


1. Introduction
The exponential rise in the volume of textual data available through various sources, ranging from social media to financial reports, makes it virtually impossible for humans to digest all the important information for their needs without spending a large amount of effort. Automatic summarization methods can mitigate this problem by shortening texts to a more concise form (Nallapati et al. Reference Nallapati, Zhou, dos Santos, Gulcehre and Xiang2016; Celikyilmaz et al. Reference Celikyilmaz, Bosselut, He and Choi2018; Song et al. Reference Song, Huang and Ruan2019; Liu and Lapata Reference Liu and Lapata2020).
Early summarization methods, mainly focusing on extractive summarization (Fang et al. Reference Fang, Mu, Deng and Wu2017; Mao et al. Reference Mao, Yang, Huang, Liu and Li2019), had limited success. The advent of deep learning led to much more powerful neural abstractive summarization methods (See, Liu, and Manning, Reference See, Liu and Manning2017; Song et al. Song et al. Reference Song, Huang and Ruan2019; Dong et al. Reference Dong, Yang, Wang, Wei, Liu, Wang, Gao, Zhou and Hon2019; Lewis et al. Reference Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov and Zettlemoyer2020; Zhang et al. Reference Zhang, Zhao, Saleh and Liu2020a), going beyond extracting unaltered sentences from the input to generating the summary using novel words and phrases that are not necessarily part of the input text.
The need to tailor the generated summary of a particular input document to the diverse interests and preferences of different users has fueled interest in controllable summarization methods. Topic-controllable summarization methods (Krishna and Srinivasan Reference Krishna and Srinivasan2018; Bahrainian et al. Reference Bahrainian, Zerveas, Crestani and Eickhoff2021) influence the summary generation towards a given input topic. Entity-based summarization methods (Fan, Grangier, and Auli Reference Fan, Grangier and Auli2018a; He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022) influence the summary towards user-specified entities. Other methods focus on specific writing style guidelines (Fan, Grangier, and Auli, Reference Fan, Grangier and Auli2018a) or other non-semantic attributes of the text, such as length (Kikuchi et al. Reference Kikuchi, Neubig, Sasano, Takamura and Okumura2016; Liu, Luo, and Zhu, Reference Liu, Luo and Zhu2018; Takase and Okazaki Reference Takase and Okazaki2019; Saito et al. Reference Saito, Nishida, Nishida, Otsuka, Asano, Tomita, Shindo and Matsumoto2020).
State-of-the-art approaches employ prepending for controlling the output of the summary (Fan, Grangier, and Auli, Reference Fan, Grangier and Auli2018a; He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022; Zhang et al. Reference Zhang, Liu, Yang, Fang, Chen, Radev, Zhu, Zeng and Zhang2023; Yang et al. Reference Yang, Li, Zhang, Chen and Cheng2023). Prepending is versatile, as it can be used for controlling the summary towards arbitrary short texts, including entities, keywords, and even topics (Passali and Tsoumakas Reference Passali and Tsoumakas2024), while also being able to control length (Fan, Grangier, and Auli, Reference Fan, Grangier and Auli2018a). However, it cannot scale to large textual contexts, like a document or a collection of documents. The latter is important in applications like news personalization, where we would like to influence the summary of an article towards the prior reading history of a user.
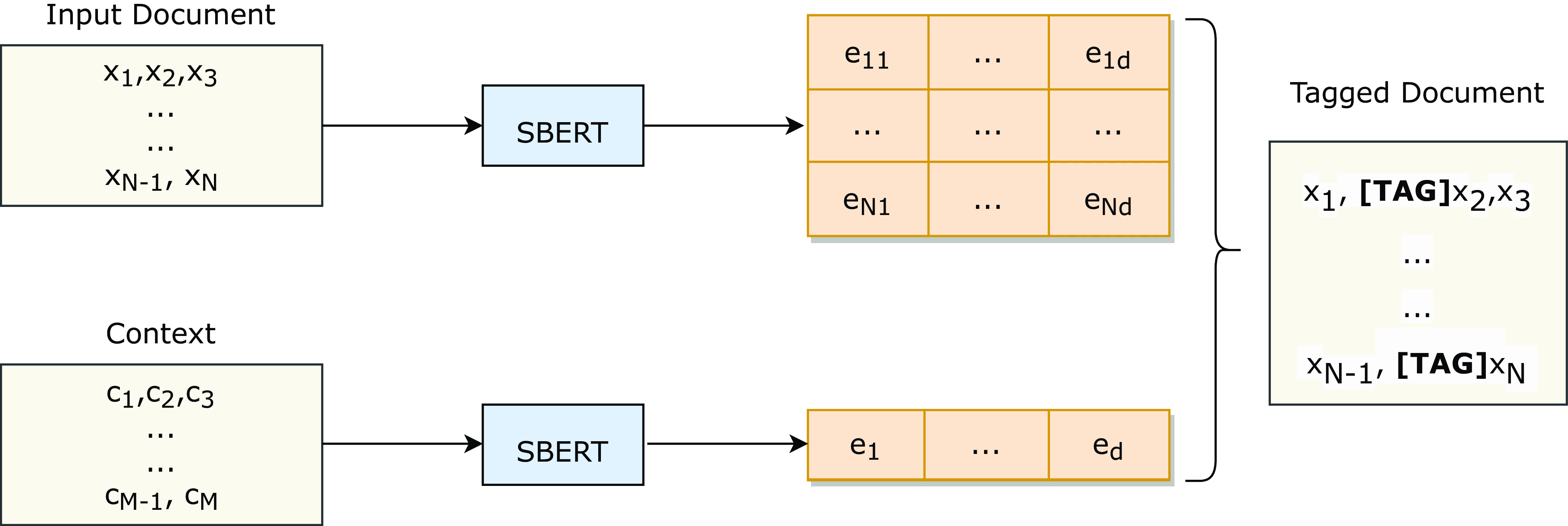
To overcome this limitation, we propose a flexible method for controlling the summary of a document towards arbitrary textual context, from a short text to a collection of documents, called contextual abstractive summarization. During inference, our method employs a pre-trained embedding model in order to obtain representations of both the context and each word of the input document. The words that are closer to the context in this embedding space are prepended with a special tag (see Figure 1). The same process is used for training any summarization model using any existing summarization dataset by considering the ground truth summary of each document as the context. This way models learn to influence the summary towards the tagged words.
Another limitation of prepending is that models tend to copy verbatim the given short text in the generated summary. While for entities this makes sense, for topics, it can lead to the introduction of misleading information that is not part of the input document (see Table 1). However, existing evaluation metrics for this task are mainly based on the presence of the given short text in the generated summary (Fan, Grangier, and Auli, Reference Fan, Grangier and Auli2018a; He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022) and can therefore be misleading in the case of topics. This limitation extends to the broader field of text generation, where there is a lack of a comprehensive and reliable evaluation metric to address these phenomena (Zhang et al. Reference Zhang, Chen, Ma and Cai2003). In this paper, we propose a new evaluation metric that assesses the similarity of the input document with the sentence of the generated summary that is closest to the context.
Examples of summaries generated by CTRLsum and the proposed
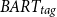 $BART_{tag}$
for different topics of the same document. Blue and violet demonstrate indicative tagged words for the topics “Science & and Health” and “Neuroscience,” respectively. Orange indicates common tagged words for both topics. Bold red indicates the artificially generated content.
$BART_{tag}$
for different topics of the same document. Blue and violet demonstrate indicative tagged words for the topics “Science & and Health” and “Neuroscience,” respectively. Orange indicates common tagged words for both topics. Bold red indicates the artificially generated content.

The contributions of this paper can be summarized as follows:
-
• We propose a flexible approach for controlling the summary of a document towards any arbitrary textual context, from a short text to a collection of documents. Our approach can be tied to any model’s architecture and can be easily combined with any of the already existing generative summarization approaches.
-
• We propose an appropriate metric to evaluate the relevance and the reliability of the generated summary to ensure that it does not contain any artificially generated content. A human evaluation study confirms the reliability of the proposed metric.
-
• We provide an extensive empirical evaluation of the proposed approach, demonstrating both its generality and its effectiveness.
-
• We demonstrate under different zero-shot setups that the proposed method can influence the summary towards different contexts while preserving the reliability of the generated summary.
The rest of the paper is structured as follows. Section 2 reviews related work on controllable summarization. Section 3 introduces the proposed contextual summarization approach, while Section 4 presents the reliability metric. Section 5 discusses the experimental results. Section 6 draws conclusions from this work and discusses interesting future research directions.
2. Related work
We first present related methods and models for controllable summarization. Then, we discuss two related fields of study: personalized summarization and query-focused summarization. Finally, we provide an overview of the contributions and differences of the proposed method compared to previous works.
2.1 Controllable summarization
Prior work on controllable summarization focused on influencing the generated summaries according to different aspects. These aspects can be related either to content, such as a thematic category (Krishna and Srinivasan Reference Krishna and Srinivasan2018; Ailem et al. Reference Ailem, Zhang and Sha2019; Wang et al. Reference Wang, Duan, Zhang, Wang, Tian, Chen and Zhou2020; Bahrainian et al. Reference Bahrainian, Zerveas, Crestani and Eickhoff2021; Passali and Tsoumakas Reference Passali and Tsoumakas2024; Bahrainian, Feucht, and Eickhoff, Reference Bahrainian, Feucht, Eickhoff, Muresan, Nakov and Villavicencio2022; Lu et al. Reference Lu, Chen, Guo, Wang and Zhou2024), an entity (Fan, Grangier, and Auli, Reference Fan, Grangier and Auli2018a; He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022; Chan, Wang, and King, Reference Chan, Wang and King2021; Dou et al. Reference Dou, Liu, Hayashi, Jiang and Neubig2021), and a narrative style (Fan, Grangier, and Auli, Reference Fan, Grangier and Auli2018b), or to form-related aspects such as the length (Kikuchi et al. Reference Kikuchi, Neubig, Sasano, Takamura and Okumura2016; Fan, Grangier, and Auli, Reference Fan, Grangier and Auli2018b; Takase and Okazaki Reference Takase and Okazaki2019; Bian et al. Reference Bian, Lin, Zhang, Yan, Tang and Zhang2019; Liu, Luo, and Zhu, Reference Liu, Luo and Zhu2020; Saito et al. Reference Saito, Nishida, Nishida, Otsuka, Asano, Tomita, Shindo and Matsumoto2020) of the output summary. This work focuses on content-related aspects.
Early approaches for controllable summarization were based on recurrent neural networks and required adaptations to the architecture of existing models (Krishna and Srinivasan Reference Krishna and Srinivasan2018; Frermann and Klementiev Reference Frermann and Klementiev2019; Bahrainian et al. Reference Bahrainian, Zerveas, Crestani and Eickhoff2021). Krishna and Srinivasan (Reference Krishna and Srinivasan2018) integrate topical embeddings with a generic pointer generator network (See et al. Reference See, Liu and Manning2017) for topic-controllable summarization. The topical embeddings are extracted from the Vox Dataset (Vox Media 2017), a topical news dataset that contains more than 180 different thematic categories. Recently, Passali and Tsoumakas (Reference Passali and Tsoumakas2024) scaled this method to Transformers by summing topic embeddings along with token and positional embeddings to guide the summary generation towards a user-requested topic. Bahrainian et al. (Reference Bahrainian, Zerveas, Crestani and Eickhoff2021) adapt the attention mechanism of a pointer generator network to work with topical information derived from an LDA model. Even though this model was trained with the topical attention mechanism, no topical information is used during inference.
Recent approaches have shown the effectiveness of special tokens and prompts for controlling the output of Transformer language models (Fan, Grangier, and Auli, Reference Fan, Grangier and Auli2018b; Keskar et al. Reference Keskar, McCann, Varshney, Xiong and Socher2019; He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022; Passali and Tsoumakas Reference Passali and Tsoumakas2024; Bahrainian et al. Reference Bahrainian, Feucht, Eickhoff, Muresan, Nakov and Villavicencio2022; Zhang et al. Reference Zhang, Liu, Yang, Fang, Chen, Radev, Zhu, Zeng and Zhang2023; Yang et al. Reference Yang, Li, Zhang, Chen and Cheng2023). Fan et al. (Reference Fan, Grangier and Auli2018b) propose a controllable model to generate summaries of a specific writing style or based on a requested entity from the input document. To influence the summary generation towards the desired entity, they prepend special entity markers in the source text. Style control is achieved in a similar way by prepending special style markers (He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022). Similarly, He et al. (Reference He, Kryscinski, McCann, Rajani and Xiong2022) perform entity-based generation using control tokens in the form of keywords or prompts. Passali and Tsoumakas (Reference Passali and Tsoumakas2024) introduced different Transformer methods for topic-controllable summarization using special tokens in prepending or tagging the most representative words based on tf-idf weights for each topic.
With the advent of large language models (LLMs) such as ChatGPT (OpenAI, 2022b), LLaMA (Touvron et al. Reference Touvron, Lavril, Izacard, Martinet, Lachaux, Lacroix, Rozière, Goyal, Hambro and Azhar2023a, Reference Touvron, Martin, Stone, Albert, Almahairi, Babaei, Bashlykov, Batra, Bhargava and Bhosaleb; Dubey et al. Reference Dubey, Jauhri, Pandey, Kadian, Al-Dahle, Letman, Mathur, Schelten, Yang and Fan2024), and Mistral (Jiang et al. Reference Jiang, Sablayrolles, Mensch, Bamford, Chaplot, Casas, Bressand, Lengyel, Lample and Saulnier2023), prompting has achieved remarkable performance in the field of controllable summarization. For example, ChatGPT has been used for topic-controllable summarization (Yang et al. Reference Yang, Li, Zhang, Chen and Cheng2023) to direct the summarization output towards a desired topic. In addition, Zhang et al. (Reference Zhang, Liu, Yang, Fang, Chen, Radev, Zhu, Zeng and Zhang2023) propose a method for controlling multiple attributes of a document, such as topic, length of summary, extractiveness, and specificity, using prompt and prefix-tuning strategies.
2.2 Personalized summarization
An interesting application of controllable summarization is the personalization of a summary according to the interests of different users. Most of the existing methods for personalized summarization are more than a decade old and extractive. These methods use either textual user annotations, such as keywords (Zhang et al. Reference Zhang, Chen, Ma and Cai2003; Móro et al. Reference Móro and Bielikova2012), or leverage information from more interactive features, such as user clicks (Yan, Nie, and Li, Reference Yan, Nie and Li2011) and gaze-based eye tracking (Dubey et al. Reference Dubey, Setia, Verma and Iyengar2020). Zhang et al. (Reference Zhang, Chen, Ma and Cai2003) use a user’s annotations, i.e., any user’s word of interest, to generate personalized summaries. Yan et al. (Reference Yan, Nie and Li2011) perform multi-document personalized summarization through interactive user clicks, while Dubey et al. (Reference Dubey, Setia, Verma and Iyengar2020) exploit users‘ reading patterns with gaze-based eye tracking during a reading session. Díaz and Gervás (Reference Díaz and Gervás2007) combine a short-term and a long-term model based on different user-defined parameters, such as domain, categories, keywords, and feedback terms. Yang et al. (Reference Yang, Wen, Chen and Sutinen2012) use a relevance-based model along with a user model to retrieve the preferences of mobile users and select higher-ranked candidate sentences for the generated summary. Some limited steps have been made towards personalized abstractive review summarization using user characteristics and user-specific word-using habits from online reviews (Li, Li, and Zong, Reference Li, Li and Zong2019) and headline generation for new articles (Ao et al. Reference Ao, Luo, Wang, Yang, Chen, Qiao, He and Xie2023).
2.3 Query-focused summarization
Another line of research that is close to controllable summarization is query-focused summarization, which refers to the task of generating a summary with respect to a given query (a question, a word, or a short title). The majority of methods for query-based summarization are extractive (Fisher and Roark, Reference Fisher and Roark2006; Daumé III and Marcu Reference Daumé and Marcu2006; Feigenblat et al. Reference Feigenblat, Roitman, Boni and Konopnicki2017; Xu and Lapata Reference Xu and Lapata2020), retrieving sentences from the input document that are closest to the given query. However, these methods typically lack coherence. Recent abstractive methods (Nema et al. Reference Nema, Khapra, Laha and Ravindran2017; Xu and Lapata Reference Xu and Lapata2021; Su, Yu, and Fung, Reference Su, Yu and Fung2021) achieve much more coherent and fluent results than extractive methods. Nema et al. (Reference Nema, Khapra, Laha and Ravindran2017) incorporate query attention into an encoder-decoder RNN model, while other works (Xu and Lapata Reference Xu and Lapata2021; Su et al. Reference Su, Yu and Fung2021) are based on the Transformer paradigm to generate even higher quality summaries.
2.4 Differences with previous methods
Our work differs from all the aforementioned approaches in several ways. First, the proposed method is model-agnostic, unlike earlier approaches that required modifications to the model’s architecture (Krishna and Srinivasan Reference Krishna and Srinivasan2018; Frermann and Klementiev Reference Frermann and Klementiev2019; Bahrainian et al. Reference Bahrainian, Zerveas, Crestani and Eickhoff2021), enabling it to be applied effortlessly across any model. Second, it can be used to guide the summary generation towards any form of textual context, whether it is part of or external to the source document. While existing methods depend on short input prompts (Fan, Grangier, and Auli, Reference Fan, Grangier and Auli2018a; He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022; Zhang et al. Reference Zhang, Liu, Yang, Fang, Chen, Radev, Zhu, Zeng and Zhang2023; Yang et al. Reference Yang, Li, Zhang, Chen and Cheng2023) to direct the summary, the proposed method is not limited to such constraints since it can incorporate arbitrary textual information to steer the focus of the output summary. This can also be extended to broader contexts, including collections of documents, as we experimentally demonstrate (see subsection 5.2.2). To the best of our knowledge, this is the first work that can be used for abstractive personalized document summarization with such diverse textual contexts, including individual documents or entire collections such as a user’s reading history.
3. Contextual abstractive summarization
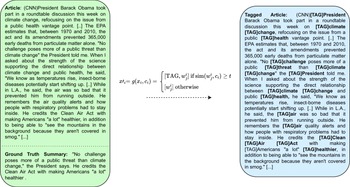
To influence the summary of an input document towards a textual context, our approach prepends during inference the special token [TAG] to the words of the input document that are semantically close to the context. Table 2 demonstrates the result of this process by considering an article from CNN/DailyMail (Hermann et al. Reference Hermann, Kocisky, Grefenstette, Espeholt, Kay, Suleyman and Blunsom2015) as the input document and two different topics (“climate change” and “science and health”) as the context.
Examples of different tagging schemes according to different topics for a document from CNN/DailyMail (Hermann et al. Reference Hermann, Kocisky, Grefenstette, Espeholt, Kay, Suleyman and Blunsom2015).

We encode each word of the input document into the same space with the given context using SBERT. Words of the input document that are semantically close to the context are prepended with the special token [TAG].
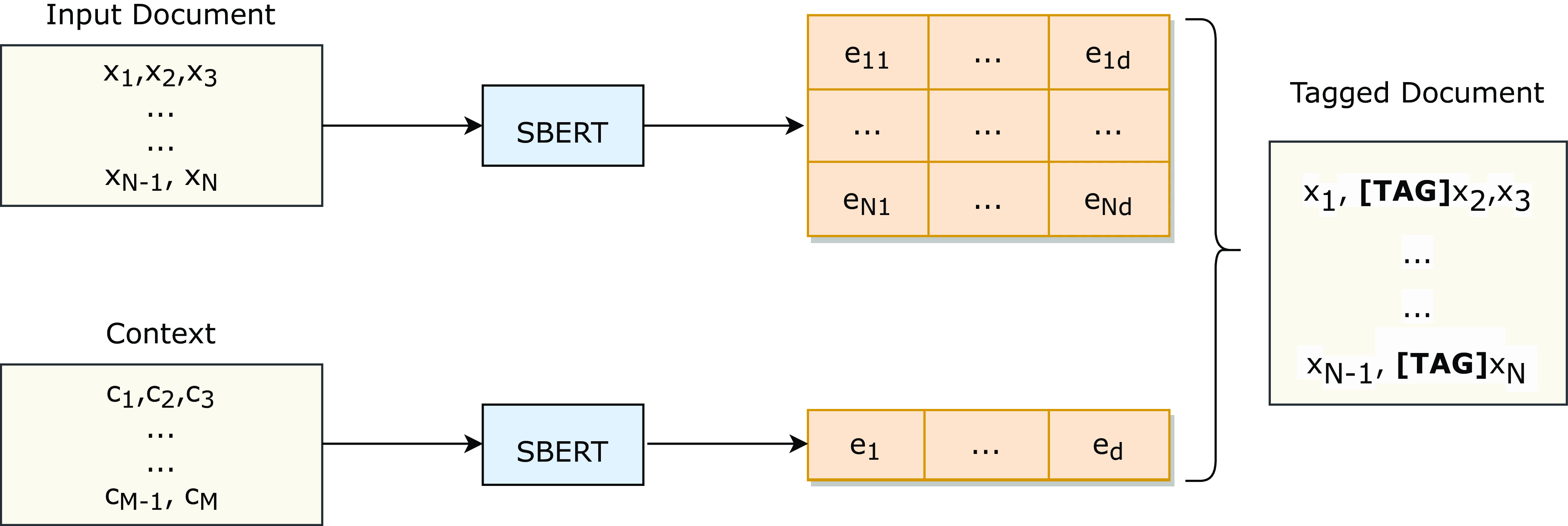
To achieve this tagging, our method employs SBERT (Reimers and Gurevych Reference Reimers and Gurevych2019), a pre-trained BERT-based sentence embedding model, in order to obtain representations of both the context and each word of the input document (see subsection 3.1). It is important to note that our method is versatile, and any embedding model could be used to obtain these representations at this stage. Then, it computes the cosine similarity between the representations of each word of the input document and the context and tags a word if this similarity is higher than a threshold (see subsection 3.2). An illustration of this process is shown in Figure 1. To train a model to influence a summary towards the tagged words, our approach relies on existing summarization datasets, treating the ground truth summaries as context (see subsection 3.3).
3.1 Context and input word encoding
One of the key advantages of our approach is that the given context can be any textual information, beyond a short text, such as a document or even a collection of documents. For instance, the collection of documents could be the history of articles that a user has read on a website, in order for summaries of other articles to be aligned with his reading interests. The document could be the Wikipedia page of a topic (e.g., climate change) or entity (e.g., Barack Obama) a user is interested in, providing a richer source of information for influencing the summary. As another example, it could be a scientific paper that a researcher is drafting; in order to obtain summaries of related papers, she is studying. Our approach can, of course, also accept short text, such as one or more entities, topics, or arbitrary keywords (e.g., battery life, screen) that are of interest to a user.
The encoding,
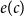 $e(c)$
, of a context,
$e(c)$
, of a context,
 $c$
, differs among the different types of context. When it is a short text, we directly give it as input to SBERT, as the number of its tokens is not expected to exceed the input size of the model:
$c$
, differs among the different types of context. When it is a short text, we directly give it as input to SBERT, as the number of its tokens is not expected to exceed the input size of the model:
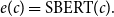 \begin{equation} e(c) = \text{SBERT}(c). \end{equation}
\begin{equation} e(c) = \text{SBERT}(c). \end{equation}
When the context is a single document, consisting of
 $n$
sentences
$n$
sentences
 $\{s_1, \ldots, s_n\}$
, we average all the sentence representations of the document into a final representation:
$\{s_1, \ldots, s_n\}$
, we average all the sentence representations of the document into a final representation:
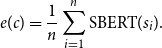 \begin{equation} e(c) = \frac {1}{n}\sum _{i=1}^{n} \text{SBERT}(s_i). \end{equation}
\begin{equation} e(c) = \frac {1}{n}\sum _{i=1}^{n} \text{SBERT}(s_i). \end{equation}
In the case of a collection of
 $n$
documents
$n$
documents
 $\{d_1, \ldots, d_n\}$
, for each document we follow the same process as in the case of a single document, and then we average all the document representations into a final representation:
$\{d_1, \ldots, d_n\}$
, for each document we follow the same process as in the case of a single document, and then we average all the document representations into a final representation:
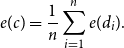 \begin{equation} e(c) = \frac {1}{n}\sum _{i=1}^{n} e(d_i). \end{equation}
\begin{equation} e(c) = \frac {1}{n}\sum _{i=1}^{n} e(d_i). \end{equation}
The encoding of each word
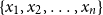 $\{x_1, x_2, \ldots, x_n\}$
of the input document
$\{x_1, x_2, \ldots, x_n\}$
of the input document
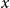 $x$
is also computed via SBERT so that it belongs to the same space as the encoding of the context:
$x$
is also computed via SBERT so that it belongs to the same space as the encoding of the context:
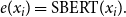 \begin{equation} e(x_i) = \text{SBERT}(x_i). \end{equation}
\begin{equation} e(x_i) = \text{SBERT}(x_i). \end{equation}
Note that since Transformers use sub-word tokenizers, words that comprise more than one token are represented by the average of the embeddings of their tokens.
The length of the context can affect the tagging process and, as a result, the quality of the generated summaries. We expect that using a larger context, such as a full document or a collection of documents, will provide a richer and more informative representation compared to a short input text, which may lack contextual depth. Our experimental results show that even with a large context, like a collection of documents, the performance remains high and is not negatively affected by the longer context length, demonstrating the versatility of our approach. At the same time, our method also performs well with shorter input contexts. This flexibility allows our approach to adapt effectively to different types and lengths of contexts.
3.2 Tagging
Given an input document
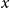 $x$
consisting of
$x$
consisting of
 $n$
words
$n$
words
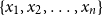 $\{x_1, x_2, \ldots, x_n\}$
and a context
$\{x_1, x_2, \ldots, x_n\}$
and a context
 $c$
, we first compute the cosine similarity between the encoding of each word
$c$
, we first compute the cosine similarity between the encoding of each word
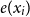 $e(x_i)$
and the encoding of the context
$e(x_i)$
and the encoding of the context
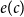 $e(c)$
. We will tag those words whose similarity to the context is higher than a threshold
$e(c)$
. We will tag those words whose similarity to the context is higher than a threshold
 $t$
.
$t$
.
To compute this threshold, we learn a Gaussian mixture model with two components from these similarities, under the assumption that one corresponds to the similarities of words that are relevant to the context and one to those that are irrelevant. A Gaussian mixture model
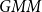 $GMM$
for each similarity
$GMM$
for each similarity
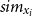 $sim_{x_i}$
between a word
$sim_{x_i}$
between a word
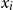 $x_i$
and the context
$x_i$
and the context
 $c$
can be defined as follows:
$c$
can be defined as follows:
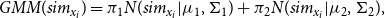 \begin{equation} GMM(sim_{x_i}) = \pi _1 N(sim_{x_i} \vert \mu _{1}, \Sigma _{1}) + \pi _2 N(sim_{x_i} \vert \mu _{2}, \Sigma _{2}), \end{equation}
\begin{equation} GMM(sim_{x_i}) = \pi _1 N(sim_{x_i} \vert \mu _{1}, \Sigma _{1}) + \pi _2 N(sim_{x_i} \vert \mu _{2}, \Sigma _{2}), \end{equation}
where
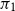 $\pi _1$
and
$\pi _1$
and
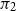 $\pi _2$
indicate the weight coefficients of each component and
$\pi _2$
indicate the weight coefficients of each component and
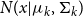 $N(x \vert \mu _{k}, \Sigma _{k})$
represents the probability density function with
$N(x \vert \mu _{k}, \Sigma _{k})$
represents the probability density function with
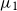 $\mu _{1}$
,
$\mu _{1}$
,
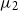 $\mu _{2}$
and
$\mu _{2}$
and
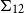 $\Sigma _{12}$
,
$\Sigma _{12}$
,
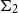 $\Sigma _{2}$
to be the mean and the variance of each component.
$\Sigma _{2}$
to be the mean and the variance of each component.
We then take
 $t$
the average of the means of the two Gaussian distributions as follows:
$t$
the average of the means of the two Gaussian distributions as follows:
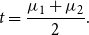 \begin{equation} t = \frac {\mu _{1} + \mu _{2} }{2}. \end{equation}
\begin{equation} t = \frac {\mu _{1} + \mu _{2} }{2}. \end{equation}
3.3 Training dataset
Large language models like Transformers typically require a large training dataset. Even though these datasets exist for general-purpose summarization, there is a lack of specific-task datasets with controllable attributes or additional information about different contexts. At the same time, existing controllable datasets with human annotations are very small (Bahrainian et al. Reference Bahrainian, Feucht, Eickhoff, Muresan, Nakov and Villavicencio2022; Zhang et al. Reference Zhang, Liu, Yang, Fang, Chen, Radev, Zhu, Zeng and Zhang2023), limiting their usefulness for training such models. Prior work for topic-controllable summarization relied mostly on synthetic datasets Krishna and Srinivasan (Reference Krishna and Srinivasan2018); Passali and Tsoumakas (Reference Passali and Tsoumakas2024). However, this raises concerns regarding the reliability of such datasets, which may potentially negatively impact the models’ performance on real-world datasets. For example, Krishna and Srinivasan (Reference Krishna and Srinivasan2018) generate a dataset for topic-controllable summarization by combining sentences from two distinct documents on different topics paired with a single summary derived from only one of them. While this approach can serve as a good baseline for evaluation, it may yield unreliable results or even be too simple for models to accurately distinguish between different topics. In practice, documents, such as news articles, will typically discuss relevant topics, making this setup unrealistic.
The proposed method overcomes these limitations by exploiting the ground truth summaries of existing summarization datasets like CNN/DailyMail (Hermann et al. Reference Hermann, Kocisky, Grefenstette, Espeholt, Kay, Suleyman and Blunsom2015), MultiNews (Fabbri et al. Reference Fabbri, Li, She, Li and Radev2019), and XSum (Narayan, Cohen, and Lapata, Reference Narayan, Cohen and Lapata2020) to tailor the summary generation towards this context. Following this process, the proposed method incorporates the inherent structure of any summarization dataset without the need for additional labeled data.
More specifically, given a summarization dataset that consists of documents accompanied by their respective target summaries, the proposed method uses these ground truth summaries as contexts and extracts their representation. The extracted context representation from the target summary is used to tag the most representative words of the input document. More specifically, given a document
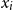 $x_i$
that consists of
$x_i$
that consists of
 $n$
words
$n$
words
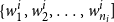 $\{w_1^i, w_2^i, \ldots, w_{n_i}^i]$
and its corresponding context
$\{w_1^i, w_2^i, \ldots, w_{n_i}^i]$
and its corresponding context
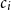 $c_i$
as extracted from the target summary, we define a similarity function
$c_i$
as extracted from the target summary, we define a similarity function
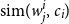 $\text{sim}(w_j^i, c_i)$
which measures the similarity between the word
$\text{sim}(w_j^i, c_i)$
which measures the similarity between the word
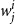 $w_j^i$
and the context
$w_j^i$
and the context
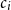 $c_i$
. This process is described by the function
$c_i$
. This process is described by the function
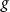 $g$
, where:
$g$
, where:
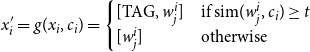 \begin{equation} x'_i = g(x_i, c_i) = \begin{cases} [\text{TAG}, w_j^i] & \text{if } \text{sim}(w_j^i, c_i) \geq t \\ [w_j^i] & \text{otherwise} \end{cases} \end{equation}
\begin{equation} x'_i = g(x_i, c_i) = \begin{cases} [\text{TAG}, w_j^i] & \text{if } \text{sim}(w_j^i, c_i) \geq t \\ [w_j^i] & \text{otherwise} \end{cases} \end{equation}
Here,
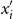 $x'_i$
represents the version of the document
$x'_i$
represents the version of the document
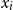 $x_i$
with specific words tagged with a special token [TAG], based on their similarity to the context exceeding the threshold
$x_i$
with specific words tagged with a special token [TAG], based on their similarity to the context exceeding the threshold
 $t$
. The process of compiling the training dataset is shown in Figure 2.
$t$
. The process of compiling the training dataset is shown in Figure 2.
Training Dataset Creation. We exploit the ground truth summaries of existing large-scale summarization datasets to tailor the summary generation towards this context.
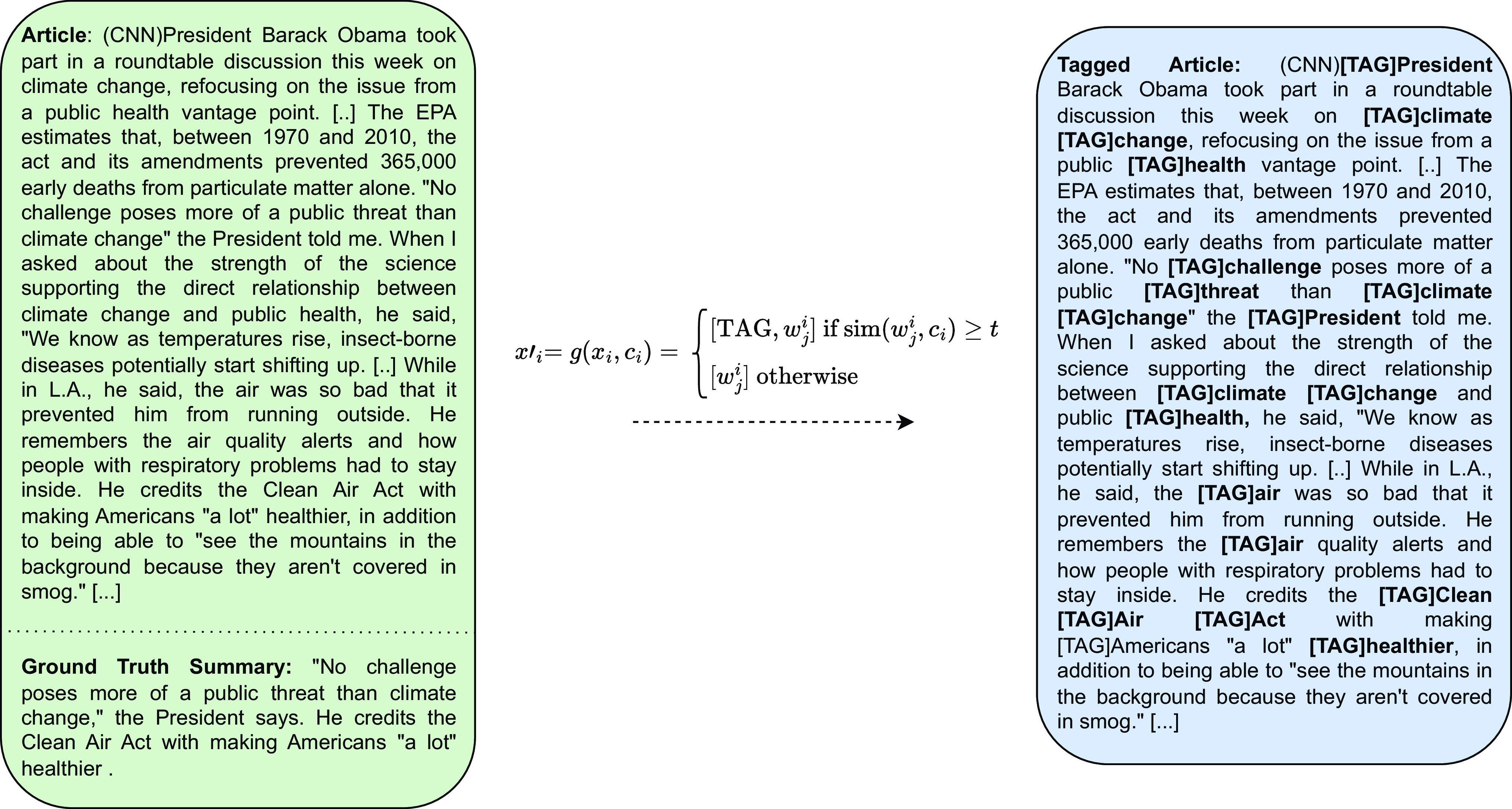
During training, the model learns to intuitively guide the summary generation towards the target summary by back-propagating the cross-entropy loss between the predicted and the ground truth summary. As a result, the model learns to intuitively give more attention to the words that are prepended with the special tag token. During inference, the model can direct the summary towards any textual representation by adjusting the position of control tokens.
4. Relevance measure
Existing controllable summarization models are prone to generating hallucinated content in order to ensure the presence of the user-requested topic in the summary. For example, CTRLsum might force the generation of the requested topic in the summary regardless of its relevance to the input document, leading to unfaithful summaries with misleading information, as shown in Table 1.
The evaluation of such models typically includes metrics that simply count how many times the requested topic appears in the summary (He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022) or compute the similarity between the generated summary and the given topic (Passali and Tsoumakas Reference Passali and Tsoumakas2024). In this way, summaries that include the requested topic might get a high relevance score without being reliable and relevant to the input document.
To overcome this limitation, we propose an unsupervised relevance measure (REL) to evaluate how faithful the generated summaries are to the input document. REL builds on the assumption that if a summary is relevant to the input document, we expect that the sentence of the generated summary that is closest to the requested topic should be close to at least one sentence of the original document. In addition, it requires only the generated summary and the input document, so it can be easily used without the need for ground truth summaries.
REL consists of the following steps: First, given a generated summary
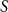 $S$
, we extract the sentence from the summary that is closest to the requested topic. Then, REL is computed as the maximum of all the similarities between the selected sentence representation and each of the sentence representations of the original document.
$S$
, we extract the sentence from the summary that is closest to the requested topic. Then, REL is computed as the maximum of all the similarities between the selected sentence representation and each of the sentence representations of the original document.
More specifically, REL is computed as follows:
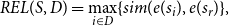 \begin{equation} REL(S, D) = \max _{i \in D} \{sim(e(s_i), e(s_r)\}, \end{equation}
\begin{equation} REL(S, D) = \max _{i \in D} \{sim(e(s_i), e(s_r)\}, \end{equation}
where
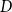 $D$
represents the set of sentences in document
$D$
represents the set of sentences in document
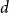 $d$
and
$d$
and
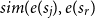 ${sim}(e(s_j), e(s_r)$
denotes the cosine similarity between the representation of the sentence
${sim}(e(s_j), e(s_r)$
denotes the cosine similarity between the representation of the sentence
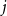 $j$
of document
$j$
of document
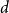 $d$
and the sentence
$d$
and the sentence
 $r$
from summary
$r$
from summary
 $s$
. The sentence
$s$
. The sentence
 $r$
is defined as
$r$
is defined as
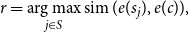 \begin{equation} r = \underset {j \in S}{\arg \max } \operatorname {sim}(e(s_j), e(c)), \end{equation}
\begin{equation} r = \underset {j \in S}{\arg \max } \operatorname {sim}(e(s_j), e(c)), \end{equation}
where
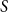 $S$
represents the set of sentences in a summary
$S$
represents the set of sentences in a summary
 $s$
and
$s$
and
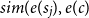 ${sim}(e(s_j), e(c)$
denotes the cosine similarity between the representation of the sentence
${sim}(e(s_j), e(c)$
denotes the cosine similarity between the representation of the sentence
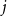 $j$
of summary
$j$
of summary
 $s$
and the context
$s$
and the context
 $c$
.
$c$
.
A high REL score indicates that the generated summary is semantically close to the document, while a lower REL score is a strong indicator that the generated summary might contain content that is not reliable. In cases where more than one sentence is semantically close to the context, REL considers the most relevant one and still can provide an indicator of the reliability of the summary. However, note that the proposed metric is not intended to replace existing metrics for summarization, such as ROUGE score, but rather to serve as an additional indicator of the reliability of a summary in relation to the provided context. Exploring alternative variations of the metric (e.g., incorporating multiple relevant sentences) is left for future research.
5. Empirical evaluation
This section presents the results of the empirical evaluation of the proposed method. First, we provide details about the experimental setup, and then we present and discuss the experimental and human evaluation results.
5.1 Experimental setup
In this subsection, we present the datasets that were used for the evaluation of the proposed methods. Also, we provide details about the models and the training as well as discuss the evaluation metrics that we used.
5.1.1 Datasets
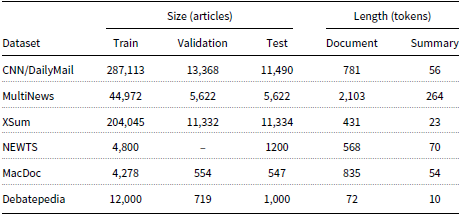
We use the six following abstractive summarization datasets for our experiments:
-
• CNN/DailyMail (Hermann et al. Reference Hermann, Kocisky, Grefenstette, Espeholt, Kay, Suleyman and Blunsom2015): a news summarization dataset that consists of more than 300K articles and summaries from CNN and DailyMail news sources. We use the non-anonymized version 3.0.0 of the dataset.
-
• MultiNews (Fabbri et al. Reference Fabbri, Li, She, Li and Radev2019): a summarization dataset with more than 56K news articles accompanied by human-written summaries from more than 1,500 websites.
-
• XSum (Narayan et al. Reference Narayan, Cohen and Lapata2020): a news summarization dataset with more than 200K articles and human-written summaries collected from the BBC website.
-
• NEWTS (Bahrainian et al. Reference Bahrainian, Feucht, Eickhoff, Muresan, Nakov and Villavicencio2022): a human-annotated topic-controllable summarization dataset based on CNN/Dailymail. It consists of 6,000 article-summary pairs annotated with topics.
-
• MacDoc (Zhang et al. Reference Zhang, Liu, Yang, Fang, Chen, Radev, Zhu, Zeng and Zhang2023): a human-annotated controllable summarization dataset from the MacSum dataset. It is based on the CNN/DailyMail dataset and contains over 5,000 articles and human-written summary pairs with five different control attributes, including topic, among others.
-
• Debatepedia (Nema et al. Reference Nema, Khapra, Laha and Ravindran2017): a dataset that contains debate topics, including pros and cons arguments for 663 topic areas, in the form of triplets with a document, query, and summary. Each debate topic can include several queries that result in a dataset of 12,695 triplets.
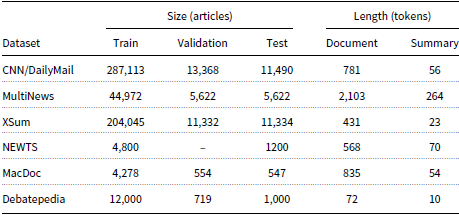
Some statistics regarding the size and length of the datasets are shown in Table 3.
Dataset statistics. Size is measured in articles for train, validation, and test set while the average length for documents and summaries is measured in tokens.
5.1.2 Context sources
We evaluate the proposed method under three different context scenarios: a) a topic mention, b) a document, and c) a collection of documents. To simulate these context representations, we employ Vox (Vox Media 2017), a topical news corpus with 23,024 articles divided into 185 thematic categories. We remove categories that are assigned to less than 30 documents as well as general categories (e.g., “The Latest,” “On Instagram,” “Vox Sentences,” “Podcasts,” “Episode of the Week,” “Reviews, ” “2016ish,” “First Person,” “Identities,” and “The Big Idea”). After preprocessing, we result in 61 out of 185 categories. We then use the filtered corpus to extract the different context representations. More specifically, in the case of the short text, we use the category itself. For a single document, we randomly select an article from the corpus, while for a collection of documents, we use all the documents that are assigned to the same category.
We use the test sets of the CNN/DailyMail, XSum, and MultiNews datasets to influence the summary according to the different context scenarios as extracted from the Vox Dataset. For each document in the dataset, we use the top-3 closest context representations for each scenario (short text, single document, document collection) to generate the tagging scheme for each document. For each document in the test set, we generate three new documents with different tagging schemes according to the different contexts. Note that since articles do not typically include highly diverse topics, we expect that the top-3 topics will be close to each other. For the Debatepedia dataset, we use the query as the context.
5.1.3 Models and training
The proposed method is built on top of two state-of-the-art summarization models, BART-large and PEGASUS-large. BART-large is a Transformer model with 12 encoder/decoder layers, a bidirectional encoder, and an autoregressive decoder. It consists of approximately 406 M parameters. PEGASUS-large is another Transformer model with 16 encoder/decoder layers and consists of more than 560 M parameters. To compare the performance of the proposed method against state-of-the-art models, we also employ a variety of LLMs, including GPT-3.5, GPT-4, LLaMA-3 8B, Mistral 7B, and Claude v2. For all the LLMs, we set the temperature to 0 for reproducibility of the experiments. Following prior work on topic-controllable summarization by Yang et al. (Reference Yang, Li, Zhang, Chen and Cheng2023), we use the following prompt: ”Summarize this article with respect to Aspect [Aspect]. Write directly the summary.”
To extract all the embedding-based representations, we use the multi-qa-distilbert-cos-v1, a lightweight DistillBERT model as introduced by Sentence Transformers Reimers and Gurevych (Reference Reimers and Gurevych2019). We use the Hugging Face (Wolf et al. Reference Wolf, Debut, Sanh, Chaumond, Delangue, Moi, Cistac, Rault, Louf, Funtowicz, Davison, Shleifer, von Platen, Ma, Jernite, Plu, Xu, Le Scao, Gugger, Drame, Lhoest and Rush2020) implementation for all the models.
We fine-tune both summarization models with a batch size set to 6 and a learning rate set to 3e-05, following He et al. (Reference He, Kryscinski, McCann, Rajani and Xiong2022). Both BART-large and PEGASUS-large were trained for 150,000 steps with early stopping on the validation set, as they typically converged before reaching this limit. Note that further fine-tuning or extensive hyperparameter searching could lead to better performance. All training experiments were conducted on an NVIDIA T4 Tensor 16 GB GPU using Google Colab. For the inference of LLMs, we used the AWS Amazon Bedrock service, while the GPT models were accessed via the OpenAI API.
The evaluation results include the following models:
-
• BART (Lewis et al. Reference Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov and Zettlemoyer2020), the vanilla BART model, based on the BART-large architecture, without controllable attributes.
-
• PEGASUS (Zhang et al. Reference Zhang, Zhao, Saleh and Liu2020a), the vanilla PEGASUS model, based on PEGASUS-large architecture, without controllable attributes.
-
•
 $BART_{tag}$
model, which is based on the BART-large architecture.
$BART_{tag}$
model, which is based on the BART-large architecture. -
•
$PEGASUS_{tag}$
model, which is based on the PEGASUS-large architecture. -
• CTRLsum (He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022), a controllable summarization model fine-tuned on the CNN/DailyMail dataset that works by prepending the requested entity to the input document.
-
• BART-FT (Su et al. Reference Su, Yu and Fung2021), a BART model for query-focused summarization that works by concatenating the query with the document using a special [SEP] token.
-
• GPT-3.5 (OpenAI, 2022a), an LLM, developed by OpenAI, based on the GPT-3 architecture with 175 billion parameters.
-
• GPT-4 (OpenAI, 2023), an improved version of GPT-3.5, also developed by OpenAI, with 1.5 trillion parameters.
-
• LLaMA 3 (Dubey et al. Reference Dubey, Jauhri, Pandey, Kadian, Al-Dahle, Letman, Mathur, Schelten, Yang and Fan2024), a family of LLMs developed by Meta AI, with multiple versions of different parameters. In this setup, we use the 8 billion version.
-
• Mistral (Jiang et al. Reference Jiang, Sablayrolles, Mensch, Bamford, Chaplot, Casas, Bressand, Lengyel, Lample and Saulnier2023), an LLM developed by Mistral AI, with 7 billion parameters.
-
• Claude (Anthropic, 2024), an LLM, developed by Anthropic AI, with 130 billion parameters.
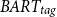
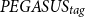
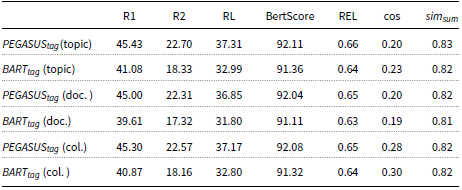
Experimental results on CNN/DailyMail dataset using different input context for a short text (topic), document (doc.), and collection of documents (col.). F-1 scores for ROUGE-1 (R1), ROUGE-2 (R2), and ROUGE-L (RL) are reported.
Examples of summaries generated by CTRLsum and the proposed
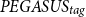 $PEGASUS_{tag}$
for different topics of the same document.
$PEGASUS_{tag}$
for different topics of the same document.

5.1.4 Evaluation metrics
We use the family of ROUGE (Lin, Reference Lin2004) metrics and BERTScore (Zhang et al. Reference Zhang, Kishore, Wu, Weinberger and Artzi2020b) for evaluating the quality of the generated summaries as well as the proposed REL metric to assess the reliability of the summary with respect to the input document. Since we do not have a ground truth summary for the different contexts, we calculate ROUGE with the target summary of the corresponding document. Even though ROUGE and BERTscore metrics are based on the target summary, they can provide an overview of whether the generated summaries are still in line with the general meaning of the input document. In addition, we report the cosine similarity (“cos”) between the generated summary and the requested topic to evaluate how close the generated summary is to the given context. The higher the cosine similarity, the closer the summary is to the given context. Also, we compute the variance (“
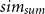 $sim_{sum}$
”) between the different summaries generated towards different contexts for the same input document. For calculating the variance, we compute the average cosine similarity between all the different pairs of the different generated summaries. A lower score indicates that the summaries have high variance, while a higher score indicates low variance with similar summaries.
$sim_{sum}$
”) between the different summaries generated towards different contexts for the same input document. For calculating the variance, we compute the average cosine similarity between all the different pairs of the different generated summaries. A lower score indicates that the summaries have high variance, while a higher score indicates low variance with similar summaries.
5.2 Results
This subsection provides the results of the experimental evaluation on different datasets. First, we discuss the results for the different textual contexts, including short (single word or phrase) and arbitrary textual contexts (document or collection of documents). Then, we proceed with a comparison with existing controllable summarization models such as CTRLsum (He et al. Reference He, Kryscinski, McCann, Rajani and Xiong2022), state-of-the-art LLMs, and query-focused models such as BART-FT (Su et al. Reference Su, Yu and Fung2021).
5.2.1 Short textual context
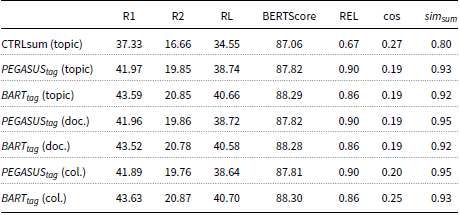
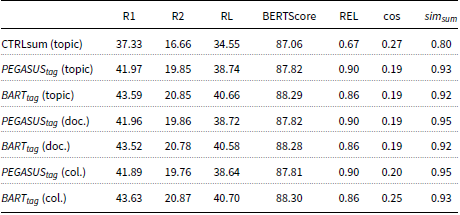
The results of the CNN/DailyMail test set for the different context scenarios are shown in Table 4. We notice that the average cosine similarity (cos) between the generated summaries and the requested short text for a single topic is similar for both the
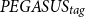 $PEGASUS_{tag}$
and
$PEGASUS_{tag}$
and
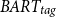 $BART_{tag}$
models (
$BART_{tag}$
models (
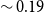 $\sim 0.19$
). Furthermore, the average similarity between the different summaries for the same document for both models is around 0.9, indicating that the models do generate slightly different summaries in different contexts. Note that since the top 3 topics that are nearest to the input document are typically similar to each other, we do not expect major changes between the different summaries.
$\sim 0.19$
). Furthermore, the average similarity between the different summaries for the same document for both models is around 0.9, indicating that the models do generate slightly different summaries in different contexts. Note that since the top 3 topics that are nearest to the input document are typically similar to each other, we do not expect major changes between the different summaries.
In addition, the evaluation results in Table 4 demonstrate a significantly higher cosine similarity for the CTRLsum model (0.29 compared to 0.19), along with a higher variance between the generated summaries. In addition, CTRLsum has a lower performance in terms of ROUGE and BERTscore metrics compared to the proposed models, which indicates that the generated summaries for the different topics might differ. On the other hand, these summaries might diverge from the general meaning of the input document. Despite the fact that the lower scores show a greater variance between the different summaries, the REL metric reveals a significant weakness in CTRLsum’s ability to generate relevant summaries with respect to the input document, in contrast to the proposed methods,
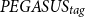 $PEGASUS_{tag}$
and
$PEGASUS_{tag}$
and
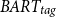 $BART_{tag}$
, which show significantly higher reliability. More specifically, a qualitative evaluation of the generated summaries shows that CTRLsum succeeds in achieving higher performance by forcing the generation of the requested topic in the output summary. Some indicative examples of this behavior are shown in Table 1 and 5.
$BART_{tag}$
, which show significantly higher reliability. More specifically, a qualitative evaluation of the generated summaries shows that CTRLsum succeeds in achieving higher performance by forcing the generation of the requested topic in the output summary. Some indicative examples of this behavior are shown in Table 1 and 5.
More specifically, we can see that CTRLsum forces the generation of the requested topic without ensuring the content validity of the summary. Thus, it can generate artificial content without preserving the document’s original meaning, resulting in unreliable summaries. For example, in Table 1 for both requested topics, Science & Health and Neuroscience, CTRLsum tends to generate inaccurate information, as shown in bold red text, that is not stated in the original document. The proposed
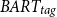 $BART_{tag}$
does not suffer from the same limitation. Similar conclusions can be drawn for the
$BART_{tag}$
does not suffer from the same limitation. Similar conclusions can be drawn for the
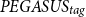 $PEGASUS_{tag}$
model, as shown in Table 5. Again, CTRLsum generates inaccurate information by imposing the requesting topic in the summarization output for both criminal justice and gun violence topics. In contrast, the proposed
$PEGASUS_{tag}$
model, as shown in Table 5. Again, CTRLsum generates inaccurate information by imposing the requesting topic in the summarization output for both criminal justice and gun violence topics. In contrast, the proposed
 $PEGASUS_{tag}$
model generates summaries that are both topic-aware and provide reliable and accurate information according to the input document.
$PEGASUS_{tag}$
model generates summaries that are both topic-aware and provide reliable and accurate information according to the input document.
Experimental results on the MultiNews dataset using different input context for a short text (topic), document (doc.), and collection of documents (col.). F-1 scores for ROUGE-1 (R1), ROUGE-2(R2), and ROUGE-L (RL) are reported.
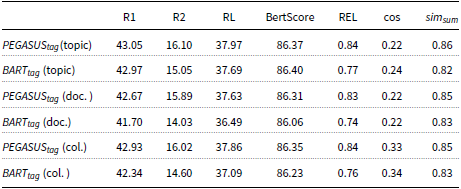
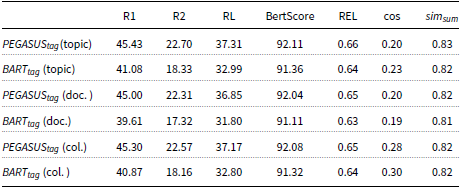
Experimental results on the XSum dataset using different input context for a short text (topic), document (doc.), and collection of documents (col.). F-1 scores for ROUGE-1 (R1), ROUGE-2(R2), and ROUGE-L (RL) are reported.
5.2.2 Arbitrary textual context
In contrast to existing controllable models like CTRLsum, the proposed method is not restricted to a specific word or entity for controlling the output summary. This means that the proposed method can also work effectively with a whole document or a collection of documents for guiding the summary generation, as shown in the second and third sections of Table 4. Note that we do not report results for CTRLsum in these sections since it cannot readily work with this type of information. More specifically, CTRLsum receives the input by prepending the requested topic in the original document. Thus, it is limited to single words or phrases since it is not possible to fit an arbitrary textual context into the input of the model. In Table 4, we notice that
 $BART_{tag}$
achieves a high cosine similarity (0.25) when more information is available (collection of documents) compared to a single document (0.13) or a single topic (0.19), while the REL metric remains high for both cases (0.86). Both the proposed models (
$BART_{tag}$
achieves a high cosine similarity (0.25) when more information is available (collection of documents) compared to a single document (0.13) or a single topic (0.19), while the REL metric remains high for both cases (0.86). Both the proposed models (
 $BART_{tag}$
and
$BART_{tag}$
and
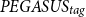 $PEGASUS_{tag}$
) achieve a high REL score, but BART seems to outperform
$PEGASUS_{tag}$
) achieve a high REL score, but BART seems to outperform
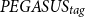 $PEGASUS_{tag}$
in terms of
$PEGASUS_{tag}$
in terms of
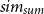 $sim_{sum}$
and cos metrics.
$sim_{sum}$
and cos metrics.
The same conclusions can be drawn when evaluating different datasets, as shown in Table 6 and 7, where the results on the MultiNews and XSum datasets are reported, respectively. More specifically, for the MultiNews dataset, we observe that the
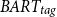 $BART_{tag}$
achieves again the higher cosine similarity (0.35) in the collection of documents setting compared to the single document (0.22) and single topic (0.24) settings. In addition, for the XSum dataset, the higher cosine similarity (0.30) is achieved with the
$BART_{tag}$
achieves again the higher cosine similarity (0.35) in the collection of documents setting compared to the single document (0.22) and single topic (0.24) settings. In addition, for the XSum dataset, the higher cosine similarity (0.30) is achieved with the
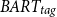 $BART_{tag}$
in the collection of documents setting.
$BART_{tag}$
in the collection of documents setting.
The higher variance that is observed between the different summaries for both the XSum and MultiNews datasets compared to the CNN/DailyMail dataset (average similarity
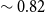 $\sim 0.82$
compared to
$\sim 0.82$
compared to
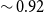 $\sim 0.92$
) confirms the effectiveness of the proposed method to generate diverse summaries according to the different topics.
$\sim 0.92$
) confirms the effectiveness of the proposed method to generate diverse summaries according to the different topics.
5.2.3 Topic-controllable summarization
We evaluate the proposed method (
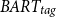 $BART_{tag}$
) on two topic-controllable summarization datasets, MacDoc (Zhang et al. Reference Zhang, Liu, Yang, Fang, Chen, Radev, Zhu, Zeng and Zhang2023) and NEWTS (Bahrainian et al. Reference Bahrainian, Feucht, Eickhoff, Muresan, Nakov and Villavicencio2022), and compare its performance with state-of-the-art models. Unlike the previous datasets (CNN/DailyMail, XSum, and MultiNews), where ground truth summaries were used to simulate context, both MacDoc and NEWTS contain human-annotated summaries explicitly annotated for different topics. In this experiment, ROUGE scores can serve as a strong indicator of the topical focus of the summary since they can measure the quality of the summaries in relation to the topic-oriented reference summaries. Therefore, higher ROUGE scores indicate better performance in generating accurate and relevant summaries that align with the requested topic.
$BART_{tag}$
) on two topic-controllable summarization datasets, MacDoc (Zhang et al. Reference Zhang, Liu, Yang, Fang, Chen, Radev, Zhu, Zeng and Zhang2023) and NEWTS (Bahrainian et al. Reference Bahrainian, Feucht, Eickhoff, Muresan, Nakov and Villavicencio2022), and compare its performance with state-of-the-art models. Unlike the previous datasets (CNN/DailyMail, XSum, and MultiNews), where ground truth summaries were used to simulate context, both MacDoc and NEWTS contain human-annotated summaries explicitly annotated for different topics. In this experiment, ROUGE scores can serve as a strong indicator of the topical focus of the summary since they can measure the quality of the summaries in relation to the topic-oriented reference summaries. Therefore, higher ROUGE scores indicate better performance in generating accurate and relevant summaries that align with the requested topic.
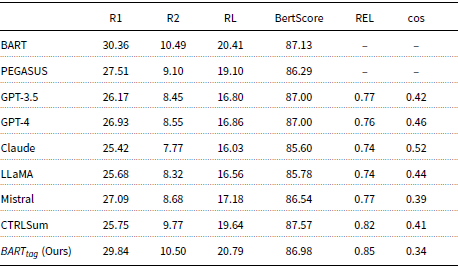
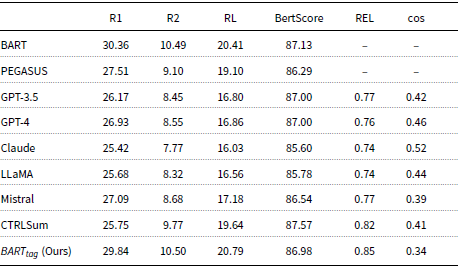
The results on the MacDoc dataset are presented in Table 8. We report the performance of both topic-controllable methods and baseline models (BART and PEGASUS) that do not incorporate topic control. It is important to note that the baseline PEGASUS and BART models, without topic control, generate the same summary for each topic, as they are not designed to adapt to different topics within the same document. Overall, we observe that the proposed
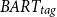 $BART_{tag}$
model outperforms all other methods in terms of ROUGE scores (R1: 29.84, R2: 10.50, RL: 20.79), demonstrating its effectiveness in generating summaries that not only align with the requested topic but also maintain high overall quality. This indicates that the proposed method can successfully shift the topic of the generated summary. At the same time, the proposed method achieves the highest REL score (0.85), showing that the summaries are trustworthy and accurately reflect the input document’s content.
$BART_{tag}$
model outperforms all other methods in terms of ROUGE scores (R1: 29.84, R2: 10.50, RL: 20.79), demonstrating its effectiveness in generating summaries that not only align with the requested topic but also maintain high overall quality. This indicates that the proposed method can successfully shift the topic of the generated summary. At the same time, the proposed method achieves the highest REL score (0.85), showing that the summaries are trustworthy and accurately reflect the input document’s content.
Experimental results on the MacDoc dataset. F-1 scores for ROUGE-1 (R1), ROUGE-2(R2), and ROUGE-L (RL) are reported.
Although the cosine similarity with the topic for
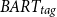 $BART_{tag}$
(0.34) is lower compared to other models, such as Claude (0.52), this is paired with a significantly higher REL metric and ROUGE scores. This suggests that while the proposed method may not align as closely with the topic in terms of cosine similarity, it produces more reliable and accurate summaries, as shown by the higher ROUGE and REL scores. Additionally, we observe that Claude’s higher cosine similarity (0.52) is accompanied by a lower reliability score (0.74 compared to 0.85) and lower overall ROUGE scores (25.42 compared to 29.84 R1). This indicates that although Claude’s summaries may be semantically closer to the requested topic, they are less aligned with the target summaries. Overall, there appears to be a correlation between ROUGE scores and the reliability metric, suggesting that the proposed REL metric is a trustworthy indicator of the topical focus and accuracy of the summaries.
$BART_{tag}$
(0.34) is lower compared to other models, such as Claude (0.52), this is paired with a significantly higher REL metric and ROUGE scores. This suggests that while the proposed method may not align as closely with the topic in terms of cosine similarity, it produces more reliable and accurate summaries, as shown by the higher ROUGE and REL scores. Additionally, we observe that Claude’s higher cosine similarity (0.52) is accompanied by a lower reliability score (0.74 compared to 0.85) and lower overall ROUGE scores (25.42 compared to 29.84 R1). This indicates that although Claude’s summaries may be semantically closer to the requested topic, they are less aligned with the target summaries. Overall, there appears to be a correlation between ROUGE scores and the reliability metric, suggesting that the proposed REL metric is a trustworthy indicator of the topical focus and accuracy of the summaries.
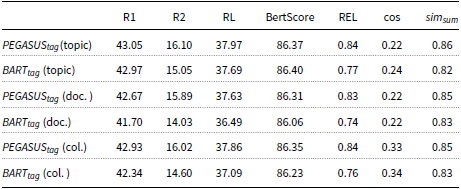
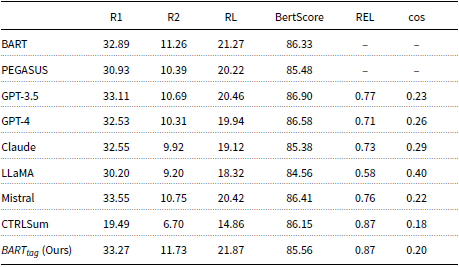
Similar conclusions can be drawn from the results on the NEWTS dataset (see Table 9). The proposed
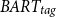 $BART_{tag}$
model consistently achieves the highest ROUGE scores across all the models. While Mistral achieves a similar ROUGE-1 score to
$BART_{tag}$
model consistently achieves the highest ROUGE scores across all the models. While Mistral achieves a similar ROUGE-1 score to
 $BART_{tag}$
(33.55 vs. 33.27), our model outperforms Mistral in terms of ROUGE-2 and ROUGE-L scores (11.73 R2 and 21.87 RL), indicating a higher overall quality of the summaries. Moreover,
$BART_{tag}$
(33.55 vs. 33.27), our model outperforms Mistral in terms of ROUGE-2 and ROUGE-L scores (11.73 R2 and 21.87 RL), indicating a higher overall quality of the summaries. Moreover,
 $BART_{tag}$
also achieves the highest REL score (0.87), confirming the trustworthiness and accuracy of the generated summaries. In contrast, while CTRLSum achieves the same high REL score (0.87), it significantly underperforms in terms of ROUGE-1 scores (19.49 compared to 33.27 R1).
$BART_{tag}$
also achieves the highest REL score (0.87), confirming the trustworthiness and accuracy of the generated summaries. In contrast, while CTRLSum achieves the same high REL score (0.87), it significantly underperforms in terms of ROUGE-1 scores (19.49 compared to 33.27 R1).
Experimental results on the NEWTS dataset. F-1 scores for ROUGE-1 (R1), ROUGE-2(R2), and ROUGE-L (RL) are reported.
Finally, we observe that models like LLaMA, which show a higher cosine similarity with the topic (0.40), demonstrate low REL and ROUGE scores. This pattern suggests that while these models generate summaries that appear closely aligned with the requested topic, those might not be reliable or well-aligned with the target summaries.
5.2.4 Query-focused summarization
We also compare the proposed method with a query-focused summarization model fine-tuned on the Debatepedia dataset, as shown in Table 10. Similar performance is observed for both models (
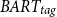 $BART_{tag}$
and BART-FT), with the latter slightly outperforming the
$BART_{tag}$
and BART-FT), with the latter slightly outperforming the
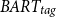 $BART_{tag}$
in terms of ROUGE and BERTScore. More specifically, both
$BART_{tag}$
in terms of ROUGE and BERTScore. More specifically, both
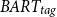 $BART_{tag}$
and BART-FT achieve
$BART_{tag}$
and BART-FT achieve
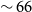 $\sim 66$
ROUGE-1 score, with the BART-FT slightly outperforming
$\sim 66$
ROUGE-1 score, with the BART-FT slightly outperforming
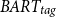 $BART_{tag}$
in ROUGE-2 (54.71 compared to 53.79) and ROUGE-L (65.39 compared to 64.68). Also, both REL and cosine similarity metrics yield the same results, indicating a close distance between the generated summary and the given query. More specifically, both models achieve a
$BART_{tag}$
in ROUGE-2 (54.71 compared to 53.79) and ROUGE-L (65.39 compared to 64.68). Also, both REL and cosine similarity metrics yield the same results, indicating a close distance between the generated summary and the given query. More specifically, both models achieve a
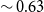 $\sim {0.63}$
REL score and 0.51 cosine similarity. These results demonstrate that the proposed method is more effective when more information is available, for example when a collection of documents is available for extracting the context representation. However, it is worth noting that query-focused summarization is a slightly different task from topic-controllable summarization. While queries can represent topics in some cases, there are scenarios, such as dealing with an arbitrary textual context, that is a collection of articles from a user’s history, where the topic cannot be easily expressed as a query. In these situations, the challenge is to control the summarization output according to a broader and more complex input; thus, query-focused summarization approaches cannot readily be applied.
$\sim {0.63}$
REL score and 0.51 cosine similarity. These results demonstrate that the proposed method is more effective when more information is available, for example when a collection of documents is available for extracting the context representation. However, it is worth noting that query-focused summarization is a slightly different task from topic-controllable summarization. While queries can represent topics in some cases, there are scenarios, such as dealing with an arbitrary textual context, that is a collection of articles from a user’s history, where the topic cannot be easily expressed as a query. In these situations, the challenge is to control the summarization output according to a broader and more complex input; thus, query-focused summarization approaches cannot readily be applied.
Experimental results on the Debatepedia dataset with the given query used as the available context. F-1 scores for ROUGE-1 (R1), ROUGE-2(R2), and ROUGE-L (RL) are reported.

5.3 Human evaluation
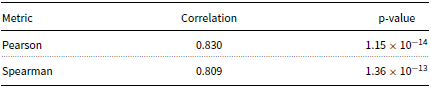
To validate the proposed REL metric, we conducted a human evaluation study. In this study, each participant was presented with the original document and its corresponding summary and asked to rate the summary’s reliability on a scale from 1 (not reliable) to 10 (highly reliable). Each participant evaluated three different summaries, resulting in a total of 33 summaries rated by 29 undergraduate students. Each summary was annotated by an average of 1.64 participants. To ensure the reliability of the data, we excluded annotators where ratings differed by more than 4 points from the mean. Inter-annotator agreement, measured with Krippendorff’s alpha coefficient (Krippendorff, Reference Krippendorff2018) with ordinal weights, was 0.852, indicating a high level of consistency among annotators.
The primary goal of this evaluation was to determine how well the REL metric aligns with human judgments. We measured the correlation between the evaluation results and the REL scores using both Spearman’s and Pearson’s correlation coefficients. The results reveal a strong correlation with Spearman’s correlation coefficient of 0.83 and Pearson’s correlation coefficient of 0.809, as shown in Table 11. The correlation coefficients being very close to 1 support the REL metric’s effectiveness in capturing the reliability of summaries as perceived by human annotators. In addition, both very low p-values (p
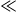 $\ll$
0.01) indicate a statistically significant correlation between the REL metric and human annotations.
$\ll$
0.01) indicate a statistically significant correlation between the REL metric and human annotations.
Correlation Between REL Metric and Human Ratings.
6. Conclusions and future work
In this work, we proposed a controllable summarization method for guiding the summary generation towards arbitrary textual context from a short text, like a topic or an entity, to a document or a collection of documents. The proposed method works by first extracting a BERT-based representation of the given context that is then used to tag the most representative words of the input document. The main advantage of our method is that it can exploit all the different types of textual information beyond a short text, such as a document or a collection of documents, in order to direct the focus of the summary generation.
In addition, our findings revealed that existing controllable summarization methods are prone to generating artificial content in order to ensure the presence of the requested topic in the generated summary. To detect this behavior, we proposed an appropriate evaluation metric to measure the reliability of the topic-oriented sentences of the summary with respect to the input document. We also conducted a human evaluation study to confirm the validity of the proposed metric. The experimental results demonstrated that our method can effectively shift the generation towards the given context under different zero-shot scenarios while surpassing state-of-the-art LLMs in preserving the quality and reliability of the generated summaries.
Even though this work is focused on news summarization, it can also be easily applied in other domains. An interesting future research direction would be to employ the proposed method for scientific article summarization to obtain personalized summaries based on the related papers that a researcher is interested in. In addition, variations of the proposed metric could be explored by incorporating multiple sentences or using an average to compute the relevance of the summary.
Acknowledgements
AWS resources were provided by the National Infrastructures for Research and Technology GRNET and funded by the EU Recovery and Resiliency Facility.
Competing interests
The authors report no conflict of interest.







 Open access
Open access