


1. Introduction
Our main question is what role computers can play in expanding our purely rational capacities and purely rational knowledge. When we learn a fact from a computer, should we think of ourselves as merely having done an experiment of sorts and thus having acquired only empirical knowledge? Or can learning something from a computer sometimes expand our nonempirical (i.e., our purely rational or a priori) knowledge?
The obvious case to focus on is mathematics. Suppose a computer tells us that some mathematical claim is true. In the right circumstances, might we then know that mathematical fact on purely rational (i.e., a priori) grounds? Presumably, the answer to this question will depend on what sort of computer we are talking about. We thus phrase our question as follows:
Main Question: Are there situations in which we can acquire a priori knowledge of a mathematical fact
 $X$
purely on the basis of a computer outputting the claim that
$X$
purely on the basis of a computer outputting the claim that
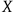 $X$
is true? If so, what sorts of situations are these?
$X$
is true? If so, what sorts of situations are these?
This question concerns the acquisition of a priori knowledge purely on the basis of a computer outputting the claim that something is true. Thus, suppose that a computer outputs the claim that some mathematical fact
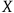 $X$
is true, and a correct proof of
$X$
is true, and a correct proof of
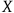 $X$
. If in some circumstances merely witnessing the computer output the claim
$X$
. If in some circumstances merely witnessing the computer output the claim
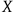 $X$
yields a priori knowledge of
$X$
yields a priori knowledge of
 $X$
, then in such circumstances a priori knowledge of
$X$
, then in such circumstances a priori knowledge of
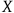 $X$
is acquired purely on the basis of the computer outputting the claim
$X$
is acquired purely on the basis of the computer outputting the claim
 $X$
. But if it is only once we check the proof of
$X$
. But if it is only once we check the proof of
 $X$
ourselves that we acquire a priori knowledge of
$X$
ourselves that we acquire a priori knowledge of
 $X$
, then it is not true that in those circumstances we come to know
$X$
, then it is not true that in those circumstances we come to know
 $X$
a priori purely on the basis of the computer outputting the claim
$X$
a priori purely on the basis of the computer outputting the claim
 $X$
.
$X$
.
Early discussions of our main question were motivated by Appel and Haken’s 1977 computer proof of the four-color theorem (4CT) (Appel and Haken Reference Appel and Haken1989), which is so long that it cannot be checked by humans. Because of this, some thought (Tymoczko Reference Tymoczko1979) that the idea that mathematical knowledge is essentially a priori had to be rejected and room created for merely empirical or experimental mathematical knowledge.
However, following Burge (Reference Burge1998), we argue in section 2 that when the running of a computer program can be understood as a mechanized exercise of ordinary human mathematical capacities, the output of a program can indeed give us a priori mathematical knowledge. In this way, Appel and Haken did acquire a priori knowledge of the truth of 4CT from the output of their computer program. Thus, our main question can be answered affirmatively in the case of Appel and Haken in 1977.
The problem, however, is that the argument of section 2 does not apply to the output of machines like deep neural networks (DNNs) and large language models (LLMs), whose inner workings are (in a sense) opaque to us but are nevertheless increasingly important to mathematicians. In section 3, we argue that outside special cases, we cannot directly acquire a priori mathematical knowledge from the reports of DNNs or LLMs. This result seems to impose a strong limitation on our ability to acquire a priori mathematical knowledge from artificial intelligence (AI).
However, in section 4, we argue that mathematicians can overcome this limitation by applying a transparent proof-checker to an appropriately structured output of a DNN or LLM. So long as this proof-checker may be understood as a mechanized exercise of human proof-checking capacities, we claim that we can acquire genuine mathematical knowledge from the output of the proof-checker, even though this knowledge may not be obtained directly from the DNN or LLM itself.
We thus arrive at the surprising result that it is possible to acquire genuine a priori knowledge of a mathematical fact
 $X$
purely on the basis of the output of a computer, where a proof of
$X$
purely on the basis of the output of a computer, where a proof of
 $X$
has been generated by a process that is entirely opaque to us and is so complex that the proof is not checkable by humans. This suggests that AI can indeed play a role in generating substantive mathematical knowledge and that there is a large set of cases in which we can answer our main question affirmatively and acquire a priori knowledge purely on the basis of the output of a computer.
$X$
has been generated by a process that is entirely opaque to us and is so complex that the proof is not checkable by humans. This suggests that AI can indeed play a role in generating substantive mathematical knowledge and that there is a large set of cases in which we can answer our main question affirmatively and acquire a priori knowledge purely on the basis of the output of a computer.
2. Knowledge of the four-color theorem
Serious discussion of our main question began in 1977 when Appel and Haken used a computer to verify 4CT (Appel and Haken Reference Appel and Haken1989). Appel and Haken argued that to prove 4CT, it sufficed to verify the four-colorability of a particular set of 1,834 finite graphs. For complex graphs, verifying four-colorability is extremely time-consuming. Appel and Haken thus used a supercomputer to verify that all 1,834 graphs were four-colorable, and this was regarded as establishing 4CT. The sheer length of this calculation meant, however, that human mathematicians could not survey it step by step. Indeed, even today, no one has produced a proof of the 4CT that can be checked without computer assistance.
Philosophers immediately began reflecting on what this meant for mathematics. Tymoczko (Reference Tymoczko1979) argued that mathematics had now become an empirical discipline in which proofs could be obtained by performing experiments, such as the running of computer programs.Footnote 1 More specifically, Tymoczko thought that our knowledge of the 4CT rested on an argument involving the following premise:
Rel: Carefully written computer programs reliably output true claims.
Tymoczko saw Rel as an empirical claim stating the reliability of a piece of scientific equipment. Knowledge obtained using Rel was thus empirical. Tymoczko concluded that our knowledge of 4CT, although genuine knowledge, was not a priori—that is, not justified purely on rational grounds—but rather merely empirical. Others concurred (Detlefsen and Luker Reference Detlefsen and Luker1980).
We, however, do not find this view compelling. Instead, we are persuaded by another way of looking at things attributable to Burge (Reference Burge1998). Rejecting the views just described, Burge argued that the output of Appel and Haken’s program gives a genuinely a prioriFootnote 2 warrant for believing 4CT.Footnote 3
2.1. Memory as a rational resource
To motivate this view, consider that in proving or surveying a theorem, we typically must use our memories. When proving a theorem, there come points where we may wonder whether we have already proven some lemma. Perhaps we pause, recall that we have, and then continue reasoning. In that pause when we ask, “Have we already proven this lemma?” and decide upon consulting our memory that we have, are we doing an experiment with our brains? Is the resulting knowledge thus merely empirical? And as with ordinary pieces of scientific equipment, can we only rely on our memory if we have empirical knowledge of its reliability?
Burge thinks that relying on our memory is not doing an experiment that yields, at most, empirical knowledge. His view is rather that we have defeasible, a priori grounds for believing what we seemingly remember. So when we have a seeming memory of proving a lemma, we are entitled on purely rational grounds to believe that we have proved the lemma. It is not the case that we must first do memory tests to establish the reliability of our memory before we have grounds to believe what we seemingly remember. Rather, Burge’s view is that we have purely rational grounds for believing the lemma because we have a memory of proving it. These grounds are, of course, defeasible. We might later realize that we were misremembering. Purely rational grounds are not infallible in this picture.
To be sure, searching our memories for an episode of proving a lemma is something like an empirical investigation. It is only an empirical fact that I proved the lemma yesterday, and it is only an empirical fact that I have a memory of this happening. Nevertheless, upon finding the memory, I have purely rational (i.e., a priori) grounds for believing the lemma. Critically, note that the lemma is not inferred from the existence of the memory—rather, the lemma is inferred from the reasoning that has been remembered.
More generally, Burge claims that even when only exercising our rational capacities, there are various resources on which we can rely. He calls these rational resources. When these rational resources offer us claims, we are (defeasibly) a priori entitled to trust them. So, for example, my memory is a rational resource that I can rely on in my reasoning, as is my visual system when I inspect a diagram in a proof. A thermometer, however, is not a rational resource because when I trust a thermometer, I am doing something going beyond mere reasoning. A thermometer is rather an empirical resource. Burge’s general claim is that “resources for rationality are, other things equal, to be believed’’ Burge (Reference Burge1998, 5). This extends to the use of these resources outside cases of pure reasoning, although we shall not dwell on this here.
2.2. Computers as rational resources
We now return to Appel and Haken’s computer program. This program is designed to go through all 1,834 basic maps and verify their four-colorability in exactly the way Appel and Haken might. It organizes these maps systematically into a list and does exactly what they would to check each case, although more quickly and indefatigably. Appel and Haken’s computer is thus simply a mechanized application of their ordinary rational capacities, performing their reasoning for them. Indeed, they understand exactly what the computer does, so at any moment, they could (in principle) say something like, “The computer is now considering map #734 and is at such-and-such a stage of checking for a four-coloring.’’ We capture this aspect of Appel and Haken’s program by saying that it is mathematically transparent to them.
Because Appel and Haken’s program simply performs their reasoning for them in this way, we view Appel and Haken’s computer as a rational resource. Because rational resources are (other things equal) to be believed, we agree with Burge that “we have a priori prima-facie entitlement to accept [the printouts of the program] as true” (Burge Reference Burge1998, 13). Thus, Appel and Haken can be understood to have defeasible, a priori grounds for believing 4CT.
Crucially, this warrant does not depend on an empirical fact like Rel about the reliability of computers. Appel and Haken infer 4CT from the reasoning that the computer has done for them. This reasoning involves only purely mathematical considerations and not Rel. Nevertheless, the warrant for believing 4CT is defeasible. For example, Appel and Haken could come to learn that the computer was malfunctioning, in which case they would no longer be justified in believing 4CT. This, however, does not mean that justification for believing 4CT first requires positive empirical grounds for thinking that the computer is not malfunctioning. Instead, they are entitled to believe the results of mathematically transparent processes so long as they lack reason for thinking the relevant resource unreliable. So it is enough that they had no reason to think that their computer was malfunctioning.
It is true that in writing the program, Appel and Haken had to perform all sorts of tests to establish that the program was behaving as expected. But this does not mean that the warrant for believing 4CT is merely empirical. Empirical tests are necessary to establish that the computer is a device that is capable of performing our reasoning for us through mathematically transparent processes. Nevertheless, once we are confident of this and use the computer as Appel and Haken did, the ultimate ground for accepting 4CT is then simply the existence of the mathematically transparent process demonstrating it. This warrant is a priori insofar as it is just a mobilization of human mathematical capacities, albeit in a way that relies on rational resources.
Thus, in the same way that ordinary mathematicians infer theorems from the existence of purely mathematical arguments not involving claims about their memories (even though they rely on their memories in convincing themselves of the existence of such arguments), so, too, Appel and Haken inferred 4CT from the existence of a purely mathematical argument that did not make any claim like Rel about computers (even though they relied on computers in convincing themselves of the existence of such an argument).
3. Transparency and artificial intelligence–assisted proof
So far, we have been talking about “old-fashioned” computing. Recently, mathematicians have turned to deep learning models (DLMs) for assistance with challenging mathematical problems in, for instance, low-dimensional topology (Davies et al. Reference Davies, Velicckovic‘c’, Buesing, Blackwell, Zheng, Tomašev, Tanburn, Battaglia, Blundell, Juhász, Lackenby, Williamson, Hassabis and Kohl2021), geometry (Trinh et al. Reference Trinh, Wu, Le, He and Luong2024), and combinatorics (Romera-Paredes et al. Reference Romera-Paredes, Barekatain, Novikov, Balog, Pawan Kumar, Dupont, Ruiz, Ellenberg, Wang, Fawzi, Kohli and Fawzi2023). One might expect that, like Appel and Haken, these mathematicians can gain a priori knowledge from computers in the right circumstances. However, the notorious opacity of DLMs creates significant differences between the use of traditional computers and contemporary AI in mathematics.
To see this, we consider the sense in which DLMs are opaque and thus not mathematically transparent to us. Creel’s account of algorithmic and structural transparency in complex computational systems is helpful here (Creel Reference Creel2020).
For Creel, computational systems can be “algorithmically” and “structurally” transparent.Footnote 4 A computational system is algorithmically transparent to the extent that the procedures governing its behavior are known and intelligible. In the case of the procedures performed in the proof of the 4CT, the rules at the algorithmic level are those describing how a mathematician might check the four-colorability of basic graphs.
The system is structurally transparent to the extent that it is possible to see how this algorithm is realized in actual code. Thus, a program is structurally transparent only when its code is surveyable, and it is possible to understand how the code generates results in accordance with the algorithm it instantiates. In cases where a computational system is algorithmically and structurally transparent (as in Appel and Haken’s program), the reliability of the computational system at run-time can be (defeasibly) trusted (Frigg and Reiss Reference Frigg and Reiss2009; Duede Reference Duede2022), even if one cannot transparently survey the running of the program in practice (Humphreys Reference Humphreys2009).
Although the computations used in Appel and Haken’s program resulted in an unsurveyable proof, the computations themselves were, in Creel’s account, algorithmically and structurally transparent. Thus, the computations were mathematically transparent in the sense discussed in the last section. However, we will argue that the DNNs and LLMs used in mathematics are often neither structurally nor algorithmically transparent.
3.1. Opacity of deep learning
It is often said that DNNs lack epistemic transparency. It is important, however, to distinguish the training of a DNN from fully trained models. The procedure for training a DNN is algorithmically and structurally transparent. In simple cases, it is algorithmically transparent that training works through the minimization of loss functions via iterative updating of weights on the connections between parameters by back-propagation of error gradients. There are extensive repositories containing structurally transparent implementations for training a wide variety of network architectures in this way, and students taking a class in machine learning are often required to write their own implementations of such algorithms. There is nothing opaque about how such models are trained.
However, fully trained DNNs are said to be epistemically opaque (Humphreys Reference Humphreys2004; Boge Reference Boge2022), meaning that the epistemically relevant factors governing the model’s behavior are fundamentally unsurveyable. In general, it is not possible to “fathom” (Zerilli Reference Zerilli2022), in any meaningful sense, the model’s algorithmic principles governing the transformation of inputs to outputs. As such, DNNs are opaque at both the algorithmic and structural levels. This lack of transparency is due to the extreme dimensionality and nonlinearity of the model, as well as the autonomous, error-driven, and semistochastic processes of weight assignment guiding the final parameterization of the model.
Of course, it is possible that with a DNN that determines four-colorability, we might be able to say at any moment which graph is being analyzed. There is also a numerically trivial sense in which the trained model is transparent insofar as the values on the weights themselves are available to inspection (although not surveyable) (Lipton Reference Lipton2018; Duede Reference Duede2023). However, unlike Appel and Haken’s program, we would not generally be able to say how that graph is being evaluated, and thus such an approach would be neither algorithmically nor structurally transparent.
3.2. Mathematical knowledge with deep neural networks
Suppose that a mathematician wants to know whether every graph in a set of graphs is four-colorable. Approaching this problem with a DNN, the mathematician trains a model on a large set of graphs known to be four-colorable and a large set of graphs known not to be four-colorable. The model is then evaluated (in the usual way) on a collection of graphs not included in the training set, and let us suppose that no graph is misclassified.
At this point, the mathematician unleashes their model on Appel and Haken’s 1,834 basic graphs. After several minutes, the model states that all are four-colorable. However, given that the model is not algorithmically transparent, we cannot regard this machine as having performed, on our behalf, the kind of reasoning we would perform in verifying the four-colorability of the graphs. Because the system is not mathematically transparent, we would not be justified in believing its output on purely rational grounds.
Because the DNN reliably classifies graphs as four-colorable or not, we do get a strong inductively justified belief in the 4CT. Such a result bears some resemblance to a case (Davies et al. Reference Davies, Velicckovic‘c’, Buesing, Blackwell, Zheng, Tomašev, Tanburn, Battaglia, Blundell, Juhász, Lackenby, Williamson, Hassabis and Kohl2021) considered by Duede (Reference Duede2023), where mathematicians used a DNN to guide mathematical attention to promising connections that led to the formulation and proof of a theorem linking specific algebraic and geometric properties of low-dimensional knots. Such cases exemplify the potential for AI to assist mathematicians in their search for promising conjectures while leaving the actual proof of the conjectures to humans. In such cases, however, knowledge is not a direct result of the DNN, insofar as the ultimate responsibility for proof lies with human mathematicians.
Consider next a hypothetical case in which a DNN trained to classify graph four-colorability classifies all of Haken and Appel’s 1,834 graphs as four-colorable, except for one that it classifies as not four-colorable. Here, the model has suggested a counterexample to 4CT. Let us suppose that whether it is a genuine counterexample is something we can check ourselves by hand, that we check it, and we find that it is indeed a counterexample. In this case, we now have genuine mathematical knowledge of a mathematical fact (namely, the falsehood of 4CT). However, this knowledge, too, cannot be said to follow directly from the output of the DNN because it required human verification.
3.3. Mathematical knowledge with large language models
LLMs are particularly useful for mathematics because they output reports that are potentially linguistically and mathematically intelligible. However, like DNNs, LLMs are algorithmically and structurally opaque, so they are afflicted by the epistemic limitations discussed in the previous section.
A recent case leveraging LLMs to achieve mathematical breakthroughs in combinatorics involves the cap set problem (Romera-Paredes et al. Reference Romera-Paredes, Barekatain, Novikov, Balog, Pawan Kumar, Dupont, Ruiz, Ellenberg, Wang, Fawzi, Kohli and Fawzi2023). A cap set is a subset of
 ${(\mathbb{Z}/3\mathbb{Z})^n}$
for which no three distinct elements sum to 0 (mod 3). For each
${(\mathbb{Z}/3\mathbb{Z})^n}$
for which no three distinct elements sum to 0 (mod 3). For each
 $n$
, the problem is to determine the size of the largest cap set. It is known that this number must be less than
$n$
, the problem is to determine the size of the largest cap set. It is known that this number must be less than
 $ \le {3^n}$
(Grochow Reference Grochow2019), but its exact value is only known for
$ \le {3^n}$
(Grochow Reference Grochow2019), but its exact value is only known for
 $n \le 6$
. Because the complexity of the solution space explodes for larger values of
$n \le 6$
. Because the complexity of the solution space explodes for larger values of
 $n$
, brute-force computational approaches are infeasible.
$n$
, brute-force computational approaches are infeasible.
Romera-Paredes et al. (Reference Romera-Paredes, Barekatain, Novikov, Balog, Pawan Kumar, Dupont, Ruiz, Ellenberg, Wang, Fawzi, Kohli and Fawzi2023) leverage an LLM to construct a cap set of size 512 for
 $n = 8$
, a result significantly greater than the previously known largest value of 496. Their approach begins by specifying an evaluation function that scores a candidate solution, where a solution is itself a Python program for generating a potential cap set. The LLM then outputs a candidate Python program that is executed and scored by the evaluation function. If the program executes sufficiently quickly and without obvious error, it is sent to a program database. The system then samples the database and passes prior output programs to the LLM as inputs to repeat the generative process. This iterative approach generatively “evolves” candidate programs. Eventually, this process identified a cap set of size 512, which human mathematicians verified to be correct.
$n = 8$
, a result significantly greater than the previously known largest value of 496. Their approach begins by specifying an evaluation function that scores a candidate solution, where a solution is itself a Python program for generating a potential cap set. The LLM then outputs a candidate Python program that is executed and scored by the evaluation function. If the program executes sufficiently quickly and without obvious error, it is sent to a program database. The system then samples the database and passes prior output programs to the LLM as inputs to repeat the generative process. This iterative approach generatively “evolves” candidate programs. Eventually, this process identified a cap set of size 512, which human mathematicians verified to be correct.
Unlike 4CT, the solution-generating computational procedure here is not mathematically transparent. However, a human mathematician can easily survey and check its output. So in this case, we get a priori knowledge that for
 $n = 8$
, there is a cap set of size 512. Nevertheless, because this involves a human mathematician verifying this fact, we cannot say that genuine mathematical knowledge has been obtained directly from the output of the computer.
$n = 8$
, there is a cap set of size 512. Nevertheless, because this involves a human mathematician verifying this fact, we cannot say that genuine mathematical knowledge has been obtained directly from the output of the computer.
3.4. Main claim
With such examples in mind, we offer the following answer to our main question posed in section 1.
Main Claim 1: If we want to acquire a priori mathematical knowledge directly from the output of a computer, then what the computer is doing must be mathematically transparent to us (as in the case of 4CT). If what a computer is doing is not mathematically transparent to us (as in the case of typical DNNs or LLMs), then we cannot directly acquire a priori mathematical knowledge from the output of a computer, even though we may be able to gain a type of inductively justified belief from it. However, even if we do not directly acquire a priori mathematical knowledge from the output of a computer, if the computer outputs a human-checkable proof or counterexample, then upon checking it appropriately, we do gain a priori mathematical knowledge (although not directly from the computer because human checking was required).
4. Transparent proof-checking
The considerations of the previous section seem to entail that although they are extraordinarily useful, DNNs and LLMs can ultimately only be of limited use in acquiring a priori mathematical knowledge. At best, their reports offer us inductively justified beliefs, and it is only when they output results that are checkable by humans that we can acquire a priori mathematical knowledge from them.
In certain cases, however, these limits may be surpassed. We focus on the case in which a machine (perhaps an LLM) outputs not only some mathematical claim
 $X$
but also something it claims to be a proof of
$X$
but also something it claims to be a proof of
 $X$
, and this proof is stored somewhere on a hard drive. If what has been stored on the drive can be checked by humans, then we can check it, and if it is indeed a correct proof, we thereby gain a priori knowledge of
$X$
, and this proof is stored somewhere on a hard drive. If what has been stored on the drive can be checked by humans, then we can check it, and if it is indeed a correct proof, we thereby gain a priori knowledge of
 $X$
.
$X$
.
Suppose, however, that the proof of
 $X$
stored on the hard drive is so long that it cannot be checked by humans. It might then appear that a priori knowledge of
$X$
stored on the hard drive is so long that it cannot be checked by humans. It might then appear that a priori knowledge of
 $X$
is beyond our reach.
$X$
is beyond our reach.
But this is not so. Let us suppose that the stored proof of
 $X$
, although enormous, is systematically organized as a tree of propositions of the sort one might encounter in a mathematical logic class. We can imagine constraining the output of the machine generating the proof to demand that its outputs be formulated in this way (as in Romera-Paredes et al. [Reference Romera-Paredes, Barekatain, Novikov, Balog, Pawan Kumar, Dupont, Ruiz, Ellenberg, Wang, Fawzi, Kohli and Fawzi2023], where the model outputs all results in Python, or as is common Avigad [Reference Avigad2024], in a formal language instantiated in Lean [De Moura et al. Reference Moura, Leonardo, Avigad, Doorn, von Raumer, Amy and Middeldorp2015]). We can permit abbreviations, additional rules, and verbose articulations of steps in the proof so that this proof has roughly the form of a human-generated proof,Footnote
5
even though it was not human generated and is so large that it cannot be surveyed by humans. These assumptions can easily be made to hold by adding some overhead to the original program.
$X$
, although enormous, is systematically organized as a tree of propositions of the sort one might encounter in a mathematical logic class. We can imagine constraining the output of the machine generating the proof to demand that its outputs be formulated in this way (as in Romera-Paredes et al. [Reference Romera-Paredes, Barekatain, Novikov, Balog, Pawan Kumar, Dupont, Ruiz, Ellenberg, Wang, Fawzi, Kohli and Fawzi2023], where the model outputs all results in Python, or as is common Avigad [Reference Avigad2024], in a formal language instantiated in Lean [De Moura et al. Reference Moura, Leonardo, Avigad, Doorn, von Raumer, Amy and Middeldorp2015]). We can permit abbreviations, additional rules, and verbose articulations of steps in the proof so that this proof has roughly the form of a human-generated proof,Footnote
5
even though it was not human generated and is so large that it cannot be surveyed by humans. These assumptions can easily be made to hold by adding some overhead to the original program.
Although we cannot check this proof ourselves, this does not stop us from writing a proof-checking program that can check it. The proof-checking program goes through the proof, verifying that it starts with genuine axioms and that each step is a legitimate application of some standard inferential rule. We can imagine a version of this proof-checker that is completely mathematically transparent and checks the proof in exactly the way a human would. When such a program runs, at any point, we can (in principle) correctly say something like, “The computer is now checking inference 15435 and is verifying that it is a correct application of modus ponens.”
Let us assume that we run this proof-checker, and it reports no errors. Just as Appel and Haken acquire a priori knowledge of the 4CT from the output of their mathematically transparent program, so, too, do we acquire a priori knowledge that there is a correct proof of
 $X$
from the output of our mathematically transparent proof-checker. Because there is a correct proof of
$X$
from the output of our mathematically transparent proof-checker. Because there is a correct proof of
 $X$
,
$X$
,
 $X$
is true, and thus we acquire a priori knowledge of
$X$
is true, and thus we acquire a priori knowledge of
 $X$
. This is true even though no human has (or ever could have) any sort of rational grasp on the process that led to the generation of the proof and no human is capable of checking the stored proof.
$X$
. This is true even though no human has (or ever could have) any sort of rational grasp on the process that led to the generation of the proof and no human is capable of checking the stored proof.
The important point is that in this case, we have a priori knowledge of
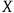 $X$
not based on the output of the LLM, whose workings are not transparent to us, but based on the output of the proof-checker, whose workings are transparent to us.
$X$
not based on the output of the LLM, whose workings are not transparent to us, but based on the output of the proof-checker, whose workings are transparent to us.
Of course, if the LLM “claims” to have proven
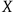 $X$
but cannot produce and store the actual proof of
$X$
but cannot produce and store the actual proof of
 $X$
, then we cannot use a proof-checker in the way just described. In this case, we see no way to acquire anything other than inductive grounds for believing
$X$
, then we cannot use a proof-checker in the way just described. In this case, we see no way to acquire anything other than inductive grounds for believing
 $X$
.
$X$
.
This leads us to the second of the two central claims of this article, which may be viewed as a counterpoint to Main Claim 1.
Main Claim 2: We can (indirectly) gain a priori knowledge from the output of a computer program that is not mathematically transparent but that stores a (not necessarily human-checkable) proof of a mathematical claim. This is accomplished by employing a mathematically transparent proof-checker to evaluate the stored proof of the claim.
5. General conclusions
Modern LLMs and DNNs are opaque to us in ways that create obstacles to obtaining mathematical knowledge from them. However, if a proof-checker transparently automating human forms of mathematical evaluation is attached to such machines, then we can obtain a priori mathematical knowledge from them. Surprisingly, this applies even when the original machines are entirely opaque to us and the proofs they output cannot be surveyed by humans.
A different question for further consideration is to what extent we may gain scientific (Kidd and Birhane Reference Kidd and Birhane2023) knowledge outside of mathematics by appending analogous transparent “checking” mechanisms to the output of otherwise opaque algorithms. This would get us closer to overcoming the perceived problems of confabulation and realizing the ambition of fully automated scientific discovery.
Acknowledgments
The authors wish to thank audiences at the Philosophy of Science Association 29th Biannual Meeting (PSA 2024), the mrc2024, the International Association for Computing and Philosophy 2024 Meeting (IACAP 2024), and the University of Chicago.
Funding statement
Funding for this work was provided by a generous grant to Duede from the Alfred P. Sloan Foundation (G-2024-22468).
Competing interests
The author(s) declare none.

 Open access
Open access