

1.1 Introduction: emergence of the variationist approach and sociohistorical linguistics
This chapter presents an overview of the variationist approach and illustrates how this theoretical and methodological framework arose through convergence of research investigating language variation and change within sociolinguistics and dialectology. This first section explains how the variationist approach was introduced and developed within (English) historical linguistics through the emergence of a research field variously called sociohistorical linguistics or historical sociolinguistics, terms often used interchangeably. Discussion of methodology follows in section 1.2, and some illustrative findings from this paradigm are presented in section 1.3. The final section (1.4) concludes with brief discussion of new tools for analysis, novel data sources, and theoretical frameworks, along with consideration of some remaining problems.
Weinreich et al.'s (Reference Weinreich, Labov, Herzog, Lehmann and Malkiel1968) ground-breaking discussion of empirical foundations for a theory of language change marks the birth of sociohistorical linguistics or historical sociolinguistics. Although the authors use neither of these terms, this publication heralded an important turning point in proposing a theory of language change embedded in both linguistic and social structure. Starting from the premise that synchronic variation of the type investigated by contemporary sociolinguists and dialectologists represents a stage in long-term change, they proposed using the present to explain the past and the past to explain the present. Most importantly, however, implementing the variationist approach requires taking account of the external history of a language in historical reconstruction and abandoning the strict Saussurean dichotomy between synchrony and diachrony.
A key tenet of the variationist approach is the idea of orderly or structured heterogeneity (Weinreich et al. Reference Weinreich, Labov, Herzog, Lehmann and Malkiel1968: 99–100). Variation is not random, but structured in regular ways along a number of internal linguistic and external social dimensions, including, for instance, linguistic context, speaker position/status, and text type (style, genre, etc.). A major finding resulting from decades of urban sociolinguistic work, much of it conducted in English-speaking communities, is that differences among social class dialects are quantitative and not qualitative. When viewed against the background of the community as a whole, variation in the speech of and between individuals previously seen as free or random is conditioned by social factors like social class, age, sex, and style in predictable ways. Inherent variability shows directional gradience through social groups, geographic space, and time. Understanding what Weinreich et al. (Reference Weinreich, Labov, Herzog, Lehmann and Malkiel1968) refer to as the ‘embedding problem’ (i.e. how variability and change are embedded in a social and linguistic matrix) in speech communities today and the social meanings attached to variants allows us to make some predictions about the pathways change follows as it moves through a community (see section 1.3).
A primary goal of sociohistorical linguistics is to provide an account of the forms and uses in which variation may manifest itself over time, and of how particular functions, uses and kinds of variation develop within particular language varieties, speech communities, social networks, individuals, texts, and genres (Romaine Reference Romaine1982). The incorporation of variability represents a significant departure from traditional historical linguistics, which focused primarily on the evolution of written standard varieties, often ignoring variation and non-literary language. Taking account of developments in a broader range of varieties, especially those from geographically or socially peripheral communities or individuals further removed from literate traditions presents opportunities for a richer account of language change because non-standard varieties used in rural and working class communities often preserve older stages of changes already completed and no longer directly observable in the standard. While standard handbooks typically treat the Great Vowel Shift as a fait accompli because they take standard English as their reference point, certain elements have yet to be implemented in some varieties of northern British English. Modern sociolinguistic studies reveal that retention of monophthongal /u:/ in words like house is a relic embedded in the most informal styles of contemporary working class speech in Scotland (Macaulay Reference Macaulay1977). Likewise, in the domain of syntax, the infiltration of WH-pronouns such as who, whose, and whom can be seen as completed in the modern standard written language and some varieties of educated spoken English, but it has not really affected modern spoken vernaculars, which prefer that or zero marking, e.g. the woman (*whom, that, Ø) I met (Romaine Reference Romaine1982, Tagliamonte Reference Tagliamonte, van Kemenade and Los2006b).
1.2 Methods
Guided by the methodological requirements for conducting synchronic research within the variationist paradigm, the main task for diachronic studies is to devise procedures for reconstructing language in its social context. Historical linguists confront similar problems when assembling two kinds of data, linguistic and social, in order to establish correlations between them. These include selecting the individuals/communities/texts to be studied, identifying the linguistic variables and their variants, collecting and analysing the data, and interpreting the results.
1.2.1 Defining the nature and locus of variation: linguistic variables
Quantitative studies of variation have been going on for at least fifty years as part of an approach to sociolinguistics sometimes referred to as ‘the quantitative paradigm’ (Bayley Reference Bayley, Chambers, Trudgill and Schilling-Estes2002) or ‘variation theory’, associated with methods Labov (Reference Labov1966) developed for investigating urban social dialects in the United States. Indeed, Henry's (Reference Henry, Chambers, Trudgill and Schilling2002: 267) observation that if language were not variable, there would be no sociolinguistics highlights the intimate relationship between this branch of sociolinguistics and variation. Variation arises from competition between grammars or elements within them. Socially speaking, these grammars are instantiated in communities and individuals. These elements can be understood in a broad sense, ranging from discourse strategies like code-switching (e.g. between English and Latin in early modern depositions), whole constructions (e.g. do periphrasis), to microvariables like h-dropping, spelling variants (e.g. Scots <quh> vs. southern English <wh> in relative and interrogative pronouns like who, which, etc.) or individual words (e.g. toilet vs. lavatory or loo). Identifying and quantifying these so-called (sociolinguistic) ‘variables’ comprise the fundamental working tool of quantitative sociolinguistics critical to the variationist approach. A variable represents a class of variants showing a regular relationship with some external dimension like social class, style, etc. as well as internal linguistic constraints such as the structural environment in which the variable occurs, e.g. variable loss of initial /h/ before vowels in stressed syllables. Examples of simple variables include those with only two relatively discrete variants like presence/absence of a consonant (e.g. initial /h/ or postvocalic /r/ in words like heart), whereas more complex ones vary continuously along one or more dimensions (e.g. the vowel of kill in Scots English, varying along two phonetic dimensions of vowel height and backing).
Syntactic variation has been much less well studied from the perspective of regional dialectology or the variationist paradigm, particularly initially when some expressed doubts about whether syntactic (and beyond that, discourse) variation met the defining criterion of a linguistic variable as alternate ways of saying the same thing (Lavandera Reference Lavandera1978, Buchstaller Reference Buchstaller2009). Some researchers circumvent this issue by adopting less stringent notions of functional comparability, and/or by devising other ways of quantifying and reporting variation within alternative theoretical frameworks like text linguistics (see Chapter 21 by Biber in this volume) or construction grammar (see Chapters 4 by Trousdale and 22 by Traugott in this volume). Beyond the issue of semantic equivalence, however, lies the more serious problem of infrequent occurrence of some syntactic constructions, which becomes even more acute during earlier historical periods. Diachronic studies of syntactic variation require large corpora representing a broad spectrum of text types spanning centuries. The amount of variation in a language may vary from time to time and it continually shifts its social and linguistic locus. Probably all changes originating in the spoken language are considerably older than their first attestations in written records (Romaine Reference Romaine1985). We cannot assume that every instance of variation will correlate with social structure in the same way or to the same extent. Most sociolinguistic variables have a complicated history and the social significance of linguistic features may vary over time, with some variables stratifying the population more finely than others.
1.2.2 Reconstructing language in social context
Diachronic variation studies assume the Uniformitarian Principle as a guideline for reconstructing language in its social context: the linguistic forces operating today and observable around us are not unlike those of the past (Labov Reference Labov1972: 275). If language of earlier periods varies in the same kinds of patterned ways as today, findings from synchronic sociolinguistics can act as controls on the process of reconstruction and as a means of informing theories of change. Methods for studying social dialects from a variationist perspective are usually speech based, relying on data obtained primarily by interviewing a sample of individuals representing social categories like working-class men, middle-class women, etc. Much of this work emphasized studying the so-called vernacular, i.e. ordinary everyday informal speech, especially among the lowest social groups, in the belief that it represented the most interesting, naturalistic, and systematic data for observing language change.
By contrast, historical research relies mainly on evidence from written texts produced in periods without sound recordings and direct access to speakers (Hernández-Campoy and Schilling Reference Hernández-Campoy and Conde-Silvestre2012; and see Chapter 9 by Mair in this volume). Nevertheless, the historian's task is not entirely one of making the ‘best use of bad data’ (Labov Reference Labov1972: 100), but discovering new ways of enhancing the use of existing resources (Nevalainen Reference Nevalainen1999b, Kytö and Walker Reference Kytö and Walker2003). Although historical linguists have no control over their data, in the sense that the textual corpus is finite, accidental, and fragmentary, data of certain kinds suffice for particular types of analysis, even in cases involving rare syntactic constructions. Wyld (Reference Wyld1927: 21) contended that ‘the drama of linguistic change is enacted not in manuscripts nor inscriptions, but in the mouths and minds of men’, but once we treat written language as a medium in its own right, documenting variation within and between texts reveals an analogous drama and dynamics. Orthographic variation can reveal change in progress in the same way as phonological variation and can be used to track sound change in progress. In some cases, spelling variation can also provide important clues about variability in spoken English. Evidence from Middle and Early Modern English, for instance, strongly suggests that h-dropping, whatever its origin, has been variable in English for centuries and had a social and stylistic function just as it does today (Milroy Reference Milroy and Blake1992b: 199–200), where it is the ‘single most powerful pronunciation shibboleth in England’ (Wells Reference Wells1982: 254). From the thirteenth to the fifteenth centuries, Middle English texts, especially from the east Midlands, East Anglia, and the south, reveal that <h> is sometimes absent where it would otherwise be expected historically, and sometimes inserted where not expected (e.g. ham ‘am’, hunkinde ‘unkind’), subject to complex grammatical constraints (Crisma Reference Crisma2007).
Nevertheless, limits on the amount and kind of available data impose constraints. By some estimates, the amount of Old English material is only about 3.5 million words. In addition, many late Old English texts are written in a relatively invariant West Saxon literary language. Approximately 20 million words of Middle English texts are available (Stockwell Reference Stockwell and Fisiak1984: 583), but the material is geographically unevenly distributed, with texts from the south and south midlands plentiful before 1350, but few extant northern and north midlands ones. Despite these limitations, however, opportunities exist for studying variation, especially in the Middle English period, which ‘exhibits by far greatest diversity in written language of any period before or since’ (Milroy Reference Milroy and Blake1992b: 156). Due to the lack of a fully institutionalized standard, widespread variability displayed at virtually every linguistic level, including spelling, morphology, syntax, and vocabulary has provided fertile ground for dialectological (LALME Reference McIntosh, Samuels and Benskin1986) and sociohistorical investigations.
Even if linguistic variation is abundant, reconstruction of social factors critical to understanding external dimensions of change may be hampered by the general restriction of education and literacy to male members of the upper social order. Indeed, before literacy was widespread, the majority of evidence for language change comes from the written output of scribes (Wagner et al. Reference Wagner, Outhwaite and Beinhoff2013). Often early data display very little social class and gender differentiation, particularly during the beginning stages of many changes when women and the lower classes were less likely to be literate. Early female writers dictated letters to male scribes, whose identities may be unknown. Margaret Paston (c.1420–84), for example, one of the most prolific female authors of the Middle English period, and the most abundant correspondent in the upwardly mobile Paston family from Norfolk, rising from peasantry to aristocracy within the space of two generations, dictated c.67,000 words of text to nineteen scribes including her sons, John II, John III, and Edmund II, and various estate employees over a period of twenty-nine years (Bergs Reference Bergs2005: 113). Continuing inequalities in status and education between men and women meant that men represented a broader spectrum of the social order. Even in the nineteenth century women did not have access to the same professional circles that their male contemporaries moved in. Hence, there are no letters between professional women matching the kind of correspondence between leading male letter writers of the time like Charles Darwin, Thomas Carlyle, etc.
In addition to numerous complexities in the historical transmission of texts that need to be considered, the changing nature of the social hierarchy over time poses problems. The transition from a society of estates or orders to a class-based society is one of the great themes of modern British social history. William Caxton's three estates of ‘clerkes, knyghtes, and laborers’ were differentiated in terms of social function, but from the eighteenth century as the Industrial Revolution opened up new avenues for the accumulation of wealth, prestige, and power other than those based on hereditary landed titles, a different perception of social structure emerged based on classes distinguished primarily in terms of economic criteria. Even if historical linguists ‘usually know very little about the social position of the writers, and not much more about the social structure of the community’ (Labov Reference Labov1994: 11) and we cannot always be sure that individuals are the authors of their own texts, social historians provide a great deal of information useful for reconstructing appropriate models of social distinctions in pre-modern English-speaking societies.
Relying on such evidence, for instance, Nevalainen and Raumolin-Brunberg (Reference Nevalainen and Raumolin-Brunberg1996a: 48–52, Reference Nevalainen and Raumolin-Brunberg2003: 32–43) adopted a social hierarchy for Tudor England rather different from that used by modern sociolinguists, comprising strata like ‘nobility’, ‘lower gentry’, ‘upper clergy’, ‘merchants’, etc., to investigate morphosyntactic variation in the Corpus of Early English Correspondence (CEEC, 1998 version). Specially designed for sociohistorical linguistic studies, the CEEC currently contains c.5.1 million words representing c.12,000 letters taken from 188 letter collections between 1403 and 1800. The beginning date of 1403 is dictated by the earliest availability of personal letters in English. A number of extralinguistic variables (e.g. writer's provenance, social and family status, sex, education, age, and relation to the recipient) were taken into account in selecting the letters written by 1,200 individuals (610 men and 168 women), and the corpus is accompanied with a database including social background information for each of the letter writers, making it an invaluable tool for sociohistorical research. The steadily increasing range and size of diachronic corpora and other text databases, beginning with the 1.6 million word multigenre Helsinki Corpus of English Texts (HC, published in 1991) covering a millennium from the eighth to the eighteenth century has opened new vistas for studying variation (see Chapter 8 by López-Couso in this volume).
1.3 Findings
This section illustrates some key findings from variationist historical linguistics, focusing especially on six of the major so-called ‘external’ factors constraining and facilitating the implementation of change and its transmission: social status, social network, gender, age, style, and region. Although spontaneous innovations occur all the time, introduced by acts of speaking/writing on the part of individuals, many will not enter the language system at all. Some changes can be quite rapid while others take centuries. The chance of survival of an innovation depends partly on where/when it is introduced into the social and linguistic system and by whom. Innovations follow predictable paths through social and linguistic structures.
1.3.1 Social stratification and status hierarchies
Social class has occupied a central place in the synchronic study of language variation as a prime factor offering important insights into change. The reconstruction of how language change diffuses socially is one, if not the major, task of sociohistorical linguistics. Synchronic sociolinguistics shows that speakers belonging to the upwardly mobile upper working and lower-middle social classes are often quick to adopt innovations, and to shun stigmatized forms. In order for changes to spread from these innovators, other adopters need to pick them up. Historical study of a number of variables like multiple negation illustrated in (1) shows clear patterns of social stratification and confirms the critical role of the upper ranks. In order for a new form to be generalized and supralocalized, it had to be adopted by the upper strata. The change towards single negation was led by males from the upper social ranks, with the lower social strata and women lagging behind. During the first half of the sixteenth century the rate of multiple negation was above 80 per cent among men from the lower social ranks, but by the latter half of the eighteenth century, it declined to 11 per cent (Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg2003: 145–50). Despite condemnation by prescriptive grammars from the nineteenth century onwards and continuing correction by generations of teachers, multiple negation persists in many non-standard varieties, but typically there is sharp class stratification, with middle-class speakers rarely using it (Wolfram Reference Wolfram1969).
(1) I thinke ye weare never yet in no grownd of mine, and I never say no man naye. (CEEC, Henry Savile 1544, 247)
The use of code-switching in letters contained in the CEEC was also related to social rank and education; merchants switched predominantly between English and French, while members of the gentry, clergy, and professionals alternated mainly between English and Latin. Merchants like Otwell Johnson (2) found French useful as a business language in dealing with continental trading partners, while professionals like John Schillingford, Mayor of Exeter (3), used Latin in proverbial or formulaic expressions or for legal terms (examples from Nurmi and Pahta Reference Nurmi and Pahta2004: 438–9).
(2) for it is no wisedome to beware of evill by other men's hindrance.
Vous estes bon et sage. (CEEC, JOHNSON 1545, Otwell Johnson, 340–1)
(3) Y pray you specially to thanke moche t[…] gentill Germyn Quasi duceret euge euge Germyn of his governaunce attis tyme, id male gaude Germyn. (CEEC, SHILLINGFORD 1447, John Shillingford, 23)
Changes like the introduction of a T/V system (a term used to refer to variation between familiar and deferential pronouns similar to modern French tu/vous ‘you’) and its subsequent loss in the history of English provide important clues to social class hierarchies because kinship terms and address systems represent key sites for encoding interpersonal attitudes, and social relations among participants in speech events (see also Chapters 3 by Mazzon and 17 by Nevala in this volume). As the old number contrast between singular and plural pronouns came to be construed as a pragmatic opposition similar, but not identical, to the T/V systems of other European languages like French, the old oblique plural pronoun you gradually became the unmarked term of singular address, with thou and other T forms indicating various affective meanings, including (but not restricted to) intimacy and familiarity. During the thirteenth century you started to be used as a polite form of the singular, and competed with the historical singular thou, which developed senses like intimacy, if used reciprocally between equals, or contempt, if used non-reciprocally (e.g. between masters and servants), as suggested by grammarian Cooper (Reference Cooper1685: 121):
‘Pro thou, thee & ye dicimus you in communi sermone, nisi emphaticè, fastidiosè, vel blandè dicimus thou’.
[In ordinary speech we say you for thou, thee and ye, but emphatically, contemptuously or caressingly we say thou]
The exchange in (4) from c.1560 taken from the Hunstanworth records of the Durham ecclesiastical court concerning the theft of some sheep illustrates non-reciprocal pronoun use between Roger Donn, the accused, and his accusers, Mr Ratcliff and Mr Antony (Hope Reference Hope1993: 86). Ratcliff's final remark addressing Donn as thou not only indexes his own superior social status, but also expresses contempt at Donn's suggestion that he is an honest man, despite his lower social rank.
(4)
Mr Antony: “Dyd not thou promess me that thou wold tell me and the parson of Hunstonworth who sold George Whitfeld sheep?” Roger Donn: “I need not unless I woll” Mr Ratcliff: “Thou breaks promess” Roger Donn: “You will know yt soon enowgh, for your man, Nicoll Dixson, stole them, that ther stands, upon Thursday bifore Christenmas then last past” ‘Donn said that he [Ratcliff] shuld never be able to prove hym a theif…’ Roger Donn: “For although ye be a gent, and I a poore man, my honestye shalbe as good as yours” Mr Ratcliff: “What saith thou? liknes thou thy honestye to myn?” [Cited from Hope Reference Hope1993: 86; for a transcription faithful to the manuscript, see ETED]
The once singular pronoun forms gradually disappeared from most kinds of writing by the early eighteenth century, except in poetry, religious texts, or elsewhere as deliberate archaisms, especially in fossilized expressions such as prythee. By the middle of the eighteenth century, however, you was the only normal spoken form and thou was restricted to high-register (especially religious) discourse. Hence, Alfred Tennyson's use of the otherwise obsolete second-person singular pronouns thou/thee/thine/thy in both his nineteenth-century literary works and letters is an eccentricity rather than a survival of this older system. Nevertheless, as seen in (5), the T forms are still distinctly marked in affective tone, and are significantly gender marked as well in nineteenth-century letters. Tennyson used the full range of T pronouns with only four addressees, including his wife, his Aunt Elizabeth Russell, and two close friends, James Spedding and William Henry Brookfield. Tennyson's switch from the emphatic and distant second-person pronoun you to the intimate and familiar pronouns thee and prithee as well as his use of Brookfield's first name William Henry can be seen as a contextualization strategy signalling a change in interactive frame and tone between himself and his friend. At a time when T pronouns had long been obsolete in normal usage, Tennyson's switch to thee represents a discourse move towards a different and more familiar footing. Tennyson wanted to make it absolutely clear to Brookfield that he was asking far too much of their friendship (Romaine Reference Romaine2010). Indeed, in a subsequent letter to Brookfield he wrote, ‘I have a sort of instinctive hatred toward annuals each and all’ (14 June 1836, Volume I, 144, see Lang and Shannon (1981–90)).
(5) Now, how have you the conscience to ask me to annualize for Yorkshire. Have I not forsworn all annuals provincial or metropolitan. I have been so beGemmed and be-Amuletted and be-forget-me-not-ted that I have given all these things up…No. I would not do it for Tennant – no – not for Hallam. Yet peradventure for thee, William Henry, I might be brought to do it. But prithee ask me no more. (3 August 1831, Volume I, 63, see Lang and Shannon (Reference Lang and Shannon1981–90))
This letter to Brookfield in (5) also represents the only instance of dearest (a term not normally used between men) Tennyson addressed to someone outside the family circle. The other six letters from Tennyson to Brookfield in Lang and Shannon's (Reference Lang and Shannon1981–90) collection contained more conventional and less intimate forms of address, i.e. (my) dear Brookfield, my dear Brooks, my dear WB. Use of intensifying superlatives such as dearest in nineteenth-century epistolary formulae also emerged as markers of stylistic affect against the backdrop of increasing conventionalization of dear in letters contained in the Corpus of Nineteenth-Century English (CONCE). Since the seventeenth century dear has become the ordinary polite form for addressing an equal, but the kind of formula in which it was embedded varied according to the nature of the relationship between the writer and addressee in terms of parameters such as social position/distance, age, and sex. By comparison with correspondence from prior centuries, nineteenth-century personal letters have a distinctly different emotional tone. Even in family letters husbands usually addressed their wives with titles such as madam and your ladyship, and occasionally as dear wife. Wives used deferential address to their socially superior husbands. Although Elizabeth Barrett Browning addressed her friends Isabella Blagden and Anna Brownell Jameson as dear/dearest Isa/Mona Nina, she never progressed to the use of reciprocal first names with her lifelong friend, Mrs James Martin, whom she always addressed as My dear/dearest Mrs. Martin (Kytö and Romaine Reference Kytö, Romaine and Watson2008). Even if Browning's My dearest Mrs. Martin sounds somewhat distant and formal to modern English ears, it becomes extremely familiar and almost intimate compared with Margaret Paston's greeting to her husband John as Ryth reuerent and worsepful husbon, I recomawnde me to ȝow wyth alle myn sympyl herte (Margaret Paston, Letter 124, 1441?).
1.3.2 Social networks
Synchronic sociolinguistic research has provided models for understanding change based on the idea of social network, a concept emphasizing the nature of contacts rather than a person's status in a society. Because networks may cut across social class boundaries and reveal differences within social groups, they offer alternatives to class-based approaches. Speakers do not simply copy the most common variants around them, but are active discriminators who aspire to membership of particular social groups. Change proceeds in favour of some variants over others because some speakers are more influential as social models depending on their place in the social hierarchy. Speaker innovation spreads from one network to another through weak ties. The language of some of the Paston brothers, particularly John II (1442–79) and John III (1444–1504), changed considerably upon their coming to London, where they adopted new forms and spellings (Davis Reference Davis and Burrow1989: 60). In or around 1467 the younger John uses a large number of new features for the first time or with higher frequency, e.g. myght (formerly myt, mygth etc.), -owght (e.g. thowght instead of thowt), th-pronouns (e.g. them instead of hem). Nevertheless, the brothers moved in quite different social circles. John II travelled much more and belonged to several loose-knit networks situated all over Europe, including royal circles while John III was more territorially bound to the area in and around Norwich. Edmund II (1445?–1504) was another innovator in the family, using fourteen present indicative verb forms ending in -s (instead of -th), but only after 1471, after a two-year stay in London at Staple Inn, where he may have adopted this new originally northern variant (Davis Reference Davis and Burrow1989: 58). During Shakespeare's time, variation between -s and -th (e.g. makes vs. maketh) was marked stylistically, with the recessive form -th used more often in formal styles. The new form -s became the main one used around 1600.
Potential innovators and early adopters are not the only prerequisites to successful actuations; linguistic space is also needed, a medium through which innovations can spread. Epistolary networks may have been significant vectors for the rise and spread of linguistic innovations. John Gay may have been responsible for introducing the epistolary formula yours sincerely in letters to his closest friends, thus breaking with previous formulae such as your most humble servant (Tieken-Boon van Ostade Reference Tieken-Boon van Ostade, Tops, Devriendt and Geukens1999). Collections like the Paston letters spanning three generations are particularly important, both linguistically and sociologically, as one of the largest and earliest bodies of private correspondence from a family in that time period (Davis Reference Davis1971). Historians of language have long recognized the value of studying letters for the potential glimpse they may offer into more informal and colloquial language. Letters mirror social relations between sender and addressee to a very high degree, equalled perhaps only by spoken texts (Görlach Reference Görlach1999a: 149). Letters function in a sense like conversations between correspondents (Fitzmaurice Reference Fitzmaurice2002c; see also Tieken-Boon van Ostade Reference Tieken-Boon van Ostade, Dossena and van Ostade2008c, Sairio Reference Sairio2009). They can, for example, provide important evidence for what Labov (Reference Labov1966) calls ‘change from below’, i.e. below the level of conscious awareness associated with lower classes in the social hierarchy.
1.3.3 Gender
Contemporary urban sociolinguistic research has established the robust contribution of patterns of sex differentiation to language change. Numerous researchers have found, for example, that women, regardless of other social characteristics such as class, age, etc., tend to use more standard forms than men and play a leading role in phonological change. Labov (Reference Labov2001) claims that chain shifts are dominated by women, and that young women consistently increase or increment their use of a variable in each succeeding generation until it becomes the community norm. In the majority of changes examined women were a full generation ahead of men.
Sociohistorical research on English has revealed a mixed picture of women in the vanguard of some changes (e.g. replacement of both the subject form ye by you, and the third-person singular present tense ending -th by -s), but laggard with respect to others (e.g. the disappearance of multiple negation and zero-marked relative clauses). In the majority of fourteen cases studied by Nevalainen and Raumolin-Brunberg (Reference Nevalainen and Raumolin-Brunberg2003: 117–32) women led change. Romaine's (Reference Romaine1982) study of variation in the relative clause marker in sixteenth century Scots English found zero marking associated with women, the lower social orders, and speech-related genres like letters. In modern standard written English the primary system of relativization uses WH-pronouns (e.g. who/whose/whom) and prohibits omission of relatives in subject position (e.g. *the man [Ø lives next door] is a carpenter). The WH-strategy is a later development historically, superimposed possibly by contact with Latin or French, onto an older system in which relative clauses are marked by the subordinator that, which may be deleted variably.
Only in the women's correspondence were there instances where relative markers were absent in subject position. The association of women with non-standard vernacular variants does not contradict the typical synchronic sociolinguistic pattern linking women with prestige forms because at earlier times in the history of English (and even today in some societies today where literacy rates for women are lower than those for men) women were more isolated, regardless of their social status, from the norms of the written (standard) language. Relativization strategies are also gender-differentiated in the Paston family, with male members preferring WH-pronouns, while women prefer that (Bergs Reference Bergs2005).
1.3.4 Style
The intersection of social class and stylistic continua is one of the most important findings of quantitative sociolinguistics: a feature occurring more frequently in working-class speech will occur more frequently in informal styles. Although the notion of style is difficult to define (Traugott and Romaine Reference Romaine1985, Moessner Reference Moessner2001), at its simplest, variation between text types, registers, and genres can be considered as kinds of stylistic variation (see Chapter 16 by Taavitsainen in this volume). Much sociohistorical variationist research has focused on style, genre, and text type as a major parameter of change (see Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg2003: 192–3 for an overview of studies). Early occurrence of a variable in text types such as letters, journals, and diaries (generally thought to be a rich source of colloquialisms) and other speech-related genres like drama, trials, depositions, sermons, etc. suggest an origin in the spoken language. While informal styles and allegro speech draw on the latest innovations, more formal styles and higher registers are often more conservative. Items lagging behind in certain changes may remain in the speech of older informants as stylistic variants. One effect of contact between standard and non-standard varieties is the spread of obligatory rules downwards from more formal styles until they become more frequent in more casual styles. Conversely, innovations introduced in casual speech may spread to more formal styles.
Romaine's (Reference Romaine1982) study of relativization in Middle Scots texts showed that choice of relativization strategy was stylistically diagnostic and that stylistic stratification was an important factor in maintaining stable variability over centuries. The WH-relativization strategy entered Middle Scots in the most syntactically complex styles (as represented by official and legal prose) and least frequently relativized syntactic positions, until it eventually spread throughout the system by working its way down a stylistic continuum containing different types of prose and verse texts ranging from the more fully Scottish styles to the most fully anglicized ones. The fact that the WH-relativization strategy seems to have ‘sneaked in the back door’ of the language via the most complex and formal styles and least frequently relativized syntactic positions of the case hierarchy is a hallmark of change from above. WH-forms occur more frequently in more formal styles, whether written or spoken, while that and zero (absence of a relative marker) occur in the less formal styles of speaking and writing.
While Romaine's investigation revealed a picture of syntactic diffusion governed by stylistic and syntactic constraints, or ‘stylistic diffusion in apparent time’, other changes emanate from the opposite end of the continuum of text types. The replacement of subject ye by you, for instance, appears to have originated in the spoken language and was completed in about eighty years, at least based on the evidence from personal letters. The change followed a typical S-curve pattern, beginning slowly with the incoming variant you occurring in fewer than 10 per cent of cases in the late fifteenth century, but then progressing rapidly in mid-course for the first eighty years of the next century as the incidence of you rises steeply, and then slowing down again in the final stages (Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg2003: 60). The replacement of the third-person singular suffix -th by -s also seems to have its origins in speech because it appeared earlier in plays, private letters, and trial transcripts than in more literate genres. Devitt's (Reference Devitt1989a) study of colonial American texts from 1640 to 1810 revealed stylistic stratification, with each of five genres adopting the -s ending at different rates. Private records and correspondence are more advanced, while religious treatises and public records are slower to implement the change.
Devitt's (Reference Devitt1989b) study of the replacement of the native Scots <quh> forms (reflexes of Old English <hw>) of the relative markers and interrogative pronouns (i.e. quhilk, quha, etc.) by the southern spelling variants beginning with <wh> (e.g. which, who) showed that the Anglicization process occurred in top-down fashion over the course of the sixteenth and seventeenth centuries. While official correspondence and religious treatises adopted the English spellings early, private letters were among the last texts to abandon the local norms. The shift towards southern norms can be seen as part of a larger trend during the sixteenth century for regional spelling variants to give way to a broader standard system (see also Meurman-Solin 1993b). Sociohistorical studies of individual authors, scribes, social groups, and genres reveal that social rank, gender, age, education all influence orthographic practices. Higher levels of education typically go hand in hand with higher social rank and greater exposure to the spelling traditions of written texts and manuscripts. The spelling of the less well educated typically displayed more variability (Salmon Reference Salmon and Lass1999).
1.3.5 Age grading and change in real vs. apparent time
Although many scholars have assumed that language change is essentially a change of grammars between generations, it is clear that adults do change their use of certain variables over their lifespan. Margaret Paston changed her usage of personal pronouns dramatically over the course of her correspondence, but with respect to relativizers, she was one of the most remarkable and homogeneous users, showing clear preferences for traditional forms and conservative language use (Bergs Reference Bergs2005: 113, 248). While ‘no actor is always and in every respect an innovator, early adopter, maintainer’ (Bergs Reference Bergs2005: 255), age grading (i.e. gradient age distributions) of a variable provide important clues of change in progress. An increase or decrease in the occurrence of a variant in apparent time may indicate expansion or recession of a change in real time. As successive generations of speakers increment their use of a new variant in the same direction over time, younger speakers are typically in the vanguard of change. Examining the shift from the third-person singular -th to -s that occurred c.1600, Nevalainen and Raumolin-Brunberg (Reference Nevalainen and Raumolin-Brunberg2003: 88) found that only the oldest CEEC letter writers born before 1550 had -th as their major variant for the third-person singular present verb form, while all others preferred -s. In the mid-sixteenth century -th was the dominant suffix among the upper ranks, professionals (like lawyers and government officials), and merchants, while -s occurred only among lower social ranks. Around 1600 -s rose rapidly among the upper ranks. Furthermore, a study by Raumolin-Brunberg (Reference Raumolin-Brunberg, Nurmi, Nevala and Palander-Collin2009) based on CEEC data shows that individuals could change their usage over time.
Researchers can now carry out repeat studies of previous investigations to see if prior patterns of age grading have in fact become changes in real time. If the original age distribution is replicated in a subsequent study, then we are likely dealing with stable age grading. By contrast, however, if the younger generation displays increased use of an incoming variant observed in the earlier study, then we are witnessing change in real time. By revisiting Norwich, Trudgill (Reference Trudgill1988) identified continuing change for four variables originally studied in 1974 (Trudgill Reference Trudgill1974), finding two new changes scarcely visible in the earlier data. Possible change in progress may also be aborted or reversed and variants of a variable may also take on different social meanings over time. Yesterday's polite form may become today's vulgarism and vice versa. For the Edwardians, for instance, toilet was a very smart word, because it came from French which was regarded as a prestige language. It went out of fashion, however, when their servants adopted it, to become a marker of non-upper-class speech as polite usage shifted to lavatory. Despite the fact that some of the linguistic forms marking the divide between the upper and middle classes have changed, the boundary persists. The OED's examples show that piss (also of French origin) was in ordinary usage until the nineteenth century, when the lack of examples from ‘polite’ literature suggests it became more restricted. H-dropping may also once have been a marker of cultured speech (Milroy Reference Milroy and Blake1992b: 203).
1.3.6 Region
Regional dialectologists recognized the role of cities as centres of population density and cultural innovations in diffusing linguistic change. The force of the city of London as a setter of national standards was already apparent from the late tenth century when its system of measurement was adopted throughout the realm (Keene Reference Keene and Wright2000). Hosting migrations from the east and central Midlands in the fourteenth century, the city was central to language change in Tudor and Stuart England, leading most of the changes studied by Nevalainen and Raumolin-Brunberg (Reference Nevalainen and Raumolin-Brunberg2003). The diffusion of the verbal suffix -s and single negation were led by the capital. The fact that you was the favoured form in the capital region as well as the preferred female variant no doubt accelerated its spread (Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg2003: 194). East Anglia and the North lagged behind until the latter half of the sixteenth century. The older distinction between ye and you remained in some regional dialects in the nineteenth century. Changes typically hop from one city to another before diffusing into rural hinterlands. While the city of Norwich is located in the generally h-retaining area of East Anglia, it has been h-less for at least the last one hundred years as h-dropping spread from London directly to Norwich, without affecting the thinly populated area between the two cities (Trudgill Reference Trudgill1983: 77).
1.4 Future directions
All change depends on variation. Much of the variation in language previously thought to be random is indeed systematic. This chapter has shown how understanding of the social and linguistic dimensions of variability provides a richer account of the history of English at the same time as it illuminates trajectories of language change. Although language change may involve multiple mechanisms and some changes may proceed with no apparent social weighting, the social evaluation of variants often plays a role in determining the fate of a change in progress as speakers make choices between rival forms based on their perceived associations with the groups using them (e.g. social class, age, gender, etc.) or the contexts (e.g. style, text types, etc.) in which they occur.
Nevertheless, the issues of status and methodology initially raised by Romaine (Reference Romaine1982) are still paramount. That is, our findings will only be as robust as our methods and the reliability of our data. The level of confidence in the results of any quantitative study depends heavily on the issues of representativeness and frequency. It is still an open question whether cases of seemingly free variation are instead the result of inadequate research methods, lack of sufficient data for analysis or some other factors. We cannot jump to the conclusion that non-occurrence of a feature in a corpus indicates its ungrammaticality. The explanation for its absence may lie in non-grammatical, contextual factors or even be due to chance (Butters Reference Butters2001). Variation is usually conditioned by multiple causes, which means that researchers need to identify multiple factors and assess the relative contribution of each. There is still much to learn about the intersection of grammatical and phonological variation and the nature of the constraints on variable systems over time. The emerging field of ‘cognitive sociolinguistics’ relying on a convergence of method and theoretical frameworks to study cognitive and social constraints on linguistic variation is beginning to make significant contributions to our understanding of changes like the replacement of -th by -s in the third-person singular present tense. Using a mixed-effects statistical model incorporating a large number of sociolinguistic, psycholinguistic, and phonological independent variables and their interaction with time, Gries and Hilpert (Reference Gries and Hilpert2010) found that a significant change occurred in the sixteenth century when writers corresponding with someone of the opposite sex were more likely to use the new suffix. Prior to that time, the old suffix prevailed regardless of who a writer wrote to.
Historians of English are fortunate because English has left a more fully documented written history than many other languages, and English is at the forefront of corpus development and tools for analysis. Theoretical linguists have relied heavily on English as the language of theorizing and exemplification, and given the predominance of English as a world language, it appears likely that data from English will continue to make substantial contributions to theories of variation and change. Much is to be gained by mining this rich source of data, which has become increasingly amenable to rigorous empirical investigation in the form of electronic texts easily searchable using a variety of analytical tools (see Chapter 2 by Hilpert and Gries and Chapter 8 by López-Couso in this volume). Tools have to be adapted to the material available at particular periods. Most conventional synchronic and diachronic multi- and single-genre corpora are still far too small for studying syntactic variables. In cases where an item or construction is rare or belongs to a genre or time period not represented in corpora, scholars wishing to push our knowledge of language change beyond the boundaries of the material currently available in corpora will need to rely on a set of best practices to optimize use of various kinds of electronic resources often developed for non-linguistic uses. Using the internet to collect data and the availability of web-based corpora and databases also pose new challenges. In 2004 Google began scanning millions of books as part of an ambitious project to make every page of every book ever published available and searchable on the internet. Now comprising more than two trillion words from fifteen million books published between 1473 and 2000 (c.11 per cent of all the books ever published) scanned from sources in over forty university libraries, Google Books is the largest megacorpus and a potentially rich resource for linguists (Michel et al. Reference Michel, Shen, Kui, Aviva, Veres, Gray, Pickett, Hoiberg, Clancy, Norvig, Orwant, Pinker, Nowak and Lieberman Aiden2011), especially for comparing change and variation in the two major varieties of English, British and American (Romaine Reference Romaine2013). Combining increasingly sophisticated statistical models and interfaces for manipulating large data sources, future prospects for the variationist approach are very bright indeed.
2.1 Introduction
English historical linguistics has a rich and long-standing tradition of corpus-based work (see the surveys in Rissanen Reference Rissanen, Lüdeling and Kytö2008, Kytö Reference Kytö, Bergs and Brinton2012). Resources such as the Helsinki Corpus, the Brown family of corpora and ARCHER have spawned active research programmes for the study of lexical and grammatical change, both long term (Curzan Reference Curzan, Lüdeling and Kytö2009) and short term (Mair Reference Mair, Lüdeling and Kytö2009). In addition, corpus resources inform the analysis of diachronic variation in genres (Hundt and Mair Reference Hundt and Mair1999), registers (Biber and Gray Reference Biber, Gray, Bhatia, Hernández and Pérez-Paredes2011b), and varieties (Tagliamonte Reference Tagliamonte, van Kemenade and Los2006b). The present chapter will discuss a currently developing line of research which uses the methods of quantitative corpus linguistics for the analysis of diachronic corpora. This research program draws on, and is informed by, the aforementioned areas, but at the same time, it uses particular kinds of data and handles that data in specific ways that merit discussion. Diachronic corpora are understood here as textual resources that represent comparable types of language use over sequential periods of time, thus comprising at least two periods, as in the Diachronic Corpus of Present-Day Spoken English (DCPSE, Wallis et al. 2006), but typically many more, as in the Corpus of Historical American English (COHA, Davies Reference Davies2010), a monitor corpus which at the time of writing samples twenty-one sequential decades of language use (see Chapter 8 by López-Couso in this volume). The English diachronic corpora that are currently available represent different varieties and text types and vary in their respective time depths, but it is a design feature of most diachronic corpora to hold the type of text constant, so that diachronic language change within a given text type may be studied with as few confounding factors as possible. Quantitative corpus linguistics (Biber and Jones Reference Biber and Conrad2009) is a research tradition in which research questions are formulated in such a way that frequency counts from corpora may provide answers. Quantitative corpus work thus often engages in hypothesis testing, so that a testable empirical question (e.g. ‘Have adolescent women been leading the development of the quotative be like in Tyneside English?’) may receive an answer in terms of either ‘yes’ or ‘no’. Of at least equal importance are so-called exploratory techniques, which are designed to transform a complex dataset into a summary (and often visual) representation (which may then be interpreted by the analyst and that may in turn lead to the formulation of hypotheses). To give an example, Szmrecsanyi (Reference Szmrecsanyi, Geeraerts, Kristiansen and Peirsman2010) studies the use of genitive constructions in different text types of British and American English in the 1960s and the 1990s, exploring whether there are changes that could be seen as Americanization or colloquialization (see Mair Reference Mair2006). The frequency counts that enter quantitative corpus studies often represent token frequencies, but a much wider variety of measures is routinely used, including measures of type frequency, dispersion, and collocation.
The main point of this chapter will be an overview of how the two, diachronic corpora and quantitative corpus linguistics, are put together in fruitful ways. Quantitative studies of how units of linguistic structure change across corpus periods can address questions of more general linguistic interest, including the following:
When and how does a given change happen?
Can a process of change be broken down into separate phases?
Do formal and functional characteristics of a linguistic form change in lock-step or independently from one another?
What are the factors that drive a change, what is their relative importance, and how do they change over time?
How do cases of language variation in the past compare to variation in the present?
It is already apparent from these questions that quantitative studies of historical change have a great deal in common with quantitative studies of synchronic variation (Tagliamonte Reference Tagliamonte2006a), both on the theoretical and the methodological level. This commonality is of course no coincidence, as language variation is one key factor for explaining why languages change over time. The remainder of this chapter is organized in the following way. Section 2.2 motivates the approach that is taken here and explains how quantitative methods usefully complement qualitative approaches in the analysis of diachronic corpus data. Section 2.3 is concerned with approaches to the diachrony of variation in language, and it discusses desiderata of such approaches. Section 2.4 turns to exploratory techniques, which can guide the researcher towards discovering new, unanticipated aspects of language change or assist in the formulation of hypotheses. Section 2.5 offers a few pointers for future research and section 2.6 concludes.
2.2 Language change by the numbers
Historical linguistics, by its very nature, depends on the observation of authentic data. However, not all research questions in historical linguistics oblige the analyst to quantify that data. Many processes of linguistic change manifest themselves in qualitative differences, so that for instance lexical items disappear from usage, or word order patterns that once were common are no longer used. (Of course, such differences can be quantified as observed frequencies becoming zero.) For instance, the Old English (OE) word order shown in (1), an example from Ælfric's Homilies of the Anglo-Saxon Church (ÆC Hom I, 1.20.1), is no longer used in Present-day English (PDE).
(1)
on twam þingum hæfde God þæs mannes sawle gegodod in two things had God the man's soul endowed ‘God had endowed man's soul with two things’
The crucial characteristic of the example is the fact that the finite verb hæfde ‘had’ appears after an initial constituent in what is called the ‘verb-second’ position (Fischer et al. Reference Fischer, Bermúdez-Otero, Denison, Hogg and McCully2000). A gloss such as With two things had God man's soul endowed, which retains this particular word order, might be acceptable as a deliberate anachronism, but it will not pass as an everyday PDE sentence. Hence in this case, a single historical example, in connection with the intuitions of a present-day speaker, is enough to establish that a change has taken place.
However, more rigorous quantification of diachronic data becomes necessary when research questions go beyond the mere detection of a change and into the internal dynamics of that change. This means that, often, approaches are required that meet the following criteria:
They are multifactorial in that they take multiple formal, functional and language-external/social features into consideration as potential causes for linguistic choices.
They involve interactions between the formal, functional, and language-external/social predictors so that one can determine whether a particular predictor has the same effect regardless of other predictors’ values. While most studies simply adopt the assumption that the effects of different predictors hold independently from one another, this need not be the case, and one can only identify such cases when tests for interactions are included.
They involve interactions of, say, Time (or Corpus) on the one hand and formal, functional and language-external/social predictors on the other hand so that one can determine whether a predictor has the same effect in each time period or whether the role a particular feature plays for speakers’ choices changes over time. Without such interactions, it is nearly impossible to make principled comparisons between different time periods.
Some studies already involve these more sophisticated approaches, usually in the form of multifactorial regression analyses. Such regression analyses try to predict the outcome of a dependent variable (or response) on the basis of one or more independent variable(s) (or predictors). Crucially, both the response and the predictors can be of different kinds, i.e., they can be binary (ditransitive vs. prepositional dative), categorical and/or ordinal (human vs. animate vs. inanimate vs. abstract), or numeric (time or length of a word in phonemes); depending on the nature of the dependent variable, one would use binary logistic regression, multinomial or ordinal logistic regression, or linear regression. Also, a central advantage of these regression models is that they allow the researcher to study the effects of several predictors (and their interactions) at the same time (Baayen Reference Baayen2008: chs. 6–7; Gries Reference Gries2013: ch. 5) so that researchers can determine which predictors affect linguistic choices significantly, in which direction (does a particular predictor make a choice more or less likely), and how strongly. In spite of these many advantages of regression modelling, there are still many studies that do not involve the proper comparisons of observed frequencies of phenomenon P in different time periods (see Gries Reference Gries, Allan and Robinson2012 for discussion of an example).
Returning to our verb-second example from above, this means that if we want to find out how verb-second word order gave way to the patterns that are in use today, neither looking at individual examples nor mere tabulated frequencies of verb-second and other orders are sufficient. Rather, we need to identify the contexts in which verb-second disappeared first, and we would need to identify the formal, functional and language-external/social features that characterize these contexts. On an abstract level, the answers that one is usually looking for derive from all three above criteria: one wants to be able to indicate that ‘during time period X, context feature Y biased speakers towards the new, incoming word order pattern with a relative strength of Z’ (Hilpert Reference Hilpert2013: 50). By analysing the impact of a range of context features over a range of time periods, we thus arrive at a differentiated picture of how the change in question proceeded. Most importantly, we learn which contextual features play an important role and which ones do not, and we can find out whether the effects of these features change in strength over time. We might also find that two contextual features interact in such a way that, for instance, they only have an effect if they co-occur, but not if they occur in isolation. Observations of these kinds are difficult, if not impossible, to make on the basis of individual examples; quantitative corpus analysis thus works like a magnifying glass, allowing the researcher to detect phenomena that would not otherwise be open to inspection.
It is important to realize that this higher level of observational detail is no end in itself: having precise information about how a given change happened is a necessary prerequisite for discussions of why the change happened in the way it did. Are we looking at a change that can be connected to social developments (Americanization, colloquialization), do the data support the idea of culture-bound, genre-specific developments (complexification, simplification), or can the change receive a structurally motivated explanation (generalization, analogical levelling)? Claims that link observations of change to these potentially competing motivations of change must be based on analyses in which alternative explanations are considered with due diligence. It is here that quantitative techniques have a decisive advantage over qualitative assessments of change: a quantitative analysis can simultaneously weigh the relative impacts of several factors, thus separating the wheat from the chaff. The analysis may for instance demonstrate that a given factor only has a very small effect, or even no effect at all, so that explanations related to that factor can be ruled out – at least for the sample that is being analysed and the population for which it is representative. Demonstrating this on the basis of qualitative data, in a way that will convince a sceptical reader, is a very difficult task. While it goes without saying that any quantitative study is of course grounded in a fundament of qualitative insights, it should equally go without saying that the analysis of language change by the numbers is an indispensable tool for extending those insights. The next two sections flesh out this statement with a number of concrete examples.
2.3 Quantitative analyses of diachronic variation in language
How does language variation in PDE compare to variation in earlier periods of English? In a study that addresses this question, Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013) use the ARCHER corpus to investigate how variation in genitive and dative constructions has changed during Late Modern English. What these constructions have in common is that they are organized in paradigmatically related pairs, so-called alternations. The member constructions of an alternation are available as alternative ways of verbalizing the same, or at least fairly similar, conceptual content. Examples of the genitive alternation and the dative alternation are shown in (2).
(2a)
the prince's horse the horse of the prince
(2b)
I wrote him an email I wrote an email to him
Synchronic analyses of both the genitive alternation (Hinrichs and Szmrecsanyi Reference Hinrichs and Szmrecsanyi2007) and the dative alternation (Bresnan et al. Reference Bresnan, Featherston and Sternefeld2007) have identified several factors that probabilistically affect speakers’ choices between the respective alternative constructions. Those factors include semantic characteristics such as animacy, pragmatic characteristics such as the topicality/givenness of referents, and formal characteristics such as definiteness, pronominality, or length of (the referents of) possessors/possessees and recipients/patients. To illustrate the workings of just one factor with regard to the genitive alternation, the s-genitive construction is relatively less tolerant towards inanimate possessors than the of-genitive construction (?the water's temperature vs. the temperature of the water). In the dative alternation, the prepositional dative construction is relatively more tolerant towards syntactically heavy constituents in the recipient slot (?I wrote my sister, who lives in Spain, an email vs. I wrote an email to my sister, who lives in Spain). Experimental studies show that PDE speakers have internalized the complex ecologies of the determining factors in these alternations (Bresnan Reference Bresnan, Featherston and Sternefeld2007), but it stands to reason that, historically, there must have been developments leading up to the status quo. The exemplary study of Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013) is a case where researchers aim to determine how these developments unfolded.
For each of the two alternations, Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013) determine a variable context and retrieve all relevant examples from the ARCHER corpus. Each example is annotated in terms of a dependent variable, which marks the respective constructional choice, and in terms of several independent/explanatory variables, or predictors, such as animacy, topicality/givenness, definiteness, and crucially also the historical time period during which the example was produced. Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013) then perform binary logistic regression analyses in order to obtain results that can be compared against earlier studies that analysed synchronic data, and that also indicate whether the impact of those factors has become weaker or stronger over time. Overall, the results that Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013) obtain reaffirm findings based on synchronic data. The factors that are analysed show effects in the expected directions, which allows the conclusion that there has been substantial diachronic stability in the use of both genitive and dative constructions.
However, there have also been changes. For the genitive alternation, Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013) find a diachronic change in the effect of the length of the possessed entity. Generally and following from a general short-before-long tendency in English, a longer possessed entity favours the s-genitive (John's sixteen-year-old stationwagon), but Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013) note that the relation is non-linear when it comes to short possessed entities, especially in their early corpus data. Very short possessed entities are thus not necessarily strongly drawn towards the of-genitive. Over time, that non-linear relation becomes more linear: in the words of Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013), length is ‘more well-behaved’ in later corpus periods. A second change involves the semantic factor of animacy. Whereas s-genitives in eighteenth- and nineteenth-century English rarely occurred with collective, locative, or temporal possessors (e.g., the Academy's decision, the island's inhabitants, today's technology), the frequencies of these options sharply increase in the twentieth century, pointing to a process of semantic generalization. As for the diachronic development of the dative alternation, animacy is also shown to play a role. Inanimate recipients, as in The herbs gave the soup a nice flavour, have become more frequent in the ditransitive construction in the twentieth century.
These findings demonstrate that the probabilistic usage patterns of constructions undergo fine-grained changes that could not be detected through the comparison of individual examples, but that do lend themselves to meaningful interpretations in terms of general processes of language change.
In another study that targets change in variation, Buchstaller (Reference Buchstaller2011) investigates quotation markers in Tyneside speech on the basis of a tripartite corpus that consists of sociolinguistic interviews collected in the 1960s, the 1990s, and the late 2000s. Whereas the variation of genitive or dative constructions involves only two alternative expressions, so that the dependent variable has only two levels, matters are a little more complex in the case of quotation markers. Here, speakers can draw on a set of several forms, and the recent addition of innovative variants such as go or be like suggests that the system of quotative markers is currently undergoing a substantial reorganization. Examples of some of the variants in Buchstaller's data (Reference Buchstaller2011: 59) are given in (3).
(3a) I never say ‘howay man’
(3b) I shouted back ‘well if you stop kicking the door…’
(3c) I just went up to him and Ø ‘excuse me mister…’
(3d) She was like ‘eeh! It's a rodent!’
(3e) She goes ‘I might not wear them’
(3f) I'm all, ‘Dude, you're not helping your cause!’
Buchstaller (Reference Buchstaller2011) sets out to investigate diachronic changes in the extralinguistic and intralinguistic factors that influence speakers’ choices in that system of variants. Again, research on synchronic variation (Buchstaller and D'Arcy Reference Buchstaller2009) has identified several determining factors, such as the content of the quote, i.e. whether a thought, utterance, or noise is quoted, the grammatical tense that frames the quotation marker, the grammatical person of the quoted speaker, the distinction between narrative and other texts, and social variables such as age, social class and gender. Buchstaller (Reference Buchstaller2011) exhaustively retrieves examples of quotation from her corpus. The results identify say as the most frequent variant throughout, which however decreases over time in relative frequency with the emergence of go and be like. But how are these frequency developments reflected in a changing ecology of determining factors? In order to approach this issue, Buchstaller (Reference Buchstaller2011) first examines each factor on its own.
As for the extralinguistic factors, the quotative system in the 1960s is differentiated by gender, but not by age or social class. This subsequently changes: with go becoming more frequent in the 1990s, and be like even surpassing it in frequency in the 2000s, age and class, in addition to gender, become relevant determinants. Young women are the speakers that adopt be like to the greatest extent. As for the intralinguistic factors of quotation content, grammatical person, and grammatical tense, these exert an influence throughout the three corpus periods, but patterns of change emerge here, too. For instance, whereas say is the preferred marker of first-person quotations in the 1960s, it has ceded that role to be like in the 2000s, during which say and go show an inclination towards third-person quotations.
With a complex dataset that reflects several factors influencing speakers’ choices between several forms, the analyst has to rely on multivariate statistics to arrive at reliable generalizations. Buchstaller (Reference Buchstaller2011) performs a multinomial regression analysis (Gries Reference Gries2013: ch. 5) of the complete dataset, which reveals that the effects of age, social class, grammatical tense, and narrative are measurably different across the three subcorpora. In other words, the emergence of new variants in the quotative system of Tyneside English goes along with a reorganization of the selection processes that speakers of different age groups and different social classes make. Unlike the system of genitive and dative constructions, which undergoes just minor rearrangements, the results show that the system of English quotation markers is currently in a state of upheaval that might either stabilize or see further change through the repeated intrusion of new variants. Buchstaller's quantitative analysis (Reference Buchstaller2011) pinpoints the exact loci of change and indicates what factors change at what time. It thus gives an affirming answer to the question whether young women have been spearheading the emergence of quotative be like, but at the same time, the results offer a picture that is much more differentiated than that.
It was mentioned in the introduction of this chapter that quantitative corpus-based methods are commonly applied in order to test hypotheses. Whereas the two case studies that were described above address fairly specific research questions, their primary aim was not to decide between two rivalling hypotheses. A study that checks the validity of a pre-existing hypothesis is presented by Geeraerts et al. (Reference Geeraerts, Gevaert, Speelman, Allan and Robinson2012), who investigate the emergence of anger as a term that ousted its near-synonyms ire and wrath during Middle English. Diller (Reference Diller, Fernández, Fuster Márquez and Calvo1994) suggests a socially motivated explanation for this development, hypothesizing that anger emerged as an expression for annoyance in lower-ranked persons, as opposed to the ire and wrath of socially powerful beings such as kings or deities. From this hypothesis, Geeraerts et al. (Reference Geeraerts, Gevaert, Speelman, Allan and Robinson2012) derive the predictions that anger should be used to describe situations in which the social status of the experiencer is low, the offense affects only the experiencer, rather than having more profound consequences, and the experiencer's reaction to the offense is non-violent. Geeraerts et al. (Reference Geeraerts, Gevaert, Speelman, Allan and Robinson2012) retrieve all tokens of ire, wrath, and anger from a collection of Middle English text and annotate those in terms of the semantic factors outlined above, as well as distinguishing between tokens from religious and non-religious text and between translated and natively produced texts. The analysis further includes historical time as a variable, distinguishing examples from approximately 1300, 1400, and 1500. Analyses of each individual semantic variable across those three time periods reveal processes of change for the social status of the experiencer and the affectedness of the experiencer, but not for the violence or non-violence of the reaction to the offense. Geeraerts et al. (Reference Geeraerts, Gevaert, Speelman, Allan and Robinson2012) then use a binary logistic regression (Gries Reference Gries2013: ch. 5) to assess the combined effects of the described factors, the dependent variable is modelled as a contrast between anger and the combined tokens of ire and wrath. The results are largely in line with Diller's hypothesis (Reference Diller, Fernández, Fuster Márquez and Calvo1994). The use of anger at 1400 is favoured by contexts of personal offences with non-violent reactions, a marginally significant effect is observed for low social ranks of the experiencer. The effect of non-violent reactions is stronger in non-religious texts than in religious texts. The data further show that over time, as anger becomes the default term for the emotion it denotes, these effects weaken. Examples from around 1500 thus have a relatively higher likelihood than earlier ones to denote public offences of high-ranking experiencers that react violently to those offenses.
In summary, the case studies presented in this section illustrate three issues. First, the variationist approach to analysing the use of alternative expressions with similar functions is fruitfully transferred to the usually regression-based analysis of variation over historical time. With a diachronic corpus that represents sequential periods of English, time can be included into the analysis as one (interacting) predictor among others, and it can be determined how variation in the present compares to variation in the past. Second, this type of analysis offers nuanced accounts of what has happened, so that it can be specified what factors had an effect at what time. The contrast between the studies by Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013) and Buchstaller (Reference Buchstaller2011) shows that the dynamics of diachronic variation may range from relative stability to substantial reorganization, which requires a fine level of observational granularity: an analysis has to do more than just ask whether or not a particular factor has an effect – it has to ask when this effect obtained and how it varied in strength over time. Third, the observations that these studies offer importantly include the absence of effects, which is evidence that can in principle serve to rule out hypotheses that predict those effects. An aspect that has not received much attention in the discussion above is that the findings from quantitative studies usefully feed back into the development of linguistic theories, either enriching already existing theoretical claims or generating altogether new hypotheses. The idea of using quantitative corpus-based methods to generate new ideas is taken up more extensively in the following section.
2.4 Quantitative analyses of diachronic change: exploratory approaches
An attractive potential of quantitative corpus-based methods that has yet to be fully realized in diachronic studies lies in exploratory, bottom-up approaches (Gries Reference Gries, Allan and Robinson2012). The label ‘bottom-up’ stands for a set of techniques in which the data are processed statistically in order to discover structures that had not necessarily been anticipated by the analyst. Compared to the approaches that were presented in the previous section, these methods often reverse the order of qualitative and quantitative analysis. Whereas for instance a logistic regression analysis requires a fundament of qualitative analysis which is subsequently scrutinized statistically, bottom-up approaches may start with the statistical processing of raw data, which then yields results that function as a stepping stone for a qualitative analysis. Starting with automated computational procedures has the benefit of a ‘fresh start’ that may serve to eliminate preconceptions and to reveal previously overlooked aspects of a given phenomenon.
One example for such an approach is Sagi et al. (Reference Sagi, Kaufmann, Clark, Allan and Robinson2012), who apply a bottom-up computational approach to the study of lexical semantic change. Whereas word meaning is usually thought of as an area of study in which the intuitions of a human analyst are completely indispensable, research in natural language processing has developed a range of methods that operationalize the meaning of a given word in terms of the elements and structures that occur in the linguistic context of that word. J. R. Firth's dictum that ‘You shall know a word by the company it keeps’ (Reference Firth1957: 11) has thus found its way into methods such as latent semantic analysis (Landauer et al. Reference Landauer, Foltz and Laham1998), which produce results that stand up to comparisons with human processing of word meaning. Latent semantic analysis uses corpus data to characterize word types in terms of frequency lists of their collocates. For instance, the noun toast frequently occurs close to nouns such as tea, cheese, slice, and coffee. A statistically processed frequency list of all collocates of toast is called its semantic vector. Semantic analysis enters the picture when semantic vectors of several words are compared. Two words are in a semantic relation if their semantic vectors are highly similar. For instance, near-synonyms such as cup and mug will have similar semantic vectors, but also converses such as doctor and patient and even antonyms such as hot and cold. If a large group of semantic vectors is analysed with a dimension-reducing technique such as multidimensional scaling (Wheeler Reference Wheeler, Köhler, Altmann and Piotrowski2005) or correspondence analysis (Greenacre Reference Greenacre2007), semantic relations between those words can be visualized in two-/three-dimensional graphs in which words with close semantic ties are positioned in close proximity whereas semantically unrelated words are placed further apart.
Whereas most applications of latent semantic analysis analyse word types, thus averaging collocate frequencies over many occurrences of the same word, Sagi et al. (Reference Sagi, Kaufmann, Clark, Allan and Robinson2012) use an approach that operates at the level of word tokens, thus capturing meaning differences between individual occurrences of the same word. In order to overcome data sparsity, that method uses not only the direct collocates of the target word, but also second-order collocates, that is, the collocates of collocates. Given a concordance line such as he prescribed tea and toast and a small bit of steak, the second-order collocates would include the word doctor (a collocate of prescribed) and coffee (a collocate of tea). The latter will be relatively more important, since it is also a collocate of toast itself. Applied in this way, latent semantic analysis can transform a simple key word concordance of a word such as toast into a two-dimensional scatterplot that arranges data points representing concordance lines with similar sets of context words in close spatial proximity while placing data points that have markedly different collocates further apart. Semantic patterns such as homonymy are thus reflected in different clusters of data points, yielding one cloud for tokens that signify roasted bread and a separate one for tokens signifying that people raise a glass and drink to someone's health. In their study, Sagi et al. (Reference Sagi, Kaufmann, Clark, Allan and Robinson2012: 171) use this procedure to investigate semantic change in the words dog and deer. The general course of the semantic developments of these elements is well-known: Old English docga semantically broadened so that the word dog today refers to not just a breed of dog, but an entire species. Conversely, Old English deor used to mean ‘animal’, today's deer has thus undergone semantic narrowing. Sagi et al. (Reference Sagi, Kaufmann, Clark, Allan and Robinson2012) exhaustively retrieve examples of dog and deer from the Helsinki Corpus, construct semantic vectors for each concordance line, and visualize the results using multidimensional scaling. For the word dog (and its earlier spelling variants), the resulting visualization, a scatterplot of points in a two-dimensional coordinate system, reflects the process of semantic broadening. Data points from earlier corpus data occupy a smaller, more densely populated area of the scatterplot; that area grows across the subsequent corpus periods. These results align with what is generally known about the semantic development of dog and thus vouch for the general feasibility of the method. Beyond that, they allow a glimpse into the temporal dynamics of that development that would be hard to infer from the analysis of individual examples.
For the word deer, the results are less straightforward. Instead of a systematic shrinkage of the clouds of data points over time, Sagi et al. (Reference Sagi, Kaufmann, Clark, Allan and Robinson2012: 177) observe successive shifts that show relatively little overlap between the different corpus periods. They interpret this as suggestive evidence that deer has undergone changes that go beyond the well-documented process of narrowing. The quantitative investigation thus prompts a more in-depth, qualitative investigation of the shifts that have taken place. What the computational procedure offers is a fresh look at data that lays bare phenomena for investigation that would have been overlooked, or perhaps considered unimportant, otherwise. Visualization techniques of the kind Sagi et al. use in that connection (see also Szmrecsanyi Reference Szmrecsanyi, Geeraerts, Kristiansen and Peirsman2010, Hilpert Reference Hilpert2011) can be of considerable help for that purpose.
The rearrangement of data to facilitate qualitative analysis also lies at the heart of an exploratory analytical method that investigates shifts in the collocational behaviour of grammatical constructions (Hilpert Reference Hilpert2006, Reference Hilpert2008). This approach draws on the method of distinctive collexeme analysis (Gries and Stefanowitsch Reference Gries and Stefanowitsch2004), which is used to contrast the collocational profiles of two or more constructions that have an open slot that accommodates different lexical types. Gries and Stefanowitsch (Reference Gries and Stefanowitsch2004: 106) exemplify the procedure with the constructions of the dative alternation. The ditransitive construction and the prepositional dative construction share a substantial number of verb types, but those shared types are not equally likely to be used in either construction. By comparing the text frequencies of both constructions against the frequencies of the verbs in either construction, verbs that significantly deviate from their expected frequencies can be identified. For instance, the ditransitive construction is significantly attracted to the verbs give, tell, and show whereas the prepositional dative construction is typically used with bring, play, and take. These preferences are in line with the idea that the two constructions differ semantically in the distance between agent and recipient (with the ditransitive construction encoding closer proximity) and with the proposal that the ditransitive construction primarily expresses that ‘X causes Y to receive Z’ whereas the prepositional dative expresses that ‘X causes Z to move to Y’ (Goldberg Reference Goldberg1995: 75–6). The purpose of a collostructional analysis is the exploratory semantic study of grammatical constructions via their most strongly attracted collocates. Applied to diachrony, the method can be used to contrast collocate sets of the same construction across a number of historical corpus periods. What the method provides are lists of significantly attracted collocates for each of the corpus periods that are analysed. Differences across those lists can be interpreted as a reflex of semantic change. If a construction broadens semantically, it will occur with a larger, semantically more diverse set of collocates. If a construction retreats into a particular semantic niche, it will increasingly occur with collocates that are semantically related to that niche.
The first process characterizes the development of the English be going to construction between the eighteenth and the twentieth century (Hilpert Reference Hilpert2008: 120). Whereas early uses of be going to attract main verbs that involve animate, intentionally acting agents as their subjects, the data from later corpus periods show how the construction broadens semantically so that the attracted elements include highly general verbs such as be or verbs such as happen, which denote spontaneous events, rather than deliberate actions.
The English future construction with the modal auxiliary shall exhibits a very different developmental trajectory. Between the sixteenth and the twentieth century, shall continually decreases in text frequency and simultaneously undergoes a change towards increased usage as a text-structuring device in expressions such as I shall return to this issue in the conclusion or I shall discuss quantum theory in Chapter 5 (Hilpert Reference Hilpert2006: 252). What this suggests is that the change in question is not necessarily semantic, but rather stylistic in nature. Like the method that Sagi et al. (Reference Sagi, Kaufmann, Clark, Allan and Robinson2012) employ to visualize phenomena of change, distinctive collexeme analysis serves to draw the analyst's attention towards those aspects of a linguistic unit that have changed over time. The quantitative method merely picks out the elements for which there is a significant difference between expected and observed frequency. A necessary second step is a qualitative analysis involving a close examination of the concrete example sentences with those significantly attracted elements, and ultimately ideally an interpretation that relates the empirical findings to a more general account of how and why the construction changed.
Other bottom-up quantitative techniques to be discussed in this overview are tools for a specific problem of diachronic corpus linguistics, namely the division of data points from different historical dates into sequential periods. All of the case studies that have been discussed up to now relied on some contrast between earlier and later data, often with intermediate stages in between. Typically, diachronic corpus data are divided into temporal stages in a way that either captures well-established historical stages of a language or, if a more fine-grained temporal resolution is desired, in a way that uses intervals of thirty to forty years to capture changes between subsequent generations of language users. Gries and Hilpert (Reference Gries and Hilpert2008, Reference Hilpert, Nevalainen and Traugott2012b) make the case that this procedure is not without its problems. By creating equidistant time periods in a top-down kind of way, the analyst may combine corpus parts that actually behave very differently, thus creating misleading statistics/trends. Thus, one approach of Gries and Hilpert's is a data-driven approach to data periodization. The basic logic of such an approach is that (1) parts of the data that exhibit similar characteristics should form part of the same corpus period and (2) breaks between different periods should be inserted at points in time where there are measurable shifts in the characteristics of the data. Thus, periods need not be equidistant, allowing for the possibility that there are longer times of stasis that are interrupted by fits and starts of development (see Figure 2.2 for one example).
Their approach is implemented as a hierarchical clustering algorithm (Gries Reference Gries2013: ch. 5). Hierarchical clustering is, like the multivariate procedures discussed earlier, a procedure that takes as its input complex datasets in which each observation (e.g., a concordance line of a particular expression in its context) is characterized in terms of a range of different variables. A common purpose of clustering approaches is to then categorize a set of n observations into m<n different, hierarchically ordered groups. For this purpose, the procedure compares observations, assesses their mutual similarities, and iteratively merges those two points of a set that exhibit the greatest mutual similarity. Of course, diachronic data require a small twist of that procedure. In a diachronic dataset, it is fully possible for two data points to be fairly similar despite the fact that they represent very distant historical periods. Gries and Hilpert's clustering algorithm can therefore only merge two data points if those data points are temporally directly adjacent, which motivates the algorithm's label variability-based neighbour clustering (VNC).
To illustrate the procedure and its advantages, Gries and Hilpert apply the algorithm to the data that informs Hilpert's analysis of shall that was discussed above. The data in question consist of collexeme strengths of the lexical verbs that occur with shall in corpus data from the sixteenth to the twentieth century, which combines parts of the Penn Parsed Corpora and the CLMET into a database of nearly twelve million words. The corpora from which the data is taken consist of six seventy-year periods which have been combined into pairs to yield three equidistant periods of 140 years in Hilpert's analysis. A question that VNC can answer is whether this particular periodization makes sense, or whether it would be more sensible to create different period boundaries. The raw input data for the VNC algorithm consists of six lists that contain the verbs occurring with shall, which add up to 1,201 types, and their respective collexeme strengths. Using a correlation statistic such as Pearson's r (Gries Reference Gries2013: sections 3.2.3 and 4.4), degrees of mutual similarity between temporally adjacent pairs can be computed. On its first iteration, the VNC algorithm finds the two lists that exhibit the greatest mutual similarity and merges the two, so that a set of only five lists remains to be analysed. The algorithm continues and finds the next pair, reiterating until all lists are merged. The result of that procedure can be visualized as a tree structure that captures mutual similarities across the six initial lists. Figure 2.1 shows the result.

Figure 2.1 VNC-based periodization of shall+V
The tree structure shows one thing very clearly, namely that lists three and four are not similar at all. What it suggests in terms of a reasonable periodization of the data would either be a binary split into an earlier and a later period, or a fourfold distinction of (1) periods 1 and 2, (2) period 3, (3) period 4, and (4) periods 5 and 6. A subsequent analysis that adopts such a periodization would have the benefit of seeing more pronounced differences between the corpus periods, so that statements about change can be made with greater accuracy and reliability.
A second practical benefit of VNC is that it can be used for the detection of outliers in historical data, that is, data points that deviate considerably from the overall trend in the data and/or from other temporally close data points, and that may therefore reflect ‘anomalies’ in the data (which in turn may result from sampling problems, author idiosyncrasies, etc.). Gries and Hilpert (Reference Gries and Hilpert2010) analyse the relative frequency of the third-person singular present tense suffixes -(e)th and -(e)s in the Parsed Corpus of Early English Correspondence, and when the relative frequency decrease of the -(e)th suffix is plotted year by year, several outlier measurements are immediately apparent to the human analyst, as can be seen in Figure 2.2. Removing outliers from datasets is a practice that is common in the empirical sciences, but ideally there should be transparent conditions on outlier removal. VNC provides such conditions. Gries and Hilpert (Reference Gries and Hilpert2010: 301) use the VNC algorithm to exclude as outliers those data points that form very small clusters (i.e. an individual year) that are surrounded by much larger clusters (i.e. more than fifty years). The logic behind this approach is simple: if a measurement is a ‘bad neighbour’, so that it differs considerably from contemporary sources which in themselves are relatively homogeneous, this is evidence that we are dealing with an outlier.

Figure 2.2 The growth of third-person singular present tense -(e)s
A second type of exploratory analysis is Hilpert and Gries's (Reference Hilpert, Gries and Th2009) iterative sequential interval estimation (ISIE). This approach is a visual tool to compare the diachronic development of observed frequencies or ratios against what would be expected on the basis of prior temporal changes and their variability. From each time period to the next, the algorithm computes and plots how more or less frequent a word/structure should be (with a kind of confidence interval) such that more recent temporal developments affect predicted developments more, and then an analyst can scan the resulting plot to determine the homogeneity of the diachronic trends and where unexpected developments occur.
In sum, exploratory tools have a lot to offer to historical corpus linguistics: they can help to discern distributional structure in data invisible to the naked eye to discover trends, temporal stages, and (un)expected diachronic trends, which can then either inform more qualitative or additional quantitative analysis (see below for an example).
2.5 Desiderata for future developments
While corpus linguistics is by definition an empirical discipline and the frequencies of (co-)occurrence and dispersion statistics it provides are a natural fit with statistical methodology, the adoption of more advanced statistical tools is a slow process. Apart from very general issues that have more to do with the reporting of quantitative analyses (see Wilkinson and the Task Force on Statistical Inference Reference Wilkinson1999) that require all practitioners’ attention, in this section, we will outline a few methodological approaches whose broader adoption we think would help elevate diachronic corpus linguistics to ‘the next level’.
First, there are a variety of ways in which particularly variationist kinds of study can be improved. While the field is slowly discovering that generalized linear regression models are a tool much superior to traditional Varbrul analysis – recall our discussion in section 2.2 – important developments still await wider adoption. For example, simple regressions can, in fact should, be followed up with model criticism and evaluation to determine when levels of predictors should be conflated – does one really need to distinguish human, animate, and inanimate possessors, or is it enough to distinguish human/animate vs. inanimate (see Bretz et al. Reference Bretz, Hothorn and Westfall2010)? Also, generalized linear mixed-effects models have become used more widely in linguistics as a whole because of their abilities to incorporate speaker/writer-specific effects, lexically specific effects, and to better handle unbalanced data of the kind that corpus linguists face. Thus, this method can also be very beneficial in diachronic studies. Two studies we have already mentioned showcase the power of this method: Gries and Hilpert (Reference Gries and Hilpert2010) follow up their VNC-based data periodization with such a model to study which factors drive the emergence of the -(e)s third-person singular, and the approach allows them to obtain a classification accuracy exceeding 94 per cent. Wolk et al. (Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013) also use this method in their studies of genitives and datives, with similarly high success. While high classification accuracies are not the ultimate goal of these studies, they reflect that with the right tools, all statistics will be more precise and, thus, more relevant to the task at hand, understanding what facilitates/inhibits change. As the development of mixed-effects models (and generalized estimating equations) matures, this method will provide ever more useful results; see also Rietveld et al. (Reference Rietveld, van Hout and Ernestus2004) for more discussion of pitfalls in quantitative corpus research.
As another example, other more sophisticated tools that can improve diachronic corpus studies involve related methods that can handle curvature/nonlinearities in the data, a frequent characteristic of diachronic data. Hilpert and Gries (Reference Hilpert, Gries and Th2009) discuss regression with breakpoints as one rather simple tool, but down the road more advanced methods – polynomial regressions, splines, generalized additive models (see Zuur et al. Reference Zuur, Ileno and Smith2010 for discussion) – will also be indispensable to the quantitative study of historical corpus data.
Similar advances in the domain of exploratory tools await adoption in diachronic corpus linguistics. There is now a variety of methods to follow up on cluster-analytic results. Dendrograms such as Figure 2.1 can be studied with regard to (1) how many clusters should be distinguished (using so-called average silhouette widths), (2) how ‘clean’ the resulting clusters are (with F-values), (3) which features are most distinctive for the clusters (using t-scores), and (4) how well they map onto other cluster-analytic results regarding the same phenomenon; see Divjak and Gries (Reference Divjak and Gries2008) for exemplification and discussion.
Finally, the statistical area of robust statistics is potentially also very useful to the study of historical corpus data. Robust statistics are statistics that are less based on the assumptions underlying many traditional statistical tools (normality, homogeneity of variances, no outliers, etc.), or that are less vulnerable in the presence of such violations, which are the rule in the kind of noisy observational data that diachronic corpus linguists study. Fields such as second-language acquisition have begun to discover this area (Larson-Hall and Herrington Reference Larson-Hall and Herrington2009), and in diachronic corpus linguistics, some work is under way. For instance, Lijffijt et al. (Reference Lijffijt, Papapetrou, Puolamäki and Mannila2011) develop an approach to the study of text frequency change that dispenses with the bag-of-words assumption. Much like language itself, diachronic corpus linguistics will continue to evolve.
2.6 Concluding remarks
This chapter has argued that quantitative methods hold considerable potential for diachronic corpus analysis. There are two main selling points. First, in order to make sense of the complex variation that is at play in processes of language change it is a simple matter of necessity to have analytical tools that can cope with that complexity and that offer the analyst a nuanced view of what happened. If we want to understand why a certain change happened, thorough understanding of how it happened is the first step towards that goal. Second, quantitative analytical methods can make phenomena visible that would otherwise not be open for inspection. These methods can offer a fresh, unbiased look at phenomena that seem familiar, but which still remain to be fully understood. Importantly, it is early days for diachronic corpus linguistics. All of the methods discussed in this chapter are still in a phase of development, awaiting further testing and replication, and we can look forward to studies that will further enlarge the toolkit of diachronic corpus linguistics in the near future. At the same time, it has to be pointed out that even a high level of analytical sophistication cannot remedy the problem of data sparseness that is one of the natural limits of endeavour in historical linguistics. Evidently, any analytical method can only produce satisfying results on the basis of rich empirical data and analysts who are aware of the inherent restrictions of their methods. When the historical record is poor, the best shot that we have at nonetheless understanding it to some degree is to take present-day variation as a model, and to see whether the historical data varies in comparable ways. To make this happen, historical corpus linguists and sociolinguistically oriented corpus linguists need to join forces both at the level of methodology and at the level of linguistic theory. Pioneering work in that direction has been carried out (Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg2003) and the recent studies that were discussed in this chapter show that the problems and pitfalls that haunt diachronic corpus linguistics are being addressed from a variety of angles.
3.1 Introduction
Within the space of about twenty years, English historical linguistics has been deeply changed and enriched by the introduction and expansion of pragmatic approaches. While, in the previous decades, English historical linguistics was concentrated on reconstructing and mapping forms, the 1980s and 1990s were the time when it started to focus on ‘meaning-making processes in past contexts’, i.e. in how meaning is negotiated, and how more is conveyed than what is said, in texts from the past (Taavitsainen and Jucker Reference Taavitsainen, Taavitsainen and Pahta2010: 6). Historical pragmatics can be defined as ‘a field of study that wants to understand the patterns of intentional human interaction (as determined by the conditions of society) of earlier periods, the historical developments of these patterns, and the general principles underlying such developments’ (Jucker Reference Jucker2008: 895). The main aims of historical pragmatics can be subsumed under two overarching research questions:
1 What do texts tell us about the way in which pragmatic functions (i.e. context-bound, negotiated meanings) were encoded in language in the past?
2 What can we reconstruct about the way in which pragmatic values of language forms develop over time in a language? (Jacobs and Jucker Reference Jacobs, Jucker and Jucker1995: 5–6)
Historical pragmatics considers language as ‘diachronic, social and dynamic and not just as a synchronic and static system’ (Taavitsainen and Jucker Reference Taavitsainen, Taavitsainen and Pahta2010: 4). It is therefore a field in which the context and the aims of communicative acts are considered important factors in the analysis of language forms; historical pragmatics focuses particularly on the specific combination of contextual features and sets of communicative intentions in each text, rather than on broad and relatively stable categories. As in other branches of pragmatics, the interface with semantics is strong, with a focus on diachronic change in semantic values, especially connotational ones. To give just one example, if we consider the English term of address sir, e.g. in dramatic dialogue or in letter openings, we can study its distribution in texts considering who addresses whom, in terms of registers (was it more or less formal in the past than it is today? Was it used more to social superiors, to equals, or to inferiors?), or we can study its change in semantic values over time (especially if we consider its relative sirrah, which started as a ‘neutral’ term of address for young men and later took on a pejorative meaning); within historical pragmatics, we would look at instances of dialogue in which the term occurs, and consider the relationship between the characters involved, the specific context of situation, and the apparent communicative intention represented in the relevant co-text, to try to determine what the term represents in that particular exchange, e.g. if it aims at conveying deference, or insult, etc. (Mazzon Reference Mazzon, Taavitsainen and Jucker2003b, Reference Mazzon2009: 26).
The present chapter first reviews the thematic and chronological development of English historical pragmatics and the input it received from neighbouring fields; then, it mentions some of the data that are studied in historical pragmatics and some of the most promising results; finally, it discusses the challenges and limitations of this approach as against the aims outlined.
3.2 The development of historical-pragmatic and sociopragmatic approaches
This development had several precursors, i.e. studies that were not unified by any theoretical framework, but that are still the starting point of much current research. The decisive step towards the present expansion of the field was the application of theories and frameworks from synchronic European pragmatics (itself recognized as a separate field only about a decade earlier) to documents from the past. Authoritative and comprehensive works on (particularly English) historical pragmatics started to be published in the early 1990s (a precursor was Stein 1985b; see, e.g., Busse Reference Busse1991, Ehlich Reference Ehlich, Watts, Ide and Ehlich1992, the fundamental Jucker Reference Jucker1995, and the Journal of Historical Pragmatics, which was started in 2000) and are now being published at a growing rate (see Jucker and Taavitsainen Reference Jucker, Fried, Östman and Verschueren2010, relevant chapters or sections in Bergs and Brinton Reference Bergs and Brinton2012 and in Nevalainen and Traugott Reference Nevalainen, Bergs and Brinton2012); the corresponding multiplication of conferences, workshops, and projects in this area further testifies to the liveliness of this field.Footnote 1 The subfields that most directly contributed to what, already some years ago, Jucker et al. (Reference Jucker, Jucker, Fritz and Lebsanft1999b: 14) defined as the ‘pragmaticization of English historical linguistics’, were intercultural (or cross-cultural) pragmatics (Blum-Kulka et al. Reference Blum-Kulka, House and Kasper1989, Wierzbicka Reference Wierzbicka1991) and variational pragmatics (Schneider Reference Schneider, Fried, Östman and Verschueren2010, Pichler Reference Pichler2013); within these branches, scholars realized the potential (and subsequently the limitations) of studying the pragmatics of groups separated by a distance.Footnote 2 The possibility of developing comparative studies of different communities concerning single pragmatic issues stimulated the idea that similar efforts could be directed at studying groups separated by time rather than by space or culture. This was followed by input from relational and interactional pragmatics, Gricean pragmatics, and politeness theory (see Kopytko Reference Kopytko1993, Traugott Reference Traugott, Horn and Ward2006: 540–8, Jucker and Taavitsainen Reference Jucker, Nevalainen and Traugott2012), and, more recently, from interpersonal pragmatics (Locher and Graham Reference Locher and Graham2010) and impoliteness theory (Culpeper Reference Culpeper2011).
Another element that contributed to historical pragmatics was the development of historical sociolinguistics, a branch that has also grown rapidly (see Chapter 1 by Romaine in this volume). Particularly relevant to historical pragmatics are studies based on network analysis (Milroy Reference Milroy1992a), or on the partly overlapping concept of ‘community of practice’, where specific linguistic markers contribute to defining group membership (see, e.g., McColl Millar Reference Millar2012: 9).Footnote 3 Nevalainen (Reference Nevalainen, Bergs and Brinton2012) reports on historical applications of other approaches, such as sociology of language and social dialectology (see also Chapter 17 by Nevala in this volume), or correlational sociolinguistics and interactional sociolinguistics (in turn, influenced by functional approaches; Palander-Collin et al. Reference Palander-Collin, Nevala, Nurmi, Nurmi, Nevala and Palander-Collin2009: 1–2).Footnote 4
In particular, interactional sociolinguistics has contributed to historical pragmatics by adding the micro-elements of personal background, social networking, and communicative function to the analysis of correspondence (Fitzmaurice Reference Fitzmaurice2002c, Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg2003, Tieken-Boon van Ostade Reference Tieken-Boon van Ostade, Juan and Hernández-Campoy2005), and has offered new insight into dialogue studies, e.g. by tracing power dynamics in interaction, also in terms of ‘conversational dominance’ (Itakura Reference Itakura2001, Locher Reference Locher2004). This ‘cross-fertilization’ has been termed sociopragmatics, and, according to one recent definition, ‘focuses on the way in which speakers exploit [socially conditioned language] norms to generate particular meanings, take up particular social positionings’ (Culpeper Reference Culpeper, Andreas and Taavitsainen2010: 73; see also the studies in Pahta et al. Reference Pahta, Nevala, Nurmi and Palander-Collin2010). The study of genres and text-types, connected to the notion of language register, is within the subfield of sociopragmatics, and so is the study of politeness conventions and facework within discourse communities and, as mentioned, ‘social networks’, keeping in mind the impact of class- and gender-related variation.
Historical discourse analysis is closely related to, and often overlaps with, historical pragmatics (Brinton Reference Brinton, Schiffrin, Tannen and Hamilton2001, Taavitsainen Reference Taavitsainen, Fanego, Méndez-Naya and Seoane2002, Hiltunen and Skaffari Reference Hiltunen and Skaffari2003, Skaffari et al. Reference Skaffari, Peikola, Carroll, Hiltunen and Wårvik2005). It principally deals with the fact that language items diachronically take on (and may eventually lose) discourse-organizing functions. At the same time, the existence of separate discourse communities, practising different discourse styles, can be traced back to the past – in fact, the features identifying text-types and discourse levels can be even more prominent for times in which there was a strict separation between ‘clerics’ and (largely illiterate) lay people. Courtroom discourse (Archer Reference Archer2005), scientific and didactic discourse (Fries Reference Fries, Borgmeier, Grabes and Jucker1998, Taavitsainen and Pahta Reference Taavitsainen, Taavitsainen and Pahta2004), religious discourse (Kohnen Reference Kohnen, Pahta, Taavitsainen, Nevalainen, Tyrkkö, Jucker, Schreier and Hundt2009, Rütten Reference Ratia2011), and news discourse (Raymond Reference Raymond2006, Valle Reference Valle and Brownlees2006), have received the highest degree of attention so far, with the contribution of historical stylistics, which also partly concentrates on text-type-specific features (Studer Reference Studer2008; see relevant chapters in Jucker and Taavitsainen Reference Jucker, Fried, Östman and Verschueren2010 and Claridge Reference Claridge, Bergs and Brinton2012; see also Chapter 16 by Taavitsainen in this volume). Historical discourse analysis investigates the codification of conventions pertaining to specific text types as indicative of the existence, degree of cohesion, and diachronic change of ‘communities of practice’ and discourse communities. It studies, for instance, degree of formality, information structure, and level of personal involvement and stance marking in various text types, addresser–addressee relationships, text-specific language structures, and vocabulary items and their developments (Diller and Görlach Reference Diller, Diller and Görlach2001, Claridge Reference Claridge, Bergs and Brinton2012). It also studies the ‘discursivization’ paths of specific items, e.g. connectors, markers, etc. (Jucker and Taavitsainen Reference Jucker, Nevalainen and Traugott2012: 302–3), which often involves meaning shift and a range of processes that lead a language item to acquire discourse-internal meanings and/or functions; this step can also be followed by a further shift towards subjectification, i.e. ‘towards meanings increasingly situated in the speaker's subjective believe-state or attitude’ (Brinton Reference Brinton, van Kemenade and Bettelou2006: 310; for original theorizations, see Traugott Reference Traugott, Lehmann and Malkiel1982), and further towards intersubjectification, i.e. ‘subjectified meanings may in turn be recruited to convey the speaker's attention to the addressee’ (López-Couso Reference Lange2010: 131).
3.3 Aims, objects of study, methods, and results
The first research question mentioned above (i.e. how were pragmatic functions encoded in the past?) has produced mostly synchronic studies of one period, text type, or communicative environment, e.g. investigating how terms of address conveyed social and pragmatic values in EModE, or how textual organization was encoded in correspondence between eighteenth-century scientists. Many such studies are within pragmaphilology (a term introduced by Jacobs and Jucker Reference Jacobs, Jucker and Jucker1995), i.e. they concentrate on single texts or groups of texts, taking into account not only internal elements but also the extralinguistic context of its production and use (Traugott Reference Traugott, Horn and Ward2006: 538, Jucker Reference Jucker, Fried, Östman and Verschueren2010); examples of such studies are Mazzon (Reference Mazzon and Hart2003a), which studies the area of modal meanings within a restricted time span and in a relatively homogeneous set of text types (i.e. Chancery documents), Pakkala-Weckström (Reference Pakkala-Weckström, Jucker and Taavitsainen2010), and Busse and Busse (Reference Busse, Busse, Jucker and Taavitsainen2010), where the emphasis is on the pragmatic meanings encoded by individual authors, respectively Chaucer and Shakespeare, through their use of terms of address, speech acts, discourse markers, and other relevant items.
The second type of question (i.e. how do the pragmatic values of a language item develop over time?), which is addressed by the approach often separately defined as diachronic pragmatics (Jacobs and Jucker Reference Jacobs, Jucker and Jucker1995), has led scholars to investigate, for instance, how a main clause with a propositional content such as you know or I mean, or an adverb like well, lose their literal meanings and become discourse markers with textual or interactive functions over time (form-to-function mapping), or, conversely, how a certain communicative function (e.g. greeting or apologizing) has changed its realizations over time (function-to-form mapping; see Jucker Reference Jucker, Fried, Östman and Verschueren2010: 110). Most such studies compare occurrences of the relevant items in various contexts, and draw on a variety of external and internal factors (e.g. relation between the interlocutors/correspondents/characters, or specific, independently ascertained communicative aim of the dialogue) in order to assess the pragmatic values conveyed.
3.3.1 Pragmatically sensitive items
The pragmatic approach started by focusing on specific items, trying to ascertain their interactional significance and pragmatic values. For instance, one of the first foci was the use of pronouns and terms of address in early literary works, already studied by traditional philologists and critics (e.g. Finkenstaedt Reference Finkenstaedt1963). Newer studies considered address as a key to interpreting social and ‘affective’ relations between characters, similarly to what has been done on modern languages by Ervin-Tripp (Reference Ervin-Tripp, Pride and Holmes1972) and other sociolinguists and anthropologists (e.g. Friedrich Reference Friedrich, Gumperz and Hymes1986). A turning point was marked by the systematic application of politeness theory to historical drama (Brown and Gilman Reference Brown and Gilman1989), which gave rise to a number of subsequent studies (e.g. Busse Reference Busse, Taavitsainen and Jucker2003, Mazzon Reference Mazzon, Kastovsky and Mettinger2000, Reference Mazzon, Taavitsainen and Jucker2003b, Reference Mazzon2009, Walker Reference Walker2007). These contributions are relatively systematic surveys of the ways in which dramatic texts (1) employ terms of insult, endearment, deference, or mocking, in order to represent specific social roles and communicative aims, and (2) show variable distribution of thou and you to represent not only the social rank of characters, but also the context and tone of the exchange; the emotions involved and the communicative intentions determined the choice of pronouns at the micro-level, i.e. within the same stretch of dialogue between the same interlocutors.
Another large field of study is the development of discourse (or pragmatic) markers from adverbials or clauses such as well, now, I guess (Traugott Reference Traugott1995b; Brinton Reference Brinton1996, Reference Brinton2008, Reference Brinton, Jucker and Taavitsainen2010); research has here tried to outline this development chronologically (i.e. when and how the pragmatic functions start to appear in texts) and through the processes it involves, often in reference to grammaticalization but also to pragmaticalization and to lexicalization. Discourse markers typically occur in positions in the sentence that are not typical of the item they derive from (contrast Well, I know him vs. I know him well) and tend to become fixed and invariable in structure, as is typical of lexical items rather than constructions (She will be there, I guess vs. *She will be there, I have guessed; or I'm afraid you'll have to leave vs. *I'm often afraid you'll have to leave).Footnote 5 Similar attention has been devoted to the study of modality markers (Arnovick Reference Arnovick1990), interjections (Gehweiler Reference Gehweiler, Jucker and Taavitsainen2010), and degree modifiers (Traugott 2012a).
Diachronic speech-act analysis is another very productive subfield (Arnovick Reference Arnovick1990, Reference Arnovick1999, Taavitsainen and Jucker Reference Taavitsainen2007) that tries to describe trends, changes, and continuities in cultural scripts of speech practices and in the extent to which the realization of specific speech acts is routinized (Taavitsainen and Jucker Reference Jucker2008: 6–8). Promises, requests, compliments, and insults are among the speech acts that have been investigated most intensively (Taavitsainen and Jucker Reference Taavitsainen2007, Archer Reference Archer, Jucker and Taavitsainen2010).
More and more often, in the last few years, analyses of individual items or elements of sociopragmatic or discourse-organizational relevance are carried out within historical dialogue analysis. The ways in which dialogue is represented in texts was one of the first interests to emerge (e.g. Rudanko Reference Rudanko1993, Fritz Reference Fritz and Jucker1995, Bergner Reference Bergner, Borgmeier, Grabes and Jucker1998), and has profited from contributions from stylistics (Herman Reference Herman1995, Culpeper et al. Reference Culpeper, Short and Verdonk1998); its theoretical and methodological foundations were systematized by an important collection (Jucker et al. Reference Jucker, Fritz and Lebsanft1999a). Most of the initial work concerned the analysis of dramatic texts, but this subfield has also profited from a wider knowledge of non-literary texts, such as scientific, legal, and instructional texts and letters (among the many studies available, see, e.g., Taavitsainen Reference Taavitsainen, Jucker, Fritz and Lebsanft1999, Fitzmaurice Reference Fitzmaurice2002c, Valle Reference Valle, Hiltunen and Watanabe2004, contributions in Dossena and Fitzmaurice Reference Dossena and Fitzmaurice2006, Nurmi et al. Reference Nurmi, Jucker, Schreier and Hundt2009), and trial records (for example, Archer Reference Archer2005, Reference Archer2006, Culpeper and Archer Reference Culpeper, Archer, Jucker and Taavitsainen2008, Kryk-Kastovsky Reference Kryk-Kastovsky2009), which in their different ways contain elements of ‘interactivity’, whether the actual addressees are internal or external to the texts themselves, i.e. a reading public.
For instance, a personal letter may be considered a rather ‘dialogic’ text type, reflecting in a more or less direct way the social relations between two people, but in the past its structure could be highly conventionalized, and it could be a more public text than now, often involving secretaries or scribes, and a wider audience than just the recipient, when read aloud; conversely, a scientific treatise may appear as a formalized text, with hardly any element of interaction and very distant from speech-like elements, but if we consider Chaucer's Treatise on the Astrolabe, addressed to the author's son, a number of textual features will be noticed, especially terms of address and discourse markers, that reveal that its ‘dialogic’ or interactive character is much more prominent than it is in modern representatives of this text type (Mazzon Reference Mazzon, Dance and Wright2012). While several ME scientific treatises are written in dialogue form for mnemonic purposes and within the ancient dialogue tradition, and therefore do not show any noticeably ‘speech-like’ features, others (and particularly EModE ones) introduce direct address of the reader and other dialogic elements (Taavitsainen Reference Taavitsainen, Bergs and Brinton2012b; see the collection Mazzon and Fodde Reference Mazzon, Dance and Wright2012).
As mentioned, network analysis has been used to describe communal change, and to highlight correlations between changes in social structures and language change (Conde-Silvestre Reference Conde-Silvestre, Hernández-Campoy and Conde-Silvestre2012: 336). Such studies, e.g. on the role of London as a catalyst for the gradual emergence of third-person singular -(e)s in EModE (Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg2003), or the correlation between the biographies of the members of the Paston family and different use of relative markers in their letters (Bergs Reference Bergs2005, see also Chapter 1 by Romaine in this volume), or the use of relative markers within the Spectator's network in the early eighteenth century (Fitzmaurice Reference Fitzmaurice2007), have also been relevant to historical pragmatics through the establishment of hypotheses about ‘default variants’ in a certain communicative context – in other words, they have helped establish a grid of the most common uses, against which marked uses (i.e. those of potential pragmatic relevance) can be measured.
Chronologically, the application of pragmatic and sociopragmatic frameworks to past texts has on occasion, but not systematically, concerned OE (Danet and Bogoch Reference Danet, Bogoch and Gibbons1994, Shippey Reference Shippey, Sinclair, Hoey and Fox1993, Kohnen Reference Kohnen, Pahta, Taavitsainen, Nevalainen, Tyrkkö, Jucker and Taavitsainen2008; overview in Lenker Reference Lenker, Bergs and Brinton2012); a higher number of studies concern ME and EModE, where more tokens of different text types are available, as well as greater knowledge of the background (overview in Archer Reference Archer, Bergs and Brinton2012b). LModE, which has been initially neglected by these approaches as by others, is now more frequently an object of study (overview in Lewis Reference Lewis, Bergs and Brinton2012).
3.3.2 Metapragmatics
At the meta-level of observing the changing attitudes towards language and language use, an important line of research is the study of standardization processes as they took place between late ME and the end of EModE, as well as the various waves of purism and prescriptivism that followed (see, e.g., the collections Wright Reference Wright2000, Watts and Trudgill Reference Watts and Trudgill2002). Looking at reflections of cultural history on language ideology can help to determine the associations between specific language variants and certain social levels or different text types, or levels of prestige (Sairio and Palander-Collin Reference Sairio, Palander-Collin, Hernández-Campoy and Conde-Silvestre2012), and what extralinguistic values were linked to different languages and varieties (on multilingualism and code-switching in earlier written English, see, e.g., the collection Schendl and Wright Reference Schendl and Wright2011), all factors that can be pragmatically relevant. For instance, medieval drama tends to be composed in order to be understandable, even enjoyable, for the audience, and therefore displays several features of speech mimesis; however, Latin is inserted not only in the prayers and stage directions, but also when a character is stressing his status in the clerical hierarchy (within which Latin was of course the language of prestige) in a specific dialogue, to increase his ‘conversational dominance’ (Mazzon Reference Mazzon2009: 183–92). The meta-level of investigation involves looking at the way in which politeness was perceived at different times, i.e. what already Klein (Reference Klein1994), and increasingly more scholars (e.g. Archer Reference Archer, Bergs and Brinton2012b, Jucker Reference Jucker, Nevalainen and Traugott2012) term ‘politeness1’, to connect it with the way in which this is conveyed in texts, and also to verify the connection with modern theories (‘politeness2’). Studies within this strand investigate, for instance, the ways in which concepts such as ‘proper language’ or ‘civil conversation’ developed in Britain, and how they impacted on text-producers’ choices.
3.4 Challenges and limitations
The challenge faced by historical pragmatics is related first of all to the nature of the evidence: pragmatic values are more likely to emerge in speech, while our evidence is at the utmost ‘speech-like’ written text; moreover, there is the problem of the piecemeal preservation of only a few text-types in patchy distribution, mostly produced by a narrow subset of text-producers. A further problem is the lack of ‘common ground’ between the researcher and the text-producers, a limitation first identified by intercultural pragmatics (for a diachronic perspective see Jucker and Taavitsainen 2012: 300; see also Chapter 15 by Fitzmaurice in this volume); this reduces drastically the amount of information on the communicative situations investigated. In other words, the challenge is that of trying to glean from texts something that goes beyond the literal without having direct access to the world knowledge and to the ‘communicative competence’ of the speakers who produced those texts, or of the recipients of such communicative acts (Taavitsainen Reference Taavitsainen, Bergs and Brinton2012b: 1464). This challenge has been taken up widely, and historical pragmatics, sociopragmatics, and discourse analysis are today among the liveliest branches of English historical linguistics; at the same time, the related limitations, hurdles, and possible pitfalls briefly mentioned here, are only escapable if we consider written texts as valid objects of study in their own right (Jucker et al. Reference Jucker, Jucker, Fritz and Lebsanft1999b: 16), i.e. without yielding to the temptation of considering the language indicators present in texts in the same way as we consider recorded spoken language tokens. A useful review of the problems in historical pragmatics is offered by Taavitsainen and Jucker (Reference Taavitsainen, Taavitsainen and Pahta2010: 15–20) – at the forefront is a semasiological problem, related to the difficulty of identifying the precise function of a certain form, and of determining the intended meaning of an item in a text or group of texts belonging to a certain time, space, and text type: how can we hope to reconstruct the exact shades of meaning (or layers of meaning) conveyed by a certain item in a context whose specifications are largely unknown to us?
This problem is intertwined with another major methodological problem, especially of sociopragmatics, i.e. overcoming the dichotomy between the macro-level of social structure and its linguistic expression on the one side, and the micro-level represented by the piecemeal and indirect evidence of individual texts on the other.Footnote 6 There is an overall problem of generalizability and representativeness within a research field formed by scattered and hybrid evidence (see Section 2 of this volume), given the impossibility of accessing comparable amounts of evidence from different groups, and to the difficulty of creating solid social models and of categorizing ‘informants’ in any uncontroversial way, with the partial exception of gender (see, e.g., Nurmi Reference Nurmi, Granger and Petch-Tyson2003a, Lutzky Reference Lutzky, Mazzon and Fodde2012; see also Chapter 1 by Romaine in this volume).
A further challenge is trying to overcome the inevitability of superimposing the modern perspective, i.e. reading history backwards in view of ensuing developments, a danger of all historical research (Auer and Voeste Reference Auer, Voeste, Hernández-Campoy and Conde-Silvestre2012). This is made more difficult by the haphazard, socially conditioned, or editorially manipulated survival of documents, which makes more acute the dangers of falling into ‘historiographic elitarianism’ and of feeding various possible myths of a unified history of the language (Milroy Reference Milroy, Watts and Trudgill2002, Watts Reference Watts2011). Another considerable range of problems, as mentioned, comes from the danger of ‘reification’ or overgeneralization of results, especially related to the gap between spoken and written language. Deeper reflections on the orality–literacy relationship (e.g. see the precursor studies in the collection Stein Reference Stein1992; and later Arnovick Reference Arnovick2006, Taavitsainen and Fitzmaurice Reference Fitzmaurice2007: 18–21, Schaefer Reference Schaefer, Bergs and Brinton2012) are contributing to the development towards a more realistic and heuristically correct stance in this respect.
By way of example of the limitations of the field, let us reconsider the advances in historical speech-act analysis, which are based on the interpretation of the intended speech act as it emerges from the text. Of course, there are possible pitfalls in such interpretations, as the classification of acts often relies on the presence of explicit performative verbs (e.g. promise), as well as of additional elements such as modality items and other boosters or downtoners (e.g. absolutely), from which one can infer the relative force of the speech act. Recent research shows sensitivity to this potential circularity, while extensive corpus studies on wider samples allow for a more precise mapping of the possible illocutionary force conveyed by specific items in certain text types. As in the case of PDE speech-act analysis, where exhaustive and uncontroversial classifications do not seem possible, the key to such descriptions could lie in the adoption of a prototypical approach that allows us to establish categories that are not watertight, but relatively fuzzy (Taavitsainen and Jucker Reference Taavitsainen2007: 108, Culpeper and Archer Reference Culpeper, Archer, Jucker and Taavitsainen2008: 47); this is valid especially when it comes to the reconstruction of indirect speech acts, which can often only be revealed by the analysis of metapragmatics and of the whole ‘pragmatic space’, i.e. adjacent speech acts (Culpeper and Archer Reference Culpeper, Archer, Jucker and Taavitsainen2008: 57ff.).
3.4.1 Possible solutions – modelling the data
The methodologies of historical pragmatics (systematically addressed e.g. in Fitzmaurice and Taavitsainen Reference Fitzmaurice2007) have been deeply influenced, as those of other branches of English historical linguistics, by the increasing availability of digitalized corpora of texts (see Rissanen Reference Rissanen, Lüdeling and Kytö2008, Kytö Reference Kytö, Jucker and Taavitsainen2010; Chapter 8 by López-Couso in this volume). It could seem that this abundance of easily accessible data may affect pragmatic and sociolinguistic analysis in a less direct way than, say, morphological analysis; however, while not a substitute for qualitative analysis, corpus studies can in fact highlight several aspects of language variation and use in context. Biber and Finegan (Reference Biber, Finegan, Aarts and Meijs1986, Reference Biber, Finegan, Aijmer and Altenberg1991) were the first to suggest a model for this kind of investigation, later applied to diachronic and historical analyses that increasingly used corpus-based data sources and techniques. These contributions have shown that it is possible to study pragmatically sensitive items as they emerge from texts by taking a bird's-eye perspective, in order to identify general trends and diachronic changes, before and above qualitatively examining individual tokens to determine their communicative values. More recently, new perspectives have been opened by the sociopragmatic annotation of some corporaFootnote 7 (Archer and Culpeper Reference Archer, Culpeper, Wilson, Rayson and McEnery2003, Archer Reference Archer, Bergs and Brinton2012b, Lutzky Reference Lutzky, Mazzon and Fodde2012).
Increasingly, the preoccupation in historical pragmatics is with the construction of models that can adequately map different evidence on an axis representing degrees of closeness vs. distance from the mimicry of speech. A first model proposed by Koch and Oesterreicher (Reference Koch and Oesterreicher1985) was adopted in various studies, until advance in research, including the creation of specific corpora such as the Corpus of English Dialogues (CED), has led to the production of a more fine-grained model (Culpeper and Kytö Reference Kytö, Jucker and Taavitsainen2010), in which there is an attempt to map different (sub)text types in terms of their relation to speech reproduction. This helps constructing subcorpora and classifying data in a more subtle way, but the limitations indicated in the previous section remain, especially those connected with the differences between speech and writing and with the different social and pragmatic values of communicative events at different times.
3.5 Conclusion
As I hope to have shown in these pages, historical pragmatics has contributed a great deal to historical linguistics; in the last few years, acting synergistically with historical sociolinguistics and corpus linguistics, it has expanded and produced interesting results. There is no doubt that a lot is still to be done; the metapragmatic level mentioned above represents one of the subfields that looks more promising for future research, and so do dialogue studies, as well as all those approaches that combine sociolinguistic, discourse-analytic, conversation-analytic, and pragmatic methodologies to increase our understanding of texts as dynamic products. In particular, a promising direction seems to lie in the integrated analysis of several indicators whose combination conveys a specific pragmatic effect. In short, historical pragmatics represents a possible way in which we can try to fill the linguistic and sociocultural gap that separates us from texts produced in the past, allowing us to consider them not as fixed objects, but as the expression of culturally determined communicative processes.
4.1 Introduction
This chapter provides a review of some of the ways in which the framework of construction grammar has been used to explain patterns of change in English, with a focus on morphological, morphosyntactic, and semantic change. While there are a number of variants of construction grammar, the research reported on here takes a largely usage-based, cognitive approach to the architecture of language (see Langacker Reference Langacker1987, Bybee Reference Bybee2010); some comments relating to the use of a more formal model of construction grammar in accounting for language change appear in section 4.4. The chapter is organized as follows. Section 4.2 outlines some of the principles of constructional approaches to language (see Goldberg Reference Goldberg, Hoffmann and Trousdale2013), and establishes those features which are particularly relevant to language change (on which, see Fried Reference Fried, Hoffmann and Trousdale2013, Hilpert Reference Hilpert2013, Traugott and Trousdale Reference Traugott and Trousdale2013). The objective is to sketch briefly how early constructional approaches challenged some of the dominant linguistic theories in the late twentieth century, then go on to show their application to historical linguistics. Some reference is made to methodological issues in a usage-based approach to language change, but for more detail see Chapter 2 by Hilpert and Gries in this volume.
Section 4.3 considers applications of construction grammar to areas of English historical linguistics, focusing on the development of and changes to morphological and syntactic schemas, and the development of grammatical and lexical micro-constructions. The focus is on how construction grammar helps to elucidate some problematic issues in theories of language change, but also consider ways in which current approaches to constructional change might be refined or developed.
The discussion of morphological schemas (section 4.3.1) is couched within the framework of constructional morphology (see particularly Booij Reference Booij2010). The focus will be on quantitative approaches to productivity changes in the history of English (the V-ment construction, Hilpert Reference Hilpert2013), and the relationship between lexicalization and the development of word-formation schemas (the X-dom construction; Haselow Reference Haselow2011, Traugott and Trousdale Reference Traugott and Trousdale2013). The subsection on syntactic schemas (4.3.2) looks at changes to existing constructions (illustrated by semantic specialization in the English ditransitive construction; see Colleman and De Clerck Reference Colleman and Clerck2011) as well as the creation of new constructions (illustrated by the development of cleft constructions in English (Traugott Reference Traugott, Cooper and Kempson2008, Patten Reference Patten2012)). The section on the loss of schemas (4.3.3) focuses on reduction in constructional space, such as when a productive word-formation schema or argument structure construction falls into disuse. Examples are taken from recent work on constructional change.
The fourth section provides a brief overview of the advantages and disadvantages of a constructional approach to change, with some comments regarding future directions of research. A brief concluding section summarizes the main issues discussed.
4.2 Construction grammar: an introductory sketch, and its application to historical linguistics
Goldberg (Reference Goldberg, Hoffmann and Trousdale2013) identifies the following as features common to varieties of construction grammar which distinguish them from mainstream generative approaches to the architecture of human language:
From lexical items to phrasal constructions, language is a system of linked, conventionalized, form–meaning pairings.
There are no operations (such as merge or move) which transform one structure into another.
Language is a conceptual network (see also Hudson Reference Hudson2007 for a related model) in which inheritance and extension links serve to associate one constructional node with another.
Language is a variable phenomenon; similarities across languages can be accounted for either by properties of the constructions themselves, or by ‘domain-general cognitive processes’ (Goldberg Reference Goldberg, Hoffmann and Trousdale2013: 16).
Goldberg then notes one other feature that is shared by many but not all constructional approaches, namely that knowledge of language is a product of language use (the ‘usage-based model’). This is an important feature for work in historical linguistics, and contrasts sharply with some other approaches to language change. One area of intersection between historical linguistics more generally, and construction grammar, is historical–comparative reconstruction. I do not discuss this topic in the present chapter (see Barðdal Reference Barðdal, Hoffmann and Trousdale2013 for a summary of current thinking).
The features listed above serve to establish what is generally shared across the various ‘constructional’ approaches to language, such as Radical Construction Grammar (e.g. Croft Reference Croft2001) and Cognitive Construction Grammar (e.g. Goldberg Reference Goldberg2006). As is generally the case for linguistic theories, construction grammar was originally designed as a tool to model the linguistic knowledge of speakers synchronically, rather than as a theory of language change. It developed as a reaction to mainstream generative linguistics in the United States in the 1980s and 1990s, and shared some – but not all – features with other cognitive theories of language being developed at the time, including Notional Grammar (e.g. Anderson Reference Anderson1977), Word Grammar (e.g. Hudson Reference Hudson1984), and Cognitive Grammar (e.g. Langacker Reference Langacker1987), all of which, like construction grammar, have since been used to account for historical changes. Fillmore (Reference Fillmore, Hoffmann and Trousdale2013: 111) notes that Berkeley Construction Grammar developed from work ‘centered on discovering the idiomatic and “irregular” parts of language, demonstrating their frequency in text and their centrality in the linguistic knowledge of speakers’. Precisely such topics are of concern to historical linguists, as the following suggests:
Work on grammaticalization (e.g. Lehmann Reference Lehmann1985, Hopper and Traugott Reference Hopper and Traugott2003) and lexicalization (e.g. Brinton and Traugott Reference Brinton and Traugott2005) has tried to explore how the ‘idiomatic’ parts of language are associated with both procedural meaning (e.g. the aspectual composite predicates such as take a walk) and contentful semantics (e.g. other composite predicates such as take offence at).
The issue of what is ‘regular’ and ‘irregular’ (and how something that was irregular at one point comes to be regular later in the history of a language) is at the heart of debates surrounding the relationship between reanalysis and analogy (see Fischer Reference Fischer2007 and De Smet Reference De Smet2009).
Frequency – including changes in frequency – has been of importance to usage-based approaches to the structure of language (see much of the work of Joan Bybee, especially Bybee Reference Bybee2007, Reference Bybee2010). This has come to be of particular importance as work in sociolinguistics has influenced theories of language change, with the adoption of particular kinds of quantitative methodologies in studies of language change (see Chapter 2 by Hilpert and Gries in this volume).
Textual evidence (whether original manuscripts or computerized corpora) provides most of the data for work in historical linguistics. Crucially, the importance of both cotext and context (see Bergs and Diewald Reference Bergs, Diewald, Bergs and Diewald2009) for understanding how new grammatical forms develop is of significant importance for usage-based models.
Establishing what speakers know unites practically all fields of linguistic enquiry. Work in historical linguistics interfaces with work on language acquisition and language contact, and both of these topics have been addressed within a constructional model.
Thus the kinds of questions relevant to (English) historical linguistics show considerable overlap with those that have driven aspects of work in construction grammar from its outset. More recently, the issue has arisen as to what precisely a ‘diachronic version’ of construction grammar would look like, and what questions in historical linguistics a constructional model could answer. For example, one topic which has been hotly debated in recent years has been the relationship between grammaticalization and constructional change (Noël Reference Noël2007, Gisborne and Patten Reference Gisborne, Patten, Narrog and Heine2011, Fried Reference Fried, Hoffmann and Trousdale2013, Hilpert Reference Hilpert2013, Traugott and Trousdale Reference Traugott and Trousdale2013). Another issue has concerned how change might be modelled within a particular variant of construction grammar (e.g. Fried Reference Fried, Bergs and Diewald2008). In what follows, I present an overview of some of the issues which appear to be particularly pertinent to work on the history of English, and use only English case studies as a source of data. There will be minimal reference to methodological issues, given that this topic is covered elsewhere in the present volume (see Chapter 22 by Traugott in this volume), but it is important to underline the close interplay between the methods adopted and the research questions which drive particular projects. Quantitative and qualitative approaches are complementary, not competing, and both provide insights into how constructions emerge, change, and fade over time.
4.3 Constructional change
In this section, an overview of different kinds of constructional change is provided. Section 4.3.1 is concerned with the emergence of and change to word-formation schemas in English; section 4.3.2 is concerned with similar features associated with grammatical constructions such as cleft constructions. In section 4.3.3, the focus is on loss, and what happens to isolated micro-constructions when a schema disappears over time.
4.3.1 Morphological schemas
As noted in section 4.2, the constructional approach relies on a non-modular framework of language, and treats it as a conceptual network. The constructions which form the nodes of this network are put to use by language users in different ways; here I consider the development of and changes to those constructions whose function is primarily referential and contentful. In modular frameworks, both ‘lexical’ items like watch and ‘grammatical’ items like the English past tense morpheme -ed are said to be stored in the lexicon, and various combinatorial rules or constraints determine the nature of a compositional expression like watched. The relationship between the internal structure of a word and the complex structure of a clause is important in constructional approaches to language. As Michaelis and Lambrecht (Reference Michaelis and Lambrecht1996: 216) observe, ‘the grammar represents an inventory of form–meaning–function complexes, in which words are distinguished from grammatical constructions only with regard to their internal complexity’. Indeed, some ‘words’ have an internal complexity similar to that of phrases and clauses, and the constructional model allows for a uniform treatment of changes affecting both lexical items and grammatical constructions. While what is discussed below is applicable to the development of inflectional morphology, the examples come from changes to the derivational morphology of English.
In this section, a review is presented of work which adopts a model of constructional morphology (Booij Reference Booij2010). This model treats word-formation patterns as schemas, abstractions across instances of use which in turn sanction new instances of use, consistent with the usage-based model. An example of a morphological schema is given as (1):
(1) [[x]V er]N ‘one who Vs’ (Booij Reference Booij2010: 2)
Schemas of this kind display prototype effects, partly as a reflection of frequency. Because lexical constructions are organized in the same way as grammatical constructions (i.e. in a taxonomic network with inheritance links), a unified approach to variation across subschemas is possible. As Booij (Reference Booij2010: 77–80) observes, the formal part of the schema in (1) maps onto a range of different semantic subtypes, such as instruments (I bought a new blender) and events (He's on a bit of a downer at the moment ‘He's in a low mood at the moment’). These semantic differences may be specified at the level of subschema.
The two case studies discussed here are the development of English – the V-ment construction (Hilpert Reference Hilpert2013) and the X-dom construction (Haselow Reference Haselow2011, Traugott and Trousdale Reference Traugott and Trousdale2013).Footnote 1 The former is used to illustrate how quantitative analysis may shed light on developments in word formation, the latter to illustrate the relationship between the development of word-formation schemas and traditional accounts of lexicalization.
Hilpert's study of the V-ment construction uses data from the Oxford English Dictionary. Its focus is ‘on a combination of a stem with the suffix, and on changes that pertain to this particular pattern’ (Hilpert Reference Hilpert2013: 112). Drawing on previous research by Dalton-Puffer (Reference Dalton-Puffer and Fisiak1996) and Bauer (Reference Bauer2001), Hilpert shows how the V-ment construction arose as a generalization across borrowings from French in the ME period (in cases such as payment, for instance, the stem is clearly verbal); once established, the construction was used by speakers with verbs that were Germanic in origin: the lexical increase here was therefore not a consequence of borrowing, but of a newly productive pattern in English morphology. The productivity of the pattern, however, has declined over time, such that it is not considered a productive pattern in contemporary English.
In terms of frequency, Hilpert's study (in partial contrast to earlier work by Anshen and Aronoff (Reference Anshen and Aronoff1999) and Bauer (Reference Bauer2001)) suggests a rise in the frequency of new types from 1300 to about 1500, then a gradual decline, i.e. ‘a fairly regular rise and fall pattern that is consistent with the idea that the V-ment construction started out as a young hopeful but did not retain its initial momentum’ (Hilpert Reference Hilpert2013: 127). In terms of productivity, Hilpert (Reference Hilpert2013) discusses several ways in which a corpus may be used to measure morphological productivity (e.g. realized, potential, and global productivity). In the case of the V-ment construction, Hilpert (Reference Hilpert2013: 131) argues in favour of expanding productivity as the appropriate measure. Expanding productivity is established by ‘dividing the number of hapaxes of a construction by the overall number of hapaxes in the corpus’ (Hilpert Reference Hilpert2013: 130). From the perspective of construction grammar, this is preferable as it allows us to see how productive a given morphological construction is in relation to similar constructions: ‘In the case of the V-ment construction, we not only learn that its productivity declined, but also that it declined relative to the productivity of other constructions in the grammar of English’ (Hilpert Reference Hilpert2013: 133). Using a set of univariate and multivariate analyses, Hilpert demonstrates how a range of factors is associated with the changing frequency of the V-ment construction in the ME and ModE periods.Footnote 2 These include the morphological structure and etymological source of the stem, and the degree of transitivity and semantic type of the entire construction. He finds that the various subtypes of the construction have their own trajectory, some of which are short-lived, some of which continue to the present, and that the period between 1250 and 1400 is particularly noticeable with regard to formal and functional variation as the construction develops. The dominant type – ‘with a native, transitive, internally complex verbal stem and an action interpretation’ (Hilpert Reference Hilpert2013: 153), exemplified by enlargement – continues to be productive from about 1400 until the construction as a whole decreases in frequency in the twentieth century.
In identifying various subtypes of the V-ment construction, some of which are associated with formal features, and some with semantics, Hilpert (Reference Hilpert2013) demonstrates how a constructional model provides some advantages over other accounts of morphological change. The developments summarized here show that a constructional network (rather than a single word-formation process) with schemas and subschemas is an appropriate means for modelling the kinds of changes that a quantitative analysis of the data suggest.
Traugott and Trousdale (Reference Traugott and Trousdale2013: 22) have also used aspects of Booij's constructional morphology model to account for the development of new word-formation schemas. Their approach differs from Hilpert's in that it is qualitative rather than quantitative, and distinguishes constructional change (which affects one level of a construction) from constructionalization, which they characterize in part as follows:
Constructionalization is the creation of formnew–meaningnew (combinations of) signs. It forms new type nodes, which have new syntax or morphology and new coded meaning, in the linguistic network of a population of speakers. It is accompanied by changes in degree of schematicity, productivity, and compositionality. The constructionalization of schemas always results from a succession of micro-steps and is therefore gradual.
In the rest of this section, key aspects of the constructionalization of a lexical schema are discussed. A fuller account is provided by Traugott and Trousdale (Reference Traugott and Trousdale2013). The change concerns the development of the OE lexical item dom, meaning ‘state’ or ‘judgement’.Footnote 3 As far back as the OE period, dom regularly occurred as the right (head) element of a compound. Haselow (Reference Haselow2011: 112) observes that dom ‘progressively changed its status into that of a suffix by adopting a more abstract, categorical meaning and undergoing phonological reduction. It is therefore difficult to determine a cut-off point which separates formations with dōm being compounds from those being genuine derivatives.’ Use as a free form and as a determinatum in a compound is exemplified by (2a) and (2b) respectively:
(2a)
for ðam ðe hit is Godes dom for that that it is God.GEN law.NOM ‘because it is God's law’ (Deut (c1000 OE Heptateuch) B 8. 1.4.5 [DOEC])
(2b)
for ðan þe he æfter cristes þrowunge ærest for that that he after Christ.GEN suffering first martyrdom geðrowade martyrdom suffered ‘because he was the first to suffer martyrdom after Christ's suffering’ (c1000 ÆCHom I.3 [DOEC])
The suffix developed into a bound form that is part of a new lexical constructional schema (3):
(3) [Xi -dom]N ↔ [‘condition associated with Xi’]
While such a schema might be proposed, it does not appear to have been well entrenched in OE. Dietz (Reference Dietz and Hans2007) records about fifty types with apparent affixal -dom. Of these wisdom is the most frequent with over nine hundred tokens. Haselow (Reference Haselow2011: 154) finds twenty-two types in a less extensive corpus, considers this to be low type frequency and concludes that the high token frequency relates to individual micro-constructions like wisdom ‘wisdom’, cristendom ‘christianity’, and martyrdom ‘martyrdom’: ‘the occurrence of -dom as the second element in compounds was restricted to a small number of highly frequent formations’ (Haselow Reference Haselow2011: 152). High token frequency of this sort but low type frequency suggests that the more abstract schema is not well entrenched (Croft and Cruse Reference Croft and Cruse2004, Barðdal Reference Barðdal2008). Later in the history of English, members of the schema given in (3) fell into disuse: in the words of Dalton-Puffer (Reference Dalton-Puffer and Fisiak1996: 76) ‘the picture is one of stagnation and eventual decline’. Part of the reason for this is potential competition (and the subsequent establishment of niches) in a neighbouring part of the network, with other expressions that were developing as suffixes, and had the meaning ‘state’ or ‘condition’, such as -had > -hood, -ness, and -scipe > -ship.
This brief summary of the development of -dom again supports a constructional morphology model, but looks beyond the network of ‘internal’ subschemas (see Hilpert Reference Hilpert2013 on V-ment) to the various niches that language users carve out for different constructional schemas. The network model is still relevant: for both sets of changes, we see links that can be established between and across schemas based on associations of form and meaning.
4.3.2 Syntactic schemas
This section considers two different kinds of change from a constructional perspective. The first involves semantic change occurring at the level of the syntactic schema. At a trivial level, since words are conventional symbolic units, change at the semantic level of a lexical item constitutes a constructional change, so traditional examples of broadening (OE brydde ‘small bird’ > ModE bird), narrowing (OE fugol ‘bird’ > ModE fowl ‘bird found on farms, typically for human consumption’), amelioration (ModE sick ‘ill’ > ‘very good’), and pejoration (OE cræftig ‘skilful’ > ModE crafty ‘deceptive’) may all be included. However, a more instructive finding would be if any such changes affected the semantics of more general and complex constructional types.
Colleman and De Clerck (Reference Colleman and Clerck2011) present a study of changes in the English ditransitive construction, which sought to explore the hypothesis that, if constructions are like words (i.e. conventional pairings of form and meaning), then some semantic changes said to affect words might also affect constructions. Particularly, the study is an attempt to investigate semantic narrowing in the ditransitive (or double object) construction, using data from the first sub-period (1710–80) of the Corpus of Late Modern English (Extended Version; De Smet Reference De Smet2005). Because the corpus is not syntactically annotated, nor tagged for parts of speech, only a limited search of the corpus was undertaken, and therefore only a partial picture of the change is presented. Colleman and De Clerck (Reference Colleman and Clerck2011) retrieved all instances of the construction where a personal pronoun was followed by an article, possessive pronoun, or quantifier. This resulted in 2,205 instances of the construction, with 111 different verbs.
Colleman and De Clerck found significant continuity between the semantics of the English ditransitive construction in the late modern period and that in the present day. There were some instances of losses and of gains affecting the construction which are not of core concern, namely the development of a new subschema in which the verbs denote the instrument of communication (e.g. email/fax/text), and the loss of (a polysemy of) an individual lexical item (e.g. bespeak, ‘order, arrange for’). More central to the present topic are cases where the verb itself continues to be used in contemporary English but is no longer readily admissible in the ditransitive construction. This incompatibility affects verbs such as banish.
Colleman and De Clerck (Reference Colleman and Clerck2011) identify five broad categories whose members are no longer readily associated with the ditransitive construction: verbs of banishment, ‘pure’ benefaction, communication, emotion/attitude, and disposition. The first three are illustrated by (4), with examples from the CLMETEV:
(4) Banishment: I therefore for the present dismiss'd him the Quarter deck (Cook, 1711)
‘Pure’ benefaction: so snatching out his pocket-book, and the young Benedictine holding him the torch as he wrote, he set it down as a new prop to his system of Christian names (Sterne, 1767)
Communication: I wish, my dear, you understood Latin, that I might repeat you a sentence in with the rage of a tigress that hath lost her young is described (Fielding, 1751)
With verbs expressing feelings and attitudes, Colleman and De Clerck (Reference Colleman and Clerck2011) found a decrease in frequency of ditransitive constructions with envy and forgive, and found no instances of verbs of dispossession (though some sporadic occurrences can be found in later corpora).
While not all sets change at the same rate, there appears to be evidence of a degree of semantic specialization/narrowing. This seems to be complete for some subschemas (e.g. banishment), but is ongoing in others (e.g. with the set of verbs expressing feelings and attitudes). In addition to supporting claims of a polysemous ditransitive construction in English (Goldberg Reference Goldberg1995), this research suggests that the semantics of schematic constructions may subject to similar types of change as those affecting lexical items. Furthermore, since it appears to be peripheral subschemas of the ditransitive construction that are affected most readily by this narrowing or specialization (consider the relationship between the lexical semantics of verbs like envy, and the degree of fit with the central semantics of the ditransitive), the changes lend further weight to the claim that constructions are organized in a network with prototypical instances and less typical extensions.
The change described above is one which affected an existing schema. However, as was the case with the word-formation schemas V-ment and X-dom discussed in section 4.3.1, grammatical schemas (such as cleft constructions) can also come into being. One such example in the history of English are the all- and what-pseudo clefts (as in All he did was laugh and What John did was laugh). These form part of another network of constructions, including the it-cleft (it was John who laughed) and th-clefts (The one who laughed was John). Patten (Reference Patten2012) identifies an overarching schema (a non-derived specificational construction) which, like the V-ment lexical schema discussed above, has several subtypes.Footnote 4 Some subtypes cohere into subschemas (like the it-cleft subschema) while others (like the pseudo-clefts) are simply individual constructional types. Patten (Reference Patten2012) suggests that over time, there has been a gradual coalescence of the various members of the specificational schema: it-clefts in OE focus NPs, but there is host-class expansion in the sense of Himmelmann (Reference Himmelmann, Bisang, Himmelmann and Wiemer2004) such that in ME, it-clefts can focus AdvP, and in ModE, clauses; conversely, all- and wh-clefts can now be used to focus NPs.
While it-clefts arose in OE (Patten Reference Patten2012, contra Ball Reference Ball1994), pseudo-clefts are attested in the EModE period (Traugott Reference Traugott, Cooper and Kempson2008). There was another, related specificational construction attested at the time, namely the th-cleft; there was also an information structuring (but non-specificational) construction, left dislocation, which appears to have been obsolescing in the EModE period (Pérez-Guerra and Tizón-Couto Reference Paradis2008), but variants with BE as the main verb share some structural similarity to wh-clefts. So while there were constructions in existence which had related functions or related forms, nothing with the precise form and function of the pseudo-cleft appears to have been in existence prior to the late sixteenth century (Traugott Reference Traugott, Cooper and Kempson2008). In the late sixteenth and early seventeenth centuries, examples such as (5a) and (5b) can be found in the standard corpora:
-
(5a) For it is more then death unto me, that her majestie should be thus ready to interpret allwayes hardly of my service,…All her majestie can laye to my charge ys going a little furder then she gave me commission for. (1585–6 Earl of Leicester, Letter to Walsyngham [CEECS])
(5b) thereby to insinuate, That what he did, was only to Preach to such, as could not come to our Churches. (1661 Stillingfleet, Unreasonableness of Separation [CEEC])
Notice that in (5a), all means only, and in both instances the syntax is biclausal and the complement of BE is factual, properties which characterize the modern wh-pseudo clefts, though subsequent constructional changes take place between the sixteenth century and the contemporary period which give rise to the construction in use today (see further Traugott Reference Traugott, Cooper and Kempson2008, Patten Reference Patten2012, Traugott and Trousdale Reference Traugott and Trousdale2013). These examples suggest new construction types emerging in the history of English which have distinctive syntactic and semantic properties, but which are nevertheless networked with the existing it- and th-clefts. Traugott (Reference Traugott, Cooper and Kempson2008) linked the developments to standard accounts of grammaticalization: an information-structuring pattern has become fixed, do bleaches from a main verb to a pro-verb, and there is a shift in the case of wh-clefts from biclausal to monoclausal structures (see also Lehmann 2008).
4.3.3 The loss of schemas
The examples discussed so far have all been concerned with the creation of new schemas, whether these be to create new referential constructions (as in the case of the early history of noun forming schemas V-ment and X-dom), or information-structuring constructions like the clefts. But there is evidence in the history of the language that schemas fall into disuse over time. Indeed we have seen this with the loss of productivity of the morphological constructions discussed above. But this is a property also of argument–structure constructions. In the case of the ditransitive construction, we saw semantic narrowing at the schematic level; in the case of the English impersonals, the entire constructional schema is lost, as the English transitive expands (Trousdale Reference Trousdale, Fitzmaurice and Minkova2008b). In OE, a number of subschemas of the impersonal construction existed. Following Elmer (Reference Elmer1981) and Allen (Reference Allen1995), we can identify these as N, I, and II. Type N (a subschema whose predicate includes verbs like lystan ‘desire’) had nominal arguments inflected for genitive and dative/accusative case; Type I (a subschema whose predicate includes verbs like laþian ‘loathe’) had nominal arguments inflected for nominative and dative case; Type II (a subschema whose predicate includes verbs like behofian ‘have need of’) had nominal arguments inflected for genitive and nominative case. In a manner that parallels the ‘competition in constructional space’ that was suggested for the loss of the X-dom word-formation schema, as speakers came to code more and more two-place predicates using the transitive schema (with source and experiencer arguments inflected for subject and oblique case), fewer and fewer instances in all of the subschemas persisted. The change was a gradual one: it was still possible in the EModE period for speakers to use like in its ‘impersonal’ sense (i.e. where the subject has the role of source and the object the role of experiencer). In twenty-first century English, the only remnant of this pattern is the expression methinks. Having been isolated from any recognizable schema, the form has been newly analysed by speakers as an epistemic adverb meaning ‘in my opinion’.
A rather different kind of loss is manifest in some of the changes often referred to as lexicalizations in the history of the language. Examples of this kind include cobweb (< OE coppe ‘spider’ + web), earwig (< OE eare ‘ear’ + wicga ‘one that moves’), and mermaid (< OE mere ‘sea’ + mægden ‘maiden’) (examples from Brinton and Traugott Reference Brinton and Traugott2005: 50). In these cases we have the development of fully specified forms (there are no open slots, as is the case with V-ment or the wh-clefts), but one element of the historical compound remains transparent. Other examples of lexicalization provided by Brinton and Traugott (Reference Brinton and Traugott2005: 50) include gospel (< OE god ‘good’ + spel ‘news’), gossip (< OE god ‘god’ + sibb(e) ‘relation’), and halibut (< OE halig ‘holy’ + butte ‘flatfish’). In these cases, again there are no open slots in the new construction, but here no element remains transparent. Constructional morphology can explain these patterns as the gradual development of unanalysable wholes: examples in the first set are more analysable than the second, but even in the first set we see variability – cobweb is more transparent than mermaid, and the latter is more transparent than earwig. The parallel becomes even clearer when different types of idiom are considered (Nunberg et al. Reference Nunberg, Sag and Wasow1994): idiomatically combining expressions like pull strings ‘exert influence’ are more analysable than idiomatic phrases like red herring ‘a false trail’.
4.4 Comparisons with other accounts of change and future directions
As discussed in section 4.3, some researchers have proposed ways in which a constructional model of language (change) has advantages over other models, and as noted in the first section of this chapter, there are certain ways in which the very fundamentals of construction grammar set it apart from other frameworks. While some differences (on modularity, and on the precise relation between use and structure, for example) are likely to remain contentious for some time, there are other ways in which some constructional approaches to change and some generative approaches have independently reached similar conclusions.Footnote 5 One such area concerns the relative importance of reanalysis and analogy in change. Both Traugott and Trousdale (Reference Traugott, Jucker and Taavitsainen2010) and Roberts (Reference Roberts, Traugott and Trousdale2010), for example, privilege reanalysis above analogy. There also appears to be convergence on what it means to say that change is gradual. For example, Traugott and Trousdale (Reference Traugott and Trousdale2013) recognize that constructionalization involves a sequence of changes, but that each individual micro-step is discrete; this appears to be consistent with the nature of upwards reanalysis in a generative model of change which relies on a clausal hierarchy in which category distinctions are very fine-grained (Cinque Reference Cinque1999, Roberts Reference Roberts, Traugott and Trousdale2010).
In terms of future directions, there are many possibilities. One concerns the relationship between micro-constructions and the schemas with which they are aligned, and the degree of granularity at which changes occur. For instance, there is general consensus that change begins in constructs (understood as tokens, attested instances of use), and that a systematic change involves the creation of a new micro-construction (low-level types). But if constructions exist in a taxonomic network, how far do the effects of change spread (both in terms of extensions to other micro-constructions, and in terms of the more general schemas that sanction micro-constructions)? It is recognized that constructional templates vary in their degree of specificity but to what extent and in what way are the more abstract templates affected by change at a micro-constructional level, and how would this be measured? Here it is likely that the kind of quantitative work associated with (diachronic) collostructional analysis (see, e.g., Hilpert Reference Hilpert, Nevalainen and Traugott2012b, Stefanowitsch Reference Stefanowitsch, Hoffmann and Trousdale2013) will shed some light on the effects of change. A related issue is the extent to which patterns which could be brought under a single schema are indeed categorized as such by speakers, or whether speakers treat such relations as a kind of family resemblance. This is connected with the kinds of claims made regarding differences between it-cleft and pseudo-cleft constructions above, where the former is treated as subschema, and the latter as a set of separate micro-constructions. The issue of relationship between change in the mental representation of the individual speaker (i.e. the constructional knowledge characterized by an idiolect) and the change in the ‘linguistic network of a community of speakers’ (Traugott and Trousdale Reference Traugott and Trousdale2013: 22) also needs to be considered in greater depth.
The relationship between a formal model of change and a constructional model of change was briefly addressed above. Formal models tend to have an advantage over non-formal models in terms of the preciseness of the representation of the grammar. Some constructional models (e.g. Sign-Based Construction Grammar; Sag Reference Sag, Boas and Ivan2012, Michaelis Reference Michaelis, Hoffmann and Trousdale2013) have a specific formal representation, and one possible future direction is to see whether and how some of the changes described in the literature on constructional change could be modelled in that framework. Fried (Reference Fried, Bergs and Diewald2008) has articulated some principles of formal constructional change as applied to aspects of the history of Czech in a related constructional model; there appear to be fewer such descriptions of changes in English.
In this final section I have had rather less to say about English and more about more general issues of historical linguistics. There are clearly many other areas of English grammar which could be explored using a constructional model. Indeed, there already have been many such studies on English and related languages (e.g. on raising to subject and raising to object (Noël and Colleman Reference Noël and Colleman2010); on passive and copular constructions (Petré Reference Petré2014); causatives (Hollmann Reference Hollmann2003); on future constructions (Hilpert Reference Hilpert2008), to name just a few). Clearly the greater the number of different case studies, the more hypotheses can be tested across different data sets. Furthermore, both in terms of synchrony and diachrony, construction grammar has had rather less to say about phonological change than about change at any other level.
4.5 Conclusions
Many of the principles that are shared across different variants of construction grammar have been explored from the perspective of language change, and particularly in terms of changes affecting English constructions. Some of these changes have occurred at one ‘level’ in the construction (e.g. changes affecting the semantics of a lexical construction, or a grammatical schema); others have involved the creation of new constructions (including word-formation schemas, and information-structuring constructions like clefts). These topics have been approached using quantitative and qualitative methods; both methodologies have provided rich insights into the nature of constructional change, the relationship between constructional change and other accounts of change, and some of the ways in which English has evolved over time. New directions might include a more precise formalization of aspects of change, research into ongoing changes, particularly in new varieties of English that have been the product of substantial contact between speakers.
5.1 Introduction
In this chapter, I will outline the basic philosophy behind generative grammar and how that view has an impact on the relationship between generative grammar and English historical linguistics. I provide an overview of the shifts that generative grammar has undergone in the last sixty years, from a system with highly specific phrase structure rules to a system of feature checking. The discussion will mostly be limited to morphosyntactic change and will only briefly mention phonological change. I will finish with a discussion of the advantages and the disadvantages that this model offers to linguists working in the history of English and vice versa.
Generative grammar has its beginnings in the late 1950s with the work of Noam Chomsky and emphasizes innate linguistic knowledge, or Universal Grammar. Children use their innate knowledge and, on the basis of the language they hear spoken, also known as the E(xternalized)-Language, come up with a grammar, also known as the I(nternalized)-Language (see Chomsky Reference Chomsky1986: 19–24). Generative grammar focuses on the ability of native speakers to speak and understand grammatical sentences.
Since the focus of generative grammar is on the linguistic knowledge present in the mind of a native speaker, many generativists think that it is impossible to study historical stages of a language because native speakers of, for instance, Old English are unavailable. This lack of native-speaker intuitions is the main reason behind the criticisms one encounters using data from Old, Middle, and later English in a generative framework.Footnote 1
Because generative grammar has evolved in the last sixty years, I will provide some background on early work but then focus on the two most recent approaches, namely the Principles and Parameters (P&P) model of the 1980s and 1990s and the Minimalist Program of the 1990s to the present. Principles hold true for all languages and include, for instance, the basic shape of phrases (with a head and a complement), the requirement that movement is local, and that sentences are hierarchically structured rather than linearly. Parameters account for cross-linguistic differences and are to be set depending on the evidence the learner is faced with. If, for instance, the language the learner hears places the object before the verb, the parameter is set as Verb-final.
The P&P approach to historical linguistics examines differences that exist in the syntax of different stages, such as variant word order and the presence or absence of Verb-movement. A change in word order is seen as a parametric change from Object–Verb (OV) to Verb–Object (VO). Old English has OV in (1) because the object medoful ‘cup’ precedes the verb ætbær ‘brought’ but Modern English has VO in (2) because the verb precedes the object. This change is accounted for by a resetting of the headedness parameter from Verb-final to Verb-initial.
(1)
þæt hio Beowulfe … medoful ætbær that she Beowulf … meadcup brought ‘that she brought the cup to Beowulf.’ (Beowulf 623–4)
(2) She brought the cup.
In Minimalism, the emphasis is very different. This model focuses on how the lexical and grammatical items differ cross-linguistically in their features. For instance, in Modern English, declarative sentences have to have a Subject precede the Verb and this is accounted for by a feature (named the EPP feature on the T(ense) head). The OV/VO difference is also accounted for by means of features, as will be shown in section 5.5.
The outline of this chapter is as follows. In section 5.2, I examine the basic philosophy of generative grammar and the implications for historical syntax. In section 5.3, I consider early generative grammar and, in section 5.4, I discuss its early instantiations and look at the P&P approach, perhaps the most popular approach (even today) among practitioners of English historical generative syntax. In section 5.5, more recent models are discussed, features and cartography. Section 5.6 provides a short assessment on how generative grammar and English historical linguistics can work together fruitfully.
5.2 Generative grammar and historical linguistics
In this section, I first discuss the general generative attitude towards historical linguistics. I also note that mainstream English historical linguists do not always see generative grammar as helpful.
Generative grammar is interested in how a child acquires a grammar on the basis of the language the child is exposed to. If the language the child hears has changed or is changing from that which the parents/caregivers grew up with, the child will have a different input and may come up with a grammar (I-Language) different from that of the preceding generation. Generative grammar proposes principles that account for how a child constructs an internal grammar. Generative linguists are most interested in language change if this change happens in connection with the learning process. External change modifies the linguistic input, the E-Language available to the child, and the real interest is in how the child deals with this in terms of parameter resetting. If children hear more Verb–Object (VO) sentences than Object–Verb (OV) ones, a change possibly due to linguistic contact, they will assume that the word order is VO and set their parameter for Verb-headedness as head-initial rather than as head-final.
There are of course many ways in which language change can provide insights into the (generative) language faculty. For instance, changes that have not yet been attested may show restrictions imposed by Universal Grammar and, in turn, frequently attested changes that are reanalyses of the input by the child shed light on the language faculty. One example of a frequent change is that prepositions are reanalysed as complementizers, e.g. for and after in the history of English and not the other way round. This is a unidirectional change that gives us insight into the language faculty. Thus, (3a) is earlier than (3b) and (4a) earlier than (4b). The prepositional use of (3a) and (4a) is typical of Old English, whereas the first instances of complementizer use is in Early Middle English.
(3a)
hlynode for hlawe made.noise before mound ‘It made noise before/around the gravehill’ (Beowulf 1120)
(3b) I would prefer for John to stay in the 250 class. (British National Corpus ED2 626)
(4a) Ercenberht rixode æfter his fæder
‘E. ruled after/following his father’ (Anglo Saxon Chronicle A, anno 640)
(4b) After she'd hung up, she went through into the kitchen. (British National Corpus GWO1402)
Note that the change from preposition to complementizer shows some intermediate stages, e.g. one where the entire prepositional phrase is preposed (see van Gelderen Reference Gelderen2011b).
Possibly because of the early emphasis on introspection and grammaticality judgements by a native speaker, work in historical generative syntax was not mentioned or referred to in Chomsky. The exception is the work on phonological change in Chomsky and Halle (Reference Chomsky and Halle1968) and that was most likely due to Halle's interests (as evidenced in Halle Reference Halle1962). Since Chomsky has set the agenda for generative linguists for at least fifty years, it has been ‘less popular’ to pursue historical linguistics, although there have been many exceptions.
Thus, there has always been a group of generative linguists interested in historical change, arguing that such change gives a special insight into the innate language faculty. Work by Closs (later Closs Traugott), King, Kiparsky, Klima, Lakoff, and Lightfoot testifies to that. Starting in 1990 in York, generative historical linguists have come together through the DiGS (Diachronic Generative Syntax) conference which is devoted entirely to diachronic generative syntax. Many of the DiGS conferences had selected papers appear, e.g. as Battye and Roberts (Reference Battye and Roberts1995), van Kemenade and Vincent (Reference Kemenade, van Kemenade and Vincent1997), Pintzuk et al. (Reference Pintzuk, Tsoulas, Warner, Pintzuk, Tsoulas and Warner2000b), and Crisma and Longobardi (Reference Crisma and Longobardi2009), and I return to these publications later.
As mentioned above, generative syntax has typically relied on introspective data, i.e. asking a native speaker for grammaticality judgements, because of the model's emphasis on the internalized grammar. These grammaticality judgements have involved complex constructions, requiring the hearer to judge whether the sentence in (5) is grammatical or not.
(5) *What did you see the man that ate?
The intended meaning of this ungrammatical sentence is to ask what the man ate; a grammatical alternative is (6).
(6) What did the man you saw eat?
Generative grammar assumes that words such as what move from the position they occupy as subject or object of a particular verb – in (5) and (6) what is the object of the verbs ate and eat respectively – to the position they occupy to indicate that the sentence is a question. In (7), the original position of what is indicated by an underscore; what is moved out of a relative clause.
(7)
*What did you see the man [that ate __]? Relative Clause Island
The ungrammaticality of (5) shows that what cannot be moved from the relative clause. Ross (Reference Ross1967) identifies structures out of which movement is not possible and calls them ‘islands’. Since, in (5), what is taken from a relative clause, the construction is called a Relative Clause Island. Compare (5) to sentences such as (8) and (9): what is moved from a main clause in (8) and from a complement clause in (9). These movements result in grammatical sentences unlike the movement in (7).
(8) What did the man [you saw] eat __?
(9) What did you say [that the man ate __]?
Sentences such as these have never been taught to (native) speakers of English and yet they have clear grammaticality judgements. This ability to judge grammaticality then is due to their I-Language, constrained by principles of Universal Grammar.
Allen (Reference Allen1977), working with non-electronic texts, finds instances relevant to islands. In (10), the wh-word hwaet has been moved from the position of the subject of the predicate sie forcuðre to the beginning of the sentence.
(10)
Ac hwaet saegst ðu ðonne ðaet __ sie forcuðre But what say you then that be wickeder ðonne sio ungesceadwisnes? than be foolishness ‘But what do you say is wickeder than foolishness?’ (Boethius 36.8, from Allen Reference Allen1977: 122)
This movement results in an ungrammatical sentence in Modern English when it leaves that adjacent to the gap. (Some speakers of English do not find these sentences ungrammatical in Modern English and Fischer (Reference Fischer2007: 41) suggests the ungrammaticality may be a feature of written English.)
The absence of native speakers of Old English to check sentences like (10) and the reliance on written texts and (now) electronic corpora kept some generative grammarians from going into historical linguistics. Many generative linguists that went into historical linguistics have embraced work with the Penn Corpora of Historical English, including the Penn-Helsinki Parsed Corpus of Early Modern English, the Penn Parsed Corpus of Modern British English, the York–Toronto–Helsinki Parsed Corpus of Old English Prose, the Penn-Helsinki Parsed Corpus of Middle English. The Corpus of Historical American English is tagged for parts-of-speech and non-parsed texts are available from the Dictionary of Old English and the Middle English Compendium, to name but a few electronic resources.
A practical consequence of the uneasy relationship between generative grammar and historical linguistics is that generative conferences and journals do not see historical linguistics as a crucial component to their enterprise of understanding the faculty of language. Apart from the DiGS conference, mentioned above, other venues are generative or historical but not both. For instance, NELS (North East Linguistic Society) is a prominent generative conference and rarely includes historical work. If many generative linguists are sceptical about historical linguistics, the reverse is also true. Many (non-generative) historical linguists often see generative work as data-poor, over-theoretical, and not very insightful. This can be seen from the impact, or rather lack thereof, of generative linguists on mainstream historical linguistics conferences. For instance, conferences such as ICHL (International Conference on Historical Linguistics) and ICEHL (International Conference on English Historical Linguistics) will have generative papers and occasional plenary addresses using that framework, but generative grammar is a minor framework.
The field of English historical linguistics, as evidenced by the programmes of ICEHL and SHEL (Studies in the History of the English Language), is very theoretically diverse. The fields of pragmatics and discourse studies have really taken off and constraints from information structure are being used to account for syntactic variation, in particular for word order variation and pronoun choice. Many syntacticians of English historical linguistics have broadened their interest from syntactic issues to pragmatics. Ans van Kemenade (e.g. Reference Kemenade, Hinterhölzl and Petrova2009), Bettelou Los (e.g. Reference Kemenade, Milićev, Jonas, Whitman and Garrett2012), Susan Pintzuk and Ann Taylor (e.g. Pintzuk and Taylor Reference Pintzuk and Taylor2011), and Augustin Speyer (e.g. Reference Speyer2008) now focus on the relation between word order and information structure. See also Meurman-Solin et al. (Reference Meurman-Solin, López-Couso and Los2012) and the special issue of the Catalan Journal of Linguistics (2011) edited by Montserrat Batllori and Lluïsa Hernanz.
Having introduced the general emphasis of generative grammar, I now turn to some specific work in the next section.
5.3 Transformational generative grammar
In this section, I discuss some early generative approaches to language change for which King (Reference King1969) provides a good overview. This work involves both phonological change and syntactic change but I will focus on the latter, in particular Closs's work on English modals.
Closs (Reference Closs1965), Klima (Reference Klima1965), Kiparsky (Reference Kiparsky1965), and Chomsky and Halle (Reference Chomsky and Halle1968) emphasize learning as the cause of change. The latter authors state that ‘speakers are by and large unaware of the changes that their language is undergoing’ (1968: 250) and that, where adults can only add or delete minor rules, children can reorganize the system. This view goes back to Halle (Reference Halle1962: 64, 66–7). Closs (Reference Closs1965: 415) concludes that ‘language changes by means of the addition of single innovations to an adult's grammar, by transmission of these innovations to new generations, and by the reinterpretation of grammars such that mutations occur’.
Klima (Reference Klima1965: 83) formulates a model of generative language change emphasizing the discontinuous nature of change and reanalysis by the learner.Footnote 2 I adapt it as Figure 5.1 which is also based on Andersen (Reference Andersen1973). It includes changes that adults can make (minor innovations) and that are then the input for the new generation. Figure 5.1 expresses that the exposure to a language triggers a grammar in an individual that is referred to as I-Language which, in turn, produces an E(xternal)-Language.
Closs (Reference Closs1965), Kiparsky (Reference Kiparsky1965), Lakoff (Reference Lakoff1968), Closs Traugott (Reference Traugott1972), and Lightfoot (Reference Lightfoot, Anderson and Jones1974, Reference Lightfoot1979) use this model in various forms. Their explanations depend on the then current model of phonology and syntax. The model of phonology is fairly abstract with a large number of rules and the syntax has a phrase structure component and a set of ordered transformations. Most change was seen as change in the phonological and transformational rules, either by rule loss, rule reordering and addition, and restructuring/simplification.
Closs (Reference Closs1965) is, of course, the basis of much later work on auxiliaries, both in terms of the data as well as the analysis. She is concerned with the phrase structure rules and how the shape of AUX is different in Old English and suggests ways to account for the difference. The phrase structures for Old English are formulated as in (11); MV stands for main verb, Vt for a transitive verb, Vi for an intransitive one (with ‘move’ indicating a movement verb), PrP and PP for Present and Past Participle, and ‘env’ for ‘environment’.
(11)

Closs thus argues that modals are a class separate from main verbs, as they are in Modern English, but that the main verb is in final position (as can be seen from the NP–V rule). She also accounts for the Old English have–be auxiliary split: transitive verbs have a perfect with have and intransitive ones have one with an auxiliary be. The main difference between Old and Modern English is that in Old English, in addition to the main verb and a modal, only one other auxiliary can appear. The AUX rule stipulates that.
She then looks at Middle English and argues that by the thirteenth century the word order is as in Modern English where the AUX precedes the main verb and the T and M precede the other auxiliaries. This is represented by (12) where the lexical verb also precedes the object NP. Other major changes that occur by the late sixteenth century: have is the generalized perfect for all verbs except those of movement, the spread of auxiliary or periphrastic do and the progressive passive. This gets us the following rules for Early Modern English.
(12)

Closs chronicles the types of changes: reversal of the order, loss of restrictions, addition and loss of formants, and ‘finally…really radical changes of system membership, e.g. when do, which was a member of the lexical system, gave rise to an operator in the syntactic system’ (p. 412). Her final conclusion is that ‘language changes by means of the addition of single innovations to an adult's grammar, by transmission of these innovations to new generations, and by the reinterpretation of grammars such that mutations occur’ (p. 415). This conclusion fits perfectly with the model presented in Figure 5.1.
Lightfoot (Reference Lightfoot, Anderson and Jones1974), also focusing on modals, formulates the phrase structure rules for the modals a little differently from Closs (Reference Closs1965) but they are similar enough that I need not reproduce them. Unlike Traugott, Lightfoot argues that modal verbs are full verbs in Old English because they bear number agreement and act like main verbs in negative placement and inversion. After Old English, a number of seemingly isolated changes take place in pre-modals, namely the gradual loss of having an object and of inflection, that cause the child to assume a different I-Language from that of the earlier generation. Lightfoot calls this reanalysis a ‘radical change in the deep structure’ and a ‘radical restructuring’ (1974: 234). One of the advantages of generative analyses is to capture the relationships among phenomena that are not otherwise explainable. By assuming the modals and infinitival to and pleonastic do occupy a separate position around 1400, i.e. an I(nflection) or T(ense) position, one can explain the introduction of otherwise unrelated phenomena such as split infinitives, single modals, and the complementary distribution of modals, do, and to (see also van Gelderen Reference Gelderen1993).
The contemplation of the rapid changes in modals leads Lightfoot to adapting a principle from phonological change to syntax. Kiparsky (Reference Kiparsky and Dingwall1971) argues that, if the phonological representation of e.g. writer is /rayt-ər/ (the I-Language form) but the phonetic form is [rajder] (the E-Language form), there may be a reanalysis of the phonological form so that it resembles the phonetic form more closely. He calls this principle the Opacity Principle. If we need many rules to derive the phonetic form, the phonological form is opaque and the learner will make it more like the phonetic representation. Lightfoot adapts the Opacity Principle to syntax but formulates it in a positive way, namely that the grammar avoids opacity and favours transparency. He calls this principle the Transparency Principle and it explains that once, ‘the category membership of pre-modals became opaque…the grammar moved to avoid such opacity’ (1974: 244).
In this early period of the development of the generative framework, the change from verb to auxiliary, just described, is not identified as a special process. This process can be referred to as grammaticalization and had been recognized by von der Gabelentz (Reference Gabelentz1901) and Meillet (Reference Meillet1912). Grammaticalization is often defined as a change of a lexical item to a (more) grammatical one through a loss of semantic features. A typical example of grammaticalization was given in (3) and (4) where a spatial preposition for and a temporal preposition after are reanalysed as conjunctions introducing clauses. Even though Traugott's data present prototypical examples of grammaticalization (a verb being reanalysed as a modal auxiliary) and although she mentions the ‘jump’ of do from a lexical to grammatical class, the term grammaticalization does not appear till much later in her work (e.g. Traugott Reference Traugott, Lehmann and Malkiel1982).
Concluding, early generative approaches concentrate on formulating phrase structure rules such as those in (11) and (12). The next period focuses on principles and parameters, is more comparative, and becomes interested in how to account for grammaticalization.
5.4 Principles and Parameters
Parameters have been used in generative grammar since the so-called Principles and Parameters approach (Chomsky Reference Chomsky, Anderson and Kiparsky1973). As mentioned above, principles are valid for all languages but parameters need to be set and are therefore the locus of change. In this section, I first explain a little more what principles and parameters are in the P&P framework. I then look at work in the history of English that focuses on the headedness parameter and on Verb-movement.
Early examples of parameters include determining if a language has pro-drop (Rizzi Reference Rizzi1982), its headedness (e.g. Verb-last or Verb-first), and whether wh-elements move or not. Pro-drop is the cover term for a set of related phenomena centring on the absence of the subject in a finite clause. Thus, Italian is pro-drop but English is not. Whether the head of a phrase is initial or final (a VO language is head-initial and an OV language head-final), is an important way to characterize a language, with Modern English being head-initial and Old English (mostly) head-final, as we have seen in (1) and (2). Wh-movement characterizes Germanic languages, the various stages of English included, but this is not universally true, with Chinese being an example of non-movement.
Important work in the period from the mid 1970s to the early 1990s is done on word order and headedness. Canale (Reference Canale1978) argues that Old English changes its headedness around 1200 when it changes from an OV to VO language. Van Kemenade (Reference Kemenade1987) examines the word order in Old English and devises a phrase structure with a V-final VP and an I(nflection) position outside of the S(entence). She identifies two changes in the history of English, a change from OV to VO around 1200, echoing Canale, and a change in the position of the I(nflection). She argues that Verb-movement (to second position) becomes more limited in scope and is different from Verb-second in modern Verb-second languages, such as German or Dutch. Exploring the position of auxiliaries in relation to verbs leads to an examination of the inventory and order of the functional categories. Functional categories express aspect, mood, tense, pragmatic and semantic role, and are also known as closed categories. Work on determiners (Philippi Reference Philippi, van Kemenade and Vincent1997), complementizers (van Gelderen Reference Gelderen1993), the position of the I(nflection) (Pintzuk Reference Pintzuk1991), and auxiliaries (Warner Reference Warner1993) is the result.
A much more sophisticated model of word order starts to take shape. For instance, van Kemenade recognizes that wh-elements and negatives in initial, pre-V position trigger absolute V-second but that, with topicalized elements, the subject pronoun can precede the verb resulting in V-third, as (13) shows.
(13)
Ðas þing we habbað be him gewritene… these things we have about him written ‘These things we have written about him.’ (Chronicle E, 1087, 143, van Kemenade Reference Kemenade1987: 110)
A slightly updated tree for (13) is given in (14); I have kept the pronoun as a clitic to C, as in van Kemenade. This tree also shows the general clausal structure assumed from the mid 1980s on, with a C(omplementizer) Phrase and an I(nflection) Phrase (the latter replaced by T(ense) Phrase later on).
(14)
This work provides the seed to the current shift by van Kemenade and others, e.g. Los (Reference Los, Meurman-Solin, López-Couso and Los2012), to connecting word order and information structure. Topicalized elements, such as Ðas þing in (13), bring about very different structures from wh-elements, which are focus elements. In terms of information structure, a topic is often old information and a focus may present new information.
Constructions such as (13) also lead Kroch and Taylor (Reference Kroch, Taylor, van Kemenade and Vincent1997) to investigate the regional variation in the Verb-third construction and find that the south deviates more from the strict Verb-second pattern. Speyer (Reference Speyer2008) revisits the issue and argues that the choice between Verb-second and Verb-third is determined by a requirement to avoid two focused elements next to each other.
In the early 1990s, many linguists start looking at the category of I and C cross-linguistically and at Verb-movement (also known as inversion). Pintzuk (Reference Pintzuk1991) looks at the position of I in Old English, Roberts (Reference Roberts1993) at Verb-movement, auxiliaries, and I in French and English, Kiparsky (1995) at V-to-C movement in early Indo-European and Germanic, Eythórrson (Reference Eythórsson1995) at early Germanic Verb-movement, and van Gelderen (Reference Gelderen1993) and Los (Reference Los2005) look at the status of infinitives and the position of to in English.
Battye and Roberts (Reference Battye and Roberts1995), in the first volume to come out of the earlier-mentioned DiGS conferences, review the diachronic work done within the P&P framework. The title of that volume includes ‘Clause Structure’ and that is very apt since much of the work around this time is on formulating the clausal skeleton of CP, IP, and VP, i.e. parametric differences in V-to-I and V-to-C, in pronouns and clitics. In van Kemenade and Vincent (Reference Kemenade, van Kemenade and Vincent1997), entitled Parameters of Morphosyntactic Change, we can see the beginning of the shift towards Minimalism with its emphasis on morphosyntactic features. Most of the papers continue to be more in the P&P framework, as do those in Pintzuk et al. (Reference Pintzuk, Tsoulas, Warner, Pintzuk, Tsoulas and Warner2000b). Typical topics are null arguments, negatives and polarity, position of subjects, the change to VO order, and Verb-movement.
This is a period that becomes influenced by the cartographic model which aims to provide a unique position for each functional category. Following these cartographic ideas, Roberts (Reference Roberts, Brandner and Ferraresi1996) argues that clitics, such as the subject we in (13), are in the Spec of a Fin(ite) Phrase and that the V is in a Fin(ite) head position. I have shown this in (15), which uses a CP split into a Top(ic) Phrase and a Fin(ite) Phrase.
(15)
In wh-questions, the wh-element is in the Spec of a Focus Phrase and the V is in the head of this Focus Phrase. Note that there is no evidence for such an expanded main clause CP in northern dialects, as shown by the examples in Kroch and Taylor (Reference Kroch, Taylor, van Kemenade and Vincent1997: 321). In the northern glosses, the verb is always in second position even with topics.
In Old English, most subordinate clauses are Verb-final. Hence, these show no evidence of V-to-I movement although, once in a while, there is one that looks as if it has a topic with a verb moved to I, as in (16), from Pintzuk (Reference Pintzuk1991).
(16)
þæt his aldres wæs ende gegongen that his life was end come ‘The end of his life had come’ (Beowulf 822, from Pintzuk Reference Pintzuk1991: 187)
Pintzuk (Reference Pintzuk1991), of course, says that verbs always move to I but that the position of I is variable.
Thus, in the 1990s, historical generative syntax continues to be concerned with clause structure and the parameter of Verb-movement. It starts to pay attention to information structure and to use cartographic structures in the late 1990s.
5.5 Current generative grammar: cartography and featuresFootnote 3
At the moment, the emphasis in the Minimalist Program is on principles not specific to the language faculty, but to ‘general properties of organic systems’ (Chomsky Reference Chomsky and Belletti2004: 105), labelled third factor principles in Chomsky (Reference Chomsky2005, Reference Chomsky, Sauerland and Gärtner2007). For instance, Chomsky (e.g. Reference Chomsky and Belletti2004, Reference Chomsky, Sauerland and Gärtner2007) and Richards (Reference Richards, Heck, Müller and Trommer2008) attribute as little as possible to the role of parameters and to Universal Grammar in general. Apart from this move away from language-specific principles, a second change is that Minimalist parameters consist of choices of feature specifications as the child acquires a lexicon. All parameters are lexical and determine the linear order of the words; therefore, they account for the variety of languages. As Pintzuk et al. (Reference Pintzuk, Tsoulas, Warner, Pintzuk, Tsoulas and Warner2000b: 7) put it, ‘the lexicon…must be the locus of syntactic change’.
Both developments, the move towards general principles and towards parametric features, make it easier to account for grammaticalization, a very frequent change that was left unmentioned in early generative work and one that I will discuss in this section. First, I will say a little more on the cartographic approach whose goal it is to map the order of the functional elements precisely and hence the name (with the main works being Rizzi Reference Rizzi and Haegeman1997 and Cinque Reference Cinque1999). This approach was introduced in the previous section because it emerges from the P&P model. It provides an answer to the problem of how grammatical categories, such as the various auxiliaries and adverbs, are ordered. Cinque comes up with a Functional Hierarchy, as in (17), for a subset of cases.
(17)
Tpast Tfut Moodir Modnec Modpos ASPhab ASPrep once then perhaps necessarily possibly usually again ASPfreq often (from Cinque Reference Cinque1999: 107)
Roberts’ tree in (15) represents a cartographic representation of the highest layer of the clause, namely how clitics and topics are ordered in the expanded CP domain. Other diachronic work using this approach is, for instance, that by Wood (Reference Wood2003) on the DP and van Kemenade (Reference Kemenade, van Kemenade and Vincent1997) on the CP layer. More could be done in the domain of modal verbs and adverbs as they grammaticalize. Under the Roberts and Roussou (Reference Roberts and Roussou2003) and van Gelderen (Reference Gelderen2004) approaches to grammaticalization, modals and adverbs would move from right to left on the Hierarchy in (17).
The more Minimalist change in direction has been to focus on features. Here, I discuss two such initiatives: one to account for grammaticalization in terms of features and a second to account for word order that way.
Van Gelderen (Reference Gelderen2011b) argues that grammaticalization can be understood as a change from semantic to formal features. An Old English verb such as wolde ‘wanted’ in (18a) has [volition, expectation, intention] features. These features are simplified when will is reanalysed as having the grammatical feature [future] in (18b).
(18a) Ta þreo kingess…forenn till Herode king To witenn whatt he wollde.
‘The three kings went to King Herod to know what he wanted.’ (Ormulum 6571, from the Middle English Dictionary)
(18b) I'll never forget the judge saying that Lindy would be put into jail for life…(COCA 2012 news)
Subsequently, verbs like go and want go through this same reanalysis as future markers in (19) and (20).
(19) Let's get inside. It's going to rain. (COCA 2011 fiction)
(20) We have an overcast day today that looks like it wants to rain. (Nesselhauf Reference Nesselhauf2012: 115)
Biberauer and Roberts (Reference Biberauer, Roberts and Eythórsson2008) in examining the shift in word order from OV to VO rely crucially on a feature that has been called the EPP-feature. This feature (in languages that have it) is responsible for making a subject move to sentence initial position. If the T(ense) position bears this feature, a D head will move to T or a DP will move to the specifier of the TP, as is the case in Modern English. Languages can also have a VP or vP satisfy the EPP feature. This is the option chosen in Old English: the VP is moved rather than stranded as it is in Modern English. Thus, Biberauer and Roberts derive the Old English word orders by raising V to the light verb v, VP raising to the specifier of vP, and vP raising to the specifier of TP, as in (21) for sentence (22).
(21)
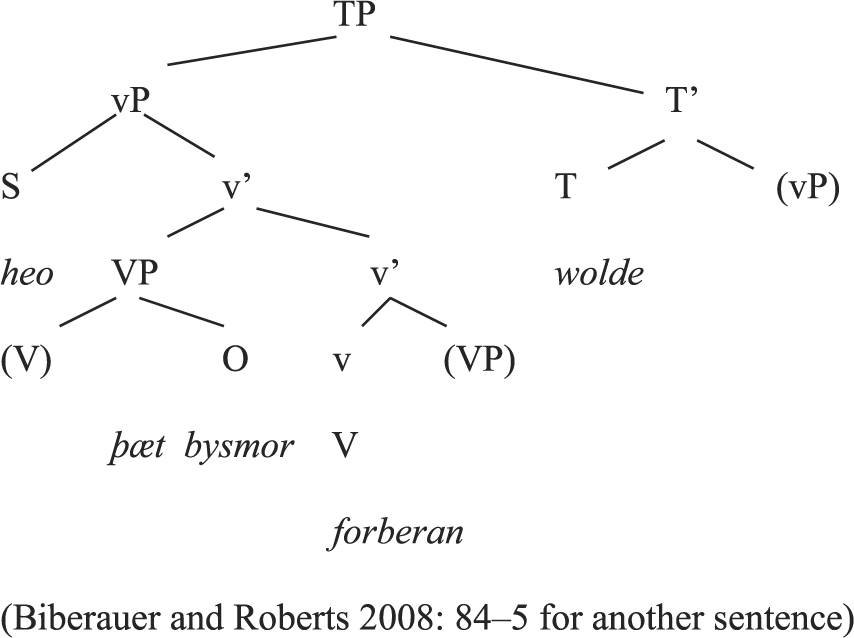
(22)
gif heo þæt bysmor forberan wolde if she that disgrace tolerate would ‘if she would tolerate that disgrace.’ (ALS [Eugenia]: 185.305, from Pintzuk and Taylor Reference Pintzuk and Taylor2011)
To be more precise, in (22), the V forberan ‘tolerate’ first moves to little v and the VP with just the object in it moves to the specifier of the vP, resulting in the OV order. Then, the subject is combined (also known as ‘merged’) to a second specifier position in the vP and the entire vP is moved to the Specifier of the TP.
Various other word orders can be derived as well depending on whether the entire vP is moved to the specifier of the TP or just the subject. In the latter case, we derive (23).
(23)
Martianus hæfde his sunu ær befæst Martin had his son earlier established ‘Martin had earlier established his son’ (ALS_[Julian_and_Basilissa]: 184.1049, from Pintzuk and Taylor Reference Pintzuk and Taylor2011)
In short, current generative historical linguists are using both the cartographic model and feature checking mechanisms to account for grammaticalization and word order variation. In the next section, I provide a more general evaluation of what generative grammar and English historical linguistics can contribute to each other.
5.6 Generative grammar and English historical linguistics
English historical linguistics is most beneficial for generative grammar, in my mind, when it can provide evidence for recurring patterns of change, such as the frequent grammaticalizations. Because written sources in English go back at least 1,500 years, we can see these changes recur, as in the case of the emergence of future markers. These then provide a window on the acquisition process, so crucial to generative grammar. If different varieties all change in the same direction (all renew in a similar way), there must be a universal force driving that.
English historical linguistics, in its turn, benefits by the novel questions generative grammar asks, such as what is the role of certain features in Old English. We have had recent innovative work on changes in word order and information structure that would not have been done if generative grammar had not provided the cartography of the clause (and the nominal). This has given rise to a renewed examination of data from older stages. For Old English, it has meant a closer look at the kinds of topicalizations and the structure of Verb-third constructions. There is thus a lot of opportunity for English historical linguistics and generative grammar to have a mutually beneficial influence.
5.7 Conclusion
In this chapter, I have sketched the basic philosophy behind generative grammar and how that view impacts the relationship of generative grammar with English historical linguistics. In the last sixty years, there has been a shift from a system with highly specific phrase structure rules to a system of feature checking.
Generative grammar is concerned with the linguistic knowledge in the mind of a speaker and it focuses on how children acquire their internal grammars based on the available evidence. In this model, the child is the main reason for (internal) linguistic change. If language change can be shown to be regular, this gives us a window on the language faculty. Lexical words grammaticalize to grammatical ones and this can be accounted for if it is the child that extrapolates grammatical features from lexical ones during language acquisition. Language acquisition in this model is discontinuous and linguistic change need not be gradual: a parameter can be set differently by the next generation, with major changes as a result. Currently, the emphasis on features makes it possible to also consider gradual change, such as that characterized by changes in future marking and the change from preposition to complementizer.
6.1 Introduction: the nature and purpose of philological study
What is meant by the word ‘philology’ is by no means universally agreed upon, though a commonly held conception of the matter is that it is an aggregate of the various modes of inquiry required for the editing of texts in extinct languages (see, e.g., Gumbrecht Reference Gumbrecht2003: 1–4), an endeavour that has for most of its history had as its chief aim recovering authorial versions of texts altered in the course of transmission (though alternative views are mentioned below). Philology may thus involve historical and comparative linguistics and the study of manuscripts (including palaeography, codicology, the study of how manuscripts are related to one another, and scribal practices), orthographic systems (including orthoepy), poetic metre, rhyme, translators’ practices, and numismatics, among other concerns. In connection with English historical linguistics, many of these same concerns are brought to bear by the philologist, and thus, the philological component of historical linguistic study may be regarded as the extralinguistic contexts of linguistic data, or the relation between contexts and data. Linguistic features of historical texts may accordingly be influenced by such extralinguistic contextual factors as the genre and communicative purpose of the text; conventions employed such as orthographic standards, which may be in competition with authorial habits and the residue of intermediate textual states in the process of a text's transmission, involving such concerns as dialect translation and updating of archaic linguistic forms by agents like editors, compilators, and scribes; the text's intended audience, which may demand attention to such concerns as social distance, gender, authority, and age; errors introduced in the process of reproducing a text, for example by scribes and typesetters; and the material features of the medium in which the text is transmitted, such as the space available in a book or document, which may result in purposeful omissions, increased density of abbreviation, and so forth.
In historical language study, philology is thus deployed not in the service of textual editing but of mediating between the demands of linguistic methodology and the limitations that beset the records of prior states of the language available for linguistic analysis, since those records do not directly and unproblematically represent earlier linguistic stages of English. For example, nearly all the surviving prose from the later Anglo-Saxon period is preserved in the West Saxon dialect, roughly half of which is commonly called ʻÆthelwoldianʼ or ʻÆlfricianʼ and is characterized by relative uniformity of orthography and morphology, along with some distinctive and characteristic lexical choices. It is apparent that this linguistic variety is fairly artificial and bookish, having been promulgated by Æthelwold, Bishop of Winchester (963–84), and his prolific student Ælfric as a way of standardizing the language. Of the remaining prose, the considerable majority, to various degrees, gives the impression of heterogeneity in orthography, morphology, and lexis. Although the reason for this is not universally agreed upon, it seems likely that it is a result of the history of individual texts, many of which appear to have been composed in other dialects and only later ʻtranslatedʼ into West Saxon, with varying degrees of thoroughness (see, e.g., Fulk Reference Fulk, Fitzmaurice and Minkova2008, Reference Fulk, Jurasinski, Oliver and Rabin2010, Reference Fulk, Denison, Bermúdez-Otero, McCully and Moore2012, with references). Such ʻtranslationʼ from one dialect to another, resulting in a mixture of dialect features in a single text, is undeniable in connection with English texts from the later Middle Ages: see LALME 1: 12–23, with extensive discussion of this and other sources of textual mixture. Epigraphic traditions not associated with manuscript production may provide a more realistic impression of spoken medieval varieties of English (see Colman Reference Colman1984). Although no medieval text is unambiguous in nature as a witness to an earlier state of the language, the varieties of recorded Late West Saxon just described illustrate well the sorts of historical and cultural concerns that differentiate medieval sources from the kinds of data available for present-day languages, and which it is the philologist's concern to make explicit in connection with diachronic studies of English.
6.2 The rise of philology and the fields it originally encompassed
The current role of philology in historical linguistics was moulded by the historical forces that shaped linguistics as a discipline. The modern study of earlier stages of English may be said to have begun in earnest with Matthew Parker, Archbishop of Canterbury (1559–75), who set out to instruct himself and others of his circle in the Old English language, for the purpose of demonstrating that certain practices of the newly formed Church of England regarded as heretical by the Roman Catholic Church, such as clerical marriage and the translation of Scripture into the vernacular, were also practices of the Anglo-Saxon Church, and that the Anglican Church thus represented a return to a more original state of Christianity. The translation and dissemination of Old English texts therefore served an immediate political purpose. Parker's method of learning Old English was of a philological nature, relying upon Old English translations of Latin, glossed texts, and the Latin grammar (in Old English) of Ælfric, working out the grammar and lexicon of the unknown language by reference to the known one.
Although work on Old English continued apace after Parker's day, it was not until the appearance of the Thesaurus of George Hickes (1703–5) that the study of earlier stages of the language began to assume the appearance of a philological endeavour in the current understanding of the phrase. Hickes perceived the importance of numismatics to the study of the language, and he included a section on Anglo-Saxon coins in the work. He also made an attempt to distinguish varieties of Old and Middle English, differentiating Anglo-Saxon from ʻDano-Saxonʼ, ʻNortmanno-Saxonʼ, and ʻSemi-Saxonʼ (see Cain 2010). Most important, however, was his recognition of the value of comparative language study, since he drew direct comparisons between Old English and Gothic and Icelandic, and he included grammars of Old High German and Old Icelandic in the Thesaurus. It would be many years before the English language was again presented in such a thoroughly comparative framework. Hickes's Thesaurus remains of importance today chiefly because its second volume, compiled by Humphrey Wanley, is a catalogue of Anglo-Saxon manuscripts in British archives (at a time when studying Old English texts usually meant working from manuscript, so few editions had appeared), many of which manuscripts have subsequently undergone loss or damage, so that Wanley's descriptions and his incipits and explicits remain vital sources of information. Wanley's careful work laid the foundation for what remains a vital philological enterprise: the cataloguing and detailed description of manuscript sources (for bibliography, see Wright Reference Wright2016a and Reference Wright2016b).
Yet the most important development in the rise of philology as a discipline was the discovery of the Indo-European family of languages and the realization that they must descend from a common tongue. The beginning of Indo-European studies is usually dated to a 1786 lecture by Sir William Jones in which he pointed out similarities among Greek, Latin, and Sanskrit, with related observations about Gothic, Celtic, and Persian, though it is plain now that Jones was not the first to recognize similarities of this sort, some observations having been made as early as the sixteenth century (see Murray Reference Murray2015). The first full flowering of Indo-European language studies was Franz Bopp's comparative grammar of the Indo-European languages (1833–52), a systematic study on scientific principles (despite some missteps, such as Bopp's attempt to bring Malayo-Polynesian and the Caucasian languages into the Indo-European family). What made possible the study of language history on a scientific basis was the discovery of sound laws – rules for phonetic change comparable to the laws of mechanics or chemistry – the earliest significant example of which was the description by Jacob Grimm (Reference Grimm1822, in some respects anticipated by Rask Reference Rask1818) of regular correspondences between the sounds of the Germanic languages and of other Indo-European languages (e.g., f in English father and fee corresponding to p in Latin pater and pecu), pointing to a systematic set of sound changes in prehistory now referred to as Grimm's law or the first sound shift (see Prokosch Reference Prokosch1939: 47–60). Diachronic linguistics was thus established as a science and became itself a model for other scientific endeavours, most notably in the way Charles Darwin, in theorizing about natural selection, conceived of the development of species as analogous to the development of languages (see Alter Reference Alter1999).
As long as the focus of linguistic inquiry remained on diachrony, the term ʻphilologyʼ could be used to designate the field of historical linguistics, as it commonly did in the nineteenth century. In these early days of philology there was no very notable disjunction between those aspects of it devoted to language study and those to textual criticism. The great linguists of the nineteenth century were mostly editors, as well: Grimm, for example, edited a variety of medieval texts (not to mention the work for which he is now best known, the fairy tales that he compiled with his brother Wilhelm); Rask edited the two eddas; and Eduard Sievers, the most brilliant figure in the school of Junggrammatiker dominating the field in the latter half of the century, edited the Heliand and the Old English Genesis B and formulated the metrical principles on which the editing of early Germanic poetry depends vitally to this day. Similarly, the philological journals of the day were plainly devoted to both linguistics and literature, the two types of studies being mixed indifferently in almost any published issue of periodicals like Archiv für das Studium der neueren Sprachen und Literaturen(1846–), Transactions of the Philological Society (1854–), Zeitschrift für deutsche Philologie (1869–), Beiträge zur Geschichte der deutschen Sprache und Literatur (1874–), Zeitschrift für deutsches Altertum und deutsche Literatur (1876–), Anglia: Zeitschrift für englische Philologie (1877–), Englische Studien (1877–1944), Nordisk Tidsskrift for filologi (1877–), Arkiv för nordisk filologi (1883–), Neuphilologische Mitteilungen (1899–), Journal of English and Germanic Philology (1903–), Modern Philology (1903–), Studies in Philology (1906–), Maal og minne (1909–), Neophilologus (1915–), English Studies (1919–), Philological Quarterly (1922–), Acta Philologica Scandinavica (1926–88), Studia Neophilologica (1928–), and other philologically inclined journals. It will be observed from this list, which includes just one British journal (Transactions of the Philological Society), that it was in the German and Scandinavian academy that the principles of philological study were first elaborated, the Dutch and American journals being later additions. The British attitude towards the discipline in fact was generally hostile for much of the time that philology dominated language study elsewhere in the Germanic-speaking world (see, e.g., Momma Reference Momma2013).
6.3 The varieties of work subsumed within philology
A perusal of these same journals also reveals the range of epistemologies involved in the practice of nineteenth- and early twentieth-century philology, though that range can perhaps be illustrated more effectively by a selection of some of the better-known philological achievements and instances of philological discovery in connection with the history of English. Among the most familiar of these is the remarkable hypothesis of Sievers (Reference Sievers1875) that lines 235–851 of the Old English poem Genesis (the portion now referred to as Genesis B, and which had already been recognized as different in style from the rest of the poem) is translated from a Continental Saxon original (for an account, see Doane Reference Doane1991: 3–8). The hypothesis was dramatically confirmed in 1894, when a fragment of an Old Saxon versified Genesis was discovered in a manuscript in the Vatican Library, and its first twenty-five lines were found to correspond closely to lines 790–816 of the Old English poem. Sievers's hypothesis was based upon observations of similarity between Genesis B and the Old Saxon Heliand in the use of poetic formulae, vocabulary, and shared phrases, and it demonstrates not only the power of philological reasoning but also its utility in respect to linguistic investigation, since the strong influence of Old Saxon upon the language of Genesis B indicates that the poem is not to be used as linguistic evidence for Old English poetic language.
Sievers (Reference Sievers1885, Reference Sievers1893) was also the chief architect of our understanding of Old English poetic metre, though of course his analysis is indebted to earlier work. He arrived at his conclusions on the basis of comparison to Old Norse verse, of painstaking observation of patterns of stress and alliteration, and of abstract reasoning aided by a profound knowledge of etymology. Even at their first formulation his principles were rigid enough to reveal ways in which the recorded forms of Old English poems must differ from the forms they took when initially composed. His findings have thus proved an indispensable aid to the editing of poetic texts, and they have shed important light on the problem of determining the date and dialect of origin of Old English poems, which are almost uniformly preserved in late copies much altered in the course of scribal transmission. The analysis of Sievers in turn enabled a discovery by H. Kuhn (Reference Kuhn1933) about the relation between syntax and stress that is perceptible only on the basis of poetic metre: words of variable stress, such as pronouns, monomorphemic adverbs, and finite verbs, are stressed unless they appear in the group of syllables that comprise the first unstressed position in the clause. The phenomenon is relatable to Indo-European clausal patterns and lends support to common views about the dating of Old English poems.
The identification and localization of the dialect of the early or mid ninth-century Old English gloss on the Vespasian Psalter is a remarkable accomplishment. Since the psalter itself is Kentish in origin, it was at first thought that the gloss must be, too. Sweet (Reference Sweet1882) was the first to recognize that the dialect must be an archaic variety of the Midland dialect known as Mercian, a conclusion he reached on both codicological grounds – an existing Mercian charter seems to have been written on a blank leaf of the book that was later separated from the manuscript – and linguistic, by comparison to the language of known Mercian charters of an early date. Restriction of the provenance to the westernmost portion of Mercia was established by Tolkien (Reference Tolkien1929), due to his discovery of remarkable similarities between the language of the psalter gloss and of a group of Middle English texts (the ʻKatherine Groupʼ) associable with the medieval diocese of Hereford, and Millett (Reference Millett1992: 219) would narrow the relevant area to southern Shropshire. Such a localization accords well with certain features derivable from modern dialect surveys.
The localization of Middle English dialects has made tremendous strides in the past half century due chiefly to the research undertaken in conjunction with the production of the Linguistic Atlas of Late Mediaeval English (LALME; see Chapter 7 by Horobin in this volume). One reason for this progress is the development of the so-called fit-technique, whereby unlocalizable texts are assigned a geographical position by triangulation on the basis of features shared with texts of known provenance (see Benskin Reference Benskin and Riddy1991). The result of such careful attention to diatopic issues is some remarkable findings about the localization of Middle English texts, such as the ability to discern in the B-text of Piers Plowman a set of linguistic features discoverable on the basis of poetic alliteration and associated with a closely circumscribed area of western Worcestershire, including the Malvern Hills, where the poet is known to have spent his youth (see Samuels Reference Samuels and Smith1988). What is remarkable about this is that Piers Plowman is to be found in so many manuscripts copied at so many different locations in which local features were added to the text, though no surviving manuscript was made in western Worcestershire.
Determining the pronunciation of Elizabethan English is obviously a prerequisite to its phonological analysis. Since that pronunciation is recoverable (to the extent that it is recoverable at all) only by philological means, this is an area of study in which the value of philological investigation to linguistic analysis is particularly plain. Some of the most detailed studies have focused on the pronunciation of a single individual, most prominently William Shakespeare (see Cercignani Reference Cercignani1981, with a critique of prior research going back to 1861 on pp. 2–21). There is a certain irony in this practice of studying a single speaker, since the pronunciation of no single Elizabethan is fully recoverable, especially an individual like Shakespeare, whose native dialect was not that of London, though he worked in the city, and who may have employed pronunciations other than his own for dramatic or comic effect. Still, the study of one individual's speech, when tempered with what can be determined about the pronunciation of others, reduces the effect of linguistic heterogeneity that inevitably arises in the study of such a cosmopolitan setting as London c.1600. The evidence for Shakespeare's pronunciation is both internal and external. The most important internal evidence is to be derived from rhyme and metre in his poetry, though puns and spellings, it has sometimes been argued, are relevant. External evidence is of various sorts. It includes what is known about antecedent states of the language (as divined on the basis, once again, of internal and external evidence), the evidence of the language in modern times, and, what is most important, the witness of early grammarians and rhetoricians as to the pronunciation of the language in the sixteenth and seventeenth centuries (treated in detail by Dobson Reference Dobson1968). These last include, for example, works of orthoepy, which are tracts intended to prescribe correct usage, devise phonetic descriptions, or promote spelling reform, publications which began to appear in the sixteenth century, when the expansion of the merchant class and the commercial success of the printing press had created a market for such works and made their dissemination economically feasible. Likewise in early modern studies, philological concerns have aided immensely in studies of authorship. For example, in an influential essay, Forker (Reference Forker and Howard-Hill1989), on the basis of an examination of style, idiom, vocabulary, and spelling, is able to confirm the widespread belief that three pages added to the sole manuscript of the drama Sir Thomas More, by Anthony Munday and others, must be in the hand of Shakespeare.
What these examples illustrate is the great variety of concerns addressed by philological inquiry. Such a variety of concerns naturally draws on a wide field of resources, so that the pursuit of philology very commonly draws on rather diverse aids to analysis, such as historical concordances and dictionaries, catalogues, and indexes of primary sources (manuscripts, early printed books, specific collections, or genres, etc.), historical dialect atlases, handbooks of poetic form, historical grammars and manuals of etymology, manuscript facsimiles, and bibliographic reference works, among many others, including an ever-increasing array of electronic resources. In the face of such diverse aims and aids, it is not possible to provide comprehensive instruction in philological methods in any very concise way. The best way to learn such methods is to examine individual cases like these and study them for what they demonstrate about how philology is practised.
6.4 The relation of philology to English historical linguistics and literary studies
As these examples illustrate, many kinds of evidence, both linguistic and extralinguistic, are involved in philological discoveries, and those discoveries tend to be of service both to historical linguistics and to textual criticism. It was thus inevitable that the term ʻphilologyʼ should at first have encompassed many areas of study besides diachronic language study. But the turn towards synchrony as the primary focus of linguistic research in the twentieth century eventually made it plain that philology and historical linguistics were not synonymous, since the latter incorporated methods developed in synchronic linguistics that were of no great relevance to the textual principles that remained central to the philological enterprise. The particularizing and contextualizing aims of philology in fact came to seem, to some, an impediment to the practice of historical linguistics on the basis of the same generalizing and abstractly inclined aims that prevail in the study of living languages (see, e.g., Hogg Reference Hogg1992a: vii–viii).
The conflict may be illustrated by the example of a study by Toon (Reference Toon1983: 90–118) in which orthographic variation between <a> and <o> before nasal consonants is taken to evidence the rise and decline of a sound change in various Old English dialects, though in texts of the later Middle Ages and in modern dialect surveys rounding of this vowel is attested securely only in the West Midlands. To analyse the data as attesting to the progress of such a change is to treat written records as if they were direct representations of speech, when in fact it is likely that a number of contextual factors have conditioned the spelling in these early documents, including the cultural influence exerted by the politically dominant West Midland kingdom of Mercia, which plainly affected the language of these documents in other ways, and uncertainty about how best to represent sounds for which there was no distinctive character in the alphabet that the Anglo-Saxons inherited from Roman and Irish missionaries. This latter consideration is particularly relevant in the present instance, because if, as is generally assumed, the vowel in question was /ɔ/, which occurred only before nasal consonants, it is possible that in the earlier stages of the Old English orthographic tradition there had not yet developed the convention of using <o> to represent this sound that was neither /ɑ/ nor /o/. That this is the correct interpretation is suggested by the word ōnettae ‘anticipated (?)’, which appears in the earliest relevant document, a document that does not show any instances of <o> from a before nasal consonant and thus is assumed by Toon to antedate the change. This word ōnettae appears to show compensatory lengthening of initial /ɔ/ in *anhǣtidæ (Luick Reference Luick1914–40: §110 Anm. 2), indicating that rounding of the vowel before nasal consonants had already taken place. These are perhaps among the reasons why Kitson (Reference Kitson and Fisiak1995: 102) calls Toon's ʻa mad bookʼ; see Lowe Reference Lowe2001 for specific criticisms of methodology.
What the example illustrates, then, is how considerations that are not strictly linguistic in nature but which fall under the rubric of philology are indispensable to the linguistic analysis of historical records. To approach such records the same way a linguist would approach an objective transcript of a sample of a living language is to incur the danger of engaging in historical and linguistic fallacies. The problem is a serious one because it raises certain obstacles to the application of many modern linguistic methods to the analysis of earlier stages of English, with the result that to some it has seemed that English historical linguistics is mired in the methods of the nineteenth century and makes wholly inadequate use of the sorts of insights to be derived from newer methodologies. The failure to apply the insights of sociolinguistics in connection with social stratification has been particularly noticeable (see, e.g., Toon Reference Toon, Koopman, van der Leek, Fischer and Eaton1987, Hogg Reference Hogg, Kastovsky and Bauer1988: 188) up until the advent of sociohistorical and, later on, historical sociolinguistic methodology (see, e.g., Romaine Reference Romaine1982, Tieken-Boon van Ostade Reference Tieken-Boon van Ostade1987, and Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg1996a, Reference Nevalainen and Raumolin-Brunberg2003; see also Chapter 1 by Romaine and Chapter 17 by Nevala in this volume).
A result of the philological obstacles raised to the analysis of earlier stages of the language using current linguistic methods is that in the course of the twentieth century philology grew increasingly marginalized as a methodology. Whereas it had traditionally allied the fields of linguistics and textual and literary criticism, it came to play a vastly reduced role in the former, and in regard to textual criticism some of its prevailing tenets, such as the value of stemmatics (determination of the genetic relations of manuscripts or other media) and the rationale of textual emendation, came under increasing attack; for an account of the debates in textual criticism, see Greetham (Reference Greetham1999). But at the same time that philology grew ever more estranged from the field of linguistics, its role as the chief method of literary study came to an end as literary criticism came to be dominated by modes of analysis derived from British aestheticism, at first particularly (in Britain) the so-called practical criticism and (in America) the New Criticism, which regarded textual criticism as ancillary to aesthetic concerns (see, e.g., Graff Reference Graff1987). Philology thus remained most firmly tied to textual editing, though it never relinquished its stake in both linguistics and literary analysis, which remained indispensable to its operations.
6.5 New directions for philology
Under these circumstances, countless excellent editions of early texts continued to be produced on the basis of traditional philological methods, but a small though extremely vocal minority of philologists attempted to develop a new basis for philology that could be reconciled with the synchronic analysis of early texts rather than the prevailing model anchored in textual reconstruction. The most self-conscious of these attempts was a collection of articles, a self-characterized ʻcall to armsʼ, proclaiming the establishment of the so-called New Philology (Nichols Reference Nichols1990), a set of practices centred on the conviction that the study of textual variance as an expression of cultural conditions coeval with the manuscripts in which they occur is a more fitting object of philological scholarship than textual reconstruction. The New Philology was thus to be intensely manuscript-centred, since the manuscripts themselves, in all their textual and extra-textual aspects, are the key to unlocking pre-modern language and culture. The linguistic area in which such an approach seemed likeliest to be fruitful was identified as pragmatics, though grammar was also identified as a major topic for exploration on the assumption that the grammar of (quasi-)oral discourse, as represented by medieval texts, is not as rule-bound as the grammar of literate discourse (see Fleischman Reference Fleischman1990).
The New Philology never achieved the status of an established methodology, for a variety of understandable reasons, but its promise of a way to wed philology to modern linguistic methods was not to be ignored, and many of its premises endure by their incorporation into current manuscript studies and into varieties of historical dialectology and pragmatics, as detailed below. But the reinvigoration of philology that was one of the stated aims of the New Philology has been furthered more effectively by the development of digital resources. This may at first seem an ironic development, since the view of many at the dawn of the age of digitized resources was that the advent of digital editions presaged the end at last of philology by placing the traditional functions of the editor in the hands of the ultimate user of the edition. For example, Szarmach (Reference Szarmach, Keefer and O'Brien O'Keeffe1998: 107) remarked: ʻUltimately, the computer is likely to subvert the authority of the editor, who will become an inputter of text, a programmer if lucky, but never again the sole arbiter of meaning.ʼ Conner (Reference Conner, Keefer and O'Brien O'Keeffe1998: 115) concurred: ʻThere are many ways to examine a text, and the electronic edition must try to make as many of them available to the scholar as possible. Thus the editor becomes the technician who makes it possible for the scholar to assemble the information from the edition he or she would like to explore.ʼ There are several reasons why such a revolution did not occur, but the most relevant one in the present context is that the kinds of resources made available by digitization are of considerably greater use to editors than to the readers of editions. For example, most digital editions include both a digital facsimile of one or more manuscripts plus an edited text, but glosses and textual commentary are linked to the edited text rather than the facsimile, so that the experience of using a digital edition differs only in detail from that of using a conventional critical edition in conjunction with a facsimile. The utility of digitization to editors, as opposed to end users, is well illustrated by a project outside the realm of English studies, Skaldic Poetry of the Scandinavian Middle Ages (Clunies Ross et al. Reference Rossouw and van Rooy2012). Here more than fifty contributing editors work under the direction of six general editors, preparing editions of skaldic verse in both print and online versions, many of the materials necessary for which are made available on the project web site, including manuscript images, transcripts of the manuscripts, dictionaries in electronic databases, concordances, digital scans of major editions and reference works, and detailed editorial guidelines, among many others. From projects like this one it should be apparent that digitization has the potential to breathe new life into the field of philology simply by rendering its practice less daunting and inconvenient. But ʻpotentialʼ is perhaps not the right word, since many editors can testify that digital resources have already contributed enormously to the compilation of editions that have appeared only in print.
The emphasis on manuscript text and incidentals championed by the New Philology dovetailed with an important and influential feature of the LALME project: its insistence upon the graphemic, rather than phonological, basis of dialect variance. It is not, of course, that all graphic variation is void of phonological significance, but some of it is (e.g., the alternation of <gh> and <ȝ> in words of identical derivation in Middle English manuscripts), and so methodological consistency demanded that LALME reflect a dialectology of purely graphemic variation. The confluence of such a dialectology of signs with the rising impulse toward a version of philology based on manuscripts has resulted in a strong infusion of philological concerns in the areas of historical dialectology, pragmatics, and corpus linguistics. In regard to historical dialectology, this is evident in regard to the ongoing revisions to and digitization of LALME and the related dialect projects based in Edinburgh (see Institute for Historical Dialectology, currently Angus McIntosh Centre for Historical Linguistics).
In the recently developed area of historical pragmatics, philological concerns have come to play an increasingly prominent role – so much so that a term has been coined for this area of study, ʻpragmaphilologyʼ, which ʻdescribes the contextual aspects of historical texts, including the addressers and addressees, their social and personal relationship, the physical and social setting of text production and text reception, and the goal(s) of the textʼ (Jacobs and Jucker Reference Jacobs, Jucker and Jucker1995: 11; see also Chapter 3 by Mazzon in this volume). Because pragmaphilology was developed long after literary criticism ceased to be dominated by philological methods, differentiating its concerns from those of literary criticism has been a matter of some concern (see, e.g., Taavitsainen and Fitzmaurice Reference Fitzmaurice2007: 22–5, Pakkala-Weckström Reference Pakkala-Weckström, Jucker and Taavitsainen2010: 219). Yet most studies in this area are concerned with the same sorts of issues that have historically dominated the field of pragmatics and are not common topics in literary criticism. For example, Pakkala-Weckström (Reference Pakkala-Weckström, Jucker and Taavitsainen2010), in surveying studies of Chaucer in the pragmaphilological mode, lists their concerns as speech acts (insults, threats, and promises), forms and pronouns of address, personal affect features (including oaths, exclamations, modal auxiliaries, and deictics), and politeness strategies.
One similarity between classical philology and pragmaphilology is their connection to textual editing, since it is an express concern of historical pragmatists that their findings be taken into account in the production of critical editions (see, e.g., Busse and Busse Reference Busse, Busse, Jucker and Taavitsainen2010: 248). Yet the connection to textual editing is not an uncomplicated one, since a particular aspect of pragmaphilology that moves beyond the traditional bounds of linguistic pragmatics in the direction of some of the historical concerns of classical philology and the New Philology is its emphasis on the use of manuscripts or diplomatic texts rather than edited texts (see Lass Reference Lass, Dossena and Lass2004b). The rationale for this preference is the observation that manuscript texts are closer to authentic representations of historical language varieties than edited texts, since edited texts are interpretative. Editors alter manuscript readings, admit some scribal changes and omit others, supply modern punctuation, and, especially in the case of Old English, alter word or morpheme divisions (see Dury Reference Dury, Dossena and Fitzmaurice2006: 195–9). Even if the unaltered manuscript readings are not unmediated examples of natural language, they are closer to the source than any edited version. Some of the obstacles to using manuscript texts the way living informants are used in synchronic studies were pointed out above, in connection with the discussion of the artificiality of medieval scribal conventions, but the more relevant concern is probably not whether manuscripts are somehow more ʻauthenticʼ but whether the differences between edited and manuscript texts have sufficient impact upon pragmatic studies to justify the considerable effort and philological expertise required to work with manuscript texts.
One study that demonstrates with particular clarity the value of manuscript study in the context of historical pragmatics is a paper by Stenroos (Reference Stenroos2010) that addresses the question whether William Langland, the author of the Middle English Piers Plowman, used ye (as opposed to thou) as a singular pronoun, the way vous may be used in French. Prior studies have sometimes held that singular ye in this text is due to scribal interference. The issues are complex, since Piers Plowman is preserved in at least three versions in more than fifty manuscripts, and so a great deal of philological spadework is required to allow Stenroos to reach the conclusion that scribal alteration of the pronouns of address was minimal, and Langland was as apt as Chaucer to use singular ye.
Since much research in historical pragmatics is conducted on the principles of corpus linguistics, it is natural that scholars concerned with fidelity to manuscript conditions should want to use corpora in which the details of those conditions are encoded. Considerable discussion has in fact been devoted to the problems and possibilities associated with the compilation of philologically suitable corpora and editions: see, e.g., Bailey Reference Bailey, Curzan and Emmons2004, Dury Reference Dury, Dossena and Fitzmaurice2006, Kytö et al. Reference Kytö, Walker and Grund2007, along with Honkapohja et al. Reference Honkapohja, Kaislaniemi, Marttila, Jucker, Schreier and Hundt2009, Kytö et al. Reference Kytö, Grund and Walker2011b, and Marttila Reference Marttila2014.
Attention to manuscript features is a prominent aspect of a number of corpus encoding projects. One encoding project that is particularly thorough in marking manuscript features is the Middle English Grammar Corpus (MEG-C). For example, expunction (indication of deletion by the insertion of points) is indicated by the switches <exp>…</exp>, with similar switches for rubrics, underlining, crossed-out text and rubbed-out text, and for various kinds of additions to the text, among them interlinear and marginal insertions, as well as for different causes of illegibility. While the main text is transcribed in capital letters, the expanded letters of abbreviations are lower case, and the flourishes at the ends of words that in Latin texts indicate abbreviations but in Middle English texts notoriously may sometimes be nothing more than decoration are recorded with a tittle (∼). Capitals in the manuscript itself are indicated with a preceding asterisk (*), and extra-large capitals by a pair of asterisks. There is thus a great deal of philological information encoded in the project's transcripts, since this may be relevant especially to the study of pragmatics in older written sources. Some other projects that encode manuscript features are Digital Editions for Corpus Linguistics (DECL, Honkapohja et al. 2012); the Corpus of Scottish Correspondence (CSC, Meurman-Solin Reference Meurman-Solin, Lenker and Meurman-Solin2007); and the Málaga Corpus of Late Middle English Scientific Prose (Miranda García 2011).
Corpus linguistics thus points the way to facilitating increased attention to the influence of extralinguistic factors on historical texts (see Chapter 8 by López-Couso in this volume). Even with the advances marked by corpus linguistics, obstacles remain to the unqualified application of linguistic methods to historical texts, such as variation in the principles and degree of precision employed by editors and compilers of corpora to record the text of their primary sources, the inevitable loss of information whenever a handwritten text is transcribed in machine-readable form, and problems in equating the analysis of written texts with that of spoken language. Still, recent developments plainly hold forth the promise of a reinvigorated role for philology in historical linguistics.
6.6 Conclusion
Although philology has probably never been in any real danger of dying out altogether as a methodology, the establishment of linguistics and literary criticism as separate disciplines certainly lessened its influence, and it continually faces the problem of replenishing the ranks of competent philologists, given how many different epistemologies must be mastered for its effective prosecution. Yet the successful integration of philological concerns into historical dialectology, pragmatics, and corpus linguistics in relation to handwritten and printed sources from the Middle Ages to very recent times is reason for optimism about the future of philological pursuits, as are comparable developments in medieval and early modern studies without a particular linguistic focus, since there digital resources likewise have rendered philological interests more accessible and convenient to pursue.
Despite persistent calls by prominent literary theorists for a ʻreturn to philologyʼ as a way of reinvigorating the study of language and literature (see, e.g., de Man Reference de Man1986: 21–6, Patterson Reference Patterson and Van Engen1994, Gumbrecht Reference Gumbrecht2003, Said Reference Said2004: 57–84; cf. Ziolkowski Reference Ziolkowski2005), such a development seems unlikely to occur. Yet philology still has a vital role to play in all the scholarly fields it once encompassed, and particularly in the area of English historical linguistics, both in its more traditional form as a method for dealing with the obstacles to the linguistic analysis of historical data and in its more recent employment as a means to access long-neglected aspects of historical texts through manuscript study.
7.1 Introduction
Printing was not introduced into England until the final quarter of the fifteenth century; before then books were copied by hand and are known today as ‘manuscripts’. As a consequence, the vast majority of sources for studying Old and Middle English are in manuscript form. Because of their individual and often idiosyncratic status, manuscripts must be treated differently from early printed books, which were generally reproduced in large numbers of very similar copies and therefore present fewer problems. As a consequence, this chapter will focus primarily on the issues involved in analysing manuscripts, although there is some discussion about the specific problems encountered when dealing with printed texts at the end of the chapter. In this chapter, then, I will consider the various scholarly approaches that are appropriate for dealing with these types of evidence, and examine the resources available to researchers wishing to exploit them.
7.2 Why work with manuscripts?
Since many Old and Middle English works are conveniently available in modern editions, handily accessible on the shelves of most research libraries, you may wonder why it is necessary to consult manuscript materials at all. The reason is that modern editions are not straightforward reproductions of a medieval original; all modern editors make interventions designed to make the text more accessible to a modern audience. The extent to which a modern editor intervenes when reproducing a medieval work depends on the kind of editorial approach adopted. There are essentially three types of edition, each of which treats the original source in very different ways (Greetham Reference Greetham and Gibaldi1991, Reference Greetham1994, McCarren and Moffat Reference McCarren and Moffat1998). The most useful type of edition for the historical linguist is the diplomatic edition, which aims to represent the manuscript source as closely as possible. Rather than trying to reconstruct an authorial original from all surviving copies, a diplomatic edition seeks to supply a close reproduction of a single witness. An example of the diplomatic edition is the series of editions of the various manuscript witnesses to the Early Middle English work Ancrene Riwle/Wisse, published by the Early English Text Society (Day Reference Day1952, Wilson Reference Wilson1954, Tolkien Reference Tolkien1962, Mack and Zettersten Reference Mack and Zettersten1963, Dobson Reference Dobson1972, Zettersten Reference Zettersten1976, Zettersten and Diensberg Reference Zettersten and Diensberg2000). Rather than issuing a single, conflated, edition of this complex text, the EETS commissioned a series of diplomatic editions of each of these important witnesses, enabling readers to analyse them as manuscripts in their own right and carry out their own collations and comparisons across witnesses. These editions are most useful because of their principle of fidelity to the manuscript witness, although the editorial tendency to introduce modern punctuation, expand abbreviations, combined with the necessity of altering the text's layout, mean that the diplomatic edition will never fully replace consultation of the original manuscript, or a high-quality facsimile reproduction. One further important caveat worth bearing in mind when working with diplomatic editions is that editors tend to differ in the extent to which they consider it acceptable to interfere with the text they are editing. While modern editors tend to restrict this kind of tinkering to a minimum, editions produced in the nineteenth and early twentieth centuries are often considerably more interventionist.
Related to the diplomatic edition is the ‘best-text’ edition, which chooses one of the surviving manuscripts as its base text and follows it closely in establishing its text. This edition differs from the diplomatic edition in allowing an editor to alter his base text by drawing upon other witnesses where his base manuscript is lacking text or is clearly inferior. The degree of such editorial intervention is often dictated by the audience for which the edition is intended. Editions designed for a general or undergraduate readership will typically involve modernization of spelling and the introduction of modern punctuation at the very least, whereas an edition intended for a scholarly audience is more likely to preserve the spelling of its base manuscript. A good example of a best-text edition is Norman Blake's (Reference Blake1980) edition of Chaucer's Canterbury Tales, based closely upon the ‘Hengwrt’ manuscript (National Library of Wales MS Peniarth 392D), preserving its spelling and grammar, but modernizing its punctuation.
The edition that causes the most difficulties for the historical linguist is what is known as an ‘eclectic’ or ‘open’ edition. While other types of edition are based upon a single manuscript witness, this edition selects each reading from all of the surviving witnesses on the basis of its individual merits, regardless of its manuscript support. The key distinction here is that, while a best-text editor sticks closely to his base manuscript unless it is clearly erroneous or deficient, the eclectic editor frequently departs from the base manuscript in favour of readings from other sources. A key principle behind the selection of individual readings is known as ‘lectio difficilior’, meaning that the editor identifies the ‘more difficult’ reading, that is, the reading that is least likely to be the result of scribal error and consequently most likely to be authorial. This is supplemented by consideration of other factors such as consistency of grammar, lexis, authorial linguistic habits, and metrical features. Where best-text editors place their faith in a particular witness to be more reliable than others, eclectic editors place greater confidence in their own ability to determine a correct reading from a collection of spurious ones. An example of eclectic editing can be found in the three volumes of the Athlone edition of William Langland's Piers Plowman; while each volume has a base manuscript text from which the edited text's spelling and grammar are derived, the editors frequently introduced readings from other witnesses where these are considered to be superior (Kane Reference Kane1960, Kane and Donaldson Reference Kane and Donaldson1988, Russell and Kane Reference Russell and Kane1997).
Electronic editions of individual texts or manuscripts are becoming more common, especially of the works of major canonical writers such as Chaucer and Langland, of important manuscript anthologies, such as the Exeter Book (Muir Reference Muir2000) and the Auchinleck Manuscript (Burnley and Wiggins Reference Burnley and Wiggins2003), or utilitarian sources, such as witness depositions (see ETED Reference Kytö, Grund and Walker2011 and Chapter 27 by Walker in this volume) or recipe collections (see Marttila Reference Marttila2014). The Canterbury Tales Project has published CD-ROM editions of individual parts of the work, covering the General Prologue, Miller's Tale, Wife of Bath's Prologue, and Nun's Priest's Tale (Robinson Reference Robinson1996, Reference Robinson2004, Solopova Reference Solopova2000a, Thomas Reference Thomas2006). Rather than privilege a single witness, or reduce the numerous witnesses to a single conflated text, these editions offer diplomatic transcriptions of all extant manuscript and pre-1500 printed witnesses to the work. These transcriptions stick very closely to the manuscript text, preserving scribal punctuation and retaining abbreviation marks rather than expanding them. The Piers Plowman Electronic Archive differs from the Canterbury Tales Project in focusing exclusively on single-witness format editions; seven CD-ROM editions of manuscripts of Langland's poem have been released so far. There are a further two CD-ROM editions issued by the Canterbury Tales Project which focus on single witnesses. The first of these is a digital facsimile of the Hengwrt manuscript, complete with accompanying transcription of the full text of this manuscript, as well as that of another important early witness, the Ellesmere manuscript. The second full-text edition presents the two editions of the Canterbury Tales issued by William Caxton (1476, 1482) (see Bordalejo Reference Bordalejo2003). This last provides valuable evidence for the study of early printed texts, a surprisingly neglected area. Access to data for the analysis of early printed books has been significantly facilitated in recent years by the availability of Early English Books Online (EEBO), a resource which provides access to images of complete copies of some 125,000 texts printed between 1475 and 1700. In addition to these scanned images, EEBO also offers fully searchable transcriptions of approximately 70,000 of these printed works. But, while this is a useful collection of electronic data, it does not represent a balanced or representative selection of data and cannot, therefore, be used in the same way as a corpus assembled according to modern scholarly standards (see Chapter 8 by López-Couso in this volume).
The advent of electronic methods for digitizing manuscripts and making them available via CD-ROM or the World Wide Web has begun to transform the ways in which historical linguists access and analyse original manuscripts. While access to original documents via printed facsimiles or editions is limited in various ways outlined above, digitization of manuscripts is transforming scholarly access to original sources. But while this is a development to be gratefully welcomed by scholars, there are certain reservations which need to be considered. Digitization projects tend to be driven by librarians rather than scholars; consequently, the end results may not be best suited to the research needs of an individual researcher. Libraries may choose to focus their energies on manuscripts of particular cultural significance, or those which are visually particularly impressive, rather than on documents of particular linguistic significance. Where libraries do aim to provide digital surrogates of complete collections rather than just the best-known instances, these often encompass a highly diverse selection of manuscripts, containing works of various periods in a variety of different languages. An important and very valuable exception to this policy is the John Rylands Library in Manchester, which has produced a focused resource by bringing together a digital collection of its Middle English manuscripts, accompanied by physical descriptions of the manuscripts and their contents. Because of funding constraints, libraries often make available images of individual folios of particular manuscripts, rather than complete codices, restricting the kind of analysis that is possible. Even more useful are examples of digitized manuscripts where digital photos are accompanied by electronic transcripts of the text. As with any edition of a manuscript, these transcripts are most useful where there has been very little editorial intervention. Unlike printed editions, electronic transcripts accompanied by digital photographs of the manuscript can be checked for accuracy and for fidelity to the original. Another huge advantage over conventional printed editions is that electronic transcripts are searchable, allowing a researcher to capture all instances of individual forms under analysis. As we will see below, one of the limitations imposed by working with manuscript sources is that it is often necessary to rely on sampling of data; with electronic analysis it becomes possible to interrogate the text in its entirety with complete accuracy, a form of analysis simply not possible when working by hand.
7.3 Working with manuscripts
Working with original manuscripts will in most cases require travel to the repository in which a codex is held to consult it. For a useful discussion of how to approach a repository, and helpful suggestions concerning important preparatory work, see the relevant section in Clemens and Graham (Reference Clemens and Graham2007: 71–81), Introduction to Manuscript Studies. This is less problematic in the case of early printed texts, which frequently survive in multiple copies; in such cases all that is needed is access to a major research library. In some instances it will be possible to employ a printed facsimile in place of the original, but only a small proportion of the surviving corpus of medieval manuscripts has been published in this format. Where facsimiles are available, they must be used with caution, since they frequently do not faithfully preserve certain physical features of a manuscript, such as its original dimensions or its use of coloured inks.
For those wishing to work on manuscripts containing Middle English verse texts, an invaluable bibliographical resource is the New Index of Middle English Verse (Boffey and Edwards Reference Boffey and Edwards2005). An additional tool which surveys the same material is available as an online open-access database, compiled and edited by Linne Mooney, Daniel W. Mosser, and Elizabeth Solopova: the Digital Index of Middle English Verse. Although both resources set out to cover the same manuscript materials, the digital edition is as yet incomplete; however, once complete it will ultimately have the advantage of allowing rolling revision, correction and updating. Both of these resources are based upon, and ultimately replace, the earlier The Index of Middle English Verse (Brown et al. Reference Brown and Robbins1943) and its Supplement (Brown and Robbins Reference Brown and Robbins1965). Middle English prose texts which have been made available in modern printed editions are catalogued by Lewis et al. (Reference Lewis, Blake and Edwards1985). Manuscript copies of prose texts are surveyed in the ongoing Index of Middle English prose project, whose individual volumes supply complete listings of prose contents in Middle English manuscripts by repository. To date, twenty volumes in this series have been published, comprising the major British libraries, as well as smaller and lesser-known collections, e.g. Yorkshire Libraries (Pickering and Powell Reference Pickering and Powell1989), Midland Libraries (Edden Reference Edden2000), Parisian Collections (Simpson Reference Simpson1989), and Scandinavian Collections (Taavitsainen Reference Taavitsainen2007 [1994]). These volumes enable researchers to identify texts by their incipits (opening words of a text), and to locate additional witnesses of a particular text. For researchers interested in scientific and medical writings, an important resource is the Scientific and Medical Writings in Old and Middle English: An Electronic Reference (eVK) by Linda Ehrsam Voigts and Patricia Deery Kurtz (Reference Voigts and Kurtz2000), an electronic database published on CD-ROM, which contains records of texts extant in almost two thousand manuscripts.Footnote 1 A further resource covering Late Middle English scientific materials is the Malaga Scientific Prose corpus, which covers the contents of manuscripts dealing with medicine, botany, and pharmacopoeia held in the Hunterian Collection at Glasgow University Library and the Wellcome Library in London. Because individual volumes deal exclusively with either verse or prose, and only with texts written in Middle English, these surveys do not supply a complete inventory of a manuscript's contents. For researchers whose interests lie in an individual manuscript rather than a particular text, there are various resources which offer a physical description of the codex, a complete listing of its contents, and a bibliography of relevant published works. An important starting point is a library catalogue, which generally offers descriptions and listings of contents of all manuscripts in a particular collection. However, not all libraries have published catalogues; in some cases where catalogues are available these are outdated and, at best, provide only skeleton descriptions. In recent times, some of the larger repositories, including the British Library and the Bodleian Library, have begun the process of updating their catalogues and making them available online. Because such projects are extensive and expensive, they are progressing slowly. The Parker Library in Cambridge, which houses one of the largest and most important collections of Anglo-Saxon manuscripts in the world, has published electronic facsimiles of all of its manuscripts, complete with an online catalogue. However, the catalogue itself remains essentially that compiled by M. R. James (Reference James1909–13). Another important published resource is a modern critical edition of a work or works found in the manuscript. While editions vary as to the amount of detail supplied concerning manuscript witnesses, all modern editions will supply some account of the manuscript's date, contents, and further references, which should be consulted before beginning an analysis. Editions published by the EETS, one of the most important series of Old and Middle English editions, include brief descriptions covering features such as date, physical dimensions, materials, contents, layout, and provenance. The standard resources for beginning research into Old English manuscripts are N. R. Ker's Catalogue of Manuscripts Containing Anglo-Saxon (Reference Ker1990 [1957]), and Helmut Gneuss's Handlist of Anglo-Saxon Manuscripts (Reference Gneuss2001, Reference Gneuss2003, Reference Gneuss2011). Descriptions of medieval manuscripts in British Libraries outside the major repositories can be found in the four volumes compiled by N. R. Ker, Medieval Manuscripts in the British Isles, with a further volume containing Indexes and addenda edited by I. C. Cunningham and A. G. Watson (1969–2002). For the post-medieval period there are the four volumes of Peter Beal's Index of English Literary Manuscripts (1980–93), covering the period 1450–1700. This will be supplemented by the ongoing Catalogue of English Literary Manuscripts, which will offer a freely accessible online database comprising descriptions of thousands of manuscripts representing the work of more than 200 authors for the period 1450–1700. For listings of early printed material, researchers should consult the English Short Title Catalogue (ESTC), which is a comprehensive listing of early printed books, newspapers, and printed ephemera from the period between 1473 and 1800. The database contains more than 450,000 entries, representing the collections from more than 2,000 libraries from around the world, and is available online via an institutional subscription.
7.4 Dating and localizing sources
One of the problems of dealing with manuscript sources is that they seldom contain dates or places of production: information which we are accustomed to finding in printed texts. There are some exceptions to this: chronicles that consist of a series of annalistic entries preserve dates, although we cannot always assume that the date of an entry is necessarily the date at which the entry was written. A good example of this is the Peterborough Chronicle, which was written in distinct periods: the so-called First Continuation covers the period up to 1131, while the Final Continuation, stretching from 1132 to 1154, was written retrospectively in 1154 (Clark 1970). But in most cases surviving manuscripts are undated. To make matters more complex, there is often a considerable time lag between the composition of a text and the date on which a particular manuscript was copied. Which of these dates should be the basis of an analysis of the language of that particular manuscript? An awareness of the difficulties of precise dating of sources can be particularly important when considering texts that straddle period boundaries. For instance, there are a number of texts copied in the twelfth and thirteenth centuries which are copies of Old English originals; should these be considered to be instances of Old or Middle English? Several late Middle English texts survive only in copies produced in the sixteenth or seventeenth centuries. A good example of this is the single extant witness to the poem The Destruction of Troy, Glasgow University Library MS Hunter 388; this manuscript was copied in the mid-sixteenth century, although the text it preserves was composed c.1400 (Panton and Donaldson Reference Panton and Donaldson1869, 1874). Drawing boundaries that divide up the history of English into distinct historical periods is a controversial activity which is made considerably more complex once one takes into account the evidence for the dating of the sources upon which these scholarly entities are constructed (Kitson Reference Kitson and Fisiak1997, Lass Reference Lass, Taavitsainen, Nevalainen, Pahta and Rissanen2000a).
Another difference between manuscript and printed books is the lack of explicit evidence for a manuscript's place of production. This information is of particular significance for the study of regional variation; without such information one can study a manuscript's evidence for dialect usage, but be unable to make a statement as to which dialect is being investigated. Even in cases where a manuscript's provenance can be established, this may not have any bearing upon the scribal dialect it preserves. The Vespasian Psalter (British Library Cotton Vespasian a.1) can be confidently located in Canterbury in the ninth century, when an interlinear gloss was added in Old English (S. H. Kuhn Reference Kuhn1965). But the dialect of the glossator can be shown to be Mercian rather than Kentish, reminding us that scribes, like manuscripts and texts, were mobile. There are some exceptions to the lack of an established provenance: legal documents, parliamentary records, memorandum books of local trade and religious guilds, ecclesiastical charters, and so on. However, documents of these kinds frequently pose problems of their own that limit their usefulness as linguistic documents: they are frequently short, formulaic, and are often written in highly conservative forms of language.
7.5 Dealing with variation
Another issue associated with manuscripts is that, unlike printed books, where a single text may be reproduced in numerous identical copies, manuscript books vary from each other to a greater or lesser extent. The works of the major Middle English literary authors John Gower, Geoffrey Chaucer, and William Langland are found in over fifty manuscript copies each (for details see the relevant entries in Boffey and Edwards Reference Boffey and Edwards2005). Anonymous texts such as Cursor Mundi, Prick of Conscience, and Speculum Vitae survive in large numbers of copies. These witnesses typically span a period of some hundred years from the date of composition, and have been copied throughout the country in a wide range of regional dialects enabling scholars to map their transmission through a study of their dialects (Lewis and McIntosh Reference Lewis and McIntosh1982, Beadle Reference Beadle, Laing and Williamson1994). More recently, attempts have been made to exploit hypertext technology to provide ‘cultural mappings’ of the 183 surviving copies of the Middle English prose Brut, produced between the fourteenth and seventeenth centuries, bringing linguistic evidence into dialogue with provenance, textual affiliation, readership, and patronage (the Imagining History project). While some of these extensive manuscript traditions preserve copies that are closer in time and location to the authorial original, there are very few instances of medieval works which survive in manuscripts copied by the author himself, known as a ‘holograph’ manuscript; nearly all such manuscripts are at least one stage removed from the author's original copy. The small number of instances of authorial holographs from the medieval period includes Bodleian Library MS Junius 1, containing The Ormulum, written by its author, an Augustinian canon named Orm from Bourne, Lincolnshire, between 1180 and 1190 (Burchfield Reference Burchfield1956, Parkes Reference Parkes, Stanley and Grey1983; see the Orrmulum Project by Nils-Lennart Johannesson). British Library MS Arundel 57 contains the Ayenbite of Inwyt, containing a colophon stating that its author, Dan Michel, wrote it in his ‘oȝene hand’ in Canterbury in 1340, when he would have been at least seventy years old (Gradon Reference Gradon1965–79, Hanna Reference Hanna and Kelly2011). Fifteenth-century holographs include manuscript collections of his own verse by the London poet Thomas Hoccleve and copies of works by the hagiographer and Augustinian friar of Lynn, Norfolk, John Capgrave (Lucas Reference Lucas1997, Burrow and Doyle Reference Burrow and Doyle2002). While these texts might seem ideal candidates for linguistic analysis, they represent but a small proportion of the extant corpus of medieval manuscripts. Furthermore, they represent a limited range of dialects, London, Norfolk, Lincolnshire, and Kent, leaving large sections of the country completely unrepresented. Literary texts of the Old English and Early Middle English periods tend to survive in smaller numbers of copies than ones composed in the later Middle English period (Laing Reference Laing1993). The Early Middle English period also suffers from a patchy coverage of texts; the majority of surviving manuscripts can be localized to the Western or Eastern counties, leaving the central Midlands poorly attested (Laing Reference Laing, Taavitsainen, Nevalainen, Pahta and Rissanen2000).
Another issue that needs to be confronted when analysing manuscripts concerns the scribes’ treatment of the language of their exemplars. In a seminal essay published in 1963, Angus McIntosh observed that a scribe setting out to copy an exemplar could approach the task in one of three ways:
1 He could copy his exemplar exactly: carrying out a ‘literatim’, i.e. letter-by-letter, transcription of the original.
2 He could translate the language of his copytext into his own dialect.
3 He could do something in between types 1 and 2, thereby producing a mixture of his own forms and those of his exemplar.
Subsequent work in the field of Middle English dialectology by Michael Benskin and Margaret Laing (Reference Benskin, Laing, Benskin and Samuels1981) revealed that Early Middle English scribes, who were more accustomed to copying a fixed language such as Latin, and to writing in a more formal script, were more likely to copy literatim, preserving the language of their copytexts with considerable fidelity. A good example of a literatim scribe is found in British Library MS Cotton Caligula A.ix of the Owl and the Nightingale. This text was copied in the late thirteenth century by a single copyist but contains two completely distinct spelling systems, with abrupt switches from one system to the other. The only possible explanation for this scenario is that the scribe was copying literatim an exemplar that was written by two different scribes with two different spelling systems (Stanley Reference Stanley1960).
In the later Middle English period it appears to have been more common for scribes to translate the language of their copytexts into their own usages, taking us further away from the language of the exemplar and the original from which it ultimately derives. While this copying practice tends to obscure all traces of an author's own usage, it does shed considerable light on a wider range of Middle English varieties than if all such copyists simply preserved the spelling of the authorial text. An important exception to this generalization concerns the fifteenth-century manuscript tradition of Gower's Confessio Amantis, a work composed in the late fourteenth century. Gower employed an idiosyncratic dialect, comprising a mixture of Kentish and Suffolk features (Smith Reference Smith and Echard2004), which was deliberately preserved by later copyists throughout the fifteenth century (Smith Reference Smith, Samuels and Smith1988a). By contrast, the manuscripts of works by Chaucer and Langland have been more thoroughly translated into a variety of scribal varieties, obscuring much of the evidence for the authors’ own usages, but providing us with a wider range of scribal usages than would have been the case if all such scribes had merely reproduced those of their originals (Horobin Reference Horobin2003, Samuels Reference Samuels1985).
7.6 Approaches to manuscripts
A particularly important development in the use of manuscript evidence for the study of linguistic variation in Middle English was the Middle English Dialect project, which culminated in the publication of A Linguistic Atlas of Late Mediaeval English (LALME). The LALME project began in the 1950s and was published in 1986; an electronic version of LALME has recently been released online, hosted by the Institute for Historical Dialectology at the University of Edinburgh.
The Middle English Dialect project based its analyses on original manuscripts where possible, although in many cases it relied on modern editions. Modern printed sources utilized in the LALME survey include editions of historical documents, such as wills, deeds, charters, and collections of letters, often published by local history societies. Because these texts were edited for historians rather than for linguists, and because they were frequently published in the nineteenth or early twentieth centuries, they are often inconsistent in their fidelity to the language of the originals. But reliance upon edited texts rather than original manuscripts was not limited to historical documents. Because of the difficulty of getting access to original sources, the LALME editors frequently turned to edited versions of literary works as well. Works which survive in diplomatic editions in parallel text format were particularly well suited to this kind of use. A good example of a text treated in this way is the Cursor Mundi, which was edited by Richard Morris for the EETS in 1874. This edition prints four important manuscript copies of the work in parallel, as diplomatic transcripts with minimal editorial intervention.
As a further compromise, necessitated by the length of some Middle English works, the LALME editors analysed tranches of text rather than texts in their entirety. In the case of the Cursor Mundi, for example, the chosen extract comprises the first 2,000 lines of the poem. The most obvious difficulty with this manner of analysing the sources is that it supplies only a partial account of the linguistic features of a particular manuscript. It may be that this partial account is entirely representative of the remainder of the manuscript, but it is also possible that it is not. Additional forms not recorded in the opening 2,000 lines might occur at a later point, while forms found in the opening section might fall out of use later in the text. We saw above, in discussing McIntosh's typology, that scribes were prone to change the way they copied during the transcription process. While the linguistic profiles make no attempt to give exact counts for particular forms that they record, they do supply an indication of relative frequency of usage, placing less-common forms in single brackets and especially rare forms in double brackets. Although this is little more than a rough way of indicating frequency of usage, it is highly likely that such frequencies would change if the entire text were to be analysed.
If the localizations are to be considered reliable then it is important that the data for each linguistic profile be accurate in their totality. A recent reconsideration of the LALME handling of original sources with reference to British Library MS Cotton Nero A.X, the unique surviving witness to Sir Gawain and the Green Knight and other alliterative poems by the same author, by Ad Putter and Myra Stokes (Reference Adams2007), has shown the extent to which the LALME linguistic profile misrepresents the language of the original manuscript through omissions and inaccuracies, leading the authors of this study to conclude that ‘LP 26 is so imprecise that it can hardly be trusted to provide more than a rough indicating of the scribe's locale’ (p. 487). Another significant limitation in the LALME profile concerns the very partial reporting of context and distribution. For instance, under the item SHE (third-person singular pronoun), LALME LP 26 reports the majority form ho, and a minor variant scho is given in double brackets. But what this indication of frequency fails to note is that five of the six instances of scho are found to cluster in a short stretch of text within Gawain. This distribution is significant because it strongly suggests that the forms are not those of the scribe, but that they were inherited from an exemplar, one which is likely to be different from that used for the other poems in the Cotton Nero manuscript.
Once again, we see that the difficulties presented by the availability of original sources led to a number of compromises. Instead of using only original materials, the LALME editors were compelled to draw upon edited texts, including ones which were not especially faithful to the linguistic features of the original manuscript. The sheer scope of the project also led to compromises in the amount of data to be analysed, which resulted in linguistic profiles which provide only a partial account of the variant forms attested in a particular source, and only a relative indication of their frequency and distribution.
These limitations were partly necessitated by the form of the original sources and difficulties of access; the successor project to LALME, the Linguistic Atlas of Early Middle English (LAEME), has attempted to provide a much more comprehensive overview of the earlier Middle English period. Because of the more restricted corpus, LAEME has produced an extensive electronic corpus of the surviving textual materials, rather than basing its own survey on a selective analysis. As a result, the LAEME project has made available an electronic corpus of Early Middle English texts that has been explicitly produced for linguistic analysis, preserving features of spelling, punctuation, abbreviation, and even, in some cases, distinctions in letter forms. In addition to providing the transcriptions, the LAEME editors have also applied a series of tags, encoding lexical meaning and grammatical function, for every word in their corpus, allowing it to be searched by part of speech and word, as well as by spelling form. Having completed this project, the LAEME team has now returned to the LALME project and released an online version, with a number of revisions and corrections of the data presented in the original publication. Although revision of linguistic profiles has necessarily been piecemeal, given constraints of time and funding, these have generally set out to address some of the perceived shortcomings described above, replacing profiles that were based upon untrustworthy editions with ones taken directly from manuscripts and separating out profiles which represent the work of more than one scribe.
Since the publication of LALME, scholars have sought to build upon and extend this valuable resource. Researchers at the University of Glasgow and the University of Stavanger are constructing an electronic corpus of Middle English texts based upon localizations provided in LALME. To date the corpus comprises 500,000 words of Middle English, transcribed directly from manuscript or from a printed facsimile. The ultimate goal of this project is the compilation of a Middle English Scribal Texts Archive (MESTA), which will comprise a series of corpora, with texts arranged according to a wide range of linguistic and non-linguistic criteria. Rather than focusing simply on geography as a means of understanding linguistic variation, this project will consider a broader range of criteria for classification, including codicological phenomena such as script, decoration, mise-en-page, and other textual factors.
Researchers at the University of Birmingham exploited the LALME localizations in a different way, in order to describe the ‘literary geography’ of the West Midlands area. The Manuscripts of the West Midlands project produced A Catalogue of Vernacular Manuscript Books of the English West Midlands, c.1300–c.1475. The completed resource includes descriptions and images of 150 manuscripts whose scribal dialects were located by LALME to the West Midland counties of Gloucestershire, Herefordshire, Shropshire, Staffordshire, Warwickshire, and Worcestershire. By bringing together both linguistic and palaeographical evidence, this resource opens up new possibilities for an integrated approach to the study of language and script.
The analysis of the outputs of prolific scribal copyists is another valuable method of analysing linguistic and palaeographical variation in combination. Research in this field builds upon Jeremy Smith's groundbreaking work on an important copyist of Middle English literary manuscripts (known as ‘Scribe D’) (Smith Reference Smith, Samuels and Smith1988b); the recent completion of the Late Medieval English Scribes database (Mooney et al.), freely accessible over the web, has made available palaeographical and dialectological information for several hundred Middle English scribes. Using this database it is now possible to construct detailed linguistic profiles, examining how language is conditioned by text-type, register, the status of the particular manuscript. In addition, this resource enables scholars to assemble graphetic profiles of the kind first proposed by Angus McIntosh in Reference McIntosh1975, but abandoned because of the difficulties in handling the quantities of data involved in the pre-electronic era. Another important electronic resource is the database of manuscripts entitled The Production and Use of English Manuscripts 1060 to 1220, compiled by Orietta Da Rold, Takako Kato, Mary Swan, and Elaine Treharne. The post-conquest period, which saw many of the most significant changes in this history of English, is surprisingly under-researched; particularly marginalized are copies of Old English works by important prose writers such as Ælfric and Wulfstan, produced after the Conquest, despite the important evidence they preserve about the way Old English linguistic conventions were preserved or reorganized for a later audience. A focus on literary manuscripts in this period has led to the neglect of a large body of non-literary material, such as legal texts comprising writs, charters, and land grants (Treharne Reference Treharne2012). While such texts can present a specific set of challenges for linguists, because of their textual transmission, length, and formulaic nature, they have been shown to preserve valuable evidence for contemporary usage as well as for the reception of Old English in the eleventh and twelfth centuries (Lowe Reference Lowe2001).
The availability of electronic editions of complete manuscripts enables scholars to extend the LALME analyses of individual manuscripts comprising multiple texts. Above I noted the limitations imposed by the LALME requirement to sample manuscripts, rather than analyse them in their entirety. Now that complete manuscripts have begun to be digitized it has become possible to analyse a scribal output on the basis of an exhaustive linguistic profile. The recent digitization and transcription of the entirety of the ‘Vernon’ manuscript (Bodleian Library, MS Eng. Poetry a.1) has enabled a more fine-grained analysis of the linguistic output of the two scribes responsible for copying the vast collection of texts it comprises than was possible in the two linguistic profiles offered in LALME (Scase Reference Scase2011, Horobin and Smith 2011). The opportunities offered by electronic analysis of complete texts for scribal identification were demonstrated by Alison Wiggins, who used complete scribal profiles to argue that Scribes 1 and Scribes 6 of the Auchinleck manuscript were indeed distinct copyists (Wiggins Reference Wiggins2004, see also Runde Reference Runde, Cloutier, Hamilton-Brehm and Kretzschmar2010). Analysis of scribal profiles of complete transcriptions of manuscripts of Jacob van Maerlant's Scolastica, a Middle Dutch translation/adaptation of Peter Comestor's Medieval Latin Historia scholastica by K. H. van Dalen-Oskam (Reference Dalen-Oskam2012) has implications for scholars working with digitized editions of medieval English manuscripts. Jacob Thaisen (Reference Thaisen2013) has applied similar techniques to copies of early witnesses of Chaucer's Canterbury Tales to determine the likely number of exemplars on which these extant copies were based. Developments in the discipline of historical pragmatics have also drawn upon manuscript evidence, especially features of mise-en-page and layout. Analysis of the organization of the manuscript page – the integration of headings, paragraph markers, the provision of marginal glosses, and the use of red ink and white space – has shed light on the ways in which a manuscript may communicate visually with the reader (see the essays collected in Pahta and Jucker Reference Pahta, Taavitsainen and Pahta2011 and Chapter 28 by Moore in this volume). Close reading of the provision and organization of visual devices, such as speaker markers, can inform our understanding of authorial attempts to communicate the form of a text, as well as the ways scribes and readers responded to such efforts (Echard Reference Echard1997, Pearsall Reference Pearsall, Matsuda, Linenthal and Scahill2004). Study of layout and mise-en-page can also be usefully applied to non-literary manuscripts. In her study of handwritten business correspondence in the nineteenth century, Marina Dossena has emphasized the importance of calligraphy, ornamental lettering and the generous provision of white space as politeness and ‘face-enhancing’ moves which extend beyond strictly linguistic choices (Dossena Reference Dossena, Pahta and Jucker2011). Work in the field of historical sociolinguistics has drawn heavily upon collections of correspondence, since these can provide autograph evidence of a known individual's linguistic usage. But such work has often relied upon edited collections rather than manuscripts, with the consequence that they focus on grammar, lexis, and pragmatics, rather than orthography and phonology. A good example is a study of letter collections of the late medieval and early Tudor periods by Nevalainen and Raumolin-Brunberg (Reference Nevalainen and Raumolin-Brunberg2003), which draws upon the Corpus of Early English Correspondence (CEEC), a collection of 2.7 million words representing 6,000 letters scanned from 96 edited collections. The increasing availability of freshly edited letter collections, such as Alison Wiggins's diplomatic edition of 234 original letters to and from Bess of HardwickFootnote 2 (c.1521/2–1608), will make reliance upon untrustworthy sources less necessary. Similar projects have been undertaken under the aegis of the Centre for Editing Lives and Letters at University College London.Footnote 3
A neglected feature of both manuscripts and early printed books of considerable significance for both linguistic and literary studies concerns authorial, scribal, and compositorial punctuation practices. Malcolm Parkes's (Reference Parkes1992) magisterial overview of the history of western punctuation, Pause and Effect, remains the major survey of this field; a more recent study of the use of parentheses by John Lennard (Reference Lennard1991) provides a similar diachronic overview of a single punctuation feature. However, we continue to lack detailed interrogation of specific usages in manuscript and printed books which would enable a more nuanced understanding of the development in what Parkes has termed the ‘grammar of legibility’. Small-scale studies have been carried out on the punctuation of major literary writers (e.g. Killough Reference Killough1982 on Chaucer, McKenzie Reference McKenzie, Salmon and Burness1987 and Warren Reference Warren, Salmon and Burness1987 on Shakespeare), or on specific manuscripts (e.g. Solopova Reference Solopova and Fein2000b on British Library MS Harley 2253), but we lack a more comprehensive, diachronic overview covering both literary and non-literary practices. More recently, attention has been paid to the pragmatic functions of punctuation in specific varieties (e.g. Smith and Kay Reference Smith, Kay, Pahta and Jucker2011 on Older Scots), or specific textual traditions (e.g. Parkes Reference Parkes, Oguro, Beadle and Sargent1997 on Nicholas Love, Mirror of the Blessed Life of Jesus Christ). A recent monograph on methods of marking speech in Middle English manuscripts and early printed texts has demonstrated the value of drawing upon both traditional linguistic features in combination with punctuation practices, in tracing the diachronic development of modes of speech marking in both manuscript and print (Moore Reference Moore2011).
7.7 Manuscript to print
The transforming impact of printing for the establishment of a standard variety of English is generally assumed, but has received surprisingly little detailed study. Relevant work in this area has been focused on individual textual traditions, such as Caxton's editions of Reynard the Fox (Blake Reference Blake1965), Chaucer's Canterbury Tales (Horobin Reference Horobin2001), Chaucer's Romaunt of the Rose (Caie Reference Caie, Pahta and Jucker2011), or Caxton's printing practices more generally (Fisher Reference Fisher1996). The development of new resources which will enable manuscripts to be compared with printed versions of the same text, such as the Malory Project, which brings together the ‘Winchester’ manuscript of Malory's Morte Darthur with Caxton's printed edition of 1469–70, will offer new possibilities for the study of the linguistic implications of the shift from manuscript to print (Kato and Hayward). Printed books of the sixteenth and seventeenth centuries are a particularly neglected area, although detailed work on the printed tradition of Spenser's Shepheardes Calender demonstrates what can be achieved through careful analysis of this extensive body of primary material (Rutkowska Reference Rutkowska2013). Recent attention to the spelling practices of printed copies of early modern dramatic works has supplemented the findings of authorship attribution studies. Douglas Bruster (Reference Bruster2013) has argued that variant spellings found in the Additional Passages attested by the 1602 quarto of Thomas Kyd's play The Spanish Tragedy, lend support to the theory that these lines were authored by Shakespeare. Laurie Maguire and Emma Smith (Reference Maguire and Smith2012) suggest that the First Folio text of Shakespeare's All's Well That Ends Well (1623) preserves contractions and orthographical preferences typical of Thomas Middleton, leading them to propose the play was the product of collaboration between the two playwrights. Unusual spellings witnessed by the Shakespeare First Folio has led Saul Frampton (Reference Frampton2013) to propose that the edition was subjected to metrical, stylistic, and linguistic intervention from the Italian lexicographer and translator of Montaigne, John Florio. The spelling habits of early modern printers more generally have been assessed by N. E. Osselton (Reference Osselton1963, Reference Osselton, Blake and Jones1984); linguistic standards among printers of the eighteenth century have been surveyed by Ingrid Tieken-Boon van Ostade (Reference Tieken-Boon van Ostade, Fisiak and Krygier1998). More recently, Anita Auer has embarked on a collaborative project, Emerging Standards: Urbanisation and the Development of Standard English, c.1400–1700, designed to investigate the development of standard English from the perspective of urban vernaculars of major regional centres.Footnote 4 This project will involve producing a corpus of manuscript and printed materials from 1475 to 1700, and analysing it according to factors such as date, text-type, social stratification, and migration patterns. So, while working with original documents is a necessary feature of all historical linguistic research, it presents a number of distinct challenges which must be given detailed consideration before a research project is carried out. While it is possible to use an edited text as a substitute for the original document, this should only be done following a detailed assessment of the nature of the edition and its manner of representing the original and is not an appropriate substitute for the original in many cases. The reliance upon edited texts is particularly problematic for research into orthography, phonology, punctuation, and historical pragmatics. Yet, the increasing availability of manuscript facsimiles and diplomatic transcriptions in electronic form is making reliance upon such sources unnecessary. Particularly neglected areas of research in this field concern the impact of printing upon the written language: what models were adopted by early printers and how standardized were their practices? While scholars have carried out studies of individual printers, or on the relationship between manuscript and print of particular texts, we lack any large-scale investigation into the linguistic usages of the early printers. The developing field of historical pragmatics also raises a number of questions which will be of great interest in future work on manuscript sources, concerning the communicative functions of features of layout and ordinatio. We also lack detailed studies of individual punctuation practices, as well as a clear diachronic overview of developments in usage. The increasing availability of electronic corpora, which bring together large quantities of such data in electronic form are transforming the kinds of research questions that can be asked of such data; this is the subject of the following chapter (Chapter 8 by López-Couso in this volume).
8.1 ‘Old’ material in new formats
The use of textual material as a window into the linguistic system of past stages of the language has a long tradition in English historical linguistics. Classic examples of the use of what Svartvik (Reference Svartvik and Facchinetti2007: 12) calls ‘language corpora BC, i.e. “before computers”’, can be found in the work by James Murray for the Oxford English Dictionary and in Otto Jespersen's A Modern English Grammar on Historical Principles (1909–49), where the various linguistic structures being discussed are conveniently and generously exemplified with quotations from the literary works of renowned authors.
Although English historical linguistics has always been heavily anchored in textual evidence, the last three decades or so have witnessed an increasing interest in the compilation of structured and systematic collections of texts from earlier periods of the language, mostly in computerized form. The availability of ‘old’ material in new formats, including not only electronic corpora, but also electronic dictionaries and online collections of texts, which provide quick and easy access to a large amount and a wide variety of data, has undoubtedly stimulated new research methods and approaches (see, e.g., Szmrecsanyi Reference Szmrecsanyi, Krug and Schlüter2013a and Chapter 2 by Hilpert and Gries in this volume) and has enabled scholars to ask new questions and to reconsider old questions in a different light.
In this context, this chapter offers a compact overview of the kind of material available to students and researchers interested in the analysis of variation and change in the history of English. Given the limitations of space, rather than providing detailed descriptions of the most influential English diachronic corpora and of all their potentialities for research,Footnote 1 the chapter can only attempt to give a small-scale survey of a selection of these resources (see section 8.2.2), placing these corpora in the context of the history of English, highlighting their advantages and weaknesses, and offering some examples of the kind of data which have been obtained from them. Although the emphasis is on the long diachrony from Old English to Present-day English, sources for the study of recent and ongoing change in contemporary English are considered as well (see section 8.2.3). The chapter also mentions in passing some major concerns related to the design, compilation, and development of historical corpora, among others the issues of corpus size, the restriction of the available data mostly to the written medium, and the lack of sociolinguistic information about many (particularly) early texts.Footnote 2
In addition to corpora, this chapter also pays attention (though in a highly summary fashion) to other types of electronic material which can be employed as corpora or be used to complement the data provided by corpora (see section 8.3). These include, among others, electronic dictionaries and atlases, full-text collections, and online text archives and repositories of texts from different periods, which, though not necessarily designed for linguistic analysis, offer a wealth of possibilities for investigating language variation and change.
The chapter closes with some comments on the future of electronic corpora (see section 8.4), including some suggestions for the compilation of further historical corpora representing, for example, regional grammatical differences and specific registers in various historical periods.
8.2 Computerized historical corpora
8.2.1 A privileged window into the past
The introduction of electronic corpora and the application of recent advances in corpus methodology have radically transformed the field of linguistics over the last few decades. This is particularly noticeable in certain areas of analysis, such as historical linguistics, where native-speaker introspection necessarily gives way to a strong (almost exclusive) dependence on empirical data.
Although English historical linguistics has always relied heavily on the use of authentic data, mostly for the sake of illustration (see section 8.1), since the early 1980s we have witnessed an exponential growth in the use of structured collections of texts digitally stored in computer-readable format for the purposes of linguistic analysis. As a consequence, the amount and variety of historical corpora available for English today is much larger than for any other language. Computerized corpora have in fact revolutionized the study of English historical linguistics by giving the researcher access to incredibly large quantities of data (some otherwise inaccessible to many analysts), which can be searched in a systematic and reliable fashion with the help of related computer technology, thus reducing significantly the time needed for data collection and analysis. Moreover, as will become apparent from the examples provided below, electronic corpora have helped to enhance our understanding of how, why, when, and under which circumstances English has changed over time, and of theoretical issues of central concern in prominent domains such as grammaticalization, semantic change, sociohistorical linguistics, and historical pragmatics, among many others (see sections 8.2.2 and 8.2.3). Computerized historical corpora have also opened up fresh and exciting possibilities for the study of language change in ‘real’ time, of the statistical significance of the co-occurrence of variables of various kinds (see Gries and Hilpert Reference Gries and Hilpert2010, Szmrecsanyi Reference Szmrecsanyi, Börjars, Denison and Scott2013b, Wolk et al. Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013; see also Chapter 2 by Hilpert and Gries in this volume) and of the implementation of linguistic changes through different areas of grammar, different groups of speakers, different varieties of the language, and different registers (see Pérez-Guerra and Martínez-Insua Reference Pahta, Nevala, Nurmi and Palander-Collin2010 for an example). In this context, as will be shown in the sections that follow, electronic corpora have contributed greatly to many areas of the historical study of English, including morphosyntax, lexis, semantics, grammaticalization, pragmatics, and sociolinguistics.Footnote 3 Further examples of the application of corpus-based evidence in several of these domains are offered by Curzan (Reference Curzan, Lüdeling and Kytö2009: 1099–104) and Kytö (Reference Kytö, Bergs and Brinton2012: 1519–21). Missing from these surveys is historical phonology, a research area for which the potential of computerized corpora is far more limited (Curzan Reference Curzan, Lüdeling and Kytö2009: 1097, Kytö Reference Kytö, Bergs and Brinton2012: 1521), though, as shown by Corrigan (Reference Corrigan, Nevalainen and Traugott2012) and Ritt (Reference Ritt, Nevalainen and Traugott2012), questions of phonological variation (e.g. vowel variants) and change (e.g. vowel lengthening before consonant clusters) can also be addressed with the help of electronic corpora.
8.2.2 A brief survey of the history of English historical corpora
The 1970s and the 1980s saw the emergence of the first electronic resources for the study of the history of English, among them the Dictionary of Old English Corpus (DOEC), a project initiated by Antonette diPaolo Healey in 1975 (see section 8.3), and Louis Milić's Augustan Prose Sample, completed in 1972 at Cleveland State University, a resource which includes selections from the works of fifty-two Augustan English authors, covering the period 1675–1725, and which is now freely available through the Oxford Text Archive.
8.2.2.1 Looking into the long diachrony: Helsinki Corpus and ARCHER
The major landmark in the brief but intensive history of English historical corpora was, however, the completion and publication of the Helsinki Corpus of English Texts (HC) in 1991, a project launched by Matti Rissanen at the Department of English of the University of Helsinki in 1984. The HC is a 1.5-million-word corpus, available in CD-ROM format and through the Oxford Text Archive, which spans the time of the earliest written records (the oldest text in the corpus is the eighth-century Cædmons’ Hymn) to the year 1710. Though a relatively small corpus by modern standards (consider, for example, the 400-million-word COHA; see section 8.2.2.2), the HC is an excellent resource for the diagnostic exploration of long-term developments between Old English and the early eighteenth century,Footnote 4 which can successfully be used as a source for benchmark results and observations to be tested against – and complemented by – more thorough and comprehensive analyses in specialized corpora (see section 8.2.2.2).
The HC consists of about 400 samples of running text, with extracts ranging from 2,000 to 20,000 words, conveniently arranged into eleven sub-periods of 70 to 100 years. This periodization allows the analyst to compare the results obtained from sequential subcorpora comprising material from successive stages in the history of the language (see López-Couso and Méndez-Naya Reference López-Couso and Méndez-Naya2001, Méndez-Naya Reference Méndez-Naya, Dury, Gotti and Dossena2008, Rissanen Reference Rissanen, Meurman-Solin and Lenker2011). In addition to the wide temporal coverage of the corpus, the texts in the HC represent a broad set of more than thirty different genres, including both the most formal kinds of writing (e.g. the Bible, philosophical and educational treatises, official correspondence) and more informal text-types (e.g. fiction, comedies), both public and private (personal letters, diaries) writings, as well as texts originally composed for oral delivery (e.g. homilies, sermons, and plays) and those produced in the spoken medium (e.g. trial proceedings) (for full details, cf. Kytö Reference Kytö1996). The multi-genre character of the HC makes it a particularly useful resource to trace back, for example, processes of language change originating at different loci of the broad spectrum of genres represented in the corpus. Interestingly, the textual coding of the corpus (following the COCOA format) also provides, where possible, information as regards dialect, relationship to a foreign original, relationship between the writer and the receiver (e.g. intimate vs. distant), and sociolinguistic information on authors (e.g. age, gender, social rank), among other parameter values.
After more than two decades of life, the HC still remains a backbone of the research in English historical linguistics. However, a number of complementary and supplementary corpora have been released since the publication of the original corpus back in 1991. For example, the potentialities of the original ‘raw’ version have expanded significantly with the development of annotated (tagged or parsed) editions for different sub-periods, which facilitate particular types of morphosyntactic research. These tagged and parsed versions of the corpus allow searching not only for words or word sequences (see Rissanen Reference Rissanen, Meurman-Solin and Lenker2011, Reference Rissanen, Hegedűs and Fodor2012 on adverbial connectives), but also for syntactic structure, including empty subjects, zero relativizers and complementizers, word order, etc. (see Johansson Reference Johansson, Peters, Collins and Smith2002 on pied-piping and stranding in Middle English, and van Kemenade and Westergaard Reference Kemenade, Milićev, Jonas, Whitman and Garrett2012 on the variation between V2 and non-V2 word order in Middle English declaratives). The Penn historical corpora include the Brooklyn–Geneva–Amsterdam–Helsinki Corpus of Old English, the Penn–Helsinki Parsed Corpus of Middle English, second edition (PPCME2), and the Penn–Helsinki Parsed Corpus of Early Modern English (PPCEME).Footnote 5 Moreover, a new XML annotated version of the HC, the Helsinki Corpus TEI XML edition, released in 2011, represents the updating of the original edition of the corpus, with its COCOA annotation scheme, to a modern encoding system and more widely used metalanguage, the TEI XML standard.Footnote 6
Though a significant breakthrough for corpus-based research on the history of English, the HC does not contain material beyond the first decade of the eighteenth century. This gap is filled by ARCHER, A Representative Corpus of Historical English Registers (see Biber et al. Reference Biber, Finegan, Atkinson, Fries, Tottie and Schneider1994a, Reference Biber, Finegan, Atkinson, Beck, Burges, Burges, Kytö, Rissanen and Wright1994b), available for in-house use at the departments collaborating in the ARCHER project as well as online via the internet. ARCHER is a multi-genre corpus containing different text-types of both British and American English covering the time span between the seventeenth century and the present day. Like the HC, it contains material from a variety of registers, both formal (e.g. science) and informal (e.g. letters), and both written (e.g. fiction prose) and speech-like registers (e.g. drama). Due to its wide generic coverage, ARCHER has become a widely used resource for the analysis of register-based variation in Late Modern English. For example, using a multidimensional approach (see Biber 1988), Biber and Finegan (Reference Biber, Finegan, Nevalainen and Kahlas-Tarkka1997) show how registers such as drama and medical prose have changed considerably between 1650 and 1990 along the ‘involved-informational dimension’. The ARCHER material also proves relevant to the analysis of morphosyntactic issues in the Late Modern English period, such as the frequency of the progressive (Núñez-Pertejo Reference Núñez-Pertejo, Pérez-Guerra, González-Álvarez, Bueno-Alonso and Rama-Martínez2007), the decline and final disappearance of the passival (The house is building) and the rise of the progressive passive (The house is being built) (see Hundt Reference Hundt, Lindquist and Mair2004), the grammaticalization of the get-passive (Hundt Reference Hundt2001) and of emerging modals (Krug Reference Krug2000), the use of be and have as perfect auxiliaries with intransitive verbs (Kytö Reference Kytö, Rissanen, Kytö and Heikkonen1997), simultaneity clauses (Broccias and Smith Reference Broccias and Smith2010), and genitive alternation (Szmrecsanyi Reference Szmrecsanyi, Börjars, Denison and Scott2013b), among many others.
Despite the pronounced similarities between the HC and ARCHER (both are multi-genre multi-purpose diachronic corpora), the two corpora differ in important ways. One of these differences concerns the dichotomy of static vs. dynamic corpora. While the HC is a static corpus which contains a finite body of text material that has remained stable over time, ARCHER is a dynamic corpus which has undergone considerable changes in its make-up over the years and has been (and still is) open to the addition of further material. The original version of ARCHER (ARCHER 1), compiled in the early 1990s by Douglas Biber (Northern Arizona) and Edward Finegan (Southern California), consisted of 1,037 texts and around 1.7 million words in all, of both British and American English, though for the latter variety only texts corresponding to the second half of the eighteenth, nineteenth, and twentieth centuries were included. By contrast, ARCHER 3.2, the most recent edition of the ARCHER project,Footnote 7 completed in 2013 by a consortium of participants at fourteen universities in seven different countries, involved the incorporation of new material representing legal opinion and the language of advertising, the split of the category journals-diaries into two separate registers, and the expansion of the corpus to the first half of the seventeenth century (1600–49). As a result of these changes, the size of ARCHER 3.2 amounts to 3.3 million words in all. The ARCHER project is still continuing with the aim of further improving the corpus. In the new phase (ARCHER 3.3), certain gaps in the material for specific genres (especially for the American English data) will be filled and structural mark-up will be included in the fiction texts to distinguish fictional prose from fictional dialogue.
8.2.2.2 Moving to second-generation corpora and beyond
As seen in the previous section, much has already been accomplished with the compilation of ‘first-generation’ multi-purpose historical corpora like the HC and ARCHER. It seems, however, that the evidence provided by these ‘diagnostic’ corpora (Rissanen Reference Rissanen, Lüdeling and Kytö2008: 59) is not sufficient to provide answers to more specific questions related to the language of individual authors, periods, genres, and dialects, or to the history of low-frequency items and constructions, which may remain unnoticed unless large amounts of data are used. Hence the need is felt for more specialized corpora which can supplement the HC and ARCHER and be used to overcome some of their limitations.
A wider coverage of text material can be achieved, for example, through the use of focused corpora covering specific periods in the history of the language, such as the Corpus of Middle English Prose and Verse (CMEPV), the Century of Prose Corpus (COPC; cf. Milić Reference Milić1990, Reference Milić1995), and the Corpus of Nineteenth-Century English (CONCE, see Kytö et al. Reference Kytö, Rudanko and Smitterberg2000). The CMEPV forms part of the Middle English Compendium, together with two other major electronic resources: the Middle English Dictionary (see section 8.3.2) and a HyperBibliography of Middle English Prose and Verse. In turn, the COPC is a carefully structured corpus covering the period 1680–1780 which has been compiled by Louis Milić on the basis of the Augustan Prose Sample (see above). It is divided into two parts: part A (c.300,000 words in all) contains text samples by twenty major prose writers of the period (e.g. Addison, Dryden, Hume, Locke, and Swift, among others); part B, on the other hand, consists of one hundred selections of 2,000 running words each from the writings of secondary writers of the same period illustrating ten different genres: biography, periodicals, educational writings, essays, fiction, history, letters and memoirs, polemical writings, science, and travel. Also covering the time span of one century is the one-million-word corpus CONCE, compiled by Merja Kytö (Uppsala) and Juhani Rudanko (Tampere), which contains material from seven genres: debates, trials, drama, fiction, letters, history, and science. Given that letters constitute more than one third of the corpus, CONCE seems to be particularly suited for the in-depth analysis of individual linguistic features in this genre. The corpus is also suitable for approximating the spoken language of the Victorian period (note that CONCE contains four speech-based registers: debates, trials, drama, and fiction) as well as for addressing questions related to academic writing (history and science). Examples of valuable contributions based on the CONCE material dealing with grammatical developments in the nineteenth century are the studies on the progressive by Smitterberg (Reference Smitterberg, Bermúdez-Otero, Denison, Hogg and McCully2000, Reference Smitterberg2005) and Smitterberg et al. (Reference Smitterberg, Bermúdez-Otero, Denison, Hogg and McCully2000) and the examination of connective adverbials in Grund and Smitterberg (2014).
Late Modern British English is also covered by the Corpus of Late Modern English Texts, version 3.0 (CLMET3.0), created by Hendrik De Smet, Hans-Jürgen Diller, and Jukka Tyrkkö as an offshoot of a larger project on the development of a database of descriptors of English electronic texts (see Diller et al. Reference Diller, De Smet and Tyrkkö2010). CLMET3.0 covers the period 1710–1920, divided into three seventy-year sub-periods, and contains about 34 million words of running text drawn from various online archives freely available from the internet, among others the Project Gutenberg and the Oxford Text Archive. The corpus is part-of-speech tagged and roughly genre-balanced between five major categories: narrative fiction, narrative non-fiction, drama, letters, and treatises, in addition to a number of unclassified texts. Noël's (Reference Noël2008) study on the nominative and infinitive construction (e.g. The deal is thought to be worth £200m) and Rissanen's (Reference Rissanen, Meurman-Solin and Lenker2011) on adverbial subordinators constitute two apt illustrations of the use of the CLMET material for both quantitative and qualitative analyses of historical syntax.
Of particular interest among second-generation corpora are genre-specific collections which provide crucial evidence for the diachronic evolution of particular types of writing.Footnote 8 A pioneering resource among genre-based corpora of English is represented by the Corpora of Early English Correspondence family. The project was initiated by Terttu Nevalainen and Helena Raumolin-Brunberg at the University of Helsinki in 1993 with the aim of facilitating sociolinguistic research in earlier stages of English and of providing scholars with a particularly suitable testing ground for the application of modern sociolinguistic methods to historical data (see Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg1996a). The original corpus, the Corpus of Early English Correspondence (CEEC, 1410–1680), was completed in 1998 and its sampler version, the Corpus of Early English Correspondence Sampler (CEECS), containing the non-copyrighted materials included in the CEEC, was publicly released that same year. At present, the CEEC family of corpora consists of five daughter subcorpora, amounting to over 5 million words in all, and covering the period from 1403 to 1800; in addition to CEEC and CEECS, it contains the Parsed Corpus of Early English Correspondence (PCEEC), available since 2006, the eighteenth-century extension Corpus of Early English Correspondence Extension (CEECE), and the Corpus of Early English Correspondence Supplement (CEECSU), the latter two currently in preparation. The wide variety of topics which can be investigated using the CEEC family of corpora includes, among others, the application of conceptual metaphor theory to the study of the politeness lexicon (Nevalainen and Tissari Reference Nevalainen, Tissari and Hickey2010), diachronic changes in metaphorical mapping (Koivisto-Alanko and Tissari Reference Koivisto-Alanko, Tissari, Stefanowitsch and Gries2006), ongoing changes in real time between the fifteenth and seventeenth centuries (Nevalainen et al. Reference Nevalainen, Raumolin-Brunberg and Mannila2011), diachronic variation in part-of-speech frequencies (Säily et al. Reference Säily, Nevalainen and Siirtola2011), and sociolinguistic variation in derivational productivity (Säily Reference Säily2014).
Making the spoken language of past stages accessible by proxy is also the target of two most welcome additions to the set of genre-based English historical corpora: the Corpus of English Dialogues 1560–1760 (CED) and the Old Bailey Corpus (OBC). Compiled by Merja Kytö (Uppsala) and Jonathan Culpeper (Lancaster) and released in 2006, the CED contains material from five different text-types divided into two categories: on the one hand, ‘authentic dialogue’ (trial proceedings and witness depositions) and, on the other, ‘constructed dialogue’ (drama comedy, didactic works, and prose fiction). The total number of words in the CED amounts to 1,183,690. In view of the kind of text material included in the corpus, the CED provides an extremely useful tool to approach spoken interaction in the Early Modern English period in order to undertake research into a wide variety of topics particularly – though not exclusively – within the wide domain of historical pragmatics, such as politeness, discourse markers, conversational structure, and so on (for a couple of relevant examples, see Walker Reference Walker2007 and Culpeper and Kytö Reference Kytö, Jucker and Taavitsainen2010). Interestingly, a subsection of the CED (comedy plays and trial proceedings from 1640 to 1760) has been tagged with sociopragmatic annotation.Footnote 9 Relevant references to work based on the sociopragmatic corpus include Archer and Culpeper (Reference Archer, Culpeper, Wilson, Rayson and McEnery2003, Reference Archer and Culpeper2009), Archer (Reference Archer2005), and Lutzky and Demmen (Reference Lutzky and Demmen2013*).
A much larger collection of data (c.14 million words) is found in the OBC, which documents spoken English from 1720 to 1913. Based on the Proceedings of the Old Bailey, London's central criminal court, every utterance in the corpus contains sociobiographical speaker information (e.g. gender, age, occupation, social class), pragmatic information (i.e. speaker role in the courtroom: judge, victim, defendant, witness, etc.), and textual information (i.e. scribe, printer, and publisher of the Proceeding). Such detailed annotation makes the OBC a precious source of data for historical sociolinguistic approaches to the language of the eighteenth and nineteenth centuries (see Huber Reference Huber, Meurman-Solin and Nurmi2007), such as the examination of historical courtroom interaction (see Rama-Martínez Reference Rama-Martínez2013). The OBC has also proved useful for the analysis of grammaticalization and subjectification processes such as those undergone by the degree modifiers a bit and pretty (see Claridge and Kytö Reference Claridge, Kytö, Taavitsainen, Jucker and Tuominen2014).
Other relevant corpora for the study of genre variation in the history of English are:
The Corpus of Early English Medical Writing (CEEM). This is another ambitious project on the compilation of genre-based resources carried out by various teams at VARIENG, University of Helsinki, under the direction of Irma Taavitsainen. It consists of three diachronic subcorpora of English vernacular medical writing representing a variety of textual categories (e.g. academic treatises, surgical treatises, and remedybooks) from the period 1375–1800: Middle English Medical Texts (MEMT, released in 2005, see Taavitsainen et al. Reference Taavitsainen, Skaffari, Peikola, Carroll, Hiltunen and Wårvik2005), Early Modern English Medical Texts (EMEMT, released in Reference Taavitsainen and Pahta2010, see Taavitsainen and Pahta Reference Taavitsainen and Pahta2010), and Late Modern English Medical Texts (LMEMT, in preparation). The estimated size of the corpus, once the project is completed, is c.3.75 million words in all. The contributions in Taavitsainen and Pahta (Reference Taavitsainen and Pahta2010, Reference Taavitsainen and Pahta2011) testify to the wide range of topics open for investigation with the materials in these corpora, from intensifiers to code-switching and the expression of stance, among others.
The Lampeter Corpus of Early Modern English Tracts (LC). Compiled in the 1990s at Chemnitz University under the direction of Josef Schmied (see Schmied and Claridge Reference Schmied, Claridge, Hickey, Kytö, Lancashire and Rissanen1997, Siemund and Claridge Reference Siemund and Claridge1997), the LC is a collection of pamphlets published between 1640 and 1740 on various subject matters, including politics, religion, trade, and law. It amounts to c.1,200,000 words of running text.
The Zurich English Newspaper Corpus (ZEN). This is a collection of early English newspaper texts published between 1661 and 1791, from the first issues of the London Gazette to the period of the appearance of The Times. ZEN, compiled by Udo Fries and associates, consists of 349 complete newspaper issues, amounting to 1.6 million words (see Fries and Schneider Reference Fries, Schneider and Ungerer2000).
The Corpus of English Novels (CEN). Compiled by Hendrik De Smet, CEN contains novels written by twenty-five British and American authors during a very limited time-frame, 1881–1922, and provides a very extensive coverage of over 26 million words of running text. Such a configuration responds to the compiler's intention to design a special-purpose corpus which would ‘allow tracking of short-term language change and comparing usage across individual authors’ (see corpus home page).
As mentioned in section 8.2.2.1, the different text samples in the HC have been given dialect parameter values. For the periods preceding the establishment of a standard language (Old and Middle English), information about geographical localization is provided as accurately as possible. By contrast, for Early Modern English all texts are selected as representing the Southern British standard. The obvious limitations of the HC as regards geographical variation in this period have partially been overcome by the development of supplementary corpora representing the early stages of regional varieties. One of these is the Helsinki Corpus of Older Scots (HCOS, see Meurman-Solin Reference Meurman-Solin1995), compiled by a team led by Anneli Meurman-Solin, in accordance with the principles and coding conventions of the HC. The HCOS, which was released in 1995 and is available on the ICAME CD-ROM, contains over 800,000 words of seventy-one prose texts and samples and a collection of private and official correspondence dating from the period between 1450 and 1700. The corpus therefore offers essential material for the study of the rise of Scottish English as a distinctive form of English and of the Anglicization of Scots, as well as for the analysis of specific linguistic features in this variety (Meurman-Solin Reference Meurman-Solin1993b, Reference Meurman-Solin and Jones1997, Reference Meurman-Solin, Lenker and Meurman-Solin2007).
Other corpora providing evidence of historical varieties of English are the Corpus of Early Ontario English, pre-Confederation Section (CONTE-pC, c.125,000 words), compiled by Stefan Dollinger and spanning the period from the earliest Ontarian English texts (1776) to the middle of the nineteenth century, and the Corpus of Oz Early English (COOEE), a 2-million-word corpus of material written in Australia, New Zealand, and the Norfolk Island between 1788 and 1900. A wider temporal coverage is offered in the Corpus of Irish English (CIE), which contains texts from a variety of genres from the early fourteenth to the twentieth century, including poetry, glossaries of dialect material, drama, and a regional novel from the early nineteenth century (Castle Rackrent by Maria Edgeworth). The material, compiled by Raymond Hickey at the University of Duisburg-Essen, was released in 2003 together with the software Corpus Presenter (see Hickey Reference Hickey2003a). Another ongoing ambitious project on dialect English is the Salamanca Corpus: Digital Archive of English Dialect Texts (SC), which consists of documents representative of literary dialects and dialect literature from 1500 to 1950, thus providing important data for a better understanding of regional varieties of English in the Early and Late Modern periods.
A major achievement in the compilation of dialect-based English diachronic corpora has been the release in 2010 of the Corpus of Historical American English (COHA, see Davies Reference Davies2010) as a ‘companion’ to the Corpus of Contemporary American English (COCA), which contains texts dating from 1990 to 2012. The importance of COHA, however, goes far beyond its relevance as a corpus comprising historical material from a particular variety of English. Given its size, more than 400 million words of running text covering the period 1810–2009, COHA is representative of a completely new type of corpora: the so-called mega-corpora. The benefits of the recent arrival of very large corpora like COCA and COHA are immediately obvious: they expand our ability to undertake detailed investigations of certain linguistic aspects that cannot successfully and comprehensively be explored with far smaller corpora of the types discussed so far in this chapter. Thus, for example, mega-corpora are particularly useful for investigating low-frequency phenomena which may easily go unnoticed in more reduced collections of data (see above; see also Davies Reference Davies2012a, Reference Davies, Nevalainen and Traugott2012b).
COHA, which is freely accessible online, is annotated at the word level for lemma and part of speech, and is distributed in a balanced way from decade to decade between four different genres: fiction, popular magazines, newspapers, and non-fiction books. Being the largest structured corpus of historical English to date, it offers a wealth of possibilities for the in-depth analysis of linguistic change in American English over the last couple of centuries. Thus, it allows for a broad range of research on lexical features in the Late Modern English period (collocates, synonyms, lexical change, etc.). COHA also provides rich insights into word formation (see Hilpert Reference Hilpert2013 on V-ment construction) and into morphosyntactic developments, such as the competition between the go-V and go-and-V constructions (see Bachmann Reference Bachmann, Hasselgård, Ebeling and Ebeling2013), changes in the noun phrase (see Hilpert Reference Hilpert, Nevalainen and Traugott2012b on many a + noun), and complementation patterns (see Egan Reference Egan, Hegedűs and Fodor2012 on the variation between the to-infinitive and the -ing construction with prefer, and Rudanko Reference Rudanko, Mukherjee and Huber2012a on the out of -ing pattern). COHA has also proved an effective tool for the analysis of pragmatic developments, including comment clauses (see Kaltenböck Reference Kaltenböck, Aarts, Close, Leech and Wallis2013), concessive parentheticals (see Hilpert Reference Hilpert2013), and various pragmatic markers (see Claridge Reference Claridge2013 on as it were, so to speak, and if you like).
8.2.3 Examining variation and change in the recent history of the language
As seen in the preceding section, COHA can provide interesting insights into recent and ongoing changes in American English, given its broad chronological coverage. Twentieth-century American English material is also offered by the genre-based TIME Magazine Corpus, which contains 100 million words of texts from the TIME archive from 1923 to the present day. Interesting results based on data from this corpus have been obtained for a variety of topics, including changing frequencies in the use of modal verbs (see Millar Reference Millar2009), various complementation patterns (see Rudanko Reference Rudanko, Hoffmann, Rayson and Leech2012b, Davies Reference Davies, Aarts, Close, Leech and Wallis2013), and the grammaticalization of the construction the idea is…into an intention marker (see Krug and Schützler Reference Krug, Schützler, Aarts, Close, Leech and Wallis2013). British English from the twentieth century, in turn, is represented in ARCHER (see section 8.2.2.1). Developments taking place in British English over the latter half of the twentieth century can also be traced in the Diachronic Corpus of Present-Day Spoken English (DCPSE), compiled by a team of researchers based at the Survey of English Usage, University College London. The DCPSE is a parsed corpus of spoken English which includes c.400,000 words from the London–Lund Corpus of Spoken English (LLC), with data from the late 1960s to the early 1980s, and c.400,000 words from the International Corpus of English – the British component (ICE-GB), containing material collected in the early 1990s. The samples represent different spoken text-categories with varying degrees of formality, from face-to-face and telephone conversations to broadcast interviews and parliamentary language.
A valuable source of evidence for the study of variation and change in the recent history of the language is provided by the so-called Brown family of corpora, a set of parallel, matching, or comparable corpora,Footnote 10 following the same design and sampling frame (500 samples of c.2,000 words each, 15 different text categories), which represent twentieth-century British and American English from various decades separated by a thirty-year gap. The Standard Corpus of Present-day Edited American English, known as the Brown Corpus and compiled by W. Nelson Francis and Henry Kučera at Brown University in the 1960s, was in fact the first computer-readable corpus specifically designed for linguistic research on contemporary English. In subsequent years, the Brown Corpus served as the model for the compilation of other corpora in the family, all of them distributed through ICAME: the Lancaster–Oslo/Bergen Corpus (LOB), the first of Brown's clones, containing British English material from the 1960s, the Freiburg–Brown Corpus of American English (Frown), and the Freiburg–LOB Corpus of British English (FLOB), the 1990s counterparts of Brown and LOB, respectively. Although the ‘Brown quartet’ of corpora are not historical corpora in the strict sense of the word,Footnote 11 they have served as the basis for relevant corpus-based research dealing with changes taking place in British and American English from 1961 to 1991 (see Mair and Hundt Reference Mair and Hundt1995, Hundt and Mair Reference Hundt and Mair1999, Krug Reference Krug2000, Smith Reference Smith, Peters, Collins and Smith2002, the contributions in Leech et al. Reference Leech, Hundt, Mair and Smith2009, Hundt and Leech Reference Hundt2012, and some of the articles in Aarts et al. Reference Aarts, Close, Leech and Wallis2013).Footnote 12 Given their small size (only 1 million words), the Brown family of corpora seems to be particularly useful for the analysis of high-frequency phenomena (e.g. modal auxiliaries, the passive), although they have also been used for the investigation of low-frequency patterns and constructions (see López-Couso and Méndez-Naya Reference López-Couso and Méndez-Naya2012 on so-called ‘comparative complementizers’). The picture of twentieth-century English will progressively be completed as a result of the development of additional matching corpora (not all of them yet available) replicating Brown, LOB, Frown, and FLOB with texts published in both earlier (B-Brown, BLOB-1901, and BLOB-1931) and later (AmE06 and BE06, cf. Baker Reference Baker2009) decades. Davies (Reference Davies2012a) notes that the corpora belonging to the Brown family present two important limitations: on the one hand, their small size (they may be unsuitable for the analysis of certain types of linguistic changes; see Baker Reference Baker2011 on vocabulary change); on the other, the issue of granularity (since they only contain texts from every thirty years, changes taking place during the in-between periods may be overlooked). It is undeniable, however, that small corpora like those of the Brown family also have important strengths, including careful sampling, accurate tagging, exhaustive scrutiny, and whole-text access (Hundt and Leech Reference Hundt2012: 178–80), which make them essential resources for ‘philological’ qualitative analysis (Mair Reference Mair, Krug and Schlüter2013b: 181).
8.3 Electronic collections and other digital resources
In addition to computerized corpora (see section 8.2), there has been an exponential growth of other electronic collections and of online resources available to researchers and teachers of English historical linguistics. These include such diverse materials as electronic editions of individual texts and authors, online collections and repositories of texts (see section 8.3.1), electronic dictionaries, thesauruses, and lexicons (see section 8.3.2), linguistic atlases (see section 8.3.3), and even the World Wide Web and recently developed online applications such as Google Books Ngram Viewer (see section 8.3.4). The usefulness of these resources is definitely beyond doubt. Some of them can be used as – or under the guise of – historical corpora (e.g. the Oxford English Dictionary). In turn, digital archives like Early English Books Online (see below) and the Project Gutenberg may provide sources from which researchers can create their own tailor-made corpora which suit best their needs and purposes.Footnote 13 On other occasions, these resources can serve as a helpful complement to corpora and compensate for some of their deficiencies. Thus, for example, textual databases, some of which contain millions of words of running text, can be used as an effective means of complementing the information on low- and medium-frequency linguistic phenomena provided by small stratified corpora (see Curzan and Palmer Reference Curzan, Palmer, Facchinetti and Rissanen2006).
8.3.1 Electronic collections and text archives
In-depth analyses of individual authors or individual works from various historical periods are made possible with resources of the kind of Electronic Beowulf (see Prescott Reference Prescott1997), the Canterbury Tales Project, and the Open Source Shakespeare.Footnote 14 Although according to standard corpus definitions, electronic resources of this kind do not qualify as corpora in the strict sense of the term, they may be regarded ‘as extreme cases of highly focused corpora’ (Claridge Reference Claridge, Lüdeling and Kytö2008: 242) of the type discussed in section 8.2.2.2. Full-text collections such as the Dictionary of Old English Corpus can also be included in this group of resources. While most historical corpora are made up of text samples, the DOEC contains practicallyFootnote 15 all extant Old English texts (c.600–1150), amounting to 3,060 texts and c.3 million running words, together with c.1 million running words of Latin. Though showing certain important limitations (e.g. it does not allow for lemmatized searches), the main advantage of the DOEC is that it is the largest and most complete database of the language of the Old English period and can therefore be used for comprehensive surveys of particular linguistic features (see López-Couso Reference López-Couso, Lenker and Meurman-Solin2007a on the subordinator þy læs (þe) ‘lest’ and variants).
Size is also the major advantage of large text archives and online collections and repositories of texts such as Early English Books Online (EEBO), Eighteenth Century Collections Online (ECCO), and Literature Online (LION). Despite the fact that they were not specifically designed for the purposes of linguistic analysis, resources of this kind can provide crucial complementary evidence to that yielded by standard corpora given the massive amount of data they offer. With over 350,000 works of poetry, prose, and drama from the eighth century to the present day, LION is the world's largest literature collection, containing the complete contents of fourteen Chadwyck-Healey literature collections, and its own search engine. In spite of all the potential limitations of such a large (unstructured) electronic collection for corpus-like use, its value as a source of data is self-evident.Footnote 16 EEBO, in turn, contains over 125,000 texts dating from the period 1473–1700, which are reproduced as digital images of the original books,Footnote 17 while its sequel, ECCO, comprises over 180,000 works (more than 30 million pages of text) printed during the eighteenth century. In view of the limitations of what can be searched in digital images, the EEBO Text Creation Partnership (TCP), based at the library of the University of Michigan and funded by more than 150 libraries worldwide, aims at creating SGML/XML text editions (with direct links to the digital versions) for a large number of works contained in EEBO, which can then be accessed with standard corpus tools.
8.3.2 Electronic dictionaries
Another type of digital resource of enormous relevance for the analysis of variation and change in the history of English, in particular in the domains of lexis and semantics, is that of electronic and online dictionaries, thesauruses, and lexicons. Among dictionaries, the Dictionary of Old English (DOE), the Middle English Dictionary (MED), and the Oxford English Dictionary (OED) are key projects. The DOE project at the University of Toronto, based on the computerized DOEC (see section 8.3.1), is still underway; at present only the entries from letters A to G (about one-third of the dictionary, over 12,000 entries) are available. Distributed by site license to institutions and individuals, it offers the possibility of simple searches on one field of the dictionary entries (e.g. part of speech) as well as Boolean searches combining two or more fields. The electronic MED, part of the Middle English Compendium (see section 8.2.2.2), is a freely accessible resource which offers all the contents of the print MED (Kurath et al. 1954–2001) in electronic form. The over 50,000 entries included in the MED and the whole of the quotation database can be searched in different ways, from rather simple look-ups (e.g. looking for a head word or a variant form) to advanced Boolean and proximity searches in both the entries and the quotations.Footnote 18
The online version of the OED is probably the most prominent example of the possibility of combining a dictionary project with corpus methodology. The importance of the OED as a source of information for English historical linguistics has long been recognized, already from the time of its printed versions (see Chapter 23 by Durkin in this volume). However, first its publication on CD-ROM and, more recently, the launching of its online version (November 2010) have opened new ways of exploring the wealth of evidence it contains that were unthinkable not too long ago. The digitized version of the dictionary offers both simple word look-ups as well as more sophisticated kinds of searches through its approximately 38 million words of text from about 3 million quotations and across different fields (e.g. language of origin, part of speech, date of first citation, etc.). Its size makes it an unparalleled resource for the analysis of (primarily, though not exclusively) lexical and semantic change in the history of English (e.g. Allan Reference Allan, Winters, Tissari and Allan2010 on metonymy and Allan Reference Allan, Allan and Robinson2012 on the semantic development of metaphorically polysemous lexemes). Interestingly, over the last few years the utility of the OED has expanded beyond its use as an extraordinary collection of dictionary entries. Despite its obvious limitations,Footnote 19 the quotation database of the OED has been successfully used as a corpus for the investigation of a wide range of constructions, including various cases of incipient and incomplete grammaticalization (Mair Reference Mair, Lindquist and Mair2004), the variation between infinitival clauses and prepositional gerunds (Rohdenburg Reference Rohdenburg, Krug and Schlüter2013b), the competition between cannot help -ing and related structures (Rohdenburg Reference Rohdenburg, Hasselgård, Ebeling and Ebeling2013a), and the development of reflexive verbs (Siemund Reference Siemund2014).
OED Online also provides links to relevant entries in the online versions of the DOE and the MED (see above), thus offering quick and easy access to complementary data for the early stages of the history of the language. It also includes full integration of the Historical Thesaurus of English (HTE), which provides a taxonomic organization of the contents of the OED, grouping senses and words according to their subject (see Kay et al. 2009; see also Chapter 13 by Kay and Allan, and Chapter 23 by Durkin in this volume). Most of the definitions in the dictionary can be related with those terms classified as synonyms in the thesaurus with a simple click. However, the HTE offers the possibility not only of looking up synonymous terms used for particular concepts and meanings, but also of exploring the relationship between associated semantic fields over time and of serving as the basis for the analysis of polysemy, neologism, and obsolescence, among other issues. An interesting example of the use of the HTE for the analysis of metaphorical mapping is found in Allan (Reference Allan, Stefanowitsch and Th. Gries2006), which examines the link between the source concept density and the target concept intelligence from Old English to the present day. A similar resource dedicated to the language of the Old English period is the Thesaurus of Old English (TOE), which served as a kind of pilot study for the HTE.
An interesting resource for research on the Early Modern English period is the Lexicons of Early Modern English (LEME), a project deriving from the Early Modern English Dictionaries Database (EMEDD) developed by Ian Lancashire between 1996 and 1999. LEME is a growing database which currently gives access to more than 700,000 word entries from over 200 monolingual, bilingual, and polyglot dictionaries, glossaries, and lexical treatises from the beginning of printing in England to 1702. There are two versions of LEME, a public one and a licensed one, the latter offering advanced retrieval options such as Boolean and proximity queries and restricted searches by date, subject, language, etc.
8.3.3 Electronic linguistic atlases
Of particular interest for the study of regional variation in the medieval period are the interactive atlases developed at the Institute of Historical Dialectology at the University of Edinburgh: A Linguistic Atlas of Late Mediaeval English (eLALME) and its two daughter projects: A Linguistic Atlas of Early Middle English (LAEME) and A Linguistic Atlas of Older Scots (LAOS). eLALME is a revised electronic edition of A Linguistic Atlas of Mediaeval English (LALME), published in 1986 by Angus McIntosh (Edinburgh), Michael L. Samuels (Glasgow), and Michael Benskin (Oslo). The contents of the original atlas, covering the time-span 1350–1450, have been revised and supplemented, and made available as a freely accessible website in 2013. The period immediately preceding that of eLALME is covered by LAEME, compiled by Margaret Laing. Version 3.2 of LAEME, which incorporates considerable revisions of tagging, and a simpler layout of the web pages, among other improvements, was also released in 2013. The third daughter electronic atlas in the project is LAOS, whose current version (1.1) covers the period between 1380 and 1500.
8.3.4 The web
The brief account of electronic and online resources in English historical linguistics provided in this chapter would not be complete without referring to the web. One of the major uses of the web in the field of corpus linguistics is to serve as the source of material for the compilation of customized corpora (see Nesselhauf Reference Nesselhauf, Hundt, Nesselhauf and Biewer2007), just like other large text archives and repositories of texts (see above).Footnote 20 In addition to its use for corpus-building, the web has also been effectively used as a corpus for more than a decade now.Footnote 21 Of particular interest in the context of this chapter is its use as a valuable source of data in the study of recent and ongoing change in English, which may serve to complement the corpus resources discussed in section 8.2.3. The relevance of the web as a corpus for such purposes is brought to the fore in several of the contributions in Hundt et al. (Reference Hundt2007). Mair (Reference Mair, Hundt, Nesselhauf and Biewer2007), for instance, shows that the web can safely be used for linguistic analysis given a few methodological precautions, such as checking the validity of web-derived findings against the results from more traditional and structured corpora. Mair (Reference Mair, Nevalainen and Traugott2012), in turn, demonstrates that the web can facilitate tracing neglected cases of recent morphosyntactic change, such as do-support with got (to) (e.g. Do I got time enough to get in this window?). The obvious strengths of the web as a corpus, among them its massive size (of special relevance for the analysis of low-frequency patterns), its recency (which makes it an exceptional source of evidence for ongoing changes and recent innovations), and its diversity (the web contains material from various standard and non-standard varieties of English worldwide) (see Mair Reference Mair, Nevalainen and Traugott2012), seem to compensate its major weaknesses, which include the dubious quality of some of the material, the instability of the data (which prevents replicability of results), and the lack of fully reliable search engines and statistics.Footnote 22 It is hoped that some of these limitations of the web will be overcome (at least partially) in the near future, so that we will come closer to exploiting the web as a corpus to its full potential. Tools and resources such as WebCorp (see Renouf et al. Reference Renouf, Kehoe, Banerjee, Hundt, Nesselhauf and Biewer2007), in particular the diachronic search facilities provided by the WebCorp Linguist's Search Engine (see Kehoe and Gee Reference Kehoe, Gee and Kehoe2009), will undoubtedly play a role in such improvements. Another valuable device is the Google Books Ngram Viewer, developed in 2010 by a group of Harvard researchers concerned with Culturomics. The Viewer is an online tool which charts the yearly counts of selected n-grams (a contiguous sequence of letters or words of any length) in a corpus of several millions of digitized texts from Google Books.Footnote 23 A recent application of the Ngram Viewer (combined with the Google Book Search) is Diller's (Reference Diller, McConchie, Juvonen, Kaunisto, Nevala and Tyrkkö2013) analysis of the use and frequency of the nouns anger and wrath in the seventeenth century.
8.4 Looking ahead
As shown in sections 8.2 and 8.3, the study of language variation and change in English today relies on an impressive range of high-quality corpora and other electronic and online resources. It seems, however, that despite the considerable progress made over the last couple of decades, the need and interest for the creation of further materials of the kinds surveyed in this chapter is still alive.
The demand for more and better resources is particularly strongly felt in certain research areas in English historical linguistics. The development of new specialized corpora and corpus-like resources is called for in domains like cross-linguistic and interdisciplinary studies (see Kytö Reference Kytö, Bergs and Brinton2012: 1523), multilingualism and other contact phenomena (see Kytö and Pahta Reference Pahta, Nevalainen and Traugott2012: 131–2), and the history of regional varieties of the language. As regards regional variation, although much has been accomplished with the development of dialect-based corpora such as HCOS, CIE, and COHA, among others (see section 8.2.2.2), and electronic atlases such as LAOS (see section 8.3.3), there is still room for improvement. Kortmann and Wagner (Reference Kortmann, Wagner and Hickey2010: 270–1, 290–1), for instance, complain about the lack of sufficient and satisfactory material for the study of non-standard morphosyntax in various periods of the language, and make a plea for ‘appropriate data necessary for adding the many missing pieces to our puzzle of grammatical variation among dialects in the history of English’ (2010: 291). Very little is known also of the historical development of New Englishes, given the scarcity of suitable data. It seems, however, that resources like the 91-million-word Corpus of Legislative Council Proceedings from the Hong Kong Hansard (1858–2012) can offer interesting insights into the evolution of the lexicon of Hong Kong English (see Evans Reference Evans2015) and may serve as a possible model to investigate the history of other varieties of English worldwide.
We further need corpora for specific registers or genres in various historical periods for which extensive documentation in the form of a specialized corpus is still lacking. This is the case, for example, of legal English. Although both the HC and ARCHER contain law texts (see section 8.2.2), the size of the legal components in these two diachronic corpora is too small for a detailed linguistic analysis of legal English across time.Footnote 24 In the near future, the ARCHER material will be complemented by a corpus of British English legal opinions, the Corpus of Historical English Law Reports (CHELAR) which is being compiled by the research group Variation, Linguistic Change, and Grammaticalization at the University of Santiago de Compostela, and which will allow research into the development of this particular text-type from the early seventeenth century to the present day (see Rodríguez-Puente Reference Rodríguez-Puente2011).
The rapid increase of internet facilities, the technological advances in corpus compilation and annotation, and the development of ever more sophisticated software tools for the analysis of corpus data offer promising prospects for research in English historical linguistics in the next few decades. It is indispensable, however, that the historical corpus linguist be ready to combine both quantitative and qualitative approaches to the study of language variation and change, paying attention not only to the unquestionable relevance of statistical corpus findings yielded by structured third-generation mega-corpora, but also to careful philological analysis and close reading of individual examples from more specialized and balanced corpora.
9.1 Introduction
When William Caxton established his printing press in London in 1476 or even when Dr Johnson published his Dictionary in 1755, the phrase ‘listening to the past’ did not make sense except on a metaphorical level. As the present chapter will argue, this has changed, and it is time historical linguists took this change into account in their work. We have had sound recording of the human voice for more than a century – since 1877, to be precise. From the early part of the twentieth century technical quality rose to a level which makes linguistic analysis possible. A large but sometimes badly documented and geographically dispersed body of relevant data has accumulated, and a hundred years is certainly a decent time depth for the study of phonetic change, and the history of the spoken language more generally, on the basis of authentic audio data and in real time.
In order to assess the potential of audio recordings as linguistic data, we have to clarify the relationship between sound and speech, which is trivial only as long as we are dealing with the medium of transmission of the linguistic signal. Koch and Oesterreicher (Reference Koch and Oesterreicher1985) were among the first to systematically explicate the properties of spoken language beyond the level of the medium, coining the terms ‘medial orality’ and ‘conceptual orality’ to capture the different aspects of the phenomenon. With regard to the medium, the distinction between spoken and written (or signed) language is clear. The signal is acoustic in the former case, but visual in the latter. In a ‘medium’ perspective, the value of historical audio recordings therefore resides in the fact that they preserve past acoustic signals, which for the study of past pronunciations is usually preferable to reconstructions based on indirect evidence such as puns, rhymes, orthoepist literature, or other metalinguistic commentary. We can profit from direct access to historical sound irrespective of the discourse function or the sociolinguistic status of the recorded utterance in question.
In Koch and Oesterreicher's terms, what is oral ‘medially’ can be in a complex relation to orality as conceived of ‘conceptually’. A news broadcast and an oral-history interview are both examples of spoken language on the medial level. Conceptually, however, news broadcasts are typically based on written texts composed to be read out on air (and in a standard accent), sharing more of their syntactic, lexical, and textual structure with written news reportage in the press than with a face-to-face discussion of political issues. This may be different in the oral-history interview, which may allow spontaneous speech to surface, even though the recording situation is usually semi-formal and biased toward the narrative monologue; in comparison to the news broadcast, the oral-history interview is also far more likely to feature vernacular linguistic forms in addition to standard ones. A good oral-history interview may easily move from a relatively formal, conceptually ‘written’ opening to genuine medial and conceptual orality later on in the discourse. On the conceptual level, the distinction between speech and writing is obviously no longer binary but gradual, and all sorts of hybrid and mixed manifestations are possible.
In giving direct access to the past acoustic signal, historical audio recordings are a definite boon to historical phonology. However, since there is quite clearly also a place for the historical study of spoken language in a wider context and on the plane of ‘conceptual orality’ as defined above, they may be additionally relevant to the study of the lexicogrammatical and discourse features of older stages of spoken, non-standard, and vernacular English – in other words, to the booming fields of historical pragmatics and historical sociolinguistics. Here, however, a damper of sorts is presented by the fact that especially in the early stages of sound recording the material which was produced tended to be of a conceptually written nature. The voices of the great and the famous recorded in formal settings in the early twentieth century can definitely tell us a lot about standard pronunciation in formal oratory, but not necessarily about the lexicogrammatical peculiarities of informal conversation. For this, a fictional representation of dialogue in a 1920s novel may well be the better source.
On the whole, however, the increasing volume and time-depth of our recorded acoustic heritage is excellent news. It has the potential to revolutionize the study of sound change by widening the window for ‘real time’ studies to almost a hundred years in favourable circumstances, and it will complement and enrich the existing database for historical-sociolinguistic and historical-pragmatic studies of English from the beginning of the twentieth century. The advantages will become even more obvious in the future, because technological advances and more inclusive social notions of what is worthy of being preserved for posterity have led to better coverage of informal-conversational and vernacular language. Audio recordings have thus definitely begun to help fill a gap which was sorely felt by some of the great language historians of the past.
Hermann Paul, pioneer of nineteenth-century historical and comparative linguistics, for example, was keenly aware of the tension between the spoken and written modalities of language in synchrony and diachrony:
Ferner ist zu berücksichtigen, dass zwischen schriftsprache und umgangssprache immer ein stilistischer gegensatz besteht, dessen beseitigung gar nicht angestrebt wird. In folge davon erhalten sich in der ersteren constructionsweisen, wörter und wortverbindugen, die in der letzteren ausser gebrauch gekommen sind, andererseits dringt in die letztere manches neue ein, was die erstere verschmäht.
Eine absolute übereinstimmung beider gebiete in dem, was in ihnen als normal anerkannt wird, gibt es also nicht. Sie sind aber auch noch abgesehen von den beiden hervorgehobenen punkten immer von der gefahr bedroht nach verschiedenen richtungen hin auseinander zu gehen. Die massgebenden persönlichkeiten sind in beiden nur zum teil die gleichen, und der grad des einflusses, welchen der einzelne ausübt, ist in dem einen nicht der selbe wie in dem anderen. Dazu kommt in der schriftsprache das immer wider erneuerte eingreifen der älteren schriftsteller, während in der umgangssprache direct nur die lebende generation wirkt. Um einen klaffenden riss zu vermeiden, muss daher immer von neuem eine art compromiss zwischen beiden geschlossen werden, wobei jede der anderen etwas nachgibt.
Further we must bear in mind that there will always be a stylistic gap between the written standard and the colloquial spoken language which speakers do not even attempt to bridge. As a result, the former contains constructions, words, and phrases which have fallen out of use in the latter, while the latter absorbs innovations which remain disdained in the former.
Thus, an absolute congruence between what is considered normal in speech and writing is impossible. Quite apart from the two points mentioned, they run the risk of drifting apart for other reasons, as well. The influential agents are only partly identical in the two, and the strength of the individual speaker's influence is not the same in one as in the other. In addition, written texts are characterized by the continuous re-appearance and presence of older writers, while it is only the living generation which directly shapes colloquial speech. To avoid a gaping rift, a compromise between the two modes must forever be found, with each side making its concessions to the other. [translated by Christian Mair]
Most language change originates in the colloquial baseline style which Paul mentions and which is characterized by the following four features: it is spoken, spontaneous, vernacular, and interactive/dialogic. For the greater part of the history of English, however, our reconstruction of developments is usually based on sources which tend to be the exact opposite of this stylistic baseline, namely texts which are written, edited, standardized, and monologic. Ideally, a comprehensive history of a language should be based on spoken data which preserve the signal (medial orality) or, where this is not possible, closely approximate to informal conversational and/or vernacular usage, thus maximizing conceptual orality.
Sections 9.2 and 9.3 will briefly address some of the logistical challenges arising in the language-historical study of sound recordings. Section 9.4 will present one promising source of relevant data, namely the recordings made with the help of British prisoners of war during the First World War by the Königlich Preußische Phonographische Kommission between 1916 and 1918, with a view to assessing its potential for historical-linguistic research. Section 9.5 will refer to some relevant recent and ongoing research projects. This will be complemented by a brief conclusion and an appendix pointing the reader to a selection of resource centres.
9.2 Various types of data: potential and limitations
The year 1877 and, in practical terms, the early twentieth century represent barriers which cannot be pushed back when it comes to the preservation of the acoustic signal. However, this does not mean that historical-linguistic research based on audio data is disconnected from work on older stages of the language. As stated above, there is indirect evidence for the reconstruction of past pronunciations, and conceptually oral, speech-like, or speech-based genres allow us to study other aspects of spoken usage (lexicogrammar, discourse norms) ‘by proxy’, as it were. This is done, for example, in the Corpus of English Dialogues 1560–1760 (Culpeper and Kytö Reference Kytö, Jucker and Taavitsainen2010; for the guide to CED, see Kytö and Walker Reference Kytö and Walker2006). Culpeper and Kytö (Reference Culpeper and Kytö2010) present a thoughtful discussion of the ways in which such writing partially and variably approximates the structure of spontaneous speech. Among the methodologically intriguing issues they raise is the question of whether the best written representation of real speech is found in factual transcriptions such as the trial records of the Old Bailey Corpus (OBC, Huber Reference Huber, Meurman-Solin and Nurmi2007) or in the fictional evocations of speech in novels and plays (Mair Reference Mair, Andersen and Bech2013c; for these corpora, see also Chapter 8 by López-Couso in this volume). Putting the question in this way, of course, disregards another issue, namely the immense variability in the type and quality of dialect representation in literary works (see, e.g., Corrigan Reference Corrigan1996, McCafferty Reference McCafferty2005, or Fennell Reference Fennell2008 for examples from eighteenth- and nineteenth-century Scotland and Ireland).
Another avenue worth exploring is to sift the inexhaustible sands of standard writing for the nuggets of vernacular literacy. Thus, pauper letters and emigrant correspondence have been used in a variety of contexts to reconstruct the history of spoken English (Montgomery Reference Montgomery1995, García-Bermejo Giner and Montgomery Reference García-Bermejo Giner, Montgomery and Thomas1997, Fairman Reference Fairman, Barton and Hall2000, Boling Reference Boling, Smyth, Montgomery and Robinson2006). Self-evidently, none of these written data fully compensate for the absence of the phonetic dimension, as pronunciation and intonation are rendered imperfectly and unsystematically even where an effort is made to represent them through non-standard spellings. For example, the selective availability of conventionalized spellings for informal and vernacular items distorts representation, as does eye dialect as a purely visual index of non-standardness without any phonetic equivalent at all.Footnote 1
At the risk of some simplification, Table 9.1 displays the potential and limitations of the various types of data available for the historical study of spoken English.
Table 9.1 Potential and limitations of various types of data available for the historical study of spoken English
| real (vs. fabricated/fictional) | vernacular (vs. standardized) | spontaneous (vs. edited) | dialogic/interactive (vs. monologic) | spoken (vs. written) textual genre | acoustic (vs. graphic) physical realization | |
|---|---|---|---|---|---|---|
| vernacular fiction (e.g. Mark Twain, Huckleberry Finn) | − | + | − | −/+ | + | − |
| early nineteenth-century pauper letters | + | +/− | − | −/+ | − | − |
| emigrant correspondence | + | −/+ | − | −/+ | − | − |
| witness depositions (e.g. Old Bailey) | + | −/+ | +/− | +/− | + | − |
| recorded public oratory (e.g. King Edward VIII's resignation broadcast) | + | − | − | − | +/− | + |
| oral history collections and folklore archives (e.g. National Folklore Collection at UC Dublin) | + | + | +/− | +/− | + | + |
| surreptitiously recorded conversations (e.g. Watergate Tapes) | + | − | + | + | + | + |
Note that of the six criteria in Table 9.1 it is only ‘physical realization’ that is binary, because it exclusively refers to medial orality. A text is either sound-recorded or written. If the recording is transcribed, the transcription's status is derived and secondary in relation to the spoken original. By the same token, a broadcast reading from a written text (such as Twain's Huckleberry Finn) is derived from – and hence secondary to – the written original.
The five remaining criteria refer to conceptual orality and are therefore gradient. A formal public speech is usually read aloud from a written text, which minimizes the scope for spontaneous improvisation. (Written and spoken) narratives are basically monologic but may contain stretches of reported or enacted dialogue, and so forth. Where such mixed and transitional constellations are particularly likely, this is represented by ‘–/+’ or ‘+/–’ in the relevant boxes in Table 9.1 (with the first symbol in the series indicating the more expected value). For example, the ‘–/+’ value for the Old Bailey texts in the column for ‘vernacular’ indicates that these data were systematically standardized and edited by the reporting clerks but still contain traces of the original spoken vernacular (see Chapter 18 by Beal in this volume; see also Archer Reference Archer, Nevalainen and Traugott2012a: 147–9).
As becomes apparent in the rightmost column of Table 9.1 (‘physical realization’), the phonetic dimension is absent by definition for all types of speech-like writing; we will never have audio recordings of the original trials documented in the Old Bailey Corpus, of nineteenth-century paupers reading their letters aloud, or of Samuel Clemens reading the text of Huckleberry Finn in the pronunciation he considered appropriate. As has been pointed out above, this need not be a problem for many types of investigation into the history of spoken and vernacular English. In the fictional evocation of a spoken text, the lexicon and grammar often preserve important aspects of the sociolinguistic profile of informal and vernacular speech of the time. For example, the choice between thou and you, between third-person singular present -eth or -s, or multiple negation can all be safely studied on the basis of such data (see, e.g., Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg2003 based on correspondence; for thou vs. you in trial proceedings, witness depositions and drama, see Walker Reference Walker2007; for -eth vs. -s in witness depositions, see Chapter 27 by Walker in this volume).
This is patently not so with the phonetic details which elude the English spelling system, and reliability and consistency are generally low even where conventionalized non-standard spellings exist, such as, for example, gonna, gimme, or lemme (for going to, give me, or let me). A contracted pronunciation (e.g. /gɪmɪ/) cannot be ruled out when we read <give me> in a transcription, nor is the presence of the non-standard spelling gimme in the transcription absolute proof that the form was pronounced as a contraction. Lay transcribers generally tend to over-standardize what they hear in the transcription, but they may also assign non-standard spellings to individuals they perceive or stereotype as non-standard speakers. To research the history of such phonetically reduced forms, transcripts are not enough. We need historical audio recordings – and preferably not the public oratory which is easiest to obtain for the first half of the twentieth century, but spontaneous dialogic data of the type illustrated by the Watergate Tapes.Footnote 2
9.3 Working with historical audio recordings: technical, legal, and ethical challenges
The nineteenth century saw a number of experimental attempts at recording voice and music (see Picker Reference Picker2003). As hinted at above, the very early period of sound recording produced a patchy legacy of data, with a quality which is generally too low to warrant linguistic analysis. What is conventionally considered the dawn of the era of mechanical recording of the human voice is the year 1877, when Thomas Alva Edison successfully recorded himself reciting the nursery rhyme ‘Mary Had A Little Lamb’ on his phonograph. The medium for storage being wax-coated cylinders, mass production and mass dissemination were not feasible at first, but became possible when Emil Berliner developed the gramophone, using shellac discs (or records) as the carrier medium from 1888. In the early days, their quality also fell short of what one would like to have for linguistic analysis, but from the early twentieth century, that is, for over a hundred years now, recordings of sufficient quantity and quality have accumulated to warrant investigation.
Until relatively recently few linguists would have been tempted to use old audio recordings as data for their research because of obvious technical obstacles. The development of recording technology has always been very fast, with older storage media becoming obsolete and inaccessible to anyone but specialists within a short while. Just as in the 1930s it was impossible for most linguists to work with 1890s wax cylinders, most present-day dialectologists lack the equipment needed to play 1960s reel tapes or even 1980s cassette tapes. More importantly, damage to the carrier meant the end of the recording. Some practical illustrations of this issue may be found in Allen Reference Allen, Beal, Corrigan and Moisl2007.
As a result, many potential language-historical treasures remained widely dispersed in libraries, archives, and collections – public and private, commercial and non-commercial – all around the world; constituting unexplored ‘hidden depths’, to cite the title of Widdowson (Reference Widdowson1999). This has only really changed recently in the course of the digital revolution, which has produced transportable formats such as ‘.mp3’Footnote 3 and facilitated access through the World Wide Web. This is illustrated very well by the material which will be discussed in section 9.4, which somewhat unexpectedly survived the Second World War and the subsequent Cold War in two Berlin archives, was largely forgotten and only rediscovered and digitized in the 1990s. Parts of it are now made available freely to the public by the British Library. For the first time since their collection, this has created a situation in which the data have become widely accessible to interested researchers again, and many legal issues surrounding access and use have been clarified, too. Readers requiring a comprehensive and detailed survey of the technical and legal challenges of archiving and curating audio data are referred to Linehan (Reference Linehan2001), a collection of essays written by experts in the field who exemplify the issues with a wide range of examples spanning the gamut from early recorded music via oral history and performance to wildlife recordings.
From the ethical point of view, working with historical recordings is generally less problematic than analysing more recently recorded spontaneous conversational data, which requires the subjects’ informed consent before the data are obtained and appropriate measures to protect their privacy when the data are published (see Cameron Reference Cameron2001: 19–25). Obviously, some of the historical data which we may want to analyse were not gathered in accordance with current ethical recommendations in linguistics. The Watergate Tapes are an obvious case in point. However, even in such cases the data will usually have been in the public domain for some time before becoming available for linguistic analysis, so that informant rights are rarely infringed on by linguists for the first and crucial time.
9.4 The recordings of the Königlich Preußische Phonographische Kommission: an early source for the study of real speech in real time?Footnote 4
9.4.1 A unique resource
In 1915 the Königlich Preußische Phonographische Kommission was founded by a number of mostly Berlin-based linguists who realized that the presence of a large number of prisoners of war provided a unique opportunity to record speech samples and music from a population of very diverse linguistic and cultural background, including for example colonial troops speaking ‘exotic’ non-Indo-European languages. The Anglicist Alois BrandlFootnote 5 was an active member of this group, recognizing an opportunity to assemble a large collection of folk songs and dialect recordings from all over Britain and Ireland. He subsequently analysed and disseminated a small portion of the material in a number of publications (Brandl Reference Brandl1926–7), some of which – a quite innovative feature at the time – came out accompanied with (now mostly lost) phonographic records. However, this unique resource was largely forgotten until recently – in spite of its obvious value as the largest extant database of early twentieth-century British dialect speech. Fortunately, however, most of the recordings, which were part of the Berliner Lautarchiv, survived and were digitized professionally in the 1990s, though not in a specialist-linguistic project but as part of a wider campaign to save Berlin's audio-visual heritage.Footnote 6 The originals were single-channel (‘mono’) recordings on shellac discs (78 rotations per minute). Digitization was based on the audio compact-disc standard sampling rate of 44.1 kHz (i.e. 44,100 samples per second) and 16-bit resolution.
Copies of 821 recordings were subsequently obtained by the British Library in 2008 and are catalogued as ‘Berliner Lautarchiv: British and Commonwealth Recordings’. Of these, 66 have been made available for public listening through the Library's website.Footnote 7
Although the recordings comprise several hours of speech in their totality, they do not add up to a balanced corpus of spoken English. Speakers were asked to read passages from the Bible, in particular the Parable of the Prodigal Son (Luke XV, 11–32), to tell short folk tales, recite folk poetry, sing songs, or – in some cases – simply to count. Given the state of recording technology at the time and the research priorities of the compilers, the recording of informal conversation was neither feasible nor considered desirable. These shortcomings notwithstanding, the data represent a unique resource for the study of historical dialect phonology. As will be shown below, at least two of the key diachronic developments in English dialects in the twentieth century, namely the loss of post-vocalic /r/ and the glottalization of /t/, can be investigated in acoustic analysis with good results.
A research question which these data could shed considerable light on is the loss of traditional rural dialects and the emergence of modern koinés in England in the course of the twentieth century. As we can learn from the classic dialectological sources (Ellis Reference Ellis1889, Reference Ellis1890, Wright Reference Wright1898–1905), large portions of the English dialect landscape still showed rhoticity in the late nineteenth century. This assessment is likely to reflect the usage of conservative speakers, who – in the methodological spirit of traditional dialectology – were considered the best informants and the bearers of the authentic dialect. The prisoners of war recorded by the Lautarchiv, by contrast, represent a random sample of mostly youngish males from the same regions. If their pronunciations conform to the dialect descriptions in the reference works, this can count as additional corroboration. However, what if their pronunciation turned out to be different or just variable? Should we consider this as the starting point of modern koinéization? Or is the issue one of methodology, with variation being much older and just being left out of an artificially sanitized dialectological record?
The Lautarchiv data also lend themselves well to a comparison with the Survey of English Dialects (SED) recordings (parts of which are, incidentally, also made available via the British Library's website). Both the Lautarchiv informants and the SED ones were generally born in the later decades of the nineteenth century. Again, we can compare the pronunciation of a socially heterogeneous group of speakers recorded as young adults or middle-aged men during the First World War and a very homogeneous group of elderly farm labourers recorded in their old age around four decades later. Alternatively, holding social background constant and focusing on those prisoners who were farm hands, we could compare (degree of) dialect use across different stages of the lifespan.
Here I will briefly discuss the audio record available for one English county, Norfolk, which happens to be covered fairly well in the Lautarchiv recordings and whose dialect history from the nineteenth to the twenty-first centuries is thoroughly documented generally (Orton and Tilling Reference Orton and Tilling1969, Trudgill Reference Trudgill1974, Reference Trudgill, Foulkes and Docherty1999b, Reference Trudgill, Kortmann and Schneider2004b, Britain Reference Britain2005a). For Norfolk, the Lautarchiv offers nine recordings of about 13 minutes’ total duration from three individuals:
1 Lewis Wright, born in 1879, from Gorleston on Sea, who reads from the Bible (recording time 03:03, i.e. three minutes and three seconds). The British Library biographical comment, based on the notes of the recorder, reads: ‘Lived at Gorleston on Sea until 1914. Educated at an elementary school in Gorleston on Sea. Can read but cannot write in English … Occupation: carman and horseman’ (http://sounds.bl.uk/Accents-and-dialects/Berliner-Lautarchiv-British-and-Commonwealth-recordings/021M-C1315X0001XX-0581V0).
2 Fred Eccles, born in 1898,Footnote 8 from Aslacton, who reads from the Bible (two recordings of 01:54 and 00:55 min. respectively), sings the song ‘Farmer Giles’ (00:36) and gives the essential numerals from 1 to 100 (00:23). British Library biographical comment: ‘Lived in Norwich until he joined the army. Educated at a[n] elementary school at Norwich. Father and mother from Foulshamhe [sic]. Can read and write in English. Can play the flute and sing’ (http://sounds.bl.uk/Accents-and-dialects/Berliner-Lautarchiv-British-and-Commonwealth-recordings/021M-C1315X0001XX-0629V0).
3 Walter Chapman, born in 1877, from Martham, who reads from the Bible (03:14), tells the ‘True Story of Farmer Fellows’ (02:17), partly sings and partly recites ‘Scarborough Churchyard’ (03:28), and gives the essential numerals up to 1,000 (00:21). British Library biographical comment: ‘Born on 14 January 1877 in great [sic] Yarmouth. His father was a market gardener. His parents had 16 children, 12 of them still alive and living in London. Has done a mixture of jobs due to the death of his father who was a blacksmith. Went to sea for 9 months as a fisherman, then cleaned engines on the railroad, then back to sea. Lived until 20 in Ornesby (near Martham), then moved to G[o]rleston. Went to public school in Ornesby. Both his parents from Norfolk. Can read and write in English…Occupation: heater’ (http://sounds.bl.uk/Accents-and-dialects/Berliner-Lautarchiv-British-and-Commonwealth-recordings/021M-C1315X0001XX-0759V0).
Note that of these three individuals only Lewis Wright corresponds to the type of informant recorded for the SED. The British Library holds all the recordings mentioned but has only made available the readings from the Bible on its website. The recording which is potentially most interesting from a linguistic point of view is Chapman's retelling of the ‘True Story of Farmer Fellows’, because it comes closest to spontaneous speech.
To test their potential for research, I will survey the data with regard to three variables which have been subject to rapid change in the recent history of English dialects, namely glottalization of voiceless consonants (particularly /t/), /h/-dropping, and rhoticity.
9.4.2 Glottalization
While glottalization of intervocalic and word-final /p, t, k/ is not documented for Norfolk in Ellis and Wright, all three Norfolk speakers show variable glottalization of /t/. According to Wells (Reference Wells1982), glottalization is not rare in the traditional dialects of Southern England and East Anglia. In the SED instances of glottalization are documented, as well. Trudgill (Reference Trudgill1974) claims East Anglia to be one of the centres from which this linguistic feature has diffused geographically. The youngest of the three Norfolk speakers, Fred Eccles, seems to use glottalized variants most often, though of course statistical generalizations on the basis of such limited and partly incongruous data remain precarious.
9.4.3 /h/-dropping
Although Trudgill (Reference Trudgill, Foulkes and Docherty1999b) states there is no /h/-dropping in the traditional dialects of East Anglia, Ellis (Reference Ellis1890), Wright (Reference Wright1898–1905), and the SED record instances. Almost all /h/-dropping in the Lautarchiv recordings occurs in synsemantic rather than autosemantic words and is thus unremarkable.
9.4.4 Rhoticity
Ellis (Reference Ellis1890) attests rhoticity for most regions of England in the 1860s, and many traditionally rhotic areas were still described as mainly rhotic when the SED research was conducted in the 1950s. Britain, on the other hand, argues that ‘we can comfortably assume…that the actual area of loss was much greater and had penetrated further into the west and south-west [than can be inferred from SED data] simply because the data come (deliberately) from the most conservative speakers of the community – old rural nonmobile men – and exclude those who are likely to have pushed further the innovatory drive toward r-lessness’ (Britain Reference Britain2009: 130). Rhoticity is one of the variables frequent enough in the data to allow at least rudimentary quantitative analysis. For Norfolk, this yielded a very low rhoticity rate of 2.3 per cent (or 7 out of 302 instances),Footnote 9 which characterizes the dialect as a non-rhotic one in practical terms.
By contrast, the Lautarchiv data for the county of Kent, as solidly non-rhotic as Norfolk today, are more highly variable, with 66.7 per cent rhoticity for Sevenoaks and 38 per cent for Hunton. The informant for Sevenoaks was born in the town in 1883 and went to school locally until he became a polisher's apprentice in London. He returned to Sevenoaks, where he lived until the age of 20, and then went to India. The Hunton informant, also born in 1883, grew up in the village, where he became a blacksmith, probably in his father's business. At the age of 17 he left home to join the army for three years, and lived in London for another five after that. In his personal protocol form, Brandl quotes the speaker as saying: ‘If I set my mind to it, I can talk the language of the farmers.’ London was already described as non-rhotic by Ellis (Reference Ellis1890: 58) and we can assume that several years in London must have brought both informants into close contact with non-rhotic speakers.
Instrumental analysis of the data is tempting, but of course beset with a number of problems. Comparison across time requires that we be able to distinguish real change in the sound and distortions introduced by the different types of recording apparatus used at different times. When the original cylinders and shellac discs were digitized in the 1990s and early 2000s, the non-lossless .mp3-format (rather than, for example, the lossless .wav-format) was chosen as the standard, which may be another slight disadvantage in this case. In addition, the PRAAT response is likely to differ between the relatively noisy historical data studied here and present-day studio-quality input. Figure 9.1 presents the measurements of one Norfolk informant's long high back and stressed central vowels (lexical sets GOOSE and STRUT).

Figure 9.1 Measurements for vowels in two sons, produced by Norfolk informant (Fred Eccles), recorded in 1917
Even if comparison across time should be undertaken with caution in view of the caveats formulated above, comparison within the Lautarchiv corpus itself remains a possibility – helped by the highly standardized procedure of data gathering employed. As most informants were asked to narrate the Parable of the Prodigal Son, the phrase chosen here for illustration, two sons, occurs in most recordings. A considerable number of informants also recited the numerals, which establishes a convenient frame of comparison for potentially interesting diphthong variables (five, nine) or rhoticity (four, fourteen, forty), for example.
9.5 The historical linguistics of sound: ongoing projects and research perspectives
As has been mentioned above, some of the Lautarchiv recordings were transcribed, analysed and published in a series of twenty short pamphlets describing British dialects by Alois Brandl himself (Brandl Reference Brandl1926–7). The framework for presentation was a traditional-dialectological one, and the material mainly served the purpose of realistic illustration. In fact, Brandl's most interesting observations on the data are not found in these publications but rather in a personal memoir, where he writes:
Indem wir aber die Platten umschrieben und die Umschriften miteinander verglichen, ging uns der ganze alte Dialektbegriff in eine Illusion auf. Wir hatten von einer festen Redeform eines Dorfes, vielleicht sogar einer Dörfergruppe geträumt und fanden statt dessen bei genauem Hinhorchen überall ein merkwürdiges Schwanken. Selbst der einzelne Sprecher wechselte und konnte eigentlich kein Sätzchen in gleicher Weise reproduzieren. Dies wurde besonders deutlich durch die Erfindung des Oszillographen, der den Luftstrom der gesprochenen Rede aus den Vertiefungen der Schallplatte haarscharf herausholt, die Schwingungen dieses Luftstroms zu zollgroßen Kurven elektrisch vergrößert und sie gleichzeitig photographiert.
Und nun fangen bei sorgsamer Vergleichung diese scheinbar willkürlichen Eigenheiten jedes Sprechers in jeder Stimmung zu erzählen an: was aus der Schriftsprache und was aus Nachbargemeinden herangekommen ist, wie die Schule, der Beruf und die Gesellschaft am Sprecher gearbeitet haben und vieles Erstaunliche von Entfaltung der seelischen Elemente. Die Sprache erscheint nicht mehr als etwas Festes und Beharrliches, sondern als ein steter Wechsel. Was an ihr einheitlich erscheint, ist durch Schule, Geschäftsverkehr, Nachbarumgang hineingelangt. Durch die Beobachtungsmöglichkeiten des Weltkrieges ist der ganze Begriff umgemodelt.
But as we were transcribing the records and comparing the transcripts, the entire traditional notion of dialect revealed itself as one big illusion. We had dreamt of a stable speech form of a village, maybe even a group of villages, and what we found instead on listening closely was strange fluctuation. Even the individual speaker varied and was basically incapable of repeating the same sentence the same way. This was made especially clear by the invention of the oscillograph, which reconstructs the stream of the spoken word from the grooves of a record and plots the airwaves on a photograph…And now, after careful comparison, the ostensibly arbitrary idiosyncrasies of the various speakers in their various moods start to tell a story: what has come in from the written language and from neighbouring communities, how school, work, and society have exerted their influences, and much involving the development of the psyche. Language no longer appears to be something solid and stable, but rather something ever changing. That which appears uniform has entered the language through school, business, and neighbourhood contacts. The new opportunities to study language afforded by the World War have changed our entire notion of what language is. [translated by Christian Mair]
This statement is vivid testimony to the power of recording technology, which instils awareness in the linguist of the fluidity and sociolinguistic variability of the vernacular. The fact that it is found in a personal memoir rather than one of the author's scholarly publications, on the other hand, shows that the time was not ripe for him to follow up on this observation in his research – or, in other words, to take the step from a traditional-dialectological to a sociolinguistic-variationist perspective in the study of language variation and change. As the material was largely forgotten later, the new perspective has never been systematically applied to it since.
However, there are several other projects which illustrate the potential of language-historical analyses supported by genuine audio recordings. Harrington et al. (Reference Harrington, Palethorpe and Watson2000, Reference Harrington, Palethorpe, Watson, Hardcastle and Beck2005) is a study of changes in British RP in the course of the second half of the twentieth century which became widely known even outside linguistics because of the high profile of its informant, Queen Elizabeth II. Comparing the Queen's Christmas Broadcasts from the 1950s and the 1980s, the authors show that some of the informant's vowels moved closer to variants associated with younger and less upper-class speakers. Radio news broadcasts produced in Australia during the same period were used by Price (Reference Price2008, Reference Price, Nevalainen and Traugott2012) to demonstrate the decolonization of Australian media language. British RP, the exclusive norm in the early period, gave way to a more local Australian accent. In addition to analysing archival broadcasts, the study profited from the fact that some of the announcers were still available for off-air interviews in their ‘real’ voices at the time the research was carried out.
Both these projects used media data and focused on standard pronunciation. This is different in research on early New Zealand English audio data which were discovered by Elizabeth Gordon and extensively analysed by herself, Jennifer Hay, Peter Trudgill, and others (see Trudgill et al. Reference Trudgill, Gordon, Lewis and Maclagan2000, Trudgill et al. Reference Trudgill, Maclagan and Lewis2003, Gordon et al. Reference Gordon, Campbell, Hay, Maclagan, Sudbury and Trudgill2004). The recordings were produced by the New Zealand Broadcasting Service's ‘Mobile Unit’, who travelled the country from 1946 to 1948 to record interviews with around 300 mostly elderly informants.Footnote 10 Beyond recording individuals and, possibly, charting diachronic changes in their pronunciation, this broad and heterogeneous demographic base makes it possible to move beyond the idiolect and explore the complexities of variety genesis.
A pioneering vernacular resource with a similarly broad base, though less remote in time, was NECTE, the Newcastle Electronic Corpus of Tyneside English, which brought together two collections of recordings and integrated them into a state-of-the-art digital corpus. The data comprised the Tyneside Linguistic Survey, a sociolinguistic documentation carried out under the direction of Barbara Strang in the late 1960s and early 1970s, and the PVC (Phonological Variation and Change) corpus compiled by James Milroy and co-workers from 1991 to 1994 (see the NECTE website for further details). NECTE was subsequently incorporated into the Diachronic Electronic Corpus of Tyneside English (DECTE), which has added contemporary data in order to produce a monitor corpus for the study of ongoing changes in their historical context (see http://research.ncl.ac.uk/decte/pvc.htm and Corrigan Reference Corrigan, Nevalainen and Traugott2012 for a case study on changes in the GOAT vowel).
Historic early blues recordings (Miethaner Reference Miethaner2000) and ex-slave narratives (Schneider Reference Schneider1989, Poplack and Tagliamonte Reference Poplack and Tagliamonte2001) have helped the study of older African-American English. In fact, a forthcoming collection of studies bearing the significant title Listening to the Past (Hickey forthcoming) shows that there is virtually no major region of the English-speaking world for which hitherto unexplored historical audio recordings are unavailable. As the editor's project website informs, the book aims to look at:
the earliest audio recordings for a number of varieties of English, probably from the beginning, or at least from the first half, of the twentieth century. The reason for examining such recordings is that they often show accents prior to key developments of the mid-to-late twentieth century in the United States, Canada, England, Scotland, Ireland – to mention just a few anglophone countries where this would apply. The opposite may also be the case, i.e. that early audio records do indeed show features thought to be recent. The speakers on early recordings are often of a fairly advanced age offering apparent-time information for varieties spoken in the late nineteenth century.
England will be covered by four case studies devoted to Tyneside, Liverpool, London Cockney, and RP, Ireland and Scotland by one each (Dublin and Glasgow). Five contributions will deal with the US, two with Canada, and one each with Jamaica, West Africa, South Africa, Australia, New Zealand, and Tristan da Cunha.
9.6 Conclusion
Historical sound recordings of the human voice have accumulated for more than a century – and in quantities which, for a language such as English at least, constitutes a potentially rich and valuable store of data. Over the past two decades, significant technological advances in the digital conversion, storage, and dissemination of the data have brought them into the reach of the ordinary linguist. As the present chapter has demonstrated, this has led to the beginnings of a boom in research which was to be expected. The most immediate area to benefit from this boom is historical phonology, both of standard and non-standard speech. Careful analysis of historical sound recordings will enable researchers to check existing assumptions for accuracy on new data, to achieve a more precise chronology of known developments and, at least in a small number of instances, will also force unexpected corrections. The cursory analysis of the Berliner Lautarchiv English dialect data carried out for purposes of demonstration here, for example, has shown that the dialect landscape of the late nineteenth and early twentieth centuries presented in sources such as Ellis or the SED is certainly not wrong but involves a significant degree of abstraction from the full extent of variability which – then as now – resulted from complex interaction of regional with social and stylistic variation.
As most early recordings do not provide spontaneous speech (or where they do restrict themselves to certain textual genres such as the folk anecdote or the oral history narrative) the recordings are less likely to benefit the study of historical morphosyntax. Here future generations of historical linguists will still have to fall back on speech-like and speech-based written genres as the most likely source to provide ‘speech by proxy’. In research on recent and ongoing processes of grammaticalization, the one-hundred-year time window opened up by audio data may allow us to trace phonetic reduction of highly frequent chunks ([have] got to → gotta, etc.) in real time. Here as elsewhere, however, in view of the time typically taken by grammaticalization and similar changes: if we want the full picture, we shall have to look back in time further than the ‘watershed’ year of 1877, when Edison's invention made it possible to conserve the evanescent sound of the human voice for posterity.
10.1 Introduction
The grammatical tradition in the Modern English period (1500–1900) has become a thriving topic in historical linguistics, albeit after a period of neglect due to the negative associations of eighteenth-century grammar books and the ‘intimidating’ amount of nineteenth-century material to explore (see Görlach Reference Görlach1999a: 7–8, Beal et al. Reference Beal, Hodson and Fitzmaurice2012: 201–2). The 1970s and 1980s witnessed a change of outlook, with scholars such as Leitner calling for ‘more teaching and research into “grammaticology”, the cross-disciplinary study of grammars’, which, as he put it, is ‘more than desirable’ for the understanding of the history of linguistics (1986: 1334). Pioneering work dates from the early twentieth century, with Kennedy's (Reference Kennedy1927) bibliography, and Leonard's (Reference Leonard1929) and Poldauf's (Reference Poldauf1948) studies. Bibliographic resources and access to evidence improved in the 1960s with Alston (Reference Alston1965) and the English Linguistics facsimile series (Alston Reference Alston1967–73). Michael's (Reference Michael1970, Reference Michael1987) and Vorlat's (Reference Vorlat1975) monographs are arguably the most comprehensive studies of the development of linguistic thought during the Early and Late Modern English periods. On a smaller scale, early studies focused on specific grammar writers such as Robert Lowth (Pullum Reference Pullum1974) and William Ward (Subbiondo Reference Subbiondo1975); or on specific linguistic features like double negation (Tieken-Boon van Ostade Reference Tieken-Boon van Ostade1982), phrasal verbs (Hiltunen Reference Hiltunen1983), and auxiliary do (Tieken-Boon van Ostade Reference Tieken-Boon van Ostade1987). In the 1990s Sundby et al.'s Dictionary of English Normative Grammar (Reference Sundby, Bjørge and Haugland1991) contributed an exhaustive analysis of the proscriptions laid down in two hundred eighteenth-century normative works, and a number of case studies on literary authors and social networks followed (Tieken-Boon van Ostade Reference Tieken-Boon van Ostade1991, Wright Reference Wright, Fernández, Fuster and Calvo1994, Percy Reference Percy and Britton1996). The account of normative linguistics in Tieken-Boon van Ostade (Reference Tieken-Boon van Ostade, Auroux, Koerner, Niederehe and Versteegh2000a) testifies to the development of this field. Easier access via online resources (Early English Books Online, Eighteenth Century Collections Online, the Eighteenth-Century English Grammars database)Footnote 1 allowed for a change in research perspective and gave the field a boost. Scholars turned to the original materials and to the grammar writers and demonstrated that historical grammars are a source of evidence in their own right. A number of dissertations and monographs have investigated linguistic features such as past and past participle forms (Oldireva Gustafsson Reference Oldireva Gustafsson2002), the subjunctive (Auer Reference Auer2009), and preposition stranding (Yáñez-Bouza Reference Yáñez-Bouza2015a); others have focused on the grammar writers themselves, including Ann Fisher (Rodríguez-Gil Reference Rodríguez-Gil2002), Joseph Priestley (Straaijer Reference Straaijer2011), and Robert Lowth (Tieken-Boon van Ostade Reference Tieken-Boon van Ostade2011). The state of the art on several topics in the field is illustrated in edited volumes (Beal et al. Reference Beal, Nocera and Sturiale2008, Tieken-Boon van Ostade Reference Tieken-Boon van Ostade2008b, Hickey Reference Hickey2010, Yáñez-Bouza and Rodríguez-Gil Reference Yáñez-Bouza and Rodríguez-Gil2013b), conference series (Perspectives on Prescriptivism 2003, 2006, 2009, 2013), and large-scale projects (The Codifiers and the English Language, Leiden University). While the focus has fallen primarily on the seventeenth and eighteenth centuries, the nineteenth century remains largely underexplored, although interest is now growing here too (Michael Reference Michael1997, Görlach Reference Görlach1998a, Anderwald Reference Anderwald2012, the Collection of Nineteenth-Century Grammars).
This chapter aims to illustrate how grammars from the early and late Modern English periods have become a serious object of study in the field of English historical linguistics, not only as sources for the norms of present-day written standard English, but also as evidence of language use, variation, and change. First, their production is contextualized in relation to the process of standardization of English and the descriptivism–prescriptivism continuum (section 10.2). This is followed by a survey of the main approaches in the study of historical grammars, which will highlight the strands to which historical grammaticology can contribute and the various ways in which grammars can be examined. Section 10.3 reports on the influence of precept on usage, the interference of precept in change related to linguistic and sociolinguistic factors, and the descriptive adequacy of grammarians and their grammars. Section 10.4 touches on the potential of less researched areas such as subsidiary content in grammars, grammars attached to other works, and the paratext of grammar books.
10.2 English grammar writing
The production of grammars of English increased dramatically during the four centuries of the Modern English period, though not at a steady pace, as shown in Figure 10.1.Footnote 2 The history of English grammar writing begins with William Bullokar's Bref Grammar for English in 1586, one of only two grammars known to have appeared in the late sixteenth century; by the end of the seventeenth century only twenty-one ‘explicitly English grammars’ were in existence (Michael Reference Michael1970: 151). Production in the early eighteenth century is still modest, with fewer than forty new grammars. This is in stark contrast to the rapid growth during the second half of the century, which yielded over 200 works and over 1,600 printings, with remarkable peaks in the 1770s and 1790s. This itself was but a preamble to the ‘hyperactive production’ during the nineteenth century, when an average of eight or nine new works were produced each year: approximately 860 new grammars and over 3,600 printings overall, with salient peaks during the 1840s and 1870–1880s (Michael Reference Michael1997).

Figure 10.1 Production of English grammars per decade from 1586 to 1900
The development of English grammar writing can be said to run parallel to the process of standardization and the changing attitudes towards Latin (for standardization, see Chapter 18 by Beal in this volume). Little attention was given to the grammar of English in the early Modern period, primarily because the term grammar conveyed notions of Latin grammar until well into the eighteenth century (Yáñez-Bouza Reference Yáñez-Bouza2015b). Latin was the only model that early grammarians had to hand, and this was reflected in the approach to the structure of English (trying to fit English into Latin) and in teaching methods (exercises of bad English, parsing exercises, etc.). Following Nevalainen and Tieken-Boon van Ostade's (Reference Nevalainen, Tieken-Boon van Ostade, Hogg and Denison2006: 274–87) account of standardization, we can argue that the need for English grammar writing during the sixteenth and seventeenth centuries responded to attempts to elaborate the functions of the English language against the dominance of Latin, most commonly in vocabulary, spelling, and style, but also in relation to grammar. The beginning of the grammatical tradition was a timely response to the cultural climate created by the Renaissance, the Reformation, and the Humanist movement, which together favoured the emancipation of English from Latin culture and raised the prestige of English in schools (see Vorlat Reference Vorlat1975: 3–6). John Wallis's (Reference Wallis1653) Grammatica Linguæ Anglicanæ marked a new era of interest in the vernacular by pointing out the structural differences between English and Latin, paving the way for a conscious movement of reform ‘which sought to give English a grammar in its own right’ (Michael Reference Michael1970: 210). In the eighteenth century, Beal (Reference Beal2004: 101) notes that the increasing interest in vernacular education was ‘[p]erhaps the most pressing and practical reason for the production of grammars’. The eighteenth century also witnessed the last two stages of the standardization process: codification and prescription. Codification is the phase when rules are laid down in grammars, dictionaries, and other sorts of self-education handbooks regarded by their readers as authoritative manuals; once the language is codified, the prescription stage involves the implementation of the codified norms in written language (see Nevalainen and Tieken-Boon van Ostade Reference Nevalainen, Tieken-Boon van Ostade, Hogg and Denison2006: 282–4). The two phases are said to coexist from around 1745 to the 1770s (Tieken-Boon van Ostade Reference Tieken-Boon van Ostade and van Ostade2008a: 7–8), after which there was a spate of practical and utilitarian grammars targeting new and wider audiences. The shadow of Latin persisted during the eighteenth and nineteenth centuries, especially in the description of parts of speech, but the ‘irregularities’ of the Latin–English mapping were ‘repeatedly denounced’ by nineteenth-century grammarians, and Latin gradually lost ground (Dekeyser Reference Dekeyser1975: 28).
The approach to grammar writing has often been presented as a binary opposition: those who describe actual usage versus those who evaluate usage and prescribe recommendations about how language ought to be used. But we should rather see attitudes ranging along a descriptive–prescriptive continuum. Vorlat suggests a threefold distinction:
(1) descriptive registration of language, without value judgements and including ideally – as a very strong claim – all language varieties; (2) normative grammar, still based on language use, but favoring the language of one or more social or regional groups and more than once written with a pedagogical purpose; (3) prescriptive grammar, not based on usage but on a set of logical (and other) criteria.
In the sixteenth and seventeenth centuries the normative approach prevails, leaning more or less towards the descriptive. The prescriptive approach is first made explicit in Christopher Cooper's Grammatica Linguæ Anglicanæ (Reference Cooper1685), but at that time prescriptivism ‘is in the making, not yet made’ (Vorlat Reference Vorlat1979: 137). The shift from normative to prescriptive grammar becomes apparent towards the mid-eighteenth century when incorrect and improper usage was given more attention and the ideal of correctness led to the practice of imposing norms on language users; it was the beginning of the heyday of the prescriptive era, which, as Vorlat (Reference Vorlat and Schmitter2007: 512) puts it, ‘grew into a mania’ during the nineteenth century. As Bailey notes, attitudes towards grammatical correctness and propriety ‘hardened into ideology’ (Reference Bailey1996: 215) during this century, particularly in the latter half, when it was commonly felt that ‘everyone ought to consult’ grammars and dictionaries (1996: 3). That said, the nineteenth century can be better described as ‘a continual alternating between descriptivism and prescriptivism’ (Dekeyser Reference Dekeyser1975: 4), when the dominance of the latter approach came up against the influence of the New Philology. Linguistic thought had come to be occupied with speculative theories of language discussed in universal grammars. A major influence here was John Horne Tooke's theory of etymological derivations based on the relation of language and mind, a priori reasoning, and the belief that there is only one true primitive meaning for each word (Diversions of Purley, 1786). It is only in the 1830s and 1840s that Benjamin Thorpe (1782–1870) and John Mitchell Kemble (1807–57) introduced from the continent the empirical and a posteriori methods that would be followed by the founders of the Oxford English Dictionary in its incipient stages during the 1850s and 1860s, as well as by historical grammarians such as Robert Gordon Latham in An Elementary English Grammar for the Use of Schools (1843) and Henry Sweet in A New English Grammar (1891–8). The latter half of the nineteenth century then witnessed ‘the transition from old to new, from amateurism to linguistic professionalism’ grounded in a scientific approach to analysis and description (Dekeyser Reference Dekeyser1975: 24).
10.3 Approaches and findings
This section surveys approaches taken in the literature and summarizes the main findings. For reasons of space, only a small number of case studies can be discussed; the Appendix to this chapter complements this account with a more complete list of linguistic features.
10.3.1 The effect of precept on usage
A fundamental aim in the study of historical grammars is to assess the effect of linguistic thought on actual language usage. Normative grammars, in particular eighteenth-century grammars, have often been held responsible for the stigmatization of linguistic features or for imposing a specific variant as the ‘correct’, standard form. Given that traditional accounts are often proposed without supporting empirical evidence, a number of scholars have embarked on a reassessment of language myths through a close scrutiny of precept corpora (i.e. meta-linguistic comments from the grammars) and usage corpora (i.e. collections of language practice such as letters and literary works). In order to demonstrate the influence of the former on the latter there needs to be a time gap of several decades; in the absence of such a gap one might argue that usage led to precept and not vice versa (see, for instance, Auer Reference Auer, Dalton-Puffer, Kastovsky, Ritt and Schendl2006). Three main trends have been observed in the literature: precept triggered change, precept reinforced an existing trend, precept had only a marginal influence on usage.
Large-scale studies have confirmed that some critical precepts of normative grammars have triggered language change, usually a decline in usage and a subsequent disappearance (see Appendix (A), code TR). For instance, late seventeenth- and early eighteenth-century usage shows morphological levelling in the past and past participle paradigm of strong verbs like write, with wrote as the most frequent variant in both functions (write–wrote–have wrote), but late eighteenth-century grammars criticized the lack of perspicuity in this paradigm and recommended the three-form function pattern modelled on Latin morphology (write–wrote–have written) (see Oldireva Gustafsson Reference Oldireva Gustafsson2002). At times the impact of the given precept has only had a temporary effect. The seventeenth-century rule that in the first-person shall indicates a prediction and will indicates threat or promise was echoed throughout the eighteenth century and was often complied with during the nineteenth century; however, this was ‘artificial’ and lasted only ‘until prescription ha[d] run its course and the proscribed feature re-emerge[d]’ (Arnovick Reference Arnovick, Cheshire and Stein1997: 145). The nineteenth century also witnessed a temporary increase in the use of the inflected subjunctive as the ‘polite’ form in response to favourable comments in late eighteenth-century grammar books; this feature had been in decline since the seventeenth century and continued in decline after the nineteenth century ‘blip’ (Auer Reference Auer, Dalton-Puffer, Kastovsky, Ritt and Schendl2006: 47).
Scholars have also provided evidence that, rather than triggering stigmatization, normative works reinforced an ongoing trend; in other words, grammarians took notice of language variation and change and with their proscriptive comments they contributed to the decline of a particular variant (Appendix (A), code RE). The effect was permanent with regard to features such as double periphrastic comparatives (more lovelier, González-Díaz Reference González-Díaz and Tieken-Boon van Ostade2008) and multiple negation (I don't want no milk, Tieken-Boon van Ostade Reference Tieken-Boon van Ostade, Beal, Nocera and Sturiale2008d). In both cases usage had already decreased in the language of educated speakers by the end of the seventeenth century. The severe criticism attested in eighteenth-century grammar books reinforced the decline and contributed further to the social downgrading of these as non-standard features. In the case of preposition stranding, the increase in use during the Early Modern English period (1500–1700) came to a halt at the start of the early eighteenth century; the impact of proscriptions in eighteenth-century works was limited to a transient decline during the late eighteenth and early nineteenth centuries, and the construction swiftly gained ground once more in the late nineteenth century as the influence of prescriptivism started to diminish (Yáñez-Bouza Reference Yáñez-Bouza2015a).
At times, linguistic authority has been shown to be marginal or non-effective (Appendix (A), code NI). Wild (Reference Wild2010) argues that claims as to the influence of precept on phrasal verbs are at best speculative, for, despite a downturn in formal texts, their use in fact increased from Old English to the present day. Another example is the progressive passive (e.g. the house is being built): in spite of vicious attacks in nineteenth-century grammar books, it replaced the old passival construction and became accepted by the end of the nineteenth century (Anderwald Reference Anderwald2012). For the nineteenth century itself, Dekeyser (Reference Dekeyser1975) and Bailey (Reference Bailey1996) are sceptical about the true long-term effect of prescriptivism, with Bailey arguing that ‘the popularity of the incorrect forms might have increased even more rapidly without their strictures’ and that ‘the features where no significant change took place might have fluctuated even more widely without their attention’ (1996: 261). Dekeyser (Reference Dekeyser1975) points out that nineteenth-century meta-linguistic comments on case agreement such as who versus whom had only a moderate effect: while it is true that the prescribed forms are more frequent overall, they do not show a notable increase over time, and some proscribed forms (e.g. I wonder who you are talking to) have not disappeared from the spoken stratum. In other words, precept retarded linguistic change but did not succeed in curtailing natural trends.
The effects of prescriptivism on individual authors have been demonstrated in a number of micro-linguistic studies (Appendix (B)). For instance, William Clift (1775–1849), of humble and provincial origin, dramatically changed his grammar and spelling practices shortly after moving to London to work as an amanuensis with the surgeon John Hunter. Although there is no evidence that Clift consulted grammar books, his letters (1792–1801) show a conscious improvement towards the standard language of the day, the language of the educated elite of London. Dialect forms and non-standard features like be-plural levelling and multiple negation were dropped within two years of his arrival in the capital (see Austin 1994). While Clift was motivated by intellectual aspirations, the self-editorial corrections in Captain James Cook's (1728–9) voyage journals came in response to an increasing awareness that his work would be published: by the third voyage (1776–9), his language had become ‘much more correct’, to the extent that most marked variants, morphological and orthographical, had decreased or disappeared altogether (Percy Reference Percy and Britton1996: 339).
10.3.2 Precept and change
The study of historical grammars has often been conducted within the field of historical sociolinguistics: the comparison of a precept corpus with a usage corpus can shed light on whether language change responds to a change from below – unconscious natural development – or a change from above – imposed consciously by normative precepts. Scholars have thus investigated the relation between precept and linguistic factors, such as paradigmatic variation, and sociolinguistic factors, such as rank, age, and gender.
Milroy and Milroy point out that the process of standardization is ‘partly aimed at preventing or inhibiting language change’ (Reference Milroy and Milroy2012: 30) and one of the main principles invoked for this purpose is the suppression of optional variability (2012: 6). Thus prescriptive changes from above have eliminated morphological variation in the past participle of strong verbs like write (e.g. have wrote/written/writ) and spelling variation in the past and past participle forms of weak -ed verbs (e.g. lived/livd/liv'd) (see Oldireva Gustafsson Reference Oldireva Gustafsson2002). The Early Modern spread of second-person you was and of the counterfactual perfect infinitive also seem to have been thwarted by eighteenth- and nineteenth-century proscriptive precepts (Molencki Reference Molencki, Dossena and Jones2003, Laitinen Reference Laitinen, Nurmi, Nevala and Palander-Collin2009). One of the consequences of the principle of suppression of variation is that ‘non-standard varieties can be observed to permit more variability than standard ones’ (Milroy and Milroy Reference Milroy and Milroy2012: 6). This can indeed be observed in the effect of historical grammars (Appendix (A), code StE). Morphological levelling of the past tense form of verbs with a/u alternation (e.g. sing–sang–have sung) has resisted prescriptive forces trying to impose a formal distinction and is still attested in some British English dialects today; in fact, it seems to have ‘gained social ground, having become a frequent feature’ of London middle-class teenagers in the 1990s (Anderwald Reference Anderwald2011: 103). Similarly, the present-day standard form you were replaced you was over the course of the eighteenth century, but the latter has never disappeared from non-standard speech; you was acted as a ‘bridge phenomenon’ in the transition process of you were from plural to singular after the loss of singular thou, and that functional distinction has been preserved in dialects to the present day (Tieken-Boon van Ostade Reference Tieken-Boon van Ostade, Lenz and Möhlig2002).
Comparison between diachronic trends of precept evaluation and real-time language change has also offered new insights into the grammarians’ reactions to natural language processes. In her study of verb tense and aspect in nineteenth-century English, Anderwald (Reference Anderwald2012) examines precept in relation to four factors: the stage of the change in the S-curve (old/new), speed (slow/rapid), salience (noticeable/unnoticed), and text frequency (rare/frequent). Anderwald observes that rapid changes in new features tend to draw strong criticism, as with the progressive passive in the early nineteenth century. On the other hand, new variants which have developed gradually and represent almost completed changes are not opposed: in the case of variation in the be/have perfect with intransitive verbs, auxiliary have is well accepted in the nineteenth century, while the old form be is considered obsolete and less proper. It has also been observed that slow changes in their incipient stages, such as the rise of the progressive, usually go unnoticed, and so do rare or infrequent constructions. Salience and text frequency seem to play a crucial role too.
Linguistic grammaticology has also served to investigate the correlation between precept and sociolinguistic factors such as social rank, gender, age, and social networks. Social network analyses have yielded differing results depending on the linguistic feature. Whereas network ties possibly influenced Elizabeth Montagu's (1738–78) use of the progressive, her social network does not seem to have had an impact on her choice of spelling variants in contractions of auxiliary verbs and -ed weak verbs, or on her aversion to preposition stranding (Sairio Reference Sairio2009). The social rank of the addressee does play a role, though, in that Montagu used less preposition stranding with correspondents of a higher social status (2009: 202). It has been suggested that eighteenth-century grammarians picked on multiple negation because, although no longer used by educated speakers, the construction was still found in lower-class speech (Tieken-Boon van Ostade Reference Tieken-Boon van Ostade, Beal, Nocera and Sturiale2008d: 200). Age is shown to correlate with innovative forms undergoing levelling in the verb paradigm: younger eighteenth-century social climbers incline towards the prescribed -ed variant in weak verbs (vs. ’d/-d) and towards the prescribed past participle written (have written vs. have wrote/writ), even though these variants were not the most frequent forms (Oldireva Gustafsson Reference Oldireva Gustafsson2002: 119). The analysis of variation in you was/were conflicts with the traditional Labovian gender roles: in the eighteenth century it is men that lead the change towards you were, as they adopt the prescribed form earlier and slightly more quickly than women, who maintain the non-standard you was for longer (Laitinen Reference Laitinen, Nurmi, Nevala and Palander-Collin2009: 211). It is also important to mention that the analysis of meta-language has shown grammarians’ sensitivity to subtle register differences in terms of formal/informal contexts as well as verse/prose language; in these cases, influence usually persists in formal contexts, but not in informal contexts (see, e.g., Wild Reference Wild2010 on phrasal verbs).
10.3.3 Descriptive adequacy
The linguistic potential of investigating historical grammars has come to be recognized for the insights that grammars can offer as supplementary evidence for early English. Linguistic historiographers have thus addressed the matter of grammatical descriptive adequacy: do their descriptions match our present-day knowledge of historical English? And did grammarians record contemporary usage or their own usage? Dons (Reference Dons2004) shows that, overall, descriptive adequacy regarding parts of speech and syntax increases over the course of the Early Modern English period, but the level of adequacy varies with the linguistic feature being described (see Appendix (C)). In the seventeenth century, Charles Butler's (1634) and Guy Miège's (1688) grammars provide an adequate description of the possessive markers ’s/his and the ending of the third-person singular present tense -th/-s, whereas the subjunctive mood, the ending of the second-person singular present tense -st, and the account of the possessive determiners thy/thine are inadequately described (Moessner Reference Moessner, Bermúdez-Otero, Denison, Hogg and McCully2000). Moessner concludes that, as far as the grammarians’ own usage is concerned, Miège is ‘representative’ of our understanding of late seventeenth-century English, while Butler ‘deviates’ in some respects from our view of early seventeenth-century English (2000: 413). The description of phrasal verbs from the eighteenth to the twentieth centuries seems to have been adequate on the whole (Wild Reference Wild2010), and so has the description of paradigmatic variation in past and past participle strong verbs in seventeenth- and eighteenth-century works. With regard to the latter, Oldireva Gustafsson clarifies that ‘only a few sporadic variant forms are absent’ (2002: 187), and that, naturally, grammarians failed to recognize some of the variants characteristic of private writings like wrote and other -tt variants (e.g. writt) in past participle function (2002: 277). On the other hand, grammarians did not reflect actual usage when they criticized Irish speakers for their misuse or non-use of shall: it has been shown that ‘at least in the first part of the nineteenth century, the Irish employed shall with first-person subject even more frequently than the English’ (Facchinetti Reference Facchinetti, Kastovsky and Mettinger2000: 131); precept in this case was ‘socially biased’ (Facchinetti Reference Facchinetti, Kastovsky and Mettinger2000: 116). The close evaluation of descriptive adequacy in terms of authors’ precepts and usage in their grammars (Appendix (Cii)) has challenged the traditional claim that Robert Lowth's (Reference Lowth1762) rules were totally arbitrary: the features observed in his personal letters are often at odds with the strictures of his own grammar (e.g. you was, past participle wrote); according to Tieken-Boon van Ostade (Reference Tieken-Boon van Ostade2000b), Lowth's norms were modelled neither on his own usage nor on the usage of his middle-class peers, but on the language of the upper classes.
The linguistic potential of early grammar books has also come to be recognized ‘for the light they throw’ on matters of present-day grammar, usage, and style: ‘attitudes to correctness may both be elucidated by and help to put in proper perspective the findings of modern linguists’ (Sundby Reference Sundby and Leitner1986: 397–8). (See further in Appendix (D).) For instance, the analysis of subject–verb concord in early grammars can help to explain current principles and subtle stylistic differences (Bjørge Reference Bjørge, Breivik, Hille and Johansson1989). Adamson (Reference Adamson2007) has also observed how the ‘internalised norms’ derived from precepts on gender and animacy of pronouns (e.g. who for persons, which for things) can lead to misreadings, such as a failure to appreciate instances of literary personification. Another good illustrative example is the study of punctuation theory, as Salmon (Reference Salmon1988: 295) argues that the greater eighteenth-century awareness of syntactic structures such as relative clauses may well have derived from an increasing treatment in grammar books of punctuation marks for the sake of clarity and precision in reading written texts:
Early punctuation theory is also of relevance to contemporary linguists because it was largely – if not entirely – through the evolution of punctuation theory that insights into the supra-segmental features of English developed, and led to the present-day treatment of intonation and stress. It is also likely that the study of punctuation led to an increasingly sophisticated awareness of the structure of English sentences.
10.4 The study of historical grammars beyond morphosyntax
This section draws attention to some under-explored aspects of historical grammars in the belief that further research here can shed light on the understanding of the term ‘grammar’ as well as on the growing importance of grammar knowledge.
10.4.1 Subsidiary content in grammar books
Research to date has been focused primarily on morphosyntax, as the topics in the Appendix illustrate. This is not surprising, since syntax and ‘etymology’ in the early sense of ‘parts of speech’ were essential divisions of grammar in the seventeenth and eighteenth centuries (Michael Reference Michael1970: 184–9). Spelling and punctuation, prosody and elocution, rhetoric and style were, nonetheless, salient topics among the subsidiary content discussed in grammar texts (see Yáñez-Bouza and Rodríguez-Gil Reference Yáñez-Bouza and Rodríguez-Gil2013a: 156–7).
Alongside the codification of grammar, the late eighteenth century also witnessed the codification of proper pronunciation with an unprecedented increase in the publication of works on elocution and of pronouncing dictionaries. A good delivery and a proper pronunciation in public speech had become a major concern for those who aspired to social and political advancement. Grammar became not only ‘the art of writing correctly’ but ‘the art of speaking and writing with propriety’, as defined in Lindley Murray's (Reference Murray1795) English Grammar. Beal (Reference Beal2013), based on data from ECEG, reports on the treatment of phonology in eighteenth-century grammar texts: sections on prosody (accent and quality) and elocution, and directions for reading or exercises on pronunciation are found throughout the century and become more frequent in the late decades. Some grammars at this time, such as George Wright's The Principles of Grammar (Reference Wright1794), also show the influence of elocutionists like John Walker (1732–1807).
As part of the classical trivium of grammar–rhetoric–logic, rhetoric had long been ‘complementary to grammar’, concerned with good expression, stylistic appropriateness, and what we understand today as text syntax or composition (Görlach Reference Görlach2001: 21). In the eighteenth century classical rhetoric and the New Rhetoric (1748–93) became a frame for language consciousness which strengthened the notion of correctness characteristic of normative grammars (McIntosh Reference McIntosh1998: 167). Rhetoric books discussed grammatical correctness, and grammars discussed rhetorical propriety. In ECEG approximately sixty per cent of stand-alone grammars touch on matters related to rhetoric, elocution, versification, prosody, or style.Footnote 3 These grammars often have prosody as a primary division and include remarks on grammatical figures such as ‘figurative syntax’, defined by Samuel Saxon (Reference Saxon1737) as the art that ‘teacheth the artificial Order or Disposition of Words’ with a wide scope of possible elements, from ellipsis and transposition to syncope (see also Sundby et al. Reference Sundby, Bjørge and Haugland1991: 10–12). Principles of rhetoric also guided the anti-variationist approach of normative grammarians, above all perspicuity, precision, and purity. For instance, the semantic distinction shall/will with first-person subjects, the criticism of preposition stranding, the criticism of that as a relative pronoun and conjunction, and the levelling of past and past participle in strong verbs, all result in part from the use of rhetoric in grammar books: variation is frowned upon because the sense of the sentence is obscure and ambiguous. Likewise, canons of rhetoric such as harmony, euphony, vivacity, and strength played a role in the criticism of phrasal verbs, stranded prepositions, monosyllables, contractions in auxiliary verbs and in -ed weak verbs: they sound harsh and have insufficient weight, and thus they are inelegant. Murray's (Reference Murray1795) strictures, for example, are full of epithets derived from rhetorical principles: he was concerned with clearness, accuracy, and terseness, but rules bearing on aesthetics, such as elegance and ease of conversation, also rate highly, especially in terms of word order (see Vorlat Reference Vorlat and van Ostade1996). A fresh look at the realm of rhetoric in grammar books will offer new insights into the evolution of prose style in English.
Punctuation was usually taught in spelling books and elementary readers, but it also featured prominently in grammar books from the mid-seventeenth century onwards, and is in fact the most frequent subsidiary section in eighteenth-century works (55 per cent of the grammars in ECEG; see Yáñez-Bouza and Rodríguez-Gil Reference Rodríguez-Álvarez and Rodríguez-Gil2013a: 156–7). The teaching of punctuation had a double function: a syntactic-semantic function, on how punctuation marks indicate the logical structure of the sentence to prevent ambiguity or obscurity of the intended sense, and a rhetorical function, as a guide to pronunciation and reading aloud, for example, full stops to signal pauses and capital letters for emphasis. Attention to punctuation increased, in particular, in the mid-eighteenth century on the grounds that ‘the great and elegant utility of Punctuation [adds] much to the extent, certainty, and precision’ of the art of orthography (McKnight 1928: 418, in Görlach Reference Görlach2001: 85).
10.4.2 Grammars attached to other works
Sections on grammatical knowledge became increasingly popular in eighteenth-century dictionaries, letter-writing manuals, and spelling books: 40 per cent of the grammars in ECEG are in fact prefatory grammars rather than stand-alone grammar books.
Dictionary grammars first appeared in Thomas Dyche and William Pardon's New General English Dictionary (1735) and gradually gained popularity, to the extent that in the latter quarter of the eighteenth century, with grammars now considered a marketable commodity, not having a grammar in a dictionary ‘could be seen as a shortcoming by potential customers’ (Tyrkkö Reference Tyrkkö2013b: 189). Thus does Mitchell (Reference Mitchell1994) note an inversion of roles: in the seventeenth century grammar embraces lexicography, but in the eighteenth century lexicography embraces grammar. Tyrkkö (Reference Tyrkkö2013b) examined some thirty dictionary grammars in ECEG and observed that they are usually brief, underlining their utilitarian aspect; they deal primarily with parts of speech and syntax and rarely with prosody; they tend to use visual forms like tables; they are often addressed to ‘the youth’; and only a few mention women explicitly.
Grammars also became a staple part of letter-writing manuals during the eighteenth century. Letter writing was a social practice for literate people of all ranks, especially the rising merchant middle classes, for whom knowledge of ‘proper’ and ‘correct’ grammar was necessary for a good reputation in business. Just as grammar books devoted sections to the composition of letters and the correct use of abbreviations and superscripts, letter-writing handbooks gradually incorporated English grammars as prefatory material, emphasizing that the elements of grammar should be taught first: ‘laying the Foundation of our Design well, and as it ought to be. The Rudiments of a Tongue once obtain'd, we proceed easily on to raise our Superstructure; without this we do nothing’ (The Complete Letter-Writer 1755: A2r). Like dictionary grammars, subsidiary grammars in letter-writing manuals tend to be short in length and elementary in content (e.g. ‘plain’, ‘concise’), yet they usually cover the three main divisions of orthography, etymology (parts of speech), and syntax. Although used in schools, they were in fact designed as self-help manuals and for youth or adults, men more often than women.Footnote 4
10.4.3 The paratext of grammars
Paratext refers to the textual and visual means that surround the core text of a book and present it to potential customers and the intended reader (see Genette Reference Genette1997; see also Chapter 28 by Moore in this volume). Genette distinguishes between the peritext, the devices found physically around the text, like title pages and prefaces, and the epitext, outside the book, such as periodical reviews. The paratext is in essence a marketing and discursive strategy created by the publisher or printer in order to mediate between the author's text and its readership: a ‘threshold’ to persuade readers to enter the book's world and to influence their interpretation of the main text. Genette's theory is originally based on modern fiction works but can be extended to historical and nonfiction texts,Footnote 5 including normative grammars. For instance, in a sociopragmatic study of the prefatory material of grammar books published between 1624 and 1762, Watts (Reference Watts and Jucker1995) observes that the most frequent types of peritext are the approbation of censor, title page, dedication to a patron or to the reader, comments or complementary quotations by third persons, and the preface. He concludes that the common core of discourse strategies lies in the title page and the preface, and that there are certain parts of the prefatory sections that are ‘symptomatic of the sense of a discourse community of grammar writers’ (1995: 147). The title page in particular ‘embeds the grammar within the wider discourse of education’ and thus its design and function changes over time along with changes in attitudes towards language and education (1995: 156). The prefaces of eighteenth-century schoolbooks have been further explored in Rodríguez-Álvarez and Rodríguez-Gil (Reference Rodríguez-Álvarez and Rodríguez-Gil2013), who identified four major common sets of objectives in the grammarians’ discourse community, namely the justification for grammars, the scope of the book, methodological matters, and persuasive strategies, each of which involves a variety of persuasive arguments of their own.Footnote 6 As far as the epitext is concerned, the vital role of periodical reviews in the eighteenth century has been demonstrated by Percy, based on evidence from her database of linguistic and stylistic criticism in the Monthly Review (1749–89) and the Critical Review (1756–89): not only did reviewers intensify writers’ linguistic awareness and insecurity with their pedantic criticism, they also ‘catalysed the rise of prescriptivism’ by exemplifying bad grammar in contemporary authors; they were entertainers but also educators and ‘cultural upstarts’ (see Percy Reference Percy, van Ostade and van der Wurff2009). As these few studies show, study of the grammars’ paratext can shed more light on the development of the grammatical tradition and lends itself to interdisciplinary approaches; as Shevlin pointed out, paratexts ‘embody the potential to illuminate not just individual works, but reading processes, authorial composition, publishing practices, marketing trends, and generic transformations as well’ (1999: 43–4).
10.5 Concluding notes
This chapter has shown that early grammars can help to account for change in the frequency of a particular construction and for the loss of linguistic variation, as not all linguistic changes result from internal forces – changes from below; some come from external, prescriptive norms – changes from above. Sometimes grammatical precepts triggered permanent change, at times they only resulted in temporary change, and on occasions they retarded natural developments; very often they reinforced an existing trend, and in this sense grammars can be studied as evidence of contemporary usage. The study of grammarians’ evaluative comments has the added value of providing insights into sociocultural attitudes towards language in earlier times, such as regarding the social and dialect status of linguistic features. This chapter has also shown that the study of grammars can shed light on aspects beyond morphosyntax, including phonology, rhetoric, spelling, and punctuation. Attention has also been drawn to underexplored areas which have the potential to contribute further to the history of grammar writing and historical linguistics, such as subsidiary grammars and the paratext of grammar books.
Of course, one must also bear certain pitfalls in mind. For instance, historical grammars, as part of the standardization process of written English, were aimed at written language, with the implication that colloquial and dialectal features were often criticized or indeed not recorded. Descriptive adequacy needs to be examined cautiously: grammarians might be discussing their own usage or the usage of the social class they aspired to, and not necessarily common, widespread usage. There might also be a time lag between the time a new use emerges or dies out and the time this is recorded in grammar books, for it naturally takes a few decades for change to be noticed, especially a change which develops slowly. Another important point is the difficulty of assessing the extent to which grammars were actually read, in that education was for the most part a privilege that few could afford, and the kind of schools that the lower and lower middle classes had access to would not always have had the resources to buy many books. Thus, as mentioned in relation to William Clift, there are indications, although not always direct evidence, that certain authors read grammars. For these reasons, the analysis of evidence from grammars is better when complemented with the study of usage corpora.
Historical grammars from the Early and Late Modern English periods have gradually received more attention, and their use as evidence for the study of historical linguistics has slowly but solidly come to be recognized in the disciplines of historical sociolinguistics and normative linguistics. With due caution, then, the study of historical grammars can help to explain language use in the past, and today, can shed light on early and modern conceptualization of linguistic features, and can help us trace language change and (the loss of) variation.
11.1 Introduction
This chapter addresses the question of how historical linguists extract data from the material examined. Material here refers to the actual evidence of language use that we have at our disposal (typically spoken or written texts). The researcher's data comprise the relevant observations on which the empirical analysis is based, and which are extracted from the material. By way of exemplification, let us assume that the research question concerns the substitution of the progressive passive (e.g. the house is being built) for the so-called passival construction, which is active in form but passive in meaning (e.g. the house is building). In this case, the most important data are likely to be attestations of these two constructions as they occur in texts. Those data may allow the researcher to construct a quantitative picture of the change and show how the progressive passive accounts for an increasing proportion of the data over time. If there is material available from different categories of language users (e.g. men and women from different socio-economic groups) or texts (e.g. speech-related and expository genres), the quantitative picture can be refined by the addition of such extralinguistic parameters to the analysis (see section 11.3.1). The linguistic context of the data may also provide important information (see section 11.2.3); for instance, it may be that the progressive passive first appeared in certain types of verb phrase and then spread to other parts of the paradigm.
In addition to examples of the linguistic constructions themselves, important clues may be available in contemporary comments on usage. In the case of the progressive passive, such comments demonstrate that this incoming construction met with near-universal condemnation in normative sources (see, e.g., Anderwald Reference Anderwald2012: 36–9); such opposition may constrain the spread of an innovative feature in at least some genres. I will focus on data that comprise attestations of linguistic features in this chapter, but it should be noted that, in fields such as historical phonology, contemporary comments may be the most important type of data (see section 11.3.2). These two types of data can also complement each other. Dekeyser (Reference Dekeyser1975) investigates number and case relations in nineteenth-century English (e.g. the choice between possessive and objective pronouns as subjects in gerundial clauses like his/him winning the contest in I was surprised by his/him winning the contest). By considering both actual usage and commentary, Dekeyser succeeds in presenting a many-faceted picture of linguistic variation during the 1800s.
The rest of this chapter is structured as follows. Section 11.2 is concerned with general issues relevant to data extraction from historical material, with a focus on electronic corpora; while the account focuses on historical English morphosyntax, large parts of it will also be applicable to other sub-disciplines, such as historical pragmatics and sociolinguistics. Most of the examples that I use to illustrate the account will be taken from Early and Late Modern English. Section 11.3 addresses some special challenges that historical linguists face as regards the nature of the material, phonological analysis, spelling, and corpus annotation. The chapter ends with a brief concluding discussion of possible future developments in the field in section 11.4.
11.2 The identification of data in English historical linguistics
11.2.1 Common types of data
What is used as data for a linguistic investigation of course depends on the research question. One important distinction concerns whether the data consist of tokens or of types. The token frequency is the number of occurrences of the relevant linguistic feature in the material. The type frequency, in contrast, is the number of different types of occurrences in the same material. If the researcher is interested in the progressive passive (see section 11.1), the token frequency would be the total number of progressive passives in his/her material. The type frequency, in contrast, may be the total number of different main verbs that are used in progressive passive verb phrases in the same material. Most studies treated in this chapter are primarily based on token frequencies, but there are cases in, for instance, historical phonology where type frequencies are more important. Britton (Reference Britton, Denison, Bermúdez-Otero, McCully and Moore2012) studies the process by which English lost geminate consonants, as in Early Middle English sunne [sunnə] ‘sun’, which would have contrasted with sune [sunə] ‘son’ (see section 11.3.2 for a more detailed account of Britton's study). In such a context, the number of different contrastive pairs of this kind that can be established for a given variety of English (that is, the type frequency) is more important than the number of times the pairs occur in the material.
In other investigations, it may be the relation between type frequency and token frequency that is in focus; for instance, the researcher may be interested in the lexical diversity of the progressive passive in different texts. This can be measured by dividing the number of types with the number of tokens to produce a type/token ratio. However, comparisons of type/token ratios for different groups of texts are sensitive to the number of tokens. In the above example, most tokens of progressive passive verb phrases are likely to belong to a limited set of types (i.e. main verbs). A difference in token frequency between two sets of material will thus typically not be paralleled by a similar difference in type frequency, because most of the difference in token frequency is likely to involve types that are already represented in both sets of material. All other things being equal, high token frequencies in texts thus tend to result in comparatively low type/token ratios. One way of avoiding this problem is to extract a random sample of the same number of tokens from each set of material and base calculations on those samples.
Assuming that the investigation focuses on token frequencies, the next question that arises concerns what the token frequency should be measured against. The most common choice in research is between relativizing the frequency of the feature to a given text length and relativizing it to the frequency of one or several other features (see Smith and Rayson Reference Smith2007: 134–5 for a discussion of these frequency measures applied to the progressive passive). Essentially, the choice between these two methods is related to how easy it is to establish a variable which comprises at least two linguistically different ways (variants) of expressing the same meaning that co-vary in actual usage (for further discussion, see Chapter 1 by Romaine in this volume; see also Tagliamonte Reference Tagliamonte2012: 3–19 for further discussion of the linguistic variable).
One option is to relativize the frequency of the feature to a quantity of text (e.g. occurrences per 1,000 words); for instance, if a 460,000-word text contains 80 progressive passives, the normalized frequency of the construction will be c.0.17 occurrences per 1,000 words. If this perspective is applied, the researcher does not assume that the linguistic feature is chosen instead of one or several other, semantically equivalent features, which could have been chosen but were not. This is typically the case for investigations of phrasal verbs, i.e. combinations of a verb and an adverbial particle, as in give up (see, e.g., Smitterberg Reference Smitterberg, Nevalainen, Taavitsainen, Pahta and Korhonen2008). While some phrasal verbs do have near-synonyms that are simplex verbs (e.g. put off vs. postpone), in others the particle rather contributes aspectual meaning (e.g. burn up vs. burn), and sometimes it may seem almost redundant (e.g. lose out vs. lose). It would thus be difficult to measure the overall frequency of phrasal verbs in a text in relation to the frequency of equivalent simplex verbs. Instead, raw frequencies of phrasal verbs in different samples are normalized to a common base such as 1,000 words in order to make the frequencies independent of text length.
The alternative perspective is to consider the linguistic feature as one of two or more variants, which are then regarded as equivalent ways of saying ‘the same thing’. For example, a nineteenth-century speaker could express the combination of an operator and not as a contracted form (e.g. won't or wont) or as an uncontracted form (e.g. will not). The analyst then typically considers both variants as data and retrieves their raw frequencies in his/her material. Since the frequencies of the variants can be compared with one another, they can be expressed as proportions of the total frequency; for instance, the analyst may find that the ratio of contracted forms to uncontracted forms is higher in late nineteenth-century texts than in texts from the early 1800s and conclude that not-contraction became more frequent across time in nineteenth-century English.
The latter, variationist approach has several advantages. To begin with, text length ceases to be important (provided that enough material to make the results statistically robust is considered), as proportions of occurrence are independent of the length of the text the occurrences are taken from. Second, the distribution of the different variants can be subjected to statistical analysis, which can show what differences in frequency are likely to be due to random variation. Third, a variant field will provide a truer picture of linguistic variation than will measuring the frequency per 1,000 words of one or several of the variants, because a variationist approach relates the number of actual occurrences of a variant to the number of potential occurrences.
However, a variationist set-up also demands more of the researcher. To begin with, s/he must make sure that all the variants of the variable are included. In order for the analysis to reach accountability, ‘all the relevant forms in the subsystem’ investigated must be included in analyses (Tagliamonte Reference Tagliamonte2012: 10; for the ‘principle of accountability’, see Labov Reference Labov1972). This can be difficult at times; for instance, some variables (e.g. relative markers) have zero variants, i.e. variants that lack overt linguistic expression (as in the book Ø I read about yesterday). The occurrence of zero variants should also be taken into account, but they may be difficult to retrieve given that there is no surface expression to search for. This is problematic chiefly if the collection of data is based on concordancers or similar software rather than manual identification: it is difficult to instruct programs to retrieve zero expressions.
Another important issue concerns which linguistic contexts allow all variants to occur. So-called knock-out factors may rule out the occurrence of one or several variants; for instance, a zero relative marker is not possible when the marker would be the complement of a preposition and follow that preposition (*the book about Ø I read yesterday). Such instances should be excluded from the counts, as they do not represent the outcome of a choice. In many cases, deciding whether variation is possible is a straightforward matter, but researchers may also disagree regarding what to count as variation. In López-Couso's (Reference López-Couso, Pérez-Guerra, González-Álvarez, Bueno-Alonso and Rama-Martínez2007b) analysis of not-contraction, questions where a subject intervenes between operator and not, as in Was she not here when it happened?, were excluded, since she is argued to block contraction of was and not. In contrast, Smitterberg (Reference Smitterberg, Markus, Iyeiri, Heuberger and Chamson2012) included such examples as uncontracted forms and thus considered Was she not here…and Wasn't she here…as variants of the same variable. Moreover, knock-out factors can be difficult to isolate in historical investigations. Given the limited textual material we have at our disposal for early English, the non-occurrence of a given feature in a certain linguistic context does not necessarily mean that it could not be used, and one important tool for making decisions in this regard is unavailable to historical linguists: native-speaker intuition. Consulting a panel of native speakers of English may be a useful way of establishing whether or not a pattern is grammatical in a variety of Present-day English. In contrast, as McEnery et al. (Reference McEnery2006: 96) note, ‘the intuitions of modern speakers have little to offer regarding the language used hundreds or even tens of years before’. In addition, in diachronic investigations, the researcher is often interested in linguistic features that are undergoing change, which may mean that knock-out factors will not be the same over time. In all such cases, it is crucial that the researcher report carefully what decisions s/he made, to help to increase reproducibility (see section 11.2.4).
The underlying assumption of the variationist approach, viz. that all variants are ways of saying ‘the same thing’, can also be problematic in itself. Non-phonological variants, such as morphemes, words, or phrases, have meaning, and perfect synonymy is very rare in language; it can thus be argued that such variants do not mean exactly the same thing, which calls the variationist approach into question (see, for instance, Romaine Reference Romaine1984). As noted by Tagliamonte (Reference Tagliamonte2012: 16–18), alternative notions of equivalence have also been suggested; for instance, two or more forms that are structurally equivalent in the sense that they ‘are found in the same type of context in the language’ (Tagliamonte Reference Tagliamonte2012: 17) can be studied as variant realizations of a variable. In a diachronic investigation, there is an important additional complication: sameness of meaning, structural equivalence, or some other notion of equivalence has to be assumed for the entire period covered by the study. For instance, if the object of inquiry is variation between clauses with and without auxiliary do in Middle and Early Modern English (e.g. She built it vs. She did build it), the comparison of the variants is complicated by the fact that auxiliary do has been argued to have expressed specific meanings such as causation and perfective aspect (see Fischer Reference Fischer and Blake1992b: 267–76) during its development into a more or less semantically ‘empty’ auxiliary. A variationist perspective on the distribution of forms will then be more easily justified for those periods when auxiliary do is assumed to have carried little semantic weight than for those periods where an interpretation in terms of, say, causation or perfectivity is plausible. However, this of course does not mean that researchers should limit their analyses to periods for which a variationist set-up is relatively valid. Stages when a linguistic feature can be assumed to have had several different potential meanings in various linguistic contexts, and when ambiguity between those meanings may have obtained, are of great interest to historical linguists, as such circumstances may help to bring about language change (see, e.g., Traugott Reference Traugott and Kytö2012b for a discussion of ambiguity between future and non-future meanings of be going to before its grammaticalization as an expression of futurity). But differences in meaning among variants should be noted as a possible limitation of a variationist approach. For instance, Grund and Walker (Reference Grund2006) study variation in adverbial clauses between the indicative (e.g. If the story is true,…), the subjunctive (e.g. If the story be true,…), and constructions with modal auxiliaries (e.g. If the story should be true,…). While they apply what is essentially a variationist framework, they discuss the problems involved in this choice and alert the reader to the fact that they ‘adopt a fairly wide definition of semantic equivalence’ (Grund and Walker Reference Grund2006: 92).
11.2.2 Data retrieval: ensuring validity
Johannesson (Reference Johannesson1993: 50) notes that the data-identification stage can be described as a categorization process in that the material is divided into two main categories: data and non-data. To be able to separate data from non-data and include only the former in the counts, the researcher has to define the linguistic feature(s) investigated, typically with the aid of previous research. The definition of the linguistic feature is crucial in order to achieve a central desideratum in empirical analyses: validity.
The validity of a process of data identification can be described as the extent to which the dataset contains (i) all relevant instances of the linguistic feature(s) investigated and (ii) no irrelevant instances. If the researcher comes close to meeting criterion (i), the retrieval has high recall and there are few false negatives; if the researcher comes close to meeting criterion (ii), the retrieval has high precision and there are few false positives. In other words, if a linguistic analysis has high validity, the researcher has really investigated what s/he set out to examine. For instance, the topic of an investigation may be variation in gerundial clauses between objective/common-case subjects (e.g. I hope you don't mind me/John reading your paper) and possessive/genitive subjects (e.g. I hope you don't mind my/John's reading your paper). There is evidence in previous research that the objective/common-case variant increased at the expense of the possessive/genitive variant during the Late Modern English period (Dekeyser Reference Dekeyser1975, Lyne Reference Lyne2011). In order to test a hypothesis to that effect, the researcher would first need to identify all gerundial clauses with overt subjects in his/her material. However, it is often the case that there are other constructions that may look similar to the construction in which the analyst is interested. In Late Modern English, two structures that may look similar to a gerundial clause are those where the -ing form is a present participle rather than a gerund (e.g. I caught him unlocking the door, where his cannot be substituted for him) and those where the gerund is nominal in nature and is thus not part of a verb phrase (e.g. We were surprised by Steve's sensitive handling of the matter, where Steve cannot be substituted for Steve's). While many such constructions can be separated from relevant data by the researcher quite easily, there are often indeterminate cases that prove difficult to classify.
What should be done, then, with instances that resist easy classification as data or non-data? For instance, a gerundial construction like my arriving here in within half-a-minute of my arriving here lacks a clear indication of whether the gerund arriving is nominal (‘within half-a-minute of my arrival here’) or verbal (‘within half-a-minute of me arriving here’) (Lyne Reference Lyne2011: 61; Lyne's example is from the British National Corpus, but the ambiguity holds for Late Modern English as well). The recommended practice is to place such instances in a third, ‘indeterminate’ category for the time being (Johannesson Reference Johannesson1993: 50). The main advantage of doing so is that, if three categories of material are established (‘clearly data’, ‘clearly non-data’, ‘indeterminate’), only the third category will need to be re-examined at a later stage.
However, some instances will often remain in the indeterminate category even after close scrutiny. The gerund arriving above, for instance, really cannot be placed in either the nominal (‘clearly non-data’) or the verbal (‘clearly data’) category with any degree of certainty. The researcher then has two main options:
1 Include such instances in the data (i.e. conflate ‘clearly data’ and ‘indeterminate’). This would ensure high recall but may lower precision.
2 Exclude such instances from the data (i.e. conflate ‘clearly non-data’ and ‘indeterminate’). This would guarantee high precision, but may decrease recall.
Övergaard's (Reference Övergaard1995) study of the mandative subjunctive in twentieth-century English exemplifies the first option. Övergaard includes items that exhibit no morphological distinction between indicative and subjunctive forms, e.g. leave in I demanded that they leave at once, and classifies them as subjunctive ‘[i]f no indicatives appear in parallel instances’ (Övergaard Reference Övergaard1995: 93); the alternative would have been to exclude them as non-data because there is no formal variation between the indicative and the subjunctive here. However, the first option is relatively rare: most researchers find precision more important than recall in such cases. Lyne (Reference Lyne2011), for instance, did not include structures like my arriving here in the counts. If the ‘indeterminate’ category remains large, it may also be possible to include it in the counts, but as a category separate from the convincing instances; readers would then in effect be able to make the choice between recall and precision themselves. Yet another option is for the researcher to compute results for both (1) and (2) above, and then select the solution that seems to be more suitable for the purposes of his/her investigation.
11.2.3 The co-text of the data
Section 11.2.2 outlined how the selection of data from the material may be carried out. However, the classification of the rest of the material as non-data does not of course mean that it is irrelevant to the investigation. This part of the material is the linguistic context, also known as the co-text, of the data. For many investigations, the co-text is a vital source of information. To begin with, examining the co-text is often necessary in order to select the correct dataset from the material; for instance, if the co-text of the ambiguous gerundial example discussed in section 11.2.2 (within half-a-minute of my arriving here) had also included a manner adverb (e.g. within half-a-minute of my arriving here safely), that would have been enough to classify the gerund as verbal and thus as part of the data (Lyne Reference Lyne2011: 53–5). Similarly, the co-text is the researcher's most important tool in order to interpret examples; for instance, Traugott (Reference Traugott and Kytö2012b: 232–8) uses the co-text of late Middle and Early Modern English examples of be going to + infinitive to discuss whether they mainly imply futurity or other meanings such as motion.
Moreover, co-textual analysis is often an important part of the classification stage of the investigation, which follows the identification stage. This is because the distribution of the data is often assumed to be influenced by the co-text in various ways, and coding the data for co-textual parameters enables researchers to test hypotheses about such influence. Gries's (Reference Gries2003) multi-factorial analysis of particle placement with transitive phrasal verbs (e.g. pick up the book vs. pick the book up) exemplifies this use of co-text. One of the parameters investigated by Gries is whether particle placement is influenced by whether the referent of the direct object (the book in the above example) has been mentioned in the preceding co-text. Gries's analysis shows that this parameter indeed influences particle placement: the word order in pick the book up is more likely if the referent of the direct object has been mentioned previously.
The above examples illustrate the importance of making full use of the co-text in empirical investigations. Since the co-text is thus often essential in making sense of the distribution of data, it should always be possible to return to the co-text of the data examined. In addition, like the identification of data, any classification of data that is based on co-textual features should be reproducible (see section 11.2.4).
11.2.4 Reporting decisions: increasing reproducibility
A crucial feature of data retrieval and classification in empirical investigations is reproducibility. This is the ability of an experiment – here, a process of data retrieval and/or classification – to be reproduced by, for instance, another scholar working independently of the researcher. Reproducibility is one of the cornerstones of empirical research. If the research is not reproducible, it becomes impossible for other scholars to repeat the experiment in order to see whether they would arrive at the same dataset or classification. The researcher typically describes how s/he arrived at his/her dataset in the method section of a study, which may include elements such as a specification of the primary material, a definition of the linguistic feature studied, an account of the method of retrieval, and a description of the way in which the potential data retrieved were post-processed in order to exclude irrelevant instances. The researcher's account of the classification process may also be given in the method section, but is often placed in the results section where the feature classified is treated.
Since linguistics is fundamentally an interpretative science, it may be impossible to reach full reproducibility. For example, Grund and Smitterberg (Reference Grund and Smitterberg2014) were interested in the distribution of conjuncts, i.e. adverbials that express how language users view connections between linguistic units. Consider the adverb thus in (1):
(1) For instance; – by the adoption of a certain kind of frame 1 man performs ye. work of 7 – 6 are thus thrown out of business. (CONCE, Letters, Byron, 1800–30, p. II.165)
In cases like (1), the decision whether to count thus as an adjunct (‘in this way’) or as a conjunct (‘for this reason’) is frequently dependent on close readings of individual instances, and the contextual cues that cause the analyst to favour the one or the other reading can be difficult to pin down in generalizable terms. (Such examples would be classified as ‘indeterminate’ in the first classification round – see section 11.2.2.) It therefore becomes necessary to state general principles such as that of including only examples that were clear-cut cases of the feature examined (i.e. conflating the ‘clearly non-data’ and ‘indeterminate’ groups).
Example (1) above also illustrates another important point. It is usually not enough that the principles of data selection and classification are stated and described; they also need to be illustrated by representative corpus examples. Such examples form an important bridge between, on the one hand, the material or co-text and, on the other hand, the data that will help readers to understand the researcher's decisions and see whether they agree with them. For this reason, not all corpus examples should be clear-cut cases. Indeed, it is often the examples of indeterminate cases that are the most informative, since they tell readers how examples that could be interpreted as either meeting or not meeting the criteria for being included in the dataset – or for being classified in a certain way on a given classificational parameter – were dealt with.
11.3 Challenges for historical linguists
Although most of the example studies chosen in section 11.2 were historical, much of the discussion would be equally valid for an investigation of Present-day English. In this section, in contrast, I address some challenges that are arguably characteristic especially of historical linguistic research: the special nature of historical material, implications for historical phonology, the variable spelling that characterizes many historical texts, and problems involved in compiling and annotating historical corpora.
11.3.1 Historical material
In this section, I move outside the process of extracting data from the material and consider aspects of the material itself; this is necessary because the material available will crucially influence the quantity and quality of the data that can be extracted. Historical material differs from present-day material in several ways that affect linguistic research. Two important differences are that for most periods researchers can work only with written language and cannot create their own material under experimental conditions (see section 11.3.2 for the special implications that working with written-only data has for historical phonology; see also Chapter 25 by Minkova and Zuraw in this volume).
Two obvious limitations of being restricted to the study of writing are (i) that past speech cannot be accessed directly (see also section 11.3.2) and (ii) that we have access only to texts produced by speakers with at least partial literacy (although these speakers may of course reproduce the language of other, illiterate speakers within the framework of, for instance, a witness deposition). As many linguistic changes are assumed to originate in spoken interaction, the first limitation makes it important to study speech-related written texts. The second limitation is problematic because literacy has been a socio-economically stratified skill for most of the history of English: chiefly male speakers from the upper echelons of society have been able to write (and their texts are also more likely to have been preserved). This means that texts which provide information on the language of illiterate speakers – and of other speaker groups who are underrepresented in the historical record – are of great importance to historical linguists. In many cases, the same types of text are used to circumvent both limitations; for instance, drama texts contain constructed speech, some of which may represent the playwright's attempt to re-create the language of lower-class speakers, and court records such as depositions and trial proceedings contain scribal representations of language spoken by a cross-section of past societies. By using and comparing several such genres, researchers can shed light on at least some aspects of past speech (see, e.g., Culpeper and Kytö Reference Kytö, Jucker and Taavitsainen2010) and of the language of the lower echelons of society. Other windows on the past in this regard include informal letters that incorporate spoken features and documents produced by semi-literate speakers with limited schooling (see, e.g., Fairman Reference Fairman, Kytö, Rydén and Smitterberg2006 for exemplification).
Another important issue concerns what the basis is for the texts that are included in corpora (see below and section 11.3.4) or otherwise used for linguistic research. Many historical texts are available in published form as later editions of the original manuscripts, and the question then arises how faithfully the original manuscript has been preserved in the edition. Especially if the edition was compiled for historical rather than linguistic purposes, it may not represent all linguistic features of the original manuscript faithfully (see Kytö and Walker Reference Kytö and Walker2003: 231–41 for discussion and case studies; see also Chapter 7 by Horobin in this volume). In addition, if a text is available in several manuscripts that differ linguistically, the editor will have had to make choices as regards how to represent this variation, and those choices will eventually have consequences for any empirical results that are based on the edition (see also section 11.4).
A related limitation of historical linguistics is relevant to choice of material as well as research design: the lack of experimental conditions. At least for some areas of research on Present-day English, researchers can create experiments that are specifically designed to answer certain research questions. This is not possible in historical linguistics; instead, researchers have to adapt their research design to the material that is already available. Thus, when Walker (Reference Walker2007) examined the influence of extralinguistic factors on the choice between thou and you forms in Early Modern English by classifying speakers on the parameters of sex, age, and rank, her data came from texts that happened to have been preserved since that period, not from experiments designed by the researcher.
As the example from Walker (Reference Walker2007) shows, if the relevant information is available, researchers can classify their data on extralinguistic parameters in addition to features of the co-text (see section 11.2.3). But editors, researchers, and corpus compilers alike are frequently faced with a dearth of extralinguistic information on their texts. It is often possible to assign a historical text to a genre (see below for a discussion of this concept) and to supply an approximate date or period of composition, although not all texts can be dated with accuracy; for older texts, there may also be a considerable difference between the probable date of original composition and the date of the manuscript(s) or imprint(s) to which the researcher has access (Kohnen Reference Kohnen, Pahta, Taavitsainen, Nevalainen and Tyrkkö2007a). In some cases, information on the age, gender, and socio-economic status of the relevant language users may also be available. However, the amount of work necessary to be able to take such parameters into account is considerable. Not only is it time-consuming and labour-intensive to access the information itself, but the information must also be placed in its proper historical context; as Nevalainen and Raumolin-Brunberg (Reference Nevalainen and Raumolin-Brunberg2003: 30) note, ‘historical sociolinguistics can only be successful if its analyses draw on the social conditions that prevailed during the lifetimes of the informants’. Nevalainen and Raumolin-Brunberg (Reference Nevalainen and Raumolin-Brunberg2003: 32–8, 136–8) therefore devote considerable space to discussing the reconstruction of social order in Tudor and Stuart England. For diachronic studies, the changes which that social order inevitably undergoes become an additional complication, as ‘one and the same model hardly does justice to the differences’ in the social fabric between the beginning and the end of the period investigated (Nevalainen and Raumolin-Brunberg Reference Nevalainen and Raumolin-Brunberg2003: 137).
Other parameters are even more elusive. The extensive information required to reconstruct a social network of historical letter-writers or to classify them with regard to the intimacy of their acquaintance is often unavailable; yet such parameters are likely to have influenced stylistic and pragmatic choices made by interactants. Generally speaking, the problems are particularly noticeable regarding texts that are old, were not produced by well-known language users, and/or were not considered as being of great importance in the society in which they were produced (Kytö and Pahta Reference Pahta, Nevalainen and Traugott2012: 127–8). Thus, while Britton (Reference Britton, Denison, Bermúdez-Otero, McCully and Moore2012) is able to reach convincing conclusions regarding singleton/geminate consonant contrasts of the type [n] vs. [nn] for ‘an idealised generically “East Midland”, Orm-like variety of the late twelfth century’ (p. 239), it would be impossible to discuss the distribution of the data in terms of, for instance, differences in the age or socio-economic status of informants.
One way of minimizing the potential sources of error that arise from basing research on ‘written documents whose survival is fragmentary, haphazard, and skewed’ (Kytö and Pahta Reference Pahta, Nevalainen and Traugott2012: 125) is to group those documents into categories established on extralinguistic grounds, which are here called genres: examples include ‘drama comedy’, ‘private correspondence’, and ‘academic writing’. (See Kytö and Smitterberg Reference Kytö, Smitterberg, Biber and Reppen2015 for a fuller account of the use of the genre concept in historical linguistics.) Comparing texts from the same genre across time reduces the risk that a linguistic difference between collections of texts from different periods is due to differences in the genre composition of the collections rather than to language change. In recent decades, historical research has been revolutionized by the use of corpora, that is, machine-readable sets of authentic material that has been sampled in order to represent a language variety (McEnery et al. Reference McEnery2006: 5). Corpora will be addressed in more detail in section 11.3.4, but it should be noted here that one of the advantages of using corpora is that the genre parameter is typically an important part of corpus design (for corpora, see also Chapter 8 by López-Couso in this volume). Most historical corpora contain material that is stratified according to genre, either because the corpus focuses on a single genre or because the same number of texts from each genre has been included in the corpus; it is thus easy to use genre as an independent variable in corpus-based research.
The genre concept is thus both important and valuable, but it is important to approach genres critically. First, far from all genres have an unbroken existence through the recorded history of English; for instance, legal texts in English are absent from much of the Middle English period, during which Latin and French were used for these purposes (Claridge Reference Claridge, Bergs and Brinton2012: 240). If the researcher focuses only on those genres that have textual witnesses from all periods under scrutiny, considerable amounts of linguistic variation that existed in the speech community of each period will thus be excluded from observation. In corpus-linguistic terms, the period samples become more comparable, but each period sample will be less representative of the language of its period as a whole (Leech Reference Leech, Hundt, Nesselhauf and Biewer2007, Kytö and Smitterberg Reference Kytö, Smitterberg, Biber and Reppen2015). Genres may also change over time, which calls into question the extent to which two documents from different periods that belong to the ‘same’ genre are necessarily comparable (see Chapter 16 by Taavitsainen in this volume). For instance, while the novel as a genre has existed for several centuries, subgenres like detective fiction have a less extensive history (Leech and Smith Reference Leech and Smith2005: 90), and the presence or absence of subgenres in different periods affects the composition of the genre as a whole. Again, a choice between focusing on the subgenres that are comparable across the whole period covered and including the subgenres that are maximally representative of each period studied may be necessary.
11.3.2 Phonological data
Many of the matters discussed in section 11.2 are also relevant to phonological variation. Indeed, the variationist framework was originally applied to phonology; as phonemes do not in themselves have meaning, the problem of assuming semantic equivalence does not arise. Taking the linguistic co-text into account is also a vital part of historical phonology. For instance, the bath/trap split, whereby words belonging to the bath lexical set (e.g. bath, dance, and half) came to be pronounced with present-day /ɑ:/ rather than /æ/ in some varieties of English, took place in specific phonological contexts such as before pre-consonantal /s/ (see Beal Reference Beal2004: 138–41). However, there are also characteristics of historical phonological research that are unique to this field of inquiry.
For a small part of the history of English, speech can be studied directly, because there are sound recordings available. While scholars interested in twentieth-century pronunciation cannot create their own experimental conditions (see section 11.3.1), they can draw on faithful recordings of the spoken medium as such (see Chapter 9 by Mair in this volume). This section, however, will be concerned with the large part of the history of English pronunciation that predates the availability of recorded speech. The fact that we have only written evidence of past speech is a complicating factor, but historical phonologists have devised several strategies to address the problems that arise through careful examination and comparison of the different types of evidence for historical pronunciation that are available.
The types of written evidence that historical phonologists draw on can be divided into two main categories. Indirect evidence comes from sources that ‘involve writers inadvertently providing clues about their own or their contemporaries’ pronunciation’ (Beal Reference Beal2004: 126). Direct evidence, in contrast, comprises ‘contemporary comments on linguistic behaviour’ (Smith Reference Smith2007: 29). I will comment briefly on the most common types of evidence below.
Indirect evidence can be divided into different categories, the two most important of which are the writing system and verse practices. As regards the writing system, the alphabet used to represent English is basically phonographic; graphemes like <f> can thus be expected to map onto phonemes (in this case, /f/). However, the researcher cannot count on there being a one-to-one correspondence between the graphemes that occur in a written text and the phoneme inventory of the writer. Contrasts that existed in speech may be absent from the writing system. No distinction is typically made between long and short vowels in Old English manuscripts, even though vowel length was contrastive in that variety; the difference between /ɡod/ ‘god’ and /ɡo:d/ ‘good’ is thus absent in the common written representation <god>. Conversely, distinctions may be made in writing that do not exist in speech. The vowel /i:/ is often represented in present-day writing by <ea> (as in sea) or <ee> (as in see), and in many cases this difference in spelling reflects a distinction between the reflexes of Middle English /ɛ:/ and /e:/ that has not been made by most speakers for centuries. Nonetheless, if assessed with due caution, the English writing system can provide valuable indications of phonological change. Britton (Reference Britton, Denison, Bermúdez-Otero, McCully and Moore2012), for instance, uses orthographic evidence in an analysis of the loss of geminate consonants in English, i.e. the process through which pairs such as sunne ‘sun’, with a geminate [nn], and sune ‘son’ became homophonous (see also section 11.3.1). As Britton (Reference Britton, Denison, Bermúdez-Otero, McCully and Moore2012: 236) notes, orthographic evidence for this process consists both of ‘singleton spellings where historically a geminate sequence occurred’ and of ‘double consonant graphs between vowel graphs where formerly no geminate had been present’. That is, when these pairs no longer contrasted in speech, writers would not maintain the historical distinction in writing.
The analysis of ‘the rhyming, alliterating, and scansion practices adopted by poets’ (Smith Reference Smith2007: 36) is another major source of evidence for historical phonologists. Verse practices as a source of data must be used with caution; for instance, what look like rhymes in verse may really be ‘eye-rhymes’ such as love: prove (Beal Reference Beal2004: 127), or ‘conventional’ rhymes which may have reflected earlier rather than current pronunciations, e.g. eighteenth-century rhymes like sea: say (Smith Reference Smith2007: 38). But if used judiciously, data from verse can reveal variation in pronunciation that may be indicative of ongoing change; for instance, Mugglestone (Reference Mugglestone1991) presents evidence of the loss of non-prevocalic /r/ based on rhymes such as dawn: scorn.
While our knowledge of Old and Middle English phonology is based chiefly on indirect evidence, an increasing amount of direct evidence is available for the period after 1500 (Beal Reference Beal2004: 126–7). Especially for the study of Late Modern English, direct evidence is considered important, since there is a great deal of it available, and since developments such as the standardization of English spelling mean that many texts are of limited value as indirect evidence; it is chiefly informal texts produced by speakers who had not received much schooling that are useful in this regard (Beal Reference Beal2004: 127). The main difficulty with direct evidence is instead that it may be biased towards prescribed and educated usage. Although, as Beal (Reference Beal2004: 128–33) notes, pronouncing dictionaries etc. can provide very valuable information on contemporary pronunciation, the phonological system that they describe is chiefly that of the most prestigious variety of English at the time. However, it is also possible to gain some insight into phonological variation from comments on pronunciations considered ‘vulgar’ etc. in such works. As with all types of evidence in historical phonology, and indeed in historical linguistics in general, direct evidence of pronunciation is potentially of great significance as long as it is used with due caution.
11.3.3 Spelling
The notion that each word has one ‘correct’ spelling – apart from a small number of exceptions with variable spellings, such as hono(u)r – may seem natural to a present-day observer, but is in fact a comparatively new phenomenon in the history of English. Not until the Late Modern English period did spelling variation cease to be an inherent part of written English, and, as Osselton (Reference Osselton, Rydén, Tieken-Boon van Ostade and Kytö1998 [1984]) has shown, variant spellings lived on in handwritten texts for some time after they had largely disappeared from print.
Depending on the research question, the fact that English spelling has been variable for most of the recorded history of the language can mean either a problem or an opportunity. For scholars interested in variation and change in pronunciation, spelling variation is one of the most important sources of data (see section 11.3.2). For analysts who focus on morphosyntax or lexis, however, spelling variation can be a considerable complication as regards the automatic retrieval of forms from an electronic corpus (see also section 11.3.4). It is often necessary to create a word list to identify all possible spellings of the relevant forms in the corpus texts before retrieval. A further complication arises in cases where variant spellings create homographs; for instance, in Walker's (Reference Walker2005) study of second-person singular pronouns in Early Modern English, the pronoun form thee was found to have the variant spellings <the> and <ye> (see the published version of the study, Walker Reference Walker2007). As these spellings were also used for the definite article in Walker's material, it proved necessary to examine these cases manually to ensure high recall and precision (Walker Reference Walker2005: 22) – a time-consuming task given the high frequency of both personal pronouns and definite articles. However, as will be shown in section 11.3.4, there are several ways in which information may be added to corpora in order to minimize or remove such additional work; such computer-assisted processing of historical texts is becoming increasingly central to corpus-linguistic endeavours.
11.3.4 Corpora and annotation
There are several advantages of using electronic corpora (see also section 11.3.1 and Chapter 8 by López-Couso in this volume) to study language history. First, as mentioned in section 11.3.1, the genre parameter typically forms part of the corpus set-up, so that suitable textual witnesses of each genre included are present in each of the periods covered by the corpus. Second, considerable care will have gone into the selection and transcription of texts for the corpus, which improves the quality of research based on it. Third, in terms of data retrieval, corpora enable the researcher to run automated searches for linguistic features. For instance, in an analysis of subjects of gerunds such as that discussed in section 11.2.2, lexical searches for words ending in -ing (together with possible spelling variants) will ensure virtually complete recall, and the manual post-processing stage can be devoted to maximizing the precision of the analysis by removing irrelevant instances.
In the case of some research questions, though, the grammatical category in which the researcher is interested cannot be retrieved automatically in this fashion; for instance, there is no reliable way of retrieving all adjectives in a corpus of English using lexical searches, as there are no affixes that reliably identify English adjectives. Moreover, as mentioned in section 11.3.3, the widespread spelling variation that characterizes much of the history of English can also make lexical searches unfeasible even when the data could in principle be retrieved lexically. Using a corpus would still be valuable in that the texts would have been carefully selected to ensure that they are representative and/or comparable (see section 11.3.1), but the researcher would have to go through the corpus texts manually to find all relevant examples of the linguistic feature studied.
However, various forms of annotation have been devised that enable researchers to make more efficient use of corpora. Some important types of such annotation will be mentioned here. First, historical corpus texts can be normalized with regard to spelling using software such as VARD (Variant Detector, see, e.g., Lehto et al. Reference Lehto2010). This would eliminate the need to go through forms such as <the> to ensure complete retrieval of the pronoun thee in Early Modern English texts (see section 11.3.3). Lemmatized annotation would take the process one step further by relating all forms of a word to its base form; for instance, using lemmatized annotation, it would be possible to search for all forms of the verb be using a simple search for the base form rather than listing all possible forms that belong to the paradigm of the verb during a given period. Part-of-speech (POS) tagging instead adds a syntactic layer to the material in a corpus. In a POS-tagged corpus, each lexical unit has been supplied with a part-of-speech classification; for instance, each noun in the corpus may be followed by a tag like ‘_N’. (In many cases, POS tagging in fact provides more detail than merely the part of speech; for example, it may distinguish singular and plural nouns.) In a tagged corpus, <the> representing thee may thus be classified as a pronoun, while <the> for the would be classified as an article, a determiner, etc., depending on the tagset used. Finally, parsed corpora provide even more syntactic information. In a parsed corpus, information on how the lexical units in the text form larger syntactic categories such as phrases and clauses has been added.
Of the annotations mentioned above, POS tagging is probably the one that has been used most extensively on historical texts. However, applying such tools to historical materials is not always a straightforward process. Although programs such as taggers have been designed to identify and label linguistic units automatically, in practice the involvement of the researcher in the annotation process is often required, as taggers, parsers, etc. have typically not been developed for handling historical texts. First, such programs may rely on lexis and spelling to some extent; for instance, the form <you> may be tagged as a pronoun automatically. In a text written in early English, the equivalent form may instead be e.g. <yow>, <ye>, <ge>, or <eow>, depending on factors such as the age of the text and the syntactic function of the pronoun (if it has singular reference, thou forms are also possible equivalents). The existence of widespread variation in orthography becomes problematic for taggers that assign POS tags based partly on such criteria. However, if the spelling in the corpus has been normalized (see section 11.3.3), this difficulty is reduced: while the tagger would still need to be instructed to treat a form like ye as a pronoun, variant spellings such as <ȝe> or <yhe> would not cause further difficulty. Second, the tagger's or parser's ‘rules’ for Present-day English will not be wholly applicable to historical stages of the language. Late Modern English printed texts can often be used as input to taggers and parsers with little difficulty. From the late eighteenth century on, spelling was fairly standardized at least in print, and most grammatical differences between Late Modern and Present-day English concern quantitative shifts in usage rather than qualitative differences such as the existence of syntactic variants that no longer occur in English (exceptions include the passival construction in A new house is building mentioned in section 11.1). I have shown elsewhere (Smitterberg Reference Smitterberg2005: 51) that only c.1.3 per cent of the words in a manually checked subset of A Corpus of Nineteenth-century English (CONCE) had been tagged erroneously (although c.2.5 per cent of the words had been given several possible tags). But the amount of work required to achieve a result that can be reliably used for automated retrieval increases with the linguistic and orthographic distance between the variety used in the text and the variety for which the software was designed.
The importance of computerized corpora – and of various forms of annotation of those corpora – is likely to continue to increase in the field of English historical linguistics. However, it will remain necessary for analysts to be thoroughly acquainted with their material in order to ensure the validity of their datasets. While automated techniques can facilitate research considerably, they can never replace the in-depth knowledge of a historical variety of English that comes from engaging directly with the textual evidence.
11.4 Trends and possible future developments
As the present chapter has demonstrated, the textual basis that linguists have at their disposal for the study of the history of English is a source of challenges as well as opportunities. In addition to fulfilling all the methodological requirements of a synchronic study, the researcher must also gain familiarity with the special demands peculiar to the period(s) studied. However, some of the difficulties facing historical linguists also open up possibilities that are not easily available to synchronic researchers; for instance, the lack of a fixed spelling, which creates problems for automatic retrieval using concordancers, also enables historical phonologists to study past speech through the written medium.
As regards possible future developments in data collection in English historical linguistics, two separate but complementary trends can be mentioned. First, an ever increasing range of original documents are being made available electronically. Several digital archives make it possible to access large numbers of primary sources online. These sources can of course be accessed directly as part of a manual process of data collection. However, partly by drawing on such electronic archives, corpus compilers are also assembling increasingly extensive corpora that enable automatic retrieval procedures. Especially for the Early and Late Modern English periods, large numbers of texts are becoming available for corpus-based research for the first time. Techniques like Optical Character Recognition (OCR) are likely to become increasingly important in converting documents to corpus texts.
At the same time, however, the early twenty-first century has witnessed increased interest in returning to the original manuscripts of older texts. Several researchers have noted that there is a need for editions that ‘aim at reproducing the original manuscripts faithfully, and avoid normalizing, modernizing, or otherwise emending the original manuscript texts’ (Kytö et al. Reference Kytö, Walker and Grund2007: 66). For instance, Grund (Reference Grund2006: 106) notes that an edition which incorporates ‘readings from several different manuscript witnesses into the text of the edition’ presents ‘an eclectic or hybrid text for which there is no actual historical witness’. Grund (Reference Grund2006: 119) also raises the issue of whether texts which exist in several witnesses that differ linguistically ‘should be considered manifestations of the same text or independent texts’ in corpus compilation.
Ideally, these two trends may be combined in electronic editions of texts (for examples, see Chapter 7 by Horobin in this volume). Electronic editions can incorporate linguistic variation among witnesses, yet still remain faithful to each individual witness. In addition, provided that the edition comes together with (or is compatible with) concordancers and other forms of corpus-linguistic software, some versions of the texts can be made available in searchable form, with different degrees of normalization; for instance, while one searchable version of the text can be rendered with normalized spelling that would facilitate tagging, retrieval, etc., another can preserve the original spelling of the text. A clear desideratum in this regard would be the development of common standards as regards the software and editorial conventions used for such electronic editions, which would ultimately enable researchers to create their own computerized corpora by combining texts from different electronic editions, each of which has been compiled by – and for – linguists. While the large amount of funding and time required to produce such editions is likely to impose limitations on development, electronic editions of this kind may ultimately combine philological and corpus-linguistic perspectives in a way that will provide researchers with the best of both worlds in terms of data retrieval.





