{\partial^3}{4\kappa^2-\partial^2}\big]q\,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\Big)\,(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}} \\ &\qquad\lesssim \big\|\big[\psi_h^6, \tfrac{\partial^3}{4\kappa^2-\partial^2}\big]q\big\|_{L_h^\infty L_t^\infty H^{-(s+1)}}\big\|\psi_h^6(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} -\tfrac12 r\big)\big\|_{L_h^1 L_t^2 H^{s+1}}\\ & \qquad\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}\|q(0)\|_{H^s_\kappa}. \end{align*} $$
Using also (5.16), we estimate
 $$ \begin{align*} &\left| \int\int_0^t\int\tfrac{\partial^3(\psi_h^6q)}{4\kappa^2-\partial^2}\,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\Big)\,(\phi_R^2)'\,dx\,d\tau\,dh\right|\\ &\qquad\lesssim \big\| \tfrac{\partial^3(\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_h^\infty L_t^2 H^{-(s+1)}} \big\| \psi_h^6(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\big)\big\|_{L_h^1 L_t^2 H^{s+1}}\\ &\qquad \lesssim \kappa^{-(2s+1)} \|(\psi_h^6q)'\|_{L_h^\infty L^2_t H_\kappa^{s}} \|q(0)\|_{H^s} \\ & \qquad\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}+ \kappa^{-\frac32(1+2s)} \log^2(2\kappa) \|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} &\left| \int\int_0^t\int\tfrac{\partial^3(\psi_h^6q)}{4\kappa^2-\partial^2}\,\psi_h^6\,\Big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\Big)\,(\phi_R^2)'\,dx\,d\tau\,dh\right|\\ &\qquad\lesssim \big\| \tfrac{\partial^3(\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_h^\infty L_t^2 H^{-(s+1)}} \big\| \psi_h^6(\phi_R^2)'\big( (2\varkappa - \partial)\tfrac{g_{21}}{2 + \gamma} - r\big)\big\|_{L_h^1 L_t^2 H^{s+1}}\\ &\qquad \lesssim \kappa^{-(2s+1)} \|(\psi_h^6q)'\|_{L_h^\infty L^2_t H_\kappa^{s}} \|q(0)\|_{H^s} \\ & \qquad\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}+ \kappa^{-\frac32(1+2s)} \log^2(2\kappa) \|q(0)\|_{H^s}^3. \end{align*} $$
Arguing similarly, we also obtain
 $$ \begin{align*} &\bigg\| \int \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q\,\psi_h^6\,\big(\tfrac{g_{21}}{2 + \gamma}\big)' \,(\phi_R^2)"\,dx\bigg\|_{L^1_{t,h}} \lesssim R^{-1}\kappa^{-2(1+s)}\|q(0)\|_{H^s}\|q(0)\|_{H^s_\kappa}, \\ &\varkappa\bigg\| \int \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q \,\psi_h^6\,r(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}} \lesssim \varkappa\kappa^{-2(1+s)}\|q(0)\|_{H^s}\|q(0)\|_{H^s_\kappa} \end{align*} $$
$$ \begin{align*} &\bigg\| \int \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q\,\psi_h^6\,\big(\tfrac{g_{21}}{2 + \gamma}\big)' \,(\phi_R^2)"\,dx\bigg\|_{L^1_{t,h}} \lesssim R^{-1}\kappa^{-2(1+s)}\|q(0)\|_{H^s}\|q(0)\|_{H^s_\kappa}, \\ &\varkappa\bigg\| \int \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q \,\psi_h^6\,r(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}} \lesssim \varkappa\kappa^{-2(1+s)}\|q(0)\|_{H^s}\|q(0)\|_{H^s_\kappa} \end{align*} $$
and
 $$ \begin{align*} &\bigg\| \int \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\,\psi_h^6\,\big(\tfrac{g_{21}}{2 + \gamma}\big)' \,(\phi_R^2)"\,dx \bigg\|_{L^1_{t,h}}\\ &\qquad\qquad \lesssim R^{-1}\kappa^{-2(1+s)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}+ R^{-1}\kappa^{-(\frac52+3s)}\log^2(2\kappa)\|q(0)\|_{H^s}^3,\\ &\varkappa\bigg\| \int \int_0^t\int \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2} \,\psi_h^6\,r(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}}\\ &\qquad\qquad\lesssim \varkappa\kappa^{-2(1+s)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}+\varkappa\kappa^{-(\frac52+3s)}\log^2(2\kappa)\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} &\bigg\| \int \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\,\psi_h^6\,\big(\tfrac{g_{21}}{2 + \gamma}\big)' \,(\phi_R^2)"\,dx \bigg\|_{L^1_{t,h}}\\ &\qquad\qquad \lesssim R^{-1}\kappa^{-2(1+s)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}+ R^{-1}\kappa^{-(\frac52+3s)}\log^2(2\kappa)\|q(0)\|_{H^s}^3,\\ &\varkappa\bigg\| \int \int_0^t\int \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2} \,\psi_h^6\,r(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}}\\ &\qquad\qquad\lesssim \varkappa\kappa^{-2(1+s)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}+\varkappa\kappa^{-(\frac52+3s)}\log^2(2\kappa)\|q(0)\|_{H^s}^3. \end{align*} $$
This leaves us to handle the high-frequency contribution to the penultimate term in (6.8), which involves the combination
 $$ \begin{align*} \tfrac{4\kappa^2q}{4\kappa^2-\partial^2} \cdot \Big(\big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]r + \tfrac{\partial^2(\psi_h^6 r)}{4\kappa^2-\partial^2}\Big) \psi_h^6 + \Big(\big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q + \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\Big) \cdot r\,\psi_h^6. \end{align*} $$
$$ \begin{align*} \tfrac{4\kappa^2q}{4\kappa^2-\partial^2} \cdot \Big(\big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]r + \tfrac{\partial^2(\psi_h^6 r)}{4\kappa^2-\partial^2}\Big) \psi_h^6 + \Big(\big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q + \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\Big) \cdot r\,\psi_h^6. \end{align*} $$
We illustrate the estimation of these contributions using the latter summand. Using (2.11), (6.5), and (6.9), we get
 $$ \begin{align*} \bigg\| \int \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q\cdot r\,\psi_h^6\,\rho \,(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}} &\lesssim \big\| \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q\big\|_{L^\infty_{t,h} H^{-s}} \| r \|_{L^\infty_{t} H^s} \big\| \psi_h^6 (\phi_R^2)' \rho \big\|_{L^1_h L_t^2 H^{s+1}}\\ &\lesssim \kappa^{-(1+2s)} \|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}^3, \\ \bigg\| \int \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\,r \,\rho\,\psi_h^6 \,(\phi_R^2)'\,dx \bigg\|_{L^1_{t,h}} &\lesssim \big\| \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_h^\infty L_t^2 H^{-s}} \|q\|_{L_t^\infty H^s} \|\rho\|_{X^{s+1}}\\ & \lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}^3+\kappa^{-\frac32(1+2s)}\log^2(2\kappa)\|q(0)\|_{H^s}^5. \end{align*} $$
$$ \begin{align*} \bigg\| \int \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q\cdot r\,\psi_h^6\,\rho \,(\phi_R^2)'\,dx\bigg\|_{L^1_{t,h}} &\lesssim \big\| \big[\psi_h^6, \tfrac{\partial^2}{4\kappa^2-\partial^2}\big]q\big\|_{L^\infty_{t,h} H^{-s}} \| r \|_{L^\infty_{t} H^s} \big\| \psi_h^6 (\phi_R^2)' \rho \big\|_{L^1_h L_t^2 H^{s+1}}\\ &\lesssim \kappa^{-(1+2s)} \|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}^3, \\ \bigg\| \int \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\,r \,\rho\,\psi_h^6 \,(\phi_R^2)'\,dx \bigg\|_{L^1_{t,h}} &\lesssim \big\| \tfrac{\partial^2(\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L_h^\infty L_t^2 H^{-s}} \|q\|_{L_t^\infty H^s} \|\rho\|_{X^{s+1}}\\ & \lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s_\kappa}\|q(0)\|_{H^s}^3+\kappa^{-\frac32(1+2s)}\log^2(2\kappa)\|q(0)\|_{H^s}^5. \end{align*} $$
The proof may now be completed exactly as in the NLS case.
7. Convergence of the difference flows
Our main goal in this section is to prove the following:
Proposition 7.1 (Difference flow approximates the identity).
Let
 $\delta>0$
be sufficiently small and fix
$\delta>0$
be sufficiently small and fix
 $\star \in \{ \mathrm {NLS},\mathrm {mKdV}\}$
. Given
$\star \in \{ \mathrm {NLS},\mathrm {mKdV}\}$
. Given
 $Q\subset B_\delta \cap \mathcal {S}$
that is equicontinuous in
$Q\subset B_\delta \cap \mathcal {S}$
that is equicontinuous in
 $H^s$
and
$H^s$
and
 $\varkappa \geq 4$
, we have
$\varkappa \geq 4$
, we have
 $$\begin{align*}\psi_h^{12} g_{12}\big(\varkappa;e^{tJ\nabla(H_\star - H_{\star}^{\kappa})}q\big)\rightarrow \psi_h^{12} g_{12}(\varkappa;q)\text{ in }\mathcal C([-1,1];H^{s+1})\text{ as }\kappa\rightarrow\infty, \end{align*}$$
$$\begin{align*}\psi_h^{12} g_{12}\big(\varkappa;e^{tJ\nabla(H_\star - H_{\star}^{\kappa})}q\big)\rightarrow \psi_h^{12} g_{12}(\varkappa;q)\text{ in }\mathcal C([-1,1];H^{s+1})\text{ as }\kappa\rightarrow\infty, \end{align*}$$
uniformly for
 $q\in Q$
and
$q\in Q$
and
 $h\in {{\mathbb {R}}}$
.
$h\in {{\mathbb {R}}}$
.
Proof for (NLS-diff).
Applying Proposition 4.6, we see that
 $$\begin{align*}Q^* = \{e^{tJ\nabla(H_{\mathrm{NLS}} - H_{\mathrm{NLS}}^{\kappa})}q:q\in Q,\, t\in {{\mathbb{R}}}\} \end{align*}$$
$$\begin{align*}Q^* = \{e^{tJ\nabla(H_{\mathrm{NLS}} - H_{\mathrm{NLS}}^{\kappa})}q:q\in Q,\, t\in {{\mathbb{R}}}\} \end{align*}$$
is equicontinuous in
 $H^s$
. By Proposition 3.2, for any
$H^s$
. By Proposition 3.2, for any
 $\varkappa \geq 1$
, the map
$\varkappa \geq 1$
, the map
 $q\mapsto g_{12}(\varkappa )$
is a diffeomorphism from
$q\mapsto g_{12}(\varkappa )$
is a diffeomorphism from
 $B_\delta \rightarrow H^{s+1}$
; moreover, this map commutes with spatial translations. Thus, the set
$B_\delta \rightarrow H^{s+1}$
; moreover, this map commutes with spatial translations. Thus, the set
 $$\begin{align*}\{g_{12}(\varkappa;q):q\in Q^*\} \quad\text{and so also}\quad \{\psi_h^{12}g_{12}(\varkappa;q):q\in Q^*, \, h\in {{\mathbb{R}}}\} \end{align*}$$
$$\begin{align*}\{g_{12}(\varkappa;q):q\in Q^*\} \quad\text{and so also}\quad \{\psi_h^{12}g_{12}(\varkappa;q):q\in Q^*, \, h\in {{\mathbb{R}}}\} \end{align*}$$
is equicontinuous in
 $H^{s+1}$
. As a consequence, it suffices to show that
$H^{s+1}$
. As a consequence, it suffices to show that
 $$ \begin{align} \lim\limits_{\kappa\rightarrow\infty}\sup\limits_{q\in Q}\sup\limits_{h\in {{\mathbb{R}}}}\left\| i\frac d{dt}\left(\psi_h^{12} g_{12}(\varkappa;e^{tJ\nabla(H_{\mathrm{NLS}}-H_{\mathrm{NLS}}^{\kappa})}q)\right)\right\|_{L^1_tH^{-4}} = 0. \end{align} $$
$$ \begin{align} \lim\limits_{\kappa\rightarrow\infty}\sup\limits_{q\in Q}\sup\limits_{h\in {{\mathbb{R}}}}\left\| i\frac d{dt}\left(\psi_h^{12} g_{12}(\varkappa;e^{tJ\nabla(H_{\mathrm{NLS}}-H_{\mathrm{NLS}}^{\kappa})}q)\right)\right\|_{L^1_tH^{-4}} = 0. \end{align} $$
Using the identities (3.12) for
 $g_{12}$
and (3.11) for
$g_{12}$
and (3.11) for
 $\gamma $
, we may write
$\gamma $
, we may write
 $$\begin{align*}-g_{12}(\varkappa)" + 2qrg_{12}(\varkappa) + 2q^2g_{21}(\varkappa) = - 4\varkappa^2g_{12}(\varkappa) -[1 + \gamma(\varkappa)] \,(2\varkappa + \partial)q. \end{align*}$$
$$\begin{align*}-g_{12}(\varkappa)" + 2qrg_{12}(\varkappa) + 2q^2g_{21}(\varkappa) = - 4\varkappa^2g_{12}(\varkappa) -[1 + \gamma(\varkappa)] \,(2\varkappa + \partial)q. \end{align*}$$
Thus, we may rewrite (4.35) as
 $$\begin{align*}i\frac d{dt}g_{12}(\varkappa) = \sum\limits_{j=1}^{11}\mathbf{err}_j, \end{align*}$$
$$\begin{align*}i\frac d{dt}g_{12}(\varkappa) = \sum\limits_{j=1}^{11}\mathbf{err}_j, \end{align*}$$
where we define
 $$ \begin{align*} &\mathbf{err}_1 = \tfrac{4\varkappa^4}{\kappa^2 - \varkappa^2}g_{12}(\varkappa),\qquad \mathbf{err}_2 = \tfrac{4\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2}[1 + \gamma(\varkappa)]\tfrac{(2\varkappa + \partial)q}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_3 = [1 + \gamma(\varkappa)]\tfrac{(2\varkappa + \partial)\partial^2 q}{4\kappa^2-\partial^2}, \qquad\mathbf{err}_4=-\tfrac{32\kappa^4\varkappa^2}{\kappa^2-\varkappa^2}g_{12}(\varkappa)\,\tfrac{q}{4\kappa^2-\partial^2}\,\tfrac{r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_5 =\tfrac{16\kappa^4\varkappa}{\kappa^2 - \varkappa^2}g_{12}(\varkappa)\Big[\tfrac{q}{4\kappa^2 - \partial^2}\,\tfrac{\partial r}{4\kappa^2 - \partial^2} -\tfrac{\partial q}{4\kappa^2 - \partial^2}\,\tfrac{r}{4\kappa^2 - \partial^2}\Big],\\ &\mathbf{err}_6= \big[\tfrac{8\kappa^4}{\kappa^2 - \varkappa^2}+16\kappa^2\big]g_{12}(\varkappa) \,\tfrac{\partial q}{4\kappa^2 - \partial^2}\,\tfrac{\partial r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_7 = - 8\kappa^2g_{12}(\varkappa)\partial^2\Big[\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\Big],\\ &\mathbf{err}_8 =2g_{12}(\varkappa)\,\tfrac{\partial^2q}{4\kappa^2 - \partial^2}\,\tfrac{\partial^2r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_9 = \tfrac{2\kappa^3\varkappa}{\kappa^2-\varkappa^2}[1+\gamma(\varkappa)]\, \Big[-g_{12}^{[\geq3]}(\kappa)+g_{12}^{[\geq3]}(-\kappa) \Big],\\ &\mathbf{err}_{10} = - \tfrac{2\kappa^4}{\kappa^2 - \varkappa^2}[1+\gamma(\varkappa)]\, \Big[ g_{12}^{[\geq3]}(\kappa)+g_{12}^{[\geq3]}(-\kappa) \Big],\\ &\mathbf{err}_{11} = g_{12}(\varkappa)\Big[\tfrac{2\kappa^3}{\kappa - \varkappa}\gamma(\kappa)^{[\geq 4]} + \tfrac{2\kappa^3}{\kappa + \varkappa}\gamma(-\kappa)^{[\geq 4]}\Big]. \end{align*} $$
$$ \begin{align*} &\mathbf{err}_1 = \tfrac{4\varkappa^4}{\kappa^2 - \varkappa^2}g_{12}(\varkappa),\qquad \mathbf{err}_2 = \tfrac{4\kappa^2\varkappa^2}{\kappa^2 - \varkappa^2}[1 + \gamma(\varkappa)]\tfrac{(2\varkappa + \partial)q}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_3 = [1 + \gamma(\varkappa)]\tfrac{(2\varkappa + \partial)\partial^2 q}{4\kappa^2-\partial^2}, \qquad\mathbf{err}_4=-\tfrac{32\kappa^4\varkappa^2}{\kappa^2-\varkappa^2}g_{12}(\varkappa)\,\tfrac{q}{4\kappa^2-\partial^2}\,\tfrac{r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_5 =\tfrac{16\kappa^4\varkappa}{\kappa^2 - \varkappa^2}g_{12}(\varkappa)\Big[\tfrac{q}{4\kappa^2 - \partial^2}\,\tfrac{\partial r}{4\kappa^2 - \partial^2} -\tfrac{\partial q}{4\kappa^2 - \partial^2}\,\tfrac{r}{4\kappa^2 - \partial^2}\Big],\\ &\mathbf{err}_6= \big[\tfrac{8\kappa^4}{\kappa^2 - \varkappa^2}+16\kappa^2\big]g_{12}(\varkappa) \,\tfrac{\partial q}{4\kappa^2 - \partial^2}\,\tfrac{\partial r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_7 = - 8\kappa^2g_{12}(\varkappa)\partial^2\Big[\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\Big],\\ &\mathbf{err}_8 =2g_{12}(\varkappa)\,\tfrac{\partial^2q}{4\kappa^2 - \partial^2}\,\tfrac{\partial^2r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_9 = \tfrac{2\kappa^3\varkappa}{\kappa^2-\varkappa^2}[1+\gamma(\varkappa)]\, \Big[-g_{12}^{[\geq3]}(\kappa)+g_{12}^{[\geq3]}(-\kappa) \Big],\\ &\mathbf{err}_{10} = - \tfrac{2\kappa^4}{\kappa^2 - \varkappa^2}[1+\gamma(\varkappa)]\, \Big[ g_{12}^{[\geq3]}(\kappa)+g_{12}^{[\geq3]}(-\kappa) \Big],\\ &\mathbf{err}_{11} = g_{12}(\varkappa)\Big[\tfrac{2\kappa^3}{\kappa - \varkappa}\gamma(\kappa)^{[\geq 4]} + \tfrac{2\kappa^3}{\kappa + \varkappa}\gamma(-\kappa)^{[\geq 4]}\Big]. \end{align*} $$
It remains to bound each of the terms
 $\mathbf {err}_j$
. We will rely on the a priori estimate (4.12) and the local smoothing estimate (5.18), which yield
$\mathbf {err}_j$
. We will rely on the a priori estimate (4.12) and the local smoothing estimate (5.18), which yield
 $$ \begin{align} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} = \|q\|_{L^\infty_t H^s}+ \|q\|_{X^{s+\frac12}_\kappa} \lesssim \|q(0)\|_{H^s}. \end{align} $$
$$ \begin{align} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} = \|q\|_{L^\infty_t H^s}+ \|q\|_{X^{s+\frac12}_\kappa} \lesssim \|q(0)\|_{H^s}. \end{align} $$
We will also employ the estimates recorded in Corollary 5.7, as well as the bounds
 $$ \begin{align} \|q\|_{X^{-(s+\frac12)}_\kappa} \lesssim \kappa^{-\frac23(2s+1)}\|q(0)\|_{H^s}, \end{align} $$
$$ \begin{align} \|q\|_{X^{-(s+\frac12)}_\kappa} \lesssim \kappa^{-\frac23(2s+1)}\|q(0)\|_{H^s}, \end{align} $$
 $$ \begin{align} \|g_{12}(\varkappa)\|_{X^{s+\frac32}_\kappa} \lesssim\|q(0)\|_{H^s}\quad\text{and}\quad \|\gamma(\varkappa)\|_{X^{s+\frac32}_\kappa}\lesssim\|q(0)\|_{H^s}^2, \end{align} $$
$$ \begin{align} \|g_{12}(\varkappa)\|_{X^{s+\frac32}_\kappa} \lesssim\|q(0)\|_{H^s}\quad\text{and}\quad \|\gamma(\varkappa)\|_{X^{s+\frac32}_\kappa}\lesssim\|q(0)\|_{H^s}^2, \end{align} $$
which follow from (2.9), (7.2), (3.33), and (3.35).
As
 $\varkappa $
is fixed, we allow implicit constants to depend on this parameter. Throughout the proof, we will take
$\varkappa $
is fixed, we allow implicit constants to depend on this parameter. Throughout the proof, we will take
 $\kappa \geq 2\varkappa $
. When it is convenient to argue by duality, we will write
$\kappa \geq 2\varkappa $
. When it is convenient to argue by duality, we will write
 $\phi $
for a generic function in
$\phi $
for a generic function in
 $L^\infty _t H^4$
of unit norm.
$L^\infty _t H^4$
of unit norm.
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_1}$
. We apply the estimate (3.24) to bound
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_1}$
. We apply the estimate (3.24) to bound
 $$\begin{align*}\left\|\psi_h^{12}\mathbf{err}_1\right\|_{L^1_tH^{-4}}\lesssim \kappa^{-2}\|g_{12}(\varkappa)\|_{L^\infty_tH^{s+1}}\lesssim \kappa^{-2}\|q(0)\|_{H^s}. \end{align*}$$
$$\begin{align*}\left\|\psi_h^{12}\mathbf{err}_1\right\|_{L^1_tH^{-4}}\lesssim \kappa^{-2}\|g_{12}(\varkappa)\|_{L^\infty_tH^{s+1}}\lesssim \kappa^{-2}\|q(0)\|_{H^s}. \end{align*}$$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_2}$
. Similarly, using duality and (3.27), we may bound
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_2}$
. Similarly, using duality and (3.27), we may bound
 $$ \begin{align*} \left\|\psi_h^{12} \mathbf{err}_2\right\|_{L^1_tH^{-4}} &\lesssim \big\|\psi_h^{12}[1+\gamma(\varkappa)]\big\|_{L^\infty_tH^{s+1}}\big\|\tfrac{(2\varkappa + \partial)q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tH^{-(s+1)}}\lesssim\kappa^{-2(1+s)}\|q(0)\|_{H^s}. \end{align*} $$
$$ \begin{align*} \left\|\psi_h^{12} \mathbf{err}_2\right\|_{L^1_tH^{-4}} &\lesssim \big\|\psi_h^{12}[1+\gamma(\varkappa)]\big\|_{L^\infty_tH^{s+1}}\big\|\tfrac{(2\varkappa + \partial)q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tH^{-(s+1)}}\lesssim\kappa^{-2(1+s)}\|q(0)\|_{H^s}. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_3}$
. We estimate
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_3}$
. We estimate
 $$ \begin{align*} \big\|\psi_h^{12} [1+\gamma(\varkappa)]\tfrac{(2\varkappa + \partial)\partial^2 q}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}} &\lesssim \big\| \psi_h^6[1+\gamma(\varkappa)] \tfrac{(2\varkappa + \partial)\partial^2 (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}}\\ & \quad + \big\|\psi_h^6[1+\gamma(\varkappa)] [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^2 }{4\kappa^2-\partial^2}]q\big\|_{L^1_tH^{-4}}. \end{align*} $$
$$ \begin{align*} \big\|\psi_h^{12} [1+\gamma(\varkappa)]\tfrac{(2\varkappa + \partial)\partial^2 q}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}} &\lesssim \big\| \psi_h^6[1+\gamma(\varkappa)] \tfrac{(2\varkappa + \partial)\partial^2 (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}}\\ & \quad + \big\|\psi_h^6[1+\gamma(\varkappa)] [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^2 }{4\kappa^2-\partial^2}]q\big\|_{L^1_tH^{-4}}. \end{align*} $$
We will bound both of these terms using duality. Using (7.3) and (7.4), we get
 $$ \begin{align*} \big\| \psi_h^6[1+\gamma(\varkappa)] \tfrac{(2\varkappa + \partial)\partial^2 (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}} &\lesssim \sup_\phi \|\phi[1+\gamma(\varkappa)]\|_{X^{s+\frac32}_\kappa} \|q\|_{X^{-(s+\frac12)}_\kappa}\\ &\lesssim \big[\kappa^{-1} + \|q(0)\|_{H^s}^2\big] \kappa^{-\frac23(2s+1)}\|q(0)\|_{H^s}\\ &\lesssim \kappa^{-\frac23(2s+1)}\|q(0)\|_{H^s}. \end{align*} $$
$$ \begin{align*} \big\| \psi_h^6[1+\gamma(\varkappa)] \tfrac{(2\varkappa + \partial)\partial^2 (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}} &\lesssim \sup_\phi \|\phi[1+\gamma(\varkappa)]\|_{X^{s+\frac32}_\kappa} \|q\|_{X^{-(s+\frac12)}_\kappa}\\ &\lesssim \big[\kappa^{-1} + \|q(0)\|_{H^s}^2\big] \kappa^{-\frac23(2s+1)}\|q(0)\|_{H^s}\\ &\lesssim \kappa^{-\frac23(2s+1)}\|q(0)\|_{H^s}. \end{align*} $$
Using instead (3.27) and (2.11), we may bound
 $$ \begin{align*} &\big\|\psi_h^6[1+\gamma(\varkappa)] [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^2 }{4\kappa^2-\partial^2}]q\big\|_{L^1_tH^{-4}}\\ &\quad\lesssim\sup_\phi \|\psi_h^6\phi [1+\gamma(\varkappa)]\|_{L_t^\infty H^{s+1}} \big\| [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^2 }{4\kappa^2-\partial^2}]q\big\|_{L_t^\infty H^{-(s+1)}}\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}. \end{align*} $$
$$ \begin{align*} &\big\|\psi_h^6[1+\gamma(\varkappa)] [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^2 }{4\kappa^2-\partial^2}]q\big\|_{L^1_tH^{-4}}\\ &\quad\lesssim\sup_\phi \|\psi_h^6\phi [1+\gamma(\varkappa)]\|_{L_t^\infty H^{s+1}} \big\| [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^2 }{4\kappa^2-\partial^2}]q\big\|_{L_t^\infty H^{-(s+1)}}\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_4}$
. Using
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_4}$
. Using
 $L^1\subset H^{-4}$
and
$L^1\subset H^{-4}$
and
 $H^{s+1}\subset L^\infty $
together with (3.24), we get
$H^{s+1}\subset L^\infty $
together with (3.24), we get
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_4\|_{L^1_tH^{-4}}&\lesssim \kappa^{2}\|g_{12}(\varkappa)\|_{L^\infty_{t,x}}\big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}^2\lesssim \kappa^{-2(1+s)} \|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_4\|_{L^1_tH^{-4}}&\lesssim \kappa^{2}\|g_{12}(\varkappa)\|_{L^\infty_{t,x}}\big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}^2\lesssim \kappa^{-2(1+s)} \|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_5}$
. Arguing as for
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_5}$
. Arguing as for
 $\mathbf {err}_4$
, we may bound
$\mathbf {err}_4$
, we may bound
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_5\|_{L^1_tH^{-4}}\lesssim \kappa^2 \|g_{12}(\varkappa)\|_{L^\infty_{t,x}}\big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}\big\|\tfrac {\partial q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_5\|_{L^1_tH^{-4}}\lesssim \kappa^2 \|g_{12}(\varkappa)\|_{L^\infty_{t,x}}\big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}\big\|\tfrac {\partial q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_6}$
. Using that
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_6}$
. Using that
 $L^1\subset H^{-4}$
and Corollary 5.7, we may bound
$L^1\subset H^{-4}$
and Corollary 5.7, we may bound
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_6\|_{L^1_tH^{-4}} &\lesssim \kappa^2\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\| \psi_h^6\tfrac{\partial q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}^2 \lesssim \kappa^{-\frac23(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_6\|_{L^1_tH^{-4}} &\lesssim \kappa^2\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\| \psi_h^6\tfrac{\partial q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}^2 \lesssim \kappa^{-\frac23(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_7}$
. We estimate
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_7}$
. We estimate
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_7\|_{L^1_tH^{-4}} &\lesssim \kappa^2\big\|\psi_h^6g_{12}(\varkappa)\partial^2 \big[\psi_h^6\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L^1_tH^{-4}}\\ &\quad+\kappa^2\big\|\psi_h^6g_{12}(\varkappa)[\psi_h^6,\partial^2] \big[\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L^1_tH^{-4}}. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_7\|_{L^1_tH^{-4}} &\lesssim \kappa^2\big\|\psi_h^6g_{12}(\varkappa)\partial^2 \big[\psi_h^6\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L^1_tH^{-4}}\\ &\quad+\kappa^2\big\|\psi_h^6g_{12}(\varkappa)[\psi_h^6,\partial^2] \big[\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L^1_tH^{-4}}. \end{align*} $$
Using that
 $L^1\subset H^{-4}$
, we estimate the commutator term by
$L^1\subset H^{-4}$
, we estimate the commutator term by
 $$ \begin{align*} &\kappa^2\big\|\psi_h^6g_{12}(\varkappa)[\psi_h^6,\partial^2] \big[\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L^1_tH^{-4}}\\ &\qquad \lesssim \kappa^2\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\|\tfrac{q}{4\kappa^2 - \partial^2}\big\|_{L_t^\infty H^1} \big\|\tfrac{q}{4\kappa^2 - \partial^2}\big\|_{L_t^\infty L^2}\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} &\kappa^2\big\|\psi_h^6g_{12}(\varkappa)[\psi_h^6,\partial^2] \big[\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L^1_tH^{-4}}\\ &\qquad \lesssim \kappa^2\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\|\tfrac{q}{4\kappa^2 - \partial^2}\big\|_{L_t^\infty H^1} \big\|\tfrac{q}{4\kappa^2 - \partial^2}\big\|_{L_t^\infty L^2}\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
To estimate the remaining term, we argue by duality. Using (7.4), we have
 $$ \begin{align} &\kappa^2\big\|\psi_h^6g_{12}(\varkappa)\partial^2 \big[\psi_h^6\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L^1_tH^{-4}}\\ &\qquad\lesssim \kappa^2\|q(0)\|_{H^s} \big\| \sqrt{4\kappa^2-\partial^2} \big[\psi_h^6\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L_t^2 H^{-(s+\frac12)}} \notag \end{align} $$
$$ \begin{align} &\kappa^2\big\|\psi_h^6g_{12}(\varkappa)\partial^2 \big[\psi_h^6\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L^1_tH^{-4}}\\ &\qquad\lesssim \kappa^2\|q(0)\|_{H^s} \big\| \sqrt{4\kappa^2-\partial^2} \big[\psi_h^6\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\big\|_{L_t^2 H^{-(s+\frac12)}} \notag \end{align} $$
Employing Lemma 2.8, breaking into Littlewood–Paley pieces and using Bernstein’s inequality, we deduce that
 $$ \begin{align*} \text{LHS}({7.5}) &\lesssim \|q(0)\|_{H^s}\!\!\! \sum_{N_2\leq N_1}\!\!\!\tfrac{\kappa^2 (\kappa+N_1+N_2)}{(\kappa+N_1)^2 (\kappa+N_2)^2} \|(\psi_h^3q)_{N_1}\|_{L_{t,x}^2} N_2^{\frac12-s}\|(\psi_h^3q)_{N_2}\|_{L^\infty_t H^s}. \end{align*} $$
$$ \begin{align*} \text{LHS}({7.5}) &\lesssim \|q(0)\|_{H^s}\!\!\! \sum_{N_2\leq N_1}\!\!\!\tfrac{\kappa^2 (\kappa+N_1+N_2)}{(\kappa+N_1)^2 (\kappa+N_2)^2} \|(\psi_h^3q)_{N_1}\|_{L_{t,x}^2} N_2^{\frac12-s}\|(\psi_h^3q)_{N_2}\|_{L^\infty_t H^s}. \end{align*} $$
Invoking Corollary 5.7 and evaluating the resulting sum, we ultimately find
 $$ \begin{align*}\mathbf{err}_7\lesssim \kappa^{-\frac23(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*}\mathbf{err}_7\lesssim \kappa^{-\frac23(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_8}$
. Using
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_8}$
. Using
 $L^1\subset H^{-4}$
and Corollary 5.7, we bound
$L^1\subset H^{-4}$
and Corollary 5.7, we bound
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_8\|_{L^1_tH^{-4}} &\lesssim\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\| \psi_h^6\tfrac{\partial^2 q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}^2 \lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_8\|_{L^1_tH^{-4}} &\lesssim\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\| \psi_h^6\tfrac{\partial^2 q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}^2 \lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_9}$
. Using (3.27), (3.35), and (5.33), we may bound
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_9}$
. Using (3.27), (3.35), and (5.33), we may bound
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_9\|_{L^1_tH^{-4}} &\lesssim \kappa^{-\frac43(2s+1)} \sup_\phi{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert (2\varkappa+\partial)\big(\phi[1+\gamma(\varkappa)]\big) \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} \|q(0)\|_{H^s}^3\\ &\lesssim \kappa^{-\frac43(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_9\|_{L^1_tH^{-4}} &\lesssim \kappa^{-\frac43(2s+1)} \sup_\phi{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert (2\varkappa+\partial)\big(\phi[1+\gamma(\varkappa)]\big) \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} \|q(0)\|_{H^s}^3\\ &\lesssim \kappa^{-\frac43(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{10}}$
. Arguing as for
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{10}}$
. Arguing as for
 $\mathbf {err}_9$
and using (5.36) in place of (5.33), we find
$\mathbf {err}_9$
and using (5.36) in place of (5.33), we find
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{10}\|_{L^1_tH^{-4}} &\lesssim \kappa^{-\frac43(2s+1)}\sup_\phi{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert (2\varkappa+\partial)\big(\phi[1+\gamma(\varkappa)]\big) \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} \|q(0)\|_{H^s}^3\\ &\lesssim \kappa^{-\frac43(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{10}\|_{L^1_tH^{-4}} &\lesssim \kappa^{-\frac43(2s+1)}\sup_\phi{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert (2\varkappa+\partial)\big(\phi[1+\gamma(\varkappa)]\big) \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{NLS}_\kappa} \|q(0)\|_{H^s}^3\\ &\lesssim \kappa^{-\frac43(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{11}}$
. Using (3.24) and (5.35), we obtain
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{11}}$
. Using (3.24) and (5.35), we obtain
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{11}\|_{L^1_tH^{-4}} &\lesssim \kappa^2 \|g_{12}\|_{L_{t,x}^\infty} \big\| \gamma(\pm\kappa)^{[\geq 4]} \psi_h^{12}\big\|_{L_{t,x}^1} \lesssim \kappa^{-\frac43(2s+1)}\|q(0)\|_{H^s}^5. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{11}\|_{L^1_tH^{-4}} &\lesssim \kappa^2 \|g_{12}\|_{L_{t,x}^\infty} \big\| \gamma(\pm\kappa)^{[\geq 4]} \psi_h^{12}\big\|_{L_{t,x}^1} \lesssim \kappa^{-\frac43(2s+1)}\|q(0)\|_{H^s}^5. \end{align*} $$
Collecting all our estimates for the error terms yields (7.1).
Proof for (mKdV-diff).
It suffices to show the following analogue of (7.1):
 $$ \begin{align} \lim\limits_{\kappa\rightarrow\infty}\sup\limits_{q\in Q}\sup\limits_{h\in {{\mathbb{R}}}}\left\| \frac d{dt}\left(\psi_h^{12} g_{12}(\varkappa;e^{tJ\nabla(H_{\mathrm{mKdV}}-H_{\mathrm{mKdV}}^{\kappa})}q)\right)\right\|_{L^1_tH^{-4}} = 0. \end{align} $$
$$ \begin{align} \lim\limits_{\kappa\rightarrow\infty}\sup\limits_{q\in Q}\sup\limits_{h\in {{\mathbb{R}}}}\left\| \frac d{dt}\left(\psi_h^{12} g_{12}(\varkappa;e^{tJ\nabla(H_{\mathrm{mKdV}}-H_{\mathrm{mKdV}}^{\kappa})}q)\right)\right\|_{L^1_tH^{-4}} = 0. \end{align} $$
Using the identities (3.12) for
 $g_{12}$
and (3.11) for
$g_{12}$
and (3.11) for
 $\gamma $
, we may write
$\gamma $
, we may write
 $$ \begin{align*} &-g_{12}(\varkappa)"' + 6qrg_{12}(\varkappa)' + 6qq'g_{21}(\varkappa) + 6rq'g_{12}(\varkappa)-4\kappa^2g_{12}(\varkappa)' + \tfrac{8\kappa^4\varkappa}{\kappa^2-\varkappa^2}g_{12}(\varkappa)\\ &= g_{12}(\varkappa) \big[ \tfrac{8\varkappa^5}{\kappa^2-\varkappa^2} +4\varkappa qr + 2rq' - 2qr' \big]- [1 + \gamma(\varkappa)] \big[ q" +2\varkappa q' + 4(\kappa^2+\varkappa^2)q -2q^2r\big]. \end{align*} $$
$$ \begin{align*} &-g_{12}(\varkappa)"' + 6qrg_{12}(\varkappa)' + 6qq'g_{21}(\varkappa) + 6rq'g_{12}(\varkappa)-4\kappa^2g_{12}(\varkappa)' + \tfrac{8\kappa^4\varkappa}{\kappa^2-\varkappa^2}g_{12}(\varkappa)\\ &= g_{12}(\varkappa) \big[ \tfrac{8\varkappa^5}{\kappa^2-\varkappa^2} +4\varkappa qr + 2rq' - 2qr' \big]- [1 + \gamma(\varkappa)] \big[ q" +2\varkappa q' + 4(\kappa^2+\varkappa^2)q -2q^2r\big]. \end{align*} $$
As a consequence, we may write (4.36) as
 $$\begin{align*}\frac d{dt}g_{12}(\varkappa) = \sum\limits_{j=1}^{16}\mathbf{err}_j, \end{align*}$$
$$\begin{align*}\frac d{dt}g_{12}(\varkappa) = \sum\limits_{j=1}^{16}\mathbf{err}_j, \end{align*}$$
where we define
 $$ \begin{align*} &\mathbf{err}_1 = \tfrac{8\varkappa^5}{\kappa^2 - \varkappa^2}g_{12}(\varkappa),\qquad \mathbf{err}_2 = \tfrac{8\kappa^2\varkappa^3}{\kappa^2 - \varkappa^2}[1 + \gamma(\varkappa)]\tfrac{(2\varkappa + \partial)q}{4\kappa^2 - \partial^2} + 4\varkappa^2[1 + \gamma(\varkappa)]\tfrac{\partial^2q}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_3 = [1 + \gamma(\varkappa)]\tfrac{(2\varkappa + \partial)\partial^3 q}{4\kappa^2-\partial^2}, \qquad\mathbf{err}_4=-\tfrac{64\kappa^4\varkappa^3}{\kappa^2-\varkappa^2}g_{12}(\varkappa)\,\tfrac{q}{4\kappa^2-\partial^2}\,\tfrac{r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_5 =\tfrac{32\kappa^4\varkappa^2}{\kappa^2 - \varkappa^2}g_{12}(\varkappa)\Big[\tfrac{q}{4\kappa^2 - \partial^2}\,\tfrac{\partial r}{4\kappa^2 - \partial^2} -\tfrac{\partial q}{4\kappa^2 - \partial^2}\,\tfrac{r}{4\kappa^2 - \partial^2}\Big],\\ &\mathbf{err}_6= \tfrac{16\kappa^4\varkappa}{\kappa^2 - \varkappa^2}g_{12}(\varkappa) \,\tfrac{\partial q}{4\kappa^2 - \partial^2}\,\tfrac{\partial r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_7 = -16\kappa^2\varkappa g_{12}(\varkappa)\Big[\tfrac{ \partial^2q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}+\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^2r}{4\kappa^2 - \partial^2}\Big] ,\\ &\mathbf{err}_8 =4\varkappa g_{12}(\varkappa)\,\tfrac{\partial^2q}{4\kappa^2 - \partial^2}\,\tfrac{\partial^2r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_9 = 16\kappa^2g_{12}(\varkappa)\Big[\tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\, \tfrac{\partial r}{4\kappa^2 - \partial^2}-\tfrac{\partial q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^2 r}{4\kappa^2 - \partial^2}\Big] ,\\ &\mathbf{err}_{10}=-8\kappa^2g_{12}(\varkappa) \partial \Big[\tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\, \tfrac{ r}{4\kappa^2 - \partial^2} - \tfrac{ q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^2 r}{4\kappa^2 - \partial^2}\Big] ,\\ &\mathbf{err}_{11}= 2g_{12}(\varkappa)\Big[\tfrac{\partial^3 q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^2 r}{4\kappa^2 - \partial^2}-\tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^3r}{4\kappa^2 - \partial^2}\Big],\\ &\mathbf{err}_{12} =- \tfrac{4\kappa^5}{\kappa^2-\varkappa^2}[1+\gamma(\varkappa)]\, \Big[ g_{12}(\kappa)^{[\geq 3]}-g_{12}(-\kappa)^{[\geq 3]}-\tfrac1{2\kappa^3} q^2r \Big],\\ &\mathbf{err}_{13} = - \tfrac{4\kappa^4\varkappa}{\kappa^2 - \varkappa^2}[1+\gamma(\varkappa)]\, \Big[ g_{12}(\kappa)^{[\geq 3]}+g_{12}(-\kappa)^{[\geq 3]} \Big],\\ &\mathbf{err}_{14} = \tfrac{4\kappa^4\varkappa}{\kappa^2 - \varkappa^2}g_{12}(\varkappa)\Big[\gamma(\kappa)^{[\geq 4]} + \gamma(-\kappa)^{[\geq 4]}\Big],\\ &\mathbf{err}_{15} = \tfrac{4\kappa^5}{\kappa^2 - \varkappa^2}g_{12}(\varkappa)\Big[\gamma(\kappa)^{[\geq 4]} -\gamma(-\kappa)^{[\geq 4]}\Big],\\ &\mathbf{err}_{16} = -\tfrac{2\varkappa^2}{\kappa^2 - \varkappa^2}[1+\gamma(\varkappa)] q^2r. \end{align*} $$
$$ \begin{align*} &\mathbf{err}_1 = \tfrac{8\varkappa^5}{\kappa^2 - \varkappa^2}g_{12}(\varkappa),\qquad \mathbf{err}_2 = \tfrac{8\kappa^2\varkappa^3}{\kappa^2 - \varkappa^2}[1 + \gamma(\varkappa)]\tfrac{(2\varkappa + \partial)q}{4\kappa^2 - \partial^2} + 4\varkappa^2[1 + \gamma(\varkappa)]\tfrac{\partial^2q}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_3 = [1 + \gamma(\varkappa)]\tfrac{(2\varkappa + \partial)\partial^3 q}{4\kappa^2-\partial^2}, \qquad\mathbf{err}_4=-\tfrac{64\kappa^4\varkappa^3}{\kappa^2-\varkappa^2}g_{12}(\varkappa)\,\tfrac{q}{4\kappa^2-\partial^2}\,\tfrac{r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_5 =\tfrac{32\kappa^4\varkappa^2}{\kappa^2 - \varkappa^2}g_{12}(\varkappa)\Big[\tfrac{q}{4\kappa^2 - \partial^2}\,\tfrac{\partial r}{4\kappa^2 - \partial^2} -\tfrac{\partial q}{4\kappa^2 - \partial^2}\,\tfrac{r}{4\kappa^2 - \partial^2}\Big],\\ &\mathbf{err}_6= \tfrac{16\kappa^4\varkappa}{\kappa^2 - \varkappa^2}g_{12}(\varkappa) \,\tfrac{\partial q}{4\kappa^2 - \partial^2}\,\tfrac{\partial r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_7 = -16\kappa^2\varkappa g_{12}(\varkappa)\Big[\tfrac{ \partial^2q}{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}+\tfrac{q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^2r}{4\kappa^2 - \partial^2}\Big] ,\\ &\mathbf{err}_8 =4\varkappa g_{12}(\varkappa)\,\tfrac{\partial^2q}{4\kappa^2 - \partial^2}\,\tfrac{\partial^2r}{4\kappa^2 - \partial^2},\\ &\mathbf{err}_9 = 16\kappa^2g_{12}(\varkappa)\Big[\tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\, \tfrac{\partial r}{4\kappa^2 - \partial^2}-\tfrac{\partial q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^2 r}{4\kappa^2 - \partial^2}\Big] ,\\ &\mathbf{err}_{10}=-8\kappa^2g_{12}(\varkappa) \partial \Big[\tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\, \tfrac{ r}{4\kappa^2 - \partial^2} - \tfrac{ q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^2 r}{4\kappa^2 - \partial^2}\Big] ,\\ &\mathbf{err}_{11}= 2g_{12}(\varkappa)\Big[\tfrac{\partial^3 q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^2 r}{4\kappa^2 - \partial^2}-\tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\, \tfrac{\partial^3r}{4\kappa^2 - \partial^2}\Big],\\ &\mathbf{err}_{12} =- \tfrac{4\kappa^5}{\kappa^2-\varkappa^2}[1+\gamma(\varkappa)]\, \Big[ g_{12}(\kappa)^{[\geq 3]}-g_{12}(-\kappa)^{[\geq 3]}-\tfrac1{2\kappa^3} q^2r \Big],\\ &\mathbf{err}_{13} = - \tfrac{4\kappa^4\varkappa}{\kappa^2 - \varkappa^2}[1+\gamma(\varkappa)]\, \Big[ g_{12}(\kappa)^{[\geq 3]}+g_{12}(-\kappa)^{[\geq 3]} \Big],\\ &\mathbf{err}_{14} = \tfrac{4\kappa^4\varkappa}{\kappa^2 - \varkappa^2}g_{12}(\varkappa)\Big[\gamma(\kappa)^{[\geq 4]} + \gamma(-\kappa)^{[\geq 4]}\Big],\\ &\mathbf{err}_{15} = \tfrac{4\kappa^5}{\kappa^2 - \varkappa^2}g_{12}(\varkappa)\Big[\gamma(\kappa)^{[\geq 4]} -\gamma(-\kappa)^{[\geq 4]}\Big],\\ &\mathbf{err}_{16} = -\tfrac{2\varkappa^2}{\kappa^2 - \varkappa^2}[1+\gamma(\varkappa)] q^2r. \end{align*} $$
To bound the error terms, we will rely on the a priori estimate (4.12) and the local smoothing estimate (5.22), which yield
 $$ \begin{align} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} = \|q\|_{L^\infty_t H^s}+ \|q\|_{X^{s+1}_\kappa} \lesssim \|q(0)\|_{H^s}. \end{align} $$
$$ \begin{align} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} = \|q\|_{L^\infty_t H^s}+ \|q\|_{X^{s+1}_\kappa} \lesssim \|q(0)\|_{H^s}. \end{align} $$
We will also employ the estimates recorded in Corollary 5.9, as well as the bounds
 $$ \begin{align} \|q\|_{X^{-s}_\kappa} \lesssim \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}, \end{align} $$
$$ \begin{align} \|q\|_{X^{-s}_\kappa} \lesssim \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}, \end{align} $$
 $$ \begin{align} \|g_{12}(\varkappa)\|_{X^{s+2}_\kappa} \lesssim\|q(0)\|_{H^s}\quad\text{and}\quad \|\gamma(\varkappa)\|_{X^{s+2}_\kappa}\lesssim\|q(0)\|_{H^s}^2, \end{align} $$
$$ \begin{align} \|g_{12}(\varkappa)\|_{X^{s+2}_\kappa} \lesssim\|q(0)\|_{H^s}\quad\text{and}\quad \|\gamma(\varkappa)\|_{X^{s+2}_\kappa}\lesssim\|q(0)\|_{H^s}^2, \end{align} $$
which follow from (2.9), (7.7), (3.33), and (3.35).
We will allow implicit constants to depend on
 $\varkappa $
. Throughout the proof, we will take
$\varkappa $
. Throughout the proof, we will take
 $\kappa \geq 2\varkappa $
. As before, when arguing by duality, we write
$\kappa \geq 2\varkappa $
. As before, when arguing by duality, we write
 $\phi $
for a function in
$\phi $
for a function in
 $L^\infty _t H^4$
of unit norm.
$L^\infty _t H^4$
of unit norm.
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_1}$
. We apply the estimate (3.24) to bound
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_1}$
. We apply the estimate (3.24) to bound
 $$\begin{align*}\left\|\psi_h^{12}\mathbf{err}_1\right\|_{L^1_tH^{-4}}\lesssim \kappa^{-2}\|g_{12}(\varkappa)\|_{L^\infty_tH^{s+1}}\lesssim \kappa^{-2}\|q(0)\|_{H^s}. \end{align*}$$
$$\begin{align*}\left\|\psi_h^{12}\mathbf{err}_1\right\|_{L^1_tH^{-4}}\lesssim \kappa^{-2}\|g_{12}(\varkappa)\|_{L^\infty_tH^{s+1}}\lesssim \kappa^{-2}\|q(0)\|_{H^s}. \end{align*}$$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_2}$
. Similarly, using duality and (3.27), we may bound
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_2}$
. Similarly, using duality and (3.27), we may bound
 $$ \begin{align*} &\left\|\psi_h^{12} \mathbf{err}_2\right\|_{L^1_tH^{-4}}\\ &\qquad\lesssim \big\|\psi_h^{12}[1+\gamma(\varkappa)]\big\|_{L^\infty_tH^{s+1}}\big[\big\|\tfrac{(2\varkappa + \partial)q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tH^{-(s+1)}}+\big\|\tfrac{\partial^2q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tH^{-(s+1)}}\big]\\ &\qquad\lesssim\kappa^{-(1+2s)}\|q(0)\|_{H^s}. \end{align*} $$
$$ \begin{align*} &\left\|\psi_h^{12} \mathbf{err}_2\right\|_{L^1_tH^{-4}}\\ &\qquad\lesssim \big\|\psi_h^{12}[1+\gamma(\varkappa)]\big\|_{L^\infty_tH^{s+1}}\big[\big\|\tfrac{(2\varkappa + \partial)q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tH^{-(s+1)}}+\big\|\tfrac{\partial^2q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tH^{-(s+1)}}\big]\\ &\qquad\lesssim\kappa^{-(1+2s)}\|q(0)\|_{H^s}. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_3}$
. We estimate
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_3}$
. We estimate
 $$ \begin{align*} \big\|\psi_h^{12} \mathbf{err}_3\big\|_{L^1_tH^{-4}} &\lesssim \big\| \psi_h^6[1+\gamma(\varkappa)] \tfrac{(2\varkappa + \partial)\partial^3 (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}}\\ & \quad + \big\|\psi_h^6[1+\gamma(\varkappa)] [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^3 }{4\kappa^2-\partial^2}]q\big\|_{L^1_tH^{-4}}. \end{align*} $$
$$ \begin{align*} \big\|\psi_h^{12} \mathbf{err}_3\big\|_{L^1_tH^{-4}} &\lesssim \big\| \psi_h^6[1+\gamma(\varkappa)] \tfrac{(2\varkappa + \partial)\partial^3 (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}}\\ & \quad + \big\|\psi_h^6[1+\gamma(\varkappa)] [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^3 }{4\kappa^2-\partial^2}]q\big\|_{L^1_tH^{-4}}. \end{align*} $$
We will bound both of these terms using duality. Using (7.8) and (7.9), we get
 $$ \begin{align*} \big\| \psi_h^6[1+\gamma(\varkappa)] \tfrac{(2\varkappa + \partial)\partial^3 (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}} &\lesssim \sup_\phi\|\phi[1+\gamma(\varkappa)]\|_{X^{s+2}_\kappa} \|q\|_{X^{-s}_\kappa}\\ &\lesssim \big[\kappa^{-1} + \|q(0)\|_{H^s}^2\big] \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}\\ &\lesssim \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}. \end{align*} $$
$$ \begin{align*} \big\| \psi_h^6[1+\gamma(\varkappa)] \tfrac{(2\varkappa + \partial)\partial^3 (\psi_h^6q)}{4\kappa^2-\partial^2}\big\|_{L^1_tH^{-4}} &\lesssim \sup_\phi\|\phi[1+\gamma(\varkappa)]\|_{X^{s+2}_\kappa} \|q\|_{X^{-s}_\kappa}\\ &\lesssim \big[\kappa^{-1} + \|q(0)\|_{H^s}^2\big] \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}\\ &\lesssim \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}. \end{align*} $$
To estimate the commutator term, we use (2.12) and (3.27), as follows:
 $$ \begin{align*} &\big\|\psi_h^6[1+\gamma(\varkappa)] [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^3 }{4\kappa^2-\partial^2}]q\big\|_{L^1_tH^{-4}}\\ & \lesssim \sup_\phi\|\psi_h^6\phi [1+\gamma(\varkappa)]\|_{L_t^\infty H^{s+1}} \big\| [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^3 }{4\kappa^2-\partial^2}]q\big\|_{L_t^2 H^{-(s+1)}}\lesssim \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}. \end{align*} $$
$$ \begin{align*} &\big\|\psi_h^6[1+\gamma(\varkappa)] [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^3 }{4\kappa^2-\partial^2}]q\big\|_{L^1_tH^{-4}}\\ & \lesssim \sup_\phi\|\psi_h^6\phi [1+\gamma(\varkappa)]\|_{L_t^\infty H^{s+1}} \big\| [\psi_h^6,\tfrac{(2\varkappa + \partial)\partial^3 }{4\kappa^2-\partial^2}]q\big\|_{L_t^2 H^{-(s+1)}}\lesssim \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}. \end{align*} $$
Collecting our estimates, we obtain
 $$\begin{align*}\|\psi_h^{12} \mathbf{err}_3\|_{L^1_tH^{-4}}\lesssim \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}. \end{align*}$$
$$\begin{align*}\|\psi_h^{12} \mathbf{err}_3\|_{L^1_tH^{-4}}\lesssim \kappa^{-\frac12(2s+1)}\|q(0)\|_{H^s}. \end{align*}$$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_4}$
. Using
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_4}$
. Using
 $L^1\subset H^{-4}$
and
$L^1\subset H^{-4}$
and
 $H^{s+1}\subset L^\infty $
together with (3.24), we get
$H^{s+1}\subset L^\infty $
together with (3.24), we get
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_4\|_{L^1_tH^{-4}}&\lesssim \kappa^{2}\|g_{12}(\varkappa)\|_{L^\infty_{t,x}}\big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}^2\lesssim \kappa^{-2(1+s)} \|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_4\|_{L^1_tH^{-4}}&\lesssim \kappa^{2}\|g_{12}(\varkappa)\|_{L^\infty_{t,x}}\big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}^2\lesssim \kappa^{-2(1+s)} \|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_5}$
. Arguing as for
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_5}$
. Arguing as for
 $\mathbf {err}_4$
, we may bound
$\mathbf {err}_4$
, we may bound
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_5\|_{L^1_tH^{-4}}\lesssim \kappa^2 \|g_{12}(\varkappa)\|_{L^\infty_{t,x}}\big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}\big\|\tfrac {\partial q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_5\|_{L^1_tH^{-4}}\lesssim \kappa^2 \|g_{12}(\varkappa)\|_{L^\infty_{t,x}}\big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}\big\|\tfrac {\partial q}{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2}\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_6}$
. Using
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_6}$
. Using
 $L^1\subset H^{-4}$
and Corollary 5.9, we may bound
$L^1\subset H^{-4}$
and Corollary 5.9, we may bound
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_6\|_{L^1_tH^{-4}} &\lesssim \kappa^2\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\| \psi_h^6\tfrac{\partial}{4\kappa^2-\partial^2}q\big\|_{L_{t,x}^2}^2 \lesssim \kappa^{-(1+s)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_6\|_{L^1_tH^{-4}} &\lesssim \kappa^2\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\| \psi_h^6\tfrac{\partial}{4\kappa^2-\partial^2}q\big\|_{L_{t,x}^2}^2 \lesssim \kappa^{-(1+s)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_7}$
. Arguing as for
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_7}$
. Arguing as for
 $\mathbf {err}_6$
, we may bound
$\mathbf {err}_6$
, we may bound
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_7\|_{L^1_tH^{-4}} &\lesssim \kappa^2\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2} \big\| \psi_h^6\tfrac{\partial^2}{4\kappa^2-\partial^2}q\big\|_{L_{t,x}^2}\\ &\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_7\|_{L^1_tH^{-4}} &\lesssim \kappa^2\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\|\tfrac q{4\kappa^2 - \partial^2}\big\|_{L^\infty_tL^2} \big\| \psi_h^6\tfrac{\partial^2}{4\kappa^2-\partial^2}q\big\|_{L_{t,x}^2}\\ &\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_8}$
. Arguing as for
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_8}$
. Arguing as for
 $\mathbf {err}_6$
again, we bound
$\mathbf {err}_6$
again, we bound
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_8\|_{L^1_tH^{-4}} &\lesssim\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\| \psi_h^6\tfrac{\partial^2 q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}^2 \lesssim \kappa^{-2(1+s)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_8\|_{L^1_tH^{-4}} &\lesssim\|g_{12}(\varkappa)\|_{L^\infty_{t,x}} \big\| \psi_h^6\tfrac{\partial^2 q}{4\kappa^2-\partial^2}\big\|_{L_{t,x}^2}^2 \lesssim \kappa^{-2(1+s)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_9}$
. Using (2.11) and then (7.7) yields
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_9}$
. Using (2.11) and then (7.7) yields
 $$ \begin{align} \big\|\psi_h^6 \tfrac{\partial q}{4\kappa^2 - \partial^2}\big\|_{L_t^2 H^{s+1}} &\lesssim \kappa^{-1} \| q \|_{L^\infty_t H^s} + \kappa^{-1}\big\| \tfrac{\psi^6 q}{\sqrt{4\kappa^2-\partial^2}} \|_{L_t^2 H^{s+2}} \lesssim \kappa^{-1} \|q(0)\|_{H^s}. \end{align} $$
$$ \begin{align} \big\|\psi_h^6 \tfrac{\partial q}{4\kappa^2 - \partial^2}\big\|_{L_t^2 H^{s+1}} &\lesssim \kappa^{-1} \| q \|_{L^\infty_t H^s} + \kappa^{-1}\big\| \tfrac{\psi^6 q}{\sqrt{4\kappa^2-\partial^2}} \|_{L_t^2 H^{s+2}} \lesssim \kappa^{-1} \|q(0)\|_{H^s}. \end{align} $$
Analogously, but also breaking at frequency
 $N=\sqrt {\kappa }$
, we find
$N=\sqrt {\kappa }$
, we find
 $$ \begin{align} \big\|\psi_h^6 \tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\big\|_{L_t^2 H^{-1-s}} &\lesssim \kappa^{-2-2s}\| q \|_{L_t^\infty H^{s}} + \kappa^{-2} N^{1-2s} \| (\psi_h^6 q)_{\leq N} \|_{L^\infty_t H^s} \notag\\ & \quad {}+ \kappa^{-1} N^{-(1+2s)} \| (\psi_h^6 q)_{> N} \|_{X_\kappa^{s+1}} \\ &\lesssim \kappa^{-1-\frac12(1+2s)} \|q(0)\|_{H^s}.\notag \end{align} $$
$$ \begin{align} \big\|\psi_h^6 \tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\big\|_{L_t^2 H^{-1-s}} &\lesssim \kappa^{-2-2s}\| q \|_{L_t^\infty H^{s}} + \kappa^{-2} N^{1-2s} \| (\psi_h^6 q)_{\leq N} \|_{L^\infty_t H^s} \notag\\ & \quad {}+ \kappa^{-1} N^{-(1+2s)} \| (\psi_h^6 q)_{> N} \|_{X_\kappa^{s+1}} \\ &\lesssim \kappa^{-1-\frac12(1+2s)} \|q(0)\|_{H^s}.\notag \end{align} $$
Combining these bounds, we deduce that
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_9\|_{L^1_tH^{-4}} &\lesssim \kappa^2\|g_{12}\|_{L^\infty_t H^{s+1}} \big\|\psi_h^6 \tfrac{\partial q}{4\kappa^2 - \partial^2}\big\|_{L_t^2 H^{s+1}} \big\|\psi_h^6 \tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\big\|_{L_t^2 H^{-1-s}} \\ &\lesssim \kappa^{-\frac12{(1+2s)}}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_9\|_{L^1_tH^{-4}} &\lesssim \kappa^2\|g_{12}\|_{L^\infty_t H^{s+1}} \big\|\psi_h^6 \tfrac{\partial q}{4\kappa^2 - \partial^2}\big\|_{L_t^2 H^{s+1}} \big\|\psi_h^6 \tfrac{\partial^2 q}{4\kappa^2 - \partial^2}\big\|_{L_t^2 H^{-1-s}} \\ &\lesssim \kappa^{-\frac12{(1+2s)}}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{10}}$
. Our goal, here, is to employ (5.28). Given
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{10}}$
. Our goal, here, is to employ (5.28). Given
 $\phi \in L^\infty _t H^4$
, we have
$\phi \in L^\infty _t H^4$
, we have
 $$ \begin{align*} [\phi \psi_h^{12} g_{12} ]' \tfrac{\partial^2 q }{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2} = m\big[ q,r, \tfrac{(\psi_h^{12}\phi)'}{\psi_h^{12}}, \psi_h^{12} \tfrac{(2\varkappa+\partial)g_{12}}{2\varkappa+\partial}\big] + m\big[ q,r, g_{12}', \psi_h^{12} \tfrac{(2\varkappa+\partial)\phi}{2\varkappa+\partial}\big], \end{align*} $$
$$ \begin{align*} [\phi \psi_h^{12} g_{12} ]' \tfrac{\partial^2 q }{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2} = m\big[ q,r, \tfrac{(\psi_h^{12}\phi)'}{\psi_h^{12}}, \psi_h^{12} \tfrac{(2\varkappa+\partial)g_{12}}{2\varkappa+\partial}\big] + m\big[ q,r, g_{12}', \psi_h^{12} \tfrac{(2\varkappa+\partial)\phi}{2\varkappa+\partial}\big], \end{align*} $$
where the paraproduct m has symbol
 $$ \begin{align*}m(\xi_1,\ldots,\xi_4) = \tfrac{\xi_1^2}{(4\kappa^2+\xi_1^2)(4\kappa^2+\xi_2^2)}. \end{align*} $$
$$ \begin{align*}m(\xi_1,\ldots,\xi_4) = \tfrac{\xi_1^2}{(4\kappa^2+\xi_1^2)(4\kappa^2+\xi_2^2)}. \end{align*} $$
In this way, we see that
 $$ \begin{align*} \kappa^2 \bigg\| \int \phi \psi_h^{12} g_{12} \cdot \partial \big[\tfrac{\partial^2 q }{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\,dx \bigg\|_{L^1_{t}} \lesssim \kappa^{-(1+2s)} \| \phi\|_{L^\infty_t H^4} \|q(0)\|_{H^s}^3 \end{align*} $$
$$ \begin{align*} \kappa^2 \bigg\| \int \phi \psi_h^{12} g_{12} \cdot \partial \big[\tfrac{\partial^2 q }{4\kappa^2 - \partial^2}\, \tfrac{r}{4\kappa^2 - \partial^2}\big]\,dx \bigg\|_{L^1_{t}} \lesssim \kappa^{-(1+2s)} \| \phi\|_{L^\infty_t H^4} \|q(0)\|_{H^s}^3 \end{align*} $$
and thence that
 $$ \begin{align*}\|\psi_h^{12} \mathbf{err}_{10}\|_{L^1_tH^{-4}} \lesssim \kappa^{-(1+2s)} \|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*}\|\psi_h^{12} \mathbf{err}_{10}\|_{L^1_tH^{-4}} \lesssim \kappa^{-(1+2s)} \|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{11}}$
. Arguing as for (7.10), we first use (2.11) and (7.7) to see that
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{11}}$
. Arguing as for (7.10), we first use (2.11) and (7.7) to see that
 $$ \begin{align*} \big\| \psi_h^6 \tfrac{\partial^2 q}{4\kappa^2 - \partial^2} \big\|_{L^2_t H^{s+1}} \lesssim \| q\|_{L^\infty_t H^s} + \| q \|_{X^{s+1}_\kappa} \lesssim \|q(0)\|_{H^s} \end{align*} $$
$$ \begin{align*} \big\| \psi_h^6 \tfrac{\partial^2 q}{4\kappa^2 - \partial^2} \big\|_{L^2_t H^{s+1}} \lesssim \| q\|_{L^\infty_t H^s} + \| q \|_{X^{s+1}_\kappa} \lesssim \|q(0)\|_{H^s} \end{align*} $$
and
 $$ \begin{align*} \big\| \psi_h^6 \tfrac{\partial^3 q}{4\kappa^2 - \partial^2}\big\|_{L^2_t H^{-(s+1)}} \lesssim \kappa^{-(1+2s)}\| q\|_{L^\infty_t H^s} + \kappa^{-(1+2s)} \| q \|_{X^{s+1}_\kappa} \lesssim \kappa^{-(1+2s)} \|q(0)\|_{H^s}. \end{align*} $$
$$ \begin{align*} \big\| \psi_h^6 \tfrac{\partial^3 q}{4\kappa^2 - \partial^2}\big\|_{L^2_t H^{-(s+1)}} \lesssim \kappa^{-(1+2s)}\| q\|_{L^\infty_t H^s} + \kappa^{-(1+2s)} \| q \|_{X^{s+1}_\kappa} \lesssim \kappa^{-(1+2s)} \|q(0)\|_{H^s}. \end{align*} $$
Thus,
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{11}\|_{L^1_tH^{-4}} &\lesssim \|g_{12}(\varkappa)\|_{L_t^\infty H^{s+1}} \big\| \psi_h^6 \tfrac{\partial^2 q}{4\kappa^2 - \partial^2} \big\|_{L^2_t H^{s+1}} \big\| \psi_h^6 \tfrac{\partial^3 q}{4\kappa^2 - \partial^2}\big\|_{L^2_t H^{-(s+1)}} \\ &\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{11}\|_{L^1_tH^{-4}} &\lesssim \|g_{12}(\varkappa)\|_{L_t^\infty H^{s+1}} \big\| \psi_h^6 \tfrac{\partial^2 q}{4\kappa^2 - \partial^2} \big\|_{L^2_t H^{s+1}} \big\| \psi_h^6 \tfrac{\partial^3 q}{4\kappa^2 - \partial^2}\big\|_{L^2_t H^{-(s+1)}} \\ &\lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{12}}$
. We first note that (3.27) and (3.35) imply
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{12}}$
. We first note that (3.27) and (3.35) imply
 $$ \begin{align*} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert (2\varkappa+\partial)\big(\phi[1+\gamma(\varkappa)]\big) \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} \lesssim 1 + {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} \lesssim 1 \end{align*} $$
$$ \begin{align*} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert (2\varkappa+\partial)\big(\phi[1+\gamma(\varkappa)]\big) \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} \lesssim 1 + {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} \lesssim 1 \end{align*} $$
for any
 $\phi \in L^\infty _t H^4$
of unit norm. Thus, it follows from (5.45) that
$\phi \in L^\infty _t H^4$
of unit norm. Thus, it follows from (5.45) that
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{12}\|_{L^1_tH^{-4}} &\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{12}\|_{L^1_tH^{-4}} &\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{13}}$
. Arguing as for
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{13}}$
. Arguing as for
 $\mathbf {err}_{12}$
and using (5.44) in place of (5.45), we get
$\mathbf {err}_{12}$
and using (5.44) in place of (5.45), we get
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{13}\|_{L^1_tH^{-4}} &\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{13}\|_{L^1_tH^{-4}} &\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}^3. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{14}}$
. Using
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{14}}$
. Using
 $L^1\subset H^{-4}$
together with (3.24) and (5.46), we get
$L^1\subset H^{-4}$
together with (3.24) and (5.46), we get
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{14}\|_{L^1_tH^{-4}} &\lesssim \kappa^2 \|g_{12}\|_{L_{t,x}^\infty} \big\| \gamma(\pm\kappa)^{[\geq 4]} \psi_h^{12}\big\|_{L_{t,x}^1} \lesssim \kappa^{-\frac12-(2s+1)}\|q(0)\|_{H^s}^5. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{14}\|_{L^1_tH^{-4}} &\lesssim \kappa^2 \|g_{12}\|_{L_{t,x}^\infty} \big\| \gamma(\pm\kappa)^{[\geq 4]} \psi_h^{12}\big\|_{L_{t,x}^1} \lesssim \kappa^{-\frac12-(2s+1)}\|q(0)\|_{H^s}^5. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{15}}$
. The argument, here, is essentially a recapitulation of the proof of (5.47). For example, from (5.49), we have
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{15}}$
. The argument, here, is essentially a recapitulation of the proof of (5.47). For example, from (5.49), we have
 $$ \begin{align*} \kappa^3 \big\|\psi_h^{12} g_{12}(\varkappa) \gamma^{[\geq 6]}(\pm\kappa)\big\|_{L^1_tH^{-4}} &\lesssim \kappa^{-(1+2s)} \|g_{12}\|_{L_{t,x}^\infty} \|q(0)\|_{H^s}^6 \lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^7. \end{align*} $$
$$ \begin{align*} \kappa^3 \big\|\psi_h^{12} g_{12}(\varkappa) \gamma^{[\geq 6]}(\pm\kappa)\big\|_{L^1_tH^{-4}} &\lesssim \kappa^{-(1+2s)} \|g_{12}\|_{L_{t,x}^\infty} \|q(0)\|_{H^s}^6 \lesssim \kappa^{-(1+2s)}\|q(0)\|_{H^s}^7. \end{align*} $$
In order to repeat the treatment of the
 $\gamma ^{[4]}$
terms given previously, we need one additional piece of information, namely, that f defined by
$\gamma ^{[4]}$
terms given previously, we need one additional piece of information, namely, that f defined by
 $$ \begin{align*} \tfrac{f}{2\kappa-\partial} = \phi\, g_{12}(\varkappa) \tfrac{q}{2\kappa-\partial} \end{align*} $$
$$ \begin{align*} \tfrac{f}{2\kappa-\partial} = \phi\, g_{12}(\varkappa) \tfrac{q}{2\kappa-\partial} \end{align*} $$
satisfies
 $$ \begin{align*} \| f\|_{L^\infty_t H^s} \lesssim \| q\|_{L^\infty_t H^s} \quad\text{and}\quad {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} \lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} \end{align*} $$
$$ \begin{align*} \| f\|_{L^\infty_t H^s} \lesssim \| q\|_{L^\infty_t H^s} \quad\text{and}\quad {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert f \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} \lesssim {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}_\kappa} \end{align*} $$
for every
 $\phi \in L^\infty _t H^4$
of unit norm. These assertions follow readily from (2.16), (3.24), and (3.33). Thus, we may conclude that
$\phi \in L^\infty _t H^4$
of unit norm. These assertions follow readily from (2.16), (3.24), and (3.33). Thus, we may conclude that
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{15}\|_{L^1_tH^{-4}} &\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}^5. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{15}\|_{L^1_tH^{-4}} &\lesssim \kappa^{-(2s+1)}\|q(0)\|_{H^s}^5. \end{align*} $$
 $\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{16}}$
. Breaking at frequency
$\underline{\mathrm{Estimate}\ \mathrm{for}\ \mathbf {err}_{16}}$
. Breaking at frequency
 $N=\sqrt \kappa $
and using (7.7), we find
$N=\sqrt \kappa $
and using (7.7), we find
 $$ \begin{align*} \| \psi_h^6 q \|_{L_t^2 H^{s+1}}&\lesssim N \|q\|_{L_t^\infty H^s} + \tfrac{\kappa}{N} \|q\|_{X_\kappa^{s+1}}\lesssim \kappa^{\frac12}\|q(0)\|_{H^s}. \end{align*} $$
$$ \begin{align*} \| \psi_h^6 q \|_{L_t^2 H^{s+1}}&\lesssim N \|q\|_{L_t^\infty H^s} + \tfrac{\kappa}{N} \|q\|_{X_\kappa^{s+1}}\lesssim \kappa^{\frac12}\|q(0)\|_{H^s}. \end{align*} $$
Thus, arguing by duality and using (3.24), we estimate
 $$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{16}\|_{L^1_tH^{-4}}&\lesssim \kappa^{-2} \|q\|_{L_t^\infty H^s} \|\psi_h^6 q\|_{L_t^2 H^{s+1}}^2 \sup_\phi\|\phi[1+\gamma(\varkappa)]\|_{L_t^\infty H^{s+1}} \\ &\lesssim \kappa^{-1}\|q(0)\|_{H^s}^3. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12} \mathbf{err}_{16}\|_{L^1_tH^{-4}}&\lesssim \kappa^{-2} \|q\|_{L_t^\infty H^s} \|\psi_h^6 q\|_{L_t^2 H^{s+1}}^2 \sup_\phi\|\phi[1+\gamma(\varkappa)]\|_{L_t^\infty H^{s+1}} \\ &\lesssim \kappa^{-1}\|q(0)\|_{H^s}^3. \end{align*} $$
Combining our estimates for all the error terms, we deduce (7.1), which then completes the proof of the mKdV case of Proposition 7.1.
8. Well-posedness
In this section, we prove Theorem 1.1. While we have already established the necessary prerequisites to obtain global well-posedness in
 $H^s$
for
$H^s$
for
 $-\frac 12<s<0$
, we begin this section with one additional equicontinuity result that will be applied to yield well-posedness at higher regularity.
$-\frac 12<s<0$
, we begin this section with one additional equicontinuity result that will be applied to yield well-posedness at higher regularity.
This equicontinuity relies on a certain macroscopic conservation law, which we introduce through its density
 $$\begin{align*}\widetilde\rho(\varkappa) := qr - 2\varkappa\rho(\varkappa). \end{align*}$$
$$\begin{align*}\widetilde\rho(\varkappa) := qr - 2\varkappa\rho(\varkappa). \end{align*}$$
That this density satisfies a conservation law follows readily from Corollary 4.14 and the conservation of mass. The associated microscopic conservation law will be essential for proving local smoothing estimates at positive regularity in the next section.
For later reference, we note that
 $$ \begin{align} \widetilde\rho^{[2]}(\varkappa) = \tfrac12\Big(q \cdot \tfrac{r'}{2\varkappa+ \partial} -\tfrac{q'}{2\varkappa - \partial}\cdot r \Big). \end{align} $$
$$ \begin{align} \widetilde\rho^{[2]}(\varkappa) = \tfrac12\Big(q \cdot \tfrac{r'}{2\varkappa+ \partial} -\tfrac{q'}{2\varkappa - \partial}\cdot r \Big). \end{align} $$
Using
 $\widetilde \rho $
, we prove the following analogue of Proposition 4.4:
$\widetilde \rho $
, we prove the following analogue of Proposition 4.4:
Proposition 8.1. Let
 $0\leq \sigma < \frac 12$
. Then there exists
$0\leq \sigma < \frac 12$
. Then there exists
 $\delta>0$
so that for any
$\delta>0$
so that for any
 $q(0)\in \mathcal {S}$
satisfying
$q(0)\in \mathcal {S}$
satisfying
 $\|q(0)\|_{L^2}\leq \delta $
, the solution
$\|q(0)\|_{L^2}\leq \delta $
, the solution
 $q(t)$
of (NLS) or (mKdV) satisfies
$q(t)$
of (NLS) or (mKdV) satisfies
 $$ \begin{align} \|q(t)'\|_{H^{\sigma-1}_\kappa}^2 \lesssim \|q(0)'\|_{H^{\sigma-1}_\kappa}^2 + \kappa^{2\sigma-1}\delta^2\|q(0)\|_{L^2}^2, \end{align} $$
$$ \begin{align} \|q(t)'\|_{H^{\sigma-1}_\kappa}^2 \lesssim \|q(0)'\|_{H^{\sigma-1}_\kappa}^2 + \kappa^{2\sigma-1}\delta^2\|q(0)\|_{L^2}^2, \end{align} $$
uniformly for
 $t\in {{\mathbb {R}}}$
and
$t\in {{\mathbb {R}}}$
and
 $\kappa \geq 1$
.
$\kappa \geq 1$
.
Proof. Using (3.24), (3.25), and (3.28), we get
 $$ \begin{align*} \|g_{12}(\varkappa)\|_{L^2}\lesssim \varkappa^{-1} \|q\|_{L^2}, \quad \|g_{12}^{[\geq 3]}(\varkappa)\|_{L^2}\lesssim \varkappa^{-2} \|q\|_{L^2}^3, \quad \|\gamma(\varkappa)\|_{L^\infty}\leq \varkappa^{-1}\|q\|_{L^2}^2. \end{align*} $$
$$ \begin{align*} \|g_{12}(\varkappa)\|_{L^2}\lesssim \varkappa^{-1} \|q\|_{L^2}, \quad \|g_{12}^{[\geq 3]}(\varkappa)\|_{L^2}\lesssim \varkappa^{-2} \|q\|_{L^2}^3, \quad \|\gamma(\varkappa)\|_{L^\infty}\leq \varkappa^{-1}\|q\|_{L^2}^2. \end{align*} $$
Consequently, using (3.39) and (4.14), we obtain
 $$ \begin{align} \|\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\|_{L^2}\lesssim \varkappa^{-2}\delta^2\|q\|_{L^2}, \quad\text{and so}\quad \|\widetilde\rho^{[\geq 4]}(\varkappa)\|_{L^1} \lesssim \varkappa^{-1}\delta^2\|q\|_{L^2}^2 \end{align} $$
$$ \begin{align} \|\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\|_{L^2}\lesssim \varkappa^{-2}\delta^2\|q\|_{L^2}, \quad\text{and so}\quad \|\widetilde\rho^{[\geq 4]}(\varkappa)\|_{L^1} \lesssim \varkappa^{-1}\delta^2\|q\|_{L^2}^2 \end{align} $$
whenever
 $0<\delta \ll 1$
is sufficiently small. Employing (8.1) and (8.3), we get
$0<\delta \ll 1$
is sufficiently small. Employing (8.1) and (8.3), we get
 $$\begin{align*}\pm \operatorname{Re}\int\widetilde\rho(x;\varkappa)\,dx = \|q'\|_{H^{-1}_\varkappa}^2 + \mathcal O\big(\varkappa^{-1}\delta^2\|q\|_{L^2}^2\big). \end{align*}$$
$$\begin{align*}\pm \operatorname{Re}\int\widetilde\rho(x;\varkappa)\,dx = \|q'\|_{H^{-1}_\varkappa}^2 + \mathcal O\big(\varkappa^{-1}\delta^2\|q\|_{L^2}^2\big). \end{align*}$$
If
 $\sigma = 0$
, we simply set
$\sigma = 0$
, we simply set
 $\varkappa =\kappa $
. If
$\varkappa =\kappa $
. If
 $0<\sigma < \tfrac 12$
, we apply the estimate (2.7) to obtain
$0<\sigma < \tfrac 12$
, we apply the estimate (2.7) to obtain
 $$\begin{align*}\int_\kappa^\infty \varkappa^{2\sigma}\Bigg(\pm \operatorname{Re}\int\widetilde\rho(x;\varkappa)\,dx\Bigg)\,\tfrac{d\varkappa}\varkappa \approx \|q'\|_{H^{\sigma-1}_\kappa}^2 + \mathcal O\big(\kappa^{2\sigma-1}\delta^2\|q\|_{L^2}^2\big). \end{align*}$$
$$\begin{align*}\int_\kappa^\infty \varkappa^{2\sigma}\Bigg(\pm \operatorname{Re}\int\widetilde\rho(x;\varkappa)\,dx\Bigg)\,\tfrac{d\varkappa}\varkappa \approx \|q'\|_{H^{\sigma-1}_\kappa}^2 + \mathcal O\big(\kappa^{2\sigma-1}\delta^2\|q\|_{L^2}^2\big). \end{align*}$$
As the mass and left-hand sides in these estimates are conserved under both (NLS) and (mKdV), the claim (8.2) now follows.
Proof of Theorem 1.1.
In view of the history discussed in the Introduction, it suffices to treat regularities
 $-\frac 12<s<0$
for (NLS) and
$-\frac 12<s<0$
for (NLS) and
 $-\frac 12<s<\frac 14$
for (mKdV). With the tools at our disposal, we are able to give a uniform treatment of both equations over the range
$-\frac 12<s<\frac 14$
for (mKdV). With the tools at our disposal, we are able to give a uniform treatment of both equations over the range
 $(-\frac 12, \frac 12)$
, so this is what we do. As the arguments for (NLS) and (mKdV) are identical, we provide details in the case of (NLS).
$(-\frac 12, \frac 12)$
, so this is what we do. As the arguments for (NLS) and (mKdV) are identical, we provide details in the case of (NLS).
We first consider initial data
 $q\in H^s$
, where
$q\in H^s$
, where
 $-\frac 12<s<0$
. Let
$-\frac 12<s<0$
. Let
 $0<\delta \ll 1$
be sufficiently small and, rescaling according to (1.3), assume that
$0<\delta \ll 1$
be sufficiently small and, rescaling according to (1.3), assume that
 $q\in B_\delta $
. Let
$q\in B_\delta $
. Let
 $\{q_n\}_{n\geq 1}\subset B_\delta \cap \mathcal {S}$
so that
$\{q_n\}_{n\geq 1}\subset B_\delta \cap \mathcal {S}$
so that
 $q_n\rightarrow q$
in
$q_n\rightarrow q$
in
 $H^s$
as
$H^s$
as
 $n\rightarrow \infty $
.
$n\rightarrow \infty $
.
In view of Propositions 4.6 and 6.4, the set
 $$\begin{align*}Q:= \left\{e^{tJ\nabla H_{\mathrm{NLS}}}q_n:n\geq 1,\;t\in [-1,1]\right\} \end{align*}$$
$$\begin{align*}Q:= \left\{e^{tJ\nabla H_{\mathrm{NLS}}}q_n:n\geq 1,\;t\in [-1,1]\right\} \end{align*}$$
is equicontinuous and tight in
 $H^s$
. Further, by Proposition 4.4, we may find some
$H^s$
. Further, by Proposition 4.4, we may find some
 $C = C(s)\geq 1$
so that
$C = C(s)\geq 1$
so that
 $Q\subset B_{C\delta }\cap \mathcal {S}$
.
$Q\subset B_{C\delta }\cap \mathcal {S}$
.
For fixed
 $\varkappa \geq 4$
, let
$\varkappa \geq 4$
, let
 $g_{12}(\cdot ) = g_{12}(\varkappa ;\cdot )$
and
$g_{12}(\cdot ) = g_{12}(\varkappa ;\cdot )$
and
 $\kappa \geq 2\varkappa $
. Let
$\kappa \geq 2\varkappa $
. Let
 $R\geq 1$
,
$R\geq 1$
,
 $\phi _R$
be as in Section 6, and
$\phi _R$
be as in Section 6, and
 $\chi _R\in \mathcal {S}$
be a nonnegative function so that
$\chi _R\in \mathcal {S}$
be a nonnegative function so that
 $1\leq \phi _R^2 + \chi _R^2$
. We then bound
$1\leq \phi _R^2 + \chi _R^2$
. We then bound
 $$ \begin{align*} &\|g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}}q_n) - g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}}q_m)\|_{L^\infty_tH^{s+1}}\\ &\qquad \lesssim \|g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}^\kappa}q_n) - g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}^\kappa}q_m)\|_{L^\infty_tH^{s+1}}\\ &\qquad\qquad + \sup\limits_{q\in Q^*}\|\chi_Rg_{12}(e^{tJ\nabla (H_{\mathrm{NLS}} - H_{\mathrm{NLS}}^\kappa)}q) - \chi_Rg_{12}(q)\|_{L^\infty_tH^{s+1}}\\ &\qquad\qquad + \sup\limits_{n\geq 1}\|\phi_Rg_{12}(e^{tJ\nabla H_{\mathrm{NLS}}}q_n)\|_{L^\infty_tH^{s+1}}, \end{align*} $$
$$ \begin{align*} &\|g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}}q_n) - g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}}q_m)\|_{L^\infty_tH^{s+1}}\\ &\qquad \lesssim \|g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}^\kappa}q_n) - g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}^\kappa}q_m)\|_{L^\infty_tH^{s+1}}\\ &\qquad\qquad + \sup\limits_{q\in Q^*}\|\chi_Rg_{12}(e^{tJ\nabla (H_{\mathrm{NLS}} - H_{\mathrm{NLS}}^\kappa)}q) - \chi_Rg_{12}(q)\|_{L^\infty_tH^{s+1}}\\ &\qquad\qquad + \sup\limits_{n\geq 1}\|\phi_Rg_{12}(e^{tJ\nabla H_{\mathrm{NLS}}}q_n)\|_{L^\infty_tH^{s+1}}, \end{align*} $$
where the set
 $$\begin{align*}Q^* := \left\{e^{J\nabla\left(tH_{\mathrm{NLS}} + sH_{\mathrm{NLS}}^{\kappa}\right)}q_n:n\geq 1,\;\kappa\geq 2\varkappa,\;t,s\in [-1,1]\right\}. \end{align*}$$
$$\begin{align*}Q^* := \left\{e^{J\nabla\left(tH_{\mathrm{NLS}} + sH_{\mathrm{NLS}}^{\kappa}\right)}q_n:n\geq 1,\;\kappa\geq 2\varkappa,\;t,s\in [-1,1]\right\}. \end{align*}$$
By Propositions 4.4 and 4.12, we have
 $Q^*\subset B_{C\delta }\cap \mathcal {S}$
, while by Proposition 4.6,
$Q^*\subset B_{C\delta }\cap \mathcal {S}$
, while by Proposition 4.6,
 $Q^*$
is equicontinuous in
$Q^*$
is equicontinuous in
 $H^s$
.
$H^s$
.
By Proposition 4.12 and the diffeomorphism property of Proposition 3.2, we have
 $$\begin{align*}\lim\limits_{n,m\rightarrow\infty}\|g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}^{\kappa}}q_n) - g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}^{\kappa}}q_m)\|_{L^\infty_tH^{s+1}} = 0. \end{align*}$$
$$\begin{align*}\lim\limits_{n,m\rightarrow\infty}\|g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}^{\kappa}}q_n) - g_{12}(e^{tJ\nabla H_{\mathrm{NLS}}^{\kappa}}q_m)\|_{L^\infty_tH^{s+1}} = 0. \end{align*}$$
Using Proposition 7.1, we obtain
 $$ \begin{align*} &\lim\limits_{\kappa\rightarrow\infty}\sup\limits_{q\in Q^*}\|\chi_Rg_{12}(e^{tJ\nabla (H_{\mathrm{NLS}} - H_{\mathrm{NLS}}^{\kappa})}q) - \chi_Rg_{12}(q)\|_{L^\infty_tH^{s+1}}\\ &\qquad \lesssim_R \lim\limits_{\kappa\rightarrow\infty}\sup\limits_{q\in Q^*}\sup\limits_{h\in {{\mathbb{R}}}}\|\psi_h^{12}g_{12}(e^{tJ\nabla (H_{\mathrm{NLS}} - H_{\mathrm{NLS}}^{\kappa})}q) - \psi_h^{12}g_{12}(q)\|_{L^\infty_tH^{s+1}} = 0. \end{align*} $$
$$ \begin{align*} &\lim\limits_{\kappa\rightarrow\infty}\sup\limits_{q\in Q^*}\|\chi_Rg_{12}(e^{tJ\nabla (H_{\mathrm{NLS}} - H_{\mathrm{NLS}}^{\kappa})}q) - \chi_Rg_{12}(q)\|_{L^\infty_tH^{s+1}}\\ &\qquad \lesssim_R \lim\limits_{\kappa\rightarrow\infty}\sup\limits_{q\in Q^*}\sup\limits_{h\in {{\mathbb{R}}}}\|\psi_h^{12}g_{12}(e^{tJ\nabla (H_{\mathrm{NLS}} - H_{\mathrm{NLS}}^{\kappa})}q) - \psi_h^{12}g_{12}(q)\|_{L^\infty_tH^{s+1}} = 0. \end{align*} $$
Finally, from the estimate (6.1) and the fact that
 $Q\subset B_{C\delta }\cap \mathcal {S}$
is tight, we have
$Q\subset B_{C\delta }\cap \mathcal {S}$
is tight, we have
 $$\begin{align*}\lim\limits_{R\rightarrow\infty}\sup\limits_{n\geq 1}\|\phi_Rg_{12}(e^{tJ\nabla H_{\mathrm{NLS}}}q_n)\|_{L^\infty_tH^{s+1}} = 0. \end{align*}$$
$$\begin{align*}\lim\limits_{R\rightarrow\infty}\sup\limits_{n\geq 1}\|\phi_Rg_{12}(e^{tJ\nabla H_{\mathrm{NLS}}}q_n)\|_{L^\infty_tH^{s+1}} = 0. \end{align*}$$
Thus,
 $\{g_{12}(e^{tJ\nabla H_{\mathrm {NLS}}}q_n)\}$
is Cauchy in
$\{g_{12}(e^{tJ\nabla H_{\mathrm {NLS}}}q_n)\}$
is Cauchy in
 $\mathcal C([-1,1];H^{s+1})$
and from the diffeomorphism property, we conclude that
$\mathcal C([-1,1];H^{s+1})$
and from the diffeomorphism property, we conclude that
 $\{e^{tJ\nabla H_{\mathrm {NLS}}}q_n\}$
is Cauchy in
$\{e^{tJ\nabla H_{\mathrm {NLS}}}q_n\}$
is Cauchy in
 $\mathcal C([-1,1];H^s)$
. This yields local well-posedness of (NLS) in
$\mathcal C([-1,1];H^s)$
. This yields local well-posedness of (NLS) in
 $H^s$
on the time interval
$H^s$
on the time interval
 $[-1,1]$
.
$[-1,1]$
.
From the estimate (4.12) with
 $\kappa =1$
, we obtain the estimate
$\kappa =1$
, we obtain the estimate
 $$\begin{align*}\|e^{tJ\nabla H_{\mathrm{NLS}}}q\|_{H^s}\leq C\|q\|_{H^s}, \end{align*}$$
$$\begin{align*}\|e^{tJ\nabla H_{\mathrm{NLS}}}q\|_{H^s}\leq C\|q\|_{H^s}, \end{align*}$$
uniformly for
 $t\in {{\mathbb {R}}}$
and
$t\in {{\mathbb {R}}}$
and
 $q\in B_\delta \cap \mathcal {S}$
. Using this bound, we may iterate the local well-posedness argument to complete the proof of global well-posedness in
$q\in B_\delta \cap \mathcal {S}$
. Using this bound, we may iterate the local well-posedness argument to complete the proof of global well-posedness in
 $H^s$
.
$H^s$
.
Now, consider initial data
 $q\in H^\sigma $
, where
$q\in H^\sigma $
, where
 $0\leq \sigma <\frac 12$
. Let
$0\leq \sigma <\frac 12$
. Let
 $0<\delta \ll 1$
be sufficiently small and
$0<\delta \ll 1$
be sufficiently small and
 $\{q_n\}_{n\geq 1}$
be a sequence of Schwartz functions so that
$\{q_n\}_{n\geq 1}$
be a sequence of Schwartz functions so that
 $q_n\to q$
in
$q_n\to q$
in
 $H^\sigma $
as
$H^\sigma $
as
 $n\to \infty $
. After possibly rescaling, assume that
$n\to \infty $
. After possibly rescaling, assume that
 $\|q_n\|_{L^2}\leq \delta $
for all
$\|q_n\|_{L^2}\leq \delta $
for all
 $n\geq 1$
.
$n\geq 1$
.
Applying our well-posedness result with
 $s = -\frac 14$
, the sequence of solutions
$s = -\frac 14$
, the sequence of solutions
 $\{e^{tJ\nabla H_{\mathrm {NLS}}}q_n\}$
is Cauchy in
$\{e^{tJ\nabla H_{\mathrm {NLS}}}q_n\}$
is Cauchy in
 $\mathcal C([-1,1];H^{-\frac 14})$
. Applying the estimate (8.2), we see that the corresponding set Q is equicontinuous in
$\mathcal C([-1,1];H^{-\frac 14})$
. Applying the estimate (8.2), we see that the corresponding set Q is equicontinuous in
 $H^\sigma $
, and hence the sequence
$H^\sigma $
, and hence the sequence
 $\{e^{tJ\nabla H_{\mathrm {NLS}}}q_n\}$
is also Cauchy in
$\{e^{tJ\nabla H_{\mathrm {NLS}}}q_n\}$
is also Cauchy in
 $\mathcal C([-1,1];H^\sigma )$
. This gives local well-posedness in
$\mathcal C([-1,1];H^\sigma )$
. This gives local well-posedness in
 $H^\sigma $
.
$H^\sigma $
.
Employing the estimate (8.2) with
 $\kappa = 1$
, and the conservation of mass, we obtain the estimate
$\kappa = 1$
, and the conservation of mass, we obtain the estimate
 $$\begin{align*}\|e^{tJ\nabla H_{\mathrm{NLS}}}q\|_{H^\sigma}\lesssim \|q\|_{H^\sigma}, \end{align*}$$
$$\begin{align*}\|e^{tJ\nabla H_{\mathrm{NLS}}}q\|_{H^\sigma}\lesssim \|q\|_{H^\sigma}, \end{align*}$$
uniformly for
 $t\in {{\mathbb {R}}}$
and
$t\in {{\mathbb {R}}}$
and
 $q\in \mathcal {S}$
satisfying
$q\in \mathcal {S}$
satisfying
 $\|q\|_{L^2}\leq \delta $
. This suffices to complete the proof of global well-posedness in
$\|q\|_{L^2}\leq \delta $
. This suffices to complete the proof of global well-posedness in
 $H^\sigma $
.
$H^\sigma $
.
9. Proof of Theorems 1.2 and 1.3
In this section, we prove Theorems 1.2 and 1.3. We start by considering (NLS):
Proof of Theorem 1.2.
The estimate (1.7) follows from (5.12) and rescaling. It remains to prove the continuity statement in Theorem 1.2.
Let
 $0<\delta \ll 1$
be sufficiently small and, by rescaling, assume the initial data
$0<\delta \ll 1$
be sufficiently small and, by rescaling, assume the initial data
 $q(0)\in B_\delta $
. Let
$q(0)\in B_\delta $
. Let
 $\{q_n(0)\}_{n\geq 1}\subseteq B_\delta \cap \mathcal {S}$
so that
$\{q_n(0)\}_{n\geq 1}\subseteq B_\delta \cap \mathcal {S}$
so that
 $q_n(0)\to q(0)$
in
$q_n(0)\to q(0)$
in
 $H^s$
as
$H^s$
as
 $n\to \infty $
, and denote the corresponding solutions by
$n\to \infty $
, and denote the corresponding solutions by
 $q(t) = e^{tJ\nabla H_{\mathrm {NLS}}}q(0)$
and
$q(t) = e^{tJ\nabla H_{\mathrm {NLS}}}q(0)$
and
 $q_n(t) = e^{tJ\nabla H_{\mathrm {NLS}}}q_n(0)$
. It suffices to prove that
$q_n(t) = e^{tJ\nabla H_{\mathrm {NLS}}}q_n(0)$
. It suffices to prove that
 $q_n\rightarrow q$
in
$q_n\rightarrow q$
in
 $X^{s+\frac 12}$
as
$X^{s+\frac 12}$
as
 $n\to \infty $
.
$n\to \infty $
.
Decomposing into low and high frequencies, we may bound
 $$ \begin{align*} \|q_n - q_m\|_{X^{s+\frac12}} &\leq \|P_{\leq \kappa}(q_n - q_m)\|_{L^\infty_tH^{s+\frac12}} + 2\sup\limits_{n\geq 1}\sup\limits_{h\in {{\mathbb{R}}}}\|P_{>\kappa}(\psi_h^6q_n)\|_{L^2_tH^{s+\frac12}}\\ &\lesssim \sqrt{\kappa}\|q_n - q_m\|_{L^\infty_tH^s} + \sup\limits_{n\geq 1}\sup\limits_{h\in {{\mathbb{R}}}}\|(\psi_h^6q_n)'\|_{L^2_tH^{s-\frac12}_\kappa}. \end{align*} $$
$$ \begin{align*} \|q_n - q_m\|_{X^{s+\frac12}} &\leq \|P_{\leq \kappa}(q_n - q_m)\|_{L^\infty_tH^{s+\frac12}} + 2\sup\limits_{n\geq 1}\sup\limits_{h\in {{\mathbb{R}}}}\|P_{>\kappa}(\psi_h^6q_n)\|_{L^2_tH^{s+\frac12}}\\ &\lesssim \sqrt{\kappa}\|q_n - q_m\|_{L^\infty_tH^s} + \sup\limits_{n\geq 1}\sup\limits_{h\in {{\mathbb{R}}}}\|(\psi_h^6q_n)'\|_{L^2_tH^{s-\frac12}_\kappa}. \end{align*} $$
As the set
 $\{q_n(0)\}_{n\geq 1}$
is equicontinuous in
$\{q_n(0)\}_{n\geq 1}$
is equicontinuous in
 $H^s$
, we may apply (5.13) from Proposition 5.4 to obtain
$H^s$
, we may apply (5.13) from Proposition 5.4 to obtain
 $$\begin{align*}\lim\limits_{\kappa\rightarrow\infty}\sup\limits_{n\geq 1}\sup\limits_{h\in {{\mathbb{R}}}}\|(\psi_h^6q_n)'\|_{L^2_tH^{s-\frac12}_\kappa} = 0. \end{align*}$$
$$\begin{align*}\lim\limits_{\kappa\rightarrow\infty}\sup\limits_{n\geq 1}\sup\limits_{h\in {{\mathbb{R}}}}\|(\psi_h^6q_n)'\|_{L^2_tH^{s-\frac12}_\kappa} = 0. \end{align*}$$
Finally, from Theorem 1.1, we have
 $q_n\rightarrow q$
in
$q_n\rightarrow q$
in
 $\mathcal C([-1,1];H^s)$
as
$\mathcal C([-1,1];H^s)$
as
 $n\to \infty $
, which completes the proof that
$n\to \infty $
, which completes the proof that
 $q_n\rightarrow q$
in
$q_n\rightarrow q$
in
 $X^{s+\frac 12}$
.
$X^{s+\frac 12}$
.
The corresponding result for (mKdV), Theorem 1.3, is proved almost identically: When
 $-\frac 12<s<0$
, we replace Proposition 5.4 by Proposition 5.5, whereas at higher regularity we use the following:
$-\frac 12<s<0$
, we replace Proposition 5.4 by Proposition 5.5, whereas at higher regularity we use the following:
Proposition 9.1. Let
 $0\leq \sigma <\frac 12$
. Then there exists
$0\leq \sigma <\frac 12$
. Then there exists
 $\delta>0$
so that for any
$\delta>0$
so that for any
 $q(0)\in \mathcal {S}$
satisfying
$q(0)\in \mathcal {S}$
satisfying
 $\|q(0)\|_{L^2}\leq \delta $
, the solution
$\|q(0)\|_{L^2}\leq \delta $
, the solution
 $q(t)$
of (mKdV) satisfies the estimate
$q(t)$
of (mKdV) satisfies the estimate
 $$ \begin{align} \|q\|_{X^{\sigma+1}}\lesssim \|q(0)\|_{H^\sigma}. \end{align} $$
$$ \begin{align} \|q\|_{X^{\sigma+1}}\lesssim \|q(0)\|_{H^\sigma}. \end{align} $$
Further, we have the high-frequency estimate
 $$ \begin{align} \|(\psi_h^6q)"\|_{L^2_tH^{\sigma-1}_\kappa}^2\lesssim \|q(0)'\|_{H^{\sigma-1}_\kappa}^2 + \kappa^{2\sigma-1}\|q(0)\|_{L^2}^2, \end{align} $$
$$ \begin{align} \|(\psi_h^6q)"\|_{L^2_tH^{\sigma-1}_\kappa}^2\lesssim \|q(0)'\|_{H^{\sigma-1}_\kappa}^2 + \kappa^{2\sigma-1}\|q(0)\|_{L^2}^2, \end{align} $$
uniformly for
 $h\in {{\mathbb {R}}}$
and
$h\in {{\mathbb {R}}}$
and
 $\kappa \geq 1$
.
$\kappa \geq 1$
.
To prove Proposition 9.1, we use the microscopic conservation law for
 $\widetilde \rho (\varkappa )$
,
$\widetilde \rho (\varkappa )$
,
 $$\begin{align*}\partial_t\widetilde\rho + \partial_x\widetilde j_{\mathrm{mKdV}} = 0, \end{align*}$$
$$\begin{align*}\partial_t\widetilde\rho + \partial_x\widetilde j_{\mathrm{mKdV}} = 0, \end{align*}$$
where the current
 $$\begin{align*}\widetilde j_{\mathrm{mKdV}} (\varkappa):= (qr)" - 3(q'r' + q^2r^2) - 2\varkappa j_{\mathrm{mKdV}}(\varkappa). \end{align*}$$
$$\begin{align*}\widetilde j_{\mathrm{mKdV}} (\varkappa):= (qr)" - 3(q'r' + q^2r^2) - 2\varkappa j_{\mathrm{mKdV}}(\varkappa). \end{align*}$$
We will first establish analogues of (5.4), (5.7), and (5.9). We then use these as in the proof of Proposition 5.5 to derive (9.1) and (9.2).
We start with the analogues of the estimates (5.4) and (5.7).
Lemma 9.2. Let
 $q\in \mathcal {S}$
satisfy
$q\in \mathcal {S}$
satisfy
 $\|q\|_{L^2}\leq \delta $
, and let
$\|q\|_{L^2}\leq \delta $
, and let
 $\Psi _h$
be as in (5.2). Then
$\Psi _h$
be as in (5.2). Then
 $$ \begin{align} \left|\operatorname{Re}\int \widetilde\rho(x;\varkappa)\,\Psi_h(x)\,dx\right|&\lesssim \|q'\|_{H_\varkappa^{-1}}^2 + \varkappa^{-1}\|q\|_{L^2}^2, \end{align} $$
$$ \begin{align} \left|\operatorname{Re}\int \widetilde\rho(x;\varkappa)\,\Psi_h(x)\,dx\right|&\lesssim \|q'\|_{H_\varkappa^{-1}}^2 + \varkappa^{-1}\|q\|_{L^2}^2, \end{align} $$
 $$ \begin{align} \operatorname{Re} \int \widetilde j_{\mathrm{mKdV}}^{[2]}(x;\varkappa)\,\psi_h^{12}(x)\,dx & = \mp 3\|(\psi_h^6q)"\|_{H^{-1}_\varkappa}^2 +\mathcal O\Big( \|q'\|_{H^{-1}_\varkappa}^2+ \varkappa^{-2}\|q\|^2_{L^2}\Big)\\ &\quad + \mathcal O\Big(\|(\psi_h^6 q)"\|_{H^{-1}_\varkappa}\big(\|q'\|_{H^{-1}_\varkappa} + \varkappa^{-1}\|q\|_{L^2}\big)\Big),\notag \end{align} $$
$$ \begin{align} \operatorname{Re} \int \widetilde j_{\mathrm{mKdV}}^{[2]}(x;\varkappa)\,\psi_h^{12}(x)\,dx & = \mp 3\|(\psi_h^6q)"\|_{H^{-1}_\varkappa}^2 +\mathcal O\Big( \|q'\|_{H^{-1}_\varkappa}^2+ \varkappa^{-2}\|q\|^2_{L^2}\Big)\\ &\quad + \mathcal O\Big(\|(\psi_h^6 q)"\|_{H^{-1}_\varkappa}\big(\|q'\|_{H^{-1}_\varkappa} + \varkappa^{-1}\|q\|_{L^2}\big)\Big),\notag \end{align} $$
uniformly for
 $\varkappa \geq 1$
and
$\varkappa \geq 1$
and
 $h\in {{\mathbb {R}}}$
.
$h\in {{\mathbb {R}}}$
.
Proof. Using (8.1), we estimate
 $$ \begin{align*} \left|\operatorname{Re}\int \widetilde\rho^{[2]}(x;\varkappa)\,\Psi_h(x)\,dx\right| &=\left|\operatorname{Re} \int \tfrac{\xi^2}{4\varkappa^2+\xi^2} \hat q(\xi) \overline{\widehat{q\Psi_h}}(\xi)\, d\xi\right|\\ &\lesssim \|q'\|_{H^{-1}_\varkappa}\|(\Psi_h q)'\|_{H^{-1}_\varkappa}\lesssim \|q'\|_{H^{-1}_\varkappa}^2 + \varkappa^{-1}\|q'\|_{H^{-1}_\varkappa}\|q\|_{L^2}. \end{align*} $$
$$ \begin{align*} \left|\operatorname{Re}\int \widetilde\rho^{[2]}(x;\varkappa)\,\Psi_h(x)\,dx\right| &=\left|\operatorname{Re} \int \tfrac{\xi^2}{4\varkappa^2+\xi^2} \hat q(\xi) \overline{\widehat{q\Psi_h}}(\xi)\, d\xi\right|\\ &\lesssim \|q'\|_{H^{-1}_\varkappa}\|(\Psi_h q)'\|_{H^{-1}_\varkappa}\lesssim \|q'\|_{H^{-1}_\varkappa}^2 + \varkappa^{-1}\|q'\|_{H^{-1}_\varkappa}\|q\|_{L^2}. \end{align*} $$
Combining this with (8.3) yields (9.3).
We turn now to (9.4). The quadratic part of the current satisfies
 $$\begin{align*}\widetilde j_{\mathrm{mKdV}}^{[2]}(\varkappa) = \big(\widetilde{\mathbf{R}}[q,r]\big)" - 3\widetilde{\mathbf{R}}[q',r'], \end{align*}$$
$$\begin{align*}\widetilde j_{\mathrm{mKdV}}^{[2]}(\varkappa) = \big(\widetilde{\mathbf{R}}[q,r]\big)" - 3\widetilde{\mathbf{R}}[q',r'], \end{align*}$$
where the paraproduct
 $\widetilde {\mathbf {R}}[q,r]$
has symbol
$\widetilde {\mathbf {R}}[q,r]$
has symbol
 $$\begin{align*}\widetilde R(\xi,\eta) := \tfrac{-i\xi}{2(2\varkappa - i\xi)} + \tfrac{i\eta}{2(2\varkappa + i\eta)}. \end{align*}$$
$$\begin{align*}\widetilde R(\xi,\eta) := \tfrac{-i\xi}{2(2\varkappa - i\xi)} + \tfrac{i\eta}{2(2\varkappa + i\eta)}. \end{align*}$$
Notice also that (8.1) shows
 $$\begin{align*}\widetilde\rho^{[2]}(x;\varkappa) = \widetilde{\mathbf{R}}[q,r](x) = \tfrac1{2\pi}\int \widetilde R(\xi,\eta)\hat q(\xi)\hat r(\eta) e^{ix(\xi + \eta)}\,d\xi\,d\eta. \end{align*}$$
$$\begin{align*}\widetilde\rho^{[2]}(x;\varkappa) = \widetilde{\mathbf{R}}[q,r](x) = \tfrac1{2\pi}\int \widetilde R(\xi,\eta)\hat q(\xi)\hat r(\eta) e^{ix(\xi + \eta)}\,d\xi\,d\eta. \end{align*}$$
Taking the real part, we have
 $$\begin{align*}\operatorname{Re}\int \widetilde{\mathbf{R}}[(\psi_h^6q)',(\psi_h^6r)']\,dx = \pm \|(\psi_h^6q)"\|_{H^{-1}_\varkappa}^2, \end{align*}$$
$$\begin{align*}\operatorname{Re}\int \widetilde{\mathbf{R}}[(\psi_h^6q)',(\psi_h^6r)']\,dx = \pm \|(\psi_h^6q)"\|_{H^{-1}_\varkappa}^2, \end{align*}$$
and hence, we may write
 $$ \begin{align} \operatorname{Re}\int \widetilde j_{\mathrm{mKdV}}^{[2]}(\varkappa)\,\psi_h^{12}\,dx &= \mp 3\|(\psi_h^6q)"\|_{H^{-1}_\varkappa}^2 + \operatorname{Re} \int \widetilde{\mathbf{R}}[q,r](\psi^{12}_h)"\,dx\\ &\quad - 3\operatorname{Re}\int \Big(\psi_h^{12}\widetilde{\mathbf{R}}[q',r'] - \widetilde{\mathbf{R}}[(\psi_h^6q)',(\psi_h^6r)']\Big)\,dx.\notag \end{align} $$
$$ \begin{align} \operatorname{Re}\int \widetilde j_{\mathrm{mKdV}}^{[2]}(\varkappa)\,\psi_h^{12}\,dx &= \mp 3\|(\psi_h^6q)"\|_{H^{-1}_\varkappa}^2 + \operatorname{Re} \int \widetilde{\mathbf{R}}[q,r](\psi^{12}_h)"\,dx\\ &\quad - 3\operatorname{Re}\int \Big(\psi_h^{12}\widetilde{\mathbf{R}}[q',r'] - \widetilde{\mathbf{R}}[(\psi_h^6q)',(\psi_h^6r)']\Big)\,dx.\notag \end{align} $$
Proceeding as in the proof of (9.3), we may bound the second term on
 $\mathrm {RHS}$
(9.5) by
$\mathrm {RHS}$
(9.5) by
 $$\begin{align*}\left|\operatorname{Re}\int \widetilde\rho^{[2]}(x;\varkappa)\,(\psi^{12}_h)"(x)\,dx\right|\lesssim \|q'\|_{H^{-1}_\varkappa}^2 + \varkappa^{-2}\|q\|_{L^2}^2. \end{align*}$$
$$\begin{align*}\left|\operatorname{Re}\int \widetilde\rho^{[2]}(x;\varkappa)\,(\psi^{12}_h)"(x)\,dx\right|\lesssim \|q'\|_{H^{-1}_\varkappa}^2 + \varkappa^{-2}\|q\|_{L^2}^2. \end{align*}$$
The remaining term on
 $\mathrm {RHS}$
(9.5) is given by
$\mathrm {RHS}$
(9.5) is given by
 $$ \begin{align*} &-3 \operatorname{Re}\int \Big(\psi_h^{12}\widetilde{\mathbf{R}}[q',r'] - \widetilde{\mathbf{R}}[(\psi_h^6q)',(\psi_h^6r)']\Big)\,dx\\ &\quad= 3 \operatorname{Re} \int \Big( [\psi_h^6, \tfrac{\partial^3}{4\varkappa^2 - \partial^2}]q\cdot (\psi_h^6 r)' - [\psi_h^6, \tfrac{\partial^3}{4\varkappa^2 - \partial^2}]q\cdot (\psi_h^6)' r -\tfrac{(\psi^6_hq)"'}{4\varkappa^2-\partial^2}(\psi_h^6)' r\Big)\,dx. \end{align*} $$
$$ \begin{align*} &-3 \operatorname{Re}\int \Big(\psi_h^{12}\widetilde{\mathbf{R}}[q',r'] - \widetilde{\mathbf{R}}[(\psi_h^6q)',(\psi_h^6r)']\Big)\,dx\\ &\quad= 3 \operatorname{Re} \int \Big( [\psi_h^6, \tfrac{\partial^3}{4\varkappa^2 - \partial^2}]q\cdot (\psi_h^6 r)' - [\psi_h^6, \tfrac{\partial^3}{4\varkappa^2 - \partial^2}]q\cdot (\psi_h^6)' r -\tfrac{(\psi^6_hq)"'}{4\varkappa^2-\partial^2}(\psi_h^6)' r\Big)\,dx. \end{align*} $$
Integrating by parts, we may bound
 $$ \begin{align*} &\left|\operatorname{Re}\int\Big(\psi_h^{12}\widetilde{\mathbf{R}}[q',r'] - \widetilde{\mathbf{R}}[(\psi_h^6q)',(\psi_h^6r)']\Big)\,dx\right|\\ &\quad \lesssim\|(\psi_h^6 q)"\|_{H^{-1}_\varkappa} \big(\|q'\|_{H^{-1}_\varkappa} + \varkappa^{-1}\|q\|_{L^2}\big) +\|q'\|_{H^{-1}_\varkappa}^2 + \varkappa^{-2}\|q\|^2_{L^2}, \end{align*} $$
$$ \begin{align*} &\left|\operatorname{Re}\int\Big(\psi_h^{12}\widetilde{\mathbf{R}}[q',r'] - \widetilde{\mathbf{R}}[(\psi_h^6q)',(\psi_h^6r)']\Big)\,dx\right|\\ &\quad \lesssim\|(\psi_h^6 q)"\|_{H^{-1}_\varkappa} \big(\|q'\|_{H^{-1}_\varkappa} + \varkappa^{-1}\|q\|_{L^2}\big) +\|q'\|_{H^{-1}_\varkappa}^2 + \varkappa^{-2}\|q\|^2_{L^2}, \end{align*} $$
which completes the proof of (9.4).
It remains to prove an analogue of the estimate (5.9). To this end, we denote
 $$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2 := \|q\|_{X^1}^2 + \|q\|_{L^\infty_tL^2}^2, \end{align*}$$
$$\begin{align*}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2 := \|q\|_{X^1}^2 + \|q\|_{L^\infty_tL^2}^2, \end{align*}$$
which corresponds to the local smoothing norm in the case
 $s = 0$
.
$s = 0$
.
Lemma 9.3. Let
 $q\in \mathcal C([-1,1];\mathcal {S})$
satisfy
$q\in \mathcal C([-1,1];\mathcal {S})$
satisfy
 $\|q(0)\|_{L^2}\leq \delta $
. We have
$\|q(0)\|_{L^2}\leq \delta $
. We have
 $$ \begin{align} \left\|\operatorname{Re}\int \widetilde j_{\mathrm{mKdV}}^{[\geq 4]}(\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \end{align} $$
$$ \begin{align} \left\|\operatorname{Re}\int \widetilde j_{\mathrm{mKdV}}^{[\geq 4]}(\varkappa)\,\psi_h^{12}\,dx\right\|_{L^1_t}\lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \end{align} $$
uniformly for
 $\varkappa \geq 1$
and
$\varkappa \geq 1$
and
 $h\in {{\mathbb {R}}}$
.
$h\in {{\mathbb {R}}}$
.
Proof. We first establish several variants of the estimates in Corollary 3.5, inspired by the decomposition (9.12) below. Using that
 $$ \begin{align} \|f\|_{L^\infty}\lesssim \|f'\|_{L^2}^{\frac12} \|f\|_{L^2}^{\frac12}, \end{align} $$
$$ \begin{align} \|f\|_{L^\infty}\lesssim \|f'\|_{L^2}^{\frac12} \|f\|_{L^2}^{\frac12}, \end{align} $$
we obtain
 $$ \begin{align} \|\psi^3_h q\|_{L^4_tL^\infty_x} \lesssim\|(\psi^3_h q)'\|_{L^2_{t,x}}^{\frac12}\|\psi^3_h q\|_{L^\infty_tL^2_x}^{\frac12}\lesssim \delta^{\frac12} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^{\frac12}. \end{align} $$
$$ \begin{align} \|\psi^3_h q\|_{L^4_tL^\infty_x} \lesssim\|(\psi^3_h q)'\|_{L^2_{t,x}}^{\frac12}\|\psi^3_h q\|_{L^\infty_tL^2_x}^{\frac12}\lesssim \delta^{\frac12} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^{\frac12}. \end{align} $$
Thus, using (2.31) and (3.20), we may bound
 $$ \begin{align*} \|\psi^3_h g_{12}^{[1]}(\varkappa)\|_{L^4_tL^\infty} \lesssim \varkappa^{-1}\delta^{\frac12} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^{\frac12}. \end{align*} $$
$$ \begin{align*} \|\psi^3_h g_{12}^{[1]}(\varkappa)\|_{L^4_tL^\infty} \lesssim \varkappa^{-1}\delta^{\frac12} {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^{\frac12}. \end{align*} $$
From (3.28), we get
 $$ \begin{align} \|\gamma(\varkappa)\|_{L_{t,x}^\infty}\lesssim \varkappa^{-1}\delta^2, \end{align} $$
$$ \begin{align} \|\gamma(\varkappa)\|_{L_{t,x}^\infty}\lesssim \varkappa^{-1}\delta^2, \end{align} $$
and thence using (2.31) again, we find
 $$ \begin{align*} \|\psi^3_h g_{12}^{[\geq 3]}(\varkappa)\|_{L^4_tL^\infty}&\lesssim \varkappa^{-1}\|\psi^3_h q\|_{L^4_tL^\infty_x} \|\gamma(\varkappa)\|_{L_{t,x}^\infty}\lesssim \varkappa^{-2}\delta^{\frac52}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^{\frac12}. \end{align*} $$
$$ \begin{align*} \|\psi^3_h g_{12}^{[\geq 3]}(\varkappa)\|_{L^4_tL^\infty}&\lesssim \varkappa^{-1}\|\psi^3_h q\|_{L^4_tL^\infty_x} \|\gamma(\varkappa)\|_{L_{t,x}^\infty}\lesssim \varkappa^{-2}\delta^{\frac52}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^{\frac12}. \end{align*} $$
From the identity (3.31) and the estimate (9.9), taking
 $0<\delta \ll 1$
sufficiently small, we obtain
$0<\delta \ll 1$
sufficiently small, we obtain
 $$\begin{align*}\|\psi^6_h\gamma(\varkappa)\|_{L^2_tL^\infty} \lesssim \|\psi^3_hg_{12}\|_{L^4_tL^\infty}\|\psi^3_hg_{21}\|_{L^4_tL^\infty} \lesssim \varkappa^{-2}\delta {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}. \end{align*}$$
$$\begin{align*}\|\psi^6_h\gamma(\varkappa)\|_{L^2_tL^\infty} \lesssim \|\psi^3_hg_{12}\|_{L^4_tL^\infty}\|\psi^3_hg_{21}\|_{L^4_tL^\infty} \lesssim \varkappa^{-2}\delta {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}. \end{align*}$$
Consequently, using (3.12), we get
 $$ \begin{align*} \|\psi^6_h g_{12}^{[\geq 3]}(\varkappa)\|_{L^2_tH^1_\varkappa} &\lesssim \|q\|_{L^\infty_tL^2}\|\psi^6_h\gamma(\varkappa)\|_{L^2_tL^\infty}+\big\| (\psi_h^6)'\tfrac{q\gamma(\varkappa)}{2\varkappa-\partial}\big\|_{L^2_{t,x}} \\ &\lesssim \varkappa^{-2}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}} + \varkappa^{-1} \|q\|_{L^\infty_t L^2} \|\gamma(\varkappa)\|_{L_{t,x}^\infty}\lesssim \varkappa^{-2}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}. \end{align*} $$
$$ \begin{align*} \|\psi^6_h g_{12}^{[\geq 3]}(\varkappa)\|_{L^2_tH^1_\varkappa} &\lesssim \|q\|_{L^\infty_tL^2}\|\psi^6_h\gamma(\varkappa)\|_{L^2_tL^\infty}+\big\| (\psi_h^6)'\tfrac{q\gamma(\varkappa)}{2\varkappa-\partial}\big\|_{L^2_{t,x}} \\ &\lesssim \varkappa^{-2}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}} + \varkappa^{-1} \|q\|_{L^\infty_t L^2} \|\gamma(\varkappa)\|_{L_{t,x}^\infty}\lesssim \varkappa^{-2}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}. \end{align*} $$
Recalling the identity (3.39) and using (3.11) to write
 $\gamma '$
in terms of
$\gamma '$
in terms of
 $q,r,g_{12},g_{21}$
, we may apply these estimates to obtain
$q,r,g_{12},g_{21}$
, we may apply these estimates to obtain
 $$ \begin{align} \|\psi^6_h\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\|_{L^2_tH^1_\varkappa} \lesssim\varkappa^{-2}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}. \end{align} $$
$$ \begin{align} \|\psi^6_h\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 3]}\|_{L^2_tH^1_\varkappa} \lesssim\varkappa^{-2}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}. \end{align} $$
Using (2.31) and (3.12) again, we may bound
 $$\begin{align*}\|\psi_h^9 g_{12}^{[\geq3]}(\varkappa)\|_{L^{\frac43}_tL^\infty}\lesssim \varkappa^{-1}\|\psi_h^3q\|_{L^4_tL^\infty}\|\psi_h^6\gamma(\varkappa)\|_{L^2_tL^\infty}\lesssim \varkappa^{-3}\delta^{\frac32}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^{\frac32}, \end{align*}$$
$$\begin{align*}\|\psi_h^9 g_{12}^{[\geq3]}(\varkappa)\|_{L^{\frac43}_tL^\infty}\lesssim \varkappa^{-1}\|\psi_h^3q\|_{L^4_tL^\infty}\|\psi_h^6\gamma(\varkappa)\|_{L^2_tL^\infty}\lesssim \varkappa^{-3}\delta^{\frac32}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^{\frac32}, \end{align*}$$
Using the identity (3.32), we estimate
 $$ \begin{align*} \|\psi_h^{12}\gamma^{[\geq 4]}\|_{L^1_tL^\infty} &\lesssim \|\psi_h^6\gamma\|_{L^2_tL^\infty}^2 + \|\psi_h^9g_{12}^{[\geq 3]}\|_{L^{\frac43}_tL^\infty}\|\psi_h^3g_{21}\|_{L^4_tL^\infty} +\|\psi_h^3g_{12}^{[1]}\|_{L^4_tL^\infty}\|\psi_h^9g_{21}^{[\geq 3]}\|_{L^{\frac43}_tL^\infty}\\ &\lesssim \varkappa^{-4}\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12}\gamma^{[\geq 4]}\|_{L^1_tL^\infty} &\lesssim \|\psi_h^6\gamma\|_{L^2_tL^\infty}^2 + \|\psi_h^9g_{12}^{[\geq 3]}\|_{L^{\frac43}_tL^\infty}\|\psi_h^3g_{21}\|_{L^4_tL^\infty} +\|\psi_h^3g_{12}^{[1]}\|_{L^4_tL^\infty}\|\psi_h^9g_{21}^{[\geq 3]}\|_{L^{\frac43}_tL^\infty}\\ &\lesssim \varkappa^{-4}\delta^2 {\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
Applying (3.12) once again, we obtain
 $$ \begin{align*} \|\psi_h^{12}g_{12}^{[\geq 5]}(\varkappa)\|_{L^1_tH^1_\varkappa} &\lesssim \|q\|_{L^\infty_tL^2}\|\psi_h^{12}\gamma^{[\geq 4]}(\varkappa)\|_{L^1_tL^\infty}\lesssim \varkappa^{-4}\delta^3{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
$$ \begin{align*} \|\psi_h^{12}g_{12}^{[\geq 5]}(\varkappa)\|_{L^1_tH^1_\varkappa} &\lesssim \|q\|_{L^\infty_tL^2}\|\psi_h^{12}\gamma^{[\geq 4]}(\varkappa)\|_{L^1_tL^\infty}\lesssim \varkappa^{-4}\delta^3{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
Finally, we use the identity (3.40) with the above estimates, as well as (3.11) to replace
 $\gamma '$
, to obtain
$\gamma '$
, to obtain
 $$ \begin{align} \|\psi_h^{12}\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\|_{L^1_tH^1_\varkappa} \lesssim \varkappa^{-4}\delta^3{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align} $$
$$ \begin{align} \|\psi_h^{12}\big(\tfrac{g_{12}(\varkappa)}{2 + \gamma(\varkappa)}\big)^{[\geq 5]}\|_{L^1_tH^1_\varkappa} \lesssim \varkappa^{-4}\delta^3{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align} $$
We turn now to estimating the current. Using Corollary 4.14, we have
 $$ \begin{align} \widetilde j_{\mathrm{mKdV}}^{[\geq 4]} (\varkappa)&= -2\varkappa q"\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} + 2\varkappa r"\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\\ &\quad - 4\varkappa^2(2\varkappa + \partial) q\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} + 4\varkappa^2(2\varkappa - \partial) r\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\notag\\ &\quad + 4\varkappa q^2r\tfrac{g_{21}}{2 + \gamma} - 4\varkappa r^2q\tfrac{g_{12}}{2 + \gamma} - 3q^2r^2.\notag \end{align} $$
$$ \begin{align} \widetilde j_{\mathrm{mKdV}}^{[\geq 4]} (\varkappa)&= -2\varkappa q"\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} + 2\varkappa r"\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\\ &\quad - 4\varkappa^2(2\varkappa + \partial) q\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]} + 4\varkappa^2(2\varkappa - \partial) r\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\notag\\ &\quad + 4\varkappa q^2r\tfrac{g_{21}}{2 + \gamma} - 4\varkappa r^2q\tfrac{g_{12}}{2 + \gamma} - 3q^2r^2.\notag \end{align} $$
For the first two terms, we apply the estimate (9.10) to bound
 $$ \begin{align*} &\left\|\int 2\varkappa q"\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \varkappa \|\psi_h^6 q"\|_{L^2_tH^{-1}_\varkappa} \|\psi_h^6\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\|_{L^2_tH^1_{\varkappa}}\\ &\qquad\lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}\big(\|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa} + \|q'\|_{L^\infty_tH^{-1}_\varkappa}+ \varkappa^{-1}\|q\|_{L_t^\infty L^2}\big), \end{align*} $$
$$ \begin{align*} &\left\|\int 2\varkappa q"\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \varkappa \|\psi_h^6 q"\|_{L^2_tH^{-1}_\varkappa} \|\psi_h^6\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\|_{L^2_tH^1_{\varkappa}}\\ &\qquad\lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}\big(\|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa} + \|q'\|_{L^\infty_tH^{-1}_\varkappa}+ \varkappa^{-1}\|q\|_{L_t^\infty L^2}\big), \end{align*} $$
which is acceptable.
We bound the sextic and higher order contributions of the remaining terms using (9.10) and (9.11), as follows:
 $$ \begin{align*} \left\|\int 4\varkappa^2(2\varkappa + \partial) q\cdot \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 5]}\ \psi_h^{12}\,dx\right\|_{L^1_t} & \lesssim \varkappa^2 \|q\|_{L^\infty_tL^2}\|\psi_h^{12}\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}\|_{L^1_tH^1_\varkappa}\\ &\lesssim \varkappa^{-2}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2,\\ \left\|\int 4\varkappa q^2r\cdot \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\ \psi_h^{12}\,dx\right\|_{L^1_t} & \lesssim \varkappa\|q\|_{L^\infty_tL^2}\|\psi_h^3q\|_{L^4_tL^\infty}^2\|\psi_h^6\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\|_{L^2_{t,x}}\\ &\lesssim \varkappa^{-2}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
$$ \begin{align*} \left\|\int 4\varkappa^2(2\varkappa + \partial) q\cdot \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 5]}\ \psi_h^{12}\,dx\right\|_{L^1_t} & \lesssim \varkappa^2 \|q\|_{L^\infty_tL^2}\|\psi_h^{12}\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 5]}\|_{L^1_tH^1_\varkappa}\\ &\lesssim \varkappa^{-2}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2,\\ \left\|\int 4\varkappa q^2r\cdot \big(\tfrac{g_{21}}{2 + \gamma}\big)^{[\geq 3]}\ \psi_h^{12}\,dx\right\|_{L^1_t} & \lesssim \varkappa\|q\|_{L^\infty_tL^2}\|\psi_h^3q\|_{L^4_tL^\infty}^2\|\psi_h^6\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[\geq 3]}\|_{L^2_{t,x}}\\ &\lesssim \varkappa^{-2}\delta^4{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2. \end{align*} $$
It remains to consider the contributions of
 $$ \begin{align*} \mathbf{err}_1 &:= 4\varkappa q^2r\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[1]} - 4\varkappa r^2q\cdot\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]} - 2q^2r^2,\\ \mathbf{err}_2 &:= - 4\varkappa^2(2\varkappa + \partial) q\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[3]} + 4\varkappa^2(2\varkappa - \partial) r\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[3]} - q^2r^2. \end{align*} $$
$$ \begin{align*} \mathbf{err}_1 &:= 4\varkappa q^2r\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[1]} - 4\varkappa r^2q\cdot\big(\tfrac{g_{12}}{2 + \gamma}\big)^{[1]} - 2q^2r^2,\\ \mathbf{err}_2 &:= - 4\varkappa^2(2\varkappa + \partial) q\cdot\big(\tfrac{g_{21}}{2 + \gamma}\big)^{[3]} + 4\varkappa^2(2\varkappa - \partial) r\cdot \big(\tfrac{g_{12}}{2 + \gamma}\big)^{[3]} - q^2r^2. \end{align*} $$
For
 $\mathbf {err}_1$
, we use the identity (3.38) to write
$\mathbf {err}_1$
, we use the identity (3.38) to write
 $$\begin{align*}\operatorname{Re} \mathbf{err}_1 = q^2r \tfrac{r"}{4\varkappa^2 - \partial^2} + qr^2\tfrac{q"}{4\varkappa^2 - \partial^2}, \end{align*}$$
$$\begin{align*}\operatorname{Re} \mathbf{err}_1 = q^2r \tfrac{r"}{4\varkappa^2 - \partial^2} + qr^2\tfrac{q"}{4\varkappa^2 - \partial^2}, \end{align*}$$
so we may bound
 $$ \begin{align*} &\left\|\operatorname{Re} \int \mathbf{err}_1\ \psi_h^{12}\,dx \right\|_{L^1_t}\\ &\qquad \lesssim \|q\|_{L^\infty_tL^2}\|\psi_h^3q\|_{L^4_tL^\infty}^2\Big(\varkappa^{-1}\|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa} + \big\|[\psi_h^6, \tfrac{\partial^2}{4\varkappa^2-\partial^2}]q\big\|_{L^2_{t,x}}\Big)\\ &\qquad \lesssim \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}} \Big(\varkappa^{-1}\|(\psi_h^6 q)"\|_{H^{-1}_\varkappa} + \varkappa^{-2}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}} \Big), \end{align*} $$
$$ \begin{align*} &\left\|\operatorname{Re} \int \mathbf{err}_1\ \psi_h^{12}\,dx \right\|_{L^1_t}\\ &\qquad \lesssim \|q\|_{L^\infty_tL^2}\|\psi_h^3q\|_{L^4_tL^\infty}^2\Big(\varkappa^{-1}\|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa} + \big\|[\psi_h^6, \tfrac{\partial^2}{4\varkappa^2-\partial^2}]q\big\|_{L^2_{t,x}}\Big)\\ &\qquad \lesssim \delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}} \Big(\varkappa^{-1}\|(\psi_h^6 q)"\|_{H^{-1}_\varkappa} + \varkappa^{-2}{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}} \Big), \end{align*} $$
which is acceptable.
Recalling the identities (3.20), (3.21), (3.22), and (3.38), we may integrate by parts to obtain
 $$ \begin{align*} \int \mathbf{err}_2\,\psi_h^{12}\,dx &=\int 4\varkappa^2(2\varkappa + \partial)q\cdot[\psi_h^{12},\tfrac1{2\varkappa +\partial} ] \big( r\cdot \tfrac q{2\varkappa - \partial}\cdot \tfrac r{2\varkappa + \partial}\big)\,dx\\ &\quad + \int 4\varkappa^2(2\varkappa - \partial)r\cdot [\psi_h^{12},\tfrac1{2\varkappa - \partial}]\big(q\cdot \tfrac r{2\varkappa + \partial}\cdot \tfrac q{2\varkappa - \partial}\big)\,dx\\ &\quad + \int 6\varkappa^2 \Big(\tfrac {q'}{2\varkappa - \partial}\cdot r - \tfrac {r'}{2\varkappa + \partial}\cdot q\Big) \tfrac r{2\varkappa + \partial}\cdot \tfrac q{2\varkappa - \partial}\,\psi_h^{12}\,dx\\ &\quad+\int 2\varkappa qr\Big(\tfrac{q'}{2\varkappa - \partial}\cdot\tfrac r{2\varkappa + \partial}- \tfrac q{2\varkappa - \partial}\cdot\tfrac{r'}{2\varkappa + \partial}\Big)\psi_h^{12}\,dx\\ &\quad - \int 2\varkappa^2 \Big(q' \cdot \tfrac r{2\varkappa + \partial}- r' \cdot \tfrac q{2\varkappa - \partial}\Big) \tfrac r{2\varkappa + \partial}\cdot \tfrac q{2\varkappa - \partial}\,\psi_h^{12}\,dx\\ &\quad + \int qr\cdot\tfrac{q'}{2\varkappa - \partial}\cdot\tfrac{r'}{2\varkappa + \partial}\,\psi_h^{12}\,dx. \end{align*} $$
$$ \begin{align*} \int \mathbf{err}_2\,\psi_h^{12}\,dx &=\int 4\varkappa^2(2\varkappa + \partial)q\cdot[\psi_h^{12},\tfrac1{2\varkappa +\partial} ] \big( r\cdot \tfrac q{2\varkappa - \partial}\cdot \tfrac r{2\varkappa + \partial}\big)\,dx\\ &\quad + \int 4\varkappa^2(2\varkappa - \partial)r\cdot [\psi_h^{12},\tfrac1{2\varkappa - \partial}]\big(q\cdot \tfrac r{2\varkappa + \partial}\cdot \tfrac q{2\varkappa - \partial}\big)\,dx\\ &\quad + \int 6\varkappa^2 \Big(\tfrac {q'}{2\varkappa - \partial}\cdot r - \tfrac {r'}{2\varkappa + \partial}\cdot q\Big) \tfrac r{2\varkappa + \partial}\cdot \tfrac q{2\varkappa - \partial}\,\psi_h^{12}\,dx\\ &\quad+\int 2\varkappa qr\Big(\tfrac{q'}{2\varkappa - \partial}\cdot\tfrac r{2\varkappa + \partial}- \tfrac q{2\varkappa - \partial}\cdot\tfrac{r'}{2\varkappa + \partial}\Big)\psi_h^{12}\,dx\\ &\quad - \int 2\varkappa^2 \Big(q' \cdot \tfrac r{2\varkappa + \partial}- r' \cdot \tfrac q{2\varkappa - \partial}\Big) \tfrac r{2\varkappa + \partial}\cdot \tfrac q{2\varkappa - \partial}\,\psi_h^{12}\,dx\\ &\quad + \int qr\cdot\tfrac{q'}{2\varkappa - \partial}\cdot\tfrac{r'}{2\varkappa + \partial}\,\psi_h^{12}\,dx. \end{align*} $$
We then bound each of these terms by applying (2.31) with (9.8) as follows:
 $$ \begin{align*} &\left\|\int 4\varkappa^2(2\varkappa + \partial)q\cdot[\psi_h^{12},\tfrac1{2\varkappa +\partial} ] \big( r\cdot \tfrac q{2\varkappa - \partial}\cdot \tfrac r{2\varkappa + \partial}\big)\,dx\right\|_{L^1_t}\\ &\qquad \lesssim \varkappa^2 \|(2\varkappa + \partial)q\|_{L^\infty_tH^{-1}_\varkappa}\|[\psi_h^{12},\tfrac1{2\varkappa +\partial} ] \big( r\tfrac q{2\varkappa - \partial} \tfrac r{2\varkappa + \partial}\big)\|_{L^2_tH^1_\varkappa}\\ &\qquad \lesssim \varkappa^{-1}\|q\|_{L^\infty_tL^2}^2\|\psi_h^3q\|_{L^4_tL^\infty}^2\lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \\ &\left\|\int 6\varkappa^2 \tfrac {q'}{2\varkappa - \partial}\cdot r \cdot \tfrac q{2\varkappa - \partial}\cdot \tfrac r{2\varkappa +\partial}\,\psi_h^{12}\,dx\right\|_{L^1_t} +\left\|\int 2\varkappa qr\tfrac{q'}{2\varkappa - \partial}\tfrac r{2\varkappa + \partial}\,\psi_h^{12}\,dx\right\|_{L^1_1}\\ &\qquad + \left\|\int 2\varkappa^2 q' \cdot \tfrac r{2\varkappa + \partial}\cdot \tfrac q{2\varkappa - \partial}\cdot \tfrac r{2\varkappa + \partial}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\qquad \lesssim \varkappa^{-1}\|\psi^3_h q\|_{L^4_tL^\infty}^2\|\psi_h^6q'\|_{L^2_{t,x}}\|q\|_{L^\infty_tL^2} \lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \\ &\left\|\int qr\tfrac{q'}{2\varkappa - \partial}\tfrac{r'}{2\varkappa + \partial}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \varkappa^{-1}\|\psi^3 q\|_{L^4_tL^\infty}^2\|\psi^6_h q'\|_{L^2_{t,x}}\|\tfrac{q'}{2\varkappa - \partial}\|_{L^\infty_tL^2}\lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \end{align*} $$
$$ \begin{align*} &\left\|\int 4\varkappa^2(2\varkappa + \partial)q\cdot[\psi_h^{12},\tfrac1{2\varkappa +\partial} ] \big( r\cdot \tfrac q{2\varkappa - \partial}\cdot \tfrac r{2\varkappa + \partial}\big)\,dx\right\|_{L^1_t}\\ &\qquad \lesssim \varkappa^2 \|(2\varkappa + \partial)q\|_{L^\infty_tH^{-1}_\varkappa}\|[\psi_h^{12},\tfrac1{2\varkappa +\partial} ] \big( r\tfrac q{2\varkappa - \partial} \tfrac r{2\varkappa + \partial}\big)\|_{L^2_tH^1_\varkappa}\\ &\qquad \lesssim \varkappa^{-1}\|q\|_{L^\infty_tL^2}^2\|\psi_h^3q\|_{L^4_tL^\infty}^2\lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \\ &\left\|\int 6\varkappa^2 \tfrac {q'}{2\varkappa - \partial}\cdot r \cdot \tfrac q{2\varkappa - \partial}\cdot \tfrac r{2\varkappa +\partial}\,\psi_h^{12}\,dx\right\|_{L^1_t} +\left\|\int 2\varkappa qr\tfrac{q'}{2\varkappa - \partial}\tfrac r{2\varkappa + \partial}\,\psi_h^{12}\,dx\right\|_{L^1_1}\\ &\qquad + \left\|\int 2\varkappa^2 q' \cdot \tfrac r{2\varkappa + \partial}\cdot \tfrac q{2\varkappa - \partial}\cdot \tfrac r{2\varkappa + \partial}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\qquad \lesssim \varkappa^{-1}\|\psi^3_h q\|_{L^4_tL^\infty}^2\|\psi_h^6q'\|_{L^2_{t,x}}\|q\|_{L^\infty_tL^2} \lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \\ &\left\|\int qr\tfrac{q'}{2\varkappa - \partial}\tfrac{r'}{2\varkappa + \partial}\,\psi_h^{12}\,dx\right\|_{L^1_t}\\ &\qquad\lesssim \varkappa^{-1}\|\psi^3 q\|_{L^4_tL^\infty}^2\|\psi^6_h q'\|_{L^2_{t,x}}\|\tfrac{q'}{2\varkappa - \partial}\|_{L^\infty_tL^2}\lesssim \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \end{align*} $$
with identical estimates for the symmetric terms.
Combining the estimates for
 $\widetilde j_{\mathrm {mKdV}}^{[\geq 4]}$
, we obtain the estimate (9.6).
$\widetilde j_{\mathrm {mKdV}}^{[\geq 4]}$
, we obtain the estimate (9.6).
Proof of Proposition 9.1.
We now argue as in the proof of Proposition 5.5, with
 $\rho ,j_{\mathrm {mKdV}}$
replaced by
$\rho ,j_{\mathrm {mKdV}}$
replaced by
 $\widetilde \rho ,\widetilde j_{\mathrm {mKdV}}$
, respectively, and the estimates (5.7), (5.4), (5.9) replaced by the estimates (9.3), (9.4), (9.6), respectively, to obtain
$\widetilde \rho ,\widetilde j_{\mathrm {mKdV}}$
, respectively, and the estimates (5.7), (5.4), (5.9) replaced by the estimates (9.3), (9.4), (9.6), respectively, to obtain
 $$ \begin{align*} \|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa}^2 &\lesssim \varepsilon\|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa}^2 + (1 + \tfrac1\varepsilon)\big(\|q'\|_{L^\infty_tH^{-1}_\varkappa}^2 + \varkappa^{-1}\|q\|_{L^\infty_tL^2}^2\big)\\ &\quad + \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \end{align*} $$
$$ \begin{align*} \|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa}^2 &\lesssim \varepsilon\|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa}^2 + (1 + \tfrac1\varepsilon)\big(\|q'\|_{L^\infty_tH^{-1}_\varkappa}^2 + \varkappa^{-1}\|q\|_{L^\infty_tL^2}^2\big)\\ &\quad + \varkappa^{-1}\delta^2{\left\vert\kern-0.25ex\left\vert\kern-0.25ex\left\vert q \right\vert\kern-0.25ex\right\vert\kern-0.25ex\right\vert}_{\mathrm{mKdV}}^2, \end{align*} $$
where the implicit constant is independent of
 $h,\varkappa ,\varepsilon $
. Taking
$h,\varkappa ,\varepsilon $
. Taking
 $\varepsilon $
sufficiently small to defeat the implicit constant above and using (8.2) and the conservation of mass, we may bound
$\varepsilon $
sufficiently small to defeat the implicit constant above and using (8.2) and the conservation of mass, we may bound
 $$ \begin{align*} \|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa}^2 &\lesssim \|q(0)'\|_{H^{-1}_\varkappa}^2+\varkappa^{-1}\|q(0)\|_{L^2}^2 + \delta^2\varkappa^{-1}\|q\|_{X^1}^2. \end{align*} $$
$$ \begin{align*} \|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa}^2 &\lesssim \|q(0)'\|_{H^{-1}_\varkappa}^2+\varkappa^{-1}\|q(0)\|_{L^2}^2 + \delta^2\varkappa^{-1}\|q\|_{X^1}^2. \end{align*} $$
Arguing as in Proposition 5.5 and using the conservation of mass to bound the low frequencies, we obtain the estimates (9.1) and (9.2) in the case
 $\sigma = 0$
.
$\sigma = 0$
.
If
 $0<\sigma <\frac 12$
, we first use (9.1) with
$0<\sigma <\frac 12$
, we first use (9.1) with
 $\sigma = 0$
to bound
$\sigma = 0$
to bound
 $\|q\|_{X^1}$
and then integrate using (2.7) to obtain
$\|q\|_{X^1}$
and then integrate using (2.7) to obtain
 $$ \begin{align*} \|(\psi_h^6 q)"\|_{L^2_tH^{\sigma-1}_\kappa}^2 &\approx \int_\kappa^\infty \varkappa^{2\sigma}\|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa}^2\,\tfrac{d\varkappa}\varkappa \lesssim \|q(0)'\|_{H^{\sigma-1}_\kappa}^2+ \kappa^{2\sigma-1}\|q(0)\|_{L^2}^2, \end{align*} $$
$$ \begin{align*} \|(\psi_h^6 q)"\|_{L^2_tH^{\sigma-1}_\kappa}^2 &\approx \int_\kappa^\infty \varkappa^{2\sigma}\|(\psi_h^6 q)"\|_{L^2_tH^{-1}_\varkappa}^2\,\tfrac{d\varkappa}\varkappa \lesssim \|q(0)'\|_{H^{\sigma-1}_\kappa}^2+ \kappa^{2\sigma-1}\|q(0)\|_{L^2}^2, \end{align*} $$
and the proof of the estimates (9.1) and (9.2) is completed similarly.
A Ill-posedness
The key observation that drives everything in this section is the following:
Lemma A.1. If
 $\psi :{{\mathbb {R}}}\to \mathbb {C}$
is a Schwartz function and
$\psi :{{\mathbb {R}}}\to \mathbb {C}$
is a Schwartz function and
 $\psi _\lambda (x):=\lambda \psi (\lambda x)$
, then
$\psi _\lambda (x):=\lambda \psi (\lambda x)$
, then
 $$ \begin{align} \int \psi(x)\,dx &=0 \quad\text{implies}\quad \| \psi_\lambda \|_{H^{\sigma}({{\mathbb{R}}})}^2 \lesssim_\psi \begin{cases} 1 & : \sigma=-\tfrac12 \\ \lambda^{-1} + \lambda^{1+2\sigma} & :\sigma<-\frac12\end{cases} , \end{align} $$
$$ \begin{align} \int \psi(x)\,dx &=0 \quad\text{implies}\quad \| \psi_\lambda \|_{H^{\sigma}({{\mathbb{R}}})}^2 \lesssim_\psi \begin{cases} 1 & : \sigma=-\tfrac12 \\ \lambda^{-1} + \lambda^{1+2\sigma} & :\sigma<-\frac12\end{cases} , \end{align} $$
whereas
 $$ \begin{align} \int \psi(x)\,dx &\neq 0 \quad\text{implies}\quad \| \psi_\lambda \|_{H^\sigma ({{\mathbb{R}}})}^2 \gtrsim_\psi \begin{cases} \log \lambda& :\sigma=-\tfrac12 \\ 1 & :\sigma<-\frac12 \end{cases} \end{align} $$
$$ \begin{align} \int \psi(x)\,dx &\neq 0 \quad\text{implies}\quad \| \psi_\lambda \|_{H^\sigma ({{\mathbb{R}}})}^2 \gtrsim_\psi \begin{cases} \log \lambda& :\sigma=-\tfrac12 \\ 1 & :\sigma<-\frac12 \end{cases} \end{align} $$
uniformly for
 $\lambda \geq 2$
.
$\lambda \geq 2$
.
This follows from direct computation. Better bounds are possible in the
 $\sigma <-\frac 12$
case of (A.1), but simplicity is preferable.
$\sigma <-\frac 12$
case of (A.1), but simplicity is preferable.
In order to exploit Lemma A.1, we need solutions for our flows that initially have mean zero but later have nonzero mean. For just (NLS) or (mKdV), this is trivial. However, we wish to consider all evolutions in the hierarchy simultaneously (excepting translation and phase rotation). For this reason, it is convenient to work with the generating function
 $A(\kappa )$
for the Hamiltonians and then expand in inverse powers of
$A(\kappa )$
for the Hamiltonians and then expand in inverse powers of
 $\kappa $
. Under the
$\kappa $
. Under the
 $A(\kappa )$
flow,
$A(\kappa )$
flow,
 $$ \begin{align} \tfrac{d}{dt} \int q \,dx = i \int g_{12}(x;\kappa)\,dx. \quad\text{Moreover,}\quad \int g_{12}^{[1]}(x;\kappa)\,dx = - \tfrac1{2\kappa}\int q \,dx. \end{align} $$
$$ \begin{align} \tfrac{d}{dt} \int q \,dx = i \int g_{12}(x;\kappa)\,dx. \quad\text{Moreover,}\quad \int g_{12}^{[1]}(x;\kappa)\,dx = - \tfrac1{2\kappa}\int q \,dx. \end{align} $$
These assertions follow from (4.20) and (3.20), respectively. Delving further, shows
 $$ \begin{align} \int g_{12}^{[3]}(x;\kappa)\,dx = \tfrac{\pm 1}{4\kappa^3\sqrt{2\pi}} \sum_{\ell=0}^\infty \int \big(\tfrac{i}{2\kappa}\big)^\ell \hat q(\eta-\xi) \hat q(\xi) \overline{\hat q(\eta)} \, \tfrac{\xi^{\ell+1}-\eta^{\ell+1}}{\xi-\eta}\,d\xi\,d\eta. \end{align} $$
$$ \begin{align} \int g_{12}^{[3]}(x;\kappa)\,dx = \tfrac{\pm 1}{4\kappa^3\sqrt{2\pi}} \sum_{\ell=0}^\infty \int \big(\tfrac{i}{2\kappa}\big)^\ell \hat q(\eta-\xi) \hat q(\xi) \overline{\hat q(\eta)} \, \tfrac{\xi^{\ell+1}-\eta^{\ell+1}}{\xi-\eta}\,d\xi\,d\eta. \end{align} $$
Proposition A.2. Both (NLS) and (mKdV) exhibit instantaneous inflation of the
 $H^{\sigma }$
norm, in the sense of (1.4), for every
$H^{\sigma }$
norm, in the sense of (1.4), for every
 $\sigma \leq -\frac 12$
. Indeed, this also holds for all higher flows in the hierarchy (focusing or defocusing).
$\sigma \leq -\frac 12$
. Indeed, this also holds for all higher flows in the hierarchy (focusing or defocusing).
Proof. We first consider a fixed Schwartz solution
 $u:{{\mathbb {R}}}\times {{\mathbb {R}}}\to \mathbb {C}$
of our chosen equation. For even numbered Hamiltonians of the hierarchy, such as (NLS), we choose initial data
$u:{{\mathbb {R}}}\times {{\mathbb {R}}}\to \mathbb {C}$
of our chosen equation. For even numbered Hamiltonians of the hierarchy, such as (NLS), we choose initial data
 $\widehat {u_0}(\xi ) = a \xi ^2 e^{-\xi ^2}$
, where
$\widehat {u_0}(\xi ) = a \xi ^2 e^{-\xi ^2}$
, where
 $a>0$
will be chosen small shortly. For odd numbered Hamiltonians, such as (mKdV), we choose
$a>0$
will be chosen small shortly. For odd numbered Hamiltonians, such as (mKdV), we choose
 $\widehat {u_0}(\xi ) = a [\xi ^2+\xi ^3] e^{-\xi ^2}$
. The key criterion for selecting these initial data and for choosing
$\widehat {u_0}(\xi ) = a [\xi ^2+\xi ^3] e^{-\xi ^2}$
. The key criterion for selecting these initial data and for choosing
 $a>0$
is that
$a>0$
is that
 $$ \begin{align} \int u(0,x)\,dx =0 \quad\text{but}\quad \int u(t_1,x)\,dx \neq 0 \end{align} $$
$$ \begin{align} \int u(0,x)\,dx =0 \quad\text{but}\quad \int u(t_1,x)\,dx \neq 0 \end{align} $$
for some
 $t_1>0$
and any sufficiently small
$t_1>0$
and any sufficiently small
 $a>0$
. The existence of such a
$a>0$
. The existence of such a
 $t_1$
will follow if we show nonvanishing of the cubic terms in the time derivative of
$t_1$
will follow if we show nonvanishing of the cubic terms in the time derivative of
 $\int u$
at time
$\int u$
at time
 $t=0$
. This is precisely the role of (A.4).
$t=0$
. This is precisely the role of (A.4).
For even numbered Hamiltonians (i.e.,
 $\ell $
even), the integrand in (A.4) is sign definite, and so (A.5) is clear. For odd numbered Hamiltonians, we first symmetrize under
$\ell $
even), the integrand in (A.4) is sign definite, and so (A.5) is clear. For odd numbered Hamiltonians, we first symmetrize under
 $\eta \leftrightarrow \xi $
and then under simultaneous inversion in
$\eta \leftrightarrow \xi $
and then under simultaneous inversion in
 $\eta $
and
$\eta $
and
 $\xi $
; this then leads to an integrand with a sign-definite imaginary part.
$\xi $
; this then leads to an integrand with a sign-definite imaginary part.
In the case
 $\sigma =-\tfrac 12$
, we choose
$\sigma =-\tfrac 12$
, we choose
 $q=a u_\lambda $
using the rescaling of u given by (1.3): One chooses a small to guarantee that the initial data have size
$q=a u_\lambda $
using the rescaling of u given by (1.3): One chooses a small to guarantee that the initial data have size
 $\varepsilon $
and then
$\varepsilon $
and then
 $\lambda $
large to guarantee that
$\lambda $
large to guarantee that
 $\lambda ^{-m}t_1<\varepsilon $
and that the norm exceeds
$\lambda ^{-m}t_1<\varepsilon $
and that the norm exceeds
 $\varepsilon ^{-1}$
at this time.
$\varepsilon ^{-1}$
at this time.
When
 $\sigma <-\tfrac 12$
, we need an extra idea: Consider the solution q with initial data
$\sigma <-\tfrac 12$
, we need an extra idea: Consider the solution q with initial data
 $$ \begin{align*}q(0,x) = \sum_{n=1}^N a u_\lambda(0,x+nL). \end{align*} $$
$$ \begin{align*}q(0,x) = \sum_{n=1}^N a u_\lambda(0,x+nL). \end{align*} $$
Note that
 $\sum a u_\lambda (t,x+nL)$
is almost a solution and becomes more so as
$\sum a u_\lambda (t,x+nL)$
is almost a solution and becomes more so as
 $L\to \infty $
. As all equations in the hierarchy are known to admit a perturbation theory in high regularity spaces [Reference Grünrock20, Reference Kenig, Ponce and Vega34], we know that the approximate solution differs little from
$L\to \infty $
. As all equations in the hierarchy are known to admit a perturbation theory in high regularity spaces [Reference Grünrock20, Reference Kenig, Ponce and Vega34], we know that the approximate solution differs little from
 $q(t,x)$
uniformly for
$q(t,x)$
uniformly for
 $t\in [0,\lambda ^{-m}t_1]$
provided we take L large enough. The ill-posedness result now follows by choosing N and L large enough to guarantee large norm at time
$t\in [0,\lambda ^{-m}t_1]$
provided we take L large enough. The ill-posedness result now follows by choosing N and L large enough to guarantee large norm at time
 $\lambda ^{-m}t_1$
and ensuring that
$\lambda ^{-m}t_1$
and ensuring that
 $\lambda $
is large enough to place this time in
$\lambda $
is large enough to place this time in
 $[0,\varepsilon ]$
and to make the norm small at time
$[0,\varepsilon ]$
and to make the norm small at time
 $t=0$
.
$t=0$
.
Evidently, this argument cannot be applied to (mKdVℝ
), because
 $\int q$
is conserved. Nevertheless, we are able to show the following form of norm inflation in the focusing case:
$\int q$
is conserved. Nevertheless, we are able to show the following form of norm inflation in the focusing case:
Proposition A.3. For any sequence of times
 $t_n\to 0$
, there is a sequence of (real-valued) Schwartz-class solutions
$t_n\to 0$
, there is a sequence of (real-valued) Schwartz-class solutions
 $q_n$
to focusing (mKdVℝ
) that satisfy
$q_n$
to focusing (mKdVℝ
) that satisfy
 $$ \begin{align} \| q_n(0) \|_{\dot H^{-\frac12}} \lesssim 1 \quad\text{and}\quad \| q_n(t_n) \|_{H^{-\frac12}} \to \infty. \end{align} $$
$$ \begin{align} \| q_n(0) \|_{\dot H^{-\frac12}} \lesssim 1 \quad\text{and}\quad \| q_n(t_n) \|_{H^{-\frac12}} \to \infty. \end{align} $$
Moreover, instantaneous norm inflation in the sense of (1.4) holds when
 $\sigma <-\frac 12$
.
$\sigma <-\frac 12$
.
Note that at time zero, these solutions belong to the homogeneous Sobolev space; this is a stronger requirement than belonging to
 $H^{-1/2}({{\mathbb {R}}})$
and enforces that
$H^{-1/2}({{\mathbb {R}}})$
and enforces that
 $\int q_n(0,x)\,dx = 0$
. (Unlike for (NLS) and (mKdV), this mean-zero property is preserved by (mKdVℝ
).) Nevertheless, the (weaker) inhomogeneous norm diverges.
$\int q_n(0,x)\,dx = 0$
. (Unlike for (NLS) and (mKdV), this mean-zero property is preserved by (mKdVℝ
).) Nevertheless, the (weaker) inhomogeneous norm diverges.
For
 $\sigma =-\frac 12$
, we show norm inflation for initial data of size one, rather than for arbitrarily small initial data. It is only in this sense that the result is weaker than (1.4).
$\sigma =-\frac 12$
, we show norm inflation for initial data of size one, rather than for arbitrarily small initial data. It is only in this sense that the result is weaker than (1.4).
Proof. All that is required is a careful inspection of the two-soliton solutions
 $$ \begin{align*}u(t,x) := 6\frac{ 2\cosh(x-t)-\cosh(2x-8t) }{\,\cosh(3x-9t)+9\cosh(x-7t)-8} \quad\text{and}\quad u_\lambda(t,x) = \lambda u(\lambda^3 t,\lambda x). \end{align*} $$
$$ \begin{align*}u(t,x) := 6\frac{ 2\cosh(x-t)-\cosh(2x-8t) }{\,\cosh(3x-9t)+9\cosh(x-7t)-8} \quad\text{and}\quad u_\lambda(t,x) = \lambda u(\lambda^3 t,\lambda x). \end{align*} $$
Fix
 $\sigma <-\frac 12$
. As rescalings of a single mean-zero Schwartz function,
$\sigma <-\frac 12$
. As rescalings of a single mean-zero Schwartz function,
 $$ \begin{align*}\| u_\lambda (0) \|_{\dot H^{-\frac12}({{\mathbb{R}}})}^2 \approx 1 \quad\text{and}\quad \| u_\lambda (0) \|_{H^\sigma({{\mathbb{R}}})}^2 \lesssim \lambda^{-1} + \lambda^{1+2\sigma} \end{align*} $$
$$ \begin{align*}\| u_\lambda (0) \|_{\dot H^{-\frac12}({{\mathbb{R}}})}^2 \approx 1 \quad\text{and}\quad \| u_\lambda (0) \|_{H^\sigma({{\mathbb{R}}})}^2 \lesssim \lambda^{-1} + \lambda^{1+2\sigma} \end{align*} $$
uniformly for
 $\lambda \geq 1$
. On the other hand, for
$\lambda \geq 1$
. On the other hand, for
 $\lambda _n^2 t_n^{ } \gtrsim 1$
, we see that the solution resolves into two sign-definite Schwartz solitons (each of width
$\lambda _n^2 t_n^{ } \gtrsim 1$
, we see that the solution resolves into two sign-definite Schwartz solitons (each of width
 $\approx \lambda _n^{-1}$
) separated by a distance
$\approx \lambda _n^{-1}$
) separated by a distance
 $\approx \lambda _n^2 t_n^{ }$
. In this way, one readily shows that
$\approx \lambda _n^2 t_n^{ }$
. In this way, one readily shows that
 $$ \begin{align*}\| u_{\lambda_n} (t_n) \|_{H^{-\frac12}({{\mathbb{R}}})}^2 \approx \log( \lambda_n ) \quad\text{and}\quad \| u_{\lambda_n} (t_n) \|_{H^\sigma({{\mathbb{R}}})}^2 \gtrsim 1. \end{align*} $$
$$ \begin{align*}\| u_{\lambda_n} (t_n) \|_{H^{-\frac12}({{\mathbb{R}}})}^2 \approx \log( \lambda_n ) \quad\text{and}\quad \| u_{\lambda_n} (t_n) \|_{H^\sigma({{\mathbb{R}}})}^2 \gtrsim 1. \end{align*} $$
The claim (A.6) follows at once by choosing
 $\lambda _n$
appropriately. Norm inflation in
$\lambda _n$
appropriately. Norm inflation in
 $H^\sigma ({{\mathbb {R}}})$
follows via the same summation device employed in the proof Proposition A.2.
$H^\sigma ({{\mathbb {R}}})$
follows via the same summation device employed in the proof Proposition A.2.
Acknowledgments
We would like to thank the referees for carefully reading this article and their many insightful suggestions. R.K. was supported by National Science Foundation (NSF) grant DMS-1856755. M.V. was supported by NSF grant DMS-1763074. This work was completed while B.H.-G. was a member of the Department of Mathematics at University of California, Los Angeles.
Competing interests
The authors have no competing interest to declare.
















 Open access
Open access