We partner with a secure submission system to handle manuscript submissions.
Please note:
You will need an account for the submission system, which is separate to your Cambridge Core account. For login and submission support, please visit the
submission and support pages.
Please review this journal's author instructions, particularly the
preparing your materials
page, before submitting your manuscript.
Click Proceed to submission system to continue to our partner's website.
To save this undefined to your undefined account, please select one or more formats and confirm that you agree to abide by our usage policies. If this is the first time you used this feature, you will be asked to authorise Cambridge Core to connect with your undefined account.
Find out more about saving content to .
To send this article to your Kindle, first ensure no-reply@cambridge.org is added to your Approved Personal Document E-mail List under your Personal Document Settings on the Manage Your Content and Devices page of your Amazon account. Then enter the ‘name’ part of your Kindle email address below. Find out more about sending to your Kindle.
Find out more about saving to your Kindle.
Note you can select to save to either the @free.kindle.com or @kindle.com variations. ‘@free.kindle.com’ emails are free but can only be saved to your device when it is connected to wi-fi. ‘@kindle.com’ emails can be delivered even when you are not connected to wi-fi, but note that service fees apply.
Large-scale assessment data typically include numerous variables, often affected by missing values. Motivated by the challenges arising in this framework, we extend the knockoffs method for selecting predictors to settings with missing values. Our proposal relies on a preliminary phase of multiple imputation (MI) of missing values. Each imputed dataset is then processed using a suitable knockoff filter. We evaluate the performance of the proposed method through simulation studies, showing satisfactory results consistent with a recently advocated cutting-edge method. We apply the method to large-scale assessment data collected by INVALSI on test scores of Italian students in grade 5, including many background variables. This case study is challenging, as most predictors have unordered categories, a setting not considered by traditional knockoff methods. In addition, some of the key predictors are affected by missing values. Our proposal to implement the knockoffs method within an MI framework is feasible, flexible, and effective.
This article develops an analysis pipeline for quantifying and relating mouth shape variation to the emotions perceived from facial expressions. We use open-source data that contains ratings from 802 fairgoers on 27 smile-like expressions. Each rater was given a list of seven emotions (happy, sad, anger, contempt, fear, surprise, and disgust) and asked to select all of the words that best described the facial expression. To develop a generalizable method for quantifying mouth shape variation, we leverage statistical shape analysis techniques to parameterize each mouth’s shape in terms of 30 systematically placed landmarks that outline the upper and lower lips. Furthermore, we demonstrate that a three-dimensional representation of these landmark coordinates produces an interpretable feature set that outperforms the original and full-dimensional feature sets in terms of predictive performance. To connect the mouth shape features to the emotion ratings, we develop a nonparametric multinomial regression model that is capable of shrinkage and selection with high-dimensional predictors. Our results demonstrate that the proposed method can produce easily interpretable model predictions that enhance our understanding of the nature in which subtle variations in mouth shape affect the perception of a facial expression.
Traditional perceptual models are ill-equipped for the high-dimensional data, such as text embeddings, central to modern psychology and AI. We introduce the double machine learning lens model, a framework that utilizes machine learning to handle such data. We applied this model to analyze how a modern AI and human perceivers judge social class from 9,513 aspirational essays written by 11-year-olds in 1969. A systematic comparison of 45 analytical approaches revealed that regularized linear models using dimensionality-reduced language embeddings significantly outperformed traditional dictionary-based methods and more complex non-linear models. Our top model accurately predicted human $(R^{2}_{CV} =0.61)$ and AI $(R^{2}_{CV} =0.56)$ social class perceptions, capturing over 85% of the total accuracy. These results suggest that “unmodeled knowledge” in perception may be an artifact of insufficient measurement tools rather than an unmeasurable intuitive process. We find that both AI and humans use many of the same textual cues (e.g., grammar, occupations, and cultural activities), only a subset of which are valid. Both appear to amplify subtle, real-world patterns into powerful, yet potentially discriminatory heuristics, where a small difference in actual social class creates a large difference in perception.
Longitudinal mental health assessments in mobile health (mHealth) settings are useful for monitoring subjects’ mental health statuses but are often difficult to analyze because they generally appear on an ordinal scale and at unequal time intervals. In this article, we explore the use of Gaussian processes (GPs) and hierarchical modeling techniques to understand mental health trajectories based on repeated multi-item mHealth surveys on a Likert scale. We introduce the GP model for health trajectories, which is based on item response theory. In the study of trajectories, a subject’s longitudinal collection of mHealth responses can be thought of as a single high-dimensional observation. We show how the GP is flexible enough to capture trends in individual trajectories even with the challenges associated with high-dimensional data. We also demonstrate how basis splines can be used to effectively capture nonlinear trends in the mean function of the GP. The high-dimension and ordinal nature of the data often make sampling from the posterior distribution in a Bayesian setting too slow to be practical. We show that using a Hilbert approximation for the GP trajectories can facilitate efficient sampling. We apply these methods to a longitudinal study that monitored college students’ self-esteem.
Psychological research has long centered around questionnaire assessments, but now digital devices, especially smartphones, enable the collection of real-world behavioral data through mobile sensing. While this data collection method offers unique opportunities, it also introduces new methodological challenges, as mobile-sensing data are highly complex and high in dimensionality (i.e., timestamped events with millisecond resolution), requiring advanced preprocessing to derive psychologically meaningful variables. This article highlights these challenges by reviewing the current state of data preprocessing based on app usage logs from smartphones. Afterward, it presents three preprocessing cases that vary in complexity across the dimensions of data enrichment—which involves adding context to raw data by integrating information from external and internal sources (including ecological momentary assessments)—and data aggregation—which entails summarizing data in different ways, from basic descriptive statistics to sophisticated machine-learning models. For each case, potential pitfalls are identified, and extensions are discussed to refine our preprocessing pipelines and accommodate different data types and research questions. By outlining these preprocessing strategies, this manuscript demonstrates the rich potential of mobile-sensing data for extracting nuanced behavioral variables beyond simple person-level summaries and aims to inspire the development of more advanced research questions based on sensing data.
The growing use of computer-based assessments has produced complex process data that capture learners’ cognitive and behavioral processes in real time. Among these, eye-tracking data provide rich temporal information on how individuals attend to and process visual information during problem solving. Yet, analyzing such high-dimensional, temporally dependent, and multimodal data remains a methodological challenge. This study introduces a two-component data-analytic framework (DAK) for integrating and interpreting structured and unstructured data in educational assessments. The first component employs a time-aware long short-term memory Autoencoder to extract latent features representing dynamic visual attention patterns. The model extends conventional architectures by incorporating fixation duration and elapsed time between actions, using a data-driven temporal decay function, and optimizing a multi-target reconstruction objective. The second component integrates these extracted features through clustering, categorical data analyses, and mixed-effects modeling to generate construct-relevant validity evidence for test-taking and learning behaviors. We demonstrate the DAK using structured scores and unstructured eye-tracking data from a spatial rotation learning program. Results reveal distinct behavioral patterns linked to test performance and intervention effectiveness, highlighting the potential of multimodal process data to advance psychometric modeling and instrument design.
In psychometric sciences, such as social or behavioral sciences, and, similarly, in medical sciences, it is increasingly common to deal with longitudinal data organized as high-dimensional multidimensional arrays, also known as tensors. Within this framework, the time-continuous property of longitudinal data often implies a smooth functional structure on one of the tensor modes. To help researchers investigate such data, we introduce a new tensor decomposition approach based on the PARAFAC decomposition. Our approach allows researchers to represent a high-dimensional functional tensor as a low-dimensional set of functions and feature matrices. Furthermore, to capture the underlying randomness of the statistical setting more efficiently, we introduce a probabilistic latent model in the decomposition. A covariance-based block-relaxation algorithm is derived to obtain estimates of model parameters. Thanks to the covariance formulation of the solving procedure and thanks to the probabilistic modeling, the method can be used in sparse and irregular sampling schemes, making it applicable in numerous settings. Our approach is applied in the psychometric setting to help characterize multiple neurocognitive scores observed over time in the Alzheimer’s Disease Neuroimaging Initiative study. Finally, intensive simulations show a notable advantage of our method in reconstructing tensors.
Understanding spatial navigation and memory formation is critical to exploring how humans learn and adapt in complex environments. To investigate these processes, we conducted an experiment using the Minecraft Memory and Navigation Task, collecting detailed three-dimensional (3D) path data in a virtual open-world setting. Statistically, we developed a novel methodology to convert complex high-dimensional 3D movement data into functional representations, enabling standardized comparisons and analyses across participants and environments. We applied techniques such as functional clustering and regression to identify navigation patterns and their relationships with cognitive map development and memory retention. Our analysis uncovered two significant insights: first, participants who adopted moderately exploratory behaviors during training demonstrated superior retention of object locations; second, inefficient navigation strategies were strongly linked to poorer spatial memory and navigation performance. These findings highlight the effectiveness of our methodology in advancing the study of navigation behaviors and cognitive processes in dynamic 3D environments.
Neuroimaging studies, such as the Human Connectome Project (HCP), often collect multifaceted data to study the human brain. However, these data are often analyzed in a pairwise fashion, which can hinder our understanding of how different brain-related measures interact. In this study, we analyze the multi-block HCP data using data integration via analysis of subspaces (DIVAS). We integrate structural and functional brain connectivity, substance use, cognition, and genetics in an exhaustive five-block analysis. This gives rise to the important finding that genetics is the single data modality most predictive of brain connectivity, outside of brain connectivity itself. Nearly 14% of the variation in functional connectivity (FC) and roughly 12% of the variation in structural connectivity (SC) is attributed to shared spaces with genetics. Moreover, investigations of shared space loadings provide interpretable associations between particular brain regions and drivers of variability. Novel Jackstraw hypothesis tests are developed for the DIVAS framework to establish statistically significant loadings. For example, in the (FC, SC, and substance use) subspace, these novel hypothesis tests highlight largely negative functional and structural connections suggesting the brain’s role in physiological responses to increased substance use. Our findings are validated on genetically relevant subjects not studied in the main analysis.
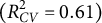 and AI $(R^{2}_{CV} =0.56)$
and AI $(R^{2}_{CV} =0.56)$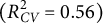 social class perceptions, capturing over 85% of the total accuracy. These results suggest that “unmodeled knowledge” in perception may be an artifact of insufficient measurement tools rather than an unmeasurable intuitive process. We find that both AI and humans use many of the same textual cues (e.g., grammar, occupations, and cultural activities), only a subset of which are valid. Both appear to amplify subtle, real-world patterns into powerful, yet potentially discriminatory heuristics, where a small difference in actual social class creates a large difference in perception.
social class perceptions, capturing over 85% of the total accuracy. These results suggest that “unmodeled knowledge” in perception may be an artifact of insufficient measurement tools rather than an unmeasurable intuitive process. We find that both AI and humans use many of the same textual cues (e.g., grammar, occupations, and cultural activities), only a subset of which are valid. Both appear to amplify subtle, real-world patterns into powerful, yet potentially discriminatory heuristics, where a small difference in actual social class creates a large difference in perception.