


1 Introduction
Applied proof theory, also known as proof mining, is a subfield of logic that uses ideas and techniques from proof theory to produce new theorems in different areas of mainstream mathematics and computer science. This usually proceeds via a careful analysis of existing proofs in those areas, and can result in both quantitative and qualitative improvements of the corresponding theorems. While the use of proof-theoretic techniques for this purpose was first proposed by Kreisel in the 1950s [Reference Kreisel29, Reference Kreisel30], the field was brought to maturity through the work of Kohlenbach and others, an overview of which is documented in the monograph [Reference Kohlenbach17] and the more recent survey papers [Reference Kohlenbach18, Reference Kohlenbach20].Footnote 1
Progress in applied proof theory tends to assume one of two main forms: Concrete case studies in which proof-theoretic techniques are used to obtain new results, often through the analysis of a single or a collection of related proofs; and so-called logical metatheorems which explain those case studies as instances of general logical phenomena, typically guaranteeing the extractability of (highly uniform) computational information within a specific setting. For example, early case studies in metric fixed point theory (e.g., [Reference Kohlenbach14, Reference Kohlenbach15, Reference Kohlenbach and Leuştean23]) were explained in [Reference Kohlenbach16] (later generalised in [Reference Gerhardy and Kohlenbach10]), while the more recent metatheorems [Reference Kohlenbach and Pischke26, Reference Pischke40, Reference Pischke44] cover a range of case studies on accretive and monotone set-valued operators (including but not limited to [Reference Dinis and Pinto7, Reference Kohlenbach19, Reference Kohlenbach21, Reference Kohlenbach and Koutsoukou-Argyraki22, Reference Kohlenbach and Powell27, Reference Leuştean, Nicolae and Sipoş31]). Current efforts to bring proof mining to bear on probability theory (building on earlier work in measure theory [Reference Avigad, Dean and Rute1, Reference Avigad, Gerhardy and Towsner2]) exemplify this pattern further, with initial case studies on martingale convergence [Reference Neri and Powell37, Reference Neri and Powell38], laws of large numbers [Reference Neri32, Reference Neri33] and stochastic optimization [Reference Neri, Pischke and Powell35, Reference Pischke and Powell45] being developed in tandem with new logical metatheorems [Reference Neri and Pischke34].
In the case studies, proof-theoretic ‘workings’ are often suppressed and streamlined, with everything presented in standard mathematical language and in a style suited to the area of application (which is indeed crucial, as in most cases this work is published in specialist journals within that area of application). Metatheorems, on the other hand, are expressed in the language of formal logic, and require sophisticated proof-theoretic machinery that includes proof interpretations (and above all Gödel’s Dialectica [Reference Gödel11]), logical relations based on majorizability [Reference Howard and Troelstra12], and abstract types [Reference Kohlenbach16]. The point here is that the connection between metatheorem and case study is subtle: Metatheorems are never used directly (and certainly not bureaucractically) to obtain new applications. It is rather the case that practitioners of proof mining carry in their mind a broad and constantly evolving proof-theoretic intuition, one that can in a given context be made rigorous and formal through logical metatheorems, but which can also be utilised without explicit reference to formal logic and in conjunction with ordinary mathematical insights to obtain concrete results. But as a consequence, it is not necessarily obvious to a non-specialist precisely how proof theory was used to obtain those results.
Our article explores a space between the purely mathematical case studies, and the fully formal metatheorems, where we seek to capture in a dynamic manner the way in which proof-theoretic insights are used to produce concrete theorems in mathematics. We present a new case study in convex optimization, but offer an alternative style of presentation where we attempt to make explicit some of the underlying proof-theoretic intuitions involved in “unwinding” the proof in question, making use in particular of an informal type of proof tree. This is certainly not standard in applied proof theory, and technically not necessary to prove the main results. However, it is hoped that this presentation will be of independent interest, hinting at ways in which proof mining could be effectively implemented (or even partially automated) in a proof assistant by focusing on ‘high-level’ inference rules that represent commonly occurring mathematical patterns, along with transformations that indicate how these patterns can be manipulated to obtain computational information.
Our starting point is an elegant proof on the convergence of greedy approximation schemes, given as Theorem 3.4 of [Reference Darken, Donahue, Gurvits and Sontag6]. Our analysis of this proof exhibits many of the characteristic features of proof mining, namely:
-
(i) the proof is at first glance non-constructive (establishing that a limit inferior must be zero by showing that it can’t be positive), and yet one can nevertheless extract direct rates of convergence with very low computational complexity;
-
(ii) the theorem applies to arbitrary Banach spaces with certain geometric properties (in this case uniform smoothness), but the rates are highly uniform and only depend on the appropriate modulus of uniform smoothness along with some other basic data;
-
(iii) the initial quantitative analysis can be extended to produce several qualitative strengthenings of the original result, including a weakening of the convergence condition on the error terms and an extension to fixed step sizes.
We analyse this proof, and in doing so provide a first application of proof theory to greedy approximation schemes. We anticipate that further work in this direction would be of interest, given that there exists a wealth of related nonconstructive convergence proofs that depend on geometric properties of Banach spaces (e.g., [Reference Temlyakov47, Reference Tewari, Ravikumar and Dhillon48]), which are in turn directly relevant to solving high-dimensional problems in machine learning and statistics.
However, we consider our presentation of the extraction process to be the central contribution of the article: Firstly, in doing so we provide an expository account of the way in which proof theory can be used to generate new theorems in mathematics; secondly, and more importantly, given the ever increasing capabilities and widespread use of proof assistants, we envisage that high-level descriptions of the underlying proof transformations of the kind studied here might provide insight into the sort of mathematical libraries and tactics that would be helpful in both formalising or even partially automating the proof mining process. Indeed, we conjecture that the development of domain-specific logical systems that, much like our informal proof rules, are designed to capture the high-level structures on which proof mining operates, will be essential for any practical automation of the proof mining process.
1.1 Structure of the article
The article has been written to appeal to a reader who is more interested in how an applied proof theorist might manipulate proofs in general, than in the specific mathematical details of the situation at hand. For that reason, the necessary mathematical background is presented in a self-contained manner in Section 2, and logic and analysis are subsequently separated as much as possible, so that the reader primarily interested in the former can skim over passages concerning the latter while still appreciating the main points.
2 Mathematical background
We start by presenting the main subject of our case study, along with the convergence theorem whose proof we will analyse. The reader interested in the deeper mathematical context is encouraged to consult the references, particularly the original paper of Darken et al. [Reference Darken, Donahue, Gurvits and Sontag6] in which our chosen proof is just one among a series of results on convex approximation schemes in Banach spaces, and the more recent monograph on greedy algorithms by Temlyakov [Reference Temlyakov47].
2.1 Greedy approximation schemes
The following definitions and notation are taken from [Reference Darken, Donahue, Gurvits and Sontag6]. Let X be a real Banach space, and suppose that
 $S\subseteq X$
is some arbitrary set. Let
$S\subseteq X$
is some arbitrary set. Let
 $\mathrm {co}({S})$
denote the set of all convex combinations of elements of S, that is, objects of the form
$\mathrm {co}({S})$
denote the set of all convex combinations of elements of S, that is, objects of the form
 $$ \begin{align*} \lambda_1 y_1+\cdots +\lambda_n y_n \end{align*} $$
$$ \begin{align*} \lambda_1 y_1+\cdots +\lambda_n y_n \end{align*} $$
for
 $n\geq 1$
,
$n\geq 1$
,
 $y_1,\ldots ,y_n\in S,$
and
$y_1,\ldots ,y_n\in S,$
and
 $\lambda _1,\ldots ,\lambda _n\in [0,1]$
with
$\lambda _1,\ldots ,\lambda _n\in [0,1]$
with
 $\lambda _1+\cdots +\lambda _n=1$
. Now suppose that
$\lambda _1+\cdots +\lambda _n=1$
. Now suppose that
 $x^\ast \in \overline {\mathrm {co}({S})}$
, where
$x^\ast \in \overline {\mathrm {co}({S})}$
, where
 $\overline {\mathrm {co}({S})}$
denotes the closure of
$\overline {\mathrm {co}({S})}$
denotes the closure of
 $\mathrm {co}({S})$
. A natural question arises:
$\mathrm {co}({S})$
. A natural question arises:
Can we construct incremental approximates to
 $x^\ast $
from elements of
$x^\ast $
from elements of
 $\mathrm {co}({S})$
where each approximant is improved by forming a convex combination with a single new element of S?
$\mathrm {co}({S})$
where each approximant is improved by forming a convex combination with a single new element of S?
In other words, we consider incremental sequences
 $(x_n)$
of the form
$(x_n)$
of the form
 $$ \begin{align*} x_{n+1}=(1-\lambda_n)x_n+\lambda_ny_n \end{align*} $$
$$ \begin{align*} x_{n+1}=(1-\lambda_n)x_n+\lambda_ny_n \end{align*} $$
for
 $x_0\in S$
,
$x_0\in S$
,
 $y_n\in S,$
and
$y_n\in S,$
and
 $\lambda _n\in [0,1)$
(we assume that
$\lambda _n\in [0,1)$
(we assume that
 $\lambda _n<1$
else we would have
$\lambda _n<1$
else we would have
 $x_{n+1}=y_n\in S$
and we are back where we started). The most natural way of choosing
$x_{n+1}=y_n\in S$
and we are back where we started). The most natural way of choosing
 $y_n$
and
$y_n$
and
 $\lambda _n$
at each step is to require them to be optimal, which leads naturally to the following slightly more general notion.
$\lambda _n$
at each step is to require them to be optimal, which leads naturally to the following slightly more general notion.
Definition 2.1. A sequence
 $(x_n)$
of elements of X is called greedy with respect to
$(x_n)$
of elements of X is called greedy with respect to
 $x^\ast \in X$
and S if for all
$x^\ast \in X$
and S if for all
 $n\in \mathbb {N}$
:
$n\in \mathbb {N}$
:
 $$ \begin{align*} \|{x_{n+1}-x^\ast}\|\leq \inf\{ {\|{(1-\lambda)x_n+\lambda y-x^\ast}\|} \ | \ {y\in S, \lambda\in [0,1)}\}. \end{align*} $$
$$ \begin{align*} \|{x_{n+1}-x^\ast}\|\leq \inf\{ {\|{(1-\lambda)x_n+\lambda y-x^\ast}\|} \ | \ {y\in S, \lambda\in [0,1)}\}. \end{align*} $$
To account for the fact that S may not be compact, and thus the infimum in the above definition not attained, we loosen the notion in order to incorporate error terms
 $(\epsilon _n)$
, leading to our main definition of greedy approximation scheme.
$(\epsilon _n)$
, leading to our main definition of greedy approximation scheme.
Definition 2.2. Let
 $(\epsilon _n)$
be a sequence of positive real numbers. A sequence
$(\epsilon _n)$
be a sequence of positive real numbers. A sequence
 $(x_n)$
of elements of X is called
$(x_n)$
of elements of X is called
 $(\epsilon _n)$
-greedy with respect to
$(\epsilon _n)$
-greedy with respect to
 $x^\ast \in X$
and S if for all
$x^\ast \in X$
and S if for all
 $n\in \mathbb {N}$
:
$n\in \mathbb {N}$
:
 $$ \begin{align*} \|{x_{n+1}-x^\ast}\|\leq \inf\{ {\|{(1-\lambda)x_n+\lambda y-x^\ast}\|} \ | \ {y\in S, \lambda\in [0,1)}\}+\epsilon_n. \end{align*} $$
$$ \begin{align*} \|{x_{n+1}-x^\ast}\|\leq \inf\{ {\|{(1-\lambda)x_n+\lambda y-x^\ast}\|} \ | \ {y\in S, \lambda\in [0,1)}\}+\epsilon_n. \end{align*} $$
Greedy approximation schemes in Hilbert spaces were first studied by Jones [Reference Jones13], where convergence to
 $x^\ast \in \overline {\mathrm {co}({S})}$
with rate
$x^\ast \in \overline {\mathrm {co}({S})}$
with rate
 $\mathcal {O}(1/\sqrt {n})$
is proven, and the connection of such schemes to artificial neural networks is highlighted where, roughly speaking, improving an approximant by combining with a new element of S can be seen as a generalisation of improving the accuracy of a neural network by adding an additional neuron (see [Reference Jones13, Section 4] or [Reference Darken, Donahue, Gurvits and Sontag6, Section 1.3] for further details of this connection).
$\mathcal {O}(1/\sqrt {n})$
is proven, and the connection of such schemes to artificial neural networks is highlighted where, roughly speaking, improving an approximant by combining with a new element of S can be seen as a generalisation of improving the accuracy of a neural network by adding an additional neuron (see [Reference Jones13, Section 4] or [Reference Darken, Donahue, Gurvits and Sontag6, Section 1.3] for further details of this connection).
When X is a general Banach space, on the other hand, convergence is no longer guaranteed. The example given in [Reference Darken, Donahue, Gurvits and Sontag6] is
 $\mathbb {R}^2$
under the
$\mathbb {R}^2$
under the
 $L^1$
norm: Here, if we take
$L^1$
norm: Here, if we take
 $S:=\{(0,-1),(2,1/2),(-2,1/2)\}$
so that
$S:=\{(0,-1),(2,1/2),(-2,1/2)\}$
so that
 $(0,0)\in \mathrm {co}({S})$
, the only greedy incremental scheme starting from
$(0,0)\in \mathrm {co}({S})$
, the only greedy incremental scheme starting from
 $x_0:=(0,-1)$
is
$x_0:=(0,-1)$
is
 $x_0=x_1= x_2=\cdots $
, since there is no way to strictly decrease the distance to
$x_0=x_1= x_2=\cdots $
, since there is no way to strictly decrease the distance to
 $(0,0)$
through convex combinations with
$(0,0)$
through convex combinations with
 $(2,1/2)$
or
$(2,1/2)$
or
 $(-2,1/2)$
. Geometrically speaking, the problem here is that the unit ball in this space is a diamond, and the line segment between
$(-2,1/2)$
. Geometrically speaking, the problem here is that the unit ball in this space is a diamond, and the line segment between
 $(0,-1)$
and
$(0,-1)$
and
 $(2,1/2)$
only intersects this unit ball at
$(2,1/2)$
only intersects this unit ball at
 $(0,-1)$
, which would not be the case with the Euclidean metric.
$(0,-1)$
, which would not be the case with the Euclidean metric.
The critical issue is connected to the notion of smoothness (more informally, spaces where “balls don’t have corners”). It turns out that one can establish convergence of greedy algorithms in general Banach spaces by assuming additional smoothness properties. However, the proofs are more difficult, and do not always come with corresponding rates. Establishing rates in such cases is one of the goals of this article.
2.2 Geometric properties of Banach spaces
In what follows we present some basic facts about Banach spaces: Further details for this section can be found in, e.g., [Reference Chidume3, Chapter 2] and [Reference Temlyakov47, Chapter 6]. Let
 $X^\ast $
denote the dual of X, and
$X^\ast $
denote the dual of X, and
 $J:X\to 2^{X^\ast }$
the so-called normalized duality mapping function defined by
$J:X\to 2^{X^\ast }$
the so-called normalized duality mapping function defined by
 $$ \begin{align*} J(x):=\{ {y\in X^\ast} \ | \ {y(x)=\|{x}\|^2=\|{y}\|^2}\}. \end{align*} $$
$$ \begin{align*} J(x):=\{ {y\in X^\ast} \ | \ {y(x)=\|{x}\|^2=\|{y}\|^2}\}. \end{align*} $$
A space X is defined to be smooth if J is single-valued, in which case we let
 $j:X\to X^\ast $
denote the corresponding unique duality map.
$j:X\to X^\ast $
denote the corresponding unique duality map.
In the special case that X is a Hilbert space the duality map is just the inner product
 $j(x)=\langle {x,-}\rangle $
, and as such the duality map often plays the role of mimicking an inner product in Banach spaces. Crudely speaking, the nicer the duality map, the more X behaves like a Hilbert space. In this respect, an important notion is the modulus of smoothness
$j(x)=\langle {x,-}\rangle $
, and as such the duality map often plays the role of mimicking an inner product in Banach spaces. Crudely speaking, the nicer the duality map, the more X behaves like a Hilbert space. In this respect, an important notion is the modulus of smoothness
 $$ \begin{align*} \rho_X(t):=\sup\left\{\left.\frac{\|{x+ty}\|+\|{x-ty}\|}{2}-1 \, \right| \, \|{x}\|=\|{y}\|=1 \right\} \end{align*} $$
$$ \begin{align*} \rho_X(t):=\sup\left\{\left.\frac{\|{x+ty}\|+\|{x-ty}\|}{2}-1 \, \right| \, \|{x}\|=\|{y}\|=1 \right\} \end{align*} $$
for
 $t\in (0,\infty )$
, which in a certain sense gives a quantitative measure of ‘niceness’ in this context. A Banach space X is uniformly smooth if
$t\in (0,\infty )$
, which in a certain sense gives a quantitative measure of ‘niceness’ in this context. A Banach space X is uniformly smooth if
 $$ \begin{align*} \lim_{t\to 0}\frac{\rho_X(t)}{t}=0. \end{align*} $$
$$ \begin{align*} \lim_{t\to 0}\frac{\rho_X(t)}{t}=0. \end{align*} $$
The following standard lemma (cf. [Reference Temlyakov47, Lemma 6.1]) connects the duality map with the modulus of smoothness. We give its proof in full as this forms part of the overall proof that will be analysed.
Lemma 2.3. Suppose that X is smooth. Take
 $x\neq 0$
and let
$x\neq 0$
and let
 $F_x:=j(x)/\|{x}\|$
. Then for any
$F_x:=j(x)/\|{x}\|$
. Then for any
 $y\in X$
and
$y\in X$
and
 $t\in (0,\infty )$
:
$t\in (0,\infty )$
:
 $$ \begin{align*} \|{x+ty}\|\leq \|{x}\|\left(1+2\rho_X\left(t\|{y}\|/\|{x}\|\right)\right)+tF_x(y). \end{align*} $$
$$ \begin{align*} \|{x+ty}\|\leq \|{x}\|\left(1+2\rho_X\left(t\|{y}\|/\|{x}\|\right)\right)+tF_x(y). \end{align*} $$
Proof From the definition of
 $\rho _X$
we obtain
$\rho _X$
we obtain
 $$ \begin{align*} \|{x+ty}\|+\|{x-ty}\|\leq 2\|{x}\|\left(1+\rho_X\left(t\|{y}\|/\|{x}\|\right)\right) \end{align*} $$
$$ \begin{align*} \|{x+ty}\|+\|{x-ty}\|\leq 2\|{x}\|\left(1+\rho_X\left(t\|{y}\|/\|{x}\|\right)\right) \end{align*} $$
and using in addition that from
 $\|{F_x}\|=1$
we have
$\|{F_x}\|=1$
we have
 $$ \begin{align*} \|{x-ty}\|\geq F_x(x-ty)=F_x(x)-tF_x(y)=\|{x}\|-tF_x(y) \end{align*} $$
$$ \begin{align*} \|{x-ty}\|\geq F_x(x-ty)=F_x(x)-tF_x(y)=\|{x}\|-tF_x(y) \end{align*} $$
the result follows.
Remark 2.4. Using Lemma 2.3 in along with
 $\|{x+ty}\|\geq F_x(x+ty)=\|{x}\|+tF_x(y)$
proves
$\|{x+ty}\|\geq F_x(x+ty)=\|{x}\|+tF_x(y)$
proves
 $$ \begin{align*} 0\leq \|{x+ty}\|-\|{x}\|-tF_x(y)\leq 2\rho_X\left(t\|{y}\|/\|{x}\|\right). \end{align*} $$
$$ \begin{align*} 0\leq \|{x+ty}\|-\|{x}\|-tF_x(y)\leq 2\rho_X\left(t\|{y}\|/\|{x}\|\right). \end{align*} $$
For
 $\|{x}\|=\|{y}\|$
it follows that
$\|{x}\|=\|{y}\|$
it follows that
 $$ \begin{align*} 0\leq \frac{\|{x+ty}\|-\|{x}\|}{t}-F_x(y)\leq \frac{2\rho_X(t)}{t} \end{align*} $$
$$ \begin{align*} 0\leq \frac{\|{x+ty}\|-\|{x}\|}{t}-F_x(y)\leq \frac{2\rho_X(t)}{t} \end{align*} $$
and thus uniformly smooth spaces have the nice geometric property that
 $$ \begin{align*} \lim_{t\to 0}\left(\frac{\|{x+ty}\|-\|{x}\|}{t}\right)=F_x(y) \end{align*} $$
$$ \begin{align*} \lim_{t\to 0}\left(\frac{\|{x+ty}\|-\|{x}\|}{t}\right)=F_x(y) \end{align*} $$
and moreover the limit is attained uniformly in x and y with
 $\|{y}\|=\|{x}\|$
. In other words, X has a uniformly Gâteuax differentiable norm, and in fact this is an equivalent characterisation of being uniformly smooth.
$\|{y}\|=\|{x}\|$
. In other words, X has a uniformly Gâteuax differentiable norm, and in fact this is an equivalent characterisation of being uniformly smooth.
2.3 Convergence of greedy incremental sequences in Banach spaces
We now state and prove the main result that we will analyse: Roughly speaking, this says that if X is uniformly smooth, if
 $(x_n)$
is an
$(x_n)$
is an
 $(\epsilon _n)$
-greedy approximation schemes with respect to
$(\epsilon _n)$
-greedy approximation schemes with respect to
 $x^\ast $
, then
$x^\ast $
, then
 $x_n\to x^\ast $
provided that
$x_n\to x^\ast $
provided that
 $\sum _{i=0}^\infty \epsilon _i<\infty $
. The material in this section is taken entirely from [Reference Darken, Donahue, Gurvits and Sontag6], with the proof only very slightly reformulated from its original presentation.
$\sum _{i=0}^\infty \epsilon _i<\infty $
. The material in this section is taken entirely from [Reference Darken, Donahue, Gurvits and Sontag6], with the proof only very slightly reformulated from its original presentation.
We first require a lemma that applies smoothness to greedy algorithms, essentially showing that sequences that are
 $(\epsilon _n)$
-greedy with respect to
$(\epsilon _n)$
-greedy with respect to
 $x^\ast $
are, in particular, quasi-Fejér monotone with respect to
$x^\ast $
are, in particular, quasi-Fejér monotone with respect to
 $x^\ast $
in a certain sense (see [Reference Combettes4, Reference Combettes5] for surveys of this fundamental concept and its role in convex optimization). The result below incorporates Lemma 3.3 of [Reference Darken, Donahue, Gurvits and Sontag6], along with part of the main proof of Theorem 3.4 from the same paper, and we have deliberately re-structured things in this way in order to separate out those parts of the proof that use functional analysis of some kind. This is convenient because it allows us, in the proof of Theorem 2.6, to focus on the main combinatorial structure of the overall proof, making it easier to organise the quantitative analysis that follows.
$x^\ast $
in a certain sense (see [Reference Combettes4, Reference Combettes5] for surveys of this fundamental concept and its role in convex optimization). The result below incorporates Lemma 3.3 of [Reference Darken, Donahue, Gurvits and Sontag6], along with part of the main proof of Theorem 3.4 from the same paper, and we have deliberately re-structured things in this way in order to separate out those parts of the proof that use functional analysis of some kind. This is convenient because it allows us, in the proof of Theorem 2.6, to focus on the main combinatorial structure of the overall proof, making it easier to organise the quantitative analysis that follows.
Lemma 2.5 (Cf. Lemma 3.3 of [Reference Darken, Donahue, Gurvits and Sontag6])
Let X be a Banach space with modulus of smoothness
 $\rho _X$
. Suppose that
$\rho _X$
. Suppose that
 $S\subseteq X$
and
$S\subseteq X$
and
 $x^\ast \in \overline {\mathrm {co}({S})}$
, that
$x^\ast \in \overline {\mathrm {co}({S})}$
, that
 $(x_n)$
is
$(x_n)$
is
 $(\epsilon _n)$
-greedy with respect to
$(\epsilon _n)$
-greedy with respect to
 $x^\ast $
and S, and
$x^\ast $
and S, and
 $K>0$
is such that
$K>0$
is such that
 $\sup \{ {\|{y-x^\ast }\|} \ | \ {y\in S}\}\leq K$
. Then for any
$\sup \{ {\|{y-x^\ast }\|} \ | \ {y\in S}\}\leq K$
. Then for any
 $n\in \mathbb {N}$
and
$n\in \mathbb {N}$
and
 $b>0$
, we have
$b>0$
, we have
 $$ \begin{align*} \|{x_{n+1}-x^\ast}\|\leq (1-\alpha(b))\|{x_n-x^\ast}\|+\epsilon_n \end{align*} $$
$$ \begin{align*} \|{x_{n+1}-x^\ast}\|\leq (1-\alpha(b))\|{x_n-x^\ast}\|+\epsilon_n \end{align*} $$
whenever
 $\|{x_n-x^\ast }\|\geq b$
, where
$\|{x_n-x^\ast }\|\geq b$
, where
 $$ \begin{align*} \alpha(b):=\sup\left\{\left.\lambda\left(1-\frac{2K}{b}\cdot\frac{\rho_X(u(b,\lambda))}{u(b,\lambda)}\right)\ \right| \ \lambda\in [0,1)\right\} \end{align*} $$
$$ \begin{align*} \alpha(b):=\sup\left\{\left.\lambda\left(1-\frac{2K}{b}\cdot\frac{\rho_X(u(b,\lambda))}{u(b,\lambda)}\right)\ \right| \ \lambda\in [0,1)\right\} \end{align*} $$
for
 $u(b,\lambda ):=\lambda K/(1-\lambda )b$
.
$u(b,\lambda ):=\lambda K/(1-\lambda )b$
.
Proof Fix
 $n\in \mathbb {N}$
and assume that
$n\in \mathbb {N}$
and assume that
 $\|{x_n-x^\ast }\|\geq b>0$
. For
$\|{x_n-x^\ast }\|\geq b>0$
. For
 $y\in S$
and
$y\in S$
and
 $\lambda \in [0,1)$
, writing
$\lambda \in [0,1)$
, writing
 $$ \begin{align*} \|{(1-\lambda)x_n+\lambda y-x^\ast}\|=(1-\lambda)\|{(x_n-x^\ast)+\lambda(y-x^\ast)/(1-\lambda)}\| \end{align*} $$
$$ \begin{align*} \|{(1-\lambda)x_n+\lambda y-x^\ast}\|=(1-\lambda)\|{(x_n-x^\ast)+\lambda(y-x^\ast)/(1-\lambda)}\| \end{align*} $$
and applying Lemma 2.3 to the right hand side we have
 $$ \begin{align*} \begin{aligned} &\|{(1-\lambda)x_n+\lambda y-x^\ast}\|\\&\quad \leq (1-\lambda)\left(1+2\rho_X\left(\frac{\lambda \|{y-x^\ast}\|}{(1-\lambda)\|{x_n-x^\ast}\|}\right)\right)\|{x_n-x^\ast}\|+\lambda F_n(y-x^\ast) \end{aligned} \end{align*} $$
$$ \begin{align*} \begin{aligned} &\|{(1-\lambda)x_n+\lambda y-x^\ast}\|\\&\quad \leq (1-\lambda)\left(1+2\rho_X\left(\frac{\lambda \|{y-x^\ast}\|}{(1-\lambda)\|{x_n-x^\ast}\|}\right)\right)\|{x_n-x^\ast}\|+\lambda F_n(y-x^\ast) \end{aligned} \end{align*} $$
where we write
 $F_n:=j(x_n-x^\ast )/\|{x_n-x^\ast }\|$
. Using the standard fact that the modulus of smoothness is monotone, it follows from
$F_n:=j(x_n-x^\ast )/\|{x_n-x^\ast }\|$
. Using the standard fact that the modulus of smoothness is monotone, it follows from
 $b\leq \|{x_n-x^\ast }\|$
and
$b\leq \|{x_n-x^\ast }\|$
and
 $\|{y-x^\ast }\|\leq K$
for
$\|{y-x^\ast }\|\leq K$
for
 $y\in S$
that
$y\in S$
that
 $$ \begin{align*} \begin{aligned} (1-\lambda)\rho_X\left(\frac{\lambda \|{y-x^\ast}\|}{(1-\lambda)\|{x_n-x^\ast}\|}\right)&\leq (1-\lambda)\rho_X\left(\frac{\lambda K}{(1-\lambda)b}\right)\\ &=\frac{\lambda K}{b}\cdot\frac{\rho_X(u(b,\lambda))}{u(b,\lambda)}=:\beta(\lambda,n) \end{aligned} \end{align*} $$
$$ \begin{align*} \begin{aligned} (1-\lambda)\rho_X\left(\frac{\lambda \|{y-x^\ast}\|}{(1-\lambda)\|{x_n-x^\ast}\|}\right)&\leq (1-\lambda)\rho_X\left(\frac{\lambda K}{(1-\lambda)b}\right)\\ &=\frac{\lambda K}{b}\cdot\frac{\rho_X(u(b,\lambda))}{u(b,\lambda)}=:\beta(\lambda,n) \end{aligned} \end{align*} $$
for
 $u(b,\lambda )$
as defined in the statement of the result. Putting these together and defining
$u(b,\lambda )$
as defined in the statement of the result. Putting these together and defining
 $\beta (\lambda ,n)$
as indicated in the previous equation, we obtain
$\beta (\lambda ,n)$
as indicated in the previous equation, we obtain
 $$ \begin{align} &\|{(1-\lambda)x_n+\lambda y-x^\ast}\|\nonumber\\ &\leq \left[1-\lambda\left(1-2\beta(\lambda,n)\right)\right]\|{x_n-x^\ast}\|+\lambda F_n(y-x^\ast). \end{align} $$
$$ \begin{align} &\|{(1-\lambda)x_n+\lambda y-x^\ast}\|\nonumber\\ &\leq \left[1-\lambda\left(1-2\beta(\lambda,n)\right)\right]\|{x_n-x^\ast}\|+\lambda F_n(y-x^\ast). \end{align} $$
Now, since
 $x^\ast \in \overline {\mathrm {co}({S})}$
, we can make the positive part of
$x^\ast \in \overline {\mathrm {co}({S})}$
, we can make the positive part of
 $F_n(y-x^\ast )$
arbitrary small, in the sense that for all
$F_n(y-x^\ast )$
arbitrary small, in the sense that for all
 $\varepsilon>0$
there exists
$\varepsilon>0$
there exists
 $y\in S$
such that
$y\in S$
such that
 ${F_n(y-x^\ast )\leq \varepsilon }$
. To see this, pick some
${F_n(y-x^\ast )\leq \varepsilon }$
. To see this, pick some
 $z\in \mathrm {co}({S})$
such that
$z\in \mathrm {co}({S})$
such that
 $\|{z-x^\ast }\|\leq \varepsilon $
. Writing
$\|{z-x^\ast }\|\leq \varepsilon $
. Writing
 $z=\sum _{i=1}^k\lambda _iy_i$
for
$z=\sum _{i=1}^k\lambda _iy_i$
for
 $y_i\in S$
, we must have
$y_i\in S$
, we must have
 $F_n(y_i-x^\ast )\leq \varepsilon $
for some
$F_n(y_i-x^\ast )\leq \varepsilon $
for some
 $i=1,\ldots ,k$
, else, using that
$i=1,\ldots ,k$
, else, using that
 $F_n$
is linear and
$F_n$
is linear and
 $\|{F_n}\|\leq 1$
we have
$\|{F_n}\|\leq 1$
we have
 $$ \begin{align*} \varepsilon=\varepsilon\sum_{i=1}^k\lambda_i<\sum_{i=1}^k \lambda_i F_n(y_i-x^\ast)=F_n(z-x^\ast)\leq \|{z-x^\ast}\|\leq \varepsilon \end{align*} $$
$$ \begin{align*} \varepsilon=\varepsilon\sum_{i=1}^k\lambda_i<\sum_{i=1}^k \lambda_i F_n(y_i-x^\ast)=F_n(z-x^\ast)\leq \|{z-x^\ast}\|\leq \varepsilon \end{align*} $$
Therefore
 $\inf \{F_n(y-x^\ast )\, | \, y\in S\}\leq 0$
, and more generally the infimum over
$\inf \{F_n(y-x^\ast )\, | \, y\in S\}\leq 0$
, and more generally the infimum over
 $y\in S$
and
$y\in S$
and
 $\lambda \in [0,1)$
of the quantity
$\lambda \in [0,1)$
of the quantity
 $$\begin{align*}\left(1-\lambda\left(1-2\beta(\lambda,n)\right)\right)\|{x_n-x^\ast}\|+\lambda F_n(y-x^\ast) \end{align*}$$
$$\begin{align*}\left(1-\lambda\left(1-2\beta(\lambda,n)\right)\right)\|{x_n-x^\ast}\|+\lambda F_n(y-x^\ast) \end{align*}$$
is bounded by
 $$\begin{align*}\left(1-\sup\left\{\left.\lambda\left(1-2\beta(\lambda,n)\right)\ \right| \ \lambda\in [0,1)\right\}\right)\|{x_n-x^\ast}\|, \end{align*}$$
$$\begin{align*}\left(1-\sup\left\{\left.\lambda\left(1-2\beta(\lambda,n)\right)\ \right| \ \lambda\in [0,1)\right\}\right)\|{x_n-x^\ast}\|, \end{align*}$$
which is just
 $(1-\alpha (b))\|{x_n-x^\ast }\|$
. Thus combining the above with (*) and the definition of being
$(1-\alpha (b))\|{x_n-x^\ast }\|$
. Thus combining the above with (*) and the definition of being
 $(\epsilon _n)$
-greedy we have
$(\epsilon _n)$
-greedy we have
 $$ \begin{align*} \|{x_{n+1}-x^\ast}\|&\leq \inf\{\|{(1-\lambda)x_n+\lambda y-x^\ast}\| \, | \, y\in S,\, \lambda \in [0,1)\}+\epsilon_n\\ &\leq (1-\alpha(b))\|{x_n-x^\ast}\|+\epsilon_n \end{align*} $$
$$ \begin{align*} \|{x_{n+1}-x^\ast}\|&\leq \inf\{\|{(1-\lambda)x_n+\lambda y-x^\ast}\| \, | \, y\in S,\, \lambda \in [0,1)\}+\epsilon_n\\ &\leq (1-\alpha(b))\|{x_n-x^\ast}\|+\epsilon_n \end{align*} $$
and the lemma is proven.
The main result can now be stated and proved using little more than elementary analysis.
Theorem 2.6 (Cf. Theorem 3.4 of [Reference Darken, Donahue, Gurvits and Sontag6])
Let X be a Banach space with modulus of smoothness
 $\rho _X$
and
$\rho _X$
and
 $S\subseteq X$
be bounded. Suppose that
$S\subseteq X$
be bounded. Suppose that
 $x^\ast \in \overline {\mathrm {co}({S})}$
, and that
$x^\ast \in \overline {\mathrm {co}({S})}$
, and that
 $(x_n)$
is
$(x_n)$
is
 $(\epsilon _n)$
-greedy with respect to
$(\epsilon _n)$
-greedy with respect to
 $x^\ast $
and S for some sequence
$x^\ast $
and S for some sequence
 $(\epsilon _n)$
of positive reals with
$(\epsilon _n)$
of positive reals with
 $\sum _{i=0}^\infty \epsilon _i<\infty $
. Then
$\sum _{i=0}^\infty \epsilon _i<\infty $
. Then
 $x_n\to x^\ast $
as
$x_n\to x^\ast $
as
 $n\to \infty $
.
$n\to \infty $
.
Proof Define
 $a_n:=\|{x_n-x^\ast }\|$
and let
$a_n:=\|{x_n-x^\ast }\|$
and let
 $a_\infty :=\liminf _{n\to \infty } a_n$
. Using the fact that
$a_\infty :=\liminf _{n\to \infty } a_n$
. Using the fact that
 $(x_n)$
is
$(x_n)$
is
 $(\epsilon _n)$
-greedy, we have
$(\epsilon _n)$
-greedy, we have
 $a_{n+1}\leq a_n+\epsilon _n$
by definition (by simply setting
$a_{n+1}\leq a_n+\epsilon _n$
by definition (by simply setting
 $\lambda =0$
), and thus more generally
$\lambda =0$
), and thus more generally
 $$ \begin{align*} a_{n+m}\leq a_n+\sum_{i=n}^{n+m-1}\epsilon_i\leq a_n+\sum_{i=n}^\infty \epsilon_i \end{align*} $$
$$ \begin{align*} a_{n+m}\leq a_n+\sum_{i=n}^{n+m-1}\epsilon_i\leq a_n+\sum_{i=n}^\infty \epsilon_i \end{align*} $$
for any
 $m,n\in \mathbb {N}$
. But since
$m,n\in \mathbb {N}$
. But since
 $\sum _{i=n}^\infty \epsilon _i\to 0$
as
$\sum _{i=n}^\infty \epsilon _i\to 0$
as
 $n\to \infty $
, we must in fact have
$n\to \infty $
, we must in fact have
 $a_n\to a_\infty $
as
$a_n\to a_\infty $
as
 $n\to \infty $
. It therefore suffices to show that
$n\to \infty $
. It therefore suffices to show that
 $a_\infty =0$
.
$a_\infty =0$
.
To this end, suppose for contradiction that
 $a_\infty>0$
. Since S is bounded there exists
$a_\infty>0$
. Since S is bounded there exists
 $K>0$
is such that
$K>0$
is such that
 $\sup \{ {\|{y-x^\ast }\|} \ | \ {y\in S}\}\leq K$
, and since
$\sup \{ {\|{y-x^\ast }\|} \ | \ {y\in S}\}\leq K$
, and since
 ${a_\infty /2\leq a_n}$
for n sufficiently large, we can apply Lemma 2.5 to show that
${a_\infty /2\leq a_n}$
for n sufficiently large, we can apply Lemma 2.5 to show that
 $$ \begin{align*} a_{n+1}\leq (1-\alpha(a_\infty/2))a_n+\epsilon_n \end{align*} $$
$$ \begin{align*} a_{n+1}\leq (1-\alpha(a_\infty/2))a_n+\epsilon_n \end{align*} $$
for n sufficiently large. Taking the limit as
 $n\to \infty $
and using that
$n\to \infty $
and using that
 $a_n\to a_\infty $
and
$a_n\to a_\infty $
and
 $\epsilon _n\to 0$
yields
$\epsilon _n\to 0$
yields
 $$ \begin{align*} a_\infty\leq (1-\alpha(a_\infty/2))a_\infty \end{align*} $$
$$ \begin{align*} a_\infty\leq (1-\alpha(a_\infty/2))a_\infty \end{align*} $$
and therefore
 $\alpha (a_\infty /2)\leq 0$
. But we have
$\alpha (a_\infty /2)\leq 0$
. But we have
 $u(a_\infty /2,\lambda )\to 0$
as
$u(a_\infty /2,\lambda )\to 0$
as
 $\lambda \to 0$
, and therefore by uniform smoothness of X it follows that
$\lambda \to 0$
, and therefore by uniform smoothness of X it follows that
 $$ \begin{align*} \frac{\rho_X(u(\lambda,a_\infty/2))}{u(\lambda,a_\infty/2)}\to 0 \ \ \ \text{as } \lambda \to 0 \end{align*} $$
$$ \begin{align*} \frac{\rho_X(u(\lambda,a_\infty/2))}{u(\lambda,a_\infty/2)}\to 0 \ \ \ \text{as } \lambda \to 0 \end{align*} $$
from which we see that
 $\alpha (a_\infty /2)>0$
, a contradiction. Thus
$\alpha (a_\infty /2)>0$
, a contradiction. Thus
 $a_\infty =0$
and we are done.
$a_\infty =0$
and we are done.
3 A high-level analysis of the proof
In this section, we start to apply proof-theoretic reasoning to the ideas presented so far. More specifically, we carry out a series of steps that apply to the high-level structure of the proof of Theorem 2.6, our end goal being a computational version of Theorem 2.6, namely, a rate of convergence for
 $x_n\to x^\ast $
as
$x_n\to x^\ast $
as
 $n\to \infty $
, by which we mean a computable function
$n\to \infty $
, by which we mean a computable function
 $f:(0,\infty )\to \mathbb {N}$
satisfying
$f:(0,\infty )\to \mathbb {N}$
satisfying
 $$\begin{align*}\forall \varepsilon>0\, \forall n\geq f(\varepsilon)\left(\|{x_n-x^\ast}\|<\varepsilon\right). \end{align*}$$
$$\begin{align*}\forall \varepsilon>0\, \forall n\geq f(\varepsilon)\left(\|{x_n-x^\ast}\|<\varepsilon\right). \end{align*}$$
We represent the proof via a series of proof trees in natural deduction style, where inferences typically represent a whole series of formal steps conflated into one. Our main goal in representing the proof this way is to identify its main features, and then carry out a series of transformations on the proof which pay special attention to the following questions:
-
1. If we have used an assumption in part of the proof, can we in fact replace it with a weaker assumption?
-
2. Can we phrase formulas in a more uniform way by expressing them in terms of bounds?
-
3. How does computational information flow through the proof?
Most of these questions can be tackled formally using proof-theoretic methods, such as logical metatheorems, majorizability, and variants of the Dialectica interpretation ([Reference Kohlenbach17] is the standard reference). However, here we aim to show how one might transform a proof “by hand” and in a semi-formal manner, ignoring parts of the proof that are uninteresting and focusing on the key mathematical rather than logical steps. We envisage that the kind of high-level inference rules we sketch below, along with the manipulations performed on them, could become formally captured in a domain-specific logical system specially designed for the computational analysis of proofs of a particular shape, though the precise design of such a system is something we leave to future work!
One important thing to note is that, initially at least, we analyse the proof as it is, resulting in a preliminary rate of convergence that is a direct reflection of the convergence proof as found in [Reference Darken, Donahue, Gurvits and Sontag6] (and as presented in the previous section). We then introduce improvements of the proof in the following section, where the initial analysis helps in identifying parts that can be optimized, resulting in both improved rates and qualitative strengthenings of the convergence theorem itself.
3.1 The overall structure of the proof of Theorem 2.6
For the remainder of this section, we will fix several things: X will be a Banach space with
 $\rho $
its modulus of smoothness,
$\rho $
its modulus of smoothness,
 $S\subseteq X$
and
$S\subseteq X$
and
 $x^\ast \in X$
. We suppose that
$x^\ast \in X$
. We suppose that
 $K>0$
is such that
$K>0$
is such that
 $\|{y-x^\ast }\|\leq K$
for all
$\|{y-x^\ast }\|\leq K$
for all
 $y\in S$
, which in particular exists whenever S is bounded. Finally, for now we let
$y\in S$
, which in particular exists whenever S is bounded. Finally, for now we let
 $(x_n)$
be an arbitrary sequence in X and
$(x_n)$
be an arbitrary sequence in X and
 $(\epsilon _n)$
an arbitrary sequence of nonnegative real numbers. We treat these throughout as global parameters, and also for convenience fix the notation
$(\epsilon _n)$
an arbitrary sequence of nonnegative real numbers. We treat these throughout as global parameters, and also for convenience fix the notation
 $a_n:=\|{x_n-x^\ast }\|$
. The goal is therefore to prove that
$a_n:=\|{x_n-x^\ast }\|$
. The goal is therefore to prove that
 $a_n\to 0$
.
$a_n\to 0$
.
The main technical lemma we required—Lemma 2.5—can then be represented as the single inference

where “
 $(\epsilon _n)\text {-}x^\ast \text {-greedy}$
” is shorthand for the statement “
$(\epsilon _n)\text {-}x^\ast \text {-greedy}$
” is shorthand for the statement “
 $(x_n)$
is
$(x_n)$
is
 $(\epsilon _n)$
-greedy with respect to
$(\epsilon _n)$
-greedy with respect to
 $x^\ast $
” and the predicate P is defined by
$x^\ast $
” and the predicate P is defined by
 $$ \begin{align*} P(b,a,a',\epsilon):=a'\leq (1-\alpha(b))a+\epsilon \end{align*} $$
$$ \begin{align*} P(b,a,a',\epsilon):=a'\leq (1-\alpha(b))a+\epsilon \end{align*} $$
for
 $\alpha (b)$
defined as in Lemma 2.5. Rather than immediately analysing the somewhat intricate proof of that lemma, we will leave it for now and consider how it fits into the main proof of Theorem 2.6. Letting
$\alpha (b)$
defined as in Lemma 2.5. Rather than immediately analysing the somewhat intricate proof of that lemma, we will leave it for now and consider how it fits into the main proof of Theorem 2.6. Letting
 $a_\infty :=\liminf _{n\to \infty }a_n$
, the first step in the main proof has the overall form
$a_\infty :=\liminf _{n\to \infty }a_n$
, the first step in the main proof has the overall form

Of course, there are a number of additional (elementary) steps involved in inferring
 $a_n\to a_\infty $
from the two premises, but we note that the property of being
$a_n\to a_\infty $
from the two premises, but we note that the property of being
 $(\epsilon _n)$
-greedy is used in a weak way, in that we only require
$(\epsilon _n)$
-greedy is used in a weak way, in that we only require
 $a_{n+1}\leq a_n+\epsilon _n$
. Moving on to the second main step of the proof, we now include an open assumption
$a_{n+1}\leq a_n+\epsilon _n$
. Moving on to the second main step of the proof, we now include an open assumption
 $\{{a_\infty>0}\}$
with the aim of reaching a contradiction:
$\{{a_\infty>0}\}$
with the aim of reaching a contradiction:

and we label this derivation (Γ2
). Here,
 $N_\exists $
is simply some natural number that we know to exist by definition of
$N_\exists $
is simply some natural number that we know to exist by definition of
 $a_\infty $
(where the notation is chosen to indicate that this is essentially an epsilon term for which we do not have an explicit value). The conclusion of (Γ2
) is simply the statement that
$a_\infty $
(where the notation is chosen to indicate that this is essentially an epsilon term for which we do not have an explicit value). The conclusion of (Γ2
) is simply the statement that
 $$ \begin{align*}a_{n+1}\leq (1-\alpha(a_\infty/2))a_n+\epsilon_n\end{align*} $$
$$ \begin{align*}a_{n+1}\leq (1-\alpha(a_\infty/2))a_n+\epsilon_n\end{align*} $$
for n sufficiently large. Continuing, we have the following crucial step:

where we use the shorthand

to represent the proof tree (Γ1
), and similarly for (Γ2
). The final inference in (Γ3
) represents taking the limit as
 $n\to \infty $
to establish
$n\to \infty $
to establish
 $$ \begin{align*}a_\infty\leq (1-\alpha(a_\infty/2))a_\infty.\end{align*} $$
$$ \begin{align*}a_\infty\leq (1-\alpha(a_\infty/2))a_\infty.\end{align*} $$
We reach our contradiction by using uniform smoothness of the space, with an inference we mark as
 $(\star )$
below, and from this can therefore derive
$(\star )$
below, and from this can therefore derive
 $a_\infty =0$
using classical logic, eliminating the open assumption
$a_\infty =0$
using classical logic, eliminating the open assumption
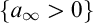 $\{{a_\infty>0}\}$
:
$\{{a_\infty>0}\}$
:

Formally, there is now one final step in the proof, namely:

and thus expanding the definition of (Γ5 ) in full would give us a complete (high-level) representation of the proof of Theorem 2.6. We now set out to analyse this proof with the three main questions posed at the beginning of the section in mind. We start at the bottom and work back up.
3.2 Using
 $a_\infty =0$
in the final step
$a_\infty =0$
in the final step

We start by considering precisely how the final step is proven, and asking whether we can extract any computational information at this stage. We first note that in the special case that
 $(a_n)$
is a sequence of nonnegative reals, the otherwise more complex statement
$(a_n)$
is a sequence of nonnegative reals, the otherwise more complex statement
 $a_\infty =0$
can be expressed as
$a_\infty =0$
can be expressed as
 $$ \begin{align} \forall b>0,m\in\mathbb{N}\,\exists n\geq m(a_n< b). \end{align} $$
$$ \begin{align} \forall b>0,m\in\mathbb{N}\,\exists n\geq m(a_n< b). \end{align} $$
So assuming that we have proven (*), how exactly do we derive
 $a_n\to 0$
from
$a_n\to 0$
from
 $a_n\to a_\infty $
? For a start, we observe that we do not require the full statement
$a_n\to a_\infty $
? For a start, we observe that we do not require the full statement
 $a_n\to a_\infty $
at all: It is sufficient to notice that two premises used to prove this in (Γ1
)—which is in general a more complex argument—can be combined with (*) in a simple way to establish
$a_n\to a_\infty $
at all: It is sufficient to notice that two premises used to prove this in (Γ1
)—which is in general a more complex argument—can be combined with (*) in a simple way to establish
 $a_n\to 0$
. To be more specific, suppose that
$a_n\to 0$
. To be more specific, suppose that
 $f:(0,\infty )\to \mathbb {N}$
is a rate of convergence for
$f:(0,\infty )\to \mathbb {N}$
is a rate of convergence for
 $\sum _{i=0}^\infty \epsilon _i<\infty $
in the sense that
$\sum _{i=0}^\infty \epsilon _i<\infty $
in the sense that
 $$ \begin{align*} \forall b>0\left(\sum_{i=f(b)}^\infty \epsilon_i<b\right). \end{align*} $$
$$ \begin{align*} \forall b>0\left(\sum_{i=f(b)}^\infty \epsilon_i<b\right). \end{align*} $$
Then for any
 $n\geq f(b)$
, using that
$n\geq f(b)$
, using that
 $\forall n(a_{n+1}\leq a_n+\epsilon _n)$
we must have
$\forall n(a_{n+1}\leq a_n+\epsilon _n)$
we must have
 $$ \begin{align*} a_{n+k}\leq a_n+\sum_{i=n}^{n+k-1}\epsilon_i\leq a_n+\sum_{i=f(b)}^\infty \epsilon_i< a_n+b \end{align*} $$
$$ \begin{align*} a_{n+k}\leq a_n+\sum_{i=n}^{n+k-1}\epsilon_i\leq a_n+\sum_{i=f(b)}^\infty \epsilon_i< a_n+b \end{align*} $$
for any
 $n,k\in \mathbb {N}$
and
$n,k\in \mathbb {N}$
and
 $b>0$
. Now suppose that we have a computable bound for n in (*) for
$b>0$
. Now suppose that we have a computable bound for n in (*) for
 $m:=f(b),$
i.e., a function
$m:=f(b),$
i.e., a function
 $\Phi :(0,\infty )\to \mathbb {N}$
such that
$\Phi :(0,\infty )\to \mathbb {N}$
such that
 $$ \begin{align*} \forall b>0\,\exists n\in [f(b);\Phi(b)](a_n< b), \end{align*} $$
$$ \begin{align*} \forall b>0\,\exists n\in [f(b);\Phi(b)](a_n< b), \end{align*} $$
where we use the notation
 $[f(b);\Phi (b)]:=[f(b),\Phi (b)]\cap \mathbb {N}$
. Then it is not hard to see that
$[f(b);\Phi (b)]:=[f(b),\Phi (b)]\cap \mathbb {N}$
. Then it is not hard to see that
 $\Phi (b/2)$
must be a rate of convergence for
$\Phi (b/2)$
must be a rate of convergence for
 $a_n\to 0$
, and thus we have not only proved that
$a_n\to 0$
, and thus we have not only proved that
 $a_n\to 0$
but shown exactly what quantitative information we need from the assumption
$a_n\to 0$
but shown exactly what quantitative information we need from the assumption
 $a_\infty =0$
to obtain a rate. In terms of our proof trees, we have essentially transformed (Γ5
) into the following computational derivation, eliminating the original (Γ1
), where
$a_\infty =0$
to obtain a rate. In terms of our proof trees, we have essentially transformed (Γ5
) into the following computational derivation, eliminating the original (Γ1
), where
 $b>0$
is now some global free variable:
$b>0$
is now some global free variable:

where now (
 $\Gamma _4^c$
) is some (currently hypothetical) computation transformation of (Γ4
) that allows us to replace
$\Gamma _4^c$
) is some (currently hypothetical) computation transformation of (Γ4
) that allows us to replace
 $a_\infty =0$
with a derivation of
$a_\infty =0$
with a derivation of
 $$\begin{align*}\exists n\in [f(b); \Phi(b)](a_n< n) \end{align*}$$
$$\begin{align*}\exists n\in [f(b); \Phi(b)](a_n< n) \end{align*}$$
for some explicit function
 $\Phi $
. The challenge has now shifted to transforming the original derivation (Γ4
) to a computational one (
$\Phi $
. The challenge has now shifted to transforming the original derivation (Γ4
) to a computational one (
 $\Gamma _4^c$
).
$\Gamma _4^c$
).
3.3 Simplifying (Γ4)
A crucial observation at this stage is that (Γ4
) simplifies: Because we have only used
 $a_\infty =0$
in the weakened form,
$a_\infty =0$
in the weakened form,
 $$ \begin{align} \exists n\geq f(b)(a_n< b), \end{align} $$
$$ \begin{align} \exists n\geq f(b)(a_n< b), \end{align} $$
where
 $b>0$
is now some ambient free variable, we can try to substitute this in the conclusion of (Γ4
) and then replace the open assumption
$b>0$
is now some ambient free variable, we can try to substitute this in the conclusion of (Γ4
) and then replace the open assumption
 $\{{a_\infty>0}\}$
with the stronger negation of (**), i.e., the more concrete assumption
$\{{a_\infty>0}\}$
with the stronger negation of (**), i.e., the more concrete assumption
 $$\begin{align*}\{{\forall n\geq f(b)(a_n\geq b)}\}, \end{align*}$$
$$\begin{align*}\{{\forall n\geq f(b)(a_n\geq b)}\}, \end{align*}$$
and simplify the proof tree accordingly. This process involves a series of straightforward heuristic steps. Starting with (Γ2
), we observe that here
 $\{{a_\infty>0}\}$
is crucially used to establish that
$\{{a_\infty>0}\}$
is crucially used to establish that
 $\forall n\geq N_\exists (a_\infty /2\leq a_n)$
for sufficiently large
$\forall n\geq N_\exists (a_\infty /2\leq a_n)$
for sufficiently large
 $N_\exists $
, where
$N_\exists $
, where
 $a_\infty /2>0$
. For now we see if we can just replace
$a_\infty /2>0$
. For now we see if we can just replace
 $a_\infty /2$
with b, and set
$a_\infty /2$
with b, and set
 $N_\exists :=f(b)$
as follows:
$N_\exists :=f(b)$
as follows:

By a simple substitution, (Γ3 ) then becomes

and then the entire modified version of (Γ4 ) would become

where here replacing
 $a_\infty /2$
with b makes no difference to the way in which we derive a contradiction. Though not yet fully computational, (Γs
4
) represents a simplified and more explicit version of (Γ4
), reflecting throughout our weakened use of
$a_\infty /2$
with b makes no difference to the way in which we derive a contradiction. Though not yet fully computational, (Γs
4
) represents a simplified and more explicit version of (Γ4
), reflecting throughout our weakened use of
 $a_\infty =0$
.
$a_\infty =0$
.
3.4 Analysing
$(\Gamma _4^s)$

We have demonstrated that in order to obtain a computable rate of convergence for
 $a_n\to 0$
it suffices to find a bound
$a_n\to 0$
it suffices to find a bound
 $\Phi (b)$
for the existential quantifier in
$\Phi (b)$
for the existential quantifier in
 $\exists n\geq f(b)(a_n<b)$
, where f is a rate of convergence for
$\exists n\geq f(b)(a_n<b)$
, where f is a rate of convergence for
 $\sum _{i=0}^\infty \epsilon _i<\infty $
. We propose to do this by analysing the simplified version (Γs
4
) of (Γ4
) arrived at above.
$\sum _{i=0}^\infty \epsilon _i<\infty $
. We propose to do this by analysing the simplified version (Γs
4
) of (Γ4
) arrived at above.
Here a key observation is that if we can weaken the open assumption with a bound on how many
 $n\geq f(b)$
are needed in order to be able to reach a contradiction as before, then this will be exactly the bound we are looking for. In other words, we want to produce
$n\geq f(b)$
are needed in order to be able to reach a contradiction as before, then this will be exactly the bound we are looking for. In other words, we want to produce
 $\Phi (b)$
satisfying
$\Phi (b)$
satisfying

Focusing first on the final derivation above, one immediate observation is that
 $\alpha (b)$
is not necessarily computable, which might pose a problem in the likely case that we want to use property
$\alpha (b)$
is not necessarily computable, which might pose a problem in the likely case that we want to use property
 $\alpha (b)>0$
in a computational way. Here we make another assumption that we hope to verify later on, namely, the existence of a computable function
$\alpha (b)>0$
in a computational way. Here we make another assumption that we hope to verify later on, namely, the existence of a computable function
 $\xi :(0,\infty )\to (0,1)$
witnessing that
$\xi :(0,\infty )\to (0,1)$
witnessing that
 $\alpha (b)>0,$
i.e., such that
$\alpha (b)>0,$
i.e., such that
 $\alpha (b)\geq \xi (b)>0$
for any
$\alpha (b)\geq \xi (b)>0$
for any
 $b>0$
.
$b>0$
.
We now shift up the proof tree to the final inference of (Γs
3
), where we take the limit as
 $n\to \infty $
to establish
$n\to \infty $
to establish
 $P(b,a_\infty ,a_\infty ,0),$
i.e.,
$P(b,a_\infty ,a_\infty ,0),$
i.e.,
 $$ \begin{align} a_\infty\leq (1-\alpha(b))a_\infty. \end{align} $$
$$ \begin{align} a_\infty\leq (1-\alpha(b))a_\infty. \end{align} $$
Given the infinitary nature of (†) it is not clear at first glance how we could weaken our open assumption
 $\{{\forall n\geq f(b)(a_n\geq b)}\}$
to being true only in a finite range. However, a natural question to ask here is the following: If
$\{{\forall n\geq f(b)(a_n\geq b)}\}$
to being true only in a finite range. However, a natural question to ask here is the following: If
 $P(b,a_n,a_{n+1},\epsilon _n)$
fails to be true in the limit—in the sense of (†)—can we show that it also fails to hold for n sufficiently large? In particular, here the only property of
$P(b,a_n,a_{n+1},\epsilon _n)$
fails to be true in the limit—in the sense of (†)—can we show that it also fails to hold for n sufficiently large? In particular, here the only property of
 $a_n\to a_{\infty }$
that is important is that
$a_n\to a_{\infty }$
that is important is that
 $a_n$
and
$a_n$
and
 $a_{n+1}$
converge to the same value, so could we replace this with
$a_{n+1}$
converge to the same value, so could we replace this with
 $a_n$
and
$a_n$
and
 $a_{n+1}$
being sufficiently close together?
$a_{n+1}$
being sufficiently close together?
To this end, let us take some
 $\delta>0$
. Then by
$\delta>0$
. Then by
 $a_n\to a_\infty $
and
$a_n\to a_\infty $
and
 $\epsilon _n\to 0$
there exists, more concretely, some
$\epsilon _n\to 0$
there exists, more concretely, some
 $k\geq f(b)$
such that
$k\geq f(b)$
such that
 $a_k-a_{k+1}<\delta $
and
$a_k-a_{k+1}<\delta $
and
 $\epsilon _k<\delta $
. Then from
$\epsilon _k<\delta $
. Then from
 $P(b,a_k,a_{k+1},\epsilon _k)$
and our assumption
$P(b,a_k,a_{k+1},\epsilon _k)$
and our assumption
 $\alpha (b)\geq \xi (b)$
it follows that
$\alpha (b)\geq \xi (b)$
it follows that
 $$ \begin{align*} a_{k+1}\leq (1-\xi(b))(a_{k+1}+\delta)+\delta, \end{align*} $$
$$ \begin{align*} a_{k+1}\leq (1-\xi(b))(a_{k+1}+\delta)+\delta, \end{align*} $$
which can be rearranged as
 $$ \begin{align*} \frac{\xi(b)\cdot a_{k+1}}{2-\xi(b)}\leq \delta. \end{align*} $$
$$ \begin{align*} \frac{\xi(b)\cdot a_{k+1}}{2-\xi(b)}\leq \delta. \end{align*} $$
But using also that
 $b\leq a_{k+1}$
, the above fails for
$b\leq a_{k+1}$
, the above fails for
 $$ \begin{align*} \delta_{\xi,b}:=\tfrac{1}{2}\xi(b)\cdot b, \end{align*} $$
$$ \begin{align*} \delta_{\xi,b}:=\tfrac{1}{2}\xi(b)\cdot b, \end{align*} $$
so we have reached a contradiction, and we can replace the final inference of (Γs
3
) with a finitary version which does not use the whole limit as
 $n\to \infty $
. We now formulate this finitisation of (Γs
3
) as the following proof tree
$n\to \infty $
. We now formulate this finitisation of (Γs
3
) as the following proof tree
 $(\Gamma _3^f)$
, where
$(\Gamma _3^f)$
, where
 $\delta _{\xi ,b}$
is defined as above:
$\delta _{\xi ,b}$
is defined as above:

Then we have obtained our contradiction as follows:

We now ask: How much of the assumption
 $\{{\forall n\geq f(b)(a_n\geq b)}\}$
do we need to obtain this contradiction? Inspecting (Γf
3
) it is readily apparent that if
$\{{\forall n\geq f(b)(a_n\geq b)}\}$
do we need to obtain this contradiction? Inspecting (Γf
3
) it is readily apparent that if
 $\Psi (b)$
is a bound on a witness for
$\Psi (b)$
is a bound on a witness for
 $\exists k\geq f(b)(a_k-a_{k+1},\epsilon _k<\delta _{\xi ,b})$
, then we can replace the open assumption with
$\exists k\geq f(b)(a_k-a_{k+1},\epsilon _k<\delta _{\xi ,b})$
, then we can replace the open assumption with
 $$ \begin{align*} \{{\forall n\in [f(b);\Psi(b)+1](a_n\geq b)}\} \end{align*} $$
$$ \begin{align*} \{{\forall n\in [f(b);\Psi(b)+1](a_n\geq b)}\} \end{align*} $$
(here the
 $+1$
is necessary from our additional use of the assumption for
$+1$
is necessary from our additional use of the assumption for
 $b\leq a_{k+1}$
), and thus
$b\leq a_{k+1}$
), and thus
 $\Psi (b/2)+1$
is a rate of convergence for
$\Psi (b/2)+1$
is a rate of convergence for
 $a_n\to 0$
.
$a_n\to 0$
.
3.5 The final step
All that remains in order to obtain our rate of convergence—aside from some assumptions involving uniform smoothness that we have postponed to later—is to analyse the following fragment of our modified proof tree:

We will actually provide a bound
 $\Psi (N,\delta )$
for the more general statement
$\Psi (N,\delta )$
for the more general statement
 $$ \begin{align*} \forall N,\delta\exists k\geq N(a_k-a_{k+1},\epsilon_k<\delta) \end{align*} $$
$$ \begin{align*} \forall N,\delta\exists k\geq N(a_k-a_{k+1},\epsilon_k<\delta) \end{align*} $$
and then
 $$ \begin{align} \Phi(b):=\Psi(f(b/2), \delta_{\xi,b/2})+1 \end{align} $$
$$ \begin{align} \Phi(b):=\Psi(f(b/2), \delta_{\xi,b/2})+1 \end{align} $$
would be our rate of convergence for
 $a_n\to 0$
. Witnessing the above turns out to be simpler that it might look: From
$a_n\to 0$
. Witnessing the above turns out to be simpler that it might look: From
 $\sum _{i=0}^\infty \epsilon _i<\infty $
we clearly have
$\sum _{i=0}^\infty \epsilon _i<\infty $
we clearly have
 $\epsilon _k<\delta $
for all
$\epsilon _k<\delta $
for all
 $k\geq f(\delta )$
sufficiently large, and then finding k such that we also have
$k\geq f(\delta )$
sufficiently large, and then finding k such that we also have
 $a_k-a_{k+1}<\delta $
does not in any way require the assumption
$a_k-a_{k+1}<\delta $
does not in any way require the assumption
 $a_n\to a_\infty $
, rather we simply need a bound on a single element of
$a_n\to a_\infty $
, rather we simply need a bound on a single element of
 $(a_n)$
. We now present this construction in general terms as follows.
$(a_n)$
. We now present this construction in general terms as follows.
Lemma 3.1. Let
 $(a_n)$
,
$(a_n)$
,
 $(K_n),$
and
$(K_n),$
and
 $(\epsilon _n)$
be sequences of nonnegative reals with
$(\epsilon _n)$
be sequences of nonnegative reals with
 $K_n\geq a_n$
for all
$K_n\geq a_n$
for all
 $n\in \mathbb {N}$
and
$n\in \mathbb {N}$
and
 $\epsilon _n\to 0$
as
$\epsilon _n\to 0$
as
 $n\to \infty $
with rate f. Let
$n\to \infty $
with rate f. Let
 $$ \begin{align*} \Psi(N,\delta):=M_{N,\delta}+\Big\lceil \frac{K_{M_{N,\delta}}}{\delta}\Big\rceil \ \ \ \text{for} \ \ \ M_{N,\delta}:=\max\{N,f(\delta)\}. \end{align*} $$
$$ \begin{align*} \Psi(N,\delta):=M_{N,\delta}+\Big\lceil \frac{K_{M_{N,\delta}}}{\delta}\Big\rceil \ \ \ \text{for} \ \ \ M_{N,\delta}:=\max\{N,f(\delta)\}. \end{align*} $$
Then for any
 $N\in \mathbb {N}$
and
$N\in \mathbb {N}$
and
 $\delta>0$
there exists some
$\delta>0$
there exists some
 $k\in [N;\Psi (N,\delta )]$
such that
$k\in [N;\Psi (N,\delta )]$
such that
 $a_k-a_{k+1}<\delta $
and
$a_k-a_{k+1}<\delta $
and
 $\epsilon _k<\delta $
.
$\epsilon _k<\delta $
.
Proof Suppose that
 $a_k-a_{k+1}\geq \delta $
for all
$a_k-a_{k+1}\geq \delta $
for all
 $k\in [M_{N,\delta };\Psi (N,\delta )]$
. Then we have
$k\in [M_{N,\delta };\Psi (N,\delta )]$
. Then we have
 $$ \begin{align*} K_{M_{N,\delta}}\geq a_{M_{N,\delta}}&\geq a_{M_{N,\delta}+1}+\delta\\ &\geq \dots\\ &\geq a_{M_{N,\delta}+\lceil K_{M_{N,\delta}}/\delta\rceil+1}+(\lceil K_{M_{N,\delta}}/\delta\rceil+1)\delta\\ &\geq (\lceil K_{M_{N,\delta}}/\delta\rceil+1)\delta\\ &>K_{M_{N,\delta,}} \end{align*} $$
$$ \begin{align*} K_{M_{N,\delta}}\geq a_{M_{N,\delta}}&\geq a_{M_{N,\delta}+1}+\delta\\ &\geq \dots\\ &\geq a_{M_{N,\delta}+\lceil K_{M_{N,\delta}}/\delta\rceil+1}+(\lceil K_{M_{N,\delta}}/\delta\rceil+1)\delta\\ &\geq (\lceil K_{M_{N,\delta}}/\delta\rceil+1)\delta\\ &>K_{M_{N,\delta,}} \end{align*} $$
which is a contradiction. Therefore there exists some
 $$\begin{align*}k\in [M_{N,\delta};\Theta(N,\delta)]\subseteq [N;\Theta(N,\delta)] \end{align*}$$
$$\begin{align*}k\in [M_{N,\delta};\Theta(N,\delta)]\subseteq [N;\Theta(N,\delta)] \end{align*}$$
such that
 $a_k-a_{k+1}<\delta $
, and since
$a_k-a_{k+1}<\delta $
, and since
 $k\geq M_{N,\delta }\geq f(\delta )$
it also follows that
$k\geq M_{N,\delta }\geq f(\delta )$
it also follows that
 $\epsilon _k<\delta $
by definition of f.
$\epsilon _k<\delta $
by definition of f.
Assuming for simplicity that f is monotone, so that we can simplify
 $\max \{f(b/2),f(\delta _{\xi ,b/2})\}=f(\delta _{\xi ,b/2})$
, and supposing that
$\max \{f(b/2),f(\delta _{\xi ,b/2})\}=f(\delta _{\xi ,b/2})$
, and supposing that
 $\sum _{i=0}^\infty \epsilon _i\leq L$
, by which we have
$\sum _{i=0}^\infty \epsilon _i\leq L$
, by which we have
 $a_n\leq a_0+\sum _{i=0}^\infty \epsilon _i\leq K+L$
for all
$a_n\leq a_0+\sum _{i=0}^\infty \epsilon _i\leq K+L$
for all
 $n\in \mathbb {N}$
, we then obtain a concrete rate of convergence for
$n\in \mathbb {N}$
, we then obtain a concrete rate of convergence for
 $a_n\to 0$
from (+), namely,
$a_n\to 0$
from (+), namely,
 $$ \begin{align} \Phi(b):=f(\mu_{\xi,b})+\Big\lceil \frac{K+L}{\mu_{\xi,b}}\Big\rceil+1 \ \ \ \text{for} \ \ \ \mu_{\xi,b}:=\frac{b}{4}\cdot \xi\left(\frac{b}{2}\right). \end{align} $$
$$ \begin{align} \Phi(b):=f(\mu_{\xi,b})+\Big\lceil \frac{K+L}{\mu_{\xi,b}}\Big\rceil+1 \ \ \ \text{for} \ \ \ \mu_{\xi,b}:=\frac{b}{4}\cdot \xi\left(\frac{b}{2}\right). \end{align} $$
Equipped with this high-level quantitative understanding of the main combinatorial structure of the proof, we now start to put things together in an ordinary mathematical style.
4 The main result
We complete our quantitative analysis of the proof of Theorem 2.6 by first formalising and optimizing the ideas of the previous section into abstract quantitative convergence lemmas, and second dealing with the hitherto postponed treatment of uniform smoothness. It is at this stage that we start to make greater use of ideas and techniques from the broader proof mining literature.
4.1 Abstract convergence lemmas
The result of Section 3 was a preliminary rate of convergence for
 $\|{x_n-x^\ast }\|\to 0$
in some (as yet hypothetical) computable function
$\|{x_n-x^\ast }\|\to 0$
in some (as yet hypothetical) computable function
 $\xi $
satisfying
$\xi $
satisfying
 $0<\xi (b)\leq \alpha (b)$
for all
$0<\xi (b)\leq \alpha (b)$
for all
 $b>0$
, with
$b>0$
, with
 $\alpha (b)$
defined in terms of the modulus of smoothness of the space as in Lemma 2.5. While there is nothing preventing us from just using this rate directly, it is sensible to first ask whether we can optimize the construction—in particular, whether there are local modifications that either improve our initial convergence rate or weaken any assumptions used. Here we now depart from our rigid analysis of the original proof of Theorem 2.6 and inject into it new insights.
$\alpha (b)$
defined in terms of the modulus of smoothness of the space as in Lemma 2.5. While there is nothing preventing us from just using this rate directly, it is sensible to first ask whether we can optimize the construction—in particular, whether there are local modifications that either improve our initial convergence rate or weaken any assumptions used. Here we now depart from our rigid analysis of the original proof of Theorem 2.6 and inject into it new insights.
Let us consider our analysis of (Γs
4
) in Section 3.4. The core of this part of the proof, which allows us to derive our contradiction, is the limiting step in (Γs
3
), which uses
 $\sum _{i=0}^\infty \epsilon _i<\infty $
in the weaker form of
$\sum _{i=0}^\infty \epsilon _i<\infty $
in the weaker form of
 $\epsilon _n\to 0$
as
$\epsilon _n\to 0$
as
 $n\to \infty $
. A natural question arises: Can we either exploit the strong property
$n\to \infty $
. A natural question arises: Can we either exploit the strong property
 $\sum _{i=0}^\infty \epsilon _i<\infty $
in this step to gain a better bound
$\sum _{i=0}^\infty \epsilon _i<\infty $
in this step to gain a better bound
 $\Phi (b)$
, or replace
$\Phi (b)$
, or replace
 $\sum _{i=0}^\infty \epsilon _i<\infty $
with the weaker property
$\sum _{i=0}^\infty \epsilon _i<\infty $
with the weaker property
 $\epsilon _n\to 0$
and
$\epsilon _n\to 0$
and
 $n\to \infty $
throughout the proof? We now show that both are possible.
$n\to \infty $
throughout the proof? We now show that both are possible.
Our first result captures a refined analysis of (Γs
4
) that makes full use of the property
 $\sum _{i=0}^\infty \epsilon _i<\infty $
. We no longer spell out the details using proof trees, now instead adopting a standard presentation.
$\sum _{i=0}^\infty \epsilon _i<\infty $
. We no longer spell out the details using proof trees, now instead adopting a standard presentation.
Lemma 4.1. Let
 $(a_n)$
and
$(a_n)$
and
 $(\epsilon _n)$
be sequences of nonnegative reals, and
$(\epsilon _n)$
be sequences of nonnegative reals, and
 ${\xi :[0,\infty )\to [0,1)}$
be a function with
${\xi :[0,\infty )\to [0,1)}$
be a function with
 $\xi (0)=0$
and
$\xi (0)=0$
and
 $\xi (b)>0$
for
$\xi (b)>0$
for
 $b>0$
, such that for all
$b>0$
, such that for all
 $n\in \mathbb {N}$
and
$n\in \mathbb {N}$
and
 $b\geq 0,$
$b\geq 0,$
 $$\begin{align*}a_{n+1}\leq (1-\xi(b))a_n+\epsilon_n \end{align*}$$
$$\begin{align*}a_{n+1}\leq (1-\xi(b))a_n+\epsilon_n \end{align*}$$
whenever
 $a_n\geq b$
. Suppose that
$a_n\geq b$
. Suppose that
 $a_0\leq K$
and
$a_0\leq K$
and
 $\sum _{i=0}^\infty \epsilon _i\leq L$
with rate f. Then
$\sum _{i=0}^\infty \epsilon _i\leq L$
with rate f. Then
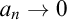 $a_n\to 0$
as
$a_n\to 0$
as
 $n\to \infty $
with rate
$n\to \infty $
with rate
 $$\begin{align*}\Phi(b):=f\left(\frac{b}{2}\right)+\Big\lceil \frac{K+L}{\mu_{\xi,b}}\Big\rceil \ \ \ \text{for} \ \ \ \mu_{\xi,b}:=\frac{b}{2}\cdot\xi\left(\frac{b}{2}\right). \end{align*}$$
$$\begin{align*}\Phi(b):=f\left(\frac{b}{2}\right)+\Big\lceil \frac{K+L}{\mu_{\xi,b}}\Big\rceil \ \ \ \text{for} \ \ \ \mu_{\xi,b}:=\frac{b}{2}\cdot\xi\left(\frac{b}{2}\right). \end{align*}$$
Proof Fix
 $b>0$
. We show that there exists some
$b>0$
. We show that there exists some
 $n\in [f(b/2);\Phi (b)]$
such that
$n\in [f(b/2);\Phi (b)]$
such that
 $a_n<b/2$
. If this were not the case, then for all n in that range we would have
$a_n<b/2$
. If this were not the case, then for all n in that range we would have
 $$\begin{align*}\mu_{\xi,b}\leq a_n\cdot\xi\left(\frac{b}{2}\right)\leq a_n-a_{n+1}+\epsilon_n, \end{align*}$$
$$\begin{align*}\mu_{\xi,b}\leq a_n\cdot\xi\left(\frac{b}{2}\right)\leq a_n-a_{n+1}+\epsilon_n, \end{align*}$$
and therefore summing both sides
 $$\begin{align*}K+L<\sum_{i=f(b/2)}^{\Phi(b)}\mu_{\xi,b}\leq \sum_{i=f(b/2)}^{\Phi(b)}(a_i-a_{i+1}+\epsilon_i)\leq a_{f(b/2)}+\sum_{i=f(b/2)}^{\Phi(b)}\epsilon_i \end{align*}$$
$$\begin{align*}K+L<\sum_{i=f(b/2)}^{\Phi(b)}\mu_{\xi,b}\leq \sum_{i=f(b/2)}^{\Phi(b)}(a_i-a_{i+1}+\epsilon_i)\leq a_{f(b/2)}+\sum_{i=f(b/2)}^{\Phi(b)}\epsilon_i \end{align*}$$
and now also using that
 $a_{n+1}\leq a_n+\epsilon _n$
for all
$a_{n+1}\leq a_n+\epsilon _n$
for all
 $n\in \mathbb {N}$
, we have
$n\in \mathbb {N}$
, we have
 $$\begin{align*}a_{f(b/2)}+\sum_{i=f(b/2)}^{\Phi(b)}\epsilon_i\leq a_0+\sum_{i=0}^{f(b/2)-1} \epsilon_i+\sum_{i=f(b/2)}^{\Phi(b)}\epsilon_i\leq a_0+\sum_{i=0}^\infty \epsilon_i \end{align*}$$
$$\begin{align*}a_{f(b/2)}+\sum_{i=f(b/2)}^{\Phi(b)}\epsilon_i\leq a_0+\sum_{i=0}^{f(b/2)-1} \epsilon_i+\sum_{i=f(b/2)}^{\Phi(b)}\epsilon_i\leq a_0+\sum_{i=0}^\infty \epsilon_i \end{align*}$$
and thus we have shown that
 $$\begin{align*}K+L<a_0+\sum_{i=0}^\infty \epsilon_i\leq K+L \end{align*}$$
$$\begin{align*}K+L<a_0+\sum_{i=0}^\infty \epsilon_i\leq K+L \end{align*}$$
a contradiction. Therefore let
 $n\in [f(b/2);\Phi (b)]$
be such that
$n\in [f(b/2);\Phi (b)]$
be such that
 $a_n<b/2$
. But then just as in Section 3.2 we have
$a_n<b/2$
. But then just as in Section 3.2 we have
 $$\begin{align*}a_{n+k}\leq a_n+\sum_{i=f(b/2)}^\infty \epsilon_i<a_n+\frac{b}{2}<b \end{align*}$$
$$\begin{align*}a_{n+k}\leq a_n+\sum_{i=f(b/2)}^\infty \epsilon_i<a_n+\frac{b}{2}<b \end{align*}$$
for any
 $k\in \mathbb {N}$
, and so the result follows.
$k\in \mathbb {N}$
, and so the result follows.
It is instructive to compare the rate given in Lemma 4.1 above to the initial rate (R): The former is an improvement of the latter, but shares the same basic structure. Generally speaking, Lemma 4.1 is more broadly applicable to algorithms that are quasi-Fejér monotone and enjoy a certain type of regularity property, here represented by the function
 $\xi $
. The general quantitative study of quasi-Fejér monotone sequences from the perspective of proof mining began explicitly in [Reference Kohlenbach, Leuştean and Nicolae25], was further developed in [Reference Pischke42] (notably under regularity assumptions), and recently lifted to a stochastic setting in [Reference Neri, Pischke and Powell35], where, for example, Theorem 3.4 of [Reference Neri, Pischke and Powell35] is a direct generalisation of Lemma 4.1 applicable to stochastic algorithms.
$\xi $
. The general quantitative study of quasi-Fejér monotone sequences from the perspective of proof mining began explicitly in [Reference Kohlenbach, Leuştean and Nicolae25], was further developed in [Reference Pischke42] (notably under regularity assumptions), and recently lifted to a stochastic setting in [Reference Neri, Pischke and Powell35], where, for example, Theorem 3.4 of [Reference Neri, Pischke and Powell35] is a direct generalisation of Lemma 4.1 applicable to stochastic algorithms.
Our next result now keeps the analysis of (Γs
4
) intact, but instead adjusts (Γ1
), replacing the weaker property
 $a_{n+1}\leq a_n+\epsilon _n$
with the stronger recurrence inequality satisfied by
$a_{n+1}\leq a_n+\epsilon _n$
with the stronger recurrence inequality satisfied by
 $\epsilon _n$
-greedy algorithms in uniformly smooth Banach spaces, conversely allowing us to weaken the assumption
$\epsilon _n$
-greedy algorithms in uniformly smooth Banach spaces, conversely allowing us to weaken the assumption
 ${\sum _{i=0}^\infty \epsilon _i<\infty }$
to
${\sum _{i=0}^\infty \epsilon _i<\infty }$
to
 $\epsilon _n\to 0$
as
$\epsilon _n\to 0$
as
 $n\to \infty $
throughout the proof. To obtain a rate of convergence that is uniform in
$n\to \infty $
throughout the proof. To obtain a rate of convergence that is uniform in
 $(a_n)$
we now require an explicit bound on the whole sequence
$(a_n)$
we now require an explicit bound on the whole sequence
 $(a_n)$
, though boundedness of
$(a_n)$
, though boundedness of
 $(a_n)$
is not required as an assumption in order to establish convergence. The result is inspired by a similar recurrence inequality used in [Reference Powell and Wiesnet46] (cf. Lemma 3.1 of that paper) in the somewhat different context of Krasnoselskii–Mann type algorithms for computing fixpoints of weakly contractive mappings.
$(a_n)$
is not required as an assumption in order to establish convergence. The result is inspired by a similar recurrence inequality used in [Reference Powell and Wiesnet46] (cf. Lemma 3.1 of that paper) in the somewhat different context of Krasnoselskii–Mann type algorithms for computing fixpoints of weakly contractive mappings.
Lemma 4.2. Let
 $(a_n)$
and
$(a_n)$
and
 $(\epsilon _n)$
be sequences of nonnegative reals, and
$(\epsilon _n)$
be sequences of nonnegative reals, and
 ${\xi :[0,\infty )\to [0,1)}$
be a function with
${\xi :[0,\infty )\to [0,1)}$
be a function with
 $\xi (0)=0$
and
$\xi (0)=0$
and
 $\xi (b)>0$
for
$\xi (b)>0$
for
 $b>0$
, such that for all
$b>0$
, such that for all
 $n\in \mathbb {N}$
and
$n\in \mathbb {N}$
and
 $b\geq 0,$
$b\geq 0,$
 $$\begin{align*}a_{n+1}\leq (1-\xi(b))a_n+\epsilon_n \end{align*}$$
$$\begin{align*}a_{n+1}\leq (1-\xi(b))a_n+\epsilon_n \end{align*}$$
whenever
 $a_n\geq b$
. Suppose that
$a_n\geq b$
. Suppose that
 $\epsilon _n\to 0$
as
$\epsilon _n\to 0$
as
 $n\to \infty $
with rate f. Then
$n\to \infty $
with rate f. Then
 $a_n\to 0$
as
$a_n\to 0$
as
 $n\to \infty $
with rate
$n\to \infty $
with rate
 $$\begin{align*}\Phi(b):=f(\mu_{\xi,b})+\Big\lceil \frac{L}{\mu_{\xi,b}}\Big\rceil+1 \ \ \ \text{for} \ \ \ \mu_{\xi,b}:=\frac{b}{4}\cdot \xi\left(\frac{b}{2}\right), \end{align*}$$
$$\begin{align*}\Phi(b):=f(\mu_{\xi,b})+\Big\lceil \frac{L}{\mu_{\xi,b}}\Big\rceil+1 \ \ \ \text{for} \ \ \ \mu_{\xi,b}:=\frac{b}{4}\cdot \xi\left(\frac{b}{2}\right), \end{align*}$$
where
 $L>0$
is any bound on
$L>0$
is any bound on
 $(a_n)$
.
$(a_n)$
.
Proof Fix
 $b>0$
and apply Lemma 3.1 for
$b>0$
and apply Lemma 3.1 for
 $N:=f(\mu _{\xi ,b})$
and
$N:=f(\mu _{\xi ,b})$
and
 $\delta :=\mu _{\xi ,b}$
, by which there exists
$\delta :=\mu _{\xi ,b}$
, by which there exists
 $k\in [f(\mu _{\xi ,b});\Theta (b)]$
such that
$k\in [f(\mu _{\xi ,b});\Theta (b)]$
such that
 $a_k-a_{k+1},\epsilon <\mu _{\xi ,b}$
for
$a_k-a_{k+1},\epsilon <\mu _{\xi ,b}$
for
 $$\begin{align*}\Theta(b):=f(\mu_{\xi,b})+\Big\lceil \frac{K_b}{\mu_{\xi,b}}\Big\rceil, \end{align*}$$
$$\begin{align*}\Theta(b):=f(\mu_{\xi,b})+\Big\lceil \frac{K_b}{\mu_{\xi,b}}\Big\rceil, \end{align*}$$
where
 $K_b$
is any bound for
$K_b$
is any bound for
 $a_{f(\mu _{\xi ,b})}$
. Suppose for contradiction that
$a_{f(\mu _{\xi ,b})}$
. Suppose for contradiction that
 $a_l\geq b/2$
for all
$a_l\geq b/2$
for all
 $l\in [f(\mu _{\xi ,b});\Theta (b)+1]$
. Then in particular we have
$l\in [f(\mu _{\xi ,b});\Theta (b)+1]$
. Then in particular we have
 $$\begin{align*}a_{k+1}\leq (1-\xi(b/2))(a_{k+1}+\mu_{\xi,b})+\mu_{\xi,b} \end{align*}$$
$$\begin{align*}a_{k+1}\leq (1-\xi(b/2))(a_{k+1}+\mu_{\xi,b})+\mu_{\xi,b} \end{align*}$$
and therefore
 $$\begin{align*}\mu_{\xi,b}\leq \frac{a_{k+1}}{2}\cdot\xi\left(\frac{b}{2}\right)< \frac{\xi(b/2)\cdot a_{k+1}}{2-\xi(b/2)}\leq \mu_{\xi,b}. \end{align*}$$
$$\begin{align*}\mu_{\xi,b}\leq \frac{a_{k+1}}{2}\cdot\xi\left(\frac{b}{2}\right)< \frac{\xi(b/2)\cdot a_{k+1}}{2-\xi(b/2)}\leq \mu_{\xi,b}. \end{align*}$$
Thus there exists
 $l\in [f(\mu _{\xi ,b});\Theta (b)+1]$
such that
$l\in [f(\mu _{\xi ,b});\Theta (b)+1]$
such that
 $a_l<b/2$
, and we now show by induction that
$a_l<b/2$
, and we now show by induction that
 $a_{l+m}<b$
for all
$a_{l+m}<b$
for all
 $m\in \mathbb {N}$
. For the induction step, we first note that since
$m\in \mathbb {N}$
. For the induction step, we first note that since
 $l+m\geq l\geq f(\mu _{\xi ,b})$
we have
$l+m\geq l\geq f(\mu _{\xi ,b})$
we have
 $\epsilon _{l+m}<\mu _{\xi ,b}$
. We then consider two cases: Either
$\epsilon _{l+m}<\mu _{\xi ,b}$
. We then consider two cases: Either
 $a_{l+m}<b/2$
, and then
$a_{l+m}<b/2$
, and then
 $$\begin{align*}a_{l+m+1}\leq a_{l+m}+\epsilon_{l+m}<\frac{b}{2}+\mu_{\xi,b}<b, \end{align*}$$
$$\begin{align*}a_{l+m+1}\leq a_{l+m}+\epsilon_{l+m}<\frac{b}{2}+\mu_{\xi,b}<b, \end{align*}$$
or otherwise we have
 $b/2\leq a_{l+m}<b$
, and then
$b/2\leq a_{l+m}<b$
, and then
 $$\begin{align*}a_{l+m+1}\leq (1-\xi(b/2))a_{l+m}+\mu_{\xi,b}\leq a_{l+m}-2\mu_{\xi,b}+\mu_{\xi,b}<b. \end{align*}$$
$$\begin{align*}a_{l+m+1}\leq (1-\xi(b/2))a_{l+m}+\mu_{\xi,b}\leq a_{l+m}-2\mu_{\xi,b}+\mu_{\xi,b}<b. \end{align*}$$
Therefore
 $a_n\to 0$
as
$a_n\to 0$
as
 $n\to \infty $
with convergence rate
$n\to \infty $
with convergence rate
 $\Theta (b)+1$
, and setting
$\Theta (b)+1$
, and setting
 $K_b:=L$
for some uniform bound L on
$K_b:=L$
for some uniform bound L on
 $(a_n)$
gives the result.
$(a_n)$
gives the result.
4.2 Handling uniform smoothness
Up until now, we have postponed the fact that we need to deal with uniform smoothness in a computational way: So far, our computational analysis has dealt with nothing beyond sequences of real numbers. Interestingly, and as is very often the case in applied proof theory, these results on the convergence of sequence of reals contain the core computational content of the original proof (see [Reference Franci and Grammatico9] for a comprehensive survey on the general importance of such results in analysis, and [Reference Neri and Powell36] for a recent discussion of the role they play in the context of applied proof theory, which also contains references to some the many places in which quantitative versions of such results have played a role). Indeed, the only computational role that uniform smoothness plays in the proof of Theorem 2.6 is in establishing that
 $\alpha (b)>0$
for
$\alpha (b)>0$
for
 $\alpha $
defined as in Lemma 2.5, which explicitly involves the modulus of smoothness
$\alpha $
defined as in Lemma 2.5, which explicitly involves the modulus of smoothness
 $\rho _X$
, or more precisely, a rate of convergence for
$\rho _X$
, or more precisely, a rate of convergence for
 $\rho _X(t)/t\to 0$
as
$\rho _X(t)/t\to 0$
as
 $t\to 0$
.
$t\to 0$
.
For the vast majority of case studies in applied proof theory that take place in uniformly smooth Banach spaces, such a rate of convergence is essentially all that is required (though see [Reference Findling and Kohlenbach8] for an example where additional properties of the modulus of smoothness are needed). In such cases, it is often convenient to reformulate the proof using the following alternative definition of uniform smoothness: A Banach space is uniformly smooth if and only if for any
 $\varepsilon>0$
there exists
$\varepsilon>0$
there exists
 $\delta>0$
such that
$\delta>0$
such that
 $$ \begin{align} \|{x}\|=1\wedge \|{y}\|\leq \delta\implies \|{x+y}\|+\|{x-y}\|\leq 2+\varepsilon\|{y}\| \end{align} $$
$$ \begin{align} \|{x}\|=1\wedge \|{y}\|\leq \delta\implies \|{x+y}\|+\|{x-y}\|\leq 2+\varepsilon\|{y}\| \end{align} $$
for any
 $x,y\in X$
. This characterisation of uniform smoothness is simpler from a logical perspective, and admits a direct computational interpretation in the form of a so-called modulus of uniform smoothness
$x,y\in X$
. This characterisation of uniform smoothness is simpler from a logical perspective, and admits a direct computational interpretation in the form of a so-called modulus of uniform smoothness
 $\omega :(0,\infty )\to (0,\infty )$
, which is defined to be any function that for any
$\omega :(0,\infty )\to (0,\infty )$
, which is defined to be any function that for any
 $\varepsilon>0$
returns some witness for
$\varepsilon>0$
returns some witness for
 $\delta $
in (US). Moduli of uniform smoothness, which are distinct from the (uniquely defined) modulus of smoothness, were first used in [Reference Kohlenbach and Leuştean24] and appear in many other places in proof mining as a quantitative analogue of uniform smoothness.
$\delta $
in (US). Moduli of uniform smoothness, which are distinct from the (uniquely defined) modulus of smoothness, were first used in [Reference Kohlenbach and Leuştean24] and appear in many other places in proof mining as a quantitative analogue of uniform smoothness.
For the purpose of our case study, our main task is therefore to reformulate the main lemmas on uniform smoothness in terms of the simpler logical modulus. We start with Lemma 2.3.
Lemma 4.3. Let
 $(X,\omega )$
be a uniformly smooth Banach space with modulus of uniform smoothness
$(X,\omega )$
be a uniformly smooth Banach space with modulus of uniform smoothness
 $\omega $
. Take
$\omega $
. Take
 $x\neq 0$
and let
$x\neq 0$
and let
 $F_x:=j(x)/\|{x}\|$
. Then
$F_x:=j(x)/\|{x}\|$
. Then
 $$ \begin{align*} \frac{t\|{y}\|}{\|{x}\|}\leq \omega(\varepsilon)\implies \|{x+ty}\|\leq \|{x}\|\left(1+\frac{\varepsilon t\|{y}\|}{\|{x}\|}\right)+tF_x(y) \end{align*} $$
$$ \begin{align*} \frac{t\|{y}\|}{\|{x}\|}\leq \omega(\varepsilon)\implies \|{x+ty}\|\leq \|{x}\|\left(1+\frac{\varepsilon t\|{y}\|}{\|{x}\|}\right)+tF_x(y) \end{align*} $$
for any
 $y\in X$
and
$y\in X$
and
 $t\in (0,\infty )$
.
$t\in (0,\infty )$
.
Proof Analogous to the proof of Lemma 2.3.
We now give a computational version of Lemma 2.5, which is formulated in terms of the modulus
 $\omega $
instead of
$\omega $
instead of
 $\rho _X$
, and implicitly replaces the function
$\rho _X$
, and implicitly replaces the function
 $\alpha (b)$
defined there with a function
$\alpha (b)$
defined there with a function
 $\xi (b)$
computable in
$\xi (b)$
computable in
 $\omega $
.
$\omega $
.
Lemma 4.4. Let
 $(X,\omega )$
be a uniformly smooth Banach space. Suppose that
$(X,\omega )$
be a uniformly smooth Banach space. Suppose that
 $S\subseteq X$
and
$S\subseteq X$
and
 $x^\ast \in \overline {\mathrm {co}({S})}$
, that
$x^\ast \in \overline {\mathrm {co}({S})}$
, that
 $(x_n)$
is
$(x_n)$
is
 $(\epsilon _n)$
-greedy with respect to
$(\epsilon _n)$
-greedy with respect to
 $x^\ast $
and S, and
$x^\ast $
and S, and
 $K>0$
is such that
$K>0$
is such that
 $\sup \{ {\|{y-x^\ast }\|} \ | \ {y\in S}\}\leq K$
. Using our notation
$\sup \{ {\|{y-x^\ast }\|} \ | \ {y\in S}\}\leq K$
. Using our notation
 ${a_n:=\|{x_n-x^\ast }\|}$
, for any
${a_n:=\|{x_n-x^\ast }\|}$
, for any
 $n\in \mathbb {N}$
and
$n\in \mathbb {N}$
and
 $b>0$
, if
$b>0$
, if
 $b\leq a_n$
then
$b\leq a_n$
then
 $$ \begin{align*} a_{n+1}\leq (1-\xi(b))a_n+\epsilon_n \end{align*} $$
$$ \begin{align*} a_{n+1}\leq (1-\xi(b))a_n+\epsilon_n \end{align*} $$
for
 $$ \begin{align*} \xi(b):=\frac{1}{4}\min\left\{\frac{b}{K}\cdot\omega\left(\frac{b}{2K}\right),1\right\}. \end{align*} $$
$$ \begin{align*} \xi(b):=\frac{1}{4}\min\left\{\frac{b}{K}\cdot\omega\left(\frac{b}{2K}\right),1\right\}. \end{align*} $$
Proof Fix
 $n\in \mathbb {N}$
,
$n\in \mathbb {N}$
,
 $b,\varepsilon>0,$
and
$b,\varepsilon>0,$
and
 $\lambda \in (0,1)$
. Suppose that
$\lambda \in (0,1)$
. Suppose that
 $b\leq a_n$
. If
$b\leq a_n$
. If
 $$ \begin{align} \frac{\lambda K}{(1-\lambda)b}\leq \omega(\varepsilon b) \end{align} $$
$$ \begin{align} \frac{\lambda K}{(1-\lambda)b}\leq \omega(\varepsilon b) \end{align} $$
then analogously to the proof of Lemma 2.5, by Lemma 4.3 we have
 $$ \begin{align*} &\|{(x_n-x^\ast)+\lambda (y-x^\ast)/(1-\lambda)}\|\\ &\quad \leq \|{x_n-x^\ast}\|\left(1+\frac{\varepsilon b \lambda\|{y-x^\ast}\|}{(1-\lambda)\|{x_n-x^\ast}\|}\right)+\lambda F_n\left(\frac{y-x^\ast}{1-\lambda}\right) \end{align*} $$
$$ \begin{align*} &\|{(x_n-x^\ast)+\lambda (y-x^\ast)/(1-\lambda)}\|\\ &\quad \leq \|{x_n-x^\ast}\|\left(1+\frac{\varepsilon b \lambda\|{y-x^\ast}\|}{(1-\lambda)\|{x_n-x^\ast}\|}\right)+\lambda F_n\left(\frac{y-x^\ast}{1-\lambda}\right) \end{align*} $$
for any
 $y\in S$
and thus
$y\in S$
and thus
 $$ \begin{align*} \|{(1-\lambda)x_n+\lambda y-x^\ast}\|&\leq (1-\lambda)a_n\left(1+\frac{\varepsilon\lambda K}{1-\lambda}\right)+\lambda F_n(y-x^\ast)\\ &\leq (1-\lambda(1-\varepsilon K))a_n+\lambda F_n(y-x^\ast), \end{align*} $$
$$ \begin{align*} \|{(1-\lambda)x_n+\lambda y-x^\ast}\|&\leq (1-\lambda)a_n\left(1+\frac{\varepsilon\lambda K}{1-\lambda}\right)+\lambda F_n(y-x^\ast)\\ &\leq (1-\lambda(1-\varepsilon K))a_n+\lambda F_n(y-x^\ast), \end{align*} $$
where as before we write
 $F_n:=F_{x_n-x^\ast }$
. Now, if we define
$F_n:=F_{x_n-x^\ast }$
. Now, if we define
 $$\begin{align*}\lambda_\varepsilon:=\frac{1}{2}\min\left\{\frac{b\cdot\omega(\varepsilon b)}{K},1\right\} \end{align*}$$
$$\begin{align*}\lambda_\varepsilon:=\frac{1}{2}\min\left\{\frac{b\cdot\omega(\varepsilon b)}{K},1\right\} \end{align*}$$
then (*) holds for
 $\lambda :=\lambda _\varepsilon $
, and so using again the fact that
$\lambda :=\lambda _\varepsilon $
, and so using again the fact that
 $$\begin{align*}\inf\{F_n(y-x^\ast)\mid y\in S\}\leq 0 \end{align*}$$
$$\begin{align*}\inf\{F_n(y-x^\ast)\mid y\in S\}\leq 0 \end{align*}$$
we have
 $$ \begin{align*} &\inf\{\|{(1-\lambda)x_n+\lambda y-x^\ast}\|\mid y\in S, \lambda\in [0,1)\}\\ &\quad\leq \inf\{(1-\lambda_\varepsilon(1-\varepsilon K))a_n+\lambda_\varepsilon F_n(y-x^\ast)\mid y\in S\}\\ &\quad\leq(1-\lambda_\varepsilon(1-\varepsilon K))a_n \end{align*} $$
$$ \begin{align*} &\inf\{\|{(1-\lambda)x_n+\lambda y-x^\ast}\|\mid y\in S, \lambda\in [0,1)\}\\ &\quad\leq \inf\{(1-\lambda_\varepsilon(1-\varepsilon K))a_n+\lambda_\varepsilon F_n(y-x^\ast)\mid y\in S\}\\ &\quad\leq(1-\lambda_\varepsilon(1-\varepsilon K))a_n \end{align*} $$
and so finally, setting
 $\varepsilon :=1/2K$
we have
$\varepsilon :=1/2K$
we have
 $$\begin{align*}a_{n+1}\leq (1-\lambda_\varepsilon/2)a_n+\epsilon_n=(1-\xi(b))a_n+\epsilon_n \end{align*}$$
$$\begin{align*}a_{n+1}\leq (1-\lambda_\varepsilon/2)a_n+\epsilon_n=(1-\xi(b))a_n+\epsilon_n \end{align*}$$
for
 $\xi (b)$
defined as in the statement of the lemma.
$\xi (b)$
defined as in the statement of the lemma.
We can now simply combine Lemma 4.3 with Lemmas 4.1 and 4.2 to get our main result—a computational interpretation (and qualitative strengthening) of Theorem 2.6.
Theorem 4.5. Let
 $(X,\omega )$
be a uniformly smooth Banach space. Suppose that
$(X,\omega )$
be a uniformly smooth Banach space. Suppose that
 $S\subseteq X$
and
$S\subseteq X$
and
 $x^\ast \in \overline {\mathrm {co}({S})}$
, that
$x^\ast \in \overline {\mathrm {co}({S})}$
, that
 $(x_n)$
is
$(x_n)$
is
 $(\epsilon _n)$
-greedy with respect to
$(\epsilon _n)$
-greedy with respect to
 $x^\ast $
and S, and
$x^\ast $
and S, and
 $K>0$
is such that
$K>0$
is such that
 $\sup \{ {\|{y-x^\ast }\|} \ | \ {y\in S}\}\leq K$
.
$\sup \{ {\|{y-x^\ast }\|} \ | \ {y\in S}\}\leq K$
.
-
(a) Suppose that
$\epsilon _n\to 0$
as
$n\to \infty $
with rate f. Then
$x_n\to x^\ast $
as
$n\to \infty $
with rate where
$$\begin{align*}\Phi(b):=f(\mu_{\omega,b,K})+\Big\lceil \frac{L}{\mu_{\omega,b,K}}\Big\rceil+1, \end{align*}$$
and
$$\begin{align*}\mu_{\omega,b,K}:=\frac{b}{16}\min\left\{\frac{b}{2K}\cdot \omega\left(\frac{b}{4K}\right),1\right\} \end{align*}$$
$L>0$
is any bound on
$(\|{x_n-x^\ast }\|)$
.
-
(b) In the special case that
$\sum _{i=0}^\infty \epsilon _i\leq L$
with rate f, the rate of convergence for
$x_n\to x^\ast $
as
$n\to \infty $
can be simplified to for
$$\begin{align*}\Phi(b):=f\left(\frac{b}{2}\right)+\Big\lceil \frac{K+L}{2\mu_{\omega,b,K}}\Big\rceil \end{align*}$$
$\mu _{\omega ,b,K}$
as defined in part (a).













Proof We apply Lemmas 4.2 and 4.1, respectively, to obtain parts (a) and (b), with
 $a_n:=\|{x_n-x^\ast }\|$
and
$a_n:=\|{x_n-x^\ast }\|$
and
 $\xi (b)$
defined as in Lemma 4.3 for
$\xi (b)$
defined as in Lemma 4.3 for
 $b>0$
, and extended to
$b>0$
, and extended to
 $b=0$
by setting
$b=0$
by setting
 $\xi (0):=0$
, noting that
$\xi (0):=0$
, noting that
 $(a_n)$
and
$(a_n)$
and
 $\xi (b)$
satisfy the premises of Lemmas 4.1 and 4.2 by Lemma 4.3, where for the case
$\xi (b)$
satisfy the premises of Lemmas 4.1 and 4.2 by Lemma 4.3, where for the case
 $b=0$
we have
$b=0$
we have
 $a_{n+1}\leq a_n+\epsilon _n$
by definition of
$a_{n+1}\leq a_n+\epsilon _n$
by definition of
 $(x_n)$
being
$(x_n)$
being
 $(\epsilon _n)$
-greedy with respect to
$(\epsilon _n)$
-greedy with respect to
 $x^\ast $
.
$x^\ast $
.
5 Extensions
There are many different ways in which our analysis can be further generalised by exploiting our careful examination of the proof. We briefly discuss two such extensions, highlighting the fact that much of the power of proof-theoretic reasoning lies not merely in the ability to directly unwind a particular proof, but in deriving qualitative strengthenings of results by analysing those proofs further.
5.1 Rates of convergence for fixed step sizes
A natural question to ask once we have established convergence of greedy approximation schemes for optimal step sizes is whether we can establish an analogous result when the step sizes are fixed in advance. A number of results of this kind, for
 $\lambda _n:=1/(n+1)$
, are provided in [Reference Darken, Donahue, Gurvits and Sontag6] in the special case that X has modulus of smoothness of the form
$\lambda _n:=1/(n+1)$
, are provided in [Reference Darken, Donahue, Gurvits and Sontag6] in the special case that X has modulus of smoothness of the form
 $\rho (u)\leq \gamma u^t$
for
$\rho (u)\leq \gamma u^t$
for
 $t>1$
, though no such result is given in the general case, the authors simply noting in reference to the proof analysed in this article that “The stepwise selection of
$t>1$
, though no such result is given in the general case, the authors simply noting in reference to the proof analysed in this article that “The stepwise selection of
 $\lambda =\lambda _n$
in the above proof apparently depends upon the modulus of smoothness
$\lambda =\lambda _n$
in the above proof apparently depends upon the modulus of smoothness
 $\rho (u)$
”. We now provide a general convergence theorem for fixed step sizes, in terms of the alternative modulus of smoothness
$\rho (u)$
”. We now provide a general convergence theorem for fixed step sizes, in terms of the alternative modulus of smoothness
 $\omega $
, exploiting our quantitative analysis. We label a sequence
$\omega $
, exploiting our quantitative analysis. We label a sequence
 $(x_n) (\lambda _n)\text {-}(\varepsilon _n)$
-greedy with respect to
$(x_n) (\lambda _n)\text {-}(\varepsilon _n)$
-greedy with respect to
 $x^\ast $
and S if for all
$x^\ast $
and S if for all
 $n\in \mathbb {N}$
:
$n\in \mathbb {N}$
:
 $$\begin{align*}\|{x_{n+1}-x^\ast}\|\leq \inf\left\{\|{(1-\lambda_n)x_n+\lambda_n y-x^\ast}\|\mid y\in S\right\}+\epsilon_n, \end{align*}$$
$$\begin{align*}\|{x_{n+1}-x^\ast}\|\leq \inf\left\{\|{(1-\lambda_n)x_n+\lambda_n y-x^\ast}\|\mid y\in S\right\}+\epsilon_n, \end{align*}$$
where now
 $(\lambda _n)\subset [0,1)$
is some fixed sequence. We also assume that
$(\lambda _n)\subset [0,1)$
is some fixed sequence. We also assume that
 $$\begin{align*}\inf\left\{\|{(1-\lambda_n)x_n+\lambda_n y-x^\ast}\|\mid y\in S\right\}\leq \|{x_n-x^\ast}\| \end{align*}$$
$$\begin{align*}\inf\left\{\|{(1-\lambda_n)x_n+\lambda_n y-x^\ast}\|\mid y\in S\right\}\leq \|{x_n-x^\ast}\| \end{align*}$$
for all
 $n\in \mathbb {N,}$
i.e., step sizes in
$n\in \mathbb {N,}$
i.e., step sizes in
 $[0,1)$
are meaningful in that they do not worsen our estimate. By a simple adaptation of the results of the previous section we obtain the following.
$[0,1)$
are meaningful in that they do not worsen our estimate. By a simple adaptation of the results of the previous section we obtain the following.
Theorem 5.1. Let
 $(X,\omega )$
be a uniformly smooth Banach space. Suppose that
$(X,\omega )$
be a uniformly smooth Banach space. Suppose that
 $S\subseteq X$
and
$S\subseteq X$
and
 $x^\ast \in \mathrm {co}({S})$
, that
$x^\ast \in \mathrm {co}({S})$
, that
 $(x_n)$
is
$(x_n)$
is
 $(\lambda _n)\text {-}(\varepsilon _n)$
-greedy with respect to
$(\lambda _n)\text {-}(\varepsilon _n)$
-greedy with respect to
 $x^\ast $
and S for some fixed step sizes
$x^\ast $
and S for some fixed step sizes
 $(\lambda _n)\subset [0,1)$
,
$(\lambda _n)\subset [0,1)$
,
 $K>0$
is such that
$K>0$
is such that
 ${\sup \{\|{y-x^\ast }\|\mid y\in S\}\leq K}$
, and
${\sup \{\|{y-x^\ast }\|\mid y\in S\}\leq K}$
, and
 $\sum _{i=0}^\infty \epsilon _i\leq L$
with rate f. Finally, suppose that
$\sum _{i=0}^\infty \epsilon _i\leq L$
with rate f. Finally, suppose that
 $\xi :(0,\infty )\to (0,1)$
is such that for all
$\xi :(0,\infty )\to (0,1)$
is such that for all
 $b>0,$
$b>0,$
 $$\begin{align*}2\xi(b)\leq \lambda_n\leq \frac{1}{2}\min\left\{\frac{b}{K}\cdot \omega\left(\frac{b}{2K}\right),1\right\} \end{align*}$$
$$\begin{align*}2\xi(b)\leq \lambda_n\leq \frac{1}{2}\min\left\{\frac{b}{K}\cdot \omega\left(\frac{b}{2K}\right),1\right\} \end{align*}$$
for all
 $n\in [f(b/2);\Phi _\xi (b)]$
, where
$n\in [f(b/2);\Phi _\xi (b)]$
, where
 $\Phi _\xi $
is defined in terms of
$\Phi _\xi $
is defined in terms of
 $\xi $
as in Lemma 4.1. Then
$\xi $
as in Lemma 4.1. Then
 $x_n\to x^\ast $
as
$x_n\to x^\ast $
as
 $n\to \infty $
with rate
$n\to \infty $
with rate
 $\Phi _\xi $
.
$\Phi _\xi $
.
Proof Fix
 $n\in [f(b/2);\Phi (b)]$
and
$n\in [f(b/2);\Phi (b)]$
and
 $b>0$
. Suppose that
$b>0$
. Suppose that
 $b\leq a_n$
. Then using the upper bound on
$b\leq a_n$
. Then using the upper bound on
 $\lambda _n$
we have
$\lambda _n$
we have
 $$\begin{align*}\frac{\lambda_n K}{(1-\lambda_n)b}\leq \omega(b/2K) \end{align*}$$
$$\begin{align*}\frac{\lambda_n K}{(1-\lambda_n)b}\leq \omega(b/2K) \end{align*}$$
and so just as in the proof of Lemma 4.4 (for
 $\varepsilon :=1/2K$
) it follows that
$\varepsilon :=1/2K$
) it follows that
 $$\begin{align*}\|{(1-\lambda_n)x_n+\lambda_n y-x^\ast}\|\leq (1-\lambda_n/2)a_n+\lambda_n F_n(y-x^\ast) \end{align*}$$
$$\begin{align*}\|{(1-\lambda_n)x_n+\lambda_n y-x^\ast}\|\leq (1-\lambda_n/2)a_n+\lambda_n F_n(y-x^\ast) \end{align*}$$
for
 $a_n:=\|{x_n-x^\ast }\|$
and
$a_n:=\|{x_n-x^\ast }\|$
and
 $F_n:=F_{x_n-x^\ast }$
as usual, and thus also
$F_n:=F_{x_n-x^\ast }$
as usual, and thus also
 $$\begin{align*}a_{n+1}\leq (1-\lambda_n/2)a_n+\epsilon_n\leq (1-\xi(b))a_n+\epsilon_n, \end{align*}$$
$$\begin{align*}a_{n+1}\leq (1-\lambda_n/2)a_n+\epsilon_n\leq (1-\xi(b))a_n+\epsilon_n, \end{align*}$$
where for the second inequality we now use the lower bound on
 $\lambda _n$
. Since we also have
$\lambda _n$
. Since we also have
 $a_{n+1}\leq a_n+\epsilon _n$
(for any
$a_{n+1}\leq a_n+\epsilon _n$
(for any
 $n\in \mathbb {N}$
), we have established that the recurrence inequality of Lemma 4.1 is satisfied for
$n\in \mathbb {N}$
), we have established that the recurrence inequality of Lemma 4.1 is satisfied for
 $\xi $
(extended by
$\xi $
(extended by
 $\xi (0):=0$
) but now only for
$\xi (0):=0$
) but now only for
 $n\in [f(b/2);\Phi (b)]$
. But a simple inspection of the proof of Lemma 4.1 reveals that we only require the full recurrence inequality to hold in that range to establish the existence of some
$n\in [f(b/2);\Phi (b)]$
. But a simple inspection of the proof of Lemma 4.1 reveals that we only require the full recurrence inequality to hold in that range to establish the existence of some
 $n\in [f(b/2);\Phi (b)]$
such that
$n\in [f(b/2);\Phi (b)]$
such that
 $a_n<b/2$
(though we also need
$a_n<b/2$
(though we also need
 $a_{n+1}\leq a_n+\epsilon _n$
for any
$a_{n+1}\leq a_n+\epsilon _n$
for any
 $n\in \mathbb {N}$
), and then
$n\in \mathbb {N}$
), and then
 $a_{n+k}<b$
for any
$a_{n+k}<b$
for any
 $k\geq \Phi (b)$
follows immediately.
$k\geq \Phi (b)$
follows immediately.
For example, by setting
 $\omega (\varepsilon ):=\varepsilon ^r$
,
$\omega (\varepsilon ):=\varepsilon ^r$
,
 $\xi (b):=b^s$
, and
$\xi (b):=b^s$
, and
 $\lambda _n:=n^{-t}$
we can use Theorem 5.1 to obtain conditions on
$\lambda _n:=n^{-t}$
we can use Theorem 5.1 to obtain conditions on
 $r,s$
, and t such that convergence of
$r,s$
, and t such that convergence of
 $(x_n)$
is guaranteed with a simple rate of the form
$(x_n)$
is guaranteed with a simple rate of the form
 $O(n^{-k})$
, a result similar in spirit to, e.g., [Reference Darken, Donahue, Gurvits and Sontag6, Theorem 3.5], but now for more general step-sizes. However, we stress that Theorem 5.1 is not proposed as an improvement to the more refined convergence rates of [Reference Darken, Donahue, Gurvits and Sontag6], but rather a simple illustration of how our proof-theoretic analysis can be readily extended.
$O(n^{-k})$
, a result similar in spirit to, e.g., [Reference Darken, Donahue, Gurvits and Sontag6, Theorem 3.5], but now for more general step-sizes. However, we stress that Theorem 5.1 is not proposed as an improvement to the more refined convergence rates of [Reference Darken, Donahue, Gurvits and Sontag6], but rather a simple illustration of how our proof-theoretic analysis can be readily extended.
5.2 Greedy algorithms in hyperbolic spaces
A far deeper extension of our analysis would involve working over a more general class of spaces. One candidate here is represented by hyperbolic spaces, which informally speaking are metric spaces
 $(X,d)$
that come equipped with a function
$(X,d)$
that come equipped with a function
 $\oplus $
and associated axioms that allow one to reason abstractly about convex combinations
$\oplus $
and associated axioms that allow one to reason abstractly about convex combinations
 $(1-\lambda )x\oplus \lambda y$
of elements
$(1-\lambda )x\oplus \lambda y$
of elements
 $x,y\in X$
(see [Reference Kohlenbach16] for a formal definition widely used in the context of proof mining, and a discussion on the relationship of this definition to various others in the literature). As such, the notion of an
$x,y\in X$
(see [Reference Kohlenbach16] for a formal definition widely used in the context of proof mining, and a discussion on the relationship of this definition to various others in the literature). As such, the notion of an
 $(\epsilon _n)$
-greedy algorithm can be readily extended from normed spaces to this more general setting, as a sequence
$(\epsilon _n)$
-greedy algorithm can be readily extended from normed spaces to this more general setting, as a sequence
 $(x_n)$
of elements satisfying
$(x_n)$
of elements satisfying
 $$\begin{align*}d(x_{n+1},x^\ast)\leq \inf\left\{d((1-\lambda)x\oplus \lambda y,x^\ast)\mid y\in S, \lambda\in [0,1)\right\}+\epsilon_n. \end{align*}$$
$$\begin{align*}d(x_{n+1},x^\ast)\leq \inf\left\{d((1-\lambda)x\oplus \lambda y,x^\ast)\mid y\in S, \lambda\in [0,1)\right\}+\epsilon_n. \end{align*}$$
However, in order to establish convergence we would need a suitable notion of uniform smoothness for hyperbolic spaces, which would in turn presumably require an appropriate notion of duality. Only recently have such generalisations of concepts from normed spaces been explored, notably via the smooth hyperbolic spaces of Pinto [Reference Pinto39] and the dual systems of Pischke [Reference Pischke41]. We therefore propose that the convergence of greedy algorithms in hyperbolic spaces represents an interesting case study that could build on this recent work, though we leave this open for now.
6 Outlook: Formalising and automating proof mining
As stated at the beginning of the article, both our choice of case study and the manner in which we have presented our proof-theoretic analysis were intended to prove insights into how the proof mining process could potentially be formalised and partially automated. We conclude in this spirit with a short list of ideas and conjectures in that direction. While these have some parallels with the general programme of formalising proofs with explicit computational content articulated by Koutsoukou-Argyraki in [Reference Koutsoukou-Argyraki28], rather than focusing on toy examples, everything that we propose is firmly tethered to a real and representative case study in proof mining.
Firstly, can we develop domain-specific logical systems specifically designed for proof mining in particular areas? We envisage that these might contain high-level, sound inference rules of the kind we considered in Section 3, which when embedded into a proof assistant would allow us to automate various operations on derivations in those systems. In particular, we would hope that the use of high-level rules would facilitate the automatic extraction of readable bounds by implicitly suppressing unnecessary bureaucracy.
More generally, it is natural to ask whether there are useful procedures and tactics that can be developed organically within a proof assistant that allow for proof mining as done in practice to be more easily formalised. Here the aim is to circumvent any formal application of the Dialectica interpretation or associated logical metatheorems (many implementations of which already exist, most recently in Lean by ChevalFootnote 2 ), which is of course not how proof mining is done in reality. Ideas in this direction include: tactics that draw quantifiers out of formulas in the proof assistant’s ambient type theory; the automatic identification of assumptions that can potentially be weakened (as done in an ad-hoc way in Section 4.1); tactics that dynamically inform us how much of a quantified statement is currently being used (as illustrated in our manipulations on proof trees in Section 3, and in particular our extension to fixed step-sizes in Section 5.1); or procedures on a meta-level that automatically lift proofs to more general spaces (as discussed in the context of the present case study in Section 5.2).Footnote 3
Finally, what libraries would be useful for practical proof mining? One simple suggestion here are libraries that translate mathematical moduli to their logical counterpart. A concrete example would be a library that formulates standard lemmas on uniformly smooth Banach spaces phrased in terms of the modulus
 $\rho _X$
to equivalent results in terms of the proof-theoretic modulus
$\rho _X$
to equivalent results in terms of the proof-theoretic modulus
 $\omega $
(as done in Section 4.2), where here one could potentially consider a partially automated translation from the former to the latter. A more far reaching effort would be the systematic formalisation of abstract convergence lemmas (two examples of which are given in Section 4.1) along with their associated computational content:Footnote
4
Convergence lemmas of this kind are used throughout optimization (as recently surveyed in [Reference Franci and Grammatico9]), and quantitative variants thereof play a central role in proof mining, as discussed in [Reference Neri and Powell36]. In particular, the quantitative analysis of stochastic recurrence inequalities via martingale methods lies at the heart of recent applications of proof mining in stochastic optimization, including [Reference Neri, Pischke and Powell35, Reference Neri and Powell37, Reference Neri and Powell38, Reference Pischke43, Reference Pischke and Powell45]. The potential use of such a library in conjunction with automated reasoning techniques to generate computer-checked, quantitative convergence proofs for both deterministic and stochastic algorithms is an extremely exciting prospect, but one we firmly postpone to future work!
$\omega $
(as done in Section 4.2), where here one could potentially consider a partially automated translation from the former to the latter. A more far reaching effort would be the systematic formalisation of abstract convergence lemmas (two examples of which are given in Section 4.1) along with their associated computational content:Footnote
4
Convergence lemmas of this kind are used throughout optimization (as recently surveyed in [Reference Franci and Grammatico9]), and quantitative variants thereof play a central role in proof mining, as discussed in [Reference Neri and Powell36]. In particular, the quantitative analysis of stochastic recurrence inequalities via martingale methods lies at the heart of recent applications of proof mining in stochastic optimization, including [Reference Neri, Pischke and Powell35, Reference Neri and Powell37, Reference Neri and Powell38, Reference Pischke43, Reference Pischke and Powell45]. The potential use of such a library in conjunction with automated reasoning techniques to generate computer-checked, quantitative convergence proofs for both deterministic and stochastic algorithms is an extremely exciting prospect, but one we firmly postpone to future work!
Acknowledgments
The author is grateful to the anonymous referee for their comments, and to Sam Sanders and particularly Nicholas Pischke for helpful suggestions and discussion.
Funding
The author was partially supported by the Engineering and Physical Sciences Research Council grant EP/W035847/1. No new data were created during this study.

 Open access
Open access