


1. Introduction
Philosophers of science have long held that when considering competing hypotheses, scientists typically rely on theoretical virtues in choosing which to adopt. Quine (Reference Quine1966) identifies these virtues as simplicity, familiarity, scope, fecundity, and success under testing, while Quine and Ullian (Reference Quine and Ullian1970) provide the closely related list of conservatism, modesty, simplicity, generality, refutability, and precision. With the notable exception of the values-in-science literature, it is surprising how little attention has been paid to how these virtues impact epistemic success.Footnote 1 This paper takes up this question.
In doing so, this paper will draw on two areas of research in network epistemology. The first is the use of landscape models to examine the evolution of epistemic communities. In these models, a scientific community investigating a given domain is represented as a group of agents traversing an abstract landscape, with discrete points in the landscape corresponding to unique research approaches or potential sets of beliefs.Footnote 2 Not knowing in advance how successful a given position in the landscape will be, agents explore the landscape both independently and cooperatively in hopes of finding the epistemically best location. While early research in this area examined landscapes where the optimal location was relatively easy to locate (Weisberg and Muldoon Reference Weisberg and Muldoon2009; Grim Reference Grim2009), this paper builds on more recent work using NK landscapes to more realistically model scientific domains where finding the global optimum is a more difficult task (Alexander et al. Reference Alexander, Himmelreich and Thompson2015).
The second area of research concerns the impact of connectivity on the success of epistemic communities. In one of the most widely cited papers in network epistemology, Zollman (Reference Zollman2010) uses the two-armed bandit model to show that when confronted with an empirical problem with noisy data, increased connectivity between agents can hinder, rather than help, a community’s long-term epistemic success. This is because when relevant information is broadly shared within a community, beliefs tend to converge more quickly. This reduction in what Zollman calls “transient diversity” leads to the under-consideration of potentially beneficial alternative beliefs.Footnote 3 Similar conclusions were drawn independently by Lazer and Friedman (Reference Lazer and Friedman2007) using NK landscape models instead. Extending Lazer and Friedman’s results, Wu (Reference Wu2024) has more recently suggested that introducing an element of randomness when selecting among research approaches can be effective in mitigating the negative impact of increased connectivity. However, as simulations presented in this paper will show, this strategy is only partially effective.
This paper further builds on the NK landscape models introduced by Lazer and Friedman by suggesting an alternative approach to reducing the potential epistemic harm caused by increased communal connectivity. Simulation results produced for this paper show that when scientists in a community rely on the theoretical virtues of conservatism, modesty, and familiarity in choosing between sets of beliefs—retaining as many previous beliefs as possible when updating—agents in a community differ epistemically for longer periods of time. Because of this increase in transient diversity, communities of agents that factor in these virtues tend to be more successful in the long run. In contrast to the findings of both Zollman (Reference Zollman2010) and Lazer and Friedman (Reference Lazer and Friedman2007), this benefit becomes more pronounced as the community becomes more connected. The incorporation of theoretical virtues in belief updating may then provide an effective way of combating the negative effects associated with increased connectivity, potentially providing an important contributing factor to the long-term success of real-world epistemic communities.
The structure of this paper is as follows. Section 2 introduces the NK landscape modeling framework, along with the three belief-updating strategies to be examined. Section 3 presents simulation results indicating that when agents in a connected community adopt a “Conservative” updating strategy, they typically achieve higher long-run epistemic success, with this effect becoming more pronounced as interconnectedness among agents increases. The concluding section assesses the real-world plausibility of the updating strategies considered and highlights the potential relevance of the results presented to the recent debate over the rationality of Inference to the Best Explanation.
2. Modeling framework
2.1. Epistemic landscape models
The modeling framework used in this paper is one adopted from evolutionary biology. The pioneering geneticist Wright (Reference Wright1932) envisioned genotypes as locations in an abstract space, with the height of the “landscape” at a given location corresponding to the fitness of an organism with a given genotype—i.e., how well suited the features, or phenotype, associated with a given genotype are to surviving the adaptive pressures imposed by an organism’s environment. Weisberg and Muldoon (Reference Weisberg and Muldoon2009), as well as Grim (Reference Grim2009), have suggested that this same type of approach could be used to model the epistemic evolution of a scientific community. In this framework, unique positions in abstract space can be seen as representing particular research approaches in a given scientific domain, with the height of the landscape corresponding to the degree to which the approach leads to success in the scientific enterprise.
Consider a simple example proposed by Grim (Reference Grim2009) involving the treatment of a particular type of cancer. Here, discrete positions in the x-dimension of an abstract space are taken to represent potential radiotherapy treatment options, while positions in the y-dimension represent potential chemotherapy treatments. The height of the landscape at any (x,y) location is taken to correspond to the “epistemic fitness” of the combined treatments—for instance, the proportion of patients who are rendered cancer-free after undergoing the corresponding treatments. In order to maintain real-world plausibility, it is assumed that there is no way to initially survey the entire landscape, since choosing the set of treatments that maximizes fitness would then become a trivial task. Instead, scientists engaged in research are viewed as agents traversing the landscape in hopes of finding the optimal position.
While acknowledging the relevance of this general modeling framework, Alexander et al. (Reference Alexander, Himmelreich and Thompson2015, 445) suggest two real-world features of science that simple landscape models of the type just described generally fail to capture. First, rather than smooth landscapes where a simple hill-climbing strategy will reliably reach the global maximum, epistemic landscapes characteristic of most scientific problems are rugged. That is, they contain numerous local maxima and minima, with a global maximum that is relatively difficult for scientists to locate. Second, and relatedly, they observe that components of a research approach often exhibit significant interdependence, interacting in complex ways that can either enhance or diminish fitness. For instance, the efficacy of a specific radiation treatment might depend on the accompanying type of chemotherapy used and vice versa. Alexander et al. propose that the NK landscape modeling paradigm can be used to more easily capture these features, providing a more plausible framework for modeling the epistemic evolution of real-world scientific communities.
2.2. NK landscape models
While the movement of agents in a two-dimensional abstract space is relatively easy to visualize, the higher number of dimensions typically involved in NK landscapes makes them far more difficult to picture. The key concepts of adjacency, distance, and height, however, remain just as applicable to these complex landscapes as they do to the simple model outlined in the previous subsection. Keeping this in mind will help in navigating the technical details that follow.
Like landscape models more generally, NK landscapes were first introduced as a way of modeling biological systems (Kauffman and Levin Reference Kauffman and Levin1987; Kauffman Reference Kauffman1993; Kauffman and Weinberger Reference Kauffman and Weinberger1989). Consider haploid organisms with gene sequences of fixed length N. Assuming each position in the sequence can be occupied by one of two bases,
 $2^{N}$
unique sequences are possible. Now take the fitness of an organism to be completely determined by its genotype, stable across time, and specifiable using a real number. A functional mapping of binary vectors of length N to scalar fitness values completely specifies the fitness landscape involved.
$2^{N}$
unique sequences are possible. Now take the fitness of an organism to be completely determined by its genotype, stable across time, and specifiable using a real number. A functional mapping of binary vectors of length N to scalar fitness values completely specifies the fitness landscape involved.
This framework provides a convenient way of modeling the genetic evolution of organisms over time. For instance, a single random mutation corresponds to flipping a randomly selected component of the binary vector encoding an organism’s genotype from 0 to 1 or 1 to 0, depending on its current value. The change in fitness that results from this genetic mutation can be thought of as the change in height that occurs in moving from one location in the fitness landscape to an adjacent one.
The second model parameter, K, an integer in the range
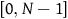 $[0,N-1]$
, is used to specify the extent to which genetic components interact in determining an organism’s overall fitness. More specifically, it is the number of other vector components that influence a given component’s contribution to overall fitness.
$[0,N-1]$
, is used to specify the extent to which genetic components interact in determining an organism’s overall fitness. More specifically, it is the number of other vector components that influence a given component’s contribution to overall fitness.
To illustrate, consider the simplest case where
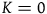 $K=0$
. Here, a function
$K=0$
. Here, a function
 $c_{i}$
will be used to specify a mapping from the i-th vector component’s binary value to its fitness contribution. An example involving
$c_{i}$
will be used to specify a mapping from the i-th vector component’s binary value to its fitness contribution. An example involving
 $N=3$
is shown below, with the scalar contribution of each vector component kept in the range [0, 1] for the sake of simplicity.
$N=3$
is shown below, with the scalar contribution of each vector component kept in the range [0, 1] for the sake of simplicity.

Given these N functions, the height of the fitness landscape at any given position is uniquely determined. For instance, the overall fitness of an organism with gene sequence (0, 1, 1) can be calculated as
 $c_{1}(0)+c_{2}(1)+c_{3}(1)=0.3+0.4+0.5=1.2$
.
$c_{1}(0)+c_{2}(1)+c_{3}(1)=0.3+0.4+0.5=1.2$
.
When
 $K=0$
, each vector component’s contribution to overall fitness is independent, resulting in a fitness landscape that is extremely smooth. From any location in the landscape, the simple strategy of successively moving to an adjacent position that has higher fitness is guaranteed to reach the global maximum in N steps or less. In the above example, this overall maximum is located at (1, 0, 1), with a fitness value of
$K=0$
, each vector component’s contribution to overall fitness is independent, resulting in a fitness landscape that is extremely smooth. From any location in the landscape, the simple strategy of successively moving to an adjacent position that has higher fitness is guaranteed to reach the global maximum in N steps or less. In the above example, this overall maximum is located at (1, 0, 1), with a fitness value of
 $1.0+0.9+0.5=2.4$
at this location.
$1.0+0.9+0.5=2.4$
at this location.
Now consider a more complex example where
 $K=1$
. Here, the contribution of a given vector component to overall fitness is influenced by the binary value of exactly one other vector component. For instance, take the contribution of the first component to be influenced by the second component, the contribution of the second component to be influenced by the third component, and the contribution of the third component to be influenced by the first. In order to handle all possible combinations,
$K=1$
. Here, the contribution of a given vector component to overall fitness is influenced by the binary value of exactly one other vector component. For instance, take the contribution of the first component to be influenced by the second component, the contribution of the second component to be influenced by the third component, and the contribution of the third component to be influenced by the first. In order to handle all possible combinations,
 $2^{K+1}$
scalar values will need to be specified for each function
$2^{K+1}$
scalar values will need to be specified for each function
 $c_{i}$
. The table below provides an example, with the first argument to
$c_{i}$
. The table below provides an example, with the first argument to
 $c_{i}$
specifying the binary value of the i-th component and the second argument the value of its influencing vector component.
$c_{i}$
specifying the binary value of the i-th component and the second argument the value of its influencing vector component.

As with the simple case where
 $K=0$
, this collection of functional mappings can be used to determine the overall fitness value associated with any possible binary vector of length 3. For example, the fitness associated with the point (0, 1, 1) can be calculated as
$K=0$
, this collection of functional mappings can be used to determine the overall fitness value associated with any possible binary vector of length 3. For example, the fitness associated with the point (0, 1, 1) can be calculated as
 $c_{1}(0,1)+c_{2}(1,1)+c_{3}(1,0)=0.5+0.3+0.1=0.9$
.
$c_{1}(0,1)+c_{2}(1,1)+c_{3}(1,0)=0.5+0.3+0.1=0.9$
.
When K is greater than 0, the fitness contribution of every vector component will depend on the binary value of at least one other component. As a result, the simple hill-climbing strategy previously outlined is not guaranteed to reach the global maximum. In the example just considered where
 $K=1$
, the global fitness maximum can be found at (0, 0, 0), with a fitness value of
$K=1$
, the global fitness maximum can be found at (0, 0, 0), with a fitness value of
 $0.9+0.8+1.0=2.7$
at that location. The overall fitness at location (1, 1, 1) is
$0.9+0.8+1.0=2.7$
at that location. The overall fitness at location (1, 1, 1) is
 $0.7+0.3+0.8=1.8$
but, like the global maximum, it is surrounded in all directions by adjacent positions with lower fitness. Since there is no purely uphill path from this local maximum to the global maximum, a simple hill-climbing strategy could potentially get stuck in this sub-optimal location.
$0.7+0.3+0.8=1.8$
but, like the global maximum, it is surrounded in all directions by adjacent positions with lower fitness. Since there is no purely uphill path from this local maximum to the global maximum, a simple hill-climbing strategy could potentially get stuck in this sub-optimal location.
In broad strokes, the parameter N then provides a way to specify the size of an NK landscape, while the parameter K provides an easy way to adjust its smoothness—landscapes typically getting more rugged as K gets larger. As is often done when using models of this type, assume that each of the
 $c_{i}$
function scalar values are uniformly randomly selected from the range [0, 1]. When
$c_{i}$
function scalar values are uniformly randomly selected from the range [0, 1]. When
 $K=0$
each vector component contributes independently to overall fitness, with no local maxima resulting. When
$K=0$
each vector component contributes independently to overall fitness, with no local maxima resulting. When
 $K=N-1$
, the fitness values at different locations in the landscape will be completely unrelated. This will typically result in many local maxima, with an overall maximum that is difficult to locate. For K values between 0 and
$K=N-1$
, the fitness values at different locations in the landscape will be completely unrelated. This will typically result in many local maxima, with an overall maximum that is difficult to locate. For K values between 0 and
 $N-1$
, the ruggedness of the landscape will vary between these two extremes.
$N-1$
, the ruggedness of the landscape will vary between these two extremes.
While NK landscapes straightforwardly apply to biological systems of the type described, this same modeling framework has proved valuable in non-biological contexts. In management science, for instance, NK landscapes have been used to examine how organizational structure impacts business success (e.g., Levinthal Reference Levinthal1997) as well as how best to approach product innovation (e.g., Sommer and Loch Reference Sommer and Loch2004). This paper will follow Alexander et al. (Reference Alexander, Himmelreich and Thompson2015) in using NK landscapes to model the epistemic evolution of scientific communities.
2.3. NK epistemic landscapes
Weisberg and Muldoon (Reference Weisberg and Muldoon2009, 228) suggest that “a single epistemic landscape corresponds to the research ‘topic’ that engages a group of scientists,” with the size of a landscape giving some indication of the breadth of the captured domain. They take their own models to be fairly narrow in scope, corresponding to a topic “a specialized research conference or advanced level monograph might be devoted to” (Weisberg and Muldoon Reference Weisberg and Muldoon2009, 228). Examples of such topics might include phase transitions in statistical physics, pretend play in psychology, chemical communication in botany, opioid reception in neuroscience, or HIV treatment in medicine. Grim (Reference Grim2009) provides other concrete examples, suggesting that hypotheses concerning the location of a specific shipwreck or the timing of the K-T asteroid collision might plausibly be captured by a landscape of this type.
In considering NK landscapes specifically, Alexander et al. (Reference Alexander, Himmelreich and Thompson2015) take N to correspond to the number of propositions relevant to a given topic that members of a scientific community could potentially believe or disbelieve. Within this framework, an NK landscape represents the
 $2^{N}$
belief states that scientists can assume, with the propositions currently believed or disbelieved by a scientist determining their current position in the landscape. In characterizing these propositions, Alexander et al. (Reference Alexander, Himmelreich and Thompson2015, 446) write that they may range from “abstract general statements of high theory” to “specific statements of particular laboratory technique.” In the case of locating a shipwreck, the propositions involved could include statements concerning whether the ship of interest hit an iceberg, whether the ship was loaded with cargo, whether northern ocean currents were present at the time, and so forth. Larger distance jumps in the landscape will involve greater changes in beliefs, with the maximal distance resulting when epistemic attitudes for all propositions of interest are reversed.
$2^{N}$
belief states that scientists can assume, with the propositions currently believed or disbelieved by a scientist determining their current position in the landscape. In characterizing these propositions, Alexander et al. (Reference Alexander, Himmelreich and Thompson2015, 446) write that they may range from “abstract general statements of high theory” to “specific statements of particular laboratory technique.” In the case of locating a shipwreck, the propositions involved could include statements concerning whether the ship of interest hit an iceberg, whether the ship was loaded with cargo, whether northern ocean currents were present at the time, and so forth. Larger distance jumps in the landscape will involve greater changes in beliefs, with the maximal distance resulting when epistemic attitudes for all propositions of interest are reversed.
For Alexander et al. (Reference Alexander, Himmelreich and Thompson2015, 446), K indicates the degree of interconnectedness of the Quinean “web of belief” in the particular domain to be captured. Higher values of K indicate more interconnection among beliefs, while lower values of K indicate that beliefs function more independently in terms of determining overall fitness. Recall that in general the greater the value of K, the greater the ruggedness of the landscape.
The speed at which scientists in a given community revise their beliefs will vary greatly depending on the field of inquiry involved. One obvious factor is how quickly researchers can gather the empirical data needed to evaluate fitness at a given landscape position. This will depend on the availability of tools and methods needed to gather such data, as well as the inherent timescale involved in making measurements in a given domain. For instance, verifying a theory concerning the location of a shipwreck may take just a few hours if the relevant body of water is shallow and easily accessible. By contrast, validating a hypothesis about disease treatment could span many months or even years, while testing a hypothesis in high-energy physics could take several decades.
2.4. Network structure
As in the biological case, where organisms with different genotypes occupy different positions in the fitness landscape simultaneously, scientists in a community investigating a given domain often hold different epistemic attitudes concurrently. Taking scientists to have a shared goal of maximizing epistemic fitness, communities of scientists can be seen as agents simultaneously exploring a common landscape, cooperatively communicating measured fitness values as they update their beliefs.
In examining the communal dynamics involved in such a scenario, simulations are run with various degrees of connectivity between agents. This is implemented using the Erdős–Rényi algorithm for generating random graphs (Erdős and Rényi Reference Erdős and Rényi1959), with nodes representing agents and edges representing bidirectional channels of communication between agents. In generating networks using this algorithm, the parameter p is used to specify the probability that any given pair of agents is immediately connected. For instance, when
 $p=0$
, no agents are connected; when
$p=0$
, no agents are connected; when
 $p=1$
, every agent is immediately connected to every other agent, with a complete graph resulting; and when
$p=1$
, every agent is immediately connected to every other agent, with a complete graph resulting; and when
 $p=0.5$
, the Erdős–Rényi model has the special feature that every possible graph is generated with equal probability. Additionally, only connected graphs will be used in simulations—i.e., communities where there is a direct or indirect path from every agent to every other agent in the community. This requirement is imposed to guarantee desirable convergence properties, ensuring that, for each search strategy considered, all agents will eventually reach the same landscape position with probability 1.
$p=0.5$
, the Erdős–Rényi model has the special feature that every possible graph is generated with equal probability. Additionally, only connected graphs will be used in simulations—i.e., communities where there is a direct or indirect path from every agent to every other agent in the community. This requirement is imposed to guarantee desirable convergence properties, ensuring that, for each search strategy considered, all agents will eventually reach the same landscape position with probability 1.
2.5. Search strategies
In searching the belief space, it seems sensible to assume that scientists will generally employ some combination of “exploration” and “exploitation” strategies. That is, they will sometimes act alone in evaluating the fitness of a potential new set of beliefs, and sometimes at least consider whether to adopt the beliefs of other scientists with whom they are connected. The parameter V will be used to specify the probability that on a given simulation round a given scientist will engage in exploitation, rather than exploration.Footnote
4
For example, if V is set to
 $0.2$
, there is a 20% chance that a given agent will use an exploitation strategy in a given round rather than an exploration strategy. Only V values less than 1 will be considered in simulations, reflecting the fact that scientists working in a given domain are unlikely to be pure exploiters.
$0.2$
, there is a 20% chance that a given agent will use an exploitation strategy in a given round rather than an exploration strategy. Only V values less than 1 will be considered in simulations, reflecting the fact that scientists working in a given domain are unlikely to be pure exploiters.
Following Lazer and Friedman (Reference Lazer and Friedman2007, 675) and Wu (Reference Wu2024, 1193), we will take exploration strategies to be “local” in nature. When engaged in a search of this type, agents will evaluate the fitness of a randomly selected adjacent position in the landscape. If that position is epistemically better than an agent’s current position, the agent will move to the new location. If the position is worse, the agent will maintain their current beliefs by staying in their current position.Footnote 5
Exploitation occurs when, rather than acting in isolation, agents consider whether to move to locations in the landscape occupied by agents to whom they are directly connected. Exploitation will then generally be more “global” in nature, with large leaps in belief space possible in a given round. This paper’s main focus is on comparing the relative success of epistemic communities when agents employ one of three exploitation strategies.
The first exploitation strategy considered is the “Best” strategy first proposed by Lazer and Friedman (Reference Lazer and Friedman2007, 675). Here, agents simply survey their immediate network neighbors and jump to the location of the neighbor who has the highest reported epistemic fitness.Footnote 6 If no neighbor is at a location with higher fitness—i.e., the agent’s current position is already better than that of any immediate neighbor—the agent instead engages in a local search of the type previously outlined.
The second global strategy considered is the “Better” strategy suggested by Wu (Reference Wu2024). Here, an agent first determines which of their immediate network neighbors occupy a better position in the epistemic landscape. The agent then randomly jumps to one of these better locations. As with the Best strategy, if an agent has no neighbors with higher fitness, the agent engages in a local search.
Finally, this paper introduces a third “Conservative” global search strategy for comparison. Drawing on the virtues identified by Quine (Reference Quine1966) and Quine and Ullian (Reference Quine and Ullian1970), this strategy aims to capture a collection of closely related theoretical virtues: conservatism, modesty, and familiarity. Of these three, conservatism is the most clearly explained, with Quine and Ullian (Reference Quine and Ullian1970, 69) writing that by conservatism they mean “conservation of past beliefs.”Footnote 7
There are, of course, varying degrees of conservation that a search strategy could exhibit. The most extreme form would involve never modifying any beliefs. But an agent who clings to their beliefs come what may would hardly seem to qualify as a scientist. A somewhat less conservative strategy would be the local search strategy already outlined, where only one belief is modified in updating. However, agents employing this strategy function in complete isolation, disregarding the beliefs and activities of other scientists in the community. A plausible strategy that is both conservative and social is one where an agent adopts the beliefs of an epistemically better-positioned neighbor, but always the neighbor whose beliefs most closely match their own. In doing so, an agent conserves as many beliefs as possible while still factoring in the beliefs of better-situated members of the community when updating.
In motivating the theoretical virtue of conservatism, Quine and Ullian (Reference Quine and Ullian1970, 67) write that “[t]he truth may indeed be radically remote from our present system of beliefs, so that we may need a long series of conservative steps to attain what might have been attained in one rash leap.” This aligns with the strategy just outlined. Rather than jumping to the location of the neighbor with the highest fitness, as in the Best strategy, or a random neighbor with higher fitness, as in the Better strategy, agents who employ the Conservative strategy move to the location of the closest neighbor with higher fitness—where closeness is measured using Euclidean distance in N-dimensional space. Over time, an agent employing the Conservative strategy may end up near the location of the neighbor currently reporting the highest fitness, but they will likely get there through a series of smaller steps rather than a single giant leap in belief space. For consistency with the other global search strategies considered, if there are no neighbors at a location with higher fitness, the agent will engage in a local search.
3. Simulation results
3.1. Parameters explored
In producing the simulation results discussed in this section, 1000 simulations were run for every combination of the following parameters:
-
NK epistemic landscape parameters:
-
– Number of beliefs, N: 20
-
– Number of influencing beliefs, K: 5, 10
-
-
Community parameters:
-
– Number of scientists, S: 100
-
– Probability of edge between agents, p: 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0
-
-
Search parameters:
-
– Global search strategies: Best, Better, Conservative
-
– Probability of scientist employing global search per round, V: 0.5, 0.3, 0.2, 0.1
-
-
Simulation parameters:
-
– Agent starting position: randomly selected binary vector of length N
-
In setting up the NK landscape, the K other vector components that influence the fitness contribution of a given vector component are randomly selected without replacement. For each possible combination of values for a vector component and its influencing components, the contribution to overall fitness is determined by selecting a random number in the range [0, 1]. Following Lazer and Friedman (Reference Lazer and Friedman2007, 692), all reported fitness values from simulations are normalized. This is done by first dividing all fitness values in a landscape by the global maximum fitness. This is meant to ensure consistency in comparing results across different landscapes. These normalized fitness values are then raised to the eighth power in order to more accurately reflect the fact that random combinations of beliefs in most scientific domains will typically result in very low fitness.
The NK landscape, network configuration, and starting positions for each agent are kept the same when running corresponding simulations for each of the three global search strategies considered. This is intended to reduce noise when comparing simulation results across strategies.
3.2. Long-run epistemic fitness and speed of convergence
We begin by examining how the choice of global search strategy impacts both the long-run epistemic fitness of a community and its speed of convergence. Figure 1 shows typical average epistemic fitness per simulated round for the three exploitation strategies considered.
Average epistemic fitness for different global search strategies when
 $p=0.6$
,
$p=0.6$
,
 $V=0.3$
, and
$V=0.3$
, and
 $K=10$
.
$K=10$
.

As can be seen, the Conservative strategy achieves the highest long-run epistemic fitness, followed by the Better strategy, with the Best strategy exhibiting the lowest long-run value. When it comes to speed of convergence, however, this ordering is reversed: the Best strategy reaches its long-run fitness most quickly, followed by the Better strategy, with the Conservative strategy taking the longest to reach its maximum. Both of these rankings hold for all combinations of parameters considered. An explanation will be offered in Section 3.4 for this trade-off between speed and accuracy.
3.3. Connectivity and long-run epistemic fitness
Next, we consider how increased connectivity within a community impacts long-run epistemic success. Figure 2 shows typical average long-run fitness values for a range of Erdős–Rényi network p values. Recall that higher p values typically produce more connected networks of agents, with a p value of 1 corresponding to a complete graph.
Average long-run epistemic fitness for different global search strategies and levels of connectivity when
 $V=0.2$
and
$V=0.2$
and
 $K=5$
.
$K=5$
.

One of Lazer and Friedman’s (Reference Lazer and Friedman2007, 681) major claims in considering the Best search strategy is that “because the less dense networks are better at preserving diversity … as long as all actors are connected through some path, the fewer connections the better in the long run.” Figure 2 shows that this result holds up in the simulations considered in this paper. As the connectivity of agents increases, the average long-run epistemic fitness shows a clear downward trend when the Best strategy is employed. This general downward trend in fitness as connectivity increases is seen for all combinations of parameter values considered.
Wu (Reference Wu2024, 6) claims that, unlike the Best strategy, her proposed Better exploitation strategy “seems to be an effective strategy to counter-balance the dangers of too much connection.” The fact that the Better strategy exhibits higher long-run fitness than the Best strategy for all p values considered seems to back up this claim. However, as Figure 2 shows, this counter-balancing is only partial. While the drop in average epistemic fitness with increased connectivity is not as rapid when a community uses the Better strategy rather than the Best strategy, fitness still shows an overall downward trend as connectivity increases. This is seen for all combinations of parameter values considered.
When it comes to combating the epistemic “dangers” of too much connectivity, it seems that the Conservative strategy is more effective. As seen in Figure 2, communities that use the Conservative strategy display a clear upward trend in long-run epistemic fitness as connectivity between agents increases. That is, communities of agents actually perform better when agents are more connected. This result also holds for all combinations of parameters considered.
3.4. Connectivity and transient diversity
In explaining the results presented in the previous two subsections, it is useful to begin by getting a better handle on how transient diversity varies with network connectivity for each of the three exploitation strategies considered. Figure 3 shows typical results for the average number of unique landscape positions occupied by agents at the end of each simulated round. This can be interpreted as the average number of unique theories scientists in a community endorse, with the plotted values providing a proxy for the average epistemic diversity in a community over time. In order to show how diversity varies with agent connectivity, lines with bold colors are used to show results for highly connected communities (i.e., when
 $p=1$
) while lines with more muted colors are used to show results for poorly connected communities (i.e., when
$p=1$
) while lines with more muted colors are used to show results for poorly connected communities (i.e., when
 $p=0.1$
).
$p=0.1$
).
Average number of unique landscape positions per round for different global search strategies and levels of connectivity when
 $V=0.3$
and
$V=0.3$
and
 $K=5$
.
$K=5$
.

Recall that simulations always begin with agents placed at random locations in the NK landscape. Figure 3 shows that all 100 agents are typically in unique landscape positions before the simulation begins (i.e., in round 0). Given the relatively small number of agents compared to the number of unique positions in the landscape, this is unsurprising. Since only connected networks of agents are allowed in simulations, agents will, with probability 1, eventually end up at the exact same location. The “transient” phase of the simulation occurs between the start of the simulation, where agents typically all occupy unique positions in the landscape, and this point of convergence.
During this transient phase, the more positions in the landscape being explored—i.e., the more “diverse” the community—the more likely a higher fitness location in the landscape will be found via a local search. As seen in Figure 3, the Conservative strategy exhibits the highest level of transient diversity, followed by the Better strategy, with the Best strategy exhibiting the lowest level. This holds for all combinations of parameters considered. A cost of maintaining this diversity is that it delays the convergence of agents to a single landscape position. This explains the trade-off between higher long-run epistemic fitness and speed of convergence seen in Figure 1.
Both the Better and Best strategies have lower transient diversity when the connectivity of agents is high compared to when it is low. This is seen in the muted orange line being strictly above the bold orange line and the muted blue line being strictly above the bold blue line during the transient phase of simulation. Taking transient diversity to generally increase the chances of finding preferable fitness locations, it is then unsurprising that long-term epistemic fitness decreases with network connectivity when either of these global search strategies is used. By contrast, when communities of agents employ the Conservative strategy, transient diversity increases as network connectivity increases, as demonstrated by the bold black line being strictly above the muted black line during the transient phase of simulation. Long-run epistemic fitness then tends to increase with connectivity when the Conservative search strategy is used. These general patterns in the three search strategies hold for all parameter values considered.
A straightforward explanation can be given for this difference. Neither the Best nor the Better search strategies take into account an agent’s current position in updating beliefs. It makes no difference to agents employing these strategies whether a single belief is changed or all of them are changed when considering a potential new position in the landscape, with only the fitness values at the different locations of importance. This makes it more likely that scientists will coalesce around a single region or position in the landscape. By contrast, the Conservative strategy takes into account the number of epistemic attitudes that change when considering a new position in the landscape, selecting the higher-fitness location that is closest to an agent’s current position. Agents will then tend to remain more spread out over time, reaching consensus through a series of small steps rather than a few large steps in the landscape. The more agents directly connected to a given agent, the more likely that there is a neighbor who has similar epistemic attitudes to the agent but higher fitness. This explains why the long-run fitness advantage of using the Conservative strategy becomes more pronounced as the connectivity of agents increases (as seen in Figure 2).
4. Conclusion
This paper has shown that the Conservative search strategy outperforms both the Better and Best strategies with regards to long-run epistemic fitness. Additionally, the long-term performance of communities employing the Conservative strategy improves as communal interconnectedness increases, while the performance of those employing the Best and Better strategies worsens. The Conservative strategy then protects against the epistemic harm caused by increased connectivity in a way that neither the Better nor the Best strategy can, with this difference explainable in terms of relative degrees of transient diversity.
In order to get a better handle on the real-world relevance of the simulation results presented, it is worth briefly considering the plausibility of each of the search strategies considered. The Best strategy proposed by Lazer and Friedman (Reference Lazer and Friedman2007) seems highly plausible. Scientists who are set on maximizing short-term gains with no concern for the potential long-term costs of abandoning their current beliefs would seem likely to behave in this manner. By contrast, Wu’s (Reference Wu2024) Better strategy appears less plausible. There seems to be little reason to think that scientists behave randomly when selecting among competing theories. Wu (Reference Wu2024, 1196) suggests that intrinsic motivators, like “intellectual playfulness,” and extrinsic motivators, like funding provided for exploratory work, may produce something approximating this type of behavior. However, neither of these suggestions seems to satisfactorily account for why an agent would be motivated to jump to a potentially very distant position in the landscape already occupied by another scientist, rather than explore a novel research approach more closely resembling their current one. Of course, agents employing the Conservative strategy also move to locations in the landscape already occupied by other scientists, but this seems in keeping with the theoretical virtues this strategy is meant to capture.
An argument for the real-world plausibility of the Conservative strategy has already been provided based on the incorporation of theoretical virtues like conservatism, modesty, and familiarity by scientists in updating their beliefs. There are, however, other potential reasons that could be given as to why real-world scientists would update their beliefs in this manner. Thoma (Reference Thoma2015, 496) has suggested that medium-range jumps, rather than long-range jumps, in an epistemic landscape may “be the more credible representation of actual scientific practice” because of the costs associated with radically changing research approaches. Frey and Šešelja (Reference Frey and Šešelja2020, 1424) similarly suggest that scientists exhibit a certain degree of “rational inertia,” citing both optimism about the potential for improving one’s current approach through slight modifications and the fact that “changing one’s inquiry usually includes a number of costs (for example, acquiring additional knowledge, new equipment, and so on).” Finally, motivation for not adopting the beliefs of agents whose epistemic position is very different from your own may come from distrust in reported fitness values. O’Connor and Weatherall (Reference O’Connor and Owen Weatherall2018), for instance, have suggested that distrust between agents plausibly increases with epistemic dissimilarity.Footnote 8
Several recent papers have used formal modeling approaches to examine the epistemic consequences of scientific conservatism. Using the two-armed bandit modeling paradigm, Kummerfeld and Zollman (Reference Kummerfeld and Zollman2016) argue that conservatism negatively impacts the success of scientific communities by preventing the exploration of hypotheses that currently appear less promising.Footnote 9 O’Connor (Reference O’Connor2019) uses an evolutionary model to argue that scientists will generally be biased towards conservatism due to the riskiness involved in pursuing completely new research directions. O’Connor takes conservatism to be linked with Kuhn’s (Reference Kuhn1970) idea of “normal” science, contrasting it with the “risky” science associated with scientific revolutions.
The general worry expressed by Kummerfeld and Zollman (Reference Kummerfeld and Zollman2016) and O’Connor (Reference O’Connor2019)—a worry also apparent in recent work by Stanford (Reference Stanford2019) and Currie (Reference Currie2019)—is that conservative forces in science tend to reduce the amount of high-risk research undertaken by scientists and that this could potentially be detrimental to the epistemic success of scientific communities. Results presented in this paper point to a different worry. If scientists do not spend enough time engaged in incrementally improving already established research directions, as encouraged by the Conservative strategy, and instead freely abandon their beliefs to pursue whatever approach is currently seen as most promising, as encouraged by the Best strategy, scientific communities may also be less successful. While these worries may initially seem at odds, both are actually rooted in the same problem. When scientists prematurely coalesce around a single set of beliefs, suboptimal epistemic consensus can result. Having scientists pursue risky new research directions is one obvious way to prevent this. As this paper demonstrates, having epistemically diverse scientists conserve their beliefs is another.
One potential criticism of the virtue-based interpretation of the Conservative search strategy presented is that it fails to accurately capture how scientists balance different virtues in theory selection. There are many theoretical virtues and only some of them recommend staying close to your current epistemic position when updating beliefs. Virtues like success and scope seem to instead suggest that an agent jump to the location in the landscape that has the highest fitness. It could be argued that a more realistic version of a virtue-based search strategy would incorporate both distance from an agent’s current location and the magnitude of increase in fitness when assessing potential new sets of beliefs.
This suggestion is certainly a plausible one. By restricting potential new locations to only those that are higher than an agent’s current position, this idea is captured by the Conservative strategy to some degree. However, it does seem that this could be modeled in a more sophisticated way. For instance, if there were a closer position that provided only a marginal gain in fitness and a far-away location that provided a significant gain in fitness, there could be a linear weighting of the two factors involved in determining which location an agent jumps to. Of course, the appropriate trade-off between increased fitness and distance is not obvious, and the relative weighting of these two factors may vary considerably between scientists or even domains of inquiry. Further research would be needed to explore this type of parameterization of the Conservative strategy more thoroughly. It seems likely, however, that as long as there remains at least some degree of pressure keeping agents closer to their current position when updating beliefs, transient diversity should increase via the mechanism identified in this paper. The general claim that the incorporation of theoretical virtues in belief updating results in better long-term epistemic outcomes will then likely still hold, even in simulations involving this more complex model.
The research presented in this paper might also be extended in other ways. Plausibly, scientists investigating a problem in a given domain may use different search strategies when exploring the epistemic landscape. Examining simulations with mixtures of agents employing the Best, Better, and Conservative strategies may provide some insight as to whether this type of diversity is beneficial to the community as a whole. It is also possible that the Conservative search strategy is particularly important for communal success either early on in exploration or closer to the point of communal convergence. These possibilities could be examined by having agents switch strategies at various points in simulation or by modifying the linear weighting in the proposed parameterization of the Conservative strategy over time.
Finally, there is another area of research in network epistemology to which the results presented in this paper appear relevant. Douven (Reference Douven2022) has recently offered a spirited defense of Inference to the Best Explanation (IBE) against the charge that IBE-based credence updating is irrational. Taking the diachronic Dutch book argument typically relied on in this regard to be essentially pragmatic in nature, he argues that, at least in some circumstances, there are compelling pragmatic reasons to prefer IBE as a method for updating beliefs. In Douven (Reference Douven2013), Douven shows that when simulated agents update credences regarding the possible bias of a coin using a probabilistic version of IBE, they reach high levels of credence in the true hypothesis faster than when using Bayesian updating, at the cost of a slight decrease in accuracy. Douven and Wenmackers (Reference Douven and Wenmackers2017) extend this model to contexts involving communities of epistemic agents, with agents updating their credences based both on relevant new evidence and the credence values assigned by other agents within some epistemic distance.Footnote 10 In this social setting, they find that communities of agents employing IBE-based updating epistemically outperform communities of Bayesian agents in terms of both speed and accuracy.
It is often assumed that explanatory virtues and theoretical virtues coincide. Agents that incorporate theoretical virtues in belief updating can then plausibly be viewed as agents employing IBE-type reasoning. Under this interpretation, the results presented in this paper provide further evidence of the potential pragmatic benefits gained by incorporating explanatory considerations in belief updating. However, in contrast to Douven’s (Reference Douven2013) observation that IBE-based updating involves sacrificing accuracy for speed, and Douven and Wenmackers’ (Reference Douven and Wenmackers2017) claim that both speed and accuracy improve when IBE-based updating occurs in a communal setting, the results presented in this paper indicate that the increased accuracy that results from incorporating theoretical virtues is accompanied by a cost in terms of reduced speed of convergence. More research is needed to understand this apparent discrepancy. One potential direction this research could take would involve attempting to unify the large, but relatively noise-free, landscape models used in this paper with the smaller, but evidentially noisy, models examined by Douven and Wenmackers.Footnote 11
Acknowledgments
I would like to thank Thomas Barrett and two anonymous referees for their helpful comments.
Funding statement
None to declare.
Declarations
None to declare.











 Open access
Open access