


1. Introduction
Iterative learning control (ILC) is a practical branch of learning in system design for repetitive tasks [Reference Longman1, Reference Bristow, Tharayil and Alleyne2]. The advantages of the ILC can be listed as: reducing the complexity of tuning parameters [Reference Longman1], increasing the performance of the tracking system for repetitive actions [Reference Bristow, Tharayil and Alleyne2], and engineering practicability [Reference Liu and Nie3]. The repetition of tasks will become handy for stationary systemsFootnote 1 and require less precaution in practice; many successful examples were reported in the literature [Reference Liu and Alleyne4–Reference Wang, Freeman and Rogers8]. A case study showed success in the application of the ILC in both identification and control for a single-link linear-time-varying rotary system [Reference Liu and Alleyne4]. This integrated version presented faster convergence in tracking errors in comparison with a system with fixed parameters. The ILC with the base of a proportional-derivative (PD) controller was implemented on a five-degree-of-freedom (DoF) manipulator [Reference Tayebi and Islam5]. The results showed error reduction in circular trajectory tracking and recorded convergence up to 50 iterations. Meng et al. presented the method on a robotic arm under input constraint [Reference Meng and He6]. A composite energy function was designed that led to a dual-loop iteration design for a saturated feedback law; the ILC was implemented on a Quanser platform and demonstrated vibration suppression in the output. Freeman applied the ILC on a constrained point-to-point system design [Reference Freeman7]. The stationary test setup was a mass-spring-damper rotary platform with torsional springs. A proportional-integral-derivative (PID) input law was used for the pre-stabilization of the system. Pick-and-place was exercised with ILC as an example of a repetitive job for a robot [Reference Wang, Freeman and Rogers8]. The number of trials was reported as 5, and the error reduction experienced a jump at the beginning, then it converged towards zero.
The learning becomes more challenging when the system is not stationary, such as wheeled mobile robots [Reference Kang, Lee and Han9, Reference Shan, Sun, Wang and Chang10], biped walking/running systems [Reference Hu, Ott and Lee11, Reference Zhang, Chee-Meng, Zhou, Zhao and Li12], or flying platforms [Reference Buelta, Olivares and Staffetti13, Reference Giernacki14]; where in those cases, the workspace becomes unlimited. Failure in learning will not cause damage in wheeled mobile platforms; however, for biped and flying systems, it generates falls/crashes and damage to the system. Moreover, collisions are risks for all mobile systems mentioned. Therefore, the execution of the ILC demands more caution for those cases, especially the flying ones, which is the focus of this work.
Designing a stable controller and then tuning the gains using machine learning and optimization algorithms is one way to proceed with learning in flight [Reference Giernacki14]. The ILC was applied for quadrotor control for trajectory tracking in frequency domain learning [Reference Hehn and D’Andrea15]. Abbeel et al. applied reinforcement learning to aerobatic flight maneuvers of a helicopter [Reference Abbeel, Coates, Quigley and Ng16]. A pilot first performed the flight to provide a model and data to the reinforcement learning approach. Bøhn et al. used data-efficient learning for attitude control of a fixed-wing system in flight [Reference Bøhn, Coates, Reinhardt and Johansen17]. The learning part of the controller acted on top of the nonlinear design and needed three minutes of flight data for tuning. As was mentioned and also observed in the literature, a base controller is needed to keep the system stable in flight and then tune or apply learning to reduce errors and enhance performance. ILC-based methods are popular for quadrotor learning methods [Reference Qian, Xu and Niu18, Reference Meraglia and Lovera19]. Zhao et al. presented the ILC on a system of multiple unmanned aerial robots. Interconnection and Damping Assignment Passivity-Based Control was enhanced by the ILC in another example and showed error reduction in experimental flights [Reference Montoya-Morales, Guerrero-Sánchez, Valencia-Palomo, Hernández-González, López-Estrada and Félix-Herrán20]. Schoellig et al. implemented an ILC-based approach to the quadrotor drone experimentally [Reference Schoellig, Mueller and D’Andrea21]. The system benefited from a disturbance estimation and was tested on a linear trajectory. The estimation of the dynamics was used to present an initial guess for the robot to perform the initial flights successfully. Here in this current work, the use of nonlinear optimal control is suggested to preset a stable base controller instead of an initial guess and to control the system in a continuous repeated trajectory. The state-dependent Riccati equation (SDRE) is selected as the basis of the design for the pre-stabilization of the flying system before the execution of the learning phase. The PD, the PID, or other control techniques can be used as the base controller, though the advantages of the SDRE and the contribution of this topic in nonlinear optimal control motivated this selection. Including the nonlinearity of the dynamics, especially for the orientation part, is a clear advantage over linear controllers. The translation part of the quadrotor dynamics indeed represents a linear system, though the contribution of the rotation matrix (which includes orientation nonlinearity) to the input force vector of thrust makes this part also nonlinear. This justifies the usage of the nonlinear optimal control in this work.
In principle, to stabilize the system with a conventional controller and refine it through the ILC, other techniques might be used. An example is the control Lyapunov function approach that was widely used in drone control [Reference Yesildirek and Imran22, Reference Do, Blanchini, Miani and Prodan23]. The CLF method has the advantage of decreasing the energy of the system over time and was applied to different fields, such as chaos control [Reference Shafei, Shafei and Momeni24]. While the SDRE is selected to be in charge of the base control of the drone, other controllers, such as CLF, linear, and nonlinear ones, can adapt the design of this work and be implemented along with the ILC.
The SDRE exponentially diverged in applications in the late 90s, though the main highlight was in the aerospace field back then [Reference Mracek, Cloutier, Cloutier and Mracek25–Reference Wise and Sedwick27]. The similarity of the SDRE structure to the linear quadratic regulator (LQR) controller generated the replication of many developments in nonlinear form, originating in the LQR. Flexibility in the structure, optimality, systematic design, and nonlinear weighting matrices of the SDRE provoked wide-range utilization of this method in control engineering. Recent advances in the SDRE method in aerospace vary from unmanned flapping wing control [Reference Nekoo and Ollero28], experimental backward integration in flight [Reference Nekoo and Ollero29], to more industrial applications, such as multi-rotor regulation [Reference Stkepien, Pawlak and Giernacki30], and aircraft trajectory tracking [Reference Mlayeh and Khedher31]. The flight of a quadrotor was practiced [Reference Nekoo and Ollero32]; however, in this current work, the focus is on the learning part for repetitive trajectories.
The SDRE has the potential for applications in neural networks and learning methods; the primary objective would be tuning the weighting matrices, though other practices such as obstacle avoidance, state-constraint design, and disturbance rejection could be explored. A neural network was implemented to present a fast solution SDRE approach for a mockup satellite [Reference da Costa, Saotome, Rafikova and Machado33]. A hidden layer and 30 neurons were used in the experimental tests; they presented similar results to the algebraic solution to Riccati. Albi et al. used SDRE solutions as training data for equivalent feedforward design using a neural network as a substitution for a conventional solver [Reference Albi, Bicego and Kalise34]. A data-driven modeling and control of a soft robot were presented in task-space design [Reference Bhattacharya, Rotithor and Dani35]. The neural network was trained the system to find the state-dependent coefficient (SDC) matrices and consequently converge the system as an asymptotically stable optimal closed-loop tracking controller. Nekoo et al. introduced the ILC as an augmentation to the SDRE controller to reduce error in both regulation (point-to-point) control and trajectory tracking [Reference Nekoo, Acosta, Heredia and Ollero36]. The ILC plus SDRE was implemented on a stationary variable-pitch rotor pendulum experimentally.
There are reinforcement learning approaches that can stabilize a quadrotor from the first loop in flight; some examples can be found in Refs. [Reference Hwangbo, Sa, Siegwart and Hutter37–Reference Wu, Sun, Spasojevic and Kumar39]. Concerning the learning flight, the algorithm ought to be conservative but stable for complex tasks [Reference Hwangbo, Sa, Siegwart and Hutter37]. Yoo et al. presented reinforcement learning for quadrotor control [Reference Yoo, Jang, Kim and Johansson40]. Ferede et al. implemented neural-network learning for the trajectory tracking of a quadrotor [Reference Ferede, de Croon, De Wagter and Izzo41]. To limit the risks to flight, the authority of the stable inner loop controller increased to secure the flight tracking, and the neural network was implemented on top of that to increase precision. The variety of machine learning, artificial intelligence methods, and learning techniques has expanded quite recently. In this work, the ILCl has been targeted to perform flight control via learning. The ILC is selected since it presents stable learning from the first iteration loop, thanks to the base controller. This combination allows the generalization of an initial tuning gain of the SDRE for various paths; then, one leaves the role of increasing precision to the ILC when the possibility of repetition of tasks exists.
The SDRE is well known in creating a balance between energy consumption and error reduction or accuracy. The disturbance and uncertainty are two phenomena that accompany the control systems, especially in experimentation. Observer design was reported to overcome this challenge and reduce this effect during the control task [Reference Dam, Thabet, Ali and Guerin42–Reference Thanh, Huynh, Vu, Mung, Phi, Hong and Vu44]. Here, in this current work, the structure of the drone has been designed in a symmetrical, simplified way to avoid the mismatch between the dynamics and the model, and thanks to the OptiTrack’s precise and clean feedback, there is no expected noise in the feedback part of the control system.
Main contribution: to apply the ILC using the SDRE controller as the base stabilizer to control quadrotor flight trajectory tracking in theory and experiment. This work is motivated by Ref. [Reference Nekoo, Acosta, Heredia and Ollero36] but with experimental implementation on a real flight, which is a challenge in the learning domain and the main novelty here.
Outline: Section 2 describes the ILC and the SDRE structure. The system dynamics and quadrotor equations of motion in the state-space form are expressed in Section 3. The control implementation is presented in Section 4. The details of the experimental setup and conditions of the tests are reported in Section 5. The simulation results are reported in Section 6.1, and the experimental results are illustrated in Section 6.2. Finally, the concluding remarks and the summary of the work are arranged in Section 7.
2. Control design
2.1. The SDRE structure
The SDRE is applied to a class of an affine-in-control nonlinear time-invariant system of the form:
 \begin{equation} \dot {\mathbf{x}}(t)=\mathbf{f}(\mathbf{x}(t))+\mathbf{g}(\mathbf{x}(t),\mathbf{u}(t)), \end{equation}
\begin{equation} \dot {\mathbf{x}}(t)=\mathbf{f}(\mathbf{x}(t))+\mathbf{g}(\mathbf{x}(t),\mathbf{u}(t)), \end{equation}
where
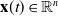 $\mathbf{x}(t)\in \mathbb{R}^n$
denotes a state vector, and
$\mathbf{x}(t)\in \mathbb{R}^n$
denotes a state vector, and
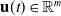 $\mathbf{u}(t)\in \mathbb{R}^m$
an input one. The equilibrium point of the system is
$\mathbf{u}(t)\in \mathbb{R}^m$
an input one. The equilibrium point of the system is
 $\mathbf{f}(\mathbf{0})=\mathbf{0}$
and both vectors
$\mathbf{f}(\mathbf{0})=\mathbf{0}$
and both vectors
 $\mathbf{f}(\mathbf{x}(t))\,:\,\mathbb{R}^n\to \mathbb{R}^n$
and
$\mathbf{f}(\mathbf{x}(t))\,:\,\mathbb{R}^n\to \mathbb{R}^n$
and
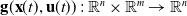 $\mathbf{g}(\mathbf{x}(t),\mathbf{u}(t))\,:\,\mathbb{R}^n\times \mathbb{R}^m\to \mathbb{R}^n$
are piecewise-continuous smooth vector-valued functions that satisfy locally the Lipschitz condition.
$\mathbf{g}(\mathbf{x}(t),\mathbf{u}(t))\,:\,\mathbb{R}^n\times \mathbb{R}^m\to \mathbb{R}^n$
are piecewise-continuous smooth vector-valued functions that satisfy locally the Lipschitz condition.
System (1) is transformed into apparent linearization or SDC parameterization form [Reference Çimen45]:
 \begin{equation} \dot {\mathbf{x}}(t)=\mathbf{A}(\mathbf{x}(t))\mathbf{x}(t)+\mathbf{B}(\mathbf{x}(t))\mathbf{u}(t), \end{equation}
\begin{equation} \dot {\mathbf{x}}(t)=\mathbf{A}(\mathbf{x}(t))\mathbf{x}(t)+\mathbf{B}(\mathbf{x}(t))\mathbf{u}(t), \end{equation}
in which
 \begin{equation*} \begin{split} \mathbf{A}(\mathbf{x}(t))&\,:\,\mathbb{R}^n\to \mathbb{R}^{n\times n},\\[3pt] \mathbf{B}(\mathbf{x}(t))&\,:\,\mathbb{R}^n\to \mathbb{R}^{n\times m}. \end{split} \end{equation*}
\begin{equation*} \begin{split} \mathbf{A}(\mathbf{x}(t))&\,:\,\mathbb{R}^n\to \mathbb{R}^{n\times n},\\[3pt] \mathbf{B}(\mathbf{x}(t))&\,:\,\mathbb{R}^n\to \mathbb{R}^{n\times m}. \end{split} \end{equation*}
The SDC pair of
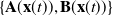 $\{\mathbf{A}(\mathbf{x}(t)),\mathbf{B}(\mathbf{x}(t))\}$
in (2) must be a completely controllable parameterization of system (1) for all
$\{\mathbf{A}(\mathbf{x}(t)),\mathbf{B}(\mathbf{x}(t))\}$
in (2) must be a completely controllable parameterization of system (1) for all
 $\mathbf{x}(t)$
in
$\mathbf{x}(t)$
in
 $t\in \mathbb{R}^+$
.
$t\in \mathbb{R}^+$
.
The SDC matrices of the SDRE are state-dependent and unlike a LQR, which presents a constant pair
 $\{\mathbf{A},\mathbf{B}\}$
, the controllability condition on the SDC pair
$\{\mathbf{A},\mathbf{B}\}$
, the controllability condition on the SDC pair
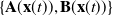 $\{\mathbf{A}(\mathbf{x}(t)),\mathbf{B}(\mathbf{x}(t))\}$
should be computed over time to guarantee the solution to SDRE and the controllability of the system. To check the controlability over the time span of the control task, the controllability matrix should be fully ranked [Reference Nekoo and Ollero46]:
$\{\mathbf{A}(\mathbf{x}(t)),\mathbf{B}(\mathbf{x}(t))\}$
should be computed over time to guarantee the solution to SDRE and the controllability of the system. To check the controlability over the time span of the control task, the controllability matrix should be fully ranked [Reference Nekoo and Ollero46]:
 \begin{equation*} \mathcal{M}_{\mathrm{c}}= \begin{bmatrix} \mathbf{B}(\mathbf{x}(t)) & \mathbf{A}(\mathbf{x}(t)) \mathbf{B}(\mathbf{x}(t)) & \cdots & \mathbf{A}^{n-1}(\mathbf{x}(t)) \mathbf{B}(\mathbf{x}(t)) \end{bmatrix}. \end{equation*}
\begin{equation*} \mathcal{M}_{\mathrm{c}}= \begin{bmatrix} \mathbf{B}(\mathbf{x}(t)) & \mathbf{A}(\mathbf{x}(t)) \mathbf{B}(\mathbf{x}(t)) & \cdots & \mathbf{A}^{n-1}(\mathbf{x}(t)) \mathbf{B}(\mathbf{x}(t)) \end{bmatrix}. \end{equation*}
The controlability matrix includes states and can be computed during the simulation or experiments. To check this matrix before the simulation and evaluate the rank, the dynamics of the system should be replaced in the SDC pair and analyzed; more details can be seen in ref. [Reference Korayem and Nekoo47]. It must be noted that quadrotor dynamics has singular points in orientation dynamics, which consequently makes the SDC matrices singular. Clearly, those configurations (
 $\pi /2(\mathrm{rad})$
rotation in roll and pitch) must be avoided in control and path planning to avoid singularity and then violation of the controllability matrix.
$\pi /2(\mathrm{rad})$
rotation in roll and pitch) must be avoided in control and path planning to avoid singularity and then violation of the controllability matrix.
The cost function integral of optimal control is defined as [Reference Nekoo48]:
 \begin{equation} J(\!\cdot \!)=\frac {1}{2} \int _{0}^{\infty } \bigg ( \mathbf{x}^\top (t) \mathbf{Q}(\mathbf{x}(t)) \mathbf{x}(t) + \mathbf{u}^\top (t) \mathbf{R}(\mathbf{x}(t)) \mathbf{u}(t) \bigg ) \,\mathrm{d}t, \end{equation}
\begin{equation} J(\!\cdot \!)=\frac {1}{2} \int _{0}^{\infty } \bigg ( \mathbf{x}^\top (t) \mathbf{Q}(\mathbf{x}(t)) \mathbf{x}(t) + \mathbf{u}^\top (t) \mathbf{R}(\mathbf{x}(t)) \mathbf{u}(t) \bigg ) \,\mathrm{d}t, \end{equation}
where
 $\mathbf{Q}(\mathbf{x}(t)) \, : \, \mathbb{R}^n \to \mathbb{R}^{n \times n}$
and
$\mathbf{Q}(\mathbf{x}(t)) \, : \, \mathbb{R}^n \to \mathbb{R}^{n \times n}$
and
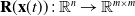 $\mathbf{R}(\mathbf{x}(t)) \, : \, \mathbb{R}^n \to \mathbb{R}^{m \times m}$
. Moreover,
$\mathbf{R}(\mathbf{x}(t)) \, : \, \mathbb{R}^n \to \mathbb{R}^{m \times m}$
. Moreover,
 $\mathbf{R}(\mathbf{x}(t))=\mathbf{R}^\top (\mathbf{x}(t))\gt \mathbf{0}$
penalizes the input variables, and
$\mathbf{R}(\mathbf{x}(t))=\mathbf{R}^\top (\mathbf{x}(t))\gt \mathbf{0}$
penalizes the input variables, and
 $\mathbf{Q}(\mathbf{x}(t))=\mathbf{Q}^\top (\mathbf{x}(t)) \geq \mathbf{0}$
penalizes the state ones.
$\mathbf{Q}(\mathbf{x}(t))=\mathbf{Q}^\top (\mathbf{x}(t)) \geq \mathbf{0}$
penalizes the state ones.
The pair of
 $\{\mathbf{A}(\mathbf{x}(t)),\mathbf{Q}^{1/2}(\mathbf{x}(t))\}$
must be a completely observable parameterization of system (1) for all
$\{\mathbf{A}(\mathbf{x}(t)),\mathbf{Q}^{1/2}(\mathbf{x}(t))\}$
must be a completely observable parameterization of system (1) for all
 $\mathbf{x}(t)$
in
$\mathbf{x}(t)$
in
 $t\in \mathbb{R}^+$
where
$t\in \mathbb{R}^+$
where
 $\mathbf{Q}^{1/2}(\mathbf{x}(t))$
is the Cholesky decomposition of
$\mathbf{Q}^{1/2}(\mathbf{x}(t))$
is the Cholesky decomposition of
 $\mathbf{Q}(\mathbf{x}(t))$
in (5).
$\mathbf{Q}(\mathbf{x}(t))$
in (5).
The observability condition can be checked by computing the rank of the observability matrix [Reference Nekoo and Ollero46]:
 \begin{equation*} \mathcal{M}_{\mathrm{o}}= \begin{bmatrix} \mathbf{Q}^{1/2}(\mathbf{x}(t))\\[3pt] \mathbf{Q}^{1/2}(\mathbf{x}(t)) \mathbf{A}(\mathbf{x}(t))\\[3pt] \vdots \\[3pt] \mathbf{Q}^{1/2}(\mathbf{x}(t)) \mathbf{A}^{n-1}(\mathbf{x}(t)) \end{bmatrix}, \end{equation*}
\begin{equation*} \mathcal{M}_{\mathrm{o}}= \begin{bmatrix} \mathbf{Q}^{1/2}(\mathbf{x}(t))\\[3pt] \mathbf{Q}^{1/2}(\mathbf{x}(t)) \mathbf{A}(\mathbf{x}(t))\\[3pt] \vdots \\[3pt] \mathbf{Q}^{1/2}(\mathbf{x}(t)) \mathbf{A}^{n-1}(\mathbf{x}(t)) \end{bmatrix}, \end{equation*}
where the same argument of the controllability matrix can be presented to check the observability condition before simulation or experiments.
Mathematical derivation and applying optimality conditions,
 $\frac {\partial \mathcal{H}(\mathbf{x}(t),\mathbf{u}(t),\boldsymbol{\lambda }(t))}{\partial \mathbf{u}(t)}=\mathbf{0}$
and
$\frac {\partial \mathcal{H}(\mathbf{x}(t),\mathbf{u}(t),\boldsymbol{\lambda }(t))}{\partial \mathbf{u}(t)}=\mathbf{0}$
and
 $\frac {\partial \mathcal{H}(\mathbf{x}(t),\mathbf{u}(t),\boldsymbol{\lambda }(t))}{\partial \boldsymbol{\lambda }(t)}=\dot {\mathbf{x}}(t)$
, on the Hamiltonian function of optimal control (
$\frac {\partial \mathcal{H}(\mathbf{x}(t),\mathbf{u}(t),\boldsymbol{\lambda }(t))}{\partial \boldsymbol{\lambda }(t)}=\dot {\mathbf{x}}(t)$
, on the Hamiltonian function of optimal control (
 $\boldsymbol{\lambda }(t)$
is the co-state vector of optimal control):
$\boldsymbol{\lambda }(t)$
is the co-state vector of optimal control):
 \begin{equation*} \mathcal{H}(\mathbf{x}(t),\mathbf{u}(t),\boldsymbol{\lambda }(t))= \boldsymbol{\lambda }^\top (t)\{ \mathbf{A}(\mathbf{x}(t))\mathbf{x}(t)+\mathbf{B}(\mathbf{x}(t))\mathbf{u}(t) \} +\frac {1}{2} [\mathbf{x}^\top (t) \mathbf{Q}(\mathbf{x}(t)) \mathbf{x}(t) + \mathbf{u}^\top (t) \mathbf{R}(\mathbf{x}(t)) \mathbf{u}(t)], \end{equation*}
\begin{equation*} \mathcal{H}(\mathbf{x}(t),\mathbf{u}(t),\boldsymbol{\lambda }(t))= \boldsymbol{\lambda }^\top (t)\{ \mathbf{A}(\mathbf{x}(t))\mathbf{x}(t)+\mathbf{B}(\mathbf{x}(t))\mathbf{u}(t) \} +\frac {1}{2} [\mathbf{x}^\top (t) \mathbf{Q}(\mathbf{x}(t)) \mathbf{x}(t) + \mathbf{u}^\top (t) \mathbf{R}(\mathbf{x}(t)) \mathbf{u}(t)], \end{equation*}
lead to the Hamilton–Jacobi–Bellman partial differential equation, which, as an approximate solution, one can generate the SDRE equation as follows [Reference Nekoo48]:
 \begin{equation} \mathbf{Q}(\mathbf{x}(t)) + \mathbf{K}(\mathbf{x}(t))\mathbf{A}(\mathbf{x}(t)) + \mathbf{A}^\top (\mathbf{x}(t)) \mathbf{K}(\mathbf{x}(t)) - \mathbf{K}(\mathbf{x}(t))\mathbf{B}(\mathbf{x}(t))\mathbf{R}^{-1}(\mathbf{x}(t))\mathbf{B}^\top (\mathbf{x}(t))\mathbf{K}(\mathbf{x}(t))=\mathbf{0}, \end{equation}
\begin{equation} \mathbf{Q}(\mathbf{x}(t)) + \mathbf{K}(\mathbf{x}(t))\mathbf{A}(\mathbf{x}(t)) + \mathbf{A}^\top (\mathbf{x}(t)) \mathbf{K}(\mathbf{x}(t)) - \mathbf{K}(\mathbf{x}(t))\mathbf{B}(\mathbf{x}(t))\mathbf{R}^{-1}(\mathbf{x}(t))\mathbf{B}^\top (\mathbf{x}(t))\mathbf{K}(\mathbf{x}(t))=\mathbf{0}, \end{equation}
in which
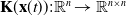 $\mathbf{K}(\mathbf{x}(t)):\mathbb{R}^n\to \mathbb{R}^{n\times n}$
is the symmetric-positive-definite suboptimal gain of the control law:
$\mathbf{K}(\mathbf{x}(t)):\mathbb{R}^n\to \mathbb{R}^{n\times n}$
is the symmetric-positive-definite suboptimal gain of the control law:
 \begin{equation} \mathbf{u}(t)=-\mathbf{R}^{-1}(\mathbf{x}(t))\mathbf{B}^\top (\mathbf{x}(t))\mathbf{K}(\mathbf{x}(t))\mathbf{x}(t). \end{equation}
\begin{equation} \mathbf{u}(t)=-\mathbf{R}^{-1}(\mathbf{x}(t))\mathbf{B}^\top (\mathbf{x}(t))\mathbf{K}(\mathbf{x}(t))\mathbf{x}(t). \end{equation}
Eq. (9) regulates the system to the zero equilibrium point. To generalize the regulation to any set point in the workspace, it can be modified as
 \begin{equation} \mathbf{u}(t)=-\mathbf{R}^{-1}(\mathbf{x}(t))\mathbf{B}^\top (\mathbf{x}(t))\mathbf{K}(\mathbf{x}(t))\mathbf{e}(t), \end{equation}
\begin{equation} \mathbf{u}(t)=-\mathbf{R}^{-1}(\mathbf{x}(t))\mathbf{B}^\top (\mathbf{x}(t))\mathbf{K}(\mathbf{x}(t))\mathbf{e}(t), \end{equation}
where
 $\mathbf{e}(t)=\mathbf{x}(t)-\mathbf{x}_{\mathrm{des}}$
is error vector for regulation to constant set point and
$\mathbf{e}(t)=\mathbf{x}(t)-\mathbf{x}_{\mathrm{des}}$
is error vector for regulation to constant set point and
 $\mathbf{e}(t)=\mathbf{x}(t)-\mathbf{x}_{\mathrm{des}}(t)$
is the one for trajectory tracking in which “des” stands for desired values.
$\mathbf{e}(t)=\mathbf{x}(t)-\mathbf{x}_{\mathrm{des}}(t)$
is the one for trajectory tracking in which “des” stands for desired values.
The development of the controller in this subsection was based on the infinite horizon state-dependent Riccati equation. The penalization of the states at the final time of the control task is relaxed in this case, and there is no control over time to finish the job sooner. To apply the SDRE in a finite horizon, the upper bound of the integral in the cost function (5) must be changed to
 $t_{\mathrm{f}}$
, along with addition of finite time weighting matrix term outside the integral as
$t_{\mathrm{f}}$
, along with addition of finite time weighting matrix term outside the integral as
 $\mathbf{x}^\top (t_{\mathrm{f}})\mathbf{F}\mathbf{x}(t_{\mathrm{f}})$
where
$\mathbf{x}^\top (t_{\mathrm{f}})\mathbf{F}\mathbf{x}(t_{\mathrm{f}})$
where
 $\mathbf{F}=\mathbf{F}^\top \geq \mathbf{0}$
. The finite horizon changes the algebraic matrix SDRE (8) to a differential equation with a final boundary condition. Solving a differential Riccati equation is challenging, and the combination of that with ILC increases the complexity; hence, the SDRE is selected as the base controller. Moreover, the trajectory tracking controls the states in time, and finishing the control task sooner than the original predefined time, the final time will not be necessary.
$\mathbf{F}=\mathbf{F}^\top \geq \mathbf{0}$
. The finite horizon changes the algebraic matrix SDRE (8) to a differential equation with a final boundary condition. Solving a differential Riccati equation is challenging, and the combination of that with ILC increases the complexity; hence, the SDRE is selected as the base controller. Moreover, the trajectory tracking controls the states in time, and finishing the control task sooner than the original predefined time, the final time will not be necessary.
2.2. The iterative learning control: the gradient descent training
The conventional SDRE control law, Eq. (10), regulates the system to a set point or tracks a desired trajectory based on the defined control gain
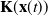 $\mathbf{K}(\mathbf{x}(t))$
which is obtained from (8). It always delivers the same performance if the control task is repeated and the weighting matrices
$\mathbf{K}(\mathbf{x}(t))$
which is obtained from (8). It always delivers the same performance if the control task is repeated and the weighting matrices
 $\mathbf{Q}(\mathbf{x}(t))$
and
$\mathbf{Q}(\mathbf{x}(t))$
and
 $\mathbf{R}(\mathbf{x}(t))$
are left as initially tuned. This subsection presents the addition of the ILC to the basic optimal input law. Adding the ILC changes the performance of the system in each loop, creating a learning mechanism. To achieve this learning, a feedforward time-varying term is added to the control law (10):
$\mathbf{R}(\mathbf{x}(t))$
are left as initially tuned. This subsection presents the addition of the ILC to the basic optimal input law. Adding the ILC changes the performance of the system in each loop, creating a learning mechanism. To achieve this learning, a feedforward time-varying term is added to the control law (10):
 \begin{equation} \mathbf{u}_{j}(t)=-\mathbf{R}^{-1}(\mathbf{x}_j(t))\mathbf{B}^\top (\mathbf{x}_j(t))\mathbf{K}(\mathbf{x}_j(t))\mathbf{e}_{j}(t)+\mathbf{H}_{j}(t), \end{equation}
\begin{equation} \mathbf{u}_{j}(t)=-\mathbf{R}^{-1}(\mathbf{x}_j(t))\mathbf{B}^\top (\mathbf{x}_j(t))\mathbf{K}(\mathbf{x}_j(t))\mathbf{e}_{j}(t)+\mathbf{H}_{j}(t), \end{equation}
where
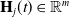 $\mathbf{H}_{j}(t)\in \mathbb{R}^m$
is the learning term for the
$\mathbf{H}_{j}(t)\in \mathbb{R}^m$
is the learning term for the
 $j$
-th loop control, and
$j$
-th loop control, and
 $j=1,\cdots ,N_{\mathrm{i}}$
in which
$j=1,\cdots ,N_{\mathrm{i}}$
in which
 $N_{\mathrm{i}}$
denotes number of the last learning loop.
$N_{\mathrm{i}}$
denotes number of the last learning loop.
The gradient descent method is used to train the learning vector. The performance criterion of trajectory tracking is defined as [Reference Nekoo, Acosta, Heredia and Ollero36]:
 \begin{equation} J_{\mathrm{L}}(t)=\frac {1}{2}\sum _{j=1}^{N_{\mathrm{i}}} \bigg |\bigg | \mathbf{H}_{j}(t) - \mathbf{S}_{\mathrm{d}}(t) \bigg |\bigg |^2, \end{equation}
\begin{equation} J_{\mathrm{L}}(t)=\frac {1}{2}\sum _{j=1}^{N_{\mathrm{i}}} \bigg |\bigg | \mathbf{H}_{j}(t) - \mathbf{S}_{\mathrm{d}}(t) \bigg |\bigg |^2, \end{equation}
where
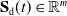 $\mathbf{S}_{\mathrm{d}}(t)\in \mathbb{R}^m$
is the desired dynamics of the system and
$\mathbf{S}_{\mathrm{d}}(t)\in \mathbb{R}^m$
is the desired dynamics of the system and
 $||\cdot ||$
is matrix norm. Since by substitution of the desired trajectory in the nonlinear dynamics, one receives similar data,
$||\cdot ||$
is matrix norm. Since by substitution of the desired trajectory in the nonlinear dynamics, one receives similar data,
 $\mathbf{S}_{\mathrm{d}}(t)$
does not change in the learning loops and acts like a reference system for the learning process. Therefore, it appears without counter
$\mathbf{S}_{\mathrm{d}}(t)$
does not change in the learning loops and acts like a reference system for the learning process. Therefore, it appears without counter
 $j$
in (12) and other equations. The cost function in trajectory tracking compares the learning term in the control law with desired dynamics that include the ideal trajectory. This cost function is common in ILC design and proposed in the literature [Reference Ahn, Chen and Moore49]. This is a good choice since minimizing
$j$
in (12) and other equations. The cost function in trajectory tracking compares the learning term in the control law with desired dynamics that include the ideal trajectory. This cost function is common in ILC design and proposed in the literature [Reference Ahn, Chen and Moore49]. This is a good choice since minimizing
 $||\mathbf{H}_j(t)-\mathbf{S}_{\mathrm{d}}(t)||$
uniformly reduces the worst-case tracking error for all inputs [Reference Bouakrif50, Reference Amann, Owens and Rogers51].
$||\mathbf{H}_j(t)-\mathbf{S}_{\mathrm{d}}(t)||$
uniformly reduces the worst-case tracking error for all inputs [Reference Bouakrif50, Reference Amann, Owens and Rogers51].
The gradient descent method is applied to (12), which results in the following training rule:
 \begin{equation} \mathbf{H}_{j}(t)=\mathbf{H}_{j-1}(t)-\beta \frac {\partial J_{\mathrm{L}}(t)}{\partial \mathbf{H}_{j-1}(t)}=\mathbf{H}_{j-1}(t)-\beta \Big ( \mathbf{H}_{j-1}(t) - \mathbf{S}_{\mathrm{d}}(t) \Big ), \end{equation}
\begin{equation} \mathbf{H}_{j}(t)=\mathbf{H}_{j-1}(t)-\beta \frac {\partial J_{\mathrm{L}}(t)}{\partial \mathbf{H}_{j-1}(t)}=\mathbf{H}_{j-1}(t)-\beta \Big ( \mathbf{H}_{j-1}(t) - \mathbf{S}_{\mathrm{d}}(t) \Big ), \end{equation}
where
 $0\lt \beta \lt 1$
is a training factor.
$0\lt \beta \lt 1$
is a training factor.
3. System dynamics
Consider a plus-shaped quadrotor drone in a Cartesian global frame denoted by
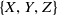 $\{X,Y,Z\}$
. The moving body frame is attached to the center-of-mass (CoM) of the quadrotor, denoted by
$\{X,Y,Z\}$
. The moving body frame is attached to the center-of-mass (CoM) of the quadrotor, denoted by
 $\{x_{\mathrm{c}},y_{\mathrm{c}},z_{\mathrm{c}}\}$
. The axis definition and rotor numbers are demonstrated in Figure 1. Motors one and three have clockwise propellers, and motors two and four have counter-clockwise ones.
$\{x_{\mathrm{c}},y_{\mathrm{c}},z_{\mathrm{c}}\}$
. The axis definition and rotor numbers are demonstrated in Figure 1. Motors one and three have clockwise propellers, and motors two and four have counter-clockwise ones.
The axis definition and rotor numbers of the quadrotor. CW stands for clockwise and CCW for counterclockwise.

The generalized coordinates of the system are collected in
 \begin{equation*} \mathbf{q}(t)=\begin{bmatrix} \boldsymbol{\xi }_1(t)\\[3pt] \boldsymbol{\xi }_2(t) \end{bmatrix}, \end{equation*}
\begin{equation*} \mathbf{q}(t)=\begin{bmatrix} \boldsymbol{\xi }_1(t)\\[3pt] \boldsymbol{\xi }_2(t) \end{bmatrix}, \end{equation*}
where
 $\boldsymbol{\xi }_1(t)=[x_{\mathrm{c}}(t),y_{\mathrm{c}}(t),z_{\mathrm{c}}(t)]^\top$
includes the CoM coordinate variables and
$\boldsymbol{\xi }_1(t)=[x_{\mathrm{c}}(t),y_{\mathrm{c}}(t),z_{\mathrm{c}}(t)]^\top$
includes the CoM coordinate variables and
 $\boldsymbol{\xi }_2(t)=[\phi (t),\theta (t),\psi (t)]^\top$
takes in the Euler angles.
$\boldsymbol{\xi }_2(t)=[\phi (t),\theta (t),\psi (t)]^\top$
takes in the Euler angles.
The linear and angular velocities of the drone are set in the following vectors
 \begin{equation*} \boldsymbol{\upsilon }_1(t)=\begin{bmatrix} u(t)\\[3pt] v(t)\\[3pt] w(t)\\[3pt] \end{bmatrix},\, \boldsymbol{\upsilon }_2(t)=\begin{bmatrix} p(t)\\[3pt] q(t)\\[3pt] r(t) \end{bmatrix}. \end{equation*}
\begin{equation*} \boldsymbol{\upsilon }_1(t)=\begin{bmatrix} u(t)\\[3pt] v(t)\\[3pt] w(t)\\[3pt] \end{bmatrix},\, \boldsymbol{\upsilon }_2(t)=\begin{bmatrix} p(t)\\[3pt] q(t)\\[3pt] r(t) \end{bmatrix}. \end{equation*}
Two transformations exist between the local and global coordinates, presented by the kinematics equations:
 \begin{equation} \begin{split} \dot {\boldsymbol{\xi }}_1(t)= & \mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t),\\[4pt] \dot {\boldsymbol{\xi }}_2(t)= & \mathbf{T}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t), \end{split} \end{equation}
\begin{equation} \begin{split} \dot {\boldsymbol{\xi }}_1(t)= & \mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t),\\[4pt] \dot {\boldsymbol{\xi }}_2(t)= & \mathbf{T}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t), \end{split} \end{equation}
where
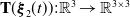 $\mathbf{T}(\boldsymbol{\xi }_2(t)): \mathbb{R}^3 \to \mathbb{R}^{3 \times 3}$
and
$\mathbf{T}(\boldsymbol{\xi }_2(t)): \mathbb{R}^3 \to \mathbb{R}^{3 \times 3}$
and
 $\mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t)): \mathbb{R}^3 \to \mathbb{R}^{3 \times 3}$
are rotation matrices [Reference Nekoo, Acosta, Gomez-Tamm and Ollero52]:
$\mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t)): \mathbb{R}^3 \to \mathbb{R}^{3 \times 3}$
are rotation matrices [Reference Nekoo, Acosta, Gomez-Tamm and Ollero52]:
 \begin{equation*} \mathbf{T}(\boldsymbol{\xi }_{2}(t))= \begin{bmatrix} 1 &\quad s_{\phi } t_{\theta } &\quad c_{\phi } t_{\theta } \\ 0 &\quad c_{\phi } &\quad -s_{\phi } \\ 0 &\quad s_{\phi } / c_{\theta } &\quad c_{\phi } / c_{\theta } \end{bmatrix}, \end{equation*}
\begin{equation*} \mathbf{T}(\boldsymbol{\xi }_{2}(t))= \begin{bmatrix} 1 &\quad s_{\phi } t_{\theta } &\quad c_{\phi } t_{\theta } \\ 0 &\quad c_{\phi } &\quad -s_{\phi } \\ 0 &\quad s_{\phi } / c_{\theta } &\quad c_{\phi } / c_{\theta } \end{bmatrix}, \end{equation*}
 \begin{equation*} \mathbf{R}_{XYZ}(\boldsymbol{\xi }_{2}(t))= \begin{bmatrix} c_{\psi } c_{\theta } &\quad -c_{\phi } s_{\psi } + s_{\phi } s_{\theta } c_{\psi } &\quad s_{\phi } s_{\psi } + c_{\phi } s_{\theta } c_{\psi } \\ s_{\psi } c_{\theta } &\quad c_{\phi } c_{\psi } + s_{\phi } s_{\theta } s_{\psi } &\quad -s_{\phi } c_{\psi } + c_{\phi } s_{\theta } s_{\psi } \\ -s_{\theta } &\quad c_{\theta } s_{\phi } &\quad c_{\theta } c_{\phi } \end{bmatrix}. \end{equation*}
\begin{equation*} \mathbf{R}_{XYZ}(\boldsymbol{\xi }_{2}(t))= \begin{bmatrix} c_{\psi } c_{\theta } &\quad -c_{\phi } s_{\psi } + s_{\phi } s_{\theta } c_{\psi } &\quad s_{\phi } s_{\psi } + c_{\phi } s_{\theta } c_{\psi } \\ s_{\psi } c_{\theta } &\quad c_{\phi } c_{\psi } + s_{\phi } s_{\theta } s_{\psi } &\quad -s_{\phi } c_{\psi } + c_{\phi } s_{\theta } s_{\psi } \\ -s_{\theta } &\quad c_{\theta } s_{\phi } &\quad c_{\theta } c_{\phi } \end{bmatrix}. \end{equation*}
Selecting the generalized coordinates and velocity of the drone on the local frame as the state variables of the system:
 \begin{equation*} \mathbf{x}(t)=[\boldsymbol{\xi }_1^\top (t),\boldsymbol{\xi }_2^\top (t),\boldsymbol{\upsilon }_1^\top (t),\boldsymbol{\upsilon }_2^\top (t)]^\top , \end{equation*}
\begin{equation*} \mathbf{x}(t)=[\boldsymbol{\xi }_1^\top (t),\boldsymbol{\xi }_2^\top (t),\boldsymbol{\upsilon }_1^\top (t),\boldsymbol{\upsilon }_2^\top (t)]^\top , \end{equation*}
the state-space representation of the quadrotor is found:
 \begin{equation} \dot {\mathbf{x}}(t)= \begin{bmatrix} \dot {\boldsymbol{\xi }}_1(t)\\[4pt] \dot {\boldsymbol{\xi }}_2(t)\\[4pt] \dot {\boldsymbol{\upsilon }}_1(t)\\[4pt] \dot {\boldsymbol{\upsilon }}_2(t) \end{bmatrix}= \begin{bmatrix} \mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t)\\[4pt] \mathbf{T}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t)\\[4pt] \mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \ddot {\boldsymbol{\xi }}_1(t)-\dot {\mathbf{R}}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t) \right )\\[4pt] \mathbf{T}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \ddot {\boldsymbol{\xi }}_2(t)-\dot {\mathbf{T}}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t) \right ) \end{bmatrix}. \end{equation}
\begin{equation} \dot {\mathbf{x}}(t)= \begin{bmatrix} \dot {\boldsymbol{\xi }}_1(t)\\[4pt] \dot {\boldsymbol{\xi }}_2(t)\\[4pt] \dot {\boldsymbol{\upsilon }}_1(t)\\[4pt] \dot {\boldsymbol{\upsilon }}_2(t) \end{bmatrix}= \begin{bmatrix} \mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t)\\[4pt] \mathbf{T}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t)\\[4pt] \mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \ddot {\boldsymbol{\xi }}_1(t)-\dot {\mathbf{R}}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t) \right )\\[4pt] \mathbf{T}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \ddot {\boldsymbol{\xi }}_2(t)-\dot {\mathbf{T}}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t) \right ) \end{bmatrix}. \end{equation}
The derivatives of velocities (
 $\dot {\boldsymbol{\upsilon }}_1(t)$
and
$\dot {\boldsymbol{\upsilon }}_1(t)$
and
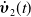 $\dot {\boldsymbol{\upsilon }}_2(t)$
) in (20) were substituted using kinematics Eq. (16). Substituting the acceleration of the generalized coordinates in the global frame,
$\dot {\boldsymbol{\upsilon }}_2(t)$
) in (20) were substituted using kinematics Eq. (16). Substituting the acceleration of the generalized coordinates in the global frame,
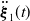 $\ddot {\boldsymbol{\xi }}_1(t)$
and
$\ddot {\boldsymbol{\xi }}_1(t)$
and
 $\ddot {\boldsymbol{\xi }}_2(t)$
, the state-space Eq. (20) is rewritten as
$\ddot {\boldsymbol{\xi }}_2(t)$
, the state-space Eq. (20) is rewritten as
 \begin{equation} \dot {\mathbf{x}}(t)= \begin{bmatrix} \mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t)\\[4pt] \mathbf{T}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t)\\[4pt] \mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \frac {1}{m} \mathbf{R}_{XYZ,3}(\boldsymbol{\xi }_2(t))T_{\mathrm{B}}(t)-g\mathbf{e} -\frac {\mathbf{D}}{m}\dot {\boldsymbol{\xi }}_1(t) -\dot {\mathbf{R}}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t) \right )\\[4pt] \mathbf{T}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \mathbf{J}^{-1}(\boldsymbol{\xi }_2(t)) \left [ \boldsymbol{\tau }_{\mathrm{B}}(t)-\mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))\dot {\boldsymbol{\xi }}_2(t) \right ] -\dot {\mathbf{T}}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t) \right ) \end{bmatrix}, \end{equation}
\begin{equation} \dot {\mathbf{x}}(t)= \begin{bmatrix} \mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t)\\[4pt] \mathbf{T}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t)\\[4pt] \mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \frac {1}{m} \mathbf{R}_{XYZ,3}(\boldsymbol{\xi }_2(t))T_{\mathrm{B}}(t)-g\mathbf{e} -\frac {\mathbf{D}}{m}\dot {\boldsymbol{\xi }}_1(t) -\dot {\mathbf{R}}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t) \right )\\[4pt] \mathbf{T}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \mathbf{J}^{-1}(\boldsymbol{\xi }_2(t)) \left [ \boldsymbol{\tau }_{\mathrm{B}}(t)-\mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))\dot {\boldsymbol{\xi }}_2(t) \right ] -\dot {\mathbf{T}}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t) \right ) \end{bmatrix}, \end{equation}
in which
 $m$
is mass of the drone,
$m$
is mass of the drone,
 $g$
is gravity constant,
$g$
is gravity constant,
 $\mathbf{e}=[0,0,1]^\top$
,
$\mathbf{e}=[0,0,1]^\top$
,
 $\mathbf{R}_{XYZ,3}(\boldsymbol{\xi }_2(t))$
is the third column of rotation matrix,
$\mathbf{R}_{XYZ,3}(\boldsymbol{\xi }_2(t))$
is the third column of rotation matrix,
 $\mathbf{D}\in \mathbb{R}^{3\times 3}$
is the drag matrix,
$\mathbf{D}\in \mathbb{R}^{3\times 3}$
is the drag matrix,
 $T_{\mathrm{B}}(t)\in \mathbb{R}$
is the total thrust produced by the propellers,
$T_{\mathrm{B}}(t)\in \mathbb{R}$
is the total thrust produced by the propellers,
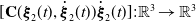 $[\mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))\dot {\boldsymbol{\xi }}_2(t)]: \mathbb{R}^3 \to \mathbb{R}^3$
includes the Coriolis and centrifugal terms,
$[\mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))\dot {\boldsymbol{\xi }}_2(t)]: \mathbb{R}^3 \to \mathbb{R}^3$
includes the Coriolis and centrifugal terms,
 $\mathbf{J}(\boldsymbol{\xi }_2(t)) \, : \, \mathbb{R}^3 \to \mathbb{R}^{3 \times 3}$
is the inertia matrix, and
$\mathbf{J}(\boldsymbol{\xi }_2(t)) \, : \, \mathbb{R}^3 \to \mathbb{R}^{3 \times 3}$
is the inertia matrix, and
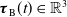 $\boldsymbol{\tau }_{\mathrm{B}}(t)\in \mathbb{R}^3$
is the input torque to the system. The details of
$\boldsymbol{\tau }_{\mathrm{B}}(t)\in \mathbb{R}^3$
is the input torque to the system. The details of
 $\mathbf{J}(\boldsymbol{\xi }_2(t))$
and
$\mathbf{J}(\boldsymbol{\xi }_2(t))$
and
 $\mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))$
are as follows [Reference Nekoo, Acosta, Gomez-Tamm and Ollero52]:
$\mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))$
are as follows [Reference Nekoo, Acosta, Gomez-Tamm and Ollero52]:
 \begin{equation*} \mathbf{J}(\boldsymbol{\xi }_2(t))=\mathbf{W}^\top (\boldsymbol{\xi }_2(t)) \mathbf{I} \mathbf{W}(\boldsymbol{\xi }_2(t)), \end{equation*}
\begin{equation*} \mathbf{J}(\boldsymbol{\xi }_2(t))=\mathbf{W}^\top (\boldsymbol{\xi }_2(t)) \mathbf{I} \mathbf{W}(\boldsymbol{\xi }_2(t)), \end{equation*}
 \begin{equation*} \mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))= \begin{bmatrix} 0 &\quad C_{12}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{13}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) \\[4pt] C_{21}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{22}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{23}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) \\[4pt] C_{31}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{32}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{33}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) \\[4pt] \end{bmatrix}, \end{equation*}
\begin{equation*} \mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))= \begin{bmatrix} 0 &\quad C_{12}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{13}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) \\[4pt] C_{21}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{22}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{23}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) \\[4pt] C_{31}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{32}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) &\quad C_{33}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t)) \\[4pt] \end{bmatrix}, \end{equation*}
in which
 $\mathbf{I}=\mathrm{diag}(I_{\mathrm{xx}},I_{\mathrm{yy}},I_{\mathrm{zz}})$
is the inertia matrix and
$\mathbf{I}=\mathrm{diag}(I_{\mathrm{xx}},I_{\mathrm{yy}},I_{\mathrm{zz}})$
is the inertia matrix and
 $\mathbf{W}(\boldsymbol{\xi }_2(t))=\mathbf{T}^{-1}(\boldsymbol{\xi }_2(t))$
, and:
$\mathbf{W}(\boldsymbol{\xi }_2(t))=\mathbf{T}^{-1}(\boldsymbol{\xi }_2(t))$
, and:
 \begin{equation*} \begin{split} C_{12}=&\dot {\theta } \mathrm{sin}(2 \phi ) (I_{\mathrm{yy}}/2-I_{\mathrm{zz}}/2)-(\dot {\psi } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}+I_{\mathrm{yy}} \mathrm{cos}(2 \phi )-I_{\mathrm{zz}} \mathrm{cos}(2 \phi )))/2,\\[4pt] C_{13}=&-(\dot {\theta } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}+I_{\mathrm{yy}} (2 \mathrm{cos}^2(\phi )-1)-I_{\mathrm{zz}} (2 \mathrm{cos}^2(\phi )-1)))/2-\\[4pt] &\dot {\psi } \mathrm{cos}(\phi ) \mathrm{cos}^2(\theta ) \mathrm{sin}(\phi ) (I_{\mathrm{yy}}-I_{\mathrm{zz}}),\\[4pt] C_{21}=&(\dot {\psi } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}+I_{\mathrm{yy}} \mathrm{cos}(2 \phi )-I_{\mathrm{zz}} \mathrm{cos}(2 \phi )))/2-(\dot {\theta } \mathrm{sin}(2 \phi ) (I_{\mathrm{yy}}-I_{\mathrm{zz}}))/2,\\[4pt] C_{22}=&-(\dot {\phi } \mathrm{sin}(2 \phi ) (I_{\mathrm{yy}}-I_{\mathrm{zz}}))/2,\\[4pt] C_{23}=&(\dot {\phi } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}+I_{\mathrm{yy}} \mathrm{cos}(2 \phi )-I_{\mathrm{zz}} \mathrm{cos}(2 \phi )))/2-\\[4pt] &\dot {\psi } \mathrm{cos}(\theta ) \mathrm{sin}(\theta ) (I_{\mathrm{xx}}-I_{\mathrm{zz}}-I_{\mathrm{yy}} \mathrm{sin}^2(\phi )+I_{\mathrm{zz}} \mathrm{sin}^2(\phi )),\\[4pt] C_{31}=&\dot {\psi } \mathrm{cos}(\phi ) \mathrm{cos}^2(\theta ) \mathrm{sin}(\phi ) (I_{\mathrm{yy}}-I_{\mathrm{zz}})-(\dot {\theta } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}-I_{\mathrm{yy}} (2 \mathrm{cos}^2(\phi )-1)+I_{\mathrm{zz}} (2 \mathrm{cos}^2(\phi )-1)))/2,\\[4pt] C_{32}=&\dot {\psi } \mathrm{cos}(\theta ) \mathrm{sin}(\theta ) (I_{\mathrm{xx}}-I_{\mathrm{zz}}-I_{\mathrm{yy}} \mathrm{sin}^2(\phi )+I_{\mathrm{zz}} \mathrm{sin}^2(\phi ))-\\[4pt] &(\dot {\phi } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}-I_{\mathrm{yy}} (2 \mathrm{cos}^2(\phi )-1)+I_{\mathrm{zz}} (2 \mathrm{cos}^2(\phi )-1)))/2-\dot {\theta } \mathrm{cos}(\phi ) \mathrm{sin}(\phi ) \mathrm{sin}(\theta ) (I_{\mathrm{yy}}-I_{\mathrm{zz}}),\\[4pt] C_{33}=&\dot {\phi } (I_{\mathrm{yy}} \mathrm{cos}(\phi ) \mathrm{cos}^2(\theta ) \mathrm{sin}(\phi )-I_{\mathrm{zz}} \mathrm{cos}(\phi ) \mathrm{cos}^2(\theta ) \mathrm{sin}(\phi ))-\\[4pt] &\dot {\theta } (I_{\mathrm{zz}} \mathrm{cos}^2(\phi ) \mathrm{cos}(\theta ) \mathrm{sin}(\theta )-I_{\mathrm{xx}} \mathrm{cos}(\theta ) \mathrm{sin}(\theta )+I_{\mathrm{yy}} \mathrm{cos}(\theta ) \mathrm{sin}^2(\phi ) \mathrm{sin}(\theta )). \end{split} \end{equation*}
\begin{equation*} \begin{split} C_{12}=&\dot {\theta } \mathrm{sin}(2 \phi ) (I_{\mathrm{yy}}/2-I_{\mathrm{zz}}/2)-(\dot {\psi } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}+I_{\mathrm{yy}} \mathrm{cos}(2 \phi )-I_{\mathrm{zz}} \mathrm{cos}(2 \phi )))/2,\\[4pt] C_{13}=&-(\dot {\theta } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}+I_{\mathrm{yy}} (2 \mathrm{cos}^2(\phi )-1)-I_{\mathrm{zz}} (2 \mathrm{cos}^2(\phi )-1)))/2-\\[4pt] &\dot {\psi } \mathrm{cos}(\phi ) \mathrm{cos}^2(\theta ) \mathrm{sin}(\phi ) (I_{\mathrm{yy}}-I_{\mathrm{zz}}),\\[4pt] C_{21}=&(\dot {\psi } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}+I_{\mathrm{yy}} \mathrm{cos}(2 \phi )-I_{\mathrm{zz}} \mathrm{cos}(2 \phi )))/2-(\dot {\theta } \mathrm{sin}(2 \phi ) (I_{\mathrm{yy}}-I_{\mathrm{zz}}))/2,\\[4pt] C_{22}=&-(\dot {\phi } \mathrm{sin}(2 \phi ) (I_{\mathrm{yy}}-I_{\mathrm{zz}}))/2,\\[4pt] C_{23}=&(\dot {\phi } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}+I_{\mathrm{yy}} \mathrm{cos}(2 \phi )-I_{\mathrm{zz}} \mathrm{cos}(2 \phi )))/2-\\[4pt] &\dot {\psi } \mathrm{cos}(\theta ) \mathrm{sin}(\theta ) (I_{\mathrm{xx}}-I_{\mathrm{zz}}-I_{\mathrm{yy}} \mathrm{sin}^2(\phi )+I_{\mathrm{zz}} \mathrm{sin}^2(\phi )),\\[4pt] C_{31}=&\dot {\psi } \mathrm{cos}(\phi ) \mathrm{cos}^2(\theta ) \mathrm{sin}(\phi ) (I_{\mathrm{yy}}-I_{\mathrm{zz}})-(\dot {\theta } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}-I_{\mathrm{yy}} (2 \mathrm{cos}^2(\phi )-1)+I_{\mathrm{zz}} (2 \mathrm{cos}^2(\phi )-1)))/2,\\[4pt] C_{32}=&\dot {\psi } \mathrm{cos}(\theta ) \mathrm{sin}(\theta ) (I_{\mathrm{xx}}-I_{\mathrm{zz}}-I_{\mathrm{yy}} \mathrm{sin}^2(\phi )+I_{\mathrm{zz}} \mathrm{sin}^2(\phi ))-\\[4pt] &(\dot {\phi } \mathrm{cos}(\theta ) (I_{\mathrm{xx}}-I_{\mathrm{yy}} (2 \mathrm{cos}^2(\phi )-1)+I_{\mathrm{zz}} (2 \mathrm{cos}^2(\phi )-1)))/2-\dot {\theta } \mathrm{cos}(\phi ) \mathrm{sin}(\phi ) \mathrm{sin}(\theta ) (I_{\mathrm{yy}}-I_{\mathrm{zz}}),\\[4pt] C_{33}=&\dot {\phi } (I_{\mathrm{yy}} \mathrm{cos}(\phi ) \mathrm{cos}^2(\theta ) \mathrm{sin}(\phi )-I_{\mathrm{zz}} \mathrm{cos}(\phi ) \mathrm{cos}^2(\theta ) \mathrm{sin}(\phi ))-\\[4pt] &\dot {\theta } (I_{\mathrm{zz}} \mathrm{cos}^2(\phi ) \mathrm{cos}(\theta ) \mathrm{sin}(\theta )-I_{\mathrm{xx}} \mathrm{cos}(\theta ) \mathrm{sin}(\theta )+I_{\mathrm{yy}} \mathrm{cos}(\theta ) \mathrm{sin}^2(\phi ) \mathrm{sin}(\theta )). \end{split} \end{equation*}
4. Implementation
A quadrotor drone has four actuators contributing to total thrust generation. Considering the fully coupled six-DoF model presented in Section 3, it must be noted that the control design faces an underactuated system [Reference Emran and Najjaran53, Reference Yang, Yuanfang, Delin, Haibin and Zhengyu54]. To solve this issue, a cascade control design was proposed to control the translation of the system [Reference Qiao, Zhu and Zhao55]. The design was based on splitting the system dynamics into translation and orientation ones, but in a coupled structure. A quadrotor drone possesses a vertical force in the local
 $z_{\mathrm{c}}$
-axis direction, but in order to generate lateral forces (
$z_{\mathrm{c}}$
-axis direction, but in order to generate lateral forces (
 $X$
- and
$X$
- and
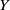 $Y$
-axis), the orientation of the quadrotor must be changed; in other words, the drone must be inclined.
$Y$
-axis), the orientation of the quadrotor must be changed; in other words, the drone must be inclined.
Assuming that the system is fully actuated, a translation control is designed to find a force vector
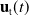 $\mathbf{u}_{\mathrm{t}}(t)$
, and based on that, the desired orientation angles will be computed to regulate the system in the Cartesian coordinate [Reference Jia, Guo, Yu, Guo and Xie56, Reference Cao, Wang, Ma, Zhu, Ji and Zhang57]. The dynamics equation in six-DoF, Eq. (21), can be split into:
$\mathbf{u}_{\mathrm{t}}(t)$
, and based on that, the desired orientation angles will be computed to regulate the system in the Cartesian coordinate [Reference Jia, Guo, Yu, Guo and Xie56, Reference Cao, Wang, Ma, Zhu, Ji and Zhang57]. The dynamics equation in six-DoF, Eq. (21), can be split into:
 \begin{equation} \dot {\mathbf{x}}_{\mathrm{t}}(t)= \begin{bmatrix} \mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t)\\[4pt] \mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \frac {1}{m} \mathbf{R}_{XYZ,3}(\boldsymbol{\xi }_2(t))T_{\mathrm{B}}(t)-g\mathbf{e} -\frac {\mathbf{D}}{m}\dot {\boldsymbol{\xi }}_1(t) -\dot {\mathbf{R}}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t) \right ) \end{bmatrix}, \end{equation}
\begin{equation} \dot {\mathbf{x}}_{\mathrm{t}}(t)= \begin{bmatrix} \mathbf{R}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t)\\[4pt] \mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \frac {1}{m} \mathbf{R}_{XYZ,3}(\boldsymbol{\xi }_2(t))T_{\mathrm{B}}(t)-g\mathbf{e} -\frac {\mathbf{D}}{m}\dot {\boldsymbol{\xi }}_1(t) -\dot {\mathbf{R}}_{XYZ}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_1(t) \right ) \end{bmatrix}, \end{equation}
 \begin{equation} \dot {\mathbf{x}}_{\mathrm{o}}(t)= \begin{bmatrix} \mathbf{T}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t)\\[4pt] \mathbf{T}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \mathbf{J}^{-1}(\boldsymbol{\xi }_2(t)) \left [ \tau _{\mathrm{B}}(t)-\mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))\dot {\boldsymbol{\xi }}_2(t) \right ] -\dot {\mathbf{T}}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t) \right ) \end{bmatrix}, \end{equation}
\begin{equation} \dot {\mathbf{x}}_{\mathrm{o}}(t)= \begin{bmatrix} \mathbf{T}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t)\\[4pt] \mathbf{T}^{-1}(\boldsymbol{\xi }_2(t)) \left ( \mathbf{J}^{-1}(\boldsymbol{\xi }_2(t)) \left [ \tau _{\mathrm{B}}(t)-\mathbf{C}(\boldsymbol{\xi }_2(t),\dot {\boldsymbol{\xi }}_2(t))\dot {\boldsymbol{\xi }}_2(t) \right ] -\dot {\mathbf{T}}(\boldsymbol{\xi }_2(t))\boldsymbol{\upsilon }_2(t) \right ) \end{bmatrix}, \end{equation}
where subscript “t” stands for translation and “o” for orientation. The corresponding state vectors are
 $\dot {\mathbf{x}}_{\mathrm{t}}(t)=[\boldsymbol{\xi }_1^\top (t),\boldsymbol{\upsilon }_1^\top (t)]^\top$
and
$\dot {\mathbf{x}}_{\mathrm{t}}(t)=[\boldsymbol{\xi }_1^\top (t),\boldsymbol{\upsilon }_1^\top (t)]^\top$
and
 $\dot {\mathbf{x}}_{\mathrm{o}}(t)=[\boldsymbol{\xi }_2^\top (t),\boldsymbol{\upsilon }_2^\top (t)]^\top$
.
$\dot {\mathbf{x}}_{\mathrm{o}}(t)=[\boldsymbol{\xi }_2^\top (t),\boldsymbol{\upsilon }_2^\top (t)]^\top$
.
The SDC parameterization of the translation dynamics (25) is formed; they will be updated by each learning loop:
 \begin{equation*} \mathbf{A}_{\mathrm{t}}(\mathbf{x}_j(t))= \begin{bmatrix} \mathbf{0}_{3 \times 3} &\quad \mathbf{R}_{XYZ}(\boldsymbol{\xi }_{2, \, j}(t))\\[4pt] \mathbf{0}_{3 \times 3} &\quad -\mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \left ( \frac {\mathbf{D}}{m}\mathbf{R}_{XYZ}(\boldsymbol{\xi }_{2, \, j}(t)) + \dot {\mathbf{R}}_{XYZ}(\boldsymbol{\xi }_{2, \, j}(t)) \right ) \end{bmatrix}, \end{equation*}
\begin{equation*} \mathbf{A}_{\mathrm{t}}(\mathbf{x}_j(t))= \begin{bmatrix} \mathbf{0}_{3 \times 3} &\quad \mathbf{R}_{XYZ}(\boldsymbol{\xi }_{2, \, j}(t))\\[4pt] \mathbf{0}_{3 \times 3} &\quad -\mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \left ( \frac {\mathbf{D}}{m}\mathbf{R}_{XYZ}(\boldsymbol{\xi }_{2, \, j}(t)) + \dot {\mathbf{R}}_{XYZ}(\boldsymbol{\xi }_{2, \, j}(t)) \right ) \end{bmatrix}, \end{equation*}
 \begin{equation*} \mathbf{B}_{\mathrm{t}}(\mathbf{x}_j(t))=\begin{bmatrix} \mathbf{0}_{3 \times 3}\\[4pt] \frac {1}{m} \mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_{2, \, j}(t))\end{bmatrix}. \end{equation*}
\begin{equation*} \mathbf{B}_{\mathrm{t}}(\mathbf{x}_j(t))=\begin{bmatrix} \mathbf{0}_{3 \times 3}\\[4pt] \frac {1}{m} \mathbf{R}_{XYZ}^{-1}(\boldsymbol{\xi }_{2, \, j}(t))\end{bmatrix}. \end{equation*}
Setting adequate weighting matrices for the subsystem (25) and also considering the learning counter in the formulation, the control law of translation with the assumption of full actuation is found:
 \begin{equation} \mathbf{u}_{\mathrm{t}, \, j}(t)=-\mathbf{R}^{-1}_{\mathrm{t}}(\mathbf{x}_j(t))\mathbf{B}^\top _{\mathrm{t}}(\mathbf{x}_j(t))\mathbf{K}_{\mathrm{t}}(\mathbf{x}_j(t))\mathbf{e}_{\mathrm{t}, \, j}(t)+\mathbf{H}_{\mathrm{t}, \, j}(t), \end{equation}
\begin{equation} \mathbf{u}_{\mathrm{t}, \, j}(t)=-\mathbf{R}^{-1}_{\mathrm{t}}(\mathbf{x}_j(t))\mathbf{B}^\top _{\mathrm{t}}(\mathbf{x}_j(t))\mathbf{K}_{\mathrm{t}}(\mathbf{x}_j(t))\mathbf{e}_{\mathrm{t}, \, j}(t)+\mathbf{H}_{\mathrm{t}, \, j}(t), \end{equation}
where the learning part of the translation
 $\mathbf{H}_{\mathrm{t}, \, j}(t)$
is shaped by training rule (13) with desired dynamics:
$\mathbf{H}_{\mathrm{t}, \, j}(t)$
is shaped by training rule (13) with desired dynamics:
 \begin{equation*} \mathbf{S}_{\mathrm{d,t}}(t)=m\ddot {\boldsymbol{\xi }}_{1,\mathrm{des}}(t)+\mathbf{D}\dot {\boldsymbol{\xi }}_{1,\mathrm{des}}(t). \end{equation*}
\begin{equation*} \mathbf{S}_{\mathrm{d,t}}(t)=m\ddot {\boldsymbol{\xi }}_{1,\mathrm{des}}(t)+\mathbf{D}\dot {\boldsymbol{\xi }}_{1,\mathrm{des}}(t). \end{equation*}
The total thrust is built based on virtual input (29) as [Reference Yao, Nekoo and Xin58]:
 \begin{equation*} T_{\mathrm{B}, \, j}(t)=m \mathbf{R}_{XYZ,3}^\top (\boldsymbol{\xi }_{2, \, j}(t)) \left [ \mathbf{u}_{\mathrm{t}, \, j}(t) + \mathbf{e} g \right ]. \end{equation*}
\begin{equation*} T_{\mathrm{B}, \, j}(t)=m \mathbf{R}_{XYZ,3}^\top (\boldsymbol{\xi }_{2, \, j}(t)) \left [ \mathbf{u}_{\mathrm{t}, \, j}(t) + \mathbf{e} g \right ]. \end{equation*}
The desired yaw angle
 $\psi _{\mathrm{des}}$
can be set independently; however, the desired roll and pitch angles are time-varying based on the values of lateral and vertical forces of the drone in (29) as [Reference Lopez-Sanchez and Moreno-Valenzuela59]:
$\psi _{\mathrm{des}}$
can be set independently; however, the desired roll and pitch angles are time-varying based on the values of lateral and vertical forces of the drone in (29) as [Reference Lopez-Sanchez and Moreno-Valenzuela59]:
 \begin{equation} \begin{split} &\phi _{\mathrm{des}, \, j}(t)=\mathrm{tan}^{-1} \frac {\cos (\psi _{\mathrm{des}}) \Big ( u_{\mathrm{t,1}, \, j}(t) \mathrm{sin} (\psi _{\mathrm{des}}) - u_{\mathrm{t,2}, \, j}(t) \mathrm{cos} (\psi _{\mathrm{des}}) \Big ) } {u_{\mathrm{t,3}, \, j}(t)+mg},\\ &\theta _{\mathrm{des}, \, j}(t)=\mathrm{tan}^{-1} \frac {u_{\mathrm{t,1}, \, j}(t) \mathrm{cos} (\psi _{\mathrm{des}}) + u_{\mathrm{t,2}, \, j}(t) \mathrm{sin} (\psi _{\mathrm{des}})} {u_{\mathrm{t,3}, \, j}(t)+mg}, \end{split} \end{equation}
\begin{equation} \begin{split} &\phi _{\mathrm{des}, \, j}(t)=\mathrm{tan}^{-1} \frac {\cos (\psi _{\mathrm{des}}) \Big ( u_{\mathrm{t,1}, \, j}(t) \mathrm{sin} (\psi _{\mathrm{des}}) - u_{\mathrm{t,2}, \, j}(t) \mathrm{cos} (\psi _{\mathrm{des}}) \Big ) } {u_{\mathrm{t,3}, \, j}(t)+mg},\\ &\theta _{\mathrm{des}, \, j}(t)=\mathrm{tan}^{-1} \frac {u_{\mathrm{t,1}, \, j}(t) \mathrm{cos} (\psi _{\mathrm{des}}) + u_{\mathrm{t,2}, \, j}(t) \mathrm{sin} (\psi _{\mathrm{des}})} {u_{\mathrm{t,3}, \, j}(t)+mg}, \end{split} \end{equation}
where, i.e.,
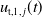 $u_{\mathrm{t,1}, \, j}(t)$
is the first component of
$u_{\mathrm{t,1}, \, j}(t)$
is the first component of
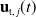 $\mathbf{u}_{\mathrm{t}, \, j}(t)$
.
$\mathbf{u}_{\mathrm{t}, \, j}(t)$
.
The orientation control design is straightforward. The SDC parameterization of the orientation dynamics (26) is
 \begin{equation*} \mathbf{A}_{\mathrm{o}}(\mathbf{x}_j(t))= \begin{bmatrix} \mathbf{0}_{3 \times 3} &\quad \mathbf{T}(\boldsymbol{\xi }_{2, \, j}(t))\\[4pt] \mathbf{0}_{3 \times 3} &\quad -\mathbf{T}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \left ( \mathbf{J}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \mathbf{C}(\boldsymbol{\xi }_{2, \, j}(t),\dot {\boldsymbol{\xi }}_{2, \, j}(t))\mathbf{T}(\boldsymbol{\xi }_{2, \, j}(t)) +\dot {\mathbf{T}}(\boldsymbol{\xi }_{2, \, j}(t)) \right ) \end{bmatrix}, \end{equation*}
\begin{equation*} \mathbf{A}_{\mathrm{o}}(\mathbf{x}_j(t))= \begin{bmatrix} \mathbf{0}_{3 \times 3} &\quad \mathbf{T}(\boldsymbol{\xi }_{2, \, j}(t))\\[4pt] \mathbf{0}_{3 \times 3} &\quad -\mathbf{T}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \left ( \mathbf{J}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \mathbf{C}(\boldsymbol{\xi }_{2, \, j}(t),\dot {\boldsymbol{\xi }}_{2, \, j}(t))\mathbf{T}(\boldsymbol{\xi }_{2, \, j}(t)) +\dot {\mathbf{T}}(\boldsymbol{\xi }_{2, \, j}(t)) \right ) \end{bmatrix}, \end{equation*}
 \begin{equation*} \mathbf{B}_{\mathrm{o}}(\mathbf{x}_j(t))=\begin{bmatrix} \mathbf{0}_{3 \times 3}\\[4pt] \mathbf{T}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \mathbf{J}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \end{bmatrix}. \end{equation*}
\begin{equation*} \mathbf{B}_{\mathrm{o}}(\mathbf{x}_j(t))=\begin{bmatrix} \mathbf{0}_{3 \times 3}\\[4pt] \mathbf{T}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \mathbf{J}^{-1}(\boldsymbol{\xi }_{2, \, j}(t)) \end{bmatrix}. \end{equation*}
The control law of the orientation dynamics is
 \begin{equation} \mathbf{u}_{\mathrm{o}, \, j}(t)=-\mathbf{R}^{-1}_{\mathrm{o}}(\mathbf{x}_j(t))\mathbf{B}^\top _{\mathrm{o}}(\mathbf{x}_j(t))\mathbf{K}_{\mathrm{o}}(\mathbf{x}_j(t))\mathbf{e}_{\mathrm{o}, \, j}(t)+\mathbf{H}_{\mathrm{o}, \, j}(t), \end{equation}
\begin{equation} \mathbf{u}_{\mathrm{o}, \, j}(t)=-\mathbf{R}^{-1}_{\mathrm{o}}(\mathbf{x}_j(t))\mathbf{B}^\top _{\mathrm{o}}(\mathbf{x}_j(t))\mathbf{K}_{\mathrm{o}}(\mathbf{x}_j(t))\mathbf{e}_{\mathrm{o}, \, j}(t)+\mathbf{H}_{\mathrm{o}, \, j}(t), \end{equation}
where the learning term
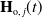 $\mathbf{H}_{\mathrm{o}, \, j}(t)$
is found by the training rule, updated by the orientation desired dynamics:
$\mathbf{H}_{\mathrm{o}, \, j}(t)$
is found by the training rule, updated by the orientation desired dynamics:
 \begin{equation} \mathbf{S}_{\mathrm{d,o}}(t)= \mathbf{J}(\boldsymbol{\xi }_{2,\mathrm{des}}(t)) \ddot {\boldsymbol{\xi }}_{2,\mathrm{des}}(t)+ \mathbf{C}(\boldsymbol{\xi }_{2,\mathrm{des}}(t),\dot {\boldsymbol{\xi }}_{2,\mathrm{des}}(t)) \dot {\boldsymbol{\xi }}_{2,\mathrm{des}}(t). \end{equation}
\begin{equation} \mathbf{S}_{\mathrm{d,o}}(t)= \mathbf{J}(\boldsymbol{\xi }_{2,\mathrm{des}}(t)) \ddot {\boldsymbol{\xi }}_{2,\mathrm{des}}(t)+ \mathbf{C}(\boldsymbol{\xi }_{2,\mathrm{des}}(t),\dot {\boldsymbol{\xi }}_{2,\mathrm{des}}(t)) \dot {\boldsymbol{\xi }}_{2,\mathrm{des}}(t). \end{equation}
Then, it is noted that the desired velocities and accelerations of the orientation variables (32) must be computed, numerically or analytically, to be used in learning computation of the control law, specifically in Eq. (35) and (36).
5. Experimental setup
5.1. Electronics and physical characteristics of the drone
A quadrotor experimental platform needs four motors, drivers, a processing unit, regulators, and a pulse-width-modulation (PWM) generator as minimum devices for flying in an indoor testbed, provided that the full state feedback is available for the controller. Opening the back plate of the experimental setup, the arrangement of the electronics is shown inside a protected area close to the CoM of the drone, presented in Figure 2.
The electronics details of the customized quadrotor system.

The objective of designing and building this platform has been to fly strictly in an indoor, segregated workspace for testing new control algorithms. Hence, the propellers are installed inside a cage for easier interaction and safety between the user and the multirotor in the tuning phase. The indoor testbed flying zone is equipped with 28 cameras to locate objects while moving, the so-called OptiTrack system or the motion capture system. The flight area is
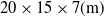 $20\times 15\times 7(\mathrm{m})$
with a soft floor for the protection of the drone in case of falling. With this system, position accuracy can be gained
$20\times 15\times 7(\mathrm{m})$
with a soft floor for the protection of the drone in case of falling. With this system, position accuracy can be gained
 $\approx 2 (\mathrm{mm})$
plus orientation angles, which provide full state feedback for control design. The processor of the quadrotor is a Raspberry Pi 3B+ with an Ubuntu operating system, which communicates through WiFi with the server of the OptiTrack system. VRPN –Virtual Reality Peripheral Network–protocol is employed for reading the position data using ROS1 to make nodes and calling them by a Python code.
$\approx 2 (\mathrm{mm})$
plus orientation angles, which provide full state feedback for control design. The processor of the quadrotor is a Raspberry Pi 3B+ with an Ubuntu operating system, which communicates through WiFi with the server of the OptiTrack system. VRPN –Virtual Reality Peripheral Network–protocol is employed for reading the position data using ROS1 to make nodes and calling them by a Python code.
The brushless direct-current motors of the system are DJI E305 2312E; they possess mass of
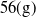 $56(\mathrm{g})$
with
$56(\mathrm{g})$
with
 $800(\mathrm{rpm/V})$
. The DJI 9450 model of propellers was used; the mass of each one is
$800(\mathrm{rpm/V})$
. The DJI 9450 model of propellers was used; the mass of each one is
 $13(\mathrm{g})$
with
$13(\mathrm{g})$
with
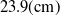 $23.9(\mathrm{cm})$
diameter. Without the installation of the battery, the weight of the system is
$23.9(\mathrm{cm})$
diameter. Without the installation of the battery, the weight of the system is
 $1.298(\mathrm{kg})$
. The maximum thrust per rotor is
$1.298(\mathrm{kg})$
. The maximum thrust per rotor is
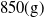 $850(\mathrm{g})$
at
$850(\mathrm{g})$
at
 $14.8(\mathrm{V})$
, combining the mentioned motor and propeller model. The motor drivers are DJI 430 LITE E series electronics speed controllers (ESC), working up to
$14.8(\mathrm{V})$
, combining the mentioned motor and propeller model. The motor drivers are DJI 430 LITE E series electronics speed controllers (ESC), working up to
 $20(\mathrm{A})$
persistent and
$20(\mathrm{A})$
persistent and
 $30(\mathrm{A})$
peak current, compatible with 3S and 4S batteries [Reference Nekoo and Ollero32].
$30(\mathrm{A})$
peak current, compatible with 3S and 4S batteries [Reference Nekoo and Ollero32].
The physical characteristics and parameters of the multirotor drone.

The Raspberry Pi boards can generate PWM signals; however, using PWM modules facilitates the control of motors, especially when the number of motors increases. PCA9685 is selected for PWM generation, and it supports up to 16 motors. The input commands to PCA9685 come from the Raspberry Pi through the SPI (serial peripheral interface) protocol, and the output of it goes to ESCs to run the motors. The battery is Gens ace 4S1P LiPo with
 $5300(\mathrm{mAh})$
capacity and
$5300(\mathrm{mAh})$
capacity and
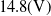 $14.8(\mathrm{V})$
. Considering the weight of the battery, the total mass of the system is
$14.8(\mathrm{V})$
. Considering the weight of the battery, the total mass of the system is
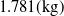 $1.781(\mathrm{kg})$
. The physical parameters of the quadrotor drone are presented in Table I.
$1.781(\mathrm{kg})$
. The physical parameters of the quadrotor drone are presented in Table I.
5.2. Control implementation in practice
Python is used to execute the control loop in the Ubuntu operating system (MATE 18.04). ROS1 nodes send the information of the object through geometry messages, and the control loop subscribes to the nodes to call them at each loop. The first part of the control Python code is dedicated to initialization, the definition of the limits, gains, time, and trajectory. Next, the code starts up the motors using the Adafruit PCA9685 library to generate/send the PWM signals.
To learn in practice, a quadrotor needs to repeat a task several times. Trajectory tracking is selected since the end of one loop can be designed as the beginning of the next learning loop.
Remark. The coincidence of the initial condition with the final condition of the last loop is similar to repetitive control [Reference Cuiyan, Dongchun and Xianyi60]. In repetitive control, by tending time to infinity and repetition of control loops, the error of the system converges to zero using a specific filter design. Here, in this work, the concept of iterative learning is used, and the coincidence of the initial-final condition was done since, in practice, if a drone stops in the middle of the motion and continues again with the same path, it will sound unnatural. More details on the difference between the ILC and repetitive control can be found in ref. [Reference Wang, Gao and Doyle61].
There are three parts in the control loop: a) the regulation, b) the repeated learning loop, and c) the landing. The first regulation loop flies the drone from the ground to the beginning of the trajectory and hovers there until the error on the position with respect to the initial point of the path is less than the allowable bound. Then the control goes to the next learning loops (part b), following a trajectory with learning vector zero
 $\mathbf{H}_{\mathrm{t},1}(t)=\mathbf{H}_{\mathrm{o},1}(t)=\mathbf{0}$
. Finishing the first loop, the robot reaches the beginning of the next loop with an iteration of the dynamics with respect to the desired one
$\mathbf{H}_{\mathrm{t},1}(t)=\mathbf{H}_{\mathrm{o},1}(t)=\mathbf{0}$
. Finishing the first loop, the robot reaches the beginning of the next loop with an iteration of the dynamics with respect to the desired one
 $\mathbf{H}_{\mathrm{t}, \, j}(t)=\mathbf{H}_{\mathrm{o}, \, j}(t) \neq \mathbf{0}$
for
$\mathbf{H}_{\mathrm{t}, \, j}(t)=\mathbf{H}_{\mathrm{o}, \, j}(t) \neq \mathbf{0}$
for
 $j\gt 1$
. The declaration of the learning loops is based on the time of the trajectory as it continues.
$j\gt 1$
. The declaration of the learning loops is based on the time of the trajectory as it continues.
The control regulation and tracking work around the equilibrium point of the drone, defined for
 $Z$
-axis force (gravity) by a shift in the motors’ signals, set as
$Z$
-axis force (gravity) by a shift in the motors’ signals, set as
 $\mathrm{PWM}_{0,i}$
for
$\mathrm{PWM}_{0,i}$
for
 $i=1,\cdots ,4$
, that almost lifts the multirotor from the ground. Then, the PWM signals are defined as
$i=1,\cdots ,4$
, that almost lifts the multirotor from the ground. Then, the PWM signals are defined as
 \begin{equation} \mathrm{PWM}_{1, \, j}(t)=\mathrm{PWM}_{0,1}+\mathrm{int}(\! -u_{\theta , \, j}(t)+u_{\psi , \, j}(t)+u_{z, \, j}(t)), \end{equation}
\begin{equation} \mathrm{PWM}_{1, \, j}(t)=\mathrm{PWM}_{0,1}+\mathrm{int}(\! -u_{\theta , \, j}(t)+u_{\psi , \, j}(t)+u_{z, \, j}(t)), \end{equation}
 \begin{equation} \mathrm{PWM}_{2, \, j}(t)=\mathrm{PWM}_{0,2}+\mathrm{int}(\! -u_{\phi , \, j}(t)-u_{\psi , \, j}(t)+u_{z, \, j}(t)), \end{equation}
\begin{equation} \mathrm{PWM}_{2, \, j}(t)=\mathrm{PWM}_{0,2}+\mathrm{int}(\! -u_{\phi , \, j}(t)-u_{\psi , \, j}(t)+u_{z, \, j}(t)), \end{equation}
 \begin{equation} \mathrm{PWM}_{3, \, j}(t)=\mathrm{PWM}_{0,3}+\mathrm{int}(\! +u_{\theta , \, j}(t)+u_{\psi , \, j}(t)+u_{z, \, j}(t)), \end{equation}
\begin{equation} \mathrm{PWM}_{3, \, j}(t)=\mathrm{PWM}_{0,3}+\mathrm{int}(\! +u_{\theta , \, j}(t)+u_{\psi , \, j}(t)+u_{z, \, j}(t)), \end{equation}
 \begin{equation} \mathrm{PWM}_{4, \, j}(t)=\mathrm{PWM}_{0,4}+\mathrm{int}(\! +u_{\phi , \, j}(t)-u_{\psi , \, j}(t)+u_{z, \, j}(t)), \end{equation}
\begin{equation} \mathrm{PWM}_{4, \, j}(t)=\mathrm{PWM}_{0,4}+\mathrm{int}(\! +u_{\phi , \, j}(t)-u_{\psi , \, j}(t)+u_{z, \, j}(t)), \end{equation}
in which
 $\mathrm{int}(\!\cdot \!)$
is a function that changes the input values to integer ones. The quadrotor needs a minimum angular velocity, produced by the rotors, to stay stationary in the air. Then the controller regulates the position of the drone around that equilibrium point by changing the rotor velocity. In this way, the slightest change in the error can be multiplied by the control gain and fed to the inputs as corrections.
$\mathrm{int}(\!\cdot \!)$
is a function that changes the input values to integer ones. The quadrotor needs a minimum angular velocity, produced by the rotors, to stay stationary in the air. Then the controller regulates the position of the drone around that equilibrium point by changing the rotor velocity. In this way, the slightest change in the error can be multiplied by the control gain and fed to the inputs as corrections.
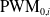 $\mathrm{PWM}_{0,i}$
is the equivalent minimum angular velocity for flying stationary in the air, compensating for the gravity force. The PWMs inputs (37) – (40) include the input torques and vertical force of the system, defined as
$\mathrm{PWM}_{0,i}$
is the equivalent minimum angular velocity for flying stationary in the air, compensating for the gravity force. The PWMs inputs (37) – (40) include the input torques and vertical force of the system, defined as
 \begin{equation} u_{\phi , \, j}(t)=-K_{\mathrm{I},\phi } \int _{0}^{t}e_{\phi }(\tau ) \mathrm{d}\tau +u_{\mathrm{o},1, \, j}(t), \end{equation}
\begin{equation} u_{\phi , \, j}(t)=-K_{\mathrm{I},\phi } \int _{0}^{t}e_{\phi }(\tau ) \mathrm{d}\tau +u_{\mathrm{o},1, \, j}(t), \end{equation}
 \begin{equation} u_{\theta , \, j}(t)=-K_{\mathrm{I},\theta } \int _{0}^{t}e_{\theta }(\tau ) \mathrm{d}\tau +u_{\mathrm{o},2, \, j}(t), \end{equation}
\begin{equation} u_{\theta , \, j}(t)=-K_{\mathrm{I},\theta } \int _{0}^{t}e_{\theta }(\tau ) \mathrm{d}\tau +u_{\mathrm{o},2, \, j}(t), \end{equation}
 \begin{equation} u_{\psi , \, j}(t)=-K_{\mathrm{I},\psi } \int _{0}^{t}e_{\psi }(\tau ) \mathrm{d}\tau +u_{\mathrm{o},3, \, j}(t), \end{equation}
\begin{equation} u_{\psi , \, j}(t)=-K_{\mathrm{I},\psi } \int _{0}^{t}e_{\psi }(\tau ) \mathrm{d}\tau +u_{\mathrm{o},3, \, j}(t), \end{equation}
 \begin{equation} u_{z, \, j}(t)=-K_{\mathrm{I},z} \int _{0}^{t}e_z(\tau ) \mathrm{d}\tau +u_{\mathrm{t},3, \, j}(t), \end{equation}
\begin{equation} u_{z, \, j}(t)=-K_{\mathrm{I},z} \int _{0}^{t}e_z(\tau ) \mathrm{d}\tau +u_{\mathrm{t},3, \, j}(t), \end{equation}
which includes integrators for eliminating steady-state error caused by a mismatch between the theoretical model and experimental platform, i.e.,
 $K_{\mathrm{I},\psi }$
is a positive integral gain of
$K_{\mathrm{I},\psi }$
is a positive integral gain of
 $\psi$
input torque. To reset the integrator role in the learning process and also avoid an accumulation of errors in input laws (41) – (44), the integral error values are set to zero at the beginning of each learning loop, except for height, which disrupts the height of the system.
$\psi$
input torque. To reset the integrator role in the learning process and also avoid an accumulation of errors in input laws (41) – (44), the integral error values are set to zero at the beginning of each learning loop, except for height, which disrupts the height of the system.
The PWM signals are sent to the ESCs through “
 $\mathrm{pwm.set\_pwm()}$
” command in experiments; however, those signals must be converted back to force/torque scale for the simulation section as in the form of:
$\mathrm{pwm.set\_pwm()}$
” command in experiments; however, those signals must be converted back to force/torque scale for the simulation section as in the form of:
 \begin{equation} \begin{bmatrix} T_{\mathrm{B}, \, j}(t)\\[3pt] \boldsymbol{\tau }_{\mathrm{B}, \, j}(t) \end{bmatrix}=\alpha \mathbf{M}_{\mathrm{x}} \left ( \begin{bmatrix} \mathrm{PWM}_{1, \, j}(t)\\[3pt] \mathrm{PWM}_{2, \, j}(t)\\[3pt] \mathrm{PWM}_{3, \, j}(t)\\[3pt] \mathrm{PWM}_{4, \, j}(t)\end{bmatrix}-\mathrm{PWM}_0 \right )+ \begin{bmatrix} mg\\[3pt] \mathbf{0}_{3 \times 1} \end{bmatrix}, \end{equation}
\begin{equation} \begin{bmatrix} T_{\mathrm{B}, \, j}(t)\\[3pt] \boldsymbol{\tau }_{\mathrm{B}, \, j}(t) \end{bmatrix}=\alpha \mathbf{M}_{\mathrm{x}} \left ( \begin{bmatrix} \mathrm{PWM}_{1, \, j}(t)\\[3pt] \mathrm{PWM}_{2, \, j}(t)\\[3pt] \mathrm{PWM}_{3, \, j}(t)\\[3pt] \mathrm{PWM}_{4, \, j}(t)\end{bmatrix}-\mathrm{PWM}_0 \right )+ \begin{bmatrix} mg\\[3pt] \mathbf{0}_{3 \times 1} \end{bmatrix}, \end{equation}
where
 $\alpha$
is a scaling factor and the mixer matrix is
$\alpha$
is a scaling factor and the mixer matrix is
 \begin{equation*} \mathbf{M}_{\mathrm{x}}=\begin{bmatrix} 0.25&\,0.25&\,0.25&\,0.25\\[3pt] 0&\,-0.5&\,0&\,0.5\\[3pt] -0.5&\,0&\,0.5&\,0\\[3pt] 0.25&\,-0.25&\,0.25&\,-0.25\end{bmatrix}. \end{equation*}
\begin{equation*} \mathbf{M}_{\mathrm{x}}=\begin{bmatrix} 0.25&\,0.25&\,0.25&\,0.25\\[3pt] 0&\,-0.5&\,0&\,0.5\\[3pt] -0.5&\,0&\,0.5&\,0\\[3pt] 0.25&\,-0.25&\,0.25&\,-0.25\end{bmatrix}. \end{equation*}
Eq. (45) is employed only in the simulation section, in the integration of the dynamic Eq. (21).
6. Results
6.1. Simulation
A circular trajectory is selected to test the learning augmentation of the proposed controller. The path is a circle with a radius of
 $3(\mathrm{m})$
at a constant height of
$3(\mathrm{m})$
at a constant height of
 $0.65(\mathrm{m})$
, at the center of the workspace, represented by
$0.65(\mathrm{m})$
, at the center of the workspace, represented by
 \begin{equation*} \begin{split} x_{\mathrm{c,des}}(t)&=-3\cos \omega t,\\ y_{\mathrm{c,des}}(t)&=-3\sin \omega t,\\ z_{\mathrm{c,des}}(t)&=0.65,\end{split} \end{equation*}
\begin{equation*} \begin{split} x_{\mathrm{c,des}}(t)&=-3\cos \omega t,\\ y_{\mathrm{c,des}}(t)&=-3\sin \omega t,\\ z_{\mathrm{c,des}}(t)&=0.65,\end{split} \end{equation*}
The translation and orientation states of the quadrotor drone simulation.

where
 $\omega =\frac {2\pi }{t_{\mathrm{f}}}$
in which the final time for each circular path (loop) is set
$\omega =\frac {2\pi }{t_{\mathrm{f}}}$
in which the final time for each circular path (loop) is set
 $t_{\mathrm{f}}=35(\mathrm{s})$
. The number of learning loops is set
$t_{\mathrm{f}}=35(\mathrm{s})$
. The number of learning loops is set
 $N_{\mathrm{i}}=30$
. The weighting matrices are selected as
$N_{\mathrm{i}}=30$
. The weighting matrices are selected as
 \begin{equation*} \begin{split} \mathbf{R}_{\mathrm{t}}&=0.1\times \mathbf{I}_{3\times 3},\\ \mathbf{R}_{\mathrm{o}}&=\mathbf{I}_{3\times 3},\\ \mathbf{Q}_{\mathrm{t}}&=\mathrm{diag}(0.0074,0.0074,75.525,0,0,24.51),\\ \mathbf{Q}_{\mathrm{o}}&=\mathrm{diag}(0.1852,0.2536,0.1935,0.1448,0.1662,4.8393).\end{split} \end{equation*}
\begin{equation*} \begin{split} \mathbf{R}_{\mathrm{t}}&=0.1\times \mathbf{I}_{3\times 3},\\ \mathbf{R}_{\mathrm{o}}&=\mathbf{I}_{3\times 3},\\ \mathbf{Q}_{\mathrm{t}}&=\mathrm{diag}(0.0074,0.0074,75.525,0,0,24.51),\\ \mathbf{Q}_{\mathrm{o}}&=\mathrm{diag}(0.1852,0.2536,0.1935,0.1448,0.1662,4.8393).\end{split} \end{equation*}
The learning factors for translation and orientation controllers are set as
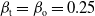 $\beta _{\mathrm{t}}=\beta _{\mathrm{o}}=0.25$
. The physical characteristics of the drone in Section 5.1 have been considered in the simulation. The control gains are also set based on the experimental results to deliver a realistic simulator for the learning. The only parameters that differ from the experimental results are
$\beta _{\mathrm{t}}=\beta _{\mathrm{o}}=0.25$
. The physical characteristics of the drone in Section 5.1 have been considered in the simulation. The control gains are also set based on the experimental results to deliver a realistic simulator for the learning. The only parameters that differ from the experimental results are
 $\mathbf{R}_{\mathrm{t}}$
,
$\mathbf{R}_{\mathrm{t}}$
,
 $\beta _{\mathrm{t}}$
, and
$\beta _{\mathrm{t}}$
, and
 $\beta _{\mathrm{o}}$
.
$\beta _{\mathrm{o}}$
.
The translation states of the drone are illustrated in Figure 3. The initial point of the drone was set at the beginning of the trajectory with zero velocity; hence, the first loop experienced the biggest error value. The continuation of the loops provides the initial velocity at the beginning of the other loops; hence, the learning also reduces the error, and a tendency of convergence to desired values is seen in the results. The velocity states are shown in Figure 4. The peak of the error started from
 $1.5(\mathrm{m})$
and was reduced to
$1.5(\mathrm{m})$
and was reduced to
 $0.14(\mathrm{m})$
in 30 learning loops, presented in Figure 5. The trajectories of the quadrotor in the simulation are presented in Figure 6. Since the tuned control parameters and actuator limits were used in the simulation section, the steady-state error could not be less than
$0.14(\mathrm{m})$
in 30 learning loops, presented in Figure 5. The trajectories of the quadrotor in the simulation are presented in Figure 6. Since the tuned control parameters and actuator limits were used in the simulation section, the steady-state error could not be less than
 $14(\mathrm{cm})$
, which is close to reality. Increasing the gains of the controller will reduce the error. To compare the results of the SDRE controller with learning capacity with another controller, the same structure of learning and parameters of the robot, trajectory, and the simulation condition were held, and the SDRE was replaced with a PD controller with the following gains:
$14(\mathrm{cm})$
, which is close to reality. Increasing the gains of the controller will reduce the error. To compare the results of the SDRE controller with learning capacity with another controller, the same structure of learning and parameters of the robot, trajectory, and the simulation condition were held, and the SDRE was replaced with a PD controller with the following gains:
 \begin{equation*} \begin{split} \mathbf{K}_{\mathrm{P,t}}&=\mathrm{diag}(0.0855,0.0855,8.5500),\\ \mathbf{K}_{\mathrm{D,t}}&=\mathrm{diag}(0.1425,0.1425,6.8400),\\ \mathbf{K}_{\mathrm{P,o}}&=\mathrm{diag}(16.5300,16.5300,13.7940),\\ \mathbf{K}_{\mathrm{D,o}}&=\mathrm{diag}(11.9700,11.9700,68.9700),\end{split} \end{equation*}
\begin{equation*} \begin{split} \mathbf{K}_{\mathrm{P,t}}&=\mathrm{diag}(0.0855,0.0855,8.5500),\\ \mathbf{K}_{\mathrm{D,t}}&=\mathrm{diag}(0.1425,0.1425,6.8400),\\ \mathbf{K}_{\mathrm{P,o}}&=\mathrm{diag}(16.5300,16.5300,13.7940),\\ \mathbf{K}_{\mathrm{D,o}}&=\mathrm{diag}(11.9700,11.9700,68.9700),\end{split} \end{equation*}
where “t” denotes translation, “o” denotes orientation, “P” proportional, and “D” derivative. The selection of the gains was done to present a fair comparison, hence the order of gains results in a similar order of the input law of the SDRE gain,
 $-\mathbf{R}^{-1}(\mathbf{x}(t))\mathbf{B}^\top (\mathbf{x}(t))\mathbf{K}(\mathbf{x}(t))$
. The results of the error reduction are shown in Figure 7. The amplitude of the linear control design is approximately threefold more than the SDRE plus ILC design, which shows the effectiveness of the design.
$-\mathbf{R}^{-1}(\mathbf{x}(t))\mathbf{B}^\top (\mathbf{x}(t))\mathbf{K}(\mathbf{x}(t))$
. The results of the error reduction are shown in Figure 7. The amplitude of the linear control design is approximately threefold more than the SDRE plus ILC design, which shows the effectiveness of the design.
The translation and orientation velocity states of the quadrotor drone simulation.

The translation error of the drone in different loops of the simulation. The error is defined by comparing the 3D coordinate of the system with the desired path.

The trajectories of the multirotor in the simulation.

The translation error of the drone in different loops of the simulation using a PD plus ILC controller.

The learning rule was applied for both translation and orientation dynamics of the drone in simulations; however, in experimentation, it will be applied only to the translation due to the sensitivity of the flight stability to the orientation dynamics, presented in Subsection 6.2.
The translation and orientation states of the drone in flight experiments.

6.2. Experiment
The parameters of the drone in the control Python loop are based on characteristics of the system in Section 5.1 and control parameters in Section 6.1, except for the weighting matrix of the inputs for the translation dynamics which is
 $\mathbf{R}_{\mathrm{t}}=\mathbf{I}_{3\times 3}$
and training factors
$\mathbf{R}_{\mathrm{t}}=\mathbf{I}_{3\times 3}$
and training factors
 $\beta _{\mathrm{t}}$
and
$\beta _{\mathrm{t}}$
and
 $\beta _{\mathrm{o}}$
.
$\beta _{\mathrm{o}}$
.
One difference between the simulation and experiment is that the orientation dynamics do not act perfectly in reality due to a mismatch in modeling, feedback error, and unbalanced forces of the rotors. The abrupt changes in the orientation angles play a more important role in the stability of the flight. As a result, during the experiments and learning loops, the orientation error changes without any particular pattern. This random but controlled behavior of the orientation dynamics provides useless information for the learning part of the orientation. It means, at a certain point on the trajectory, the orientation error is showing a set of specific Euler angles; however, in the next loop of learning, on the same point, the orientation error shows another value, completely unrelated to the previous pose. Then, removing the orientation dynamics from the learning process increases the precision of tracking in each loop. In the flight experiments, learning is only devoted to translation dynamics, and the training factors are
 $\beta _{\mathrm{t}}=0.05$
and
$\beta _{\mathrm{t}}=0.05$
and
 $\beta _{\mathrm{o}}=0$
. Noting the training factor, it can be seen that a very slow rate of learning was considered for the experiments for the safety of the flights. Even this small training factor for the translation part demonstrated error convergence at a rate more than the rate in the simulation, which confirms the gap between the ideal dynamics in theory and the reality of the quadrotor dynamics. The allowable error for the first regulation part of the take-off phase was set to
$\beta _{\mathrm{o}}=0$
. Noting the training factor, it can be seen that a very slow rate of learning was considered for the experiments for the safety of the flights. Even this small training factor for the translation part demonstrated error convergence at a rate more than the rate in the simulation, which confirms the gap between the ideal dynamics in theory and the reality of the quadrotor dynamics. The allowable error for the first regulation part of the take-off phase was set to
 $10(\mathrm{cm})$
.
$10(\mathrm{cm})$
.
The number of learning loops cannot be more than three or four since the battery voltage level drops and the performance of the tracking and, as a result, the whole loops of learning will be disrupted. Here in this series of experiments, three learning loops,
 $N_{\mathrm{i}}=3$
, were considered. Time is continuous, and when we repeat the learning loops, it does not restart like the simulations. This is the reason that the presentation of the results is different from Section 6.1. Here, the signals are continuous, and the end of one loop sets the initial condition of the next loop. Since the behavior of the robot in different loops is not the same, the time of each loop ends up in a distinct value, i.e., in this experiment, the time of each loop is as
$N_{\mathrm{i}}=3$
, were considered. Time is continuous, and when we repeat the learning loops, it does not restart like the simulations. This is the reason that the presentation of the results is different from Section 6.1. Here, the signals are continuous, and the end of one loop sets the initial condition of the next loop. Since the behavior of the robot in different loops is not the same, the time of each loop ends up in a distinct value, i.e., in this experiment, the time of each loop is as
 $35.03,34.98,34.96(\mathrm{s})$
, respectively. The position of the drone followed the desired path, periodic motion for
$35.03,34.98,34.96(\mathrm{s})$
, respectively. The position of the drone followed the desired path, periodic motion for
 $X$
- and
$X$
- and
 $Y$
-axis, presented in Figure 8(a) and (b), and a constant set point for height Figure 8(c). The desired roll and pitch angles were found to be time varying based on (32), illustrated in Figure 8(d) and (e). The desired yaw angle was set to a constant value, zero, though it deviated approximately
$Y$
-axis, presented in Figure 8(a) and (b), and a constant set point for height Figure 8(c). The desired roll and pitch angles were found to be time varying based on (32), illustrated in Figure 8(d) and (e). The desired yaw angle was set to a constant value, zero, though it deviated approximately
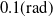 $0.1(\mathrm{rad})$
around that, as shown in Figure 8(f).
$0.1(\mathrm{rad})$
around that, as shown in Figure 8(f).
The velocities of the orientation and translation variables are illustrated in Figure 9; they showed more oscillations in the output due to rapid changes (but limited) in the drone’s orientation in flights. The PWM signals are presented in Figure 10, bounded between the upper and lower limits. The translation error of the system is demonstrated in Figure 11. It shows deviations and unpredictable behavior in the convergence of the error; however, the median of the error in each loop converges, which shows the effectiveness of the learning. The integrators of the controller were reset at the beginning of each learning loop to ideally focus on the role of the ILC in the error convergence of the system. The learning parameters of
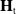 $\mathbf{H}_{\mathrm{t}}$
are shown in Figure 12. In the first loop, the learning components are zero, and by each iteration, they grow toward the desired translation dynamics. The median error of the robot in 3D Cartesian coordinate
$\mathbf{H}_{\mathrm{t}}$
are shown in Figure 12. In the first loop, the learning components are zero, and by each iteration, they grow toward the desired translation dynamics. The median error of the robot in 3D Cartesian coordinate
 $e_{\mathrm{3D}}=\sqrt {(x_{\mathrm{c}}-x_{\mathrm{c,des}})^2+(y_{\mathrm{c}}-y_{\mathrm{c,des}})^2+(z_{\mathrm{c}}-z_{\mathrm{c,des}})^2}$
and also in 2D planer view
$e_{\mathrm{3D}}=\sqrt {(x_{\mathrm{c}}-x_{\mathrm{c,des}})^2+(y_{\mathrm{c}}-y_{\mathrm{c,des}})^2+(z_{\mathrm{c}}-z_{\mathrm{c,des}})^2}$
and also in 2D planer view
 $e_{\mathrm{2D},XY}=\sqrt {(x_{\mathrm{c}}-x_{\mathrm{c,des}})^2+(y_{\mathrm{c}}-y_{\mathrm{c,des}})^2}$
are reported as
$e_{\mathrm{2D},XY}=\sqrt {(x_{\mathrm{c}}-x_{\mathrm{c,des}})^2+(y_{\mathrm{c}}-y_{\mathrm{c,des}})^2}$
are reported as
 \begin{equation*} \begin{split} e_{\mathrm{3D}}&=[0.2769,0.1764,0.1407](\mathrm{m})\,\,\mathrm{for\,loop}=1,2,3,\\ e_{\mathrm{2D},XY}&=[0.2756,0.1761,0.1391](\mathrm{m})\,\,\mathrm{for\,loop}=1,2,3.\ \end{split} \end{equation*}
\begin{equation*} \begin{split} e_{\mathrm{3D}}&=[0.2769,0.1764,0.1407](\mathrm{m})\,\,\mathrm{for\,loop}=1,2,3,\\ e_{\mathrm{2D},XY}&=[0.2756,0.1761,0.1391](\mathrm{m})\,\,\mathrm{for\,loop}=1,2,3.\ \end{split} \end{equation*}
The trajectories of the multirotor are plotted in Figure 13. The deviations of the system from the desired trajectory are observable in this plot, though the error in each loop becomes less than the previous one.
The translation and orientation velocity states of the drone in flight experiments.

The PWM signals of the drone in flight experiments.

The error convergence in the learning of flight experiments.

The learning terms of the input law in the flight experiments.

The trajectories of the multirotor during the three loops of learning in experiments.

The error (m) in three loops of learning for 12 repetitions of the experiments.

The error convergence of the experiments for 12 repetitions to test the reliability of the design.

The reliability tests. To check the performance of the system in various tests and verify the repeatability of the learning in flight, a series of 12 experiments has been conducted. The same initial condition and tuning were considered for all tests. The results of error convergence are illustrated in Figure 14. It is shown that in all experiments, the error was reduced in each loop of learning. The error values for each loop for all 12 experiments are reported in Table II. The median of the error in three loops for all tests was found as
 \begin{equation*} \mathrm{mean}(e_{\mathrm{3D}})=[0.2885,0.1968,0.1540](\mathrm{m})\,\,\mathrm{for\,loop}=1,2,3. \end{equation*}
\begin{equation*} \mathrm{mean}(e_{\mathrm{3D}})=[0.2885,0.1968,0.1540](\mathrm{m})\,\,\mathrm{for\,loop}=1,2,3. \end{equation*}
In the literature, a combination of the SDRE with ILC in flight has not been reported. The ILC-based controllers reported a greater reduction in error, but this shows that the initial guess of the desired dynamics for the ILC was not so good; hence, the ILC improved the learning process significantly. Here, since the abrupt changes provoked the risk of a crash in flights, the base controller presented a decent error, and the ILC improved that.
7. Conclusions
The concept of learning in control engineering has become the highlight of research, leading to many diverse implementations of artificial intelligence, neural networks, and learning methods on different platforms. A system might fail in the early stages of learning and continue to learn for better performance, such as crawling prototypes; however, for flying systems, stable learning is needed to avoid crashes and prevent endangering the system and the environment. The ILC has the potential of augmentation with a stable base control law to increase precision through learning in repetitive tasks. Hence, the base control law can deliver a stable regulation while the ILC can tune the system to high-precision tracking in a few loops. Here, the SDRE was selected as the base of the regulation, and the ILC was combined with it to perform the learning part. This combination was reported before, but applied only to a stationary system ref. [Reference Nekoo, Acosta, Heredia and Ollero36]. Here, in this work for the first time, the combination of the ILC plus the SDRE has been applied to a system in a flight experiment. The control design results in error reduction in consecutive loops as
 $e_{\mathrm{3D}}=[0.2769,0.1764,0.1407](\mathrm{m})$
in 3D measurement and
$e_{\mathrm{3D}}=[0.2769,0.1764,0.1407](\mathrm{m})$
in 3D measurement and
 $e_{\mathrm{2D},XY}=[0.2756,0.1761,0.1391](\mathrm{m})$
for 2D measurement, by excluding height from the coordinates, for three loops. The results showed convergence of error, and the tests were performed 12 times to confirm the repeatability of the results. All 12 reported data showed error reduction in each loop, due to the correction of the ILC on the SDRE base controller.
$e_{\mathrm{2D},XY}=[0.2756,0.1761,0.1391](\mathrm{m})$
for 2D measurement, by excluding height from the coordinates, for three loops. The results showed convergence of error, and the tests were performed 12 times to confirm the repeatability of the results. All 12 reported data showed error reduction in each loop, due to the correction of the ILC on the SDRE base controller.
Author contributions
Saeed Rafee Nekoo: Writing – review & editing, writing – original draft, visualization, validation, methodology, investigation, formal analysis, data curation, conceptualization. Anibal Ollero: Writing – review & editing, supervision,resources, project administration.
Financial support
The authors acknowledge support from the European Commission, the “Safe Inspection and Maintenance supporting workers with modular robots, Artificial intelligence, and augmented Reality,” SIMAR Project, Grant agreement ID: 101070604.
Competing interests
None.
Ethical standards
Not applicable.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0263574725102919.
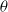












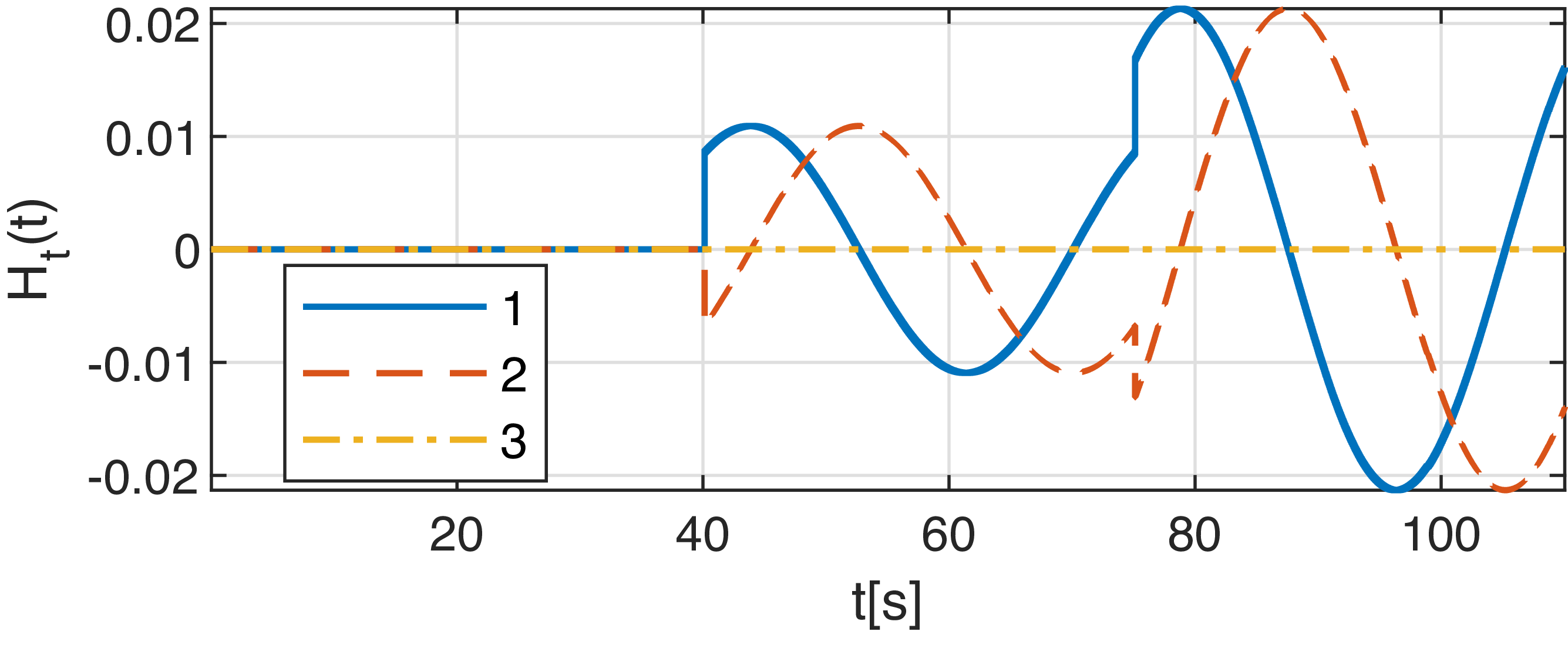

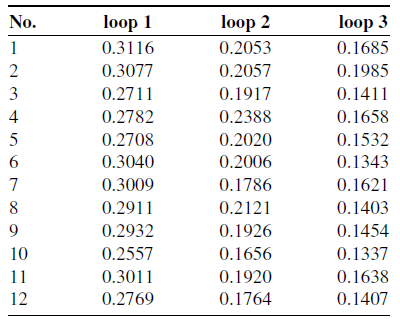




 Open access
Open access