Refine search
Actions for selected content:
28 results
The Influence of Commitment, Trust, Satisfaction, and Involvement on Donor Retention
-
- Journal:
- Voluntas: International Journal of Voluntary and Nonprofit Organizations / Volume 22 / Issue 4 / December 2011
- Published online by Cambridge University Press:
- 01 January 2026, pp. 757-778
-
- Article
- Export citation
11 - Posterior-Based Specification Testing and Model Selection
- from Part III - Bayesian Estimation and Inferences
-
- Book:
- Financial Econometrics
- Published online:
- 20 February 2025
- Print publication:
- 27 February 2025, pp 340-377
-
- Chapter
- Export citation
10 - Hypothesis Testing Statistics Based on Posterior Output with Applications in Financial Econometrics
- from Part III - Bayesian Estimation and Inferences
-
- Book:
- Financial Econometrics
- Published online:
- 20 February 2025
- Print publication:
- 27 February 2025, pp 306-339
-
- Chapter
- Export citation
A Test Can Have Multiple Reliabilities
-
- Journal:
- Psychometrika / Volume 86 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 869-876
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Latent Hidden Markov Model for Process Data
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 205-240
-
- Article
- Export citation
An Estimating Equations Approach for the LISCOMP Model
-
- Journal:
- Psychometrika / Volume 63 / Issue 2 / June 1998
- Published online by Cambridge University Press:
- 01 January 2025, pp. 165-182
-
- Article
- Export citation
Item Response Theory with Estimation of the Latent Population Distribution Using Spline-Based Densities
-
- Journal:
- Psychometrika / Volume 71 / Issue 2 / June 2006
- Published online by Cambridge University Press:
- 01 January 2025, pp. 281-301
-
- Article
- Export citation
Simultaneous Analysis of Multivariate Polytomous Variates in Several Groups
-
- Journal:
- Psychometrika / Volume 54 / Issue 1 / March 1989
- Published online by Cambridge University Press:
- 01 January 2025, pp. 63-73
-
- Article
- Export citation
A Latent Variable Model for Discrete Multivariate Psychometric Waiting Times
-
- Journal:
- Psychometrika / Volume 64 / Issue 1 / March 1999
- Published online by Cambridge University Press:
- 01 January 2025, pp. 69-82
-
- Article
- Export citation
Goodman and Kruskal’s Gamma Coefficient for Ordinalized Bivariate Normal Distributions
-
- Journal:
- Psychometrika / Volume 85 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 905-925
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating the Parameters of the Latent Population Distribution
-
- Journal:
- Psychometrika / Volume 42 / Issue 3 / September 1977
- Published online by Cambridge University Press:
- 01 January 2025, pp. 357-374
-
- Article
- Export citation
Using Phantom and Imaginary Latent Variables to Parameterize Constraints in Linear Structural Models
-
- Journal:
- Psychometrika / Volume 49 / Issue 1 / March 1984
- Published online by Cambridge University Press:
- 01 January 2025, pp. 37-47
-
- Article
- Export citation
Recognize the Value of the Sum Score, Psychometrics’ Greatest Accomplishment
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 84-117
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rejoinder to McNeish and Mislevy: What Does Psychological Measurement Require?
-
- Journal:
- Psychometrika / Volume 89 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1175-1185
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Maximum likelihood estimation for spinal-structured trees
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 October 2024, pp. 234-268
- Print publication:
- March 2025
-
- Article
- Export citation
-
We investigate some aspects of the problem of the estimation of birth distributions (BDs) in multi-type Galton–Watson trees (MGWs) with unobserved types. More precisely, we consider two-type MGWs called spinal-structured trees. This kind of tree is characterized by a spine of special individuals whose BD
 $\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by
$\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by 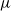 $\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate
$\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate 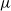 $\mu$ and
$\mu$ and  $\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of
$\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of 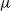 $\mu$ and
$\mu$ and  $\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if
$\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if 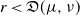 $r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and
$r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and 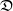 $\mathfrak{D}$ is a divergence measuring the dissimilarity between
$\mathfrak{D}$ is a divergence measuring the dissimilarity between 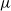 $\mu$ and
$\mu$ and  $\nu$.
$\nu$.


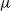

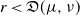
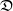
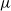

Estimating the Ideology of Political YouTube Videos
-
- Journal:
- Political Analysis / Volume 32 / Issue 3 / July 2024
- Published online by Cambridge University Press:
- 13 February 2024, pp. 345-360
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Coup-proofing: latent concept and measurement
-
- Journal:
- Political Science Research and Methods / Volume 12 / Issue 4 / October 2024
- Published online by Cambridge University Press:
- 29 January 2024, pp. 799-820
-
- Article
- Export citation

Adaptive Inventories
- A Practical Guide for Applied Researchers
-
- Published online:
- 08 July 2022
- Print publication:
- 28 July 2022
-
- Element
- Export citation
15 - How Far Can Measurement Be Culture-Free?
- from Part 3 - Culture and Assessment
-
-
- Book:
- Methods and Assessment in Culture and Psychology
- Published online:
- 21 January 2021
- Print publication:
- 18 February 2021, pp 319-340
-
- Chapter
- Export citation
7 - Joint Species Distribution Modelling
- from Part II - Building a Joint Species Distribution Model Step by Step
-
- Book:
- Joint Species Distribution Modelling
- Published online:
- 18 May 2020
- Print publication:
- 11 June 2020, pp 142-183
-
- Chapter
- Export citation
