

7.1 Introduction
The Spanish vowel system is one of the most common systems cross-linguistically (Disner Reference Disner and Maddieson1984), consisting of five contrastive vowels that are distinguished by three degrees of height and backness. Despite the simplicity of the system, however, considerable research on both monolingual and bilingual Spanish vowel systems has revealed that vowels are highly influenced by a variety of linguistic and extralinguistic factors. This chapter begins with a brief description of the basic articulatory and acoustic properties of Spanish vowels to help familiarize readers with some of the terminology that will be employed throughout. The following two portions of the chapter focus on addressing the influence of linguistic factors on vowel production, namely syllable structure and lexical stress. Subsequent sections describe additional sources of variation, including speech style and speaking rate, dialect, and sociolinguistic factors. A brief description of bilingual vowel systems is presented next, followed by directions for future research. The chapter concludes with some general closing remarks.
7.2 Basic Articulatory and Acoustic Properties of Spanish Vowels
In articulatory terms, the five vowel phonemes of Spanish are categorized based on their height, backness, and the presence or absence of lip rounding (Hualde Reference Hualde2005). The elevation of the tongue body produces three distinct levels of vowel height, such that /i/ and /u/ are classified as high, /e/ and /o/ as mid, and /a/ as low. Vowels are further classified along the front–back dimension based on the proximity of the tongue body to the anterior or posterior portion of the buccal cavity: /i/ and /e/ are front vowels, /a/ is a central vowel, and /o/ and /u/ are back vowels. The back vowels are also considered rounded given that they are produced with lip rounding, while the other three phonemes are unrounded. Figure 7.1 presents the articulatory classification of the Spanish vowel system (based on Hualde Reference Hualde2005).
| front | central | back | |
|---|---|---|---|
| high | i | u | |
| mid | e | o | |
| low | a | ||
| unrounded | rounded | ||
Figure 7.1 Articulatory classification of Spanish vowels
The distinct positions of the tongue and lips upon producing the Spanish vowel phonemes result in their being characterized by different vocal tract resonances, or formants, which consist of concentrations of energy in certain frequency ranges. The first two formant frequencies (hereafter F1 and F2) are sufficient to distinguish the Spanish vowels (Martínez Celdrán Reference Martínez Celdrán1995). Figure 7.2 depicts the organization and distribution of the Spanish vowels within the acoustic space based on the F1 and F2 values presented in Quilis and Esgueva (Reference Quilis, Esgueva, Esgueva and Cantarero1983), which were obtained from 16 male speakers of Spanish from various parts of Spain and Latin America. Note that the vowels are distributed fairly symmetrically and are relatively equidistant from one another.

Figure 7.2 Acoustic distribution of Spanish vowels: mean formant values of male speakers of Spanish
The duration of Spanish vowels has not been discussed extensively in the literature, although those studies that do include analyses of duration (e.g. Chládková et al. Reference Chládková, Escudero and Boersma2011; Marín Gálvez Reference Marín Gálvez1995; Ronquest Reference Ronquest2012) have revealed intrinsic duration (i.e. high vowels are shorter than low vowels; see, for example, Lehiste Reference Lehiste1970). As will be described at various points throughout this chapter, vowel duration is also influenced by factors such as consonantal context, stress, speech style, and gender.
The simplicity and symmetry characteristic of the Spanish vowel system appears to have led to the assumption of little variability in their production, or at least less variation than that observed in the consonantal system. Indeed, Navarro Tomás (Reference Navarro Tomás1918, sec. 43) noted that the timbre (quality) of Spanish vowels is generally stable throughout their articulation, although he does state that contextual and stylistic factors can result in minor phonetic differences. An examination of some of the earliest studies of Spanish vowels reveals four recurrent claims concerning the (lack of) variability in the Spanish vowel system:
1 The mid vowels have at least two distinct allophones depending on the type of syllable (closed or open) in which they occur.
2 Lexical stress has little impact on vowel quality and duration.
3 Vowels produced in rapid speech and more spontaneous styles tend to be centralized relative to those produced in slower, more controlled speech.
4 The Spanish vowels are relatively stable across dialects.
Each of these points will be discussed in Sections 7.3 through 7.6 by summarizing the impressionistic and acoustic studies related to each topic. The remainder of the chapter is dedicated to describing additional sources of variation and suggesting ways in which they may be addressed in future studies.
7.3 Syllable Structure and Consonantal Context
Navarro Tomás (Reference Navarro Tomás1918) was one of the first to note distinct quality differences in vowels based on their surrounding consonantal context. He argued that all five vowel phonemes have at least three distinct allophones depending on the nature of the adjacent consonants and/or if the syllable is closed or open. Of greatest interest here are the close and open allophones of the mid vowels, as they have received the most attention in the literature.Footnote 1 According to Navarro Tomás, the distribution of the mid vowel allophones – close [e] and [o] and open [ɛ] and [ɔ], respectively – depends not only on if the syllable is closed or open, but also on which consonant closes the syllable. While the close allophones of both vowels are argued to surface in open syllables with primary or secondary stress, [e] is also described as occurring in syllables closed by orthographic d, m, n, s, z. The open allophones [ɛ] and [ɔ] occur when preceded or followed by /r/ or preceding /x/, but also in closed syllables, again, depending on the consonantal context: [ɛ] surfaces in syllables closed by consonants other than d, m, n, s, z, and [ɔ] in syllables closed by any consonant and in accented position between an /a/ and a following /l/ or /r/. Despite the detailed descriptions of the contexts in which each of these allophones occurs, he argued that the differences between the open, close, and relaxed versions of Spanish vowels are very slight, although the difference between the close and open allophones of the mid vowels are described as more noticeable than the same differences in the high vowels.
Acoustic investigations of the allophonic differences described by Navarro Tomás (Reference Navarro Tomás1918), however, have generally failed to reveal compelling evidence that the variations in openness are robust enough to warrant distinct allophones. Although in general terms most studies have documented more open vowels in closed syllables and close vowels in open syllables, some investigations did not employ statistical analyses, or, if quantitative methods were applied, the differences failed to reach statistical significance (Martínez Celdrán Reference Martínez Celdrán1984; Matluck Reference Matluck1952; Morrison Reference Morrison2004; Servín and Rodríguez Reference Servín, Rodríguez and Herrera2001).Footnote 2 The only acoustic investigations that seem to have confirmed the presence of mid vowel allophones were conducted by Skelton (Reference Skelton1969) and Jurado and Arenas (Reference Jurado and Arenas2005). Skelton, who analyzed vowels produced by 20 speakers from Spain and Latin America, argued that the overlap of the /e/ in open syllables with the space of /i/ evidenced two distinct allophones for the front mid vowel. Jurado and Arenas concluded that open [ɛ] and [ɔ] occurred only in syllables that were closed by /r/, thus confirming Navarro Tomás’ (Reference Navarro Tomás1918) observations, but their study analyzed the speech of only one male speaker from Argentina.
Given the lack of overwhelming evidence supporting the presence of open and close mid vowel allophones based on syllable structure alone, differences in vowel quality and duration might be better understood taking into consideration consonantal context in addition to syllable structure. Research examining coarticulatory effects between vowels and surrounding consonants in other languages has proven that the place and manner of adjacent segments have a significant impact on vowel quality (Stevens and House Reference Stevens and House1963) and duration (House and Fairbanks Reference House and Fairbanks1953; Peterson and Lehiste Reference Peterson and Lehiste1960). With specific reference to the Spanish language, Chládková et al. (Reference Chládková, Escudero and Boersma2011) reported that some of the differences between Iberian and Peruvian Spanish vowels stemmed from the articulatory and acoustic properties of a following /s/. Bradlow’s (Reference Bradlow, Gussenhoven and Warner2002) analysis of the high vowels in the context of /bV/ and /dV/ revealed considerable lowering of F2 of /u/ in the context of /b/ relative to /d/, although the same trend was not observed for /i/. Recasens (Reference Recasens1987) also described that, for some CVC sequences in Spanish and Catalan, the magnitude of coarticulatory effects depended on the degree of articulatory constraint.
Analyses of vowel duration have also revealed a complex interplay of syllable structure and consonantal context. Quilis and Esgueva (Reference Quilis, Esgueva, Esgueva and Cantarero1983), for example, found that vowels were shortest in the context of /p/, longer when adjacent to /m/, and longest in contact with /b/. Additionally, Chládková et al. (Reference Chládková, Escudero and Boersma2011) noted that, in the context of /f/ and /s/, the non-back vowels produced by women were longer than those produced by men. Furthermore, Marín Gálvez (Reference Marín Gálvez1995) reported that vowels followed by fricatives in closed syllables were longer than vowels followed by fricatives in open syllables, but that the opposite pattern was observed for vowels that occurred in contact with nasal and liquid consonants.
Combined research focusing on syllable structure and consonantal context confirms that the acoustic properties of the Spanish vowels are influenced by the phonetic environment in which they are produced. The fine-grained phonetic differences based on the surrounding consonantal context described in previous studies, however, may very well reflect a cross-linguistic tendency, suggesting that coarticulation with adjacent segments may play an equally important (or perhaps larger) role in influencing Spanish vowel quality and quantity (duration) than does syllable structure alone.
7.4 Stress
Despite the observation in Navarro Tomás (Reference Navarro Tomás1918) that unstressed (atonic) vowels tend to be more “relaxed” than stressed (tonic) vowels, especially in rapid speech, the general assumption is that unstressed vowels in Spanish are not characterized by the same magnitude of reduction typical in English and other languages. While Delattre’s (Reference Delattre1969) acoustic examination of stressed and unstressed vowels in English, German, French, and Spanish confirmed less reduction in Spanish than in English, additional research does reveal the presence of fine-grained phonetic and durational differences. Quilis and Esgueva (Reference Quilis, Esgueva, Esgueva and Cantarero1983) noted slight quality differences between tonic and atonic vowels produced by both male and female speakers, describing a tendency for tonic vowels to be more open than their atonic counterparts. Sadowsky (Reference Sadowsky2012) reported similar tendencies in his analysis of Chilean Spanish, also describing that atonic vowels tended to be slightly more centralized along the F2 dimension, but the trend was not consistent for all vowels within the system and differed depending on if the unstressed vowel was pre- or post-tonic. Willis (Reference Willis2008) noted substantial centralization of unstressed vowels in Dominican Spanish semi-spontaneous speech, although individual speakers varied in terms of the magnitude and direction of the effects. Nadeu’s (Reference Nadeu2014) investigation of Catalan and Spanish vowel systems revealed that, while Catalan speakers showed consistent trends of unstressed vowel reduction, Spanish speakers’ productions were highly variable and no clear or consistent pattern could be observed. Finally, durational differences between stressed and unstressed vowels in Peninsular Spanish were reported by Marín Gálvez (Reference Marín Gálvez1995), who found that, with the exception of /u/, unstressed vowels were always shorter than their stressed counterparts. In conjunction, investigations of the impact of lexical stress on vowels produced by monolingual speakers of Spanish do reveal some minor quality and durational differences, although none suggest the presence of a schwa-like vowel that is characteristic of English. As will be discussed in Section 7.8, however, bilingual speakers of Spanish often exhibit larger stress-induced quality and quantity differences than those described for monolinguals.
7.5 Speech Style and Speaking Rate
Unlike syllable type and stress, the influence of speech style and speaking rate on Spanish vowels has not been addressed extensively in the literature. Even though (or perhaps because) Navarro Tomás (Reference Navarro Tomás1918) mentioned that vowels produced in slow, emphatic speech are characterized by more stable and consistent timbre than those produced in rapid speech, much of the initial research on Spanish vowel systems has entailed analyses of vowels produced in isolated CVCV (nonce) words or within words embedded in a carrier phrase (Bradlow Reference Bradlow1995; Godínez Reference Godínez1978; Martínez Celdrán Reference Martínez Celdrán1995; Morrison and Escudero Reference Morrison and Escudero2007; Quilis and Esgueva Reference Quilis, Esgueva, Esgueva and Cantarero1983, among others). Harmegnies and Poch-Olivé’s (Reference Harmegnies and Poch-Olivé1992) acoustic investigation was one of the first to directly examine the impact of speech style (i.e. controlled versus (semi-) spontaneous) on vowel quality in Castilian Spanish.Footnote 3 Although their study analyzed the speech of only one male informant, they found that vowels produced in the semi-directed interview (spontaneous style) were more centralized in the acoustic space relative to those produced in the word list. Subsequent investigations of stylistic variation in other dialects confirm a general trend of vowel space expansion in controlled speech in both monolingual (Martín Butragueño Reference Martín Butragueño, Herrera and Barriga2014; Poch-Olivé et al. Reference Poch-Olivé, Harmegnies and Butragueño2008; Willis Reference Willis2008) and bilingual (Alvord and Rogers Reference Alvord and Rogers2014; Bradlow Reference Bradlow, Gussenhoven and Warner2002; Ronquest Reference Ronquest2016; Willis Reference Willis2005) varieties.Footnote 4 Nadeu (Reference Nadeu2014) reported similar effects in her examination of speaking rate, in which vowels produced in the fast condition were centralized relative to those that were produced at a normal speaking rate. Style- and speaking rate-induced variability in Spanish is not surprising, given that vowel space expansion in controlled speech has been documented in other languages and likely represents a cross-linguistic tendency (see, for example, Ferguson and Kewley-Port Reference Ferguson and Kewley-Port2007; Moon and Lindblom Reference Moon and Lindblom1994; Smiljanić and Bradlow Reference Smiljanić and Bradlow2005, among others).
7.6 Dialectal Variation
As mentioned in Section 7.2, the Spanish vowel system is traditionally described as both simple and symmetrical – a characterization that has, perhaps, contributed to the notion that vowels are produced relatively similarly throughout the Spanish-speaking world. According to Hualde (Reference Hualde2005:128), “[v]owel qualities are remarkably stable among Spanish dialects. There is nothing in Spanish like the differences in vowel quality we find across geographical and social varieties of English.” Although certainly true in comparative terms, impressionistic and acoustic research has revealed at least some regional variation in vowel production. This section of the chapter includes a summary of several cross-dialectal comparisons of the vowel system as a whole, followed by a description of some region-specific pronunciations of certain vowels.
Acoustic investigations of cross-dialectal variation have revealed some notable differences in terms of both vowel quality and quantity, although the effects are often limited to specific vowels and are not systematic. A comparison of Mexican, Argentine, and Peninsular vowels presented in Godínez (Reference Godínez1978), for example, revealed a more condensed vowel space in Peninsular Spanish relative to the other two varieties. In addition, he reported a higher position of /e/ and /i/ in the Argentine variety compared to the Mexican and Peninsular varieties, with /e/ in Argentine Spanish higher than /e/ in Mexican Spanish and /i/ in Argentine Spanish higher than /i/ in Peninsular Spanish. Quilis and Esgueva (Reference Quilis, Esgueva, Esgueva and Cantarero1983) analyzed vowels produced by male and female speakers from Mexico, Ecuador, Chile, and various regions throughout Spain. They noted distributional differences across speakers from different regions, but no clear pattern emerged. With respect to duration, however, they found that, on average, the vowels produced by Latin American speakers were slightly longer than those produced by Spaniards. Willis (Reference Willis2008) also described differences in distribution between Dominican Spanish vowels and those presented in Quilis and Esgueva, although he acknowledges that the vowels analyzed in his study were obtained from a different type of speech (semi-spontaneous). O’Rourke (Reference O’Rourke and Ortega-Llebaria2010) offers a comparison of Spanish vowels produced in Lima and Cuzco, Peru, reporting a more condensed vowel space for the Lima speakers relative to those from Cuzco. She hypothesizes that the differences in distribution could stem from language contact with Quechua. Finally, Sadowsky (Reference Sadowsky2012) compared vowels produced by the Chilean speakers in his study to nearly all of the formant values obtained from previous works. A visual comparison of the vowel spaces suggests that no two dialects of Spanish are characterized by the exact same distribution and formant values, although, again, the type of speech in which vowels were produced and the gender, age, and social class of the speakers vary across studies.
Two additional investigations conducted by Morrison and Escudero (Reference Morrison and Escudero2007) and Chládková et al. (Reference Chládková, Escudero and Boersma2011) compared the vowel systems of speakers from Lima, Peru, and Madrid, Spain, taking into consideration both vowel quality and quantity. The results of Morrison and Escudero’s analyses revealed that Peruvian vowels were characterized by longer duration and higher fundamental frequency (F0).Footnote 5 Comparisons of individual vowel quality, however, revealed that only /o/ differed across the two varieties, as it was characterized by a lower F2 (i.e. more retracted) in Peruvian Spanish. A larger-scale study carried out by Chládková et al. confirmed Morrison and Escudero’s initial finding of lengthened duration in Peruvian Spanish compared to Iberian Spanish, attributing the durational variation to differences in speaking rate. Cross-system comparisons revealed additional quality differences and a general trend for more peripheral vowels in Peruvian Spanish relative to Iberian Spanish. A closer examination of coarticulatory effects based on the surrounding consonantal context revealed that the cross-dialectal differences were particularly robust in the context of /s/, in which Peruvian Spanish /o/ and /u/ were produced further back and /i/ further front than their Iberian counterparts. The tendency for Iberian Spanish vowels to centralize in the /s/ context was attributed to articulatory and acoustic differences concerning the production of /s/ itself: Iberian Spanish /s/, which is concave and apico-alveolar in north-central varieties, was characterized by a lower center of gravity than the dental /s/ of Peruvian, ultimately resulting in the observed differences in F2. Taken together, the results indicate that the acoustic properties of Spanish vowels are fairly similar across dialects, although differences in speaking rate and variation in the pronunciation of the consonants may actually influence the phonetic properties of the Spanish vowels.
Despite the relative similarity of vowels across dialects of Spanish, a number of vowel-related dialectal phenomena, such as quality differences in final mid vowels and subsequent vowel harmony, raising of unstressed final vowels, and unstressed vowel reduction or devoicing, have been documented in various regions throughout Spain and Latin America. In the eastern portions of Andalusia, for example, where word-final /s/ is often deleted, the mid and low vowels (i.e. /e/, /o/, and /a/) can vary in quality as a means to signal the morphological difference between singular and plural. As impressionistically described by Alvar (Reference Alvar1991), the mid vowels are produced with the more open allophones [ɛ] and [ɔ] in plural forms as compared to singular forms (cf. pobre ‘poor’ [poβɾe] vs. pobres ‘poor.pl.’ [poβɾɛ]; niño ‘boy’ [niɲo] vs. niños ‘boys’ [niɲɔ]). The low vowel /a/ is also affected, and typically produced with a more fronted articulation in the plural. The final vowel in the plural noun niñas ‘girls,’ for example, is more advanced, and can even approximate a very open form of –e (Alvar Reference Alvar1991:235) which Hualde (Reference Hualde2005:130) approximates with English /æ/. Vowel harmony, in which the quality of the final vowel may also spread to other vowels within the word, is also common in this region, resulting in pronunciations such as [lɔβɔ] for lobos ‘wolves’ (Hualde Reference Hualde2005:130 and references therein).Footnote 6
Several impressionistic and acoustic studies have described the raising of unstressed final mid vowels (e.g. leche ‘milk’ [leʧe] produced as [leʧi]) in parts of Spain, Puerto Rico, and Mexico (Barajas Reference Barajas2014; Holmquist Reference Holmquist1985, Reference Holmquist, Paradis, Vincent, Deshaies and LaForest1998, Reference Holmquist and Sayahi2005; Oliver Rajan Reference Oliver Rajan, Holmquist, Lorenzino and Sayahi2007). Holmquist (Reference Holmquist1985) documented raising of final /o/ to [u] in northwestern Spain, and Holmquist (Reference Holmquist, Paradis, Vincent, Deshaies and LaForest1998, Reference Holmquist and Sayahi2005) and Oliver Rajan (Reference Oliver Rajan, Holmquist, Lorenzino and Sayahi2007) reported the raising of both mid vowels in Puerto Rico, although final /o/ was raised somewhat more frequently than /e/. Holmquist’s (Reference Holmquist, Paradis, Vincent, Deshaies and LaForest1998, Reference Holmquist and Sayahi2005) investigations also revealed a greater likelihood of raising when the vowel was in contact with a preceding palatal and/or a following high tonic vowel. Barajas’ (Reference Barajas2014) extensive acoustic study in Michoacán, Mexico, confirmed many of the findings reported in earlier, impressionistic work.Footnote 7 She found that target vowels that were situated in pronouns, in words in utterance-final position, and in words with penultimate stress, and vowels that were preceded or followed by a palatal consonant, were characterized by the most raising. In addition, the length of the word (number of syllables) influenced vowel raising differently: while raising of /e/ was more frequent in shorter words, longer words promoted raising of /o/. In contrast to previous studies, however, Barajas reported that /e/ was raised more frequently than /o/, and the number of independent variables found to influence raising differed for each vowel. Analysis of vowel formants indicated that the raised variants of both /e/ and /o/ were fronted along the F2 dimension, resulting in the raised /e/ converging on the acoustic space of /i/, but the raised /o/ moving away from /u/. Combined, the results of this large-scale study revealed that the influence of linguistic and extralinguistic factors on mid vowel raising in the Mexican community was not necessarily identical for both vowel phonemes. As will be described in the next section of this chapter, a variety of social factors was found to influence the presence and frequency of mid vowel raising in all of the studies described above.
An additional dialectal phenomenon concerns the reduction of unstressed mid vowels in word-internal position, which has been documented in parts of central Mexico and the Andean region. Henríquez Ureña (Reference Henríquez Ureña1938) was the first to comment that the atonic vowels in Mexican Spanish were very short in duration, “reduced,” and often deleted in certain contexts. Further exploration of this topic has revealed that reduction and/or deletion of the unstressed mid vowels is most common in the context of voiceless consonants, and more specifically, when preceding /s/ (Lope Blanch Reference Lope Blanch1963; Matluck Reference Matluck1952). Matluck argued that the position of the vowel within the word influenced the frequency of reduction, with word-final vowels reducing and deleting more than word-medial vowels. He also observed reduction in word-initial position, which often resulted in a lengthened following consonant (e.g. enero ‘January’ as [n:eɾo]). Conversely, Lope Blanch (Reference Lope Blanch1963) argued that consonantal context was more influential than word position, reporting the most reduction in the context of a preceding voiceless stop (i.e. /ptk/) and a following /s/. Cases of true deletion were primarily limited to two lexical items, namely pues ‘well’ and entonces ‘then.’
Delforge’s (Reference Delforge, Colantoni and Steele2008) acoustic examination of the same phenomenon in Andean Spanish confirmed many of the details presented in earlier, impressionistic work, among them the gradient nature of reduction and the greater likelihood (in general) of reduction in word-final position. In contrast, however, Delforge reported that unstressed vowel “reduction” might be better described as devoicing, in that more than half of the unstressed vowel tokens analyzed exhibited varying degrees of devoicing as opposed to actual quality (i.e. F1 and F2) differences. In addition, she noted that /e/, /i/, and /u/ were the vowels most likely to undergo some form of devoicing, and that contact with consonants such as assibilated /r/ and affricates, as well as /s/, promoted devoicing.
In summary, although the Spanish vowel system is simple in nature, considerable research has documented at least some minor differences in formant values and duration across dialects. Impressionistic and acoustic analyses of region-specific characteristics indicate that, like the consonantal system, the pronunciation of the Spanish vowels does vary geographically.
7.7 Sociolinguistic Factors
Research on Spanish vowels has also established a connection between vowel production and sociolinguistic factors such as gender, sexual orientation, social class, age, and social networks. Investigations of vowels produced by male and female speakers of various dialects have revealed lengthened duration and a generally larger vowel space (i.e. higher frequencies) for women compared to men (Chládková et al. Reference Chládková, Escudero and Boersma2011; Quilis and Esgueva Reference Quilis, Esgueva, Esgueva and Cantarero1983, among others). These findings are expected given the physiological differences (i.e. vocal tract length) between men and women, and such trends are well documented in other languages (see, for example, Hillenbrand, Getty, Clark, and Wheeler Reference Hillenbrand, Getty, Clark and Wheeler1995). The impact of sexual orientation on vowel quality in Puerto Rican and Peninsular Spanish has also been investigated by Mack (Reference Mack2009) and Osle Ezquerra (Reference Osle Ezquerra2015), respectively. Mack reported that higher F2 values of /e/ correlated with a greater likelihood of a speaker being perceived as gay, whereas Osle Ezquerra described that the height (F1) of the back vowels differed among gay and straight males. Thus, while the impact of gender on vowel quality is well understood, the relationship between the acoustic properties of Spanish vowels and sexual orientation has yet to be fully explored.
Soto-Barba (Reference Soto-Barba2007) and Sadowsky (Reference Sadowsky2012) noted that the acoustic distribution of vowels varied considerably based on social class. Soto-Barba’s examination of vowels produced by speakers of three different social classes (urban upper class, urban lower class, and rural lower class) in the province of Ñuble, Chile, revealed that rural speakers produced vowels more peripherally than the other two groups, and especially the urban upper class, whose vowels were the most centralized in the acoustic space. The author attributes the greater dispersion of the rural speakers’ vowels to lengthened duration, which permits additional stability in formants. Sadowsky (Reference Sadowsky2012) also reported that the vowel systems of men and women residing in Concepción, Chile, contain multiple allophones that are socially stratified. In contrast to Soto-Barba, however, he found that vowels produced by women of the elite class were the most peripheral, and that allophonic differences in women’s speech were more numerous than those in men’s speech. As the women of the lower-middle and middle class exhibited the greatest number of allophonic variations, he concluded that the vowel system of Concepción is undergoing restructuring, with middle-class women leading a change in progress.
Returning to some of the dialectal phenomena discussed in Section 7.6, unstressed vowel raising has also been found to correlate with multiple social factors (Barajas Reference Barajas2014; Holmquist Reference Holmquist1985, Reference Holmquist, Paradis, Vincent, Deshaies and LaForest1998, Reference Holmquist and Sayahi2005; Oliver Rajan Reference Oliver Rajan, Holmquist, Lorenzino and Sayahi2007). Despite the different locations and populations described in each of these studies, several general trends emerge. Vowel raising tended to be most common among older speakers, those with lower levels of education, those with less mobility (i.e. spend more time in the community), and among members of dense social networks. Holmquist (Reference Holmquist1985) reported greater frequency of vowel raising among male speakers in Spain, although his subsequent investigations of men and women in Puerto Rico (Reference Holmquist, Paradis, Vincent, Deshaies and LaForest1998, Reference Holmquist and Sayahi2005, respectively) revealed similar tendencies across genders.
Although brief, the literature survey above confirms that sociolinguistic factors play an important role in shaping the Spanish vowel system. As will be discussed in greater detail in Section 7.9, future studies may consider exploring these relationships further.
7.8 Vowel Systems of Bilingual Spanish Speakers
Investigations of bilingual speech have revealed a number of important differences and similarities between the vowel systems of monolingual and bilingual speakers of Spanish and other languages. As a complete review of all of the bilingual literature will not be possible here given space limitations, this section will focus on summarizing some of the major trends observed in Spanish vowels produced by English learners of Spanish, Spanish–English balanced bilinguals, and heritage speakers of Spanish.Footnote 8 When relevant, reference to other bilingual populations will be presented.Footnote 9
A recurring observation across studies of bilingual Spanish vowel systems concerns differences in acoustic organization and distribution. Generally speaking, the vowel systems of most learners and bilinguals tend to be less symmetrical, and vowels are often not distributed as equidistantly as they are traditionally depicted, especially among lower-level learners and less-proficient bilinguals (Boomershine Reference Boomershine2012; Cobb and Simonet Reference Cobb and Simonet2015; Menke and Face Reference Menke and Face2010; Ronquest Reference Ronquest2012; Willis Reference Willis2005). All of the aforementioned studies, as well as Grijalva et al. (Reference Grijalva, Piccinini and Arvaniti2013), have noted that /u/ is more fronted in learner and bilingual speech when compared to monolingual norms. Boomershine (Reference Boomershine2012) and Ronquest (Reference Ronquest2012) reported a raised and backed /e/ and a more greatly dispersed front vowel space relative to the back vowel space. Cobb and Simonet (Reference Cobb and Simonet2015) also found variation in the production of /e/, but, as will be discussed below, differences across groups were significant only when taking into consideration the presence or absence of lexical stress. In addition to a more fronted /u/, Willis (Reference Willis2005) also observed that the bilingual speakers’ /a/ was fronted relative to monolingual /a/ (based on values presented in Quilis and Esgueva Reference Quilis, Esgueva, Esgueva and Cantarero1983) and that it approached the location of English /æ/. Distributional differences have also been reported for bilingual speakers of Spanish and Quechua. As pointed out by O’Rourke (Reference O’Rourke and Ortega-Llebaria2010), Quechua–Spanish bilinguals produced /a/ and /u/ similarly to the native monolingual speakers of Spanish, but their /e/ more closely approximated that produced by the Spanish learners, resulting in a hybrid system for the bilinguals.
Bilinguals, and especially English learners of Spanish at low and intermediate levels, have also been shown to reduce unstressed vowels more than monolingual controls, although not all vowels are affected equally (Bland Reference Bland2016; Cobb and Simonet Reference Cobb and Simonet2015; Menke and Face Reference Menke and Face2010). Bland (Reference Bland2016), for example, found that unstressed vowels were shorter and more centralized along the F2 dimension in the speech of L2 learners at three different levels. Cobb and Simonet (Reference Cobb and Simonet2015) reported that stress differences manifested only in the intermediate learners’ productions of /e/, in that tonic /e/ was situated higher in the acoustic space than atonic /e/. All three groups of bilingual speakers (first-, second-, and third-generation immigrants of Cuban descent) described in Alvord and Rogers’ (Reference Alvord and Rogers2014) investigation exhibited at least some differences in stressed and unstressed vowel quality, although the patterns were not consistent across groups and dimensions. Most unstressed vowels exhibited a slight movement toward the center along the F2 dimension, but were actually higher (lower F1) in the acoustic space and therefore not centralized in the direction of schwa (with the exception of /a/). Ronquest’s (Reference Ronquest, Howe, Blackwell and 164Lubbers Quesada2013) investigation of Spanish vowels produced by heritage speakers revealed similar trends with respect to quality, as well as a proportionally larger durational difference between tonic and atonic vowels than has been reported for monolinguals: heritage speakers’ atonic vowels were approximately 30 percent shorter than tonic vowels, whereas Marín Gálvez (Reference Marín Gálvez1995) reported a 20 percent decrease in monolingual speech. When taken together, the influence of stress on bilingual vowel systems reflects some general tendencies observed in monolingual varieties (e.g. inconsistency across the system, centralization along the front–back dimension, shorter atonic vowels), but also differs with respect to the magnitude of the effects.
Despite the differences mentioned above, the impact of speech style appears to have a similar influence on bilingual and learner systems as it does in monolingual varieties. Bland’s (Reference Bland2016) comparisons of mid vowels produced in a narrative and a picture task revealed that native speakers and learners alike produced vowels more peripherally in controlled speech (i.e. picture task). Alvord and Rogers (Reference Alvord and Rogers2014) found that vowels produced in the word list (i.e. most controlled task) were more peripheral than those produced in the interview. Ronquest (Reference Ronquest2016) confirmed the same pattern for heritage speakers, also reporting minor differences in duration for some vowels: /a/ and /o/ were significantly shorter in the most spontaneous task (i.e. narrative) compared to the more controlled picture and carrier phrase tasks.
The brief overview of the bilingual literature presented above describes some of the ways in which bilingual Spanish vowel systems differ from, or are similar to, those of monolingual native speakers. While some bilingual populations exhibit the same trends as those observed in monolingual groups, the effects are, at times, less consistent and/or magnified. Age of onset of bilingualism (or age of onset of learning) has a strong influence on the pronunciation of vowels, as the overall vowel space tends to shift toward monolingual norms as proficiency or experience with Spanish increase (Bland Reference Bland2016; Cobb and Simonet Reference Cobb and Simonet2015; Menke and Face Reference Menke and Face2010). Still, like those of monolingual native speakers, bilingual vowel systems are characterized by considerable variation that merits further investigation.
7.9 Future Directions in Vowel Research
Returning to the four main assumptions this chapter set out to address, the conjunct of research summarized herein suggests that (i) open and close mid vowel allophones are likely the result of both syllable structure and coarticulatory effects; (ii) lexical stress does influence vowel quality and duration in Spanish, but the influence manifests itself differently in Spanish as compared to languages with phonological reduction such as English and Catalan; (iii) vowels have a tendency to centralize in rapid speech and less controlled styles; and (iv) dialectal differences in the vowel system do exist, although they may not be as numerous as in other languages. Combined with the results of studies examining sociolinguistic factors and bilingual vowel systems, these findings indicate that even the simple vowel system of Spanish is rich with variation. Nevertheless, there is still much to be explored, as will be outlined below.
In light of the influence of language-internal and -external factors described throughout this chapter, future investigations should be cautious in directly comparing raw formant values and duration across studies, as contextual, stylistic, and sociolinguistic factors likely vary across works. Comparisons of patterns, however, may still prove insightful, so long as researchers acknowledge that distinct methodologies and analyses may produce distinct results. On a related note, future investigations focusing on dialectal and/or social variation in particular might consider assessing the acoustic properties not only of the vowels themselves, but also of the surrounding consonants. As pointed out by Chládková et al. (Reference Chládková, Escudero and Boersma2011), some of the variation in vowel production may be due, in part, to cross-dialectal differences in the pronunciation of certain consonants. Examining characteristics such as speaking rate and style are also of vital importance. The differences in distribution (i.e. more or less peripheral vowels) in some dialects versus others may very well be a consequence of speaking rate, as vowels produced at faster rates are more likely to centralize (Nadeu Reference Nadeu2014).
Additional suggestions concerning methodology and analysis entail further assessment of the interaction between variables, examination of the dynamic properties of vowels in addition to the static, and a movement away from comparisons of aggregate patterns. As described throughout this chapter, much of the research on Spanish vowels has focused on linguistic factors such as stress and syllable type. Fewer investigations have examined the influence of extralinguistic and social factors, and even fewer have investigated the interaction between multiple factors (however, see Barajas Reference Barajas2014; Chládková et al. Reference Chládková, Escudero and Boersma2011; Ronquest Reference Ronquest2012; Sadowsky Reference Sadowsky2012). The inclusion of multiple variables in future studies, as well as a thorough exploration of how they interact, will facilitate our understanding of the complexity of the Spanish vowel system.
Analyses of the dynamic properties of vowels in conjunction with static measures of F1 and F2 are also important to consider in future vowel research. While their study primarily focused on English vowels, Konopka and Pierrehumbert (Reference Konopka and Pierrehumbert2010), for example, reported that although many of the static characteristics of vowels were similar across groups, the differences were rooted in the dynamic properties, such as vowel-inherent spectral change and duration ratios between stressed and unstressed vowels. Spanish vowel research will also benefit from the inclusion of such variables, as well as further investigation of vowel duration in general, which has received considerably less attention in the literature in comparison to vowel quality.
Much of the acoustic vowel research conducted within the past few decades consists of comparisons of mean formant values and aggregate patterns. Future studies of Spanish vowels may consider the analysis of median values as opposed to means, as done by Escudero et al. (Reference Escudero, Boersma, Rauber and Bion2009) in their investigation of Brazilian and European Portuguese vowels. They argue that such an approach may help reduce the impact of potential errors in measurement. Additionally, as pointed out by Nadeu (Reference Nadeu2014), when individual speakers exhibit distinct or opposite patterns of variation, aggregate reporting can, in a sense, “cancel out” the effects, therefore obscuring important individual behaviors. Such variation may be key to understanding cross-linguistic and cross-speaker differences, and is therefore an important avenue to pursue.
Of additional importance, in reviewing the literature presented in this chapter, it is clear that many of the studies of Spanish vowels consist of descriptive, acoustic characterizations. While such descriptions serve as an important first step in understanding the vowel system as a whole, notably absent (from my own work as well) are studies which situate their research questions, predictions, and results within specific theoretical frameworks. Important exceptions include Bradlow (Reference Bradlow1995), who calls upon the basic tenets of quantal theory, dispersion theory, and language-specific base of articulation when describing differences between the (semi-) analogous vowels of Spanish and English, and Nadeu (Reference Nadeu2014), who references localized hyperarticulation in her comparison of stress and speaking rate effects on Spanish and Catalan vowels. Future research incorporating specific phonetic and phonological theories, or a stronger theoretical grounding, are the next step beyond the descriptive phase in vowel research.
On a final note, while this chapter has provided a comprehensive review of studies examining vowel production, additional insight into the Spanish vowel system can be gained via analyses of vowel perception. Perceptual models such as the Speech Learning Model (SLM; Flege Reference Flege and Strange1995), the Perceptual Assimilation Model (PAM; Best Reference Best and Strange1995), and the Second Language Linguistic Perception Model (L2LP; Escudero Reference Escudero2005) are particularly relevant when investigating bilingual speakers and L2 learners, in that each provides mechanisms for both predicting and understanding the patterns observed in production. As a complete description of the models and review of vowel perception literature will not be possible here, interested readers may consult Chapter 11 in this volume for a more complete overview.
7.10 Conclusions
To conclude, the findings of research on Spanish vowels presented in this chapter offer important insight into how distinct linguistic and extralinguistic variables influence their acoustic properties. Advances in technology, methodology, and statistics have facilitated larger-scale studies and complex analyses, all of which have permitted researchers to move beyond basic impressionistic accounts of vowels to more in-depth, acoustic examinations of the systems of different speaker populations. Future research in the field focusing on topics such as regional, social, and individual variation will no doubt offer more insight into the variable nature of the Spanish vowel system.
8.1 Introduction
This chapter offers an overview of the consonants of Spanish, focusing on the main phonemes, both in terms of the dialectal variation and the phonological processes that affect them. The topic of Spanish consonants is vast and has given rise to many studies from different perspectives, from generative phonology to Optimality Theory (OT) approaches (see also Chapters 1 and 2, this volume). Due to space limitations, I focus only on some of the main issues that have been explored in the literature. In what follows, I will introduce the reader to the most prominent topics, give relevant references for further exploration and point out some of the current developments. My approach is to focus on phenomena that have received recent attention and benefited from methodological developments, mainly the use of instrumental techniques and the concentration on phonological variation. In revising previous assumptions and accounts of phonological processes in Spanish, I will emphasize the fact that phonological variation is at the core of many recent studies and advances in phonology, and the role it plays in building our assumptions and advancing phonological theory. After giving a general classification of the Spanish consonants, I will discuss them in natural classes according to their manner of articulation.
8.2 Phonemic Consonant Classification
Consonant sounds are defined as being produced with some degree of constriction in the vocal tract, which differentiates them from vowel or vocoid sounds (see also Chapter 7, this volume). Spanish consonants are classified by three articulatory parameters: place of articulation, manner of articulation, and voicing (see Ladefoged and Johnson Reference Ladefoged and Johnson2014 for more on articulatory descriptions). Table 8.1 includes the main consonant phonemes of the language according to their articulatory features, taking into account classifications by Quilis (Reference Quilis1993), Martínez-Celdrán et al. (Reference Martínez-Celdrán, Fernández-Planas and Carrera-Sabaté2003), Hualde (Reference Hualde2005), and Morgan (Reference Morgan2010), among others. It should be noted that there is dialectal variation in the Spanish consonantal phonemic inventory, and the parentheses around some of the consonants in Table 8.1 (/θ, ʎ/) denote that they are present only in some dialects, as discussed in later sections. In some cases, the classification of certain sounds is the subject of debate in the literature, most notably the palatal obstruent /ɟ/, which is discussed in Section 8.3.
Table 8.1 Main Spanish consonant phonemes
Sounds on the left-hand side of any given cell are voiceless and those on the right are voiced.
| bilabial | labiodental | interdental | dental† | alveolar | alveopalatal | palatal | velar | |
|---|---|---|---|---|---|---|---|---|
| Stop | p b | t̪ d̪ | ɟ | k ɡ | ||||
| Fricative | f | (θ) | s | x | ||||
| Affricate | tʃ | |||||||
| Nasal | m | n | ɲ | |||||
| Lateral | l | (ʎ) | ||||||
| Tap | ɾ | |||||||
| Trill | r |
† I omit the dental diacritic from /t, d/ in the rest of the chapter, following other authors’ practice (e.g. Hualde Reference Hualde2005).
8.3 Stops
Oral stops are produced with a complete interruption of the airflow as a result of a full closure of the vocal tract. Spanish includes a series of unaspirated voiceless stops /p, t, k/, and another of voiced ones /b, d, ɡ/. Stops may be found in onset position and, with a more limited distribution, in coda position. After continuant sounds, Spanish voiced stops are produced with an approximation of the articulators, rather than with a full closure, resulting in a continuant production with varying degrees of constriction (Martínez-Celdrán Reference Martínez Celdrán2013). These approximant allophones are represented as [β̞, ð̞, ɣ̞].Footnote 1 This contextually-defined alternation between voiced stops and approximants is called spirantization, and it has attracted a considerable amount of attention from a myriad of perspectives. The examples in (8.1) illustrate the distribution of the two allophones: voiced stops occur at the beginning of an utterance, sometimes referred to as a post-pausal environment (8.1a), and after a homorganic nasal or lateral consonant (8.1b); the approximant allophones are produced elsewhere, more precisely after a vowel (8.1c) and any consonant that is not an homorganic nasal or lateral (8.1d).
(8.1) Distribution of stop and approximant allophonesFootnote 2
a.
[ˈbenɡa] venga ‘let’s go’ [ˈdiselo] díselo ‘say it to her/him’ [ɡaˈnaɾon] ganaron ‘they won’ b.
[ˈsamba] samba ‘samba’ [ˈsen̪da] senda ‘path’ [ˈpoŋɡo] pongo ‘I put’ [ˈsal̪do] saldo ‘balance’ c.
[ˈkaβa] cava ‘sparkling wine’ [ˈaða] hada ‘fairy’ [ˈlweɣo] luego ‘later’ d.
[ˈselβa] selva ‘jungle’ [ˈalɣo] algo ‘something’ [ˈbaɾβa] barba ‘beard’ [ˈaɾðe] arde ‘it burns’ [ˈlaɾɣo] largo ‘long’ [ezˈβoso] esbozo ‘sketch’ [dezˈðen] desdén ‘disdain’ [ˈmuzɣo] musgo ‘moss’
The analysis of Spanish spirantization has been a fruitful avenue of inquiry for formal phonological analyses, and has helped to advance different theoretical approaches. Formal analyses of spirantization differ in their understanding of the process as weakening or fortition. Several authors view spirantization as an instance of weakening, where voiced stops weaken to continuant sounds, lacking a complete closure (e.g. Harris Reference Harris1984a). On the other hand, spirantization has also been viewed as a case of fortition by which obstruents strengthen to stops when they follow non-continuant consonants and after a pause (e.g. Baković Reference Baković, Giordano and Ardron1997). However, most authors agree that spirantization is an assimilatory process with respect to the continuancy of the preceding phonological context. Another aspect that differentiates formal analyses of spirantization is the nature of the underlying representation, i.e. whether voiced obstruents are fully or partially specified with respect to the feature [continuant]. Many derivational accounts of Spanish spirantization couched within generative phonology assume underspecification of [continuant] and, consequently, the occurrence of one allophone or the other depends on a series of ordered rules that determine their surface specification as either [+continuant] or [–continuant] (Lozano Reference Lozano1979; Harris Reference Harris1984a; Mascaró Reference Mascaró1991; Hualde Reference Hualde1989a). According to these analyses, the surface representation of voiced obstruents is totally conditioned by the phonological context where they occur and these sounds do not contrast with respect to their continuancy.
More recent formal analyses of spirantization have been couched within OT (see also Chapter 2, this volume), where the focus shifts from the underlying representation of the consonants to the ranking of constraints that account for the surface allophonic alternation. Consequently, these analyses do not make use of underspecification but rather propose ranked constraints to explain the process. Those that view spirantization as a weakening phenomenon posit a constraint that bans the occurrence of stops after vowels and continuant consonants, which is in conflict with another constraint that penalizes changes with respect to continuancy (Martínez-Gil Reference Martínez-Gil, Kempchinsky and Piñeros2003; González Reference González, Face and Klee2006). These analyses do not posit any restrictions on the underlying representation, which can be fully or partially specified (but see Baković Reference Baković, Giordano and Ardron1997 for a fortition analysis within OT).
All of the formal analyses discussed so far assume that the alternation between voiced stops and approximants is a binary, categorical process, oftentimes represented by the use of [±continuant]. However, instrumental studies on the alternation have presented acoustic and articulatory data showing that there is a great degree of variation in the precise realization of the allophones. The degree of constriction for the continuant allophones is gradient and depends on factors such as stress, vocalic context, speech style and rate, and dialect (Cole et al. Reference Cole, Hualde, Iskarous, Fujimura, Joseph and Palek1999; Ortega-Llebaria Reference Ortega-Llebaria and Face2004; Eddington Reference Eddington2011; Carrasco et al. Reference Carrasco, Hualde and Simonet2012). These facts have fueled formal analyses that attempt at capturing this variation. Most notably, some authors have argued that spirantization takes place in order to reduce articulatory effort in post-continuant contexts (Piñeros Reference Piñeros2002). Within OT, these analyses posit phonetically-grounded constraints, Lazy or “minimize articulatory effort,” that penalize articulatory effort, which can be quantified taking into account the context where the sound in question occurs. In the case of Spanish spirantization, the articulatory effort incurred by a continuant consonant in intervocalic position is less than that of a stop in the same context. These effort-based analyses, where phonetic information plays a crucial role, are capable of capturing the gradient nature of the continuant allophones and the fact that the process is conditioned by factors such as stress and speech rate. Colina (Reference Colina and Núñez Cedeño2016) offers a different approach to explaining phonetic variation within a formal analysis of spirantization by making use of output or surface underspecification (Keating Reference Keating1988). According to Colina, Spanish obstruents are produced without a target for continuancy after continuant sounds, and, as a result, the exact production of this feature is conditioned by the phonological context and other factors that affect speech production. Spanish spirantization is an example of how phonological variation unmasked through instrumental techniques and phonological theory have advanced hand in hand.
Several dialects have been described as having a more restricted distribution of approximant allophones, where voiced stops are produced in contexts in which approximants are expected. This pattern of limited spirantization has been observed in central America, Colombia, and Mexico (Canfield Reference Canfield1981; Quilis Reference Quilis1993; Moreno-Fernández Reference Moreno-Fernández2009). Recent quantitative studies have revealed two dialectal patterns of limited spirantization. In some varieties, we find approximant realizations only after a vowel, while, in other contexts, i.e. after any consonant, stop-like productions are more common, for example [ˈselba], [ˈaɾde], [ˈmuzɡo], etc. (cf. Example 8.1d above). Costa Rican Spanish displays this behavior as described in the acoustic study of Carrasco et al. (Reference Carrasco, Hualde and Simonet2012). Other varieties, such as Yucatan Spanish, seem to show a split between stops and approximants after vowels and also consonants, showing a similar distribution of allophones in both environments (Michnowicz Reference Michnowicz2011). It is worth noting that some of the recent work on limited spirantization has focused on contact varieties of Spanish, such as Peruvian Amazonian Spanish and Yucatan Spanish, and the production of voiced stops and their allophones is helping advance our understanding of the nature of bilingual phonological inventories and tease apart effects of language contact and incomplete second language acquisition (Michnowicz Reference Michnowicz, Lacorte and Leeman2009, Reference Michnowicz2011; O’Rourke and Fafulas Reference O’Rourke, Fafulas and Willis2015).
Spanish voiceless stops may undergo voicing in certain dialects, namely Cuban Spanish, Canary Islands Spanish, and some Peninsular varieties (Quilis Reference Quilis1993; Lewis Reference Lewis2001). This voicing occurs when the stop is next to a voiced sound, especially in intervocalic position. Recent acoustic studies have shown that this voicing process is gradient, and the resulting sound may present partial voicing, fully voicing or be lenited to an approximant (e.g. [taˈkon] ~ [taˈɡon] ~ [taˈɣon] ‘heel’; Martínez Celdrán Reference Martínez Celdrán2009; Torreira and Ernestus Reference Torreira and Ernestus2011). Within the dialects that present voicing, there is a considerable amount of interspeaker variation, although recent studies have identified gender and speech rate as two factors that may account for some of this individual variation (Nadeu and Hualde Reference Nadeu and Hualde2015). This voicing phenomenon has been interpreted as a type of weakening and placed within a broader phenomenon of Spanish obstruent weakening, together with voiced stops and their spirantization (Hualde et al. Reference Hualde, Simonet and Nadeu2011).
The voicing contrast among stops is neutralized in coda position, where only differences in place of articulation are usually maintained (Navarro Tomás Reference Navarro Tomás1977; Hualde Reference Hualde2005). These sounds present great variability in this context and their realization in coda ranges from a voiceless stop to a voiced approximant, with other intermediate realizations. Different degrees of obstruction and voicing are possible depending on stylistic factors and the phonetic environment (Navarro Tomás Reference Navarro Tomás1977; Hualde Reference Hualde2005:146). The examples in Table 8.2 illustrate the range of possible productions for voiced and voiceless stops in coda position. The crucial observation is that voiced and voiceless stops are not systematically differentiated in this syllabic context.
Table 8.2 Neutralization of stop voicing contrast in coda position
| Variable productions | Orthography | Gloss |
|---|---|---|
| [ˈkapto ~ ˈkab̥to ~ ˈkabto ~ ˈkaβto] | capto | ‘I capture’ |
| [opsoˈleto ~ ob̥soˈleto ~ obsoˈleto ~ oβsoˈleto] | obsoleto | ‘obsolete’ |
| [ˈetnja ~ ˈed̥nja ~ ˈednja ~ ˈeðnja] | etnia | ‘ethnic group’ |
| [atkiˈɾiɾ ~ at̥kiˈɾiɾ~ adkiˈɾiɾ ~ aðkiˈɾiɾ] | adquirir | ‘purchase’ |
| [ˈakto ~ ˈaɡ̥to ~ ˈaɡto ~ ˈaɣto] | acto | ‘act’ |
| [akˈnostiko ~ aɡ̥ˈnostiko ~ aɡˈnostiko ~ aɣˈnostiko] | agnóstico | ‘agnostic’ |
Voicing neutralization in coda has been taken as one piece of evidence for the existence of the three archiphonemes /B, D, G/ for Spanish stops in coda position (e.g. Alarcos Llorach Reference Alarcos Llorach1965; Quilis Reference Quilis1993:205). An archiphoneme is a formal phonological unit that is used to represent the result of a contextually-conditioned neutralization, and it includes the features common to the phonemes involved in the neutralization. Thus, /B, D, G/ include only those features shared by the voiced–voiceless pairs and leave out the voicing feature since it is not contrastive. As a result, these sounds have variable production of their voicing, which can be conditioned by different factors. This formal analysis resembles an underspecification account, according to which the sounds resulting from the neutralization do not have a specification for voicing, resulting in variable voicing production. This last approach relies on output underspecification in a very similar vein to Colina’s (Reference Colina and Núñez Cedeño2016) analysis of Spanish voiced stops.
The basic neutralization facts regarding coda stops discussed above present dialectal differences. In northern-central Peninsular dialects, voiced stops in coda position tend to undergo devoicing and fricativization, resulting in voiceless fricative productions. This is especially true for coda /ɡ/, that is pronounced as [x] (e.g. [ˈdoxma] dogma ‘dogma’) and coda /d/, that is realized as [θ] (e.g. [seθ] sed ‘thirst’) (González Reference González2002; see below for more on Castilian /θ/). Chilean Spanish presents vocalization of coda voiced and voiceless stops, resulting also in neutralization. More precisely, /p, b/ are vocalized to [w], /t, d/ to [j], and /k, g/ to [w] or [j] depending on the dialect (e.g. /apto/ [ˈawto] ‘apt,’ /etniko/ [ˈejniko] ‘ethnic’; Lenz Reference Lenz1940; Oroz Reference Oroz1966). Caribbean dialects display an extreme case of coda stop neutralization, where these sounds lose their contrast not only in voicing but also in place of articulation. The resulting sound is usually a velar consonant or a glottal stop (e.g. [aɣmiˈtiɾ] admitir ‘admit,’ [ˈeʔniko] étnico ‘ethnic’; Guitart Reference Guitart1976:23). Finally, coda stop deletion is widespread in Peninsular Spanish and it is also present, although to a lesser extent, in Latin American Spanish (e.g. [eˈsamen] ~ [eɣˈsamen] examen ‘exam’; Hualde Reference Hualde2005:147). It is important to notice that all of these phenomena that affect coda stops in different dialects may also affect other sounds in this syllabic context. This has been taken as evidence to propose that coda position is an unstable context, where consonants tend to undergo weakening, and in fact the behavior of stops has been analyzed in tandem with that of other consonants, such as fricatives, in this context (e.g. Gerfen Reference Gerfen2002).
Orthographic y, ll, and hi followed by a non-high vowel correspond with a voiced palatal obstruent, which we represent as /ɟ/ here. This sound, which occurs only in onset position, displays much variation in terms of its degree of constriction, which has been found to depend on a number of factors including phonological environment, style, speech rate, and dialect (Aguilar Reference Aguilar1997). Its production ranges from a stop [ɟ] or an affricate [ɟ͡ʝ] to a very open approximant [ʝ]. In general, we observe an alternation between a continuant and a non-continuant allophone following a similar distribution to that of the voiced stop/approximant alternation resulting from spirantization. More precisely, the voiced palatal continuant [ʝ] tends to occur after a vowel or a continuant consonant (e.g. [ˈkaʝe] calle ‘street,’ [ˈmaʝo] mayo ‘May,’ [laˈʝena] la hiena ‘the hyena’), and the non-continuant allophone, which may be realized as a stop [ɟ] or an affricate [ɟ͡ʝ], occurs after a nasal, a lateral or a pause (e.g. [ˈkonjɟuxe] cónyuge ‘spouse,’ [eljɟaˈβeɾo] el llavero ‘the keychain’). As in the case of voiced stops, this alternation presents some dialectal differences (Jiménez Sabater Reference Jiménez Sabater1975; Martín Butragueño Reference Martín Butragueño, Gómez and Molina-Martos2013). Given the similar distribution of the palatal obstruent and voiced stops, we classify this palatal sound as a stop /ɟ/, i.e. the non-continuant obstruent is taken as the phonemic representation emphasizing the parallel behavior with voiced stops (see also Morgan Reference Morgan2010). Other authors also adopt a non-continuant obstruent as the phonemic representation but as an affricate /ɟ͡ʝ/ (Martínez Celdrán et al. Reference Martínez-Celdrán, Fernández-Planas and Carrera-Sabaté2003). On the other hand, some authors classify this obstruent as /ʝ/ (e.g. Quilis Reference Quilis1993; Hualde Reference Hualde2005), taking the continuant palatal as the phonemic representation. In addition, the phonemic status of [ɟ ~ ʝ] has been amply debated in the phonological literature (e.g. Harris Reference Harris1969, Reference Harris1983; Cressey Reference Cressey1978; Whitley Reference Whitley1995; Hualde Reference Hualde1997, Reference Hualde, Chand, Kelleher, Rodríguez and Schmeiser2004). One approach is to view this sound as an allophone of the vowel /i/ that results from fortition in word initial position. On the other hand, this palatal sound can be analyzed as an independent consonantal phoneme (see Hualde Reference Hualde, Chand, Kelleher, Rodríguez and Schmeiser2004 for further discussion).
Some dialects, mainly those spoken in the Rioplatense region of Argentina and Uruguay, present a different pronunciation of [ʝ ~ ɟ] (see references below). In these varieties, we find a voiced or voiceless prepalatal fricative [ʒ ~ ʃ] in contexts where the palatal obstruent is used in other dialects (e.g. [ˈkaʒe] calle ‘street,’ [ˈmaʒo] mayo ‘May,’ [laˈʒena] la hiena ‘the hyena’). This phenomenon is called žeísmo (or rehilamiento). Orthographic hi has been traditionally claimed to not be part of this development and to present a production similar to other dialects. However, recent studies have shown that this grapheme can also be realized as a prepalatal fricative (e.g. [ˈʒelo] hielo ‘ice’; Colantoni Reference Colantoni2001). Žeísmo is reported as far back as the end of the 18th century (Fontanella de Weinberg Reference Fontanella de Weinberg1995). The sound was originally voiced and the process of devoicing emerged at the end of the 1940s (Wolf and Jiménez Reference Wolf, Jiménez and Barrenechea1979). The devoicing of the prepalatal has been widely explored as a sound change in progress, both impressionistically and with instrumental techniques. The focus has been the social distribution of the devoicing in an effort to draw conclusions regarding the extent of the change. Recent studies present acoustic data that suggests that the change is complete for young speakers born after 1975, while older speakers present variability between voiced and voiceless productions (Chang Reference Chang, Westmoreland and Thomas2008, Rohena-Madrazo Reference Rohena-Madrazo2011). These studies, and King (Reference King2009), also conclude that variation between [ʒ] and [ʃ] is phonetically, socially, and stylistically conditioned. In general, devoicing of žeísmo has been a fruitful avenue for exploring methodologies to study sound changes in progress. As with many other sound processes and changes, devoicing is gradient, and this, together with the fact that a phonemic contrast is not involved, poses a challenge for determining the status of the allophone and of the change, more generally. Instrumental techniques have proven crucial in overcoming this challenge. For instance, Rohena-Madrazo (Reference Rohena-Madrazo2015) develops a system-internal criterion to establish the degree of [ʒ] devoicing. More precisely, he establishes a baseline for this devoicing by using the amount of voicing of [s] in between vowels, a sound that does not present socially-conditioned allophonic voicing in this context. Based on this methodology and also the phonological patterning of the prepalatal allophones, the author concludes that the change is complete for younger middle-class speakers, and he proposes that the underlying representation for this group is /ʃ/ (see Harris and Kaisse Reference Harris and Kaisse1999 for a formal analysis of žeísmo and a different approach to the underlying representation).
8.4 Fricatives and Affricates
Fricative consonants are produced with a narrowing of the vocal tract, through which the airflow passes uninterrupted, resulting in frication noise. Spanish fricatives include /f, θ, s, x/ although the precise inventory and production of these sounds is subject to dialectal variation. The labiodental fricative /f/ is found only in onset position (e.g. [ˈfoka] foca ‘seal,’ [kaˈfe] café ‘coffee’), although it might be found in coda in some borrowings (e.g. afgano ‘afgan’). The alveolar fricative /s/ occurs in onset and coda position and has two main types of articulation depending on the dialect. This sound presents an apico-alveolar production [s̺] in northern-central Peninsular Spanish and a pre-dorso- or lamino-alveolar realization [s̻] in the rest of the dialects. Furthermore, the phenomenon known as /s/ weakening is prevalent in many dialects of Spanish and results in a wide range of reduced productions, from debuccalization – i.e. [h], also known as aspiration – to deletion. This weakening, which is variable, has attracted a lot of attention in the literature (see studies cited below and, among many others, Terrell Reference Terrell1979; Alba Reference Alba and Alba1982; Lipski Reference Lipski1985; Amastae Reference Amastae1989; Carvalho Reference Carvalho2006; Erker Reference Erker2010), and it is a clear example of how instrumental data has helped explore the nature of the phenomenon and its patterning.
The phenomenon of /s/ weakening is found in southern and central Peninsular varieties, the Canary Islands, and in many parts of Latin America, with the exceptions of Mexico, Guatemala, central Costa Rica, and the Andean region (Lipski Reference Lipski1994; Hualde Reference Hualde2005:161). The degree and frequency of the weakening and its resulting production vary across dialects. Furthermore, much of this variation is conditioned by linguistic and social factors, which show certain commonalities across varieties. Socioeconomic status and style have been shown to influence the degree of weakening in many dialects, with higher rates of reduction among less educated speakers and in more casual styles (Alba Reference Alba2004). However, it should be noted that in many varieties /s/ weakening is the de facto norm and there is no apparent social stigma attached to it, although the precise realization, whether for example aspiration or deletion, might present a socially-conditioned distribution (Chappell Reference Chappell2013). The phonological context also has an effect on /s/ weakening. Pre-consonantal contexts result in the highest degrees of weakening (e.g. [ˈkahpa] caspa ‘dandruff’), followed by prepausal environments (e.g. [ˈbamoh] vamos ‘let’s go’). For this reason, the phenomenon is usually described as affecting syllable-final /s/. However, /s/ may also weaken before a vowel (e.g. [lah ˈalah] las alas ‘the wings,’ [la heˈmana] la semana ‘the week’). Although this phonological context usually presents the lowest rates of weakening, there are some dialects where pre-vocalic /s/ shows the highest degree of /s/ reduction (e.g. New Mexico Spanish; Brown and Torres Cacoullos Reference Brown and Torres Cacoullos2002). Lexical frequency has also been found to influence /s/ weakening with high-frequency words displaying higher rates of reduction and lower-frequency words favoring unreduced productions (Brown Reference Brown2005; File-Muriel Reference File-Muriel2009). In fact, this phenomenon has been used as a testing ground for usage-based approaches to phonological patterns, and the role of factors related to use such as frequency on weakening has been taken as evidence for these kinds of models (see e.g. Bybee Reference Bybee2001)
The outcome of /s/ weakening varies from dialect to dialect. High rates of deletion are found in the most extreme dialects, such as Caribbean varieties, where there are reports of hypercorrection, i.e. cases of /s/ insertion in words where there is no etymological fricative (e.g. fisno instead of fino; Morgan Reference Morgan, Gutierrez-Rexach and del Valle1998). This behavior has led some authors to argue that /s/ is not present in the underlying representation of these innovative varieties (Terrell Reference Terrell, Núñez Cedeño, Páez Urdaneta and Guitart1986 for Dominican Spanish; Chappell Reference Chappell2014 for Nicaraguan Spanish). In some Andalusian varieties, /s/ deletion is accompanied by lengthening or gemination of the following consonant (e.g. [ˈbokke] bosque ‘forest,’ [ˈmimmo] mismo ‘same’), with possible pre-aspiration of the lengthened consonants in some cases (Gerfen Reference Gerfen2002). Merging of /s/ and the following consonant has also been documented in Andalusian Spanish, resulting in a long (or sometimes short) sound that combines features from both consonants (e.g. [reffaˈlaɾ] resbalar ‘to slide,’ [loθeˈβaneh] los desvanes ‘the attics’; Penny Reference Penny2000; see Martínez-Gil Reference Martínez-Gil, Hualde, Olarrea and O’Rourke2012 for a survey of formal analyses to these two patterns of /s/ weakening). In western Andalusian Spanish, we find yet another type of outcome for /s/ weakening before a voiceless stop. In this environment, a post-aspirated stop or an affricate surfaces as the result of /s/ reduction (e.g. [ˈpethe ~ ˈpetse] peste ‘plague,’ [ˈetha ~ ˈetsa] esta ‘this’; Parrell Reference Parrell2012; Torreira Reference Torreira2012). These types of productions have been analyzed within Articulatory Phonology (Browman and Goldstein Reference Browman and Goldstein1989) as a change in the timing of the articulatory gestures involved in the /s/ + consonant sequence after the oral gesture for the fricative is lost due to the weakening (Torreira Reference Torreira2012). In Nicaraguan Spanish, word-final /s/ before a vowel may be realized as a glottal stop (e.g. [loʔ ˈotɾo] los otros ‘the others’), which has been analyzed as a strategy to resolve a hiatus (Chappell Reference Chappell2013). Beyond production, recent studies have explored the perception of /s/ weakening by native speakers, especially how this phenomenon can convey sociophonetic information (Boomershine Reference Boomershine, Klee and Face2006; Schmidt Reference Schmidt, Beaudrie and Carvalho2013) and how it is processed by L2 learners of Spanish (Schmidt Reference Schmidt2011; see also Chapters 11 and 30, this volume).
In /s/-retaining dialects, this fricative undergoes voicing assimilation to a following voiced consonant, both within and across words (e.g. [ˈmuzɣo] musgo ‘moss,’ [lozˈβaɾkos] los barcos ‘the ships’).Footnote 3 Recent instrumental studies have shown that this assimilation is in fact gradient and oftentimes incomplete (Schmidt and Willis Reference Schmidt, Willis and Alvord2011; Campos-Astorkiza Reference Campos-Astorkiza, Côte and Mathieu2014, Reference Campos-Astorkiza, Klassen, Liceras and Valenzuela2015).Footnote 4 These findings challenge formal phonological accounts of the phenomenon that analyze it as a change in the featural specification of /s/ depending on the following consonant (Hualde Reference Hualde, Kirschner and DeCesaris1989b; Martínez-Gil Reference Martínez-Gil, Campos and Martínez-Gil1991). More recent analyses, couched within Optimality Theory, argue that /s/ is unspecified for voicing in coda position and, consequently, its voicing realization is dependent upon that of the surrounding consonants (Bradley Reference Bradley2005; Bradley and Delforge Reference Bradley, Delforge, Gess and Arteaga2006). However, this approach fails to capture cases that instrumental studies have found where there is no /s/ voicing before a voiced consonant (Campos-Astorkiza Reference Campos-Astorkiza, Côte and Mathieu2014, Reference Campos-Astorkiza, Klassen, Liceras and Valenzuela2015). This pattern, as well as the effects that stress and manner of articulation of the following consonant have on the degree of voicing, have led some authors to analyze /s/ voicing assimilation as an instance of gestural blending within Articulatory Phonology (Campos-Astorkiza Reference Campos-Astorkiza, Côte and Mathieu2014, Reference Campos-Astorkiza, Klassen, Liceras and Valenzuela2015).
The interdental fricative /θ/ is found in northern and central Peninsular dialects, where we observe a phonemic contrast between /s/ and /θ/ (e.g. [ˈmasa] masa ‘mass’ vs. [ˈmaθa] maza ‘sledgehammer’). The presence of this contrast is known as distinción in the Hispanic linguistics literature (Hualde Reference Hualde2005:153). In the majority of dialects, including most of Latin America, Andalusia, and the Canary Islands, this contrast is not present, and we find only the alveolar fricative /s/ (e.g. [ˈmasa] masa ‘mass’ vs. [ˈmasa] maza ‘sledgehammer’). This phenomenon is called seseo (Hualde Reference Hualde2005:153). This lack of contrast has yet another manifestation which is what we encounter in a few dialects that have only a dental fricative, very similar to /θ/. This is called ceceo and can be found mainly in eastern Andalusia and some parts of central America (Hualde Reference Hualde2005:153–154; Quesada Pacheco Reference Quesado Pacheco2010). However, this three-way dialectal division is not as clear-cut in Andalusia, where speakers may present variation between ceceo, seseo, and distinción. More precisely, speakers of certain Andalusian regions alternate their production between an alveolar and an interdental resulting in productions such as [masa ~ maθa] for both masa and maza. Recent studies have explored this variable phenomenon, focusing on regions that have been traditionally been described as ceceantes. What they have found is that younger speakers and women tend to prefer seseo or distinción over ceceo, leading some authors to suggest that ceceo is leaving the phonological system of these regions, which are becoming more similar to prestigious varieties that display only seseo or distinción (Dalbor Reference Dalbor1980; Hernández-Campoy and Villena Ponsoda Reference Hernández-Campoy and Villena Ponsoda2009).
The velar fricative /x/, which occurs in syllabic onset position but rarely in coda position, presents the following main realizations [x, χ, h, ç] depending on the dialect. Velar productions are found mainly in Mexico and most of South America (Hualde Reference Hualde2005:155). In northern-central Peninsular Spanish, the production of this phoneme is more retracted and it is usually realized as a uvular fricative [χ], especially before a back vowel (e.g. [ˈχuŋɡla] jungla ‘jungle,’ [ˈtaχo] Tajo ‘Tagus’). In the Caribbean, central America, Andalusia, and the Canary Islands, we find glottal productions [h] (e.g. [haˈβon] jabón ‘soap,’ [ˈaho] ajo ‘garlic’). In Chilean Spanish, /x/ before a front vocoid [e, i, j] has an anterior articulation and is produced as a palatal fricative [ç] (e.g. [çeneˈɾal] general ‘general,’ [ˈaçil] ágil ‘agile’ vs. [kaˈxon] cajón ‘drawer’; Lipski Reference Lipski1994:201; Hualde Reference Hualde2005:155). In fact, this alternation is part of a broader phenomenon called velar fronting that affects all velar consonants /k, ɡ, x/ in Chilean Spanish, and results in palatal productions of these sounds when preceding a front vocoid (e.g. [ˈcema] quema ‘it burns,’ [iˈʝeɾa] higuera ‘fig tree’; examples taken from González Reference Gonzalez, Côte and Mathieu2014, who offers an OT analysis of the process).
Affricates present two phases in their production: they start with a complete closure, followed by a narrow opening of the vocal tract. Acoustically, they are characterized by a period without energy followed by frication. Spanish has one affricate phoneme /tʃ/, a voiceless alveopalatal which occurs only in onset position (e.g. [ˈkatʃo] cacho ‘piece,’ [ˈtʃaɾko] charco ‘puddle’). In some dialects, the affricate weakens to a voiceless prepalatal fricative [ʃ] (e.g. [ˈkaʃo] cacho ‘piece’), where the closure phase is lost. These productions can be found most notably in Andalusia, Chile, and the Caribbean (Hualde Reference Hualde2005:22–24).
8.5 Nasals
Nasal consonants are produced with a complete oral closure and an opening of the passage to the nasal cavity, so that the airflow passes through the nose. Spanish has three nasal consonant phonemes /m, n, ɲ/ that are contrastive in their place of articulation only in onset position within the word (e.g. /kama/ cama ‘bed,’ /kana/ cana ‘gray hair,’ /kaɲa/ caña ‘cane’). In word-initial position, we may find a contrast between /m, n/ but the palatal /ɲ/ is very rare in this context. In coda position, nasals undergo place assimilation and adopt the place feature of the following consonant, both within and across words (8.2a). Before a following vowel or a pause, the nasal is usually alveolar [n] (8.2b), except in velarizing dialects, where it is produced as a velar [ŋ] (8.2c). Velarization is common in the Caribbean, the Pacific coast of South America, the Canary Islands, and several regions in Spain including Asturias, León, Galicia, and Andalusia (Quilis Reference Quilis1993:239–242; Piñeros Reference Piñeros, Martínez-Gil and Colina2006). In some varieties of Colombia, and in Yucatan Spanish, a final non-assimilated nasal can be produced as a bilabial [m] (Michnowicz Reference Michnowicz2008).
(8.2) Distribution of nasal allophones
a.
[ˈkampo] campo ‘field’ [eɱfaˈðaðo] enfadado ‘angry’ [ˈsen̪da] senda ‘path’ [ˈdenso] denso ‘dense’ [ˈkonjtʃa] concha ‘shell’ [ˈaŋɡulo] ángulo ‘angle’ b.
[salˈmon] salmón ‘salmon’ [kon ˈeβa] con Eva ‘with Eve’ c.
[salˈmoŋ] salmón ‘salmon’ [koŋ ˈeβa] con Eva ‘with Eve’
Within an autosegmental phonological framework, nasal place assimilation results from the spreading of the place of articulation (PA) features from a following consonant to the preceding nasal, which does not have any PA feature specification due to coda neutralization. Those nasals in coda position that are not followed by a consonant with which to share PA features get assigned a default alveolar value (Goldsmith Reference Goldsmith and Napoli1981; Harris Reference Harris, Aronoff and Oehrle1984b; for earlier generative analyses see Harris Reference Harris1969; Cressey Reference Cressey1978, and for structuralist accounts using the concept of a nasal archiphoneme see Alarcos Llorach Reference Alarcos Llorach1965; Quilis Reference Quilis1993:228). In the case of velarizing dialects, one would have to assume that the default value is velar. Within Optimality Theory, nasal place assimilation has been analyzed by making use of a constraint that requires that adjacent sounds have the same place of articulation specification, Agree(PA) (Baković Reference Baković, Minnic Fox, Williams and Kaiser2000; Piñeros Reference Piñeros, Martínez-Gil and Colina2006). Another important element in the OT analysis is the constraint, Ident(PA), with which Agree(PA) conflicts and calls for identity between the input and the output, i.e. it penalizes changes in PA. Agree(PA) dominates this identity constraint, since there is assimilation. However, it affects only nasals in coda position. This is the result of a highly-ranked constraint, IdentOnset(PA) that protects onsets from any PA featural changes. Beyond the specific OT details, this kind of analysis capitalizes on the difference between onsets and codas, and singles out the latter as a context more prone to phonological changes, along the lines of what was discussed in relation to coda stop neutralization in Section 8.3.
Some recent studies have focused on exploring the phonetic details of nasal place assimilation in Spanish and on the characterization of the process as either categorical or variable (Martínez Celdrán and Fernández Planas Reference Martínez Celdrán and Fernández Planas2007; Kochetov and Colantoni Reference Kochetov and Colantoni2011; Ramsammy Reference Ramsammy and Herschensohn2011). Ramsammy (Reference Ramsammy and Herschensohn2011), based on acoustic data from Peninsular Spanish, finds no difference in the production of a nasal assimilated to alveolar from that assimilated to velar. The author concludes that this assimilatory process is not categorical and argues that pre-consonantal nasals are underspecified for place of articulation in the surface (see above for output underspecification), resulting in high levels of coarticulation with the surrounding sounds. On the other hand, Kochetov and Colantoni (Reference Kochetov and Colantoni2011) present articulatory data indicating that the assimilation is almost complete and categorical, except before fricative consonants, where nasals present more variation in their production. The authors compare Argentine and Cuban Spanish and conclude that both dialects present the phonological process of assimilation but the actual implementation differs from one dialect to the other. These recent instrumental findings, although reaching different conclusions, offer an innovative way to explore nasal assimilation in Spanish and open the door to adopting similar techniques for dialectal and second language acquisition studies.
Velarization of coda nasals in several Spanish dialects (see Example 8.2c above) has attracted much attention from the phonological literature, especially within the framework of Optimality Theory. The puzzle that velarization poses for formal phonological accounts is that alveolar (i.e. coronal) is argued to be the unmarked place of articulation and, thus, we expect this place of articulation in neutralizing environments where no assimilation takes place. The fact that some dialects present a velar production is unexpected given what is considered as a phonological tenet. Baković (Reference Baković, Minnic Fox, Williams and Kaiser2000) approaches the issue by arguing that, in fact, velar productions are placeless nasals, a kind of output underspecification that auditorily resembles velar consonants. However, Ramsammy (Reference Ramsammy2013) presents electropalatography data that refutes Baković’s claim. More precisely, Ramsammy analyzes articulatory data from speakers of a Peninsular velarizing dialect and finds that their production presents a velar closure for the nasals, leading the author to conclude that velar nasals are not placeless but rather have a clear velar specification. Piñeros (Reference Piñeros, Martínez-Gil and Colina2006) also moves away from the underspecification analysis, and instead argues that velarization is an instance of consonant weakening. The author offers a detailed account of dialectal differences within velarizing varieties, and explains that nasal velarization is frequently accompanied by nasalization of the preceding vowel, resulting in complete nasal absorption by the vowel in many cases. Piñeros claims that nasal velarization and absorption are in fact two manifestations of the same phonological force, namely the weakening of consonants in coda position, which affects other consonants in these velarizing dialects. Based on some descriptions of the phenomenon, the author further notes that nasal velarization and absorption are not categorical, but rather variable and gradient within a continuum of consonant weakening. Piñeros argues that this situation can be interpreted as a change in progress from a full coda nasal consonant to a nasalized vowel. This claim makes certain predictions based on what we know about sound change, and opens the door for cross-dialectal sociophonetic analyses of Spanish nasals as a way to test them.
8.6 Liquids: Laterals and Rhotics
Lateral and rhotic sounds are usually grouped together under the phonological class of liquids due to their similar patterning cross-linguistically (Quilis Reference Quilis1993; Ladefoged and Maddieson Reference Ladefoged and Maddieson1996). In Spanish, these two types of sounds share some similarities in their distribution since these are the only consonants that can be the second member of a complex onset. Furthermore, the process of liquid neutralization, or trueque de líquidas, that takes place in coda position is presented as evidence for the connection between rhotics and laterals.
Laterals are produced with a complete closure in the central part of the oral cavity, while the sides of the tongue are open and the air escapes through that opening. Most dialects of Spanish only have one lateral phoneme /l/, which may occur in onset or coda position (e.g. [ˈlaɣo] lago ‘lake,’ [pasˈtel] pastel ‘cake’). In coda position, the lateral assimilates in place of articulation to a following coronal consonant, i.e. a following (inter)dental, alveolar or palatal, both within and across words (see Example 8.3a for assimilation within words). Before a non-coronal consonant, a vowel or a pause, the lateral is produced as the alveolar [l] (8.3b). Generally, lateral and nasal place assimilation have been analyzed as the same phenomenon (Cressey Reference Cressey1978; Piñeros Reference Piñeros, Martínez-Gil and Colina2006). According to this unified account, lateral and nasals share the features [+sonorant, +continuant] and they constitute the class of sounds that is affected by place assimilation in Spanish. The fact that laterals do not assimilate to non-coronal consonants is captured by the markedness of laterals that are not coronals.
(8.3) Distribution of lateral allophones
a.
[ˈsal̪to] salto ‘jump’ [ˈbolsa] bolsa ‘bag’ [koljˈtʃon] colchón ‘mattress’ b.
[ˈkalβo] calvo ‘bald’ [delˈfin] delfín ‘dolphin’ [ˈalɣo] algo ‘something’ [el ˈotɾo] el otro ‘the other’ [sol] sol ‘sun’
There is another lateral phoneme, a palatal lateral /ʎ/, that can be found in some dialects, especially in northern Argentina, Paraguay, the Andean region, and north and central Spain, although many of these areas show very limited use of this lateral sound (Zampaulo Reference Zampaulo2013). This palatal sound corresponds with orthographic ll and stands in contrast with the palatal obstruent /ɟ/ (see Section 8.3). This situation, where there are two contrasting palatal phonemes, is called lleísmo (e.g. [kaˈʎo] calló ‘became quiet’ vs. [kaˈʝo] cayó ‘fell’; see Zampaulo Reference Zampaulo2013, who refers to this situation as “distinction” and discusses other dialectal variants of the palatal sound). The lack of such a contrast is referred to as yeísmo and it is the most common situation across the Spanish-speaking world. Even in regions where the palatal lateral has been documented, there is a move towards yeísmo among younger speakers (Gómez and Molina-Martos Reference Gómez and Molina-Martos2013; Zampaulo Reference Zampaulo2013).
Spanish has two rhotics, a tap /ɾ/ and a trill /r/. Both are canonically produced with a brief, complete closure; one in the case of the tap and two or more for the trill (Martínez Celdrán and Fernández Planas Reference Martínez Celdrán and Fernández Planas2007). The two Spanish rhotics are contrastive only in intervocalic position within a word (8.4a). Word-initially and after a heterosyllabic consonant, only the trill occurs (8.4b), and, in complex onsets, only the tap is possible (8.4c). In coda position before a consonant, there is stylistic variation between a tap and a trill with the trill preferred in emphatic contexts (8.4d, Hualde Reference Hualde2005:182). When a coda rhotic resyllabifies with a following word-initial vowel, we find only the tap (8.4e).
(8.4) Distribution of the tap and trill
a.
[ˈpeɾo] pero ‘but’ [ˈpero] perro ‘dog’ b.
[ˈrosa] rosa ‘rose’ [sonˈrisa] sonrisa ‘smile’ c.
[ˈtiɣɾe] tigre ‘tiger’ [tɾes] tres ‘three’ d.
[ˈnoɾte ~ ˈnorte] norte ‘north’ [poɾ faβoɾ ~ por faβor] por favor ‘please’ e.
[maɾ aˈsul] mar azul ‘blue sea’
The tap and trill may be produced without a complete closure resulting in continuant realizations ranging from fricatives to approximants (Blecua Reference Blecua2001). Furthermore, rhotics display a wide range of productions across and within dialects of Spanish. This variation has been documented extensively, from impressionistic dialectological studies to instrumental production and perception studies. Assibilation of rhotics is a feature of several varieties including those of the Andean region, parts of Mexico and central America, Paraguay, and northern Argentina (Lipski Reference Lipski1994; Moreno de Alba Reference Moreno de Alba1994; Bradley Reference Bradley and Face2004). These assibilated productions are characterized by strident frication noise and can be found in different contexts depending on the dialect. For instance, assibilated rhotics are widely reported in coda position in Mexico (e.g. [ˈkařta]Footnote 5 carta ‘letter’) and in onset position where we would expect a trill in Andean Spanish (e.g. [ˈpeřo] perro ‘dog’), although Bradley (Reference Bradley and Face2004) presents acoustic data showing assibilation also in coda position in Ecuadorian Spanish. Assibilation also affects complex onsets, especially tr, in Chile, Costa Rica, Ecuador, and La Rioja, Spain. In this case, the resulting production is a voiceless affricate [tř̥] (Quilis Reference Quilis1993:352–354). Bradley (Reference Bradley, Authier, Bullock and Reed1999, Reference Bradley and Face2004) has analyzed rhotic assibilation as the result of gestural reduction and extreme coarticulation, taking into account the distribution and variation of these assibilated productions. Dorsal rhotics, where a trill would be expected, can be found in several Caribbean dialects, especially in Puerto Rican Spanish, and they range from velar fricatives [x] to uvular rhotics [ʀ] (Quilis Reference Quilis1993:350–351, Delgado-Díaz and Galarza Reference Delgado-Díaz, Galarza, Willis, Butragueño and Zendejas2015). These dorsal productions occur in place of the trill both word-initially and medially (e.g. [ˈxoho] rojo ‘red,’ [ˈpexo] perro ‘dog’). In other Caribbean varieties, we can find pre-aspirated realizations of trills. Instrumental studies have revealed that these productions in fact involve pre-breathy voice followed by an alveolar tap [ɦɾ] or a trill [ɦr] (Willis Reference Willis2007).
The study of Spanish rhotic variation has been especially fruitful in contexts of language contact, where the phonemic contrast between the tap and trill may be lost, or reinterpreted as a contrast between other rhotics, due to the sociolinguistic situation. Lipski (Reference Lipski1985) reports that the intervocalic tap–trill contrast has been lost in Equatorial Guinea Spanish, possibly due to the contact between this variety of Spanish and local languages that do not have this rhotic contrast or a trill in their inventory. O’Brien (Reference O’Brien2013) instrumentally confirms Lipski’s observation and shows that Guinean speakers do not maintain a rhotic contrast based on manner of articulation or duration differences. The author concurs with Lipski and concludes that this dialect presents neutralization of the rhotic contrast. On the other hand, Balam (Reference Balam2013) analyzes rhotic production in Orange Walk, Belize, where Spanish is in contact with English, and finds that the contrast is maintained but realized as a distinction between a tap and a retroflex approximant rhotic [ɻ], rather than a trill. A similar situation is observed in the Spanish of Puerto Ricans in Lorain, Ohio, by Ramos-Pellicia (Reference Ramos-Pellicia, Holmquist, Lorenzino and Sayahi2007). More precisely the contrast is maintained but the author finds a high number of retroflex rhotics especially among second- and third-generation speakers. Exploring other contexts of contact between Spanish and English, Lopez Alonzo (Reference Lopez Alonzo2016) quantitatively analyzes rhotic production in Bluefields, Nicaragua, a multilingual community where Spanish, English Kriol, and several indigenous languages are spoken. The author acoustically identifies several distinct rhotic productions and concludes that the contrast is maintained, although the linguistic background of the speakers has an impact on possible cases of neutralization. All in all, these studies argue that rhotic variation presents a high degree of correlation with sociolinguistic features in language-contact situations and suggest that these sounds might be perceived differently depending on the context and community.
Neutralization of the liquid contrast in coda position, known as trueque de líquidas, can be found in several dialects, where there is reportedly no difference between lexical items such as /maɾ/ mar ‘sea’ and /mal/ mal ‘bad.’ The resulting sound depends on the dialect (Hualde Reference Hualde2005:188). Rhotacism involves the production of coda /l/ as a rhotic, similar to a tap, and it is most commonly found in Andalusia, the Canary Islands, and some Caribbean regions. Lambdacism refers to the production of a coda rhotic as a lateral and is prevalent in the Caribbean varieties.Footnote 6 Impressionistic descriptions of lambdacism suggest that the resulting sound is a mix between a rhotic and a lateral (Navarro Tomás Reference Navarro Tomás1948; López Morales Reference López Morales1983). In fact, recent studies focusing on Puerto Rican Spanish have shown that the neutralization is usually incomplete both in production and in perception (Simonet et al. Reference 189Simonet, Rohena-Madrazo, Paz, Colantoni and Steele2008; Beaton Reference Beaton2015), and that the resulting sound is different from an underlying lateral. An interesting finding of these studies is that listeners from varieties that do not have trueque de líquidas perceive the result of lambdacism and a lateral as the same, meaning that they perceive the sounds as neutralized. On the other hand, listeners from the Puerto Rican dialect can perceive the production differences and distinguish between the two intended sounds. Despite these advances in our understanding of liquid neutralization, the precise articulation of these “mixed sounds” is still not clear and this issue would greatly benefit from the analysis of articulatory data.
8.7 Conclusion
This chapter has provided an overview of the consonants of Spanish, including the main phonemes, dialectal variation, and phonological processes that affect this type of sounds. Given the breadth of the topic, I have offered only a brief survey of the topics that have been more widely discussed in the literature, focusing on recent advances and contributions to these discussions from studies employing instrumental methodologies. The aim has been to bring to the forefront the impact that phonetically-informed approaches to sound variation and change have had on phonological representations and models. Traditional assumptions, especially regarding the categoricity and systematicity of certain phenomena, have been challenged by findings that uncover the gradiency and variability of consonant production in Spanish. Different authors have adopted and developed new approaches to account for the newly-uncovered patterns, including surface or output underspecification, Articulatory Phonology, usage-based models, etc. At the same time, this chapter has identified new avenues for further research, including the status of voicing among stops, especially the incipient voicing of voiceless stops and its implications for sound change; the articulation of nasal and lateral place assimilation as either two faces of the same phenomenon or indeed two distinct processes; and the status of consonantal neutralization processes in Spanish varieties.
9.1 Introduction
Syllable: From Gr. συλλαβή syllabḗ meaning “what is taken together.”
As its etymology suggests, a syllable is a group of segments articulated as a unit. It is normally defined as a set of segments grouped around a sonority peak, but it is also a prosodic unit that imposes structure on top of segmental strings. The syllable plays an important role in speech planning, word-form encoding, and lexical access.
The existence of Sumerian tablets with syllabic writings dating back to 2800 BCE is a good indication that the syllable is not a modern construct. However, we had to wait until the end of the 19th century to arrive at definitions of the syllable as a linguistic unit (Whitney Reference Whitney1873; Sievers Reference Sievers and Cook1885). From the outset, the syllable has been a unit subject to dispute mostly because it has no single acoustic or articulatory correlate; and the intuition that it is generated by chest pulses, cycles of the jaw or breath groups, has not been corroborated by phonetic studies. Still, this should not be problematic for a phonological unit. The lack of constant physical correlates does not negate the existence or relevance of the syllable. To be clear, there is plenty of evidence for the syllable. Language games often consist of inserting, deleting or moving syllables around. In speech errors, syllables can be omitted or misplaced and when consonants are misplaced from an onset they normally land on another onset. Aphasics may not recall a word but still be aware of the number of syllables in the word. Similarly, in tip-of-the-tongue phenomena we may have a sense of the syllables without being able to access their phonemic content. Multiple studies of lexical access suggest that the syllable plays an important role, and they provide empirical support for syllabic constituents. Finally, phonological processes that have the syllable as its domain (e.g. emphatic spreading in Arabic); morphological reduplication; stress assignment; and a plethora of phonological alternations that take place in specific syllabic positions – all provide a solid motivation for positing this prosodic constituent at the center of the phonological enterprise.
For a short period, though, many linguists in the generative framework were not convinced. Syllables cannot be phonetically measured (Ladefoged Reference Ladefoged1967; Ladefoged and Maddieson Reference Ladefoged and Maddieson1996) and syllabic generalizations can often be expressed at the segmental level (e.g. coda can be formalized as before consonant or word-finally). Following Occam’s razor, classic generative phonology did not include the syllable as a linguistic unit. By the end of the 70s this restrictive position had been eroded thanks to researchers such as Joan Hopper and Daniel Kahn. By the 80s, the syllable and prosodic structure were argued to be a central part of phonological representations (Harris Reference Harris1983; Selkirk Reference Selkirk1984; Ito Reference Ito1986). Still, there is some opposition to the idea that the syllable is organized into peaks and valleys of sonority. Ohala and Kawasaki-Fukumori (Reference Ohala, Kawasaki-Fukumori, Eliasson and Jahr1997), for instance, are quick to point out that sonority itself is not a solid concept and that it should not be the foundation of the syllabic building. In more recent years the syllable has come to occupy a central space in phonological explanation due to the insights that Optimality Theory can offer through constraints on syllabic structures and universal markedness.
9.2 The Syllable as a Prosodic Constituent
The syllable is a prosodic unit at the base of the prosodic hierarchy (see Liberman and Prince Reference Liberman and Prince1977; Selkirk Reference Selkirk and Fretheim1978, Reference Selkirk1986; Nespor and Vogel Reference Nespor and Vogel1986; Beckman and Pierrehumbert Reference Beckman and Pierrehumbert1986). Selkirk (Reference Selkirk1986:384) depicts the hierarchy as in Figure 9.1. This structure is built on top of the segmental string and the assumption is that all utterances can be parsed exhaustively into these units. The Strict Layer Hypothesis (Selkirk Reference Selkirk1984) posits that prosodic units are ordered hierarchically into layers as in Figure 9.1 and that prosodic units cannot dominate units of the same level (i.e. each unit is properly contained in a unit of the next higher level).
Figure 9.1 Depiction of prosodic hierarchy in Selkirk (Reference Selkirk1986)
( ) Utterance
( )( ) Intonational Phrases
( )( )( ) Prosodic Phrases
( )( )( )( )( ) Prosodic Words
( )( )( )( )( )( )( )( ) Feet
(--)(--)(--)(--)(--)(--)(--)(--)(--)(--)(--)(--)(--)(--)(--) Syllables
9.2.1 Structural Constraints
The syllable is a prosodic unit composed of smaller constituents. Syllabic constituents are assumed to be maximally branching and only syllable > rhyme > nucleus are obligatory. Figure 9.2 illustrates the maximal syllable allowed by this model. The evidence for syllabic constituents comes from speech errors, language games, experimental blending tasks, etc., but most importantly from phonological processes that have syllabic constituents as their domain. Spanish /s/ aspiration, for instance, takes place when the sound is in a coda. The constituent with weaker support is the rhyme (see Davis Reference Davis1988). Other than rhyming in poetry there are not many phonological processes or restrictions that crucially require the rhyme. One exception could be the limit of three segments proposed for the Spanish rhyme by Harris (Reference Harris1983).
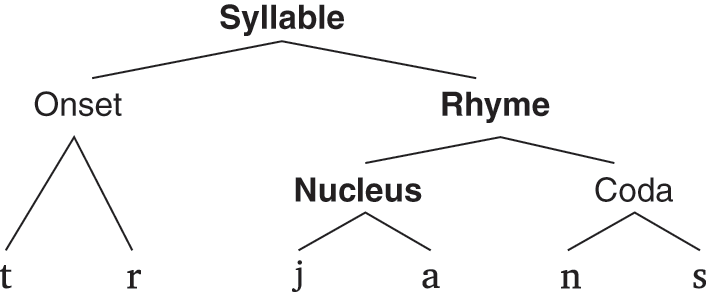
Figure 9.2 Model of syllabic structure
The template in Figure 9.2 illustrates the most common syllable structure, but there are other proposals in the literature. For Kahn (Reference Kahn1976) and Clements and Keyser (Reference Clements and Keyser1983) the syllabic node directly dominates segments. Pike (Reference Pike1947), Hocket (Reference Hockett1955), and Davis (Reference Davis1988) assume three constituents at the same level. Duanmu (Reference Duanmu2009) assumes that the maximal syllable has the form CVX and examples exceeding this template are considered morphological appendices or coarticulated segments. McCarthy (Reference McCarthy1979), Kubozono (Reference Kubozono1989), and Yi (Reference Yi1999) posit a body node dominating onset and nucleus. Codas attach directly under the syllabic node. This position is compatible with the moraic view which posits that the syllable dominates up to two morae and the onset attaches to the syllable node. Moraic theory has been often presented as incompatible with syllabic constituents because both morae and syllabic constituents compete for the space above the segmental tier. Compare Figure 9.3 with Figure 9.2. In fact, cross-linguistic phonological data seems to support both the mora (to account for weight, rhythm, and timing) and syllabic constituents (to account for alternations restricted to sub-syllabic domains). The moraic approach provides optimal representations for encoding weight. The basic tenet is that a short vowel is monomoraic and that a long vowel is bimoraic, as illustrated in Figure 9.4; example representations of moraic structure are provided in Figure 9.5.
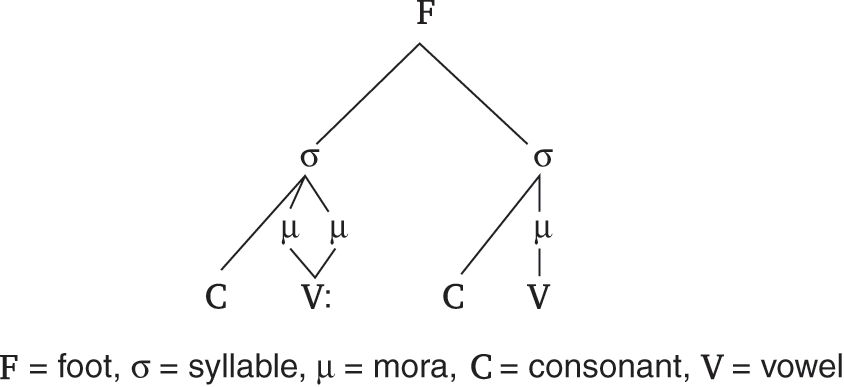
Figure 9.3 Moraic view of the syllable

Figure 9.4 Moraic view of short and long vowels
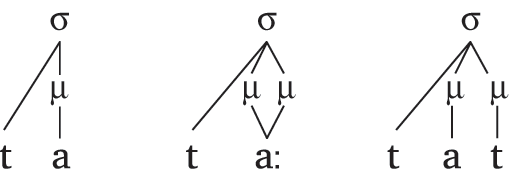
Figure 9.5 Example representations of moraic structure
Consonant weight is parametric and languages can be classified as quantity-sensitive (Latin, Turkish, Menomini, Lardil, etc.) or quantity-insensitive (Japanese, Icelandic, Warao, etc.). A typical quantity-sensitive language, such as Latin, would have syllable types as in Figure 9.5. For other languages only long vowels, or only long vowels and sonorants, contribute extra weight. Reaching a clear conclusion on the weight status of Spanish codas is not an easy matter. There is no lack of data pointing in the direction of syllabic weight in the Spanish stress system. However, this evidence can be attributed to the fact that Latin, not necessarily Spanish, was a quantity-sensitive language. The phonemic length of Classical Latin had already been lost in Vulgar Latin before 200 CE (Lehmann Reference Lehmann2005) and has not been preserved in the Romance Languages. It is not typical for systems lacking contrastive length to have moraic consonants. See Piñeros (Reference Piñeros and Núñez-Cedeño2016) for recent arguments regarding the lack of moraicity of Spanish codas.
The structure in Figure 9.2 depicts a maximal CCVVCC template. Given the optionality of codas and onsets, the minimal template has a simple nucleus. The intermediate templates in Figure 9.6 are derived from the logical permutations of optional constituents and the branching parameter.
Figure 9.6 Structure of intermediate templates
Not all templates are equally frequent. Cross-linguistic frequencies mostly reflect universal markedness. Being marked entails a degree of disfavor for some structural options or cross-linguistic unusualness. Markedness correlates with complexity, articulatory effort, perceptual difficulty, repair strategies, and delayed acquisition. The unmarked syllable par excellence has a CV template, and this means that it does not go against universal constraints; that it is expected to be present in all languages; and that it will be the first syllable acquired by children. As we move up from the CV syllable in Figure 9.6, complexity increases, and with it markedness. We expect then to find these templates with increasingly lower frequency in cross-linguistic sampling. To the right, VC and V do not add structural complexity, but go against the universal constraint that requires syllables to have an onset. The onset is an important part of the sonority contrast in that it maximizes the movement that takes articulation from a low valley to the peak. The coda, instead, is just a prolongation of the peak. It is not essential and its presence increases complexity and articulatory effort. The fact that markedness is at the base of syllable typology explains why a theory that essentially frames phonology as a conflict between faithfulness and markedness (Optimality) is especially suited to account for syllable typology and syllabic processes (e.g. Colina Reference Colina2009).
There are at least three types of languages: those with simple syllables such as Senufu (about 13 percent of the languages covered in the World Atlas of Language Structure: Dryer and Haspelmath Reference Dryer and Haspelmath2013); those that also allow CVC or CCV syllables such as Hungarian (56 percent); and languages such as English that allow the more complex templates (31 percent). This can be modeled as the result of universal parameters or, as in Optimality Theory, variation in the ranking of syllable-markedness constraints with respect to faithfulness.
The complexity of the Spanish syllable lies somewhere in between Senefu and English. Moreno Sandoval et al. (Reference Moreno Sandoval, Torre, Curto, Torre, Buera, Lleida, Miguel and Ortegae2006) and Guerra (Reference Guerra, Esgueva and Cantarero1983) have calculated the percentages shown in Table 9.1. These percentages clearly show that complex codas are very infrequent. This is in sharp contrast to traditional descriptions and accounts of the Spanish syllable that give undue prominence to complex constituents in general, and especially to complex codas. The Spanish syllable does not belong in the simple syllable group with Senefu, but it is actually farther away from languages in the third group like English.
Table 9.1 Complexity of the Spanish syllable
| Moreno Sandoval et al. Reference Moreno Sandoval, Torre, Curto, Torre, Buera, Lleida, Miguel and Ortegae2006 | Guerra Reference Guerra, Esgueva and Cantarero1983 | |
|---|---|---|
| CV | 51.35 | 55.81 |
| CVC | 18.03 | 21.61 |
| V | 10.75 | 9.91 |
| VC | 8.60 | 8.39 |
| CVV | 3.37 | N/A |
| CVVC | 3.31 | N/A |
| CCV | 2.96 | 3.14 |
| CCVC | 0.88 | 0.98 |
| VCC | N/A | 0.13 |
| CVCC | N/A | 0.02 |
| CCVCC | N/A | 0.01 |
9.2.2 Sequential Constraints: Sonority
If you were to take out random tiles from a Scrabble box and arrange them following the structure in Figure 9.2, the chances of forming a well-formed syllable in any language are exceedingly low. This is because languages impose sequential restrictions on what sounds can combine to form well-formed syllables. Speech sounds must follow a sonority profile such that the most sonorous element occupies the central part while less sonorous segments are peripheral. Sonority is the relative loudness, intensity, or energy of a sound. When we want to be heard at a distance or call for help we will probably utter a vocalic sound. There is a high correlation between sonority and degree of aperture. A number of linguists going back more than a century (Sievers, Jespersen, Saussure, Grammont, Hooper, Kiparsky, Steriade, Selkirk, Clements, among many others) have recognized the importance of the Sonority Sequencing Principle (SSP). This principle states that every syllable has one sonority peak that forms the nucleus and then the syllable margins show a sonority slope that rises toward the nucleus. The syllable [plan] is well-formed according to the SSP, but *[lpan] is not (Figure 9.7).

Figure 9.7 Examples of sonority sequencing
The SSP can account for the typically attested combinations of two segments in complex onsets (pr, *rp), complex nuclei (je, *oe), and complex codas (ns, *sn). Although the Spanish syllable is eminently consistent with the SSP, many other languages seem to tolerate some sonority reversals. For instance, the Swedish word skælmsk ‘roguishly’ is a well formed monosyllable. As is often the case with exceptions, a good number of formal devices such as non-exhaustive parsing, extrasyllabicity, adjunction, semisyllables, and empty nuclei have been posited to explain cases that seem to question the universal validity of the SSP (see Cho and King Reference Cho, King, Féry and van de Vijver2003 for a review). Sonority conceived as a relative term gives origin to sonority scales. Although there are many different scales that have been proposed over the years, most differences have to do with the number of levels posited, rather than with the relative sonority of each natural class. See Figure 9.8 for a typical sonority scale.

Figure 9.8 Depiction of typical sonority scale
The SSP rules out most non-attested combinations such as [lkotn] or [tganl] but would still allow some sequences such as [psi] or [pne] that, while found in some languages (e.g. classical Greek), are not allowed in Spanish. To account for these parametric differences, we need to introduce the notion of sonority distance within syllable constituents and posit that while in Greek the minimal sonority distance of a complex onset is one degree (assuming the scale in Figure 9.8), for Spanish it must be at least three degrees.
9.2.3 Constraints on Syllabic Constituents
While sonority explains many limitations on the possibilities of the syllable there are some gaps that are not directly related to sonority sequencing and tend to be interpreted as restrictions on syllabic constituents.
Onset
All Spanish consonants are possible in an onset – though [ɾ] and [ɲ] are restricted word-initially. Complex onsets are mainly governed by the SSP, which predicts that sequences of an obstruent followed by a liquid such as /bɾ/, /bl/, /pɾ/, /pl/, /fɾ/, /fl/, /tɾ/, /dɾ/, /gɾ/, /gl/, /kɾ/, /kl/ are all well formed. */tl/, */dl/, */sɾ/, */θɾ/, */sl/, */xɾ/, and */xl/ have also a positive sonority slope, but are not found in Spanish.
In Mexico /tl/ can appear word-initially in borrowings from Nahuatl. We have words such as tlapalería ‘hardware store’ and names of a handful of towns such as Tlalnepantla or Tlascala. Word-internally this sequence tends to be parsed heterosyllabically as in at.las or at.lán.tico, but in most areas of Latin America and in some Peninsular varieties a.tlas is fine. On the other hand, /dl/ is a non-attested type of onset.
The absence, or avoidance, of /tl/, /dl/ is typically analyzed as a result of a lack of alternation at the feature level and disallowed by the Obligatory Contour Principle (OCP) (Leben Reference Leben1973; Goldsmith Reference Goldsmith1976). /t/ and /l/ share a coronal node and a [–cont] feature, but the degree of similarity (see Frisch et al. Reference Frisch, Pierrehumbert and Broe2004) is less than what obtains for /dl/ because in this case the feature [+voice] is also shared.
To account for the absence of fricative+liquid (when the fricative is not /f/) we need to posit that there is a minimum distance requirement between the members of the complex onset such that the fricative+liquid sequence falls below the minimal threshold. Once the sequence fricative+liquid is ruled out, something needs to be done to account for the well-formedness of /fɾ/, /fl/.Martínez-Gil (Reference Martínez-Gil, Herschensohn, Mallen and Zagona2001) argues that /f/ is unspecified for [cont] and behaves as a stop; even if well motivated, this seems a fairly ad hoc solution.
In a rule-based approach, the SSP does not have a clear place in the grammar. The same is true of other principles such as the OCP or even markedness. These inadequacies motivated to a great extent the innovations in Optimality Theory. OT is a theory of constraint interaction, and both markedness and sonority are in essence constraints. This is in itself an improvement, but an OT account (since it operates with output constraints), introduces a new problem for the Spanish syllable that so far has escaped the gaze of most researchers. The issue is how to account for well-formed outputs that contain two approximants in the onset (e.g. abrir [a.ˈβ̞ɾiɾ] ‘to open’) while at the same time ruling out fricative+liquid sequences that in terms of sonority would be better.
Another issue that will need to be addressed in future research is that the well-formedness of onset sequences is not a binary choice. We have seen that /tl/ seems to enjoy a higher degree of acceptance than /dl/. Similarly, /sɾ/ is better than /θɾ/ and /xɾ/ is better than /xl/. At the base of these gradations we have phonetic factors that have to do with which gestures can be coarticulated; which are in conflict; and which combinations face aerodynamic or motor control difficulties.
Sounds with higher than approximant sonority cannot be onsets in Spanish. This correctly implies that prenuclear glides will not adjoin to the onset and normally belong to the nucleus. However, in those few cases where they are better parsed in the onset their sonority must decrease. This is what we normally call glide fortition.
The alveolar trill is not possible in a complex onset. There are accounts that see the trill as a sequence of two underlying taps (Harris Reference Harris1983). Under this assumption, it makes sense that [r] cannot occupy the second slot of an onset. Even if [r] is not assumed to be structurally complex it is at least clear that it is stronger (in terms of tension and duration) than the typical short and quick transition that this position favors.
Malmberg (Reference Malmberg1965) pointed out that onset clusters may have a svarabatic vowel breaking up the sequence of two consonants (e.g. preciosa [peɾe.ˈθjo.sa] ‘beautiful’). When the second consonant is lateral the svarabatic vowel is less common. The intrusive vowel has a very short duration and the same quality as the following vowel and, importantly, does not affect stress assignment or judgments about number of syllables. This final characteristic is problematic for an OT account because in the output the svarabatic vowel should be a peak. Future research will need to continue studying the interactions between the phonological and phonetic components.
Nucleus
The nuclear node has its own restrictions. In Spanish only vocoids are allowed in the nucleus. All vowels can appear under a simple nucleus and a complex nucleus has an initial glide. Other languages impose different sonority restrictions for the nucleus. Languages such as Kabardian set the minimum sonority at the level of mid vowels. Nahuatl admits vowels and excludes glides and consonants. In Sanskrit a rhotic can be the peak, while in English the set is expanded to include liquids and nasals. Nuclear fricatives (Hoard Reference Hoard, Bell and Hooper1978) and even obstruents (Dell and Elmedlaoui Reference Dell and Elmedlaoui1985) have been reported.
Diphthongs can have rising sonority (Venecia ‘Venice’) or falling sonority (jaula ‘cage’). Triphthongs have rising and falling sonority: buey [ˈβwej] ‘ox.’ A priori, it is not clear which of these vocalic sequences can form a complex nucleus. Hualde (Reference Hualde, Campos and Martinez-Gil1991) argues – on the basis of language games, hypocoristics, rhyme restrictions, and vowel harmony – that only glide+vowel form a complex nucleus. Accordingly, postvocalic glides are in the coda. Sequences such as [ji], [wu], [wo] go against the Obligatory Contour Principle.
Coda
Word-finally, only coronals are frequent: más [ˈmas] ‘more,’ arroz [a.ˈroθ] ‘rice,’ sed [ˈseð] ‘thirst,’ dolor [do.ˈloɾ] ‘pain,’ canción [kan̪.ˈθjon] ‘song,’ papel [pa.ˈpel] ‘paper,’ rey [ˈrej] ‘king.’ The palatal /tʃ/ is not possible because it is an obstruent with a complex structure. Similar complexity claims have been made for /ɲ, ʎ/ (see Carreira Reference Carreira1988). Reloj [re.ˈlox] ‘watch’ is unexpected but a very frequent lexical token. Although it is a word of Greek origin it is likely a modern borrowing from Catalan. There are some 15 other words that can be found in dictionaries that end with orthographic <j>, but only two – carcaj [kaɾ.ˈkax] ‘quiver’ and boj [ˈbox] ‘boxwood’ – can reasonably be expected to be part of the lexicon of an educated native speaker. The former is of Persian origin and the latter again comes from Catalan. Obstruent coronals are far from frequent and tend to be lenited. When an obstruent such as /d/ sed appears in final position it undergoes fricativization [ˈseð], and devoicing [ˈseθ] or deletion [ˈse]. The broad generalization for the Spanish final coda is that it optimally licenses one sonorant coronal.
Word-internally, it is common to read that all consonants, with the exception of the palatals /ɲ/ and /ʎ/ and the velar /x/, can close a syllable. Indeed, it is not difficult to find examples with obstruents (obtuso [ob̥.ˈtu.so] ‘obtuse,’ admirar [ad.mi.ˈɾaɾ] ‘to admire,’ Magdalena [maɣ.ða.ˈle.na] ‘female proper name,’ tacto [ˈtak.to] ‘touch,’ atlas [ˈat.las], etc.). However, a quick count reveals that these codas are far from common. In fact, word-internal codas also prefer sonorant coronals ({/ɾ,l,n/}), glides ({[j,w]}) or the coronal fricatives ({/s,θ/}). The other consonants have very low frequencies and have been preserved in formal varieties by normative efforts and orthographic conventions. In spontaneous and informal speech, these less-common codas are lenited.
Since in Latin most consonants were allowed in codas (only /f, g, h/ were restricted), the preference for coronal sonorants is a relatively modern development. The loss of contrastive length and with it moraic codas can explain lenition tendencies and the narrowing of the sonority threshold; markedness can also be a factor in the preference for coronals.
Many descriptions state that Spanish allows complex codas of the form /-Cs/ where C is normally {/ɾ, l, n/} or {[w, j]} with a few examples of {/b, d/}. These complex codas again have exceedingly low frequencies and arise mostly from combinations of consonant initial stems with prefixes such as ad-, ab-, ex-, per-, trans-, sub-. Another source is medical terms such as toraks or biceps. Finally, many often-cited examples come from loanwords, but since loanwords often have their own adaptation constraints that may not coincide with native patterns (Ito and Mester Reference Ito, Mester and Goldsmith1995), it is better to study them separately.
Interestingly the set of allowed consonants in C1 of a complex coda exactly corresponds to the set of consonants allowed in single codas. Since /s/ cross-linguistically has exceptional sonority and Spanish prefixes are an independent syllabification domain (Hualde Reference Hualde, Campos and Martinez-Gil1991; Wiltshire Reference Wiltshire, Colina and Martínez-Gil2006; Colina Reference Colina2009), it makes sense to conclude that the Spanish coda cannot be complex and that /s/ is actually an appendix. Again, future research should take into account these observations.
9.3 Syllabification
In most languages syllabic structure is predictable and non-contrastive. Moreover, morphemes typically do not conform to syllabic constraints. Since redundant information is assumed to be absent from the lexicon, syllable structure needs to be derived.
One possibility is to posit a set of ordered rules (see Hualde Reference Hualde, Campos and Martinez-Gil1991). In OT, syllables are built by the Generator and it is the role of the Evaluator to select outputs. The Evaluator uses a language-specific ranking of universal constraints. The two central syllabification constraints, Onset and *Coda, follow from the observation that all languages have onsets, but not all have codas. Regardless of ranking, the asymmetrical definition of these two constraints correctly predicts that in all languages a string tata will be syllabified [ta.ta], and not [tat.a] (Figure 9.9). In a rule-based approach this result is derived by ordering the onset rule before the coda rule.

Figure 9.9 Maximum Onset Principle (Kahn Reference Kahn1976)
9.3.1 Resyllabification
In Spanish maximum onset applies both word-internally and postlexically (Example 9.1).
(9.1)
a dos adas [a.ðo.sa.ðas] ‘to two fairies’ adosadas [a.ðo.sa.ðas] ‘adjoined fem.’ las alas [la.sa.las] ‘the wings’ la salas [la.sa.las] ‘you salt it fem.’ un ido [u.ni.ðo] ‘a crazy person’ unido [u.ni.ðo] ‘united’
However, onset maximization has some well-known exceptions (Example 9.2).
(9.2)
sub+liminal [suβ.li.mi.ˈnal] sublime [su.ˈβli.me] sub+rayar [suβ.ra.ˈʝaɾ] ‘underline’ sobrar [so.ˈβraɾ] ‘have left’ club lindo [ˈkluβ.ˈlin̪.do] ‘nice club’ cable [ˈka.βle] des+hielo [des.ˈʝe.lo] ‘thaw’ desierto [de.ˈsjeɾ.to] ‘desert’
A similar pattern of exceptionality can be seen in cases of /s/ aspiration that happen in spite of the target segment not being in coda position in the surface (Example 9.3):
a.
mes [ˈmeh] ‘month’ dos [ˈdoh] ‘two’ b.
mes anterior [ˈme.han̯.te.ˈɾjoɾ] ‘prior month’ dos amigos [ˈdo.ha.ˈmi.ɣo] ‘two friends’ deshacer [de.ha.ˈθeɾ] ‘undo’
Hualde (Reference Hualde, Campos and Martinez-Gil1991) argues that the syllabification domain in Spanish excludes prefixes. To account for (9.2) syllabification must apply a second time postlexically but without the complex onset rule. Since OT is non-derivational, ordering aspiration between syllabifications is not possible. In OT the typical account of (9.2) posits an alignment constraint requiring that the edges of words coincide with the edge of a syllable. For the data in (9.3) an Output-to-output (O-O) constraint of morpheme identity can do the trick (see Colina Reference Colina, Lee, Geeslin and Clements2002).
9.3.2 Vocalic Sequences
Vocalic sequences can occur word-internally (leal [le.ˈal] ‘loyal’) or across words (esta encuesta [ˈes.ta.en.ˈkwes.ta] ‘this survey’). In general, sequences of two nonhigh vowels (VV) are heterosyllabic while sequences containing a high vowel (iV, uV, Vi, Vu) form a diphthong. In guarded speech esta encuesta can be pronounced maintaining the V.V sequence, but in spontaneous speech the two syllables have a strong tendency to be reduced and coalesce. The reduction can be the result of fusion (a+a → a), diphthongization (e+u → ew), deletion of one of the vowels (a+o → o) or a number of phonetically intermediate realizations. Chicano Spanish has a consistent system for V.V resolution: it deletes or glides the first vowel. In other varieties the solution typically depends on a number of factors such as stress, vowel quality, content vs. functional word, open vs. closed syllable, or even word frequency.
From an OT perspective, in words such as teatro ‘theater,’ peor ‘worst,’ roedor ‘rodent,’ and meollo ‘core,’ faithfulness is the force behind hiatus preservation. Between words there is the potential of additional pressure from alignment constraints between the edge of the prosodic word and the syllable. In Spanish neither faithfulness to vocalic aperture nor syllable–word alignment seem to have a high ranking. In opposition to faithfulness and alignment, we have markedness constraints that are behind the universal antihiatic tendency. These constraints are the SSP and *Struc (Prince and Smolensky Reference Prince, Smolensky and McCarthy2004, Zoll Reference Zoll1996). Structural economy favors syneresis (merging the two vowels in a single syllable), and the SSP requires a sonority slope for the merged syllable.
Word-internally, sequences of decreasing sonority are realized as falling diphthongs [Vj, Vw] (e.g. boina ‘beret,’ reina ‘queen’). Sequences of rising sonority normally form diphthongs but for a number of lexical entries a hiatus is possible. Factors such as origin, word-initial position, morphological boundaries, and analogical pressure are at play, but none of these factors has a consistent correlation with the contrast. For many speakers the words in Example 9.4a have diphthongs while the words in (9.4b) allow at least two realizations.
a.
piedra [ˈpje.ðɾa] ‘stone’ hueso [ˈwe.so] ‘bone’ liebre [ˈlje.βɾe] ‘hare’ ambiente [am.ˈbjen̪.te] ‘environment’ guardián [gwaɾ.ˈðjan] ‘guardian’ asiduo [a.ˈsi.ðwo] ‘regular’ Daniel [da.ˈnjel] cuatro [ˈkwa.tɾo] ‘four’ b.
miope [mi.ˈo.pe] ~ [ˈmjo.pe] ‘short sighted’ jesuita [xe.su.ˈi.ta] ~ [xe.ˈswi.ta] ‘Jesuit’ piano [pi.ˈa.no]~[ˈpja.no] ‘piano’ diadema [di.a.ˈðe.ma] ~ [dja.ˈðe.ma] ‘diadem’ biela [bi.ˈe.la] ~ [ˈbje.la] ‘rod’ violento [bi.o.ˈlen̪.to] ~ [bjo.ˈlen̪.to] ‘violent’ mutua [ˈmu.tu.a]~[ˈmu.twa] ‘mutual’
There are examples of minimal pairs (pie [ˈpje] ‘foot’ vs. pié [pi.ˈe] ‘I chirped’) but they have different morphology. Considering quasi-minimal pairs, we can have examples that do not involve morphology:
pliegue pl[je]gue ‘fold’ vs. cliente cl[i.e]nte ‘client’
duelo d[we]lo ‘mourning’ vs. dueto d[u.e]to ‘duet’
siendo s[je]ndo ‘being’ vs. riendo r[i.e]ndo ‘laughing’
Still, to avoid redundant underlying representations most researchers assume that glides are not phonemic. Devices such as underspecification and prespecification can encode an underlying contrast between /i/ and /j/ (Padgett Reference Padgett2008). Given that there are no language-specific restrictions on the input (“Richness of the Base”), it is even harder to justify that no syllabic information is present in the underlying representation. Assuming that the difference between Examples 9.4a and 9.4b is encoded in the lexical entry, we just need to account for syneresis. This is not problematic in an OT account that manipulates the ranking of markedness and faithfulness. On the other hand, if there is no underlying contrast then the goal is to account for the blocking of antihiatic tendencies (markedness) but without the help of faithfulness – in OT this is, at best, tricky.
Hualde and Chitoran (Reference Hualde, Chitoran, Solé, Recasens and Romero2003) note that, while Latin allowed heterosyllabic i.V, u.V sequences, the Romance languages show a range of hiatus avoidance that has Portuguese at one extreme and French at the other. Where French consistently has diphthongs Portuguese preserves the Latin hiatus. Spanish is in between the two extremes. This idea of an incomplete evolution is consistent with the attested dialectal and individual variability.
9.4 The Syllable as a Source of Phonological Alternations
Many phonological alternations can be described as processes that affect specific syllable constituents. In English /l/ velarization happens only in a coda. In Dutch a labiodental approximant becomes labial in the same context. In many varieties of Spanish /n/ is velarized and /s/ is aspirated, again in the same context.
As mentioned above the Spanish coda is a constituent with many restrictions and the language is abundant in lenition processes that are triggered to enforce them. At the other end of the syllable the onset calls for strong variants, and fortition processes are triggered to satisfy this need. The syllable is a movement of the articulators: a transition from a sonority valley to a sonority peak. In physical movements, the maximal energy is normally applied at the onset of movement. After reaching a peak, dampening sets in, and the motion initiates a descent. With repeated movements, a renewed push of energy creates cycles. Understanding the coda as an attempt to prolong the peak resisting the natural tendency to descend, we can grasp the source of the forces in conflict that account for the different processes we find at different points of the syllable.
9.4.1 Onset Processes
A pair such as viviendo [bi.ˈβjen̪.do] ‘living’ and yendo [ˈʝen̪.do] ‘going’ illustrates onset fortition. Since the glide is in both cases the first segment of the same morpheme, the different output must be a matter of syllabification. In the first example the root provides an onset and the glide is better parsed in a complex nucleus. In the second example the glide is optimally parsed in the onset. Since the onset requires low sonority, it is the tension between avoiding a complex nucleus, the need to have an onset, and the SSP that determines the consonantization of the glide. In some dialects it can be an approximant [jen̪.do], in others a fricative ([ʝen̪.do], [ʃen̪.do], [ʒen̪.do]), and in others a plosive [ɟen̪.do]. With the back glide, the situation is a bit different (huevo /uebo/ → [gwe.βo]~[we.βo] ‘egg’). Here, the glide remains in the nucleus, and instead of consonantization there is epenthesis of a velar consonant. Since [w] is labiovelar, it makes sense to see the velar as an extension of the glide. Epenthesis is preferred in this case because consonantization of [w] would generate marked outputs in Spanish. While the consonantization of the front glide is a standard process in all Spanish varieties the back counterpart remains circumscribed to very informal registers. Fortition also takes place between words (una y una [ˈu.na.ˈʝu.na] ‘one plus one’ vs. una y dos [ˈu.naj.ˈðos] ‘one plus two’), but this does not apply to the back glide (uno u otro [u.no.wo.tro] ‘one or the other’).
One alternation that clearly correlates with syllable position is the distribution of rhotics. Trills appear in strong syllable positons and taps in weak ones. The fact that under emphasis the trill can appear in places where we would normally find a tap further supports the view that this alternation has to do with fortition and lenition.
Epenthesis is often presented as a repair strategy for sC onsets (esprin < sprint). This kind of epenthesis is a hallmark feature of Spanish speakers pronouncing English ([es.ˈtan.daɾ], [es.ˈpot], [es.ˈtejk]) or other languages that have appendices or syllabic consonants. Importantly, we never have *[se.ˈteik]. In OT the locus of the epenthetic vowel is normally determined by the imperative not to break an underlyingly contiguous string. As Lipski (Reference Lipski and Núñez-Cedeño2016) rightly notes, at the right edge of the word contiguity does not seem to matter, so the Arabic name Sadr is repaired as [ˈsa.ðeɾ] not *[ˈsa.ðɾe] and the Austrian surname Krankl as [ˈkraŋ.kel] not *[ˈkraŋ.kle]. Interestingly enough, this pattern of final epenthesis also runs against the most basic syllabification constraints: Onset and *Coda. In these cases, however, the offending consonant is parsed in a coda, in spite of codas being marked. Other cases often considered epenthetic (e.g. the /e/ in the plural allomorph /-es/ or in the diminutive /-ecito/) are better analyzed as historical processes or lexicalized allomorphs.
9.4.2 Nuclear Processes
Spanish vowels are remarkably stable. They can be nasalized when there is a nasal in the coda (aman /ˈaman/ → [ˈa.mãn] ‘they love’). The fact that this is uncommon when the nasal is in an onset points to a syllabic process. Many traditional descriptions also note that mid vowels can be lowered, shortened, and relaxed in closed syllables as in e.g. Vélez [ˈbe.le̞θ] ‘surname’; gordo [ˈgo̞ɾ.ðo] ‘fat.’ Both nasalization and shortening have the effect of limiting the overall duration of the rhyme.
9.4.3 Coda Processes
The Spanish coda is weak and favors lenition. Obstruents lack enough sonority to be in the coda and peripheral articulations (labial or velar) are also out because they require extra effort. The repair strategies conspire to narrow the range of articulatory movement of the tongue body in coda consonants to the sweet spot surrounding the resting position (coronal sonorants). In its extreme version, this tendency ends up eliminating the coda.
/s/ aspiration (e.g. dos [ˈdoh] ‘two,’ vienes [ˈbje.neh] ‘you are coming’) is the most common and better-studied repair. Aspiration is often seen as the first step in a chain of weakening processes that ends with the deletion of the coda. Lipski (Reference Lipski1985) sees these processes as “merely numerical, gradations of a single process.” The alternative term “debuccalization” captures the fact that the oral features of /s/ are lost and what remains is the laryngeal specification. The process is arguably triggered by minimization of articulatory effort (after all, /s/ is an obstruent). As for the other fricatives, /x/ in the word reloj [re.ˈloh] ‘watch’ is also aspirated. In fact, any coda can be aspirated (e.g. acto [ˈah.to] ‘actˈ, Magda [ˈmah.ða] ‘female proper name’). In terms of feature geometry, aspiration can be analyzed as the delinking of the supralaryngeal node. However, according to Widdison (Reference Widdison1995), aspiration would be better understood as a case of devoicing timing (reverse image of VOT). Aspiration is a partial devoicing that takes place when the vocal cords start opening during the vocalic articulation in anticipation of the upcoming /s/. Even in non-aspirating dialects there is a degree of devoicing in the vowel before /s/. Aspirating dialects are those that have extended this breathy phonation and have lost the buccal features of the /s/. Although this view gives us a better understanding of the nature of the process it is still the case that the coda consonant needs to be lenited for the breathy phonation to be extended into the timing unit in the coda. The fact that in more advanced dialects aspiration results in elision suggests that the coda weakening is for the most part independent of aspiration.
Aspiration is an old process that can be traced to the Peninsular Andalusian dialect and was extended to Latin America through colonization. It can now be found in southern Spain, the Canary Islands, the Caribbean, and all of the Pacific coast from Mexico to Chile. In Argentina, Uruguay, Paraguay, and parts of Bolivia it is also common. In the varieties where the process is more advanced (Andalusian or the Caribbean varieties) word-internal codas favor aspiration and word-final ones, elision.
In areas of El Salvador, Honduras, and New Mexico, /s/ can be aspirated word-initially (e.g. la semana [la.he.ˈma.na] ‘the week’). This seems to contradict the claim that this is a coda process. However, these data should be interpreted against the background of the resyllabification examples mentioned above (e.g. los amos [lo.ˈha.moh] ‘the owners’). Cases of word-initial aspiration are not instances of resyllabification but can be seen as the result of analogical extension, or morphological uniformity, from cases in which the aspirated /s/ surfaces word-initially after resyllabification (e.g. las semanas [la.he.ˈma.nah] ‘the weeks’). In central Spain /s/ can be lenited to /ɾ/ (e.g. los nietos [loɾ.ˈnje.to] ‘the grandsons’). This is a way of avoiding an obstruent at the end of the syllable. The tap requires only a quick and short articulation with a flip of the tip that leaves the tongue body mostly unaffected.
Rhotacism (/l/ → /ɾ/) and lambdacism (/ɾ/ → /l/) are two salient processes that are associated with the Spanish coda (e.g. amor [a.ˈmoɾ]~[a.ˈmol] ‘love,’ malvado [mal.ˈβa.ðo]~[maɾ.ˈβao̯] ‘evilˈ). Rhotacism is spread all over southern Spain, the Canary Islands and to a lesser extent can be found in Puerto Rico and the Dominican Republic (Quilis Reference Quilis1993). Lambdacism can be found sporadically in southern Spain, but is characteristic of Caribbean varieties (especially Puerto Rico). This distribution suggests that rhotacism was the initial repair and lambdacism may be seen as ensuing confusion or hypercorrection. Since Navarro Tomás (Reference Navarro Tomás1948) the neutralized Puerto Rican liquid has been described as an articulation in between the tap and the lateral. However, Simonet et al. (Reference Simonet, Rohena-Madrazo, Paz, Colantoni and Steele2008) show that Puerto Rican speakers can actually tell them apart – it is the speakers of other dialects that do not perceive the difference when Puerto Ricans are speaking.
Gliding of coda liquids is a related process that is characteristic of the Cibao region in the Dominican Republic (Jiménez Sabater Reference Jiménez Sabater1975). In this variety, coda liquids are lenited by making them palatal glides (e.g. revólver [re.ˈboj.bej]; celda ‘cell’ and cerda ‘bristle’ are both [ˈsej.ða] – see Guitart (Reference Guitart, Martínez-Gil and Morales-Front1997).
Rhotacism, lambdacism, and gliding are all part of a lenition continuum that leads to deletion. Indeed, phrase-finally, where the linking with a following consonant does not help, elision of the liquid is quite common. The range of possibilities that may affect a liquid coda is broad. The proper name Encarna can be pronounced [eŋ.ˈkaɾ.na] (careful speech), but also [eŋ.ˈkar.na] (under emphasis), [eŋ.ˈkal.na] (lambdacism), [eŋ.ˈkan.na] (gemination), [eŋ.ˈkaŋ.ŋa] (velarization with gemination), [eŋ.ˈkaɳ.ɳa] (retroflexion and gemination), [eŋ.ˈkah.na] (aspiration), [eŋ.ˈka.na] (deletion), etc. There is a hilarious sketch available online (Empanadilla de Móstoles by Martes y trece) that illustrates quite well some of these alternations.
Since /ɾ/ and /l/ are already [+son] and [cor] one may wonder why they are affected by coda weakening. They should be fine in a coda and indeed they are for most dialects, except the radical ones. The same varieties that have rampant elision of codas also tend to mix the liquids. From an articulatory effort point of view the tap has a slight advantage with respect to /l/ – obviously not enough to set a clear direction for the process, but perhaps enough to set it in motion. Finally, the fact that acoustically /ɾ/ and /l/ are not sufficiently different makes this a notoriously marked contrast, cross-linguistically.
N velarization (e.g. melón [me.loŋ], jamón [xa.moŋ] ‘ham’), is attested before a pause in most of the same areas as aspiration and in northern Spain. Word internally n velarization is not common because place assimilation takes precedence. Between words some dialects have velarization after resyllabification, but this is not as common as with aspiration. Before consonant-initial words place assimilation again gets in the way. The fact that velarization also affects other consonants (e.g. étnico [ˈeɡ.ni.ko] ‘ethnic,’ concepto [kon̪.ˈθek.to] ‘concept,’ himno [ˈiŋ.no] ‘hymn,’ pepsi [ˈpek.si]) suggests that this is the same general coda weakening rather than a property of nasals. According to Trigo (Reference Trigo1988), the final velar nasal reported in many studies sounds, and is typically transcribed as, a dorsal because the lowering of the velum necessary to articulate the nasal is perceived as a dorsal articulation. She interprets the lenited coda as a debuccalized nasal glide that lacks an oral place of articulation. This account is in line with the kind of coda lenition that we have been reviewing in this section. When an oral consonant is debuccalized what remains is the laryngeal features but when the nasal is debuccalized what remains is the nasality and the segment is perceived as a velar nasal.
Voice is not a feature licensed by the coda. Coda sonorants are spontaneously voiced. The few cases with voiced obstruents tend to be devoiced word-finally (sed [sed̥]~[seθ]). Voiced counterparts arise only before voiced consonants (admitir [ad.mi.ˈtiɾ]~[að.mi.ˈtiɾ] ‘to admit’). The only obstruent that appears frequently in the coda, /s/, assimilates to a following voiced consonant (mismo [ˈmiz.mo] ‘same’) and this can also happen with other obstruents (juzgar [xuð̟.ˈɣaɾ] ‘to judge,’ hipnosis [ib.ˈno.sis] ‘hypnosis.’ This voicing is licensed by the following consonant, not the coda.
The coda does not license its own point of articulation either. This explains the preference for default coronals and predicts that all consonants in coda position will try to assimilate in point of articulation to a following consonant. Nasals and laterals do assimilate whenever the result is phonetically possible (e.g. lateral labials are not possible). /s/ and /ɾ/ do not assimilate in place arguably because of the Principle of Structure preservation (see Kiparsky Reference Kiparsky, van der Hulst and Smit1982) but they do participate in total assimilation.
Gemination (mismo [ˈmimmo]~[ˈmihm.mo] ‘same,’ carta [ˈkat.ta]~[ˈkaht.ta] ‘card’) is a process that seems to contradict the claim of a general coda weakening as it generates surface coda obstruents. Importantly, in the chain of lenition processes aspiration precedes gemination, and it is only after debuccalization that, by compensatory lengthening, the onset spreads to the available space in the coda. Cross-linguistically, geminates display inalterability and fail to be affected by lenition, allowing coda consonants that otherwise are not possible. These exceptional consonants are licensed by the onset, not the coda.
9.5 Conclusion
In spite of some past controversies, the syllable occupies nowadays a privileged position among phonological units. Thanks to the syllable we can explain the connection between many tendencies that would otherwise be seen as independent processes. The syllable is governed by sonority, and since sonority is a universal tendency we can say that the Spanish syllable is shaped by the same macro currents as those that are active in other languages. It just happens that those currents are not manifested the same way in different contexts because there are local factors at play. OT is particularly good at implementing constraints for those macro currents and factors and for modeling their contribution in different contexts. Besides sonority the other strong current that has been especially highlighted in this chapter is the tendency to have a strong start followed by dampening after reaching a peak. The constraints Onset and *Coda are important members of this current, but the move towards strong segments in the onset and weak ones in the coda goes beyond these constraints. We have seen that the Spanish onsets and nuclei license all phonemic contrasts and can be complex. The coda, on the other hand, is not complex, does not license voicing contrasts, and disfavors labial and dorsal points of articulation. In Spanish multiple processes of lenition and fortition conspire to enforce these preferences. All languages tend to prefer weak codas, but in Spanish this tendency is particularly strong. Besides the major forces there are a number of local factors and details that may sometimes obfuscate the general picture. These details have to do with lexicalization, phonologization, analogy, language change, language contact, the phonology–phonetics–morphology interface, etc. In this chapter we have tried to provide a balanced review of the macro currents while paying attention to the rich and variegated details of the phonological processes associated with the Spanish syllable.
10.1 Introduction
Linguistic prosody has traditionally been referred to as “the music of speech.” The acoustic correlates of prosody include the actual melody of speech (the so-called intonation), plus the rhythmic and durational patterns which typically characterize a given linguistic variety, as well as its intensity patterns. In addition to uniquely characterizing a given linguistic dialect or sociolect, prosodic patterns in speech provide it with a set of important linguistic and communicative functions. From a typological point of view, Spanish – like all Romance languages – belongs to the group of so-called intonation languages, that is, languages that use intonation not to distinguish lexical items (as do tonal languages), but rather to express a range of discourse meanings that often affect the interpretation of sentences in discourse. It is well known that pitch contours (together with other prosodic features) in a language like Spanish are key contributors to the semantico-pragmatic interpretation of sentences. Prosody conveys various communicative meanings that range from speech act marking (assertion, question, request, etc.), information status (focus, given vs. new information), belief status (or epistemic position of the speaker with respect to the information exchange), and politeness and affective states, to indexical functions such as gender, age, and the sociolectal and dialectal status of the speaker (see Prieto Reference Prieto2015). For example, depending on how a speaker of Spanish utters the sentence Tiene frío ‘(S)he is cold,’ it can convey a variety of non-propositional meanings such as “Can you please close the window?,” “He is surprisingly cold,” “He is cold, and I am contradicting you,” “I am not sure whether he is cold or not,” “He is cold, I believe you should know,” and “He is uncomfortably cold,” among others.Footnote 1
Another important function of prosody is that of marking prosodic phrasing (also called prosodic grouping), where speakers use prosody to group constituents into spoken chunks of information in order to give the listener key information about syntactic groupings. Prosodic phrasing is necessary in Spanish (as well as in many other languages) to disambiguate utterances. Consider, for example, the sentence Fueron con la madre de Helena y María. If a speaker places a prosodic boundary after Helena, the hearer will probably interpret the sentence as meaning that “They went out with Helena’s mother and María.” Conversely, if no phrase boundary is placed between Helena and María, then the hearer will probably understand that “They went out with Helena and María’s mother.” English is another language that uses prosody to mark prosodic phrasing, as illustrated by the well-known apocryphal book dedication “To my parents, Ayn Rand and God,” which is syntactically ambiguous. This ambiguity can be resolved through the use of intonation. If the speaker places a phrase boundary after “parents” and “Ayn Rand,” he/she is dedicating the book to his/her parents as well as to Ayn Rand and God. If the speaker does not place a phrase boundary after “parents,” he/she is claiming to be the lucky offspring of Ayn Rand and God (Nielsen Hayden Reference Nielsen Hayden1994).
In addition to the marking of syntactic groupings, intonation plays an important role as an acoustic correlate of information structure. Information structure is commonly thought to be related with the management of common ground information in discourse and involves certain basic concepts like focus, givenness, and topic (see Krifka Reference Krifka2008 for a review). In English, information that has just been given in the immediate context is usually realized with prosodic reduction and lack of accentuation (typically by means of (very) compressed pitch movements associated with the stressed syllable). By contrast, focalized information is realized through strong pitch accentuation (typically by means of expanded pitch movements associated with the stressed syllable). In Spanish, focalization can be achieved by means of different strategies, either syntactic or intonational, which may vary according to the dialect and other factors (such as the type of focus and the syntactic function of the focalized element) (see Vanrell and Fernández-Soriano 2017). In “Narrow Focus Statements” (in Section 10.5.2 below) we will deal briefly with the intonational strategies of focusing used in Spanish.
Despite the importance of prosody in the linguistic system of languages, and specifically Spanish, its study has been relatively neglected in traditional grammars, which have typically concentrated on the description of syntactic and morphological patterns of the language, as well as the study of sounds. The first detailed description of Spanish prosody (based on central Peninsular Spanish read speech) was put forward by Navarro Tomás in his Manual de pronunciación española (Reference Navarro Tomás1918), which included long sections dedicated to stress, rhythm, and intonation. This was followed up by his detailed Manual de entonación española (Reference Navarro Tomás1944), still one of the most comprehensive books on Spanish intonation and prosody. Decades later, Quilis (Reference Quilis1981, Reference Quilis, Morales and Vaquero1987, Reference Quilis1993) carried out phonetic comparisons of intonational contours of several dialectal varieties of Spanish, including those of Madrid, Mexico City, and Puerto Rico.
In the last two decades, the Autosegmental-Metrical framework of intonation (henceforth AM framework: Pierrehumbert Reference Pierrehumbert1980; Pierrehumbert and Beckman Reference Pierrehumbert and Beckman1988; Gussenhoven Reference Gussenhoven2004; Ladd Reference Ladd2008) has been established as one of the standard and most influential models of intonation, leading to an ample consensus among prosody researchers that intonation has a phonological status in natural languages. The AM framework has provided the basis for developing a diverse set of Tones and Break Indices (ToBI) annotation conventions for a large set of typologically diverse languages, all of which have closely followed the tenets of the AM model (see Jun Reference Jun2005, Reference Jun2014 for a review). The AM model describes intonational pitch contours as sequences of two main types of phonologically distinctive tonal units, namely pitch accents and edge tones. Pitch accents are intonational movements that associate with stressed syllables, rendering them intonationally prominent or accented. Edge tones (which can be separated into phrase accents and boundary tones) are also fundamental frequency movements that associate with the ends of prosodic phrases. These units are represented in terms of H(igh) and L(ow) targets. By convention, for pitch accents an asterisk “*” indicates association with stressed syllables (e.g. H*, L*, L+H*, and H+L*), and for edge tones “%” indicates association with the final edges of utterances (L%, H%, and LH%, among other possibilities) whereas “-” indicates association with utterance-internal phrase boundaries (L- and H-, among other possibilities). This phonological representation of tones is mapped onto a phonetic representation through language-specific implementation rules (see Gussenhoven Reference Gussenhoven2004; Ladd Reference Ladd2008, for a review).
Within the AM model, Sosa (Reference Sosa1999) offered the first integrated analysis of basic intonational contours in a large number of Spanish varieties, from both the Iberian peninsula (based on the speech of informants from Seville, Barcelona, Pamplona, and Madrid) and Latin America (Buenos Aires, Bogotá, Mexico City, San Juan de Puerto Rico, Caracas, Havana, and Lima). The first Spanish ToBI model was proposed by Beckman and colleagues in Reference Beckman, Díaz-Campos, McGory and Morgan2002 (Beckman et al. Reference Beckman, Díaz-Campos, McGory and Morgan2002) and has been revised several times since then (see Prieto and Roseano Reference Prieto and Roseano2010, and Hualde and Prieto Reference Hualde, Prieto, Frota and Prieto2015 for a review). Most recently, the work of several groups of researchers investigating ten different geographical varieties of Spanish – namely Castilian, Cantabrian, Canarian, Dominican, Puerto Rican, Venezuelan Andean, Ecuadorian Andean, Chilean, Argentine, and Mexican – was compiled in Prieto and Roseano (Reference Prieto and Roseano2010), which offers a fully integrated ToBI analysis of these varieties and thus represents a key reference for any dialectal comparison of prosody in Spanish. Finally, Hualde and Prieto (Reference Hualde, Prieto, Frota and Prieto2015) sum up this knowledge in a general and cross-dialectal overview of work-related Spanish prosody.
Typically, the study of Spanish prosody has been separated into four main topics, each the focus of independent study, namely, stress, rhythm, prosodic phrasing, and intonation. This chapter will accordingly address the stress patterns (Section 10.2), rhythmic patterns (Section 10.3), phrasing (Section 10.4), and intonation patterns (Section 10.5) of Spanish. Importantly, Section 10.4 explains the basics of how to transcribe Spanish intonation and phrasing patterns following the most recent version of the Spanish ToBI labeling system (Sp_ToBI) (for an in-depth hands-on transcription of Spanish prosody, see Spanish Training Materials, Aguilar et al. Reference Aguilar, De-la-Mota and Prieto2009).
Though in this chapter we will note the systematic prosodic differences that exist across Spanish dialectal varieties, for purely practical reasons many of the examples given will be based on Peninsular Spanish. For more information on dialectal variation, we invite the reader to access specific dialectal monographs and also listen to the recordings available via the online Interactive Atlas of Spanish Intonation (Prieto and Roseano Reference Prieto and Roseano2009–2013), which at present contains audio examples of 18 different sentence types from 23 locales across the Spanish-speaking world (as well as a video interview and other interactive recordings), and/or AMPER-ESP, the Spanish section of the Atlas Multimédia de la Prosodie de l’Espace Roman (Martínez Celdrán and Fernández Planas Reference Martínez Celdrán and Fernández Planas2003–2016), which currently offers audio examples of two sentence types from 36 Spanish-speaking locales.
10.2 Stress
Like most Romance languages, Spanish has lexical stress (also called word stress). Lexically stressed syllables are typically one of the last three syllables of the word, except for a few verbs with final enclitics (e.g. mirándomelo ‘looking at it.me,’ where boldface indicates the stressed syllable). Though Spanish has a few minimal triplets contrasting in lexical stress position (e.g. célebre ‘famous’ vs. celebre ‘celebrate.3sg.sbjv’ vs. celebré ‘I celebrated’), there are clear tendencies in stress placement which work differently for the nominal and verbal paradigms. Nouns ending in a vowel in the singular typically have penultimate stress (casa ‘house’), with some marked antepenultimate stress patterns (bolígrafo ‘pen’) and some exceptional cases of final stress (dominó ‘domino’). By contrast, nouns ending in a consonant in the singular tend to have final stressFootnote 2 (e.g. camión ‘truck’), whereas penultimate stress is less common (lápiz ‘pencil’), and antepenultimate stress is exceptional (análisis ‘analysis’). In quantitative terms, more than 95 percent of all nouns, adjectives, and adverbs follow the unmarked patterns (Morales-Front Reference Morales-Front, Núñez-Cedeño and Morales-Front1999:211). In the verbal paradigm, stress is either penultimate or final in the present tense (camino ‘I walk,’ caminamos ‘we walk,’ camináis ‘you walk’) and morphologically triggered in other tenses, with stress falling either on the syllable which contains that conjugation or theme vowel (caminaba ‘I was walking,’ caminábamos ‘we were walking’) or on the tense morpheme (caminaré ‘I will walk,’ caminaremos ‘we will walk’). Function words are typically unstressed (e.g. mi casa ‘my house,’ su casa ‘his/her house’) with some exceptions (e.g. una casa ‘a house,’ esta casa ‘this house’) (for further details on stressed and unstressed functional words, see Quilis Reference Quilis1993:390–395 and Hualde Reference Hualde2005:233). The unstressed–stressed distinction can give rise to phrasal minimal pairs, as in para los caballos ‘for the horses’ vs. para los caballos ‘s/he stops the horses/stop the horses!’ or bajo la mesa ‘under the table’ vs. bajo la mesa ‘I lower the table’ (Hualde Reference Hualde2005:233–235).
Lexically-stressed syllables have been reported to have clear acoustic correlates, namely longer durations,Footnote 3 higher fundamental frequency, and higher intensity than unstressed syllables (see Pamies Bertrán Reference Pamies Bertrán1993 for a review of acoustic correlates of stress in Spanish and other languages). However, it is important to note that the pitch correlates of stress (that is, whether the stressed syllable is associated with a high or low tone) will depend mainly on the intonational pattern of the sentence in question (see Section 10.5). For example, while the final stressed syllable of a rising intonation contour such as ¿Tienen mandarinas? ‘Do you have any tangerines?’ bears the lowest levels of pitch within the word mandarinas (see Figure 10.9 in Section 10.5.3), the contrary is true in a sentence like ¡Tienen mandarinas! ‘They have tangerines!’ in which this same syllable bears the highest pitch level. The position of the target word within the sentence will also play a role in pitch levels. On the other hand, the duration correlates of stress are mainly dependent on the phrasal level of prominence that stressed syllables attain. Cross-linguistic evidence has demonstrated that increased duration is an important acoustic correlate of prosodic heads (or prominent units) and edges of prosodic phrases (see Prieto et al. Reference Prieto, Vanrell, Astruc, Payne and Post2012 for a review). First, in Spanish, as in other Romance languages, nuclear stress (or main phrasal stress) is the most prominent stress in the sentence and typically falls on the last content word of the sentence, except for very marked cases of emphatic or contrastive focus (Zubizarreta and Nava Reference Zubizarreta and Nava2011; see “Narrow Focus Statements” in Section 10.5.2 below). In comparison with English, which exhibits a greater flexibility in the location of nuclear stress, Romance languages usually show greater flexibility in word order and a more consistent tendency to place nuclear stress at the end of an utterance, e.g. English JOHN bought them vs. Spanish Las compró JUAN (Ladd Reference Ladd2008; Zubizarreta and Nava Reference Zubizarreta and Nava2011). Thus, in Spanish, nuclear stressed syllables exhibit the most prominent stress within the sentence and are one of the longest syllables in the sentence, together with phrase-final syllables.
Similarly to nuclear stressed syllables, non-nuclear stressed syllables (also called prenuclear stressed syllables) quite systematically serve as the anchoring site for pitch accents, giving rise to a high pitch accent density. Pitch accents are realized as visible pitch excursions and/or characterized by expanded duration. This one-to-one correspondence between stressed syllables and pitch accents is a feature that contrasts with English pronunciation, which has many more cases of stressed syllables with no associated pitch accent (e.g. Spanish Vino por detrás de Juliana vs. English He came after Juliana). However, the common one-to-one association between stress and pitch accentuation sometimes breaks down. First, in rhetorical, didactic, or emphatic speech, lexically unstressed (and pretonic) syllables often receive a pitch accent (e.g. importante vs. importante ‘important’; see Hualde Reference Hualde2007, Reference Hualde2009; Hualde and Nadeu Reference Hualde, Nadeu and van der Hulst2014). Second, it is also possible for stressed syllables to surface as unaccented. A contextual prosodic factor leading to de-accentuation is stress clash. For example, an utterance like detrás suyo ‘after him/her’ is typically produced with one pitch accent over the last stressed syllable (in other words, the pitch accent we would typically expect on detrás is not realized due to clash). Although the prominence of the stressed syllable in such cases tends to be conveyed by duration in the absence of a pitch excursion, complete de-accentuation is also possible (see examples in Hualde and Prieto Reference Hualde, Prieto, Frota and Prieto2015).
10.3 Rhythm
Rhythm refers to the organization of timing in speech, and it has been shown to be different across languages (see Ramus et al. Reference Ramus, Nespor and Mehler1999 for a review). Spanish, together with languages such as Italian, has been classified as a syllable-timed language, as opposed to stress-timed languages like English or Dutch. In stress-timed languages stressed syllables are significantly longer than unstressed syllables, creating the sensation of a Morse-type rhythmic effect; by contrast, syllable-timed languages like Spanish create a stronger perception of equal prosodic saliency across syllables.
Work on linguistic rhythm has strongly correlated the differences in rhythmic percept found between languages with a set of language-specific phonetic and phonological properties, of which the two most often cited are syllabic structure and vowel reduction. While stress-timed languages like English have a greater range of syllable structure types, allowing for more complex codas and onsets, and also exhibit vowel reduction, syllable-timed languages like Spanish, by contrast, tend to have a significant proportion of open syllables and no vowel reduction. It has been suggested that the coexistence of these sets of phonological properties is responsible for promoting either a strong saliency of stressed syllables in relation to other syllables – yielding the “stress-timed” effect – or the percept of equal salience between syllables – yielding the “syllable-timed” effect.
Apart from this tendency, cross-linguistic studies on speech rhythm have investigated the timing (or duration patterns) of speech and have found differences in overall timing patterns across languages, as well as what has been called “rhythm metrics” (see Prieto et al. Reference Prieto, Vanrell, Astruc, Payne and Post2012 for a review). In a recent study, Prieto et al. (Reference Prieto, Vanrell, Astruc, Payne and Post2012) showed that when syllable structure properties are controlled for, timing patterns for Spanish and English can be traced back to the duration measures of prominent positions (e.g. accented, nuclear accented, and stressed syllables) and edge positions (e.g. distances to phrase-final positions).
10.4 Intonation and Phrasing
Intonation is what we call in daily language “the melody of an utterance.” In more technical terms, it is the linguistic use of the modulation of F0 (or fundamental frequency, which is the lowest harmonic in voiced parts of speech). As noted in the Introduction, intonation has two main linguistic functions: (i) to mark phrasing (see “Levels of Prosodic Phrasing” in Section 10.4.1), and (ii) to encode speech act distinctions, sentence modality, focus (see Section 10.5.2), and belief state (see “Statements of the Obvious” and “Uncertainty Statements,” also in Section 10.5.2). We will start this section by explaining the basics of prosodic transcription in Spanish using the Sp_ToBI conventions (see Section 10.4.1). As we do so, however, it is important to bear in mind that dialectal variation (also called diatopic or geographic variation) affects all aspects of Spanish, including intonation.
10.4.1 Transcription of Spanish Prosody Using the Sp_ToBI System
As mentioned, the most common system used at present to transcribe the intonation of Spanish relies on the premises of the Autosegmental-Metrical model and is known by the acronym Sp_ToBI (see the Introduction, Section 10.1). Since its inception nearly two decades ago (Beckman et al. Reference Beckman, Díaz-Campos, McGory and Morgan2002) Sp_ToBI has been periodically updated (Hualde Reference Hualde and Prieto2003, Face and Prieto Reference Face and Prieto2007, Estebas Vilaplana and Prieto Reference Estebas Vilaplana and Prieto2008, Prieto and Roseano Reference Prieto and Roseano2010, Hualde and Prieto Reference Hualde, Prieto, Frota and Prieto2015), so that it can now be used to transcribe the intonation of virtually all dialects of Spanish. The existence of a common transcription system allows for easy comparison of the intonation and phrasing patterns of the different geographic varieties of the language.
An example of Sp_ToBI transcription can be seen in Figure 10.1 for the imperative question ¿Callaréis? ‘Will you be quiet?’ as uttered by a speaker of southern Peninsular Spanish (Henriksen and García-Amaya Reference Henriksen and García-Amaya2012). The three labeling tiers below the acoustic plot contain an orthographic (or phonetic) transcription of the sentence (top tier), followed by the prosodic annotation in two tiers, namely the Break Indices tier (second tier) and the Tones tier (third tier). The content of the Break Indices and Tones tiers is explained in the following sections (“Levels of Prosodic Phrasing” and “Pitch Accents and Boundary Tones”).
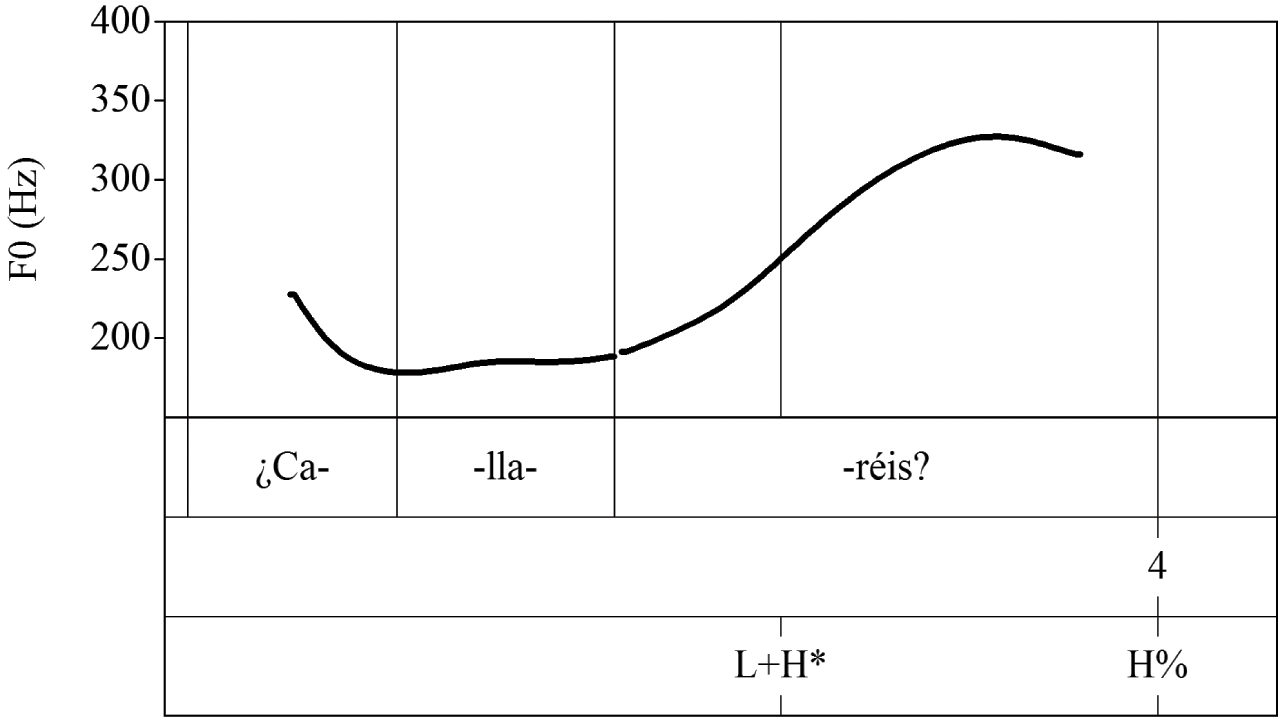
Figure 10.1 Prosodic features of the imperative question ¿Callaréis? ‘Will you be quiet?’ as uttered by a speaker of southern Peninsular Spanish
Levels of Prosodic Phrasing
Two levels of prosodic structure are relevant in the Sp_ToBI notation system: the Intonation Phrase (IP) and the intermediate phrase (ip). The IP is the domain of the minimal tune, and consists of at least one pitch accent followed by a boundary tone. The ip is a minor domain located below the IP which usually corresponds to different types of syntactic elements such as a clause, a dislocated element, a parenthetic element, the subject of the utterance, each element of an enumeration, and so on. In every ip there may be one or more prosodic words (or PW). A PW, in its turn, is made up of one accented word and the adjacent unstressed elements, like articles, prepositions, and so on.
When transcribing the prosody of an utterance according to the Sp_ToBI system, the prosodic phrasing is reflected in the Break Indices or “BI tier,” which contains information about the edges of prosodic units. A 4 in this tier marks the end of an IP, while a 3 marks the end of a non-final ip. A 1 marks the end of a PW and 0 can be used (optionally) to mark the end of an unstressed element. Finally, according to the Sp_ToBI Training Materials (Aguilar et al. Reference Aguilar, De-la-Mota and Prieto2009), a level 2 break index is supposed to mark two different types of breaks that are less common, namely a perceived disjuncture with no intonation effect, or an apparent intonational boundary that lacks slowing or other break cues.
Pitch Accents and Boundary Tones
Sp_ToBI makes use of two different sets of symbols for tonal events. On the one hand, there are pitch accents (henceforth PA), which are the tonal events anchored to a stressed syllable. On the other, there are boundary tones (henceforth BT), which are the tonal events anchored to phrase-final edges. PAs can appear in either nuclear or prenuclear position (see the Introduction, Section 10.1). The combination of the last PA of an utterance and the following BT is called the nuclear configuration. In Romance languages, the nuclear configuration usually contains the most important information transmitted by intonation (see Section 10.5 for some examples of how different nuclear configurations encode sentence modality). Although the main difference between two pitch contours typically lies in the nuclear configuration, the prenuclear part can also differ.
Table 10.1 contains a description of the most frequent PAs found in Spanish ToBI systems, which may be grouped into four families: flat, rising, falling, and rising–falling (based on Prieto and Roseano Reference Prieto and Roseano2010, Hualde and Prieto Reference Hualde, Prieto, Frota and Prieto2015). Some of these PAs are used in all dialects (like L+H*), while others seem to have a very specific geographic distribution (like L+H*+L, which appears only in Argentine dialects). Most pitch accents may appear in either nuclear position (i.e. associated with the last stressed syllable) or prenuclear position (i.e. associated with any stressed syllable except the last). A few pitch accents (like L+<H*), on the other hand, do not appear in nuclear position. Figures 10.2–10.16 offer different examples of the various PA types.
Table 10.1 Schematic representation, Sp_ToBI labels, and phonetic descriptions of the most common pitch accents in Spanish
| Monotonal pitch accents | ||
|---|---|---|
 | L* | This pitch accent is phonetically realized as a low plateau at the minimum of the speaker’s pitch range. |
 | H* | This accent is phonetically realized as a high plateau with no preceding F0 valley. |
 | ¡H* | This accent is phonetically realized as a rise from a high plateau to an extra-high level. |
| Bitonal pitch accents | ||
|---|---|---|
 | L+H* | This accent is phonetically realized as a rising pitch movement during the stressed syllable with the F0 peak located at the end of this syllable. |
 | L+¡H* | This pitch accent is phonetically realized as rise to a very high peak located in the accented syllable. It contrasts with L+H* in F0 scaling. |
 | L+<H* | This accent is phonetically realized as a rising pitch movement in the stressed syllable with the F0 peak in the post-accentual syllables. |
 | L*+H | This accent is phonetically realized as a F0 valley on the stressed syllable with a subsequent rise on the post-accentual syllable. |
 | H+L* | This accent is phonetically realized as a F0 fall from a high level within the stressed syllable. |
| Tritonal pitch accent | ||
|---|---|---|
 | L+H*+L | This pitch accent displays a rising–falling pattern within the stressed syllable. |
Note: In the schematic representations, white rectangles represent unstressed syllables and gray rectangles represent stressed syllables.
In general, Spanish displays quite a rich inventory of boundary tones, which are the tones associated with the right edge of either an IP (in this case they are marked with a % symbol) or an ip (in this case a - symbol is used). Nonetheless, not all Spanish dialects are equally rich in BTs: while some, like Castilian Spanish, have up to six boundary tones, other varieties like Dominican Spanish – which has only four BTs – make use of a more limited set (Willis Reference Willis, Prieto and Roseano2010).
Boundary tones may have different degrees of complexity, being either monotonal or bitonal. Table 10.2 contains a schematic representation and detailed description of the most frequent BTs found in Spanish (based on Aguilar et al. Reference Aguilar, De-la-Mota and Prieto2009, Prieto and Roseano Reference Prieto and Roseano2010, Hualde and Prieto Reference Hualde, Prieto, Frota and Prieto2015).
Table 10.2 Schematic representation, Sp_ToBI labels, and phonetic descriptions of the most common boundary tones in Spanish
| Monotonal boundary tones | ||
|---|---|---|
 | L% | This boundary tone is phonetically realized as a low or falling tone at the baseline of the speaker. |
 | !H% | This boundary tone is phonetically realized as a rising or falling movement to a target mid point. |
 | H% | This boundary tone is phonetically realized as a rising pitch movement coming from a low or rising pitch accent. |
| Bitonal boundary tones | ||
|---|---|---|
 | LH% | This boundary tone is phonetically realized as a F0 valley followed by a rise. |
 | L!H% | This boundary tone is phonetically realized as a F0 valley followed by a rise into a mid pitch. |
 | HL% | This boundary tone is phonetically realized as a F0 peak followed by a fall. |
Note: In the schematic representations, white rectangles represent stressed syllables and gray rectangles represent final unstressed syllables.
The intonation contours illustrated in the following section will be analyzed as a series of Sp_ToBI pitch accents and boundary tones.
10.5 Main Intonation Contours
As we have observed (see the Introduction, Section 10.1), one of the main functions of intonation in Spanish is to mark speech act information, in other words, to indicate whether we intend a sentence to be interpreted as an assertion, a question, a request, etc. Within these speech acts, intonation can also mark information status (focus, given vs. new information), as well as belief status (epistemic position of the speaker with respect to the information exchange). In this section, we will exemplify the most common intonation contours characterizing assertions (Sections 10.5.1 and 10.5.2), yes–no questions (Sections 10.5.3 and 10.5.4), wh-questions (Section 10.5.5), imperatives (Section 10.5.6), and vocatives/calls (Section 10.5.7).
A comprehensive description of the intonation contours of the most important sentence-types in the major Spanish dialects would require a few hundred pages (Prieto and Roseano Reference Prieto and Roseano2010 being a case in point). For this reason, in the following pages we will focus on the intonation patterns of a few sentence types found in Castilian Spanish (also known as central Peninsular Spanish) and limit ourselves to noting only the most salient differences between Castilian and other Spanish dialects. The reason why Castilian Spanish has been chosen is that it is one of the varieties that has been described most extensively from a prosodic point of view. The reader will find the actual sound files as well as more complete acoustic representations of those files and dialectal recordings of similar sentences online in the Interactive Atlas of Spanish Intonation (Prieto and Roseano Reference Prieto and Roseano2009–2013).
10.5.1 Broad Focus Statements
A broad focus statement is a sentence that typically communicates a piece of information that is new to the hearer. The information is given neutrally, without any further added nuance (like surprise, doubt, and so on). For example, imagine that a parent calls home to find out what his/her children, named María and Juan, are doing. Juan’s answer illustrated in (10.1) is usually realized as a broad focus statement.
(10.1)
Speaker A (parent): What are you guys up to?
Speaker B (juan): María’s drinking her lemonade.
In most dialects of Spanish, broad focus statements display a pitch contour that is similar to that represented in Figure 10.2. It is characterized by a pitch rise associated with the first stressed syllable (a L+< H* pitch accent in the example below) followed by a set of optional rising pitch accents. The sentence ends in a nuclear stress (or main phrasal stress), which is the most prominent stress in the sentence and is typically realized with a low or falling pitch movement L* followed by a low final boundary tone L%.

Figure 10.2 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the broad focus statement Bebe una limonada ‘He/she’s drinking a [his/her] lemonade’ in Castilian Spanish
One notable exception to the general tendency of Spanish dialects to have a falling pitch movement at the end of assertions is the so-called entonación circunfleja (“circumflex intonation”) seen in some American varieties like Mexican and Chilean Spanish. Note, however, that in these two dialects the circumflex pattern applied to broad focus statements is an alternative to but does not completely replace the falling contour (Ortiz et al. Reference Ortiz, Fuentes, Astruc, Prieto and P. Roseano2010; Martín Butragueño and Mendoza Reference Martín Butragueño, Mendoza, García and Uth2017). This circumflex pattern, characterized by a rise associated with the last stressed syllable (L+H*) and a final fall to a low level (L%), is represented in Figure 10.3, adapted from Martín Butragueño and Mendoza (Reference Martín Butragueño, Mendoza, García and Uth2017).

Figure 10.3 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the broad focus statement Me encantó la película ‘I loved the film’ as uttered by a speaker of Mexican Spanish
In addition, other dialects diverge in the choice of prenuclear pitch accents. For example, varieties like Puerto Rican Spanish use L*+H instead of L+<H* (Armstrong Reference Armstrong, Prieto and Roseano2010).
10.5.2 Biased Statements
As mentioned above, two of the main functions of intonation are to mark information structure and belief status (e.g. the epistemic position of the speaker with respect to the information exchange). In this section we describe the typical intonation patterns found for narrow focus statements, statements of the obvious, and uncertainty statements.
Narrow Focus Statements
Whereas in broad focus statements all information is new for the listener, in narrow focus statements only part of the information is in focus. For example, the question–answer test in (10.2) shows that the focused material in the response sentence corresponds to the constituent mi hermana, while the information that precedes it (i.e. Las ha comprado) is mutually assumed by the two interlocutors.
(10.2)
Speaker A: ¿Quién ha comprado manzanas?
Speaker B: Las ha comprado mi hermana.
In Spanish focus marking can alter the canonical SVO order (see Chapter 17, this volume, for an overview). In the example in (10.2), the subject has moved to final position, where it receives main stress in a nuclear stress (or main phrasal stress), which is the most prominent stress in the sentence and is typically realized with a low or falling pitch accent L* followed by a low final boundary tone L%. The intonation of informative narrow focus statements in Spanish is usually the same as that of broad focus statements (Section 10.5.1).
There are two main kinds of narrow focus statement, informative and corrective/contrastive. While the response in (10.2) constitutes an example of informative narrow statement, the examples in (10.3a) and (10.3b) exemplify two types of corrective or contrastive narrow focused statements which challenge and replace information given previously in the discourse. The contrastively focused element may either appear in its canonical position (like in 10.3a) or be displaced (as in 10.3b) (Vanrell et al. Reference Vanrell, Stella, Gili-Fivela and Prieto2013).
(10.3)
Speaker A: Quiero un quilo de limones.
Speaker B: ¿Qué has dicho, que quieres mandarinas?
a.
Speaker A:
No. Quiero LIMONES. No. want.1sg LEMONS. b.
Speaker A:
No. LIMONES, quiero. No. lemons want.1sg
Independently from its position within the sentence, many Spanish dialects signal this corrective focused element through a salient F0 movement, typically a pitch rise, which allows the listener to easily identify it. In all the Spanish dialects documented, this contour is different from that seen in broad focus statements. Although there are differences among dialects, the focal pitch accent is mostly either high or rising. In Castilian Spanish, for example, the focused element is characterized by a rising L+H* accent and a final low boundary tone (L%), as can be seen in Figure 10.4.
Figure 10.4 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the narrow focus statement No, de LIMONES ‘No, [I want a kilo] of LEMONS’ as uttered by a speaker of Castilian Spanish
Although the strategy described above is very common, it is not the only one. More details on the different focus marking strategies in Spanish may be found in Face (Reference Face2002) and Vanrell and Fernández-Soriano (Reference Vanrell, Fernández-Soriano, García and Uthin press), among others.
Statements of the Obvious
By using a statement of the obvious, a speaker expresses his/her opinion that the listener should already know the information. Imagine, for example, that two friends are speaking about a mutual long-term acquaintance, María, as in (10.4). They both know that she has been dating her boyfriend, Guillermo, since they were very young. Speaker A tells B that María is now pregnant and B asks who the father is. Speaker A tells her it is Guillermo, astonished that Speaker B should not have drawn the obvious conclusion.
(10.4)
Speaker A: María’s pregnant.
Speaker B: Whose baby is it?
Speaker A: It’s Guillermo’s, of course!
While some languages mark obviousness with a lexical item (like “of course” in English), some dialects of Spanish employ a specific intonational pattern to convey the same meaning. The pattern used to express obviousness in many Peninsular Spanish dialects (like Castilian, Cantabrian, and Canarian Spanish) and some Latin American varieties (like Puerto Rican and Mexican Spanish) is a complex rise-fall-rise pitch movement (L+H* L!H% in Sp_ToBI terms). The F0 contour in Figure 10.5 illustrates this rise-fall-rise pitch contour on the word Guillermo.

Figure 10.5 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the statement of the obvious Sí, mujer, ¡de Guillermo! ‘[It’s] Guillermo’s [of course]!’ as uttered by a speaker of Castilian Spanish
Other Latin American Spanish varieties like Dominican, Venezuelan Andean, Ecuadorian Andean, Chilean, and Argentine Spanish tend to express obviousness using the same intonation pattern as that seen in narrow focus statements (discussed above).
Uncertainty Statements
Uncertainty statements are used by speakers to convey a lack of commitment to the truth-content of the proposition being expressed. The conversational exchange in (10.5) illustrates a context for low commitment statement, where A asks B whether he/she has bought a gift for C, a person that A does not know very well. B answers positively, but adds that he/she is not sure whether C will like the gift or not.
(10.5)
Speaker A: Have you bought a gift for C?
Speaker B: Yes, I have. But she may not like it.
While some languages mark uncertainty with a set of lexical items (such as modal verbs like “might” or epistemic adverbs like “possibly”), some Spanish dialects can also employ specific intonational patterns to convey this meaning. For example, Castilian Spanish expresses uncertainty by means of a final rising–falling movement that does not fall to the baseline of the speaker’s range (L+H* !H% in Sp_ToBI terms), as illustrated in Figure 10.6.

Figure 10.6 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the uncertainty statement Puede que no le guste el regalo que le he comprado … ‘S/he may not like the gift I have bought him/her’ as uttered by a speaker of Castilian Spanish
10.5.3 Information-Seeking Yes–No Questions
Information-seeking yes–no questions are used to ask for a piece of information, with no expectation about the possible answer. Research has shown that the intonation of information-seeking yes–no questions can differ sharply among the different dialects of Spanish (Navarro Tomás Reference Navarro Tomás1944; Quilis Reference Quilis1993; Sosa Reference Sosa1999; Prieto and Roseano Reference Prieto and Roseano2010). In very broad terms, interrogative pitch contours can be classified into rising and falling contours. Central and southern Peninsular Spanish, Ecuadorian Andean, Chilean, and Mexican Spanish all use a pitch contour characterized by a final low-rise. On the other hand, a second dialect cluster including Canarian, Argentine, Venezuelan Andean, and several Caribbean varieties (like Cuban, Dominican, and Puerto Rican) use a pitch contour with a final falling pattern. Figure 10.7 illustrates a rising pattern (the one used in Castilian Spanish), while Figures 10.8 and 10.9 offer examples of falling patterns from, respectively, Puerto Rican (Armstrong Reference Armstrong2015) and Argentine Spanish (Kaisse Reference Kaisse, Herschensohn, Mallen and Zagona2001; Gabriel et al. Reference Gabriel, Feldhausen, Pešková, Colantoni, Lee, Arana, Labastía, Prieto and Roseano2010). The rise–fall pitch contour seen in Argentine Spanish has a very characteristic final long fall.

Figure 10.7 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the information-seeking yes–no question ¿Tiene mermelada? ‘Do you have any jam?’ as uttered by a speaker of Castilian Spanish

Figure 10.8 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the information-seeking yes–no question ¿Hay reunión mañana? ‘Is there a meeting tomorrow?’ as uttered by a speaker of Puerto Rican Spanish

Figure 10.9 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the information-seeking yes–no question ¿Tienen mandarinas? ‘Do you have any tangerines?’ as uttered by a speaker of Argentine Spanish
10.5.4 Biased Yes–No Questions
Biased yes–no questions are a rather heterogeneous group that includes several kinds of polar questions that a speaker asks when his/her intention is not simply to ask for a piece of information about which he/she has no expectation. Among them, confirmation questions, imperative questions, and echo questions are the most common.
Confirmation-Seeking Questions
When someone asks a confirmation question, he/she has some kind of expectation about the answer. Some languages, like English, usually encode this expectation by means of a tag question, which means that the speaker utters a statement followed by a confirmation tag like “isn’t it?” This can happen in Spanish too, where the most common confirmation tags are ¿no? and ¿verdad? ‘[isn’t that the] truth?’ In addition to this lexical marking of confirmation-seeking, several varieties of Spanish have specific contours that appear in confirmation-seeking yes–no questions.Footnote 4 Speakers of Castilian Spanish, for example, may use the falling pattern exemplified in Figure 10.10 (transcribed as H+L* L% in Sp_ToBI terms), which is radically different from the rising contour of information-seeking yes–no questions that we saw in Section 10.5.3 (Figure 10.7).

Figure 10.10 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the confirmation question ¿Tienes frío? ‘Are you cold?’ as uttered by a speaker of Castilian Spanish
Echo Questions
An echo question is a question that repeats more or less verbatim an element that precedes it in the exchange, as illustrated by Speaker A’s final “It’s nine o’clock?” in (10.6). Echo questions may indicate that a person is not sure he/she has understood what an interlocutor has said, as in (10.6), but they may also be used to show that the speaker has understood the preceding utterance but is surprised or even astonished by it, as in (10.7).
(10.6)
Speaker A: What time is it?
Speaker B (whispering): It’s nine o’clock.
Speaker A: What? It’s nine o’clock?
(10.7)
Speaker A: Have you heard anything about Tracy lately?
Speaker B: She’s marrying Sam.
Speaker A: She’s marrying Sam?! Wow!
Echo questions show considerable interdialectal variation in Spanish. One of the most common nuclear configurations used for echo questions is the rise–fall tune, which is characterized by a rise to an extra-high level in the last stressed syllable followed by a fall (L+¡H* L% in ToBI transcription). This contour is found in, among other dialects, Canarian and Castilian (Figure 10.11). The more incredulous echo questions like that exemplified in (10.7) are realized either with the contour described above but with an expanded pitch range, or with a specific incredulity pitch contour (see a description of the incredulity interrogative contour L* HL% in Armstrong Reference Armstrong2015).

Figure 10.11 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the echo question ¿Las nueve? ‘Nine o’clock?’ as uttered by a speaker of Castilian Spanish
10.5.5 Information-Seeking wh-Questions
Information-seeking wh-questions are used when speakers ask for a specific piece of information without any further pragmatic intention. The pitch contour of this sentence type displays as much dialectal variation as that seen in yes–no questions. Nevertheless, the general tendency is for wh-questions to end with a low tone, as illustrated in Figure 10.12.
Figure 10.12 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the information-seeking wh-question ¿De dónde has llegado? ‘Where have you arrived from?’ as uttered by a speaker of Castilian Spanish
10.5.6 Commands and Requests
Imperatives are linguistic expressions which communicate either an order or a request, depending on the intonation used. For example, the intonation of “Come here!” as spoken by a dog owner to his/her errant dog will reflect the full authority the speaker feels relative to the animal. By contrast, the intonation of “Come on, man!” as spoken by someone trying to cajole a friend into forgetting their work obligations and accompanying him/her to the cinema will reflect a much more peer-to-peer kind of relationship.
In most dialects of Spanish, intonational pitch contours used for orders typically show a final fall or a rise–fall. In other words, they tend to use either the same pitch contour as that used for broad focus statements (Venezuelan Andean, Ecuadorian Andean, and Argentine Spanish) or the pitch contour used for narrow focus statements (Castilian, Canarian, Chilean, and Mexican Spanish). Figure 10.13 provides an example of an imperative in Castilian Spanish, where orders are expressed by means of a rising–falling final movement (L+H* L% in Sp_ToBI terms).

Figure 10.13 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the command ¡Ven! ‘Come here!’ as uttered by a speaker of Castilian Spanish
Though imperative requests in Spanish are typically also encoded by means of lexical items like va ‘come on’ or por favor ‘please,’ intonation (as well as a much slower speech rate) plays a key role in conveying this intention. Most dialects use a configuration that is different from that used for orders. In the case of Castilian Spanish, for example, the imperative request contour is characterized by a complex fall–rise–fall pitch contour (L* HL%). While the low part of the nuclear configuration (L*) is temporally associated with the final stressed syllable, the final rise–fall boundary tone (HL%) is associated with the post-tonic syllables. This intonation contour is exemplified in Figure 10.14.

Figure 10.14 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the cajoling imperative request Va, vente al cine, ¡hombre! ‘Come on, come to the cinema, man!’ as uttered by a speaker of Castilian Spanish
10.5.7 Calls
Vocatives are used to call someone’s attention, with different degrees of insistence and/or imperativeness. In several intonational languages calls are characterized by a chanted intonation (L+H* !H% in Sp_ToBI terms). This contour, which is found in most Spanish dialects, shows an F0 rise in the stressed syllable, followed by a fall to a mid level in the following unstressed syllables (which are usually considerably lengthened), like what we see in Figure 10.15.

Figure 10.15 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the call ¡Marina! ‘Marina!’ uttered with the common calling contour
A slightly different pitch contour, which seems to convey a more insistent or imperative nuance in several varieties of Spanish, is characterized by a rise in the stressed syllable that ends in the post-tonic stretch and a final fall to the baseline of the speaker’s range (L+H* HL% in Sp_ToBI labels). Figure 10.16 offers an example of this contour.
Figure 10.16 F0 contour, spectrogram, orthographic transcription, and prosodic annotation of the insistent call ¡¡Marina!! ‘Marina!!’
10.6 Summary and Conclusion
This chapter has presented a brief overview of the main features of Spanish prosody and intonation. From a typological perspective, Spanish is a prominence-final language which tends to assign nuclear prominence (or nuclear stress) to the last stressed syllable of the intonational phrase. This contrasts with English, which has a more flexible placement of nuclear stress within the intonational phrase (see Section 10.2). With regard to rhythm, Spanish is a syllable-timed language and therefore does not exhibit a sharp durational difference between stressed and unstressed syllables, unlike stress-timed languages like English (see Section 10.3). Another difference concerns pitch accent density: while Spanish has a tendency to show a one-to-one correspondence between stressed syllables and pitch accents, this is not the case for languages like English.
From an intonational point of view, Spanish is an intonational language which uses melodic modulations for a wide set of pragmatic functions, including speech act marking, epistemic marking, and information structure marking. The present chapter has presented the most common melodic contours used to mark these distinctions (see Sections 10.4 and 10.5). Though most of the examples are drawn from the Peninsular Spanish varieties, we have also illustrated some clear differences between dialects, such as the so-called Mexican declarative circumflex contour (Sosa Reference Sosa1999; Martín Butragueño and Mendoza Reference Martín Butragueño, Mendoza, García and Uth2017) or the long fall of Argentine interrogatives (see Kaisse Reference Kaisse, Herschensohn, Mallen and Zagona2001; Gabriel et al. Reference Gabriel, Feldhausen, Pešková, Colantoni, Lee, Arana, Labastía, Prieto and Roseano2010). For readers interested in these interdialectal differences in Spanish intonation, we recommend accessing the audio and video recordings of nine dialects of Spanish available at the Interactive Atlas of Spanish Intonation website (Prieto and Roseano Reference Prieto and Roseano2009–2013).
Finally, throughout the chapter we have made use of the most recent version of Sp_ToBI, a consensus prosody transcription system based on the Autosegmental-Metrical model (see Section 10.4.1). Importantly, the fact that full Sp_ToBI descriptions of many of the dialectal varieties of Spanish are now available has meant that cross-dialectal comparisons of Spanish prosody can now be very easily made.
11.1 Introduction
Speech perception is the process by which sounds are heard, mapped from speech signal to mental representation, and understood. Because languages differ in their sound inventories, second/foreign language learners may have difficulty distinguishing speech sounds in a non-native language. For example, monolingual Spanish speakers can struggle to perceive (and produce) a difference in word-final nasals in English, given that Spanish nasals undergo a process of neutralization in certain word-final contexts (Morgan Reference Morgan2010). Because in much of the Spanish-speaking world two or more languages are in contact (Spanish–English, Spanish–Portuguese, Spanish–Quechua, Spanish–Catalan, etc.), Spanish speakers’ sound systems are affected by this contact. In addition, there is often quite a bit of variation within a given language, and speech perception studies allow us to understand how listeners hear and process sounds in other dialects and varieties of their first or second language(s). In order for communication to occur, listeners must be able to understand the speech that talkers use, and understanding how listeners process speech is important to better understand how and why speakers produce speech the way they do. In general, speech perception and production have been investigated separately, as each field poses its own challenges and methodologies.
11.1.1 Models of Speech Perception
When speech is perceived, there are several processes that occur. The listener must first detect the acoustic signal, the lexicon is then activated, and then language comprehension occurs (Johnson and Mullennix Reference Johnson and Mullennix1997; Pisoni Reference Pisoni1993). Studies have found that listeners retain in long-term memory non-linguistic information about the speaker’s gender, dialect, speaking rate, and emotional state, and that these properties influence the initial perceptual encoding and retention of spoken words (Pisoni Reference Pisoni1993). There are also varying approaches to the nature of perceptual representations, including abstract representations, exemplar-based representations (Johnson and Mullennix Reference Johnson and Mullennix1997; Werker and Tees Reference Werker and Tees1984), and how these representations are formed (Kuhl et al. Reference Kuhl, Conboy, Coffey-Corina, Padden, Rivera-Gaxiola and Nelson2008).
There are several models of second language (L2) speech perception, but the two most widely used are the Perceptual Assimilation Model (PAM) (Best Reference Best and Strange1995) and the Speech Learning Model (SLM) (Flege Reference Flege and Strange1995). Best’s PAM, based on articulatory phonetics, provides possible cross-language category assimilation patterns and predicts their consequences. This model assumes that, from birth, listeners perceive everything in the speech signal with great detail, but, as we receive more exposure to our native language, we become more attuned to differences that are important in discriminating sounds in that language. This means that listeners, even in their first year, conceive sounds as groups of gestures that connect to produce distinctive sounds, improving processing speed and efficiency in our first language (L1). This model predicts, then, that sounds that are distinct in a listener’s L1 will be more easily perceived in the L2. Those sounds that are not contrastive in the L1 are more difficult to perceive in the L2. Best’s model predicts that three things can happen when hearing a non-native sound: (i) it is assimilated to an existing L1 category, (ii) it is heard as a non-native sound, or (iii) it is heard as a non-speech sound.
Flege’s SLM is based on the premise that a listener’s system for categorizing sounds develops throughout their life, maintaining contrasts that are important to the languages they use. His model posits that listeners must be able to hear some of the acoustic differences between sounds in order to be able to perceive them as different. If the sounds are not acoustically different enough, the listener will not perceive them as unique sounds. On the other hand, if they are acoustically different, even if neither sound is present in the listener’s L1, the listener will be able to distinguish them based on phonetic cues. The SLM also suggests that bilingual speakers store phones from all of the languages they speak in one space, allowing there to be more of a role for phonetic cues rather than simply phonemic processing.
11.1.2 Techniques Used in Speech Perception
The three most commonly used experimental techniques for measuring speech perception are perceptual similarity rating, speeded discrimination, and identification tasks (Boomershine et al. Reference Boomershine, Hall, Hume, Johnson, Avery, Dresher and Rice2008; Johnson and Babel Reference Johnson and Babel2010; Logan and Pruitt Reference Logan, Pruitt and Strange1995). In a perceptual similarity rating task, listeners are presented with two stimulus items and are asked to rate how similar or different they sound to and from each other using a scale. Previous research (Boomershine et al. Reference Boomershine, Hall, Hume, Johnson, Avery, Dresher and Rice2008; Huang Reference Huang2004) has shown that the perceptual similarity rating task can reveal cross-linguistic differences that relate to phonological differences between languages. In a speeded discrimination task, on the other hand, listeners are presented with stimulus items and are asked to determine if they are the same or different. The stimuli can be presented in pairs or in groups of three. With three stimuli, the listener is asked to determine either if the third token was similar to the first or the second (ABX discrimination) or if the middle token was similar to the first or the third token (AXB discrimination). Both ABX and AXB tasks have found that listeners are often biased to respond that X=B or X=A, respectively (Gerrits and Schouten Reference Gerrits and Schouten2004). To avoid this bias, researchers often use just two stimuli for an AX discrimination task, where listeners are to decide if the stimuli are the same or different. This technique, however, often leads listeners to only respond ‘different’ if the stimuli are very different; otherwise, the listeners label most items as being the same (Gerrits and Schouten Reference Gerrits and Schouten2004). Finally, identification tasks are those that present listeners with stimulus items, one at a time, and ask them to identify the sound or word they hear. Identification tasks, because they usually force listeners to associate sounds to written items, are often greatly impacted by the amount of academic exposure listeners have had in the language being studied. Therefore, identification tasks tend to tell researchers more about a listener’s literacy level and orthographic accuracy than their ability to perceive sounds (Johnson and Babel Reference Johnson and Babel2010). The remainder of this chapter will look at what we know about how a listener’s first language is processed (Section 11.2) and how listeners perceive sounds in bilingual speech (Section 11.3). We will end by discussing challenges faced within the field of speech perception and opportunities for future research.
11.2 First Language Speech Perception
11.2.1 Infant Studies
Infants have unlimited potential to acquire speech sounds of any human language. Studies have found that infants as young as six months of age are able to distinguish speech sounds that do not exist in their mother tongue (Werker and Tees Reference Werker and Tees1984). It is still debatable whether infants are born equipped with a linguistic blueprint with language-general phonetic boundaries that help them process speech sounds (Eimas Reference Eimas1975; Hoonhorst et al. Reference Hoonhorst, Colin, Markessis, Radeau, Deltenre and Serniclaes2009) or whether statistical learning of phonetic categories takes place after infants’ initial exposure to language (Kuhl et al. Reference Kuhl, Conboy, Coffey-Corina, Padden, Rivera-Gaxiola and Nelson2008). However, there is no doubt that native language has a large effect on the way infants process speech sounds and that this effect occurs early in life. At birth, infants hear differences among all the sounds that exist in human languages, but this language-general ability of speech perception transforms into a language-specific one during the first year of life (Kuhl and Iverson Reference Kuhl, Iverson and Strange1995). This section provides evidence from various empirical studies that shows infants’ perceptual reorganization at different stages during the first year of life.
Consonants
Most research on Spanish-learning infants’ perception of consonants has been done on stop voicing contrasts (e.g. /b/ vs. /p/). One of the strongest acoustic cues that separate them is voice onset time (VOT). In Spanish, there is a two-way contrast with a 0 ms VOT boundary that separates voiced /b, d, g/ (< 0 ms) from voiceless /p, t, k/ (0~30 ms) stops. Lasky et al. (Reference Lasky, Syrdal-Lasky and Klein1975) examined whether 4–6.5 month-old Spanish-learning infants are able to distinguish bilabial stop pairs of different VOT boundaries. Results showed that the infants distinguished the –60/–20 and the +20/+60 ms pairs, but not the –20/+20 ms pairs. This is an unexpected outcome, given that the –20/+20 ms pair is the one with the VOT boundary that separates Spanish voiced and voiceless stops. The authors argued that there may be two language-general VOT boundaries that distinguish stops, one between –60 and –20 ms and another between +20 and +60 ms, to which infants, regardless of their native language, are innately predisposed.
Language-specific VOT boundaries are acquired at the second half of the first year. Eilers et al. (Reference Eilers, Gavin and Wilson1979) examined the perception of bilabial voicing contrasts by Spanish- and English-learning infants at six to eight months of age and found that, while Spanish-learning infants were able to separate +10/–20 and +10/+40 ms pairs, English-learning infants were only able to distinguish the +10/+40 ms pairs. This, together with the findings of Lasky et al. (Reference Lasky, Syrdal-Lasky and Klein1975), imply that, while the English-like VOT boundary is an acoustically salient boundary that is unaffected by linguistic environment, the Spanish-like VOT boundary may need to be acquired through exposure to a language with stop voicing contrasts at this phonetic boundary.
Vowels
Perceptual reorganization has also been observed in Spanish-learning infants’ perception of vowels. For instance, Bosch and Sebastián-Gallés (Reference Bosch and Sebastián-Gallés2003) examined the perception of /e/–/ɛ/ contrast by four- and eight-month-old Spanish monolingual, Catalan monolingual, and Catalan–Spanish bilingual infants. This vowel distinction is phonological in Catalan, while it is not in Spanish. Previous studies on adult Catalan–Spanish bilinguals have shown that Spanish-dominant bilinguals tend to have difficulties distinguishing this contrast (Sebastián-Gallés and Soto-Faraco Reference Sebastián-Gallés and Soto-Faraco1999). With respect to infants, Bosch and Sebastián-Gallés (Reference Bosch and Sebastián-Gallés2003) found that, while all infants distinguished the /e/–/ɛ/ contrast at four months of age, at eight months only the Catalan monolinguals were able to do so; such sensitivity declined for Spanish monolingual and Catalan–Spanish bilingual infants regardless of language dominance. While Spanish monolinguals’ difficulty in /e/–/ɛ/ discrimination is an expected outcome, as this contrast does not exist in Spanish, it is interesting that the same was observed with the bilingual infants who were exposed to both Catalan and Spanish.
Interestingly, the discrimination ability that was once thought to be lost was regained for 12-month-old bilingual infants, presenting a U-shaped pattern. Moreover, this ability can last throughout the second year of life, although factors such as increased experience with cross-language cognates and input variability (for example, Spanish-accented Catalan) may eventually lead to difficulties in perceiving the contrast (Ramon-Casas et al. Reference Ramon-Casas, Fennel and Bosch2016).
U-shaped patterns are also observed in Catalan–Spanish bilinguals’ perception of vowel contrasts that exist in both languages. Sebastián-Gallés and Bosch (Reference Sebastián-Gallés and Bosch2009) found that, when perceiving the /o/–/u/ contrast, only bilingual infants showed a U-shaped pattern, while monolingual infants were successful in distinguishing the contrast at all ages. This indicates that bilingual infants may undergo a developmental process that is different from that of monolingual infants.
Prosody
From early on, infants are able to extract global rhythmic properties from utterances and detect a switch of utterances spoken in languages of different rhythmic classes (stress-timed, syllable-timed, and mora-timed) (Mehler et al. Reference Mehler, Jusczyk, Lambertz, Halsted, Bertoncini and Amiel-Tison1988). During the first six months, infants’ sensitivity to speech input becomes more fine-tuned to their native language, to the point that they can distinguish languages or dialects of the same rhythmic class as their native language. Bosch and Sebastián-Gallés (Reference Bosch and Sebastián-Gallés1997, Reference Bosch and Sebastián-Gallés2001) found that, at four months, Spanish- and Catalan-learning monolingual infants, as well as Catalan–Spanish bilingual infants, were able to tell Spanish and Catalan apart, even though they are both syllable-timed languages. Although this finding suggests that even at four months infants are sensitive to fine-grained rhythmic properties of their native language(s), further research needs to be conducted to corroborate this, as research on infant-directed speech has shown that vowel spectral information is a stronger cue than fine-grained rhythmic properties in distinguishing dialects of the same rhythmic class (Ortega-Llebaria and Bosch Reference Ortega-Llebaria, Bosch, Romero and Riera2016).
There have also been studies regarding the perception of stress. Using disyllabic pseudo-words with stress on the first (trochee) and last syllable (iamb), Skoruppa et al. (Reference Skoruppa, Pons, Christophe, Bosch, Dupoux, Sebastián-Gallés, Limissuri and Pepperkamp2009) examined whether nine-month-old infants learning Spanish and French are able to discriminate the two stress patterns. The nature of stress is different in the two languages, in that, while Spanish is a language with lexical stress, which means that stress is phonologically contrastive (número ‘number’ vs. numero ‘I number’ vs. numeró ‘numbered.3sg’) (Hualde Reference Hualde2005), stress in French is fixed to the last syllable of each phrase. Results showed that, while both groups distinguished trochaic and iambic stimuli when the only difference between the two was the location of stress (/ˈpima/ vs. /piˈma/), with segmental variability (/ˈlapi/ vs. /kiˈbu/), only the Spanish-learning infants perceived the difference in stress pattern. However, when testing six-month-old infants, Skoruppa et al. (Reference Skoruppa, Pons, Bosch, Christophe, Cabrol and Pepperkamp2013) found that neither Spanish- nor French-learning infants succeeded in distinguishing the two stress patterns when there was segmental variability. This suggests that infants are able to perceive acoustic correlates of stress (longer duration, higher pitch, and higher intensity), while only those whose native language has lexical stress learn to process stress in an abstract, phonological way between six and nine months of age.
Apart from the discrimination of stress patterns, Pons and Bosch (Reference Pons and Bosch2010) further examined whether Spanish-learning infants have trochaic bias (Allen and Hawkins Reference Allen, Hawkins, Bell and Hooper1978), which has been observed in English-learning infants (Jusczyk et al. Reference Jusczyk, Friederici and Wessels1993). However, recent research on infants learning languages of different rhythmic properties found that infants do not show any preference toward a particular stress pattern (Hochbert Reference Hochbert1988). Pons and Bosch (Reference Pons and Bosch2010) support this view in their study with nine-month-old Spanish-learning infants. They found that Spanish-learning infants did not show any stress pattern bias when listening to disyllabic pseudo-words with open syllables (CV.CV). However, when one of the two syllables was closed, they seemed to prefer stress on that syllable (trochaic for CVC.CV and iambic for CV.CVC), suggesting that syllable weight may play a larger role in infants’ initial stress assignment.
11.2.2 Adult Native Speakers
Perceptual reorganization during infancy is a necessary process for an effective processing of native speech sounds. However, as the reorganization process reaches stability, the sensitivity to perceive phonological contrasts that do not exist in the native language declines. Thus, difficulties in distinguishing non-native speech sounds are clearly attested in adult listeners.
Consonants
Most research on the perception of consonants has been carried out regarding stop consonants. As mentioned previously in the section on “Consonants” in infant studies, Spanish has a two-way stop voicing contrast, the main distinction of which is VOT. Although VOT is one of the most salient acoustic cues that separate Spanish voiced from voiceless stops, this contrast can also be distinguished by other acoustic properties, such as closure duration. Spanish voiceless stops are generally produced with longer closure duration than voiced stops (Green et al. Reference Green, Zampini and Magloire1997). Zampini et al. (Reference Zampini, Clarke and Norrix2002) examined whether Spanish listeners are sensitive to this cue when perceiving stop voicing contrast. Using nonce words with initial stops preceded by various degrees of closure duration, they found that Spanish listeners’ VOT boundaries decreased as the closure duration increased, which indicates that the listeners perceived the stimuli as voiceless stops more often when the closure duration was longer.
There is more evidence that VOT is not the only cue to which Spanish listeners attend when perceiving stop voicing contrast. By removing the prevoicing portion of Spanish voiced stops, Williams (Reference Williams1977) examined whether Spanish listeners are able to identify voiced stops without this critical information. Although the percent of voiced responses decreased when the prevoicing portion was edited out, the Spanish listeners still judged voiced stops as such significantly more than voiceless stops. Williams (Reference Williams1977) suggested two possible acoustic correlates for voicing in Spanish stops: presence of a strong burst and presence of low-frequency periodic energy at articulatory release. He found that when there was a strong burst or high-frequency periodic energy at the moment of release, listeners tended to perceive the stimuli as voiceless.
Native language phonology can also influence listeners’ perceived distance between sounds. Boomershine et al. (Reference Boomershine, Hall, Hume, Johnson, Avery, Dresher and Rice2008) examined Spanish listeners’ perceptual distinction among [d], [ð], and [ɾ] and compared their behavior to that of English listeners. The three phones exist in both Spanish and English, but the phonological relationship among them differs in the two languages. While [d] and [ð] are contrastive in English (/d/ vs. /ð/), in Spanish they are allophones of the same phoneme /d/ (stop [d] vs. approximant [ð̞]). Moreover, [d] and [ɾ] in Spanish are from two different phonemes (/d/ vs. /r/), while in English they are in an allophonic relationship. Concerning [ð] and [ɾ], they are contrastive in both languages, but they belong to different phonemes: the two phones are from /d/ and /r/ in Spanish and /ð/ and /d/ in English. Results showed that Spanish listeners perceived the [d]–[ð] contrast more similarly and the [d]–[ɾ] contrast more differently, compared to English listeners. This suggests that sound pairs that are allophonic in the native language ([d]–[ð]) are perceived as more similar than those that contrast phonologically ([d]–[ɾ]).
Apart from perceptual distance, stop–approximant allophony also has an effect on Spanish listeners’ perception of stress location. Using resynthesized disyllabic stimuli /baba/ with varying stop [b, d, g] and approximant [β̞, ð̞, ɣ̞] locations, Shea and Curtin (Reference Shea and Curtin2010) found that Spanish native listeners perceived [b]-initial syllables as stressed more frequently than [β̞]-initial syllables, regardless of whether this sound was followed by a stressed vowel ([ˈbaβ̞a], [β̞aˈba]) or an unstressed vowel ([baˈβ̞a], [ˈβ̞aba]), and showed illusory stress perception even when the first and the second vowels were held steady.
Vowels
With regard to vowels, Escudero and colleagues (Elvin et al. Reference Elvin, Escudero and Vasiliev2014; Escudero and Williams Reference Escudero and Williams2012) examined Spanish listeners’ perception of vowel contrasts of languages whose vowel inventory is larger than Spanish. They found that Spanish listeners generally have less sensitivity in distinguishing the vowel contrasts, compared to listeners whose native language vowel system contains more vowels than Spanish (Dutch, Australian English, Brazilian Portuguese). However, although vowel inventory size is a good predictor of the discrimination ability of non-native vowel contrasts, it may not be the only one. Elvin et al. (Reference Elvin, Escudero and Vasiliev2014) found that Spanish listeners outperformed Australian English listeners when distinguishing Brazilian Portuguese vowels, even though Australian English has a much larger vowel inventory (12 monophthongs) than Spanish (five monophthongs). Given that the spectral information of Spanish vowels is more similar to those of Brazilian Portuguese than of Australian English, the authors suggested that acoustic properties may be a stronger predictor of non-native vowel discrimination ability than vowel inventory size.
The importance of acoustic properties is also shown when comparing listeners of different varieties of Spanish. For instance, Escudero and Williams (Reference Escudero and Williams2012) compared Iberian Spanish (IS) and Peruvian Spanish (PS) listeners’ perception of Dutch vowel contrasts. They found differences in the perception of the two dialectal groups, which may be explained by the dialect-specific differences in the spectral properties of IS and PS vowels. Specifically, even though Dutch /a/–/ɑ/ contrast does not exist in Spanish, as IS /a/ and /o/ have first formant (F1) values closer to Dutch /a/ and /ɑ/, compared to PS /a/ and /o/, IS listeners were better at distinguishing the Dutch vowel contrast.
Prosody
Concerning L1 Spanish prosody, Soto-Faraco et al. (Reference Soto-Faraco, Sebastián-Gallés and Cutler2001) investigated whether Spanish listeners attend to suprasegmental cues for lexical processing, using a cross-modal fragment priming paradigm, in which fragments of real word pairs that differed only in the position of lexical stress (PRINCI… from principio ‘beginning’ or príncipe ‘prince’) were auditorily presented as primes, followed by a visual target word (principio or príncipe). Results showed that, compared to the control condition, in which there was no segmental or suprasegmental overlap between the prime and the target, the response time was faster when the stress pattern of the prime matched that of the target, whereas it slowed down when they did not match. This suggests that Spanish listeners use both segmental and suprasegmental cues for lexical processing. Moreover, using an ABX discrimination task, Dupoux et al. (Reference Dupoux, Pallier, Sebastián-Gallés and Mehler1997) compared Spanish and French listeners’ perception of nonce word triplets in three conditions: phoneme-only (fídape–lídape–fídape), stress-only (fídape–fidápe–fídape), and phoneme and stress (fídape–lidápe–fídape). They found that Spanish listeners’ reaction time was fastest in the redundant condition and equally slow in the other two conditions, while the reaction time of the French listeners was the slowest in the stress-only condition and equally fast in the other two conditions. This finding indicates that Spanish listeners use both segmental and suprasegmental information at low-level phonetic perception.
Overall, the findings of L1 speech perception studies provide empirical evidence that native speakers undergo a language-general to language-specific reorganization process during infancy, which later on helps them attend to fine-grained acoustic properties that are necessary for successful processing of native speech sounds.
11.3 Bilingual Speech Perception
11.3.1 Simultaneous Bilinguals
This section emphasizes the perception by those speakers who were exposed to two languages (primarily Spanish–Catalan) from birth (“simultaneous bilinguals”).
Vowels
Spanish and Catalan are in contact in eastern Spain, and both are official languages in the Spanish autonomous communities of Catalonia, the Balearic Islands, and Valencia. This unique situation of contact in which both languages are valued by the speakers and the government allows for a rich research environment on the simultaneous acquisition of two languages. Multiple studies have been conducted on the perception of Catalan vowel contrasts by simultaneous bilingual speakers of Catalan and Spanish.
In their study, Navarra et al. (Reference Navarra, Sebastián-Gallés and Soto-Faraco2005) used an implicit method for measuring the L1 effects on the perception of L2 sounds. They asked Catalan–Spanish simultaneous bilinguals who had grown up either in Spanish-speaking homes or in Catalan-speaking homes to categorize the first syllable of bisyllabic stimuli. The only difference in the stimulus items was the vowel in the second syllable – it could contain a Catalan contrastive variation (/ɛ/–/e/) or no variation. Catalan dominants responded more slowly in lists where the second syllable varied from trial to trial, suggesting an indirect effect of the /ɛ/–/e/ discrimination. Spanish dominants did not suffer this interference, performing indistinguishably from Spanish monolinguals. A similar study was conducted by Sebastián-Gallés et al. (Reference Sebastián-Gallés, Echeverría and Bosch2005). They investigated how simultaneous and early sequential Catalan–Spanish bilinguals in Barcelona perceived the mid-vowel contrast found in Catalan. The results of their lexical decision task demonstrated that L1 Spanish, L2 Catalan bilinguals had difficulty distinguishing stimuli whose only difference was a contrast found in Catalan, but not Spanish. They also found that the simultaneous bilinguals tended to have a dominant language which affected their perception of Catalan contrasts.
Mora et al. (Reference Mora, Keidel and Flege2010) investigated the perception of mid (/e/–/ɛ/, /o/–/ɔ/) and high-mid (/i/–/e/, /u/–/o/) vowel continua by Spanish–Catalan simultaneous bilinguals. The researchers found that all Spanish–Catalan bilinguals perceived the high-mid vowel contrasts more categorically than the mid-mid vowel contrasts, with the size of the difference being affected by how frequently Catalan was used. Notably, this study underscores the importance of understanding language dominance and use by bilingual speakers in perception studies. Sounds that are not contrastive in the dominant language are less easily distinguished than those that are contrastive in both languages. A similar study was conducted by Mora and Nadeu (Reference Mora and Nadeu2012) into the effects of an L2 (Spanish) on the perception of L1 (Catalan) contrastive sounds. They found that all participants performed at near ceiling levels in the tasks, but the reaction time for those participants who had more exposure to Spanish than Catalan was slower than for the Catalan-dominant speakers. The findings suggest that extensive L2 use of/exposure to Spanish and Spanish-accented Catalan in a bilingual language contact setting may modify Catalan natives’ phonetic categories.
Prosody
In addition to studying how simultaneous bilinguals perceive segmental features, researchers have also conducted studies on their perception of suprasegmental features. As with the perception of segments, there are few studies on the perception of suprasegmentals by simultaneous bilinguals (compared to sequential bilinguals or L2 learners). Dupoux et al. (Reference Dupoux, Peperkamp and Sebastián-Gallés2010) investigated the perception of Spanish stress by simultaneous French–Spanish bilinguals. Spanish, unlike French, has word-level lexical stress as part of the phonological system. The researchers studied the perception of lexical stress as a means to better understand how simultaneous bilingual speakers process suprasegmental features. Their participants were raised in bilingual French–Spanish homes, with some participants being raised by a Spanish-speaking mother and others a French-speaking mother. They found that the simultaneous bilinguals performed at a level that was intermediate to L1 French speakers of Spanish and L1 Spanish speakers. They also found that the performance of the simultaneous bilinguals showed a bimodal distribution – depending on the dominant language of each participant. In other words, each speaker has only one language that processes speech sounds and segments in a native-like way. More research needs to be conducted on how simultaneous bilinguals process input as adults so that this population’s perception can be better understood.
11.3.2 Second Language Speakers
Research related to the acquisition of L2 sounds by language learners has traditionally focused on the production of those sounds, but, due to the link between perception and production, more researchers are turning their attention to the perception of L2 sounds by learners. This section will focus on the perception of Spanish sounds by L1 English speakers who are learning Spanish after adolescence, but attention will also be given to the perception of Spanish sounds by L1 speakers of other languages, as well as to the perception of English sounds by L1 Spanish speakers.
Consonants
Unlike children acquiring their native language (Section 11.2.1) or early bilingual speakers (Section 11.3.1), second language learners often exhibit difficulty perceiving L2 sounds that are non-contrastive in their native language. In the Boomershine et al. (Reference Boomershine, Hall, Hume, Johnson, Avery, Dresher and Rice2008) study described above, participants tapped into their L1 phonology when rating the contrastive and allophonic pairs. The researchers found that speakers of a language in which a particular pair of sounds is contrastive at a phonemic level perceive that pair as being more perceptually distinct than do speakers of a language in which the pair is not phonemically contrastive.
Shea and Renaud (Reference Shea and Renaud2014) also studied the perception of consonants, with a focus on the effects of task type on perception. L1 and L2 speakers of Spanish participated in a similarity rating study in which they heard pairs of stimuli containing [Ɉʝ] (affricate) and [ʝ] (fricative). They were asked to rate how similar the stimulus items were, using a scale of 1 (very similar) to 5 (very different). The results indicated that the L2 speakers of Spanish rated these sounds as being very different on average, while the L1 Spanish speakers rated them as both different (62 percent) and similar (29 percent). In other words, the L1 Spanish ratings were not uniform, unlike the L2 listeners’. Shea and Renaud also conducted a speeded AX discrimination task with L1 and L2 Spanish speakers. They found that, unlike the L1 speakers, the L2 speakers’ reaction times were significantly different only for the medial position, not word-initially. The results point towards a native-language effect even at low-level phonetic perception.
Vowels
The perception of L2 vowels has also been studied. Most notably, Morrison (Reference Morrison2006) investigated the perception of the English /i, ɪ, e, ɛ/ and Spanish vowels /i, e, ei/ by L1 English speakers of Spanish and L1 Spanish speakers of English. In his study, the participants were asked to listen to words in a carrier phrase and indicate how good a representation the target word was to the words on the screen. He found that L1 Spanish speakers of English had difficulty distinguishing English /i/ and /ɪ/. With increased exposure to English, he found that they distinguished English /i/ and /ɪ/ via a category–goodness–difference assimilation, using duration cues, along with spectral cues, to help distinguish the two English vowels. Because Spanish does not distinguish /i/ and /ɪ/, or /e/ and /ɛ/, at the phonemic level (or even allophonic level for most varieties), L1 Spanish speakers learning English must use a variety of perceptual cues to be able to distinguish these contrastive sounds in English.
Studies have also found the target dialect being learned affects the speaker’s perception of L2 sounds. Escudero and Boersma (Reference Escudero and Boersma2004) conducted a study into the perception of Scottish and Southern British English vowels (/i, ɪ/) by L1 Spanish speakers. In a forced identification task, the listeners heard two tokens and were asked to indicate whether the sound they heard was the same as the one in sheep (/i/) or the one in ship (/ɪ/). This identification task differed from others in that they were shown images of the targets, rather than written words, in order to avoid any orthographic association between sounds and letters. The researchers found that the listener’s experience and exposure to specific target dialects affected which cues they used when completing the task. Those participants who had more experience with Southern British English tended to use duration as a cue when perceiving the stimuli, but the participants who were more accustomed to Scottish English used spectral cues.
Other studies looked at the amount and type of exposure to the L2 and how that affects speech perception. Flege et al.’s study (Reference Flege, Bohn and Jang1997) assessed the effect of English-language experience on non-native speakers’ perception of English vowels. L1 Spanish speakers were presented with stimuli on the /i/–/ɪ/ and /ɛ/–/æ/ continua, one at a time, and were asked to indicate if the vowel they heard occurred in beat, bit, bet, or bat. They found that the L1 Spanish speakers who had greater experience with English used spectral cues more when perceiving these English vowels than the Spanish speakers with limited experience with English. The authors noted, however, that there was probably orthographic interference during the study, as both /i/ and /ɪ/ more closely approximate the Spanish sound represented by Spanish <i>, and thus listeners with limited experience with written English may have been more likely to select bit over beat due to orthographic similarity.
Prosody
Linguists have also studied the perception of suprasegmental features in Spanish by L2 speakers. In his study, Face (Reference Face2005) presented listeners with nonce words with equal stress on all syllables, and asked them to indicate which syllable they perceived as being the stressed syllable. The participants were divided into three groups based on Spanish level – beginner, intermediate, and advanced. He found that as students progressed through their Spanish studies, they were more likely to perceive stress according to the unmarked stress patterns in Spanish (as paroxytones).
Ortega-Llebaria et al. (Reference Ortega-Llebaria, Gu and Fan2013) also conducted a study on the perception of Spanish stress by L1 English speakers of Spanish. In their identification task, listeners were presented with stimuli containing the word mamá or mama with final and penultimate stress. The stimuli were manipulated for duration, intensity, and pitch. The participants were asked to indicate whether they heard a word with final stress or penultimate stress. The findings demonstrate that L2 Spanish speakers did not perceive variations of duration and f0 in relation to stress in the same manner as L1 Spanish speakers, causing difficulties for the L2 Spanish speakers when perceiving stress in Spanish. The study also found that no one acoustic cue aids or hinders stress perception in Spanish – but rather a cluster of cues are needed to accurately perceive stress placement in Spanish.
Improving Second Language Perception
In addition to investigating how L2 speakers perceive non-native sounds, there are also studies that determine what practices can improve L2 speech perception. Kissling (Reference Kissling2015) conducted a study in which L1 English speakers who were enrolled in Spanish courses of various levels participated in an AX discrimination task at various times throughout the course of a semester. The participants were divided into two groups – one which received explicit phonetics instruction and the other which did not. The results of the study demonstrate that the group that received explicit phonetics instruction was able to more accurately discriminate the target phones when compared to the group that did not receive phonetics instruction. While the improvement throughout the semester did not occur immediately following the instruction in all cases, the author posits that the listeners used the information gained from the phonetics instruction to become more attuned to the phonetic cues that distinguish these sounds, allowing them to more accurately perceive relevant differences across phones.
Another study that focused on improving L2 perception is Zampini’s study of the perception of varying VOT in Spanish and English stops. Zampini (Reference Zampini1998) conducted a study in which L1 English speakers learning Spanish were presented with stimuli containing a bilabial stop, with the VOT ranging from 40 to 56 ms, and were asked to indicate if the token started with a /p/ or a /b/. They participated in the study three times during the semester. She found that, initially, their perceptual boundaries for Spanish /p/ and /b/ were similar to monolingual English speakers, but, over the course of the semester, their boundaries shifted to those of bilingual Spanish–English speakers.
11.3.3 Heritage Speakers
Apart from L2 speakers and simultaneous bilinguals, another type of bilinguals merits attention. We are referring to heritage speakers – descendants of immigrants who grow up speaking an ethnic minority language in a society where a different language is spoken as the majority language. Heritage speakers are linguistically a unique population, because, although they generally acquire the heritage language first, a shift to the majority language is often observed among them as they grow up, given that their first language is a minority language. With regard to heritage speakers of Spanish, because Spanish is the most spoken non-English language in the US (González-Barrera and Lopez Reference González-Barrera and Lopez2013), research on this population has been done mainly in this context, and this section will therefore focus on US Spanish heritage speakers.
Consonants
A number of studies have shown that Spanish heritage speakers produce certain sounds differently from Spanish monolinguals, possibly due to influence from English (Amengual Reference Amengual2012; Au et al. Reference Au, Oh, Knightly, Jun and Romo2008; Rao Reference Rao2015; Henriksen Reference Henriksen2015). However, little is known about their perception. Regarding the perception of Spanish consonants, Mazzaro et al. (Reference Mazzaro, Cuza, Colatoni, Tortora, den Dikken, Montoya and O’Neill2016) investigated Spanish heritage speakers’ ability to distinguish Spanish stop voicing contrasts, and compared their behavior to that of Hispanic immigrants who had lived in the US for a long period of time and of Spanish native controls who had recently moved to the US. Results showed that the heritage speakers performed similarly to the control group when distinguishing Spanish stop voicing contrast, even better than the long-term immigrants.
Similarly, in a perception study using cross-spliced stimuli, Kim (Reference Kim2011) found that Spanish heritage speakers perceive Spanish stops in a similar manner to Spanish native controls. That is, when listening to stimuli with contrasting acoustic information in the consonant portion and the vowel portion (/b/ from /be/ + /e/ from /pe/), both the heritage speakers and the native controls attended to the consonant portion more than the vowel portion, such as the VOT, closure duration, and presence of burst/low-frequency amplitude at the articulatory release (Williams Reference Williams1977; Zampini et al. Reference Zampini, Clarke and Norrix2002). Although further investigation should be conducted for the generalizability of the results, due to the study’s small sample size, it supports Mazzaro et al.’s (Reference Mazzaro, Cuza, Colatoni, Tortora, den Dikken, Montoya and O’Neill2016) findings in that early exposure to the heritage language has long-lasting effects on heritage speakers’ ability to distinguish heritage language phonological contrasts.
Vowels
Little is known about how heritage speakers perceive Spanish vowels: to our knowledge, the only study that has investigated this topic is Mazzaro et al. (Reference Mazzaro, Cuza, Colatoni, Tortora, den Dikken, Montoya and O’Neill2016), mentioned above. Mazzaro et al. (Reference Mazzaro, Cuza, Colatoni, Tortora, den Dikken, Montoya and O’Neill2016) examined whether heritage speakers are able to distinguish Spanish front (/e/–/i/) and back vowel contrasts (/o/–/u/). Similarly to the results of stop voicing contrasts, the authors found that the heritage speakers performed more similarly to the control group than did the long-term immigrants. This is an interesting finding, because the long-term immigrants were more dominant in Spanish than were the heritage speakers. Although further investigation is needed, due to the study’s small sample size, the findings imply that continued exposure to a L2 may affect the perception of native speech sounds.
The studies above, as well as the studies on simultaneous bilinguals, suggest that the age of L2 acquisition has an effect on listeners’ perception of L1 and L2 speech sounds. That is, early exposure to two languages is advantageous in maintaining phonological contrasts in both L1 and L2 (Chang et al. Reference Chang, Yao, Haynes and Rhodes2011). However, with regard to heritage speakers, there may be lasting effects of sequential learning. Casillas and Simonet (Reference Casillas and Simonet2016) found that, when presented with English /æ/–/ɑ/ continua, Spanish heritage speakers did not perceive the two low vowels categorically, as English monolinguals did. Rather, similarly to L1 Spanish speakers of English, heritage speakers processed these vowels as one category, possibly because they assimilated them to Spanish low vowel /a/. This finding suggests that, although heritage speakers behave similarly to Spanish native controls, they do not behave the same way as English controls, despite English being the more dominant language. However, as the authors noted, further research should be carried out in heritage speakers’ linguistic input; as heritage speakers generally live in a bilingual environment, it is likely that they are exposed to both Spanish and Spanish-accented English.
Prosody
Heritage speakers’ advantage in the perception of heritage language speech sounds also applies to prosody. Kim (Reference Kim, Willis, Martín Butragueño and Herrera Zendejas2015) examined Spanish heritage speakers’ perception of lexical stress in Spanish using stress minimal pairs (canto ‘I sing’ vs. cantó ‘he/she/you (formal) sang’). Studies in L2 phonology have shown that English L2 speakers of Spanish experience great difficulties identifying the location of lexical stress in Spanish (Saalfeld Reference Saalfeld2009), because, unlike English in which both segmental and suprasegmental information provides cues to lexical stress, suprasegmental information plays a larger role in the identification of lexical stress in Spanish. Results showed that heritage speakers, as well as Spanish monolinguals, were able to distinguish paroxytones (canto) and oxytones (cantó), unlike L2 learners who, showed bias toward paroxytones.
With regard to intonation, Zárate-Sández (Reference Zárate-Sández2015) examined Spanish heritage speakers’ perception of peak alignment. In Spanish, pitch contour varies depending on the context in which a word is located. In phrase-final position of a declarative sentence (La nena lloraba. ‘The girl was crying.’), pitch (f0) peak is aligned with the stressed syllable, while it is generally displaced to a following syllable when the word is located in a non-phrase final position (La nena lloraba.) (Prieto et al. Reference Prieto, van Santen and Hirschberg1995). However, early f0 alignment can also occur if the word in the non-phrase final position carries emphatic information. Using resynthesized stimuli with f0 peak in various locations, Zárate-Sández (Reference Zárate-Sández2015) found that Spanish heritage speakers, as well as Spanish monolinguals, perceived f0 peak alignment categorically as either emphatic or non-emphatic, based on whether the f0 peak was positioned before or after stressed vowel offset. However, for L2 English speakers and English monolinguals, a significantly earlier threshold was found within the stressed vowel.
The findings of heritage speakers’ perception studies converge, in that heritage speakers, despite shift of language dominance to English, seem to be resistant to influence from English; they are able to maintain their L1 sound categories like Spanish monolinguals. This is different from the findings of production studies that have shown differences in heritage speakers’ behaviors from those of Spanish monolinguals. Although more research is needed for the generalizability of the findings, the results of the perceptual studies indicate that investigating heritage speakers’ perception or production alone will provide only a one-sided view of their phonological system. Therefore, further research should be conducted into both heritage speakers’ perception and production.
11.4 Conclusions and Future Directions
As discussed in this chapter, the field of speech perception is one that is growing within Hispanic linguistics. Perception studies have advanced our understanding of how infants acquire language and process speech, how an adult’s phonological system is affected by their experiences in life, and how L2 (or late bilingual) speakers perceive and process sounds in their first and second languages in comparison to heritage speakers and early bilingual speakers. We have also seen that there are limited studies on how explicitly working to improve L2 speech perception can improve accuracy and acquisition overall. The field could benefit from further studies into speech perception in Spanish, especially with regard to the perception of variable input in the L1 and L2. Also needed are studies that investigate the perception of simultaneous bilingual speakers of Spanish, including studies that investigate the perception of Spanish sounds by simultaneous bilingual speakers of indigenous languages in Latin America.




























