


1. Introduction
There are several cases in physics where the mathematical formalism of a theory appears to have redundancy: there are objects in the theory that don’t seem to play any role in capturing the empirical content of the theory. There have been attempts to formalize the idea of a theory having redundancy through the notion of ‘excess structure’:Footnote 1 a theory has excess structure when it has distinct, non-isomorphic models that are taken to represent the same physical situation. And what it is to remove excess structure is to come up with a new theory with less structure—in particular, without the structure distinguishing the problematic models—that captures the same empirical content. This notion has been fruitfully applied to several cases to understand the sense in which a theory does, or does not, have redundancy: from formulations of classical mechanics (North Reference North2009; Barrett Reference Barrett2015a), to formulations of spacetime theories (Barrett Reference Barrett2015b; Weatherall Reference Weatherall2018), to formulations of electromagnetism (Weatherall Reference Weatherall2016b).
One context where the term ‘redundancy’ is used by both physicists and philosophers is in the context of gauge theories; indeed, sometimes a ‘gauge theory’ is used to mean just a theory with redundancy.Footnote 2 And this is not just an observation; taking gauge theories to have redundancy motivates the procedure of ‘reduction’, which involves reformulating a gauge theory by effectively removing the ‘excess’ quantities from the formalism.
On the other hand, Weatherall (Reference Weatherall2016b) argues that some theories that are called ‘gauge theories’—namely, (the standard formulations of) Yang–Mills theory and General Relativity—are not theories with excess structure in the sense defined above. The reason is that the ‘gauge symmetries’ act as isomorphisms in the theory, and so they do not give rise to distinct models of the theory. It follows that whether a gauge theory is a candidate for excess structure depends on the particular formulation of the theory, and therefore, whether reduction is motivated by considerations of excess structure depends on how the gauge theory that one reduces is formulated.
A standard procedure for reduction, known as ‘symplectic reduction’, takes place in the Hamiltonian formulation of gauge theories. The Hamiltonian formalism provides a useful framework for formulating gauge theories because, as originally shown by Dirac (Reference Dirac1964), one can connect gauge symmetry to constraints on the Hamiltonian variables.Footnote 3 There is, therefore, a natural question to ask: is it the case that the Hamiltonian formulation of gauge theories has excess structure? While many discussions on the Hamiltonian formulation of gauge theories suggest that this is the case,Footnote 4 there has not been an explicit attempt to formalize this claim. The aim of this paper is to rectify that.
The question is complicated by the fact that there are disputes about how to characterize a Hamiltonian gauge theory—in particular, which transformations constitute the gauge transformations—that comes down to a disagreement about the equivalence class of Hamiltonians that generate the dynamics. The standard view is that the ‘Extended Hamiltonian’ is the right equivalence class of Hamiltonians and that gauge transformations are generated by arbitrary combinations of first-class constraints. The alternative view—argued for, most prominently, by Pitts (Reference Pitts2014b)Footnote 5—is that the ‘Total Hamiltonian’ is the right equivalence class of Hamiltonians and that gauge transformations are generated by a particular combination of first-class constraints. In attempting to answer the question above, we will therefore consider whether different characterizations of a Hamiltonian gauge theory lead to different answers to this question.
In fact, I will show that the formulation of a Hamiltonian gauge theory that takes the Extended Hamiltonian to be the equivalence class of Hamiltonians has less structure than the formulation that takes the Total Hamiltonian to be the equivalence class of Hamiltonians. This suggests that the theory formulated in terms of the Total Hamiltonian is one with excess structure, and that the theory formulated in terms of the Extended Hamiltonian is precisely a way of removing this excess structure. This is interesting in itself; it suggests that an argument for the standard view can be made in terms of considerations of excess structure. Moreover, it opposes a recent argument made by Pitts (Reference Pitts2022, Reference Pitts2024) that the Extended Hamiltonian is (at best) a ‘trivial reformulation’ of the Total Hamiltonian.
With the theory in terms of the Extended Hamiltonian as a starting point, we then ask whether this is a theory with excess structure by considering whether symplectic reduction can be said to remove structure from this theory. I show that symplectic reduction does not, in fact, result in a theory with less structure than the theory characterized by the Extended Hamiltonian. This might appear surprising, given that the theory characterized by the Extended Hamiltonian has symmetries of precisely the kind that are removed via symplectic reduction. However, I will argue that this appearance results from a misunderstanding of the relationship between the number of gauge symmetries a theory has, the amount of structure it has, and whether it has redundancy.
More carefully, I will argue that there is a way to characterize the kind of redundancy that a gauge theory has compared to the symplectic reduced theory, but that it is conceptually distinct from the kind of redundancy at issue in the context of excess structure. This kind of redundancy is rather one that Bradley and Weatherall (Reference Bradley and Weatherall2020) call ‘representational redundancy’: the redundancy comes from the fact that the theory has the freedom to represent a particular physical situation in lots of different ways. Applying the notion of representational redundancy in the context of Hamiltonian gauge theories helps to clarify the motivations for moving to the symplectic reduced theory, and how these motivations differ from the motivations for moving to a theory without excess structure.
The rest of the paper will go as follows. In section 2, I discuss the notion of ‘excess structure’ and how the tools of category theory can be usefully applied to formalize this notion. In section 3, I give an overview of the constrained Hamiltonian formalism for describing gauge theories. In section 4, I argue that the theory corresponding to the Extended Hamiltonian removes excess structure from the theory corresponding to the Total Hamiltonian, using the tools described in section 2. In section 5, I turn to the relationship between the Extended Hamiltonian theory and the theory obtained via symplectic reduction. I show that the latter does not remove excess structure from the former, and I discuss the sense in which symplectic reduction is nonetheless motivated. In section 6, I conclude with some broader lessons.
2. Defining excess structure
As a starting point, we will take a theory to have ‘excess structure’ whenever it admits non-isomorphic models that are taken to represent the same physical situation. This allows for various refinements.
First, one might argue that if a theory contains distinct models that are taken to represent the same physical situation, yet no plausible alternative theory captures the same empirical content without such distinct models, then one shouldn’t regard the theory as having excess structure.Footnote 6 The underlying thought is that structure counts as ‘excess’ only if it can, in principle, be dispensed with. On this view, a theory has excess structure only when there exists another theory with less structure that nonetheless captures the same empirical content. In what follows, we will at least presume that presenting such an alternative theory is a way of determining that the first theory has excess structure.
Second, there are different ways that one might spell out what it is for two models to represent the same physical situation, or what it is for two different theories to have the same empirical content. Some philosophers have tried to narrow down the sense in which two models represent the same physical situation through an account of ‘symmetries’ between models of a theory.Footnote 7 However, there are challenges with providing a general account of this kind,Footnote 8 and for our purposes here it suffices that there is a way to spell out the sense in which two models or theories are empirically equivalent on a case-by-case basis. For example, Barrett (Reference Barrett2019) discusses how empirical equivalence between (hyperregular) Lagrangian and Hamiltonian formulations of a theory can be captured in terms of agreement about the collection of integral curves that represent solutions to the equations of motion, under the map that takes a model of Lagrangian mechanics to one of Hamiltonian mechanics and vice versa. Later, when we discuss Hamiltonian gauge theories, we will similarly specify the relevant sense in which the theories in question share the same ‘empirical content’. This leaves open that there might be other ways of comparing and interpreting the theories such that they are not regarded as empirically equivalent. Indeed, we will return to the importance of the choice of comparison in determining whether two theories are empirically equivalent in section 4.
Finally, to say whether one theory has excess structure over another theory, we need a way to compare the structure of two theories. First, we can ask what it means for one model—understood as a single mathematical object—to possess more structure than another model. A criterion for comparing the amount of structure of two mathematical objects has recently been proposed by Barrett (Reference Barrett2015a,b):
(SYM
 $^*$
): A mathematical object X has at least as much structure as an object Y if
$^*$
): A mathematical object X has at least as much structure as an object Y if
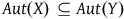 $\mathrm{Aut}(X)\subseteq \mathrm{Aut}(Y)$
.
$\mathrm{Aut}(X)\subseteq \mathrm{Aut}(Y)$
.
The intuitive idea behind this criterion is that the amount of structure a mathematical object possesses is related to its isomorphisms, since an isomorphism is, by definition, a structure-preserving map. In particular, the fewer isomorphisms a mathematical object has, the more structure it has. And vice versa—more isomorphisms indicate less structure.
However, there are some limitations of this account. First, it only applies when one can compare the set of automorphisms of X and Y, which itself relies on X and Y being similar in a certain way, such as having the same underlying domain.Footnote 9 Second, in order to say whether one theory has excess structure over another, what we care about is not just whether a single model of one theory has more structure than a single model of the other, but whether one theory as a whole—understood as a collection of models with structure-preserving maps between these models—has more structure than the other.
To extend the above criterion to theories more generally, we can make use of the tools of category theory.Footnote 10 To think about a physical theory categorically, we take the objects of the category to be the models of the theory, and the arrows between objects to be the isomorphisms between models of the theory. Relations between theories are described by functors between the categories representing those theories, where a functor is a structure-preserving map between categories that takes objects to objects and arrows to arrows.
A functor
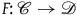 $F\colon {\mathscr{C}} \rightarrow \mathscr{D}$
from the category
$F\colon {\mathscr{C}} \rightarrow \mathscr{D}$
from the category
 $\mathscr{C}$
to the category
$\mathscr{C}$
to the category
 $\mathscr{D}$
is said to be full if for every pair of objects A,B of
$\mathscr{D}$
is said to be full if for every pair of objects A,B of
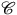 $\mathscr{C}$
the map
$\mathscr{C}$
the map
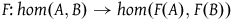 $F\colon {hom}(A,B) \rightarrow {hom}(F(A),F(B))$
induced by F is surjective, where
$F\colon {hom}(A,B) \rightarrow {hom}(F(A),F(B))$
induced by F is surjective, where
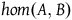 ${hom}(A,B)$
is the collection of arrows from A to B. Similarly, F is said to be faithful if for every pair of objects the induced map on arrows is injective. Finally, F is said to be essentially surjective if for every object X of
${hom}(A,B)$
is the collection of arrows from A to B. Similarly, F is said to be faithful if for every pair of objects the induced map on arrows is injective. Finally, F is said to be essentially surjective if for every object X of
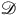 $\mathscr{D}$
, there is some object A of
$\mathscr{D}$
, there is some object A of
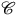 $\mathscr{C}$
such that F(A) is isomorphic to X. Using this terminology, we say (following Weatherall Reference Weatherall2016b) that a theory represented by category
$\mathscr{C}$
such that F(A) is isomorphic to X. Using this terminology, we say (following Weatherall Reference Weatherall2016b) that a theory represented by category
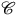 $\mathscr{C}$
has more structure than a theory represented by category
$\mathscr{C}$
has more structure than a theory represented by category
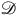 $\mathscr{D}$
if a functor
$\mathscr{D}$
if a functor
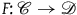 $F\colon \mathscr{C} \rightarrow \mathscr{D}$
is not full (but is faithful and essentially surjective). In this case, we say that F forgets (only) structure.
$F\colon \mathscr{C} \rightarrow \mathscr{D}$
is not full (but is faithful and essentially surjective). In this case, we say that F forgets (only) structure.
We therefore say that a theory, represented by a category
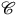 $\mathscr{C} $
, has ‘excess structure’ relative to another theory
$\mathscr{C} $
, has ‘excess structure’ relative to another theory
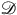 $\mathscr{D}$
when there is a functor
$\mathscr{D}$
when there is a functor
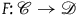 $F\colon \mathscr{C} \rightarrow \mathscr{D}$
that forgets (only) structure while preserving empirical content. The intuitive reason that such a formal notion captures what it is for one theory to have excess structure over another is that a functor failing to be full means that there are some isomorphisms in the second theory that are not mapped to by any isomorphisms in the first theory. In other words, the isomorphisms of the second theory are ‘wider’ than the isomorphisms of the first. If we take on board the principle that more isomorphisms indicates less structure, this suggests that a functor failing to be full captures precisely the idea that we have moved to a theory with overall less structure.
$F\colon \mathscr{C} \rightarrow \mathscr{D}$
that forgets (only) structure while preserving empirical content. The intuitive reason that such a formal notion captures what it is for one theory to have excess structure over another is that a functor failing to be full means that there are some isomorphisms in the second theory that are not mapped to by any isomorphisms in the first theory. In other words, the isomorphisms of the second theory are ‘wider’ than the isomorphisms of the first. If we take on board the principle that more isomorphisms indicates less structure, this suggests that a functor failing to be full captures precisely the idea that we have moved to a theory with overall less structure.
However, there are other interesting relationships between theories represented as categories. For example, if the functor
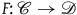 $F\colon \mathscr{C} \rightarrow \mathscr{D}$
is not faithful (but full and essentially surjective), we say that F forgets (only) stuff. To draw out the interpretation of a theory having more ‘stuff’, it is helpful to consider an example.Footnote 11 Take a category
$F\colon \mathscr{C} \rightarrow \mathscr{D}$
is not faithful (but full and essentially surjective), we say that F forgets (only) stuff. To draw out the interpretation of a theory having more ‘stuff’, it is helpful to consider an example.Footnote 11 Take a category
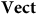 $\bf{Vect}$
whose objects are two-dimensional vector spaces and whose arrows are linear transformations. Similarly, take a category
$\bf{Vect}$
whose objects are two-dimensional vector spaces and whose arrows are linear transformations. Similarly, take a category
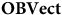 $\bf{OBVect}$
whose objects are two-dimensional vector spaces with a fixed, ordered basis, with basis-preserving maps as arrows. Then, there is a functor from
$\bf{OBVect}$
whose objects are two-dimensional vector spaces with a fixed, ordered basis, with basis-preserving maps as arrows. Then, there is a functor from
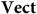 $\bf{Vect}$
to
$\bf{Vect}$
to
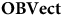 $\bf{OBVect}$
that takes all objects in
$\bf{OBVect}$
that takes all objects in
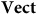 $\bf{Vect}$
to a single object in
$\bf{Vect}$
to a single object in
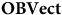 $\bf{OBVect}$
, and all arrows in
$\bf{OBVect}$
, and all arrows in
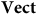 $\bf{Vect}$
to the identity map on the chosen object in
$\bf{Vect}$
to the identity map on the chosen object in
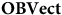 $\bf{OBVect}$
. This functor is full and essentially surjective, but not faithful, and so it forgets stuff. The reason is that the objects in
$\bf{OBVect}$
. This functor is full and essentially surjective, but not faithful, and so it forgets stuff. The reason is that the objects in
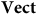 $\bf{Vect}$
have multiple automorphisms that correspond, via the functor, to the identity map on the corresponding model in
$\bf{Vect}$
have multiple automorphisms that correspond, via the functor, to the identity map on the corresponding model in
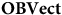 $\bf{OBVect}$
. We can understand this difference as characterizing the fact that there are multiple ways that one can ‘use’ the objects of
$\bf{OBVect}$
. We can understand this difference as characterizing the fact that there are multiple ways that one can ‘use’ the objects of
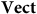 $\bf{Vect}$
to represent some ordered basis (such as a choice of ‘North’ and ‘East’) via its non-trivial automorphisms, whereas there is no corresponding freedom using the objects of
$\bf{Vect}$
to represent some ordered basis (such as a choice of ‘North’ and ‘East’) via its non-trivial automorphisms, whereas there is no corresponding freedom using the objects of
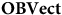 $\bf{OBVect}$
, because one ordered basis is privileged from the rest.
$\bf{OBVect}$
, because one ordered basis is privileged from the rest.
Does this correspond to a kind of redundancy? One relevant observation is that there also exists a functor in the opposite direction, from
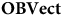 $\bf{OBVect}$
to
$\bf{OBVect}$
to
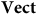 $\bf{Vect}$
, that forgets only structure. Indeed, this captures the fact that the objects of
$\bf{Vect}$
, that forgets only structure. Indeed, this captures the fact that the objects of
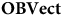 $\bf{OBVect}$
are just those of
$\bf{OBVect}$
are just those of
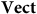 $\bf{Vect}$
plus the structure of a fixed ordered basis. So in this case the theory that has more ‘stuff’ is really the one with less structure. We therefore might see the additional ‘stuff’ that
$\bf{Vect}$
plus the structure of a fixed ordered basis. So in this case the theory that has more ‘stuff’ is really the one with less structure. We therefore might see the additional ‘stuff’ that
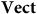 $\bf{Vect}$
has as being a feature of the fact that it is a theory without redundancy.Footnote 12
$\bf{Vect}$
has as being a feature of the fact that it is a theory without redundancy.Footnote 12
On the other hand, one might argue that there is a kind of redundancy associated with the fact that there are multiple automorphisms of the models of
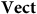 $\bf{Vect}$
: it indicates that there is nothing privileged about one vector over any linear transformation of that vector, and yet such vectors correspond to distinct vectors in the vector space. Bradley and Weatherall (Reference Bradley and Weatherall2020) label the idea that a model can represent some object or physical situation in multiple ways via its non-trivial automorphisms ‘representational redundancy’. One might argue that removing this kind of redundancy can be achieved by moving to OBVect or, depending on one’s representational concerns, by moving to a category whose objects are equivalence classes of vectors under the linear transformations, where the only automorphisms are the identity map.
$\bf{Vect}$
: it indicates that there is nothing privileged about one vector over any linear transformation of that vector, and yet such vectors correspond to distinct vectors in the vector space. Bradley and Weatherall (Reference Bradley and Weatherall2020) label the idea that a model can represent some object or physical situation in multiple ways via its non-trivial automorphisms ‘representational redundancy’. One might argue that removing this kind of redundancy can be achieved by moving to OBVect or, depending on one’s representational concerns, by moving to a category whose objects are equivalence classes of vectors under the linear transformations, where the only automorphisms are the identity map.
This suggests that there are different ways one could interpret the fact that one category has more ‘stuff’ than another. It might be that the first is regarded as a theory without excess structure, or it might be that the first is regarded as a theory with redundancy, as captured by ‘representational redundancy’. Which is regarded as the ‘right’ interpretation might depend on the particular representational concerns one has in some context. As we will discuss in section 5, this is precisely the situation in the context of symplectic reduction. However, to make the point in this context, we first need to discuss how one should formulate (the structure of) a Hamiltonian gauge theory. To do this, we will make use of the ‘constrained Hamiltonian formalism’, to which we now turn.
3. The constrained Hamiltonian formalism
The standard geometric way of formulating a Hamiltonian theory is to take its state space to be a symplectic manifold.Footnote 13 A symplectic manifold consists of a pair
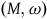 $(M, \omega)$
where M is a smooth manifold and
$(M, \omega)$
where M is a smooth manifold and
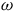 $\omega$
is a symplectic form: it is a two-form (a smooth, anti-symmetric tensor field of rank (0,2)) that is closed and non-degenerate. A Hamiltonian theory is a theory whose state space is given by the cotangent bundle of configuration space
$\omega$
is a symplectic form: it is a two-form (a smooth, anti-symmetric tensor field of rank (0,2)) that is closed and non-degenerate. A Hamiltonian theory is a theory whose state space is given by the cotangent bundle of configuration space
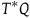 $T^*Q$
, i.e. the points of the manifold are
$T^*Q$
, i.e. the points of the manifold are
 $\{(q_i,p_i), i=1,\ldots,N\}$
, where
$\{(q_i,p_i), i=1,\ldots,N\}$
, where
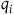 $q_i$
are the generalized positions and
$q_i$
are the generalized positions and
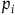 $p_i$
the generalized (canonical) momenta.
$p_i$
the generalized (canonical) momenta.
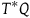 $T^*Q$
comes naturally equipped with a one-form, the Poincaré one-form, given by
$T^*Q$
comes naturally equipped with a one-form, the Poincaré one-form, given by
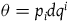 $\theta=p_i dq^i$
. The corresponding symplectic two-form is given by
$\theta=p_i dq^i$
. The corresponding symplectic two-form is given by
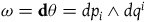 $\omega={\bf{d}}\theta = dp_i \wedge dq^i$
.
$\omega={\bf{d}}\theta = dp_i \wedge dq^i$
.
Given a function
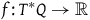 $f\colon T^*Q \rightarrow \mathbb{R}$
, one can uniquely define a smooth tangent vector field
$f\colon T^*Q \rightarrow \mathbb{R}$
, one can uniquely define a smooth tangent vector field
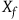 $X_f$
through
$X_f$
through
 $\omega(X_f, \cdot) = {\bf{d}}f,$
$\omega(X_f, \cdot) = {\bf{d}}f,$
where
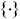 $\{\cdot\}$
represents any vector field tangent to
$\{\cdot\}$
represents any vector field tangent to
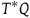 $T^*Q$
. An important function is the Hamiltonian
$T^*Q$
. An important function is the Hamiltonian
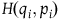 $H(q_i,p_i)$
, where the unique vector field associated with H via the above equation is interpreted as the generator of the solutions to the equations of motion, i.e. the equations of motion can be expressed as
$H(q_i,p_i)$
, where the unique vector field associated with H via the above equation is interpreted as the generator of the solutions to the equations of motion, i.e. the equations of motion can be expressed as
 $\omega(X_H, \cdot)={\bf{d}}H.$
$\omega(X_H, \cdot)={\bf{d}}H.$
The ‘constrained Hamiltonian formalism’ concerns a collection of Hamiltonian theories where there are constraints of the form
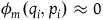 $\phi_m(q_i,p_i)\approx0$
for
$\phi_m(q_i,p_i)\approx0$
for
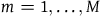 $m=1,\ldots,M$
, where M is the number of constraints and the meaning of
$m=1,\ldots,M$
, where M is the number of constraints and the meaning of
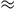 $\approx$
is that one can substitute the left-hand side for the right only on the subspace where the equation holds.Footnote 14 Constraints that arise from the definition of the canonical momenta
$\approx$
is that one can substitute the left-hand side for the right only on the subspace where the equation holds.Footnote 14 Constraints that arise from the definition of the canonical momenta
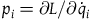 $p_i={\partial{L}}/{\partial \dot{q}_i}$
for the Lagrangian function L are called the primary constraints. We can think of the primary constraints as defining a submanifold of
$p_i={\partial{L}}/{\partial \dot{q}_i}$
for the Lagrangian function L are called the primary constraints. We can think of the primary constraints as defining a submanifold of
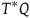 $T^*Q$
, which we call the primary constraint surface,
$T^*Q$
, which we call the primary constraint surface,
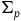 $\Sigma_{p}$
.
$\Sigma_{p}$
.
The Total Hamiltonian is the equivalence class of Hamiltonians defined as
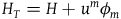 $H_{T}=H+u^m\phi_m$
(using the Einstein summation convention), where
$H_{T}=H+u^m\phi_m$
(using the Einstein summation convention), where
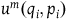 $u^m(q_i,p_i)$
are arbitrary functions, which is equivalent to H when one restricts to the points of
$u^m(q_i,p_i)$
are arbitrary functions, which is equivalent to H when one restricts to the points of
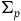 $\Sigma_{p}$
. Taking the Total Hamiltonian to generate the dynamics on
$\Sigma_{p}$
. Taking the Total Hamiltonian to generate the dynamics on
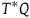 $T^*Q$
means that there are multiple possible solutions given some initial state. In other words, it leads to the failure of a well-posed initial value problem. This apparent indeterminism is the root of gauge symmetry in the Hamiltonian context: gauge symmetries are understood to relate states or solutions that are equivalent from the perspective of restoring unique evolution.
$T^*Q$
means that there are multiple possible solutions given some initial state. In other words, it leads to the failure of a well-posed initial value problem. This apparent indeterminism is the root of gauge symmetry in the Hamiltonian context: gauge symmetries are understood to relate states or solutions that are equivalent from the perspective of restoring unique evolution.
We can alternatively see the underdetermination in the dynamics by formulating the theory intrinsically on
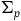 $\Sigma_{p}$
. To do this, we define an induced two-form
$\Sigma_{p}$
. To do this, we define an induced two-form
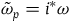 $\tilde{\omega}_{p} = i^*\omega$
, where
$\tilde{\omega}_{p} = i^*\omega$
, where
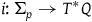 $i\colon \Sigma_{p} \rightarrow T^*Q$
is the inclusion map. We say that a (primary) constraint is first-class when its associated vector field is tangent to
$i\colon \Sigma_{p} \rightarrow T^*Q$
is the inclusion map. We say that a (primary) constraint is first-class when its associated vector field is tangent to
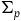 $\Sigma_{p}$
(and second-class when it is not tangent to
$\Sigma_{p}$
(and second-class when it is not tangent to
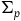 $\Sigma_{p}$
). Whenever there are first-class primary constraints,
$\Sigma_{p}$
). Whenever there are first-class primary constraints,
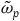 $\tilde{\omega}_{p}$
is presymplectic, which means that it is degenerate: it has null vector fields—vector fields X that satisfy
$\tilde{\omega}_{p}$
is presymplectic, which means that it is degenerate: it has null vector fields—vector fields X that satisfy
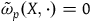 $\tilde{\omega}_{p}(X, \cdot)=0$
—that correspond to the primary first-class constraints. This means that the equations of motion, written intrinsically as
$\tilde{\omega}_{p}(X, \cdot)=0$
—that correspond to the primary first-class constraints. This means that the equations of motion, written intrinsically as
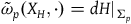 $\tilde{\omega}_{p}(X_H, \cdot) = dH|_{\Sigma_{p}}$
, have non-unique solutions: they are unique up to arbitrary combinations of vector fields associated with the primary first-class constraints.
$\tilde{\omega}_{p}(X_H, \cdot) = dH|_{\Sigma_{p}}$
, have non-unique solutions: they are unique up to arbitrary combinations of vector fields associated with the primary first-class constraints.
However, the theory formulated intrinsically on
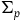 $\Sigma_{p}$
may be such that the solutions to the equations of motion are not well defined everywhere, i.e. the vector fields
$\Sigma_{p}$
may be such that the solutions to the equations of motion are not well defined everywhere, i.e. the vector fields
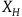 $X_H$
that define the solutions to this equation may not be tangent to the primary constraint surface everywhere. For the solutions to be tangent to the constraint surface, it must be that
$X_H$
that define the solutions to this equation may not be tangent to the primary constraint surface everywhere. For the solutions to be tangent to the constraint surface, it must be that
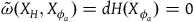 $\tilde{\omega}(X_H,X_{\phi_a})=dH(X_{\phi_a})=0$
for vector fields
$\tilde{\omega}(X_H,X_{\phi_a})=dH(X_{\phi_a})=0$
for vector fields
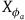 $X_{\phi_a}$
associated with the primary constraints. This may define a further collection of constraints called secondary constraints, and we can think of these additional constraints as leading to the specification of a further submanifold. Continuing this process of requiring that the solutions to the equations of motion be tangent to the constraint surface terminates in a final constraint surface,
$X_{\phi_a}$
associated with the primary constraints. This may define a further collection of constraints called secondary constraints, and we can think of these additional constraints as leading to the specification of a further submanifold. Continuing this process of requiring that the solutions to the equations of motion be tangent to the constraint surface terminates in a final constraint surface,
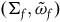 $(\Sigma_{f}, \tilde{\omega}_{f})$
, with dynamics given in terms of
$(\Sigma_{f}, \tilde{\omega}_{f})$
, with dynamics given in terms of
 $H|_{\Sigma_{f}}$
via
$H|_{\Sigma_{f}}$
via
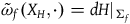 $\tilde{\omega}_{f}(X_H, \cdot)=dH|_{\Sigma_{f}}$
, which has solutions everywhere that are unique up to an arbitrary combination of the vector fields associated with the primary and secondary first-class constraints. The integral curves of the null vector fields of
$\tilde{\omega}_{f}(X_H, \cdot)=dH|_{\Sigma_{f}}$
, which has solutions everywhere that are unique up to an arbitrary combination of the vector fields associated with the primary and secondary first-class constraints. The integral curves of the null vector fields of
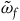 $\tilde{\omega}_{f}$
are sometimes called the gauge orbits.
$\tilde{\omega}_{f}$
are sometimes called the gauge orbits.
We can alternatively think of the dynamics on the final constraint surface in terms of solutions on
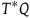 $T^*Q$
where, instead of taking the Total Hamiltonian to generate the dynamics, one takes the Extended Hamiltonian to generate the dynamics, defined as
$T^*Q$
where, instead of taking the Total Hamiltonian to generate the dynamics, one takes the Extended Hamiltonian to generate the dynamics, defined as
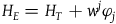 $H_E=H_T+w^j\varphi_j$
, where
$H_E=H_T+w^j\varphi_j$
, where
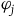 $\varphi_j$
are the first-class secondary constraints and
$\varphi_j$
are the first-class secondary constraints and
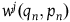 $w^j(q_n,p_n)$
are arbitrary functions. Indeed, Dirac (Reference Dirac1964) argued that the Extended Hamiltonian is the ‘right’ equivalence class of Hamiltonians, and correspondingly that the gauge transformations are generated by arbitrary combinations of first-class constraints, which connect solutions generated by the Extended Hamiltonian. This is now the standard view.
$w^j(q_n,p_n)$
are arbitrary functions. Indeed, Dirac (Reference Dirac1964) argued that the Extended Hamiltonian is the ‘right’ equivalence class of Hamiltonians, and correspondingly that the gauge transformations are generated by arbitrary combinations of first-class constraints, which connect solutions generated by the Extended Hamiltonian. This is now the standard view.
However, some have found this position unfounded; in particular, Pitts (Reference Pitts2014b) argues that the Extended Hamiltonian is unmotivated because he takes the Total Hamiltonian to correctly generate the dynamics, and so he takes the gauge transformations between solutions to be more restrictive than the transformations relating solutions to the Extended Hamiltonian. One can take Pitts to be arguing that a Hamiltonian theory should be formulated intrinsically on the primary constraint surface, and not on the final constraint surface.
There are two reactions that one could have to the disagreement between the standard view and that of Pitts. First, one could maintain that the question of whether arbitrary combinations of first-class constraints generate gauge transformations or not comes down to whether the Total Hamiltonian or Extended Hamiltonian is considered the right equivalence class of Hamiltonians, and this needs to be independently settled. Second, one could maintain that what the debate shows is that there is no Hamiltonian-independent way to characterize the gauge transformations, but that we can think of these different forms of the Hamiltonian as equivalent, and so there is no conflict.Footnote 15 We will presently argue that the first option is right: there is a way to settle the question of which equivalence class of Hamiltonians should be regarded as the right one through considerations of excess structure.
4. The Extended Hamiltonian removes excess structure
We have already seen that there is a sense in which the Total Hamiltonian and the Extended Hamiltonian naturally correspond to the theories formulated intrinsically on the primary constraint surface and the final constraint surface, respectively. However, given the inconsistencies that arise with the intrinsic dynamics on
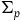 $\Sigma_{p}$
, the corresponding theory will need to be such that it essentially takes the dynamics to be defined only at those points that satisfy the secondary constraints. We will therefore think of the theory characterized by the Total Hamiltonian as being defined geometrically in terms of the structure
$\Sigma_{p}$
, the corresponding theory will need to be such that it essentially takes the dynamics to be defined only at those points that satisfy the secondary constraints. We will therefore think of the theory characterized by the Total Hamiltonian as being defined geometrically in terms of the structure
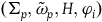 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
where H is the Hamiltonian restricted to the primary constraint surface and
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
where H is the Hamiltonian restricted to the primary constraint surface and
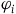 $\varphi_i$
are the secondary constraints, and we will take the dynamics of this theory to be given by two equations:
$\varphi_i$
are the secondary constraints, and we will take the dynamics of this theory to be given by two equations:
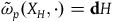 $\tilde{\omega}_{p}(X_H, \cdot) = {\bf{d}}H$
and
$\tilde{\omega}_{p}(X_H, \cdot) = {\bf{d}}H$
and
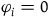 $\varphi_i=0$
. Similarly, we can think of the theory described by the Extended Hamiltonian as characterized geometrically by the structure
$\varphi_i=0$
. Similarly, we can think of the theory described by the Extended Hamiltonian as characterized geometrically by the structure
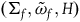 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
, where H is the Hamiltonian restricted to the final constraint surface, and the dynamics are given by the single equation
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
, where H is the Hamiltonian restricted to the final constraint surface, and the dynamics are given by the single equation
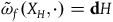 $\tilde{\omega}_{f}(X_H, \cdot) = {\bf{d}}H$
.
$\tilde{\omega}_{f}(X_H, \cdot) = {\bf{d}}H$
.
Characterizing the theories in this way naturally provides a sense in which the Extended Hamiltonian theory regards more solutions as equivalent compared to the Total Hamiltonian theory. Consider the vector fields of the form
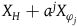 $X_H+a^jX_{\varphi_j}$
where
$X_H+a^jX_{\varphi_j}$
where
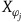 $X_{\varphi_j}$
are the vector fields associated with the secondary first-class constraints
$X_{\varphi_j}$
are the vector fields associated with the secondary first-class constraints
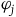 $\varphi_j$
. These vector fields correspond to equivalent solutions according to the Extended Hamiltonian theory, since the solutions to
$\varphi_j$
. These vector fields correspond to equivalent solutions according to the Extended Hamiltonian theory, since the solutions to
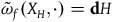 $\tilde{\omega}_{f}(X_H, \cdot) = {\bf{d}}H$
are unique up to arbitrary combinations of vector fields associated with the first-class constraints. On the other hand, they are distinct solutions according to the Total Hamiltonian theory, in the sense that they are solutions to distinct Hamiltonian functions on
$\tilde{\omega}_{f}(X_H, \cdot) = {\bf{d}}H$
are unique up to arbitrary combinations of vector fields associated with the first-class constraints. On the other hand, they are distinct solutions according to the Total Hamiltonian theory, in the sense that they are solutions to distinct Hamiltonian functions on
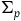 $\Sigma_{p}$
. The reason is that
$\Sigma_{p}$
. The reason is that
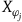 $X_{\varphi_j}$
are not null vector fields of
$X_{\varphi_j}$
are not null vector fields of
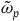 $\tilde{\omega}_{p}$
, while they are of
$\tilde{\omega}_{p}$
, while they are of
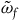 $\tilde{\omega}_{f}$
.
$\tilde{\omega}_{f}$
.
However, in another sense, these theories are empirically equivalent. The reason is that the solutions that Total Hamiltonian theory distinguishes between that the Extended Hamiltonian theory does not are solutions that correspond to distinct Hamiltonian functions, according to the Total Hamiltonian theory, only at points that lie outside of the final constraint surface. Since the points that do not lie on the final constraint surface are regarded as empirically inaccessible according to both theories, this suggests that by the lights of both theories, there is no way to empirically distinguish such solutions—they are generated by Hamiltonians that are equivalent at all points that are empirically accessible.Footnote 16
We can therefore say that the theories agree about empirical content but disagree about which curves on the state space correspond to (physically) equivalent solutions. This suggests that we are precisely in a situation of ‘excess structure’: the Total Hamiltonian theory draws distinctions that one does not need to make in order to capture the empirical content of the theory.
Let us spell this out precisely, starting with the idea that a Total Hamiltonian theory has fewer symmetries, or isomorphisms, than the associated Extended Hamiltonian theory. Take the symmetries of the Total Hamiltonian theory to be given by diffeomorphisms of
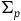 $\Sigma_{p}$
,
$\Sigma_{p}$
,
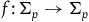 $f\colon\Sigma_{p}\rightarrow \Sigma_{p}$
, that preserve the two-form
$f\colon\Sigma_{p}\rightarrow \Sigma_{p}$
, that preserve the two-form
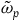 $\tilde{\omega}_{p}$
in the sense that
$\tilde{\omega}_{p}$
in the sense that
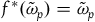 $f^*(\tilde{\omega}_{p})=\tilde{\omega}_{p}$
and preserves the Hamiltonian H and secondary constraints
$f^*(\tilde{\omega}_{p})=\tilde{\omega}_{p}$
and preserves the Hamiltonian H and secondary constraints
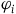 $\varphi_i$
in the sense that
$\varphi_i$
in the sense that
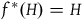 $f^*(H)=H$
and
$f^*(H)=H$
and
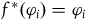 $f^*(\varphi_i)=\varphi_i$
. Similarly, take the symmetries of the Extended Hamiltonian theory to be given by diffeomorphisms of
$f^*(\varphi_i)=\varphi_i$
. Similarly, take the symmetries of the Extended Hamiltonian theory to be given by diffeomorphisms of
 $\Sigma_{f}$
,
$\Sigma_{f}$
,
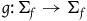 $g\colon\Sigma_{f}\rightarrow \Sigma_{f}$
such that
$g\colon\Sigma_{f}\rightarrow \Sigma_{f}$
such that
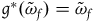 $g^*(\tilde{\omega}_{f})=\tilde{\omega}_{f}$
and
$g^*(\tilde{\omega}_{f})=\tilde{\omega}_{f}$
and
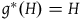 $g^*(H)=H$
. In other words, the symmetries are just the automorphisms of the structures
$g^*(H)=H$
. In other words, the symmetries are just the automorphisms of the structures
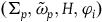 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
and
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
and
 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
respectively. Notice that these symmetries preserve solutions to the equations of motion since the solutions are determined by the two-form and the Hamiltonian. Then:
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
respectively. Notice that these symmetries preserve solutions to the equations of motion since the solutions are determined by the two-form and the Hamiltonian. Then:
Proposition 1. The automorphisms of
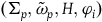 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
, restricted to their action on
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
, restricted to their action on
 $\Sigma_{f}$
, are a subset of the automorphisms of
$\Sigma_{f}$
, are a subset of the automorphisms of
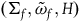 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
.Footnote 17
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
.Footnote 17
The core part of the proof of this proposition is contained in the fact that the null vector fields of
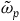 $\tilde{\omega}_{p}$
are a subset of the null vector fields of
$\tilde{\omega}_{p}$
are a subset of the null vector fields of
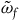 $\tilde{\omega}_{f}$
(when we consider the action of these vector fields on the final constraint surface) and arbitrary transformations along the null vector fields are automorphisms of the respective structure. This shows that there are ‘fewer’ isomorphisms of the Total Hamiltonian theory compared to the Extended Hamiltonian theory. As we pointed out in section 2, having more isomorphisms is associated with having less structure. Therefore, the above proposition suggests that the Total Hamiltonian theory should be thought to have more structure than the Extended Hamiltonian theory.Footnote 18
$\tilde{\omega}_{f}$
(when we consider the action of these vector fields on the final constraint surface) and arbitrary transformations along the null vector fields are automorphisms of the respective structure. This shows that there are ‘fewer’ isomorphisms of the Total Hamiltonian theory compared to the Extended Hamiltonian theory. As we pointed out in section 2, having more isomorphisms is associated with having less structure. Therefore, the above proposition suggests that the Total Hamiltonian theory should be thought to have more structure than the Extended Hamiltonian theory.Footnote 18
We can spell out the comparison of structure more precisely using tools from category theory.
Define the category TotHam (the category of Total Hamiltonian theories) as having as objects the models
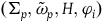 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
and as arrows between objects
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
and as arrows between objects
 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
,
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
,
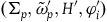 $(\Sigma_{p}, \tilde{\omega}_{p}', H',\varphi_i')$
the diffeomorphisms
$(\Sigma_{p}, \tilde{\omega}_{p}', H',\varphi_i')$
the diffeomorphisms
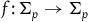 $f\colon \Sigma_{p} \rightarrow \Sigma_{p}$
such that
$f\colon \Sigma_{p} \rightarrow \Sigma_{p}$
such that
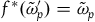 $f^*(\tilde{\omega}_{p}')=\tilde{\omega}_{p}$
,
$f^*(\tilde{\omega}_{p}')=\tilde{\omega}_{p}$
,
 $f^*(H')=H$
, and
$f^*(H')=H$
, and
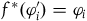 $f^*(\varphi_i')=\varphi_i$
, i.e. the symmetries are taken to be the symplectomorphisms that preserve the Hamiltonian and the secondary constraints.
$f^*(\varphi_i')=\varphi_i$
, i.e. the symmetries are taken to be the symplectomorphisms that preserve the Hamiltonian and the secondary constraints.
Similarly, define the category ExtHam (the category of Extended Hamiltonian theories) as having as objects the models
 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
and as arrows between objects
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
and as arrows between objects
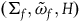 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
,
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
,
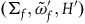 $(\Sigma_{f}, \tilde{\omega}_{f}', H')$
the diffeomorphisms
$(\Sigma_{f}, \tilde{\omega}_{f}', H')$
the diffeomorphisms
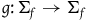 $g\colon \Sigma_{f} \rightarrow \Sigma_{f}$
such that
$g\colon \Sigma_{f} \rightarrow \Sigma_{f}$
such that
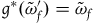 $g^*(\tilde{\omega}_{f}')=\tilde{\omega}_{f}$
and
$g^*(\tilde{\omega}_{f}')=\tilde{\omega}_{f}$
and
 $g^*(H')=H$
.
$g^*(H')=H$
.
Consider the functor
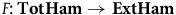 $F\colon \bf{TotHam}\rightarrow \bf{ExtHam}$
that takes each model
$F\colon \bf{TotHam}\rightarrow \bf{ExtHam}$
that takes each model
 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
to its restriction to the points that satisfy the constraints
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
to its restriction to the points that satisfy the constraints
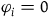 $\varphi_i=0$
, i.e. the associated model
$\varphi_i=0$
, i.e. the associated model
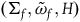 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
, and that takes the arrow f to its action on
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
, and that takes the arrow f to its action on
 $\Sigma_{f}$
(since f preserves the secondary constraints, f preserves
$\Sigma_{f}$
(since f preserves the secondary constraints, f preserves
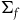 $\Sigma_{f}$
, and so this is well defined). Then:
$\Sigma_{f}$
, and so this is well defined). Then:
Proposition 2
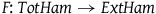 $F\colon {TotHam} \rightarrow {ExtHam}$
forgets (only) structure.Footnote 19
$F\colon {TotHam} \rightarrow {ExtHam}$
forgets (only) structure.Footnote 19
Inasmuch as forgetting structure in category-theoretic terms captures what it means for one theory to have less structure than another, this proposition captures a precise sense in which the Extended Hamiltonian formalism removes structure from the Total Hamiltonian formalism. Moreover, F preserves empirical content because it takes the Hamiltonian in the model
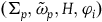 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
to its restriction to the points of
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
to its restriction to the points of
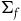 $\Sigma_{f}$
, which are precisely the points where the Hamiltonian is empirically accessible. Therefore, the proposition allows us to capture in precise terms the sense in which characterizing gauge theories in terms of the Total Hamiltonian has ‘excess structure’: there is an alternative way to characterize the empirical content of such theories but with less structure, by characterizing the theories in terms of the Extended Hamiltonian.
$\Sigma_{f}$
, which are precisely the points where the Hamiltonian is empirically accessible. Therefore, the proposition allows us to capture in precise terms the sense in which characterizing gauge theories in terms of the Total Hamiltonian has ‘excess structure’: there is an alternative way to characterize the empirical content of such theories but with less structure, by characterizing the theories in terms of the Extended Hamiltonian.
An interesting consequence of this argument is that it provides a response to a recent argument by Pitts (Reference Pitts2022, Reference Pitts2024) that moving to the Extended Hamiltonian is a ‘trivial reformulation’ of the theory characterized by the Total Hamiltonian. In particular, Pitts argues that we can always add new ‘gauge’ transformations by adding new terms to the Hamiltonian while preserving empirical content. To support this, Pitts invites us to consider a simple example. Take a Lagrangian given by
 $L_1={{1}\over{2}}\dot{q}^2.$
$L_1={{1}\over{2}}\dot{q}^2.$
This describes a particle moving in a straight line with uniform velocity; the equation of motion is
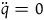 $\ddot{q}=0$
. Now consider the Lagrangian
$\ddot{q}=0$
. Now consider the Lagrangian
 $L_2={{1}\over{2}}(\dot{q}-\dot{\mu})^2,$
$L_2={{1}\over{2}}(\dot{q}-\dot{\mu})^2,$
where
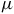 $\mu$
is either an arbitrary function of time or a dynamical variable. This Lagrangian is invariant under the transformation
$\mu$
is either an arbitrary function of time or a dynamical variable. This Lagrangian is invariant under the transformation
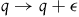 $q \rightarrow q + \epsilon$
,
$q \rightarrow q + \epsilon$
,
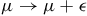 $\mu \rightarrow \mu + \epsilon$
, where
$\mu \rightarrow \mu + \epsilon$
, where
 $\epsilon$
is an arbitrary function of time. Since not all choices of
$\epsilon$
is an arbitrary function of time. Since not all choices of
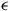 $\epsilon$
are symmetries of
$\epsilon$
are symmetries of
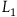 $L_1$
, Pitts argues that we have added symmetries by moving from
$L_1$
, Pitts argues that we have added symmetries by moving from
 $L_1$
to
$L_1$
to
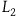 $L_2$
. Moreover,
$L_2$
. Moreover,
 $L_2$
gives rise to the equation of motion
$L_2$
gives rise to the equation of motion
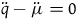 $\ddot{q}-\ddot{\mu} =0$
, which says that
$\ddot{q}-\ddot{\mu} =0$
, which says that
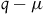 $q-\mu$
represents a particle moving in a straight line with uniform velocity. Therefore, the argument goes, we have added symmetries while keeping the empirical content the same.
$q-\mu$
represents a particle moving in a straight line with uniform velocity. Therefore, the argument goes, we have added symmetries while keeping the empirical content the same.
In the Hamiltonian framework, the move from
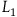 $L_1$
to
$L_1$
to
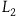 $L_2$
can be seen to add gauge symmetries in the following way: there are no constraints corresponding to
$L_2$
can be seen to add gauge symmetries in the following way: there are no constraints corresponding to
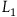 $L_1$
and so there is no gauge freedom. However, treating
$L_1$
and so there is no gauge freedom. However, treating
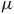 $\mu$
as a dynamical variable, we find that the Hamiltonian formulation of
$\mu$
as a dynamical variable, we find that the Hamiltonian formulation of
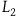 $L_2$
has a constraint,
$L_2$
has a constraint,
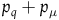 $p_q+p_{\mu}$
, which is first-class. So, there are new gauge transformations in the Hamiltonian formulation; the transformations
$p_q+p_{\mu}$
, which is first-class. So, there are new gauge transformations in the Hamiltonian formulation; the transformations
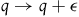 $q \rightarrow q + \epsilon$
,
$q \rightarrow q + \epsilon$
,
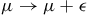 $\mu \rightarrow \mu + \epsilon$
generated by the first-class constraint.
$\mu \rightarrow \mu + \epsilon$
generated by the first-class constraint.
Pitts calls this process of revising a Lagrangian by adding a new variable (or ‘splitting one quantity into two’) and thereby adding new symmetries ‘de-Ockhamization’. Arguably, it is a trivial way of adding symmetries, as demonstrated by the above example. But, Pitts argues, this is exactly what is going on when one moves from the Total to the Extended Hamiltonian: one adds a new term to the Hamiltonian—some arbitrary function of the secondary constraints—and in doing so, one introduces new symmetries while preserving empirical content. Therefore, these additional gauge symmetries that the Extended Hamiltonian theory is associated with should not be regarded as ‘genuine’ gauge transformations, in just the same way that the symmetries of
 $L_2$
are not physically interesting symmetries.
$L_2$
are not physically interesting symmetries.
However, once we understand the relationship between the Total Hamiltonian and the Extended Hamiltonian in terms of Propositions 1 and 2, we can see that the process of ‘de-Ockhamization’ is not what is going on when one moves from the Total Hamiltonian to the Extended Hamiltonian. The reason is that one cannot set up a proposition analogous to Proposition 1 in the case of de-Ockhamization and simultaneously maintain that the two theories are empirically equivalent. To see this, recall that Proposition 1 stated that the symmetries of the Total Hamiltonian theory are a subset of those of the Extended Hamiltonian theory, when we consider their action on the same state space. This last clause is important: to compare the symmetries of two theories, we need some mapping between the two theories so that we can say which symmetries are being identified.
If we want to claim that
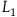 $L_1$
and
$L_1$
and
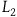 $L_2$
are empirically equivalent, then the natural choice of mapping is to take q to represent the position of the particle in
$L_2$
are empirically equivalent, then the natural choice of mapping is to take q to represent the position of the particle in
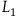 $L_1$
and
$L_1$
and
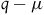 $q-\mu$
to represent the position of the particle in
$q-\mu$
to represent the position of the particle in
 $L_2$
.Footnote 20 Therefore, we ought to consider the relationship between the symmetries under this standard of comparison. But now we run into a problem: the transformations of q that preserve the Euler–Lagrange equations for
$L_2$
.Footnote 20 Therefore, we ought to consider the relationship between the symmetries under this standard of comparison. But now we run into a problem: the transformations of q that preserve the Euler–Lagrange equations for
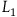 $L_1$
are the same as the transformations of
$L_1$
are the same as the transformations of
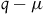 $q-\mu$
that preserve the Euler–Lagrange equations for
$q-\mu$
that preserve the Euler–Lagrange equations for
 $L_2$
. Indeed, all we have done is effectively change the label of the variable that represents position. This is clearly a trivial kind of reformulation. However, it does not support the claim that
$L_2$
. Indeed, all we have done is effectively change the label of the variable that represents position. This is clearly a trivial kind of reformulation. However, it does not support the claim that
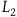 $L_2$
has additional symmetries, since under the standard of comparison where q is identified with
$L_2$
has additional symmetries, since under the standard of comparison where q is identified with
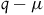 $q-\mu$
, the Lagrangians are empirically equivalent and also have the same symmetries.
$q-\mu$
, the Lagrangians are empirically equivalent and also have the same symmetries.
One might try to respond by saying the following: we have added symmetries by moving to
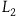 $L_2$
because the transformations
$L_2$
because the transformations
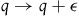 $q \rightarrow q+\epsilon$
,
$q \rightarrow q+\epsilon$
,
 $\mu\rightarrow \mu+\epsilon$
, where
$\mu\rightarrow \mu+\epsilon$
, where
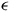 $\epsilon$
is an arbitrary function of time, are symmetries of
$\epsilon$
is an arbitrary function of time, are symmetries of
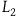 $L_2$
that are not symmetries of
$L_2$
that are not symmetries of
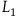 $L_1$
and that preserve the equations of motion. But under the identification of q with
$L_1$
and that preserve the equations of motion. But under the identification of q with
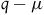 $q-\mu$
, these transformations are symmetries of
$q-\mu$
, these transformations are symmetries of
 $L_1$
, since they correspond to the identity transformation on q in
$L_1$
, since they correspond to the identity transformation on q in
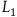 $L_1$
. What this response points out is that there are many symmetries of
$L_1$
. What this response points out is that there are many symmetries of
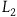 $L_2$
, differing over the choice of
$L_2$
, differing over the choice of
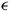 $\epsilon$
, that correspond to a single symmetry of
$\epsilon$
, that correspond to a single symmetry of
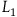 $L_1$
. However, this is not sufficient to set up an analogous proposition to that of Proposition 1; one cannot say that there is a symmetry of
$L_1$
. However, this is not sufficient to set up an analogous proposition to that of Proposition 1; one cannot say that there is a symmetry of
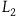 $L_2$
that is not a symmetry of
$L_2$
that is not a symmetry of
 $L_1$
when we identify q in
$L_1$
when we identify q in
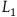 $L_1$
with
$L_1$
with
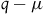 $q-\mu$
in
$q-\mu$
in
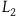 $L_2$
.
$L_2$
.
The upshot is that there is no way to maintain simultaneously that
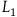 $L_1$
and
$L_1$
and
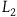 $L_2$
are empirically equivalent and that the symmetries of
$L_2$
are empirically equivalent and that the symmetries of
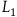 $L_1$
are a subset of the symmetries of
$L_1$
are a subset of the symmetries of
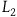 $L_2$
. Under the mapping that preserves empirical content, every symmetry of the first theory is a symmetry of the second theory and vice versa. Since Propositions 1 and 2 show that the symmetries of the Total Hamiltonian theory are a subset of those of the Extended Hamiltonian theory under the map that preserves empirical content—namely, the map that takes every point on the final constraint surface to itself—this suffices to show that de-Ockhamization is not what is going on in the move from the Total Hamiltonian to the Extended Hamiltonian. Therefore, whether de-Ockhamization is a way of trivially adding gauge symmetries is orthogonal to the question of the significance of moving from the Total Hamiltonian to the Extended Hamiltonian.
$L_2$
. Under the mapping that preserves empirical content, every symmetry of the first theory is a symmetry of the second theory and vice versa. Since Propositions 1 and 2 show that the symmetries of the Total Hamiltonian theory are a subset of those of the Extended Hamiltonian theory under the map that preserves empirical content—namely, the map that takes every point on the final constraint surface to itself—this suffices to show that de-Ockhamization is not what is going on in the move from the Total Hamiltonian to the Extended Hamiltonian. Therefore, whether de-Ockhamization is a way of trivially adding gauge symmetries is orthogonal to the question of the significance of moving from the Total Hamiltonian to the Extended Hamiltonian.
5. Symplectic reduction does not remove further structure
Given that we have convinced ourselves that the theory characterized by the Extended Hamiltonian removes excess structure from the theory characterized by the Total Hamiltonian, a natural question arises: is the theory characterized by the Extended Hamiltonian a theory without excess structure, or is there some other theory that has even less structure while preserving empirical content? Indeed, the standard way of removing what is regarded as excess structure from a Hamiltonian gauge theory is to undergo symplectic reduction. We therefore want to consider the relationship between the theory one gets via symplectic reduction and the theory characterized by ExtHam.
On the face of it, models of ExtHam have a kind of redundancy: states along the gauge orbits on
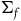 $\Sigma_{f}$
cannot be distinguished by the induced two-form, and so the theory doesn’t depend upon which point along a gauge orbit one chooses to represent the state of a system. In light of this, it is tempting to make the following interpretive move: one should treat gauge-related states/solutions as being equivalent. Therefore, only gauge-invariant quantities (the ‘observables’) should be interpreted as physically meaningful. However, if we want to interpret gauge-related states/solutions as being equivalent, then, the argument goes, we should find a new mathematical formalism for describing Hamiltonian gauge theories such that gauge-related states/solutions are identified. The symplectic reduced theory is such a formalism.
$\Sigma_{f}$
cannot be distinguished by the induced two-form, and so the theory doesn’t depend upon which point along a gauge orbit one chooses to represent the state of a system. In light of this, it is tempting to make the following interpretive move: one should treat gauge-related states/solutions as being equivalent. Therefore, only gauge-invariant quantities (the ‘observables’) should be interpreted as physically meaningful. However, if we want to interpret gauge-related states/solutions as being equivalent, then, the argument goes, we should find a new mathematical formalism for describing Hamiltonian gauge theories such that gauge-related states/solutions are identified. The symplectic reduced theory is such a formalism.
For example, Thébault (Reference Thébault2012) says that one could interpret a theory in the constrained Hamiltonian formalism by ‘instituting a many-to-one relationship between gauge-related sequences of points on the constraint surface and the unique sequences of instantaneous states they represent’ but that this ‘does nothing about removing what would seem like superfluous mathematical structure—to dispense with this surplus structure we need to move to the reduced phase space’. Similarly, Belot (Reference Belot2003) says that ‘because the points of such orbits are dynamically indifferent, the
 $x_i$
[the gauge variables] are dynamically irrelevant—any way of setting their value leads to the “same” evolution. This suggests in turn that it may be possible to drop the
$x_i$
[the gauge variables] are dynamically irrelevant—any way of setting their value leads to the “same” evolution. This suggests in turn that it may be possible to drop the
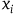 $x_i$
from our theory altogether’. These quotes suggest that reduction provides an option for removing redundancy present in a model of ExtHam since the points of the reduced space are just the equivalence class of points along the gauge orbits.
$x_i$
from our theory altogether’. These quotes suggest that reduction provides an option for removing redundancy present in a model of ExtHam since the points of the reduced space are just the equivalence class of points along the gauge orbits.
In more detail, symplectic reduction works as follows: we take the theory defined on the final constraint surface, and then we ‘quotient out’ the gauge symmetries by effectively equivocating between the points along the gauge orbits.Footnote 21 More precisely, we can define a smooth, differentiable manifold
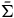 $\bar{\Sigma}$
by taking the quotient of
$\bar{\Sigma}$
by taking the quotient of
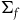 $\Sigma_{f}$
by the kernel of
$\Sigma_{f}$
by the kernel of
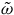 $\tilde{\omega}$
, i.e. the null vector fields of
$\tilde{\omega}$
, i.e. the null vector fields of
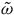 $\tilde{\omega}$
. Next, we can define an open, surjective projection map
$\tilde{\omega}$
. Next, we can define an open, surjective projection map
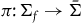 $\pi\colon \Sigma_{f} \rightarrow \bar{\Sigma}$
such that we define the reduced two-form
$\pi\colon \Sigma_{f} \rightarrow \bar{\Sigma}$
such that we define the reduced two-form
 $\bar{\omega}$
via
$\bar{\omega}$
via
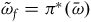 $\tilde{\omega}_{f}=\pi^*(\bar{\omega})$
, which acts according to
$\tilde{\omega}_{f}=\pi^*(\bar{\omega})$
, which acts according to
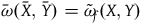 $\bar{\omega}(\bar{X},\bar{Y})=\tilde{\omega}_{f}(X,Y)$
where
$\bar{\omega}(\bar{X},\bar{Y})=\tilde{\omega}_{f}(X,Y)$
where
 $\bar{X}=\pi_*(X)$
. One can show that
$\bar{X}=\pi_*(X)$
. One can show that
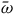 $\bar{\omega}$
is well defined and is symplectic. We can also define a reduced Hamiltonian
$\bar{\omega}$
is well defined and is symplectic. We can also define a reduced Hamiltonian
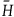 $\bar{H}$
as the value of H on the equivalence class of points along the gauge orbits, i.e.
$\bar{H}$
as the value of H on the equivalence class of points along the gauge orbits, i.e.
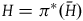 $H = \pi^* (\bar{H})$
. This is well defined because H is constant along the gauge orbits on the final constraint surface. We can therefore write the equations of motion on the reduced space in terms of the reduced Hamiltonian as
$H = \pi^* (\bar{H})$
. This is well defined because H is constant along the gauge orbits on the final constraint surface. We can therefore write the equations of motion on the reduced space in terms of the reduced Hamiltonian as
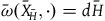 $\bar{\omega}(\bar{X}_{\bar{H}},\cdot)=d\bar{H}$
, whose solutions are the projection of the solutions to the equations of motion on
$\bar{\omega}(\bar{X}_{\bar{H}},\cdot)=d\bar{H}$
, whose solutions are the projection of the solutions to the equations of motion on
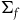 $\Sigma_{f}$
to
$\Sigma_{f}$
to
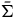 $\bar{\Sigma}$
. We can think of the dynamics on the reduced space as just the dynamics for the gauge-invariant variables. This provides the sense in which the reduced theory preserves empirical content: the predictions for the ‘physical’ variables are the same.
$\bar{\Sigma}$
. We can think of the dynamics on the reduced space as just the dynamics for the gauge-invariant variables. This provides the sense in which the reduced theory preserves empirical content: the predictions for the ‘physical’ variables are the same.
In order to evaluate the argument that reduction removes excess structure, let us consider the relationship between the reduced theory and the theory defined on the final constraint surface given by ExtHam. Unlike in the case of moving from the Total Hamiltonian theory to the Extended Hamiltonian theory, we cannot think about the automorphisms of the Extended Hamiltonian theory and the reduced theory as acting on the same state space, since
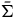 $\bar{\Sigma}$
is not a submanifold of
$\bar{\Sigma}$
is not a submanifold of
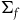 $\Sigma_{f}$
or vice versa. Instead, we think of
$\Sigma_{f}$
or vice versa. Instead, we think of
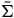 $\bar{\Sigma}$
as the projection of
$\bar{\Sigma}$
as the projection of
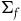 $\Sigma_{f}$
under a map that collapses distinctions between the points along the gauge orbits. Therefore, we cannot say that the automorphisms of one are a subset of the other in the same way. Instead, what we can say is that:
$\Sigma_{f}$
under a map that collapses distinctions between the points along the gauge orbits. Therefore, we cannot say that the automorphisms of one are a subset of the other in the same way. Instead, what we can say is that:
Proposition 3 Every automorphism of
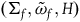 $(\Sigma_{f}, \tilde{\omega}_{f},H)$
, under the projection
$(\Sigma_{f}, \tilde{\omega}_{f},H)$
, under the projection
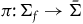 $\pi\colon\Sigma_{f} \rightarrow \bar{\Sigma}$
, is an automorphism of
$\pi\colon\Sigma_{f} \rightarrow \bar{\Sigma}$
, is an automorphism of
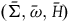 $(\bar{\Sigma}, \bar{\omega},\bar{H})$
, and every automorphism of
$(\bar{\Sigma}, \bar{\omega},\bar{H})$
, and every automorphism of
 $(\bar{\Sigma}, \bar{\omega},\bar{H})$
corresponds to some automorphism(s) of
$(\bar{\Sigma}, \bar{\omega},\bar{H})$
corresponds to some automorphism(s) of
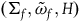 $(\Sigma_{f}, \tilde{\omega}_{f},H)$
under
$(\Sigma_{f}, \tilde{\omega}_{f},H)$
under
 $\pi$
.Footnote 22
$\pi$
.Footnote 22
Since this proposition says that all of the symmetries of the Extended Hamiltonian theory correspond to symmetries of the reduced theory, we cannot infer that one theory has more structure than the other by drawing an analogy with Proposition 1. So let us see whether the category-theoretic approach can shed light on the structural relationship between these theories.
An issue that we face is that some of the models in ExtHam are, essentially, partial reductions of other models in ExtHam, since we didn’t restrict the dimension of the final constraint surface when defining this category, nor the dimension of the null space. Given that we want to capture the relationship between theories and their reduced counterpart, we will restrict to the case where the models of ExtHam have the same dimensions, which excludes the case of objects within the category ExtHam being related by (partial) reduction.
We can define the category HamRed as having objects
 $(\bar{\Sigma},\bar{\omega},\bar{H})$
and arrows between objects
$(\bar{\Sigma},\bar{\omega},\bar{H})$
and arrows between objects
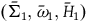 $(\bar{\Sigma}_1,\bar{\omega}_{1},\bar{H}_1)$
and
$(\bar{\Sigma}_1,\bar{\omega}_{1},\bar{H}_1)$
and
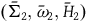 $(\bar{\Sigma}_2,\bar{\omega}_{2},\bar{H}_2)$
to be given by diffeomorphisms
$(\bar{\Sigma}_2,\bar{\omega}_{2},\bar{H}_2)$
to be given by diffeomorphisms
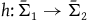 $h\colon \bar{\Sigma}_1 \rightarrow \bar{\Sigma}_2$
such that
$h\colon \bar{\Sigma}_1 \rightarrow \bar{\Sigma}_2$
such that
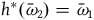 $h^*(\bar{\omega}_{2})=\bar{\omega}_{1}$
and
$h^*(\bar{\omega}_{2})=\bar{\omega}_{1}$
and
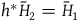 $h^*\bar{H}_2=\bar{H}_1$
. Take the functor G that takes the object
$h^*\bar{H}_2=\bar{H}_1$
. Take the functor G that takes the object
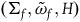 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
to
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
to
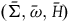 $(\bar{\Sigma},\bar{\omega},\bar{H})$
and that takes an arrow
$(\bar{\Sigma},\bar{\omega},\bar{H})$
and that takes an arrow
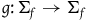 $g\colon \Sigma_{f} \rightarrow \Sigma_{f}$
to
$g\colon \Sigma_{f} \rightarrow \Sigma_{f}$
to
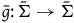 $\bar{g}\colon \bar{\Sigma}\rightarrow \bar{\Sigma}$
where
$\bar{g}\colon \bar{\Sigma}\rightarrow \bar{\Sigma}$
where
 $\bar{g}(\bar{x})=g(\bar{x})$
, i.e.
$\bar{g}(\bar{x})=g(\bar{x})$
, i.e.
 $\bar{g}$
is the action of g on the gauge orbits, such that whenever g acts by moving points of
$\bar{g}$
is the action of g on the gauge orbits, such that whenever g acts by moving points of
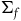 $\Sigma_{f}$
along the gauge orbits,
$\Sigma_{f}$
along the gauge orbits,
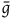 $\bar{g}$
acts as the identity on
$\bar{g}$
acts as the identity on
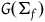 $G(\Sigma_{f})$
. This is well defined because every arrow
$G(\Sigma_{f})$
. This is well defined because every arrow
 $g\colon \Sigma_{f} \rightarrow \Sigma_{f}$
preserves the gauge orbits. Then, the following is true:
$g\colon \Sigma_{f} \rightarrow \Sigma_{f}$
preserves the gauge orbits. Then, the following is true:
Proposition 4
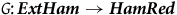 $G\colon \boldsymbol{ExtHam}\rightarrow \boldsymbol{HamRed}$
is full and essentially surjective but not faithful, i.e. G forgets only stuff.Footnote 23
$G\colon \boldsymbol{ExtHam}\rightarrow \boldsymbol{HamRed}$
is full and essentially surjective but not faithful, i.e. G forgets only stuff.Footnote 23
This shows us that symplectic reduction is not a way of removing ‘excess structure’ from ExtHam. In a way, this was to be expected: we already established that gauge symmetries are isomorphisms of the models of ExtHam, and so this theory already captures the idea that gauge symmetries relate physically equivalent situations. Nevertheless, the fact that the functor G forgets ‘stuff’ remains significant. As we suggested in section 2, one can think about a theory with more stuff as exhibiting ‘representational redundancy’: the models of that theory can be used to represent some object or physical situation in lots of different ways through its non-trivial automorphisms. This seems to correctly capture the role of the gauge transformations in ExtHam: they reflect the fact that any point along the gauge orbit is equally well suited to represent some physical state.Footnote 24 Moreover, removing this ‘redundancy’ seems well motivated from the perspective of pursuing a well-posed initial value problem. Therefore, while symplectic reduction does not remove excess structure, Proposition 4 might nonetheless indicate that it removes a relevant form of redundancy from the theory on the final constraint surface—one associated with the failure of a well-posed initial value problem.
However, as we also discussed in section 2, having more ‘stuff’ can indicate that the theory has less ‘structure’, and therefore that the two notions of redundancy can pull in different directions. Indeed, notice that a different way of removing the ‘representational redundancy’ that ExtHam has would be to pick out a representative for each gauge orbit—that is, to fix a gauge. By analogy, one might regard symplectic reduction as adding structure insofar as it is effectively like fixing a representative for each gauge orbit.
Of course, much more could be said about the similarities and differences between symplectic reduction and gauge fixing. But at the very least, the foregoing discussion shows that the notions of structure and stuff must be handled with care in the context of gauge theories, and that the corresponding types of redundancy they track should not be conflated. This observation may have important implications, for instance, when considering the motivations behind standard quantization procedures that proceed through—or are equivalent to proceeding through—the reduced theory.
6. Conclusion
We have examined two central questions. First, what is the relationship between the structure of the Total Hamiltonian theory and that of the Extended Hamiltonian theory? Second, what is the relationship between the structure of the Extended Hamiltonian theory and the symplectic reduced theory? We argued that the first relation is best understood in terms of excess structure, whereas the second concerns representational redundancy. We used this to argue that the motivations for symplectic reduction differ, conceptually, from the motivations for moving from the Total Hamiltonian to the Extended Hamiltonian.
While our focus has been on the context of Hamiltonian gauge theories, there are broader takeaways. First, our intuitions about whether one theory is simpler or more complicated than another can diverge from whether it possesses more or less structure. In particular, counting terms in the Hamiltonian or dimensions of the state space is not sufficient to capture the amount of structure that the theories commit to. In moving from the Total to the Extended Hamiltonian, additional terms appear in the Hamiltonian, but no new structure is thereby introduced. Conversely, in symplectic reduction, while the theory is formulated on a lower-dimensional space with the same empirical content, this does not entail that it has less structure.
Second, to say that one theory has ‘excess structure’ relative to another, one needs to be able to say two things simultaneously. First, one theory has more structure than the other. Second, the two theories have the same empirical content. While one might be able to say both things relative to two different maps between the theories, being able to say both things relative to a single map is importantly different. In section 4, we discussed how this differentiates Pitts’ notion of ‘de-Ockhamization’ from the move from the Total Hamiltonian to the Extended Hamiltonian. However, it is also relevant in the context of symplectic reduction.Footnote 25 Indeed, Proposition 3 highlights that there is a sense in which the reduced theory and the Extended Hamiltonian theory have the ‘same’ symmetries, under the map that preserves empirical content: when points on the reduced space correspond to the collection of points along the corresponding gauge orbit, there is no symmetry of one theory that is not a symmetry of the other. Therefore, even though ExtHam might be said to have less ‘structure’ than HamRed, relative to a functor between the categories, it seems inappropriate to regard HamRed as having excess structure, at least in the same way that, for example, the Total Hamiltonian theory has compared to the Extended Hamiltonian theory.
Finally, the discussion here emphasizes the conceptual differences between a theory having ‘representational redundancy’ and a theory having ‘excess structure’. While both are related to the amount of structure that a theory has, as represented as a category, the interpretational significance is importantly different. In particular, whether ‘representational redundancy’ is regarded as a genuine sort of redundancy depends on what one’s representational aims are. As we have seen through our exploration of Hamiltonian gauge theories, the distinction between the two notions is especially important for understanding the relationship between theories where the dimension of the state spaces is different; in particular, when the state space of one can be understood as the quotient, under some symmetry group, of the state space of the other.
Acknowledgements
I am especially grateful to Jim Weatherall for helpful guidance on the proofs of the propositions in the paper and for comments on a previous version. I also thank Karim Thébault and Sean Gryb for several conversations that have helped me better understand the constrained Hamiltonian formalism. Finally, I am grateful to the audience at PSA 2024 for their feedback on the material in section 4, and to Brian Pitts for correspondence.
Funding statement
None to declare.
Declarations
None to declare.
Appendix A. Proofs of propositions
A.1. Proposition 1
We need to show that every automorphism of
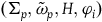 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
, restricted to its action on
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
, restricted to its action on
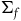 $\Sigma_{f}$
, is an automorphism of
$\Sigma_{f}$
, is an automorphism of
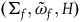 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
, but that there is some automorphism of
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
, but that there is some automorphism of
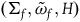 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
that is not an automorphism of
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
that is not an automorphism of
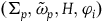 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
on
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
on
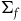 $\Sigma_{f}$
. The first follows from the fact that every automorphism of
$\Sigma_{f}$
. The first follows from the fact that every automorphism of
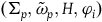 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
preserves the points where
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
preserves the points where
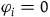 $\varphi_i=0$
(since it preserves
$\varphi_i=0$
(since it preserves
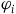 $\varphi_i$
) and so preserves
$\varphi_i$
) and so preserves
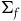 $\Sigma_{f}$
, and that
$\Sigma_{f}$
, and that
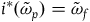 $i^*(\tilde{\omega}_{p}) = \tilde{\omega}_{f}$
, where
$i^*(\tilde{\omega}_{p}) = \tilde{\omega}_{f}$
, where
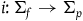 $i\colon\Sigma_{f} \rightarrow \Sigma_{p}$
is the inclusion map.
$i\colon\Sigma_{f} \rightarrow \Sigma_{p}$
is the inclusion map.
For the second, consider the diffeomorphism
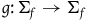 $g\colon\Sigma_{f} \rightarrow \Sigma_{f}$
that takes each point on
$g\colon\Sigma_{f} \rightarrow \Sigma_{f}$
that takes each point on
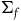 $\Sigma_{f}$
to another arbitrary point along the gauge orbit associated with the secondary first-class constraints
$\Sigma_{f}$
to another arbitrary point along the gauge orbit associated with the secondary first-class constraints
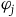 $\varphi_j$
at that point. We can represent g as the flow of the vector field associated with
$\varphi_j$
at that point. We can represent g as the flow of the vector field associated with
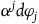 $\alpha^j d \varphi_j$
, where
$\alpha^j d \varphi_j$
, where
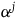 $\alpha^j$
are arbitrary functions. Since
$\alpha^j$
are arbitrary functions. Since
 $d\varphi_j=0$
on
$d\varphi_j=0$
on
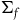 $\Sigma_{f}$
,
$\Sigma_{f}$
,
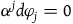 $\alpha^j d \varphi_j=0$
. This means that
$\alpha^j d \varphi_j=0$
. This means that
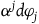 $\alpha^jd\varphi_j$
is closed, i.e.
$\alpha^jd\varphi_j$
is closed, i.e.
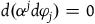 $d(\alpha^jd\varphi_j) = 0$
. But this means that one can (locally) associate a vector field Y with
$d(\alpha^jd\varphi_j) = 0$
. But this means that one can (locally) associate a vector field Y with
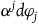 $\alpha^jd\varphi_j$
via
$\alpha^jd\varphi_j$
via
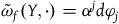 $\tilde{\omega}_{f}(Y,\cdot)=\alpha^jd\varphi_j$
. It follows that the flow of Y on
$\tilde{\omega}_{f}(Y,\cdot)=\alpha^jd\varphi_j$
. It follows that the flow of Y on
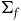 $\Sigma_{f}$
consists of maps that preserve
$\Sigma_{f}$
consists of maps that preserve
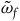 $\tilde{\omega}_{f}$
.Footnote 26 So g is a diffeomorphism that takes
$\tilde{\omega}_{f}$
.Footnote 26 So g is a diffeomorphism that takes
 $\tilde{\omega}_{f}$
to itself. Moreover,
$\tilde{\omega}_{f}$
to itself. Moreover,
 $g^*H=H$
because H is gauge invariant on the final constraint surface. So g is an automorphism of
$g^*H=H$
because H is gauge invariant on the final constraint surface. So g is an automorphism of
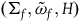 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
.
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
.
Now consider the diffeomorphism
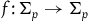 $f\colon\Sigma_{p} \rightarrow \Sigma_{p}$
that takes each point on
$f\colon\Sigma_{p} \rightarrow \Sigma_{p}$
that takes each point on
 $\Sigma_{p}$
to another point along the vector field associated with the secondary first-class constraints at that point. We can similarly consider f to be the flow of the vector field associated with
$\Sigma_{p}$
to another point along the vector field associated with the secondary first-class constraints at that point. We can similarly consider f to be the flow of the vector field associated with
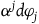 $\alpha^jd\varphi_j$
. In order to associate a vector field X with
$\alpha^jd\varphi_j$
. In order to associate a vector field X with
 $\alpha^jd\varphi_j$
via
$\alpha^jd\varphi_j$
via
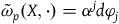 $\tilde{\omega}_{p}(X,\cdot)=\alpha^jd\varphi_j$
, it must be that
$\tilde{\omega}_{p}(X,\cdot)=\alpha^jd\varphi_j$
, it must be that
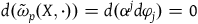 $d(\tilde{\omega}_{p}(X,\cdot))=d(\alpha^j d\varphi_j)=0$
. But
$d(\tilde{\omega}_{p}(X,\cdot))=d(\alpha^j d\varphi_j)=0$
. But
 $d_b(\alpha^jd_a\varphi_j) = \alpha^j d_b d_{a}\varphi_j + d_{[a}\varphi_jd_{b]}\alpha^j$
. The first term vanishes since
$d_b(\alpha^jd_a\varphi_j) = \alpha^j d_b d_{a}\varphi_j + d_{[a}\varphi_jd_{b]}\alpha^j$
. The first term vanishes since
 $d(d\varphi_j)=0$
by Poincaré’s lemma. However, the second term does not necessarily vanish, since
$d(d\varphi_j)=0$
by Poincaré’s lemma. However, the second term does not necessarily vanish, since
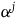 $\alpha^j$
is an arbitrary function of the canonical coordinates (so
$\alpha^j$
is an arbitrary function of the canonical coordinates (so
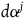 $d\alpha^j$
is not necessarily zero). In such cases, one cannot associate with f a vector field via
$d\alpha^j$
is not necessarily zero). In such cases, one cannot associate with f a vector field via
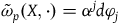 $\tilde{\omega}_{p}(X,\cdot)=\alpha^jd\varphi_j$
, and so the flow of the vector field associated with
$\tilde{\omega}_{p}(X,\cdot)=\alpha^jd\varphi_j$
, and so the flow of the vector field associated with
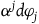 $\alpha^jd\varphi_j$
does not take
$\alpha^jd\varphi_j$
does not take
 $\tilde{\omega}_{p}$
to itself. Therefore, there are automorphisms of
$\tilde{\omega}_{p}$
to itself. Therefore, there are automorphisms of
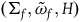 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
that do not correspond to an automorphism of
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
that do not correspond to an automorphism of
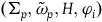 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
.
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
.
A.2. Proposition 2
We want to show that F is not full, i.e. that it fails to be surjective on arrows, but that it is faithful and essentially surjective. That F is not full follows from Proposition 1: the arrows
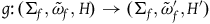 $g\colon (\Sigma_{f}, \tilde{\omega}_{f}, H) \rightarrow (\Sigma_{f}, \tilde{\omega}_{f}', H')$
in ExtHam such that
$g\colon (\Sigma_{f}, \tilde{\omega}_{f}, H) \rightarrow (\Sigma_{f}, \tilde{\omega}_{f}', H')$
in ExtHam such that
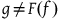 $g \neq F(f)$
for any arrow f in TotHam are transformations along the null vector fields associated with secondary first-class constraints. That F is essentially surjective follows from the fact that every object of ExtHam is the restriction of some object
$g \neq F(f)$
for any arrow f in TotHam are transformations along the null vector fields associated with secondary first-class constraints. That F is essentially surjective follows from the fact that every object of ExtHam is the restriction of some object
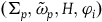 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
to the surface defined by
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
to the surface defined by
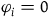 $\varphi_i=0$
. Finally, to show that F is faithful, we need to show that if two arrows f,g between objects
$\varphi_i=0$
. Finally, to show that F is faithful, we need to show that if two arrows f,g between objects
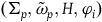 $(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
,
$(\Sigma_{p}, \tilde{\omega}_{p}, H,\varphi_i)$
,
 $(\Sigma_{p}, \tilde{\omega}_{p}', H',\varphi_i')$
of TotHam are distinct, then their action on
$(\Sigma_{p}, \tilde{\omega}_{p}', H',\varphi_i')$
of TotHam are distinct, then their action on
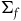 $\Sigma_{f}$
is distinct. In other words, we want to show that if
$\Sigma_{f}$
is distinct. In other words, we want to show that if
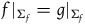 $f|_{\Sigma_{f}}=g|_{\Sigma_{f}}$
, then
$f|_{\Sigma_{f}}=g|_{\Sigma_{f}}$
, then
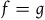 $f=g$
.
$f=g$
.
Suppose that
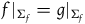 $f|_{\Sigma_{f}}=g|_{\Sigma_{f}}$
. If f, g are arbitrary gauge transformations, then the only way that f and g could differ is if they move points on
$f|_{\Sigma_{f}}=g|_{\Sigma_{f}}$
. If f, g are arbitrary gauge transformations, then the only way that f and g could differ is if they move points on
 $\Sigma_{p}$
that lie outside of
$\Sigma_{p}$
that lie outside of
 $\Sigma_{f}$
by differing amounts along the vector fields associated with the primary first-class constraints. But H is not constant along the vector fields associated with the primary first-class constraints outside of
$\Sigma_{f}$
by differing amounts along the vector fields associated with the primary first-class constraints. But H is not constant along the vector fields associated with the primary first-class constraints outside of
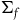 $\Sigma_{f}$
. Since f, g must preserve H by definition, f must be equal to g. If f, g are symplectomorphisms that are flows along vector fields other than the vector fields associated with the primary first-class constraints, then the only way that f and g could differ is if at least one changes the secondary constraints. But since f, g must preserve
$\Sigma_{f}$
. Since f, g must preserve H by definition, f must be equal to g. If f, g are symplectomorphisms that are flows along vector fields other than the vector fields associated with the primary first-class constraints, then the only way that f and g could differ is if at least one changes the secondary constraints. But since f, g must preserve
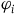 $\varphi_i$
by definition, f must be equal to g. So F is faithful.
$\varphi_i$
by definition, f must be equal to g. So F is faithful.
A.3. Proposition 3
That every automorphism of
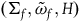 $(\Sigma_{f}, \tilde{\omega}_{f},H)$
, under the projection
$(\Sigma_{f}, \tilde{\omega}_{f},H)$
, under the projection
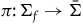 $\pi\colon\Sigma_{f} \rightarrow \bar{\Sigma}$
, is an automorphism of
$\pi\colon\Sigma_{f} \rightarrow \bar{\Sigma}$
, is an automorphism of
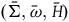 $(\bar{\Sigma}, \bar{\omega},\bar{H})$
follows from the fact that
$(\bar{\Sigma}, \bar{\omega},\bar{H})$
follows from the fact that
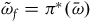 $\tilde{\omega}_{f}=\pi^*(\bar{\omega})$
and
$\tilde{\omega}_{f}=\pi^*(\bar{\omega})$
and
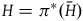 $H=\pi^*(\bar{H})$
, and so every transformation from
$H=\pi^*(\bar{H})$
, and so every transformation from
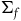 $\Sigma_{f}$
to itself that preserves
$\Sigma_{f}$
to itself that preserves
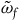 $\tilde{\omega}_{f}$
and H must preserve
$\tilde{\omega}_{f}$
and H must preserve
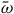 $\bar{\omega}$
and
$\bar{\omega}$
and
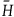 $\bar{H}$
under
$\bar{H}$
under
 $\pi$
. That every automorphism of
$\pi$
. That every automorphism of
 $(\bar{\Sigma}, \bar{\omega},\bar{H})$
corresponds to some automorphism(s) of
$(\bar{\Sigma}, \bar{\omega},\bar{H})$
corresponds to some automorphism(s) of
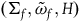 $(\Sigma_{f}, \tilde{\omega}_{f},H)$
under
$(\Sigma_{f}, \tilde{\omega}_{f},H)$
under
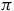 $\pi$
follows from the fact that every transformation on
$\pi$
follows from the fact that every transformation on
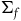 $\Sigma_{f}$
that preserves the equivalence class of points along the gauge orbits is an automorphism of
$\Sigma_{f}$
that preserves the equivalence class of points along the gauge orbits is an automorphism of
 $(\Sigma_{f}, \tilde{\omega}_{f},H)$
by the proof of Proposition 1 (since these transformations correspond to moving along the gauge orbits at each point).
$(\Sigma_{f}, \tilde{\omega}_{f},H)$
by the proof of Proposition 1 (since these transformations correspond to moving along the gauge orbits at each point).
A.4. Proposition 4
That G is essentially surjective follows from the fact that every model of the reduced theory is the reduction of some model on the final constraint surface by definition. To show that G is full, notice that if there is an arrow h between
 $G(\Sigma_{f}, \tilde{\omega}_{f}, H)$
,
$G(\Sigma_{f}, \tilde{\omega}_{f}, H)$
,
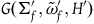 $G(\Sigma_{f}', \tilde{\omega}_{f}', H')$
, then there is a transformation between
$G(\Sigma_{f}', \tilde{\omega}_{f}', H')$
, then there is a transformation between
 $(\Sigma_{f}, \tilde{\omega}_{f}, H), (\Sigma_{f}', \tilde{\omega}_{f}', H')$
that preserves the equivalence class of points along the integral curves of the null vector fields of
$(\Sigma_{f}, \tilde{\omega}_{f}, H), (\Sigma_{f}', \tilde{\omega}_{f}', H')$
that preserves the equivalence class of points along the integral curves of the null vector fields of
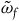 $\tilde{\omega}_{f}$
,
$\tilde{\omega}_{f}$
,
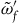 $\tilde{\omega}_{f}'$
. Since
$\tilde{\omega}_{f}'$
. Since
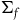 $\Sigma_{f}$
,
$\Sigma_{f}$
,
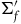 $\Sigma_{f}'$
are of the same dimension (by assumption), this implies that there exists a diffeomorphism
$\Sigma_{f}'$
are of the same dimension (by assumption), this implies that there exists a diffeomorphism
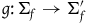 $g\colon \Sigma_{f} \rightarrow \Sigma_{f}'$
such that
$g\colon \Sigma_{f} \rightarrow \Sigma_{f}'$
such that
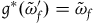 $g^*(\tilde{\omega}_{f}')=\tilde{\omega}_{f}$
. Moreover, since H, H’ are invariant along the gauge orbits, and give rise to isomorphic reduced Hamiltonians, it must be that
$g^*(\tilde{\omega}_{f}')=\tilde{\omega}_{f}$
. Moreover, since H, H’ are invariant along the gauge orbits, and give rise to isomorphic reduced Hamiltonians, it must be that
 $g^*(H')=H$
. So g is an arrow between
$g^*(H')=H$
. So g is an arrow between
 $(\Sigma_{f}, \tilde{\omega}_{f}, H), (\Sigma_{f}', \tilde{\omega}_{f}', H')$
and
$(\Sigma_{f}, \tilde{\omega}_{f}, H), (\Sigma_{f}', \tilde{\omega}_{f}', H')$
and
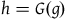 $h=G(g)$
. Therefore, every arrow between
$h=G(g)$
. Therefore, every arrow between
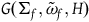 $G(\Sigma_{f}, \tilde{\omega}_{f}, H)$
,
$G(\Sigma_{f}, \tilde{\omega}_{f}, H)$
,
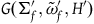 $G(\Sigma_{f}', \tilde{\omega}_{f}', H')$
is mapped to by at least one arrow between
$G(\Sigma_{f}', \tilde{\omega}_{f}', H')$
is mapped to by at least one arrow between
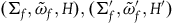 $(\Sigma_{f}, \tilde{\omega}_{f}, H), (\Sigma_{f}', \tilde{\omega}_{f}', H')$
, and so G is full.
$(\Sigma_{f}, \tilde{\omega}_{f}, H), (\Sigma_{f}', \tilde{\omega}_{f}', H')$
, and so G is full.
G is not faithful if there are two distinct arrows in ExtHam that map to the same arrow in HamRed. Consider some model
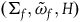 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
where
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
where
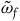 $\tilde{\omega}_{f}$
has at least one null vector field, and consider two arrows
$\tilde{\omega}_{f}$
has at least one null vector field, and consider two arrows
 $g_1,g_2$
from
$g_1,g_2$
from
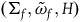 $(\Sigma_{f}, \tilde{\omega}_{f}, H)$
to itself corresponding to distinct gauge transformations, i.e. two different ways of moving the points of
$(\Sigma_{f}, \tilde{\omega}_{f}, H)$
to itself corresponding to distinct gauge transformations, i.e. two different ways of moving the points of
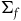 $\Sigma_{f}$
to other points along the gauge orbits (as long as
$\Sigma_{f}$
to other points along the gauge orbits (as long as
 $\tilde{\omega}_{f}$
has at least one null vector field, one can find such distinct
$\tilde{\omega}_{f}$
has at least one null vector field, one can find such distinct
 $g_1$
,
$g_1$
,
 $g_2$
). Then
$g_2$
). Then
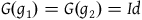 $G(g_1)=G(g_2)=Id$
since
$G(g_1)=G(g_2)=Id$
since
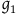 $g_1$
and
$g_1$
and
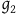 $g_2$
preserve the gauge orbits. So G is not faithful.
$g_2$
preserve the gauge orbits. So G is not faithful.

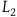

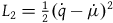
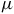
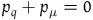
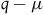
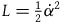

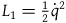
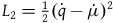

 Open access
Open access