We improve and expand in two directions the theory of norms on complex matrices induced by random vectors. We first provide a simple proof of the classification of weakly unitarily invariant norms on the Hermitian matrices. We use this to extend the main theorem in Chávez, Garcia, and Hurley (2023, Canadian Mathematical Bulletin 66, 808–826) from exponent 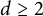 $d\geq 2$ to
$d\geq 2$ to 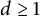 $d \geq 1$. Our proofs are much simpler than the originals: they do not require Lewis’ framework for group invariance in convex matrix analysis. This clarification puts the entire theory on simpler foundations while extending its range of applicability.
$d \geq 1$. Our proofs are much simpler than the originals: they do not require Lewis’ framework for group invariance in convex matrix analysis. This clarification puts the entire theory on simpler foundations while extending its range of applicability.


