

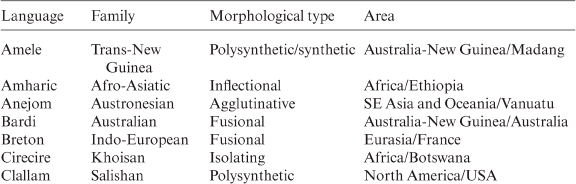
Part II. Cross-linguistic analysis
3 Word-formation processes combining free morphemes
The study of language universals has been a major focus of modern linguistics for at least the past three decades.
If the above quotation holds true, at present we may extend the period of intensive research into language universals and language typology to fifty years. Of that, comparatively little attention has been devoted to word-formation. In our research into typology in word-formation we primarily follow Anderson’s (Reference Anderson and Shopen1985: 9) view of typological studies (cf. ‘Antecedents’ in the ‘Introduction’). For this reason, one of our objectives has been to identify/ verify associations between language families, inflectional types, and word order with respect to word-formation processes and categories.
This chapter focuses on word-formation processes combining morphemes and devotes a section to compounding (3.1), reduplication (3.2) and blending (3.3). Emphasis is laid on compounding, with a review of different types and processes within compounding.
3.1 Compounding
Libben (Reference Libben, Libben and Jarema2006: 2) considers compounding a language universal, and in some languages compounding is reported to be extremely productive: according to the data in Ceccagno and Basciano (Reference Ceccagno, Basciano, Lieber and Štekauer2009), approximately 80 per cent of Chinese words are compounds and over 90 per cent of all new words in The Contemporary Chinese Dictionary (Yuan, Zhang and Chen Reference Yuan, Zhang and Chen2002) are compounds. In the study sample, compounding is recorded in the languages shown in Table 3.1 (90.91 per cent in the study sample):

3.1.1 Types of compounds
The scope of the book does not allow the survey of all possible types of compounds here. Therefore, focus is on the most widespread types: adjective + adjective compounds (3.1.1.1), compound verbs (3.1.1.2) and noun + noun compounds (3.1.1.4).
3.1.1.1 Adjective + adjective compounds
Adjective + adjective compounds have been recorded in the languages shown in Table 3.2.


3.1.1.1.1 Formal characteristics
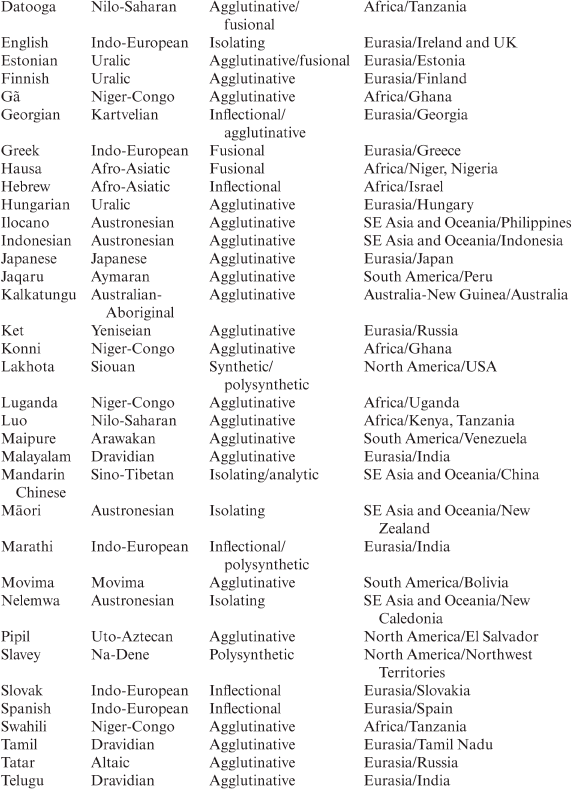
Formally, adjective + adjective compounds can occur without and with a linking element. Examples are given in Table 3.3.1
Table 3.3. Adjective + adjective compounding with/out a linking element
The members of the compounds can be stems, but also inflected forms, as in Finnish (11) and Udihe (12) and (13). The latter can combine a content element and the copula verb bi- ‘be’ and, sometimes, also ede- ‘become’ in the corresponding form. The content element may be an adverb, a derived adjective or an ideophonic adverb:
(11)
- Finnish
vaalea-n-sininen
light-gen-blue
‘light blue’
(Laakso)
(12)
- Udihe
bei-bi-
in.vain-be
‘simple’
(13)
- Udihe
täsi bi-
very.much-be
‘full’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 200)
Adjective + adjective compounds can be, to use Scalise and Bisetto’s (Reference Scalise, Bisetto, Lieber and Štekauer2009) terminology, attributive (14) and coordinate (15):
(14)
- Serbian-Croatian
svetloplav
‘light blue’
(15)
- Spanish
italo-argentino
‘Italian-Argentinean’
Subordinative compounds usually present a structure of modifier + head sequence, but the opposite is also possible, as illustrated in (16):
(16)
- Romanian
galben-auriu
yellow-golden
‘golden-yellow’
3.1.1.1.2 Semantic characteristics
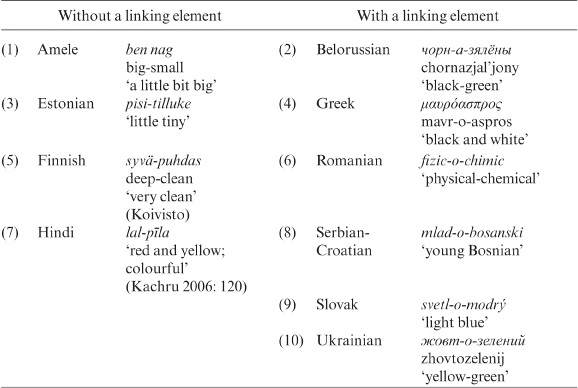
Semantically, three types of meaning have been identified in the study sample: a purely compositional meaning,2 a modified meaning,3 and a new concept motivated by the adjectival constituents, as shown in Table 3.4:
Table 3.4. Semantic types in adjective + adjective compounding
Māori presents an ambiguous case: according to Harlow (pers. comm.), there is only one example of adjective + adjective compound in this language (29) and even this seems to be questionable:
(29)
- Māori
hari-koa
happy-happy
‘happy, pleased’
According to W. Bauer (Reference Bauer1997: 77), Māori does not have the word-class adjective, which in this language is rather a class of verbs.4 These verbs can occur as modifiers in post-nuclear position in noun phrases, as in (30) (W. Bauer Reference Bauer1997: 303):
(30)
3.1.1.2 Compound verbs
Compound verbs, i.e. compounds whose head is verb, as in to spotlight or to stagemanage, are a controversial case in word-formation in languages like English. While the status of nominal and adjectival compounds is relatively clear, the existence of compound verbs in English has been called into question by a considerable number of morphologists, like Marchand (Reference Marchand1960) or Lieber (Reference Lieber2004: 48). The former calls this type of structure pseudocompounds and explains their formation by processes other than compounding. This is common in the literature and a number of sources have been cited for the alleged compound verbs, e.g. back-formation from other compounds (Marchand Reference Marchand1960: 59; Adams Reference Adams1973; Allen 1978: 214), zero-derivation from other compounds (Marchand Reference Marchand1960: 59; Adams Reference Adams1973, Reference Adams2001: 101)5 or noun incorporation (Štekauer Reference Štekauer2009: 282).6
Interestingly, Adams (Reference Adams1973) cites Pennanen (Reference Pennanen1966: 7.5)7 in support of her view that compound verbs may be based on analogical formation, while her 2001 revision (Adams Reference Adams2001: 109) assumes that ‘genuine verb compounding is not likely to develop in modern English’. The controversy on the existence of a verb-forming process of compounding in English is unavoidable when L. Bauer and Renouf (Reference Bauer and Renouf2001: 110) identify neologisms such as dry-burn, test-release, thumb-strum and slow-bake as compound verbs. Kiparsky (Reference Kiparsky and Yang1982a: 16) considers compound verbs with adverbials as left-hand constituents (English hand-pick, sun-dry, etc.) to be a class of systematic exceptions to the First Sister Principle. Kiparsky emphasizes that ‘the process which derives these compound verbs . . . e.g. air-condition, is the same which forms all compounds including synthetic compounds’ (1982a: 19). This process is based on the rule [Y Z]X, with X being a verb.
Compound verbs are recorded in the languages shown in Table 3.5.
Table 3.5. Verb + verb compounding in the study sample
3.1.1.2.1 Formal characteristics
Leaving aside noun incorporation (which produces verbal compounds with a noun as an argument of the incorporating verb), verbal compounds mostly include combinations of two verbs (cf. left column in Table 3.6). Following Scalise and Bisetto (Reference Scalise, Bisetto, Lieber and Štekauer2009), these can be classified as two types:
(a) the two verbs associate two individual elements without reference to any of them as a separate entity, as in true dvandva compounds in the left column of Table 3.6, or
(b) they express two properties associated with an entity, in this case, two aspects of action, as in the right column of Table 3.6.
Table 3.6. Two types of reference in compound verbs


In Amele, these structures, very common with the verbs q-oc ‘hit’ and m-ec ‘put’, represent a borderline case. Roberts (Reference Roberts1987: 309) maintains that, while this sort of verbal compound often has an idiomatic meaning which cannot be determined from the meanings of the constituents, q-oc and m-ec function in such expressions rather as copula verbs, because they can combine productively with almost any nominal and adjectival element. Examples of combinations of these verbs with another verb are shown in (41) to (43):
(41)
- Amele
cahug q-oc
smell-hit
‘be smelly’
(42)
- Amele
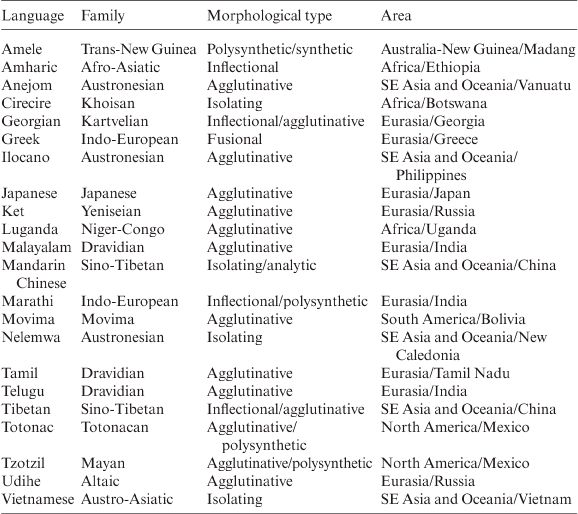
qel-I q-oc
throw hit
‘thunder.v’
Hudson (pers. com.) describes a very productive process of formation of compound verbs in Amharic. The so-called say-composite verbs are formed with a particular form of the verb ‘say’ and a word of indefinite word-class (used only in these compounds and uninflected) regularly derived from another verb:
(44)
- Amharic
käfätt alä’
open-it/he.said
‘It opened gradually’

This compound is based on the root k-f-t ‘open’ and the past tense form of the verb ‘say’, alä ‘he said’. Literally, it means ‘it/he said “käfätt”’, where käfätt is not translatable alone.
In Malayalam, a highly productive process of verb + verb compounding produces ‘hybrid compounds’, combining an English verb and Malayalam ceyyuka ‘do’ (Asher and Kumari Reference Asher and Kumari1997: 404). A sort of borderline case is represented by those noun + verb compounds in Malayalam whose verbal constituent may be treated, according to Asher and Kumari (Reference Asher and Kumari1997: 403), as a lexical or grammatical element. The source is always an abstract noun which usually expresses emotion. Verbs are formed by addition of peʈuka ‘fall’ or ‘get into or under’:
(45)
- Malayalam
a. bhayappeʈuka
bhayam-peʈuka
fear-fall
‘be afraid’
b. aaSappeʈuka
aa∫a-peʈuka
desire-fall
‘long for’
(Asher and Kumari Reference Asher and Kumari1997: 389)
Adjective + verb structures are also common in other languages:
(47)
- Catalan
malparlar
ill-speak
‘speak ill’
(48)
- Japanese
近寄る
tika-yoru
near-approach
‘go near’
(Kageyama Reference Kageyama, Lieber and Štekauer2009: 513)
Japanese also offers a variant of the adjective + verb compound. Kageyama (Reference Kageyama, Lieber and Štekauer2009: 513) refers to AN + V compounds, where AN stands for adjectival noun, i.e. ‘noun-like adjectives that take the -na inflection instead of the adjectival inflection -i in pronominal position’ as in (49):
(49)
- Japanese
高価過ぎる
kooka-sugiru
expensive-exceed
‘be too expensive’
While the majority of verbal compounds leave the form of motivating constituents intact, modifications of the first stem may occur, as exemplified by Amele:
(50)
- Amele
ji fec
jec-fec
eat-see
‘taste.v’
Apart from prototypical cases characterized by the combination of two verbal stems (if we disregard noun incorporation) which also exist as independent words of a language without formal modification of the constituent stems, there are also peripheral instances of verbal compounds. Two types will be mentioned here. One is eroded roots in Ket: many finite verbs in Ket consist of an infinitive in the incorporate slot and a semantically eroded morpheme in the root slot which conveys some notion of aspect. These could be considered verbal compounds, as in (51):
(51)
- Ket
il-ba-g-a-qan
singing-1sg.sbj-ade-thm-icp
‘I begin to sing’
The other peripheral case is verbal compounds in Cirecire, which can come into existence by reduplication of verbal stems, as in (52):
(52)
- Cirecire
quu~quu
go/move~rdp
‘look around, hunt’
3.1.1.2.2 Semantic characteristics
As with any other type of compounds, the meaning of verbal compounds can be based on the principle of compositionality or it can be more than a mere sum of the meanings of the motivating constituents, as shown in Table 3.7.
Table 3.7. Compositional and non-compositional meaning in verbal compounding

3.1.1.3 Noun incorporation
Noun incorporation is recorded in the languages shown in Table 3.8. (38.18 per cent in the study sample):


Incorporation is considered here a verb-forming process whereby a nominal stem is fused with a verbal stem to yield a larger, derived verbal stem, according to the definition proposed for the purposes of our research by L. Bauer (pers. comm.). Noun incorporation follows after the section of compound verbs (3.1.1.2) because instances of noun incorporation are prevailingly viewed as compound verbs.
While a broad approach to incorporation does not seem to make a distinction between incorporation and polysynthetism, our findings are in accordance with Aikhenvald’s (Reference Aikhenvald and Shopen2007: 6, 12) observation that not all polysynthetic languages have noun incorporation and languages with incorporation need not be polysynthetic.
On the other hand, the non-existence of compounding in these languages is confirmed by the absence of incorporation. This observation corresponds with what is assumed by Leza (Reference Leza, Haspelmath, König, Oesterreicher and Raible2001: 718), according to whom not all Amerindian languages feature noun incorporation even if they are polysynthetic. Noun incorporation is productively used in many non-polysynthetic languages.
3.1.1.3.1 Formal characteristics
While the prototypical case of incorporation is nominal incorporation, specifically one in which the incorporated noun functions as an object argument of the verb, a number of peripheral types of incorporation have been reported in the literature and have been found in the languages sampled here.
Thus, Werner (Reference Werner1998: 58ff.) demonstrates that languages like Ket, Kott and Yugh, which are Yeniseian languages spoken in Eurasia, make use of ‘nominal incorporation’ in which a compound adjective in the function of the modifier and a noun as the head form a unity. The view that these expressions involve noun incorporation is supported by their ability to include possessive prefixes which are usually combined with nouns and, in certain cases, also with verbs. Examples of this kind of nominal incorporation are given in (57) and (58):
(57)
- Ket
qä-γit,
4qä-2ki?t
big-price
‘expensive’
(58)
- Yugh
χεgit
2χε?-2ki?t’
big-price
‘expensive’
Adjective incorporation also occurs in Pipil, although it is reportedly rare:
(59)
- Pipil
sek-kalaki
cold-enter
‘get cold’
A similar case occurs in Estonian, where a small group of verbs formed by incorporation usually have as the first component an adjective stem, but a noun is also possible. Estonian syntax prefers to express the meanings of such nominal stems as adverbials. Thus, (60a) is more marked than (60b):
(60)
- Estonian
a. sügav-künd-ma
deep-plough.v-sup
‘plough deep.v’
b. sügavalt.adr kündma.v
deeply-plough.v-sup
‘plough deep.v’
Examples of frequently used Estonian incorporated verbs are:
(61)
- Estonian
kuri-tarvita-ma
evil-use-sup
‘abuse.v’
(62)
- Estonian
häda-maandu-ma
hardship-land.v-sup
‘force-land, make emergency landing’
Lakhota is a source of insights into various aspects of noun incorporation. The following is based on de Reuse’s (1994) account of this Siouan language. In Lakhota noun incorporation is treated as a type of compounding with which it also shares phonological properties, like the following three different stress patterns:
(a) noun incorporations with a single main stress (labelled lexical compounds) are controlled by the Dakota Accent Rule, which places stress on the second syllable of a word regardless of whether this syllable is a part of the first or of the second compound constituent. This type of noun incorporation is, phonologically, a tight unit, often with lexicalized meaning, and its productivity is low compared to so-called syntactic compounds,
(b) noun incorporation with stress weakening on the second syllable of the second constituent imposed on it (as well as on the first constituent by the Dakota Accent Rule before the process of incorporation). This type is semantically more transparent and more productive. Since the former, the lexical compound type of noun incorporation, is phonologically very tight, the noun stem undergoes various phonological modifications (truncation), like voicing of the final stop (final /t/ and /č/ become /l/) and devoicing of a final fricative. Cases of coalescence of the final vowel of the first constituent and the initial vowel of the second constituent accompany both types of noun incorporation, as shown in Table 3.9.
(c) noun incorporation which maps compounding, labelled noun stripping, because the noun ‘is stripped of the articles, determiners, and case-marking elements that usually accompany it, and then juxtaposed to the verb’ (de Reuse Reference de Reuse1994: 206):
(65)(65)
- Lakhota
napé yúzA
hand.ins-take.hold
‘shake hands’
Table 3.9. Noun incorporation with truncation and with coalescence in Lakhota

Noun incorporation need not be restricted to the left-hand position of the incorporated noun. In Clallam (68) the nominal object, expressed by a lexical suffix rather than by a root, takes right-hand position. Examples where the incorporated noun takes right-hand position can be found in other languages too:
(67)
- Anejom
esjaalak
esjañ-nalak
put.down-roller
‘put down rollers (for a canoe)’
(68)
- Clallam
λ’əmé?qw
λ’ə’m’-e?qw
be bumped-head
‘get bumped on the head’
(69)
- Nelemwa
thu-naar-e
do-oven-tr
‘cook it in the oven’
The position of the incorporated noun in these languages matches Mardirussian’s (1975: 384) observation that the incorporated noun attaches to the right of the verb in verb-initial languages. Word order in Clallam is VSO, VOS in Anejom and, in Nelemwa, ‘nominal arguments come after the predicate, either as VS (where [S] is the absolutive nominal argument of an intransitive verb) or VOA (where O stands for the second argument/patient and A for the agent of a transitive verb)’ (Bril Reference Bril and Haspelmath2004: 500). Interestingly, the examples from Anejom, Clallam and Nelemwa contradict the generalization made by Caballero et al. (2006), according to which the order of noun and verb in languages with unproductive noun incorporation is noun + verb, while in languages with productive noun incorporation it follows the order of words in syntax.10
3.1.1.3.2 Semantic characteristics
The description of noun incorporation mentions that an incorporated noun functions as an argument (usually object) of the predicative verb. Remarkably, in none of the latter examples does the noun function as an object: instead it identifies location. This has been reported in the literature both in general and in a number of languages. According to Gerdts (Reference Gerdts, Spencer and Zwicky1998: 87), while incorporated nouns are typically related to objects or to subjects of inactive predicates,11 they can also express locatives, instruments or passive agents and they do not generally correspond to subjects of active intransitives or transitives, to indirect objects or to benefactives. Mithun (Reference Mithun, Lieber and Štekauer2009: 576) remarks that the variety of relations that hold in Mohawk between the noun incorporation members is much like what we find with noun + noun compounds in English and that ‘the same Mohawk verb root can . . . occur with incorporated nouns with quite different semantic roles’. Similarly, Kageyama (Reference Kageyama1982: 244) claims that the incorporated noun functions as a direct object in about 50 per cent of this type of Japanese compound verbs ((70) and (73)), as an adverbial in about 25 per cent ((71) and (74)), and as a subject of intransitive predicates in about 25 per cent ((72) and (75)) (see Table 3.10).
Table 3.10. Incorporated noun as direct object, as adverbial and as subject in Japanese

In line with the above, the languages sampled here show that it is not only internal arguments of verbs that can be incorporated. In Mandarin Chinese, where noun incorporation is reportedly very productive, there are, beside the default cases of object, numerous instances of the incorporated noun in other functions, as shown in Table 3.11.
Table 3.11. Incorporated nouns as other than object in Lakhota and Mandarin Chinese
Pipil offers examples where the incorporated noun performs the function of an instrumental prefix (83), as well as standard examples (84):15
(84)
- Pipil
ku:-tapa:na
wood-break.v.open
‘split firewood.v’
(Campbell Reference Campbell1985: 97)
These examples of Pipil lead to the role of locative and instrumental prefixes in noun incorporation in Lakhota. According to de Reuse (Reference de Reuse1994: 210ff.), incorporations of the structure [n+[loc+v]] and [n+[ins+v]] are very common. They usually co-exist parallel to prefixless noun incorporations. The prefixed and prefixless constructions may differ in valence and meaning. Table 3.12 presents various combinations of locative and instrumental arguments and prefixes in Lakhota:
Table 3.12. Combinations of noun incorporation in Lakhota

Constructions with both locative and instrumental prefixes incorporated by a verb (n+[loc+[ins+v]]) are also possible (de Reuse Reference de Reuse1994: 212):
(89)
- Lakhota
wé ayúš ?e
blood-loc-ins-drop
‘drop blood on (somebody)’
While noun incorporation is connected with incorporating a single noun in the vast majority of cases, Lakhota also allows a rare case of two incorporated nouns, mostly combined with locative and instrumental prefixes. One such example, whose structure is [n+[loc+[n+[loc+[loc+v]]]]], is given in (90):16
(90)
- Lakhota
xta ?ómakhiyokpazA
evening-loc-earth-loc-loc-be.dark
‘grow dusk’
In Ket (Vajda, pers. comm.), noun incorporation is limited to a handful of verb stems like eat, make, pour or have:
(91)
- Ket
d-qus-i-bet
1sg.sbj-tent-thm-make
‘I engage in tent-making’
What makes noun incorporation in Yeniseian languages attractive is that in the finite verb form these nominal incorporations are split into two parts: the determining constituent always assumes position 12 and the basic constituent the zero position. If the determining constituent is a compound itself, the first constituent takes position 13 and the second constituent takes position 12 (Werner Reference Werner1998: 99).17
Noun incorporation is productive in Tamil. According to Schiffman (1996), the commonest and most general of the incorporating verbs is  ஹஊ (pannu) ‘make, do’. It can be added to a noun to make a verb. This is the most common way of making verbs out of borrowed English words. Sometimes Tamil even borrows words for lexical items which are already available in the language:
ஹஊ (pannu) ‘make, do’. It can be added to a noun to make a verb. This is the most common way of making verbs out of borrowed English words. Sometimes Tamil even borrows words for lexical items which are already available in the language:
(93)
- Tamil
·
ை ஹஊdraiv pannu
‘drive (a car)’
(94)
- Tamil
- ‘ ஹஊ
vaakking pannu
‘take a walk, go walking’
 ‘
‘

Schiffman explains that ஹஊ (pannu) can be attached to both nouns and verbs (usually borrowed from English), but always with the effect of having been added to nouns, i.e. what precedes pannu is a noun phrase in Tamil, regardless of whether it is a noun phrase or a verb phrase in English. Thus, ·
 ை draiv in (93), though a verb in English ‘drive.v’, is treated as a noun in Tamil.
ை draiv in (93), though a verb in English ‘drive.v’, is treated as a noun in Tamil.
Noun incorporation in Slavey may be illustrated with a set of three examples (Rice, pers. comm.). In the first (95), the pre-verb and stem together mean ‘sg.stand’, the incorporate is -tse ‘cry.n’ and d- is a prefix that occurs with an incorporate indicating an oral activity. In the second, (96), the noun stem tthí ‘head’ is incorporated, the verb stem is -chu and the prefix e- is required with this. This verb without the incorporate means ‘handle sg.object around’. Finally, in the third example, (97), the incorporate is shé ‘food’, because this stem does not occur independently:
(95)
- Slavey
ná-tse-de-we
preverb-cry-qualifier-stm
‘S/he stands crying’
(96)
- Slavey
k’e-tthí-e-chu
around-head-qualifier-stm
‘S/he turns his/her head’
(97)
- Slavey
shé-tiN
food-stm
‘S/he eats’
This is similar to Kwakw’ala, where there is a group of incorporating verbs that only occur with their objects incorporated (Anderson Reference Anderson1992: 269).
According to Pingali, in addition to prototypical incorporation in Telugu (98), a set of auxiliary verbs participate in constructing what Pingali calls ‘quasi-compounds’. Auxiliary verbs also attach to English borrowings, as in (99) and (100):
(98)
- Telugu
purugu paTTu
insect-catch
‘be infested by insects’

(99)
- Telugu
dress avvu
dress-happen
‘get dressed’

(100)
- Telugu
swim ceeyi
swim-do
‘swim.v’

Examples of noun incorporation in other languages are shown in (101) to (106):
(101)
- Catalan
cama-trencar
leg-break-inf
‘cause (something) to break its leg’
(102)
- Greek
αφισοκολλώ
afis-o-kolo
poster-stick
‘stick posters (on the wall)’
(103)
- Tibetan
- ག་
lug-rdzi
sheep-tend
‘shepherd.v’
 ག་
ག་
(104)
- Totonac
laka-lás-a
face-slap-ipf
‘slap (somebody) in the face’
(105)
- Tzotzil
t!šút!š-ul púšil-an
small.pieces-fold.repeatedly
‘fold (something) smaller and smaller’
(Cowan Reference Cowan1969: 95)
(106)
- Wichí
yenlhipeya
o-yen-lhip-ey-a
3sbj-make-piece-pl-acc
make-pieces
‘S/he chops’
3.1.1.4 Noun + noun compounds
Noun + noun compounding is recorded in the languages shown in Table 3.13.

Noun + noun compounds may appear without a linking element and with a linking element, as shown in Table 3.14.


This section now reviews first noun + noun compounds without a linking element and then noun + noun compounds with a linking element.
3.1.1.4.1 Formal characteristics of noun + noun compounds without a linking element
In nominal compounding, the left-hand position of the modifying noun is a default case. However, the languages sampled offer alternative distributions, like right-hand position for the modifier or either position, i.e with the modifier in the left-hand position or in the right-hand position, as in the Hindi and Vietnamese examples in Table 3.15.


Modifiers in compounds therefore do not always seem to be restricted to one position. Position is, however, used for a classification in some languages, like Breton, where strict compounds are right-headed (130) and loose compounds are left-headed (131) (see Table 3.16).
Table 3.16. Strict (right-headed) vs loose (left-headed) compounding in Breton

3.1.1.4.2 Semantic characteristics of compounds without a linking element
Section 3.1.1.2 shows that the non-applicability of the principle of compositionality is not a universal feature of compounds. Further examples of noun + noun compounds whose meanings can be computed as a sum of the meanings of their constituents and which are figurative meanings are given in Table 3.17. In the table, (132) and (138) are instances of the so-called pleonastic compounds, where the head is a hyperonym of the non-head.


Typical dvandva compounds in the field of kinship terms are offered by Georgian (144) and Maipure (145): 20
(144)
- Georgian
დედ-მამ
ded-mama
father-mother
‘parents’
(145)
- Maipure
ani-kiwakané
son-father
‘husband’
3.1.1.4.3 Formal characteristics of compounds with a linking element
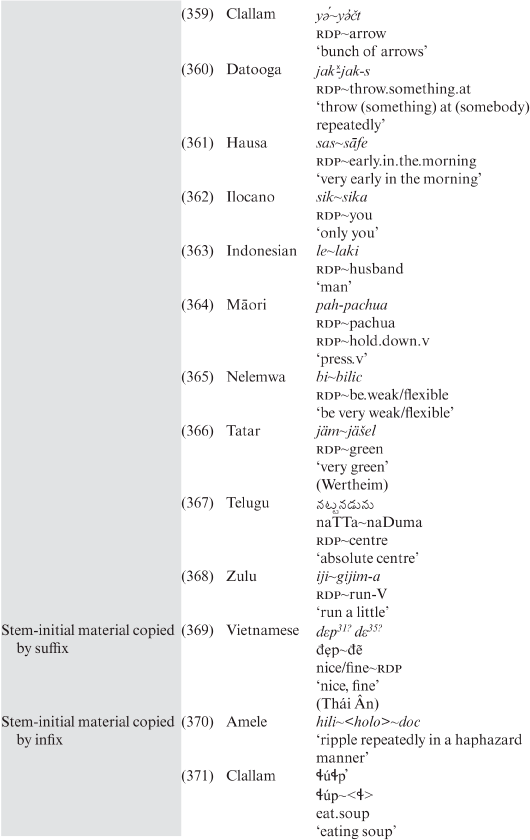
Compounding with a linking element is recorded in the languages shown in Table 3.18.
Table 3.18. Compounding with a linking element in the study sample

Perhaps the best-known and theoretically most extensively discussed linking elements of compounding are in German, as in Arbeitslohn, Alterungsprozess, etc. The discussion about this issue usually concerns the status of -s-, -n-, -e and of other linking elements that are historically developed from genitive and plural morphemes (Neef Reference Neef, Lieber and Štekauer2009).21
However, linking elements are not an exclusive feature of a particular genetically related group of languages, in this case the Germanic genus,22 or of a particular inflectional type or geographic area. Admittedly, links are not equally frequent in all linking languages. Thus, although they are rare in the Dravidian language Telugu, they can still be found in such languages, as shown in (146):
(146)
- Telugu
penk-u-Tillu
tile-lnk-house
‘tiled house’

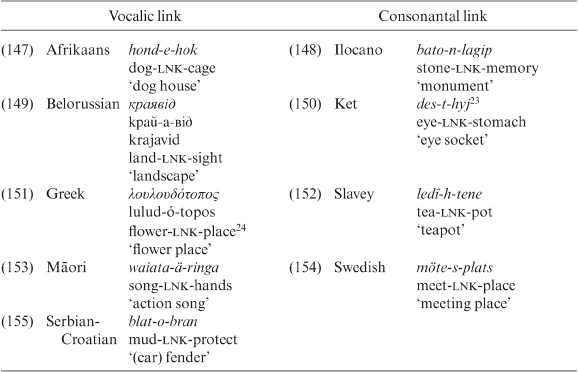
Links appear to be mainly single-phoneme elements, either vowels or consonants. If an interfix is formed by a vowel, then it is usually a back vowel (low or mid), while for consonants there does not seem to be any pattern. Examples are given in Table 3.19.
Table 3.19. Vocalic and consonantal links in compounding
3.1.1.5 Exocentric compounds
Exocentric compounding is recorded in the languages shown in Table 3.20.

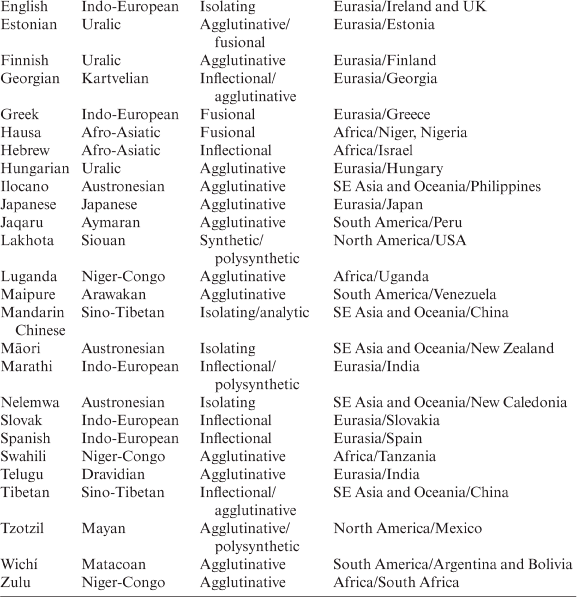
Compounds have traditionally been divided into endocentric and exocentric. The former are characterized by the binary structure of determinant–determinatum with the compound being a hyponym of its determinatum (head). The latter are said to have no head constituent (cf., among others, Scalise and Bisetto Reference Scalise, Bisetto, Lieber and Štekauer2009) or zero determinatum (i.e. one lying outside the compound; Marchand Reference Marchand1960: 11) and, therefore, the compound cannot be a hyponym of the determinatum, e.g. English paleface, redskin, etc.
This classification has raised much debate. In this respect, the position of this book is one that these compounds are generated in the same way as endocentric compounds. Two arguments can be raised:
(a) the psychological reasons can be found in both classical structuralist and onomasiological approaches. Marchand (Reference Marchand1960: 11) points out the general tendency of speakers ‘to see a thing identical with another already existing and at the same time different from it’. This principle, which Kastovsky (Reference Kastovsky1982: 152) calls the ‘identification-specification scheme’ is a key to one of the fundamental principles of Marchand’s and Kastovsky’s theories based on the binary, syntagmatic structure of motivated words: each word-formation syntagma is based on the determinant–determinatum relation, where the latter identifies and the former specifies (cf. 1.1.2.). The same principle underlies the onomasiological conception25 and Natural Morphology, although in a different way in the latter: the most natural coinages are the most diagrammatic (a new meaning is accompanied with a new form), e.g. read-er, where there is ‘a diagrammatic analogy between semantic and morphotactic compositionality (or transparency)’ (Dressler, Mayerthaler, Panagl and Wurzel Reference Dressler, Mayerthaler, Panagl and Wurzel1987: 102), and
(b) there is no reason to surmise that there is any other cognitive process underlying a small group of exocentric compounds deviating from the identification–specification scheme, because this way of conceptual analysis is the essence of naming in general. Štekauer (Reference Štekauer1998) explains exocentric compounds as a two-step process in which only the first step has word-formation relevance. It consists in the formation of an auxiliary, onomasiologically complete (i.e. with both the base and the mark included), compound complex word. The second step is based on shortening, which is sometimes not considered to be a word-formation process. By implication, this type of complex word can be analyzed on a par with the underlying full, auxiliary, version, although the latter has not come to be used (institutionalized). Hence, redskin can be analyzed as ‘redskin + person’, sabretooth as ‘sabretooth + tiger’, garde-manger as ‘garde-manger + place’ and killjoy as ‘killjoy + person’.
Ten Hacken (Reference Ten Hacken, Booij, Lehmann and Mugdan2000: 358) maintains that ‘in view of their problematic nature, it is not surprising that it has sometimes been proposed that exocentric compounds are irregular and unproductive’. Contrary to this assumption, Ten Hacken (Reference Ten Hacken, Booij, Lehmann and Mugdan2000: 358) maintains that the English possessive adjective + noun type of exocentric compound does ‘not constitute a closed class and new coinages can be interpreted on a regular basis’ and the verb + noun type ‘is productive in Romance languages’.
The data used here bear witness to:
(a) a relatively strong position of figurativeness in natural languages, and
(b) the universal tendency to a speaker-friendly (but not listener-friendly) economy of expression which at all language levels struggles with the listener-friendly and not speaker-friendly tendency towards clarity of expression.
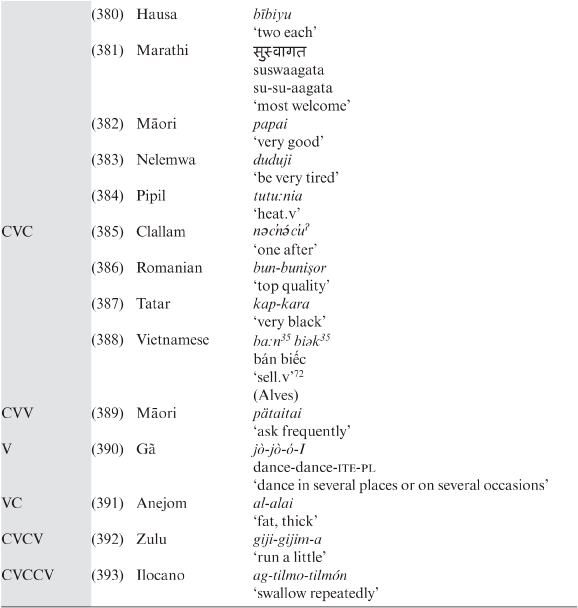
The relative popularity of this word-formation process means that, in this particular case, the tendency towards the economy of expression overpowers the opposite trend towards the clarity of expression, even if the cumulative meaning of the constituents of many exocentric compounds is indicative of their final meaning.
Our questionnaire examined the occurrence of two different types of exocentric compounds:
(a) the redskin type (meaning a ‘person with a red skin’ or a ‘potato with a red skin’), in which the expressed constituents identify the feature of the unexpressed head (base, determinatum), and
(b) the garde-manger type (lit. ‘keep food’, i.e. ‘pantry’), where a verb and its object are used to denote an entity with a new meaning.
Exocentric compounding of the redskin type is recorded in all the languages listed in Table 3.20 except Maipure and Swahili. Exocentric compounding of the garde-manger type is recorded in the languages shown in Table 3.21.

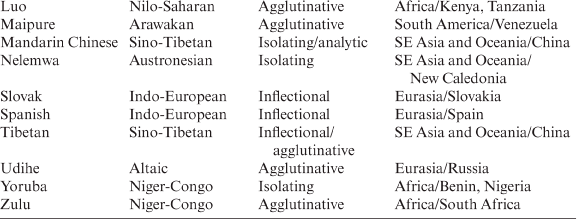
3.1.1.5.1 Formal characteristics
Chung (Reference Chung1994) discusses verb + noun compounds, i.e. exocentric compounds of the garde-manger type, in Chinese, French and Spanish. She argues that Spanish has two predictable and invariable forms of this type of compound: the third person singular indicative form of a verb plus a plural noun (156) and the second element is not in plural. Chung, however, notes that some exocentric compounds of this type have an alternate form with a pluralized nominal constituent:
(156)
- a.
- Spanish
limpiadientes
cleans-teeth
‘toothpick.ins’
(Chung Reference Chung1994: 4)
- French
couvre-lit
covers-bed
‘bedspread’
(Chung Reference Chung1994: 10)
- b.
- Spanish
lavaplatos
washes-dishes
‘dishwasher.ag’
(Chung Reference Chung1994: 7)
- French
garde-malade
watches-sick.person
‘nurse.n’
(Chung Reference Chung1994: 10)
- c.
- Spanish
saltamontes
jumps.over-hills
‘grasshopper’26
(Chung Reference Chung1994: 7)
In either case, the principles postulated by level-ordering models are violated, because inflection precedes the word-formation process of compounding. According to Spencer (Reference Spencer, Štekauer and Lieber2005: 74), this is frequent in Romance languages:
(157)
- Catalan
eixugamà
dries-hand
‘towel’
(158)
- Italian
porta-lettere
carries-letters
‘postman, mailman’
(159)
- Portuguese
guarda-roupa
keeps-clothings
‘piece of furniture used to keep the clothes’
(160)
- Romanian
pierde-vară
loses-summer
‘dawdler, slowcoach’
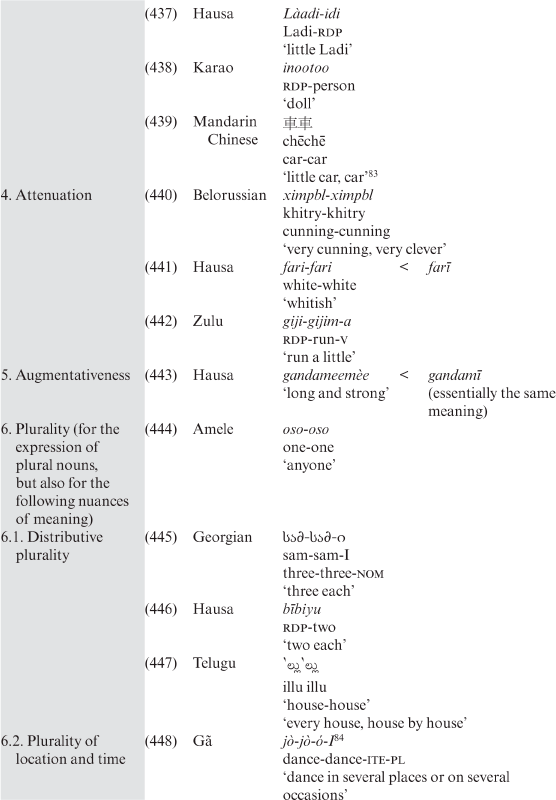
While the number of exocentric compounds of the garde-manger type is much smaller in Mandarin Chinese than in French and Spanish, their semantics map the three basic groups identified for the latter two languages (agents,27 instruments and animals/plants), even if such compounds in Chinese are ‘often semantically more opaque – even to a native speaker – than in e.g. Spanish and French’ (Chung Reference Chung1994: 14) (see Table 3.22).


According to Berman (pers. comm.), verb + object compounds are common in Hebrew, but restricted to verbs in the so-called benoni form, which functions as a participial and as a present tense verb and is often lexicalized as a noun (either agent or instrument). However, it is more usual for verbs to be in an exclusively nominal pattern.29
Interestingly, as noted by Chung, some Spanish exocentric compounds of this type can become a part of a new compound of the same type:
(167)
- Spanish
portaparaguas
(porta + [par(a) + aguas])
holds-stops-waters
‘umbrella stand’
(Chung Reference Chung1994: 9)
Exocentric compounds are quite common in Indian languages like Malayalam (here, only of the garde-manger type) (168) and Marathi (169):
(168)
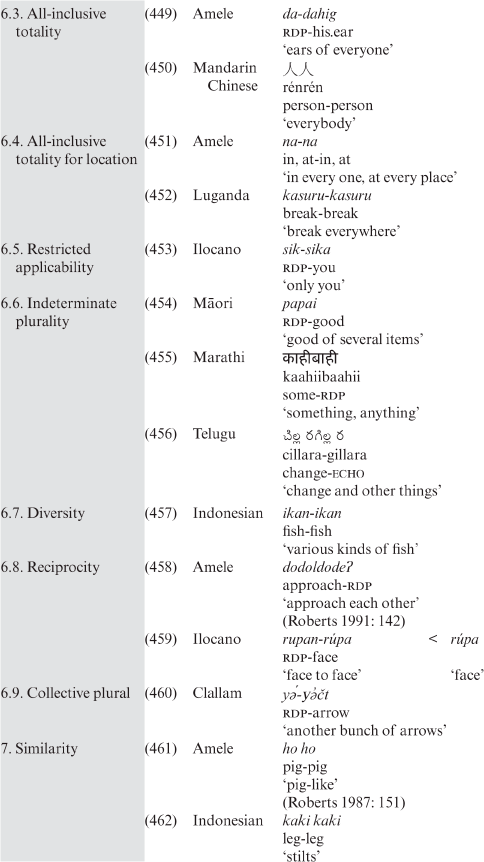
- Malayalam
kuttuvaakkə
kuttuka-vaakkə
pierce.v-word
‘taunt.v’
(Asher and Kumari Reference Asher and Kumari1997: 400)
(169)
- Marathi
िपक
नpikale paana
matured-leaf
‘a person likely to die due to age’

 न
नComrie (Reference Comrie1989: 26ff.) maintains that the morphology of a language reflects its syntax. Chung’s analysis confirms this assumption in terms of the order of the constituents of the examined compounds, i.e. the verb is followed by the noun in the SVO type of the languages examined. By contrast, in Burmese, a Sino-Tibetan language spoken in South East Asia and Oceania, and Persian, an Indo-European language spoken in Eurasia, the order of constituents in compounds of this type is reversed, which reflects the Burmese (170) and Persian (171) SOV syntax:
Table 3.23 reviews exocentric compounds of the redskin and garde-manger types.
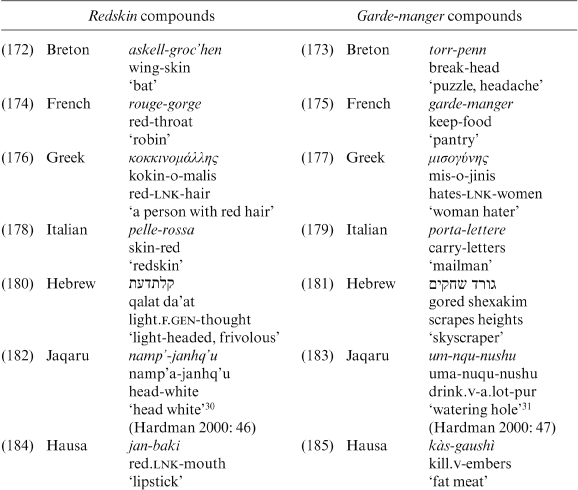

3.1.1.5.2 Semantic characteristics
The languages sampled indicate that the prototypical semantics of exocentric compounds encompasses first, human beings, animals and plants whose explicit part (i.e. surface name) refers to the characteristic quality and, second, instruments of action. This is in accordance with Chung’s observation (1994) that compounds of the garde-manger type usually denote agents (specialized professions), instruments and animals and plants as in Table 3.23. It follows from her analysis that many exocentric compounds of this type have isomorphic equivalents in other languages. This does not mean that other meanings might not occur (see Table 3.24).


3.1.1.6 Coordinative compounds
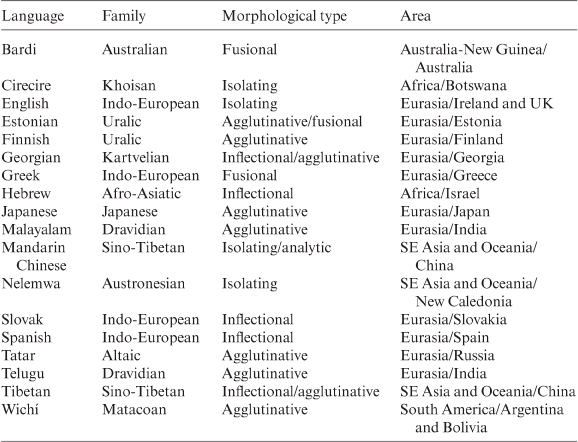
Coordinative (copulative) compounds or co-compounds are in principle double-head structures, because their constituents are not related by semantic or structural subordination. Coordinative compounding of the noun + noun type is recorded in the languages shown in Table 3.25.
Table 3.25. Coordinative compounding of the noun + noun type
Coordinative compounding of the adjective + adjective type is recorded in the languages shown in Table 3.26.
Table 3.26. Coordinative compounding of the adjective + adjective type

The contents of Table 3.25 and Table 3.26 comply with the observations of Wälchli (Reference Wälchli2005: 2), according to whom co-compounds are mainly found in the languages of Asia, easternmost Europe and New Guinea.
3.1.1.6.1 Formal characteristics
Certain formal differences may occur between coordinative and other compound types, as in Malayalam. As pointed out by Fabb (Reference Fabb, Spencer and Zwicky1998: 67), coordinative compounds may have properties by which they differ from other types of compound, e.g. they do not accept gemination.
While dvandva compounds admit, theoretically, the reordering of their members without violating the meaning, the sequence of constituents is practically fixed. The fixed order is, according to Kageyama (Reference Kageyama1982: 236), determined by various linguistic, social and cultural factors.33
3.1.1.6.2 Semantic characteristics
Semantically, not all coordinative compounds are equal in nature, with dvandva compounds representing a subclass of coordinative compounds. In spite of this, Scalise and Bisetto (Reference Scalise, Bisetto, Lieber and Štekauer2009: 36) point out that the Sanskrit term dvandva is often used inappropriately for the whole class of coordinative compounds. L. Bauer’s (Reference Bauer, Lieber and Štekauer2009b: 351–2) analysis of coordinative compounds distinguishes the following types (cf. also L. Bauer Reference Bauer2008):
(a) translative, e.g. Paris-Rome [flight],
(b) co-participant, e.g. Russian-Turkish [war],
(c) appositional, e.g. owner-director,
(d) compromise, e.g. blue-green,
(e) generalizing, e.g. Mordvin, a Uralic language spoken in Eurasia, t’ese-toso (lit. ‘here there’, i.e. ‘everywhere’), and
(f) dvandva, which may be subclassified as additive, co-hyponymic, co-synonymic, approximate, and endocentric.
A different position is represented by Wälchli (Reference Wälchli2005), who takes inherence-based ‘natural coordination’34 as the criterion of co-compoundhood, and disregards copulative compounds which violate this principle. As a result, Wälchli eliminates from the scope of co-compoundhood types (a) to (d) of L. Bauer’s classification. The analysis of co-compounds presented here is based on the approach represented by Bauer.
Thus, the meaning of coordinative compounds can be completely based on the principle of compositionality or the motivating constituents may develop a new quality. A source of the latter is Hindi, because the meaning of a number of coordinative compounds in Hindi is more than the mere sum of the meanings of their motivating words: they constitute a new conceptual meaning both in nominal and in adjectival compounds (see Table 3.27).
Table 3.27. Non-compositional nominal and adjectival compounding in Hindi (examples by Kachru Reference Kachru2006: 119–20)

A similar technique can be found in other languages too:
(211)
- Telugu
tallitanDrulu
mother-father-pl
‘parents’

(212)
- Tibetan
ར་
གra-lug
goat-sheep
‘domestic animals’
As noted by Kachru (Reference Kachru2006: 120) ‘a number of such compounds have one item from Indo-Aryan and one from Perso-Arabic source, both with identical meaning’:
(213)
- Hindi
धन-
लतdhən-dOlət
‘wealth’
 लत
लत(214)
- Hindi
तन-बदन
tən-bədən
‘body’
Conversely, the second member of some compounds may have an opposite meaning to that of the first constituent:
(215)
- Hindi
- न-न
den-len
give-take
‘reciprocity’
 न-
न-(216)
- Hindi
आ
-aga-pīcha
front-back
‘future in light of past experience’
(Kachru Reference Kachru2006: 120)
 -
-

Examples of coordinative compounds based on the compositional principle and of those which are not are given in Table 3.28.
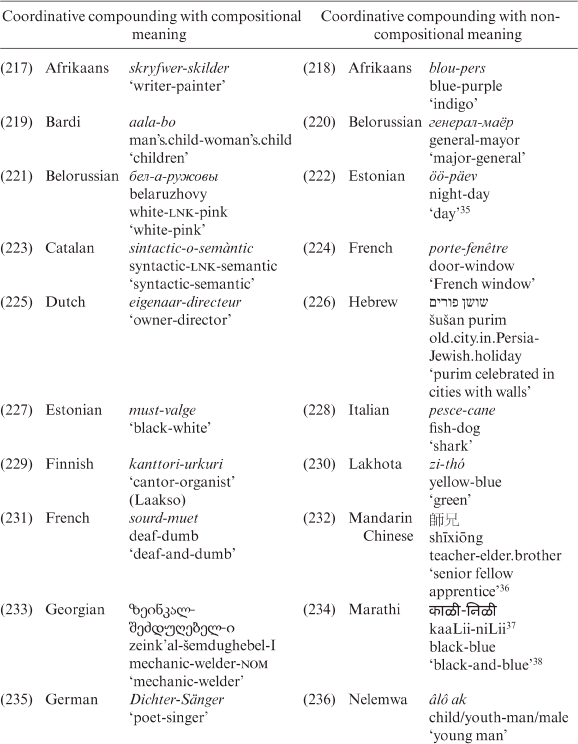

Asher and Kumari (Reference Asher and Kumari1997: 399) maintain that the compositional principle may be reflected in the attachment of the plural morpheme, as in Malayalam, where the coordinative compounds with the feature [+ human] are always in plural (suffix -maar). If the feature is [– human], the plural suffix -kaì is used:
(246)
3.1.2 Recursiveness in compounding
Recursive compounding is recorded in the languages shown in Table 3.29.

We understand recursiveness as a repetition of a word-formation process, such as recursive conversion in (247), or a formally or semantically grounded word-formation rule, as in (248):39
(247)
- English
to sur´vey > a ´survey > to ´survey
(L. Bauer and Valera Reference Bauer, Valera, Bauer and Valera2005: 12)
(248)
- Slovak
mal<il><il><il>ink-ý
small-dim-dim-dim-dim-m.sg.nom
‘very very very very small’
The latter example illustrates the repetition of a semantically based rule of diminutive-formation based on a combination of two different formally defined rules. The -il infixing rule is recursive and follows a single, non-recursive application of another diminutivizing rule which is based on the suffix -ink. Examples of recursive compounding are the following:
(249)
- Afrikaans
kat-kos-bak-winkel-venster
cat-food-bowl-shop-window
‘window of a shop that sells bowls for cat food’
(250)
- Dutch
hand-doeken-rek
hand-towel-rack
‘towel rack’
(251)
- Estonian
mets-maasika-moosN
forest-strawberry-jam
‘wild strawberry jam’
(252)
- Greek
αγροτοελαιοκαλλιέργεια
agrot-o-ele-o-kalierjia
farmer-lnk-olive-lnk-culture
‘olive cultures by farmers’
(253)
- Hungarian
villany-szerelő-mester
electricity-technician-master
‘electrician’
(254)
- Italian
direzione ufficio acquisti
direction-office-purchases
‘management of the purchasing office’
(255)
- Jaqaru
wank-nayr-aq˝i
wanka-nayra-aq˝i
person.from.Huancayo-eye-cave
‘Cave of the Huanca eye’40
(Hardman Reference Hardman2000: 47)
(256)
- Portuguese
conta-poupança-habitação
account-saving-inhabitation
‘inhabitation saving account’
(257)
- Slavey
gah-wέh-tlˡá-ˡe
rabbit-skin-bottom-clothing
‘rabbit skin pants’
(Rice Reference Rice, Lieber and Štekauer2009: 551)
(258)
- Tzotzil
pat mak na
back-lid-house
‘behind the door of the house’
(Haviland Reference Haviland1980)
Recursiveness is frequent in some languages and infrequent in others. In Germanic languages recursiveness frequently gives rise to long expressions:
(259)
- Dutch
weersvoorspellingsdeskundigencongres
‘weather forecast experts conference’
(Don Reference Don, Lieber and Štekauer2009: 370)
(261)
- German
Riesentunnelbaumaschine
‘giant-tunnel-building-machine’
(262)
- Swedish
vägg-bok-hylle-bok-stöd
(lit. ‘wall-book-shelf-book-end’)
‘book end for a book-shelf on a wall’
Recursiveness is also common in languages of other families, like Malayalam, where ‘native words of compounds can be combined with loans from Sanskrit, English or elsewhere’ (Asher and Kumari Reference Asher and Kumari1997: 400):
(263)
(264)
(265)
Deviations from the prototypical case in our sample include:
(a) a compound with verbal stems inserted between nominal stems:
(266)(266)
- Totonac
kilhpi:li:tzi:lakamiyá:lh
kilhpi:-li:tzí:n-laka-min-ya:lh
jawline-laugh-face-come-stand
‘stand looking this way laughing out of the side of one’s mouth’
(b) a combination of verbal and nominal stems:
(267)(267)
- Mandarin Chinese
收音機開關
shōuyīnjīkāiguān
receive-sound-machine-open-close
‘radio knob’
(c) a combination of adjectival and nominal stems:
(268)(268)
- Tibetan
- ད་་ག་མད
bod-rgya-tshig-mdzod
Tibetan-Chinese-Word-Treasury
‘Tibetan–Chinese bilingual dictionary’
(d) a present participle between nominal stems, the first of which is in genitive:
(269)(269)
- Finnish
parran-ajo-kone
beard-gen-driving-machine
‘razor’
(Koivisto)
(e) a combination of various categories:
(270)(270)
- Hebrew
אף על פי כן
‘af ‘al pi xen < ‘af ‘al pi < ‘al pi
also-on-mouth-so < also on mouth < on-mouth
‘nevertheless, all the more so’
(f) a combination of an ordinal numeral with a nominal stem:
(271)(271)
- Serbian-Croatian
prvo-bratučed
‘first cousin’
(g) one of the nouns in plural:
(272)(272)
- Telugu
kaLLa jooDu peTTe
eyes-pair-box
‘spectacle case’
 ད་
ད་ ་
་ ག་མ
ག་མ ད
ད
While compounding is right-headed in the majority of languages, the most productive compounding rule in Breton yields left-headed compounds. This is also reflected in recursive application of such a compound rule (Stump, pers. comm.):
(273)
- Breton
toull-maen-gad
hole-stone-rabbit
‘a vent-hole above the door in a traditional oven, which was sometimes plugged with a rock called a maen-gad [stone-rabbit]’
By contrast, recursiveness is strictly limited in Slavic languages, where recursive compounding is in principle unproductive and restricted to specific cases, like copulative adjectives in Russian and Slovak:41
(274)
- Russian
англо-немецко-японско-руско-венгерский словар
anglo-nemecko-yaponsko-rusko-vengersky slovar
‘English-German-Japanese-Russian-Hungarian dictionary’
(275)
- Slovak
červeno-modro-biela (zástava)
‘red-blue-white (flag)’
In Konni, it is possible to add more than one adjective to a noun to form a compound. According to Cahill’s (pers. comm.) data, three adjectives in a word is the maximum:
(276)
- Konni
jà-kù-y
lÌ-kpÍÍ-!káthing-old-white-big-the
‘the old big white thing’
(Cahill 1999)42

Finally, in another non-recursive language, Spanish, recursiveness can be identified for some exocentric verb + noun compounds of the garde-manger type:
(277)
- Spanish
limpia-para-brisas
limpia-[para-brisas]
cleans-stops-breeze
‘windscreen wipers’
In some other languages, the productivity of recursive compounding is questionable, as in Lakhota, where recursiveness has been cited for noun incorporation allowing two incorporated nouns to produce the structure [N+[N+[V]]], as in (278) and (279):
(278)
- Lakhota
šų(g)mník?u
dog-water-give
‘water houses’
 hoth
hoth
However, these cases are controversial and, thus, Pustet (pers. comm.) maintains that cases of double incorporation as above do not appear in her database, nor in any other Lakhota source except in de Reuse’s (1994) paper. Although the pattern exists, Pustet suspects that they may be idiosyncratic cases of lexicalization.
3.1.3 Word-formation base modification in compounding
Base modification in compounding is recorded in the languages shown in Table 3.30.
Table 3.30. Base modification in compounding
The nature of modifications varies and is manifested in diverse ways. Table 3.31 includes the types found here with examples.



3.2 Reduplication
Reduplication is recorded in the languages shown in Table 3.32 (80 per cent of the study sample):

Reduplication can be both inflectional and derivational, although the latter is more frequent (Bybee Reference Bybee1985: 97).48 Wiltshire and Marantz (Reference Wiltshire, Marantz, Booij, Lehmann and Mugdan2000: 557) define reduplication as a type of affixation ‘in which the phonological form of an affix is determined in whole or in part by the phonological form of the base to which it attaches’. Example (296) compares non-reduplicated and reduplicated forms:
(296)
A disputable point of this definition is the term affix, because in full reduplication it is the base that is reduplicated and, therefore, it can hardly be considered to function as an affix. Another reason why use of the term affix for the definition of reduplication is controversial is that each affix is a generalization in terms of the meaning applicable to a (relatively) high number of word-formation bases, unlike reduplicated elements of partial reduplication.
As a result, a number of approaches have arisen which propose alternative views. Inkelas and Zoll (Reference Inkelas and Zoll2005), among others, treat reduplication as morphological copying, which brings full reduplication closer to compounding. Others (McCarthy and Prince Reference McCarthy, Prince and Goldsmith1994; Urbanczyk Reference Urbanczyk2001) distinguish between affix-like and compound-like reduplication. The latter approach seems to be reasonable, because what is covered by the term reduplication are processes of a different nature. The repetition of a stem, i.e. a bilateral sign, is different from making use of a combination of phonemes which do not carry any meaning in isolation.
Himmelmann (Reference Himmelmann, Adelaar and Himmelmann2005: 121) states that ‘reduplication is probably the most pervasive morphological process in western Austronesian languages in that it is a productive process in all of them’. Similarly, Wiltshire and Marantz (Reference Wiltshire, Marantz, Booij, Lehmann and Mugdan2000: 561) argue that ‘reduplication plays a major role in the formation of words in members of the Austronesian family . . ., while it is less common in the Indo-European family members’ and that ‘reduplication also seems to be found in languages of all morphological types’.
A question may be raised how to qualify languages like English in terms of reduplication. The existence of full reduplication is sometimes denied in English and only constructions of the type helter-skelter are cited (Carstairs-McCarthy, pers. comm.). Formations of precisely this type are treated by Marchand (Reference Marchand1960: 345ff.) as pseudocompounds and labelled as rime combinations. Marchand also identifies as reduplications so-called ablaut combinations like chitchat and singsong. Similar reduplications occur in other languages of our sample too, e.g. in German, as in Heckmeck ‘fuss’ and ruckzuck ‘very quickly’.
Carstairs-McCarthy’s position means that he disregards the existence in English of cases of complete (total) reduplications, each of whose individual parts carries a meaning of its own and contributes to the overall meaning of the complex word. In his (2004) analysis, Hohenhaus discusses cases like job-job, jealous-jealous, and others under the label identical constituent compounding. Hohenhaus stresses two facts:
(a) the reduplicated constituent contributes to the modification of the basic, prototypical meaning of the simple word, and
(b) reduplication is a genuine word-formation process.51
Hohenhaus also shows that the common semantic pattern for identical compounds in English is ‘an XX is a proper/prototypical X’ for nouns and ‘XX = really/properly/extremely X’ for adjectives, adverbs and verbs. Hohenhaus’s review of the literature (specifically, Wierzbicka Reference Wierzbicka1991 and Mau Reference Mau2002) shows that this phenomenon is vivid in other languages. The sample studied here provides examples of reduplication inside and outside the Indo-European family:
(297)
- Italian
neri neri
‘really black, very black, jet black’
(298)
By contrast, some examples from the literature raise questions, e.g. Spanish mina mina and cuidad cuidad (Mau Reference Mau2002): mina and cuidad, being noun and verb respectively, are hardly likely to be reduplicated, because they are not gradable or are not perceived as such by Spanish speakers. In fact, reduplication in Spanish is based on adjectives (301). Examples (299) and (300) illustrate a noun and a verb which could be reduplicated, even if this device is used rarely:
(299)
- Spanish
Es un coche~coche
is-a-car~car
‘It is a very good car’
(300)
- Spanish
?/*Hoy trabaja~trabaja
today-work~work
‘Today, work a lot’
(301)
- Spanish
Es malo~malo
is-bad~bad
‘It is really bad’
These and other examples demonstrate that ‘at least within the realm of Indo-European languages, including Germanic, Romance and Slavic languages, the phenomenon does have some footing’ (Hohenhaus Reference Hohenhaus2004: 319). What matters, however, is the cross-linguistic semantic unity of this type of reduplication, captured above.
Reduplication need not occur as the only word-formation process in a naming act (Inkelas Reference Inkelas and Brown2006: 417). Table 3.33 shows several possibilities in which reduplication accompanies, or is accompanied by, another process in various languages.
Table 3.33. Reduplication and affixation, and reduplication and compounding
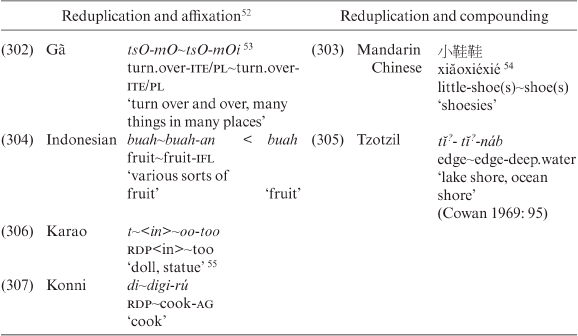
In Tzotzil, reduplication may also be combined with a suffix attached to so-called stative stems. If a stative stem combines with the suffix -tik ‘pretty . . .’, ‘somewhat . . .’, it is always formed by root reduplication. Such a reduplicated form never occurs alone (308):
Tzotzil also provides an example of reduplication of an affixed stem, the so-called radical (309):
(309)
- Tzotzil
mákan~mákan
repeatedly.close.off~repeatedly.close.off
‘keep on taking over (as land)’
Reduplication in Jaqaru is interesting in several respects:
(a) in all of its cases it is complete, but the morphophonological rule causes the last vowel in the reduplicated preposed constituent to drop,
(b) it may be based on both roots (310) and stems (311), and
(c) the reduplication of intensive adjectives includes a linking element -y- giving the structure C1V1C2V2yC1V1C2V2 (312), while the reduplication of intensive verbs includes the linking element -x- resulting in the structure C1V1C2V2chC1V1C2V2 (313):
(310)(310)
- Jaqaru
ut~uta
rdp~house
‘place where there are many houses’
(311)(311)
- Jaqaru
taj-nuq~taj-nuqu
rdp~step.on
‘walk step by step, very carefully’
(312)(312)
- Jaqaru
janhq’u~y~janhq’u
white-lnk-white
‘very white’
(313)(313)
- Jaqaru
jayra~ch~jayra
dance~lnk~dance
‘dance untiringly’
3.2.1 Types of reduplication
Structurally, we distinguish two basic types of reduplication, complete and partial.56 Complete reduplication is recorded in the languages shown in Table 3.34.

Table 3.34 shows that complete reduplication is widespread in the sample. Bourchier (2008) also reports a high percentage (87 per cent) in her research into thirty languages.57 As we will see with other reduplication data, our data and Bourchier’s are very similar. What makes this agreement even more surprising is that her research encompasses both inflectional and derivational categories. It may therefore be assumed that, if present in a language, reduplication is used for both inflectional and derivational purposes.
Partial reduplication is recorded in the languages shown in Table 3.35.


Specifically, partial preposing reduplication is recorded in the languages shown in Table 3.36.

Partial postposing reduplication is recorded in the languages shown in Table 3.37.


The occurrence of both partial preposing and partial postposing reduplication is again similar to what is reported in Bourchier (2008). Infixation is the only type of reduplication for which our data differ considerably from Bourchier’s. Infixing reduplication is recorded in the languages shown in Table 3.38.
Table 3.38. Infixing reduplication in the study sample

While our data comply with the general resistance of languages to the violation of the integrity of stem (root) morphemes, Bourchier’s data diverge markedly, also because infixing reduplication occurs in languages which do not permit infixation proper: ‘the prevalence of infixation within reduplication remains an unresolved issue. It is not clear why infixation should be more readily permitted for reduplicated morphemes than for fixed-segment morphemes, especially given that both cause the same disturbance to root integrity and prosody’ (Bourchier 2008: 14).
3.2.1.1 Formal characteristics
Roberts (Reference Roberts and Dutton1991) notes that reduplications like those in (314) and (315) have a reduplicated stem:
(314)
(315)
This indicates the repeated action (iterative aspect), and then a vowel alternation which indicates the haphazard manner of the repeated action. Without vowel alternation in the reduplicated formant, the meaning is ‘repeated action’, whereas with vowel alternation, the meaning is ‘repeated action + irregular motion’. Thus, a process of vowel alternation indicates a grammatical category of ‘irregular motion’. The meaning of this ‘irregular motion’ category will be different for the context of the action expressed by each verb. The form of the alternation is different depending on the operative vowel in the verb stem. According to Roberts, eight possibilities have been observed (see Table 3.39).
Table 3.39. Vowel alternation in reduplication in Amele

Some languages, like Amele (Roberts Reference Roberts and Dutton1991) or Indonesian, make use of both complete and partial reduplication. The following are some examples of complete reduplication in Indonesian and Karao:
(316)
- Indonesian
jalan~jalan
walk~walk
‘walk around’
(317)
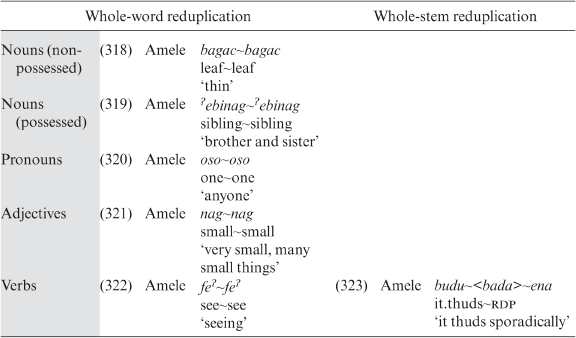
In Amele, complete reduplication can be divided into whole-word reduplication (including inflectional morpheme) and whole-stem reduplication. While the former applies to all major word-classes, the latter only applies to verbs. Examples are given in Table 3.40.
Table 3.40. Whole-word and whole-stem reduplication in Amele by word-class
By contrast, partial reduplication in Amele is primarily leftward from the base form, probably as a compensating device for the absence of prefixation, because regular inflection is by suffixation (Roberts Reference Roberts and Dutton1991: 120).59 Roberts demonstrates that leftward reduplication usually copies the first CV of the base form (324) and (325), but V and VC types also exist (326):
(324)
- Amele
da~dahig
rdp~his.ear
‘ears of everyone’
(326)
- Amele
ab~abale?
rdp~search.with.hands
‘search repeatedly with hands’
Partial infixing reduplication is also present in Amele:
(327)
Example (328) illustrates partial preposing reduplication in Karao:
(328)
- Karao
me~so~sodok
me-rdp~solok
sta.irr-dim-more.than
‘be a little more than’
Specific cases can be found concerning reduplication, e.g. reduplication in Nelemwa can also be accompanied by stem modification:
(329)
- Nelemwa
ko~xole
ko~kole
rdp~throw.away/empty
‘scatter, spread, sow’
Reduplication is most frequently used with verbs and nouns, but other word-classes are also possible, mainly adjectives. The word-formation reduplication of adverbs, pronouns and numerals is relatively rare, in descending order. Reduplication is productive in Amele (Roberts, pers. comm.) and in Japanese (Kimenyi Reference Kimenyi2008). In the latter it is especially so with stem reduplication of words that consist of two syllables. This complies with the cross-linguistic preference for a disyllabic foot melodic template as suggested in Mutaka and Hyman (Reference Mutaka and Hyman1990). All types of words (verbs, nouns, adjectives, numerals, adverbs, pronouns, prepositions) can occur in the reduplicated form. Examples in (330) and (331) illustrate disyllabic structures and examples in (332) and (333) illustrate double reduplication in Japanese in which words with two independent stems reduplicate them both:
(330)
- Japanese
ヒリヒリ
hiri~hiri
‘taste hot’
(331)
- Japanese
生き生き
iki~iki
‘lively, fresh’
(332)
- Japanese
正ʑ堂ʑ
sei~sei~dô~dô
‘play fair and square’
(333)
- Japanese
戦ʑ恐ʑ
sen~sen~kyô~kyô
‘with fear and trembling’
As illustrated by Kimenyi, the Rendaku rule, the voicing of the consonant of the first syllable in Japanese compounds, also applies in reduplication:
(334)
- Japanese
はるばる
haru~baru
‘all the way’
Some languages, like Pipil, make use of partial reduplication only. Apart from using reduplication for the expression of plurality, it is frequently used with verbs. As stated by Campbell (Reference Campbell1985: 80), reduplication in verbs can be of two types:
both reduplicate the initial consonant(s) and the first vowel of the root, or only the vowel if no consonant occurs. In both cases the vowel is short. They differ in that one has only this form (i.e. CV-) while the other takes an additional h (i.e. CVh-). The latter is quite productive . . . The former (CV-) is not productive, but many examples of it exist, typically with -ka, or -tsa verbs . . . It means that plural objects or repetition of the action are involved.
(336)
- Pipil
a. ki~kinaka
‘complain.v’
b. tu~tu:nia
‘heat.v’
c. tsu~tsu:na
‘play (a musical instrument)’
(337)
- Pipil
ah~ahwa
rdp-bark.v, scold.v
‘scold.v, bark.v’
(338)
- Pipil
pah~pachua
rdp-hold.down.v
‘press.v’
In addition, reduplication is also used with the so-called diffusion verbs62 to express repetition. If the verb is intransitive, it ends in -ka and, if it is transitive, it ends in -tsa (see Table 3.41).
Table 3.41. Intransitive and transitive verbs with reduplication in Pipil

Kwakw’ala has formally a highly differentiated system of complete and partial reduplication, where partial preposing reduplication includes a number of cases (Boas Reference Boas, Boas Yampolsky and Harris1947: 220).63 Hindi can completely reduplicate nouns (341), adjectives (342), participles (343) and adverbs (344) and participles admit partial preposing reduplication (Kachru Reference Kachru2006: 122):
(341)
- Hindi
घर~घर
ghər~ ghər
house~house
‘every house’

 ~
~(343)
- Hindi
िलख ~िलख कर
likh~likh kər
‘having written repeatedly’
(344)
- Hindi
पल ~पल
pəl~pəl
‘every moment’
Ambiguous cases can also be found concerning the existence or not of reduplication in a given language. According to Schiffman (1996) in Tamil, as in other South Asian languages, there is a kind of reduplication process which consists in taking a lexical item and following it with the same item reduplicated, except that the first consonant and vowel are replaced by the CV sequence. The general meaning of this construction is ‘(item) and other things like it’:

(346)
- Tamil
- · ·
paratte~kiratte
‘nasty words, aspersions, etc.’
(Schiffman Reference Schiffman1996)


Schiffman also gives examples of the distributive function of reduplication aimed at specifying different kinds of things, at linking different things in a certain relationship or at distributing qualities among various members of a set of things. In this case, reduplication is complete (the final vowel of the first constituent and the initial vowel of the second constituent merge):
(347)
- Tamil
அவ
~அவகavang~avanga
rdp~avanga
‘all kinds of different people’
(Schiffman Reference Schiffman1996)
 ~அவ
~அவ ~அ
~அ
Another ambiguous case is that of Dangaléat, where the separation inflection vs derivation is involved. According to Shay (pers. comm.), there is some evidence of derivational reduplication in verb stems of Dangaléat with the structure C1VC2C1VC2. These represent rightward reduplication of the root consonants and insertion of a high vowel, which matches the final consonant for the feature [+ round]. The newly formed syllable has the same tone as the original syllable. Reduplicated verb stems show evidence of derivation from both Dangaléat and Arabic:
In Shay’s view, such reduplication may once have been inflectional, e.g. to encode plurality or intensity of an event.
A final case of ambiguity of reduplication involves the distinction between compounding and reduplication. Thái Ân (pers. comm.) notes that sometimes there is no clear distinction between compounding and reduplication in Vietnamese. An example of indisputable reduplication is given in (351):
(351)
- Vietnamese
ɲE21 ɲE31?
nhè~nhẹ.adv
rdp~light
‘gently, lightly’
(Thái Ân)
Finally, reduplication may be recursive. The literature cites several cases: Harrison (Reference Harrison1973: 426),66 Moravcsik (Reference Moravcsik and Greenberg1978: 301)67 and Wiltshire and Marantz (Reference Wiltshire, Marantz, Booij, Lehmann and Mugdan2000: 559)68 speak of ‘triplication’ and Rose (Reference Rose2003: 114) cites examples of Tigré, an Afro-Asiatic language spoken in Africa.69 That these cases are not rare also follows from Moravcsik’s (1978: 312) observation of ‘instances of multiple reduplication in many languages and possibly in all’, even if this claim seems to be rather strong. The existence of recursive reduplication has been expressly denied for several languages (e.g. Ilocano, Karao or Telugu). In Hausa, triplication is not common according to Newman (pers. comm.), although it does occur with ideophones. As far as the sample studied here is concerned, examples of recursive reduplication may be found in Slovak diminutives, as in (248).
As to the distribution of the reduplicated material, as maintained by Wiltshire and Marantz (Reference Wiltshire, Marantz, Booij, Lehmann and Mugdan2000: 560), ‘the position of the material in the base that is copied in reduplication may vary . . . material copied from base-initial position may appear in prefix, suffix or infix position. Base-final material may be copied by prefixes, suffixes, or infixes as well.’ In the case of partial reduplication, the most frequent position of the reduplicated material is at the beginning of a base (Rubino Reference Rubino and Haspelmath2005a: 114) (see Table 3.42).


One of the formal features of partial reduplication recorded is that the stem material is copied on the side from which it is taken, i.e. prefixes tend to copy stem-initial material, suffixes stem-final material and infixes stem-internal material. This seems to relate to Marantz’s account of reduplication as an affixation process. He argues that the reason why all the diverse morphological processes labelled as reduplication are subsumed under this general label ‘is the resemblance of the added material to the stem being reduplicated’ (Marantz Reference Marantz1982: 436). In his view, reduplication is the affixation of a CV skeleton (a reduplicating morpheme) of an autosegmental tier, e.g. the phonemic melody, from the stem to which the reduplicating morpheme affixes.
Apart from the absolute linear position of the reduplicated material, segmental vowelhood and consonantality are crucial for the formal description of reduplications (Moravcsik Reference Moravcsik and Greenberg1978: 305, 307). Table 3.43 shows the most frequent structures of reduplicated material in our sample.

A final case concerning formal characteristics is that of echo compounding.
According to Kachru (Reference Kachru2006: 128), echo compounding is characteristic of South Asian languages. It is based on the principle of copying the first constituent except for the first consonant. In Hindi, the first consonant of the echo constituent is always v-. This means that, whatever the initial consonant of the first constituent is, it is changed to v- in the echo constituent. The meaning of the echo constituent (which never occurs on its own) is ‘and the like’:72
(394)
- Hindi
िक
ब-िवबkitab-vitab
‘books and the like’
(395)
- Hindi
- दर-दर
sundər-vundər
‘beautiful and the like’

 दर-
दर-
Similar examples can be found in other languages:
(396)
- Indonesian
sayur-mayur
‘various sorts of vegetable’
(397)
(398)
- Telugu
paalu-giilu
‘milk and other things’

3.2.1.2 Semantic characteristics
Reduplication has received considerable attention for its importance in non-European languages. Moravcsik’s (1978: 316) review of reduplication in a number of languages finds out that the meanings associated with reduplication strikingly recur across languages. What follows agrees with this statement, but also disagrees with her view that ‘there is no a priori reason why reduplication . . . should serve as the expression of some meanings rather than as that of others’ (Moravcsik Reference Moravcsik and Greenberg1978: 316).
The fact that the most common meanings of reduplicated forms are intensification and iterativity suggests that the role of iconicity, in particular diagrammaticity, is crucial. This is in accordance with the assumptions of Natural Morphology: extended form is accompanied by semantic enlargement, in other words, the reduplication of a particular form is an indicator of a growing quantity of items, actions or quality in general, as in the numeral ‘two’ in Kalkatungu, where doubling the form doubles the meaning:
(399)
- Kalkatungu
lyuati~lyuati
two~two
‘four’
Thus, while Regier’s (1994: 3–4) radial category model identifies repetition as the core semantic concept, the core semantic concept may be specified more generally, in particular, as increased quantity (of various kinds), with a range of manifestations mentioned by Moravcsik (Reference Moravcsik and Greenberg1978), Nomura and Kiyomi (1993)74 and Regier (Reference Regier1994), among others. However, the same process of reduplication may have different and even contradictory semantic effects in the same language with two different word-classes: in Hausa, many adverbs comply with the core meaning of increased quantity when reduplicated (400), but adjectives generally run counter to this core meaning and reduplication leads to reduced quantity (401):75
(400)
- Hausa
maza-maza
fast-fast
‘very fast’
(401)
This is not an isolated case of the violation of the iconicity principle. In fact, the quantity-raising meanings of reduplication, like intensity, iterativity, continuity or augmentativity have their counterparts in the quantity-reducing meanings of approximation, attenuation, diminutiveness, distribution, hypocoristics, etc. Thus, one and the same process can have two opposite effects in terms of iconicity, and this has attracted considerable interest.76
Mattes (2006)77 discusses full reduplication in Bikol, an Austronesian language spoken in South East Asia and Oceania which can produce both augmentative and diminutive meanings of the same form, and presents a different view: these are different realizations of the underlying concept of the change of quantity, with both types of meaning being iconic.
The languages studied here illustrate a wide range of meanings and shades of meaning that can be expressed by reduplication. Among these, the most frequent variants of the basic semantic concept of increased quantity are iterativity (in compliance with Regier Reference Regier1994) and intensification, i.e. the meanings which correspond to the basic natural iconic function of reduplication (see Table 3.44).




Among the semantic features of reduplication, the basic semantic concept expressed by reduplication in word-formation apparently is the natural concept of increased quantity, mainly represented as iterativity and intensification of action. This overview of various categories of meaning and diverse shades of meaning indicates the extreme semantic capacity of reduplication as a word-formation process which, outside Indo-European languages, approaches the capacity of affixation processes. In languages like Amele,86 in which the semantic changes expressed by reduplication may be accompanied by word-class change, the possibility to distinguish between class-changing and class-maintaining reduplication strengthens the analogy to affixation processes.
3.3 Blending
Blending is discussed within this chapter because the underlying principle of its formation is identical to any other type of complex words covered here: blends are based on a combination of stems. Unlike the other stem-based processes, the formation process continues by speaker-friendly form-reduction which often eliminates the morphosemantic transparency of this kind of coinage.
Blending is recorded in the languages shown in Table 3.45 (23.64 per cent of the study sample).


As Table 3.45 shows, blending is mainly a feature of Indo-European languages. Each of these languages makes productive use of compounding, which supports the postulate that both compounding and blending are based on the same word-formation principles and that blending is compounding with subsequent form-reduction (Štekauer Reference Štekauer, Štekauer and Lieber2005: 217). In the study sample, blending often co-occurs with compounding and adjectival coordinative compounding (the latter with the exception of Vietnamese).
In general, blending is a peripheral phenomenon. It could be considered as word-formation in the service of stylistics. Examples outside the English-speaking world are mostly restricted to advertisements, product names and related areas. Thus, Japanese has blending as a word-formation process, but it is generally limited to the fanciful naming of new products and, thus, is not as productive as in English. Probably the best-known example, according to Kageyama (pers. comm.), is (475):
(475)
Examples of blends can be given for a number of other languages:
(476)
- Afrikaans
selfoon
sellulêre telefoon
cellular-telephone
‘cell phone’
(477)
- French
photocopillage
photocopy-pillage
‘illegal photocopying’
(478)
- Greek
παντo
panto
palto-manto
coat-light.coat
‘coat’
- Georgian
კოლმეურნეობა
k’olmeurneoba
k’olektiur-i-meurneoba
collective-lnk-farming
‘collective farming’
(480)
- Hebrew
ערפיח
‘arpiax
‘arafel-piax
fog-soot
‘smog’
(481)
- Ilocano
sariugma
sarita-ugma
story-ancient
‘legend’
(482)
- Italian
cantautore
cantante-autore
sing-author
‘singer-songwriter’
(483)
- Nelemwa
ceemode
ceego-mode
bite-break
‘cut with one’s teeth’
(484)
- Portuguese
portunhol
português-espanhol
‘Portuguese-Spanish’
(485)
- Romanian
zdrumica
zdrobi-dumica
crush.v-crumble.v
‘crunch.v’
(486)
- Serbian-Croatian
fiskultura
fizička-kultura
physical-culture
‘physical culture’
(487)
- Slovak
sladucha (in poetry)
sladká-mladucha
sweet-bride
‘sweet bride’
(488)
- Swedish
ekomjölk
ekologiskt-mjölk
ecological-milk
‘ecologically produced milk’
3.4 Summary
The chapter reviews various types of word-formation processes which combine free morphemes, like compounding, incorporation, reduplication and blending. Within these, subtypes are discussed, like adjective + adjective compounds, verbal compounds, noun + noun compounds, exocentric and endocentric compounds, and borderline and/or ambiguous cases. The discussion of verbal compounds focuses on their description as such or as a different word-formation process, according to the interpretations available in the literature, and this discussion leads to the concept of noun incorporation. Formal and semantic effects of compounding and of incorporation are discussed, showing a diversity of types which makes it difficult to find cross-linguistic patterns.
1 Here exemplified with a common linking element in Indo-European languages: -o-.
2 Interestingly, the majority of examples in our sample denote colours. According to Newman, about half of twenty compound adjectives in Hausa have the structure ruwan X ‘colour-of-X’:
- Hausa
ruwan tōkaà
colour.of-ash
‘grey’
3 Let us also mention the noun + adjective compound type in Udihe (Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 200), which combines a noun and a semantically light (quantifying) adjective, e.g. egdi ‘many’ or maŋga ‘strong, very much’, with intensifying meaning:
- Udihe
meje egdi
‘clever, intelligent’
- Udihe
kui(-ni) maŋga
‘strong’
4 According to Lynch (pers. comm.), Anejom does not have adjectives either.
5 Compound verbs formed by back-formation, such as globe-trot from globetrotter, or globe-trotting, are explained by Adams (Reference Adams1973: 106) as a reinterpretation of their constituent structure, e.g. from [globe] + [trot[ter]] to [globe] + [trot] + er. As a result, the suffix -er does not belong to the stem trot-, but to the compound stem globe-trot-, and can be removed leaving the compound verb globe-trot. Other examples are the verbs brainwash, computer-generate, etc. (Adams Reference Adams2001: 101).
6 Cf. Chung (Reference Chung2006) on verbal compounds in Mandarin Chinese and Ralli (Reference Ralli2009) in Greek.
7 ‘The reciprocal influence of the various patterns of word-formation plays an important role. The existence of composite verbs of a given type, formed for instance by retrograde derivation, will encourage and facilitate the formation of similar verbs by other means of word-formation, for instance by conversion or compounding, and vice versa’ (Pennanen Reference Pennanen1966: 7.5). Thus, chain-smoke is a back-formation from chain-smoker but chain-drink (1958) is an analogical formation.
8 In technical language only (Dalton-Puffer, pers. comm.).
9 Meaning ‘a situation beyond control’.
10 Caballero, G., Houser, M. J., Marcus, N., McFarland, T., Pycha, A., Toosarvandani, M., Wilhite, S. and Nichols, J. 2006. ‘Nonsyntactic ordering effects in syntactic noun incorporation’. Manuscript. University of California at Berkeley CA.
11 Inactive predicates are process verbs, stative verbs or adjectives (Gerdts Reference Gerdts, Spencer and Zwicky1998: 87).
12 With two incorporated nouns.
13 Literal.
14 Metaphorical.
15 Such a prefix ‘is basically an incorporated noun, usually a body-part term, which semantically signals instrument by which the action of the verb is realized. These have been called instrumental prefixes because in some languages the incorporated elements appear in a changed, abbreviated form somewhat different from the full nouns from which they are derived’ (Campbell Reference Campbell1985: 96).
15 Pipil is also interesting for the concentration of the most productive noun incorporation within the lexical field of body parts (cf. Mithun Reference Mithun1984: 860):
- Pipil
ta-te:n-na:miki
rdp.ite-mouth-meet/encounter
‘kiss.v’
(Campbell Reference Campbell1985: 98–100)
16 For examples of multiple incorporation with causatives, cf. Gerdts (Reference Gerdts, Spencer and Zwicky1998: 87).
17 Ket is characterized by a rigid template of prefix and suffix position classes, with each position reserved for a particular grammatical category. The following is a template of prefix position classes:

However, various sources give different numbers of positions. Werner’s (Reference Werner1998) ‘maximum model’ of verbal forms in Ket distinguishes 14 positions. This maximum model varies according to the specific type of verb.
18 A song accompanied by hand and body actions.
19 A toponym. There are many toponyms among noun + noun compounds in Jaqaru.
20 According to Pingali (pers. comm.), noun + noun compounds in Telugu also have a plural suffix inside them.
21 Kastovsky (Reference Kastovsky, Lieber and Štekauer2009: 331) stresses the fact that these linking elements acted in Indo-European compounds as stem formatives and inflectional endings. In the course of time, they lost their original morphological status and developed into a purely formal compound marker. This is proved, Kastovsky notes, by modern examples where the linking elements cannot be the appropriate inflectional ending, e.g. Liebesdienst ‘favour’ (lit. ‘service out of love’) or Universitätsbibliothek ‘university library’, because neither Liebes nor Universitäts are genitives of feminine Liebe and Universität, respectively. For discussion on linking elements in German cf. also Lieber (Reference Lieber1981), Becker (Reference Becker1992), Anderson (Reference Anderson1992), Beard (Reference Beard1995), Wegener (Reference Wegener2003), Barz (Reference Barz2005) or Neef (Reference Neef, Lieber and Štekauer2009).
22 L. Bauer (Reference Bauer, Lieber and Štekauer2009a: 406) shows that the left-hand element of Danish compounds selects a particular linking element. While rare, there are instances of two different linking elements distinguishing the meaning of otherwise identical compounds, e.g. landmand ‘farmer’ (lit. ‘land-man’) vs landsmand ‘fellow countryman’.
23 The link is an etymological possessive clitic.
24 As noted by Ralli (pers. comm.), Greek compounds have stems as their first member. Their structure is stem + stem or stem + word and they also include a linking element -o- between the first and the second member. However, there are also some loose multi-word compounds, the structure of which is word + word. This category does not have linking elements.
25 ‘The phenomenon to be named is usually identified with a specific conceptual class having its categorial expression in the particular language and subsequently, within the limits of this class, it is determined by a mark. The conceptual class enters the onomasiological structure as a determined constituent – the onomasiological base, the mark as a determining constituent – the onomasiological mark. The onomasiological base may stand for a conceptual genus or a more general conceptual class’ (Dokulil Reference Dokulil1962: 29).
26 An animal.
27 Agent nouns of this type are mainly generated by means of two productive verb elements, sī ‘manage.v, control.v’ and lĭng ‘lead.v’.
28 A plant that can withstand low temperatures.
29 I.e. it protects the place it inhabits by eating insect pests.
30 A corn species.
31 A toponym.
32 A military faction in Argentina.
33 E.g. meaning (positive comes before negative), sex (male before female), age (elder before younger) and other factors.
34 Unlike ‘accidental coordination’, ‘natural coordination’ is the ‘coordination of items which are expected to co-occur, which are closely related in meaning, and which form conceptual units’ (Wälchli Reference Wälchli2005: 5).
35 Twenty-four hours.
36 As a term of respect.
37 L = retroflex ‘l’.
38 The colour of skin after hitting something.
39 Cf. Mukai (Reference Mukai2008) on recursive compounding and, for a comparison of English and Spanish, Bauer, L., Díaz-Negrillo, A. and Valera, S. 2009, ‘Recursiveness in neoclassical compounds’, paper presented at the SLE 42nd Annual Meeting, 9–12 September 2009, Lisbon.
40 A toponym.
41 In Dutch it is limited to noun + noun compounds and, under certain conditions, to verb + noun compounds.
42 Cahill, M. 1999. ‘Aspects of the morphology and phonology of Konni’. PhD dissertation, Ohio State University, OH.
43 This is true of Slavey subordinate compounds which share this feature with possessive constructions: an initial fricative of the possessed item is voiced (Rice Reference Rice, Lieber and Štekauer2009: 558).
44 As pointed out by Amiridze (pers. comm.), -a is probably a nominalizer/adjectivizer.
45 With a negative reading, if used with clothes, when dressed tastelessly. However, with meadows full of flowers the reading of č'rel-a-č'rul-a is not negative.
46 With lenition of bran.
47 I.e. with high (H) and low (L) tone.
48 In accordance with Moravcsik (Reference Moravcsik and Greenberg1978: 301), our analysis ignores syntactic cases of the type ‘very very bright’. It also ignores onomatopoetic reduplications, as in the examples below:
- Hindi
cẽ~cẽ
‘chirping’
- Hindi
bhən~bhən
‘buzzing’
(Kachru Reference Kachru2006: 127).
49 With two participants.
50 With more than two participants. Cf. also example (306) for a combined reduplication–affixation process.
51 Hohenhaus is aware of the difficulties connected with distinguishing between reduplicated lexical units and mere repetition in syntax. He proposes two criteria: the contrastive frame ‘(I do) not (mean) YX, but XX’, and interrogative co-text (Hohenhaus Reference Hohenhaus2004: 305–6).
52 As observed by Cahill (1999: 58), agentive derivations in Konni take, besides the agentive suffix, ‘a reduplicative prefix consisting of the first consonant of the stem and a high vowel that generally agrees in roundness (or the [dorsal] nature) . . . and atr with the following stem’.
53 The reduplicated element is an affixed stem: the suffix -mO is used to derive the iterative/pluractional form of the verb. The reduplicated form then takes the suffix -i (Kropp Dakubu, pers. comm.).
54 Only in baby talk (Chung, pers. comm.).
55 The root is too [to¾o] ‘person’. In the case of _tinootoo_, the reduplicated portion appears to be the whole word. It should be noted that in Karao a sequence of vowels is always separated by a glottal stop, which is not represented orthographically because it is predictable. Therefore, _too_ is phonetically [to?o] (Brainard, pers. comm.).
56 Rubino (Reference Rubino and Hurch2005c) is a useful outline of various types and semantic functions of reduplication.
57 Bourchier, L. 2008. ‘Re-dupli-ca-cate this’. Unpublished manuscript. Wellington: Victoria University.
58 According to Brainard (pers. comm.), Karao, like many Northern Philippine languages, has a number of reduplication patterns that occur in both verbs and nouns. In (317), the adjective otik ‘little’ or ‘few’ can function as a verb of manner when it is completely reduplicated as otik-otik ‘little by little’.
59 According to Roberts, partial rightward reduplication is also possible. It involves so-called mirror-image reduplication. A CV string becomes a reduplicated VC string with an epenthetic glottal stop inserted. Mirror-image reduplication occurs with some of the locative pronouns and also with some of the postpositions:
- Amele
ene-?~en
here~rdp
‘It is here’
60 In Indonesian partial reduplication is based on the repetition of the initial stem syllable with vowels usually being reduced. Full reduplication is much more productive in word-formation (Mojdl Reference Mojdl2006: 73). Reduplication may also occur in compound words (Mojdl Reference Mojdl2006: 78):
- Indonesian
surat-khabar~surat-khabar
letter-news~letter-news
‘newspaper’
61 For a detailed analysis of reduplication in Japanese, cf. Kimenyi (Reference Kimenyi2008).
62 Campbell uses the term diffusion verbs to refer to all verbs of sound (including verbs denoting action which produces sounds, such as breaking and tearing).
63 For a thorough overview, cf. Boas (Reference Boas, Boas Yampolsky and Harris1947: 220ff.).
64 Possible source from Dangaléat.
65 Possible source from Chadian Arabic, an Afro-Asiatic language spoken in Africa.
66 Triplication in Mokilese, an Austronesian language spoken in South East Asia and Oceania, here expresses continuative. Reduplication expresses progressive aspect:
67 Triplication in Mokilese here illustrates continuous action:
68 These authors illustrate it in reference to Zhang’s (Reference Zhang, Bosh, Need and Schiller1987: 379) example of adjectives whose semantics is different from reduplication in the Southern Min dialect of Chinese, also known as Taiwanese:
69 Reduplication here causes increasing attenuation:
70 With two participants.
71 With more than two participants.
72 Pejorative.
73 Although the process is less common than in, say, Tamil and in Kannada, a Dravidian language spoken in Eurasia, compounds are sometimes formed by the juxtaposition of a noun root and a partially reduplicated form of the same root. The variation is in the first syllable, in which the base form is usually a consonant-initial. Both consonant and vowel, long or short, are retained. The most usual initial syllable of the echo is ki-, but other plosive-vowel sequences are possible. The meaning of an echoed word ‘X’ is ‘X and that sort of thing’ (Asher and Kumari Reference Asher and Kumari1997: 399).
74 Nomura, M. and Kiyomi, S. 1993. ‘How to motivate the meanings of verbal reduplication: cognitive and typological perspectives’, Handout at Berkeley/UCSD Cognitive Linguistics Workshop. University of California, San Diego, CA.
75 The process also involves shortening of the final vowel.
76 Cf. Kiyomi (Reference Kiyomi1995), Abraham (Reference Abraham and Hurch2005), Bakker and Parkval (Reference Abraham and Hurch2005) and Kouwenberg and LaCharité (Reference Kouwenberg, LaCharité and Hurch2005), among others.
77 Mattes, V. 2006. ‘One form – opposite meanings? Diminutive and augmentative interpretation of full reduplication in Bikol’, paper presented at the Tenth International Conference on Austronesian Linguistics, 17–20 January 2006, Puerto Princesa City, Palawan, Philippines. URL: http://www.sil.org/asia/philippines/ical/papers/mattes-Diminutive%20and%20Augmentative%20Bikol.pdf
78 Emphatic.
79 Roberts (Reference Roberts and Dutton1991: 130ff.) describes two types of iterativity for Amele: regular (420) and irregular (430). The latter refers to a repeated action that is irregular in some way, i.e. haphazard, spasmodic, intermittent, etc. This form involves reduplication of the verb stem but with a vowel change.
80 The root is oli [¾oli] ‘return.v’.
81 A type of modification of continuous action is graduality, as in this example from Estonian:
82 Reduplication in Karao expresses continuity productively, i.e. an action occurs over an extended period of time. Brainard (pers. comm.) notes that the verb forms singsingked and mandodotho signal on-going action, in contrast to non-continuous actions in singked (where -in- is an allomorph of -iy-) and mandotoak:
Whether reduplication expresses a continuous action (or state) or repetition of an action appears to depend on the semantics of the verb root itself.
83 Addressing a child.
84 Also classifiable under 2.2. in this table.
85 Pejorative.
86 Reduplicated adjectives in Amele may convey the meaning ‘many things with the quality X’ (Roberts Reference Roberts and Dutton1991: 120–1):
This suggests that, if reduplication of an adjective is not followed by a governing noun, it is class-changing. The reduplicated noun often performs the functions associated to adjectives or adverbs:
- Amele
gemo-gemo
middle-middle
‘through the middle’
(Roberts Reference Roberts and Dutton1991: 3)
4 Word-formation processes with bound morphemes
[D]iachronically, the transmutation of a ‘blurred’ compound into an affixal derivative is an almost trivial phenomenon.
As with any other word-formation process, the significance of affixation in natural languages varies substantially. If we disregard the non-existence of any of the affixation processes in various languages, its distribution may range from about 400 suffixes in use in West Greenlandic to one genuine prefix in Estonian and Finnish. Affixes are in principle well-defined elements in linguistics by being labelled as bound morphemes. However, this term encompasses a range of phenomena which differ in their functional characteristics, in their degree of naturalness and in their role in word-formation.
This chapter discusses the status of affixes (4.1) and reviews the role of suffixation and prefixation (4.1.1), with emphasis on recursiveness (4.1.1.1) and base modification (4.1.1.2) and then on one-to-many (4.1.2) and many-to-one relations (4.1.3) within affixation. The chapter then presents minor types of affixation (4.2), notably infixation (4.2.1), prefixal-suffixal derivation (4.2.2), circumfixation (4.2.3), and prefixal-infixal and infixal-suffixal derivation (4.2.4).
4.1 Affixation
Morphology sometimes alludes to affixes as well-defined elements that in fact may vary considerably. A number of examples illustrate the difficulty in defining the boundaries of derivational affixes with respect to inflectional affixes or to other structural units.
Thus, Malkiel (Reference Malkiel and Greenberg1978) refers to German elements, most of which are formally and semantically paralleled by prepositions and/or adverbs (cf. Table 2.1). This might suggest that words containing these elements are compounds. However, the existence of prefixes without any corresponding lexical counterparts like be-, er-, ge- and ver- suggests that these words result from affixation. Malkiel (Reference Malkiel and Greenberg1978: 127–8) argues that it would be counterintuitive to separate be-, er-, ge- and ver- from the remainder of German prefixes with which they interact paradigmatically. A similar situation characterizes the majority of Latin verbal prefixes.
In fact, as pointed out by Kastovsky (Reference Kastovsky, Lieber and Štekauer2009: 327), affixes often go back to compound members due to loss of their content. Thus, English -less goes back to Old English less meaning ‘devoid of, free from’, -ship to Old English scipe ‘form, state’ and -dom to Old English dōm ‘evil fate’. Synchronically, this source may be traced in the existence of the so-called semiaffixes (English -berry, -man, etc., cf. Marchand Reference Marchand1960: 290ff.). These semiaffixes share features of bound morphemes (reduced pronunciation, loss of stress, generalized meaning, high productivity) and features of free morphemes as constituents of compounds, and justify Malkiel’s quotation in the chapter’s motto. Malkiel mentions cases like German -wärts in rückwärts ‘back’ and vorwärts ‘forward, ahead’ and English -ward which developed from the word meaning ‘turn, bent, slant’, a cognate of Latin vertere. Evidence of a similar development can be found in Ket, Kott and Yugh: their verbal semiaffixes developed from root morphemes, occurring in a series of compound words which are no longer used as an independent word. This can be illustrated with the Ket semi-suffix -bet(Werner Reference Werner1998: 105ff.):
(1)
- Ket
il’-bet
broken/destroyed-make
‘break, destroy’
(2)
- Ket
nan’bet
bread-make
‘bake bread’
Werner also gives examples of semantic bleaching of some common Ket morphemes used in compound nouns through which they have come to resemble derivational affixes. For instance, -git‘man’ now signifies the young of any animal or tree:
For Kastovsky (Reference Kastovsky, Lieber and Štekauer2009: 327), the diachronic shift from a compound constituent to a bound morpheme results in a synchronic cline. Kastovsky does not find the postulation of semiaffixes acceptable, as it ‘replaces a two-way by a three-way distinction adding an additional stepping stone on something which for diachronic reasons must be viewed as a cline without providing criteria for delimitation’.
The blurred limits of affixes also manifest themselves in the vague boundary between inflectional and derivational affixes, as in the infinitive suffix in Romance languages (Malkiel Reference Malkiel and Greenberg1978: 129), because many infinitives are subject to nominalization. The nominalized infinitives then behave like other nominalizations resulting from suffixation. In Romanian, all the original infinitives were nominalized and subsequently replaced by a new set of infinitives. The same kind of nominalization, e.g. lesen ‘read.v’ vs das Lesen ‘reading.n’ is very productive in German. In general, this is closely related to the role of inflectional paradigms as derivational devices. Thus, the Slovak adjective domáci ‘domestic’ can be converted into the corresponding noun meaning ‘landlord’ and also into a plural noun meaning ‘the home team’. If accounted for as zero-derivation or derivation by zero morpheme (e.g. Marchand Reference Marchand1960; Kastovsky Reference Kastovsky1969, Reference Kastovsky1982), then this and other cases of conversion fall within the scope of affixation.
Kwakw’ala provides another borderline case. As explained by Anderson (Reference Anderson and Shopen1985: 26), many suffixes are noun-like, verb-like or adjective-like, i.e. they correspond to nouns, verbs and adjectives in other languages. In addition, there are also suffixes that function as conjunctions. All in all, there are bound elements in Kwakw’ala corresponding to all major word-classes. Kwakw’ala is a good example of the difficulties inherent in the category of affix and in its subcategories, in that an affix can sometimes be analyzed as either a suffix or infix (Anderson Reference Anderson and Shopen1985: 32): the suffix -əm, which indicates that things whose location is specified by a following locative suffix are plural, may also be analyzed as an infix:
(4)
Anderson assumes that -əm- may be said to be infixed into a stem ending in a locative suffix and placed immediately before that.
This introduction finally presents another ambiguous case which illustrates how complex the issues in question may be. This time, it concerns the decision between the allomorphic vs morphemic status of Slovak prefix(es) pre- and prie- as in pre-behnút ‘run.v.pfv’ vs prie-beh ‘course (of events)’. Formally, they differ in quantity, as the former has a short vowel and the latter a diphthong. Furdík (Reference Furdík2004: 44) generalizes that in these and other similar cases we should speak about variants at morphematic level rather than at word-formation level, because the diphthongized variant does not result from a word-formation process, unlike the short variant which is an unambiguous case of prefixation from behat ‘run.v.ipfv’. In the subsequent word-formation step, prie- is not treated as a prefix. Instead, it is considered to be a part of the base. Some other examples cited by Furdík are na-/ná-(narazit ‘strike.v’ > náraz ‘stroke’), pri-/prí-(prisúdiť ‘predicate.v’ > prísudok ‘predicate.N’), etc.
While this non-derivational assumption holds for these pairs, this is not quite so in relation to pre-/prie- pairs, i.e. the short/long vowel opposition in other than pre-/prie- pairs occurs between a motivating verb and the resulting noun. In the pre-/prie- pairs this opposition often concerns the relation between two nouns. Consequently, as pointed out by Slančová(pers. comm.), while the prefix prie- is a quantitative variant of pre-, the quantitative difference may also have a semantic distinctive force, i.e. while prie- refers to location, pre- indicates action:
(5)
(6)
Unfortunately, this basic semantic specialization does not apply in all cases and sometimes the meanings may overlap partly or completely:
(7)
(8)
There are also cases when only one of the prefixes forms an actual word:
(9)
Thus, while a semantic difference supports the hypothesis of two prefixes, the inconsistency with which this opposition is applied and the semantic merger in other cases show that it is very difficult to make an unambiguous judgement about the status of pre-/prie- in the Slovak word-formation system.
4.1.1 Suffixation and prefixation
Suffixation is recorded in the languages shown in Table 4.1(96.36 per cent of the study sample).

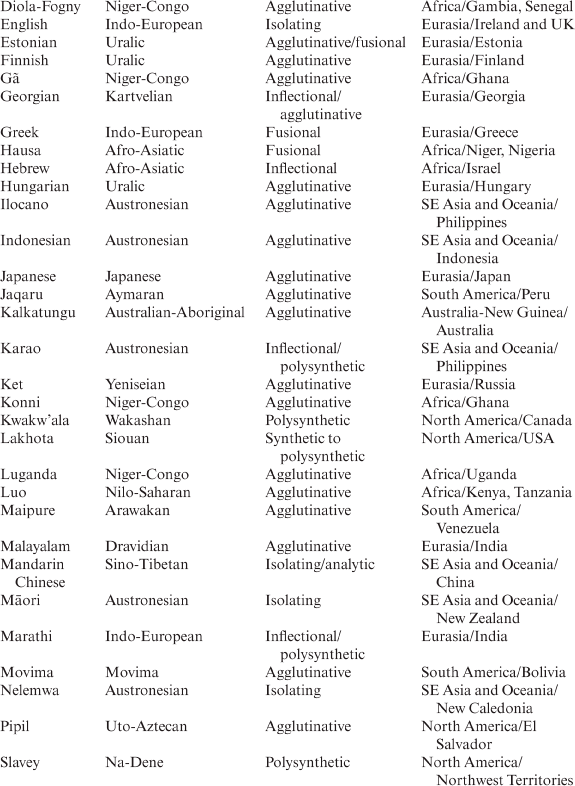

Prefixation is recorded in the languages shown in Table 4.2(70.91 per cent of the study sample).


There are only two languages in the study sample that do not use suffixation for coining new words: Vietnamese, which, as an isolating language par excellence, has no affixation at all, and Yoruba, another isolating language, which makes only use of prefixation. By contrast, prefixation is not so widespread, and this deserves further comment. It was pointed out in the opening lines of this chapter that Estonian has only one prefix, eba- ‘false, pseudo-, quasi-’ (Kilgi, pers. comm.),1 even if certain morphemes are sometimes also considered prefixes, e.g. mitte ‘non-, un-’, ala ‘under-, sub-’ and üli ‘over-, super-, ultra-, hyper-’:
(10)
- Estonian
mitte-soovitav
‘inadvisable’
(11)
- Estonian
ala-jaotis
‘subdivision’
(12)
- Estonian
üli-agar
‘overeager’
In Finnish there is also one prefix (epä- for negation),2 and even this is not considered very productive (Laakso, pers. comm.): it is applied to some adjectives and to even fewer nouns, and the meaning is not completely predictable. These are examples of the limited cross-linguistic frequency of prefixation, which has been reported in the literature to be lower than that of suffixation (E. Sapir Reference Sapir1921: 67; Cutler, Hawkins and Gilligan Reference Cutler, Hawkins and Gilligan1985: 747; Laca Reference Laca, Haspelmath, König, Oesterreicher and Raible2001).
This observation gives support to the view that the difference between suffixation and prefixation is not merely positional. In this connection, let us recall Marchand’s viewpoint (1967) which assigns prefixation and compounding to the word-formation processes of expansion, while suffixation is based on different principles and is a special case of transposition. Marchand’s distinction should be much appreciated, even if we cannot agree with all his arguments, in particular with the assumption that suffixes always function as determinata(heads), while prefixes are always determinants(modifiers). This assumption, later formulated by Williams (Reference Williams1981) as the Right-hand Head Rule, is a rather radical position which was subject to extensive criticism and raised discussion on headedness in terms of the content of the notion of head, its defining characteristics and, what is more important for the present topic, the capacity of prefixes to act as heads.3 Štekauer (Reference Štekauer2001) argues in favour of the capacity of prefixes to function as heads, on a par with suffixes, for formal and semantic reasons:
(a) like suffixes, prefixes can also be divided into class-changing and class-maintaining; in view of their postulated treatment as heads they may be preferably labelled as class-changing and class-confirming, and
(b) while one of the basic features of heads (determinata, onomasiological bases) is that they stand for a general conceptual group, a class or a species, modifiers (determinants, onomasiological marks) restrict their scope (Dokulil Reference Dokulil1962). Therefore, in complex words which contain ‘both a word-formation base and affix, the latter is the head because affixes stand for a more general category’(Štekauer Reference Štekauer2001: 352).
Consequently, although they are different processes, suffixation and prefixation play an equally important role in word-formation because both can function as heads. Furthermore, even if suffixation is recorded in a higher percentage in the sample, prefixation also plays a major role both in terms of the number of languages which use it for coining new words and for its functional load. This is so in a large number of languages, especially in Slavic and Romance languages, where a high productivity of prefixing derivation can be observed:
(13)
Latin examples are similarly comprehensive:
(14)
In reference to similar examples in Russian, Malkiel (Reference Malkiel and Greenberg1978: 135) notes that one can observe a ‘uniquely close enmeshment of aspect, tense and prefixation within the verbal system’. Example series (13) and (14) demonstrate that the scope of prefixes in the verbal system of these and a number of other languages by far exceeds the limits of aspect, as they can express very subtle shades of meaning. This contributes significantly to the word-formation capacity of these languages.
Prefixes may be selective in their combinability, a phenomenon which is well described for English. The restrictions may be various in nature. In Telugu, for example, prefixation occurs only with words of Sanskrit origin (Pingali, pers. comm.).
4.1.1.1 Recursiveness in affixation
4.1.1.1.1 Recursive suffixation
Recursive suffixation is recorded in the languages shown in Table 4.3.


Recursiveness varies widely from language to language. Slavic and Germanic languages offer a wealth of examples, Tibetan less so, and Slavey shows constraints, in that recursiveness is restricted to possessed augmentatives and diminutives. In some other languages, recursiveness depends on the standpoint taken. In Gã the only possible case of co-occurrence of two suffixes is the combination of the reduplication and suffixation processes. In particular, verbs that have the iterative suffix -mO may reduplicate to show distributive event, often with the additional suffix -i:
(15)
- Gã
tsO-mO-tsO-mO-i
turn-over-turn-over-sfx
‘turn over and over, many things in many places’
The number of permissible suffixes in a word also varies cross-linguistically. Hardman (Reference Hardman2000: 51) characterizes Jaqaru in terms of recursiveness as follows: ‘the processes of nominalization and verbalization are recursive. It is not uncommon for nouns to be verbalized and then renominalized, or vice versa.’ Apart from simpler cases like (16) and (17), there are also much more complex recursive derivations as in (18) and (19)(see Table 4.4).
Table 4.4 Recursive suffixation in Jaqaru

Jaqaru is also interesting for the capacity of some of its suffixes to recur on the same verb root:6
(20)
- Jaqaru
yanh-shi-rqay-ishi
yanh-ishi-rqaya-ishi
help-mut-everyone-mut
‘help each other’
Fortescue (Reference Fortescue1980: 261) maintains that there can be up to a dozen affixal morphemes in a West Greenlandic verb form and up to four of the same category. In his view, there are over 400 suffixes in West Greenlandic, ranging from fully productive to fully lexicalized. As in Jaqaru, these can be used recursively to build up complex verbs and nouns, with possible switches back and forth between verbal and nominal base several times within a single word:7
(21)
- West Greenlandic
allattu-i-vvi-ssaaliqi-sar-sima-qa-anga
write.down-aps-loc.of-lack-fre-pfv-int-
1sg.ind
‘I was really short of notebooks’
Unlike English, derivational suffixes in West Greenlandic may reverse their relative order, the result of which is a change of meaning, as in the following example (Fortescue Reference Fortescue1984: 313):
(22)
- West Greenlandic
a. Urnik-kusun-niqar-puq
come.to-want-pas-3sg.ind
‘Somebody wanted to come to him’
b. Urnin-niqa-rusup-puq
come.to-pas-want-3sg.ind
‘He wanted somebody to come to him’
The relative freedom of suffixes in Kwakw’ala is also a source of a specific sort of recursiveness, because it permits alternate orders of suffixes corresponding to distinct meanings. Anderson (Reference Anderson and Shopen1985: 33) gives an example of the suffixes -amas ‘cause’ and -exsd ‘want’. From the verb ne’nakw ‘go home’, we can form ne’nakw’exsd ‘want to go home’. By attaching the suffix -amas we obtain ne’nakw’exsdamas ‘cause to want to go home’. On the other hand, from q’aq’oλa ‘learn’ we can make q’aq’oλaamas ‘cause to learn, teach’ and, from this, q’aq’oλamadzexsd ‘want to teach’ can be formed in turn. In these examples, the same suffixes appear in opposite orders, corresponding to different meanings ‘cause to want’ vs ‘want to cause’. Consequently, new forms of arbitrary complexity can be produced (‘want to cause to want to cause to . . .’).
According to Cowan (Reference Cowan1969: 97), it is quite common for a radical stem in Tzotzil to be formed by a root followed by three derivational suffixes. Sometimes, a derivational affix is preceded by a perfective, referential,8 passive or subjunctive morpheme. Cowan considers these morphemes to be derivational, because they may be followed by other derivational suffixes:
(23)
(24)
According to Volpe (pers. comm.), recursive suffixation is also very productive in Japanese, in particular, in cases like (25) and (26):
(25)
(26)
The dominating word-classes in recursive suffixation are nouns and verbs, but examples of adjectives are also possible. Table 4.5 gives examples of all three cases.



Like simple suffixation, recursive suffixation can result in a change of word-class. This is fairly common, especially in the direction from verb to noun, as in (46) to (52), but is also possible in the direction from noun to verb (53) and from verb to adjective (54):
(46)
- Afrikaans
skei-baar-heid
separate-able-ity
‘separability’
(47)
(48)
- Indonesian
pakai-an-nya
wear-nmr-def
‘the clothes’
(49)
- Maipure
sunua-ta-tí
sit-cau-nmr
‘chair’
(50)
- Marathi
- गल-मय-
mangala-maya-taa
holy-full.of/with-abn.mrk
‘holiness’
 गल-मय-
गल-मय-(51)
- Telugu
prem-inc-aDam
love-vl.sfx-grn
‘the act of loving’

(52)
- Tibetan
ཐ་ག་པ
thag-a-pa
weave-nmr-pef
‘weaver’
(53)
- Kalkatungu
mimi-yan-ati
breast-having-become
‘getting breasts’
(54)
- Belorussian
буд-аў-нiч-ы
budaynichy
build-v.sfx-adj.sfx-adj(m.sg.nom)
‘building.adj’
4.1.1.1.2 Recursive prefixation
Recursive prefixation is recorded in the languages shown in Table 4.6.

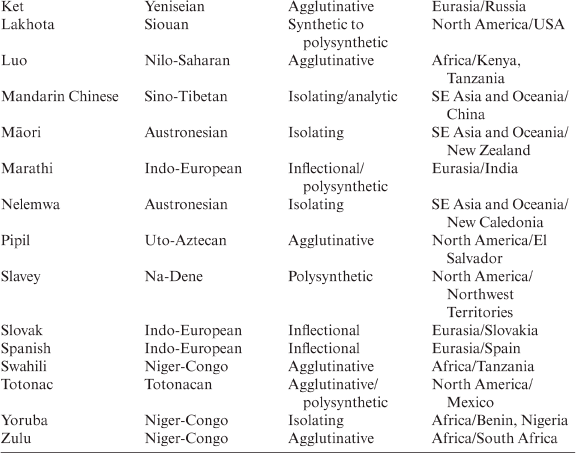
While the identification of prefixes in terms of both form and meaning is usually easy (but cf. 4.1.1 above), the analysis is not always simple and it may influence the assumption of the (non-)existence of recursive prefixation. A case in point is the combination of prefixes mem- and per- in Indonesian:
(55)
- Indonesian
memper-kenal-kann
tr.act-know-tr
‘introduce (somebody)’
Müller (pers. comm.) maintains that, although memper- in cases like (55) can be analyzed as consisting of two prefixes (mem- and per-), it does not follow the usual morphophonemic constraints of the prefix mem-(specifically, the [p] following mem- should elide but it does not). So, if memper- is analyzed as two prefixes, then Indonesian has recursive prefixation, otherwise it does not.
Table 4.7 provides examples for nouns, verbs as well as adjectives, showing that recursive prefixation is bound to the same word-class. While suffixal recursiveness is cross-linguistically most characteristic of nouns, prefixal recursiveness is most typical of verbs.


Recursive prefixation, like simple prefixation, may have class-changing effects:
(74)
- Anejom
awo-nev-edou
cau-qsn-way
‘how to do (something)’
(75)
- French
dés-en-cadrer(un tableau)
neg-in-frame
‘take (a picture) out of its frame’
(76)
- Lakhota
i-wá-na
ˋuprx-prx-hear
‘radio’
 ˋu
ˋu(77)
- Māori
kai-whaka-haere
ag-cau-go
‘organizer’
(78)
- Romanian
ne-des-facut
prx-prx-touch
‘intact, untouched’
This analysis takes into consideration that in some polysynthetic languages it is very difficult to speak about word-classes at all:
(79)
- Clallam
nəsx wčɬɬqčšɬšá
nə-sx w-čɬ-ɬ qčšɬšá
my-cau-adv-affect-fifty
‘Fifty of them got me’
(80)
- Nelemwa
Hli pe-fa-k‚laxi I hli
3dua.rcp-cau-be.ashamed.of-3dua
‘They are making each other mutually ashamed’
Recursive derivational prefixation appears to occur in languages in which there is recursive derivational suffixation, with three exceptions in the study sample: Lakhota, Māori and Yoruba (the last of which does not use suffixation for word-formation processes) show recursive prefixation but not recursive suffixation. Recursive compounding also appears to occur in languages where recursive derivational suffixation occurs and, again, some languages show recursive compounding but not recursive suffixation: Amele and Movima.
4.1.1.2 Base modification in affixation
4.1.1.2.1 Word-formation base modification in suffixation
Base modification in suffixation is recorded in the languages shown in Table 4.8.
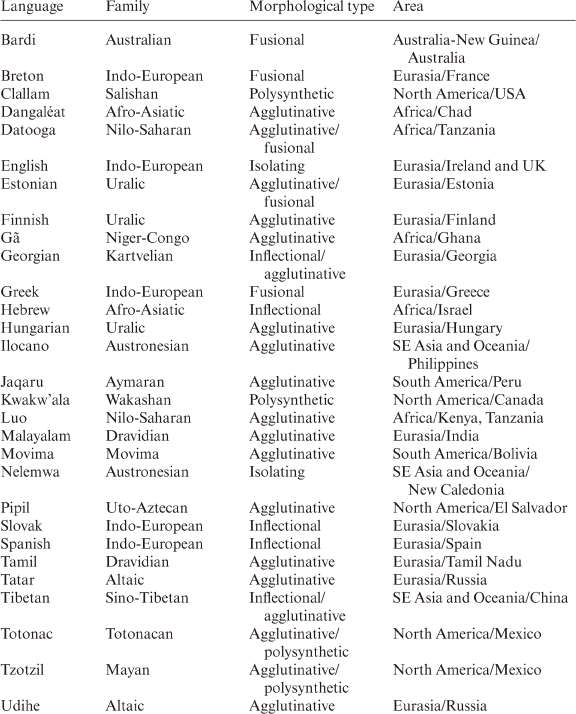

As in prefixation, the changes are mostly caused by assimilation, but other types of changes are also possible, as in Bardi, where suffixes with o cause vowel harmony, and -n initial suffixes cause trill deletion (rr + n > n)(Bowern, pers. comm.). A range of morphophonological stem modifications within the same language is illustrated by Estonian. Most common changes of the stem during the word-formation process of suffixation in Estonian are shown in Table 4.9.
Table 4.9 Base modification and suffixation in Estonian16

According to Laakso (pers. comm.), some suffixes in another Finno-Ugric language, Finnish, consist (in the traditional analysis) of vowels that replace the stem-final vowel by regular (morpho-)phonological processes, such as the labial vowel in action derivatives (historically going back to a *w suffix):
(86)
(87)
Other suffixes may contain satellite vowels which replace the stem-final vowel:
(88)
- Finnish
koivi-kko
koivu-kko
birch.tree.col
‘birch grove’
(89)
- Finnish
pahe-ne
paha-ne
bad-trn.v
‘get worse’
A characteristic change in the base due to the change of intransitive verbs to transitive verbs by suffixation in Malayalam is consonant gemination. Asher and Kumari (Reference Asher and Kumari1997: 275–6) distinguish five types of gemination:17
(a) the result of doubling k > kk, ʈ > ʈʈ , r > rr: kayar- ‘climb’ vs kayarr- ‘cause to climb’,
(b) a change from double nasal or homorganic nasal + plosive to the corresponding double plosive: ŋŋ > ŋk, mp > pp: kuump- ‘fold-intr’ vs kuupp- ‘fold-tr’,
(c) a change from a lateral to a double plosive: l > ʈʈ, l > rr: cuzȥal- ‘rotate’ vs cuzȥarr- ‘cause to rotate’,
(d) the addition of a double plosive: Ø > tt: poʈʈ- ‘break-intr’ vs poʈʈikk- ‘break-tr’, and
(e) the replacement of one double plosive by another: kk > tt: nilkk- ‘stop-intr’ vs nirtt- ‘stop-tr’.
In principle, stem modifications may be divided into vowel modifications (Table 4.10) and consonant modifications (Table 4.11).



Example (104) from Ilocano shows the influence of suffix in a prefixal-suffixal derivation:
(104)
In (105), the suffix selects the Latin participle emiss- instead of the regular emesso:
(105)
- Italian
emissione
‘emission’
The formation of diminutives is a frequent source of morphophonological change. Example (106) illustrates diminutive formation accompanied by vowel alternation:
(106)
- Tibetan
rtevu
rta-vu
‘horse-dim’


A special variant of vowel change due to diminutive formation is Slovak diphthongization:
(107)
- Slovak
žienka
žen-k-a
‘woman-dim-f.nom.sg’
The category of diminutiveness brings us at the same time to the area of stem consonant changes, because it is a general phenomenon in Slavic languages, as illustrated in Serbian-Croatian and Slovak, but also in some other languages, like Romanian, and in Zulu, where root-medial and final labial consonants become palatal in the diminutive (also in the locative and the passive):
(108)
- Serbian-Croatian
ruč-ic-a
ruk-a
hand-dim-f.nom.sg
‘little hand, handle’
(109)
- Slovak
rúč-k-a
ruka-dim-f.nom.sg
hand-dim
‘little hand’
(110)
(111)
Stem consonant changes are not limited to the category of diminutiveness. Some other cases are shown in Table 4.11.
Table 4.11 Consonant modification and suffixation
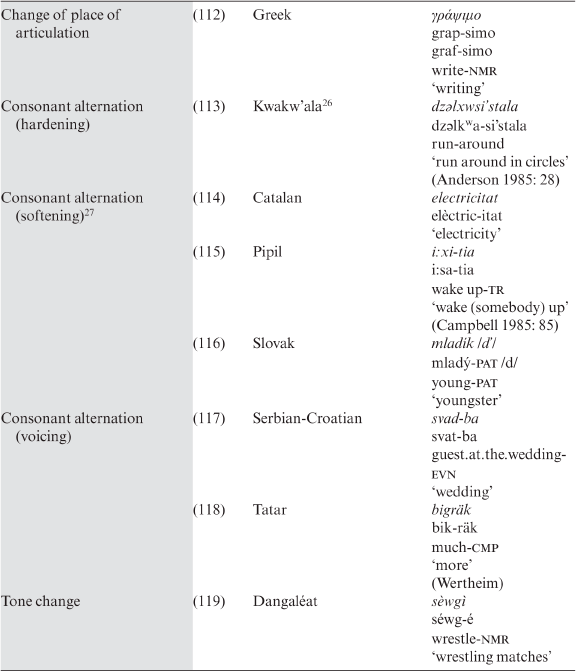
When the Tzotzil suffix -ol ‘act of’ combines with intransitive roots of the shape CVC plus -in, the final n changes to m:
The stem-final /n/ may change to /m/ also in Udihe and the causative suffix changes to -uAn-:
(121)
- Udihe
lagbam-uan-
stick-cau
‘glue (something)’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 301)
With certain verbs (Class II), the stem-final /n/ in Udihe merges with suffix-initial /g/ of the repetitive suffix -gi-, which results in -ŋi-:
(122)
- Udihe
ilaktan-ŋi-
ilaktan-gi
appear-ite
‘appear again’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 317)
As in Nelemwa prefixation and in Nelemwa suffixation, stem modification mostly concerns phonological lenition, in this case with transitive (123) and with possessive suffixes on nouns (traces of proto-stems)(124), while another example illustrates extension of stem due to suffixation (125):
(123)
- Nelemwa
cawi
cap-I
escape-tr
‘escape from (something)’
(124)
- Nelemwa
jixela-ny
jixet-pos.1sg
rifle-pos.1sg
‘my rifle’
(125)
- Nelemwa
haroon
aroo-n
husband-pos.3sg
‘marry.v’
As in English, suffixes in Spanish and Totonac may cause stress shift. In the latter case, the nominalizing suffix shifts the stress leftwards:
(126)
- Spanish
horroroso /oroɻóso/
horror-oso /oróɻ/
horror-sfx.adj
‘horrific’
(127)
Finally, Romanian shows a combination of vowel and consonant alternations ia ~ ie/ t ~ ţ:
(128)
- Romanian
băiat – băieţel – băieţaş – băieţandru – băieţoi
‘boy – ‘urchin’ – ‘a slip of a boy’ – ‘youngster’ –
‘tomboy, hoyden’
4.1.1.2.2 Word-formation base modification in prefixation
Base modification in prefixation is recorded in the languages shown in Table 4.12.

While prefixation with base modification is reportedly rare in Catalan, English, Hebrew and Russian, it is frequent in other languages, like Datooga, and occurs systematically in Breton, because it participates in the system of mutations (Stump, pers. comm.):
(129)
- Breton
digoulouma~n
di-koulouma~n
‘un-tie’
In Afrikaans, the only change in the base is orthographic: capitalization disappears in the names of languages after prefixation:
(130)
- Afrikaans
ver-afrikaans
vr-Afrikaans
‘make Afrikaans’
According to Carstens (pers. comm.), any other changes in the base are not a result of the prefix with which it combines, but a coincidental occurrence where fossilized ablaut has become associated with the use of a prefix in a particular complex word:
(131)
The changes recorded are of diverse nature and seem to be highly language-specific, often even affix-specific. Müller (pers. comm.) remarks that, although some processes may exist and indeed be very productive, they may be so only for a very small number of affixes. Müller illustrates this observation with an example from Indonesian, where morphophonemic alternation of the stem when adding a prefix occurs productively with the various allomorphs of the prefixes peng- and meng-, but not with any other Indonesian prefixes:
(132)
- Indonesian
mem-egang
meng-pegang
tr-hold
‘take hold of’
In Slavey, the changes bear on the voicing alternations of stem-initial fricatives determined by the immediately preceding prefix. The so-called D-effect combines a prefix d- with a stem-initial fricative or glottal stop.
As noted by Brainard (pers. comm.), Karao displays a set of complex morphophonological alternations in connection with prefixes and infixes. The processes are governed by the canonical shape of the affix and the root and may affect both the affix and the root. If the canonical shapes of the affix and root are eligible to undergo a particular process, then the process will automatically apply.28 Thus, when a prefix ending in N attaches to a root beginning with a CV (C) syllable, N assimilates to the same point of articulation as the root-initial consonant, and the root-initial consonant is then deleted. When e- attaches to a root beginning with a CeCV (C) root, the prefix changes to iya-, e is deleted and the root-initial consonant changes to its syllable-final allomorph (if it is different):
(133)
- Karao
ena-cha
eN-cha-cha
ag-help
‘help.v’
(134)
- Karao
iyalpek
e-depek
pas.real-wet
‘be wet’
In Bardi, all (C)V- prefixes cause changes in obstruent-initial roots and there is also a set of complex cluster reduction rules (Bowern, pers. comm.):
In Zulu, the root -mb- ‘dig’ becomes -emb- after a prefix ending in -a:
(136)
- Zulu
basemba
ba-sa-mb-a
‘They are still digging’
The vowel -a of the prefix falls away before e- and so (as assumed by van der Spuy, pers. comm.) this situation could be alternatively interpreted as the root changing a preceding -a to -e. However, there are only about five roots in the language that display this phenomenon. Other changes are shown in Table 4.13.
Table 4.13 Prefixation and base modification

4.1.2 One-to-many relation in affixation
The title of this section avoids speaking about polysemy/homonymy of affixes, because it is often unclear which of the two is present.34 In many cases, the borderline is fuzzy. Owing to the absence of clear criteria for the distinction between polysemy and homonymy in general and between polysemy and homonymy of affixes in particular, these cases are considered here as a combination of a single form with several meanings, without examining the degree of semantic relatedness which may lead to an interpretation as polysemy or as homonymy.
The one-to-many relation in prefixation is recorded in the languages shown in Table 4.14.
Table 4.14 One-to-many relation in prefixation in the study sample

The one-to-many relation in suffixation is recorded in the languages shown in Table 4.15.
Table 4.15 One-to-many relation in suffixation in the study sample

As with any other phenomenon, the degree and the extent of the one-to-many relation between form and meaning varies cross-linguistically. In Greek, Ket and Zulu it is rare, in Georgian suffixes tend to show one-to-one correspondence between form and meaning,35 and in Gã and Nelemwa each prefix and suffix has a single meaning, with the exception of the middle-reciprocal Nelemwa prefix pe-, which features significant polysemy/homonymy, as shown in Table 4.16 (Bril Reference Bril2005: 42), and of the gerundive Gã suffix -mO, which can form a gerundive but also derive an iterative/pluractional form of the verb (145).
(145)
Various semantic differences/semantic shades of pe-(collective (146), reciprocal (147) and spontaneous action (148)) are possible (Bril Reference Bril2005: 42):
(146)
(147)
(148)
In Mandarin Chinese, the one-to-many relation seems to be restricted to some verbal prefixes which have a basic (149) and an extended meaning (150):
(149)
- Mandarin Chinese
死別
sĭbié
die/death-part/be.parted
‘be parted by death’
(150)
- Mandarin Chinese
死等
sĭděng
death-wait
‘wait interminably (to the death)’
This is common in other languages too. Thus, in Hausa the most productive polysemantic/homonymous prefix is ma-, which derives agentive (151), instrumental (152) and locative nouns (153):38
(151)
- Hausa
maà-ikàc-ī
ag-work-m.sg
‘worker’
(152)
- Hausa
ma-girbī
‘harvesting tool’
(153)
- Hausa
majēmā
‘tannery’
The polysemy/homonymy of affixes has been widely discussed in the literature on Indo-European languages, especially in relation to the categories agent, instrument and, partly, location. To these categories, the category patient, defined as a ‘bearer of state’, should be added. The difference between agent and patient nouns is thus one between action and state, i.e. between the features [+ dynamic] and [– dynamic].
Table 4.16. Meanings of Nelemwa pe- in relation to the lexical category of the root

The following examples illustrate that the one-to-many relation between the form and the meaning of affixes in relation to the four semantic categories above is not restricted to Indo-European languages. A trivial condition for such a relation is the existence in a language of suffixation and/or prefixation processes. However, it should be noted that a similar kind of overlap can also be found in the relation between agents and patients formed by compounding, as illustrated by Cirecire (154) and Vietnamese (155):
(154)
- Cirecire
cóõ-coo
herbs-coo
‘doctor’
(155)
- Vietnamese
-
ŋɯəj21 dɯək31? fawŋm313 vən35
người được phỏng vần
human-pas-interview.v
‘interviewee’
(Thái Ân)
In Vietnamese, được is used to express passive meaning and functions as a constituent morpheme forming patient nouns. Since, however, its presence is not always necessary, an agent noun may look like a patient noun.
Otherwise, the affixal overlap does not seem to be restricted geographically or genetically. This is an important indication also in terms of what was pointed out by Rainer (Reference Rainer, Booij, Guevara, Ralli, Sgroi and Scalise2005: 29), in particular, that ‘we still don’t have even an approximate idea about how frequent our polysemy really is in the languages of the world’. This is largely due to the lack of research and relevant data in this field. Rainer (Reference Rainer, Booij, Guevara, Ralli, Sgroi and Scalise2005) provides a summary of the approaches to this problem, including a diachronic–synchronic discussion of agentive and instrumental nouns where he refers to several possible sources of the formal identity of agentive, instrumental and locative suffixes, notably reinterpretation and approximation,39 both based on semantic shift, and instances of non-semantic motivation, in particular ellipsis, homonymization and borrowing. Table 4.17 illustrates the multiplicity and diversity of one-to-many relations in the categories agent, patient and instrument across the languages of our sample.40

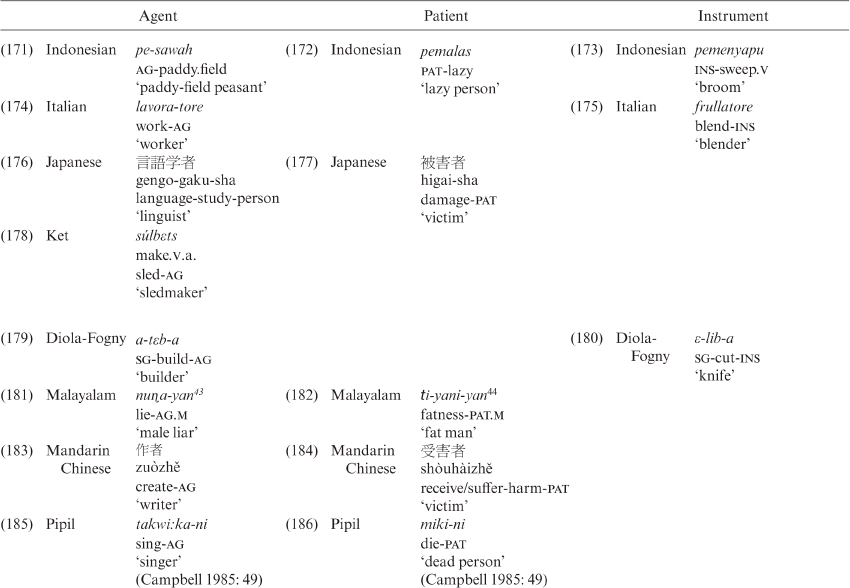

The complete series along with location can be observed in (199a) to (199d):
(199)
- Tzotzil
a. j-?ábtel
ag-work
‘worker’
(Cowan Reference Cowan1969: 109)
b. j-chamel
pat-sickness
‘a sick person’
(Haviland Reference Haviland1980)
c. k!áxan-eb < *k!áxan
harvest.it-ins
‘harvesting instrument’
(Cowan Reference Cowan1969: 105)45
d. váy-eb
sleep-loc
‘place for sleeping, bed’
(Cowan Reference Cowan1969: 105)
It seems from this brief overview that the one-to-two and even one-to-three relations between form and meaning of affixes have few geographic or genetic restrictions. The data also seem to suggest that it is the category agent (rather than patient) which conditions the existence of polysemantic/homonymous instrumental affixes, as there are no instances in our sample of patient/instrument polysemy/homonymy with no agent in this relation. On the other hand, the patient’s absence in the one-to-many relation between agent/instrument is quite common.
The one-to-many relations between form and meaning in word-formation are not limited to the above categories. The following reviews the diversity of one-to-many relations in some languages, first in suffixation and then in prefixation.
In general, the range of combinations of meanings bound to a single suffixal form in Estonian is large. However, according to Kilgi (pers. comm.), there are three groups of suffixes in Estonian:
(a) suffixes which have only one meaning,
(b) suffixes that have mostly one meaning but may have more than one, and
(c) suffixes that have a very general meaning (Table 4.18).
Table 4.18 One-to-many relation in Estonian suffixes

Similar tables could be designed for a number of languages: Finnish -iö combines the meanings of location (209a) and individual (209b)(Koivisto, pers. comm.):
(209)
- Finnish
a. keitt-iö
cooking-sfx
‘kitchen’
b. el-iö
live-sfx
‘organism’
Hebrew ון -on may express diminutive-derogatory (210a), periodical (210b), collection (210c) or other meanings (210d):
(210)
Hungarian -gat/-get combines iterativity (211a) and diminutiveness (211b):
(211)
- Hungarian
a. nyit-ogat
open-ite
‘open repeatedly’
b. dolgoz-gat
he.works-dim
‘go on working slowly’
Italian -ino combines the meanings of relational adjective (212a), diminutiveness (212b) and instrument (212c):
(212)
- Italian
a. sal-ino
salt-rel
‘saline’
b. tavol-ino
table-dim
‘small table’
c. spazz-ino
sweep-ins
‘road-sweeper’
Breton -enn has a range of uses: it is usually a singulative suffix (213a), but can also be used to name a countable unit of a substance named by a mass noun (213b), to name a particular object made of a substance (213c) or to name an expanse consisting of a substance named by a mass noun (213d):
(213)
The Malayalam infinitive suffix -uka(and its variants -a, -ka, -ika) can also have a nominalizing function and form verbal nouns, as in (214), where the verbal noun functions as subject of a sentence (Asher and Kumari Reference Asher and Kumari1997: 385):
(214)
The following examples from Russian are parallel to the notorious case of English -er:
(215)
- Russian
a. утр-ен-ник
utrennik
morning-lnk-sfx
‘matinee’
b. дн-ев-ник
dnevnik
day-lnk-sfx
‘diary’
c. началь-ник
nachal’nik
begin-ag
‘chief’
d. нoч-ник
nochnik
night-ins
‘night lamp’
While in Zulu (van der Spuy, pers. comm.) suffixes usually have only one meaning, there are exceptions: -is-(causative) means ‘make (somebody) do (something)’, but it can also mean ‘help (somebody) do (something)’; similarly, -el ‘on behalf of’ can also mean ‘in the direction of’:
(216)
- Zulu
w-a-gijim-el-a e-ndl-ini
‘He ran into the house’
Swahili illustrates the homonymy of an agentive (217a) and a negative present tense suffix (217b):
(217)
- Swahili
a. m-wind-i
n.class.prx.1-hunt-ag
‘hunter’
b. h-a-wind-i
neg-3sg.sbj-hunt-neg.prs
‘S/he does not hunt’
Finally, the following examples of Wichí combine stative (218a) and locative (218b):
(218)
- Wichí
a. o-awanta-hi
3sbj-to bear-sta
‘S/he bears’
b. o-yukwaj-hi
3sbj-bite.v-loc.in
‘S/he chews’
Prefixation also provides ample examples of diverse combinations of meanings. The following examples from Karao illustrate this point in relation to the fuzzy nature of the relation between inflection and derivation:
(219)
- Karao
a. pan-dotho/impan-dotho
nmr-cook
‘act of cooking, time of cooking’
b. pan-chinel-an mo-ak
ite-depend.on-ipf.pat erg.2sg-abs.1sg
‘You can always depend on me’
c. pan-apal taha
ipf.cau.pat-jealous 1sg/2sg
‘I will make you jealous of each other’
d. pan-dotho ka!
imp-cook abs.2sg
‘Cook!’
Acording to Stump (pers. comm.), the Breton prefix di- can be negative (220a), privative (220b) and reversative (220c) and em- can express reciprocity (221a) and reflexiveness (221b):
(220)
(221)
- Breton
a. em-gav49
rcp-find/meet
‘rendez-vous’
b. em-laz
rfl-kill
‘suicide.v’
The combination of reciprocity and reflexiveness is quite common cross-linguistically. It also characterizes the Karao verbal prefix man-/iyan-(intransitive form)(222a) and (222b) and the Wichí prefix lhi-, which indicates co-referentiality between subject and object like a reflexive (223a) and reciprocity, if the plural suffix is added (223b):
(222)
- Karao
a. manbakal
man-bakal
ipf.ag/pat-fight
‘fight each other’
b. manna-mes
man-na-mes
ipf.ag/pat-bathe
‘bathe oneself’
(223)
- Wichí
a. n’-lhi-w’en
1sbj-rfl-see
‘I see myself’
b. n’-lhi-w’en-hen
1sbj-rcp-see-pl
‘We see each other’
The reflexive-reciprocal combination of meanings is also a common feature of derivation in Slavic languages like Czech, Russian or Slovak, and it may be postulated to be one of the most regular types of the derivational one-to-many relation:
(224)
- Slovak
a. umývať sa
‘wash oneself’
b. nenávidieť sa
‘hate (each other)’
On the other hand, in Marathi, the prefix उप- upa- can express various semantic shades of secondariness, as in (225a) and (225b), and the prefix  र- gaira- may express semantic shades of negation, as in (226a) and (226b):
र- gaira- may express semantic shades of negation, as in (226a) and (226b):
(225)
- Marathi
a. उप-आ
कupa-ayukta
‘deputy-commissioner’
b. उप-
मupa-naama
‘second/alternative-name’
 क
क(226)
- Marathi
a.
र-हजरgaira-hajara
‘not present, absent’
b.
र-परgaira-vaapara
‘wrong-use’
 पर
परIn Pipil (Campbell Reference Campbell1985: 77ff.), the prefix ta- can express ‘unspecified object’ referring to a (non-human) object of a transitive verb, especially if the focus is on the verb and the object is of little relevance (227a), reduplicated ta-(with an additional h) is used productively for repetitive action (227b) and also with nouns derived from transitive verbs (227c):
(227)
- Pipil
a. ni-ta-hkwilua
I-something-write
‘I write (something)’
b. tah-taketsa
rdp-talk
‘chat.v’
c. ta-chalis
ta-chiya
nmr-look
‘sight’
Finally, the following examples are illustrative of an extremely rich polysemy/homonymy of prefixes in Slavic languages. Slovak pre- can express perfectiveness/completion of action (228a), excessiveness (228b) or change/modification (228c) and the Serbian-Croatian suffix ne- may express negation (229a), oppositeness (229b), evil (229c) or inconvenience (229d):50
(228)
- Slovak
a. pre-piť
cpl-drink
‘drink away’
b. pre-soliť
exc-salt
‘oversalt.v’
c. pre-hodnodiť
chn-evaluate
‘re-evaluate.v’
(229)
- Serbian-Croatian
a. ne-puš-ač
neg-smoke-ag
‘non-smoker’
b. ne-red
neg-order
‘disorder’
c. ne-delo
neg-deed
‘crime’
d. ne-doba
neg-time
‘bad time, wrong moment’
4.1.3 Many-to-one relation in affixation
This section examines the opposite relation between form and meaning, in particular, the existence of variants of affixes used in word-formation. A discussion on synonymy of affixes is also included in chapter 6. It is illustrated with numerous examples of both rival affixes and rival word-formation processes which can be used to express various semantic categories. The many-to-one relation in prefixation is recorded in the languages shown in Table 4.19.


The many-to-one relation in suffixation is recorded in the languages shown in Table 4.20.


Two interesting conclusions can be drawn from Table 4.19 and from Table 4.20: one is that the many-to-one relation between form and meaning appears to be more frequent than the opposite relation, and the other is that there is a conspicuous analogy between prefixes and suffixes in both of the examined relations.
4.1.3.1 Suffixation
The most frequent reason for the existence of suffix variants is phonological conditioning (assimilation). Thus, in Estonian a suffix beginning with a vowel cannot be added to a vowel-final stem. Therefore, the stem is often shortened (230) and, if the stem is too short to be shortened, other variants of the suffix are used, such as -mus, -dus, -vus, -tus(Kilgi, pers. comm):
(230)
Another example of assimilation shows that, in Udihe, with certain verbs (Class II), the stem-final /n/ merges with the suffix-initial /g/ of the repetitive suffix -gi-, which results in -ŋi-(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 301):
(231)
Further examples of this phenomenon are shown in Table 4.21. They illustrate a number of phonologically conditioned forms in Belorussian ((232) and (233)), Estonian ((239) and (240)) and Malayalam ((243) to (246)) or different realizations of suffixes according to what precedes and/or follows them (Luo (236) to (238)):

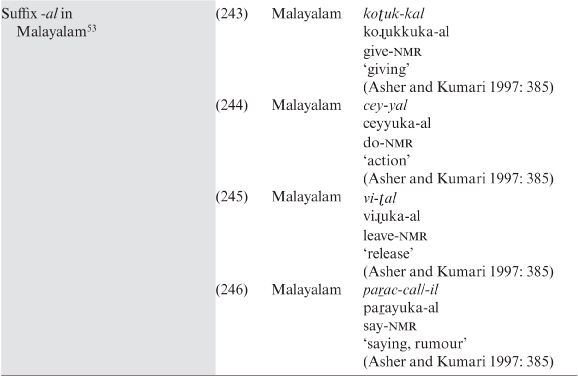
Dissimilation is sometimes at play as well. Cowan (Reference Cowan1969: 99, 101) shows that the variants of the Tzotzil intransitivizing suffix -ub ‘developmental’ and the transitivizing suffix -Vn are controlled by the dissimilation principle: the former suffix appears as -ib if the stem contains a back vowel and as -ub after other vowels. But when the stem vowel is o, the suffix vowel is also o(247). The latter suffix occurs with i after back vowels of root and with u after others (248):
(247)
- Tzotzil
a. p!ĭx-ub
wise-intr
‘become wise’
b. kúš-ib
rust, mould-intr
‘rust.v, mould.v’
c. šók-ob
šókol-ub
empty, unoccupied-intr
‘be unoccupied’
In Jaqaru, variants of suffixes result from systematic vowel-drop in combination with certain other suffixes following them. Hardman (Reference Hardman2000: 90) explains that ‘all suffixes with two vowels will drop at least one of the vowels in most constructions’. An example with the diminutive suffix -uña is given below:
(249)
- Jaqaru
utxitx t”ak-uñ-cha-qa
‘It is a little tiny road’
Swahili provides an example of allomorphy due to the opposition of vocalic vs consonantal environment. In Contini-Morava’s examples, the variants illustrate post-vocalic allomorphy in the applicative suffix combined with the vowel-harmony principle:
(250)
- Swahili
fik-ish-i-a
arrive-cau-app-ind
‘cause to arrive for (somebody)’
(251)
- Swahili
chuku-li-a
carry-app-ind
‘carry for (somebody)’
This brings us to another source of suffix variants, such as vowel harmony, which is typical of agglutinative languages. The following examples come from Hungarian:
(252)
- Hungarian
a. költöz-és
költözni-és
remove-nmr
‘removal’
b. ollóz-ás
ollóz-ás
plagiarize-nmr
‘plagiarism’
(253)
- Hungarian
a. barát-ság
friend-stt
‘friendship’
b. pék-ség
baker-loc
‘bakery’
Pipil illustrates an influence of an affix upon the form of another affix. In particular, the short variant of the adjectival suffix -a:wa-k/-a-k occurs in combination with the following suffix. From the inchoative verb we get the adjective chipa:wa-k ‘clear’ where -wa is an inchoative suffix. If the suffix -nah is attached, the long suffix -a:wak is reduced to -ak(Campbell Reference Campbell1985: 62).
Another source of suffixal variants is the so-called Rhythmical Law. This law imposes a requirement upon Slovak words to avoid two long syllables next to each other. The operation of the law is illustrated for the agentive suffix variants -ík(long variant) in (254a) and short -ik(short variant) in (254b):
(254)
- Slovak
a. rečn-ík
speak-ag
‘speaker’
b. básn-ik
poem-ag
‘poet’
In Zulu, there is a co-existence of a productive variant -kazi(phonologically identical with the augmentative) and a rare unproductive variant allomorph -azi:
Finally, Stump (pers. comm.) points out that several Breton suffixes participate in alternations of the form X ~ iX with lexical conditioning, though with some partial phonological regularities:
(256)
- Breton
a. gaou-iad
lie.n-sfx
‘lying’
b. hegar-ad
affable-sfx
‘amiable’
(257)
- Breton
a. ober-iant
do-sfx
‘active’
b. beg-ant
point-sfx
‘pointed’
There are also unpredictable variants. Cowan (Reference Cowan1969: 98ff.) illustrates this possibility with one of eight intransitivizing suffixes used in Tzotzil. This suffix is based on the combination of a V (owel) and x, where V is realized unpredictably as a, e, i, o or u:
(258)
- Tzotzil
a. tšáp-ax
roll it up56-intr
‘be taken care of, have affairs arranged by officials’
b. nát-ex
tall-intr
‘grow tall, long’
c. k!óp-ox
language-intr
‘talk’
The last example, taken from Dutch, is of similar flavour. At the same time, it demonstrates how complex the relation between variants of a morpheme may be in word-formation. Don (pers. comm.) refers to De Haas and Trommelen (Reference de Haas and Trommelen1993: 298), for whom the distribution of ‘-lijk and -elijk is not fully complementary and hence also not fully predictable’.57 De Haas and Trommelen discuss five tendencies which are summarized by Don as follows:
(a) after a stem-final syllable containing schwa, we get -lijk: open > openlijk, *openelijk ‘openly’,
(b) after a stem-final plosive we get -elijk: hoop > hopelijk ‘be hoped’,
(c) after a fricative there is preference for -elijk: stof > stoffelijk ‘material’(but also forms in -lijk are found after fricatives),
(d) after a stem-final long vowel followed by a nasal or liquid, we find -lijk: natuurlijk ‘natural’, and
(e) after a stem-final diphthong or glide, we usually get -elijk: vrouwelijk ‘female’.
4.1.3.2 Prefixation
As with suffixal allomorphy, the dominant reason for the existence of prefixal allomorphs is phonological conditioning. In Hausa, ma- often assimilates to /mu/ when the vowel in the following syllable is /u/(259). Some patronymic prefixes in Totonac also have variant forms, as in (260) and (261):
(259)
(260)
- Totonac
laka-/laʿha-
‘face’
(261)
- Totonac
aʿk-/aʿh-/kuk-/hoh-
‘head’
Phonological condition applies also in the transitive active verbal prefix me- in Indonesian (Mojdl Reference Mojdl2006: 46–8). It exists in five different variants depending on the stem-initial phoneme:
(a) the variant mem- is used before stem-initial -b-, -p- and -f-, as in mempakai ‘wear’,
(b) the variant men- is used before stem-initial -t-, -d-, -c- and -j-, as in mencari ‘look for, find’,
(c) the variant meng- is used before stem-initial -k-, -g-, -h- and before a vowel, as in mengolah ‘cheat.v’,
(d) the variant meny- is used before stem-initial -s- and -sy-(the initial -s- and -sy- is dropped), as in menyewa ‘rent.v’(from sewa ‘rent.n’), and
(e) the variant me- is used before -m-, -n-, -ng-, -ny-, -l-, -r-, -w- and -y-, as in melompat ‘jump.v’.
Phonological conditioning occurs in other languages, too (see Table 4.22).

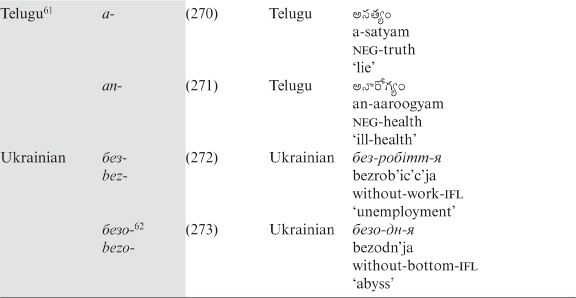
The following example of Breton shows a different type of phonological conditioning in which, unlike the prototypical cases of phonological conditioning, there is no complementary distribution of the allomorphs:
(274)
- Breton
a. ken-vreur
together-brother
‘fellow member’
b. kevlusk
together-movement
‘commotion’
Stump (pers. comm.) explains that the alternation in the prefix ken-/kev- is phonologically conditioned in a rather weak sense: ken- can appear with essentially any stem and kev- appears with stems beginning with oral sonorant sounds. Similarly, the alternation in the prefix ad-/as- is phonologically conditioned in a weak way: ad- can appear with essentially any stem and as- appears with stems beginning with voiceless obstruents. In neither instance is the distribution complementary: ken-, like kev-, can precede an oral sonorant and ad-, like as-, can precede a voiceless obstruent. In this way, as noted by Stump, they are reminiscent of im-/in-(with the meaning ‘in’) in English: im- precedes bilabial sounds (import, immigrate), while in- precedes any sort of sound, including bilabials (inmate, input).
This leads to free variants, as exemplified by the Afrikaans prefix dis-. The choice between the two variants is reportedly arbitrary:
(275)
- Afrikaans
dis-infekteer
des-infekteer
‘disinfect’
Another important factor is stress. In Clallam, unstressed schwas tend to be deleted (Montler, pers. comm.):
(276)
- Clallam
nsƛ
ˀnə-s-ƛ’eʹˀ
my-nmr-like
‘I like it’
 ˀ
ˀAnother different type of allomorphy, i.e. other than phonologically conditioned, is illustrated by Tzotzil: according to Cowan (Reference Cowan1969: 109), the allomorph ax- of the prefix x- occurs after a pronoun:
(277)
- Tzotzil
a. x-?ábtel
ag-work
‘worker’
b. k ax-?ábtel
‘my hired help’
The following example from Zulu (van der Spuy, pers. comm.) shows a word-class-conditioned selection of allomorphs. Zulu adjectives and certain adverbial forms can be used as predicates. There, the prefix sa- ‘still’ is combined with verbs (278a) and se- with non-verbal predicates (278b):
(278)
- Zulu
a. si-sa-sebenz-a
we-still-work-v
‘We are still working’
b. si-se-khona
we-still-here
‘We are still here’
A completely different condition for the existence of variants of a prefix is mentioned by Hudson (pers. comm.): the use of the causative prefix a-/as- in Amharic is determined by the category of transitivity such that a- is used for intransitives and as- for transitives (however, with many exceptions):
(279)
- Amharic
a.
afälla
a-fla
cau-boil
‘He boiled’
b.
as-fällägä
as-flg
cau-seek
‘It made seek (~was necessary)’


The relations between the asymmetric form-meaning prefixal relations and the influence of prefixation on the form of the word-formation base are very diverse (see Table 4.23).
Table 4.23 Prefixation vs suffixation: discrepancies between one-to-many and many-to-one relations
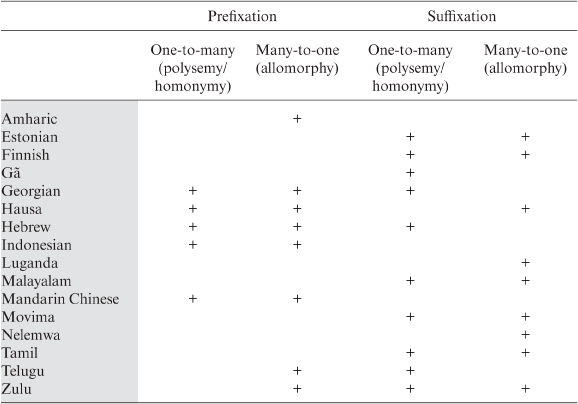
4.1.4 Suffixation, prefixation and word order
Croft and Deligianni (2001) maintain that, cross-linguistically, the VO and OV word orders are found in approximately half of the world’s languages and are equally likely.63 However, our sample is characterized by a dominant position of the VO type. The OV word order is recorded in the languages shown in Table 4.24(25.45 per cent of the study sample).64
Table 4.24 The OV word order in the study sample
The VO word order is recorded in the languages shown in Table 4.25(52.73 per cent of the study sample).


One of the first achievements of extensive typological research in the second half of the twentieth century was an observation that inflectional prefixes are bound to languages with the default VO word order while suffixes occur in both VO and OV languages (cf., among others, Hawkins and Gilligan Reference Hawkins, Gilligan, Hawkins and Holmback1988: 219). Grandi and Montermini (Reference Grandi, Montermini, Booij, Guevara, Ralli, Sgroi and Scalise2005: 144) extended this assumption to derivational morphology, suggesting that prefixes may also occur in OV languages ‘although they are rarer than in VO languages’. The relation between word-formation processes and word order is analyzed in chapter 7.
4.2 Minor types of affixation
Minor word-formation processes may be labelled as less natural or even unnatural from the perspective of Natural Morphology. Conversion (5.1.1), derivation by stress (5.1.2) and tone/pitch change (5.1.3) are characterized by the absence of diagrammaticity (constructional iconicity) or even by anti-diagrammaticity, as in the case of subtracting techniques (back-formation, 5.2.1). Some of those processes are viewed in chapter 5, but we also include here those word-formation processes which violate the integrity of morphemes, either stem morphemes (infixation, 4.2.1), or derivational morphemes (like circumfixation, 4.2.3), or which produce new words by adding derivational material at two different points (prefixal-suffixal derivation (4.2.2) and prefixal-infixal derivation and infixal-suffixal derivation (4.2.4). Dressler (Reference Dressler and Dressler1987) predicts that these word-formation processes should be less frequent cross-linguistically than natural word-formation processes like prefixation, suffixation and compounding. Figure 7.1 confirms this in our sample (cf. 7.2).
4.2.1 Infixation
Moravcsik (2000: 546) defines a prototypical infix as an affix which is positioned inside the base such that the preceding and following portions are not meaningful by themselves. Moravcsik also mentions a number of peripheral types of infixation, such as those in which an infix is a free form or, instead of violating the integrity of the base, is inserted between two morphemes of the base. Infixation is recorded in the languages shown in Table 4.26(25.45 per cent of the study sample).
Table 4.26 Infixation in the study sample

Infixation has been described in the literature as chiefly derivational (Ultan Reference Ultan and Seiler1975: 160; Bybee Reference Bybee1985: 97). This is understandable because derivational infixes reflect ‘the closer semantic link between base and derivational affix than what holds between base and inflectional affix’(Moravcsik 2000: 548). In other words, inflectional morphemes serve to express grammatical relations between words, and placing them inside a word-base would mean an obstacle for this function. As usual, the picture is not completely clear in this respect. Thus, if transfixation (root-and-pattern) is viewed as a case of infixation, then infixation is productive in Arabic and Hebrew, where it would also cover inflectional processes.
The importance of laying emphasis on the word-formation nature of the infix follows from its definitions. Thus, Krupa and Genzor (Reference Krupa and Genzor1996) define infix in their encyclopedic book on languages of the world as a grammatical or derivational morpheme inserted in a word root. Similarly, the morphematic dictionary of Slovak (Sokolová, Moško, Šimon and Benko 1999: 48) defines infixes as extending morphemes, either grammatical (i.e. thematic submorphemes) or derivational (interfixed submorphemes) which can be attached in two different ways: they extend a grammatical or a derivational morpheme (Buzássyová, pers. comm.):
(280)
(281)
(282)
An interesting borderline case is offered by Wichí. According to Nercesian (pers. comm.), there are no infixes in Wichí. However, a root can be interrupted by a suffix and behave like an infix. Such is the case when a suffix, generally indicating direction, is co-lexicalized with root, but if any other suffix (e.g. plural) is added, then it occurs between the root and the co-lexicalized suffix:
(283)
- Wichí
a. ta-taypho
3sbj-sits.down
‘S/he sits down’
b. ta-ta. . .-che. . .pho
3sbj-sit down. . .-pl
‘They sit down’
An infix, like other affixes, is a bilateral unit with form and meaning. It must be distinguished from interfixes (empty morphs), as the latter ‘regularly intervene between stems and derivational suffixes or between two stems in composition, are not associated with any particular semantic or grammatical value, and are very often optional, as for instance, the morph -et- in Spanish lam-et-ón or the morph -s- in German Verfassung-s-treue’(Laca Reference Laca, Haspelmath, König, Oesterreicher and Raible2001: 1220–1). Szymanek (Reference Szymanek, Lieber and Štekauer2009) shows that interfixes, too, can play an important role in word-formation by being an inherent part of productive word-formation rules (albeit a formal one). This is characteristic of the so-called interfix-suffixing derivation and interfix-paradigmatic derivation. In the former, an interfix and a suffix together function as exponents of the category (Szymanek Reference Szymanek, Lieber and Štekauer2009: 468). Examples can be cited for Polish (284) and also for Czech (285) and Slovak (286):
(284)
- Polish
prac-o-daw-ca
praca-o-dawaċ-ca
job-itx-give-ag
‘employer’
(285)
- Czech
zákon-o-dár-ce
law-itx-give-ag
‘legislator’
(286)
- Slovak
nosorožec65
nose-itx-horn-pat
‘rhinoceros’
Sometimes, as observed by Szymanek (Reference Szymanek, Lieber and Štekauer2009: 469) the gender of the compound may differ from that of the head word when used separately. This, in turn, means that the compound belongs to a different inflection class. In that case, the word-formation process is labelled as interfix-paradigmatic:
(287)
- Polish
wod-o-głow-ie [+ntr]
woda-o-głowa-f
water-itx-head-ifl
‘hydrocephalus’
A slightly different example comes from Slovak, where the formation is of the same gender as the head constituent slov-o ‘word’([+neuter]), but the declensional paradigm changes:
(288)
- Slovak
tvar-o-slov-ie
form-itx-word-ifl
‘inflectional morphology’
Finally, the interfix also plays its role of formal indicator of compounding in formations whose second constituent is a converted deverbal noun with a zero marker of the nominative singular. Two of Szymanek’s examples (2009: 469) are:
(289)
- Polish
kork-o-ciag-ø
korek-o-ciagnąċ
cork-pull
‘corkscrew’
(290)
- Polish
śrub-o-kręt-ø
śruba-o-kręciċ'
screw-twist
‘screwdriver’
In many cases, the converted unit does not exist independently, e.g. *mierz or *kręt. There are also analogical formations in Slovak and other Slavic languages:
(291)
(292)
- Slovak
blesk-o-zvod-ø67
blesk-o-zvod
lightning-conductor,lead
‘lightning conductor’
A limited use of infixation in the languages of the world may be explained by the universal preference for morphotactic transparency, in particular, by the preference for continuous (rather than discontinuous) morphemes (Dressler Reference Dressler, Štekauer and Lieber2005: 273). It is probably for this reason that there are no languages which make use of infixation without employing prefixation or suffixation (Greenberg Reference Greenberg and Greenberg1963). From this it follows that, if a language makes use of infixation, it may also be expected to employ prefixation and/or suffixation in word-formation (cf. Plank Reference Plank2007: 58). Exceptions to this assumption include Yoruba, which uses infixation but not suffixation, and Tatar, which uses infixation but not prefixation.
4.2.1.1 Formal characteristics
It has been shown that infixes invariably appear near one of the edges of a root, a stem or a word (Yu 2003, 2007).68 Yu calls this the Edge-Bias Effect, and it has been explained diachronically by Plank (Reference Plank2007: 59–60): infixes developed from adfixes primarily by phonological reordering in order to optimize prosodic structures.69
According to Ultan (Reference Ultan and Seiler1975: 164–8), it is primarily the beginning of the base that serves for infixation. This clearly follows from the hierarchy of infix positions identified by Ultan according to frequency.70
The limited data on infixation available in the sample do not allow conclusions to be drawn on the formal and semantic patterns of infixing derivation. In principle, the data follow Ultan’s (1975: 162–4) and Moravcsik’s (2000: 547) observations that infixes seem to prefer to involve at least one consonant, and that the participating consonants tend to be sonorants, i.e. liquids and nasals and glides. The vowels, according to Ultan, are usually short and are mainly high or central.
Ultan (Reference Ultan and Seiler1975: 162–4) also identifies C, CC, CV and VC as the most frequent infix structures, and the data also support this expectation. While our sample provides examples of various formal structures of infixes, the most frequent are structures with a consonant, especially the VC structure with a nasal or liquid (cf. the relevant examples of infixes in Belorussian -im-, Ilocano -um-, Indonesian -el- and Karao -im-), but other types of consonants also occur in this infix structure type, e.g. plosives, as in Spanish (-it-). Other structures include CV with a glide, as in Clallam (-yə) and a plosive, as in Mandarin Chinese (-bù-), VCV (with a fricative consonant), as in Serbian-Croatian (-iva-), single consonant (glottal stop in Clallam and -t- in Tatar), VCVC in Spanish (-isim-) and two (low) vowels, as in Dangaléat (-áa-).
As to word-classes, verbal infixation clearly dominates, but the semantics of verbal infixation ranges over a large number of different categories. This also confirms Moravcsik’s assumption (2000: 548) that the meaning of infixes covers ‘a broad semantic range’.
4.2.1.2 Semantic characteristics
The range of semantic categories found is shown in Table 4.27.
Table 4.27 Semantic range of infixes
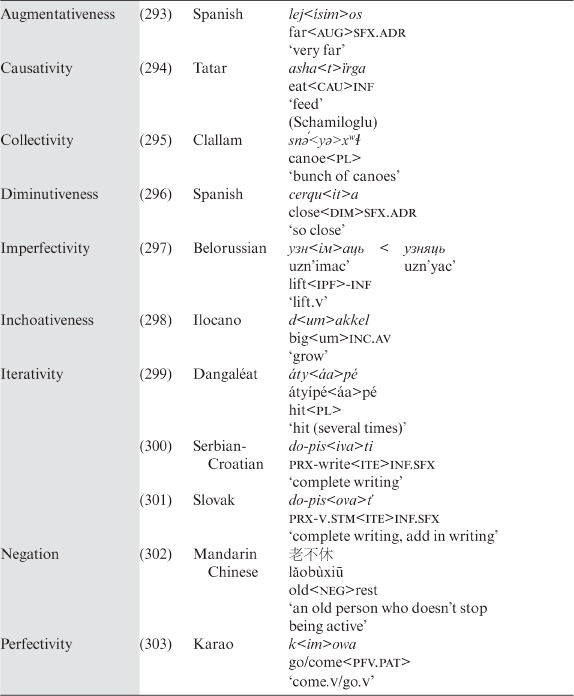
4.2.2 Prefixal-suffixal derivation
It has been claimed that ‘clear examples of circumfixation are rare or nonexistent’(Carstairs-McCarthy Reference Carstairs-McCarthy and Brown2006: 86). This view does not separate prefixal-suffixal derivation from circumfixation: ‘a circumfix is a combination of a prefix and a suffix that co-occur (at least with bases of specified type) to fulfil a joint function’(Carstairs-McCarthy Reference Carstairs-McCarthy and Brown2006: 85). One of the few examples accepted as circumfixation in this framework is derivation of verbs meaning ‘become X’ from adjectival roots:
(304)
An opposite view is that of Hall (Reference Hall, Booij, Lehmann and Mugdan2000: 535), who defines circumfix as ‘an affix of which one part is bound before, and the other part after, the base’. It is this understanding of circumfixation that was used for this book, such that circumfixation is explained as the case when ‘the two parts of circumfix cannot exist independently. They represent a single meaning’(cf. Appendix II). Circumfixation is thus distinguished from prefixal-suffixal derivation,71 which is based on actual affixes and is defined for our research as follows: ‘the two forms represent two different morphemes each of them contributing to
the meaning of the word-formation base. Both of them are attached simultaneously, within a single word-formation process’(cf. Appendix II). Prefixal-suffixal derivation is recorded in the languages shown in Table 4.28(32.73 per cent of the study sample).


Malkiel (Reference Malkiel and Greenberg1978: 146) observes that this type of word-formation, sometimes called parasynthesis, is very productive with German adjectives in -lich. This suffix usually requires one of a long series of prefixes, as exemplified in (305):
(305)
As with other word-formation processes, the boundary between prefixal-suffixal derivation and circumfixation may be fuzzy. A borderline case can be found in Karao, where prefixal-infixal derivation and infixal-suffixal derivation are considered types of circumfixation because, according to Brainard (pers. comm.), both affixes are required and unique meanings cannot be assigned to each affix. Thus, two affixes are combined in Karao, which implies prefixal-infixal, infixal-suffixal type of derivation. Since, however, the two affixes cannot be assigned specific semantic contributions to a new word, the pattern resembles circumfixation.
Indonesian is also unclear in this respect. Mojdl (pers. comm.) notes that the suffix -an, which is a part of the confixes pe- -an, per- -an and ke- -an, can also be used independently for productive derivation.72 Consequently, from the synchronic point of view, the confixes per- -an and ke- -an are somewhere between the prefixal-suffixal and circumfixal status, because neither per- nor ke- is used for independent derivation. On the other hand, the verbal confixes me- -kan, di- -kan, me- -i, di- -i, memper- -kan, diper- -kan, memper- -i, diper- -i, ber- -an, ber- -kan, etc. are used for prefixal-suffixal derivation covering a diversity of verbal meanings. An outline of this system, including examples, is given in Table 4.29. The confixes form transitive verbs (and sometimes also causatives) from intransitive verbs, nouns and adjectives (Mojdl Reference Mojdl2006: 132–40).
Further examples of prefixal-suffixal derivation are given in (314) to (327):
(314)
- Afrikaans
ge-lag-ery
pst-laugh-nmr
‘laughing.n’
(315)
- Belorussian
пры-бярэж-н-ы
pryb’yarezhny
near-bank-adj.sfx(m.sg.nom/acc)
‘riverside.adj’
(316)
(317)
- English
em-bold-en
make-bold-make
(Carstairs-McCarthy)
(318)
(319)
- Hebrew
חד-כיװנ
xad-kivun-i
one-direction-adj.sfx
‘one-way.adj’
(320)
- Ilocano
agallayada
agaC-laya-da
smell.like-ginger-3pl
‘They smell like ginger’
(321)
- Japanese
無意識的
mu-ishiki-teki
non-conscious-adj.sfx
‘unconsciously’
(322)
- Lakhota
wa-ká
a-piprx-make-sfx
‘statue’
 a-pi
a-pi(323)
- Luo
kii-neet-at
nom-teach-nom
‘teaching’
(324)
- Marathi
- -आगत-अह
su-aagata-arha
good-come-like
‘which can be welcomed’
 -आगत-अह
-आगत-अह(326)
- Serbian-Croatian
na-prst-ak
prx-finger-sfx
‘thimble’
Table 4.29 Confixes in Indonesian

4.2.3 Circumfixation
Circumfixation is recorded in the languages shown in Table 4.30(21.82 per cent of the study sample):
Table 4.30 Circumfixation in the study sample

Circumfixation is not a widespread means of word-formation but, as noted by Hall (Reference Hall, Booij, Lehmann and Mugdan2000: 540), it occurs in a large number of language families. Brainard (pers. comm.) remarks that, traditionally, Philippinists have analyzed co-occurring discontinuous affixes as circumfixation, because it is not possible to assign independent meanings to each affix consistently. Some linguists, however, do not accept this analysis. From this it follows that Karao circumfixations may also be classified as prefixal-suffixal derivation. This reduces the cross-linguistic power of circumfixation as a word-formation process even more and highlights the problems of its delimitation observed by Hall (Reference Hall, Booij, Lehmann and Mugdan2000: 542ff.). Some examples of circumfixation are given below:
(328)
- Ilocano
pag-basa-an
loc-read-loc
‘school’
(330)
- Maipure
ma-wana-tení
pri-body-pri
‘one who has no body’75
(Zamponi Reference Zamponi2003: 28)
(331)
- Totonac
xma:le:ni:má:ka’
ix-ma:-le:n-i:-má:-ka’
pst-cs-take-cau-prg-idf
‘S/he was being made to take it’
The evidence gathered here suggests that circumfixation is not bound to a single word-class. While nouns dominate, as exemplified in (328) to (330) and in Table 4.31, circumfixation in Romanian (333), Spanish (335), Totonac (331) is bound to verbs.
Table 4.31 Nominal and verbal circumfixation

Other possible word-classes are ordinal numbers (337):
(337)
- Georgian
მე-სამ-ე
me-sam-e
crx-three-crx
‘third’
4.2.4 Prefixal-infixal and infixal-suffixal derivation
Prefixal-infixal and infixal-suffixal types of derivation are even less natural than prefixal-suffixal derivation, because they violate the principles of naturalness by expressing the word-formation meaning by means of two separate elements and also violate the integrity of the word-formation base. These two word-formation processes are therefore rare. Prefixal–infixal derivation is recorded in the languages shown in Table 4.32(7.27 per cent of the study sample).
Table 4.32 Prefixal-infixal derivation in the study sample

Infixal-suffixal derivation is recorded in the languages shown in Table 4.33(10.91 per cent of the study sample).
Table 4.33 Infixal-suffixal derivation in the study sample

Prefixal-infixal derivation is used in the same group of languages as infixal-suffixal derivation, with the exception of Luganda and Mandarin Chinese. It should be noted that in Hebrew the infixation part of the process corresponds with the use of transfixes, as in (338) and (339):
(338)
(339)
According to Brainard (pers. comm.), prefixal-infixal derivation occurs in Karao in restricted classes of words, e.g. verbs in which the action may be performed reciprocally but the action is not inherently reciprocal. Within this restricted class, prefixal-infixal derivation is frequent:
(340)
- Karao
manchina-cha
man-cha-cha-in-
rcp.ipf-help-__
‘help each other’
Examples from some of the other languages are given in (341) to (343):
(341)
- Ilocano
pinnintasan
pintas{inn}-an
beauty{rcp}-N
‘beauty contest’
(342)
- Mandarin Chinese
傻里傻氣
shǎlishǎqì
silly-emp-silly-air
‘goofy, silly’
(343)
- Slovak
pretrvávať
pre-trv-áv-ať
prx-last.v-dur.ifx-inf.sfx
‘persist.v’
(Buzássyová)
4.3 Summary
Suffixation is the most frequent affixation process, followed by prefixation. The reason is obvious: these two types of affixation are natural word-formation processes. Both suffixation and prefixation are recursive in a number of languages, with the possibility of the class-change effect. Assimilation stands out as the major type of base modification.
The types of affixation which violate the integrity of morphemes, either stem morphemes (infixation) or derivational morphemes (circumfixation) or which produce new words by addition of affixes at two different points (prefixal-suffixal derivation, prefixal-infixal derivation and infixal-suffixal derivation or root-and-pattern derivation) are comparatively rare and allow for a variety of formal and semantic features, as well as for borderline cases.
1 The prefix eba- can also function as a stem: some words are formed by adding suffixes, e.g. eba-rd ‘monster, freak’ and eba-le-ma ‘hesitate.v’. In its capacity to combine with affixes, it resembles the combining forms of English neoclassical compounds.
2 This is, historically, a present participle of the negation verb e-.
3 Cf. Hudson (Reference Hudson1980), Lieber (Reference Lieber1981, Reference Lieber1992), Selkirk (Reference Selkirk1982), Zwicky (Reference Zwicky1985), Di Sciullo and Williams (Reference Di Sciullo and Williams1987), Scalise (Reference Scalise1988), L. Bauer (Reference Bauer1988, Reference Bauer1990), Anderson (Reference Anderson1992) and Kastovsky (Reference Kastovsky, Ahrens, Bald and Hüllen1995).
4 There is also the possibility of double prefixation by means of the prefix po- combining the durative and the perfective meanings: po-do-pisovať(‘ite-write into’), po-pre-pisovať(‘ite-re-write’), po-za-pisovať(‘ite-write down’), po-vy-pisovať(‘ite-write out’). In these cases, it is combined with durative versions of the prefixed ‘write’-based words.
5 The derivational suffixes are -ni and -w.
6 The two that most often recur are -ishi mutual/reflexive and -ya causative. When -ishi occurs twice, it is a lexicalization in the first occurrence, with the mutuality/reflexiveness coming from the second occurrence. The double occurrence of -ya results in a causation (Hardman Reference Hardman2000: 88).
7 Cf. Fortescue (Reference Fortescue1980, Reference Fortescue1984) for examples of many of them.
8 If a transitive clause is both perfective and passive, its verb is referential (i.e. inflected as though there were a referent).
9 Each other.
10 From the intransitive stem karaŋŋ-.
11 ken- is a prefix meaning ‘together’(cf. Latin con-), here lenited by di- and assimilated to the place of articulation of the following stop: ken > gem.
12 The ji- intensifier is only used (i.e. is potentiated) by the preceding diminutive or augmentative prefixes.
13 To get adverse effect by switching something, e.g. TV programmes at random.
14 Prefixes: teh ‘water’, ka ‘out of’.
15 A modified stem of niesť ‘carry’.
16 This rule applies regularly with vowels and s.
17 Gemination also accompanies other types of suffixation, e.g. the derivation of agentive names by the suffix -kaaran as in tooÔÔakkaaran < tooÔÔam-kaaran(garden-agent) ‘gardener’.
18 Before inceptive suffix.
19 The shortening of a long stem vowel is characteristic of Slovak, and is connected with the operation of the so-called Rhythmical Law. Cf. also (252).
20 Stump (pers. comm.) maintains that in Breton -enn causes a stem-final ou to change to aou. Because stress is penultimate, -enn puts the preceding syllable in tonic position, causing the vowel change. Other Breton suffixes may also have this effect.
21 Vowel alternation here restitutes the etymological vowel in Proto-Oceanic *taqun ‘year’.
22 In Hungarian adjectives end in a vowel if a causative suffix is added.
23 According to Hardman (Reference Hardman2000: 9), ‘each suffix of the language carries as part of its identity rules governing its combination with other morphemes of the language, subject to alternation for grammatical purposes. That is, some suffixes require the preceding morpheme to drop its vowel . . . some require that the preceding vowel be retained.’ Specifically, ‘the first vowel of all roots is never deleted. Three vowel roots normally lose at least one vowel when entering into derivational or inflectional constructions; where two vowel roots would lose one vowel, the three vowel roots may lose one or two of the vowels’(Hardman Reference Hardman2000: 5).
24 In Tzotzil, the stem loses its vowel when the intransitivizing suffix -Vx is attached to a stative stem (unlike transitive stems which preserve the vowel). When the suffix -Om ‘act’ or ‘process’ is combined with a transitive stem, the stem loses a vowel:
- Tzotzil
?ǐkatsnom
?ǐkatsin-om
carry.it.as.a.load-nmr
‘act of carrying loads’
(Cowan Reference Cowan1969: 106)
25 Insertion of an epenthetic vowel between the stem and the causative suffix -wAn-.
26 In Kwakw’ala there are two types of stem-final consonant modification by suffixes: hardening (glottalizing) and softening (voicing)(Boas Reference Boas, Boas Yampolsky and Harris1947: 226).
27 Here illustrated with an example of the so-called softening determined by the quality of the following [i](114). In (115) it is illustrated with velar softening. In the latter case the vowel reduction following stress shift is phonological.
28 Cf. Brainard (Reference Brainard1994).
29 Cf. irr-jambala ‘their feet’.
30 Caused by prefixation with git-.
31 Often caused by prefixation with ma-.
32 Often caused by prefixation with ma-.
33 For the stress shift due to Class 1 affixation in English, cf. Allen, M. R. 1978. ‘Morphological investigations’. Doctoral dissertation, University of Connecticut, Storrs, CT or Siegel (Reference Siegel1979).
34 This is also noted by Rice (pers. comm.), who emphasizes that the answer to this question depends on the theoretical framework from which the problem may be approached: ‘This depends on analysis. For instance, [in Slavey] ná- is analyzed as several morphemes, including continuative and “down”. The prefix d- is analyzed as an inceptive, as a noun class marker, as a self-benefactive, and as other things, including something with no identifiable meaning.’
35 However, the so-called thematic suffixes, among which -eb is most productive, have no clear single function. They are used with causatives, as a present marker, etc.
36 This refers to patients which are set in a symmetrical relation by an agent, as in (147).
37 Independent, deictic or anaphoric pronouns; pe- is never prefixed to subject or object personal pronouns.
38 Derivation of agent nouns by ma- is reportedly productive: according to Newman, one could morphologically create an agent noun from almost any verb. Most nouns of location end in -ā. A smaller number end in -ī.
39 According to Rainer (Reference Rainer, Booij, Guevara, Ralli, Sgroi and Scalise2005: 23), reinterpretation includes three stages: at first, there are only agentive formations, then some of them acquire an instrumental interpretation due to semantic shift and, finally, the instrumental formations are reinterpreted as an independent word-formation pattern. Approximation skips the second stage.
41 This apparently goes against Booij’s (Reference Booij1986) claim that this kind of polysemy/homonymy does not exist in Finnish.
42 The suffix variant ó is used for stems with back vowels, and the variant ő for stems with front vowels.
43 Compare its feminine counterpart:
- Malayalam
nuîa-cci
lie-ag.f
‘female liar’
44 Compare its feminine counterpart:
- Malayalam
taʈi-cci
fatness-pat.f
‘fat woman’
45 The asterisk means that the stem does not occur alone, without an affix.
46 di- + gwir.
47 di- + mamm.
48 di- + koulouma~n.
49 em- + kav.
50 All Serbian-Croatian examples are combinations of the prefix ne- and a noun.
51 From gubàa.
52 From ālìibī.
53 Possible realizations are -al, -tal, -kkal, -ccal and -ccil(Asher and Kumari Reference Asher and Kumari1997: 385).
54 The asterisk means that the stem does not occur alone.
55 From n-komo-azi.
56 As rope.
57 Translation by Jan Don.
58 The form eri- occurs before consonants and the form er- occurs before vowels.
59 In prevocalic position (Campbell Reference Campbell1985: 75–6).
60 Unlike Anejom and Telugu, Romanian requires that the prefix-final and the stem-intial phonemes be of the same type, i.e. two consonants or two vowels.
61 The form a- occurs before consonants and the forman- occurs before vowels.
62 With an epenthetic vowel between the consonant-final prefix and a consonant-initial stem.
63 Croft, W. and Deligianni, E. Reference Croft2001. ‘Asymmetries in NP word order’, paper presented at the International Symposium on Deictic Systems and Quantification in Languages Spoken in Europe and Northern and Central Asia, May Reference Croft2001, Udmurt State University, Izhevsk, Russia.
64 Amele is listed along with OV languages but not with SOV languages, and in chapter 7 it is not considered with the rest of the languages which are recorded as SOV in this table.
65 Also in Czech.
66 Also in Czech, where it is derived from psát ‘write.v’.
67 In Czech blesk-o-svod-ø is derived from svod, with the same meaning as in this example.
68 Yu, A. C. L. 2003. ‘The morphology and phonology of infixation’. PhD thesis, Department of Linguistics, University of California, Berkeley, CA.
69 ‘Edge-boundedness, with “edge” defined prosodically, and external occurrence in the case of some edges strongly support the analysis of “infixes” as created by phonological reordering from morphological adfixes’(Plank Reference Plank2007: 60).
70 In the following order, from most to least frequent: after the first consonant, after the first consonant cluster, after the first vowel, after the first syllable, after the second consonant, after the vowel of the penultimate syllable, before the final syllable, and before the final consonant. Other options are also possible, e.g. the infix is after the first consonant of the second syllable, as in the following examples:
- Spanish
lej-ísim-os
far<aug>sfx.adr
‘very far’
- Spanish
cerqu-it-a
close-<dim> sfx.adr
‘so close’
In the second example, there is an orthographical variation: to retain the phoneme /k/(spelt ‘c’ before ‘a’, ‘o’ or ‘u’, and ‘qu’ before ‘e’ and ‘i’).
71 Cases when a single morpheme is realized by two or more affixes are labelled as synaffixes by L. Bauer (Reference Bauer1988). Certainly, morpheme is then necessarily defined as an ‘abstract entity, which is realized by morphs’(L. Bauer Reference Bauer1988: 17). Out of a number of examples adduced from various languages, let us mention the derivational morpheme -istic, as in characteristic or stylistic. As stated by Bauer, the two affixes -ist and -ic should be treated as a single morpheme, borne out by such words as stylistic, which in terms of semantics cannot be considered as derived from stylist. Synaffixes may have a different structure, including cases with more than one prefix, more than one infix, suffix plus prefix, suffix plus infix, etc.
72 The prefixes per- and ke- used to be productive in the past, but are no longer used for derivation. The prefix pe- is synchronically productive, but its meaning is different from that in the confix pe- -an.
73 This suffix is used to derive deverbal nouns.
74 As in Toy pengedaan mo i? ‘Where will you get it?’(Brainard, pers. comm.)
75 I.e. ‘spirit’.
5 Word-formation without addition of derivational material and subtractive word-formation
If we had set out from Māori, rather than from Indo-European languages, I doubt that we’d have come up with such a concept [as conversion]!
The previous two chapters in Part II discuss word-formation processes in which derivational material is added to the base and which abide by the constructional iconicity principle, compounding and affixation. This chapter gives an overview of word-formation processes which run counter to the constructional iconicity principle: a new meaning is added which is not supported by any derivational morpheme. For convenience, the chapter groups together processes which may have little in common, e.g. stress shift and stem modification.
This chapter reviews conversion (5.1.1), stress (5.1.2), tone/pitch (5.1.3) and internal stem modification (5.1.4) within the same section. Back-formation, an even less natural process, in which the addition of new meaning is accompanied by the reduction of form, is discussed in 5.2.1.
5.1 Word-formation without addition of derivational material
5.1.1 Conversion
The term conversion is connected, in the majority of English-written literature, with the prototypical case of English conversion as a process of forming a new word which belongs to a different word-class without any formal change. From the point of view of constructional iconicity, conversion is not a natural word-formation process: unlike compounding and affixation, the new meaning is not expressed by an additional form (Dressler Reference Dressler, Štekauer and Lieber2005: 269).
This definition of conversion is, however, tricky for the vagueness of notions like word-class and lack of formal change. As noted by L. Bauer and Valera (Reference Bauer, Valera, Bauer and Valera2005: 8), ‘virtually all of this has been questioned at one point or another and yet the concept of conversion remains in use, very much as the conventional system of word-classes does in languages for which it is theoretically inadequate’.1 This remark shifts the focus to the issue of word-classes for cross-linguistic description. A case in point is Māori (W. Bauer, pers. comm.):
one can make a case for saying that Māori doesn’t really have a vocabulary classified into parts of speech, as most bases can be used in both nominal and verbal constituents without change of form, though they change their sense appropriately in the two contexts. This underlies Bruce Biggs’s classification of words in Māori (1969) into a small number of classes, one of which he called Universals – i.e., precisely those which are regularly found in both nominal and verbal constituents.
Therefore, while conversion may seem justified from the Indo-European linguistic perspective, it may not be so in other language families. The message of the motto of this chapter is in no way exceptional:2 it can also be said of other Polynesian languages (W. Bauer Reference Bauer1997: 65)3 and is apparent from Spencer’s (Reference Spencer, Booij, Lehmann and Mugdan2000: 316) examples of inflected verbs used as nouns in Navajo, a Na-Dene language spoken in North America:
(1)
More importantly, this gives support to the view that lexical entries are neutral as regards word-classes (Farrell Reference Farrell2001). The implication for the theory of conversion is, as pointed out by L. Bauer and Valera (Reference Bauer, Valera, Bauer and Valera2005: 9), ‘that the relationship between nouns and verbs of related form (e.g. [English] a bridge and to bridge) is no more than a matter of inflection’. This view has found support in the literature (Myers Reference Myers1984; Josefsson Reference Josefsson1997; Giegerich Reference Giegerich1999), but it is admittedly rejected more often than not.
Conversion is recorded in the languages shown in Table 5.1 (61.82 per cent of the study sample).


Conversion can be found in a number of languages: Serbian-Croatian dobro may be an adjective (‘good’), a noun (‘property’) and an adverb (‘well’). In Ket it is common for nouns, adjectives and sometimes verbal infinitives to have the same form (cf. (18)), and in Maipure, the same entry may also be a stative verb, an adjective and an adverb (Zamponi Reference Zamponi2003: 46) (cf. (20)). Similarly, in Amele abul-doc can mean ‘struggle.v’ as well as ‘struggle.n’ and ihan-ec can mean ‘sacrifice.v’ as well as ‘sacrifice.n’.4 In Hausa, simple adjectives have the same form as nouns, create feminines and plurals essentially like nouns and use the same genitive linker as nouns; in fact, many words exist in Hausa both as nouns and adjectives (Newman, pers. comm.).
Thái Ân (pers. comm.) explains the high productivity of conversion in Vietnamese by referring to Spencer (Reference Spencer, Orgun and Sells2004: 3), who maintains that ‘in so-called “isolating languages” it is common for a single word to have the syntax of a noun or a verb indiscriminately, but arguably we are better talking of categorical indeterminacy here rather than mixing’. This must be distinguished from the situation in Jaqaru, where there is a common pro-root which ‘functions as a stand-in for all other roots. The pro-root {inchi} may be a pro-noun or a pro-verb or simply a filler. It may carry any or all suffixes of nouns, verbs or sentence suffixes or it may stand alone as a particle’ (Hardman Reference Hardman2000: 8).5
Probably as a consequence of the different word-class systems that can be found in different languages, individual cases of conversion may feature various degrees of transfer to a new word-class. Nikolaeva and Tolskaya (Reference Nikolaeva and Tolskaya2001: 166–8) illustrate different degrees of nominalization of verbs in Udihe:
(2)
(3)
These converted nouns show some verbal properties: they preserve the valency of the corresponding verb and can be modified by an adverbial. The function of converted nouns is to fill the object valency of certain verbs.6 By contrast, other converted nouns, as (4) and (5), have undergone further nominalization and take all inflections typical of nouns:
(4)
(5)
Apart from the prototypical cases of non-homonymous conversion or, rather, conversion as it is understood in Indo-European languages, examples of other subtypes can also be found, e.g. intra-categorial conversion or secondary word-class conversion. In Swahili, the noun sauti means ‘voice’ if accompanied by Class 9 concord and ‘thick/harsh voice’ if accompanied by Class 5 concord.7 Examples (6) and (7) illustrate this process in other languages too:
(6)
(7)
Another borderline case can be found in Bardi, where, according to Bowern (pers. comm.), all adjectives and many nouns can be used as coverbs in complex predicates:
(8)
However, it seems better not to consider these and similar cases of conversion for their dependence on another verb, i.e. they cannot occur independently and, in this respect, they resemble clitics.
All these facts bring the description back to Hockett’s (Reference Hockett1958: 221) almost forgotten rejection of the traditional concept of word-classes and to the proposal of new categories like AV, NA, VN and NAV, depending on whether the respective lexeme functions both as an adjective and a verb, a noun and an adjective, etc.8 This book does not pursue this issue and limits itself to providing cross-linguistic evidence which might contribute to answering the question of the correctness or falsity of this direction of consideration.
In our sample, the majority of languages where conversion is recorded allow conversion within the categories adjective, noun, verb and, less markedly, adverb. No records of other word-classes have been cited. It should be emphasized, however, that the following analysis reflects the limited scope of data bound to a single item in our questionnaire examining the existence of a productive word-formation process of conversion.
5.1.1.1 Formal characteristics
Homonymous conversion is perhaps the most canonical view of conversion. It occurs in examples (9) to (27):
(9)
(10)
(11)

 qa > swqa
‘man’ ‘be a man’
qa > swqa
‘man’ ‘be a man’(12)
(13)
(14)
(15)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
(27)
As far as the identical form criterion is concerned, this rather general definition lends itself for analytic, non-inflecting languages, but can hardly be applied without modification to inflectional ones. It has been argued, however, that the form of the stem – rather than the form of the word – is important. In the majority of cases, it remains intact. Thus, the situation in Slavic languages shows that, from the formal point of view, this phenomenon is far from being as simple as it might seem when we limit our focus to English. Smirnickij and Achmanova (1952) and Smirnickij (Reference Smirnickij1953, Reference Smirnickij1954, Reference Smirnickij1956) point out that conversion in Russian is based on the change of paradigm. Smirnickij (1953: 24) maintains that conversion in Russian is one of the so-called morphological word-formation processes, where morphological is synonymous with inflectional paradigm. From this it follows that, while no derivational affix is added, formal changes occur. The paradigm thus fulfils the function of a derivational affix (cf. Dokulil Reference Dokulil and Isačenko1968: 218).
Consequently, unlike in English, where in the vast majority of cases conversion entails formal identity, and only a minor group of conversion pairs bear some formal change (re’cord.v vs ’record.n), conversion is not homogeneous cross-linguistically:
(28)
(29)
(30)
(31)
(33)
(35)
Another subtype can be illustrated by German schneiden ‘cut.v’ vs Schnitt ‘cut.n’, which shows that one of the stems need not be a citation form.11 Such cases are not unique cross-linguistically. A relatively frequent source of conversion are participles. This poses serious theoretical problems as to the status of e.g. -ing participles/adjectives in English, which, in turn, comes back to the issue of the definition of conversion, especially as participles, both present as in (36), (37), and past (38), take part in conversion in a number of languages:
(36)
(37)
(38)
In Udihe, resultative participles derived with the suffix -ktu are converted to adjectives that can be modified by degree adverbials, like c’o ‘most’ or belem ‘even more’, and can head a comparative adjective phrase (Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 197):
(39)
- Udihe
koŋo-ktu
‘lean, thin’
(40)
- Udihe
soŋo-ktu
‘crying, whining’
Similarly, passive is used in Karao (41) and past tense forms may be used in Ilocano (42):
(41)
(42)
The status of imperative as a converting form in Telugu, as in (43), is ambiguous according to Pingali (pers. comm.):
(43)
For Pingali, verb roots in Telugu are bound forms and they become words with the affixation of at least a suffixal vowel. It is unclear how conversion should be captured as a process, whether the -u in derived caduwu should be seen as an epenthetic vowel (since words cannot end in consonants) or whether conversion is to be seen as converting the imperative form, which is caduwu with the imperative suffix -u.
Another formal variant of conversion is one which encompasses the addition of a stem-forming morpheme (theme), as illustrated by the following example from Marathi:
(44)
Czech examples are zelenat, zelenět, zelenit ‘be green’, for which Dokulil (1968: 225) postulates stem-forming grammatical morphemes, i.e. thematic morphemes (-a-, -e/ě-, -i-) rather than a derivational suffix.
Conversion may also be accompanied by vowel/consonant alternations, as in Czech and Hindi:
(45)

 <
<  mela milna
‘fair’ ‘meet.
mela milna
‘fair’ ‘meet.Conversion may also be a part of a combined word-formation process and so, for Slovak, a range of conversion variants can be distinguished (see Table 5.2).14


The productivity of conversion may differ both cross-linguistically and inside one particular language, if various conversion subtypes are taken into account. In Udihe ‘virtually every adjective may receive certain nominal properties within headless noun phrase’ (Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 169). In Hindi, the infinitive suffix -na yields an abstract noun and therefore, except for the invariable cahiye ‘should, ought to’, Hindi verbs have infinitive forms which can act as abstract nouns (Kachru Reference Kachru2006: 115). In addition, the root of the verb may be used in Hindi as an abstract noun. By contrast, conversion is reportedly rare in other languages, like Finnish, even if some examples can be found:15
(56)
(57)
In Finnish, Laakso (pers. comm.) notes that there are some cases where the stem-final vowel of a noun coincides with the one-vowel suffix of a verb. In Laakso’s view, from a synchronic perspective, these could be classified as cases of conversion because they share the stem paini- ‘wrestle.v’ and paini ‘wrestling’ and both ultimately go back to paina- ‘press.v’. Laakso notes that there is also a handful of noun–verb ambiguous stems (tuule-, nom.sg.tuuli ‘wind’, tuule- ‘blow.v (of the wind)’). As there is no clear morphosyntactic boundary between adjectives and nouns, this adjective–noun ambiguity might be considered a kind of conversion.
Given the above-mentioned difficulties concerning the limits of conversion, our cross-linguistic research examines conversion as the formation of new complex words by shift of categorial meaning (following Cetnarowska Reference Cetnarowska1993: 86) in the framework of the conventional system of word-classes, prototypically, without formal change in the stem.16
5.1.1.2 Semantic characteristics
Conversion offers a wide range of meanings which, despite the scepticism of Clark and Clark (1979), seem to be fairly well predictable for the individual novel converted complex words. Štekauer’s (2006) data show that, with the majority of this kind of neologisms, there is usually one, rarely two dominant meanings, much more predictable than the other potential readings of the coinage. Table 5.3 shows a hint of the wide semantic capacity of conversion as a word-formation process.
Table 5.3. Semantic diversity in conversion

5.1.2 Stress
Stress is recorded in the languages shown in Table 5.4 (7.27 per cent of the study sample).
Table 5.4. Change in stress in the study sample

Even in these languages, stress does not play any significant role in word-formation, or at least its function as an independent word-formation device is questionable. Such is the case of English, where examples of stress as a word-formation process are traditionally associated with conversion:
(72)
(73)
However, in these and similar examples of word-class-conditioned stress change, the position of stress results from the main word-formation process (conversion) which shifts stress to the status of a secondary phenomenon. Štekauer (1996: 55–95) argues that stress difference as in (72) and (73) does not result from an independent word-formation process and that such pairs should be treated as a specific subgroup within conversion.
The value of stress as a word-formation device is perhaps better appreciated comparing English and Luganda: while stress shift may be viewed in English as a by-product of certain cases of conversion (disyllabic nouns, verbs and adjectives), conversion does not exist in Luganda and yet stress shift has the same derivational effect:
(74)
In yet other languages, like Hebrew, the examples are diverse in nature: some noun–verb pairs parallel the above examples of English and therefore raise the same doubts. Hebrew does not seem to make relevant use, if any, of stress as a word-formation device. Semantic unrelatedness occurs in similar examples of Romanian and Ukrainian, where the total absence of any semantic relation argues against the word-formation status of stress:
(75)
(76)
These are different from the example taken from Ukrainian (77), which is a case of semantic divergence from one and the same source word, i.e. a diachronic process rather than one of word-formation:
(77)
This is supported by Slovak and Czech equivalents, both of these pairs having the same form, i.e. they are homonyms: Slovak zámok and Czech zámek. However, the two meanings (identical to those in Ukrainian) are not distinguished by stress.
Another borderline case includes examples for Belorussian and Vietnamese, where stress shift is at the border between inflection and derivation:
(78)
 ь vs paccbınaь
rassypac’ rassypac’
‘spill.pfv’ ‘spill.ipf’
ь vs paccbınaь
rassypac’ rassypac’
‘spill.pfv’ ‘spill.ipf’(79)
5.1.3 Tone/pitch
Like stress shift, the role of tone/pitch in word-formation seems comparatively minor, except in tonal languages. Tone/pitch is recorded in the languages shown in Table 5.5 (12.73 per cent of the study sample).
Table 5.5. Tone/pitch in the study sample

Chebanne (pers. comm.) explains that Cirecire has two fundamental tones, high and low (H and L, respectively), and two derived tones that are super-high (SH) in the context of consecutive HH tones in sentence-final position and super-low (SL) in the context of consecutive LL tones in sentence-final position. Tone has a derivational function in the following examples:
(80)
(81)
Tonal properties of verbal and nominal derived forms are given in (82) to (84):
(82)
(83)
(84)
Tone in Cirecire interacts with other word-formation processes, as illustrated in Table 5.6.
Table 5.6. Tone and other word-formation processes in Cirecire

Tone is an important aspect of Datooga inflection, which also has repercussions in derivational morphology. With respect to tonal behaviour, we have to identify tone-integrative suffixes, i.e. suffixes that impose tone patterns onto the noun as a whole, overriding lexical tone patterns. All the nominal plural suffixes do so. There is also a process of tone conversion by which plurals are derived from singulars: generally speaking, a switch from tone class 2 (H(H)L) to tone class 1 (L(L)H) derives a plural form from singulars in 0 and in -èe. Nouns with the primary suffix 0 that display tone conversion are shown in Table 5.7.
Table 5.7. Tone conversion in Datooga (nouns with primary suffix 0)

Nouns with the primary suffix -èe display tone conversion. Some are shown in Table 92.
Table 5.8. Tone conversion in Datooga (nouns with primary suffix -èe)

Newman’s (pers. comm.) examples for Hausa are verbal nouns derived from stems of a particular grade: monosyllabic H-tone verbs ending in short i have verbal nouns that end in a long -ī and have a falling tone:
(113)
In Dangaléat, tone can distinguish gender (114) and in Mandarin Chinese tone is sometimes used as a basis for morphological class (115):
(114)
Interestingly, tone does not function as a word-formation device in Vietnamese, even though it is a tone language19. It can only have a meaning-distinctive function in homonymous lexemes, as in (116):
(116)
The same can be found in Konni (117):
(117)
5.1.4 Word-formation by internal modification
5.1.4.1 Stem vowel alternation
Stem vowel alternation is recorded in the languages shown in Table 5.9 (23.64 per cent of the study sample):
Table 5.9. Stem vowel alternation in the study sample

5.1.4.1.1 Formal characteristics
Stem vowel alternation is frequent in Arabic and Hebrew. Vowel alternation is their fundamental word-formation process and is generally labelled root-and-pattern. According to Schwarzwald (2001: 23), ‘the number of roots [in Hebrew] runs somewhere between 3,000 and 4,500 roots. The number of patterns is limited to approximately 200. A single root may be inserted into many patterns’, e.g. g-d-l in nouns, verbs and adjectives (see Table 5.10).


At the same time, one and the same pattern can be used for the derivation of many new words (Schwarzwald Reference Schwarzwald2001: 23):
(131)
According to Zwarts (pers. comm.), the derivation in the following examples from Luo consists of merely a floating [+ atr] feature that autosegmentally attaches itself to the vowels of the verb root. Thus, the derivation process is based on changing a vowel from [- atr] to [+ atr]. Remarkably, the resulting agentive noun is in plural:
(132)
(133)
There are also combined types of stem modification, in which a vowel change accompanies the main word-formation process. Vowel modification is often combined with other processes, as with reduplication in Konni and Tibetan, with stem vowel modification in Marathi or with suffixation in Breton and Malayalam (see Table 5.11).
Table 5.11. Vowel modification in combination with other word-formation processes

5.1.4.1.2 Semantic characteristics
The range of functions of vowel modification as a word-formation process is broad and no generalizations seem to be possible. It is used to derive verbal nouns in Dangaléat (139), German (140) and Hausa (141):20
(139)
(140)
(141)
Other semantic changes caused by vowel alternation are shown in Table 5.12.
Table 5.12. Semantic diversity of vowel alternation

5.1.4.2 Stem consonant alternation
Stem consonant alternation is recorded in the languages shown in Table 5.13 (7.27 per cent of the study sample).
Table 5.13. Stem consonant alternation in the study sample

This word-formation process seems to play an important role only in Malayalam derivation. However, even this depends on the interpretation, because processes like vowel alternation and consonant alternation in Malayalam can also be interpreted as instances of affixation (Mohanan, pers. comm.):
(147)
In English (148) there are cases of denominal verb formation by consonant alternation, but this process is not productive (Carstairs-McCarthy, pers. comm.). Similar examples can be found in Datooga (with change of q to g) (149) and Slovak (150):
(148)
(149)
(150)
5.2 Subtractive word-formation processes
5.2.1 Back-formation
Back-formation is recorded in the languages shown in Table 5.14 (16.36 per cent of the study sample).
Table 5.14. Back-formation in the study sample

This process may be regarded as a truly peripheral one. This is especially so as the question may be raised whether back-formation is not relevant only from a diachronic point of view, as assumed by Marchand (1960). From the synchronic point of view, Marchand (1960: 3) proposes the following equation for English back-formation: peddle : peddler = write : writer. This means that, synchronically, back-formation is analyzed analogically with suffixation. This makes sense because, logically, the cutting off of an affix postulates the prior attachment of this affix, even if the corresponding word-formation base was not in use before.
It has already been noted that, unlike Marchand, Kiparsky (1982a) explains the process of forming verbs like air-condition.v or spotweld.v (traditionally explained by back-formation) as compounding, based on the rule [Y Z]x, with X being V. Similarly, Štekauer (Reference Štekauer1998, Reference Štekauer, Štekauer and Lieber2005) explains this type of example on a par with other word-formation processes, based on the Morpheme-to-Seme-Assignment Principle.
All these approaches, from the synchronic perspective, call into doubt the process of back-formation, and further undermine its status among word-formation processes from both cross-linguistic and language-specific points of view. The scarcity of back-formation does not, however, preclude it from ranging over various categories in some languages, as illustrated by Romanian (see Table 5.15).
Table 5.15. Back-formation in Romanian

In the majority of cases, the direction is from nouns to verbs, which express the action contained in the meaning of the motivating noun. This applies to several languages:
(155)
(156)
(157)
(158)
Sometimes the back-formation process does not reach beyond the boundaries of a particular word-class, as in the following examples from Serbian-Croatian and Slovak:
(160)
Aside from denominal verbs like (161), Finnish provides examples of an opposite direction, i.e. from verb to noun (162):
(161)
(162)
Clearly, back-formation is a typical European (plus all types of Englishes) matter, covering Germanic, Romance and Slavic. Back-formation in Finno-Ugric languages is non-existent or very rare. According to Kilgi (pers. comm.), there are some examples of back-formation in the history of Estonian, but it is not a productive word-formation process nowadays (cf. however (163) and (164)) and in Finnish it depends on the account of relatively rare compound verbs traditionally explained either as calques (165) or back-formations (166) (Laakso, pers. comm.):
(163)
(164)
(165)
- Finnish
alle-kirjoittaa
under-write
‘(under)sign’
(166)
There are few exceptions to the Eurocentric nature of back-formation in our sample. An example is taken from Marathi:
(167)
 kara karaNe
‘hand’ ‘do.v’
kara karaNe
‘hand’ ‘do.v’5.3 Summary
This chapter reviews word-formation processes which do not involve the addition of derivational material, or which involve subtraction. The former type refers to conversion, stress, pitch/tone and stem alternation. Of these, conversion best exemplifies how the description of certain linguistic concepts is, probably unavoidably, based on the theoretical framework developed for Indo-European languages. As a result, it relies on concepts which otherwise would naturally not be used. By contrast, stress and, more clearly, pitch/tone, are rather foreign to this tradition. Back-formation is presented as the only subtractive word-formation process considered in this book. Its theoretical implications are briefly discussed and it is illustrated in some languages.
1 Filipec and Čermák (Reference Filipec and Čermák1985: 104) take over Dokulil’s term transflexion (Reference Dokulil1982) and define conversion in Czech as derivation of new words by the change of inflectional paradigm, and Furdík (Reference Furdík2004: 68–9) defines conversion in Slovak as the transition to a different inflectional pattern. Word-class change is not a necessary condition in their view. Consequently, cases like Slovak sused ‘neighbour.m’ >suseda ‘neighbour.f’ or Czech kmotr ‘godfather’ > kmotra ‘godmother’ are also treated as conversion. This is in line with Dokulil’s (Reference Dokulil and Isačenko1968: 230) view that the basic feature of conversion is ‘the participation of the word in morphological oppositions’ (translation by Salvador Valera). Let us also mention cases of semantic conversion included in the realm of conversion by Stein (Reference Stein, Brekle and Kastovsky1977: 229–35), like English container ‘magazine, bin’ > container ‘the contents of the magazine, bin’.
2 Cf. the following quotation from Boas (Reference Boas, Boas Yampolsky and Harris1947: 280) about Kwakw’ala: ‘there is no clear cut distinction between noun and verb. Any “verb” preceded by an article is a noun: yexa k!waεs ‘the one who sits on the ground’; any noun with predicative endings is a verb: εne´k°eda begwa´nem ‘that one said, it was the man’; begwa´nemeda εne´k a ‘it was the man he said’. The two forms mean the same.’
3 Thus, in Kambera, an Austronesian language spoken in South East Asia and Oceania, a lexeme ‘can function either as a verb or as a noun without having an overt morpheme relating these two categories derivationally’ (Klamer Reference Klamer1998: 109). Similarly, Taba, an Austronesian language spoken in South East Asia and Oceania, like many other Austronesian languages, has many roots which do not belong to a specific word-class (Bowden Reference Bowden2001: 93).
4 In Amele, ‘adverbs are not formally distinguished from nouns and adjectives’ (Roberts Reference Roberts1987: 158). Similarly, ‘many verbs can function as nouns in their nominalized form . . . the nominalized form of the verb is identical to the infinitive form’ (Roberts Reference Roberts1987: 325).
5 This should be distinguished from what happens in Slavey, where many stems can be used as a noun and as a verb, but the verb always has at least one prefix with it (Rice, pers. comm.):
6 In this case they take the accusative suffix -wa, but they may not inflect for person:
- Udihe
Sagdi ma:ma ča:la-inji bu-gi-we sita-wa
big grandmother want-3sg give-ite-acc child-acc
‘The great grandmother agrees to give the child’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 167)
7 Normally amplicatives are formed by replacing the noun class prefix with zero but, if the source noun lacks a prefix, its concord can signal amplicative reading (Contini-Morava, pers. comm.).
8 Consider also Halliday’s (Reference Halliday, Bazell, Catford, Halliday and Robins1966) proposal of the so-called scattering of a lexeme.
9 Stative verb.
10 D = D-element.
11 Schnitt is the stem of preterite and past participle.
12 The saamaanyarup suffix is a stem-forming suffix.
13 -na is an infinitive suffix.
14 Examples by Horecký and Ološtiak and by Štekauer et al. (Reference Štekauer2001: 74).
15 Especially one’s nationality, country.
16 Cf. Biese (Reference Biese1941: 6), Pennanen (Reference Pennanen and Hovdhaugen1975: 221), Lieber (Reference Lieber1981: 126, Reference Lieber1992: 159), Kastovsky (Reference Kastovsky1982: 78–9, Reference Kastovsky and Britton1994: 95, Reference Bauer, Bendjaballah, Dressler, Pfeiffer and Voeikova2000: 121), L. Bauer (Reference Bauer1983: 32, Reference Bauer, Bauer and Valera2005), Tournier (Reference Tournier1985: 49, 169, 197), Vogel (Reference Bauer1996: 1), Štekauer (Reference Bauer, Bendjaballah, Dressler, Pfeiffer and Voeikova2000: 14–17) or Plank (Reference Plank2010).
17 I.e. both ém and út are stressed vs only út is stressed.
18 In these cases, a first-tone noun becomes fourth tone when used as a verb (‘pound in (a nail)’).
19 As emphasized by Alves (pers. comm.), this assumption is true with the exception of Southern Vietnamese third person pronouns derived from family terms. Thus, oˆng aˆ’y /sir - that/ ‘He (older, respectful)’ in official/standard Vietnamese is equivalent to oˆng (where ? represents the rising hoi tone) in Southern Vietnamese. This pattern is consistent with other referential terms and some location terms (cf. L. C. Thompson Reference Thompson1967).
20 The vowel change combined with suffixation is due to the penultimate position of stress; -enn puts the preceding syllable in tonic position, causing the vowel to change (Stump, pers. comm.).
21 English causatives like lay vs lie or raise vs rise are considered scarcely productive (Carstairs-McCarthy, pers. comm.). Carstairs-McCarthy notes that it is unhelpful to talk in these cases of constituent morphemes. For many morphologists, there is only one morpheme in these forms.
22 This example illustrates a rare case of prefix elimination.
6 An onomasiological description
Typologists must realize that they cannot base their comparisons on formal categories, and need to resort to semantic-pragmatic or phonetic substance as a foundation of their classification and generalizations.
This chapter deals with the ways in which the most common semantic categories are expressed in word-formation. This approach has been almost totally ignored in Western twentieth-century linguistics, mainly due to the influence of the form-centred Bloomfieldean structuralism whose position was later taken over by the generative mainstream in linguistics. However, it is an approach that requires at least as much attention as the form-based one. This follows from the semiotic and cognitive foundations of word-formation, i.e. from the formation of new linguistic signs. This approach, it should be noted, complies with insistence by Greenberg (Reference Greenberg and Greenberg1966: 74), Croft (Reference Croft2003) and Haspelmath (Reference Haspelmath2007: 126), among others, on the crucial role of semantics in typological research.
This chapter reviews the possible realizations of semantic categories by groups: the nominal (6.2), evaluative (6.3), verbal (6.4) and word-class changing categories (6.5). Each of these subsections devotes a part to one semantic category.
6.1 Introduction
The purpose of the onomasiological method is to find out how cognitively grounded categories are linguistically represented through the individual word-formation processes. The selection of a particular word-formation process and of a particular word-formation rule within the process is not pre-determined by strictly prescribed rules of the particular language. There is always space for a creative approach to the linguistic realization of a cognitively captured and processed object that should be named in a language. This is the fundamental idea underlying our concept of creativity within productivity constraints (Štekauer Reference Štekauer, Štekauer and Lieber2005; Štekauer, Chapman, Tomaščíková and Franko Reference Štekauer, Chapman, Tomaščíková and Franko2005).
The selection of a particular naming strategy is always an interplay between on the one hand the limits imposed on the naming process by language through the available productive rules and constraints on productivity and on the other individual naming preferences and knowledge of language determined by factors like education, profession, age or family language background. The overall naming situation in a language is thus a result of all the individual acts of naming implemented by individual language users in a particular environment. It is for this reason that an onomasiological approach lays emphasis on the cognitive and extra-linguistic factors affecting the process of naming and it is for this reason too that a formal description of word-formation processes must be complemented with an onomasiological one.
One may raise the question of why, then, so much attention has been devoted to typology in the form-oriented first part of this volume. There are several reasons. First, the form-centred approach has a very long tradition, including the terminology and procedures used. It greatly contributes to the progress in understanding word-formation processes, rules, the internal structure, the relations in complex words and, in fact, all the major issues of word-formation theory. Any new approach inevitably faces numerous difficulties of acceptance, which sometimes may result in its falling into oblivion. Second, there are very few comprehensive descriptions of word-formation systems (such as Dokulil (Reference Dokulil1962, Reference Dokulil, Panevová and Skoumalová1997) for the Czech language, Horecký, Buzássyová and Bosák (Reference Horecký, Buzássyová and Bosák1989) for Slovak and Rainer (Reference Rainer1993) for Spanish) which might serve as a basis for contrastive typological research from the onomasiological perspective. We believe that the semasiological (form-centred) and the onomasiological (cognitive, meaning-centred) approaches are mutually complementary.
There are two important limitations on the onomasiological part of this book. First, it has no pretence to cover all semantic categories, largely for the procedure used for data collection: the response tolerance of the informants had to be taken into consideration to ensure a sufficient return rate of questionnaires. Existing grammatical descriptions could not be used either: if the description of word-formation in the great majority of languages is rather poor, the onomasiological viewpoint, i.e. the way of expressing various semantic categories by formal word-formation processes, approaches zero. Unlike other aspects of cross-linguistic research, this is a tabula rasa. On the other hand, there is no agreement on the number of semantic/conceptual categories and, thus, there is not a universally accepted list of them. The categories included in the questionnaire were selected based on some Indo-European languages. This methodological bias seemed unavoidable. To avoid gaps in this selection, the questionnaire invited informants to adduce any other important semantic/conceptual categories in their respective languages. A long list of examples of these categories indicates a cross-linguistic multiplicity and diversity of these categories and the unequal role played by these categories in various languages of the world. Second, this book does not cover all the possible ways of expressing the selected categories in individual languages. This would exceed the scope of any similar work. In fact, it may be regarded as a highly desired long-term goal requiring extensive cooperation. Nonetheless, the examples given illustrate the individual semantic/conceptual categories and indicate the prevailing tendencies in their expression in individual languages as they represent typical ways of declaring the respective categories, as well as tendencies across languages.
The onomasiological analysis is based on semantic categories which may reflect essential categories of life in human communities. Life is based on activity (conceptual category of action) as a centre of gravity of human existence. This justifies to some extent the selection of the categories agent (as a ‘person performing some activity’), patient (as a ‘person who is the bearer of state’1), instrument (as actions are typically performed by means of instruments) and location (each action takes place at some place). On the other hand, nature depends on the existence of male and female beings, and language reflects this duality by gender. Quantities and emotions intersect in the field of evaluative morphology, specifically in the formation of augmentatives and diminutives. We should therefore ask whether and how this interplay is reflected by word-formation. The inclusion in the questionnaire of the category of action nouns is self-explanatory in light of the central position of activity and action in life. The same applies to all the consequences of human activity: is activity oriented at somebody/something and what is its consequence? This justifies the action-related categories of causativity, intransitivity and transitivity on the one hand, and of the categories of iterativity and intensity of action on the other. Finally, the category of abstract nouns reflects what is characteristic of human beings: the cognitive processes of abstraction and generalization proper to naming acts, but highly demanding in terms of abstract qualities.
Therefore, four groups of semantic categories were analyzed overall. The first group covers the basic nominal categories: agent, patient, instrumental and locative. They commonly share the same formal means and raise extensive synchronic and diachronic debate on the reasons for and the nature of polysemy/homonymy of affixes representing these categories. A small fraction of nouns related to the formal expression of the male vs female opposition in human languages, as a reflection of the paternal principles of the organization of human society worldwide, is also examined here in terms of feminines and masculines.
The second group comprises augmentative and diminutive. This is a relevant group in view of the postulates for some languages of the existence of a third subdiscipline of morphology, i.e. evaluative morphology (cf. Scalise Reference Scalise1984). Unlike the group of nominal categories, these are not bound to any one word-class. Rather, in some languages they (especially diminutives) range not only over major word-classes of nouns, verbs, adjectives and adverbs, but also numerals, interjections, etc.
The third group concerns verbs and is subdivided into three subgroups: causative; intransitive and transitive; and frequentative and intensive. The second subgroup, intransitive and transitive, is included here despite having typically inflectional characteristics, in particular, the relation it expresses to other words in a sentence structure. In other words, the intransitive vs transitive opposition consists in whether a verb does or does not require internal arguments. There are several reasons for including these categories in the discussion of word-formation processes: valence is sometimes considered to be derivational (Bybee Reference Bybee1985: 83)2, their opposition is based on an additional word-formation meaning, specifically directedness of action, they lack the systematic (automatic) nature of inflectional categories, and, last but not least, transitiveness is derivationally very closely related to causativity. The latter has been well-known in typological research (cf. Comrie Reference Comrie and Shopen1985). The final two semantic categories, the iterativity and the intensity of action, were selected to represent the borderline category of aspect or, more properly, Aktionsart.
The fourth group focuses on cross-linguistically fairly productive semantic categories, each of which is based on word-class change.
6.2 Nominal categories
6.2.1 Agents
Agent noun formation is recorded in the languages shown in Table 6.1 (89.09 per cent of the study sample).


Table 6.2 shows the diversity of word-formation processes used for agent formation.


Each of the processes above has peculiarities in one or the other language. Thus, Afrikaans relies on a wide range of options (including allomorphs) for the expression of agentive nouns. This is characteristic of many languages (even if not noticeably so) and is, therefore, a good example for the overview of the expression of the category agent (see Table 6.3).

Hausa (Neuman, pers. comm.) is a highly productive agent-forming language and does not restrict the formation of agents to a single word-formation process. Reportedly, derivation of agent nouns by the prefix -ma, as in (8), is common and, in principle, an agent noun could be created morphologically from almost any verb.5
Compounding may be of several types. Hausa illustrates a relatively rare case of agent formation by compounding, in particular, by means of compounds whose left-hand constituent is äan ‘person of’ or àbōkin ‘friend’, followed by the linking element -n- and a constituent denoting particular profession, activity or place of origin:
(40)
- Hausa
ɗan-ƙwàayā
person.of-drug
‘drug user’
(41)
- Hausa
ɗan-sìyāsàa
person.of-politics
‘politician’
Exocentric compounds of the redskin and of the garde-manger type are also possible, although the former are rarer (see Table 6.4).
Table 6.4. Compounding of the redskin and garde-manger types for the category agent

Prefixation is used for the category agent in languages in which it is the major word-formation process, like Yoruba (47), but also in other languages, like Ilocano (48), in particular with the prefix maNCV-, and Karao (49), where an active verbal prefix cross-references the agent:
(47)
- Yoruba
ọ-de.
ag-hunt.v
‘hunter’
(48)
- Ilocano
mannaniw
maNCV-daniw
ag-poem
‘poet’
(49)
- Karao
mengemag
meN-amag
ipf.ag-do/make
‘the one who does/makes’
Cahill (pers. comm.) points out that a special kind of prefixal-suffixal derivation exists in Konni, where the CV prefix reduplicates the initial consonant and the vowel is [i~i]. The suffix is either [-tU] or [-rU]:
(50)
- Konni
gbi-gbari-tƱ
ag.rdp-watch-ag
‘watcher’
(51)
- Konni
di-digi-rú
ag-rdp-cook-ag
‘cook.n’
Cahill also notes that a few common agent nouns omit the prefix part:
(52)
- Konni
kpàà-rƱ
kpaa-rƱ
plant.v-ag
‘farmer’
(53)
Suffixation in Zulu is based on attaching the suffix -i to a verb root and placing the resulting stem in class 1/2 by using the prefix m- or ba- respectively (van der Spuy, pers. comm.). This implies a sort of prefixal-suffixal derivation:
(54)
- Zulu
m-lim-i
C1-plough-ag
‘farmer’
Not all agent nouns are derived from uninflected stems. Thus, in Ket ‘man’ is added to verbal infinitives (55) and in Tibetan the suffixes -pa and -po are added to the present stem of verbs (56):
(55)
- Ket
assano-ket
‘hunting-man’
(56)
- Tibetan
ག
ད་gcod-po
‘cutter’
 ད་
ད་
Suffixes may also be selective in terms of the etymology of the base, as in Swedish, where different suffixes combine with elements of specific origins (see Table 6.5).
Table 6.5. Swedish suffixes and specific bases for the category agent

Similarly, the formation of agent nouns is usually not limited to a combination of an affix with just one category of word-formation base. They usually can be combined with bases of various word-classes. A case in point is Hindi, where the word-formation base can be a noun, a verb, an adjective and an adverb (Kachru Reference Kachru2006: 116–17):
(61)
- Hindi
- र
kumhar
kumbh-ar
pot-ag
‘potter’

 र
र(62)
- Hindi
- -ऊ
kha-ū
eat-ag
‘glutton’
 -ऊ
-ऊBut it is not only at the language level that agent nouns can be formed from various word-classes. The same applies to individual agentive affixes which can be used with word-formation bases of various word-classes, as in Indonesian (examples (63) and (64)), where the prefixes pe- and juru- can be attached to both nouns and verbs (Mojdl Reference Mojdl2006: 176–7), or in Udihe (examples (65) and (66)), where the suffix -ŋku, -ŋkA attaches either to verbs or nouns:
(64)
- Indonesian
a. juru-bahasa
ag-language
‘translators, interpreter’
b. juru-kira
ag-count
‘accountant’
(65)
- Udihe
kaŋma-ŋku
practise.evil/magic.v-ag
‘evil sorcerer’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 153)
(66)
- Udihe
zeu-ŋku
food-ag
‘breadwinner’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 153)
In other words, not all agentive suffixes comply with Aronoff’s (Reference Aronoff1976: 48) Unitary Base Hypothesis.
6.2.2 Patients
Patient noun formation is recorded in the languages shown in Table 6.6 (61.82 per cent of the study sample).


Table 6.7. shows the diversity of word-formation processes used for patient formation.



Since patients are bearers of state, their important sources are exocentric compounds:
(86)
- Afrikaans
maan-haar
mane-hair
‘lion with mane’
(87)
- Bardi
oowa-baawa
little-child
‘toddler’
(88)
- Belorussian
бледн-а-твар-ы
blednatvary
pale-lnk-face-m.sg.nom
‘paleface’
(89)
- Catalan
pit-roig
breast-red
‘robin’
(90)
- Georgian
რვა-ფეხ-ა
rva-pex-a
eight-foot-nmr
‘octopus’
(91)
- Hindi
- ध ह
dudhmũha
one who has milk in his mouth
‘infant’
(Kachru Reference Kachru2006: 119)
 ध
ध ह
ह(92)
- Maipure
cuyaɺúta kanía nikú
book-be-inside
‘bookcase’
(94)
- Māori
ihupuku
nose-swollen
‘sea elephant’
(95)
- Marathi
pikale paana
matured-leaf
‘a person likely to die due to age’

(96)
- Romanian
pierde-vară
loses-summer
‘dawdler’
(97)
- Serbian-Croatian
ne-zna-bog
not-knows-god
‘non-believer’
(98)
- Swedish
dumhuvud
stupid-head
‘fool’
(99)
- Telugu
suvarna rekha
golden line
‘a sort of mango’

(100)
- Tibetan
- ་བཟང
dri-bzang
good-smell
‘saffron’
 ་བཟང
་བཟངA relatively common source of patient nouns in Indo-European languages is conversion of the past participle (passive adjectives) as in (69) to (74). The past participle is not the only inflected word-formation base: in Tibetan, the suffix -pa or the suffix -bya is added to the future stem of a verb:
(101)
- Tibetan
དགག་
dgag-bya
‘negandum’

Finally, as with agent nouns, some languages make it possible to attach an affix to more than one word-class. Thus, the Udihe suffix -ŋku, -ŋkA can be attached either to a verb or a noun:
(102)
- Udihe
boxoli-ŋku
humpack-pat
‘humpbacked’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 153)
6.2.3 Instrumentals
Instrumental noun formation is recorded in the languages shown in Table 6.8 (63.64 per cent of the study sample).


Table 6.9 shows the diversity of word-formation processes used for instrumental formation



As with agent and patient nouns, exocentric compounds are an important source of instrumental nouns in some languages. Examples are given in (121) to (123) below:
(121)
- Catalan
eixuga-mà
dry.3sg.prs.ind-hands
‘towel’
(122)
- Nelemwa
bwaa nok
head-fish
‘piece of wood to measure the size of the mesh’
(123)
- Portuguese
guarda-roupa
keeps-clothings
‘a piece of furniture used to keep the clothes’
Almost all affix-based instrumental nouns are attached to a verbal base. An exception is the Clallam causal prefix sxw-, which in (110) above attaches to a noun + noun compound. The Tzotzil suffix -Ob sometimes attaches to stems which never occur independently (Cowan Reference Cowan1969: 105):
(124)
- Tzotzil
k!áxan-eb
*k!áxan (cf. k!áx ‘harvest it’)-ins
‘harvesting instrument’
6.2.4 Locatives
Locative noun formation is recorded in the languages shown in Table 6.10 (69.09 per cent of the study sample).


Table 6.11 shows the diversity of word-formation processes used for locative formation.



Examples of exocentric locative compounds come from French and Vietnamese:
(147)
- French
garde-manger
keep-food
‘pantry’
(148)
- Vietnamese
tiəm31? baɲ35
tiệm bánh
shop-cake
‘bakery’
(Thái Ân)
6.2.5 Gender in animate beings
Feminine noun formation is recorded in the languages shown in Table 6.12 (43.64 per cent of the study sample).


Table 6.13 shows the diversity of word-formation processes used for feminine formation.


Prefixation is used for feminines only in Datooga, where derives personal names for feminines from any noun, and in Luo. In addition to those of Table 6.13, examples of compounding come from Vietnamese (159) and also from Ket, which forms female names by adding am ‘mother’ to a noun that by default is used to denote masculine gender or generic gender. Finally, in Mandarin Chinese 女 nü3 ‘female’ is combined with a noun, but usually just one morpheme-syllable is taken from a default masculine disyllabic compound to make it feminine.
Masculine noun formation is recorded in the languages shown in Table 6.14 (21.82 per cent of the study sample).
Table 6.14. The category masculine in the study sample

Table 6.15 shows the diversity of word-formation processes used for masculine formation:
Table 6.15. Word-formation processes for the category gender (masculine)

Malayalam makes use of specific suffixes for male vs female persons: masculine -kaaran vs feminine -kaari (Asher and Kumari Reference Asher and Kumari1997: 383–4), as in (164), or masculine suffix -an vs feminine -cci, -i, -ti (-cci being the most productive) attached to an abstract noun (165):
(164)
(165)
Hindi chooses from two strategies to form male nouns from female nouns: the choice is conditioned phonologically. According to Kachru (Reference Kachru2006: 47), if an inherently feminine noun ends in -ī, the masculine counterpart is formed by replacing -ī with -a; if the noun ends in a consonant, the masculine counterpart is formed by adding the derivational suffix -a:
(166)
 < बक
< बक bəkra bəkrī
‘goat.m’ ‘goat.f’
bəkra bəkrī
‘goat.m’ ‘goat.f’(167)
 ई
ई < ई
bheɻa bheɻ
‘ram’ ‘sheep’
< ई
bheɻa bheɻ
‘ram’ ‘sheep’6.3 Evaluative categories
6.3.1 Augmentatives and diminutives
Augmentative formation is recorded in the languages shown in Table 6.16 (34.55 per cent of the study sample).


Table 6.17 shows the diversity of word-formation processes used for augmentative formation.


Diminutive formation is recorded in the languages shown in Table 6.18 (67.27 per cent of the study sample).


Table 6.19 shows the diversity of word-formation processes used for diminutive formation.

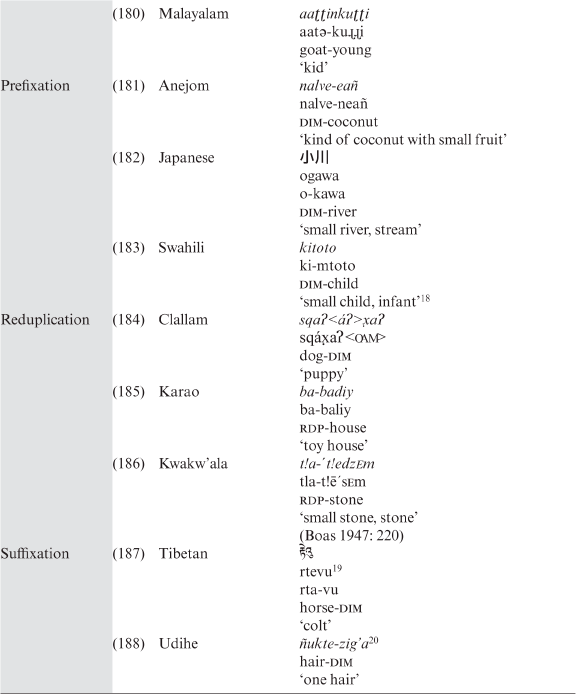
The data gathered do not allow us to provide any examples of infixation21 or submorphemic formation in which ‘phonemes are modified in a systematic way to express diminution’ (Bakema and Geeraerts Reference Bakema, Geeraerts, Booij, Lehmann and Mugdan2000: 1045).22
6.3.1.1 Formal characteristics
Bakema and Geeraerts (Reference Bakema, Geeraerts, Booij, Lehmann and Mugdan2000: 1046) maintain that:
augmentatives are less widespread than diminutives. The two categories are related by an implicational universal: the existence of augmentatives in a language implies the presence of diminutives, but the reverse does not hold. If a language has both categories, diminutives are more frequent and can be formed in more ways than augmentatives.
Our sample gives support to this assumption, and we find two special cases: in Hausa, suffixation is used (even if the productivity is low) to derive a few augmentative adjectives from abstract bases (Newman, pers. comm.), as in (189). In Ilocano, augmentatives are formed from statives only, not from nominals, by prefixal-suffixal derivation (nag- -en, nain- -an), as exemplified in (190):
(189)
- Hausa
gamɗasheesheè
gàmɻasaà-sfx
break.off.a.large.chunk-aug
‘huge and muscular’
(190)
- Ilocano
nag-dakkel-en
aug-big-aug
‘how big!’
An interesting thing happens in Swedish. Olofsson (pers. comm.) maintains that the adjective stor ‘big/great/large’ can be used with a prefix-like function and so can små ‘small’ (used in plural). There are many lexicalized combinations formed in present-day Swedish, like stordator ‘mainframe computer’, stormarknad ‘hypermarket’, etc. Furthermore, as pointed out by Olofsson, both små- and stor- can be used with verbs, too: småle ‘smile a little’, storgråta ‘weep, cry profusely’. This reflects a close relation between the category of augmentativeness and intensity. The same holds (more with små- than with stor-) for adjectives and their derived adverbs, but there are fewer examples: smårolig ‘fairly funny’, storbelåten ‘very pleased’.
6.3.2 Phonetic iconicity
According to Universal #1926 (formerly #1932) of the Konstanz Archive (Plank and Filimonova Reference Plank and Filimonova2000), there is an iconic tendency in augmentatives and diminutives: augmentatives tend to contain high back vowels, whereas diminutives tend to contain high front vowels. This expectation is not confirmed by our data. Table 6.20 shows examples of diminutives whose affixes comply and do not comply with Universal #1926:23
Table 6.20. Diminutive affixes and Universal #1926 of the Konstanz Archive (Plank and Filimonova Reference Plank and Filimonova2000)


Besides the above, there are special cases like Hungarian, where the principle of vowel harmony influences the character of diminutive suffixes -cska/-cske, -ka/-ke, which, therefore, occur in two variants, with front vowel and with back vowel (209):
(209)
- Hungarian
tető-cske
‘small roof’
Finally, there are several languages in which both affixes with front vowels and affixes with back vowels are employed. In Slovak, where diminutives are unified by the /k/-type suffixes (i.e. velar consonant) and where the form of the suffix depends on gender, we can find, among others, the -ík/-ik affix, as in stolík ‘small table’ from stôl ‘table’, -ček/-tek as in stromček ‘small tree’ from strom ‘tree’, but also -ka as in knižka ‘small book’ from kniha ‘book’, and -ko as in okienko ‘small window’ from okno ‘window’ (Furdík Reference Furdík2004: 90). Similar instances can be found in Finnish and West Greenlandic:
Universal #1926 assumes that augmentatives are formed by high back vowels. Romanian offers examples of both use of a back vowel in augmentatives (212a) and use of both types of vowels (212b). In Ilocano, augmentatives are based on prefixal-suffixal derivation, which may include both types of vowel, as in (213), but also back vowels only (nain- -an):
(212)
- Romanian
a. grăs-an
‘fat man’
b. lăd-oaie
‘big chest/big trunk’
(213)
Other languages whose augmentative affixes do not conform with the prediction include Belorussian (214), Hausa (215), Kwakw’ala (216), Russian (217) and Serbian-Croatian (218):
(214)
- Belorussian
збан-iшч-а
zbanišča
jug-aug-gnd
‘very big jug’
(215)
(216)
(217)
- Russian
столище
stol’-ishche
table-aug
‘big table’
(218)
In principle, our observations correspond with Ultan (Reference Ultan and Greenberg1978), who, based on an analysis of 136 languages,27 concluded that, while front and high vowels prevail as diminutive markers, we can hardly speak of a language universal. What seems to be more relevant is an areal approach to the problem of augmentative/diminutive symbolism, as also assumed by Nichols (Reference Nichols1971) with regard to a systematic diminutive consonant symbolism in the languages of western North America.28 L. Bauer (Reference Bauer1996) examined evaluative morphology in fifty languages. His detailed analysis of a language sample from various perspectives29 concludes that ‘phonetic iconicity is not a very strong factor in the development of augmentative and diminutive markers cross-linguistically’ (L. Bauer Reference Bauer1996: 197).
6.3.3 Word-classes
L. Bauer (Reference Bauer1997: 540) proposes a hierarchy of base types for augmentivization and diminutivization (first noun, second adjective and verb, third adverb, numeral, pronoun and interjection and, finally, determinative). This should be read as follows: ‘for a word-class to be used as the base in evaluative morphology in a particular language, word-classes from each step above that must also be so used in that language’ (L. Bauer Reference Bauer1997: 540). From this it follows that diminutive formation from adverbs is conditioned by the existence in that language of diminutives formed from adjectives or verbs.
While the great majority of augmentatives and diminutives maintain the word-class of the motivating words, as pointed out, among others, by Merlini Barbaresi (Reference Merlini Barbaresi and Frawley2003: 439), there are infrequent cases of class-changing formations, as in Hausa (219) and Japanese (220):
(219)
- Hausa
gabjeejeè
gabzaà-rdp
heap.up.a.lot.of.something-dim
‘bulky’
6.3.3.1 Semantic characteristics
The vast majority of examples express the meaning of smallness. However, the range of meanings of diminutives is large (cf. Jurafsky Reference Jurafsky, Guenter, Kaiser and Zoll1993). Examples with Hindi suffixes -iya, -Ña/-Ñī illustrate three different dimensions of evaluative morphology (see Table 6.21).
Table 6.21. Three dimensions of evaluative morphology in Hindi

Other possible nuances are hypocoristics, as in section 3.2.1. The attenuative meaning is connected in Udihe with the semelfactive, which is built by means of the suffix -ndA-:
(224)
- Udihe
eme-nde-
come-dim
‘come for a short time’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 311)
The attenuative meaning can also be expressed in Udihe by the deintensifying suffix -lA: in the case of colour terms, this is implemented by truncation within which the suffix -lA replaces the suffix -ligi (the bare stem never occurs independently, Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 186):\
(225)
Other adjectives with attenuative meaning are derived by -lA suffixation:
(226)
- Udihe
saza-la
foolish-dim
‘a little foolish’
6.4 Verbal categories
6.4.1 Causatives
Causative verb formation is recorded in the languages shown in Table 6.22 (76.36 per cent of the study sample).


Table 6.23 shows the diversity of word-formation processes used for causative formation.



Table 6.23 should be complemented with Table 6.24, which shows formation of causatives by various types of incorporation in Amele (Roberts Reference Roberts1987: 309–12) and Cirecire.
Table 6.24. Incorporation for the category causative

In many cases, causatives are formed by turning intransitive verbs into transitive verbs, as in the following examples from Ilocano and Māori:
(248)
(249)
- Māori
whaka-roa
cau-long
‘lengthen’
Causatives may also be formed from transitive verbs. In Ket, this is limited to a class of verbs with inanimate class objects, in which case the original object is preposed to the verbal infinitive form in P7 (Vajda Reference Vajda2004: 71):
(250)
- Ket
danánbètqajit
da8-nán/bet7-q5-a4-(j)-t0
3f.sbj8-bread/make7-cau5–3m.obj4-(ms)-mom.tr0
‘She causes him to start baking bread’
In Malayalam, according to Asher and Kumari (Reference Asher and Kumari1997: 272ff.), the causative verb is usually the last stage of the intransitive-transitive-causative chain. The causative verb is formed by suffixes -(i)kk-, -(i)ppikk- (and their phonologically conditioned variants), which are attached to a transitive verb. The latter of them, -(i)ppikk-, is regarded as a sequence of two causative suffixes, -(i)kk- + -(i)pp-:
(251)
- Malayalam
ceyy-ikk-uka
do-cau-inf
‘cause to do’
(252)
(253)
An example of the above-mentioned chain is given below:
(254)
It follows from this example that forms with -(i)kk- and -(i)ppikk-, respectively, need not differ in their meaning.
In several languages both transitive and intransitive verbs can be used as bases for causatives, sometimes imposing different resources for the derivation, sometimes not. Thus, Amharic uses the prefix a- for intransitives (255a) and as- for transitives (255b) (even if there are many exceptions in this language), Ket uses the single-consonant morpheme q called determiner to derive causatives from both intransitive and transitive verbs (256) and Pipil uses the suffix -tia (-ltia) for both transitive (257a) and intransitive (257b) stems (Campbell Reference Campbell1985: 85):
(255)
- Amharic
a. a-fälla < fla
cau-boil boil
‘He boiled’
b. as-fällägä < flg
cau-seek seek
‘It made seek (~was necessary)’
(256)
- Ket
daúsqajit
3f.sbj8-warm7-cau5–3m.obj4-mom.tr0
‘She warms him up’
(257)
The combinability in terms of the transitive/intransitive nature of the underlying verb can also be observed in Udihe, where the suffix -wAn- can attach to virtually every verb (Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 287):
(258)
- Udihe
etete-wen-
work-cau
‘cause to work’
(259)
(260)
- Udihe
diga-wan-
eat-cau
‘cause to eat, feed’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 302)
This feature of Udihe is not unique. Comrie (Reference Comrie and Shopen1985: 332) refers to Turkish ‘where virtually any verb (including a causative verb) can form a causative’.
As for the word-class of the base, verbs dominate with only some exceptions, among others in Amele, Luo and Slovak, where verbs as well as adjectives can serve as bases for causative formations:
(261)
6.4.2 Transitivity
As with other semantic categories, this word-formation process may be very idiosyncratic. Thus, Finnish does not have general categories like transitive and intransitive. Instead it has numerous, more or less productive, verbal derivation suffixes for different Aktionsarten (Laakso, pers. comm.):
(262)
- Finnish
pako-tta-
‘make do, force’
(263)
- Finnish
hidas-ta-
‘slow.v’
It was noted in section 6.4.1 that transitive verbs sometimes serve to derive causative verbs and that they function in some languages as a link in the intransitive-transitive-causative chain. Let us illustrate this with an example from Pipil (264), where the suffix -tia (-ltia) can be added to intransitive verbs (Campbell Reference Campbell1985), and from Udihe (265), where causative derivation from intransitive verbs by means of the suffix -wAn leads to transitivization (Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 302):
(264)
- Pipil
machtia
mati-tia
know-tr
‘teach.v’
(265)
- Udihe
zegde-wen-
burn-cau
‘set fire to’
The opposite is also possible: Tzotzil can form intransitives from transitives by means of the suffixes -van ‘characteristic mode’, -Vn and -av:
(266)
(267)
In Japanese, transitive verbs are changed into intransitive verbs by substituting an intransitive suffix for a transitive suffix. Still, Kageyama (pers. comm.) points out that there are many idiosyncratic lexical pairings and that this process is not productive in Japanese:
(268)
Transitive verb formation is recorded in the languages shown in Table 6.25 (49.09 per cent of the study sample).


Table 6.26 shows the diversity of word-formation processes used for transitivity formation.


The formation of transitives allows for a number of possibilities in the languages considered here. According to Bowern (pers. comm.), there are about thirty verbs (out of 250) in Bardi which alternate in transitivity. They use a transitive prefix n- ~ a-, but they are not productively derived. Many verbs are derived with the use of a light verb -joo- ‘say’.40 In Māori, many transitive verbs are derived by the prefix whaka- (W. Bauer Reference Bauer1997: 44–5).41 Examples of a transitive formed by this prefix from an action intransitive is given in (277) and from a state intransitive in (278):
(277)
- Māori
whaka-haere
tr-move
‘run (something)’
(278)
- Māori
whaka-mārama
tr-clear
‘explain, make clear’
In some languages, word-formation-based transitivization can rely on several word-formation processes. The basic device for the formation of transitive verbs in Indonesian is prefixation by me- (with its five phonologically conditioned allomorphs), attached to verbs (279), nouns (280) and adjectives (281) (Mojdl Reference Mojdl2006: 48), but a number of confixes are also used (282) (Mojdl Reference Mojdl2006: 126ff.):42
(279)
- Indonesian
me-makan
tr.prx-eat
‘eat (something)’
(280)
- Indonesian
me-lombong
tr.prx-mine.n
‘mine.v’
(281)
- Indonesian
me-tinggi
tr.prx-high
‘increase.v’
(282)
- Indonesian
me-mandi-kan
tr-have.a.bath.v-tr
‘bath (somebody)’
Datooga generates transitive verbs by paradigmatic formation, i.e. conversion of a verb from Class 1 to Class 2 (283), by stem modification (284) and by suffixation (285):
(283)
(284)
(285)
- Datooga
ɲa
-jbe.broken-tr
‘break.v’
 -j
-jAccording to Brainard (pers. comm.), Karao makes very productive use of suffixes (-en, -an), prefixes (i-) and circumfixes (i- -an). Nelemwa may form transitives by suffixation (286) and by prefixal-suffixal derivation (cf. (273)):
(286)
- Nelemwa
aw-îlî43
laugh.v-tr
‘laugh at (something)’
Finally, Totonac forms transitives by prefixation (287) and suffixation (288):
(287)
- Totonac
li:-a’hlhche’hxlá:
ins-trip
‘trip on (something)’
(288)
- Totonac
pa’hlh-ní
burst-ben
‘burst (something for somebody)’
As regards word-classes, transitive verbs are derived not only from verbal bases: the examples of Indonesian in (279) to (282) show that nouns and adjectives may also serve as bases for this purpose. This is confirmed, for instance, by the data of Kalkatungu, where the suffix -puni is attached to nominal stems (289), and of Kwakw’ala, which may attach suffixes both to intransitive verbs and to adjectives, as in (290) and (291):
(289)
- Kalkatungu
yarrka-puni
far-make
‘put at a distance’
(290)
(291)
- Kwakw’ala
‘amx-a
watertight-cau
‘make watertight’
(Boas Reference Boas, Boas Yampolsky and Harris1947: 241)
6.4.3 Intransitivity
Intransitive verb formation is recorded in the languages shown in Table 6.27 (40 per cent in the study sample):
Table 6.27. The category intransitive in the study sample

Table 6.28 shows the diversity of word-formation processes used for intransitive formation:
Table 6.28. Word-formation processes for the category intransitive

How complex the derivation of intransitive verbs can be is illustrated in Table 6.29 by Tzotzil and its eight different intransitivizing suffixes (Cowan Reference Cowan1969: 98–100), each of them combining with a specific type of roots and/or stems.


As regards word-classes, intransitive verbs, like transitive ones, are mostly derived from verbal bases. Nominal bases are frequently used as in the case of conversion in Breton (cf. (292)) or suffixation in Kalkatungu (Blake, pers. comm.), where the suffix -(th)ati is attached to a nominal stem (310), and Udihe (312), where the suffix -mA- forms intransitive verbs with the prototypical meaning ‘catch, hunt for’ and the basic noun functions as instrument, and Ukrainian (311):4647
(310)
- Kalkatungu
thail-ati
hard-intr
‘grow hard’
(311)
- Ukrainian
учител-ювати
uchitel’uvati
teacher-ntr
‘act as teacher’
(312)
- Udihe
dukta-ma-
ski-intr
‘ski.v’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 291)
Affixation to adjectives is also possible in Tzotzil (cf. Table 6.29) and in Slovak (313):
(313)
- Slovak
star-nút’
starý-intr
old-intr
‘grow older’
6.4.4 Iterativity and/or intensification
Iterativity and/or intensification verb formation is recorded in the languages shown in Table 6.30 (78.18 per cent of the study sample).


Table 6.31 shows the diversity of word-formation processes used for iterativity and/or intensification formation:


As emphasized by Vajda (pers. comm.), there are numerous ways of expressing frequentative meaning in Ket and other Yeniseian languages. Werner (Reference Werner1998) cites ten different ways. Two of them, taken from Yugh, a Yeniseian language spoken in Eurasia, are given below: replacement of root morphemes in the zero position (326) and replacement of stem (327):52
(326)
(327)
The suffix -ela in Kwakw’ala shows how specific a frequentative meaning can be (328). Similarly, in Udihe, the intensifying suffix -wAlA strengthens a qualitative feature (329), while the suffix -ndima marks a high degree of a feature or marks the absolute degree of comparison used without an overtly expressed standard of comparison (330):
(328)
- Kwakw’ala
ō'xlosdē's-ela
‘carry on back up the beach, one person, but an action requiring many steps’
(Boas Reference Boas, Boas Yampolsky and Harris1947: 306)
(329)
(330)
Regarding word-classes, the following example from Ilocano shows that iterativity is not exclusively bound to the category of verbs, as it can also feature in nouns:
(331)
6.5 Word-class changing categories
6.5.1 Action nouns
Formation of action nouns is recorded in the languages shown in Table 6.32 (76.36 per cent of the study sample).


Table 6.33 shows the diversity of word-formation processes used to form action nouns.


In Estonian, it is possible to form action nouns from all the verbs using the suffix -mine or -us (Kilgi, pers. comm.):5556
(343)
(344)
The formation of action nouns need not be restricted to a single suffix or a single word-formation process. Finnish and Tzotzil may use several suffixes (see Table 6.34).
Table 6.34. Suffixes for action nouns in Finnish and Tzotzil

Similarly, more than one word-formation process is used, among others, in Datooga ((353) and (354)) and Telugu ((355) and (356)): Datooga makes use of suffixation, in which case Class 1 verbs derive their action nouns by adding the primary nominal suffixes zero, -oo, -id or -ee preceding the secondary nominal suffix -da (353). Class 2 verbs take the prefix gii- in addition to the same nominalizing suffixes (354). Telugu uses suffixes -pu, -ta, -uDu, -aDam (355) and conversion (356) (see Table 6.35).
Table 6.35. Word-formation processes for action nouns in Datooga and Telugu

Suffixal homonymy/polysemy is present in this semantic category. Thus, in present-day Swedish the suffix -ande/-ende is homonymous with the suffix for the present participle:
(358)
- Swedish
beteende
‘behaviour’
As to word-classes, while the vast majority of action nouns are derived from verbs, the examples from Indonesian (Table 6.36) illustrate that other word-classes may serve this purpose, too (Mojdl Reference Mojdl2006: 152–5):58
Table 6.36. Formation of action nouns by confixation in Indonesian

6.5.2 Abstract nouns
Formation of abstract nouns is recorded in the languages shown in Table 6.37 (70.91 per cent of the study sample).


Table 6.38 shows the diversity of word-formation processes used for the formation of abstract nouns.
Table 6.38. Word-formation processes for the formation of abstract nouns

Deverbal abstract nouns appear to be a widespread word-formation pattern. In some languages, like Amele (371), Nelemwa (372),60Udihe (373) and Yoruba (374), it is an exclusive source of abstract nouns:
(371)
- Amele
tanaw-ec
‘peace’
(373)
- Udihe
bude-ŋku
die-nmr
‘death’
(Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 152)
(374)
- Yoruba
ì-s.
nmr-break.v
‘poverty’

In other languages, the verbal source is frequent, like in Hindi (375). Specifically, in Hindi, conversion from verbal roots is also a frequent process of abstract nouns. According to Kachru (Reference Kachru2006: 115), ‘the infinitive suffix -na combined with the root of the verb yields an abstract noun, e.g. cəlna “to move, movement” . . . Therefore, all verbs, except the invariable cahiye “should, ought to”, have infinitive forms in Hindi which function as abstract nouns.’ In addition, the root of the verb in Hindi is sometimes used as an abstract noun and, if applicable, the root vowel undergoes the rules of morphophonemic alternations. An example from Lakhota is given in (376):
(375)
 cəmək cəməkna
‘shine.n’ ‘shine.v’
cəmək cəməkna
‘shine.n’ ‘shine.v’(376)
- Lakhota
wo-wayazañ
nmr-be.sick
‘sickness’
In addition to conversion, Hindi abstract nouns may be derived using suffixes:
(377)
- Hindi
- व
ghum-av
ghūmna-av
turn.v-nmr
‘twist.n’

(378)
- Hindi
कर
kər-nī
kərna
do.v-nmr
‘deed’

None of these languages forms abstract nouns on all three word-classes. Lakhota can also derive them from adjectives by prefixation; and so can Tzotzil, from adjectives by suffixation. Still, there are languages, like Dangaléat (Shay, pers. comm.), which admit all three word-classes as a source of abstract nouns.
Some of the languages studied, like Tzotzil (379), use one suffix, while others, like Hausa, use several different suffixes, as exemplified in (380)–(382):
(380)
- Hausa
ādal-cìi
just/honest (person)-nmr
‘fairness, justice’
(381)
- Hausa
kutur-tàa
leper-nmr
‘leprosy’
(382)
- Hausa
dàngàntakàa
kin/relatives-nmr
‘relationship’
Suffixation for this purpose may use nouns as a base, but also adjectives and personal pronouns (see Table 6.39).


In some languages more than one word-formation process is used. In Gã, for instance, abstract nouns from nouns are formed by the suffix -mO or by vowel length (Kropp Dakubu, pers. comm.). In Hindi both suffixation (396) and prefixation (397) from other nouns61can be found:
(396)
- Hindi
- हप
bəhna-pa
‘sisterhood’
 हप
हप(397)
- Hindi
अन-
ən-honī
‘impossible event’

In fact, Hindi makes use of a number of other prefixes, mostly of Sanskrit origin. Kachru (Reference Kachru2006: 114) maintains that ‘in general, prefixation is not the preferred process in Hindi; most of the prefixes are restricted to borrowed items. However, some of them are currently being utilized heavily in the creation of technical terms in the official register used in administration’.
Similarly, Georgian makes use of suffixation (398) and circumfixation (399) and Mandarin Chinese makes use of derivation by the suffix ©Ê (xing4) ‘character, -ness’ to an adjective (400) or conversion (401):
(398)
- Georgian
ახალგაზრდ-ობა
axalgazrd-oba
young-nmr
‘youth or the property of being young’
(399)
- Georgian
სი-ლამაზ-ე
si-lamaz-e
nmr-pretty-nmr
‘beauty’
(400)
- Mandarin Chinese
公平性
gōngpíngxìng
public-even-ness
‘fairness’
(401)
6.6 Summary
Some semantic categories are represented across most of the sample studied (agents, causative verbs, frequentative and intensive verbs, action nouns). In two oppositions, masculine vs feminine and augmentative vs diminutive, the values are dissimilar. The hierarchy of the categories of intransitivity, transitivity and causativity in terms of the use of word-formation strategies is explained as a relatively common sequence from intransitive to transitive and then to causative verbs.
Grandi and Montermini (Reference Grandi, Montermini, Booij, Guevara, Ralli, Sgroi and Scalise2005: 144) maintain that ‘in a single language a derivational category tends not to be expressed both by prefixes and suffixes’ and that ‘a derivational category can be cross-linguistically expressed both by prefixes and suffixes’. The tables at the beginning of each section that present the diversity of word-formation processes for the semantic categories considered here provide an overview of the cross-linguistic multiplicity of word-formation processes in general.
1 The category state is one of three variants of the general category action – state, action proper and process.
2 ‘Valence-changing categories produce large meaning changes in verbs, since an event can be changed substantially if the number of participants and the nature of their roles change. Thus kill differs from die, and send differs from go in the events being described. So it is not surprising that in the cross-linguistic survey, valence was found to be frequently mentioned as a derivational category for verbs’ (Bybee Reference Bybee1985: 83).
3 Here, conversion creates plural nouns. It works through changing the vowel to [+ atr].
4 The agent is usually followed by object noun.
5 Hausa agents are (usually) built on verbs. Many of these verbs are built on simple nouns by means of the suffix -ta, as in the following example:
Many agent nouns in Hausa feature a combination of the suffix -ta and the prefix ma-. Newman (pers. comm.) explains that this is not really a combination of prefix + suffix, rather it is an instance of potentiation. This is comparable to English unsuccessful, i.e. success + ful gives successful, and then the prefix un- is attached.
5 In a small number of cases, such as mazìnàacii, the verb *zinaata does not actually occur as such, and must be viewed as a derivational step:
6 The form được is used to express passive meaning (it also functions as a constituent morpheme of patient nouns but not necessarily). Since được does not always exist, an agent noun may look like a patient noun.
7 A plant that can withstand low temperatures.
8 The infinitive of some verbs is used as an instrumental noun (Kachru Reference Kachru2006: 117).
9 The prefix ma- is attached to deverbal nouns. All instrumental nouns end in -ī, which marks masculine singular (Newman pers. comm.).
10 In Amharic, root-and-pattern plays its role in the formation of instrumental nouns indirectly: instrumental nouns are formed by adding suffixes to the infinitive. However, infinitive formation varies according to root type, which are about fifteen in number. This example refers to the sbr root.
11 Deverbal noun with prefix ma-. According to Newman (pers. comm.), most nouns of location end in -ā, and a smaller number end in -ī.
12 The actual prefix is kaap-.
13 The prefix e- ~ o- is reportedly extremely productive; it is usually (but not always) accompanied by the suffix -ini ~ -eni. Another prefix is kwa-, which attaches to a person’s name or a word designating a person:
- Zulu
KwaZulu
loc-Zulu
‘landof the Zulus’
14 The Zulu name for Durban.
15 As with instrumentals, the role of root-and-pattern is indirect in Amharic: to form infinitives from which locatives are formed by prefixal-suffixal derivation:
- Amharic
m-adärdär-iya
loc-arrange.v-loc
‘shelf’
16 In Mandarin Chinese 男 nan2 ‘male’ is combined with nouns.
17 Telugu may also use the suffix -waaDu:
Pingali (pers. comm.) points out that agent nouns in Telugu are usually realized as masculine or feminine (barring the suffix -ari, which is gender neutral). Hence there is some overlap between the masculine/feminine suffixes and agentive suffixes.
18 The choice of a diminutive prefix depends on inflectional characteristics of the base. A noun class prefix is replaced with ki- (Class 7) or vi- (plural, Class 8).
19 In Tibetan, suffixation is accompanied by vowel alternation, in particular with raising the root vowel.
20 20 In Udihe, the diminutive suffix -zig’a, combined with mass nouns, denotes singularity (Nikolaeva and Tolskaya Reference Nikolaeva and Tolskaya2001: 150). This is a counter-iconic formation (addition of form leads to reduction of quantity).
21 According to Brainard (pers. comm.), reduplication in Karao is sometimes accompanied by infixation.
22 These authors provide an example from Basque:
23 One of several affixes which are not compliant with Universal #1926 in Karao is the suffix -an used with a restricted class of transitive verbs:
Another anti-iconic example comes from Portuguese:
24 Change of noun class to the 10/11 pair.
25 Other similar Finnish affixes are -ykkä and -käinen, as in lehd-ykkä ~ lehdy-käinen ‘leaflet’, -eli as in hauv-eli ‘dog-aff’, but also -onen as in laps-onen ‘small child’, and even -u as in nen-u ‘nose-aff’.
26 Another similar West Greenlandic affix is -nnguaq ‘little, dear’, as in miirannguaq ‘little child’ formed by miiraq-nnguaq.
27 The sample of languages contained a high number of Amerindian languages (forty-eight) and also Dravidian languages (eleven).
28 In particular, the diminutivization is expressed by ‘hardening or strengthening shifts. In general the point of articulation is unchanged in these shifts, and a more forceful manner of articulation signals the diminutive. A hierarchy of hardness from lenis to fortis to ejective stop or affricate, from continuant to non-continuant, or from any obstruent or sonorant to its glottalized counterpart, is associated with increasing diminutiveness’ (Nichols Reference Nichols1971: 828–9).
29 Including the predictions of Mayerthaler (Reference Mayerthaler1988) and Dressler and Karpf (Reference Dressler and Karpf1995), among others, concerning the role of consonants such that palatal consonants are said to be characteristic of diminutives and velar consonants of augmentatives.
30 The form chan is a corruption of the polite affix san ‘Mr/Ms’, and is used for the young and intimates (Volpe, pers. comm.).
31 Indonesian uses two confixes for this purpose: memper- -kan and memper- -i as below:
32 Infix-based causative formation in Marathi is characterized by infixation of the consonant + vowel sequence -va-. Ability verbs have the same form: karavaNe ‘get done (able to do/possible to do)’.
33 Lengthening of the last syllable of the verb or adjective in Luo.
34 Nelemwa uses the prefix pa-fct, or fa-cau + v + tr.sfx.
35 The prefix is awo-. Its variant awor- is used before a vowel.
36 A number of different prefixes like po-, o-, ras-/raz-, u-.
37 Causatives in Hebrew are formed especially by the pattern hif'il.
38 Stem modification is a part of a more complex process in Malayalam. According to Asher and Kumari (Reference Asher and Kumari1997: 272ff.), transitive verbs are derived from intransitive verbs by modification of the stem, by changes of consonants and by adding a suffix. This means that the stems of all transitive verbs derived from intransitive verbs end in a double consonant (it may also include a change of a double nasal or a nasal plus a homorganic consonant into a double plosive). Phonetically, it is a long voiceless stop:
39 Zulu transitives are formed by the causative suffix -is- or the applicative suffix -el-. The meaning of the latter is ‘do on behalf of’:
- Zulu
-m-el-
stand-app
‘represent.v’
40 Light verb is accounted for by Baker and Fasola (Reference Baker, Fasola, Lieber and Štekauer2009: 605) as ‘a verb that has a very general “bleached” meaning, contributing aspectual information or argument structure properties to the construction it appears in, but little or no encyclopedic meaning’. Mapudungun, an Araucanian language spoken in South America, also provides examples of verb + verb compounds with light verbs, such as pütre-n-tüku-n (burn-inf-put-inf, ‘set on fire’), rütre-wül-n (push-give-inf, ‘give a push’), and kintu-wül-n (look-give-inf, ‘give a look’) (Baker and Fasola Reference Baker, Fasola, Lieber and Štekauer2009: 605).
41 ‘Many transitive verbs created in this way [by the prefix whaka-] have come to be associated with one specific transitive sense, which may obscure the relationship, but it is nevertheless true that, if a new intransitive verb is created in Māori, a transitive whaka- form can be created from it with a meaning which is predictable at the time of the creation’ (W. Bauer Reference Bauer1997: 44–5).
42 Other confixes are memper- -an, memper- -i and me- -i, the last of which can also be used with verbs, nouns and adjectives:
43 From ap ‘laugh’.
44 Reflexivization by the so-called reflexive pronoun, as ся -s’a in Russian, is possible in Slavic languages.
45 Accompanied by final C alternation.
46 Where C is a reduplication of the initial consonant of the root.
47 Where V can be realized as a, i, or u.
48 Affix ‑ass‑.
49 Suffix -kala/-kälä/-gala/-gälä.
50 Suffix -e accompanied by the loss of clusters in verb stem.
51 The most productive iterative suffix is -sar/-tar and the most productive intensifying suffix is -qi-. Its indicative form is qaaq.
52 Position –1 is assumed by the derivational elements -n- or -η.
53 In Marathi, action nominals are formed from verbs by dropping Ne.
54 This is an example of a rare case of verb + verb compounding.
55 The prefix u- (n.class.prx.4) or m- (n.class.prx.3) is attached to a verb stem together with the suffix -o:
- Swahili
m-chang-o
anx-collect-anx
‘collecting’
56 The prefix ta- attaches to nouns derived from transitive verbs by a suffix.
57 In the sense of ‘acquisition of knowledge’.
58 The most productive confixes include pe- -an, per- -an and ke- -an. Words derived by these confixes can function in sentences as Adjectives, Verbs and Nouns (Mojdl: pers. comm.)
59 Prefixation on a nominal base in (367) and on adjectival bases in the rest of examples in this table.
60 Nelemwa makes use of stative verbs, which are combined with the nominalizing prefix u-:
61 Mainly Sanskrit loan words, though some of the processes have been extended to Hindi according to Kachru (Reference Kachru2006). Most of the prefixes are also of Sanskrit origin. In addition to ə-, ən ‘not without’ in (397), the following can also be cited: ənu- ‘after’ as in ənu-krəməη ‘sequence’, əbhi- ‘toward, intensity’ as in əbhi-prerəη ‘motivation’, a- ‘to, toward, up to’ as in a-gəmən ‘arrival’, ku- ‘bad, deficient’ as in ku-kərm ‘evil deed’, du- ‘two’ as in du-vidha ‘double-mindedness, uncertainty’ or ni- ‘inner’ as in ni-rīkSəη ‘inspection’ (Kachru Reference Kachru2006: 112–13).
7 Results and discussion
Typology will only be as good as the language particular descriptions it can draw on.
This chapter presents the analysis carried out on the sample studied. The approach is therefore one of data analysis and interpretation of results, specifically relating independent variables to types of word-formation processes and semantic roles. The aim is to identify preferences or associations between three independent variables and word-formation processes in general, as well as between types within word-formation processes (e.g. different types of compounding). Statistical analyses are used for associations, but these associations are not followed by a specific motivation for the association or by ensuing predictions based on these associations when such a motivation or prediction would be a matter of speculation rather than of clear linguistic facts.
This chapter describes the approach to data analysis (7.1), with emphasis on the method used (7.1.1), and the results obtained with that method (7.2).
7.1 Introduction
It has been argued that typological research should have a predictive value (Anderson Reference Anderson and Shopen1985: 10):
The discovery that language X differs from language Y in respect of property p is only of typological interest if something follows from it: that is, if p is always associated with some apparently distinct property p′, such that the discovery that X has p will allow us to predict that it will also have p′.
Although this chapter presents results about the occurrence of linguistic properties and associations between them, no predictions are made about the occurrence of linguistic properties in languages or in language families for two reasons:
(a) the purpose of the book is not to provide predictions, but to offer a general overview of word-formation across languages which may pave the way for precisely that kind of predictive contributions and
(b) the data and the findings that these data lead to do not always lend themselves to regularities or predictions. This may be because the picture they give requires further research (for example, for associations which are difficult to understand), but it may also be because the findings reflect associations or facts which may just not be interpretable: what the data reflect can be interpreted in a number of ways and it is difficult to decide, based on this initial cross-linguistic study, which of the possible interpretations is right.
7.1.1 Method
The data are classified as two sets: one for twenty word-formation processes1 and the other for specific types within some of those processes, specifically for suffixation, compounding, prefixation and reduplication.2 The first set of data – i.e. word-formation processes – is analyzed by evaluation of the fit of data and by Multiple Correspondence Analysis (MCA, StatSoft 2001) (see below). The second set of data – i.e. the types of word-formation processes – is analyzed only with MCA, as the results obtained with this analysis alone are clear enough.
The twenty word-formation processes of the first set of data were measured against three independent variables:
(a) language family,
(b) morphological type, and
(c) word order.
Language genus was not considered for the low sample size throughout all the language families. Each independent variable comprised a number of types. Not all types were considered for their low sample size. Table 7.1 shows the types studied within each independent variable.
Table 7.1. Types of languages and their sample size within the independent variables

For the occurrence or not of types of processes and/or semantic categories in relation to languages, the questionnaire’s dichotomous data (yes vs no) were converted to numerical values for computation in accordance with the answers given by the informants as follows: 1s (if the process or category in question was marked as yes in the questionnaire) vs 0s (if the process or category was marked as no in the questionnaire). Uncertain answers by the informants were marked as ? and these computed as 0 in the counts. The productivity measurements originally requested from the informants were not used for productivity assessment because each informant’s perception of productivity may have been widely subjective, even on the 1-to-5 Likert scale used. These data were therefore converted to 1 (occurrence) when a given degree of productivity was reported, and 0 otherwise. This resulted in a table of dichotomous data which were then used, e.g. for computation of the frequency of occurrence of each of the independent variables (language family, morphological type and word order).
Two different statistical approaches were followed. One is based on the evaluation of the fit of data (frequency of occurrence or not) to an arbitrary set of expected frequencies by means of the chi square test (Zar Reference Zar1984). For each class of each independent variable with a high enough sample size (lowest threshold being three, as shown in Table 7.1), the frequency of occurrence or not of each word-formation process was tested against frequencies expected at random (50 per cent). For example, out of six Austronesian languages, the observed frequency of occurrence of prefixation was six. This was tested against an expected random frequency of occurrence (or not) of three. This yields a chi square value whose p (0.014) establishes the significance of the association between the two variables (here, the occurrence or not of the process and the language family). In this example, prefixation occurs more frequently than expected in Austronesian languages. This approach has two limitations:
(a) it is sensitive to low sample size; the low sample size disallows detection of significances throughout the whole dataset but, where they appear, they do so as the result of a strong pattern, as they appear even with a low sample size, and
(b) because a number of hypotheses are tested with the same dataset, a correction must be used for apparently significant results which are not: the Bonferroni correction is applied to avoid significant results which are due to chance. Out of the twenty processes studied and their corresponding tests, one may reportedly appear to be significant when in fact it is not. The Bonferroni correction here lowers the significance threshold from 0.05 to 0.0025. This may give a false negative in some cases of the dataset. Therefore, more findings may exist than are reported, but those which are reported here are clear. The results in section 7.2 give data with and without the Bonferroni correction (Sokal and Rohlf Reference Sokal and Rohlf1995).
The other statistical approach is the MCA. This is a descriptive/exploratory technique designed to analyze the structure of categorical variables included in multi-way tables containing some measure of correspondence between the rows and columns. This technique represents the similarities between the row and column points in a table in a manner that retains all or almost all of the information about the differences between the rows and the columns. In other words, it produces a simplified (low-dimensional) representation of the information in a large frequency table. The distances of the points in a low-dimensional space (e.g. a two-dimensional display) are informative in that, for instance, row points that are close to each other are similar with regard to the pattern of relative frequencies across the columns. It is important to remark that, in such plots, one can only interpret the distances between row points and the distances between column points, but not the distances between row points and column points. However, it is appropriate to make general statements about the nature of the dimensions, based on which side of the origin particular points fall. Thus, it can be concluded that an axis separates some row category from the other row categories and that such categories differ in the relative frequency of a second variable (e.g. column). An additional goal of MCA is to find theoretical interpretations (i.e. meaning) for the extracted dimensions but, in general, the meaning of the gradients shown by the dimensions used here needs further study.
The procedure used was as follows: an MCA was first run with all the processes and language families and the amount of variance (i.e. inertia) explained and the quality of representation of each row point (i.e. language family) and of each column point (i.e. process) in the coordinate system defined by the dimensions extracted was explored. A low quality means that the current number of dimensions does not represent well the respective row (or column). The rows with low quality were then discarded and an MCA was run again after checking that such a procedure increased the percentage of variance explained. No processes with low-quality values were discarded, because the processes considered here are the essential processes in a study of word-formation, whereas the languages studied are just languages which may be present or not in a study sample and are, therefore, not essential by themselves. Nonetheless, after excluding the languages with low quality, the quality of the processes increased. The languages for which no data were applicable have been deleted from the dataset. This discards some language families in some types of processes while keeping as much information as possible. Which languages are discarded for which types of processes is explained in the description of the results of the MCA analysis for each particular process in section 7.1.1.
Both approaches allow a complementary overview of tendencies across the word-formation processes and the independent variables. Moreover, the results derived from the MCA analysis are also used to assess the tendencies obtained from the chi analysis. All the statistical analyses were performed with the STATISTICA software package (StatSoft 2001).
Finally, we calculate the frequency of occurrence of the semantic roles described in the last chapter among the twenty word-formation processes, using our fifty-five-language sample, based on the same conversion of the questionnaire’s dichotomous data (yes vs no) described for the previous analyses to 1s and 0s respectively. Uncertain answers by the informants were computed as 0 in the counts (absence). For each semantic role, we convert the frequencies of languages which use each word-formation process into percentages referred to the total number of languages that occur in each semantic role. For example, for the semantic role patient, thirty-four languages use some type of the word-formation process studied. Of these thirty-four languages, 70.59 per cent (twenty-four out of thirty-four languages) use suffixation, 8.82 per cent (three languages) use prefixation and so on. For each semantic role, we select the word-formation processes with the three highest percentages.
7.2 Results and discussion
The first approach analyzes the first dataset, i.e. general word-formation processes without specification of their types, by evaluation of the fit of frequency of occurrence of each language family in each word-formation process.
Figure 7.1 and Figure 7.2 present an overview of the occurrence of word-formation processes in the study sample.

Figure 7.1. Cross-linguistic use of word-formation processes in the study sample (absolute values with respect to fifty-five languages)

Figure 7.2. Cross-linguistic use of word-formation processes (percentages)
Table 7.2 presents significant associations between occurrence or not of word-formation processes vs the independent variables (language family, morphological type and word order) and gives the p values of the observed frequency per word-formation process. The table shows both uncorrected values, which have the value of tendencies, and Bonferroni-corrected values (squared cells), which are fully statistically significant associations.
Table 7.2. Significance of the chi square tests for the fit of the frequency of occurrence for each independent variable and each word-formation process (numbered 1 to 20)

Notes:
Blank cells stand for non-significant values at p > 0.10. Higher frequency than expected at random is in bold face. Lower frequency than expected is in shaded font. Shown are non-corrected p values. * < 0.05; ** < 0.01; *** < 0.001. The values with statistical significance after the Bonferroni correction are marked with a square.
The following major conclusions can be drawn from these results:
(a) in general, four word-formation processes occur consistently more frequently than expected: prefixation, suffixation, compounding and reduplication. They occur regardless of the internal classifications used (by language family, morphological type or word order), even if only suffixation does so for all the types within the independent variables. Two more processes occur more frequently than expected, but they differ from the former processes in one or other respect: conversion occurs more frequently than expected in each of the independent variables, but it does so markedly less consistently than the former four processes. Incorporation occurs more frequently than expected, but only by one of the independent variables (word order). Incorporation also differs from the former four processes in that it occurs less frequently than expected by morphological type. Prefixation, suffixation, compounding and reduplication are therefore different from conversion and substantially different from incorporation;
(b) all the remaining word-formation processes occur less frequently than expected, regardless of the internal classifications used (by language family, morphological type or word order) with the exception of incorporation, which occurs more frequently than expected by word order, as noted above;
(c) after the Bonferroni correction, all the processes that occur more frequently than expected still do so where sample size is large enough (morphological type and word order). These processes are prefixation, suffixation, compounding and reduplication. Prefixation differs from the rest in that it does not reach statistical significance by morphological type. Conversion and incorporation cease to be significant after the Bonferroni correction, thus confirming that they belong in a different group from prefixation, suffixation, compounding and reduplication; and
(d) similarly, after the Bonferroni correction, all the processes showing significantly low frequency of occurrence still do so where the sample size allows (morphological type and word order), except for infixation, prefixation-suffixation and vowel alternation, which no longer reach statistical significance. Of these, vowel alternation remains significant by morphological type.
Differences in sample size can also bias the results, in that the occurrence of processes in language types (be it family, morphological type or word-order type) with a large sample size may be due to an actual significant association or precisely to the large sample size. Similarly, the non-occurrence of processes in language types with a small sample size may be due to an actual significant association or precisely to the small sample size (the sample is too small to detect the real frequency of the occurrence of a process). Therefore, and to be on the safe side, conclusions are drawn here only from high frequencies in categories with small samples and from low frequencies in categories with large samples. This is a safeguard against the bias that different sample sizes can introduce. For this purpose, the variables (language family, inflectional type and word order) have been divided into a higher sample size set and a lower sample size set, as presented in Table 7.3.
Table 7.3. Categories within independent variables divided into two sets by sample size

Thus, limiting the presentation of results to those which have been confirmed by the Bonferroni correction, associations between the independent variables and the word-formation processes can be found (Table 7.4 and Table 7.5). No statistical claims can be made regarding language family for the low n of families of each type present in the sample, therefore there is not a table of correspondences for language families and word-formation processes.


Table 7.5. Statistically significant associations between word-formation processes and word order. Higher frequency than expected of word-formation processes with high sample size are presented for information purposes (shaded font)

Application of an MCA analysis to the same dataset (i.e. the second approach described in section 7.1.1) provides additional results. As mentioned above, this analysis produces a simplified representation of the information according to the distance between the points in a two-dimensional display, so that the row points (e.g. languages) that are close to each other are similar with regard to the pattern of relative frequencies across the columns (e.g. processes). For example, Figure 7.3 shows the distances among languages with regard to the pattern of relative frequencies across the processes, with the languages which have similar occurrence/non-occurrence of word-formation processes being closer.

Figure 7.3. Language families by word-formation process occurrence or not
A first analysis with all languages explains a low percentage of variance (15.7 per cent) and shows that a few languages, namely Afro-Asiatic, Austro-Asiatic and Indo-European, have a high quality, i.e., they are well discriminated by the dimensions extracted. This makes sense, since a general classification on the basis of global processes can have less discriminatory power than classifications on more specific processes (e.g. prefixation, suffixation, etc.), as can be seen in the analyses below. Figure 7.3 shows that the three language families mentioned above are the most dissimilar to the rest, whereas the rest are more similar, even if several groups of languages with similar preferences can be distinguished (e.g. Altaic, Australian, Movima and Trans-New Guinean, or Niger-Congo, Nilo-Saharan and Sino-Tibetan).
Figure 7.4 shows similitudes between processes. In this case, the presence of a process is associated with the presence of the rest of the processes, and the same applies for their absence. This is shown in the figure in the form of .1s and .0s occurring together. As a result, two groups can be observed:
(a) a loose group for the presence of processes, and
(b) a more compact one for the absence of processes.
Subgroups can therefore be found mainly within the presences: for example, the presence of infixation-suffixation (represented as 7.1) is associated with the presence of root-and-pattern (represented as 8.1), and the absence of compounding (represented as 13.0) is associated with the absence of prefixation (represented as 1.0). In fact, prefixation (represented as 1.) and tone/pitch (represented as 20.) are an exception, in that their presence (1.1 and 20.1 respectively) are closer to the absence (.0s) of most other processes.

Figure 7.4. Presence (represented as .1) and absence (represented as .0) of word-formation processes in the study sample. The word-formation processes are represented by their numbers as in Table 7.2
Figuring out the association between language families and processes is possible by comparing Figure 7.3 and Figure 7.4. However, since the variance explained is low, we preferred to discard those languages with low-quality values (< 0.008). Only the language families Afro-Asiatic, Austro-Asiatic and Indo-European (quality values > 0.23) and all the processes were included in the analysis. With this subset, the variance explained rises to 46.8 per cent. Figure 7.5 suggests an association between the Austro-Asiatic language family and the absence of suffixation (represented as 2.0). It also suggests that the Indo-European family is associated with the absence of tone/pitch (represented as 20.0) and the presence of prefixation (represented as 1.1) and suffixation (represented as 2.1), as can also be seen in Table 7.2. Afro-Asiatic is associated at least with the presence of suffixation (represented as 2.1) and reduplication (represented as 15.1), thus confirming the results expressed in Table 7.2 that could not be confirmed after the Bonferroni correction due to low sample size.

Figure 7.5. Associations between language families and word-formation processes. Presence is represented as .1 and absence is represented as .0. The word-formation processes are represented by their numbers as in Table 7.2
The classifications (i.e. word-formation processes) used for the above associations may seem too broad and, thus, the discrimination ability may be low, with the result that only three language families (Afro-Asiatic, Austro-Asiatic and Indo-European) show distinct patterns. Finer distinctions can be made only when classifications are more precise, as can be seen below, where the processes are divided into types, e.g. types of compounding.
The analysis of the second set of data referred to at the beginning of section 7.1.1 can be broken down into four groups, one for each of the word-formation processes considered: prefixation, suffixation, compounding and reduplication.
The first group, prefixation, discarded some languages for which questionnaire data did not apply. Whereas this suppressed completely some language families (Altaic, Austro-Asiatic, Aymaran, Eskimo-Aleut, Khoisan, Movima, Trans-New Guinea and Wakashan), some other families were still represented even though they lost some cases. All the types of prefixation were included. The language families with high-quality values (> 0.10) are Afro-Asiatic, Australian, Dravidian, Indo-European, Japanese, Kartvelian, Sino-Tibetan and Uralic. The quality value for the rest was ≤ 0.09. The variance explained is 48.8 per cent.
Figure 7.6 shows that types of prefixation form a gradient where associations of language families can be established for example, Sino-Tibetan with Kartvelian and Indo-European at one end of the gradient, Dravidian with Uralic at the other, and Australian with Japanese in between.

Figure 7.6. Associations between language families and types of prefixation. Presence is represented as .1 and absence is represented as .0 (the chart discards language families as described in the text)
Regarding processes, presence and absence seem to arrange themselves on the left- and right-hand sides of the chart respectively, i.e. they show a consistent pattern except for absence of prefixation with base modification, which occurs in between the groups of presences and absences at either end of the chart.
Regarding language family and types of prefixation, the major associations seem to occur between the Afro-Asiatic, Australian and Japanese language families and presence of prefixation with base modification; between Indo-European and presence of polysemic prefixation, recursive prefixation and prefixation variants; and between Dravidian and Uralic and absence of polysemic prefixation, of recursive prefixation and of prefixation variants.
The second group, suffixation, discarded one language family (Austro-Asiatic) for which questionnaire data did not apply. All the processes were included. The language families with high-quality values (> 0.10) are Afro-Asiatic, Australian, Indo-European, Kartvelian, Khoisan, Matacoan, Siouan, Trans-New Guinea and Uralic. The quality value for the rest was ≤ 0.09. This subset explains 43.3 per cent of the variance.
Figure 7.7 shows that types of suffixation establish a gradient where most of the language families place themselves at one or the other end of the gradient. Thus, an association can be noticed between Khoisan, Siouan. Trans-New Guinea and Afro-Asiatic, on the one hand, and between Indo-European, Uralic, Kartvelian and Matacoan, on the other. Subgroups can be identified at each end, too: Siouan, Khoisan and Trans-New Guinea are comparatively closer together. So, at the other end, are Kartvelian and Matacoan on the one hand, and Uralic and Indo-European on the other. The family Australian appears to be different from all the others. Dimension 2 adds in the separation of languages established above according to Dimension 1, in that it separates Kartvelian and Matacoan from Australian as two groups.

Figure 7.7. Associations between language families and types of suffixation. Presence is represented as .1 and absence is represented as .0 (the chart discards language families as described in the text)
Regarding processes, presence and absence seem to arrange themselves parallel on the right- and left-hand sides of the chart respectively, i.e., they show a consistent pattern, in that presences are associated with presences and absences with absences.
Regarding language family and types of suffixation, the language families Khoisan, Siouan and Trans-New Guinea are associated with absence of recursiveness, polysemy and base modification. Afro-Asiatic shows the same pattern, although some of its languages deviate in showing the presence of some of these types of suffixation. Uralic and Indo-European have presence of polysemy, base modification, recursiveness and suffix variants. Kartvelian and Matacoan also seem to be related to the presence of polysemy, base modification and recursiveness, but less markedly than Uralic and Indo-European.
The third group, compounding, discards the languages for which questionnaire data on compounding do not apply. This excludes nine languages, although only four language families (Eskimo-Aleut, Salishan, Uto-Aztecan and Wakashan) are no longer represented as a result of this. The first analysis with the languages of the sample explains 20.3 per cent of the variance. Only languages with a high-quality index (> 0.11) were retained: Altaic, Indo-European, Niger-Congo, Sino-Tibetan and Totonacan. The remaining ones had quality values below 0.07. All types of compounding were included. The analysis done with this subset explains more than 51 per cent of the variance.
Figure 7.8 shows associations between language families, associations between presence of types with the presence of other types and the absence of types with the absence of types, and associations between language families and types of compounding.

Figure 7.8. Associations between language families and types of compounding. Presence is represented as .1 and absence is represented as .0 (the chart discards language families as described in the text)
Language families have fairly distinct patterns of presence/absence, as can be seen from their separation along the axis for Dimension 1. Thus, Dimension 1 discriminates two groups:
(a) Sino-Tibetan appears to be associated with Indo-European as regards the presence of most types of compounding, and
(b) Totonacan appears to be associated with Altaic and Niger-Congo as regards the absence of most types of compounding.
Regarding processes, the picture is less clear but, in general, presences appear to be associated with presences and absences with absences. Thus, for example, the presence of recursive compounding is associated with the presence of adjective + adjective compounding, and the absence of adjective + adjective compounding is associated with the absence of copulative compounding. Some exceptions can be noted: presences of some processes are associated with absences, like the presence of verbal compounding and the absence of phonological change.
Finally, concerning the association between language families and processes, the separation of languages into two groups is paralleled by the separation between absence and presence of types of compounding. The clearest association seems to occur between the language family Totonacan and the absence of noun stem + noun stem compounding, both high along Dimension 2.
For the last group, reduplication, all languages were initially taken into consideration and language families with high-quality values (> 0.10) were then selected, namely Afro-Asiatic, Austronesian, Movima, Niger-Congo, Trans-New Guinea and Uralic. The quality value for the remaining languages was < 0.07. The variance explained with this subset was 46.8 per cent, which is considerably higher than the 15.06 per cent of the variance explained when all the languages were taken into consideration. All the types of reduplication were included.
Regarding language families, Figure 7.9 shows that reduplication discriminates well among the language families selected, as all of them are well apart from each other. As in compounding, Dimension 1 establishes a gradient between language families which show presence of all types of reduplication (Trans-New Guinea), absence of all types of reduplication (Uralic), and languages with varying degrees of presence/absence in between (Austronesian, Afro-Asiatic, Movima and Niger-Congo).

Figure 7.9. Associations between language families and types of reduplication. Presence is represented as .1 and absence is represented as .0 (the chart discards language families as described in the text)
Presence and absence of processes seem to arrange themselves parallel on the left- and right-hand sides of the chart respectively, i.e., they show a consistent pattern.
Finally, concerning language family and types, the clearest association seems to be that between presence of infixation and the language families Trans-New Guinea and Movima, both high on Dimension 2. High frequency of preposing reduplication, partial reduplication and complete reduplication are also associated with the Austronesian language family, both on Dimension 1 and 2.
It can be observed from the figures above that a limited number of language families appear in the general processes and that types of those word-formation processes open the range to new language families. This is an added value of exploring not only the presence/absence of certain language families in word-formation processes in general, but also in types of certain word-formation processes (here prefixation, suffixation, compounding and reduplication). The results of this approach can be summarized in Table 7.6, which lists language families with high-quality values in relation to word-formation processes and with types of word-formation processes.
This table reveals that the pattern of presence/absence of processes in the Afro-Asiatic and Indo-European language families is distinct in word-formation processes in general, and also in the types of three out of four word-formation processes (Afro-Asiatic has a high quality in prefixation, suffixation and reduplication, and Indo-European has a high quality in prefixation, suffixation and compounding). By contrast, for Austro-Asiatic only the pattern of presence/absence of general word-formation processes, not of types of word-formation processes, is distinct enough to be well represented.
The distinctiveness of presence/absence in some language families holds in several types of word-formation processes (e.g. Uralic in types of reduplication, prefixation and suffixation), while in other language families it holds only in one word-formation process (e.g. Altaic and Totonacan in compounding, Austronesian and Movima in reduplication, Dravidian and Japanese in prefixation, and Khoisan, Matacoan and Siouan in suffixation). Whether this is due to the peculiarity of each language family or to the sample size within each language family requires further research. The low sample size of six out of the nine language families (one language per family) makes their representation appear more peculiar than it probably is. A more accurate description of these families is only possible with a higher sample size. Still, Dravidian (studied in terms of three languages) and, especially, Austronesian (studied in terms of six languages) are genuinely peculiar as regards their presence/absence in types of prefixation and types of reduplication respectively. The Dravidian languages show virtually total absence of prefixation types and the Austronesian languages show presence of complete, partial and preposing reduplication.
It can also be concluded that prefixation and suffixation are the processes that yield distinctive patterns of presence/absence of word-formation processes for more language families (eight and nine language families respectively).
Table 7.6. Language families with respect to word-formation processes and to types of prefixation, suffixation, compounding and reduplication

If we compare the results obtained from the two statistical approaches mentioned in 7.1.1 and presented above, we find that some results obtained from the chi square analysis are confirmed by the results obtained from the MCA analysis.
Concerning word-formation processes in general, the two approaches confirm that the Indo-European family is associated with the presence of prefixation, suffixation and compounding, and with the absence of tone/pitch, and also that the Afro-Asiatic family is associated with the presence of suffixation and reduplication.
Concerning types of the four word-formation processes studied, specifically compounding, the two approaches confirm that the Indo-European family seems to be associated with the presence of certain types of compounds. By contrast, the two approaches differ in respect of the association between the Niger-Congo and types of compounding: while the chi square approach gives a significant value for compounding in Niger-Congo languages in Table 7.2 (although not significant after the Bonferroni correction), the Niger-Congo family seems to be associated in Figure 7.8 with the absence of most types of compounding. This suggests that compounding in Niger-Congo languages is mainly of the type noun stem + noun stem, which is the most frequent type of compounding recorded in the languages sampled for this family.
The two approaches confirm the high frequency level of reduplication of Afro-Asiatic, Austronesian and Niger-Congo languages. MCA analysis shows that this high frequency is due mainly to the presence of preposing, complete and partial reduplication. The two approaches also confirm that the Indo-European family is associated with presence of prefixation, specifically, according to the MCA analysis, of polysemic and recursive prefixation. Finally, the two approaches also confirm that the language families Indo-European and Uralic have a high frequency of presence of suffixation.
Overall, both approaches agree in a considerable number of tendencies. These tendencies, detected by a conservative use of the chi square analysis and confirmed by MCA analysis, can therefore be considered reliable.
Onomasiologically, Figure 7.10 and Figure 7.11 show the semantic categories considered in chapter 6, with respect to the number of languages in the study sample in which the individual semantic categories listed above have word-formation relevance.
Figure 7.10. Word-formation relevance of semantic categories in the study sample (absolute values with respect to fifty-five languages)

Figure 7.11. Word-formation relevance of semantic categories (percentages)
The expression of semantic categories shows a clear pattern as regards the use by each word-formation process (see Table 7.7). Table 7.7 and Figure 7.12 show that suffixation is the process which is used most by the sample languages throughout all the semantic categories studied. Specifically, suffixation ranks first within a range of 50 per cent to 70.5 per cent of use across all the semantic categories except two, namely the categories benefactive and frequentative, each for different reasons:
(a) benefactive has a low sample size (four languages, 7.27 per cent of the study sample) and the processes, suffixation included, distribute themselves evenly throughout the sample, and
(b) frequentative shows a prevalence of a different process, namely reduplication, but even in this category suffixation ranks second.
Leaving aside the exception in the category benefactive, in some categories the third lowest value is shared by two processes, even if Table 7.7 represents only one. These processes are compounding and prefixation-suffixation in agentive, instrumental, causative and action nouns, and compounding and conversion in patient.
Table 7.7. Percentage of occurrence of semantic categories with respect to word-formation processes in the languages sampled. Only the three word-formation processes which occur most frequently for each semantic category are presented. Blank cells stand for low frequency of occurrence or for absence of languages which express these semantic roles by these word-formation processes.


Figure 7.12. Percentage of occurrence of semantic categories with respect to the most frequently used word-formation processes in the languages sampled
7.3 Summary
Certain statistical associations can be established between word-formation processes and semantic categories as two separate datasets with respect to three independent variables: language family, morphological type and word order. Suffixation, compounding and, to a lesser extent, reduplication and prefixation, are the word-formation processes that play a major role in word-formation. Finer distinctions and specific associations can be established with respect to the independent variables but, in general, the picture given by the language sample is clearly in the direction of concatenative word-formation and constructional iconicity. Suffixation is the process which is most frequently used throughout all the semantic categories studied.
1 Prefixation, suffixation, infixation, circumfixation, prefixation and suffixation, prefixation and infixation, infixation and suffixation, root-and-pattern, vowel alternation, prefixation and vowel alternation, suffixation and vowel alternation, consonant alternation, compounding, incorporation, reduplication, conversion, back-formation, blending, stress, and tone/pitch.
2 The types considered in compounding are: recursive, adjective + adjective, verb, noun + noun, stem-link, with phonological modification, copulative, copulative compound nouns, copulative compound adjective, exocentric, exocentric of the redskin type, and exocentric of the garde-manger type. The types for reduplication are: complete, partial, preposing, postposing and infixing. The types for prefixation and for suffixation are: recursive, polysemous, affixation with variants, and affixation with base modification.
3 Types were pooled based on their proximity in the variable Morphological for a bigger sample size. The type agglutinative mixed encompasses agglutinative-fusional (two languages), agglutinative-inflectional (two languages), agglutinative-suffixal (two languages) and agglutinative-polysynthetic (two languages).
Epilogue
At the beginning of this volume we identified as the most important, central objective of this book the search for cross-linguistic associations between word-formation processes and/or the individual parameters of word-formation processes. A number of associations were identified, but the picture obtained is not very optimistic for those who may have expected a solid system of regular distribution of word-formation processes depending on genetic and/or morphological characteristics of languages.
Word-formation is an inherent feature of every language. This is both trivial and crucial. A language can only exist if it is able to give names to new objects invented, discovered, designed, encountered, obtained, produced, etc. by the members of a particular speech community. Exclusive use of borrowings and/or descriptive/analytic devices may be viewed as a symptom of a serious disease in a language, as has been confirmed for Bardi where, according to Bowern (pers. comm.), there is not much in the way of productive word-formation. This might be partly because of language death (there are only twenty-five speakers), but a lack of productive derivational morphology has also been noted for some other Australian Aboriginal languages.
There is no language without concatenating word-formation. This has confirmed one of the fundamental postulates of Natural Morphology concerning constructional iconicity as a most natural way of forming new words. This is also in accordance with the fundamental principles of Marchandean and Dokulilean approaches to word-formation, according to which an object is first conceptually processed as a member of a larger class of similar objects and, subsequently, is distinguished from them by highlighting one of its most characteristic features.
Suffixation and compounding, in this order, prevail, and reduplication and prefixation are frequent in the languages studied. Prefixal-infixal derivation, stem consonant alternation and stress shift are rare. Agent formation prevails over other semantic categories, e.g. patient. Diminutives prevail over augmentatives and feminines over masculines. Certain associations can be found between the above and the independent variables like language family, morphological type or word order, but individual word-formation processes and their features depend more on their genetic rather than morphological characteristics.
Languages may be divided into derivationally rich and derivationally poor. Derivationally rich languages make productive use not only of the major but also of the minor word-formation processes. Typical derivationally rich languages are, e.g. Clallam, English, Hebrew, Ilocano, Indonesian, Karao, Konni, Nelemwa, Marathi, Slovak and Totonac. Derivationally poor languages are those whose word-formation capacity is restricted to a minimum (Bardi, Cirecire) and those which make use of a limited number of word-formation processes, like Kalkatungu, Kwakw’ala, Lakhota, Tatar, Tzotzil and West Greenlandic. From this list it follows that at the poor end of the scale there are mostly agglutinative and polysynthetic languages, the latter exclusively from North America. The rich pole of the scale is fairly heterogeneous. These two groups of languages represent opposite ends on the word-formation richness scale. The other languages can be classified between them in terms of the number of processes used and of their productivity. From the point of view of various morphological classifications of languages, it is understandable, as there are no pure types and, thus, one cannot expect that word-formation features of these languages will be homogeneous.
A sample of fifty-five languages lends itself well to the identification of cross-linguistic default values, but it is not possible to draw any generalizations for families represented by a minimum number of languages. Why certain processes or categories prevail, as has been presented here, is hard to interpret. It may well be that there is not just one explanation, and an interplay of factors gives rise to the use of the same resource in a number of respects. From the perspective of this book, it is our belief that future effort should be guided in three major directions:
(a) an increase in the total number of languages sampled in order to confirm or improve the precision of the findings of this book,
(b) a search for associations between word-formation processes inside selected language families and/or genera represented by a sufficient number of languages, and
(c) as the questionnaire used covered only selected areas of word-formation, an extended scope of the word-formation characteristics covered.
A fascinating feature of any cross-linguistic research is that it makes it possible to reveal the wonderful diversity of individual phenomena. This has been shown, as we believe, in the examples cited in the volume. This diversity ranges over individual languages, families and morphological types. This diversity is a source/reason?/explanation? of the existence of fuzzy boundaries between the individual word-formation processes and also between inflectional morphology and syntax and derivation. In spite of this, the diversity constitutes the unity of the individual phenomena and processes through their most frequent cases that tower over all the less frequent manifestations.
This book draws generalizations based on empirical data, points out associations in word-formation processes cross-linguistically, demonstrates the multifarious manifestations of broadly defined word-formation categories in the languages of the world and illustrates the observations with examples. The aim was to instigate even more extensive and more comprehensive research in this intriguing area of language universals and typology, a task which is insurmountable for one or two linguists. By implication, since it was just the first, tentative probe, many more interesting findings remain to be discovered.























































































































































